Embed Size (px)
Citation preview

Intelligenza Artificiale: Appunti per un’Introduzione
Paola Mello e Maurelio Boari Dipartimento di Informatica – Scienza e Ingegneria, Università di Bologna
e-mail: [email protected], [email protected]
Sommario
Obiettivo di questo articolo divulgativo, è presentare in modo semplice, necessariamente sintetico e ovviamente non esaustivo, la disciplina dell’Intelligenza Artificiale (IA), le sue origini, le sfide affrontate, i principali risultati ottenuti e le domande, alcune ancora senza risposta, su cosa aspettarsi da questa disciplina nel futuro più immediato. In particolare, verranno presentate, ad alto livello ed in modo intuitivo, alcune tecnologie e tecniche sviluppate nell’ambito dell’IA e ritenute significative per la sua comprensione, ed esempi significativi delle sue molteplici applicazioni. Saranno menzionati anche aspetti etici, economici e sociali di questa affascinante disciplina, che sarà sempre maggiormente presente nel futuro di tutti. Questo lavoro può quindi essere anche concepito come base e materiale di riferimento per gli studenti in una lezione introduttiva alla disciplina dell’IA nei Corsi di Intelligenza Artificiale.
L’articolo è organizzato come segue:
1 Introduzione ................................................................................................................................. 3
2 Alcuni Cenni Storici..................................................................................................................... 4
3 Le mille sfaccettature dell’IA: quale definizione? ....................................................................... 8
4 Le tecnologie .............................................................................................................................. 13
4.1 La rappresentazione della conoscenza e la soluzione di problemi ...................................... 13
4.1.1 Sistemi basati sulla conoscenza e sistemi esperti......................................................... 15
4.1.2 Conoscenza di buon senso comune e Web Semantico ................................................ 17
4.1.3 La logica e il ragionamento, la dimostrazione automatica e Prolog ............................ 19
4.2 L’apprendimento ................................................................................................................. 23
4.2.1 Apprendimento simbolico ............................................................................................ 24
4.2.2 Apprendimento sub-simbolico e Reti neurali .............................................................. 27
5 Le grandi sfide e i risultati raggiunti .......................................................................................... 33
5.1 Il gioco degli scacchi e Deep Blue ...................................................................................... 34
5.2 Watson e la risposta a domande .......................................................................................... 36
5.3 Il gioco del GO e AlphaGo.................................................................................................. 37
5.4 I robot giocano a calcio ....................................................................................................... 39
6 Verso il futuro (aspetti economici, sociali e etici) ..................................................................... 39
6.1 Aspetti economici e sociali.................................................................................................. 40
6.2 Aspetti etici.......................................................................................................................... 42

7 Le maggiori Associazioni Scientifiche e Conferenze di IA ....................................................... 47
8 Conclusioni ................................................................................................................................ 47
Ringraziamenti ................................................................................................................................... 48
Riferimenti ......................................................................................................................................... 49

1 Introduzione La disciplina dell’Intelligenza Artificiale (IA) è affascinante, ma anche controversa e discussa. Dalla sua nascita, più di 60 anni fa, si è data obiettivi a volte ritenuti e poi rivelatisi troppo ambiziosi, ma ha anche ottenuto risultati importanti ed esaltanti e vinto sfide prestigiose. Grazie alla feconda attività di ricerca svolta in questo campo in molte aree applicative quali, ad esempio, la visione artificiale, la comprensione del linguaggio naturale, i sistemi di supporto alle decisioni, e la robotica, i risultati dell’IA oggi come oggi sono manifesti ed evidenti e hanno grandi ricadute a livello applicativo, destando interesse non solo da parte degli addetti ai lavori, ma anche presso un vasto e variegato pubblico. Si pensi, ad esempio, ai sistemi di supporto alle decisioni che ci aiutano a scelte più informate in svariati campi applicativi, agli assistenti digitali a controllo vocale, ai sistemi per l’assistenza agli anziani, e alle automobili con guida autonoma, solo per citarne alcuni.
Questa presenza dell’IA nella vita di tutti i giorni sta generando grande interesse ed è, recentemente, al centro di notizie su quotidiani e mass media che hanno grande risalto ed impatto sul pubblico, alimentando entusiasmi, ma anche domande, interrogativi e a, volte, anche preoccupazioni su cosa aspettarsi nel prossimo futuro. Alcuni film di fantascienza dagli aspetti inquietanti (si pensi al famoso Blade Runner) potranno diventare realtà? Ci troveremo davanti ad agenti intelligenti, magari antropomorfi, con un grado di intelligenza superiore a quella umana e in grado di prendere decisioni, anche pericolose, autonomamente? Il loro sviluppo porterà le macchine a sostituire l’uomo nei posti di lavoro producendo disoccupazione e maggiore povertà nella società?
Scriveva Alan Turing nel 1950 [1]:
“I believe that in about fifty years' time it will be possible, to programme computers, with a storage capacity of about 109, to make them play the imitation game so well that an average interrogator will not have more than 70 per cent chance of making the right identification after five minutes of questioning. The original question, “Can machines think?” I believe to be too meaningless to deserve discussion. Nevertheless I believe that at the end of the century the use of words and general educated opinion will have altered so much that one will be able to speak of machines thinking without expecting to be contradicted”.
Siamo certo ancora lontani dai risultati previsti da Turing, ma va comunque sottolineato che l’IA ha raggiunto nel corso degli anni risultati significativi in molte applicazioni, alternando momenti di entusiasmo e di delusione, di vittorie e di sconfitte, di colorate primavere e di cupi inverni. Ora, grazie alle sempre crescenti capacità computazionali e all’enorme mole di dati e informazioni disponibili, assieme ad algoritmi efficaci ed efficienti soprattutto nel campo dell’apprendimento automatico, l’IA sta vivendo una nuova primavera.
Scrive il filosofo Alessandro Di Caro [2]:
“Sempre di più oggi dobbiamo tenere conto della macchina. Molti mestieri sono sostituiti dalla macchina... Auto che si guidano da sole, eserciti di robot, Deep Blue che sconfigge Kasparov, “Jeopardy” (un gioco a premi nordamericano) che viene vinto da Watson, un computer della IBM. Tutto questo è solo un modo letterario o fantascientifico di prevedere il futuro o invece è una direzione inaspettata a cui la civiltà umana (o transumana? O post-umana) non ha per nulla pensato?”
Senza immaginare futuri e inquietanti mondi possibili in cui le macchine potranno superare e sovrastare l’uomo, è indubbio che l’IA sarà sempre maggiormente presente nel futuro di tutti, e che è quindi nostro compito già ora conoscerla nelle sue mille declinazioni, e svilupparla ed utilizzarla con l’ottica di portare vantaggi e benefici all’evoluzione della nostra società.
Obiettivo di questo lavoro, di tipo divulgativo, è presentare in modo semplice, necessariamente sintetico e non esaustivo, la disciplina dell’IA, le sue origini, le sfide affrontate, i principali risultati ottenuti e le domande, alcune ancora senza risposta, su cosa ci possiamo aspettare nel futuro più immediato. Verranno presentate

inoltre, sempre ad alto livello ed in modo intuitivo, alcune tecnologie e tecniche sviluppate dall’IA ritenute significative per la sua comprensione con l’obiettivo di rendere accessibili, anche ad un vasto pubblico, i maggiori risultati e i più recenti sviluppi dell’IA. L’articolo si conclude con una sintetica panoramica sugli aspetti di tipo etico, economico e sociale sempre più importanti da considerare visti i più recenti sviluppi di questa affascinante disciplina. Questo lavoro può quindi essere anche concepito come base e materiale di riferimento per gli studenti in una lezione introduttiva alla disciplina dell’IA nei Corsi di Intelligenza Artificiale.
2 Alcuni Cenni Storici Si potrebbe affermare che l’IA è vecchia quanto il mondo e trae le sue origini a partire dalle domande più profonde relative alla mente umana ed alle sue caratteristiche. In questo senso, coinvolge non solo l’informatica intesa come disciplina più moderna, ma anche la filosofia, la psicologia cognitiva, le neuroscienze, la logica, la matematica, la linguistica, la cibernetica ecc. A tale proposito, riportiamo nel seguito alcune considerazioni estratte dal “Discorso sul Metodo” di Cartesio del 1637 in cui si pongono già domande ben articolate e precise sulla possibilità di costruire macchine dal comportamento “intelligente”, e in cui lo scetticismo è connesso soprattutto alla capacità di intrattenere conversazioni completamente assimilabili a quelle di un umano in linguaggio naturale e alla presenza, nella macchina autonoma, di una conoscenza sostanzialmente puramente sintattica, ignara del significato profondo di parole e simboli.
“Qui in particolare mi ero fermato per far vedere che se ci fossero macchine con organi e forma di scimmia o di qualche altro animale privo di ragione, non avremmo nessun mezzo per accorgerci che non sono in tutto uguali a questi animali; mentre se ce ne fossero di somiglianti
ai nostri corpi e capaci di imitare le nostre azioni per quanto di fatto possibile, ci resterebbero sempre due mezzi sicurissimi per riconoscere che, non per questo, sono uomini veri. In primo luogo, non potrebbero mai usare parole o altri segni combinandoli come facciamo noi per comunicare agli altri i nostri pensieri. Perché pur nel concepire che una macchina sia fatta in modo tale da proferire parole e ne proferisca anzi in relazione a movimenti corporei che provochino qualche cambiamento nei suoi organi; che chieda, ad esempio, che cosa si vuole da
lei se la si tocca in qualche punto, o se si tocca in un altro gridi che le si fa male e così via; ma
non si può immaginare che possa combinarle in modi diversi per rispondere al senso di tutto quel che si dice in sua presenza, come possono fare gli uomini, anche i più ottusi. L'altro criterio è che quando pure facessero molte cose altrettanto bene o forse meglio di qualcuno di noi, fallirebbero inevitabilmente in altre, e si scoprirebbe così che agiscono non in quanto conoscono, ma soltanto per la disposizione degli organi.” [3]
A testimonianza del grande desiderio di “mimare” il ragionamento umano, nato ben prima della disciplina dell’IA, ricordiamo il noto caso del “Turco” creato nel 1770 dal nobile ungherese Wolfgang von Kempelen e presentato alla corte d'Austria come un automa in grado di giocare a scacchi, mentre era invece manovrato da un uomo di bassa statura nascosto al suo interno. Solo nel 1997, come meglio si discuterà nella sezione 5.1, un prodotto di IA batterà il campione mondiale di scacchi in piena autonomia.
Avvicinandoci alla storia più recente, anche se la nascita del termine “Artificial Intelligence” è da ascrivere al convegno del Dartmouth College del 1956, lo studio dell’IA ha la sua prima gestazione nei decenni precedenti, con lo studio dei sistemi formali, della dimostrazione automatica, delle basi teoriche relative all’informatica, e del calcolatore. Già Gödel nel 1931 [4] si era posto domande sui sistemi formali ed i loro limiti mostrando che ci sono affermazioni vere che non possono essere dimostrate dalle regole logiche. Analogamente, Turing nel 1936 [5] aveva riproposto questo limite riferendosi ad un modello di calcolatore teorico e “universale” (la

“Macchina di Turing” - base teorica fondamentale per tutti i calcolatori che verranno poi sviluppati) e mostrando che non tutte le funzioni sono computabili su tale macchina.
Nel 1943, W.S. McCulloch e Walter Pitts pubblicarono un lavoro basilare per lo sviluppo dell’IA: “A logical calculus of the ideas immanent in nervous activity" [6], introducendo i neuroni artificiali e la possibilità di connetterli per costituire opportune reti neurali.
Nel 1950 poi, Turing nel famoso articolo “Computing Machinery and Intelligence” [1] propose il “gioco dell’imitazione” nel tentativo di rispondere a una domanda certamente basilare per l’IA: “Le macchine possono pensare”? La macchina, dal punto di vista formale, poteva essere definita sulla base della macchina “universale” di Turing (e quindi con un computer digitale), mentre il termine “pensare” è difficilmente definibile in modo univoco e non ambiguo. Per questo la formulazione della domanda e la conseguente definizione di intelligenza portarono ad una nuova formulazione del problema nei termini di un gioco (appunto il gioco dell’imitazione). Sinteticamente, ed in modo semplificato possiamo descrivere il gioco come segue. Vi sono tre partecipanti, separati tra di loro in tre stanze diverse: una persona, una macchina (computer), e un’altra persona. La prima persona, attraverso la formulazione di domande ai restanti partecipanti (e valutando le loro risposte), deve determinare in un tempo finito quale sia l’uomo e quale la macchina. La domanda, allora, si può riformulare come segue: “È possibile che computer con adeguata memoria e potenza di calcolo e adeguatamente programmati, possano ingannare l’interrogante comportandosi come un essere umano?”
Da questa domanda, strettamente connessa al gioco dell’imitazione, consegue una definizione “funzionale” o “comportamentista” dell’IA. La macchina si comporta “come se” fosse umana, l’approccio è di tipo ingegneristico, ai “morsetti” ed emulativo. Non richiede necessariamente di mimare o simulare all’interno modalità peculiari dell’intelligenza umana, ma di riprodurne gli effetti all’esterno. Ovviamente, tale approccio ha portato a notevoli ed appassionanti discussioni nell’ambito dell’IA da parte di filosofi nei decenni successivi (si veda il testo di Russel e Norvig [7] per una sintesi di tali discussioni). Dal punto di vista prettamente tecnico, riferendosi al test di Turing, il computer deve necessariamente avere capacità evolute ed integrate in molti ambiti quali l’elaborazione del linguaggio naturale, la rappresentazione della conoscenza, il ragionamento e l’apprendimento automatico.
Fra i primi tentativi di sviluppare un dialogo uomo—macchina che “mimi” un dialogo uomo—uomo non si può non menzionare il chatbot Eliza: sviluppato da Weizenbaum nel 1966 [8], impersonava una psico-terapeuta. Eliza rivelò tutti i limiti e le incoerenze di un approccio puramente sintattico: le domande e le risposte erano formulate seguendo schemi predefiniti e utilizzando manipolazioni sintattiche basate sulle affermazioni del paziente stesso.
Anche oggi esistono varie sfide e competizioni per cercare di emulare il test di Turing almeno parzialmente (si veda il Loebner Prize1), a volte con risultati discutibili. Numerosi assistenti digitali, anche a controllo vocale, sono entrati a far parte dell’esperienza comune, e hanno raggiunto buoni livelli nell’interazione e il dialogo (si pensi a SIRI di Apple, CleverBot, Cortana di Microsoft, Echo e Alexa di Amazon, Home di Google, solo per citarne alcuni). Sono inoltre stati proposti nel corso degli anni altri test nell’ottica di Turing, volti a enfatizzare anche altre capacità ritenute essenziali quali, ad esempio, le senso-motorie, creative, emotive e il ragionamento di buon senso. Ad esempio, citiamo la formulazione di nuovi test basati sugli schemi di Winograd [9], dove all’agente intelligente viene richiesta non solo una mera capacità di analisi sintattica, ma anche spiccate capacità di interpretazione e di ragionamento di buon senso comune. Negli schemi di Winograd infatti il computer deve rispondere a domande del tipo: “Giovanna aveva ringraziato Maria per il regalo che Lei aveva ricevuto. A chi si riferisce il pronome Lei?”. Rispondere a questa domanda richiede di risolvere l’ambiguità relativa al pronome “Lei”, che potrebbe essere riferito sia a Giovanna, sia a Maria. Per risolvere tale ambiguità una pura conoscenza sintattica non basta, ma è necessaria anche una conoscenza semantica: solo sapendo il significato dei verbi “ringraziare”, “ricevere”, e del termine “regalo” si può correttamente rispondere
1 http://www.loebner.net/Prizef/loebner-prize.html, consultato il 13 Giugno 2017.

“Giovanna”. Per noi umani risulta un’operazione semplice, ma per il computer il problema richiede una conoscenza ampia sul significato dei termini della frase, e risulta ancora di difficile soluzione nei casi più generali. Per una visione aggiornata di come si può concepire ed estendere oggi il test di Turing si consulti il recente numero speciale “Beyond the Turing Test” della rivista AI Magazine [10].
Si è soliti far risalire la nascita dell’IA, intesa come disciplina, al 1956, quando presso il Dartmouth College (Stati Uniti) si tenne un workshop al quale parteciparono nomi noti nell’area dello studio dei sistemi intelligenti
(J. McCarthy—Dartmouth College, M. L. Minsky—Harvard University, N. Rochester—I.B.M.
Corporation, C. E. Shannon—Bell Telephone Laboratories) con l’obiettivo proprio di definire la disciplina dell’IA e sviluppare alcuni progetti di ricerca per simulare l’intelligenza umana. Nella proposta del workshop si legge [11]:
“We propose that a 2 month, 10 man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College in Hanover, New Hampshire. The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it. An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.”
All’epoca, quindi, si ritenne che in poco tempo si sarebbero ottenuti risultati eclatanti: il tutto si rivelò in realtà molto più complicato di quanto previsto.
Gli anni successivi furono particolarmente ricchi per la disciplina dell’IA. L’attenzione si spostò da una visione in cui il computer era principalmente un elaboratore aritmetico, a quella in cui veniva concepito come una macchina di alto livello capace di risolvere problemi ed elaborare simboli. Ad esempio, è del 1959, la nascita del linguaggio di programmazione LISP, ad opera di McCarthy [12]. Contemporaneamente, la ricerca si concentrò sullo sviluppo di programmi generali per la soluzione di problemi e giochi dove, a livello architetturale, era prevista una netta separazione fra la formalizzazione dei problemi (base di conoscenza) e le tecniche (euristiche) di risoluzione (motore di inferenza o controllo) [13].
Nei decenni successivi la disciplina dell’IA attraversò momenti di luce ed ombre, risultati entusiasmanti e grosse delusioni. Sicuramente gli strumenti computazionali a disposizione dei primi programmatori di IA erano poveri se confrontati con quelli odierni, ma alcuni programmi esibivano comunque comportamenti interessanti nella risoluzione di problemi (ad esempio, si considerino i risultati relativi alla ricerca sulle reti neurali). Diventò comunque chiaro e manifesto che gli obiettivi dell’IA, nella loro generalità, erano difficili se non impossibili da raggiungere a breve termine a causa delle elevatissime capacità di calcolo richieste e della difficoltà di trattare i problemi e la conoscenza non solo a livello di forma (visione sintattica) ma di sostanza e contenuto (visione semantica).
Alcuni programmi non erano davvero competenti (si pensi ad Eliza [8] e ai suoi dialoghi sintattici), mentre altri erano intrattabili a causa dell’esplosione combinatoria. Le reti neurali, invece, si rivelavano spesso inadeguate nel trattare problemi di classificazione apparentemente semplici. Lo stesso Minsky evidenziò le limitazioni del percettrone [14] nel risolvere problemi di classificazione non lineare, cioè riferiti a domini in cui i casi/esempi positivi e negativi da classificare, se rappresentati in uno spazio a due (o a n-dimensioni in generale) non sono separabili mediante una retta (o iperpiano). Questo comportava che anche funzioni apparentemente semplici quali la funzione XOR non potevano essere opportunamente rappresentate tramite reti neurali.
Negli anni Settanta del Ventesimo secolo comparvero i primi Sistemi Esperti: sistemi di IA che cercano di risolvere un particolare compito emulando un umano, esperto del settore in un dominio limitato e specializzato,

