Embed Size (px)
DESCRIPTION
NTP
Citation preview

Information Extraction for Vietnamese Real-
Estate Advertisements
Phạm Vi Liên
Trường Đại học Công nghệ
Luận văn ThS ngành: Khoa học máy tính; Mã số: 60 48 01
Người hướng dẫn: TS. Phạm Bảo Sơn
Năm bảo vệ: 2012
Abstract: In recent years, real-estate market in Vietnam is growing rapidly which
creates a lot of information about real-estate, especially information on advertising
for buying and selling activities of real-estate development. This poses an essential
demand for building an information extraction system to help users deal with the
increasing amount of real-estate advertisements on the Internet. We propose a
rule-based approach to build an information extraction system for online real-
estate advertisements in Vietnamese. At the same time, we set up a process to
build an annotated corpus wich can be used in machine learning approaches at a
later stage. Our system achieve promising results with F-measures of above 90%.
Our approach is particularly suitable for under-resourced languages where an
annotated corpus of a decent size is not readily available.
Keywords: Công nghệ thông tin; Quảng cáo; Bất động sản; Khai thác thông tin
Content
Chương 1: Giới thiệu
1.1 Vấn đề và Ý tưởng:
Với sự ra đời và phát triển của Internet, ngày càng nhiều dữ liệu được gởi lên Internet và
chúng ta đang "ngập lụt" bởi chúng. Mặc dù, các công cụ tìm kiếm như Google1, Bing
2,
1 http://www.google.com 2 http://www.bing.com

Yahoo3,... đã được tạo ra để giúp con người tìm kiếm thông tin, nhưng chúng vẫn chưa
thật sự đáp ứng được mong đợi của người dùng. Vì vậy, các nhà nghiên cứu đã nhìn vào
các lĩnh vực như khai thác thông tin, tóm tắt văn bản, để khắc phục vấn đề quá tải thông
tin và cung cấp những thông tin hữu ích cho người sử dụng.
Rút trích thông tin là một trong những nhiệm vụ quan trọng của xử lý ngôn ngữ tự
nhiên. Ý tưởng chính của các hệ thống rút trích thông tin đó là rút trích các mẩu thông tin
từ các văn bản có cấu trúc hoặc bán cấu trúc để điền vào một mẫu có cấu trúc đã được
định nghĩa sẵn gọi là template. Rút trích thông tin đang dần xuất hiện trong nhiều lĩnh
vực như chính trị, xã hội, tài chính, bất động sản,... của nhiều ngôn ngữ khác nhau như
Anh, Pháp, Trung Quốc,… Tuy nhiên, đối với Tiếng Việt của chúng ta thì nó vẫn là một
vấn đề tương đối khá mới mẻ, đặc biệt là lĩnh vực quảng cáo nhà đất trực tuyến.
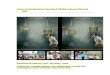
Figure 1: Dữ liệu đầu vào và kết quả đầu ra của hệ thống chúng tôi.
Trong Luận văn này, chúng tôi đề xuất một phương pháp tiếp cận dựa trên hệ luật để
xây dựng một hệ thống rút trích thông tin quảng cáo nhà đất trực tuyến của Tiếng Việt.
Đồng thời, chúng tôi cũng xây dựng một tập ngữ liệu gán nhãn cho nhiệm vụ này.
1.2 Phạm vi nghiên cứu
Với sự phát triển của Internet, quảng cáo trực tuyến là thực tế và ngày càng phổ biến.Nó
là một giải pháp quảng cáo hiệu quả cho các cá nhân quảng cáo, cơ quan và người xem.
Như vậy, các nguồn dữ liệu từ các quảng cáo là cực kỳ lớn và đa dạng. Luận án của
chúng tôi tập trung vào xử lý văn bản trực tuyến miễn phí quảng cáo Việt Nam trong lĩnh
vực bất động sản.
1.3 Cấu trúc của luận văn:
Luận văn của chúng tôi được tổ chức thành 5 chương như sau:
3 http://www.yahoo.com

