Embed Size (px)
Citation preview

深層学習の画像認識・処理への応用の現在と今後
岡谷貴之東北大学大学院情報科学研究科
理化学研究所革新知能統合研究センター

ディープラーニングの汎用性と特殊性
• 機械学習全体が緩やかに進展する中,ディープラーニングのみ速いペースで発展(≒応用分野を拡大)
• 画像・音声のような「生データ」を扱う問題で圧倒的
…
• 数多くの「ディープラーニングを要しない問題」が機械学習の適用を待っている
(深層学習)
2
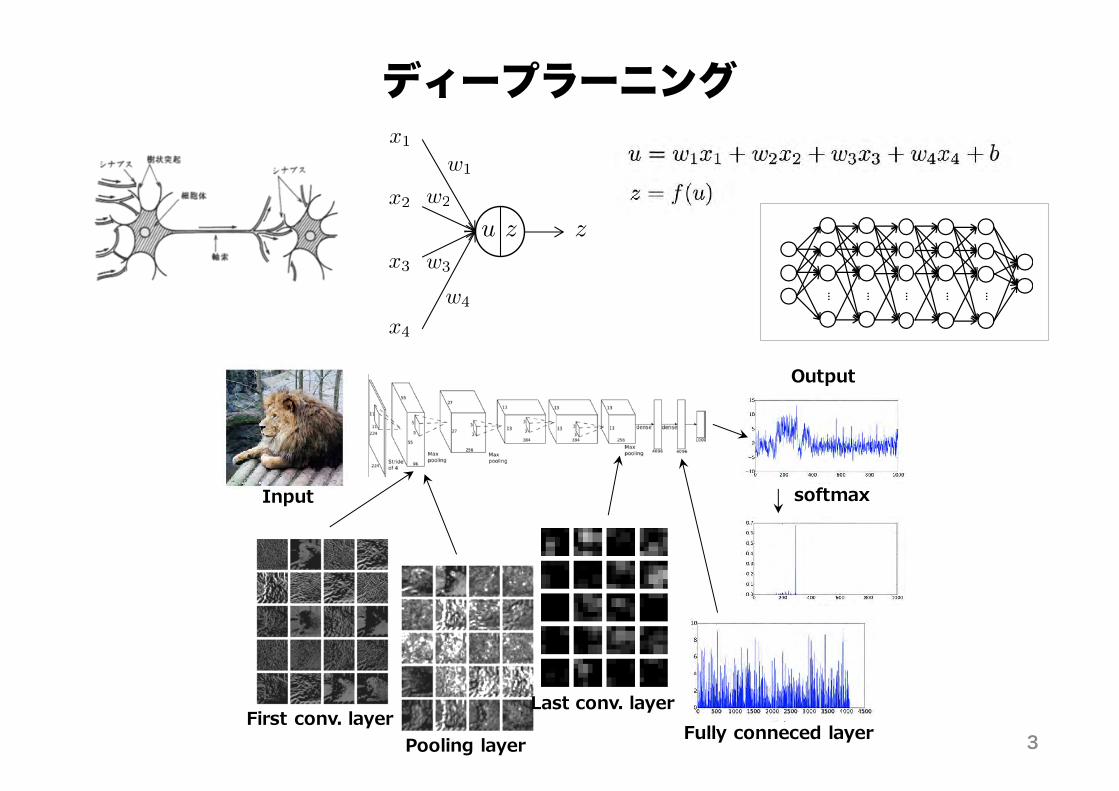
ディープラーニングx1
x2
x3
x4
zu z
w1
w2
w3
w4
.
..
. ..
……… … …
3
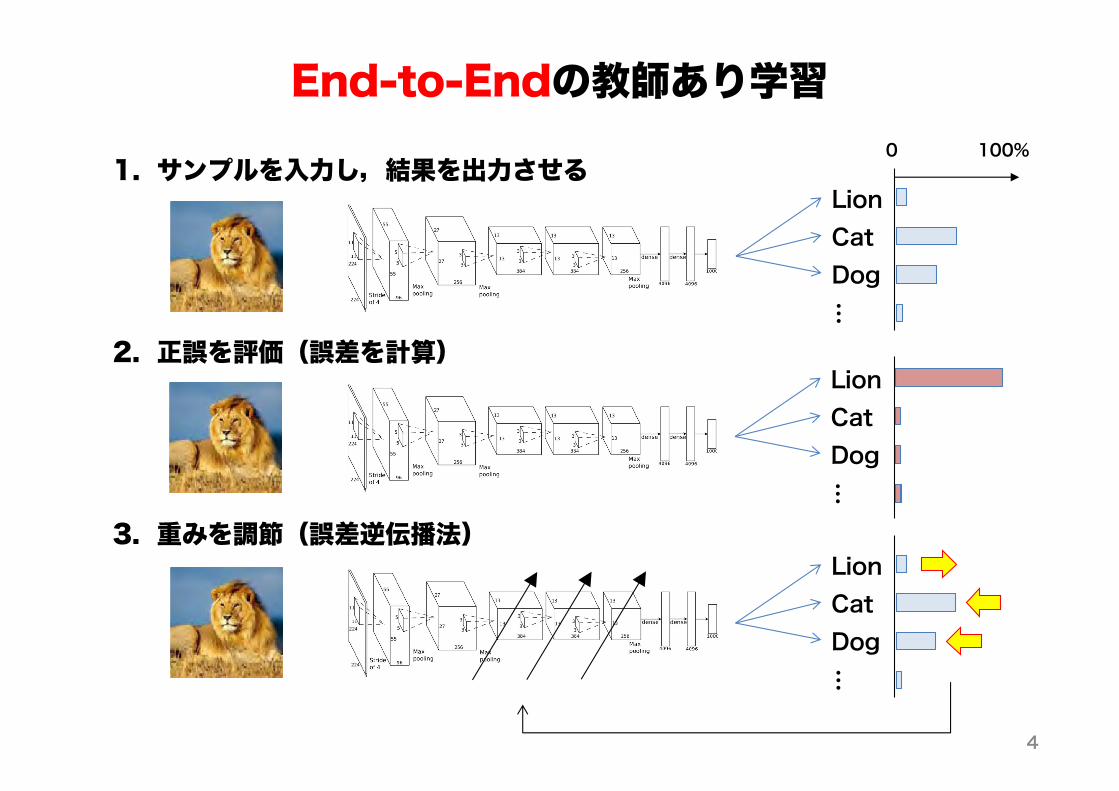
End-to-Endの教師あり学習1. サンプルを入力し,結果を出力させる
2. 正誤を評価(誤差を計算)
3. 重みを調節(誤差逆伝播法)
LionCatDog…
LionCatDog…
0 100%
LionCatDog…
4
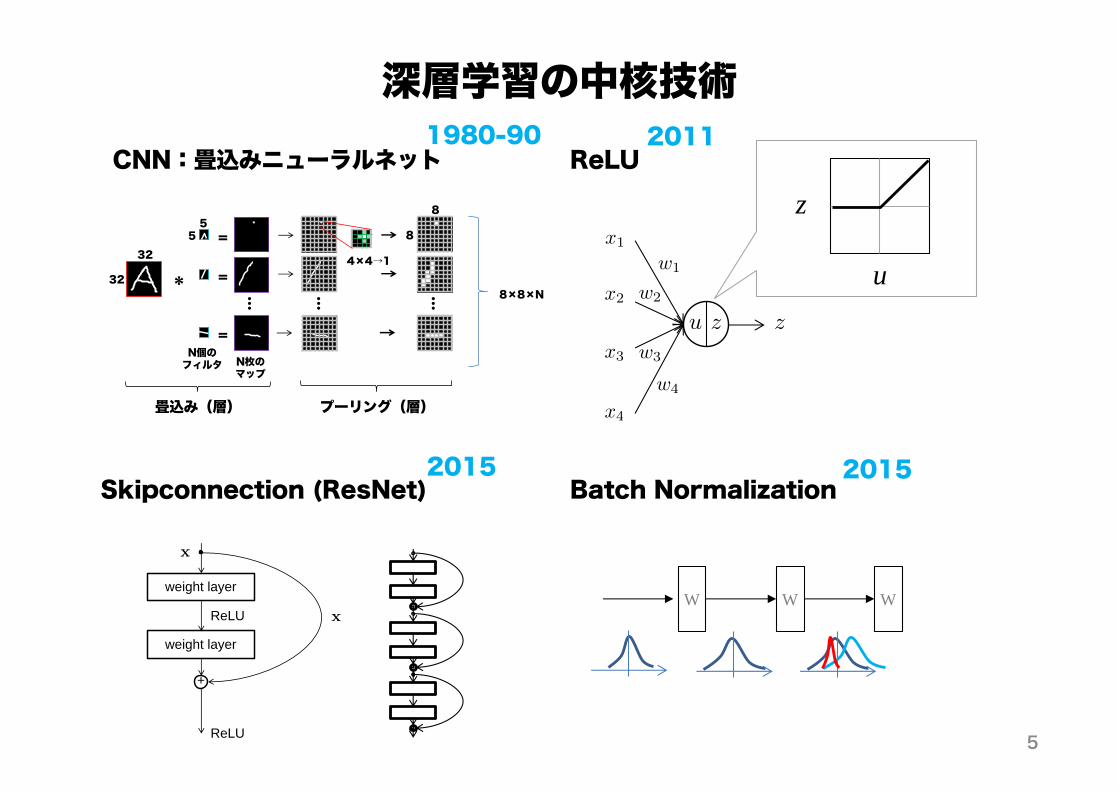
深層学習の中核技術
Skipconnection (ResNet)
ReLU
Batch Normalization
CNN:畳込みニューラルネット
*
=
=
=
32
8
畳込み(層) プーリング(層)
N個のフィルタ N枚の
マップ
… … …
4×4→1
8×8×N
5
32
5 8x1
x2
x3
x4
zu z
