Embed Size (px)
Citation preview

Data Mining : A First Data Mining : A First ViewView
DATA MINING - A Tutorial Based DATA MINING - A Tutorial Based PrimerPrimer
2008. 3. 20
서 진 이HPC Lab , UOS

2
목 차목 차 1.1 Data Mining: A Definition 1.2 What Can Computers Learn? 1.3 Is Data Mining Appropriate for My Problem? 1.4 Expert Systems or Data Mining? 1.5 A Simple Data Mining Process Model 1.6 Why Not Simple Search? 1.7 Data Mining Applications

3
1.1 Data Mining: A Definition1.1 Data Mining: A Definition Data Mining
컴퓨터 학습기법을 사용하여 데이터들로부터 지식을 자동으로 분석하거나 추출하는 과정
데이터속에 감추어져있는 경향을 패턴을 찾는것이 목적 Induction-based Learning
학습되어질 개념의 세부 사례들을 관찰하여 그것을 일반화된 개념 정의를 만들어 가는 과정 의미
Knowledge Discovery in Databases (KDD) 과학적 연구방법을 데이터마이닝에 적용하는 것 일반적인 KDD 모델은 DM 작업 수행후 그에 따라 의사결정하는 것 데이터를 준비하고 추출하는 방법론까지를 포함 데이터 추출과 준비가 가장 많은 시간이 걸림

4
Integration of techniques
Must be scalable Must extract high-level information
DBMSMachine learning
Data visualization
StatisticsInformation retrieval
PatternRecognition
DM/KDD
1.1 Data Mining: A Definition 1.1 Data Mining: A Definition

5
1.2 What Can Computers Learn?1.2 What Can Computers Learn?
Four Levels of Learning Facts ( 사실 )
참 혹은 진리인 내용
Concepts( 개념 ) 어떤 공통된 특징을 잦는 객체 , 기호 , 사건들로 묶여진 집합
Procedures( 절차 ) 목표를 이루지위해 행하여지는 행위의 순차적 과정
Principles( 원리 ) 다른 진리에 기본 및 근거가 되는 일반화된 진리나 법칙을 의미 학습의 가장 높은 레벨
Computers & Learning 컴퓨터는 개념학습에 유용 개념은 DM 의 산출물 DM Tool 을 통해 학습된 개념은 Tree 구조 , rule, network 구조 , 수학공식의 형태를
지님

6
1.2 What Can Computers Learn?1.2 What Can Computers Learn?
Three Concept Views Classical View
모든 개념들은 명확하게 정의되는 속성을 가짐 정의가 명확하기 때문에 잘못 해석할 여지가 없음 명확하게 정의된 속성들을 가지고 어떤 item 이 어떤 개념의 사례인지 아닌지를
판단
Probabilistic View 구성원들의 확률적 속성들에 의하여 표현
Exemplar View 한 인스턴스가 어떤 개념의 사례와 충분히 유사하다면 그 인스턴스를 그 개념의
사례라고 함 사람들이 개념의 전형적인 사례를 저장하고 그것을 사용하여 새로운 인스턴스를
분류하는데에 사용한다는 가정을 사용함

7
1.2 What Can Computers Learn?1.2 What Can Computers Learn?
Supervised Learning (Decision Tree Example) Table data 를 일반화하여 Tree 형태로 표현 귀납적 학습기법 (induction-based learning) 을 사용하여 개념 정의 동물 , 사물 혹은 건물 모양등과 같은 개념의 인스턴스를 보고 이름을 듣고 개념을
정의하는데 사용되는 여러가지 특징 요소를 정하고 자신만의 분류 모델을 만들어냄 Decision tree 로 data 를 일반화하고 정확한 진단에 필요한 중요한 attribute, attribute
들간의 관계에 대한 요약을 볼 수 있음 Model 의 정확도를 test set 으로 측정 목적
학습하려고 하는 개념의 인스턴스들로 부터 supervised 학습을 사용하여 분류모델을 만들고자 함 ( 귀납적 )
분류모델이 만들어지면 그것을 사용하여 새로 주어진 인스턴스를 분류하기 위함( 연역적 )
장점 이해가 쉽고 규칙의 형태로 쉽게 변환이 되고 비교적 실험결과가 좋음

