Embed Size (px)
Citation preview

ANKARA ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
ÖLÇME VE DEĞERLENDİRME ANABİLİM DALI
FARKLI ÖRNEKLEM BÜYÜKLÜKLERİNDE VE KAYIP VERİ ÖRÜNTÜLERİNDE
ÖLÇEKLERİN PSİKOMETRİK ÖZELLİKLERİNİN KAYIP VERİ BAŞ ETME
TEKNİKLERİ İLE İNCELENMESİ
DOKTORA TEZİ
Ufuk AKBAŞ
Ankara
Temmuz, 2014

ANKARA ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
ÖLÇME VE DEĞERLENDİRME ANABİLİM DALI
FARKLI ÖRNEKLEM BÜYÜKLÜKLERİNDE VE KAYIP VERİ ÖRÜNTÜLERİNDE
ÖLÇEKLERİN PSİKOMETRİK ÖZELLİKLERİNİN KAYIP VERİ BAŞ ETME
TEKNİKLERİ İLE İNCELENMESİ
DOKTORA TEZİ
Ufuk AKBAŞ
Tez Danışmanı
Prof. Dr. Ezel TAVŞANCIL
Ankara
Temmuz, 2014


iv
ÖZET
FARKLI ÖRNEKLEM BÜYÜKLÜKLERİNDE VE KAYIP VERİ ÖRÜNTÜLERİNDE
ÖLÇEKLERİN PSİKOMETRİK ÖZELLİKLERİNİN KAYIP VERİ BAŞ ETME
TEKNİKLERİ İLE İNCELENMESİ
AKBAŞ, Ufuk
Doktora, Ölçme ve Değerlendirme Anabilim Dalı
Tez Danışmanı: Prof. Dr. Ezel TAVŞANCIL
Temmuz 2014, 174 sayfa
Bu çalışmanın amacı, ölçeklerin psikometrik özelliklerinin farklı kayıp
veri baş etme teknikleriyle incelenmesidir. Bu amaç doğrultusunda örneklem
büyüklüğünün 250, 500 ve 1000; madde sayısının 10 ve 15 düzeylerinde
manipüle edildiği 100 farklı yapay veri seti üretilmiştir. Eksiksiz veri setleri
üzerinde tümüyle seçkisiz kayıp, seçkisiz kayıp ve seçkisiz olmayan kayıp
koşulları altında %2, %5 ve %10 oranlarında silme işlemi gerçekleştirilmiştir.
Kayıp verilerin bulunduğu veri setleri üzerinde liste bazında silme, Öklid
uzaklığına dayalı benzer tepki örüntüsüne dayalı atama, stokastik regresyonla
değer atama, beklenti – maksimizasyon algoritması ve çoklu değer atama
teknikleri uygulanmıştır.
Eksiksiz veri setlerinde tümüyle seçkisiz kayıp koşulunun sağlanması
aşamasında veri setindeki toplam hücre sayısı arasından rastgele değerler
seçilmiş ve ilgili hücrelerdeki veriler silinmiştir. Seçkisiz kayıp koşulunun
sağlanması aşamasında birinci değişkene göre yapılan sıralama üzerinden
diğer değişkenlerden, birinci değişkenin ortancasının üzerinde kalan
satırlardan %80, ortancanın altında kalan satırlardan ise %20 oranında silme
işlemi gerçekleştirilmiştir. Seçkisiz olmayan kayıp koşulunun sağlanması
aşamasında ise her bir değişken ayrı ayrı büyükten küçüğe sıralanmış ve en
üst sırada kalan ölçümlerden %80, en alt sırada kalan ölçümlerden %20
oranında silme işlemi gerçekleştirilmiştir.

v
Eksiksiz veri setlerinden elde edilen değerler, kayıp veri baş etme
teknikleriyle elde edilen kestirimler için referans olarak kullanılmıştır.
Güvenirliğe ilişkin incelemeler, Cronbach α, McDonald ve W kestirimleri;
geçerliğe ilişkin incelemeler ise temel bileşenler analizi kapsamında açıklanan
toplam varyans oranları ve D2 istatistiği, doğrulayıcı faktör analizi kapsamında
model – veri uyumuna ilişkin indeks değerleri üzerinden gerçekleştirilmiştir.
İncelemeler sonucunda, araştırmalarda sıklıkla kullanılan liste bazında
silme tekniğinin ciddi sorunlara yol açabileceği; beklenti-maksimizasyon
algoritması ve çoklu değer atama tekniklerinin ise genel olarak yüksek
performans gösterdiği sonucuna ulaşılmış olmakla beraber, tüm durumlarda
kullanılabilecek ve kesin olarak en iyi sonuçları veren tek bir yöntemin
olmadığı görülmüştür.
Anahtar Kelimeler: Kayıp veri, kayıp veri teknikleri, güvenilirlik,
geçerlilik

vi
ABSTRACT
INVESTIGATION OF PSYCHOMETRIC PROPERTIES OF SCALES WITH
MISSING DATA TECHNIQUES FOR DIFFERENT SAMPLE SIZES AND
MISSING DATA PATTERNS
AKBAŞ, Ufuk
Ph.D, Department of Measurement and Evaluation
Advisor: Prof. Dr. Ezel TAVŞANCIL
July 2014, 174 pages
The purpose of this study is to investigate the psychometric properties
of scales with different missing data techniques. For this purpose 100 data
sets were generated under different conditions for sample sizes (250, 500 and
1000) and number of items (10 and 15) respectively. Data points were deleted
under missing completely at random, missinng at random and missing not at
random conditions by two, five and ten percent. Listwise deletion, similar
response pattern imputation based on Euclidian distance, stochastic
regression imputation, expectation – maximization algorithm and multiple
imputation were carried out on incomplete data sets.
To ensure missing completely at random mechanism, random numbers
were generated based on number of items and sample size, and
corresponding data points were deleted. For missing at random mechanism,
data sets were sorted for the first item and data points over median were
deleted with a probability of 0,8; data points under median were deleted with a
probability of 0,2. And for missing not at random mechanism, all items were
sorted individualy. Highest values were deleted at the ratio of 0,8 and lowest
values were deleted at the ratio of 0,2.
Estimations from complete data sets were used as a base criteria for
those calculated by different missing data techniques. Bias of Cronbach α,
McDonald and W coefficients were investigated for reliability estimates.
Extracted variances and D2 statistic obtained by principal component analysis

vii
and different indices obtained by confirmatory factor analysis are investigated
for validity.
Results show that listwise deletion, which is often applied as a default
missing data technique, may cause serious problems. On the other hand
expectation – maximization algorithm and multiple imputation generaly
outperformed but none of the techniques are the best for all conditions.
Keywords: Missing data, missing data techniques, reliability, validity

viii
ÖNSÖZ
Eğitim ve psikoloji alanındaki çalışmalara konu olan özelliklerin
ölçülmesi amacıyla geliştirilen, uyarlanan veya güncellenen ölçme araçlarının
güvenirlik ve geçerliğinin sağlanması, sorgulanması ve nesnel kanıtlara dayalı
olarak sunulması araştırmacıların temel sorumluluklarındandır. Bu sorumluluk
bazı durumlarda, başlı başına dikkatli ve titiz bir şekilde planlanması gereken
araştırma süreçlerini gerekli kılar.
Kayıp veriler, hemen hemen her araştırma sürecinde karşılaşılan genel
bir problemdir. Alanyazında çok sayıda kayıp veri baş etme tekniğine
rastlanmakla beraber, bu tekniklerin güvenirlik ve geçerlik kanıtlarını ne yönde
etkilediğine ilişkin detaylı incelemelere ihtiyaç duyulmaktadır. Yapay veriler
üzerinde gerçekleştirilmiş olan bu çalışmanın, gerçek veri setlerinde kayıp
verilerle karşılaşan araştırmacılara yol göstermesi beklenmektedir.
Tez çalışmamamın her aşamasında bana yol gösteren, sürekli
destekleyen, eleştiri ve önerileriyle çalışmama katkıda bulunan değerli hocam
Prof. Dr. Ezel TAVŞANCIL’a teşekkürlerimi sunarım. Tez jürimde bulunarak
değerli eleştiri ve katkılarından yararlanma fırsatı bulduğum saygıdeğer
hocalarım Prof. Dr. Nizamettin KOÇ’a, Prof. Dr. Şener BÜYÜKÖZTÜRK’e,
Doç. Dr. Duygu ANIL’a ve Doç. Dr. Ömay ÇOKLUK’a teşekkürlerimi sunarım.
Bana mesleki ve akademik açıdan büyük destek sağlayan hocalarım
Prof. Dr. Mustafa TAN’a, Prof. Dr. Bilal GÜNEŞ’e ve Doç. Dr. Mustafa
KARADAĞ’a; yoğun mesai saatlerinde yükümü hafifleterek bu çalışmayı
tamamlamamda önemli payı olan meslektaşım Elif Gökçen DOĞAN’a
teşekkür ederim. Yazılım geliştirme alanındaki muhteşem becerilerini
sergiledikleri, bana zaman ayırdıkları ve hayallerimin çok ötesinde imkânlar
sundukları için Şeyhmus AYDOĞDU’ya ve Samet UYMAZ’a teşekkürlerimi
sunarım. Onlar olmasaydı çalışmamı bu şekilde yürütemezdim.
Hayatımın tüm evrelerinde yorulduğum, umutsuzluğa ve karamsarlığa
kapıldığım zamanlarda beni kucaklayan ve karşılıksız destek sağlayan
babama, doğduğu günden beri bize enerji ve gurur kaynağı olan kardeşime ve
özellikle, büyük fedakârlıklarla hepimizi ayakta tutan anneme sonsuz
teşekkürlerimi sunarım. Bu çalışmayı aileme ve aramızdan ayrıldığı günden
beri sesi kulaklarımdan eksik olmayan dostum Güçlü GÜRLER’e adıyorum.

ix
İÇİNDEKİLER
JÜRİ ÜYELERİ İMZA SAYFASI ..................................................................... iii
ÖZET .............................................................................................................. iv
ABSTRACT .................................................................................................... vi
ÖNSÖZ ......................................................................................................... viii
İÇİNDEKİLER ................................................................................................. ix
ÇİZELGELER LİSTESİ .................................................................................. xi
ŞEKİLLER LİSTESİ ..................................................................................... xiii
EKLER LİSTESİ ........................................................................................... xiv
BÖLÜM I ......................................................................................................... 1
GİRİŞ ............................................................................................................... 1
Problem ........................................................................................................ 1
Amaç .......................................................................................................... 20
Önem ......................................................................................................... 21
Varsayımlar ................................................................................................ 21
Sınırlılıklar .................................................................................................. 22
Kısaltma Listesi .......................................................................................... 23
BÖLÜM II ...................................................................................................... 24
İLGİLİ ARAŞTIRMALAR............................................................................... 24
BÖLÜM III ..................................................................................................... 31
YÖNTEM ....................................................................................................... 31
Araştırmanın Modeli ................................................................................... 31
Verilerin Üretilmesi ............................................................................... 31
Verilerin Silinmesi ................................................................................. 34
Kayıp Verilerin Tamamlanması ............................................................ 37
Verilerin Analizi .......................................................................................... 38
BÖLÜM IV ..................................................................................................... 43
BULGULAR VE YORUMLAR ....................................................................... 43
1. Güvenirliğe İlişkin Bulgular ..................................................................... 43
a. Cronbach α Kestirimlerinin Yanlılığına İlişkin Bulgular ........................ 43
b. McDonald Kestirimlerinin Yanlılığına İlişkin Bulgular ....................... 57

x
c. Ağırlıklandırılmış (w) Kestirimlerinin Yanlılığına İlişkin Bulgular ..... 61
2. Geçerliğe İlişkin Bulgular ........................................................................ 71
a. Açıklanan Varyans Oranlarının Yanlılığına İlişkin Bulgular ................. 71
b. D2 İstatistiği İçin Ulaşılan Bulgular....................................................... 77
c. Doğrulayıcı Faktör Analizine İlişkin Bulgular ....................................... 95
BÖLÜM V .................................................................................................... 104
SONUÇ VE ÖNERİLER .............................................................................. 104
Sonuçlar ................................................................................................... 104
Güvenirliğe İlişkin Sonuçlar ................................................................... 104
Geçerliğe İlişkin Sonuçlar ...................................................................... 106
Öneriler .................................................................................................... 109
KAYNAKÇA ................................................................................................ 112
EKLER ........................................................................................................ 121

xi
ÇİZELGELER LİSTESİ
Çizelge 1. Sekiz Farklı Ölçeğin Kullanıldığı Bir Araştırma İçin Üç Form
Deseniyle Elde Edilen Kayıp Veri Örüntüsü ............................... 3
Çizelge 2. Genel Yetenek ve İş Performansı Ölçümleri İçin Üç Farklı Kayıp
Veri Örüntüsü ............................................................................. 4
Çizelge 3. Eksiksiz Veri Setlerinden Elde Edilen İç Tutarlılık Katsayılarına
İlişkin Betimsel İstatistikler ........................................................ 33
Çizelge 4. Eksiksiz Veri Setlerinden Elde Edilen Temel Bileşenler Analizi
Sonuçları .................................................................................. 33
Çizelge 5. Eksiksiz Veri Setlerinden Elde Edilen Doğrulayıcı Faktör Analizi
Sonuçları .................................................................................. 34
Çizelge 6. Liste Bazında Silme Tekniği İçin Örneklem Büyüklüğüne Ait
Betimsel İstatistikler .................................................................. 37
Çizelge 7. Liste Bazında Silme Tekniği İle Elde Edilen Cronbach α
Kestirimlerine İlişkin Betimsel İstatistikler ................................. 44
Çizelge 8. Öklid Uzaklığı Üzerinden Benzer Tepki Örüntüsüne Dayalı Atama
Tekniği İle Elde Edilen Cronbach α Kestirimlerine İlişkin Betimsel
İstatistikler ................................................................................ 45
Çizelge 9. Stokastik Regresyonla Değer Atama Tekniği İle Elde Edilen
Cronbach α Kestirimlerine İlişkin Betimsel İstatistikler .............. 46
Çizelge 10. Beklenti-Maksimizasyon Algoritması İçin Cronbach α
Kestirimlerine İlişkin Betimsel İstatistikler ................................. 46
Çizelge 11. Çoklu Değer Atama Tekniği İle Elde Edilen Cronbach α
Kestirimlerine İlişkin Betimsel İstatistikler ................................. 47
Çizelge 12. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi
Sonuçları (Örneklem Büyüklüğü:250, Madde Sayısı:10) .......... 50
Çizelge 13. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü
Varyans Analizi Sonuçları (Örneklem:250, Madde Sayısı:10) .. 53
Çizelge 14. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Dunnett C
Çoklu Karşılaştırma Testi Sonuçları (Örneklem Büyüklüğü:250,
Madde Sayısı:10) ..................................................................... 54
Çizelge 15. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Dunnett C
Çoklu Karşılaştırma Testi Sonuçları ......................................... 56
Çizelge 16. McDonald Kestirimlerine İlişkin Betimsel İstatistikler ............... 58
Çizelge 17. Mcdonald Fark Puanları İçin Grup Değişkenine Göre Dunnet C
Çoklu Karşılaştırma Testi Sonuçları ......................................... 60
Çizelge 18. Ağırlıklandırılmış Kestirimlerine İlişkin Betimsel İstatistikler .... 62
Çizelge 19. Ağırlıklandırılmış Fark Puanları İçin Grup Değişkenine Göre
Dunnet C Çoklu Karşılaştırma Testi Sonuçları ......................... 64
Çizelge 20. Cronbach α Katsayısı Mcdonald Katsayısından Daha Büyük
Olan Veri Setlerinin Örneklem Büyüklüğü, Kayıp Veri Oranı Ve
Kayıp Veri Baş Etme Tekniğine Göre Dağılımı ......................... 70

xii
Çizelge 21. Liste Bazında Silme Tekniği İle Elde Edilen Açıklanan Varyans
Oranlarına İlişkin Betimsel İstatistikler ...................................... 72
Çizelge 22. Öklid Uzaklığı Üzerinden Benzer Tepki Örüntüsüne Dayalı Atama
Tekniği İle Elde Edilen Açıklanan Varyans Oranlarına İlişkin
Betimsel İstatistikler .................................................................. 72
Çizelge 23. Stokastik Regresyonla Değer Atama Tekniği İle Elde Edilen
Açıklanan Varyans Oranlarına İlişkin Betimsel İstatistikler ....... 73
Çizelge 24. Beklenti - Maksimizasyon Algoritması İle Elde Edilen Açıklanan
Varyans Oranlarına İlişkin Betimsel İstatistikler ........................ 74
Çizelge 25. Çoklu Değer Atama Tekniği İle Elde Edilen Açıklanan Varyans
Oranlarına İlişkin Betimsel İstatistikler ...................................... 74
Çizelge 26. Açıklanan Varyans Oranı Fark Puanları İçin Grup Değişkenine
Göre Çoklu Karşılaştırma Testi Sonuçları ................................ 76
Çizelge 27. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:250,
Madde Sayısı:10) ..................................................................... 78
Çizelge 28. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:250,
Madde Sayısı:15) ..................................................................... 81
Çizelge 29. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:500,
Madde Sayısı:10) ..................................................................... 84
Çizelge 30. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:500,
Madde Sayısı:15) ..................................................................... 86
Çizelge 31. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem
Büyüklüğü:1000, Madde Sayısı:10) .......................................... 89
Çizelge 32. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem
Büyüklüğü:1000, Madde Sayısı:15) .......................................... 92
Çizelge 33. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:250,
Madde Sayısı:10) ..................................................................... 96
Çizelge 34. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:250,
Madde Sayısı:15) ..................................................................... 97
Çizelge 35. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:500,
Madde Sayısı:10) ..................................................................... 98
Çizelge 36. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:500,
Madde Sayısı:15) ..................................................................... 99
Çizelge 37. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:1000,
Madde Sayısı:10) ................................................................... 100
Çizelge 38. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:1000,
Madde Sayısı:15) ................................................................... 101

xiii
ŞEKİLLER LİSTESİ
Şekil 1. Normal Dağılım Gösterdiği Varsayılan Puanlara Ait Örnek Sütun
Grafiği ............................................................................................... 48
Şekil 2. Cronbach α Fark Puanları İçin Kayıp Veri Türü ve Kayıp Veri Baş
Etme Tekniği Etkileşimi Grafiği ......................................................... 51
Şekil 3. Cronbach α Fark Puanları İçin Kayıp Veri Oranı ve Kayıp Veri Baş
Etme Tekniği Etkileşimi Grafiği ......................................................... 52

xiv
EKLER LİSTESİ
Ek 1. Veri Üretimi Aşamasında Kullanılan Mplus Komut Dosyası Örnekleri 122
Ek 2. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:250, Madde Sayısı:15) ................................... 123
Ek 3. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:500, Madde Sayısı:10) ................................... 124
Ek 4. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:500, Madde Sayısı:15) ................................... 125
Ek 5. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:1000, Madde Sayısı:10) ................................. 126
Ek 6. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:1000, Madde Sayısı:15) ................................. 127
Ek 7. Mcdonald Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:250, Madde Sayısı:10) ................................... 128
Ek 8. Mcdonald Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:500, Madde Sayısı:10) ................................... 129
Ek 9. Mcdonald Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları
(Örneklem Büyüklüğü:1000, Madde Sayısı:10) ................................. 130
Ek 10. W Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem
Büyüklüğü:250, Madde Sayısı:15) .................................................... 131
Ek 11. W Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem
Büyüklüğü:500, Madde Sayısı:15) .................................................... 132
Ek 12. W Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem
Büyüklüğü:1000, Madde Sayısı:15) .................................................. 133
Ek 13. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi
Sonuçları (Örneklem Büyüklüğü:250, Madde Sayısı:10) .................. 134
Ek 14. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi
Sonuçları (Örneklem Büyüklüğü:250, Madde Sayısı:15) .................. 135
Ek 15. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi
Sonuçları (Örneklem Büyüklüğü:500, Madde Sayısı:10) .................. 136
Ek 16. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi
Sonuçları (Örneklem Büyüklüğü:500, Madde Sayısı:15) .................. 137
Ek 17. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi
Sonuçları (Örneklem Büyüklüğü:1000, Madde Sayısı:10) ................ 138
Ek 18. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi
Sonuçları (Örneklem Büyüklüğü:1000, Madde Sayısı:15) ................ 139
Ek 19. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü
Varyans Analizi Sonuçları ................................................................. 140
Ek 20. Mcdonald Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü
Varyans Analizi Sonuçları ................................................................. 141

xv
Ek 21. W Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü Varyans
Analizi Sonuçları ............................................................................... 142
Ek 22. Açıklanan Varyans Oranı Fark Puanları İçin Grup Değişkenine Göre
Tek Yönlü Varyans Analizi Sonuçları ................................................ 143
Ek 23. Eksiksiz Veri Setleri İçin Doğrulayıcı Faktör Analizinden Elde Edilen
İndekslere Ait Betimsel İstatistikler .................................................... 144
Ek 24. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:10)
.......................................................................................................... 145
Ek 25. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:10)
.......................................................................................................... 146
Ek 26. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:10)
.......................................................................................................... 147
Ek 27. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen
İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde
Sayısı:10) .......................................................................................... 148
Ek 28. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:10)
.......................................................................................................... 149
Ek 29. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:15)
.......................................................................................................... 150
Ek 30. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:15)
.......................................................................................................... 151
Ek 31. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:15)
.......................................................................................................... 152
Ek 32. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen
İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde
Sayısı:15) .......................................................................................... 153
Ek 33. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250, Madde Sayısı:15)
.......................................................................................................... 154
Ek 34. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:10)
.......................................................................................................... 155
Ek 35. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:10)
.......................................................................................................... 156

xvi
Ek 36. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:10)
.......................................................................................................... 157
Ek 37. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen
İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde
Sayısı:10) .......................................................................................... 158
Ek 38. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:10)
.......................................................................................................... 159
Ek 39. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:15)
.......................................................................................................... 160
Ek 40. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:15)
.......................................................................................................... 161
Ek 41. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:15)
.......................................................................................................... 162
Ek 42. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen
İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde
Sayısı:15) .......................................................................................... 163
Ek 43. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500, Madde Sayısı:15)
.......................................................................................................... 164
Ek 44. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:10)
.......................................................................................................... 165
Ek 45. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:10)
.......................................................................................................... 166
Ek 46. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:10)
.......................................................................................................... 167
Ek 47. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen
İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde
Sayısı:10) .......................................................................................... 168
Ek 48. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:10)
.......................................................................................................... 169
Ek 49. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:15)
.......................................................................................................... 170

xvii
Ek 50. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:15)
.......................................................................................................... 171
Ek 51. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:15)
.......................................................................................................... 172
Ek 52. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen
İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde
Sayısı:15) .......................................................................................... 173
Ek 53. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere
Ait Betimsel İstatistikler (Örneklem Büyüklüğü:1000, Madde Sayısı:15)
.......................................................................................................... 174

1
BÖLÜM I
GİRİŞ
Bu bölümde araştırmanın problemi, amacı ve önemi tanımlanmıştır. Bu
tanımlamaların ardından araştırmanın varsayımlarına, sınırlılıklarına kısaltma
listesine yer verilmiştir.
Problem
Eğitim ve psikolojideki ölçmelere konu olan değişkenler çoğunlukla
doğrudan gözlenemeyen gizil özelliklerdir. Bu özellikler, kendileriyle ilgili
olduğu düşünülen ve gözlenebilen başka değişkenler yardımıyla
ölçülebilmektedir. Bireylerin gözlenebilen değişkenlere verdikleri tepkilerden
yola çıkarak, gizil özelliklere yönelik çıkarımlar yapılır.
Gizil özelliklerin ölçülmesi amacıyla kullanılacak ölçme araçlarının
geliştirilmesi, uyarlanması veya önceden geliştirilmiş bir aracın güncellenmesi
başlı başına dikkatli ve titiz bir şekilde planlanması gereken bir araştırma
sürecini ifade eder. Bu süreçte, söz konusu ölçme aracının geçerliğini ve
güvenirliğini sağlamak, sorgulamak ve kanıtlarıyla birlikte sunmak araştırmayı
yapan kişi ya da kişilerin temel sorumluluğudur.
Geçerlik ve güvenirliğe ilişkin nesnel kanıtların elde edilmesi
aşamasında farklı istatistiksel tekniklerden yararlanılabilir. Veri analizi
aşamasında kullanılan teknikler çeşitlilik göstermekle birlikte, istatistiksel
işlemler eksiksiz veri setlerinde kullanılmak üzere geliştirilmiştir. Araştırma
süreci uzman kişilerce çok dikkatli bir şekilde planlanmış bile olsa, uygulama
sonucunda elde edilen verilerde kayıpların olması genel bir problemdir. Kayıp
veriler, söz konusu değişkenlere ilişkin bilgiyi ve dolayısıyla ulaşılan bulgular
ile bu bulgulara dayalı yorumları sınırlamaktadır.
Alanyazında kayıp verilere ve kaybın nedenlerine ilişkin farklı
tanımlamalara rastlanmaktadır. Örnekleme giren bireylere ulaşılamaması,
bazı bireylerin ölçme aracındaki maddelere cevap vermek istememesi ya da
cevap verecek durumda olmaması birim yanıtlamama (unit nonresponse);
örneklemde yer alan bireylerin bir ya da birden fazla maddeye ait verisinin
olmaması ise madde yanıtlamama (item nonresponse) olarak

2
adlandırılmaktadır. Madde yanıtlamama durumunda veri setinde bazı
hücrelerde kayıplar bulunurken, birim yanıtlamama durumda araştırmacının
elinde bireye ilişkin hiç bilgi yoktur (Heerwegh, 2005; De Luca ve Peracchi,
2007).
Field (2005), çok sayıda madde içeren anketlerin uygulandığı
çalışmalarda katılımcıların bazı soruları atlayabileceklerini, verilerin mekanik
araçlarla toplandığı durumlarda yaşanan teknik aksaklıkların, veri girişi
sırasındaki dikkatsizliğin veya hatalı kodlamaların kayıp veriler üretebileceğini
ifade etmektedir. Bu sebeplere ek olarak Goregebeur, De Boeck ve
Molenberghs (2010), hız testlerinde zamanın sınırlı olmasına bağlı olarak
kayıp verilerle karşılaşılabileceğini belirtmektedirler.
Boylamsal çalışmalarda kayıp verilerle, dalgalı (wave) ya da dönüşsüz
(attrition / dropout) bir şekilde karşılaşılabilmektedir. Dalgalı kayıpta birey,
bazı zaman noktalarında araştırmaya katılmazken ilerleyen aşamalarda tekrar
dönmektedir. Dönüşsüz kayıpta ise bir zaman noktasında sonra bireye ait hiç
veri bulunmamaktadır (Schafer ve Graham, 2002).
Enders (2010), araştırma deseninde veri toplama sürecinin yan ürünü
olarak kayıp verilerle karşılaşılabileceğini ifade etmektedir. Örneğin iki farklı
işlemin uygulandığı deneysel bir araştırmada denekler, her iki koşul altında
hipotetik ölçümlere sahip olacaklardır. Fakat böyle çalışmalarda deneklerin
sadece bir koşul altındaki durumlarına ilişkin ölçümler alınabilecek, diğer
koşuldaki ölçümleri kayıp olacaktır. Kontenjan dışında kalıp üniversiteye
yerleşemeyen öğrencilerin akademik not ortalamalarının hesaplanamaması
kayıp veriler için başka bir örnek durumdur. Ek olarak, anketlerde bir maddeye
verilen cevap bir ya da birkaç maddenin atlanmasını gerektirebilir. Bu tür
kayıp veriler araştırmacının kontrolü ve bilgisi dâhilinde ortaya çıktığı için
herhangi bir kayıp veri baş etme tekniğinin uygulanmasına da ihtiyaç yoktur.
Bazı durumlarda da kayıp veriler araştırma deseninin bir parçası
olabilmektedir. Graham, Hofer ve MacKinnon (1996), üç form deseninin (three
form design), özellikle karmaşık bir örüntüye sahip olan değişkenlerin
ölçülmesinin amaçlandığı çalışmalarda kullanılabileceğini ifade etmektedir. Bu
desende X, A, B ve C şeklinde dört gruba ayrılmış olan madde kümeleri
örneklemin üçte birlik kısımlarına dengeli bir şekilde dağıtılır. X formu bütün

3
gruplar için ortak olmak üzere gruplara, XAB - XAC - XBC şeklindeki madde
kümeleri uygulanır.
Her biri 10 madde içeren 8 ölçeğin kullanılacağı bir araştırma, bu
desene örnek gösterilebilir. Bireylerin toplamda 80 maddeyi cevaplamaya
yetecek dikkate ya da zamana sahip olmayacağını öngören bir araştırmacı,
madde havuzunu dört farklı kümeye (X, A, B ve C) ayırarak oluşturduğu üç
farklı formu uygulayabilir (Çizelge 1).
Çizelge 1. Sekiz Farklı Ölçeğin Kullanıldığı Bir Araştırma İçin Üç Form
Deseniyle Elde Edilen Kayıp Veri Örüntüsü
Ölçek Kümeleri
X A B C
Form Ö1 Ö2 Ö3 Ö4 Ö5 Ö6 Ö7 Ö8
1 – – 2 – – 3 – –
Madde Sayısı 10 10 10 10 10 10 10 10
Çizelge 1 incelendiğinde, araştırmaya katılan bireylerin üç farklı gruba
ayrıldığı ve kullanılan ölçeklerin gruplara XAB, XAC ve XBC şeklinde
uygulandığı görülmektedir. Bu sayede bireylere 60 maddelik ölçek kümelerinin
uygulanmasıyla toplamda 80 maddelik veriye ulaşılabilmektedir. Bu tip veri
setlerinin elde edilmesi durumunda araştırmacılar, maksimum olabilirlik
kestirimleri veya çoklu değer atama tekniği ile istatistiksel analizleri
gerçekleştirebilmektedir (Enders, 2010).
Kayıp veriler için genel kabul gören sınıflandırma Rubin (1976)
tarafından yapılmıştır. Bu sınıflamaya göre kayıp veriler, herhangi bir verinin
kayıp olma olasılığı ile veriler arasındaki ilişkiler göz önüne alınarak tümüyle
seçkisiz kayıp (TSK / missing completely at random, MCAR), seçkisiz kayıp
(SK / missing at random, MAR) ya da seçkisiz olmayan kayıp (SOK / missing
not at random, MNAR) olmak üzere üç farklı yapıda olabilmektedir.
Bir kurumun, iş başvurusunda bulunan adaylara uyguladığı bir genel
yetenek testine ve takip eden 6 aylık stajyerlik süresi sonunda bireylerin iş
performanslarına ilişkin puanları, kayıp veri türlerinin açıklanmasında örnek bir
durum olarak incelenebilir. Eksiksiz ölçümler ile farklı kayıp veri türlerini temsil
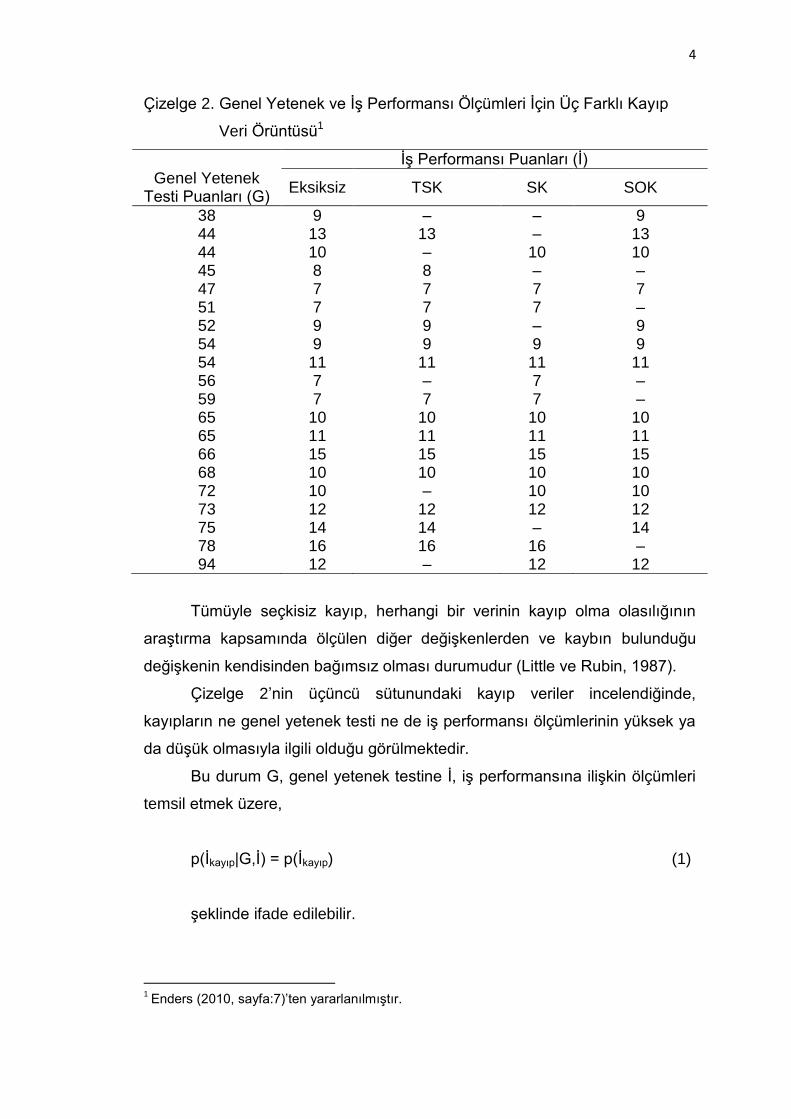
eden durumlar Çizelge 2’de verilmiştir.
4
Çizelge 2. Genel Yetenek ve İş Performansı Ölçümleri İçin Üç Farklı Kayıp
Veri Örüntüsü1
İş Performansı Puanları (İ)
Genel Yetenek Testi Puanları (G)
Eksiksiz TSK SK SOK
38 9 – – 9 44 13 13 – 13 44 10 – 10 10 45 8 8 – – 47 7 7 7 7 51 7 7 7 – 52 9 9 – 9 54 9 9 9 9 54 11 11 11 11 56 7 – 7 – 59 7 7 7 – 65 10 10 10 10 65 11 11 11 11 66 15 15 15 15 68 10 10 10 10 72 10 – 10 10 73 12 12 12 12 75 14 14 – 14 78 16 16 16 – 94 12 – 12 12
Tümüyle seçkisiz kayıp, herhangi bir verinin kayıp olma olasılığının
araştırma kapsamında ölçülen diğer değişkenlerden ve kaybın bulunduğu
değişkenin kendisinden bağımsız olması durumudur (Little ve Rubin, 1987).
Çizelge 2’nin üçüncü sütunundaki kayıp veriler incelendiğinde,
kayıpların ne genel yetenek testi ne de iş performansı ölçümlerinin yüksek ya
da düşük olmasıyla ilgili olduğu görülmektedir.
Bu durum G, genel yetenek testine İ, iş performansına ilişkin ölçümleri
temsil etmek üzere,
p(İkayıp|G,İ) = p(İkayıp) (1)
şeklinde ifade edilebilir.
1 Enders (2010, sayfa:7)’ten yararlanılmıştır.

5
Eşitlik 1, İ değişkenine ait ölçümlerin kayıp olma olasılığının G ve İ
değişkenlerinden bağımsız olduğunu ifade etmektedir (Schafer ve Graham,
2002; Allison, 2003; Enders, 2010).
Seçkisiz kayıp, herhangi bir verinin kayıp olma olasılığının kaybın
bulunduğu değişkenin kendisinden bağımsız, fakat araştırma kapsamında
ölçülen diğer bir değişkene (ya da değişkenlere) bağımlı olması durumudur
(Little ve Rubin, 1987).
Çizelge 2’nin dördüncü sütunundaki kayıp veriler incelendiğinde, iş
performansı ölçümlerindeki kayıpların iş performansı değerinden bağımsız,
fakat yanlı olarak genel yetenek testinden alınan puana bağımlı olduğu
görülmektedir. Verinin kayıp olmasının iş performansı ölçümlerinin düşük ya
da yüksek olmasıyla ilişkili olmadığı, fakat genel yetenek testinden düşük
puan almayla yanlı olarak ilişkili olduğu görülmektedir. Bu durum,
p(İkayıp|G,İ) = p(İkayıp|G) (2)
şeklinde ifade edilebilir.
Eşitlik 2, İ’ye ait ölçümlerin kayıp olma olasılığının İ’den bağımsız fakat
G’ye bağımlı olduğunu ifade etmektedir (Schafer ve Graham, 2002; Allison,
2003; Enders, 2010).
Seçkisiz olmayan kayıp, herhangi bir verinin kayıp olma olasılığının
kaybın bulunduğu değişkenin değerine bağlı olma durumudur (Little ve Rubin,
1987). Bu durumu Rubin (1976), tümüyle seçkisiz kayıp ve seçkisiz kayıp
şartlarının sağlanmaması olarak tanımlamaktadır.
Çizelge 2’nin beşinci sütunundaki kayıp veriler incelendiğinde, iş
performansı ölçümlerindeki kayıpların genel yetenek testi puanlarından
bağımsız, fakat yanlı olarak iş performansı puanlarına bağımlı olduğu
görülmektedir. Verinin kayıp olmasının genel yetenek testi ölçümlerinin düşük
ya da yüksek olmasıyla ilişkili olmadığı fakat iş performansına ilişkin
ölçümlerden düşük puan almayla yanlı olarak ilişkili olduğu görülmektedir. Bu
durum,
p(İkayıp|G,İ) = p(İkayıp|İ) (3)

6
şeklinde ifade edilebilir.
Eşitlik 3, İ’ye ait ölçümlerin kayıp olma olasılığının G’den bağımsız, İ’ye
bağımlı olduğunu ifade etmektedir (Schafer ve Graham, 2002; Allison, 2003;
Enders, 2010).
Kayıp verilerin bir örüntü oluşturması, kayıp veri miktarına göre daha
önemli bir sorundur. Ek olarak, kayıp verilerin veri setine seçkisiz olmayan bir
şekilde dağılması elde edilen sonuçların genellenebilirliğini olumsuz
etkilemektedir. Büyük bir veri setinde az sayıda kayıpların bulunması ciddi bir
sorun yaratmamakta ve hemen hemen bütün kayıp veri baş etme teknikleriyle
birbirine benzer sonuçlar elde edilmektedir. Öte yandan, küçük ya da orta
büyüklükteki veri setlerinde çok sayıda kayıpların bulunması çok ciddi
sorunlar yaratabilmektedir (Tabachnick ve Fidell, 1996).
Veri setinde kayıpların bulunması halinde, kayıp verilerin dağılımına
ilişkin seçkisizliğin incelenmesi gerekmektedir. Bu süreçte, araştırmacıların
gerçekleştirebileceği bazı testler bulunmaktadır.
Kayıp verilerin dağılımının seçkisizliğine ilişkin incelemeler, veri setinde
kayıp veriye sahip olan ve olmayan satırların iki kategorili bir kukla değişken
(dummy variable) yardımıyla iki gruba ayrılması şeklinde gerçekleştirilebilir.
Bu sayede, elde edilen grupların diğer değişkenlerdeki ölçümlerine ilişkin
aritmetik ortalamaları arasındaki fark istatistiksel olarak test edilebilir. Aritmetik
ortalamalar arasındaki farkın manidar olmaması, kayıp verilerin bir örüntü
oluşturmadığı, diğer bir deyişle seçkisiz bir dağılıma sahip olduğu yönünde
kanıt olarak öne sürülebilir (Tabachnick ve Fidell, 1996; Enders, 2010).
Kayıp veri dağılımının seçkisizliğine ilişkin gerçekleştirilebilecek diğer
bir test Little (1988) tarafından geliştirilmiş olan (Little’s MCAR test) tümüyle
seçkisiz kayıp testidir. Bu test, kukla değişken kullanılarak gerçekleştirilen ikili
karşılaştırmalara benzer şekilde, veri setinde aynı kayıp veri örüntüsüne sahip
olan grupların aritmetik ortalamalarının karşılaştırılması şeklinde
gerçekleştirilir. Test istatistiği, aynı kayıp veri örüntüsüne sahip alt grupların
aritmetik ortalamaları ile genel ortalama arasındaki farkın standartlaştırılması
ve ağırlıklı ortalamaların toplanması ile elde edilir. Alt grupların aritmetik
ortalamalarının genel ortalamanın örnekleme hatasına ilişkin aralıkta yer
alması, kayıp verilerin dağılımının rastgele olduğuna işaret eder (Enders,
2010).

7
Kayıpların tümüyle seçkisiz kayıp koşulunu sağlayıp sağlamadığına
ilişkin istatistiksel testler bulunumasına rağmen, seçkisiz kayıp koşulunu test
etmek için böyle bir yaklaşım bulunmamaktadır. Kayıp verilerin,
araştırmacının kontrolünün dışında olduğu ve dağılıma ait kesin bilgilerin
bulunmadığı durumlarda, seçkisiz kayıp olarak nitelendirilmesi sadece bir
varsayımdır. Kayıplar, ilgili bireylere tekrar ulaşılarak tamamlanmadığı sürece
seçkisiz kayıp koşulu için gerçekleştirebilecek bir istatistiksel test
bulunmamaktadır (Schafer ve Graham, 2002). Kayıpların seçkisiz olmayan
kayıp koşuluna uygun bir örüntü sergilemesi halinde, bu durumun kesin olarak
ortaya koyulabilmesi için ilgili gözleme ihtiyaç duyulacağından, seçkisiz
olmayan kayıp koşulunu doğrulayacak bir test de bulunmamaktadır.
Veri setindeki kayıpların bir örüntü sergileyip sergilemediğine yönelik
incelemeler sonucunda, araştırmacıların bir kayıp veri baş etme tekniği
kullanmama gibi bir seçenekleri yoktur. İstatistiksel analizler eksiksiz veri
setleri üzerinde gerçekleştirilebilmektedir ve analiz aşamasında, kayıp veri
bulunduran satırların veri setinden çıkarılması, kayıp verilerle baş etmede
kullanılan tipik bir yöntem halini almış durumdadır. Schafer (1997), pek çok
istatistik paket programının, eksik veri içeren satırları otomatik bir şekilde
analiz dışında bıraktığını ve bu işlemin, kayıp veriye sahip bireylerin oranının
düşük (örneğin %5 veya daha az) olduğu durumlarda savunulabilir bir çözüm
olduğunu ifade etmektedir.
Çok değişkenli veri setlerinde kayıpların birden fazla değişkene
yayılması halinde, kayıp veri içeren satırlar veri setinin önemli bir kısmını
oluşturabilir. Bu gibi bir durumda, kayıp veri içeren satırların dışarıda
bırakılması hem verimsiz hem de çok miktarda bilginin gözden çıkarılmasına
yol açan bir işlem halini alacaktır. Kim ve Curry (1977), toplamda %2’lik bir
kaybın bulunması halinde, veri setindeki kişi sayısında %18,3’e varan bir
düşüşün gözlenebileceğini belirtmektedir.
Kayıp veri içeren satırların analiz dışında bırakılması, kayıp veriye
sahip bireyler ile tam veriye sahip bireyler arasında sistematik farklılıklar
olduğu oranda yanlılığa da yol açabilecek ve veri setinde kalan bireyler
evrenin temsilcisi olmaktan uzaklaşacaktır (Montalto ve Sung, 1996; Schafer,
1997).

8
Veri setinde kayıpların olması halinde, kayıp veriye sahip bireylere
tekrar ulaşarak verinin tamamlanması (follow-up) en iyi yaklaşım olarak
önerilmektedir. Veri setindeki kayıpların bu şekilde tamamlanması ile analizler
sorunsuz bir şekilde gerçekleştirilebilmekte ve sonuçların yanlılık içerme
olasılığı ortadan kalkmaktadır. Ancak tüm avantajlarına rağmen bu yaklaşım,
uygulamalardaki sınırlılıklara bağlı olarak çoğu araştırma kapsamında
kullanılabilir olmaktan uzaktır (Van Ginkel, Sijtsma, Van der Ark ve Vermunt,
2010).
Huisman, Krol ve Van Sonderen (1998), ortopedik operasyon geçirmiş
hastalara uygulanan bir dizi ankette kayıp verisi bulunan kişilere tekrar
ulaşarak veri setini tamamlamaya çalışmışlardır. Kayıp veri miktarının az
olduğu bireylere telefonla ulaşılmış; fazla miktarda kayıp veriye sahip bireylere
ise anketlerin ilgili sayfalarının birer kopyası posta yoluyla iletilmiştir. Altı
haftalık çabanın sonunda veri setindeki kayıpların büyük ölçüde giderildiği
(%75) fakat kayıp veri sorunun tam anlamıyla çözülemediği görülmüştür.
Kayıp verilerin hemen her araştırmada karşılaşılan bir problem olması
ve kayıpların ilgili bireylere tekrar ulaşarak tamamlanmasındaki zorluklar, veri
analizi aşamasında bazı istatistiksel tekniklerin geliştirilmesine zemin
oluşturmuştur. Kayıp veri baş etme tekniklerinin kullanılmasıyla eksiksiz veri
setlerine ulaşılabilmekte ve dolayısıyla istatistiksel hesaplamalar sorunsuz bir
şekilde gerçekleştirilebilmektedir. Alanyazın incelendiğinde kayıp verilerle
başa çıkmada kullanılabilecek çok sayıda tekniğe rastlanmaktadır. Bu
kısımda, kayıp verilerle baş etmede kullanılan bazı tekniklerle ilgili bilgiler
sunulmuştur.
Liste bazında silme (LBS / Listwise deletion): Eksiksiz bireylerin analizi
(complete case analysis) adıyla da anılan bu teknikte, herhangi bir değişkene
ait bir gözlemin bulunmaması durumunda kayıp veri içeren bireye ilişkin tüm
gözlemler veri setinden çıkarılmaktadır. Bu tekniğin uygulanmasıyla eksiksiz
bir veri setine ulaşıldığı için her türlü istatistiksel analiz
gerçekleştirilebilmektedir (Enders, 2010).
Liste bazında silme yönteminin tümüyle seçkisiz kayıp koşulunda
kullanılması, veri setinde kalan gözlemler eldeki verinin rastgele bir alt
örneklemi olacağından parametre tahminlerinde yanlılığa yol açmayacaktır.
Benzer şekilde, standart hata tahminlerinde de yanlılık gözlenmeyecektir. Bu

9
durumun tersine, tümüyle seçkisiz kayıp şartının sağlanmadığı durumlarda,
liste bazında silme tekniğinin kullanılmasıyla elde edilen alt örneklem, tüm
gözlemlerin rastgele bir alt örneklemi olmayacağından parametre tahminleri
yanlılık içerecektir (Allison, 2003; McKnight, McKnight, Sidani ve Figueredo,
2007; Rosenthal ve Rosnow, 2008; Enders, 2010).
Tümüyle seçkisiz kayıp koşulunun sağlanıp sağlanmadığından
bağımsız olarak bu tekniğin kullanılması, veri setindeki kişi sayısını
düşüreceği için kullanılan istatistiksel testin gücünün ve sonuçların
genellenebilirliğinin olumsuz etkilenmesi gibi iki temel sorunu beraberinde
getirmektedir (McKnight ve diğ., 2007; Alpar, 2011).
Çift bazında silme (ÇBS / Pairwise deletion): Eldekilerin tümü yaklaşımı
(all available approach) olarak da adlandırılan bu teknik, ortalama ve standart
sapma gibi dağılımı tanımlayıcı ölçülerin ve korelasyon ve kovaryans gibi ilişki
ölçülerinin elde edilmesinde gözlenmiş veri çiftlerinin dikkate alınması esasına
dayanır. Hesaplamalar her bir değişken ya da değişken çifti için eksiksiz
veriye sahip bireyler üzerinden yapılır. Bu teknik sayesinde, iki değişken
arasındaki gözlem sayısını maksimize ederek korelasyon katsayılarını
hesaplamak ve dolayısıyla örneklemdeki tüm ikili bilgiyi kullanmak mümkün
olur. Çift bazında silme tekniğinin ayırt edici özelliği, her bir korelasyon için
ayrı gözlem çiftlerinin ve her hesaplamada farklı sayıda gözlemin
kullanılmasıdır. Bu teknikle elde edilen korelasyonlar, bütün örneklemin
temsilcisi olarak kabul edilir ve değer ataması yapılmaz (Alpar, 2011).
Liste bazında silme tekniğiyle karşılaştırıldığında çift bazında silme
tekniği, kestirimlerin örneklemden elde edilen verinin daha büyük bir kısmı
üzerinden yapılmasına imkân tanımaktadır. Öte yandan farklı bireyler ve farklı
büyüklükteki gözlem çiftleri üzerinden yapılan hesaplamalar; korelasyon
katsayıları arasında tutarsızlıkların görülme olasılığını artırmaktadır. Çift
bazında silme tekniği ayrıca, kestirilen kovaryans / standart sapma oranının
[-1, +1] aralığının dışında kalmasına yol açabilmekte ve özdeğerleri negatif
değerler içeren veya pozitif tanımlı olmayan korelasyon matrisleri
üretebilmektedir (Schafer ve Graham, 2002; Enders, 2010; Alpar, 2011).
Kayıp verilerin örüntüsüne bağlı olarak karşılaşılan daha genel bir sorun ise,
standart hatanın isabetli bir şekilde kestirilmesindeki güçlüktür (Allison, 2003).

10
Enders (2010), tümüyle seçkisiz kayıp koşulunun sağlanmadığı
durumlarda çift bazında silme tekniğinin, liste bazında silme tekniğinde olduğu
gibi parametre kestirimlerinde yanlılığa yol açabildiğini belirtmektedir.
Veri setindeki eksiklerin yerine değer ataması yapılması halinde
eksiksiz bir veri setine ulaşılmaktadır. Bu durum, liste bazında silme ve çift
bazında silme tekniklerinin örneklem büyüklüğü üzerindeki olumsuz etkilerine
karşı değer atama yöntemlerinin temel avantajıdır (Enders, 2010; Schafer ve
Graham, 2002).
Ortalama değer atama (Mean substitution): Koşulsuz ortalama değerini
atama (unconditional mean imputation) olarak da adlandırılan bu teknikte, her
bir değişken için tam gözlemlerin ortalaması, bu değişkene ilişkin kayıp
verilerin yerine atanmakta ve böylece eksiksiz bir veri setine ulaşılmaktadır.
Her bir değişken için, bu şekilde yapılan atama sonucunda eksiksiz
gözlemlerin ortalaması ile tamamlanmış veri setinden elde edilen ortalama
birbirine eşit olmaktadır. İlgili değişkende kayıp verisi olan bireylerin hepsine
aynı değerin atanması merkeze doğru bir yığılmaya yol açtığından,
tamamlanmış veri setinden elde edilen varyans, gerçek varyanstan düşük
olmaktadır (Little ve Rubin, 1987).
Bir değişkende, gözlenmemiş olan tüm verilerin yerine atanan aynı
ortalama değer, bu verilerin gözlenmiş olması halinde alacakları değerlerle
muhtemelen örtüşmeyecektir (Pigott, 2001). Ek olarak bu yöntem, varyansın
düşmesine paralel olarak kovaryans ve korelasyon değerlerini de düşürmekte
ve tümüyle seçkisiz kayıp koşulunda bile parametre tahminlerinde yanlılığa
yol açmaktadır. Veri setindeki kayıp miktarı arttıkça yanlılık da artmaktadır.
Ortalama değer atama yönteminin, hiçbir durumda kullanılmaması gerektiği
belirtilmektedir (Enders, 2010; Pigott, 2001).
Grup ortalamasının atanması (Group mean substitution): Ortak
değişkenler üzerinden aritmetik ortalamanın atanması (mean conditional on
the covariates) ismiyle de anılan bu teknikte kayıp veriler yerine, gözlenen
diğer bir değişken ya da değişkenler üzerinden yapılan gruplama işlemiyle
elde edilen aritmetik ortalama atanmaktadır (Hair, Black, Babin, Anderson ve
Tatham, 2006). Örneğin, örneklemde yer alan erkeklerin herhangi bir
değişkendeki kayıp verilerinin yerine, diğer erkeklerin bu değişkene ilişkin
gözlemlerinin aritmetik ortalaması atanmaktadır.

11
McKnight ve diğerleri (2007), bu tekniğin kullanılması halinde ortak
değişkenin dikkatli seçilmesi gerektiğini ifade etmektedir. Atama işlemine
temel oluşturacak değişkenin, kayıp verilerin bulunduğu değişkenle güçlü bir
ilişki göstermesine dikkat edilmelidir. İlişki zayıfladıkça, atama işlemi rastgele
bir sürece dönüşecektir. Öte yandan, ortalamanın hesaplandığı grup
değişkeninin test edilen istatistiksel modele dâhil edilmesi, değişkenler
arasındaki ilişkinin yapay olarak artmasına da neden olabilir. Örneğin kayıp
veriler, yaşa göre yapılan gruplama ile elde edilen ortalamalar üzerinden
tamamlanır ve yaş değişkeni regresyon modelinde yordayıcı olarak yer alırsa
bu teknik, sonuçlar üzerinde istenmeyen bir etki yaratabilir.
Regresyonla değer atama (Regression imputation): Bu teknikte kayıp
veriler, kayıp veri içermeyen diğer değişkenler kullanılarak kurulan bir
regresyon denklemine göre tahmin edilmektedir. Regresyon denklemi, kayıp
veri içeren değişkenin yordanan, kayıp veri içermeyen diğer değişkenlerin ise
yordayıcı konumunda olacağı şekilde kurulur. Yordanan değişkende kayıp
olan gözlemler, diğer değişkenlere ait değerlerin bu denklemde yerine
konulmasıyla tahmin edilmekte ve eksiksiz bir veri setine ulaşılmaktadır
(Enders, 2010).
Regresyonla değer atama yönteminin veri setinde yaratacağı en büyük
problem, aynı denklem kullanılarak atanan değerlerin tam olarak regresyon
doğrusu üzerinde yer alması, diğer bir deyişle atanan değer ile denklemdeki
yordayıcı değişkenin değerleri arasında mükemmel bir ilişkinin olmasıdır. Bu
durumda, yordayıcı ve atanan değerler arasında kurulan regresyon
denkleminde hata varyansı sıfır olmaktadır (Enders, 2010; Little ve Rubin,
1987).
Regresyonla değer atamanın yaratabileceği diğer bir problem ise,
atanan değerlerin ilgili özellik için söz konusu olan ranjın dışında olabilmesidir.
Örneğin, bireylerin belli bir davranışı son bir ay içerisinde kaç gün
gösterdiklerine ilişkin ölçümlerdeki kayıpların regresyonla atanması
durumunda -10 ya da 31 gibi değerlerle karşılaşılabilir. Bu durumda atanan
değerler, araştırma kapsamında toplanan diğer verilerle karşılaştırıldığında
anlamsız kalacaktır (McKnight ve diğ., 2007).
Stokastik regresyonla değer atama (STR / Stochastic regression
imputation): Bu tekniğin regresyonla değer atama tekniğinden farkı, kayıp

12
verinin tahmin edilmesi amacıyla kurulan doğrusal denkleme normal dağılım
gösteren bir hata teriminin eklenmesidir. Regresyon denklemiyle kestirilen
değere, standart normal dağılımdan rastgele seçilen bir değer ile regresyon
denkleminin standart hatası çarpılarak elde edilen hata terimi eklenmektedir.
Böylece kayıp verilerin regresyonla atanmasında karşılaşılan hata varyansının
sıfır olması problemi ortadan kalkmaktadır. Hata teriminin eklenmesi, veri
setindeki varyansı artırmakta ve yanlılığı düşürmektedir (Enders, 2010).
Baraldi ve Enders (2010), stokastik regresyonla değer atama tekniğinin
özellikle tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında, regresyonla
değer atama yöntemine göre daha iyi sonuçlar vereceğini ve yansız
kestirimler yapabileceğini belirtmektedirler.
Hot deck atama (Hot deck imputation): Bu atama yönteminde, verideki
diğer gözlemlerden yararlanılır ve eksik gözlemin tam verilerine benzeyen
gözlemler arasından rastgele seçilecek bir gözlemin ilgili değer(ler)i, eksik
veriye sahip gözlemdeki eksik yer(ler)e atanır. Dolayısıyla hot deck atama
için, atama yapılacak gözleme benzeyen tam gözlemler kümesinin var olması
ve tanımlanması gerekir (Alpar, 2010).
Bu yöntemin tipik uygulaması, eksik verilerin yerine bazı değişkenler
açısından benzer örüntüye sahip olan ve tam verinin elde edildiği bireylerin
ilgili değişkendeki gözleminin atanması şeklinde gerçekleştirilir. Örneğin,
nüfus özelliklerinin belirlenmeye çalışıldığı bir tarama çalışmasında aylık gelir
düzeyine ilişkin kayıpların olması durumunda yaş, cinsiyet, medeni durum ve
benzeri değişkenler açısından aynı grup içerisinde yer alan ve eksiksiz bir alt
örnekleme ait gelir değeri kayıp verilerin yerine atanabilir (Enders, 2010).
Siddique ve Belin (2008) bu yöntemin, kayıp veri yerine atanan değerin
veri seti içinde gözlenmiş olmasının gerçekçi bir yaklaşım olması; regresyon
temelli atama yöntemleriyle karşılaşılabilen ranjın dışında bir değerin elde
edilmesi sorununu ortadan kaldırması ve kayıp verilerin dağılımına ilişkin bir
model tanımlanmasına gerek olmaması gibi avantajları olduğunu ifade
etmektedir.
Myers (2011) özellikle küçük örneklemlerde, kayıp veriye sahip
bireylere benzer niteliklerde bireylerin bulunamamasına bağlı olarak atama
işleminin yapılmasının mümkün olmayabileceğini ifade etmektedir. Hot deck
atama yönteminin korelasyon ve regresyon katsayılarının kestiriminde yanlılık

13
gösterdiği (Schafer ve Graham, 2002); standart hata kestiriminde ise küçük
değerler ürettiği belirtilmektedir (Enders, 2010).
Benzer tepki örüntüsüne dayalı atama (EUC / Similar response pattern
imputation): Bu teknikte kayıp veri yerine (alıcı), gözlenmiş olan diğer
değişkenlerdeki değerlere en çok benzerliği gösteren (verici / donör) başka bir
bireyin ilgili değişkendeki değeri atanmaktadır (Enders, 2010).
Gözlenen değişkenler üzerinden Öklid uzaklığının hesaplanması, kayıp
veriye sahip olan bireye en çok benzerliği gösteren bireyin bulunmasında
kullanılan yöntemlerden biridir. Öklid uzaklığının belirlenmesi için izlenen
adımlar şu şekildedir (Yeşilova, Kaya ve Almalı, 2011):
1. Veri setinin kayıp içeren ve içermeyen iki alt gruba ayrılması
2. Xi kayıp veri içermeyen alt grubu; xij i. bireyin j. değişkene ilişkin
gözlenmiş değerini; Yi kayıp veri içeren alt grubu ve ykj k. bireyin j. değişkene
ilişkin gözlenmiş değerini temsil etmek üzere eşitlik 4’e göre Öklid
uzaklıklarının (d) hesaplanması
2
1
( )n
ij kj
j
d x y
(4)
3. Bütün kayıp veri örüntüleri için hesaplanan uzaklıklar üzerinden
kayıp verinin seçileceği satırın belirlenmesi ve atama işleminin yapılması
Aynı uzaklık ölçüsüne sahip olan birden çok verici satırın bulunması
halinde kayıp veri yerine bu satırların ilgili değişkene ait ortalamalarının
atandığı bu yöntemin tümüyle seçkisiz kayıp koşulunda isabetli parametre
tahminleri vermesine rağmen, seçkisiz kayıp koşulunda yanlı sonuçlar
vermeye eğilimli olduğu belirtilmektedir (Enders, 2010).
Beklenti – maksimizasyon algoritması (BM / Expectation –
maximization algorithm): Beklenti – maksimizasyon algoritmasında, kayıp
değerlerin gözlenen değerler üzerinden kurulan bir regresyon denklemiyle
tahmin edildiği beklenti adımı ve bu sayede ulaşılan eksiksiz veri seti
üzerinden regresyon denkleminin yeniden kurulduğu maksimizasyon adımı
tekrarlı (iterative) bir süreçte birbirini izlemektedir (Enders, 2010). Kayıp
verilerin yerine değer atama tekniği olarak beklenti – maksimizasyon
algoritması kullanılırken izlenen işlem adımları şu şekildedir (Allison, 2003):

14
1. Ortalamalar ve kovaryans matrisi için başlangıç değerlerinin
seçilmesi.
2. Kayıp veri içeren değişkenin, eldeki parametreler kullanılarak diğer
değişkenler üzerindeki doğrusal regresyonu hesaplanması (bu işlem her bir
kayıp veri örüntüsü için ayrı ayrı yapılmaktadır).
3. Kurulan regresyon denklem(ler)i kullanılarak kayıp veriler yerine
değer atama işleminin yapılması.
4. Bütün kayıp veriler için değer atama işleminin tamamlanmasının
ardından varyans ve kovaryanslar için bir düzeltme yapılarak ortalamalar ve
kovaryans matrisinin tekrar hesaplanması.
5. Değişmeyen kestirimlere ulaşıncaya kadar 2., 3. ve 4. adımlardaki
işlemler tekrarlanması.
Enders (2010) ve Schafer ve Graham (2002) beklenti – maksimizasyon
algoritması ile tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında yansız
parametre tahminleri elde edilebildiğini belirtmektedir.
Çoklu değer atama (ÇDA / Multiple imputation): Rubin (1987)
tarafından geliştirilmiş olan çoklu değer atama tekniğinde, veri setindeki
kayıpların yerine iki ya da daha fazla değerin atanması söz konusudur. Bu
teknikte, verinin kayıp olmasından kaynaklanan belirsizliğe bağlı olarak tek ve
kesin bir değer ataması yapılmamaktadır.
Çoklu değer atama tekniği, m>1 sayıda eksiksiz veri seti elde edilecek
şekilde atama işleminin yapılması, elde edilen m farklı veri setinin standart
tekniklerle analiz edilmesi ve elde edilen sonuçların birleştirilmesinden oluşan
üç aşamalı bir süreçtir (Schafer ve Graham, 2002).
Atama işleminin yapıldığı aşama, stokastik regresyonla değer atama
tekniğinin tekrarlı bir süreçte gerçekleştirilmesi esasına dayanmaktadır. Kayıp
verinin yordanan değişken olduğu regresyon denklemiyle elde edilen değere
bir hata terimi eklenmekte ve regresyon denklemi aynı değişkenler üzerinden
kayıp verinin bulunmadığı varsayılarak tekrar kurulmaktadır. Eklenen hata
terimindeki çarpanın rastgele seçilmesi, her tekrarda elde edilen değerlerin
birbirinden farklı olmasını da beraberinde getirmektedir. İstatistiksel analizler,
her atama sonunda elde edilen eksiksiz veri setleri üzerinden
gerçekleştirilmektedir (Enders, 2010). Çoklu değer atama tekniğinin

15
kullanılması durumunda 3 – 10 arasında değer atama işleminin yapılmasının
yeterli olacağı belirtilmektedir (McKnight ve diğ., 2007).
Burada açıklananların dışında, veri setinde kayıpların olması
durumunda kullanılabilecek çok sayıda kayıp veri baş etme tekniği
bulunmaktadır. Bu kısımda, uygulanmalarındaki benzer özellikleri ve
sınırlılıkları göz önüne alınarak bazı kayıp veri baş etme teknikleri kısaca
açıklanmıştır.
Yakın noktaların medyanının atanması, yakın noktaların ortalamasının
atanması, doğrusal interpolason, noktanın doğrusal eğimi gibi tekniklerde
atanan değerler, kayıp verinin bulunduğu satırın altında ve üstünde bulunan
gözlemler kullanılarak belirlenmektedir. Bu işlemin doğal bir sonucu olarak
atanan değerler, kayıp verinin hangi satırda bulunduğundan (ölçek ya da test
numarasından) etkilenmektedir. Bu tekniklerin kullanılmasıyla atanan kayıplar,
verilerin bilgisayar ortamına aktarılma sırasına veya herhangi bir değişkene
göre yeniden sıralanmasına göre farklı değerler alabilmektedir. Bazı
durumlarda ise önceki veya sonraki gözlemin de kayıp olmasına bağlı olarak,
atamanın yapılamadığı durumlarla karşılaşılabilmektedir. Bu tekniklerin
kullanılması veri setinin mantıksal bir sıralamayı takip ettiği durumlar için
uygun olabilir.
Genel ortalamanın atanması, ortak değişkenler üzerinden ortalama
değerin atanması, madde ortalamasının atanması gibi teknikler veri setinde
merkeze doğru bir yığılmaya yol açmakta ve dolayısıyla varyansı düşürerek
sonuçların yanlılık içerme olasılığını artırmaktadır. Genel olarak aritmetik
ortalamaya dayalı atama yöntemlerinin hiçbir koşulda kullanılmaması gerektiği
belirtilmektedir (Enders, 2010). Aritmetik ortalamanın esas alındığı tekniklere
benzer şekilde, rastgele ya da sabit bir değerin atanması gibi teknikler, sosyal
bilimlerdeki çalışmalarda dikkatli bir şekilde kullanılmalıdır.
Öztemel (2003), yapay sinir ağlarının, kendilerine örnekler halinde
verilen örüntüleri kendileri veya diğerleri ile ilişkilendirebildiklerini, örneklerin
kümelenmesi ile bir sonraki verinin hangi kümeye dahil olacağına karar
verilmesi konularında kullanılabileceklerini ve ağa, eksik bilgiler içeren
örüntüler verildiğinde eksik bilgilerin tamamlanması konusunda başarılı
olduklarını belirtmektedir. Yapay sinir ağlarının bu avantajlarının yanında,
eğitim adımının tamamlanması için ağın örnekler üzerindeki hatasının belirli

16
bir değerin altına indirilmesi gerektiği, optimum sonuçlar veren bir
mekanizmanın henüz bulunamamış olduğu ve bir probleme çözüm üretildiği
zaman, bunun neden ve nasıl olduğuna ilişkin bir ipucunun bulunmadığı ifade
edilmektedir. Yapay sinir ağlarının, geçerlik ve güvenirlik kapsamında bir
kayıp veri baş etme tekniği olarak ele alınabilmesi için, farklı girdi ve
aktivasyon fonksiyonlarının karşılaştırıldığı öncül çalışmalara ihtiyaç
duyulmaktadır.
Cold deck atama yöntemi, genel olarak hot deck atama yöntemine
benzerlik göstermekle birlikte, verici hücrenin seçilmesi aşamasında
araştırmacının elinde önceden elde edilmiş bir veri setine ihtiyaç
duyulmaktadır (Brown, 1994).
Çoklu grup yaklaşımı (multiple group approach) ve tam bilgi maksimum
olabilirlik (full information maximum likelihood) tekniklerinde, kayıpların yerine
değer ataması yapılmamakta, veri setindeki kayıp verilerin her bir örüntüsü
için ayrı bir olabilirlik fonksiyonu tanımlanmaktadır (Enders, 2001). Bu
yaklaşımın kullanılabilmesi için veri setinde az sayıda kayıp veri örüntüsünün
bulunması gerektiği belirtilmektedir (Arbuckle, 1996). Çoklu grup yaklaşımında
aynı kayıp veri örüntüsüne sahip gruplar üzerinden yapılan kestirimler, tam
bilgi maksimum olabilirlik tekniğinde bireyler üzerinden gerçekleştirilmektedir.
Son gözlemin ilerletilmesi (last obsevation carried forward), bir sonraki
gözlemin öncelenmesi (next observation carried backward) gibi tekniklerin
özel olarak, tekrarlı ölçümlerin alındığı boylamsal araştırmalarda ve belli bir
zaman noktasında kayıp verilerle karşılaşılması durumunda kullanılması
uygun olabilir.
Leeuw, Hox ve Huisman (2003), veri setinde kayıpların olmasının
önüne tam anlamıyla geçilemeyeceğinden hareketle, kaybın nedenine ilişkin
sorgulamaların yapılması gerektiğini belirtmektedir. Araştırmacılar, kayıp
verilerle karşılaşılması durumunda veri toplama yönteminin, ölçme aracının,
örneklemde yer alan bireylerin karakteristik özelliklerinin ve hatta veri giriş
aşamalarının yakından incelenmesini önermektedirler.
Graham, Cumsille ve Elek-Fisk (2003) kayıp veri tekniklerinin,
araştırmacının çıkarı doğrultusunda kullanabileceği araçlar olarak değil, veri
kaybını en aza indiren ve kısmi de olsa her verinin kullanılmasına olanak
tanıyan süreçler olarak değerlendirilmesi gerektiğini vurgulamaktadır.

17
Bazı kayıp veri tekniklerinin diğerlerine göre açık üstünlükleri olmakla
birlikte hiçbir teknik “iyi” olarak tanımlanamaz. Kayıp veri problemine karşı
gerçekten tek iyi çözüm, veri setinde kayıpların olmamasıdır. Araştırma
sürecinin tasarlanması ve gerçekleştirilmesi aşamalarında kayıp verileri en
aza indirecek çabanın sergilenmesi gerekir. Araştırmanın özensiz bir şekilde
yürütülmesi, istatistiksel düzeltmelerle telafi edilemez (Allison, 2001).
Demir ve Parlak (2012), Türkiye’de, 2009 – 2011 yılları arasında
yayınlanmış olan dört farklı eğitim bilimleri dergisinde yer alan makaleler
üzerinde yürüttükleri araştırmada, kayıp veri sürecinin raporlaştırılmasında
ciddi eksikliklerin bulunduğunu tespit etmişlerdir. İncelenen 708 makaleden
405’inde, örneklem seçiminin Türkiye evrenine dayandığı ve istatistiksel analiz
süreçlerine yer verildiği görülmüştür.
Bu makalelerin 203’ü eksiksiz veri setleri üzerinde yürütülürken,
161’inde veri setinde kayıpların bulunup bulunmadığına dair bir bilgiye
rastlanmamış, sadece 31 çalışmada kayıp veri bulunduğuna ilişkin kesin
bilgilere yer verilmiştir. Söz konusu 31 çalışmadan sadece dördünde kayıp
veri örüntüsünün incelendiği ve bu araştırmalardan sadece birinde temel
kayıp veri varsayımlarının dikkate alındığı belirlenmiştir. Kayıp veri sorununun
söz konusu olduğu araştırmalardan yedisinde farklı kayıp veri tekniklerinin
kullanıldığı, sadece bir araştırmada kayıp veri mekanizmasının incelendiği ve
uygun bir tekniğin kullanıldığı bilgisine ulaşılmıştır.
Sonuç olarak, eğitim araştırmalarında ve bu araştırmaların
raporlaştırılmasında önemli eksikliklerin bulunduğu; üst düzey istatistiksel
süreçlerin kullanıldığı ve kayıp veri içerdiği açıkça belli olan durumlarda bile
yeterli incelemenin yapılmadığı ve kayıp veri sorununa neredeyse tamamen
ilgisiz kalındığı ifade edilmiştir.
Dong ve Peng (2013) tarafından gerçekleştirilen benzer bir çalışmada,
2009 ve 2010 yıllarında eğitim psikolojisi alanındaki bir dergide yayınlanan
makaleler arasından seçilen 68 çalışmanın 46’sında kayıp verilerden söz
edildiği ya da örneklem büyüklüğü ve serbestlik derecesi arasındaki
tutarsızlıklara bağlı olarak kayıp verilerin bulunduğu çıkarımına ulaşıldığı
belirtilmektedir. Makalelerin 11’inde kayıp veri bulunup bulunmadığı
belirlenememiş ve 11’inde de kayıp verinin bulunmadığı tespit edilmiştir.

18
Kayıp veri sorunun söz konusu olduğu 46 makaleden 17’sinde
herhangi bir kayıp veri baş etme tekniğinin kullanılmadığı görülmüştür. 29
makalede tekniklerin kullanıldığı fakat sadece 2 makalede kayıp verilere ve
kayıp veri baş etme tekniğine ilişkin bir açıklamanın yapıldığı görülmüştür. Bu
iki makaleden birinde tam bilgi maksimum olabilirlik tekniğine bir değer atama
yöntemi olarak yer verildiği, diğerinde de hangi tekniğin kullanıldığına ilişkin
şüpheli bir durumun söz konusu olduğu görülmüştür.
Temel bileşenler analizi ve doğrulayıcı faktör analizi gibi çok değişkenli
istatistiksel teknikler, psikolojik özelliklerinin ölçülmesi amacıyla kullanılan
ölçme araçlarının yapı geçerliğine ilişkin kanıtların elde edilmesi sürecinde
sıklıkla kullanılmaktadır. Peterson (2000), 1964 – 1999 yılları arasında çok
sayıda bilimsel dergide yayınlanmış olan toplam 803 faktör analizi sonucu
üzerinde yaptığı meta – analiz çalışması ile temel bileşenler analizinin yapı
geçerliğinin incelenmesinde en sık kullanılan yöntem olduğunu ortaya
koymuştur. Büyüköztürk (2010), temel bileşenler analizi ile elde edilen
açıklanan varyans oranının yüksek olmasının, ilgili kavram ya da yapının o
denli iyi ölçüldüğünün bir göstergesi olduğunu belirtmektedir.
İç tutarlılık anlamında yorumlanan katsayılar, pek çok araştırmada
güvenirliğe ilişkin bir kanıt olarak sunulmaktadır. Özel olarak Cronbach α’nın,
psikoloji alanında yapılan çalışmalarda güvenirlik kanıtı olarak en sık
raporlaştırılan katsayı olduğu belirtilmektedir (Dunn, Baguley ve Brunsden,
2013). Maddelere ilişkin ortalama, standart sapma ve kovaryans değerlerinin
farklı olduğu durumlarda, konjenerik ölçmelere uygun güvenirlik katsayılarının
hesaplanması önerilmektedir (McDonald, 1985; Yurdugül, 2006).
Alanyazında, farklı kayıp veri baş etme tekniklerinin etkinliklerinin Cronbach α
kestirimleri çerçevesinde incelendiği araştırmalar bulunmakla beraber,
konjenerik güvenirlik katsayılarının kayıp veri baş etme tekniklerine göre
incelendiği bir araştırmaya rastlanmamıştır.
Kayıp verilerin, geçerlik ve güvenirlik kapsamında incelendiği
çalışmalarda kullanılan verilerin çok değişkenli istatistiksel tekniklerin temel
varsayımlarından biri olan süreklilik varsayımını karşılamada yetersiz kaldığı
ve genel olarak önerilmeyen veya uygun olmayan kayıp veri baş etme
tekniklerine yer verildiği görülmektedir. Ayrıca bu çalışmalarda, örneklem
büyüklüğü, kayıp veri örüntüsü ve miktarının manipüle edilmesindeki

19
sınırlılıklar da göz önüne alındığında, araştırma sonuçlarının
genellenebilirlikten uzak olduğu görülmektedir. Veri setindeki kayıpların belli
bir örüntü sergilemesinin, kayıp veri miktarına göre daha ciddi bir problem
olmasına benzer şekilde, farklı kayıp veri baş etme teknikleriyle elde edilen
sonuçların eksiksiz veri setine göre yanlılık gösterip göstermediğinin
belirlenmesi gerekmektedir. Bu gerekçelere dayanarak, kayıp verilerle baş
etmede kullanılan tekniklerin güvenirlik ve geçerlik kanıtları üzerindeki
etkilerinin, farklı örneklem büyüklüğü ve kayıp veri koşulları altında
incelenmesine gerek duyulmaktadır.