w1
w2
w3
w4
u
z
ReLU
ReLU
x
+
x
weight layer
weight layer
WWW1
W
1980-90 2011
2015 2015
5
5 7 GF9 H 6
5 G 6
52 65 I 6
54 7 6
01 01 01
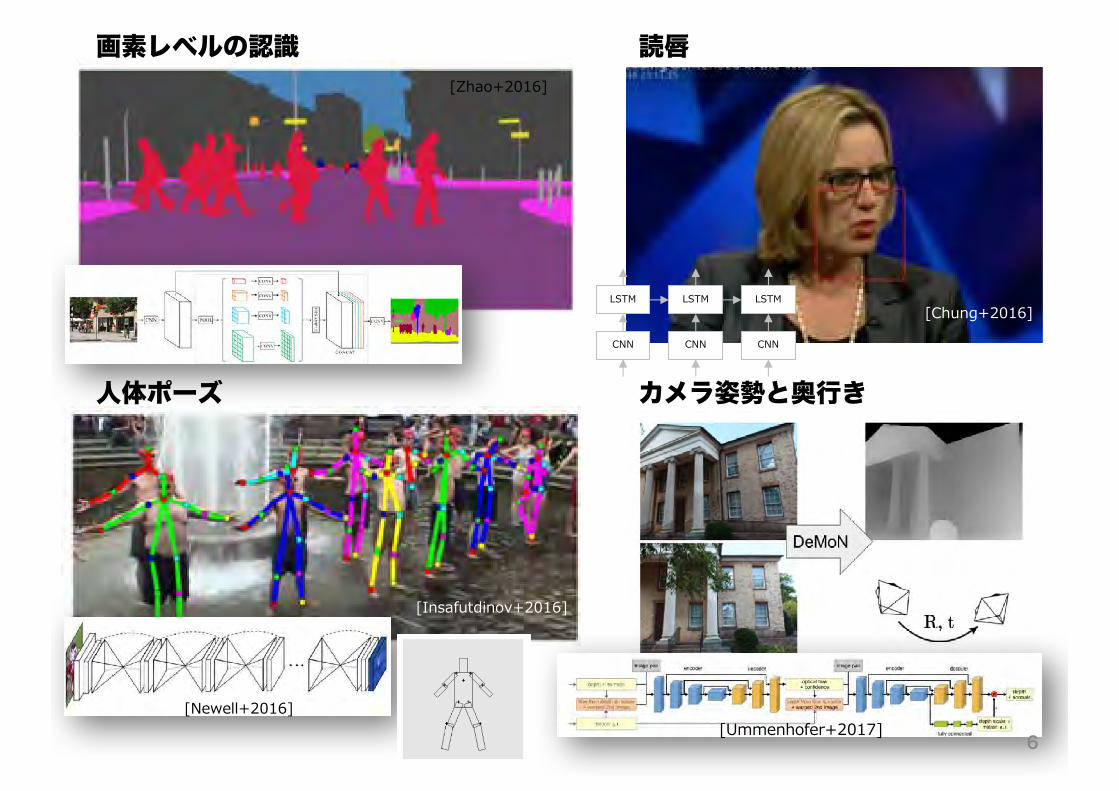
画素レベルの認識 読唇
人体ポーズ カメラ姿勢と奥行き
6

スタイル変換 画像変換
超解像
生成ネットワーク
(Generator)
識別ネットワーク
(Discrim
inator)
ノイズ
or 画像
or テキスト
偽の画像
真の画像
or偽の画像
真or 偽
Conditional GAN
5 7F 6
5 7 6
5Ledig+20166 7
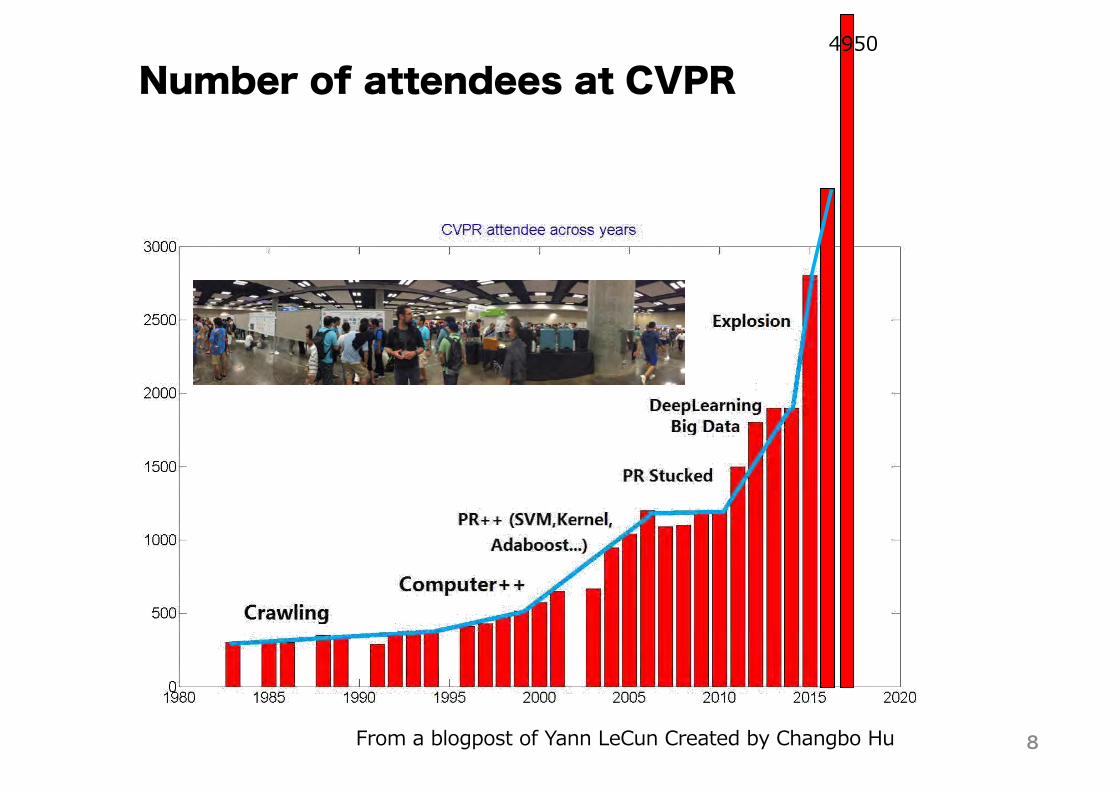
7 C F 7 G 7F 9 7 +G
Number of attendees at CVPR
8
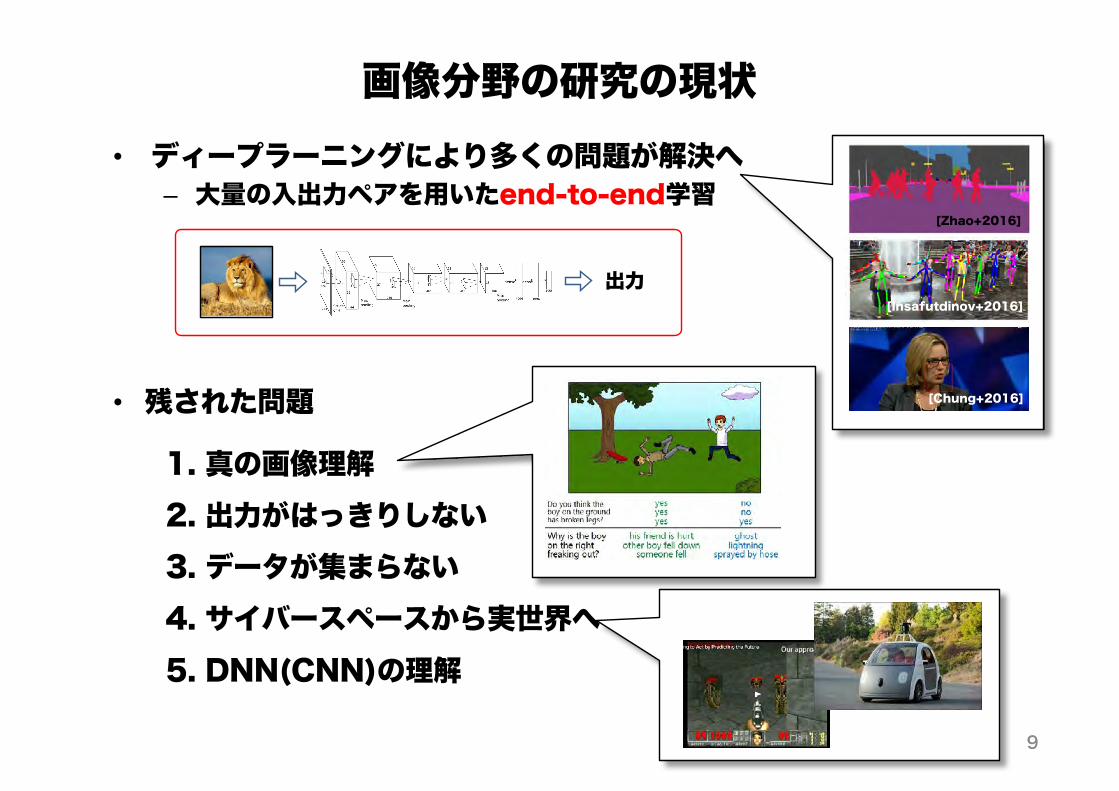
• ディープラーニングにより多くの問題が解決へ– 大量の入出力ペアを用いたend-to-end学習
画像分野の研究の現状
[Insafutdinov+2016]
[Zhao+2016]
出力
[Chung+2016]
1. 真の画像理解2. 出力がはっきりしない3. データが集まらない4. サイバースペースから実世界へ5. DNN(CNN)の理解
• 残された問題
9
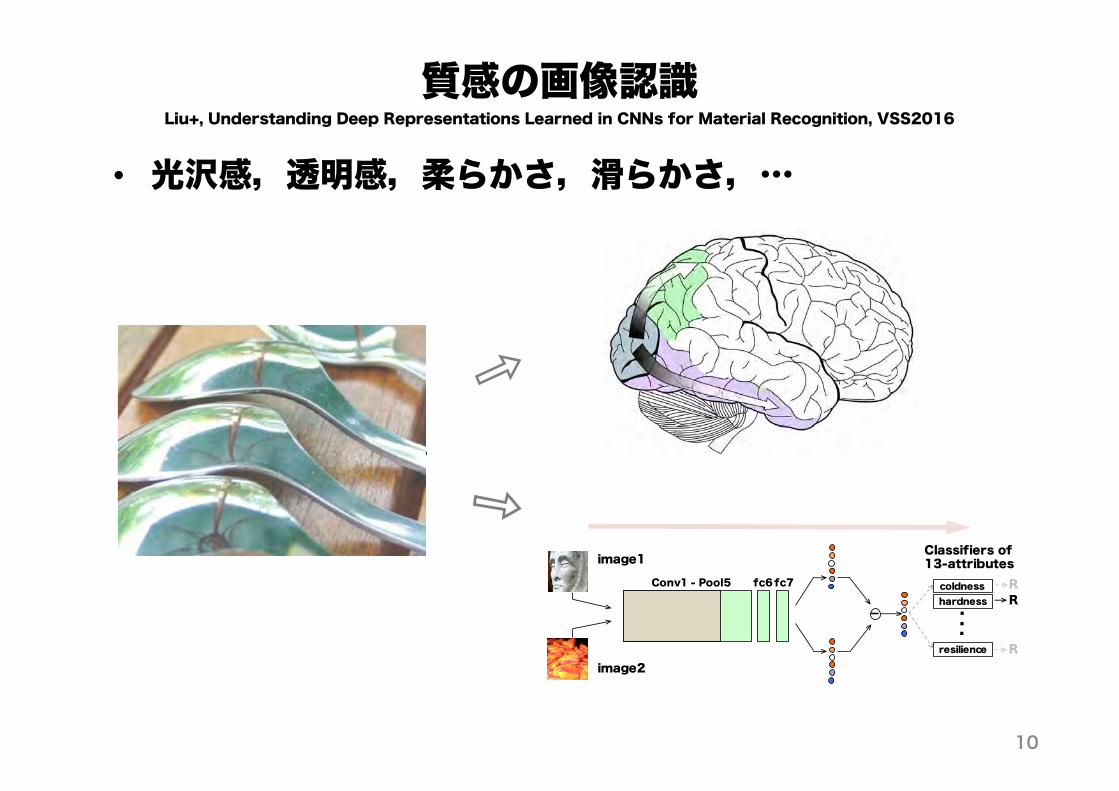
