Embed Size (px)
Citation preview

IT 09 004
Examensarbete 30 hpFebruari 2009
Evaluation of Inlining Heuristics in Industrial Strength Compilers for Embedded Systems
Pär Andersson
Institutionen för informationsteknologiDepartment of Information Technology


Teknisk- naturvetenskaplig fakultet UTH-enheten Besöksadress: Ångströmlaboratoriet Lägerhyddsvägen 1 Hus 4, Plan 0 Postadress: Box 536 751 21 Uppsala Telefon: 018 – 471 30 03 Telefax: 018 – 471 30 00 Hemsida: http://www.teknat.uu.se/student
Abstract
Evaluation of Inlining Heuristics in Industrial StrengthCompilers for Embedded Systems
Pär Andersson
Function inlining is a well known compiler optimization where a function call issubstituted with the body of the called function. Since function inlining in generalincreases the code size one might think that function inlining is a bad idea forembedded systems where a small code size is important. In this thesis we will showthat function inlining is a necessary optimization for any industrial strength C/C++compiler . We show that both the generated code size and execution time of theapplication can benefit from function inlining. We study and compare the inliningheuristics of 3 different industrial strength compilers for the ARM processorarchitecture.
We also present a new inlining heuristic which makes inlining decisions based onseveral different properties. The study shows that the inlining heuristic proposed inthis thesis is able to generate both smaller and faster code compared to the otherinlining heuristics studied.
Tryckt av: Reprocentralen ITC
Sponsor: IAR Systems ABIT 09 004Examinator: Anders JanssonÄmnesgranskare: Sven-Olof NyströmHandledare: Jan-Erik Dahlin


Contents
1 Introduction 11.1 Inlining heuristics . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Terminology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2.1 Module . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2.2 Call Graph . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2.3 Control Flow Graph . . . . . . . . . . . . . . . . . . . . . 31.2.4 Dominators . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2.5 Unreachable-Code Elimination . . . . . . . . . . . . . . . 3
2 Inlining heuristics in studied compilers 52.1 IAR Inliner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 RealView Inliner . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 GNU Compiler Collection (GCC) Inliner . . . . . . . . . . . . . . 6
3 A new inliner 73.1 Ideas for a new inliner . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1.1 Selective inlining . . . . . . . . . . . . . . . . . . . . . . . 73.1.2 Heuristics for call sites . . . . . . . . . . . . . . . . . . . . 83.1.3 Unreachable-Code Elimination . . . . . . . . . . . . . . . 83.1.4 Termination of inlining . . . . . . . . . . . . . . . . . . . 9
4 Implementing the new inliner 104.1 Analyzing functions for parameter dependency . . . . . . . . . . 104.2 Building the edge queue . . . . . . . . . . . . . . . . . . . . . . . 114.3 Inline driver . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.3.1 Updating data structures after inlining of one call site . . 134.3.2 User interaction . . . . . . . . . . . . . . . . . . . . . . . 15
4.4 Avoid getting stuck in local parts of the call graph . . . . . . . . 15
5 Test suite 165.1 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
5.1.1 Dinkum . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165.1.2 Open Physics Abstraction Layer (OPAL) . . . . . . . . . 175.1.3 Persistence of Visions Ray-tracer (POV-Ray) . . . . . . . 175.1.4 Turing Machine Simulator . . . . . . . . . . . . . . . . . . 175.1.5 SPEC2000 CPU . . . . . . . . . . . . . . . . . . . . . . . 17
5.2 What we measure . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
6 Test framework 196.1 Tools and target . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
6.1.1 Simulator . . . . . . . . . . . . . . . . . . . . . . . . . . . 196.1.2 Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
7 Measurements 207.1 Intermediate code vs generated code . . . . . . . . . . . . . . . . 207.2 Compilers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
8 Conclusions and future work 23
i

A Appendix 24A.1 IAR New Inliner Code growth . . . . . . . . . . . . . . . . . . . . 25A.2 IAR New Inliner Cycles used . . . . . . . . . . . . . . . . . . . . 27A.3 All inliners together . . . . . . . . . . . . . . . . . . . . . . . . . 29
References 31
ii

1 Introduction
Function inlining (Procedure integration, Inline substitution) is an interproce-dural optimization where we replace a function call by the body of the calledfunction. This is an optimization that is used to increase the execution speedof the program, you would trade larger size of the program for less executioncycles.
Some of the reasons why we should expect a speed increase are because ofthe fact that when we inline a function call we remove the overhead of callinga function. Another reason is that when we integrate the body of the calledfunction into the callee we will expose more code for other global optimizationsto take advantage of. The reasons why we should expect a larger size is becausewe are likely to get multiple copies of the same function.
So if we want a faster program we could just inline all calls and thereforeget it to run as fast as possible? No, there are many reasons why we shouldbe careful when choosing to inline. Too much inlining could for example makethe body of the caller grow to an unmanageable size which would result inunreasonable long compilation time. There are also e�ects of too much inliningthat can have a negative impact on the execution speed of the program [15]. Toomuch inlining could for example result in more resource con�icts which makes itharder for the register allocator to do a good job which in the end would lead tomore variable spills. Another example is where caller �ts in the L1 instructioncache before the inlining of any calls but grow too large after inlining so that itno longer �ts in the L1 instruction cache.
The compilers we will study in this thesis are targeted for embedded systems,more speci�cally we will use an ARM1[1] based back-end. Therefore we shouldhave in consideration that size is often a crucial part when building embeddedapplications. For a desktop application we seldom care much about the size,if we can make the application faster by using inline substitution we probablywon't care how much the application grows, it's just some more space occupiedon our hard drive.
For embedded applications it's a completely di�erent picture, if the programgrows above some limit it could result in the need of using di�erent hardwarewith more memory, which in the end would lead to higher production costs.When we look at the results of code growth in the thesis we should thereforehave this in mind, an expansion of more than 20% in the context of this thesisis most likely too much.
The goal of this thesis is to evaluate the existing inliner in IAR SystemsC and C++ compiler (ICC), compare it with competitors RealView and GNUGCC, invent a new inliner and implement it, evaluate the new inliner.
1ARM1136JF-S
1

1.1 Inlining heuristics
There are properties of a function and function calls that we probably shouldtake into consideration when deciding if we should inline or not [16, 17].
1. Size of the function (smaller is better).
2. Number of calls to the function.
3. If the function is called inside a loop.
4. A particular call contains constant-valued parameters.
5. If there is only one call site it can be inlined (needs to be static, addressnever taken, and could a�ect register pressure/cache in a bad way).
6. Size of the function is smaller than the overhead size of the function call.
7. If a particular call site to the function represents a large fraction of allcall to the function then that particular call site can be inlined whereasthe other call sites will not be inlined (need static program analysis orprogram pro�ling data).
8. Stack frame size (activation record size) of the function.
9. Language speci�c keywords such as the inline keyword in C++ (and C99).
10. Recursive functions, if inlined when do we stop?
Using these properties one can create a heuristic for inlining, for example Morgan[16] suggests one heuristic based on the size of the function being inlined, thenumber of call sites, and the frequency information for the calls. If a functionis small enough (number 6 above) it is always inlined. If the function is largerthan that but has a small number of call sites it can also be inlined.
2