- Chương 1: Chúng tôi giới thiệu về vấn đề và ý tưởng để xây dựng một hệ thống rút
trích thông tin từ các quảng cáo trực tuyến về nhà đất trong Tiếng Việt.
- Chương 2: Chúng tôi trình bày tổng quan về các nghiên cứu liên quan của rút trích
thông tin nói chung và lĩnh vực nhà đất nói riêng.
- Chương 3: Chúng tôi mô tả chi tiết làm thế nào để xây dựng hệ thống rút trích thông
tin từ các quảng cáo trực tuyến về nhà đất trong Tiếng Việt.
- Chương 4: Chúng tôi trình bày các kết quả thực nghiệm của chúng tôi và phân tích
một số nguyên nhân gây ra lỗi.
- Chương 5: Chúng tôi tổng kết những điểm đạt được của hệ thống và thảo luận hướng
phát triển hệ thống trong tương lai.

Chương 2: Các nghiên cứu liên quan
2.1 Cách tiếp cận:
Các nghiên cứu về rút trích thông tin có thể được phân thành 3 hướng tiếp cận như sau:
Hướng tiếp cận dựa trên hệ luật [2], [3].
Hướng tiếp cận học máy [4], [5].
Hướng tiếp cận lai [6], [7].
Sử dụng hệ luật là một trong những phương pháp truyền thống khi xây dựng các hệ
thống rút trích thông tin. Những hệ thống này thường dựa trên các đặc trưng như cú pháp
của thông tin (ví dụ: từ loại của từ), ngữ cảnh của thông tin [8], hình thái của thông tin (ví
dụ: chữ hoa, chữ thường, số,...) hoặc sử dụng Gazetteer [8]. Đến nay, có nhiều nghiên
cứu đã sử dụng phương pháp này [9], [10] hoặc [11] và đạt được hiệu suất khá cao bao
gồm các nhiệm vụ cho tiếng Việt [2], [3].
Có nhiều công trình sử dụng phương pháp học máy như Hidden Markov Model [12],
Maximum Entropy [4], Support Vector Machine [13], [5] để tận dụng lợi thế của tập ngữ
liệu đã được gán nhãn. Về vấn đề rút tích thông tin, có những nghiên cứu thu được hiệu
quả khá cao [14] nằm trong khoảng 81% theo thước đo F-measure. Những phương pháp
này cũng đã thành công khi áp dụng cho Tiếng Việt [15] với F-measure khoảng 83%.
Phương pháp lai là sực kết hợp của hai phương pháp trên, để tận dụng lợi thế của từng
phương pháp và mang lại hiệu suất cao. Hệ thống của Srihari [7] và Fang [6] đã cho kết
quả rất tốt Tiếng Trung. Nhưng cho đến nay, chưa có nhiều nghiên cứu cho Tiếng Việt
của chúng ta.
Có một số công trình về rút trích thông tin từ các quảng cáo nhà đất cho Tiếng Anh
[16], [17], nhưng những công trình này sử dụng cách tiếp cận wrapper induction trên các
tài liệu html. Điều này khác rất nhiều từ công việc của chúng tôi khi chúng tôi tập trung
vào văn bản phi cấu trúc, tức là văn bản không có thẻ html như là những manh mối để
nhận dạng các thực thể.
2.2 GATE framework:
GATE là một kiến trúc, một nền tảng và một môi trường phát triển giao diện cho các
ngôn ngữ kỹ thuật. Nó được tạo ra và phát triển bởi một nhóm các nhà phát triển dẫn đầu
bởi giáo sư Cunningham tại đại học Sheffield từ năm 1995. Hiện nay, nó được sử dụng

rộng rãi trên thế giới bởi cộng đồng các nhà nghiên cứu thuộc nhiều lĩnh vực của xử lý
ngôn ngữ, đặc biệt là rút trích thông tin. Nó được sử dụng cho nhiều dự án rút trích thông
tin của nhiều ngôn ngữ và miền vấn đề. Một ví dụ điển hình của hệ thống rút trích thông
tin là ANNIE (A Nearly-New Information Extraction System). Nó được đóng gói như
một plugin trong GATE.
GATE là một bộ công cụ Java và nó cũng là một phần mềm nguồn mở dưới giấy phép
GNU. Người dùng nhận sự hỗ trợ miền phí từ cộng đồng người dùng và các nhà phát
triển qua website chính thức của GATE.
Chúng tôi sử dụng GATE để giải quyết bài toán của chúng tôi.

