Embed Size (px)
DESCRIPTION
statica
Citation preview

Elementi di Teoria dell’Inferenza
Elementi di Teoria dell’Inferenza Slide 2
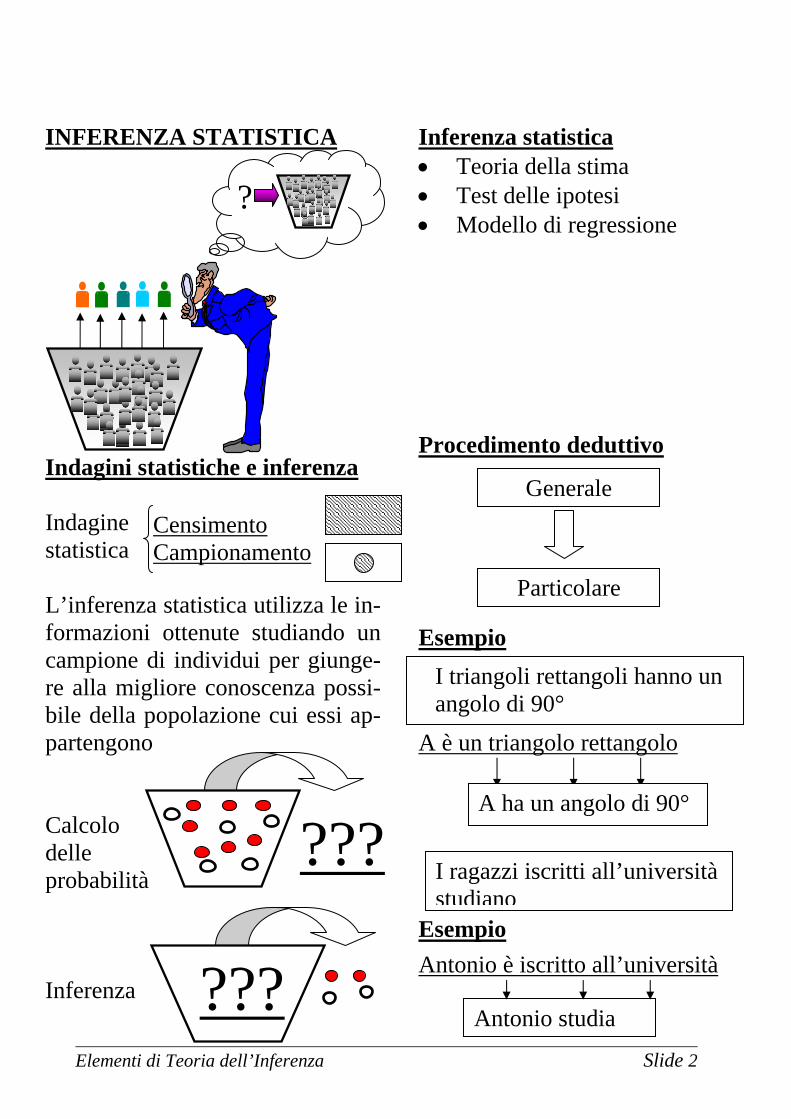
INFERENZA STATISTICA Indagini statistiche e inferenza Indagine statistica L’inferenza statistica utilizza le in-formazioni ottenute studiando un campione di individui per giunge-re alla migliore conoscenza possi-bile della popolazione cui essi ap-partengono Calcolo delle probabilità Inferenza
Inferenza statistica • Teoria della stima • Test delle ipotesi • Modello di regressione Procedimento deduttivo Esempio
A è un triangolo rettangolo
Esempio Antonio è iscritto all’università
Censimento Campionamento
???
???
Generale
Particolare
I triangoli rettangoli hanno un angolo di 90°
A ha un angolo di 90°
I ragazzi iscritti all’università studiano
Antonio studia
?

Elementi di Teoria dell’Inferenza Slide 3
Procedimento induttivo Si effettua un esperimento Si generalizzano le conclusioni Esempio Esame universitario
Nel procedimento induttivo vi è sempre possibilità di ERRORE
Campionamento “Target population”: popolazione su cui si vuole indagare “Sampled population”: popolazio-ne da cui si estrae il campione Viene descritta mediante una va-riabile casuale Campione: è un sottoinsieme della popolazione Come devono essere scelte le uni-tà appartenenti al campione? ⇒ Campione casuale
Motivi del campionamento ⇒ Costo di ispezione ⇒ Tempestività ⇒ Rilevazione distruttiva ⇒ precisione
Campionamento X f x~ ;ϑa f ← popolazione X1, X2,⋅⋅⋅⋅⋅⋅,Xn ← Campione → Spazio campionario x1, x2,⋅⋅⋅⋅,xn ← Campione osservato
Generale
Particolare
Poche domande
Livello di preparazione
N.B. X f xi ~ ;ϑa f
Con rimessa
Xi i.i.d
Senza rimessa
Xi dipendenti

Elementi di Teoria dell’Inferenza Slide 4
Stimatori X f x~ ;ϑa f x1, x2,⋅⋅⋅⋅⋅,xn ⎯???→ϑ “Stimatore”
, , ,Θ = ⋅⋅ ⋅t X X Xn1 2a f Stima
, , ,ϑ = ⋅ ⋅ ⋅t x x xn1 2a f
Proporzione campionaria X B p~ ,1a f p E X= a f P
nXi
i
n= ∑
=
11
• E P pc h =
• Var P p pn
c h a f=
⋅ −1
• Teorema di De Moivre-Laplace
La media campionaria X f x~ ;ϑa f Var Xa f = < ∞σ 2
t X X Xn
X Xn ii
n
n1 21
1, , ,⋅ ⋅ ⋅ = ∑ ==
a f
• E Xnb g=µ
• Var Xnnb g=σ2
• E Xnb g e Var Xnb g non dipendono da f x;ϑa f
• X N~ ,µ σ 2d i ⇒ X N nn ~ ,µ σ 2d i • Teorema del limite centrale
Stima puntuale • Come si sceglie tra stimatori al-
ternativi?
Proprietà degli stimatori • Come si costruiscono gli stima-
tori
Metodi di costruzione degli stimatori
µ= =E Xa f ???
p=???
Variabile casuale