1.2 Terminology
1.2.1 Module
In C or C++ this is the input to the compiler after preprocessing an input source�le. One .c or .cpp �le is regarded as one module. Inlining across modulesis only possible if we do inlining in the linker or if the compiler is presentedwith more than one source �le at the time (perhaps merged together to one bigmodule). In ICC, the latter is called Multi-File Compilation (MFC).
1.2.2 Call Graph
The Call Graph (CG) of a module is a directed multi-graph G=(V,E) where eachnode in V is a function. An edge in E occurs between two nodes F1 and F2 ifthere is a call from F1 to F2. Since it is a multi-graph it is possible that severaledges between F1 and F2 occur. The CG could also include nodes which arefunctions that are externally declared, these nodes are however not candidatesfor inlining.
1.2.3 Control Flow Graph
The Control Flow Graph (CFG) for a function is represented as a directed graphG=(V,E) where each node in V is a basic block. An edge in E occurs betweentwo nodes B1 and B2 when there is a branch statement in B1 with a possibledestination in B2. The CFG also contain a single entry node entry and a singleexit node exit. The CFG tells us about what possible paths the program mightexecute when the function is executed.
1.2.4 Dominators
Given a CFG G=(V,E) with single entry node entry and single exit node exit,a node D is a dominator to node N in V if every path from entry to N must gothrough D.
A node N is a postdominator of D if any path from D to exit must go throughN.
A node N is the immediate postdominator of D if N is the �rst postdominatoron any path from D to exit.
1.2.5 Unreachable-Code Elimination
For any given function the CFG G=(V,E) with single entry node entry andsingle exit node exit the unreachable basic blocks are simply those which thereare no path to from entry.
Unreachable code is code in basic blocks which we know for sure cannotbe executed, the elimination of unreachable code does not necessarily have adirect e�ect on the execution speed of a program but is guaranteed to decreasethe size of the program. It is however possible to get faster execution speedas the result of unreachable code elimination, the size of the function could forexample get small enough to �t in the L1 instruction cache as the result ofremoving unreachable-code.
Another possible way to get a speed increase as the result of removing un-reachable code is that we sometimes can use straightening [17] on the CFG.
3

Straightening is an optimization where we detect pairs of basic blocks (B1,B2)where B1 only have B2 as successor and B2 only have B1 as predecessor, thismeans that there is an unconditional jump from B1 to B2 and we can thereforereplace the jump with B2.
4

2 Inlining heuristics in studied compilers
In this thesis we study the inliner in 3 di�erent compilers.
2.1 IAR Inliner
The inlining is done in the global optimizer (middle-end) of the compiler whichmeans that the inliner is back-end independent and works on an intermediaterepresentation of the code. This also means that in general the inliner will notmake any back-end speci�c decisions.
The current inlining heuristic is solely based on the expected size of a func-tion. It is the expected size of a function since we are working with intermediatecode but also because we do inlining in an early phase of the optimizer and lateroptimizations can a�ect the size.
The optimizer will start by building a call graph and go through the functionsin reverse invocation order (i.e leafs and up, bottom-up), for every function thathas callers the decision to inline or not is taken based on a combination of someof the properties mentioned in 1.1. If the inliner decides that the function shouldbe inlined it is inlined at all call sites. There are two #pragmas that can be usedto override the heuristics, one that forces a function to be inlined and one thatprevents a function from being inlined.
There are some situations that can occur in a call graph where this inliningheuristic will refuse to inline. In Figure 1a there is a back-edge on B whichmeans that B has a call to itself. This inliner will never inline recursive calls.
A program where the call graph has a cycle like in Figure 1b it's neverpossible that both edges in the cycle get inlined. The only possible inlining inthe cycle is that either D inlines the call to E, or E inlines the call to D. If bothedges are suitable for inlining we will inline the edge which we look at �rst.
When we inline a function which itself contains function calls we get newedges in the call graph, in Figure 1c inlining of D into C has resulted in a newedge from C. New edges that are the result of inlining are never considered forinlining in this inliner (i.e only the original call graph will be considered).
A
B
(a) Recursion
C
D E
(b) Cycles
{C:D}
D E
(c) New edges
Figure 1: Situations in call graph where the current ICC inliner refuse to inline
5

2.2 RealView Inliner
RealView software development tools are sold by ARM [1], although they haveseveral software development tools what we're interested in for this thesis isof course their C and C++ compiler called armcc. According to the compilerdocumentation the inlining decision is ultimately based on a �complex decisiontree� [9]. But as a general rule the following criteria are taken into considerationwhen deciding if a function should be inlined.
• The size of the function and how many times it is called, smaller functionsare more likely to be inlined.
• Optimizations �ags -Otime and optimization level in general.
• Large functions are normally not inlined.
• Reserved keywords that the programmer can use to increase the chancesof a function being inlined.
The documentation describes a heuristic that sounds similar to the heuristicused in the IAR compiler. A guess is that they also choose to inline at allcall sites or none, the fact that they mention the number of call sites in thecriteria indicates a heuristic like this. Some experimenting with the inliner alsoindicated that RealView choose to inline in an all or none fashion.
2.3 GNU Compiler Collection (GCC) Inliner
The GCC compiler supports a number of di�erent programming languages andtargets. The compiler is open source and free to use under the GNU GeneralPublic License (GPL)2. In this thesis we use a GCC compiler with an ARMback-end provided by CodeSourcery [3].
This is by far the compiler studied in this thesis that has the most possibil-ities for the user to con�gure the inliner by using parameters. Inlining boundssuch as, maximum growth of module, maximum depth when inlining recursivefunctions, maximum size of a function, etc. can all be set by using di�erent op-tions to the compiler. Typically a user would use the default values for all theseparameters (perhaps not even aware about inlining at all), but it's importantto know about this as.
This means that if a user thinks inlining expands the code too much, there'salways the possibility to set the upper limit of growth explicitly and try again.Neither IAR nor RealView support this kind of work �ow.
There is a document about the GCC call graph module and interproceduraloptimizations [14] that talks about inlining in GCC. However since the documentis from 2004 we decided to gather information about the inliner straight fromthe source code to make sure that we get an up to date view of the heuristics.The inliner in GCC works as follows, begin by inlining functions that are smallenough that they should always be inlined (i.e call cost is higher or equal toinlining the function). After this GCC inlines functions that are considered�small enough�, the upper bound for what is considered small or not can be setwith parameters to the compiler. The calls to the �small enough� functions are
2http://www.gnu.org/licenses/gpl-3.0.txt
6

