Embed Size (px)
DESCRIPTION
Esercitazioni. Software. Textpad ( editor di testo) Arlequin (Pacchetto per genetica di popolazioni) Past (analisi varie). Esercitazioni: Contenuti. Stima parametri Intra-popolazione ( MtDNA , Y Chr.) Stima parametri demografici ( MtDNA ) - PowerPoint PPT Presentation
Citation preview

Esercitazioni

Software
Textpad (editor di testo)
Arlequin (Pacchetto per genetica di popolazioni)
Past (analisi varie)

Esercitazioni: Contenuti
Stima parametri Intra-popolazione (MtDNA, Y Chr.)
Stima parametri demografici (MtDNA)
Stima parametri Inter-popolazione (MtDNA, Y Chr.)
Rappresentazioni grafiche (PAST) (MtDNA, Y Chr.)

Flusso genico differenziale Pigmei Bantu
PIGMEI•Cacciatori raccoglitori•Piccole dimensioni•Bassa taglia effettiva•Struttura sociale variabile
BANTU•Agricoltori•Grandi dimensioni•Alta taglia effettiva•Patrilocali•Poliginia
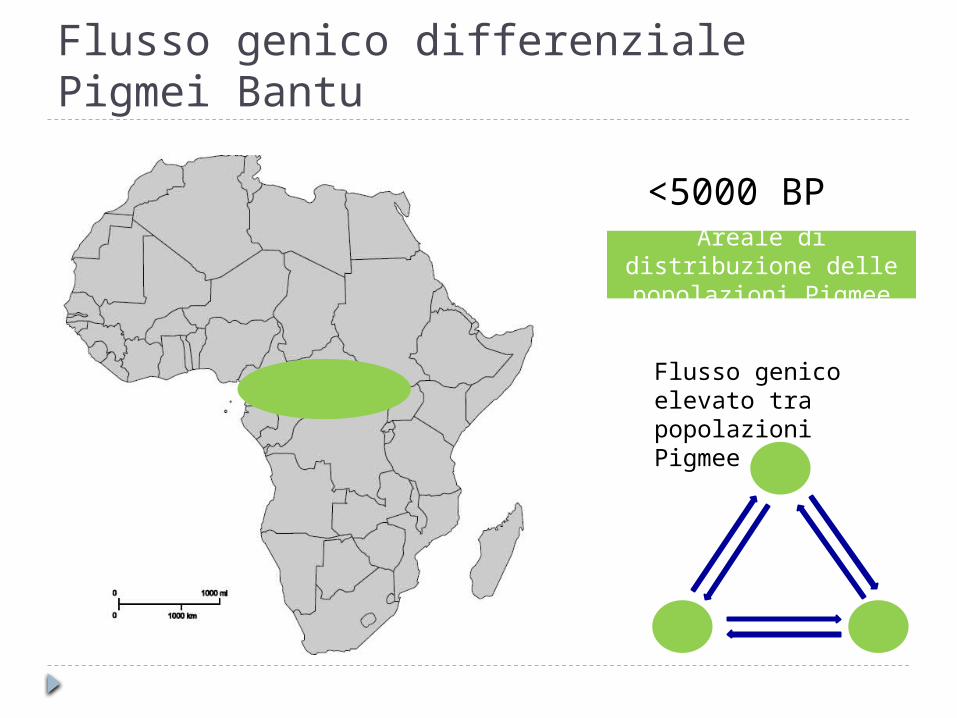
Flusso genico differenziale Pigmei Bantu
<5000 BPAreale di distribuzione
delle popolazioni Pigmee
Flusso genico elevato tra popolazioni Pigmee

