Embed Size (px)
Citation preview

Chapter 7
403
7分析機能
Chapter
ワークシートに入力した数値データの分析機能とグラフ化した直線や曲線に対して実行する分析機能について解説します。フィッティング機能の項目については例題を元に一通り操作をし、操作方法を習得してください。

ORIGIN6.0
404
Chapter7 - 01 ワークシートの統計計算
ワークシートにおける基本的な統計計算の方法について解説します。
データの準備
ここでは統計量として標準偏差、平均値の標準誤差、合計、標本数を求めるための機能について解説します。これ以外の検定、分散分析などに関する項目は、それぞれの項目を参照してください。はじめに次のようなサンプルデータを準備してください。
サンプルデータ
ワークシートツールバー
ワークシートにおけるデータセット(列)または行の統計計算は、「解析」メニューの「列の統計」/「行の統計」または「ワークシートデータ操作」ツールバーを用いて行います。ここでは「ワークシートデータ操作」ツールバーを使用します。「表示」メニューから「ツールバー」を選択して、ワークシートデータ操作の項目をチェックします。

Chapter 7
405
ツールバーダイアログ
次に示すワークシートデータ操作ツールバーが画面上に表示されます。
ワークシートデータ操作ツールバー
統計計算の実行
目的の列/行を選択して、「ワークシートデータ操作」ツールバーのボタンをクリックします。ここでは、列の統計値を求めます。行の統計値を求める場合は、行を選択してください。
列の統計量を求める

ORIGIN6.0
406
この計算結果は新しいワークシートに表示されます。
統計量を表示するウィンドウ
データの変更
一度統計量を求めた後で、ワークシート内の数値を変更した場合は、ワークシートの上側にある再計算ボタンを押します。即座に最新のワークシート内容を反映した結果が得られます。

Chapter 7
407
Chapter7 - 02 微分と積分
データセットの変化率を求める微分機能と面積計算を行う積分機能について解説します。
ORIGINの微分/積分機能はいずれもグラフを作成した状態から実行します。次のサンプルデータから「線+シンボル」グラフを作成し、それを元に微分/積分計算を行ってください。
サンプルデータ
サンプルのグラフ
微分
ORIGINの微分機能には2つの方法が用意されています。簡単にその違いを説明します。
微分 隣接する2点との勾配の平均を求めます。
微分/スムージングSavitzky-Golayの手法を用います。計算に使用するデータポイント数を決める必要があります。

ORIGIN6.0
408
ここでは「解析」メニューの「微分・積分」から「微分/スムージング」を選択してください。
「微分」の計算
「微分/スムージング」を選択してください。次に示すダイアログが表示されます。
「微分/スムージング」ダイアログ
スムージングでは多項式による回帰式を利用して微分計算を実行します。9次式まで利用できます。スムージング計算に利用するポイント数を決めます。
微分の次数を決めます。1次または2次を指定することができます。
この計算結果は次の通りです。
「微分/スムージング」による計算結果
微分の次数を指定

Chapter 7
409
微分計算の結果のグラフは常に「Deriv」というウィンドウに表示され、各データポイントのデータは、「smoothed」という名前のワークシートに作られます。
ワークシートに追加された微分計算データの一部
積分
元のグラフを表示した状態で、「解析」メニューの「微分・積分」から「積分」を選択します。すると即座に積分計算が実行され結果ログウィンドウに計算結果が表示されます。
積分計算の結果を表示する結果ログウィンドウ
このウィンドウには面積、ピーク位置、ピーク幅、ピークの高さが表示されます。ピークの分析に関する詳細は、Chapter7-04「ピーク分析」の項目を参照してください。
積分計算の結果、得られたデータセットはテンポラリエリアに格納されます。このワークシートを参照したり、計算に利用する場合はスクリプトウィンドウで次のコマンドを実行してください。
Copy _integ_area データセット名 [改行]
ここでは、「test」という名前のデータセットを指定します。

ORIGIN6.0
410
スクリプトウィンドウ
edit testを実行するとtestというワークシートが画面表示されます。
画面上に表示したワークシート「test」

Chapter 7
411
Chapter7 - 03 データマスク
データマスク機能は、ORIGIN6.0から提供される新しい機能で、データの一部にマスクをして、データ解析時にそのデータを使用しないようにできます。これにより、外れ値が解析結果に影響を及ぼすのを防いだり、範囲から外れているデータを表示しない、または強調して表示するといったことに使用できます。
データマスクは、データマスクツールバーで行います。
表示メニューのツールバーを選択してください。「ツールバーのカスタム化」ダイアログからマスク操作を選択してください。次のようなツールバーが表示されます。
ツールバーダイアログ
マスク操作ツールバー

ORIGIN6.0
412
次のようなサンプルデータを用意してください。
マスク機能を使った場合と使わない場合を比較するために、最初にマスク機能を使わないで「線+シンボル」グラフを作成してみましょう。グラフができたら、「解析」メニューから「フィット:線形」を選びます。
線形フィットについては、Chapter7-06「単回帰」を参照してください。
(5,1)、(9,6)、(10,7)の3つの点に引っ張られて、線形フィット曲線が下方向に偏っています。
サンプルデータ

