Embed Size (px)
Citation preview

CARTAS DE CONTROLE
MULTIVARIADAS BASEADAS NO
MÉTODO KERNEL-STATIS PARA
MONITORAMENTO DE PROCESSOS
NÃO-LINEARES
DANILO MARCONDES FILHO (UFRGS)
Flávio Sanson Fogliatto (UFRGS)
luiz paulo luna de oliveira (UNISINOS)
Processos industriais que ocorrem em bateladas são empregados com
freqüência na produção de alguns itens. Tais processos disponibilizam
uma estrutura de dados bastante peculiar e, diante disso, existe um
crescente interesse no desenvolvimennto de cartas de controle
multivariadas mais apropriadas para seu monitoramento. Destaca-se aqui
uma abordagem recente que utiliza cartas de controle baseadas no método
Statis. O Statis constitui-se numa técnica exploratória que permite avaliar
similaridade entre matrizes de dados. Entretanto, essa técnica avalia a
similaridade no contexto linear, isto é, investiga estruturas lineares de
correlação nos dados. Neste artigo, propõe-se a utilização de cartas de
controle baseadas no Statis em conjunto com um kernel para
monitoramento de processos com presença de não-linearidades. Através
dos kernels, definem-se funções não-lineares dos dados para melhor
representação da estrutura a ser caracterizada pelo método Statis. Esta
nova abordagem, denominada Kernel-Statis, é desenvolvida e avaliada
utilizando dados de um processo simulado.
Palavras-chaves: Cartas de controle multivariadas, Kernels, Método
Statis, Processos em bateladas
XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUÇÃO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão.
Salvador, BA, Brasil, 06 a 09 de outubro de 2009

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
2
1. Introdução
Processos industriais automatizados disponibilizam uma grande quantidade de informações sobre
seu desempenho. Em tais processos são geradas medições simultâneas e em tempo real de
diversas variáveis de processo. Obtêm-se então dados em quantidade suficiente para habilitar um
monitoramento preciso do desempenho de operações industriais. Parte dessas indústrias conduz
seus processos em bateladas.
Processos em bateladas apresentam uma série de operações e eventos complexos que provocam
efeitos não-lineares significativos nos dados, isto é, correlações não-lineares costumam estar
presentes entre as variáveis de processo. Frente a essa evidência, cartas de controle (CCs)
multivariadas mais apropriadas para seu monitoramento foram propostas na literatura.
As principais abordagens não-lineares de controle de processos em bateladas baseiam-se em
extensões não-lineares da MPCA (Multiway Principal Components Analisys – Análise de
Componentes Principais Multidirecionais), denominadas Non-Linear PCA (NLPCA – PCA não-
linear). As CCs baseadas em NLPCA são obtidas a partir do uso da PCA em conjunto com
modelos de redes neurais, algoritmo de curvas principais ou kernels. Martin & Morris (1996) e
Lee et al. (2004a;b) apresentam uma discussão comparativa de CCs baseadas em NLPCA.
Uma abordagem alternativa, denominada Statis, proposta por Lavit et al. (1994), utiliza um
arranjo de dados distinto em relação à MPCA. O Statis constitui-se em uma técnica exploratória
que oferece uma representação sumária do grau de similaridade entre matrizes de dados através
da utilização da ACP (Análise de Componentes Principais). As CCs baseadas no método Statis
foram propostas originalmente por Scepi (2002) e expandidas para o monitoramento on-line e off-
line de processos em bateladas por Fogliatto & Niang (2008). A caracterização dos dados
oferecida pelo Statis traz um acréscimo em relação ao arranjo usado na ACPM, pois permite a
construção de CCs para avaliar o desempenho do processo explicitamente a cada instante.
Entretanto, assim como as demais abordagens lineares, a técnica avalia a similaridade no
contexto linear, isto é, investiga apenas estruturas de correlação lineares nos dados.
Propõe-se aqui o desenvolvimento de CCs baseadas em uma modificação do Statis que incorpore
também não-linearidades presentes nos dados: o Kernel-Statis. Através dos kernels, definem-se
funções não-lineares dos dados para melhor representação da estrutura a ser caracterizada pelo
método Statis. A proposta apresenta duas importantes contribuições ao estado da arte sobre
monitoramento de processos não-lineares. Primeiro, as CCs baseadas no Kernel-Statis são de
natureza não-paramétrica, ao contrário de outras propostas disponíveis na literatura; tal
característica aumenta suas possibilidades de utilização. Segundo, a utilização do Statis como
base teórica para o desenvolvimento das CCs permite extensões para contemplar situações
especiais, tais como o controle de processos em bateladas com durações distintas e a utilização do
Statis Dual, uma análise alternativa pertencente ao ferramental do método Statis, como
ferramenta de diagnóstico de causas especiais. Tais desenvolvimentos encontram-se disponíveis
na literatura para o caso de processos lineares.
