Embed Size (px)
Citation preview

Esercitazione di Social Media Management A. A. 2015‐2016
Regressione Lineare Antonino Furnari ‐ http://www.dmi.unict.it/~furnari/ ‐ [email protected]
Prof. Giovanni Maria Farinella ‐ http://www.dmi.unict.it/~gfarinella/ ‐ [email protected]
In questa esercitazione impareremo come:
Analizzare un insieme di osservazione mediante Principal Component Analysis (PCA);
Costruire un modello di regressione lineare per predire la “memorability” di una immagine a partire
di features di tipo Bag of Visual Words;
Stimare l’accuratezza del modello mediante errore assoluto medio (Mean Absolute Error ‐ MAE) e
indice di correlazione di Pearson.
Durante l’esercitazione vi verrà richiesto di rispondere ad alcune domande e svolgere alcuni semplici esercizi
al fine di verificare la comprensione dei concetti fondamentali.
1. Dataset e Rappresentazione In questa esercitazione utilizzeremo un dataset di immagini acquisite nel contesto di uno studio su “Image
Memorability” (Isola, Xiao, Torralba, & Oliva, 2011). Il dataset contiene 2222 immagini con risoluzione 256256 pixels. Le immagini sono corredate da una serie di valori stimati mediante un gioco di memoria visuale
al quale hanno partecipato diversi soggetti mediante la piattaforma Amazon Mechanical Turk. Tra i valori
forniti, noi considereremo gli “hits”, ovvero il numero di volte in cui ogni immagine è stata effettivamente
riconosciuta come “già vista” quando ripresentata ai partecipanti. Il dataset è disponibile all’indirizzo
http://web.mit.edu/phillipi/Public/WhatMakesAnImageMemorable/. Tuttavia, considerate le dimensioni
dell’archivio (1.7 GB), per questa esercitazione utilizzeremo una versione “più leggera” del dataset in cui tutte
le immagini sono state compresse in formato JPEG.
Scarichiamo il dataset da http://151.97.253.8/memorability.zip e scompattiamo l’archivio nella nostra
directory di lavoro. All’interno della cartella “memorability” troviamo:
2222 immagini in formato JPEG. Il nome di ogni file è un numero da 0001 a 2222 che definisce un
ordinamento univoco.
Il file “hits.mat”, che contiene il numero “hits” per ogni immagine. I valori sono ordinati secondo la
numerazione definita dai nomi dei file JPG;
Il file “regression_features.mat”, che contiene le features di tipo Bag Of Visual Words pre‐computate
per ogni immagine come specificato di seguito.
Carichiamo il contenuto del file “hits.mat” e costruiamo una struttura di tipo “ImageSet”:
load('memorability\hits'); dataset = imageSet('memorability');
A questo punto possiamo visualizzare le immagini del dataset con il relativo numero di “hits” per analizzare
il contenuto del dataset:
for i=1:numel(hits) imshow(read(dataset,i)), title(['Hits: ' num2str(hits(i))]); pause end
Domanda 1.1: notate una correlazione tra contenuto visivo dell’immagine e numero di hits?

Esercizio 1.1: visualizzare le immagini con il numero più basso e più alto di hits.
Partizioniamo il dataset in due parti: “training” (70%) e “test” (30%):
[trainingSets, testSets] = partition(dataset, 0.7); trainingHits = hits(1:trainingSets.Count); testHits = hits(trainingSets.Count+1:dataset.Count);
Non abbiamo utilizzato il tag “randomize” come fatto in passato per non perdere la corrispondenza tra i valori
di “hits” e le immagini del dataset. Non preoccupatevi: l’ordine di immagini e hits è stato precedentemente
“randomizzato” mantenendone però la corrispondenza.
Creiamo adesso un modello Bag Of Visual Words e utilizziamolo per estrarre le features da ogni immagine.
Utilizzeremo i valori di default di MATLAB:
bag = bagOfFeatures(trainingSets); trainingFeatures = encode(bag,trainingSets); testFeatures = encode(bag,testSets); Dato che l’operazione può essere molto dispendiosa in termini di tempo computazionale, carichiamo il
modello e le feature pre‐computate per questa esercitazione:
load('memorability/regression_features');
Domanda 1.2: Che dimensioni hanno le matrici “testFeatures” e “trainingFeatures”? Questo tipo di matrice ha un nome particolare in machine learning, quale?