Chapter 7
413
次に、(5,1)、(9,6)、(10,7)の3点にマスクをかけて、同じグラフを作成してみましょう。データをマスク化するのは、ワークシート上でも、グラフ上でも行うことができます。ここでは、ワークシート上で行います。
ワークシートを表示して、点(5,1)を表わしているB(Y)列のデータ「1」のセルを選択してください。そして、「マスク操作」ツールバーの左から2番目の「範囲のマスク」ボタンを押します。(1つしか指定しなくても、「範囲のマスク」です。)
セルが塗りつぶされました。この塗りつぶしの色は、グラフ上のデータシンボルにも適用されます。この色を変更するには、「マスク操作」ツールバーの右から3番目の「マスクカラー変更」ボタンをクリックします。クリックする毎に順に色が変わっていきます。何回か押し続けると元の色に戻ります。
同じように、点(9,6)と点(10,7)を表わしているB(Y)列のデータ「6」及び「7」の連続したセルをドラッグして選択してください。そして、マスク操作ツールバーから「範囲のマスク」ボタンを押します。
マスク化したワークシート
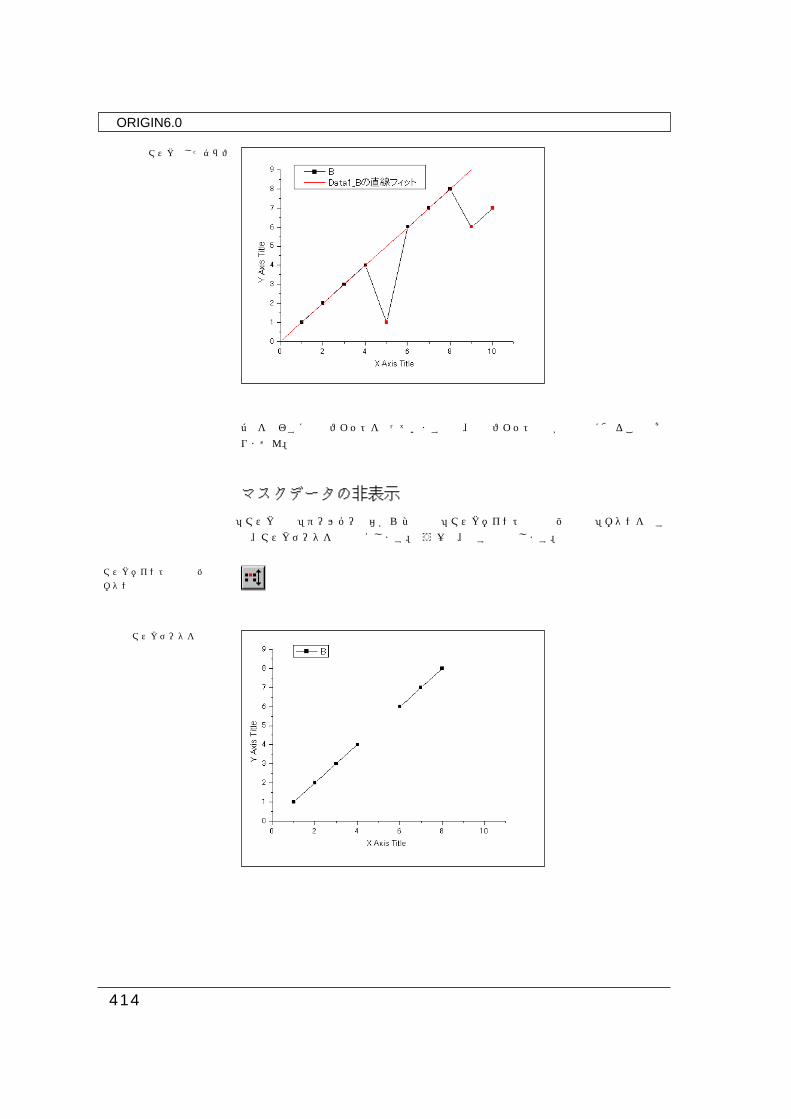
このワークシートを使って、「線+シンボル」グラフを作成します。グラフの作成方法は、同じです。マスク化したデータシンボルには、色が付いて表示されます。先ほどと同じように「解析」メニューから「フィット:線形」を選びます。
範囲のマスクボタン
マスクカラー変更ボタン
ORIGIN6.0
414
3点を使わすに線形フィットを行っていますので、線形フィット曲線が下方向に偏ることはありません。
マスクデータの非表示
「マスク操作」ツールバーの右から2番目の「マスクポイントの表示/非表示」ボタンを押すと、マスクデータを非表示にします。もう一度、押すと表示します。
マスクデータを非表示
マスク化したグラフ
マスクポイントの表示/非表示ボタン

Chapter 7
415
マスクデータの逆転
「マスク操作」ツールバーの左から4番目の「マスクの逆転」ボタンを押すと、マスクデータとそうでないデータが逆転します。
マスクデータを逆転
マスク機能を一時的に使用不可にする
「マスク操作」ツールバーの一番右の「マスク操作の利用可/不可」ボタンを押すと、マスク機能を一時的に使用しないようにします。もう一度押すと、マスク機能を使用するモードに切り替わります。このとき、マスクデータのマスクは解除されません。
「マスク操作」ツールバーの左から3番目の「範囲のマスク取り外し」ボタンを押すと、マスクデータのマスクをすべて解除します。
マスクの逆転ボタン
マスクの解除
範囲のマスク取り外しボタン
特定のマスクだけを解除する場合は、「マスク操作」ツールバーの一番左の「ポイントマスクのスイッチ」ボタンを押します。このボタンは、マスク化/マスク解除をポイント毎に行います。
ポイントマスクのスイッチボタン
マスク操作の利用可/不可ボタン

ORIGIN6.0
416
Chapter7 - 04 ピーク分析
プロットしたデータのピーク値(XY座標)の検出を行うピーク分析の手法について解説します。ORIGIN6.0では、正のピーク値検出に加えて、負のピーク値も検出できるようになりました。
データの準備
角度の単位を確認します。「ツール」メニューの「オプション」から角度の単位を「度」にします。
次にデータの準備をしましょう。空のワークシートで、X変数にセルインデックス「i」を利用して1から400までの整数を入力し、Y変数には次式の計算値を入力します。いずれも「列」メニューの「列値の設定」を利用します。
変数Yの計算式:3+sin(i*5)*cos(i)+2*cos(i/0.5)
列値の設定ダイアログ
この結果のワークシートの一部を次に表示します。

