Embed Size (px)
Citation preview

防患于未然——灾害风险管理
于汐防灾科技学院

第二篇 灾害风险分析
第一章 灾害风险识别与度量1
第二章 损失分布与风险估计2
第三章 区域自然灾害风险评估模型3
第五章 地震灾害风险分析4
第四章 生命统计价值评估3

第二章 损失分布与风险估计
n 引言n 第一节 损失分布n 第二节 风险评估模型

第一节 损失分布
n 引言n 一、 概率论与数理统计基本概念n 二、 常用损失分布及性质n 三、 获得损失分布的一般过程

引言
n 风险管理措施依赖于事先对风险做出定量预测,预测的结果就是损失分布。
n 风险是未来的损失(或收益)不确定性,无法用一个数值描述,只能用汇总所有结果的概率分布来描述。
n 概率论与数理统计是损失分布与风险估计的基础。

一、概率论与数理统计的基本概念
(一)概率论基本概念1.随机事件与样本空间
Ø 广义从某一研究目的出发,对随机现象进行观察或测量的过程均可称为随机试验,其结果也称随机事件;一个过程结果的某种集合称为一个事件;
Ø 随机试验的所有基本事件的集合称为此试验的样本空间,其中每一个结果称为样本点。

一、概率论与数理统计的基本概念
(一)概率论基本概念2.概率的定义
Ø 古典概率定义(结果发生必须是等可能的):假设一个试
验包括n种不同的基本事件,这些基本事件发生的可能性都
是相同的。如果在这n个结果种,有m种属于事件A,那么P
(A)=m/n;
Ø 概率的统计定义:将一个试验在相同条件下重复n次,假设
事件A出现了m次。当试验的重复次数足够多时,事件A发生
的概率可以用事件A发生的频率来近似,即 P(A)=m/n。

一、概率论与数理统计的基本概念
(一)概率论基本概念2.概率的定义
Ø 主观概率定义,主观概率也称贝叶斯概率。
Ø 主观概率是指区间[0,1]内的数值,表示个人对一个事件会
在未来发生或者不发生的相信程度(相信度),这种相信
度(信心度)是根据已有的相关知识K做出的最佳判断,假
设给定K,则判断事件E发生的主观概率P(E/K),即依赖K
的条件概率。

2.概率的定义
Ø 全概率公式用于某一事件的概率计算,如果事件组满
足:
Ø ① A1 ,A2,… An两两互斥,且P(Ai)>0(i=1,…,n);
Ø ② A1 +A2+… +An=U(U为整个样本空间),则对任何一事件B
则有,
Ø 当我们对一个事件知道更多时,概率应该被修正。
1( ) ( ) ( \ )
n
i ii
P B P A P B A
一、概率论与数理统计的基本概念
( ) ( \ )( \ )( ) ( \ ) ( ) ( \ )
P A P B AP A BP A P B A P A P B A

一、概率论与数理统计的基本概念

一、概率论与数理统计的基本概念

(二)随机变量与概率分布
1.定义:
Ø 一个随机变量是指这样一个变量,对于过程中的每个结果,都有一个由可能性决定的唯一的数值与之对应。Ø 如果变量的数值有限或可数,则称这个随机变量为一个离散
随机变量。
Ø 如果一个随机变量有无限多取值,这些数值能够和一种没有间断的连续刻度的度量联系起来,则称这种随机变量为连续随机变量。
Ø 一个概率分布(probability distribution)表示随机变量每个值的概率图、表或公式。
一、概率论与数理统计的基本概念

2.随机变量的数字特征Ø 期望值:如果随机试验无限重复下去,我们所期望得到
的平均值。
Ø 方差:表示随机变量取值与其期望值偏离程度。
Ø 定义:离散随机变量X的期望值
Ø 其中 是随机变量X的第i个取值,
Ø 离散随机变量X的方差
i iE x p
iP xip 为 ( )
一、概率论与数理统计的基本概念
ix
2 2( )i ip x 随机变量X的期望值。

Ø 连续随机变量X的期望值
Ø
Ø 为随机变量X的取值,
Ø 为随机变量X的概率密度函数。连续随机变量用函
数形式表示概率分布称为概率密度函数
E ( )xf x dx=
x( )f x
一、概率论与数理统计的基本概念
2 2( ) ( )x f x dx
Ø 连续随机变量X的方差

(二)数理统计基本概念
1、统计推断:
Ø 如果概率论属于演绎研究方法,数理统计则属于归纳法;
Ø 统计推断定义为抽取样本观察,整理分析判断,得出一般结论,并对推断结论可信度做出计量。
一、概率论与数理统计的基本概念

2、总体、样本与分布
定义:
Ø 按照统计研究目的而确定的同类事物或出现现象
的全体称为总体,它是个体或特体性质的集合。
样本(sample)指从总体中抽取若干个元素而构
成的集体。
Ø 数理统计中,一般采用概率抽样,即每个单位都
有指定概率被选中,便于基于概率论推断总体。
一、概率论与数理统计的基本概念

Ø 总体的数值分布的规律称为总体分布,其中的特征数称为参数。
Ø 从总体中抽取容量为n的样本,样本观察值的分布称为经验分布。
Ø 使用样本数据来估计总体参数的公式或过程称为估计量。
Ø 用来近似总体参数的特征数值或数值的范围称为估计值。
Ø 样本数据平均值称为样本均值,样本数据的方差和标准差分别称为样本方差和样本标准差。
一、概率论与数理统计的基本概念

3.偏度Ø 矩也称为动差。以零为中心矩称为原点k阶矩,
Ø 当k=l 时,就是算术平均数,即1阶原点矩就是算术平均数。
一、概率论与数理统计的基本概念

一、概率论与数理统计的基本概念

Ø 矩偏度是以变量的三阶中心动差除以标准差三次方,来衡
量分布不对称程度,或偏斜程度的指标。
Ø 当α > O时,为正偏,右偏,分布曲线右尾端较厚;
Ø 当α < O时,为负偏,左偏,分布曲线左尾端较厚。
一、概率论与数理统计的基本概念

Ø 皮尔逊偏度系数( Pearson )以平均值与中位数或众数之差与标准差之比来衡量偏斜的程度,用SK表示偏斜系数。
Ø 偏度(skewness是统计数据分布非对称程度的数字特征,表征概率分布密度曲线相对于平均值不对称程度。
Ø 偏度的统计(spss)计算公式:
一、概率论与数理统计的基本概念

