Embed Size (px)
Citation preview

Hsin-Hsi Chen 10-1
Chapter 10Cross-Language Information Retrieval
Hsin-Hsi Chen ( 陳信希 )
Department of Computer Science and Information Engineering
National Taiwan University

Hsin-Hsi Chen 10-2
Outlines
Multilingual Environments What is Cross-Language Information
Retrieval? Interdisciplinary relationship in CLIR Major Problems in CLIR Major Approaches in CLIR Summary

Hsin-Hsi Chen 10-3
Multilingual Collections
There are 6,703 languages listed in the Ethnologue Digital libraries
– OCLC Online Computer Library Center serves more than 17,000 libraries in 52 countries and contains over 30 million bibliographic records with over 500 million records ownership attached in more than 370 languages
World Wide Web– Around 40% of Internet users do not speak English, ho
wever, 80% of Web sites are still in English
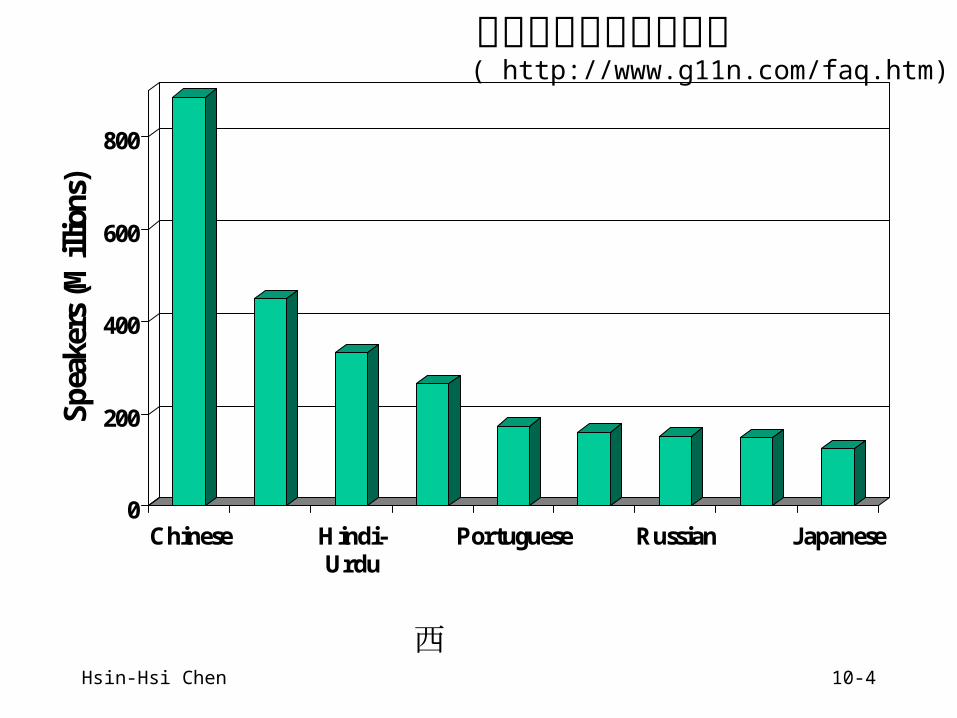
Hsin-Hsi Chen 10-4
0
200
400
600
800
Spea
kers
(M
illio
ns)
Chinese Hindi-Urdu
Portuguese Russian Japanese
真實世界語言使用人口( http://www.g11n.com/faq.htm)
中文 英語 印度
語 西班牙
語 葡萄牙
語 孟加拉
語 俄語 阿拉伯
語 日語
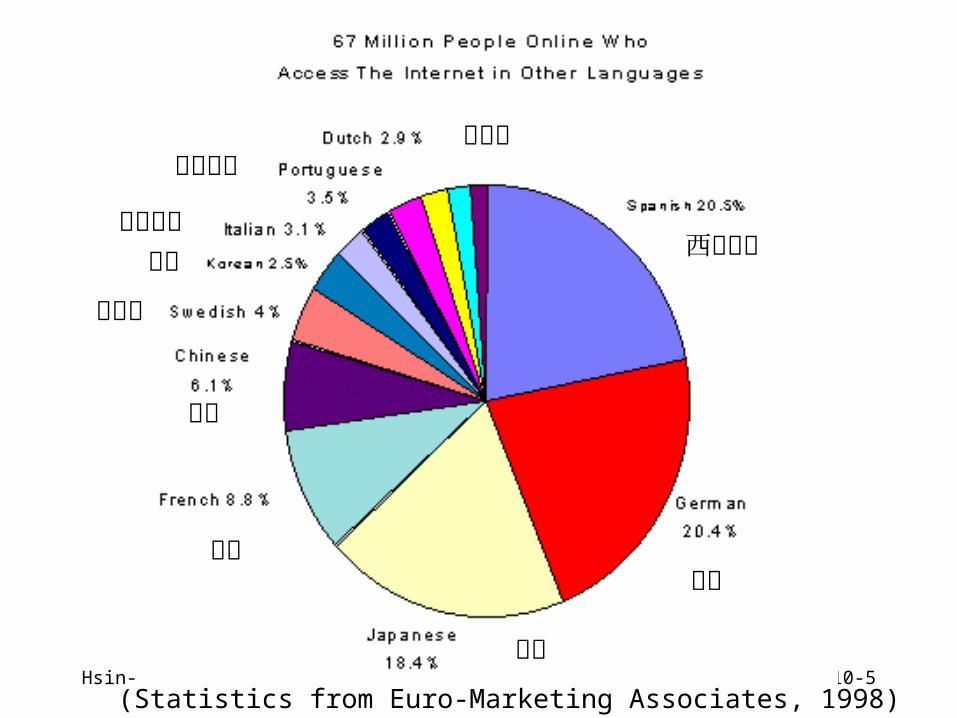
Hsin-Hsi Chen 10-5(Statistics from Euro-Marketing Associates, 1998)
西班牙語
德語
日語
法語
中文
荷蘭語葡萄牙語
義大利語
瑞典語
韓文
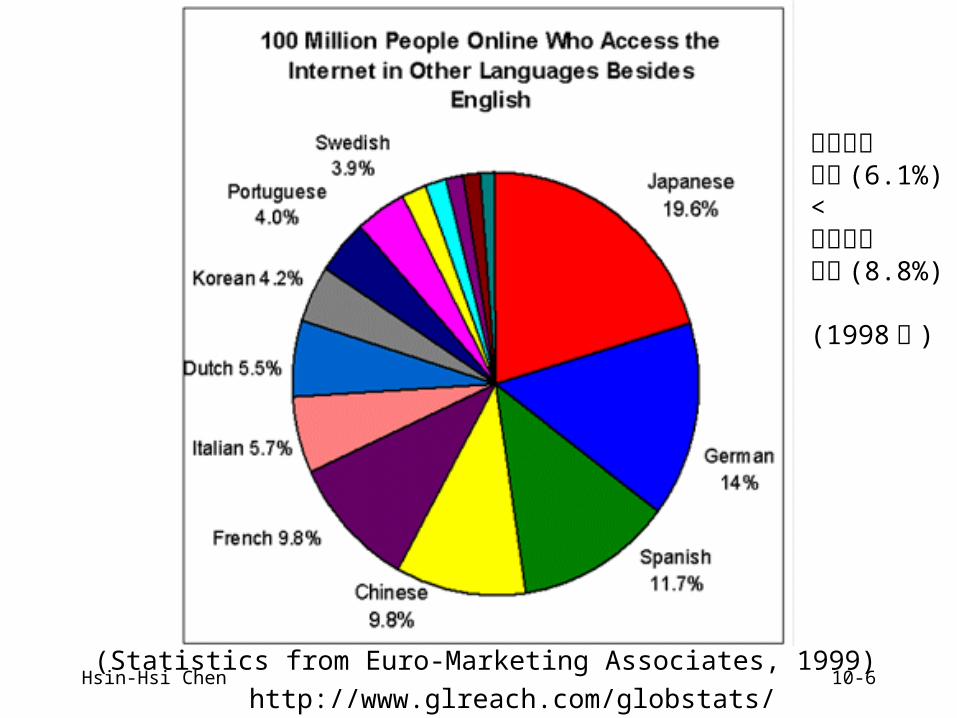
Hsin-Hsi Chen 10-6http://www.glreach.com/globstats/
(Statistics from Euro-Marketing Associates, 1999)
中文人口比例 (6.1%)<法文人口比例 (8.8%)
(1998 年 )
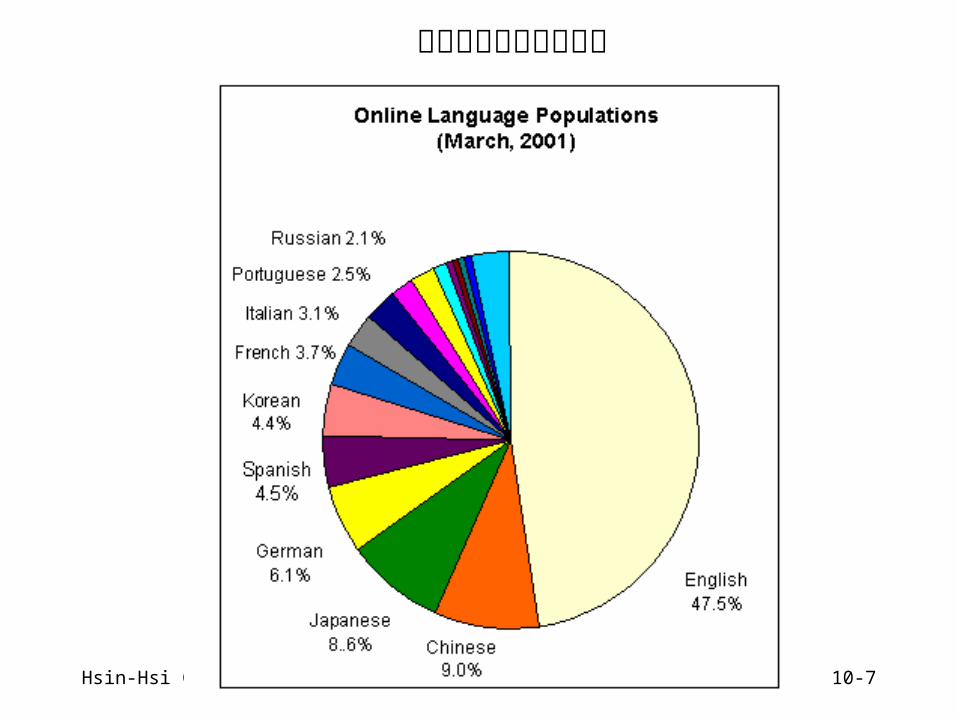
Hsin-Hsi Chen 10-7
網路世界語言使用人口
Hsin-Hsi Chen 10-8
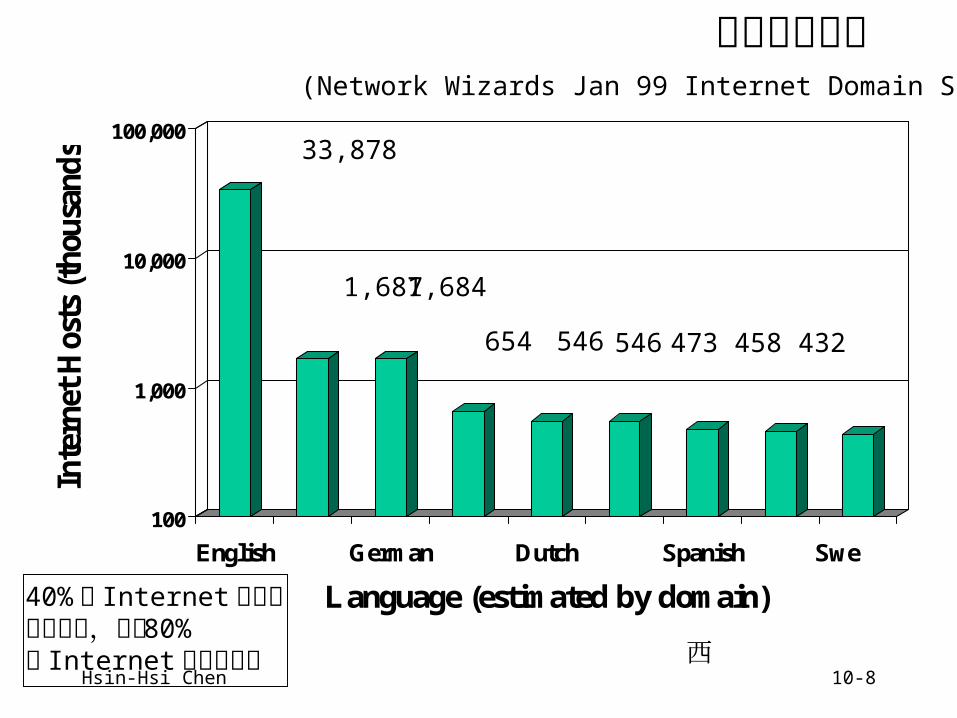
網際網路內容
100
1,000
10,000
100,000
Inte
rnet
Hos
ts (
thou
sand
s)
English German Dutch Spanish Swe di s h
Language (estimated by domain)
(Network Wizards Jan 99 Internet Domain Survey)
英語
日語 德語 法語 荷蘭
語 芬蘭
語西班牙
語中文 瑞
典語
33,878
1,687 1,684
654 546 473 458 432546
40% 的 Internet 使用者不懂英文,但是 80%的 Internet 內容是英文