Chapter 7
417
列値の設定機能で作成したデータの一部
このデータを使って、「作図」メニューから「折れ線」を選択します。
サンプルデータから作成したグラフ
ピーク分析
このグラフでピーク分析を実行します。特に複数のデータをプロットしている場合は目的の曲線がアクティブになっていることを、「データ」メニューで確認しておきましょう(アクティブなデータセットにはチェックマークが付きます)。「ツール」メニューから「ピーク検出ツール」を選択します。「ピーク検出」ダイアログが表示されます。

ORIGIN6.0
418
ピーク検出ダイアログ
ピーク検出ダイアログの項目について解説します。
検索するピークの種類正のピーク、負のピーク、正負両方のピークを選択します。
長方形検索領域長方形の幅と高さを設定します。ここに入力する数値はプロットされた曲線の百分率です。単位を小さくとれば、より小さなピークを検出することができます。
最小の高さピークとして検出するための、高さの最小値です。これ以下のピーク高(百分率)では、ピークとして検出しません。
表示オプションピーク分析したプロットに表示するオプションを設定します。「ピークにマークをつける」は、検出したピーク値のところに印をつけます。「ピークX座標のラベル表示」は、検出したピーク値のXの値をラベル表示します。
ここでは、「検索するピークの種類」を「正負両方」、「長方形検索領域」の「高さ」と「幅」を「3」としてピーク検索実行ボタンをクリックしてください。プロットに対するピーク分析が実行されます。

Chapter 7
419
ピーク分析の実行結果
分析の結果
ピークインデックス データのインデックス番号ピークタイプ 正のピークまたは負のピークX座標 ピーク座標のX値Y座標 ピーク座標のY値正のピークラベル 正のピーク座標のラベル負のピークラベル
PEAKSワークシートで、正のピークラベルをPEAK1、PEAK2、PEAK3とし、負のピークラベルをPEAK4、PEAK5とします。
ピーク分析を実行するとプロット上にピーク検出ダイアログで設定したオプションが表示され、かつ、PEAKSウィンドウが作成されます。PEAKSウィンドウには次の6項目の値が入力されます。
負のピーク座標のラベル

ORIGIN6.0
420
ピークラベルを変更
その時のグラフの様子は次の通りです。
ラベルを編集したプロット
異なる非線形曲線の重畳した波形に対してのピーク値の検出には、PFM(ピークフィッティングモジュール)を使用する必要があります。PFMについては、「vol2.分析編」で詳細に解説しています。?Hint

Chapter 7
421
Chapter7 - 05 基線ツール
基線ツールによるピーク分析、基線を利用した積分計算の方法について解説します。
サンプルデータの準備
基線ツールによる解析を行うためのサンプルデータを次のようにして準備します。空のワークシートでデータセットA(X)のセル1から360までに「i/50+0.5」で計算した値を列値の設定機能で入力します。同様にB(Y)には「sin(i*4)+2」を使ってデータ入力します。この時、角度の単位が度に設定されていることを「ツール」メニューの「オプション」を選択して「オプション」ダイアログを表示し、「数値の表示形式」タブで確認してください。
データセットB(Y)に対する列値の設定
サンプルデータの一部
このサンプルデータから折れ線グラフを作成してください。

ORIGIN6.0
422
サンプルグラフ
作成したグラフに対して基線ツールを使ってみましょう。「ツール」メニューから「基線ツール」を選択します。基線ダイアログが表示されます。
基線ダイアログ - 基線タブ
ピークと基線に関する分析は基線タブ、ピークタブ、面積タブの順番で行います。
基線タブダイアログを表示すると基線タブが開いている状態になります。ここでは基線を作成し、それを元の状態に戻すなどの操作を行います。基線の作成には、「自動作成」、「ユーザー定義式を利用」、「既存のデータセット」の3つの方法があり、「ユーザー定義式を利用」ボタン及び「既存のデータセット」ボタンの下には、それぞれユーザー定義式を入力する「Y=」項目とデータセットを入力する「データセット」項目があります。
ここでは、「自動作成」ボタンをクリックしてください。

Chapter 7
423
グラフ中に基線が表示されます。続けて、基線の変更項目で「基線分の減算」ボタンをクリックしてください。グラフは次のようになります。
基線の減算を行ったグラフ
ピークタブピークの検出を行います。検出条件はピークの特性項目で行います。これらのテキストボックスに入力する数値の単位は描画しているデータポイント数に対する割合(%)です。
今回はデフォルトの状態で「検索開始」ボタンをクリックします。
基線ダイアログ - ピークタブ

ORIGIN6.0
424
ピーク分析を実行
「ピーク分析」の項で解析したときと同じように、検出条件に応じてピークを検出し、ラベルが付加されました。表示オプションで表示したいラベルを設定します。
面積タブ
基線ダイアログ - 面積タブ
基線タブで減算を行っておりますので、表示された面積タブで「y=0から」ボタンをクリックしてください。結果ログウィンドウに面積計算の結果が出力されます。

Chapter 7
425
ピークの検出だけを行うのであれば、なるべくピークツールを利用しましょう。

ORIGIN6.0
426
Chapter7 - 06 単回帰
散布図からデータの相関関係を調べるために利用します。単回帰の実行方法と解析結果の見方について説明します。
次のようなデータを用意してください。
サンプルデータ
このデータから散布図を作成してください。
サンプルグラフ

Chapter 7
427
このようなデータに単回帰を実行する場合は、「解析」メニューから「フィット:線形」を選択します。単回帰が実行され、グラフに回帰直線が加えられ、さらに単回帰分析の結果ログウィンドウと単回帰式による理論値のワークシート(LinerFitというワークシートウィンドウ)が作成されます。
結果ログウィンドウの項目について
単回帰実行後のグラフ
単回帰分析を実行した結果の解析結果がこの結果ログウィンドウに表示されます。
結果ログウィンドウ
単回帰式はY=A+BXの形で表わされ、その時のAおよびBと、その誤差が表示されます。さらに相関を示す、相関係数Rと標準偏差、データの個数N、そして最後にRが0になる(無相関)可能性をPとして表示します。

