Embed Size (px)
Citation preview

Eine Einführung in die Architektur moderner Graphikprozessoren
Seminarvortrag von Sven Schenk
WS 2005/2006Universität Mannheim, Lehrstuhl für Rechnerarchitektur

2
Inhalt• Historische Eckpunkte
• Einführung einiger grundlegender Begriffe
• Betrachtung einer Architektur am Beispiel des NV40 von NVIDIA– Vertex Shader– Pixel Shader
– Speichersystem
• Ausblick in die Zukunft
• Quellenangabe

3
Historische Eckpunkte• Frühe 80er Jahre: erste 3D Systeme von SGI
– Pipeline auf mehrere Boards verteilt
– Nutzten u.a. Motorola 680x0 Prozessoren (4 – 1.3 µm)
– Geometrie Engine mit 5 Weitek 3332 Prozessoren (je 20 MFLOPS)

4
Was geschieht wenn ein 3D Objekt auf den Bildschirm gebracht wird?
Object Space Camera Space
Transform
Quellen[14][15]
vertex,pl.: vertices

5
Rasterisierung
Early Z Test
• Mehr dedizierte Hardware für die einzelnen Schritte
• Nachteil: weniger Kontrolle
• DirectX 8: Einführung programmierbarer Shadereinheiten
Quelle[6]

6
Quad Basiertes Rendering• Quad-Pipelines in den GPUs (Graphic Processing Unit)• 4 Pipes, die auf 2x2 Pixeln arbeiten 4 Pixel/Takt• spart Steuer- und Datenflusslogik• manche Berechnungen nur auf Quads sinnvoll
(LOD, level of detail)
Einzelne Pipes Quad-Pipeline
2x2 Pixel bzw. Quad
Quelle: [4]

7
SIMD, VLIW• SIMD: single instruction multiple data
• VLIW: very long instruction wordsiehe VL RA2
• NVIDIA‘s Design ist Kombination aus SIMD und VLIW
– viele Daten (4 Pixel), viele parallele Recheneinheiten
– Instruktionen mehrere Operationen spart Steuerlogik VLIW macht Instruction Sequencer unnötig
• Treiber muss GPU stets möglichst gut auslasten, dafür mehr Transistoren verfügbar
• Nachteil SIMD: nicht alle Daten genutzt Rechenleistung verpufftBsp.: Ränder von Dreiecken
• Nachteile VLIW: Abhängigkeit von gutem Compilergrößere Shaderprogramme

8
Batchesund die Auswirkungen auf dynamische Verzweigungen
• Einteilung der Pixel in Quad-Batches:Mehrere hundert Pixel pro Batch(Schätzwert NV40: 256 Quads 1024 Pixel)
• Auf allen Pixeln eines Batches wird das gleiche Programm ausgeführthilft Latenzen des Textursamplings zu verstecken
Quelle: [4]4 (2/2)Loop / endloop
2Ret
2Call
6 (2/2/2)If / else / endif
4 (2/2)If / endif
Kosten [Takte]Instruktion
Overhead für Flow-Control Operationen im Shader Programmen
• nur ein Instruction Pointer je Quad-Pipeline
Doppelte Berechnung von Batches, also 1024 Pixel !

9
Der NV40 (GeForce 6800) im Überblick• Host CPU schickt
Kommandos, Texturen, Vertexdaten
• Kommandos werden geparsed
• Vertex Fetch Unit liest benötigte Vertices ein
• Kommandos, Vertices wandern zu den nächsten Pipelinestufen Vertex Shader
Blockdiagramm der NV40 Architektur Quelle: [4]

10
Der Vertex Shader (1/2)(Vertex Processor)
• 16 Inputregister32 temporäre Registermit je vier 32Bit Werten
• Verbindung zum Textur-cache
• Vertex-caches
• Programmlänge: 512 statische und 65536 dynamische Instruktionen
• Overhead Branches und Loops: mind. 2 Takte
• Jeder Vertex Shader hat eigenen Instruction Pointer
Quelle: [4]