Flusso genico differenziale Pigmei Bantu
5000 – 3000 BP
Areale di distribuzione delle popolazioni
Pigmee
Origine espansione Bantu
Frammentazione dell’areale dei Pigmei
Diminuzione del flusso genico tra i Pigmei
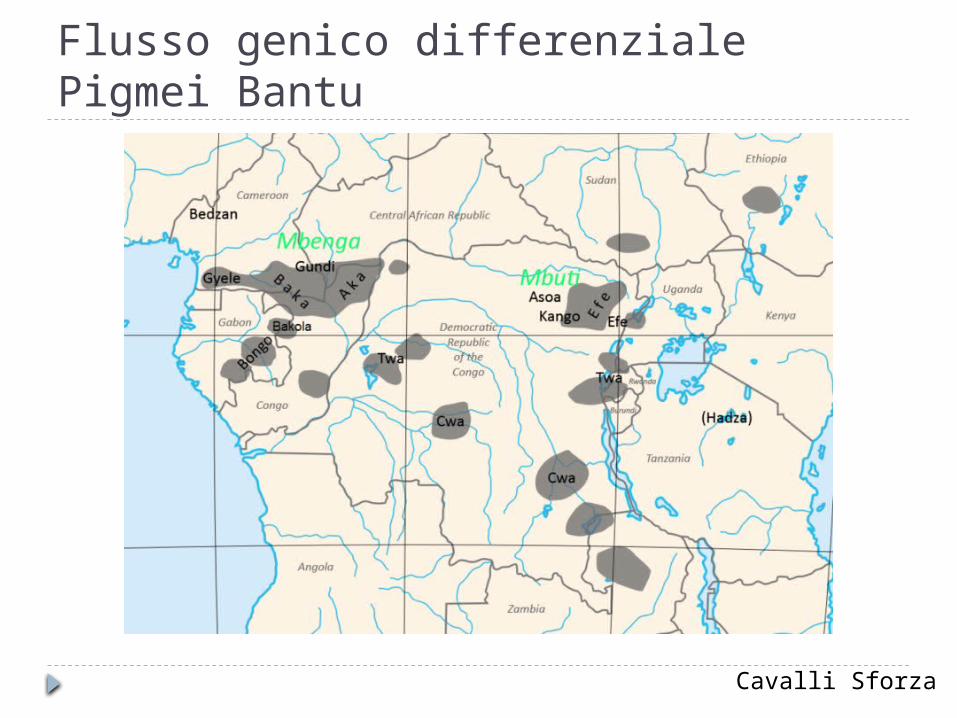
Flusso genico differenziale Pigmei Bantu
Cavalli Sforza

Flusso genico differenziale Pigmei Bantu

Flusso genico differenziale Pigmei Bantu
L’ipotesi
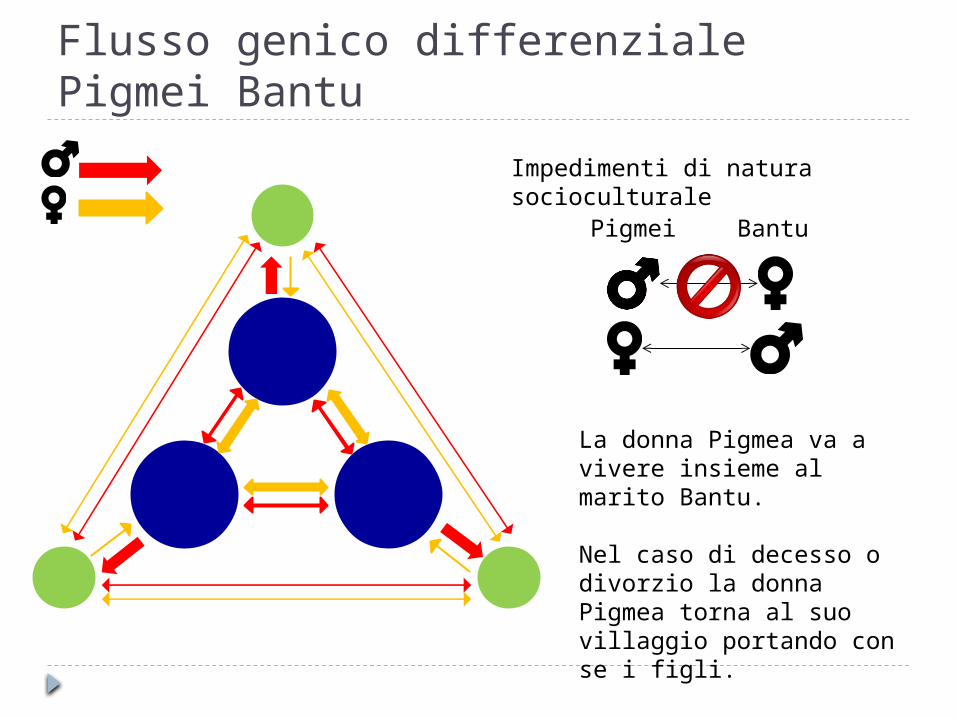
Flusso genico differenziale Pigmei Bantu
Impedimenti di natura socioculturale
Pigmei Bantu
La donna Pigmea va a vivere insieme al marito Bantu.
Nel caso di decesso o divorzio la donna Pigmea torna al suo villaggio portando con se i figli.