質感の画像認識
• 光沢感,透明感,柔らかさ,滑らかさ,…
Conv1 - Pool5 fc6fc7 coldnesshardness
resilience
Classifiers of 13-attributes
...RR
R
image1
image2
Liu+, Understanding Deep Representations Learned in CNNs for Material Recognition, VSS2016
10

Aged:
Wet:
Transparent:
Hard:
13 Attributes
.
.
.
>
> <
>
< <
> >
…
…
…
…
学習データ=質感形容詞の比較データ
11
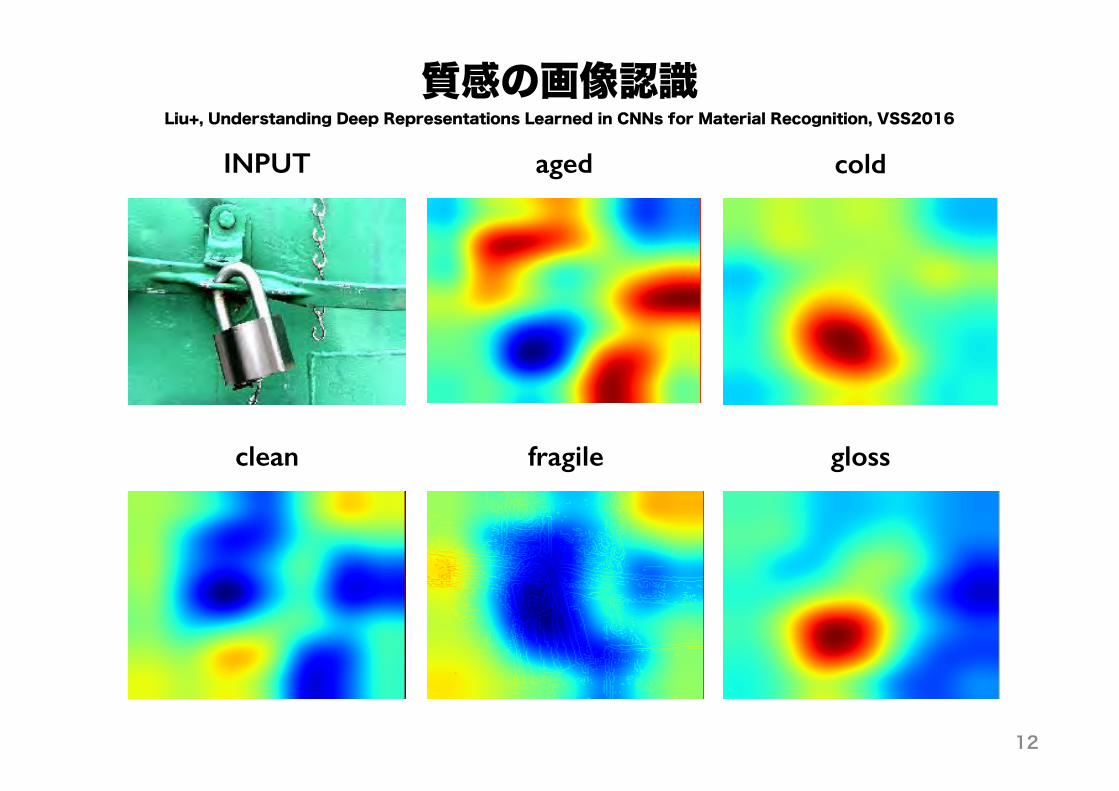
質感の画像認識coldaged
clean fragile gloss
INPUT
Liu+, Understanding Deep Representations Learned in CNNs for Material Recognition, VSS2016
12

曖昧な「正解」
どちらがより「冷たく」感じますか?(5人中)
vs
vs
vs
5
4
3
0
1
2
13
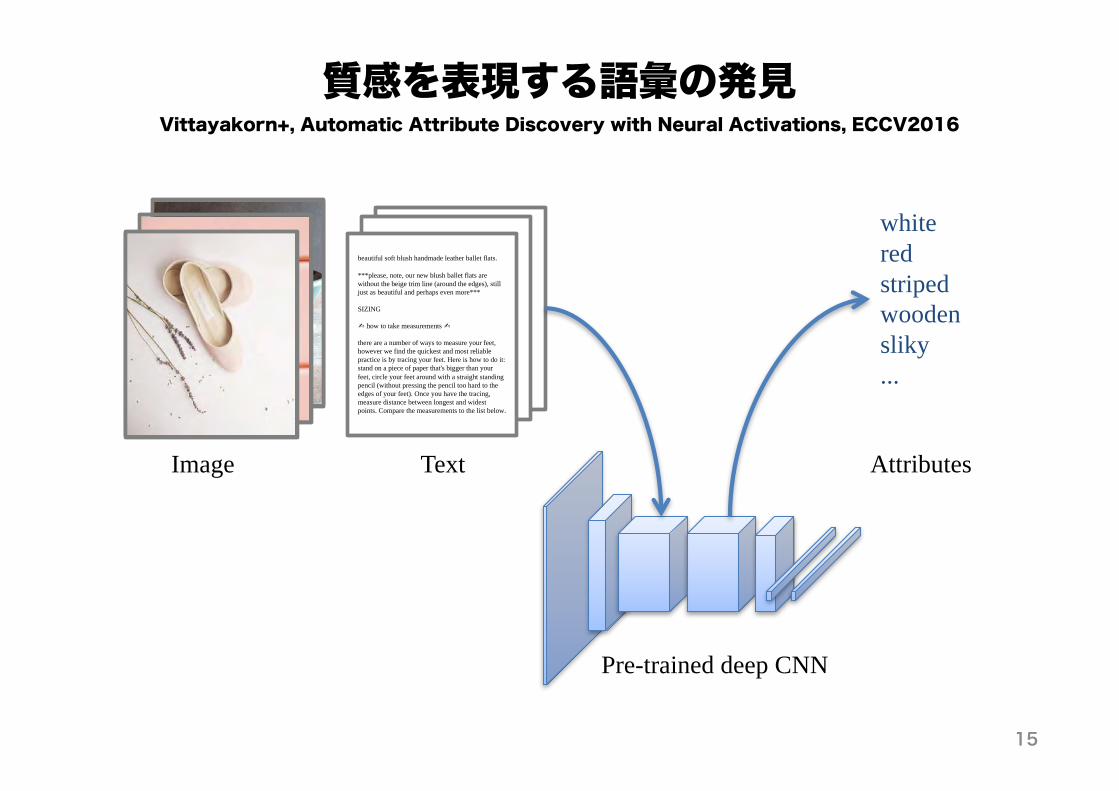
質感を表現する語彙の発見
Pre-trained deep CNN
beautiful soft blush handmade leather ballet flats.