Ø 将数据按照大小依次排列,处于中间位置的数值称为中
位数,出现最多的那个数值称为众数。
Ø 如果数据的均值、中位数和众数三者是相同的,则这个
分布是对称分布,没有偏态。
Ø 根据众数、中位数与均值各自的性质,通过比较众数或
中位数与均值来衡量偏斜度的。
Ø 如果一个分布的众数小于中位数,则称其为正偏或右偏,
反之称为负偏或左偏。
一、概率论与数理统计的基本概念
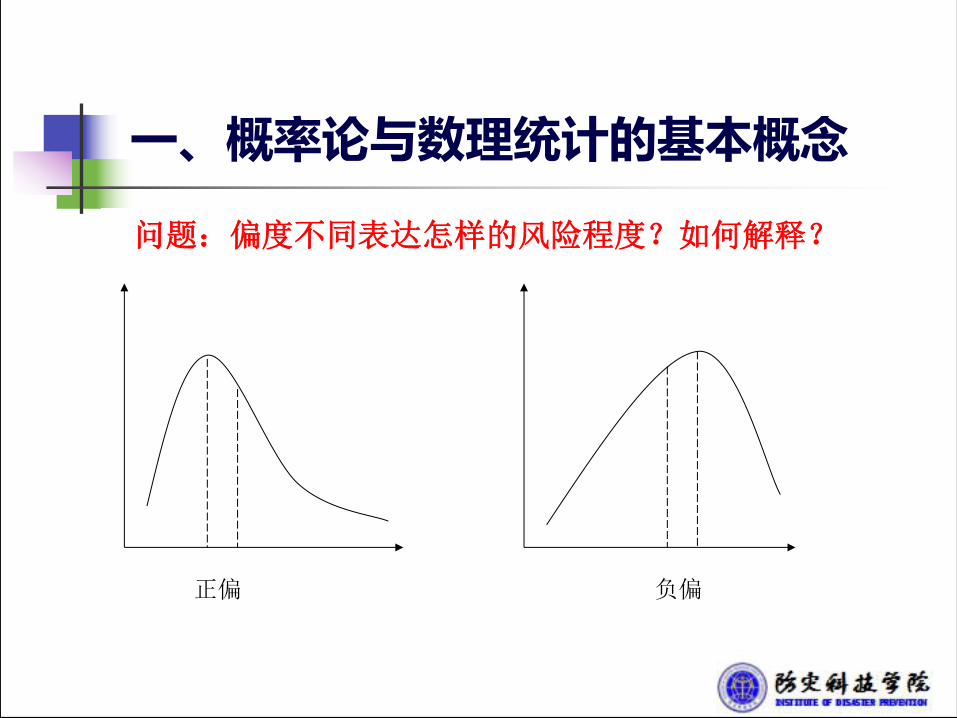
一、概率论与数理统计的基本概念
问题:偏度不同表达怎样的风险程度?如何解释?
正偏 负偏

4、峰度Ø 峰度又称峰态系数。表征概率密度分布曲线在平均值处峰
值高低的特征数,峰度反映了峰部的尖度。
Ø 设若先将数据标准化,则峰度(系数)相当于标准化数据序列的四阶中心矩。
Ø 峰度是以变量的四阶中心动差除以标准差的四次方,并将结果再减去3,用来衡量频数分布的集中程度,也是衡量分布曲线尖峭程度的指标。
一、概率论与数理统计的基本概念