Flusso genico differenziale Pigmei Bantu
Valutare la presenza di questo pattern attraverso gli effetti sulla variabilità genetica
BANTUPIGMEI
Variabilità interna
mtDNA
Y chr
Variabilità inter-popolazione
•mtDNA diversità più marcata tra Bantu e Pigmei
•Y chr Diversità meno marcata tra Bantu e Pigmei
Parametri demografici
•Bantu segnali di espansione
•Pigmei segnali di stazionarietà

Flusso genico differenziale Pigmei Bantu
PIGMEIBabingaBakaBakolaBiakaMbenzele
BANTUBakakaBassaBatekeEwondoNgoumba
DNA mitocondriale (HVR1) Cromosoma Y (6 STR)

Arlequin
Arlequin è un pacchetto di software per analisi che fornisce all’utente di genetica di popolazione un gran numero di metodi di base e test statistici, al fine di estrarre informazioni sulle caratteristiche genetiche e demografiche di una raccolta di campioni di popolazione.

Settaggio e preparazione file Arlequin[Profile] NbSamples=1 DataType=STANDARD # - {DNA, RFLP, MICROSAT, STANDARD, FREQUENCY} GenotypicData=0 # - {0, 1} GameticPhase=1 # - {0, 1} LocusSeparator=WHITESPACE # - {TAB, WHITESPACE, NONE} RecessiveData=0 # - {0, 1} MissingData='?' # A single character specifying missing data# Some advanced settings the experienced user can uncomment# Frequency= ABS # - {ABS, REL}# FrequencyThreshold= 1.0e-5 # - (Any real number, usually between 1.0e-7 and 1.e-3)# EpsilonValue= 1.0e-7 # - (Any real number, usually between 1.0e-12 and 1.0e-5)
[Data]
[[Samples]]
SampleName="Name of Population number 1" SampleSize= 6 #Fictive number, but must match the sume of haplotype frequencies given below
SampleData= { #Example of a sample consisiting of haplotypic data (2 haplotypes, 2 loci): h1 2 TC h2 4 GT }

Variabilità Intra-Popolazione (MtDNA e cromosoma Y)

Arlequin: Variabilità Intra-Popolazione (MtDNA)
S: Number of polymorphic sites (numero di siti polimorfi)Numero di posizioni dove è presente una mutazione (SNP). Relazionando questo numero alla lunghezza della sequenza considerata si ha un’idea della variabilità nucleotidica (Nucleotide diversity)H: Number of Haplotypes (numero di aplotipi diversi)Il numero di aplotipi diversi trovati nella popolazione
HD: Haplotype diversity (Gene diversity)La probabilità che due aplotipi (alleli) presi a caso all’interno del pool siano diversi.
n= numero di individuiK= numero diverso di aplotipiP= frequenza dell’i-esimo aplotipoPermette di fare confronti dal momento che tiene in considerazione la taglia
del campione (N)

Arlequin: Variabilità Intra-Popolazione (MtDNA)
MNPD: Mean number of paiwise differences (numero medio di differenze a coppie)Numero di differenze ,al livello di sequenze, tra tutti gli individui della popolazione confrontati a coppie.
k= il numero di differenze tra le sequenze generiche i e jn= numero di sequenze nel campionen(n-1)/2=numero di confronti totaleAMOVA: Analysis of Molecular Variance
Analisi per valutare il grado di strutturazione delle popolazioni.Un analisi gerarchica della varianza basata sulle frequenze geniche e le differenze tra aplotipi:La varianza è poi suddivisa in componenti relative a:•Diversità all’interno delle popolazioni•Diversità tra popolazioni all’interno dei gruppi•Diversità tra gruppi

Arlequin: Variabilità Intra-Popolazione (Cromosoma Y)
h, Hd, MNPD, AMOVA
Garza-Williamson index (G-W)Indice sensibile a recenti colli di bottiglia
k=numero di alleli in un dato locusR= range allelico
Valori bassi di G-W: collo di bottigliaValori prossimi a 1 di G-W: popolazione stazionaria
R: Allelic range (range allelico)Il range di alleli differenti per ogni locus
S: Number of alleles (numero di alleli)Numero di alleli per ogni locus

Parametri demografici(MtDNA)

Arlequin: Parametri demografici (mtDNA)
Test di selezione basati sul confronto tra i vari stimatori del parametro =4Nµ (2Nµ per i sistemi aploidi). MtDNA e Cromosoma Y non soggetti a selezione quindi i test stimano gli effetti della demografia sulla struttura genetica delle popolazioni
(Hom): una stima che si ottiene dall’omozigosità osservata (S): una stima che si ottiene dal numero osservato di siti segreganti (k): una stima che si ottiene dal numero osservato di alleli (π): una stima che si ottiene dal numero medio di differenze a coppie
Le variazioni della taglia effettiva di una popolazione nel tempo
•Non tutti i metodi sono utilizzabili con i diversi marcatori•In definitiva tutti questi metodi dovrebbero dare lo stesso risultato•Dal momento che ogni metodo fa delle assunzioni a priori e differenze nella stima possono essere interpretate come una violazione di tali assunzioni

Arlequin: Parametri demografici (mtDNA)
TAJIMA’S DTest basato sul modello a siti infiniti senza ricombinazione quindi adatto per MtDNA
Tante mutazioni di cui poche condivise tra aplotipi diversi D>0Selezione bilanciante o Espansione demografica
Poche mutazioni di cui molte condivise tra aplotipi diversi D<0Neutralità selettiva o Stazionarietà
La significatività è calcolata tramite simulazioni di popolazioni in equilibrio.Il P-Value è la probabilità di ottenere valori di D minori o uguali all’osservato.