Chapter 3: Information Extraction for Vietnamese Real-Estate Advertisements
3.1 Định nghĩa Template
Qua quá trình quan sát các dữ liệu thu thập được, chúng tôi quyết định chọn template cho
hệ thống của chúng tôi như thể hiện trong hình 2. Template này bao quát hầu hết các
thông tin mà những người đăng tin mô tả cũng như những gì người xem cần tìm kiếm
trong một quảng cáo nhà đất.
Hình 2: Template của hệ thống
3.2 Phát triển Copus:
3.2.1 Điều kiện chọn lọc dữ liệu:
Những bản tin được chọn lọc cho hệ thống của chúng tôi phải đảm bảo các điều kiện sau:
Một tập tin dữ liệu chỉ có duy nhất 1 bản tin quảng cáo nhà đất. Nếu trong một tập
tin có nhiều hơn một bản tin quảng cáo, chúng tôi sẽ phải chia thành nhiều tập tin
khác nhau. Nói cách khác, mỗi tập tin dữ liệu đầu vào sẽ có duy nhất một template
tại đầu ra.
Các bản tin là phi cấu trúc. Do trọng tâm công việc của chúng tôi là xử lý các văn
bản phi cấu trúc, chúng tôi loại bỏ tất cả các thẻ html và chỉ giữ lại các văn bản
của quảng cáo thu thập được.
3.2.2 Chọn lọc dữ liệu:
Để phát triển và kiểm thử hệ thống, chúng tôi xây dựng một bộ ngữ liệu bằng cách thu
thập dữ liệu từ các trang web có uy tín cung cấp các quảng cáo về nhà đất trực tuyến và
miễn phí như http://vnexpress.net/rao-vat/13/the-house-dat/, http://raovat.thanh-
nien.com.vn/pages/default .aspx,... Đây là những trang web thu hút một số lượng lớn
những người đăng tin cũng như người xem tin.
3.2.3 Data normalization
+ Loại tin (TypeEstate) + Loại nhà (CategoryEstate) + Diện tích (Area) + Giá tiền (Price) + Khu vực (Zone) + Liên hệ (Contact)
o Tên liên hệ (Fullname) o Điện thoại (Telephone) o Thư điện tử (Email) o Địa chỉ (Address)

Chúng tôi thực hiện chuẩn hóa dữ liệu một phần là tự động để loại bỏ một số nhập nhằng,
một phần là có sự hỗ trợ của con người trong quá trình gán nhãn. Quá trình chuẩn hóa dữ
liệu hoặc bước tiền xử lý phải đảm bảo rằng nội dung của các quảng cáo vẫn còn nguyên
vẹn. Quá trình chuẩn hóa của chúng tôi bao gồm các bước như sau:
Thứ nhất, chúng tôi thêm dấu chấm câu vào sau các câu.
Thứ hai, chúng tôi trộn nhiều đoạn thành 1 đoạn suy nhất, bởi vì các bản tin này
thường không quá dài.
Thứ ba, chúng tôi chuẩn hóa các dấu câu; loại bỏ khoảng trống thừa, viết hoa cho
các từ sau dấu chấm câu.
Thứ tư, chúng tôi chuẩn hóa số điện thoại, giá tiền, diện tích, tên người,… thành
các định dạng phổ biến.
Cuối cùng, chúng tôi thay thế một vài từ viết tắt bởi các từ đầy đủ của chúng.
Trong các bước ở trên, bước thứ 4 là khó nhất. Bước này đóng góp rất quan trọng để
cải thiện tỉ lệ nhận dạng cho hệ thống của chúng tôi.
3.2.4 Gán nhãn tập ngữ liệu:
Sau khi các tài liệu đã được tự động chuẩn hóa, chúng sẽ được tự gán nhãn bằng tay theo
template đã được định nghĩa ở phần trước. Chúng tôi sử dụng công cụ Callisto để hỗ trợ
cho quá trình gán nhãn cho dữ liệu. Callisto là một công cụ được phát triển để phụ vục
công việc gán nhãn cho dữ liệu văn bản. Quá trình gán nhãn cho bộ ngữ liệu của chúng
tôi được thực hiện song song với quá trình tạo ra quy tắc của hệ thống. Điều này giảm tải
cho quá trình gán nhãn và cũng có thể cung cấp cái nhìn sâu sắc để cải thiện các quy tắc
tốt hơn.
3.3 Hệ thống Vietnamese Real-Estate:
3.3.1 Tokenizer
Một sự khác biệt điển hình giữa tiếng Việt và tiếng Anh là tách từ khi tiếng Việt là một
ngôn ngữ đơn âm. Một từ trong tiếng Việt có thể chứa một hoặc nhiều token. Chất lượng
của hệ thống phụ thuộc vào bước này. Chúng tôi kế thừa từ công trình nghiên cứu [18]
về tách từ và gán nhãn từ loại, và chúng tôi đóng gói chúng thành một plugin của Gate
trong hệ thống của chúng tôi. Thành phần Tokenizer sẽ tạo ra hai nhãn là "Word" và
"Split".

