Embed Size (px)
Citation preview

EVOLUZIONE MODELLI DI CALCOLO A LHC
T. Boccali, A. De Salvo, C. Grandi, D. Elia, V. Vagnoni

Outline (a grana grossa) • Computing a LHC: condizioni al contorno
• Run 1 (2010-2013): • Modello di calcolo degli esperimenti • Lezioni imparate
• Nuove condizioni al contorno per il Run 2015-2018
• Evoluzione dei modelli di calcolo
• (Oltre il 2018)
2

LHC, condizioni al contorno I piani storici
Anno Bunch spacing (pp)
Energy (pp) per nucleone
Energy (HI) per nucleone
Lumi Inst (pp)
Lumi Inst (HI)
<pile up> interactions, pp
Integrated lumi (pp)
Live time (pp)
Live time (HI)
2005 25 ns 14 TeV 5.5 TeV 2x1033 5x1026 5 10 1/fb 107 O(106)
2006 25 ns 14 TeV 5.5 TeV
2x1033 5x1026
5 10 1/fb
107
O(106)
2007 25 ns 14 TeV 5.5 TeV
2x1033
5x1026
5 10 1/fb
107
O(106)
3

Aspettative degli esperimenti (~ 2005) • Data rates
• 40 MHz interaction rate (1/25ns) – pp • 4 kHz - HI • O(100-300) Hz salvati alla fine della selezione su tape • ~1 MB/ev RAW data size (pp), ~ 10 MB/ev (HI)
• Eventi raccolti in un anno • pp: 100Hz * 107 sec = 1 Miliardo l’anno -> 1 PB/anno • HI: 100Hz * 106 sec = 100 Milioni l’anno -> 1 PB/anno
• Utenti attivi : una percentuale (ottimisticamente) fissata intorno al 30-50% della collaborazione • ~1000 per ATLAS/CMS • ~200 per LHCB/ALICE
4

Altri parametri in gioco • Eventi ricostruiti: 0.5-1x dei RAW, possibili formati ridotti
~10x piu’ piccoli
• Reprocessing: previsti almeno un paio l’anno
• Tempi CPU per processing • Reconstruction: 20-50 sec/ev • Simulation (Geant4): 100-400 sec/ev • Analisi: 0.1 sec/ev
5
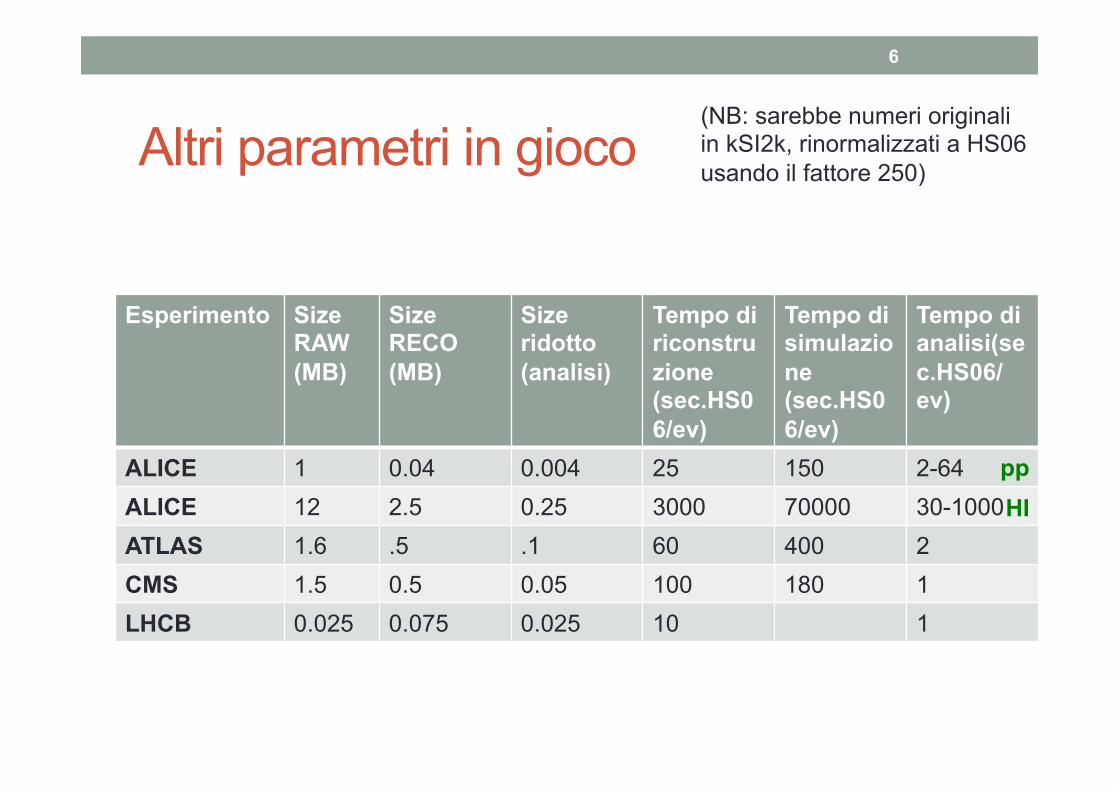
Altri parametri in gioco
Esperimento Size RAW (MB)
Size RECO (MB)
Size ridotto (analisi)
Tempo di riconstruzione (sec.HS06/ev)
Tempo di simulazione (sec.HS06/ev)
Tempo di analisi(sec.HS06/ev)
ALICE 1 0.04 0.004 25 150 2-64 ALICE 12 2.5 0.25 3000 70000 30-1000 ATLAS 1.6 .5 .1 60 400 2 CMS 1.5 0.5 0.05 100 180 1 LHCB 0.025 0.075 0.025 10 1
HI
6
pp
(NB: sarebbe numeri originali in kSI2k, rinormalizzati a HS06 usando il fattore 250)

Come avviene davvero la presa dati? • La DAQ+L1+L2+HLT (comunque si voglia chiamare la
sequenza che scrive eventi persistenti RAW su supporto storage permanente) seleziona 100-300 Hz di eventi • Tale storage deve essere GARANTITO: almeno 2 copie, tape
preferibile
• Deve esserci un sistema che li ricostruisce (velocemente: la guerra e’ aperta)
• Deve esserci un sistema che ripete le ricostruzioni 2-5 volte l’anno, una volta che le calibrazioni ottimali siano state realizzate
• Deve esserci un sistema di analisi accessibile all’utente
• (il tutto 2x per la presenza parallela di eventi simulati)
7
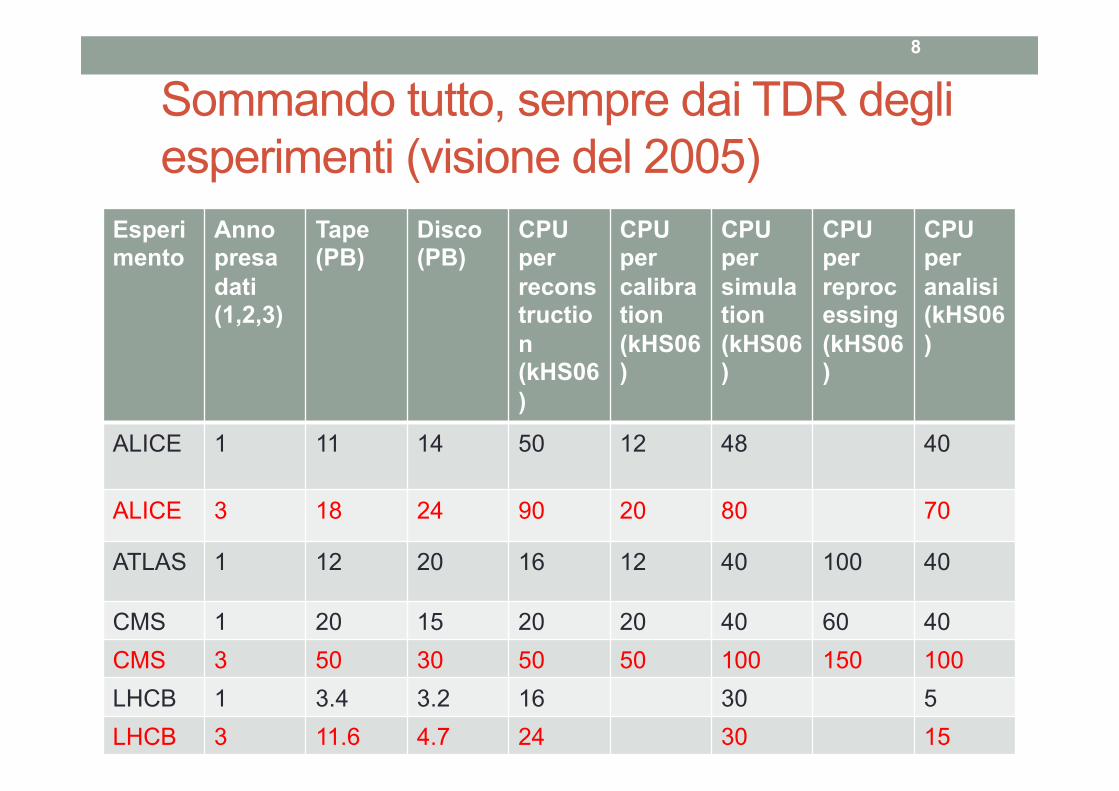
Sommando tutto, sempre dai TDR degli esperimenti (visione del 2005)
Esperimento
Anno presa dati (1,2,3)
Tape (PB)
Disco (PB)
CPU per reconstruction (kHS06)
CPU per calibration (kHS06)
CPU per simulation (kHS06)
CPU per reprocessing (kHS06)
CPU per analisi (kHS06)
ALICE 1
11 14 50 12 48 40
ALICE 3 18 24 90 20 80 70
ATLAS 1 12 20 16 12 40 100 40
CMS 1 20 15 20 20 40 60 40 CMS 3 50 30 50 50 100 150 100 LHCB 1 3.4 3.2 16 30 5 LHCB 3 11.6 4.7 24 30 15
8