Arlequin: Parametri demografici (mtDNA)
P-Value del D è calcolato attraverso un approccio di simulazione che fornisce la probabilità di ottenere valori di D minori o uguali da una popolazione selettivamente neutrale generata a random.
Espansione
Stazionarietà
Stazionarietà

Arlequin: Parametri demografici (mtDNA)
Fs di FuTest basato sul modello a siti infiniti senza ricombinazione quindi adatto per MtDNAValuta la differenza tra la variabilità osservata e quella attesa secondo un modello di evoluzione neutrale.
Si calcola prima la probabilità (S’) di osservare un campione neutrale con un numero di alleli minore o uguale al valore osservato, dato il numero di differenze a coppie (stima di )
Fs positivo: il numero di alleli minore rispetto all’attesoselezione positiva o bottleneck recenteFs negativo: il numero di alleli maggiore rispetto all’attesoselezione bilanciante o espansione demograficaFs vicino allo zero: assunzioni modello rispettateNeutralità selettiva o popolazione stazionaria
Anche per Fs di Fu la significatività è calcolata tramite simulazioni di popolazioni in equilibrio.Il P-Value è la probabilità di ottenere valori di Fs minori o uguali all’osservato.
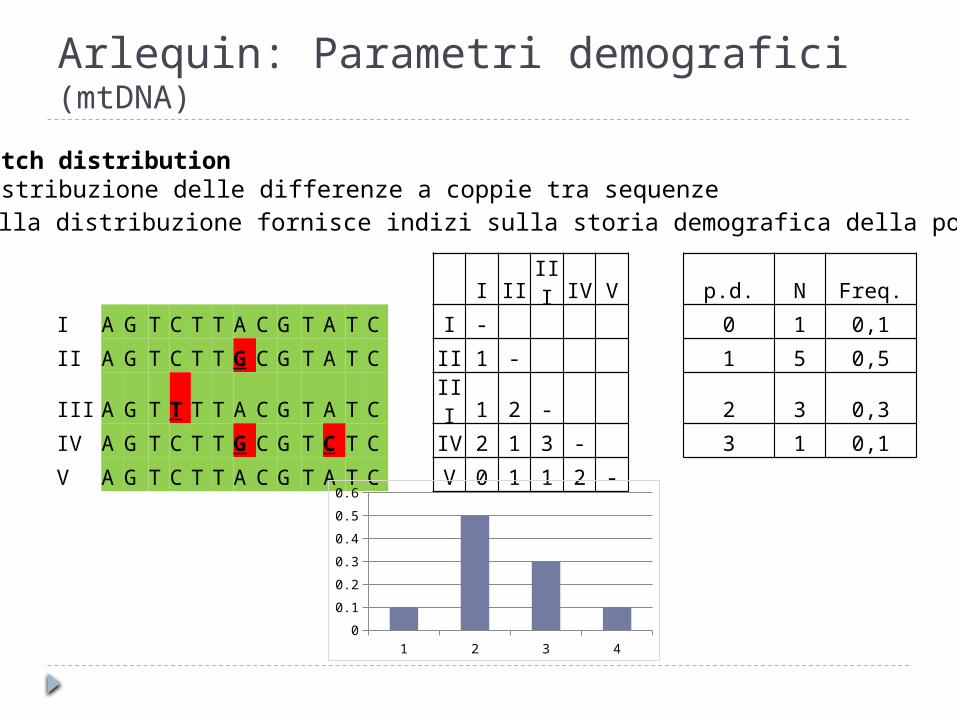
Arlequin: Parametri demografici (mtDNA)
Mismatch distributionLa distribuzione delle differenze a coppie tra sequenze
La forma della distribuzione fornisce indizi sulla storia demografica della popolazione
I II III IV V p.d. N Freq.
I A G T C T T A C G T A T C I - 0 1 0,1
II A G T C T T G C G T A T C II 1 - 1 5 0,5
III A G T T T T A C G T A T C III 1 2 - 2 3 0,3
IV A G T C T T G C G T C T C IV 2 1 3 - 3 1 0,1
V A G T C T T A C G T A T C V 0 1 1 2 -
1 2 3 40
0.1
0.2
0.3
0.4
0.5
0.6
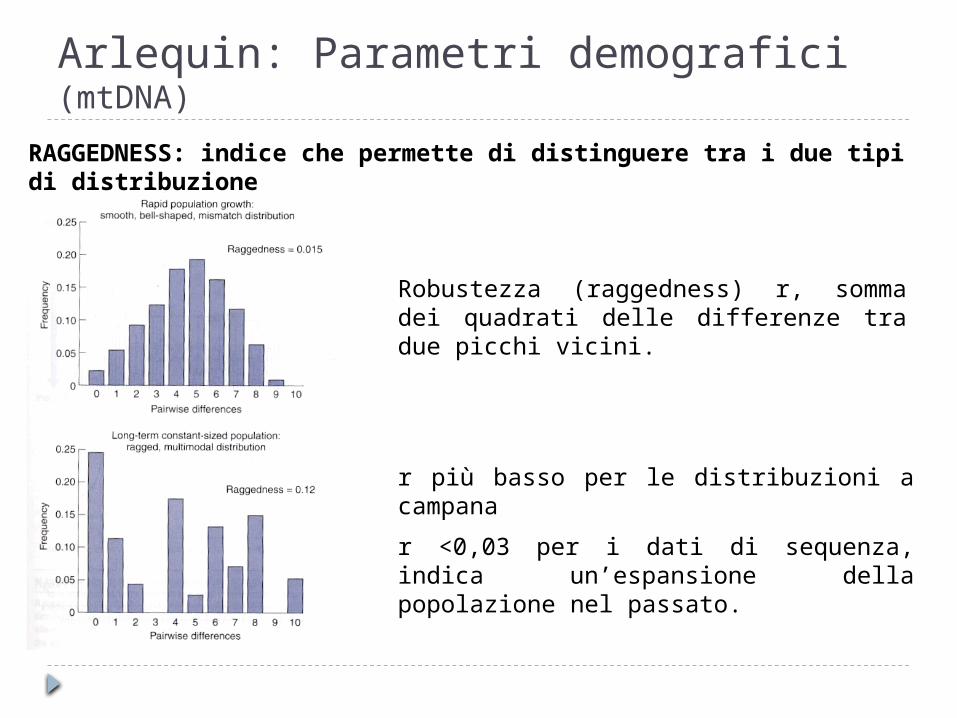
Arlequin: Parametri demografici (mtDNA)
RAGGEDNESS: indice che permette di distinguere tra i due tipi di distribuzione
Robustezza (raggedness) r, somma dei quadrati delle differenze tra due picchi vicini.
r più basso per le distribuzioni a campana
r <0,03 per i dati di sequenza, indica un’espansione della popolazione nel passato.

