Embed Size (px)
Citation preview

2019年6月25日@統計モデリング
担当:田中冬彦
統計モデリング第十一回 配布資料
文献:a) R. Tibshirani: Regression Shrinkage and Selection via the Lasso.
J. R. Statist. Soc. B, 58 (1996), 267—288.
配布資料の一部は以下からもDLできます. 短縮URL http://tinyurl.com/lxb7kb8
b) K. Hirose and M. Yamamoto: Sparse estimation via nonconcave penalized likelihood in factor analysis model.Statistics and Computing, 25 (2015), pp. 863-875.c) 青木 繁伸: Rによる統計解析 第6章多変量解析, 2009, オーム社, 東京. d) 永田 靖, 棟近 雅彦: 多変量解析法入門, 2001, サイエンス社, 東京.e) 坂巻 隆治, 里洋平: ビジネス活用事例で学ぶデータサイエンス入門, 2014, SBクリエイティブ, 東京.

2回に分けてスパースモデリングの基本についてみていく
ここからの内容
スパースモデリング
参考:
7/2 :第二回 グループ発表
7/9: 基礎工入試で休講
7/16 : 講義最終 (第十二回)
7/23 : 第三回 グループ発表
1. スパース推定の概略
2. スパース推定を利用する統計モデルの例(因子分析)
3. スパース推定を利用する統計モデルの例(GLM)
第11,12回でとりあげるテーマ
謝辞: 廣瀬先生(2015年下平研究室 助教 → 現在、九州大学IMI准教授)のゼミ資料をかなり参考にさせていただきました。

x
y
第十一回スパースモデリング1・因子分析
第十二回スパースモデリング2・GLM
第十三回 グループ発表3
第十回 グループ発表2今後の予定

第三回グループ発表(7/23 開催)
第三回の要件
・1または2について, スパース推定で分析
・実データを扱う
・ベイズ的なアプローチは不要
・正則化項や正則化パラメータはいろいろ試す (2では, 可能ならCV)
※そのほかの要件は第一回配布資料参照

今日の内容
1.スパース推定の概要2.因子分析モデル3.最尤推定による分散の推定4.因子分析モデルにおけるスパース推定5.分析例

本日の主役
因子分析モデル
εµ +Λ+= FX),0(N~ mI( )TmFFF ,,1 = m 変量標準正規分布
),0(N~ Ψε 0>Ψ
ε,F 独立
分散共分散行列

1. スパース推定の概要

なりきりボクサー
HP: 10MP: 25とくちょう:早いとうけい3級
すごく運がいいと・・・
普通は ようかいウオッカ
HP: 1MP: 2とくちょう:とても弱いとうけい4級
スーパーレア(SR)
強いカード!
ノーマル (N)
弱いカード!
6月の特別ガチャ【有料】
モラコレはガチャでカードを集めて相手と戦い上位を目指す人気のゲーム; 毎月, ランキングイベントも開催
SNSゲーム:モンスターラブコレクションとうけいの精霊
とうけいドラゴーン

運営サイドの課題
何がユーザの課金額に影響しているんだろう?
モラコレの現状
・毎月のランキングイベントの参加者数は順調に増えている・しかし, 各ユーザの課金額は減少している
ユーザごとの課金額や登録情報を集計すると・・・・

ビッグデータの時代
UserID 開始日 最終ログイン課金額(累計)
先月の課金額 性別 職業 Lv 戦闘数 ・・
14556634 2017年3月30日 2019年6月25日 1089900 23900 0 会社員 43 450014367894 2017年3月30日 2019年5月20日 1034500 0 0 会社員 35 367013312789 2017年3月30日 2019年6月25日 215500 5000 0 無職 19 26012311695 2017年3月30日 2019年6月20日 363000 35000 1 学生 40 1233
ユーザごとのデータイメージ
ユーザごとのデータが大量に出てきた・・・・

カテゴリカル説明変数の扱い【第九回】
(*k通りの分類なら k-1個の2値変数)
2
10ix
=
ニート 主婦・主夫
→ 分析する場合, ダミー変数(*)が大量に入る
それ以外 3
10ix
= それ以外
4
10ix
=
会社員
それ以外
例: i 番目のユーザの職業
以上を踏まえて先月の課金額を説明するモデルを立てると
5
10ix
=
学生
それ以外