2. Fundamentação teórica

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
3
A presente seção divide-se em duas partes. Inicialmente, revisa-se o estado da arte sobre Controle
Estatístico Multivariado de Processos (CEMP) não-lineares. Na sequência são apresentados os
fundamentos analíticos do método Statis.
2.1. Estado-da-arte sobre CEMP para processos não-lineares
Gráficos univariados de controle de processos, tais como os gráficos de Shewhart e CUSUM (de
somas acumuladas), vêm sendo utilizados com êxito no monitoramento e melhoria da qualidade
de processos industriais (MONTGOMERY, 2001). Entretanto, gráficos univariados de controle
apresentam um desempenho deficiente quando aplicados a processos multivariados. Para
contornar essa deficiência, diversas estratégias de controle de processos foram desenvolvidas
utilizando métodos estatísticos multivariados como a análise de componentes principais (ACP) e
mínimos quadrados parciais. Os trabalhos de Nomikos & McGregor (1995) e Kourti et al. (1996)
exemplificam esses desenvolvimentos.
A ACP é a técnica de análise multivariada de dados mais utilizada no monitoramento de
processos (WISE & GALLAGHER, 1996), devido a sua capacidade de projetar, sem grande
perda de informação, bancos de dados de grandes dimensões, compostos por variáveis altamente
correlacionadas, em espaços de representação de menores dimensões, nos quais técnicas de
controle da qualidade são implementadas (mais especificamente, gráficos T2
e Q na fase de
detecção, e gráficos de contribuição na fase de diagnóstico). Entretanto, o CEMP baseado em
ACP apresenta um desempenho inadequado se aplicado no controle de processos não-lineares,
conforme demonstrado por Xu et al., 1992.
Para contornar o problema imposto por processos não-lineares, diversas abordagens foram
propostas na literatura. Kramer (1992) desenvolveu um método baseado em ACP não-linear e
redes neurais auto-associativas. A arquitetura da rede neural utilizada apresenta cinco camadas:
(i) de entrada, (ii) de mapeamento, (iii) camada gargalo, (iv) de mapeamento reverso, e (v) de
saída. Os nodos das camadas (ii) e (iv) são não-lineares, ao passo que as demais camadas são
lineares. Um algoritmo de gradiente conjugado é utilizado para treinar a rede. Como a dimensão
da camada (iii) é menor do que a dimensão de (i) e (v), a rede é forçada a desenvolver uma
representação compacta dos dados de entrada. O autor atinge esse objetivo introduzindo funções
não-lineares nos nodos das camadas de mapeamento e mapeamento reverso, em uma extensão da
ACP não-linear. Entretanto, a rede proposta é de difícil treino já que contém cinco camadas.
Além disso, a determinação do número de nodos a ser usado em cada camada não é tarefa trivial.
Dong & McAvoy (1996) também propuseram uma versão não-linear da ACP, combinando
curvas principais e redes neurais, para o controle de processos não-lineares contínuos e em
bateladas. Os escores e pontos amostrais corrigidos para as amostras de treinamento são obtidos
pelo método da curva principal; o modelo de rede neural é utilizado para mapear os dados
originais em seus respectivos escores, os quais são então mapeados para obter os pontos
amostrais corrigidos. Construindo a rede neural, uma estratégia de adaptação on-line pode ser
desenvolvida. A abordagem de Dong & McAvoy (1996) apresenta duas limitações: (i) o
algoritmo da curva principal pressupõe que a função não-linear possa ser aproximada por uma
combinação linear de diversas funções univariadas (isto é, a função não-linear pode ser
decomposta como uma soma de funções das variáveis individuais), o que limita a aplicação do

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
4
algoritmo a estruturas que apresentem comportamento do tipo aditivo; e (ii) deve-se resolver um
problema de otimização não-linear para calcular as curvas principais e treinar a rede neural e,
para tanto, o número de componentes principais deve ser especificado antes de treinar a rede;
assim, sempre que o número de componentes for alterado, o procedimento de modelagem deverá
ser rodado novamente.
Versões alternativas para a ACP não-linear foram também propostas por Hiden et al. (1999) e Jia
et al. (2001). Na abordagem em Hiden et al. (1999), as não-linearidades presentes no sistema são
explicitamente representadas em uma forma funcional, cuja natureza é otimizada usando um
processo evolutivo baseado em programação genética. Jia et al. (2001) propõem uma abordagem
combinando ACP e uma rede neural de entrada e treinamento (ITNN – input-training neural
network), de forma a considerar separadamente correlações lineares e não-lineares presentes nos
dados. Geng & Zhu (2005) reportam uma aplicação prática do método em Jia et al. (2001) no
monitoramento de um processo químico.