Variabilità Inter-Popolazione (MtDNA e cromosoma Y)

Arlequin:Variabilità inter-popolazione
Una metapopolazione è una popolazione suddivisa in sottopopolazioni parzialmente isolate; ciò determina un deficit di eterozigoti (no equilibrio Hardy Weinberg).
Il processo di suddivisione genera una struttura gerarchica della popolazione. Ogni volta che i dati non rispecchiano il random mating possiamo pensare ad una struttura nella popolazione e quindi possiamo misurare la distribuzione di variabilità.
Fst
Parametro di distanza genetica che misura il grado di variabilità di una metapopolazione suddivisa in subpopolazioni.
Fst = Vp/ p (1-p)
dove p e Vp sono la media e la varianza delle frequenze geniche tra le due subpopolazioni;Misura la porzione di varianza totale nelle frequenze alleliche tra le
subpopolazioni
0<Fst<1

Arlequin:Variabilità inter-popolazione DISTANZA GENETICA Fst TRA DUE POPOLAZIONI AD UN LOCUS CON DUE ALLELI
Fst= Vp / P (1-P)
p = frequenza allelica
P = frequenza allelica media
1 e 2 = popolazione 1 e 2
Varianza =(X-Xm)2/N
La devianza/N
Devianza = (X- Xm)2
Somma degli scarti al
quadrato
scarto: un valore X sottratto
rispetto alla media
aritmeticaFst = (p1-P)2 + (p2-P)2
2x
1
P (1-P)

Arlequin:Variabilità inter-popolazione ESEMPIO DI CALCOLO DELLA DISTANZA GENETICA Fst
POP 1 POP 2
p1=0,3 p2=0,7
POP 1 POP 2
p1=0,1 p2=0,9
P=0,5 P=0,5
(0,3-0,5)2 + (0,7-0,5)2
2 x [0,5 x (1-0,5)]= =0,16 Fst
(0,1-0,5)2 + (0,9-0,5)2
2 x [0,5 x (1-0,5)]= =0,64