Elementi di Teoria dell’Inferenza Slide 5
Proprietà degli stimatori ⇒ n finito • sufficienza • correttezza (non distorsione) • efficienza ⇒ n →∞ (proprietà asintotiche) • sufficienza • correttezza (non distorsione) • efficienza • consistenza • normalità • robustezza Correttezza (non distorsione) X f x~ ;ϑa f
, , ,Θ = ⋅⋅ ⋅ →t X X Xn1 2a f ϑ
Distorsione E Θd i ≠ ϑ d Eϑ ϑd i d i= −Θ
Sufficienza Lo stimatore opera una sintesi del-le informazioni campionarie
X X Xn1 2, , ,⋅ ⋅ ⋅a f
, , ,Θ = ⋅⋅ ⋅t X X Xn1 2a f Uno stimatore si dice sufficiente (per un parametro) se operando ta-le sintesi non disperde informa-zioni rilevanti rispetto al parame-tro. Esempi • Media campionaria E Xnb g = µ
• Proporzione campionaria E P pc h =
• Varianza campionaria
Sn
X Xn i ni
n2 2
1
1= ⋅ −∑
=b g
E S nnn
2 2 21d i = −⋅ ≠σ σ
Sn
X Xn i ni
n2 2
1
11
=−
⋅ −∑=b g
E Sn2 2d i = σ
In probabilitàIn media quadratica
ϑ = E Θd i
fΘ ϑa fE Θd i = ϑ
E Θd i
fΘ ϑa f
ϑ

Elementi di Teoria dell’Inferenza Slide 6
Come si sceglie tra più stimatori? ϑ µ= n=3
• T X X X1 1 2 313
13
13
= + +
• T X X X2 1 2 323
16
16
= + +
• E T E T1 2a f a f= = µ
• Var T Var T1
2
2
2
3 2a f a f= < =
σ σ
Errore quadratico medio E E E E
E E d
E E
E d d
E E
d E E E d
Θ Θ Θ Θ
Θ Θ
Θ Θ
Θ Θ
Θ Θ
Θ Θ
− = − + − =
= − + =
= + +RST+ ⋅ − ⋅ + =
= −RSTUVW +
− ⋅ ⋅ − + =
ϑ ϑ
ϑ
ϑ ϑ
ϑ ϑ
d i d i d ie jd i a f{ }d id i a f a f }d i
a f d i a f
2 2
2
2
2
2
2
2
2
E Var dΘ Θ−LNMOQP = + =ϑ ϑd i d i a f2 2
N.B. E E VarΘ Θ Θd i d i d i= ⇒ −LNM OQP =ϑ ϑ
2
Efficienza L’efficienza relativa riguarda la variabilità (o concentrazione della distribuzione) dello stimatore in-torno al valore vero del parametro.
ϑ ϑ− ⇒ ϑ ϑ−d i2 ⇒ E Θ − ϑd i2
Rapporto di efficienza L’efficienza è generalmente un “concetto relativo”
e T TE T
E T2 1
12
22a f a f
a f=−
−
ϑ
ϑ
e T T Te T Te T T T
2 1 2
2 1
2 1 1
111
a fa fa f
> ⇒
= ⇒
< ⇒
indifferente
Nota E T E T1 2a f a f= = ϑ
e T TVar TVar T2 1
1
2a f a f
a f=
µ
f tT2a f
f tT1a f
Errore di stima
“Costo” Errore di stima
Funzione Rischio
Errore quadratico medio
ϑ
f tT1a f f tT2
a f
E Θd i E Θd i = ϑ

Elementi di Teoria dell’Inferenza Slide 7
limite di Cramer-Rao
:Θ ΘEd i = ϑ Var L C R. . .Θd i ≥ N.B. L.C.R. dipende da f xX a f Correttezza asintotica
, , , , ,Θ Θ Θ Θ1 2 3 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅n E E E E n, , , , ,Θ Θ Θ Θ1 2 3d i d i d i d i⋅ ⋅ ⋅ ⋅ ⋅ ⋅ limn nE
→∞=Θd i ϑ
Esempio:
Sn
X Xn i ni
n2 2
1
1= ⋅ −∑
=b g
E S nnn
2 21d i = −⋅σ
limn nE S
→∞=2 2d i σ
Proprietà asintotiche n t X= =1 1 1 1Θ a f n t X X= =2 2 2 1 2,Θ a f n t X X X= =3 3 3 1 2 3, ,Θ a f n t X X X Xn n n, , , ,Θ = ⋅⋅ ⋅1 2 3a f
Come si comporta Θn quando n → +∞? Efficienza asintotica
, , , , ,Θ Θ Θ Θ1 2 3 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅n E E E E n, , , , ,Θ Θ Θ Θ1 2 3d i d i d i d i⋅ ⋅ ⋅ ⋅ ⋅ ⋅
Var Var Var Var n, , , , ,Θ Θ Θ Θ1 2 3d i d i d i d i⋅ ⋅ ⋅ ⋅ ⋅ ⋅ limn nE
→∞=Θd i ϑ
lim. . .n
nVarL C R→∞
=Θd i
1
Stimatori Stimatori corretti
Se sono soddisfatte alcune condizioni di regolarità
Θ è il migliore nella classe degli stimatori non distorti
E
Var L C R. .
Θ
Θ
d id i
=
=
ϑ

Elementi di Teoria dell’Inferenza Slide 8
Consistenza in probabilità
limn nP
→+∞− < =Θ ϑ εd i 1
Consistenza in media quadratica
limn nE
→∞−LNM OQP =Θ ϑd i2 0
lim
limn n
n n
E
Var→∞
→∞
=
=
Θ
Θ
d id i
ϑ
0
Legge debole dei grandi numeri X f x~ ;ϑa f Var Xa f = < ∞σ 2 lim
n nP X→+∞
− < =µ εb g 1
dimostrazione
E X Var Xnn nb g b g= =µ σ,
2
Disuguaglianza di Chebyshev
1 12− ≤ − < ≤Var X
P Xnn
b g b gε
µ ε
1 12
2−⋅
≤ − < ≤σ
εµ ε
nP Xnb g
n → +∞ 1 1≤ − < ≤P Xn µ εb g Consistenza in media Quadratica per Xn E X n
Var Xn
n
n
n
b gb g
= ∀
= → → +∞
µ
σ 20 per
n=20n=10
µ
n=200n=50
n=10
ϑ ε ϑ ϑ ε− +
n=200 n=50 n=20
ϑ
n=200 n=50
n=20n=10