Os trabalhos a seguir utilizam a Kernel-ACP como técnica de ACP não-linear. A Kernel-ACP,
originalmente proposta por Scholkopf & Smola (2002), é capaz de calcular componentes
principais de forma eficiente em espaços característicos (feature spaces) de grandes dimensões
através de operadores integrais e funções kernel não-lineares. Em sua essência, a Kernel-ACP
consiste de duas operações: (i) o espaço de entrada (input space) é mapeado, através de funções
não-lineares, em um espaço característico, e (ii) uma ACP linear é aplicada no espaço
característico para obter componentes principais. Comparada a outros métodos não-lineares, a
Kernel-ACP apresenta a vantagem de não demandar um procedimento de otimização não-linear;
sua utilização envolve somente operações de álgebra linear, sendo de aplicação tão simples
quanto a ACP padrão. A Kernel-ACP demanda a extração de autopares (autovalores e
autovetores) do espaço característico e não requer que o número de componentes principais a ser
extraído seja conhecido a priori. Como pode ser operacionalizada usando diferentes kernels, a
Kernel-ACP pode ser eficiente na representação de diferentes tipos de não-linearidades.
Lee et al. (2004) apresentam um procedimento para o monitoramento de processos contínuos no
espaço característico obtido aplicando funções kernel sobre os dados de processo. Os autores
ilustram o procedimento em um processo de tratamento de resíduos líquidos onde os dados de
processo são mapeados no espaço característico através de uma função kernel de base radial.
Uma vez disponível a representação dos dados de entrada no espaço característico, o
procedimento proposto é essencialmente o mesmo proposto por Nomikos & McGregor (1995),
utilizando ACP linear. Mais especificamente, a estatística de Hotelling é usada para medir a
variação dentro do modelo Kernel-ACP, e a estatística , dada pelo quadrado do erro de
predição, provê uma medida de ajuste entre uma amostra qualquer e o modelo Kernel-ACP. O
monitoramento proposto pelos autores somente permite o controle on-line de processos
contínuos, já que sua operacionalização demanda, como amostra de entrada, a matriz completa de
dados do processo de interesse, não disponível, no caso de processos em bateladas, antes de seu
término.
Lee, Yoo & Lee (2004) estendem o procedimento em Lee et al. (2004) para o monitoramento on-
line e off-line de processos em bateladas. O esquema proposto para o monitoramento off-line
replica os desenvolvimentos propostos por Lee et al. (2004), já que o monitoramento on-line de
processos contínuos e off-line de processos em bateladas se equivalem em termos metodológicos.

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
5
Com relação ao monitoramento on-line de processos em bateladas, Lee, Yoo & Lee (2004)
propõem completar a matriz de dados de processo proveniente da batelada em curso utilizando
uma metodologia onde valores futuros são antecipados como uma média ponderada dos escores
disponíveis até o tempo atual da batelada e dos escores previamente calculados na distribuição de
referência. O procedimento é ilustrado em um processo de fermentação para produção de
penicilina.
Cho et al. (2005) propõem um método para o diagnóstico de pontos fora-de-controle sinalizados
nos gráficos e desenvolvidos por Lee et al. (2004). A contribuição em Lee et al. (2004)
limitou-se à fase de detecção do controle da qualidade, não trazendo propostas para o diagnóstico
de eventuais pontos fora-de-controle. O método de diagnóstico em Cho et al. (2005) está baseado
no cálculo do gradiente da função kernel utilizando no mapeamento dos dados de processo no
espaço característico, sendo aplicável no diagnóstico de sinais registrados nos gráficos e . O
método é ilustrado usando dados simulados de dois processos contínuos.
Cui et al. (2008) também abordam o problema do diagnóstico de pontos fora-de-controle em
gráficos baseados em Kernel-ACP, além de analisar estratégias para reduzir a dimensão da matriz
kernel durante a fase de treinamento da Kernel-ACP. Com relação ao problema do diagnóstico,
os autores propõem o uso conjunto da Kernel-ACP e da análise discriminante de Fisher (método
para extração de características e redução dimensional de grandes amostras. Para reduzir a
dimensão da matriz kernel, os autores propõem identificar subconjuntos de dados no banco
completo de dados de processo suficientes para expressar todos os dados no espaço característico
como uma combinação linear dos dados nos subconjuntos reduzidos. Os desenvolvimentos no
artigo são ilustrados utilizando dados simulados de processos previamente analisados por Lee,
Yoo & Lee (2004) e Cho et al. (2005).
Finalmente, Choi et al. (2008) combinam as proposições em Lee et al. (2004) e Cho et al. (2005)
para propor um novo esquema de monitoramento de processos não-lineares. O artigo enfatiza o
problema da detecção de eventos anormais ocorridos em escalas muito distintas. Em sua essência,
os autores propõem substituir o método de padronização de dados, prévio à Kernel-ACP,
proposto por Scholkopf & Smola (2002), pela utilização da transformação Wavelet. Na etapa de
diagnóstico, os autores propõem a utilização da transformação Wavelet inversa para mapear
dados do espaço característico no espaço de entrada.