11
Quelle: [4]
Der Vertex Shader (2/2)(Vertex Processor)
• 4:1 Aufbau:Vektor4 – Skalar
• je Takt:eine MAD (multiply add)auf Vektor4 undeine Spezialfunktion auf Skalar
• Spezialfunktionen: sin, cos, sqrt (squareroot), etc.für SM3.0 nötig
12
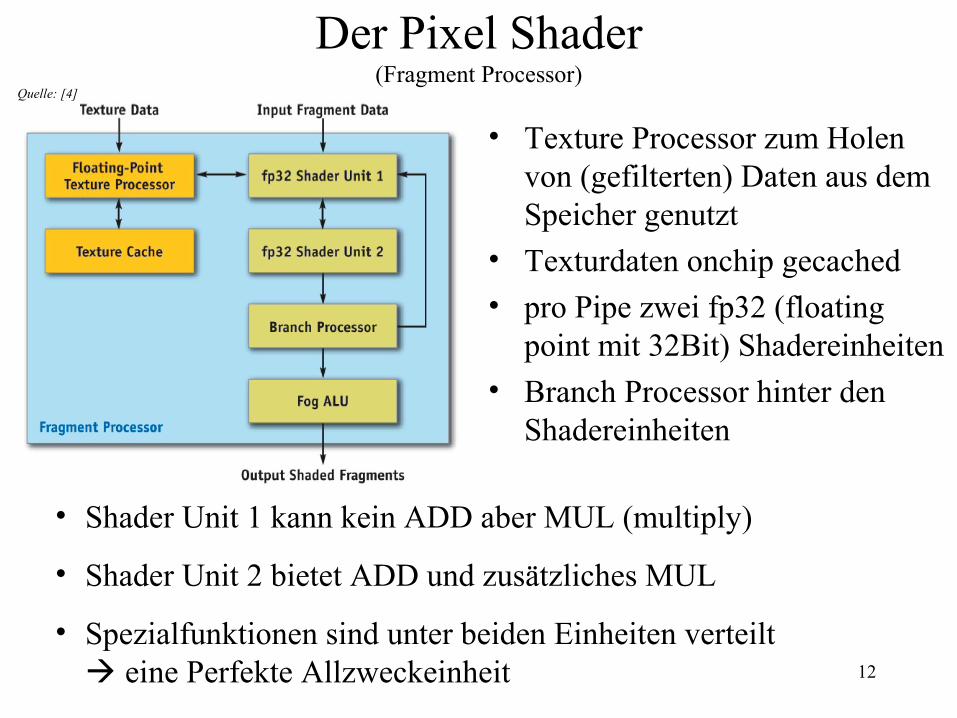
• Texture Processor zum Holen von (gefilterten) Daten aus dem Speicher genutzt
• Texturdaten onchip gecached
• pro Pipe zwei fp32 (floating point mit 32Bit) Shadereinheiten
• Branch Processor hinter den Shadereinheiten
• Shader Unit 1 kann kein ADD aber MUL (multiply)
• Shader Unit 2 bietet ADD und zusätzliches MUL
• Spezialfunktionen sind unter beiden Einheiten verteilt eine Perfekte Allzweckeinheit
Quelle: [4]
Der Pixel Shader(Fragment Processor)
13
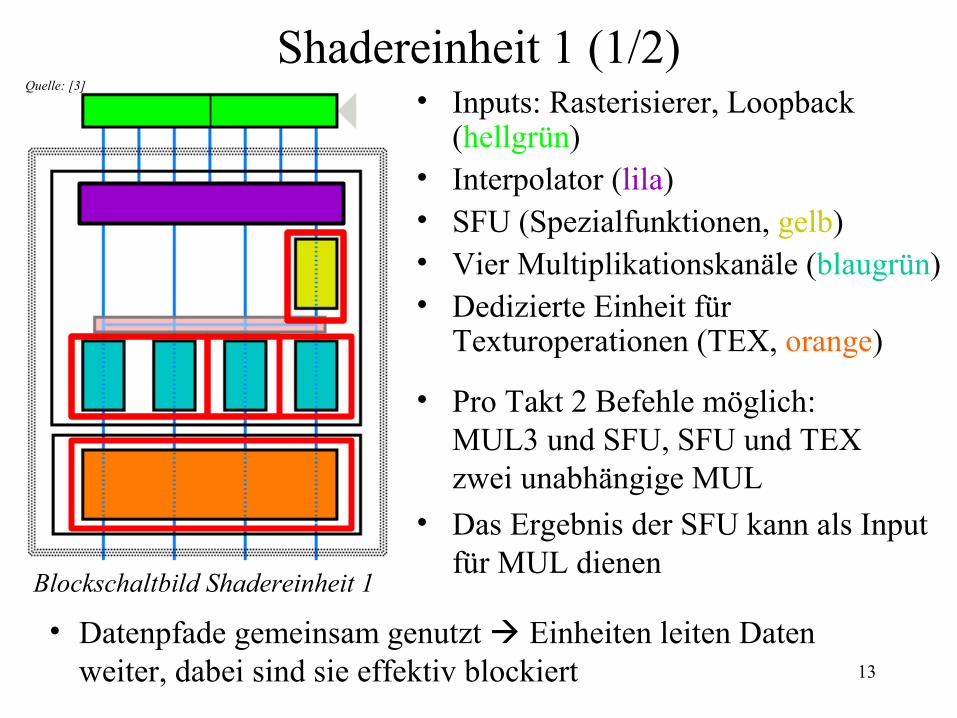
Shadereinheit 1 (1/2)• Inputs: Rasterisierer, Loopback
(hellgrün)• Interpolator (lila)• SFU (Spezialfunktionen, gelb)• Vier Multiplikationskanäle (blaugrün)• Dedizierte Einheit für
Texturoperationen (TEX, orange)
Quelle: [3]
Blockschaltbild Shadereinheit 1
• Pro Takt 2 Befehle möglich:MUL3 und SFU, SFU und TEXzwei unabhängige MUL
• Das Ergebnis der SFU kann als Input für MUL dienen
• Datenpfade gemeinsam genutzt Einheiten leiten Daten weiter, dabei sind sie effektiv blockiert