Hsin-Hsi Chen 10-9(Source: http://www.emarketer.com)

Hsin-Hsi Chen 10-10
What is Cross-Language Information Retrieval?
Definition: Select information in one language based on queries in another.
Terminologies– Cross-Language Information Retrieval
(ACM SIGIR 96 Workshop on Cross-Linguistic Information Retrieval)
– Translingual Information Retrieval(Defense Advanced Research Project Agency - DARPA)
Hsin-Hsi Chen 10-11
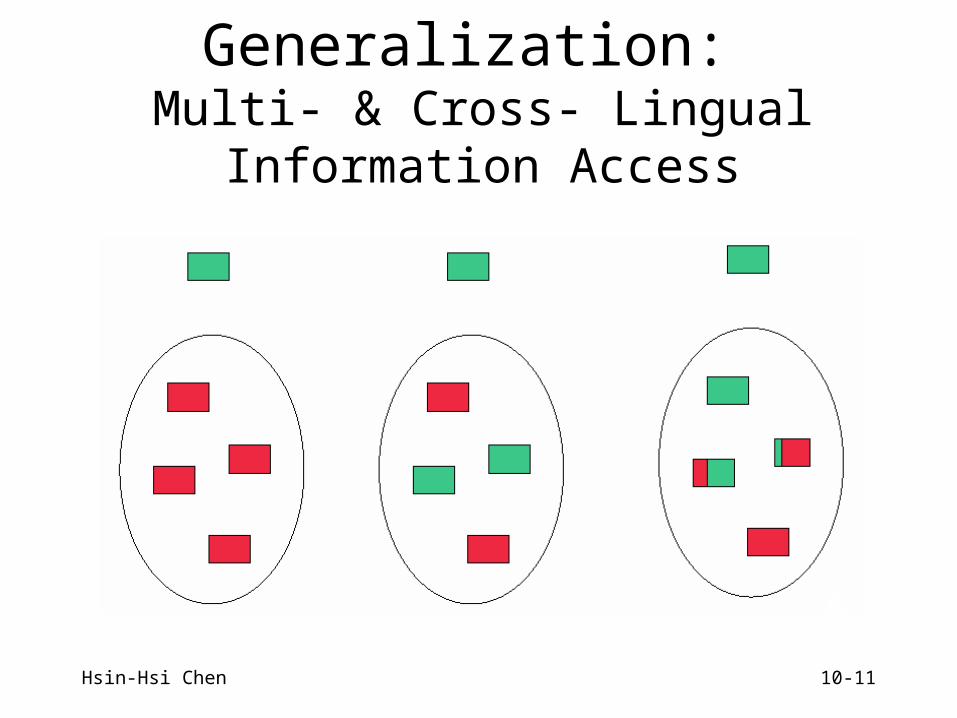
Generalization: Multi- & Cross- Lingual Information Access

Hsin-Hsi Chen 10-12
MLIR Applications
Multilingual information access in multilingual country, organization, enterprise, etc.
Cross- language information retrieval for users who read a second language (large passive vocabulary) but are not able to formulate good queries (small active vocabulary).
Monolingual users may retrieve images by taking advantage of multilingual captions.
Monolingual users may retrieve documents and have them translated (automatically or manually) in their language.

Hsin-Hsi Chen 10-13
Why is Cross- Language Information Retrieval Important?
More information workers with less time require fast access to global resources
global B2B interactions (virtual enterprises) global B2C interactions (online trading, travell
ing) time critical information (translation comes to
o late)

Hsin-Hsi Chen 10-14
History
1970 Salton runs retrieval experiments with a small English/ German dictionary
1972 Pevzner shows for English and Russian that a controlled thesaurus can be used effectively for query term translation
1978 ISO Standard 5964 for developing multilingual thesauri (revised in 1985)
1990 Latent Semantic Indexing (LSI) applied to CLIR

Hsin-Hsi Chen 10-15
History (Continued)
1994 1st PhD thesis on CLIR by Khaled Radwan
1996 Similarity thesaurus applied to CLIR (ETH Zurich)
1996 Dictionary based retrieval applied to CLIR (Umass & XEROX Grenoble)
1997 Generalized Vector Space Model (GVSM) applied to CLIR (CMU)

Hsin-Hsi Chen 10-16
History (Continued)
1997 CLIR (Cross- Language Information Retrieval) track starts within TREC
1998 NTCIR starts in Japan 1999 TIDES (Translingual Information Det
ection, Extraction, and Summarization) starts in U. S.
2000 CLEF starts in Europe
Hsin-Hsi Chen 10-17
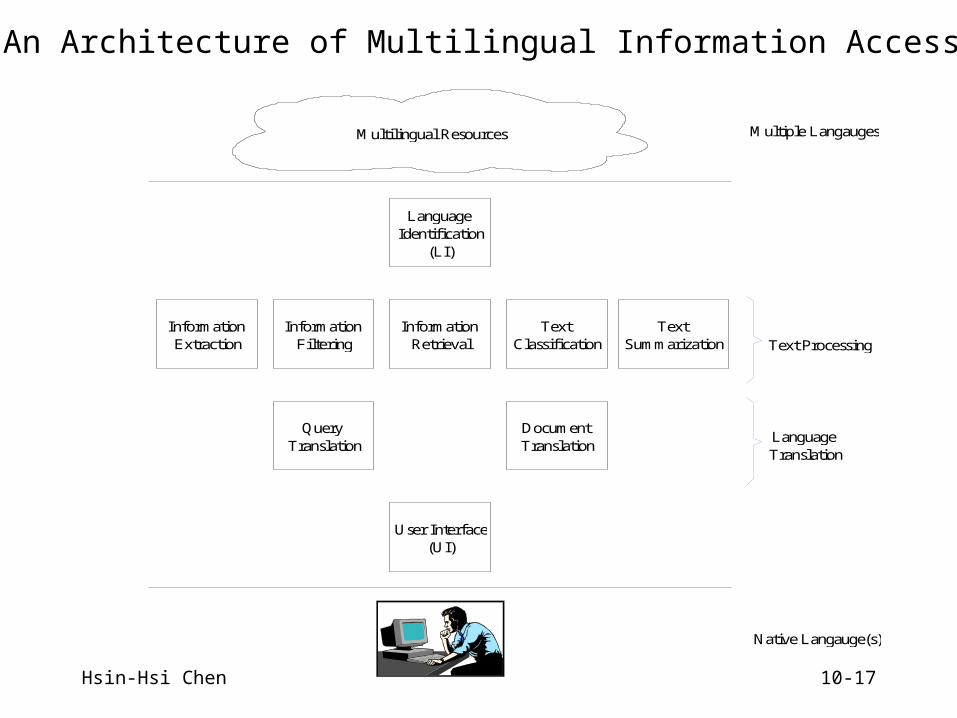
An Architecture of Multilingual Information Access
Query Translation
Document Translation
User Interface(UI)
Language Identification
(LI)
Information Extraction
Information Filtering
Information Retrieval
Text Summarization
Text Classification
Multilingual Resources Multiple Langauges
Native Langauge(s)
Text Processing
Language Translation
Hsin-Hsi Chen 10-18
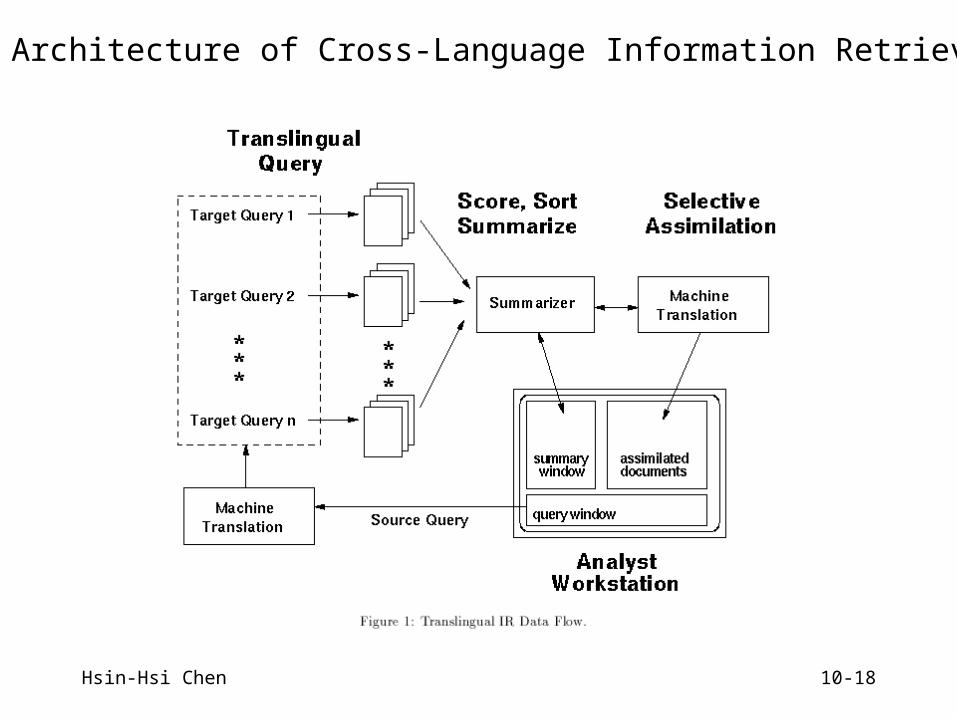
An Architecture of Cross-Language Information Retrieval

