Embed Size (px)
Citation preview

Ecole Doctorale De Sciences Cognitives
Université Lumière Lyon2
Mémoire rédigé dans le cadre du Master 2 Recherche en Informatique
Spécialité Extraction de Connaissances à partir des Données
Par
Maguy MEDLEJ
FOUILLE DANS LES ENTREPÔTS DE DONNÉES
Encadrée par
Mme Fadila BENTAYEB [email protected]
Stage réalisé au sein du Laboratoire ERIC
(Equipe de Recherche en Ingénierie des Connaissances)
Université Lyon 2 5 Avenue Pierre Mendès-France
69676 BRON Cedex - France ht tp: / /er ic .univ- lyon2. fr
Année Universitaire : 2004-2005

REMERCIEMENTSREMERCIEMENTSREMERCIEMENTSREMERCIEMENTS
Je t iens à remercier Mr Nicolas Nicoloyannis pour son accuei l au sein du laboratoire ERIC (Equipe de recherche en Ingénierie de Connaissances ) de l ’Université Lumière Lyon2.
Nul mot ne pourrait exprimer ma vive reconnaissance et mes remerciements chaleureux à l ’égard de monsieur le professeur Djamel Zighed, responsable de la spécial ité ECD (Extraction des connaissances à partir des données) pour m’avoir accordé l ’occasion de suivre cette spécial ité .
Mes s incères remerciements sont à l ’adresse de Mme Fadila Bentayeb pour m’avoir intégré au se in de l ’équipe BDD (BaseS de Données Décisionnelles ) . Je lui suis reconnaissante de m’avoir encadrée , aidée et dirigée durant tout le stage. Je la remercie pour sa disponibi l ité , ses suggestions inest imables et correct ions judic ieuses afin d’amél iorer mon travai l et me permettre de bénéfic ier de sa profonde connaissance.
Je remercie Céci le Favre et Lotfi Settouti pour leur présence et leur aide pendant les moments cruciaux de ce stage.
Merci aussi à Monsieur Stéphane Lall ich pour ses consei ls et ses explications.
J ’adresse de même mes remerciements à mes professeurs pour leur contribution à ma formation scientifique.
Ahmad, Benoit, Djallal , Elie , Rémi, Stéphane, Sylvain un remerciement à votre égard pour votre présence et encouragement continus et votre soutien.
Merci pour les étudiants du Master pour les moments qu’on a passé ensemble .
J ’aimerai également remercier tous les membres de l ’ équipe surtout M.Omar Boussaid pour sa présence quand j ’en avais besoin.
Un grand merci pour mon ange gardien, mon frère et tous mes amis au Liban. Merci pour votre soutien morale qui m’a aidée à surmonter maintes difficultés . C’était très gentil et aimable de votre part .
Je n’oublie pas ma famil le qui m’a soutenue de lo in, merci . Merci papa et maman pour vos consei ls vos encouragements , vos pr ières qui m’accompagnent tout au long de ce chemin.
Pour les personnes que j ’ai oubl iées de mentionner, veui l lez m’excuser .

Résumé Les besoins grandissants des entreprises en termes d’analyse sur leurs données ont conduit à la mise en place d’entrepôts de données (ED). Cependant, la volumétrie qu’atteignaient les ED aujourd’hui nous pousse à adapter des approches de fouille de données afin de pouvoir mieux exploiter ceux-ci. Nous nous intéressons dans ce mémoire au développement des techniques de fouille de données intégrées au sein des systèmes de gestion de bases de données (SGBD). Nous désirons, plus précisément appliquer ces techniques sur un entrepôt de données suivant l’approche ROLAP (Relational On-Line Analytical Processing), sans être limités par la taille des bases à traiter. La solution que nous proposons est d’appliquer les algorithmes de fouille, en particulier les méthodes dites par « arbres de décision », sur des cubes de données construits à partir d’un entrepôt de données. Nous montrons que les effectifs nécessaires à la construction des arbres de décision peuvent être contenus dans le cube de données sous forme de données agrégées. Pour valider notre approche, nous implémentons la méthode ID3 (Induction Decision Tree) sous forme de procédures stockées PL/SQL sous le SGBD Oracle. Mots-clés : Fouille de données, Intégration, cubes de données, entrepôts de données, arbre de décision, ID3, fouille dans les cubes, approche ROLAP.
Abstract The increasing needs for analyzing data have lead many companies to turn to data warehousing. However, growing volumes of data warehouses nowadays conduct us to adapt data mining approaches for a better exploitation of these data. Our main focus in this internship is to develop data mining techniques that are integrated within the data base management system (DBMS) framework. More precisely, we aim at applying these techniques on a data warehouse according to the Relational On-Line Analytical Processing (ROLAP) approach, without being limited by the volume of data to be treated. The solution that we suggest is to apply data mining algorithms, particularly the methods known as “decision trees”, on data cubes constructed on the basis of a data warehouse. We will show that the effectives that are required to construct decision trees can be contained within the data cube in the form of aggregated data. To validate our approach, we implemented the ID3 method (Induction Decision Tree) in the form of PL/SQL stored procedures within the Oracle DBMS. Keywords: Data Mining, Integration, Data Cube, Data warehouse, Decision Tree, ID3, Mining Cube, ROLAP approach.

Table des Matières
Introduction ..................................................................................................................... 1
Chapitre I :4Etat de l’art ................................................................................................. 4
I.1- Approche classique de la fouille de données ..................................................................... 4
I.2- Intégration des outils de fouille de données par les éditeurs de SGBD ............................. 5
I.3 Utilisation des concepts de bases de données pour la fouille de données ..........................6
I.4 Intégration de la fouille de données dans un environnement OLAP...................................6
I.5 Discussion ........................................................................................................................... 7
Chapitre II : Cubes de données dans l’approche ROLAP ............................................. 9
II.1 Contexte : Entrepôt de données et Fouille de données....................................................... 9
II.2 Définitions : Outils d’exploration d’un entrepôt de données ........................................... 10 II.2.1 Le monde décisionnel OLAP.................................................................................................. 10 II.2.2 Les outils OLAP et les cubes de données .............................................................................. 11 II.2.3 MOLAP vs. ROLAP.............................................................................................................. 13
Chapitre III : Cubes de données et Arbres de décision................................................ 14
III.1 Introduction..................................................................................................................... 14
III.2 Principe des arbres de décision...................................................................................... 14 III.2.1 Principe de construction de ID3 ............................................................................................ 15 III.2.2 Entropie et Gain d’information.............................................................................................. 16
III.3 Exemple d’entrepôt pour la fouille de données.............................................................. 16 III.3.1 Cubes et Arbres de décision .................................................................................................. 18 III.3.2 Construction de l’arbre de décision ....................................................................................... 22
Chapitre IV : Implémentation et discussion ................................................................. 25
IV.1 Implémentation.............................................................................................................. 25
IV.2 Discussion....................................................................................................................... 29
Conclusion et perspectives............................................................................................. 30
Bibliographie.................................................................................................................. 32

1
Introduction Avec l’accroissement potentiel des Systèmes de Gestion de Bases de Données (SGBD) et l’évolution d’Internet, la masse des informations produite dans le monde ne cesse de croître de façon exponentielle. Les entreprises se sont rendues compte que ces données pouvaient être une source d’information mise à leur service. Il faut donc définir des environnements permettant de mémoriser de grands jeux de données et d’en extraire de l’information. Les bases de données relationnelles constituent depuis longtemps une structure de stockage importante pour ces données. Leur exploitation transactionnelle fait que leur vocation est principalement la gestion des données. De plus, le flot important de ces dernières et le besoin de les analyser nécessite une nouvelle organisation de stockage et de recherche d’informations. Ainsi, des bases de données relationnelles, dont la taille atteignait quelques dizaines de giga-octets, nous sommes passés aux entrepôts de données dont la taille varie de quelques centaines de giga-octets à des dizaines de téraoctets. Cependant, alors que la quantité de données à traiter augmente énormément, le volume d’informations fournies aux utilisateurs n’augmente lui que très peu [Han01]. Ces réservoirs de connaissances doivent être explorés via des systèmes d’analyse de plus en plus performants. Ces systèmes doivent assurer différentes fonctionnalités : exploration très fines, représentation synthétique de l’information recueillie et des nouvelles connaissances déduites. En amont, ils doivent permettre la collecte, la sélection et le filtrage des données disponible dans les bases spécialisées. Face à ces problèmes, la fouille de données offre, grâce aux processus de statistiques ou d’intelligence artificielle, de traiter ces grandes masses de données afin d’en extraire une information cruciale. Celle-ci sera déterminante pour une prise de décision efficace. Toutefois, les données issues des entrepôts ne sont pas facilement exploitables par des techniques de fouille de données. En effet, la plupart des techniques que nous utilisons ne traitent que des tableaux attributs-valeurs [ZR00] et se heurtent au problème de limitation de la taille de la mémoire centrale dans laquelle les données sont traitées. En aval, certaines méthodes sont plus contraignantes que d’autres. Elles peuvent par exemple exiger des données binaires, comme c’est le cas des premières techniques de recherche de règles d’association. Une organisation et une préparation particulière des données s’avèrent nécessaires pour appliquer les méthodes de fouille de données sur les grandes bases de données. Une nouvelle approche intéressante est développée afin de profiter des informations apportées par ces dernières. L’idée consiste à intégrer les méthodes de fouille de données au sein des SGBD.

2
Pour atteindre cet objectif, sont utilisés uniquement les concepts de bases de données pour implémenter les différents algorithmes de fouille dans les SGBD en tirant profit des outils offerts par ces derniers (tables, vues,..). De récents travaux de recherche ont démontré l’efficacité de l’intégration des arbres de décision dans les SGBD dans le cadre de grandes bases sans limitation de taille [BD02]. Toutefois, des temps de traitements élevés ont été constatés dans l’approche présentée dans [BD02]. Ce, en raison d’accès récurrents en lecture à la base. Dans [UBDB03], le remplacement de la table d’apprentissage par la table de contingence a constitué une phase de préparation des données au cœur des SGBD. Les algorithmes sont alors adaptés pour s’appliquer à cette table de contingence plutôt qu’à la base initiale. L’intérêt de la table de contingence, qui contient les effectifs pré-agrégés des populations, réside dans le fait que sa taille est généralement inférieure à celle de la base initiale. Une autre optimisation proposée par [Fav03] vise à éviter l’accès aux données en utilisant les index bitmap. L’intégration des méthodes de fouille au sein des SGBD joue un rôle fondamental dans l’extraction des connaissances interprétables, utiles et exploitables à partir de grandes bases de données. Notre travail de recherche s’inscrit dans la continuité des travaux présentés ci-dessus. Cependant, alors que ces approches de fouille intégrées appliquent les algorithmes de fouille sur les grandes bases de données, nous nous intéressons dans ce travail à appliquer ces mêmes techniques sur des données entreposées. Dans cette optique, la constitution d’un entrepôt de données, regroupant sous une forme homogène toutes les données de l’entreprise par exemple, offre des perspectives nouvelles aux utilisateurs, notamment en terme d’extraction de connaissances grâce aux outils de fouille de données. Il s’agit donc d’adapter les algorithmes classiques opérant sur des données sources pour qu’ils puissent s’appliquer à des données agrégées. Nous nous intéressons en particulier aux techniques des arbres de décision comme C4.5 ou ID3 dans le cadre de ce travail. C’est une méthode d’analyse d’un ensemble d’enregistrements préalablement classifiés permettant de générer une structure arborescente optimale pour la classification des autres enregistrements disponibles. Ceci est fait en partitionnant successivement la population initiale des enregistrements de sorte à isoler au mieux les enregistrements d’une même classe. Cette technique est basée sur le calcul des effectifs (comptage) permettant de déterminer le critère de partitionnement des nœuds en sous-partitions ou à conclure qu’un nœud est une feuille. Nous devons donc, effectuer un comptage sur toutes les données sources. Or, un cube de données extrait à partir d’un entrepôt peut contenir tous les effectifs nécessaires à un algorithme d’arbre de décision dans le cas où le comptage constitue la fonction d’agrégat. Ainsi, une phase de prétraitement pour la fouille de données peut consister à construire le cube à partir de l’entrepôt. L’extraction de connaissances s’effectuera sur ce cube. Or, un cube représente une structure multidimensionnelle de données sur lesquelles sont appliquées les opérateurs d’analyse en ligne OLAP (On-Line Analytical Processing). Les applications OLAP sont intimement associées aux entrepôts de données - c'est-à-dire les bases qui, au sein d'une plate-forme de business intelligence, se chargent de consolider (par le biais d'outils d'intégration de données notamment) l'ensemble des informations métier d'une activité, en vue d'en permettre ensuite l'analyse. En fait, un entrepôt de données se résume en une architecture trois