Arlequin:Variabilità inter-popolazione
Rst:Misura della distanza genetica equivalente all’Fst ma adattata ai loci microsatellite. Assume un modello stepwise ad alto tasso di mutazione.
Ax-yi = Numero di ripetizioni per il locus i nelle popolazioni x e y

Arlequin:Variabilità inter-popolazione
Bisogna valutare se il valore ottenuto sia significativo, quindi se la suddivisione della popolazione è maggiore di quella attesa per caso
Bisogna escludere che:
•La popolazione non sia differenziata
•Le differenze tra le frequenze alleliche siano dovute al campionamento
•L’accoppiamento sia casuale
Il test è realizzato mediante permutazioni o Monte-Carlo method (si usano numeri casuali).
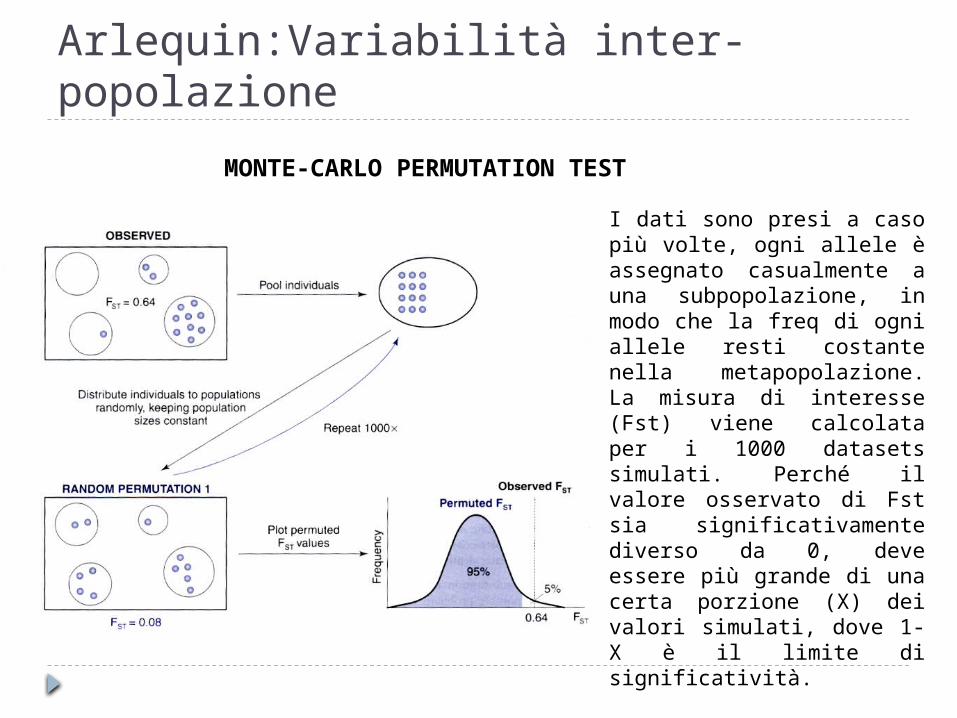
Arlequin:Variabilità inter-popolazione
I dati sono presi a caso più volte, ogni allele è assegnato casualmente a una subpopolazione, in modo che la freq di ogni allele resti costante nella metapopolazione. La misura di interesse (Fst) viene calcolata per i 1000 datasets simulati. Perché il valore osservato di Fst sia significativamente diverso da 0, deve essere più grande di una certa porzione (X) dei valori simulati, dove 1-X è il limite di significatività.
Per es. se il valore di Fst è più grande in più di 950 simulazioni su 1000, il livello di significatività sarà del 5%.
MONTE-CARLO PERMUTATION TEST

Past: rappresentazioni grafiche
ANALISI MULTIVARIATE
CLUSTER ANALISYSSeleziona e raggruppa elementi omogenei all’interno di un set di dati. Esistono diversi metodi (algoritmi) suddivisi principalmente in due categorie
Clustering partitivo: L’appartenenza ad un gruppo è definita dalla distanza da un punto rappresentativo del cluster (centriode etc..) avendo determinato a priori il numero di cluster (K-means)
Clustering gerarchico: Si costruisce una gerarchia di partizioni caratterizzata da un numero decrescente di cluster (UPGMA, Neighbour joining etc..)