Quindi … • CPU (2010; 2012 nella realta’) era prevista ~ 400 kHS06 per
esperimento (almeno, per ATLAS e CMS) • DISK: ~30 PB per esp • TAPE: ~50 PB per esp
• (poi vediamo cosa sono stati davvero…)
• PROBLEMA: anche considerando sempre valida la legge di Moore, e dando per 2010 ~ 8 HS06 a processore e 2 TB/disco, sono (sempre per esperimento) • Almeno 50000 CPU (che allora erano 50000 computers) • Almeno 15000 dischi • Almeno 50000 cassette
9

10
Slide del 2005 (per il primo anno di presa dati) ….
~400 kHS06

Come gestirle? Volonta’ anche politica si andare su calcolo geograficamente distribuito
1. Le funding agencies si comprano risorse invece di mandare soldi al CERN
2. Si crea un knowledge distribuito sul calcolo scientifico 3. La CERN/IT puo’ concentrarsi sugli aspetti piu’ vicini alla presa
dati
• Usando GRID come MW, MONARC come template del modello di calcolo
11

MONARC e le reti • Gli esperimenti “producono” dati a ~450 MB/s (se a 300 Hz) di
flusso RAW, piu’ un flusso Ricostruito simile • La parte di produzione MC mette circa un altro fattore 2, e poi
c’e’ la parte ricostruita • L’analisi deve accedere a questi dati in modo caotico, da parte
di ~ 1000 utenti (jobs di analisi sono dimensionati a circa 1 Mbit/s/HS06, e ci sono ~100kHS06 per l’analisi)
• Sommando il tutto, si arriva ad una stima di 20 Gbit/s+100 Gbit/s; quindi O(150Gbit/s) caotici fra ~50 siti (gli istituti + importanti)
• Le reti previste per il 2010 NON potevano garantire queste bande fra un numero grande e variabile di istituti
12

Per cui MONARC … • E’ sostanzialmente Data Driven: i dati devono seguire
rotte prevedibili con rate prevedibili, in modo che solo queste vadano “garantite”
• Si ottiene naturalmente una distinzione fra i siti, che non
sono tutti uguali.
• Solo fra alcuni di questi e’ necessario dare garanzie di banda.
13
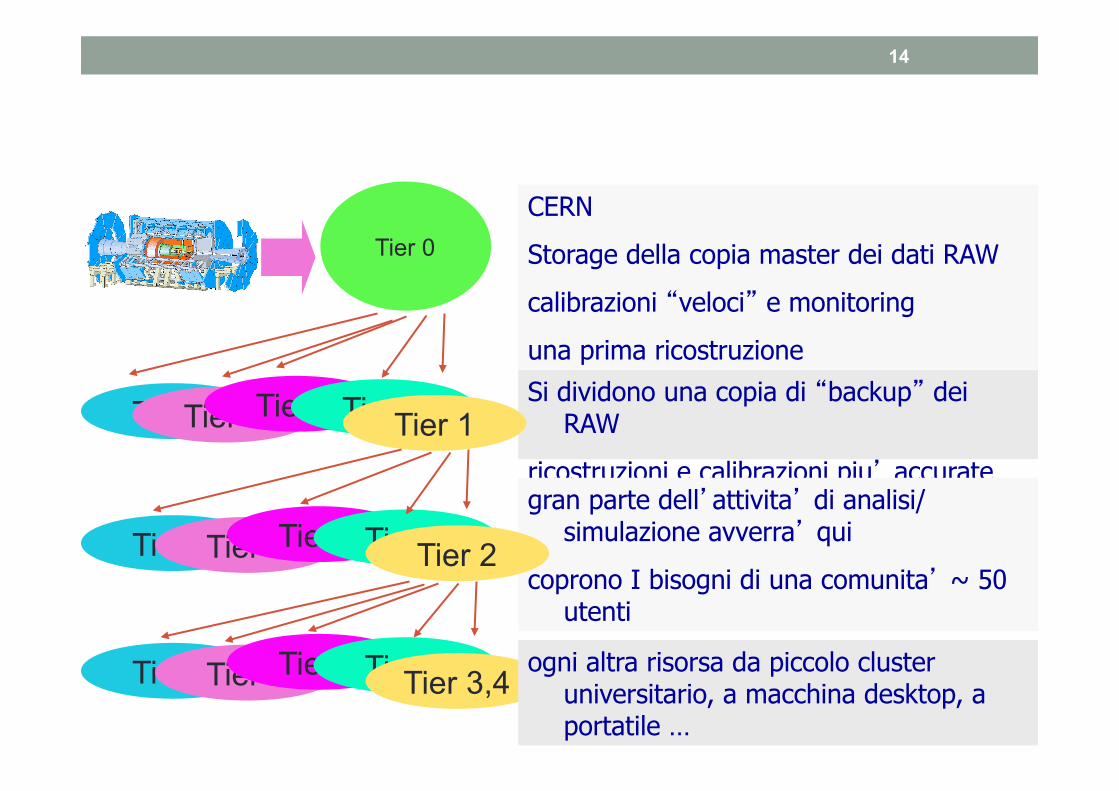
14
30/3/2005 Tommaso Boccali 14
Si dividono una copia di �backup� dei RAW
ricostruzioni e calibrazioni piu� accurate gran parte dell�attivita� di analisi/
simulazione avverra� qui
coprono I bisogni di una comunita� ~ 50 utenti
Tier 1 Tier 1 Tier 1 Tier 1 Tier 1
Tier 2 Tier 2 Tier 2 Tier 2 Tier 2
CERN
Storage della copia master dei dati RAW
calibrazioni �veloci� e monitoring
una prima ricostruzione
Tier 0
Tier 2 Tier 2 Tier 2 Tier 2 Tier 3,4 ogni altra risorsa da piccolo cluster
universitario, a macchina desktop, a portatile …

La rete e MONARC • LHCOPN fra T0 <-> T1s per la parte “garantita”
• Dall’inizio almeno 10 Gbit/s daverso CERN
• Fra T1 e T2 e fra T2: nulla di davvero garantito • In pratica lasciato alle NREN senza particolari richieste aggiuntive
15
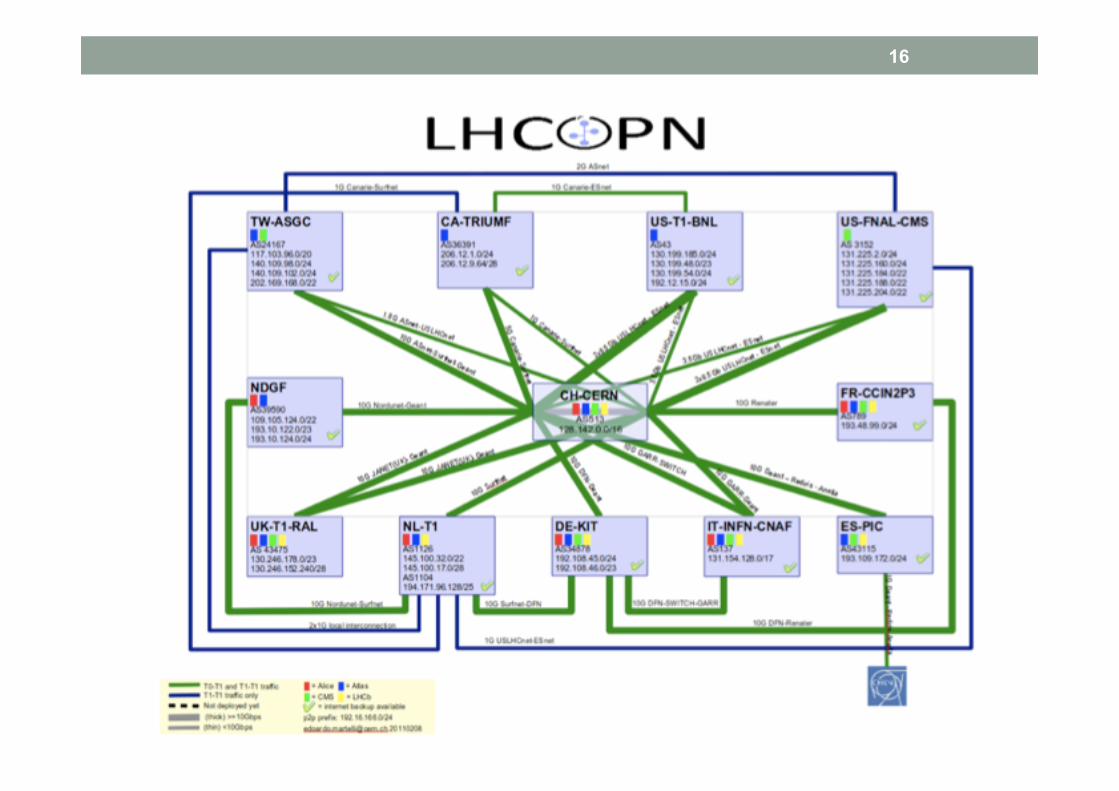
16