offrendo spesso anche spiegazioni sul meccanismo di ragionamento impiegato. Dal punto di vista architetturale, i Sistemi Esperti sono sistemi basati sulla conoscenza, dove la base di conoscenza è costituita e derivata dalla conoscenza dell’esperto di dominio, ed è tipicamente rappresentata sotto forma di regole. I meccanismi di ragionamento adottati per risolvere il problema sfruttano tale base di conoscenza, e sono realizzati invece mediante un motore di inferenza che implementa opportuni algoritmi di ragionamento. Uno dei primi Sistemi Esperti sviluppato in questo periodo è MYCIN [15] che, utilizzando opportune regole e ragionamento incerto, era in grado di produrre diagnosi relative ad infezioni batteriche del sangue, suggerendo anche un’opportuna terapia antibiotica.
Negli anni 80 del ventesimo secolo i primi successi dei Sistemi Esperti, applicati in vari campi quali la diagnosi, la progettazione, il monitoraggio, l’interpretazione di dati e la pianificazione, produssero un grande entusiasmo: come effetto, l’IA “uscì” dal mondo della ricerca per trasferirsi, in parte, all’ambito industriale. Molte aziende, specialmente americane e giapponesi, mostrarono grande interesse per queste nuove applicazioni: negli Stati Uniti, in Europa e in Giappone sostanziosi fondi per la ricerca furono impiegati per finanziare progetti di IA. È di questo periodo, ad esempio, il progetto giapponese “Fifth Generation Computing” [16], il cui scopo era la progettazione di nuove macchine di tipo inferenziale basate sulla programmazione logica. A quei tempi si riteneva che nuove architetture dei computer – ispirate ai linguaggi simbolici e ai sistemi di IA – avrebbero sostituito le architetture tradizionali dei computer (basate invece sulla macchina di Von Neumann). Si parlava, allora, di Prolog, Lisp e “Connection Machines” per definire macchine specificatamente progettate, anche a livello hardware, per poter eseguire in modo efficiente, rispettivamente, linguaggi simbolici per IA basati sulla logica, sulle funzioni matematiche o su reti neurali artificiali. In realtà lo sviluppo tecnologico che seguì non rese sufficientemente competitive queste nuove architetture.
Anche le reti neurali, negli anni 80, dopo un periodo di pessimismo sulle loro potenzialità, furono oggetto di rinnovato interesse in ambito applicativo: ciò avvenne in conseguenza della definizione di nuove architetture di reti con più strati e potenti algoritmi di apprendimento, che consentirono di risolvere il problema della separabilità non lineare evidenziata a suo tempo da Marvin Minsky. Notevole successo ebbe l’algoritmo di apprendimento per reti neuronali multistrato di propagazione all’indietro dell'errore (“error backpropagation”), proposto nel 1986 da David E. Rumelhart, G. Hinton e R. J. Williams [17].
I successivi anni 90 si caratterizzarono, invece, come momento di delusione e di ridimensionamento delle aspettative generate precedentemente, a cui seguì un periodo di riflessione e seria riconsiderazione dei punti di forza e debolezza degli approcci utilizzati, e dei risultati prodotti nel settore. Presto si giunse alla consapevolezza che i Sistemi Esperti presentavano evidenti limiti di generalità nel risolvere i problemi, e di colli di bottiglia nella loro realizzazione, questi ultimi soprattutto derivanti dalla difficoltà di costruire ed aggiornare manualmente le basi di conoscenza. In molti campi, quindi, ai Sistemi Esperti si preferirono sistemi di supporto alle decisioni (ancora basati su regole) capaci di affiancare l’utente, senza però completamente sostituire gli esperti umani in attività specializzate.
Negli anni 90 la nascita del World Wide Web (WWW) e del primo browser con un’interfaccia grafica ebbe come effetto un’ampia e rapida diffusione di Internet, consentendo l’accesso a grandi quantità di informazioni e conoscenze, e aprendo quindi nuove prospettive per l’IA. Negli ultimi venti anni si è quindi assistito ad una nuova primavera dell’IA, in cui lo sviluppo degli algoritmi e delle applicazioni è stato facilitato dalla disponibilità di enormi quantità di dati non strutturati (resi disponibili su Web), e da una sempre maggiore disponibilità di potenza di calcolo a basso costo.
Sistemi ed algoritmi di apprendimento sono diventati sempre più efficaci ed efficienti, con un grande perfezionamento di tecniche legate ad architetture neurali (anche a più strati) con apprendimento incrementale e non necessariamente supervisionato (si veda a questo riguardo quanto riportato più avanti a proposito degli algoritmi di apprendimento e deep learning nella sezione 4.2 e 5.4). L’apprendimento automatico è stato applicato con successo, ad esempio, nella classificazione e nell’elaborazione di documenti, nella comprensione

del linguaggio naturale, nella bioinformatica e nell’elaborazione delle immagini. Sono stati sviluppati metodi sempre più efficaci per il riconoscimento del parlato e la classificazione delle immagini, applicati con successo alla robotica e alla visione artificiale. Molti algoritmi di ricerca su web, traduttori, riconoscitori vocali, classificatori di immagini e foto che usiamo quotidianamente traggono vantaggio da queste tecniche e si stanno sempre più perfezionando. Nel 2012, ad esempio, un [18] programma basato su una rete neurale profonda (denominata AlexNet [18]) ha vinto l’ImageNet Challenge2, una sfida basata sulla corretta classificazione di milioni di immagini.
Sempre in questo periodo, l’attenzione della comunità di IA e anche dei mass-media si è concentrata su due importanti sfide che sistemi di IA hanno affrontato con successo. La prima sfida ha riguardato la capacità di rispondere a domande di cultura general, poste in linguaggio naturale, e nel contesto di un noto quiz televisivo americano (Jeopardy). La seconda sfida ha riguardato il gioco del GO, un gioco a due giocatori molto complesso. In entrambe le sfide i sistemi di IA (Watson e AlphaGO, rispettivamente) sono riusciti a battere i campioni umani. Presenteremo più estesamente queste sfide nella Sezione 5.
Nelle parole di Oliviero Stock, primo direttore editoriale di “ Intelligenza Artificiale”, da vent’anni rivista dell’Associazione Italiana per l’IA, i quattro trend principali dell’ IA da sottolineare oggi sono “un forte interesse a sfruttare la grande quantità di dati offerta dall’esplosione del web; il rinnovato interesse per l’intelligenza nella sua interezza; la nuova opportunità di contribuire alla comprensione della connessione tra
mente e cervello; e il consolidamento della dimensione dell’intelligenza, della pianificazione e dell’azione
sociale” [19]. Inoltre, l’IA può assistere le nuove tecnologie, in rapida evoluzione, sia per quanto riguarda la progettazione degli strumenti più adatti, sia in termini di apporto metodologico. Ad esempio, assistiamo in questo periodo allo sviluppo di sensori sempre più sofisticati dal punto di vista tecnologico. Tali sensori richiedono lo sviluppo di sistemi avanzati in grado di processare in modo intelligente e, a volte, in tempo reale le informazioni che essi producono per comprendere automaticamente le situazioni di interesse e pianificare in contesti potenzialmente dinamici. L’utilizzo di tecniche di IA consente un’ampia gamma di applicazioni, che va dai sistemi integrati per la sorveglianza, il monitoraggio e la diagnosi, ai sistemi di teleassistenza e di pianificazione dei trasporti logistici, nonché agli attualissimi veicoli a guida autonoma. La disponibilità di strumenti tecnologici per la domotica apre la possibilità di applicazioni nelle problematiche relative all'invecchiamento della popolazione. Un altro campo applicativo molto interessante è il cosiddetto “Internet del futuro” caratterizzato come una rete aperta, composta da entità auto-organizzate e intelligenti, siano esse software (agenti, servizi web, softbot, avatar), hardware (“cose”, sensori, robot) o esseri umani. Lo studio, la comprensione, la gestione, la simulazione e la regolazione di questo tipo di ambiente complesso, globale, aperto, interattivo è una questione di grande rilievo ed interesse per la ricerca nel campo dell’IA. Tutti i temi menzionati, inoltre, svolgono un ruolo centrale nell'ambito del Programma quadro per la ricerca e l'innovazione della Commissione Europea, denominato Horizon 20203 e nell’ambito di Industria 4.04 mostrando come oramai l’IA sia una disciplina consolidata, fondamentale per lo sviluppo di applicazioni anche in ambito sociale quali sistemi che supportino le attività urbane, la mobilità, le comunicazioni, i consumi energetici, i servizi, il clima, la sicurezza e la salute.
3 Le mille sfaccettature dell’IA: quale definizione? Nella sezione precedente abbiamo volutamente dato una definizione di Intelligenza Artificiale (IA) in modo intuitivo e funzionale. Questo perché in realtà, a tutt’oggi, non esiste una definizione generale e comunemente
2 http://www.image-net.org/challenges/LSVRC/ 3 http://ec.europa.eu/research/horizon2020 4 http://www.mise.gov.it/index.php/it/industria40

accettata di questo termine, a causa della sua soggettività dovuta a sua volta al termine “intelligenza”, anche questo dal significato variegato nel sentire comune.
Il dibattito sul significato e sulla definizione dell’IA è stato ed è ancora molto acceso, ed ha coinvolto varie discipline: dalla psicologia alla filosofia, dalla logica alle neuroscienze, dall’informatica alla linguistica. È stato osservato che lo stesso termine IA è contradditorio, un ossimoro, poiché tende ad attribuire il termine artificiale alla parola intelligenza, spesso ritenuta, invece, una prerogativa distintiva e naturale dell’uomo [20]. Nel seguito riportiamo alcune definizioni del termine IA senza alcuna pretesa di essere esaustivi al riguardo.
La prima definizione che consideriamo è strettamente legata al test di Turing. L’IA può essere infatti definita come, secondo M. L. Ginsberg [21]:
“... l’impresa di costruire sistemi di simboli fisici che possono passare in maniera affidabile il Test di Turing”
Questa definizione, essendo legata al Test di Turing, si riferisce quindi al comportamento osservabile all’esterno (“ai morsetti”) ed è di tipo emulativo. Di fatto, segue un approccio “ingegneristico” al problema ed è stata alla base di gran parte dei risultati applicativi dell’IA (si pensi alle capacità di ragionamento, comprensione del linguaggio naturale e apprendimento).
Più generale, ma anche di più generica interpretazione proprio perché strettamente connessa al termine Intelligenza, è la voce correlata all’AI dell’Enciclopedia Britannica che scrive:
“Artificial Intelligence (AI) is the ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings. The term is frequently applied to the project of developing systems endowed with the intellectual processes characteristic of humans, such as the ability to reason, discover meaning, generalize, or learn from past experience” [22].
Altre due definizioni di IA, molto simili, sono riportate nel seguito:
“L’IA studia i fondamenti teorici, le metodologie e le tecniche che consentono di progettare sistemi hardware e sistemi di programmi software atti a fornire all’elaboratore elettronico prestazioni che, a un osservatore comune, sembrerebbero essere di pertinenza esclusiva dell’intelligenza umana.”, dall’Enciclopedia della Scienza e della Tecnica Treccani [23].
L’IA è “lo studio di come far fare ai calcolatori cose per le quali al momento gli uomini sono migliori”, Rich e Knight, [24].
Le ultime due definizioni riportate sono, per certi versi, transitorie nel loro significato. Si pensi, ad esempio, al gioco degli scacchi, ritenuto storicamente una palestra degli umani per misurarsi in una sfida in termini di intelligenza e strategia. Nel momento in cui una macchina, Deep Blue, ha battuto il campione internazionale di scacchi Kasparov (si veda la sezione 5 al riguardo), la risoluzione di questo problema, secondo la precedente definizione, non ricade più nelle applicazioni ritenute peculiari dell’IA. Lo studio dell’IA quindi si dovrà dedicare ancora e ancora a nuove sfide non risolte e sempre più difficili.
Altre definizioni di IA tendono a non legare necessariamente l’intelligenza (artificiale) agli umani e sottolineano maggiormente l’interazione con il mondo esterno e le capacità di adattarsi ad esso.
A questo proposito, N. J. Nilsson scrive in [25]:
“For me, artificial intelligence is that activity devoted to making machines intelligent, and intelligence is that quality that enables an entity to function appropriately and with foresight in its environment”.

Si noti che, in accordo con questa definizione anche gli animali, i vegetali, gli oggetti e le macchine possono essere ritenute intelligenti se riescono ad interagire in modo utile con l’ambiente che li circonda.
Le definizioni di IA sopra riportate possono ascriversi a quella che viene definita IA “debole”, che considera macchine che si comportano “come se” fossero intelligenti. Il termine si contrappone all’IA “forte”, interessata a macchine che possano davvero pensare autonomamente fino ad avere una mente ed un’autocoscienza propria (si consulti a questo riguardo il fondamentale lavoro di John Searle, in [26]).
Per una discussione più completa di cosa sia l’IA e quante e quali definizioni si possano presentare per essa in base al “punto di vista” con cui si osserva un sistema di IA e all’ambiente in cui lo si voglia fare operare, si consulti il capitolo 1.1 di “Intelligenza Artificiale –Un approccio Moderno” [7], un testo di riferimento ampliamente utilizzato in tutto il mondo nei corsi universitari di Intelligenza Artificiale. In esso le definizioni di IA sono classificate mediante due categorizzazioni: quanto si riferiscono a processi di ragionamento o invece di comportamento, quanto assomiglino ad un’attività peculiare dell’uomo a quanto invece ad un’idea astratta di razionalità.
Questi “punti di vista” hanno portato, quindi, a concepire sistemi di IA molto diversi fra loro sia come impostazione metodologica, sia come risultati e comportamento attesi. Si può, quindi, distinguere [20] fra un'impostazione “funzionale” e un’impostazione “strutturale”. L’impostazione funzionale è detta anche "comportamentista" perché concepisce l’intelligenza in modo indipendente dalla struttura fisica dell’elaboratore che implementa il sistema intelligente. L’intelligenza può quindi essere semplicemente emulata (anche in modo selettivo). Secondo l’impostazione strutturale, detta anche “costruttivista” o “connessionista”, l’intelligenza si ottiene invece simulando il cervello umano e riproducendone la sua stessa struttura e caratteristiche. Figlie di questo filone sono le architetture connessioniste e le reti neurali anche se, normalmente, gli algoritmi che le riproducono sono eseguiti oggi in modo efficiente su architetture hardware di tipo general-purpose.
Più operativamente, ma in modo strettamente collegato ai punti vista enunciati precedentemente, possiamo identificare due differenti approcci all’IA: quello “top down” e quello “bottom up”, già individuati da Turing nel 1948 in un articolo che si può considerare come il primo manifesto dell’IA [27].
L’approccio top-down è, per certi versi, indipendente dal livello sottostante (quale esso sia, computer o cervello) ed adotta tipicamente un approccio simbolico: gli stati mentali vengono identificati con rappresentazioni di tipo simbolico all’interno di un sistema simbolico-fisico (si consulti al riguardo il lavoro di Newell e Simon in [28]). Gli insiemi di simboli possono poi essere combinati in strutture più complesse e trasformabili a loro volta. I sistemi formali elaborati dai logici sono un esempio di sistema simbolico.
L’ approccio bottom-up o connessionista, invece, parte dalle architetture, da reti di neuroni artificiali che simulano i neuroni celebrali (si veda il lavoro di Warren McCulloch e Walter Pitts del 1943 [6]) per costruire strutture e modalità di ragionamento più complesse.
Gli approcci simbolici concepiscono quindi il ragionamento in modo formale come il risultato di una manipolazione di simboli, mentre negli approcci neurali o connessionisti il ragionamento si determina in modo implicito quale risultato dell’interconnessione ed elaborazione distribuita di molte e semplici unità computazionali. Ne segue che gli approcci simbolici sono più trasparenti e di facile interpretabilità dagli umani, mentre gli approcci connessionisti gestiscono con più facilità realtà mutabili, incerte, non complete e dinamiche. I recenti sviluppi e i grandi risultati raggiunti negli ultimi tempi dagli approcci di tipo bottom-up
relativi alle reti neurali mostrano sempre più l’efficacia di tali metodologie, soprattutto per quello che riguarda l’ambito percettivo.
Per capire la differenza fra i due approcci mediante un esempio concreto, immaginiamo di voler costruire un sistema di IA in grado di classificare diverse tipologie di triangoli (equilatero, isoscele e scaleno).

L’approccio simbolico partirebbe da una descrizione delle caratteristiche dei tre diversi tipi di triangoli in termini di angoli, dimensioni dei lati ecc. (ottenuta automaticamente mediante tecniche di apprendimento simbolico o elicitata manualmente dagli umani), e poi, con questa descrizione simbolica – di facile comprensione per un essere umano e quindi di alto livello – andrebbe a classificare i singoli esempi di triangolo.
Un approccio botton-up di tipo neurale, invece, dopo avere ottenuto un’opportuna configurazione della rete neurale mediante la presentazione di esempi di diversi triangoli già classificati, e “rafforzati” mediante opportuni algoritmi di apprendimento il contributo dei neuroni che portano implicitamente ad una corretta classificazione, andrebbe a classificare i nuovi esempi utilizzando la rete configurata in cui la “conoscenza” sui vari tipi di triangolo e le loro caratteristiche è “nascosta” e “compilata” in modo efficiente ma incomprensibile agli umani nell’architettura della rete di neuroni e nelle loro connessioni.
Verso la fine degli anni 80 è iniziata un’ampia discussione che ha portato, da parte di alcuni ricercatori, ad una critica sull’eccessiva preponderanza della parte intellettuale e razionale tipica dell’uomo nella concezione dell’IA. Citiamo a questo proposito l’articolo di Brooks, “Intelligence without representation” [29], in cui si tende a sottolineare l’importanza degli aspetti percettivi e ambientali per una corretta interpretazione dei sistemi intelligenti. Scrive Brooks al riguardo: “I wish to build completely autonomous mobile agents that co-exist in the world with humans, and are seen by those humans as intelligent beings in their own right. I will call such agents Creatures”. Questa visione è molto collegata alla robotica che in quegli anni faceva passi da gigante, portando ad identificare spesso l’IA con la definizione e realizzazione di agenti autonomi e, in particolare, di agenti intelligenti.
Una definizione di agente, secondo Wooldridge [30], è:
“A computer system that is situated in some environment, and that is capable of autonomous action in this environment in order to meet its design objectives.”
Quindi gli agenti sono “situati” in un ambiente, ricevono da esso percezioni (mediante sensori) e agiscono sull’ambiente mediante azioni (attuatori). Gli agenti possono essere puramente reattivi, ma anche razionali e deliberativi, capaci di porsi autonomamente obiettivi da realizzare, avere credenze e intenzioni, e comunicare con altri agenti in base alle esigenze dell’ambiente e dell’applicazione per cui sono costruiti.
Il comportamento intelligente degli agenti non necessariamente richiede un approccio simbolico e di tipo deliberativo. In alcuni casi può anche essere di tipo reattivo, ed emergere sotto forma di “pattern”, in modo non prevedibile, dall’interazione di comportamenti funzionalmente semplici, senza la necessità di un coordinamento globale o centralizzato. L’osservazione della natura è una grande sorgente di ispirazione in questo contesto ed è innegabile che mostri costantemente la realizzazione di comportamenti “intelligenti” in un’ottica collettiva. Si pensi, a questo riguardo, alla coordinazione che si instaura tra insetti sociali che vivono in colonie quali le termiti e che sono in grado, lavorando assieme, di costruire sorprendenti opere di alta ingegneria senza una visione globale a priori. Altro esempio affascinante è quello del formarsi di sciami di api o di uccelli configurati in modo perfetto grazie al coordinamento di comportamenti collettivi. Per descrivere questi fenomeni si utilizza in IA il termine “swarm intelligence”.
Scrive Gerardo Beni al riguardo [31]:
“One characteristic of intelligent behavior is the production of something ordered, i.e., unlikely to occur: an improbable outcome. Another is the fact that this outcome should not be predictable. A manufacturing machine produces a mechanical piece (ordered pattern, improbable outcome) but in a predictable way. We do not consider that machine intelligent. On the other hand the designer that produces the design of that mechanical piece is considered intelligent. Nobody knew what the designer would come up with. She was unpredictable. But of course just unpredictability is not intelligence; a roulette is not