***please, note, our new blush ballet flats are without the beige trim line (around the edges), still just as beautiful and perhaps even more***
SIZING
� how to take measurements �
there are a number of ways to measure your feet, however we find the quickest and most reliable practice is by tracing your feet. Here is how to do it: stand on a piece of paper that's bigger than your feet, circle your feet around with a straight standing pencil (without pressing the pencil too hard to the edges of your feet). Once you have the tracing, measure distance between longest and widest points. Compare the measurements to the list below.
Image Text
whiteredstripedwoodensliky...
Attributes
Vittayakorn+, Automatic Attribute Discovery with Neural Activations, ECCV2016
15
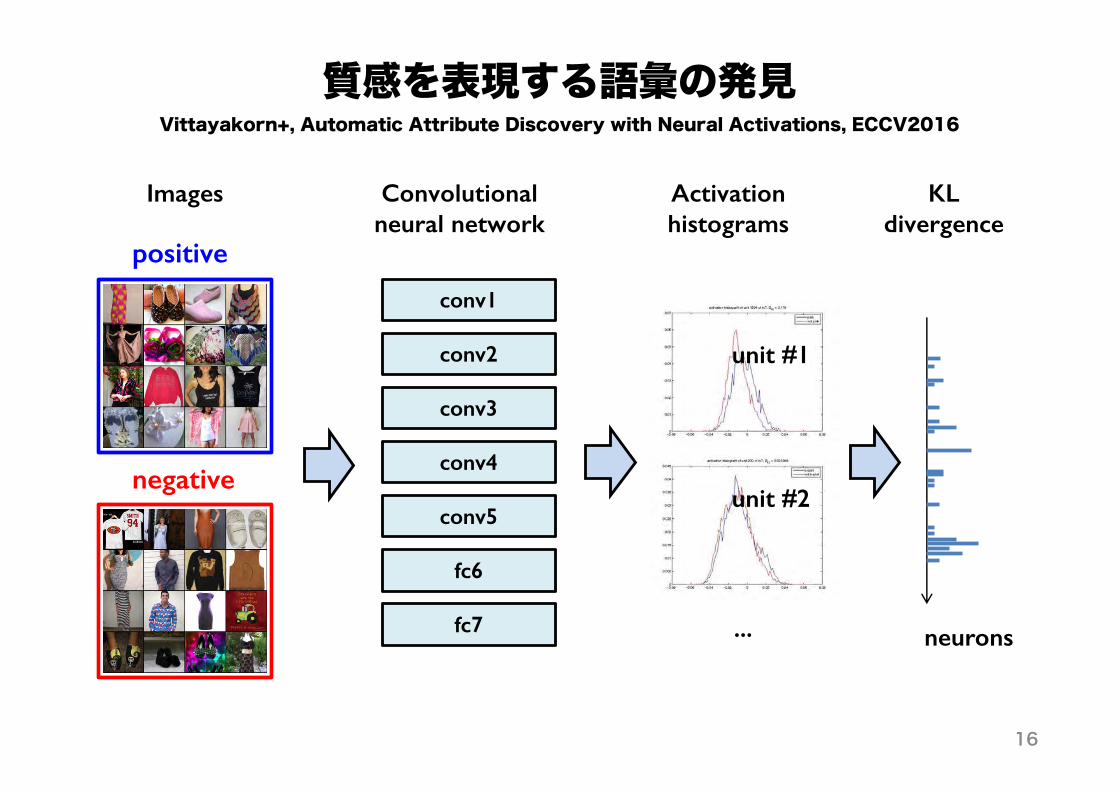
質感を表現する語彙の発見
conv1
conv2
conv3
conv4
conv5
fc6
fc7
positive
negative
Convolutional neural network
Activation histograms
unit #1
unit #2
...
KL divergence
Images
neurons
Vittayakorn+, Automatic Attribute Discovery with Neural Activations, ECCV2016
16
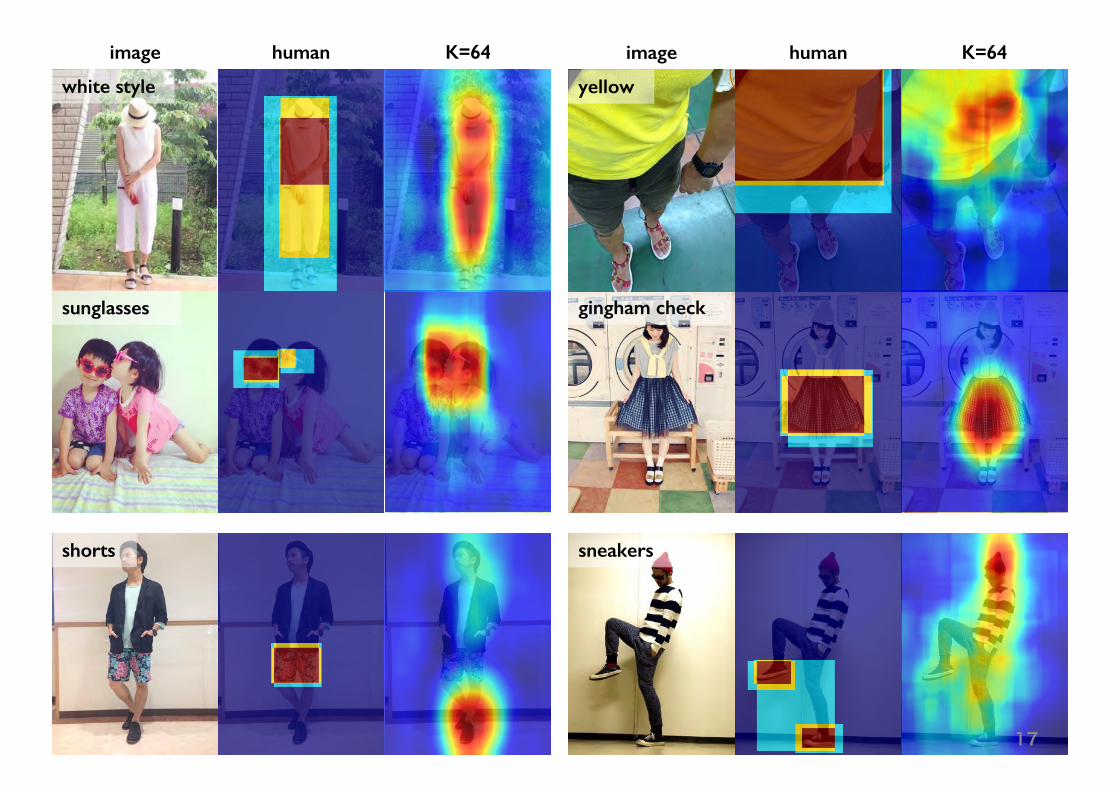
image
sunglasses
shorts sneakers
gingham check
white style yellow
human K=64 image human K=64
17
• ディープラーニングにより多くの問題が解決へ– 大量の入出力ペアを用いたend-to-end学習
画像分野の研究の現状
[Insafutdinov+2016]
[Zhao+2016]
出力
[Chung+2016]
1. 真の画像理解2. 出力がはっきりしない3. データが集まらない4. サイバースペースから実世界へ5. DNN(CNN)の理解
• 残された問題
18
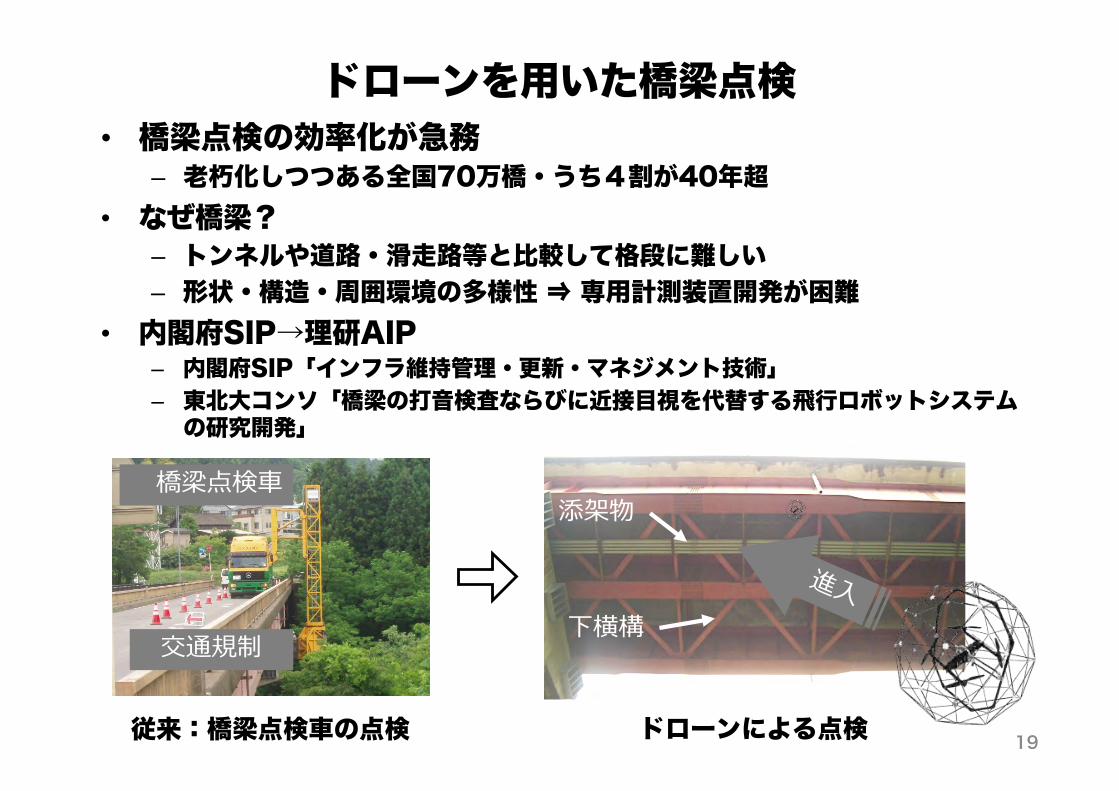
ドローンを用いた橋梁点検• 橋梁点検の効率化が急務
– 老朽化しつつある全国70万橋・うち4割が40年超• なぜ橋梁?