20
Amaç
Bu araştırmanın genel amacı, farklı örneklem büyüklüğü ve kayıp veri
örüntülerinde ölçümlerin güvenirlik ve geçerlik kanıtlarının, kayıp verilerle baş
etmede kullanılan teknikler ile yapay veri setleri üzerinden tartışılmasıdır. Bu
genel amaç doğrultusunda iki alt amaç tanımlanmıştır. Araştırmada aşağıdaki
sorulara cevap aranacaktır.
Farklı örneklem büyüklüğü, faktör yapısı, kayıp veri örüntüsü ve kayıp
veri oranlarında liste bazında silme, Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama, stokatik regresyonla değer atama, beklenti-
maksimizasyon algoritması ve çoklu değer atama teknikleriyle elde edilen veri
setleri için;
1. Güvenirlik çerçevesinde,
a. Cronbach α kestirimleri, eksiksiz veri setlerine göre
yanlılık göstermekte midir?
b. McDonald kestirimleri, eksiksiz veri setlerine göre
yanlılık göstermekte midir?
c. Ağırlıklandırılmış (w) kestirimleri, eksiksiz veri
setlerine göre yanlılık göstermekte midir?
2. Geçerlik çerçevesinde,
a. Temel bileşenler analizi ile elde edilen açıklanan varyans
oranları, eksiksiz veri setlerine göre yanlılık göstermekte
midir?
b. Eksiksiz veri setlerine en yakın faktör yapısı hangi kayıp
veri baş etme tekniğiyle elde edilmektedir?
c. Doğrulayıcı faktör analizi sonuçları nasıldır?

21
Önem
Bu araştırma ile elde edilen bulguların, büyük ölçüde duyarsız kalındığı
ifade edilen kayıp veri sorunuyla gerçek veri setlerinde karşılaşılması halinde,
araştırmacılara yol göstermesi beklenmektedir.
Gerçek veriler üzerinde yapılan çalışmalarda, verinin eksiksiz olduğu
durum bilinemediğinden, kayıp verilerle baş etme tekniklerinin etkinlikleri tek
bir veri seti üzerinden göreceli olarak tartışılabilmektedir. Yapay veriler
kullanılarak gerçekleştirilen bu çalışmada, kayıp veri baş etme teknikleri ile
elde edilen veri setleri ile verinin kayıp olmadığı durumlar, 100 farklı veri seti
üzerinden karşılaştırılmıştır. Dolayısıyla, elde edilen bulguların
genellenebilirliğinin yüksek olması, bu araştırmanın önemini artırmaktadır.
Yapay olarak üretilen verilerin sürekli bir yapıda olmasının, istatistiksel
analizlerde genellikle varsayım olarak ele alınan sınırlılığı sağlaması
açısından önemli olduğu düşünülmektedir.
Araştırmada liste bazında silme gibi basit düzey, çoklu değer atama
gibi ileri düzey kayıp veri tekniklerine ek olarak, daha önceki çalışmalarda
güvenirlik ve geçerlik kapsamında sınırlı sayıda çalışmada ele alınmış olan
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniğine
karşılaştırmalı bir şekilde verilmesinin, özel olarak kayıp veri alanyazınına
katkı sağladığı söylenebilir.
Varsayımlar
Araştırmada bağımlı değişken olarak kullanılan fark puanları ve D2
değerleri, eksiksiz veri setlerinden elde edilen değerler üzerinden
hesaplanmıştır. Karşılaştırmanın yapılabilmesi için kayıp veri teknikleriyle
oluşan veri setleri ile eksiksiz veri setlerinin aynı faktör yapısında olması
gerekmektedir. Bu doğrultuda, tüm veri setlerinin veri üretimi aşamasında
belirlenen bir ya da iki faktörlü yapıyı koruduğu varsayılmıştır.

22
Sınırlılıklar
Araştırma, güvenirlik ve geçerlik kanıtları üzerindeki etkileri incelenen
bağımsız değişkenler ve bu değişkenlerin düzeyleri ile sınırlıdır. Araştırmada,
kayıp veri baş etme tekniği olarak liste bazında silme, Öklid uzaklığı üzerinden
benzer tepki örüntüsüne dayalı atama, stokastik regresyonla değer atama,
beklenti-maksimizasyon algoritması ve çoklu değer atama tekniklerine yer
verilmiştir. Örneklem büyüklüğü n=250, n=500 ve n=1000; madde sayısı 10 ve
15, madde sayısına bağlı olarak değişen faktör sayısı 1 ve 2; kayıp veri oranı
ise %2, %5 ve %10 düzeylerinde ele alınmıştır.
İki faktörlü veri setleri için temel bileşenler analizi çerçevesinde sadece
varimax dik döndürme yöntemine yer verilmiş ve araştırma kapsamında uç
değerlere ilişkin bir inceleme yapılmamıştır.

23
Kısaltma Listesi
BM : Beklenti – maksimizasyon algoritması
ÇBS : Çift bazında silme
ÇDA : Çoklu değer atama
EUC : Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama
LBS : Liste bazında silme
SK : Seçkisiz kayıp
SOK : Seçkisiz olmayan kayıp
STR : Stokastik regresyonla değer atama
TSK : Tümüyle seçkisiz kayıp

24
BÖLÜM II
İLGİLİ ARAŞTIRMALAR
Alanyazında, kayıp verileri ve çeşitli kayıp verilerle baş etme tekniklerini
konu edinen çok sayıda araştırmaya rastlanmaktadır. Kayıp verilerin hemen
her araştırmada karşılaşılan genel bir sorun olması psikoloji, iktisat, tıp,
meteoroloji ve hatta arkeoloji gibi alanlarda konuyla ilgili çalışmaların
yapılmasını gerektirmiştir. Bu araştırmalarda ele alınan kayıp veri baş etme
teknikleri ve istatistiksel analizler de çeşitlilik göstermektedir.
Bu kısımda, kayıp verilerin ölçümlerin güvenirliği ve geçerliği
kapsamında ele alındığı bazı araştırmalara yer verilmiştir. Bu araştırmalar,
araştırmanın amaçlarına uygun şekilde sırasıyla güvenirlik ve geçerlik
çerçevesinde sunulmuştur. Öncelikle yurt dışında yapılan araştırmalara ve
sonrasında Türkiye’de yapılmış olan iki araştırmaya yer verilmiştir.
Enders (2003), farklı kayıp veri koşulları altında beklenti –
maksimizasyon algoritması, liste bazında silme, çift bazında silme, ortalama
değer atama ve bireysel ortalamanın atanması tekniklerinin performanslarını
Cronbach α katsayısı kestirimleri temelinde incelemiştir. Araştırmada,
örneklem büyüklüğü (n=100, n=300 ve n=500), madde sayısı (k=10 ve k=20),
ölçekteki derece sayısı (c=3, c=5 ve c=7) ve kayıp veri oranı (%15 ve %30)
değişkenleri manipüle edilmiştir. Cronbach α kestirimleri yanlılık,
standartlaştırılmış yanlılık, hataların ortalama karekökü ve güven aralığı
temelinde incelenmiştir. Araştırma kapsamında manidarlık testi yapılmamış,
incelmeler betimsel bir yaklaşımla gerçekleştirilmiştir. Beklenti –
maksimizasyon algoritması ve çift bazında silme tekniklerinin diğerlerine göre
daha yüksek kestirimler üretmesine rağmen, ele alınan kayıp veri oranları için
tüm tekniklerin negatif yanlı kestirimler ürettiği görülmüştür. Tümüyle seçkisiz
kayıp koşulu için bazı durumlarda liste bazında silme tekniğinin negatif yanlı
olduğu ve beklenti - maksimizasyon algoritmasıyla elde edilen sonuçların
örneklem büyüklüğü ve madde sayısının artmasına paralel bir şekilde daha iyi
sonuçlar ürettiği görülmüştür. Seçkisiz olmayan kayıp koşulu için elde edilen

25
tüm kestirimlerin negatif yanlı olduğu ve en iyi sonucun bireysel ortalamanın
atanması tekniğiyle elde edildiği görülmüştür.
Enders (2004), başka bir araştırmada tümüyle seçkisiz kayıp ve
seçkisiz kayıp koşulları altında liste bazında silme, çift bazında silme,
ortalama değer atama ve beklenti – maksimizasyon algoritmasının Cronbach
α kestirimleri üzerindeki etkisini incelemiştir. 1000 farklı yapay veri seti
üzerinde gerçekleştirilen araştırmada, kayıp veri tekniklerinin etkinlikleri
yanlılık, hataların ortalama karekökü ve güven aralığı kapsamı çerçevesinde
incelenmiştir. Tümüyle seçkisiz kayıp koşulu altında beklenti – maksimizasyon
algoritması, liste bazında silme ve çift bazında silme teknikleriyle yansız,
ortalamanın atanması yöntemiyle ise negatif yanlı güvenirlik kestirimleri elde
edilmiş, seçkisiz kayıp koşulu altında ise sadece beklenti – maksimizasyon
algoritmasının yansız, diğer yöntemlerin negatif yanlı kestirimler ürettiği
görülmüştür. Kayıp verilerin yerine ortalamanın atandığı durumda, hataların
ortalama karekökü değerlerinin evrene ilişkin güvenirlik değerinden daha
düşük bir değer etrafında dağılım gösterdiği görülmüştür. Seçkisiz kayıp
koşulu altında, evrene ilişkin güvenirlik değerine en yakın sonuç beklenti –
maksimizasyon algoritmasıyla elde edilmiştir. Güven aralığı kapsamına ilişkin
ulaşılan sonuçlar, her iki kayıp veri koşulu için beklenti – maksimizasyon
algoritmasının baskınlığını ortaya koymuştur. Tümüyle seçkisiz kayıp koşulu
için isabetli sonuçların elde edildiği liste bazında silme ve çift bazında silme
teknikleri, seçkisiz kayıp koşulu altında kabul edilebilir sınırın altında sonuçlar
vermiştir. Ortalamanın atanması yöntemiyle elde edilen sonuçlar ise her iki
durumda büyük ölçüde isabetsizdir.
Van Ginkel (2007), 20 maddeden oluşan 100 farklı yapay veri setinde,
altı farklı kayıp veri baş etme tekniğinin etkinliğini Cronbach α, Loevinger’in
ölçeklenebilirlik katsayısı H ve Mokken’in madde kümeleme algoritması
üzerinden incelemiştir. Sonuçlar, eksiksiz veri setleri ile farklı koşullar altında
kestirilen Cronbach α katsayıları arasındaki farkların bağımlı, araştırma
kapsamında manipüle edilen değişkenlerin bağımsız değişken olarak
kullanıldığı çok yönlü varyans analiziyle incelenmiştir. Cronbach α kestirimleri
için hata terimi içeren iki yönlü atama ve düzeltilmiş madde ortalamasını
atama tekniklerinin %5 kayıp veri oranı için diğer tekniklere göre daha yüksek
performans gösterdiği; kayıp veri oranının %15’e çıktığı durumda ise rastgele

26
değer atama tekniği haricinde tüm tekniklerle benzer sonuçlar elde edildiği
görülmüştür. Çoklu değer atama tekniğinin beklenenden farklı olarak negatif
yanlı sonuçlar verdiği görülmüştür.
Bernaards ve Sijtsma (1999) tarafından gerçekleştirilen çalışma, çok
boyutlu çok kategorili gizil değişken modeline (multidimensional polytomous
latent trait model) uygun yapay veri setleri üzerinden gerçekleştirilmiştir.
Araştırmada örneklem büyüklüğü (100 ve 500), kayıp veri oranı (%5, %10 ve
%20), kayıp veri türü (tümüyle seçkisiz kayıp ve seçkisiz kayıp), kayıp veri baş
etme tekniği (liste bazında silme, beklenti – maksimizasyon algoritması,
rastgele değer atama, genel ortalamanın atanması, ortak değişkenlere göre
ortalama değer atama, madde ortalaması atama, birey ortalaması atama),
faktörleştirme yöntemi (temel bileşenler analizi ve en büyük olabilirlik), eksen
döndürme yöntemi (varimax ve procrustes) ve maddelerin iki gizil değişken
üzerindeki ağırlıkları (1:0, 3:1 ve 1:1) manipüle edilmiştir. Sonuçlar, D2 ve
Tucker ϕ istatistikleri temelinde incelenmiş ve temel bileşenler analizi ile en
büyük olabilirlik yöntemleri arasında manidar bir fark bulunmamıştır.
Neredeyse bütün durumlar için beklenti – maksimizasyon algoritması ile elde
edilen D2 değerlerinin ortalamasının ve standart sapmasının en küçük olduğu
görülmüştür. Maddelerin 1:0, 3:1 ve 1:1 şeklinde ağırlıklandırılması koşulu
altında farklı kayıp veri türü, kayıp veri yüzdesi ve örneklem büyüklükleri için
genel olarak en düşük ve s(D2) değerleri beklenti – maksimizasyon
algoritmasıyla elde edilmiştir. Beklenti – maksimizasyon algoritmasına en
yakın sonuç bireysel ortalamanın atanması yöntemiyle elde edilmiş olmakla
beraber bireysel ortalama, madde ortalaması, ortak değişkenler üzerinden
hesaplanan ortalama ve genel ortalamanın atandığı yöntemler birbirine yakın
sonuçlar vermiştir. Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları için
istisnai olarak liste bazında silme tekniği dışındaki teknikler benzer sonuçlar
vermiştir. Araştırma kapsamında ele alınan diğer bağımlı değişken olan ϕ, tüm
durumlarda 0,98 ve üzerinde değerler almıştır.
Bernaards ve Sijtsma (2000)’nın çok boyutlu çok kategorili gizil
değişken modeline uygun olarak yapay veri setleri üzerinden
gerçekleştirdikleri diğer bir araştırmada kaybın ihmal edilemez bir yapıda
olduğu durumlar incelenmiştir. Araştırmada, gizil değişkenler arasındaki

27
korelasyonlar (0, 0,24 ve 0,5), maddelerin gizil değişkenler üzerindeki
ağırlıkları (3:1, 1:1 ve 1:0), kayıp veri yüzdesi (%5, %10 ve %20), kayıp veri
teknikleri (genel ortalama, koşullu ortalama, madde ortalaması, bireysel
ortalama, iki yönlü atama, düzeltilmiş madde ortalaması ve iki farklı beklenti –
maksimizasyon algoritması), örneklem büyüklüğü (100 ve 500), kayıp veri türü
(iki farklı ihmal edilemez kayıp ve tümüyle seçkisiz kayıp) değişkenleri
manipüle edilmiştir. Kayıp veri baş etme tekniklerinin etkinlikleri max / min
oranı, çarpımı ve D2 değerleri üzerinden incelenmiştir. Diğer yöntemlerle
karşılaştırıldığında beklenti – maksimizasyon algoritmasının genel olarak
ve değerleri için daha iyi sonuçlar verdiği görülmüştür. Beklenti –
maksimizasyon algoritması ile elde edilen ve ortalamaları farklı kayıp
veri yüzdesi, faktörler arası korelasyon ve ağırlıklandırma koşullarında benzer
değerler almıştır.
Marsh (1998), çift bazında silme tekniğini doğrulayıcı faktör analizi
çerçevesinde ele almıştır. Örneklem büyüklüğünün (n=200, 500 ve 1000) ve
kayıp veri oranının (%0, %1, %10, %25 ve %50) manipüle edildiği
araştırmada, her biri üçer gözlenen değişkenle temsil edilen üç gizil değişkene
ait yapay veri setleri üretilmiştir. Araştırmada ÇBS tekniğinin, elde edilen
kovaryans matrislerinin pozitif tanımlı olma durumları, parametre
kestirimlerinin yanlılığı, 2 değeri ile RNI (göreli merkezi olmayan indeks -
relative noncentrality index), NNFI (Tucker–Lewis indeks / TLI, olarak da
bilinen normlaştırılmamış uyum indeksi) ve RMSEA (yaklaşık hataların
ortalama karekökü - root mean square error of approximation) uyum indeksleri
üzerindeki etkisi incelenmiştir. Ortalama 2 değerlerinin, örneklemin
küçülmesi ve kayıp veri oranının artmasına bağlı olarak beklenen değeri olan
24’ten uzaklaştığı ve standart sapmasının arttığı görülmüştür. RNI, NNFI ve
RMSEA için elde edilen sonuçlar, 2 değeri için elde edilen sonuçlara
paralellik göstermiştir.
Brown (1994) liste bazında silme, çift bazında silme, ortalama değer
atama, hot-deck atama ve benzer tepki örüntüsüne dayalı atama tekniklerini
doğrulayıcı faktör analizi çerçevesinde incelemiştir. Araştırma, 10 maddenin

28
ve 4 gizil değişkenin bulunduğu bir yapısal model kullanılarak ve örneklem
büyüklüğünün 100 ve 500; kayıp veri oranının %2, %4, %8, %12 ve %16
olduğu durumlar üzerinden tümüyle seçkisiz kayıp koşulu altında
yürütülmüştür. Araştırmada yer verilen tekniklerin tüm kayıp veri oranları için,
kestirimlerde negatif ya da pozitif yanlılık gösterebileceği; farklı örneklem
büyüklükleri için liste bazında silme tekniğinin en büyük, benzer tepki
örüntüsüne dayalı atama tekniğinin ise en düşük yanlılığı gösterdiği ve kayıp
veri oranı arttıkça kestirimlerdeki yanlılığın da arttığı görülmüştür. Ortalama
değer atama tekniğinin liste bazında silme tekniğine göre daha iyi sonuçlar
vermesine rağmen yüksek kayıp veri oranları için yanlılığının arttığı; çift
bazında silme, hot-deck atama ve benzer tepki örüntüsüne dayalı atama
tekniklerinin genel olarak birbirine yakın sonuçlar verdiği görülmüştür.
Enders ve Bandalos (2001) tam bilgi maksimum olabilirlik, liste bazında
silme, çift bazında silme ve benzer tepki örüntüsüne dayalı atama tekniklerini
doğrulayıcı faktör analizi çerçevesinde ele almışlardır. Tümüyle seçkisiz kayıp
ve seçkisiz kayıp koşullarında yürütülen araştırmada, örneklem büyüklüğü
100, 250, 500 ve 750; kayıp veri oranı %2, %5, %10, %15 ve %25
düzeylerinde manipüle edilmiştir. Tam bilgi maksimum olabilirlik ve çift
bazında silme tekniklerinin en yüksek yakınsama oranını gösterdikleri, en
düşük oranın ise liste bazında silme tekniğiyle elde edildiği görülmüştür.
Parametre kestirim yanlılığı açısından yapılan incelemede küçük
örneklemlerde ve faktör yükünün düşük olduğu durumlarda negatif yanlılıklar
görülmüştür. Model uyumu açısından yapılan incelemelerde, tam bilgi
maksimum olabilirlik ve liste bazında silme tekniklerin yüksek; çift bazında
silme ve benzer tepki örüntüsüne dayalı atama tekniklerinin ise düşük
performans sergilediği görülmüştür.
Chen, Wang ve Chen (2011) tarafından gerçekleştirilen araştırma,
tümüyle seçkisiz kayıp koşulu altında %10, %20, %30 ve %50 oranında
kayıplar içeren veri setleri üzerinde gerçekleştirilmiştir. Liste bazında silme,
seri ortalaması atama, doğrusal interpolasyon, doğrusal eğilim, beklenti –
maksimizasyon algoritması ve regresyonla değer atama teknikleri, açımlayıcı
ve doğrulayıcı faktör analizi çerçevesinde değerlendirilmiştir. Açımlayıcı faktör
analizi sonuçlarına göre açıklanan varyans oranının %54 ile %99,16 arasında
değiştiği, kullanılan altı farklı kayıp veri baş etme tekniğinin benzer sonuçlar

29
ürettiği ve beklenti – maksimizasyon algoritmasının diğer tekniklere göre daha
yüksek performans gösterdiği görülmüştür. Doğrulayıcı faktör analizi
çerçevesinde 2, NNFI, SRMR ve RMSEA değerleri incelenmiş, kayıp veri
miktarının artmasına paralel olarak liste bazında silme ve beklenti –
maksimizasyon algoritmasıyla elde edilen sonuçların modele uyumunun
düşük olduğu görülmüştür.
Kayıp verilerin geçerlik ve güvenirlik çerçevesinde ele alındığı diğer bir
araştırma Çokluk ve Kayri (2011) tarafından gerçekleştirilmiştir. Araştırma, 10
maddeden oluşan tek faktörlü yapının ortaya konduğu bir ölçek ile 200 kişilik
bir örneklemden elde edilen veriler üzerinde yürütülmüştür. Eksiksiz veri
setindeki değerler rastgele silinerek, her bir değişkendeki kayıp veri oranının
yaklaşık olarak %15 - %20 ve %0 - %50 aralığında değiştiği iki farklı veri seti
elde edilmiştir. Tek faktörlü yapı için eksiksiz veri seti üzerinden elde edilen
özdeğer, açıklanan varyans oranı, maddelere ilişkin faktör yük değerleri,
düzeltilmiş madde – toplam korelasyonları ve Cronbach α iç tutarlılık
katsayısı; seri ortalaması, yakın noktaların ortalaması, yakın noktaların
medyanı, doğrusal değer kestirimi ve noktanın doğrusal eğimi yöntemleriyle
elde edilen değerlerle karşılaştırılmıştır. Eksiksiz veri seti üzerinde yapılan
analiz sonucunda, 5. ve 9. maddelerin en yüksek faktör yük değerine sahip
oldukları ve bu durumun bütün yöntemlerle 5. maddenin faktör yükü için
korunduğu görülmüştür. Kayıp veri oranının %15 - %20 aralığında manipüle
edildiği veri seti için açıklanan varyans oranlarının, eksiksiz veri setinden elde
edilen orandan düşük olduğu; en yakın oranın düşük faktör yük değerine bağlı
olarak bir maddenin çıkarılmasının ardından doğrusal değer kestirimi
yöntemiyle elde edildiği görülmüştür. Eksiksiz veri seti için 0,83 olan Cronbach
α katsayısına en yakın güvenirlik değeri, noktanın doğrusal eğimi yöntemiyle
0,80 düzeyinde kestirilmiştir.
Demir (2013)’in, 527517 öğrencinin SBS 2011 matematik testi A
kitapçığı verileri üzerinde yaptığı çalışmada, farklı kayıp veri tekniklerinin
etkinlikleri yapı geçerliği, madde parametreleri, test parametreleri ve güvenirlik
kapsamında incelenmiştir. Araştırma kapsamında dizin silme, 0 atama, seri
ortalamaları atama, gözlem birimi ortalaması atama, yakın noktaların
ortalamasını atama, yakın noktaların medyanını atama, doğrusal

30
interpolasyon, doğrusal eğilim noktası, regresyonla atama, beklenti –
maksimizasyon algoritması, veri çoğaltma ve çoklu veri atama-MCMC olmak
üzere 12 farklı teknik kullanılmıştır. Matematik testinde yer alan 20 maddenin
her birinde %2 ile %34,4 arasında değişen kayıplar bulunduğu görülmüş ve
bu 12 farklı tekniğin uygulanmasıyla elde edilen veriler üzerinden, yapı
geçerliği için açımlayıcı ve doğrulayıcı faktör analizleri gerçekleştirilmiş,
madde parametreleri (güçlük, ayırt edicilik, çift serili korelasyon, nokta çift
serili korelasyon, madde güvenirliği), test parametreleri (ortalama, standart
sapma, standart hata, basıklık ve çarpıklık katsayıları) ve iç tutarlılık
katsayıları (Cronbach α) kestirilmiştir. Dizin silme ve 0 atama yöntemlerinin, iki
kategorili puanlanan testlerde kayıp verilerle başa çıkmada kullanılmaya
uygun olmadığı, basit atama tekniklerinin yanlı kestirimler üretme olasılığının
yüksek olduğu ve en çok olabilirlik ve çoklu veri atama tekniklerinin bu tür
verilerde kullanılabilecek en uygun teknik olduğu belirtilmiştir.
Kayıp verileri konu edinen bu araştırmaların çoğu yapay veri setleri
üzerinde gerçekleştirilirken, bazılarında gerçek veriler kullanılmıştır. Verilerin
yapay olarak üretildiği araştırmalarda madde sayısı, örneklem büyüklüğü,
kayıp veri koşulu, kayıp veri oranı gibi değişkenler manipüle edilmiştir. Bu
değişkenlerin farklı kombinasyonları dikkate alınarak gerçekleştirilen
araştırmalarda çok sayıda veri seti bulunduğundan birkaç kayıp veri baş etme
tekniğine yer verilebilmiş; analiz sonuçları eksiksiz veri setlerinden elde edilen
sonuçlarla karşılaştırılmıştır. Gerçek verilerin kullanıldığı araştırmalarda ise
çok sayıda kayıp veri baş etme tekniğinin performansı test edilebilmiş, kayıp
veri tekniklerinin performansları göreceli olarak karşılaştırılmıştır.

31
BÖLÜM III
YÖNTEM
Bu bölümde araştırmanın modeli, verilerin üretilmesi, istenen koşullara
uygun kayıplar içeren veri dosyalarının elde edilmesi, kayıp veri içeren veri
setlerinin farklı kayıp veri teknikleriyle tamamlanması ve verilerin analiz süreci
ile ilgili bilgilere yer verilmiştir.
Araştırmanın Modeli
Araştırma, farklı kayıp veri baş etme tekniklerinin güvenirlik ve geçerlik
kanıtları üzerindeki etkilerinin yapay veri setleri kullanılarak incelendiği bir
temel araştırma niteliğindedir. Temel araştırmalar, var olan bilgiye yenilerini
katmayı amaçlayan araştırmalardır (Karasar, 2007). Araştırmada kayıp veri
baş etme tekniklerinin etkinlikleri, örneklem büyüklüğü, madde sayısı, kayıp
veri örüntüsü ve kayıp veri oranı değişkenlerinin farklı düzeyleri üzerinden
açımlayıcı bir yaklaşımla incelenmiştir.
Verilerin Üretilmesi
Araştırma kapsamında kullanılan verilerin üretilmesinde Muthen ve
Muthen (2012) tarafından geliştirilmiş olan ve örneklem büyüklüğü, madde
sayısı ve faktör yapısının manipüle edilebilmesine olanak sağlayan Mplus 8.0
programı kullanılmıştır.
Temel bileşenler analizinin yapı geçerliğinin incelenmesinde en sık
kullanılan yöntem olduğunu belirten Peterson (2000), faktör sayısının 2 – 3;
madde sayısının ise 1 – 10 ve 11 – 20 arasında değiştiği durumların baskın
bir şekilde gözlendiğini ifade etmektedir. Bu çalışmada veri setleri, bir faktör
için 10 maddeden, iki faktör için 15 maddeden oluşacak şekilde üretilmiştir.
Kayıp veriler üzerinde yapılmış olan benzer çalışmalar (Bernaards ve
Sijtsma, 1999, 2000; Olinsky, Chen ve Harlow, 2003, Dural, 2010) göz önüne
alındığında, küçük ve büyük örneklemleri temsil eden verilerin genel olarak
n=100 ve n=500 şeklinde belirlendiği görülmektedir. Araştırma kapsamında 15

32
maddelik veri setlerine ve liste bazında silme tekniğine yer verildiği için
örneklem büyüklüğü küçük, orta ve büyük örneklemleri temsil etmek üzere
250, 500 ve 1000 olmak üzere üç düzeyde ele alınmıştır.
Tümüyle seçkisiz kayıp koşulu altında, 15 maddelik veri setleri için
kayıp veri oranının %10’un üzerine çıkması durumunda örneklem
büyüklüğünün beklenen değerinde %20’nin altına inen bir küçülme söz
konusudur. Bu küçülme %2 kayıp veri oranı için yaklaşık olarak %74; %5
kayıp veri oranı için %46’dır. Kayıp veri oranı düşük, orta ve yüksek düzeyleri
temsil etmek üzere %2, %5 ve %10 düzeylerinde manipüle edilmiştir.
Araştırmanın amacına uygun olarak 250, 500 ve 1000 kişilik
örneklemlerden oluşan veri setleri bir faktörlü yapı için 10, iki faktörlü yapı için
15 madde içermektedir. İki faktörlü veri setlerinde birinci faktör altında 9, ikinci
faktör altında 6 madde yer almaktadır. Aynı örneklem büyüklüğü ve madde
sayısına sahip 100 ve toplamda 600 farklı dosyadan oluşan veri setleri
üretilmiştir. Veri üretme aşamasında kullanılan Mplus komutları ekte (Ek 1)
verilmiştir.
Mplus 8.0 (Muthen ve Muthen, 2012) programı veri dosyalarını, .dat
uzantısı ile metin belgesi olarak sunmaktadır. Bu dosyalar değer atama
işlemlerinin ve istatistiksel analizlerin gerçekleştirileceği PASW (SPSS, Inc,
2009) programına uyumlu olması amacıyla, .sav uzantılı dosyalara
dönüştürülmüştür.
Araştırma kapsamında üretilen veri setlerine ait analiz sonuçları, kayıp
veri tekniklerinin uygulanmasıyla elde edilen veri setlerine ait sonuçların
karşılaştırılmasında ölçüt olarak kullanılmıştır. Bu amaçla analizler öncelikle
eksiksiz veri setleri üzerinde gerçekleştirilmiştir.
Eksiksiz veri setlerinden elde edilen Cronbach α, McDonald ve w
katsayılarına ilişkin betimsel istatistikler Çizelge 3’te verilmiştir.
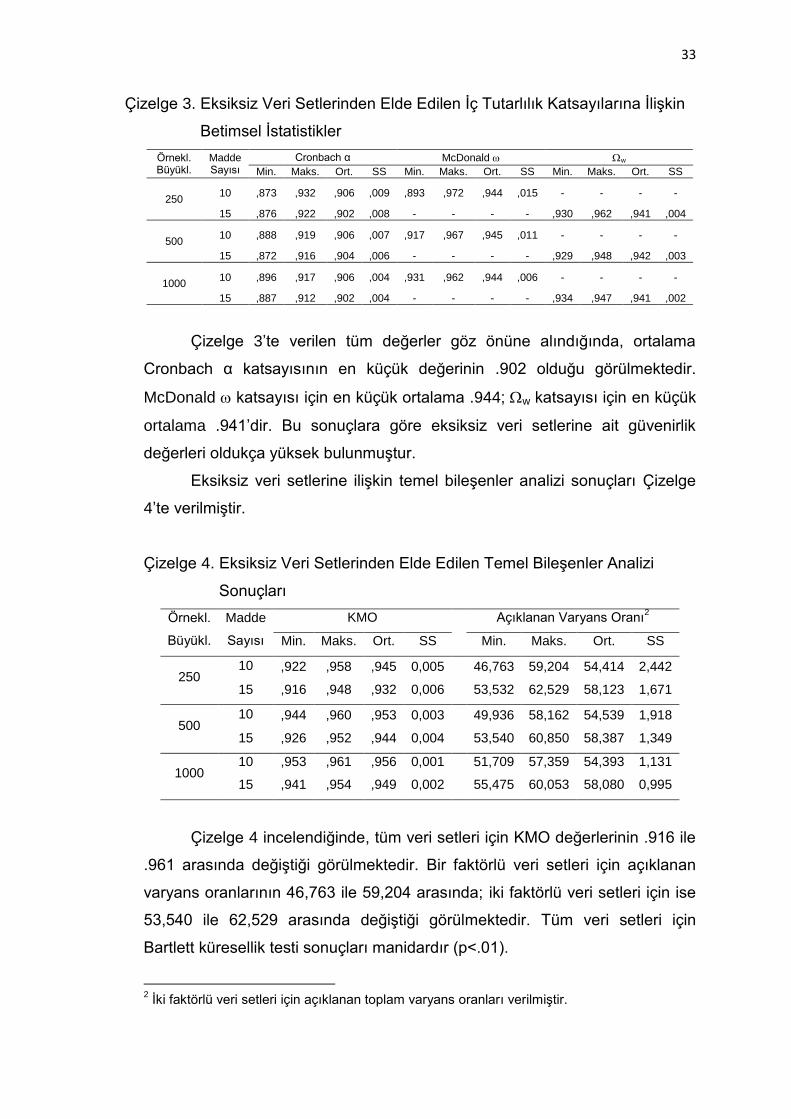
33
Çizelge 3. Eksiksiz Veri Setlerinden Elde Edilen İç Tutarlılık Katsayılarına İlişkin
Betimsel İstatistikler
Örnekl. Büyükl.
Madde Sayısı
Cronbach α McDonald w
Min. Maks. Ort. SS Min. Maks. Ort. SS Min. Maks. Ort. SS
250 10 ,873 ,932 ,906 ,009 ,893 ,972 ,944 ,015 - - - -
15 ,876 ,922 ,902 ,008 - - - - ,930 ,962 ,941 ,004
500 10 ,888 ,919 ,906 ,007 ,917 ,967 ,945 ,011 - - - -
15 ,872 ,916 ,904 ,006 - - - - ,929 ,948 ,942 ,003
1000 10 ,896 ,917 ,906 ,004 ,931 ,962 ,944 ,006 - - - -
15 ,887 ,912 ,902 ,004 - - - - ,934 ,947 ,941 ,002
Çizelge 3’te verilen tüm değerler göz önüne alındığında, ortalama
Cronbach α katsayısının en küçük değerinin .902 olduğu görülmektedir.
McDonald katsayısı için en küçük ortalama .944; w katsayısı için en küçük
ortalama .941’dir. Bu sonuçlara göre eksiksiz veri setlerine ait güvenirlik
değerleri oldukça yüksek bulunmuştur.
Eksiksiz veri setlerine ilişkin temel bileşenler analizi sonuçları Çizelge
4’te verilmiştir.
Çizelge 4. Eksiksiz Veri Setlerinden Elde Edilen Temel Bileşenler Analizi
Sonuçları
Örnekl.
Büyükl.
Madde
Sayısı
KMO Açıklanan Varyans Oranı2
Min. Maks. Ort. SS Min. Maks. Ort. SS
250 10 ,922 ,958 ,945 0,005 46,763 59,204 54,414 2,442
15 ,916 ,948 ,932 0,006 53,532 62,529 58,123 1,671
500 10 ,944 ,960 ,953 0,003 49,936 58,162 54,539 1,918
15 ,926 ,952 ,944 0,004 53,540 60,850 58,387 1,349
1000 10 ,953 ,961 ,956 0,001 51,709 57,359 54,393 1,131
15 ,941 ,954 ,949 0,002 55,475 60,053 58,080 0,995
Çizelge 4 incelendiğinde, tüm veri setleri için KMO değerlerinin .916 ile
.961 arasında değiştiği görülmektedir. Bir faktörlü veri setleri için açıklanan
varyans oranlarının 46,763 ile 59,204 arasında; iki faktörlü veri setleri için ise
53,540 ile 62,529 arasında değiştiği görülmektedir. Tüm veri setleri için
Bartlett küresellik testi sonuçları manidardır (p<.01).
2 İki faktörlü veri setleri için açıklanan toplam varyans oranları verilmiştir.
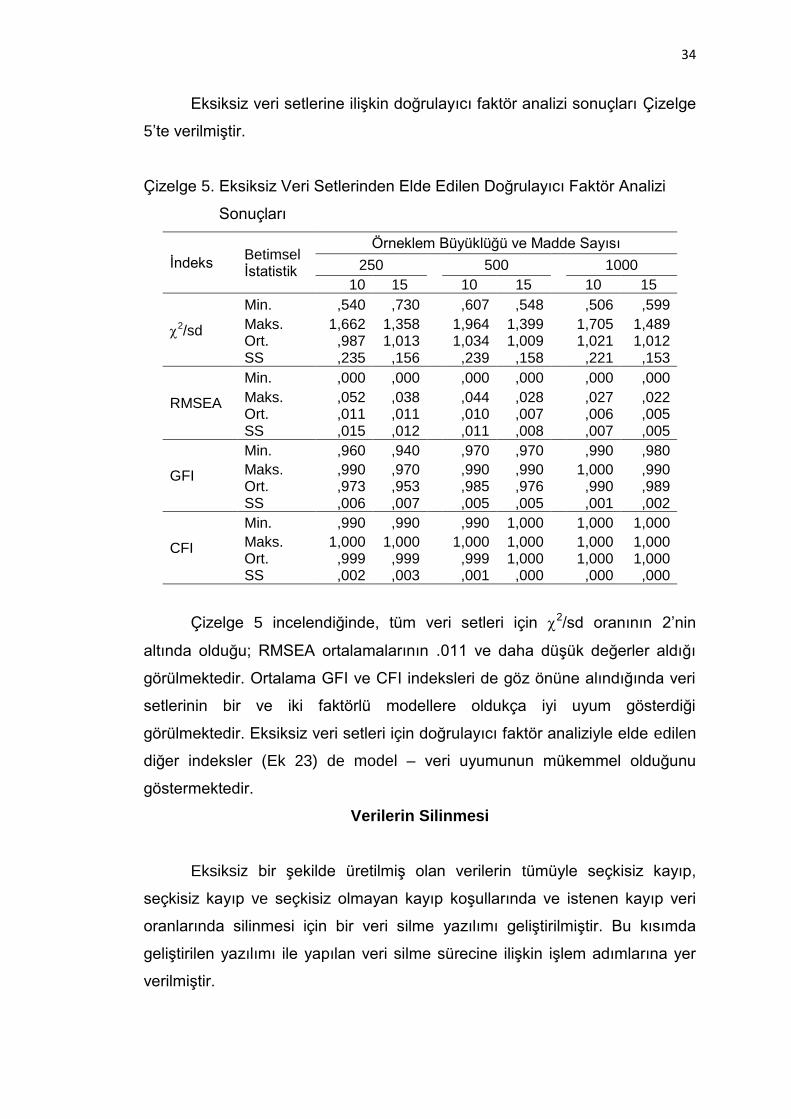
34
Eksiksiz veri setlerine ilişkin doğrulayıcı faktör analizi sonuçları Çizelge
5’te verilmiştir.
Çizelge 5. Eksiksiz Veri Setlerinden Elde Edilen Doğrulayıcı Faktör Analizi
Sonuçları
İndeks Betimsel İstatistik
Örneklem Büyüklüğü ve Madde Sayısı
250 500 1000
10 15 10 15 10 15
2/sd
Min. ,540 ,730 ,607 ,548 ,506 ,599
Maks. 1,662 1,358 1,964 1,399 1,705 1,489 Ort. ,987 1,013 1,034 1,009 1,021 1,012 SS ,235 ,156 ,239 ,158 ,221 ,153
RMSEA
Min. ,000 ,000 ,000 ,000 ,000 ,000
Maks. ,052 ,038 ,044 ,028 ,027 ,022 Ort. ,011 ,011 ,010 ,007 ,006 ,005 SS ,015 ,012 ,011 ,008 ,007 ,005
GFI
Min. ,960 ,940 ,970 ,970 ,990 ,980
Maks. ,990 ,970 ,990 ,990 1,000 ,990 Ort. ,973 ,953 ,985 ,976 ,990 ,989 SS ,006 ,007 ,005 ,005 ,001 ,002
CFI
Min. ,990 ,990 ,990 1,000 1,000 1,000
Maks. 1,000 1,000 1,000 1,000 1,000 1,000 Ort. ,999 ,999 ,999 1,000 1,000 1,000 SS ,002 ,003 ,001 ,000 ,000 ,000
Çizelge 5 incelendiğinde, tüm veri setleri için 2/sd oranının 2’nin
altında olduğu; RMSEA ortalamalarının .011 ve daha düşük değerler aldığı
görülmektedir. Ortalama GFI ve CFI indeksleri de göz önüne alındığında veri
setlerinin bir ve iki faktörlü modellere oldukça iyi uyum gösterdiği
görülmektedir. Eksiksiz veri setleri için doğrulayıcı faktör analiziyle elde edilen
diğer indeksler (Ek 23) de model – veri uyumunun mükemmel olduğunu
göstermektedir.
Verilerin Silinmesi
Eksiksiz bir şekilde üretilmiş olan verilerin tümüyle seçkisiz kayıp,
seçkisiz kayıp ve seçkisiz olmayan kayıp koşullarında ve istenen kayıp veri
oranlarında silinmesi için bir veri silme yazılımı geliştirilmiştir. Bu kısımda
geliştirilen yazılımı ile yapılan veri silme sürecine ilişkin işlem adımlarına yer
verilmiştir.

35
Tümüyle seçkisiz kayıp koşulunun sağlanması için, herhangi bir verinin
kayıp olma olasılığının başka bir hücredeki verinin kayıp olma olasılığına eşit
olması ve bu olasılıkların birbirinden bağımsız olması gerekmektedir.
Bu koşulun sağlanması amacıyla, öncelikle veri setindeki satır (n) ve
sütun (m) sayıları çarpılmıştır. Araştırma kapsamında yer verilen her bir kayıp
veri oranı için, silinmesi gereken ölçüm sayısı belirlenmiş ve yazılımın 1 ile
m.n aralığında rastgele belirlediği sayılara karşılık gelen hücrelerdeki veriler
silinerek bu değerler yerine “9” değeri yazılmıştır. Bir hücredeki verinin daha
önceden silinmiş olması durumunda, istenen kayıp veri oranına ulaşana kadar
yeniden rastgele sayılar üretilmiştir.
Seçkisiz kayıp koşulunun sağlanması için, herhangi bir verinin kayıp
olması olasılığının eksiksiz veriye sahip olan başka bir değişkenle ilişkili
olması ve bu değişkene göre koşullu olasılıkların eşit olması gerekmektedir.
Seçkisiz kayıp koşulunun sağlanması amacıyla Collins, Schafer ve
Kam (2001) ve Van Ginkel, Kroonenberg ve Kiers (2013)’e benzer bir şekilde,
veri setleri birinci değişkene göre sıralanmış ve birinci değişken silme işlemi
dışında tutulmuştur. Silme işlemi birinci değişkenin ortancasının altında ve
üstünde kalan satırlar için ayrı ayrı gerçekleştirilmiştir.
Araştırma kapsamında yer verilen her bir kayıp veri oranı için, birinci
değişkenin ortancasının üzerinde ve altında kalan satırlardaki verilerin %50-
%50 oranında silinmesi, tümüyle seçkisiz kayıp koşuluna benzer sonuçlar
üreteceğinden, bu oranlar %80-%20 şeklinde değiştirilmiştir. Böylece,
ortancanın üzerinde kalan satırlardaki değerlerin kayıp olma olasılığı,
ortancanın altında kalan hücrelerdeki değerlerin kayıp olma olasılığının dört
katına çıkarılmıştır. Silme işlemi, ortancanın altında ve üstünde kalan grup için
tümüyle seçkisiz kayıp koşuluna benzer şekilde rastgele üretilen değerlere
göre gerçekleştirilmiş ve silinen verilerin yerine “9” değeri yazılmıştır.
Seçkisiz olmayan kayıp koşulunun sağlanması için, herhangi bir verinin
kayıp olma olasılığının ilgili değişkenin değeriyle ilişkili olması gerekmektedir.
Bu koşulda, herhangi bir verinin kayıp olma olasılığı için rastgelelik söz
konusu değildir.
Seçkisiz olmayan kayıp koşulunun sağlanması amacıyla silme işlemi,
Scheffer (2002) ve Dural (2010)’a benzer şekilde her bir değişken için ayrı
ayrı yapılan sıralamalar üzerinden gerçekleştirilmiştir. Değişkenler büyükten

36
küçüğe sıralanmış ve istenen kayıp veri oranı sağlanana kadar her bir
değişkenin en büyük ve en küçük değerlerinden başlanarak silme işlemi
gerçekleştirilmiştir. Seçkisiz kayıp koşuluna benzer bir şekilde, araştırma
kapsamında yer verilen kayıp veri oranlarına ulaşılıncaya kadar en büyük
değerlerden %80 ve en küçük değerlerden %20 oranında silme işlemi
gerçekleştirilmiş ve silinen hücrelere “9” değeri yazılmıştır.
Birim yanıtlamama şeklindeki kayıplar, örnekleme giren bir bireyin tüm
değişkenlerdeki verilerinin kayıp olması durumudur. Bu durum liste bazında
silme tekniği açısından, tek bir değişkende kayıp verinin bulunması ile benzer
sonuçlar üretmektedir. Öte yandan, birim yanıtlamamanın söz konusu olduğu
veri setlerinde, diğer kayıp veri baş etme teknikleriyle değer atama işlemi
gerçekleştirilememektedir.
Tümüyle seçkisiz kayıp ve seçkisiz olmayan kayıp koşulları altında %2,
%5 ve %10 oranlarında gerçekleştirilen silme işlemleri sonucunda elde edilen
veri setleri, birim yanıtlamama durumu açısından incelenmiştir. Tümüyle
seçkisiz kayıp koşulu altında birim yanıtlamama durumunun söz konusu
olduğu veri setlerinde silme işlemi, bu durum ortadan kalkana kadar
tekrarlanmıştır. Seçkisiz olmayan kayıp koşulu altında birim yanıtlamama
durumunun söz konusu olduğu veri setleri ise aynı örneklem büyüklüğü ve
madde sayısına sahip yeni veri setleri ile değiştirilerek silme işlemi ve
sonrasında yapılan bu kontrol tekrarlanmıştır. Seçkisiz kayıp koşulunda,
birinci değişken silme işlemi dışında tutulduğu için birim yanıtlamama
durumuyla karşılaşılmamıştır.
Liste bazında silme tekniğinde, herhangi bir verinin kayıp olması
halinde ilgili satırlar analizlere dâhil edilmemektedir. Dolayısıyla kayıp veri
miktarına bağlı olarak örneklemin küçülmesi söz konusudur. Silme işlemi
sonrasında, kayıp veri koşullarına ve kayıp veri oranlarına göre liste bazında
silme tekniği ile ulaşılan örneklem büyüklüğü değerleri Çizelge 6’da verilmiştir.

37
Çizelge 6. Liste Bazında Silme Tekniği İçin Örneklem Büyüklüğüne Ait
Betimsel İstatistikler
Örnekl. Büyükl.
Madde Sayısı
Bet. İst.
Kayıp Veri Koşulu ve Oranı
TSK
SK
SOK
2 5 10
2 5 10
2 5 10
250
10
Min. 200 138 71
206 159 105
208 168 112
Maks. 208 159 99
215 177 122
228 197 146
Ort. 204,06 149,33 87,05
209,72 167,33 112,57
216,04 181,50 131,61
SS 1,78 3,43 5,37
1,89 3,42 3,95
3,54 5,08 6,87
15
Min. 179 107 40
185 130 71
192 143 80
Maks. 191 126 68
200 148 92
211 170 116
Ort. 184,59 116,35 51,39
191,30 138,84 81,41
201,49 157,19 97,54
SS 2,50 4,62 4,72
2,84 3,69 4,29
3,78 5,17 6,49
500
10
Min. 402 286 155 414 314 211 424 345 242
Maks. 416 315 186 425 337 239 449 382 289
Ort. 408,31 299,30 174,35 419,15 326,11 225,64 434,27 360,53 265,82
SS 2,65 5,34 6,51 2,28 4,43 5,73 4,46 6,87 9,15
15
Min. 361 215 87 375 251 150 395 282 175
Maks. 381 247 120 390 285 179 417 330 219
Ort. 369,57 231,04 103,68 382,14 266,71 163,01 405,92 308,40 196,44
SS 3,37 6,20 6,94 3,41 5,70 5,69 5,61 8,41 10,03
1000
10
Min. 809 578 326 829 631 433 849 695 501
Maks. 826 617 370 848 671 467 884 744 561
Ort. 816,81 599,06 350,03 838,31 652,66 450,42 867,09 720,02 529,38
SS 3,63 7,08 8,52 3,36 6,55 6,61 6,88 9,63 12,10
15
Min. 727 438 178 753 508 308 795 597 357
Maks. 751 482 226 774 550 350 834 650 423
Ort. 738,42 462,57 206,38 763,92 533,06 325,78 811,50 616,40 391,73
SS 5,30 9,42 9,79 4,51 8,14 7,65 7,68 10,235 13,25
Çizelge 6 incelendiğinde, kayıp veri miktarındaki artışın tümüyle
seçkisiz kayıp koşulunda örneklem büyüklüğü üzerinde ciddi bir düşüşe yol
açtığı görülmektedir. Özellikle 15 maddeden oluşan veri setlerinde %10’luk
kayıpların bulunması örneklem büyüklüğünü %16’ya kadar düşürmüştür.
Seçkisiz kayıp ve seçkisiz olmayan kayıp koşulları için örneklem
büyüklüğünün, kayıp verilerin aynı satırda bulunma olasılığının artmasına
bağlı olarak tümüyle seçkisiz kayıp koşuluna göre daha az etkilendiği
görülmektedir.
Kayıp Verilerin Tamamlanması
Araştırma kapsamında yer verilen liste bazında silme, stokastik
regresyonla değer atama, beklenti-maksimizasyon algoritması ve çoklu değer
atama teknikleri PASW Statistics 18 paket programında yer alan “Missing
Value Analysis” ve “Mulitple Imputation” modülleri ile gerçekleştirilmiştir.
Stokastik regresyonla değer atama tekniğinde, hata terimleri standart normal

38
dağılımdan rastgele seçilen değerlerle çarpılmış; çoklu değer atama tekniği ile
5 farklı veri seti oluşturulmuştur.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği,
veri silme sürecinde kullanılan programa eklenen bir değer atama modülü ile
gerçekleştirilmiştir. Bu modül kullanılarak, kayıp veri barındıran satırların
gözlenen değerleri üzerinden eksiksiz veriye sahip olan alt örneklemde yer
alan satırlar arasındaki Öklid uzaklıkları hesaplanmış ve noktasal uzaklığın en
küçük olduğu satırlar belirlenerek kayıp veri ataması yapılmıştır.
Verilerin Analizi
Güvenirliğe ilişkin incelemeler Cronbach α, McDonald ve
ağırlıklandırılmış (w) katsayıları üzerinden gerçekleştirilmiştir.
İç tutarlılık anlamında yorumlanan ve araştırmalarda sıklıkla
raporlaştırılan Cronbach α katsayısı Eşitlik 5’e göre hesaplanmaktadır.
2
1
21
1
i
K
Y
i
X
K
K
(5)
Formülde yer alan K, ölçme aracındaki madde sayısını; 2
iY , madde
varyansını ve 2
X , toplam puan varyansını temsil etmektedir (Cronbach,
1990).
Bir faktörlü veri setleri için güvenirlik, McDonald (1985) tarafından
geliştirilen ve yapısal güvenirlik olarak da adlandırılan (Nunnally ve Bernstein,
1994) katsayısı Eşitlik 6’ya göre hesaplanmaktadır.
2
1
2
1 1
k
i
i
k k
i i
i i
(6)
Formülde yer alan değerleri bir faktörlü veri setleri için doğrulayıcı
faktör analizi ile elde edilen standartlaştırılmamış faktör yüklerini, ise hata
varyansını temsil etmektedir.

39
McDonald katsayısı, maddelerin farklı boyutlar altındaki ağırlıklarına
duyarsız olduğu için tek faktörlü ölçümler için uygundur (Widhiarso, 2007).
Hancock ve Mueller (2001) McDonald katsayısını çok faktörlü modeller için
ağırlıklandırarak yeniden düzenlemiştir. Ağırlıklandırılmış (w) katsayısı
Eşitlik 7’ye göre hesaplanmaktadır.
2
21
2
21
1
11
p
i
i i
W p
i
i i
l
l
l
l
(7)
Formülde yer alan l değerleri doğrulayıcı faktör analizi ile elde edilen
standartlaştırılmış faktör yüklerini temsil etmektedir.
Kayıp veri tekniklerinin güvenirlik kestirimleri üzerindeki performansının
incelenmesi amacıyla öncelikle, eksiksiz veri setinden elde edilen güvenirlik
katsayıları ile farklı kayıp veri türü, kayıp veri oranı ve kayıp veri baş etme
tekniği altında elde edilen güvenirlik katsayıları arasındaki farklar
hesaplanmıştır. Örneklem büyüklüğü ve madde sayısı değişkenlerinin her bir
kombinasyonu için fark puanlarının bağımlı, kayıp veri türü, kayıp veri oranı ve
kayıp veri baş etme tekniğinin bağımsız değişken olarak kullanıldığı çok yönlü
varyans analizleri gerçekleştirilmiştir. Çok yönlü varyans analizi sonuçlarına
göre, ortalamalar arasındaki farkların manidar olduğu görülmüş, bu farklılığın
hangi gruplar arasında olduğunu belirlemek için tek yönlü varyans analizleri
gerçekleştirilmiştir. Varyansların homojenliği varsayımı karşılanmadığı için
çoklu karşılaştırma testi olarak Dunnett C kullanılmıştır. Analizlerde manidarlık
düzeyi olarak .05 esas alınmıştır.
Farklı kayıp veri teknikleriyle elde edilen sonuçların temel bileşenler
analizi çerçevesinde incelenmesinde kullanılabilecek yöntemlerden biri Tucker
(Tucker, 1951; Ten Berge, 1977 akt. Bernaards ve Sijtsma, 1999)
değerinin incelenmesidir.
a ve b, aynı değişkenler için farklı yöntemlerle elde edilen faktör yükleri
vektörlerini temsil etmek üzere Tucker ,

40
1/2( , ) ( )T T Ta b a b a ab b (8)
eşitliği ile hesaplanmaktadır. -1 ile +1 değerleri arasında değişen
Tucker istatistiği, a ve b vektörlerinden biri diğerinin katı olduğu durumlarda
mükemmel uyuşumu temsil eden +1 değerini almaktadır. Tucker
istatistiğinin 0,85 ve üstü değerler alması durumunda faktör yüklerinin eşit
olduğu kabul edilmektedir (Ten Berge, 1977 akt. Bernaards ve Sijtsma, 1999).
Diğer bir yöntem, biri eksiksiz diğeri kayıp veri baş etme tekniğiyle elde
edilen veri setine ait kovaryans matrislerinin incelenmesidir. k, madde sayısını
E , eksiksiz veri setine ait evren kovaryans matrisini K , kayıp veri baş etme
tekniğiyle elde edilen veri setine ait evren kovaryans matrisini E ve K
kestirilen kovaryans matrislerini temsil etmek üzere; 1,... k özdeğerleri için
E K şeklindeki yokluk hipotezi aşağıdaki Eşitlik 9‘dan yola çıkılarak test
edilmektedir.
1
ˆ ˆ ˆ ˆ
K E E KX X X X (9)
Eşitlik 9’da X, 1
ˆ ˆ
E K özdeğerine karşılık gelen özvektörü ifade
etmektedir (Anderson, 2003). Kayıp veri baş etme tekniğiyle elde edilen veri
setine ait kovaryans matrisinin K, eksiksiz veri setine ait kovaryans matrisi
E ile birebir örtüşmesi durumunda
1ˆ ˆ
E K matrisinin tüm özdeğerleri bire
eşit olmaktadır.
Bernaards ve Sijtsma (1999), karşılaştırmaların bu matrise ait
özdeğerlerin ortalamaları, çarpımları veya max / min oranın 1’e ne ölçüde
yaklaştığının incelenmesi şeklinde yapılabileceğini belirtmektedir.
Bu istatistiklerin elde edilmesi, çalışmada yer verilen veri setlerindeki
madde sayısı (10 ve 15) kadar satır ve sütundan oluşan matrislerin öz
değerlerinin hesaplanmasını sağlayan özel yazılımların kullanılmasını
gerektirdiğinden araştırma dışında bırakılmıştır.

41
Temel bileşenler analizi çerçevesinde, faktör yükleri matrislerinin
benzerliği D2 istatistiği üzerinden incelenmiştir. X, eksiksiz veri seti üzerinden
elde edilen faktör yükleri matrisini; Y, kayıp veri baş etme tekniğinin
uygulanmasıyla elde edilen faktör yükleri matrisini ve m, faktör sayısını temsil
etmek üzere D2, Eşitlik 10’a göre hesaplanmaktadır.
2 [( ) ( )] / [( )( ) ] /T TD tr X Y X Y m tr X Y X Y m (10)
Bu değerin, ulaşabileceği en büyük değer madde sayısı ve faktör
yüklerine göre değişmekle birlikte sıfıra eşit olması, faktör yükleri matrislerinin
birebir eşit olduğu anlamına gelmektedir. Elde edilen değer sıfıra yakın olduğu
ölçüde faktör yükleri matrislerinin benzerliği artmaktadır (Bernaards ve
Sijtsma, 1999). Bu istatistik sayesinde farklı kayıp veri teknikleriyle elde edilen
veri setlerine ait faktör yükleri matrislerinin, eksiksiz veri setiyle elde edilen
faktör yükleri matrisine ne derece yaklaştığı belirlenebilmektedir.
Kayıp veri tekniklerinin temel bileşenler analiziyle elde edilen açıklanan
varyans oranları üzerindeki performansının incelenmesi amacıyla öncelikle,
eksiksiz veri setinden elde edilen açıklanan varyans (iki faktörlü veri setleri
için toplam varyans) oranları ile farklı kayıp veri türü, kayıp veri oranı ve kayıp
veri baş etme tekniği ile elde edilen oranlar arasındaki farklar hesaplanmıştır.
Örneklem büyüklüğü ve madde sayısı değişkenlerinin her bir kombinasyonu
için fark puanlarının bağımlı, kayıp veri türü, kayıp veri oranı ve kayıp veri baş
etme tekniğinin bağımsız değişken olarak kullanıldığı çok yönlü varyans
analizleri gerçekleştirilmiştir. Çok yönlü varyans analizi sonuçlarına göre,
ortalamalar arasındaki farkların manidar olduğu görülmüş, bu farklılığın hangi
gruplar arasında olduğunu belirlemek için tek yönlü varyans analizleri
gerçekleştirilmiştir. Varyansların homojenliği varsayımı karşılanmadığı için
çoklu karşılaştırma testi olarak Dunnett C kullanılmıştır. Analizlerde manidarlık
düzeyi olarak .05 esas alınmıştır.
Doğrulayıcı faktör analizi çerçevesinde, farklı kayıp veri tekniklerinin
uygulanmasıyla elde edilecek veri setlerinin, veri üretimi aşamasında
öngörülen tek faktörlü ve iki faktörlü modellere uyumu incelenmiştir.

42
Doğrulayıcı faktör analizlerinin gerçekleştirilmesinde LISREL 8.80 (Jöreskog
ve Sörbom, 2007) paket programı kullanılmıştır.

43
BÖLÜM IV
BULGULAR VE YORUMLAR
Bu bölümde araştırmanın amaçları doğrultusunda elde edilen bulgulara
yer verilmiştir. Bugular, araştırmanın amaçlarına uygun şekilde sırasıyla
güvenirlik ve geçerlik kapsamında sunulmuştur.
1. Güvenirliğe İlişkin Bulgular
Araştırmada liste bazında silme, Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama, stokastik regresyonla değer atama, beklenti-
maksimizasyon algoritması ve çoklu değer atama tekniklerinin güvenirlik
kestirimlerindeki yanlılık durumları Cronbach α, Mcdonald ve W katsayıları
üzerinden incelenmiştir. Farklı güvenirlik katsayılarına ilişkin bulgular, büyük
ölçüde benzer olduğu için bir arada yorumlanmıştır.
a. Cronbach α Kestirimlerinin Yanlılığına İlişkin Bulgular
Araştırma kapsamında yer verilen kayıp veri baş etme teknikleri ile
örneklem büyüklüğü, madde sayısı, kayıp veri türü, kayıp veri oranı
değişkenlerinin her bir kombinasyonu için ilgili veri setlerine ait Cronbach α
katsayıları hesaplanmıştır. Liste bazında silme, Öklid uzaklığı üzerinden
benzer tepki örüntüsüne dayalı atama, stokastik regresyonla değer atama,
beklenti-maksimizasyon algoritması ve çoklu değer atama teknikleriyle elde
edilen Cronbach α katsayılarına ilişkin aritmetik ortalama ve standart sapma
değerleri, sırasıyla Çizelge 7 –Çizelge 11’de verilmiştir.
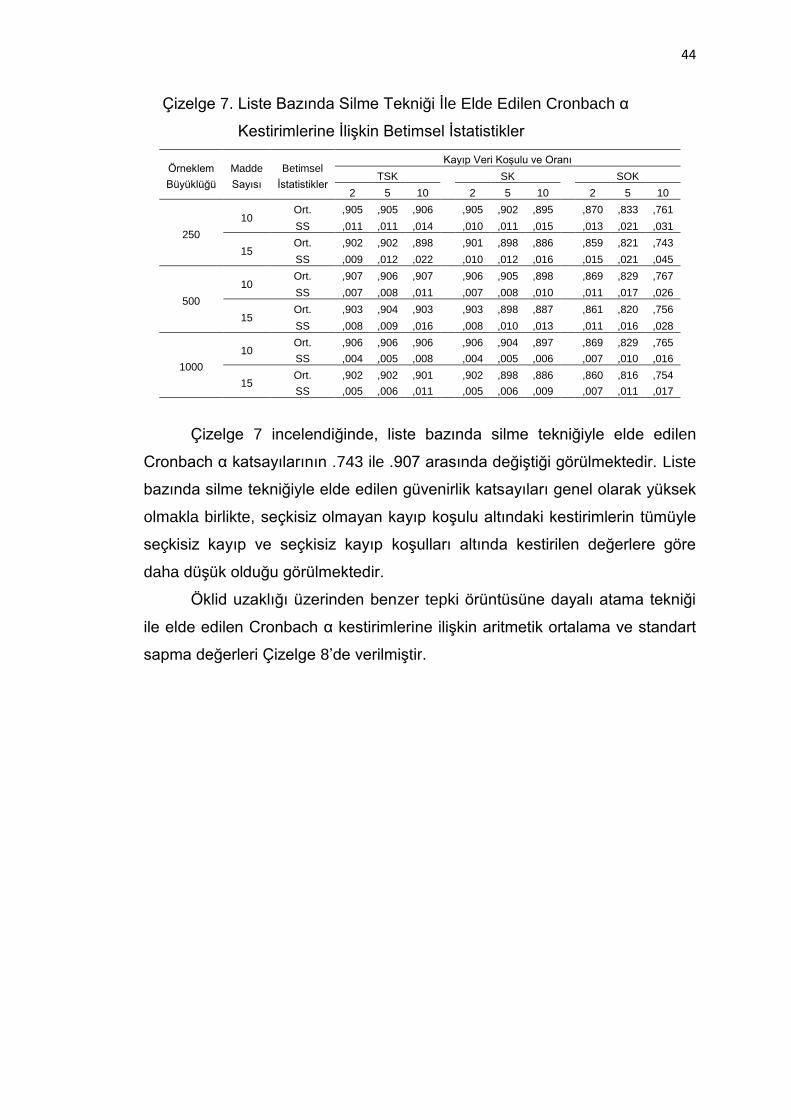
44
Çizelge 7. Liste Bazında Silme Tekniği İle Elde Edilen Cronbach α
Kestirimlerine İlişkin Betimsel İstatistikler
Örneklem
Büyüklüğü
Madde
Sayısı
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. ,905 ,905 ,906
,905 ,902 ,895
,870 ,833 ,761
SS ,011 ,011 ,014 ,010 ,011 ,015 ,013 ,021 ,031
15 Ort. ,902 ,902 ,898
,901 ,898 ,886
,859 ,821 ,743
SS ,009 ,012 ,022 ,010 ,012 ,016 ,015 ,021 ,045
500
10 Ort. ,907 ,906 ,907
,906 ,905 ,898
,869 ,829 ,767
SS ,007 ,008 ,011 ,007 ,008 ,010 ,011 ,017 ,026
15 Ort. ,903 ,904 ,903
,903 ,898 ,887
,861 ,820 ,756
SS ,008 ,009 ,016 ,008 ,010 ,013 ,011 ,016 ,028
1000
10 Ort. ,906 ,906 ,906
,906 ,904 ,897
,869 ,829 ,765
SS ,004 ,005 ,008 ,004 ,005 ,006 ,007 ,010 ,016
15 Ort. ,902 ,902 ,901
,902 ,898 ,886
,860 ,816 ,754
SS ,005 ,006 ,011 ,005 ,006 ,009 ,007 ,011 ,017
Çizelge 7 incelendiğinde, liste bazında silme tekniğiyle elde edilen
Cronbach α katsayılarının .743 ile .907 arasında değiştiği görülmektedir. Liste
bazında silme tekniğiyle elde edilen güvenirlik katsayıları genel olarak yüksek
olmakla birlikte, seçkisiz olmayan kayıp koşulu altındaki kestirimlerin tümüyle
seçkisiz kayıp ve seçkisiz kayıp koşulları altında kestirilen değerlere göre
daha düşük olduğu görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği
ile elde edilen Cronbach α kestirimlerine ilişkin aritmetik ortalama ve standart
sapma değerleri Çizelge 8’de verilmiştir.
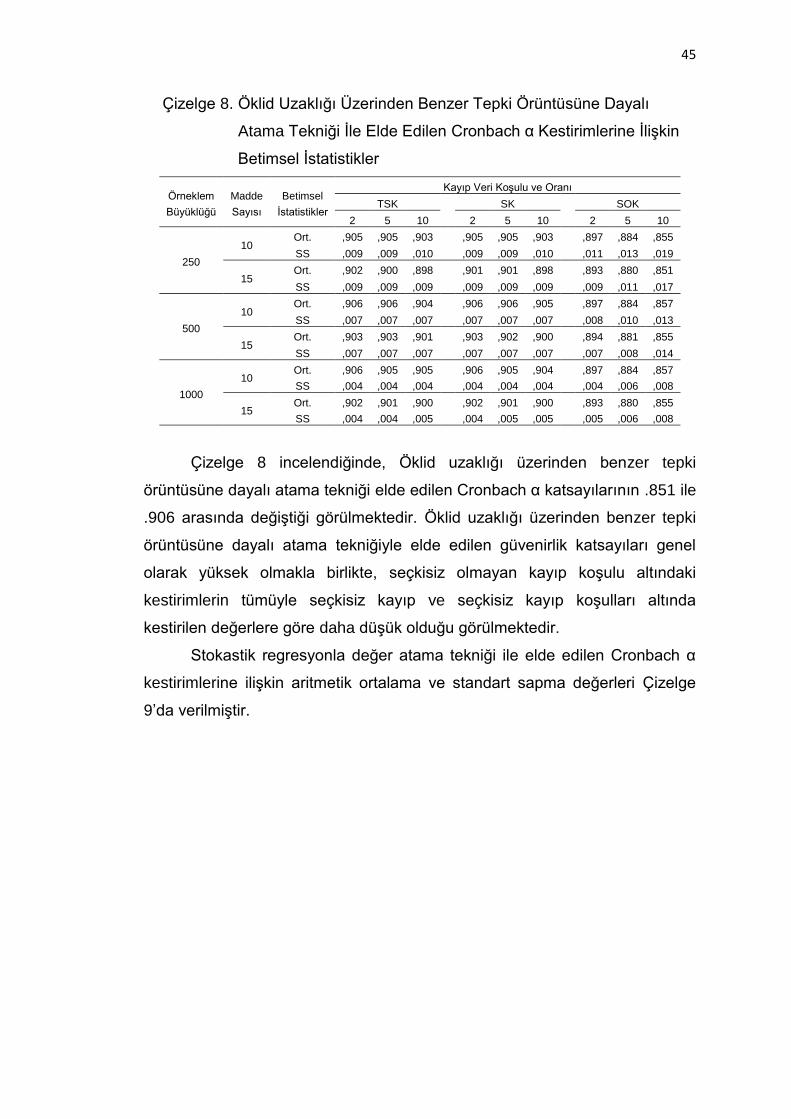
45
Çizelge 8. Öklid Uzaklığı Üzerinden Benzer Tepki Örüntüsüne Dayalı
Atama Tekniği İle Elde Edilen Cronbach α Kestirimlerine İlişkin
Betimsel İstatistikler
Örneklem
Büyüklüğü
Madde
Sayısı
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. ,905 ,905 ,903
,905 ,905 ,903
,897 ,884 ,855
SS ,009 ,009 ,010 ,009 ,009 ,010 ,011 ,013 ,019
15 Ort. ,902 ,900 ,898
,901 ,901 ,898
,893 ,880 ,851
SS ,009 ,009 ,009 ,009 ,009 ,009 ,009 ,011 ,017
500
10 Ort. ,906 ,906 ,904
,906 ,906 ,905
,897 ,884 ,857
SS ,007 ,007 ,007 ,007 ,007 ,007 ,008 ,010 ,013
15 Ort. ,903 ,903 ,901
,903 ,902 ,900
,894 ,881 ,855
SS ,007 ,007 ,007 ,007 ,007 ,007 ,007 ,008 ,014
1000
10 Ort. ,906 ,905 ,905
,906 ,905 ,904
,897 ,884 ,857
SS ,004 ,004 ,004 ,004 ,004 ,004 ,004 ,006 ,008
15 Ort. ,902 ,901 ,900
,902 ,901 ,900
,893 ,880 ,855
SS ,004 ,004 ,005 ,004 ,005 ,005 ,005 ,006 ,008
Çizelge 8 incelendiğinde, Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama tekniği elde edilen Cronbach α katsayılarının .851 ile
.906 arasında değiştiği görülmektedir. Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama tekniğiyle elde edilen güvenirlik katsayıları genel
olarak yüksek olmakla birlikte, seçkisiz olmayan kayıp koşulu altındaki
kestirimlerin tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında
kestirilen değerlere göre daha düşük olduğu görülmektedir.
Stokastik regresyonla değer atama tekniği ile elde edilen Cronbach α
kestirimlerine ilişkin aritmetik ortalama ve standart sapma değerleri Çizelge
9’da verilmiştir.
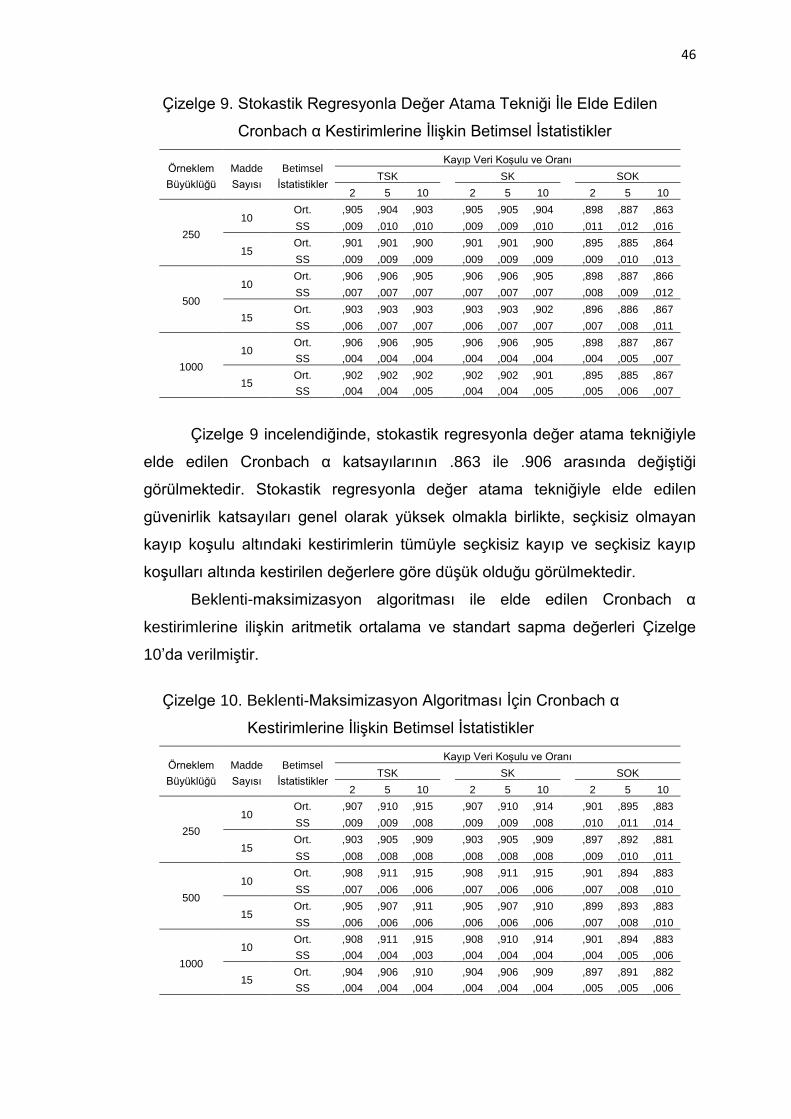
46
Çizelge 9. Stokastik Regresyonla Değer Atama Tekniği İle Elde Edilen
Cronbach α Kestirimlerine İlişkin Betimsel İstatistikler
Örneklem
Büyüklüğü
Madde
Sayısı
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. ,905 ,904 ,903
,905 ,905 ,904
,898 ,887 ,863
SS ,009 ,010 ,010 ,009 ,009 ,010 ,011 ,012 ,016
15 Ort. ,901 ,901 ,900
,901 ,901 ,900
,895 ,885 ,864
SS ,009 ,009 ,009 ,009 ,009 ,009 ,009 ,010 ,013
500
10 Ort. ,906 ,906 ,905
,906 ,906 ,905
,898 ,887 ,866
SS ,007 ,007 ,007 ,007 ,007 ,007 ,008 ,009 ,012
15 Ort. ,903 ,903 ,903
,903 ,903 ,902
,896 ,886 ,867
SS ,006 ,007 ,007 ,006 ,007 ,007 ,007 ,008 ,011
1000
10 Ort. ,906 ,906 ,905
,906 ,906 ,905
,898 ,887 ,867
SS ,004 ,004 ,004 ,004 ,004 ,004 ,004 ,005 ,007
15 Ort. ,902 ,902 ,902
,902 ,902 ,901
,895 ,885 ,867
SS ,004 ,004 ,005 ,004 ,004 ,005 ,005 ,006 ,007
Çizelge 9 incelendiğinde, stokastik regresyonla değer atama tekniğiyle
elde edilen Cronbach α katsayılarının .863 ile .906 arasında değiştiği
görülmektedir. Stokastik regresyonla değer atama tekniğiyle elde edilen
güvenirlik katsayıları genel olarak yüksek olmakla birlikte, seçkisiz olmayan
kayıp koşulu altındaki kestirimlerin tümüyle seçkisiz kayıp ve seçkisiz kayıp
koşulları altında kestirilen değerlere göre düşük olduğu görülmektedir.
Beklenti-maksimizasyon algoritması ile elde edilen Cronbach α
kestirimlerine ilişkin aritmetik ortalama ve standart sapma değerleri Çizelge
10’da verilmiştir.
Çizelge 10. Beklenti-Maksimizasyon Algoritması İçin Cronbach α
Kestirimlerine İlişkin Betimsel İstatistikler
Örneklem
Büyüklüğü
Madde
Sayısı
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. ,907 ,910 ,915
,907 ,910 ,914
,901 ,895 ,883
SS ,009 ,009 ,008 ,009 ,009 ,008 ,010 ,011 ,014
15 Ort. ,903 ,905 ,909
,903 ,905 ,909
,897 ,892 ,881
SS ,008 ,008 ,008 ,008 ,008 ,008 ,009 ,010 ,011
500
10 Ort. ,908 ,911 ,915
,908 ,911 ,915
,901 ,894 ,883
SS ,007 ,006 ,006 ,007 ,006 ,006 ,007 ,008 ,010
15 Ort. ,905 ,907 ,911
,905 ,907 ,910
,899 ,893 ,883
SS ,006 ,006 ,006 ,006 ,006 ,006 ,007 ,008 ,010
1000
10 Ort. ,908 ,911 ,915
,908 ,910 ,914
,901 ,894 ,883
SS ,004 ,004 ,003 ,004 ,004 ,004 ,004 ,005 ,006
15 Ort. ,904 ,906 ,910
,904 ,906 ,909
,897 ,891 ,882
SS ,004 ,004 ,004 ,004 ,004 ,004 ,005 ,005 ,006
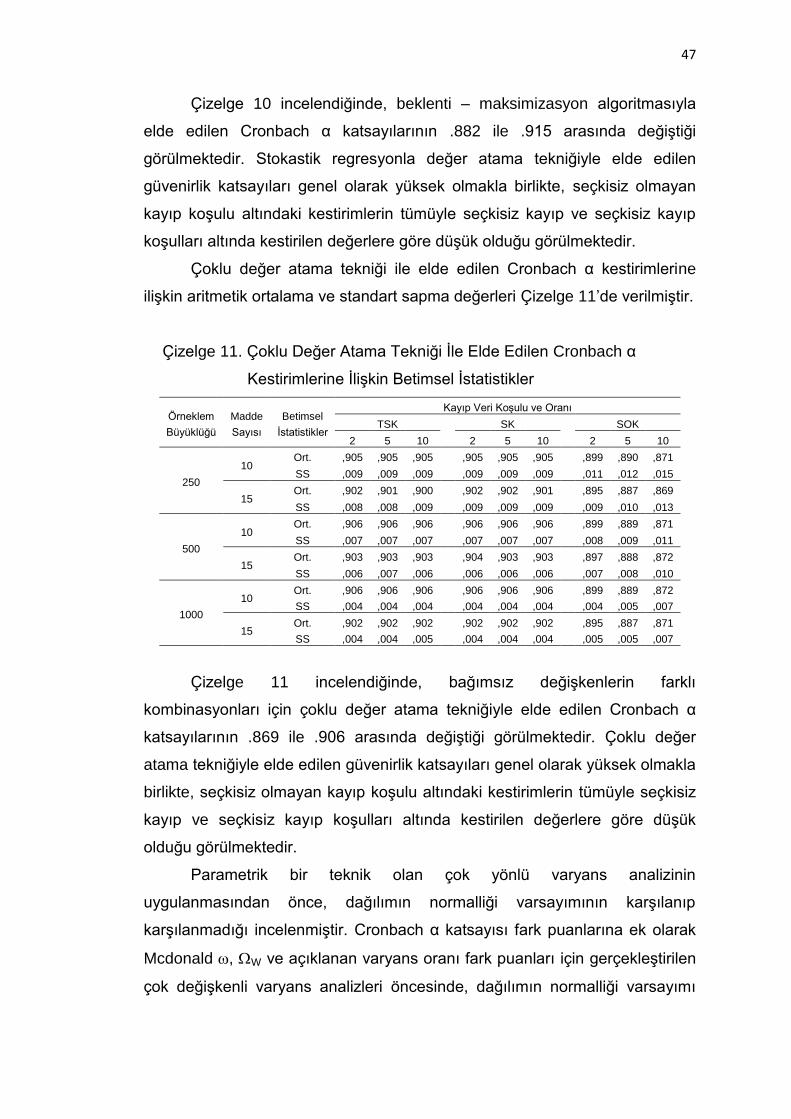
47
Çizelge 10 incelendiğinde, beklenti – maksimizasyon algoritmasıyla
elde edilen Cronbach α katsayılarının .882 ile .915 arasında değiştiği
görülmektedir. Stokastik regresyonla değer atama tekniğiyle elde edilen
güvenirlik katsayıları genel olarak yüksek olmakla birlikte, seçkisiz olmayan
kayıp koşulu altındaki kestirimlerin tümüyle seçkisiz kayıp ve seçkisiz kayıp
koşulları altında kestirilen değerlere göre düşük olduğu görülmektedir.
Çoklu değer atama tekniği ile elde edilen Cronbach α kestirimlerine
ilişkin aritmetik ortalama ve standart sapma değerleri Çizelge 11’de verilmiştir.
Çizelge 11. Çoklu Değer Atama Tekniği İle Elde Edilen Cronbach α
Kestirimlerine İlişkin Betimsel İstatistikler
Örneklem
Büyüklüğü
Madde
Sayısı
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. ,905 ,905 ,905
,905 ,905 ,905
,899 ,890 ,871
SS ,009 ,009 ,009 ,009 ,009 ,009 ,011 ,012 ,015
15 Ort. ,902 ,901 ,900
,902 ,902 ,901
,895 ,887 ,869
SS ,008 ,008 ,009 ,009 ,009 ,009 ,009 ,010 ,013
500
10 Ort. ,906 ,906 ,906
,906 ,906 ,906
,899 ,889 ,871
SS ,007 ,007 ,007 ,007 ,007 ,007 ,008 ,009 ,011
15 Ort. ,903 ,903 ,903
,904 ,903 ,903
,897 ,888 ,872
SS ,006 ,007 ,006 ,006 ,006 ,006 ,007 ,008 ,010
1000
10 Ort. ,906 ,906 ,906
,906 ,906 ,906
,899 ,889 ,872
SS ,004 ,004 ,004 ,004 ,004 ,004 ,004 ,005 ,007
15 Ort. ,902 ,902 ,902
,902 ,902 ,902
,895 ,887 ,871
SS ,004 ,004 ,005 ,004 ,004 ,004 ,005 ,005 ,007
Çizelge 11 incelendiğinde, bağımsız değişkenlerin farklı
kombinasyonları için çoklu değer atama tekniğiyle elde edilen Cronbach α
katsayılarının .869 ile .906 arasında değiştiği görülmektedir. Çoklu değer
atama tekniğiyle elde edilen güvenirlik katsayıları genel olarak yüksek olmakla
birlikte, seçkisiz olmayan kayıp koşulu altındaki kestirimlerin tümüyle seçkisiz
kayıp ve seçkisiz kayıp koşulları altında kestirilen değerlere göre düşük
olduğu görülmektedir.
Parametrik bir teknik olan çok yönlü varyans analizinin
uygulanmasından önce, dağılımın normalliği varsayımının karşılanıp
karşılanmadığı incelenmiştir. Cronbach α katsayısı fark puanlarına ek olarak
Mcdonald , W ve açıklanan varyans oranı fark puanları için gerçekleştirilen
çok değişkenli varyans analizleri öncesinde, dağılımın normalliği varsayımı
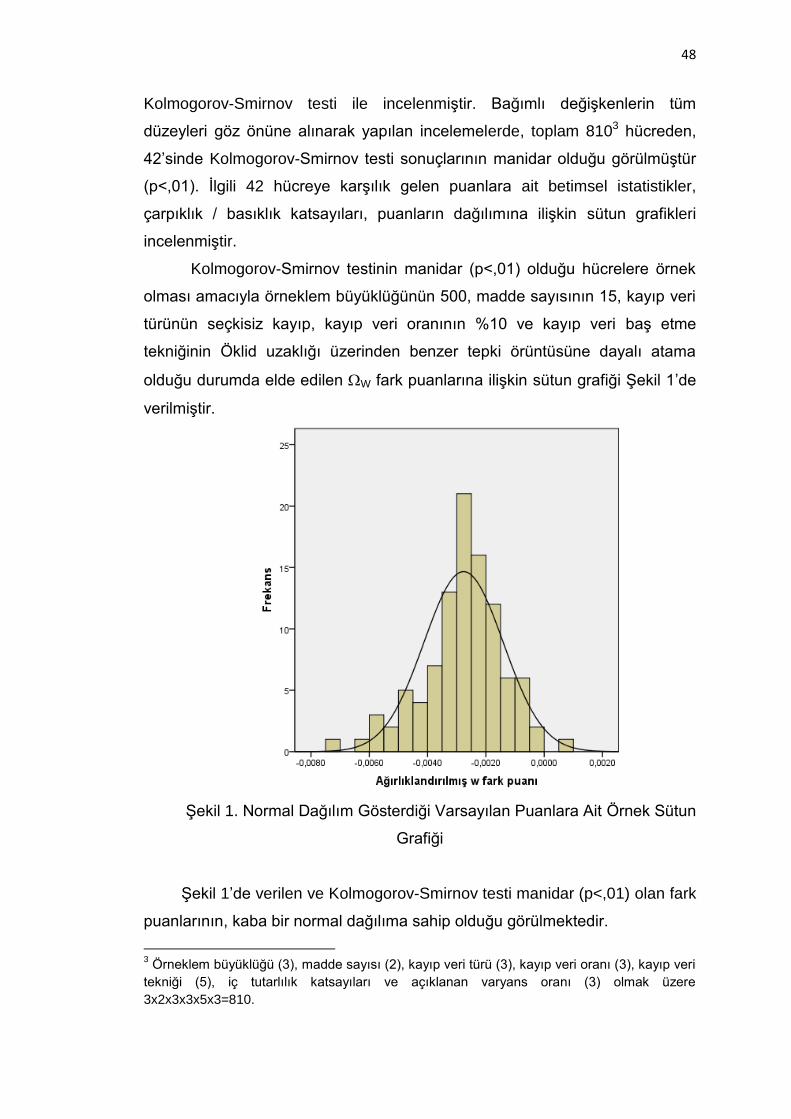
48
Kolmogorov-Smirnov testi ile incelenmiştir. Bağımlı değişkenlerin tüm
düzeyleri göz önüne alınarak yapılan incelemelerde, toplam 8103 hücreden,
42’sinde Kolmogorov-Smirnov testi sonuçlarının manidar olduğu görülmüştür
(p<,01). İlgili 42 hücreye karşılık gelen puanlara ait betimsel istatistikler,
çarpıklık / basıklık katsayıları, puanların dağılımına ilişkin sütun grafikleri
incelenmiştir.
Kolmogorov-Smirnov testinin manidar (p<,01) olduğu hücrelere örnek
olması amacıyla örneklem büyüklüğünün 500, madde sayısının 15, kayıp veri
türünün seçkisiz kayıp, kayıp veri oranının %10 ve kayıp veri baş etme
tekniğinin Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama
olduğu durumda elde edilen W fark puanlarına ilişkin sütun grafiği Şekil 1’de
verilmiştir.
Şekil 1. Normal Dağılım Gösterdiği Varsayılan Puanlara Ait Örnek Sütun
Grafiği
Şekil 1’de verilen ve Kolmogorov-Smirnov testi manidar (p<,01) olan fark
puanlarının, kaba bir normal dağılıma sahip olduğu görülmektedir.
3 Örneklem büyüklüğü (3), madde sayısı (2), kayıp veri türü (3), kayıp veri oranı (3), kayıp veri
tekniği (5), iç tutarlılık katsayıları ve açıklanan varyans oranı (3) olmak üzere
3x2x3x3x5x3=810.