intelligent. It seems that somehow both unpredictability and the creation of some order are necessary to be able to speak of “intelligence”.
Un altro esempio di “swarm intelligence” è costituito dagli algoritmi a “formiche artificiali”, cioè algoritmi sviluppati a partire da un modello semplificato del comportamento delle formiche che riescono a trovare il percorso più breve tra il formicaio e un punto in cui vi sia del cibo senza utilizzare informazioni visive, ma solo segnali odorosi. Quando una formica ha trovato del cibo, ritorna al formicaio depositando sul terreno una certa quantità di una sostanza chimica, detta feromone, che attira altre formiche in modo proporzionale alla sua concentrazione. Col passare del tempo, le tracce odorose di feromone sul terreno evaporano, ma possono anche essere rinforzate dal passaggio di altre formiche. Dopo un transitorio in cui le formiche vanno in direzioni diverse e disordinate, si arriverà ad una situazione stabile in cui la maggior parte delle formiche seguirà uno stesso itinerario e, poiché il feromone evapora nel tempo, quell’itinerario sarà anche quello più breve, perché più volte “rimarcato” dal passaggio di più formiche.
Lo studio (interdisciplinare) di questi fenomeni ha permesso di sviluppare sistemi intelligenti basati su modelli e processi naturali robusti ed adattativi, ed utilizzati per risolvere problemi di ricerca, pianificazione ottimizzazione, analisi di dati e coordinamento di robot. Nel futuro potrebbero essere SmartPhone, automobili, generici oggetti “smart” nell’ambito dell’Internet of Things (IoT), e anche droni, gli agenti elementari da cui partire e da comporre in sciami coordinati per raggiungere obiettivi globali. Possibili obiettivi per la moderna società potrebbero essere l’ottenimento di comportamenti virtuosi e ottimizzati nel traffico, nel consumo energetico e nell’ambiente. Per approfondimenti sulla Swarm Intelligence e le sue applicazioni si consulti [32].
Sempre partendo dall’osservazione della natura e, in particolare, dalla selezione della specie per adattarsi all’ambiente, sono stati definiti gli algoritmi genetici (e la computazione evolutiva in generale) che traggono ispirazione dalla teoria dell'evoluzione naturale e sono stati sviluppati da John Holland a partire dagli anni 70 [33].
In questi algoritmi la ricerca di una soluzione è basata sull’individuazione di una particolare generazione “vincente”. In modo semplificato, a partire da una configurazione iniziale ed evolvendo in base a leggi “naturali”, si può creare una nuova generazione (che potrebbe essere interpretata come soluzione). La fitness (non sempre definibile in modo semplice come una funzione che valuta la “bontà” di una generazione o soluzione) assicura che vengano preferite per la riproduzione le soluzioni “migliori”; la mutazione assicura l’introduzione di elementi di novità in modo casuale all’interno delle generazioni, mentre la riproduzione garantisce la combinazione di buone soluzioni in una nuova. Il sistema evolve di generazione in generazione fino ad arrivare ad una generazione (ovvero soluzione) considerata soddisfacente. Molte sono le applicazioni della computazione evolutiva, ad esempio nella robotica, nella progettazione, nell’ottimizzazione, nell’analisi di dati e nella previsione.
Recentemente l’interpretazione dell’IA come tentativo di “mimare” l’intelligenza umana è stata ritenuta ambigua e fuorviante da alcuni ricercatori, che preferiscono concepire applicazioni di IA che affianchino l’essere umano in alcune attività o compiti. Scrive IBM al riguardo [34]:
“The term “artificial intelligence” historically refers to systems that attempt to mimic or replicate human thought. This is not an accurate description of the actual science of artificial intelligence, and it implies a false choice between artificial and natural intelligences.”
ed ancora:
“We feel that “cognitive computing” or “augmented intelligence” — which describes systems designed to augment human thought, not replicate it — are more representative of our approach.”.

Il termine Intelligenza Artificiale viene quindi sostituito dal termine Intelligenza Aumentata per enfatizzare maggiormente la capacità dei sistemi di IA di collaborare e interagire con gli umani, non per sostituirli, ma per aiutarli nelle loro decisioni e accrescere la loro esperienza e capacità nella soluzione di problemi, nello spirito dei Sistemi Intelligenti Collaborativi descritti da Barbara Grosz in [35]).
Volendo sintetizzare, l’IA dalla sua prima definizione fino agli sviluppi impressionanti dei giorni nostri può essere vista sotto molte interpretazioni diverse. Poiché ci riserva infinite sfaccettature sia dal punto di vista teorico-fondazionale, sia dal punto di vista realizzativo, appare evidente che a tutt’oggi ogni tentativo di classificazione o definizione univoca risulti essere fatalmente semplicistico.
4 Le tecnologie Da quanto discusso nelle sezioni precedenti, possiamo pensare ad una diversificazione dell’IA in due grandi filoni con differenti risvolti tecnologici. Quello del “Soft Computing” a cui si possono ascrivere tecniche di IA quali Reti Neurali, Algoritmi genetici, Swarm Intelligence applicate tendenzialmente a problemi, quali, ad esempio, quelli di natura percettiva in cui risulta difficile, se non impossibile, la modellazione e la soluzione in termini simbolici e in cui non risulta necessaria una spiegazione del comportamento del sistema. A questo si oppone il filone dell’“Hard Computing”, di alto livello e simbolico a cui si ascrivono sistemi e tecnologie che modellano problemi e soluzioni usando conoscenza esplicita quali, ad esempio sistemi basati sulla conoscenza, sistemi basati sulla logica, architetture “dichiarative” ispirate alla macchina di Turing (regole di produzione), ontologie. Questi sistemi sono in grado di spiegare il loro comportamento e le modalità con cui arrivano alla soluzione, ma spesso hanno difficoltà nel trattare problemi complessi e difficilmente modellabili ad alto livello.
Molti dei sistemi simbolici sono particolarmente abili nella soluzione di problemi, giochi di tipo logico e razionale (si pensi al gioco degli scacchi, ai sistemi di supporto alle decisioni e sistemi esperti in campo medico), ma hanno ancora grossi problemi quando devono affrontare attività, ritenute semplici dagli umani ed affrontabili anche da bambini molto piccoli, quali la percezione, il riconoscimento di immagini, del parlato, il coordinamento senso-motorio.
Il termine IA, in alcuni contesti, è stato associato alla declinazione più simbolica e logica, relativa al ragionamento, mentre si è utilizzato il termine Intelligenza Computazionale (Computational Intelligence) per riferirsi a metodi ispirati alla biologia, alla natura ed alle neuroscienze quali i sistemi evolutivi, le reti neurali e la swarm intelligence. Questa suddivisione storica, però, non è sempre chiara e comunemente accettata.
I due filoni dell’IA introdotti sopra hanno prodotto risultati impensabili fino a qualche anno fa, rivelando però i loro reciproci limiti. Solo da un’integrazione di queste tecniche in opportune architetture ibride si potranno sfruttare appieno i loro punti di forza e superare le loro limitazioni in un’ottica sinergica e unificante.
Nel seguito richiameremo in modo sintetico e semplificato alcune tecniche che si ascrivono a questi due filoni e le aree applicative in cui si sono maggiormente utilizzate.
4.1 La rappresentazione della conoscenza e la soluzione di problemi
Se interpretiamo l’intelligenza come la capacità di risolvere problemi, meccanizzare l’intelligenza significa, secondo l’interpretazione più classica dell’IA, essere in grado di descrivere un problema mediante una rappresentazione simbolica che ne specifichi lo “stato iniziale”, l’”obiettivo” (o goal, o stato finale) e un insieme di “operatori” o regole di transizione. Il motore di inferenza applicando tali operatori genera e modifica descrizioni simboliche (che non sono altro che possibili stati del problema) cercando di raggiungere (magari dopo anche un’ampia ricerca) l’obiettivo ovvero, di fatto, la soluzione [28].
La generazione della soluzione diventa quindi una “ricerca” in questo “spazio degli stati” e può essere rappresentata come un albero o un grafo diretto (nel caso di stati ripetuti) in cui i nodi rappresentano gli stati

raggiungibili e gli archi gli operatori o regole di transizione applicate per raggiungerli. Una soluzione al problema è allora una strada (ovvero una sequenza di azioni) all’interno del grafo che connette il nodo/stato iniziale al nodo/stato finale (o goal/obiettivo) [7]. Ovviamente, man mano che il problema diventa più complesso (come sono quelli che si ascrivono in generale all’IA), si dovranno applicare opportune strategie euristiche dipendenti dal problema in esame per “potare” l’albero o grafo e quindi rendere possibile la ricerca della soluzione, guidandola verso strade più promettenti ed evitando, se possibile, l’esplosione combinatoria che si determinerebbe da un’esplorazione esaustiva di tutte le possibili strade all’interno del grafo.
Nel tempo sono stati sviluppati sistemi specializzati ed efficienti per la ricerca della soluzione. Fra questi citiamo i risolutori per problemi di Soddisfacimento di Vincoli (Constraint Satisfaction Problems – CSP, [7]). In un CSP il problema può essere rappresentato come un insieme di variabili i cui valori appartengono ad un determinato dominio e sono legate da opportuni vincoli. Una soluzione diventa, allora, un assegnamento ad ogni variabile di un valore appartenente al suo dominio che rispetti tutti i vincoli del problema. Tipico problema giocattolo interpretabile come un CSP è il problema delle “otto regine”, che consiste nel piazzare 8 regine su una scacchiera in modo che non si attacchino. In questo caso le variabili possono essere le 8 colonne della scacchiera, i domini associati ad ogni colonna i valori da 1 a 8 che rappresentano la posizione di riga all’interno della specifica colonna, mentre i vincoli imporranno che su ogni riga, colonna e diagonale della scacchiera ci possa essere una sola regina posizionata. A partire da questa modellazione del problema, i risolutori di CSP individuano in modo efficiente l’assegnamento ad ogni variabile di un valore del dominio che soddisfi i vincoli imposti dal problema ovvero, nel nostro caso di esempio, una disposizione delle regine sulla scacchiera che garantisca che non si attacchino l’una con l’alta. I sistemi di CSP hanno numerose applicazioni di successo nel campo della configurazione, nella schedulazione di attività con vincoli sulle risorse da allocare e sui tempi di esecuzione, nei sistemi di supporto alle decisioni e nell’ottimizzazione nell’allocazione e gestione di risorse.
Altri sistemi che presentano metodi di soluzione specifici sono quelli di pianificazione, in grado di determinare un insieme ordinato di mosse o azioni che, dato uno stato iniziale, siano in grado di portare alla soluzione o stato finale. Anche in questo caso le applicazioni sono notevoli nell’ambito della navigazione autonoma e dei robot che si muovono in ambienti fisici o virtuali. Altra area con tecniche specializzate per la soluzione di problemi è quella dei giochi di cui parleremo nella Sezione 5. Per maggiori dettagli sui vari metodi di soluzione di problemi adottati in IA si consulti [7].
L’interpretazione della soluzione di problemi adottata in IA ha portato, nel tempo, ad identificare un’architettura di riferimento per questi sistemi composta da due parti che normalmente dovrebbero essere concepite come separate: la “base di conoscenza” che esprime la conoscenza sul problema in modo il più possibile indipendente dal suo utilizzo e un “motore di inferenza” che, dato un goal o obiettivo, utilizza al meglio la conoscenza sul problema per cercare di arrivare alla soluzione partendo dalla situazione iniziale.
In pratica, la base di conoscenza esprime conoscenza dichiarativa, il “Cosa”, mentre il motore di inferenza esprime la conoscenza procedurale, ovvero il “Come” e, per consentire la massima generalità, queste due parti dovrebbero essere tenute separate. La conoscenza dichiarativa è utilizzata in gran parte dei sistemi di IA chiamati appunto “Sistemi basati sulla Conoscenza” sotto forma di regole e ontologie, nei dimostratori automatici di teoremi sotto forma di asserzioni della logica, e anche in linguaggi di programmazione quali Prolog [36] [37], che rappresentano un programma in termini di asserzioni logiche (clausole definite) che rappresentano fatti e regole.
Risulta quindi essenziale in questi sistemi di AI adottare un metodo di rappresentazione della conoscenza sufficientemente espressivo da riuscire ad esprimere in modo completo e naturale il dominio di interesse. La logica proposizionale [38], ad esempio, che non consente di esprimere variabili e quantificatori, risulta essere spesso troppo povera per esprimere basi di conoscenza in molti domini applicativi.
Altra caratteristica di un metodo di rappresentazione è la capacità di strutturare la conoscenza in modo che ne venga facilitato e velocizzato l’utilizzo e l’accesso durante la risoluzione del problema, evitando eccessive

ridondanze. Organizzare la conoscenza in strutture, concetti, oggetti o frames [39] [40], connessi in reti o gerarchie, rende più efficace ed efficiente il suo utilizzo e facilita forme di ragionamento specifiche quali l’ereditarietà di attributi o proprietà. Se pensiamo ad una opportuna struttura (o “frame”) che descriva, ad esempio, un ristorante, essa potrà consentire la definizione di attributi (o “facet”) quali menu, valutazione degli utenti, piatti speciali e, se classificato come sotto-insieme o sott-classe di locale pubblico, potrà invece da esso ereditare attributi quali indirizzo, orario di apertura, ecc. Altro requisito importante di una rappresentazione della conoscenza risulta essere flessibilità e facile modificabilità: la conoscenza, per sua natura, si accresce con il tempo e va in molti casi aggiornata per evitare di divenire obsoleta. Regole, oggetti, asserzioni logiche risultano particolarmente modulari e di facile modifica se confrontati con sistemi informatici dalla struttura più procedurale ed algoritmica.
4.1.1 Sistemi basati sulla conoscenza e sistemi esperti
A partire dagli anni 80 del secolo scorso sono stati sviluppati “sistemi esperti” in larga scala, e specializzati in vari settori applicativi quali diagnosi, pianificazione, progettazione, previsione, interpretazione e monitoraggio. Un sistema esperto è un “sistema basato sulla conoscenza” in grado di risolvere problemi in un dominio limitato, ma con prestazioni simili a quelle di un esperto umano del dominio stesso. La sua base di conoscenza ad esempio può essere descritta tramite regole della forma: “se antecedente/i allora conseguente”. Il motore di inferenza esamina un largo numero di possibilità e costruisce dinamicamente una soluzione.
Cruciale, nella costruzione di questi sistemi, è la qualità e quantità di conoscenza che viene rappresentata per supportare i sistemi stessi. L’“intelligenza” di sistemi di questo tipo si misura proprio sulla loro capacità di utilizzare questa conoscenza al fine di giungere alla soluzione. In particolare, Edward Feigenbaum scrive in [41]:
“... the problem-solving power exhibited in an intelligent agent's performance is primarily a consequence of the specialist's knowledge employed by the agent, and only very secondarily related to the generality and power of the inference method employed.”
Si consideri, come semplice esempio, la definizione di un sistema basato sulla conoscenza adibito alla soluzione di un problema di diagnosi, in cui si vuole trovare la causa di un malfunzionamento mediante l’osservazione di alcuni guasti. L’obiettivo è eseguire una riparazione adeguata per una bicicletta in base ad alcuni malfunzionamenti riferiti dal cliente: formalmente, esprimeremo tale obiettivo con il predicato logico attua_riparazione(X), dove X rappresenta una variabile. Tale variabile X, al termine del processo di ragionamento, dovrà assumere come valore la riparazione identificata come più appropriata dal sistema esperto.
Nella base di conoscenza saranno inseriti fatti e regole. In particolare, i fatti rappresenteranno conoscenze specifiche sui guasti e il cliente, e potranno essere già noti od inseriti dinamicamente nel sistema quando necessario. Consideriamo qui solo due semplici fatti con ovvio significato in linguaggio naturale:
impenna_bicicletta. concorda_cliente(riparazione_freno).
Nel seguito riportiamo poi alcune possibili regole espresse come implicazioni logiche del tipo:
<antecedente> → <conseguente>
Il significato di regole espresse in questa forma è molto intuitivo: se l’antecedente (che può essere una formula logica composta mediante i connettivi logici AND o OR) è vero allora possiamo derivare il conseguente.
R1: sbanda_bicicletta → pneumatico_forato. Se la bicicletta sbanda allora potrebbe essersi forato il pneumatico.
R2: impenna_bicicletta → guasto_freno.

Se la bicicletta si impenna allora potrebbe essere guasto il freno.
R3: pneumatico_forato OR pneumatico_consumato → consigliato(cambia-pneumatico). Se il pneumatico è forato oppure è consumato allora è consigliato cambiarlo
R4: consigliato(X) AND concorda_cliente(X) → attua_riparazione(X) Se è consigliata una certa riparazione e il cliente concorda con tale riparazione, allora si può attuare tale riparazione
R5: guasto_freno → consigliato(revisiona_freno). Se è guasto il freno allora è consigliato revisionarlo
Utilizzando le regole riportate qui sopra all’indietro o “backward”, cioè a partire dall’obiettivo ed applicandole ripetutamente, concatenandole dal conseguente all’antecedente fino a raggiungere fatti noti o domande per l’utente, il sistema è in grado di produrre una diagnosi di riparazione come sintetizza la seguente sessione di interazione con l’utente:
– Sistema: La bicicletta sbanda?
– Cliente: NO.
– Sistema: La bicicletta si impenna?
– Cliente: SI.
– Sistema: Cosa ne dici se revisionassi il freno?
– Cliente: SI.
– Sistema: Allora procedo alla revisione del freno.
Il sistema, inoltre, è trasparente ed è in grado di spiegare come giunge alla diagnosi in modo molto comprensibile per l’utente finale. Ad esempio, alla domanda dell’utente su perché consigli la revisione del freno, il sistema può rispondere ripercorrendo la linea di “ragionamento” seguita dal motore di inferenza: può spiegare cioè che è giunto alla conclusione perché il freno è rotto, e questo ancora è stato determinato dall’osservazione dell’impennarsi della bicicletta.
Nell’ambito dello sviluppo di sistemi basati sulla conoscenza sono nate, sempre a partire dagli anni 80 del secolo scorso, anche piattaforme ed ambienti di sviluppo specializzati. Fra i più utilizzati oggi citiamo la piattaforma Drools [42], un ambiente di sviluppo scritto in linguaggio Java, che consente di rappresentare la conoscenza in termini di regole e oggetti. Ogni regola è formata da una parte di pre-condizioni e una di conseguenze che vengono eseguite se tutte le pre-condizioni sono verificate. Il sistema Drools svolge in modo molto efficiente ragionamenti in avanti o “forward”, duali a quelli backward discussi nell’esempio precedente. In questo caso, partendo da una base di fatti e applicando, ricorsivamente, le regole che hanno pre-condizioni soddisfatte, si generano nuovi fatti (dalle conclusioni delle regole applicate), fino ad arrivare ad una conclusione che rappresenta il goal o obiettivo che si voleva raggiungere.
Anche se Drools nasce come sistema a regole integrato con la possibilità di descrivere gli oggetti coinvolti nel ragionamento mediante classi Java, è poi stato esteso con altre funzioni quali, ad esempio, il ragionamento temporale, sia qualitativo sia quantitativo, e l’analisi di eventi complessi. Drools è attualmente utilizzato per lo sviluppo di molte applicazioni di supporto alle decisioni in ambito industriale, come documentato ad esempio in [43].
I Sistemi Esperti o, meglio, i sistemi basati sulla conoscenza, hanno avuto alti e bassi nella storia delle applicazioni dell’IA, presentando spesso difficoltà nello sviluppo e producendo spesso aspettative esagerate, seguite poi da pesanti delusioni. Le basi di conoscenza su cui si basano tali sistemi possono risultare essere molto estese e complesse, e contenere migliaia di regole estratte faticosamente, mediante colloqui con esperti e consultazione di documenti scientifici. Le fonti sono spesso diverse, parziali e non sempre concordi