8
1.2 What Can Computers Learn? 1.2 What Can Computers Learn?
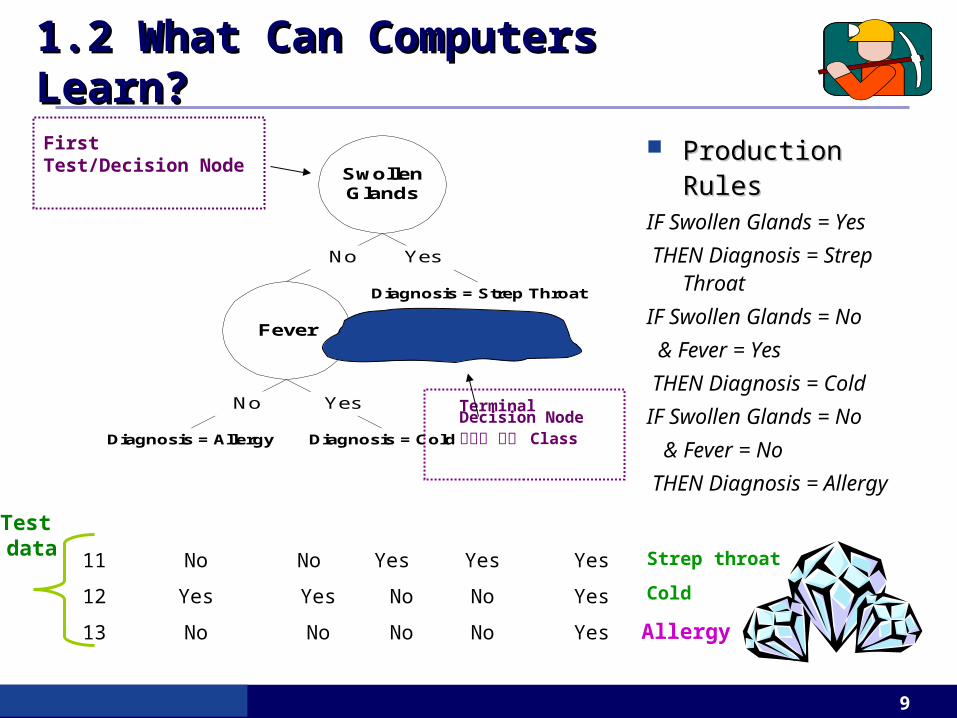
Table 1.1 • Hypothetical Training Data for Disease Diagnosis
Patient Sore Swollen ID# Throat Fever Glands Congestio
n Headache Diagnosis
1 Yes Yes Yes Yes Yes Strep throat 2 No No No Yes Yes Allergy 3 Yes Yes No Yes No Cold 4 Yes No Yes No No Strep throat 5 No Yes No Yes No Cold 6 No No No Yes No Allergy 7 No No Yes No No Strep throat 8 Yes No No Yes Yes Allergy 9 No Yes No Yes Yes Cold
10 Yes Yes No Yes Yes Cold
Input Attribute= Variable
Output Attribute= Target Variable
= Class
Instance = Case
Training data
9
1.2 What Can Computers 1.2 What Can Computers Learn?Learn?
SwollenGlands
Fever
No
Yes
Diagnosis = Allergy Diagnosis = Cold
No
Yes
Diagnosis = Strep Throat
First Test/Decision Node
Terminal Decision Node결정된 결과 Class
11 No No Yes Yes Yes
12 Yes Yes No No Yes
13 No No No No Yes
Test data Strep throat
Cold
Production RulesProduction RulesIF Swollen Glands = Yes
THEN Diagnosis = Strep Throat
IF Swollen Glands = No
& Fever = Yes
THEN Diagnosis = Cold
IF Swollen Glands = No
& Fever = No
THEN Diagnosis = Allergy
Allergy