3
tiers : une base relationnelle qui stocke et structure les contenus, une couche d'analyse OLAP en tant que telle (ou serveur OLAP) et les interfaces client de reporting. L’avantage de notre approche de fouille que nous appliquons dans un environnement d’entrepôt relationnel ROLAP (Relational OLAP), est qu’elle présente une solution technique pour faire la fouille de données dans les cubes. En effet, notre approche offre la possibilité d’extraire des connaissances à partir de données agrégées (cubes de données extraits de l’entrepôt) sans accéder aux données sources. Une combinaison de l’analyse en ligne et de la fouille pourrait alors être faite grâce à notre approche. En outre, en appliquant la fouille de données sur ces cubes, l’accès aux entrepôts de données est diminué et la charge de travail des services d’information est fortement réduite. De plus, le temps de construction de l’arbre de décision sera accéléré. Ces avantages sont multipliés : fiabilité, gain en temps et en coût d’exploitation. Le présent rapport expose en cinq parties, les étapes de notre démarche méthodologique pour répondre à cet objectif. Dans un premier temps, il conviendra d’établir une étude bibliographique permettant de mettre en perspective notre travail et de situer le contexte de notre analyse. Dans un second temps, nous présenterons les cubes de données dans l’approche ROLAP et nous établirons une comparaison entre le ROLAP et le MOLAP (Multidimensional OLAP). Nous proposerons ensuite notre approche qui effectue l’extaction des connaissance à partir des cubes de données, approche qui sera validée par une implémentation en PL/SQL sous Oracle 9i. Finalement, des ouvertures et des perspectives seront évoquées en conclusion.

4
Chapitre I
Etat de l’art Différents travaux de recherche ont traité de la possibilité d’extraire les connaissances à partir de grandes bases de données. Cet état de l’art va constituer une synthèse des différentes approches qui ont été proposées dans ce domaine. Trois grandes approches seront distinguées. Nous présenterons, tout d’abord, les approches classiques qui appliquent les algorithmes de fouille de données en mémoire. Nous verrons ensuite les approches intégrées qui appliquent les algorithmes de fouille de données dans les SGBD. Nous terminerons, enfin, par les approches traitant de l’intégration de la fouille de données dans un environnement OLAP.
I.1- Approche classique de la fouille de données
Les algorithmes de fouille de données traditionnels opèrent en mémoire sur des tableaux attributs-valeurs [ZR00]. Ceci pose un problème dans le cas des bases d’apprentissage volumineuses, ce qui s’avère être de plus en plus le cas. Pour cela, une préparation de ces données s’avère utile afin d’homogénéiser ces données et de les disposer en tableau attributs-valeurs. Ceci peut se faire au moyen d’API (« Application Programming Interface ») pour exporter les données à partir des bases de données. Mais, vue la croissance exponentielle des données, ces algorithmes se heurtent au problème de la limitation de la mémoire centrale dans laquelle les données sont traitées. Par conséquent, une série de transformations doit être choisie afin d’obtenir des données adaptées aux méthodes de fouille. Le prétraitement concerne la mise en forme des données entrées selon leur type ainsi que le nettoyage des données, le traitement des données manquantes, la sélection d’instances ou la sélection d’attributs [GE03].
La technique d’échantillonnage par exemple, présentée dans [[CR00] consiste à définir un filtre qui permet de sélectionner les lignes ou les colonnes les plus pertinentes par rapport aux préoccupations de l’utilisateur. L’apprentissage sur un bon échantillon de la population s’avère aussi efficace que l’apprentissage sur l’ensemble de celle-ci. Dans le cas des méthodes basées sur les arbres de décision, la diminution du temps d’apprentissage et la non dégradation de la qualité de celui-ci sont remarquables. Pour construire un arbre de décision sur une base très volumineuse, la meilleure stratégie est de procéder à un ré échantillonnage sur chaque nœud de l’arbre. Cependant, le meilleur résultat n’est obtenu qu’en conservant l’ensemble de données dont nous disposons. D’où l’intérêt des outils qui permettent de traiter de grandes bases de données, voire des entrepôts de données. Pour cela, l’intégration des méthodes de fouille de données au sein des SGBD s’avère intéressante.

5
I.2- Intégration des outils de fouille de données p ar les éditeurs de SGBD Pendant longtemps, le processus de fouille de données était dissocié du SGBD. Ce dernier n’était considéré dans ce cas que comme un système de stockage auquel la fouille de donnée accédait via des API. Par la suite, afin d’améliorer l’efficacité de ces systèmes, les éditeurs de SGBD ont intégré les outils de fouille de données directement au sein de leur SGBD [Chau98]. Cette recherche est liée à l’avènement des entrepôts de données et de l’analyse en ligne plus particulièrement [Cod93]. Différentes approches ont été proposées pour mener à bien cette intégration. On peut citer des extensions de SQL [SD00], l’articulation entre le processus de fouille de données et celui des données relationnelles [NK05], les extensions du langage de requêtes des opérateurs OLAP afin de simuler des techniques de fouille… Une vue consistante et intégrée sur les données pertinentes est cruciale pour une tâche d’analyse. L’intégration de la fouille de données par les éditeurs de SGBD vise à présenter un outil d’analyse de bases de données volumineuses [Cios, Kurgan, 2002]. Les éditeurs, IBM [IBM01], Microsoft [Mic00] et Oracle [Ora01], ont mis cette intégration en œuvres au sein de leur SGBD, malheureusement de manière opaque. Leur objectif était de faciliter aux utilisateurs qui se servent d’un système de gestion de bases de données l’application des méthodes de fouille de donnée [CK02]. La technologie présentée par IBM intégrait des modules qui exécutaient des fonctions de fouille de données [IBM02]. En effet, Intelligent Miner de IBM est l’un des produits qui permettait le développement des applications de fouille et qui implémentait des algorithmes de fouille de données tels que la régression, les règles d’associations. De son côté, les composants des services d’analyse de SQL Server 2000 de Microsoft proposent le même type de service à travers une extension de l’interface OLE-DB dédiée à la fouille de donnée [NCBF00], [TK00]. Ces interfaces permettent l’enregistrement et l’intégration des algorithmes de fouille de données afin de créer des modèles de fouille. En effet, cette extension d’interface s’adapte bien dans l’environnement du relationnel et permet le développement rapide et simple des applications utilisant la technologie de fouille de données. Les interfaces permettant d’accéder aux données et aux modèles de fouille sont similaires : tous ces modèles sont représentés par des tables avec des colonnes et des types de données auxquels on adjoint les données nécessaires pour les algorithmes de fouille de données [SH98] . Cependant, cette approche nécessite une optimisation ultérieure dans l’exécution des algorithmes de fouille intégrée [Chau98]. Des méthodes de fouille ont été également intégrées dans Oracle. En effet, Oracle 9i Data Mining est constitué d’API de fouille de données permettant l’application des algorithmes de fouille dans les bases de données [Ora02]. Cependant, cette intégration présentée par les éditeurs de logiciels prend la forme de boîte noire dans laquelle ont été introduites des méthodes existantes. On peut également noter que cela ne résout pas totalement le problème de limitation des volumes de

6
données pouvant être traités. Une alternative récemment proposée, a intégré des méthodes de type « arbre de décision » dans les SGBD en utilisant uniquement les outils offerts par ces derniers. Cette solution sera présentée dans ce qui suit.
I.3 Utilisation des concepts de bases de données po ur la fouille de données Des travaux innovants ont permis l’intégration des méthodes de fouille de données dans les SGBD. Seuls, les outils offerts par ces derniers tels que les tables, les vues , les index, … ont été utilisés pour appliquer les algorithmes de fouille de données sur de grandes bases de données. Les index bitmaps, par exemple, ont été utilisés pour l’extraction des règles d’association [MZ98]. Une implémentation de méthodes d’arbres de décision telles que ID3, C4.5 et CART a été aussi mis en œuvre en utilisant le concept de « vues relationnelles ». L’algorithme ID3 a été adapté à l’environnement des SGBD. En effet, une analogie entre un arbre de décision, composé d’un ensemble de nœuds, et un arbre composé de vues relationnelles, a été développée dans [BD02]. Ces vues sont utilisées pour dénombrer les effectifs de chaque classe au niveau de chaque nœud. Ces comptages servant à déterminer le critère de partitionnement des nœuds en sous partitions sont obtenues par les requêtes SQL utilisant la fonction COUNT() et la clause GROUP BY. Cette approche résout le problème de limitation de la taille posé par les approches classiques. Cependant, le temps de traitement se révèle élevé étant données les nombreuses lectures de la base. Dans [BDU04] et [Udr04], une amélioration consiste à préparer les données au sein des SGBD en remplaçant la table d’apprentissage initiale par la table de contingence. Ainsi, les algorithmes sont adaptés à cette table de contingence qui contient les effectifs pré-agrégés des populations plutôt que sur la base elle-même. Cela réduit de manière considérable la taille de la base d’apprentissage, donc le temps d’exécution. Un autre travail d’optimisation a été proposé dans [BDU04] et [Udr04]. Dans ces travaux, l’utilisation des index bitmaps de jointure pour la construction des arbres de décision a permis un gain substantiel aussi bien en espace qu’en temps de réponse. Étant donné le récent engouement pour les entrepôts de données, il est naturel de s’intéresser à l’intégration des méthodes de fouille dans un environnement OLAP.
I.4 Intégration de la fouille de données dans un en vironnement OLAP L’application des méthodes de fouille sur les entrepôts de données est une nouvelle piste de recherche. L’approche utilisée consiste à adapter les algorithmes d’apprentissage afin d’assurer leur migration vers l’environnement multidimensionnel. Une exploration des entrepôts de données est nécessaire afin de profiter de la richesse des données multidimensionnelles et d’y faire une analyse approfondie.