(rappresentando i punti di vista di diversi esperti). Inoltre, in molti casi applicativi, la conoscenza non è esatta e i dati od osservazioni sono soggetti a rumore: i valori di verità delle regole e dei fatti devono essere mediati da valori incerti di verità, quali, ad esempio, fuzzy o probabilistici (si consulti al riguardo [7], Capitoli 13 e 14). La conoscenza utilizzata, infine, evolve nel tempo, si modifica con l’acquisizione di nuove informazioni e fonti documentali, e non è sempre manifesta od esplicita. L’acquisizione della conoscenza è quindi ritenuto il vero “collo di bottiglia” dei Sistemi Esperti, limitandone l’applicazione e la diffusione. Lo sviluppo di tecniche di apprendimento, sempre più utilizzate con successo negli ultimi anni, può aiutare a risolvere questo problema consentendo, in certi casi, la definizione di regole e il loro aggiornamento mediante tecniche semi-automatiche che partano dai dati (tecniche di data mining).
Dopo i primi entusiasmi, col tempo si è sempre più accettata e consolidata l’idea che l’esperto nella sua “creatività” e “competenza” non può essere completamente sostituito, ma può essere utilmente coadiuvato da tali sistemi, soprattutto quando si affrontano casi ripetitivi in cui più facilmente l’esperto può avere un calo di attenzione o interesse, introducendo errori. Si preferisce oggi parlare non più di Sistemi Esperti, ma di Sistemi di Consultazione o di “Supporto alle Decisioni”, in pratica assistenti al servizio dell’uomo. L’IA nella concezione di questi sistemi diventa quindi più una sorta di Intelligenza Aumentata (Augmented Intelligence) in cui macchine e umani collaborano utilmente ciascuno con le sue peculiarità.
4.1.2 Conoscenza di buon senso comune e Web Semantico
Gli esseri umani possiedono, certo, conoscenza approfondita, specialistica che nasce dall’ esperienza scolastica, professionale e lavorativa, ma anche una conoscenza più generica e condivisa sul mondo. Sappiamo ad esempio che gli asini non volano, che se piove devo prendere l’ombrello per non bagnarmi, che un oggetto fragile si può rompere, che i giorni della settimana sono sette ecc. Milioni e milioni di informazioni e conoscenza che tutti noi più o meno condividiamo e che ci aiutano a svolgere diverse forme di ragionamento nella vita di tutti i giorni su spazio, tempo, misure, peso, numeri ecc. Come poter rendere tutta questa conoscenza, definita di “buon senso comune”, fruibile alle machine e come strutturarla per arricchire le basi di conoscenza e potenziare la capacità di risolvere problemi è ancora una domanda aperta ed una sfida per l’IA.
La conoscenza di buon senso comune è definita dal Cambridge Dictionary come segue
“Common sense consists of knowledge, judgement, and taste which is more or less universal and which is held more or less without reflection or argument.”
ed è così vasta da risultare impossibile da formalizzare in modo completo, pur essendo fondamentale nel ragionamento. Scrivono Guha e Lenat al riguardo [44]:
“So, the mattress in the road to AI is lack of knowledge, and the anti-mattress is knowledge. But how much does a program need to know to begin with? A non-trivial fraction of consensus reality - the millions of things that we all know and that we assume everyone else knows.”
Rappresentazioni della conoscenza strutturate quali ad esempio le reti semantiche [45], i frames [39], o linguaggi ontologici quali OWL [46] cercano di dare, anche se con modalità diverse, una risposta a questa domanda proponendo la possibilità di descrivere concetti in base al loro contenuto semantico come insiemi di proprietà, relazioni fra essi (ad esempio vocabolari, tassonomie) e di realizzare, quindi, specifici meccanismi di inferenza per gestire, ad esempio, ereditarietà ed eccezioni.
Fra i vari sistemi che consentono la rappresentazione e l’utilizzo di informazioni ontologiche e semantiche citiamo WordNet [47], una sorta di ampio dizionario organizzato come una rete semantica di connessioni fra concetti, e Cyc [48], nato nel 1984 per opera di Lenat, con l’obiettivo di costruire una enorme base di conoscenza per il ragionamento di buon senso comune. Tali sistemi sono particolarmente utili per

l’elaborazione del linguaggio naturale e la disambiguazione dei termini, e per la ricerca di informazioni su Web.
Le ontologie permettono di strutturare la conoscenza ed esprimere legami tra i concetti, risolvendo anche le ambiguità che possono essere presenti in frasi del linguaggio naturale. Si consideri, ad esempio, la descrizione tassonomica rappresentata in Figura 1. Le frecce esprimono relazioni gerarchiche di tipo IS-A (in particolare relazioni di classe e sottoclasse in questo caso), mentre termini all’interno degli stessi riquadri indicano possibili sinonimi.
Supponiamo di voler cercare su Web immagini di felino. Alcuni siti di social network (ad es. Facebook, Flickr, ecc.) offrono già la possibilità di aggiungere etichette alle immagini, semplificando così la ricerca. Immaginiamo di avere quindi a disposizione su Web immagini etichettate rispettivamente con <gatto> e <leone>. Se però cerchiamo queste immagini solo tramite la parola chiave sintattica <felino>, nessuna delle immagini menzionate sopra verrà restituita come risultato. Tramite l’ontologia della figura precedente, invece, si può sfruttare l’informazione semantica che gatto e leone sono due sottoclassi del concetto di felino e quindi, al momento della ricerca, anche queste immagini saranno restituite tra i risultati, sebbene originariamente non etichettate come <felino>. Con riferimento alle ambiguità, in Italia il termine <felino> è riferito anche ad una cittadina in provincia di Parma, dove viene prodotto un noto salame chiamato appunto di tipo “felino”. Una ricerca puramente sintattica restituirebbe anche l’immagine del gustoso salame, mentre questo non accadrebbe nel caso di una ricerca di tipo semantico con informazioni riferite al contesto di interesse relativo agli animali.
Generalizzando, a partire da questo esempio, sappiamo che Internet contiene enormi quantità di informazioni e potrebbe quindi essere, per certi versi, considerata come un’enorme, sempre aggiornata base di conoscenza, anche se spesso incorretta e incoerente, ma fruibile da umani e macchine se opportunamente strutturata in modo semantico. Questo ambizioso tentativo di rappresentazione e uso della conoscenza su Web che permetta anche diverse forme di inferenza e ragionamento prende il nome di Semantic Web [49] e condivide gran parte delle tematiche dell’IA legate alla rappresentazione della conoscenza. Un tentativo in tal senso è l’iniziativa di DBpedia [50] che offre i contenuti di Wikipedia [51] organizzati in un grafo su base semantica.
Scrivono Berners-Lee e i suoi colleghi nel 2006 [52]:
Animale, bestia
Mammifero
Felino Cane
Gatto, micio
Certosino
Leone
Figura 1: Esempio di descrizione tassonomica

“We expect the developments, methodologies, challenges, and techniques we’ve discussed here to not only give rise to a Semantic Web but also contribute to a new Web Science—a science that seeks to develop, deploy, and understand distributed information systems, systems of humans and machines, operating on a global scale. AI will be one of the
contributing disciplines.”
Rappresentare in modo esplicito e semantico gran parte della conoscenza che normalmente utilizziamo consentirebbe indubbi vantaggi in vaste aree applicative quali ad esempio la comprensione del linguaggio naturale (in cui riuscire ad interpretare parole ambigue in base al contesto è cruciale), i sistemi di supporto alle decisioni (in cui una vasta conoscenza consentirebbe sistemi più completi e raffinati nel proporre una soluzione all’utente ed una sua spiegazione), o i sistemi che forniscono risposte consultando le informazioni su web. Avere a disposizione questa ricca, ampia e strutturata base di conoscenza su gran parte dello scibile umano resta comunque un progetto complesso e ancora di difficile realizzazione nella sua completezza. In risposta a tale difficoltà, si stanno affermando negli ultimi tempi tecniche sub-simboliche alternative basate su reti neurali profonde di cui parleremo più estesamente nel seguito, per apprendere da esempi in modo implicito i significati e le interpretazioni dipendenti dal contesto di parole ed immagini.
4.1.3 La logica e il ragionamento, la dimostrazione automatica e Prolog
Uno dei linguaggi maggiormente utilizzati per la rappresentazione della conoscenza in IA è la logica. La logica, come tutti sappiamo, ha origini antichissime che risalgono alla filosofia dell’antica Grecia e la sua storia è legata ad una delle esigenze più forti dell’uomo: condividere con gli altri le modalità del ragionamento. Il suo padre fondatore è Aristotele (384-321 a.C. circa), che definì anche il concetto di sillogismo, per trarre conclusioni a partire da premesse ritenute valide.
Un sillogismo aristotelico classico è quello che a partire da affermazioni logiche del tipo: “Tutti gli uomini sono mortali” e “Socrate è un uomo” è in grado di concludere che “Socrate è mortale”. A metà del diciannovesimo secolo, George Boole, di fatto, fondò la logica matematica moderna di tipo proposizionale (ovvero senza variabili e quantificatori), espressa mediante equazioni algebriche, e propose un metodo meccanico per la derivazione di proposizioni. Gottlob Frege sviluppò poi un’assiomatizzazione (assiomi e regole di inferenza) per la logica del primo ordine, più espressiva di quella proposizionale, in quanto consente di inserire nelle formule logiche variabili quantificate universalmente o esistenzialmente. Ulteriori studi e sviluppi della logica portarono alla definizione del “calcolo dei predicati”, un linguaggio logico molto ricco in cui è possibile scrivere basi di conoscenza e realizzare diverse forme di ragionamento mediante opportune regole di inferenza (ovvero regole di trasformazione sintattica di formule sintatticamente corrette in altre formule ancora sintatticamente corrette).
La potenza del formalismo logico, il suo potere espressivo, nonché la possibilità di svolgere ragionamento mediante inferenza ne fecero subito un ottimo candidato ad essere il linguaggio basilare per la rappresentazione della conoscenza in IA.
Si considerino ad esempio le seguenti formule logiche del calcolo dei predicati come asserzioni di una base di conoscenza, dove il simbolo ∀ deve essere interpretato come “Per Qualunque”:
∀X uomo(X) ⟶ mortale (X). (regola 1) uomo(socrate). (fatto 1)
Utilizzando opportune regole di inferenza è possibile da queste formule derivarne altre. Ad esempio, utilizzando la Specializzazione Universale che ci dice che se una formula vale per qualunque X allora vale per un qualunque termine del dominio di interesse, si può derivare dalla regola precedente:
uomo(socrate) ⟶ mortale (socrate). (regola 2)

Applicando poi la regola di inferenza del Modus Ponens, che afferma che date le forme sintattiche del tipo A⟶B e A, dove A e B sono espressioni logiche sintatticamente corrette e ritenute vere, allora è possibile derivare la verità di B. Riprendendo il precedente esempio, a partire dal (fatto 1) e dalla (regola 2) si potrà derivare la nuova formula mortale(socrate). È stato applicato così il metodo “deduttivo”, in cui la verità delle premesse garantisce la verità delle conclusioni. Si noti che il metodo deduttivo è un metodo corretto, ma che non consente di “imparare” nuova conoscenza.
Nel metodo “induttivo”, invece, definito da Francis Bacon (1561-1626), è possibile introdurre conoscenza “nuova”, ma questo può avvenire a scapito della correttezza. Ad esempio, dalla semplice osservazione di alcuni uccelli che volano e generalizzando mediante l’applicazione del metodo induttivo, è possibile indurre la regola ∀ X uccello(X) ⟶ vola (X). Essendo tale regola basata solo su una serie di osservazioni o evidenze, potrebbe essere resa non più valida a fronte di altre osservazioni: ad esempio, dall’osservazione di un pinguino che, ovviamente, è un uccello ma non è in grado di volare. La regola quindi è vera solo in un certo numero di casi (in modo probabilistico).
Un’altra forma di ragionamento, particolarmente utilizzata nella diagnosi, è il ragionamento “ipotetico” o “abduttivo” definito da Charles Sanders Peirce (1839-1914). E’ il duale del Modus Ponens, perché osservando il conseguente di una regola ne “ipotizza” la verità dell’antecedente. In pratica, se si considerano regole che esprimono relazioni fra cause (antecedenti) ed effetti (conseguenti), il ragionamento abduttivo cerca di risalire alle cause mediante l’osservazione degli effetti. Nell’esempio precedente, se si considera la (regola 2) precedentemente introdotta, dall’osservazione di mortale(socrate), un sistema di ragionamento abduttivo produrrebbe come ipotesi uomo(socrate). Anche questa forma di ragionamento non è sempre corretta: l’ipotesi uomo(socrate), infatti, potrebbe essere sconfessata da altre osservazioni e quindi non necessariamente essere vera (si pensi al caso in cui Socrate sia, ad esempio, il nome di un gatto). La verità delle ipotesi formulate tramite abduzione deve quindi essere opportunamente pesata in modo probabilistico o vagliata mediante alcuni vincoli dipendenti dal dominio. Risulta evidente che un’area applicativa di questo ragionamento è quella della diagnosi di malattie o malfunzionamenti. In questo caso le cause saranno le malattie (o malfunzionamenti) mentre gli effetti i sintomi (o guasti). A partire da tali effetti o sintomi l’obiettivo del sistema sarà produrre ipotesi su malattie e funzionamenti con diversi gradi di “probabilità” o confidenza.
Un’altra forma di ragionamento è quello “per analogia” (anche denominato metaforico o case-based). Non richiede necessariamente la presenza di molti esempi o dati o di un modello generale, ma lavora per somiglianza. Se Socrate e Platone si “assomigliano” e Socrate ama la filosofia allora plausibilmente anche Platone la ama. Il ragionamento analogico si ritiene fondamentale nel ragionamento scientifico, nell’ambito del pensiero creativo e nelle attività artistiche.
La maggior parte dei sistemi in IA che utilizzano la logica per la dimostrazione automatica di teoremi sono basati sulla deduzione e, in particolare, sul metodo di risoluzione definito dal logico e matematico J.A. Robinson nel 1965 [53]. Il metodo di risoluzione lavora per contraddizione: a partire da un insieme di asserzioni logiche non contradditorie e da una formula (o goal) da dimostrare, la dimostrazione per contraddizione o per “assurdo” nega il goal, lo aggiunge alle asserzioni di partenza e cerca di dimostrare la contraddizione logica (tipicamente individuata dall’affermazione di una formula e del suo contrario), utilizzando ripetutamente la regola di inferenza di risoluzione. La risoluzione lavora sintatticamente, con formule della logica del primo ordine (chiamate clausole) scritte in forma normale come disgiunzioni (connesse quindi dal connettivo logico “OR”) di letterali (i letterali sono formule atomiche positive o negate mediante il connettivo “NOT”). Se le clausole contengono variabili queste sono quantificate universalmente e il loro campo d’azione è la singola clausola.

Si consideri il seguente esempio, dove sono date due clausole5:
C1: a(X) OR b(X,Y) OR c(Y) C2: NOT a(s1) OR d(Z) OR e(s2).
La regola di inferenza della risoluzione deriva la nuova clausola:
C3: b(s1,Y) OR c (Y) OR d(Z) OR e(s2)
ottenuta eliminando i due letterali “complementari” a(X) e NOT a(s1), che possono essere resi uguali con un’opportuna “sostituzione unificatrice” che lega la variabile X ad s1 e componendo in OR i letterali rimanenti di C1 e C2. La sostituzione unificatrice viene poi applicata anche alla nuova clausola così ottenuta.
L'esempio seguente riporta una dimostrazione molto semplice ottenuta applicando il metodo di risoluzione. La base di conoscenza contiene le seguenti asserzioni:
X è mortale oppure X non è un uomo (cioè: se X è un uomo, allora X è mortale) Socrate è un uomo
Più formalmente, in clausole:
C1: mortale(X) OR NOT uomo(X). C2: uomo(socrate).
E si supponga di voler dimostrare il teorema: (in realtà si tratta ancora del sillogismo aristotelico)
Socrate è mortale.
Il metodo di risoluzione esegue la dimostrazione per assurdo: si suppone che Socrate non sia mortale, e si cerca di dimostrare che tale ipotesi porta ad una contraddizione, da cui si inferisce la verità del teorema di partenza.
Dunque, la dimostrazione procede a partire dall'asserzione:
C3: NOT mortale(socrate).
che costituisce appunto la negazione del teorema che vogliamo dimostrare. Si applica poi la regola di inferenza della risoluzione: mediante la sostituzione di X con socrate ed utilizzando le clausole 1 e 3 si otterrà la nuova clausola:
C4: NOT uomo(socrate)
che è una contraddizione rispetto a C2 (viene infatti affermato sia l’atomo positivo sia il suo negato), per cui la formula mortale(socrate) di partenza risulta essere dimostrata.
Dal metodo di risoluzione è nata anche la programmazione logica, e il linguaggio Prolog (PROgramming in LOGic) in particolare, sviluppato nei primi anni 70 da alcuni ricercatori delle Universita di Edimburgo e Marsiglia. Robert Kowalski, a Edimburgo, definì concettualmente la programmazione logica e le sue interessanti caratteristiche come linguaggio di programmazione, mentre Alain Colmerauer a Marsiglia realizzò, nel 1972, il primo interprete per il linguaggio Prolog [36] [37].
Il linguaggio Prolog è stato utilizzato, soprattutto in Europa, come linguaggio di programmazione per la scrittura di basi di conoscenza e di programmi di IA. Condivide, con i metodi di rappresentazione basati sulla logica, la possibilità di descrivere i problemi e i programmi in modo dichiarativo, esprimendo la conoscenza (il “cosa”) nel modo il più possibile indipendente dal suo utilizzo (il “come”). In particolare, un programma Prolog è un insieme di clausole logiche che rappresentano fatti e regole. L’interprete Prolog, inteso come motore di inferenza, utilizza poi tali clausole nel modo più opportuno per risolvere il problema in base al goal o obiettivo da dimostrare. Rispetto alla visione più algoritmica dei linguaggi procedurali, a partire dalla conoscenza e dall’obiettivo, è il motore di inferenza o interprete di Prolog a generare l’algoritmo più opportuno
5 Per conformità alla sintassi standard del linguaggio Prolog, le variabili sono indicate come stringhe che iniziano con una lettera maiuscola, mentre le costanti e i simboli di predicato iniziano con una lettera minuscola.