assigned a score that is based on the number of call sites to the function and ifthe call is nested, the call sites are then inserted into a heap sorted on this score.Call sites are then removed from the heap and inlined until it is either empty(i.e empty call graph, all possible inline candidates are inlined) or until an upperbound in total growth is met (this upper bound can also be set explicitly withparameters), this means that GCC can inline a subset of call sites to a function.After this a last pass over functions that only have one call site are considered.GCC also handles inlining of recursive functions in a way so that the functionis inlined down to a given depth. GCC also supports inlining decisions basedon pro�ling data from an earlier run of the application.
3 A new inliner
3.1 Ideas for a new inliner
We believe that the biggest problem with the current ICC heuristics is that itinlines too much, results (Figure 1 on page 22) in this thesis will also show thatthe current heuristics generates a large code growth. Since the current heuristicsis solely based on an estimation for each function which is then compared toa given limit it means that the inliner will inline without any control over thetotal code growth. If there are many functions that pass the upper limit thegrowth will sometimes be very large.
The new heuristic include a more detailed analysis of the functions and callsites to be able to make more accurate inlining decisions and also prevent thecode from growing out of control. To do this every call site will be assignedwith a badness value which is calculated by a score function, here badness(x) <badness(y) would mean that call site x is inlined before call site y. To preventthe code from growing too much we shall also keep a history of how earlierinlining decisions have a�ected the code growth.
3.1.1 Selective inlining
For the new heuristic where a call site is assigned a badness value it's obviouslynot a good idea to go for the old heuristic style with inlining all or nothing of afunction since this would make it impossible to have a ranking among call sitesto the same function. The new heuristic can therefore handle inlining of just asubset of the call sites to a given function, the reason for this is that some callsites are likely to be more suitable for inlining and these should not be ruledout because there are other calls to the same function that are less likely to begood inlining candidates.
As an example consider the pseudo-code in Listing 1, we have 5 di�erentcalls to a function A. With the old heuristics we would either inline all thesecalls or none but now that every call site has a corresponding badness value(rather than a badness value for the whole function) we have the possibility tohave a ranking between these call sites.
7

Listing 1: Selective inlining
A( )A( )forforA()
A( )A( )
This is one example why we should support selective inlining. It is howeverimportant to remember that the number of call sites to a function should stillbe part of the evaluation, but it should not be enough to rule out a speci�c callsite for inlining.
3.1.2 Heuristics for call sites
We want the inliner to be able to make some kind of estimation of how likelyit is that a call site is used often. De�ne the hotness(X) of a call site X so thathotness(X) > hotness(Y ) means that it's more likely that call site X is executedmore often than Y. Some compilers (GCC for example) have support for usingpro�ling data as input to the inliner, the pro�ling information can then be usedto give a good approximation of which calls are hot and which are not.
Currently we do not have the possibility for such feedback from the IAREmbedded Workbench Pro�ler but we still would like the inliner to give callsites that are likely to be hot a little boost. To do this we use a very simpleanalysis that checks the loop-depth of a call site. Where a higher loop-depthwould increase hotness.
With the addition of code hotness analysis to the inlining heuristics weshould be able to rank the nested call to A in Figure 1 higher than the othercalls to A, and perhaps only choose to inline this call. Without selective inliningthis kind of call site boosting would not be possible.
3.1.3 Unreachable-Code Elimination
The idea of predicting further optimizations on functions as a results of inliningfor was �rst described by J. Eugene Ball in a research article [12]. We can thinkof this as the results of a constant propagation made over function calls whichresults in the possibility to do unreachable code elimination.
Every function is analyzed for parameter dependency and then annotatedwith information about which parameters and what possible savings are possibleif the parameters were replaced by constants. Consider the program in Listing2.
8

Listing 2: Unreachable code elimination possibilities after inlining.
1 void f oo ( int x )2 {3 i f ( x == 1) { . . . }4 else { . . . }5 }67 void bar ( )8 {9 foo ( randomNumber ( ) ) ;
10 foo ( 1 ) ;11 }
The function foo have a dependency on the parameter x because if we knowthe value of x the optimizer can remove the conditional statement and replacethe if/else branches with the appropriate branch depending on the value of x.The function foo is therefore annotated with information about the possibilityto remove unreachable code if the function is inlined at a call site with a pa-rameter that at compile time has a known constant. The function bar that isa caller of foo can then use this information when considering inlining of thecalls.
The call to foo at line 9 has an unknown parameter value at compile time,therefore we must expect that we need a copy of the full function foo if weinline at this call site. When considering the call at line 10 the inliner should beable use the information annotated with foo and realize that all code in the elsebranch will be removed if the call is inlined. The inliner can therefore assignthe second call a lower badness value compared to the �rst call.
3.1.4 Termination of inlining
There are a number of di�erent ways for an inliner to terminate. With thecurrent ICC inliner we terminate when all callees in the call graph has beenexamined, but with the new inliner we have other possibilities. Since the newinliner is going to keep a badness value for all edges in the call graph one way toterminate would be to inline until the currently lowest badness-value are abovea certain limit. Another way to terminate is that the inliner runs until a certainlimit in growth is met. The new inliner will terminate on one of the followingcriteria.
1. No more edges in the call graph.
2. The next edge to inline has a badness value higher than a given limit.
3. The next edge to inline would result in a growth larger than a given limit.
9

4 Implementing the new inliner
4.1 Analyzing functions for parameter dependency
We need to annotate every function with information about the possible savingsthat can be achieved if the functions is called with some constant parameters.We use this information in a later stage when assigning the badness value toedges in the call graph. To do this we scan the function and search for con-ditional statements (if/else/switch) and �nd out if any of the conditions arefully dependent on any of the formal parameters to the function. What we arelooking for are conditions that can be composed as follows:
1. The condition is composed only of parameters and constants, the param-eters must not have been rede�ned before the condition.
2. The condition is composed of local variables that are de�ned by formalsand constants (again no rede�nition of the formals before the de�nition ofthe local).
When a condition like this is discovered we know that if constants are available atcompile time we can at least evaluate the condition and remove the conditionalstatement, it's also possible that we will be able do remove dead code as a resultof the elimination of the the condition. The condition will be saved along withthe function with information about what parameters it is dependent on. Sinceit's possible that the condition is dependant on more than just one parameter wesave a bit-vector where the dependant parameters are set and parameters that'snot used in the statement are cleared. The algorithm in Algorithm 1 is usedto �nd out which basic blocks are unreachable if we know what the conditionevaluates to (true or false).
Algorithm 1 Calculate unreachable basic blocks
1 PD = ImmediatePostDominator (T)2 Al l = BFS(T, PD)3 TD = TrueBranch (T)4 FD = FalseBranch (T)5 UnreachableI fTrue = All−BFS(TD, PD)6 Unreachab l e I fFa l s e = All−BFS(FD, PD)
From the node T which includes the conditional statement �nd out the postdominating node PD, do a Breadth-�rst search (BFS) from T to PD. The basicblocks found during this BFS are all reachable if we don't know the result ofthe condition.
Now assume that the condition is true and collect all the basic blocks reach-able from the block we jump to, to the post dominating block. After this do thesame thing but assume that the condition is false. To �nd out if some nodes areno longer reachable if the condition is true just subtract the reachable nodes inthe true-branch from the all-nodes. Then do the same for the false-branch. Thesets with unreachable blocks are then saved together with the node T for lateruse.
10