統計モデルとビッグデータ
ni ,,2,1 =
),0(~ 2σε Ni
iiii xxY εββα ++++= 5000500011
統計モデルの例
i : ユーザアカウント(i=1,...,n)
iY i 番目のユーザアカウントが月に投入する課金額
ijx i 番目のユーザアカウントの情報(j=1,..., 5000)
ビッグデータの時代
ゲームの例に限らず, SNS, 購買サイト, マンガサイトなどのネット上のサービスでは, ユーザごとに大量の情報(説明変数)が収集できる
1ix 性別
2 3 20, , ,i i ix x x 職業ダミー変数,….

従来のパラメータ推定方法
iiii xxY εββα ++++= 5000500011
線形モデル
α1β 2β 4999β
5000β
従来の推定方法だと・・・推定値の大小に差があるがどれも0にはならない!
500021 03.09.108.01.2 iiii xxxy +++−=

スパース推定の場合
α 1β3β
4999β5000β
中途半端に残すのではなく0が大量に出てくる!
499931 65.38.13.2 iiii xxxy ++−=
2β
本質的な変数のみ残る
課金額に影響を与える本質的な変数が見えてくる!

スパース推定とは?
Sparse; 疎, まばら (←→ Dense; 密)スパース
たくさんパラメータがある場合に, その多くが 0であることをあらかじめ仮定して, 推定すること
統計モデルパラメータのスパース推定
重要な注意
組み合わせ最適化(の近似解法)になるため,単純に推定値が小さいものを0に置きなおすわけではない!

スパース推定の原理
例:データ数2; パラメータ数3の場合
誤差なしの人工的なモデル 0≡iε
→ パラメータ a, b, c を方程式の解とみると解は一意には定まらない(ここまでは線形代数!)
cbawcbaw+−==
++==22
,33
2
1
iiii czbyaxw ++=
スパース性を仮定すると解は唯一に定まる.

スパース推定の利点
1.スパース推定
2.ベイズ推定
0の設定箇所の組み合わせがきわめて多くなる
→ 後で見るように近似的な方法(LASSO推定)を利用
iiii xxY εββα ++++= 5000500011
実際のスパース推定
パラメータ数 > データ数 の場合
単純なパラメータ推定 (最小二乗やMLE)は不可
→
100,,2,1 =i

2. 因子分析モデル
多変量データ
例
p 組のデータ (p 変量) × n 件
npn
p
xx
xx
,,
,,
1
111
5教科の点数(100点満点) × 100 人分
プロ野球のバッターの1シーズンの成績(安打数, ホームラン数, 盗塁.) × 30人分
地方自治体の基礎データ(人口、気候、犯罪件数、失業率、平均寿命) × 40件
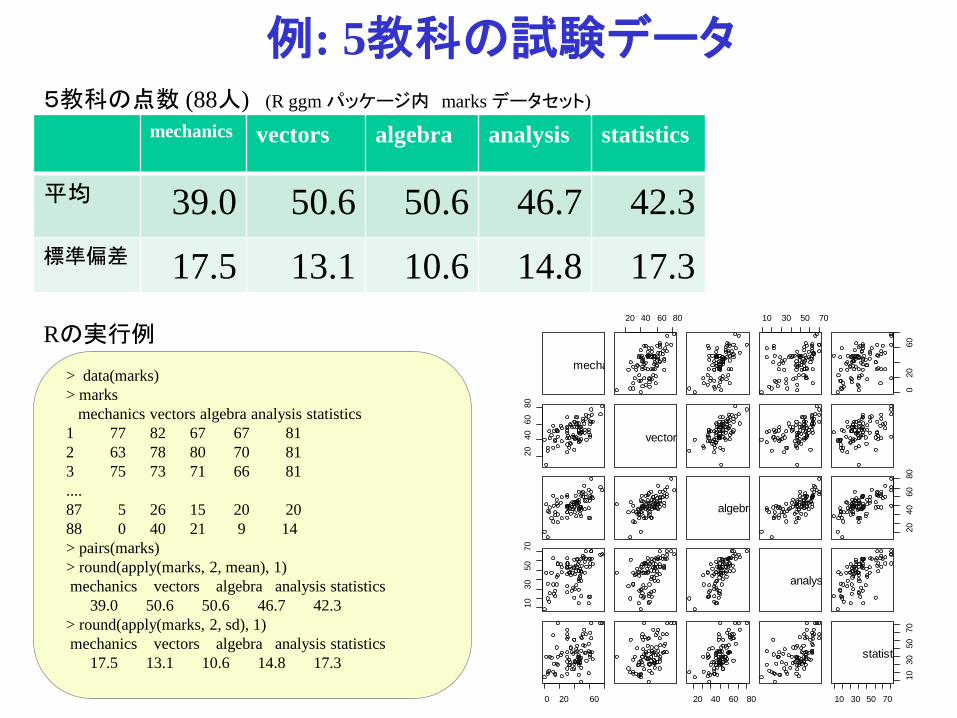
mechanics vectors algebra analysis statistics
平均 39.0 50.6 50.6 46.7 42.3標準偏差 17.5 13.1 10.6 14.8 17.3
例: 5教科の試験データ5教科の点数 (88人) (R ggm パッケージ内 marks データセット)
> data(marks)> marks
mechanics vectors algebra analysis statistics1 77 82 67 67 812 63 78 80 70 813 75 73 71 66 81....87 5 26 15 20 2088 0 40 21 9 14> pairs(marks)> round(apply(marks, 2, mean), 1)mechanics vectors algebra analysis statistics
39.0 50.6 50.6 46.7 42.3 > round(apply(marks, 2, sd), 1)mechanics vectors algebra analysis statistics
17.5 13.1 10.6 14.8 17.3
mecha
20 40 60 80 10 30 50 70
020
60
2040
6080
vectors
algebra
2040
6080
1030
5070
analys
0 20 60 20 40 60 80 10 30 50 70
1030
5070
statisti
Rの実行例

