Embed Size (px)
Citation preview

기관고유연구사업 결과 보고
결
재
과제책임자 과 장 부 장
본인이 수행한 2008~2010년도 기관고유연구사업 과제 연구결과를 붙임과
같이 보고합니다.
과제명Whole genome exon array를 통한 위암관련 유전자
의 alternative splice variation 발굴 및 검증
과제책임자
(소속, 성명)기능유전체연구과 고 성 호
총연구비390,000천원
(2008년: 130,000, 2009년:130,000, 2010년: 130,000천원)
총연구기간 2008년 1월 1일 ~2010년 12월 31일
붙임 : 기관고유연구사업 최종보고서 1부
2010년 12월 31일
과제책임자 고 성 호

기관고유연구사업 최종보고서
(과제번호 : 0810160)
Whole genome exon array를 기반으로한 위암특이적
alternative splice variant의 발굴 및 검증
Discovery of alternative splice variations of stomach cancer
related genes through whole genome exon array
과제책임자 : 고 성 호
국 립 암 센 터

1. 이 보고서는 국립암센터 기관고유연구
사업 최종보고서입니다.
2. 이 보고서 내용을 인용할 때에는 반드시
국립암센터 연구사업 결과임을 밝혀야
합니다.

제 출 문
국립암센터 원장 귀하
이 보고서를 기관고유연구사업 “Whole genome exon array를 통한 위암관
련 유전자의 alternative splice variation 발굴 및 검증” 과제의 최종보고서
로 제출합니다.
2010. 12. 31.
국 립 암 센 터
과 제 책 임 자 : 고 성 호
참 여 연 구 원 : 이 연 수
〃 : 최 일 주
과 제 연 구 원 : 이 병 찬
〃 : 노 현 욱

목 차
< 요 약 문 >
(한글) ···········································································································1
(영문) ···········································································································3
1. 연구의 최종목표 ·····················································································5
2. 연구의 내용 및 결과 ···········································································15
3. 연구결과 고찰 및 결론 ·······································································78
4. 연구성과 및 목표달성도 ·····································································80
5. 연구결과의 활용계획 ···········································································84
6. 참고문헌 ·································································································86
7. 첨부서류 ·································································································88

- 1 -
< 요 약 문 >
연구분야(코드) T-3 과제번호 0810160
과 제 명Whole genome exon array를 통한 위암관련 유전자의 alternative splice
variation 발굴 및 검증
연구기간/연구비(천원)
합계 2008년 1월 1일 ~ 2010년 12월 31일 390,000
1차년도 2008년 1월 1일 ~ 2008년 12월 31일 130,000
2차년도 2009년 1월 1일 ~ 2009년 12월 31일 130,000
3차년도 2010년 1월 1일 ~ 2010년 12월 31일 130,000
과제책임자성 명 고성호 주민등록번호
전화번호 031-920-2567 전 자 우 편 [email protected]
색인단어국문 유전체, 알터너티브 스플라이싱, 마이크로어레이
영문 Genome, alternative splicing, microarray
◆ 연구목표<최종목표>
Whole genome exon array를 통하여 정상조직과 위암조직사이에 차별적으로 나타나는 위암관련
특이적 alternative splice variants를 발굴하고 위암 발생기전에 관련된 splice variants의 생물학
적 기능을 세포수준에서 규명한다.
<당해년도 목표>
위암관련 유전자의 alternative splice variant의 생물학적 기능, 발암기전분석 및 위암특이적
biomarker개발
◆ 연구내용 및 방법
(1) 위암환자로부터 alternative splice variant data 생산
가. 위암 환자로부터 정상-암 조직샘플링
한국인에서 높은 빈도로 발생하는 것으로 알려진 위암을 대상으로 암의 발생 및 분화단
계에 따라 동일한 stage의 정상 및 종양조직을 3 pair이상 수집한다. 수집된 조직에는 반
드시 자세한 임상정보를 동반하여 수집한다.
나. 정상-암 조직에서 whole genome exon array를 위한 RNA추출 및 정제
다. Whole genome exon array실험
Affymetrix Exon1.0ST chip을 사용하여 whole genome exon expression을 측정한다.
라. Exon array data로부터 NI (normalized index)와 SI (Splice index)분석
각 exon에 대해 다음과 같이 정의된 gene-level normalized intensity (NI)와 splicing index
(SI)를 core level에 해당하는 233,001개 probe sets에 대하여 계산한다.
마. RMA를 이용한 CEL file의 normalized data분석
각 cancer-normal pair의 data를 normalize한 후 233,001개의 core level probe set들을 대상
으로 tissue type을 범주형 data의 factor로 하여 ANOVA 분석을 실시하고 이를 통하여
alternative spliced gene을 분석한다.

- 2 -
바. Alternative spliced gene들의 Gene Ontology 분석
Alternative splicing을 보이는 유전자들 중 tissue type간의 p-value가 0.01이하의 유의한
차이를 보이는 유전자들을 대상으로 NIAID/NIH의 DAVID Bioinformatics Resource를
이용하여 gene ontology를 분석하여 세포내의 location 및 관여하는 biological process를
확인하여 위암 발생기전에 보다 유의한 관련이 있는 유전자를 선정한다.
(2) Alternative splice variant의 위암 특이성 검증
가. 위암에 있어서 pathology data에 따른 각 cancer stage에 특이적인 splice variant의 선정
SI ratio를 산출하고 ANOVA test를 통하여 normal vs. cancer별, cancer에서 stage별
representative splice variant가 존재하는 유전자를 선별한다.
나. Splice variant의 validation
Splice variant의 transcript수준에서의 발현 양을 파악하기 위한 validation으로 real-time
PCR을 통하여 각 cancer별, stage별, metastasis유무에 따른 발현 차이를 검증한다.
(3) 위암관련 유전자의 alternative splice variant의 생물학적 기능 분석
가. Splice variant의 over-expression과 repression을 통하여 세포수준에서의 생물학적
기능을 분석한다.
나. 검증된 분석데이터를 기반으로 위암 특이적이며 stage에 유의한 차이를 검출할 수 있는
전사수준에서의 biomarker의 개발가능성 검증
다. 위암관련 유전자 variant의 세포수준에서의in vitro 기능분석을 통한 치료 target으로서의
개발 가능성을 검증한다.
◆ 연구성과
-정량적 성과
구분 달성치/목표치1)
달성도(%)
SCI 논문 편수 2/2 150%
IF 합 9.871/8 123%
기타 성과
1) 총연구기간내 목표 연구성과로 기 제출한 값
-정성적 성과- 한국인 호발성 암의 전이에 관련한 유전자의 alternative spliced variant data의 축적
- Stomach cancer에서 differential gene expression이나 alternative exon usage의 detection을
위한 최적의 reference gene의 탐색하여, stomach cancer에서 최적으로 normalization 할 수
있는reference gene을 규명.
◆ 참여연구원
(최종연도 참여인원)
성 명
고성호, 이연수, 최일주, 이병찬, 노현욱
주민등록번호
- 3 -
Project Summary
Title of ProjectDiscovery of alternative splice variations of stomach cancer related
genes through whole genome exon array
Key Words Genome, alternative splicing, microarray
Project Leader Sung-Ho Goh
Associated Company Not applicable
<Final Research Goal>
Discover alternative splice variants that are represented in cancer specific manner in
stomach tissue using whole genome exon array platform, and characterize the splice
variants' functions that related to tumorigenesis at cell level in vitro.
<Research Methods and Results>
1. Alternative splice variant data generation from stomach cancer tissues.
A. Tissue sampling from gastric cancer patients
The tissues corresponding to stomach cancer lesion and peri-tumoral region were collected
by endoscopic ressection. For each collected samples, detailed pathological staging
information was appended afterward.
B. RNA extraction and purification from collected tissues.
C. Whole genome exon array experiments
Exon-wise expression of paired gastric tissues were detected using Affymetrix Exon1.0ST
platform.
D. Normalized index (NI) and splice index (SI) from exon array data
For each exons, gene-level normalized intensity, NI and splicing index (SI) for 233,001
probesets were calculated.
E. Analyses of CEL files using RMA
Each cancer-normal paired data were normalized and ANOVA test was performed for
233,001 probesets based on normal vs. cancer category. This results were applied to
screening alternative spliced genes.
F. Gene ontology analysis of alternatively spliced genes
Among the candidate alternatively spliced genes, the p-values of which are statistically
significant (p<0.001) were chosen, and then analysed through DAVID Bioinformatic resource
of NIAID/NIH to select more plausible candidate genes related to stomach cancer
development.

- 4 -
2. Validation of stomach cancer specificity
A. Selection of splice variants specific for each cancer stage accroding to pathological data
of stomach cancer
Based on ANOVA test results and SI value, representative splice variants from the
comparisosns of normal vs. cancer and for each cancer stages.
B. Validation of splice variants
For the validation of splice variant at transcription level, the candidate splice variants were
confirmed by RT-(q)PCR and compared to clarify relation to cancer and its stage and/or
metastasis.
3. Analyses of biological function of stomach cancer related splice variants
A. Biological functions were analyzed by comparing cell phenotypes by gain/loss of function
studies.
B. The probability of splice variants as a biomarker development was assessed based on
analyzed data. The level of biomarkers are confined to the transcription level.
C. The potential of splice variants as therapeutic targets were evaluated based on in vitro
cellular function study.
<Accomplishments>
Ÿ Quantitative
- Publication on SCI Journal: 2 papers/Cumulative IF 11.262/112.6%
Ÿ Qualitative
- Obtaining alternative spliced variant data on most frequent cancers in Korean population
- Finding reference genes for evaluating diferential gene expression profiles in stomach
cancer

- 5 -
1. 연구의 최종목표
Whole genome exon array를 통한 정상조직과 위암조직사이에 차별적으로 나타나는 위암관련
특이적 alternative splice variants를 발굴하고 위암 발생기전에 관련된 splice variants의 생물
학적 기능을 세포수준에서 규명한다.
(1) 연구배경
가. Alternative splicing과 genome complexity
다양한 생물 종들의 genome project가 수행되고 완결되면서 밝혀진 충격적인 사실 중의 하나
는 한 종에서 밝혀진 단백질을 코딩하고 있는 유전자의 숫자(complexity)가 실제 우리가 관찰
할 수 있는 세포수준에서의 complexity와 일치하지 않는 다는 사실이다. 이러한 불일치는 단
백질 코딩유전자의 complexity가 일반적으로 cellular complexity보다 낮은 결과로 나타난다.
예를 들어 노랑초파리(Drosophila melanogaster)의 경우 gene complexity가 약 14,000으로
19,000인 예쁜꼬마선충(Caeranorhabditis elegans)보다 낮으며, 식물인 아기장대 (Arabidopsis
thaliana)의 complexity는 약 25,000으로 효모인 Saccharomyces cerevisiae의 6,000의 4배를
약간 상회하는 정도의 수준이다. 사람의 경우에도 약 150,000개에 이르는 유전자가 있을 것으
로 예상되었으나, 충격적이게도 2001년 Human genome project의 initial sequencing이 끝났을
때는 약 32,000개의 유전자가 있는 것으로 보고되었으며, 2005년 HGP가 완결되면서는 이보다
더 적은 25,000개의 protein coding 유전자가 존재하는 것으로 보고되었다. 그러나 실제로 데
이터베이스에 축적된 mRNA나 ESTs (expressed sequence tags)의 종류는 밝혀진 유전자의
숫자보다 훨씬 많으며, 이는 alternative splicing에 의해 complexity가 커졌을 것이라는 가설
에 힘을 실어주게 된다.
그림 1. Computational identification of alternative splicing (Moderek and Lee, 2002, Nature
Genetics 30: 13-19)
분자생물학의 발전과정에 있어서 alternative splicing에 관한 연구는 새로운 유전자 자체의 발
견이나 transcriptional regulation등의 연구에 비하여 지금까지 그다지 많은 관심을 받지 못하
였으나, alternative splicing의 개념은 1978년 Walter Gilbert에 의해 제안되었다. Gilbert는

- 6 -
1977년 adenovirus의 hexon 유전자에서 exon과 intron이 나뉘어 진 보고에 근거하여 서로 다
른 exon들의 조합으로 서로 다른 isoform의 mRNA를 만들어낼 수 있음을 제안하게 된다
(Why genes in pieces? Nature 271:501, 1978). 이후, alternative splicing에 의한 유전자 다양
성이 몇몇 유전자들에서 밝혀지게 되고 1990년대 초반에는 고등한 진핵생물의 경우 약 5%정
도의 유전자들에서 alternative splicing이 일어날 것으로 추정하게 된다. 그러나 1990년대 말
부터, 대량의 유전자 염기서열결정기술의 발달하면서 많은 연구그룹에서 human genome
project와 더불어 다양한 생물 종과 각 생물 종의 서로 다른 조직과 각 조직에서의 발생분화
단계별로 EST sequencing을 하고 그 데이터베이스화하게 된다. 이에, 생물정보학 분야에서는
축적된 ESTs를 상호간에 비교하거나 그림 1과 같이 EST들을 genomic DNA에 align함으로
써 각각 38%와 42-59%의 human genes에서 alternative splicing이 발생할 것으로 추정하였
다. 이에 최근에는 exon을 유전자 발현의 최소단위로 여기고, 발현조절 기작으로서
alternative splicing을 연구하는 “exonomics"라는 용어가 탄생되었다 (Stockheim & Nees,
2007, Int. J . Biochem & Cell Biol. 39: 1432-1449).
나. Splicing mechanism과 alternative splicing의 요인들
Splicing의 가장 대표적인 형태는 일단의 단백질들과 ribonucleoprotein (RNP)들이
spliceosome이라는 구조물을 형성하여 RNA polymerase II에 의해 전사된 mRNA에서 intron
의 경계가 되는 염기서열을 인식하므로 써 일어나게 되며 GU로 시작하는 5' donor site와
AG로 끝나는 3‘ acceptor site를 인식하여 일어난다(그림 2). 5 splice site, branch site, 그리
고 3‘ splice site는 각각 U1 snRNP와 U2 snRNP, U2AF에 의해 인식되며, U4, U5, U6
snRNP가 참여하게 되면서 splicing reaction이 완성된다(그림 2). Major case의 경우 GU-AG
rule에 의하여 (그림 3A) 5’ splice donor site와 3‘ splice acceptor site가 결정되며, 이외에도
GU-AG대신 non-canonical 한 donor-acceptor site인 AU-AC를 인식하여 splicing이 일어나
는 minor한 case도 존재한다. Alternative splicing이 이러한 과정에서 발생할 수 있는 가능
성은 그림 3C에서와 같이, splice site의 염기서열이 canonical form에서 변함으로써
spliceosome protein에 대한 affinity가 약해지는 경우, 그리고 그림 3D에서처럼 exon이나
intron내부에 이러한 weak site들에 대하여 이들이 보다 잘 이용되게 하거나 이용되어지는 것
을 저해하는 enhancer (ESE: exonic splice enhancer, ISE: intronic splice enhancer)나
silencer(ESS: exonic splice silencer, ISS: intronic splice silencer)가 존재하고 이들이 특정
SR (Ser-Arg rich) protein을 splice site에 binding하게 하거나 binding하는 것을 방해하므로
써 splicing의 변화를 가져오게 된다고 알려져 있다.

- 7 -
그림 2. Splicing의 진행과정.
그림 3. Splicing을 조절하는 cis-acting sequences.
또한 이와 더불어 최근에는 RNA polymerase II promoter의 구조와 여기에 어떠한
transcription factor와 결합하는가의 여부에 따라 alternative splicing을 조절한다는 연구결과
가 나오고 있다. 그림 4와 같이 PolII의 promoter가 강력하여 elongation rate, 즉 procssivity
가 빠른 경우 weak splice site를 갖는 exon boundary는 skip되나, promoter가 약한 경우
polII의 processivity가 느려져서 transcript가 천천히 만들어지게 되고 이 경우 weak splice
site에도 SR protein들이 인식하여 binding할 수 있는 기회를 충분히 제공하여 이 exon이 포
함된 transcript가 만들어진다는 것이다. Chromatin의 구조 또한 splicing에 영향을 끼치는데,
histone acetylation이나 DNA methylation에 의해 chromatin이 open 혹은 closed structure를
취하는 양상이 달라지므로 써 polII elongation의 efficiency가 달라져 alternative splicing을 유
발할 수 있다. 또한 진핵생물의 유전자에 있어서는 하나 이상의 promoter가 존재하므로 써 각
생리적 상황에 맞는 promoter가 이용되고, 그에 따라 서로 다른 first exon이 선택되므로 써
(그림 5B) 다양한 transcript들을 만들어 낼 수 있다.

- 8 -
그림 4. PolII promoter의 elongation rate에 의한 alternative splicing. 강력한 alpha-globin
promoter의 경우 weak splice site를 갖는 exon의 skipping이 일어나며, 약한 promoter를 갖
는 경우 polII의 processivity가 줄어들어 spliceosome이 weak splice site에 binding할 충분한
시간이 확보되어 exon inclusion이 일어난다.
이러한 결과로 다음 그림 5A와 같이 여러 종류의 alternative splicing이 발생하며 그림 5B와
같이 promoter의 선택에 의해 첫 번째 exon의 사용이 달라지는 것이다.
그림 5. A. 다양한 모드의 alternative splicing결과. B. 첫 번째 exon의 사용이 달라지는 경우.
이렇게 alternative splicing이라는 결과를 가져오는 데는 위에서 언급한 요인들뿐만 아니라,
CELF (CUG-BP and ETR3-like factors)처럼 splice site의 선택을 조절하는 단백질이나 세포
신호전달과 alternative splicing을 연계하는 STAR family (Signal transduction and
activation of RNA) 같은 RNA binding protein들이 발견됨에 따라 더욱 복잡하고 미묘한 메
커니즘이 존재함이 속속 밝혀지고 있다.
다. Alternative splicing연구방법 및 platform의 발전
Human genome project이전에는 의심이 되는 유전자의 변이에 대하여 Northern blot이나
PCR을 이용하여 detection하는 것이 전부였으며, genome wide alternative splicing survey는
human genome과 transcriptome의 정보가 축적되어가고 bioinformatics의 협력이 이루어지면
서 급격하게 증가하면서 microarray를 기반으로 한 platform이 개발된다. Microarray를 이용
한 연구는 fiber optic array에 alternative splicing을 profiling한 Yeakley를 필두로 (2002,

- 9 -
Nat. Biotech 20:353-358), ink-jet spotted exon-junction microarray에 (그림 6) 52개 human
tissue로부터 alternative splicing을 연구한 결과가 발표되며 (Johnson et al., 2003 Science
302:2141-2144), 뒤를 이어 chemically synthesized oligonucleotide와(Pan et al. 2004 Mol.
Cell 16:929-941) ink-jet oligonucleotide synthesizer를 이용한 연구가(Frey et al. 2005 Nat.
Genet. 37:991-996) 보고되었다. 이러한 개발에 이어 현재 상업적으로 이용가능 한
microarray chip은 Affymetrix사에서 제조하는 Gene Chip Human Exon 1.0ST이 유일하며,
이 칩은 NCBI의 RefSeq와 full-length mRNA로 구성된 17,800 "Core" transcript cluster를 포
함한 총 262,000 transcript clusters에 대하여 1,500,000 이상의 data point로부터 정보를 수집
하여 alternative splicing을 분석하게 된다. 이 platform을 이용하여 10개의 colon cancer pair
로부터 alternative splicing의 연구결과가 (Gardina et al. 2006 BMC Genomics 7:325) 보고되
었다. 물론 microarray를 기반으로 하지 않은 방법들도 최근까지 보고되고 있으나 (Zhang C.
et al. 2005 BMC Bioinfo. 7:202 DASL exon-junction microarray; Zhu J. et al. 2003
Science 301:836-838, Splice variants amplified in parallel on solid phase; Thill G. et al.
2006 Genome Res. 16:776-786, ASEtrap; Venables J.P. & Burn J. 2006 Nucl. Acids Res.
34:e103, EASI-Enrichment of alternatively spliced isoform) 아직까지 상업화 된 platform은
없다.
그림 6. Microarray 기반의 alternative splicing detecion 방법. Exon 내부의 unique sequence
를 probe로 디자인하는 경우와 exon간의 경계를 probe로 design하여 사용하는 방법이 각각
보고되어 있다.
라. Exon expression study가 기존의 gene expression profiling과 다른 점
Alternative splicing을 detection하기 위해 개발된 exon array의 경우 축적된 실제 데이터를
바탕으로 알려지거나 prediction에 의해 등록된 모든 exon들에 대하여 probe가 디자인 되고
이용된다. 기본적으로 gene chip에 의한 expression profiling은 한 유전자의 발현에 있어서
mRNA의 3' region내지는 3' untranslated region을 중심으로 probe가 design된다. 따라서 5‘
region이나 middle region에 splice variant가 생겨 missing되었을 경우에도, gene expression
array로는 앞부분에 이상이 있음에도 불구하고 같은 level의 expression을 보이는 것으로
report할 수 있다. 그러나 그림 7에서와 같이 exon array에서는 이 부분의 차별적인 발현을
고스란히 report할 수 있는 장점이 있다.

- 10 -
그림 7. Genome Browser에서 splice variant가 밝혀진 CSHL1 유전자에 대하여 Exon array
와 Gene expression array의 probe가 cover하는 유전자의 영역을 표시하고 있다. Exon array
에서는 존재하나 gene expression array에서는 cover하지 못하는 probe를 화살표로 표시하였
다.
(2) Cancer에서의 alternative splicing연구의 필요성
가. Alternative splicing과 cancer에 대한 기존의 연구결과
Alternative splicing은 다양한 질병과 관련이 있음이 보고되어왔는데, 여기에는 growth
hormone deficiency, parkinson's disease, cystic fibrosis, retinitis pigmentosa, myotonic
dystrophy 등의 질병을 포함한다. Cancer의 발생에 있어서 핵심이 되는 유전자들의
alternative splicing은 표 1 (Venables 2004 Cancer Res. 64:7647-7654)에 제시된 바와 같이
apoptosis, proliferation, cell cycle/division의 조절, 세포신호전달, cell adhesion, angiogenesis,
invasion과 motility, chromatin remodeling, proteolysis 그리고 metastasis에 이르는 분야에
다양한 cancer에서 다양한 기능에 해당하는 여러 유전자에서 alternative splicing이 발생함을
알 수 있다.
이러한 alternative splicing과 cancer에 관한 연구가 어느 정도로 진행되고 있는지 NCBI의
PubMed에서 두 가지 검색어를 투입하여 검색해보면 총 2,100건의 보고가 되어있으며, 표 2와
같이 2004-2006년의 검색결과만 500건에 달한다 (Skotheim & Nees 2007 IJBCB
39:1432-1449). 또한 2007년 동안 140건의 논문이 발표되었다. 이 보고들에 의하면 다양한 유
전자들의 alternative splicing이 다양한 type의 cancer tissue에서 나타나며 이 보고들이 최근
들어 증가하고 있음을 알 수 있다. 이렇게 다양한 생물학적 기능에 관련된 alternative splice
variant중 signal transduction의 조절에 의해 apoptosis에 영향을 주는 것에는 BCL-X와 Fas
를 비롯한 많은 molecule에 대하여 보고되었다 (그림 8, Shin C. & Manley J.L. 2004 Nat.
Rev. Mol. Cell Biol. 5: 727-738). 이외 에도 splicing control에 영향을 받는 apoptosis관련
유전자에는 metastasis의 suppressor인 CC3 (pro-apoptotic) vs TC3 (anti-apoptotic),
caspase-1, 2, 6, 7, 8, 9, caspase regulator인 FLIP 등이 보고되어있다.

- 11 -
표 1. Seleted examples of cancer-specific alternative splicing.
표 2. Alternative splicing과 cancer를 검색어로 한 NCBI database의 2004-2006년 검색결과

- 12 -
그림 8. Alternative splicing에 의한 pro-apoptotic form과 anti-apoptotic form 의 선택. (Shin
and Manley, 2004 Nat. Rev. Mol. Cell Biol. 5: 727-738)
위의 표 2에서 언급된 p53과 더불어 p63, 073의 alternative spliced variant역시 cancer와 연관
되어있고 그 p63/p73의 존재 없이 p53이 apoptosis에 관여할 수 없는 것과 관련하여 p63/73의
variant가 p53 activity에 alteration을 가져오는 사실이 밝혀졌다 (Murray-Zmijewski et al.
2006 Cell Death and Diff. 13: 962-972). 같은 해인 2006년에는 Knudsen 등에 의해 cancer에
서 과 발현되는 cell cycle 조절유전자인 cyclin D1의 intron retention variant인 cyclin D1b가
발견되었으며, 이 cyclinD1b가 잠재적으로 cell proliferation, transcription factor action, 그리
고 cellular transformation의 조절에 있어 지금까지 알려진 cyclin D1과는 다른 mechanism을
사용할 것으로 보임에 따라 새로운 therapeutic의 개발 가능성도 엿보이고 있다.
이렇듯 cancer에서 다양한 유전자의 splice variant가 발견되는 것에 미루어 볼 때 cancer에
있어서의 splicing은 정상조직의 splicing보다 매우 왜곡되어 있음을 짐작할 수 있는데, 그림 9
에서와 같이 129개 정상 조직과 60개 cancer tissue의 proteome data로부터 splicing의
trans-acting factor인 spliceosome component의 발현 양을 비교해본 보고에서 정상과 cancer
조직 간에 splicing regulator의 발현차이를 뚜렷하게 확인할 수 있다. 또한, cancer에서 나타
나는 챤-acting factor인 splice site의 mutation은 somatic mutation중 10-15%를 차지한다고
보고되어있다 (Beroud et al. 2005 Hum. Mut. 26:184-191).

- 13 -
그림 9. Normal tissue와 cancer 및 cancer cell line에서 splicing factor의 발현의 비교. 많은
splicing associated factor들의 발현이 normal tissue에 비해 현저히 증가한 것을 볼 수 있다.
(Skotheim R.I. & Nees M. 2007 IJBCB 39: 1432-1449)
Cancer에서 alternative splicing의 genome wide study는 사실 human genome project가 끝나
기 이전부터 시작되었는데, 2003년 미국 National Cancer Institute의 Wang 등은 (Cancer
Res. 63:655-657) 생물정보학적인 방법으로 약 350만개의 human EST와 1만1천개의 RefSeq
를 비교하여 이중 845개의 cancer associated variant를 찾아내었고 여기에서 54개는 liver
cancer와 연관이 있음을 밝혀내었다. 같은 해 Xu와 Lee는 (Nucl. Acids Res. 31: 5635-5643)
6,900여개의 human EST library로부터 2백만 개의 EST를 비교분석하여 316개의
cancer-specific splice variant를 발견하였다. 최근에는 fiber-optics를 기반으로 DASL이라는
platform을 이용하여 prostate cancer의 alternative splicing isoform연구가 보고되어있으며
(Zhang et al. 2006 BMC Bioinformatics 7:202), Affymetrix의 Exon 1.0ST를 기반으로 colon
cancer에서의 splice variant profiling이 (Gardina et al. 2006 BMC Genomics 7:325)보고되어
있는 상태이다.
따라서 현재까지 whole genome exon을 대상으로 alternative splice variant를 profiling하는
연구는 아직 초기단계라 할 수 있다.
나. Cancer에서 alternative splicing 연구의 중요성

- 14 -
앞에서 언급한 바와 같이 사람에서 전체 유전자들 중 38-59%의 유전자들에서 alternative
splicing을 나타내며, cancer에서는 somatic mutation중 splice site에 관여한 비율은 15%에 달
하는 등, carcinogenesis에는 유전자 발현의 정량적인 차이뿐만 아니라 유전자의 변이에도 비
중 있는 요인이 있음이 밝혀지고 있다. 따라서 전통적인 발현양의 차이만을 연구하는
microarray기반 연구로부터 splice variant의 발현을 tumor나 stromal cell에 연관시키는 연구
로 전향하므로 써, exon수준에서 유전자발현의 차이를 알아내게 되어 매우 유용한 정보를 획
득하게 되며, cancer와 연관된 alternative splice variant의 생물학적 기능에 대한 이해가 증진
될 것이다. 이렇게 얻어진 정보들은 cancer와 연관된 cell division regulation, apoptosis,
metastasis, signal transduction 등 각 분야에 커다란 영향을 미치리라 사료된다. 또한 밝혀진
alternative splice variant의 정보들은 각 cancer type과 stage 및 cancer metastasis의 진단
및 예후 판정을 위한 unique한 biomarker의 개발과 더 나아가서는 therapeutic의 개발의 근거
가 될 것임이 자명하다고 할 수 있다.

- 15 -
2. 연구의 내용 및 결과
<연구방법>
(1) Whole genome exon array의 수행
가. 한국인 호발성 암인 위암환자로부터 정상-암 조직샘플링
1) 한국인에서 높은 빈도로 발생하는 것으로 알려진 위암을 대상으로 조직은행 혹은 내시경
실에 내원하는 환자의 생체조직을 위암의 발생단계에 따라 동일한 stage의 정상 및 종양조
직의 pair를 3 pair이상 수집한다. 수집된 시료의 개체 수가 증가하게 되면 실험 data의 통
계적 power가 증가하게 되며 동일한 stage에서 추출한 data로부터 outlier를 파악할 수 있
게 된다.
2) 조직의 수집 시부터 실험 시까지 시료의 안정성을 유지하기 위하여, 모든 조직은 RNA
later 용액과 섞어준 상태에서 실온에서 5분가량 incubation한 뒤 -80oC에 보관한다.
3) 수집된 조직에는 반드시 자세한 임상정보를 동반하도록 하며, 임상정보는 추후 데이터의
분석 시 normalization의 factor로 사용될 수 있으므로 database화 하여 보관한다.
나. 정상-암 조직에서 whole genome exon array를 위한 RNA추출 및 정제
1) 실험결과의 consistency를 유지하기 위하여, whole genome exon array에 사용 될 RNA의
추출 및 정제는 다음의 방법을 따른다.
2) Total RNA의 extraction
가) Tissue의 homogenization
l Tissue는 RNA later solution을 모두 제거한 후 2 ml Surelock tube로 옮겨 milligram
단위로 무게를 측정한다.
l 측정된 무게 100 mg당 1 ml의 비율로 Trizol reagent와 stainless steel bead 1개를 넣
어 준다. TissueLyser (Qiagen)에 조직샘플이 담겨있는 tube를 장착한 뒤 30 Hz로 1
분간 작동하여 tissue homogenize를 한다. Tube를 탈거하여 조직의 homogenization상
태를 확인한 후, 조직이 완전히 homogenize되지 않은 경우 재 장착하여 같은 조건으
로 tissue를 homogenize한다.
나) Trizol reagent를 이용한 total RNA의 추출 및 정제
l Homogenize된 tissue는 Trizol reagent의 standard protocol을 따라 RNA를 정제하도
록 한다. 최종적으로 얻어진 pellet의 RNA는 완전히 마르지 않은 상태로 다음의
clean-up 과정으로 넘어가도록 한다.
l 얻어진 RNA pellet은 Qiagen RNeasy Mini column을 이용하여 genomic DNA를 제거
하고 남은 impurities를 함께 제거한다.
다. Whole genome exon array실험

- 16 -
그림 10. Whole genome exon array를 위한 Whole transcript sense target labeling의
work-flow.
모든 protocol은 Affymetrix사의 GeneChip Whole transcript sense target labeling assay
manual을 따른다. (그림 10)
1) Day 1

- 17 -
l 정량된 RNA sample 1 ug을 poly-A control과 함께 섞어 주고 rRNA reduction step으
로 진행한다
l 차례대로 1st
cycle, 1st
strand cDNA 합성 - 1st
cycle 2nd
strand합성 - 1st
cycle in
vitro transcription (over night)을 진행한다.
2) Day 2
l 1st
cycle cRNA를 clean-up한다.
l 차례대로 2nd cycle, 1st strand cDNA synthesis - cRNA hydrolysis - clean-up of
sense strand DNA - fragmentation - terminal labeling을 진행한다.
3) Day 3
l Hybridization control을 label된 sense strand와 함께 mix한 후 Exon 1.0ST array에
apply한 후 hybridization oven에서 overnight incubation한다.
4) Day 4
l Hybridization된 array로부터 solution을 제거하고 washing을한다.
l Scanning하여 data를 collect한다.
l Expression concole software에서 QC를 진행한다.
라. Exon array data로부터 NI (normalized index)와 SI (Splice index)분석
각 exon에 대해 다음과 같이 정의된 gene-level normalized intensity (NI)와 splicing index
(SI)를 core level에 해당하는 233,001개 probe들에 대하여 계산한다. 만약 sample 1에서는
probe set의 intensity가 500이고 sample 2에서는 600일 때, 직접적으로 비교할 때는 sample 1
에서의 해당 exon에 대한 signal이 더 높으나, 전체 gene에 대한 expression level이 각각 500
과 6,000이라 할 때 sample 1에 대한 NI = 500/500 = 1.0이고 sample 2에 대한 NI는
600/6,000 = 0.1이므로 sample 1이 10배의 inclusion level을 갖게 된다. 따라서 이를 기반으로
SI를 구하면 SI = log2(1.0/0.1) = 3.32가 된다.
(1)
(2)
마. RMA를 이용한 CEL file의 normalized data분석
PARTEK Genomics Suite 6.3 software를 이용하여 각 pair의 CEL file들을 normalize한 후
233,001개의 core level probe set들을 대상으로 tissue type을 범주형 data의 factor로 하여
ANOVA 분석을 실시하고 이를 통하여 alternative spliced gene을 분석한다.

- 18 -
바. Alternative spliced gene들의 Gene Ontology 분석
Alternative splicing을 보이는 유전자들 중 tissue type간의 p-value가 0.01이하의 유의한 차
이를 보이는 유전자들을 대상으로 NIAID/NIH의 DAVID Bioinformatics Resource 2007을 이
용하여 gene ontology를 분석한다.
(2) 다양한 알고리즘을 통한 splice variant의 분석
가. 위암과 관련된 유전자의 alternative exon usage의 유의성을 높이기 위한 위암환자군
alternative splice variant data의 생물정보학적 접근 및 분석
l 다음의 4종류의 알고리즘을 이용하여 exon array의 데이터를 분석하였음.
1) XRAY3.92: Alternative splicing detected by nested mixed model of ANOVA & DABG
(detection above background)
Ÿ Array data로부터 normalization을 수행.
Ÿ 'CORE' probeset들만을 filtering한 후 GC %가 너무 낮거나 너무 높은 probeset들을 제
외하였음 (GC가 각 probe전체에서 6-17개 범위인 것들을 선별).
Ÿ Background level을 교정하고 이 중 아무런 변화가 없는 probeset들을 제외하였음.
Ÿ 각 sample의 whole genome exon array를 통하여 구한 NI value를 이용하여 동일한
sample group내에서의 평균과 표준편차를 구하고 outlier를 배제시킨 뒤 조합간의 SI
ratio를 산출하였음.
Ÿ exon의 SI ratio를 하나의 transcript cluster (gene)을 기준으로 나열 (display)하여 비교
대상간의 exon expression의 차이를 살펴보고 ANOVA test를 통하여 significance를 산
출하고, p<0.001이하인 범주를 accept하였음.
Ÿ 상기의 기준을 통하여 stomach cancer에서 stage별, 동일 stage에서 pathological
difference에 따른 representative splice variant가 존재하는 유전자를 선별하였음.
2) JETTA: Junction and exon array toolkit for transcriptome analysis
Ÿ 전체 probeset중에서 'CORE' probe set만을 선별하고 각 transcript cluster ID 중 적어
도 probeset이 2개 이상인 transcript cluster를 다시 선별하였음.
Ÿ Probeset의 expression level이 상위 20%내에 속하는 것들과 하위 20%에 속하는 것들을
제외함. 이중 normal과 tumor사이의 전체발현양 차이가 2배 이상되는 probeset들도 제외
하였음. (전체 발현양 차이에 의하여 exon usage의 차이가 있는 것으로 나타나는 false
positive를 배제하기 위한 절차)
Ÿ Gene-normalized exon intensity를 계산하였음.
Ÿ Pair-wise correlation coefficient가 0.7이상인 exon들 만을 선별하고 분류의 기준에 따라
서 그룹을 만들었음.