Elementi di Teoria dell’Inferenza Slide 9
Relazione tra le forme di consi-stenza
Numerosità campionaria P Xn − < = − ⋅µ ε δb g 1 2
PX
n nn −
<FHG
IKJ = − ⋅
µσ
εσ
δ1 2
Pn
Zn
− < ≤FHG
IKJ = − ⋅
εσ
εσ
δ1 2
n z n z0
10
12 2
2=⋅
⇒ =⋅− −δ δσ
εσ
ε
Normalità asintotica Esempi Media campionaria
T.L.C. Xn
Nnn− →∞µ
σ~ ,0 1a f
Proporzione campionaria
T.L.C. ~ ,P pp p n
Nn−
⋅ −
→∞
10 1a f a f
Numerosità campionaria P P P p− < = − ⋅ε δd i 1 2
PP p
p pn
p pn
−
⋅ −<
⋅ −
F
H
GGGG
I
K
JJJJ= − ⋅
1 11 2a f a f
ε δ
Pp p
n
Zp p
n
−⋅ −
< ≤⋅ −
F
H
GGG
I
K
JJJ= − ⋅
ε ε δ1 1
1 2a f a f
Consistenza in media quadratica
Consistenza in probabilità
~ ,ϑ ϑϑ
n
n
n
VarN− →∞
d ia f0 1
Z N~ ,0 1a f
n=???Xn
µ−ε µ µ+ε
εσ δn
z= −1
n≥n0
−ε
σ n ε
σ n
1-2δ
n=???P
p−ε p p+ε
( )21
0 2
1z p pn δ
ε− ⋅ ⋅ −
=
maxp
p p n z⋅ − = ⇒ > ⋅ −1 1
414
12
2a f δ
ε
( ) 11z
p pn
δε
−=⋅ −

Elementi di Teoria dell’Inferenza Slide 10
Proprietà Xn • Non distorsione • Efficienza • Consistenza in media quadra-
tica Consistenza in probabilità (legge debole dei grandi numeri) • Normalità asintotica (teorema del limite centrale)
Teoria della robustezza • Modello approssimato • Code più pesanti • Minoranze dei dati da un mo-
dello diverso • Errori nei dati • Errori grossolani • Errore locale lo stimatore è affidabile anche per “piccole” differenze tra modello reale e modello teorico?
Proprietà P • Non distorsione • Efficienza • Consistenza in media quadratica Consistenza in probabilità (legge debole dei grandi numeri Ber-noulli) • Normalità asintotica (teorema De Moivre-Laplace)
Costruzione stimatori • Metodo dei momenti • Metodo della massima verosi-
miglianza • Metodo dei minimi quadrati
Var X nnb g = =σ 2 L.C.R. Var P p pn
L C R. . .c h a f=
⋅ −=
1

Elementi di Teoria dell’Inferenza Slide 11
Il metodo dei momenti X f x~ ;ϑa f; ϑ ϑ ϑ ϑ= ⋅ ⋅ ⋅1 2, , , lk p
µ ϑ ϑ ϑ1 1 1 2= ⋅ ⋅ ⋅g l, , ,a f 1) µ ϑ ϑ ϑ2 2 1 2= ⋅ ⋅ ⋅g l, , ,a f
µ ϑ ϑ ϑl l lg= ⋅ ⋅ ⋅1 2, , ,a f
2) , , ,µ µ
µ
11
22
1
1
1 1
1
= ∑ = ∑ ⋅⋅ ⋅
= ∑
= =
=
nx
nx
nx
ii
n
ii
n
l il
i
n
, , ,µ ϑ ϑ ϑ1 1 1 2= ⋅ ⋅ ⋅g la f
3) , , ,µ ϑ ϑ ϑ2 2 1 2= ⋅ ⋅ ⋅g la f
, , ,µ ϑ ϑ ϑl l lg= ⋅ ⋅ ⋅1 2a f (Pearson 1894)
Massima verosimiglianza La stima di massima verosimi-glianza è il valore del parametro che rende massima la probabilità (densità di probabilità) congiunta del campione osservato.
Metodo dei momenti Proprietà • Semplicità • Versione parametrica e non pa-
rametrica • consistenza Inconvenienti • Soluzioni multiple Funzione di verosimiglianza X f x~ ;ϑa f X X Xn1 2, , ,⋅ ⋅ ⋅⋅ x x xn1 2, , ,⋅ ⋅ ⋅ ⋅ ⋅ f x f x f xn1 2; , ; , , ;ϑ ϑ ϑa f a f a f⋅⋅ f x x x f x Ln i
i
n
1 21
, , , ; ;⋅ ⋅ ⋅ = ∏ ==
ϑ ϑ ϑa f a f a f
p=P( )=2/3 p=P( )=1/3
p=P( )=??? X f xi ~ ;ϑa findipendenti

Elementi di Teoria dell’Inferenza Slide 12
Stimatori di massima verosimi-glianza
:ϑ ϑ ϑ ϑL Ld i b g≥ ∀ (grafico caso uniparametrico) L x x x f xn i
i
nϑ ϑ; , , , ;1 2
1⋅ ⋅ ⋅ = ∏
=a f a f
l L x x xnϑ ϑa f a f= ⋅ ⋅ ⋅log ; , , ,1 2 max maxϑ ϑ ϑ
ϑ ϑ= =l La f a f
Proprietà M.L.E. Consistenza (quasi certa) P
n nlim→+∞
= =Θ ϑe j 1
• efficienza • normalità
Proprietà M.L.E. • Sufficienza (generalmente) • Efficienza Se esiste uno stimatore non distor-to ed efficiente questo coincide con lo stimatore di massima vero-simiglinza Invarianza M.L.E. ϑ ϑ= →M.L.E. γ ϑ= ga f ??? = M.L.E.→ γ M.L.E.→ = =γ γ ϑgd i esempio X N~ ,µ σ 2d i
Sn
x xii
n2 2
1
1= −∑
=a f = M.L.E.→σ 2
S2 → M.L.E.→σ
M.L.E.
B.A.N.
L ϑd i
ϑ
( )L ϑ

Elementi di Teoria dell’Inferenza Slide 13
Intervallo casuale
X f x~ ;ϑa f ~ , , ,Θ t X X Xn1 2 ⋅ ⋅ ⋅a f
~ , , ,ϑ t x x xn1 2 ⋅ ⋅ ⋅a f
Quanto dista la stima dal valore vero del parametro? Intervallo casuale I Intervallo che “verosimilmente” contiene il valore fissato ma inco-gnito del parametro P Iϑ α∈ = −a f 1
------------------------------------------ …un intervallo confidenza è la re-alizzazione di un intervallo casua-le. Per l l1 2x xa f a f, non si può più parlare di probabilità! l l1 2x xa f a f, appartiene ad una fa-
miglia di intervalli dei quali una percentuale (1-α)⋅100 contiene il valore vero del parametro.
Intervallo di confidenza I L L= 1 2X Xa f a f, L t X X Xn1 1 1 2Xa f a f= ⋅⋅, , , L t X X Xn2 2 1 2Xa f a f= ⋅⋅, , ,
→ I è un intervallo casuale Obiettivo: P L L1 2 1X Xa f a f≤ ≤ = −ϑ α
Un intervallo casuale è un inter-vallo che contiene il valore vero del parametro con probabilità pre-fissata. …dopo l’estrazione del campione si ottiene: l t x x xn1 1 1 2xa f a f= ⋅⋅, , , l t x x xn2 2 1 2xa f a f= ⋅⋅, , , l l1 2x xa f a f, è un intervallo di con-
fidenza. Costruzione degli Intervalli di confidenza • Livello di confidenza 1-α • Quantità Pivot • Distribuzione della quantità pi-
vot • Estremi dell’intervallo
ϑ = ???
Livello di confidenza
ϑ