多変量解析
因果関係は不明瞭だが, 各変量の間の何らかの関係を明らかにするデータ解析
多変量解析
興味のある変数(目的変数) y とそれを説明する変数(説明変数) x という役割は固定していた
これまでのモデル
)(xfy =

多変量解析と統計モデル
多変量解析の手法
・主成分分析
・因子分析・正準相関分析・グラフィカルモデリング・・・・・・多次元尺度法
分析目的やデータの種類に応じて、様々な手法が提案
統計モデルの設定の有無
主成分分析 ・・・ 設定しない(相関係数行列のみを利用)グラフィカルモデリング・・・ 設定
ここでは因子分析(統計モデルを設定)を紹介
因子分析 ・・・ 設定したり、設定しなかったり

因子分析
( )TXXX 51 ,, =→ 5変量のデータ
直接観測できない、少数の潜在的な能力(?)で、各教科の点数(観測できる変数)同士の関係を説明したい!
国語 数学 理科 社会 英語
1X 2X 3X 4X 5X
因子分析でやりたいこと
例: 5教科の点数

因子分析モデルの構築
観測されているもの(例: 5教科の点数)
観測変数に影響を与える「何か」b) 潜在変数(共通因子)
国語 数学 理科 社会 英語
1X 2X 3X 4X 5X
因子1
1F因子2
2F
2種類の変数
a) 観測変数
モデルの概念図(因子数2の場合)
線の太さ(影響の強さ)
分析後に解釈を与える

観測変数と共通因子の関係(1/3)
重み (負もあり)
EngEngEngEng FF ελλµ +++ 22,11,
英語の平均点数
英語独自のゆらぎ(独自因子)
=EngX
EngX
1F 2F1,Engλ
2,Engλ
例:英語の点数を2個の共通因子で説明する場合

121211111 ελλµ +++= FFX
525215155 ελλµ +++= FFX
観測変数と共通因子の関係(2/3)
例:5教科すべての点数を2個の共通因子で説明する場合
英語
96点社会
96点理科
78点数学
96点国語
96点
1
2
35,47
FF==

)(1
)(212
)(1111
)(1
jjjj FFX ελλµ +++=
)(5
)(252
)(1515
)(5
jjjj FFX ελλµ +++=
確率変数としてモデル化(正規分布などを仮定)
Nj ,,2,1 =
確率変数とパラメータ【後で詳しく】
5121 ,,;, εε FF
11 12 52 1 5, , , ; , ,λ λ λ µ µ
未知パラメータ (1人1人に共通の定数)
観測変数と共通因子の関係(3/3)例:N人についてまとめたモデル
1
2
35,47
FF==
1
2
20,62
FF==