49
Araştırmanın birinci alt amacı olan liste bazında silme, Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama, stokastik regresyonla değer
atama, beklenti – maksimizasyon algoritması ve çoklu değer atama
tekniklerinin, güvenirlik kestirimlerindeki yanlılığının belirlenebilmesi için
örneklem büyüklüğü ve madde sayısı değişkenlerinin her bir düzeyi üzerinden
çok yönlü varyans analizleri gerçekleştirilmiştir. Analizler, önce örneklem
büyüklüğü sonra madde sayısının düzeylerine göre yapılan sıralama
üzerinden Cronbach α, McDonald ve w katsayıları için ayrı ayrı
gerçekleştirilmiştir. Bulgular güvenirlik kapsamında bir arada yorumlanmıştır.
Örneklem büyüklüğünün 250 ve madde sayısının 10 olduğu durumda
Cronbach α katsayısı fark puanları için gerçekleştirilen çok yönlü varyans
analizi sonuçları Çizelge 12’de verilmiştir.
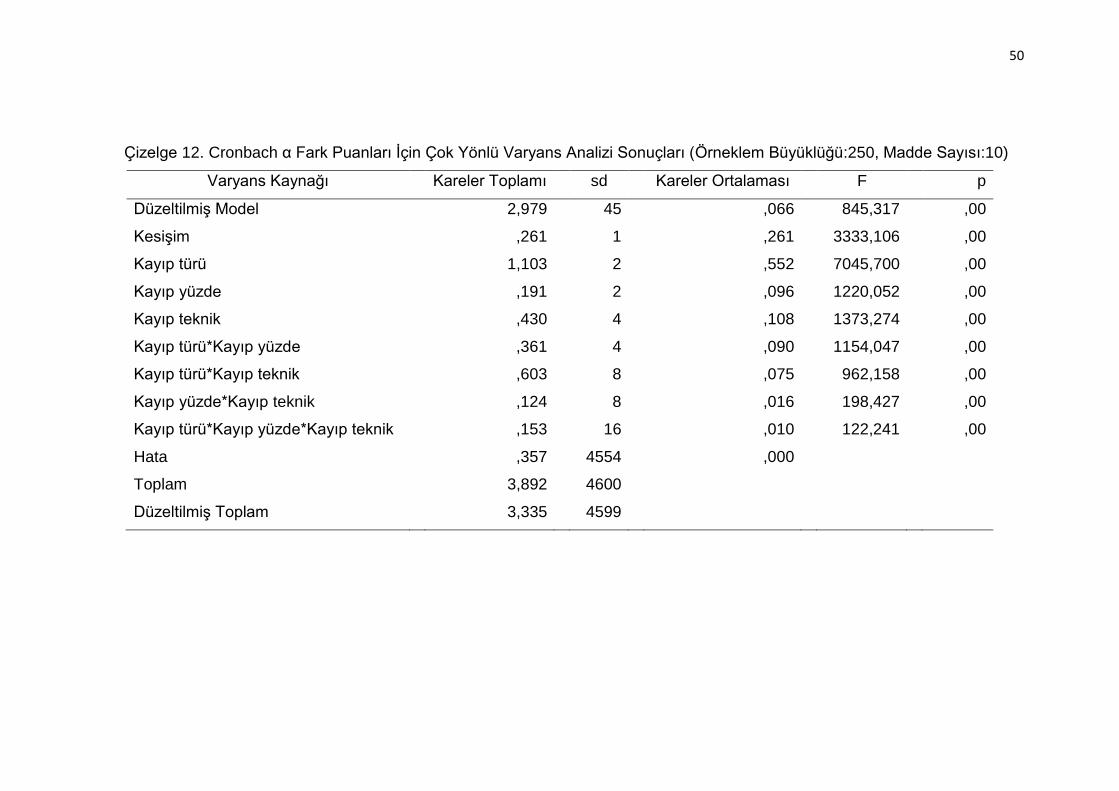
50
Çizelge 12. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:250, Madde Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 2,979 45 ,066 845,317 ,00
Kesişim ,261 1 ,261 3333,106 ,00
Kayıp türü 1,103 2 ,552 7045,700 ,00
Kayıp yüzde ,191 2 ,096 1220,052 ,00
Kayıp teknik ,430 4 ,108 1373,274 ,00
Kayıp türü*Kayıp yüzde ,361 4 ,090 1154,047 ,00
Kayıp türü*Kayıp teknik ,603 8 ,075 962,158 ,00
Kayıp yüzde*Kayıp teknik ,124 8 ,016 198,427 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,153 16 ,010 122,241 ,00
Hata ,357 4554 ,000
Toplam 3,892 4600
Düzeltilmiş Toplam 3,335 4599
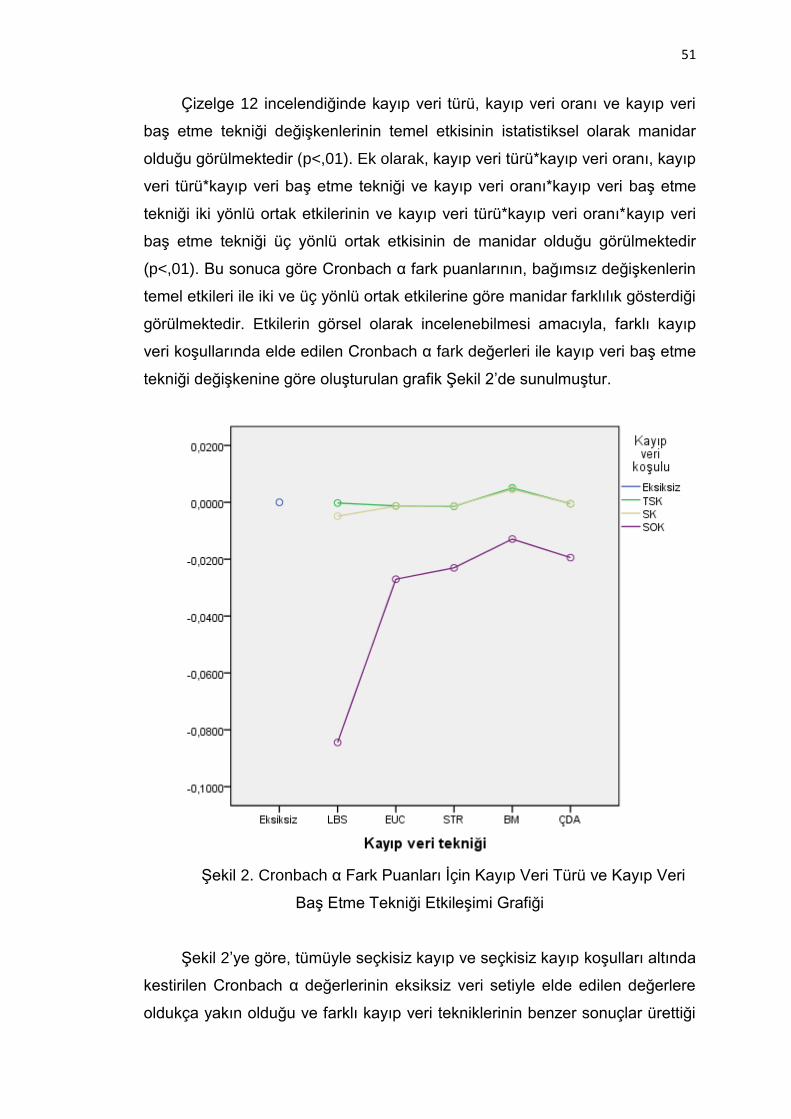
51
Çizelge 12 incelendiğinde kayıp veri türü, kayıp veri oranı ve kayıp veri
baş etme tekniği değişkenlerinin temel etkisinin istatistiksel olarak manidar
olduğu görülmektedir (p<,01). Ek olarak, kayıp veri türü*kayıp veri oranı, kayıp
veri türü*kayıp veri baş etme tekniği ve kayıp veri oranı*kayıp veri baş etme
tekniği iki yönlü ortak etkilerinin ve kayıp veri türü*kayıp veri oranı*kayıp veri
baş etme tekniği üç yönlü ortak etkisinin de manidar olduğu görülmektedir
(p<,01). Bu sonuca göre Cronbach α fark puanlarının, bağımsız değişkenlerin
temel etkileri ile iki ve üç yönlü ortak etkilerine göre manidar farklılık gösterdiği
görülmektedir. Etkilerin görsel olarak incelenebilmesi amacıyla, farklı kayıp
veri koşullarında elde edilen Cronbach α fark değerleri ile kayıp veri baş etme
tekniği değişkenine göre oluşturulan grafik Şekil 2’de sunulmuştur.
Şekil 2. Cronbach α Fark Puanları İçin Kayıp Veri Türü ve Kayıp Veri
Baş Etme Tekniği Etkileşimi Grafiği
Şekil 2’ye göre, tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında
kestirilen Cronbach α değerlerinin eksiksiz veri setiyle elde edilen değerlere
oldukça yakın olduğu ve farklı kayıp veri tekniklerinin benzer sonuçlar ürettiği
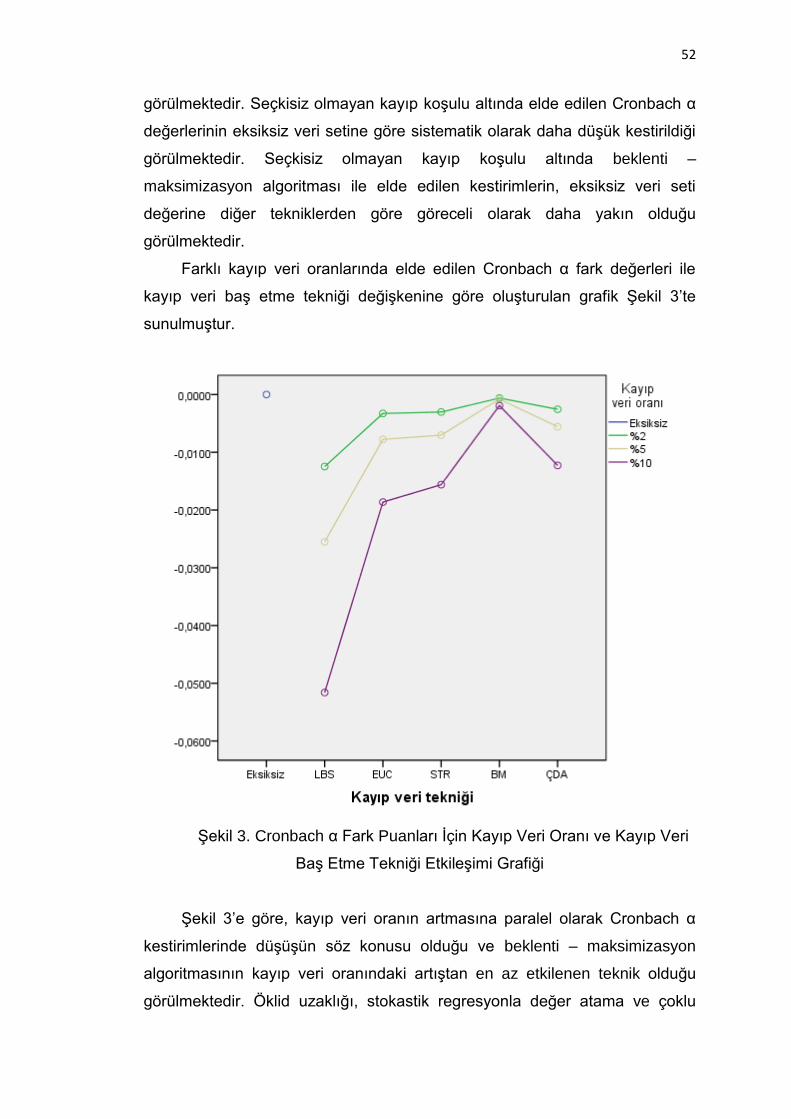
52
görülmektedir. Seçkisiz olmayan kayıp koşulu altında elde edilen Cronbach α
değerlerinin eksiksiz veri setine göre sistematik olarak daha düşük kestirildiği
görülmektedir. Seçkisiz olmayan kayıp koşulu altında beklenti –
maksimizasyon algoritması ile elde edilen kestirimlerin, eksiksiz veri seti
değerine diğer tekniklerden göre göreceli olarak daha yakın olduğu
görülmektedir.
Farklı kayıp veri oranlarında elde edilen Cronbach α fark değerleri ile
kayıp veri baş etme tekniği değişkenine göre oluşturulan grafik Şekil 3’te
sunulmuştur.
Şekil 3. Cronbach α Fark Puanları İçin Kayıp Veri Oranı ve Kayıp Veri
Baş Etme Tekniği Etkileşimi Grafiği
Şekil 3’e göre, kayıp veri oranın artmasına paralel olarak Cronbach α
kestirimlerinde düşüşün söz konusu olduğu ve beklenti – maksimizasyon
algoritmasının kayıp veri oranındaki artıştan en az etkilenen teknik olduğu
görülmektedir. Öklid uzaklığı, stokastik regresyonla değer atama ve çoklu

53
değer atama tekniklerinin genel olarak birbirine yakın; liste bazında silme
tekniğinin ise tüm kayıp veri oranları için daha düşük değerler ürettiği
görülmektedir.
Kayıp veri türü, kayıp veri oranı ve kayıp veri baş etme tekniği
değişkenlerinin ortak etkisinin hangi gruplar arasında manidar fark yarattığının
incelenmesi amacıyla, “100*kayıp veri türü+10*kayıp veri oranı+kayıp veri
tekniği” şeklinde yeni bir grup değişkeni tanımlanmış ve Cronbach α
katsayıları için tek yönlü varyans analizi gerçekleştirilmiştir. Tek yönlü varyans
analizi sonuçları Çizelge 13’te verilmiştir.
Çizelge 13. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü
Varyans Analizi Sonuçları (Örneklem:250, Madde Sayısı:10)
Varyansın Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Gruplar arası 2,979 45 ,066 845,317 ,00
Gruplar içi ,357 4554 ,000
Toplam 3,335 4599
Çizelge 13 incelendiğinde, Cronbach α fark puanları için gerçekleştirilen
tek yönlü varyans analizi sonucunda grup ortalamaları arasında manidar bir
farkın bulunduğu görülmektedir (p<.01). Puan dağılımlarının normallik
varsayımını tam anlamıyla karşılamamasına benzer şekilde, gruplar arasında
varyansların homojenliğini test eden Levene testi sonuçlarının da manidar
olduğu görülmüştür (p<.01).
Stevens (2002), güçlü bir parametrik test olan varyans analizi için,
deneysel kontrolün yüksek ve gruplardaki gözlem sayılarının birbirine eşit
olduğu durumlarda varyansların homojenliği varsayımın ihlal edilebileceğini
ifade etmektedir. İstatistik paket programlarında da bu varsayımın
karşılanmadığı durumlarda kullanılabilecek çoklu karşılaştırma testleri yer
almaktadır.
Bu araştırmanın, iç geçerliği tehdit eden faktörlere son derece kapalı
olduğu ileri sürülebilir. Tüm gruplardaki ölçüm sayılarının da birbirine eşit
(100) olduğu göz önüne alınmış ve incelemeler, bu gibi durumlarda
kullanılması önerilen (Field, 2005) Dunnet C çoklu karşılaştırma testi ile
gerçekleştirilmiştir.

54
Ortalamalar arasındaki manidar farkın hangi gruplar arasında olduğunu
bulmak amacıyla yapılan Dunnett C çoklu karşılaştırma testi sonucunda, 111
şeklinde kodlanan eksiksiz veri setinin ortalaması ile manidar farklılık gösteren
gruplar Çizelge 14’te verilmiştir.
Çizelge 14. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Dunnett
C Çoklu Karşılaştırma Testi Sonuçları (Örneklem
Büyüklüğü:250, Madde Sayısı:10)
Kayıp Veri Baş Etme Tekniği
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS - - - - -
EUC - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - - -
Çizelge 14’te boş bırakılan hücreler, fark puanlarına ilişkin ortalamanın
sıfırdan farklı olmadığını, diğer bir deyişle kestirimlerin yansızlığını; “-” ve “+”
şeklinde verilen işaretler ise ilgili kayıp veri baş etme tekniği için Cronbach α
kestirimlerdeki manidar yanlılığın yönünü göstermektedir. Örneğin, tümüyle
seçkisiz kayıp koşulu altında, Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama tekniği (EUC), %5 ve %10 kayıp veri oranları için
eksiksiz veri setlerine göre daha düşük Cronbach α değerleri üretirken, bu
koşul altındaki bütün kayıp veri oranları için beklenti – maksimizasyon
algoritması ile elde edilen değerler eksiksiz veri setlerinden daha yüksektir. Bu
koşulda, liste bazında silme ve stokastik regresyonla değer atama
teknikleriyle elde edilen kestirimlerin yansız; çoklu değer atama tekniği ile elde
edilen kestirimlerin ise sadece kayıp veri oranının %10 olduğu durumda
negatif yanlı olduğu görülmektedir.
Seçkisiz kayıp koşulu altında, liste bazında silme tekniğinin %5 ve %10
kayıp veri oranı için ve Öklid uzaklığı üzerinden benzer tepki örüntüsüne
dayalı atama tekniğinin tüm kayıp veri oranları için negatif yanlı; beklenti –
maksimizasyon algoritmasının ise tüm kayıp veri oranları için pozitif yanlı
kesitirimler ürettiği görülmüştür. Stokastik regresyonla değer atama tekniği,

55
tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında yansız kestirimler
üretmiştir. Benzer bir durum, tümüyle seçkisiz kayıp koşulu ve %10 kayıp
oranı haricindeki durumlar için çoklu değer atama tekniği için de geçerlidir.
Seçkisiz olmayan kayıp koşulu altında tüm kayıp veri oranları için
araştırmada yer verilen bütün tekniklerin negatif yanlı sonuçlar ürettiği
görülmüştür.
Örneklem büyüklüğü ve madde sayısı değişkenlerinin diğer ikili
kombinasyonları için kayıp veri türü, kayıp veri oranı ve kayıp veri baş etme
tekniğinin bağımsız; Cronbach α fark puanları değişkeninin bağımlı değişken
olduğu çok yönlü varyans analizi sonuçlarına göre değişkenlerin temel, iki
yönlü ve üç yönlü ortak etkilerinin istatistiksel olarak manidar olduğu
görülmüştür (p<.01). Grup değişkenine göre gerçekleştirilen tek yönlü varyans
analizi sonuçları da benzer şekilde manidardır. Çok yönlü ve tek yönlü
varyans analizi sonuçlarına ilişkin diğer çizelgeler ekte (Ek 2 - Ek 6, Ek 19)
verilmiştir.
Bu kısımda, Cronbach α fark puanları üzerinden örneklem büyüklüğü ve
madde sayısı değişkenlerinin farklı düzeyleri için grup değişkenine göre
yapılan tek yönlü varyans analizleri sonrasında gerçekleştirilen Dunnett C
çoklu karşılaştırma testi sonuçlarına ilişkin bulgular verilmiştir. Örneklem
büyüklüğünün 250 ve madde sayısının 15, örneklem büyüklüğünün 500 ve
madde sayısının 10-15, örneklem büyüklüğünün 1000 ve madde sayısının 10-
15 olduğu durumlar için elde edilen bulgular Çizelge 15’te verilmiştir.

56
Çizelge 15. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Dunnett C
Çoklu Karşılaştırma Testi Sonuçları
Örneklem
Büyüklüğü
Madde
Sayısı
Kayıp Veri
Baş Etme Tekniği
TSK SK SOK
2 5 10 2 5 10 2 5 10
250 15
LBS - - - - -
EUC - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - - - - -
500
10
LBS - - - -
EUC - - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - -
15
LBS - - - - -
EUC - - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - - - -
1000
10
LBS - - - - -
EUC - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - -
15
LBS - - - - -
EUC - - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA + - - -
Çizelge 15 incelendiğinde, kayıp veri baş etme tekniklerinin, örneklem
büyüklüğü ve madde sayısı değişkenlerinin farklı düzeyleri için benzer
performans gösterdikleri görülmektedir.
Tümüyle seçkisiz kayıp koşulunda, liste bazında silme ve stokastik
regresyonla değer atama teknikleri ile elde edilen kestirimler bütün kayıp veri
oranları için yansızdır. Bu koşul altında, beklenti – maksimizasyon algoritması
ile elde edilen tüm kestirimlerin pozitif, öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama tekniğiyle elde edilen kestirimlerin ise genel olarak

57
negatif yanlı olduğu görülmektedir. Çoklu değer atama tekniği ile genel olarak
yansız, örneklem büyüklüğünün 250 ve 500 olduğu bazı durumlarda negatif
yanlı kestirimler elde edildiği görülmektedir.
Seçkisiz kayıp koşulunda, stokastik regresyonla değer atama tekniği ile
elde edilen kestirimler in yansız olduğu görülmektedir. Bu koşul altında,
beklenti – maksimizasyon algoritması ile elde edilen tüm kestirimlerin pozitif,
öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniğiyle elde
edilen kestirimlerin ise genel olarak negatif yanlı olduğu görülmektedir. Kayıp
veri oranının düşük olduğu durumlarda liste bazında silme tekniği ile elde
edilen kestirimlerin yansız olduğu, bu teknik ile elde edilen kestirimlerin kayıp
veri oranının artmasıyla beraber negatif yanlı bir hal aldığı görülmektedir.
Çoklu değer atama tekniği için, %2 ve %5 oranında kayıpların bulunduğu
durumlarda elde edilen kestirimler yansız iken, kayıp veri oranının %10
olduğu durumlarda ise negatif ya da pozitif yanlı kestirimler elde edilmiştir.
Seçkisiz olmayan kayıp koşulu altında tüm kayıp veri oranları için
araştırmada yer verilen bütün tekniklerin negatif yanlı sonuçlar ürettiği
görülmüştür.
b. McDonald Kestirimlerinin Yanlılığına İlişkin Bulgular
Araştırma kapsamında yer verilen kayıp veri teknikleri ile örneklem
büyüklüğü, kayıp veri türü, kayıp veri oranı değişkenlerinin her bir
kombinasyonu için 10 maddeden oluşan (bir faktörlü) veri setlerine ait
McDonald katsayıları hesaplanmıştır. Liste bazında silme, Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama, stokastik regresyonla değer
atama, beklenti – maksimizasyon ve çoklu değer atama teknikleriyle elde
edilen McDonald katsayılarına ilişkin aritmetik ortalama ve standart sapma
değerleri Çizelge 16’da verilmiştir.
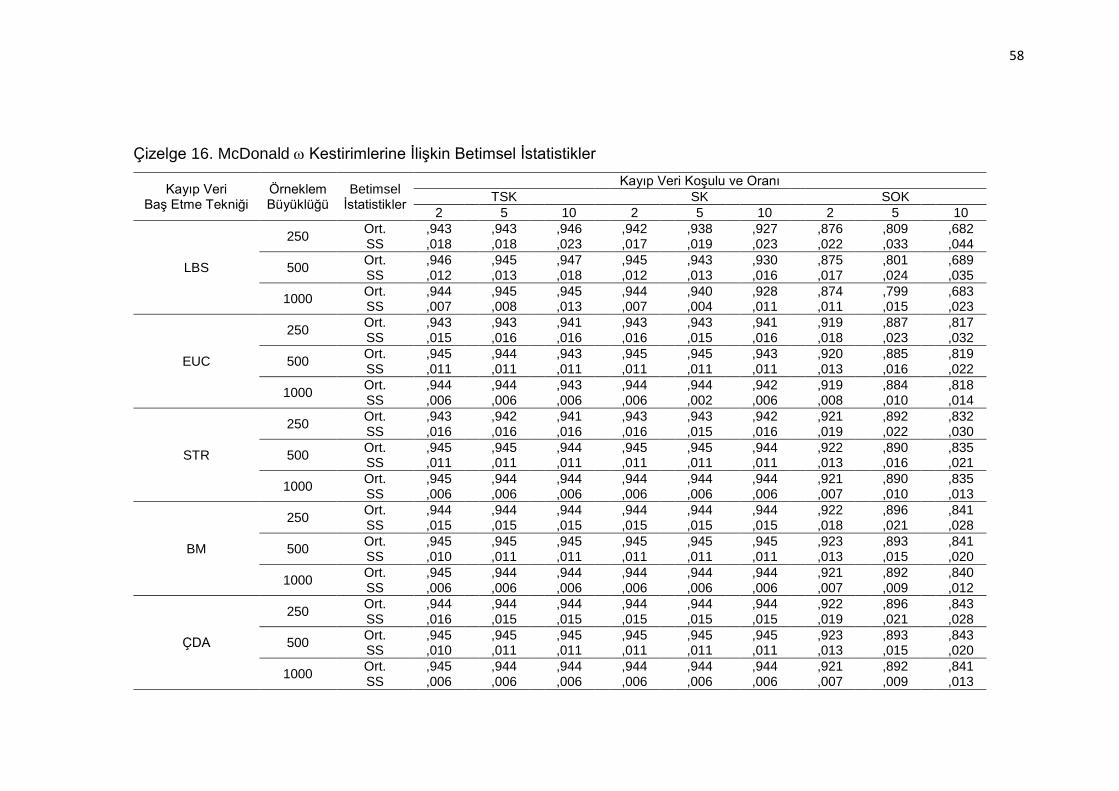
58
Çizelge 16. McDonald Kestirimlerine İlişkin Betimsel İstatistikler
Kayıp Veri Baş Etme Tekniği
Örneklem Büyüklüğü
Betimsel İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
250 Ort. SS
,943 ,018
,943 ,018
,946 ,023
,942 ,017
,938 ,019
,927 ,023
,876 ,022
,809 ,033
,682 ,044
500 Ort. SS
,946 ,012
,945 ,013
,947 ,018
,945 ,012
,943 ,013
,930 ,016
,875 ,017
,801 ,024
,689 ,035
1000 Ort. SS
,944 ,007
,945 ,008
,945 ,013
,944 ,007
,940 ,004
,928 ,011
,874 ,011
,799 ,015
,683 ,023
EUC
250 Ort. SS
,943 ,015
,943 ,016
,941 ,016
,943 ,016
,943 ,015
,941 ,016
,919 ,018
,887 ,023
,817 ,032
500 Ort. SS
,945 ,011
,944 ,011
,943 ,011
,945 ,011
,945 ,011
,943 ,011
,920 ,013
,885 ,016
,819 ,022
1000 Ort. SS
,944 ,006
,944 ,006
,943 ,006
,944 ,006
,944 ,002
,942 ,006
,919 ,008
,884 ,010
,818 ,014
STR
250 Ort. SS
,943 ,016
,942 ,016
,941 ,016
,943 ,016
,943 ,015
,942 ,016
,921 ,019
,892 ,022
,832 ,030
500 Ort. SS
,945 ,011
,945 ,011
,944 ,011
,945 ,011
,945 ,011
,944 ,011
,922 ,013
,890 ,016
,835 ,021
1000 Ort. SS
,945 ,006
,944 ,006
,944 ,006
,944 ,006
,944 ,006
,944 ,006
,921 ,007
,890 ,010
,835 ,013
BM
250 Ort. SS
,944 ,015
,944 ,015
,944 ,015
,944 ,015
,944 ,015
,944 ,015
,922 ,018
,896 ,021
,841 ,028
500 Ort. SS
,945 ,010
,945 ,011
,945 ,011
,945 ,011
,945 ,011
,945 ,011
,923 ,013
,893 ,015
,841 ,020
1000 Ort. SS
,945 ,006
,944 ,006
,944 ,006
,944 ,006
,944 ,006
,944 ,006
,921 ,007
,892 ,009
,840 ,012
ÇDA
250 Ort. SS
,944 ,016
,944 ,015
,944 ,015
,944 ,015
,944 ,015
,944 ,015
,922 ,019
,896 ,021
,843 ,028
500 Ort. SS
,945 ,010
,945 ,011
,945 ,011
,945 ,011
,945 ,011
,945 ,011
,923 ,013
,893 ,015
,843 ,020
1000 Ort. SS
,945 ,006
,944 ,006
,944 ,006
,944 ,006
,944 ,006
,944 ,006
,921 ,007
,892 ,009
,841 ,013

59
Çizelge 16 incelediğinde, McDonald kestirimlerine ilişkin
ortalamaların .682 ile .947 arasında değiştiği görülmektedir. Araştırma
kapsamında yer verilen kayıp veri baş etme tekniklerinin, farklı koşullar
altındaki performanslarının büyük ölçüde benzer olduğu ve seçkisiz olmayan
kayıp koşulu altında kestirilen McDonald katsayılarının tümüyle seçkisiz
kayıp ve seçkisiz kayıp koşulu altında kestirilen katsayılara göre daha küçük
değerler aldığı görülmektedir.
McDonald güvenirlik katsayısı temelinde karşılaştırmaların
yapılabilmesi için öncelikle, farklı kayıp veri tekniklerinden ve eksiksiz veri
setlerinden elde edilen değerler arasındaki farklar hesaplanmıştır. Tek boyutlu
ölçmeler için önerilen McDonald katsayısına ilişkin değerler, 10 maddelik
veri setleri üzerinden gerçekleştirilen çok yönlü varyans analizi ile
incelenmiştir.
Farklı örneklem büyüklükleri için kayıp veri türü, kayıp veri oranı ve kayıp
veri baş etme tekniğinin bağımsız, McDonald fark puanlarının bağımlı
değişken olarak kullanıldığı çok yönlü varyans analizi sonuçlarına göre,
bağımsız değişkenlerin temel, iki yönlü ve üç yönlü ortak etkilerinin istatistiksel
olarak manidar olduğu görülmüştür (p<.01). Çok yönlü ve grup değişkenine
göre gerçekleştirilen tek yönlü varyans analizi sonuçlarına ilişkin çizelgeler
ekte (Ek 7 - Ek 9, Ek 20) verilmiştir.
Bu kısımda, örneklem büyüklüğü değişkeninin farklı düzeyleri için,
Mcdonald fark puanları üzerinden gerçekleştirilen tek yönlü varyans analizi
ve Dunnett C çoklu karşılaştırma testi sonuçlarına ilişkin bulgular verilmiştir.
10 maddelik veri setleri için örneklem büyüklüğünün 250, 500 ve 1000 olduğu
durumlarda elde edilen bulgular Çizelge 17’de verilmiştir.

60
Çizelge 17. Mcdonald Fark Puanları İçin Grup Değişkenine Göre Dunnet C
Çoklu Karşılaştırma Testi Sonuçları
Örneklem
Büyüklüğü
Kayıp Veri Baş
Etme Tekniği
TSK SK SOK
%2 %5 %10 %2 %5 %10 %2 %5 %10
250
LBS - - - - -
EUC - - - - - - -
STR - - -
BM - - -
ÇDA - - -
500
LBS - - - -
EUC - - - - - - -
STR - - -
BM - - -
ÇDA - - -
1000
LBS - - - - -
EUC - - - - - - - -
STR - - -
BM - - -
ÇDA - - -
Çizelge 17 incelendiğinde, tümüyle seçkisiz kayıp koşulu altında liste
bazında silme, stokastik regresyonla değer atama, beklenti – maksimizasyon
algoritması ve çoklu değer atama teknikleri ile elde edilen Mcdonald
kestirimlerinin yansız olduğu görülmektedir. Bu koşul altında Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama tekniği ile elde edilen
kestirimlerin ise genel olarak negatif yanlı olduğu görülmektedir.
Seçkisiz kayıp koşulu altında stokastik regresyonla değer atama,
beklenti – maksimizasyon algoritması ve çoklu değer atama teknikleri ile elde
edilen Mcdonald kestirimlerinin yansız olduğu, liste bazında silme ve Öklid
uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama teknikleri ile elde
edilen kestirimlerin ise özellikle kayıp veri oranının yüksek olduğu durumlarda
negatif yanlı olduğu görülmektedir.
Seçkisiz olmayan kayıp koşulu altında tüm kayıp veri oranları için
araştırmada yer verilen bütün tekniklerin negatif yanlı sonuçlar ürettiği
görülmüştür.

61
c. Ağırlıklandırılmış (w) Kestirimlerinin Yanlılığına İlişkin Bulgular
Araştırma kapsamında yer verilen kayıp veri teknikleri ile örneklem
büyüklüğü, kayıp veri türü, kayıp veri oranı değişkenlerinin her bir
kombinasyonu için 15 maddeden oluşan (iki faktörlü) veri setlerine ait w
katsayıları hesaplanmıştır. Liste bazında silme, Öklid uzaklığı üzerinden
benzer tepki örüntüsüne dayalı atama, stokastik regresyonla değer atama,
beklenti – maksimizasyon algoritması ve çoklu değer atama teknikleriyle elde
edilen w katsayılarına ilişkin aritmetik ortalama ve standart sapma değerleri
Çizelge 18’de verilmiştir.
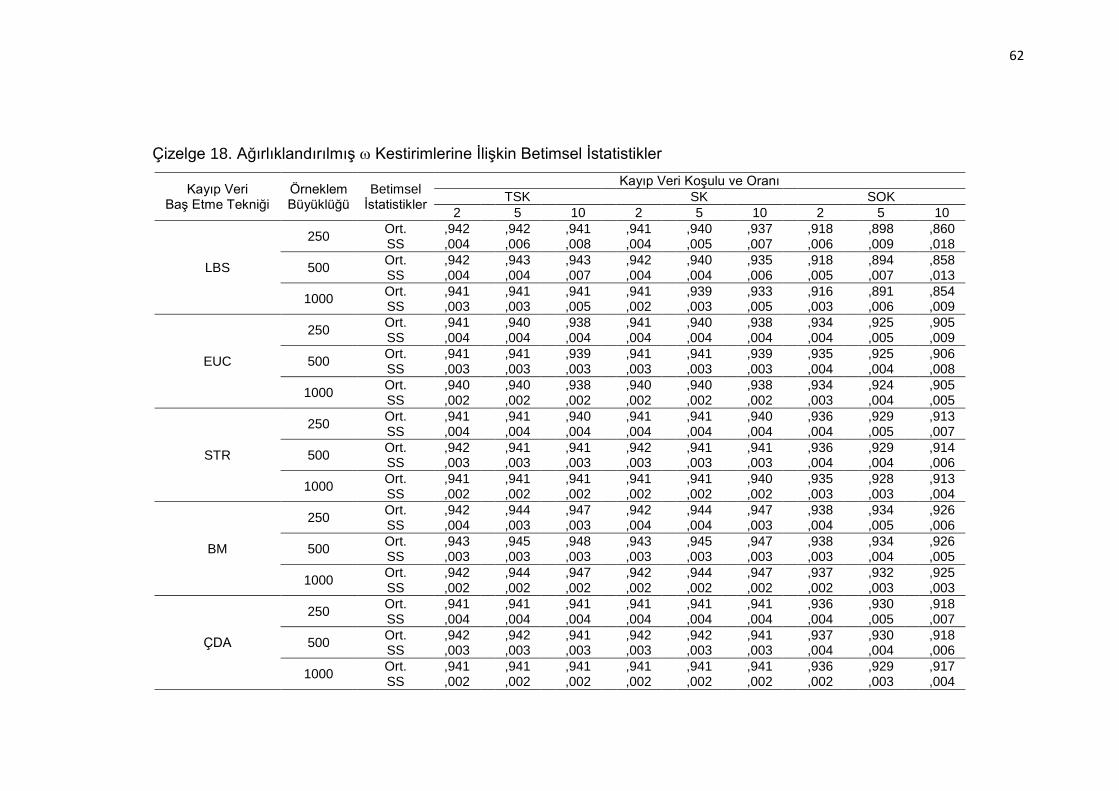
62
Çizelge 18. Ağırlıklandırılmış Kestirimlerine İlişkin Betimsel İstatistikler
Kayıp Veri Baş Etme Tekniği
Örneklem Büyüklüğü
Betimsel İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
250 Ort. SS
,942 ,004
,942 ,006
,941 ,008
,941 ,004
,940 ,005
,937 ,007
,918 ,006
,898 ,009
,860 ,018
500 Ort. SS
,942 ,004
,943 ,004
,943 ,007
,942 ,004
,940 ,004
,935 ,006
,918 ,005
,894 ,007
,858 ,013
1000 Ort. SS
,941 ,003
,941 ,003
,941 ,005
,941 ,002
,939 ,003
,933 ,005
,916 ,003
,891 ,006
,854 ,009
EUC
250 Ort. SS
,941 ,004
,940 ,004
,938 ,004
,941 ,004
,940 ,004
,938 ,004
,934 ,004
,925 ,005
,905 ,009
500 Ort. SS
,941 ,003
,941 ,003
,939 ,003
,941 ,003
,941 ,003
,939 ,003
,935 ,004
,925 ,004
,906 ,008
1000 Ort. SS
,940 ,002
,940 ,002
,938 ,002
,940 ,002
,940 ,002
,938 ,002
,934 ,003
,924 ,004
,905 ,005
STR
250 Ort. SS
,941 ,004
,941 ,004
,940 ,004
,941 ,004
,941 ,004
,940 ,004
,936 ,004
,929 ,005
,913 ,007
500 Ort. SS
,942 ,003
,941 ,003
,941 ,003
,942 ,003
,941 ,003
,941 ,003
,936 ,004
,929 ,004
,914 ,006
1000 Ort. SS
,941 ,002
,941 ,002
,941 ,002
,941 ,002
,941 ,002
,940 ,002
,935 ,003
,928 ,003
,913 ,004
BM
250 Ort. SS
,942 ,004
,944 ,003
,947 ,003
,942 ,004
,944 ,004
,947 ,003
,938 ,004
,934 ,005
,926 ,006
500 Ort. SS
,943 ,003
,945 ,003
,948 ,003
,943 ,003
,945 ,003
,947 ,003
,938 ,003
,934 ,004
,926 ,005
1000 Ort. SS
,942 ,002
,944 ,002
,947 ,002
,942 ,002
,944 ,002
,947 ,002
,937 ,002
,932 ,003
,925 ,003
ÇDA
250 Ort. SS
,941 ,004
,941 ,004
,941 ,004
,941 ,004
,941 ,004
,941 ,004
,936 ,004
,930 ,005
,918 ,007
500 Ort. SS
,942 ,003
,942 ,003
,941 ,003
,942 ,003
,942 ,003
,941 ,003
,937 ,004
,930 ,004
,918 ,006
1000 Ort. SS
,941 ,002
,941 ,002
,941 ,002
,941 ,002
,941 ,002
,941 ,002
,936 ,002
,929 ,003
,917 ,004

63
Çizelge 18 incelediğinde, w kestirimlerine ilişkin ortalamaların .854 ile
.948 arasında değiştiği görülmektedir. Araştırma kapsamında yer verilen kayıp
veri baş etme tekniklerinin, farklı koşullar altındaki performanslarının büyük
ölçüde benzer olduğu ve seçkisiz olmayan kayıp koşulu altında kestirilen w
katsayılarının tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulu altında
kestirilen katsayılara göre daha küçük değerler aldığı görülmektedir.
Ağırlıklandırılmış (w) katsayısı temelinde karşılaştırmaların
yapılabilmesi için öncelikle, farklı kayıp veri tekniklerinden ve eksiksiz veri
setlerinden elde edilen kestirimler arasındaki farklar hesaplanmıştır. w
katsayısına ilişkin kestirimler, 15 maddelik veri setleri üzerinden
gerçekleştirilen çok yönlü varyans analizi ile incelenmiştir.
Farklı örneklem büyüklükleri için kayıp veri türü, kayıp veri oranı ve
kayıp veri baş etme tekniğinin bağımsız, w fark puanlarının bağımlı değişken
olarak kullanıldığı çok yönlü varyans analizi sonuçlarına göre, bağımsız
değişkenlerin temel, iki yönlü ve üç yönlü ortak etkilerinin istatistiksel olarak
manidar olduğu görülmüştür (p<.01). Çok yönlü ve grup değişkenine göre
gerçekleştirilen tek yönlü varyans analizi sonuçlarına ilişkin çizelgeler ekte (Ek
10 - Ek 12, Ek 21) verilmiştir.
Bu kısımda, örneklem büyüklüğü değişkenin farklı düzeyleri için, w fark
puanları üzerinden gerçekleştirilen tek yönlü varyans analizi ve Dunnett C
çoklu karşılaştırma testi sonuçlarına ilişkin bulgular verilmiştir. 15 maddelik
veri setleri için örneklem büyüklüğünün 250, 500 ve 1000 olduğu durumlarda
elde edilen bulgular Çizelge 19’da verilmiştir.

64
Çizelge 19. Ağırlıklandırılmış Fark Puanları İçin Grup Değişkenine Göre
Dunnet C Çoklu Karşılaştırma Testi Sonuçları
Örneklem
Büyüklüğü
Kayıp Veri Baş
Etme Tekniği
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
LBS - - - -
EUC - - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - - -
500
LBS - - - - -
EUC - - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - - -
1000
LBS - - - - -
EUC - - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - -
Çizelge 19 incelendiğinde, tümüyle seçkisiz kayıp koşulu altında liste
bazında silme ve stokastik regresyonla değer atama teknikleri ile elde edilen
w kestirimlerinin yansız olduğu görülmektedir. Genel olarak yansız
kestirimler üretmekle birlikte çoklu değer atama tekniği, örneklem
büyüklüğünün 250 ve kayıp veri oranının %10 olduğu tek bir durumda negatif
yanlılık göstermiştir. Bu koşul altında tüm kayıp veri oranları için, Öklid
uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği ile elde
edilen kestirimler negatif; beklenti – maksimizasyon algoritması ile elde edilen
kestirimler ise pozitif yanlıdır.
Seçkisiz kayıp koşulunda stokastik regresyonla değer atama tekniği ile
elde edilen w kestirimlerin yansız olduğu görülmektedir. Genel olarak yansız
kestirimler üretmekle birlikte çoklu değer atama tekniği, örneklem
büyüklüğünün 500 ve kayıp veri oranının %10 olduğu tek bir durumda negatif
yanlılık göstermiştir. Liste bazında silme tekniği ile elde edilen kestirimlerin
özellikle yüksek kayıp veri oranları için negatif yanlı olduğu görülmektedir.
Tüm kayıp veri oranları için, Öklid uzaklığı üzerinden benzer tepki örüntüsüne

65
dayalı atama tekniği ile elde edilen kestirimler negatif, beklenti –
maksimizasyon algoritması ile elde edilen kestirimler ise pozitif yanlıdır.
Seçkisiz olmayan kayıp koşulu altında tüm kayıp veri oranları için
araştırmada yer verilen bütün tekniklerin negatif yanlı sonuçlar ürettiği
görülmüştür.
Farklı kayıp veri tekniklerinin güvenirlik kapsamındaki performanslarına
ilişkin bulgular, sırasıyla Cronbach α, McDonald ve W katsayıları temelinde
ve sonrasında karşılaştırmalı bir şekilde değerlendirilmiştir.
Cronbach α katsayısına ilişkin bulgular incelendiğinde genel olarak,
tüm tekniklerin seçkisiz olmayan kayıp koşulu altındaki kestirimlerde negatif
yanlı olduğu görülmektedir. Seçkisiz olmayan kayıp koşulu altında, madde
puanlarının en büyük ve en küçük değerleri silinmiş olduğu için veri setinde
kalan gözlemlerin merkeze doğru bir yığılma göstermesi söz konusudur. Elde
edilen kestirimlerdeki negatif yanlılığın, seçkisiz olmayan kayıp koşulunun
hem madde puanları üzerindeki doğrudan, hem de ölçekten elde edilen
toplam puanlar üzerindeki dolaylı etkisinden kaynaklandığı düşünülebilir.
Liste bazında silme tekniği ile tümüyle seçkisiz kayıp koşulu altında
elde edilen kestirimlerin yansız olduğu görülmüştür. Bu tekniğin seçkisiz kayıp
koşulu altında ve kayıp veri oranının %2 olduğu durumda da yansız
kestirimler ürettiği görülmüştür. Seçkisiz kayıp koşulu altında kayıp veri
oranının artmasıyla birlikte, elde edilen kestirimlerde negatif yanlılıklar
gözlenmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği
tümüyle seçkisiz kayıp koşulu altında ve %2 kayıp veri oranı için n=250 ve
n=1000 büyüklüğündeki örneklemlerde yansız kestirimlerde bulunmaktadır.
Kayıp veri miktarının arttığı veya kayıp veri koşulunun seçkisiz kayıp olduğu
diğer durumlarda elde edilen kestirimler negatif yanlıdır.
Stokastik regresyonla değer atama tekniği, tümüyle seçkisiz kayıp ve
seçkisiz kayıp koşulları altında ve tüm kayıp veri oranları için yansız
kestirimler üretmiştir. Elde edilen sonuçlar çerçevesinde stokastik regresyonla
değer atama tekniğinin, Cronbach α kestirimlerinde öne çıktığı görülmektedir.

66
Beklenti – maksimizasyon algoritması ile elde edilen kestirimlerin,
tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında ve tüm kayıp veri
oranları için pozitif yanlı olduğu görülmektedir.
Çoklu değer atama tekniğinin genel olarak 10 maddeden oluşan veri
setlerinde yansız kestirimlerde bulunduğu görülmüştür. 15 maddeden oluşan
veri setlerinde ve kayıp veri oranının düşük olduğu durumlarda elde edilen
kestirimler genel olarak yansız iken, kayıp veri oranının %10 olduğu
durumlarda Cronbach α kestirimleri negatif ya da pozitif yanlılık
gösterebilmektedir.
McDonald katsayısına ilişkin bulgular incelendiğinde, seçkisiz
olmayan kayıp koşulu altındaki kestirimlerin negatif yanlı olduğu; stokastik
regresyonla değer atama, beklenti – maksimizasyon algoritması ve çoklu
değer atama teknikleri ile tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları
altında elde edilen kestirimlerin ise tüm kayıp veri oranları için yansız olduğu
görülmektedir.
Liste bazında silme tekniğinin tümüyle seçkisiz kayıp koşulu altında
yansız, seçkisiz kayıp koşulu altında ve yüksek kayıp veri oranlarında negatif
yanlı kestirimler ürettiği görülmektedir. Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama tekniğinin ise genel olarak negatif yanlı kestirimlerde
bulunduğu görülmüştür.
Ağırlıklandırılmış katsayısı için ulaşılan bulgular incelendiğinde,
seçkisiz olmayan kayıp koşulu altındaki kestirimlerin negatif yanlı olduğu
görülmektedir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında tüm kayıp
veri oranları için Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı
atama tekniği ile elde edilen kestirimlerin negatif, beklenti – maksimizasyon
algoritması ile elde edilen kestirimlerin ise pozitif yanlı olduğu görülmektedir.
Liste bazında silme tekniği ile tümüyle seçkisiz kayıp koşulu altında yansız
kestirimler elde edilmekle beraber, seçkisiz kayıp koşulu altında %2’nin
üzerindeki kayıp veri oranları için negatif yanlı sonuçlar elde edilmiştir.
Stokastik regresyonla değer atama tekniği, araştırmada yer verilen tüm
kayıp veri oranları için tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında

67
yansız kestirimlerde bulunmaktadır. Bu tekniğin seçkisiz olmayan kayıp
koşulu haricindeki tüm güvenirlik kestirimlerinde öne çıktığı görülmektedir.
Çoklu değer atama tekniği ile seçkisiz olmayan kayıp koşulu haricinde
elde edilen kestirimlerin ise genel olarak yansız olduğu görülmektedir.
Cronbach α için ulaşılan sonuçların Enders (2003; 2004)’in ulaştığı
sonuçlar ile büyük ölçüde tutarlı olduğu görülmektedir. Enders (2003)
beklenmedik bir şekilde, liste bazında silme tekniği ile tümüyle seçkisiz kayıp
koşulu altında negatif yanlı sonuçlara ulaştığını belirtmektedir. Bu
araştırmada, liste bazında silme tekniğinin genel olarak tümüyle seçkisiz kayıp
koşulunda tüm kayıp veri oranları için yansız kestirimlerde bulunduğu;
seçkisiz kayıp koşulu için ise kayıp veri oranının yüksek olduğu durumlarda
negatif yanlı sonuçlar ürettiği görülmüştür. Liste bazında silme tekniği için bu
araştırma ile elde edilen sonuçlar, tümüyle seçkisiz kayıp koşulunda
analizlerin yürütüldüğü örneklemin, tüm veri setinin seçkisiz bir alt örneklemi
olduğu ve dolayısıyla kestirimlerin yansız olması gerektiği yönündeki
beklentiye uygundur.
Cronbach α kestirimleri için genel olarak basit atama tekniklerinin,
Çokluk ve Kayri (2011)’nin bulgularına benzer şekilde negatif yanlılık
gösterme eğiliminde olduğu görülmüştür. Seçkisiz olmayan kayıp koşulu
altında tüm tekniklerin negatif yanlılık gösterdiği yönündeki bulgular ise
Enders (2003)’in ulaştığı sonuçlar ile de tutarlıdır. Seçkisiz olmayan kayıp
koşulu altına ulaşılan negatif yanlı kestirimlerin, örneklemde kalan bireylerin
benzerliğinin artmasından ve ölçümlerin merkeze doğru yığılma
göstermesinden kaynaklanan doğal bir sonuç olduğu düşünülebilir.
Stokastik regresyonla değer atama tekniğinde, regresyon denklemi ile
tahmin edilen değere rastgele seçilen hata terimleri eklenmektedir. Enders
(2010) ve Van Buuren (2013), bu tekniğin tümüyle seçkisiz kayıp ve seçkisiz
kayıp koşulları altındaki kestirimlerde yanlılığı düşüreceğini belirtmektedirler.
Bu araştırmada, tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında elde
edilen Cronbach α kestirimlerinin alanyazında belirtildiği şekilde yansız olduğu
görülmüştür.
Enders (2003; 2004), beklenti – maksimizasyon algoritmasının
Cronbach α kestirimlerinde en iyi sonuçları vermesine rağmen negatif yanlı
performans gösterebildiğini ifade etmektedir. Bu araştırmada da beklenti –

68
maksimizasyon algoritmasıyla elde edilen sonuçların, eksiksiz veri setlerine
ait Cronbach α değerlerine oldukça yakın olmakla birlikte, pozitif yanlı olduğu
görülmüştür. Bu farklılığın, söz konusu araştırmalarda kullanılan veri setlerinin
3, 5 ve 7 dereceli Likert tipi ölçme araçlarını temsil etmesinden ve bu
araştırmadaki veri setlerinin sürekli verilerden oluşmasından
kaynaklanabileceği düşünülmektedir.
Çoklu değer atama tekniğinin, seçkisiz olmayan kayıp koşulunda
negatif yanlı, tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında ve kayıp
veri oranının düşük olduğu durumlarda ise genel olarak yansız kestirimler
ürettiği görülmüştür. Van Ginkel (2007)’in bulgularına benzer şekilde,
diğerlerine göre daha güçlü istatistiksel temellere dayanan çoklu değer atama
tekniği ile elde edilen sonuçlar beklendiği ölçüde performans sergilememiştir.
Çoklu değer atama tekniği ile elde edilen sonuçlarda kayıp veri koşuluna ve
oranına göre pozitif ya da negatif yanlı kestirimlerin elde edilebileceği
görülmüştür. McKnight ve diğ. (2007), 3 – 10 arasında atamanın yeterli
olacağı belirtilmektedir. Bu araştırmada atama sayısı 5 olarak belirlenmiştir.
Çoklu değer atama tekniği ile daha fazla sayıda atamanın yapıldığı
durumlarda yansız kestirimlerin elde edilmesi beklenebilir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği
ile elde edilen Cronbach α kestirimlerinin, hemen her durumunda negatif yanlı
olduğu görülmüştür. Bu tekniğin, sadece tümüyle seçkisiz kayıp koşulunun
sağlandığı ve kayıp veri oranının düşük olduğu durumlarda yansız kestirimler
ürettiği görülmüştür.
Konjenerik güvenirlik katsayıları için ulaşılan bulgular incelendiğinde,
seçkisiz olmayan kayıp koşulu altındaki bütün kayıp veri oranları için
Cronbach α kestirimlerine benzer şekilde negatif yanlı kestirimlerin elde
edildiği görülmüştür.
Tek faktörlü modeller için stokastik regresyonla değer atama, beklenti –
maksimizasyon algoritması ve çoklu değer atama tekniklerinin tümüyle
seçkisiz kayıp ve seçkisiz kayıp koşullarında yansız kestirimler ürettiği, Öklid
uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği ile elde
edilen kestirimlerin ise kayıp veri oranının artmasına bağlı olarak negatif
yanlılık gösterdiği bilgisine ulaşılmıştır.