2. Principal Component Analysis (PCA) Quando si utilizza l’equazione normale per trovare i parametri ottimali di un regressore lineare, si possono
avere problemi relativi alla non‐invertibilità di , dove è la matrice delle osservazioni. Ciò è
generalmente dovuto alla presenza di “ridondanza” tra le feature (diverse parole visuali che codificano
pattern visivi molto simili, nel nostro caso) o all’eccessivo numero di feature rispetto al numero di
osservazioni. Per prevenire questo tipo di problema, trasformeremo i nostri dati utilizzando una tecnica
chiamata Principal Component Analysis (PCA).
Data una matrice di osservazioni (con numero di osservazioni e numero di feature), la PCA
trova una matrice tale che: , dove è la matrice delle osservazioni centrata nello
zero ( , con valore medio di nel training set), è la pseudo‐inversa di e è una
matrice contenente osservazioni di dimensionalità generalmente ridotta .
In questa sede, non scenderemo nei dettagli matematici della PCA. Ci basta solo sapere che la nuova matrice
delle osservazioni , ha le seguenti caratteristiche:
Le features sono ordinate dalla “più importante” alla “meno importante”. Ciò vuol dire che la maggior
parte dell’informazione è contenuta nelle prime feature;
Le features sono generalmente “decorrelate” e quindi sono meno incline a presentare dipendenza
lineare;
Una volta conosciute le medie e la matrice , è possibile applicare la stessa trasformazione al test set in
modo da avere dati dalle caratteristiche analoghe. In questo caso il test set verrà centrato sui valori medi
calcolati dal training set invece che sui propri valori medi. Questi due passi (calcolare la trasformazione PCA
sul training set e applicarla sia al training che al test set), si ottengono con le seguenti righe di codice MATLAB:
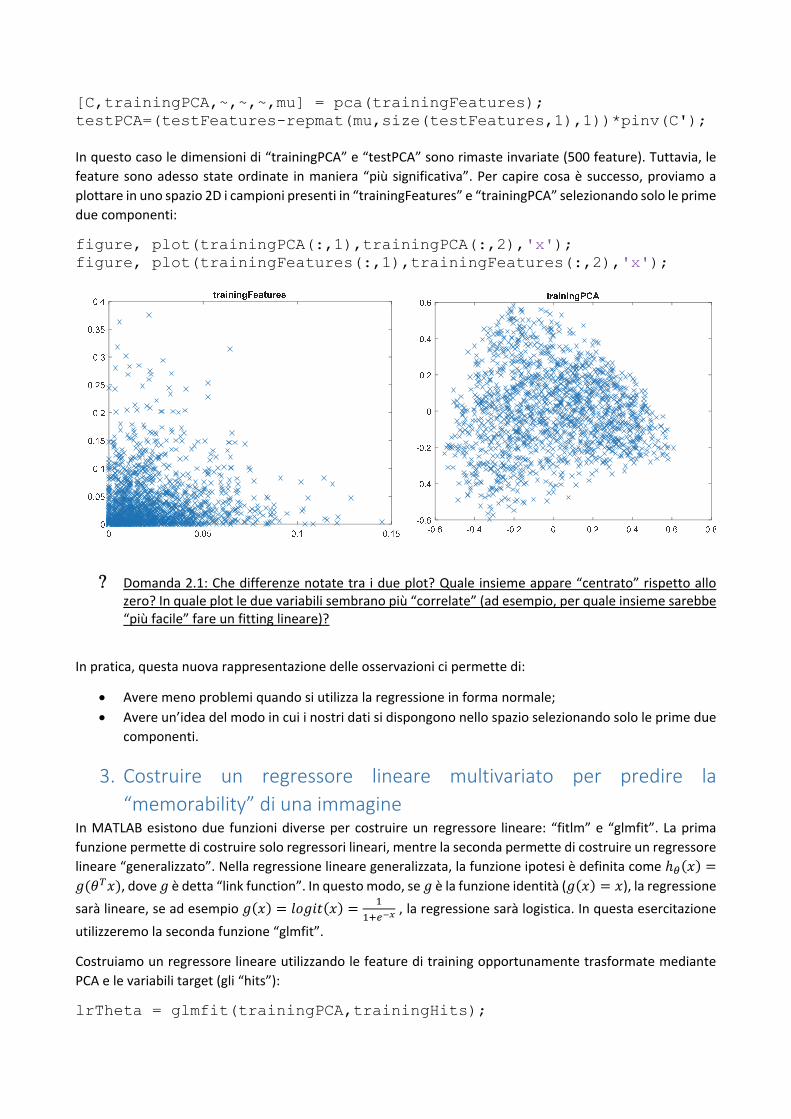
[C,trainingPCA,~,~,~,mu] = pca(trainingFeatures); testPCA=(testFeatures-repmat(mu,size(testFeatures,1),1))*pinv(C'); In questo caso le dimensioni di “trainingPCA” e “testPCA” sono rimaste invariate (500 feature). Tuttavia, le
feature sono adesso state ordinate in maniera “più significativa”. Per capire cosa è successo, proviamo a
plottare in uno spazio 2D i campioni presenti in “trainingFeatures” e “trainingPCA” selezionando solo le prime
due componenti:
figure, plot(trainingPCA(:,1),trainingPCA(:,2),'x'); figure, plot(trainingFeatures(:,1),trainingFeatures(:,2),'x');
Domanda 2.1: Che differenze notate tra i due plot? Quale insieme appare “centrato” rispetto allo zero? In quale plot le due variabili sembrano più “correlate” (ad esempio, per quale insieme sarebbe “più facile” fare un fitting lineare)?