1 void f oo ( int p1 , int p2 )2 {3 int l o ca l 1 , l o c a l 2 ;4 l o c a l 1 = p2 ∗2 ;5 i f ( l o c a l 1 > 10)6 {7 i f ( p2 > 12)8 {9 p2 = g loba l 1 ;10 }11 else
12 {13 l o c a l 1 = p2 ;14 }15 g l oba l 1 = p2 ;16 }17 else
18 {19 for ( p2=0;p2<10;p2++)20 g l oba l 1+=p2 ;21 }2223 i f ( p1 > 10)24 {25 g l oba l 2 = p1 ;26 }27 }
(a) C-Source
B0 Line 5
B1 Line 7 B5 Line 17
Line 9 B2 B3 Line 13 B6 B7
B4 Line 15
B8 Line 23
Line 25 B9
B10
(b) Control �ow graph
Figure 2: Analysing a function for constant dependencies
Consider the example in Figure 2. Assume that the left path in Figure 2bis taken if the condition is false.
The �rst conditional statement discovered is the conditional statement at line5 which correspond to the basic block B0. The condition is examined and wedetect that the condition is dependent on a local variable local1 and a constant10. We then have a look at the de�nition of local1 and �nd out that it is de�nedby the parameter p2 and a constant 2. This means that the condition in B0 isfully depend ant on the parameter p2 so this is a candidate for test eliminationand unreachable code removal. In this situation we save the actual condition(call this Test1) along with enough information so that we can map variablesused in the expression to parameters and then we run the algorithm describedin Algorithm 1. The result of Algorithm 1 will be PD=B8, TD=B5, FD=B1 and thesets All={B1,B2,B3,B4,B5,B6,B7}, UnreachableIfTrue={B5,B6,B7},
UnreachableIfFalse={B1,B2,B3,B4}.The sets UnreachableIfTrue and UnreachableIfFalse will now be saved
together with Test1. There will also be a Test2 and Test3 saved with thisfunction. Where Test2 is the conditional statement at line 9 and Test3 isthe conditional statement at line 23. The function have then been analyzedfor constant parameter dependencies and we will be able to calculate possiblesavings if the function is inlined at call sites with known constant parameters.
4.2 Building the edge queue
Given a call graph for the program we construct a minimum priority queuewhich hold all edges in the call graph. The edges in the queue will be keyed on
11

the badness value. For every edge in the call graph that is an inline candidatethe following properties is used to calculate a badness value.
• The loop depth of this call site.
• Constant parameters at this call site.
• The size of the callee (expected).
• Number of calls to the callee.
• Does the callee have the inline keyword.
• Recursion penalty (optional) see chapter 4.4.
If the callee is tagged with possible dead code elimination and the call site haveconstants available for these parameters the size of the callee will be estimatedto a new smaller size depending on how much we expect to save.
4.3 Inline driver
The inline driver is where the actual inlining takes place, this is where we pickedges from the queue created in the analysis part and inline them. The inlinedriver described in this chapter is heavily inspired by the inline analysis driverpresented in research article about inlining [13] written by D. Chakrabarti etal. As described by Chakrabarti we sometimes need to update some of theremaining edges in the queue after we inline a function, we used the samemethod as proposed in the article and keep a look up table to validate the edgeswe extract from the queue.
The pseudo code for the inline driver is pictured in Algorithm 2. For themoment just assume there is an algorithm UPDATE which given an edge that hasbeen inlined, the queue, the look up table and the current call graph will updateall necessary data structures. How the UPDATE algorithm works is described inthe next section.
12

Algorithm 2 Inline driver
GET_BEST(Q, L)va l i d = f a l s ewhi l e ! v a l i d :
e = POP(Q)i f L . e x i s t s ( e . key ) and L [ e . key ] . badness == e . badness :
v a l i d = truei f Q. empty :
re turn nu l lr e turn e
DRIVER(Q, CG)L <− emptygrowth = 0whi le growth < allowedgrowth
edge = GET_BEST(Q,L)i f edge == nu l l or edge . s co r e > badne s s l im i t
re turngrowth += INLINE( e )(CG, Q, L) = UPDATE( e , Q, L , CG)
4.3.1 Updating data structures after inlining of one call site
After we inline a call site the call graph change and we need to calculate newbadness values. We could rebuild the entire call graph and calculate new badnessvalues for all the edges in the new call graph just like we did in the initializationphase but this would not be e�cient and it's not necessary to recalculate allbadness values.
Algorithm 3 describes the dependencies and necessary updates we need todo after inlining a call site.
13

Algorithm 3 Updating call graph and edges after inlining
1 UPDATE(e, Q, L, CG)
2 caller = e.Caller
3 callee = e.Callee
4 CG = RemoveEdge(e, CG)
5 for all c in callee.Callees:
6 newedge = NewEdge(caller , c)
7 CG = AddEdge(newedge , CG)
8 Q.push(newedge)
9 updatededge = NewEdge(callee ,c)
10 Q.push(updatededge)
11 L[updatededge.key] = updatededge
12 for all c2 in c.Callers:
13 updatededge = NewEdge(c2 , c)
14 Q.push(updatededge)
15 L[updatededge.key] = updatededge
16 for all c in callee.Callers:
17 updatededge = NewEdge(c, callee)
18 Q.push(updatededge)
19 L[updatededge.key] = updatededge
20 for all c in caller.Callers:
21 updatededge = NewEdge(c, caller)
22 Q.push(updatededge)
23 L[updatededge.key] = updatededge
24 return (CG , Q, L)
To understand what the di�erent parts of Algorithm 3 is needed for considerthe call graph given in Figure 3a as part of a much larger call graph, we assumethat the edge with the currently lowest badness value is the edge DE and thatthe inline driver have inlined the DE edge and now calls UPDATE to make surethat dependent edges are updated. The result of inlining DE is shown in Figure3b.
14