Past: rappresentazioni grafiche
Una matrice di distanza genetiche ha tante dimensioni quante sono le popolazioni quindi è impossibile da visualizzare graficamente a meno che non si riassume l’informazione in modo che possa essere rappresentata in due dimensioni.
MDS (Multidimensional scaling)
costrizione delle distanze genetiche in uno spazio a due dimensioni
con la minor perdita di informazione possibile (minore distorsione
possibile)
La distorsione è rappresentata dal parametro stress
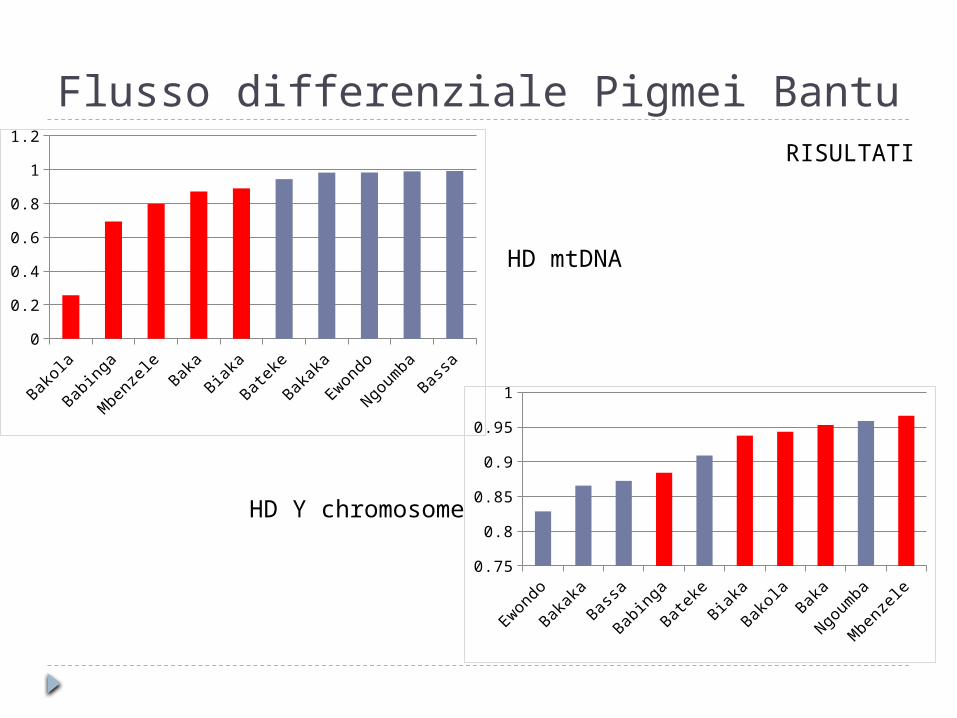
Flusso differenziale Pigmei BantuRISULTATI
Bakola
Babinga
Mbe
nzele
Baka
Biaka
Batek
e
Bakak
a
Ewon
do
Ngoum
ba
Bassa
0
0.2
0.4
0.6
0.8
1
1.2
HD mtDNA
Ewon
do
Bakak
a
Bassa
Babinga
Batek
e
Biaka
Bakola
Baka
Ngoum
ba
Mbe
nzele
0.75
0.8
0.85
0.9
0.95
1
HD Y chromosome