4、峰度
Ø 峰度指标是以正态分布的峰度为比较标准(正态分布的峰
度=0 ),来比较不同频数分布的尖峭程度。
Ø 当峰度> 0,表示频数分布比正态分布更集中,分布呈尖
峰状态,平均数代表性更高。
Ø 当峰度<0时,表示频数分布比正态分布更分散,分布呈平
坦峰,平均数代表性较低。
Ø 峰度的统计(spss)计算公式,
一、概率论与数理统计的基本概念
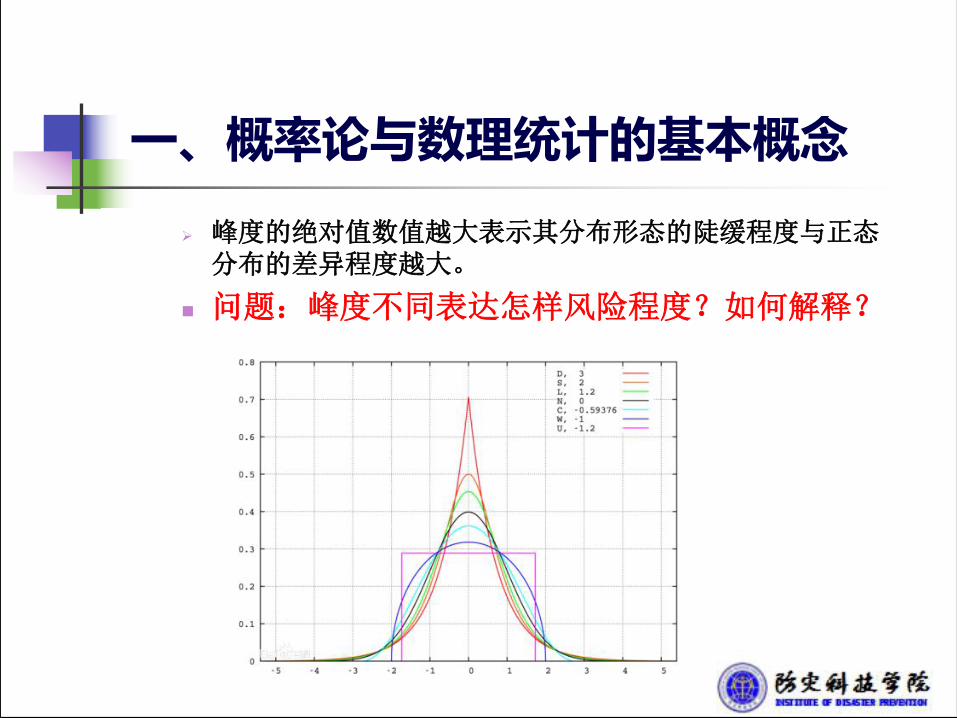
Ø 峰度的绝对值数值越大表示其分布形态的陡缓程度与正态分布的差异程度越大。
n 问题:峰度不同表达怎样风险程度?如何解释?
一、概率论与数理统计的基本概念
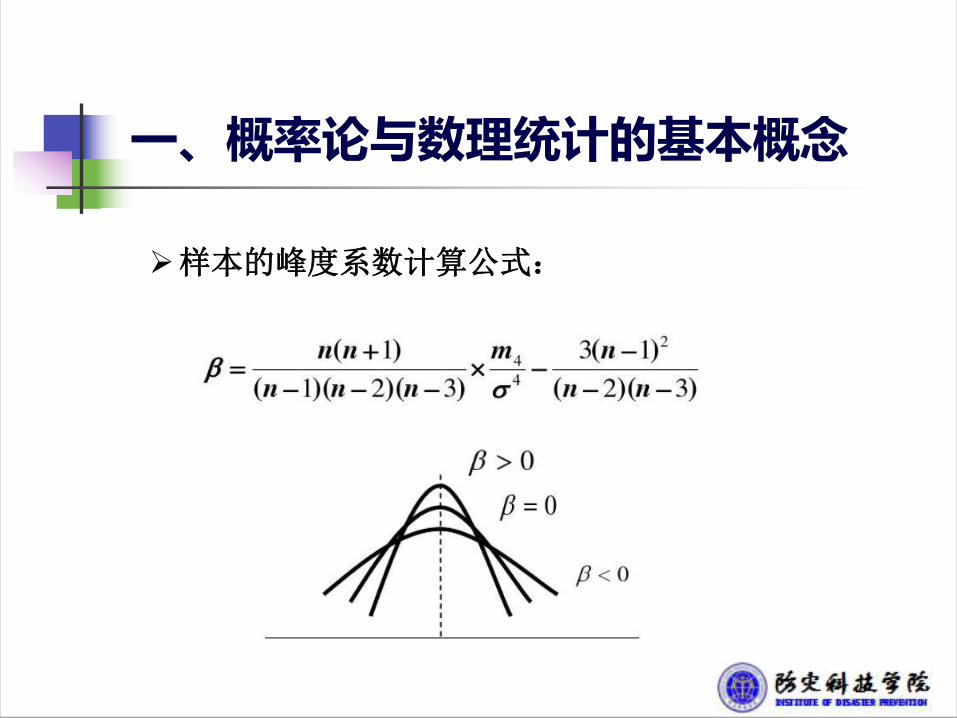
Ø样本的峰度系数计算公式:
一、概率论与数理统计的基本概念
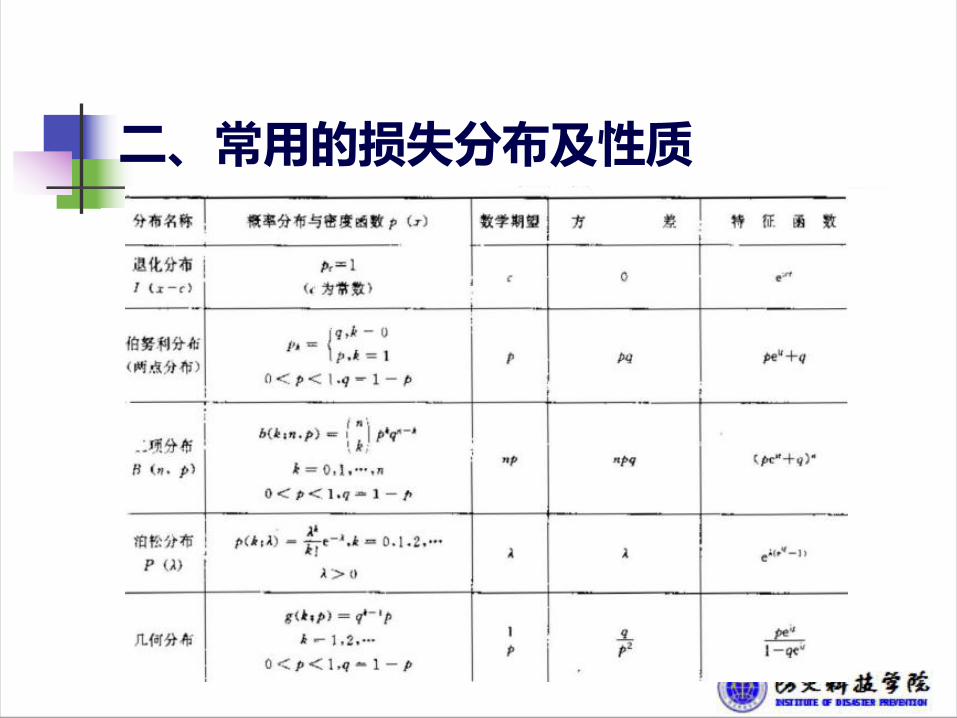
二、常用的损失分布及性质

二、常用的损失分布及性质

二、常用的损失分布及性质

二、常用的损失分布及性质

二、常用的损失分布及性质

二、常用的损失分布及性质

三、获得损失分布的一般过程
获得损失分布方法:
Ø 经典统计法是指在数据相对完备的条件下,通过总
体信息和样本信息来确定损失的概率分布、估计其
未知参数。
Ø 贝叶斯方法采用先验概率、损失函数等主观信息来
估计未知参数,估计损失的概率分布。
Ø 随机模拟应用计算机程序对实际过程进行模拟,在
模拟结果的基础上对损失分布进行估算。

(一)经典统计方法
Ø 基于总体信息和样本信息进行的统计推断被称为经
典统计学。
Ø 其过程如下:
(1)获得损失分布的大体轮廓得出密度函数曲线
(2)选择分布类型
(3)估计参数,确定概率分布:用矩法或极大似然法
(4)对分布及参数进行检验:卡方检验
二、常用的损失分布及性质

(二)贝叶斯方法
Ø 经典统计方法是建立在具有独立性和代表性的样本信息基础上,但在风险管理实践中,有时对损失分布的估计需要加入主观判断,并利用获得的数据修正原来的估计的方法就是贝叶斯方法。
Ø 在风险管理实践中,难以获得足够样本信息,或者现有样本信息不符合对统计样本的理论要求,此时,对损失分布的估计就需要加入评估人的主观判断,并利用新获得的证据来修正原来的估计。
二、常用的损失分布及性质

Ø 设损失变量X的分布函数为 ,连续情形下相
应的密度函数族为 。
Ø 估计 的贝叶斯方法和经典统计方法区别:贝叶斯
将 看做一个随机变量。其步骤如下:
Ø (1)选择先验分布;
Ø (2)确定似然函数;
Ø (3)确定参数 的后验分布;
Ø (4)选择损失函数并估计参数。
( , )F x ( , ).f x
二、常用的损失分布及性质

