Embed Size (px)
Citation preview

Il sorprendente ruolo della statistica nella società moderna, dalla valutazione
dei farmaci agli algoritmi di apprendimento automatico
Leonardo [email protected]
local.disia.unifi.it/grilli
Anno scolastico 2016/17

La StatisticaLa Statistica è l’arte e la scienza di imparare dai datiIn origine era una disciplina arida che consisteva nel manipolare lunghe sequenze di numeri (senza l’aiuto di calcolatrici!)
Molti credono che sia ancora oggi così …
… ma la Statistica è diventata una disciplina assai diversa: ai calcoli ci pensa il computer, lo statistico è un investigatore che usa la metodologia statistica e la tecnologia informatica per individuare degli ‘andamenti’, delle ‘regolarità’ nella complessa realtà fisica, biologica, sociale, economica …
Come i telescopi, i microscopi, i raggi X e i radar, la Statistica moderna consente di vedere cose invisibili a occhio nudo. David Hand

Non solo numeriLa statistica si occupa essenzialmente dell’analisi di dati numerici (= l’input è una serie di numeri)
In alcuni casi è necessario un pre-processing per trasformare le informazioni in numeri
• I testi (tweet, annunci pubblicitari, referti medici …) sono trasformati in frequenze di apparizione delle parole
• Le immagini (foto satellitari, immagini di un organo da risonanza magnetica …) sono trasformate in numeri attraverso le intensità dei colori primari dei pixel

Valutare l’efficacia di un vaccino: il
caso del vaccino di Salk contro la poliomielite

Valutazioni di efficacia in medicina In ambito medico per valutare se un farmaco è efficace si
effettua un esperimento controllato:• Si reclutano i soggetti• Tirando a sorte si assegnano i soggetti a due gruppi:o Il gruppo di trattamento riceve il farmacoo Il gruppo di controllo no (spesso il gruppo di controllo riceve un ‘finto
trattamento’ chiamato placebo, per evitare l’effetto placebo)• Dopo un tempo stabilito si confrontano i due gruppi in base
a una quantità di interesse, ad es. la percentuale di soggetti che sono guariti o la media del livello di colesterolo
In un esperimento controllato i due gruppi (trattamento e controllo) sono in media identici in tutto (età, condizioni di salute, profilo genetico ecc.). Al momento in cui si somministra il farmaco, i due gruppi diventano diversi appunto per il fatto di prendere o non prendere il farmaco e quindi la differenza di risultato è attribuibile al farmaco. In teoria è semplice, ma in pratica sorgono mille problemi. Vediamo un caso concreto.

Il vaccino di Salk Poliomielite: malattia epidemica dalle gravi conseguenze
Vaccino: negli anni ’50 Salk mette a punto un vaccino
Popolazione oggetto della sperimentazione: bambini che nel 1954 frequentano le classi I, II e III negli USA
Prima strategia ipotizzata: somministrare il vaccino a tutti i bambini i cui genitori sono consenzienti• ma la polio è una malattia epidemica con grandi variazioni naturali
(60000 casi nel 1952, 30000 nel 1953) … come si fa a separare l’effetto del vaccino dall’evoluzione naturale? Strategia scartata!
Strategia scelta: esperimento con gruppo di trattati e gruppo di controllo – ok, ma come assegnare i bambini ai due gruppi?• Infatti, la procedura migliore è l’assegnazione casuale (cioè, tirando a
sorte), ma molti bambini assegnati al gruppo di trattamento non possono assumere il vaccino perché i genitori non sono consenzienti