– トンネルや道路・滑走路等と比較して格段に難しい– 形状・構造・周囲環境の多様性 ⇒ 専用計測装置開発が困難
• 内閣府SIP→理研AIP– 内閣府SIP「インフラ維持管理・更新・マネジメント技術」– 東北大コンソ「橋梁の打音検査ならびに近接目視を代替する飛行ロボットシステムの研究開発」
YN
SMLTU
従来:橋梁点検車の点検 ドローンによる点検 19
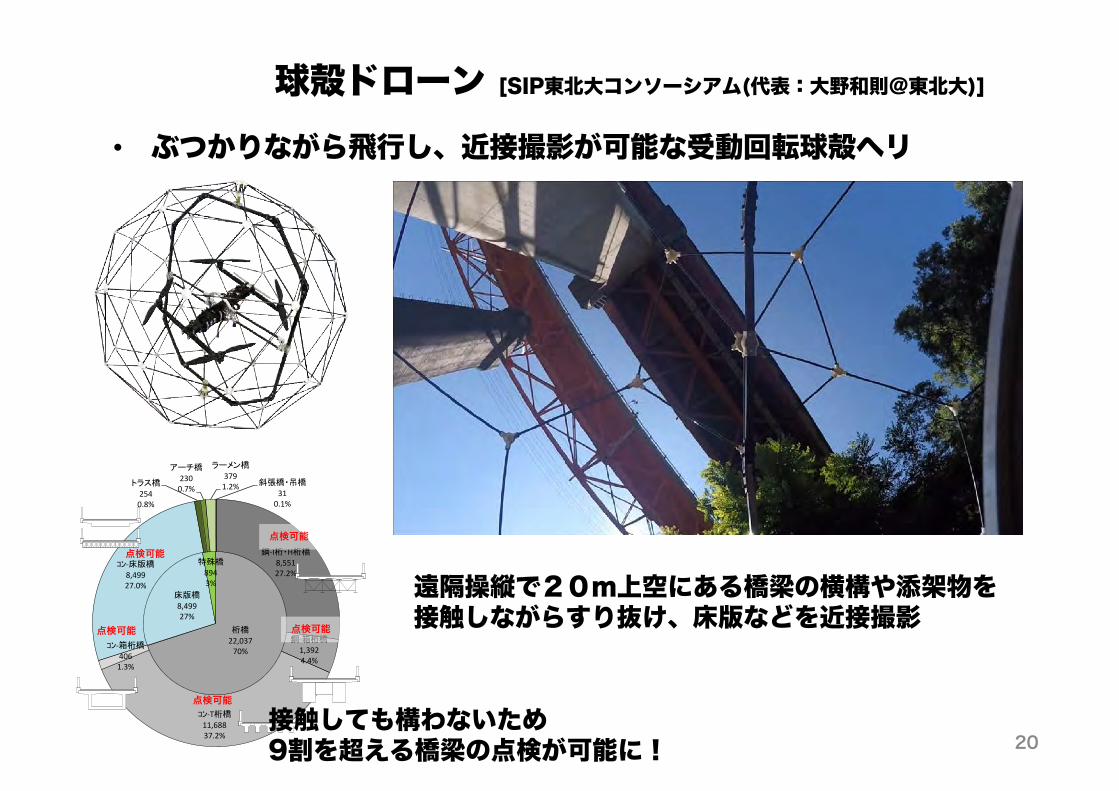
球殻ドローン [SIP東北大コンソーシアム(代表:大野和則@東北大)]
• ぶつかりながら飛行し、近接撮影が可能な受動回転球殻ヘリ
遠隔操縦で20m上空にある橋梁の横構や添架物を接触しながらすり抜け、床版などを近接撮影
�-I��H��8,55127.2%
�-��1,3924.4%
��-T��11,68837.2%
��-��4061.3%
��-���8,49927.0%
�� �
2540.8%
����
2300.7%
�����
3791.2% ������
310.1%
��
22,03770%
���
8,49927%
��
8943%
点検可能
点検可能
点検可能
点検可能
点検可能
接触しても構わないため9割を超える橋梁の点検が可能に! 20
• ディープラーニングにより多くの問題が解決へ– 大量の入出力ペアを用いたend-to-end学習
画像分野の研究の現状
[Insafutdinov+2016]
[Zhao+2016]
出力
[Chung+2016]
1. 真の画像理解2. 出力がはっきりしない3. データが集まらない4. サイバースペースから実世界へ5. DNN(CNN)の理解
• 残された問題
23