B
D
E
C
F
AAD
BD
DECE
EF
(a) Initial call graph
B
{D:E}
E
C
F
AAD’
BD’
CE’
EF’
{D:E}F
(b) Call graph after DE is inlined
Figure 3: Demonstration of Algorithm 3
We begin by removing the edge that got inlined by calling RemoveEdge online 5.
After this the �rst for-loop updates the edges going out from E which in thisexample results in a new edge EF' , there is also a new edge {D:E}F which isadded both to the call graph and to the queue. The nested for loop on line 12makes sure that all other edges to F would get updated too. The reason we needto update all the old edges to F is because F now has one more caller.
The for-loop that starts on line 16 updates edges going in to E. In thisexample this means that the edge CE is updated and becomes CE'. We need toupdate this edge because there are fewer callers to E now. The last for-loopupdates callers to caller. In the call graph we can see that A and B are callersof {D:E} and these edges should therefore be updated since it's likely that thesize of {D:E} is larger (or at least di�erent) than D.
For all edges that are updated we save the new edge in the look up table Lto make sure that we extract valid edges from Q the next iteration in the inlinedriver.
4.3.2 User interaction
The badness and maximum growth limits are given as parameters to the com-piler, we have tried the inliner with many di�erent combinations of these twolimits (see Appendix A).
4.4 Avoid getting stuck in local parts of the call graph
Consider the call-graph in Figure 4 and think of it as part of a larger call-graph.Assume that currently the edge with the lowest badness value is the one betweenC and A so the inliner choose to inline this edge which will result in the call-graphshown in Figure 4b.
The inliner then choose to inline the edge between {C:A} and B which resultsin the call-graph shown in Figure 4c, this call-graph looks exactly like the onewe started with. If we don't have any history of earlier inlining decisions thismeans that the inliner would inline the same edges again and again until it stopsbecause of code growth, thus it's stuck in a local maximum here and no otheredges outside this part of the call-graphs will get inlined.
15

To prevent this from happening we annotate edges that are the result ofearlier inlining. In Figure 4b the edge between {C:A} and B is annotated with[A] because it is the results of inlining A into C and in Figure 4c the edgebetween {C:A:B} and A is annotated with both [A,B]. The inliner will penalizeedges where it have already been, this means the the annotated edge in Figure 4bis not penalized, but the annotated edge in Figure 4c is penalized. The penaltydepends on the nested depth of the edge and penalties are accumulated.
It's still possible for the inliner to inline in the same order again, but forevery time it choose these edges the new edges created will get a larger penalty.By annotating the edges we make it possible for the badness calculation to takethese situations into consideration and penalize edges so we don't get stuck ina local maximum of the call graph.
C
A B
(a) Initial
{C:A}
A B
[A]
(b) Inline1
{C:A:B}
A B
[A:B]
(c) Inline2
Figure 4: Annotating edges to avoid local maximum in a pseudo-cycle.
5 Test suite
5.1 Applications
To �nd out how the inliner performs on real code we use a number of di�erenttest applications where we are interested in size and speed with and withoutinlining. Inlining will not be made across modules unless otherwise is stated.
We want to test the inliners on rather large applications since it's more likelythat the inliner will �nd candidates for inlining then. However it is not as easy asit may sound to �nd a set of applications to compile and run, the ICC compileronly supports a subset of C++ called Embedded C++ (EC++) which meansthat we cannot just take a random open source C++ application and compileit. It can be hard enough to �nd applications to compile when you only have toconsider using one compiler and in this thesis we have to make sure it compileswith 3 di�erent compilers.
5.1.1 Dinkum
The Dinkum C++ proofer [5] test suite is used to test for C++ standard com-pliance, the source code is therefore not like typical application code. Thestructure of the di�erent tests are basically the same, one or more �paragraphs�in the C++ standard is tested and this means that one or more �sub tests� forevery tests needs to be done. Basically what we're doing here is unit testingparagraphs in the ANSI standard.
For each sub test made a �check� function is called to make sure that theresult is what we expected, this means that if a test �le includes a lot of sub
16

tests then there will be a lot of calls to these check functions. Even thoughthis test suite does not represent typical application code it is interesting in thisthesis anyway because the Dinkum test suite will make use of a huge amount ofSTL code and the results will show that the current IAR inliner have a lot ofproblems with some of the constructs in these tests.
The result presented for Dinkum is all tests put together, a total of 97 C++source �les.
5.1.2 Open Physics Abstraction Layer (OPAL)
OPAL[7] is an open source low-level physics engines written in C++ that canbe used in games, robotics simulations, etc. We will benchmark the test suitethat comes with the source code package.
5.1.3 Persistence of Visions Ray-tracer (POV-Ray)
An open source ray-tracer called POV-Ray [8], we will use the included bench-mark for POV-Ray to do our benchmarking. Because it takes a lot of time torun this benchmark we use the Freescale hardware mentioned in section 5.1.3when running this application.
5.1.4 Turing Machine Simulator
An open source Turing machine simulator [11] written in C++, uses a lot ofSTL code.
5.1.5 SPEC2000 CPU
We will use 6 of the applications in the SPEC2000 [10] integer benchmark suite,there is a total number of 12 applications that use C or C++ in this suite butbecause we didn't get a copy of SPEC until very late we only had time to patch3
the applications that were the easiest to get through the compiler.It's important to note that the results from SPEC presented in this thesis is
not SPEC benchmarks, we will only use the source code and test data from theSPEC benchmark suite and never intend to get actual SPEC benchmark scores(to get real benchmarks would require too much work).
We also tried the Multi-File-Compilation (MFC) feature of the IAR compileron some of the applications which means that the inliner is able to do crossmodule inlining.
5.2 What we measure
The di�erence in size when enabling inlining is of course interesting. When wetalk about size in this thesis we refer to the code segment (.text) of the output�le. We expect none or very small changes to the data segment when enablinginlining and if the data segment was to be included in the size it's possiblethat a large code segment increase would �drown� in the data segment when wepresent relative di�erences.
3None of the applications could be compiled out of the box. A typical patch is argc/argvparameter support
17

It is possible that enabling inlining will change the amount of library usage.To demonstrate this consider the example in Listing 3.
Listing 3: Example where inlining would reduce the amount of library usage
extern void A( ) ;extern void B( ) ;
stat ic void f oo ( int x ){
i f ( x == 0)A( ) ;
elseB( ) ;
}
stat ic void bar ( ){
foo ( 0 ) ;}
Assume that A and B are de�ned in a library, there are no other references toA or B other than the one shown and there are no other calls to foo other thanthe one shown. If we do not allow inlining the linker4 will have to include bothA and B in the executable since there are references to both A and B from foo.However if inlining is enabled and foo is inlined to bar further optimizationswill detect that the if-statement is always true and the else part that includethe call to B will be unreachable and therefore removed.
After inlining foo into bar we will also remove the only reference to foo andthe linker can therefore remove foo and there will be no more references to B,the linker will therefore only include the function A from the library.
Because the inlining can a�ect the amount of library usage we will removethe overhead of library code usage in the base con�guration before comparingsize di�erences.
Compilers for C and C++ typically come with their own implementation ofthe standard libraries5. The applications we test the inliners on will of courseuse the standard libraries available for C and C++ and to make the comparisonsmore fair we choose to use the same standard library for all compilers. Thismeans that all compilers will be faced with the same input and get the samepossibilities to inline, no #pragmas or other compiler speci�c keywords will beused in the source code we benchmark.
4With linker we mean the IAR Systems ILINK linker or any other linker that performsimilar optimizations.
5All compilers studied in this thesis comes with a di�erent implementation of the standardlibraries
18