per risolvere il problema specifico, guadagnando quindi in generalità.
Si consideri, come esempio, questa semplice base di conoscenza espressa in programmazione logica, che contiene due regole alternative per la definizione di genitore. Le variabili (quantificate universalmente) sono scritte con lettere maiuscole mentre le regole hanno i conseguenti in testa seguiti dagli antecedenti e separati dal simbolo “:-“ che va inteso come l’ implicazione logica ( ⟵ ).
R1: genitore(X, Y) :- madre(X, Y). “Se X è madre di Y allora X è genitore di Y”
R2: genitore(X, Y) :- padre(X, Y). “Se X è padre di Y allora X è genitore di Y”
Immaginiamo, poi, di avere la conoscenza di alcuni fatti:
madre(maria, chiara). madre(maria, andrea). padre(carlo, chiara). padre(carlo, andrea).
Utilizzando la risoluzione il linguaggio Prolog può inferire nuovi fatti o asserzioni quali:
genitore(maria,chiara). genitore(maria,andrea). genitore(carlo,chiara). genitore(carlo,andrea).
In particolare, può rispondere anche a domande più generali del tipo:
?- genitore(X,chiara). “Esiste un X che è genitore di Chiara?” Risposta: Yes, X= maria; X=carlo.
?- genitore(maria,X) “Esiste un X che di cui maria è genitore?” Risposta; Yes, X=chiara; X=andrea
Per maggiori dettagli sul linguaggio Prolog si consulti [54].
L’utilizzo della logica in IA è stato ed è ancora molto ampio ed articolato, ma anche soggetto a critiche o dubbi. Molte critiche sono legate all’approccio logico stesso, poiché si ritiene che non rappresenti in toto il modo di ragionare degli umani, ma più semplicemente il modo con cui gli uomini cercano di spiegare alcune forme di ragionamento in ambito formale. Inoltre, il teorema di incompletezza di Gödel rende tutto l’apparato debole dal punto di vista della possibilità di dimostrare in modo automatico la verità o falsità di qualunque formula.
Si ritiene, inoltre, che per molte applicazioni, la logica classica sia povera e troppo rigida, non consentendo di trattare in modo semplice l’incertezza (le proposizioni sono solo o vere o false nella logica classica a due valori), le eccezioni (che possono generare conoscenza contraddittoria), la modifica dinamica della conoscenza (i sistemi di logica classica sono monotoni e non possono consentire di invalidare formule precedentemente dimostrate vere). Questo ha portato allo sviluppo di logiche diverse da quella classiche, che cercano di trattare ancora con un apparato formale tali caratteristiche della conoscenza e all’introduzione di aspetti probabilistici all’interno della rappresentazione logica e delle relative tecniche inferenziali.
I sistemi di dimostrazione automatici basati sulla logica, molto potenti, sono poi spesso inefficienti e soggetti ad esplosione combinatoria nel caso più generale. Sono stati quindi definiti particolari sottoinsiemi della logica (clausole definite per Prolog, Logiche Descrittive per sistemi ontologici e Semantic Web) e metodi di inferenza specializzati per produrre sistemi più trattabili dal punto di vista computazionale, a scapito però, della

generalità dell’apparato logico e del ragionamento.
4.2 L’apprendimento
L’ imparare dall’esperienza, dai propri sbagli, da insegnanti, da altri esseri umani, dall’ambiente che ci circonda, è riconosciuta da tutti come una capacità peculiare e sostanziale dell’intelligenza. Questa caratteristica dell’intelligenza è ben sottolineata anche da Turing che nel 1950 [1] scrive:
“Instead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child's? If this were then subjected to an appropriate course of education one would obtain the adult brain.”
“The idea of a learning machine may appear paradoxical to some readers. How can the rules of operation of the machine change? … The explanation of the paradox is that the rules which get changed in the learning process are of a rather less pretentious kind, claiming only an ephemeral validity”
Lo studio di come le macchine possano apprendere e lo sviluppo di algoritmi di “machine learning” è stata ed è una delle aree di ricerca più feconde e ricche di applicazioni della moderna IA. Nell’epoca dei “big-data”, in cui abbiamo moli sempre più voluminose di dati non strutturati provenienti dalle fonti più disparate, gli algoritmi di apprendimento hanno acquisito sempre importanza nel tentativo di dominare questa complessità e entropia dell’informazione, ed estrarne conoscenza potenzialmente utile.
L’apprendimento utilizza principalmente il metodo induttivo. Si parte da un insieme di fatti o fenomeni (esempi o per cui è già conosciuto il risultato di interesse (training set) e che possono essere direttamente osservati nell’ambiente o impartiti da un insegnante, e si cerca di astrarre da questi, formando una conoscenza o teoria più generale in grado non solo di includere i risultati già noti relativi agli esempi dati, ma anche di predire i risultati per nuovi esempi non osservati.
Se si osserva, ad esempio, in un significativo insieme di casi (istanze) uccelli che volano, e in casi differenti altri animali (non uccelli) che non volano, le tecniche di apprendimento potrebbero inferire, applicando il metodo induttivo, che “tutti gli uccelli volano”.
Si noti che il metodo di inferenza di tipo induttivo, differentemente da quello deduttivo, può non essere corretto e soggetto ad essere falsificato da successive osservazioni. Potrei osservare un’eccezione (un pinguino ad esempio che non vola) che invalida la regola generale indotta. Diventa quindi fondamentale trovare un buon compromesso fra la capacità di generalizzare, ovvero saper descrivere il maggior numero di casi senza compiere troppi errori, e la capacità di specializzare che, se eccessiva (in questo caso si parla di “overfitting”), porterebbe ad includere nella base di conoscenza nel caso più estremo solo i risultati per gli esempi già noti (quelli del training set) perdendo, di fatto, la capacità di astrazione peculiare dell’apprendimento.
Un altro problema da affrontare riguarda anche la selezione del numero di attributi da utilizzare nella descrizione degli esempi (multi-dimensionalità). Uno scarso numero di attributi potrebbe precludere un buon apprendimento, ma un alto numero di attributi potrebbe rendere il problema non trattabile dal punto di vista computazionale e complesso a causa della presenza di attributi non significativi.
In alcuni casi l’apprendimento è guidato o impartito da un insegnante (“apprendimento supervisionato”) mentre nell’apprendimento “non supervisionato” dall’esterno non arriva alcun aiuto, ma è il sistema stesso che si incarica di analizzare le informazioni di cui dispone, di classificarle e strutturarle e di formare autonomamente conoscenze più generali.
Esiste poi un approccio che si può considerare intermedio fra il metodo supervisionato e non supervisionato: l’“apprendimento mediante rinforzo”. In questo caso l’obiettivo è apprendere un comportamento ottimale a partire da esperienze passate. Non si possiede (all’inizio) un insieme di esempi da cui imparare, ma è possibile

comunque osservare in modo critico il risultato buono o cattivo delle azioni o scelte fatte (anche mediante premi e punizioni), e cercare di modificare il comportamento di conseguenza. Questo metodo di apprendimento trova molte applicazioni ad esempio in robotica, ed una sua estensione è stata applicata con successo a reti neurali profonde da Google DeepMind [55].
Uno degli ambiti in cui maggiormente si utilizzano tecniche di apprendimento è la “classificazione”, il cui scopo è attribuire ad un oggetto od esempio o istanza, descritto mediante un insieme di attributi o proprietà una classe o categoria di appartenenza (anche detta etichetta). Tecniche di “classificazione” e “clustering” sono ampiamente usate nell’importante area applicativa che prende il nome di “pattern recognition”. Fra le numerosissime applicazioni, menzioniamo il riconoscimento di immagini, testi e caratteri, voce ecc..
Mentre la classificazione è un metodo di apprendimento tipicamente supervisionato, in cui le classi sono note a priori e si impartiscono al sistema un insieme di esempi (dati, eventi o azioni già opportunamente classificate), i metodi di “clustering” sono non-supervisionati e non hanno una conoscenza delle classi a priori. Gli algoritmi di “clustering” raggruppano quindi nuovi casi, non ancora etichettati, in classi in base ad opportune misure di vicinanza o similarità dei loro attributi. Fra gli algoritmi di clustering utilizzati spesso nell’area del “data-mining” per estrarre informazioni significative dai dati, citiamo K-means [56], un algoritmo di apprendimento iterativo che raggruppa le informazioni in un certo numero di insiemi o classi in base ad un’opportuna misura di similarità degli attributi. Fra gli algoritmi di classificazione uno dei più semplici è il K-nearest-neighbor che cerca di attribuire una classe ad un nuovo oggetto sulla base della “somiglianza” rispetto ad altri oggetti già classificati [57]. All’oggetto viene assegnata la classe più comune fra quelle dei suoi K vicini, dove la vicinanza è misurata utilizzando un’opportuna funzione di distanza (ad esempio Euclidea, di Manhattan).
Dal punto di vista tecnico, possiamo distinguere due grandi filoni delle tecniche di apprendimento a seconda del tipo di approccio seguito: simbolico o sub-simbolico. Nel seguito li introduciamo brevemente senza pretesa di essere esaustivi. Tantissimi sono oggi gli algoritmi di apprendimento e le loro applicazioni. Scrive Pedro Domingos al riguardo nel Prologo del suo libro sull’apprendimento automatico che consigliamo di leggere: “Forse non lo sapete, ma il “machine learning ci ha circondato” (dal Prologo di [58]). Per una presentazione tecnica delle varie metodologie di apprendimento si consultino anche [7] [59], mentre per una ricca libreria di programmi al riguardo si acceda a [60].
4.2.1 Apprendimento simbolico
Nel seguito riportiamo alcuni semplici esempi di apprendimento induttivo supervisionato, utilizzando linguaggi simbolici di rappresentazione della conoscenza quali gli alberi di decisione, le regole (della forma “SE antecedente/i ALLORA conseguente/i”) e logica dei predicati del primo ordine.
Consideriamo per semplicità un esempio di classificazione in cui esista una sola classe o categoria. E immaginiamo che un esempio sia composto da una descrizione di un’istanza del dominio e da un’etichetta che può essere “+”, se l’istanza appartiene al concetto da apprendere, o “–“ se l’istanza non gli appartiene (controesempio). L’insieme di esempi e controesempi prende il nome di “training set”. Si noti che non sempre è possibile avere anche un insieme significativo e sufficientemente rappresentativo di esempi negativi. Ad esempio, si considerino i domini applicativi dove gli esempi negativi sono guasti, anomalie o deviazioni: tipicamente questi casi sono pochi rispetto a quelli di normale funzionamento e spesso ignoti o impredicibili.
A partire dal training set l’algoritmo di apprendimento dovrà essere in grado di costruire un classificatore opportuno che, data in ingresso una nuova istanza, dovrà restituire valore vero se l’istanza appartiene al concetto, o falso se l’istanza non appartiene al concetto.
Quale esempio, ispirato ad un caso presentato in [59], si supponga che le istanze siano descrizioni di hotel in una certa città selezionata per le vacanze, e che il concetto da apprendere sia “hotel adatto per una vacanza ”. Supponiamo anche di aver individuato 4 attributi rilevanti per apprendere il concetto: “stelle”, “costo”,
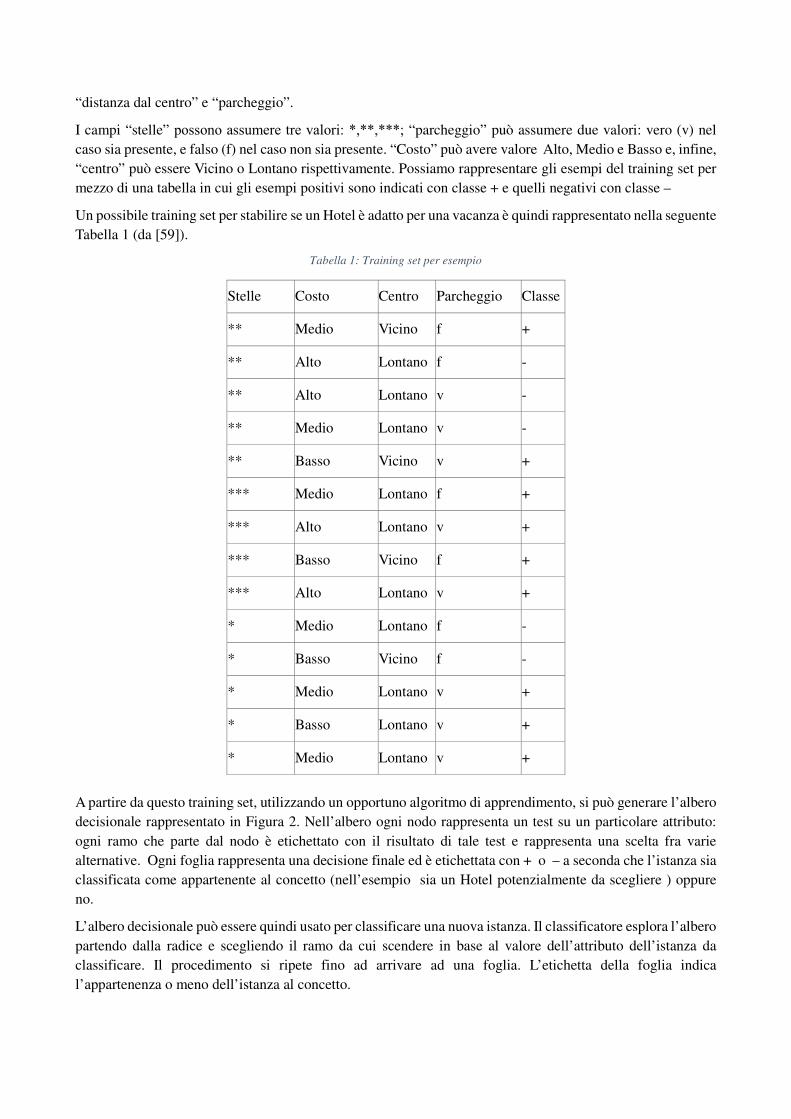
“distanza dal centro” e “parcheggio”.
I campi “stelle” possono assumere tre valori: *,**,***; “parcheggio” può assumere due valori: vero (v) nel caso sia presente, e falso (f) nel caso non sia presente. “Costo” può avere valore Alto, Medio e Basso e, infine, “centro” può essere Vicino o Lontano rispettivamente. Possiamo rappresentare gli esempi del training set per mezzo di una tabella in cui gli esempi positivi sono indicati con classe + e quelli negativi con classe –
Un possibile training set per stabilire se un Hotel è adatto per una vacanza è quindi rappresentato nella seguente Tabella 1 (da [59]).
Tabella 1: Training set per esempio
Stelle Costo Centro Parcheggio Classe
** Medio Vicino f +
** Alto Lontano f -
** Alto Lontano v -
** Medio Lontano v -
** Basso Vicino v +
*** Medio Lontano f +
*** Alto Lontano v +
*** Basso Vicino f +
*** Alto Lontano v +
* Medio Lontano f -
* Basso Vicino f -
* Medio Lontano v +
* Basso Lontano v +
* Medio Lontano v +
A partire da questo training set, utilizzando un opportuno algoritmo di apprendimento, si può generare l’albero decisionale rappresentato in Figura 2. Nell’albero ogni nodo rappresenta un test su un particolare attributo: ogni ramo che parte dal nodo è etichettato con il risultato di tale test e rappresenta una scelta fra varie alternative. Ogni foglia rappresenta una decisione finale ed è etichettata con + o – a seconda che l’istanza sia classificata come appartenente al concetto (nell’esempio sia un Hotel potenzialmente da scegliere ) oppure no.
L’albero decisionale può essere quindi usato per classificare una nuova istanza. Il classificatore esplora l’albero partendo dalla radice e scegliendo il ramo da cui scendere in base al valore dell’attributo dell’istanza da classificare. Il procedimento si ripete fino ad arrivare ad una foglia. L’etichetta della foglia indica l’appartenenza o meno dell’istanza al concetto.

In questo modo anche nuove istanze, non considerate nel training set, si potranno classificare. Ad esempio, un hotel a due stelle di prezzo basso ma lontano non sarà scelto, mentre sarà considerato come da scegliere un hotel a tre stelle con prezzo basso, vicino e col parcheggio. Entrambe queste istanze non appartenevano al training set di partenza, ma sono state comunque classificate correttamente sulla base degli esempi precedenti.
La qualità dei classificatori è spesso valutata in termini di alcune specifiche metriche: una misura frequentemente utilizzata è l’“accuratezza”, definita come il numero delle istanze classificate correttamente rispetto a tutte quelle presentate al classificatore (quest’ultimo insieme prende il nome di test set).
Esistono numerosi sistemi di apprendimento che generano alberi di decisione: esempi sono ID3 e successivamente C4.5, sviluppati da Ross Quinlan [61], che costruiscono alberi di decisione dividendo iterativamente l’insieme degli esempi, fino a riuscire a classificare ciascun esempio in una sola categoria. La scelta di quale attributo considerare come discriminante durante la costruzione dell’albero è la decisione fondamentale e più critica, per via dell’influenza che assume l’attributo scelto sulla qualità dell’albero decisionale che si va a produrre. L'idea è quella di selezionare l’attributo che più di ogni altro riesce a fornire una buona classificazione e discriminazione degli esempi. Si utilizzano, a questo scopo, vari criteri quali l’accuratezza e il guadagno in termini di informazione utile per la categorizzazione. Si noti che abbiamo utilizzato in questo esempio attributi discreti. Nel caso di attributi continui, per evitare la rappresentazione di alberi decisionali di ampiezza teoricamente infinita, si possono impostare delle opportune soglie. Ad esempio, potremmo inserire un attributo costo (con dominio sui valori reali) e discriminare in base al fatto che sia minore o maggiore di 100 euro.
Una rappresentazione simbolica alternativa è sotto forma di regole che vengono direttamente apprese come generalizzazione dagli esempi. Se si considera l’albero decisionale mostrato precedentemente, è facile derivare da esso un insieme di regole di classificazione. Nel seguito sono riportate alcune di tali regole, volutamente semplificate e scritte in linguaggio naturale:
Se l’hotel è a tre stelle allora è da considerare. Se l’hotel è a due stelle ed è vicino al centro allora è da considerare. Se l’hotel è a due stelle e non è vicino al centro allora non è da considerare. Se l’hotel è a una stella ed ha il parcheggio allora è da considerare.
Anche se l’esempio è molto semplice, ci aiuta a capire come queste tecniche di apprendimento simbolico si possano utilizzare in modo effettivo per arricchire automaticamente basi di conoscenza.
Uno dei linguaggi simbolici più espressivi per rappresentare la conoscenza ed apprenderne di nuova è la logica e la programmazione logica in particolare. Si consideri la semplice base di conoscenza espressa in programmazione logica, presentata nella sezione 4.1.3, che contiene due regole alternative per la definizione di genitore.
Figura 2: Albero decisionale generato a partire dal training set

R1: genitore(X,Y) :- madre(X,Y). “Se X è madre di Y allora X è genitore di Y”
R2: genitore(X,Y) :- padre(X,Y). “Se X è padre di Y allora X è genitore di Y”
In questo caso, si può immaginare di non avere la base di conoscenza, ma di volerla apprendere mediante il metodo induttivo, e avendo a disposizione solo la conoscenza di alcuni fatti che riportiamo nel seguito (“background knowledge”):
madre(maria,chiara). madre(maria,andrea). padre(carlo,chiara). padre(carlo,andrea).
Immaginiamo poi che gli esempi positivi siano espressi dal seguente insieme:
genitore(maria,chiara). genitore(maria,andrea). genitore(carlo,chiara). genitore(carlo,andrea).
Mentre un esempio negativo sia il seguente:
not genitore(maria,carlo)).
Mediante opportuni algoritmi di apprendimento sarà allora possibile sintetizzare nuove regole e costruire automaticamente una base di conoscenza più generale, che potrebbe essere composta proprio dalle regole R1 e R2 riportate sopra.
L’area di ricerca che si occupa dell’apprendimento di programmi logici prende il nome di Programmazione Logica Induttiva ed ha prodotto notevoli risultati e sistemi per l’apprendimento automatico. Fra questi citiamo il sistema Progol di Muggleton [62].
4.2.2 Apprendimento sub-simbolico e Reti neurali
Le reti neurali differiscono grandemente rispetto all’approccio simbolico. L’idea da cui si parte è quella di simulare direttamente sul computer un modello ispirato al funzionamento del cervello, progettando una macchina intelligente a partire da neuroni artificiali. La potenza dei neuroni, unità computazionali di per sé stesse semplici se prese singolarmente, sta nella possibilità di essere connessi in reti topologicamente complesse che prendono il nome di architetture “connessioniste”. Tali architetture sono costituite da un grande numero di unità di elaborazione molto semplici e ispirate ai neuroni, e da un grande numero di connessioni pesate tra queste unità semplici. Il cervello umano, infatti, processa l’informazione mediante miliardi di neuroni interconnessi.
La conoscenza in una rete neurale non è quindi espressa in modo esplicito sotto forma di simboli, fatti, regole, asserzioni logiche, alberi decisionali, ma insita nella struttura della rete e “nascosta” nei pesi delle connessioni. Essendo queste architetture particolarmente complesse, i pesi delle connessioni non possono essere definiti a priori, ma sono invece determinati mediante varie tecniche di apprendimento.
Dal punto di vista matematico, un neurone è un’entità computazionale che riceve un insieme di ingressi, ne fa una somma pesata ed applica poi a tale somma una funzione di attivazione per calcolare l’uscita del neurone.

