Embed Size (px)
Citation preview

© Hortonworks Inc. 2013
Hortonworks: We Do Hadoop. Our mission is to enable your Modern Data Architecture
by delivering One Enterprise Hadoop
November 2013
Page 1

© Hortonworks Inc. 2013
Recent Announcements
Hortonworks Data Platform 2.0 GA Culmination of years of work, Hortonworks delivers YARN from the
community to the enterprise to further cements Hadoop’s role in the data architectures of tomorrow
– YARN
– Stinger Phase 2
– Platform and Operational Services
Real Time Stream Processing with Storm Announcing Hortonworks investment roadmap for deeply
integrating Apache Storm with Hadoop for analyzing sensor and
machine data
Page 2
October
15
October
23
© Hortonworks Inc. 2013
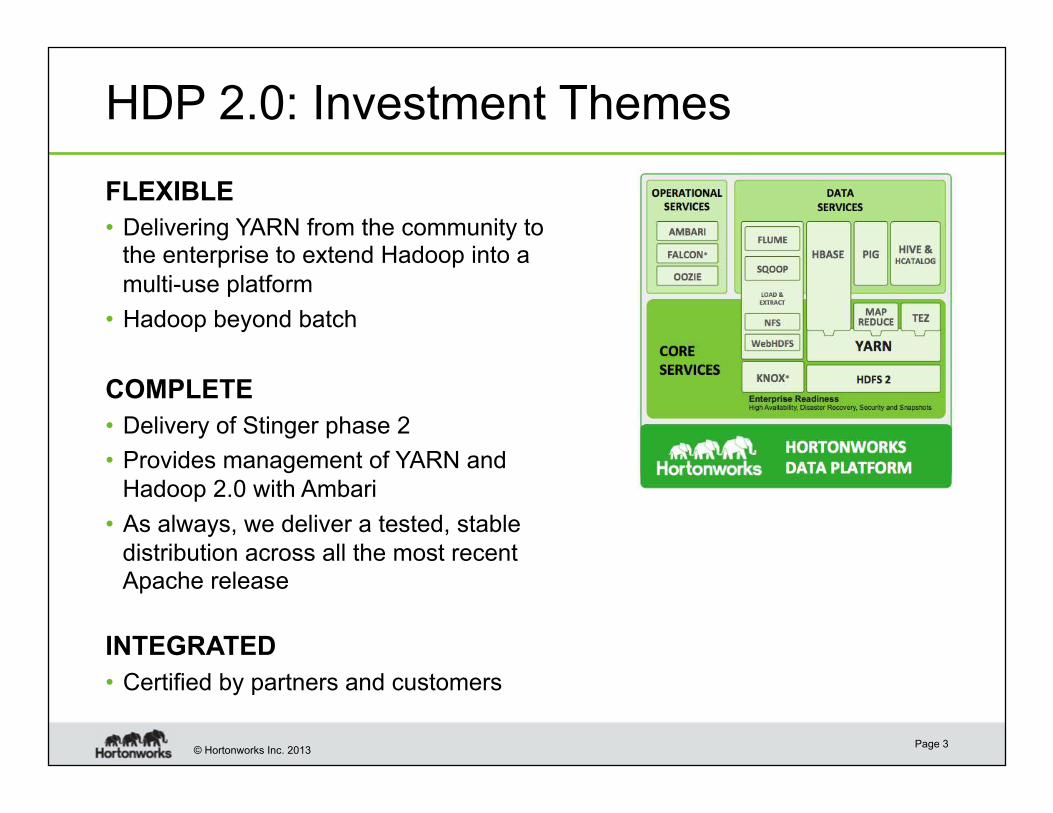
HDP 2.0: Investment Themes
FLEXIBLE
• Delivering YARN from the community to the enterprise to extend Hadoop into a
multi-use platform
• Hadoop beyond batch
COMPLETE
• Delivery of Stinger phase 2
• Provides management of YARN and
Hadoop 2.0 with Ambari
• As always, we deliver a tested, stable
distribution across all the most recent Apache release
INTEGRATED
• Certified by partners and customers
Page 3
© Hortonworks Inc. 2013
Flu
me
H
ad
oo
p
P
ig
H
Ca
talo
g
H
ive
H
Base
S
qo
op
O
ozie
Z
oo
keep
er
M
ah
ou
t
A
mb
ari
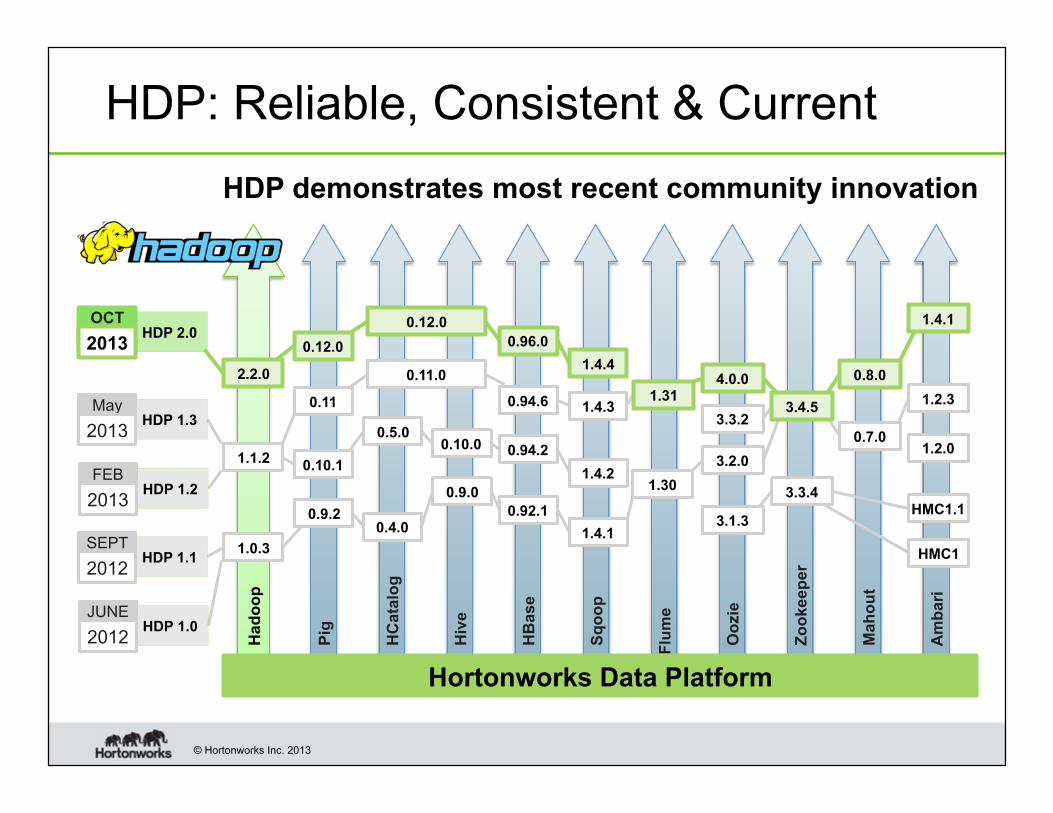
HDP: Reliable, Consistent & Current
2.2.0
1.1.2
1.0.3
0.5.0
0.4.0
0.11.0
0.10.0
0.9.0
0.94.6
0.94.2
0.92.1
1.4.3
1.4.2
1.4.1
3.3.2
3.2.0
3.1.3
3.3.4
1.2.3
1.2.0