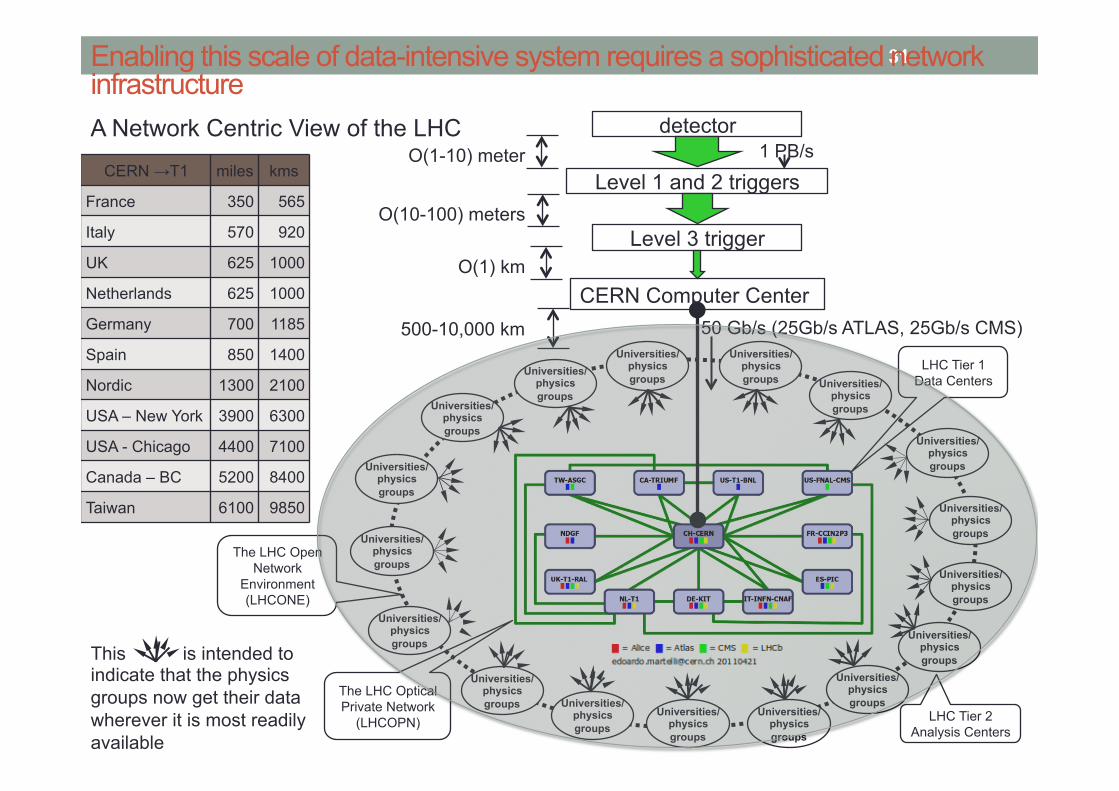
17 Enabling this scale of data-intensive system requires a sophisticated network infrastructure
CERN →T1 miles kms
France 350 565
Italy 570 920
UK 625 1000
Netherlands 625 1000
Germany 700 1185
Spain 850 1400
Nordic 1300 2100
USA – New York 3900 6300
USA - Chicago 4400 7100
Canada – BC 5200 8400
Taiwan 6100 9850
CERN Computer Center
The LHC Optical Private Network
(LHCOPN)
LHC Tier 1 Data Centers
LHC Tier 2 Analysis Centers
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups Universities/
physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
The LHC Open Network
Environment (LHCONE)
50 Gb/s (25Gb/s ATLAS, 25Gb/s CMS)
detector
Level 1 and 2 triggers
Level 3 trigger
O(1-10) meter
O(10-100) meters
O(1) km
1 PB/s
500-10,000 km
This is intended to indicate that the physics groups now get their data wherever it is most readily available
A Network Centric View of the LHC

Effetti di essere Data- Driven • Difficolta’ di spostamento di dati fra NREN diverse, se non
utilizzabile LHCOPN • Traffico T2 – T2 per esempio
• Necessita’ di non generare traffico caotico fuori controllo • L’attivita’ di analisi e’ essenzialmente locale, utilizza solo lo storage
locale • Necessita’ di preallocazione “smart“ dei dati nei T2 per non avere
bassa efficienza di analisi • Necessita’ di copie multiple di dati interessanti (almeno una per
continente)
18

Occhio: peculiarieta’ • Il modello qui descritto vale bene per ATLAS e
CMS
• ALICE fin dall’inizio e’ stata meno rigida nel suo modello: ai T1 e’ riservato solo il ruolo di reprocessing dei dati, tutto il resto dove c’e’ disponibilita’ di calcolo • considerando la rete come di fatto infinita, il che ha
spesso funzionato bene, a volte creato problemi nei centri
• LHCb ha dei Tier2 ridotti, senza disco. In pratica tutte le attivita’ che necessitino di accesso allo storage sono al Tier1 o “nelle vicinanze”.
19

20
WLCG as the orchestrator • “Grid” is a computing paradigm
• WLCG governs the interoperation since 2002 between the number of “concrete GRID implementations” (a number of, the main ones being OSG, LCG, NurduGrid, …)
• WLCG was crucial in planning, deploying, and testing the infrastructure before 2010, and is crucial for operations now
As of today, from REBUS • CPU 1.8 MHS06 (~180k
computing cores) • DISK 175 PB (~80k HDDs) • TAPE 170 PB (20-80k
tapes) • # Sites exceeding 200
20
ATLAS > 100k jobs/day CMS > 100 TB moved /day
Still increasing …
Da Krakow’12
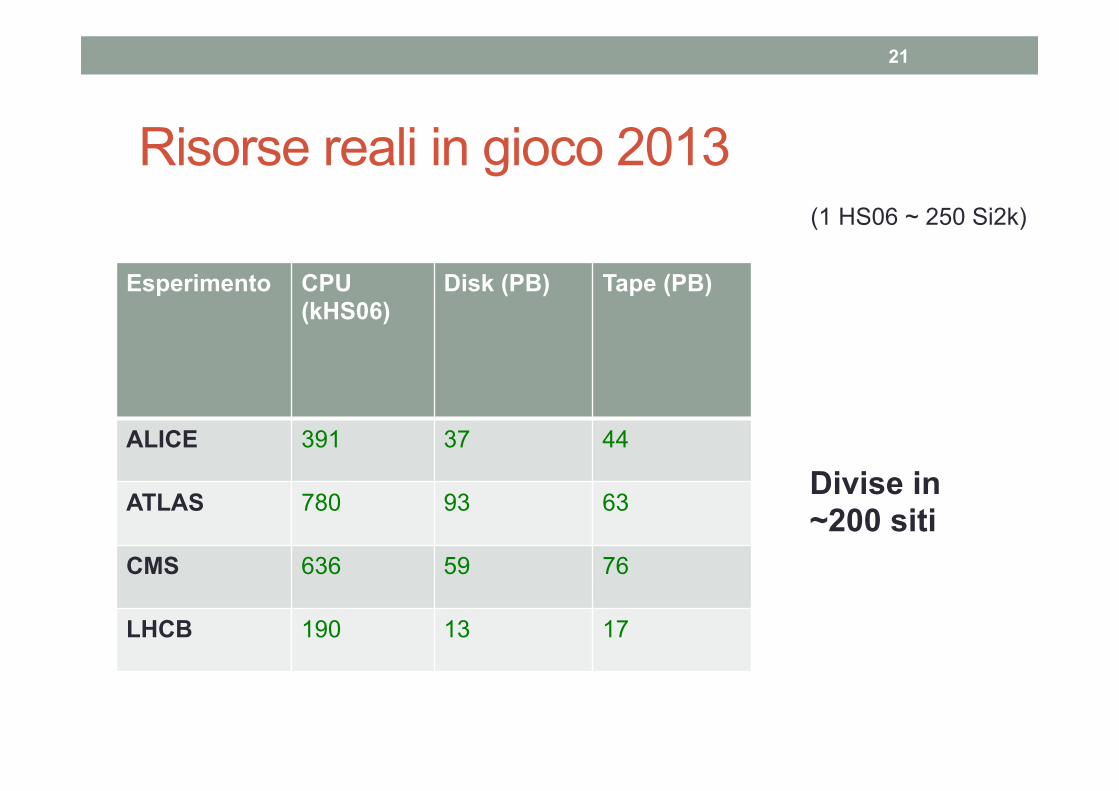
Risorse reali in gioco 2013
21
Esperimento CPU (kHS06)
Disk (PB) Tape (PB)
ALICE 391 37 44
ATLAS 780 93 63
CMS 636 59 76
LHCB 190 13 17
Divise in ~200 siti
(1 HS06 ~ 250 Si2k)