Il suo funzionamento può quindi essere sintetizzato attraverso la Figura 3, dove x1, x2, x3 sono gli ingressi (che possono in generale essere l’uscita di altri neuroni, se connessi in rete), mentre w1, w2, w3 sono i pesi associati agli ingressi e sono parametri che possono essere “imparati” con qualche algoritmo di apprendimento. Infine, la funzione di attivazione f trasforma gli ingressi pesati nell’uscita del neurone y. Il neurone si attiva quando la somma pesata dei suoi ingressi supera un certo valore di soglia: la funzione di attivazione consente proprio la determinazione di tale comportamento. Spesso fra gli ingressi è aggiunto un ulteriore valore prefissato x0 normalmente posto a -1 con il corrispondente peso w0 (peso di bias). In tal modo si può agevolmente modificare la soglia rappresentata dalla funzione di attivazione (normalmente posta al valore 0) e indicata col valore b in Figura 3, e determinare la soglia effettiva per l’attivazione del neurone (rappresentata dal valore w0).
Funzione di attivazione tipiche sono la sigmoide, quella a soglia (con valori fra 0 e 1), e quella a gradino (con valori fra -1 e 1). Una funzione a soglia può essere espressa formalmente come:
���� � �1� � 00� 0
La funzione sigmoide ha invece la seguente formula:
Figura 3: Modello neurone binario a soglia
���� � 11 + ��
Come si può notare la funzione sigmoide è continua e derivabile e viene quindi utilizzata in tutti quei modelli neurali che richiedono l’utilizzo di derivate nell’algoritmo di apprendimento.
Il neurone binario a soglia fu il primo modello matematico di neurone ispirato ai neuroni biologici: fu proposto nel 1943 da McCulloch e Pitts [6] ed era in grado di rappresentare diverse funzioni booleane. Nel 1958, Rosenblatt [63] propose il modello del “percettrone”, definito come un neurone artificiale a soglia a singola uscita. I pesi delle connessioni potevano essere modificati iterativamente da un algoritmo di apprendimento in modo da minimizzare una qualche misura dell’errore nel valore di uscita calcolato. Questa calibrazione dei pesi poteva quindi produrre, dopo un insieme finito di passi, una configurazione finale del percettrone in modo da produrre la classificazione desiderata.
Per cercare di capire in modo intuitivo come il percettrone possa lavorare per rappresentare un sistema decisionale ci ispiriamo all’esempio presentato nella sezione 4.2.1 e immaginiamo di volere modellare in modo sub-simbolico la scelta di un certo Hotel per le vacanze sulla base delle caratteristiche: vicinanza dal centro e presenza del parcheggio. Possiamo rappresentare queste caratteristiche come due ingressi binari x1 e x2 di un percettrone, x1 sarà 1 se è vicino al centro, 0 altrimenti; x2 sarà 1 se possiede il parcheggio e 0 se non lo possiede. La scelta dell’Hotel sarà rappresentata dall’uscita binaria del percettrone: 1 se scelgo l’Hotel 0 se non lo scelgo. Risulta abbastanza evidente che in base ai valori assegnati ai pesi potrò realizzare diversi modelli decisionali. Se desidero assolutamente andare in automobile la presenza del parcheggio potrebbe essere assolutamente decisiva e per certi versi indipendente dalla vicinanza o meno al centro. In questo caso potrei determinare un valore alto per il peso w2 e basso per il peso w1. Ad esempio, attribuendo il valore 4 a w2, 2 a w1 e 3 alla soglia w0 il percettrone sceglierà sempre l’Hotel proposto solo se ha il parcheggio in modo indipendente dalla vicinanza o meno al centro. Se invece attribuissimo a w1 il valore 3 e alla soglia w0 il valore 2, la scelta ricadrebbe sull’Hotel se ha il parcheggio oppure se è vicino al centro.
Queste configurazioni dei pesi si determineranno dinamicamente in base agli esempi ed all’utilizzo di opportuni algoritmi di apprendimento.
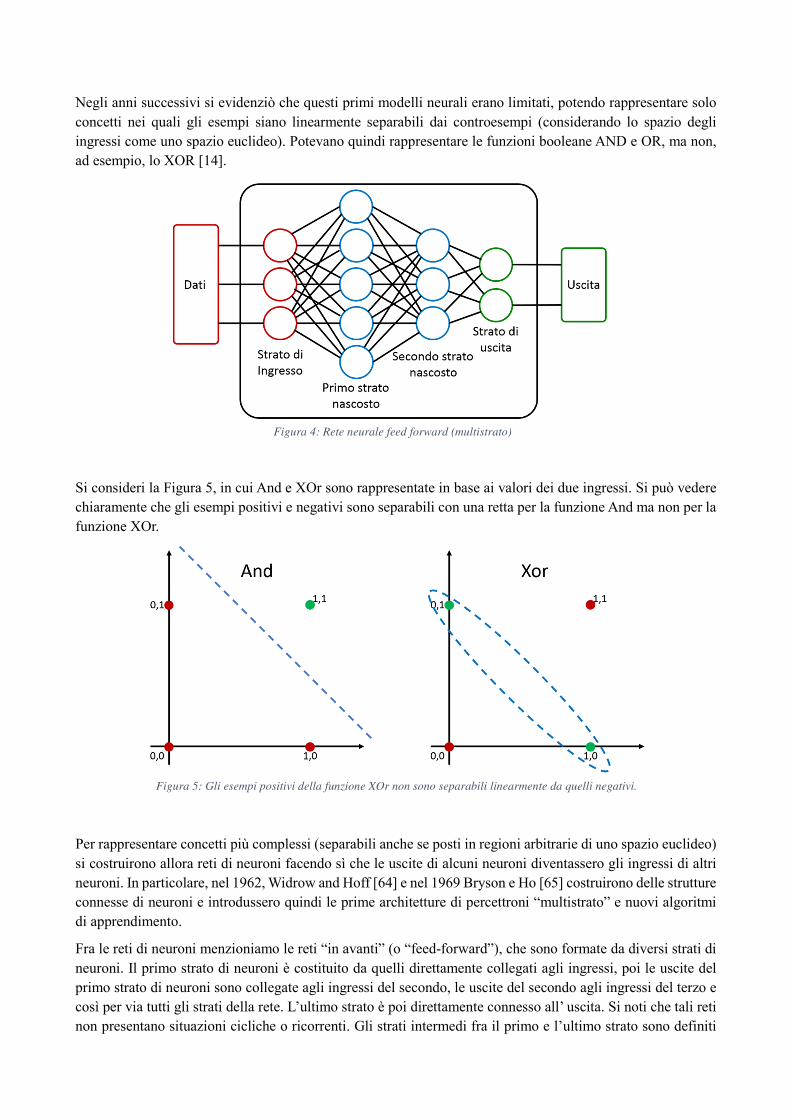
Negli anni successivi si evidenziò che questi primi modelli neurali erano limitati, potendo rappresentare solo concetti nei quali gli esempi siano linearmente separabili dai controesempi (considerando lo spazio degli ingressi come uno spazio euclideo). Potevano quindi rappresentare le funzioni booleane AND e OR, ma non, ad esempio, lo XOR [14].
Si consideri la Figura 5, in cui And e XOr sono rappresentate in base ai valori dei due ingressi. Si può vedere chiaramente che gli esempi positivi e negativi sono separabili con una retta per la funzione And ma non per la funzione XOr.
Per rappresentare concetti più complessi (separabili anche se posti in regioni arbitrarie di uno spazio euclideo) si costruirono allora reti di neuroni facendo sì che le uscite di alcuni neuroni diventassero gli ingressi di altri neuroni. In particolare, nel 1962, Widrow and Hoff [64] e nel 1969 Bryson e Ho [65] costruirono delle strutture connesse di neuroni e introdussero quindi le prime architetture di percettroni “multistrato” e nuovi algoritmi di apprendimento.
Fra le reti di neuroni menzioniamo le reti “in avanti” (o “feed-forward”), che sono formate da diversi strati di neuroni. Il primo strato di neuroni è costituito da quelli direttamente collegati agli ingressi, poi le uscite del primo strato di neuroni sono collegate agli ingressi del secondo, le uscite del secondo agli ingressi del terzo e così per via tutti gli strati della rete. L’ultimo strato è poi direttamente connesso all’ uscita. Si noti che tali reti non presentano situazioni cicliche o ricorrenti. Gli strati intermedi fra il primo e l’ultimo strato sono definiti
Figura 4: Rete neurale feed forward (multistrato)
Figura 5: Gli esempi positivi della funzione XOr non sono separabili linearmente da quelli negativi.

“strati nascosti”. In Figura 4 è rappresentata una rete neurale feed-forward con quattro livelli di cui due nascosti. Una rete è definita come multi-strato se ha almeno uno strato nascosto, mentre normalmente si definiscono come “reti neurali profonde” o Deep-Neural Networks (DNN) reti neurali con più di uno strato nascosto. Secondo questa definizione, quindi, la Figura 4 rappresenta una rete neurale profonda.
L’algoritmo di apprendimento più diffuso applicato a reti neurali multistrato, e che ha contribuito a destare nuovo interesse per l’approccio neurale, è quello denominato di “back-propagation” (si veda il famoso lavoro di Rumelhart, Hinton e Williams del 1986 [17] al riguardo). L’algoritmo è composto da due fasi: una di propagazione in avanti e una di propagazione all’indietro e aggiornamento. Durante la propagazione in avanti i valori di ingresso della rete si propagano verso i valori di uscita di ogni neurone. Durante la propagazione all’indietro, invece, si calcola l’errore delle uscite e si propaga poi iterativamente all’indietro verso gli strati interni della rete, fino a raggiungere lo strato di ingresso. In base all’errore si producono poi delle modifiche dei valori dei pesi al fine di ridurre l’errore globale.
Più in dettaglio il funzionamento dell’algoritmo di apprendimento può essere così descritto:
1. Si inizializzano tutti i pesi della rete con un valore casuale. 2. Si seleziona un esempio quale coppia input/output e si applica l’input alla rete. 3. Si calcola l’output della rete. 4. Si calcola l’errore tra l’output della rete e l’output desiderato. 5. Si aggiustano i pesi della rete in modo da minimizzare l’errore, procedendo all’indietro dagli strati
più alti agli strati più bassi. Si ripetono i passi da 2 a 5 per ogni esempio di addestramento, finché l’errore sull’intero insieme non è accettabilmente basso.
Come già precedentemente sottolineato, le reti neurali consentono di progettare ottimi classificatori mediante la determinazione di un’adeguata struttura della rete ed un buon addestramento per la determinazione dei pesi più adeguati per le connessioni. In pratica, dovendo classificare un esempio od istanza, si inserirà l’esempio come ingresso della rete, che dovrà quindi essere configurata con tanti ingressi quanti gli attributi dell’esempio ritenuti significativi. Si dovrà poi avere tante uscite quanto le possibili classi in cui l’esempio potrebbe ricadere.
Nel seguito si riporta un semplice esempio estratto da [66] che descrive un’applicazione tipica delle reti neurali relativa al riconoscimento/classificazione di cifre manoscritte.
Si immagini di volere addestrare una rete neurale multi-strato a riconoscere le cifre manoscritte da 0 a 9. Gli ingressi saranno quindi tanti quanti gli MxN pixel dell'immagine che rappresenta la cifra in esame, con valori binari 0/1 a seconda che siano neri o bianchi, mentre le uscite saranno le possibili cifre da riconoscere (quindi 10). Ad esempio, il vettore di uscita [0,0,0,1,0,0,0,0,0,0] indica la cifra 3. Il training set sarà l’insieme di coppie formate dagli ingressi e le uscite note, mentre la valutazione dell’errore sarà legata alle coppie classificate correttamente. A tale scopo vale la pena sottolineare che esiste un dataset MNIST6 , che fornisce 60.000 immagini di cifre scritte a mano e che potrebbero essere utilizzate come training set per la rete.
La rete neurale sfrutterà quindi una modalità di apprendimento supervisionato, poiché nel corso dell’apprendimento le classi di uscita saranno note per ciascun esempio del training. Mediante l’applicazione iterata dell’algoritmo di back-propagation, si varieranno opportunamente i pesi delle connessioni fino a raggiungere un valore accettabile per l’errore di uscita. A questo punto la rete neurale così configurata sarà in grado di classificare nuovi esempi e quindi riconoscere nuove scritte raffiguranti cifre, plausibilmente con un errore trascurabile.
Volendo comprendere i limiti delle reti neurali, si è già osservato che il percettrone può rappresentare solo funzioni lineari. Se però si considerano reti multi-strato, il potere espressivo aumenta notevolmente. Un risultato teorico molto importante che si applica alle reti neurali è il teorema di approssimazione universale,
6 http://yann.lecun.com/exdb/mnist/

che stabilisce che una rete feed-forward con uno strato nascosto e un finito numero di neuroni può approssimare con la desiderata precisione qualsiasi funzione continua [67], [68]. Come si intuisce, il teorema è di particolare interesse perché stabilisce, in sostanza che, per qualunque funzione f, è possibile costruire una rete neurale feed-forward in grado di approssimare l’uscita y = f(X) per qualunque ingresso X.
Il teorema è teoricamente interessante, ma non dice nulla sulle modalità con cui configurare tale rete neurale e su come applicare, quindi, opportuni algoritmi di apprendimento per ottenere una buona approssimazione. Il teorema, infatti, afferma che la rete neurale che approssima la funzione esiste, ma non dice quanti neuroni nello strato nascosto saranno necessari per costruirla: il loro numero potrebbe essere troppo elevato dal punto di vista computazionale. Dal punto di vista pratico, non esiste alcuna garanzia di riuscire poi ad addestrare la rete affinché si possa ottenere l’approssimazione desiderata mediante un appropriato valore dei pesi, e senza problemi di “overfitting” (cioè eccessiva specializzazione). In molti casi, per poter meglio affrontare applicazioni reali, potrebbe essere utile aggiungere ulteriori strati nascosti costruendo, di fatto, reti neurali più profonde in grado di rappresentare diversi livelli gerarchici di conoscenza.
Diventa quindi importante riuscire a configurare la rete con un adeguato numero di neuroni e strati affinché sia in grado di classificare con buona accuratezza gli esempi, ma anche evitare di introdurne un numero eccessivo che può causare scarse performances ed eccessiva specializzazione.
Dagli anni 80 ad oggi sono stati sviluppati quindi modelli sempre più dettagliati e complessi per i neuroni artificiali, sono state utilizzate funzioni, non lineari, diverse da quella a soglia (molto usata è la sigmoide), sono state identificate svariate architetture e modalità di connessione in rete, e sono stati sviluppati algoritmi di apprendimento sempre più sofisticati per modificare i pesi delle connessioni. Le reti neurali si sono quindi evolute recentemente in DNN con molti neuroni e strati nascosti, funzioni di attivazione tipicamente non-lineari, particolari configurazioni della rete orientate ai dati e stratificate secondo diversi criteri ed astrazioni.
Le DNN oggi maggiormente utilizzate consistono di un numero di livelli (profondità) compreso tra 7 e 50. Si sono, di fatto, sperimentate anche reti con più di 100 livelli, che hanno tendenzialmente mostrato prestazioni un leggermente migliori, ma che richiedono risorse computazionali enormi per garantire prestazioni accettabili. La complessità di una DNN è poi determinata anche dal numero di neuroni, di connessioni e quindi di pesi: AlexNet [18] [69], ad esempio, è una potente DNN utilizzata per il riconoscimento di immagini, e presenta 8 livelli e 650K neuroni. Per un approfondimento si consulti [70].
Negli ultimi tempi, grazie alla presenza di masse di informazioni non strutturate (big data) che possono servire come esempi (si pensi ad archivi quali ImageNet [69] con milioni di immagini e decine di migliaia di classi) e una grande capacità di memoria e potenza di calcolo determinata da architetture parallele e distribuite sempre più avanzate ed efficienti, le tecniche di apprendimento (deep-learning) applicate a tali reti sono diventate sempre più efficaci, ottenendo risultati applicativi impensabili fino a qualche anno fa. Nel 2011, l’errore degli algoritmi di Intelligenza Artificiale nel riconoscimento e nella classificazione delle immagini era circa del 26 per cento, mentre oggi è calato in modo considerevole assestandosi sul 3 per cento.
L’algoritmo di back-propagation, se applicato a reti con molti strati, tende a rendere spesso ininfluente l’errore che viene propagato fra i vari strati e ad avere prestazioni spesso non soddisfacenti. Nasce quindi la necessità di semplificare ed adattare questo algoritmo per trattare le DNN [66], utilizzando ad esempio metodi di apprendimento locali e gerarchici, applicati strato per strato [71].
In molti algoritmi di deep learning si utilizzano anche metodi di apprendimento non supervisionato, poiché si possono applicare a dati e informazioni senza bisogno di un addestramento su un insieme già precedentemente classificato (che spesso non è disponibile). Un esempio di queste applicazioni è dato dall’algoritmo di DeepMind AlphaGo [72], che ha imparato senza supervisione, ma mediante apprendimento con rinforzo applicato a DNN, a giocare con ottimi risultati a ben 49 diversi giochi per Atari 2600 [73] e ha recentemente battuto il campione mondiale nel gioco del GO (si veda la Sezione 1). In questo caso, grazie alla generalità dell’algoritmo di apprendimento adottato, non si utilizzano principalmente tecniche simboliche specifiche