69
İki faktörlü modeller için ulaşılan bulgular incelendiğinde, beklenti –
maksimizasyon algoritmasının tümüyle seçkisiz kayıp ve seçkisiz kayıp
koşulları altında tüm kayıp veri oranları için pozitif yanlı kestirimler ürettiği
görülmüştür. Bu sonuçlara göre, araştırma kapsamında güvenirlik temelinde
elde edilen bulguların büyük ölçüde benzer olduğu görülmüştür.
Aynı veri setinden elde edilen McDonald ve Cronbach α
katsayılarının birbirlerine göre değerleri için farklı görüşler vardır. Bacon ve
diğ. (1995) ve Yurdugül (2006), tüm ölçmeler için McDonald ’nın Cronbach
α’ya eşit ya da daha yüksek değerler aldığını ifade etmekte; Raykov (1997) ve
Gu, Little ve Kingston (2013) ise bu farkın Cronbach α lehine olabileceğini
belirtmektedir.
Kuramsal açıdan farklı görüşlerin bulunduğu tartışmaya katkı
sağlaması amacıyla, elde edilen güvenirlik katsayılarının bu araştırma
kapsamında da karşılaştırılması uygun görülmüştür. Bağımsız değişkenlerin
düzeyleri dışarıda bırakılarak, her bir veri seti için elde edilen Cronbach α ve
McDonald (iki faktörlü veri setleri için W) katsayıları arasındaki farklar
incelenmiştir.
Örneklem büyüklüğü ve madde sayısına göre eksiksiz olan 600 ve
bağımsız değişkenlerin farklı kombinasyonları altında elde edilen 27000 adet
olmak üzere toplam 27600 veri setinden 2336’sında, Cronbach α
kestirimlerinin McDonald ’dan daha büyük olduğu görülmüştür. Farkın
Cronbach α lehine olduğu dosyalar incelenmiş ve bu durumun sadece 10
maddelik veri setlerinde söz konusu olduğu görülmüştür. Bu bulguya göre,
Raykov (2001)’un, Cronbach α katsayısının güvenirliğin alt sınırını temsil
etmeyebileceği yönündeki ifadesi güç kazanmaktadır.
Kayıp veri koşulu açısından yapılan incelemede, tümüyle seçkisiz kayıp
koşulu altındaki güvenirlik kestirimlerinin McDonald lehine olduğu
görülmüştür. Seçkisiz kayıp koşulu altında örneklem büyüklüğünün 250, kayıp
veri oranın 10 ve kayıp veri baş etme ekniğinin liste bazında silme olduğu tek
bir veri dosyasında Cronbach α’nın McDonald ’dan daha büyük olduğu;
diğer 2335 veri setinde ise kayıpların seçkisiz olmayan kayıp koşulu altında
yer aldığı görülmüştür. Söz konusu 2335 veri setinin, örneklem büyüklüğü,

70
kayıp veri oranı ve kayıp veri baş etme tekniği değişkenlerine ilişkin dağılımı
Çizelge 20’de verilmiştir.
Çizelge 20. Cronbach α Katsayısı Mcdonald Katsayısından Daha Büyük
Olan Veri Setlerinin Örneklem Büyüklüğü, Kayıp Veri Oranı Ve
Kayıp Veri Baş Etme Tekniğine Göre Dağılımı
Örneklem Büyüklüğü
Kayıp Veri Oranı
LBS EUC STR BM ÇDA Toplam
250 %2 28 2 2 2 2 36 %5 98 35 31 42 26 232 %10 100 100 100 100 99 499
500 %2 20 - - - - 20 %5 100 46 35 57 29 267 %10 100 100 100 100 100 500
1000 %2 8 - - - - 8 %5 100 56 27 69 21 273 %10 100 100 100 100 100 500
Genel Toplam 654 439 395 470 377 2335
Çizelge 20 incelendiğinde, kayıp veri oranının %10 olduğu veri
setlerinin neredeyse tamamında, %5 olduğu veri setlerinin yarıdan fazlasında
ve %2 olduğu veri setlerinin 64’ünde Cronbach α katsayısının Mcdonald
katsayısından daha büyük olduğu görülmektedir.
Raykov (1997) ve Gu ve diğerlerinin (2013) tartışmaları doğrultusunda,
ilgili veri setlerine ait doğrulayıcı faktör analizi çıktıları incelenmiştir.
İncelemeler sonucunda, klasik test kuramının temel varsayımlarından biri olan
hata terimleri arasındaki kovaryansın sıfır olduğu yönündeki varsayımının ihlal
edilmesi ve ek olarak, en az bir madde için faktör yükünün manidar olmaması
gibi problemlerin söz konusu olduğu görülmüştür. Çizelge 20’de verilen veri
setlerinde, Rae (2006)’nin de belirttiği üzere, hata kovaryanslarının pozitif
olmasına bağlı olarak Cronbach α katsayılarının olduğundan daha yüksek
kestirilmesi söz konusudur.
Çokluk, Şekercioğlu ve Büyüköztürk (2010), faktör yükünün manidar
olmaması halinde ilgili maddenin modelden çıkarılması gerektiğini
belirtmektedir. Bu noktada, araştırmanın varsayımına bağlı kalınmış;
modelden madde çıkarılması halinde eksiksiz veri setleri üzerinden yapılan

71
karşılaştırmalarda yeni sorunlar ortaya çıkacağı için bu yönde bir işlem
yapılmamıştır.
Hata kovaryansları sıfır olmayan ve modelde yer verilmesine rağmen
faktör yükü manidar olmayan madde sayısının, kayıp veri oranı ile birlikte
arttığı görülmüştür. Bu durum, seçkisiz olmayan kayıp koşulundaki kayıpların,
araştırma kapsamında yer verilen tekniklerle düzeltilemeyecek ölçüde ciddi bir
sorun yarattığı yönünde yorumlanabilir.
2. Geçerliğe İlişkin Bulgular
Araştırmada liste bazında silme, Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama, stokastik regresyonla değer atama, beklenti –
maksimizasyon algoritması ve çoklu değer atama tekniklerinin temel
bileşenler analizi ile elde edilen geçerlik kanıtları üzerindeki etkileri, açıklanan
varyans oranı ve D2 istatistiği; doğrulayıcı faktör analizi ile elde edilen geçerlik
kanıtları üzerindeki etkileri ise veri – model uyumuna ilişkin indeksler
temelinde incelenmiştir. Temel bileşenler analizi çerçevesinde, açıklanan
varyans oranı ve D2 istatistiği için ulaşılan bulgular bir arada
değerlendirilmiştir.
a. Açıklanan Varyans Oranlarının Yanlılığına İlişkin Bulgular
Araştırma kapsamında yer verilen kayıp veri teknikleri ile örneklem
büyüklüğü, madde sayısı, kayıp veri türü, kayıp veri oranı değişkenlerinin her
bir kombinasyonu için, veri setlerine ait temel bileşenler analizi
gerçekleştirilmiş ve açıklanan varyans oranları hesaplanmıştır.
Liste bazında silme tekniği ile elde edilen açıklanan varyans oranlarına
ilişkin aritmetik ortalama ve standart sapma değerleri Çizelge 21’de verilmiştir.
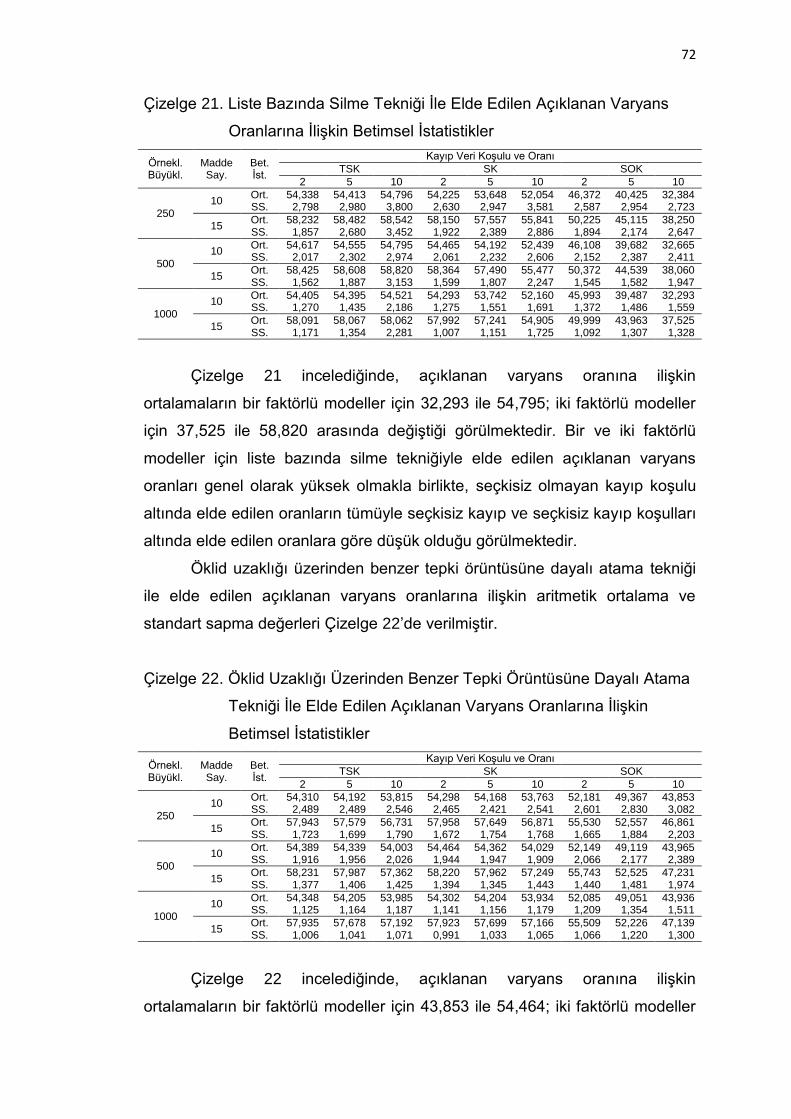
72
Çizelge 21. Liste Bazında Silme Tekniği İle Elde Edilen Açıklanan Varyans
Oranlarına İlişkin Betimsel İstatistikler
Örnekl. Büyükl.
Madde Say.
Bet. İst.
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. SS.
54,338 2,798
54,413 2,980
54,796 3,800
54,225 2,630
53,648 2,947
52,054 3,581
46,372 2,587
40,425 2,954
32,384 2,723
15 Ort. SS.
58,232 1,857
58,482 2,680
58,542 3,452
58,150 1,922
57,557 2,389
55,841 2,886
50,225 1,894
45,115 2,174
38,250 2,647
500
10 Ort. SS.
54,617 2,017
54,555 2,302
54,795 2,974
54,465 2,061
54,192 2,232
52,439 2,606
46,108 2,152
39,682 2,387
32,665 2,411
15 Ort. SS.
58,425 1,562
58,608 1,887
58,820 3,153
58,364 1,599
57,490 1,807
55,477 2,247
50,372 1,545
44,539 1,582
38,060 1,947
1000
10 Ort. SS.
54,405 1,270
54,395 1,435
54,521 2,186
54,293 1,275
53,742 1,551
52,160 1,691
45,993 1,372
39,487 1,486
32,293 1,559
15 Ort. SS.
58,091 1,171
58,067 1,354
58,062 2,281
57,992 1,007
57,241 1,151
54,905 1,725
49,999 1,092
43,963 1,307
37,525 1,328
Çizelge 21 incelediğinde, açıklanan varyans oranına ilişkin
ortalamaların bir faktörlü modeller için 32,293 ile 54,795; iki faktörlü modeller
için 37,525 ile 58,820 arasında değiştiği görülmektedir. Bir ve iki faktörlü
modeller için liste bazında silme tekniğiyle elde edilen açıklanan varyans
oranları genel olarak yüksek olmakla birlikte, seçkisiz olmayan kayıp koşulu
altında elde edilen oranların tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları
altında elde edilen oranlara göre düşük olduğu görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği
ile elde edilen açıklanan varyans oranlarına ilişkin aritmetik ortalama ve
standart sapma değerleri Çizelge 22’de verilmiştir.
Çizelge 22. Öklid Uzaklığı Üzerinden Benzer Tepki Örüntüsüne Dayalı Atama
Tekniği İle Elde Edilen Açıklanan Varyans Oranlarına İlişkin
Betimsel İstatistikler
Örnekl. Büyükl.
Madde Say.
Bet. İst.
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. SS.
54,310 2,489
54,192 2,489
53,815 2,546
54,298 2,465
54,168 2,421
53,763 2,541
52,181 2,601
49,367 2,830
43,853 3,082
15 Ort. SS.
57,943 1,723
57,579 1,699
56,731 1,790
57,958 1,672
57,649 1,754
56,871 1,768
55,530 1,665
52,557 1,884
46,861 2,203
500
10 Ort. SS.
54,389 1,916
54,339 1,956
54,003 2,026
54,464 1,944
54,362 1,947
54,029 1,909
52,149 2,066
49,119 2,177
43,965 2,389
15 Ort. SS.
58,231 1,377
57,987 1,406
57,362 1,425
58,220 1,394
57,962 1,345
57,249 1,443
55,743 1,440
52,525 1,481
47,231 1,974
1000
10 Ort. SS.
54,348 1,125
54,205 1,164
53,985 1,187
54,302 1,141
54,204 1,156
53,934 1,179
52,085 1,209
49,051 1,354
43,936 1,511
15 Ort. SS.
57,935 1,006
57,678 1,041
57,192 1,071
57,923 0,991
57,699 1,033
57,166 1,065
55,509 1,066
52,226 1,220
47,139 1,300
Çizelge 22 incelediğinde, açıklanan varyans oranına ilişkin
ortalamaların bir faktörlü modeller için 43,853 ile 54,464; iki faktörlü modeller
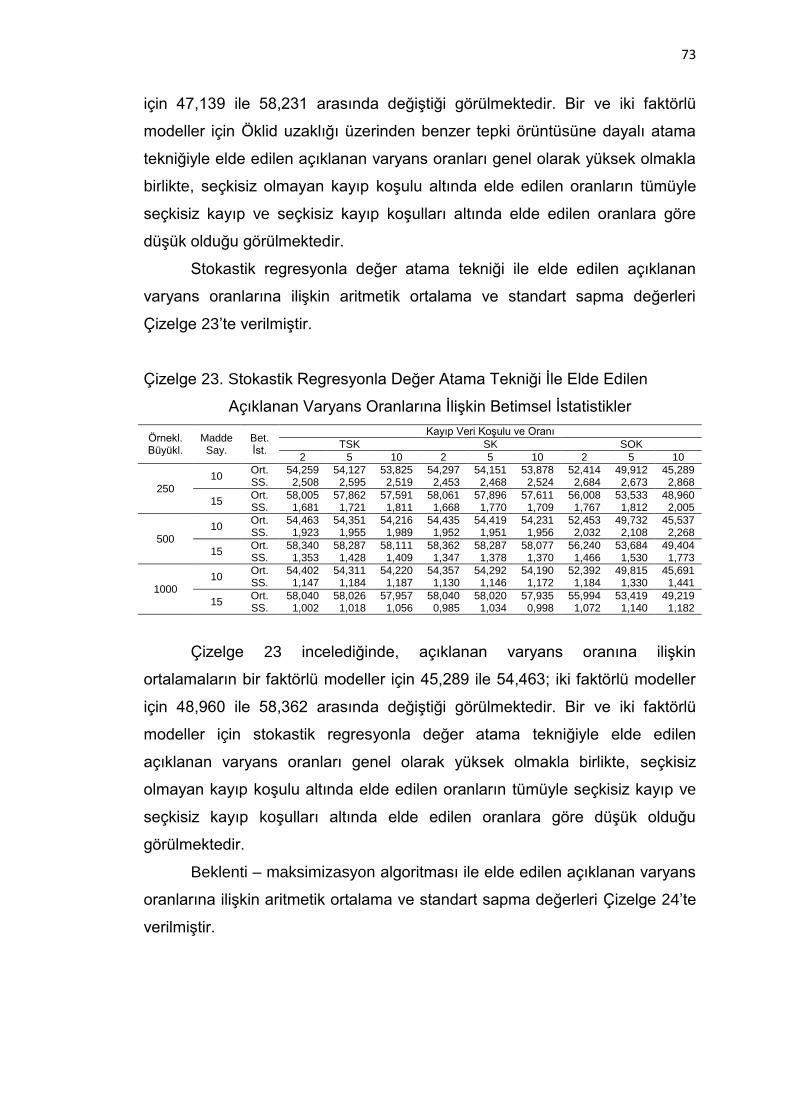
73
için 47,139 ile 58,231 arasında değiştiği görülmektedir. Bir ve iki faktörlü
modeller için Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama
tekniğiyle elde edilen açıklanan varyans oranları genel olarak yüksek olmakla
birlikte, seçkisiz olmayan kayıp koşulu altında elde edilen oranların tümüyle
seçkisiz kayıp ve seçkisiz kayıp koşulları altında elde edilen oranlara göre
düşük olduğu görülmektedir.
Stokastik regresyonla değer atama tekniği ile elde edilen açıklanan
varyans oranlarına ilişkin aritmetik ortalama ve standart sapma değerleri
Çizelge 23’te verilmiştir.
Çizelge 23. Stokastik Regresyonla Değer Atama Tekniği İle Elde Edilen
Açıklanan Varyans Oranlarına İlişkin Betimsel İstatistikler
Örnekl. Büyükl.
Madde Say.
Bet. İst.
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. SS.
54,259 2,508
54,127 2,595
53,825 2,519
54,297 2,453
54,151 2,468
53,878 2,524
52,414 2,684
49,912 2,673
45,289 2,868
15 Ort. SS.
58,005 1,681
57,862 1,721
57,591 1,811
58,061 1,668
57,896 1,770
57,611 1,709
56,008 1,767
53,533 1,812
48,960 2,005
500
10 Ort. SS.
54,463 1,923
54,351 1,955
54,216 1,989
54,435 1,952
54,419 1,951
54,231 1,956
52,453 2,032
49,732 2,108
45,537 2,268
15 Ort. SS.
58,340 1,353
58,287 1,428
58,111 1,409
58,362 1,347
58,287 1,378
58,077 1,370
56,240 1,466
53,684 1,530
49,404 1,773
1000 10
Ort. SS.
54,402 1,147
54,311 1,184
54,220 1,187
54,357 1,130
54,292 1,146
54,190 1,172
52,392 1,184
49,815 1,330
45,691 1,441
15 Ort. SS.
58,040 1,002
58,026 1,018
57,957 1,056
58,040 0,985
58,020 1,034
57,935 0,998
55,994 1,072
53,419 1,140
49,219 1,182
Çizelge 23 incelediğinde, açıklanan varyans oranına ilişkin
ortalamaların bir faktörlü modeller için 45,289 ile 54,463; iki faktörlü modeller
için 48,960 ile 58,362 arasında değiştiği görülmektedir. Bir ve iki faktörlü
modeller için stokastik regresyonla değer atama tekniğiyle elde edilen
açıklanan varyans oranları genel olarak yüksek olmakla birlikte, seçkisiz
olmayan kayıp koşulu altında elde edilen oranların tümüyle seçkisiz kayıp ve
seçkisiz kayıp koşulları altında elde edilen oranlara göre düşük olduğu
görülmektedir.
Beklenti – maksimizasyon algoritması ile elde edilen açıklanan varyans
oranlarına ilişkin aritmetik ortalama ve standart sapma değerleri Çizelge 24’te
verilmiştir.
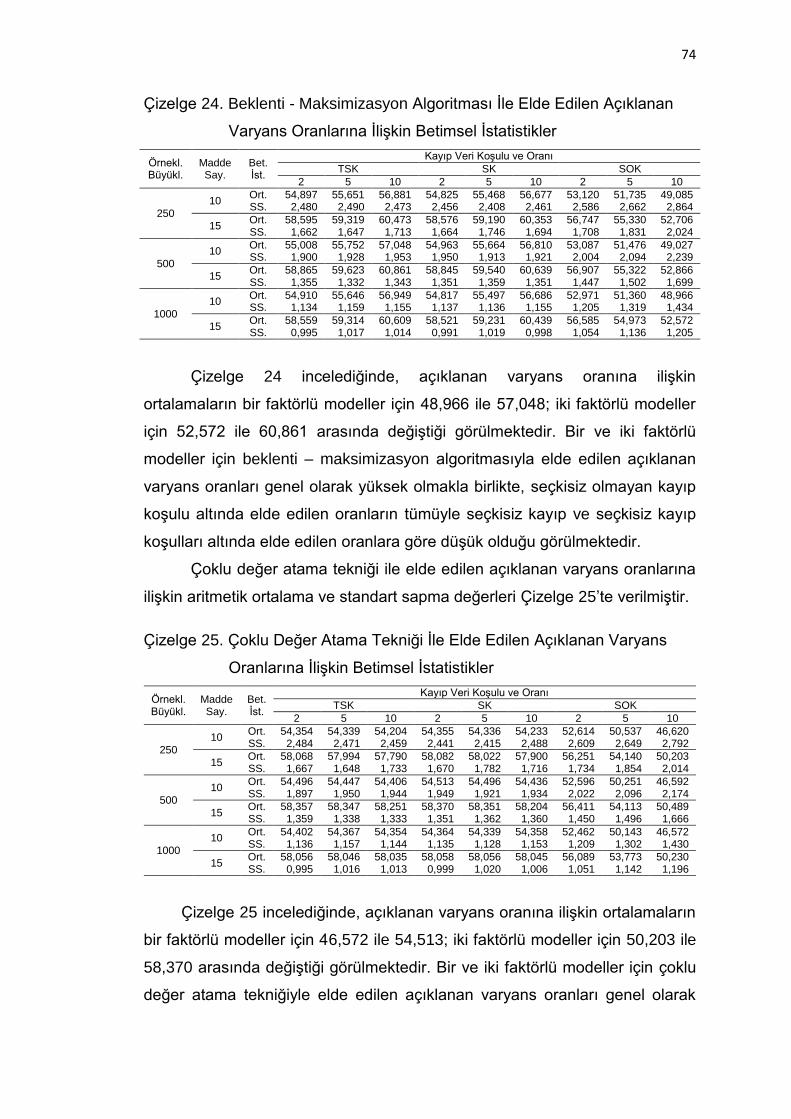
74
Çizelge 24. Beklenti - Maksimizasyon Algoritması İle Elde Edilen Açıklanan
Varyans Oranlarına İlişkin Betimsel İstatistikler
Örnekl. Büyükl.
Madde Say.
Bet. İst.
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. SS.
54,897 2,480
55,651 2,490
56,881 2,473
54,825 2,456
55,468 2,408
56,677 2,461
53,120 2,586
51,735 2,662
49,085 2,864
15 Ort. SS.
58,595 1,662
59,319 1,647
60,473 1,713
58,576 1,664
59,190 1,746
60,353 1,694
56,747 1,708
55,330 1,831
52,706 2,024
500
10 Ort. SS.
55,008 1,900
55,752 1,928
57,048 1,953
54,963 1,950
55,664 1,913
56,810 1,921
53,087 2,004
51,476 2,094
49,027 2,239
15 Ort. SS.
58,865 1,355
59,623 1,332
60,861 1,343
58,845 1,351
59,540 1,359
60,639 1,351
56,907 1,447
55,322 1,502
52,866 1,699
1000
10 Ort. SS.
54,910 1,134
55,646 1,159
56,949 1,155
54,817 1,137
55,497 1,136
56,686 1,155
52,971 1,205
51,360 1,319
48,966 1,434
15 Ort. SS.
58,559 0,995
59,314 1,017
60,609 1,014
58,521 0,991
59,231 1,019
60,439 0,998
56,585 1,054
54,973 1,136
52,572 1,205
Çizelge 24 incelediğinde, açıklanan varyans oranına ilişkin
ortalamaların bir faktörlü modeller için 48,966 ile 57,048; iki faktörlü modeller
için 52,572 ile 60,861 arasında değiştiği görülmektedir. Bir ve iki faktörlü
modeller için beklenti – maksimizasyon algoritmasıyla elde edilen açıklanan
varyans oranları genel olarak yüksek olmakla birlikte, seçkisiz olmayan kayıp
koşulu altında elde edilen oranların tümüyle seçkisiz kayıp ve seçkisiz kayıp
koşulları altında elde edilen oranlara göre düşük olduğu görülmektedir.
Çoklu değer atama tekniği ile elde edilen açıklanan varyans oranlarına
ilişkin aritmetik ortalama ve standart sapma değerleri Çizelge 25’te verilmiştir.
Çizelge 25. Çoklu Değer Atama Tekniği İle Elde Edilen Açıklanan Varyans
Oranlarına İlişkin Betimsel İstatistikler
Örnekl. Büyükl.
Madde Say.
Bet. İst.
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10 Ort. SS.
54,354 2,484
54,339 2,471
54,204 2,459
54,355 2,441
54,336 2,415
54,233 2,488
52,614 2,609
50,537 2,649
46,620 2,792
15 Ort. SS.
58,068 1,667
57,994 1,648
57,790 1,733
58,082 1,670
58,022 1,782
57,900 1,716
56,251 1,734
54,140 1,854
50,203 2,014
500
10 Ort. SS.
54,496 1,897
54,447 1,950
54,406 1,944
54,513 1,949
54,496 1,921
54,436 1,934
52,596 2,022
50,251 2,096
46,592 2,174
15 Ort. SS.
58,357 1,359
58,347 1,338
58,251 1,333
58,370 1,351
58,351 1,362
58,204 1,360
56,411 1,450
54,113 1,496
50,489 1,666
1000
10 Ort. SS.
54,402 1,136
54,367 1,157
54,354 1,144
54,364 1,135
54,339 1,128
54,358 1,153
52,462 1,209
50,143 1,302
46,572 1,430
15 Ort. SS.
58,056 0,995
58,046 1,016
58,035 1,013
58,058 0,999
58,056 1,020
58,045 1,006
56,089 1,051
53,773 1,142
50,230 1,196
Çizelge 25 incelediğinde, açıklanan varyans oranına ilişkin ortalamaların
bir faktörlü modeller için 46,572 ile 54,513; iki faktörlü modeller için 50,203 ile
58,370 arasında değiştiği görülmektedir. Bir ve iki faktörlü modeller için çoklu
değer atama tekniğiyle elde edilen açıklanan varyans oranları genel olarak

75
yüksek olmakla birlikte, seçkisiz olmayan kayıp koşulu altında elde edilen
oranların tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında elde edilen
oranlara göre düşük olduğu görülmektedir.
Temel bileşenler analizi ile elde edilen açıklanan varyans oranlarının
farklı kayıp veri baş etme teknikleri ile incelenebilmesi amacıyla, örneklem
büyüklüğü ve madde sayısı değişkenlerinin her bir kombinasyonu için eksiksiz
veri setlerine ve farklı kayıp veri teknikleri ile elde edilen veri setlerine ilişkin
açıklanan varyans oranları arasındaki farklar hesaplanmıştır. Elde edilen fark
puanları, çok yönlü varyans analizlerinde bağımlı değişken olarak
kullanılmıştır.
Analiz sonuçlarına göre, kayıp veri koşulu, kayıp veri oranı ve kayıp veri
baş etme tekniği değişkenlerinin temel, iki yönlü ve üç yönlü etkilerinin
istatistiksel olarak manidar olduğu görülmüştür (p<,01). İlgili çok yönlü varyans
analizlerine ait çizelgeler ekte (Ek 13 - Ek 18) sunulmuştur.
Kayıp veri türü, kayıp veri oranı ve kayıp veri baş etme tekniği
değişkenlerinin ortak etkisinin hangi gruplar arasında manidar fark yarattığının
incelenmesi amacıyla, grup değişkenine göre açıklanan varyans oranları için
tek yönlü varyans analizleri gerçekleştirilmiş, bu analizlere ilişkin sonuçlar ekte
(Ek 22) sunulmuştur.
Ortalamalar arasındaki manidar farkın hangi gruplar arasında olduğunu
bulmak amacıyla yapılan Dunnett C çoklu karşılaştırma testi sonucunda, 111
şeklinde kodlanan eksiksiz veri setinin ortalaması ile manidar farklılık gösteren
gruplar Çizelge 26’da verilmiştir.

76
Çizelge 26. Açıklanan Varyans Oranı Fark Puanları İçin Grup Değişkenine
Göre Çoklu Karşılaştırma Testi Sonuçları
Örneklem Büyüklüğü
Madde Sayısı
Kayıp Veri Baş Etme Tekniği
TSK SK SOK
2 5 10 2 5 10 2 5 10
250
10
LBS - - - - - EUC - - - - - - - - STR - - - BM + + + + + + - - -
ÇDA - - - -
15
LBS - - - - EUC - - - - - - - - - STR - - - BM + + + + + + - - -
ÇDA - - - - - -
500
10
LBS - - - - EUC - - - - - - - - - STR - - - BM + + + + + + - - -
ÇDA - - -
15
LBS - - - - - EUC - - - - - - - - - STR - - - BM + + + + + + - - -
ÇDA - - - - -
1000
10
LBS - - - - - EUC - - - - - - - - STR - - -
BM + + + + + + - - -
ÇDA - - -
15
LBS - - - - -
EUC - - - - - - - - -
STR - - -
BM + + + + + + - - -
ÇDA - - -
Çizelge 26 incelendiğinde farklı kayıp veri baş etme tekniklerinin,
örneklem büyüklüğü ve madde (faktör) sayısı değişkenlerinin tüm düzeyleri
için benzer sonuçlar verdiği görülmektedir.
Tümüyle seçkisiz kayıp koşulunda, tüm kayıp veri oranları için liste
bazında silme ve stokastik regresyonla değer atama teknikleri ile elde edilen
açıklanan varyans oranları yansız olduğu görülmektedir. Bu koşul altında,
beklenti – maksimizasyon algoritması ile elde edilen açıklanan varyans
oranları pozitif yanlılık göstermekte iken, Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama tekniği ile elde edilen açıklanan varyans oranlarının
genel olarak negatif yanlı olduğu görülmektedir. Çoklu değer atama tekniği ile
büyük örneklemlerde genel olarak yansız sonuçların elde edildiği, kayıp veri
oranının yüksek olduğu küçük örneklemlerde ise negatif yanlı sonuçlara
ulaşıldığı görülmektedir.

77
Seçkisiz kayıp koşulunda, tüm kayıp veri oranları için stokastik
regresyonla değer atama tekniği ile elde edilen açıklanan varyans oranlarının
yansız olduğu görülmektedir. Çoklu değer atama tekniği ile elde edilen
açıklanan varyans oranlarının da, %10 oranında kayıpların bulunduğu iki
durum haricinde yansız olduğu görülmektedir. Liste bazında silme tekniği ile
elde edilen açıklanan varyans oranlarının, %2 oranında kayıpların bulunduğu
durumlarda yansız olduğu, kayıp veri oranının artmasına bağlı olarak
açıklanan varyans oranlarının negatif yanlılık gösterdiği görülmektedir.
beklenti – maksimizasyon algoritması ile elde edilen açıklanan varyans
oranları her kayıp veri oranı için pozitif yanlı iken, Öklid uzaklığı üzerinden
benzer tepki örüntüsüne dayalı atama tekniği ile elde edilen açıklanan
varyans oranları genel olarak negatif yanlıdır.
Seçkisiz olmayan kayıp koşulu altında elde edilen açıklanan varyans
oranlarının, araştırma kapsamında yer verilen kayıp veri baş etme teknikleri
ve kayıp veri oranları için eksiksiz veri setlerine göre negatif yanlı olduğu
görülmektedir.
b. D2 İstatistiği İçin Ulaşılan Bulgular
Temel bileşenler analizi çerçevesinde, faktör yükü matrislerinin
benzerliği sayfa 41’de verilen D2 istatistiği üzerinden incelenmiştir. Örneklem
büyüklüğü ve madde sayısı değişkenlerinin tüm kombinasyonları için elde
edilen D2 değerleri çizelgelerde (Çizelge 27 - Çizelge 32) verilmiştir.
Örneklem büyüklüğünün 250 ve madde sayısının 10 olduğu durumda
elde edilen D2 değerlerine ait betimsel istatistikler Çizelge 27’de verilmiştir.
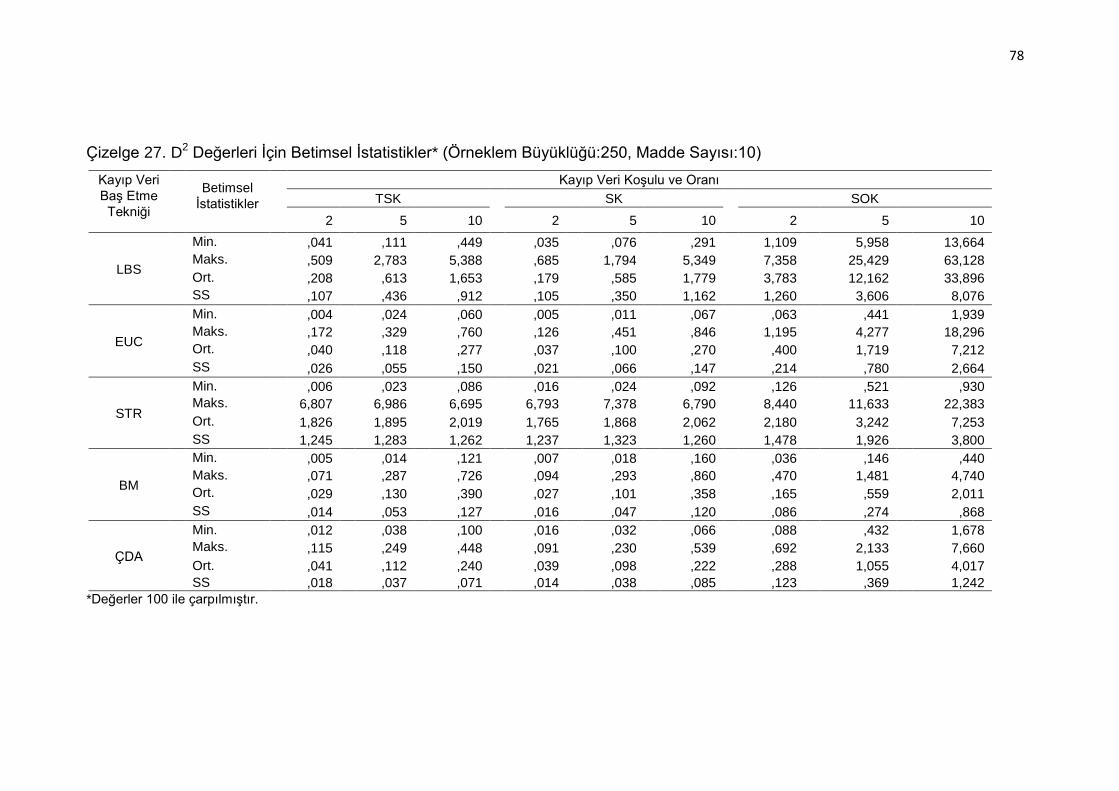
78
Çizelge 27. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:250, Madde Sayısı:10)
Kayıp Veri
Baş Etme
Tekniği
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
Min. ,041 ,111 ,449 ,035 ,076 ,291 1,109 5,958 13,664
Maks. ,509 2,783 5,388 ,685 1,794 5,349 7,358 25,429 63,128
Ort. ,208 ,613 1,653 ,179 ,585 1,779 3,783 12,162 33,896
SS ,107 ,436 ,912 ,105 ,350 1,162 1,260 3,606 8,076
EUC
Min. ,004 ,024 ,060 ,005 ,011 ,067 ,063 ,441 1,939
Maks. ,172 ,329 ,760 ,126 ,451 ,846 1,195 4,277 18,296
Ort. ,040 ,118 ,277 ,037 ,100 ,270 ,400 1,719 7,212
SS ,026 ,055 ,150 ,021 ,066 ,147 ,214 ,780 2,664
STR
Min. ,006 ,023 ,086 ,016 ,024 ,092 ,126 ,521 ,930
Maks. 6,807 6,986 6,695 6,793 7,378 6,790 8,440 11,633 22,383
Ort. 1,826 1,895 2,019 1,765 1,868 2,062 2,180 3,242 7,253
SS 1,245 1,283 1,262 1,237 1,323 1,260 1,478 1,926 3,800
BM
Min. ,005 ,014 ,121 ,007 ,018 ,160 ,036 ,146 ,440
Maks. ,071 ,287 ,726 ,094 ,293 ,860 ,470 1,481 4,740
Ort. ,029 ,130 ,390 ,027 ,101 ,358 ,165 ,559 2,011
SS ,014 ,053 ,127 ,016 ,047 ,120 ,086 ,274 ,868
ÇDA
Min. ,012 ,038 ,100 ,016 ,032 ,066 ,088 ,432 1,678
Maks. ,115 ,249 ,448 ,091 ,230 ,539 ,692 2,133 7,660
Ort. ,041 ,112 ,240 ,039 ,098 ,222 ,288 1,055 4,017
SS ,018 ,037 ,071 ,014 ,038 ,085 ,123 ,369 1,242
*Değerler 100 ile çarpılmıştır.

79
Çizelge 27 incelendiğinde, en düşük D2 değerlerinin beklenti –
maksimizasyon algoritması ve çoklu değer atama teknikleri ile elde edildiği
görülmektedir. Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama
tekniğiyle elde edilen D2 değerlerinin de bu tekniklere oldukça yakın olduğu
görülmektedir. Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları için en
büyük değerler stokastik regresyonla değer atama tekniğiyle, seçkisiz
olmayan kayıp koşulu için en büyük değerler ise liste bazında silme tekniğiyle
elde edilmiştir. Her bir kayıp veri baş etme tekniği için D2 değerleri, kayıp veri
oranına paralel olarak artış göstermiştir.
Bu bulgular, çalışmalarında çok sayıda kayıp veri baş etme tekniğine
yer veren Bernaards ve Sijtsma (1999; 2000)’nın beklenti – maksimizasyon
algoritması ve liste bazında silme teknikleriyle tek boyutlu ölçümler için elde
ettikleri sonuçlarla örtüşmektedir. Güçlü bir kayıp veri baş etme tekniği olduğu
belirtilen çoklu değer atama (Graham, 2012) ile elde edilen sonuçların da
diğer tekniklere göre oldukça iyi olduğu görülmektedir.
Seçkisiz olmayan kayıp koşulu altında %10 kayıp veri oranı için
hesaplanan D2 değerlerinin ortalaması .338 ve en büyük değeri .631’dir. Diğer
koşullara göre uç değer özelliği gösteren bu değerlerin elde edildiği veri setleri
özel olarak incelenmiştir.
İnceleme sonucunda, 10 maddenin bir faktör altında yer alacağı
şekilde üretilen veri setlerinde, bazı maddelerin faktör yüklerinin Tabachnick
ve Fidell (1996) tarafından önerilen alt sınır olan .32 değerinin altına
düşmesine ek olarak, birden büyük özdeğer sayısının 4’e çıkacak ölçüde
değişmesi gibi sorunlarla karşılaşılmıştır. Aynı kayıp veri koşulu ve kayıp veri
oranı için diğer tekniklerle en yüksek D2 değerlerinin elde edildiği veri
setlerinde böyle sorunların ortaya çıkmadığı, diğer bir deyişle eksiksiz veri
setlerindeki faktör yapısının korunduğu görülmüştür. Seçkisiz olmayan kayıp
koşulu altında, liste bazında silme tekniğinin uygulanması ile elde edilen
geçerlik kanıtlarının, verinin eksiksiz olduğu durumda elde edilenlere göre
oldukça farklı olabileceği görülmüştür.
Çizelge 26’da verilen ve örneklem büyüklüğünün 250, madde sayısının
10 olduğu durumda elde edilen açıklanan varyans oranlarının yanlılığına
ilişkin bulgular incelendiğinde stokastik regresyonla değer atama tekniğinin,
Enders (2010)’in ifadelerine uygun olarak tümüyle seçkisiz kayıp ve seçkisiz

80
kayıp koşullarında yansız sonuçlar ürettiği görülmektedir. Bu sonuçlar ile
Çizelge 27’de verilen D2 istatistiğine ilişkin bulgular birlikte değerlendirildiğinde
ise bu koşullar altında stokastik regresyonla değer atama tekniğinin en yüksek
D2 değerlerini ürettiği görülmektedir. Beklenti – maksimizasyon algoritması ile
elde edilen açıklanan varyans oranları pozitif yanlılık göstermesine rağmen bu
teknik ile elde edilen D2 değerleri incelendiğinde ölçümlerin faktör yapısının
korunduğu görülmektedir. Tümüyle seçkisiz kayıp ve seçkisiz kayıp
koşullarında çoklu değer atama tekniğinin; seçkisiz olmayan kayıp koşulunda
ise beklenti – maksimizasyon algoritmasının eksiksiz veri setinden elde edilen
değerlere en yakın sonuçları ürettiği görülmektedir.
Örneklem büyüklüğünün 250 ve madde sayısının 15 olduğu durumda
elde edilen D2 değerlerine ait betimsel istatistikler Çizelge 28’de verilmiştir.
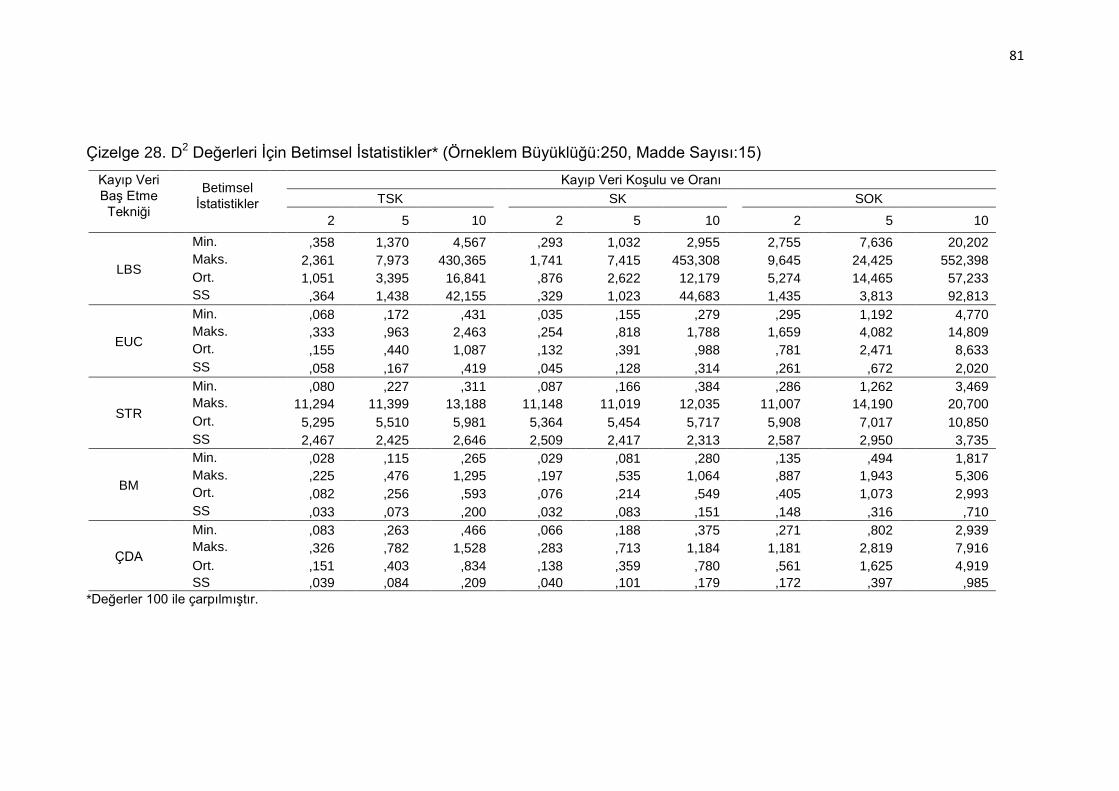
81
Çizelge 28. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:250, Madde Sayısı:15)
Kayıp Veri
Baş Etme
Tekniği
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
Min. ,358 1,370 4,567 ,293 1,032 2,955 2,755 7,636 20,202
Maks. 2,361 7,973 430,365 1,741 7,415 453,308 9,645 24,425 552,398
Ort. 1,051 3,395 16,841 ,876 2,622 12,179 5,274 14,465 57,233
SS ,364 1,438 42,155 ,329 1,023 44,683 1,435 3,813 92,813
EUC
Min. ,068 ,172 ,431 ,035 ,155 ,279 ,295 1,192 4,770
Maks. ,333 ,963 2,463 ,254 ,818 1,788 1,659 4,082 14,809
Ort. ,155 ,440 1,087 ,132 ,391 ,988 ,781 2,471 8,633
SS ,058 ,167 ,419 ,045 ,128 ,314 ,261 ,672 2,020
STR
Min. ,080 ,227 ,311 ,087 ,166 ,384 ,286 1,262 3,469
Maks. 11,294 11,399 13,188 11,148 11,019 12,035 11,007 14,190 20,700
Ort. 5,295 5,510 5,981 5,364 5,454 5,717 5,908 7,017 10,850
SS 2,467 2,425 2,646 2,509 2,417 2,313 2,587 2,950 3,735
BM
Min. ,028 ,115 ,265 ,029 ,081 ,280 ,135 ,494 1,817
Maks. ,225 ,476 1,295 ,197 ,535 1,064 ,887 1,943 5,306
Ort. ,082 ,256 ,593 ,076 ,214 ,549 ,405 1,073 2,993
SS ,033 ,073 ,200 ,032 ,083 ,151 ,148 ,316 ,710
ÇDA
Min. ,083 ,263 ,466 ,066 ,188 ,375 ,271 ,802 2,939
Maks. ,326 ,782 1,528 ,283 ,713 1,184 1,181 2,819 7,916
Ort. ,151 ,403 ,834 ,138 ,359 ,780 ,561 1,625 4,919
SS ,039 ,084 ,209 ,040 ,101 ,179 ,172 ,397 ,985
*Değerler 100 ile çarpılmıştır.

82
Çizelge 28 incelendiğinde, tüm durumlar için en küçük D2 değerlerinin
beklenti – maksimizasyon algoritmasıyla elde edildiği görülmektedir. Beklenti
– maksimizasyon algoritmasının diğer tekniklere göre daha yüksek
performans gösterdiği yönündeki bu bulgu, Bernaards ve Sijtsma (1999,
2000)’nın ulaştığı bulgularla paralellik göstermektedir. Her bir kayıp veri baş
etme tekniği için D2 değerleri, kayıp veri oranına paralel olarak artış
göstermiştir.
Tek faktörlü veri setlerinden elde edilen sonuçlara benzer şekilde
beklenti – maksimizasyon algoritmasına en yakın sonuçların Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama ve çoklu değer atama
teknikleriyle elde edildiği, stokastik regresyonla değer atama tekniğinin bu
tekniklere göre daha düşük performans gösterdiği ve liste bazında silme
tekniğinin kayıp veri oranının %10 olduğu durumlarda ölçümlerin faktör
yapısını bozduğu görülmüştür.
Liste bazında silme tekniğiyle elde edilen ve uç değer niteliği taşıyan D2
sonuçlarının elde edildiği veri setleri özel olarak incelenmiştir. İncelemeler
sonucunda tek faktörlü veri setlerinde karşılaşılan faktör yüklerinin düşük
olması ve birden büyük özdeğer sayısının eksiksiz veri setindeki sayının
üstüne çıkabilmesine ek olarak, maddelerin eksiksiz veri setlerinde belirlenen
faktör yapısıyla zıt bir şekilde faktörleşmesi gibi sorunların ortaya çıktığı
görülmüştür.
Bu sorunun, özellikle birden çok grup üzerinde yürütülen uyarlama
veya eşdeğerlik çalışmalarında model uyumunun düşük olması gibi sorunlar
yaratabileceği görülmüştür. Liste bazında silme tekniğinin, tüm kayıp veri
koşulları için %10 oranında kayıpların bulunduğu durumlarda eksiksiz veri
setlerinden farklı sonuçlar verebileceği görülmektedir.
Çizelge 26’da verilen açıklanan varyans oranına ve Çizelge 28’de
verilen D2 değerlerine ilişkin bulgular birlikte değerlendirildiğinde, açıklanan
varyans oranı üzerinde genellikle yansız sonuçların elde edildiği liste bazında
silme tekniğinin, ölçümlerin faktör yapısını bozabileceği görülmektedir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında eksiksiz veri setlerine
benzer açıklanan varyans oranlarının elde edildiği stokastik regresyonla değer
atama tekniği ise beklenti – maksimizasyon algoritması, çoklu değer atama ve

83
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniklerine
göre daha yüksek D2 değerleri üretmiştir.
En düşük D2 değerlerinin elde edildiği beklenti – maksimizasyon
algoritması ile elde edilen açıklanan varyans oranlarının, eksiksiz veri
setlerine göre daha yüksek olduğu yönündeki bulgular Chen ve diğerlerinin
(2011) iki faktörlü ölçümler için elde ettikleri bulgularla örtüşmektedir. Beklenti
– maksimizasyon algoritması ile elde edilen açıklanan varyans oranlarının
eksiksiz veri setlerine daha yüksek olduğu göz önüne alındığında, %2 ve %5
oranında kayıp verilerin bulunduğu durumlarda çoklu değer atama tekniğinin
en iyi sonuçları verdiği görülmektedir.
Örneklem büyüklüğünün 500 ve madde sayısının 10 olduğu durumda
elde edilen D2 değerlerine ait betimsel istatistikler Çizelge 29’da verilmiştir.
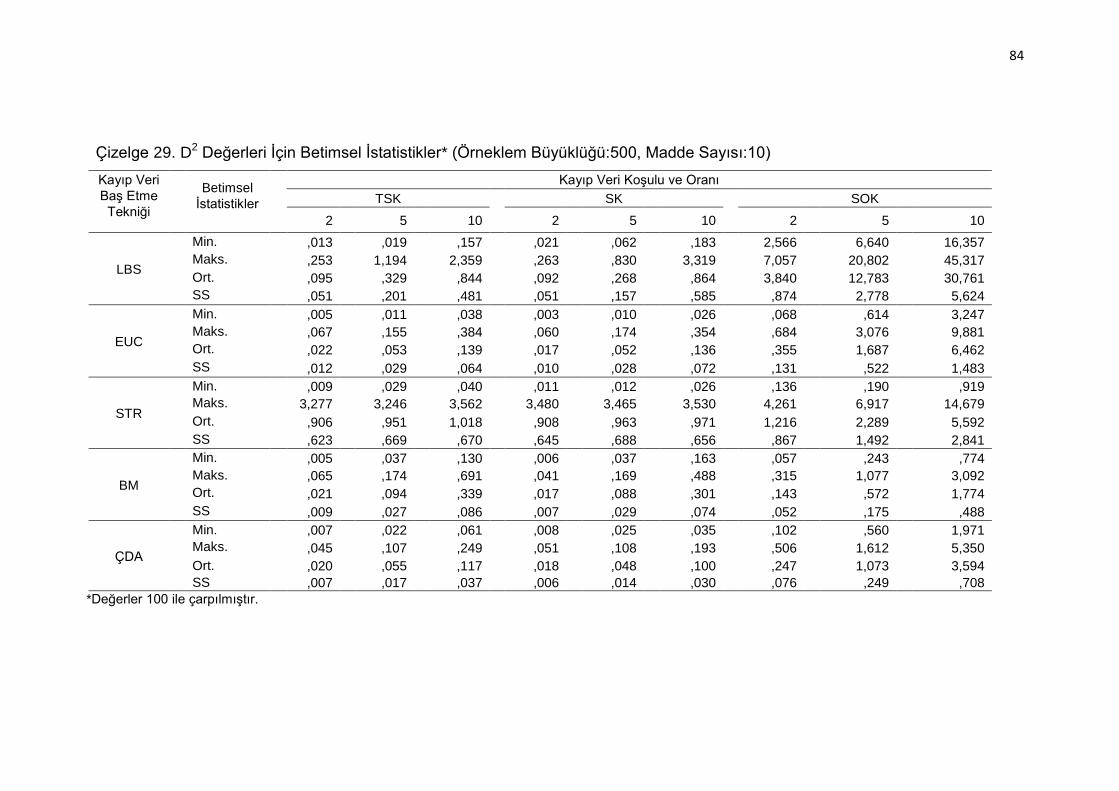
84
Çizelge 29. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:500, Madde Sayısı:10)
Kayıp Veri
Baş Etme
Tekniği
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
Min. ,013 ,019 ,157 ,021 ,062 ,183 2,566 6,640 16,357
Maks. ,253 1,194 2,359 ,263 ,830 3,319 7,057 20,802 45,317
Ort. ,095 ,329 ,844 ,092 ,268 ,864 3,840 12,783 30,761
SS ,051 ,201 ,481 ,051 ,157 ,585 ,874 2,778 5,624
EUC
Min. ,005 ,011 ,038 ,003 ,010 ,026 ,068 ,614 3,247
Maks. ,067 ,155 ,384 ,060 ,174 ,354 ,684 3,076 9,881
Ort. ,022 ,053 ,139 ,017 ,052 ,136 ,355 1,687 6,462
SS ,012 ,029 ,064 ,010 ,028 ,072 ,131 ,522 1,483
STR
Min. ,009 ,029 ,040 ,011 ,012 ,026 ,136 ,190 ,919
Maks. 3,277 3,246 3,562 3,480 3,465 3,530 4,261 6,917 14,679
Ort. ,906 ,951 1,018 ,908 ,963 ,971 1,216 2,289 5,592
SS ,623 ,669 ,670 ,645 ,688 ,656 ,867 1,492 2,841
BM
Min. ,005 ,037 ,130 ,006 ,037 ,163 ,057 ,243 ,774
Maks. ,065 ,174 ,691 ,041 ,169 ,488 ,315 1,077 3,092
Ort. ,021 ,094 ,339 ,017 ,088 ,301 ,143 ,572 1,774
SS ,009 ,027 ,086 ,007 ,029 ,074 ,052 ,175 ,488
ÇDA
Min. ,007 ,022 ,061 ,008 ,025 ,035 ,102 ,560 1,971
Maks. ,045 ,107 ,249 ,051 ,108 ,193 ,506 1,612 5,350
Ort. ,020 ,055 ,117 ,018 ,048 ,100 ,247 1,073 3,594
SS ,007 ,017 ,037 ,006 ,014 ,030 ,076 ,249 ,708
*Değerler 100 ile çarpılmıştır.

85
Çizelge 29 incelendiğinde, en küçük D2 değerlerinin Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama, beklenti – maksimizasyon
algoritması ve çoklu değer atama teknikleriyle elde edildiği ve kayıp veri
oranına bağlı olarak D2 değerlerinin arttığı görülmektedir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında en düşük
performansı stokastik regresyonla değer atama tekniğinin sergilediği ve
önceki bulgulara benzer şekilde en yüksek D2 değerlerinin seçkisiz olmayan
kayıp koşulu altında liste bazında silme tekniğiyle elde edildiği görülmektedir.
Çizelge 26’da verilen açıklanan varyans oranı ve Çizelge 29’da verilen
D2 bulguları birlikte değerlendirildiğinde, liste bazında silme ve stokastik
regresyonla değer atama tekniklerinin tümüyle seçkisiz kayıp ve seçkisiz
kayıp koşullarında açıklanan varyans oranı için yansız kestirimler
sağlamalarına rağmen göreceli olarak daha yüksek D2 değerlerini ürettiği
görülmektedir. Açıklanan varyans oranı için negatif yanlılık gösteren Öklid
uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği ile pozitif
yanlılık gösteren beklenti – maksimizasyon algoritması ile elde edilen D2
değerlerinin ise göreceli olarak daha küçük olduğu görülmektedir.
Çoklu değer atama tekniği ile tümüyle seçkisiz kayıp ve seçkisiz kayıp
koşulları altında elde edilen açıklanan varyans oranları yansızdır. Ek olarak
çoklu değer atama tekniği bu koşullarda genel olarak en küçük D2 değerlerini
üretmiştir.
Seçkisiz olmayan kayıp koşulunda, tüm tekniklerin açıklanan varyans
oranı için negatif yanlı sonuçlar verdiği göz önüne alındığında, bu koşul
altında daha küçük D2 değerleri üreten beklenti – maksimizasyon algoritması
öne çıkmaktadır.
Örneklem büyüklüğünün 500 ve madde sayısının 15 olduğu durumda
elde edilen D2 değerlerine ait betimsel istatistikler Çizelge 30’da verilmiştir.
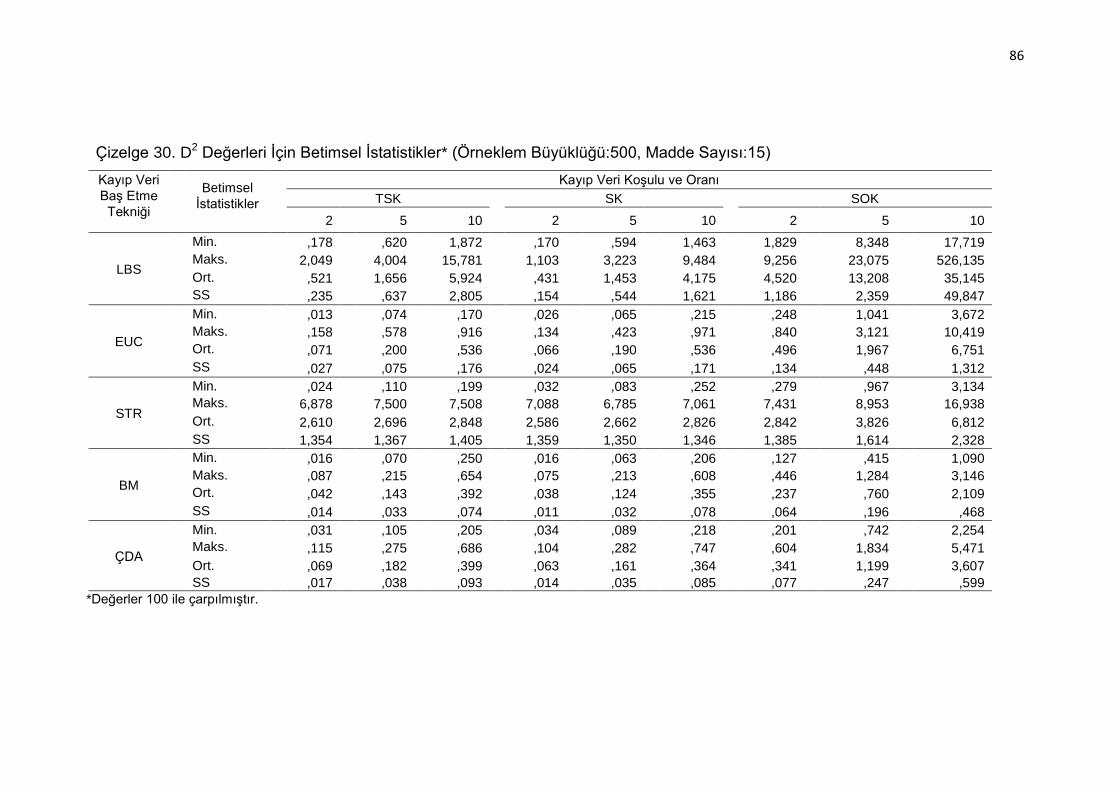
86
Çizelge 30. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:500, Madde Sayısı:15)
Kayıp Veri
Baş Etme
Tekniği
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
Min. ,178 ,620 1,872 ,170 ,594 1,463 1,829 8,348 17,719
Maks. 2,049 4,004 15,781 1,103 3,223 9,484 9,256 23,075 526,135
Ort. ,521 1,656 5,924 ,431 1,453 4,175 4,520 13,208 35,145
SS ,235 ,637 2,805 ,154 ,544 1,621 1,186 2,359 49,847
EUC
Min. ,013 ,074 ,170 ,026 ,065 ,215 ,248 1,041 3,672
Maks. ,158 ,578 ,916 ,134 ,423 ,971 ,840 3,121 10,419
Ort. ,071 ,200 ,536 ,066 ,190 ,536 ,496 1,967 6,751
SS ,027 ,075 ,176 ,024 ,065 ,171 ,134 ,448 1,312
STR
Min. ,024 ,110 ,199 ,032 ,083 ,252 ,279 ,967 3,134
Maks. 6,878 7,500 7,508 7,088 6,785 7,061 7,431 8,953 16,938
Ort. 2,610 2,696 2,848 2,586 2,662 2,826 2,842 3,826 6,812
SS 1,354 1,367 1,405 1,359 1,350 1,346 1,385 1,614 2,328
BM
Min. ,016 ,070 ,250 ,016 ,063 ,206 ,127 ,415 1,090
Maks. ,087 ,215 ,654 ,075 ,213 ,608 ,446 1,284 3,146
Ort. ,042 ,143 ,392 ,038 ,124 ,355 ,237 ,760 2,109
SS ,014 ,033 ,074 ,011 ,032 ,078 ,064 ,196 ,468
ÇDA
Min. ,031 ,105 ,205 ,034 ,089 ,218 ,201 ,742 2,254
Maks. ,115 ,275 ,686 ,104 ,282 ,747 ,604 1,834 5,471
Ort. ,069 ,182 ,399 ,063 ,161 ,364 ,341 1,199 3,607
SS ,017 ,038 ,093 ,014 ,035 ,085 ,077 ,247 ,599
*Değerler 100 ile çarpılmıştır.

87
Çizelge 30 incelendiğinde, tüm durumlar için en küçük D2 değerlerinin
beklenti – maksimizasyon algoritmasıyla elde edildiği görülmektedir. Beklenti
– maksimizasyon algoritmasının diğer tekniklere göre daha yüksek
performans gösterdiği yönündeki bu bulgu Bernaards ve Sijtsma (1999,
2000)’nın ulaştıkları bulgularla örtüşmektedir. Çoklu değer atama ve Öklid
uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama teknikleriyle elde
edilen D2 değerlerinin de beklenti – maksimizasyon algoritmasına büyük
ölçüde yakın olduğu görülmektedir. Her bir kayıp veri baş etme tekniği için D2
değerleri, kayıp veri oranına paralel olarak artış göstermiştir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında, stokastik
regresyonla değer atama tekniğine göre genel olarak daha iyi sonuçlar veren
liste bazında silme tekniği, seçkisiz olmayan kayıp koşulu altında en büyük D2
değerlerini üretmiştir.
Seçkisiz olmayan kayıp koşulu altında ve özellikle %10 kayıp veri
oranında liste bazında silme tekniği ile elde edilen D2 değerinin oldukça
yüksek olduğu görülmektedir. İlgili koşulda yüksek D2 değerinin elde edildiği
veri setleri incelenmiş ve eksiksiz veri setleri için geçerli olan faktör yapısının
bozulduğu görülmüştür.
Çizelge 26’da verilen açıklanan varyans oranı ve Çizelge 30’da verilen
D2 bulguları birlikte değerlendirildiğinde, liste bazında silme ve stokastik
regresyonla değer atama tekniklerinin tümüyle seçkisiz kayıp ve seçkisiz
kayıp koşullarında açıklanan varyans oranı için yansız kestirimler
sağlamalarına rağmen diğer tewkniklere göre daha yüksek D2 değerleri
ürettikleri görülmektedir. Açıklanan varyans oranı için negatif yanlılık gösteren
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniği ile
pozitif yanlılık gösteren beklenti – maksimizasyon algoritması ile elde edilen
D2 değerlerinin ise göreceli olarak daha küçük olduğu görülmektedir. Çoklu
değer atama tekniği, bu koşullar altında kayıp veri oranının %10’dan düşük
olduğu durumlarda yansız kestirimler sağlaması ve beklenti – maksimizasyon
algoritmasına oldukça yakın D2 değerleri üretmesi açısından bir kez daha öne
çıkmaktadır.
Tüm tekniklerin açıklanan varyans oranı için negatif yanlı sonuçlar
verdiği ve tüm kayıp veri oranlarında en küçük D2 değerlerinin beklenti –
maksimizasyon algoritması ile elde edildiği göz önüne alınırsa, seçkisiz

88
olmayan kayıp koşulu altında en yüksek performansı beklenti –
maksimizasyon algoritmasının verdiği görülmektedir.
Örneklem büyüklüğünün 1000 ve madde sayısının 10 olduğu durumda
elde edilen D2 değerlerine ait betimsel istatistikler Çizelge 31’de verilmiştir.
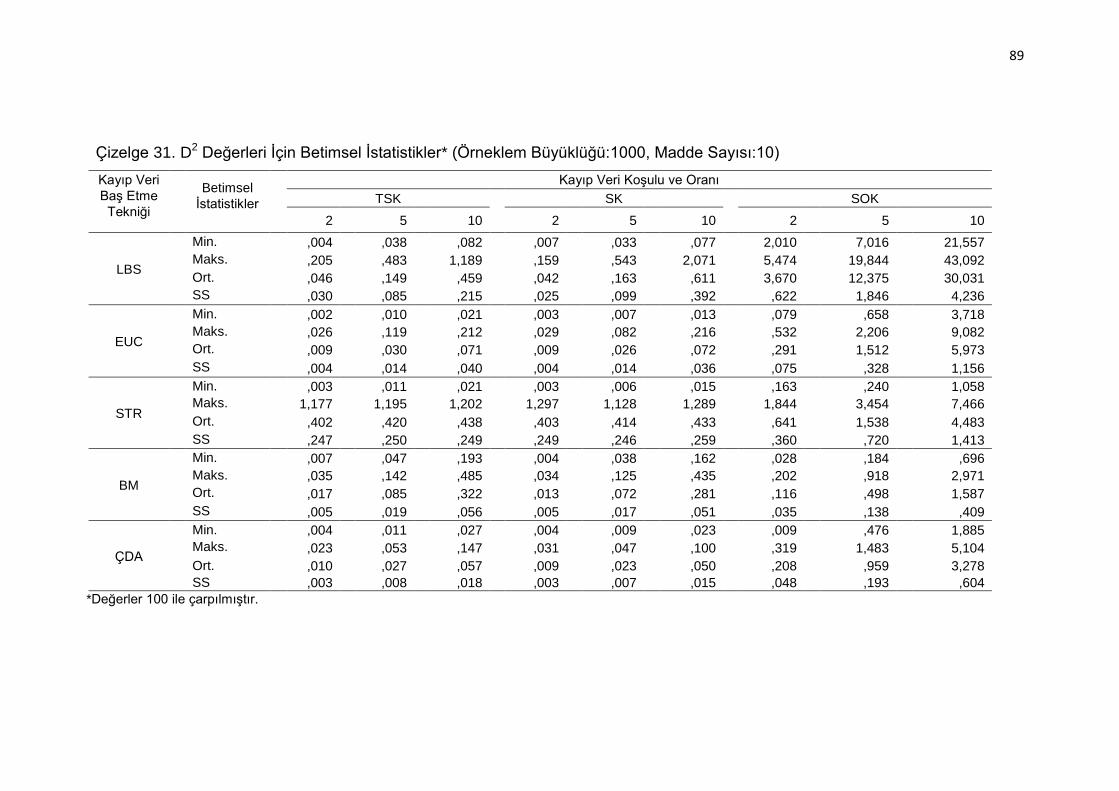
89
Çizelge 31. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:1000, Madde Sayısı:10)
Kayıp Veri
Baş Etme
Tekniği
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
Min. ,004 ,038 ,082 ,007 ,033 ,077 2,010 7,016 21,557
Maks. ,205 ,483 1,189 ,159 ,543 2,071 5,474 19,844 43,092
Ort. ,046 ,149 ,459 ,042 ,163 ,611 3,670 12,375 30,031
SS ,030 ,085 ,215 ,025 ,099 ,392 ,622 1,846 4,236
EUC
Min. ,002 ,010 ,021 ,003 ,007 ,013 ,079 ,658 3,718
Maks. ,026 ,119 ,212 ,029 ,082 ,216 ,532 2,206 9,082
Ort. ,009 ,030 ,071 ,009 ,026 ,072 ,291 1,512 5,973
SS ,004 ,014 ,040 ,004 ,014 ,036 ,075 ,328 1,156
STR
Min. ,003 ,011 ,021 ,003 ,006 ,015 ,163 ,240 1,058
Maks. 1,177 1,195 1,202 1,297 1,128 1,289 1,844 3,454 7,466
Ort. ,402 ,420 ,438 ,403 ,414 ,433 ,641 1,538 4,483
SS ,247 ,250 ,249 ,249 ,246 ,259 ,360 ,720 1,413
BM
Min. ,007 ,047 ,193 ,004 ,038 ,162 ,028 ,184 ,696
Maks. ,035 ,142 ,485 ,034 ,125 ,435 ,202 ,918 2,971
Ort. ,017 ,085 ,322 ,013 ,072 ,281 ,116 ,498 1,587
SS ,005 ,019 ,056 ,005 ,017 ,051 ,035 ,138 ,409
ÇDA
Min. ,004 ,011 ,027 ,004 ,009 ,023 ,009 ,476 1,885
Maks. ,023 ,053 ,147 ,031 ,047 ,100 ,319 1,483 5,104
Ort. ,010 ,027 ,057 ,009 ,023 ,050 ,208 ,959 3,278
SS ,003 ,008 ,018 ,003 ,007 ,015 ,048 ,193 ,604
*Değerler 100 ile çarpılmıştır.

90
Çizelge 31 incelendiğinde genel olarak Öklid uzaklığı üzerinden benzer
tepki örüntüsüne dayalı atama, beklenti – maksimizasyon algoritması ve çoklu
değer atama tekniklerinin en yüksek performansı sergiledikleri görülmektedir.
Her bir kayıp veri baş etme tekniği için D2 değerleri, kayıp veri oranına paralel
olarak artış göstermiştir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında stokastik
regresyonla değer atama tekniğine göre daha iyi sonuçlar veren liste bazında
silme tekniği, seçkisiz olmayan kayıp koşulunda tüm kayıp veri oranları için en
büyük D2 değerlerini üretmiştir.
Çizelge 26’da verilen açıklanan varyans oranlarının yanlılığı ve Çizelge
31’de verilen D2 istatistiği bulguları birlikte değerlendirildiğinde, tümüyle
seçkisiz kayıp koşulu altında varyans oranı için yansız kestirimlerin elde
edildiği liste bazında silme ve stokastik regresyonla değer atama tekniklerinin
daha yüksek D2 değerleri ürettiği görülmektedir. Göreceli olarak küçük
sayılabilecek D2 değerlerinin elde edildiği Öklid uzaklığı üzerinden benzer
tepki örüntüsüne dayalı atama tekniğinin ise açıklanan varyans oranları
üzerinde negatif yanlılığı söz konusudur. Beklenti – maksimizasyon
algoritması ise açıklanan varyans oranları üzerinde pozitif yanlıdır. Bu
teknikler ile seçkisiz kayıp koşulu altında elde edilen bulgular, tümüyle
seçkisiz kayıp koşulunda elde edilenlere büyük ölçüde benzerlik
göstermektedir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında hem varyans
oranı kestirimlerinde yansız olduğu görülen hem de en küçük D2 değerlerinin
gözlendiği çoklu değer atama tekniği öne çıkmaktadır.
Tüm tekniklerin açıklanan varyans oranı için negatif yanlı sonuçlar
verdiği ve tüm kayıp veri oranlarında en küçük D2 değerlerinin beklenti –
maksimizasyon algoritması ile elde edildiği göz önüne alınırsa, seçkisiz
olmayan kayıp koşulu altında en yüksek performansı beklenti –
maksimizasyon algoritmasının sergilediği görülmektedir.
Bir faktörlü modeller için farklı örneklem büyüklüklerinde elde edilen
bulguların (Çizelge 27, Çizelge 29, Çizelge 31) büyük ölçüde benzer olduğu
görülmektedir. Bu bulgular, Bernaards ve Sijtsma (1999, 2000)’nın, küçük ve
büyük örneklemler için ulaştığı sonuçlarla örtüşmektedir. Her iki araştırmada

91
da örneklem büyüklüğünün artmasıyla birlikte D2 değerlerinin kendi içinde
düşüş gösterdiği yönündeki bulgular, bu araştırmayla da desteklenmiştir.
Örneklem büyüklüğünün 1000 ve madde sayısının 10 olduğu durumda
elde edilen D2 değerlerine ait betimsel istatistikler Çizelge 32’de verilmiştir.
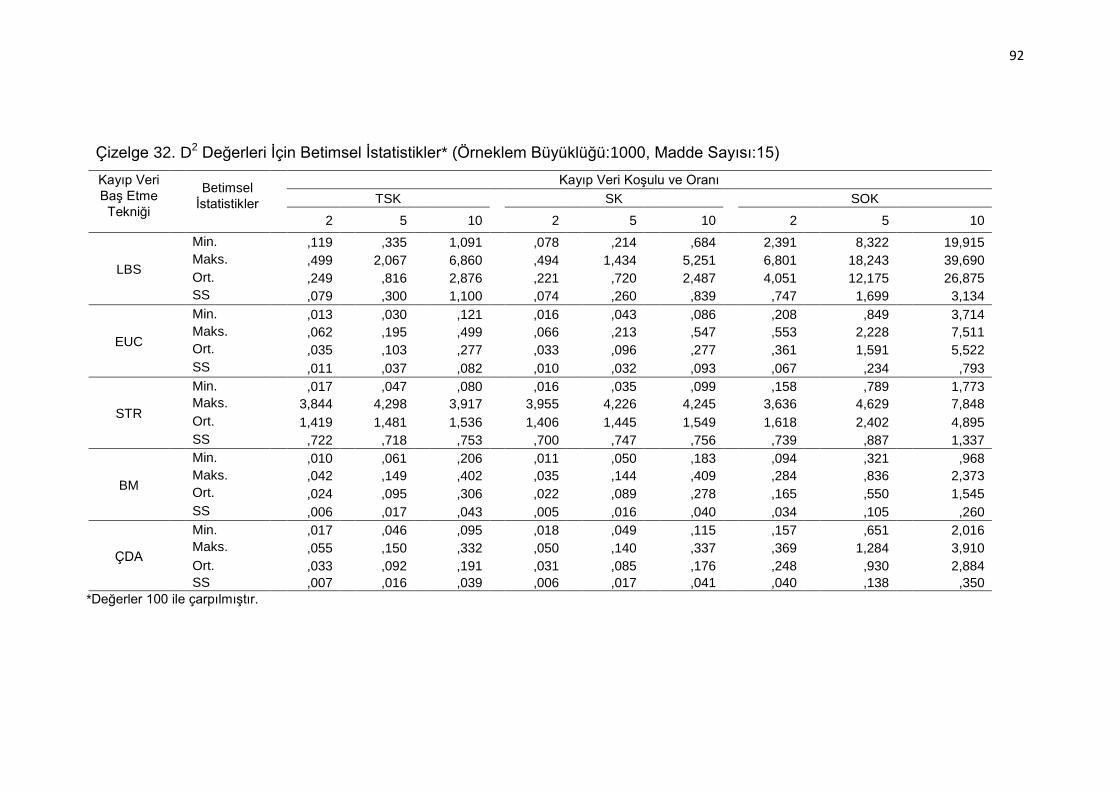
92
Çizelge 32. D2 Değerleri İçin Betimsel İstatistikler* (Örneklem Büyüklüğü:1000, Madde Sayısı:15)
Kayıp Veri
Baş Etme
Tekniği
Betimsel
İstatistikler
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
Min. ,119 ,335 1,091 ,078 ,214 ,684 2,391 8,322 19,915
Maks. ,499 2,067 6,860 ,494 1,434 5,251 6,801 18,243 39,690
Ort. ,249 ,816 2,876 ,221 ,720 2,487 4,051 12,175 26,875
SS ,079 ,300 1,100 ,074 ,260 ,839 ,747 1,699 3,134
EUC
Min. ,013 ,030 ,121 ,016 ,043 ,086 ,208 ,849 3,714
Maks. ,062 ,195 ,499 ,066 ,213 ,547 ,553 2,228 7,511
Ort. ,035 ,103 ,277 ,033 ,096 ,277 ,361 1,591 5,522
SS ,011 ,037 ,082 ,010 ,032 ,093 ,067 ,234 ,793
STR
Min. ,017 ,047 ,080 ,016 ,035 ,099 ,158 ,789 1,773
Maks. 3,844 4,298 3,917 3,955 4,226 4,245 3,636 4,629 7,848
Ort. 1,419 1,481 1,536 1,406 1,445 1,549 1,618 2,402 4,895
SS ,722 ,718 ,753 ,700 ,747 ,756 ,739 ,887 1,337
BM
Min. ,010 ,061 ,206 ,011 ,050 ,183 ,094 ,321 ,968
Maks. ,042 ,149 ,402 ,035 ,144 ,409 ,284 ,836 2,373
Ort. ,024 ,095 ,306 ,022 ,089 ,278 ,165 ,550 1,545
SS ,006 ,017 ,043 ,005 ,016 ,040 ,034 ,105 ,260
ÇDA
Min. ,017 ,046 ,095 ,018 ,049 ,115 ,157 ,651 2,016
Maks. ,055 ,150 ,332 ,050 ,140 ,337 ,369 1,284 3,910
Ort. ,033 ,092 ,191 ,031 ,085 ,176 ,248 ,930 2,884
SS ,007 ,016 ,039 ,006 ,017 ,041 ,040 ,138 ,350
*Değerler 100 ile çarpılmıştır.

93
Çizelge 32 incelendiğinde, en küçük D2 değerlerinin beklenti –
maksimizasyon algoritması ve çoklu değer atama teknikleriyle elde edildiği
görülmektedir. Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama
tekniğinin de bu tekniklere oldukça yakın D2 değerleri ürettiği de
görülmektedir. Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları için en
büyük değerler stokastik regresyonla değer atama tekniğiyle, seçkisiz
olmayan kayıp koşulu için en büyük değerler ise liste bazında silme tekniğiyle
elde edilmiştir. Her bir kayıp veri baş etme tekniği için D2 değerleri, kayıp veri
oranına paralel olarak artış göstermiştir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşulları altında, stokastik
regresyonla değer atama tekniğine göre genel olarak daha iyi sonuçlar veren
liste bazında silme tekniği, seçkisiz olmayan kayıp koşulu altında en büyük D2
değerlerini üretmiştir.
Çizelge 26’da verilen açıklanan varyans oranı ve Çizelge 32’de verilen
D2 bulguları birlikte değerlendirildiğinde, tümüyle seçkisiz kayıp koşulu altında
açıklanan varyans oranı için yansız kestirimler sağlayan liste bazında silme ve
stokastik regresyonla değer atama tekniklerinin göreceli olarak en büyük D2
değerlerini ürettiği görülmektedir. Küçük sayılabilecek D2 değerlerinin elde
edildiği Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama
tekniğinin açıklanan varyans oranları üzerinde negatif; beklenti –
maksimizasyon algoritmasının ise pozitif yanlılığı söz konusudur. Tümüyle
seçkisiz kayıp koşulu altında, açıklanan varyans oranı için yansız sonuçlar
sağlayan ve genel olarak en küçük D2 değerlerini üreten çoklu değer atama
tekniği öne çıkmaktadır.
Seçkisiz kayıp koşulu altında elde edilen sonuçlar, liste bazında silme
tekniğinin açıklanan varyans oranı için negatif yanlılık göstermeye eğilim
göstermesi haricinde, tümüyle seçkisiz kayıp koşulunda elde edilen sonuçlara
büyük ölçüde benzerdir. Seçkisiz kayıp koşulu altında çoklu değer atama
tekniğinin diğer tekniklere göre daha yüksek performans gösterdiği
görülmektedir.
Tüm tekniklerin açıklanan varyans oranı için negatif yanlı sonuçlar
verdiği ve tüm kayıp veri oranlarında en küçük D2 değerlerinin beklenti –
maksimizasyon algoritması ile elde edildiği göz önüne alınırsa, seçkisiz

94
olmayan kayıp koşulu altında en yüksek performansı beklenti –
maksimizasyon algoritmasının verdiği görülmektedir.
İki faktörlü modeller için farklı örneklem büyüklüklerinden elde edilen
bulgular (Çizelge 28, Çizelge 30, Çizelge 32) incelendiğinde, genel olarak en
yüksek performansı beklenti – maksimizasyon algoritmasının ve çoklu değer
atama tekniğinin sergilediği görülmektedir.