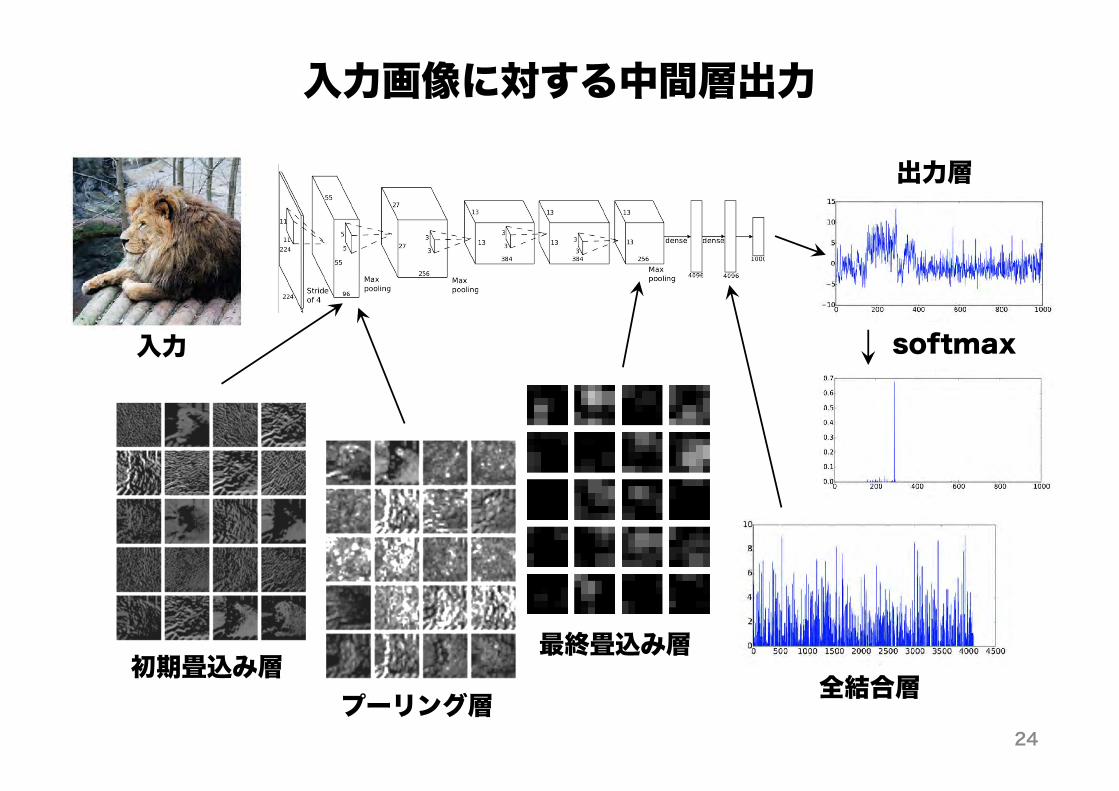
入力画像に対する中間層出力
入力
初期畳込み層プーリング層
最終畳込み層全結合層
softmax
出力層
24
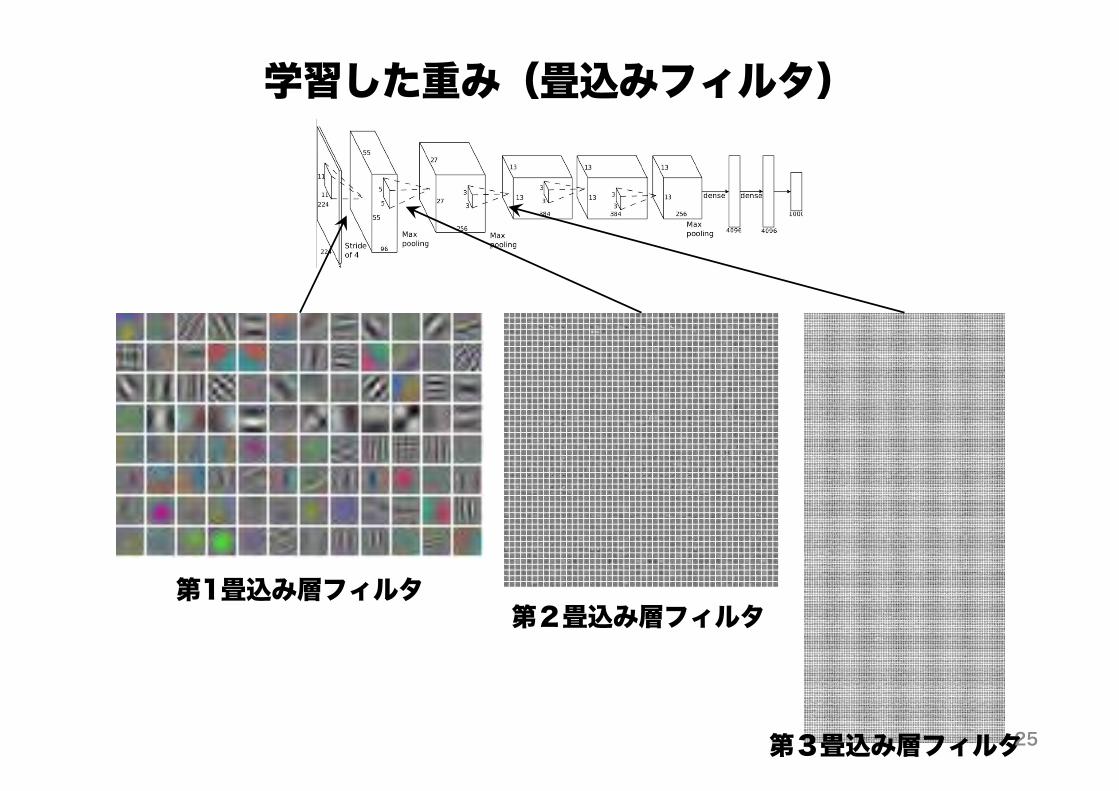
学習した重み(畳込みフィルタ)
第1畳込み層フィルタ第2畳込み層フィルタ
第3畳込み層フィルタ25
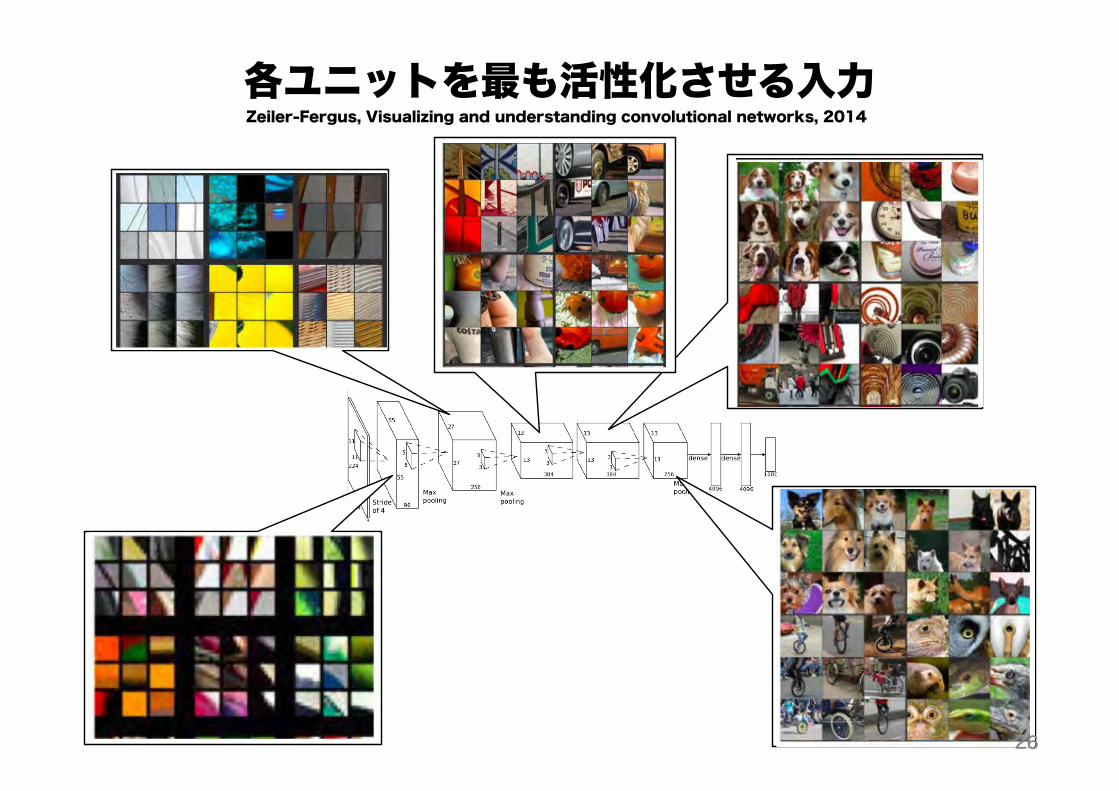
各ユニットを最も活性化させる入力
26
Zeiler-Fergus, Visualizing and understanding convolutional networks, 2014

CNNを騙すSzegedy+, Intriguing properties of neural networks, 2014
Correctlyrecognized
Additive noise
Recognizedas“Ostrich”
目立たないわずかな改変 ⇒ 誤認識 ユニバーサルな改変:画像・ネットワークによらず誤認識
[Moosavi-Dezfooli+2017]
27

CNNを騙す• 現実には懸念不要では?
– NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles [Lu+2017]
• 「ロバストな」改変は可能– Synthesizing Robust Adversarial Examples [Athalye-Sutskever2017]
28
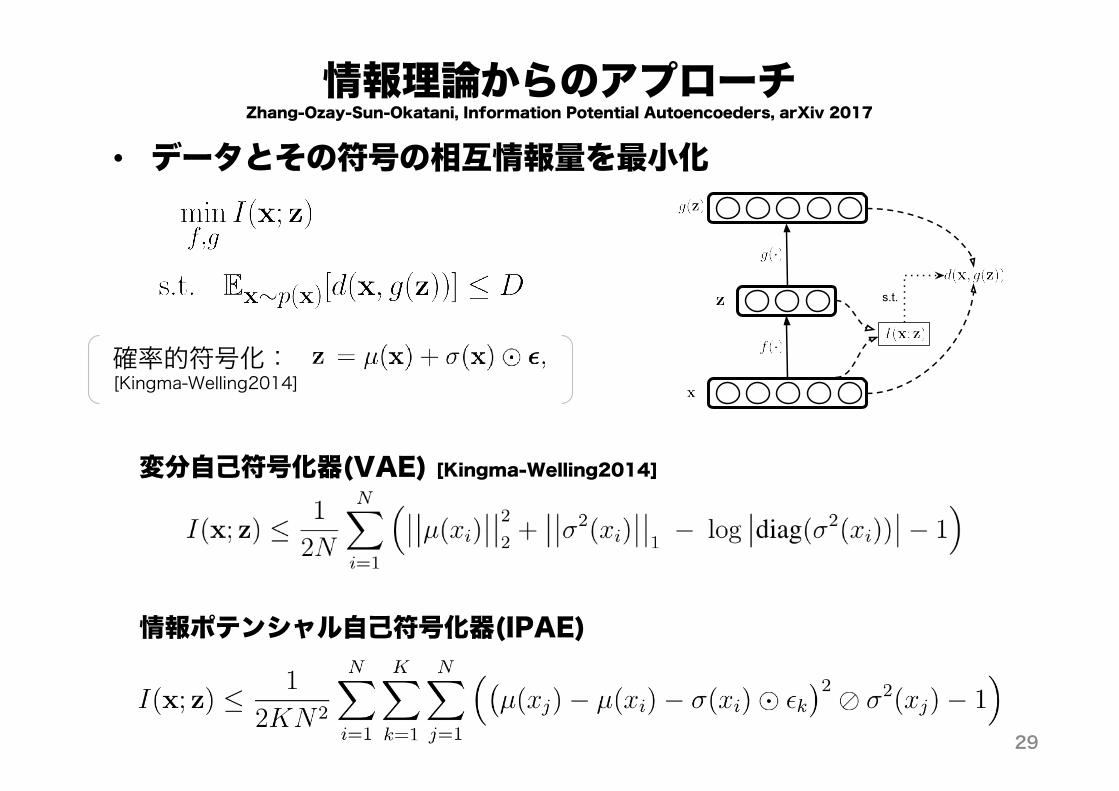
情報理論からのアプローチ• データとその符号の相互情報量を最小化
s.t.