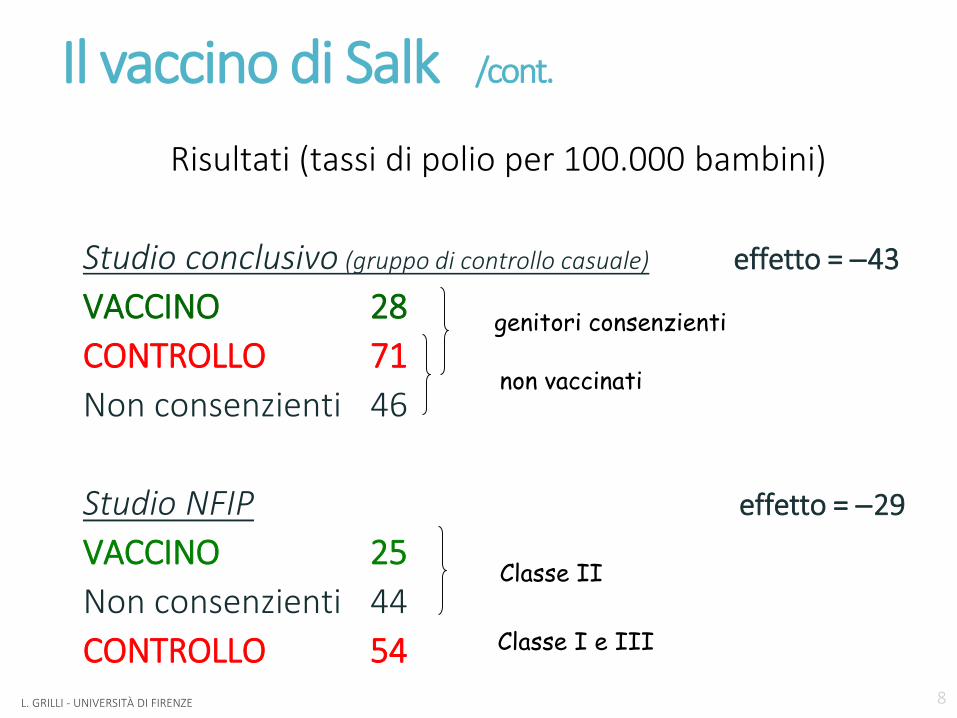
Il vaccino di Salk /cont.
Due procedure per assegnare i bambini ai gruppi di trattamento e controllo Procedura adottata dalla NFIP (National Foundation for
Infantile Paralysis): • Gruppo di trattamento: tutti i bambini di classe II (ma di
questi risultano trattati solo quelli con genitori consenzienti)
• Gruppo di controllo: tutti i bambini di classe I e classe III
Procedura adottata nello studio conclusivo: si limita l’analisi ai bambini con genitori consenzienti e si assegnano a caso (con probabilità 50%) al trattamento o al controllo
I bambini con genitori consenzienti hanno condizioni socio-economiche e igieniche migliori distorsione
L’esperimento viene condotto con l’uso di placebo in modalità doppio-cieco
Il vaccino di Salk /cont.
Risultati (tassi di polio per 100.000 bambini)
Studio conclusivo (gruppo di controllo casuale) effetto = −43
VACCINO 28CONTROLLO 71Non consenzienti 46
Studio NFIP effetto = −29
VACCINO 25Non consenzienti 44 CONTROLLO 54
genitori consenzienti
non vaccinati
Classe II
Classe I e III

Valutazioni in ambito sociale
La valutazione di efficacia di un intervento nell’ambito delle politiche economiche o sociali segue la stessa logica della valutazione dei farmaci. Tuttavia, di solito non si effettuano esperimenti controllati e questo rende molto difficile la valutazione.
Esempio Viene offerto un corso di formazione gratuito ai disoccupati La partecipazione è libera Un anno dopo il termine del corso il 60% dei partecipanti è
occupato Il corso è stato efficace?

La Statistica nelle aule dei tribunali: il caso
dell’accusa di discriminazione sessuale
nei confronti dell’Università di Berkeley

Statistica e giustizia
In molti processi la decisione del giudice si basa, in parte più o meno grande, sui risultati di un’analisi statistica Alcuni esempi:
• Valutazione probabilistica della prova del DNA• Nei processi ai dirigenti aziendali accusati di inquinamento
ambientale: comparazione dei tassi di mortalità dell’area in cui ha sede lo stabilimento con i tassi di mortalità di aree simili
• Nei processi ai datori di lavoro accusati di discriminazione nell’assunzione: comparazione dei tassi di assunzione in base a sesso, razza ecc.