95
c. Doğrulayıcı Faktör Analizine İlişkin Bulgular
Araştırmanın üçüncü alt amacı olan liste bazında silme, Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama, stokastik regresyonla değer
atama, beklenti – maksimizasyon algoritması ve çoklu değer atama teknikleri
ile elde edilen veri setleri ile eksiksiz veri setlerinde öngörülen faktör yapısının
doğrulanıp doğrulanmadığının belirlenmesi için doğrulayıcı faktör analizleri
gerçekleştirilmiştir.
LISREL 8.80 yazılımı, model – veri uyumunun değerlendirilmesinde
kullanılabilecek çok sayıda indeks vermektedir. Doğrulayıcı faktör analizi ile
ilgili olarak bu kısımdaki bulgular 2 / sd , RMSEA, GFI ve CFI indeksleri ile
sınırlandırılmıştır. Model – veri uyumunun bir bütün olarak incelenmesine
imkân sağlaması amacıyla çizelgelerde indekslerin aritmetik ortalamaları
gösterilmiştir. Diğer indekslere ait betimsel istatistikler ekte (Ek 24 - Ek 53)
verilmiştir.
Örneklem büyüklüğünün 250 ve madde sayısının 10 olduğu veri setleri
için elde edilen doğrulayıcı faktör analizi sonuçları Çizelge 33’te verilmiştir.
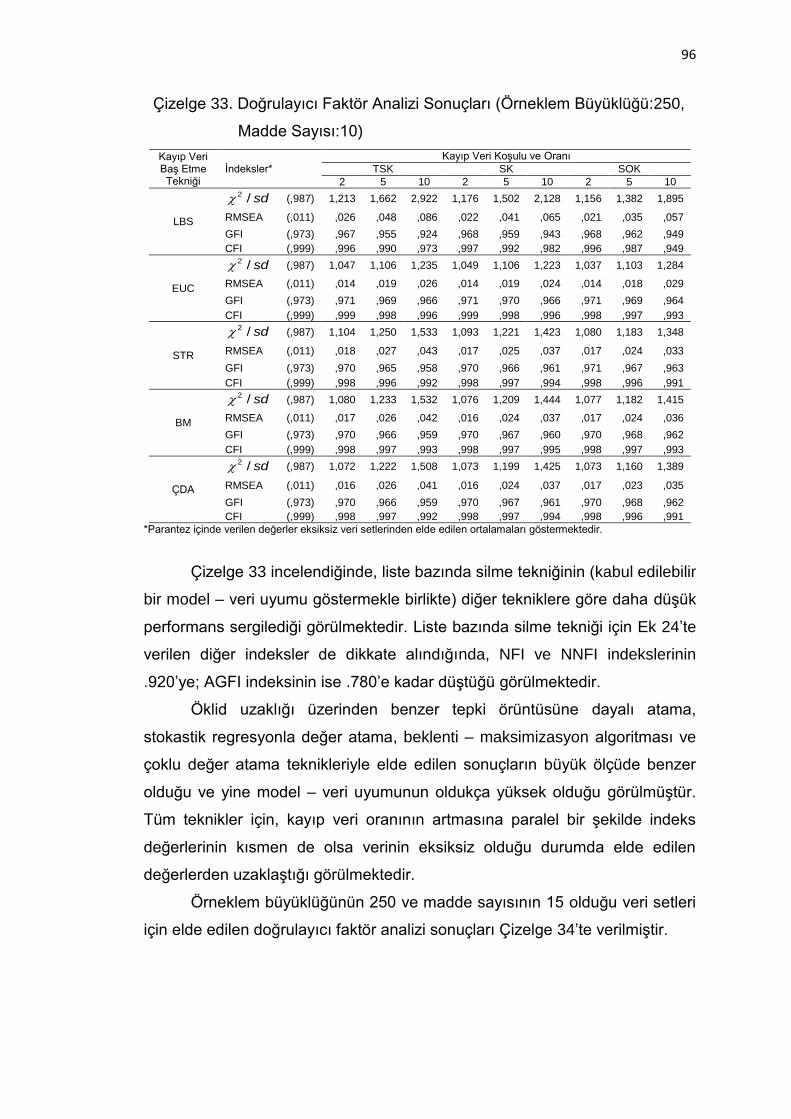
96
Çizelge 33. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:250,
Madde Sayısı:10)
Kayıp Veri Baş Etme Tekniği
İndeksler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
2 / sd (,987) 1,213 1,662 2,922 1,176 1,502 2,128 1,156 1,382 1,895
RMSEA (,011) ,026 ,048 ,086 ,022 ,041 ,065 ,021 ,035 ,057
GFI (,973) ,967 ,955 ,924 ,968 ,959 ,943 ,968 ,962 ,949
CFI (,999) ,996 ,990 ,973 ,997 ,992 ,982 ,996 ,987 ,949
EUC
2 / sd (,987) 1,047 1,106 1,235 1,049 1,106 1,223 1,037 1,103 1,284
RMSEA (,011) ,014 ,019 ,026 ,014 ,019 ,024 ,014 ,018 ,029
GFI (,973) ,971 ,969 ,966 ,971 ,970 ,966 ,971 ,969 ,964
CFI (,999) ,999 ,998 ,996 ,999 ,998 ,996 ,998 ,997 ,993
STR
2 / sd (,987) 1,104 1,250 1,533 1,093 1,221 1,423 1,080 1,183 1,348
RMSEA (,011) ,018 ,027 ,043 ,017 ,025 ,037 ,017 ,024 ,033
GFI (,973) ,970 ,965 ,958 ,970 ,966 ,961 ,971 ,967 ,963
CFI (,999) ,998 ,996 ,992 ,998 ,997 ,994 ,998 ,996 ,991
BM
2 / sd (,987) 1,080 1,233 1,532 1,076 1,209 1,444 1,077 1,182 1,415
RMSEA (,011) ,017 ,026 ,042 ,016 ,024 ,037 ,017 ,024 ,036
GFI (,973) ,970 ,966 ,959 ,970 ,967 ,960 ,970 ,968 ,962
CFI (,999) ,998 ,997 ,993 ,998 ,997 ,995 ,998 ,997 ,993
ÇDA
2 / sd (,987) 1,072 1,222 1,508 1,073 1,199 1,425 1,073 1,160 1,389
RMSEA (,011) ,016 ,026 ,041 ,016 ,024 ,037 ,017 ,023 ,035
GFI (,973) ,970 ,966 ,959 ,970 ,967 ,961 ,970 ,968 ,962
CFI (,999) ,998 ,997 ,992 ,998 ,997 ,994 ,998 ,996 ,991
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilen ortalamaları göstermektedir.
Çizelge 33 incelendiğinde, liste bazında silme tekniğinin (kabul edilebilir
bir model – veri uyumu göstermekle birlikte) diğer tekniklere göre daha düşük
performans sergilediği görülmektedir. Liste bazında silme tekniği için Ek 24’te
verilen diğer indeksler de dikkate alındığında, NFI ve NNFI indekslerinin
.920’ye; AGFI indeksinin ise .780’e kadar düştüğü görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama,
stokastik regresyonla değer atama, beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle elde edilen sonuçların büyük ölçüde benzer
olduğu ve yine model – veri uyumunun oldukça yüksek olduğu görülmüştür.
Tüm teknikler için, kayıp veri oranının artmasına paralel bir şekilde indeks
değerlerinin kısmen de olsa verinin eksiksiz olduğu durumda elde edilen
değerlerden uzaklaştığı görülmektedir.
Örneklem büyüklüğünün 250 ve madde sayısının 15 olduğu veri setleri
için elde edilen doğrulayıcı faktör analizi sonuçları Çizelge 34’te verilmiştir.
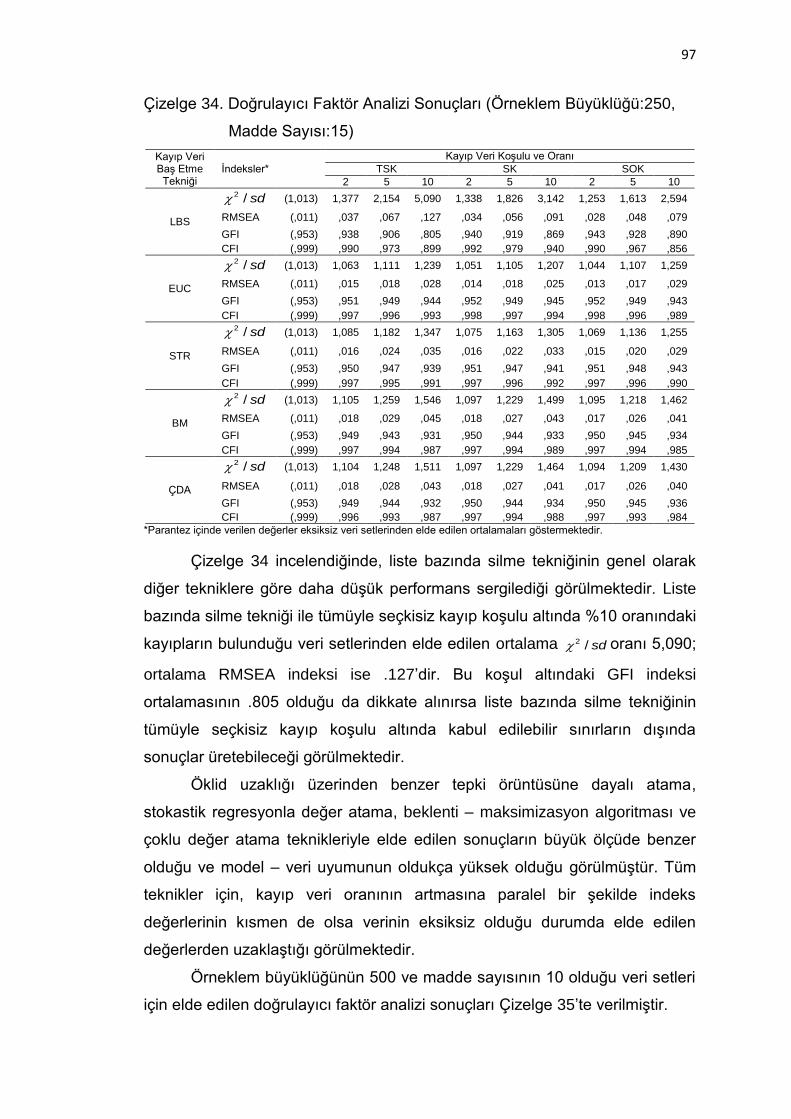
97
Çizelge 34. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:250,
Madde Sayısı:15)
Kayıp Veri Baş Etme Tekniği
İndeksler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
2 / sd (1,013) 1,377 2,154 5,090 1,338 1,826 3,142 1,253 1,613 2,594
RMSEA (,011) ,037 ,067 ,127 ,034 ,056 ,091 ,028 ,048 ,079
GFI (,953) ,938 ,906 ,805 ,940 ,919 ,869 ,943 ,928 ,890
CFI (,999) ,990 ,973 ,899 ,992 ,979 ,940 ,990 ,967 ,856
EUC
2 / sd (1,013) 1,063 1,111 1,239 1,051 1,105 1,207 1,044 1,107 1,259
RMSEA (,011) ,015 ,018 ,028 ,014 ,018 ,025 ,013 ,017 ,029
GFI (,953) ,951 ,949 ,944 ,952 ,949 ,945 ,952 ,949 ,943
CFI (,999) ,997 ,996 ,993 ,998 ,997 ,994 ,998 ,996 ,989
STR
2 / sd (1,013) 1,085 1,182 1,347 1,075 1,163 1,305 1,069 1,136 1,255
RMSEA (,011) ,016 ,024 ,035 ,016 ,022 ,033 ,015 ,020 ,029
GFI (,953) ,950 ,947 ,939 ,951 ,947 ,941 ,951 ,948 ,943
CFI (,999) ,997 ,995 ,991 ,997 ,996 ,992 ,997 ,996 ,990
BM
2 / sd (1,013) 1,105 1,259 1,546 1,097 1,229 1,499 1,095 1,218 1,462
RMSEA (,011) ,018 ,029 ,045 ,018 ,027 ,043 ,017 ,026 ,041
GFI (,953) ,949 ,943 ,931 ,950 ,944 ,933 ,950 ,945 ,934
CFI (,999) ,997 ,994 ,987 ,997 ,994 ,989 ,997 ,994 ,985
ÇDA
2 / sd (1,013) 1,104 1,248 1,511 1,097 1,229 1,464 1,094 1,209 1,430
RMSEA (,011) ,018 ,028 ,043 ,018 ,027 ,041 ,017 ,026 ,040
GFI (,953) ,949 ,944 ,932 ,950 ,944 ,934 ,950 ,945 ,936
CFI (,999) ,996 ,993 ,987 ,997 ,994 ,988 ,997 ,993 ,984
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilen ortalamaları göstermektedir.
Çizelge 34 incelendiğinde, liste bazında silme tekniğinin genel olarak
diğer tekniklere göre daha düşük performans sergilediği görülmektedir. Liste
bazında silme tekniği ile tümüyle seçkisiz kayıp koşulu altında %10 oranındaki
kayıpların bulunduğu veri setlerinden elde edilen ortalama 2 / sd oranı 5,090;
ortalama RMSEA indeksi ise .127’dir. Bu koşul altındaki GFI indeksi
ortalamasının .805 olduğu da dikkate alınırsa liste bazında silme tekniğinin
tümüyle seçkisiz kayıp koşulu altında kabul edilebilir sınırların dışında
sonuçlar üretebileceği görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama,
stokastik regresyonla değer atama, beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle elde edilen sonuçların büyük ölçüde benzer
olduğu ve model – veri uyumunun oldukça yüksek olduğu görülmüştür. Tüm
teknikler için, kayıp veri oranının artmasına paralel bir şekilde indeks
değerlerinin kısmen de olsa verinin eksiksiz olduğu durumda elde edilen
değerlerden uzaklaştığı görülmektedir.
Örneklem büyüklüğünün 500 ve madde sayısının 10 olduğu veri setleri
için elde edilen doğrulayıcı faktör analizi sonuçları Çizelge 35’te verilmiştir.
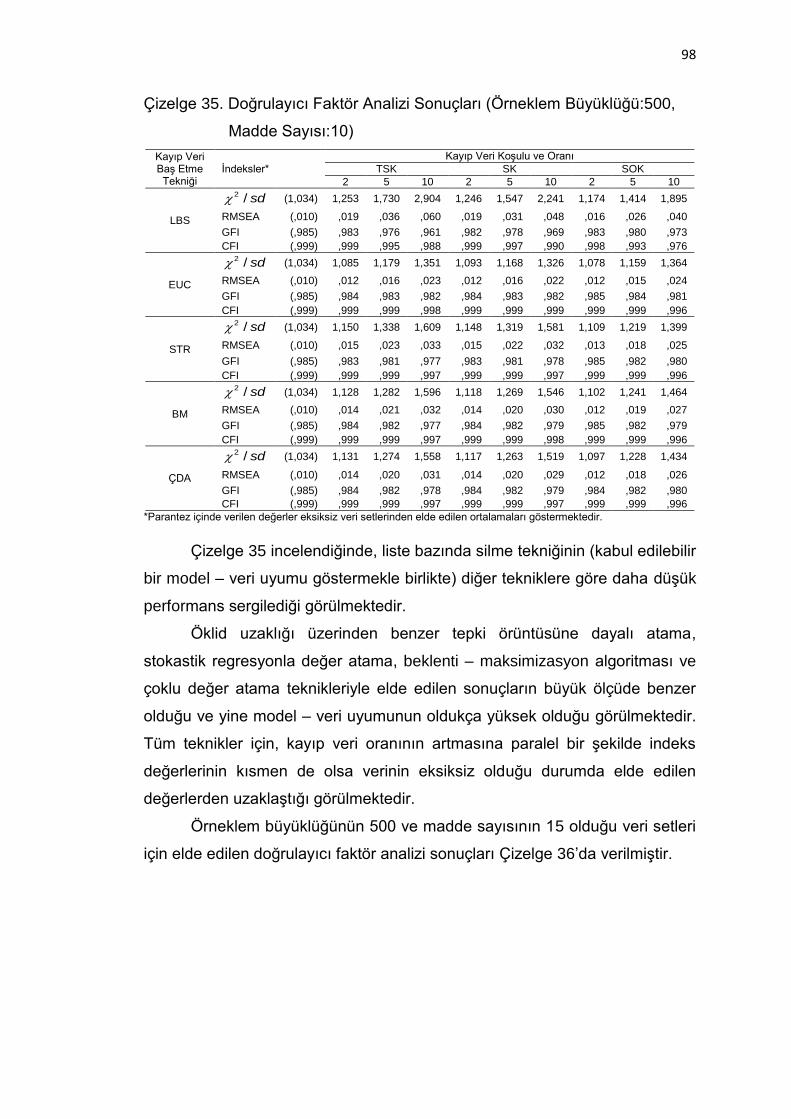
98
Çizelge 35. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:500,
Madde Sayısı:10)
Kayıp Veri Baş Etme Tekniği
İndeksler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
2 / sd (1,034) 1,253 1,730 2,904 1,246 1,547 2,241 1,174 1,414 1,895
RMSEA (,010) ,019 ,036 ,060 ,019 ,031 ,048 ,016 ,026 ,040
GFI (,985) ,983 ,976 ,961 ,982 ,978 ,969 ,983 ,980 ,973
CFI (,999) ,999 ,995 ,988 ,999 ,997 ,990 ,998 ,993 ,976
EUC
2 / sd (1,034) 1,085 1,179 1,351 1,093 1,168 1,326 1,078 1,159 1,364
RMSEA (,010) ,012 ,016 ,023 ,012 ,016 ,022 ,012 ,015 ,024
GFI (,985) ,984 ,983 ,982 ,984 ,983 ,982 ,985 ,984 ,981
CFI (,999) ,999 ,999 ,998 ,999 ,999 ,999 ,999 ,999 ,996
STR
2 / sd (1,034) 1,150 1,338 1,609 1,148 1,319 1,581 1,109 1,219 1,399
RMSEA (,010) ,015 ,023 ,033 ,015 ,022 ,032 ,013 ,018 ,025
GFI (,985) ,983 ,981 ,977 ,983 ,981 ,978 ,985 ,982 ,980
CFI (,999) ,999 ,999 ,997 ,999 ,999 ,997 ,999 ,999 ,996
BM
2 / sd (1,034) 1,128 1,282 1,596 1,118 1,269 1,546 1,102 1,241 1,464
RMSEA (,010) ,014 ,021 ,032 ,014 ,020 ,030 ,012 ,019 ,027
GFI (,985) ,984 ,982 ,977 ,984 ,982 ,979 ,985 ,982 ,979
CFI (,999) ,999 ,999 ,997 ,999 ,999 ,998 ,999 ,999 ,996
ÇDA
2 / sd (1,034) 1,131 1,274 1,558 1,117 1,263 1,519 1,097 1,228 1,434
RMSEA (,010) ,014 ,020 ,031 ,014 ,020 ,029 ,012 ,018 ,026
GFI (,985) ,984 ,982 ,978 ,984 ,982 ,979 ,984 ,982 ,980
CFI (,999) ,999 ,999 ,997 ,999 ,999 ,997 ,999 ,999 ,996
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilen ortalamaları göstermektedir.
Çizelge 35 incelendiğinde, liste bazında silme tekniğinin (kabul edilebilir
bir model – veri uyumu göstermekle birlikte) diğer tekniklere göre daha düşük
performans sergilediği görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama,
stokastik regresyonla değer atama, beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle elde edilen sonuçların büyük ölçüde benzer
olduğu ve yine model – veri uyumunun oldukça yüksek olduğu görülmektedir.
Tüm teknikler için, kayıp veri oranının artmasına paralel bir şekilde indeks
değerlerinin kısmen de olsa verinin eksiksiz olduğu durumda elde edilen
değerlerden uzaklaştığı görülmektedir.
Örneklem büyüklüğünün 500 ve madde sayısının 15 olduğu veri setleri
için elde edilen doğrulayıcı faktör analizi sonuçları Çizelge 36’da verilmiştir.
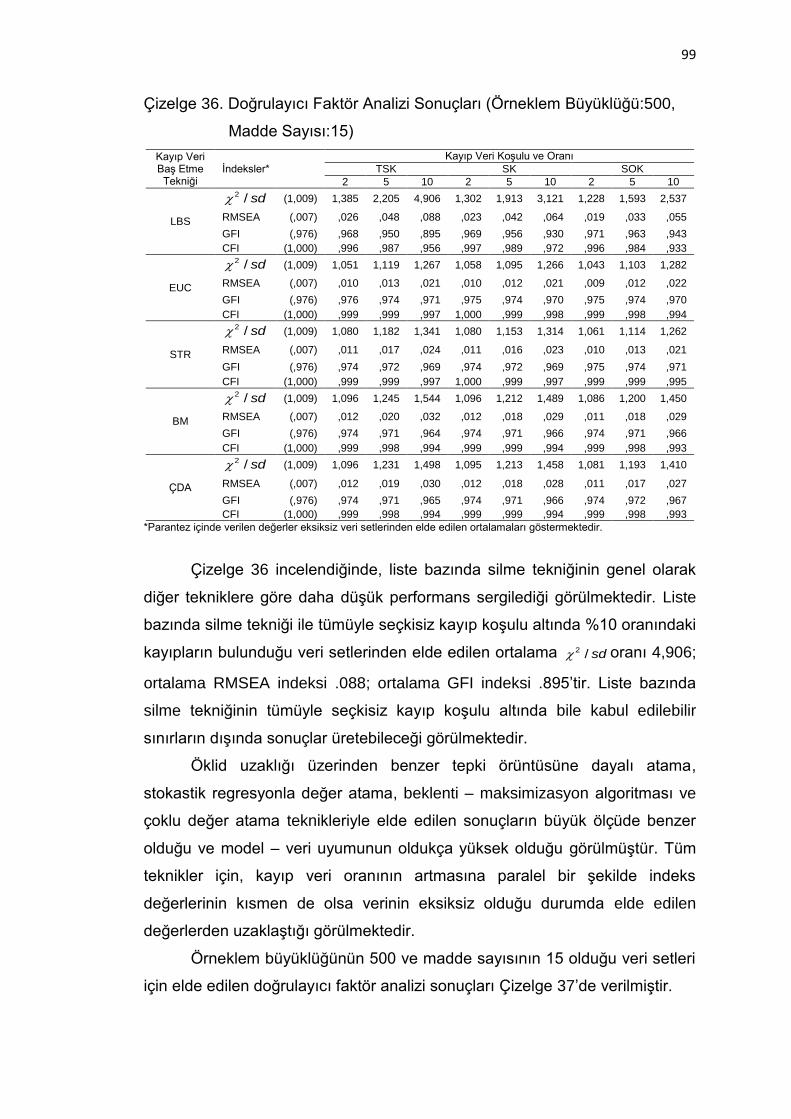
99
Çizelge 36. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:500,
Madde Sayısı:15)
Kayıp Veri Baş Etme Tekniği
İndeksler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
2 / sd (1,009) 1,385 2,205 4,906 1,302 1,913 3,121 1,228 1,593 2,537
RMSEA (,007) ,026 ,048 ,088 ,023 ,042 ,064 ,019 ,033 ,055
GFI (,976) ,968 ,950 ,895 ,969 ,956 ,930 ,971 ,963 ,943
CFI (1,000) ,996 ,987 ,956 ,997 ,989 ,972 ,996 ,984 ,933
EUC
2 / sd (1,009) 1,051 1,119 1,267 1,058 1,095 1,266 1,043 1,103 1,282
RMSEA (,007) ,010 ,013 ,021 ,010 ,012 ,021 ,009 ,012 ,022
GFI (,976) ,976 ,974 ,971 ,975 ,974 ,970 ,975 ,974 ,970
CFI (1,000) ,999 ,999 ,997 1,000 ,999 ,998 ,999 ,998 ,994
STR
2 / sd (1,009) 1,080 1,182 1,341 1,080 1,153 1,314 1,061 1,114 1,262
RMSEA (,007) ,011 ,017 ,024 ,011 ,016 ,023 ,010 ,013 ,021
GFI (,976) ,974 ,972 ,969 ,974 ,972 ,969 ,975 ,974 ,971
CFI (1,000) ,999 ,999 ,997 1,000 ,999 ,997 ,999 ,999 ,995
BM
2 / sd (1,009) 1,096 1,245 1,544 1,096 1,212 1,489 1,086 1,200 1,450
RMSEA (,007) ,012 ,020 ,032 ,012 ,018 ,029 ,011 ,018 ,029
GFI (,976) ,974 ,971 ,964 ,974 ,971 ,966 ,974 ,971 ,966
CFI (1,000) ,999 ,998 ,994 ,999 ,999 ,994 ,999 ,998 ,993
ÇDA
2 / sd (1,009) 1,096 1,231 1,498 1,095 1,213 1,458 1,081 1,193 1,410
RMSEA (,007) ,012 ,019 ,030 ,012 ,018 ,028 ,011 ,017 ,027
GFI (,976) ,974 ,971 ,965 ,974 ,971 ,966 ,974 ,972 ,967
CFI (1,000) ,999 ,998 ,994 ,999 ,999 ,994 ,999 ,998 ,993
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilen ortalamaları göstermektedir.
Çizelge 36 incelendiğinde, liste bazında silme tekniğinin genel olarak
diğer tekniklere göre daha düşük performans sergilediği görülmektedir. Liste
bazında silme tekniği ile tümüyle seçkisiz kayıp koşulu altında %10 oranındaki
kayıpların bulunduğu veri setlerinden elde edilen ortalama 2 / sd oranı 4,906;
ortalama RMSEA indeksi .088; ortalama GFI indeksi .895’tir. Liste bazında
silme tekniğinin tümüyle seçkisiz kayıp koşulu altında bile kabul edilebilir
sınırların dışında sonuçlar üretebileceği görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama,
stokastik regresyonla değer atama, beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle elde edilen sonuçların büyük ölçüde benzer
olduğu ve model – veri uyumunun oldukça yüksek olduğu görülmüştür. Tüm
teknikler için, kayıp veri oranının artmasına paralel bir şekilde indeks
değerlerinin kısmen de olsa verinin eksiksiz olduğu durumda elde edilen
değerlerden uzaklaştığı görülmektedir.
Örneklem büyüklüğünün 500 ve madde sayısının 15 olduğu veri setleri
için elde edilen doğrulayıcı faktör analizi sonuçları Çizelge 37’de verilmiştir.
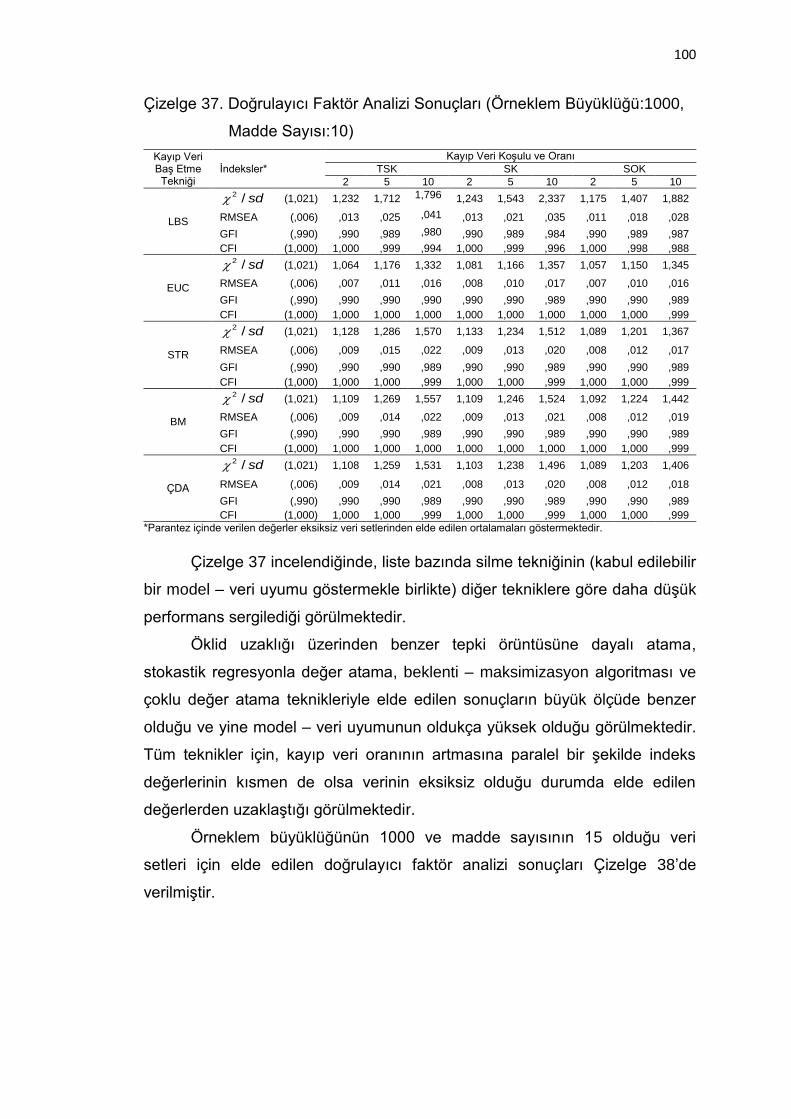
100
Çizelge 37. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:1000,
Madde Sayısı:10)
Kayıp Veri Baş Etme Tekniği
İndeksler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
2 / sd (1,021) 1,232 1,712 1,796 1,243 1,543 2,337 1,175 1,407 1,882
RMSEA (,006) ,013 ,025 ,041 ,013 ,021 ,035 ,011 ,018 ,028
GFI (,990) ,990 ,989 ,980 ,990 ,989 ,984 ,990 ,989 ,987
CFI (1,000) 1,000 ,999 ,994 1,000 ,999 ,996 1,000 ,998 ,988
EUC
2 / sd (1,021) 1,064 1,176 1,332 1,081 1,166 1,357 1,057 1,150 1,345
RMSEA (,006) ,007 ,011 ,016 ,008 ,010 ,017 ,007 ,010 ,016
GFI (,990) ,990 ,990 ,990 ,990 ,990 ,989 ,990 ,990 ,989
CFI (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,999
STR
2 / sd (1,021) 1,128 1,286 1,570 1,133 1,234 1,512 1,089 1,201 1,367
RMSEA (,006) ,009 ,015 ,022 ,009 ,013 ,020 ,008 ,012 ,017
GFI (,990) ,990 ,990 ,989 ,990 ,990 ,989 ,990 ,990 ,989
CFI (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,999
BM
2 / sd (1,021) 1,109 1,269 1,557 1,109 1,246 1,524 1,092 1,224 1,442
RMSEA (,006) ,009 ,014 ,022 ,009 ,013 ,021 ,008 ,012 ,019
GFI (,990) ,990 ,990 ,989 ,990 ,990 ,989 ,990 ,990 ,989
CFI (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,999
ÇDA
2 / sd (1,021) 1,108 1,259 1,531 1,103 1,238 1,496 1,089 1,203 1,406
RMSEA (,006) ,009 ,014 ,021 ,008 ,013 ,020 ,008 ,012 ,018
GFI (,990) ,990 ,990 ,989 ,990 ,990 ,989 ,990 ,990 ,989
CFI (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,999
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilen ortalamaları göstermektedir.
Çizelge 37 incelendiğinde, liste bazında silme tekniğinin (kabul edilebilir
bir model – veri uyumu göstermekle birlikte) diğer tekniklere göre daha düşük
performans sergilediği görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama,
stokastik regresyonla değer atama, beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle elde edilen sonuçların büyük ölçüde benzer
olduğu ve yine model – veri uyumunun oldukça yüksek olduğu görülmektedir.
Tüm teknikler için, kayıp veri oranının artmasına paralel bir şekilde indeks
değerlerinin kısmen de olsa verinin eksiksiz olduğu durumda elde edilen
değerlerden uzaklaştığı görülmektedir.
Örneklem büyüklüğünün 1000 ve madde sayısının 15 olduğu veri
setleri için elde edilen doğrulayıcı faktör analizi sonuçları Çizelge 38’de
verilmiştir.
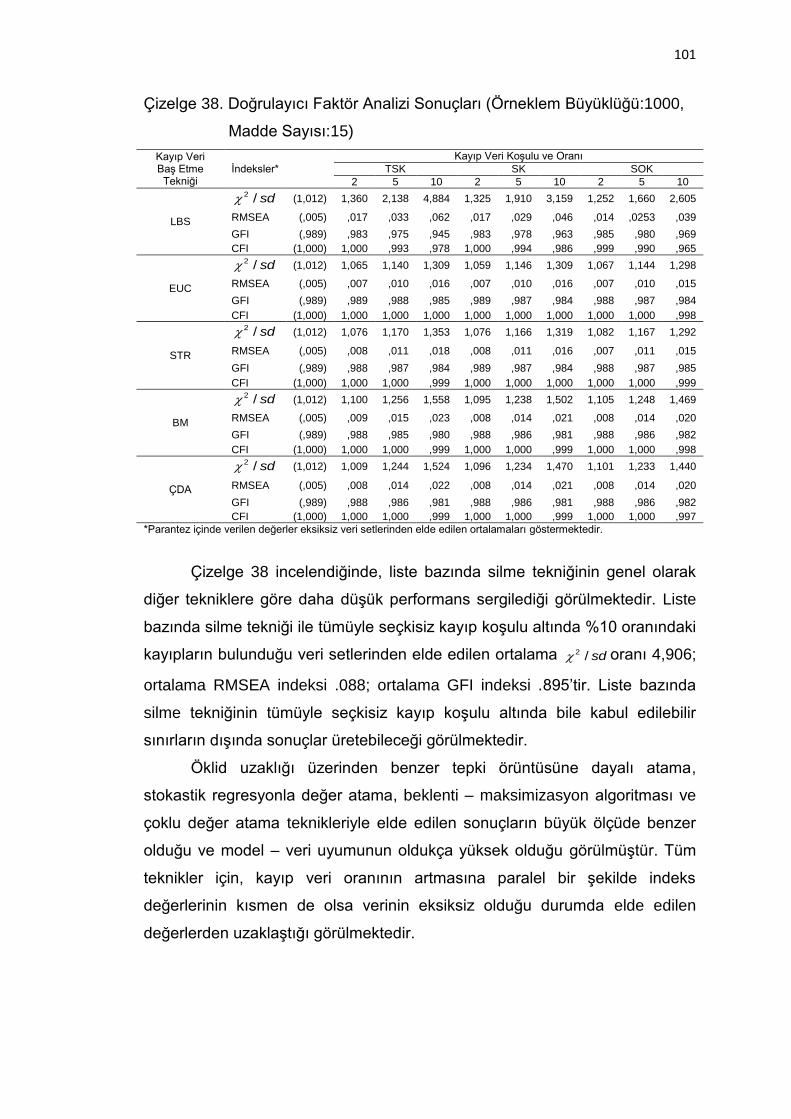
101
Çizelge 38. Doğrulayıcı Faktör Analizi Sonuçları (Örneklem Büyüklüğü:1000,
Madde Sayısı:15)
Kayıp Veri Baş Etme Tekniği
İndeksler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
LBS
2 / sd (1,012) 1,360 2,138 4,884 1,325 1,910 3,159 1,252 1,660 2,605
RMSEA (,005) ,017 ,033 ,062 ,017 ,029 ,046 ,014 ,0253 ,039
GFI (,989) ,983 ,975 ,945 ,983 ,978 ,963 ,985 ,980 ,969
CFI (1,000) 1,000 ,993 ,978 1,000 ,994 ,986 ,999 ,990 ,965
EUC
2 / sd (1,012) 1,065 1,140 1,309 1,059 1,146 1,309 1,067 1,144 1,298
RMSEA (,005) ,007 ,010 ,016 ,007 ,010 ,016 ,007 ,010 ,015
GFI (,989) ,989 ,988 ,985 ,989 ,987 ,984 ,988 ,987 ,984
CFI (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,998
STR
2 / sd (1,012) 1,076 1,170 1,353 1,076 1,166 1,319 1,082 1,167 1,292
RMSEA (,005) ,008 ,011 ,018 ,008 ,011 ,016 ,007 ,011 ,015
GFI (,989) ,988 ,987 ,984 ,989 ,987 ,984 ,988 ,987 ,985
CFI (1,000) 1,000 1,000 ,999 1,000 1,000 1,000 1,000 1,000 ,999
BM
2 / sd (1,012) 1,100 1,256 1,558 1,095 1,238 1,502 1,105 1,248 1,469
RMSEA (,005) ,009 ,015 ,023 ,008 ,014 ,021 ,008 ,014 ,020
GFI (,989) ,988 ,985 ,980 ,988 ,986 ,981 ,988 ,986 ,982
CFI (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,998
ÇDA
2 / sd (1,012) 1,009 1,244 1,524 1,096 1,234 1,470 1,101 1,233 1,440
RMSEA (,005) ,008 ,014 ,022 ,008 ,014 ,021 ,008 ,014 ,020
GFI (,989) ,988 ,986 ,981 ,988 ,986 ,981 ,988 ,986 ,982
CFI (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,997
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilen ortalamaları göstermektedir.
Çizelge 38 incelendiğinde, liste bazında silme tekniğinin genel olarak
diğer tekniklere göre daha düşük performans sergilediği görülmektedir. Liste
bazında silme tekniği ile tümüyle seçkisiz kayıp koşulu altında %10 oranındaki
kayıpların bulunduğu veri setlerinden elde edilen ortalama 2 / sd oranı 4,906;
ortalama RMSEA indeksi .088; ortalama GFI indeksi .895’tir. Liste bazında
silme tekniğinin tümüyle seçkisiz kayıp koşulu altında bile kabul edilebilir
sınırların dışında sonuçlar üretebileceği görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama,
stokastik regresyonla değer atama, beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle elde edilen sonuçların büyük ölçüde benzer
olduğu ve model – veri uyumunun oldukça yüksek olduğu görülmüştür. Tüm
teknikler için, kayıp veri oranının artmasına paralel bir şekilde indeks
değerlerinin kısmen de olsa verinin eksiksiz olduğu durumda elde edilen
değerlerden uzaklaştığı görülmektedir.

102
Çizelge 33 - Çizelge 38 genel olarak incelendiğinde liste bazında silme
tekniği haricindeki tekniklerin hemen her koşulda birbirine oldukça yakın
sonuçlar ürettiği görülmektedir.
Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama,
stokastik regresyonla değer atama, beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle tüm koşullar altında elde edilen sonuçlar genel
olarak incelendiğinde, 2 / sd oranının 1,609 ve altında değerler aldığı
görülmektedir. GFI için en küçük değerin .931; CFI için en küçük değerin .984;
RMSEA için ise en büyük değerin .045 olduğu görülmektedir. Bu sonuçlar
Çokluk ve diğerleri (2010) tarafında özetlenen kriterler açısından
değerlendirildiğinde, tüm teknikler için model – veri uyumunun mükemmel
olduğu görülmektedir.
Kayıp veri tekniklerine doğrulayıcı faktör analizi çerçevesinde yer veren
araştırmalar (Marsh, 1998; Enders ve Bandalos, 2001; Chen ve diğ., 2011;
Demir, 2013) incelendiğinde, karşılaştırılan tüm teknikler ile veri – model
uyumuna ilişkin indekslerin genel olarak ideale yakın olduğu görülmektedir.
Uç bir örnek olarak Davey, Savla ve Luo (2005) NFI, TLI ve RMSEA
indekslerinin %95 oranında kayıpların bulunduğu durumlarda bile 1’e çok
yakın değerler alabileceğini göstermişlerdir. Bu noktada, Allison (2001)’ın
hiçbir kayıp veri baş etme tekniğinin diğerlerine göre “iyi” sayılamayacağı
yönündeki ifadesi, farklı kayıp veri tekniklerinin benzer performans
gösterebileceği yönünde bir anlam da kazanmaktadır.
Örneklem büyüklüğü ve madde sayısı değişkenlerinin tüm
kombinasyonları için ekte (Ek 24 - Ek 53) sunulan diğer uyum indeksleri
incelendiğinde, en kötü değerlerin liste bazında silme tekniği ile elde edildiği;
diğer tekniklerle elde edilen değerlerin ise genel olarak iyi / mükemmel uyum
yönünde yorumlanabileceği görülmektedir.
Örneğin, örneklem büyüklüğünün 250, madde sayısının 10 olduğu
durumda liste bazında silme tekniği ile elde edilen NFI indeksi .810’a ve AGFI
indeksi .780’e kadar düşerken (Ek 24), diğer tekniklerle elde edilen en düşük
değerler sırasıyla .930 ve .890’dır. Uç bir örnek olarak, diğer kayıp veri
teknikleri için aynı koşullarda .970’in altına düşmeyen IFI indeksinin .770 ve
.930’un altında düşmeyen NFI indeksinin ise .600’e kadar düştüğü

103
görülmektedir (Ek 29). Liste bazında silme tekniği için elde edilen uyum
indekslerindeki kötüleşmenin, temel bileşenler analizi çerçevesinde D2
istatistiği ile elde edilen faktör yapısının bozulması yönündeki bulgularla tutarlı
olduğu görülmektedir.

104
BÖLÜM V
SONUÇ VE ÖNERİLER
Bu bölümde, araştırmadan elde edilen sonuçlara ve bu sonuçlara
yönelik önerilere yer verilmiştir.
Sonuçlar
Araştırmada, ölçeklerin psikometrik özellikleri farklı kayıp veri
teknikleriyle karşılaştırmalı bir şekilde ele alınmıştır. Örneklem büyüklüğü,
madde (faktör) sayısı, kayıp veri türü ve kayıp veri oranı değişkenleri
manipüle edilmiş ve beş farklı kayıp veri baş etme tekniğinin etkililiği,
ölçeklerin güvenirliğine ve geçerliğine ilişkin nesnel kanıtların sunulmasında
sıklıkla kullanılan teknikler üzerinden incelenmiştir. Ulaşılan bulguların,
araştırma kapsamında yer verilen bağımsız değişkenler ve bu değişkenlerin
düzeyleri kapsamında değerlendirilmesi uygun olacaktır.
Sonuçlar, araştırma sorularına uygun bir şekilde güvenirlik, temel
bileşenler analizi ve doğrulayıcı faktör analizi ana başlıkları altında
sunulmuştur.
Güvenirliğe İlişkin Sonuçlar
Cronbach α katsayısı için ulaşılan sonuçlar bu araştırmada yer verilen
örneklem büyüklüğü ve madde sayısı değişkenleri açısından incelendiğinde,
kestirimlerin büyük ölçüde birbirine benzer olduğu görülmüştür.
Kayıp veri koşulu ve oranı açısından yapılan incelemelerde,
araştırmada yer verilen tekniklerin tamamının seçkisiz olmayan kayıp
koşulunda negatif yanlı kestirimler ürettiği görülmüştür.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında yansız
kestirimlere ulaşmanın mümkün olduğu ve bu durumun genellikle düşük kayıp
veri oranları için geçerli olduğu görülmüştür. Tümüyle seçkisiz kayıp
koşulunda yansız kestirimler üretebilen tekniklerin, seçkisiz kayıp koşulunda
yanlılık gösterebilecekleri görülmüştür.

105
Kayıp veri baş etme tekniği açısından yapılan incelemelerde tümüyle
seçkisiz kayıp ve seçkisiz kayıp koşullarında liste bazında silme, stokastik
regresyonla değer atama ve çoklu değer atama tekniklerinin genel olarak
yansız; Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama
tekniğinin negatif ve beklenti – maksimizasyon algoritmasının ise pozitif
kestirimler ürettiği sonucuna ulaşılmıştır. Stokastik regresyonla değer atama
tekniği ile bu koşullarda elde edilen kestirimlerin tamamı yansız iken, liste
bazında silme tekniğinin seçkisiz kayıp koşulunda ve yüksek oranda kayıp
verininin bulunduğu durumlarda negatif; çoklu değer atama tekniğinin ise
özellikle %10 oranında kayıpların bulunması durumunda pozitif ya da negatif
yanlı olabileceği görülmüştür.
McDonald katsayısı için ulaşılan bulgular incelendiğinde, seçkisiz
olmayan kayıp koşulu altındaki kestirimlerin Cronbach α katsayısı için ulaşılan
bulgulara benzer şekilde negatif yanlı olduğu görülmüştür. Seçkisiz kayıp
koşulunda elde edilen kestirimlerdeki yanlılığın, tümüyle seçkisiz kayıp
koşuluna göre genel olarak daha yüksek olduğu ve bu durumun kayıp veri
oranının artmasına bağlı olarak daha belirgin bir hal aldığı görülmüştür.
Kayıp veri baş etme tekniği açısından yapılan incelemelerde liste
bazında silme, stokastik regresyonla değer atama, beklenti – maksimizasyon
algoritması ve çoklu değer atama tekniklerinin tümüyle seçkisiz kayıp
koşulunda yansız kestirimler ürettiği; Öklid uzaklığı üzerinden benzer tepki
örüntüsüne dayalı atama tekniğinin ise genellikle negatif yanlı olduğu
görülmüştür. stokastik regresyonla değer atama, beklenti – maksimizasyon
algoritması ve çoklu değer atama teknikleri seçkisiz kayıp koşulunda
yansızlıklarını korurken, liste bazında silme tekniği kayıp veri oranının
artmasıyla birlikte negatif yanlılık göstermeye başlamıştır. Bu bulguların,
araştırmada yer verilen farklı örneklem büyüklükleri için büyük ölçüde paralel
olduğu görülmüştür.
W katsayısı için ulaşılan bulgular incelendiğinde, seçkisiz olmayan
kayıp koşulu altındaki kestirimlerin negatif yanlı olduğu görülmüştür.
Güvenirlik kapsamında ulaşılan sonuçlar, herhangi bir verinin kayıp olma
olasılığının doğrudan ilgili özelliğin değerine bağlı olmasının, ölçümlerin
güvenirliğini olumsuz yönde etkilediğini ve bu sorunun araştırma kapsamında

106
yer verilen istatistiksel tekniklerle giderilmesinin mümkün olmadığını
göstermektedir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında yansız
kestirimlere ulaşmanın mümkün olduğu ve bu durumun genellikle düşük kayıp
veri oranları için geçerli olduğu görülmüştür. Tümüyle seçkisiz kayıp
koşulunda yansız kestirimler üretebilen tekniklerin, seçkisiz kayıp koşulunda
yanlılık gösterebilecekleri görülmüştür.
Liste bazında silme, stokastik regresyonla değer atama ve çoklu değer
atama tekniklerinin tümüyle seçkisiz kayıp koşulunda genellikle yansız, Öklid
uzaklığı üzerinden benzer tepki örüntüsüne dayalı atama tekniğinin negatif,
beklenti – maksimizasyon algoritmasının ise pozitif yanlı kestirimler ürettiği
görülmüştür. Stokastik regresyonla değer atama ve çoklu değer atama
teknikleri seçkisiz kayıp koşulunda yansızlıklarını korurken liste bazında silme
tekniğinin kayıp veri oranına bağlı olarak negatif yanlılık göstermesi söz
konusudur.
Sıklıkla kullanılan kayıp veri tekniklerinden biri olan liste bazında silme
tekniğinin, ölçümlerin faktör yapısını madde atmayı gerektirecek veya faktör
sayısını değiştirecek ölçüde etkileyebileceği görülmüştür. Liste bazında silme
tekniğinin kullanılması halinde karşılaşılabilen bu sorunun, kuramsal açıdan
Cronbach α katsayısına göre daha yüksek değerler alması beklenen
McDonald katsayısı üzerinde olumsuz etki yaratabileceği görülmüştür.
Geçerliğe İlişkin Sonuçlar
Araştırmada, farklı kayıp veri tekniklerinin bir ve iki faktörlü veri
setlerinden elde edilen açıklanan varyans oranları üzerindeki yanlılığı
incelenmiştir. Örneklem büyüklüğü ve madde (faktör) sayısı değişkenlerinin
tüm kombinasyonları için birbirine benzer sonuçlara ulaşılmıştır.
Sonuçlar kayıp veri koşulu açısından incelendiğinde, seçkisiz olmayan
kayıp koşulunda elde edilen açıklanan varyans oranlarının, tüm kayıp veri
teknikleri ve kayıp veri oranları için negatif yanlı olduğu görülmüştür. Tümüyle
seçkisiz kayıp ve seçkisiz kayıp koşullarında yansız kestirimlerin elde

107
edilebileceği ve bu durumun genel olarak tümüyle seçkisiz kayıp koşulu lehine
olduğu görülmüştür.
Sonuçlar kayıp veri oranı açısından incelendiğinde, düşük kayıp veri
oranları için yansız olan açıklanan varyans kestirimlerinin, kayıp veri
miktarının artmasıyla birlikte negatif yanlılık gösterebildiği sonucuna
ulaşılmıştır.
Liste bazında silme ve stokastik regresyonla değer atama tekniklerinin
tümüyle seçkisiz kayıp koşulu altında yansız kestirimler ürettiği; Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama tekniğinin negatif, beklenti –
maksimizasyon algoritmasının ise pozitif yanlı olduğu görülmüştür. Liste
bazında silme tekniği seçkisiz kayıp koşulunda sadece düşük miktarda
kayıpların bulunduğu durumlarda yansız iken diğer teknikler ile elde edilen
sonuçlar tümüyle seçkisiz kayıp koşulundaki sonuçlara benzerdir. Genel
olarak yüksek performans gösteren çoklu değer atama tekniğinin özellikle
büyük örneklemlerde daha etkili olduğu sonucuna ulaşılmıştır.
Temel bileşenler analizi sonuçları çerçevesinde elde edilen D2 değerleri
kayıp veri koşulu ve kayıp veri oranı açısından incelendiğinde; tümüyle
seçkisiz kayıp koşulunda en düşük, seçkisiz olmayan kayıp koşulunda en
büyük değerlerin elde edildiği ve D2 değerlerinin kayıp veri miktarına bağlı
olarak artış gösterdiği görülmüştür. Sonuçlar örneklem büyüklüğü ve madde
sayısı değişkenleri açısından da büyük ölçüde benzerdir.
Tümüyle seçkisiz kayıp ve seçkisiz kayıp koşullarında örneklem
büyüklüğü, madde sayısı ve kayıp veri oranlarının tüm düzeyleri için en büyük
D2 değerleri stokastik regresyonla değer atama ve liste bazında silme
teknikleriyle, en küçük değerler ise beklenti – maksimizasyon algoritması ve
çoklu değer atama teknikleriyle elde edilmiş; Öklid uzaklığı üzerinden benzer
tepki örüntüsüne dayalı atama tekniğinin de bu tekniklere yakın sonuçlar
verdiği görülmüştür.
Seçkisiz olmayan kayıp koşulu altında liste bazında silme tekniğiyle
elde edilen D2 değerleri dikkat çekici ölçüde büyüktür. Özel olarak yapılan
incelemeler sonucunda, maddelerin eksiksiz veri setine göre farklı faktörler
altında yer alması veya faktör sayısının artması gibi sorunların ortaya
çıkabileceği görülmüştür.

108
Her ikisi de faktör yüklerinin birer fonksiyonu olan açıklanan varyans
oranı ve D2 istatistiği değerleri bir arada değerlendirildiğinde, ölçümlerin faktör
yapısını koruyan teknikler arasında yer alan Öklid uzaklığı üzerinden benzer
tepki örüntüsüne dayalı atama tekniğinin negatif; beklenti – maksimizasyon
algoritmasının ise pozitif yanlılık gösterdiği görülmektedir. Stokastik
regresyonla değer atama tekniği ise açıklanan varyans oranı için yansız
kestirimler üretmekte fakat faktör yapısı üzerinde olumsuz bir etki
göstermektedir. Çoklu değer atama tekniğinin ise genel olarak diğer tekniklere
göre oldukça yüksek performans gösterdiği sonucuna ulaşılmıştır.
Araştırmada yer verilen kayıp veri teknikleri doğrulayıcı faktör analizi
çerçevesinde incelendiğinde örneklem büyüklüğü, kayıp veri koşulu ve kayıp
veri oranının tüm kombinasyonları için 2/sd, RMSEA, GFI ve CFI
indekslerinin mükemmel uyum düzeyine çıkabildiği görülmüştür.
Doğrulayıcı faktör analizi sonuçları kayıp veri teknikleri açısından
incelendiğinde Öklid uzaklığı üzerinden benzer tepki örüntüsüne dayalı
atama, stokastik regresyonla değer atama, beklenti – maksimizasyon
algoritması ve çoklu değer atama tekniklerinin birbirine oldukça yakın sonuçlar
ürettiği; liste bazında silme tekniğinin ise genel olarak iyi bir model – veri
uyumu sağlamakla birlikte bazı veri setleri için kabul edilebilir sınırların
dışında sonuçlar üretebildiği görülmüştür. Bu sonuçlar, araştırma kapsamında
yer verilen örneklem büyüklüğü ve madde sayısı değişkenlerinin tüm düzeyleri
için büyük ölçüde benzerdir.
Model – veri uyumuna ilişkin diğer indeksler bir bütün olarak
incelendiğinde, genel olarak tüm tekniklerin birbirine yakın sonuçlar ürettiği
görülmüştür. İstisnai olarak liste bazında silme tekniği ile tümüyle seçkisiz
kayıp koşulu altında bile kabul edilebilir sınırların ötesinde (NFI: .750; SRMR;
.110 ve AGFI: .650 gibi) indeks değerleri elde edilmiştir (Ek 29).
Ölçümlerin güvenirliğinin ve geçerliğinin birbirinden bağımsız olarak
düşünülemeyeceğinden hareketle araştırma kapsamında ulaşılan sonuçlar bir
bütün olarak değerlendirildiğinde, çoklu değer atamanın diğer tekniklere göre
açık bir üstünlük gösterdiği görülmüştür.

109
Öneriler
Bu bölümde araştırmadan elde edilen sonuçlar doğrultusunda;
araştırma sonuçlarına ve araştırmacılara yönelik önerilerde bulunulmuştur.
1. Araştırma kapsamında yer verilen tekniklerin oldukça yüksek
performans sergileyebileceği görülmüş olmakla birlikte kayıp verilerle baş
etme noktasında en iyi yaklaşım, hiç kaybın olmaması yönünde çabanın sarf
edilmesidir. Kayıp veri teknikleri ile eksiksiz veriye hiçbir zaman tam anlamıyla
yaklaşılamayamamaktadır. Kayıp veri problemiyle karşılaşması durumunda
istatistiksel düzeltmelerden önce, kayıpların örüntüsüne ve nedenine ilişkin
bilgilerin toplanması ve incelenmesi gerekmektedir. Özellikle seçkisiz olmayan
kayıp koşulunun geçerliği ve güvenirliği olumsuz etkileyebileceği mutlaka
dikkate alınmalıdır. Kayıp veri miktarının fazla olduğu durumlarda, öncelikle
izleme yapılarak verinin mümkün olduğunca toplanmaya çalışılması, bu
çabanın yetersiz kaldığı durumlarda ise veri toplama sürecinin tekrarlanması
düşünülebilir.
2. Sıklıkla kullanılan ve istatistik paket programlarında genellikle
otomatik bir şekilde uygulanan liste bazında silme tekniğinin, örneklem
büyüklüğü üzerinde olumsuz bir etkisi vardır. Bu tekniğin kullanılması halinde,
istatistiksel analizin gücünün düşmesi ve sonuçların daha küçük bir alt
örneklemden elde edilmesine bağlı olarak genellenebilirlik noktasında
sorunlarla karşılaşılması söz konusudur. Bu araştırmayla liste bazında silme
tekniğinin, ölçümlerin tümüyle farklı bir yapıyı temsil etmesi gibi bir soruna da
yol açabileceği görülmüştür. Liste bazında silme tekniğinin, tümüyle seçkisiz
kayıp koşulu ve düşük miktardaki kayıpların bulunduğu durumlar haricinde
kullanılmaması gerekmektedir. Bu koşullar altında, liste bazında silme
tekniğine göre daha yüksek performans gösteren ve örneklem büyüklüğünün
küçülmesine yol açmayan çoklu değer atama tekniğinin kullanılması daha
uygundur.
3. Çoklu değer atama tekniğinin paket programlarda yer bulmaya
başlamış olması da verilerin analizi sürecinde karşılaşılabilecek zorlukları
büyük ölçüde kolaylaştırmıştır. Bu araştırmada, çoklu değer atama tekniği için
atama sayısı 5 olarak belirlenmiştir. Bazı durumlarda negatif yanlılık gösteren

110
çoklu değer atama tekniği, daha fazla sayıda atamaya yer verilerek
kullanılabilir.
4. Yapay veriler kullanılarak gerçekleştirilen bu çalışmada farklı kayıp
veri tekniklerinin performansları, verinin eksiksiz olduğu durumun ölçüt olarak
kullanıldığı karşılaştırmalarla incelenebilmiştir. Gerçek veri setlerinde
kayıpların bulunmasının doğal olarak beraberinde getireceği bilinmezliğin,
kullanılan kayıp veri baş etme tekniğine bağlı olarak ayrı bir faktör yapısının
ortaya çıkması gibi fark edilmesi son derece güç sorunlar yaratabileceği
görülmüştür. Bu noktada, kayıp veri teknikleriyle ulaşılan kanıtların istatistiksel
çerçevede ele alınması; güvenirliğe ve geçerliğe ilişkin farklı yöntemlerle elde
edilen ve kuramsal olarak da desteklenen mantıksal kanıtların da sunulması
gerektiği unutulmamalıdır.
5. Araştırma kapsamında örneklem büyüklüğü (250, 500 ve 1000),
madde ve faktör sayısı (10/1 ve 15/2), kayıp veri koşulu (tümüyle seçkisiz
kayıp, seçkisiz kayıp ve seçkisiz olmayan kayıp), kayıp veri oranı (%2, %5 ve
%10) ve kayıp veri baş etme tekniği (liste bazında silme, Öklid uzaklığı
üzerinden benzer tepki örüntüsüne dayalı atama, stokastik regresyonla değer
atama, beklenti – maksimizasyon algoritması ve çoklu değer atama) bağımsız
değişkenlerine yer verilmiştir. Kayıp verilerin hemen her araştırmada
karşılaşılan genel bir sorun olmasından hareketle, bu değişkenlerin farklı
düzeylerinin ele alındığı çalışmalar planlanabilir. Özel olarak, kayıp veri
tekniklerinin geniş ölçekli testler kapsamında tartışılmasına gerek
duyulmaktadır.
6. Farklı koşullarda elde edilen veri setleri temel bileşenler analizi ve
varimax dik döndürme tekniği çerçevesinde ele alınmıştır. Kayıp veri
tekniklerinin, farklı faktör çıkarma veya eksen döndürme teknikleri
çerçevesinde incelendiği araştırmalara da ihtiyaç duyulmaktadır.
7. Kayıp veri teknikleriyle elde edilen kovaryans matrislerinin eksiksiz
veri setleriyle karşılaştırılması amacıyla kullanılabileceği önerilen özdeğer
ortalamaları, çarpımları veya max / min oranın incelenmesi gibi ölçütler bu
araştırmanın kapsamı dışında bırakılmıştır. Bu karşılaştırmaların yapılabilmesi
için ihtiyaç duyulan özel yazılımları geliştirme donanımına sahip olan

111
araştırmacıların, kayıp veri tekniklerinin performanslarını bu göstergeler
çerçevesinde incelemesi önerilebilir.
8. Doğrulayıcı faktör analizi çerçevesinde farklı kayıp veri tekniklerinin
performansları, gizil değişken sayısının ikiden fazla olduğu veya ikinci düzey
doğrulayıcı faktör analizi modellerine ek olarak, gizil özellikler arasındaki
ilişkilerin de modele dâhil edildiği yapısal modeller üzerinden incelenebilir.
9. Gerçek veri setlerinde kayıpların özel olarak incelenmesi yanında,
kayıp veri örüntüsünün öncelikle eksiksiz alt örneklemde modellendiği ve en
yüksek performansı gösteren tekniğin tüm veri setine uygulandığı araştırmalar
planlanabilir.
10. Bu araştırmada incelemeler klasik test kuramı çerçevesinde
gerçekleştirilmiştir. Farklı kayıp veri tekniklerinin madde – tepki kuramı ve
genellenebilirlik kuramı kapsamında ele alındığı araştırmalar planlanabilir.
11. Benzer tepki örüntüsüne dayalı atama tekniğinde, kayıp verilerin
atanmasında Öklid uzaklığı temel alınmıştır. Benzer tepki örüntüsüne dayalı
atama tekniğinin Manhattan ve Minkowski gibi farklı uzaklık ölçüleri üzerinden
gerçekleştirildiği araştırmalar planlanabilir.
12. Araştırmacılar kayıp verilere ek olarak, puan dağılımının çarpık ya
da basık olduğu durumlarda kullanılan düzeltme formüllerini veya ortalamayı
çarpıtan uç değerlerin belirlenmesinde kullanılan farklı uzaklık ölçülerini konu
edinen araştırmaları, güvenirlik ve geçerlik kapsamında yapay veri setleri
üzerinden gerçekleştirebilirler.

112
KAYNAKÇA
Allison, P. D. (2001). Missing Data. Thousand Oaks, CA:Sage.
Allison, P. D. (2003). Missing Data Techniques for Structural Equation
Modeling. Journal of Abnormal Psychology. 112(4), 545-557.
Alpar, R. (2010). Spor, Sağlık ve Eğitim Bilimlerinden Örneklerle Uygulamalı
İstatistik ve Geçerlik – Güvenirlik, Detay Yayıncılık.
Alpar, R. (2011). Uygulamalı Çok Değişkenli İstatistiksel Yöntemler, Detay
Yayıncılık.
Anderson, T. W. (2003). An Introduction To Mulivariate Statistical Analysis. (3.
Ed.) New York: Wiley.
Arbuckle, J. L. (1996). Full Information Estimation in the Presence Of
Incomplete Data, In G. A. Macoulides and R. E. Schumacker (Eds.),
Advanced Structural Equation Modeling: Issues and Techniques,
Mahwah, NJ: Lawrence Erlbaum.
Bacon, D. R., Sauer, P. L. ve Young, M. (1995). Composite Reliability in
Structural Equations Modeling. Educational and Psychological
Measurement. 55, 394-406.
Baraldi, A. N. ve Enders, C. K. (2010). An Introduction to Modern Missing
Data Analyses, Journal of School Psychology. 48, 5-37.
Bernaards, C. A. ve Sijtsma, K. (1999). Factor Analysis of Multidimensional
Polytomous Item Response Data Suffering from Ignorable Item
Nonresponse, Multivariate Behavioral Research. 34(3), 277 – 313.

113
Bernaards, C. A. ve Sijtsma, K. (2000). Influence of Imputation and EM
Methods on Factor Analysis When Item Nonresponse in Questionnaire
Data Is Nonignorable, Multivariate Behavioral Research. 35:3, 321 –
364.
Brown, R. L. (1994). Efficacy of the Indirect Approach for Estimating Structural
Equation Models With Missing Data: A Comparison of Methods.
Structural Equation Modeling: A Multidisciplinary Journal. 1(4), 287-316.
Büyüköztürk, Ş. (2010). Sosyal Bilimler İçin Veri Analizi El Kitabı: İstatistik,
Araştırma Deseni, SPSS Uygulamaları ve Yorum. (11. Baskı). Ankara:
PEGEM Akademi.
Chen, S-F, Wang, S. ve Chen, C-Y. (2011). A Simulation Study Using EFA
and CFA Programs Based on the Impact of Missing Data on Test
Dimensionality, Expert Systems With Applications. 39(2012), 4026 –
4031.
Collins, L. M., Schafer, J. L. ve Kam, C. (2001). A Comparison of Inclusive
and Restrictive Strategies in Modern Missing Data Procedures,
Psychological Methods. 6(4), 330-351.
Cronbach, J. L. (1990). Essentials of Psychological Testing. (5. Ed).
HarperCollinsPublishers, Inc.
Çokluk, Ö., Şekercioğlu, G. ve Büyüköztürk, Ş. (2010). Sosyal Bilimler İçin
Çok Değişkenli İstatistik: SPSS ve LISREL Uygulamaları. Pegem
Akademi Yayıncılık, Ankara.
Çokluk, Ö. ve Kayri, M. (2011). Kayıp Değerlere Yaklaşık Değer Atama
Yöntemlerinin Ölçme Araçlarının Geçerlik ve Güvenirliği Üzerindeki
Etkisi. Kuram ve Uygulamada Eğitim Bilimleri. 11 (1), 289 – 309.

114
Davey, A., Savla, J. ve Luo, Z. (2005). Issues in Evaluating Model Fit With
Missing Data. Structural Equation Modeling: A Multidisciplinary Journal.
12(4), 578-597.
De Luca, G. ve Peracchi, F. (2007). A Sample Selection Model For Unit and
Item Nonresponse in Cross-sectional Surveys. CEIS Tor Vergata -
Research Paper Series. 33(99).
Demir, E. ve Parlak, B. (2012). Türkiye’de Eğitim Araştırmalarında Kayıp Veri
Sorunu. Eğitimde Ve Psikolojide Ölçme Ve Değerlendirme Dergisi. 3(1),
230-241.
Demir, E. (2013). Kayıp Verilerin Varlığında İki Kategorili Puanlanan
Maddelerden Oluşan Testlerin Psikometrik Özelliklerinin İncelenmesi.
Yayımlanmamış doktora tezi, Ankara Üniversitesi Eğitim Bilimleri
Enstitüsü, Ankara.
Dong, Y. ve Peng, C-Y. J. (2013). Principled Missing Data Methods for
Researchers. Methodology, 2:222.
Dunn, T. J., Baguley, T. ve Brunsden, V. (2013). From Alpha to Omega: A
Practical Solution to the Pervasive Problem of Internal Consistency
Estimation. British Journal of Psychology.
Dural, S. (2010). Farklı Kayıp Veri Tekniklerinin Çok Göstergeli Örtük Büyüme
Modelleri Üzerindeki Etkisi. Yayımlanmamış doktora tezi, Ege
Üniversitesi Sosyal Bilimler Enstitüsü, İzmir.
Enders, C. K. (2001). A Primer on Maximum Likelihood Algorithms Available
for Use With Missing Data. Structural Equation Modeling: A
Multidisciplinary Journal. 8 (1), 128-141.

115
Enders, C. K. ve Bandalos, D. L. (2001). The Relative Performance of Full
Information Maximum Likelihood Estimation for Missing Data in
Structural Equation Models. Structural Equation Modeling: A
Multidisciplinary Journal. 8(3), 430-457.
Enders, C. K. (2003). Using the Expectation Maximization Algorithm to
Estimate Coefficient Alpha for Scales With Item-Level Missing Data.
Psychological Methods. 8(3), 322-337.
Enders, C. K. (2004). The Impact of Missing Data on Sample Reliability
Estimates: Implications for Reliability Reporting Practices. Educational
and Psychological Measurement. 64 (3), 419-436.
Enders, C. K. (2010). Applied Missing Data Analysis. (1. Ed.). New York: The
Guilford Publications, Inc.
Field. A. (2005). Discovering Statistics Using SPSS. (2. Ed.). London: SAGE
Publications Inc.
Goegebeur, Y., De Boeck, P. ve Molenberghs, G. (2010). Person Fit for Test
Speededness: Normal Curvatures, Likelihood Ratio Tests and Empirical
Bayes Estimates. Methodology: European Journal of Research Methods
for the Behavioral and Social Sciences. 6(1), 3 – 16.
Graham, J. W., Hofer, S. M., ve MacKinnon, D. P. (1996). Maximizing The
Usefulness of Data Obtained With Planned Missing Value Patterns: An
Application of Maximum Likelihood Procedures. Multivariate Behavioral
Research. 31(2), 197-218.
Graham, J. W., Cumsille, P. E., ve Elek-Fisk, E. (2003). Methods For
Handling Missing Data. In J. A. Schinka and W.F. Velicer (Eds),
Handbook Of Psychology: Volume:2. Research Methods in Psychology.
New York: Wiley.

116
Graham, J. W., (2012). Missing Data: Analysis and Design. New York:
Springer.
Gu, F., Little, T. D. ve Kingston, N. M. (2013). Misestimation Of Reliability
Using Coefficient Alpha And Structural Equation Modeling When
Assumptions Of Tau-Equivalance And Uncorrelated Errors Are Violated,
Methodolgy: European Journal of Research Methods for the Behavioral
and Social Sciences. 9(1), 30-40.
Hair, J. F., Black, W. C., Babin, B. J., Anderson, R. E. ve Tatham, R. L.
(2006). Multivariate Data Analysis. (6. Ed.). New Jersey: Pearson
Education, Inc.
Hancock, G. R. ve Mueller, R. O. (2001). Rethinking Construct Reliability
Within Latent Variable Systems. In R. Cudeck, S. du Toit and D. Sörbom
(Eds.), Structural Equation Modeling: Present and Future – A festschrift
in honor of Karl Jöreskog (pages. 195-216). Lincolnwood, IL: Scientific
Software International.
Heerwegh, D. (2005). Web Surveys. Explaining and Reducing Unit
Nonresponse, Item Nonresponse And Partial Nonresponse.
Yayımlanmamış doktora tezi, Katholieke Universiteit Leuven Faculteit
Sociale Wetenschappen, Leuven, Belçika.
Huisman, M., Krol, B. ve Van Sonderen, E. (1998). Handling Missing Data By
Re-aproaching Non-respondents. Quality and Quantity. 32(1), 77-91.
Jöreskog, K. G. ve Sörbom, D. (2007). LISREL 8.80: for Windows [Computer
Software] Lincolnwood, IL: Scientific Software International, Inc.
Karasar, N. (2007). Bilimsel Araştırma Yöntemi: Kavramlar, İlkeler, Teknikler.
(17. Baskı). Ankara: Nobel Yayın Dağıtım.

117
Kim, J.O. ve Curry, J. (1977). The Treatment of Missing Data in Multivariate
Analysis. Sociological Methods and Research. 6(2), 215-241.
Leeuw, E.D. de, Hox, J. ve Huisman, M. (2003). Prevention and Treatment of
Item Nonresponse. Journal of Official Statistics. 19(2), 153-176.
Little, R. J. A. ve Rubin, D. B. (1987). Statistical Analysis With Missing Data.
New York: Wiley.
Marsh, H. W. (1998). Pairwise Deletion For Missing Data in Structural
Equation Models: Nonpositive Definite Matirces, Parameter Estimates,
Goodness of Fit, and Adjusted Sample Sizes. Structural Equation
Modeling: A Multidisciplinary Journal. 5 (1), 22-36.
McDonald, R. (1985). Factor Analysis And Related Methods. Hillsdale, NJ:
Erlbaum.
McKnight, P. E., McKnight, K. M., Sidani, S. ve Figueredo, A. J. (2007).
Missing Data: A Gentle Introduction. New York: The Guilford
Publications, Inc.
Montalto, C. P. ve Sung, J. (1996). Multiple Imputation In The 1992 Survey Of
Consumer Finances. Financial Counseling and Planning. 7, 133 – 141.
Muthen, L. K. ve Muthen, B. O. (2012). Mplus (Version 8.0) [Computer
Software]. Los Angeles: Muthen & Muthen.
Myers, T. A. (2011). Goodbye, Listwise Deletion: Presenting Hot Deck
Imputation as an Easy and Effective Tool For Handling Missing Data.
Communication Methods and Measures. 5 (4), 297-310.
Nunnally, J. C. ve Bernstein, I. H. (1994). Psychometric Theory. (3. Ed.).
McGraw-Hill: New York.

118
Olinsky, A. Chen, S ve Harlow, L. (2003). The Comperative Efficacy of
Imputation Methods for Missing Data in Structural Equation Modeling.
European Journal of Operational Research. 151, 53 – 79.
Öztemel, E. (2003). Yapay Sinir Ağları. Papatya Yayıncılık, İstanbul.
Peterson, A. (2000). A Meta – Analysis of Variance Accounted for and Factor
Loadings in Exploratory Factor Analysis. Marketing Letters. 11(3), 261 –
275.
Pigott, T. D. (2001). A Review Of Methods For Missing Data. Educational
Research and Evaluation: An International Journal of Theory and
Practice. 7(4), 353-383.
Rae, G. (2006). Correcting Coefficient Aplha for Correlated Errors: Is αK a
Lower Bound to Reliability?. Applied Psychological Measurement. 30(1),
56-59.
Raykov, T. (1997). Estimation Of Composite Reliability For Congeneric
Measures. Applied Psychological Measurements. 21(2), 173-184.
Raykov, T. (2001). Bias Of Coefficient α For Fixed Congeneric Measures With
Correlated Errors. Applied Psychological Measurement. 25(1), 69-76.
Rosenthal, R. ve Rosnow, R. (2008). Essentials Of Behavioral Research:
Methods and Data Analysis. (3. Ed.). McGraw-Hill.
Rubin, D. B., (1976). Inference And Missing Data. Biometrika. 63, 581-592.
Rubin, D. B. (1987). Multiple Imputation For Nonresponse In Surveys. New
York: John Wiley & Sons, Inc.
Scheffer, J. (2002). Dealing with Missing Data. Research Letters in the
Information and Mathematical Sciences. 3, 153-160.

119
Schafer, J. L. (1997). Analysis of Incomplete Multivariate Data. New York:
Chapman & Hall/Crc.
Schafer, J. L. ve Graham, J. W. (2002). Missing Data: Our View Of The State
Of The Art. Psychological Methods, 7(2), 147 – 177.
Siddique, J. ve Belin, T. R. (2008). Multiple Imputation Using an Iterative Hot-
Deck with Distance-Based Donor Selection. Statistics in Medicine. 27,
83-102.
SPSS, Inc. (2009). PASW Statistics 18. [Computer Program].
Stevens, J. (2002). Applied Multivariate Statistics for the Behavioral Sciences
(4. Ed.). Hillsdale, NJ: Erlbaum.
Tabachnick, B. G. ve Fidel, L. S. (1996). Using Multivariate Statistics. (3. Ed).
MA: Allyn&Bacon, Inc.
Tucker, L. R., (1951). A Method For Synthesis Of Factor Analytic Studies.
Personnel Research Section Report No. 984. Washington DC:
Department of the Army.
Van Buuren, S. (2013). Flexible Imputation of Missing Data. Chapman &
Hall/CRC Press.
Van Ginkel, J. R., (2007). Multiple Imputation for Incomplete Test,
Questionnaire, and Survey Data. Yayımlanmamış Doktora Tezi, Tilburg
Üniversitesi, Hollanda.
Van Ginkel, J. R., Sijtsma, K., Van der Ark, L. A ve Vermunt, J. K. (2010).
Incidence Of Missing Item Scores In Personality Measurement, and
Simple Item – Score Imputation. Methodology: European Journal of
Research Methods for the Social Sciences. 6 (1), 17 – 30.

120
Van Ginkel, J. R., Kroonenberg, P. M. ve Kiers, H. A. L. (2013). Missing Data
In Principal Component Analysis Of Questionnaire Data: A Comparison
Of Methods. Journal of Statistical Computation and Simulation.
Widhiarso, W. (2007). Estimating Reliability For Multidimensional Measure.
Unpublished Research Summary. Faculty of Psychology, Gadjah Mada
University.
Yeşilova, A., Kaya, Y. ve Almalı, M. N. (2011). A Comparison of Hot Deck
Imputation and Substitution Methods in the Estimation of Missing Data.
Gazi University Journal of Science. 24(1), 69 – 75.
Yurdugül, H. (2006). Paralel, Eşdeğer ve Konjenerik Ölçmelerde Güvenirlik
Katsayılarının Karşılaştırılması. Ankara Üniversitesi Eğitim Bilimleri
Fakültesi Dergisi. 39(1), 15-37.