Flusso differenziale Pigmei BantuRISULTATI
MNPD mtDNA
MNPD Y chromosome
Ewon
do
Bakak
a
Bassa
Batek
e
Ngoum
ba
Bakola
Mbe
nzele
Baka
Babinga
Biaka
0
0.5
1
1.5
2
2.5
3
3.5
4
Bakola
Babinga
Mbe
nzele
Baka
Batek
e
Biaka
Ngoum
ba
Bassa
Bakak
a
Ewon
do0
2
4
6
8
10
12
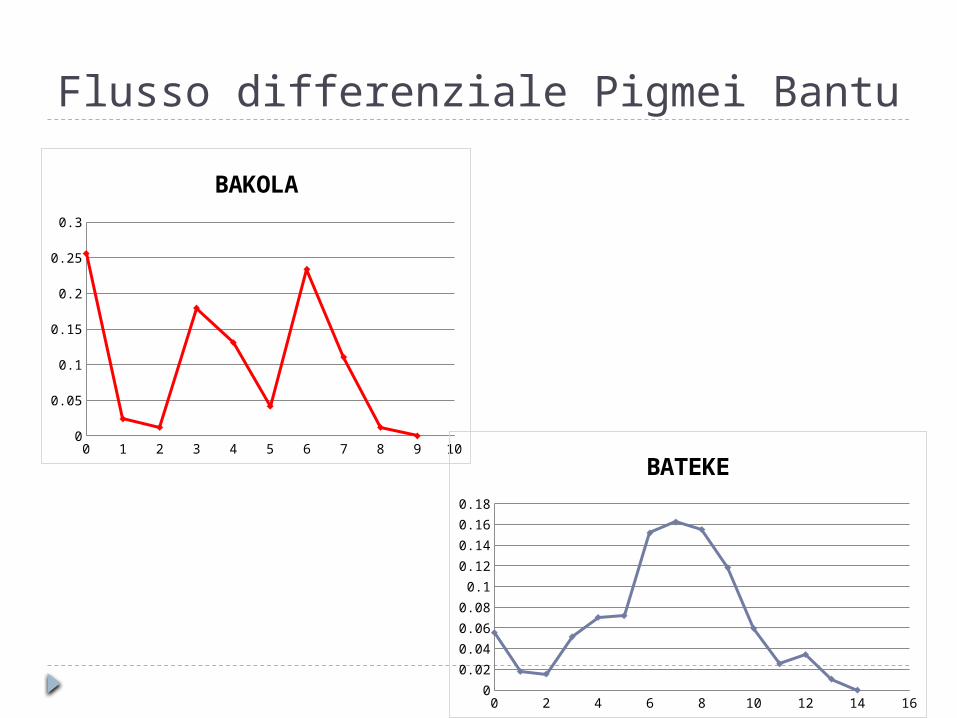
Flusso differenziale Pigmei Bantu
0 1 2 3 4 5 6 7 8 9 100
0.05
0.1
0.15
0.2
0.25
0.3
BAKOLA
0 2 4 6 8 10 12 14 160
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
BATEKE
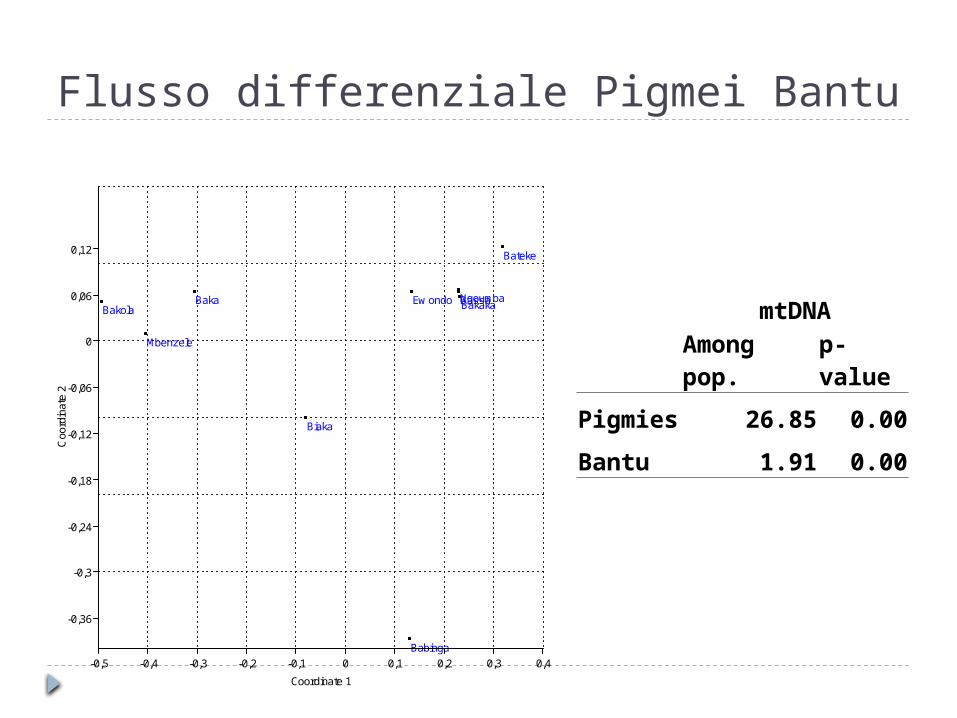
Flusso differenziale Pigmei Bantu
BakaBakola
Mbenzele
Babinga
Biaka
BassaBakaka
Bateke
Ew ondo Ngoumba
-0,5 -0,4 -0,3 -0,2 -0,1 0 0,1 0,2 0,3 0,4
Coordinate 1
-0,36
-0,3
-0,24
-0,18
-0,12
-0,06
0
0,06
0,12
Coo
rdin
ate
2
mtDNA
Among pop. p-value
Pigmies 26.85 0.00
Bantu 1.91 0.00

Flusso differenziale Pigmei Bantu
Baka
Bakola
Mbenzele
Babinga
Biaka
Bassa
Bakaka
Bateke
Ew ondo
Ngoumba
-0,4 -0,3 -0,2 -0,1 0 0,1 0,2 0,3 0,4 0,5
Coordinate 1
-0,24
-0,16
-0,08
0
0,08
0,16
0,24
0,32
Coo
rdin
ate
2
Y chromosome
Among pop. p-value
Pigmies 5.36 0.00
Bantu 11.36 0.00





