確率的符号化:[Kingma-Welling2014]
変分自己符号化器(VAE) [Kingma-Welling2014]
情報ポテンシャル自己符号化器(IPAE)
Zhang-Ozay-Sun-Okatani, Information Potential Autoencoeders, arXiv 2017
29
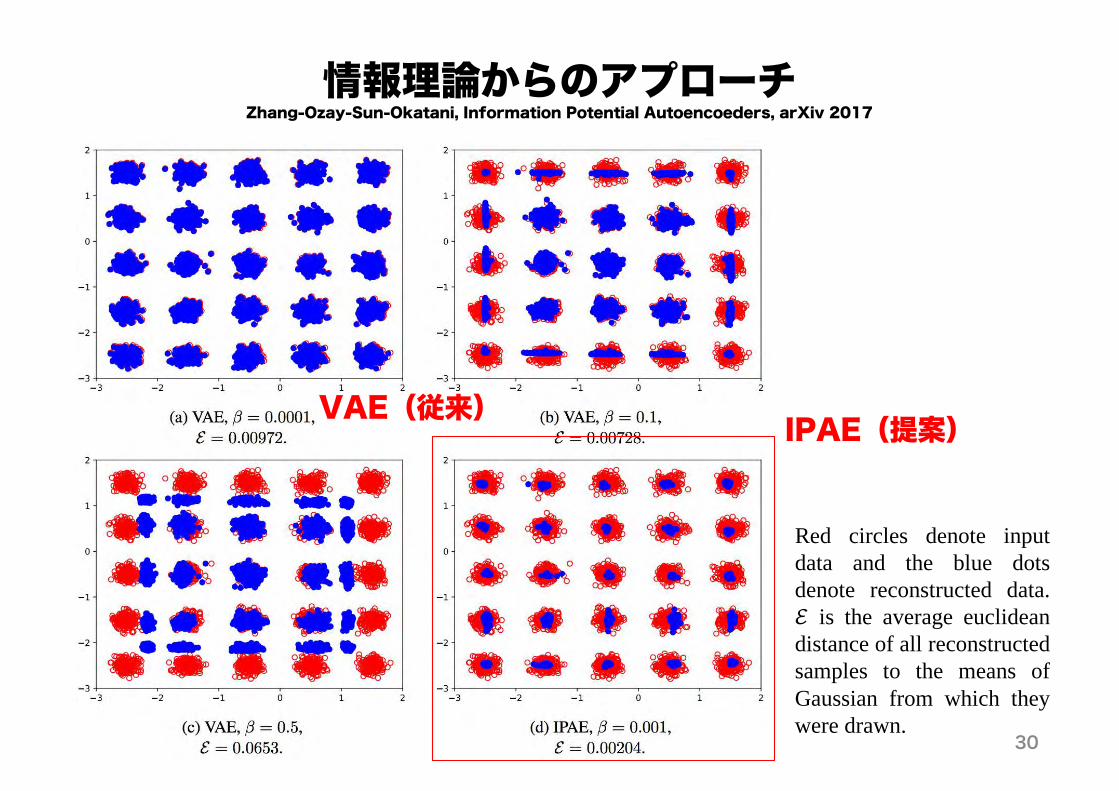
情報理論からのアプローチZhang-Ozay-Sun-Okatani, Information Potential Autoencoeders, arXiv 2017
Red circles denote inputdata and the blue dotsdenote reconstructed data.ℰ is the average euclideandistance of all reconstructedsamples to the means ofGaussian from which theywere drawn.
30
VAE(従来) IPAE(提案)
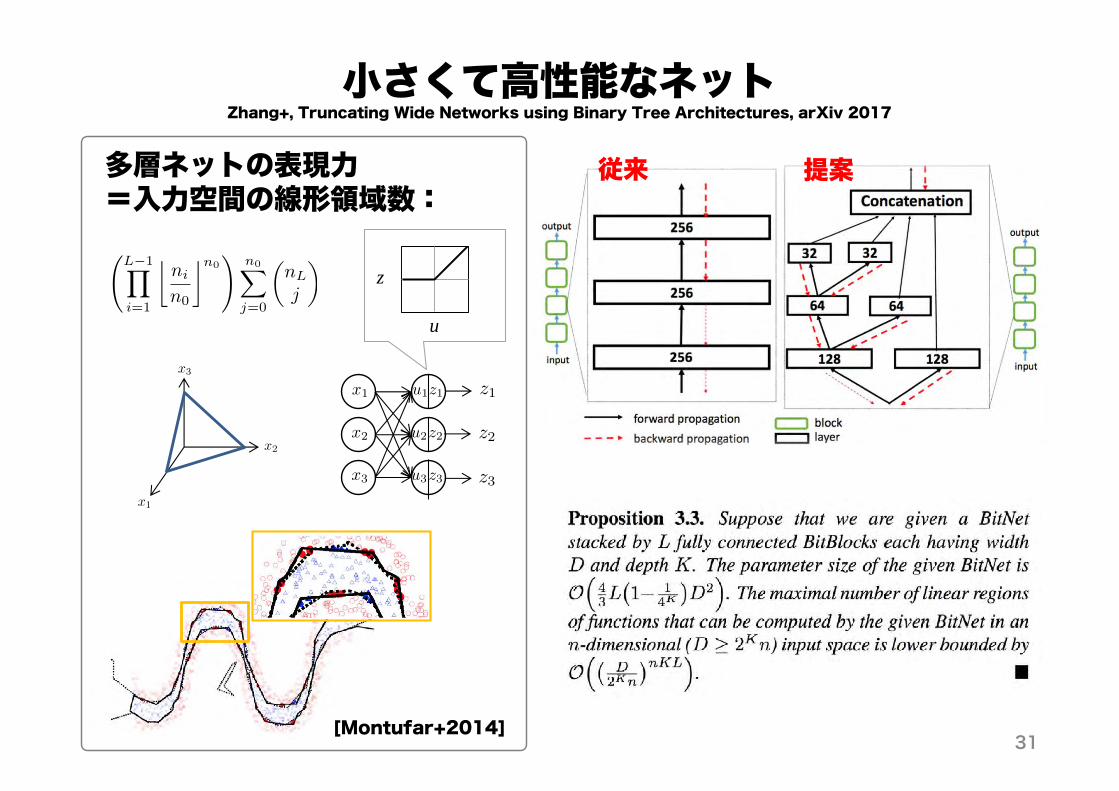
小さくて高性能なネットZhang+, Truncating Wide Networks using Binary Tree Architectures, arXiv 2017
従来 提案
x1
x2
x3
多層ネットの表現力=入力空間の線形領域数:
L�1Y
i=1
�ni
n0
⌫n0!
n0X
j=0
✓nL
j
◆
x1
x2
x3
u1
u2
u3 z3
z2
z1
z3
z2
z1
[Montufar+2014]
u
z
31
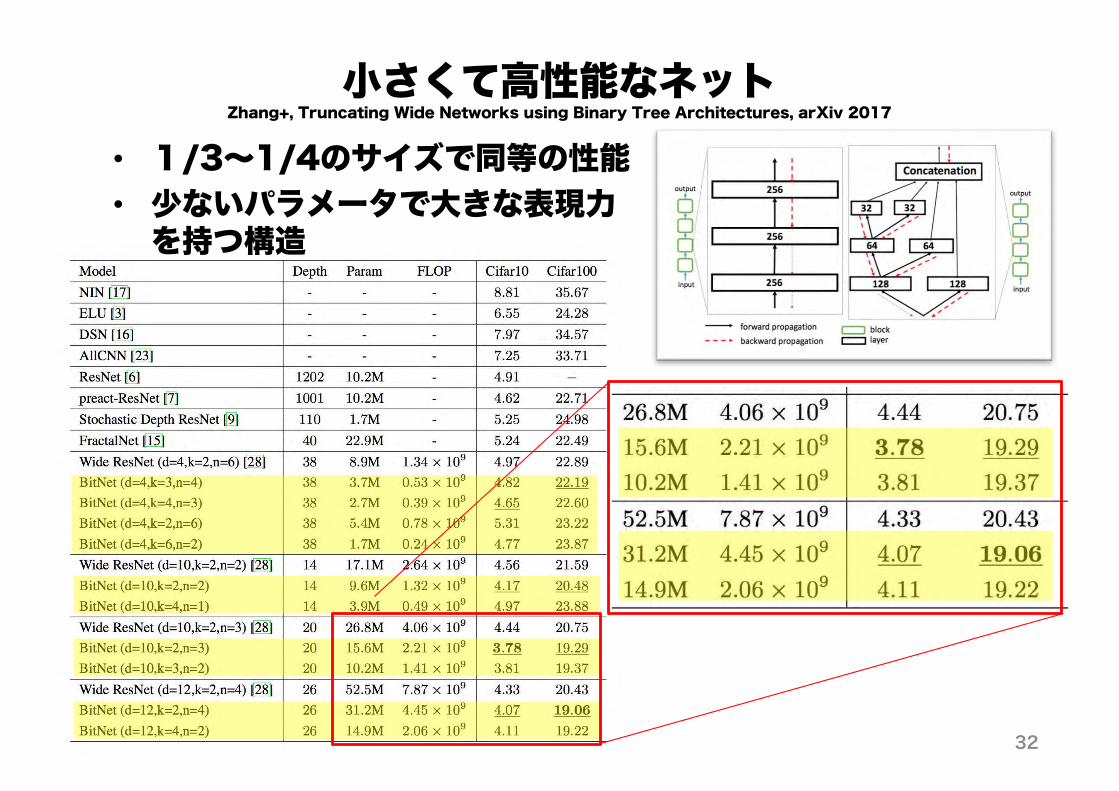
小さくて高性能なネットZhang+, Truncating Wide Networks using Binary Tree Architectures, arXiv 2017
• 1/3~1/4のサイズで同等の性能• 少ないパラメータで大きな表現力を持つ構造
32
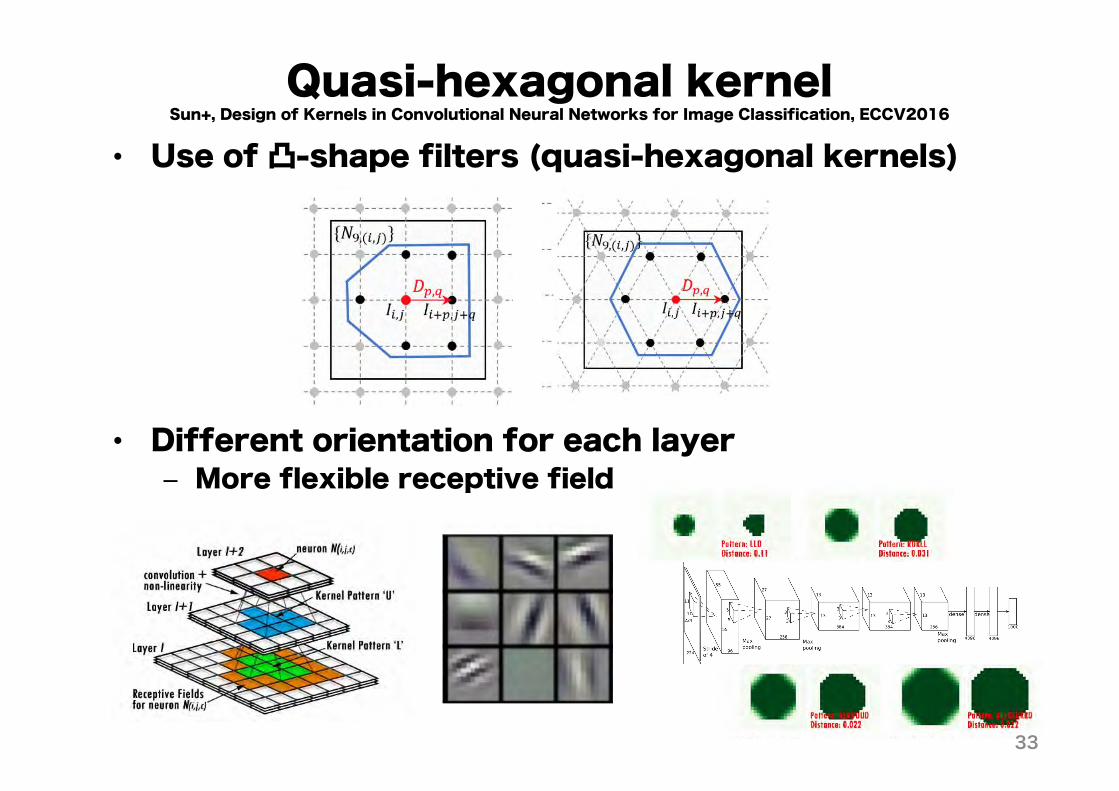
Quasi-hexagonal kernel• Use of 凸-shape filters (quasi-hexagonal kernels)
• Different orientation for each layer– More flexible receptive field
Sun+, Design of Kernels in Convolutional Neural Networks for Image Classification, ECCV2016
33
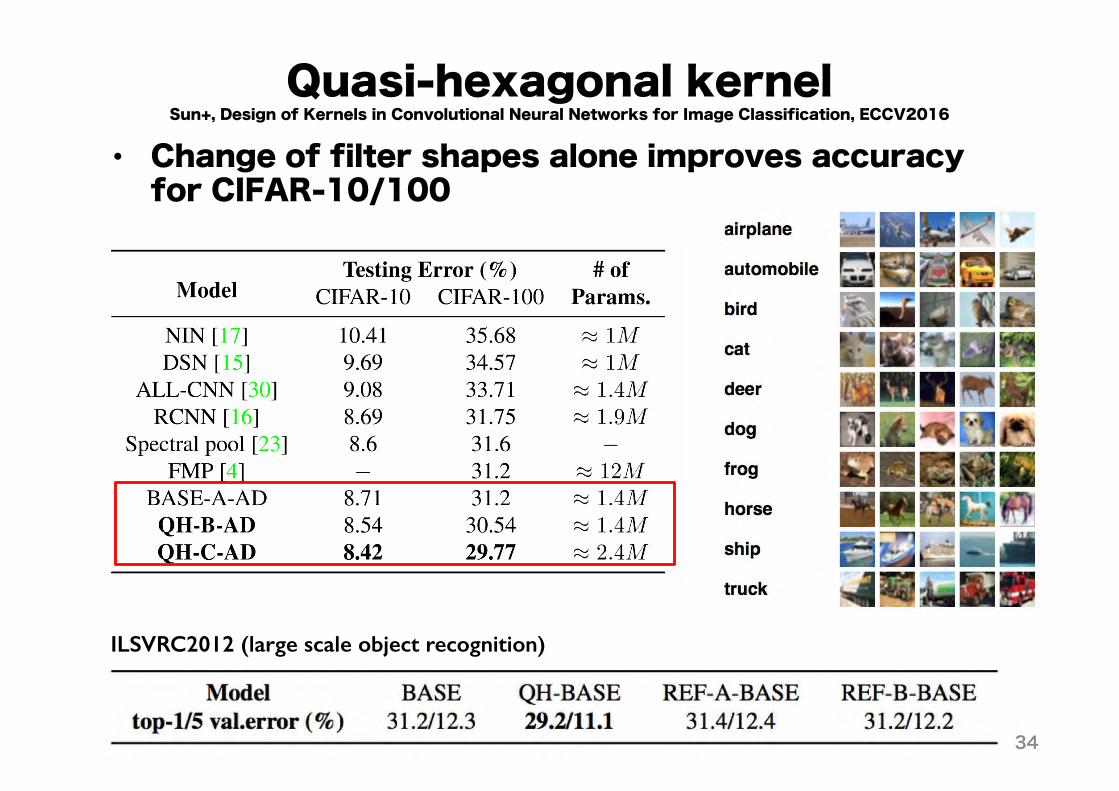
Quasi-hexagonal kernel• Change of filter shapes alone improves accuracy for CIFAR-10/100