HMC1.1
HMC1
0.7.0
Hortonworks Data Platform
HDP demonstrates most recent community innovation
0.11
0.10.1
0.9.2
0.12.0
0.12.0
0.96.0
0.8.0
1.4.1
1.4.4 4.0.0
3.4.5
HDP 2.0 OCT
2013
HDP 1.2 FEB
2013
HDP 1.1 SEPT
2012
HDP 1.0 JUNE
2012
HDP 1.3 May
2013
1.31
1.30
© Hortonworks Inc. 2013
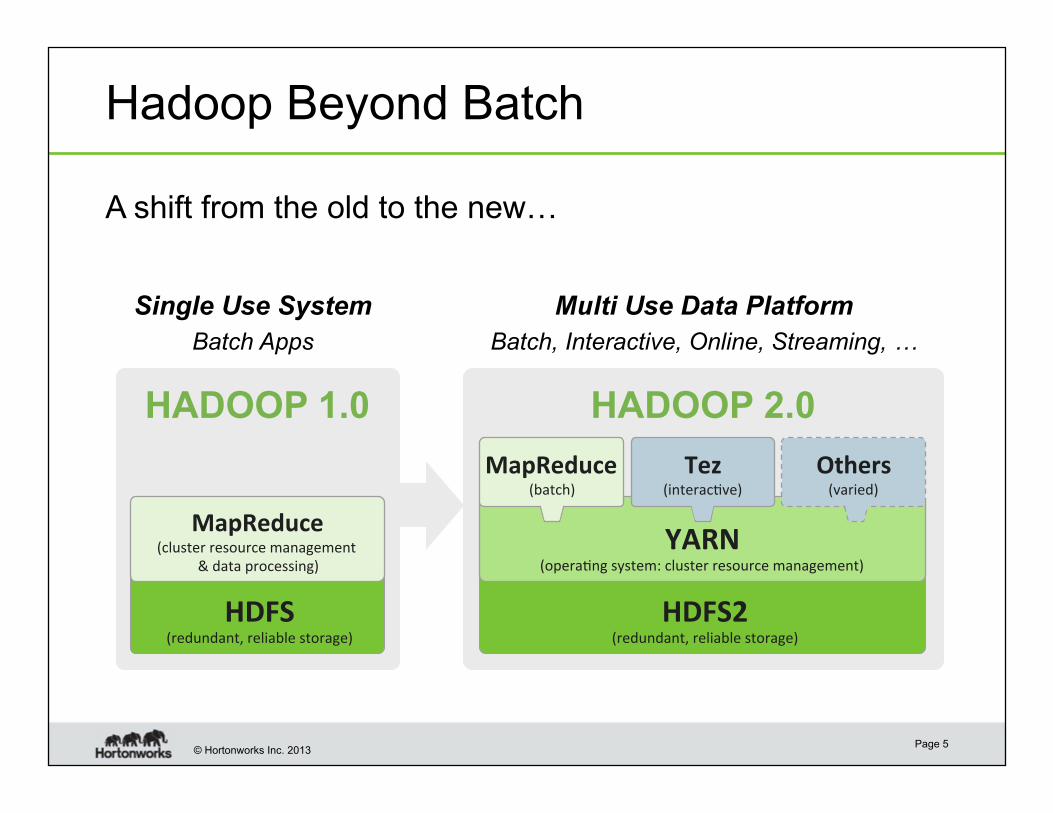
Hadoop Beyond Batch
HADOOP 1.0
HDFS (redundant, reliable storage)
MapReduce (cluster resource management
& data processing)
HDFS2 (redundant, reliable storage)
YARN (opera6ng system: cluster resource management)
MapReduce (batch)
Others (varied)
HADOOP 2.0
Single Use System
Batch Apps
Multi Use Data Platform
Batch, Interactive, Online, Streaming, …
Page 5
Tez (interac6ve)
A shift from the old to the new…
© Hortonworks Inc. 2013
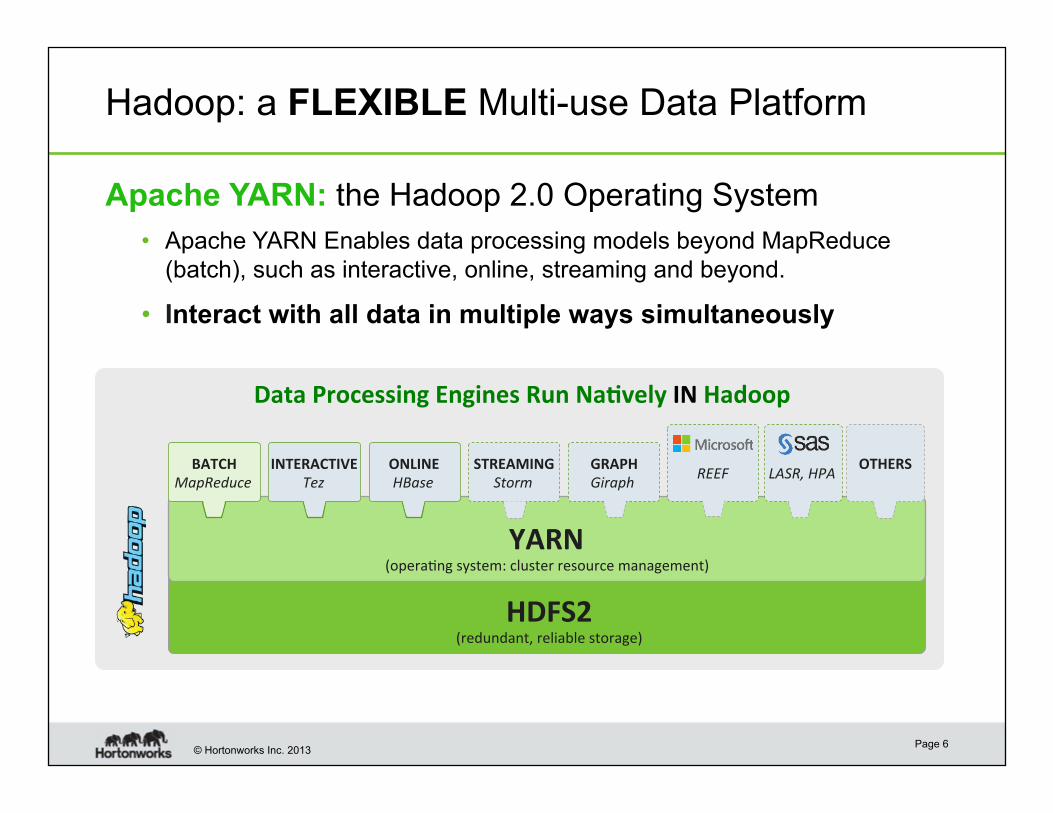
Hadoop: a FLEXIBLE Multi-use Data Platform
Apache YARN: the Hadoop 2.0 Operating System
• Apache YARN Enables data processing models beyond MapReduce
(batch), such as interactive, online, streaming and beyond.
• Interact with all data in multiple ways simultaneously
Page 6
Data Processing Engines Run Na?vely IN Hadoop
HDFS2 (redundant, reliable storage)
YARN (opera6ng system: cluster resource management)
BATCH
MapReduce
INTERACTIVE
Tez
STREAMING
Storm
GRAPH
Giraph
REEF
LASR, HPA ONLINE
HBase
OTHERS

© Hortonworks Inc. 2013
2 x
YARN: Efficiency with Shared Services
YARN allows you to double processing in Hadoop on the same hardware while providing more
predictable performance & quality of service