Hsin-Hsi Chen 10-19
SpeechRecognition
Building Blocks for CLIR
InformationScience
InformationRetrieval
ArtificialIntelligence
ComputationalLinguistics

Hsin-Hsi Chen 10-20
Information Science
User interface Interactive search technique Thesaurus construction Evaluation

Hsin-Hsi Chen 10-21
Computational Linguistics
Language identification Morphological analysis Stylistic analysis Part-of-speech tagging Identifying occurrences of phrases Using parallel corpora Using comparable corpora

Hsin-Hsi Chen 10-22
Computational Linguistics (Continued)
Aligning documents Identifying occurrences of geographic and
temporal concepts Stochastic language models Word disambiguation Lexicons (morphology, part-of-speech) Bilingual dictionaries (terms and possible
translation)

Hsin-Hsi Chen 10-23
Information Retrieval (w/o CL)
Filtering Relevance Feedback Document representation Latent semantic indexing Generalization vector space model Collection fusion Passage retrieval

Hsin-Hsi Chen 10-24
Information Retrieval (Continued)
Similarity thesaurus Local context analysis Automatic query expansion Fuzzy term matching Adapting retrieval methods to collection Building cheap test collection Evaluation

Hsin-Hsi Chen 10-25
Artificial Intelligence
Machine translation Machine learning Template extraction and matching Building large knowledge bases Semantic network

Hsin-Hsi Chen 10-26
Speech Recognition
Signal processing Pattern matching Phone lattice Background noise elimination Speech segmentation Modeling speech prosody Building test databases Evaluation

Hsin-Hsi Chen 10-27
Building Blocks Dealing withTerm Dependencies
IS: ISO-Thesaurus CL: Word disambiguation, bilingual
dictionaries AI: Semantic network SR: Stochastic language models IR: LSI, GVSM, similarity thesaurus, local
context analysis, (weighted) Boolean filters

Hsin-Hsi Chen 10-28
Major Problems of CLIR
Queries and documents are in different languages.– translation
Words in a query may be ambiguous.– disambiguation
Queries are usually short.– expansion

Hsin-Hsi Chen 10-29
Major Problems of CLIR (Continued)
Queries may have to be segmented.– segmentation
A document may be in terms of various languages.– language identification
Hsin-Hsi Chen 10-30
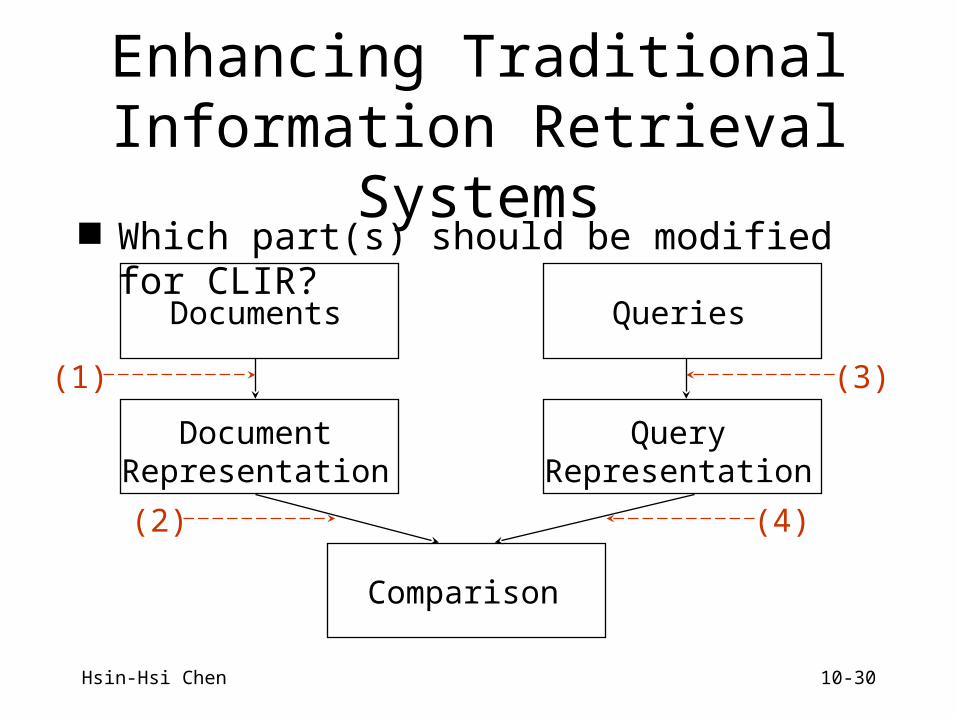
Enhancing TraditionalInformation Retrieval Systems
Which part(s) should be modified for CLIR?
Documents Queries
DocumentRepresentation
QueryRepresentation
Comparison
(3)(1)
(2) (4)

Hsin-Hsi Chen 10-31
Enhancing Traditional Information Retrieval Systems
(Continued)
(1): text translation (2): vector translation (3): query translation (4): term vector translation (1) and (2), (3) and (4): interlingual form

Hsin-Hsi Chen 10-32
What are the Problems?
Ambiguous terms (e.g., performance) Multiword phrases may correspond to single-word phra
ses (e. g. South Africa => 南非, Südafrika) Coverage of the vocabulary There is not a one-to-one mapping between two langua
ges Translating queries automatically (lack of syntax) Translating documents automatically (performance, …) Computing mixed result lists
Hsin-Hsi Chen 10-33
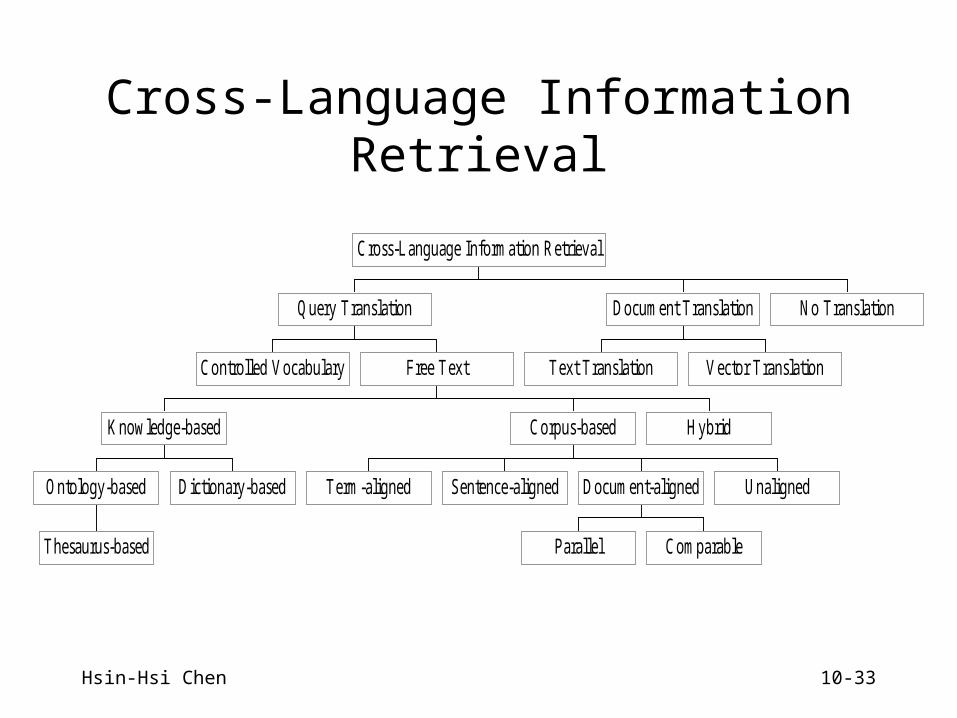
Cross-Language Information Retrieval
Controlled Vocabulary
Thesaurus-based
Ontology-based Dictionary-based
K nowledge-based
Term-aligned Sentence-aligned
Parallel Comparable
Document-aligned Unaligned
Corpus-based Hybrid
Free Text
Query Translation
Text Translation Vector Translation
Document Translation No Translation
Cross-L anguage Information Retrieval
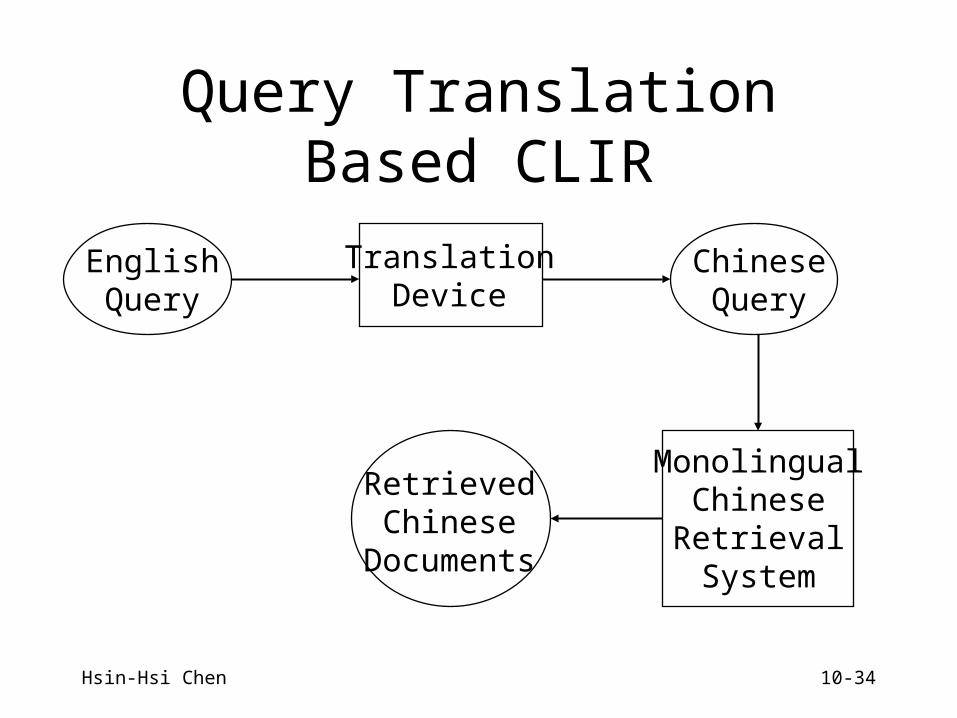
Hsin-Hsi Chen 10-34
Query Translation Based CLIR
EnglishQuery
TranslationDevice
ChineseQuery
MonolingualChineseRetrievalSystem
RetrievedChinese
Documents

Hsin-Hsi Chen 10-35
Translating the 400 Millionnon-English Pages of the WWW
... would take 100’000 days (300 years) on one fast PC. Or, 1 month on 3’600 PC’s.