7
[GChou99] a introduit la fouille de données dans l’environnement OLAP. Pour se faire, il propose des algorithmes parallèles de classification (arbre de décision, règles d’association, …) appliqués à des structures cubiques multidimensionnelles. Ces dernières sont construites en parallèle dans un environnement distribué, ce pour des données en grande dimension et de grande dimensionnalité. Le calcul d’agrégats est assuré à l’aide de requêtes OLAP afin de permettre à l’algorithme de classification par règles d’association de calculer la confiance et le support. En effet, [GChou99] utilise une transformation bidimensionnelle des données cubiques en agrégeant successivement les dimensions. A partir du cube, cette approche consiste à extraire les matrices de contingence pour chaque dimension et à chaque étape de construction de l’arbre. Des tableaux bidimensionnels intermédiaires vont contenir ces matrices. La segmentation a lieu selon la dimension gagnante choisie en se basant sur la valeur minimale de l’indice de Gini [MAR94] contenu dans ces matrices. Notons que [GChou99] essayait d’adapter la structure cubique des données aux algorithmes d’apprentissage automatique. D’autres travaux intéressants se fondent sur l’approche OLAP Mining qui permet l’intégration de la fouille dans l’environnement OLAP. Ce qui facilite une fouille intéressante sur les cubes (elle peut être faite aux différents niveaux de ces cubes). [ZAI98] introduit différentes fonctions d’OLAP Mining. Préalablement à la fouille, des opérations cubiques sont appliquées afin de sélectionner les données nécessaires. Dans un entrepôt de données important, il est crucial de rendre flexible la fouille. Ainsi, un utilisateur pourra appliquer les algorithmes de fouille de donnée sur un cube [Han97]. Dans ces travaux, la combinaison OLAP et fouille de données en se servant des cubes se situe dans l’environnement MOLAP qui nécessite une optimisation du cube afin de gérer les cellules creuses.
I.5 Discussion
Conformément aux travaux qui ont été présentés, nous distinguons quatre approches visant à mettre en œuvre un processus de fouille de données sur des bases de données volumineuses. La première exploite des approches classiques de fouille de données en faisant appel à l’échantillonnage et/ou la sélection d’attributs, etc…. Ces approches permettent l’apprentissage sur un échantillon de la population. Toutefois, des outils capables de traiter de grandes bases de données s’avèrent utiles afin de pouvoir apprendre sur la totalité de la population. Ainsi, une seconde approche présentée par les éditeurs de logiciels, consiste à intégrer les méthodes de fouille de données au sein des SGBD. Cependant, cette intégration prend la forme d’une boîte noire dans laquelle on été introduites des méthodes existantes au moyen des API, ce qui ne résout pas le problème de limitation des volumes de données pouvant être traités.

8
La troisième approche cherche à se servir des concepts bases de données pour faire la fouille de données. Uniquement, les outils dont le SGBD est muni vont être utilisés. Toutefois, cette approche présente des temps d’exécution élevés nécessitant quelques optimisations. Nous terminons, enfin, en présentant la dernière approche qui consiste à réaliser l’intégration de la fouille de données dans un environnement OLAP. Cette approche est très importante vue qu’elle essaie de faire la fouille sur les cubes de données construits à partir de l’entrepôt de données. Cependant, les travaux réalisés selon cette approche se limitent à la vision multidimensionnelle et ne prennent pas en considération l’environnement relationnel des entrepôts de données. Finalement, rappelons que notre objectif vise, dans un contexte relationnel, l’extraction des connaissances à partir des entrepôts de données et plus spécifiquement à partir des cubes extraits à partir de ces entrepôts. Nous remarquons que même si les travaux que nous avons cités, visent à appliquer la fouille de données sur des bases de données volumineuses, aucun d’eux ne répond à notre problème. Notre approche consiste à intégrer les algorithmes de fouille de données pour être appliqués sur les entrepôts de données dans un environnement ROLAP et par la suite, à appliquer l’extraction des connaissances sur un cube de données.

9
Chapitre II
Cubes de données dans l’approche ROLAP
II.1 Contexte : Entrepôt de données et Fouille de d onnées Avec le développement des technologies Intranet, l’ère du client serveur prend tout son essor à la fin des années 90. Ainsi, un environnement de concurrence, très pressant contribue à révéler l’informatique décisionnelle. Tout utilisateur ayant à prendre des décisions doit pouvoir accéder en temps réel aux données de l’entreprise, traiter ces données, en extraire l’information pertinente afin de prendre les bonnes décisions. Le système opérationnel ne peut satisfaire ces besoins pour au moins deux raisons : les bases de données opérationnelles sont trop complexes pour pouvoir être appréhendées facilement par tout utilisateur et le système opérationnel ne peut être interrompu pour répondre à des requêtes nécessitant des calculs importants. Il s’avère donc nécessaire de développer des systèmes d’information orientés vers la décision et capable de mémoriser ce grand flot de données et d’en extraire l’information. Les entrepôts de données ou data warehouse sont la réalisation de ces nouveaux systèmes d’information. L’informatique décisionnelle s’est développée dans les années 70. Elle est alors essentiellement constituée d’outils d’édition de rapports, de statistiques, de simulation et d’optimisation. Provenant des recherches en Intelligence Artificielle, les systèmes experts apparaissent. Ils sont conçus par extraction de la connaissance d’un ou plusieurs experts traduites en termes de règles. De bons résultats sont obtenus pour certains domaines d’application tels que la médecine, la géologie, la finance,… Cependant, il apparaît vite que la formalisation sous forme de règles de la prise de décision est une tâche difficile voire impossible dans de nombreux domaines. Dans les années 90, deux phénomènes se produisent simultanément. Vu l’accroissement des volumes de données à traiter, les entrepôts de données se sont développés afin de fournir aux décideurs des systèmes dédiés à l’analyse des données. Les outils d’exploitation d’un entrepôt de données peuvent être classés en deux catégories : les outils d’aide à la décision permettant d’interroger et d’analyser l’évolution des données, et les outils de data mining permettant de comprendre les relations entre les données. D’une part, les bases de données multidimensionnelles ont émergé pour répondre aux besoins spécifiques d’analyse multidimensionnelle en ligne (OLAP). D’autre part, de nombreux algorithmes permettant d’extraire des informations à partir de données brutes sont arrivés à maturité. Ces algorithmes ont des origines diverses et multiples. Certaines sont issues de la statistique, d’autres proviennent des recherches en Intelligence Artificielle, recherches qui se sont concentrées sur des projets moins ambitieux, plus ciblés. Tous ces algorithmes sont regroupés dans les logiciels de fouille de données ou Data Mining qui permettent la recherche d’informations nouvelles ou cachées à partir de données. Ainsi, les entrepôts de données et la fouille de données sont les éléments d’un domaine de recherche et de développement très actifs actuellement.

10
II.2 Définitions : Outils d’exploration d’un entrep ôt de données
II.2.1 Le monde décisionnel OLAP Un entrepôt de données est une base dédiée au décisionnel. L’information est mise à la disposition des utilisateurs mais les mises à jour ne sont jamais faites en ligne. Les seules mises à jour étant les phases de chargement provenant des données de production et se passant en mode batch. Une autre caractéristique importante des entrepôts, qui est aussi une différence fondamentale avec les bases de production, est qu’aucune information n’y est jamais modifiée. En effet, on mémorise toutes les données sur une période donnée et déterminée. Il n’y aura donc jamais à remettre en cause ces données car toutes les vérifications utiles auront été faites lors de l’alimentation. L’utilisation se résume donc à un chargement périodique, puis à des interrogations non régulières, non prévisibles, parfois longues à exécuter. L’entrepôt de données est donc bien différent des bases de données de production car les besoins pour lesquels on veut le construire sont différents. Il contient des informations historiées, globalement cohérentes, organisées selon les métiers de l’entreprise pour le processus de décision. L’entrepôt n’est pas un produit ou un logiciel mais un environnement. Il se bâtit et ne s’achète pas. Les données sont puisées dans les bases de production, nettoyées, normalisées, puis intégrées. Des méta données décrivent les informations dans cette nouvelle base pour lever toute ambiguïté quant à leur origine et leur signification. Au niveau conceptuel, on parle de modèle multidimensionnel, souvent représenté sous forme de cube, parce que les données seront toujours des faits à analyser suivant plusieurs dimensions. Une table de faits comporte des dimensions et des indicateurs. Par exemple, supposons qu’on veut gérer les informations des clients d’une entreprise et on ne s’intéresse qu’à la globalisation par mois de cette transaction. Les dimensions sont les suivantes : mois de production, type du risque et note de risque. L’indicateur c’est le chiffre d’affaire du mois. A ce stade, nous avons une base de faits du magasin « information » comportant 3 dimensions, un vrai cube. Les interrogations s’interprètent souvent comme l’extraction d’un plan, d’une droite de ce cube, ou l’agrégation de données le long d’un plan ou d’une droite (e.g Somme des montants des contrats- pour un produit donné- signés dans le mois) Au niveau logique, l’unité de base est la table comme dans le modèle relationnel. L’implémentation classique consiste à considérer un modèle en étoile avec au centre la table de faits et les dimensions comme étant des branches de l’étoile. Les branches de l’étoile sont des relations de un à plusieurs, la table des faits est énorme contrairement aux tables des dimensions. Le modèle est en cela très dissymétrique en comparaison avec les modèles relationnels des bases de production. Les faits sont qualifiés par des champs qui sont le plus souvent numériques et cumulatifs comme des prix, des quantités et des clés évidemment pour relier les faits à chaque dimension. Les tables des dimensions sont caractérisées par des champs souvent textuels. Si la table des faits ne

11
contient pas un enregistrement pour chaque élément dans chaque dimension, on interprète cette constatation en disant que beaucoup de cubes unitaires ne contiennent aucune donnée, formant ainsi une matrice creuse [GRA 97].
II.2.2 Les outils OLAP et les cubes de données Les outils OLAP reposent sur une base de données multidimensionnelle, destinée à exploiter rapidement les dimensions d’une population de données. La plupart des solutions OLAP reposent sur un même principe : restructurer et stocker dans un format multidimensionnel les données issues de fichiers plats ou de bases relationnelles. Ce format multidimensionnel, connu également sous le nom d’hyper cube, organise les données le long de dimensions. Ainsi, les utilisateurs analysent les données suivant les axes propres à leur métier. Ce type d’analyse multidimensionnelle nécessite à la fois l’accès à un grand volume de données et des moyens adaptés pour les analyser selon différents point de vue. Ceci inclut la capacité à discerner des relations nouvelles ou non prévues entre les variables, la capacité à identifier les paramètres nécessaires à manier un volume important de données pour créer un nombre illimité de dimensions et pour spécifier des expressions et conditions inter dimensions. Ces dimensions représentent les chemins de consolidation. OLAP a donc besoin d’une structure en forme de cube. Il s’agit donc d’un tableau multidimensionnel où les cellules contiennent les valeurs des dimensions qu’elles croisent. On parle alors de base de données OLAP. Lors de la création d’un cube, il faut décider de la manière de stocker les données atomiques ainsi que les agrégats. Les agrégats dans le cube de données répondent aux requêtes OLAP. Les opérations suivantes sont définies sur le cube :
• Roll-up ou forage vers le haut : consiste à représenter les données du cube à un niveau de granularité supérieur conformément à la hiérarchie définie sur la dimension.
• Drill down ou forage vers le bas : consiste à représenter les données du cube à un niveau de granularité inférieur, donc sous une forme plus détaillée.
• Pivoting ou aussi rotation : cette opération provoque la rotation du cube afin de changer l’orientation dimensionnelle. Ça peut consister à fusionner deux dimensions ou introduire une nouvelle dimension à la place d’une dimension déjà existante dans le cube.
• Slice-dicing : cette opération concerne la sélection de sous-ensemble du cube. Pour une valeur d’attribut bien précise à une dimension donnée,elle rapporte toutes les valeurs pour toutes les autres dimensions. Ça peut être visualiser par de tranches (slice) de données dans un cube de données 3D .
Les opérations utilisées par OLAP et la fouille de donnés nécessitent un accès aux données selon une dimension bien particulière ou une combinaison de dimension. En général les opérations sont de type d’agrégats selon un attribut bien particulier, représenté par une dimension dans la base de données multidimensionnelle. L’ensemble des opérations nécessaires pour OLAP et la fouille de données doivent être efficaces et avoir une bonne performance concernant la distribution des données.