Discriminazione sessuale?Negli anni Settanta l’università di Berkeley è stata accusata di discriminazione sessuale poiché il tasso di ammissione delle femmine era sostanzialmente inferiore a quello dei maschi. Per illustrare quel caso, consideriamo un esempio semplificato con 200 candidati, di cui 100 maschi e 100 femmine
Il minore tasso di assunzione delle
femmine è una prova di discriminazione
sessuale?
Maschi FemmineAssunti 55 45Non assunti 45 55Totale 100 100% assunti 55.0% 45.0%

Discriminazione sessuale? /cont.
L’analisi dei dati ha mostrato che l’accusa era palesemente infondata: infatti, considerando i tassi di ammissione per dipartimento, la situazione era rovesciata poiché nella maggior parte dei dipartimenti le femmine facevano registrare un tasso di ammissione più elevato.
Cfr. Bickel PJ, Hjammel EA, O'Connell JW (1975) Sex Bias in Graduate Admissions: Data From Berkeley. Science, 187: 398–404.E’ un esempio del noto Paradosso di Simpson http://it.wikipedia.org/wiki/Paradosso_di_Simpson
Maschi Femmine Maschi Femmine Maschi FemmineAssunti 5 30 50 15 55 45Non assunti 15 50 30 5 45 55Totale 20 80 80 20 100 100% assunti 25.0% 37.5% 62.5% 75.0% 55.0% 45.0%
TotaleFisicaSociologia

Discriminazione sessuale? /cont.
Il tasso di successo complessivo si ottiene come media pesata dei tassi di successo nei due dipartimenti, usando pesi proporzionali al numero di partecipanti.Ad es., le femmine hanno un tasso di successo di 0.375 a sociologia (dove partecipano in 80) e 0.75 a fisica (dove partecipano in 20) il tasso di successo complessivo è 0.375*(80/100)+0.75*(20/100)=0.45
Il disegno mostra che in entrambi i dipartimenti il tasso di successo delle femmine è superiore a quello dei maschi, ma per il tasso complessivo accade il contrario a causa dei pesi (le femmine partecipano in prevalenza alla selezione nel dipartimento più ‘difficile’).

La formula di Bayes:
un modello per l’apprendimento

Formula di Bayes
( | ) ( )( | )( )
=P A B P BP B A
P A
Dati due eventi A e B, la formula di Bayes consente di passare dalla probabilità condizionata di A dato B a quella B dato A
A
B non B
In questo esempio con il diagramma di Venn, prima di conoscere A si ha P(B)<0.5, ma se si viene a sapere che A è vero allora P(B|A)>0.5Dati i valori di probabilità, la formula di Bayes consente di calcolare P(B|A)
( | ) ( )( | )( )
=P effetto causa P causaP causa effetto
P effetto
Interpretando B come causa (es. bronchite) e A come effetto (es. tosse), la formula diventa un modello per l’apprendimento
Probabilità a posterioriProbabilità a priori

Test diagnostico per la Stupidite
Esito testRealtà
Positivo(Malato)
Negativo( Sano)
Malato OK70%
Falso negativo30%
Sano Falso positivo20%
OK80%
Dunque, ogni 100 malati sottoposti a test, 70 risultano positivi (giusto!) e 30 negativi (sbagliato!)
E ogni 100 sani sottoposti a test, 20 risultano positivi (sbagliato!) e 80 negativi (giusto!)
Consideriamo una ipotetica malattia chiamata Stupidite che si può diagnosticare con il test di laboratorio StupiTest. Come tutti i test diagnostici, lo StupiTest è utile ma non è perfetto:

Test diagnostico per la Stupidite /cont.
Quanto vale la probabilità a posteriori? In questa situazione ipotetica, siccome il test è risultato positivo, la probabilità a posteriori deve essere maggiore di quella a priori (10%). Ma quanto vale?
La risposta si ottiene con la formula di Bayes
Tizio effettua lo StupiTest. Se sappiamo che il test è risultato positivo, la probabilità che abbia la malattia è detta a probabilità a posteriori
Prendiamo una persona a caso dalla popolazione, Tizio. Se non conosciamo l’esito del test diagnostico, la probabilità che Tizio abbia la malattia è detta a probabilità a priori ed è pari alla percentuale di malati nella popolazione, supponiamo 10%.