10
1.2 What Can Computers Learn?1.2 What Can Computers Learn?
어떠한 결정트리도 어떠한 결정트리도 production ruleproduction rule 들로 변환시킬 수 있음들로 변환시킬 수 있음 Production rule -> If Production rule -> If 선행조건들 선행조건들 then then 결과 결과 규칙의 선행조건들은 규칙의 선행조건들은 root noderoot node 에서 에서 terminal nodeterminal node 까지의 까지의 attribattrib
ute ute 값들의 조합값들의 조합 The “tree” is upside down. The Decision Tree fits the data perfectly.
There are no errors. Accuracy = 100%.
The Decision Tree discards the unneccessary attributes
A computer algorithm to construct Decision Trees would be easy to programme, and would do the job much quicker than we humans can
11
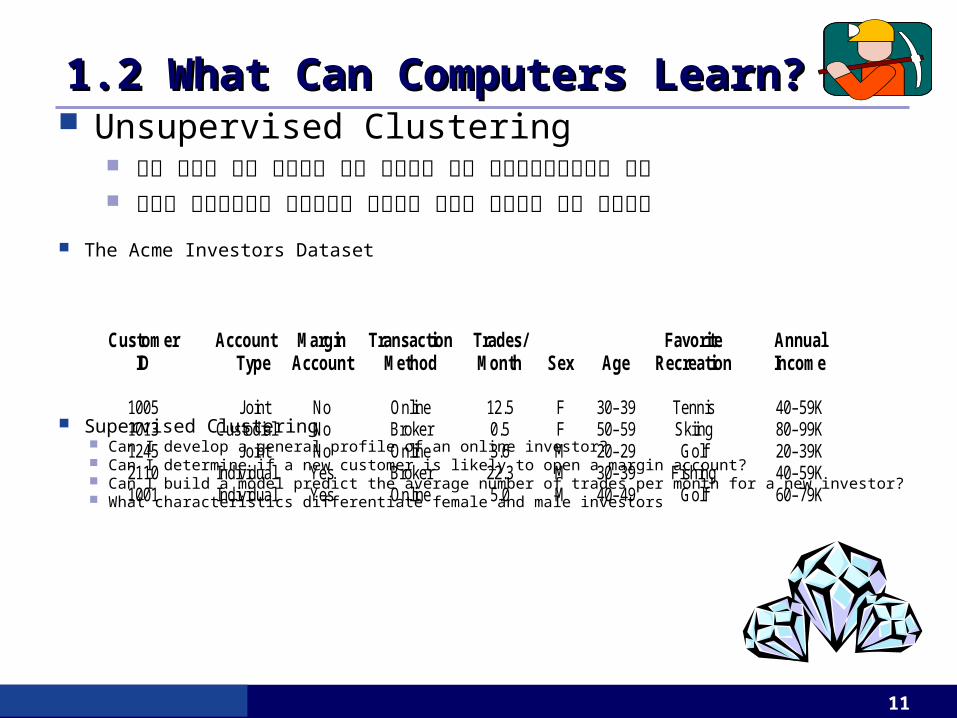
1.2 What Can Computers Learn?1.2 What Can Computers Learn? Unsupervised Clustering
모델 만들시 분류 클래스가 미리 정의되지 않은 데이터인스턴스들을 사용 데이터 인스턴스들은 클러스터링 시스템에 정의된 유사도에 의해 그룹핑됨
Customer Account Margin Transaction Trades/ Favorite Annual ID Type Account Method Month Sex Age Recreation Income
1005 Joint No Online 12.5 F 30–39 Tennis 40–59K 1013 Custodial No Broker 0.5 F 50–59 Skiing 80–99K 1245 Joint No Online 3.6 M 20–29 Golf 20–39K 2110 Individual Yes Broker 22.3 M 30–39 Fishing 40–59K 1001 Individual Yes Online 5.0 M 40–49 Golf 60–79K
The Acme Investors Dataset
Supervised Clustering Can I develop a general profile of an online investor? Can I determine if a new customer is likely to open a margin account? Can I build a model predict the average number of trades per month for a new investor? What characteristics differentiate female and male investors

12
1.2 What Can Computers Learn?1.2 What Can Computers Learn? The Acme Investors Dataset & Unsupervised Clustering
많은 unsupervised clustering system 들은 사용자가 전체 clustering 의 개수를 정함
But 일부는 자체적으로 정해지기도 함 인스턴스들을 의미있는 clustering 로 그룹지으려고 함
Production Rule If Margin Account = yes & Age=20-29 & Annual Income = 40-59K THEN Clu
ster =1 (accuracy =0.80, coverage= 0.50) If Account Type = Custodial & Favorite Recreation = Skiing & Annual Incom
e = 80-90K THEN Cluster =2 (accuracy = 0.95, coverage = 0.35) If Account Type = Joint & Trade/Month >5 & Transaction Method = Online THEN Cluster = 3 (accuracy = 0.82, coverage = 0.65
Accuracy( 정확률 ) Coverage( 적용률 )

13
1.3 Is Data Mining Appropriate for 1.3 Is Data Mining Appropriate for My ProblemMy Problem
Data Mining or Data Query? 찾으려는 것이 명확할 때 DB Query Language 와 OLAP 으로 정보를
찾거나 보고 , reporting 하는데 사용할 수 있음 It depends on the type of question you want to answer, and the type of
knowledge you want to discover.
지식 Shallow Knowledge( 단순지식 )
It can be easily stored and manipulated in a database. SQL 질의로 추출
Multidimensional Knowledge( 다차원지식 ) OLAP tools are used to manipulate multidimensional knowledgeOn-lin
Hidden Knowledge( 은닉지식 ) represents patterns or regularities in data that cannot be easily found using data
base query. data mining algorithms can find such patterns with ease.
Deep Knowledge(심층지식 ) 찾고자 하는 방향을 제공하여 줄때만 찾을 수 있음