Mỗi nhãn "Word" gồm có những đặc trưng như sau:
o POS là từ loại của từ. Ví dụ: Np, Nn,...
o string: là một chuỗi của từ. Ví dụ: "căn hộ", "Mỹ Đình",...
o upper: nếu ký tự đầu tiên của từ là viết hoa thì upper có giá trị là "true", ngược
lại nó là "false".
o Ngoài ra, cũng có một số đặc trưng khác như: kind, nation,... để giúp cho quá
trình viết luật ở bước sau.
Nhãn "Split" được tạo ra để bắt giữ các dấu câu như: ".", ";", ",", etc.
3.3.2 Gazetteer
Gazetteer bao gồm các từ điển khác nhau được tạo ra trong quá trình phát triển hệ thống.
Gazetteer nắm bắt miền tri thức về nhà đất. Chúng cung cấp các thông tin cần thiết cho
các luật nhận dạng thực thể ở các giai đoạn sau này. Mỗi từ điển đại diện cho một nhóm
từ có ý nghĩa tương đồng. Đối với hệ thống của chúng tôi, chúng tôi sử dụng các loại
gazetteers sau đây:
Gazetteers có chứa tiềm năng của tên thực thể như là: tên người, tên địa điểm (khu
vực/địa chỉ) hoặc tên loại nhà.
Gazetteers có chứa các cụm từ được sử dụng trong ngữ cảnh để viết luật như là:
tiền tố hoặc các động từ mà có khả năng theo một tên người.
Gazetteer có chứa tiềm năng của các thực thể nhập nhằng.
Vì hệ thống của chúng tôi làm việc trên văn bản phi cấu trúc mà không có bất kỳ
manh mối như thẻ html, Gazetteer đóng góp đáng kể vào hiệu quả tổng thể của hệ thống.
Đầu ra của thành phần Gazetteer là các nhãn Lookup bao gồm các từ có ngữ nghĩa rõ
ràng.
3.3.3 JAPE Transducer
JAPE Transducer là là tầng của ngữ pháp JAPE hoặc các luật. Ngữ pháp JAPE cho phép
một mẫu biểu thức chính quy cụ thể bao bọc các nhãn phù hợp. Vì vậy, kết quả thành
phần trước bao gồm tách từ, gán nhãn từ loại và từ điên có thể được sử dụng để tạo ra các
khác khác theo. Một ngữ pháp JAPE có định dạng sau:
LHS (left-hand-side) –> RHS (right-hand-side)