Hsin-Hsi Chen 10-36
Controlled Vocabulary
Sublanguage chosen by human indexers National Library of Medicine
– Unified Medical Language System (UMLS)– Integrating medical coverage of many thesauri
• English, French, German, Portuguese

Hsin-Hsi Chen 10-37
Knowledge-Based
Examples– Subject Thesaurus
• Hierarchical and associative relations.
• Unique term assigned to each node.
– Concept List• Term space partitioned into concept spaces.
– Term List• List of cross-language synonyms.
– Lexicon• Machine readable syntax and/or semantics.

Hsin-Hsi Chen 10-38
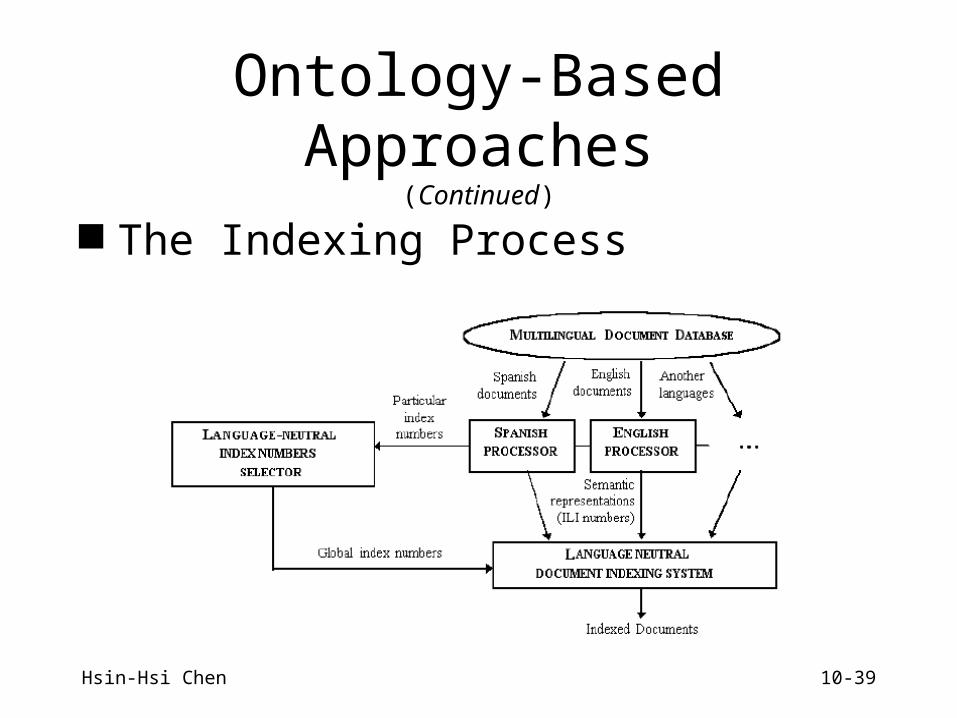
Ontology-Based Approaches
Exploit complex knowledge representations e.g., EuroWordNet
A Proposal for Conceptual Indexing using EuroWordNet
Hsin-Hsi Chen 10-39
Ontology-Based Approaches(Continued)
The Indexing Process
Hsin-Hsi Chen 10-40
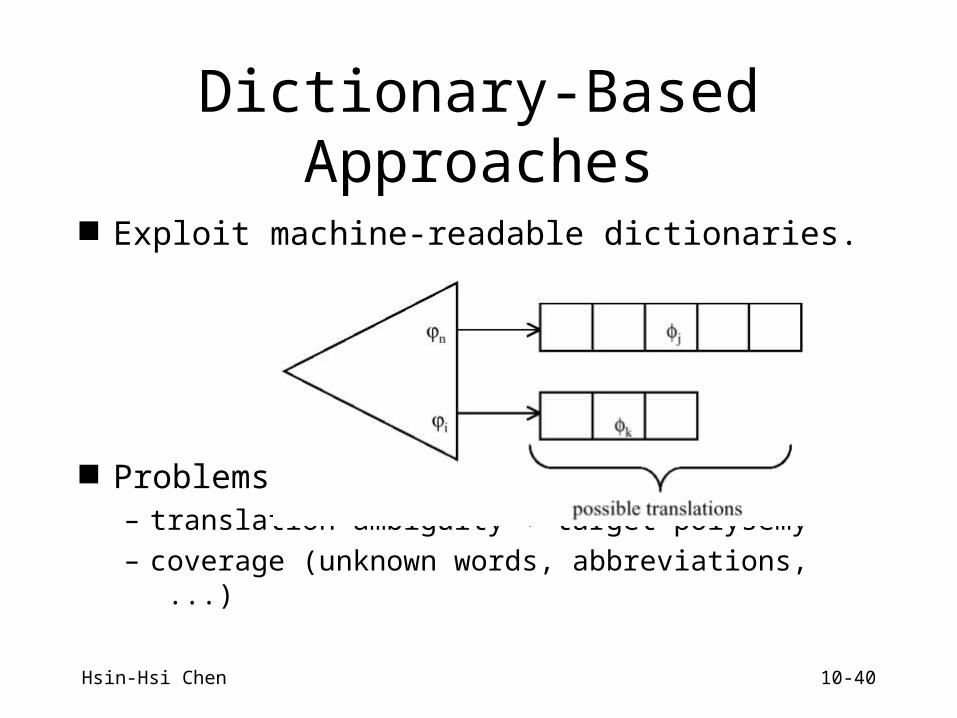
Dictionary-Based Approaches
Exploit machine-readable dictionaries.
Problems– translation ambiguity + target polysemy
– coverage (unknown words, abbreviations, ...)

Hsin-Hsi Chen 10-41
Dictionary-Based Approaches(Continued)
Issue 1: selection strategy– Select all.– Select N randomly.– Select best N.
Issue 2: which level– word– phrase

Hsin-Hsi Chen 10-42
Selection Strategy: Select All
Hull and Grefenstette 1996– Take concatenation of all term translation.
E: politically motivated civil disturbancesF: troubles civils a caractere politiquetrouble - turmoil, discord, trouble, unrest, disturbance, disordercivil - civil, civilian, courteouscaractere - character, naturepolitique - political, diplomatic, politician, policy
– Original English (0.393) vs. Automatic word-based transfer dictionary (0.235): 59.8%.
– errors: multi-word expressions and ambiguity

Hsin-Hsi Chen 10-43
Selection Strategy: Select All(Continued)
Davis 1997 (TREC5)– Replace each English query term with all of its
Spanish equivalent terms from the Collins bilingual dictionary.
– Monolingual (0.2895) vs. All-equivalent substitution (0.1422): 49.12%
Hsin-Hsi Chen 10-44
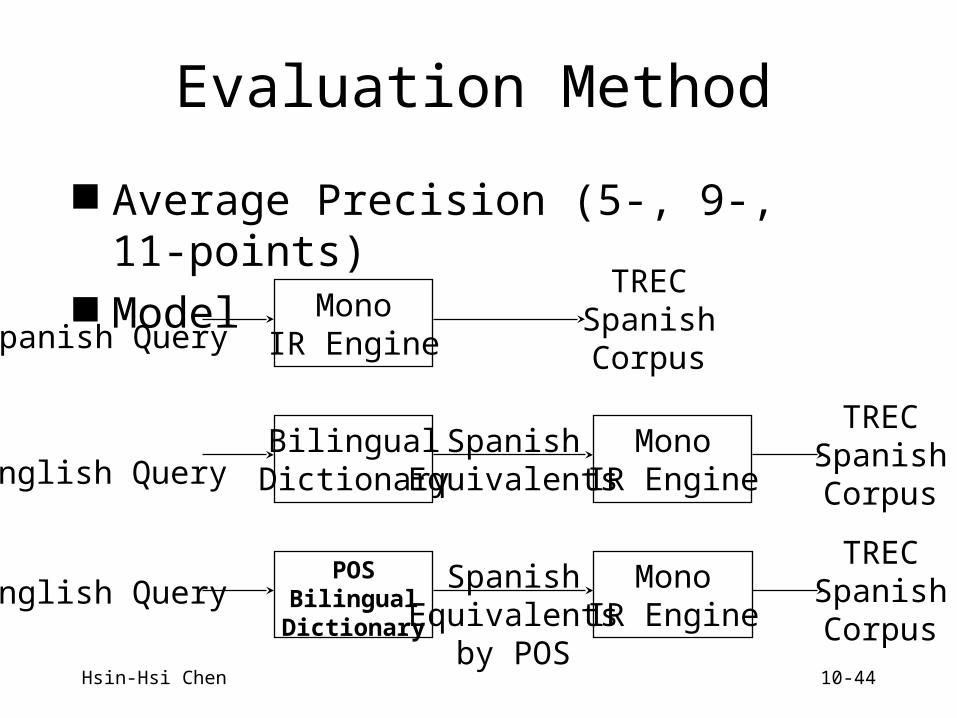
Evaluation Method
Average Precision (5-, 9-, 11-points) Model
Spanish QueryMono
IR Engine
English QueryBilingual
DictionaryMono
IR Engine
TRECSpanishCorpus
SpanishEquivalents
English Query MonoIR Engine
TRECSpanishCorpus
SpanishEquivalents
by POS
POSBilingual
Dictionary
TRECSpanishCorpus

Hsin-Hsi Chen 10-45
Selection Strategy: Select N
Simple word-by-word translation– Each query term is replaced by the word or
group of words given for the first sense of the term’s definition.
• 50-60% drop in performance (average precision)

Hsin-Hsi Chen 10-46
Selection Strategy: Select N(Continued)
word/phrase translation– Take at most three translations of each word,
one from each of the first three senses. Take phrase translation if appearing in dictionary.
• 30-50% worse than good translation
– Well-translated phrases can greatly improve effectiveness, but poorly translated phrases may negate the improvements.
• WBW (0.0244), phrasal (0.0148), good phrasal (0.0610) -39.3% +150.3%