14
지식의 종류 및 탐사기법
1.3 Is Data Mining Appropriate for1.3 Is Data Mining Appropriate for My Problem My Problem

15
1.3 Is Data Mining Appropriate for 1.3 Is Data Mining Appropriate for My Problem?My Problem?
Data Mining vs. Data Query: An Example Data set 에서 찾고자 하는 것에 대한 일반적인 가설을 만듬 가설은 data 에 대하여 우리가 옳다고 믿는것에 대한 타당한
추측을 만듬 수동 데이터 마이닝 DB 가 충분히 적거나 attribute 들과 그들간의 관계에 대하여
충분한 지식이 있다면 직절 데 이 터 집 합 에 서 몇 개 의 attribute 들 은 output attribute 를 정 확 하 게
판별해내는데 관련이 있음
16
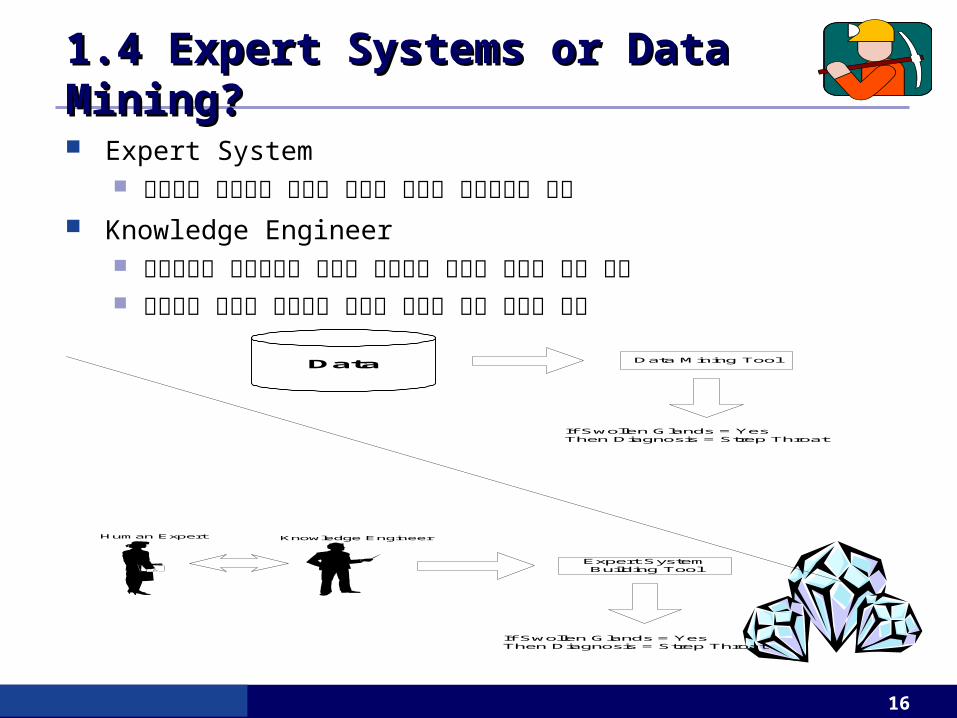
1.4 Expert Systems or Data 1.4 Expert Systems or Data Mining?Mining? Expert System
전문가의 문제해결 방법을 적용한 컴퓨터 프로그램을 의미 Knowledge Engineer
전문가와의 상호작용을 통하여 전문가의 지식을 끄집어 내는 역할 여러가지 도구를 사용하여 새로운 지식에 대한 모델을 만듬
Data Mining Tool
Expert SystemBuilding Tool
Human Expert
If Swollen Glands = YesThen Diagnosis = Strep Throat
If Swollen Glands = YesThen Diagnosis = Strep Throat
Knowledge Engineer
Data
17
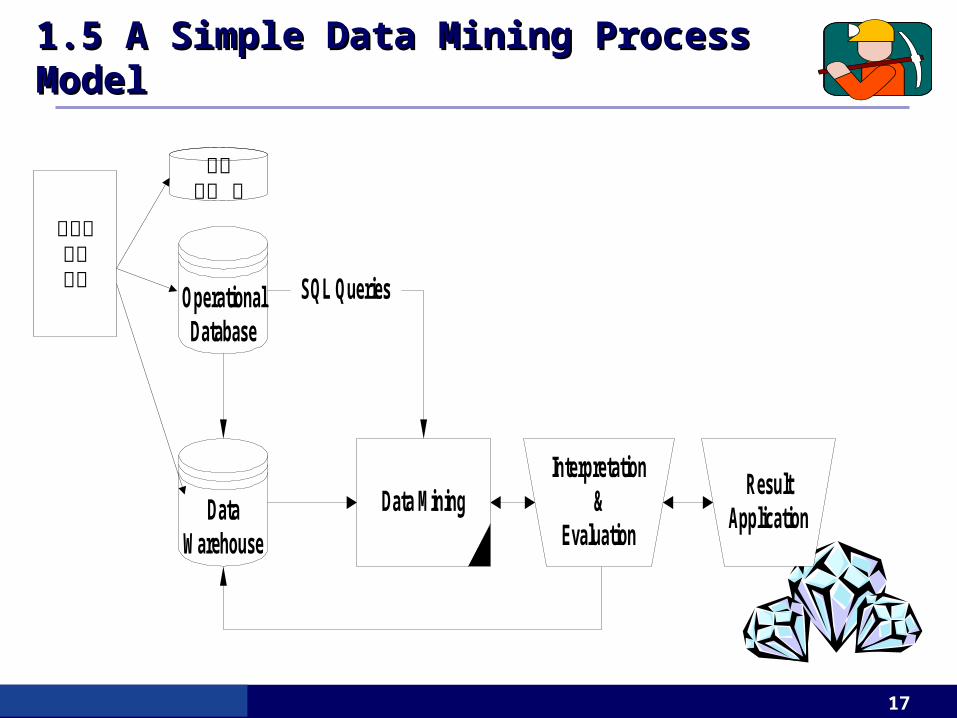
1.5 A Simple Data Mining Process 1.5 A Simple Data Mining Process ModelModel
SQL QueriesOperationalDatabase
DataWarehouse
ResultApplication
Interpretation&
EvaluationData Mining
데이터수집정리
일반화일 등