2.2. Fundamentos do método Statis
O método Statis permite a análise de estruturas tridimensionais de dados, avaliando a
similaridade entre matrizes bidimensionais em um plano de dimensões reduzidas. Cada matriz
Xb, para b=1,...,B, de dimensão (T × P), contém vetores linha padronizados (isto é, cada
variável em Xb tem os valores subtraídos da média e divididos pelo desvio padrão da sua coluna)
que representam medições de P variáveis de processo durante T instantes de tempo. Tem-se então
uma estrutura com P variáveis × T instantes de tempo × B bateladas.
O método Statis foi proposto inicialmente por Lavit et al. (1994), e sua aplicação em controle de
processos em bateladas foi proposta por Scepi (2002) e aprimorada por Fogliatto & Niang (2008).
A estruturação de dados apresentada acima cumpre dois objetivos: (i) representar em um espaço
de dimensões reduzidas a correlação entre as P variáveis das matrizes e no conjunto dos T
instantes. Está análise permite verificar o comportamento global das variáveis de uma nova

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
6
batelada em relação à estrutura de referência capturada entre as B bateladas. Este objetivo é
alcançado através da análise da inter-estrutura; (ii) representar em um espaço reduzido a
correlação média (ou de compromisso) entre os T instantes, dois a dois, considerando todas as P
variáveis de processo. Esta análise busca identificar, a cada instante de tempo transcorrido na
nova batelada, possíveis desvios significativos em relação ao comportamento temporal de
compromisso do conjunto das variáveis. Este objetivo é alcançado através da análise da intra-
estrutura.
Os parágrafos que se seguem apresentam um resumo da análise da inter-estrutura. Considere uma
matriz bbb XXW , de dimensão (T × T), onde bX indica a transposta da matriz bX .
Genericamente, pode-se escrever essa matriz da seguinte forma:
bt
btb xxW , , para tt , = 1,...,T e b=1,...,B, (1)
onde btx e b
tx representam vetores linha, de dimensão (1 × P), representando medições das P
variáveis de processo no tésimo
instante da bésima
batelada. Calcula-se agora uma medida de
similaridade entre pares de matrizes bW , através do produto interno canônico de Hilbert-Schmidt
dado por:
)( bbHSbbbb Tr DWDWWWS , (2)
onde Tr (·) representa o operador de traço matricial, e D é uma matriz diagonal, de dimensão (T ×
T), contendo os pesos de importância para os instantes de tempo. Para simplificar, consideram-se
pesos iguais e com soma unitária; assim, D=I/T.
O valor de bb S indica o grau de similaridade entre as P variáveis nas matrizes bW e bW . Essa
medida de similaridade entre matrizes é semelhante à medida de similaridade entre vetores, pois a
eq. (2) é uma extensão do produto interno entre vetores no caso de matrizes quadradas.
As correlações lineares vetoriais entre bW e bW estão descritas na matriz:
bbB
SSΔ1
, onde
B
b
B1
11 (3)
Para obter uma caracterização resumida da estrutura de correlação entre as B bateladas, aplica-se
a ACP na matriz SΔ . Isto é feito através da sua diagonalização para seleção dos maiores
autovalores λi e respectivos autovetores ui (com i=1,...,B), que representam a localização das
matrizes bW nas principais direções ortogonais de variabilidade comum em SΔ .
A representação das B bateladas nos novos eixos ortogonais é realizada utilizando os autovetores
ui. Assim, cada elemento ui,b de ui ponderado pelo desvio padrão do CP correspondente (dado
pela raiz quadrada do i-ésimo autovalor) representa a posição da b-ésima batelada no i-ésimo
eixo ortogonal. Considerando dois CPs na análise, tem-se então:

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
7
biibi ua ,, , para i=1,2 (4)
onde bia , é a coordenada que representa essa posição.
Os parágrafos que se seguem apresentam um resumo da análise da intra-estrutura. Considerando
novamente a matriz bbb XXW explicitada na eq. (1), obtém-se agora a matriz de compromisso
W, que representa a estrutura de correlação média, aos pares (considerando as B bateladas de
referência), entre os T instantes de tempo. Mais explicitamente,
B
b
bb
1
WW .
Lavit et al. (1994) demonstram que a combinação linear que melhor relaciona as matrizes Wb
com W está associada ao maior autovalor (λ1) da matriz SΔ e ao seu autovetor correspondente
(u1). Assim, têm-se os pesos bb uB
,1
1
11
, onde 1,bu representa o b-ésimo elemento do vetor
u1 referente à b-ésima batelada.
Para obter uma caracterização resumida da estrutura de correlação de compromisso das P
variáveis nos T instantes de tempo, a exemplo do que foi feito na análise da inter-estrutura,
aplica-se uma ACP na matriz WD . Isto é feito através da sua diagonalização para seleção dos
maiores autovalores δi e respectivos autovetores εi (com i=1,...,T), que descrevem a posição das
observações b
tx médias, isto é, da matriz Xb ideal, em um número reduzido de eixos, derivados
das principais direções ortogonais de variabilidade comum em WD .