( | ) ( )( | )( )
=P test positivo malato P malatoP malato test positivo
P test positivo
Test diagnostico per la Stupidite /cont.
Applichiamo la formula di Bayes al caso dello StupiTest:
Probabilità a posterioriProbabilità a priori
( ) 0.1( | ) 0.7( ) 0.7 0.1 0.2 0.9 0.25
==
= × + × =
P malatoP test positivo malatoP test positivo
Abbiamo tutti gli ingredienti:
Pertanto la probabilità a posteriori è
0.7 0.1( | ) 0.280.25×
= =P malato test positivo

Test diagnostico per la Stupidite /cont. La soluzione può anche essere ottenuta applicando le percentuali
ad una ipotetica popolazione:• I soggetti malati sono il 10%• Tra i malati, il test viene positivo nel 70% dei casi• Tra i sani, il test viene positivo nel 20% dei casi
Cosa ci aspettiamo sottoponendo al test 100 soggetti?• 10 sono malati e 90 sono sani• Tra i 10 malati, il test viene positivo a 7 soggetti• Tra i 90 sani, il test viene positivo a 18 soggetti
Nel complesso il test viene positivo a 25 soggetti, di cui 7 malati e 18 sani se prendiamo un soggetto a caso tra i 25 che hanno effettuato il test con risultato positivo, la probabilità che sia malato è 7/25 = 28%: questa è la probabilità a posteriori!
= test positivo = test negativo
m m m m m m m m m m
0% 10% 28% 70% 100%
Prob a priori Prob a posteriori Sensibilità del test

Aggiornare, aggiornare, aggiornare La formula di Bayes esprime in termini matematici la
procedura di aggiornamento della conoscenza (probabilità a priori) alla luce della nuova evidenza empirica (osservazioni o dati)
Quando arrivano nuovi dati le probabilità a posteriori diventano a priori e vengono nuovamente aggiornate tramite la formula di Bayes, e così via in un ciclo senza fine (non si finisce mai di imparare …)
Prob a priori
Prob a posteriori
dati Prob a priori
Prob a posteriori
dati= ecc…

Bloccare email spam e HIV La formula di Bayes è al centro di molti metodi di
apprendimento automatico, fra cui la diagnosi di malattie e i filtri anti-spam delle email:• Soggetto malato ⇔ Messaggio spam• Test positivo ⇔ Filtro classifica messaggio come spam
David Heckerman (ricercatore della Microsoft), ideatore del filtro anti-spam, sta collaborando allo sviluppo di un vaccino contro l’HIV
La situazione, ha raccontato Heckerman al Los Angeles Times, è praticamente la stessa: così come lo spam muta per cercare di superare le barriere erette dal filtro, allo stesso modo il virus si trasforma per aggirare le difese immunitarie del corpo umano. Il modo per combattere l'HIV, ha dichiarato Heckerman, potrebbe quindi essere lo stesso usato per lo spam: bisogna “trovare la parte che non può assolutamente mutare, il tallone d'Achille, e attaccare lì”. Nel caso delle email indesiderate, trovare il punto debole è relativamente facile, ha spiegato il ricercatore, dato che tutte in qualche modo chiedono soldi. I filtri anti-spam possono concentrarsi così su quel tipo di richiesta per individuare e bloccare le email spazzatura.http://america24.com/news/ricercatore-microsoft-combattiamo-hiv-come-lo-spam

Apprendimento automatico
(machine learning)

L'apprendimento automatico (o machine learning) è una branca dell'Intelligenza artificiale che "fornisce ai computer l'abilità di apprendere senza essere stati esplicitamente programmati"(Arthur Samuel, 1959). Viene impiegato in quei campi dell'informatica nei quali progettare e programmare algoritmi espliciti è impraticabile.
machine learning
informatica statistica Buona parte del machine learning si basa su metodi di analisi statistica multivariata

Come apprendono le macchine?Le macchine apprendono come gli umani? In generale la risposta è no, tuttavia ci sono dei metodi di machine learning che mimano il funzionamento del cervello umano.
Abbiamo già parlato dei metodi basati sulla formula di Bayes (inferenza bayesiana), che rappresenta la logica del processo di apprendimento.
Invece, le reti neurali sono modelli matematici della fisiologia del cervello (estremamente semplificati, dato che il cervello umano ha una complessità ben lungi dall’essere riproducibile su una macchina).
cerchi ⇔ neuronifrecce ⇔ sinapsi

Trovare una regola. Facile…
Per distinguere un triangolo da un quadrato c’è una semplice regola: se ha 3 lati è un triangolo, se ha 4 lati è un quadrato.