Ø 损失函数的选择及其参数估计
Ø 待估计参数的后验分布及其估计值。因为参数视为随机
变量,选择什么指标作为后验估计,取决于评估者对参
数真实值和估计值之间差距的严重程度的价值判断。这
个严重程度为损失,对损失的度量称为损失函数。
Ø 最好的估计应该使得损失函数的值最小,求损失函数期
望值的最小值:
二、常用的损失分布及性质
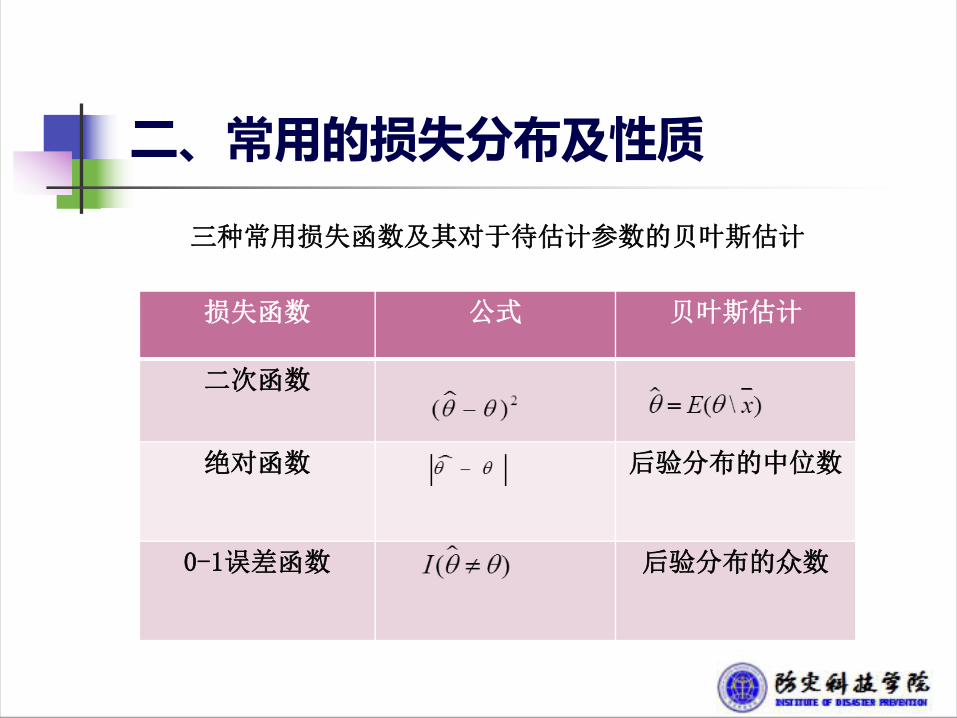
三种常用损失函数及其对于待估计参数的贝叶斯估计
二、常用的损失分布及性质
损失函数 公式 贝叶斯估计
二次函数
绝对函数 后验分布的中位数
0-1误差函数 后验分布的众数

(三)随机模拟法
二、常用的损失分布及性质

第二节 风险评估模型
n 引言
n 一、大数定律与中心极限定理
n 二、损失频率的估算
n 三、损失幅度的估算
n 四、所需暴露单位的数量

引言
n 风险评估是介于风险识别和风险措施选择之间的一个环节,这个环节非常关键。
n 风险评估主要应用基于概率论与数理统计的定量方法。

一、大数定律与中心极限定理
Ø 大数定律与中心极限定理是概率论中的两个重要
理论,在风险评估中应用普遍,也是一些重要的
风险管理措施的理论基础(保险)。
Ø 大数定律用来阐述大量随机现象平均结果稳定性
的一系列定理的统称,中心极限定理则是指随着
样本观测值的增多,平均值的概率分布越来越趋
近于钟形的正态分布。

一、大数定律与中心极限定理
(一)大数定律
n 大数定律用来阐述大量随机现象平均结果稳定性
的一系列定理的统称,中心极限定理则是指随着
样本观测值的增多,平均值的概率分布越来越趋
近于钟形的正态分布。

一、大数定律与中心极限定理

n 大数定律概念
n -组相互独立同分布的期望μ方差σ的随机变量,它们的n个变量的算数平均值的期望和方差,
一、大数定律与中心极限定理

n 根据上式得到:随着试验次数增加,n次试验的算术平均1值的数学期望将保挣不变,而其方差则随着n的增加而减少,趋于0 ,因此,算数平均值将趋于一个常数,即随机变量的期望,公式表达为,
n 若存在常数X, 使对于任何ε>0, 有
n 称随机变量序列{Xn}依概率收敛于X。
一、大数定律与中心极限定理

定理2(贝努力大数定律)设X是n次独立重复试验中事件A发生的次数,P(0 < P < l )是事件A在每次试验中发生的概率,则对于任意正欲ε> 0 , 有
一、大数定律与中心极限定理

n 这个定理说明只要试验次数足够多,一个随机变量的算术平均值将趋于常数,就是数学期望。
n 根据大数定律,如果有n个面临相同风险的风险单位,令 为共同损失期望 ,当n很大时,则平均损失趋近于 。因此,在估计类似平均损失,当n足够大时,估计的准确性就会比较高。
一、大数定律与中心极限定理

一、大数定律与中心极限定理
二、中心极限定理
1、抽样分布
在风险评估中,我们经常需要利用来自样本的信息推断总体的一些性质,如利用样本信息总体的某个数字特征,即参数。
定义:总体的数字描述性量度称为参数。从样本观察值算出的量称为统计量。某个样本统计量(含有n个观察值)的抽样分布,理论上说重复抽取容量为n的样本时,由每个样本算出的该统计量数值的频率分布。

一、大数定律与中心极限定理
二、中心极限定理
2、中心极限定理
在风险评估中,我们需要推断某个总体均值,这样
样本均值通常推断为总体参数期望的工具,中心极
限定理指出了均值的性质。
已知:
(1)随机变量X服从一个均值为 ,标准差为 的分布;(是否正态均可);
(2)所有具有相同容量n的样本都是从一个含有x个数值的总体中随机抽取。

一、大数定律与中心极限定理
结论:
(1)随样本容量增加,样本均值 趋近于正态分布;
(2)样本均值的均值将趋近于总体均值 。即结论(1)
的正态分布均值为 ;
(3)样本均值的标准差将趋于 。
上述结论公式表示:
x
/ n
lim{ } ( )/x
x x xn