Mệnh đề tài (LHS) là một biểu thức chính quy trên các nhãn. Mệnh đề phải (RHS) là
hành động được thực thi khi mệnh đề trái phù hợp.
JAPE Transduce của chúng tôi tổ chức các luật như sau:
Loại bỏ các nhãn Lookup không đúng và có thể gây ra nhập nhằng.
Nhận dạng thực thể TypeEstate.
Nhận dạng thực thể CategoryEstate dựa trên thực thể TypeEstate. Nếu một bản tin
quảng cáo có nhiều hơn một thực CategoryEstate, chúng tôi sẽ sử dụng vị trí
tương quan để giữa CategoryEstate và TypeEstate thực thể xác định nên loại bỏ
thực thể nào và giữ lại thực thể nào.
Nhận dạng thực thể Zone.
Nhận dạng thực thể Area có thể sử dụng thêm thực thể TypeEstate và
CategoryEstate để nhận dạng. Nếu một bản tin không xuất hiện manh mối nào để
nhận dạng thực thể Area, chúng tôi sử dụng TypeEstate và CategoryEstate để xác
định có hay không tồn tại thực thể này. Ví dụ: Tôi cần bán 2000 m2 đất ruộng tại
Hà Đông. (I need to sell 2000 m2 farmland in Ha Dong.)
Nhận dạng thực thể Price và loại bỏ các thực thể Price dư thừa.
Nhận dạng thực thể Telephone và loại bỏ các thực thể Telephone dư thừa.
Nhận dạng thực thể Fullname dựa trên thực thể Telephone.
Nhận dạng thực thể Address sử dụng thực thể Zone.
Nhận dạng thực thể Email.
Kết hợp các thực thể Telephone, Address, Email và Fullname thành thực thể mới
là Contact.
Loại bỏ các thực thể Zone dư thừa.
Chúng tôi loại bỏ tất cả các nhãn Lookup là một phần của các nhãn Word. Ví dụ từ
"Liên" (Liên) là một tên người nó được sử dụng để nhận dạng cho thực thể Fullname,
nhưng từ này cũng có thể là một phần của một từ khác với ý nghĩa hoàn toàn khác nhau.
Ví dụ từ "Liên hệ" được gán nhãn là Word và nói cũng là một một manh mối tiềm năng
để nhận dạng các nhãn Contact, do đó từ "Liên" không nên là một nhãn Lookup riêng
biệt.

Thực thể Zone là một trong số các thực thể đặc biệt khó khăn nhận dạng do thực tế là
các token mô tả cho thực thể Zone không được viết hoa. Hơn nữa, thực thể này thường
khá dài. Lấy một ví dụ Zone là "My dinh - tu liem - Hà Nội" thì rất khó khăn để nhận
dạng một cách chính xác nói, bởi chúng là một tên địa danh nhưng lại không được viết
hoa:
"Tôi cần mua căn hộ tại Mỹ đình – từ liêm – Hà Nội."
"I need to buy an apartment in My dinh - tu liem - Ha Noi."
3.4 Kết luận:
Trong chương này, chúng tôi trình bày khá chi tiết về hệ thống Vietnamese Real-Estate
của chúng tôi. Tại mục mở đầu của chương, chúng tôi giới thiệu về template của hệ thống
chúng tôi. Ở mục kế tiếp chúng tôi mô tả quá trình phát triển của tập ngữ liệu. Trong mục
cuối cùng, chúng tôi trình bày 3 thành phần chính của hệ thống rút trích thông tin
Vietnamese Real-Estate đó là Tokenizer, Gazetteer và JAPE Transducer. JAPE
Transducer là một thành phần rất quan trọng của hệ thống. Nó bao gồm các luật hoặc ngữ
pháp JAPE để nhận dạng thực thể.
Chapter 4: Thực nghiệm và phân tích lỗi
Trong các thực nghiệm của chúng tôi, chúng tôi sử dụng tập ngữ liệu gồm có 260 bản tin
và chúng đã được gán nhãn theo template đã được định nghĩa ở phần trên. Tập ngữ liệu
này phân chia thành hai tập Traning và Test, mỗi tập gồm có tương ứng 180 và 80 bản
tin. Hệ thống của chúng tôi được xây dựng bằng cách sử dụng các bản tin trong tập
Training và sẽ kiểm tra hệ thống bằng cách sử dụng các bản tin từ tập Test.
4.1 Thước đo đánh giá
Trong các thực nghiệm, chúng tôi các độ đo Precision, Recall và F-measure để đánh giá
hệ thống của chúng tôi. Các độ đo này được định nghĩa như sau:
Precision (P) = (c / a) x 100%
Recall (R) = (c / b) x 100%
F-measure (F) = 2 x (P x R)/ (P + R) x 100%
Trong đó:
a: Tổng số các thực thể được nhận dạng bởi hệ.
b: Tổng số các thực thể được gán nhãn bằng tay.