- 19 -
Ÿ T-test를 2회 시행하여 (less, greater) p-value가 0.001이하인 alternative splice variants
를 최종적으로 선정하였음.
그림 11. Alternative splice variant의 screening을 위한 절차.
3) FIRMA: Finding isoforms by robust microarray analysis
Ÿ 이 알고리즘은 pre-defined 그룹이 없고 실험상의 반복이 없는 경우와, 주어진 유전자가
질병과 관련이 있을 때 질병에 관련된 alternative splcing이 샘플들중 일부에만 나타나
는 경우를 가정하고 디자인 되었음
Ÿ 다른 알고리즘과 달리 sample-by-exon 특이적이며 따라서 각 샘플과 exon의 조합에 대
한 스코어를 부여하여 다른 샘플과 exon의 조합과 비교함.
4) PAC: pattern based correlation

- 20 -
그림 12. PTEN 유전자의 breast cancer에서의 변이차이를 PAC algorithm과 (좌측) PLIER
algorithm (우측)을 적용하여 비교한 결과.
l 선별된 유전자의 Gene ontology검색을 통한 세포내의 location 및 관여하는 biological
process를 확인하여 위암발생기전에 보다 유의한 관련이 있는 유전자를 선별함.
① Cellular component: Cell surface에 존재하는 receptor와 nucleus에 존재하는 molecule
들을 중심으로 biomarker 및 치료제 target의 가능성을 evaluation함.
② Biological Process: Cell proliferation, cell communication/signal-transduction에 관여하
는 유전자를 중심으로 cancer와의 연관성 분석 및 치료제 개발의 target가능성을
evaluation함.
③ Molecular function: cell division이나 protein 합성에 관련된 protein binding function
및 receptor activity관련 function에 관련되는 유전자들을 중심으로 cell내에서 종양의
발생기전에 관련될 것으로 추정되는 유전자들의 기능을 evaluation함.
④ Pathway analysis: Gene ontology의 스크리닝 결과를 기반으로 하여 KEGG및
GenMAPP database를 이용하여 alternative splicing의 결과로 pathway의 정상적인 운
용에 차질이 빚어질 가능성이 있는 유전자들을 찾아내어 validation함.
(3) alternative exon usage의 확인 및 검증
l 위암환자로부터 정상-암 조직샘플링
1) 한국인에서 높은 빈도로 발생하는 것으로 알려진 위암을 대상으로 내시경실에 내원하는
환자의 생체조직을 위암의 발생단계에 따라 동일한 stage의 정상 및 종양조직의 pair를
수집하였음.
2) 조직의 수집 시부터 실험 시까지 시료의 안정성을 유지하기 위하여, 모든 조직은 RNA
later 용액과 섞어준 상태에서 실온에서 5분가량 incubation한 뒤 -80oC에 보관하였음.
3) 수집된 조직에는 반드시 자세한 임상정보를 동반하도록 하며, 임상정보는 추후 데이터
의 분석 시 normalization의 factor로 사용될 수 있으므로 database화 하여 보관함.
l Alternative splice variant의 validation을 위한 RNA추출 및 cDNA합성
1) 실험결과의 consistency를 유지하기 위하여, whole genome exon array에 사용 될 RNA
의 추출 및 정제는 다음의 방법을 따랐다.
2) Total RNA의 extraction
가) Tissue의 homogenization
- Tissue는 RNA later solution을 모두 제거한 후 2 ml Surelock tube로 옮겨

- 21 -
milligram 단위로 무게를 측정한다.
- 측정된 무게 100 mg당 1 ml의 비율로 Trizol reagent와 stainless steel bead 1개를
넣어 준다. TissueLyser (Qiagen)에 조직샘플이 담겨있는 tube를 장착한 뒤 30 Hz로
1분간 작동하여 tissue homogenize를 한다. Tube를 탈거하여 조직의 homogenization
상태를 확인한 후, 조직이 완전히 homogenize되지 않은 경우 재 장착하여 같은 조건
으로 tissue를 homogenize한다.
나) Trizol reagent를 이용한 total RNA의 추출 및 정제
- Homogenize된 tissue는 Trizol reagent의 standard protocol을 따라 RNA를 정제하도
록 한다. 최종적으로 얻어진 pellet의 RNA는 완전히 마르지 않은 상태로 다음의
clean-up 과정으로 넘어가도록 한다.
- 얻어진 RNA pellet은 Qiagen RNeasy Mini column을 이용하여 genomic DNA를 제
거하고 남은 impurities를 함께 제거한다.
3) First strand cDNA 합성
가) cDNA합성은 1 ug의 total RNA를 이용하여 반응한다.
나) 합성된 cDNA는 1/10로 희석하여 그 중 1 ul를 real-time PCR 반응에 이용한다.
l Exon usage의 validation을 위한 exon-specific primer의 design
Exon array를 통하여 얻어진 splice variation을 validate하기 위하여, 해당하는 exon을
flanking하는 염기서열 특이적 oligonucleotide를 제작하여 RT-PCR을 수행한다. 이 때 가
능한 한 exon array에 사용된 조직의 RNA와 함께 추가적인 샘플로부터 추출한 RNA를
포함하도록 하여 exon array에 사용된 개체에만 한정되어 발견되는 splice variant인가의
여부를 판단한다.
1) Bioinformatic analysis로부터 선별된 probeset을 UCSC genome browser에서 mapping
하여 해당하는 exon의 position을 파악한다.
2) Target gene에 해당하는 NCBI RefSeq로부터 exon을 포함하는 좌우 exon의 sequence
들을 함께 수집하고, target exon이 포함되는 PCR primer를 Primer 3 website
(http://frodo.wi.mit.edu/primer3)로부터 design한다. 이때 PCR product는 150 bp내외의
길이가 되며, Tm은 60도로 한다.

- 22 -
그림 13. Exon specific primer design 과정
l Splice variant의 transcript수준에서의 발현 양을 파악하기 위한 validation으로 RT-PCR을
통하여 각 normal-cancer별, stomach cancer stage에 따른 signal 차이를 측정하였다.
l qRT-PCR primer의 design시 다음의 조건에 부합하도록 하였다.
- Primers should be selected in a region with G/C contents of 20-80%. Lower G/C
content is preferred.
- Design primers to amplify short segments of DNA within the target sequence. The
recommended amplicon size is 50 to 150 bp.
- Design at least one primer and/or probe which crosses one exon junction.
l Real-time PCR의 thermal cycling의 조건은 다음을 따랐다.
(4) Alternative exon usage를 보이는 expression open-reading frame의 동정 및 세포수준
에서의 생물학적 기능분석을 통한 tumorigenesis mechanism연구
l 2009년의 연구결과를 통하여 도출한 alternative exon usage를 보이는 5종의 유전자를 중심
으로 splice variant의 생물학적 기능을 동정하기 위하여 정상의 open-reading frame과
variant의 ORF를 인위적으로 발현시키는 연구를 수행한다. 그 절차는 다음과 같이 한다.

- 23 -
1) Wildtype gene open reading frame의 cloning
Ÿ Alternative exon usage가 확인된 유전자는 full-length mRNA를 특이적으로 증폭할 수 있
는 primer를 design하여 RT-PCR을 수행하여 실제로 variant가 존재하는가의 여부를 확인
한다. (선택적으로 constitutive하게 represent되는 유전자의 부위를 probe로 하여 Northern
blot을 수행할 수 도 있다.)
Ÿ Alternative exon usage가 확인된 유전자가 발현하는 세포주 혹은 환자의 tissue로부터 추
출한 RNA로부터 Transcriptor reverse transcription kit을 이용하여 cDNA를 합성한다.
(방법은 전년도 연구방법과 동일하게 수행한다.)
Ÿ Normal form (wild type)의 start codon에서 stop codon을 포함하는 PCR primer를
Primer3 website에서 human genome mispriming library를 선택하여 redundant한 유전자
가 unspecific하게 증폭되지 않도록 조건을 정하고, Tm = 70℃로 하고 primer의 최적 길이
는 30-mer전후가 되도록 디자인 한다. Signal이 약하거나 multiple band가 나타나는 경우
를 대비하여 gene specific primer (GSP)와 nested-GSP를 함께 디자인 하여 PCR product
의 false positive를 줄이도록 한다.
Ÿ Proof-reading activity가 있는 PCR용 polymerase를 사용하여 (Advantage HF cDNA
Taq, Clontech) 증폭한다. Gene specific primer (GSP)를 사용하여 수행한 PCR에서 signal
이 약하거나 multiple band가 나타나는 경우, agarose gel electrophoresis를 하고 이로부터
예상되는 길이의 band를 잘라내고, QuickSpin Gel Extraction kit (Qiagen)을 이용하여
PCR product를 elution한다. Elution된 DNA를 template로 하고 GSP와 함께 디자인된
nested-GSP를 이용하여 second PCR reaction을 수행한다.
Ÿ Variant의 경우, 특히 5' 끝부분이나 3'끝부분이 다른 경우 wild type의 ORF와 달리 그 양
이 적거나 정상적인 PCR조건에 의하여 증폭되지 않을 가능성도 있다. 이러한 경우
alternative하지 않은 constitutive exon의 정보를 확인하여 이를 anchor로 5'- 혹은
3'-RACE (rapid amplification of cDNA ends)를 수행하여 template를 확보한다.
Ÿ 충분한 양의 PCR product를 gel electrophoresis하여 정확하게 예측된 band를 elution한다.
여기서 elution된 DNA는 pGEM-T-easy vector에 T4 DNA ligase를 5U처리하여 4℃에서
16시간동안 ligation 한다.
Ÿ Ligates는 electroporation을 통하여 TOP10 electro-competent cell에 transformation한 후
SOC media 1ml을 가하여 37℃에서 1시간 동안 shaking incubation하여 recovery시킨 후
에, X-gal/IPTG를 함유한 LB/agar배지에 100 ul의 transformant를 spread한다. 이 배지를
37℃에서 16시간 동안 배양하여 white single colony를 확보한다.
Ÿ 다수의 single shite colonies를 확보한 후 각 클론에 대하여 cloning vector의 clodning site
양측에 존재하는 conventional한 sequencing primer인 T7/T3 혹은 M13 rev/fwd primer
를 이용하여 insert를 sequencing한다. Insert의 안쪽이 sequencing되지 않은 경우에는
internal primer를 디자인 하여 모든 insert의 sequence를 확인하도록 한다.
Ÿ Sequence가 확인된 ORF는 CMV-promoter를 갖는 mammalian expression vector로 옮긴

- 24 -
다. mammalian expression vector는 그 용도에 따라 일반적인 과발현을 위해서는
pcDNA3.1-V5/His이나 pFLAG-CMV2로, 세포내 단백질 발현위치를 확인하기 위해서는
pAcGFP로 옮기도록 한다.
2) Variant의 확보를 위한 5'-/3'-RACE
Ÿ Constitutively represented exon의 정보를 이용하여 필요한 방향으로 RACE를 수행한다.
그림 14. Variant의 확보를 위한 RACE과정. SMART system에서 SMARTer oligonucleotide
를 사용하므로써 원래의 mRNA의 5‘-end, 즉 first cDNA의 끝부분에서 terminal transferase
activity로 몇 개의 nucleotide를 결합시켜생긴 서열에 상보적으로 결합하고 이로써 추후에
PCR단계에서 사용될 primer에 해당하는 서열 (굵은 검은선으로 표시된 부분)을 RT가 합성하
여 채우게 한다. 이러한 template switch기능으로 인하여 기존의 시스템보다 더 많은
full-length cDNA를 만들게 된다.
Ÿ Constitutively represented exon을 anchor로 하여 5'-혹은 3'-cDNA들을 확보하는 경우,
기존에 밝혀지지 않은 splice variant도 모두 amplification되는 결과를 얻을 수 있다. 따라
서 이 경우 gene specific한 sub-scale cDNA library를 통하여 다양한 splice variant들도
얻어낼 수 있다.
Ÿ 모든 RACE에서의 PCR reaction은 wild type의 ORF를 amplification할 때와 마찬가지로
proofreading기능이 있는 polymerase를 사용하고, 같은 방법으로 cloning하여 insert의
sequencing을 통해 variant임을 확인하도록 한다.
3) Variant의 biological function을 보기위한 over-expression experiment 및 gene-silencing
experiment
Ÿ Variant expression construct는 그 발현이 낮게 나타난 위암 세포주 혹은 비 위암 세포주
를 대상으로 transfection하여 그 기능을 동정한다.
Ÿ Variant를 발현하면서도 동시에 wild type의 ORF를 발현하는 경우, 해당하는 세포주에

- 25 -
wild type mRNA에 specific한 siRNA (small interfereing RNA)를 제작하거나
pre-designed siRNA를 확보하여, 정상적인 유전자의 발현을 knock-down하고 alternative
exon usage를 갖는 mRNA를 차별적으로 남겨 그 영향을 확인한다. 반대로 alternative
form에 specific한 siRNA를 디자인 할 수 있는 경우, AS form을 knock-down하고 wild
type의 영향을 관찰하여 variant에 의한 영향을 관찰한다.
Ÿ Variant에 의한 영향은 tumorigenesis가 일어나는데 기본적으로 관찰되는 생물학적 기능
인, cell proliferation, cell cycle regulation, cell motility에 대하여 다음과 같은 우선순위에
입각하여 분석하고(①-③), 이러한 현상과 해당유전자의 variant와 관련된 추가적인 생물학
적 기능을 분석한다 (④, ⑤).
① Cell proliferation에 관련된 생물학적 기능분석: 6-well plate에 plating된 세포에 AS
variant에 specific한 siRNA를 처리하거나, variant expression construct를
over-expression한후 72시간 동안 CO2 incubator에서 배양하면서 매 24시간 마다,
MTT assay를 수행하여 cell proliferation에 대한 AS variant의 영향을 측정한다.
② Cell cycle regulation에 관련된 생물학적 기능분석: 해당 유전자의 WT과 AS form의
과발현이나 knock-down을 통하여 cell cycle의 변화가 생기는 것을 flow cytometry를
통하여 확인한다. 세포주에 대한 transfection을 수행한 후에는 72시간 까지 조건을 유
지하며 매 24시간마다, 현미경하에서 세포들의 분열상태를 모니터링하여 사진으로 남기
며, 각 시간대 별로 세포들을 fixation하여 propidium iodide staining하여 FACS
machine에서 Sub G0/G1 phase, G1-phase, S phase, G2-M-phase의 portion을 측정한
다.
③ Cell motility에 관련된 생물학적 기능분석: AS variant를 과발현 시킨 후 wound
healing assay 혹은 migration assay를 수행한다. 이 경우 variant의 발현이
extracellular region에 localize되는지 확인한다.
④ 해당하는 유전자의 기능이 chromatin structure에 관련된 경우: 먼저 해당하는 유전자
산물이 chromatin에 위치하는지 해당하는 단백질에 특이적인 antibody를 확보하여
binding하므로써 현미경 하에서 확인한다. AS variant에 대한 항체가 제작되는 경우 이
들의 intracellular localizaion을 시도하고 정상적인 form과 어떻게 다른 분포를 보이는
지 비교한다. siRNA 처리나 overexpression을 통하여 chromatin의 dysregulation을 현
미경하에서 관찰한다. 동일한 처리를 한 세포주를 72시간 동안 배양하면서 매 24시간
마다 aneuploidy의 발생여부를 관찰하여 AS variant의 기능에 의하여 비정상적인 염색
체 segregation이 일어나는지 관찰한다.
⑤ 해당하는 유전자가 membrane receptor로써 기능하는 경우: AS variant의 expression
construct를 발현시켜 정상적인 membrane targeting이 되는 지 먼저 확인한다. 이
receptor기능을 갖는 단백질이 membrane으로 targeting되지 않는 경우 신호전달의 체
계에 영향을 주는 것으로 판단한다. 이와 달리 membrane으로는 trafficking되나
intracellular domain쪽이 결실되거나 첨가되어 catalytic activity의 변화가 생기는 경우,
예상되는 downstream molecule을 탐색하여 그들의 phosphorylation 상태를
phospho-specific antibody와 whole protein detection antibody를 이용하여 관찰한다.

- 26 -
Serial
No.
Sex Age Stage OP PostOp
-T
PostOp
-N
Sample Encrypt
1 F 34 AGC OP T3 N3 F34_AGC_OP_T3_N3
2 F 46 EGC NO-OP T2 N0 F46_EGC_NO-OP_T2_N0
3 F 49 EGC OP T2b N3 F49_EGC_OP_pT2b_N3
4 F 50 EGC OP T1b N0 F50_EGC_OP_T1b_N0
5 F 60 EGC OP T1b N1 F60_EGC_OP_pT1b_N1
6 F 62 EGC OP T1a N0 F62_EGC_OP_T1a_N0
7 F 65 EGC OP T1b N0 F65_EGC_OP_T1b_N0
8 F 68 AGC NO-OP T3 N2M1P
1
F68_AGC_NO-OP_T3_N2
M1P1
9 F 76 EGC OP T2b N2 F76_EGC_OP_T2b_N2
10 M 41 EGC OP T1b N1 M41_EGC_OP_pT1b_N1
11 M 44 EGC OP T2b N1 M44_EGC_OP_pT2b_N1
12 M 46 EGC OP T1b N1 M46_EGC_OP_T1b_N1
13 M 49 EGC OP T2b N1 M49_EGC_OP_pT2b_N1
14 M 50 EGC OP T1a N0 M50_EGC_OP_T1a_N0
15 M 53 EGC OP T2a N0 M53_EGC_OP_T2a_N0
16 M 54 EGC NO-OP T1 N0 M54_EGC_NO-OP_T1_N0
17 M 54 EGC OP T1a N0 M54_EGC_OP_T1a_N0
18 M 58 EGC OP T1b N0 M58_EGC_OP_T1b_N0
19 M 59 AGC OP T3 N1 M59_AGC_OP_T3_N1
20 M 64 EGC OP T1b N1 M64_EGC_OP_T1b_N1
21 M 65 EGC OP T1b N0 M65_EGC_NO-OP_T1_N1
22 M 65 EGC OP T1b N1 M65_EGC_OP_pT1b_N0
l 이상의 방법을 통한 세포수준에서의 차이가 관찰되는 경우, protein interaction map과
metabolic pathway를 검색하여 관련된 유전자를 찾아내고 이들과의 상호작용을 세포학적
생화학적으로 분석하여 alternative splice variant에 의한 tumorigenesis의 mechanism의
evidence를 탐색한다.
<연구결과>
(1) 위암샘플 및 임상정보의 수집
내시경 검진을 받는 환자 중 비임상연구참여 및 유전자검사에 동의한 환자를 대상으로
endoscopic mucosal resection을 통해 환자 한 명당 50 mg 전후의 정상 및 종양조직을 채취하였
다. 위암환자의 임상정보는 성별, 나이 및 내시경 당시의 stage정보, 수술 후 T-stage 및 N-stage
정보를 다음과 같이 수집하였다.
표 3. 위암환자의 임상정보

- 27 -
Serial
No.
Sex Age Stage OP PostOp
-T
PostOp
-N
Sample Encrypt
23 M 66 EGC OP T1a N0 M66_EGC_OP_T1a_N0
24 M 67 EGC OP T2b N0 M67_EGC_OP_pT2b_N0
25 M 68 EGC OP T2a N3 M68_EGC_OP_pT2a_N3
26 M 73 EGC OP T2a N1 M73_EGC_OP_pT2a_N1
27 M 74 EGC OP T2b N2 M74_EGC_OP_T2b_N2
28 M 75 EGC OP T1b N1 M75_EGC_OP_pT1b_N1
29 M 77 EGC OP T1b N1 M77_EGC_OP_T1b_N1
30 M 78 EGC OP T1a N0 M78_EGC_OP_T1a_N0
(2) 위암 조직으로 부터 microarry를 위한 RNA 분리정제
채취한 모든 조직은 상온에서 RNA later보존용액에 담가 운반하였다. 운반한 샘플은 RNA를 추출
한 때 까지 -20℃에서 보관하였다. 보존된 시료들은 연구수행방법에 기술된 순서대로 처리하여
RNA를 추출하였으며, 1.2% formaldehyde agarose gel에 running하여 integrity를 추정하였으며
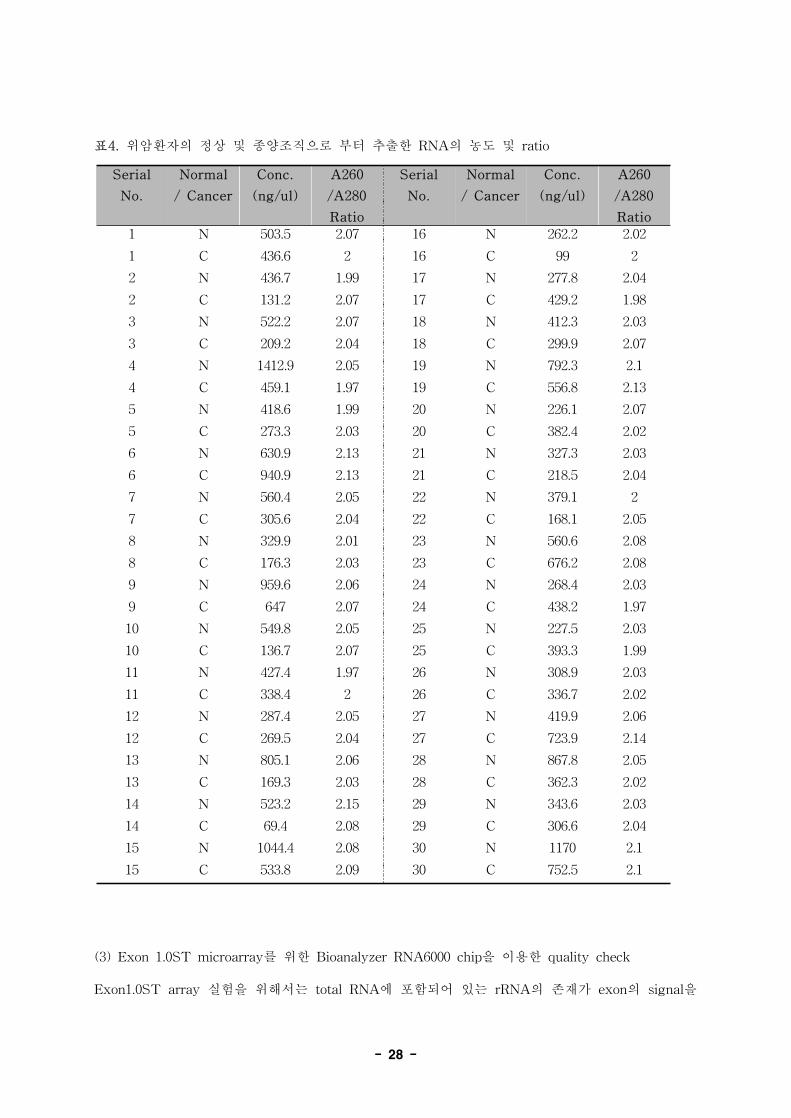
(그림 15), Nanodrop을 이용하여 농도와 순도를 측정한 후 (표 4) -80℃에서 microarray실험시 까
지 보관하였다. 시료 양의 제한으로 인하여 높은 농도의 RNA를 얻기는 어려웠으나 A260/A280
ratio의 범위가 1.97에서 2.13수준으로 다른 불순물에 의한 오염이 없는 RNA에서 이상적인 ratio
를 나타내었다. 또한 agarose gel상에서 보여지는 28S및 18S rRNA의 band 및 lane전체에 걸쳐서
낱낱히 나타나는 banding pattern에 의거하여 판단되는 total RNA의 quality는microarray를 하기
에 충분한 정도라고 판단되었다.
그림 15. 1.2% Formaldehyde gel에서 확인한 위암환자 total RNA의 integrity. 28S와 18S rRNA
의 band가 대부분의 시료에서 뚜렷하게 존재하며 rRNA이외에 mRNA의 banding pattern이 선명
하게 관찰되고 있다.
- 28 -
Serial
No.
Normal
/ Cancer
Conc.
(ng/ul)
A260
/A280
Ratio
Serial
No.
Normal
/ Cancer
Conc.
(ng/ul)
A260
/A280
Ratio
1 N 503.5 2.07 16 N 262.2 2.02
1 C 436.6 2 16 C 99 2
2 N 436.7 1.99 17 N 277.8 2.04
2 C 131.2 2.07 17 C 429.2 1.98
3 N 522.2 2.07 18 N 412.3 2.03
3 C 209.2 2.04 18 C 299.9 2.07
4 N 1412.9 2.05 19 N 792.3 2.1
4 C 459.1 1.97 19 C 556.8 2.13
5 N 418.6 1.99 20 N 226.1 2.07
5 C 273.3 2.03 20 C 382.4 2.02
6 N 630.9 2.13 21 N 327.3 2.03
6 C 940.9 2.13 21 C 218.5 2.04
7 N 560.4 2.05 22 N 379.1 2
7 C 305.6 2.04 22 C 168.1 2.05
8 N 329.9 2.01 23 N 560.6 2.08
8 C 176.3 2.03 23 C 676.2 2.08
9 N 959.6 2.06 24 N 268.4 2.03
9 C 647 2.07 24 C 438.2 1.97
10 N 549.8 2.05 25 N 227.5 2.03
10 C 136.7 2.07 25 C 393.3 1.99
11 N 427.4 1.97 26 N 308.9 2.03
11 C 338.4 2 26 C 336.7 2.02
12 N 287.4 2.05 27 N 419.9 2.06
12 C 269.5 2.04 27 C 723.9 2.14
13 N 805.1 2.06 28 N 867.8 2.05
13 C 169.3 2.03 28 C 362.3 2.02
14 N 523.2 2.15 29 N 343.6 2.03
14 C 69.4 2.08 29 C 306.6 2.04
15 N 1044.4 2.08 30 N 1170 2.1
15 C 533.8 2.09 30 C 752.5 2.1
표4. 위암환자의 정상 및 종양조직으로 부터 추출한 RNA의 농도 및 ratio
(3) Exon 1.0ST microarray를 위한 Bioanalyzer RNA6000 chip을 이용한 quality check
Exon1.0ST array 실험을 위해서는 total RNA에 포함되어 있는 rRNA의 존재가 exon의 signal을

- 29 -
측정하는데 있어서 noise가 될 수 있으므로, 실험에 사용될 모든 RNA는 Ribominus step을 거쳐
rRNA를 제거하는 과정을 거치게 되는데, 그 제거정도를 통하여 실험에 충분한 quality를 확보하
기 위하여 Bonalyzer RNA6000 chip을 이용하여 Ribominus 처리 전과 후의 rRNA의 peak 및
RNA integrity를 측정하였다. 그림 3와 같이 동일한 total RNA에 대하여 Ribominus 과정을 거치
기 전에는 rRNA peak의 FU (fluorescence unit)이 100이상에 달하는 정도 였으나 처리 후에는
rRNA peak의 FU는 4미만으로 감소하여 대부분의 rRNA가 제거되었음을 확인 하였으며, RNA
integrity number도 7.0전후의 수준을 유지하므로써 좋은 quality를 유지함을 알 수 있었다 (그림
16).
그림 16. Bioanalyzer RNA6000 chip을 통한 RNA quality 측정. Ribominus 처리 전과 (A)
Ribominus처리 후의 (B) RNA quality및 rRNA 제거정도. RNA chip 1 run에서 측정된 sample의
quality (C).
(4) Exon1.0ST micorarray 결과의 QC
Microarray를 수행한 샘플 중 수술 후 pathology를 통한 T-stage 및 N-stage정보가 없는 데이터
는 분석과정에서 제외시키고 진행하였다. 먼저 그림 17과 같이 Exon1.0ST의 제조사인 Affymetrix

- 30 -
가 제공한 area under curve 방법으로 normalization control diagnostics를 수행하였다. 값이 1에
가까울 수록 control probe들을 완벽하게 분리하여 구별할 수 있는 반면, 0.5의 값을 갖으면 구분
이 불가능하여 0.8을 기준으로 이 값 이하인 경우 array의 데이터를 사용할 수 없는 것으로 판단
한다. 본 실험에서 사용된 54개의 Exon array는 모두 0.8이상의 값을 보이므로써 정상적인 데이터
분석에 이용될 수 있었다.
그림 17. Area under curve 방법을 통한 normalization control diagnostics. 0.8이상인 array는 정
상적인 data anaysis에 이용가능하다.
다음으로 normalization 전 분석을 수행하였는데, 그림 5는 각 array에서 어떤 score의 (X축)
probe가 몇 개나 (Y축) 되는지 분포를 plotting한 것으로 사용된 array모두 normalization전임에도
일정한 분포 내에 수렴하는 것을 볼 수 있다.
그림 18. 54개 array에 대한 Non-normalized expreesion histogram.
- 31 -
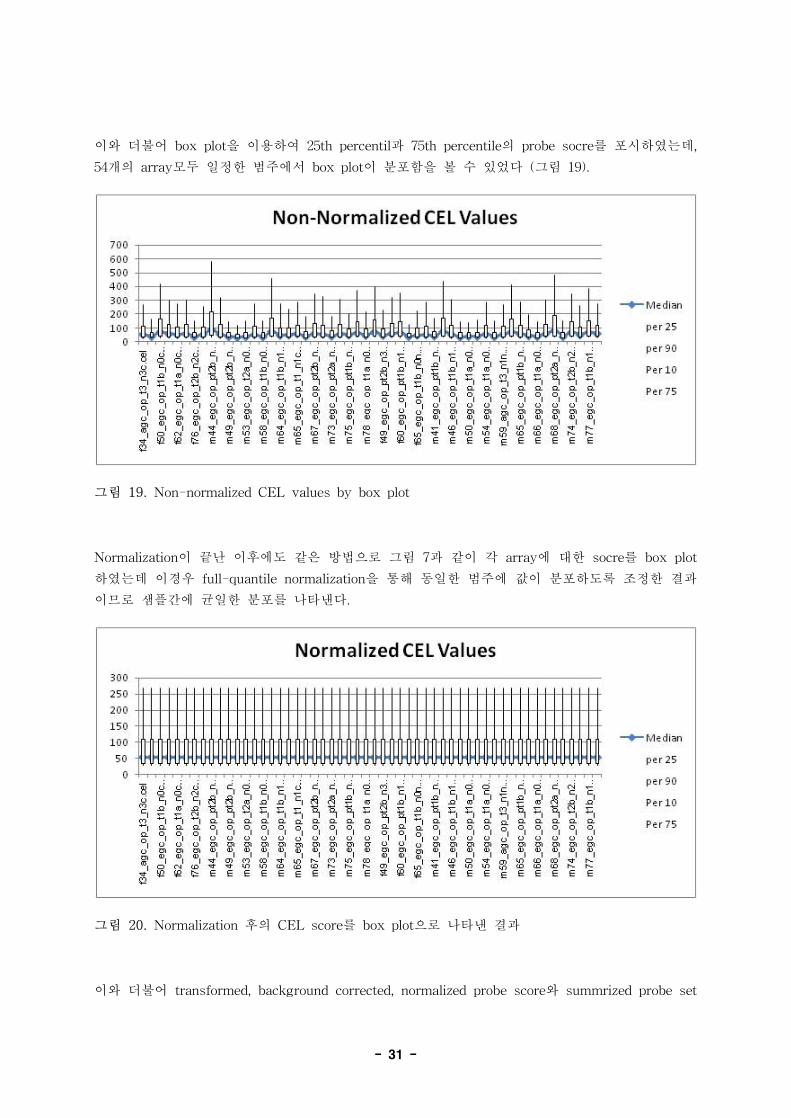
이와 더불어 box plot을 이용하여 25th percentil과 75th percentile의 probe socre를 포시하였는데,
54개의 array모두 일정한 범주에서 box plot이 분포함을 볼 수 있었다 (그림 19).
그림 19. Non-normalized CEL values by box plot
Normalization이 끝난 이후에도 같은 방법으로 그림 7과 같이 각 array에 대한 socre를 box plot
하였는데 이경우 full-quantile normalization을 통해 동일한 범주에 값이 분포하도록 조정한 결과
이므로 샘플간에 균일한 분포를 나타낸다.
그림 20. Normalization 후의 CEL score를 box plot으로 나타낸 결과
이와 더불어 transformed, background corrected, normalized probe score와 summrized probe set

- 32 -
score간의 차이를 plot하였는데 (그림 21), quality score는 Affymetrix가 제공한 ExACT package
를 이용하여 얻어졌다.
그림 21. Mean residual graph.
다음으로는 array상에 존재하는 probe에서 GC의 갯수에 따른 분포를 plot하였는데 probe의 길이
가 25mer인데 GC의 갯수가 18개 이상이거나 5개 이하인 경우 분석에 사용을 배제하였다.
그림 22. Probe의 GC-count에 때른 probe 빈도의 분포.
(5) Transcription cluster의 filtering
Human Exon1.0ST array상에는 312,368개의 transcript cluster가 존재하는데 이중 RefSeq 데이터
베이스를 기준으로한 Core probe-set에 해당하는 transcript cluster를 17,440로 filter하고 난 뒤,

- 33 -
그림 9에서 얻어진 기준에 따라 GC content로 filter하여 GC의 갯수가 6개에서 17개 사이인 probe
를 filter하고, background leve이상인 probe를 다시 filter한 뒤 남는 transcript cluster의 갯수는
모두 10,396개 였다 (표 5).
표 5. Filter과정에 따라 남은 transcript cluster
Filtering Step Filter Probes Probe-Sets T r a n s c r i p t
Clusters0 Total on Chip 5,359,576 1,404,693 312,3681 Core Probe-Sets 1,081,678 284,123 17,440(*)2 Pass Filter 1 and Probes with GC Count
between 6 and 17
990,512 249,738(**)
3 Pass Filters 1, 2, and Probe-Sets
Expressed Above Background
570,376 143,810(**)
4 No Absolute Score Filter Used 570,376 143,810(**) 5 Pass Filters 1, 2, 3, and 4, and Pass the
Invariant Probe Filter
520,767 131,340(**) 10,396(*)
Test된 transcript cluster중 normal과 cancer의 각 group에서 유의한 발현을 나타낸 유전자의 갯
수는 표 6에서와 같이 각각 7,106개와 6,625개 였다.
표 6. Normal과 cancer group에서 유의하게 발현하는 transcript cluster의 갯수
Group Number of transcript clusters with significant expression in
group
cancer 7,106 68.4% of genes tested
normal 6,625 63.7% of genes tested
이 transcript cluster에 해당하는 유전자들을 대상으로 mixed model, nested analysis of variance
를 이용하여 normal과 cancer 각 group에서 유의한 gene expression을 보이거나 alternative
splicing을 보이는 유전자들을 선별하였다. 이 유전자들은 ANOVA test를 통하여 p-value가 0.01
미만인 것으로 선별하였을때 그림 23과 같이 두 그룹 간에 유의한 발현차이를 보이는 것은 4,065
개 였으며, 유의한 exon-usage 즉, alternative splicing을 보이는 것은 모두 1,160개 였다. 또한 양
쪽 모두에서 유의한 차이를 나타내는 유전자의 개수는 722개였다.
그림 23. 유전자 발현정도와 exon usage에서 유의한 차이를 나타내는 유전자의 분포를 나타낸
Venn-dagram.

- 34 -
(6) Normal과 cancer group간의 hierarchical clustering 및 principal component analysis
Filtering된 유전자들을 기준으로 principal component analysis및 hierarchical clustering을 수행하
여 54개의 sample이 grouping되는 양상을 살펴보았다. 그림 24에서와 같이 54개의 normalized
sample에서 유의한 차이를 보이는 component를 이용하여 complete linkage hierarchical
clustering한 결과 완전하게 normal sample기리 clustering된 부분과 cancer sample끼리 cluster가
형성된 부분이 있는 반면 normal과 cancer가 혼합된 clsuter가 나타났다.
그림 24. Normal과 cancer 54개 sample에 대한 complete linkage hierarchical clustering. Normal
끼리 grouping된 (좌측) cluster와 cancer끼리 grouping된 cluster (우측), 그리고 두 그룹이 섞인
cluster (가운데)로 대별된다.
이러한 hierarchical clustering으로 두 그룹간의 분리가 명확하지 않은 점을 감안하여 principal
component analysis를 수행하여 두 그룹간의 mixing정도를 판단하여 보았다. Principal component
analysis는 normalize 후 유의한 차이를 보이는 데이터를 이용하여 plotting하였다. 그림 25에서와
같이 대부분의 normal과 cancer 샘플들은 각각의 그룹으로 수렴하나 hierarchical clustering에서처
럼 normal과 cancer모두에서 거리가 떨어진 outlier들이 일부 발견되었다.