2.実際の観測データから統計モデルのパラメータを推定
)( jkλ=Λ に興味がある
分析の流れ
1.因子数を固定
3.因子数を増やして1,2を繰り返し、あてはまりのよいモデルを選ぶ
に確率分布を仮定【後で詳しく】;F ε

従来の方法(うまくいってない例)
国語 数学 理科 社会 英語
1X 2X 3X 4X 5X
因子1
1F因子2
2F
1211 30001.0 ε++= FFX
2212 00056.010 ε++= FFX
3213 00007.05 ε++= FFX
非零だがきわめて小さい値が全部残ると、結果の解釈がしづらい
(各因子から観測変数への矢がすべてついてしまう)
*簡単のため 0µ =

スパース推定の場合
国語 数学 理科 社会 英語
1X 2X 3X 4X 5X
因子1
1F因子2
2F
1211 30 ε++= FFX
2212 010 ε++= FFX
3213 05 ε++= FFX
スパース推定を行うと係数の一部が自動的に0になる!
結果の解釈がしやすくなる!
0 310 05 00 20 1
Λ =
*簡単のため 0µ =

多変量解析におけるスパース推定の利点
多変量解析(因子分析に限らず)での目標
しばしば, 人間が解釈しやすい結果が欲しい
推定値に0 が多くなり, 解釈しやすい結果が得られる
スパース推定の利点
モデル選択などを用いても、0に近いパラメータが多数出てきて解釈しづらいことがある
次節から因子分析モデルのスパース推定の詳細をみる
従来の推定

理解度チェック:因子分析モデル
)(1
)(212
)(1111
)(1
jjjj FFX ελλµ +++=
( ) ( ) ( ) ( )1 1 2 2
j j j jp p p p pX F Fµ λ λ ε= + + +
Nj ,,2,1 =
以下はp 変量のデータを 2つの共通因子で説明するモデルである.
問: 5つの変数 (添字は省略)のうち該当するものを書きなさい, , , ,X F λ µ ε
1) 直接, 観測されるデータ
2) 直接観測できないが, 1) に影響を与えると考える因子
3) 共通因子の重み(パラメータ)
4) 各因子が0 の時に観測される値(パラメータ)

3. 最尤推定による分散の推定

尤度関数【第五回】
パラメータ の各値に対する(相対的な)もっともらしさ(likelihood)を表現
解釈
尤度(ゆうど)関数
確率関数・確率密度関数の x 部分に実際のデータを代入し, パラメータ の関数とみなしたもの.
パラメータに関係ない項を無視することもある.
)|(~ θxpX
θ
例 612=x
)|612()( θθ pL =
θ

最尤推定【統計の復習】
最尤(さいゆう)推定(Maximum Likelihood Estimate; MLE)
尤度関数の値を最大にするパラメータを推定値とする.
・対数をとった尤度(対数尤度)の最大化を考えてもよい
・実際のスパース推定は尤度関数を修正した関数を最大化
・簡単なケースをのぞくと数値的に最大化する
注意

最尤推定【統計の復習】
∞<<∞− θ
例:正規分布の平均の最尤推定2( )
21( | )2
xvp x e
v
θ
θπ
−−
=~ N( , )X vθ
公式
( )2( ) 1log ( | ) log 2
2 2xp x v
vθθ π−
= − −
x = 162の時, 対数尤度関数 (v >0 はここでは固定).
( )2( 162) 1log ( ) log 2
2 2L v
vθθ π−
= − −
最尤推定値 162ˆ =MLθ

計算してみよう1
例:平均0の正規分布の分散 v の最尤推定
~ N(0, )X v
1. データ x として対数尤度関数を書きなさい.
問題
log ( )L v = ( )ss
x π2log21
2
2
−−
2. vの最尤推定値を求めなさい. (データ x で書く)ヒント: 関数 は (>0) で最大値.
ˆMLv = 2x
( ) logaf v vv
= − − v a=