Para comparar, em cada instante, o comportamento do conjunto das P variáveis da bésima
batelada
Wb, em relação à batelada de compromisso W, obtém-se a representação de cada matriz Wb nos
novos eixos ortogonais. Utilizando dois CPs, tem-se:
i
b
t
i
b
tiT
z εw 11
,
, para i=1,2, (5)
onde iε é o vetor transposto do vetor linha iε , b
tw representa a t-ésima linha de Wb e b
tiz , é o
valor que representa a posição no i-ésimo eixo ortogonal da b-ésima batelada no t-ésimo instante
de tempo.
3. Kernel-Statis
Considere novamente os dados referentes à B bateladas contidos nas matrizes Xb. Define-se o
seguinte mapa não-linear:
Φ: IRP → F
b
tx → )( b
txΦ .
O vetor )( b
txΦ , de dimensão (1 × NF), onde NF = 1 ! !( 1)!d N d N , representa o vetor b
tx
ampliado, com elementos dados por todos os monômios de ordem d dos elementos do vetor b
tx .
Decorre disso que a matriz Xb passa a ter dimensão (T × NF), contendo assim T vetores linha
)( b
txΦ . Entretanto, os produtos internos entre os )( b
txΦ , obtidos substituindo b
tx por )( b
txΦ na
eq. (1) podem ser realizados em função das observações originais, através do produto interno

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
8
modificado entre as observações b
tx . Neste caso, o produto equivalente é dado pelo Kernel
Polinomial de ordem d, definido como (SCHOLKOPF; SMOLA, 2002):
db
t
b
t
b
t
b
tk xxxx ,, (6)
Dessa forma, tem-se a matriz kernel bW (designada por bbbk XXW ) obtida a partir das matrizes
Xb no espaço original das observações b
tx [isto é, Xb possui dimensão (T × P)]. A matriz
apresentada na eq. (1) é então reescrita como:
d
b
t
b
t
b
t
b
tb kk xxxxW ,),( , para tt , =1,...,T e b=1,...,B. (7)
Utilizando a eq. (7), procede-se então uma modificação não-linear nas estatísticas resultantes da
análise da inter-estrutura e da intra-estrutura, sumarizadas nas equações (4) e (5),
respectivamente. Esta nova abordagem é aqui denominada Kernel-Statis.
4. CCs IS e COt via Statis e Kernel-Statis
A viabilização do controle de bateladas novas através da análise Statis é operacionalizada através
da CC IS (derivada da análise da inter-estrutura) e das CCs tCO (derivadas da análise da intra-
estrutura), conforme proposto por Fogliatto & Niang (2008).
A CC IS permite verificar se a estrutura de correlação linear entre as P variáveis da batelada nova
segue a estrutura de correlação linear padrão, capturada nas B bateladas de referência. A CC kIS
(derivada do Kernel-Statis) realiza a mesma comparação em um contexto não-linear, isto é,
levando em conta as correlações “não-lineares” (quadráticas, dado o Kernel Polinomial).
As CCs tCO permitem verificar o comportamento temporal do conjunto das P variáveis de uma
batelada nova em relação ao comportamento temporal esperado em função das B bateladas de
referência. Analogamente a CC kIS, as CCs kCOt realizam esse monitoramento temporal
considerando uma estrutura não-linear nos dados. Como as CCs tCO oferecem uma
representação explícita das variáveis em cada instante, prioriza-se a sua utilização no controle on-
line do processo.
O passo seguinte consiste em obter uma região de controle para as CCs. Diferentemente do que
usualmente é feito nas CCs multivariadas tradicionais, a região de controle será determinada
através de um procedimento não-paramétrico. O procedimento que será apresentado constitui-se
numa adaptação proposta por Fogliatto & Niang (2008), para o contexto de CCs, do
procedimento em Zani et al. (1998).
Considerando a eq. (5) com dois CPs, tem-se B vetores ),( ,2,1b
tb
t zz . Inicialmente, calcula-se o
ponto que representa o vetor de média ),( ,2,1b
tbt zz . A seguir, obtém-se a distância de Mahalanobis
entre os vetores ),( ,2,1b
tb
tbt zzz e ),( ,2,1
bt
btt zzz . Tem-se então )()( 1
tbtt
btbD zzRzz ,

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
9
para b=1,...,B , onde )( tbt zz representa o vetor linha de diferenças entre os vetores b
tz e tz ,
cujo vetor transposto é dado por )( tbt zz e 1R é a matriz inversa da matriz R de covariâncias
dos vetores.