Come ha funzionato?
• Gestire il computing a LHC e’ sicuramente stato • Faticoso (come manpower necessaria a gestire servizi, spostamento di
dati, sottomissione di jobs) • Complicato (un sistema a moltissimi gradi di liberta’, difficile da ottimizzare) • Costoso (200 siti, di cui una decina molto grandi)
• … pero’ certamente dal punto di vista della fisica ha avuto successo • Luglio 2010: primi eventi di TOP presentati a Parigi, raccolti 72 ore prima • Luglio 2012: “scoperta” dell’Higgs, dati raccolti la settimana prima, spesso
gia’ riprocessati nel frattempo
22
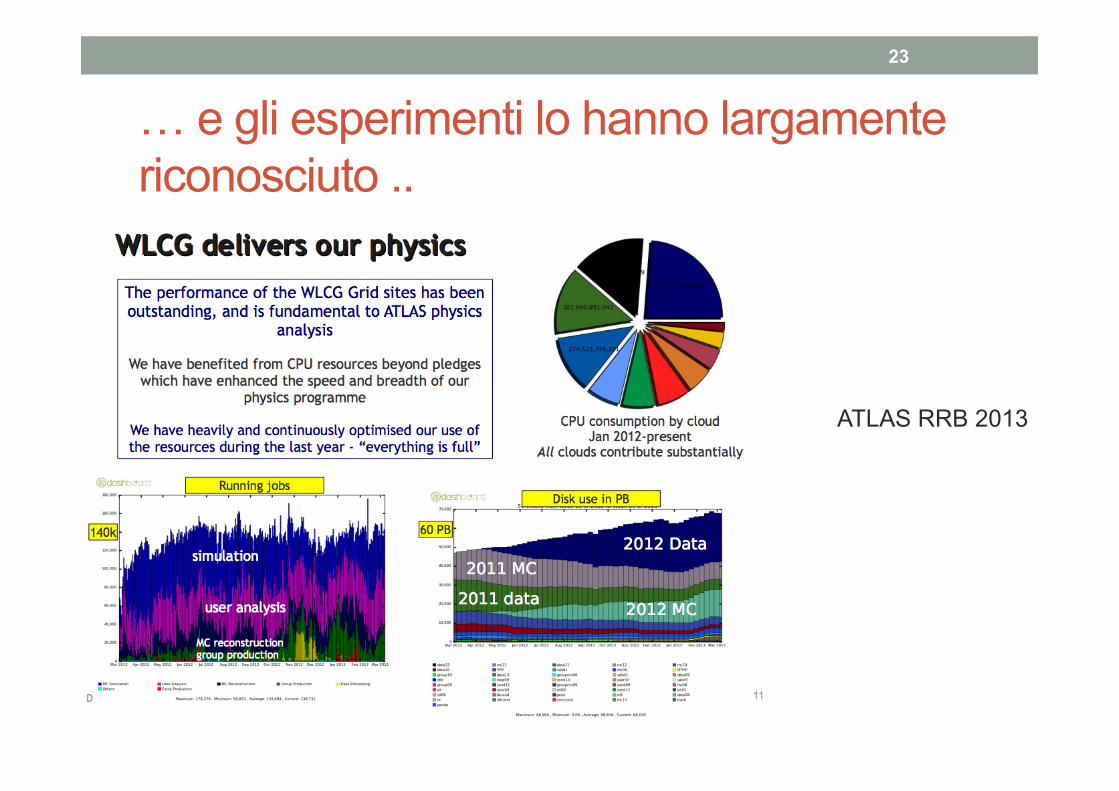
… e gli esperimenti lo hanno largamente riconosciuto ..
23
ATLAS RRB 2013
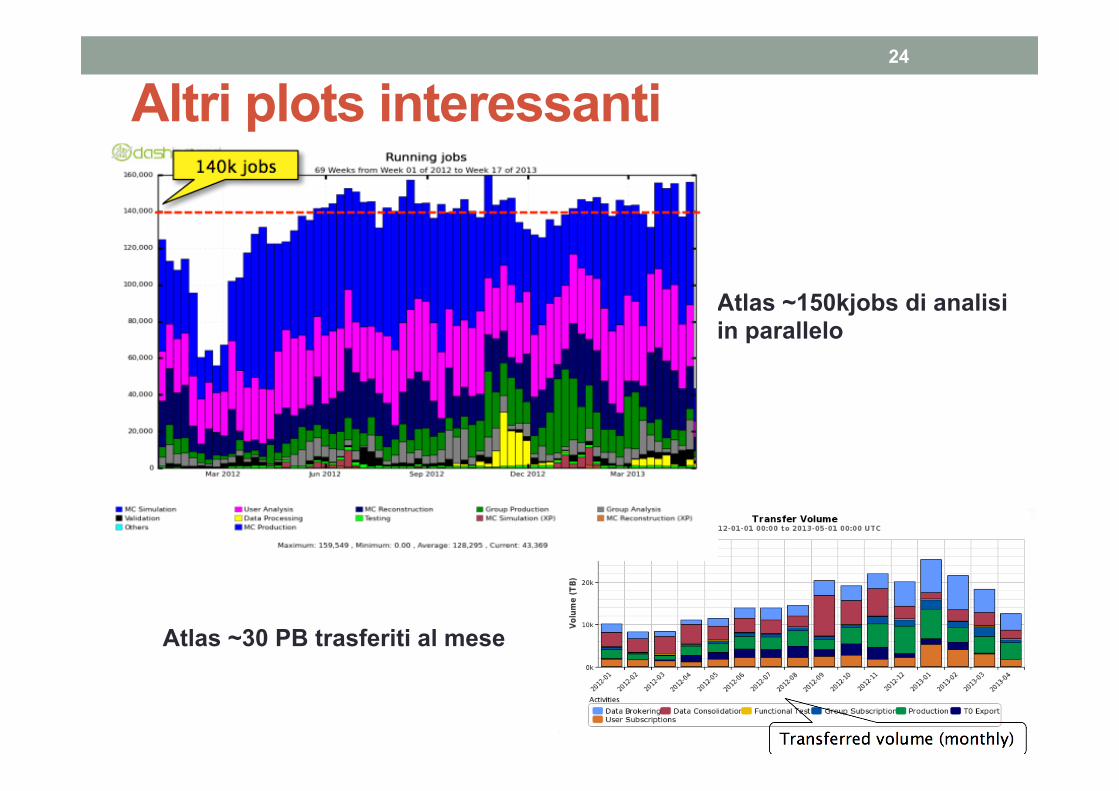
Altri plots interessanti 24
Atlas ~150kjobs di analisi in parallelo
Atlas ~30 PB trasferiti al mese
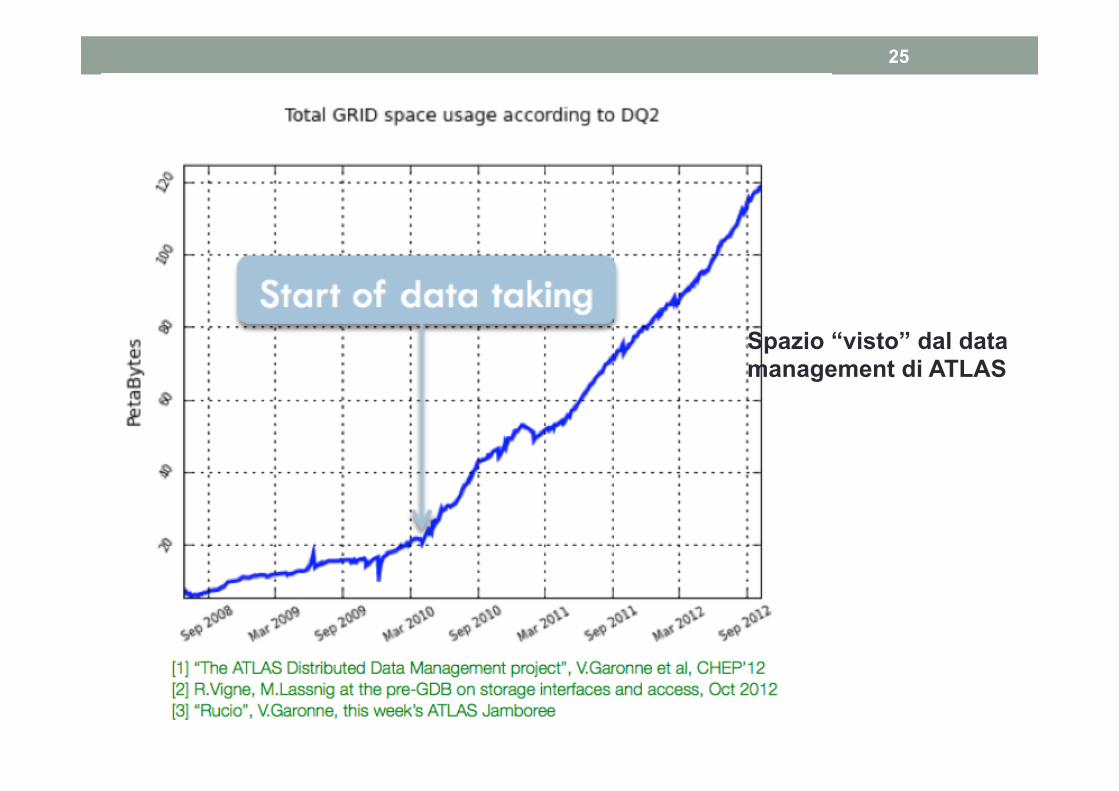
25
Spazio “visto” dal data management di ATLAS
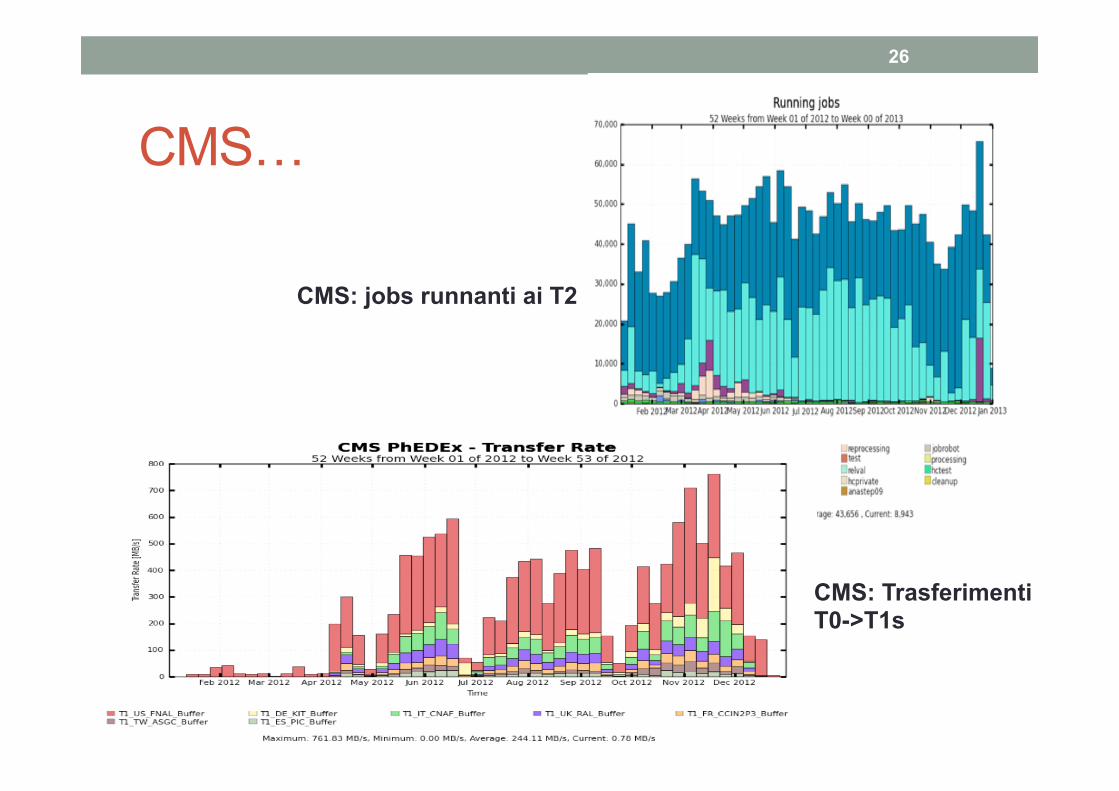
CMS…
26
CMS: jobs runnanti ai T2
CMS: Trasferimenti T0->T1s
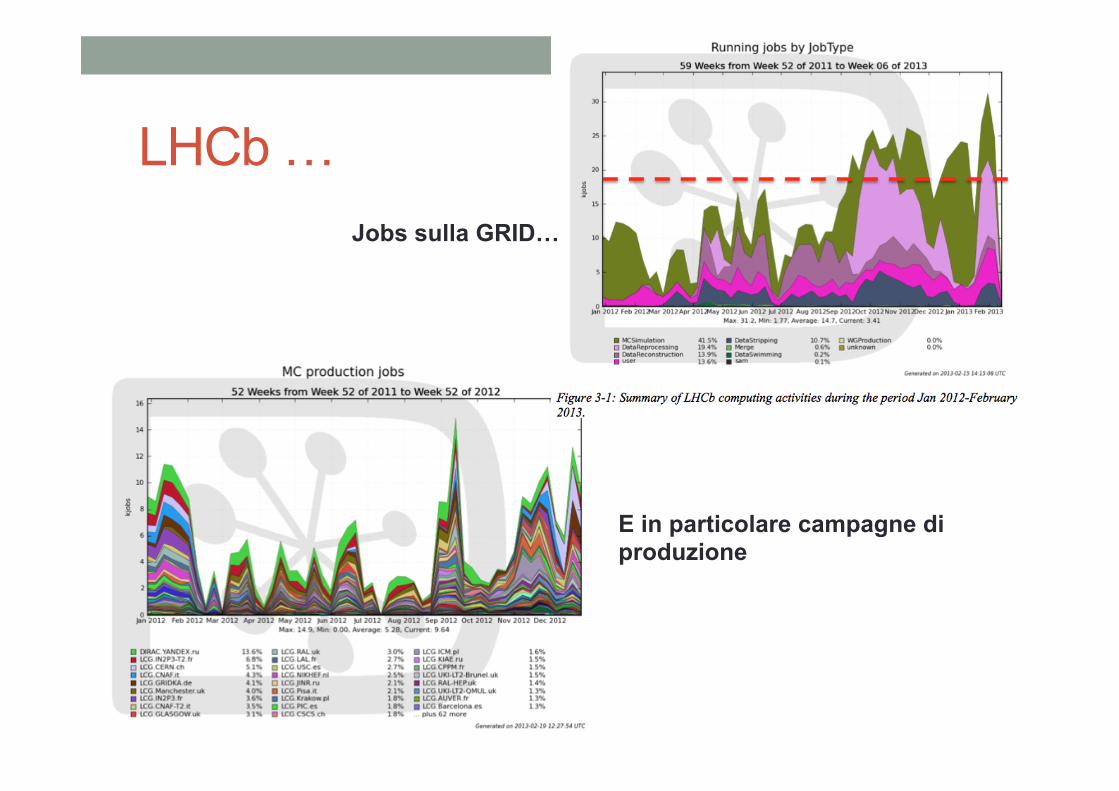
LHCb …
27
Jobs sulla GRID…
E in particolare campagne di produzione
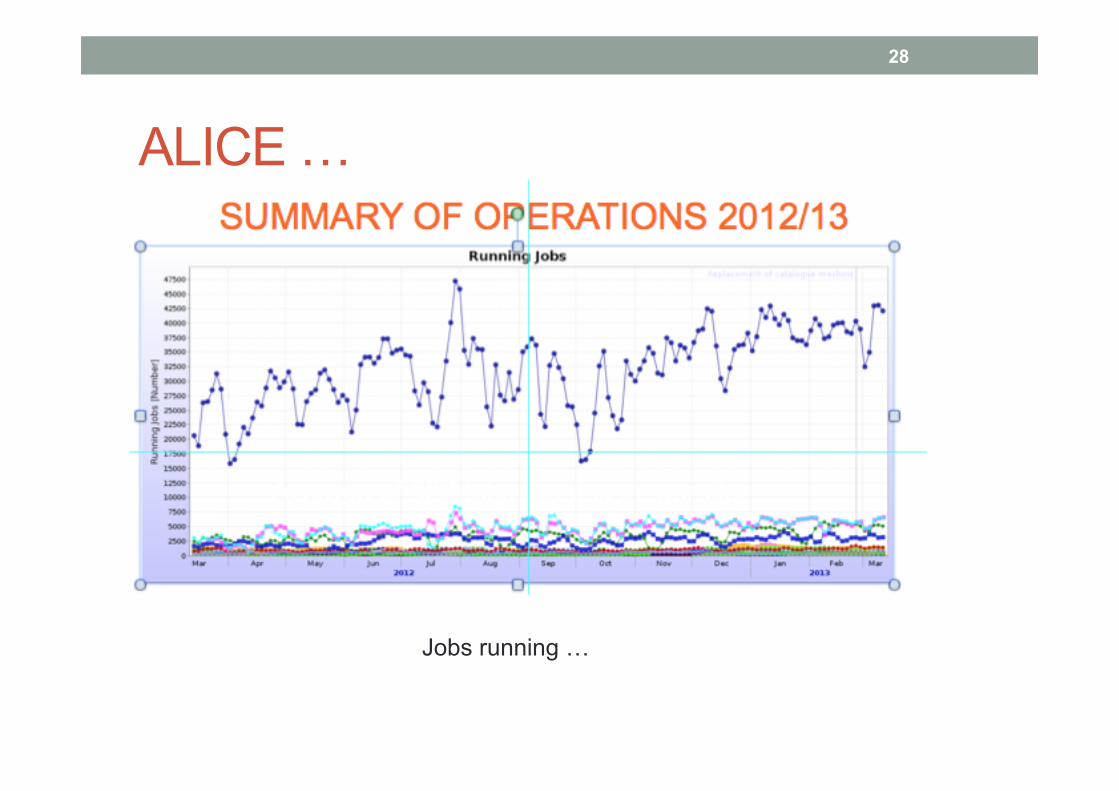
ALICE …
28
Jobs running …