← 今度は n サンプルの場合1, , ~ N(0, )nX X v
1. データ として対数尤度関数を書きなさい.
問題*
log ( )L v = ( )snxs
n
jj π2log
221
1
2 −− ∑=
2. v の最尤推定値を求めなさい.
ˆMLv = ∑=
n
jjx
n 1
21
i.i.d.
nxx ,,1
ヒント: 独立性から1つ1つの対数尤度関数の和になります.
*学部1年次の統計で習うが, 難しいと思う場合はできなくてもよい
例:平均0の正規分布の分散 v の最尤推定
計算してみよう2

多変量正規分布【統計の復習】多変量正規分布 (p 変量正規分布)
),(N Σµ意味:
),(N~ ΣµX
( )Tpµµµ ,,1 = 平均ベクトル
ijΣ=Σ [ ] 分散共分散行列 (正定値, 実対称)
p次元確率変数ベクトル が多変量正規分布に従うことを以下のように記載
( )TpXXX ,,1 =

=Σ)(log L
をひとつの”変数”と考えて、対数尤度関数を書くと・・・・
Σ
),0(N~,,1 ΣnXX
i.i.d.
推定したいパラメータ
行列(の各成分)
分散共分散行列の最尤推定(1/2)
Σ
( )1, ,T
j j jpX X X= となっていることに注意
n 件の p変量データが平均0 のp変量正規分布に従うモデル

{ })2log(detlog)(tr2
)(log 1 πpSnL +Σ+Σ−=Σ −
1, , R pnx x ∈S: の標本分散共分散行列(*1)
1
1 n
kl jk jlj
S x xn =
=
∑ pjk ,,1, =
S=Σ
SML =Σ̂
0=µ※2 数学的な証明は行列の計算がめんどうだが、 で “最大値“をとる
分散共分散行列の最尤推定(2/2)対数尤度関数
最尤推定値(*2)
※1 としているため

4. 因子分析モデルにおけるスパース推定

例: p (=5) 教科の点数, m (=2) 因子の場合
( )
+
2
12,1, F
Fjj λλj 番の科目の点数 =jX jµ jε+
=X µ FΛ+ ε+
ベクトル表記に修正
行列
j=1,…,p をタテに並べると
, ,X µ ε m× p 行列
F m 次元ベクトル
Λp 次元ベクトル
各変数の次元

因子分析の統計モデル (1/2)
m
εµ +Λ+= FX
F
観測変数 (p 次元ベクトル)X
)( ijλ=Λ 因子負荷行列 【興味がある】
因子数 ( < p )
µ 観測変数の平均【簡単のため =0 とおく】
パラメータ (固定)
確率変数 (直接観測できない)
ε共通因子
独自因子
モデルの各変数

共通因子・独立因子のモデル
mFF ~,,~1 独立な共通因子 (m 変量正規分布)
),0(N~ mI( )TmFFF ,,1 = m 変量標準正規分布
共通因子
独自因子
),0(N~ Ψε
ε,F 独立
独立性の仮定
以上から観測変数に関する最終的なモデルが計算できる
線形変換
*独自因子の分散共分散行列は対角行列を仮定
1( , , )pdiag ψ ψΨ =
0,,1 >pψψ

因子分析の統計モデル (2/2)
Ψ+ΛΛ=Σ T
),0(N~,,1 ΣnXX
i.i.d.
p 次元ベクトル(×n 人分)
むむ!!
この形, どこかでみたような気がするであります!
=ΨΛ ),(log Lを2つの”変数”と考えて、対数尤度関数を書くと・・・・ΨΛ,
観測変数のモデル

{ })(trdetlog)2log(2
),(log 1SpnL −Σ+Σ+−=ΨΛ π
パラメータの最尤推定
対数尤度関数が最大になるのは
ST =Ψ+ΛΛ=Σ
S: 標本分散共分散行列
この式は?!
これは、非常に困るであります!!
1) 推定値が存在しないから2) カメごときには手が負えない計算だから(カメハラ)3) 推定値が一つに定まらないから
Q: 上のケースで、 を推定する際に困る理由はどれか?ΨΛ,
対数尤度関数

スパース性を仮定して推定値を絞るHirose & Yamamoto (2015)
因子負荷行列 にスパース性を仮定して推定!Λ
{ })(trdetlog)2log(2
1Spn −Σ+Σ+−= π
正則化項つき対数尤度関数を最大化
),(~log ΨΛL
0>ρ 分析者が調整(因子分析では結果を見ながら調整); 一般的な調整方法はCV(第十二回で紹介予定).
∑∑= =
−p
j
m
kjk
1 1|| λρ
正則化項
スパース推定の方法(近似解法)
正則化パラメータ