18
The Data Warehouse같은 주제에 관련된 모든 데이터들을 같은 테이블에 저장 운영데이터베이스는 트랜젝션 처리에 가장 적합하나 DW는 주제중심으로 데이터의 중복성이 존재하게 됨 트랜젝션 데이터 처리보다는 의사결정지원을 위해 설계된 과거 데이터 데이터베이스를 의미
Relational Databases and Flat Files Mining the Data
Supervised 학습인가 unsupervised clustering 인가 ?Training data 와 test 로 어떻게 나눌것인가 ?어떤 attribute 를 사용할 것인가 ?학습 parameter 값의 지정 ?
Interpreting the Results Result Application
1.5 A Simple Data Mining Process 1.5 A Simple Data Mining Process ModelModel

19
DMDM 은 비구조적인 데이터를 일반화된 모델로 표현하는 데 사용은 비구조적인 데이터를 일반화된 모델로 표현하는 데 사용 분류분류 (classification) (classification) 문제해결의 다른 방법문제해결의 다른 방법 NNNN분류분류 (Nearest Neighbor Classification) (Nearest Neighbor Classification)
분류 분류 table table 만들기 – 만들기 – data tabledata table 에는 분류에는 분류 classclass 가 정해져 있는 모든 가 정해져 있는 모든 data instandata instancece 를 포함를 포함 분류하고자 하는 새로운 분류하고자 하는 새로운 instanceinstance 에 대하여 에 대하여 tabletable 에 있는 각 에 있는 각 itemitem 과 새로운 과 새로운 iteitemm 간의 유사도 점수를 계산간의 유사도 점수를 계산 nearest : smallest Euclidean distance, absolute difference, maximum distance, Minkowski distance 등을 계산하여 그 거리가 가장 가까운 것을 의미 가장 유사한 가장 유사한 table itemtable item 을 찾고 그 을 찾고 그 itemitem 의 분류의 분류 classclass 를 새로운 를 새로운 itemitem 의 분류의 분류 clasclasss 로 로 새로 분류된 새로 분류된 instanceinstance 를 분류를 분류 classclass 와 함께 와 함께 tabletable 에 추가에 추가 분류 Table 에 많은 레코드가 있다면 계산시간 많이 소요 Relevant attribute 와 irrelevant attribute 를 구분할 수 없음 Instance 들을 class 로 분류하는데 어느 attribute 가 사용되는지에 대해 알수 없음
K-nearest Neighbor Classifier 하나가 아닌 k 개의 NN을 골라서 그중에서 가정 공통되는 분류클래스를 새로운 인스턴스의 클래스로 분류됨 새로운 인스턴스가 하나의 잘못된 training 인스턴스 때문에 잘못 분류되는 가능성을 방지하여 줌
1.6 Why Not Simple Search?1.6 Why Not Simple Search?