Elementi di Teoria dell’Inferenza Slide 14
Quantità Pivot È una funzione del campione e dei parametri la cui distribuzione è completamente nota (non dipende dai valori dei parametri). Esempio: X N~ ,µ σ 2d i → X N nn ~ ,µ σ 2d i X
nNn − µ
σ~ ,0 1a f
Estremi intervallo di confidenza
P z Xn
znα α
µσ
α2 1 2 1<−
≤FHG
IKJ = −−
P z n X z nnα ασ µ σ2 1 2⋅ ≤ − ≤ ⋅ =−d i = ⋅ − ≤ − ≤ ⋅ − =−P z n X z n Xn nα ασ µ σ2 1 2d i= − ⋅ ≤ ≤ − ⋅ =−P X z n X z nn n1 2 2α ασ µ σd i =1-α
L X z nn1 1 2Xa f = − ⋅−α σ L X z nn2 2Xa f = − ⋅α σ l x z nn1 1 2xa f = − ⋅−α σ l x z nn2 2xa f = − ⋅α σ
Intervallo di confidenza per µ
X N~ ,µ σ 2d i σ 2 nota
⇒ Pivot → Xn
Nn − µσ
~ ,0 1a f ⇒ Affermazione di probabilità
P z Xn
znα α
µσ
α2 1 2 1<−
≤FHG
IKJ = −−
⇒ Estremi dell’intervallo
1 2 2 1n nP X z X zn nα α
σ σµ α−⎛ ⎞− ⋅ ≤ ≤ − ⋅ = −⎜ ⎟⎝ ⎠
Variabile casuale χ 2 Z Z Zn1 2, , ,⋅⋅ 1) Z N~ ,0 1a f 2) indipendenti
K Zii
n
n= ∑=
2
1
2~ χ
Pivot Non dipende dai parametri!
L1 L2
zα 2 z1 2−α
1-α
α/2 α/2
Gradi di libertà
• E K na f = • Var K na f = ⋅2 f(x) n>2
f(x)n=1,2

Elementi di Teoria dell’Inferenza Slide 15
Variabile casuale tn 1) Z N~ ,0 1a f 2) Y ~ χν
2 3) indipendenti
ZY
tν ν~
• ( ) 2Var tν ν< +∞ ⇒ > • ( )0,1vt Nν → +∞ → Quantità pivot per µ X N~ ,µ σ 2d i X
nn − µ
σσσ
2
2
X
ntnn
−−
µσ
~ 1
Alcuni risultati per v.c. Normali
X N~ ,µ σ 2d i Nota: σ 2 2= Sn Teorema 1
nX Xi ni
n
n− ⋅ =−∑ =
−12
2
21
2 12a f b g ~σ
σ σχ
Teorema 2 Xn e σ 2 sono indipendenti Intervallo di confidenza per µ
X N~ ,µ σ 2d i
1ˆn
nX t
nµ
σ −− ∼
P t Xn
tnα α
µσ
α2 1 2 1≤−
≤FHG
IKJ = −−
12 2
ˆ ˆ 1n nP X t X tn nα α
σ σµ α−
⎛ ⎞− ⋅ ≤ ≤ − ⋅ = −⎜ ⎟
⎝ ⎠
f(t)
0
N 0 1,a f χ n
n−
−1
2
1
Indipendenti
Xn
Xn iin= ∑ =
11
σ 22
1
1=
−∑−
= X Xn
i nin b g
L1 L2
n-1 gradi di libertà
gradi di libertà (n-1)
ν gradi di libertà
Pivot

Elementi di Teoria dell’Inferenza Slide 16
Cosa succede se X non è Norma-le
Xn
Nnn− →∞µ
σ~ ,0 1a f
Pivot asintotico
P X zn
X zn
n
n n− ⋅ ≤ ≤ − ⋅FHG
IKJ =
= − +
−12 2
1 1
α ασ µ σ
α 0a f
Intervallo asintotico Intervallo di confidenza per σ2
X N~ ,µ σ 2d i Quantità pivot:
nX Xi ni
n
n− ⋅ =−∑ =
−12
2
21
2 12a f b g ~σ
σ σχ
( )22 1ˆ
1
ni ni
X Xn
σ =−
=−
∑
( )2
2 22 1
2 2
ˆ1 1P nα ασχ χ ασ −
⎛ ⎞≤ − ⋅ ≤ = −⎜ ⎟
⎝ ⎠
( ) ( )2 22
2 21 2 2
ˆ ˆ1 11
n nP
α α
σ σσ α
χ χ−
⎛ ⎞− ⋅ − ⋅≤ ≤ = −⎜ ⎟⎜ ⎟
⎝ ⎠
Intervallo di confidenza per p
X B p~ ,1a f
Pn
Xii
n= ∑
=
11
P z P pP P
n
z nα α α2
121
1 1≤−
⋅ −≤
F
H
GGGG
I
K
JJJJ= − +
−c h a f0
( ) ( )
( )
12 2
ˆ ˆ ˆ ˆ1 1ˆ ˆ
1 0 1
P P P PP P z p P z
n n
n
α α
α
−
⎛ ⎞− −⎜ ⎟− ⋅ ≤ ≤ − ⋅ =⎜ ⎟⎝ ⎠
= − +
• E P pc h =
• Var P p pn
c h a f=
⋅ −1
L1 L2
χα 22 χ α1 2
2−
1-α
α/2 α/2
n-1 gradi di libertà