正則化項つきの最尤推定【一般】
0>ρ :正則化パラメータ
正則化項(罰則項; Penalty term)
)(~log θL )(log θL= )(θρP−
0)( ≥θP
正則化項つき対数尤度関数
正則化項(非負) として表現し、対数尤度に追加する
パラメータに関する制約条件(スパース推定以外でも使う)
)(θP
0)( =θP θ が制約条件を完全に満たす

LASSO推定量【一般】
以下を最大化する推定量(因子分析モデル以外でも一般的に使う)
∑=
−=k
jjLL
1||)(log)(~log θρθθ
ら っ そ
LASSO推定量
がスパース推定を誘導 (Tibshirani (1996))∑=
=k
jjP
1||)( θθ正則化項
スパース推定を誘導する正則化項には、現在、様々なバリエーション.注意
ら っ そ

5.分析例

因子分析 with LASSO推定
Rライブラリを利用 (R fanc* パッケージ内 fanc関数を利用; rho=0.1, gamma=Inf の結果を掲載)
X <- as.matrix(marks);# 各科目の平均、標準偏差を計算meanX <- apply(X, 2, mean); sdevX <- apply(X, 2, sd);# 各行を正規化X <- X - rep(1, nrow(X)) %o% meanX;X <- X / (rep(1, nrow(X)) %o% sdevX);
Num <- nrow(X); # サンプルサイズNumObs <- ncol(X); # 教科数(=独自因子の数)
# fit dataNumFactors <- 3; # 共通因子の数X.res <- fanc(X, NumFactors );
Rの実行例
~ N(0, )jX Σε+Λ= FX因子分析モデル
i.i.d.
*fanc = factor analysis via non-convex penalty 下平研(現鈴木讓研) 廣瀬助教(2015年当時;現在, 九州大)が作成
ここでは簡単のため因子数 = 3 として, marks データでLASSO推定
1, ,j n=

分析結果5教科の点数は ひとつの因子のみで決まる!
53532521515 ελλλ +++= FFFX
13132121111 ελλλ +++= FFFX
Mechanics Vectors Algebra Analysis Stat1X 2X 3X 4X 5X
....
=Λ
0060.00065.00080.00054.00047.0
0.470.54 0.80 0.65 0.60
確かに0が多い (スパース!)
1F 2F 3F
∞== − γρ ;10 1

正則化項を弱くした場合正則化パラメータを十分小さく設定
Mechanics Vectors Algebra Analysis Stat1X 2X 3X 4X 5X
0.54 0.44 0.16
-0.01
0.75
1F2F
3F
−−
−=Λ
75.015.0080.000042.001.088.0016.061.015.044.052.000015.054.0 3つの因子をすべて利用する推定結果.
スパースでなくなり, やたら小さい値が混ざってくる.
∞== − γρ ;10 7
0.88 0.80
0.520.61
からの矢をかきいれて上のグラフを完成させよ. 解釈はできるか?
練習問題
2F

補足:非スパースな方法
1.MLE(最尤推定量) を1組求める
TMM Λ=Λ :'
とし, が解釈しやすい形になるように調整.
1つの例
),( MM ΨΛ2.直交行列 T を選んで
※因子分析は古く(1960-1970)から心理学で使われており, 因子負荷行列を推定する方法がいろいろ提案されている.ここでは, スパースモデリングの考え方が有用な例として紹介した
M'Λ

理解度チェック:スパース推定
一般にパラメータに制約条件がある場合、適当な正則化項をつけた対数尤度関数を最大化して推定する方法がある。
統計モデルのパラメータの推定値から, しきい値を定めて, 0に近いものをすべて0に置き換えることをスパース推定という.
スパース推定の手法として, Tibshirani (1996) で提案されたNATTO推定が有名である
統計モデルによっては、(対数)尤度関数の最大化を用いても、推定値が1つに絞れない場合がある。
























![[DDBJing30] メタゲノム解析と微生物統合データベース](https://img.pdfslide.tips/doc/110x75/55a5dc761a28abcd398b4622/ddbjing30-.jpg)