In pratica, questa nuova rappresentazione delle osservazioni ci permette di:
Avere meno problemi quando si utilizza la regressione in forma normale;
Avere un’idea del modo in cui i nostri dati si dispongono nello spazio selezionando solo le prime due
componenti.
3. Costruire un regressore lineare multivariato per predire la
“memorability” di una immagine In MATLAB esistono due funzioni diverse per costruire un regressore lineare: “fitlm” e “glmfit”. La prima
funzione permette di costruire solo regressori lineari, mentre la seconda permette di costruire un regressore
lineare “generalizzato”. Nella regressione lineare generalizzata, la funzione ipotesi è definita come
, dove è detta “link function”. In questo modo, se è la funzione identità ( ), la regressione
sarà lineare, se ad esempio , la regressione sarà logistica. In questa esercitazione
utilizzeremo la seconda funzione “glmfit”.
Costruiamo un regressore lineare utilizzando le feature di training opportunamente trasformate mediante
PCA e le variabili target (gli “hits”):
lrTheta = glmfit(trainingPCA,trainingHits);

Domanda 3.1: che dimensione ha la variabile “lrTheta”? Cosa rappresentano i suoi valori?
I coefficienti contenuti in lrTheta specificano come “combinare” i valori osservati (le nostre 500 feature) per
predire il numero di hits che l’immagine totalizzerebbe nel memory game. Il nostro modello lineare può
essere scritto come:
⋯
dove è la variabile dipendente (numero di hits), , … , sono i nostri 500 predittori (le 500 feature
trasformate mediante PCA) è l’intercetta, e , … , sono i regressori che abbiamo imparato. Se
vogliamo rappresentare graficamente come il numero di hits varia al variare delle osservazioni e come si
comporta il nostro regressore lineare, selezioneremo un solo predittore, ignorando gli altri. Dal momento
che la PCA ha “ordinato” le feature per importanza, considereremo la prima feature. Il modello si riduce a:
Visualizziamo innanzitutto come la variabile dipendente varia al variare del predittore :
figure, plot(trainingPCA(:,1),trainingHits,'o') A questo punto possiamo visualizzare la retta di regressione definita dal nostro modello lineare semplificato:
hold on x= -0.6:0.1:0.8; plot(x,lrTheta(1)+lrTheta(2)*x,'LineWidth',2); Dato che stiamo effettuando una regressione multivariata, questo plot “cattura” cosa succederebbe se i
valori delle feature superiori alla prima fossero nulli. Per avere un’idea di come la regressione “si comporta”
all’aumentare del numero di feature, passiamo dallo spazio bidimensionale a quello tridimensionale
considerando i primi due predittori e . Il nostro modello lineare diventa:
Visualizziamo i dati in tre dimensioni, mediante i comandi:
figure, plot3(trainingPCA(:,1),trainingPCA(:,2),trainingHits,'o') La fuzione “plot3” è equivalente a “plot” ma permette di visualizzare dati in tre dimensioni. Il nuovo modello
lineare individua adesso un piano e non più una retta: . Per plottare il piano in MATLAB
dobbiamo i comandi:
x= -0.6:0.01:0.8; y= -0.6:0.01:0.8; [X,Y] = meshgrid(x,y); hold on; surf(X,Y,lrTheta(1)+lrTheta(2)*X+lrTheta(3)*Y); grid on; La funzione “meshgrid” permette di creare una griglia bidimensionale di valori a partire da due vettori unidimensionali. La funzione “surf” permette di plottare una superficie (un piano nel nostro caso).