6 Test framework
6.1 Tools and target
The target we build for is an ARM1136JF-S processor core and even thoughthere is a VFP6 for �oating point operations in this processor we will compilefor software �oating point because the simulator had problems simulating theVFP.
6.1.1 Simulator
We have used the ARM Symbolic Debugger [2](armsd) to measure executiontime. The number of clock cycles used from the entry of main until main returnsis considered the run time of the application.
6.1.2 Hardware
When it takes too long to run an application in the simulator we instead use realhardware, we have used a Freescale i.MX31 [6] application processor and Em-bedded Linux as operating system. Running applications under a real operatingsystem poses some problems with the C++ library that is delivered with IARcompilers. The library does only support semihosted i/o. Semihosted meansthat to do i/o (printing, reading/writing a �le, etc) you write an i/o code toone register and an address to store the result in another register and then do asoftware interrupt. The simulator running the application will then read theseregisters and to appropriate operations using the hosts i/o.
This not possible when running on real hardware with Embedded Linux. Wehave to replace the software interrupts with kernel systems calls which meansthat we get an interrupt and cache-�ushing when doing i/o. We believe thatthis overhead will have very little e�ect on the benchmarks. Time measure isdone using the standard UNIX command time.
6VFP is a coprocessor extension to ARM that provides �oating-point computation support.
19

7 Measurements
7.1 Intermediate code vs generated code
In chapter 2.1 we said that the current heuristics in ICC is based on the expectedgrowth of a function because the optimizer works with intermediate code. Tosee if it is reasonable for the optimizer to assume that the relationship betweenintermediate code and generated code is proportional we compiled 555 di�erentC and C++ source �les and the result is shown in Figure 5.
The leftmost point which deviates from the �line� is the �le graphic.c inthe SPEC benchmark vpr. When this application is built without graphicssupport all function bodies in this �le are empty and the intermediate code sizecalculation is therefore close to zero. The size presented is module by moduleand it is possible that we would get more outliers if we instead would countevery function for itself.
1000
10000
100000
Co
de
Siz
e (
By
tes)
1
10
100
1 10 100 1000 10000 100000
Co
de
Siz
e (
By
tes)
Intermediate Code Size
Figure 5: Intermediate Code/Generated Code relationship
7.2 Compilers
IAR is represented with the IAR C/C++ V5.20 compiler for ARM with the op-timization �ags -Ohs --no_inline for the base con�guration which use no in-lining and -Ohs to use the current inlining heuristics. We also added a newoption to the old heuristics where we only inline the functions in category 6 (seechapter 1.1). This con�guration are called �IAR Smaller�.
We have used the ARM C/C++ RVCT3.1 compiler from RealView with theoptimizations �ags -O3 -Otime --no_inline for the base con�guration and-O3 -Otime for the con�guration with inlining.
The GCC compiler we used is provided by a software consulting group calledCodeSourcery [3] that provides an ARM tool chain based on GNU tools. Wehave used the arm-2008q3 tool chain [4] which is based on GCC 4.3.2. Theoptimization �ags for the base con�guration are -O3 -fno-inline and the con-�guration with inlining is compiled with -O3.
20

7.3 Results
The code growth di�erence in % when using inlining compared to a base con�g-uration with no inlining is shown in Table 1 and the di�erence in execution timeis shown in Table 2. IAR New is represented in the tables by the con�gurationthat use the least number of executions cycles for that particular application.All results for the new inliner are presented in Appendix A.
The �IAR Smaller� con�guration produce good results with C++ code wherewe get both faster and smaller results. For C code this inliner does not have asmuch e�ect as with the C++ code, there is even one application (parser/MFC)where we get in increase in code growth and another application (vortex) whereexecution used more cycles compared to the base con�guration.
The current IAR inliner produce faster code for all applications tested exceptfor vpr where a 10% increase in code size also lead to 1% longer execution time.
The new IAR inliner produced faster code than the old inliner for all appli-cations except for parser and parser/MFC, especially worth noting is dinkumwhere the new inliner reduced the number of cycles used by 38% at no cost incode growth.
GCC was the compiler that generated the largest code growth on average, toit's defense we must remember that it's possible to constrain the amount of codegrowth with GCC. One of the applications (parser) got a code growth of 117%.It's likely that much of this growth can be contributed to recursive functionswhich the other inliners rejected. Unfortunately it was not possible to run thisapplication so we could not get any feedback on if the inlining of recursivefunctions had a big impact on run-time. There were only one application whereinlining had a negative impact on execution time.
The RealView inliner seems to be very restrictive with inlining, always keep-ing the code growth under 6%. One important observation regarding inliningwith RealView is that no application got a faster execution time comparedto the base con�guration with no inlining. Instead 3 of the applications tooklonger time to execute when using inlining. One possible explanation to the lowamount of inlining in RealView is that they might have annotated their ownlibraries with keywords and pragmas to guide the inliner, and without this helpthe inliner is very defensive.
21
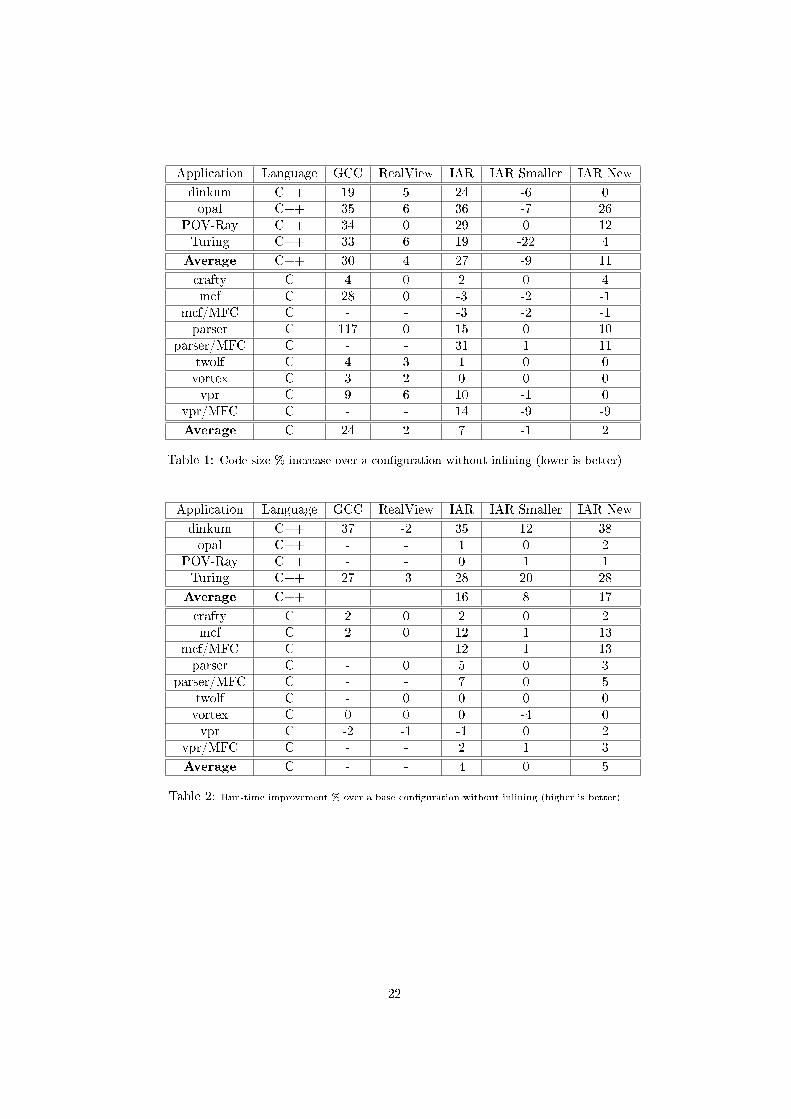
Application Language GCC RealView IAR IAR Smaller IAR New
dinkum C++ 19 5 24 -6 0opal C++ 35 6 36 -7 26
POV-Ray C++ 34 0 29 0 12Turing C++ 33 6 19 -22 4
Average C++ 30 4 27 -9 11
crafty C 4 0 2 0 4mcf C 28 0 -3 -2 -1
mcf/MFC C - - -3 -2 -1parser C 117 0 15 0 10
parser/MFC C - - 31 1 11twolf C 4 3 1 0 0vortex C 3 2 0 0 0vpr C 9 6 10 -1 0
vpr/MFC C - - 14 -9 -9
Average C 24 2 7 -1 2
Table 1: Code size % increase over a con�guration without inlining (lower is better)
Application Language GCC RealView IAR IAR Smaller IAR New
dinkum C++ 37 -2 35 12 38opal C++ - - 1 0 2
POV-Ray C++ - - 0 1 1Turing C++ 27 -3 28 20 28
Average C++ - - 16 8 17
crafty C 2 0 2 0 2mcf C 2 0 12 1 13
mcf/MFC C - - 12 1 13parser C - 0 5 0 3
parser/MFC C - - 7 0 5twolf C - 0 0 0 0vortex C 0 0 0 -4 0vpr C -2 -1 -1 0 2
vpr/MFC C - - 2 1 3
Average C - - 4 0 5
Table 2: Run-time improvement % over a base con�guration without inlining (higher is better)
22