A seguir, as B distâncias bD são ordenadas em ordem crescente e as 50% menores distâncias são
retidas. Os vetores btz correspondentes formarão o convex hull (polígono) de abrangência 50%
no primeiro plano fatorial. Neste momento, obtém-se a expansão da região formada pelo convex
hull a partir de um fator de escala. Para tanto, define-se um múltiplo l da distância bD entre o
centróide (representado pelo vetor tz , obtido a partir dos vetores representados pelos pontos
internos do polígono) e os pontos limítrofes do polígono de abrangência 50%. O valor de l é
determinado a partir da probabilidade de alarme falso α (ou erro do tipo I) desejada para a CC,
com a suposição de que os dados btz do interior do polígono (isto é, apenas os 50% de menor
valor bD ) sigam uma distribuição normal bivariada. Detalhes podem ser encontrados em
Fogliatto & Niang (2008).
5. Exemplo numérico
Considere um processo industrial em bateladas simuladas, cujo desempenho pode ser avaliado
através de duas variáveis correlacionadas X1 e X2. Suponha que as leis físicas que regem esse
processo são descritas pelo seguinte sistema de equações diferenciais:
)()( )()(
)()(
221122112
22111
cx cxnlcxa cxbx
cxbcxax
, (8)
onde a, b e nl são constantes reais e os pontos sobre as variáveis denotam derivadas temporais de
21 e XX . Note que o sistema da eq. (8) é uma perturbação não-linear do sistema linear abaixo:
).()(
)()(
22112
22111
cxa cxbx
cxbcxax
(9)
O sistema na eq. (9) tem o ponto (c1,c2) como ponto de equilíbrio. Os dois autovalores associados
são números complexos; i.e., 1,2 a ib . Assim, tem-se um comportamento oscilatório em
torno do ponto de equilíbrio (c1,c2), que é estável se 0a e instável se 0a . O coeficiente nl
define o grau de perturbação na não-linearidade.
Para transformar a eq. (9) numa forma iterativa, adotou-se o esquema de Euler (PATEL, 1993), o
que as transforma em:
.)])(( )()[(
)]()([
22112211212
22t11111
tcxcxnlcax cbxxx
tcxbcxaxx
tttttt
ttt (10)
Para as simulações das bateladas de referência, foram adotados os seguintes valores para os
coeficientes da eq. (9): ,1a 2b , c1=10, c2=20 e nl=0. Neste trabalho, Δt é suficientemente
pequeno, tal que a eq. (10) seja uma aproximação do sistema contínuo na eq. (8). Esta
XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
10
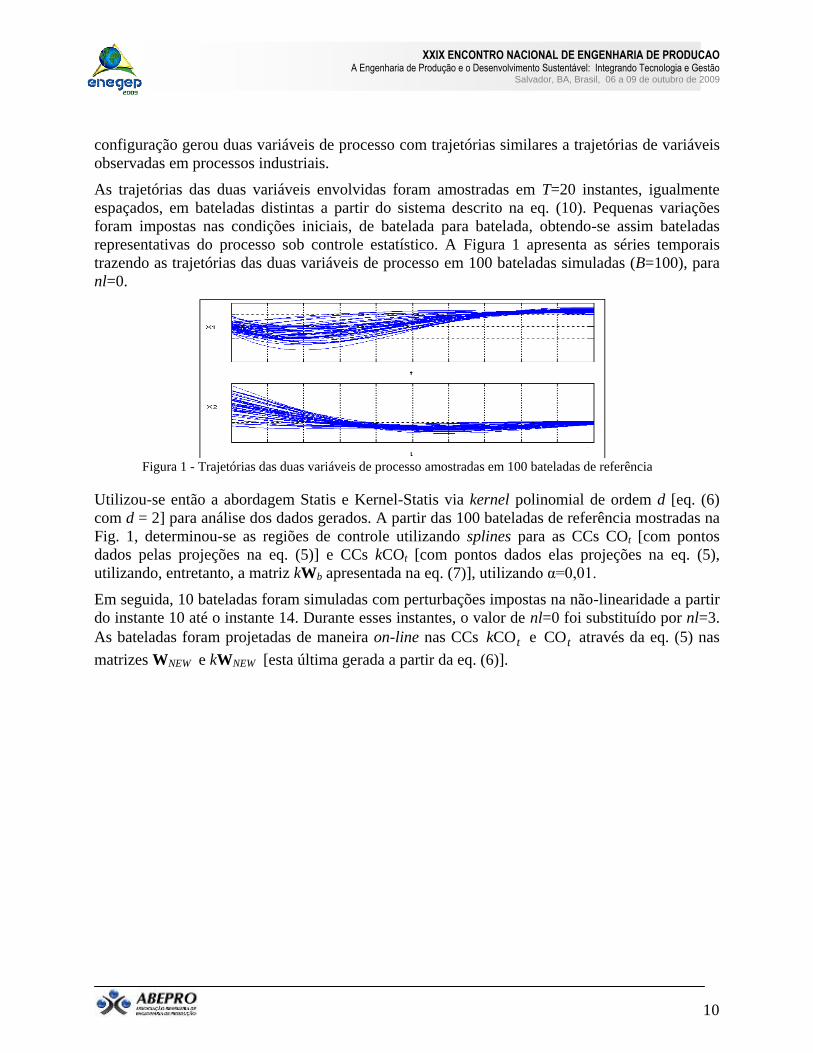
configuração gerou duas variáveis de processo com trajetórias similares a trajetórias de variáveis
observadas em processos industriais.