come per DeepBlue e Watson (si veda Sezione 1). Senza conoscenza esplicita pregressa, se non quella delle regole del gioco, AlphaGo impara a giocare come un esperto utilizzando strategie non impartite inizialmente, ma apprese dall’esperienza diretta.
Gli algoritmi di apprendimento applicati alle DNN richiedono in genere molta potenza di calcolo, e sono risultati spesso in passato di difficile applicabilità a casi reali che richiedevano, per essere modellati, una importante mole di strati nascosti e di dati da processare. Il recente evolversi delle architetture multi-core, del cloud, e delle Graphical Processing Unit (GPU), che ben si adattano ad una esecuzione efficiente di tali algoritmi mediante opportune parallelizzazioni, hanno permesso il diffondersi delle tecniche di Deep-learning e delle DNN in numerosi ambiti applicativi, con risultati inimmaginabili fino a qualche anno fa nei settori del riconoscimento vocale, del parlato e delle immagini. Nel campo del riconoscimento di immagini, ad esempio, l’apprendimento per livelli tipico del deep-learning consente di considerare le varie aree dell’immagine a partire dalle informazioni di più basso livello (ad esempio i singoli pixel) per poi arrivare a riconoscere o classificare l’immagine per astrazioni successive. Se si pensa al riconoscimento dell’immagine di un viso, a partire dai pixel, si determinano linee e curve, poi parti del viso quali naso, bocca e occhi, per arrivare infine all’intero volto. L’interpretazione delle immagini è utile in tantissime applicazioni che vanno dalla robotica alla sorveglianza, alla ricerca su web, fino alle applicazioni in campo medico. Per una carrellata delle applicazioni delle DNN nel campo medico si consulti [74].
Molte sono le possibili architetture neurali per il Deep Learning definite negli ultimi anni a partire dalle DNN con diverse caratteristiche ed aree di applicazione. Ad esempio, si può pensare di rinunciare alla struttura gerarchica delle reti multi-strato per consentire cicli all’interno della rete, in modo da rendere i neuroni dipendenti anche da ingressi precedenti e non solo da quelli attuali (Recurrent Neural Networks) oppure di individuare all’interno della rete sotto-strutture organizzate per il riconoscimento/classificazione di parti specializzate dell’input (Convolutional Neural Networks). La letteratura in questo campo è molto estesa e recente. Fra le diverse architetture neurali di interesse citiamo i Deep Autoncoder [75], le Deep Belief Networks [76], le Deep Boltzmann Machines [77], le Recurrent Neural Networks [78], e le Convolutional Neural Networks [79]. Per uno studio più approfondito sulle DNN si consiglia di consultare i testi [66] e [71].
Esistono poi piattaforme (spesso open-source) che rendono disponibili programmi ed algoritmi relativi alle DNN e non solo. Fra queste citiamo:
• Caffe http://caffe.berkeleyvision.org
• Theano http://deeplearning.net/software/theano/
• Torch http://torch.ch
• TensorFlow https://www.tensorflow.org
• Digits https://devblogs.nvidia.com/parallelforall/digits-deep-learning-gpu-training-system/
5 Le grandi sfide e i risultati raggiunti
Negli ultimi anni l'IA ha conosciuto una vera e propria rivoluzione: ha ideato sfide che sembravano impossibili da affrontare con successo, e spesso le ha vinte. È stata frequentemente al centro di notizie su quotidiani e mass media, con grande risalto ed impatto su un vasto pubblico: sono stati alimentati entusiasmi, ma anche paure.
Nel seguito introdurremo qualche esempio rappresentativo di sfide ed applicazioni vincenti dell’IA per mostrarne i risultati ottenuti, cosa l’IA ha già fatto, e cosa può invece ancora fare. Per una descrizione esaustiva

e approfondita delle applicazioni significative dell’IA in vari campi quali, ad esempio, pianificazione, visione, comprensione del linguaggio naturale, sistemi di supporto alle decisioni, rimandiamo a testi e conferenze specializzate.
5.1 Il gioco degli scacchi e Deep Blue
Come sottolineato nella Sezione 1, il gioco degli scacchi è un gioco molto antico e diffuso in tutto il mondo, ed esiste su di esso una vasta letteratura composta da libri, tesi ed articoli scientifici. Senza voler entrare nel dettaglio del gioco, basta qui ricordare che numerosi sono i fattori che determinano l’abilità di un giocatore. Un giocatore esperto, infatti, deve avere la capacità di calcolare e memorizzare rapidamente sequenze di mosse e contro-mosse, una conoscenza specifica sul gioco e sulle possibili strategie, diversi modelli di gioco e di come arrivare alla soluzione pianificando razionalmente le successive mosse anche in base a situazioni simili (“case-based reasoning” [80]) e anche a quello comunemente indicato col termine “colpo d’ occhio” o intuizione, caratteristiche queste ultime che rendono spesso il giocatore esperto creativo e imprevedibile agli dello spettatore non esperto.
A partire dal 1950 si pose il problema di come programmare un computer per giocare a scacchi, con l’obiettivo che potesse risultare vincitore nei confronti di un bravo giocatore umano. Fondamentali, a questo proposito, risultano i lavori di Turing e Shannon: Alan Turing in particolare definì un primo programma per giocare a scacchi [81], simulando un “elaboratore umano”, in quanto ancora non esistevano i moderni computer. Gli occorrevano circa 30 minuti per decidere la mossa ritenuta migliore, dopo aver esplorato un albero profondo solo due mosse. Nel 1950, Claude Shannon, ritenuto il padre della Teoria dell'Informazione, scrisse un articolo fondamentale su come programmare una macchina che giochi a scacchi [82], e pose le basi per i futuri programmi di gioco.
Solo dal 1960 in poi si costruirono effettivamente i primi programmi che giocavano a scacchi e che si basavano su particolari varianti e ottimizzazioni di un algoritmo chiamato “minimax”, ideato da John von Neumann e Oskar Morgenster [83].
In pratica, per giochi come quello degli scacchi in cui (i) l’informazione è perfetta, (ii) le regole consentite e lo scopo finale sono ben definiti, (iii) tutta l’informazione è visibile ad entrambi i giocatori e, (iv) l’effetto delle mosse è deterministico, l’approccio alla soluzione è ancora una ricerca nello spazio degli stati (si veda la Sezione 1). In questo caso, però, nel sistema da modellare esistono più agenti intelligenti che interagiscono con l’ambiente e che possono avere obiettivi diversi e contrastanti. Nel caso degli scacchi e di altri giochi da tavolo simili (ad esempio dama, schiera, go) vi sono due giocatori/agenti che muovono a turno. Gli stati finali del gioco sono valutati mediante una funzione di utilità che assumerà, ad esempio, il valore +1 nel caso di vittoria del primo giocatore (convenzionalmente chiamato MAX), il valore -1 nel caso di vittoria del secondo giocatore (convenzionalmente chiamato MIN), o il valore 0 in caso di “patta”.
Il principio base dell’algoritmo minimax può essere così riassunto. Il gioco si risolve costruendo dinamicamente un albero di ricerca (chiamato in questo caso “albero di gioco”) all’interno del quale ogni configurazione del gioco (lo stato corrente della scacchiera) corrisponde ad un nodo dell’albero, ed ogni mossa è un ramo che connette un nodo al successivo. Il primo livello dell’albero corrisponde alle possibili mosse per il primo giocatore (chiamato MAX); il secondo livello rappresenta le possibili mosse che il secondo giocatore (chiamato MIN) può fare a partire dalla mossa iniziale del primo giocatore e così via. L’algoritmo consente di scegliere in ogni momento la mossa migliore da fare nell’ipotesi di poter sviluppare l’albero di ricerca in modo completo, partendo dalla radice fino alle foglie, che sono stati finali del gioco e che saranno quindi etichettati con il valore della corrispondente funzione di utilità (si veda l’albero di ricerca in Figura 6). Per determinare la mossa migliore si propagheranno poi all’indietro ricorsivamente i valori delle funzioni di utilità dalle foglie fino alla radice dell’albero. In pratica, se il nodo è MIN, la sua funzione di utilità sarà quella a valore minimo fra quelle possibili dei nodi figli, mentre per MAX la massima dei nodi figli. Si arriverà così, iterativamente,

ad annotare tutti i nodi fino alla radice. La mossa scelta (indicata con una freccia nella Figura 7) sarà per MAX quella che porta al figlio con il valore maggiore della funzione di utilità (e dualmente col valore minore se consideriamo il giocatore MIN) ed è quella che il giocatore dovrebbe scegliere.
Riuscire ad applicare questa strategia, sviluppando completamente l’albero dalla radice alle foglie per il gioco degli scacchi o per altri giochi di una certa complessità è però un’impresa impossibile, poiché sebbene le mosse applicabili siano finite, sono comunque un numero troppo grande. Anche l’utilizzo di tecniche più efficienti per la generazione dell’albero di gioco completo e per la propagazione dei valori dalle foglie alla radice in modo incrementale non sono in grado di risolvere il problema dell’esplosione combinatoria.
La soluzione generalmente adottata in IA prevede quindi di limitare la ricerca della soluzione ad un albero parziale mediante opportune “potature” o tagli. Ciò può essere ottenuto limitandone la profondità (accorciandone i rami), cioè valutando tutte le mosse possibili per ogni posizione, solo fino ad un certo livello. Si procederà poi ad una opportuna valutazione euristica per attribuire una funzione di utilità allo stato di gioco della foglia (che potrebbe non essere quello finale). Ovviamente più si riesce ad espandere l’albero di gioco (e quindi si aumenta il suo livello di profondità), più il sistema gioca bene. Un altro modo per “potare” l’albero è ridurne le dimensioni “sfoltendolo”, ovvero eliminando dei rami a priori. Ciò può avvenire adottando una tecnica (chiamata dei “tagli alfa-beta”) che prevede di terminare la valutazione di una possibile mossa (e quindi non espanderla ulteriormente) non appena accertato che è comunque peggiore di una già valutata in
Figura 6: Albero Min-Max con etichette sulle foglie.
Figura 7: Albero Min-Max con etichette propagate a tutti i nodi, e scelta del percorso vincente dal punto di vista del giocatore Max.

precedenza, ed evitando quindi l’analisi di parti dell’albero che non sarebbero comunque importanti per la soluzione. Per maggiori dettagli su tali tecniche si consulti [7].
Anche se i primi programmi che giocavano a scacchi furono realizzati agli inizi degli anni 60, e presto se ne svilupparono un numero considerevole in grado di giocare decisamente bene, si dovette aspettare il 1997 per ottenere il risultato più eclatante: una macchina che riuscisse a battere il campione del mondo. Nel 1997 infatti, Deep Blue [84], un calcolatore appositamente progettato e costruito da IBM, sconfisse in una serie di 6 partite l’allora campione del mondo di scacchi Garry Kasparov. Per la precisione, l’incontro organizzato sotto gli auspici dell’Association for Computing Machinery (ACM) e della International Computer Chess Association (ICCA) si concluse con il punteggio di due vittorie per il computer, una vittoria per Kasparov e tre pareggi.
Per fare fronte alla necessità di spingere la ricerca ad un livello molto profondo nell’albero di gioco, elaborando quindi velocemente molte possibili mosse entro i limiti di tempo fissati, era necessario disporre di una notevole capacità di calcolo, utilizzando tecniche di calcolo parallelo. Il calcolatore Deep Blue era costituito da un’architettura altamente parallela basata su 480 processori specificatamente progettati per il gioco degli scacchi ed era quindi in grado di considerare in media 126 milioni di nodi dell’albero al secondo, raggiungendo normalmente una profondità dell’albero di 14 livelli, ma arrivando, in alcuni casi, anche a 40 livelli. Ovviamente questa capacità di ricerca è inaffrontabile da un giocatore umano, anche se campione del mondo.
Da quanto detto, risulta quindi del tutto evidente la diversità di approccio adottata da Kasparov (e da qualunque giocatore umano) rispetto a quella usata da un calcolatore. Nel caso del giocatore umano hanno grandissimo valore l’intuizione, il ragionamento, la creatività e il “colpo d’occhio”, nonché il rifarsi a situazioni note risultanti da partite giocate da grandi maestri, mentre Deep Blue basa la sua forza sulla potenza di calcolo e su semplici funzioni di ricerca e valutazione che gli permettano, teoricamente, di calcolare e ricalcolare tutte le risposte e le combinazioni per ogni singola posizione sulla scacchiera e scegliere sempre quella vincente. Il vincolo è ovviamente rappresentato dalla necessità di limitare il più possibile l’esplosione combinatoria determinata dalla ricerca, affinché la scelta della mossa ritenuta migliore possa essere fatta nei tempi consentiti dal gioco. A questo proposito, va ricordato che Kasparov, al termine della sfida, dichiarò che in alcune mosse di Deep Blue gli era sembrato di riconoscere un’intelligenza ed una creatività quasi umane e chiese ad IBM di organizzare una rivincita che non fu mai concessa. Deep Blue fu, di fatto, smantellato.
5.2 Watson e la risposta a domande
Nel gennaio del 2011 un supercomputer sviluppato da IBM, Watson [85] , è risultato vittorioso nel gioco Jeopardy, dal 1964 uno dei giochi a quiz televisivi più popolari negli Stati Uniti, battendo i giocatori che avevano ottenuto fino ad allora i migliori risultati. Il gioco Jeopardy consiste nel fornire ai partecipanti una serie di indizi in base ai quali bisogna individuare il soggetto di interesse che può essere, ad esempio, in base ad una particolare categoria che viene scelta, un personaggio famoso, un evento storico, il nome di una nazione o di una città ecc. Una volta individuato il soggetto, la risposta deve essere espressa, in un tempo massimo di tre secondi, nella forma della domanda più appropriata. Il gioco prevede pesanti penalità in caso di risposta sbagliata. Nel seguito riportiamo un semplice esempio del gioco:
Informazioni/indizi fornite ai partecipanti sotto forma di risposta: “È l’oceano più vasto”. Risposta corretta sotto forma di domanda: “Cos’è l’Oceano Pacifico?”
Come si può osservare dall’esempio gli indizi sono posti usando il linguaggio naturale, con nessun vincolo sul dominio del discorso. Essendo il dominio “aperto”, sono presenti tutte le difficoltà di interpretazione legate alla comprensione del testo, dovendo, ad esempio, tener conto delle diverse forme sintattiche che esprimono lo stesso significato (sinonimi) e del fatto che la stessa parola o frase possa avere significati diversi in contesti diversi (ambiguità). Nel tempo limite di tre secondi Watson doveva riconoscere ed analizzare la frase contenente la richiesta, comprendere cosa veniva richiesto e fornire la risposta. La tecnica di ragionamento utilizzata in Watson per rispondere alla domanda prevedeva che venissero formulate più ipotesi di soluzione,

ciascuna con il suo grado di certezza o attendibilità, per poi rendere disponibile tramite un sintetizzatore vocale la soluzione con maggiore grado di attendibilità (se superiore ad una soglia prefissata).
Negli anni di preparazione prima della sfida, Watson ha memorizzato il contenuto di decine di milioni di documenti, testi, enciclopedie (200 milioni di pagine), sia di tipo strutturato che non, compresa una versione di Wikipedia. Watson non era collegato ad internet, analogamente agli altri giocatori.
Le capacità mostrate da Watson rientrano a tutti gli effetti tra quelle dei sistemi noti come Question Answering systems (QA) le cui enormi potenzialità applicative sono facilmente intuibili. Non si tratta qui di ricercare documenti mediante parole chiavi ed in modo puramente sintattico come fanno i più noti algoritmi di ricerca su Web, ma rispondere in modo pertinente e in linguaggio naturale a richieste anche esse espresse in linguaggio naturale, e che richiedono la consultazione intelligente di numerosissimi documenti, la loro comprensione eliminando ambiguità, e l’esecuzione di opportune inferenze.
All’inizio della realizzazione di Watson, nel 2007, per rispondere ad un quesito di Jeopardy erano necessarie circa due ore di tempo di CPU utilizzando un singolo processore con 16 GB (gigabytes) di memoria. Per raggiungere tempi di risposta di tre secondi fu necessario, quindi, potenziare pesantemente la potenza di calcolo, adottando un supercomputer fornito di ben 2880 processori, 20 TB (terabytes) di memoria con una potenza di calcolo di 80 trilioni di operatori al secondo e la capacità di scandire 200 milioni di pagine di contenuto in meno di 3 secondi.
Il successo ottenuto da Watson ci insegna che l’intelligenza di un sistema in questo caso si può ottenere da un connubio di algoritmi e conoscenza che va accumulata, organizzata, integrata ed esplorata con particolare attenzione all’efficienza. Per una descrizione dettagliata e tecnica di come lavora Watson si consulti [86].
Al tempo della sua realizzazione (2007-2011) erano già avviati molti studi in campi relativi all’accesso e recupero delle informazioni, al trattamento del linguaggio naturale, ai metodi di rappresentazione della conoscenza e del ragionamento, all’apprendimento automatico e all’interazione uomo-macchina, che Watson ha utilizzato e potenziato. Attualmente Watson è evoluto verso una serie di algoritmi, piattaforme, strumenti per l’IA sviluppati da IBM e messi a disposizione degli utenti (esperti in vari settori, studenti) per consentire la consultazione intelligente di grandi quantità di documenti di qualunque tipo (strutturato e non strutturato), diversamente non accessibili nella loro totalità, utilizzando una modalità di interazione basata sul linguaggio naturale.
Il progetto complessivo sviluppato da IBM DeepQA [87], ha consentito un avanzamento in varie aree di ricerca, e sta trovando impiego in vari settori applicativi di grande interesse dal punto di vista commerciale quali la formazione e la medicina [86].
5.3 Il gioco del GO e AlphaGo
Il Go è un gioco da tavolo a due giocatori nato in Cina oltre 2500 anni fa e molto popolare in Asia orientale. Giocato da più di 40 milioni di persone in tutto il mondo, ha regole molto semplici: i giocatori, (il Bianco e il Nero) a turno devono posizionare le pedine (“pietre”) bianche o nere sulle intersezioni vuote di una scacchiera (“goban”) che rappresenta una griglia 19x19. Durante il gioco i giocatori cercano strategicamente di raggiungere la vittoria cercando di “controllare” una zona del goban più estesa di quella controllata dall’avversario. Nel disporre le pietre sul goban si deve fare attenzione a non farle attaccare e catturare dalle pietre avversarie. Una pietra (o gruppo di pietre) viene catturata quando viene completamente circondata dalle pietre dell’avversario: la strategia del gioco è la ricerca di un compromesso vincente fra la difesa delle proprie zone e l’attacco delle zone occupate dall’avversario [88]. Il gioco termina quando entrambi i giocatori passano la mano, non avendo più a disposizione alcuna possibilità di attacco o difesa. Un opportuno conteggio basato sulla configurazione finale della scacchiera determinerà poi il vincitore.

Analogamente al gioco degli scacchi, si tratta di un gioco ad informazione completa in quanto è noto l’obiettivo finale e sono note le regole consentite per i movimenti delle pietre. Tutti i giocatori hanno la stessa informazione. Da un punto di vista teorico è quindi possibile, come nel caso già esaminato degli scacchi, considerare di rappresentare la soluzione del gioco come un albero di ricerca all’interno del quale ogni configurazione del goban corrisponde ad un nodo ed ogni mossa è un ramo da un nodo al successivo.
Il gioco del Go si contraddistingue però per essere di una complessità elevatissima, sensibilmente maggiore rispetto agli scacchi. Le possibili mosse iniziali sono 361 contro le 20 degli scacchi, e le diverse possibili configurazioni sono un numero incredibilmente elevato, dell’ordine di ben 10172, contro le 1050 del caso degli scacchi come calcolato da Shannon e modificato da Allis [89]. Se quindi un approccio alla soluzione del problema come ricerca nello spazio degli stati era ancora accettabile per gli scacchi, solo però operando notevoli potature dell’albero di gioco, nel caso del Go questo approccio diventa proibitivo, volendo rispettare i tempi previsti normalmente per un turno di gara.
Nel tempo sono stati realizzati numerosi programmi che affrontavano in modo semplificato il problema del gioco del Go, ma sono sempre risultati perdenti contro un bravo giocatore umano. Questo fino al 2015, quando per costruire un sistema di IA che giocasse a Go e battesse i migliori giocatori si è utilizzato per la prima volta il programma AlphaGo [72], sviluppato da DeepMind, un’azienda inglese operante nell’area dell’IA, recentemente acquistata da Google. Usando AlphaGo, il calcolatore è riuscito a sconfiggere l’allora campione europeo nel gioco del Go. Il programma è stato poi ulteriormente migliorato e, nel Marzo del 2016, ha sconfitto in un incontro col punteggio di 4-1 il giocatore sud–coreano Lee Seedol, considerato uno dei più forti giocatore di Go a livello mondiale. Recentemente si è svolto in Cina un incontro su tre partite con l’attuale campione del mondo, il cinese Ke Jie. AlphaGo ha vinto col punteggio di 3-0. Dopo questo risultato, DeepMind ha deciso di interrompere queste sfide e di concentrarsi sull’applicazione di AlphaGo in nuovi settori applicativi.
Quello che rende particolarmente interessante il risultato di questa sfida, dal punto di vista tecnico, è che il programma AlphaGo non segue l’approccio puramente simbolico – in cui tutta la conoscenza sul gioco, le regole, la strategia e l’euristica sono inserite esplicitamente nel sistema e la soluzione è ottenuta mediante ricerca in un possibile spazio di stati – ma è in gran parte basato sull’utilizzo di tecniche di apprendimento automatico e, in particolare, di quelle basate su reti neurali profonde (si veda la Sezione 4.2.2). Tali tecniche vengono quindi utilizzate per apprendere autonomamente la mossa migliore da selezionare e l’opportuna strategia di gioco, e possono essere utilizzate in larga scala ed in modo efficiente grazie alla sempre crescente potenza di calcolo a disposizione. In particolare, il programma è stato progettato come sistema ibrido che combina utilmente sia tecniche simboliche sia tecniche sub-simboliche o connessioniste, rappresentate da tre diverse reti neurali addestrate con diverse tecniche di apprendimento.
Nel 2017 AlphaGo ha ricevuto il prestigioso premio “Inaugural IJCAI Marvin Minsky Medal for Outstanding Achievements in AI”. Le motivazioni sono state espresse da Michael Wooldridge, Chair of the IJCAI Award, come segue:
“What particularly impressed IJCAI was that AphaGo achieves what it does through a brilliant combination of classic AI techniques as well as the state-of-the-art machine learning techniques that DeepMind is so closely associated with. It’s a breathtaking demonstration of contemporary AI…”
Si noti infine che per incorporare la conoscenza necessaria a riconoscere determinate situazioni di gioco e reagire compatibilmente, AlphaGo fu sottoposto ad un lungo periodo di addestramento con un training set costituito da 30 milioni di mosse, sotto la supervisione di esperti del gioco e giocando milioni di partite contro sé stesso, imparando quindi anche dai suoi stessi errori.