c: Tổng số các thực thể được nhận dạng đúng.
Đánh giá hiệu suất của hệ thống của chúng tôi được thực hiện dựa trên các hai tiêu
tiêu sau:
Tiêu chí chặt (strict): một thực thể được nhận dạng đúng khi trùng khớp hoàn
toàn (về vị trí), và cùng kiểu với thực thể trong tập dữ liệu chuẩn.
Tiêu chí lỏng (lenient): một thực thể được nhận dạng đúng khi nó có phần chung
và cùng kiểu với thực thể trong tập dữ liệu chuẩn
4.2 Kết quả thực nghiệm
Bảng 1 và Bảng 2 cho thấy hiệu suất của hệ thống trên tập dữ liệu Training sử dụng các
tiêu chuẩn lỏng và chặt, trong khi Bảng 3 và Bảng 4 cho thấy hiệu suất của hệ thống trên
tập dữ liệu Test sử dụng các tiêu chuẩn lỏng và chặt.
Type
(1) - No. of entities annotated manually
(2) - No. of entities recognized
correctly
(3) - No. of entities recognized by
system
(4) - Precision
(5) - Recall
(6) - F-measure
(1) (2) (3) (4) (5) (6)
TypeEstate 180 180 180 100
%
100
%
100
%
CategoryEst
ate 180 176 180 98% 98% 98%
Zone 165 152 160 95% 92% 94%
Area 151 134 134 100
% 89% 94%
Price 147 146 146 100
% 99%
100
%
Contact 463 460 465 99% 99% 99%
All 128
6
124
8
126
5
99
%
97
%
98
%
Bảng 1: Hiệu suất trên tập dữ liệu Training sử dụng tiêu chí lỏng
Type
(1) - No. of entities annotated manually
(2) - No. of entities recognized
correctly
(3) - No. of entities recognized by
system
(4) - Precision
(5) - Recall
(6) - F-measure
(1) (2) (3) (4) (5) (6)
TypeEstate 180 180 180 100
%
100
%
100
%
CategoryEst
ate
180 176 180 98% 98% 98%
Zone 165 112 160 70% 68% 69%
Area 151 132 134 99% 87% 93%
Price 147 146 146 100
%
99% 100
%
Contact 463 457 465 98% 99% 98%
All 128
6
120
3
126
5
95
%
94
%
94
%
Bảng 2: Hiệu suất trên tập dữ liệu Training sử dụng tiêu chí chặt
Type
(1) - No. of entities annotated manually
(2) - No. of entities recognized
correctly
(3) - No. of entities recognized by
system
(4) - Precision
(5) - Recall
(6) - F-measure
(1) (2) (3) (4) (5) (6)
TypeEstate 80 79 80 99% 99% 99%
CategoryEst
ate 80 76 80 95% 95% 95%
Zone 72 62 69 90% 86% 88%
Area 61 51 51 100
% 84% 91%
Price 58 55 55 100
% 95% 97%
Contact 173 172 173 99% 99% 99%
All 524 495 508 97
%
94
%
96
%
Bảng 3: Hiệu suất trên tập dữ liệu Test sử dụng tiêu chí lỏng
Type
(1) - No. of entities annotated manually
(2) - No. of entities recognized
correctly
(3) - No. of entities recognized by
system
(4) - Precision
(5) - Recall
(6) - F-measure
(1) (2) (3) (4) (5) (6)
TypeEstate 80 78 80 98% 98% 98%
CategoryEst
ate 80 68 80 85% 85% 85%
Zone 72 43 69 62% 60% 61%
Area 61 51 51 100
% 84% 91%