Hsin-Hsi Chen 10-47
Selection Strategy: Select Best N
Hayashi, Kikui and Susaki 1997– search for a dictionary entry corresponding to the longe
st sequence of words from left to right– choose the most frequently used word (or phrases) in a
text corpus collected from WWW– no report for this query translation approach
Davis 1997 (TREC5)– POS disambiguation– Monolingual (0.2895) vs. All-equivalent substitution (0.
1422) vs. POS disambiguation (0.1949): near 67.3%

Hsin-Hsi Chen 10-48
Corpus-Based Approaches
Categorization– Term-Aligned– Sentence-Aligned– Document-Aligned (Parallel, Comparable)– Unaligned
Usage– Setup Thesaurus– Vector Mapping

Hsin-Hsi Chen 10-49
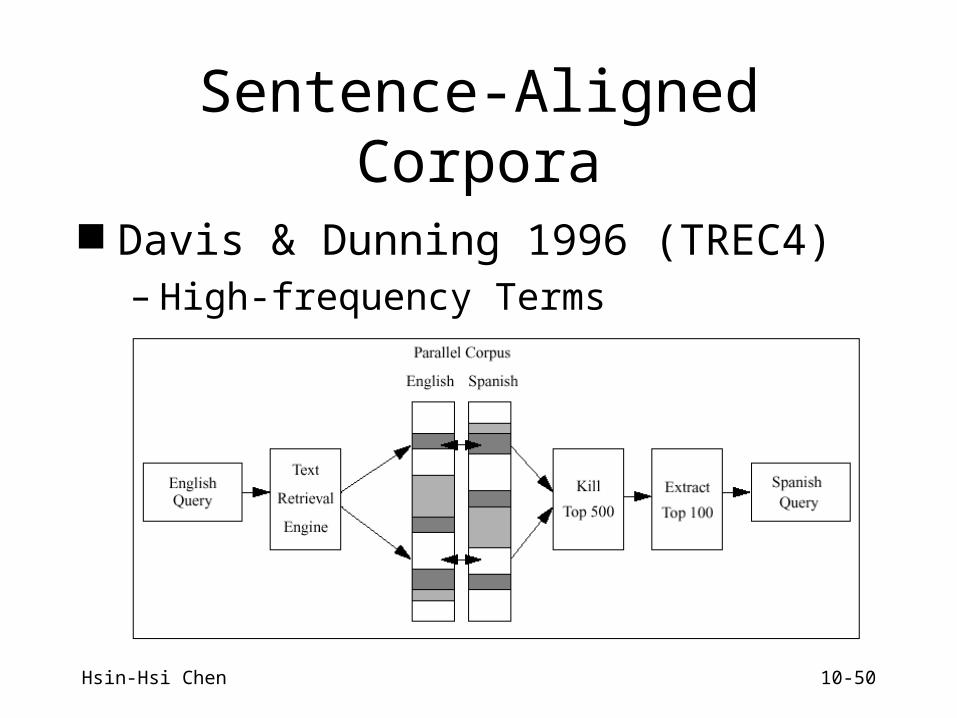
Term-Aligned Corpora
Fine-grained alignment in parallel corpora Oard 1996
– Term alignment is a challenging problem.
ParallelBinlingual
Corpus
CooccurranceStatistics
TranslationTables
MachineTranslation
System
English Query
SpanishQuery
Hsin-Hsi Chen 10-50
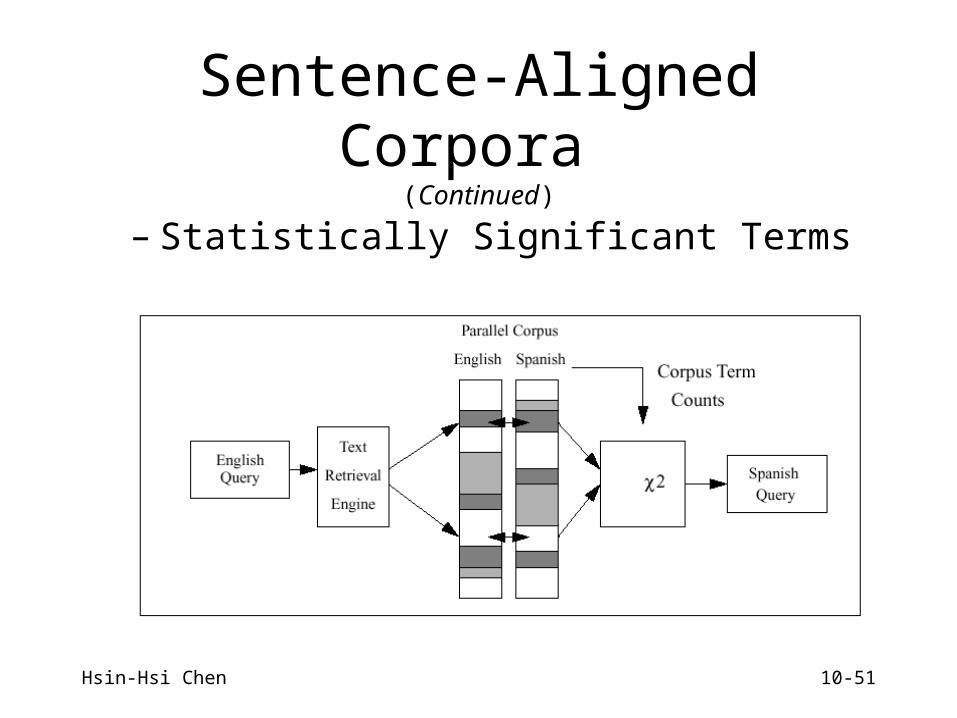
Sentence-Aligned Corpora
Davis & Dunning 1996 (TREC4)– High-frequency Terms
Hsin-Hsi Chen 10-51
Sentence-Aligned Corpora (Continued)
– Statistically Significant Terms
Hsin-Hsi Chen 10-52
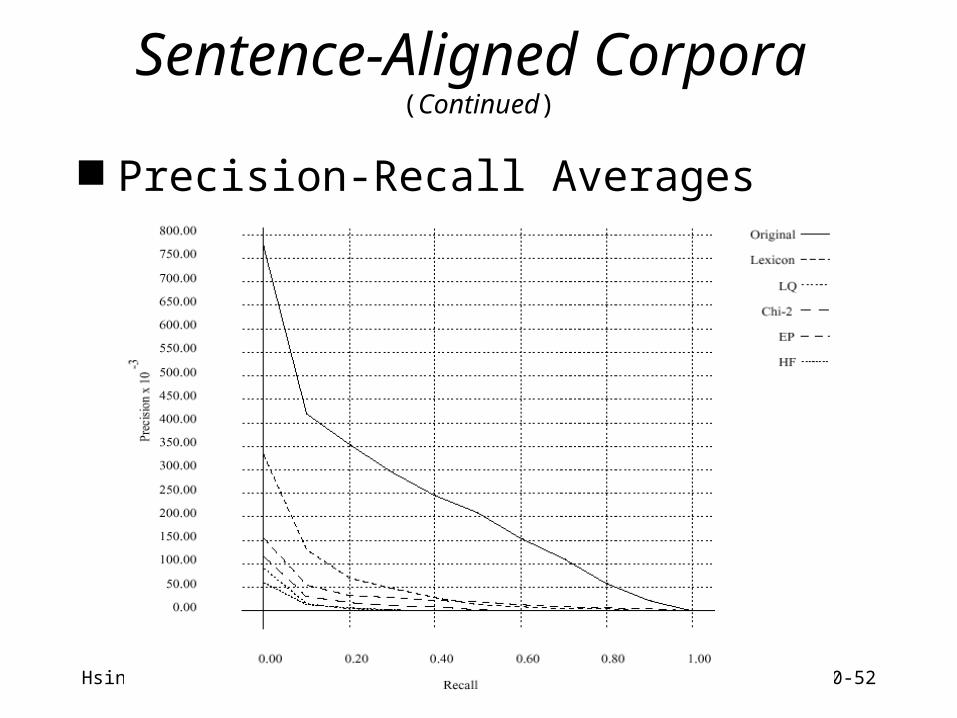
Sentence-Aligned Corpora (Continued)
Precision-Recall Averages

Hsin-Hsi Chen 10-53
Document-Aligned Corpora
Exploit parallel or comparable corpora Parallel: linked translation equivalents
– LSI mate retrieval achieve 99% effectiveness
Comparable: separate authorship, same topic– Easier to find, harder to link the documents
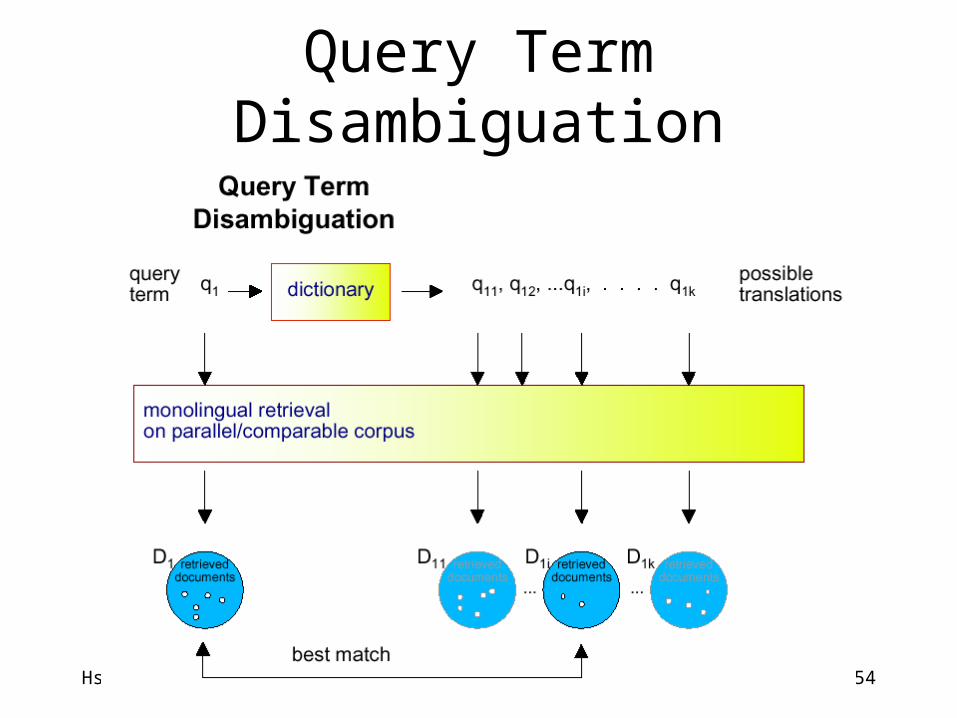
Hsin-Hsi Chen 10-54
Query Term Disambiguation

Hsin-Hsi Chen 10-55
Comparable Document-Aligned Corpora
Sheridan & Ballerini 1996– Create a comparable corpus.
Align news stories in German and Italian by topic label and date, and merge them to create pseudo-parallel documents.
– Generate co-occurrence thesaurus.– Perform translations using thesaurus.