- 35 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
number
3676763 C/N0-ATP-binding cassette, sub-family A (ABC1), member
3ABCA3 NM_001089
C-N+ ADAM metallopeptidase domain 15 (ADAM15), ADAM15 NM 207196
2544484 C-N+ adenylate cyclase 3 ADCY3 NM_004036
3846114 C/T1- amino-terminal enhancer of split AES NM 198969
2672230 C/N0+ ALS2 C-terminal like ALS2CL NM_147129
T-stage anaphase promoting complex subunit 1 (ANAPC1) ANAPC1 NM 022662
그림 25. Principal component analysis를 통한 54개 sample의 grouping
가. Alternative splice variant의 분석결과
l XRAY3.92의 분석결과
30쌍의 normal-tumor비교군의 Exon array data로부터 모두 299개, T-stage별로 분류한 비교
로부터 268개, T1과 T2 stage비교로부터 308개, N0와 N1 stage의 비교로부터 35개의
p-value < 0.001미만의 유의한 alternative exon usage를 보이는 gene들을 선별하였음.
l JETTA 분석 결과
30쌍의 normal-tumor비교군으로부터 p-value<0.001인 조건을 만족하는 probe set을 다음과
같이 선별하였음. Normal에서 skip되는 alternative splice variant candidate probeset을 모두
1,329개, tumor에서 skip되는 593개의 probeset을 선별하였음.
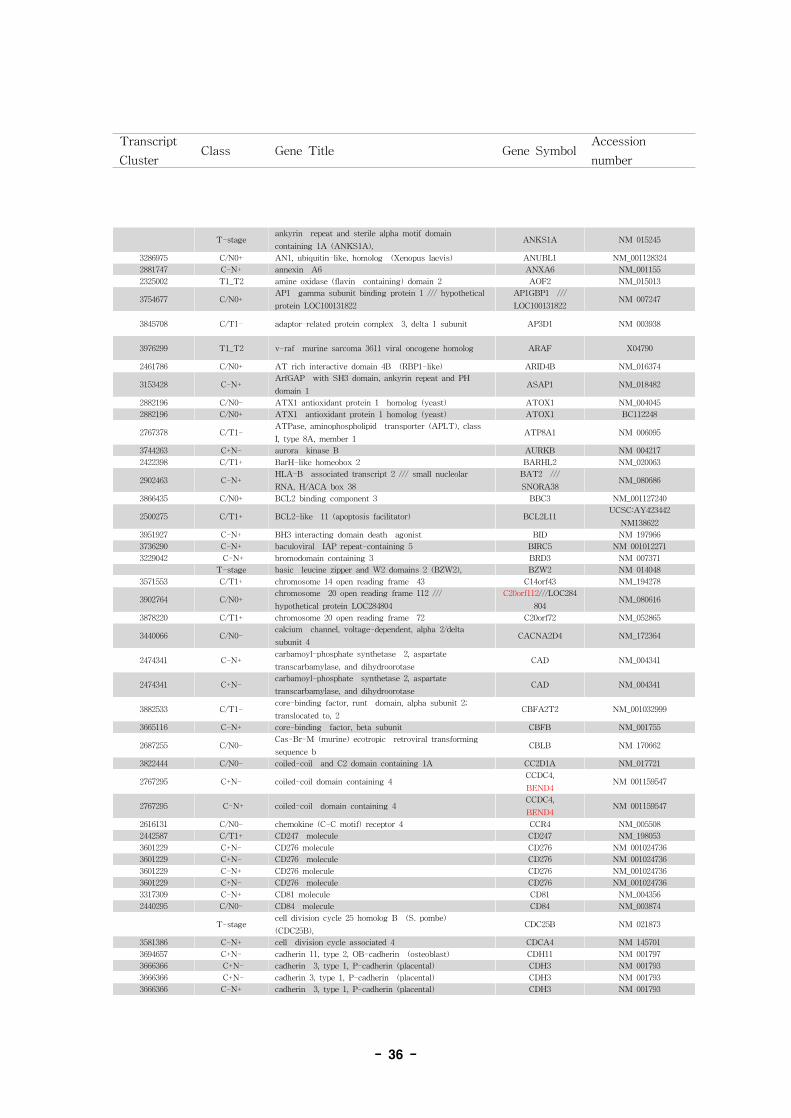
표 7에 XRAY3.92에 의한 분석결과와 JETTA에 의한 분석결과 중 p-value를 기준으로 각
group별로 상위에 속하는 candidate probeset 단위로 432개를 list-up하였음.
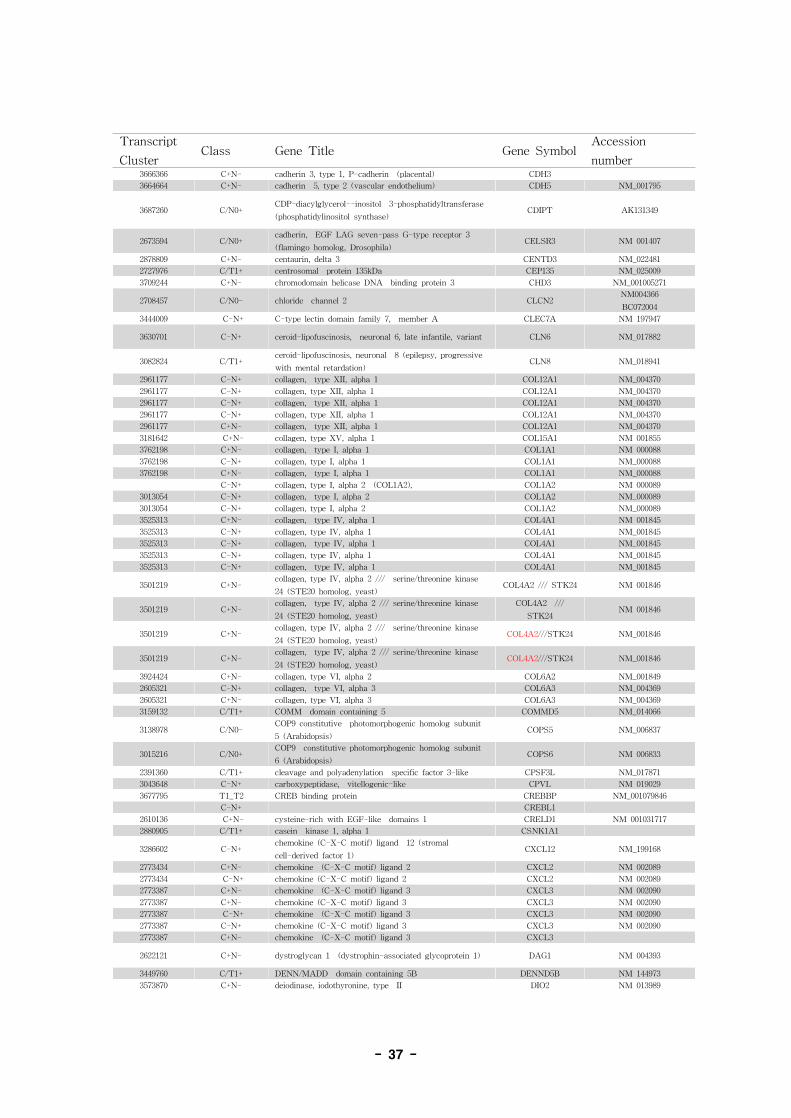
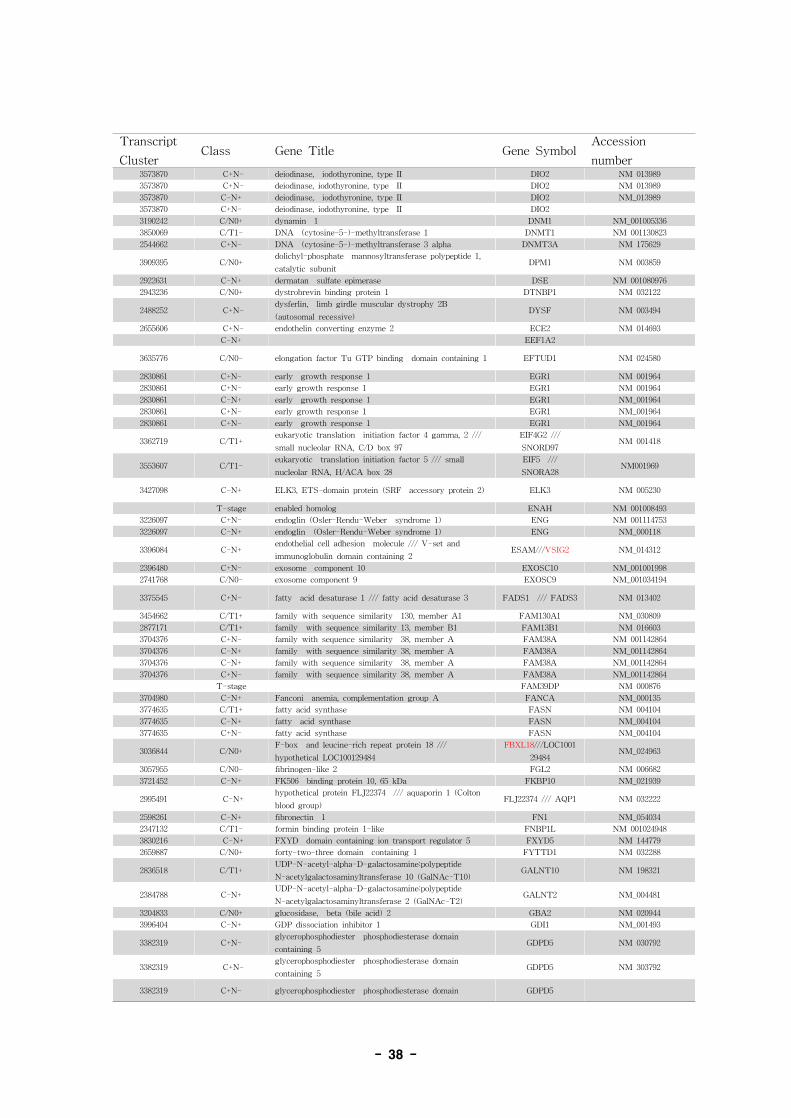
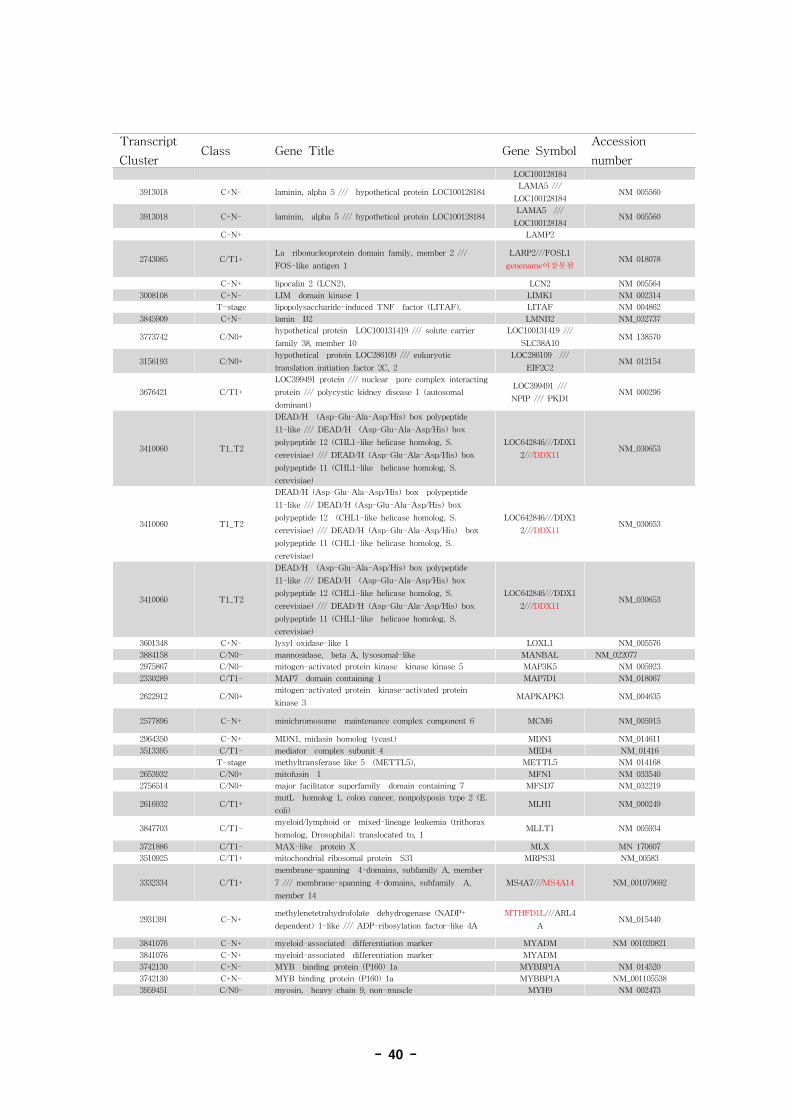
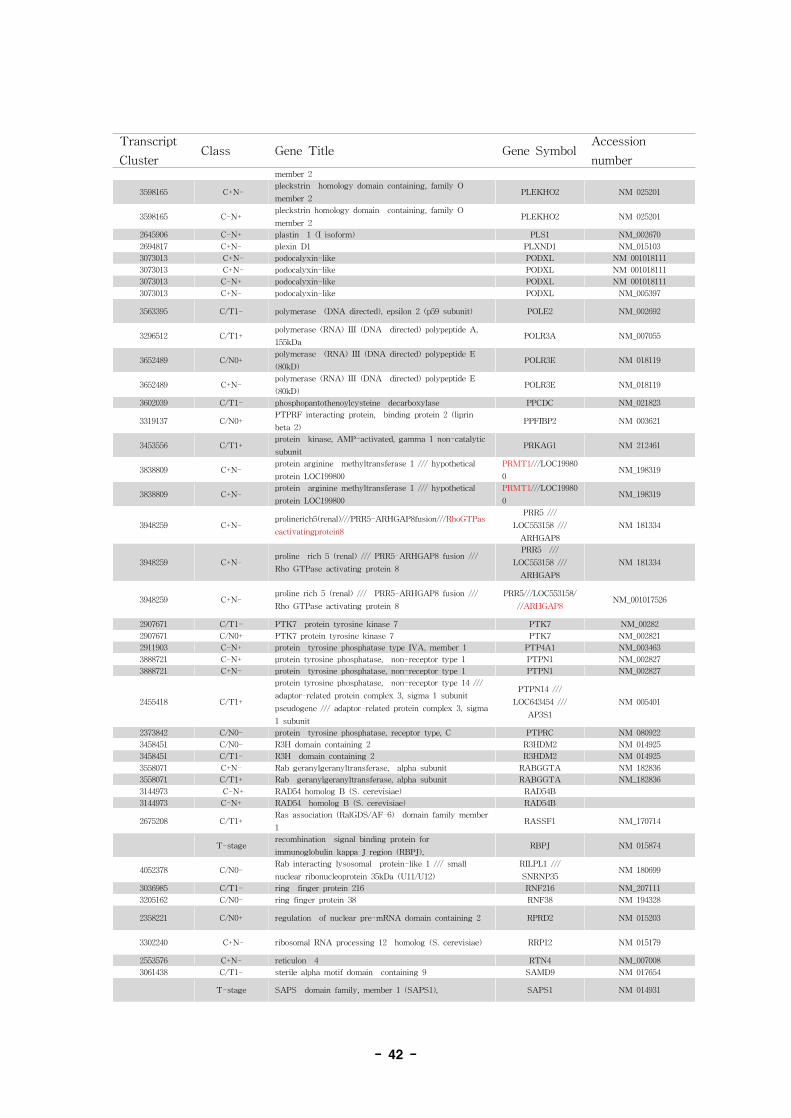
표 7. Annotation of alternative splice variant genes
- 36 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
number
T-stageankyrin repeat and sterile alpha motif domain
containing 1A (ANKS1A),ANKS1A NM 015245
3286975 C/N0+ AN1, ubiquitin-like, homolog (Xenopus laevis) ANUBL1 NM_001128324
2881747 C-N+ annexin A6 ANXA6 NM_001155
2325002 T1_T2 amine oxidase (flavin containing) domain 2 AOF2 NM_015013
3754677 C/N0+AP1 gamma subunit binding protein 1 /// hypothetical
protein LOC100131822
AP1GBP1 ///
LOC100131822NM 007247
3845708 C/T1- adaptor-related protein complex 3, delta 1 subunit AP3D1 NM 003938
3976299 T1_T2 v-raf murine sarcoma 3611 viral oncogene homolog ARAF X04790
2461786 C/N0+ AT rich interactive domain 4B (RBP1-like) ARID4B NM_016374
3153428 C-N+ArfGAP with SH3 domain, ankyrin repeat and PH
domain 1ASAP1 NM_018482
2882196 C/N0- ATX1 antioxidant protein 1 homolog (yeast) ATOX1 NM_004045
2882196 C/N0+ ATX1 antioxidant protein 1 homolog (yeast) ATOX1 BC112248
2767378 C/T1-ATPase, aminophospholipid transporter (APLT), class
I, type 8A, member 1ATP8A1 NM 006095
3744263 C+N- aurora kinase B AURKB NM 004217
2422398 C/T1+ BarH-like homeobox 2 BARHL2 NM_020063
2902463 C-N+HLA-B associated transcript 2 /// small nucleolar
RNA, H/ACA box 38
BAT2 ///
SNORA38NM_080686
3866435 C/N0+ BCL2 binding component 3 BBC3 NM_001127240
2500275 C/T1+ BCL2-like 11 (apoptosis facilitator) BCL2L11UCSC:AY423442
NM138622
3951927 C-N+ BH3 interacting domain death agonist BID NM 197966
3736290 C-N+ baculoviral IAP repeat-containing 5 BIRC5 NM 001012271
3229042 C-N+ bromodomain containing 3 BRD3 NM 007371
T-stage basic leucine zipper and W2 domains 2 (BZW2), BZW2 NM 014048
3571553 C/T1+ chromosome 14 open reading frame 43 C14orf43 NM_194278
3902764 C/N0+chromosome 20 open reading frame 112 ///
hypothetical protein LOC284804
C20orf112///LOC284
804NM_080616
3878220 C/T1+ chromosome 20 open reading frame 72 C20orf72 NM_052865
3440066 C/N0-calcium channel, voltage-dependent, alpha 2/delta
subunit 4CACNA2D4 NM_172364
2474341 C-N+carbamoyl-phosphate synthetase 2, aspartate
transcarbamylase, and dihydroorotaseCAD NM_004341
2474341 C+N-carbamoyl-phosphate synthetase 2, aspartate
transcarbamylase, and dihydroorotaseCAD NM_004341
3882533 C/T1-core-binding factor, runt domain, alpha subunit 2;
translocated to, 2CBFA2T2 NM_001032999
3665116 C-N+ core-binding factor, beta subunit CBFB NM_001755
2687255 C/N0-Cas-Br-M (murine) ecotropic retroviral transforming
sequence bCBLB NM 170662
3822444 C/N0- coiled-coil and C2 domain containing 1A CC2D1A NM_017721
2767295 C+N- coiled-coil domain containing 4CCDC4,
BEND4NM 001159547
2767295 C-N+ coiled-coil domain containing 4CCDC4,
BEND4NM 001159547
2616131 C/N0- chemokine (C-C motif) receptor 4 CCR4 NM_005508
2442587 C/T1+ CD247 molecule CD247 NM_198053
3601229 C+N- CD276 molecule CD276 NM 001024736
3601229 C+N- CD276 molecule CD276 NM 001024736
3601229 C-N+ CD276 molecule CD276 NM_001024736
3601229 C+N- CD276 molecule CD276 NM_001024736
3317309 C-N+ CD81 molecule CD81 NM_004356
2440295 C/N0- CD84 molecule CD84 NM_003874
T-stagecell division cycle 25 homolog B (S. pombe)
(CDC25B),CDC25B NM 021873
3581386 C-N+ cell division cycle associated 4 CDCA4 NM 145701
3694657 C+N- cadherin 11, type 2, OB-cadherin (osteoblast) CDH11 NM 001797
3666366 C+N- cadherin 3, type 1, P-cadherin (placental) CDH3 NM 001793
3666366 C+N- cadherin 3, type 1, P-cadherin (placental) CDH3 NM 001793
3666366 C-N+ cadherin 3, type 1, P-cadherin (placental) CDH3 NM 001793
- 37 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
number3666366 C+N- cadherin 3, type 1, P-cadherin (placental) CDH3
3664664 C+N- cadherin 5, type 2 (vascular endothelium) CDH5 NM_001795
3687260 C/N0+CDP-diacylglycerol--inositol 3-phosphatidyltransferase
(phosphatidylinositol synthase)CDIPT AK131349
2673594 C/N0+cadherin, EGF LAG seven-pass G-type receptor 3
(flamingo homolog, Drosophila)CELSR3 NM 001407
2878809 C+N- centaurin, delta 3 CENTD3 NM_022481
2727976 C/T1+ centrosomal protein 135kDa CEP135 NM_025009
3709244 C+N- chromodomain helicase DNA binding protein 3 CHD3 NM_001005271
2708457 C/N0- chloride channel 2 CLCN2NM004366
BC072004
3444009 C-N+ C-type lectin domain family 7, member A CLEC7A NM 197947
3630701 C-N+ ceroid-lipofuscinosis, neuronal 6, late infantile, variant CLN6 NM_017882
3082824 C/T1+ceroid-lipofuscinosis, neuronal 8 (epilepsy, progressive
with mental retardation)CLN8 NM_018941
2961177 C-N+ collagen, type XII, alpha 1 COL12A1 NM_004370
2961177 C-N+ collagen, type XII, alpha 1 COL12A1 NM_004370
2961177 C-N+ collagen, type XII, alpha 1 COL12A1 NM_004370
2961177 C-N+ collagen, type XII, alpha 1 COL12A1 NM_004370
2961177 C+N- collagen, type XII, alpha 1 COL12A1 NM_004370
3181642 C+N- collagen, type XV, alpha 1 COL15A1 NM 001855
3762198 C+N- collagen, type I, alpha 1 COL1A1 NM 000088
3762198 C-N+ collagen, type I, alpha 1 COL1A1 NM_000088
3762198 C+N- collagen, type I, alpha 1 COL1A1 NM_000088
C-N+ collagen, type I, alpha 2 (COL1A2), COL1A2 NM 000089
3013054 C-N+ collagen, type I, alpha 2 COL1A2 NM_000089
3013054 C-N+ collagen, type I, alpha 2 COL1A2 NM_000089
3525313 C+N- collagen, type IV, alpha 1 COL4A1 NM 001845
3525313 C-N+ collagen, type IV, alpha 1 COL4A1 NM_001845
3525313 C-N+ collagen, type IV, alpha 1 COL4A1 NM_001845
3525313 C-N+ collagen, type IV, alpha 1 COL4A1 NM_001845
3525313 C-N+ collagen, type IV, alpha 1 COL4A1 NM_001845
3501219 C+N-collagen, type IV, alpha 2 /// serine/threonine kinase
24 (STE20 homolog, yeast)COL4A2 /// STK24 NM 001846
3501219 C+N-collagen, type IV, alpha 2 /// serine/threonine kinase
24 (STE20 homolog, yeast)
COL4A2 ///
STK24NM 001846
3501219 C+N-collagen, type IV, alpha 2 /// serine/threonine kinase
24 (STE20 homolog, yeast)COL4A2///STK24 NM_001846
3501219 C+N-collagen, type IV, alpha 2 /// serine/threonine kinase
24 (STE20 homolog, yeast)COL4A2///STK24 NM_001846
3924424 C+N- collagen, type VI, alpha 2 COL6A2 NM_001849
2605321 C-N+ collagen, type VI, alpha 3 COL6A3 NM_004369
2605321 C+N- collagen, type VI, alpha 3 COL6A3 NM_004369
3159132 C/T1+ COMM domain containing 5 COMMD5 NM_014066
3138978 C/N0-COP9 constitutive photomorphogenic homolog subunit
5 (Arabidopsis)COPS5 NM_006837
3015216 C/N0+COP9 constitutive photomorphogenic homolog subunit
6 (Arabidopsis)COPS6 NM 006833
2391360 C/T1+ cleavage and polyadenylation specific factor 3-like CPSF3L NM_017871
3043648 C-N+ carboxypeptidase, vitellogenic-like CPVL NM 019029
3677795 T1_T2 CREB binding protein CREBBP NM_001079846
C-N+ CREBL1
2610136 C+N- cysteine-rich with EGF-like domains 1 CRELD1 NM 001031717
2880905 C/T1+ casein kinase 1, alpha 1 CSNK1A1
3286602 C-N+chemokine (C-X-C motif) ligand 12 (stromal
cell-derived factor 1)CXCL12 NM_199168
2773434 C+N- chemokine (C-X-C motif) ligand 2 CXCL2 NM 002089
2773434 C-N+ chemokine (C-X-C motif) ligand 2 CXCL2 NM 002089
2773387 C+N- chemokine (C-X-C motif) ligand 3 CXCL3 NM 002090
2773387 C+N- chemokine (C-X-C motif) ligand 3 CXCL3 NM 002090
2773387 C-N+ chemokine (C-X-C motif) ligand 3 CXCL3 NM 002090
2773387 C-N+ chemokine (C-X-C motif) ligand 3 CXCL3 NM 002090
2773387 C+N- chemokine (C-X-C motif) ligand 3 CXCL3
2622121 C+N- dystroglycan 1 (dystrophin-associated glycoprotein 1) DAG1 NM 004393
3449760 C/T1+ DENN/MADD domain containing 5B DENND5B NM 144973
3573870 C+N- deiodinase, iodothyronine, type II DIO2 NM 013989
- 38 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
number3573870 C+N- deiodinase, iodothyronine, type II DIO2 NM 013989
3573870 C+N- deiodinase, iodothyronine, type II DIO2 NM 013989
3573870 C-N+ deiodinase, iodothyronine, type II DIO2 NM_013989
3573870 C+N- deiodinase, iodothyronine, type II DIO2
3190242 C/N0+ dynamin 1 DNM1 NM_001005336
3850069 C/T1- DNA (cytosine-5-)-methyltransferase 1 DNMT1 NM 001130823
2544662 C+N- DNA (cytosine-5-)-methyltransferase 3 alpha DNMT3A NM 175629
3909395 C/N0+dolichyl-phosphate mannosyltransferase polypeptide 1,
catalytic subunitDPM1 NM 003859
2922631 C-N+ dermatan sulfate epimerase DSE NM 001080976
2943236 C/N0+ dystrobrevin binding protein 1 DTNBP1 NM 032122
2488252 C+N-dysferlin, limb girdle muscular dystrophy 2B
(autosomal recessive)DYSF NM 003494
2655606 C+N- endothelin converting enzyme 2 ECE2 NM 014693
C-N+ EEF1A2
3635776 C/N0- elongation factor Tu GTP binding domain containing 1 EFTUD1 NM 024580
2830861 C+N- early growth response 1 EGR1 NM 001964
2830861 C+N- early growth response 1 EGR1 NM 001964
2830861 C-N+ early growth response 1 EGR1 NM_001964
2830861 C+N- early growth response 1 EGR1 NM_001964
2830861 C+N- early growth response 1 EGR1 NM_001964
3362719 C/T1+eukaryotic translation initiation factor 4 gamma, 2 ///
small nucleolar RNA, C/D box 97
EIF4G2 ///
SNORD97NM 001418
3553607 C/T1-eukaryotic translation initiation factor 5 /// small
nucleolar RNA, H/ACA box 28
EIF5 ///
SNORA28NM001969
3427098 C-N+ ELK3, ETS-domain protein (SRF accessory protein 2) ELK3 NM 005230
T-stage enabled homolog ENAH NM 001008493
3226097 C+N- endoglin (Osler-Rendu-Weber syndrome 1) ENG NM 001114753
3226097 C-N+ endoglin (Osler-Rendu-Weber syndrome 1) ENG NM_000118
3396084 C-N+endothelial cell adhesion molecule /// V-set and
immunoglobulin domain containing 2ESAM///VSIG2 NM_014312
2396480 C+N- exosome component 10 EXOSC10 NM_001001998
2741768 C/N0- exosome component 9 EXOSC9 NM_001034194
3375545 C+N- fatty acid desaturase 1 /// fatty acid desaturase 3 FADS1 /// FADS3 NM 013402
3454662 C/T1+ family with sequence similarity 130, member A1 FAM130A1 NM_030809
2877171 C/T1+ family with sequence similarity 13, member B1 FAM13B1 NM 016603
3704376 C+N- family with sequence similarity 38, member A FAM38A NM 001142864
3704376 C-N+ family with sequence similarity 38, member A FAM38A NM_001142864
3704376 C-N+ family with sequence similarity 38, member A FAM38A NM_001142864
3704376 C+N- family with sequence similarity 38, member A FAM38A NM_001142864
T-stage FAM39DP NM 000876
3704980 C-N+ Fanconi anemia, complementation group A FANCA NM_000135
3774635 C/T1+ fatty acid synthase FASN NM 004104
3774635 C-N+ fatty acid synthase FASN NM_004104
3774635 C+N- fatty acid synthase FASN NM_004104
3036844 C/N0+F-box and leucine-rich repeat protein 18 ///
hypothetical LOC100129484
FBXL18///LOC1001
29484NM_024963
3057955 C/N0- fibrinogen-like 2 FGL2 NM 006682
3721452 C-N+ FK506 binding protein 10, 65 kDa FKBP10 NM_021939
2995491 C-N+hypothetical protein FLJ22374 /// aquaporin 1 (Colton
blood group)FLJ22374 /// AQP1 NM 032222
2598261 C-N+ fibronectin 1 FN1 NM_054034
2347132 C/T1- formin binding protein 1-like FNBP1L NM 001024948
3830216 C-N+ FXYD domain containing ion transport regulator 5 FXYD5 NM 144779
2659887 C/N0+ forty-two-three domain containing 1 FYTTD1 NM 032288
2836518 C/T1+UDP-N-acetyl-alpha-D-galactosamine:polypeptide
N-acetylgalactosaminyltransferase 10 (GalNAc-T10)GALNT10 NM 198321
2384788 C-N+UDP-N-acetyl-alpha-D-galactosamine:polypeptide
N-acetylgalactosaminyltransferase 2 (GalNAc-T2)GALNT2 NM_004481
3204833 C/N0+ glucosidase, beta (bile acid) 2 GBA2 NM 020944
3996404 C-N+ GDP dissociation inhibitor 1 GDI1 NM_001493
3382319 C+N-glycerophosphodiester phosphodiesterase domain
containing 5GDPD5 NM 030792
3382319 C+N-glycerophosphodiester phosphodiesterase domain
containing 5GDPD5 NM 303792
3382319 C+N- glycerophosphodiester phosphodiesterase domain GDPD5

- 39 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
numbercontaining 5
4054405 C-N+ gap junction protein, alpha 4, 37kDa GJA4 NM 002060
3646118 C-N+ GLIS family zinc finger 2 GLIS2 NM 032575
3837464 C/T1+glioma tumor suppressor candidate region gene 2 ///
small nucleolar RNA, C/D box 23
GLTSCR2 ///
SNORD23NM 015710
3855868 C/N0- GEM interacting protein GMIP NM_016573
3617458 T1_T2golgi autoantigen, golgin subfamily a, 8A /// golgi
autoantigen, golgin subfamily a, 8B
GOLGA8A///GOLG
A8BNM_181077
3617458 T1_T2golgi autoantigen, golgin subfamily a, 8A /// golgi
autoantigen, golgin subfamily a, 8B
GOLGA8A///GOLG
A8BNM_181077
3617574 T1_T2golgi autoantigen, golgin subfamily a, 8B /// golgi
autoantigen, golgin subfamily a, 8A
GOLGA8A///GOLG
A8BNM_001023567
3617574 T1_T2golgi autoantigen, golgin subfamily a, 8B /// golgi
autoantigen, golgin subfamily a, 8A
GOLGA8A///GOLG
A8BNM_001023567
3617574 T1_T2golgi autoantigen, golgin subfamily a, 8B /// golgi
autoantigen, golgin subfamily a, 8A
GOLGA8A///GOLG
A8BNM_001023567
2971378 C/T1-golgi associated PDZ and coiled-coil motif containing
/// c-ros oncogene 1 , receptor tyrosine kinaseGOPC /// ROS1 NM 020399
2992814 C-N+ glycoprotein (transmembrane) nmb GPNMB NM_001005340
2992814 C+N- glycoprotein (transmembrane) nmb GPNMB NM_001005340
2992814 C+N- glycoprotein (transmembrane) nmb GPNMB NM_001005340
2992814 C+N- glycoprotein (transmembrane) nmb GPNMB NM_001005341
2992814 C+N- glycoprotein (transmembrane) nmb GPNMB NM_001005340
2992814 C+N- glycoprotein (transmembrane) nmb GPNMB NM_001005340
2992814 C+N- glycoprotein (transmembrane) nmb GPNMB NM_001005340
3863522 C/T1- glycogen synthase kinase 3 alpha GSK3A NM_019884
3322717 C/T1+ general transcription factor IIH, polypeptide 1, 62kDa GTF2H1 NM_005316
2636272 C/T1+ GTP-binding protein 8 (putative) GTPBP8 NM_138485
3394183 C-N+ H2A histone family, member X H2AFX NM 002105
3881651 C-N+ hemopoietic cell kinase HCK NM 002110
3881651 C+N- hemopoietic cell kinase HCK NM_002110
3881651 C+N- hemopoietic cell kinase HCK NM_002110
3659888 C/T1- HEAT repeat containing 3 HEATR3 NM_182922
2900974 C/T1- major histocompatibility complex, class I, F HLA-F NM 001098479
3886453 C/T1+ hepatocyte nuclear factor 4, alpha HNF4A NM 000457
3834089 T1_T2 heterogeneous nuclear ribonucleoprotein U-like 1 HNRNPUL1 NM_144732
2400793 C-N+ heparan sulfate proteoglycan 2 HSPG2 NM_005529
3268333 C+N- HtrA serine peptidase 1 HTRA1 NM 002775
3038065 C/T1- islet cell autoantigen 1, 69kDa ICA1 NM 004968
2403261 C-N+ interferon, alpha-inducible protein 6 IFI6 NM_002038
2403261 C+N- interferon, alpha-inducible protein 6 IFI6 NM_002038
T-stage insulin-like growth factor 2 receptor IGF2R NM 000876
T-stage insulin-like growth factor binding protein 3 IGFBP3 NM 001013398
3339423 C-N+ inositol polyphosphate phosphatase-like 1 INPPL1 NM_001567
2610359 C+N- interleukin-1 receptor-associated kinase 2 IRAK2 NM_001570
3854982 C+N- myo-inositol 1-phosphate synthase A1 ISYNA1 NM_016368
3918779 C/T1+ intersectin 1 (SH3 domain protein) ITSN1 NM 003024
3854627 C-N+ Janus kinase 3 (a protein tyrosine kinase, leukocyte) JAK3
T-stagepotassium channel tetramerisation domain containing 5
(KCTD5),KCTD5 NM 018992
2767710 C/N0+ potassium channel tetramerisation domain containing 8 KCTD8 NM_198353
3196691 C/T1- KIAA0020 /// G protein pathway suppressor 2 KIAA0020///GPS2 NM_014878
2399620 C-N+ KIAA0090 KIAA0090 NM_015047
2399620 C+N- KIAA0090 KIAA0090 NM_015047
3435362 C-N+ kinetochore associated 1 KNTC1 NM_014708
3415320 C-N+ keratin 7 KRT7 NM_005556
3415320 C+N- keratin 7 KRT7 NM_005556
C-N+ laminin, alpha 3 (LAMA3), LAMA3 NM 198129
3913018 C+N- laminin, alpha 5 /// hypothetical protein LOC100128184 LAMA5 /// NM 005560
- 40 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
numberLOC100128184
3913018 C+N- laminin, alpha 5 /// hypothetical protein LOC100128184LAMA5 ///
LOC100128184NM 005560
3913018 C+N- laminin, alpha 5 /// hypothetical protein LOC100128184LAMA5 ///
LOC100128184NM 005560
C-N+ LAMP2
2743085 C/T1+La ribonucleoprotein domain family, member 2 ///
FOS-like antigen 1
LARP2///FOSL1
genename이잘못됨NM 018078
C-N+ lipocalin 2 (LCN2), LCN2 NM 005564
3008108 C+N- LIM domain kinase 1 LIMK1 NM 002314
T-stage lipopolysaccharide-induced TNF factor (LITAF), LITAF NM 004862
3845909 C+N- lamin B2 LMNB2 NM_032737
3773742 C/N0+hypothetical protein LOC100131419 /// solute carrier
family 38, member 10
LOC100131419 ///
SLC38A10NM 138570
3156193 C/N0+hypothetical protein LOC286109 /// eukaryotic
translation initiation factor 2C, 2
LOC286109 ///
EIF2C2NM 012154
3676421 C/T1+
LOC399491 protein /// nuclear pore complex interacting
protein /// polycystic kidney disease 1 (autosomal
dominant)
LOC399491 ///
NPIP /// PKD1NM 000296
3410060 T1_T2
DEAD/H (Asp-Glu-Ala-Asp/His) box polypeptide
11-like /// DEAD/H (Asp-Glu-Ala-Asp/His) box
polypeptide 12 (CHL1-like helicase homolog, S.
cerevisiae) /// DEAD/H (Asp-Glu-Ala-Asp/His) box
polypeptide 11 (CHL1-like helicase homolog, S.
cerevisiae)
LOC642846///DDX1
2///DDX11NM_030653
3410060 T1_T2
DEAD/H (Asp-Glu-Ala-Asp/His) box polypeptide
11-like /// DEAD/H (Asp-Glu-Ala-Asp/His) box
polypeptide 12 (CHL1-like helicase homolog, S.
cerevisiae) /// DEAD/H (Asp-Glu-Ala-Asp/His) box
polypeptide 11 (CHL1-like helicase homolog, S.
cerevisiae)
LOC642846///DDX1
2///DDX11NM_030653
3410060 T1_T2
DEAD/H (Asp-Glu-Ala-Asp/His) box polypeptide
11-like /// DEAD/H (Asp-Glu-Ala-Asp/His) box
polypeptide 12 (CHL1-like helicase homolog, S.
cerevisiae) /// DEAD/H (Asp-Glu-Ala-Asp/His) box
polypeptide 11 (CHL1-like helicase homolog, S.
cerevisiae)
LOC642846///DDX1
2///DDX11NM_030653
3601348 C+N- lysyl oxidase-like 1 LOXL1 NM_005576
3884158 C/N0- mannosidase, beta A, lysosomal-like MANBAL NM_022077
2975867 C/N0- mitogen-activated protein kinase kinase kinase 5 MAP3K5 NM 005923
2330289 C/T1- MAP7 domain containing 1 MAP7D1 NM_018067
2622912 C/N0+mitogen-activated protein kinase-activated protein
kinase 3MAPKAPK3 NM_004635
2577896 C-N+ minichromosome maintenance complex component 6 MCM6 NM_005915
2964350 C-N+ MDN1, midasin homolog (yeast) MDN1 NM_014611
3513395 C/T1- mediator complex subunit 4 MED4 NM_01416
T-stage methyltransferase like 5 (METTL5), METTL5 NM 014168
2653932 C/N0+ mitofusin 1 MFN1 NM 033540
2756514 C/N0+ major facilitator superfamily domain containing 7 MFSD7 NM_032219
2616932 C/T1+mutL homolog 1, colon cancer, nonpolyposis type 2 (E.
coli)MLH1 NM_000249
3847703 C/T1-myeloid/lymphoid or mixed-lineage leukemia (trithorax
homolog, Drosophila); translocated to, 1MLLT1 NM 005934
3721886 C/T1- MAX-like protein X MLX MN 170607
3510925 C/T1+ mitochondrial ribosomal protein S31 MRPS31 NM_00583
3332334 C/T1+
membrane-spanning 4-domains, subfamily A, member
7 /// membrane-spanning 4-domains, subfamily A,
member 14
MS4A7///MS4A14 NM_001079692
2931391 C-N+methylenetetrahydrofolate dehydrogenase (NADP+
dependent) 1-like /// ADP-ribosylation factor-like 4A
MTHFD1L///ARL4
ANM_015440
3841076 C-N+ myeloid-associated differentiation marker MYADM NM 001020821
3841076 C-N+ myeloid-associated differentiation marker MYADM
3742130 C+N- MYB binding protein (P160) 1a MYBBP1A NM 014520
3742130 C+N- MYB binding protein (P160) 1a MYBBP1A NM_001105538
3959451 C/N0- myosin, heavy chain 9, non-muscle MYH9 NM 002473