12
Les opérations sont catégorisées de la façon suivante : • Sélection d’une cellule de façon aléatoire • Sélection selon une dimension ou une combinaison de dimensions. • Sélection des valeurs des dimensions parmi un rang bien précis. • Opérations d’agrégations sur les dimensions. • Agrégation multidimensionnelle (généralisation-consolidation : du plus petit au
plus grand niveau d’hiérarchie).
La plupart des dimensions sont définies selon des hiérarchies. Les requêtes typiques d’OLAP collecte les données aux différents niveaux de l’hiérarchie. La consolidation est utilisée pour fournir les fonctions roll-up et drill-down dans les systèmes OLAP. Chaque dimension dans un cube peut avoir sa propre hiérarchie. Cette hiérarchie peut être appliquée sur tous les sous-cubes du cube de données. Une cellule dans une représentation multidimensionnelle représente un tuple dans l’espace multidimensionnel et la valeur de la mesure représente le contenu de la cellule. Les données peuvent être organisées dans des cubes de données en calculant toutes les combinaisons possibles des GROUP BY. Cette opération est utilisée pour répondre aux requêtes OLAP qui utilisent des agrégations sur les différentes combinaisons des attributs. Pour un ensemble de données de n attributs est associé 2n calculs de GROUP BY. La figure 1 montre un exemple d’un cube de données construit sur un ensemble de données à trois attributs. Dans les systèmes relationnels, une table de fait est construite, utilisant une représentation en étoile de la table d’origine. La table de fait contient les clés des tables de dimensions et contient les différents agrégats des attributs. Les requêtes accèdent aux données à travers des opérations relationnelles appropriées telles que les jointures et les projections. Dans SQL, l’opérateur cube représente le calcul d’un cube de données . Une représentation multidimensionnelle utilise une architecture hyper cube pour stocker les données organisées avec une dimension dans une structure multidimensionnelle convenable. Deux versions d’OLAP s’affrontent actuellement. Les outils MOLAP d’une part qui s’appuient sur une base de données multidimensionnelle. Les outils ROLAP d’autre part, qui représentent leur équivalent sur une base de données relationnelle. Figure 1 : Vue multidimensionnel des données
rég ion N
E
O
Produ i t
j us co la
l a i t
C rème
f ra ise
ananas
Da te 1 2 3 4 5 6 7
Cel lu les contenant les va leurs des d imensions
DIMENSION
D I ME N S I ON

13
II.2.3 MOLAP vs. ROLAP
En pratique, il y a deux formes de serveur OLAP : MOLAP et ROLAP. Les données agrégées peuvent être vue à l’aide d’un cube logique ou l’utilisateur est libre d’indexer le cube sur un ou plusieurs axes de dimensions. Dans la nomenclature d’OLAP, ce type de représentation conceptuelle du modèle est connu sous le nom de cube de données. Depuis que les cubes proposent une interprétation multidimensionnelle de l’espace de données, un nombre de vendeurs OLAP ont choisi de modéliser ce cube physiquement comme un tableau multidimensionnel. Les données du cube et les agrégations sont stockées dans une structure multidimensionnelle. Le stockage OLAP de type multidimensionnel (MOLAP) fournit un potentiel adapté aux temps de réponse les plus rapides, dépendant seulement du pourcentage d’agrégations et du modèle d’agrégation du cube. D’une façon générale, le stockage MOLAP est plus approprié pour les cubes qui sont utilisés fréquemment et nécessitent une réponse rapide. Toutefois, un problème s’impose dans l’approche MOLAP : chaque fois que le nombre de dimensions augmente, les données dans le cube deviennent de plus en plus dispersées. De cette façon, la plupart des combinaisons des données représentées dans la structure du cube ne vont pas contenir des données agrégées. Ainsi, le tableau matérialisé MOLAP risque de contenir un nombre énorme de cellules vides, aboutissant à un besoin d’un grand espace de stockage. Néanmoins, malgré l’existence des travaux qui proposent des solutions aux cubes creux, on peut éviter ce problème en faisant appel à l’approche ROLAP. Par ailleurs, ROLAP vise à exploiter le potentiel du paradigme relationnel. Au lieu d’un tableau multidimensionnel, un cube de données ROLAP est implémenté comme une collection de tables relationnelles à deux dimensions, chacune représentant une vue particulière. ROLAP stocke les agrégats dans des tables relationnelles du système de gestion de bases de données relationnelles par contre à MOLAP qui les stocke dans des tableaux multidimensionnels. Puisque le cuboïde dans l’approche ROLAP est représenté sous forme de tables, des traitements peuvent y être effectuées en utilisant des techniques du système de gestion de bases de données relationnelles. En outre, plus d’efficacité est assurée dans un grand entrepôt de données puisque seules les cellules du cube de données qui contiennent des données sont stockées dans ces tables. Les données du cube et les agrégations sont stockées dans l’entrepôt existant (bases de données relationnelles). Toutefois, les temps de réponse OLAP de type relationnel (ROLAP) aux requêtes est généralement plus long que celui du type multidimensionnel. Le mode de stockage ROLAP est généralement utilisé pour les grands jeux de données qui ne sont pas interrogés fréquemment, notamment les données historiées portant sur des années éloignées.

14
Chapitre III
Cubes de données et Arbres de décision
III.1 Introduction L’objectif de ce stage consiste à développer des approches de fouille de données intégrées au sein des SGBD. En particulier, nous désirons appliquer ces approches sur un entrepôt de données sans être limités par la taille de la base à traiter. La solution que nous proposons est d’effectuer l’extraction de connaissances à partir des cubes de données construits à partir d’un entrepôt de données. Nous désirons plus précisément adapter l’algorithme ID3 pour être appliqué sur un cube de données. Ce chapitre présente cette démarche en trois sections. La première section introduira le principe d’arbre de décision et plus précisément l’algorithme ID3. La deuxième section présentera la construction d’un entrepôt de données pour la fouille. Enfin, la troisième section exposera la construction du cube ainsi que l’application de l’algorithme ID3 sur ce cube.
III.2 Principe des arbres de décision La technique dite par « arbre de décision » est fondée sur l’idée simple de réaliser la classification d’un objet par une suite de tests sur les attributs qui le décrivent. Ces tests sont organisés de telle façon que la réponse à l’un d’eux indique à quel prochain test on doit soumettre cet objet. Le principe c’est d’organiser l’ensemble des tests possibles comme un arbre. Une feuille de cet arbre désigne une classe et à chaque nœud est associé un test portant sur un ou plusieurs attributs, éléments de l’espace de représentation. La réponse à ce test désignera le fils du nœud vers lequel on doit aller. La classification s’effectue en partant de la racine pour poursuivre récursivement le processus jusqu’à ce qu’on rencontre une feuille. Une telle structure est appelée arbre de décision. Dans une arbre de décision, chaque chemin correspond à une règle exprimée sous la forme « si condition alors conclusion » dans laquelle « condition » désigne une disjonction de conjonctions de propositions logique de type « attribut, valeur » [ZR00]. L’ensemble des règles constitue ainsi le modèle de prédiction.
15
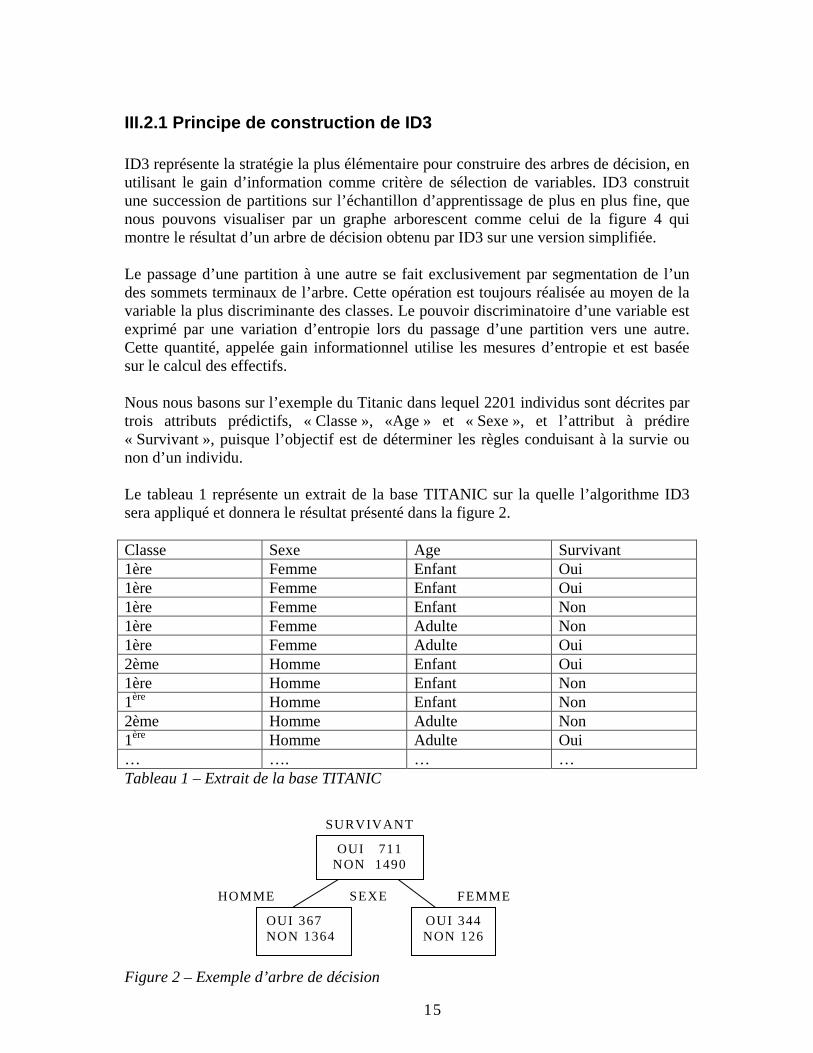
III.2.1 Principe de construction de ID3 ID3 représente la stratégie la plus élémentaire pour construire des arbres de décision, en utilisant le gain d’information comme critère de sélection de variables. ID3 construit une succession de partitions sur l’échantillon d’apprentissage de plus en plus fine, que nous pouvons visualiser par un graphe arborescent comme celui de la figure 4 qui montre le résultat d’un arbre de décision obtenu par ID3 sur une version simplifiée. Le passage d’une partition à une autre se fait exclusivement par segmentation de l’un des sommets terminaux de l’arbre. Cette opération est toujours réalisée au moyen de la variable la plus discriminante des classes. Le pouvoir discriminatoire d’une variable est exprimé par une variation d’entropie lors du passage d’une partition vers une autre. Cette quantité, appelée gain informationnel utilise les mesures d’entropie et est basée sur le calcul des effectifs. Nous nous basons sur l’exemple du Titanic dans lequel 2201 individus sont décrites par trois attributs prédictifs, « Classe », «Age » et « Sexe », et l’attribut à prédire « Survivant », puisque l’objectif est de déterminer les règles conduisant à la survie ou non d’un individu. Le tableau 1 représente un extrait de la base TITANIC sur la quelle l’algorithme ID3 sera appliqué et donnera le résultat présenté dans la figure 2. Classe Sexe Age Survivant 1ère Femme Enfant Oui 1ère Femme Enfant Oui 1ère Femme Enfant Non 1ère Femme Adulte Non 1ère Femme Adulte Oui 2ème Homme Enfant Oui 1ère Homme Enfant Non 1ère Homme Enfant Non 2ème Homme Adulte Non 1ère Homme Adulte Oui … …. … … Tableau 1 – Extrait de la base TITANIC
Figure 2 – Exemple d’arbre de décision
OUI 367 NON 1364
OUI 344 NON 126
FEMME HOMME SEXE
SURVIVANT
OUI 711 NON 1490