121
EKLER

122
Ek 1. Veri Üretimi Aşamasında Kullanılan Mplus Komut Dosyası Örnekleri
Örneklem büyüklüğünün 250, madde sayısının 10 olduğu veri setleri için veri üretme
aşamasında kullanılan komut dosyası:
TITLE: 250_10_ MONTECARLO: NAMES ARE y1-y10; NOBSERVATIONS = 250; NREPS = 100; REPSAVE = ALL; SAVE = 250_10_*.dat; SEED = 2445; MODEL POPULATION: f1 BY y1-y10*.80; f1@1; y1-y10*.65; OUTPUT: TECH9;
Örneklem büyüklüğünün 250, madde sayısının 15 olduğu veri setleri için veri üretme
aşamasında kullanılan komut dosyası:
TITLE: 250_15_ MONTECARLO: NAMES ARE y1-y15; NOBSERVATIONS = 250; NREPS = 100; REPSAVE = ALL; SAVE = 250_15_*.dat; SEED = 3387; MODEL POPULATION: f1 BY y1-y9*.8; f2 BY y10-y15*.8; f1-f2@1; f1 WITH f2*.5; y1-y15*.6; OUTPUT: TECH9;
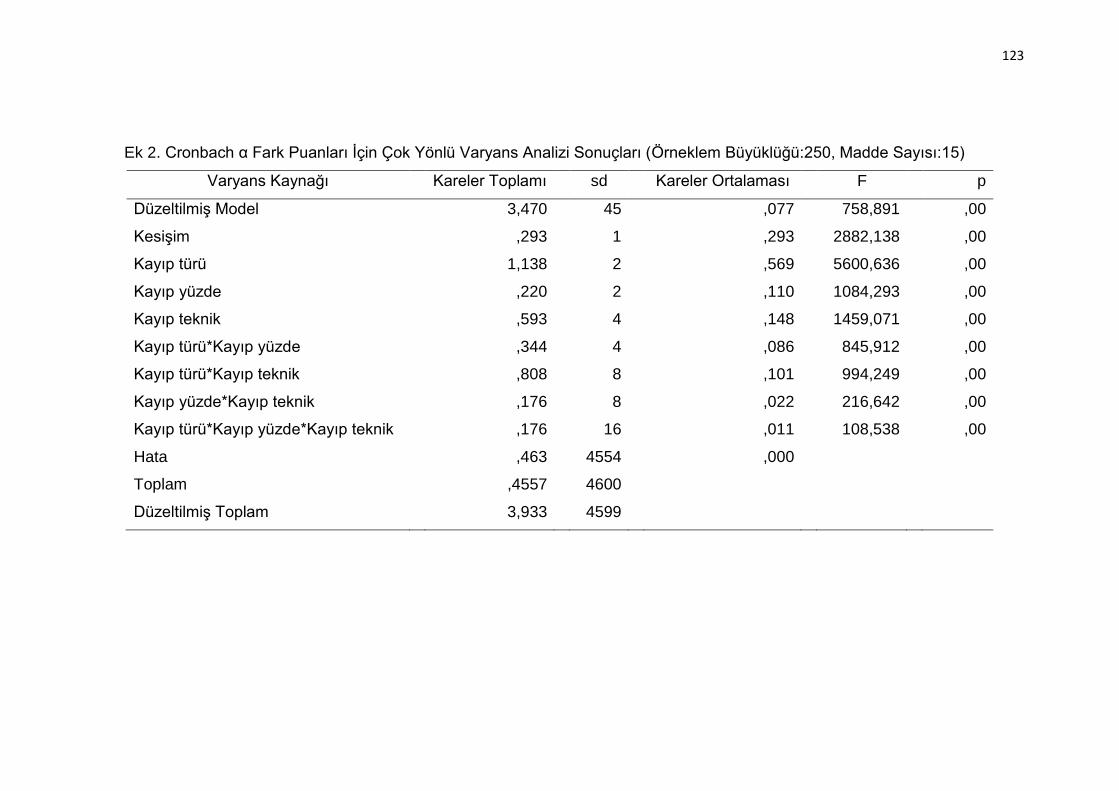
123
Ek 2. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:250, Madde Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 3,470 45 ,077 758,891 ,00
Kesişim ,293 1 ,293 2882,138 ,00
Kayıp türü 1,138 2 ,569 5600,636 ,00
Kayıp yüzde ,220 2 ,110 1084,293 ,00
Kayıp teknik ,593 4 ,148 1459,071 ,00
Kayıp türü*Kayıp yüzde ,344 4 ,086 845,912 ,00
Kayıp türü*Kayıp teknik ,808 8 ,101 994,249 ,00
Kayıp yüzde*Kayıp teknik ,176 8 ,022 216,642 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,176 16 ,011 108,538 ,00
Hata ,463 4554 ,000
Toplam ,4557 4600
Düzeltilmiş Toplam 3,933 4599
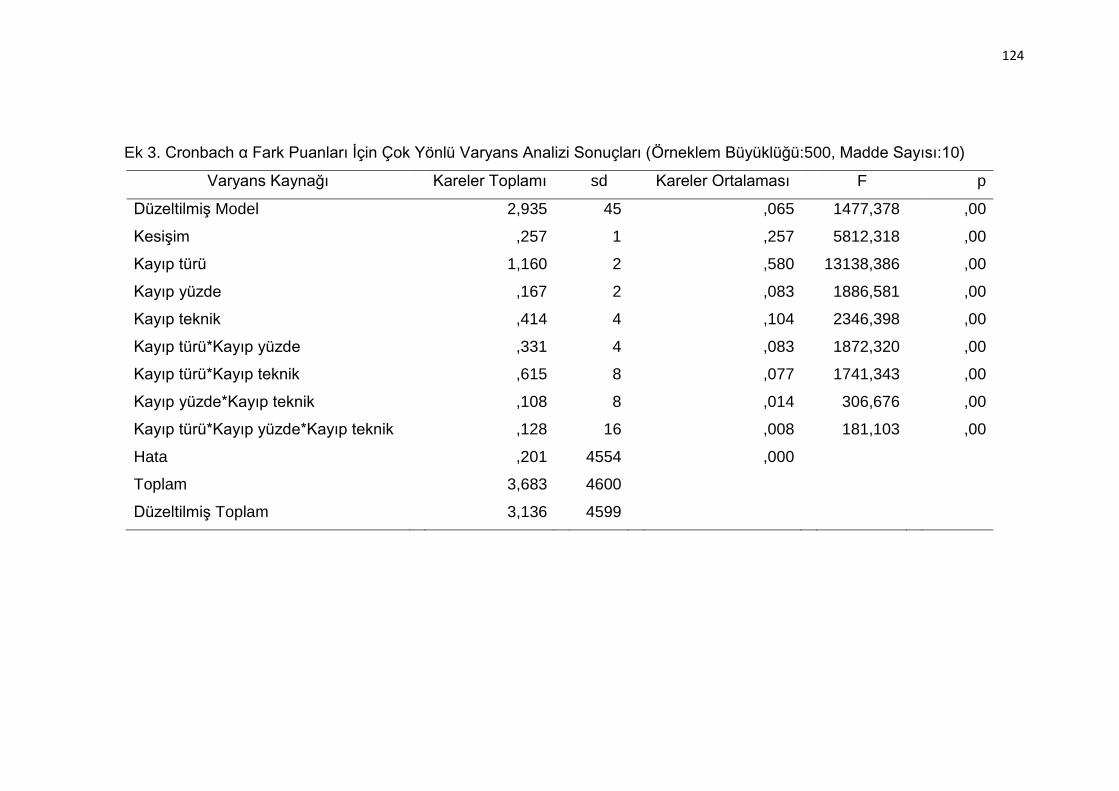
124
Ek 3. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:500, Madde Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 2,935 45 ,065 1477,378 ,00
Kesişim ,257 1 ,257 5812,318 ,00
Kayıp türü 1,160 2 ,580 13138,386 ,00
Kayıp yüzde ,167 2 ,083 1886,581 ,00
Kayıp teknik ,414 4 ,104 2346,398 ,00
Kayıp türü*Kayıp yüzde ,331 4 ,083 1872,320 ,00
Kayıp türü*Kayıp teknik ,615 8 ,077 1741,343 ,00
Kayıp yüzde*Kayıp teknik ,108 8 ,014 306,676 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,128 16 ,008 181,103 ,00
Hata ,201 4554 ,000
Toplam 3,683 4600
Düzeltilmiş Toplam 3,136 4599
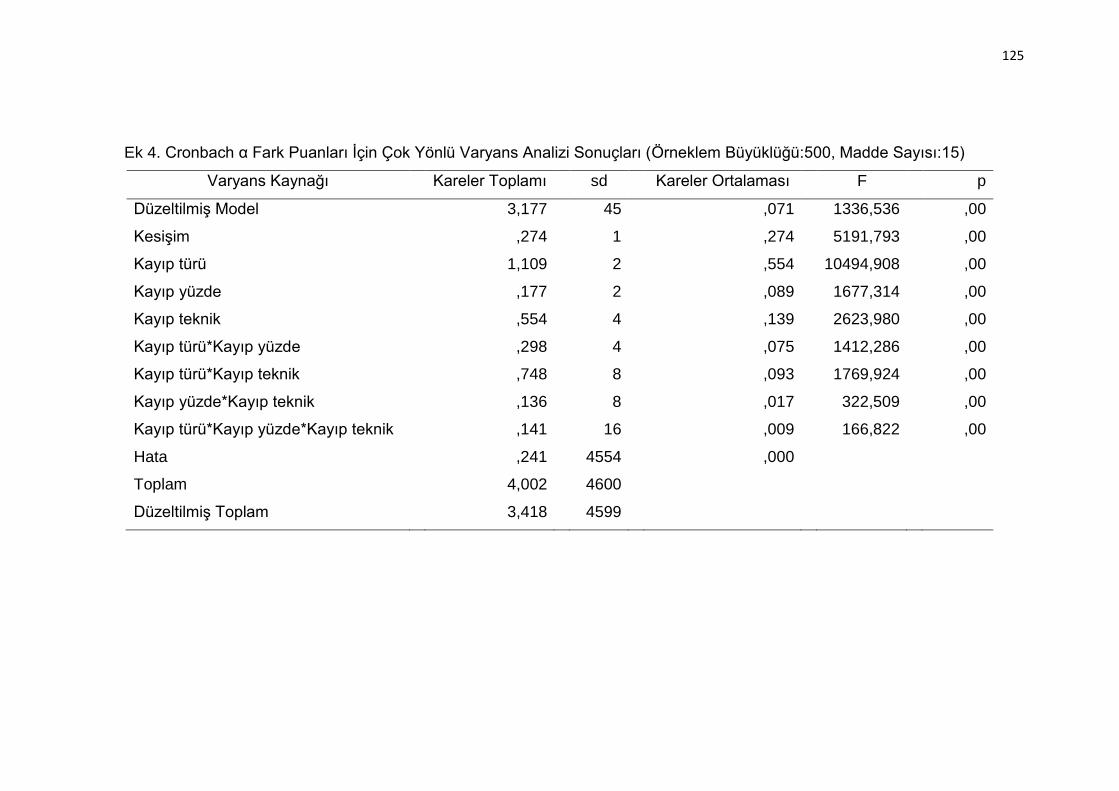
125
Ek 4. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:500, Madde Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 3,177 45 ,071 1336,536 ,00
Kesişim ,274 1 ,274 5191,793 ,00
Kayıp türü 1,109 2 ,554 10494,908 ,00
Kayıp yüzde ,177 2 ,089 1677,314 ,00
Kayıp teknik ,554 4 ,139 2623,980 ,00
Kayıp türü*Kayıp yüzde ,298 4 ,075 1412,286 ,00
Kayıp türü*Kayıp teknik ,748 8 ,093 1769,924 ,00
Kayıp yüzde*Kayıp teknik ,136 8 ,017 322,509 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,141 16 ,009 166,822 ,00
Hata ,241 4554 ,000
Toplam 4,002 4600
Düzeltilmiş Toplam 3,418 4599
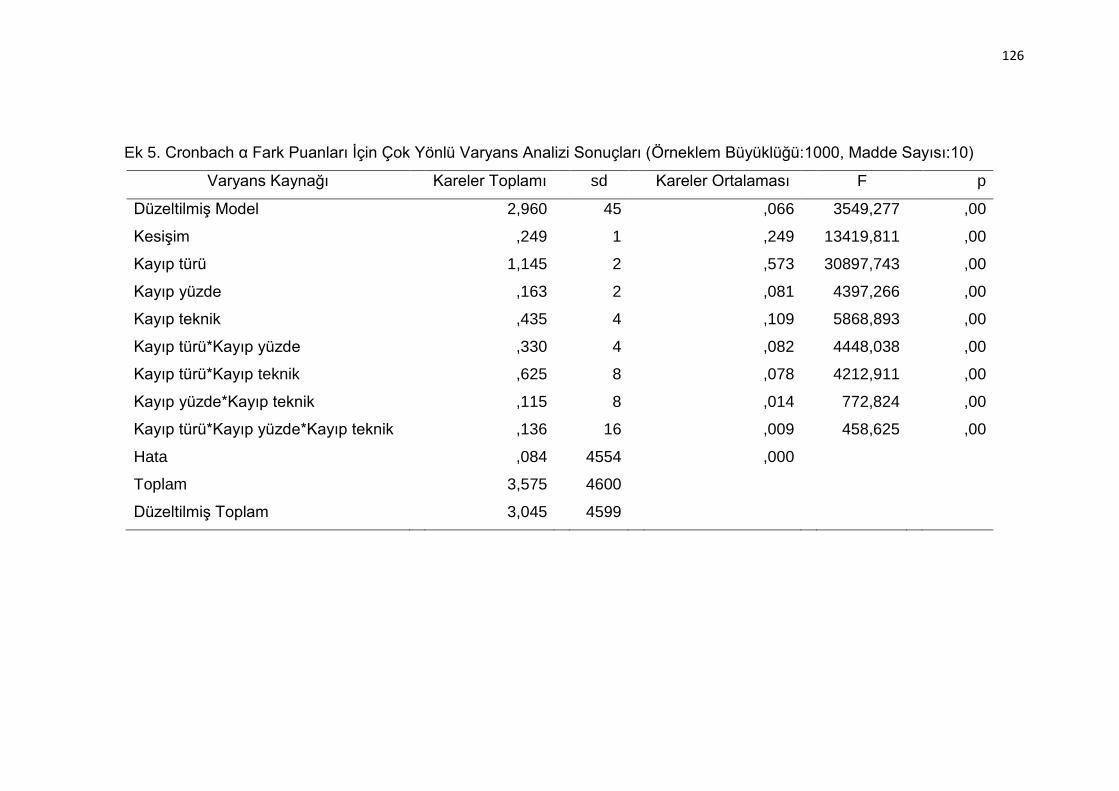
126
Ek 5. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:1000, Madde Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 2,960 45 ,066 3549,277 ,00
Kesişim ,249 1 ,249 13419,811 ,00
Kayıp türü 1,145 2 ,573 30897,743 ,00
Kayıp yüzde ,163 2 ,081 4397,266 ,00
Kayıp teknik ,435 4 ,109 5868,893 ,00
Kayıp türü*Kayıp yüzde ,330 4 ,082 4448,038 ,00
Kayıp türü*Kayıp teknik ,625 8 ,078 4212,911 ,00
Kayıp yüzde*Kayıp teknik ,115 8 ,014 772,824 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,136 16 ,009 458,625 ,00
Hata ,084 4554 ,000
Toplam 3,575 4600
Düzeltilmiş Toplam 3,045 4599
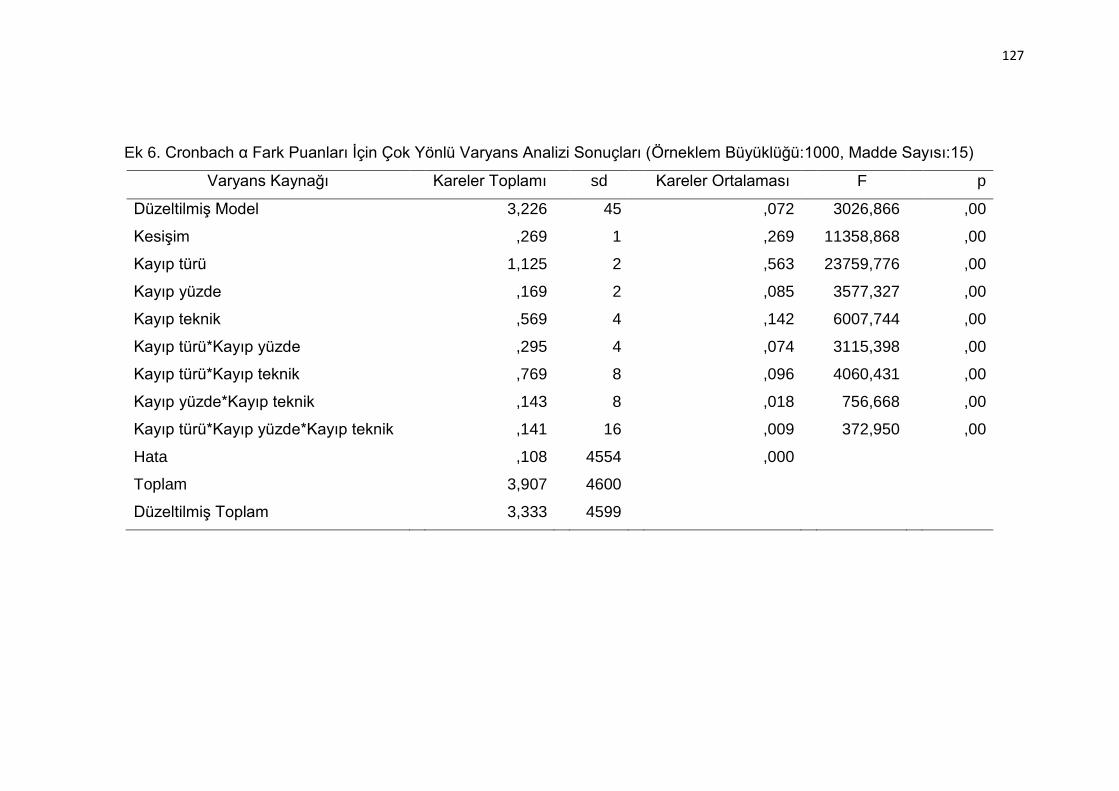
127
Ek 6. Cronbach α Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:1000, Madde Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 3,226 45 ,072 3026,866 ,00
Kesişim ,269 1 ,269 11358,868 ,00
Kayıp türü 1,125 2 ,563 23759,776 ,00
Kayıp yüzde ,169 2 ,085 3577,327 ,00
Kayıp teknik ,569 4 ,142 6007,744 ,00
Kayıp türü*Kayıp yüzde ,295 4 ,074 3115,398 ,00
Kayıp türü*Kayıp teknik ,769 8 ,096 4060,431 ,00
Kayıp yüzde*Kayıp teknik ,143 8 ,018 756,668 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,141 16 ,009 372,950 ,00
Hata ,108 4554 ,000
Toplam 3,907 4600
Düzeltilmiş Toplam 3,333 4599
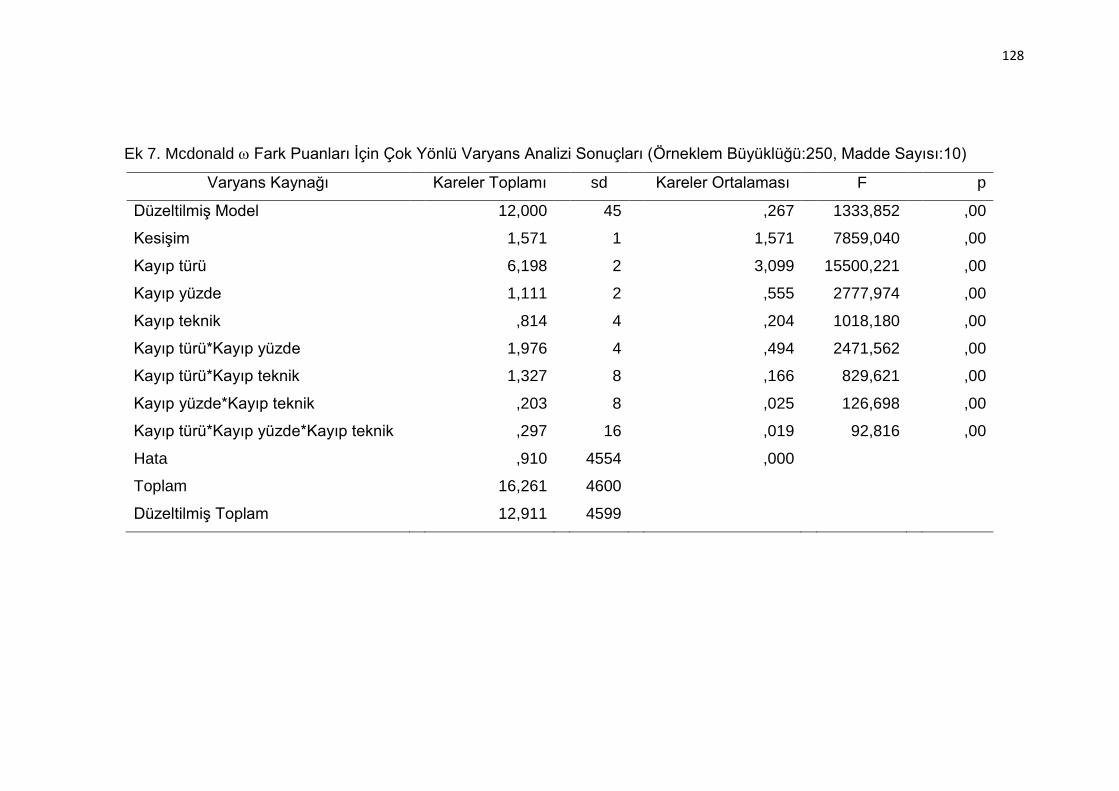
128
Ek 7. Mcdonald Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:250, Madde Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 12,000 45 ,267 1333,852 ,00
Kesişim 1,571 1 1,571 7859,040 ,00
Kayıp türü 6,198 2 3,099 15500,221 ,00
Kayıp yüzde 1,111 2 ,555 2777,974 ,00
Kayıp teknik ,814 4 ,204 1018,180 ,00
Kayıp türü*Kayıp yüzde 1,976 4 ,494 2471,562 ,00
Kayıp türü*Kayıp teknik 1,327 8 ,166 829,621 ,00
Kayıp yüzde*Kayıp teknik ,203 8 ,025 126,698 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,297 16 ,019 92,816 ,00
Hata ,910 4554 ,000
Toplam 16,261 4600
Düzeltilmiş Toplam 12,911 4599
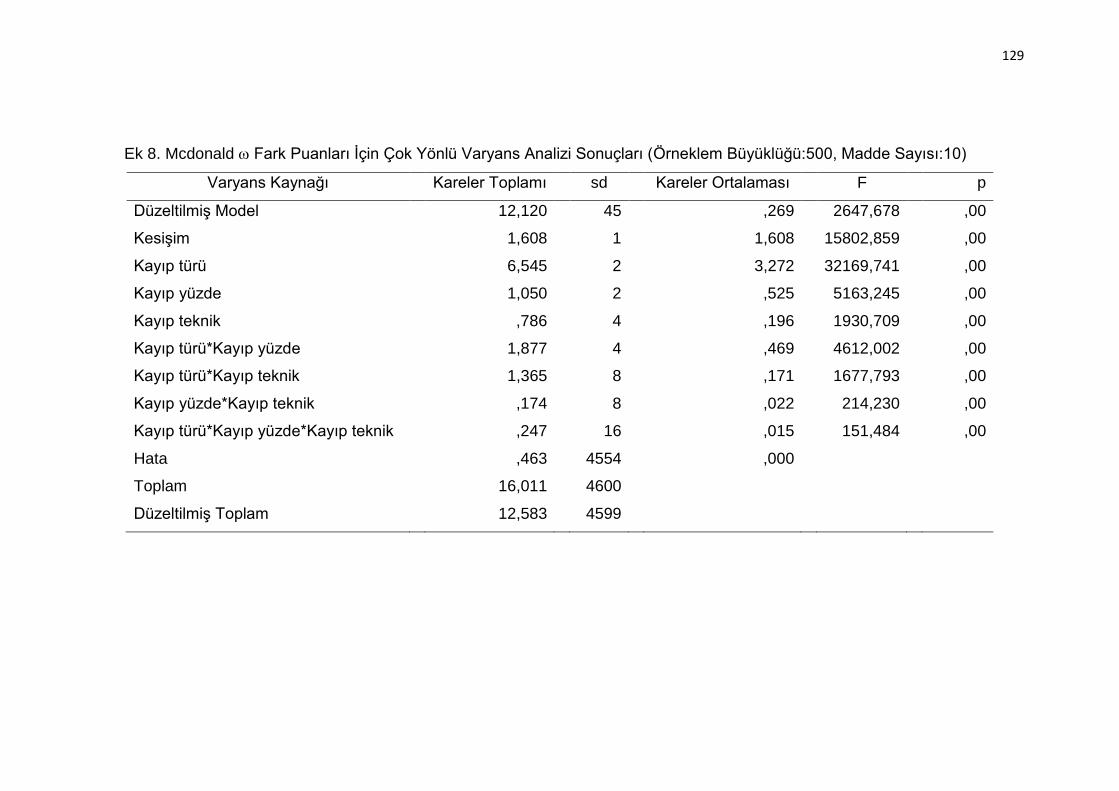
129
Ek 8. Mcdonald Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:500, Madde Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 12,120 45 ,269 2647,678 ,00
Kesişim 1,608 1 1,608 15802,859 ,00
Kayıp türü 6,545 2 3,272 32169,741 ,00
Kayıp yüzde 1,050 2 ,525 5163,245 ,00
Kayıp teknik ,786 4 ,196 1930,709 ,00
Kayıp türü*Kayıp yüzde 1,877 4 ,469 4612,002 ,00
Kayıp türü*Kayıp teknik 1,365 8 ,171 1677,793 ,00
Kayıp yüzde*Kayıp teknik ,174 8 ,022 214,230 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,247 16 ,015 151,484 ,00
Hata ,463 4554 ,000
Toplam 16,011 4600
Düzeltilmiş Toplam 12,583 4599
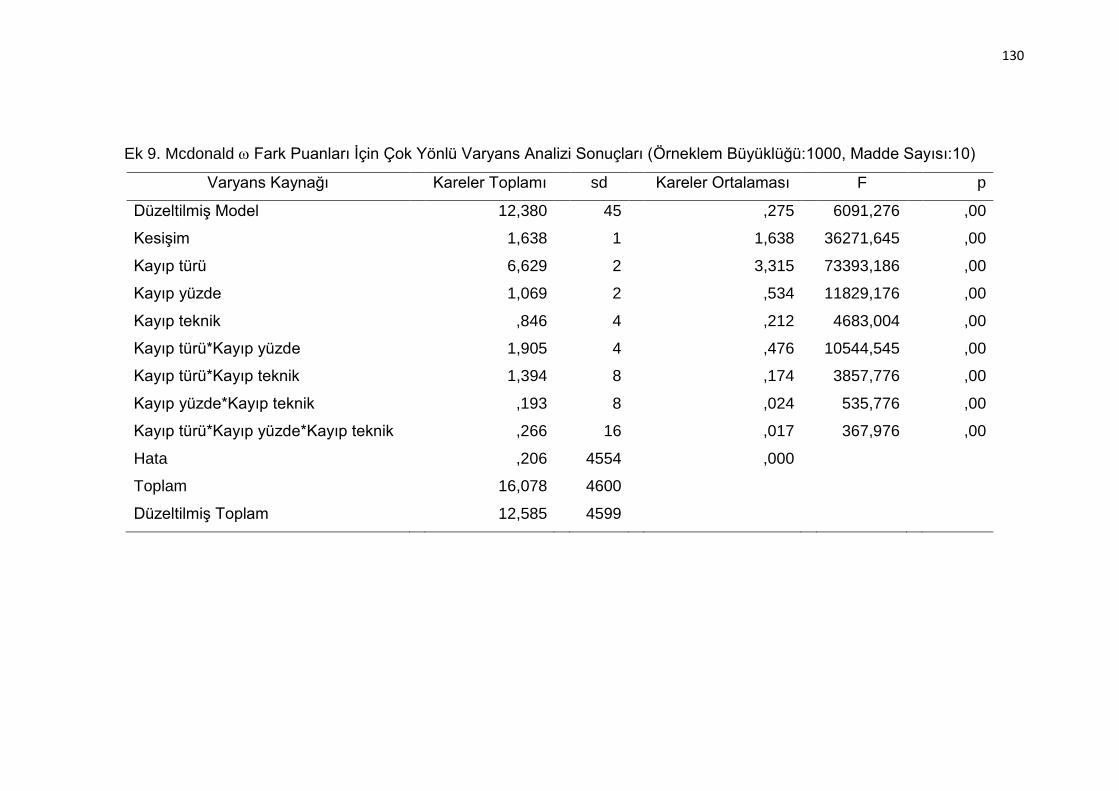
130
Ek 9. Mcdonald Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:1000, Madde Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 12,380 45 ,275 6091,276 ,00
Kesişim 1,638 1 1,638 36271,645 ,00
Kayıp türü 6,629 2 3,315 73393,186 ,00
Kayıp yüzde 1,069 2 ,534 11829,176 ,00
Kayıp teknik ,846 4 ,212 4683,004 ,00
Kayıp türü*Kayıp yüzde 1,905 4 ,476 10544,545 ,00
Kayıp türü*Kayıp teknik 1,394 8 ,174 3857,776 ,00
Kayıp yüzde*Kayıp teknik ,193 8 ,024 535,776 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,266 16 ,017 367,976 ,00
Hata ,206 4554 ,000
Toplam 16,078 4600
Düzeltilmiş Toplam 12,585 4599
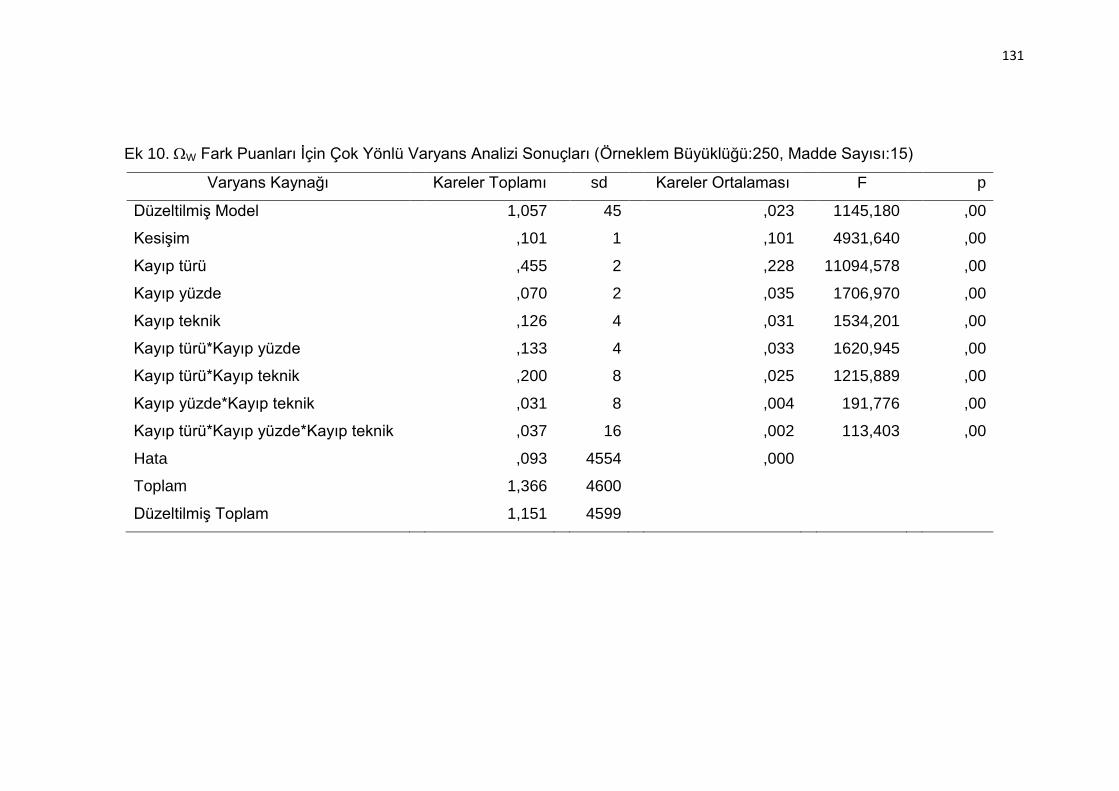
131
Ek 10. W Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:250, Madde Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 1,057 45 ,023 1145,180 ,00
Kesişim ,101 1 ,101 4931,640 ,00
Kayıp türü ,455 2 ,228 11094,578 ,00
Kayıp yüzde ,070 2 ,035 1706,970 ,00
Kayıp teknik ,126 4 ,031 1534,201 ,00
Kayıp türü*Kayıp yüzde ,133 4 ,033 1620,945 ,00
Kayıp türü*Kayıp teknik ,200 8 ,025 1215,889 ,00
Kayıp yüzde*Kayıp teknik ,031 8 ,004 191,776 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,037 16 ,002 113,403 ,00
Hata ,093 4554 ,000
Toplam 1,366 4600
Düzeltilmiş Toplam 1,151 4599
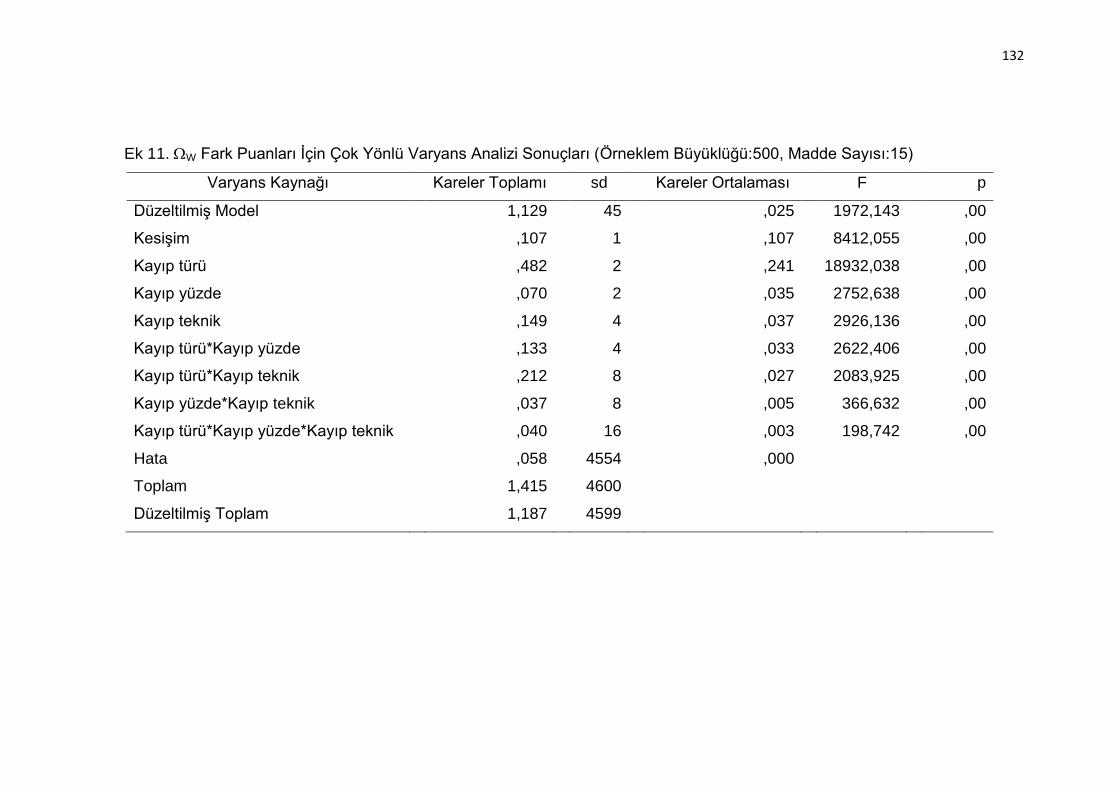
132
Ek 11. W Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:500, Madde Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 1,129 45 ,025 1972,143 ,00
Kesişim ,107 1 ,107 8412,055 ,00
Kayıp türü ,482 2 ,241 18932,038 ,00
Kayıp yüzde ,070 2 ,035 2752,638 ,00
Kayıp teknik ,149 4 ,037 2926,136 ,00
Kayıp türü*Kayıp yüzde ,133 4 ,033 2622,406 ,00
Kayıp türü*Kayıp teknik ,212 8 ,027 2083,925 ,00
Kayıp yüzde*Kayıp teknik ,037 8 ,005 366,632 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,040 16 ,003 198,742 ,00
Hata ,058 4554 ,000
Toplam 1,415 4600
Düzeltilmiş Toplam 1,187 4599
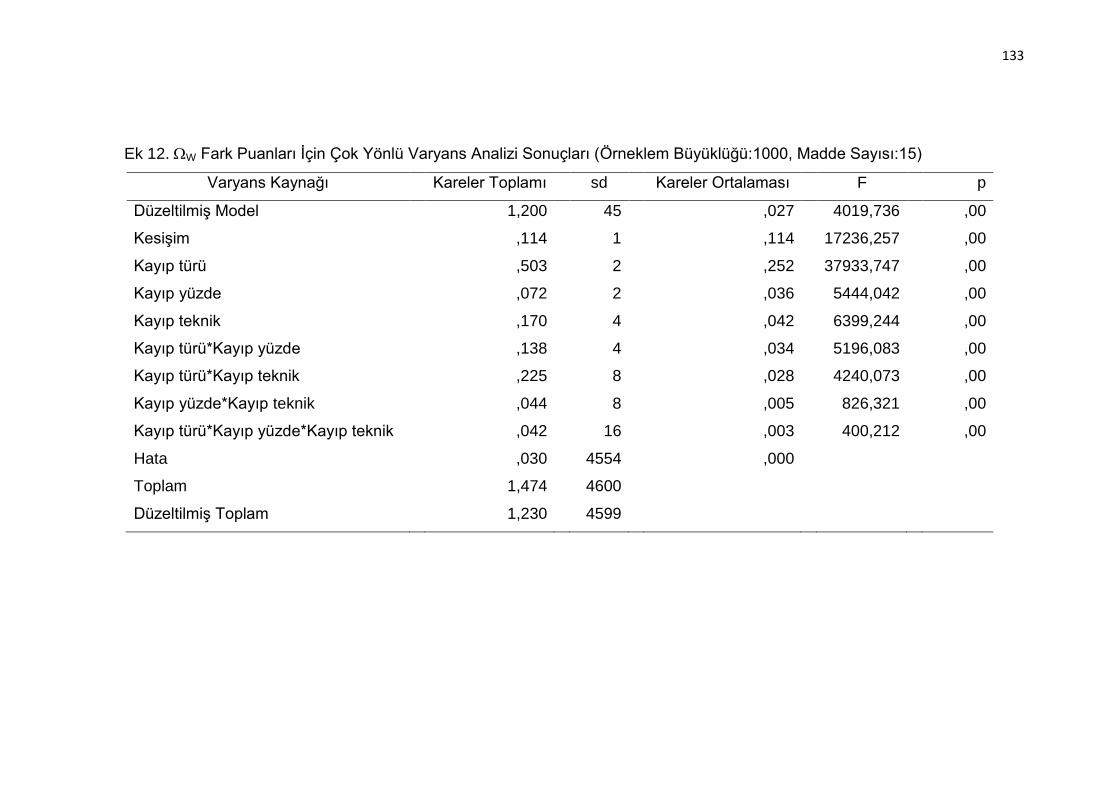
133
Ek 12. W Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:1000, Madde Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 1,200 45 ,027 4019,736 ,00
Kesişim ,114 1 ,114 17236,257 ,00
Kayıp türü ,503 2 ,252 37933,747 ,00
Kayıp yüzde ,072 2 ,036 5444,042 ,00
Kayıp teknik ,170 4 ,042 6399,244 ,00
Kayıp türü*Kayıp yüzde ,138 4 ,034 5196,083 ,00
Kayıp türü*Kayıp teknik ,225 8 ,028 4240,073 ,00
Kayıp yüzde*Kayıp teknik ,044 8 ,005 826,321 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik ,042 16 ,003 400,212 ,00
Hata ,030 4554 ,000
Toplam 1,474 4600
Düzeltilmiş Toplam 1,230 4599
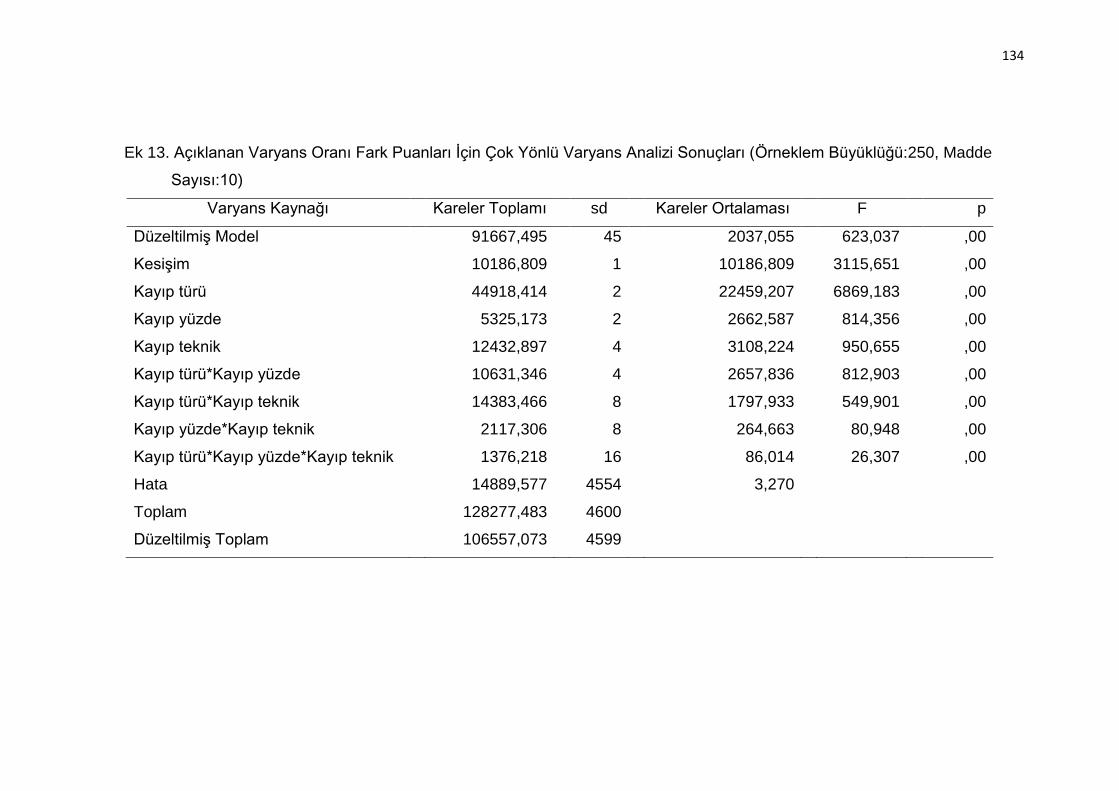
134
Ek 13. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:250, Madde
Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 91667,495 45 2037,055 623,037 ,00
Kesişim 10186,809 1 10186,809 3115,651 ,00
Kayıp türü 44918,414 2 22459,207 6869,183 ,00
Kayıp yüzde 5325,173 2 2662,587 814,356 ,00
Kayıp teknik 12432,897 4 3108,224 950,655 ,00
Kayıp türü*Kayıp yüzde 10631,346 4 2657,836 812,903 ,00
Kayıp türü*Kayıp teknik 14383,466 8 1797,933 549,901 ,00
Kayıp yüzde*Kayıp teknik 2117,306 8 264,663 80,948 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik 1376,218 16 86,014 26,307 ,00
Hata 14889,577 4554 3,270
Toplam 128277,483 4600
Düzeltilmiş Toplam 106557,073 4599
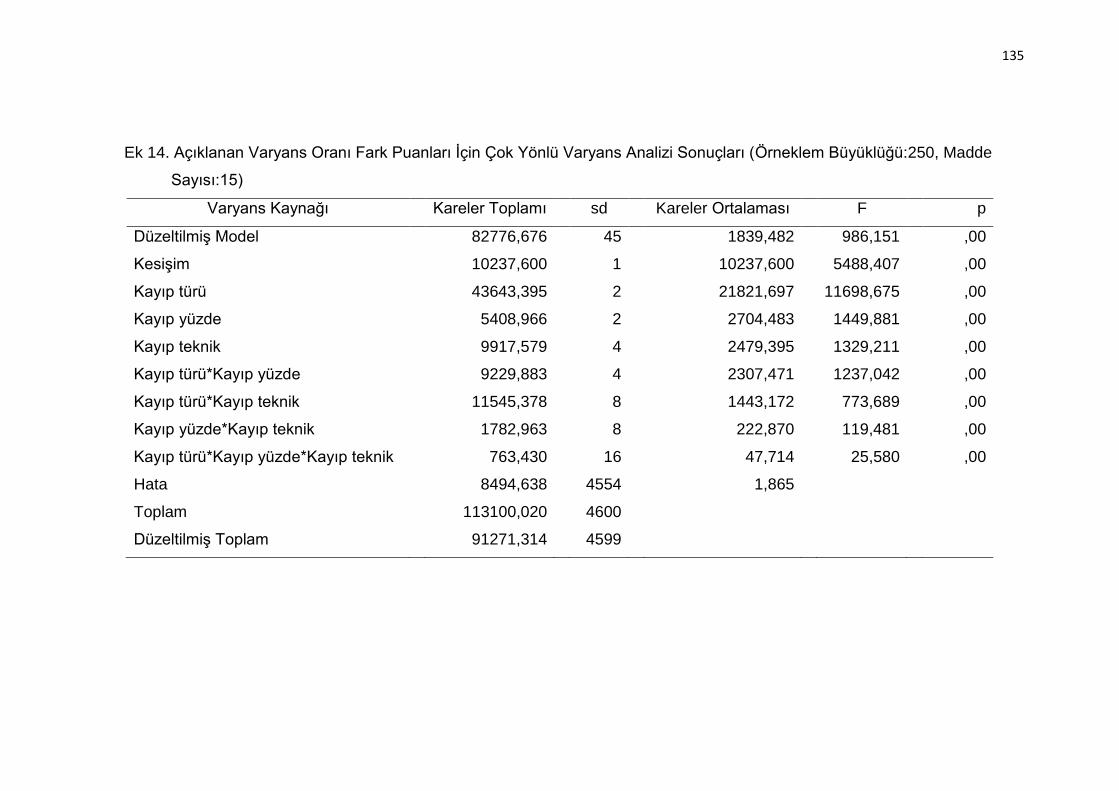
135
Ek 14. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:250, Madde
Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 82776,676 45 1839,482 986,151 ,00
Kesişim 10237,600 1 10237,600 5488,407 ,00
Kayıp türü 43643,395 2 21821,697 11698,675 ,00
Kayıp yüzde 5408,966 2 2704,483 1449,881 ,00
Kayıp teknik 9917,579 4 2479,395 1329,211 ,00
Kayıp türü*Kayıp yüzde 9229,883 4 2307,471 1237,042 ,00
Kayıp türü*Kayıp teknik 11545,378 8 1443,172 773,689 ,00
Kayıp yüzde*Kayıp teknik 1782,963 8 222,870 119,481 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik 763,430 16 47,714 25,580 ,00
Hata 8494,638 4554 1,865
Toplam 113100,020 4600
Düzeltilmiş Toplam 91271,314 4599
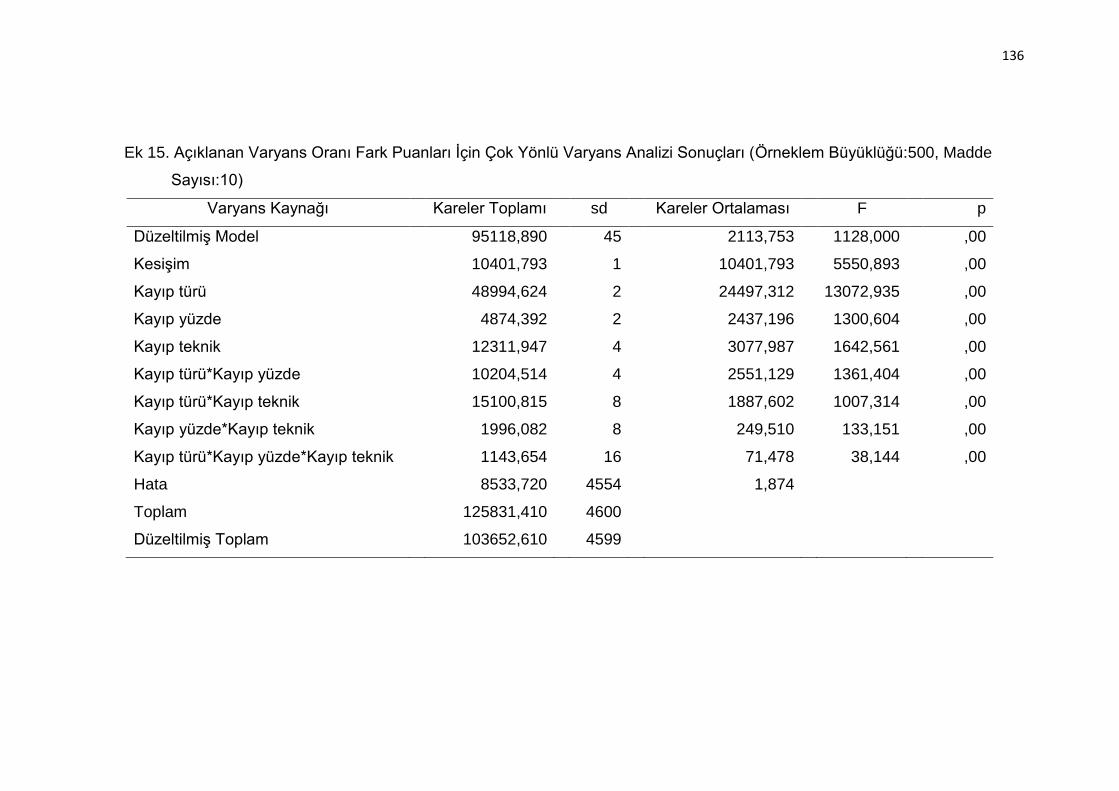
136
Ek 15. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:500, Madde
Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 95118,890 45 2113,753 1128,000 ,00
Kesişim 10401,793 1 10401,793 5550,893 ,00
Kayıp türü 48994,624 2 24497,312 13072,935 ,00
Kayıp yüzde 4874,392 2 2437,196 1300,604 ,00
Kayıp teknik 12311,947 4 3077,987 1642,561 ,00
Kayıp türü*Kayıp yüzde 10204,514 4 2551,129 1361,404 ,00
Kayıp türü*Kayıp teknik 15100,815 8 1887,602 1007,314 ,00
Kayıp yüzde*Kayıp teknik 1996,082 8 249,510 133,151 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik 1143,654 16 71,478 38,144 ,00
Hata 8533,720 4554 1,874
Toplam 125831,410 4600
Düzeltilmiş Toplam 103652,610 4599
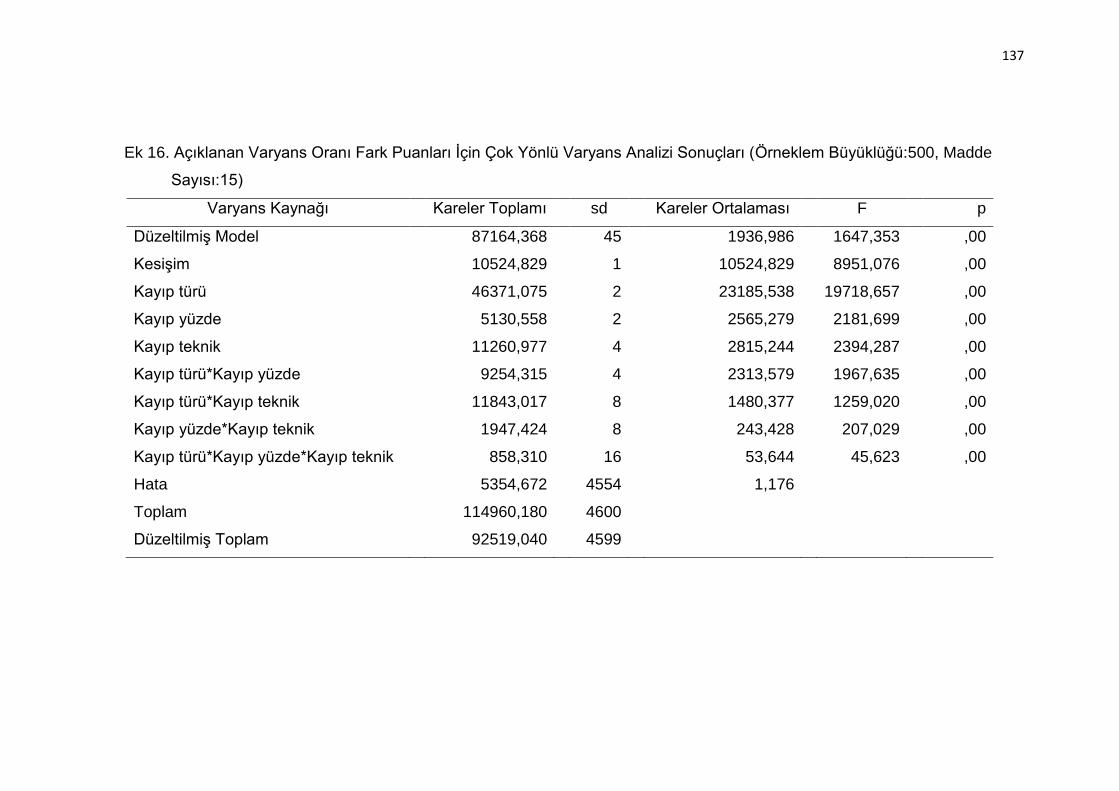
137
Ek 16. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:500, Madde
Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 87164,368 45 1936,986 1647,353 ,00
Kesişim 10524,829 1 10524,829 8951,076 ,00
Kayıp türü 46371,075 2 23185,538 19718,657 ,00
Kayıp yüzde 5130,558 2 2565,279 2181,699 ,00
Kayıp teknik 11260,977 4 2815,244 2394,287 ,00
Kayıp türü*Kayıp yüzde 9254,315 4 2313,579 1967,635 ,00
Kayıp türü*Kayıp teknik 11843,017 8 1480,377 1259,020 ,00
Kayıp yüzde*Kayıp teknik 1947,424 8 243,428 207,029 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik 858,310 16 53,644 45,623 ,00
Hata 5354,672 4554 1,176
Toplam 114960,180 4600
Düzeltilmiş Toplam 92519,040 4599
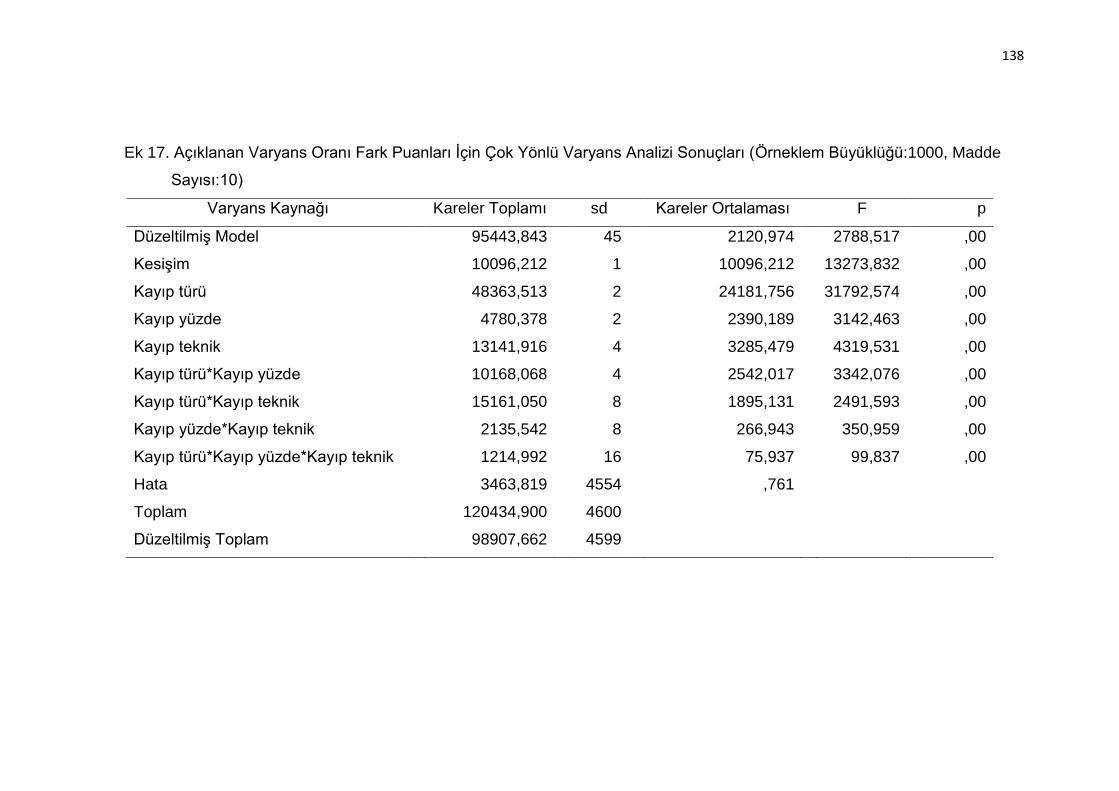
138
Ek 17. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:1000, Madde
Sayısı:10)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 95443,843 45 2120,974 2788,517 ,00
Kesişim 10096,212 1 10096,212 13273,832 ,00
Kayıp türü 48363,513 2 24181,756 31792,574 ,00
Kayıp yüzde 4780,378 2 2390,189 3142,463 ,00
Kayıp teknik 13141,916 4 3285,479 4319,531 ,00
Kayıp türü*Kayıp yüzde 10168,068 4 2542,017 3342,076 ,00
Kayıp türü*Kayıp teknik 15161,050 8 1895,131 2491,593 ,00
Kayıp yüzde*Kayıp teknik 2135,542 8 266,943 350,959 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik 1214,992 16 75,937 99,837 ,00
Hata 3463,819 4554 ,761
Toplam 120434,900 4600
Düzeltilmiş Toplam 98907,662 4599
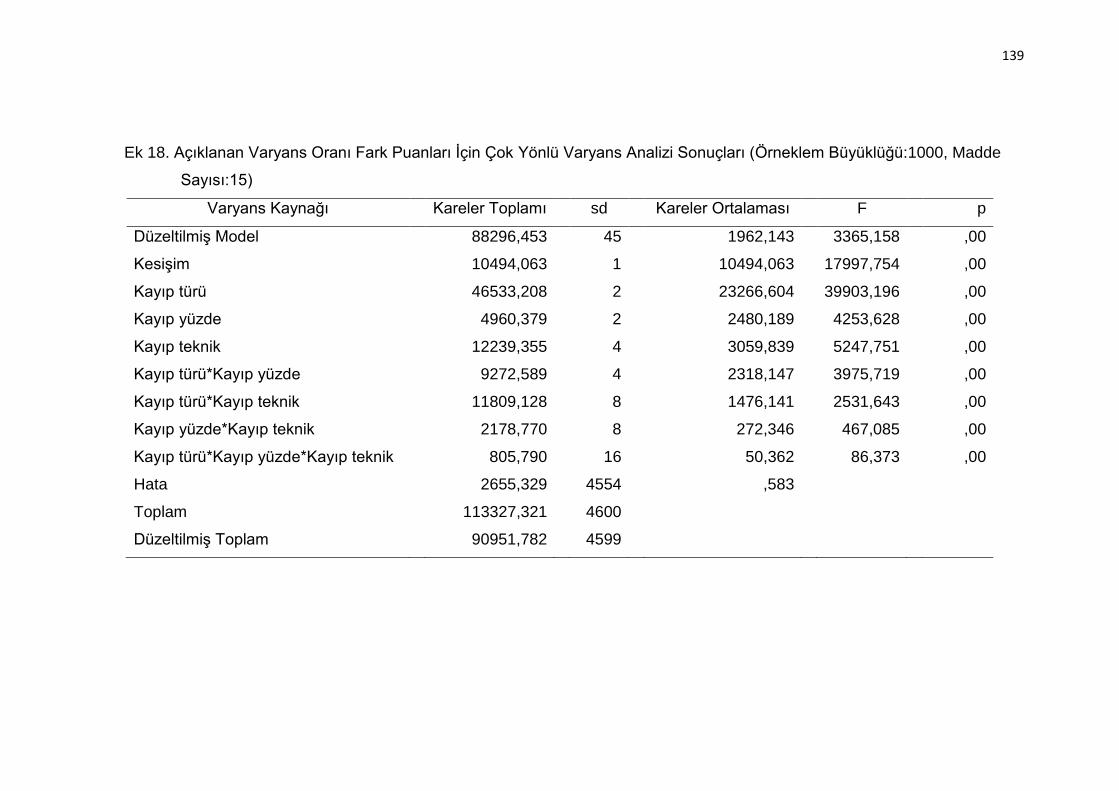
139
Ek 18. Açıklanan Varyans Oranı Fark Puanları İçin Çok Yönlü Varyans Analizi Sonuçları (Örneklem Büyüklüğü:1000, Madde
Sayısı:15)
Varyans Kaynağı Kareler Toplamı sd Kareler Ortalaması F p
Düzeltilmiş Model 88296,453 45 1962,143 3365,158 ,00
Kesişim 10494,063 1 10494,063 17997,754 ,00
Kayıp türü 46533,208 2 23266,604 39903,196 ,00
Kayıp yüzde 4960,379 2 2480,189 4253,628 ,00
Kayıp teknik 12239,355 4 3059,839 5247,751 ,00
Kayıp türü*Kayıp yüzde 9272,589 4 2318,147 3975,719 ,00
Kayıp türü*Kayıp teknik 11809,128 8 1476,141 2531,643 ,00
Kayıp yüzde*Kayıp teknik 2178,770 8 272,346 467,085 ,00
Kayıp türü*Kayıp yüzde*Kayıp teknik 805,790 16 50,362 86,373 ,00
Hata 2655,329 4554 ,583
Toplam 113327,321 4600
Düzeltilmiş Toplam 90951,782 4599
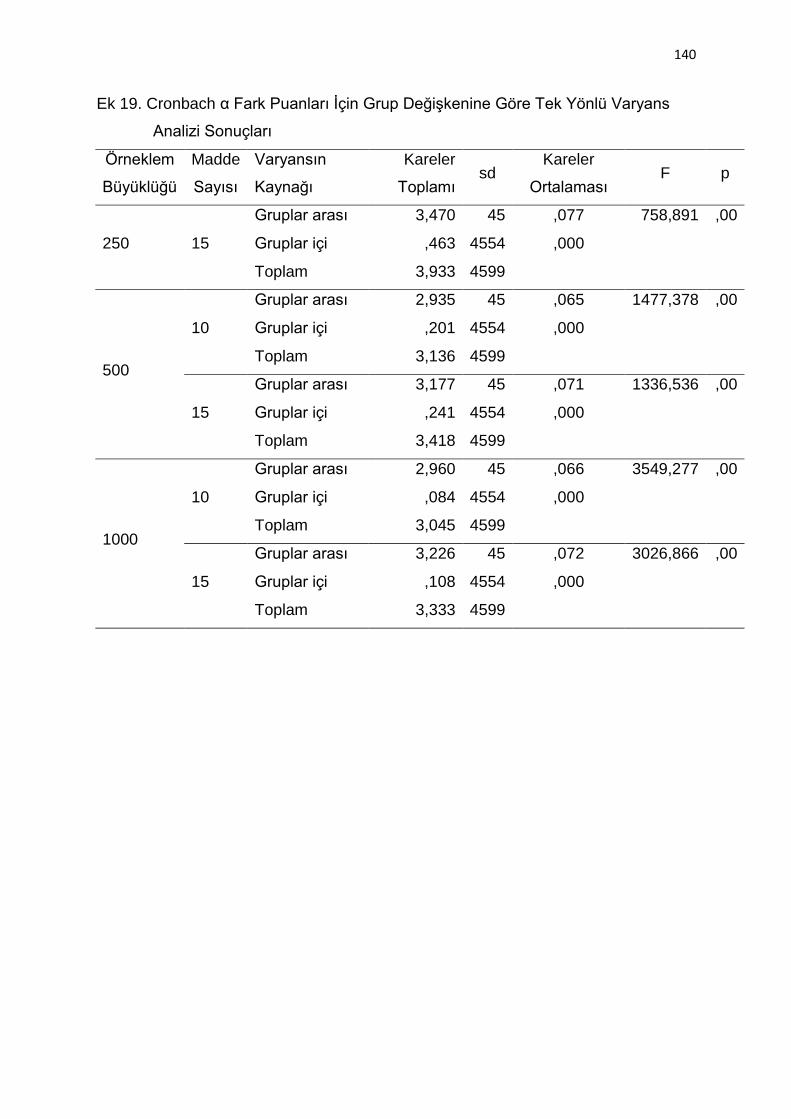
140
Ek 19. Cronbach α Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü Varyans
Analizi Sonuçları
Örneklem
Büyüklüğü
Madde
Sayısı
Varyansın
Kaynağı
Kareler
Toplamı sd
Kareler
Ortalaması F p
250 15
Gruplar arası 3,470 45 ,077 758,891 ,00
Gruplar içi ,463 4554 ,000
Toplam 3,933 4599
500
10
Gruplar arası 2,935 45 ,065 1477,378 ,00
Gruplar içi ,201 4554 ,000
Toplam 3,136 4599
15
Gruplar arası 3,177 45 ,071 1336,536 ,00
Gruplar içi ,241 4554 ,000
Toplam 3,418 4599
1000
10
Gruplar arası 2,960 45 ,066 3549,277 ,00
Gruplar içi ,084 4554 ,000
Toplam 3,045 4599
15
Gruplar arası 3,226 45 ,072 3026,866 ,00
Gruplar içi ,108 4554 ,000
Toplam 3,333 4599
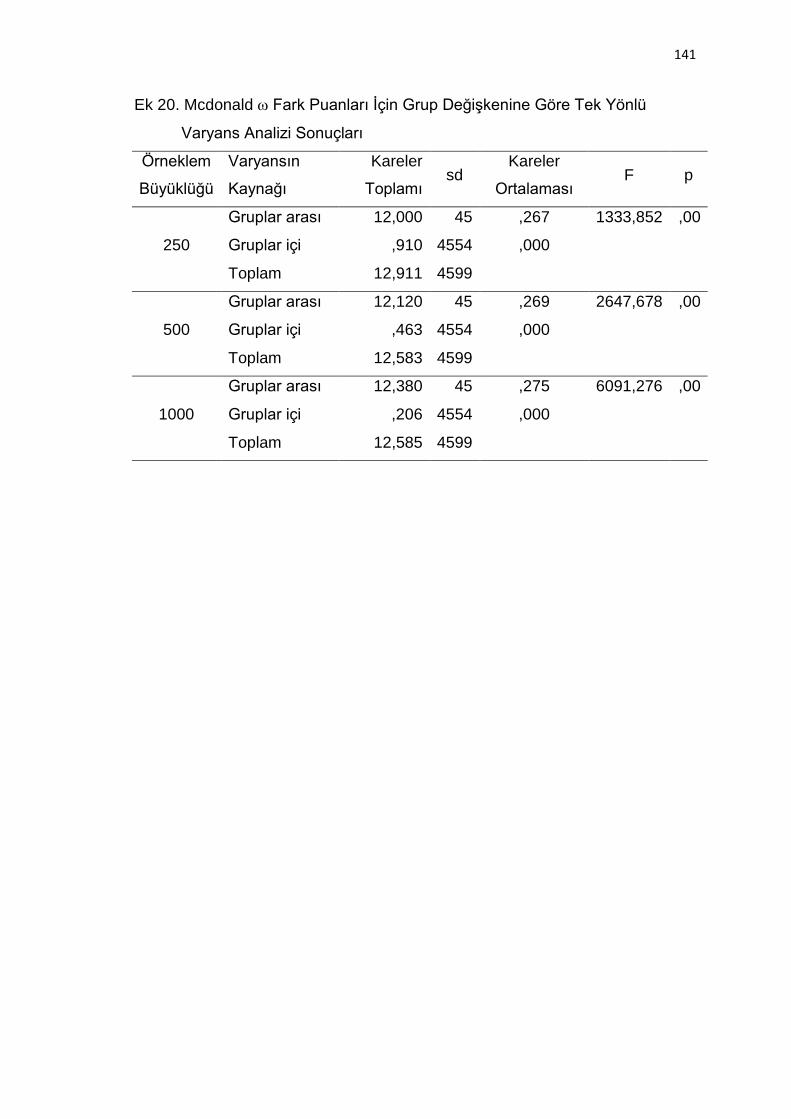
141
Ek 20. Mcdonald Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü
Varyans Analizi Sonuçları
Örneklem
Büyüklüğü
Varyansın
Kaynağı
Kareler
Toplamı sd
Kareler
Ortalaması F p
250
Gruplar arası 12,000 45 ,267 1333,852 ,00
Gruplar içi ,910 4554 ,000
Toplam 12,911 4599
500
Gruplar arası 12,120 45 ,269 2647,678 ,00
Gruplar içi ,463 4554 ,000
Toplam 12,583 4599
1000
Gruplar arası 12,380 45 ,275 6091,276 ,00
Gruplar içi ,206 4554 ,000
Toplam 12,585 4599
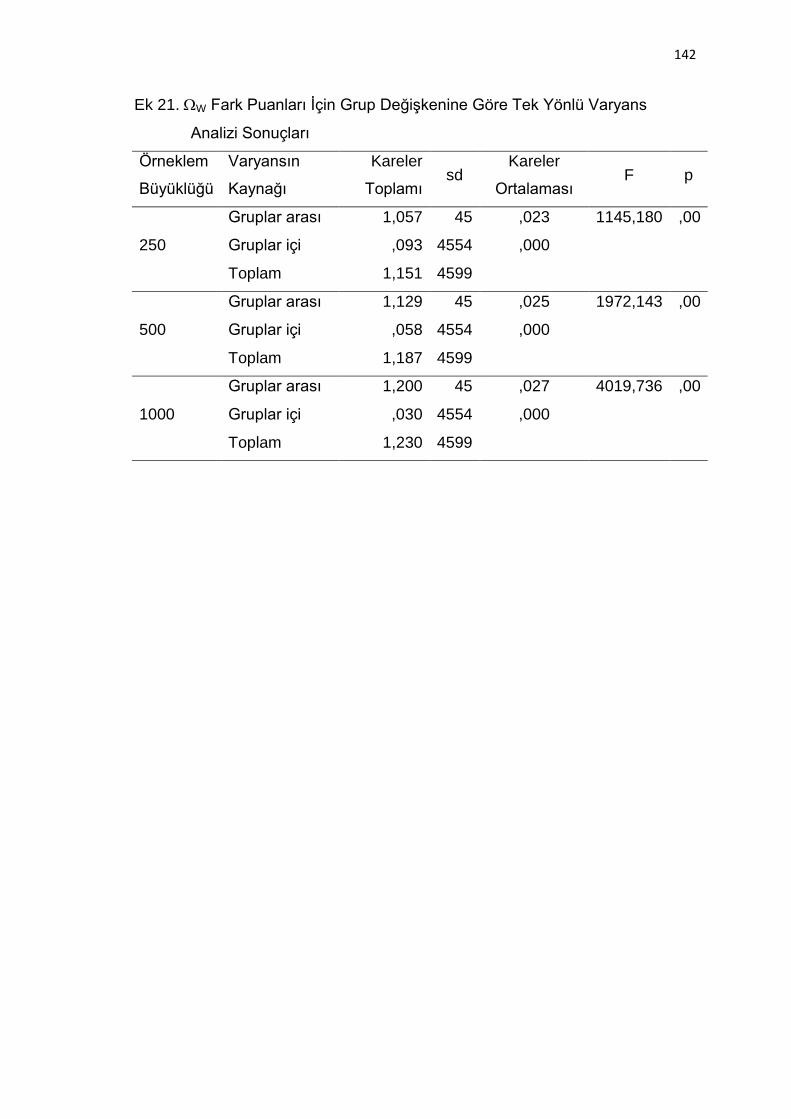
142
Ek 21. W Fark Puanları İçin Grup Değişkenine Göre Tek Yönlü Varyans
Analizi Sonuçları
Örneklem
Büyüklüğü
Varyansın
Kaynağı
Kareler
Toplamı sd
Kareler
Ortalaması F p
250
Gruplar arası 1,057 45 ,023 1145,180 ,00
Gruplar içi ,093 4554 ,000
Toplam 1,151 4599
500
Gruplar arası 1,129 45 ,025 1972,143 ,00
Gruplar içi ,058 4554 ,000
Toplam 1,187 4599
1000
Gruplar arası 1,200 45 ,027 4019,736 ,00
Gruplar içi ,030 4554 ,000
Toplam 1,230 4599
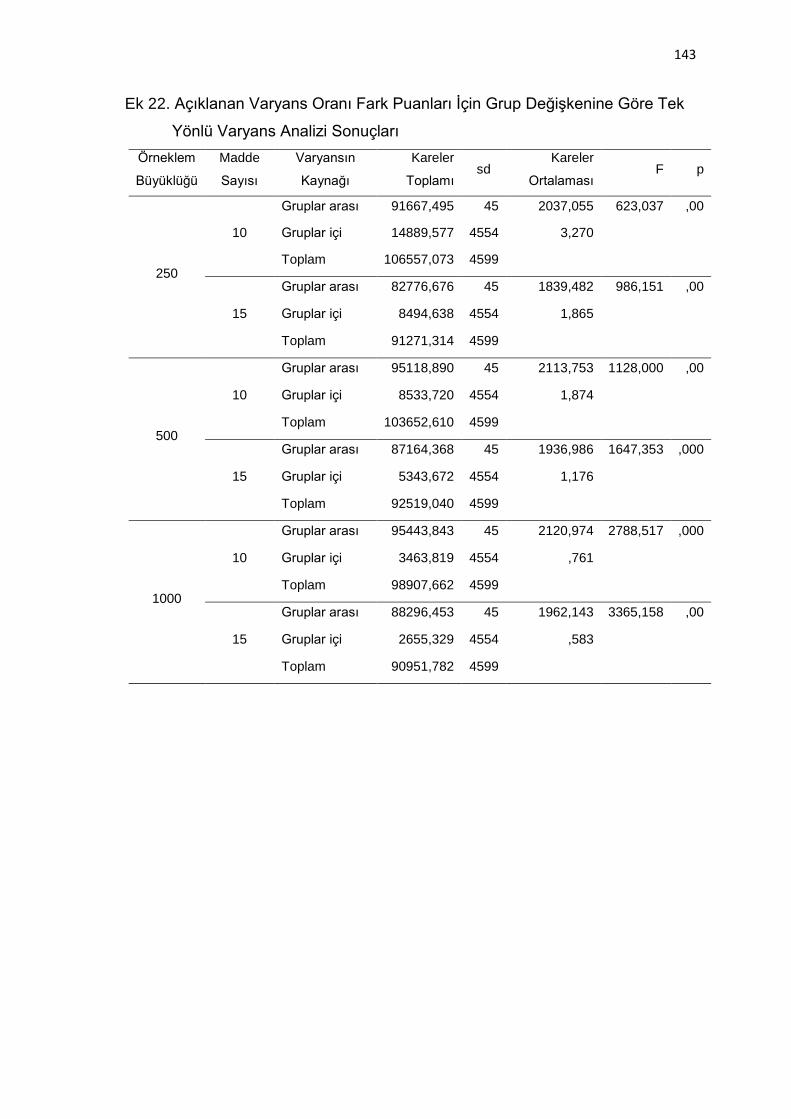
143
Ek 22. Açıklanan Varyans Oranı Fark Puanları İçin Grup Değişkenine Göre Tek
Yönlü Varyans Analizi Sonuçları
Örneklem
Büyüklüğü
Madde
Sayısı
Varyansın
Kaynağı
Kareler
Toplamı sd
Kareler
Ortalaması F p
250
10
Gruplar arası 91667,495 45 2037,055 623,037 ,00
Gruplar içi 14889,577 4554 3,270
Toplam 106557,073 4599
15
Gruplar arası 82776,676 45 1839,482 986,151 ,00
Gruplar içi 8494,638 4554 1,865
Toplam 91271,314 4599
500
10
Gruplar arası 95118,890 45 2113,753 1128,000 ,00
Gruplar içi 8533,720 4554 1,874
Toplam 103652,610 4599
15
Gruplar arası 87164,368 45 1936,986 1647,353 ,000
Gruplar içi 5343,672 4554 1,176
Toplam 92519,040 4599
1000
10
Gruplar arası 95443,843 45 2120,974 2788,517 ,000
Gruplar içi 3463,819 4554 ,761
Toplam 98907,662 4599
15
Gruplar arası 88296,453 45 1962,143 3365,158 ,00
Gruplar içi 2655,329 4554 ,583
Toplam 90951,782 4599
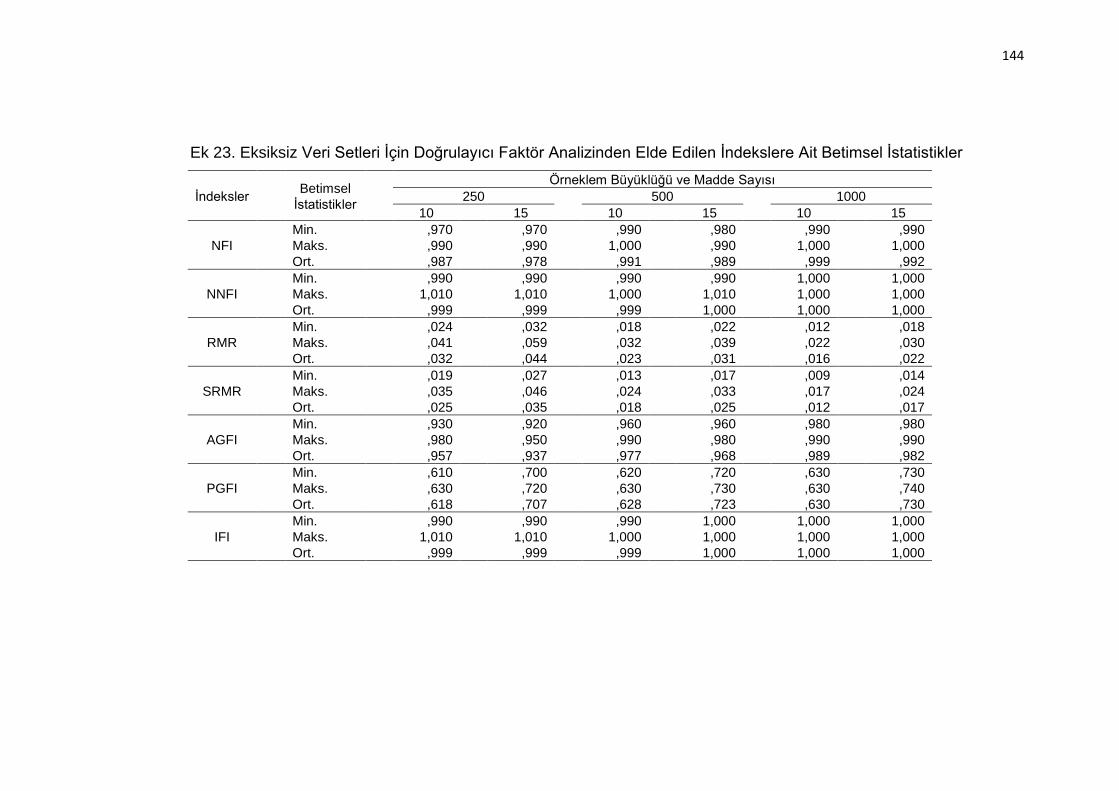
144
Ek 23. Eksiksiz Veri Setleri İçin Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler
İndeksler
Betimsel
İstatistikler
Örneklem Büyüklüğü ve Madde Sayısı
250 500 1000
10 15 10 15 10 15
NFI
Min. ,970 ,970 ,990 ,980 ,990 ,990
Maks. ,990 ,990 1,000 ,990 1,000 1,000
Ort. ,987 ,978 ,991 ,989 ,999 ,992
NNFI
Min. ,990 ,990 ,990 ,990 1,000 1,000
Maks. 1,010 1,010 1,000 1,010 1,000 1,000
Ort. ,999 ,999 ,999 1,000 1,000 1,000
RMR
Min. ,024 ,032 ,018 ,022 ,012 ,018
Maks. ,041 ,059 ,032 ,039 ,022 ,030
Ort. ,032 ,044 ,023 ,031 ,016 ,022
SRMR
Min. ,019 ,027 ,013 ,017 ,009 ,014
Maks. ,035 ,046 ,024 ,033 ,017 ,024
Ort. ,025 ,035 ,018 ,025 ,012 ,017
AGFI
Min. ,930 ,920 ,960 ,960 ,980 ,980
Maks. ,980 ,950 ,990 ,980 ,990 ,990
Ort. ,957 ,937 ,977 ,968 ,989 ,982
PGFI
Min. ,610 ,700 ,620 ,720 ,630 ,730
Maks. ,630 ,720 ,630 ,730 ,630 ,740
Ort. ,618 ,707 ,628 ,723 ,630 ,730
IFI
Min. ,990 ,990 ,990 1,000 1,000 1,000
Maks. 1,010 1,010 1,000 1,000 1,000 1,000
Ort. ,999 ,999 ,999 1,000 1,000 1,000
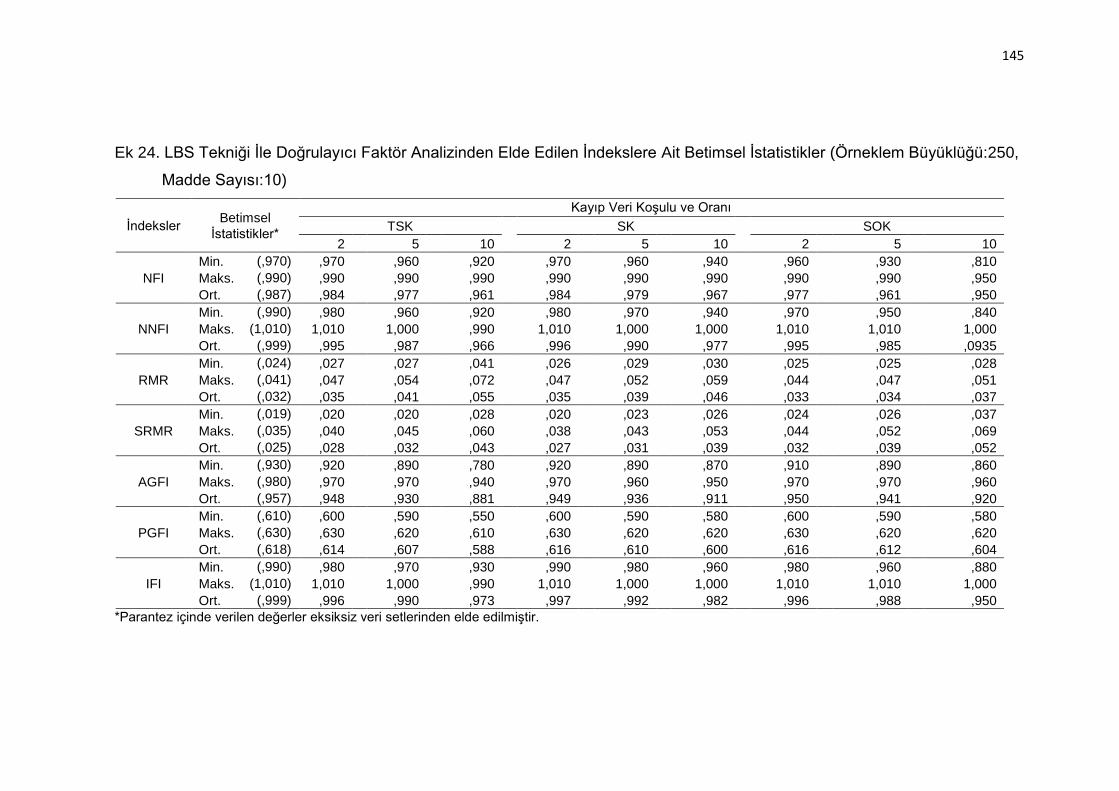
145
Ek 24. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,970 ,960 ,920 ,970 ,960 ,940 ,960 ,930 ,810
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,950
Ort. (,987) ,984 ,977 ,961 ,984 ,979 ,967 ,977 ,961 ,950
NNFI
Min. (,990) ,980 ,960 ,920 ,980 ,970 ,940 ,970 ,950 ,840
Maks. (1,010) 1,010 1,000 ,990 1,010 1,000 1,000 1,010 1,010 1,000
Ort. (,999) ,995 ,987 ,966 ,996 ,990 ,977 ,995 ,985 ,0935
RMR
Min. (,024) ,027 ,027 ,041 ,026 ,029 ,030 ,025 ,025 ,028
Maks. (,041) ,047 ,054 ,072 ,047 ,052 ,059 ,044 ,047 ,051
Ort. (,032) ,035 ,041 ,055 ,035 ,039 ,046 ,033 ,034 ,037
SRMR
Min. (,019) ,020 ,020 ,028 ,020 ,023 ,026 ,024 ,026 ,037
Maks. (,035) ,040 ,045 ,060 ,038 ,043 ,053 ,044 ,052 ,069
Ort. (,025) ,028 ,032 ,043 ,027 ,031 ,039 ,032 ,039 ,052
AGFI
Min. (,930) ,920 ,890 ,780 ,920 ,890 ,870 ,910 ,890 ,860
Maks. (,980) ,970 ,970 ,940 ,970 ,960 ,950 ,970 ,970 ,960
Ort. (,957) ,948 ,930 ,881 ,949 ,936 ,911 ,950 ,941 ,920
PGFI
Min. (,610) ,600 ,590 ,550 ,600 ,590 ,580 ,600 ,590 ,580
Maks. (,630) ,630 ,620 ,610 ,630 ,620 ,620 ,630 ,620 ,620
Ort. (,618) ,614 ,607 ,588 ,616 ,610 ,600 ,616 ,612 ,604
IFI
Min. (,990) ,980 ,970 ,930 ,990 ,980 ,960 ,980 ,960 ,880
Maks. (1,010) 1,010 1,000 ,990 1,010 1,000 1,000 1,010 1,010 1,000
Ort. (,999) ,996 ,990 ,973 ,997 ,992 ,982 ,996 ,988 ,950
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
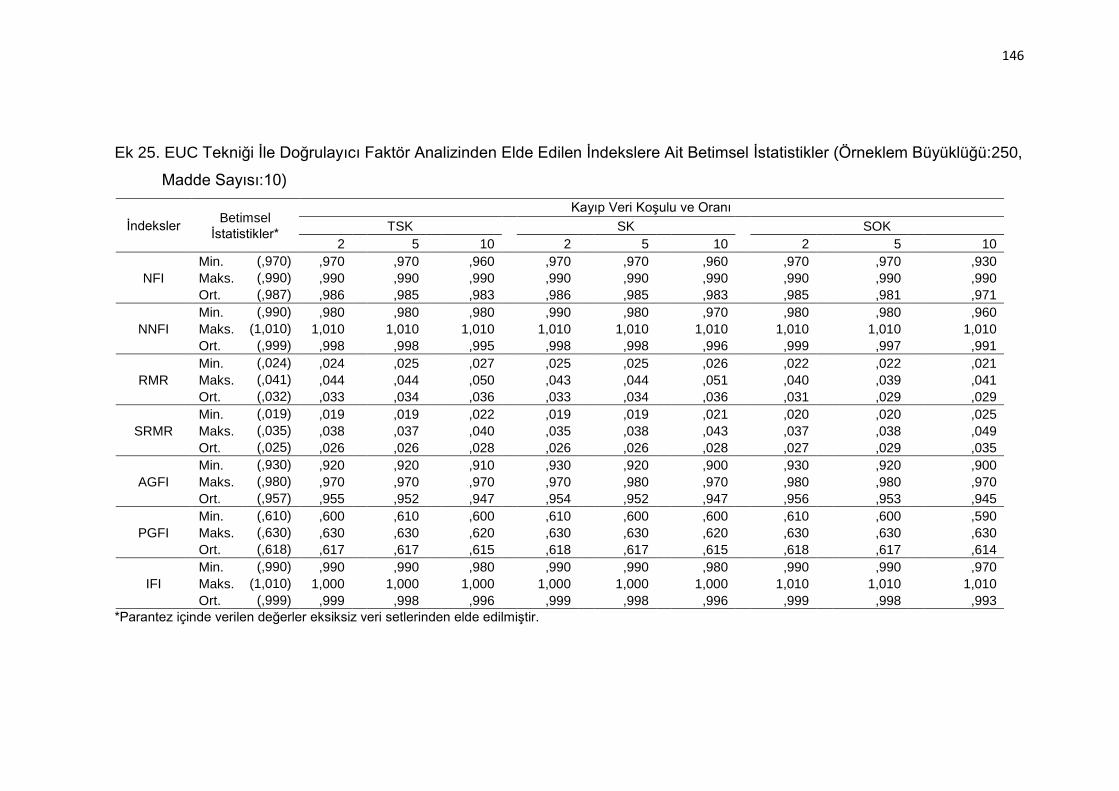
146
Ek 25. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,970 ,970 ,960 ,970 ,970 ,960 ,970 ,970 ,930
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,987) ,986 ,985 ,983 ,986 ,985 ,983 ,985 ,981 ,971
NNFI
Min. (,990) ,980 ,980 ,980 ,990 ,980 ,970 ,980 ,980 ,960
Maks. (1,010) 1,010 1,010 1,010 1,010 1,010 1,010 1,010 1,010 1,010
Ort. (,999) ,998 ,998 ,995 ,998 ,998 ,996 ,999 ,997 ,991
RMR
Min. (,024) ,024 ,025 ,027 ,025 ,025 ,026 ,022 ,022 ,021
Maks. (,041) ,044 ,044 ,050 ,043 ,044 ,051 ,040 ,039 ,041
Ort. (,032) ,033 ,034 ,036 ,033 ,034 ,036 ,031 ,029 ,029
SRMR
Min. (,019) ,019 ,019 ,022 ,019 ,019 ,021 ,020 ,020 ,025
Maks. (,035) ,038 ,037 ,040 ,035 ,038 ,043 ,037 ,038 ,049
Ort. (,025) ,026 ,026 ,028 ,026 ,026 ,028 ,027 ,029 ,035
AGFI
Min. (,930) ,920 ,920 ,910 ,930 ,920 ,900 ,930 ,920 ,900
Maks. (,980) ,970 ,970 ,970 ,970 ,980 ,970 ,980 ,980 ,970
Ort. (,957) ,955 ,952 ,947 ,954 ,952 ,947 ,956 ,953 ,945
PGFI
Min. (,610) ,600 ,610 ,600 ,610 ,600 ,600 ,610 ,600 ,590
Maks. (,630) ,630 ,630 ,620 ,630 ,630 ,620 ,630 ,630 ,630
Ort. (,618) ,617 ,617 ,615 ,618 ,617 ,615 ,618 ,617 ,614
IFI
Min. (,990) ,990 ,990 ,980 ,990 ,990 ,980 ,990 ,990 ,970
Maks. (1,010) 1,000 1,000 1,000 1,000 1,000 1,000 1,010 1,010 1,010