20
Application CaseApplication Case Fraud DetectionFraud Detection
Use historical data to build models of fraudulent behavior and use data mining to help identify similar instances (auto insurance, money laundering)
Health CareHealth Care Business and FinanceBusiness and Finance Scientific ApplicationScientific Application Sports and GamingSports and Gaming
1.7 Data Mining Applications1.7 Data Mining Applications

21
금융업에서의 적용 사례 사기행위 색출
: 과거에 사기행위로 판명된 신용카드 거래를 분석하여 사기행위의 패턴을 찾아냄 . : 신용카드 사기 행위의 전형적인 사례는 전자상가에서 짧은 기간에 많은 거래가 일어나는
경우이며 이것을 사기행위의 가능성을 알려주는 경고 신호로 인식하므로써 피해를 줄일 수 있음 . : 어떤 고객의 구매행위가 찾아낸 사기행위 패턴과 비슷할 경우 그 거래를 승인하지 않도록
시스템 (production system) 을 구성하는데 이용할 수 있음
고객집단 분류 : 특정 고객집단을 찾아내고 이 집단만을 겨냥한 차별화된 서비스를 제공 : 고객집단 편성에 관한 지식을 이용하여 특정 판촉활동에 의하여 가장 많은 효과와 혜택을 얻게 될 금융기관의 지점을 찾는 데에도 사용
라이프 싸이클 예측 관리 (predictive life-cycle management) : 은행이 고객의 시간에 따른 가치 (lifetime value) 를 예측하고 이에 따라 개개의 고객집단에 알맞은 서비스를 제공
: 이들은 가까운 장래에 수익성이 높은 고객이 될 가능성이 매우 높은 고객을 대상으로 이들에게 특별한 상품 거래를 제안하거나 수수료를 면제해 주는 것과 같은 고객 이탈방지 프로그램 같은 것을 실시할 수 있음
1.7 Data Mining Applications1.7 Data Mining Applications
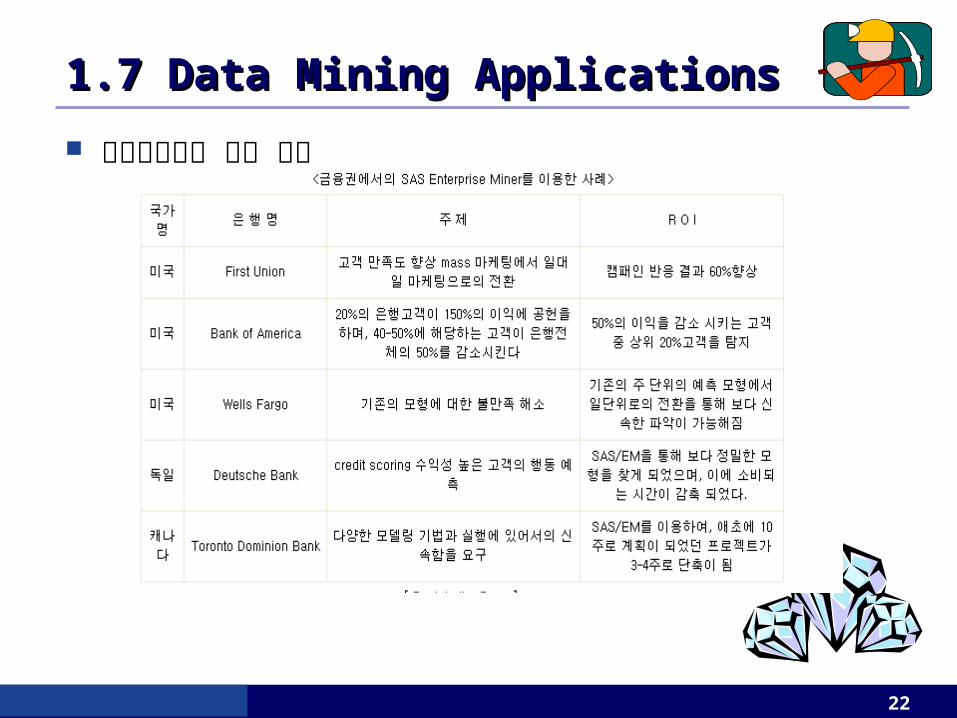
22
금융업에서의 적용 사례
1.7 Data Mining Applications1.7 Data Mining Applications