ORIGIN6.0
428
「解析」メニューの「フィット:線形」を選ぶことで、簡単にこの結果を得ることができました。しかし、ORIGINには「ツール」メニュー(グラフウィンドウ)の「線形フィットツール」を選択することで同じように単回帰分析を行い、グラフ上に回帰直線を引くことができます。
線形フィットツールバー
先ほど作成したグラフのレイヤアイコンをダブルクリックし、レイヤダイアログボックスを利用して単回帰直線をグラフから削除します。
レイヤダイアログボックス
単回帰直線のデータセット「linerfit_data1b」を左側のボックスへ移動すれば、グラフ上から回帰直線は削除されます。もちろん、これを再度、右側に移動すれば再び表れます。グラフの準備ができたところで、「ツール」メニューから「線形フィットツール」を選択します。
線形フィットツールバー - 操作タブ
このツールバーを利用すれば単回帰分析に際し、より詳細な分析やグラフの作成を行えます。
操作タブ
ゼロ通過 ...単回帰直線は原点を通ります。固定勾配 ...勾配を設定タブで指定した値に固定します。誤差は重みと見なす ...ワークシートの誤差列を選択しておきます。
誤差が表示されます。信頼帯 ...回帰直線の上下限の信頼区間を表示します。推定帯 ...回帰直線の上下95%の推定限度を表示します。

Chapter 7
429
線形フィットツールバー - 設定タブ
複数のデータに線形フィットを実行する
次のように複数のデータセットがある場合について考えましょう。
複数データのサンプル
これから散布図を描くと次のようなグラフができます。

ORIGIN6.0
430
この3種類のデータに対して同時に単回帰を実行することはできません。単回帰はアクティブなデータセットに対してのみ実行されます。実際、アクティブなデータセットはどれなのかを調べるには、「データ」メニューをクリックしてみましょう。アクティブなデータセットにはチェックが付いています。
データメニューの情報
g1は作図に利用したデータセットがグループ化されていることを示しています。結論として、複数のデータセットに個別にフィッティングしたグラフを一画面上に表示するには、各データを異なるレイヤに作図し、それぞれフィッティングを実行して行います。
サンプルグラフ

Chapter 7
431
Chapter7 - 07 多項式回帰
多項式よるフィッティングの方法と解析結果の意味について解説します。
多項式回帰は次の式を用いてフィッティングを行います。
Y=A0+A1X1+....+AnXn
多項式回帰を実行すると、その結果である回帰曲線と以下のパラメータ情報を結果ログウィンドウに表示します。
A0,A1,A2... 回帰係数とその誤差R^2 寄与率(回帰係数の平方)SD 標準偏差
次のデータを準備しましょう。
サンプルデータ
このデータから散布図を作成しましょう。

ORIGIN6.0
432
散布図の例
散布図に対して3次の多項式回帰を実行します。「解析」メニューから「フィット:多項式」を選択します。次のダイアログが表示されます。
多項式の次数は「3」とし、さらに「図中に数式を表示?」オプションをチェックしてください。ORIGINの多項式回帰で利用できる多項式の最高の次数は9です。準備ができたらOKボタンをクリックします。
多項式ダイアログ

Chapter 7
433
回帰曲線と回帰式の表示されたグラフができます。多項式回帰の実行結果は結果ログウィンドウに表示されます。
多項式回帰の結果ログウィンドウ
決定係数、標準偏差、N(データ数)、P(回帰係数が0になる確率)が表示されます。
多項式回帰を実行したグラフ

ORIGIN6.0
434
Chapter7 - 08 重回帰
重回帰分析のデータの入力方法と解析の実行方法について解説します。
ワークシートの準備重回帰分析は複数の独立変数による線形回帰分析のことです。ワークシートには複数のX独立変数を入力します。「列」メニューから「新規列の追加」を選択し、2列のデータセットを追加してください。サンプルデータには次のようなデータを入力し、A列をY変数に、B,C,D列をX変数にします。データセット列を新規に追加するとデフォルトでY変数となります。必ず、変更してください。サンプルデータ
重回帰分析を行う場合、従属変数Yはワークシートの左端に位置させてください。
重回帰分
析の実行
!Attention

Chapter 7
435
ワークシートの独立変数Xを図のように選択します。
独立変数Xを選択した
ワークシート
「解析」メニューから「多重回
帰」を選択してください。次のような確認のダイアログが現れます。OKを押すと計算を実行し、結果ログウィンドウに解析結果が表示されます。
結果ログウィンドウ
Resultウィンドウには回帰係数、決定係数、補正決定係数、推定標準偏差、ANOVAテーブルが表示されます。
確認ダイアログ

ORIGIN6.0
436
Chapter7 - 09 非線形回帰
ORIGINにはデータ解析するための非線形関数が豊富に用意されています。非線形回帰関数の選択とユーザ定義関数の利用方法について解説します。
非線形関数は既に関数式が決まっており、その変数の値がどの程度の大きさか?ということを調べるために利用するのが一般的です。生化学における反応速度の関数式における定数を調べる場合などに利用します。
非線形曲線の種類
非線形関数としてどのようなものがあるのかご紹介します。ワークシートが表示されている画面で、「解析」メニューから「非線形フィット」を選択します。次のダイアログが表示されます。
非線形曲線フィットダイアログ
ダイアログは、最初、上級モードで表示されます。「基本モード」というボタンを押せば、上級モードで表示されていたカテゴリー内の関数だけを表示します。(上級ボタンを押せば、上級モードに切り替わります。)