Ort. (,999) ,999 ,998 ,996 ,999 ,998 ,996 ,999 ,998 ,993
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
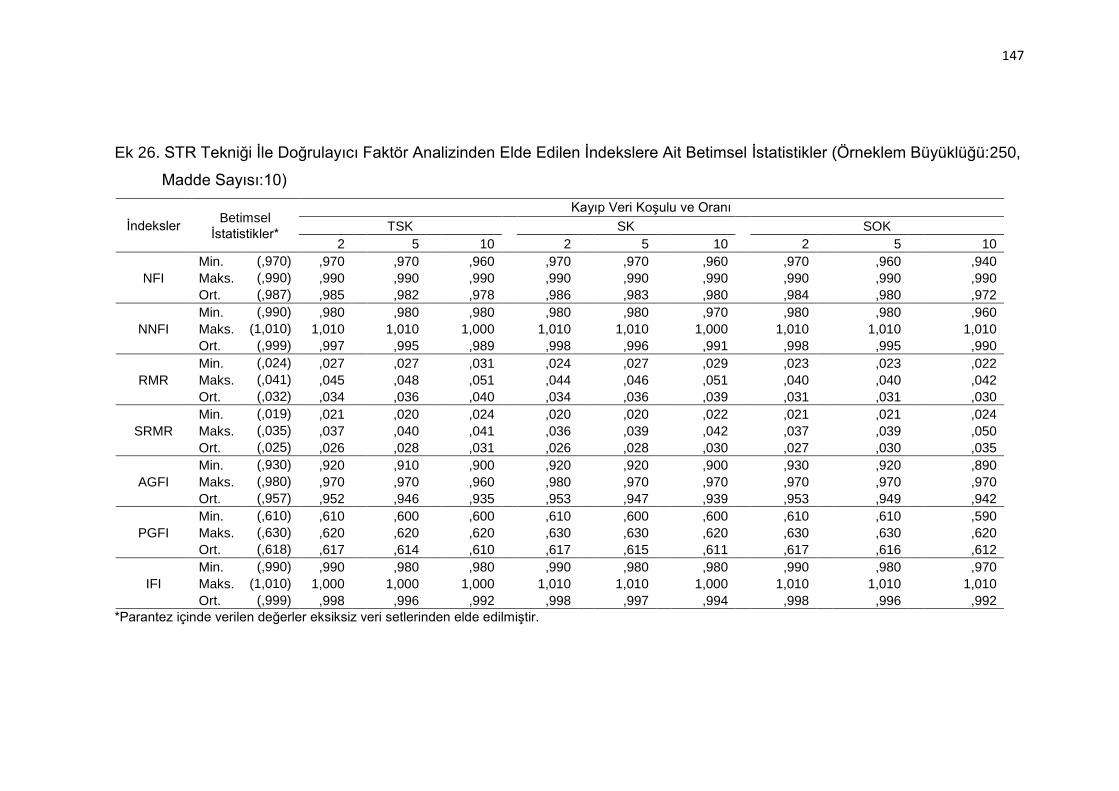
147
Ek 26. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,970 ,970 ,960 ,970 ,970 ,960 ,970 ,960 ,940
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,987) ,985 ,982 ,978 ,986 ,983 ,980 ,984 ,980 ,972
NNFI
Min. (,990) ,980 ,980 ,980 ,980 ,980 ,970 ,980 ,980 ,960
Maks. (1,010) 1,010 1,010 1,000 1,010 1,010 1,000 1,010 1,010 1,010
Ort. (,999) ,997 ,995 ,989 ,998 ,996 ,991 ,998 ,995 ,990
RMR
Min. (,024) ,027 ,027 ,031 ,024 ,027 ,029 ,023 ,023 ,022
Maks. (,041) ,045 ,048 ,051 ,044 ,046 ,051 ,040 ,040 ,042
Ort. (,032) ,034 ,036 ,040 ,034 ,036 ,039 ,031 ,031 ,030
SRMR
Min. (,019) ,021 ,020 ,024 ,020 ,020 ,022 ,021 ,021 ,024
Maks. (,035) ,037 ,040 ,041 ,036 ,039 ,042 ,037 ,039 ,050
Ort. (,025) ,026 ,028 ,031 ,026 ,028 ,030 ,027 ,030 ,035
AGFI
Min. (,930) ,920 ,910 ,900 ,920 ,920 ,900 ,930 ,920 ,890
Maks. (,980) ,970 ,970 ,960 ,980 ,970 ,970 ,970 ,970 ,970
Ort. (,957) ,952 ,946 ,935 ,953 ,947 ,939 ,953 ,949 ,942
PGFI
Min. (,610) ,610 ,600 ,600 ,610 ,600 ,600 ,610 ,610 ,590
Maks. (,630) ,620 ,620 ,620 ,630 ,630 ,620 ,630 ,630 ,620
Ort. (,618) ,617 ,614 ,610 ,617 ,615 ,611 ,617 ,616 ,612
IFI
Min. (,990) ,990 ,980 ,980 ,990 ,980 ,980 ,990 ,980 ,970
Maks. (1,010) 1,000 1,000 1,000 1,010 1,010 1,000 1,010 1,010 1,010
Ort. (,999) ,998 ,996 ,992 ,998 ,997 ,994 ,998 ,996 ,992
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
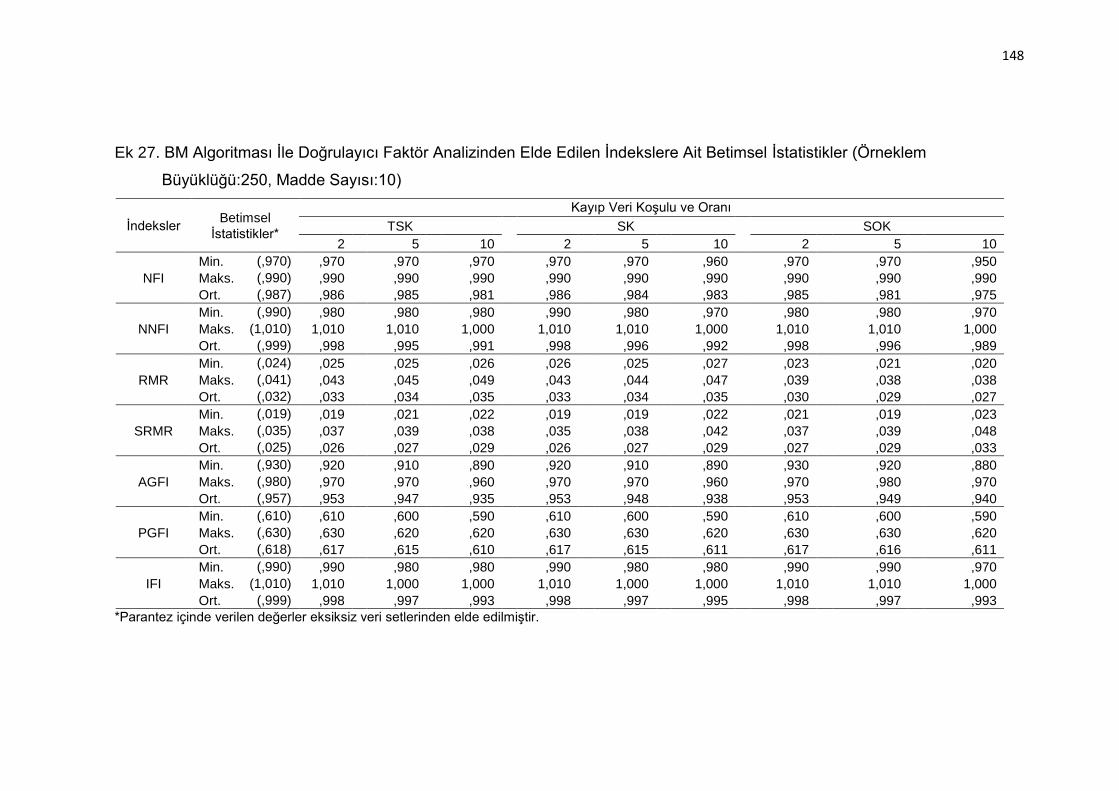
148
Ek 27. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:250, Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,970 ,970 ,970 ,970 ,970 ,960 ,970 ,970 ,950
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,987) ,986 ,985 ,981 ,986 ,984 ,983 ,985 ,981 ,975
NNFI
Min. (,990) ,980 ,980 ,980 ,990 ,980 ,970 ,980 ,980 ,970
Maks. (1,010) 1,010 1,010 1,000 1,010 1,010 1,000 1,010 1,010 1,000
Ort. (,999) ,998 ,995 ,991 ,998 ,996 ,992 ,998 ,996 ,989
RMR
Min. (,024) ,025 ,025 ,026 ,026 ,025 ,027 ,023 ,021 ,020
Maks. (,041) ,043 ,045 ,049 ,043 ,044 ,047 ,039 ,038 ,038
Ort. (,032) ,033 ,034 ,035 ,033 ,034 ,035 ,030 ,029 ,027
SRMR
Min. (,019) ,019 ,021 ,022 ,019 ,019 ,022 ,021 ,019 ,023
Maks. (,035) ,037 ,039 ,038 ,035 ,038 ,042 ,037 ,039 ,048
Ort. (,025) ,026 ,027 ,029 ,026 ,027 ,029 ,027 ,029 ,033
AGFI
Min. (,930) ,920 ,910 ,890 ,920 ,910 ,890 ,930 ,920 ,880
Maks. (,980) ,970 ,970 ,960 ,970 ,970 ,960 ,970 ,980 ,970
Ort. (,957) ,953 ,947 ,935 ,953 ,948 ,938 ,953 ,949 ,940
PGFI
Min. (,610) ,610 ,600 ,590 ,610 ,600 ,590 ,610 ,600 ,590
Maks. (,630) ,630 ,620 ,620 ,630 ,630 ,620 ,630 ,630 ,620
Ort. (,618) ,617 ,615 ,610 ,617 ,615 ,611 ,617 ,616 ,611
IFI
Min. (,990) ,990 ,980 ,980 ,990 ,980 ,980 ,990 ,990 ,970
Maks. (1,010) 1,010 1,000 1,000 1,010 1,000 1,000 1,010 1,010 1,000
Ort. (,999) ,998 ,997 ,993 ,998 ,997 ,995 ,998 ,997 ,993
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
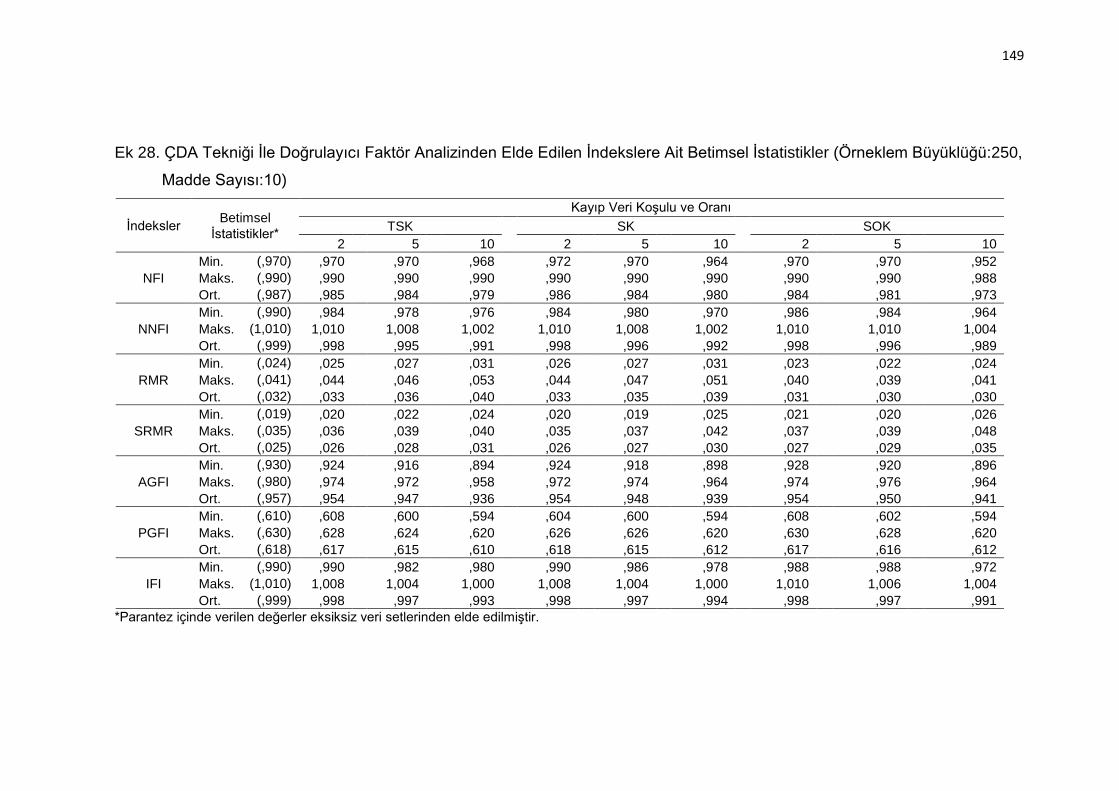
149
Ek 28. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,970 ,970 ,968 ,972 ,970 ,964 ,970 ,970 ,952
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,988
Ort. (,987) ,985 ,984 ,979 ,986 ,984 ,980 ,984 ,981 ,973
NNFI
Min. (,990) ,984 ,978 ,976 ,984 ,980 ,970 ,986 ,984 ,964
Maks. (1,010) 1,010 1,008 1,002 1,010 1,008 1,002 1,010 1,010 1,004
Ort. (,999) ,998 ,995 ,991 ,998 ,996 ,992 ,998 ,996 ,989
RMR
Min. (,024) ,025 ,027 ,031 ,026 ,027 ,031 ,023 ,022 ,024
Maks. (,041) ,044 ,046 ,053 ,044 ,047 ,051 ,040 ,039 ,041
Ort. (,032) ,033 ,036 ,040 ,033 ,035 ,039 ,031 ,030 ,030
SRMR
Min. (,019) ,020 ,022 ,024 ,020 ,019 ,025 ,021 ,020 ,026
Maks. (,035) ,036 ,039 ,040 ,035 ,037 ,042 ,037 ,039 ,048
Ort. (,025) ,026 ,028 ,031 ,026 ,027 ,030 ,027 ,029 ,035
AGFI
Min. (,930) ,924 ,916 ,894 ,924 ,918 ,898 ,928 ,920 ,896
Maks. (,980) ,974 ,972 ,958 ,972 ,974 ,964 ,974 ,976 ,964
Ort. (,957) ,954 ,947 ,936 ,954 ,948 ,939 ,954 ,950 ,941
PGFI
Min. (,610) ,608 ,600 ,594 ,604 ,600 ,594 ,608 ,602 ,594
Maks. (,630) ,628 ,624 ,620 ,626 ,626 ,620 ,630 ,628 ,620
Ort. (,618) ,617 ,615 ,610 ,618 ,615 ,612 ,617 ,616 ,612
IFI
Min. (,990) ,990 ,982 ,980 ,990 ,986 ,978 ,988 ,988 ,972
Maks. (1,010) 1,008 1,004 1,000 1,008 1,004 1,000 1,010 1,006 1,004
Ort. (,999) ,998 ,997 ,993 ,998 ,997 ,994 ,998 ,997 ,991
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
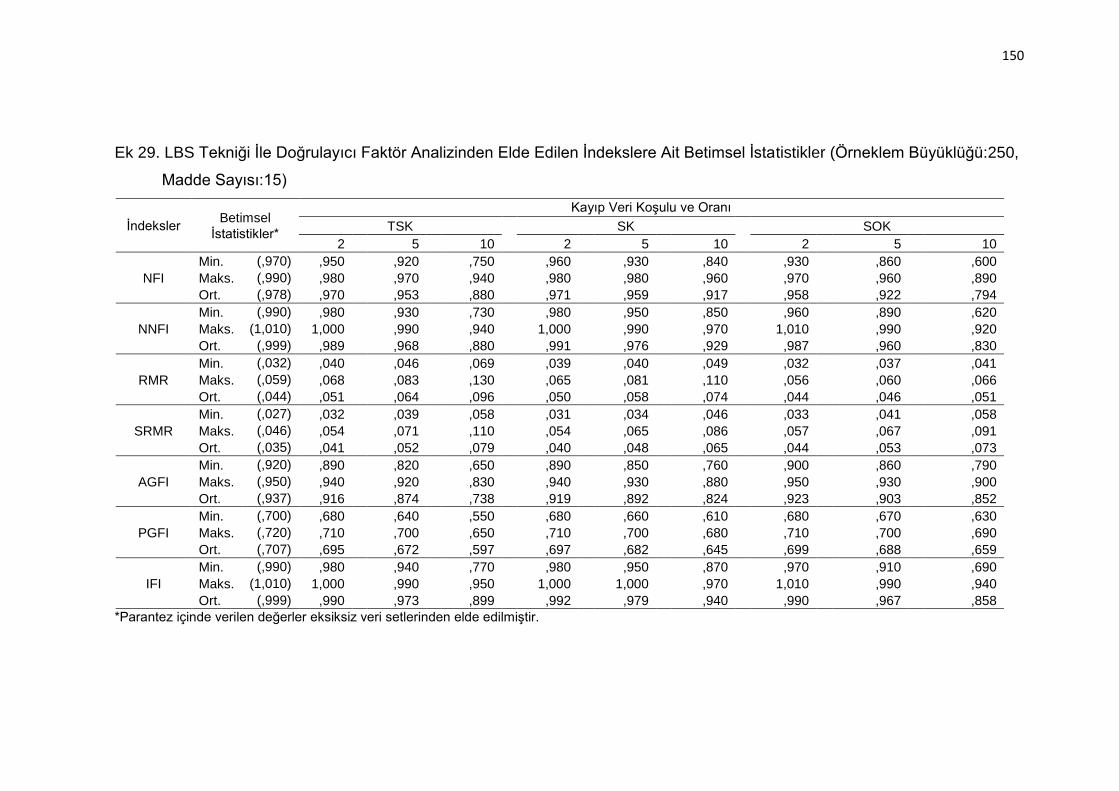
150
Ek 29. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,950 ,920 ,750 ,960 ,930 ,840 ,930 ,860 ,600
Maks. (,990) ,980 ,970 ,940 ,980 ,980 ,960 ,970 ,960 ,890
Ort. (,978) ,970 ,953 ,880 ,971 ,959 ,917 ,958 ,922 ,794
NNFI
Min. (,990) ,980 ,930 ,730 ,980 ,950 ,850 ,960 ,890 ,620
Maks. (1,010) 1,000 ,990 ,940 1,000 ,990 ,970 1,010 ,990 ,920
Ort. (,999) ,989 ,968 ,880 ,991 ,976 ,929 ,987 ,960 ,830
RMR
Min. (,032) ,040 ,046 ,069 ,039 ,040 ,049 ,032 ,037 ,041
Maks. (,059) ,068 ,083 ,130 ,065 ,081 ,110 ,056 ,060 ,066
Ort. (,044) ,051 ,064 ,096 ,050 ,058 ,074 ,044 ,046 ,051
SRMR
Min. (,027) ,032 ,039 ,058 ,031 ,034 ,046 ,033 ,041 ,058
Maks. (,046) ,054 ,071 ,110 ,054 ,065 ,086 ,057 ,067 ,091
Ort. (,035) ,041 ,052 ,079 ,040 ,048 ,065 ,044 ,053 ,073
AGFI
Min. (,920) ,890 ,820 ,650 ,890 ,850 ,760 ,900 ,860 ,790
Maks. (,950) ,940 ,920 ,830 ,940 ,930 ,880 ,950 ,930 ,900
Ort. (,937) ,916 ,874 ,738 ,919 ,892 ,824 ,923 ,903 ,852
PGFI
Min. (,700) ,680 ,640 ,550 ,680 ,660 ,610 ,680 ,670 ,630
Maks. (,720) ,710 ,700 ,650 ,710 ,700 ,680 ,710 ,700 ,690
Ort. (,707) ,695 ,672 ,597 ,697 ,682 ,645 ,699 ,688 ,659
IFI
Min. (,990) ,980 ,940 ,770 ,980 ,950 ,870 ,970 ,910 ,690
Maks. (1,010) 1,000 ,990 ,950 1,000 1,000 ,970 1,010 ,990 ,940
Ort. (,999) ,990 ,973 ,899 ,992 ,979 ,940 ,990 ,967 ,858
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
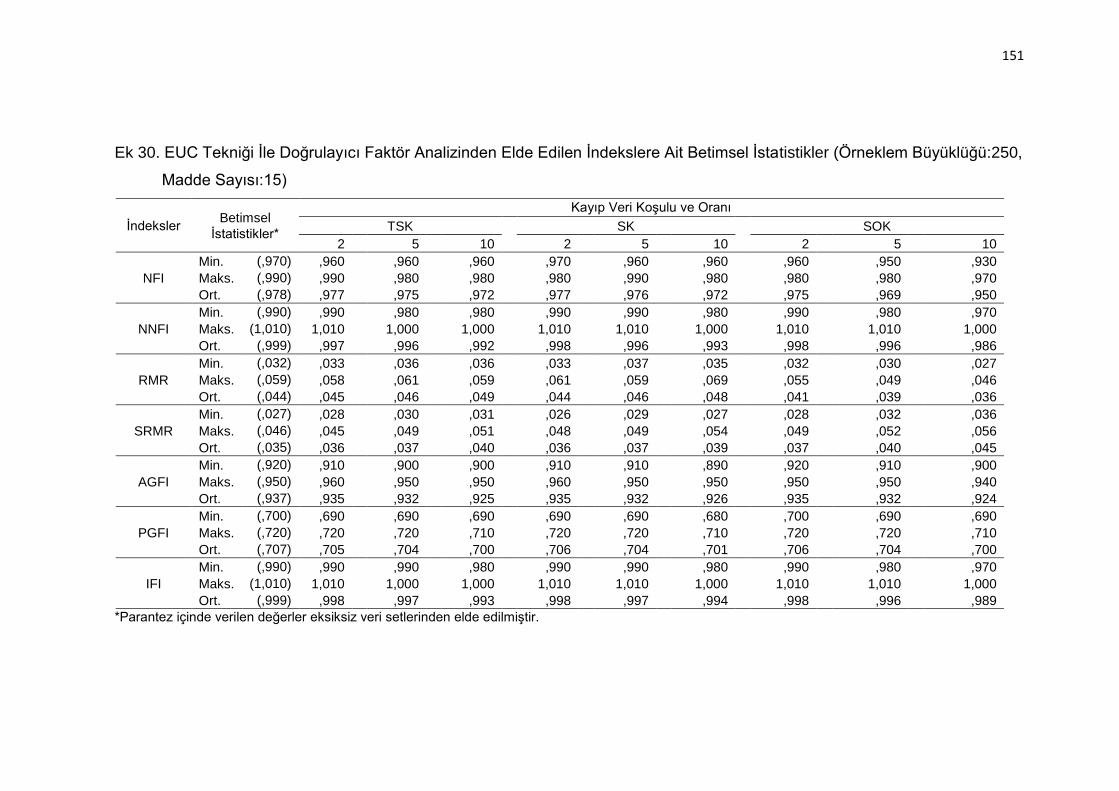
151
Ek 30. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,960 ,960 ,960 ,970 ,960 ,960 ,960 ,950 ,930
Maks. (,990) ,990 ,980 ,980 ,980 ,990 ,980 ,980 ,980 ,970
Ort. (,978) ,977 ,975 ,972 ,977 ,976 ,972 ,975 ,969 ,950
NNFI
Min. (,990) ,990 ,980 ,980 ,990 ,990 ,980 ,990 ,980 ,970
Maks. (1,010) 1,010 1,000 1,000 1,010 1,010 1,000 1,010 1,010 1,000
Ort. (,999) ,997 ,996 ,992 ,998 ,996 ,993 ,998 ,996 ,986
RMR
Min. (,032) ,033 ,036 ,036 ,033 ,037 ,035 ,032 ,030 ,027
Maks. (,059) ,058 ,061 ,059 ,061 ,059 ,069 ,055 ,049 ,046
Ort. (,044) ,045 ,046 ,049 ,044 ,046 ,048 ,041 ,039 ,036
SRMR
Min. (,027) ,028 ,030 ,031 ,026 ,029 ,027 ,028 ,032 ,036
Maks. (,046) ,045 ,049 ,051 ,048 ,049 ,054 ,049 ,052 ,056
Ort. (,035) ,036 ,037 ,040 ,036 ,037 ,039 ,037 ,040 ,045
AGFI
Min. (,920) ,910 ,900 ,900 ,910 ,910 ,890 ,920 ,910 ,900
Maks. (,950) ,960 ,950 ,950 ,960 ,950 ,950 ,950 ,950 ,940
Ort. (,937) ,935 ,932 ,925 ,935 ,932 ,926 ,935 ,932 ,924
PGFI
Min. (,700) ,690 ,690 ,690 ,690 ,690 ,680 ,700 ,690 ,690
Maks. (,720) ,720 ,720 ,710 ,720 ,720 ,710 ,720 ,720 ,710
Ort. (,707) ,705 ,704 ,700 ,706 ,704 ,701 ,706 ,704 ,700
IFI
Min. (,990) ,990 ,990 ,980 ,990 ,990 ,980 ,990 ,980 ,970
Maks. (1,010) 1,010 1,000 1,000 1,010 1,010 1,000 1,010 1,010 1,000
Ort. (,999) ,998 ,997 ,993 ,998 ,997 ,994 ,998 ,996 ,989
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
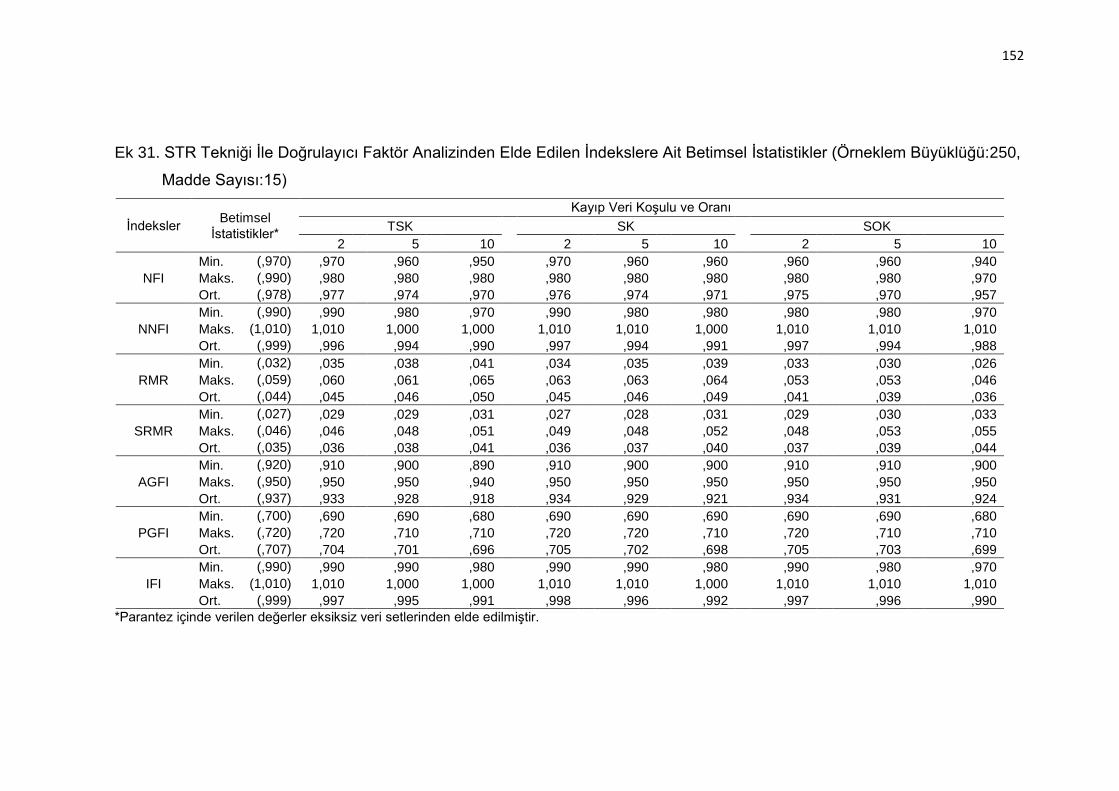
152
Ek 31. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,970 ,960 ,950 ,970 ,960 ,960 ,960 ,960 ,940
Maks. (,990) ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,970
Ort. (,978) ,977 ,974 ,970 ,976 ,974 ,971 ,975 ,970 ,957
NNFI
Min. (,990) ,990 ,980 ,970 ,990 ,980 ,980 ,980 ,980 ,970
Maks. (1,010) 1,010 1,000 1,000 1,010 1,010 1,000 1,010 1,010 1,010
Ort. (,999) ,996 ,994 ,990 ,997 ,994 ,991 ,997 ,994 ,988
RMR
Min. (,032) ,035 ,038 ,041 ,034 ,035 ,039 ,033 ,030 ,026
Maks. (,059) ,060 ,061 ,065 ,063 ,063 ,064 ,053 ,053 ,046
Ort. (,044) ,045 ,046 ,050 ,045 ,046 ,049 ,041 ,039 ,036
SRMR
Min. (,027) ,029 ,029 ,031 ,027 ,028 ,031 ,029 ,030 ,033
Maks. (,046) ,046 ,048 ,051 ,049 ,048 ,052 ,048 ,053 ,055
Ort. (,035) ,036 ,038 ,041 ,036 ,037 ,040 ,037 ,039 ,044
AGFI
Min. (,920) ,910 ,900 ,890 ,910 ,900 ,900 ,910 ,910 ,900
Maks. (,950) ,950 ,950 ,940 ,950 ,950 ,950 ,950 ,950 ,950
Ort. (,937) ,933 ,928 ,918 ,934 ,929 ,921 ,934 ,931 ,924
PGFI
Min. (,700) ,690 ,690 ,680 ,690 ,690 ,690 ,690 ,690 ,680
Maks. (,720) ,720 ,710 ,710 ,720 ,720 ,710 ,720 ,710 ,710
Ort. (,707) ,704 ,701 ,696 ,705 ,702 ,698 ,705 ,703 ,699
IFI
Min. (,990) ,990 ,990 ,980 ,990 ,990 ,980 ,990 ,980 ,970
Maks. (1,010) 1,010 1,000 1,000 1,010 1,010 1,000 1,010 1,010 1,010
Ort. (,999) ,997 ,995 ,991 ,998 ,996 ,992 ,997 ,996 ,990
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
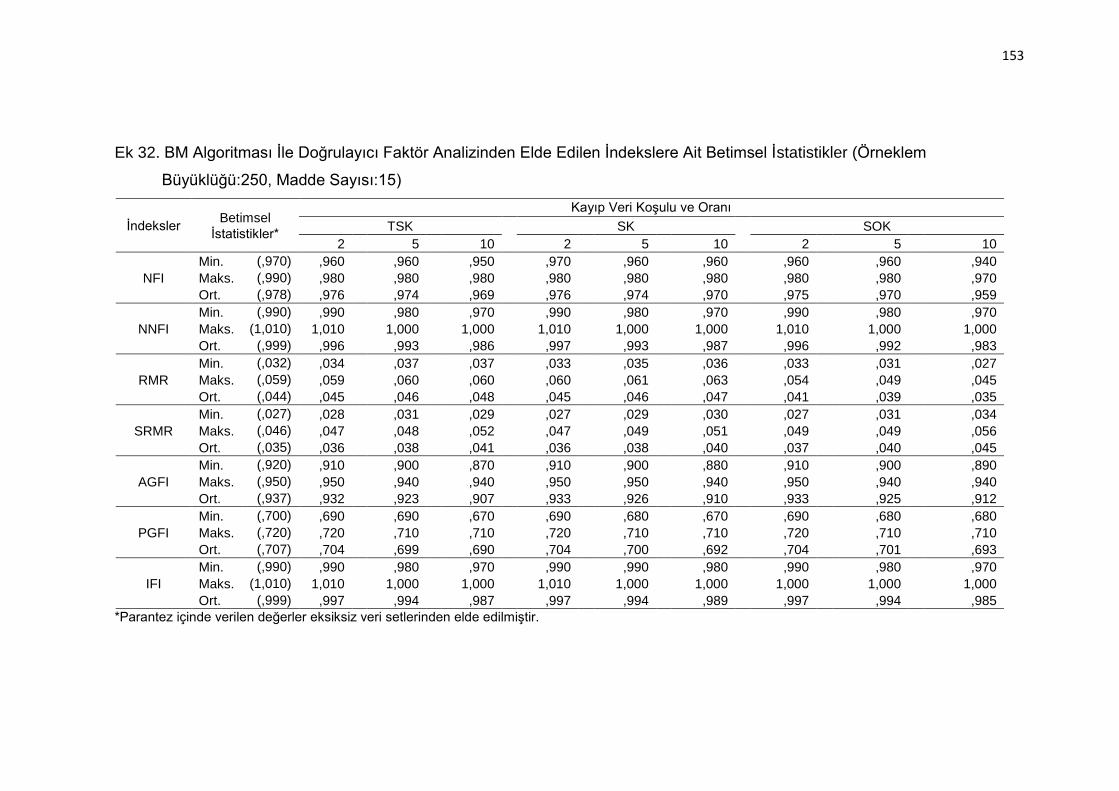
153
Ek 32. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:250, Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,960 ,960 ,950 ,970 ,960 ,960 ,960 ,960 ,940
Maks. (,990) ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,970
Ort. (,978) ,976 ,974 ,969 ,976 ,974 ,970 ,975 ,970 ,959
NNFI
Min. (,990) ,990 ,980 ,970 ,990 ,980 ,970 ,990 ,980 ,970
Maks. (1,010) 1,010 1,000 1,000 1,010 1,000 1,000 1,010 1,000 1,000
Ort. (,999) ,996 ,993 ,986 ,997 ,993 ,987 ,996 ,992 ,983
RMR
Min. (,032) ,034 ,037 ,037 ,033 ,035 ,036 ,033 ,031 ,027
Maks. (,059) ,059 ,060 ,060 ,060 ,061 ,063 ,054 ,049 ,045
Ort. (,044) ,045 ,046 ,048 ,045 ,046 ,047 ,041 ,039 ,035
SRMR
Min. (,027) ,028 ,031 ,029 ,027 ,029 ,030 ,027 ,031 ,034
Maks. (,046) ,047 ,048 ,052 ,047 ,049 ,051 ,049 ,049 ,056
Ort. (,035) ,036 ,038 ,041 ,036 ,038 ,040 ,037 ,040 ,045
AGFI
Min. (,920) ,910 ,900 ,870 ,910 ,900 ,880 ,910 ,900 ,890
Maks. (,950) ,950 ,940 ,940 ,950 ,950 ,940 ,950 ,940 ,940
Ort. (,937) ,932 ,923 ,907 ,933 ,926 ,910 ,933 ,925 ,912
PGFI
Min. (,700) ,690 ,690 ,670 ,690 ,680 ,670 ,690 ,680 ,680
Maks. (,720) ,720 ,710 ,710 ,720 ,710 ,710 ,720 ,710 ,710
Ort. (,707) ,704 ,699 ,690 ,704 ,700 ,692 ,704 ,701 ,693
IFI
Min. (,990) ,990 ,980 ,970 ,990 ,990 ,980 ,990 ,980 ,970
Maks. (1,010) 1,010 1,000 1,000 1,010 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,997 ,994 ,987 ,997 ,994 ,989 ,997 ,994 ,985
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
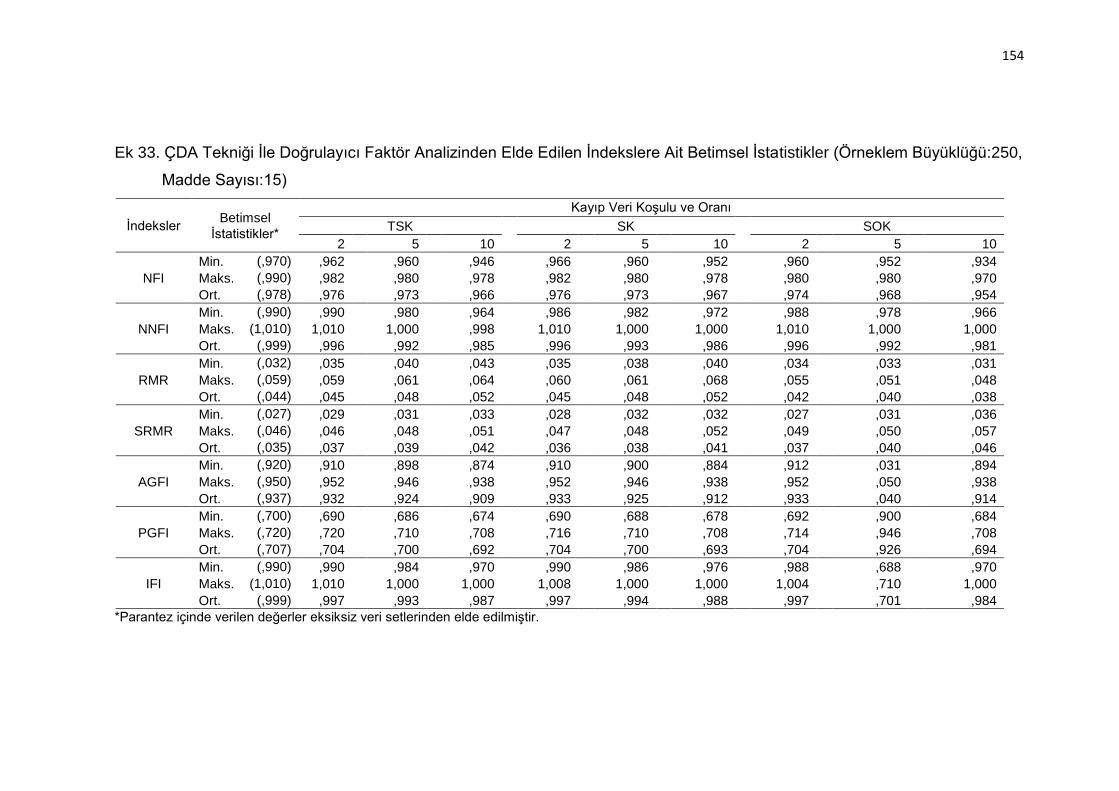
154
Ek 33. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:250,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,970) ,962 ,960 ,946 ,966 ,960 ,952 ,960 ,952 ,934
Maks. (,990) ,982 ,980 ,978 ,982 ,980 ,978 ,980 ,980 ,970
Ort. (,978) ,976 ,973 ,966 ,976 ,973 ,967 ,974 ,968 ,954
NNFI
Min. (,990) ,990 ,980 ,964 ,986 ,982 ,972 ,988 ,978 ,966
Maks. (1,010) 1,010 1,000 ,998 1,010 1,000 1,000 1,010 1,000 1,000
Ort. (,999) ,996 ,992 ,985 ,996 ,993 ,986 ,996 ,992 ,981
RMR
Min. (,032) ,035 ,040 ,043 ,035 ,038 ,040 ,034 ,033 ,031
Maks. (,059) ,059 ,061 ,064 ,060 ,061 ,068 ,055 ,051 ,048
Ort. (,044) ,045 ,048 ,052 ,045 ,048 ,052 ,042 ,040 ,038
SRMR
Min. (,027) ,029 ,031 ,033 ,028 ,032 ,032 ,027 ,031 ,036
Maks. (,046) ,046 ,048 ,051 ,047 ,048 ,052 ,049 ,050 ,057
Ort. (,035) ,037 ,039 ,042 ,036 ,038 ,041 ,037 ,040 ,046
AGFI
Min. (,920) ,910 ,898 ,874 ,910 ,900 ,884 ,912 ,031 ,894
Maks. (,950) ,952 ,946 ,938 ,952 ,946 ,938 ,952 ,050 ,938
Ort. (,937) ,932 ,924 ,909 ,933 ,925 ,912 ,933 ,040 ,914
PGFI
Min. (,700) ,690 ,686 ,674 ,690 ,688 ,678 ,692 ,900 ,684
Maks. (,720) ,720 ,710 ,708 ,716 ,710 ,708 ,714 ,946 ,708
Ort. (,707) ,704 ,700 ,692 ,704 ,700 ,693 ,704 ,926 ,694
IFI
Min. (,990) ,990 ,984 ,970 ,990 ,986 ,976 ,988 ,688 ,970
Maks. (1,010) 1,010 1,000 1,000 1,008 1,000 1,000 1,004 ,710 1,000
Ort. (,999) ,997 ,993 ,987 ,997 ,994 ,988 ,997 ,701 ,984
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
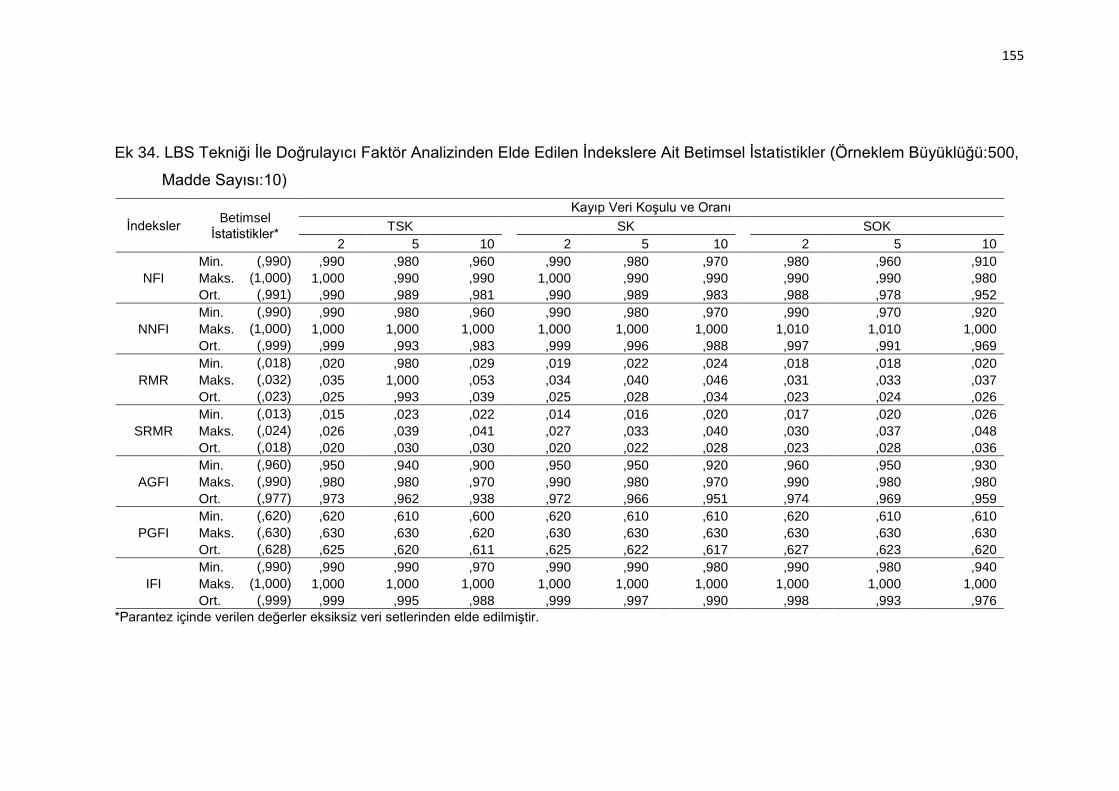
155
Ek 34. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,980 ,960 ,990 ,980 ,970 ,980 ,960 ,910
Maks. (1,000) 1,000 ,990 ,990 1,000 ,990 ,990 ,990 ,990 ,980
Ort. (,991) ,990 ,989 ,981 ,990 ,989 ,983 ,988 ,978 ,952
NNFI
Min. (,990) ,990 ,980 ,960 ,990 ,980 ,970 ,990 ,970 ,920
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,010 1,010 1,000
Ort. (,999) ,999 ,993 ,983 ,999 ,996 ,988 ,997 ,991 ,969
RMR
Min. (,018) ,020 ,980 ,029 ,019 ,022 ,024 ,018 ,018 ,020
Maks. (,032) ,035 1,000 ,053 ,034 ,040 ,046 ,031 ,033 ,037
Ort. (,023) ,025 ,993 ,039 ,025 ,028 ,034 ,023 ,024 ,026
SRMR
Min. (,013) ,015 ,023 ,022 ,014 ,016 ,020 ,017 ,020 ,026
Maks. (,024) ,026 ,039 ,041 ,027 ,033 ,040 ,030 ,037 ,048
Ort. (,018) ,020 ,030 ,030 ,020 ,022 ,028 ,023 ,028 ,036
AGFI
Min. (,960) ,950 ,940 ,900 ,950 ,950 ,920 ,960 ,950 ,930
Maks. (,990) ,980 ,980 ,970 ,990 ,980 ,970 ,990 ,980 ,980
Ort. (,977) ,973 ,962 ,938 ,972 ,966 ,951 ,974 ,969 ,959
PGFI
Min. (,620) ,620 ,610 ,600 ,620 ,610 ,610 ,620 ,610 ,610
Maks. (,630) ,630 ,630 ,620 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,628) ,625 ,620 ,611 ,625 ,622 ,617 ,627 ,623 ,620
IFI
Min. (,990) ,990 ,990 ,970 ,990 ,990 ,980 ,990 ,980 ,940
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,995 ,988 ,999 ,997 ,990 ,998 ,993 ,976
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
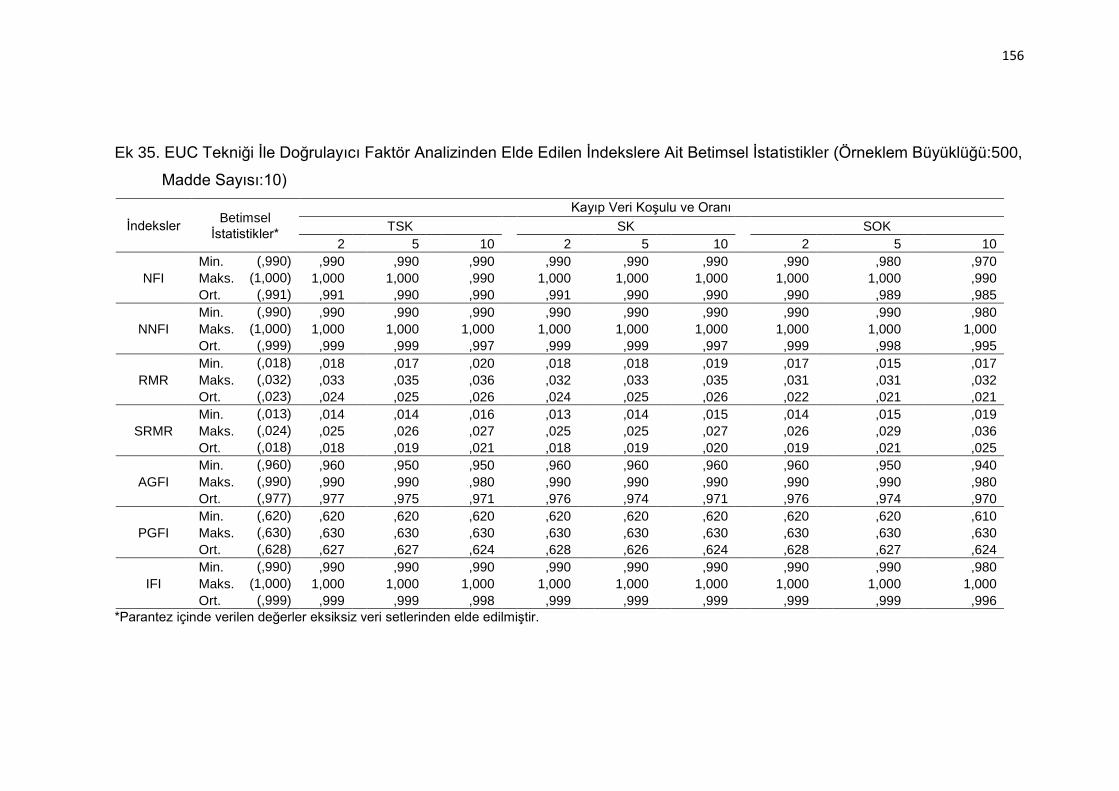
156
Ek 35. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980 ,970
Maks. (1,000) 1,000 1,000 ,990 1,000 1,000 1,000 1,000 1,000 ,990
Ort. (,991) ,991 ,990 ,990 ,991 ,990 ,990 ,990 ,989 ,985
NNFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,997 ,999 ,999 ,997 ,999 ,998 ,995
RMR
Min. (,018) ,018 ,017 ,020 ,018 ,018 ,019 ,017 ,015 ,017
Maks. (,032) ,033 ,035 ,036 ,032 ,033 ,035 ,031 ,031 ,032
Ort. (,023) ,024 ,025 ,026 ,024 ,025 ,026 ,022 ,021 ,021
SRMR
Min. (,013) ,014 ,014 ,016 ,013 ,014 ,015 ,014 ,015 ,019
Maks. (,024) ,025 ,026 ,027 ,025 ,025 ,027 ,026 ,029 ,036
Ort. (,018) ,018 ,019 ,021 ,018 ,019 ,020 ,019 ,021 ,025
AGFI
Min. (,960) ,960 ,950 ,950 ,960 ,960 ,960 ,960 ,950 ,940
Maks. (,990) ,990 ,990 ,980 ,990 ,990 ,990 ,990 ,990 ,980
Ort. (,977) ,977 ,975 ,971 ,976 ,974 ,971 ,976 ,974 ,970
PGFI
Min. (,620) ,620 ,620 ,620 ,620 ,620 ,620 ,620 ,620 ,610
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,628) ,627 ,627 ,624 ,628 ,626 ,624 ,628 ,627 ,624
IFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,998 ,999 ,999 ,999 ,999 ,999 ,996
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
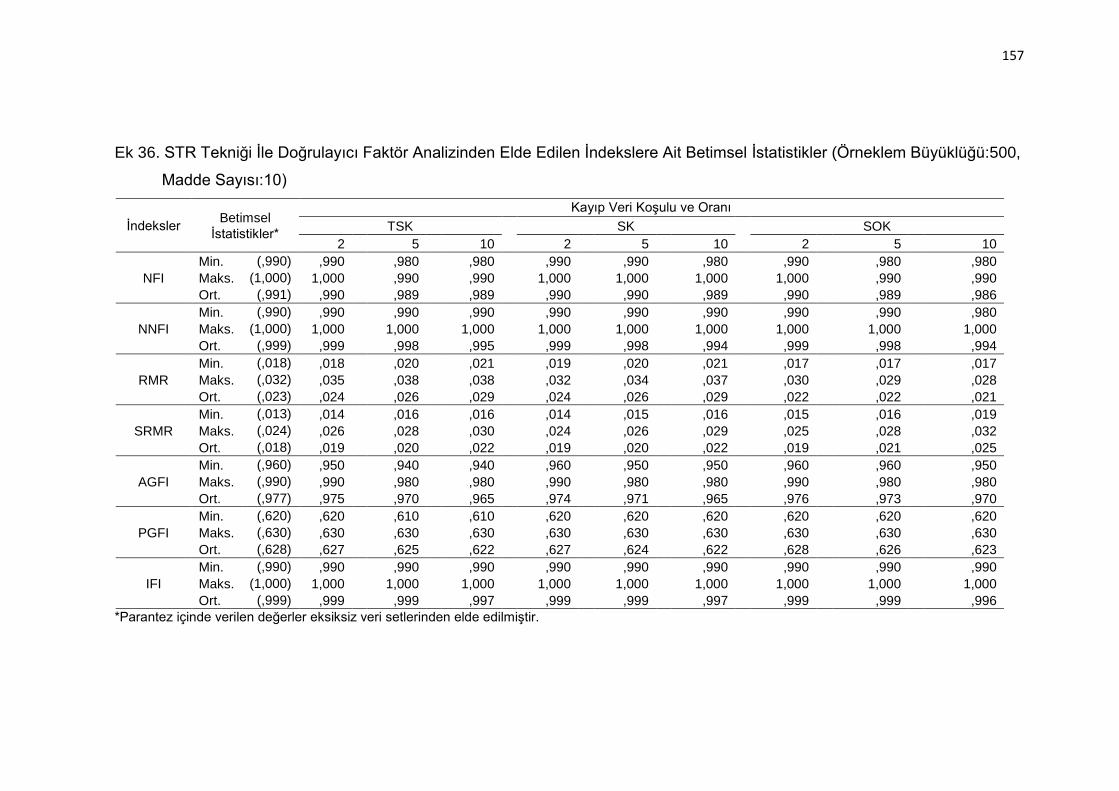
157
Ek 36. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,980 ,980 ,990 ,990 ,980 ,990 ,980 ,980
Maks. (1,000) 1,000 ,990 ,990 1,000 1,000 1,000 1,000 ,990 ,990
Ort. (,991) ,990 ,989 ,989 ,990 ,990 ,989 ,990 ,989 ,986
NNFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,998 ,995 ,999 ,998 ,994 ,999 ,998 ,994
RMR
Min. (,018) ,018 ,020 ,021 ,019 ,020 ,021 ,017 ,017 ,017
Maks. (,032) ,035 ,038 ,038 ,032 ,034 ,037 ,030 ,029 ,028
Ort. (,023) ,024 ,026 ,029 ,024 ,026 ,029 ,022 ,022 ,021
SRMR
Min. (,013) ,014 ,016 ,016 ,014 ,015 ,016 ,015 ,016 ,019
Maks. (,024) ,026 ,028 ,030 ,024 ,026 ,029 ,025 ,028 ,032
Ort. (,018) ,019 ,020 ,022 ,019 ,020 ,022 ,019 ,021 ,025
AGFI
Min. (,960) ,950 ,940 ,940 ,960 ,950 ,950 ,960 ,960 ,950
Maks. (,990) ,990 ,980 ,980 ,990 ,980 ,980 ,990 ,980 ,980
Ort. (,977) ,975 ,970 ,965 ,974 ,971 ,965 ,976 ,973 ,970
PGFI
Min. (,620) ,620 ,610 ,610 ,620 ,620 ,620 ,620 ,620 ,620
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,628) ,627 ,625 ,622 ,627 ,624 ,622 ,628 ,626 ,623
IFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,997 ,999 ,999 ,997 ,999 ,999 ,996
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
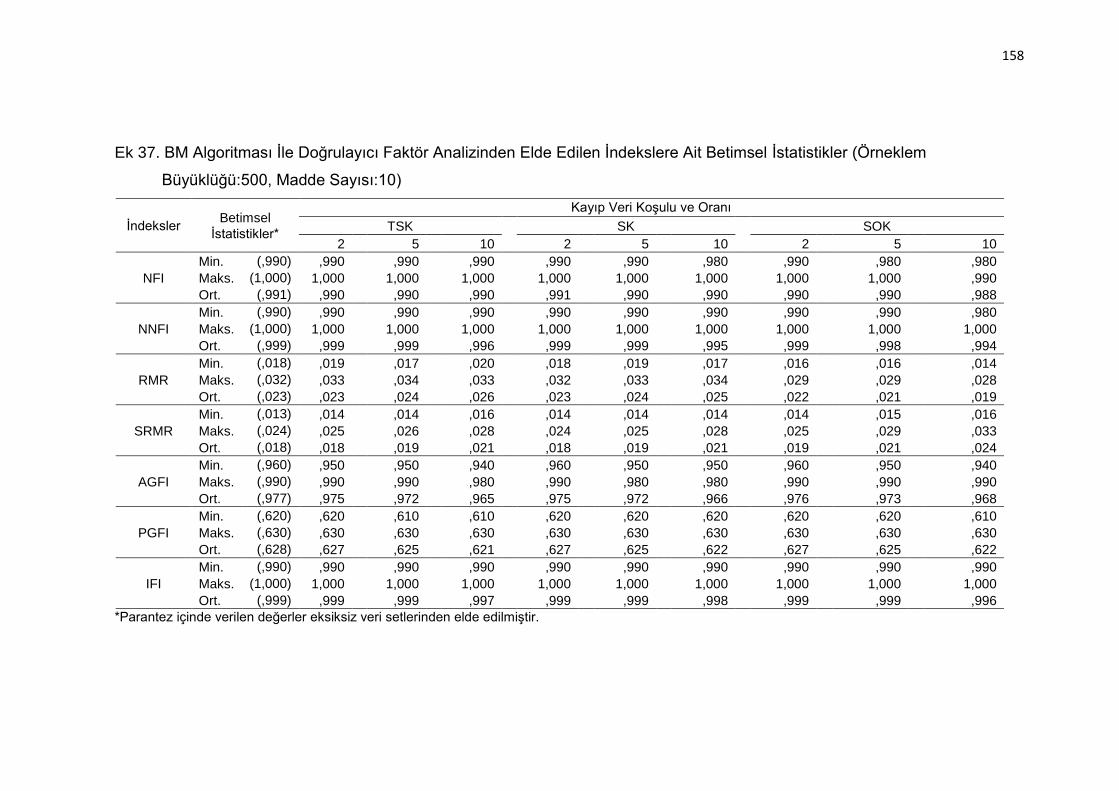
158
Ek 37. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:500, Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,980 ,990 ,980 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,990
Ort. (,991) ,990 ,990 ,990 ,991 ,990 ,990 ,990 ,990 ,988
NNFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,996 ,999 ,999 ,995 ,999 ,998 ,994
RMR
Min. (,018) ,019 ,017 ,020 ,018 ,019 ,017 ,016 ,016 ,014
Maks. (,032) ,033 ,034 ,033 ,032 ,033 ,034 ,029 ,029 ,028
Ort. (,023) ,023 ,024 ,026 ,023 ,024 ,025 ,022 ,021 ,019
SRMR
Min. (,013) ,014 ,014 ,016 ,014 ,014 ,014 ,014 ,015 ,016
Maks. (,024) ,025 ,026 ,028 ,024 ,025 ,028 ,025 ,029 ,033
Ort. (,018) ,018 ,019 ,021 ,018 ,019 ,021 ,019 ,021 ,024
AGFI
Min. (,960) ,950 ,950 ,940 ,960 ,950 ,950 ,960 ,950 ,940
Maks. (,990) ,990 ,990 ,980 ,990 ,980 ,980 ,990 ,990 ,990
Ort. (,977) ,975 ,972 ,965 ,975 ,972 ,966 ,976 ,973 ,968
PGFI
Min. (,620) ,620 ,610 ,610 ,620 ,620 ,620 ,620 ,620 ,610
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,628) ,627 ,625 ,621 ,627 ,625 ,622 ,627 ,625 ,622
IFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,997 ,999 ,999 ,998 ,999 ,999 ,996
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
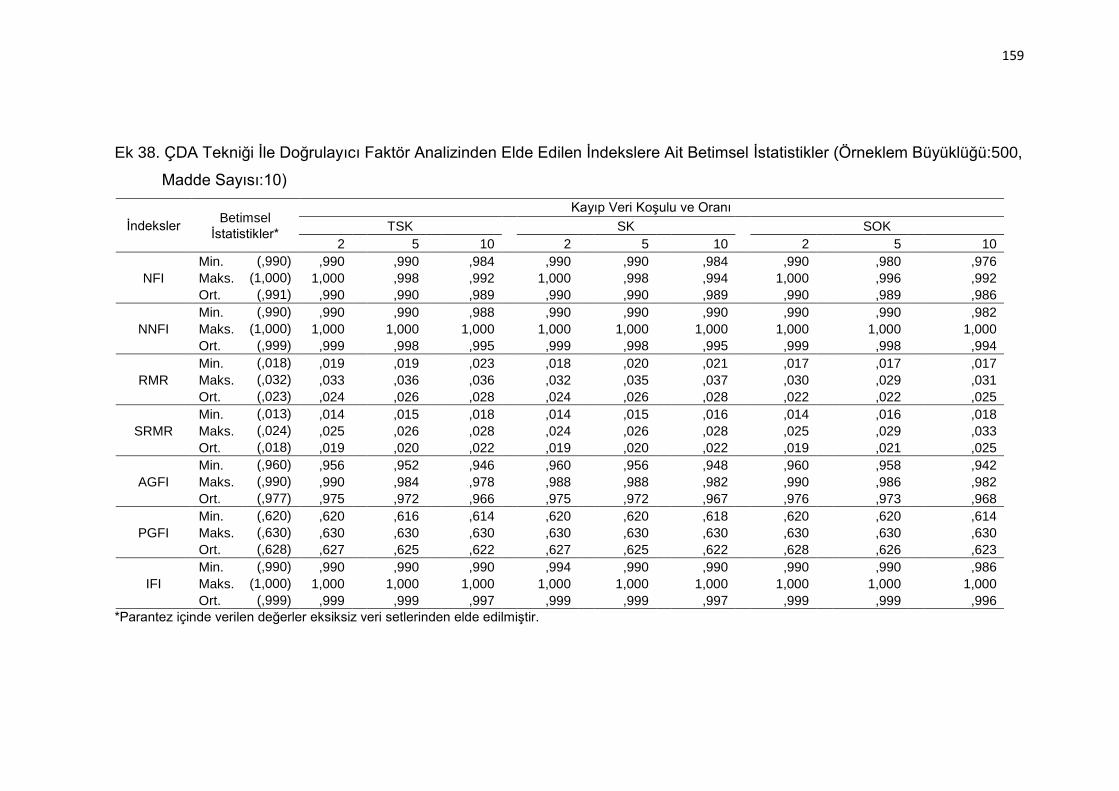
159
Ek 38. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,984 ,990 ,990 ,984 ,990 ,980 ,976
Maks. (1,000) 1,000 ,998 ,992 1,000 ,998 ,994 1,000 ,996 ,992
Ort. (,991) ,990 ,990 ,989 ,990 ,990 ,989 ,990 ,989 ,986
NNFI
Min. (,990) ,990 ,990 ,988 ,990 ,990 ,990 ,990 ,990 ,982
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,998 ,995 ,999 ,998 ,995 ,999 ,998 ,994
RMR
Min. (,018) ,019 ,019 ,023 ,018 ,020 ,021 ,017 ,017 ,017
Maks. (,032) ,033 ,036 ,036 ,032 ,035 ,037 ,030 ,029 ,031
Ort. (,023) ,024 ,026 ,028 ,024 ,026 ,028 ,022 ,022 ,025
SRMR
Min. (,013) ,014 ,015 ,018 ,014 ,015 ,016 ,014 ,016 ,018
Maks. (,024) ,025 ,026 ,028 ,024 ,026 ,028 ,025 ,029 ,033
Ort. (,018) ,019 ,020 ,022 ,019 ,020 ,022 ,019 ,021 ,025
AGFI
Min. (,960) ,956 ,952 ,946 ,960 ,956 ,948 ,960 ,958 ,942
Maks. (,990) ,990 ,984 ,978 ,988 ,988 ,982 ,990 ,986 ,982
Ort. (,977) ,975 ,972 ,966 ,975 ,972 ,967 ,976 ,973 ,968
PGFI
Min. (,620) ,620 ,616 ,614 ,620 ,620 ,618 ,620 ,620 ,614
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,628) ,627 ,625 ,622 ,627 ,625 ,622 ,628 ,626 ,623
IFI
Min. (,990) ,990 ,990 ,990 ,994 ,990 ,990 ,990 ,990 ,986
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,997 ,999 ,999 ,997 ,999 ,999 ,996
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
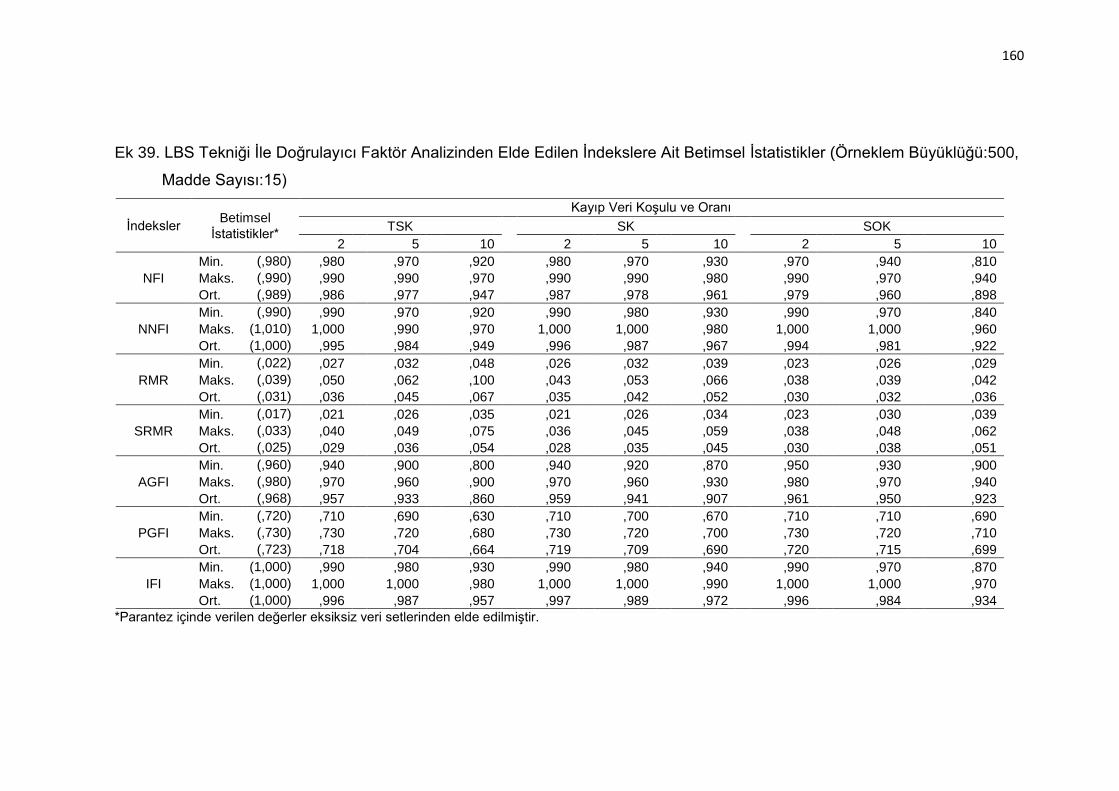
160
Ek 39. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,980) ,980 ,970 ,920 ,980 ,970 ,930 ,970 ,940 ,810
Maks. (,990) ,990 ,990 ,970 ,990 ,990 ,980 ,990 ,970 ,940
Ort. (,989) ,986 ,977 ,947 ,987 ,978 ,961 ,979 ,960 ,898
NNFI
Min. (,990) ,990 ,970 ,920 ,990 ,980 ,930 ,990 ,970 ,840
Maks. (1,010) 1,000 ,990 ,970 1,000 1,000 ,980 1,000 1,000 ,960
Ort. (1,000) ,995 ,984 ,949 ,996 ,987 ,967 ,994 ,981 ,922
RMR
Min. (,022) ,027 ,032 ,048 ,026 ,032 ,039 ,023 ,026 ,029
Maks. (,039) ,050 ,062 ,100 ,043 ,053 ,066 ,038 ,039 ,042
Ort. (,031) ,036 ,045 ,067 ,035 ,042 ,052 ,030 ,032 ,036
SRMR