16
Chaque nœud de l’arbre contient les effectifs des attributs à prédire vérifiant un critère particulier. Par exemple, au niveau 1 pour le nœud ‘HOMME’ le nombre 367 n’est que le total des attributs vérifiant le critère « sexe= ‘HOMME’ et survivant= ‘OUI’ ». Donc, la construction de l’arbre de décision est basée sur le calcul des effectifs qui sont obtenus en effectuant le total des attributs prédictifs vérifiant un critère bien précis. Ces effectifs vont servir aussi bien pour la segmentation et le choix des attributs discriminants que dans la structure de l’arbre.
III.2.2 Entropie et Gain d’information Le calcul pratique d’une entropie sur un arbre est relativement simple puisqu’il s’effectue sommet par sommet. L’entropie à la racine s0 de l’arbre est définie par :
hs(f1, f2, ……………., fm)= ∑=
−m
iii ff
12log où fi = .
n
ni
Pour un sommet quelconque sk de l’arbre, nous aurons :
∑=
−=m
i k
ik
k
ikks f
f
f
fsh
1 .2
.
log)( où fik = .n
nik et f.k = ..
n
n k
où nk est l’effectif de sk et nik le nombre d’objets de sk qui appartiennent à la classe ci. L’information portée par une partition SK de K nœuds est alors la moyenne pondérée des entropies :
E(Sk) = ∑=
K
kksk shf
1. )( = ∑ ∑
= =
−K
k
m
i k
ik
k
ikk f
f
f
ff
1 1 .2
.. )log(
Finalement, le gain informationnel associé à SK est : G(SK) = hs(sj)- E(Sk) Comme G(SK) est toujours positif ou nul, le processus de construction d’arbre de décision revient à une heuristique de maximisation de G(SK) à chaque itération et à la sélection de la variable correspondante pour segmenter un nœud donné. L’algorithme s’arrête lorsque G(SK) devient inférieur à un seuil (gain minimum) défini par l’utilisateur.
III.3 Exemple d’entrepôt pour la fouille de données Notre base d’apprentissage est un entrepôt de données construit à partir de la base de données source des passagers du Titanic. TITANIC est la base d’apprentissage utilisée dans un contexte de fouille classique. C’est un tableau attributs-valeurs sur lequel on peut appliquer des algorithmes de fouilles de données tels que les méthodes d’arbre de décision.

17
Pour obtenir l’entrepôt de données TITANIC_DW à partir de la base source TITANIC, nous définissons les différentes mesures et dimensions nécessaires. En effet, l’entrepôt de données TITANIC_DW sera élaboré par un modèle multidimensionnel constitué d’une table de faits et de tables de dimensions, dont chacune est reliée à la table de faits par une jointure. On obtient ainsi un schéma en étoile : une table de faits et quatre dimensions. Une table de faits est composée des clés étrangères (clés primaires des dimensions ) et des mesures. Voici donc les précisions concernant les constituants de la table de fait :
- La clé primaire pour identifier le passager « Id_passager ». - Les clés étrangères suivants :
o La classe de l’individu au sein du bateau est indiqué par « Classe » et peut prendre les valeurs suivantes :
� « 1ST » pour indiquer un individu de la première classe. � « 2ND » pour indiquer un individu de la deuxième classe. � « 3RD » pour indiquer un individu de la troisième classe. � « CREW »pour indiquer un individu du membre de l’équipage.
o L’age de l’individu est indiqué par l’attribut « Age» et prend les modalités « Child » et « Adult »
o Le sexe de l’individu est représenté par « Gender » et possède deux modalités « Male » et « Female ». Ces clés étrangères référencent les dimensions. Notre but est de savoir si un passager a survécu ou non. La construction de l’arbre de décision selon ID3 est basée sur les effectifs des survis et des non survis des passagers. L’attribut à prédire sera transformé en ces deux mesures: - Survivor_yes indique qu’un passager a survécu - Survivor_ no indique qu’un passager n’a pas survécu
Un modèle en étoile de notre entrepôt de données est donné dans la figure 3 :
Figure 3: Modèle en étoile de l’entrepôt de données TITANIC_DW
Id_passager
Titanic ID_passager Age Gender Class Survivor_yes Survivor_no
Gender
Gender_IAge_Id
Age
Class
ID_Cla
Passager

18
III.3.1 Cubes et Arbres de décision L’approche que nous proposons pour effectuer la fouille de données sur les entrepôts de données, en particulier générer l’arbre de décision est basée sur l’utilisation des cubes. Cette utilisation est motivée par plusieurs raisons. Un cube de données est une synthèse de données agrégées qui peuvent répondre facilement à un certain type de requêtes sans accéder aux données sources et sans même connaître les données originelles. Le contenu d’un cube prend alors tout son sens dans le cadre de notre recherche sur la méthode ID3. Les effectifs dont on a besoin pour la construction des arbres de décision correspondent exactement aux données agrégés contenues dans un cube si ces dernières sont obtenues par la fonction de comptage (COUNT()). En effet, les effectifs des différentes sous populations d’un arbre de décision peuvent être obtenus par de simples requêtes basées sur un SELECT. Le cube peut constituer alors notre base d’apprentissage. Les avantages majeurs de travailler avec les cubes est d’éviter l’accès aux données sources et de présenter une solution technique pour faire de la fouille dans les cubes. Une fois le cube construit, le travail s’effectue directement sur celui-ci. Par conséquent, ceci permet la diminution des accès récurrents à la base originelle et la réduction des temps induits par les traitements. Notre objectif est donc d’élaborer un algorithme qui utilise le cube construit à partir de la fonction de comptage « COUNT() » et de l’opérateur OLAP « CUBE » en vue de la construction des arbres de décision. Pour valider notre approche, nous avons choisi d’implémenter la méthode ID3, pour sa simplicité, au cœur d’un SGBD. Dans les arbres de décision, et plus particulièrement dans la méthode ID3, à chaque nœud, il s’agit de segmenter la population en choisissant un attribut discriminant, celui qui maximise le gain. Ainsi, à chaque nœud de l’arbre, une suite d’opérations a lieu afin de calculer le gain pour qu’on puisse choisir la variable prédictive. Durant ces opérations, il faut déterminer les effectifs et le nombre total de n-uplets pour chacune des valeurs des attributs prédictifs. Comme l’ensemble des n-uplets des nœuds fils correspond aux n-uplets de leur père, et pour chaque fils, on compte les n-uplets de l’ensemble de la collection qui lui est associée, ceci entraîne plusieurs lectures de chaque n-uplets ce qui induisent un grand coût. Un cube de données va contenir toute les populations agrégées et toutes les combinaisons possibles. Ainsi, comme les effectifs sont pré-calculés, on a plus besoin d’accéder à la base source pour faire la fouille de données, puisque toutes les combinaisons se trouvent dans ce cube. Les effectifs correspondant aux modalités de la classe à prédire, sont retrouvés facilement pour chacun des nœuds de l’arbre, par suite le temps de traitement va diminuer. Pour mieux comprendre notre raisonnement, nous nous appuyons sur l’exemple pédagogique de l’entrepôt TITANIC_DW dont la table de fait présente les données comme illustrées ci-dessous dans le tableau 2 :
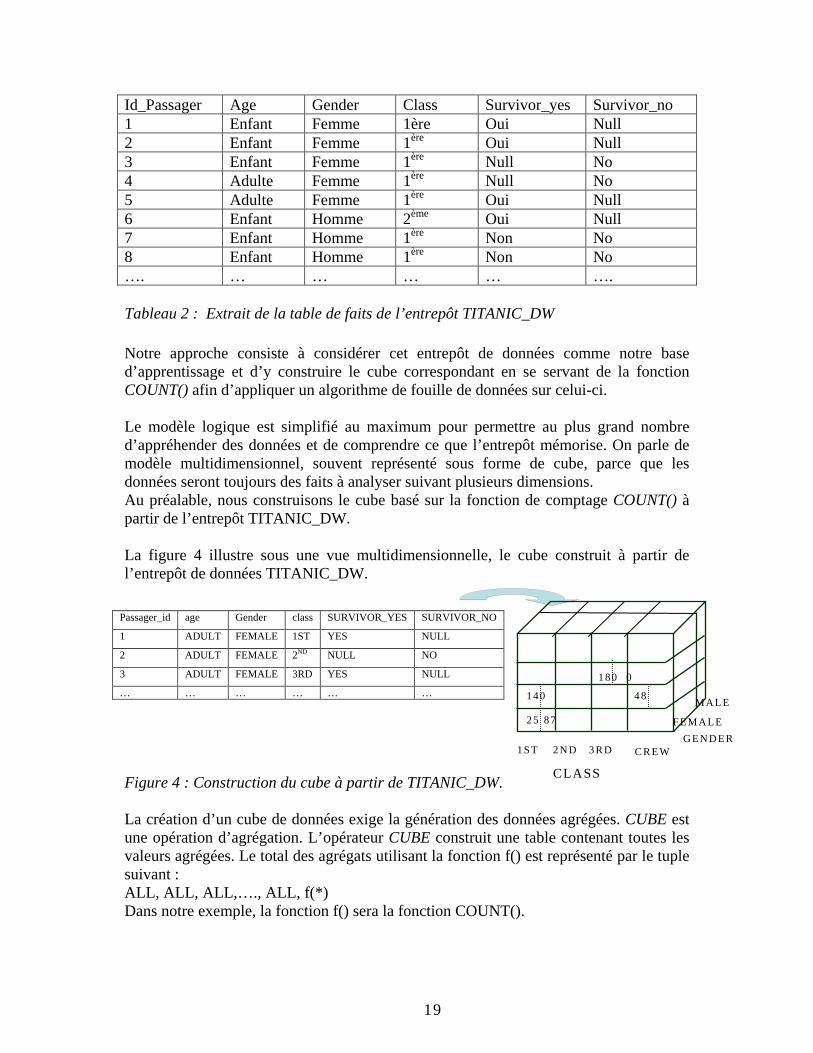
19
Id_Passager Age Gender Class Survivor_yes Survivor_no 1 Enfant Femme 1ère Oui Null 2 Enfant Femme 1ère Oui Null 3 Enfant Femme 1ère Null No 4 Adulte Femme 1ère Null No 5 Adulte Femme 1ère Oui Null 6 Enfant Homme 2ème Oui Null 7 Enfant Homme 1ère Non No 8 Enfant Homme 1ère Non No …. … … … … …. Tableau 2 : Extrait de la table de faits de l’entrepôt TITANIC_DW Notre approche consiste à considérer cet entrepôt de données comme notre base d’apprentissage et d’y construire le cube correspondant en se servant de la fonction COUNT() afin d’appliquer un algorithme de fouille de données sur celui-ci. Le modèle logique est simplifié au maximum pour permettre au plus grand nombre d’appréhender des données et de comprendre ce que l’entrepôt mémorise. On parle de modèle multidimensionnel, souvent représenté sous forme de cube, parce que les données seront toujours des faits à analyser suivant plusieurs dimensions. Au préalable, nous construisons le cube basé sur la fonction de comptage COUNT() à partir de l’entrepôt TITANIC_DW. La figure 4 illustre sous une vue multidimensionnelle, le cube construit à partir de l’entrepôt de données TITANIC_DW.
Figure 4 : Construction du cube à partir de TITANIC_DW. La création d’un cube de données exige la génération des données agrégées. CUBE est une opération d’agrégation. L’opérateur CUBE construit une table contenant toutes les valeurs agrégées. Le total des agrégats utilisant la fonction f() est représenté par le tuple suivant : ALL, ALL, ALL,…., ALL, f(*) Dans notre exemple, la fonction f() sera la fonction COUNT().
Passager_id age Gender class SURVIVOR_YES SURVIVOR_NO
1 ADULT FEMALE 1ST YES NULL
2 ADULT FEMALE 2ND NULL NO
3 ADULT FEMALE 3RD YES NULL
… … … … … …
25 87
140 4
48 12
180 0
CLASS
GENDER
1ST 2ND CREW 3RD
FEMALE
MALE