- 41 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
number3849044 C+N- myosin IF MYO1F NM 012335
3849044 C+N- myosin IF MYO1F NM 012335
T-stage myosin IXB (MYO9B), MYO9B NM 004145
3399545 C+N- non-SMC condensin II complex, subunit D3 NCAPD3 NM_015261
2924514 C-N+ nuclear receptor coactivator 7 NCOA7 NM_181782
2924514 C-N+ nuclear receptor coactivator 7 NCOA7 NM_181782
2924514 C-N+ nuclear receptor coactivator 7 NCOA7 NM_181782
2924514 C-N+ nuclear receptor coactivator 7 NCOA7 NM_181782
3649811 C-N+nudE nuclear distribution gene E homolog 1 (A.
nidulans)NDE1 NM 017668
3514849 C/N0- NIMA (never in mitosis gene a)-related kinase 3 NEK3 NM_002498
T-stage neurofibromin 2 (merlin) (NF2), NF2 NM 000268
3261643 C+N-nuclear factor of kappa light polypeptide gene enhancer
in B-cells 2 (p49/p100)NFKB2 NM 001077493
3261643 C-N+nuclear factor of kappa light polypeptide gene enhancer
in B-cells 2 (p49/p100)NFKB2 NM 001077493
3261643 C+N-nuclear factor of kappa light polypeptide gene enhancer
in B-cells 2 (p49/p100)NFKB2 NM_001077493
3261643 C+N-nuclear factor of kappa light polypeptide gene enhancer
in B-cells 2 (p49/p100)NFKB2 NM_001077493
3564620 C+N- nidogen 2 (osteonidogen) NID2 NM_007361
2522509 C/T1- NIF3 NGG1 interacting factor 3-like 1 (S. pombe) NIF3L1 NM_021824
3715368 C/T1+ nemo-like kinase NLK NM 016231
2812359 C+N- neurolysin (metallopeptidase M3 family) NLN NM 020726
4054639 C+N-
nucleolar complex associated 2 homolog (S. cerevisiae)
/// nucleolar complex associated 2 homolog (S.
cerevisiae) pseudogene
NOC2L ///
LOC401010NM 015658
4054639 C-N+
nucleolar complex associated 2 homolog (S. cerevisiae)
/// nucleolar complex associated 2 homolog (S.
cerevisiae) pseudogene
NOC2L ///
LOC401010NM 015658
3203582 C-N+ nucleolar protein family 6 (RNA-associated) NOL6 NM 022917
3203582 C-N+ nucleolar protein family 6 (RNA-associated) NOL6 NM 022917
3853108 C-N+ Notch homolog 3 (Drosophila) NOTCH3 NM 000435
2885099 C/T1- NudC domain containing 2 NUDCD2 NM_145266
3359910 C+N- nucleoporin 98kDa NUP98 NM_016320
3432514 C+N- 2'-5'-oligoadenylate synthetase 2, 69/71kDa OAS2 NM_016817
3892941 C/N0+ opioid growth factor receptor OGFR NM 007346
3892565 C/N0+ oxysterol binding protein-like 2 OSBPL2 NM 144498
3432754 C-N+ mannose-6-phosphate protein p76P76
PLBD2NM 173542
3184408 C+N-paralemmin 2 /// PALM2-AKAP2 /// A kinase
(PRKA) anchor protein 2
PALM2 ///
PALM2-AKAP2 ///
AKAP2
NM 007203
2708229 C/N0- presenilin associated, rhomboid-like PARL NM 018622
3263944 C/T1-programmed cell death 4 (neoplastic transformation
inhibitor)PDCD4 NM 145341
2340529 C+N-phosphodiesterase 4B, cAMP-specific
(phosphodiesterase E4 dunce homolog, Drosophila)PDE4B NM_002600
T-stage pellino homolog 1 (Drosophila) (PELI1), PELI1 NM 020651
2743315 C-N+ PHD finger protein 17 PHF17 NM 199320
3791482 C/T1- PH domain and leucine rich repeat protein phosphatase PHLPP NM_194449
3281068 C/N0-phosphatidylinositol-5-phosphate 4-kinase, type II,
alpha /// FLJ00409 protein
PIP4K2A///LOC6434
75NM_005028
3755359 C-N+ phosphatidylinositol-5-phosphate 4-kinase, type II, beta PIP4K2B NM 003559
3956290 C-N+ phosphatidylinositol transfer protein, beta PITPNB NM_012399
3258477 C+N- phospholipase C, epsilon 1 PLCE1 NM_016341
3157901 C/N0- plectin 1, intermediate filament binding protein 500kDa PLEC1 NM 000445
2321960 C/N0-pleckstrin homology domain containing, family M (with
RUN domain) member 2PLEKHM2 NM_015164
3598165 C+N-pleckstrin homology domain containing, family O
member 2PLEKHO2 NM 025201
3598165 C-N+ pleckstrin homology domain containing, family O PLEKHO2 NM 025201
- 42 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
numbermember 2
3598165 C+N-pleckstrin homology domain containing, family O
member 2PLEKHO2 NM 025201
3598165 C-N+pleckstrin homology domain containing, family O
member 2PLEKHO2 NM 025201
2645906 C-N+ plastin 1 (I isoform) PLS1 NM_002670
2694817 C+N- plexin D1 PLXND1 NM_015103
3073013 C+N- podocalyxin-like PODXL NM 001018111
3073013 C+N- podocalyxin-like PODXL NM 001018111
3073013 C-N+ podocalyxin-like PODXL NM 001018111
3073013 C+N- podocalyxin-like PODXL NM_005397
3563395 C/T1- polymerase (DNA directed), epsilon 2 (p59 subunit) POLE2 NM_002692
3296512 C/T1+polymerase (RNA) III (DNA directed) polypeptide A,
155kDaPOLR3A NM_007055
3652489 C/N0+polymerase (RNA) III (DNA directed) polypeptide E
(80kD)POLR3E NM 018119
3652489 C+N-polymerase (RNA) III (DNA directed) polypeptide E
(80kD)POLR3E NM_018119
3602039 C/T1- phosphopantothenoylcysteine decarboxylase PPCDC NM_021823
3319137 C/N0+PTPRF interacting protein, binding protein 2 (liprin
beta 2)PPFIBP2 NM 003621
3453556 C/T1+protein kinase, AMP-activated, gamma 1 non-catalytic
subunitPRKAG1 NM 212461
3838809 C+N-protein arginine methyltransferase 1 /// hypothetical
protein LOC199800
PRMT1///LOC19980
0NM_198319
3838809 C+N-protein arginine methyltransferase 1 /// hypothetical
protein LOC199800
PRMT1///LOC19980
0NM_198319
3948259 C+N-prolinerich5(renal)///PRR5-ARHGAP8fusion///RhoGTPas
eactivatingprotein8
PRR5 ///
LOC553158 ///
ARHGAP8
NM 181334
3948259 C+N-proline rich 5 (renal) /// PRR5-ARHGAP8 fusion ///
Rho GTPase activating protein 8
PRR5 ///
LOC553158 ///
ARHGAP8
NM 181334
3948259 C+N-proline rich 5 (renal) /// PRR5-ARHGAP8 fusion ///
Rho GTPase activating protein 8
PRR5///LOC553158/
//ARHGAP8NM_001017526
2907671 C/T1- PTK7 protein tyrosine kinase 7 PTK7 NM_00282
2907671 C/N0+ PTK7 protein tyrosine kinase 7 PTK7 NM_002821
2911903 C-N+ protein tyrosine phosphatase type IVA, member 1 PTP4A1 NM_003463
3888721 C-N+ protein tyrosine phosphatase, non-receptor type 1 PTPN1 NM_002827
3888721 C+N- protein tyrosine phosphatase, non-receptor type 1 PTPN1 NM_002827
2455418 C/T1+
protein tyrosine phosphatase, non-receptor type 14 ///
adaptor-related protein complex 3, sigma 1 subunit
pseudogene /// adaptor-related protein complex 3, sigma
1 subunit
PTPN14 ///
LOC643454 ///
AP3S1
NM 005401
2373842 C/N0- protein tyrosine phosphatase, receptor type, C PTPRC NM 080922
3458451 C/N0- R3H domain containing 2 R3HDM2 NM 014925
3458451 C/T1- R3H domain containing 2 R3HDM2 NM 014925
3558071 C+N- Rab geranylgeranyltransferase, alpha subunit RABGGTA NM 182836
3558071 C/T1+ Rab geranylgeranyltransferase, alpha subunit RABGGTA NM_182836
3144973 C-N+ RAD54 homolog B (S. cerevisiae) RAD54B
3144973 C-N+ RAD54 homolog B (S. cerevisiae) RAD54B
2675208 C/T1+Ras association (RalGDS/AF-6) domain family member
1RASSF1 NM_170714
T-stagerecombination signal binding protein for
immunoglobulin kappa J region (RBPJ),RBPJ NM 015874
4052378 C/N0-Rab interacting lysosomal protein-like 1 /// small
nuclear ribonucleoprotein 35kDa (U11/U12)
RILPL1 ///
SNRNP35NM 180699
3036985 C/T1- ring finger protein 216 RNF216 NM_207111
3205162 C/N0- ring finger protein 38 RNF38 NM 194328
2358221 C/N0+ regulation of nuclear pre-mRNA domain containing 2 RPRD2 NM 015203
3302240 C+N- ribosomal RNA processing 12 homolog (S. cerevisiae) RRP12 NM 015179
2553576 C+N- reticulon 4 RTN4 NM_007008
3061438 C/T1- sterile alpha motif domain containing 9 SAMD9 NM 017654
T-stage SAPS domain family, member 1 (SAPS1), SAPS1 NM 014931

- 43 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
number3871256 T1_T2 SAPS domain family, member 1 SAPS1 NM_014931
3871256 T1_T2 SAPS domain family, member 1 SAPS1 NM_014931
3844978 C-N+ strawberry notch homolog 2 (Drosophila) SBNO2 NM_001100122
2817053 C/T1- secretory carrier membrane protein 1 SCAMP1 NM 004866
2408499 C/N0+ sex comb on midleg homolog 1 (Drosophila) SCMH1 NM_001031694
3157751 C+N- scribbled homolog (Drosophila) SCRIB NM_015356
3309345 C+N- sideroflexin 4 SFXN4 NM_213649
3289235 C/T1- sphingomyelin synthase 1 SGMS1 NM_147156
3431892 C+N- SH2B adaptor protein 3 SH2B3 NM 005475
3431892 C+N- SH2B adaptor protein 3 SH2B3
2715580 C/N0+ SH3-domain binding protein 2 SH3BP2 NM 001122681
3380365 C/N0+ SH3 and multiple ankyrin repeat domains 2 SHANK2 NM_012309
2436985 C/N0-SHC (Src homology 2 domain containing) transforming
protein 1SHC1 NM 003029
2875491 C/N0- shroom family member 1 SHROOM1 NM_133456
3454576 C/N0-solute carrier family 11 (proton-coupled divalent metal
ion transporters), member 2SLC11A2 NM 000617
3893673 C+N- SLC2A4 regulator SLC2A4RG NM 020062
3089360 C+N- solute carrier family 39 (zinc transporter), member 14 SLC39A14 NM_015359
3542063 C/N0- solute carrier family 39 (zinc transporter), member 9 SLC39A9 NM_018375
3373845 C-N+ solute carrier family 43, member 3 SLC43A3 NM_014096
3895330 C+N-solute carrier family 4, sodium borate transporter,
member 11SLC4A11 NM 032034
3895330 C+N-solute carrier family 4, sodium borate transporter,
member 11SLC4A11 NM 032034
3895330 C+N-solute carrier family 4, sodium borate transporter,
member 11SLC4A11
2666904 C/N0-solute carrier family 4, sodium bicarbonate
cotransporter, member 7SLC4A7 NM 003615
3608787 C+N-solute carrier organic anion transporter family, member
3A1SLCO3A1 NM_013272
3318666 C/N0+ sphingomyelin phosphodiesterase 1, acid lysosomal SMPD1 NM_000543
2567583 C-N+small nucleolar RNA, C/D box 89 /// ring finger
protein 149SNORD89///RNF149 NM_173647
3899346 C/T1- sorting nexin 5 SNX5
3592109 T1_T2 sorbitol dehydrogenase SORD NM_003104
3352948 C/N0-sortilin-related receptor, L(DLR class) A
repeats-containingSORL1 NM 003105
2549092 C/T1- son of sevenless homolog 1 (Drosophila) SOS1 NM 005633
2603051 C+N- SP110 nuclear body protein SP110 NM 080424
3750785 C/T1+ sperm associated antigen 5 SPAG5 NM_006461
2882098 C-N+ secreted protein, acidic, cysteine-rich (osteonectin) SPARC NM_003118
2882098 C-N+ secreted protein, acidic, cysteine-rich (osteonectin) SPARC NM_003118
2882098 C-N+ secreted protein, acidic, cysteine-rich (osteonectin) SPARC NM_003118
3373724 C-N+ structure specific recognition protein 1 SSRP1 NM_003146
3406421 T1_T2 serine/threonine kinase receptor associated protein STRAP NM_007178
3833040 C-N+ suppressor of Ty 5 homolog (S. cerevisiae) SUPT5H NM_003169
3715703 C/T1+ suppressor of Ty 6 homolog (S. cerevisiae) SUPT6H NM 003170
T-stage symplekin (SYMPK), SYMPK NM 004819
3929325 C/N0- synaptojanin 1 SYNJ1 NM_003895
3401259 C+N- TEA domain family member 4 TEAD4 NM_003213
2768396 C+N- tec protein tyrosine kinase TEC NM 003215
3098935 C/T1+ trimethylguanosine synthase homolog (S. cerevisiae) TGS1 NM_024831
2558511 C/T1+TIA1 cytotoxic granule-associated RNA binding
proteinTIA1 NM 022173
2908008 C-N+ tight junction associated protein 1 (peripheral) TJAP1 NM 080604
3204744 C-N+ talin 1 TLN1 NM_006289
3870533 C/N0+ transmembrane channel-like 4 TMC4 NM 001145303
3502632 C/T1+ transmembrane and coiled-coil domains 3 TMCO3 NM 017905
3057520 C/N0- transmembrane protein 120A TMEM120A NM_031925
3332626 C-N+ transmembrane protein 132A TMEM132A NM_178031
2436526 C/T1- tropomyosin 3 TPM3 NM 001043353
3194896 C/T1+ TNF receptor-associated factor 2 TRAF2 NM_021138
2619120 C-N+ trafficking protein, kinesin binding 1 TRAK1 NM_014965

- 44 -
Transcript
ClusterClass Gene Title Gene Symbol
Accession
number3677752 C+N- TNF receptor-associated protein 1 TRAP1 NM_016292
2953501 C-N+ triggering receptor expressed on myeloid cells 2 TREM2 NM 018965
3360142 C/T1- tripartite motif-containing 21 TRIM21 NM_003141
3394660 C-N+ tripartite motif-containing 29 TRIM29 NM_012101
3896524 C-N+ tRNA methyltransferase 6 homolog (S. cerevisiae) TRMT6 NM 015939
3978169 C/N0- TSPY-like 2 TSPYL2 NM 022117
2970985 C/T1- TSPY-like 4 TSPYL4 NM_021648
3620799 C/N0+ tau tubulin kinase 2 TTBK2 NM 173500
2987632 C+N- tweety homolog 3 (Drosophila) TTYH3 NM 025250
2987632 C-N+ tweety homolog 3 (Drosophila) TTYH3 NM_025250
2987632 C-N+ tweety homolog 3 (Drosophila) TTYH3 NM_025250
2987632 C-N+ tweety homolog 3 (Drosophila) TTYH3 NM_025250
2987632 C+N- tweety homolog 3 (Drosophila) TTYH3 NM_025250
2987632 C+N- tweety homolog 3 (Drosophila) TTYH3 NM_025250
2987632 C+N- tweety homolog 3 (Drosophila) TTYH3 NM_025250
T-stage taxilin alpha (TXLNA), TXLNA NM 175852
3775842 C/N0+ thymidylate synthetase TYMS NM 001071
T-stageubiquitination factor E4B (UFD2 homolog, yeast)
(UBE4B),UBE4B NM 001105562
2504883 C/N0- UDP-glucose ceramide glucosyltransferase-like 1 UGCGL1 NM 020120
3608520 C/N0- unc-45 homolog A (C. elegans) UNC45A NM_018671
3608520 C/N0+ unc-45 homolog A (C. elegans) UNC45A NM_018671
2320762 C/N0+ vacuolar protein sorting 13 homolog D (S. cerevisiae) VPS13D NM 015378
3590204 C/N0- vacuolar protein sorting 18 homolog (S. cerevisiae) VPS18 NM_020857
3666649 C-N+ vacuolar protein sorting 4 homolog A (S. cerevisiae) VPS4A NM 013245
3739668 C/T1- vacuolar protein sorting 53 homolog (S. cerevisiae) VPS53 NM_001128159
3002420 C-N+V-set and transmembrane domain containing 2A ///
hypothetical protein LOC285878
VSTM2A ///
LOC285878NM 182546
3070712 C/T1+ Wiskott-Aldrich syndrome-like WASL NM 003941
3203855 C/N0+ WD repeat domain 40A WDR40A NM_015397
3643143 C+N- WD repeat domain 90 WDR90 NM_145294
2715076 C/N0-Wolf-Hirschhorn syndrome candidate 1 /// small Cajal
body-specific RNA 22
WHSC1 ///
SCARNA22NM 001042424
3968397 C/T1- WWC family member 3 WWC3 NM_01569
3282213 C/T1- YME1-like 1 (S. cerevisiae) YME1L1 NM 139312
2318364 C/N0- zinc finger and BTB domain containing 48 ZBTB48 NM_005341
2318364 C/N0- zinc finger and BTB domain containing 48 ZBTB48 NM_005341
2318364 C/N0+ zinc finger and BTB domain containing 48 ZBTB48 NM_005341
3462094 C/T1- zinc finger, C3H1-type containing ZFC3H1 NM 144982
2329752 C/T1+ zinc finger, MYM-type 4 ZMYM4 NM 005095
3707141 C/T1- zinc finger, MYND-type containing 15 ZMYND15 NM_032265
2946845 C/T1-zinc finger protein 184 /// zinc finger protein 204
pseudogeneZNF184///ZNF204 NM_007149
3243164 C/N0+ zinc finger protein 37A /// zinc finger protein 37BZNF37A ///
ZNF37BNM_001007094
T-stage ZNF638
l FIRMA분석 결과
모두 68개의 significant한 alternative spliced variant를 선별하였음. 그러나 probeset과 그에 해
당하는 genome position을 제공하지 않아 해당하는 exon을 찾아내지 못하였음.

- 45 -
그림 26. FIRMA에 의한 분석결과 candidate alternative splice vatiant로 선정된 COL1A1.
l PAC분석 결과
Pattern에 의해 classification되는 기준을 사용자의 임의로 정하여 경험에 의하여 판단하므로
너무 많은 bias를 우려하여 분석을 중단하였음.
l 총 4종의 알고리즘을 이용하여 분석한 결과 XRAY3.92와 JETTA가 가장 robust한 결과를 보
여주는 것으로 판단하였으며, 각각의 알고리즘으로부터 다양한 그룹의 비교를 통하여 선별된
alternative splice variant중 p-value를 기준으로 가장 stringent하게 선별된 probeset들을 표 1
과 같이 선정하였다. FIRMA의 경우 해당 probeset과 그 genomic position을 제공하지는 않았
으나 68 entries중 16개가 표 7의 list와 일치하였음.
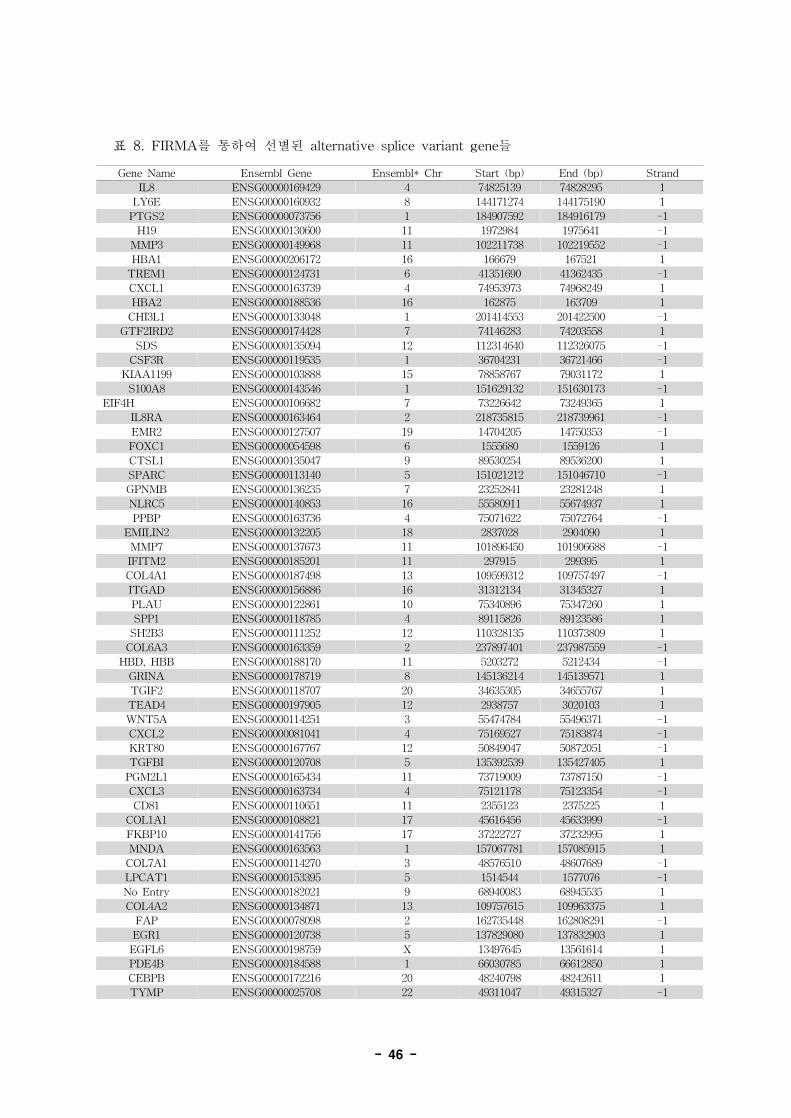
- 46 -
Gene Name Ensembl Gene Ensembl* Chr Start (bp) End (bp) Strand
IL8 ENSG00000169429 4 74825139 74828295 1
LY6E ENSG00000160932 8 144171274 144175190 1
PTGS2 ENSG00000073756 1 184907592 184916179 -1
H19 ENSG00000130600 11 1972984 1975641 -1
MMP3 ENSG00000149968 11 102211738 102219552 -1
HBA1 ENSG00000206172 16 166679 167521 1
TREM1 ENSG00000124731 6 41351690 41362435 -1
CXCL1 ENSG00000163739 4 74953973 74968249 1
HBA2 ENSG00000188536 16 162875 163709 1
CHI3L1 ENSG00000133048 1 201414553 201422500 -1
GTF2IRD2 ENSG00000174428 7 74146283 74203558 1
SDS ENSG00000135094 12 112314640 112326075 -1
CSF3R ENSG00000119535 1 36704231 36721466 -1
KIAA1199 ENSG00000103888 15 78858767 79031172 1
S100A8 ENSG00000143546 1 151629132 151630173 -1
EIF4H ENSG00000106682 7 73226642 73249365 1
IL8RA ENSG00000163464 2 218735815 218739961 -1
EMR2 ENSG00000127507 19 14704205 14750353 -1
FOXC1 ENSG00000054598 6 1555680 1559126 1
CTSL1 ENSG00000135047 9 89530254 89536200 1
SPARC ENSG00000113140 5 151021212 151046710 -1
GPNMB ENSG00000136235 7 23252841 23281248 1
NLRC5 ENSG00000140853 16 55580911 55674937 1
PPBP ENSG00000163736 4 75071622 75072764 -1
EMILIN2 ENSG00000132205 18 2837028 2904090 1
MMP7 ENSG00000137673 11 101896450 101906688 -1
IFITM2 ENSG00000185201 11 297915 299395 1
COL4A1 ENSG00000187498 13 109599312 109757497 -1
ITGAD ENSG00000156886 16 31312134 31345327 1
PLAU ENSG00000122861 10 75340896 75347260 1
SPP1 ENSG00000118785 4 89115826 89123586 1
SH2B3 ENSG00000111252 12 110328135 110373809 1
COL6A3 ENSG00000163359 2 237897401 237987559 -1
HBD, HBB ENSG00000188170 11 5203272 5212434 -1
GRINA ENSG00000178719 8 145136214 145139571 1
TGIF2 ENSG00000118707 20 34635305 34655767 1
TEAD4 ENSG00000197905 12 2938757 3020103 1
WNT5A ENSG00000114251 3 55474784 55496371 -1
CXCL2 ENSG00000081041 4 75169527 75183874 -1
KRT80 ENSG00000167767 12 50849047 50872051 -1
TGFBI ENSG00000120708 5 135392539 135427405 1
PGM2L1 ENSG00000165434 11 73719009 73787150 -1
CXCL3 ENSG00000163734 4 75121178 75123354 -1
CD81 ENSG00000110651 11 2355123 2375225 1
COL1A1 ENSG00000108821 17 45616456 45633999 -1
FKBP10 ENSG00000141756 17 37222727 37232995 1
MNDA ENSG00000163563 1 157067781 157085915 1
COL7A1 ENSG00000114270 3 48576510 48607689 -1
LPCAT1 ENSG00000153395 5 1514544 1577076 -1
No Entry ENSG00000182021 9 68940083 68945535 1
COL4A2 ENSG00000134871 13 109757615 109963375 1
FAP ENSG00000078098 2 162735448 162808291 -1
EGR1 ENSG00000120738 5 137829080 137832903 1
EGFL6 ENSG00000198759 X 13497645 13561614 1
PDE4B ENSG00000184588 1 66030785 66612850 1
CEBPB ENSG00000172216 20 48240798 48242611 1
TYMP ENSG00000025708 22 49311047 49315327 -1
표 8. FIRMA를 통하여 선별된 alternative splice variant gene들

- 47 -
Gene Name Ensembl Gene Ensembl* Chr Start (bp) End (bp) Strand
NFKB2 ENSG00000077150 10 104144219 104152271 1
TRIM28 ENSG00000130726 19 63747648 63753894 1
THBS1 ENSG00000137801 15 37660572 37681845 1
FPR1 ENSG00000171051 19 56940839 56946962 -1
GLT25D1 ENSG00000130309 19 17527460 17554965 1
AHNAK2 ENSG00000214427 14 104478985 104490816 -1
CTSB ENSG00000164733 8 11737442 11763055 -1
HTRA1 ENSG00000166033 10 124211047 124264413 1
OSM ENSG00000099985 22 28988821 28992840 -1
MMP10 ENSG00000166670 11 102146455 102156569 -1
BOP1 ENSG00000170727 8 145456928 145485928 -1
Term % Genes
GO:0005515~protein binding 9.21% CXCL2,SYMPK,PLEC1,CD276,DPM1,VPS18,SP110,ANXA6,SSRP1,MCM6,KNTC1,EXOSC10,CD247,S
NX5,COL1A2,CDH3,NCOA7,BAT2,CPSF3L,LAMA3,NID2,UGCGL1,PLCE1,NEK3,TPM3,DTNBP1,PTP
N1,RBPJ,COL6A2,MTHFD1L,TRAP1,EIF4G2,SAPS1,NF2,FBXL18,SPARC,DAG1,ITSN1,H2AFX,UNC4
5A,IRAK2,SH2B3,WHSC1,BBC3,CXCL12,IGFBP3,MYBBP1A,HSPG2,GTF2H1,AOF2,KRT7,KCTD5,SC
RIB,FADS1,HTRA1,MDN1,PLXND1,MAP3K5,ADAM15,TRAF2,DNMT3A,PIP4K2B,DNM1,SOS1,EIF2
C2,CREBL1,PHLPP,MYH9,AP3D1,FXYD5,TRIM21,BIRC5,CD84,GDI1,CBFA2T2,FN1,SHANK2,TRAK1
,AES,PTK7,CDH5,NFKB2,ELK3,CEP135,LOXL1,BZW2,TSPYL2,NOTCH3,CDC25B,ADCY3,INPPL1,N
DE1,CD81,DNMT1,BCL2L11,COL6A3,HNF4A,CREBBP,KCTD8,ATOX1,PODXL,MYO1F,CLEC7A,EX
OSC9,FASN,TRIM29,WASL,ALS2CL,CXCL3,FGL2,UBE4B,CBFB,RABGGTA,FKBP10,CHD3,SH3BP2,
TGS1,FOSL1,ANKS1A,CDH11,TRMT6,BID,PHF17,GPNMB,MED4,CLN6,PDCD4,LITAF,NOC2L,JAK3,
CCR4,TXLNA,ZMYND15,NUP98,COL12A1,MYO9B,RNF149,RNF216,GPS2,SHROOM1,SCMH1,CBLB,
RAD54B,IGF2R,LIMK1,TEC,SLC4A7,ENAH,PTPRC,IFI6,SHC1,MLH1,EEF1A2,COPS6,TJAP1,AURKB
,LAMA5,RASSF1,ARAF,COL15A1,HCK,RNF38,PKD1,PRMT1,NLK,NOL6,ENG,GMIP,ZBTB48,TLN1,
KIAA0090,FANCA,PLS1,COPS5,COL1A1,SUPT5H,RTN4,MFN1,VPS4A,STRAP,ESAM,
GO:0003824~catalytic activity 5.44% CAD,DPM1,GBA2,MCM6,EXOSC10,DIO2,DDX11,CPSF3L,PLCE1,UGCGL1,NEK3,CDIPT,RBPJ,PTPN1,
MTHFD1L,FBXL18,ABCA3,IRAK2,WHSC1,MYBBP1A,MAPKAPK3,GTF2H1,AOF2,FADS1,SUPT6H,
HTRA1,PPCDC,MDN1,DDX12,POLR3A,CSNK1A1,MAP3K5,ADAM15,DNMT3A,DNM1,PIP4K2B,PPFI
BP2,MFSD7,MYH9,PHLPP,DSE,PIP4K2A,METTL5,SORL1,FN1,ATP8A1,PTK7,YME1L1,LOXL1,CDC
25B,CPVL,ADCY3,GSK3A,EIF5,PTP4A1,INPPL1,ECE2,GALNT2,PDE4B,DNMT1,HNF4A,CREBBP,GD
PD5,SGMS1,PRKAG1,FASN,EXOSC9,UBE4B,NLN,ROS1,RABGGTA,CHD3,FKBP10,TGS1,ISYNA1,J
AK3,PTPN14,EFTUD1,RNF149,GALNT10,MYO9B,RNF216,POLE2,RAD54B,IGF2R,CBLB,LIMK1,TEC,
SORD,PTPRC,EEF1A2,OAS2,POLR3E,AURKB,PARL,ARAF,SYNJ1,HCK,PRMT1,NLK,SMPD1,GMIP,
TTBK2,TYMS,COPS5,MFN1,VPS4A,
GO:0043167~ion binding 4.12% ADCY3,CAD,ECE2,GALNT2,CLCN2,VPS18,DNMT1,SP110,ANUBL1,ANXA6,HNF4A,CREBBP,ATOX
1,ZMYM4,CENTD3,CDH3,TRIM29,NID2,CELSR3,PLCE1,NEK3,CDIPT,NLN,RABGGTA,FKBP10,CHD
3,CDH11,SLC39A9,PHF17,ZNF184,ZNF37A,ZNF638,SPARC,DAG1,ITSN1,ZMYND15,WHSC1,GLIS2,M
YO9B,GALNT10,RNF149,IGFBP3,RNF216,CBLB,FADS1,LIMK1,TEC,SLC4A7,SLC11A2,POLR3A,MAP
3K5,ADAM15,TRAF2,SORD,DNMT3A,PHLPP,TRIM21,SFXN4,BIRC5,SORL1,AURKB,RASSF1,ARAF
,RNF38,NLK,EGR1,CBFA2T2,OSBPL2,AP1GBP1,GMIP,ZBTB48,SLC2A4RG,CRELD1,ATP8A1,PLS1,C
DH5,COPS5,YME1L1,LOXL1,CACNA2D4,NOTCH3,
GO:0046872~metal ion binding 4.07% ADCY3,CAD,ECE2,GALNT2,VPS18,DNMT1,SP110,ANUBL1,ANXA6,HNF4A,CREBBP,ATOX1,ZMY
M4,CENTD3,CDH3,TRIM29,NID2,CELSR3,PLCE1,NEK3,CDIPT,NLN,RABGGTA,FKBP10,CHD3,CDH
11,SLC39A9,PHF17,ZNF184,ZNF37A,ZNF638,SPARC,DAG1,ITSN1,ZMYND15,WHSC1,GLIS2,MYO9B,
GALNT10,RNF149,IGFBP3,RNF216,CBLB,FADS1,LIMK1,TEC,SLC4A7,SLC11A2,POLR3A,MAP3K5,A
DAM15,TRAF2,SORD,DNMT3A,PHLPP,TRIM21,SFXN4,BIRC5,SORL1,AURKB,RASSF1,ARAF,RNF3
8,NLK,EGR1,CBFA2T2,OSBPL2,AP1GBP1,GMIP,ZBTB48,SLC2A4RG,CRELD1,ATP8A1,PLS1,CDH5,C
OPS5,YME1L1,LOXL1,CACNA2D4,NOTCH3,
GO:0046914~transition metal ion
binding
2.85% CAD,ECE2,GALNT2,VPS18,DNMT1,SP110,ANUBL1,HNF4A,CREBBP,ATOX1,ZMYM4,CENTD3,TRI
M29,CDIPT,NLN,RABGGTA,CHD3,SLC39A9,PHF17,ZNF184,ZNF638,ZNF37A,SPARC,ZMYND15,WH
SC1,GLIS2,RNF149,GALNT10,MYO9B,RNF216,FADS1,CBLB,LIMK1,TEC,SLC11A2,POLR3A,ADAM1
5,TRAF2,SORD,DNMT3A,PHLPP,TRIM21,SFXN4,BIRC5,SORL1,RASSF1,ARAF,RNF38,EGR1,CBFA2
나. Gene ontology의 분석
XRAY3.92와 JETTA 알고리즘에 의해 선정된 유전자들의 gene ontology를 분석한 결과는 다음과
같다.
표 9. Molecular function에 의한 분류