一、大数定律与中心极限定理
应用法则:
(1)对于容量n大于30的样本,样本均值的分布可以
较好地用一个正态分布近似。
(2)如果原始总体自身是正态分布的,则对于任意样
本容量n,样本均值都将是正态分布。

一、大数定律与中心极限定理
例题1:
设一个系统由100个相互独立作用的部件组
成,每个部件损坏的概率为0.1,必须有85
个以上的部件才能使整个系统工作,求整
个系统失效工作的概率。

一、大数定律与中心极限定理
100*0.1 15 100*0.1{ 15} { }100*0.1*0.9 100*0.1*0.9
15 100*0.1 5 0.9523100*0.1*0.9
Xp X p

一、 大数定律与中心极限定理
例题2:
设某保险公司的老年人人寿保险一年有1万人
参加,每人每年交40元。若老人死亡,公司
付给受益人2000元。设老人死亡概率为0.017,
试求保险公司在这次保险中亏本的概率。

一、大数定律与中心极限定理
解:
设老人死亡数为X,X~B(n,p),其中
n=10000,p=0.017.由题设,保险公司亏本
当且仅当2000X>40*10000,X>200.则由中
心极限定理,保险公司亏本概率为
2 0 0{ 2 0 0} { }(1 ) (1 )
2 0 01 1 2 .3 2 1 0 .0 1 0 1 7(1 )
X n p n pp X pn p p n p p
n pn p p

二、损失频率的估算
损失频率是指一定时期内某风险事故发生
的次数,很多情况下可以用理论分布估算
某种损失的频率。包括二项分布、泊松分
布、负二项分布等。

二、损失频率的估算

二、损失频率的估算
n 确定损失次数分布的方法n 假定公司有100栋房子,分析这些房子可能着火的数目。
假定每栋房子在一年内最多失火一次,那么,在这种情况下,随机变量N的可能取值为0、1、2、……、100。我们需要构造一个关于N的分布,以表示每个取值的概率。
n 分析这100栋房子的火灾历史,看没有任何房子发生火灾的年数有多少;有一栋房子失火的年数有多少;有两栋房子失火的年数有多少;如此类推。
n 利用一些概率分布模型来描述实际问题,而历史数据仅仅用来估计模型参数,而不是直接用于计算概率。

二、损失频率的估算
n 二项式模型n 用n代表风险单位的数量,每个风险单位的结果要么是0,要
么是1。另外假定,每个风险单位都以相同的概率p发生损失;模型假定n个风险单位是相互独立的。
n 总损失次数的概率分布:
n 二项式模型中只有一个参数,这就是每个风险单位发生损失的概率p。这需要通过历史数据计算得到。
n E[N]=np,VAR[N]=np(1-p)
{ } ( 0,1,...,5)x x n xnp X x C p q x

二、损失频率的估算
(一)运用二项分布进行估算例3:某企业有5栋建筑物。根据过去的损失资料可
以知道,其中任何一栋在一年内发生火灾的概率都
是0.1,且相互独立。发生两次火灾可能性极小,可
以忽略。
试计算下一年该企业
(1)不发生火灾概率
(2)两栋以上发生火灾概率
(3)火灾次数的平均值和标准差

二、损失频率的估算
解 :由已知条件可知,
(1)风险单位总数n=5,且每栋建筑物发生火灾的概率均值p=0.1;
(2)这5栋建筑物互相独立,发生火灾时不会互相影响;
(3)一栋建筑物在一年内发生两次火灾的可能性极小,可认为其概率为0。
据此,建筑物发生火灾的栋数可以用二项分布来描
述,其概率分布为
{ } ( 0,1,...,5)x x n xnp X x C p q x

二、损失频率的估算
发生火灾栋数X 概率
0 0.5905
1 0.3281
2 0.0729
3 0.0081
4 0.0004
5 0
发生火灾栋数及其概率如下表:

二、损失频率的估算
因此,(1)下一年不发生火灾的概率q=P(X=0)=0.5905
(2)两栋以上建筑物发生火灾的概率
q=P{X=3}+P{X=4}+P{X=5}
=0.0081+0.0004+0.0000=0.0085
(3)下一年发生火灾次数的平均值和标准差分别为
5 0.1 0.5
(1 ) 5 0.1 0.9 0.67
n p
np p

二、损失频率的估算
(二)运用泊松分布进行估算
每个风险单位在一定时期内最多发生一次风险事故
时,可以运用二项分布估算,但如果每个风险单位在
一定时期内可能发生多次风险事故,二项分布就不适
用了。因此,当风险单位数n很大而发生事故概率p很
小时,采用泊松分布。

二、损失频率的估算
n 在历史较短的情况下,记录中的损失次数不能完全反映实际情况。如果仅仅根据历史数据来确定损失次数的分布,就会出现历史数据不能涵盖所有可能损失次数的情况。显然,仅仅依据一段时间的观察就得到的结论是不可靠的。通常一段时间未观察到的损失次数,并不能保证以后每年都不会出现这种情况。n 用泊松模型解决上述问题:
n 式中,λ是在所考虑的时间内的平均损失次数;n 注意到也仅由一个参数决定:λ=E[N],它可以通过所观察
到的数据估计;n e是自然数,e=2.7182818。
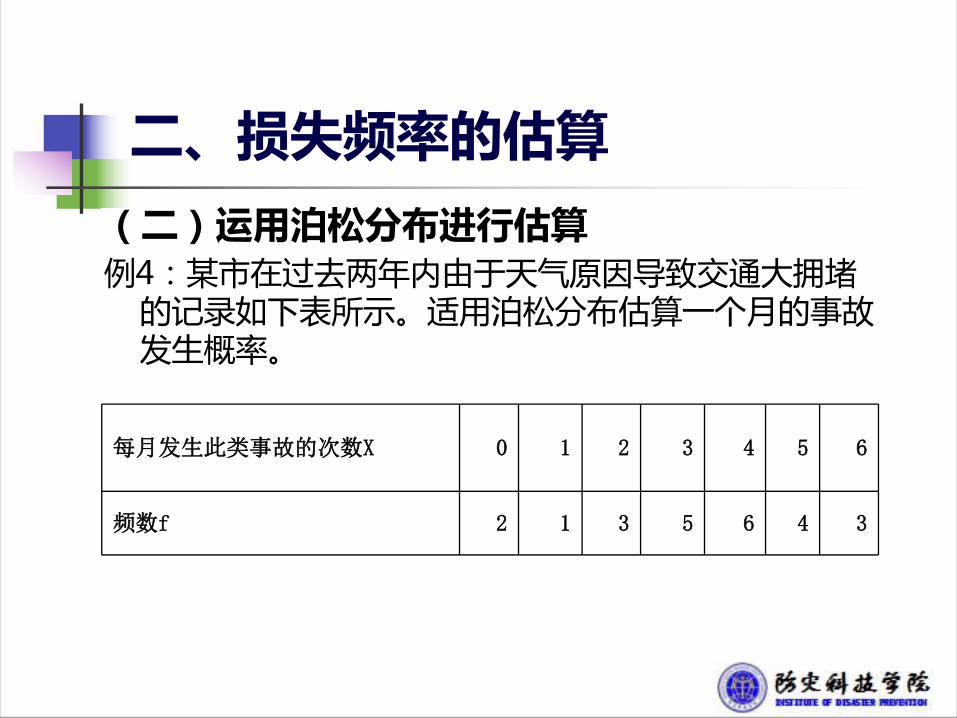
二、损失频率的估算
每月发生此类事故的次数X 0 1 2 3 4 5 6
频数f 2 1 3 5 6 4 3
(二)运用泊松分布进行估算例4:某市在过去两年内由于天气原因导致交通大拥堵
的记录如下表所示。适用泊松分布估算一个月的事故发生概率。