20
Les opérateurs de cubes de données généralisent la construction d’histogrammes tels la cross-tabulation, le roll-up, le drill-down et les sous-totaux. Une structure en treillis est utilisée pour représenter les différents calculs d’agrégats. Au niveau i, i ni ≤≤ du treillis, il y a C(n,i) sous-cubes (agrégats) avec i dimensions exactement, où la fonction C donne toutes les combinaisons pour i dimensions distinctes des n dimensions. Un
total de nn
i
inC 2),(0
=∑=
sous-cubes sont présents dans le cube de données.
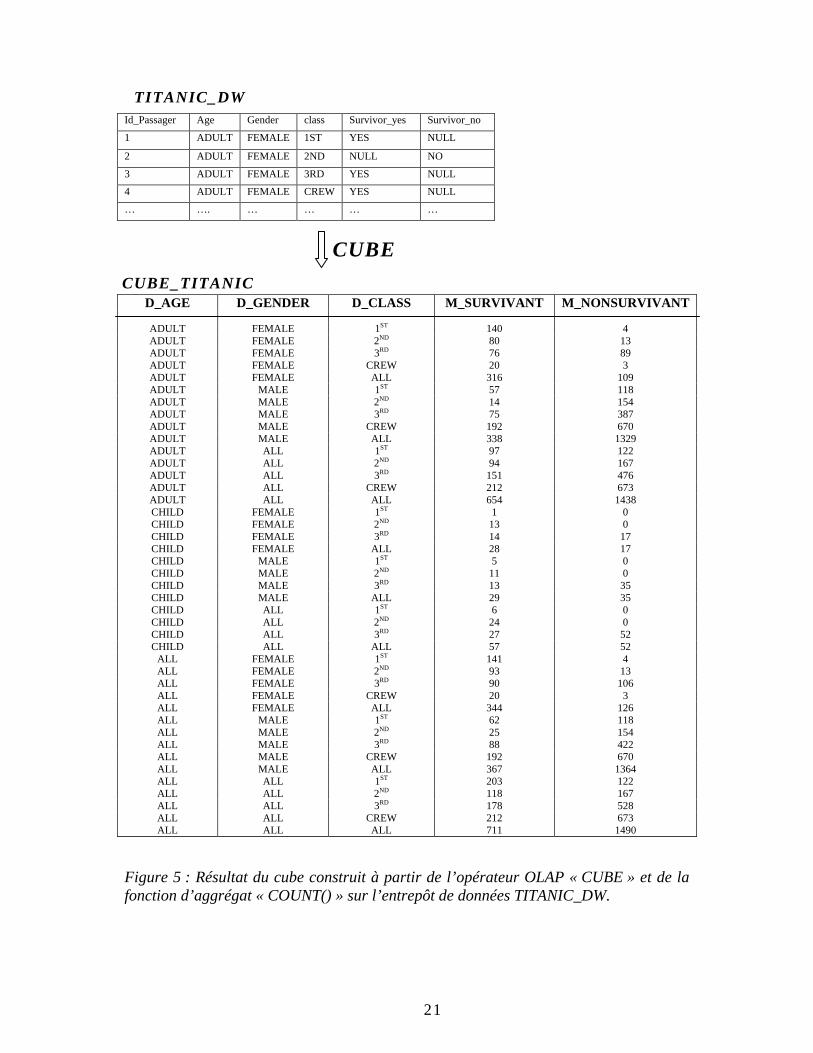
Dans l’approche ROLAP, nous sommes intéressés à construire un cube à partir de l’entrepôt de données TITANIC_DW via l’opérateur OLAP « CUBE » et la fonction d’agrégat « COUNT() ». La syntaxe qui permet de construire ce cube est la suivante : Create View Cube_titanic AS
SELECT age D_age, gender D_gender, class D_class, COUNT(SURVIVOR_YES) AS M_survivant, COUNT(SURVIVOR_NO) AS M_nonsurvivant
FROM Titanic GROUP BY CUBE (age, gender, class); Le résultat de cette requête est exposé dans la figure 5. D’une part, le cube construit, résultant de cette requête, va contenir tous les effectifs concernant les combinaisons des attributs. Ces effectifs vont être cruciale dans l’application des méthodes d’arbres de décision et plus précisément l’algorithme ID3. D’autre part, ce cube contient les populations agrégées, de taille beaucoup plus réduite que la base d’apprentissage du départ. En effet, notre point de départ était une base de 2201 tuples à partir de laquelle on a eu un cube formé de 42 tuples. Par suite, cette diminution nette de notre base d’apprentissage va permettre la fouille d’une façon très efficace.
21
Id_Passager Age Gender class Survivor_yes Survivor_no
1 ADULT FEMALE 1ST YES NULL
2 ADULT FEMALE 2ND NULL NO
3 ADULT FEMALE 3RD YES NULL
4 ADULT FEMALE CREW YES NULL
… …. … … … …
D_AGE D_GENDER D_CLASS M_SURVIVANT M_NONSURVIVANT
ADULT FEMALE 1ST 140 4 ADULT FEMALE 2ND 80 13 ADULT FEMALE 3RD 76 89 ADULT FEMALE CREW 20 3 ADULT FEMALE ALL 316 109 ADULT MALE 1ST 57 118 ADULT MALE 2ND 14 154 ADULT MALE 3RD 75 387 ADULT MALE CREW 192 670 ADULT MALE ALL 338 1329 ADULT ALL 1 ST 97 122 ADULT ALL 2 ND 94 167 ADULT ALL 3 RD 151 476 ADULT ALL CREW 212 673 ADULT ALL ALL 654 1438 CHILD FEMALE 1ST 1 0 CHILD FEMALE 2ND 13 0 CHILD FEMALE 3RD 14 17 CHILD FEMALE ALL 28 17 CHILD MALE 1ST 5 0 CHILD MALE 2ND 11 0 CHILD MALE 3RD 13 35 CHILD MALE ALL 29 35 CHILD ALL 1ST 6 0 CHILD ALL 2ND 24 0 CHILD ALL 3RD 27 52 CHILD ALL ALL 57 52
ALL FEMALE 1ST 141 4 ALL FEMALE 2ND 93 13 ALL FEMALE 3RD 90 106 ALL FEMALE CREW 20 3 ALL FEMALE ALL 344 126 ALL MALE 1 ST 62 118 ALL MALE 2 ND 25 154 ALL MALE 3 RD 88 422 ALL MALE CREW 192 670 ALL MALE ALL 367 1364 ALL ALL 1 ST 203 122 ALL ALL 2 ND 118 167 ALL ALL 3 RD 178 528 ALL ALL CREW 212 673 ALL ALL ALL 711 1490
Figure 5 : Résultat du cube construit à partir de l’opérateur OLAP « CUBE » et de la fonction d’aggrégat « COUNT() » sur l’entrepôt de données TITANIC_DW.
CUBE
TITANIC_DW
CUBE_TITANIC

22
III.3.2 Construction de l’arbre de décision Notre population d’apprentissage est donc le cube. Dans notre exemple, les attributs SURVIVOR_YES et SURVIVOR_NO sont les attributs à prédire et correspondent aux mesures qui se trouvent dans la table de faits de notre entrepôt. Les attributs prédictifs, AGE, GENDER, CLASS, ID_PASSAGER, correspondent aux dimensions du cube. La première étape consiste à créer le nœud racine. Il est caractérisé par les différents effectifs des sous-populations qui sont définies selon les modalités de la classe à prédire, sans tenir compte des valeurs des différents attributs prédictifs. Pour le nœud racine, nous cherchons donc à obtenir l’effectif de la population pour laquelle on a SURVIVOR = « yes » d’une part et celui pour laquelle SURVIVOR = « no » d’autre part. Pour cela, nous avons besoin uniquement de chercher l’effectif qui se trouve dans le cube où on a « all », « all », «all » sur tous les attributs prédictifs c’est à dire ça revient à exécuter tout simplement la requête suivante : SELECT M_SURVIVANT, M_NONSURVIVANT FROM CUBE_TITANIC WHERE D_AGE = ‘ALL’ AND D_GENDER = ‘ALL’ AND D_CLASS = ‘ALL’ ; Ainsi, on n’a plus besoin de faire des comptages ni de revenir aux données sources. Il suffit d’exécuter cette requête tout simplement et on aura les résultats nécessaires pour obtenir les effectifs du nœud racine présenté dans la figure 6.
Figure 6 : Nœud racine de l’arbre de Titanic Supposons que l’attribut prédictif qui segmente le nœud racine est l’attribut ‘GENDER’. Il s’avère que cet attribut possède deux modalités : ‘Female’ et ‘Male’. Les nœuds fils de la racine de l’arbre sont donc caractérisés par les règles GENDER = ‘Female’, d’une part et GENDER = ‘Male’ d’autre part. Etudions le nœud issu de la règle GENDER= ‘Female’. Le principe est le même pour le nœud associé à la règle GENDER = ‘Male’. Deux effectifs lui sont rattachés : celui des survivants (M_Survivant) et celui des non_survivants (M_NonSurvivant). Pour obtenir ces deux effectifs, nous exécutons la requête suivante :
YES 711 NO 1490
SURVIVOR