- 48 -
Term % Genes
T2,OSBPL2,GMIP,ZBTB48,SLC2A4RG,YME1L1,LOXL1,
GO:0016787~hydrolase activity 2.44% EIF5,CAD,RAD54B,PTP4A1,INPPL1,PDE4B,ECE2,GBA2,SUPT6H,HTRA1,CREBBP,MDN1,DDX12,MC
M6,GDPD5,EXOSC10,ADAM15,DNM1,MFSD7,EXOSC9,DDX11,FASN,PTPRC,PHLPP,MYH9,CPSF3L,
EEF1A2,PLCE1,PARL,NLN,PTPN1,SYNJ1,MTHFD1L,CHD3,SMPD1,ATP8A1,PTPN14,ABCA3,COPS5
,YME1L1,EFTUD1,MYO9B,RNF149,RNF216,MFN1,CDC25B,VPS4A,CPVL,
GO:0016740~transferase activity 2.34% GTF2H1,CAD,GSK3A,IGF2R,LIMK1,TEC,DPM1,GALNT2,ECE2,DNMT1,CREBBP,MAP3K5,CSNK1A
1,POLR3A,EXOSC10,PRKAG1,SGMS1,DNMT3A,PIP4K2B,DNM1,FASN,OAS2,UGCGL1,PIP4K2A,NE
K3,CDIPT,METTL5,POLR3E,AURKB,ARAF,HCK,ROS1,RABGGTA,NLK,PRMT1,TGS1,JAK3,TTBK
2,PTK7,TYMS,IRAK2,WHSC1,GALNT10,POLE2,MYBBP1A,MAPKAPK3,
GO:0017076~purine nucleotide binding 2.19% EIF5,CAD,GSK3A,RAD54B,LIMK1,TEC,CREBBP,MDN1,DDX12,MCM6,MAP3K5,CSNK1A1,PIP4K2B,
DNM1,MYO1F,GTPBP8,DDX11,MYH9,MLH1,EEF1A2,OAS2,NEK3,PIP4K2A,AURKB,ARAF,HCK,MT
HFD1L,ROS1,NLK,CHD3,TRAP1,JAK3,ATP8A1,TTBK2,PTK7,ABCA3,IRAK2,YME1L1,EFTUD1,MY
O9B,MFN1,VPS4A,MAPKAPK3,
GO:0032555~purine ribonucleotide
binding
2.19% EIF5,CAD,GSK3A,RAD54B,LIMK1,TEC,CREBBP,MDN1,DDX12,MCM6,MAP3K5,CSNK1A1,PIP4K2B,
DNM1,MYO1F,GTPBP8,DDX11,MYH9,MLH1,EEF1A2,OAS2,NEK3,PIP4K2A,AURKB,ARAF,HCK,MT
HFD1L,ROS1,NLK,CHD3,TRAP1,JAK3,ATP8A1,TTBK2,PTK7,ABCA3,IRAK2,YME1L1,EFTUD1,MY
O9B,MFN1,VPS4A,MAPKAPK3,
GO:0005524~ATP binding 1.88% GSK3A,CAD,RAD54B,LIMK1,TEC,CREBBP,MDN1,DDX12,MCM6,MAP3K5,CSNK1A1,PIP4K2B,MYO
1F,DDX11,MYH9,MLH1,OAS2,PIP4K2A,NEK3,AURKB,ARAF,HCK,MTHFD1L,ROS1,NLK,CHD3,TR
AP1,JAK3,ATP8A1,PTK7,TTBK2,ABCA3,IRAK2,YME1L1,MYO9B,VPS4A,MAPKAPK3,
GO:0030554~adenyl nucleotide binding 1.88% GSK3A,CAD,RAD54B,LIMK1,TEC,CREBBP,MDN1,DDX12,MCM6,MAP3K5,CSNK1A1,PIP4K2B,MYO
1F,DDX11,MYH9,MLH1,OAS2,PIP4K2A,NEK3,AURKB,ARAF,HCK,MTHFD1L,ROS1,NLK,CHD3,TR
AP1,JAK3,ATP8A1,PTK7,TTBK2,ABCA3,IRAK2,YME1L1,MYO9B,VPS4A,MAPKAPK3,
GO:0016772~transferase activity,
transferring phosphorus-containing
groups
1.53% GTF2H1,GSK3A,IGF2R,LIMK1,TEC,PRKAG1,MAP3K5,CSNK1A1,POLR3A,EXOSC10,SGMS1,DNM1,
PIP4K2B,OAS2,PIP4K2A,NEK3,POLR3E,AURKB,CDIPT,ARAF,HCK,ROS1,NLK,JAK3,PTK7,TTBK2,I
RAK2,POLE2,MYBBP1A,MAPKAPK3,
GO:0016301~kinase activity 1.22% NEK3,PIP4K2A,AURKB,GTF2H1,ARAF,GSK3A,IGF2R,LIMK1,HCK,TEC,ROS1,NLK,EXOSC10,CSNK
1A1,MAP3K5,PRKAG1,SGMS1,JAK3,PIP4K2B,DNM1,TTBK2,PTK7,IRAK2,MAPKAPK3,
GO:0016773~phosphotransferase activity,
alcohol group as acceptor
1.12% NEK3,PIP4K2A,AURKB,GTF2H1,ARAF,GSK3A,IGF2R,LIMK1,HCK,TEC,ROS1,NLK,EXOSC10,CSNK
1A1,MAP3K5,PRKAG1,JAK3,PIP4K2B,TTBK2,PTK7,IRAK2,MAPKAPK3,
GO:0004672~protein kinase activity 1.02% NEK3,AURKB,GTF2H1,ARAF,GSK3A,IGF2R,LIMK1,HCK,TEC,ROS1,NLK,EXOSC10,CSNK1A1,MAP
3K5,PRKAG1,JAK3,TTBK2,PTK7,IRAK2,MAPKAPK3,
GO:0016818~hydrolase activity, acting
on acid anhydrides, in
phosphorus-containing anhydrides
0.97% EIF5,RAD54B,CHD3,CREBBP,MDN1,MCM6,DDX12,ATP8A1,DNM1,ABCA3,DDX11,MYH9,YME1L1,E
FTUD1,MYO9B,RNF216,MFN1,EEF1A2,VPS4A,
GO:0016462~pyrophosphatase activity 0.97% EIF5,RAD54B,CHD3,CREBBP,MDN1,MCM6,DDX12,ATP8A1,DNM1,ABCA3,DDX11,MYH9,YME1L1,E
FTUD1,MYO9B,RNF216,MFN1,EEF1A2,VPS4A,
GO:0008092~cytoskeletal protein binding 0.86% BIRC5,TPM3,PLEC1,INPPL1,VPS18,NDE1,NF2,TLN1,TRAK1,ENAH,MYO1F,PLS1,MYH9,WASL,MY
O9B,FXYD5,SHROOM1,
GO:0004674~protein serine/threonine
kinase activity
0.71% NEK3,AURKB,GTF2H1,ARAF,GSK3A,LIMK1,NLK,EXOSC10,CSNK1A1,MAP3K5,PRKAG1,TTBK2,I
RAK2,MAPKAPK3,
GO:0003779~actin binding 0.66% TPM3,PLEC1,INPPL1,VPS18,TLN1,ENAH,MYO1F,PLS1,MYH9,WASL,MYO9B,FXYD5,SHROOM1,
GO:0016887~ATPase activity 0.61% ATP8A1,RAD54B,ABCA3,CHD3,DDX11,MYH9,MYO9B,RNF216,CREBBP,MDN1,DDX12,MCM6,
GO:0042802~identical protein binding 0.61% CLN6,BIRC5,MAP3K5,EXOSC10,CD247,RASSF1,DTNBP1,IRAK2,MYH9,MYO9B,ALS2CL,MCM6,
GO:0042578~phosphoric ester hydrolase
activity
0.61% PTPN1,SYNJ1,PTP4A1,INPPL1,PTPN14,PDE4B,PTPRC,PHLPP,SMPD1,CDC25B,GDPD5,PLCE1,
GO:0046983~protein dimerization activity 0.56% CLN6,BIRC5,KNTC1,MAP3K5,CD247,LIMK1,CREBL1,FOSL1,MYH9,SUPT5H,MYO9B,
GO:0016741~transferase activity,
transferring one-carbon groups
0.51% AURKB,METTL5,CAD,DNMT3A,TYMS,ECE2,PRMT1,WHSC1,DNMT1,TGS1,
GO:0016563~transcription activator
activity
0.51% MED4,RASSF1,CBFB,NFKB2,GLIS2,EGR1,COPS5,FOSL1,TEAD4,CREBBP,
GO:0008168~methyltransferase activity 0.46% AURKB,METTL5,DNMT3A,TYMS,ECE2,PRMT1,WHSC1,DNMT1,TGS1,
GO:0003702~RNA polymerase II
transcription factor activity
0.46% MED4,MLLT1,LITAF,GTF2H1,RBPJ,CBFB,ELK3,HNF4A,TEAD4,
GO:0004713~protein-tyrosine kinase
activity
0.41% NEK3,JAK3,IGF2R,LIMK1,HCK,PTK7,TEC,ROS1,
GO:0008135~translation factor activity,
nucleic acid binding
0.41% EIF5,EIF2C2,COPS5,EFTUD1,BZW2,TRMT6,EEF1A2,EIF4G2,
GO:0005201~extracellular matrix
structural constituent
0.41% COL15A1,COL1A2,COL6A2,COL4A2,COL12A1,COL1A1,COL4A1,FN1,
GO:0003743~translation initiation factor
activity
0.31% EIF5,EIF2C2,COPS5,BZW2,TRMT6,EIF4G2,
GO:0004725~protein tyrosine
phosphatase activity
0.25% PTPN1,PTP4A1,PTPN14,PTPRC,CDC25B,
GO:0003678~DNA helicase activity 0.25% RAD54B,CHD3,DDX11,DDX12,MCM6,
GO:0008009~chemokine activity 0.20% CXCL3,CXCL2,ZMYND15,CXCL12,
GO:0019992~diacylglycerol binding 0.20% RASSF1,ARAF,MYO9B,GMIP,
GO:0005100~Rho GTPase activator 0.20% SOS1,CENTD3,MYO9B,GMIP,
- 49 -
Term % Genes
activity
GO:0042379~chemokine receptor binding 0.20% CXCL3,CXCL2,ZMYND15,CXCL12,
GO:0005548~phospholipid transporter
activity
0.15% CDIPT,ATP8A1,PITPNB,
GO:0004003~ATP-dependent DNA
helicase activity
0.15% CHD3,DDX11,DDX12,
GO:0000146~microfilament motor
activity
0.15% MYO1F,MYH9,MYO9B,
GO:0005520~insulin-like growth factor
binding
0.15% IGF2R,IGFBP3,HTRA1,
GO:0005518~collagen binding 0.15% SPARC,FN1,NID2,
GO:0003886~DNA
(cytosine-5-)-methyltransferase
activity
0.10% DNMT3A,DNMT1,
GO:0008526~phosphatidylinositol
transporter activity
0.10% CDIPT,PITPNB,
GO:0016309~1-phosphatidylinositol-5-ph
osphate 4-kinase activity
0.10% PIP4K2A,PIP4K2B,
GO:0008147~structural constituent of
bone
0.10% COL1A2,COL1A1,
GO:0009008~DNA-methyltransferase
activity
0.10% DNMT3A,DNMT1,
Term % Genes
GO:0005622~intracellular 11.09% SYMPK,SAMD9,MRPS31,R3HDM2,VPS18,SP110,ANXA6,GBA2,MCM6,OGFR,EXOSC10,COL1A2,CO
MMD5,NCOA7,BAT2,DDX11,PLCE1,NEK3,TPM3,DTNBP1,RBPJ,PTPN1,SAPS1,NF2,FBXL18,NUDC
D2,ABCA3,WHSC1,MAPKAPK3,GTF2H1,FAM38A,FADS1,GLTSCR2,FNBP1L,NCAPD3,SUPT6H,M
DN1,DDX12,SLC11A2,POLR3A,CSNK1A1,TRAF2,DNMT3A,SOS1,DNM1,EIF2C2,PPFIBP2,MYH9,AP
3D1,CLN8,SFXN4,BIRC5,METTL5,GDI1,CBFA2T2,CC2D1A,FN1,AES,ELK3,YME1L1,TSPYL2,NOT
CH3,INPPL1,ECE2,GALNT2,NDE1,DNMT1,HNF4A,GDPD5,SGMS1,PRKAG1,MYO1F,CLEC7A,ZMY
M4,FASN,WASL,CDCA4,CHD3,FKBP10,ANKS1A,FOSL1,BID,PHF17,CLN6,NOC2L,TXLNA,COL12A
1,NUP98,IGF2R,RAD54B,BRD3,ENAH,GTPBP8,IFI6,MLH1,SHC1,ARID4B,POLR3E,AURKB,RASSF1,
BARHL2,COL15A1,HCK,PRMT1,NLK,EGR1,AP1GBP1,ZBTB48,TLN1,FANCA,TTBK2,RTN4,SPAG5
,MFN1,STRAP,CAD,PLEC1,DPM1,SSRP1,KNTC1,CD247,SCAMP1,CPSF3L,UGCGL1,CDIPT,COL6A2
,TMEM132A,ZNF184,EIF4G2,TRAP1,DAG1,ITSN1,H2AFX,UNC45A,GLIS2,BBC3,IGFBP3,MYBBP1A,
KRT7,AOF2,SCRIB,LMNB2,PLXND1,PIP4K2B,CREBL1,PHLPP,TRIM21,DSE,TSPYL4,COL4A2,OSB
PL2,MLX,TRAK1,SHANK2,VPS53,ATP8A1,NFKB2,CEP135,LAMP2,CDC25B,EIF5,RRP12,PTP4A1,C
OL6A3,CREBBP,ATOX1,CENTD3,EXOSC9,TRIM29,LCN2,UBE4B,NLN,CBFB,TGS1,TRMT6,COL4A
1,ZNF638,ZNF37A,MED4,PLEKHM2,GPNMB,PDCD4,LITAF,JAK3,PTPN14,GALNT10,MYO9B,RNF2
16,POLE2,SHROOM1,SCMH1,CBLB,LIMK1,TEC,TIA1,GOLGA8A,NIF3L1,EEF1A2,OAS2,COPS6,TJ
AP1,MLLT1,PARL,SYNJ1,NOL6,PITPNB,SMPD1,TEAD4,GMIP,SLC2A4RG,PLS1,FAM130A1,ARHG
AP8,COPS5,COL1A1,SUPT5H,C14orf43,VPS4A,
GO:0044424~intracellular part 10.73% SYMPK,SAMD9,MRPS31,R3HDM2,VPS18,SP110,ANXA6,GBA2,MCM6,OGFR,EXOSC10,COL1A2,CO
MMD5,NCOA7,BAT2,DDX11,PLCE1,NEK3,TPM3,DTNBP1,RBPJ,PTPN1,SAPS1,NF2,FBXL18,ABCA
3,WHSC1,MAPKAPK3,GTF2H1,FAM38A,FADS1,GLTSCR2,FNBP1L,NCAPD3,SUPT6H,MDN1,DDX
12,SLC11A2,POLR3A,CSNK1A1,TRAF2,DNMT3A,SOS1,DNM1,EIF2C2,MYH9,AP3D1,CLN8,SFXN4,
BIRC5,METTL5,GDI1,CBFA2T2,CC2D1A,FN1,AES,ELK3,YME1L1,TSPYL2,NOTCH3,INPPL1,ECE2,
GALNT2,NDE1,DNMT1,HNF4A,GDPD5,SGMS1,PRKAG1,MYO1F,CLEC7A,ZMYM4,FASN,WASL,C
DCA4,CHD3,FKBP10,ANKS1A,FOSL1,BID,PHF17,CLN6,NOC2L,TXLNA,COL12A1,NUP98,IGF2R,RA
D54B,BRD3,ENAH,IFI6,MLH1,SHC1,ARID4B,AURKB,POLR3E,RASSF1,BARHL2,COL15A1,HCK,PR
MT1,NLK,EGR1,AP1GBP1,ZBTB48,TLN1,FANCA,TTBK2,RTN4,SPAG5,MFN1,STRAP,CAD,PLEC1,
DPM1,SSRP1,KNTC1,CD247,SCAMP1,CPSF3L,UGCGL1,CDIPT,COL6A2,TMEM132A,ZNF184,EIF4G
2,TRAP1,DAG1,H2AFX,UNC45A,GLIS2,BBC3,IGFBP3,MYBBP1A,KRT7,AOF2,SCRIB,LMNB2,PIP4K
2B,CREBL1,PHLPP,TRIM21,DSE,TSPYL4,COL4A2,OSBPL2,MLX,TRAK1,SHANK2,VPS53,ATP8A1,
NFKB2,CEP135,LAMP2,CDC25B,EIF5,RRP12,PTP4A1,COL6A3,CREBBP,ATOX1,CENTD3,EXOSC9,
TRIM29,LCN2,UBE4B,NLN,CBFB,TGS1,TRMT6,COL4A1,ZNF638,ZNF37A,MED4,PLEKHM2,GPNM
B,PDCD4,LITAF,JAK3,PTPN14,GALNT10,MYO9B,RNF216,POLE2,SHROOM1,SCMH1,CBLB,LIMK1
,TEC,TIA1,GOLGA8A,NIF3L1,EEF1A2,OAS2,COPS6,TJAP1,MLLT1,PARL,SYNJ1,NOL6,PITPNB,S
MPD1,TEAD4,SLC2A4RG,PLS1,FAM130A1,COPS5,COL1A1,SUPT5H,C14orf43,VPS4A,
GO:0043229~intracellular organelle 8.90% SYMPK,MRPS31,PLEC1,R3HDM2,DPM1,VPS18,SP110,GBA2,ANXA6,SSRP1,MCM6,OGFR,KNTC1,E
XOSC10,SCAMP1,COMMD5,NCOA7,DDX11,BAT2,CPSF3L,UGCGL1,PLCE1,NEK3,CDIPT,TPM3,DT
NBP1,PTPN1,RBPJ,TMEM132A,TRAP1,ZNF184,NF2,DAG1,H2AFX,UNC45A,ABCA3,GLIS2,WHSC1,
표 9. Cellular component에 의한 분류
- 50 -
Term % Genes
BBC3,IGFBP3,MYBBP1A,MAPKAPK3,GTF2H1,AOF2,KRT7,FADS1,FAM38A,GLTSCR2,LMNB2,NC
APD3,FNBP1L,SUPT6H,MDN1,SLC11A2,DDX12,POLR3A,DNMT3A,PIP4K2B,DNM1,SOS1,CREBL1,
PHLPP,MYH9,AP3D1,TRIM21,CLN8,DSE,SFXN4,BIRC5,TSPYL4,CBFA2T2,CC2D1A,OSBPL2,MLX,
TRAK1,VPS53,AES,ATP8A1,NFKB2,ELK3,CEP135,YME1L1,LAMP2,TSPYL2,NOTCH3,CDC25B,RR
P12,PTP4A1,INPPL1,GALNT2,ECE2,NDE1,DNMT1,HNF4A,CREBBP,PRKAG1,SGMS1,MYO1F,ZMY
M4,CENTD3,EXOSC9,FASN,WASL,CDCA4,NLN,CBFB,FKBP10,CHD3,TGS1,FOSL1,TRMT6,BID,P
HF17,ZNF37A,ZNF638,GPNMB,MED4,CLN6,PDCD4,LITAF,NOC2L,JAK3,PTPN14,NUP98,MYO9B,G
ALNT10,RNF216,POLE2,SHROOM1,SCMH1,CBLB,RAD54B,IGF2R,LIMK1,BRD3,TIA1,ENAH,GOLG
A8A,IFI6,SHC1,MLH1,EEF1A2,ARID4B,OAS2,COPS6,TJAP1,POLR3E,AURKB,MLLT1,PARL,RASS
F1,BARHL2,PRMT1,NLK,NOL6,EGR1,AP1GBP1,PITPNB,SMPD1,TEAD4,ZBTB48,TLN1,SLC2A4RG,
FANCA,TTBK2,PLS1,FAM130A1,COPS5,SUPT5H,RTN4,SPAG5,MFN1,C14orf43,VPS4A,STRAP,
GO:0043231~intracellular
membrane-bound organelle
7.78% SYMPK,MRPS31,R3HDM2,DPM1,VPS18,SP110,GBA2,ANXA6,SSRP1,MCM6,OGFR,EXOSC10,KNTC
1,SCAMP1,COMMD5,NCOA7,DDX11,BAT2,CPSF3L,PLCE1,UGCGL1,NEK3,CDIPT,DTNBP1,PTPN1,
RBPJ,TMEM132A,ZNF184,TRAP1,NF2,H2AFX,UNC45A,ABCA3,GLIS2,WHSC1,BBC3,IGFBP3,MYB
BP1A,MAPKAPK3,GTF2H1,AOF2,FADS1,FAM38A,GLTSCR2,LMNB2,NCAPD3,SUPT6H,MDN1,SL
C11A2,DDX12,POLR3A,DNMT3A,PIP4K2B,SOS1,CREBL1,PHLPP,MYH9,AP3D1,TRIM21,CLN8,DSE,
SFXN4,BIRC5,TSPYL4,CBFA2T2,CC2D1A,OSBPL2,MLX,TRAK1,VPS53,AES,NFKB2,ELK3,YME1L
1,LAMP2,TSPYL2,NOTCH3,RRP12,PTP4A1,ECE2,GALNT2,DNMT1,HNF4A,CREBBP,PRKAG1,SG
MS1,ZMYM4,EXOSC9,FASN,WASL,CDCA4,NLN,CBFB,FKBP10,CHD3,TGS1,FOSL1,TRMT6,BID,P
HF17,ZNF37A,ZNF638,GPNMB,MED4,CLN6,PDCD4,LITAF,NOC2L,NUP98,GALNT10,RNF216,POLE
2,SCMH1,CBLB,RAD54B,IGF2R,LIMK1,BRD3,TIA1,GOLGA8A,IFI6,SHC1,MLH1,EEF1A2,ARID4B,O
AS2,COPS6,TJAP1,POLR3E,AURKB,MLLT1,PARL,RASSF1,BARHL2,PRMT1,NLK,NOL6,EGR1,AP1
GBP1,PITPNB,SMPD1,TEAD4,ZBTB48,SLC2A4RG,FANCA,FAM130A1,COPS5,SUPT5H,RTN4,MFN
1,C14orf43,VPS4A,STRAP,
GO:0005737~cytoplasm 7.63% SYMPK,SAMD9,MRPS31,CAD,PLEC1,DPM1,VPS18,GBA2,ANXA6,OGFR,EXOSC10,KNTC1,CD247,
SCAMP1,COL1A2,BAT2,CPSF3L,PLCE1,UGCGL1,CDIPT,TPM3,DTNBP1,PTPN1,COL6A2,TMEM13
2A,SAPS1,EIF4G2,TRAP1,NF2,FBXL18,DAG1,UNC45A,ABCA3,WHSC1,GLIS2,BBC3,MYBBP1A,MA
PKAPK3,KRT7,FAM38A,FADS1,SCRIB,FNBP1L,SLC11A2,CSNK1A1,TRAF2,DNMT3A,DNM1,PIP4
K2B,EIF2C2,CREBL1,MYH9,PHLPP,AP3D1,CLN8,TRIM21,DSE,SFXN4,BIRC5,METTL5,GDI1,COL4
A2,CC2D1A,MLX,FN1,SHANK2,TRAK1,VPS53,ATP8A1,NFKB2,CEP135,YME1L1,LAMP2,TSPYL2,
CDC25B,EIF5,PTP4A1,INPPL1,ECE2,GALNT2,NDE1,COL6A3,CREBBP,GDPD5,ATOX1,SGMS1,CLE
C7A,CENTD3,EXOSC9,FASN,TRIM29,WASL,LCN2,UBE4B,NLN,FKBP10,TGS1,ANKS1A,BID,COL4
A1,PHF17,ZNF638,GPNMB,PLEKHM2,CLN6,PDCD4,LITAF,TXLNA,PTPN14,COL12A1,MYO9B,GAL
NT10,RNF216,SHROOM1,CBLB,IGF2R,LIMK1,TEC,TIA1,ENAH,GOLGA8A,NIF3L1,IFI6,SHC1,EEF1
A2,ARID4B,OAS2,COPS6,TJAP1,PARL,RASSF1,COL15A1,SYNJ1,HCK,PRMT1,NLK,AP1GBP1,PITP
NB,SMPD1,TLN1,SLC2A4RG,FANCA,PLS1,COPS5,COL1A1,RTN4,SPAG5,MFN1,VPS4A,STRAP,
GO:0005634~nucleus 5.49% SYMPK,R3HDM2,SP110,SSRP1,MCM6,OGFR,EXOSC10,KNTC1,COMMD5,NCOA7,BAT2,DDX11,CP
SF3L,NEK3,DTNBP1,RBPJ,ZNF184,NF2,H2AFX,UNC45A,WHSC1,GLIS2,IGFBP3,MYBBP1A,MAPK
APK3,GTF2H1,AOF2,GLTSCR2,NCAPD3,LMNB2,SUPT6H,MDN1,DDX12,POLR3A,DNMT3A,SOS1,
CREBL1,MYH9,PHLPP,TRIM21,BIRC5,TSPYL4,CBFA2T2,CC2D1A,OSBPL2,MLX,TRAK1,AES,NFK
B2,ELK3,TSPYL2,NOTCH3,RRP12,DNMT1,HNF4A,CREBBP,SGMS1,PRKAG1,ZMYM4,EXOSC9,W
ASL,CDCA4,CBFB,CHD3,FOSL1,TGS1,TRMT6,PHF17,ZNF638,ZNF37A,MED4,PDCD4,NOC2L,NUP9
8,RNF216,POLE2,SCMH1,IGF2R,RAD54B,CBLB,LIMK1,BRD3,TIA1,MLH1,ARID4B,EEF1A2,OAS2,C
OPS6,POLR3E,AURKB,MLLT1,PARL,RASSF1,BARHL2,PRMT1,NLK,NOL6,EGR1,TEAD4,ZBTB48,
SLC2A4RG,FANCA,FAM130A1,COPS5,SUPT5H,RTN4,C14orf43,STRAP,
GO:0044446~intracellular organelle part 4.07% SYMPK,PLEC1,PTP4A1,ECE2,DPM1,VPS18,NDE1,DNMT1,SSRP1,CREBBP,EXOSC10,SGMS1,KNT
C1,SCAMP1,MYO1F,EXOSC9,DDX11,CPSF3L,UGCGL1,PLCE1,CDIPT,TPM3,NLN,PTPN1,RBPJ,TM
EM132A,FKBP10,CHD3,BID,ZNF638,NF2,MED4,CLN6,LITAF,H2AFX,GLIS2,NUP98,MYO9B,GALNT
10,MYBBP1A,SHROOM1,GTF2H1,KRT7,FAM38A,FADS1,IGF2R,LMNB2,NCAPD3,SLC11A2,POLR3
A,DNMT3A,PIP4K2B,DNM1,SOS1,CREBL1,MYH9,AP3D1,ARID4B,CLN8,SFXN4,COPS6,BIRC5,AUR
KB,PARL,RASSF1,NOL6,AP1GBP1,TEAD4,VPS53,TTBK2,COPS5,CEP135,RTN4,SPAG5,LAMP2,TS
PYL2,MFN1,CDC25B,VPS4A,STRAP,
GO:0043232~intracellular
non-membrane-bound organelle
2.39% SYMPK,KRT7,PLEC1,PTP4A1,INPPL1,VPS18,NDE1,LMNB2,NCAPD3,FNBP1L,DNMT1,SSRP1,KNT
C1,EXOSC10,ENAH,DNMT3A,DNM1,SOS1,MYO1F,CENTD3,EXOSC9,DDX11,MYH9,WASL,ARID4
B,BIRC5,AURKB,TPM3,RASSF1,RBPJ,NOL6,CHD3,TLN1,NF2,DAG1,JAK3,H2AFX,TTBK2,PLS1,PT
PN14,CEP135,MYO9B,SPAG5,TSPYL2,MYBBP1A,CDC25B,SHROOM1,
GO:0005856~cytoskeleton 1.63% SYMPK,PLEC1,KRT7,PTP4A1,INPPL1,NDE1,VPS18,FNBP1L,LMNB2,ENAH,KNTC1,MYO1F,DNM1
,CENTD3,WASL,MYH9,BIRC5,AURKB,TPM3,RASSF1,NF2,TLN1,DAG1,JAK3,TTBK2,PLS1,PTPN1
4,CEP135,MYO9B,SPAG5,CDC25B,SHROOM1,
GO:0044428~nuclear part 1.37% SYMPK,GTF2H1,IGF2R,NCAPD3,LMNB2,CREBBP,POLR3A,EXOSC10,DNMT3A,DDX11,EXOSC9,C
PSF3L,COPS6,RASSF1,RBPJ,NOL6,TEAD4,NF2,ZNF638,MED4,GLIS2,NUP98,COPS5,RTN4,TSPYL2,
MYBBP1A,STRAP,
GO:0043233~organelle lumen 1.27% SYMPK,GTF2H1,IGF2R,CREBBP,POLR3A,EXOSC10,DNMT3A,DDX11,EXOSC9,CPSF3L,UGCGL1,R
ASSF1,RBPJ,NLN,FKBP10,NOL6,NF2,ZNF638,TEAD4,CLN6,MED4,GLIS2,NUP98,TSPYL2,MYBBP1
A,
GO:0044421~extracellular region part 1.12% CXCL3,HSPG2,CXCL2,FGL2,LAMA5,COL15A1,COL6A2,COL4A2,COL6A3,COL4A1,HTRA1,FN1,SPA
RC,DAG1,ADAM15,COL1A2,COL12A1,COL1A1,LOXL1,CXCL12,NID2,LAMA3,
GO:0031981~nuclear lumen 1.02% SYMPK,GTF2H1,RASSF1,RBPJ,NOL6,TEAD4,ZNF638,CREBBP,NF2,MED4,EXOSC10,POLR3A,DN

- 51 -
Term % Genes
MT3A,GLIS2,EXOSC9,DDX11,NUP98,CPSF3L,TSPYL2,MYBBP1A,
GO:0044430~cytoskeletal part 1.02% BIRC5,AURKB,TPM3,RASSF1,KRT7,PLEC1,PTP4A1,VPS18,NDE1,LMNB2,KNTC1,DNM1,MYO1F,
TTBK2,CEP135,MYH9,MYO9B,SPAG5,CDC25B,SHROOM1,
GO:0005578~proteinaceous extracellular
matrix
0.86% HSPG2,LAMA5,COL15A1,COL6A2,COL4A2,COL6A3,COL4A1,FN1,SPARC,DAG1,ADAM15,COL1A2,
COL12A1,COL1A1,LOXL1,NID2,LAMA3,
GO:0031012~extracellular matrix 0.86% HSPG2,LAMA5,COL15A1,COL6A2,COL4A2,COL6A3,COL4A1,FN1,SPARC,DAG1,ADAM15,COL1A2,
COL12A1,COL1A1,LOXL1,NID2,LAMA3,
GO:0044420~extracellular matrix part 0.71% HSPG2,LAMA5,COL15A1,COL6A2,COL4A2,COL6A3,COL4A1,SPARC,DAG1,COL1A2,COL12A1,COL
1A1,NID2,LAMA3,
GO:0030054~cell junction 0.61% SHANK2,TJAP1,ENAH,SYMPK,ITSN1,LIMK1,CDH5,GJA4,PTPRC,LAMA3,TLN1,ESAM,
GO:0015629~actin cytoskeleton 0.46% DAG1,TPM3,MYO1F,PLS1,VPS18,WASL,MYH9,MYO9B,SHROOM1,
GO:0005768~endosome 0.41% VPS53,IGF2R,PTP4A1,VPS18,LAMP2,NF2,VPS4A,SLC11A2,
GO:0005604~basement membrane 0.41% HSPG2,SPARC,DAG1,LAMA5,COL4A2,COL4A1,LAMA3,NID2,
GO:0005730~nucleolus 0.41% EXOSC10,RBPJ,NOL6,EXOSC9,DDX11,TSPYL2,MYBBP1A,NF2,
GO:0005581~collagen 0.41% COL15A1,COL1A2,COL6A2,COL4A2,COL12A1,COL1A1,COL6A3,COL4A1,
GO:0005819~spindle 0.36% BIRC5,KNTC1,AURKB,RASSF1,PTP4A1,NDE1,SPAG5,
GO:0016323~basolateral plasma
membrane
0.31% LIMK1,SLC4A7,SLC4A11,PTPRC,LAMA3,TLN1,
GO:0005912~adherens junction 0.25% LIMK1,PTPRC,LAMA3,TLN1,ESAM,
GO:0010008~endosome membrane 0.25% VPS53,VPS18,LAMP2,VPS4A,SLC11A2,
GO:0005925~focal adhesion 0.20% LIMK1,PTPRC,LAMA3,TLN1,
GO:0005793~ER-Golgi intermediate
compartment
0.20% FAM38A,FN1,CLN8,UGCGL1,
GO:0005924~cell-substrate adherens
junction
0.20% LIMK1,PTPRC,LAMA3,TLN1,
GO:0005765~lysosomal membrane 0.20% LITAF,IGF2R,VPS18,LAMP2,
GO:0030055~cell-matrix junction 0.20% LIMK1,PTPRC,LAMA3,TLN1,
GO:0005626~insoluble fraction 0.15% DAG1,PLEC1,PDE4B,
GO:0005876~spindle microtubule 0.15% BIRC5,KNTC1,SPAG5,
GO:0000176~nuclear exosome (RNase
complex)
0.10% EXOSC10,EXOSC9,
GO:0005587~collagen type IV 0.10% COL4A2,COL4A1,
GO:0005584~collagen type I 0.10% COL1A2,COL1A1,
Term % Genes
GO:0008152~metabolic process 8.49% CAD,CD276,DPM1,SP110,GBA2,ANUBL1,SSRP1,MCM6,EXOSC10,KNTC1,NCOA7,DIO2,DDX11,CPS
F3L,NID2,PLCE1,UGCGL1,NEK3,CDIPT,RBPJ,PTPN1,MTHFD1L,TRAP1,EIF4G2,ZNF184,NF2,FBX
L18,DAG1,H2AFX,IRAK2,GLIS2,WHSC1,CXCL12,IGFBP3,MYBBP1A,MAPKAPK3,GTF2H1,AOF2,K
RT7,FADS1,SUPT6H,HTRA1,PPCDC,MDN1,DDX12,MAP3K5,CSNK1A1,POLR3A,ADAM15,TRAF2,
DNMT3A,PIP4K2B,PPFIBP2,EIF2C2,MFSD7,CREBL1,MYH9,AP3D1,CLN8,PIP4K2A,SORL1,METTL
5,TSPYL4,CBFA2T2,CC2D1A,OSBPL2,MLX,FN1,TRAK1,AES,ATP8A1,PTK7,GJA4,NFKB2,ELK3,Y
ME1L1,LOXL1,BZW2,LAMP2,TSPYL2,NOTCH3,CDC25B,CPVL,ADCY3,EIF5,GSK3A,PTP4A1,ANA
PC1,INPPL1,GALNT2,ECE2,CD81,DNMT1,HNF4A,CREBBP,GDPD5,ATOX1,PRKAG1,SGMS1,EXOS
C9,FASN,TRIM29,WASL,UBE4B,NLN,CBFB,ROS1,RABGGTA,FKBP10,CHD3,TGS1,FOSL1,TRMT6
,PHF17,ISYNA1,ZNF37A,ZNF638,MED4,CLN6,PDCD4,LITAF,JAK3,PTPN14,NUP98,GALNT10,RNF1
49,RNF216,POLE2,SCMH1,CBLB,RAD54B,LIMK1,TEC,TIA1,SORD,PTPRC,MLH1,EEF1A2,ARID4B,
OAS2,POLR3E,AURKB,MLLT1,RASSF1,BARHL2,ARAF,SYNJ1,HCK,RNF38,PRMT1,NLK,EGR1,PI
TPNB,SMPD1,ENG,TEAD4,GMIP,ZBTB48,TLN1,SLC2A4RG,FANCA,TTBK2,TYMS,COPS5,SUPT5
H,C14orf43,STRAP,
GO:0044238~primary metabolic process 8.09% CAD,CD276,DPM1,SP110,GBA2,ANUBL1,SSRP1,MCM6,EXOSC10,KNTC1,NCOA7,DIO2,DDX11,CPS
F3L,NID2,PLCE1,UGCGL1,NEK3,CDIPT,RBPJ,PTPN1,ZNF184,EIF4G2,TRAP1,NF2,FBXL18,DAG1,H
2AFX,IRAK2,GLIS2,WHSC1,CXCL12,IGFBP3,MYBBP1A,MAPKAPK3,GTF2H1,AOF2,KRT7,FADS1,
SUPT6H,HTRA1,MDN1,DDX12,MAP3K5,POLR3A,CSNK1A1,ADAM15,TRAF2,DNMT3A,PIP4K2B,
PPFIBP2,EIF2C2,MFSD7,CREBL1,MYH9,AP3D1,CLN8,PIP4K2A,SORL1,METTL5,TSPYL4,CBFA2T
2,CC2D1A,OSBPL2,MLX,TRAK1,AES,PTK7,GJA4,NFKB2,ELK3,YME1L1,LOXL1,BZW2,LAMP2,TS
PYL2,NOTCH3,CDC25B,CPVL,ADCY3,EIF5,GSK3A,PTP4A1,ANAPC1,GALNT2,ECE2,CD81,DNMT
1,HNF4A,CREBBP,ATOX1,PRKAG1,SGMS1,EXOSC9,FASN,TRIM29,WASL,UBE4B,NLN,CBFB,RO
S1,RABGGTA,FKBP10,CHD3,TGS1,FOSL1,TRMT6,PHF17,ISYNA1,ZNF37A,ZNF638,MED4,CLN6,P
DCD4,LITAF,JAK3,PTPN14,NUP98,GALNT10,RNF149,RNF216,POLE2,SCMH1,CBLB,RAD54B,LIM
K1,TEC,TIA1,SORD,PTPRC,MLH1,EEF1A2,ARID4B,OAS2,POLR3E,AURKB,MLLT1,RASSF1,BAR
HL2,ARAF,HCK,RNF38,PRMT1,NLK,EGR1,PITPNB,SMPD1,ENG,TEAD4,ZBTB48,TLN1,SLC2A4R
G,FANCA,TTBK2,TYMS,COPS5,SUPT5H,C14orf43,STRAP,
GO:0043170~macromolecule metabolic
process
7.17% CD276,DPM1,SP110,GBA2,ANUBL1,SSRP1,MCM6,EXOSC10,KNTC1,NCOA7,DIO2,CPSF3L,NID2,U
GCGL1,NEK3,RBPJ,PTPN1,ZNF184,EIF4G2,TRAP1,NF2,FBXL18,DAG1,H2AFX,IRAK2,WHSC1,GLI
S2,IGFBP3,CXCL12,MYBBP1A,MAPKAPK3,GTF2H1,KRT7,AOF2,SUPT6H,HTRA1,MDN1,POLR3A
표 10 Biological process 분석