In realta’ …. • Modello realmente utilizzato
2010-2013 e’ stato leggermente diverso da quello qui descritto
• Alcuni hint veloci • Rete non davvero cosi’
problematica, modello a mesh per I trasferimenti • LHCONE
• Diminuzione delle restrizioni di MONARC • Analisi ai T1 • Data placing ai siti diventato almeno
parzialmente automatico, e cosi’ anche la cancellazione (ATLAS: Victor)
29
T1
T2 T2
T2
T0
T1
T2 T2
T2
T1
T2 T2
T2
T0
T1
T2 T2
T2

LHCONE gia’ attiva • Nata dal fatto che le reti fra siti non LHCOPN e’ meglio del
previsto • Un T2 tipico in US e’ connesso a 40 Gbit/s da almeno un anno, 100
a breve • Un T2 italiano e’ a 10 Gbit/s da almeno un anno
• Gli esperimenti hanno quindi cominciato ad alleggerire le maglie, per esempio permettendo traffico diretto T2 <->T2, e formando quindi una full mesh (tutti parlano con tutti, O(200^2) links permessi)
• Puo’ essere vista piu’ come una protezione per il resto del mondo, che per il lavoro di LHC (che rischia di saturare altrimenti qualunque cosa)!
30
31 31 Enabling this scale of data-intensive system requires a sophisticated network infrastructure
CERN →T1 miles kms
France 350 565
Italy 570 920
UK 625 1000
Netherlands 625 1000
Germany 700 1185
Spain 850 1400
Nordic 1300 2100
USA – New York 3900 6300
USA - Chicago 4400 7100
Canada – BC 5200 8400
Taiwan 6100 9850
CERN Computer Center
The LHC Optical Private Network
(LHCOPN)
LHC Tier 1 Data Centers
LHC Tier 2 Analysis Centers
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups Universities/
physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
Universities/ physics groups
The LHC Open Network
Environment (LHCONE)
50 Gb/s (25Gb/s ATLAS, 25Gb/s CMS)
detector
Level 1 and 2 triggers
Level 3 trigger
O(1-10) meter
O(10-100) meters
O(1) km
1 PB/s
500-10,000 km
This is intended to indicate that the physics groups now get their data wherever it is most readily available
A Network Centric View of the LHC

LHCONE • Puo’ essere vista piu’ come una protezione per il resto del
mondo, che per il lavoro di LHC (che rischia di saturare altrimenti qualunque cosa)
• Collega oggi tutti I T2
• E’ usata per I trasferimenti programmati senza dover fare multi hop dai T1, ma in un futuro anche per accesso diretto (vedi dopo)
32