Page 7
Redundant, Reliable Storage (HDFS2)
Efficient Cluster Resource
Management & Shared Services
(Apache YARN)
Standard SQL
Processing Hive
Batch
MapReduce Interac?ve
Tez
Online Data
Processing HBase, Accumulo
Real Time Stream
Processing Storm
others
…
Shared Services YARN provides a stable,
common set of shared resources across multiple,
coordinated workloads - Manage & Monitor
- Multi-tenancy
- Security
- High Availability
- Disaster Recovery

© Hortonworks Inc. 2013
S?nger Project (announced February 2013)
Batch AND Interactive SQL-IN-Hadoop
Stinger Initiative
A broad, community-based effort to
drive the next generation of HIVE
Page 8
S?nger Phase 3
• Hive on Apache Tez • Query Service (always on)
• Buffer Cache
• Cost Based Op6mizer (Op6q)
S?nger Phase 1:
• Base Op6miza6ons
• SQL Types • SQL Analy6c Func6ons
• ORCFile Modern File Format
S?nger Phase 2:
• SQL Types
• SQL Analy6c Func6ons • Advanced Op6miza6ons
• Performance Boosts via YARN
Speed Improve Hive query performance by 100X to
allow for interactive query times (seconds)
Scale The only SQL interface to Hadoop designed
for queries that scale from TB to PB
SQL Support broadest range of SQL semantics for
analytic applications running against Hadoop
…all IN Hadoop
Goals:
Delivered September 2013 HIVE 0.12
(HDP 2.0)
Delivered May 2013
HIVE 0.11 (HDP 1.3)
Coming Soon
…70% complete
in 6 months
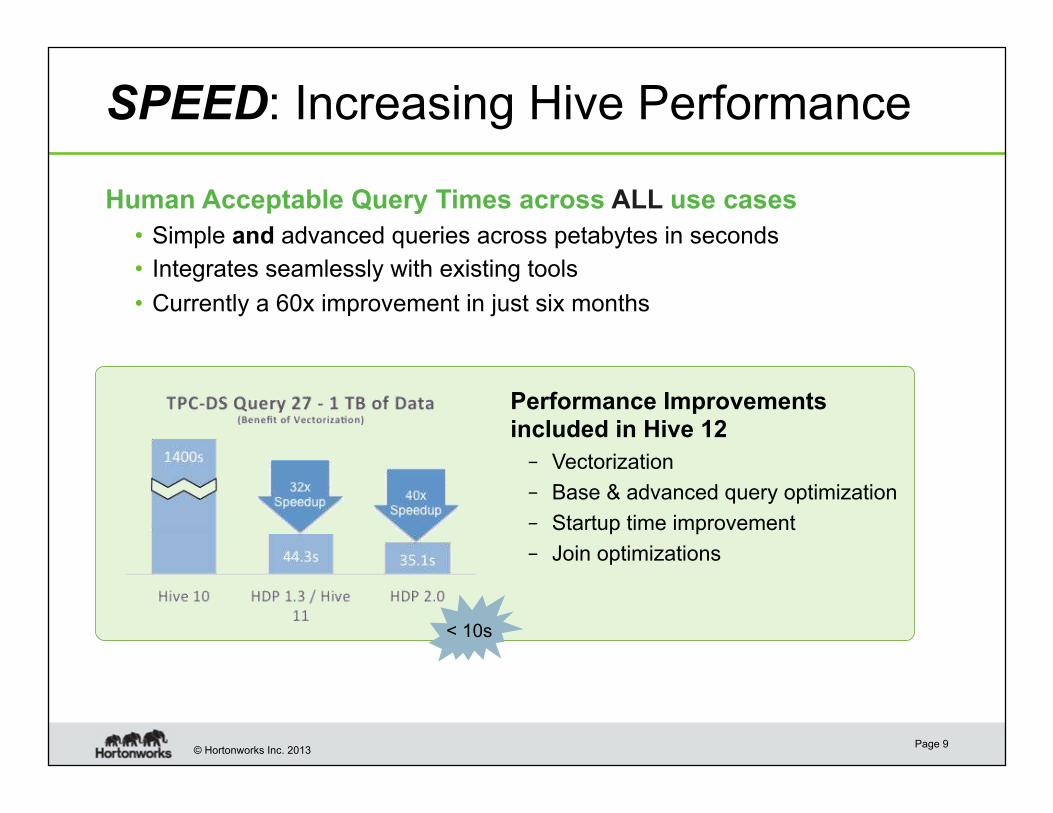
© Hortonworks Inc. 2013
SPEED: Increasing Hive Performance