- 52 -
Term % Genes
,CSNK1A1,MAP3K5,ADAM15,TRAF2,DNMT3A,PPFIBP2,EIF2C2,MFSD7,CREBL1,MYH9,AP3D1,C
LN8,METTL5,TSPYL4,CBFA2T2,CC2D1A,MLX,TRAK1,AES,PTK7,GJA4,NFKB2,ELK3,YME1L1,L
OXL1,BZW2,LAMP2,TSPYL2,NOTCH3,CDC25B,CPVL,EIF5,GSK3A,PTP4A1,ANAPC1,ECE2,GALN
T2,CD81,DNMT1,HNF4A,CREBBP,ATOX1,PRKAG1,EXOSC9,TRIM29,WASL,UBE4B,NLN,CBFB,R
OS1,RABGGTA,FKBP10,CHD3,TGS1,FOSL1,TRMT6,PHF17,ISYNA1,ZNF37A,ZNF638,MED4,CLN6,
LITAF,JAK3,PTPN14,NUP98,GALNT10,RNF149,RNF216,POLE2,SCMH1,CBLB,RAD54B,LIMK1,TE
C,TIA1,SORD,PTPRC,MLH1,EEF1A2,ARID4B,OAS2,AURKB,MLLT1,RASSF1,BARHL2,ARAF,HCK
,RNF38,PRMT1,NLK,EGR1,TEAD4,ZBTB48,TLN1,SLC2A4RG,FANCA,TTBK2,TYMS,COPS5,SUPT
5H,C14orf43,STRAP,
GO:0043283~biopolymer metabolic
process
5.95% DPM1,SP110,ANUBL1,SSRP1,MCM6,EXOSC10,KNTC1,NCOA7,DIO2,CPSF3L,NID2,UGCGL1,NEK3,
RBPJ,PTPN1,ZNF184,EIF4G2,NF2,FBXL18,H2AFX,IRAK2,WHSC1,GLIS2,IGFBP3,MYBBP1A,MAPK
APK3,GTF2H1,KRT7,AOF2,SUPT6H,POLR3A,CSNK1A1,MAP3K5,DNMT3A,PPFIBP2,CREBL1,CL
N8,METTL5,TSPYL4,CC2D1A,CBFA2T2,MLX,TRAK1,AES,PTK7,NFKB2,ELK3,YME1L1,LOXL1,T
SPYL2,LAMP2,NOTCH3,CDC25B,GSK3A,PTP4A1,ANAPC1,ECE2,GALNT2,DNMT1,CD81,HNF4A,
CREBBP,PRKAG1,EXOSC9,WASL,TRIM29,UBE4B,CBFB,ROS1,RABGGTA,CHD3,FOSL1,TGS1,TR
MT6,PHF17,ZNF638,ZNF37A,CLN6,MED4,LITAF,JAK3,PTPN14,NUP98,GALNT10,RNF149,RNF216,
POLE2,SCMH1,CBLB,RAD54B,LIMK1,TEC,PTPRC,MLH1,EEF1A2,ARID4B,OAS2,AURKB,MLLT1,
RASSF1,BARHL2,ARAF,HCK,RNF38,PRMT1,NLK,EGR1,TEAD4,ZBTB48,SLC2A4RG,FANCA,TTB
K2,TYMS,COPS5,SUPT5H,C14orf43,STRAP,
GO:0065007~biological regulation 5.80% CD276,SP110,SSRP1,MCM6,OGFR,KNTC1,NCOA7,DIO2,DDX11,LAMA3,PLCE1,TPM3,RBPJ,SAPS1,
ZNF184,EIF4G2,NF2,ITSN1,IRAK2,WHSC1,GLIS2,BBC3,IGFBP3,CXCL12,MYBBP1A,GTF2H1,KRT7
,AOF2,FADS1,SUPT6H,HTRA1,MDN1,MAP3K5,TRAF2,DNMT3A,SOS1,SLC4A11,CREBL1,MYH9,
AP3D1,CLN8,FXYD5,BIRC5,GDI1,COL4A2,CBFA2T2,CC2D1A,OSBPL2,MLX,TRAK1,AES,CDH5,NF
KB2,ELK3,BZW2,TSPYL2,NOTCH3,CDC25B,EIF5,PTP4A1,ECE2,DNMT1,CD81,BCL2L11,HNF4A,C
REBBP,SGMS1,ATOX1,TMCO3,PODXL,CENTD3,WASL,CBFB,CHD3,FOSL1,TGS1,BID,TRMT6,PH
F17,ZNF37A,GPNMB,CLN6,MED4,PDCD4,LITAF,CCR4,GPS2,SCMH1,CBLB,RAD54B,LIMK1,TIA1,P
TPRC,IFI6,SHC1,MLH1,EEF1A2,ARID4B,LAMA5,MLLT1,RASSF1,BARHL2,NLK,EGR1,ENG,TEAD
4,ZBTB48,SLC2A4RG,ARHGAP8,COPS5,SUPT5H,RTN4,C14orf43,STRAP,
GO:0050789~regulation of biological
process
5.44% CD276,SP110,SSRP1,MCM6,OGFR,KNTC1,NCOA7,DIO2,DDX11,LAMA3,PLCE1,TPM3,RBPJ,ZNF184
,EIF4G2,NF2,ITSN1,IRAK2,WHSC1,GLIS2,BBC3,IGFBP3,CXCL12,MYBBP1A,GTF2H1,KRT7,AOF2,
FADS1,SUPT6H,HTRA1,MDN1,MAP3K5,TRAF2,DNMT3A,SOS1,CREBL1,MYH9,AP3D1,CLN8,FX
YD5,BIRC5,COL4A2,CBFA2T2,CC2D1A,OSBPL2,MLX,TRAK1,AES,CDH5,NFKB2,ELK3,BZW2,TSP
YL2,NOTCH3,CDC25B,EIF5,PTP4A1,ECE2,DNMT1,CD81,BCL2L11,HNF4A,CREBBP,SGMS1,PODX
L,CENTD3,WASL,CBFB,CHD3,FOSL1,TGS1,BID,TRMT6,PHF17,ZNF37A,CLN6,MED4,GPNMB,PD
CD4,LITAF,SCMH1,RAD54B,CBLB,LIMK1,TIA1,PTPRC,IFI6,MLH1,SHC1,EEF1A2,ARID4B,LAMA5
,MLLT1,BARHL2,RASSF1,NLK,EGR1,ENG,TEAD4,ZBTB48,SLC2A4RG,ARHGAP8,COPS5,SUPT5H
,RTN4,C14orf43,STRAP,
GO:0050794~regulation of cellular
process
5.04% CD276,SP110,SSRP1,MCM6,OGFR,KNTC1,NCOA7,DIO2,DDX11,LAMA3,PLCE1,RBPJ,ZNF184,EIF4G
2,NF2,ITSN1,IRAK2,WHSC1,GLIS2,BBC3,IGFBP3,CXCL12,MYBBP1A,GTF2H1,KRT7,AOF2,FADS1,
SUPT6H,HTRA1,MAP3K5,TRAF2,SOS1,CREBL1,CLN8,FXYD5,BIRC5,CC2D1A,CBFA2T2,OSBPL2,
MLX,TRAK1,AES,CDH5,NFKB2,ELK3,BZW2,TSPYL2,NOTCH3,CDC25B,EIF5,PTP4A1,ECE2,DNM
T1,CD81,BCL2L11,HNF4A,CREBBP,SGMS1,PODXL,CENTD3,WASL,CBFB,CHD3,FOSL1,TGS1,BID,
TRMT6,PHF17,ZNF37A,CLN6,MED4,GPNMB,PDCD4,LITAF,SCMH1,RAD54B,TIA1,IFI6,PTPRC,M
LH1,SHC1,ARID4B,EEF1A2,BARHL2,RASSF1,MLLT1,LAMA5,NLK,EGR1,ENG,ZBTB48,TEAD4,SL
C2A4RG,ARHGAP8,COPS5,SUPT5H,RTN4,C14orf43,STRAP,
GO:0007154~cell communication 4.43% CXCL2,ADCY3,MS4A7,INPPL1,PDE4B,ECE2,CD81,CREBBP,PRKAG1,CD247,SNX5,COL1A2,CLEC7
A,CENTD3,LAMA3,CELSR3,PLCE1,CXCL3,FGL2,PTPN1,RBPJ,ROS1,SH3BP2,BID,NF2,MED4,SPA
RC,LITAF,ITSN1,JAK3,CCR4,IRAK2,SH2B3,BBC3,MYO9B,CXCL12,IGFBP3,GPS2,MAPKAPK3,CBL
B,FADS1,IGF2R,LIMK1,TEC,SUPT6H,HTRA1,PLXND1,MAP3K5,CSNK1A1,ADAM15,TRAF2,PIP4
K2B,DNM1,SOS1,PPFIBP2,CREBL1,PTPRC,MYH9,IFI6,SHC1,CLN8,LAMA5,RASSF1,ARAF,GDI1,C
OL15A1,HCK,PKD1,PRMT1,NLK,CC2D1A,SMPD1,ENG,GMIP,FN1,SHANK2,AES,PTK7,GJA4,TYM
S,ARHGAP8,NFKB2,ELK3,SPAG5,TSPYL2,NOTCH3,STRAP,
GO:0016043~cellular component
organization and biogenesis
4.22% EIF5,PLEC1,NDE1,VPS18,CREBBP,OGFR,KNTC1,EXOSC10,SGMS1,SCAMP1,CLEC7A,CENTD3,NC
OA7,EXOSC9,DDX11,WASL,ALS2CL,PLCE1,DTNBP1,COL6A2,CHD3,TRMT6,BID,EIF4G2,PHF17,N
F2,MED4,CLN6,DAG1,ITSN1,H2AFX,TXLNA,WHSC1,NUP98,COL12A1,BBC3,MYO9B,CXCL12,IGF
BP3,MYBBP1A,SHROOM1,AOF2,KRT7,CBLB,IGF2R,LIMK1,FNBP1L,NCAPD3,SUPT6H,HTRA1,M
DN1,ENAH,TRAF2,DNM1,MYH9,IFI6,SHC1,AP3D1,ARID4B,FXYD5,CLN8,BIRC5,SORL1,LAMA5,R
ASSF1,BARHL2,SYNJ1,TSPYL4,COL4A2,AP1GBP1,TLN1,TRAK1,FANCA,PTK7,GJA4,ARHGAP8,
NFKB2,BZW2,SUPT5H,RTN4,SPAG5,TSPYL2,MFN1,
GO:0006139~nucleobase, nucleoside,
nucleotide and nucleic acid metabolic
process
4.12% ADCY3,CAD,DNMT1,SP110,HNF4A,SSRP1,CREBBP,MCM6,EXOSC10,KNTC1,NCOA7,EXOSC9,DD
X11,TRIM29,WASL,CPSF3L,RBPJ,CBFB,CHD3,TGS1,FOSL1,TRMT6,PHF17,ZNF184,EIF4G2,ZNF37
A,ZNF638,NF2,MED4,PDCD4,LITAF,H2AFX,IRAK2,GLIS2,WHSC1,NUP98,RNF216,POLE2,MYBBP1
A,GTF2H1,SCMH1,AOF2,KRT7,FADS1,RAD54B,SUPT6H,DDX12,POLR3A,DNMT3A,PPFIBP2,EIF2
C2,CREBL1,MLH1,ARID4B,OAS2,POLR3E,MLLT1,RASSF1,BARHL2,TSPYL4,NLK,EGR1,CBFA2T2
,CC2D1A,MLX,ENG,TEAD4,ZBTB48,SLC2A4RG,TRAK1,AES,FANCA,TYMS,NFKB2,ELK3,COPS5,
SUPT5H,TSPYL2,C14orf43,NOTCH3,STRAP,
GO:0007165~signal transduction 4.12% CXCL2,ADCY3,INPPL1,MS4A7,PDE4B,ECE2,CD81,CREBBP,PRKAG1,CD247,COL1A2,CLEC7A,CEN

- 53 -
Term % Genes
TD3,CELSR3,LAMA3,PLCE1,CXCL3,FGL2,PTPN1,RBPJ,ROS1,SH3BP2,BID,NF2,MED4,SPARC,LIT
AF,ITSN1,JAK3,CCR4,IRAK2,SH2B3,BBC3,MYO9B,CXCL12,IGFBP3,GPS2,MAPKAPK3,CBLB,IGF2
R,LIMK1,TEC,SUPT6H,HTRA1,PLXND1,CSNK1A1,MAP3K5,ADAM15,TRAF2,PIP4K2B,SOS1,CRE
BL1,PTPRC,MYH9,IFI6,SHC1,LAMA5,RASSF1,ARAF,GDI1,COL15A1,HCK,PKD1,PRMT1,NLK,CC2
D1A,SMPD1,ENG,GMIP,FN1,SHANK2,AES,PTK7,TYMS,ARHGAP8,NFKB2,ELK3,SPAG5,TSPYL2,
NOTCH3,STRAP,
GO:0019538~protein metabolic process 4.07% EIF5,GSK3A,PTP4A1,CD276,ANAPC1,GALNT2,ECE2,DPM1,CD81,ANUBL1,CREBBP,ATOX1,PRKA
G1,KNTC1,DIO2,WASL,NID2,UGCGL1,NEK3,UBE4B,NLN,PTPN1,ROS1,RABGGTA,FKBP10,TRMT
6,EIF4G2,TRAP1,NF2,FBXL18,CLN6,DAG1,JAK3,PTPN14,IRAK2,NUP98,GALNT10,CXCL12,IGFBP3
,RNF149,RNF216,MAPKAPK3,KRT7,CBLB,LIMK1,TEC,TIA1,HTRA1,MDN1,CSNK1A1,MAP3K5,A
DAM15,TRAF2,EIF2C2,MFSD7,PTPRC,MYH9,EEF1A2,AP3D1,CLN8,METTL5,AURKB,BARHL2,A
RAF,HCK,RNF38,PRMT1,NLK,TLN1,TRAK1,FANCA,PTK7,TTBK2,GJA4,COPS5,YME1L1,LOXL1,
BZW2,CDC25B,CPVL,
GO:0032502~developmental process 3.97% PTP4A1,CD276,ECE2,NDE1,BCL2L11,COL6A3,OGFR,SGMS1,COL1A2,ZMYM4,CENTD3,CELSR3,L
AMA3,PLCE1,UBE4B,CBFB,CDH11,BID,PHF17,EIF4G2,NF2,SPARC,PDCD4,DAG1,LITAF,JAK3,CC
R4,UNC45A,WHSC1,GLIS2,SH2B3,COL12A1,BBC3,IGFBP3,RNF216,SHROOM1,SCMH1,FADS1,LIM
K1,TIA1,HTRA1,PLXND1,MAP3K5,TRAF2,PTPRC,PHLPP,MYH9,IFI6,SHC1,EEF1A2,AP3D1,FXYD
5,CLN8,BIRC5,LAMA5,BARHL2,COL15A1,HCK,COL4A2,PKD1,EGR1,OSBPL2,PITPNB,SMPD1,ENG
,TEAD4,AES,PTK7,FAM130A1,CDH5,GJA4,NFKB2,ELK3,COL1A1,BZW2,RTN4,TSPYL2,NOTCH3,
GO:0051179~localization 3.87% PTP4A1,CLCN2,VPS18,CD81,SLCO3A1,COL6A3,AQP1,KCTD8,ATOX1,SNX5,TMCO3,SCAMP1,PO
DXL,COL1A2,CLEC7A,VPS13D,CENTD3,WASL,LCN2,LAMA3,TPM3,COL6A2,SLC39A9,COL4A1,N
F2,ITSN1,CCR4,TXLNA,ABCA3,NUP98,COL12A1,MYO9B,RNF216,MYBBP1A,HSPG2,KCTD5,CBL
B,FADS1,IGF2R,LIMK1,SLC4A7,FNBP1L,DDX12,SLC11A2,ENAH,DNM1,MFSD7,SLC4A11,PTPRC,
MYH9,AP3D1,CLN8,FXYD5,SFXN4,BIRC5,SORL1,LAMA5,BARHL2,GDI1,COL15A1,SYNJ1,COL4A2
,OSBPL2,AP1GBP1,PITPNB,ENG,FN1,TLN1,TRAK1,VPS53,ATP8A1,GJA4,ARHGAP8,COL1A1,CAC
NA2D4,VPS4A,
GO:0044260~cellular macromolecule
metabolic process
3.76% EIF5,GSK3A,PTP4A1,CD276,ANAPC1,ECE2,GALNT2,DPM1,CD81,ANUBL1,CREBBP,ATOX1,PRKA
G1,DIO2,WASL,NID2,UGCGL1,NEK3,UBE4B,NLN,PTPN1,ROS1,RABGGTA,FKBP10,TRMT6,EIF4G
2,TRAP1,NF2,FBXL18,CLN6,JAK3,PTPN14,IRAK2,NUP98,GALNT10,RNF149,IGFBP3,CXCL12,RNF2
16,MAPKAPK3,KRT7,CBLB,LIMK1,TEC,TIA1,HTRA1,MDN1,CSNK1A1,MAP3K5,ADAM15,EIF2C2
,MFSD7,PTPRC,MYH9,EEF1A2,CLN8,METTL5,AURKB,BARHL2,ARAF,HCK,RNF38,PRMT1,NLK,
TRAK1,PTK7,TTBK2,COPS5,YME1L1,LOXL1,BZW2,LAMP2,CDC25B,CPVL,
GO:0044267~cellular protein metabolic
process
3.61% GSK3A,EIF5,PTP4A1,CD276,ANAPC1,ECE2,GALNT2,DPM1,CD81,ANUBL1,CREBBP,ATOX1,PRKA
G1,DIO2,NID2,UGCGL1,NEK3,UBE4B,NLN,PTPN1,ROS1,RABGGTA,FKBP10,TRMT6,EIF4G2,TRA
P1,NF2,FBXL18,CLN6,JAK3,PTPN14,IRAK2,NUP98,GALNT10,RNF149,IGFBP3,RNF216,MAPKAPK
3,KRT7,CBLB,LIMK1,TEC,TIA1,HTRA1,MDN1,CSNK1A1,MAP3K5,ADAM15,EIF2C2,MFSD7,PTPR
C,MYH9,EEF1A2,CLN8,METTL5,AURKB,BARHL2,ARAF,HCK,RNF38,PRMT1,NLK,TRAK1,PTK7,
TTBK2,COPS5,YME1L1,LOXL1,BZW2,CDC25B,CPVL,
GO:0019222~regulation of metabolic
process
3.46% EIF5,CD276,CD81,DNMT1,SP110,HNF4A,SSRP1,CREBBP,MCM6,KNTC1,NCOA7,DIO2,WASL,RBPJ,
CBFB,CHD3,TGS1,FOSL1,TRMT6,PHF17,ZNF184,EIF4G2,ZNF37A,NF2,MED4,CLN6,PDCD4,LITAF,
IRAK2,WHSC1,GLIS2,IGFBP3,CXCL12,MYBBP1A,GTF2H1,SCMH1,KRT7,AOF2,FADS1,RAD54B,T
IA1,SUPT6H,MDN1,CREBL1,ARID4B,CLN8,MLLT1,RASSF1,BARHL2,NLK,EGR1,CBFA2T2,CC2D1
A,ENG,MLX,TEAD4,ZBTB48,SLC2A4RG,TRAK1,AES,NFKB2,ELK3,BZW2,SUPT5H,TSPYL2,C14or
f43,NOTCH3,STRAP,
GO:0031323~regulation of cellular
metabolic process
3.36% EIF5,CD276,CD81,DNMT1,SP110,HNF4A,SSRP1,CREBBP,MCM6,KNTC1,NCOA7,DIO2,WASL,RBPJ,
CBFB,CHD3,TGS1,FOSL1,TRMT6,PHF17,ZNF184,EIF4G2,ZNF37A,NF2,MED4,CLN6,PDCD4,LITAF,
IRAK2,WHSC1,GLIS2,IGFBP3,MYBBP1A,GTF2H1,SCMH1,KRT7,AOF2,FADS1,RAD54B,TIA1,SUP
T6H,CREBL1,ARID4B,CLN8,MLLT1,RASSF1,BARHL2,NLK,EGR1,CC2D1A,CBFA2T2,ENG,MLX,T
EAD4,ZBTB48,SLC2A4RG,TRAK1,AES,NFKB2,ELK3,BZW2,SUPT5H,TSPYL2,C14orf43,NOTCH3,S
TRAP,
GO:0010468~regulation of gene
expression
3.15% EIF5,CD276,DNMT1,SP110,HNF4A,SSRP1,CREBBP,MCM6,KNTC1,NCOA7,DIO2,WASL,RBPJ,CBF
B,CHD3,TGS1,FOSL1,TRMT6,PHF17,ZNF184,EIF4G2,ZNF37A,MED4,PDCD4,LITAF,IRAK2,WHSC1
,GLIS2,MYBBP1A,GTF2H1,SCMH1,KRT7,AOF2,RAD54B,FADS1,TIA1,SUPT6H,DNMT3A,CREBL1,
ARID4B,MLLT1,RASSF1,BARHL2,NLK,EGR1,CC2D1A,CBFA2T2,ENG,MLX,TEAD4,ZBTB48,SLC2
A4RG,TRAK1,AES,NFKB2,ELK3,BZW2,SUPT5H,TSPYL2,C14orf43,NOTCH3,STRAP,
GO:0051234~establishment of localization 3.00% CLCN2,VPS18,SLCO3A1,COL6A3,AQP1,KCTD8,ATOX1,SNX5,TMCO3,SCAMP1,COL1A2,CLEC7A,
CENTD3,LCN2,COL6A2,SLC39A9,COL4A1,ITSN1,TXLNA,ABCA3,NUP98,COL12A1,MYO9B,RNF21
6,MYBBP1A,KCTD5,CBLB,FADS1,IGF2R,SLC4A7,FNBP1L,DDX12,SLC11A2,ENAH,DNM1,MFSD7,
SLC4A11,MYH9,AP3D1,CLN8,FXYD5,SFXN4,BIRC5,SORL1,GDI1,COL15A1,SYNJ1,COL4A2,AP1GB
P1,OSBPL2,PITPNB,ENG,TRAK1,VPS53,ATP8A1,GJA4,COL1A1,CACNA2D4,VPS4A,
GO:0006810~transport 2.95% CLCN2,VPS18,SLCO3A1,COL6A3,AQP1,KCTD8,ATOX1,SNX5,TMCO3,SCAMP1,COL1A2,CLEC7A,
CENTD3,LCN2,COL6A2,SLC39A9,COL4A1,ITSN1,TXLNA,ABCA3,COL12A1,NUP98,MYO9B,RNF21
6,MYBBP1A,KCTD5,CBLB,FADS1,IGF2R,SLC4A7,FNBP1L,DDX12,SLC11A2,ENAH,DNM1,MFSD7,
SLC4A11,MYH9,AP3D1,CLN8,FXYD5,SFXN4,SORL1,GDI1,COL15A1,SYNJ1,COL4A2,AP1GBP1,OSB
PL2,PITPNB,ENG,TRAK1,VPS53,ATP8A1,GJA4,COL1A1,CACNA2D4,VPS4A,
GO:0006350~transcription 2.90% DNMT1,SP110,HNF4A,SSRP1,CREBBP,MCM6,KNTC1,NCOA7,WASL,TRIM29,RBPJ,CBFB,CHD3,F
OSL1,TGS1,PHF17,ZNF184,ZNF37A,MED4,PDCD4,LITAF,IRAK2,WHSC1,GLIS2,MYBBP1A,GTF2H
1,SCMH1,AOF2,RAD54B,FADS1,SUPT6H,POLR3A,CREBL1,ARID4B,POLR3E,MLLT1,RASSF1,BA

- 54 -
Term % Genes
RHL2,NLK,EGR1,CC2D1A,CBFA2T2,ENG,MLX,TEAD4,ZBTB48,SLC2A4RG,TRAK1,AES,NFKB2,E
LK3,COPS5,SUPT5H,TSPYL2,C14orf43,NOTCH3,STRAP,
GO:0048856~anatomical structure
development
2.90% CD276,ECE2,NDE1,COL6A3,OGFR,SGMS1,COL1A2,CENTD3,LAMA3,PLCE1,CBFB,CDH11,PHF17,N
F2,SPARC,DAG1,JAK3,CCR4,UNC45A,WHSC1,GLIS2,SH2B3,COL12A1,IGFBP3,SHROOM1,SCMH1,
LIMK1,HTRA1,PLXND1,PTPRC,MYH9,SHC1,AP3D1,CLN8,FXYD5,LAMA5,BARHL2,COL15A1,HC
K,COL4A2,PKD1,EGR1,OSBPL2,SMPD1,ENG,TEAD4,AES,PTK7,GJA4,CDH5,NFKB2,ELK3,COL1A1
,BZW2,RTN4,TSPYL2,NOTCH3,
GO:0006351~transcription,
DNA-dependent
2.64% DNMT1,SP110,HNF4A,SSRP1,CREBBP,MCM6,KNTC1,NCOA7,WASL,TRIM29,RBPJ,CBFB,CHD3,F
OSL1,TGS1,PHF17,ZNF184,ZNF37A,MED4,LITAF,WHSC1,GLIS2,MYBBP1A,GTF2H1,AOF2,SCMH
1,RAD54B,SUPT6H,POLR3A,CREBL1,ARID4B,BARHL2,RASSF1,MLLT1,NLK,EGR1,CC2D1A,CBF
A2T2,MLX,ZBTB48,TEAD4,TRAK1,SLC2A4RG,AES,NFKB2,ELK3,COPS5,SUPT5H,TSPYL2,C14orf
43,NOTCH3,STRAP,
GO:0007275~multicellular organismal
development
2.49% CD276,PTP4A1,ECE2,NDE1,COL6A3,COL1A2,ZMYM4,CELSR3,LAMA3,PLCE1,CBFB,CDH11,NF2,S
PARC,JAK3,CCR4,UNC45A,GLIS2,SH2B3,COL12A1,IGFBP3,SCMH1,LIMK1,PLXND1,MYH9,PTPRC
,AP3D1,CLN8,BARHL2,LAMA5,COL15A1,HCK,COL4A2,EGR1,OSBPL2,SMPD1,PITPNB,ENG,TEAD
4,AES,PTK7,GJA4,CDH5,NFKB2,ELK3,BZW2,COL1A1,RTN4,NOTCH3,
GO:0043412~biopolymer modification 2.39% GSK3A,CBLB,LIMK1,PTP4A1,ANAPC1,TEC,DPM1,GALNT2,ECE2,CD81,DNMT1,ANUBL1,CREBB
P,MAP3K5,CSNK1A1,PRKAG1,DNMT3A,PTPRC,NID2,UGCGL1,NEK3,METTL5,AURKB,UBE4B,A
RAF,PTPN1,HCK,RNF38,ROS1,RABGGTA,PRMT1,NLK,NF2,TRAK1,FBXL18,JAK3,TTBK2,PTK7,
PTPN14,IRAK2,LOXL1,GALNT10,IGFBP3,RNF149,RNF216,CDC25B,MAPKAPK3,
GO:0006464~protein modification process 2.29% GSK3A,CBLB,LIMK1,PTP4A1,ANAPC1,TEC,GALNT2,ECE2,DPM1,CD81,ANUBL1,CREBBP,MAP3
K5,CSNK1A1,PRKAG1,PTPRC,NID2,UGCGL1,NEK3,METTL5,AURKB,UBE4B,ARAF,PTPN1,HCK,
RNF38,ROS1,RABGGTA,PRMT1,NLK,NF2,TRAK1,FBXL18,JAK3,PTK7,TTBK2,PTPN14,IRAK2,LO
XL1,GALNT10,IGFBP3,RNF149,RNF216,CDC25B,MAPKAPK3,
GO:0048731~system development 2.24% LIMK1,CD276,ECE2,NDE1,COL6A3,PLXND1,COL1A2,PTPRC,MYH9,AP3D1,LAMA3,CLN8,PLCE1,L
AMA5,BARHL2,COL15A1,CBFB,HCK,COL4A2,EGR1,OSBPL2,CDH11,SMPD1,ENG,TEAD4,NF2,SP
ARC,AES,JAK3,CCR4,UNC45A,PTK7,CDH5,GJA4,NFKB2,SH2B3,GLIS2,ELK3,COL12A1,COL1A1,B
ZW2,IGFBP3,RTN4,NOTCH3,
GO:0030154~cell differentiation
GO:0048869~cellular developmental
process
2.19% FADS1,LIMK1,CD276,ECE2,NDE1,TIA1,BCL2L11,MAP3K5,SGMS1,TRAF2,PTPRC,PHLPP,MYH9,IF
I6,EEF1A2,AP3D1,CLN8,LAMA3,BIRC5,LAMA5,UBE4B,BARHL2,COL15A1,CBFB,EGR1,BID,EIF4G2
,PHF17,NF2,PDCD4,LITAF,CCR4,UNC45A,PTK7,FAM130A1,SH2B3,GLIS2,BBC3,BZW2,IGFBP3,RT
N4,RNF216,NOTCH3,
GO:0006996~organelle organization and
biogenesis
2.09% AOF2,KRT7,PLEC1,LIMK1,NDE1,VPS18,NCAPD3,SUPT6H,CREBBP,EXOSC10,CENTD3,EXOSC9,D
DX11,MYH9,WASL,IFI6,ALS2CL,ARID4B,CLN8,PLCE1,LAMA5,RASSF1,DTNBP1,TSPYL4,CHD3,B
ID,NF2,TLN1,CLN6,H2AFX,ARHGAP8,WHSC1,NUP98,BBC3,SUPT5H,MYO9B,CXCL12,SPAG5,TSP
YL2,MFN1,SHROOM1,
GO:0007242~intracellular signaling
cascade
1.88% ADCY3,CBLB,LIMK1,INPPL1,TEC,CD81,SUPT6H,MAP3K5,TRAF2,SOS1,CLEC7A,CENTD3,IFI6,S
HC1,PLCE1,RASSF1,ARAF,GDI1,HCK,NLK,SH3BP2,CC2D1A,BID,GMIP,NF2,MED4,SHANK2,LITA
F,ITSN1,JAK3,IRAK2,TYMS,SH2B3,BBC3,MYO9B,SPAG5,GPS2,
GO:0043687~post-translational protein
modification
1.88% GSK3A,CBLB,LIMK1,PTP4A1,ANAPC1,TEC,ECE2,CD81,CREBBP,MAP3K5,CSNK1A1,PRKAG1,PT
PRC,NID2,NEK3,METTL5,AURKB,UBE4B,ARAF,PTPN1,HCK,RNF38,ROS1,PRMT1,NLK,NF2,FBX
L18,JAK3,PTK7,TTBK2,PTPN14,IRAK2,RNF149,IGFBP3,RNF216,CDC25B,MAPKAPK3,
GO:0009058~biosynthetic process 1.83% ADCY3,EIF5,CAD,KRT7,FADS1,CD276,GALNT2,DPM1,CD81,TIA1,PPCDC,DDX12,SGMS1,PRKAG1
,EIF2C2,DIO2,FASN,PTPRC,EEF1A2,AP3D1,CLN8,PLCE1,UGCGL1,CDIPT,BARHL2,MTHFD1L,RA
BGGTA,TRMT6,ISYNA1,EIF4G2,TRAK1,TYMS,COPS5,BZW2,GALNT10,RNF216,
GO:0048523~negative regulation of
cellular process
1.78% SCMH1,CD276,DNMT1,TIA1,HTRA1,SGMS1,PODXL,CENTD3,PTPRC,IFI6,MLH1,EEF1A2,CLN8,F
XYD5,BIRC5,RASSF1,RBPJ,NLK,EGR1,PHF17,EIF4G2,NF2,GPNMB,PDCD4,CDH5,ARHGAP8,GLIS2
,ELK3,SUPT5H,RTN4,IGFBP3,TSPYL2,NOTCH3,MYBBP1A,STRAP,
GO:0048518~positive regulation of
biological process
1.73% GTF2H1,CBLB,LIMK1,CD276,PTP4A1,CD81,TIA1,BCL2L11,HNF4A,CREBBP,MAP3K5,TRAF2,DDX
11,PTPRC,SHC1,BIRC5,RASSF1,BARHL2,CBFB,EGR1,FOSL1,CC2D1A,OSBPL2,BID,TEAD4,NF2,CL
N6,LITAF,ARHGAP8,GLIS2,BBC3,SUPT5H,IGFBP3,CDC25B,
GO:0048513~organ development 1.73% CD276,ECE2,COL6A3,PLXND1,COL1A2,PTPRC,MYH9,AP3D1,CLN8,LAMA3,PLCE1,LAMA5,COL15
A1,CBFB,HCK,COL4A2,EGR1,CDH11,OSBPL2,ENG,TEAD4,SPARC,AES,JAK3,UNC45A,CDH5,GJA4
,NFKB2,SH2B3,COL12A1,ELK3,COL1A1,IGFBP3,NOTCH3,
GO:0048522~positive regulation of
cellular process
1.58% GTF2H1,CD276,PTP4A1,CD81,TIA1,BCL2L11,HNF4A,CREBBP,MAP3K5,DDX11,PTPRC,SHC1,BIRC
5,RASSF1,BARHL2,CBFB,EGR1,FOSL1,CC2D1A,OSBPL2,BID,TEAD4,NF2,CLN6,LITAF,ARHGAP8,
GLIS2,BBC3,SUPT5H,IGFBP3,CDC25B,
GO:0009653~anatomical structure
morphogenesis
1.58% SCMH1,LIMK1,ECE2,HTRA1,OGFR,PLXND1,SGMS1,CENTD3,MYH9,SHC1,CLN8,FXYD5,PLCE1,L
AMA5,BARHL2,COL15A1,COL4A2,PKD1,OSBPL2,PHF17,ENG,AES,DAG1,PTK7,WHSC1,ELK3,RT
N4,IGFBP3,TSPYL2,NOTCH3,SHROOM1,
GO:0007049~cell cycle 1.58% GTF2H1,ADCY3,KRT7,RAD54B,PTP4A1,ANAPC1,NDE1,NCAPD3,DDX12,MCM6,KNTC1,DDX11,P
TPRC,SHC1,MLH1,BIRC5,NEK3,AURKB,RASSF1,FOSL1,EIF4G2,NF2,PDCD4,H2AFX,ARHGAP8,C
OPS5,SUPT5H,SPAG5,GPS2,TSPYL2,CDC25B,
GO:0006796~phosphate metabolic
process
GO:0006793~phosphorus metabolic
process
1.53% GSK3A,LIMK1,PTP4A1,INPPL1,TEC,CD81,DDX12,PRKAG1,MAP3K5,CSNK1A1,PTPRC,PIP4K2A,N
EK3,AURKB,ARAF,PTPN1,SYNJ1,HCK,ROS1,NLK,NF2,JAK3,PTK7,TTBK2,IRAK2,PTPN14,IGFBP
3,RNF216,CDC25B,MAPKAPK3,
GO:0006950~response to stress 1.48% CXCL2,GTF2H1,FADS1,RAD54B,CD276,HNF4A,SSRP1,CREBBP,ATOX1,MAP3K5,CLEC7A,CREBL
- 55 -
Term % Genes
1,MLH1,CLN8,CXCL3,PHF17,TRAP1,FN1,CCR4,FANCA,H2AFX,IRAK2,TYMS,ELK3,COL1A1,BBC3
,CXCL12,POLE2,MAPKAPK3,
GO:0007155~cell adhesion 1.37% HSPG2,SYMPK,INPPL1,COL6A3,ADAM15,PODXL,CDH3,CELSR3,NID2,LAMA3,FXYD5,LAMA5,C
D84,COL15A1,COL6A2,PKD1,CDH11,ENG,FN1,NF2,GPNMB,DAG1,PTK7,CDH5,COL12A1,CXCL12,E
SAM,
GO:0006259~DNA metabolic process 1.32% GTF2H1,KRT7,AOF2,RAD54B,DNMT1,SUPT6H,SSRP1,CREBBP,MCM6,DNMT3A,PPFIBP2,MLH1,
ARID4B,RASSF1,RBPJ,TSPYL4,CHD3,NF2,FANCA,H2AFX,TYMS,WHSC1,NUP98,SUPT5H,TSPY
L2,POLE2,
GO:0022402~cell cycle process 1.32% GTF2H1,ADCY3,KRT7,RAD54B,ANAPC1,NDE1,NCAPD3,KNTC1,DDX11,PTPRC,MLH1,SHC1,BIRC
5,NEK3,AURKB,RASSF1,FOSL1,EIF4G2,NF2,PDCD4,H2AFX,ARHGAP8,COPS5,SPAG5,TSPYL2,CD
C25B,
GO:0006811~ion transport 1.22% KCTD5,COL15A1,COL6A2,COL4A2,SLC4A7,CLCN2,SLCO3A1,SLC39A9,COL6A3,COL4A1,DDX12,S
LC11A2,KCTD8,ATOX1,ATP8A1,TMCO3,COL1A2,SLC4A11,COL12A1,COL1A1,CACNA2D4,RNF216
,FXYD5,SFXN4,
GO:0016310~phosphorylation 1.17% NEK3,PIP4K2A,AURKB,ARAF,GSK3A,LIMK1,HCK,TEC,ROS1,NLK,CD81,NF2,DDX12,CSNK1A1,M
AP3K5,PRKAG1,JAK3,TTBK2,PTK7,IRAK2,IGFBP3,RNF216,MAPKAPK3,
GO:0008219~cell death 1.12% BIRC5,UBE4B,TIA1,BCL2L11,BID,PHF17,EIF4G2,PDCD4,MAP3K5,SGMS1,LITAF,TRAF2,FAM130
A1,PTPRC,PHLPP,IFI6,BBC3,RTN4,IGFBP3,RNF216,EEF1A2,CLN8,
GO:0006915~apoptosis 1.07% BIRC5,UBE4B,TIA1,BCL2L11,BID,PHF17,PDCD4,MAP3K5,SGMS1,LITAF,TRAF2,FAM130A1,PTPR
C,IFI6,BBC3,PHLPP,RTN4,IGFBP3,RNF216,EEF1A2,CLN8,
GO:0022607~cellular component
assembly
1.02% RASSF1,EIF5,TSPYL4,TRMT6,EIF4G2,CREBBP,MDN1,TLN1,MED4,DAG1,KNTC1,TRAF2,H2AFX,
FANCA,GJA4,NUP98,BZW2,WASL,TSPYL2,AP3D1,
GO:0006468~protein amino acid
phosphorylation
1.02% NEK3,AURKB,ARAF,GSK3A,LIMK1,HCK,TEC,ROS1,NLK,CD81,NF2,CSNK1A1,MAP3K5,PRKAG1,
JAK3,PTK7,TTBK2,IRAK2,IGFBP3,MAPKAPK3,
GO:0065009~regulation of a molecular
function
0.97% BIRC5,RASSF1,GTF2H1,GDI1,CD81,SAPS1,PDCD4,MAP3K5,TRAF2,IRAK2,CENTD3,PTPRC,BBC3,
IFI6,TSPYL2,GPS2,SHC1,CLN8,PLCE1,
GO:0006629~lipid metabolic process 0.97% PIP4K2A,SORL1,CDIPT,FADS1,DPM1,CD81,GBA2,OSBPL2,PITPNB,SMPD1,HNF4A,ISYNA1,CLN6,
PRKAG1,SGMS1,PIP4K2B,FASN,CLN8,PLCE1,
GO:0006366~transcription from RNA
polymerase II promoter
0.92% MLLT1,GTF2H1,RBPJ,CBFB,DNMT1,CHD3,EGR1,FOSL1,HNF4A,TEAD4,TRAK1,MED4,LITAF,EL
K3,COPS5,TRIM29,SUPT5H,STRAP,
GO:0022403~cell cycle phase 0.86% NEK3,BIRC5,AURKB,ADCY3,KRT7,RAD54B,ANAPC1,NDE1,NCAPD3,FOSL1,KNTC1,H2AFX,DDX
11,PTPRC,SPAG5,SHC1,CDC25B,
GO:0000902~cell morphogenesis 0.86% BARHL2,LIMK1,HTRA1,PHF17,OGFR,SGMS1,PTK7,CENTD3,MYH9,RTN4,IGFBP3,TSPYL2,SHC1,
FXYD5,CLN8,SHROOM1,PLCE1,
GO:0050790~regulation of catalytic
activity
0.86% BIRC5,GTF2H1,GDI1,CD81,SAPS1,PDCD4,MAP3K5,TRAF2,CENTD3,PTPRC,IFI6,BBC3,TSPYL2,GP
S2,SHC1,CLN8,PLCE1,
GO:0044255~cellular lipid metabolic
process
0.86% PIP4K2A,SORL1,CDIPT,FADS1,DPM1,CD81,GBA2,OSBPL2,SMPD1,ISYNA1,CLN6,PRKAG1,SGMS1
,PIP4K2B,FASN,CLN8,PLCE1,
GO:0032989~cellular structure
morphogenesis
0.86% BARHL2,LIMK1,HTRA1,PHF17,OGFR,SGMS1,PTK7,CENTD3,MYH9,RTN4,IGFBP3,TSPYL2,SHC1,
FXYD5,CLN8,SHROOM1,PLCE1,
GO:0031324~negative regulation of
cellular metabolic process
0.86% RASSF1,SCMH1,RBPJ,CD276,DNMT1,EGR1,TIA1,NF2,PDCD4,GLIS2,ELK3,SUPT5H,IGFBP3,TSPY
L2,MYBBP1A,CLN8,STRAP,
GO:0007010~cytoskeleton organization
and biogenesis
0.81% LAMA5,PLEC1,KRT7,LIMK1,NF2,TLN1,ARHGAP8,CENTD3,MYH9,WASL,SPAG5,CXCL12,MYO9
B,CLN8,PLCE1,SHROOM1,
GO:0009966~regulation of signal
transduction
0.81% ECE2,NLK,CC2D1A,HTRA1,ENG,NF2,LITAF,ITSN1,SOS1,CENTD3,PTPRC,IGFBP3,TSPYL2,SHC1,
PLCE1,STRAP,
GO:0051726~regulation of cell cycle 0.76% BIRC5,GTF2H1,RASSF1,EIF4G2,NF2,KNTC1,PDCD4,ARHGAP8,DDX11,COPS5,PTPRC,TSPYL2,SH
C1,MLH1,CDC25B,
GO:0051674~localization of cell
GO:0006928~cell motility
0.76% LAMA5,TPM3,BARHL2,PTP4A1,LIMK1,NF2,FN1,TLN1,CCR4,PODXL,ARHGAP8,CENTD3,MYH9,
WASL,LAMA3,
GO:0000279~M phase 0.76% NEK3,BIRC5,AURKB,ADCY3,RAD54B,ANAPC1,NDE1,NCAPD3,FOSL1,KNTC1,H2AFX,DDX11,SP
AG5,SHC1,CDC25B,
GO:0051246~regulation of protein
metabolic process
0.76% BARHL2,KRT7,EIF5,CD276,CD81,TIA1,TRMT6,EIF4G2,NF2,MDN1,CLN6,DIO2,BZW2,CXCL12,CLN
8,
GO:0000074~regulation of progression
through cell cycle
0.76% BIRC5,GTF2H1,RASSF1,EIF4G2,NF2,KNTC1,PDCD4,ARHGAP8,DDX11,COPS5,PTPRC,TSPYL2,SH
C1,MLH1,CDC25B,
GO:0031325~positive regulation of
cellular metabolic process
0.71% GTF2H1,RASSF1,BARHL2,CD276,CBFB,EGR1,CD81,FOSL1,HNF4A,CREBBP,TEAD4,CLN6,GLIS2,
SUPT5H,
GO:0045934~negative regulation of
nucleobase, nucleoside, nucleotide and
nucleic acid metabolic process
0.66% RASSF1,SCMH1,RBPJ,DNMT1,EGR1,NF2,PDCD4,GLIS2,ELK3,SUPT5H,TSPYL2,MYBBP1A,STRA
P,
GO:0006643~membrane lipid metabolic
process
0.66% PIP4K2A,CDIPT,FADS1,DPM1,CD81,GBA2,SMPD1,ISYNA1,CLN6,SGMS1,PIP4K2B,CLN8,PLCE1,
GO:0051276~chromosome organization
and biogenesis
0.66% RASSF1,AOF2,TSPYL4,NCAPD3,CHD3,SUPT6H,CREBBP,H2AFX,WHSC1,DDX11,SUPT5H,TSPYL
2,ARID4B,
GO:0007243~protein kinase cascade 0.61% MAP3K5,LITAF,TRAF2,TEC,IRAK2,NLK,CD81,CC2D1A,SHC1,GPS2,NF2,PLCE1,
GO:0000278~mitotic cell cycle 0.61% BIRC5,NEK3,KNTC1,AURKB,ANAPC1,NDE1,NCAPD3,DDX11,FOSL1,SPAG5,SHC1,CDC25B,
GO:0042592~homeostatic process 0.61% CLN6,ATOX1,TMCO3,CCR4,SLC4A11,SP110,PTPRC,IFI6,CXCL12,CREBBP,CLN8,PLCE1,
GO:0016337~cell-cell adhesion 0.61% DAG1,CD84,COL6A2,PTK7,CDH5,PKD1,CDH3,CDH11,FXYD5,CELSR3,NF2,ESAM,
GO:0006325~establishment and/or 0.56% RASSF1,AOF2,TSPYL4,H2AFX,WHSC1,CHD3,SUPT5H,TSPYL2,SUPT6H,ARID4B,CREBBP,
- 56 -
Term % Genes
maintenance of chromatin architecture
GO:0006820~anion transport 0.56% COL15A1,COL1A2,COL6A2,COL4A2,CLCN2,SLC4A7,COL12A1,SLC4A11,COL1A1,COL6A3,COL4A1,
GO:0050793~regulation of developmental
process
0.56% LAMA5,BARHL2,FADS1,LIMK1,CD276,CENTD3,MYH9,IGFBP3,RTN4,NOTCH3,LAMA3,
GO:0007167~enzyme linked receptor
protein signaling pathway
0.56% SPARC,PTPN1,COL1A2,PTK7,ROS1,SHC1,ENG,HTRA1,FN1,STRAP,PLCE1,
GO:0006644~phospholipid metabolic
process
0.56% PIP4K2A,CDIPT,SGMS1,FADS1,PIP4K2B,DPM1,CD81,SMPD1,ISYNA1,CLN8,PLCE1,
GO:0051338~regulation of transferase
activity
0.56% PDCD4,MAP3K5,GTF2H1,TRAF2,CD81,PTPRC,SHC1,GPS2,TSPYL2,CLN8,PLCE1,
GO:0051301~cell division 0.56% BIRC5,NEK3,KNTC1,AURKB,ANAPC1,NDE1,NCAPD3,MYH9,SPAG5,TSPYL2,CDC25B,
GO:0015698~inorganic anion transport 0.56% COL15A1,COL1A2,COL6A2,COL4A2,CLCN2,SLC4A7,COL12A1,SLC4A11,COL1A1,COL6A3,COL4A1,
GO:0006461~protein complex assembly 0.56% DAG1,KNTC1,TRAF2,FANCA,GJA4,NUP98,WASL,AP3D1,CREBBP,TLN1,MDN1,
GO:0016481~negative regulation of
transcription
0.56% PDCD4,RASSF1,SCMH1,RBPJ,GLIS2,EGR1,DNMT1,ELK3,SUPT5H,MYBBP1A,STRAP,
GO:0016477~cell migration 0.56% LAMA5,BARHL2,PODXL,PTP4A1,CCR4,ARHGAP8,CENTD3,MYH9,LAMA3,FN1,NF2,
GO:0008610~lipid biosynthetic process 0.51% CDIPT,SGMS1,PRKAG1,FADS1,DPM1,CD81,FASN,ISYNA1,CLN8,PLCE1,
GO:0045859~regulation of protein kinase
activity
0.51% PDCD4,MAP3K5,GTF2H1,TRAF2,CD81,PTPRC,SHC1,GPS2,TSPYL2,PLCE1,
GO:0019725~cellular homeostasis 0.51% CLN6,ATOX1,CCR4,SLC4A11,SP110,PTPRC,IFI6,CXCL12,CLN8,PLCE1,
GO:0001775~cell activation 0.51% TRAF2,CBLB,CBFB,CD276,CLEC7A,NFKB2,CD81,EGR1,PTPRC,AP3D1,
GO:0001568~blood vessel development 0.46% PLXND1,LAMA5,COL15A1,CDH5,COL4A2,GJA4,ELK3,MYH9,ENG,
GO:0001501~skeletal development 0.46% SPARC,CBFB,CD276,COL1A2,COL12A1,COL1A1,OSBPL2,CDH11,TEAD4,
GO:0006260~DNA replication 0.46% KRT7,TYMS,NUP98,SSRP1,MLH1,TSPYL2,POLE2,NF2,MCM6,
GO:0008361~regulation of cell size 0.46% OGFR,SGMS1,IGFBP3,SHC1,TSPYL2,PHF17,HTRA1,CLN8,PLCE1,
GO:0046649~lymphocyte activation 0.46% TRAF2,CBLB,CBFB,CD276,CLEC7A,CD81,EGR1,PTPRC,AP3D1,
GO:0048878~chemical homeostasis 0.46% CLN6,ATOX1,TMCO3,CCR4,SLC4A11,PTPRC,IFI6,CXCL12,PLCE1,
GO:0001944~vasculature development 0.46% PLXND1,LAMA5,COL15A1,CDH5,COL4A2,GJA4,ELK3,MYH9,ENG,
GO:0006417~regulation of translation 0.46% BARHL2,EIF5,KRT7,CD276,DIO2,BZW2,TIA1,TRMT6,EIF4G2,
GO:0045321~leukocyte activation 0.46% TRAF2,CBLB,CBFB,CD276,CLEC7A,CD81,EGR1,PTPRC,AP3D1,
GO:0006817~phosphate transport 0.41% COL15A1,COL1A2,COL6A2,COL4A2,COL12A1,COL1A1,COL6A3,COL4A1,
GO:0030029~actin filament-based
process
0.41% LIMK1,ARHGAP8,WASL,MYH9,MYO9B,CXCL12,NF2,SHROOM1,
GO:0010324~membrane invagination 0.41% SORL1,ITSN1,IGF2R,SYNJ1,DNM1,CLEC7A,FNBP1L,AP1GBP1,
GO:0016049~cell growth 0.41% OGFR,SGMS1,IGFBP3,SHC1,TSPYL2,PHF17,HTRA1,PLCE1,
GO:0007169~transmembrane receptor
protein tyrosine kinase signaling
pathway
0.41% SPARC,PTPN1,COL1A2,PTK7,ROS1,SHC1,FN1,PLCE1,
GO:0007156~homophilic cell adhesion 0.41% DAG1,CD84,CDH5,PKD1,CDH3,CDH11,CELSR3,ESAM,
GO:0040008~regulation of growth 0.41% OGFR,BBC3,IGFBP3,SHC1,TSPYL2,PHF17,HTRA1,PLCE1,
GO:0055082~cellular chemical
homeostasis
0.41% CLN6,ATOX1,CCR4,SLC4A11,PTPRC,IFI6,CXCL12,PLCE1,
GO:0016568~chromatin modification 0.41% RASSF1,AOF2,WHSC1,CHD3,SUPT5H,TSPYL2,SUPT6H,CREBBP,
GO:0006897~endocytosis 0.41% SORL1,ITSN1,IGF2R,SYNJ1,DNM1,CLEC7A,FNBP1L,AP1GBP1,
GO:0006873~cellular ion homeostasis 0.41% CLN6,ATOX1,CCR4,SLC4A11,PTPRC,IFI6,CXCL12,PLCE1,
GO:0045944~positive regulation of
transcription from RNA polymerase II
promoter
0.36% GTF2H1,CBFB,EGR1,FOSL1,SUPT5H,HNF4A,TEAD4,
GO:0001558~regulation of cell growth 0.36% OGFR,IGFBP3,SHC1,TSPYL2,PHF17,HTRA1,PLCE1,
GO:0030003~cellular cation homeostasis 0.36% CLN6,ATOX1,CCR4,SLC4A11,PTPRC,CXCL12,PLCE1,
GO:0001525~angiogenesis 0.36% PLXND1,LAMA5,COL15A1,COL4A2,ELK3,MYH9,ENG,
GO:0042110~T cell activation 0.36% TRAF2,CBLB,CD276,CLEC7A,EGR1,PTPRC,AP3D1,
GO:0040011~locomotion 0.36% CLN6,LAMA5,PTP4A1,ARHGAP8,CENTD3,LAMA3,NF2,
GO:0046467~membrane lipid biosynthetic
process
0.36% CDIPT,SGMS1,FADS1,DPM1,CD81,ISYNA1,CLN8,
GO:0055080~cation homeostasis 0.36% CLN6,ATOX1,CCR4,SLC4A11,PTPRC,CXCL12,PLCE1,
GO:0006333~chromatin assembly or
disassembly
0.31% RASSF1,TSPYL4,H2AFX,CHD3,TSPYL2,ARID4B,
GO:0033674~positive regulation of
kinase activity
0.31% MAP3K5,TRAF2,CD81,PTPRC,SHC1,PLCE1,
GO:0008654~phospholipid biosynthetic
process
0.31% CDIPT,SGMS1,FADS1,DPM1,CD81,ISYNA1,
GO:0006730~one-carbon compound
metabolic process
0.31% AURKB,METTL5,DNMT3A,MTHFD1L,PRMT1,DNMT1,
GO:0045860~positive regulation of
protein kinase activity
0.31% MAP3K5,TRAF2,CD81,PTPRC,SHC1,PLCE1,
GO:0051270~regulation of cell motility 0.31% LAMA5,PTP4A1,ARHGAP8,CENTD3,LAMA3,NF2,
GO:0009968~negative regulation of
signal transduction
0.31% NLK,PTPRC,IGFBP3,HTRA1,NF2,STRAP,
GO:0043405~regulation of MAP kinase
activity
0.31% PDCD4,MAP3K5,CD81,SHC1,GPS2,PLCE1,