23
SELECT M_SURVIVANT, M_NONSURVIVANT FROM CUBE_TITANIC WHERE GENDER = ‘FEMALE’ AND AGE = ALL AND CLASS = ALL ;
De manière générale, pour connaître l’effectif de la population d’un nœud obtenu à partir d’un ensemble de critères Er, il suffit de chercher dans le cube les attributs « M_SURVIVANT« et « M_NONSURVIVANT » pour le tuple satisfaisant Er. Enfin, en adaptant l’algorithme ID3 sur ce cube, il devient facile et rapide de connaître le gain d’information d’un attribut prédictif puisque les différents effectifs (n, ni, nji) sont obtenues directement à partir du cube. Où ni est l’effectif du nœud ayant la valeur i pour l’attribut prédictif, n est l’effectif de la population du nœud, nji est l’effectif du nœud ayant la valeur i pour l’attribut prédictif et la valeur j pour la classe. Nous obtenons donc les nœuds suivants :
Figure 7 : Segmentation par la variable GENDER Considérons que l’attribut prédictif suivant est CLASS. CLASS est un attribut qui possède les quatre modalités ‘CREW’, ‘1ST’, ‘2ND’ et ‘3RD’, qui donnent lieu à la création de quatre nœuds fils. Chacun de ses nœuds est caractérisé par une règle qui a été précisée par rapport à la règle de leur père, GENDER= ‘Female’, par exemple. Prenons le cas de la modalités ‘1ère’. Le processus est identique pour les autres valeurs de l’attributs CLASS. La règle CLASS= ‘1ST’ doit être prise en considération ce qui aboutit à l’élimination de la règle CLASS= ALL de l’étape précédente. La requête à exécuter pour obtenir les effectifs dont on a besoin pour la construction de ce nœud sera la suivante :
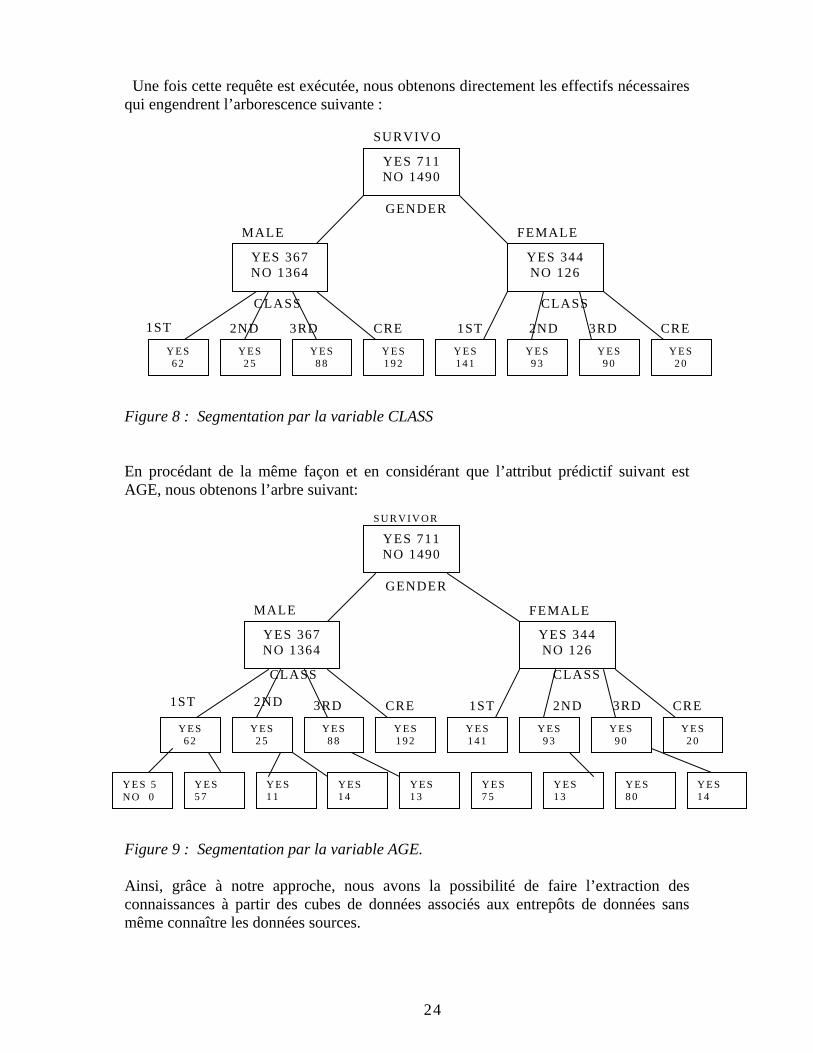
SELECT M_SURVIVANT, M_NONSURVIVANT FROM CUBE_TITANIC WHERE GENDER= ‘FEMALE’ AND AGE = ALL AND CLASS = ‘1ÈRE’ ;
SURVIVO YES 711 NO 1490
YES 367 NO 1364
MALE
YES 344 NO 126
FEMALE
GENDER
24
Une fois cette requête est exécutée, nous obtenons directement les effectifs nécessaires qui engendrent l’arborescence suivante : Figure 8 : Segmentation par la variable CLASS En procédant de la même façon et en considérant que l’attribut prédictif suivant est AGE, nous obtenons l’arbre suivant:
Figure 9 : Segmentation par la variable AGE. Ainsi, grâce à notre approche, nous avons la possibilité de faire l’extraction des connaissances à partir des cubes de données associés aux entrepôts de données sans même connaître les données sources.
1ST 2ND 3RD 3RD 1ST CRE
SURVIVO YES 711 NO 1490
YES 367 NO 1364
MALE
YES 344 NO 126
FEMALE
GENDER
YES 62 NO
YES 25 NO
YES 88 NO
YES 192 NO
YES 141
NO 4
YES 93
NO 13
YES 90 NO
YES 20
NO 3
2ND CRE
1ST 2ND 3RD 3RD 1ST CRE
SURVIVOR
YES 711 NO 1490
YES 367 NO 1364
MALE
YES 344 NO 126
FEMALE
GENDER
YES 62 NO
YES 25 NO
YES 88 NO
YES 192 NO
YES 141
NO 4
YES 93
NO 13
YES 90 NO
YES 20
NO 3
2ND CRE
CLASS CLASS
CLASS CLASS
YES 5 NO 0
YES 57 NO
YES 11 NO 0
YES 14 NO
YES 13 NO 35
YES 75 NO
YES 13 NO 0
YES 80 NO 13
YES 14 NO

25
Chapitre IV
Implémentation et discussion
IV.1 Implémentation Afin de valider notre approche, nous avons implémenté l’algorithme ID3 sous le SGBD Oracle 9i sous forme de procédure PL/SQL stockée. La véritable différence se situe lors du calcul du gain d’information pour chaque attribut prédictif et par conséquent lors du calcul de l’entropie. En effet, les implémentations de l’algorithme classique sont contraintes pour calculer le gain d’information d’un attribut prédictif de lire tous les n-uplets de la partie de la base de départ correspondant au nœud courant de l’arbre d’induction. Ceci permet de déterminer la répartition des n-uplets en fonction de chaque valeur de l’attribut prédictif et de chaque valeur de la classe. Dans notre approche, pour connaître l’effectif de la population d’un nœud obtenu à partir d’un ensemble de critère Er, il suffit de sélectionner la valeur des attributs M_SURVIVANT et M_NONSURVIVANT pour le n-uplet satisfaisant Er. Notre technique est donc plus rapide puisqu’elle n’a pas besoin de revenir aux données sources, ni de faire des calculs. L’adaptation de l’algorithme ID3 (pour le calcul de l’entropie et du gain d’information) fut donc nécessaire afin qu’il puisse s’appliquer sur le cube. Nous avons construit le cube correspondant à l’entrepôt de données, ensuite nous avons adapté l’algorithme ID3 sur le cube. Ainsi, le nom du cube qui va constituer la base d’apprentissage sera l’un des paramètres fournit par l’utilisateur. Différents objets sont nécessaires pour la construction de l'algorithme (pseudo-code) : Num : le numéro du noeud. nview : le nom de la vue relationnelle associée. Rule : la règle explicite menant à la création du noeud à partir de son père. Pour la racine, cette règle est égale à ' '. argnotuse : la liste de toutes les règles, reliées par des 'AND', ayant mené à la création du nœud père. Pour la racine, argnotuse vaut ' '. entrop : l'entropie du noeud. pop : la population du noeud. Nous utilisons également un certain nombre de piles : sauve_nom : une pile de noms des noeuds temporairement retenus. sauve_entropie : la pile de l'entropie respective des noeuds temporairement retenus. sauv_population : la pile de la population respective des noeuds temporairement retenus.

26
pile_entropie : la pile de l'entropie calculée sur un noeud, pour chaque valeur d'un champ prédictif donné. popstr : la pile de la population respective sur un noeud pour chaque valeur d'un champ prédictif donné. L’algorithme qui a été construit et implémenté afin d’appliquer l’algorithme ID3 sur un cube est le suivant :
Créer la table résultat qui contiendra l’arbre de données ; Calcul des effectifs du nœud racine : Pour i = 1 à nombre de modalités des mesures faire pop := effectif de la modalité où on a les attributs des mesures égaux à ALL ; pop_totale := pop_totale+pop ; Fin Pour Entropie := 0 ; Pour i= 1 à nombre de modalités des mesures faire Pop := l’effectif pour la modalité i ;
Entropie := entropie-( );
_(log*)
_ 2 totalepop
pop
totalepop
pop
Fin Pour Insérer dans table résultat nœud racine et informations ; Empiler dans pile stack le nœud racine ; Tant que la pile stack n’est pas vide Faire Dépiler de pile stack le nœud courant ; Initialiser max_gain à 0 et max_var à ‘’ ; Pour chaque dimension var candidat non encore utilisé pour la segmentation du
nœud courant Faire Empiler dans pile_entropie 0 ; Gain := entropie du nœud courant ; Initialiser j à 0 ; Pour chaque valeur de l’attribut candidat val courant Faire Pour chaque classe faire Pop_currenti := effectif présent dans la classei ; Pile_entropie(i) := pile_entropie(i) – (pop_current)*log2(pop_currenti) ; Si on change de valeur pour l’attribut candidat alors Gain := Gain-
( );_(log*()((*)___
12 icurrentpopjipentropytem
courantnoeuddupop+
Entropytemp(i) := );(log))(
( 2 jj
ipentropytem +

27
Fin Pour; i := i+1 ; empiler 0 dans pile_entropie; empiler j dans popstr; j := 0 ; Fin si(on change de valeur pour l’attribut candidat) ; j := j+popstr(i) ; Fin Pour(chaque valeur de l’attribut candidat) Si Gain>max_gain et Gain>gain minimum requis alors Vider les piles sauve_nom, sauve_population ; Max_gain := Gain ; Max_var := var ; i:= 1; j:= 0; Tant que j < population du noeud courant faire j := j+popstr(i) ; empiler le nom de la vue dans sauve_nom ; empiler l’entropie du fils dans sauve_entropie ; empiler popstr(i) dans sauve_population ; i := i+1 ; Fin tant que (j<population du nœud courant) ; Fin si (Gain>max_gain et Gain>gain minimum requis) ; Vider les piles pile_entropie et popstr ; Fin pour ;(chaque valeur de l’attribut candidat val courant)
Si le gain du meilleur champ prédictif >au gain minimum Alors i := 1 ; Empiler dans stack les fils du nœud courant par ce champ prédictif ; Argnotuse des fils := leur règle de création + argnotuse du nœud courant ; Actualiser la table de résultat en insérant les fils ; Fin si (le gain du meilleur champ prédictif>au gain minimum) ; Vider les piles sauve_nom, sauve_entropie et sauve population ; Fin tant que ;(pile stack n’est pas vide)
Pour implémenter ce pseudo-code, nous avons utilisé uniquement les outils fournis par Oracle : package, procédures, tables, curseurs, piles… La structure de l’arbre résultat de l’application de l’algorithme ID3 sur le cube est stockée dans une table qui peut être récupérée via une requête hiérarchique SQL. En appliquant cette approche sur le cube CUBE_TITANIC obtenu à partir de l’entrepôt TITANIC_DW nous obtenons les éléments suivants : Dimensions : D_AGE, D_CLASS, D_GENDER. Mesures : M_SUVIVOR_YES, M_SURVIVOR_NO.