Min. (,017) ,021 ,026 ,035 ,021 ,026 ,034 ,023 ,030 ,039
Maks. (,033) ,040 ,049 ,075 ,036 ,045 ,059 ,038 ,048 ,062
Ort. (,025) ,029 ,036 ,054 ,028 ,035 ,045 ,030 ,038 ,051
AGFI
Min. (,960) ,940 ,900 ,800 ,940 ,920 ,870 ,950 ,930 ,900
Maks. (,980) ,970 ,960 ,900 ,970 ,960 ,930 ,980 ,970 ,940
Ort. (,968) ,957 ,933 ,860 ,959 ,941 ,907 ,961 ,950 ,923
PGFI
Min. (,720) ,710 ,690 ,630 ,710 ,700 ,670 ,710 ,710 ,690
Maks. (,730) ,730 ,720 ,680 ,730 ,720 ,700 ,730 ,720 ,710
Ort. (,723) ,718 ,704 ,664 ,719 ,709 ,690 ,720 ,715 ,699
IFI
Min. (1,000) ,990 ,980 ,930 ,990 ,980 ,940 ,990 ,970 ,870
Maks. (1,000) 1,000 1,000 ,980 1,000 1,000 ,990 1,000 1,000 ,970
Ort. (1,000) ,996 ,987 ,957 ,997 ,989 ,972 ,996 ,984 ,934
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
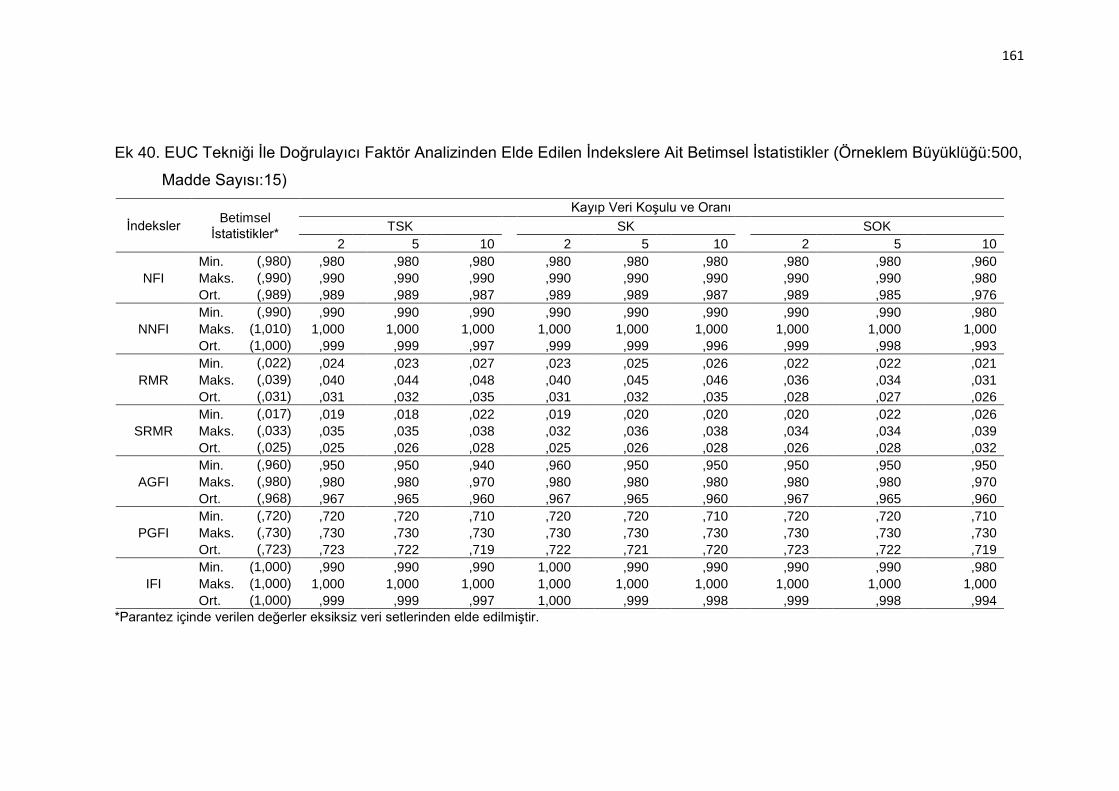
161
Ek 40. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,980) ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,960
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Ort. (,989) ,989 ,989 ,987 ,989 ,989 ,987 ,989 ,985 ,976
NNFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,010) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,999 ,997 ,999 ,999 ,996 ,999 ,998 ,993
RMR
Min. (,022) ,024 ,023 ,027 ,023 ,025 ,026 ,022 ,022 ,021
Maks. (,039) ,040 ,044 ,048 ,040 ,045 ,046 ,036 ,034 ,031
Ort. (,031) ,031 ,032 ,035 ,031 ,032 ,035 ,028 ,027 ,026
SRMR
Min. (,017) ,019 ,018 ,022 ,019 ,020 ,020 ,020 ,022 ,026
Maks. (,033) ,035 ,035 ,038 ,032 ,036 ,038 ,034 ,034 ,039
Ort. (,025) ,025 ,026 ,028 ,025 ,026 ,028 ,026 ,028 ,032
AGFI
Min. (,960) ,950 ,950 ,940 ,960 ,950 ,950 ,950 ,950 ,950
Maks. (,980) ,980 ,980 ,970 ,980 ,980 ,980 ,980 ,980 ,970
Ort. (,968) ,967 ,965 ,960 ,967 ,965 ,960 ,967 ,965 ,960
PGFI
Min. (,720) ,720 ,720 ,710 ,720 ,720 ,710 ,720 ,720 ,710
Maks. (,730) ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730
Ort. (,723) ,723 ,722 ,719 ,722 ,721 ,720 ,723 ,722 ,719
IFI
Min. (1,000) ,990 ,990 ,990 1,000 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,999 ,997 1,000 ,999 ,998 ,999 ,998 ,994
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
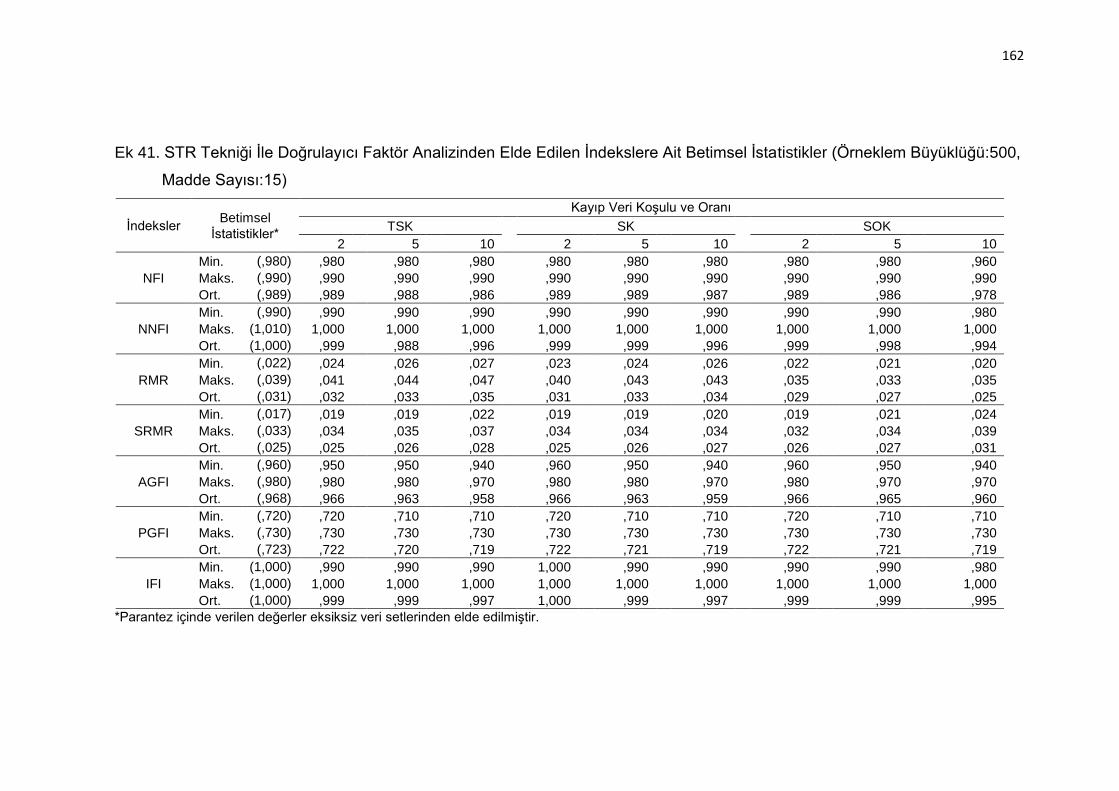
162
Ek 41. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,980) ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,960
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,989) ,989 ,988 ,986 ,989 ,989 ,987 ,989 ,986 ,978
NNFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,010) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,988 ,996 ,999 ,999 ,996 ,999 ,998 ,994
RMR
Min. (,022) ,024 ,026 ,027 ,023 ,024 ,026 ,022 ,021 ,020
Maks. (,039) ,041 ,044 ,047 ,040 ,043 ,043 ,035 ,033 ,035
Ort. (,031) ,032 ,033 ,035 ,031 ,033 ,034 ,029 ,027 ,025
SRMR
Min. (,017) ,019 ,019 ,022 ,019 ,019 ,020 ,019 ,021 ,024
Maks. (,033) ,034 ,035 ,037 ,034 ,034 ,034 ,032 ,034 ,039
Ort. (,025) ,025 ,026 ,028 ,025 ,026 ,027 ,026 ,027 ,031
AGFI
Min. (,960) ,950 ,950 ,940 ,960 ,950 ,940 ,960 ,950 ,940
Maks. (,980) ,980 ,980 ,970 ,980 ,980 ,970 ,980 ,970 ,970
Ort. (,968) ,966 ,963 ,958 ,966 ,963 ,959 ,966 ,965 ,960
PGFI
Min. (,720) ,720 ,710 ,710 ,720 ,710 ,710 ,720 ,710 ,710
Maks. (,730) ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730
Ort. (,723) ,722 ,720 ,719 ,722 ,721 ,719 ,722 ,721 ,719
IFI
Min. (1,000) ,990 ,990 ,990 1,000 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,999 ,997 1,000 ,999 ,997 ,999 ,999 ,995
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
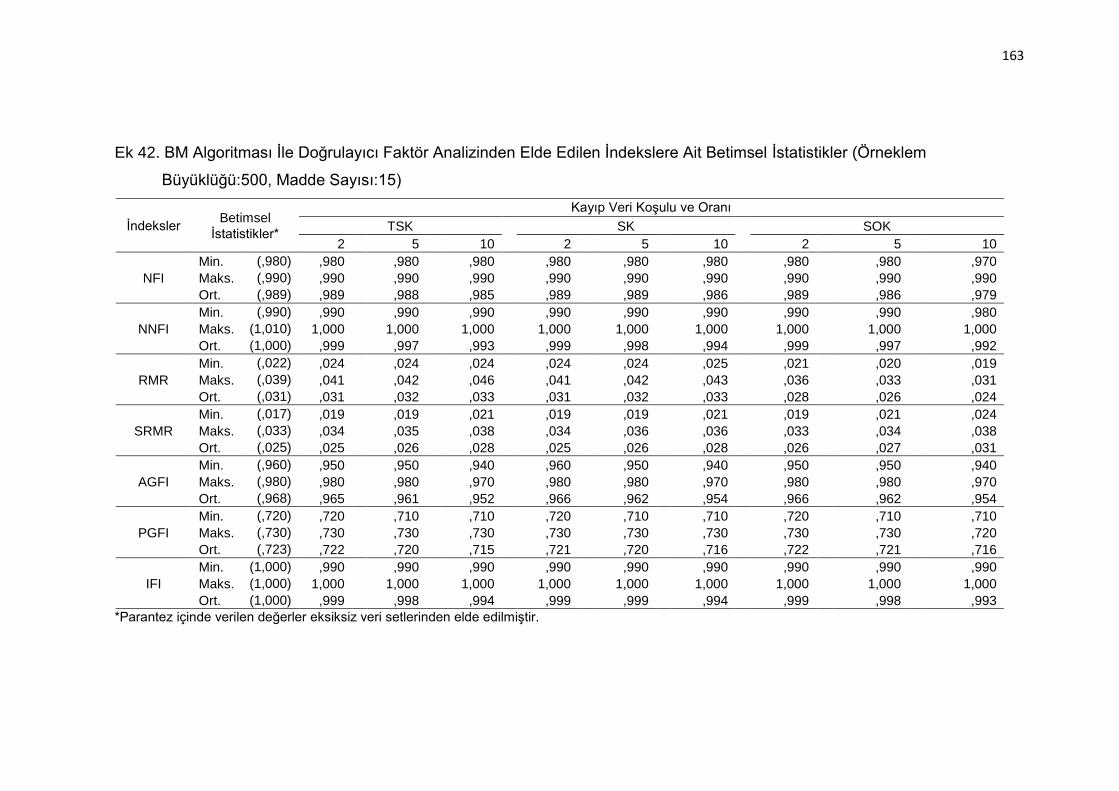
163
Ek 42. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:500, Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,980) ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,970
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,989) ,989 ,988 ,985 ,989 ,989 ,986 ,989 ,986 ,979
NNFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,010) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,997 ,993 ,999 ,998 ,994 ,999 ,997 ,992
RMR
Min. (,022) ,024 ,024 ,024 ,024 ,024 ,025 ,021 ,020 ,019
Maks. (,039) ,041 ,042 ,046 ,041 ,042 ,043 ,036 ,033 ,031
Ort. (,031) ,031 ,032 ,033 ,031 ,032 ,033 ,028 ,026 ,024
SRMR
Min. (,017) ,019 ,019 ,021 ,019 ,019 ,021 ,019 ,021 ,024
Maks. (,033) ,034 ,035 ,038 ,034 ,036 ,036 ,033 ,034 ,038
Ort. (,025) ,025 ,026 ,028 ,025 ,026 ,028 ,026 ,027 ,031
AGFI
Min. (,960) ,950 ,950 ,940 ,960 ,950 ,940 ,950 ,950 ,940
Maks. (,980) ,980 ,980 ,970 ,980 ,980 ,970 ,980 ,980 ,970
Ort. (,968) ,965 ,961 ,952 ,966 ,962 ,954 ,966 ,962 ,954
PGFI
Min. (,720) ,720 ,710 ,710 ,720 ,710 ,710 ,720 ,710 ,710
Maks. (,730) ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,720
Ort. (,723) ,722 ,720 ,715 ,721 ,720 ,716 ,722 ,721 ,716
IFI
Min. (1,000) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,998 ,994 ,999 ,999 ,994 ,999 ,998 ,993
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
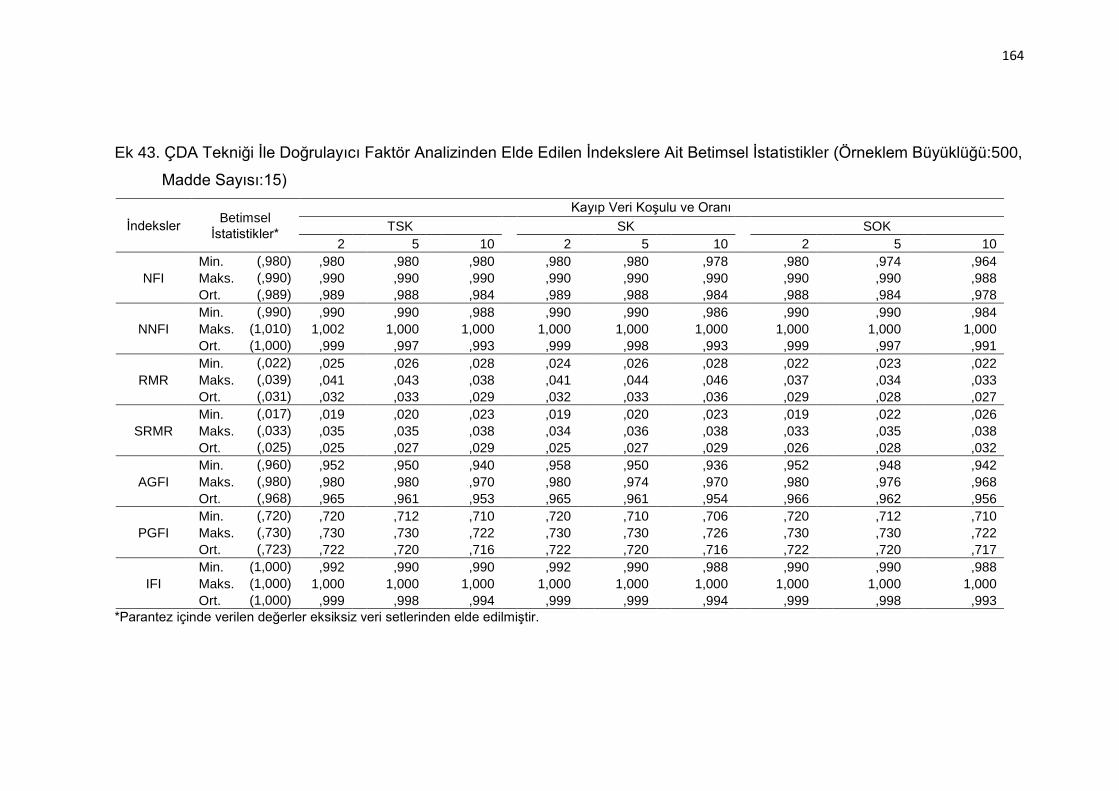
164
Ek 43. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem Büyüklüğü:500,
Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,980) ,980 ,980 ,980 ,980 ,980 ,978 ,980 ,974 ,964
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,988
Ort. (,989) ,989 ,988 ,984 ,989 ,988 ,984 ,988 ,984 ,978
NNFI
Min. (,990) ,990 ,990 ,988 ,990 ,990 ,986 ,990 ,990 ,984
Maks. (1,010) 1,002 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,997 ,993 ,999 ,998 ,993 ,999 ,997 ,991
RMR
Min. (,022) ,025 ,026 ,028 ,024 ,026 ,028 ,022 ,023 ,022
Maks. (,039) ,041 ,043 ,038 ,041 ,044 ,046 ,037 ,034 ,033
Ort. (,031) ,032 ,033 ,029 ,032 ,033 ,036 ,029 ,028 ,027
SRMR
Min. (,017) ,019 ,020 ,023 ,019 ,020 ,023 ,019 ,022 ,026
Maks. (,033) ,035 ,035 ,038 ,034 ,036 ,038 ,033 ,035 ,038
Ort. (,025) ,025 ,027 ,029 ,025 ,027 ,029 ,026 ,028 ,032
AGFI
Min. (,960) ,952 ,950 ,940 ,958 ,950 ,936 ,952 ,948 ,942
Maks. (,980) ,980 ,980 ,970 ,980 ,974 ,970 ,980 ,976 ,968
Ort. (,968) ,965 ,961 ,953 ,965 ,961 ,954 ,966 ,962 ,956
PGFI
Min. (,720) ,720 ,712 ,710 ,720 ,710 ,706 ,720 ,712 ,710
Maks. (,730) ,730 ,730 ,722 ,730 ,730 ,726 ,730 ,730 ,722
Ort. (,723) ,722 ,720 ,716 ,722 ,720 ,716 ,722 ,720 ,717
IFI
Min. (1,000) ,992 ,990 ,990 ,992 ,990 ,988 ,990 ,990 ,988
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) ,999 ,998 ,994 ,999 ,999 ,994 ,999 ,998 ,993
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
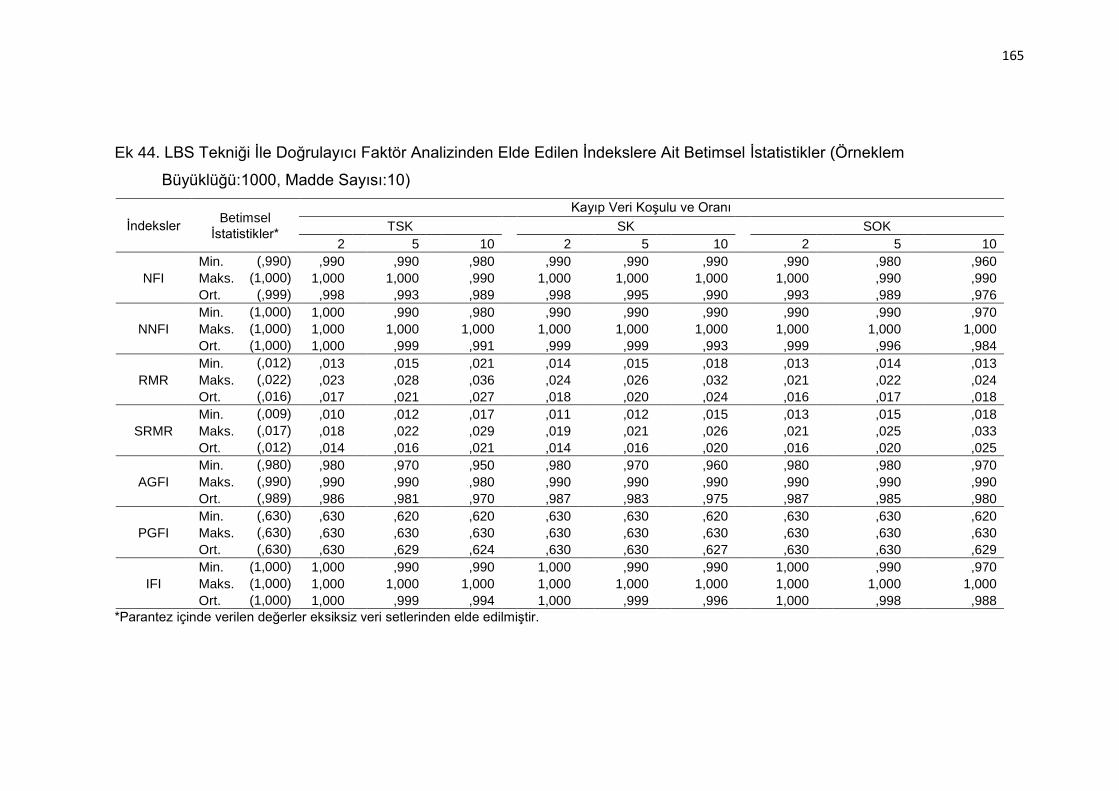
165
Ek 44. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,980 ,990 ,990 ,990 ,990 ,980 ,960
Maks. (1,000) 1,000 1,000 ,990 1,000 1,000 1,000 1,000 ,990 ,990
Ort. (,999) ,998 ,993 ,989 ,998 ,995 ,990 ,993 ,989 ,976
NNFI
Min. (1,000) 1,000 ,990 ,980 ,990 ,990 ,990 ,990 ,990 ,970
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 ,999 ,991 ,999 ,999 ,993 ,999 ,996 ,984
RMR
Min. (,012) ,013 ,015 ,021 ,014 ,015 ,018 ,013 ,014 ,013
Maks. (,022) ,023 ,028 ,036 ,024 ,026 ,032 ,021 ,022 ,024
Ort. (,016) ,017 ,021 ,027 ,018 ,020 ,024 ,016 ,017 ,018
SRMR
Min. (,009) ,010 ,012 ,017 ,011 ,012 ,015 ,013 ,015 ,018
Maks. (,017) ,018 ,022 ,029 ,019 ,021 ,026 ,021 ,025 ,033
Ort. (,012) ,014 ,016 ,021 ,014 ,016 ,020 ,016 ,020 ,025
AGFI
Min. (,980) ,980 ,970 ,950 ,980 ,970 ,960 ,980 ,980 ,970
Maks. (,990) ,990 ,990 ,980 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,989) ,986 ,981 ,970 ,987 ,983 ,975 ,987 ,985 ,980
PGFI
Min. (,630) ,630 ,620 ,620 ,630 ,630 ,620 ,630 ,630 ,620
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,630) ,630 ,629 ,624 ,630 ,630 ,627 ,630 ,630 ,629
IFI
Min. (1,000) 1,000 ,990 ,990 1,000 ,990 ,990 1,000 ,990 ,970
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 ,999 ,994 1,000 ,999 ,996 1,000 ,998 ,988
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
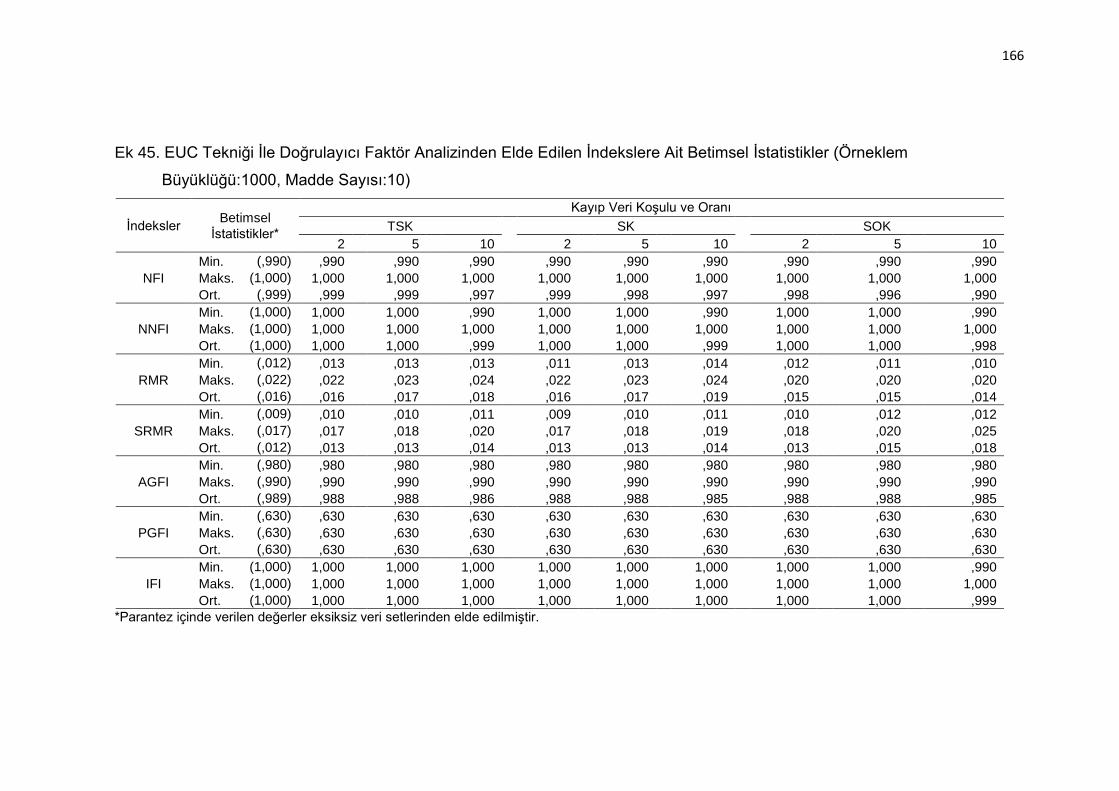
166
Ek 45. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,997 ,999 ,998 ,997 ,998 ,996 ,990
NNFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,998
RMR
Min. (,012) ,013 ,013 ,013 ,011 ,013 ,014 ,012 ,011 ,010
Maks. (,022) ,022 ,023 ,024 ,022 ,023 ,024 ,020 ,020 ,020
Ort. (,016) ,016 ,017 ,018 ,016 ,017 ,019 ,015 ,015 ,014
SRMR
Min. (,009) ,010 ,010 ,011 ,009 ,010 ,011 ,010 ,012 ,012
Maks. (,017) ,017 ,018 ,020 ,017 ,018 ,019 ,018 ,020 ,025
Ort. (,012) ,013 ,013 ,014 ,013 ,013 ,014 ,013 ,015 ,018
AGFI
Min. (,980) ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,980 ,980
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,989) ,988 ,988 ,986 ,988 ,988 ,985 ,988 ,988 ,985
PGFI
Min. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
IFI
Min. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,999
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
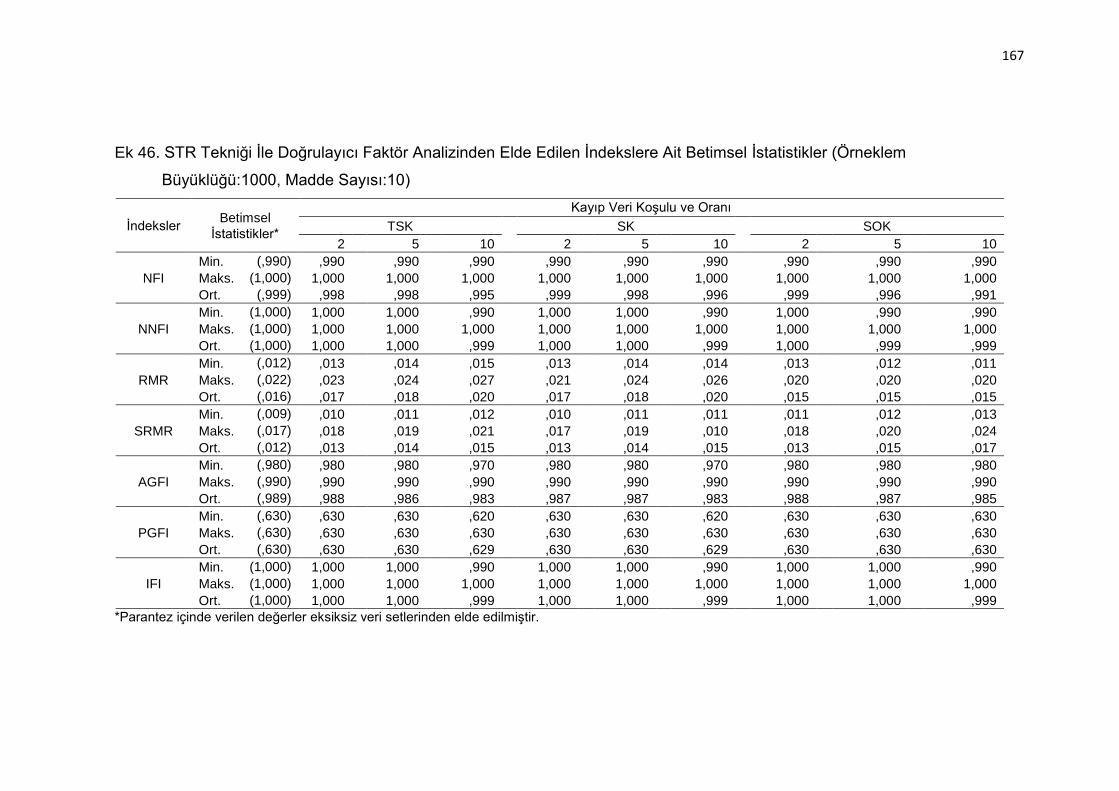
167
Ek 46. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,998 ,998 ,995 ,999 ,998 ,996 ,999 ,996 ,991
NNFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 ,999 ,999
RMR
Min. (,012) ,013 ,014 ,015 ,013 ,014 ,014 ,013 ,012 ,011
Maks. (,022) ,023 ,024 ,027 ,021 ,024 ,026 ,020 ,020 ,020
Ort. (,016) ,017 ,018 ,020 ,017 ,018 ,020 ,015 ,015 ,015
SRMR
Min. (,009) ,010 ,011 ,012 ,010 ,011 ,011 ,011 ,012 ,013
Maks. (,017) ,018 ,019 ,021 ,017 ,019 ,010 ,018 ,020 ,024
Ort. (,012) ,013 ,014 ,015 ,013 ,014 ,015 ,013 ,015 ,017
AGFI
Min. (,980) ,980 ,980 ,970 ,980 ,980 ,970 ,980 ,980 ,980
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,989) ,988 ,986 ,983 ,987 ,987 ,983 ,988 ,987 ,985
PGFI
Min. (,630) ,630 ,630 ,620 ,630 ,630 ,620 ,630 ,630 ,630
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,630) ,630 ,630 ,629 ,630 ,630 ,629 ,630 ,630 ,630
IFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,999
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
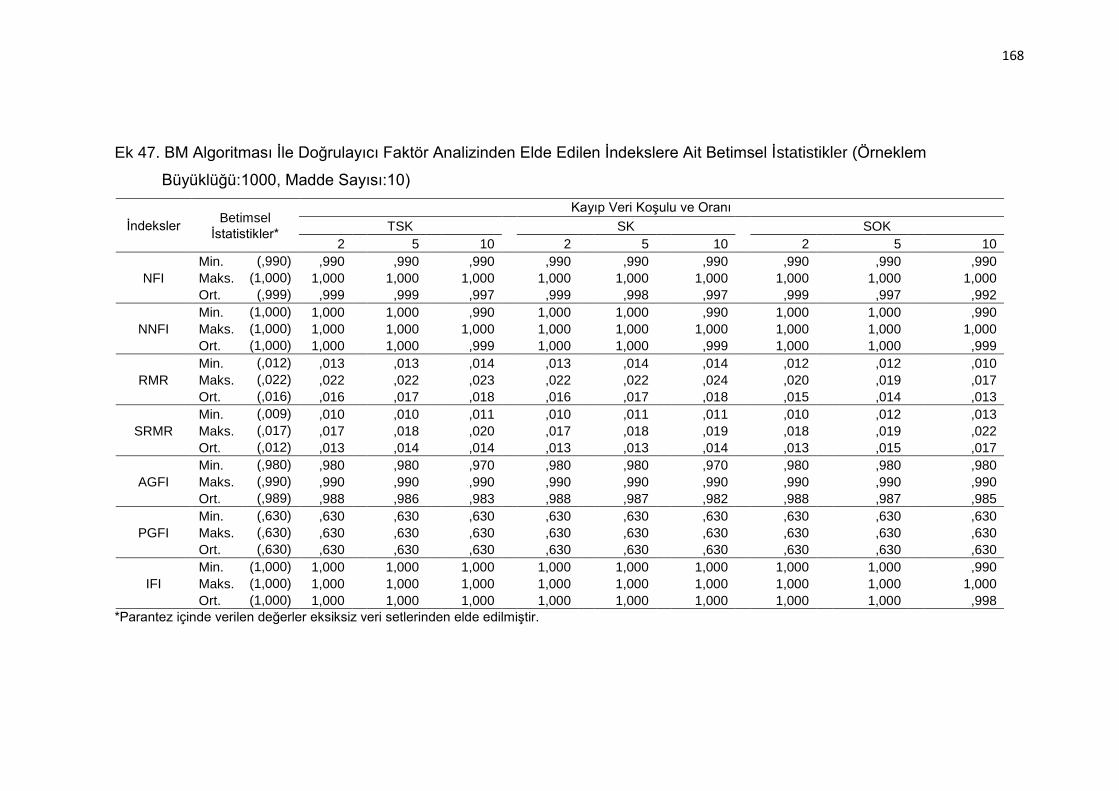
168
Ek 47. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,999 ,997 ,999 ,998 ,997 ,999 ,997 ,992
NNFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,999
RMR
Min. (,012) ,013 ,013 ,014 ,013 ,014 ,014 ,012 ,012 ,010
Maks. (,022) ,022 ,022 ,023 ,022 ,022 ,024 ,020 ,019 ,017
Ort. (,016) ,016 ,017 ,018 ,016 ,017 ,018 ,015 ,014 ,013
SRMR
Min. (,009) ,010 ,010 ,011 ,010 ,011 ,011 ,010 ,012 ,013
Maks. (,017) ,017 ,018 ,020 ,017 ,018 ,019 ,018 ,019 ,022
Ort. (,012) ,013 ,014 ,014 ,013 ,013 ,014 ,013 ,015 ,017
AGFI
Min. (,980) ,980 ,980 ,970 ,980 ,980 ,970 ,980 ,980 ,980
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,989) ,988 ,986 ,983 ,988 ,987 ,982 ,988 ,987 ,985
PGFI
Min. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
IFI
Min. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,998
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
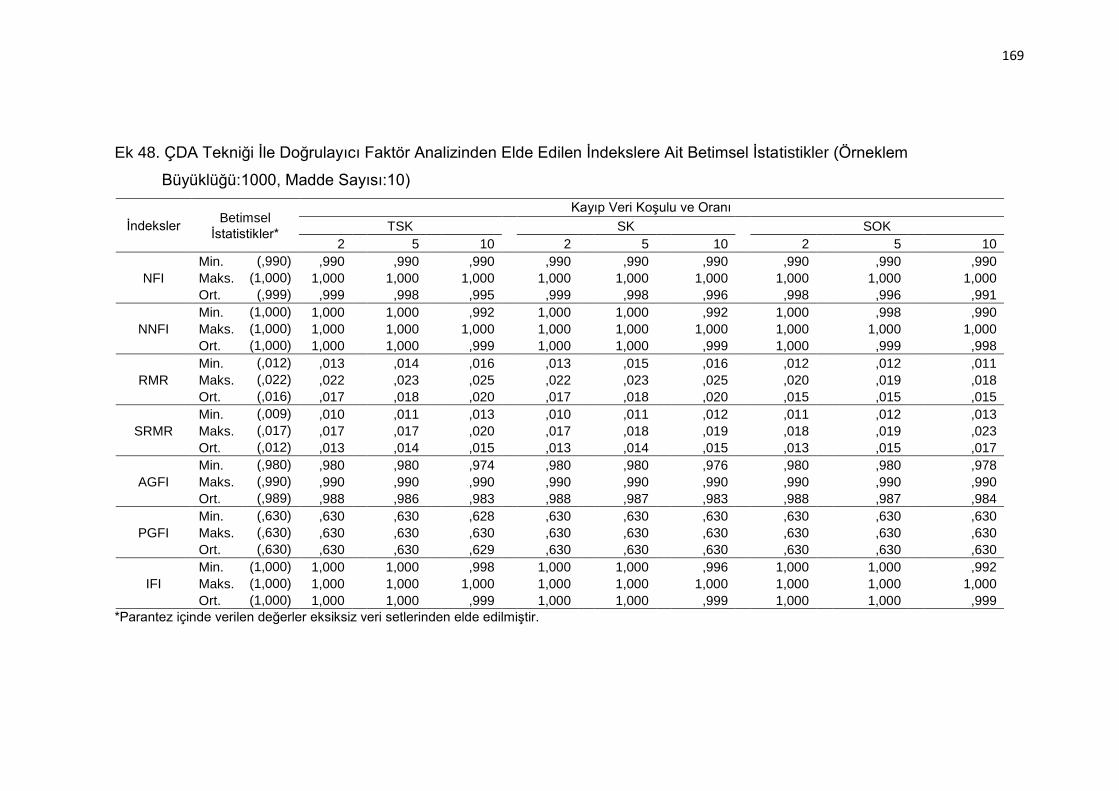
169
Ek 48. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:10)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (,999) ,999 ,998 ,995 ,999 ,998 ,996 ,998 ,996 ,991
NNFI
Min. (1,000) 1,000 1,000 ,992 1,000 1,000 ,992 1,000 ,998 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 ,999 ,998
RMR
Min. (,012) ,013 ,014 ,016 ,013 ,015 ,016 ,012 ,012 ,011
Maks. (,022) ,022 ,023 ,025 ,022 ,023 ,025 ,020 ,019 ,018
Ort. (,016) ,017 ,018 ,020 ,017 ,018 ,020 ,015 ,015 ,015
SRMR
Min. (,009) ,010 ,011 ,013 ,010 ,011 ,012 ,011 ,012 ,013
Maks. (,017) ,017 ,017 ,020 ,017 ,018 ,019 ,018 ,019 ,023
Ort. (,012) ,013 ,014 ,015 ,013 ,014 ,015 ,013 ,015 ,017
AGFI
Min. (,980) ,980 ,980 ,974 ,980 ,980 ,976 ,980 ,980 ,978
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,989) ,988 ,986 ,983 ,988 ,987 ,983 ,988 ,987 ,984
PGFI
Min. (,630) ,630 ,630 ,628 ,630 ,630 ,630 ,630 ,630 ,630
Maks. (,630) ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630 ,630
Ort. (,630) ,630 ,630 ,629 ,630 ,630 ,630 ,630 ,630 ,630
IFI
Min. (1,000) 1,000 1,000 ,998 1,000 1,000 ,996 1,000 1,000 ,992
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,999
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
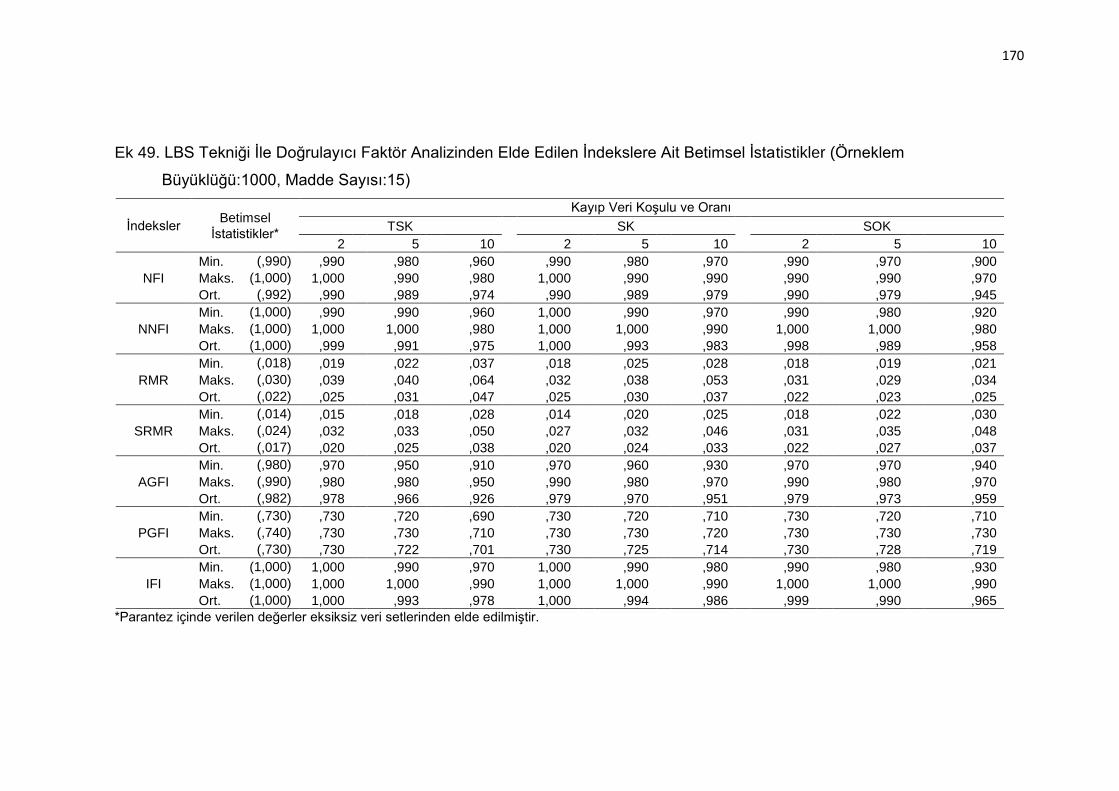
170
Ek 49. LBS Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,980 ,960 ,990 ,980 ,970 ,990 ,970 ,900
Maks. (1,000) 1,000 ,990 ,980 1,000 ,990 ,990 ,990 ,990 ,970
Ort. (,992) ,990 ,989 ,974 ,990 ,989 ,979 ,990 ,979 ,945
NNFI
Min. (1,000) ,990 ,990 ,960 1,000 ,990 ,970 ,990 ,980 ,920
Maks. (1,000) 1,000 1,000 ,980 1,000 1,000 ,990 1,000 1,000 ,980
Ort. (1,000) ,999 ,991 ,975 1,000 ,993 ,983 ,998 ,989 ,958
RMR
Min. (,018) ,019 ,022 ,037 ,018 ,025 ,028 ,018 ,019 ,021
Maks. (,030) ,039 ,040 ,064 ,032 ,038 ,053 ,031 ,029 ,034
Ort. (,022) ,025 ,031 ,047 ,025 ,030 ,037 ,022 ,023 ,025
SRMR
Min. (,014) ,015 ,018 ,028 ,014 ,020 ,025 ,018 ,022 ,030
Maks. (,024) ,032 ,033 ,050 ,027 ,032 ,046 ,031 ,035 ,048
Ort. (,017) ,020 ,025 ,038 ,020 ,024 ,033 ,022 ,027 ,037
AGFI
Min. (,980) ,970 ,950 ,910 ,970 ,960 ,930 ,970 ,970 ,940
Maks. (,990) ,980 ,980 ,950 ,990 ,980 ,970 ,990 ,980 ,970
Ort. (,982) ,978 ,966 ,926 ,979 ,970 ,951 ,979 ,973 ,959
PGFI
Min. (,730) ,730 ,720 ,690 ,730 ,720 ,710 ,730 ,720 ,710
Maks. (,740) ,730 ,730 ,710 ,730 ,730 ,720 ,730 ,730 ,730
Ort. (,730) ,730 ,722 ,701 ,730 ,725 ,714 ,730 ,728 ,719
IFI
Min. (1,000) 1,000 ,990 ,970 1,000 ,990 ,980 ,990 ,980 ,930
Maks. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Ort. (1,000) 1,000 ,993 ,978 1,000 ,994 ,986 ,999 ,990 ,965
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
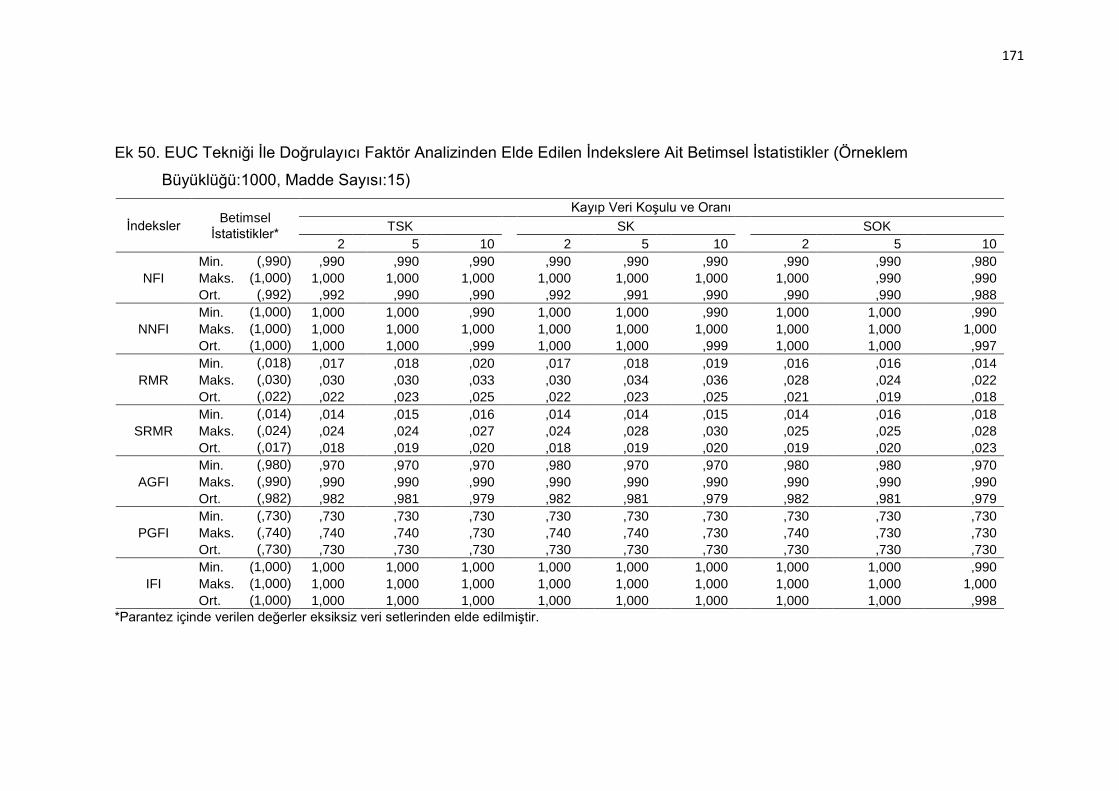
171
Ek 50. EUC Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,990 ,990
Ort. (,992) ,992 ,990 ,990 ,992 ,991 ,990 ,990 ,990 ,988
NNFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,997
RMR
Min. (,018) ,017 ,018 ,020 ,017 ,018 ,019 ,016 ,016 ,014
Maks. (,030) ,030 ,030 ,033 ,030 ,034 ,036 ,028 ,024 ,022
Ort. (,022) ,022 ,023 ,025 ,022 ,023 ,025 ,021 ,019 ,018
SRMR
Min. (,014) ,014 ,015 ,016 ,014 ,014 ,015 ,014 ,016 ,018
Maks. (,024) ,024 ,024 ,027 ,024 ,028 ,030 ,025 ,025 ,028
Ort. (,017) ,018 ,019 ,020 ,018 ,019 ,020 ,019 ,020 ,023
AGFI
Min. (,980) ,970 ,970 ,970 ,980 ,970 ,970 ,980 ,980 ,970
Maks. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,982) ,982 ,981 ,979 ,982 ,981 ,979 ,982 ,981 ,979
PGFI
Min. (,730) ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730
Maks. (,740) ,740 ,740 ,730 ,740 ,740 ,730 ,740 ,730 ,730
Ort. (,730) ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730 ,730
IFI
Min. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,998
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
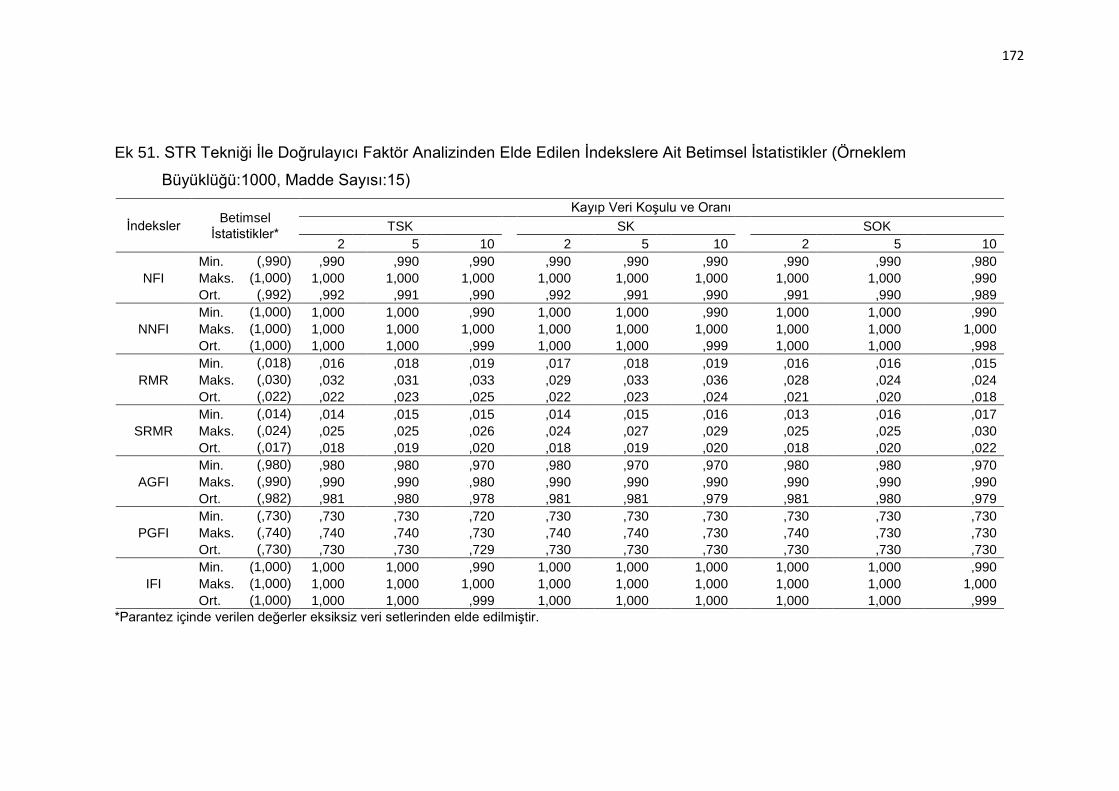
172
Ek 51. STR Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,990
Ort. (,992) ,992 ,991 ,990 ,992 ,991 ,990 ,991 ,990 ,989
NNFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,998
RMR
Min. (,018) ,016 ,018 ,019 ,017 ,018 ,019 ,016 ,016 ,015
Maks. (,030) ,032 ,031 ,033 ,029 ,033 ,036 ,028 ,024 ,024
Ort. (,022) ,022 ,023 ,025 ,022 ,023 ,024 ,021 ,020 ,018
SRMR
Min. (,014) ,014 ,015 ,015 ,014 ,015 ,016 ,013 ,016 ,017
Maks. (,024) ,025 ,025 ,026 ,024 ,027 ,029 ,025 ,025 ,030
Ort. (,017) ,018 ,019 ,020 ,018 ,019 ,020 ,018 ,020 ,022
AGFI
Min. (,980) ,980 ,980 ,970 ,980 ,970 ,970 ,980 ,980 ,970
Maks. (,990) ,990 ,990 ,980 ,990 ,990 ,990 ,990 ,990 ,990
Ort. (,982) ,981 ,980 ,978 ,981 ,981 ,979 ,981 ,980 ,979
PGFI
Min. (,730) ,730 ,730 ,720 ,730 ,730 ,730 ,730 ,730 ,730
Maks. (,740) ,740 ,740 ,730 ,740 ,740 ,730 ,740 ,730 ,730
Ort. (,730) ,730 ,730 ,729 ,730 ,730 ,730 ,730 ,730 ,730
IFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 1,000 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 1,000 1,000 1,000 ,999
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
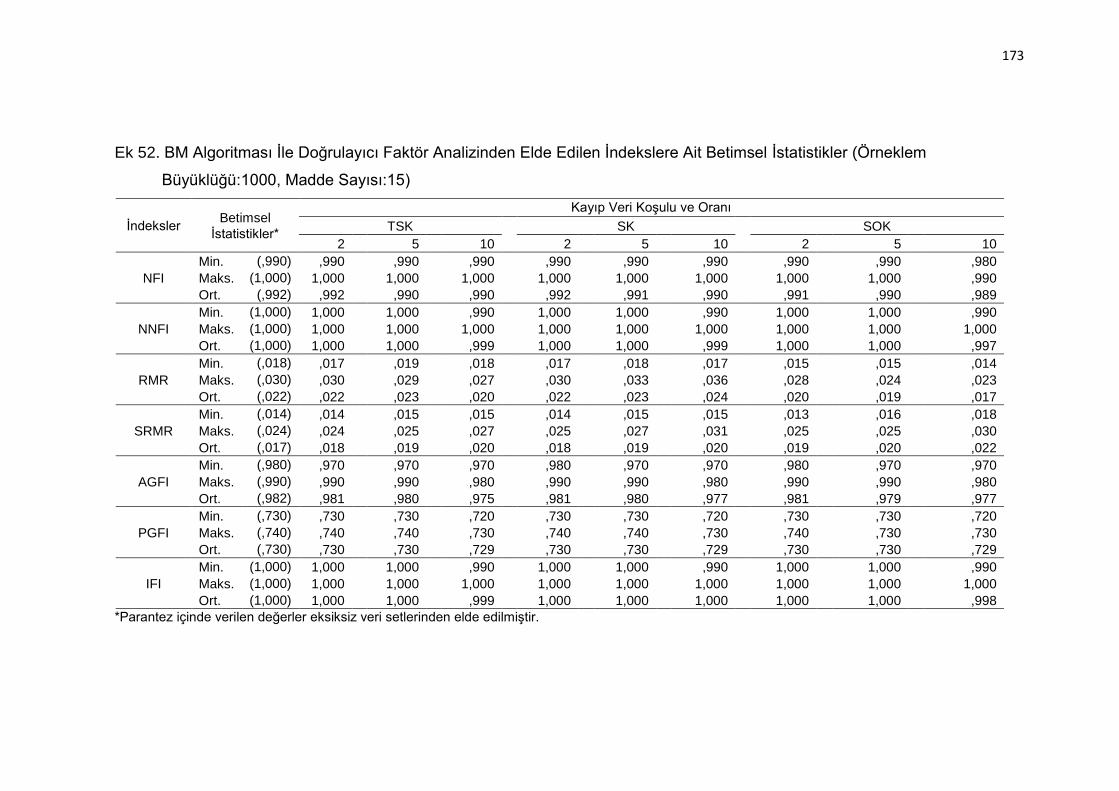
173
Ek 52. BM Algoritması İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,980
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 ,990
Ort. (,992) ,992 ,990 ,990 ,992 ,991 ,990 ,991 ,990 ,989
NNFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,997
RMR
Min. (,018) ,017 ,019 ,018 ,017 ,018 ,017 ,015 ,015 ,014
Maks. (,030) ,030 ,029 ,027 ,030 ,033 ,036 ,028 ,024 ,023
Ort. (,022) ,022 ,023 ,020 ,022 ,023 ,024 ,020 ,019 ,017
SRMR
Min. (,014) ,014 ,015 ,015 ,014 ,015 ,015 ,013 ,016 ,018
Maks. (,024) ,024 ,025 ,027 ,025 ,027 ,031 ,025 ,025 ,030
Ort. (,017) ,018 ,019 ,020 ,018 ,019 ,020 ,019 ,020 ,022
AGFI
Min. (,980) ,970 ,970 ,970 ,980 ,970 ,970 ,980 ,970 ,970
Maks. (,990) ,990 ,990 ,980 ,990 ,990 ,980 ,990 ,990 ,980
Ort. (,982) ,981 ,980 ,975 ,981 ,980 ,977 ,981 ,979 ,977
PGFI
Min. (,730) ,730 ,730 ,720 ,730 ,730 ,720 ,730 ,730 ,720
Maks. (,740) ,740 ,740 ,730 ,740 ,740 ,730 ,740 ,730 ,730
Ort. (,730) ,730 ,730 ,729 ,730 ,730 ,729 ,730 ,730 ,729
IFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,990 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 1,000 1,000 1,000 ,998
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
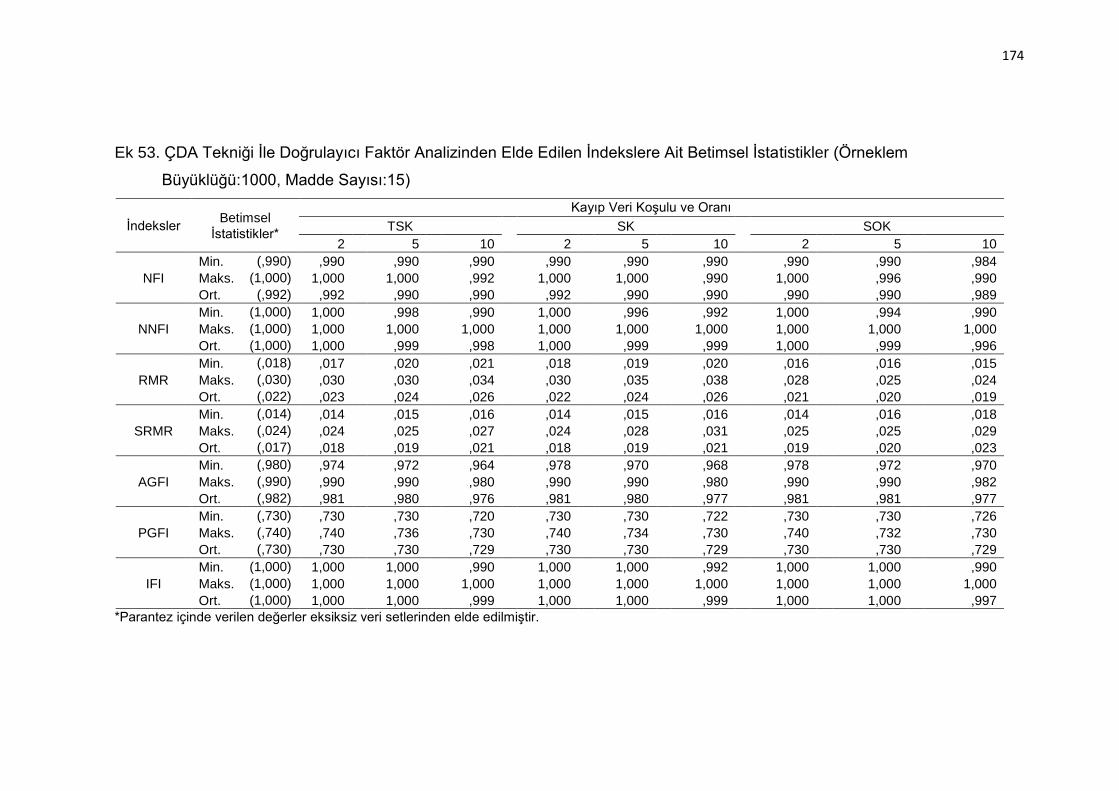
174
Ek 53. ÇDA Tekniği İle Doğrulayıcı Faktör Analizinden Elde Edilen İndekslere Ait Betimsel İstatistikler (Örneklem
Büyüklüğü:1000, Madde Sayısı:15)
İndeksler Betimsel
İstatistikler*
Kayıp Veri Koşulu ve Oranı
TSK SK SOK
2 5 10 2 5 10 2 5 10
NFI
Min. (,990) ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,990 ,984
Maks. (1,000) 1,000 1,000 ,992 1,000 1,000 ,990 1,000 ,996 ,990
Ort. (,992) ,992 ,990 ,990 ,992 ,990 ,990 ,990 ,990 ,989
NNFI
Min. (1,000) 1,000 ,998 ,990 1,000 ,996 ,992 1,000 ,994 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 ,999 ,998 1,000 ,999 ,999 1,000 ,999 ,996
RMR
Min. (,018) ,017 ,020 ,021 ,018 ,019 ,020 ,016 ,016 ,015
Maks. (,030) ,030 ,030 ,034 ,030 ,035 ,038 ,028 ,025 ,024
Ort. (,022) ,023 ,024 ,026 ,022 ,024 ,026 ,021 ,020 ,019
SRMR
Min. (,014) ,014 ,015 ,016 ,014 ,015 ,016 ,014 ,016 ,018
Maks. (,024) ,024 ,025 ,027 ,024 ,028 ,031 ,025 ,025 ,029
Ort. (,017) ,018 ,019 ,021 ,018 ,019 ,021 ,019 ,020 ,023
AGFI
Min. (,980) ,974 ,972 ,964 ,978 ,970 ,968 ,978 ,972 ,970
Maks. (,990) ,990 ,990 ,980 ,990 ,990 ,980 ,990 ,990 ,982
Ort. (,982) ,981 ,980 ,976 ,981 ,980 ,977 ,981 ,981 ,977
PGFI
Min. (,730) ,730 ,730 ,720 ,730 ,730 ,722 ,730 ,730 ,726
Maks. (,740) ,740 ,736 ,730 ,740 ,734 ,730 ,740 ,732 ,730
Ort. (,730) ,730 ,730 ,729 ,730 ,730 ,729 ,730 ,730 ,729
IFI
Min. (1,000) 1,000 1,000 ,990 1,000 1,000 ,992 1,000 1,000 ,990
Maks. (1,000) 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
Ort. (1,000) 1,000 1,000 ,999 1,000 1,000 ,999 1,000 1,000 ,997
*Parantez içinde verilen değerler eksiksiz veri setlerinden elde edilmiştir.
























![b11 hipotez [Uyumluluk Modu] - DEUkisi.deu.edu.tr/zerife.yildirim/ISTATISTIK_TEKDONEM/11...8 Dr. Mehmet Aksaraylı Bilindiğinde Z Test İstatistiği 15 Z XX n x x /2 0 Z H0RED H0RED](https://img.pdfslide.tips/doc/110x75/5e2371efa780544d4772bd8e/b11-hipotez-uyumluluk-modu-8-dr-mehmet-aksarayl-bilindiinde-z-test.jpg)