- 57 -
Term P-Value Genes
hsa04512:ECM-receptor interaction 2.22E-05 HSPG2,DAG1,LAMA5,COL1A2,COL6A2,COL4A2,CO
L1A1,COL6A3,COL4A1,LAMA3,FN1,
hsa04510:Focal adhesion 4.72E-03 LAMA5,SOS1,COL1A2,COL6A2,COL4A2,COL1A1,CO
L6A3,SHC1,COL4A1,LAMA3,TLN1,FN1,
hsa04910:Insulin signaling pathway 8.04E-02 PRKAG1,ARAF,CBLB,PTPN1,SOS1,FASN,SHC1,
hsa01430:Cell Communication 2.03E-04 LAMA5,KRT7,COL1A2,COL6A2,COL4A2,GJA4,LMN
B2,COL1A1,COL6A3,COL4A1,LAMA3,FN1,
hsa04660:T cell receptor signaling pathway 5.97E-02 CD247,CBLB,SOS1,TEC,NFKB2,PTPRC,
Term % Genes
GO:0030334~regulation of cell migration 0.31% LAMA5,PTP4A1,ARHGAP8,CENTD3,LAMA3,NF2,
GO:0030155~regulation of cell adhesion 0.25% LAMA5,PODXL,FXYD5,LAMA3,NF2,
GO:0001503~ossification 0.25% SPARC,CBFB,CD276,COL1A1,CDH11,
GO:0032259~methylation 0.25% AURKB,METTL5,DNMT3A,PRMT1,DNMT1,
GO:0006665~sphingolipid metabolic
process
0.25% CLN6,SGMS1,GBA2,SMPD1,CLN8,
GO:0007160~cell-matrix adhesion 0.25% LAMA5,ADAM15,PKD1,NF2,NID2,
GO:0007005~mitochondrion organization
and biogenesis
0.25% BBC3,IFI6,MFN1,BID,CLN8,
GO:0031214~biomineral formation 0.25% SPARC,CBFB,CD276,COL1A1,CDH11,
GO:0051348~negative regulation of
transferase activity
0.20% PDCD4,PTPRC,GPS2,CLN8,
GO:0000187~activation of MAPK
activity
0.20% MAP3K5,CD81,SHC1,PLCE1,
GO:0051251~positive regulation of
lymphocyte activation
0.20% TRAF2,CD276,CD81,PTPRC,
GO:0006493~protein amino acid O-linked
glycosylation
0.20% TRAK1,DPM1,GALNT2,GALNT10,
GO:0043414~biopolymer methylation 0.20% METTL5,DNMT3A,PRMT1,DNMT1,
GO:0030384~phosphoinositide metabolic
process
0.20% PIP4K2A,PIP4K2B,DPM1,CD81,
GO:0006446~regulation of translational
initiation
0.20% EIF5,BZW2,TRMT6,EIF4G2,
GO:0030198~extracellular matrix
organization and biogenesis
0.20% COL6A2,COL4A2,NFKB2,COL12A1,
GO:0008637~apoptotic mitochondrial
changes
0.15% BBC3,IFI6,BID,
GO:0007162~negative regulation of cell
adhesion
0.15% PODXL,FXYD5,NF2,
GO:0046488~phosphatidylinositol
metabolic process
0.15% PIP4K2A,PIP4K2B,CD81,
GO:0030516~regulation of axon
extension
0.15% BARHL2,LIMK1,RTN4,
GO:0017015~regulation of transforming
growth factor beta receptor signaling
pathway
0.15% ENG,HTRA1,STRAP,
GO:0001836~release of cytochrome c
from mitochondria
0.15% BBC3,IFI6,BID,
GO:0016458~gene silencing 0.15% SCMH1,EIF2C2,DNMT1,
GO:0048675~axon extension 0.15% BARHL2,LIMK1,RTN4,
GO:0030512~negative regulation of
transforming growth factor beta
receptor signaling pathway
0.10% HTRA1,STRAP,
GO:0015701~bicarbonate transport 0.10% SLC4A7,SLC4A11,
다. Pathway 분석
XRAY3.92와 JETTA 알고리즘에 의해 선정된 유전자들을 KEGG pathway database를 통하여 분
석한 결과는 다음과 같다.
표 11. KEGG pathway 분석결과

- 58 -
hsa00562:Inositol phosphate metabolism 5.42E-03 PIP4K2A,SYNJ1,PIP4K2B,INPPL1,ISYNA1,PLCE1,
hsa04070:Phosphatidylinositol signaling
system
2.75E-02 PIP4K2A,CDIPT,SYNJ1,PIP4K2B,INPPL1,PLCE1,
hsa05222:Small cell lung cancer 1.30E-02 LAMA5,TRAF2,COL4A2,NFKB2,COL4A1,LAMA3,F
N1,
hsa05220:Chronic myeloid leukemia 8.45E-02 ARAF,CBLB,SOS1,NFKB2,SHC1,
그림 27. KEGG pathway중 focal adhesion에 해당하는 유전자를 pathway에 mapping한 결과
그림 28. KEGG pathway중 small cell lung cancer에 해당하는 유전자를 pathway에 mapping한
결과
라. Candidate alternative splice variant들을 validation하기 위한 primer의 design

- 59 -
총 432개의 probeset들에 대하여 Tm=60℃, amplicon length = 150 ~250 bp가 되도록 하고 human
genome상의 redundancy에 의한 mispriming이 되지 않도록 Primer3에서의 조건을 조정하여,
alternative splicing이 expect된 exon에 specific한 PCR이 되도록 다음과 같이 primer를 design하
였다.
마. Candidate alternative splicce variants의 validation
총 347개 gene에 해당하는 432개의 probeset들은 우선적으로 6가지의 stomach cancer cell의
cDNA를 이용하여 RT-PCR을 수행하였으며, stomach cancer cell line들 사이에서 splice variant
가 나타나는 probeset에 해당하는 43개 유전자들을 환자의 normal-tumor tissue pair의 cDNA를
이용하여 RT-PCR 혹은 qRT-PCR을 수행하였다. 다음은 본 연구의 평가된 후속연구 대상 유전
자 대한 설명이다.
1) NOC2L
- Nucleolar complex associated 2 homolog (S. cerevisiae)
- Exon array의 분석결과에서 Exon 8은 tumor에서 exon 10은 normal에서 skip되는 양상이 관찰
된다.
그림 29. JETTA algorithm에 의해 분석된 NOC2L의 splice variation.
- 먼저 stomach cancer cell line에 대하여 normal에서 skip되는 exon 10을 확인한 결과 정상 cell
로 사용한 HMEC에서는 band의 intensity가 약하게 관찰된 반면, 모든 cancer cell line에서는 강
한 band가 관찰되었다. 이를 토대로 환자샘플에서 확인한 결과, normal tissue에서는 band가 모두
사라지지는 않으나 cancer에서 보다 현저하게 낮은 수준으로 represent됨을 관찰할 수 있었다.

- 60 -
그림 30. NOC2L의 stomach 및 non-stomach cell line에 대한 PCR conditioning.
그림 31. NOC2L의 genome 상의 alignment. 다양한 alternative splice variant가 보고되어있다.
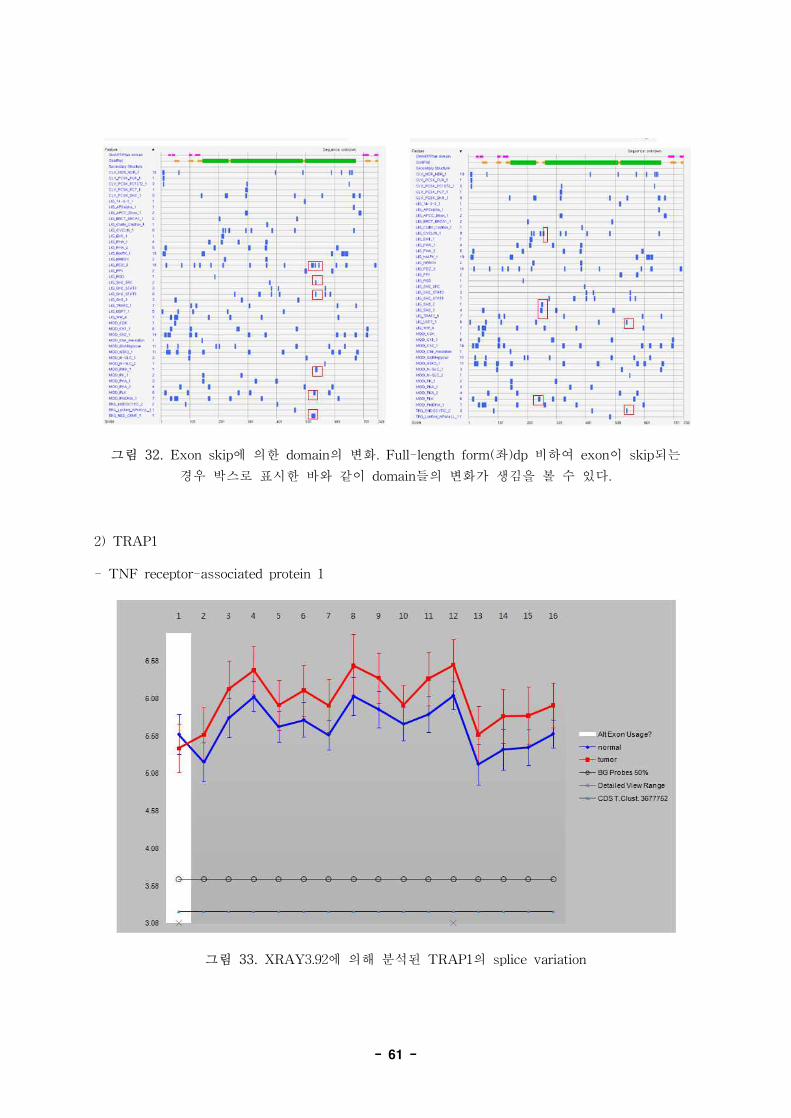
- 61 -
그림 32. Exon skip에 의한 domain의 변화. Full-length form(좌)dp 비하여 exon이 skip되는
경우 박스로 표시한 바와 같이 domain들의 변화가 생김을 볼 수 있다.
2) TRAP1
- TNF receptor-associated protein 1
그림 33. XRAY3.92에 의해 분석된 TRAP1의 splice variation
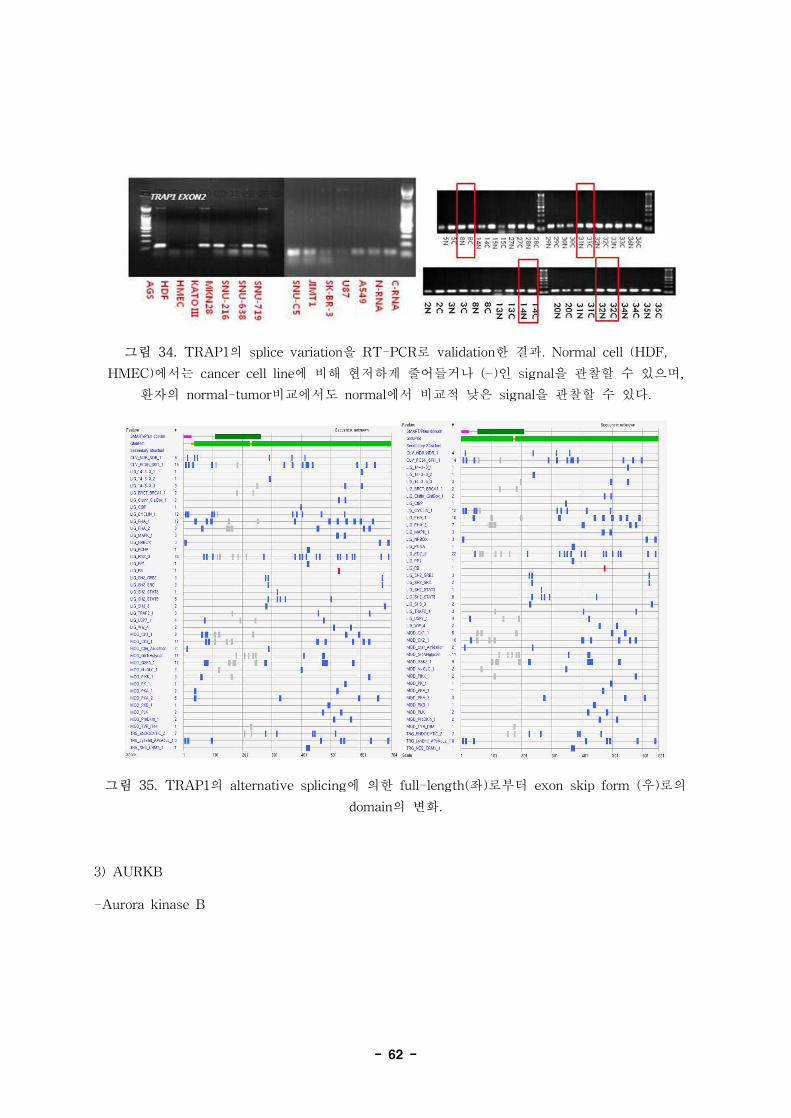
- 62 -
그림 34. TRAP1의 splice variation을 RT-PCR로 validation한 결과. Normal cell (HDF,
HMEC)에서는 cancer cell line에 비해 현저하게 줄어들거나 (-)인 signal을 관찰할 수 있으며,
환자의 normal-tumor비교에서도 normal에서 비교적 낮은 signal을 관찰할 수 있다.
그림 35. TRAP1의 alternative splicing에 의한 full-length(좌)로부터 exon skip form (우)로의
domain의 변화.
3) AURKB
-Aurora kinase B
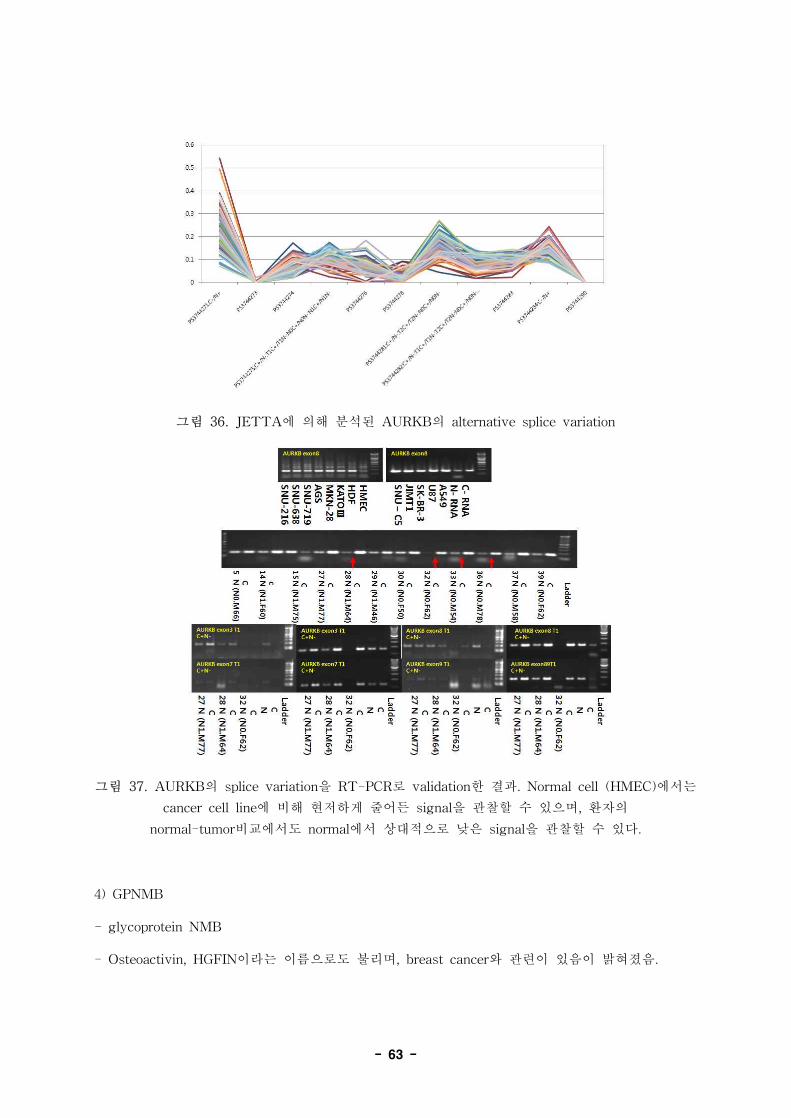
- 63 -
그림 36. JETTA에 의해 분석된 AURKB의 alternative splice variation
그림 37. AURKB의 splice variation을 RT-PCR로 validation한 결과. Normal cell (HMEC)에서는
cancer cell line에 비해 현저하게 줄어든 signal을 관찰할 수 있으며, 환자의
normal-tumor비교에서도 normal에서 상대적으로 낮은 signal을 관찰할 수 있다.
4) GPNMB
- glycoprotein NMB
- Osteoactivin, HGFIN이라는 이름으로도 불리며, breast cancer와 관련이 있음이 밝혀졌음.

- 64 -
그림 38. JETTA에 의하여 분석된 GPNMB의 alternative splice variation.
그림 39. Genome browser에서 mapping된 GPNMB와 splice variant를 detect하기 위해 design한
primer들의 위치.
그림 40 GPNMB의 splice variant를 validation하기 위한 stomach cancer patient의 exon specific
RT-PCR. 3‘쪽의 exon10의 경우 발현양의 차이가 보이지 않으나, exon5, 6, 9에서는 normal과
tumor간의 차이를 볼 수 있다.

- 65 -
그림 41 Full length의 GPNMB와 exon 9 이 skip되는 경우의 protein domain 변화비교
A
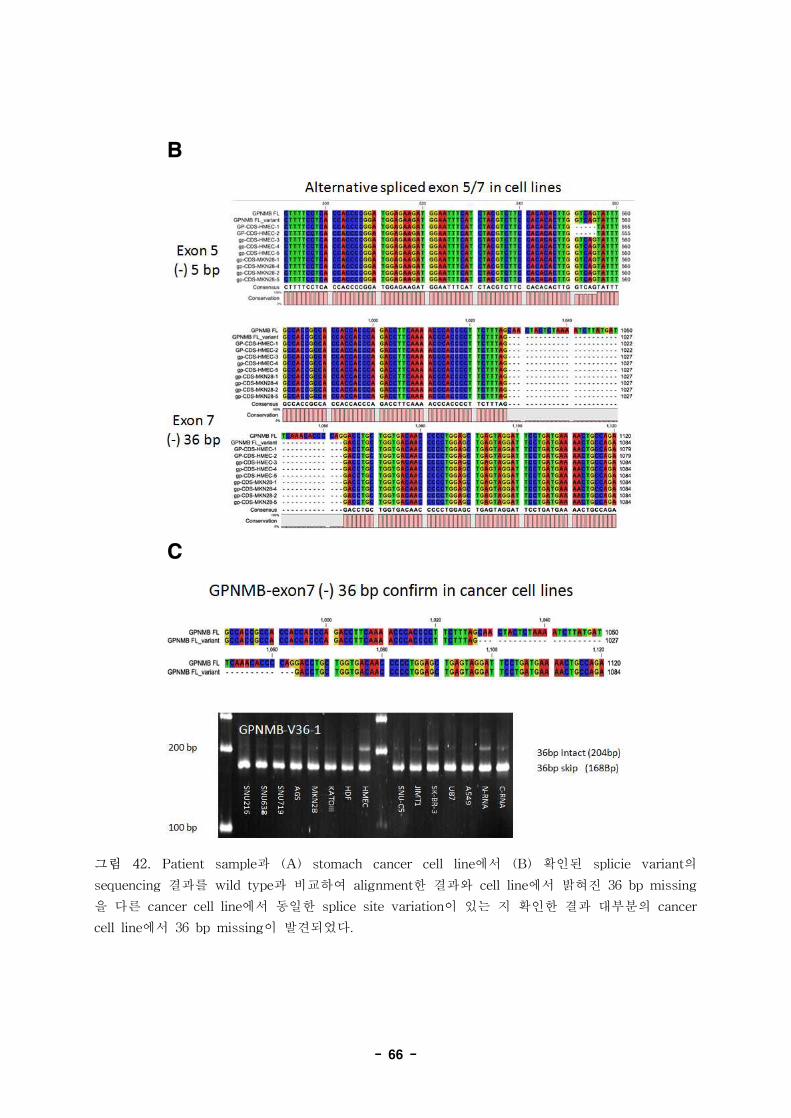
- 66 -
B
C
그림 42. Patient sample과 (A) stomach cancer cell line에서 (B) 확인된 splicie variant의
sequencing 결과를 wild type과 비교하여 alignment한 결과와 cell line에서 밝혀진 36 bp missing
을 다른 cancer cell line에서 동일한 splice site variation이 있는 지 확인한 결과 대부분의 cancer
cell line에서 36 bp missing이 발견되었다.

- 67 -
그림 43. GPNMB의 splice variant의 virtual translation을 통하여 ORF들을 alignment한 결과.
5) FLJ22374
-hypothetical protein FLJ22374
FLJ22374는 hypothetical gene으로 annotation되어있으나 실제로 transcript들은 존재하며 여러가
지 variant또한 보고되어있다. 본 연구에서는 그림 44과 같은 probe set에서 variation이 나타났고,
종양 세포주에서 그림 45와 같이 차별적인 발현이 관찰하므로써 이 결과를 validation하게되었다.
그림 44. JETTA에 의해 분석된 FLJ22374의 alternative splice variation

- 68 -
그림 45. FLJ22374의 splice variation을 RT-PCR로 validation한 결과. Normal cell
(HMEC)에서는 cancer cell line에 비해 현저하게 줄어든 signal을 관찰할 수 있으며, 환자의
normal-tumor비교에서도 normal에서 상대적으로 낮은 signal을 관찰할 수 있다.
실제로 FLJ22374에 해당하는 splice variants를 모두 cloning하려는 시도에서 보고된 variant가
protein으로 translation될 때 나타나는 protein상의 변이는 그림 46과 같이 나타나며, 이들 중
wildtype과 AS1 form은 그림 47과 같이 GFP로 tagging된 pAcGFP expression vector에 클로닝
하였다. 이들 protein을 CLUSTAL W로 align한 결과는 그림 48와 같다.
그림 46. FLJ22374의 alternative splicing에 의한 full-length로부터 splice variant에서의
domain의 변화.

- 69 -
그림 47. 환자시료와 위암 세포주로부터 얻어진 alternative spliced FLJ22374 ORF의 cloning.
그림 48. 세 가지 FLJ22374 alternative splice form과 정상 form의 protein서열을 CLUSTAL W
로 align한 결과.
위와 같이 cloning한 WT의 FLJ22374와 AS1 form의 FLJ22374를 위암 세포주인 AGS cell line에
과발현시킨뒤 세포내에서의 위치변화를 관찰하였다. Wildtype의 경우 그림 49의 왼쪽 panel과 같
이 cytoplasm 전반에 고른 분포를 보이는 반면, AS1 form의 경우 spot형태로 concentrated
distribution을 나타내었다.

- 70 -
그림 49. AGS stomach cancer cell line에 WT과 splice variant AS1을 over-expression시켰을
때 GFP로 tagging된 protein의 세포내 분포를 현미경하에서 관찰한 결과.
다음으로 그림 50과 같이 FLJ22374에서 exon에 특이적인 siRNA를 이용하여 FLJ22374의 발현을
억제하므로써 FLJ22374가 AGS 위암 세포주에서 어떠한 생물학적 기능을 하는지 살펴보았다.
그림 50. FLJ22374의 발현을 knock-down하기 위하여 사용한 siRNA의 유전자상 분포.
위에 보이는 3가지 siRNA를 AGS에 처리하고 4일간 매 24시간마다 관찰한 결과 아래 그림 51과
같이 세포분열을 저해하는 현상이 나타났다.

- 71 -
그림 51. 세가지 FLJ22374특이적 siRNA에 의한 cell proliferation에 대한 영향을 96시간 동안 24
시간 간격으로 현미경하에서 관찰한 결과. Negative control siRNA에 비교하여 FLJ22374의
siRNA들은 cell proliferation을 감소시키는 현상을 볼 수 있으며 특히 siRNA-8은 현격한 감소를
가져옴을 볼 수 있다.
siRNA에 의하여 FLj22374의 발현이 감소하는 여부는 그림 52와 같이 RT-PCR을 통하여 확인할
수 있었는데, siRNA-8에 의한 FLJ22374의 suppression이 negative control (NC)에 비하여 현저하
게 줄어들었음을 확인할 수 있다.
그림 52. FLJ22374 siRNA-8에 의한 FLJ22374의 transcript level에 관한 영향을 RT-PCR을 이용
하여 측정한 결과.

- 72 -
또한, siRNA-8에 의하여 세포분열이 감소하는 현상은 그림 53과 같이 MTT assay에 의해 확인
하였는데, 관찰이 지속된 4일동안 siRNA-8에 의하여 cell proliferation이 지속적으로 저해됨을 알
수 있다.
그림 53. FLJ22374 siRNA-5, siRNA-8 처리 시 AGS cell line의 proliferation에 미치는 영향을
MTT assay를 통하여 측정한 결과.
이러한 결과를 바탕으로 siRNA-8을 동일하게 AGS cell line에 처리시 cell cycle의 변화를 관찰하
였다. 그 결과 NC와 비교하여 siRNA-8에 의해 FLJ22374의 발현이 suppress될 때 cell death를
의미하는 sub G0/G1 population이 증가함이 그림 54와 같이 관찰되었다.
그림 54. FLJ22374 siRNA-8을 AGS cell line에 처리시 나타나는 cell cycle의 변화를 flow
cytometry를 이용하여 24시간 간격으로 96시간 동안 측정한 결과. siRNA-8의 경우 cell-death를
의미하는 sub-G0/G1 population이 negative control에 비하여 현격하게 증가함을 알 수 있다.