Modelli di calcolo: tutto bene… e allora perche’ cambiare?
• Diverse condizioni al contorno da LHC • Diverse priorita’ (abbiamo l’Higgs!) • Redesign di limitazioni del Run 1 (per esempio, della max
lumi istantanea sopportata da LHCb)
• Ma anche (purtroppo) diverse condizioni finanziarie rispetto ai primi anni 200x
33
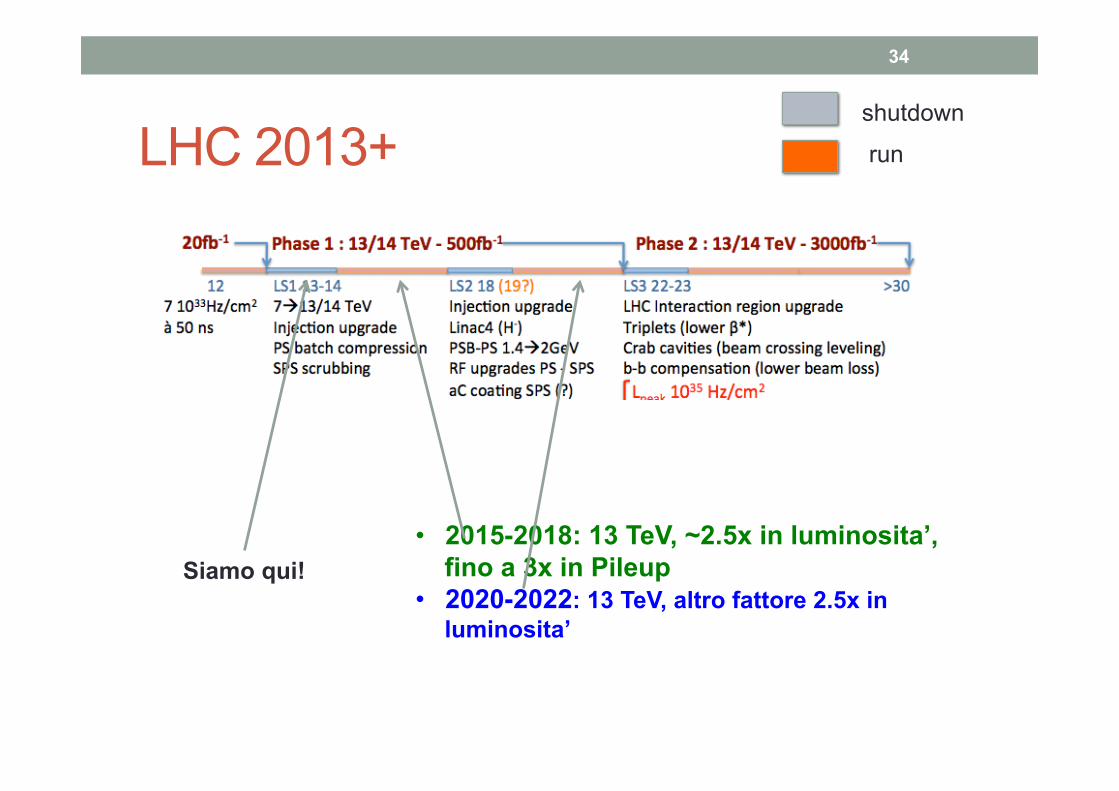
LHC 2013+
34
Siamo qui! • 2015-2018: 13 TeV, ~2.5x in luminosita’,
fino a 3x in Pileup • 2020-2022: 13 TeV, altro fattore 2.5x in
luminosita’
run
shutdown

Complessita’ del computing – a spanne (2015) • Maggiore energia: ~20% di tracce in piu’; ~30% di sezione d’urto
totale in piu’: 1.5x
• Maggiore luminosita’: piu’ eventi uno sopra l’altro. Purtroppo la nostra ricostruzione e’ + che lineare con la complessita’, per cui la differenza fa almeno un 2x (si puo’ arrivare a 80 eventi sovrapposti, +altri 80 a +50ns e altri 80 a -50ns)
• Diverso interesse di fisica: focalizzazione sull’Higgs, per lo studio delle sue proprieta’ implica NON alzare le soglie di trigger per I canali con potenziale di Higgs -> aumento del rate di eventi scritti su disco a almeno 1 KHz (da 100-300 Hz) – fattore ~3-5x • E anche maggiore copertura fisica del B da LHCb, per esempio
• QUINDI: a parita’ di tutto il resto, servirebbe un aumento di almeno 10 delle risorse da qui a inizio 2015.
35

Come “riguadagnare” questo fattore 10 • Ci sono delle deficienze (== mancanze di efficienza)
note nel nostro modo di processare
• Se usassimo MONARC “ideale”, avremmo spostamenti molto inefficienti fra i siti
• Il fatto che I jobs vadano dove sono i dati implica che I dati debbano essere preallocati bene
• Abbiamo molta difficolta’ a cancellare files (viscosita’ umana)
• Ecc … ecc… Accorgersene e’ gia’ qualcosa e infatti e’ stato lanciato uno sforzo a livello di WLCG sui Technical Evolution Groups (TEG)
36
TEG • Reports finali: qui
• Gruppi di lavoro • Storage • Databases • Operations • Workload Management • Security
37

Storage e Data management 1. Semplificare le interfacce
1. SRM serve solo ai siti con MSS 2. usare protocolli piu' standard (http, ma anche xrootd, gridftp)
dove non c'e' nastro
2. Storage federations 1. Oggi Xrootd ma in futuro anche http... NFS 4.1 ancora immaturo 2. Data caches (per esempio ai T2) 3. non solo pre-allocazione di dati ma anche spostamenti e
cancellazioni automatici
3. Sicurezza 1. lightweight security per dati read-only?
38

Workload Management 1. Basato su pilot jobs
1. Dipendenza dagli information systems molto ridotta (solo per service discovery – quindi solo info statiche)
2. Utilizzo di un gateway per l'accesso al sito ancora necessario (CE)
1. Modifiche all'interfaccia per ridurre la scala delle autorizzazioni 2. Modifiche all'interfaccia per il supporto dei job multicore
3. Clouds affrontate marginalmente 1. virtualizzazione per supportare la configurazione ai siti 2. Dopo la fine del TEG in realta' le attivita' per l'uso di Cloud sono
state dominanti mentre l'evoluzione dell'interfaccia del CE si e' praticamente fermata
39

Databases & Security • Utilizzo di tecnologia NoSQL per usi specifici • Caches (via squid) per non event data (conditions
data, software, ...) • Frontier e’ in pratica upgradato a prodotto WLCG
• Rendere obbligatorio glexec per I pilot jobs • Interazione fra security per WM e per data access non
ancora definita • Eseguibili firmati -> data access senza proxy
40

NB: dal punto di vista finanziario • I grossi progetti europei EGI-EMI (FPVII) stanno finendo
• Le funding agencies stanno avendo problemi finanziari, e garantire il personale di sito non e’ uno sforzo banale • Per l’italia solo per il T1, per i T2 INFN ha detto fin dall’inizio che
non avrebbero contribuito
• Non siamo piu’ (o non saremo a breve) in assoluto i piu’ grossi fruitori di calcolo scientifico; con l’approccio MONARC/GRID e’ difficile utilizzare risorse non costruite apposta per noi
41

E quindi, i nuovi modelli di calcolo • Linea generale: utilizzare MEGLIO cio’ che abbiamo
(perche’ tanto di piu’ non ci daranno)
• Cercare di riassorbire con efficienze operazionali il gap di risorse che non riusciremmo comunque ad avere
• Cercare di promuovere miglioramenti dello stack software (sia con ottimizzazioni di sw, sia con cambiamenti architetturali)
• • Abbracciare nuove tecnologie (Cloud, di nuovo nuove
architetture)
• Manpower limitata: cercare di avere progetti o WLCG o almeno a >1 esperimento (sia per devel, sia per supporto)
42

Concetti generali a tutti gli esperimenti • Accesso remoto diretto ai dati:
• DataDriven: i jobs vanno dove sono i dati, per non generare traffico caotico sulla WAN. • Se un sito ha CPU libere, ma dati non interessanti, non sara’ usato • Se un sito ha dati interessanti, ma tutte le CPU usate, non sara’
possibile l’accesso a questi dati
• Come organizzare l’accesso remoto? Storage Federations!
43

Storage federations • Ricetta:
• dati distribuiti su N siti • Un protocollo di accesso remoto (http, Xrootd, NFS4.1 …) • Un ”catalogo” dei files / un servizio di redirezione • (tanta tanta rete …)
• Catalogo: • Serve un DB centrale che sappia dove sono tutti i files (uhm…)
• Redirezione • I vari siti “annunciano” I loro files al redirettore
• Protocollo: • alla fine Xrootd e http sono poco diversi ad alto livello; NFS4.1 pare
tramontato
44
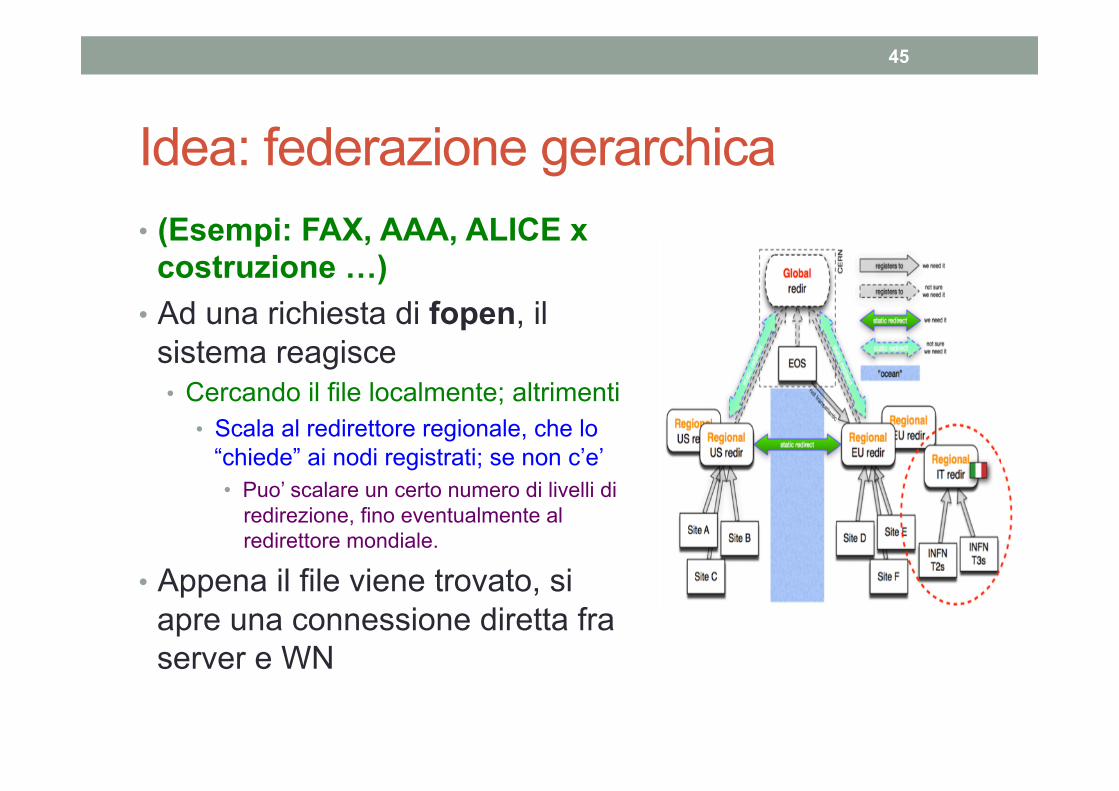
Idea: federazione gerarchica • (Esempi: FAX, AAA, ALICE x
costruzione …) • Ad una richiesta di fopen, il
sistema reagisce • Cercando il file localmente; altrimenti
• Scala al redirettore regionale, che lo “chiede” ai nodi registrati; se non c’e’ • Puo’ scalare un certo numero di livelli di
redirezione, fino eventualmente al redirettore mondiale.
• Appena il file viene trovato, si apre una connessione diretta fra server e WN
45
Bello, ma …. e i rischi? • Xrootd e’ molto efficiente come protocollo (http si vedra’),
qualche migliaio di connessioni remote possono intasare qualunque cosa
• E’ essenziale uno shaping del traffico, per limitarlo; • E’ essenziale che la maggior parte dei fopen si fermi al
primo livello • E che quindi un efficiente preplacement dei dati continui ad
avvenire
• (a meno che, chiaramente, la rete non diventi “infinita”)
46
Multicore • Fino ad ora, l’utilizzo delle macchine di calcolo e’ sempre
stato “batch seriale”: 1 core, 1 job.
• Ma in questo modo, visto che molti dei jobs che troverrano a essere eseguiti nello stesso momento sono “simili”, c’e’ un chiaro spreco di RAM perche’ la geometria (per esempio) e’ presente piu’ volte in memoria
• Soluzione: approccio multicore. Un singolo job crea processi/threads veri e propri su tutta la macchina O Almeno su una frazione non piccola del WN
47