As trajetórias das duas variáveis envolvidas foram amostradas em T=20 instantes, igualmente
espaçados, em bateladas distintas a partir do sistema descrito na eq. (10). Pequenas variações
foram impostas nas condições iniciais, de batelada para batelada, obtendo-se assim bateladas
representativas do processo sob controle estatístico. A Figura 1 apresenta as séries temporais
trazendo as trajetórias das duas variáveis de processo em 100 bateladas simuladas (B=100), para
nl=0.
Figura 1 - Trajetórias das duas variáveis de processo amostradas em 100 bateladas de referência
Utilizou-se então a abordagem Statis e Kernel-Statis via kernel polinomial de ordem d [eq. (6)
com d = 2] para análise dos dados gerados. A partir das 100 bateladas de referência mostradas na
Fig. 1, determinou-se as regiões de controle utilizando splines para as CCs COt [com pontos
dados pelas projeções na eq. (5)] e CCs kCOt [com pontos dados elas projeções na eq. (5),
utilizando, entretanto, a matriz kWb apresentada na eq. (7)], utilizando α=0,01.
Em seguida, 10 bateladas foram simuladas com perturbações impostas na não-linearidade a partir
do instante 10 até o instante 14. Durante esses instantes, o valor de nl=0 foi substituído por nl=3.
As bateladas foram projetadas de maneira on-line nas CCs tkCO e tCO através da eq. (5) nas
matrizes WNEW e kWNEW [esta última gerada a partir da eq. (6)].

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
11
Figura 2 - (a) Esquerda – CCs tCO e (b) Direita – CCs COtk
As CCs tCO [Fig. 2 (a)] e tkCO [Fig. 2 (b)] apresentam a projeção das bateladas novas em
ordem cronológica, ao longo das linhas, representadas por pontos em vermelho e lilás,
respectivamente. Observa-se que, em ambas as abordagens, o descontrole é acusado corretamente
a partir do instante 10. Entretanto, observa-se a pouca acurácia nas CCs COt para detectar que o
processo retornou ao estado sob controle no instante 15, visto que as bateladas aparecem em sua
maioria fora da região de controle após esse instante. Diferentemente, as CCs tkCO identificam
que o processo está sob controle a partir do instante 15 em todas as bateladas verificadas (quando,
de fato, cessaram as perturbações), exceto no último instante quando gerou um alarme falso (isto
é, uma batelada mal classificada). Estes resultados evidenciam um ganho na caracterização do
sistema com a utilização do kernel polinomial quando o termo tt xnlx 21 se faz presente em algum
grau (neste caso, com nl=3).
6. Conclusão
Neste artigo, foram propostas CCs multivariadas baseadas no Kernel-Statis para monitoramento
de processos em bateladas, com variáveis apresentando correlações não-lineares do tipo
quadráticas. Inicialmente foi descrito o método Statis usual em estruturas de dados oriundas de
processos em bateladas. O Statis avalia, no contexto linear, a similaridade entre matrizes
bidimencionais bX , utilizando produtos internos canônicos entre vetores de observações btx ,
descritos em matrizes bbb XXW , onde bX contém dados disponíveis de uma batelada

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
12
completa. Através da análise da inter-estrutura, captura-se resumidamente a estrutura de
correlação linear entre as P variáveis, em todos os instantes, nas diferentes bateladas, par a par;
através da análise da intra-estrutura, captura-se a estrutura de correlação linear temporal em T
instantes de tempo, das variáveis.
Em seguida, foi proposta uma abordagem para o Statis no contexto não-linear através da
utilização de kernels. Através dos kernels, definiram-se funções não-lineares de segunda ordem
dos dados a partir de um mapa polinomial não-linear de segunda ordem Φ. Dessa forma,
utilizaram-se funções )][][,][,][,][,]([)( 2122
2121
bt
bt
bt
bt
bt
bt
bt xxxxxxxΦ das observações b
tx e,
através da teoria de kernels, trabalhou-se com produtos internos modificados dos dados originais btx sem a utilização direta dos vetores )( b
txΦ .
No passo seguinte, construiu-se uma versão não-linear do Statis, denominada Kernel-Statis.
Foram redefinidas as estatísticas utilizadas na análise da inter-estrutura e da intra-estrutura para
caracterizar correlações não-lineares quadráticas dos dados. Foram apresentadas as CCs não-
lineares derivadas do Kernel-Statis, denominadas CCs kIS e kCOt.