Chapter 7
437
基本の非線形曲線フィットダイアログ
数式を見ても、曲線の概要がはっきりしない場合は「曲線のサンプル」という項目をチェックしましょう。図のようにグラフの曲線が表示されます。非線形関数の選択に関しては、このダイアログから目的のものを探し出してください。
ユーザ定義の関数
非線形曲線のフィットダイアログを使ってユーザ定義の関数を入力し、それを実際に利用することができます。それでは、例として次の数式をユーザ定義の関数として設定しましょう。
ユーザ定義関数 Y=P1*x^2+P2*sin(x)+P3P1,P2,P3は定数とします。
「非線形曲線フィット」ダイアログで、「関数」メニューから「新規」を選択します。「名前」を「Myfit」、「パラメータの数」を「3」とし、定義のボックスに目的の式を記述します。その時のダイアログを次に示します。
曲線サンプルを表示

ORIGIN6.0
438
ユーザ定義に関数の入力
保存ボタンを押すと、ユーザ定義関数は非線形関数のカテゴリー「ORIGIN Basic Functions」の関数「Myfit」で保存されます。ここで大切なポイントを2つ紹介しましょう。1)必ず保存する、2)入力した数式の種類をダイアログの一番下にある「定義形」で設定する。Y=の形で書き始める数式の場合は、この項目を「Y-スクリプト」にします。これらの設定が完了したら「保存」ボタンを押して定義した数式を保存します。保存が終了したら、「関数」メニューから「フィットの終了」を選択してダイアログを閉じます。
非線形関数/ユーザ定義関数の実行つぎのサンプルデータを準備して、散布図を作成してください。
サンプルデータ

Chapter 7
439
サンプルデータによる散布図
このグラフが作成できた時点で、「解析」メニューから「非線形フィット」を選択してください。非線形ダイアログボックスの「関数」メニューから「選択」を選んでください。そして、ここでは「Power」の「Allometric1」を利用することにしますので、カテゴリー項目から「Power」を選び、関数項目から「Allometric1」を選びます。
関数を選択
次に非線形曲線フィットダイアログの「操作」メニューから「データセット」を選択し、フィッティングするデータセットを正しく設定しましょう。この例では従属変数にデータセットBを、独立変数にデータセットAを設定します。ダイアログ内の上側にある変数ボックスで「y 従属」を選び、「利用可能データセット」項目から「data1_b」を選び、「割り当て」ボタンを押します。自動的に「--->x 独立」には、「data1_a」が割り当てられます。

ORIGIN6.0
440
データセットの設定ダイアログ
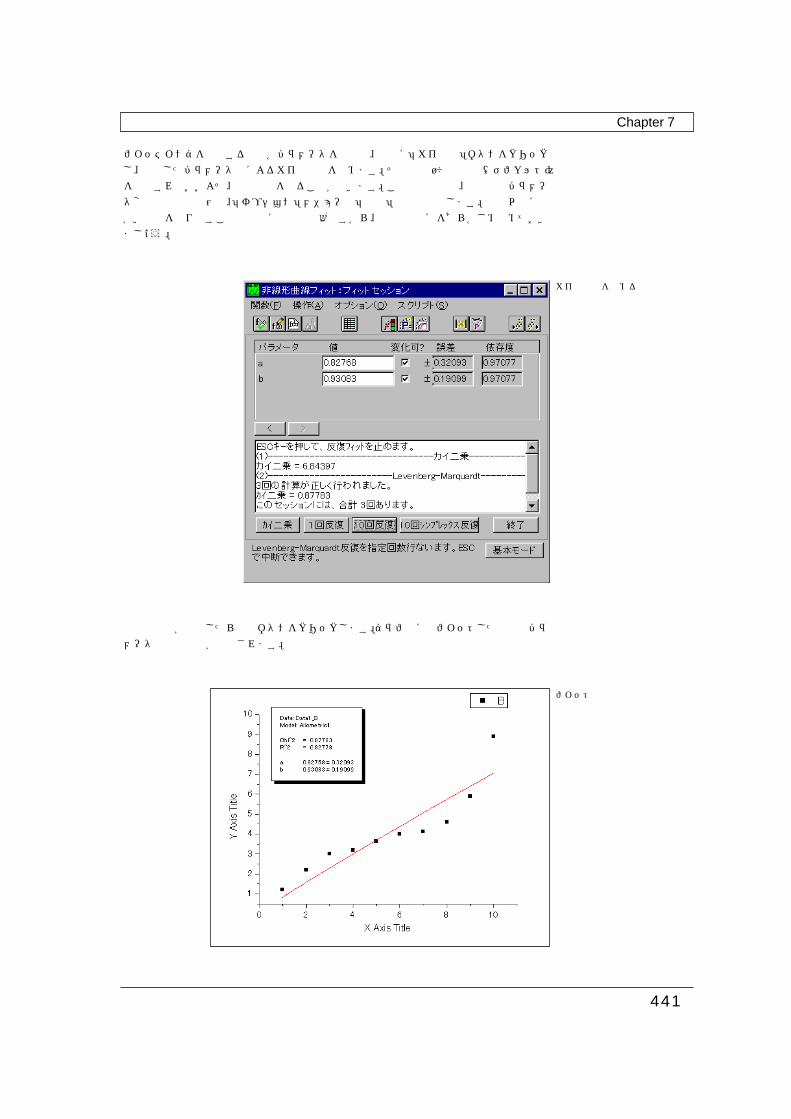
次に「操作」メニューから「フィット」を選択します。「フィットセッション」ダイアログが表示されますので、各パラメータの初期値を入力してください。非線形回帰は単回帰とは異なり、必ず初期値を入力する必要があります。これによりLevenberg-Marquardt法による繰り返し計算を実行し、カイ二乗値を最小化して、近似曲線を求めます。この時、各パラメータの初期値にはなるべく目的の値に近いものを設定することが好まれます。
パラメータの初期値を設定
Chapter 7
441
フィッティングを開始する際は各パラメータを入力後、最初に「カイ二乗」ボタンをクリックし、入力したパラメータ値によるカイ二乗値を求めます。その後は10回の反復(デフォルト)を実行すればおおよそ、目的の値を得ることができます。この反復回数や、計算時のパラメータ変化量の許容範囲は、「オプション」メニューの「制御」項目で調整します。必要以上に細かい計算を繰り返すことは単純に時間の無駄ですから、経験上の目安をあらかじめ決めておきましょう。
計算の実行が終了したら終了ボタンをクリックします。グラフ上にはフィットした曲線とパラメータなどの情報が表示されます。
カイ二乗値を求める
フィット曲線