Price 58 55 55 100
% 95% 97%
Contact 173 172 173 99% 99% 99%
All 524 467 508 92
%
89
%
91
%
Bảng 4: Hiệu suất trên tập dữ liệu Test sử dụng tiêu chí chặt
F-measures tổng thể của hệ thống trên tập dữ liệu sử dụng tiêu chí lỏng và chặt lần lượt là
96% và 91%. Tuy nhiên, chúng ta có thể dễ dàng nhìn thấy rằng sự chênh lệch về hiệu
suất giữa các thực thể. Hiệu suất trên thực thể Zone là thấp nhất, phản ánh thực tế là các
thực thể Zone khá nhập nhằng và khó nhận dạng. Điều này một phần là do thực tế các
thực thể Zone trong tiếng Việt thường khá dài và trình bày theo nhiều định dạng khác
nhau. Điều này cũng giải thích lý do tại sao hiệu suất cho các thực thể Zone được cải
thiện đáng kể khi sử dụng với tiêu chuẩn lỏng so với các tiêu chuẩn chặt.
4.3 Phân tích lỗi
Một số nguyên nhân chính gây ra lỗi cho hệ thống của chúng tôi như sau:
Phong các viết khác nhau.
Một số thực thể đặc biệt là thực thể Zone thì khá dài và khong được viết hoa cho các
từ.
Lấy 2 ví dụ sau đây:
"Tôi cần mua căn hộ tại Mỹ đình – từ liêm – Hà Nội."
"I need to buy an apartment in My Dinh - Tu Liem – Ha Noi."
"Liên hệ: anh minh - 0987214931."
"Contact: anh Minh - 0987214931."
Tên địa điểm (cụm từ "Mỹ đình – từ liêm – Hà Nội") trong ví dụ đầu tiên và tên người
(cụm từ "anh minh") trong ví dụ thứ 2 không viết viết hoa các ký tự đầu tiên của từ. Do
đó hệ thống của chúng tôi sẽ rất khó để nhận dạng đúng.
Chapter 5: Kết luận và Hướng phát triển
Chúng tôi xây dựng một hệ thống cho rút trích thông tin từ các quảng cáo nhà đất trong
Tiếng Việt. Cách tiếp cận của chúng tôi là khá hợp lý cho các nguồn lực ngôn ngữ, đặc

biệt là cho các nhiệm vụ mà không có dữ liệu gán nhãn. Hệ thống của chúng tôi đạt được
F-measure là 91% khi sử dụng tiêu chí chặt.
Trong tương lai chúng tôi sẽ cần cái thiện hiệu quả của hệ thống cho thực thể Zone.
Chúng tôi cũng sẽ thử sử dụng phương pháp học máy trên tập dữ liệu đã được gán nhãn
của chúng tôi và tìm giải pháp có thể kết hợp cả phương pháp học máy và hệ luật.
References
[1]. J. Cowie and Y. Wilks, “Information extraction,” 2000.
[2]. D. B. Nguyen, S. H. Hoang, S. B. Pham, and T. P. Nguyen, “Named entity
recognition for vietnamese,” in Proceedings of the Second international conference
on Intelligent information and database systems: Part II, ser. ACIIDS’10. Berlin,
Heidelberg: Springer-Verlag, 2010, pp. 205–214. [Online]. Available:
http://dl.acm.org/citation.cfm? id=1894808.1894834
[3]. T.-V. T. Nguyen and T. H. Cao, “Vn-kim ie: automatic extraction of vietnamese
named-entities on the web,” New Gen. Comput., vol. 25, no. 3, pp. 277–292, jan
2007. [Online]. Available: http://dx.doi.org/10.1007/s00354-007-0018-4
[4]. A. Borthwick, J. Sterling, E. Agichtein, and R. Grishman, “Exploiting dictionaries in
named entity extraction: combining semi-markov extraction processes and data
integration methods,” in Proceedings of the tenth ACM SIGKDD international
conference on Knowledge discovery and data mining, ser. KDD ’04. New York, NY,
USA: ACM, 2004, pp. 89–98. [Online]. Available: http://doi.acm.org/10.1145/
1014052.1014065
[5]. A. Mansouri, L. S. Affendey, and A. Mamat, “Named entity recognition using a new
fuzzy support vector machine,” International Journal of Computer Science and
Network Security, IJCSNS, vol. 8, no. 2, pp. 320– 325, February 2008.
[6]. X. Fang and H. Sheng, “A hybrid approach for chinese named entity recognition,” in
Proceedings of the 5th International Conference on Discovery Science, ser. DS ’02.
London, UK, UK: Springer-Verlag, 2002, pp. 297–301. [Online]. Available:
http://dl.acm.org/citation.cfm? id=647859.736133