28
En faisant une petite comparaison entre CUBE_TITANIC et la base initiale TITANIC, nous remarquons que les attributs prédictifs (AGE, GENDER, CLASS) ne sont autres que les dimensions (D_AGE, D_GENDER, D_CLASS) et que l’attribut à prédire (SURVIVOR) correspond aux deux mesures (M_SURVIVANT et M_NONSURVIVANT). L’adaptation de l’algorithme ID3 sur le cube CUBE_TITANIC a fourni les résultats stockés dans la table suivante : NIVEAU NOEUD PARENT REGLE M_SURVIVANT M_NONSURVIVANT
1 0 1490 711
2 1 0 GENDER=MALE 367 1364
3 3 1 AGE=ADULT 338 1329
3 4 1 AGE=CHILD 29 35
2 2 0 GENDER=FEMALE 344 126
3 5 2 AGE=ADULT 316 109
3 6 2 AGE=ENFANT 28 17
Tableau 3 : Résultats fournit par notre approche après application de la méthode ID3 sur le cube Cube_Titanic. Les résultats qu’on a obtenu après l’application de l’algorithme ID3 sur le cube ont été conformes à ceux fournis par le logiciel de fouille de données SIPINA :
Figure 10 : Résultat fourni par Sipina après application de la méthode ID3 sur la base d’apprentissage Titanic.

29
IV.2 Discussion Grâce à cette approche, nous avons démontré la capacité de faire de la fouille de données sur des cubes de données. Notre approche s’applique directement sur un cube construit à partir d’un entrepôt de données. En effet, le cube servant pour l’analyse OLAP constitue notre base d’apprentissage sur laquelle des techniques de fouille de données peuvent être appliquées. Ainsi, le cube peut être construit en vue de cet apprentissage uniquement. Mais, notre approche peut également être appliquée sur des cubes déjà existants. Nous avons aussi démontré que nous pouvions effectuer une fouille sans accéder aux données sources, mais tout simplement en faisant l’extraction des connaissances à partir de données agrégées (cubes de données construits à partir de l’entrepôt). En effet, dans le cadre de la méthode ID3, nous sommes amenés à faire des partitions de plus en plus fines en calculant les effectifs au niveau de chaque population. Grâce à notre approche, les effectifs nécessaires à la construction d’arbre de décision sont récupérés facilement à partir du cube par une simple requête (SELECT). Ceci réduit considérablement les accès aux bases de données et permet l’accélération des temps de traitement. L’extraction des connaissances à partir des entrepôts de données est donc une méthode intégrée, fiable et peu coûteuse.

30
Conclusion et perspectives L’intégration des méthodes de fouille au sein des SGBD est une approche prometteuse dans l’extraction de connaissances à partir de grandes bases de données. Dans ce contexte, nous avons proposé une nouvelle approche de fouille de données pour appliquer les algorithmes de fouille, plus précisément les méthodes à base d’arbres de décision, sur les entrepôts de données. L’idée clé de notre approche se base sur le constat suivant. D’une part une méthode d’arbre de décision est basée sur le calcul des effectifs. D’autre part, les cubes de données construits à partir des entrepôts de données contiennent des données agrégées. Lorsque ces données agrégées sont obtenues à l’aide de la fonction d’agrégat « count() », les effectifs nécessaires à la construction d’un arbre de décision coïncident avec les données agrégées obtenues dans le cube. Notre approche s’applique sur les entrepôts de données relationnels (approche ROLAP) et présente plusieurs avantages. D’une part, elle permet l’extraction des connaissances à partir des cubes de données sans accéder aux données sources. Le cube, constituant notre base d’apprentissage sur laquelle des techniques de fouille de données sont appliquées, sert également pour une analyse OLAP. D’autre part, contrairement aux algorithmes qui opèrent en mémoire, notre approche n’est pas limitée par la taille de l’entrepôt à traiter. Par conséquent, elle permet de traiter de grandes volumes de données et optimise le temps de traitement. Ainsi, grâce à notre approche, l’extraction des connaissances à partir des entrepôts de données est une méthode intégrée, fiable et peu coûteuse. Nous avons validé notre approche en implémentant l’algorithme ID3 pour être appliqué sur un cube construit à partir de l’opérateur OLAP « CUBE » et de la fonction d’agrégat « COUNT() ». Ce qui nous a offert la possibilité de faire l’apprentissage sur des données agrégées contenues dans ce cube sans accéder aux données sources. Enfin, nous avons implémenté notre approche en PL/SQL sous forme de procédure PL/SQL au cœur du SGBD Oracle dans un package nommé CUBE_ID3. Ces expérimentations ont fourni les mêmes résultats que ceux du logiciel de fouille de données SIPINA. A l’issu de notre investigation, différentes perspectives sont envisageables. En effet, ce travail nous montre la possibilité de faire l’extraction de connaissances à partir des cubes. Toutefois, la construction du cube via l’opérateur CUBE peut prendre du temps, puisqu’elle nécessite le calcul des agrégats pour toutes les combinaisons possibles des valeurs des dimensions. Il serait alors intéressant de calculer seulement la partie du cube contenant les données sur lesquelles un utilisateur va faire l’apprentissage. L’opérateur Roll up pourrait être utilisé pour atteindre cet objectif. Il serait intéressant de tester la performance de notre approche en comparant les temps d’exécution obtenus avec des logiciels travaillant en mémoire. Pour cela, il faut prendre en compte le fait que de tels logiciels ne travaillent pas directement avec les entrepôts de données. Une extraction préalable est alors nécessaire. En outre, une extension de l’utilisation des cubes pour d’autres méthodes telles que C4.5 et CART serait intéressante.

31
Notre approche a fournit une solution technique pour effectuer la fouille de données dans les cubes. Or, le cube se situe dans un contexte d’analyse : OLAP désigne une méthode d’analyse représentée par un cube (ou cube OLAP). Ainsi, il serait intéressant d’étudier le couplage entre OLAP et fouille de données. Ce qui permet de fournir de nouveaux contextes d'analyse pour l'exploration et l'explication des données. Il reste à signaler que notre approche soulève le problème de mise à jour qui peut avoir lieu dans l’entrepôt de données et par conséquent sur le cube. Ainsi, le cadre de l’apprentissage incrémental serait intéressant à développer. Pour cela, il faudrait étudier la fouille de données incrémentale [Utg94] et essayer d’appliquer ces méthodes sur les cubes de données. D’autres concepts intéressants tels que les triggers pour les mises à jours peuvent être aussi exploités.

32
Bibliographie
[ZR00] D A Zighed et R Rakotomalala. Graphes d’induction. Apprentissage et Data
Mining. Hermes Science Publication, 2000.
[ZAI98] Diana Zaiu. Data Mining and OLAP : Bridging the Gap. Course: CSC 2341
Advanced Data Management Systems.
[Utg94] An Improved Algorithm for Incremental Induction of Decision Trees, Paul
E.Utgoff, 1994.
[Udr04] Cédric Udréa. Fouille de données relationnelles dans les SGBD. Mémoire de
DEA ECD. Université Lyon2- France, Juin 2004.
[UBDB03] Cédric Udréa, Fadila Bentayeb, Jérôme Darmont, Omar Boussaid. Intégrati- on de méthodes de fouille de données dans les SGBD, ERIC-Université Lumière Lyon2, 2003.
[TK00] Zaohui Tang, Pyungchul(Peter) Kim. Building Data Mining Solutions with
SQL Server 2000. SQL Server Analysis Services, Microsoft Crop Redmond,
WA, 2000.
[SH98] M.A.Saleem, J.Hameed, Integration of Data Mining and Relational Databases,
Ghulam Ishaph Khan Institute of Engineering Sciences and Technology, Top,
District Swabi, NWFP, Pakistan, 1998.
[SD00] Kai-Uwe Sattler, Oliver Dunemann, SQL Database Primitive for Decision
Tree Classifiers, Department of Computer Science, University of Magdeburg,
2000.
[Ora02] Oracle corporation : Oracle 9i Data Mining www.oracle.com/technology/
products/oracle9i/pdf/o9idm_bwp.pdf,2002

33
[ORA01] Oracle. Oracle 9i data mining. White paper, June 2001.
[NK05] Ina Naydenova, Kalinka Kaloyanova. Basic Approches Of Integration
Between Data Warehouse And Data Mining, “St.Kliment Ohridski”
University of Sofia, Faculty of Mathematics and Informatics Sofia 1164,
Bulgaria, 2005.
[NCBF00] A.Netz, S.Chaudhuri, J.Bernhardt, and U.Fayyad. Integration of Data Mining
with Database Technology. In A.E.Abbadi, M.Brodie, S.Chakravarthy,
U.Dayal, N.Kamel, G.Schalgeter, and K.-Y.Whankg, editors, Proc.VLDB
2000, Cairo, Egypt,pages 719-722. Morgan Kaufman, 2000.
[MZ98] Tadeusz Morzy and Maciej Zakrzewicz. Group bitmap index: A structure for
association rules retrieval. Pages 284 – 288. International Conference on
Knowledge Discovery in Databases and Data Mining: KDD’98, 1998.
[MAR94] Manish Mehta, Rakesh Agrawal and Jorma Rissanen, SLIQ : A fast scalable classifier for Data Mining, IBM Almaden Research center. 650 Harry Road, Sam Jose CA 95120, 1994.
[IBM02] IBM: Data Mining:Extending the information warehouse framework. White
Paper, http://www.almaden.ibm.com/cs/quest/paper/Whitepaper.html, 2002.
[IBM01] IBM.Db2 intelligent miner scoring. http://www-3.ibm.com/software/
data/iminer/scoring,2001.
[Han97] Jiawei Han, OLAP Mining : An integration of OLAP with Data Mining.
Intelligent Database Systems Research Laboratory. School of computing
Science, Simon Fraser University, British Columbia, Canada, published by
Chapman & Hall. 1997.
[Han01] J.Han et M.Kamber, Data Mining : Concepts and thechniques, Morgan
Kaufmann, Accademic Press, États-Unis, 550 pages, 2001.

34
[GRA 97] GRAY J., BOSWORTH A., LEYMAN A., PIRAHESH H., "Data cube : A relational operator generalizing group-by, cross-tabs, and sub-totals", Data Mining and KnowledgeDiscovery Journal, 1(1), 1997.
[GE03] Isabelle Guyon et André Elisseeff, An Introduction to Variable and Feature
Selection, Journal of Machine Learning Research 3 (2003) 1157-1182, Submitted 11/02; Published 3/03.
[GChou99] Sanjay Goil, Alok Choudhary. Parsimony: An infrastructure for parallel
Multidimensional Analysis and Data Mining, December 31,1999.
[Fav03] Cécile Favre. Utilisation des index bitmaps pour la fouille de données.
Mémoire de DEA, Université Lumière Lyon2 – France, 2003.
[Cod93] E F Codd. Providing olap (on-line analytical processing) to user-analysts. An
it mandate. Technical report, E.F. Codd and Associates, 1993.
[CK02] Cios K.J.; Kurgan L.: Trends in Data Mining and Knowledge Discovery,
Knowledge Discovery in Advanced Information Systems, Springer, 2002.
[Chau98] Surajit Chaudhuri, Data Mining and Data Base Systems : where is the
intersection, Microsoft Research. Email: [email protected], Data
Engineering Bulletin, 21(1):4-8,1998.
[CR00] J H Chauchat et R Rakotomalala. A new sampling strategy for building
decision trees from large databases. In 7th Conference of the International
Federation of Classification Societies (IFCS 00), Belgium, 2000.
[BDU04] F Bentayeb, J Darmont, et C Udréa. Efficient integration of data mining
techniques in database management systems. In IDEAS (IDEAS 2004), IEE,
Juillet 2004.
[BD02] F. Bentayeb, J. Darmont, "Decision tree modeling with relational views", XIIIth International Symposium on Methodologies for Intelligent Systems (ISMIS 2002), Lyon, France, June 2002; LNAI, Vol. 2366, 423-431.





