Hsin-Hsi Chen 10-56
Unaligned Corpora
No document links Used in conjunction with dictionaries
– Pretranslation Local feedback (Ballesteros & Croft 1997)

Hsin-Hsi Chen 10-57
Brief Summary
dictionary-based methods– Specialized vocabulary not in the dictionaries will not
be translated.– Ambiguities will add extraneous terms to the query.
parallel/comparable corpora-based methods– Parallel corpora are not always available.– Available corpora tend to be relative small or to cover
only a small number of subjects.– Performance is dependent on how well the corpora are
aligned.

Hsin-Hsi Chen 10-58
Brief Summary (Continued)
Dictionaries are very useful.– Achieve 50% on their own
Parallel corpora have limitations.– Domain shifts
– Term alignment accuracy
Dictionaries and corpora are complementary.– Dictionaries provide broad and shallow coverage.
– Corpora provide narrow (domain-specific) but deep (more terminology) coverage of the language.

Hsin-Hsi Chen 10-59
Hybrid Methods
What knowledge can be employed?– lexical knowledge– corpus knowledge– ...

Hsin-Hsi Chen 10-60
Hybrid Methods (Continued)
Query Expansion– Issue 1: context
• pseudo relevance feedback (local feedback)::A query is modified by the addition of terms found in the top retrieved documents.
• local context analysis::Queries are expanded by the addition of the top ranked concepts from the top passages.

Hsin-Hsi Chen 10-61
Hybrid Methods (Continued)
– Issue 2: when• before query translation
• after query translation

Hsin-Hsi Chen 10-62
Pseudo- Relevance Feedback illustrated

Hsin-Hsi Chen 10-63
Query Expansion throughLocal Context Analysis
local analysis– Based on the set of documents retrieved for the
original query– Based on term co-occurrence inside documents– Terms closest to individual query terms are selected
global analysis– Based on the whole document collection– Based on term co-occurrence inside small contexts
and phrase structures– Terms closest to the whole query are selected

Hsin-Hsi Chen 10-64
Query Expansion throughLocal Context Analysis (Continued)
candidates– noun groups instead of simple keywords– single noun, two adjacent nouns, or three
adjacent nouns query expansion
– Concepts are selected from the top ranked documents (as in local analysis)
– Passages are used for determining co-occurrence (as in global analysis)

Hsin-Hsi Chen 10-65
Query Expansion throughLocal Context Analysis (Continued)
algorithm– Retrieve the top n ranked passages using the original q
uery– For each concept in the top ranked passages, the similar
ity sim(q,c) between the whole query q and the concept c is computed using a variant of tf-idf ranking
– The top m ranked concepts are added to the original query q
• Each concept is assigned a weight 1-0.9i/m (i: rank)• Each term in the original query is assigned a weight 2origina
l weight
Hsin-Hsi Chen 10-66
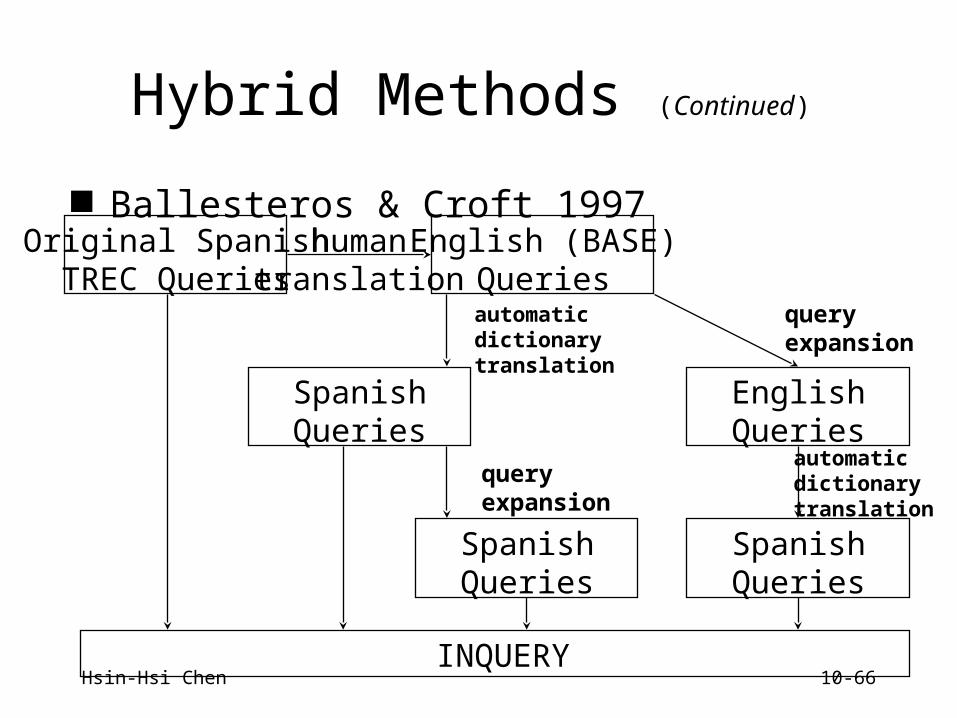
Hybrid Methods (Continued)
Ballesteros & Croft 1997Original SpanishTREC Queries
humantranslation
English (BASE)Queries
SpanishQueries
automaticdictionarytranslation
EnglishQueries
queryexpansion
SpanishQueries
queryexpansion
SpanishQueries
automaticdictionarytranslation
INQUERY

Hsin-Hsi Chen 10-67
Hybrid Methods (Continued)
– Performance Evaluation• pre-translation
MRD (0.0823) vs. LF (0.1099) vs. LCA10 (0.1139) +33.5% +38.5%
• post-translationMRD (0.0823) vs. LF (0.0916) vs. LCA20 (0.1022) +11.3% +24.1%
• combined pre- and post-translationMRD (0.0823) vs. LF (0.1242) vs. LCA20 (0.1358) +51.0% +65.0%
• 32% below a monolingual baseline

Hsin-Hsi Chen 10-68
Hybrid Methods (Continued)
Davis 1997 (TREC5)
English Query
BilingualDictionary
SpanishEquivalents
ParallelIR Engine
UN English
UN Spanish
CompareDocument
Vectors
ReducedEquivalent Set
MonoIR Engine
TRECSpanishCorpus
(POS)

Hsin-Hsi Chen 10-69
Hybrid Methods (Continued)
– corpus-based disambiguation vs. POS-based disambiguation
– MONO (0.2895) vs. ALL (0.1422) vs. 49.12%CORP (0.1153) vs. POS (0.1949) vs. 39.83% 67.32%BOTH (0.2127) 73.47%
Hsin-Hsi Chen 10-70
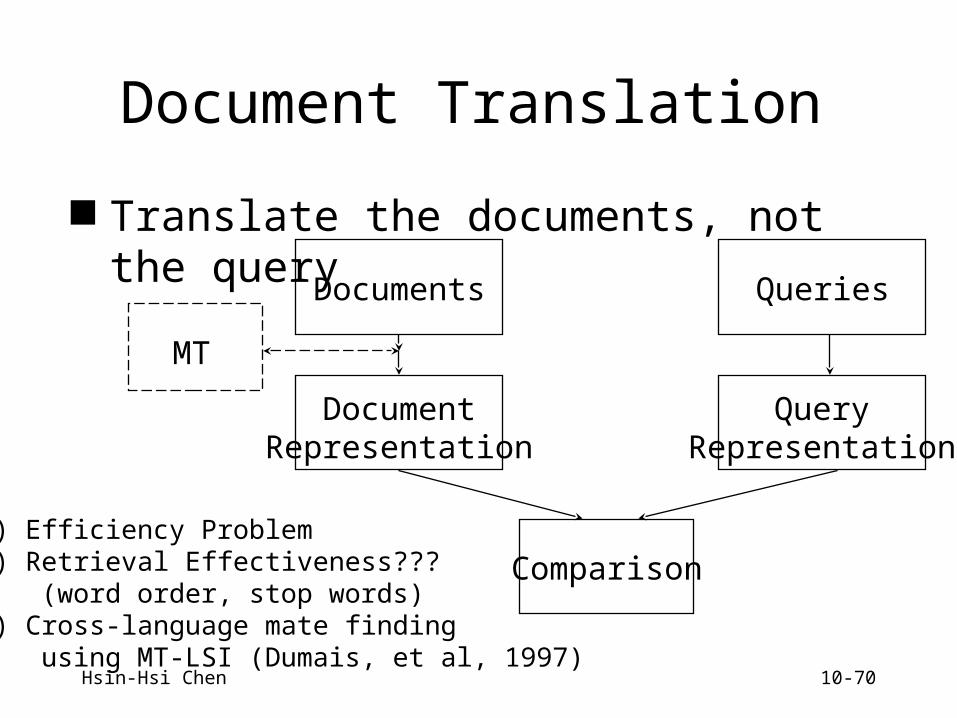
Document Translation
Translate the documents, not the query
Documents Queries
DocumentRepresentation
QueryRepresentation
Comparison
MT
(1) Efficiency Problem(2) Retrieval Effectiveness??? (word order, stop words)(3) Cross-language mate finding using MT-LSI (Dumais, et al, 1997)
Hsin-Hsi Chen 10-71
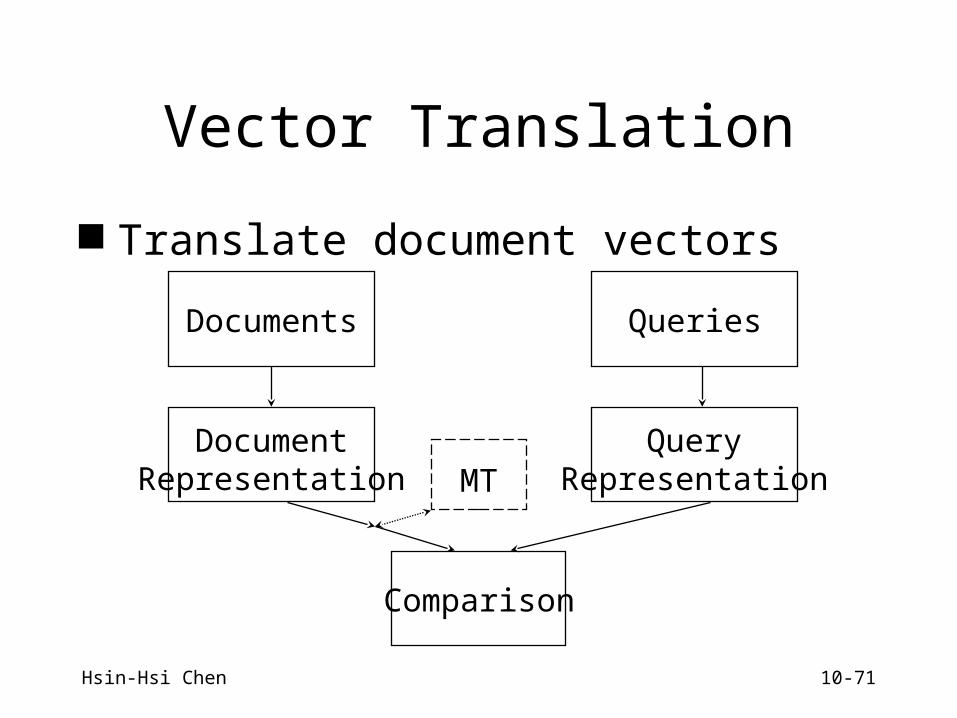
Vector Translation
Translate document vectors
Documents Queries
DocumentRepresentation
QueryRepresentation
Comparison
MT
Hsin-Hsi Chen 10-72
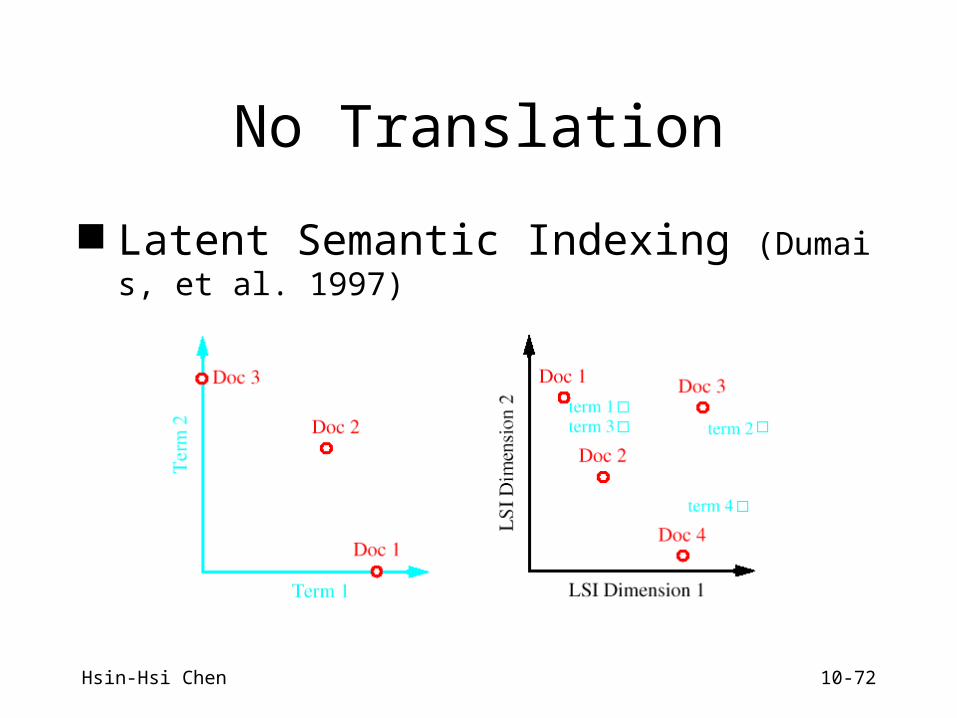
No Translation
Latent Semantic Indexing (Dumais, et al. 1997)