14
Shadereinheit 1 (2/2)• Textureinheit braucht
Texturkoordinaten als input• Einheit 1 leitet Koordinaten durch
MUL Kanäle blockiert
• SFU jedoch meist noch zur Verfügung
• TEX berechnet LOD• Schickt LOD und Texturkoordinaten
zur TMU(Textur Mapping Unit) Ergebnis als Input für Shaderunit 2
verwendbar
• Textursampling führt zu Latenz andere Quads bearbeiten
Quelle: [3]
Blockschaltbild Shadereinheit 1

15
Shadereinheit 2• Crossbar verteilt 4 Werte auf bis zu
fünf Kanäle (rot)• SFU (Spezialfunktionen, gelb)• Parallel dazu:
– Vier Multiplikationskanäle (blaugrün)
– vier kaskadierte Additionskanäle (grau) mit Zusatzverdrahtung
Skalarprodukt in einem Takt
• Auch hier: Weiterleitung von Daten,2 unabhängige Befehle je Takt
Quelle: [3]
Blockschaltbild Shadereinheit 2

16
• Shadereinheit kann zwei unabhängige Instruktionen parallel ausführen “co-issue“
• Bearbeitung von Vektor4, Vektor3 + Alpha, 2 * Vektor2
• Kombination von dual- und co-issue: bis zu 4 Befehle pro Takt
Quelle: [4]
Zusammenfassung Pixel Shader(Fragment Processor)
beide Einheiten können MUL für bestimmte Instruktionen notwendig
NV40 Pixel Shader kann u.U. so viel berechnen wie zwei herkömmliche Einheiten “dual issue“
Die 4 Kanäle einer Shadereinheit mit angewandtem dual- und co-issue

17
NV40 Fähigkeiten und BedürfnisseBetrachtungen bzgl. optimaler Nutzung der Pipeline
• PS3.0 spezifiziert noch keine DIV(divide) Funktion– Division muss per Hand gemacht werden, also RCP und MUL
– NV40 kann dies trotzdem in einem Takt in Shader Einheit 1
– Optimierer im Treiber muss die beiden Instruktionen in einen Slot packen
• Jedoch Einheit 2 noch völlig frei– mögliche Aufgaben: MAD, Skalarprodukt,
co-issue: skalares MUL und unabhängiges ADD
• Auch Registerzuteilung muss beachtet werden
Schwere Aufgabe für den Optimierer, da keine Steuerlogik zur Optimierung der Instruktionsreihenfolge vorhanden
Mit richtiger Reihenfolge der Befehle VLIWs erzeugen

18
Das Speichersystem
• Verwendung von Standard DRAM Kostenersparnis• Gerenderte Oberflächen im lokalen DRAM
Texturen und Inputdaten im lokalen DRAMund Host-Systemspeicher
• Bis zu vier unabhängige Speicherpartitionenmit je 64Bit Wortbreite
• Effizientes Arbeiten unabhängig von Größe der transferierten Datenblöcke
breites und flexibles Speichersystem erlaubt relativ kleine Speicherzugriffe nahe physikalischen Limits von 35GB/s(550MHz DDR memory clock * 256 bits per clock cycle * 2 transfers per clock cycle)

19
Vergleich Speichersysteme
• CPUs auf minimale Latenz optimiert• Fehlende Parallelität schnelle Speicherzugriffe
– Mehrstufiges Cachesystem, hoher Transistorenverbrauch
– Caches für Grafikdaten bzw. Daten mit einmaligem Zugriff ineffektiv
• GPUs auf maximalen Durchsatz optimiert– Resultiert in besserer Ausnutzung des Speichersystems
– Höhere allgemeine Leistung der Pipeline