Vantaggi 1. Miglior utilizzo delle caches dei processori 2. Scheduling di jobs a alta CPU e a alto I/O sulle stessa
macchine (ora le controlliamo “globalmente”) 3. Meno memoria utilizzata (perche’ calibrazioni etc sono
presenti una volta sola) -> disegnare algoritmi piu’ efficienti, ma che utilizzino piu’ memoria
4. Utilizzo di risorse opportunistiche con meno RAM, ad oggi a noi negate
5. Il fatto che lo scheduling non e’ piu’ per core, ma per “macchina” diminuisce di un fattore ~ 10 il carico dell’infrastruttura di computing
1. # di jobs da gestire 2. # di slots da gestire 3. # di files temporanei da gestire
48

Ma come farlo?? • Framework multithreaded e’ vitale
• Non e’ possibile esporre il fisico medio (almeno a mio parere) al parallelismo
• Pertanto in prima approssimazione, e’ il Framework che deve esserlo, schermando tutto il resto dall’utente • “parallelismo a livello di moduli”: ogni modulo e’ pensato/scritto/eseguito
come seriale; + moduli girano in parallelo
• Funziona? • Certamente si
• E’ sufficiente? • Non e’ detto: funziona nel caso in cui
• Le interdipendenza fra I moduli siano semplici / semplificabili • Non ci sia un singolo modulo che prende il 90% del tempo (e purtroppo non
ne siamo lontani… il tracking)
49

50
Are we entangled? • You can improve
parallelism by unrolling sequences
• But on the other hand global event reconstruction techniques a-la Energy Flow make everything more interdependent
Lines are input/output to modules
50

Ci sono veri motivi per averne + di uno? • Cioe’, un solo FW basterebbe per I 4 esperimenti LHC? • Secondo me si’.
• I nostri modelli di calcolo non sono troppo diversi • Tutti basiamo l’event data model su ROOT • I Workflos di ricostruzione, calibrazione, analisi sono simili
• Come al solito e’ un problema di volonta’ • Il CERN ci sta almeno provando: Concurrency Forum!
• Valutazione delle varie tecnologie (libdispatch, TBB, …) • Proposta di soluzioni (?)
51

Nuove architetture • Non mi soffermo su questo, vista la sessione
di ieri, ma alcune parti specifiche dei nostri software sono altamente parallelizzabili (seeding, tracking, island search per I jets, …))
• Nota bene: parlo di parallelizzazione ALL’INTERNO DEL SINGOLO MODULO!
• Xeon Phi, GPU sono tecnologie che sono sotto studio da parte degli esperimenti
• ARM d’altra parte e’ interessante per la riduzione dei consumi
• Ma senza i 64 bit stiamo solo giocando …
• Tipicamente solo per piccole porzioni del
codice, da iper-ottimizzare • In condizioni time-critical, come a livello di farm
di trigger
52

Miglioramenti stack software • Anche rimanendo nell’ambito x86 standard, i nostri SW
(per la parte algoritmica, almeno) sono stati in buona parte realizzati da generazioni di studenti “improvvisatisi programmatori”
• I margini di miglioramento esistono, ma non sono facili da realizzare; lo sforzo di miglioramente delle performance e’ tipicamente nelle mani di pochissimi membri della Collaborazione
• E’ un problema di “educazione”? Mia personale opinione: non e’ facile educare chi non voglia essere educato …
53

Alcune guidelines per il prossimo modello di calcolo 1. Ridurre differenze T0/T1/T2: girare dove ci sono risorse
qualunque workflow, appoggiandosi a Xrootd quando serva 2. Disaccoppiare Disco e CPU nel brokering
1. Non per la maggioranza dei jobs, ma per riottenere frazioni di efficienza
3. Transizione verso tools di analisi/produzione comuni almeno fra 2 esperimenti
1. Diminuzione del manpower per lo sviluppo e il supporto 4. MW GRID sostanzialmente congelato da usare nei nostri siti,
ma: 1. Essere pronti a sfruttare opportunita’ impreviste (slot in centri
supercalcolo, risorse opportunistiche) via CLOUD 2. Tanto lavoro da fare: intra e inter cloud scheduling; ottimizzazione
dell'accesso allo storage 5. .. E additittura volunteer computing per produzione MC
(completamente da fare)
54

Le cloud …. • Abbiamo delle sessioni specifiche a questo WS, per cui non ne parlo
troppo estesamente qui
• Per cosa possono servire a noi le cloud?
1. Per avere accesso a risorse altrimenti non utilizzabili 2. Per diminuire gli FTE necessari per manutenere i siti
3. Stack Cloud commerciali esistono indipendentemente da noi (non dobbiamo svilupparceli)
Per essere chiari: comunque per il run 2015-2018 l’utilizzo preponderante delle NOSTRE CPU sara’ via GRID; qui stiamo parlando del “resto” (< 10% a occhio)
55

Cloud per avere maggiori risorse • Consideriamo 3 use cases di risorse che OGGI gli esperimenti
avrebbero difficolta’ ad utilizzare
1. Grossi centri di supercalcolo e/o cloud non HEP, magari con architetture strane (rete di interconnessione dei nodi) offerti per brevi periodi ad un Esperimento
2. Grosse farm di calcolo dei nostri esperimenti, destinate ad altro (tipo le farm HLT) libere per frazioni del tempo
3. Grosse farm commerciali, da usare per un certo periodo (a pagamento/gratis)
Questo perche’ “una farm” per diventare “un sito” ha bisogno di servizi non immediati da installare; per esempio
56
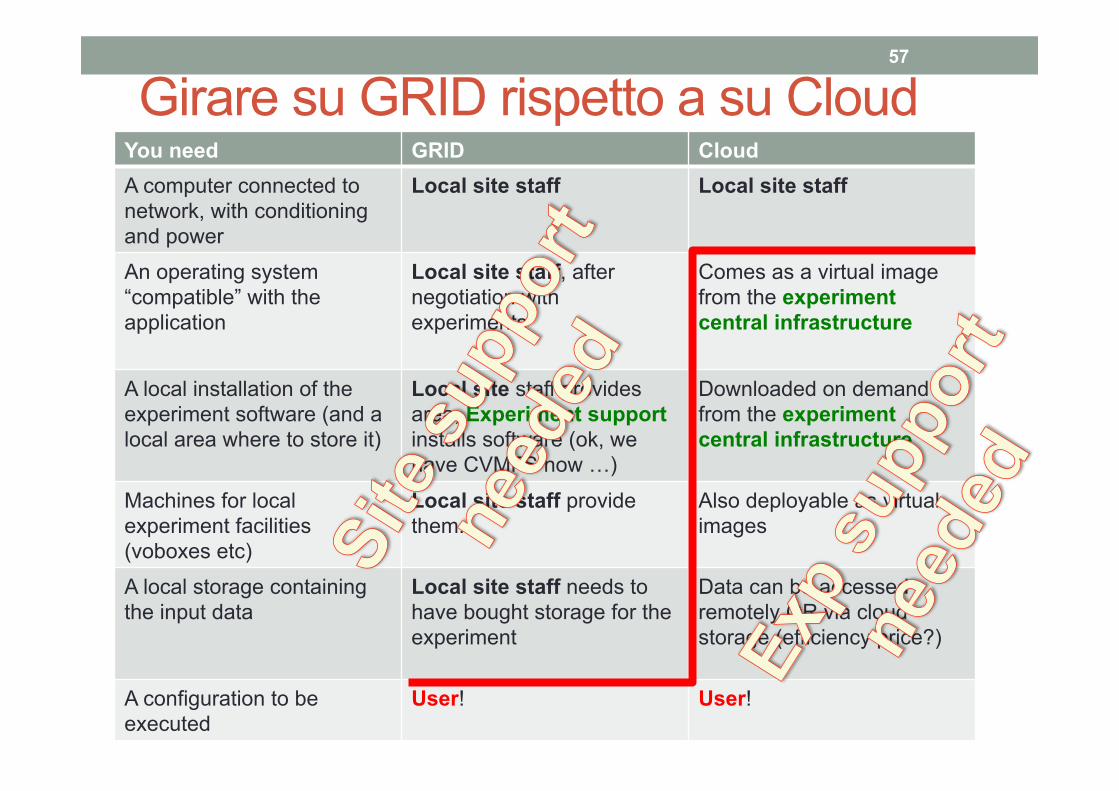
Girare su GRID rispetto a su Cloud 57
You need GRID Cloud A computer connected to network, with conditioning and power
Local site staff Local site staff
An operating system “compatible” with the application
Local site staff, after negotiation with experiments
Comes as a virtual image from the experiment central infrastructure
A local installation of the experiment software (and a local area where to store it)
Local site staff provides area, Experiment support installs software (ok, we have CVMFS now …)
Downloaded on demand from the experiment central infrastructure
Machines for local experiment facilities (voboxes etc)
Local site staff provide them.
Also deployable as virtual images
A local storage containing the input data
Local site staff needs to have bought storage for the experiment
Data can be accessed remotely OR via cloud storage (efficiency price?)
A configuration to be executed
User! User!