23
유통업에서의 적용 사례 유통업자들은 자사가 발행한 신용카드와 컴퓨터화된 결제시스템을 통하여
고객들의 매일 매일의 자세한 구매정보를 보유 바구니 분석 (basket analysis) 수행 : 바구니 분석은 일명 친화성 분석이라고도 하는데 고객들의 구매행위시 어떤 상품들이
같이 구매되는가를 밝혀낸다 . 이와 같은 지식은 상점의 진열 전략이나 재고 (stocking) 전략 , 판매촉진 등의 성과 제고에 활용
시계열 패턴 조사 (temporal pattern / sequences) : 시간에 따른 구매행위에 대한 지식은 유통업자들의 재고에 관한 의사결정에 많은
도움을 줌 . . 예측모델의 개발 : 유통업자들은 고객의 구매행위 , 예를 들어 어떤 상품의 구매행위나 할인 행사에
참여하는 행위 등을 통하여 특성을 파악할 수 있으며 특정 고객집단을 겨냥한 효과적이고 경제적인 판매 촉진 전략을 구사할 수 있음 .
1.7 Data Mining Applications1.7 Data Mining Applications
24
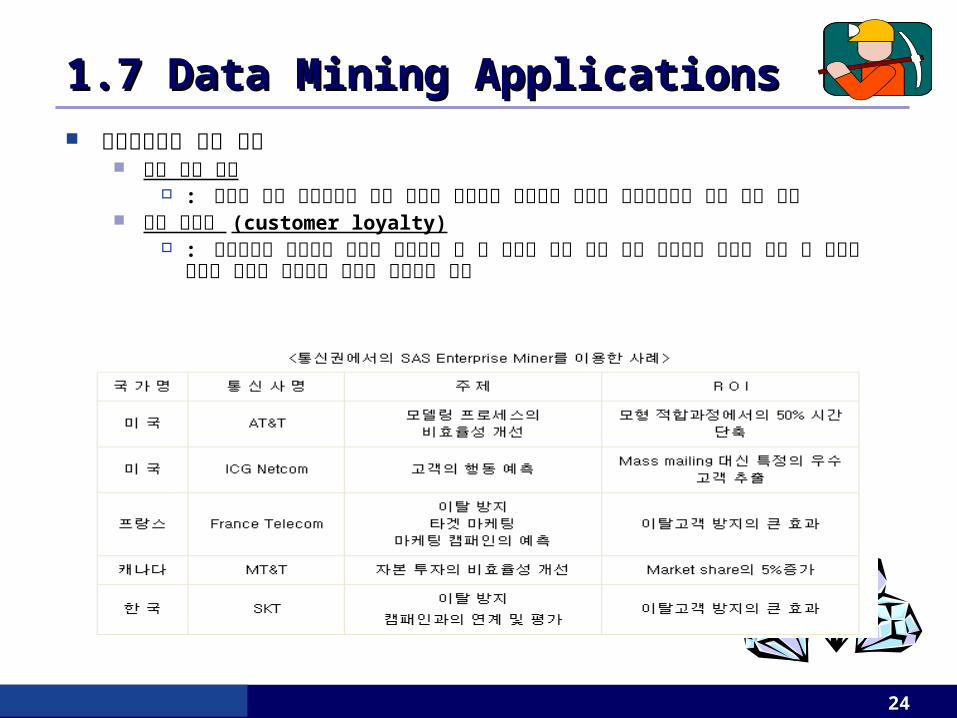
통신업에서의 적용 사례 통화 기록 분석
: 비슷한 통화 사용패턴을 가진 집단을 찾아내어 그들에게 유리한 가격정책이나 기능 등을 개발
고객 충성도 (customer loyalty) : 통신회사는 지식발견 기술을 이용하여 한 번 고객이 되면 오랜 동안 지속적인 거래를
하게 될 고객과 그들의 특성을 찾아내고 이들을 중심으로 투자
1.7 Data Mining Applications1.7 Data Mining Applications