Elementi di Teoria dell’Inferenza Slide 17
Il processo giudiziario
Innocente colpevole Assoluzione Condanna
H0 OK Errore I Tipo
H1 Errore II Tipo OK
Ipotesi statistiche Un’ipotesi statistica è una affer-mazione che specifica parzialmen-te o completamente la distribuzio-ne di una variabile aleatoria • Valore dei parametri • Forma funzionale
Test delle ipotesi Il test delle ipotesi è una regola di decisione mediante la quale si de-cide se respingere o non respinge-re un’ipotesi statistica sulla base di dati campionari e considerazioni probabilistiche. • ipotesi statistiche • Statistica/variabile test • regola di decisione • campione • decisione
Ipotesi semplici e composite X f x~ ;ϑa f • Ipotesi semplice • Ipotesi composita Unidirezionale Bidirezionale H: ϑ≥ϑ0 H: ϑ≠ϑ0 H: ϑ≤ϑ0
Ipotesi nul-la H0
Ipotesi alternativa
H1
Vera fino a prova con-traria
C’è evidenza a sufficienza per accettarla?
H: ϑ=ϑ0
H: ϑ∈Θ0
Processo
Decisione

Elementi di Teoria dell’Inferenza Slide 18
Statistica test La statistica test è una funzione delle osservazioni campionarie la cui distribuzione è nota sotto l’ipotesi nulla. T t X X Xn n= ⋅⋅1 2, , ,a f
T f tn
H~
0 a f ← nota Esempio: X N~ ,µ 1a f H0: µ=µ0
T Xn
X N nn n ii
n H= = ∑
=
1 11
00
~ ,µa f
( )0
0 ~ 0,11
HnXZ N
nµ−
=
Decisione Definita la regola di decisione l’esito del test (se respinge o non respinge l’ipotesi nulla) dipende dai risultati campionari. La deci-sione è un giudizio di coerenza fra l’evidenza campionaria e le ipotesi statistiche.
Regola di decisione La regola di decisione definisce una partizione dello spazio cam-pionario e quindi dello spazio dei valori (supporto) che può assume-re la statistica test, in: Gli errori nel test di ipotesi
Non respingo Respingo
H0 OK (1-α) Errore I Tipo (α)
H1 Errore
II Tipo (β) OK (π=1-β)
α=P(errore I Tipo)= =P(Tn∈R.C.⎜H0) β=P(errore II Tipo) =P(Tn∈R.A.⎜H1) π=1-β= P(Tn∈R.C.⎜H1)
Regione di accettazione
R.A.
Regione critica
R.C.
Non respingo H0
Respingo H0
Tn
Procedimento inferenziale
Possibilità di errore
π=Potenza del test

Elementi di Teoria dell’Inferenza Slide 19
Tra α e β vi è una relazione in-versa!!! Per ridurre sia α che β bisogna aumentare n Procedimento pratico • si definiscono le ipotesi • si fissa α • si sceglie la statistica test • sul supporto della statistica test
si sceglie una regione critica di dimensione α in modo da mi-nimizzare β
Procedimento per il test delle ipotesi Quale errore è più grave? • si fissa α livello di significativi-
tà o dimensione del test • fra tutte le regioni critiche di
dimensione α si sceglie quella che minimizza β
Test sulla media X N~ ,µ σ 2d i • H0: µ=µ0 H1: µ=µ1 • α=0.05
• statistica test Xn
Xn ii
n= ∑
=
11
• scelta regione critica Regola di decisione x cn ≤ → non respingo H0 x cn > → respingo H0
1
1 β
α
R.A. R.C.
H0 H1 Tn
β f x HX 0b g f x HX 1b g
µ0 µ1
α π
c

Elementi di Teoria dell’Inferenza Slide 20
Test sulla media X N~ ,µ σ 2d i H0: µ=µ0 H1: µ=µ1 →Regola di decisione R.A. x cn ≤ → non respingo H0 R.C. x cn > → respingo H0
α=P( Xn ∈R.C.⎜H0: µ=µ0)= =P( Xn >c⎜H0: µ=µ0)
c dipende solo dalla distribuzione di Xn sotto H0. La regola di decisione è valida an-che per le ipotesi H0: µ=µ0 H1: µ>µ0
Regola di decisione (σ noto)
H0: µ=µ0 H1: µ>µ0
( )0 ~ 0,1nX N
n
µσ−
0 1c znα
σµ −= + ⋅
R.A. 0 1nx c znα
σµ −≤ = + ⋅
R.C. 0 1nx c znα
σµ −> = + ⋅
Determinazione del valore criti-co (σ noto)
H0: µ=µ0 H1: µ>µ0 R.C. x cn >
c: P( Xn >c⎜H0: µ=µ0)=α
sotto H0 → ( )0 ~ 0,1nX Nnµ
σ−
( ) 01 1 0
nXP Z z P znα αµ µ µ α
σ− −
⎛ ⎞−> = > = =⎜ ⎟
⎝ ⎠
( )0 1 0nP X z nαµ σ µ µ α−> + ⋅ = =
Test bilaterali
X N~ ,µ σ 2d i H0: µ=µ0 H1: µ≠µ0 c1: P( Xn <c1⎜H0: µ=µ0)=α/2 c2: P( Xn >c2⎜H0: µ=µ0)=α/2
Test non distorto
µ1>µ0
f x HX 0b g f x HX 1b g
µ0 c2 µ1
β α/2 π
µ1 c1
f x HX 1b gα/2
R.C. R.C.R.A.
π
( )Zf zα
Z1-α
c
H0

Elementi di Teoria dell’Inferenza Slide 21
Regola di decisione (σ noto) H0: µ=µ0 H1: µ≠µ0
R.A. c x cn1 2≤ ≤ → non respingo H0
R.C. x cx c
n
n
<>
RST1
2 → respingo H0
Sotto H0 → ( )0 ~ 0,1nX Nnµ
σ−
c1: P( Xn <c1⎜H0: µ=µ0)=α/2 c2: P( Xn >c2⎜H0: µ=µ0)=α/2
0
2 1 2 0 1nXP z znα αµ µ µ α
σ −
⎛ ⎞−≤ ≤ = = −⎜ ⎟
⎝ ⎠
( )0 2 0 1 2 1nP z n X z nα αµ σ µ σ α−+ ⋅ ≤ ≤ + ⋅ = −
1 0 2 0 1 2c z zn nα α
σ σµ µ −= + ⋅ = − ⋅
2 0 1 2c znα
σµ −= + ⋅
Regola di decisione (σ noto) X N~ ,µ σ 2d i H0: µ=µ0 H1: µ≠µ0 R.A.:
1 2nc x c≤ ≤ R.C.:
1
2
n
n
x cx c
<⎧⎨ >⎩
1 0 1 2
2 0 1 2
c zn
c zn
α
α
σµ
σµ
−
−
= − ⋅
= + ⋅
Z
Sotto H0
c1 c2 N.B
( )0,1Z N∼
2 1 2z zα α−= −