ORIGIN6.0
442
結果ログ

Chapter 7
443
Chapter7 - 10 スムージング
3つのスムージングツールについて説明します。スムージングには次に3つの方法が用意されています。Savitzky-Golay (独立変数が等間隔の場合のみ有効)隣接平均
FFTフィルタSavitzky-Golayの方法は独立変数Xが等間隔で分布している場合しか利用できませんので注意してください。ここではサンプルのデータを作成し、それらに対してスムー
ジングを実行する方法と、結果の見方について解説します。
サンプルデータの作成ORIGINに用意されている便利な機能を使って、サンプルデータを作成してみましょう。
はじめに空のグラフシートを作成してください。
空のグラフシートが作成できたら、つぎに「マウスで作図」ツールを使って、グラフウィンドウをダブルクリックしながら、サンプルのデータを作成します。
サンプルのグラフ
このデータは不等間隔で存在していますから、これを等間隔に直してみましょう。作成したサ
ンプルデータは「draw**」と
新グラフウィンドウ
マウスで作図ツール

ORIGIN6.0
444
いう新しいデータセットに格納されています。プロジェクトエクスプローラから「draw1」をダブルクリックしてワークシートを表示しましょう。作成したデータの一部
18個のデータポイント
を作成しました。新たにデータ列Cを作成し、その属性をXとしてください。そして、列値の設定機能を使って、1から25までの整数を入力します。
等間隔のX変数を作成したデータの一部
このサンプルデータを元に「線+シンボル」グラフを再度作成します。

Chapter 7
445
等間隔のX変数によるグラフ
スムージングの実行
グラフが画面上に表示されている状態で「ツール」メニューから「スムージングツール」を選択します。スムージングのダイアログが表示されます。
目的の手法をクリックして実行
スムージングに関する設定

ORIGIN6.0
446
設定
データと原図を置き換える元のグラフを画面上から消去し、スムージングされた曲線だけを表示します。
新規ワークシートを作成曲線を追加し、さらに曲線データをワークシートに格納します。元のグラフはそのまま。
利用するポイント数を5とした時の結果を次に示します。
Savitzky-Golayによるグラフ
隣接平均によるグラフ

Chapter 7
447
FFTフィルタによるグラフ
これらのスムージング曲線のデータは元のワークシートに追加されています。
スムージングデータの追加されたワークシート

ORIGIN6.0
448
Chapter7 - 11 FFT
波形の分析機能として利用頻度の高いFFT機能の利用方法について解説します。
FFTはFast Fourier Transform(高速フーリエ変換)の頭文字を用いた略語です。時間など、独立変数の変化に伴って変化する波形を、周波数成分とスペクトルで表わします。最初にサンプルデータを用意します。
新しいグラフウィンドウを作成(「ファイル」メニューの「新規」から「グラフ」を選択。)します。「グラフ操作」メニューから「関数グラフの追加」を選択します。数式の欄に次式を入力してください。
F1(x)=15+5*sin(2*x)+3*cos(3*x)
ただし、データの点密度は248とし、角度の単位はラジアンとします。角度の単位は「ツール」メニューのオプションで確認してください。
関数の追加ダイアログ
このダイアログでOKボタンをクリックすれば、グラフが出来上がります。グラフのY軸の最大値を25に変更し、X軸の最大値を16に変更します。

Chapter 7
449
サンプルグラフ
グラフを見ると、これは一定の周期で変化していることが良く分かると思います。このサンプルグラフの波形にFFTをかけて、元の数式のような結果が得られることを確認しましょう。手順は次の通りです。
(1)「解析」メニューから「FFT」を選択します。(2)操作タブの「FFT」の項目が「フォワード」、「スペクトル」の項目が「振幅」となっていることを確認します。
(3) OKボタンをクリックします。
FFTダイアログ - 操作タブ
FFTを実行するするとスクリプトウィンドウに計算中であることを示すメッセージが表示されます。しばらくすると、結果を示すグラフとグラフの実データが格納されたワークシートが作成されます。

ORIGIN6.0
450
FFTの実行結果
FFT を実行した結果のグラフは一般のグラフと同じように編集できます。また、解析結果のワークシートも一般のワークシートと同じように操作できます。
FFTの設定タブ
「抽出間隔」は作図した元データのX変数(時間または度数)の間隔に相当します。これを調整することで、作図されるFFTグラフのスケールのみが変化します。波形の分布状態は変化しません。「ウィンドウ法」は有限長の波形を取り出すための方法です。ORIGINでは図のように5つの方法が利用できます。
●矩形●Welch●Hanning●Hamming● Blackman
FFTダイアログ - 設定タブ

Chapter 7
451
詳細はデジタルフィルタに関する専門図書を参照してください。
ORIGIN6.0の設定タブには、指数位相ファクターという項目が追加されました。これは、FFTでの指数位相ファクターの符号を設定するために、(電気)工学分野または科学分野を選択するものです。「+1科学分野」を選択すると、「Numerical Recipe in C」の「P503」に載っている公式にしたがって、位相ファクターが設定されます。
「-1工学分野」では、位相ファクターは科学分野と反対の符号になります。2つの定義は、同じ実数を与えますが、その虚数と位相角度は逆の符号を持ちます。