Sun+, Design of Kernels in Convolutional Neural Networks for Image Classification, ECCV2016
ILSVRC2012 (large scale object recognition)
34
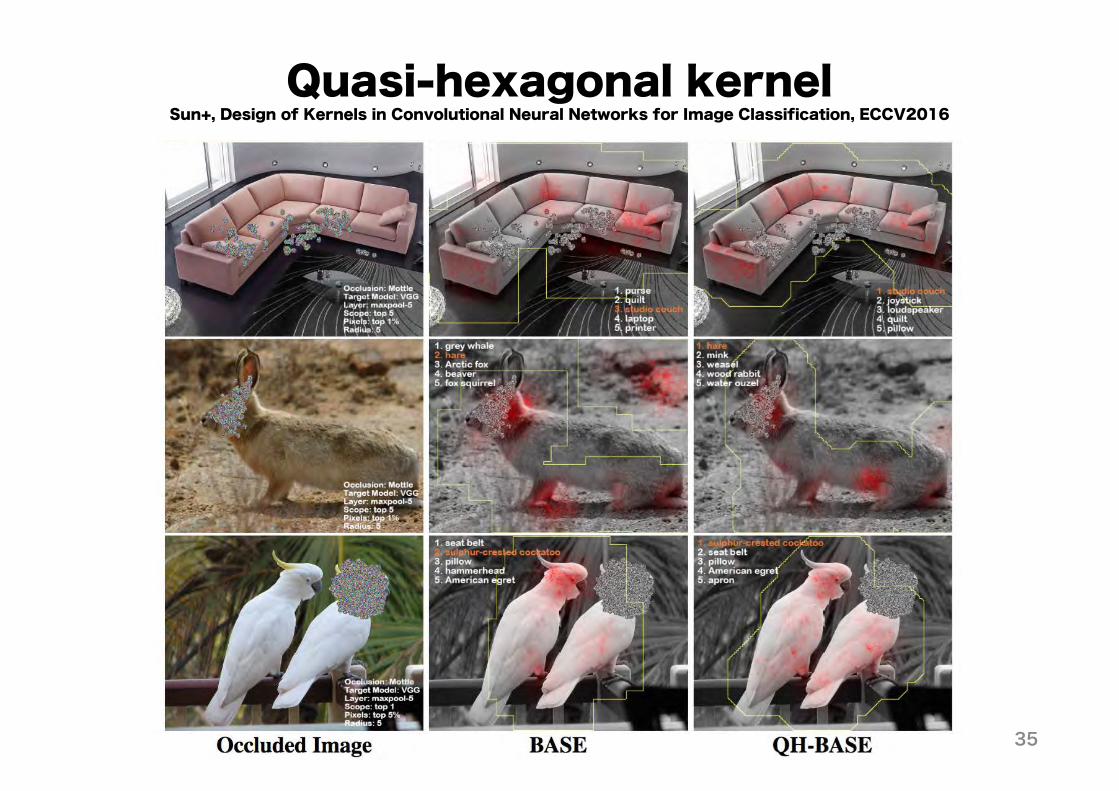
Quasi-hexagonal kernelSun+, Design of Kernels in Convolutional Neural Networks for Image Classification, ECCV2016
35

畳込みフィルタの多様体制約付き学習• フィルタの制約=行列多様体
• 同一CNN(ResNet-110)での結果
Weights (filter kernels) are updated on a manifold.
Cifar10 Cifar100RCD [Huang+2016] 6.41 27.22
Ours (One manifold) 5.91 25.39
Ours (Product of four manifolds) 5.17 23.79
RSD [Huang+2016] 5.23 24.58
Ours (One manifold) 4.73 23.09
Ours (Product of four manifolds) 4.31 22.03
W>W = I
ddiag(W>W ) = I
kWk2F = 1Sphere:
Oblique:
Stiefel:(Orthogonal)
Ozay-Okatani, arXiv2016 / Ozay-Hatsutani-Okatani, arXiv2017
36
• ディープラーニングにより多くの問題が解決へ– 大量の入出力ペアを用いたend-to-end学習
まとめ(画像分野の研究の現状)
[Insafutdinov+2016]
[Zhao+2016]
出力
[Chung+2016]
1. 真の画像理解2. 出力がはっきりしない3. データが集まらない4. サイバースペースから実世界へ5. DNN(CNN)の理解
• 残された問題
38













![ディープラーニング(深層学習) コントラスティブダイバージェンス法(contrastive di-vergence)[3]を用いた教師なし学習による層ごとの事前](https://img.pdfslide.tips/doc/110x75/5aad17687f8b9a59658dd93e/-contrastive.jpg)

![ディープラーニング(深層学習)Deep Learning 深層学習[1]は,狭い意味では,層の数が多い(深い) ニューラルネットワーク(neural network)をモデルとし](https://img.pdfslide.tips/doc/110x75/5ea530d50a2c6709a9411599/fffffffici-deep-learning-c1ioecioeoeii.jpg)