Elementi di Teoria dell’Inferenza Slide 22
Test unilaterale (σ incognita)
H0: µ=µ0 H1: µ>µ0 R.C. x cn >
c: P( Xn >c⎜H0: µ=µ0)=α
sotto H0 → Xn
tn − µσ
0 ~
( ) 01 2 1 2 0ˆ
nXP t t P tnα αµ µ µ α
σ− −
⎛ ⎞−> = > = =⎜ ⎟
⎝ ⎠
( )0 1 2 0ˆnP X t nαµ σ µ µ α−> + ⋅ = =
Test bilaterale (σ incognita) X N~ ,µ σ 2d i H0: µ=µ0 H1: µ≠µ0 R.A. 1 2nc x c≤ ≤ c1: P( Xn <c1⎜H0: µ=µ0)=α/2 c2: P( Xn >c2⎜H0: µ=µ0)=α/2
02 1 2 0 1
ˆnXP t t
nα αµ µ µ α
σ −
⎛ ⎞−≤ ≤ = = −⎜ ⎟
⎝ ⎠
0 2 0 1 2ˆ ˆ 1nP t X tn nα α
σ σµ µ α−⎛ ⎞+ ⋅ ≤ ≤ + ⋅ = −⎜ ⎟⎝ ⎠
1 0 2 0 1 2ˆ ˆc t tn nα α
σ σµ µ −= + ⋅ = − ⋅
c tn2 0 1 2= + ⋅−µ σ
α
Regola di decisione (σ incognita)
H0: µ=µ0 H1: µ>µ0
R.A. x c tnn ≤ = + ⋅−µ σ
α0 1
R.C. x c tnn > = + ⋅−µ σ
α0 1
Regola di decisione (σ incognita) R.A. c x cn1 2≤ ≤ → non respingo H0
R.C. x cx c
n
n
<>
RST1
2 → respingo H0
1 0 1 2ˆc tnα
σµ −= − ⋅
c tn2 0 1 2= + ⋅−µ σ
α
n-1 gradi di libertà
la v.a. t ha n-1 gradi di libertà
c
t
Sotto H0
c1 c2
N.B 2 1 2t tα α−= −

Elementi di Teoria dell’Inferenza Slide 23
Test delle ipotesi per la media Cosa succede se X non è Normale? Teorema del limite centrale X
nNn
H− µσ
0 00 1~ ,a f n → ∞
La distribuzione della statistica test sotto H0 è nota solo asintoti-camente
P RErrore Ia f = +α
Test delle ipotesi → p X B p~ ,1a f Statistica test:
Pn
Xii
n= ⋅ ∑
=
11
( )ˆE P p=
( ) ( )ˆ 1Var P p p n= ⋅ −⎡ ⎤⎣ ⎦
( )( )
ˆ~ 0,1
1
nP p Np p n
→∞−
−⎡ ⎤⎣ ⎦
Sotto H0: p=p0
( )( )0
0 0
ˆ~ 0,1
1
nP p Np p n
→∞−
−⎡ ⎤⎣ ⎦
Regola di decisione 1) H0: µ≤µ0 H1: µ>µ0 R.A.: x z nn ≤ + ⋅−µ σα0 1 2) H0: µ≥µ0 H1: µ<µ0 R.A.: x z nn ≥ + ⋅µ σα0 3) H0: µ=µ0 H1: µ≠µ0 R.A.:
0 2 0 1 2nz x zn nα α
σ σµ µ −+ ⋅ ≤ ≤ + ⋅
Regola di decisione 1) H0: p≤p0 H1: p>p0 R.A.:
p p zp p
n≤ + ⋅
−−0 1
0 01αa f
2) H0: p≥p0 H1: p<p0 R.A.:
p p zp p
n≥ + ⋅
−0
0 01αa f
3) H0: p=p H1: p≠p0 R.A.:
( ) ( )0 0 0 00 2 0 1 2
1 1ˆ
p p p pp z p p z
n nα α−
− −+ ⋅ ≤ ≤ + ⋅
Statistica test
Quantità pivot
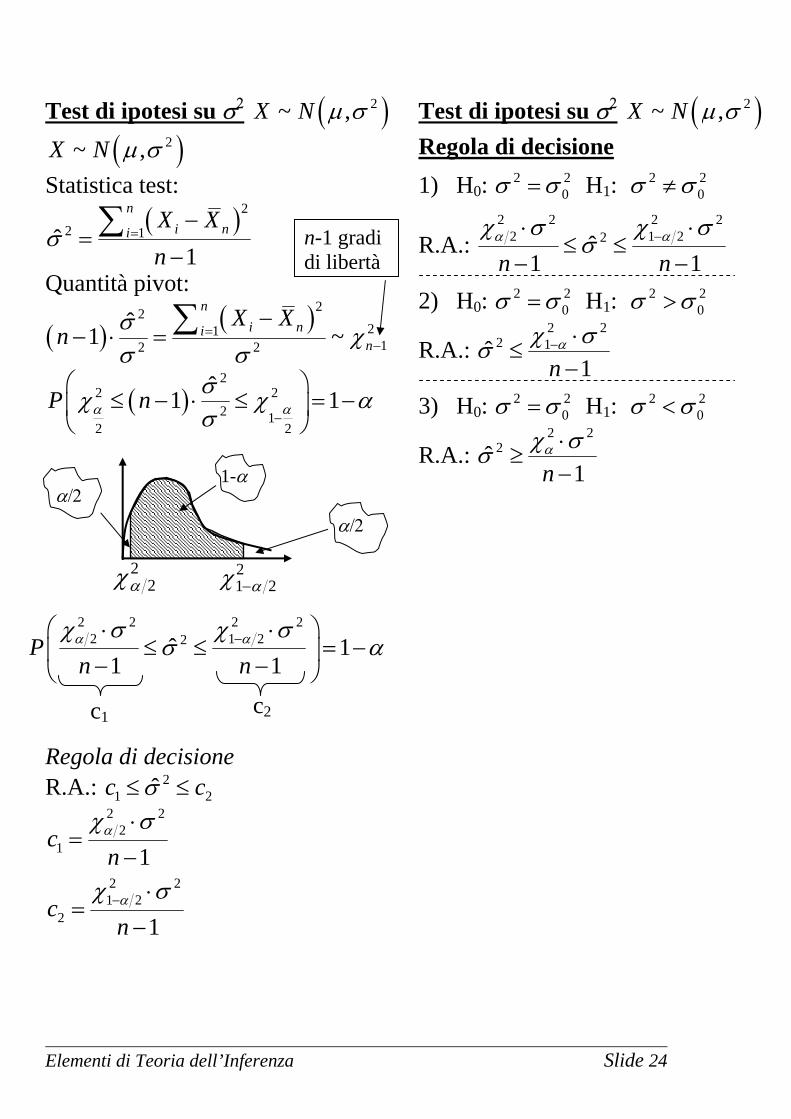
Elementi di Teoria dell’Inferenza Slide 24
Test di ipotesi su σ2 ( )2~ ,X N µ σ
( )2~ ,X N µ σ Statistica test:
( )22 1ˆ
1
ni ni
X Xn
σ =−
=−
∑
Quantità pivot:
( ) ( )2221
12 2ˆ1 ~
ni ni
n
X Xn σ χ
σ σ=
−
−− ⋅ = ∑
( )2
2 22 1
2 2
ˆ1 1P nα ασχ χ ασ −
⎛ ⎞≤ − ⋅ ≤ = −⎜ ⎟
⎝ ⎠
2 2 2 2
2 1 22ˆ 11 1
Pn n
α αχ σ χ σσ α−⎛ ⎞⋅ ⋅
≤ ≤ = −⎜ ⎟− −⎝ ⎠
Regola di decisione R.A.: 2
1 2ˆc cσ≤ ≤ 2 2
21
2 21 2
2
1
1
cn
cn
α
α
χ σ
χ σ−
⋅=
−⋅
=−
Test di ipotesi su σ2 ( )2~ ,X N µ σ Regola di decisione 1) H0: 2 2
0σ σ= H1: 2 20σ σ≠
R.A.: 2 2 2 2
2 1 22ˆ1 1n n
α αχ σ χ σσ −⋅ ⋅
≤ ≤− −
2) H0: 2 20σ σ= H1: 2 2
0σ σ>
R.A.: 2 2
2 1ˆ1n
αχ σσ − ⋅≤
−
3) H0: 2 20σ σ= H1: 2 2
0σ σ<
R.A.: 2 2
2ˆ1n
αχ σσ ⋅≥
−
c1 c2
χα 22 χ α1 2
2−
1-α
α/2 α/2
n-1 gradi di libertà