二、损失频率的估算
解:
令X表示每月由于天气原因造成的交通大拥堵,由已知条件可知,X~p( )。 根据已知数据似计算出泊松分布参数
6
06
0
3 .5i i
i
ii
x f
f

二、 损失频率的估算
交通事故数X P0 0.030191 0.10572 0.18503 0.21574 0.1888
5 0.13216 0.07717 0.03858 0.0169
将 代入泊松分布公式,所得结果如表所示:3.5

二、损失频率的估算
从计算中可以看出:(1)任何一个月不发生此类大拥堵的概率为0.03019.概率很小,意
味着不发生此类大拥堵的可能性较小;
(2)发生一次以上的概率p=1-0.03019=0.9698.即未来任何一个
月发生此类大拥堵的可能性很大;
(3)在已知历史资料中,一个月内事故发生的最高次数是6次,然而
从估计结果看,为未来任何一个月中,有可能出现多于6次的情况。
主要是我们观察的时间不够长,没有出现这样小的概率事件。

二、损失幅度的估算
n 损失程度的概率分布反映企业财产在一次损失中的损失数额的分布。
n 如果有足够的历史数据,那么根据历史上损失情况的统计分析,有可能根据各次事故发生时记录的实际损失金额得到损失程度的概率分布。
n 但是,有可能每次损失发生时,损失的数额都不同,也就是说有这100次损失中的损失数额发生的概率都是1/100=0.01。
n 可以将损失数额分段,以反映轻微损失、严重损失和致命损失发生的概率分布情况。

二、损失幅度的估算
n 例:设根据以往每次灾害发生时损失的历史数据,把损失数额分段考虑如下:

二、损失幅度的估算
n 这种按损失范围得到的概率分布仍然无法直接用于决策。可以用每个损失数额段中的一个代表性数额代替这个数额段。例如,2万元以下以1万元代替,这样就得到损失程度的概率分布:

二、损失幅度的估算
n 年总损失额的概率分布n 根据以上的方法可以获得损失次数和在一次损失
中损失额的分布。

二、损失幅度的估算
n 当损失次数为0时,总损失额为0,概率为p1;损失次数为1次时,有两种可能的损失结果,损失额分别为L1或L2;当损失次数为2时,有4种可能的损失结果:两次损失均为L1,两次损失均为L2,第一次损失L1且第二次损失L2,第一次损失L2且第二次损失L1。总损失额分别为2 L1,2 L2,L1+ L2,L2+ L1。这样,就考虑了年总损失额所有可能的情况。每年损失额的概率分布为:

二、损失幅度的估算
n 损失的次数和一次损失中损失金额的分布如下:
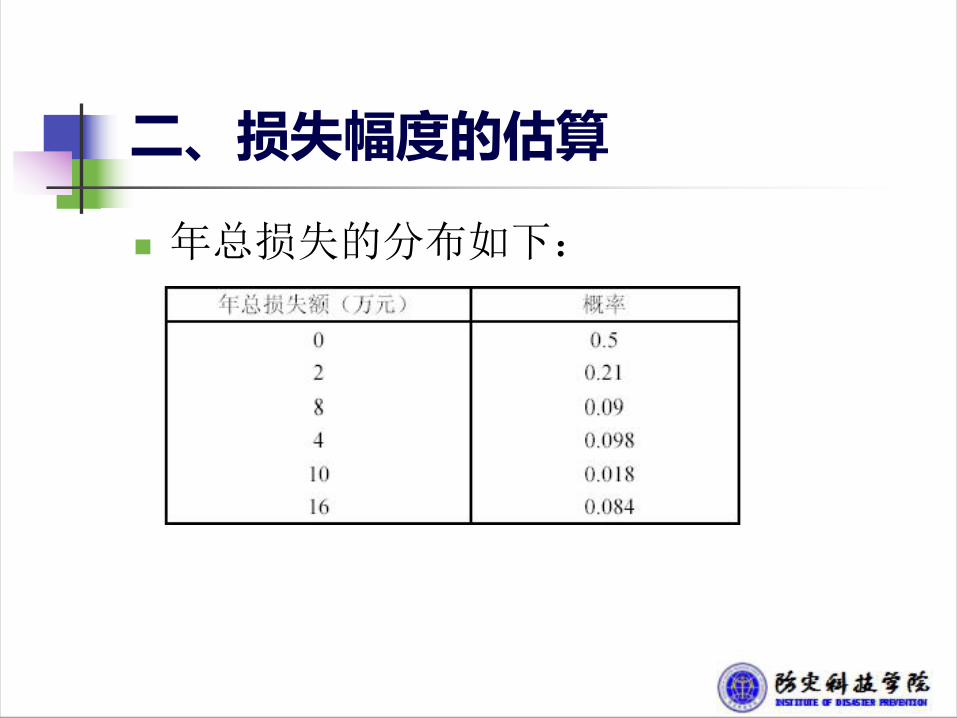
二、损失幅度的估算
n 年总损失的分布如下:

三、损失幅度的估算
(一)每次风险事故所致损失
Ø 风险事故发生的次数是离散型随机变量,全部可能发
生的次数与其相应的概率都可以一一列举出来。
Ø 但损失金额一般来说不能全部列举出来,它可以在某
一区间内取值,连续型随机变量。

三、损失幅度的估算
损失金额 5--15 15--25 25--35 35--45 45--55 55-65 65--75
次数 2 9 28 30 21 5 1
(一)每次风险事故所致损失
例5:一个村民每次遭受洪水水灾而导致的损失金额如下表:

三、损失幅度的估算
求:
(1)每次灾害所致损失金额小于500元的概率?
(2)每次灾害所致损失金额在4500-6000元之间的概率?
(3)每次灾害所致损失金额大于7500的概率?

