Embed Size (px)
DESCRIPTION
n
Citation preview
INFORME EJECUTIVO
PROBLEMA:
Determinar si los datos ausentes se distribuyen aleatoriamente a través de los casos y de las variables.
RESULTADOS
1ER METODO (DIFERENCIAS)
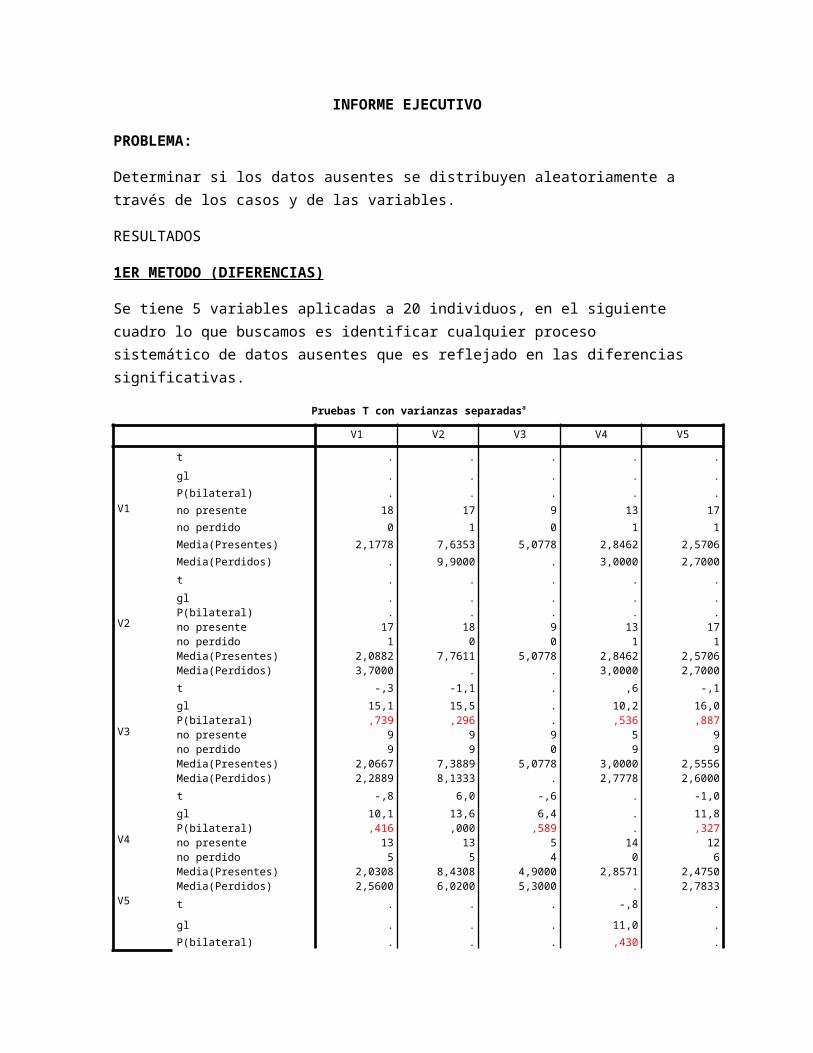
Se tiene 5 variables aplicadas a 20 individuos, en el siguiente cuadro lo que buscamos es identificar cualquier proceso sistemático de datos ausentes que es reflejado en las diferencias significativas.
Pruebas T con varianzas separadasa
V1 V2 V3 V4 V5
V1
t . . . . .
gl . . . . .P(bilateral) . . . . .no presente 18 17 9 13 17no perdido 0 1 0 1 1Media(Presentes) 2,1778 7,6353 5,0778 2,8462 2,5706Media(Perdidos) . 9,9000 . 3,0000 2,7000
V2
t . . . . .gl . . . . .P(bilateral) . . . . .no presente 17 18 9 13 17no perdido 1 0 0 1 1Media(Presentes) 2,0882 7,7611 5,0778 2,8462 2,5706Media(Perdidos) 3,7000 . . 3,0000 2,7000
V3
t -,3 -1,1 . ,6 -,1gl 15,1 15,5 . 10,2 16,0P(bilateral) ,739 ,296 . ,536 ,887no presente 9 9 9 5 9no perdido 9 9 0 9 9Media(Presentes) 2,0667 7,3889 5,0778 3,0000 2,5556Media(Perdidos) 2,2889 8,1333 . 2,7778 2,6000
V4
t -,8 6,0 -,6 . -1,0gl 10,1 13,6 6,4 . 11,8P(bilateral) ,416 ,000 ,589 . ,327no presente 13 13 5 14 12no perdido 5 5 4 0 6Media(Presentes) 2,0308 8,4308 4,9000 2,8571 2,4750Media(Perdidos) 2,5600 6,0200 5,3000 . 2,7833
V5
t . . . -,8 .
gl . . . 11,0 .P(bilateral) . . . ,430 .no presente 17 17 9 12 18no perdido 1 1 0 2 0Media(Presentes) 2,0882 7,6353 5,0778 2,8333 2,5778Media(Perdidos) 3,7000 9,9000 . 3,0000 .