Elementi di Teoria dell’Inferenza Slide 25
Test sull’adattamento
X ni ic x1 n1 1c x2 n2 2c
xk nk kc
( ) 02
2 21
1~
k Hi i
o ki i
n cc
χ χ −=
−= ∑
Test sull’indipendenza
Y X
y y yh1 2 ⋅ ⋅ ⋅
x1 n n n h11 12 1⋅ ⋅ ⋅ n1• x2 n n n h21 22 2⋅ ⋅ ⋅ n2•
xk n n nk k kh1 2 ⋅ ⋅ ⋅ nk• n n n h• • •⋅ ⋅ ⋅1 2 n
P X x Y y
P X x P Y y
i j
i j
= ∩ = =
= = ⋅ =
c ha f c h
P X x n ni i= = •a f ; P Y y n nj j= = •c h
( ) ( ) ( )ij i j i jc n n n n n n n n• • • •= ⋅ ⋅ = ⋅
Test sull’adattamento
X ni icx1 n1 1cx2 n2 2c
xk nk kc
( ) 02
2 21
1~
k Hi i
o k li i
n cc
χ χ − −=
−= ∑
Statistica test
( )
( ) ( )
2
2
1 1
2
21 1
1 1~
k hij ij
oi j ij
i jijk h
k hi ji j
n cc
n nn
nn n
n
χ
χ
= =
• •
− ⋅ −• •= =
−= =
⋅⎛ ⎞−⎜ ⎟
⎝ ⎠=⋅
∑∑
∑∑
R.C.: χ χ αo
212> −
Il test sull’indipendenza è:
• Non parametrico • Asintotico • Applicabile sia a caratteri
quantitativi che qualitativi
H0: X ed Y indipendenti
H0: P X x P X xi o i= = =a f a f;ϑ
ϑ ( )ˆi o ic n P X x ϑ= ⋅ =
Statisticatest
H0
fkχ −12 α
Regione critica
R.C.: χ χ αo
212> −
R.C.: χ χ αo2
12> −
Statistica test
in frequenze assolute osservate
ic frequenze assolute teoriche
( )i o ic n P X x ϑ= ⋅ =
H0: P X x P X xi o i= = =a f a f;ϑ
ϑ ϑ ϑ ϑ= ⋅⋅⋅1 2, , , lk p noto ϑ ϑ ϑ ϑ= ⋅⋅⋅1 2, , , lk p stimato

Elementi di Teoria dell’Inferenza Slide 26
Specificazione del modello di re-gressione lineare semplice Modello: schema rappresentativo della realtà
interpretative Finalità previsive simulazione
semplice → 2 variabili regressione → legame in media Y x= + ⋅ +β β ε0 1
Y x= + +β β ε0 1 Y x= + ⋅ +β β ε0 1 Y x= + ⋅ +β β ε0 1
2
Ipotesi classiche del modello Relativamente alla popolazione posso scrivere: Y xi i i= + ⋅ +β β ε0 1 Relativamente al campione osser-vato: y x ei i i= + ⋅ +β β0 1 Ipotesi classiche del modello di regressione: 1) y xi i i= + ⋅ +β β ε0 1 ∀ =i n1, 2) E iεa f = 0 ∀ =i n1, 3) Var iε σa f = 2 ∀ =i n1, 4) Cov i jε ε,c h = 0 ∀ ≠ =i j i j n, ,1 5) x è una variabile deterministi-
ca ed è osservata per almeno 2 valori distinti
Modello di regressione lineare semplice
Omissione di variabili Errore Errore di misura
Cattiva specificazione del modello
Causa effetto?
Discussione ipotesi modello di regressione lineare semplice • E Y xi ia f = + ⋅β β0 1 ∀ =i n1, • Var Yia f = σ 2 ∀ =i n1, • Omoschedasticità • Cov Y Yi j,c h = 0 ∀ ≠ =i j i j n, ,1 Se x è una variabile aleatoria?
E Y x xb g = + ⋅β β0 1
Altri esempi di modelli lineari nei parametri
E Y f x xa f a f= = + ⋅β β0 1
x
y
x1 x2 x3 x4
y4 y3 y2 y1