三、损失幅度的估算
损失金额 5-15 15-25 25-35 35-45 45-55 55-
65 65-75
中值xi 10 20 30 40 50 60 70
xi^2 100 400 900 1600 2500 3600 4900
频数fi 2 9 28 30 21 5 1
fixi 20 180 840 1200 1050 300 70
fixi^2 200 3600 25200 48000 52500 18000 4900
解:由已知得下表

三、损失幅度的估算
损失金额的期望值:
损失金额的标准差:
3660 38.12596
fixifi
2 22 2 152400 3660 11.57596 96
fixi fixifi fi

三、损失幅度的估算
(1)每次灾害所致损失金额小于500元的概率:
(2)每次灾害所致损失金额在4500元和6000元之间的概率:
(3)每次灾害所致损失金额大于7500元的概率:
5 38.125( 5) (5) ( ) ( 2.86)11.575
1 (2.86) 0.0021
p X F
60 38.125 45 38.125(45 60) (60) (45) ( ) ( )11.575 11.575
(1.89) (0.594) 0.47062 0.22240 0.24822
p X F F
75 38 .1 25(7 5 ) ( ) (7 5 ) ( ) ( )1 1 .5 75
( ) (3 .1 8 6 ) 1 0 .9 93 0 .0 007
p X F F

三、损失幅度的估算
(二)一定时期总损失
一定时期总损失是指在已知该时期内损失次数概率分布和每次损失金额概率分布的基础上所求的损失总额。

三、损失幅度的估算
损失次数概率分布 每次损失金额的概率分布
损失次数 概率 损失金额(元) 概率
0 0.5 1000 0.8
1 0.3 5000 0.2
2 0.2
例6:已知某一风险每年损失次数的概率分布和每次损失金额的概率分布如下表:求每年总损失金额的概率分布。
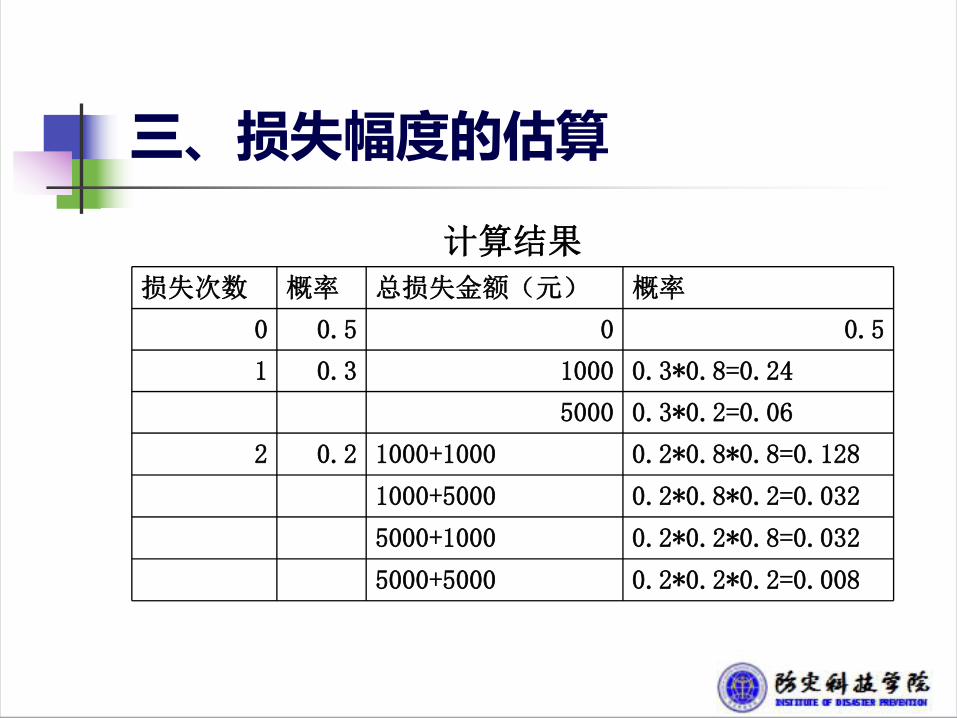
三、损失幅度的估算
计算结果
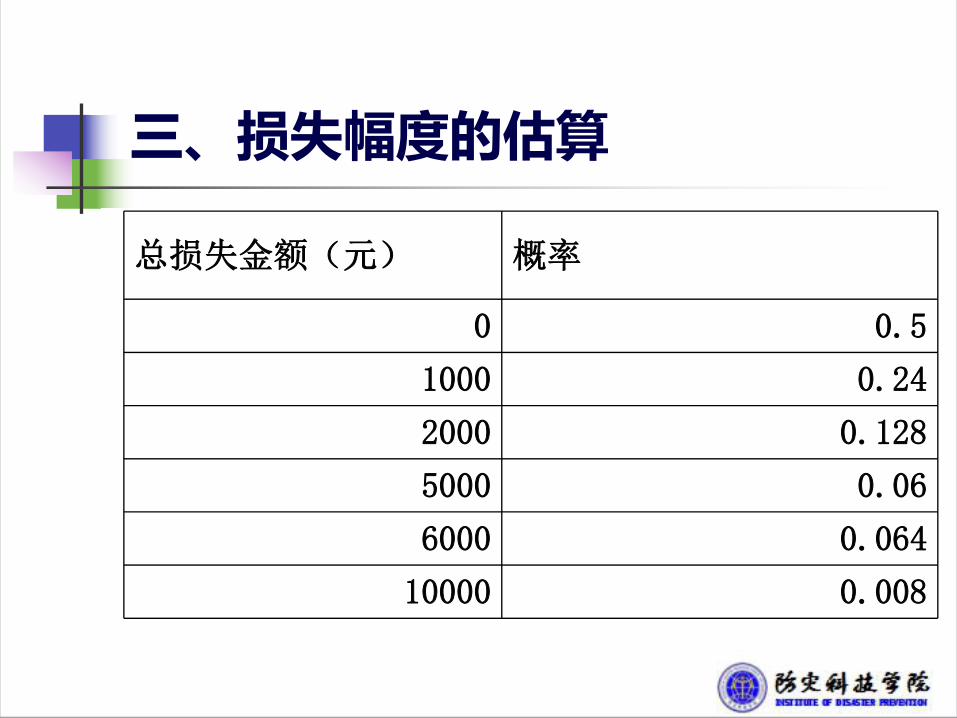
损失次数 概率 总损失金额(元) 概率
0 0.5 0 0.5
1 0.3 1000 0.3*0.8=0.24
5000 0.3*0.2=0.06
2 0.2 1000+1000 0.2*0.8*0.8=0.128
1000+5000 0.2*0.8*0.2=0.032
5000+1000 0.2*0.2*0.8=0.032
5000+5000 0.2*0.2*0.2=0.008
三、损失幅度的估算
总损失金额(元) 概率
0 0.5
1000 0.24
2000 0.128
5000 0.06
6000 0.064
10000 0.008