8 Conclusions and future work
By looking at the results we can see that inlining is an optimization that hasa much larger impact on C++ code compared to C code, regarding both thedi�erence in size and speed. It is no surprise that inlining a�ects C++ codemore than C code since an object oriented language encourages decompositionof code into smaller functions and classes which later can be reused by otherobjects.
The current IAR inliner generates a large code growth just as we had ex-pected, even though it usually means that we reduce the execution time we candraw the conclusion that the current inliner generates an unnecessarily largegrowth. We can for example compare the current inliner with the new inlinerand see that for most of the applications the new inliner produces at least as fastcode as the current inliner but at a much lower code growth. We believe thatthis is the result of an combination of inlining unnecessary function which doesnot increase performance and too much inlining which leads to more resourcecon�icts. The �IAR Smaller� con�guration seems to be a good alternative forC++ code, it's easy to implement and the results are on average good. It alsoshows that inlining is a necessary optimization to use when optimizing C++code.
The new IAR inliner seems to work good in most cases but it's not possibleto �nd one single con�guration which works best. It would be interesting to addmore properties to the heuristics and then try running the inliner with di�erentparts of the heuristics turned o�. Examples of new properties are: current sizeof caller, number of formal parameters to callee, estimation of register pressureat call site and estimation of register pressure in callee, cache awareness (keepfunction small enough to �t in level 1 cache etc.). It would also be interestingto study the behavior of the heuristics when di�erent properties are turned o�.
23

A Appendix
Every application has been compiled with the new inliner using 6 di�erent badness combinedwith 3 di�ererent growth limits. In the charts presented in this appendix a higher number su�xon badness/growth means that the limit is higher (i.e badness 2 means a higher badness limitthan badness 1).
24

A.1 IAR New Inliner Code growth
1,1
1,2
1,3
1,4
Co
de
gro
wth
BADNESS 1
BADNESS 2
BADNESS 3
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
BADNESS 3
BADNESS 4
BADNESS 5
BADNESS 6
(a) Dinkum
1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(b) Turing
1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(c) Opal
1,1
1,2
1,3
1,4C
od
e g
row
th
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(d) POV-Ray
1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(e) crafty
1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(f) mcf
Figure 6: Code growth
25

1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(a) parser
1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(b) twolf
1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(c) vortex
1,1
1,2
1,3
1,4
Co
de
gro
wth
0,7
0,8
0,9
1
GROWTH 1 GROWTH 2 GROWTH 3
Co
de
gro
wth
(d) vpr
Figure 7: Code growth
26

A.2 IAR New Inliner Cycles used
0,85
0,9
0,95
1
1,05
1,1
BADNESS 1
BADNESS 2
BADNESS 3
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
BADNESS 3
BADNESS 4
BADNESS 5
BADNESS 6
(a) Dinkum
0,85
0,9
0,95
1
1,05
1,1
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
(b) Turing
0,85
0,9
0,95
1
1,05
1,1
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
(c) Opal
0,85
0,9
0,95
1
1,05
1,1
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
(d) POV-Ray
0,85
0,9
0,95
1
1,05
1,1
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
(e) crafty
0,85
0,9
0,95
1
1,05
1,1
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
(f) mcf
Figure 8: Cycles used
27

0,85
0,9
0,95
1
1,05
1,1
Cy
cle
s u
sed
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
Cy
cle
s u
sed
(a) parser
0,85
0,9
0,95
1
1,05
1,1
Cy
cle
s u
sed
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
Cy
cle
s u
sed
(b) twolf
0,85
0,9
0,95
1
1,05
1,1
Cy
cle
s u
sed
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
Cy
cle
s u
sed
(c) vortex
0,85
0,9
0,95
1
1,05
1,1
Cy
cle
s u
sed
0,6
0,65
0,7
0,75
0,8
0,85
GROWTH 1 GROWTH 2 GROWTH 3
Cy
cle
s u
sed
(d) vpr
Figure 9: Cycles used
28