Para cada variable cuantitativa, los pares de grupos están formados por variables indicador (presente, perdido).
a. Las variables indicador con menos del 5% de los valores perdidos no se muestran.
Como se observa en el cuadro observamos diferencias significativas entre los dos grupos pero este impacto es superficial dado que los datos ausentes son pequeños.
2DO METODO (CORRELACIONES)
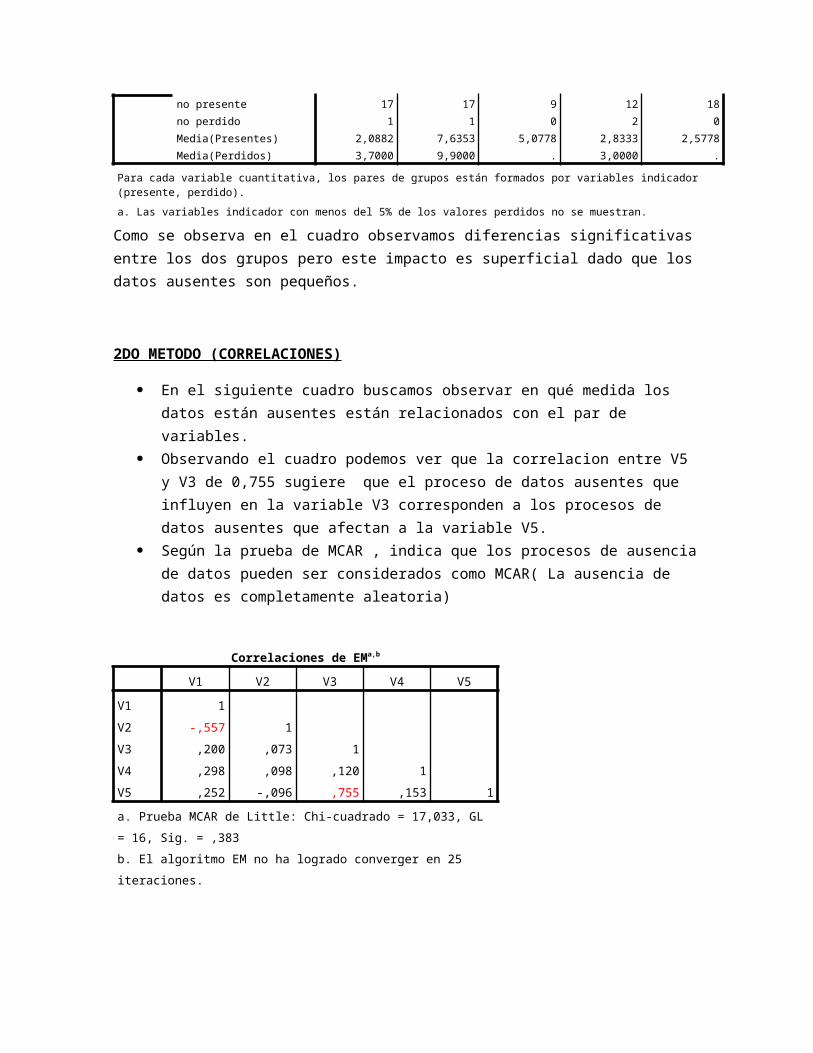
En el siguiente cuadro buscamos observar en qué medida los datos están ausentes están relacionados con el par de variables.
Observando el cuadro podemos ver que la correlacion entre V5 y V3 de 0,755 sugiere que el proceso de datos ausentes que influyen en la variable V3 corresponden a los procesos de datos ausentes que afectan a la variable V5.
Según la prueba de MCAR , indica que los procesos de ausencia de datos pueden ser considerados como MCAR( La ausencia de datos es completamente aleatoria)
Correlaciones de EMa,b
V1 V2 V3 V4 V5
V1 1
V2 -,557 1
V3 ,200 ,073 1
V4 ,298 ,098 ,120 1
V5 ,252 -,096 ,755 ,153 1
a. Prueba MCAR de Little: Chi-cuadrado = 17,033, GL = 16, Sig.
= ,383
b. El algoritmo EM no ha logrado converger en 25 iteraciones.