Performance Improvements included in Hive 12
– Vectorization
– Base & advanced query optimization
– Startup time improvement
– Join optimizations
Page 9
Human Acceptable Query Times across ALL use cases
• Simple and advanced queries across petabytes in seconds
• Integrates seamlessly with existing tools
• Currently a 60x improvement in just six months
< 10s

© Hortonworks Inc. 2013
SCALE: Interactive Query at Petabyte Scale
Sustained Query Times
Apache Hive 0.12 provides sustained acceptable query
times even at petabyte scale
Page 10
131 GB (78% Smaller)
File Size Comparison Across Encoding Methods Dataset: TPC‐DS Scale 500 Dataset
221 GB (62% Smaller)
Encoded with
Text
Encoded with
RCFile
Encoded with
ORCFile
Encoded with
Parquet
505 GB (14% Smaller)
585 GB (Original Size) • Larger Block Sizes
• Columnar format
arranges columns adjacent within the
file for compression
& fast access
Parquet
Hive 12
Smaller Footprint
Better encoding with ORCFile in Apache Hive 12 reduces resource
requirements for your cluster

© Hortonworks Inc. 2013
SQL: Enhancing SQL Semantics
Page 11
Hive SQL Datatypes Hive SQL Seman?cs
INT SELECT, INSERT
TINYINT/SMALLINT/BIGINT GROUP BY, ORDER BY, SORT BY
BOOLEAN JOIN on explicit join key
FLOAT Inner, outer, cross and semi joins
DOUBLE Sub‐queries in FROM clause
STRING ROLLUP and CUBE
TIMESTAMP UNION
BINARY Windowing Func6ons (OVER, RANK, etc)
DECIMAL Custom Java UDFs
ARRAY, MAP, STRUCT, UNION Standard Aggrega6on (SUM, AVG, etc.)