20
Zahlenspielereien• Single Core CPU
– 2 MAD in fp32 pro Takt
• GPU– 4 MAD plus 4 Multiplikationen
je Pixelpipeline (R, G, B, A) in fp32 pro Takt
– 4 MAD (Vektor4) plus 1 skalare Spezialfunktion (sin, cos...)je Vertexpipeline in fp32 pro Takt
• NV40:– 16 Pixel Pipes * 4 Kanäle * (1 MAD + 1 MUL) = 64 MAD + 64 MUL
pro Takt allein im Pixelshader
– 6 Vertex Pipes * 4 Kanäle * 1 MAD = 24 MAD pro Takt 88 MAD + 64 MUL pro Takt > 44 fache Leistung einer CPU
– 425 MHz interner Takt > 18GHz für Single Core CPU

21
Was bringt die Zukunft?• ein Instruction Pointer je einzelner Pipe bei Nachfolgegeneration• ATIs R520 besitzt einen Threading-Algorithmus:
– neue Quads kommen in die am wenigsten belastete Pipeline
– Sobald eine Quadpipe freie Kapazitäten hat bekommt sie neuen Thread Latenzen durch Textursampling verstecken
• Auflösung klassischer Pipelines:– Nur noch Threads und Units
– Allzweck Shader als nächste große Revolution in WGF (Windows Graphic Foundation) von Windows Vista, keine Trennung mehr in Vertex und Pixel Shader
Vereinfachter Architekturaufbau Effizientere Nutzung der Shader durch dynamische Lastverteilung
– Beispiel GPU in XBOX 360
• Mehr Takt, mehr Shadereinheiten, mehr Power(bedarf)

22
Quellenangabe• [1]: Carsten Wenzel, „Programmierbare Pixel- und Vertex Shader am Beispiel des
GeForce3 von NVIDIA Hauptseminar SS 2001“http://www.4fo.de/download/PixelVertexShader.pdf
• [2]: Wolfgang Engel, „Shader Programming Part I: Fundamentals of Vertex Shaders“http://www.gamedev.net/columns/hardcore/dxshader1/page4.asp
• [3]: Arne Seifert, „NV40-Technik im Detail“http://www.3dcenter.de/artikel/nv40_pipeline/
• [4]: EmmetKilgariff, Randima Fernando, „NVIDIA GPU GEMS 2“,Chapter 30: „The GeForce 6 Series GPU Architecture“http://download.nvidia.com/developer/GPU_Gems_2/GPU_Gems2_ch30.pdf
• [5]: John Owens, „NVIDIA GPU GEMS 2“,Chapter 29 „Streaming Architectures and Technology Trends“http://download.nvidia.com/developer/GPU_Gems_2/GPU_Gems2_ch29.pdf
• [6]: ATI, „ATI Radeon X800 3D Architecture White Paper“http://www.ati.com/products/radeonx800/RadeonX800ArchitectureWhitePaper.pdf
• [7]: Arne Seifert, „Ein erster Blick auf die R520-Architektur“http://www.3dcenter.de/artikel/2005/10-05_a.php
• [8]: Victor Moya1, Carlos Gonzalez, Jordi Roca, Agustin Fernandez, Roger Espasa„Shader Performance Analysis on a Modern GPU Architecture“http://www.cs.utah.edu/classes/cs7937/papers/vmoya.pdf

23
• [9]: NVIDIA, „Technical Brief CineFX 4.0“http://www.nvidia.com/object/IO_23054.html
• [10]: Arne Seifert, „Kolumne: Wir brauchen SLI“http://www.3dcenter.de/artikel/2004/11-08.php
• [11]: Arne Seifert, „Die Entwicklung der Shader zu "4.0" (WGF)“http://www.3dcenter.de/artikel/2004/09-28.php
• [12]: Volker Schauff, „Die Geschichte der Grafikkarte“http://www.3dcenter.de/artikel/graka-geschichte/
• [13]: Arne Seifert, „Die neuen Features im G70-Chip“http://www.3dcenter.de/artikel/2005/06-26_a.php
• [14]: cyril zeller, „Introduction To The Hardware Graphics Pipeline“http://download.nvidia.com/developer/presentations/2005/I3D/I3D_05_IntroductionToGPU.pdf
• [15]: Ashu Rege, „Introduction to 3D Graphics for Games“http://developer.nvidia.com/docs/IO/11278/Intro-to-Graphics.pdf
• [17]: Gerhard Lenerz, „SGIstuff: Hardware : Graphics : Clover 2“http://sgistuff.g-lenerz.de/hardware/graphics/clover2.html

Vielen Dank für Ihre Aufmerksamkeit!
Gibt es nun noch Fragen?





