Elementi di Teoria dell’Inferenza Slide 27
Somma dei quadrati degli scarti
La somma dei quadrati degli scarti si esprime come: G e y y
y x
ii
n
i ii
n
i ii
n
β β β β
β β
0 12
10 1
2
1
0 12
1
, ,a f a f a f
a f
= ∑ = −∑ =
= − + ⋅∑
= =
=
Equazioni normali Derivando G(β 0 ,β1) rispetto ad β 0 , e β1 ed uguagliando a 0 i ri-sultati si ricavano le equazioni normali:
• y xi ii
n− − ⋅ =∑
=β β0 1
10a f
• y x xi i ii
n− − ⋅ ⋅ =∑
=β β0 1
10a f
Nota: ∂
∂= − ⋅ − − ⋅∑
=
Gy xi i
i
nβ ββ
β β0 1
00 1
12
,a f a f
∂∂
= − − − ⋅ ⋅∑=
Gy x xi i i
i
nβ ββ
β β0 1
10 1
12
,a f a f
Stimatori dei minimi quadrati
gli stimatori dei minimi quadrati di β 0 e β1 si ricavano imponendo che risulti minima la funzione G(β 0 ,β1):
, : , , ,β β β β β β β β0 1 0 1 0 1 0 12G G Rd i a f< ∀ ∈
Stimatori dei minimi quadrati Risolvendo il sistema di equazioni si ricavano
• β11
21
2=− ⋅ −∑
−∑==
=
x x y yx x
SS
i iin
iin
xy
x
a f a fa f
• β β0 1= − ⋅y x
dove: x
nx y
ny
Sn
x x y y
Sn
x x
iin
iin
xy i iin
x iin
= ⋅ ∑ = ⋅ ∑
= − ⋅ −∑
= ⋅ −∑
= =
=
=
1 1
1
1
1 1
1
2 21
; ;
;a f a f
a f
y xi iβ β β β0 1 0 1,a f= + ⋅
x xi
yi β β0 1,a f
y
yi ei
(xi,yi)
e y yi i i= − β β0 1,a f Retta di regressione
y xi i= + ⋅β β0 1 e y yi i i= −
x
y
xi
yi
yi ei
(xi,yi)
La retta di regressio-ne è unica e passa sempre per il punto di coordinate x y,a f
eiin=∑ =1 0

Elementi di Teoria dell’Inferenza Slide 28
Proprietà degli stimatori dei mi-nimi quadrati • Non distorti • Migliori stimatori lineari non
distorti
Varn
xx xii
nΒ0
22
21
1c h a f= +−∑
FHG
IKJ=
σ
Varx xii
nΒ1
22
1
1c h a f=−∑ =
σ
Cov xx xii
n,Β Β0 1
22
1c h a f= −
−∑ =
σ
Stima di σ 20 1,Var VarΒ Βc h c h e
σ ε2 2 2
1
21
12
12
= =−
∑ =
−−∑
=
=
Sn
e
ny y
iin
i iin a f
S Var Sn
xx xii
nΒ Β0
20
22
21
1= = +
−∑
FHG
IKJ=
c h a fε
S Var S
x xiinΒ Β
1
21
22
1
1= =
−∑ =
c h a fε
S nn
S Sy xε β2 212 2
2=
−⋅ − ⋅
Teorema di Gauss Markov Sotto le ipotesi classiche del mo-dello di regressione lineare sem-plice gli stimatori dei minimi qua-drati sono lineari non distorti ed i più efficienti (minima varianza) tra quelli lineari e non distorti per β 0 e β1. Verifica del modello stimato Se oltre alle ipotesi del modello classico risulta: • ε σi N~ ,0 2d i Ipotesi R.A. g.l.
1. HH
0 0 0
1 0 0
::
ββ
=≠
bb
β
α0 0
1 20
−≤ −
bS
tΒ
n-2
2. HH
0 1 1
1 1 1
::
ββ
=≠
bb
β
α1 1
1 21
−≤ −
bS
tΒ
n-2
Nota: Se ε σi N~ ,0 2d i Β0 e Β1 si distribuiscono normal-mente, n S− ⋅2 2 2a f ε σ si distribui-sce come una χ n−2
2 (n-2 g.l.) Β0 e Sε
2 sono indipendenti Β1 e Sε
2 sono indipendenti
Analisi dei residui: ei

Elementi di Teoria dell’Inferenza Slide 29
Misure di accostamento
Ry y
y y
SS S
ri
i
n
ii
nxy
x yxy
2
2
12
1
2
2 22=
−∑
−∑=
⋅==
=
a fa f
rS
S Sxy xyxy
x y
2 22
2 2= =⋅
=ρ
Se ε σi N~ ,0 2d i si può effettuare anche un test per R2. Si dimostra che nel caso della re-gressione lineare semplice il test su R2 (H H0 10 0: , :ρ ρ= ≠ ) e il test su Β1 (H H0 1 1 10 0: , :β β= ≠ ) coincidono.
Osservazioni 1 Le t di Student hanno n-2 gradi li-bertà (sono i g.l. di Sε
2)
( )( )
( )2
20 12
1
1 ˆ ˆjjn
ii
x xS Var x
n x xε
=
⎛ ⎞−⎜ ⎟⋅ + = Β + Β ⋅⎜ ⎟−⎝ ⎠∑
( )( )
( )2
20 12
1
1 ˆ ˆ1 jj jn
ii
x xS Var x
n x xε ε
=
⎛ ⎞−⎜ ⎟⋅ + + = Β + Β ⋅ +⎜ ⎟−⎝ ⎠∑
Intervallo di previsione
ε σi N~ ,0 2d i • Previsione del livello medio • Previsione del valore singolo
Previsione del livello medio: E Y xj jc h = + ⋅β β0 1 per E Yjc h formuliamo il seguente intervallo di confidenza;
β β α ε0 1 12
2
21
1+ ⋅ ⋅ ⋅ +
−
−∑−=
x t Sn
x x
x xjj
iin
∓c ha f
Previsione del valore singolo: Y xj j j= + ⋅ +β β ε0 1 per Yj formuliamo il seguente in-tervallo di confidenza;
β β α ε0 1 12
2
21
1 1+ ⋅ ⋅ ⋅ + +
−
−∑−=
x t Sn
x x
x xjj
iin
∓c ha f
Osservazioni 2
Se ε σi N~ ,0 2d i ( )jE Y e Yj sono variabili casuali Normali. Se ε σi N~ ,0 2d i gli stimatori di Massima Verosimiglianza di β 0 e β1 coincidono con quelli dei mi-nimi quadrati.
R 21
00
0= =β
R211 0= >β2
11 0R β= <
R210 0= =β





