Cloud • Quanto detto e’ vero riguardo all’utilizzo opportunistico/
temporaneo di risorse “altrui”
• Ma gli stessi aspetti riguardano l’ottimizzazione (== riduzione) del manpower necessario nei nostri siti • Diminuisce la necessita’ di avere personale specializzato per una
data VO • L’unico suppoto locale davvero necessario e’ quello sistemistico,
per installare / tenere vive le macchine e per gestire lo stack Cloud locale
58

Standardizzazione! • Ci sono tanti stack Cloud disponibili
• Ma appare sempre + chiaro che il mondo HEP si stia orientando (CERN in testa) verso Openstack • Compliance EC2 (sia macchine, sia storage) gratis
• .. E un po’ meno chiaramente, verso CERN/VM come base per l’immagine virtuale di esperimento • Al momento CER/VM soddisfa completamente solo ALICE … per
costruzione !
OK fare R&D, ma teniamo presente che “il CERN ha gia’ scelto…”
59

Esempi noti 1. Centro di calcolo di UCSD offerto a CMS per un paio di
settimane ha pemesso di effettuare mesi di lavoro standard
2. Le farm di HLT nei modelli 2015+ sono utilizzate come T0 nei periodi di down di LHC, ma anche durante il paio di ore che intercorre fra un fill e l’altro di LHC • in pratica nei piani di tutti gli esperimenti, con diversa granularita’
temporale
3. Utilizzo di Amazon, RackSpace, etc …. per tamponare periodi di urgenza
• Tutti gli esperimenti stanno facendo I loro conti; adesso troppo caro in utilizzo standard ma chissa’….
60

Cloud commerciali • Al momento economicamente non sostenibile:
• CMS: spostare un mese di produzione MC (solo la parte GEANT4) su Amazon e’ ~1.3 M$
• ALICE: x spostare tutta l’attivita’ ALICE2012 su Amazon
• 40M$
• Pero’ si possono avere forti sconti (anche /10) sul mercato “spot”: • Comprare 1MOre di CPU “nel prossimo anno” (ma quando siano disponibili lo decide
Amazon) • Dare il permesso a Amazon di uccidere i jobs quando le macchine servano per usi
meglio pagati
• Interessante , vediamo come evolve….
61

E dopo ? (LS2, 2020+) • Esperimenti stanno cominciando solo adesso a pensare come
vorranno operare; saremo in rpesenza di detectors in gran parte “nuovi”
• Idee che circolano: • Processare direttamente a HLT (quindi via SW) tutto il rate
dall’esperimento (40 MHz) – eliminando hardware dedicato di L1 • Poter salvare piu’ rate su disco: non salvare RAW, ma direttamente
formato ridotto per l’analisi (permetterebbe 20x di rate su disco) • Ma serve grossa fiducia nelle calibrazioni online
• Rottura completa dello schema MONARC: delocalizzazione completa delle risorse (sia via GRID sia via Cloud: in situazione “a rete infinita” MONARC non ha molto senso).
• Calcolo eterogeneo (x86 + ARM + Phi + GPU + chissa’ cosa): come ai vecchi tempi di LEP, tornare ad avere piu’ architetture supportate allo stesso tempo
62
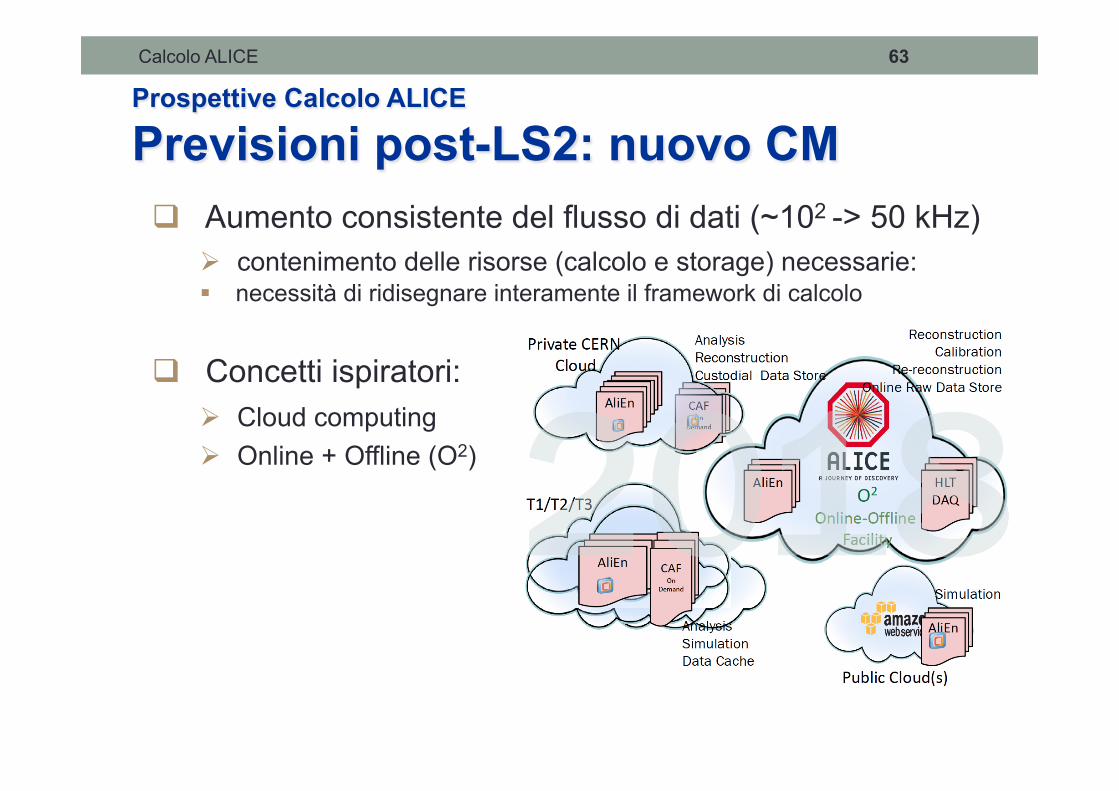
Calcolo ALICE 63
Prospettive Calcolo ALICE
Previsioni post-LS2: nuovo CM ! Aumento consistente del flusso di dati (~102 -> 50 kHz)
" contenimento delle risorse (calcolo e storage) necessarie: # necessità di ridisegnare interamente il framework di calcolo
! Concetti ispiratori: " Cloud computing " Online + Offline (O2)

Calcolo ALICE 64
Prospettive Calcolo ALICE
Previsioni post-LS2: nuovo CM ! Aumento consistente del flusso di dati (~102)
" contenimento delle risorse (calcolo e storage) necessarie: # necessità di ridisegnare interamente il framework di calcolo
! Concetti ispiratori: " Cloud computing " Online + Offline (O2)
! Progetto O2: " avviato a Marzo 2013 " organizzato in CWGs " integrerà DAQ/HLT/Offline, TDR ad Ottobre 2014

Calcolo ALICE 65
! Rivoluzione al Tier-0 (CERN): " divisione Online/HLT/Offline perderà in parte significato " ricostruzione in parte effettuata online in ambiente eterogeneo (FPGA, GPU, Multi-core CPU) e comunque tutta al CERN
! Attività ai siti esterni (Tier-1 e Tier-2) : " simulazione MC e analisi (più possibile organizzata) # in corso R&D su Cloud e Analysis Facilities “on demand”
! Principali novità in AliRoot 6.x: " dovrà girare su sistemi eterogenei, almeno in parte (GPU etc) " dovrà supportare rivelatori che operano in readout continuo " dovrà supportare la fast simulation " dovrà essere più veloce (x10) e usare meno memoria
Prospettive Calcolo ALICE
Previsioni post-LS2: nuovo CM

Post LS2? (Almeno 2020, se non 2025) • Molto molto difficile fare previsioni
• (e purtroppo e’ la seconda volta che me le chiedono $ : qui)
• Non ci sono indicazioni che la fase in cui l’aumento di potenza computazionale e’ dato dall’aumento dei cores finisca: SW pesantemente multithreaded (letteralmente centinaia di cores)
• Centri di calcolo completamente virtualizzati nelle Cloud, network sufficiente a non dover tenere conto della locazione fisica
• Abbandono lento di x86 … al momento ARM e GPU paiono le possibilita’ piu’ concrete
66

Conclusioni (in ottica CCR) • Acquisire esperienza
Cloud, preferenzialmente OpenStack: e’ un buon investimento • E per cloud storage???
• Le reti saranno ancora piu’ centrali per gli esperimenti in futuro • E la capacita’ di tunare i
cammini, se la rete non sara’ “infinita”
• Esperienza in nuove architetture di calcolo sono utili; difficilmente “moriremo x86” • Queste stesse (ARM per
esempio), sono di interesse anche per I servizi
• Il software sara’ necessariamente multi-core aware • Come rendere i nostri fisici
capaci di capirlo/scriverlo? • Possiamo contribuire a
scrivere “IL” FW multicore (se esistera’?)
67





