A partir de um processo com dados simulados de um sistema não-linear de duas variáveis,
validou-se o Kernel-Statis e verificou-se o ganho de acurácia de tal procedimento em relação ao
Statis usual no monitoramento de bateladas futuras. Verificou-se que as CCs kIS e kCOt
ofereceram uma caracterização do processo superior as CCs IS e COt (derivadas do Statis usual),
na medida que as não-linearidades quadráticas foram pronunciadas com mais intensidade no
sistema proposto.
Referências
CHO, J.-H.; LEE, J.-M.; CHOI, S.W.; LEE, D.; LEE, I.-B. Fault identification for process monitoring using
kernel principal component analysis. Chemical Engineering Science, p. 279-288, 2005.
CHOI, S.W.; MORRIS, J.; LEE, I.-B. Nonlinear multiscale modelling for fault detection and identification.
Chemical Engineering Science, no prelo, doi: 10.1016/j.ces.2008.01.022, 2008.
CUI, P.; LI, J.; WANG, G. Improved kernel principal component analysis for fault detection. Expert Systems with
Applications, Vol. 34, p. 1210-1219, 2008.
DONG, D.; MCAVOY, T.J. Nonlinear principal components analysis based on principal curves and neural
networks. Computers and Chemical Engineering, Vol. 20, p.65-78, 1996.
FOGLIATTO, F. S. & NIANG, N. Controle multivariado de processos em batelada com duração variada.
Produção, Vol. 18, p. 240-259, 2008.
GENG, Z.Q.; ZHU, Q.X. Multiscale nonlinear principal component analysis (NLPCA) and its application for
chemical process monitoring. Industrial and Engineering Chemistry Research, Vol. 44, 3585-3593, 2005.
HIDEN, H.G.; WILLIS, M.J.; THAM, M.T.; MONTAGUE, G.A. Nonlinear principal components analysis
using genetic programming. Computers and Chemical Engineering, Vol. 23, p.413-425, 1999.
JIA, F.; MARTIN, E.B.; MORRIS, A.J. Non-linear principal components analysis with application to process
fault detection. International Journal of Systems Science, Vol. 31, p.1473–1487, 2001.
KOURTI, T.; LEE, J.; MACGREGOR, J.F. Experiences with industrial applications of projection methods for
multivariate statistical process control. Computers and Chemical Engineering, Vol. 20, p.S745-S750, 1996.

XXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO A Engenharia de Produção e o Desenvolvimento Sustentável: Integrando Tecnologia e Gestão
Salvador, BA, Brasil, 06 a 09 de outubro de 2009
13
KRAMER, M.A. Autoassociative neural networks. Computers and Chemical Engineering, Vol. 16, p. 313-328,
1992.
LAVIT, C.; ESCOUFIER, Y.; SABATIER, R. & TRAISSAC, P. The ACT (STATIS method). Computational
Statistics & Data Analysis, Vol. 19, p. 97-119, 1994.
LEE, J-M.; YOO, C.; CHOI, S.W.; VANROLLEGHEM, P.A.; LEE, I-B. Nonlinear process monitoring using
kernel principal components analysis. Chemical Engineering Science, Vol. 59, p.223-234, 2004.
LEE, J.; YOO, C. K., & LEE, I.-B. Nonlinear process monitoring using kernel principal component analysis,
Chemical Engineering Science, Vol. 59, p. 223-234, 2004.
MARTIN, E. B. & MORRIS, A. J. An overview of multivariate statistical process control in continuous and batch
process performance monitoring. Trans. Inst. MC, Vol. 18, p. 51-60, 1996.
MONTGOMERY, D.C. Introduction to Statistical Quality Control, 4ª Ed. Wiley: New York, 2001.
NOMIKOS, P.; MCGREGOR, J.F. Multivariate SPC charts for monitoring batch processes. Technometrics, Vol.
37, p.41-59, 1995.
PATEL, V. A. A. Numerical Analysis. New York: Saunders College Publishing, 1993.
SCEPI, G. Parametric and non parametric multivariate quality control charts. In Multivariate Total Quality
Control, Physica-Verlang, Lauro C. et al. (eds.), 163-189, 2002.
SCHOLKOPF, B.; SMOLA, A. Learning with Kernels: Support Vector Machines, Regularization, Optimization,
and Beyond. MIT Press: Cambridge (MA), 2002.
WISE, B.M.; GALLAGHER, N.B. The process chemometrics approach to process monitoring and fault detection.
Journal of Process Control, Vol. 6, p. 329-348, 1996.
XU, L.; OJA, E.; SUEN, C.Y. Modified hebbian learning for curve and surface fitting. Neural Networks, Vol. 5, p.
441-457, 1992.
ZANI, S.; RIANI, M. & CORBELLINI, A. Robust bivariate boxplots and multiple outlier detection.
Computational Statistics & Data Analysis, v. 28, p. 257-270, 1998.





