[7]. R. Srihari, C. Niu, and W. Li, “A hybrid approach for named entity and sub-type
tagging,” in Proceedings of the sixth conference on Applied natural language
processing, ser. ANLC ’00. Stroudsburg, PA, USA: Association for Computational
Linguistics, 2000, pp. 247–254. [Online]. Available:
http://dx.doi.org/10.3115/974147.974181
[8]. I. Budi and S. Bressan, “Association rules mining for name entity recognition,” in
Proceedings of the Fourth International Conference on Web Information Systems
Engineering, ser. WISE ’03. Washington, DC, USA: IEEE Computer Society, 2003,
pp. 325–. [Online]. Available: http://dl.acm.org/citation.cfm?id=960322.960421
[9]. D. Maynard, V. Tablan, C. Ursu, H. Cunningham, and Y. Wilks, “Named entity
recognition from diverse text types,” in In Recent Advances in Natural Language
Processing 2001 Conference, Tzigov Chark, 2001.
[10]. K. Pastra, D. Maynard, O. Hamza, H. Cunningham, and Y. Wilks, “How feasible
is the reuse of grammars for named entity recognition,” in In Proceedings of the 3rd
Conference on Language Resources and Evaluation (LREC), Canary Islands, 2002.
[11]. D. Maynard, K. Bontcheva, and H. Cunningham, “Towards a semantic extraction
of named entities,” in In Recent Advances in Natural Lan-guage Processing, 2003.
[12]. D. M. Bikel, S. Miller, R. Schwartz, and R. Weischedel, “Nymble: a high-
performance learning name-finder,” in Proceedings of the fifth conference on
Applied natural language processing, ser. ANLC ’97. Stroudsburg, PA, USA:
Association for Computational Linguistics, 1997, pp. 194–201. [Online]. Available:
http://dx.doi.org/10.3115/ 974557.974586
[13]. Y.-C. Wu, T.-K. Fan, Y.-S. Lee, and S.-J. Yen, “Extracting named entities using
support vector machines,” in Proceedings of the 2006 international conference on
Knowledge Discovery in Life Science Literature, ser. KDLL’06. Berlin, Heidelberg:
Springer-Verlag, 2006, pp. 91–103. [Online]. Available:
http://dx.doi.org/10.1007/11683568_8
[14]. T. Nguyen, O. Tran, H. Phan, and T. Ha, “Named entity recognition in vietnamese
free-text and web documents using conditional random fields,” Proceedings of the

Eighth Conference on Some Selection Prob-lems of Information Technology and
Telecommunication, Hai Phong, Viet Nam, 2005.
[15]. P. T. X. Thao, T. Q. Tri, A. Kawazoe, D. Dinh, and N. Collier, “Construction of
vietnamese corpora for named entity recognition,” in Large Scale Semantic Access to
Content (Text, Image, Video, and Sound), ser. RIAO ’07. Paris, France, France: LE
CENTRE DE HAUTES ETUDES INTERNATIONALES D’INFORMATIQUE
DOCUMENTAIRE, 2007, pp. 719–724. [Online]. Available: http:
//dl.acm.org/citation.cfm?id=1931390.1931459
[16]. T. W. Hong and K. L. Clark, “Using grammatical inference to automate
information extraction from the web,” in Proceedings of the 5th European
Conference on Principles of Data Mining and Knowledge Discovery, ser. PKDD ’01.
London, UK, UK: Springer-Verlag, 2001, pp. 216–227. [Online]. Available:
http://dl.acm.org/citation.cfm?id= 645805.669995
[17]. H. Seo, J. Yang, and J. Choi, “Building intelligent systems for mining in-
formation extraction rules from web pages by using domain knowledge,” in in Proc.
IEEE Int. Symp. Industrial Electronics, Pusan, Korea, 2001, pp. 322–327.
[18]. D. D. Pham, G. B. Tran, and S. B. Pham, “A hybrid approach to vietnamese word
segmentation using part of speech tags,” in Proceedings of the 2009 International
Conference on Knowledge and Systems Engineering, ser. KSE ’09. Washington, DC,
USA: IEEE Computer Society, 2009, pp. 154–161. [Online]. Available:
http://dx.doi.org/10.1109/KSE.2009.44