DATE Advanced UDFs (ngram, Xpath, URL)
VARCHAR Sub‐queries for IN/NOT IN, HAVING
CHAR INTERSECT / EXCEPT
Expanded JOIN Syntax
Hive 0.12 (HDP 2.0)
Available
Roadmap
SQL Compliance
Hive 12 provides a wide
array of SQL datatypes
and semantics so your
existing tools integrate
more seamlessly with
Hadoop

© Hortonworks Inc. 2013
HDFS2 Highlights
• HDFS Federation/NameSpaces
(further scales # of files & nodes)
• Automated failover with a hot standby and full stack resiliency for the NameNode master service
• Standard NFS read/write access to HDFS
• Point in time recovery
with Snapshots in HDFS
• Wire Encryption for HDFS
Data Transfer Protocol
Page 12
HDFS2 (redundant, reliable storage)
YARN (opera6ng system: cluster resource management)
MapReduce (batch)
Others (varied)
HADOOP 2.0
Tez (interac6ve)

© Hortonworks Inc. 2013
HDP 2.0 Certified Partners
Page 13

© Hortonworks Inc. 2013
Announcements
Hortonworks Data Platform 2.0 GA Culmination of years of work, Hortonworks delivers YARN from the
community to the enterprise to further cements Hadoop’s role in the data architectures of tomorrow
– YARN
– Stinger Phase 2
– Platform and Operational Services
Real Time Stream Processing with Storm Announcing Hortonworks investment roadmap for deeply
integrating Apache Storm with Hadoop for analyzing sensor and
machine data
Page 14
October
15
October
23
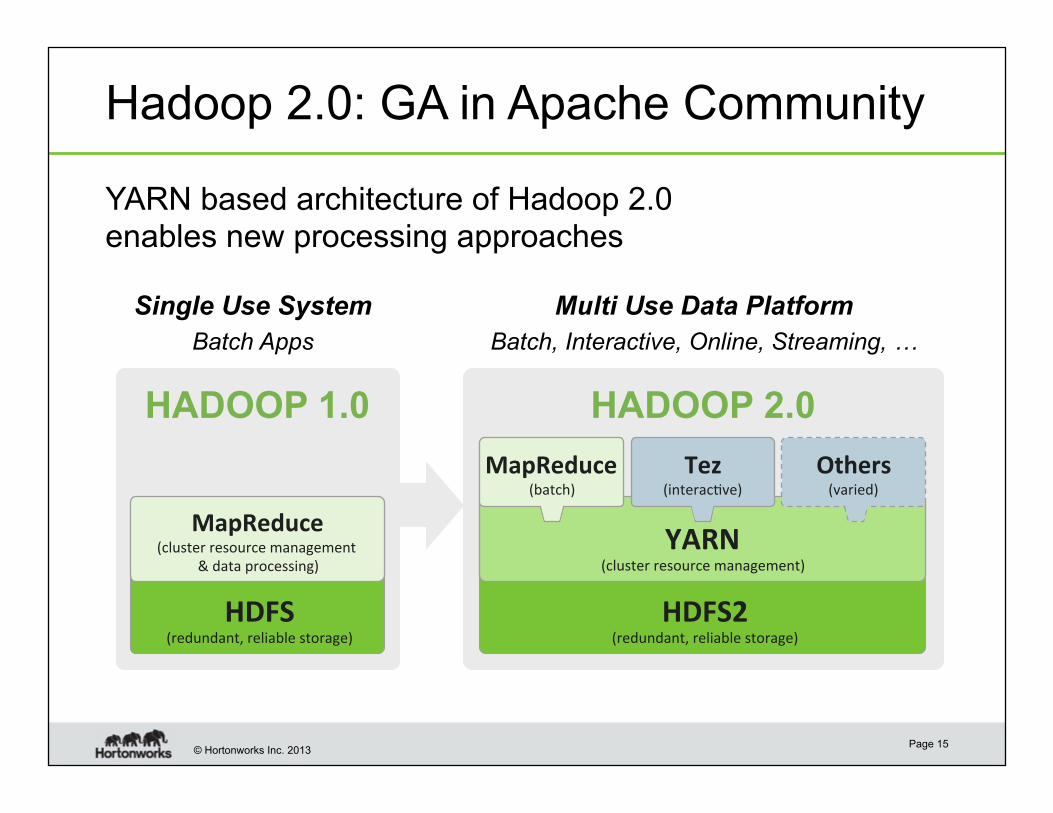
© Hortonworks Inc. 2013