Trovare una regola. Non facile…Non esistono semplici regole per riconoscere i caratteri scritti a mano. Ognuno di noi sa riconoscere i caratteri, ma non riesce a tradurre questa capacità in un insieme di regole.
Una delle prime applicazioni del machine learning è stato il riconoscimento automatico dei caratteri (OCR: Optical Character Recognition)

Apprendimento supervisionato
Il riconoscimento dei caratteri è un esempio di apprendimento supervisionato perché si addestra il sistema fornendo una serie di casi di cui è nota la classificazione (training set):
Pian piano il sistema impara a riconoscere i caratteri e quindi diventa in grado di classificare i caratteri scritti da persone che non fanno parte del training set. Naturalmente, il sistema può sbagliare (infatti fornisce un tasso di errore) – d’altra parte anche noi umani a volte non riusciamo a interpretare la scrittura a mano.
Questi sono esempi di 0
Questi sono esempi di 1
eccetera …

In alcune situazioni vi sono molti modi di fare la classificazione e a priori non si sa quale sia il migliore per raggiungere l’obiettivo.
Apprendimento non supervisionato
Classificazione n. 1 (quadrati vs triangoli)
Classificazione n. 2 (verdi vs rossi)
Classificazione n. 3 (quadrati verdi etc.)

Apprendimento non supervisionatoLa metodologia statistica più usata per l’apprendimento non supervisionato è l’analisi dei gruppi (cluster analysis)
dati originali dati raggruppati (uno dei possibili risultati)
E questa è una situazione semplice perché ci sono solo 2 variabili …

Apprendimento non supervisionato
Ad esempio, un’azienda è interessata a classificare i propri clienti in gruppi sufficientemente omogenei in modo da fare campagne pubblicitarie specifiche per ogni gruppo (segmentazione di mercato).
Questo problema ha molte possibili soluzioni: si possono fare 3 gruppi, oppure 4, oppure 5 … ma soprattutto l’assegnazione dei clienti ai gruppi può essere fatta in molti modi perché le variabili a disposizione sono molte (età, sesso, stato civile, residenza, preferenze dichiarate, abitudini di acquisto ecc.)

Applicazioni del machine learning
Credit scoring: attribuire ad una persona che chiede un prestito la probabilità che lo restituisca
Spam filtering: classificare le email in spam vs non-spam
Diagnosi medica: classificare un paziente usando i dati di anamnesi
Riconoscimento dei volti umani http://megaface.cs.washington.edu/
Suggerimenti di acquisto personalizzati (Amazon, Netflix)
Riconoscimento vocale e assistente digitale (es. Siri)
Traduzione linguistica (es. Google Translate)
Analisi dei testi (annunci pubblicitari, tweet, referti medici …)

Studiare statistica

La professione dello statisticoNelle classifiche sulla qualità del lavoro stilate dal sito americano CareerCast ai primi posti troviamo le professioni di Statistico, e quelle affini di Matematico, di Attuario e di Data Scientist
http://www.careercast.com/jobs-rated/jobs-rated-report-2016-ranking-200-jobs
Sulle prospettive di carriera si veda http://thisisstatistics.org
«La professione più attraente della prossima decade sarà quella dello statistico. L’abilità di gestire di dati – di capirli, elaborarli, estrarne valore, visualizzarli, comunicarli – sta diventando una abilità di enorme importanza nelle prossime decadi, non solo a livello professionale, ma perfino a livello di istruzione nella scuola primaria, nella scuola superiore, all’università. Perché ora noi disponiamo di dati gratuiti su quasi ogni argomento. Per cui il fattore scarso adesso è l’abilità di capire quei dati ed estrarne valore.»
Hal Varian, Professore di economia e scienza dell’informazione presso l’Università della California a Berkeley e capo economista di Google (intervista su McKinseyQuarterly, Gennaio 2009)

http://www.statistica.unifi.itPresidente: Prof.ssa Emanuela Dreassi [email protected]
Presso l’Università di Firenze è attivo un corso di laurea triennale in Statistica (l’unico in Toscana) caratterizzato dalla molteplicità dei campi applicativi (economia, demografia, industria, medicina), dai molti contenuti informatici e computazionali, e dal tirocinio curriculare presso aziende o enti pubblici.






