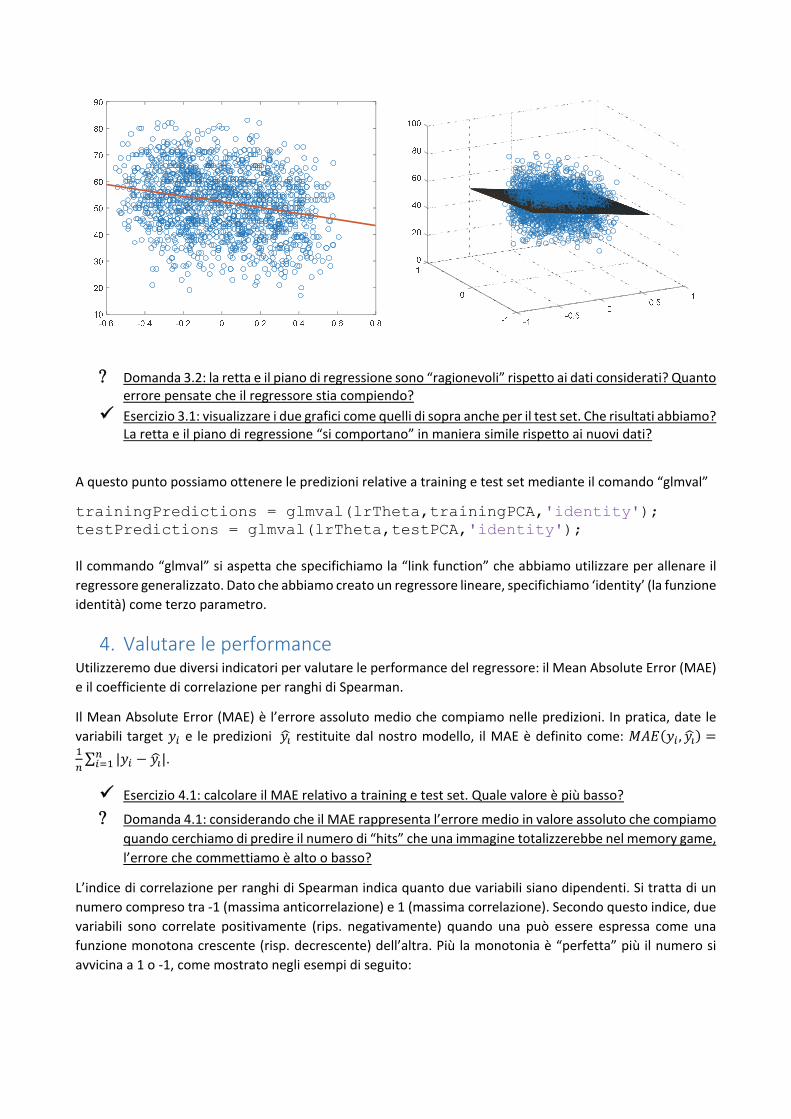
Domanda 3.2: la retta e il piano di regressione sono “ragionevoli” rispetto ai dati considerati? Quanto errore pensate che il regressore stia compiendo?
Esercizio 3.1: visualizzare i due grafici come quelli di sopra anche per il test set. Che risultati abbiamo? La retta e il piano di regressione “si comportano” in maniera simile rispetto ai nuovi dati?
A questo punto possiamo ottenere le predizioni relative a training e test set mediante il comando “glmval”
trainingPredictions = glmval(lrTheta,trainingPCA,'identity'); testPredictions = glmval(lrTheta,testPCA,'identity'); Il commando “glmval” si aspetta che specifichiamo la “link function” che abbiamo utilizzare per allenare il
regressore generalizzato. Dato che abbiamo creato un regressore lineare, specifichiamo ‘identity’ (la funzione
identità) come terzo parametro.
4. Valutare le performance Utilizzeremo due diversi indicatori per valutare le performance del regressore: il Mean Absolute Error (MAE)
e il coefficiente di correlazione per ranghi di Spearman.
Il Mean Absolute Error (MAE) è l’errore assoluto medio che compiamo nelle predizioni. In pratica, date le
variabili target e le predizioni restituite dal nostro modello, il MAE è definito come: ,
∑ | |.
Esercizio 4.1: calcolare il MAE relativo a training e test set. Quale valore è più basso?
Domanda 4.1: considerando che il MAE rappresenta l’errore medio in valore assoluto che compiamo
quando cerchiamo di predire il numero di “hits” che una immagine totalizzerebbe nel memory game,
l’errore che commettiamo è alto o basso?