25
그외 고객집단 편성
거의 모든 산업분야는 DM을 이용하여 뚜렷한 고객집단을 편성하는데 활용 자동차 제조
고객들을 위하여 맞춤 자동차를 생산하기 시작했고 따라서 어떤 특징들이 선호될 것인지 그리고 이러한 특징과 함께 어떤 점들이 요구될지를 예측 보증계약 (warranties)
제조업자는 보상 청구를 해올 고객의 수를 예측하고 이에 따른 비용을 예측 탑승객 인센티브 (frequent flier incentives)
항공사는 자사 비행기를 더 자주 이용할 수 있도록 인센티브를 제공할 고객 집단을 찾아냄 한 항공사는 짧은 거리를 매우 자주 여행하는 고객집단이 존재함 -> 비행횟수에 의해서도 항공사가 제공하는 혜택을 받을 수 있도록 규칙을 변경
제조업(Manufacturing) 공정 환경의 복잡함과 작업의 효율성과 품질의 우수성을 동시에 요구하는 현대 제조 분야에서도 DM 기법이 여러 분야에서 필요시 됨 Job shop scheduling, 공정 제어(manufacturing control)의 문제 , 화학 약품의 공정 과정(chemical process)의 최적화, 에너지 소비(energy consumption)의 최소화 혹은 품질관리(quality control)와 자동화된 검사(automated inspe
ction)에서도 활용 보건 의학 분야 (Health and medical)
환자나 병원측에서의 보험 사기(fraudulent insurance claim)에 대한 검색 각종 암이나 심장마비 등의 병을 자동 진단(automated diagnosis)에 이용
에너지와 유틸리티 (energy and utility) 에너지의 수요량을 예측(forecast)하여 날씨의 변화와 정전에 신속하게 대비 원유 탐사에 있어서 지층의 변화를 분석
1.7 Data Mining Applications1.7 Data Mining Applications
26
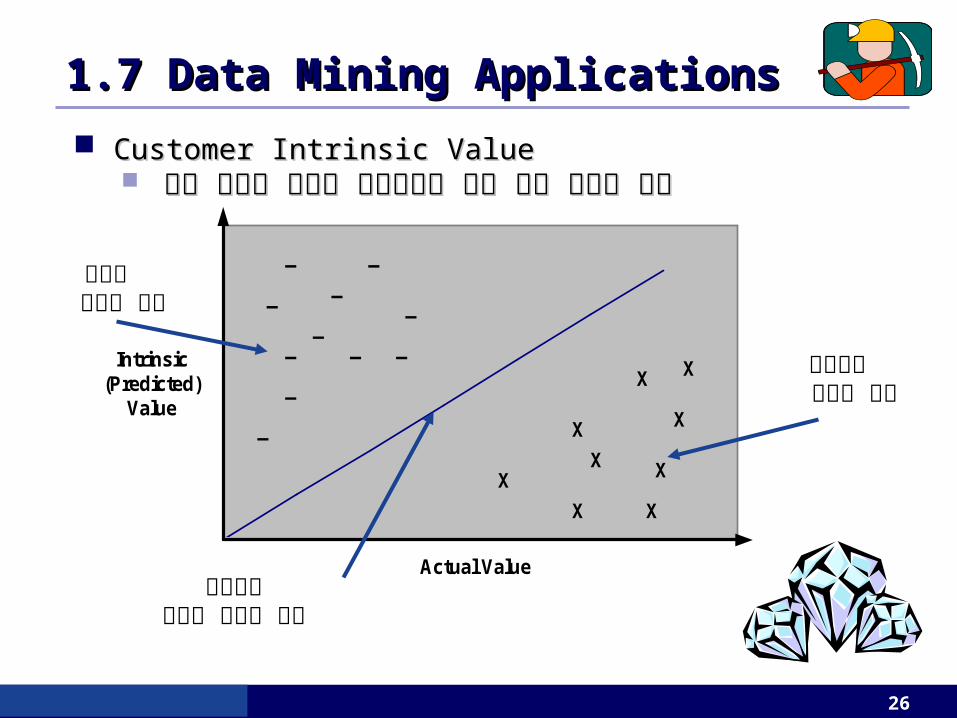
1.7 Data Mining Applications1.7 Data Mining Applications
Customer Intrinsic ValueCustomer Intrinsic Value 고객 이탈률 방지와 미래가치을 위한 전략 수립시 활용고객 이탈률 방지와 미래가치을 위한 전략 수립시 활용
X
X
X
X
X
XX
X
X
_
_
__
_
_
_
_
_
__
Intrinsic(Predicted)
Value
Actual Value중간정도
공격적 마케팅 전략
비공격적 마케팅 전략
공격적 마케팅 전략