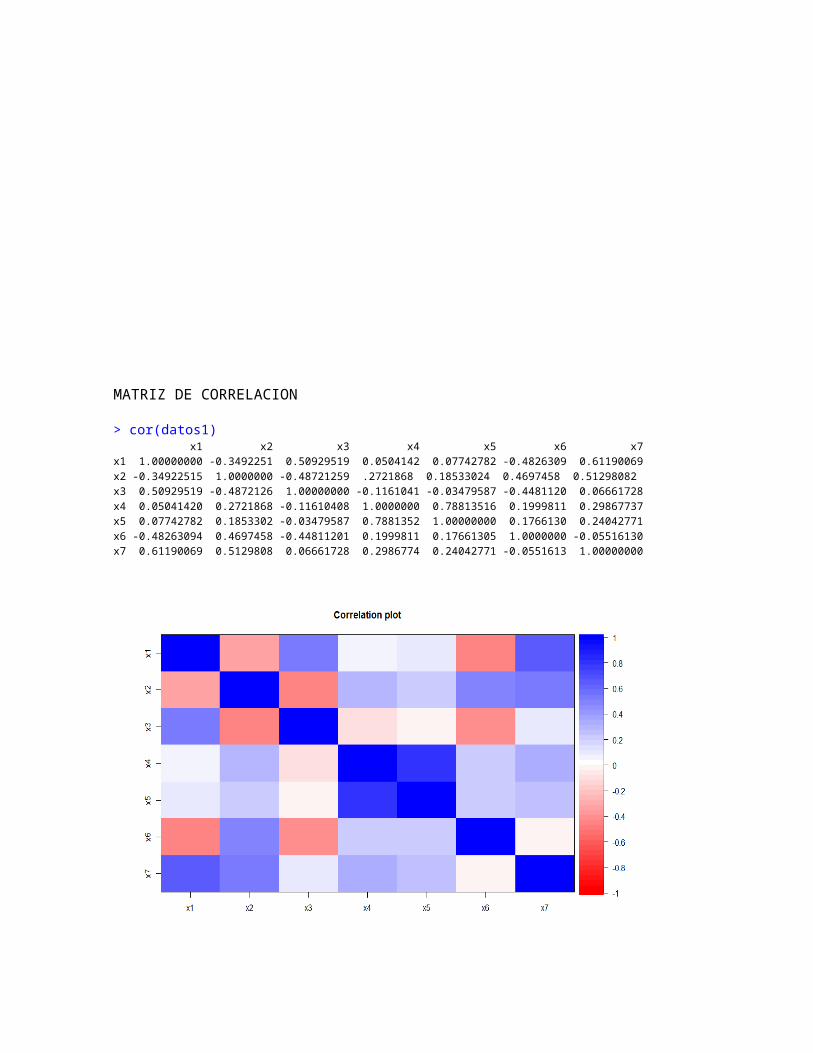
MATRIZ DE CORRELACION
> cor(datos1) x1 x2 x3 x4 x5 x6 x7x1 1.00000000 -0.3492251 0.50929519 0.0504142 0.07742782 -0.4826309 0.61190069x2 -0.34922515 1.0000000 -0.48721259 .2721868 0.18533024 0.4697458 0.51298082x3 0.50929519 -0.4872126 1.00000000 -0.1161041 -0.03479587 -0.4481120 0.06661728x4 0.05041420 0.2721868 -0.11610408 1.0000000 0.78813516 0.1999811 0.29867737x5 0.07742782 0.1853302 -0.03479587 0.7881352 1.00000000 0.1766130 0.24042771x6 -0.48263094 0.4697458 -0.44811201 0.1999811 0.17661305 1.0000000 -0.05516130x7 0.61190069 0.5129808 0.06661728 0.2986774 0.24042771 -0.0551613 1.00000000
EXISTE ASOCIACION LINEAL ENTRE LAS VARIABLES
para evaluar si el modelo factorial (o la extracción de los factores) en su conjunto es significativo.
ESFERICIDAD DE BARLET
> cortest.bartlett(cor(datos1),n=dim(datos1))$chisq[1] 567.4674 16.7773
$p.value[1] 1.094129e-106 7.245145e-01
$df[1] 21
P_valor<0.05 se puede aplicar el análisis factorial

KM2
# Indicador Kaiser-Meyer-Olkinn KMO y MSA> KMO(datos1)Kaiser-Meyer-Olkin factor adequacyCall: KMO(r = datos1)Overall MSA = 0.45MSA for each item = x1 x2 x3 x4 x5 x6 x7 0.34 0.33 0.91 0.56 0.55 0.93 0.29
Podemos ver que la relación entre las variables x2 , x1 y x7 no son muy buenas
VALORES PROPIOS
VECTORES PROPIOS
CORRELACON ENTRE LAS VARIABES Y COMPONENTES
MAXIMA VERSIMILITUD SIN ROTACION
Y CON ROTACION



