ORIGIN6.0
452
Chapter7 - 12 デジタルフィルタ
デジタルフィルタの利用方法について解説します。
サンプルデータの準備デジタルフィルタを実行するためのサンプルデータを作成しましょう。列値の設定ダイアログ
を使って、400までのセルにX変数に整数、Y変数に「sin(i*5)+2」の値を入力してください。角度の単位は「度」とします。列値の設定ダイアログ
サンプルデータ
サンプルデータ
をグラフ化すると単純なサイン波が描画されます。

Chapter 7
453
サイン波のグラフ
デジタルフィルタの実行
サンプルの波形に対してデジタルフィルタをかけてみましょう。対象となるデータは時間領域のデータです。この波形を一度フーリエ変換(FFT)する必要はありません。「解析」メニューの「FFTフィルタ」から「ハイパスフィルタ」を選択します。
FFTフィルタ(ハイパス)のダイアログ
上図のようにカットオフ周波数を「0.1」とし、「F0オフセットを適用して下さい」項目をチェックして下さい。準備ができたらOKボタンをクリックします。
ハイパスフィルタを実行した波形

ORIGIN6.0
454
それでは、ここで元のサイン波にFFTを実行して周波数成分を確認しておきましょう。元のワークシートから再度、折れ線グラフを作成してください。そして、「解析」メニューから「FFT」を選択します。タブの内容はデフォルトのままとし、OKボタンをクリックしてFFTを実行してください。
FFTダイアログ
FFTを実行した結果のグラフ
ワークシートの列値の設定ダイアログでsin(i*5)+2という数式を使って波形を作成したわけですから、限りなく0に近い単一の周波数成分が描画されることは明らかです。先ほど実行したFFTフィルタリングでカットオフ周波数を0.1としました。逆に同じ設定でローパスフィルタを実行すれば、波形はほぼ元のまま、残ると考えられます。
ノイズ閾値ORIGIN6.0では、作成したグラフで、指定したノイズ閾値より下にある周波数に相当するノイズを取り除くことができます。元のワークシートから再度、折れ線グラフを作成してください。そして、「解析」メニューの「FFTフィルタ」から「閾値」を選びます。
これを実行すると、最初、グラフにフォワードFFTをかけ、移動可能な閾値線を持つ周波数スペクトルを表示します。グラフ上部には計算された閾値が表示されます。

Chapter 7
455
閾値線を希望のレベルにドラッグし、閾値テキストボックスに閾値に対する振幅の値を入力します。「フィルタの閾値」ボタンを押すと、セットした閾値以下のすべての周波数コンポーネントをフィルタにかけ、強度閾値が表示されます。
さらに、フィルタアウトされた周波数スペクトル上で逆(inverse)FFTが実行され、除去されたノイズと元のデータを含むワークシートが作られます。
閾値線を持つ周波数スペクトル
「フィルタの閾値」の結果

ORIGIN6.0
456
Chapter7 - 13 t検定 (1集団)
基本的な統計手法であるt検定の実行方法について説明します。t検定は母平均との差に関する有意差について調べるための検定手法です。ここでは例題を元に実際にt検定を実行してみましょう。今、フローピーディスクのフォーマット作業を行うのに、平均65秒かかっていました。この時間を短縮するため、ドライブを改良しました。改良したドライブで10回の測定を行った結
果は以下の通りです。サンプルデータの入力
「解析」メニューから「t検定(1集団)」を選択します。次に表示されたダイアログで「テス
ト平均」を「65(s)」、「有
意水準」を「0.05」とします。t検定のダイアログ
OKボタンをクリッ
クすると、結果ログウィンドウに計算結果が表示されます。

Chapter 7
457
t検定の実行結果
せっかく、ドライブの改良を行いましたが、時間の短縮は実現できなかったようです。それでは、具体的に解析結果について説明します。
データA データセットAのカラムデータを分析したことを示しています。平均 64.3 データセットAの平均値です。分散 1.87333 データセットAの分散です。N 10 データセットAのサンプル数です。t=-1.6173 t検定の統計量です。「有意水準 0.05 で、二つの平均は、 有意差があるとは言えません。」
有意水準5%のときに、母平均(改良前)とサンプル(改良後)の間に平均値の差はない、という結論が得られました。