Hsin-Hsi Chen 10-73
No Translation (Continued)
Cross-Language Retrieval Using LSI resource: document-aligned parallel corpus
Hsin-Hsi Chen 10-74
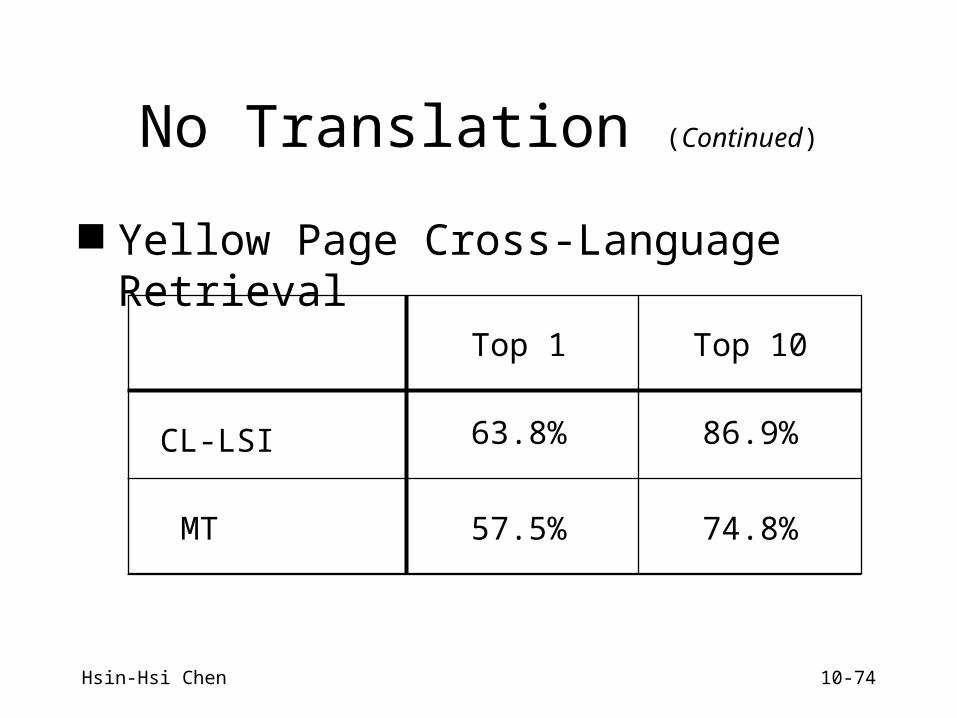
No Translation (Continued)
Yellow Page Cross-Language Retrieval
CL-LSI
MT
Top 1 Top 10
63.8%
57.5%
86.9%
74.8%

Hsin-Hsi Chen 10-75
A Comparative Evaluation
Carbonell, Yang, Frederking, et al. (CMU,LTI)
– Corpus-driven Term Translation (TMT)– Pseudo-Relevance Feedback (PRF)– Generalized Vector Space Model (GVSM)– Latent Semantic Indexing (LSI)– GVSM slightly outperforms LSI, which in turn
outperforms PRF and TMT.

Hsin-Hsi Chen 10-76
Research Directions
Comparable corpus techniques– Automatic document linking
Dictionary-based approaches– Word sense disambiguation
Evaluation– Side-by-side tests– Controllable domain shift
Hsin-Hsi Chen 10-77
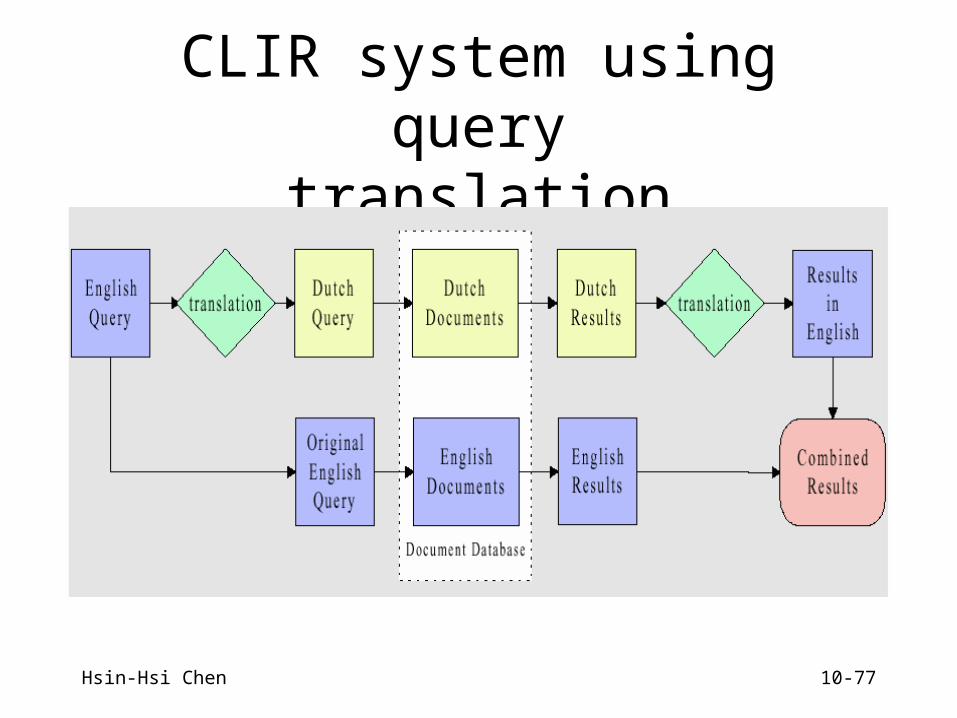
CLIR system using querytranslation

Hsin-Hsi Chen 10-78
Generating MixedRanked Lists of Documents
Normalizing scales of relevance – using aligned documents– using ranks– interleaving according to given ratios
Mapping documents into the same space– LSI– document translations

Hsin-Hsi Chen 10-79
Tools

Hsin-Hsi Chen 10-80
Types of Tools
Mark-Up Tools • Character Set/Font Handling Language Identification • Word Segmentation Stemming/Normalization • Phrase/Compound Handling Entity Recognition • Terminology Extraction Part-of-Speech taggers • Parsers/Linguistic Processors Indexing Tools • Lexicon Acquisition Text Alignment • MT Systems Speech Recognition/ OCR • Summarization Visualization

Hsin-Hsi Chen 10-81
Character Set/Font Handling
Input and Display Support– Special input modules for e.g. Asian languages– Out-of-the-box support much improved thanks
to modern web browsers
Character Set/File Format– Unicode/UTF-8– XML

Hsin-Hsi Chen 10-82
Language Identification
Different levels of multilingual data– In different sub-collections– Within sub-collections– Within items
Different approaches– Tri-gram– Stop words– Linguistic analysis

Hsin-Hsi Chen 10-83
Stemming/Normalization
Reduction of words to their root form Important for languages with rich morpholo
gy Rule- based or dictionary- based Case normalization Handling of diacritics (French, …) Vowel (re-) substitution (e.g. semitic langua
ges, …)

Hsin-Hsi Chen 10-84
Entity Recognition/Terminology Extraction
Proper Names, Locations, ...– Critical, since often missing from dictionaries– Special problems in languages such as Chinese
Domain- specific vocabulary, technical terms– Critical for effectiveness and accuracy

Hsin-Hsi Chen 10-85
Phrase/Compound Handling
Collocations (“Hong Kong“)– Important for dictionary lookup– Improves retrieval accuracy
Compounds (“Bankangestelltenlohn“ –bank employee salary)– Big problem in German– Infinite number of compounds – dictionary is n
o viable solution