三、损失幅度的估算
(三)均值和标准差的估算
当我们关心损失幅度的某个特征值,如均值和方差,
可以对总体均值和标准差进行区间估算。
1、样本容量较大,已知样本均值和抽样误差,估计总体均值。
样本容量较大时,样本均值是服从正态分布的随机变
量,则可以得到总体均值区间估计:
( ) 1a aX Xp X z X z

三、损失幅度的估算
例7:某保险公司承保汽车1500辆,随机地抽取100辆来调查过去由于意外事故的平均损失金额,整理后,数据如下表所示:
损失金额(百元) 组中值xi 车辆数fi
10--14 12 3
14--18 16 7
18--22 20 18
22--26 24 23
26--30 28 21
30--34 32 18
34--38 36 6
38--42 40 4

三、损失幅度的估算
试估算这组汽车平均损失金额。
解:根据已知可以求出样本均值和抽样误差。
22
2 6
6 .4 4
6 .4 4 0 .6 4 41 0 0
i i
i i
i
x
x fx
nf x
s xf
sn

三、损失幅度的估算
试估算这组汽车平均损失金额。
解:
• 平均损失在 ,即(2600-0.644,
2600+0.644),可靠性为为68.3%;
• 在 即(2600-2*0.644,2600+2*0.644)之
间,可靠性为95.5%;
• 在 即(2600-3*0.644,2600+3*0.644)
之间,可靠性为99.7%。
( )xx
( 2 ),xx
( 3 ),xx

三、损失幅度的估算
样本容量较小,总体为正态分布而方差未知时,估计总体均值. 样本容量较小,总体为正态分布时,统计量
服从自由度为n-1的t分布,则有
/ 1Xt
s n

三、损失幅度的估算
( ) ( ) ( )/ 1 / 1
( ) 11 1
x xp t t p t p t ts n s n
s sp x x tn n

三、损失幅度的估算
例8:某公司有30栋结构相同的建筑物,风险管
理者掌握其中一栋建筑物在过去20年内由于地
震而受损记录,共15次。这15次损失平均值为
800元,标准差80元。试估算这些建筑物因地
震所致损失的情况。

三、损失幅度的估算
解:
在95%的置信度下,总体平均损失置信区间为:
如果置信度为90%,则总体平均损失的置信区间
为:
80 80(800 2 .145 * , 800 2 .145 * )15 1 15 1
80 80(800 1.761* ,800 1.761* )15 1 15 1

三、损失幅度的估算3、样本容量较小,总体为正态分布时,估计总体方差
样本容量较小,总体为正态分布时,统计量
服从自由度为n-1的卡方(平方)分布,则
22
2
sx n

三、损失幅度的估算
例9:某公司为了估计下一年度因产品责任而可能遭受损失的索赔情况,收集了前一年索赔资料,其中的索赔金额分别为:
第一季度:42,65,75,78,87;
第二季度:45,68,72,90;
第三季度:24,65,80,80,81,85;
第四季度:36,58,77.
估算该企业平均损失金额的情况和损失金额方差。

三、损失幅度的估算
解:在95%置信度下,总体平均损失额额置信区间为:
在95%置信度下,总体方差置信区间为:
17.04 17.04(67.11 2.11* ,67.11 2.11* )17 17
5 2 2 4 .7 5 2 2 4 .7( , )3 0 9 7 .5 6

四、所暴露单位的数量
当样本不足够大时,如果风险管理者希望有(1-a)
的把握保证,组织面临的某种实际损失率与给定的
预期损失率之差的变动程度不超过E,则风险单位
数要有多大才能满足要求?
对于某个可靠程度值a,实际损失率与预期损失
率之间的差,即误差限
则所需样本容量:
/2E Zn
2/ 2ZnE

四、所暴露单位的数量
置信度 a 临界值Za/2
90% 0.1 1.645
95% 0.05 1.96
99% 0.01 2.575
表:正态分布置信度及其临界值

四、所暴露单位的数量
例10:某公司的风险管理人员,希望有95%的可
靠程度使该企业货车面临遭受灾害事故设定
的预期损失率(30%)之差不超过2%,如果损
失概率分布为正态分布,
试求:该公司要有多少辆货车才能达到此要求?

四、所暴露单位的数量
解:这里损失指的是损失个数。当n足够大时,损失个数
近似服从正态分布。由于损失个数实际上服从二项分布,
所以这个正态分布的参数可以设为
损失率指的是损失的总个数除以风险单位总数n,因此,
损失率的样本标准差为
, (1 )np np p
(1 ) / (1 ) /S np p n p p n

四、所暴露单位的数量
则
2
/2
/2
2
(1 ) /
(1 )
E Z p p n
Z p pn
E
2
2
p 0.3 E=2 1 951.96 *0.3*0.7 2017
0.02
将 = , %, = %代入上试,有
n=

四、所暴露单位的数量
例11:某保险公司在承保某种资产自然灾害
保险时,想要95%的可靠性估算发生自然灾
害的平均损失金额。从以往的资料中发现,
损失标准差s=40元。现要求估计误差不超
过8元,需要抽取多少件样本满足要求?

四、所暴露单位的数量
解:
至少抽取97件样本才能满足要求。
2 2 2/ 2
2
8,1 95% , 40,
1.96 * 40 978
E S
ZnE
则,

本章小结:
1、损失分布概率论与数理统计
(1)损失分布的概率论与数理统计应用基础
(2)常用损失分布类型及获得损失分布方法
2、大数定律与中心极限定理
(1)大数定律与中心极限定理
(2)损失频率与损失幅度的估算






