- 73 -
Gene
symbol
Accession
No.
Gene name Chr
Locus
Molecular function.
ACTB NM_001101 Beta-actin 7p15-12 Cytoskeletal structural protein
GAPDH NM_002046 Glyceraldehyde-
3-phosphate
dehydrogenase
12p13 Oxidireductase in glycolysis and
gluconeogenesis
HPRT1 NM_000194 Hypozanthine
phosphoribosyltr
ansgerase 1
Xq26 Metabolic salvage of puines
B2M NM_004048 Beta-2-microglo
bulin
15q21 .1 Beta-chain of major
hisocompatibility complex class
I molecules
18S rRNA NR_003286 18S ribosomal
RNA
22p12 Ribosome subunit
RPL29 NM_00992 Ribosomal
protein L29
3p21.3-p
21.2
Structural constituent of
ribosome
바. Stomach cancer에서 differential gene expression이나 alternative exon usage의 detection을
위한 최적의 reference gene의 탐색
Exon specific RT-PCR을 통하여 expression 양을 동정할 때 target gene expression을 여러 개체
간에 비교할 때 혹은 한 개체에서 정상과 병변조직간에 비교할 때 는 특정한 reference gene을 이
용하여 target gene의 expression을 normalize를 하여 비교하게 된다. 따라서 최적화된 reference
gene을 사용하는 것은 분석된 데이터의 신뢰성 확보차원에서 중요한 문제가 된다. 최적화된
reference gene의 조건으로는 항상 그 발현양이 일정하여야 하며, target gene과의 발현양차이가
현저하게 나서는 안되고, 세포나 개체에 처리하는 조건에 대해 변화가 적어야 그 연구조건에서
target gene의 expression을 관찰하기위한 가장 적합한 reference gene이 된다. 이러한 reference
gene을 그동안 연구자들은 일반적으로 받아들여지는 beta-actin이나 GAPDH를 무비판적으로 수
용하여 사용하여 왔으며 그 비율은 3/4정도의 논문에서 찾아볼수 있다. 따라서 본 연구에서 이용
하는 위의 정상 및 위암 조직에 대한 적절한 reference gene가 필요하였는데, 기존에 어떤 보고에
서도 위암의 연구에서 qRT-PCR결과 해석에 적합한 reference gene을 제시한 적이 없었기에 이
연구의 필수불가결한 부분으로써 최적화된 reference gene을 선별하는 연구를 진행하게 되었다.
기존에 보고된 다른 암종의 연구에 사용된 candidate reference gene들 중 비교적 많은 암종에 사
용된 6종 선택하고 이들을 위암 및 비위암 세포주, 그리고 20쌍의 위암환자로부터 얻어진
normal-tumor조직에 있어서, 그 발현양상을 분석하였다. 여섯가지 후보 reference gene은 표8와
같다.
표 12. Candidate reference genes에 대한 정보

- 74 -
Gene Forward primer sequence
[5’→3’]
Reverse primer sequence
[5’→3’]
Amplicon
length
ACTB CATCGAGCACGGCATCGTCA TAGCACAGCCTGGATAGCAA
C
211 bp
GAPDH TGCACCACCAACTGCTTA GGATGCAGGGATGATGTTC 177 bp
HPRT1 AGACTTTGCTTTCCTTGGTC
AG
TCAAGGGCATATCCTACAAC
AA
151 bp
B2M ACTGAATTCACCCCCACTGA CCTCCATGATGCTGCTTACA 114 bp
18S
rRNA
GTAACCCGTTGAACCCCATT CCATCCAATCGGTAGTAGCG 151 bp
RPL29 GGCGTTGTTGACCCTATTTC GTGTGTGGTGTGGTTCTTGG 120 bp
이 후보유전자들을 qRT-PCR에 이용하기 위한 primer의 디자인은 다음과 같이 하였다.
표 13. Candidate reference gene의 qRT-PCR을 위한 primer design
이상의 reference gene들을 각 group의 시료에 대하여 qRT-PCR을 수행하고 그 발현양을 Cp
(crossing point)를 기준으로 plotting한 결과가 그림 23과 같다. 발현양의 median과 사분위 값을
box plot으로 나타내었으며, 각 그룹에서 최소값과 최대값의 범위를 오차막대의 형태로 표시하여
variance를 표시하였다.
Cp는 amplification이 시작되어 signal이 noise background보다 유의하게 높아지기 시작하는 시점
을 표시한 값 이므로, 이 값이 작을수록 발현양이 많은 것이며 반대로 높을수록 발현양이 적다.
Stomach cancer cell line은 non-stomach cell line과 비교하였으며, stomach tissue의 경우
normal과 tumor간의 비교를 수행하였다.

- 75 -
그림 55. stomach cancer cell line, non-stomach cancer cell line, stomach cancer patients
(normal 및 tumor)그룹에서의 reference gene들의 발현양의 차이비교.
이렇게 발현양의 비교만을 통해서도 기존에 빈번하게 사용된 ACTB나 GAPDH의 경우 variance
가 굉장히 크다는 것을 알 수있으며 이와 반대로 cell line의 경우에는 B2M이나 RPL29이 tissue
의 경우에는 HPRT1이나 RPL29이 변이폭이 굉장히 적으면서 normal과 tumor간의 차이가 적게
안정적인 발현양상을 보임을 알 수 있다. 이러한 Cp값을 geNorm과 NormFinder에 적용하여 가장
최적의 reference gene을 predict하였다. geNorm은 pair-wise comparison을 통하여 최적의 두 개
의 reference gene을 제시하며, NormFinder는 model based prediction을 통하여 하나의 최적
reference gene을 제시한다. 먼저 geNorm을 통하여 각 group에 대하여 제시된 유전자는 그림 xx
와 같다. geNorm과 NormFinder모두 stability value가 낮을수록 더 최적인 reference gene임을 의
미한다.
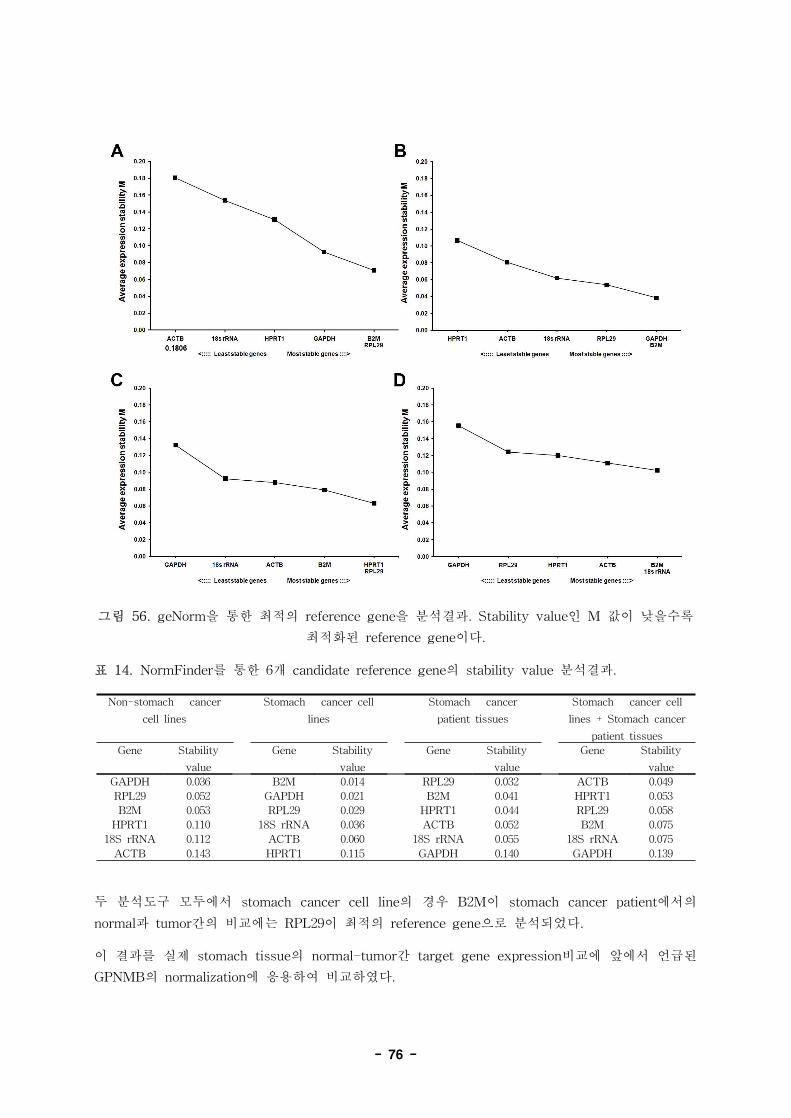
- 76 -
Non-stomach cancer
cell lines
Stomach cancer cell
lines
Stomach cancer
patient tissues
Stomach cancer cell
lines + Stomach cancer
patient tissues
Gene Stability
value
Gene Stability
value
Gene Stability
value
Gene Stability
value
GAPDH 0.036 B2M 0.014 RPL29 0.032 ACTB 0.049
RPL29 0.052 GAPDH 0.021 B2M 0.041 HPRT1 0.053
B2M 0.053 RPL29 0.029 HPRT1 0.044 RPL29 0.058
HPRT1 0.110 18S rRNA 0.036 ACTB 0.052 B2M 0.075
18S rRNA 0.112 ACTB 0.060 18S rRNA 0.055 18S rRNA 0.075
ACTB 0.143 HPRT1 0.115 GAPDH 0.140 GAPDH 0.139
그림 56. geNorm을 통한 최적의 reference gene을 분석결과. Stability value인 M 값이 낮을수록
최적화된 reference gene이다.
표 14. NormFinder를 통한 6개 candidate reference gene의 stability value 분석결과.
두 분석도구 모두에서 stomach cancer cell line의 경우 B2M이 stomach cancer patient에서의
normal과 tumor간의 비교에는 RPL29이 최적의 reference gene으로 분석되었다.
이 결과를 실제 stomach tissue의 normal-tumor간 target gene expression비교에 앞에서 언급된
GPNMB의 normalization에 응용하여 비교하였다.

- 77 -
RPL29과 HPRT1의 경우에는 20 pair의 stomach tissue에서 normal과 tumor간의 발현양차이의
pattern이 비슷하게 유지되었으나 이 두 reference gene에 의해 normalize된 패턴을 ACTB나
GAPDH와 비교하게 될 경우 동일한 유전자의 발현양상이라고 볼 수 없을정도로 deviated된 패턴
이 관찰되었으며 무려 20쌍중 8쌍에서 반대의 발현양상차이를 나타내었다. (그림 57)
그림 57. 20쌍의 stomach tissue에서 발현된 GPNMB의 exon 9의 발현양을 6개의 reference gene
에 의해 normalize하여 비교한 결과. geNorm과 NormFinder에서 예측한 최적의 reference gene인
RPL29는 2번째 순위로 제안된 HPRT1에 의한 normalization과 비교할 때 비슷한 양상을 나타내
나, ACTB나 GAPDH에 의한 normalizaiton과는 많은 차이를 보이고 있다.

- 78 -
3. 연구결과 고찰 및 결론
Ÿ 2007년 기준으로 한국인의 주요 암종의 발생분율을 살펴보면 위암이 16.0%로 1위를 차지하고
있다. 위 내시경을 통한 위암의 조기진단 사업을 통하여 진행성 위암으로 진행되기 이전에 조
기위암의 상태에서 발견되는 효과로 인하여 93년-94년에 42.8%이던 5년 생존율이 03-07년에는
61.2%로 증가하는 결과를 가져왔다. 이는 암의 발병상태를 얼마나 정확하게 진단하는 가에 따
라 치료의 완성도 및 환자의 삶의 질향상에 영향을 미치며, 이에 따라 궁극적으로도 국가적인
비용에도 영향을 준다고 할 수 있다. 그러므로, 암의 발생단계를 최대한 정확하게 진단하고 치
료의 방향을 결정하는 것은 매우 중요하다.
Ÿ 암의 병기는 임상적․병리적인 판정이 가장 최우선이나 여기에 더불어 분자적인 기반으로 표
면상으로 나타나지 않은 molecular signature를 찾아내는 것은 진단으로만 그칠 수 있는 조기
위암의 발견에서 분자적인 근거에 따른 치료방안을 개발할 수 있다는 데 보다 큰 의의가 있다.
Ÿ 인간 유전체의 해석 및 공개와 genomics 기술의 발달과 더불어 진핵생물의 유전자에 대한 재
해석이 이루어 지고 있다. 기존의 biological principle에서는 유전자에 대한 정의를 반드시 단백
질의 발현으로 연결되어야만 functional gene이며 그렇지 않은 경우 pseudogene으로 정의
(define) 했었으나, 지난 20여년가 축적되어온 수 천만건의 EST entries들을 human genome에
align하고 이를 통하여 새롭게 gene을 annotation하는 ENCODE 프로젝트의 결과로, 기껏해야
40-60%의 유전자에서 alternative splicing이 발생할 것으로 여겨졌던 (Modrek & Lee, 2003)사
실로 부터 최대 92-94%의 유전자에서 alternative splicing이 발생한다고 (Wang et al., 2008)
밝혀지는 결과까지 발전하였다. 이와 더불어 GENCODE project의 pilot results로 부터 사람의
각 장기를 대상으로 새로운 exon usage를 조사하여 본 결과 stomach는 다른 어떤 tissue 보다
도 더 다양한 novel exon usage를 보임이 발견되었다 (Denoud et al., 2007). 이것은 stomach
에서 다양한 alternative splicing이 일어남을 의미하며 stomach cancer의 발생 및 발달 그리고
전이과정에서도 alternative splcing에 의한 유전자 변이에 의해 영향을 많이 받을 수 있음을
의미한다.
Ÿ 본 연구에 사용된 platform은 150만개의 probe set를 탑재한 Exon1.0ST array이며 여기에는
RefSeq entries로 부터 annotation된 probe set만 24만개에 이른다. 최근에는 microarray로 부
터 next-generation sequencing (NGS) 라는 기술로 genome analysis platform이 이전하고 있
는 시기라고 볼 수 있는데, 현재 whole genome 기반의 exon array와 NGS의 경우 각각의 장
단점을 갖고 있어 각각의 목적에 부합하는 platform의 적용이 적절한 결과를 산출할 것이라 사
료된다. 이러한 생각에 대한 근거는 microarray의 경우 지난 10여년간의 연구에서 사용을 통하
여 통계적인 분석방법 및 알고리즘들이 안정화 되어있으며, 이에 따라 그 결과에 대한 신뢰성
그리고 validation에 의한 일치도를 모두 확보한 기술기반이 되었다. 또한, 기 언급한 바와 같
이 이 platform에는 core probeset뿐만 아니라 extended probe set를 포함하여 150만개의
probe set를 탑재하고 있으므로, gene scan에 의하여 prediction된 모든 가능한 exon에 해당하
는 probe set를 포함하고 있어 이들이 transcription되었을 때는 모두 detect할 수 있다는 장점
이 있다. 이를 단점으로 뒤집어 본다면, 그 어떠한 evidence에 의해서도 검증되거나 prediction
되지 않은 signal은 detect될 수 없다는 점이된다. NGS의 경우에는 sequencing이라는 방법을

- 79 -
massive하게 적용하므로써 원천적으로 변이가 발생하여도 이것이 transcriptome의 detection을
그 sequence로 validation한다는 특징으로 인하여 결과의 신뢰성에 의심을 할 필요가 없다. 그
러나 alternative splcing을 연구하는 관점에서는 NGS의 technical한 요소가 그다지 도움이 되
지 않을 수도 있다. 왜냐하면, 현재 popular하게 적용되는 모든 NGS platform은 Roche의 454
system을 제외하고는 read당 길이가 exon의 평균길이인 140-150 bp에 미치지 못하여, exon과
exon의 junction및 novel exon의 detection에 있어서는 한계점을 보이고 있다. 또한 이들 역시
PCR에 기반하여 tentative한 cDNA library를 만들고 이를 sequencing하는 technological base
를 갖고 있어서, PCR에 기반하지 않은 microarray probe보다 bias되어있을 가능성도 내재하고
있다.
Ÿ 본 연구에서는 core probe set를 대상으로 정상-암조직으로 구성된 30 pair의 위암 환자군 시
료를 분석한 결과, 모두 432개의 candidate splice variant를 screening할 수 있었으며, 최종적으
로 5개의 주요 후보유전자로 좁힐 수 있었다. 이 중에서 GPNMB는 그 exon의 usage에 있어서
정상-암 조직간에 뚜렸한 차이를 나타내어 환자군을 확대하여 그 통계적 유의성을 검증하는
경우 조기위암에서 정상-암의 차이를 구별할 수 있는 좋은 molecular signature로 사용될 수
있을 것이라 사료된다. 이 유전자의 경우에는 intracellular와 extracellular에 모두 분포하는 것
으로 여겨지며, 기존의 보고를 통하여 breast cancer및 ovarian cancer에서 splice variant가
prognosis의 marker로 사용할 수 있음이 제시되어 그 효용성에 보다 신뢰를 더 할 수 있으리
라 사료된다. 이와 더불어 hypothetical gene인 FLJ22374의 경우 기존에 보고가 되지 않았던
유전자이며 이 유전자의 발현이 정상-암의 비교에서 차별적인 면을 보이므로 splice variant의
관점에서 뿐 만 아니라, 발현양의 차이에 의거한 발암기전에의 영향도 고려하여 후속연구를 수
행한다면 세포증식/사멸과 관련된 새로운 유전자를 타겟으로 한 항암물질 혹은 유전자치료의
기반으로 활용할 수 있을 것이라 사료된다.
Ÿ 본 연구에서는 또한 유전자의 발현양 차이를 연구하는데 있어서 필수적인 reference gene의
validation이 위암에 대해서는 이루어지지 않은 것을 발견하였다. 따라서, 기존에 무비판적으로
수용하여온 beta-actin이나 GAPDH gene을 대신하여, 보다 unbiased된 standard를 제공할 수
있는 reference유전자들을 screening하고 통계적으로 분석한 결과 Beta-2-microglobulin (B2M)
과 RPL29 (ribosomal protein large subunit 29)의 transcript가 위암세포주 및 위암 조직에서의
transcriptional difference를 비교하는데 최적의 유전자임을 밝혀내었다. 이러한 정보는 향후 한
국인에게서 가장 빈번하게 발생하는 암종인 위암의 연구에 매우 효과적인 기여를 할 것이라
사료된다.

- 80 -
논문명저자
(저자구분1)
)저널명(I.F.)
Year;Vol(No):Page
구분2)지원과제번호
3)
eIF3m expression influences the
regulation of tumorigenesis-related
genes in human colon cancer.
고 성 호(제1)
Oncogene
(7.135)
2010;
A d v a n c e d
O n l i n e
Publication /
doi:10.1038/on
c2010.422
국외SCI
0810160
dentification of valid reference genes
for gene expression studies of human
stomach cancer by reverse
transcription-qPCR
고 성 호(교신)
BMC
Cancer
(2.736)
2010;
10(1):240~240국외SCIE 0810160
Association pattern mining of intron
retention events in human based on
hybrid learning machine
고 성 호(공동)
Gene &
Genetic
System
(1.391)
Accepted 국외SCI
0810160
Let-7 microRNAs are
developmentally regulated in
circulating human erythroid cells
고 성 호(공동)
Journal of
Translation
al Medicine.
(2.92)
2009
7:98국외SCI
없음
Cytokine-mediated increases in fetal
hemoglobin are associated with
globin gene histone modification and
transcription factor reprogrammin
고 성 호(공동)
Blood
(10.432)
2009
114(11):2299-2
306
국외SCI
없음
논문명 저자 학술대회명 지역1)지원과제번호
Reference Gene for Gene Expression
Studies of Human Gastric Cancer by
Quantitative Real-time RT-PCR
(B-71)
노현욱,
이병찬,
최은석,
최일주,
이연수,
고성호
2009
한국분자세포생물학회
정기학술대회
국내-
서울
0810160
Application of association rule mining
approach to the prediction of intron
retention events in human
Hae-Jin
Hu,
Sung-Ho
Goh &
Yeon-Su
Lee
The 7th International
Conference of
Bioinformatics
(InCoB)2008
국외 0810160
4. 연구성과 및 목표달성도
(1) 연구성과
가. 국내 및 국제 전문학술지 논문 게재 및 신청
1) 저자구분 : 교신, 제1, 공동
2) 구분 : 국내, 국내 SCI, 국내 SCIE, 국외, 국외SCI, 국외SCIE 등
3) 지원과제번호(Acknowledgement)
나. 국내 및 국제 학술대회 논문 발표
1) 지역 : 국내, 국외
- 81 -
최종목표 연차별목표 달성내용달성도(%)연차 최종
Whole genome
exon array를
통한 정상조직
과 위암조직사
이에 차별적으
로 나타나는 위
암관련 특이적
a l t e r n a t i v e
splice variants
를 발굴하고 위
암 발생기전에
관련된 splice
1차년도
위암환자군 각 stage
별 암조직-정상조직
샘플 15 pairs의 시료
확보 및 임상지표의
분석
위암 검진을 위하여 내시경검사를
받는 환자로 부터 임상시험및 유전
자 검사동의서에 서명동의한 환자
로 부터 시료를 수집하였으며, 수술
의 여부에 따라 1차년도 및 2차년
도에 걸쳐 임상자료를 수집하였음100 35
15쌍이상의 확보된
조직시료를 이용하여
whole genome exon
array 실험 및 생성
된 alternative splice
variant data의 축적
15명 이상의 환자로 부터 pair로 수
집된 위암 및 위암 주변조직으로
부터 RNA를 추출하였으며 이를 이
용하여 Exon1.0ST whole genome
exon array에 적용하여 data를 분
석하였음
구분1) 특허명 출원인 출원국 출원번호
발명특허암의 진단 및 치료를 위한eIF3m의 용도
이연수 고성호홍성혜 김인후정진숙
국내출원
10-2009-0103723 (접수번호1-1-2009-0666168-17)
발명특허
USE OF EIF3M FOR THEDIAGNOSIS AND TREATMENTOF CANCER
LEE,Yeon-Su
GOH, Sung-Ho
HONG,
Sung-Hye
KIM, In-Hoo
JEONG,
Jin-Sook
국제출원
(미국/일본)PCT/KR2010/006878
저서명 저자 발행기관(발행국, 도시) 쪽수 Chapter 제목, 쪽수(공저일 경우)
인체유전학 제8판 개념과 응용 이정주외 8명
공저
대한민국, 서울 제12장 암의 생물학
보고서명 정부정책 기여내용
다. 산업재산권
1) 구분 : 발명특허, 실용신안, 의장등록 등
라. 저 서
마. 연구성과의 정부정책 기여
바. 기타연구성과
(2) 목표달성도
가. 연구목표의 달성도

- 82 -
variants의 생물
학적 기능을 세
포수준에서 규
명한다.
및 분석
2차년도
위암과 관련된
유전자의
alternative exon
usage의 유의성을
높이기 위한
위암환자군
alternative splice
variant data의
생물정보학적 접근
및 분석
Alternative exon usage에 대한 다
양한 알고리즘 (XRAY3.9, FIRMA,
JETTA)으로 raw data를 분석하여
각 결과로 부터 통계적 유의성이
p<0.001이하인 후보유전자들을 선
별하였음. 또한 Gene ontology 및
KEGG pathway분석을 통하여 해
당 biological process에 관여하는
후보유전자를 선별하였음.
100 70
Exon에 특이적인
RT-PCR을 통한
위암 특이적
alternative exon
usage의 확인 및
검증
Exon에 특이적인 primer pair를 디
자인 하여 위암 및 비-위암세포주
그리고 정상세포에 대하여
alternative exon의 usage를 확인하
고 환자군에 대해서도 검증을 수행
하였음
3차년도
위암에서 유의한
차이를 나타내는
alternative splice
variant의
세포수준에서의
생물학적 기능과
발암기전 분석
위암에서 유의한 차이를 보이는 후
보유전자인 FLJ22374의 exon
specific한 siRNA의 처리를 통하여
세포수준에서 FLJ22374유전자의 세
포분열 및 세포사멸에 관련된 생물
학적 기능을 확인하였음.100 100
검증된
분석데이터를
기반으로 한
전사수준에서의
위암 특이적
biomarker의 개발
GPNMB유전자의 exon-wise
RT-PCR를 통하여 밝혀진 정상-암
조직간의 usage차이를 밝혀내었음.
평가의 착안점 자 체 평 가
위암의 조직시료가 확보되었으며
생물학데이터와 연관시킬
임상자료가 함께 확보되었는가?
위암 검진을 위하여 내시경검사를 받는 환자로 부터 임상
시험및 유전자 검사동의서에 서명동의한 환자로 부터 시료
를 수집하였으며, 수술의 여부에 따라 1차년도 및 2차년도
에 걸쳐 임상자료를 수집하였음
확보된 시료 중 몇 건에서 whole
genome exon array 분석이
수행되었는가?
환자로 부터 pair로 수집된 위암 및 위암 주변조직으로 부
터 RNA를 추출하였으며 이를 이용하여 Exon1.0ST whole
genome exon array에 적용하여 data를 분석하였음
다양한 알고리즘 whole genome Alternative exon usage에 대한 다양한 알고리즘
나. 평가의 착안점에 따른 목표달성도에 대한 자체평가

- 83 -
exon array 분석을 추가
수행하였는가
(XRAY3.9, FIRMA, JETTA)으로 raw data를 분석하여 각
결과로 부터 통계적 유의성이 p<0.001이하인 후보유전자들
을 선별하였음.
선별된 유전자의 변이는
생물학적으로 위암의 발생기전과
유의한 연관성이 확인되었는가?
통계적 유의성이 p<0.001이하인 후보유전자들을 선별하여
이 유전자들을 Gene ontology 및 KEGG pathway분석을
통하여 해당 biological process에 관여하는 후보유전자를
선별하였음.
임상데이터의 비교분석 시 유의한
연관이 있는 splice variant의
생물학적 기능변화를 세포수준에서
동정하고 관련메카니즘을
탐색하였는가?
위암에서 splice variant의 유의한 차이를 보이는 후보유전
자인 FLJ22374의 exon specific한 siRNA의 처리를 통하여
세포수준에서 FLJ22374유전자의 세포분열 및 세포사멸에
관련된 생물학적 기능을 확인하였음
Splice variant를 검출할 전사수준
의 biomarker개발이
수행되었는가?
위암 세포주 및 위암 조직의 정상-암 조직간 비교에서
splice variant의 차이를 보인 GPNMB유전자의 exon-wise
RT-PCR를 통하여 밝혀진 정상-암 조직간의 usage차이를
밝혀내었음.

- 84 -
5. 연구결과의 활용계획
(1) 연구종료 2년후 예상 연구성과
구 분 건 수 비 고
학술지 논문 게재 2Cancer Research (IF 7.543) x 1
Cell Death & Differentiation (IF 8.24) x 1
산업재산권 등록 1
U.S.
GPNMB유전자 isoform의 암세포진단을 위한
용도
기 타
(2) 연구성과의 활용계획
l 기대효과
- Whole genome exon array를 통하여, 각 유전자 별로 exon expression의 차이를 찾아내고
분석하므로써 기존의 expression profiling연구를 통하여 밝혀지지 않은 cancer tissue
specific, cancer stage specific, metastasis specific한 유전자의 변이를 미세한 alternative
splicing수준에서 찾아낼 수 있다. 또한 이러한 변이에 의한 유전자의 기능변화가 일으키는
metastasis의 mechanism을 밝혀낼 수 있을 것으로 기대된다.
- Alternative splicing의 변이에 의해 유전자 발현의 최종산물인 단백질의 기능과 구조에 야기
되는 변이도 함께 예측하여, 항암치료제에 대해 내성을 보이는 cancer specific한 biological
mechanism을 찾아낼 수 있으리라 사료된다.
- 한국인 호발성 암인 위암을 대상으로 cancer specific한 biomarker를 개발하므로 써 이를 환
자의 치료방법결정에 활용하여 적정한 치료를 할 수 있으리라 기대된다.
l 활용방안
- 유전자 내부의 미세한 변이를 찾아내므로 써, cancer stage specific하거나 metastasis에 관련
된 유전자를 검출할 biomarker를 개발하고 활용할 수 있다.
- 항암치료의 target이 될 가능성이 있는 유전자들을 선별하고 splice variant의 생물학적인 기
능분석을 통해 새로운 항암치료제 개발 시 유전자 변이에 따른 치료제 내성을 미리
screening하는데 활용될 수 있다.
l 후속연구 수행 필요성
1. 선행연구를 통하여 선정된 두 가지 후보 유전자의 alternative splice variation의 생물학적
기능연구필요성
1) FLJ22374의 기능연구
Alternative splice variation을 보이는 두 가지 후보 유전자중 FLJ22374는 기존에 annotation
이 되지 않은 novel한 transcript이므로 생물학적인 기능에 대하여 알려진 바가 없다. 그러나

- 85 -
전단계 연구에서, siRNA를 처리하여 loss of function study를 하였을 때 위암세포의 분열이
현격하게 감소하는 현상을 확인하였다. 따라서 후속연구를 통하여 유전자의 세포 분열 및 사멸
과 관련된 기능을 분석하여 therapeutic target으로의 가능성을 타진할 필요가 있다.
전 단계 연구에서 FLJ22374에 대하여 splice variant에 대하여 서로 다른 knock-down effect
를 가져올 수 있는 siRNA를 exon-wise하게 처리하였을 때 세포사멸의 효과 이외에
senescence현상이 나타남이 관찰되었다. 따라서, FLJ22374의 splice variant별로 나타나는
cellular effect를 기반으로 유전자 특이적이면서 exon 특이적인 shRNA를 찾아내어 potential
therapeutic으로의 가능성을 찾아낼 필요가 있다.
2) GPNMB의 기능연구
GPNMB의 경우 위의 정상조직과 종양조직사이에 매우 뚜렷한 exon usage 차이를 보였으며,
breast cancer에 있어서 tumor cell의 migration과 관련이 있다는 보고가 되어있다. 따라서,
migration의 activation에 관여하는 proteolytic cleavage에 있어서 alternative exon usage에 따
른 변화를 분석하고, exon-wise knock down을 통하여 metastasis의 변화를 분석한다.
2. 다른 암종에 대한 후보 유전자들의 alternative splice variant의 확인
정상조직과 종양조직사이에 매우 뚜렷한 exon usage 차이를 보이는 GPNMB의 경우 전 단
계 연구에서 제한된 수의 환자 시료로부터 exon usage를 확인한 경우이므로, 위암환자시료의
숫자를 늘려 alternative exon usage와 환자의 병기, 그리고 survival rate간에 관계를 통계적으
로 분석하여 significance를 assess할 필요가 있다. 이와 더불어 위암에 특이적인 splice variant
를 정의하기 위하여 간암, 폐암, 유방암 등의 암종에 대하여 환자의 시료를 대상으로 그 특이
성을 분석해야할 필요가 있다.
3. Novel splice variant를 탐색하기 위한 확장된 probe set의 분석
전단계 연구에서는 splice variant의 신뢰성을 높이기 위하여 전제 140만개의 probe set중
RefSeq mRNA에 기반한 30만개의 core probe set을 이용하여 splice variation을 screening하였
다. 그러나, ENCODE project에 의하여 새로운 genome annotation이 된 결과에 의하면 core
probe set이외의 region에서 exon usage를 발견할 가능성이 많아지며, gene과 gene사이에 디자
인된 나머지 probe set들을 대상으로 screening할 경우 bcl-abl처럼 발암원인이 될 수 있는
fusion된 유전자를 밝혀낼 수 있다. 따라서, Ensembl transcript와 EST 그리고 gene
prediction으로 부터 디자인된 probe set을 대상으로 screening을 수행한다.

- 86 -
6. 참고문헌
Béroud C, Hamroun D, Collod-Béroud G, Boileau C, Soussi T, Claustres M. UMD (UniversalMutation Database): 2005 update. 2005 Hum. Mut. 26:184-191
Denoeud F, Kapranov P, Ucla C, Frankish A, Castelo R, Drenkow J, Lagarde J, Alioto T,Manzano C, Chrast J, Dike S, Wyss C, Henrichsen CN, Holroyd N, Dickson MC, Taylor R,Hance Z, Foissac S, Myers RM, Rogers J, Hubbard T, Harrow J, Guigó R, Gingeras TR,Antonarakis SE, Reymond A. Prominent use of distal 5' transcription start sites anddiscovery of a large number of additional exons in ENCODE regions. Genome Res. 2007Jun;17(6):746-59.
Frey BJ, Mohammad N, Morris QD, Zhang W, Robinson MD, Mnaimneh S, Chang R, Pan Q,Sat E, Rossant J, Bruneau BG, Aubin JE, Blencowe BJ, Hughes TR. Genome-wide analysisof mouse transcripts using exon microarrays and factor graphs. Nat Genet. 2005Sep;37(9):991-6.
Gardina PJ, Clark TA, Shimada B, Staples MK, Yang Q, Veitch J, Schweitzer A, Awad T,Sugnet C, Dee S, Davies C, Williams A, Turpaz Y. Alternative splicing and differentialgene expression in colon cancer detected by a whole genome exon array. BMC Genomics.2006 Dec 27;7:325.
Gilbert W. Why genes in pieces? Nature. 1978 Feb 9;271(5645):501
Johnson JM, Castle J, Garrett-Engele P, Kan Z, Loerch PM, Armour CD, Santos R, SchadtEE, Stoughton R, Shoemaker DD. Genome-wide survey of human alternative pre-mRNAsplicing with exon junction microarrays. Science. 2003 Dec 19;302(5653):2141-4.
Modrek B, Lee C. A genomic view of alternative splicing. Nat Genet. 2002 Jan;30(1):13-9.
Murray-Zmijewski F, Lane DP, Bourdon JC. p53/p63/p73 isoforms: an orchestra of isoforms toharmonise cell differentiation and response to stress. 2006 Cell Death Diff. 13: 962-972
Pan Q, Shai O, Misquitta C, Zhang W, Saltzman AL, Mohammad N, Babak T, Siu H, HughesTR, Morris QD, Frey BJ, Blencowe BJ. Revealing global regulatory features of mammalianalternative splicing using a quantitative microarray platform. Mol Cell. 2004 Dec22;16(6):929-41.
Shin C. & Manley J.L. Cell signalling and the control of pre-mRNA splicing. 2004 Nat. Rev.Mol. Cell Biol. 5: 727-738
Skotheim RI, Nees M. Alternative splicing in cancer: noise, functional, or systematic? Int JBiochem Cell Biol. 2007;39(7-8):1432-49. Epub 2007 Mar 1.
Thill G, Castelli V, Pallud S, Salanoubat M, Wincker P, de la Grange P, Auboeuf D, SchächterV, Weissenbach J. ASEtrap: a biological method for speeding up the exploration ofspliceomes. 2006 Genome Res. 16:776-786
Venables J.P. & Burn J. EASI-Enrichment of alternatively spliced isoforms. 2006 Nucl. AcidsRes. 34:e103
Venables JP, Klinck R, Koh C, Gervais-Bird J, Bramard A, Inkel L, Durand M, Couture S,Froehlich U, Lapointe E, Lucier JF, Thibault P, Rancourt C, Tremblay K, Prinos P, ChabotB, Elela SA. Cancer-associated regulation of alternative splicing. Nat Struct Mol Biol. 200916(6):670-6.
Wang ET, Sandberg R, Luo S, Khrebtukova I, Zhang L, Mayr C, Kingsmore SF, Schroth GP,Burge CB. Alternative isoform regulation in human tissue transcriptomes. Nature. 2008 Nov27;456(7221):470-6.
Wang Z, Lo HS, Yang H, Gere S, Hu Y, Buetow KH, Lee MP. Computational analysis andexperimental validation of tumor-associated alternative RNA splicing in human cancer. 2003Cancer Res. 63:655-657

- 87 -
Xu Q, Lee C. Discovery of novel splice forms and functional analysis of cancer-specificalternative splicing in human expressed sequences. 2003 Nucl. Acids Res. 31: 5635-5643
Yeakley JM, Fan JB, Doucet D, Luo L, Wickham E, Ye Z, Chee MS, Fu XD. Profilingalternative splicing on fiber-optic arrays. Nat Biotechnol. 2002 Apr;20(4):353-8.
Zhang C, Li HR, Fan JB, Wang-Rodriguez J, Downs T, Fu XD, Zhang MQ. Profilingalternatively spliced mRNA isoforms for prostate cancer classification. 2005 BMC Bioinfo.7:202
Zhu J, Shendure J, Mitra RD, Church GM. Single molecule profiling of alternative pre-mRNAsplicing. 2003 Science 301:836-838

- 88 -
7. 첨부서류
(1) 연구과제와 관련된 과제책임자의 대표적 논문 4편의 초록페이지 사본

- 89 -

- 90 -

- 91 -
(2) 과제책임자의 연구실적에 게재예정으로 기재된 논문의 게재증명서

- 92 -
(3) 과제책임자 연구실적에 기재된 특허등록증 사본

- 93 -
[국제특허출원]

- 94 -

- 95 -



![최종보고서 [기관고유연구사업] - ncc.re.kr 최종보고서 [기관고유연구사업] 2015 년 10 월 일 과제책임자 : 박 원 서 (인) 국 립 암 센 터 원 장](https://img.pdfslide.tips/doc/110x75/5e46072dbcd64c045a55c7f4/oeeeoe-eeeoee-nccrekr-oeeeoe-eeeoee.jpg)
![하반기 방만경영예방 특정감사 결과 보고 - aT · Ù]ÚÛTQi ÜÝ@/ Wak ÞßàáâãàáäåØÙi ³æØÙ , äx zNFk Þ#`iTÓ k H¦L§g ! 6FNEqç@Å 3k-ä HTQ^_h 1k](https://img.pdfslide.tips/doc/110x75/60c6ea1d58cdfa3d5944e268/ee-eeoeee-e-ee-ee-at-tqi-oe-wak.jpg)



![최종보고서 [기관고유연구사업][기관고유연구사업] 2016 년 3 월 10 일 과제책임자 : 서 민 아 (인) 국 립 암 센 터 원 장 귀 하 과제고유번호1510710](https://img.pdfslide.tips/doc/110x75/5f4132a1f1661a3eb97b90e0/oeeeoe-eeeoee-eeeoee-2016-e-3.jpg)
![최종보고서 [기관고유연구사업] - ncc.re.kr [기관고유연구사업] 2016 년 3 월 11 일 과제책임자 : 최 용 두 (인) 국 립 암 센 터 원 장 귀 하 과제고유번호1310160](https://img.pdfslide.tips/doc/110x75/5f4eecf32bb7fa338b323772/oeeeoe-eeeoee-nccrekr-eeeoee.jpg)




![최종보고서 〈 목 차 〉 [기관고유연구사업] 최종보고서 [기관고유연구사업] 2015 년 10 월 28 일 과제책임자 : 최귀선 (인) 국 립 암 센 터 원](https://img.pdfslide.tips/doc/110x75/5f5a7ef5a6cf4d54e85ddcde/oeeeoe-e-eeeoee-oeeeoe-eeeoee.jpg)






![최종보고서 [기관고유연구사업] - 1 - 최종보고서 [기관고유연구사업] 2015년 10월 28일 과제책임자 : 이 호 (인) 국 립 암 센 터 원 장 귀 하](https://img.pdfslide.tips/doc/110x75/5e3793e3134c2e59fb2801a0/oeeeoe-eeeoee-1-oeeeoe-eeeoee.jpg)