ORIGIN6.0
458
Chapter7 - 14 2集団のt検定
2集団に対するt検定の実行方法について説明します。この場合、対応のあるデータと対応の無い場合で、方法を選択する必要があります。
対応の無い2集団のt検定
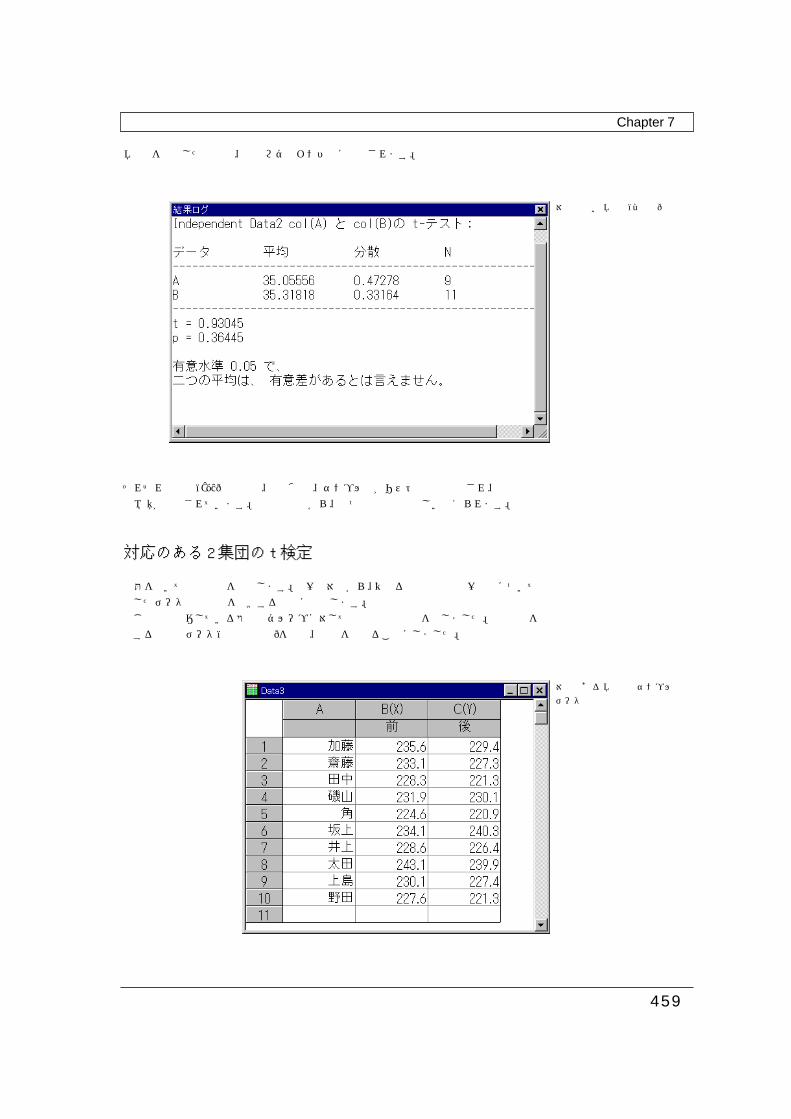
2台の機械(A,B)で製造したネジからサンプルをとって、その平均値に違いがないか、t検定によって調べてみましょう。まず、データを下図のようにワークシートに入力します。この場合は、機械Aのサンプルを9個、機械Bのサンプルを11個用意しました。もちろん、サンプル数を同じ数に合わせてもかまいません。
サンプルデータの入力
2つの列を選択して、「解析」メニューから「t検定(2集団)」を選択します。t検定の手法を選択するダイアログが表示されます。この場合は、「独立」を選択します。
t検定(2集団)の種類を選択
Chapter 7
459
t検定を実行した結果は、結果ログウィンドウに表示されます。
対応の無いt検定(2集団)の結果
それぞれの機械(A,B)の平均値、標準偏差、サンプル数がリスト形式で表示され、検定量と棄却域pが算出されています。計算の結果から、二つの平均値は等しい考えられます。
対応のある2集団のt検定
例題を用いて利用方法を説明します。同一の対象から、異なる条件下での同一項目について観測したデータの平均値を比較する場合に利用します。同じ病気で入院している患者のグループに対して特別な食事療法を施しました。食事療法を適用する前後のデータ(血糖値など)を比べ、効果を調べることにしました。
対応のあるt検定のサンプルデータ

ORIGIN6.0
460
列Bと列Cを選択して、「解析」メニューから「t検定(2集団)」を選択します。t検定の手法を選択するダイアログが表示されます。この場合は、「対データ」を選択します。
t検定(2集団)の種類を選択
t検定を実行した結果は、結果ログウィンドウに表示されます。
対応のあるt検定(2集団)の結果
すなわち、食事療法の効果があったと判断できます。

Chapter 7
461
Chapter7 - 15 一元配置の分散分析
一元配置の分散分析の実行手順に手順について解説します。
t検定は2群間の平均の差の検定でした。一元配置の分散分析とは、これを複数群間で行うためのものです。
データの準備
データセットには次のようなデータを入力します。
ANOVAのためのサンプルデータ
ANOVAを実行する対象となるデータセットをドラックして反転表示させます。ここではB(Y)からD(Y)までを選択します。「解析」メニューから「ANOVA(一元配置)」を選択します。
一元配置の分散分析の実行メニューを選択すると次のダイアログが表示されます。
一元配置の分散分析のダイアログ

ORIGIN6.0
462
このダイアログでは有意水準を設定します。ここではデフォルトの5%を採用します。そのままOKボタンをクリックしてください。
分散分析の結果を示す結果ログ
結果ログウィンドウに計算結果が表示されます。ここではp=0.61となり、平均が異なるという仮説は棄却されます。つまり、グループの平均は同じであると判断できます。ORIGINでは以上のように一元配置の分散分析の統計機能はサポートしていますが、これに用いたデータの統計的なグラフ化(各グループの平均値と標準誤差をプロットし、その平均値を結線したグラフの作成)は行えません。









![5 í ' Ä î º Ï å É ³ Û î Ù ] i...6)主電源線サイズは、CV線を使用し金属管に電線3本以下とした場合を示します。 7)配線の電圧降下は、幹線及び分岐回路のそれぞれにおいて定格電圧の2%以下が原則です。](https://img.pdfslide.tips/doc/110x75/5f4881655320ff26161a56e0/5-i-6ieccvccecec3oec.jpg)







![32A5 の点を観測します。 4 1 3 「 2: [線]道路縁(街区 線)」を選択します。3 4 A6 の点を観測します。次頁へ 1-7 測量-9 「 1:[線]道路縁(街区](https://img.pdfslide.tips/doc/110x75/60dacc590dd4880ce83bd73b/32-a5-ce-4-1-3-oe-2-ceecieoe-cie3.jpg)









![円錐曲線 - plala.or.jp円錐[定義は後述]をある平面で切断したときに切断面に現れる曲線を総称して円錐曲線という。 円錐曲線には楕円,円,放物線,双曲線がある。(1)](https://img.pdfslide.tips/doc/110x75/5f04b2f67e708231d40f43de/eoec-plalaor-eoecoeeeecoeccceoec.jpg)