Hsin-Hsi Chen 10-86
Lexicon Acquisition/Text Alignment
Goal: automatic construction of data structures such as dictionaries and thesauri– Work on parallel and comparable corpora– Terminology extraction– Similarity thesauri
Prerequisite: training data, usually aligned– Document, sentence, word level alignment

Hsin-Hsi Chen 10-87
CLIR Evaluation at TREC

Hsin-Hsi Chen 10-88
Too many factors inCLIR system evaluation
translation automatic relevance feedback term expansion disambiguation result merging test collection need to tone it down to see what happened

Hsin-Hsi Chen 10-89
TREC-6 Cross-Language Track
In cooperation with the Swiss Federal Institute of Technology (ETH)
Task Summary: retrieval of English, French, and German documents, both in a monolingual and a cross-lingual mode
Documents– SDA (1988-1990): French (250MB), German (330 MB)– Neue Zurcher Zeitung (1994): German (200MB)– AP (1988-1990): English (759MB)
13 participating groups

Hsin-Hsi Chen 10-90
TREC-7 Cross-Language Track
Task Summary: retrieval of English, French, German and Italian documents
Results to be returned as a single multilingual ranked list
Addition of Italian SDA (1989-1990), 90 MB Addition of a subtask of 31,000 structured
German social science documents (GIRT) 9 participating groups

Hsin-Hsi Chen 10-91
TREC-8 Cross-Language Track
Tasks, documents and topic creation similar to TREC-7
12 participating groups

Hsin-Hsi Chen 10-92
CLIR in TREC-9
Documents– Hong Kong Commercial Daily, Hong Kong Dai
ly News, Takungpao: all from 1999 and about 260 MB total
25 new topics built in English; translations made to Chinese

Hsin-Hsi Chen 10-93
Cross-Language Evaluation Forum
A collaboration between the DELOS Network of Excellence for Digital Libraries and the US National Institute for Standards and Technology (NIST)
Extension of CLIR track at TREC (1997-1999)

Hsin-Hsi Chen 10-94
Main Goals
Promote research in cross-language system development for European languages by providing an appropriate infrastructure for:– CLIR system evaluation, testing and tuning– Comparison and discussion of results

Hsin-Hsi Chen 10-95
CLEF 2000 Task Description
Four evaluation tracks in CLEF 2000– multilingual information retrieval– bilingual information retrieval– monolingual (non-English) information
retrieval– domain-specific IR

Hsin-Hsi Chen 10-96
CLEF 2000 Document Collection
Multilingual Comparable Corpus– English: Los Angeles Times– French: Le Monde– German: Frankfurter Rundschau+Der Speigel– Italian: La Stampa
Similar for genre, content, time

Hsin-Hsi Chen 10-97
Case Study: CLIR for NPDM

Hsin-Hsi Chen 10-98
3M in Digital Libraries/Museums
Multi-media– Selecting suitable media to represent contents
Multi-linguality– Decreasing the language barriers
Multi-culture– Integrating multiple cultures

Hsin-Hsi Chen 10-99
NPDM Project
Palace Museum, Taipei, one of the famous museums in the world
NSC supports a pioneer study of a digital museum project NPDM starting from 2000 – Enamels from the Ming and Ch’ing Dynasties – Famous Album Leaves of the Sung Dynasty – Illustrations in Buddhist Scriptures with Relativ
e Drawings

Hsin-Hsi Chen 10-100
Design Issues
Standardization– A standard metadata protocol is indispensable for the
interchange of resources with other museums.
Multimedia – A suitable presentation scheme is required.
Internationalization – to share the valuable resources of NPDM with users of
different languages
– to utilize knowledge presented in a foreign language

Hsin-Hsi Chen 10-101
Translingual Issue
CLIR– to allow users to issue queries in one language
to access documents in another language– the query language is English and the document
language is Chinese
Two common approaches– Query translation– Document translation

Hsin-Hsi Chen 10-102
Resources in NPDM pilot
an enamel, a calligraphy, a painting, or an illustration
MICI-DC– Metadata Interchange for Chinese Information– Accessible fields to users
• Short descriptions vs. full texts
• Bilingual versions vs. Chinese only
– Fields for maintenance only

Hsin-Hsi Chen 10-103
Search Modes
Free search– users describe their information need using
natural languages (Chinese or English)
Specific topic search– users fill in specific fields denoting authors,
titles, dates, and so on

Hsin-Hsi Chen 10-104
Example
Information need– Retrieval “Travelers Among Mountains and Streams, F
an K‘uan” (“ 范寬谿山行旅圖” ) Possible queries
– Author: Fan Kuan; Kuan, Fan – Time: Sung Dynasty – Title: Mountains and Streams; Travel among mountains;
Travel among streams; Mountain and stream painting – Free search: landscape painting; travelers, huge mounta
in, Nature; scenery; Shensi province
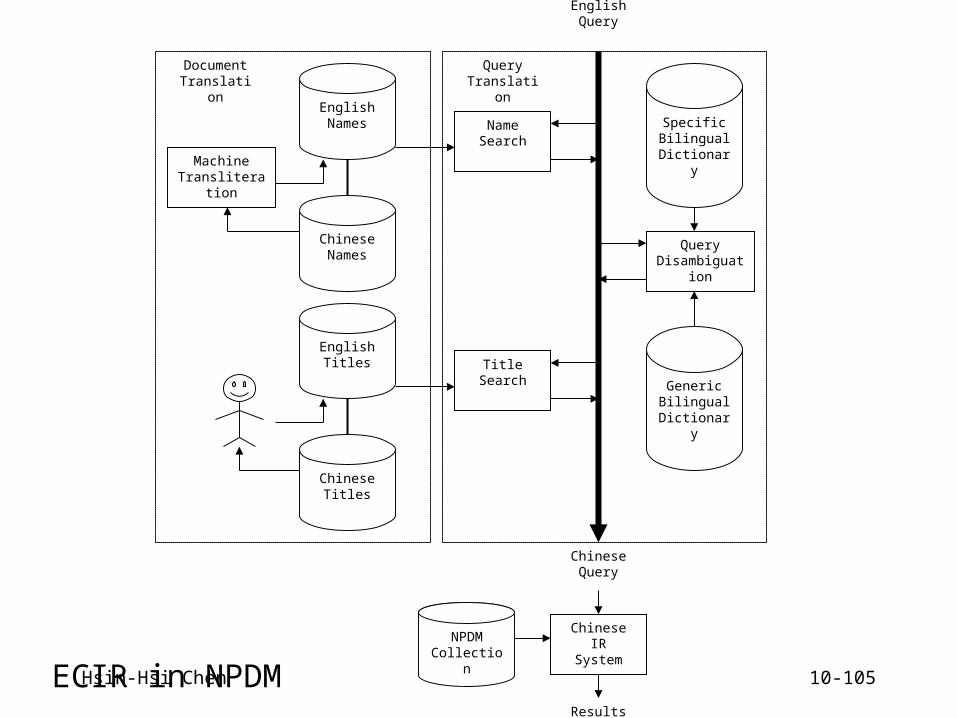
Hsin-Hsi Chen 10-105
EnglishNames
ChineseNames
MachineTransliteration
EnglishTitles
ChineseTitles
DocumentTranslation
NameSearch
TitleSearch
EnglishQuery
QueryDisambiguation
SpecificBilingual
Dictionary
GenericBilingual
Dictionary
ChineseQuery
QueryTranslation
Chinese IRSystemNPDM
Collection
Results
ECIR in NPDM

Hsin-Hsi Chen 10-106
Specific Topic Search
proper names are important query terms– Creators such as “ 林逋” (Lin P’u), “ 李建中”
(Li Chien-chung), “ 歐陽脩” (Ou-yang Hsiu), etc.
– Emperors such as “ 康熙” (K'ang-hsi), “ 乾隆” (Ch'ien-lung), “ 徽宗” (Hui-tsung), etc.
– Dynasty such as ” 宋” (Sung), “ 明” (Ming), “ 清” (Ch’ing), etc.

Hsin-Hsi Chen 10-107
Name Transliteration
The alphabets of Chinese and English are totally different
Wade-Giles (WG) and Pinyin are two famous systems to romanize Chinese in libraries
backward transliteration– Transliterate target language terms back to source language
ones
– Chen, Huang, and Tsai (COLING, 1998)
– Lin and Chen (ROCLING, 2000)

Hsin-Hsi Chen 10-108
Name Mapping Table
Divide a name into a sequence of Chinese characters, and transform each character into phonemes
Look up phoneme-to-WG (Pinyin) mapping table, and derive a canonical form for the name
Example– “林逋” “ㄌㄧㄣ ㄆㄨ” “ Lin P’
u” (WG)

Hsin-Hsi Chen 10-109
Name Similarity
Extract named entity from the query Select the most similar named entity from name mapping t
able Naming sequence/scheme
– LastName FirstName1, e.g., Chu Hsi ( 朱熹 ) – FirstName1 LastName, e.g., Hsi Chu ( 朱熹 ) – LastName FirstName1-FirstName2, e.g., Hsu Tao-ning ( 許道寧 ) – FirstName1-FirstName2 LastName, e.g., Tao-ning Hsu ( 許道寧 ) – Any order, e.g., Tao Ning Hsu ( 許道寧 ) – Any transliteration, e.g., Ju Shi ( 朱熹 )

Hsin-Hsi Chen 10-110
Title
谿山行旅圖” “ Travelers among Mountains and Streams”
"travelers", "mountains", and "streams" are basic components
Users can express their information need through the descriptions of a desired art
System will measure the similarity of art titles (descriptions) and a query

Hsin-Hsi Chen 10-111
Free Search
A query is composed of several concepts. Concepts are either transliterated or translated. The query translation similar to a small scale IR
system Resources
– Name-mapping table– Title-mapping table – Specific English-Chinese Dictionary – Generic English-Chinese Dictionary – …

Hsin-Hsi Chen 10-112
Algorithm (1) For each resource, the Chinese translations whose
scores are larger than a specific threshold are selected. (2) The Chinese translations identified from different
resources are merged, and are sorted by their scores. (3) Consider the Chinese translation with the highest
score in the sorting sequence. – If the intersection of the corresponding English description
and query is not empty, then select the translation and delete the common English terms between query and English description from query.
– Otherwise, skip the Chinese translation.

Hsin-Hsi Chen 10-113
Algorithm (Continued)
(4) Repeat step (3) until query is empty or all the Chinese translations in the sorting sequence are considered.
(5) If the query is not empty, then these words are looked up from the general dictionary. A Chinese query is composed of all the translated results.












![Hsin Hsin Ming[1]](https://img.pdfslide.tips/doc/110x75/55cf9a0d550346d033a04059/hsin-hsin-ming1.jpg)