L’indice di correlazione per ranghi di Spearman indica quanto due variabili siano dipendenti. Si tratta di un
numero compreso tra ‐1 (massima anticorrelazione) e 1 (massima correlazione). Secondo questo indice, due
variabili sono correlate positivamente (rips. negativamente) quando una può essere espressa come una
funzione monotona crescente (risp. decrescente) dell’altra. Più la monotonia è “perfetta” più il numero si
avvicina a 1 o ‐1, come mostrato negli esempi di seguito:
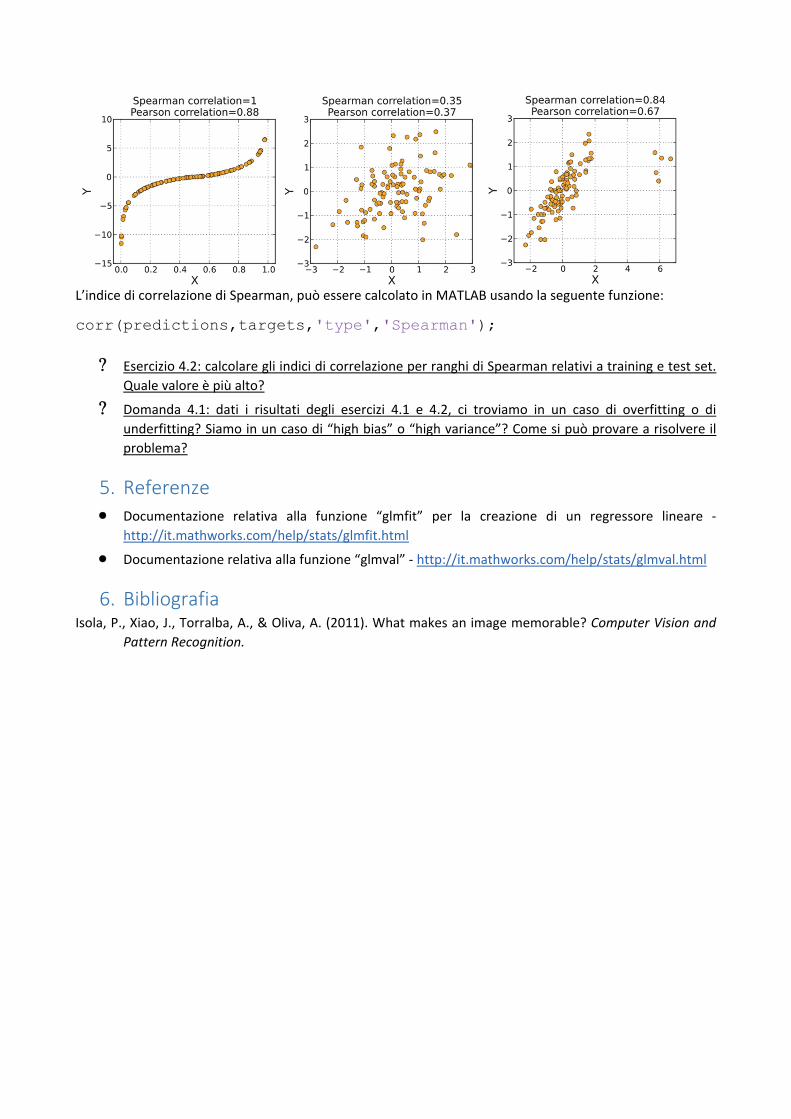
L’indice di correlazione di Spearman, può essere calcolato in MATLAB usando la seguente funzione:
corr(predictions,targets,'type','Spearman');
Esercizio 4.2: calcolare gli indici di correlazione per ranghi di Spearman relativi a training e test set.
Quale valore è più alto?
Domanda 4.1: dati i risultati degli esercizi 4.1 e 4.2, ci troviamo in un caso di overfitting o di
underfitting? Siamo in un caso di “high bias” o “high variance”? Come si può provare a risolvere il
problema?
5. Referenze Documentazione relativa alla funzione “glmfit” per la creazione di un regressore lineare ‐
http://it.mathworks.com/help/stats/glmfit.html
Documentazione relativa alla funzione “glmval” ‐ http://it.mathworks.com/help/stats/glmval.html
6. Bibliografia Isola, P., Xiao, J., Torralba, A., & Oliva, A. (2011). What makes an image memorable? Computer Vision and
Pattern Recognition.