Hadoop 2.0: GA in Apache Community
HADOOP 1.0
HDFS (redundant, reliable storage)
MapReduce (cluster resource management
& data processing)
HDFS2 (redundant, reliable storage)
YARN (cluster resource management)
MapReduce (batch)
Others (varied)
HADOOP 2.0
Single Use System
Batch Apps
Multi Use Data Platform
Batch, Interactive, Online, Streaming, …
Page 15
Tez (interac6ve)
YARN based architecture of Hadoop 2.0 enables new processing approaches
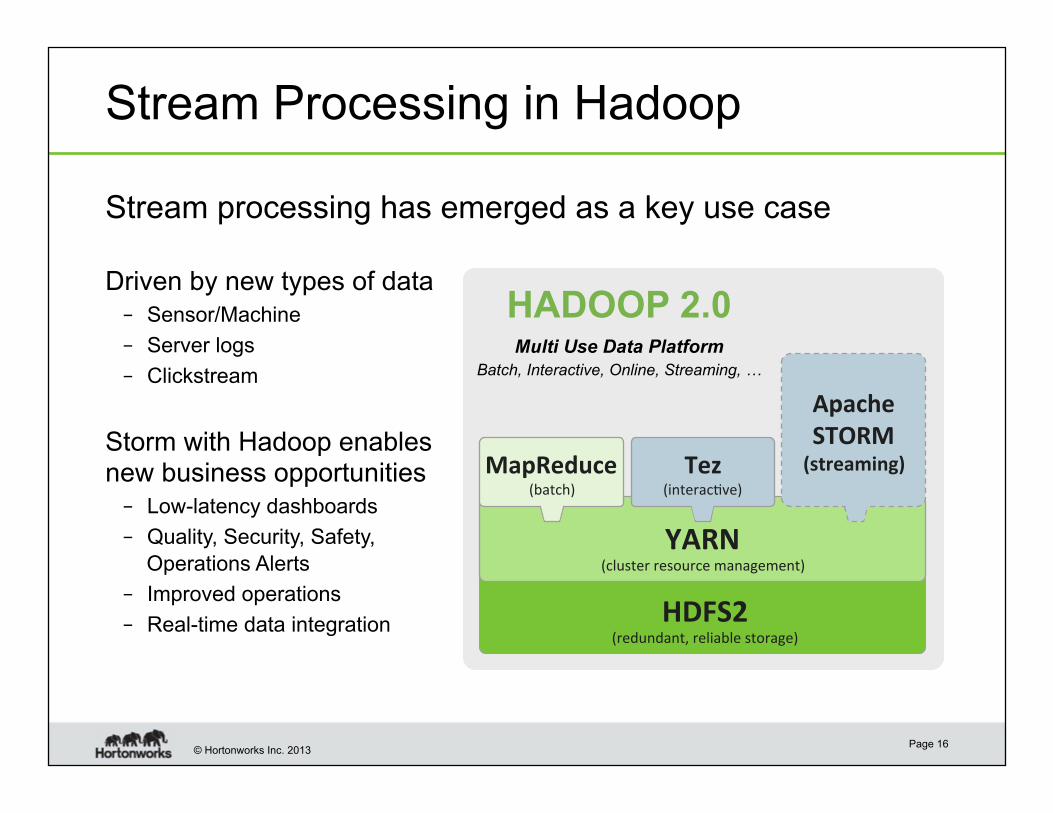
© Hortonworks Inc. 2013
Stream Processing in Hadoop
Driven by new types of data
– Sensor/Machine
– Server logs
– Clickstream
Storm with Hadoop enables new business opportunities
– Low-latency dashboards
– Quality, Security, Safety,
Operations Alerts
– Improved operations
– Real-time data integration
Page 16
HDFS2 (redundant, reliable storage)
YARN (cluster resource management)
MapReduce (batch)
Apache
STORM
(streaming)
HADOOP 2.0
Tez (interac6ve)
Multi Use Data Platform
Batch, Interactive, Online, Streaming, …
Stream processing has emerged as a key use case
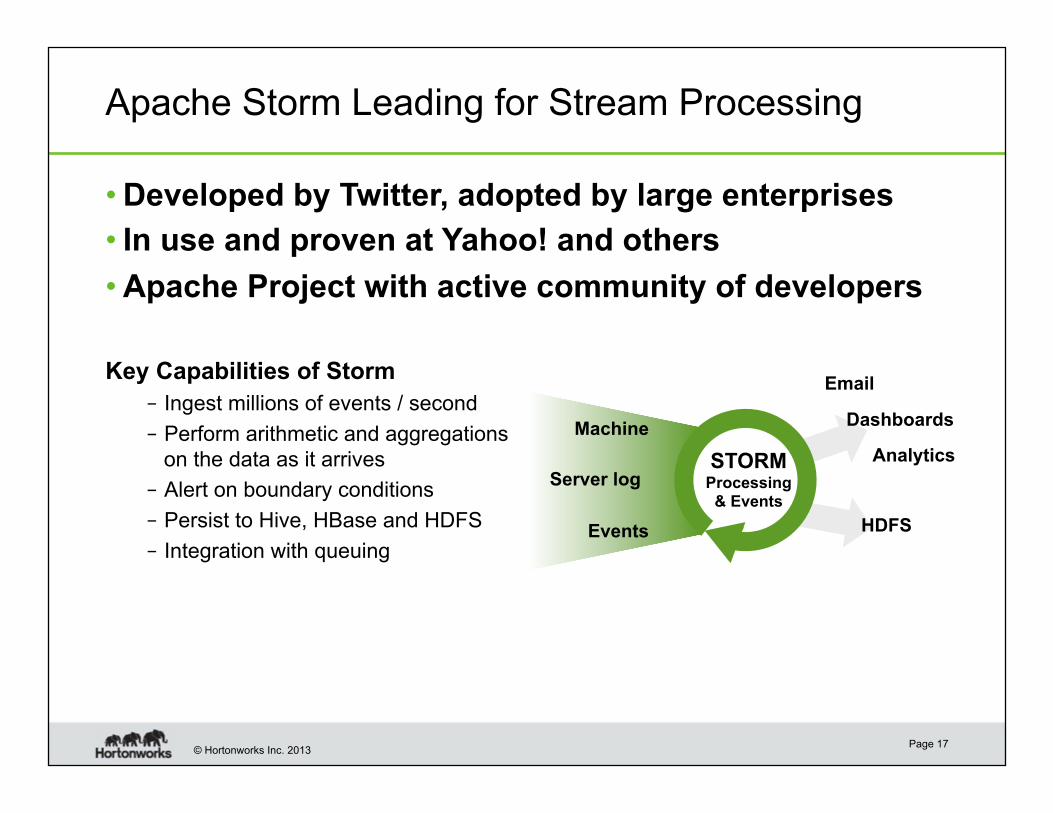
© Hortonworks Inc. 2013
Apache Storm Leading for Stream Processing
• Developed by Twitter, adopted by large enterprises
• In use and proven at Yahoo! and others
• Apache Project with active community of developers
Key Capabilities of Storm
– Ingest millions of events / second
– Perform arithmetic and aggregations