A.3 All inliners together
1,241,19
1,051
1,1
1,2
1,3
1,4
Code growth
0,94
1,00
1,05
0,88
0,65 0,62 0,63
1,02
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR New GCC RealView
Code growth
Cycles used
(a) Dinkum
1,19
1,04 1,06
1,32
1
1,1
1,2
1,3
1,4
0,80
0,72 0,72
1,03
0,73
0,78
1,04 1,06
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR New RV GCC
(b) Turing
1,36
1,26
1,06
1,35
1
1,1
1,2
1,3
1,4
1,01 0,99 0,980,93
1,06
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR New RV GCC
(c) Opal
1,29
1,11
1,34
1
1,1
1,2
1,3
1,4
1,00 1,000,99 1,00 0,99
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR New GCC RealView
(d) POV-Ray
1,041
1,1
1,2
1,3
1,4
1,00 1,021,04 1,04
1,001,000,98 0,97 0,98 1,00
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR New GCC RealView
(e) crafty
1,28
0,991,001
1,1
1,2
1,3
1,4
0,98 0,97 0,97 0,99 0,99 1,000,99
0,88 0,88 0,87 0,87
0,98
1,00
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR MFC IAR New IAR MFC
New
GCC RealView
(f) mcf
Figure 10: All inliners
29
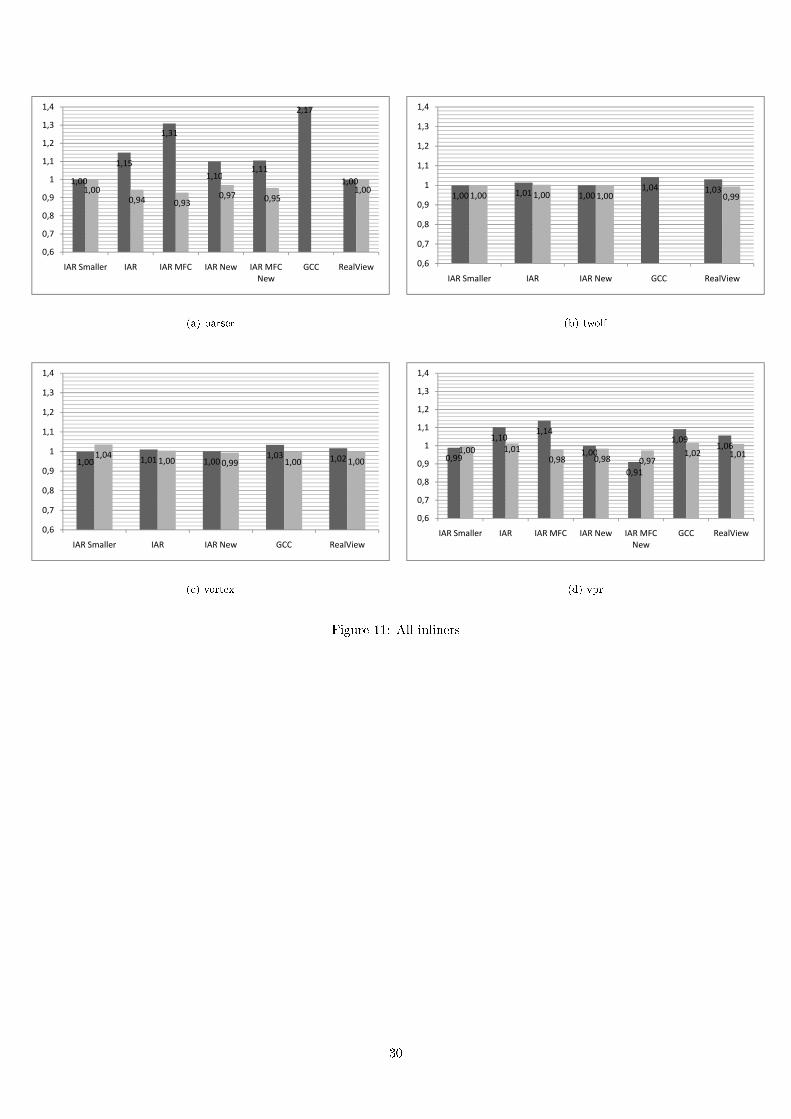
1,00
1,15
1,31
1,101,11
2,17
1,001
1,1
1,2
1,3
1,4
1,00 1,001,00
0,94 0,930,97 0,95
1,00
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR MFC IAR New IAR MFC
New
GCC RealView
(a) parser
1
1,1
1,2
1,3
1,4
1,00 1,01 1,001,04 1,03
1,00 1,00 1,00 0,99
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR New GCC RealView
(b) twolf
1
1,1
1,2
1,3
1,4
1,00 1,01 1,001,03 1,021,04
1,00 0,99 1,00 1,00
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR New GCC RealView
(c) vortex
1,101,14
1,00
1,091,06
1,00 1,011,02
1
1,1
1,2
1,3
1,4
0,991,00
0,91
1,061,00 1,01
0,98 0,98 0,971,02 1,01
0,6
0,7
0,8
0,9
1
IAR Smaller IAR IAR MFC IAR New IAR MFC
New
GCC RealView
(d) vpr
Figure 11: All inliners
30

References
[1] ARM. The world leading semiconductor intellectual property (IP) supplier.http://www.arm.com .
[2] ARMSD. Simulator and Debugger for ARM code.http://www.arm.com/products/DevTools/ARMSymbolicDebugger.html .
[3] CodeSourcery. Software tools vendor.http://www.codesourcery.com .
[4] CodeSourcery ARM toolchain. Providers of ARM back-end for GCC.http://www.codesourcery.com/gnu_toolchains/arm/ .
[5] Dinkumware. The makers of the STL library used in ICC.http://www.dinkumware.com .
[6] Freescale i.MX31 application processor. Semiconductor manufacturer.http://www.freescale.com/imx31/ .
[7] The open physics abstraction layer. A high-level C++ interface for low-level physics.http://opal.sourceforge.net .
[8] The persistence of vision raytracer. An open source raytracer written inC++.http://www.povray.org .
[9] RealView Compilation Tools. Compiler User Guide Version 3.1.Manual for RealView compiler.http://infocenter.arm.com/help/topic/com.arm.doc.dui0205h/DUI0205H_rvct_compiler_user_guide.pdf .
[10] Standard performance evaluation corporation. Non-pro�t corporation thatmaintain a standardized set of benchmarks.http://www.spec.org .
[11] Turing machine simulator. An open source C++ implementation of aTuring machine.http://sourceforge.net/projects/turing-machine/ .
[12] J. Eugene Ball. Predicting the e�ects of optimization on a procedure body.SIGPLAN Not., 14(8):214�220, 1979.
[13] D.R. Chakrabarti and Shin-Ming Liu. Inline analysis: beyond selectionheuristics. Code Generation and Optimization, 2006. CGO 2006. Interna-tional Symposium on, pages 12 pp.�, March 2006.
[14] Jan Hubicka. The gcc call graph module: A framework for inter-proceduraloptimization. In Proceedings of the GCC Developers' Summit, pages 65�78,2004.
[15] Rainer Leupers and Peter Marwedel. Function inlining under code sizeconstraints for embedded processors. In In International Conference onComputer-Aided Design (ICCAD, pages 253�256. IEEE Press, 1999.
31

[16] Robert Morgan. Building an Optimizing Compiler, chapter 9.2.Morgan Kaufmann Publishers, 2004.
[17] Steven S. Muchnick. Advanced Compiler Design & Implementation.Morgan Kaufmann Publishers, 1997.
32




