on the data as it arrives
– Alert on boundary conditions
– Persist to Hive, HBase and HDFS
– Integration with queuing
Page 17
STORM Processing & Events
Dashboards
Analytics
HDFS
Machine
Server log
Events
© Hortonworks Inc. 2013
Hortonworks
Investment in Storm
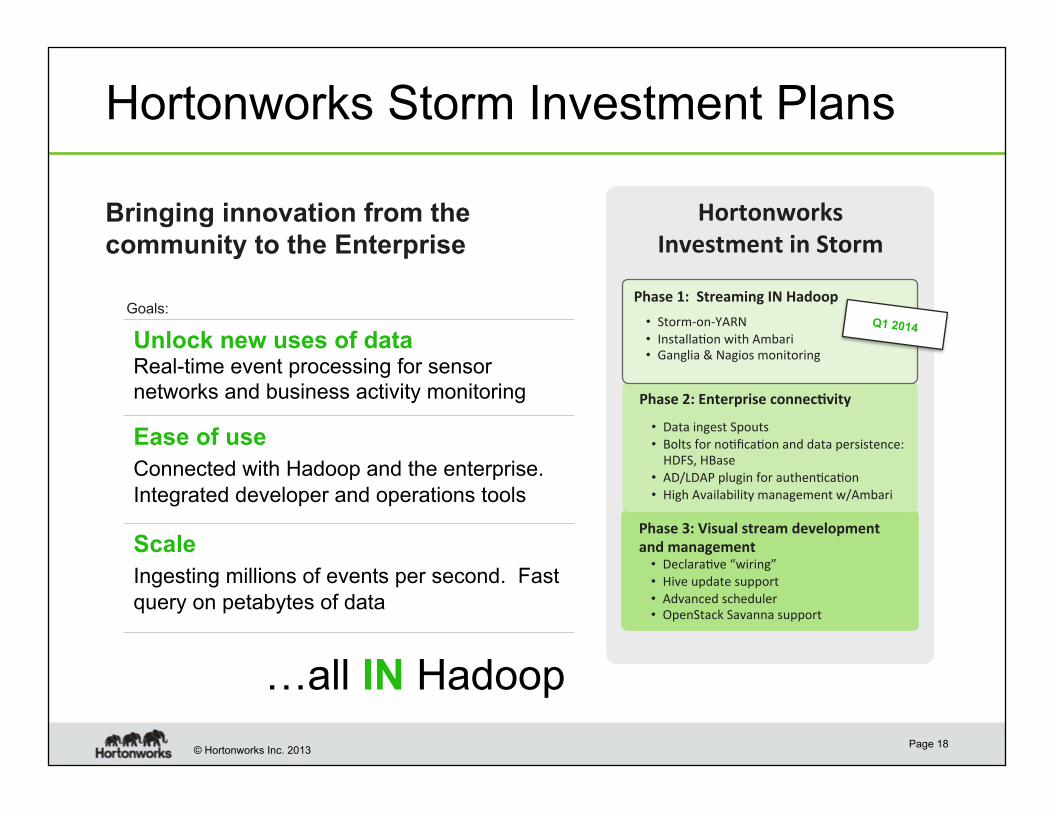
Hortonworks Storm Investment Plans
Bringing innovation from the
community to the Enterprise
Page 18
Phase 3: Visual stream development
and management • Declara6ve “wiring”
• Hive update support
• Advanced scheduler • OpenStack Savanna support
Phase 2: Enterprise connec?vity
• Data ingest Spouts
• Bolts for no6fica6on and data persistence: HDFS, HBase
• AD/LDAP plugin for authen6ca6on
• High Availability management w/Ambari
Phase 1: Streaming IN Hadoop
• Storm‐on‐YARN
• Installa6on with Ambari
• Ganglia & Nagios monitoring Unlock new uses of data Real-time event processing for sensor
networks and business activity monitoring
Ease of use Connected with Hadoop and the enterprise.
Integrated developer and operations tools
Scale Ingesting millions of events per second. Fast
query on petabytes of data
…all IN Hadoop
Goals: Q1 2014
© Hortonworks Inc. 2013
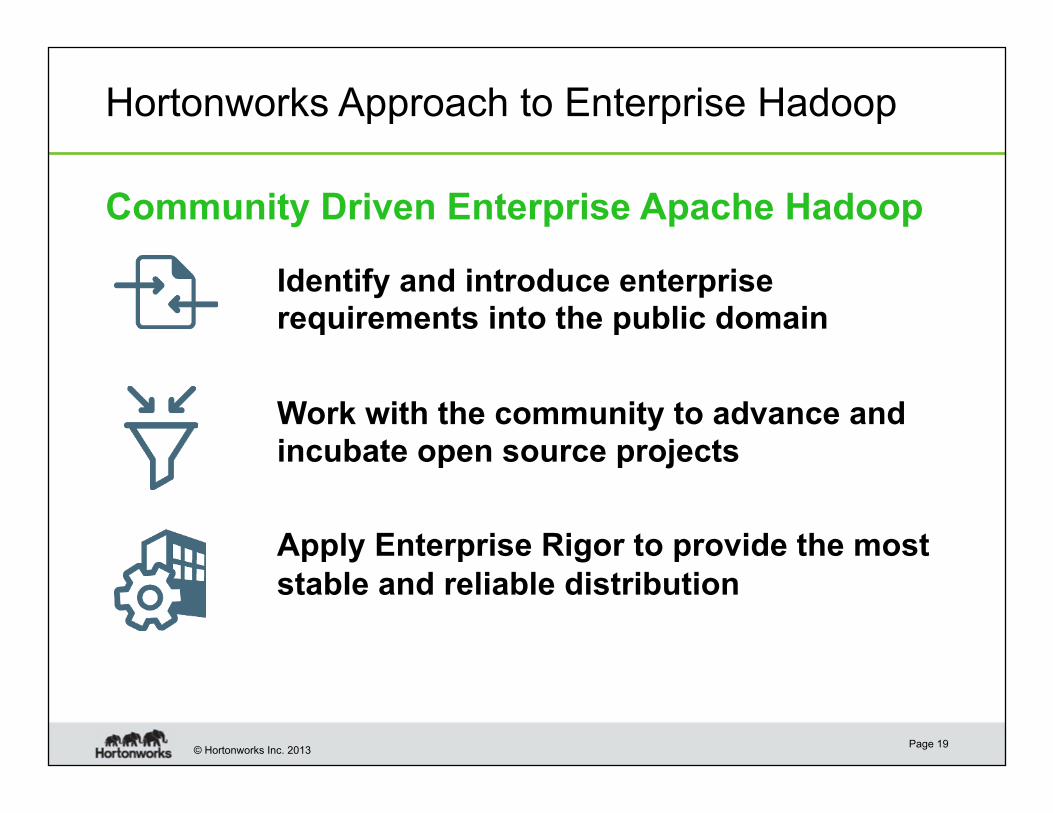
Hortonworks Approach to Enterprise Hadoop
Identify and introduce enterprise requirements into the public domain
Work with the community to advance and
incubate open source projects
Apply Enterprise Rigor to provide the most
stable and reliable distribution
Community Driven Enterprise Apache Hadoop
Page 19
© Hortonworks Inc. 2013
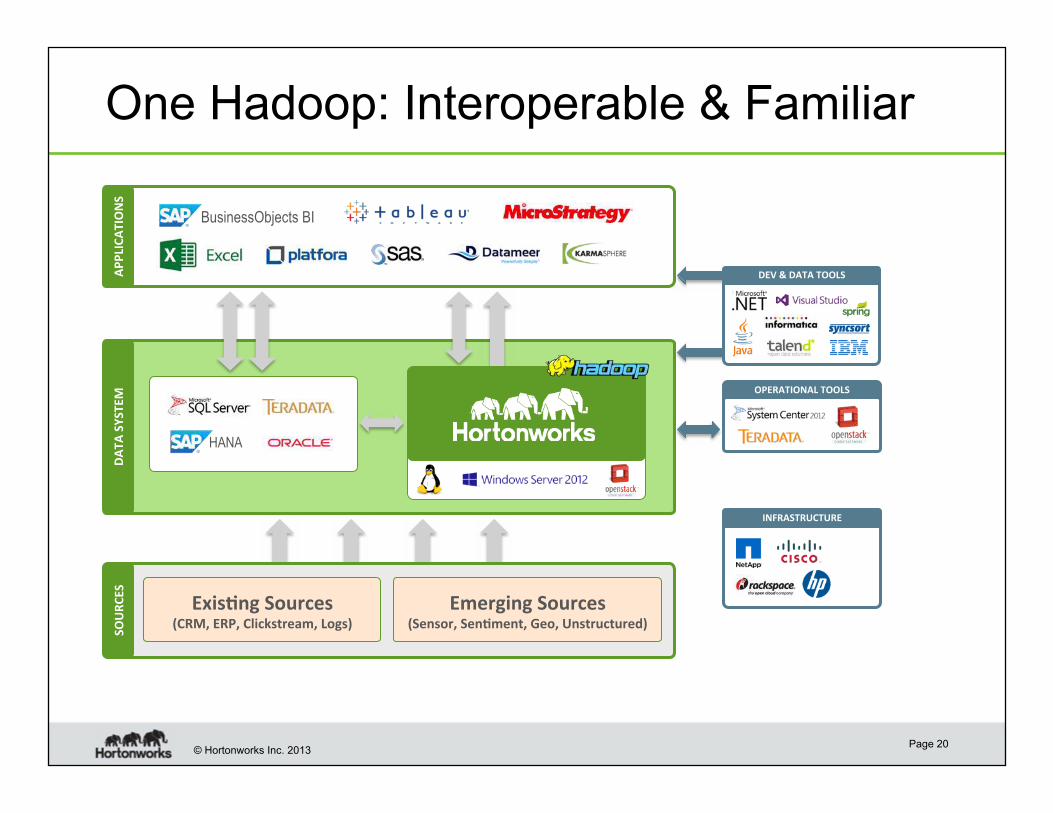
One Hadoop: Interoperable & Familiar
Page 20
APPLICATIONS
DATA SYSTEM
SOURCES
RDBMS EDW MPP
Emerging Sources (Sensor, Sen?ment, Geo, Unstructured)
HANA
BusinessObjects BI
OPERATIONAL TOOLS
DEV & DATA TOOLS
Exis?ng Sources (CRM, ERP, Clickstream, Logs)
INFRASTRUCTURE
© Hortonworks Inc. 2013
Hortonworks: The Value of “Open” for You
Page 21
Connect With the Hadoop Community We employ a large number of Apache project committers & innovators so that you are represented in the open source community
Avoid Vendor Lock Hortonworks Data Platform remain as close to the open source trunk as
possible and is developed 100% in the open so you are never locked in
The partners you rely on, rely on Hortonworks We work with partners to deeply integrate Hadoop with data center
technologies so you can leverage existing skills and investments
Certified for the Enterprise We engineer, test and certify the Hortonworks Data Platform at scale to
ensure reliability and stability you require for enterprise use
Support from the experts We provide the highest quality of support for deploying at scale. You are
supported by hundreds of years of Hadoop experience
Visit www.hortonworks.com
Try www.hortonworks.com/
sandbox
Follow twitter.com/hortonworks





