5.4 I robot giocano a calcio
Già oggi siamo circondati da robot: sono oggi utilizzati per missioni pericolose, esplorazioni spaziali, in agricoltura, nell’industria, in medicina, in casa. La possibilità di costruire automobili autonome, capaci di muoversi sulla strada in modo sicuro senza un guidatore o collaborando in modo effettivo con lui, è ormai ritenuta una realtà di grande interesse dal punto di vista della ricerca e dell’industria.
Anche in questo campo è stata concepita un’ambiziosa sfida che coinvolge l’IA e la Robotica: RoboCup. L’obiettivo, veramente difficile da raggiungere in tempi brevi, è quello di progettare, entro il 2050, una squadra di robot autonomi in grado di sfidare e battere la squadra campione mondiale di calcio [90].
I primi campionati mondiali di RoboCup si sono svolti nel 1997 in Giappone e poi, a seguire, ogni anno fino ad oggi. Nel corso del tempo le tecniche si sono ovviamente affinate e osservando i filmati dei campionati, dai più datati fino a quelli odierni che sono disponibili sulla rete, risultano evidenti gli enormi progressi che sono stati ottenuti sia dal punto di vista delle parti attuative dei robot antropomorfi (rispetto a venti anni fa, sono ora in grado di muoversi con più perizia, velocità e agilità), sia per quello che riguarda le capacità percettive, di elaborazione e interpretazione dei segnali e di strategia. La sfida internazionale di RoboCup prevede diverse categorie con l’obiettivo di sviluppare e far competere i robot non solo in una partita di calcio, ma anche in diverse situazioni critiche e di soccorso, in ambienti domestici, nell’interazione con l’uomo e coi bambini a scopi educativi e di formazione [91].
Quello che rende molto interessante questa sfida dal punto di vista tecnologico è la sua diversità e per certi versi complementarietà rispetto a quella del gioco degli scacchi, vinta da DeepBlue proprio nello stesso anno (il 1997) in cui si è svolto il primo campionato di RoboCup. Il mondo dei giochi da tavola, e degli scacchi in particolare, è un mondo “formale” e virtuale in cui tutto può essere conosciuto e modellato opportunamente, ed in cui le azioni hanno un esito certo e noto, mentre il mondo di RoboCup è quello “fisico” di una partita reale, e del mondo fisico condivide le problematiche.
Diventano quindi importanti i meccanismi percettivi — che devono esplorare l’ambiente, cercando di limitare l’errore e l’incertezza — e i meccanismi attuativi anche essi complessi e collegati ad un ambiente (e di conseguenza ad un suo modello) non completamente conosciuto e che si modifica dinamicamente. Il sistema risultante è un sistema multi-agente in cui gli agenti sono autonomi (gli umani non possono intervenire durante la partita) ed esistono sia agenti collaborativi (che lavorano nella stessa squadra ed interagiscono per raggiungere un obiettivo comune) sia agenti competitivi ed antagonisti (quelli della squadra avversaria). Ogni robot deve quindi anche tenere conto, nel costruire il proprio modello, del comportamento degli altri giocatori e dei modelli che anche gli altri agenti hanno sul mondo.
Andando oltre la pur affascinante sfida, RoboCup è sicuramente stata e sarà ancora una grande palestra in cui scienziati, studenti, industrie, semplici curiosi possono confrontarsi in differenti scenari sul grande tema dei robot autonomi e intelligenti. Cioè robot concepiti come entità fisiche situate in un ambiente reale e dotati di sensori e attuatori, che possono apprendere dall’esperienza, ed adattare il loro comportamento all’ambiente.
6 Verso il futuro (aspetti economici, sociali e etici) Nei paragrafi precedenti abbiamo esaminato lo stato attuale delle tecnologie che fanno capo all’IA e come prevedibilmente si svilupperanno in un prossimo futuro. Come già detto, e come è facile intuire, dobbiamo aspettarci un forte impatto delle nuove tecnologie nella società e nelle sue varie articolazioni, in particolare, nel nostro modo di vivere. Fin da ora molto è cambiato e molto di più dobbiamo aspettarci che cambierà nel futuro.
Cambiamenti sensibili li dovremo aspettare sicuramente in campo sociale ed economico, in quanto la progressiva automazione del lavoro e la diffusione dei robot modificheranno profondamente il modo con cui

verranno svolte attività prima principalmente affidate all’uomo. Avremo quindi problemi di tipo sociale legati alla perdita del lavoro o ad una sua profonda trasformazione.
Altrettanto rilevanti saranno i problemi di tipo etico che si dovranno affrontare con il progressivo evolversi della tecnologia. Come sarà possibile integrare principi etici nei progetti innovativi di IA? In che modo assicurare che l’IA procurerà benefici all’umanità? Quali garanzie saranno necessarie per proteggere l’enorme quantità di dati personali necessari per alimentare i sistemi di IA? Chi si prenderà la responsabilità in caso di malfunzionamento delle macchine? Riuscirà l’uomo a mantenere il controllo delle macchine prodotte? Sono temi che naturalmente interessano tecnologici, sociologi, scienziati, filosofi, giuristi e politici, ma anche i singoli cittadini.
Ognuno dei problemi citati richiederebbe un’approfondita analisi. Non può essere questa la sede per tali approfondimenti. Nel seguito, con riferimento ai problemi economici, sociali ed etici, si cercherà di chiarire la loro natura, il loro modo di influenzare aspetti della nostra vita, rinviando alla ampia documentazione delle numerose iniziative a livello mondiale, particolarmente diffuse in questo periodo, per un loro completo esame.
6.1 Aspetti economici e sociali
Un problema molto dibattuto in questi ultimi anni riguarda le prospettive future del lavoro con i conseguenti problemi di tipo sociale ed economico, a fronte del continuo sviluppo delle applicazioni di IA e della robotica. È opinione comune che queste applicazioni in modo progressivo saranno sempre più in grado di svolgere in modo efficiente la gran parte dei lavori oggi svolti dall’uomo e porteranno, di conseguenza, nei prossimi anni ad una profonda trasformazione del mondo del lavoro.
Si potrebbe affermare che questo processo non è assolutamente una novità e che già la rivoluzione industriale e l’introduzione dell’automazione in diversi ambiti ha portato profondi cambiamenti nella organizzazione del lavoro, nelle aziende e negli uffici in passato come ora. E’ interessante, ad esempio, in prospettiva storica, notare che molti dei dubbi oggetto di discussione oggi fossero già preconizzati da Keynes in un famoso studio del 1930 [92]. Mentre però in molti casi lo sviluppo industriale e il mondo dei servizi aveva consentito a questi cambiamenti di non essere causa di significative perdite di posti di lavoro e, in alcuni casi, aveva determinato un aumento della produzione e la crescita della domanda di lavoro, oggi il fenomeno appare più intenso e preoccupante. Il timore è che l’IA possa affidare alle macchine gran parte delle attività di lavoro, anche professionalizzanti, ritenute fino ad ora appannaggio esclusivo dell’uomo.
Un recente studio [93] dell’Università di Oxford, ad esempio, che ha riguardato 720 attività lavorative presenti nel mercato americano, prevede che il 47% di queste abbiano elevata probabilità di scomparire (essere automatizzate) nei prossimi 20 anni. La peculiarità delle nuove applicazioni, inoltre, farà sì che per la prima volta non saranno solamente operai ed impiegati ad essere interessati dal fenomeno, ma anche lavoratori appartenenti alla classe media, in quanto sarà possibile automatizzare funzioni una volta svolte da specialisti e professionisti qualificati. Secondo un report riservato del Gartner Group, ad esempio, già oggi specifici algoritmi compiono la metà delle transazioni finanziarie in autonomia, senza intervento umano. Come ulteriore esempio, un recentissimo studio realizzato da Citigroup prevede che il 30% degli attuali impiegati nel settore bancario in America e in Europa perderà il proprio posto di lavoro a causa delle nuove tecnologie [94].
Naturalmente cresceranno le opportunità di lavoro ed i vantaggi economici per quanti saranno gli artefici di questa rivoluzione tecnologica, ma con il risultato di accrescere le diseguaglianze di trattamento sociale ed economico tra i vari strati della popolazione, già molto evidenti nell’odierna società, e questo desta forti preoccupazioni a livello internazionale.
Nel frattempo, con l’aumento dei lavori potenzialmente automatizzabili è probabile che si assista ad un aumento della disoccupazione, a una contrazione dei salari in un numero di professioni sempre più elevato, ed alla crescita dei compensi per quelle, sempre meno numerose, che non possano essere automatizzate. Nel

recente convegno annuale del Word Economic Forum tenutosi a Davos nel gennaio del 2017 [95] è stato previsto che la cosiddetta “quarta rivoluzione industriale” porterà nei prossimi 5 anni ad una perdita di 5 milioni di posti di lavoro, e questo coinvolgerà le 15 economie mondiali più sviluppate. Anche se l’impatto, in termini relativi, non appare così significativo (stiamo parlando dello 0,3% in 5 anni), sicuramente indica una tendenza verso uno sviluppo a bassa intensità di lavoro, al quale corrisponde, come si è detto, un graduale impoverimento della classe media.
Va segnalato che non tutti gli esperti ed i ricercatori condividono la visione pessimista precedentemente discussa. Il punto di forza delle argomentazioni di chi mostra un certo scetticismo sulle paure per la distruzione dei posti di lavoro a causa della diffusione delle macchine e dell’automazione si basa su quanto già avvenuto nelle precedenti rivoluzioni industriali. Viene messo in evidenza, ad esempio, come l’introduzione della meccanizzazione in agricoltura abbia spinto moltissimi lavoratori verso le città per trovare un lavoro nell’industria e come l’automazione e la globalizzazione abbiano spostato molti lavoratori dal settore industriale a quello dei servizi. In generale, si sottolinea come la crisi di un settore generalmente spinga allo sviluppo di nuovi settori anche inaspettati ed alla creazione di nuovi bisogni da soddisfare, aprendo così nuove prospettive economiche.
Scrive Roberto Saracco in “Un futuro con i robot e senza lavoro? Le ragioni dell’ottimismo”7:
“Abbiamo visto una continua evoluzione dei nostri sistemi sociali, economici e di produzione. In certi periodi in effetti vi sono stati cambiamenti anche traumatici. Ma abbiamo anche visto che attraverso difficoltà e anche sofferenze di vari strati sociali, spesso attraverso l’ingegno che chiamiamo progresso, il mondo si è adattato ed è proseguito con le leggi base dell’economia in un contesto sociale in lenta evoluzione”.
Qui si mette l’accento, in particolare, sulla possibilità offerta dalle nuove tecnologie di trasformazione del lavoro operaio in lavoro artigiano e su come l’uso dei robot possa liberare il personale dallo svolgimento di attività ripetitive e standardizzate, permettendo nel contempo alle persone già impiegate di rendere molto più produttive le conoscenze e le abilità specializzate maturate in anni di lavoro.
Inoltre, la messa in opera dei robot richiede in genere addestramento del personale per la progettazione di software sviluppato ad hoc e la realizzazione di specifiche attrezzature hardware con conseguente elevazione della qualità del lavoro svolto.
Scrive ancora Roberto Saracco:
“Ci sono molti motivi per essere ottimisti, ma questo non significa nascondere o negare le grandi sfide e i problemi che abbiamo di fronte. Questi motivi trovano conforto nel progresso fatto e nell’evoluzione che continua. Evoluzione di cui la tecnologia rappresenta un elemento importante”
A conclusione di questa sintetica discussione su cosa potrà accadere nel mondo del lavoro con la crescente diffusione dei robot e delle applicazioni di IA, possiamo notare come entrambe le posizioni, quella “pessimistica” e quella “ottimistica”, concordino sul fatto che sarà necessario puntare fortemente nel prossimo futuro sull’ adeguamento della formazione, sia quella professionale per chi già ha un’occupazione di lavoro, sia quella del sistema scolastico, in modo da sviluppare, oltre alle competenze scolastiche tipiche dell’era industriale, anche abilità intellettuali e personali che mettano in grado i ragazzi di lavorare meglio accanto alle nuove machine intelligenti [96].
Inoltre, a fronte del rischio che la maggiore automazione produca la perdita temporanea del salario o un suo stabile peggioramento per una quota non insignificante di lavoratori, bisognerà cercare da subito dei modi per
7 https://www.agendadigitale.eu/industry-4-0/un-futuro-con-i-robot-e-senza-lavoro-le-ragioni-dell-ottimismo/

sostenere i redditi degradati e le fasce di popolazione più colpite, nonché modalità per una più equa distribuzione del reddito. Le direzioni secondo cui affrontare il problema sono ampiamente discusse e già esistono una serie di proposte sulle quali, tuttavia, non si è raggiunta una visione unitaria. Una panoramica di queste proposte la si può trovare nella bibliografia citata precedentemente. Per una più approfondita analisi si rimanda a [97] e [58].
6.2 Aspetti etici
Nei paragrafi precedenti si è messo in evidenza come le applicazioni dell’IA e della robotica abbiano avuto (e stiano avendo) un’ampia diffusione in molti settori della vita quotidiana con significativi miglioramenti della qualità della vita stessa. Basti pensare ad applicazioni nel campo medico, nell’assistenza agli anziani, nella formazione, nell’automazione della produzione industriale ecc. Il tema è ampiamente documentato anche giornalmente sui mezzi di comunicazione. Va sottolineato, tuttavia, che accanto a questi indubbi vantaggi esistono una serie di rischi per l’umanità che sono strettamente legati all’utilizzo delle applicazioni di IA ed all’impiego dei robot.
Si pensi a droni con armi a bordo utilizzati per missioni militari e che potrebbero essere responsabili di violazioni umanitarie. O si pensi a sistemi di IA che fanno previsioni ed eseguono operazioni in borsa mediante evoluti algoritmi di apprendimento, elaborando quantità enormi di dati con tempi di reazione inferiori al millesimo di secondo e che potrebbero mettere in crisi aziende, industrie e anche interi paesi dal punto di vista economico e finanziario.
Scrive Giuseppe O. Longo al riguardo in “Etica e responsabilità nell’era del post-umano” [98]:
“Negli ultimi tempi molti sono preda di una sorta di etilismo tecnologico, che li spinge ad abusare della potenza delle tecnologie e a dimenticare la grande responsabilità che ci deriva proprio da quella potenza: responsabilità verso noi stessi, verso i posteri e verso l’ambiente”.
Consci di questa grossa responsabilità, nasce quindi la necessità di definire opportuni principi per la progettazione di sistemi di IA che lavorano in autonomia affinché siano affidabili e sicuri per l’umanità. In particolare, vorremmo che tali sistemi nel prendere decisioni e trattare dati, rispettassero la legalità e seguissero opportuni principi etici. In letteratura, per indicare il complesso di questi principi etici viene utilizzato il termine “roboetica”. Tale termine è stato introdotto nel 2002 da Gianmarco Veruggio durante il primo Simposio Internazionale sulla roboetica [99], con il seguente significato:
“la roboetica è un’etica applicata, il cui scopo è sviluppare strumenti e conoscenze scientifiche, culturali e tecniche che siano universalmente condivisi, indipendentemente dalle differenze culturali, sociali e religiose. Questi strumenti potranno promuovere ed incoraggiare lo sviluppo della robotica verso il benessere della società e della persona. Inoltre, tramite la roboetica si potrà prevenire l’impiego della robotica contro gli esseri umani”.
La roboetica ha dunque come obiettivo lo studio delle conseguenze, sia positive che negative, derivate dall’utilizzo dei robot nei vari settori della società allo scopo di definire principi etici e morali che possano guidare la progettazione, lo sviluppo e l’utilizzo delle applicazioni di IA e di robotica da parte dell’uomo. In altre parole, sono regole e principi che riguardano l’uomo e a cui l’uomo deve attenersi per accrescere i vantaggi ottenibili da queste applicazioni riducendo nel contempo le possibilità di rischi ad esse associati.
Molte ed importanti iniziative sono seguite al workshop precedentemente menzionato del 2002. In particolare, la IEEE-Robotics&Automation Society8 ha dato vita, nel 2004, a un Comitato Tecnico per la Roboetica, con l’obiettivo di costituire una struttura che si occupi delle implicazioni etiche delle ricerche robotiche, attraverso la promozione di discussioni tra ricercatori di diverse aree (filosofia, scienza cognitiva, etica), e la definizione
8 http://www.ieee-ras.org/

di strumenti per trattare problemi etici nel settore della Robotica. Altre importanti iniziative sono state promosse nell’ambito della Commissione Europea ed in ambito internazionale. In particolare, vanno ricordate le prime “Ethical and Legal Recommendations” pubblicate nel 2014 dall’European RoboLaw Consortium for Ethics in Robotics nelle “Guidelines on Regulating Robotics” [100].
Di seguito si riportano un insieme di principi etici direttamente tratti da “European Civil Law Rules in Robotics” [101] che, se seguiti nella progettazione dei robot, dovrebbero garantire una maggiore sicurezza per l’umanità.
• Proteggere l’uomo da ogni possibile danno causato da un robot.
• Rispettare la volontà di non essere assistito da un robot.
• Garantire che l’uomo sia sempre in grado di obbligare un robot ad eseguire i suoi ordini.
• Proteggere l'umanità dalle violazioni della privacy commesse da un robot.
• Mantenere il controllo su informazioni catturate ed elaborate da un robot.
• Evitare che per certe categorie di persone possa istaurarsi un senso di empatia artificiale con i robot.
• Evitare che l’utilizzo dei robot favorisca la perdita dei legami sociali.
• Garantire uguali opportunità di accesso all’utilizzo dei robot.
• Controllare l’utilizzo di tecnologie che tendono a modificare le caratteristiche fisiche e mentali dell’uomo.
In tutti i casi elencati precedentemente, e, in generale, quando si parla di roboetica, il comportamento etico dei robot dipende strettamente da quanto richiesto e realizzato dal progettista. La situazione si sta però rapidamente modificando negli ultimi tempi, man mano che cresce l’autonomia dei robot, cioè la loro capacità di apprendere dall’ambiente esterno e di prendere decisioni anche a fronte di eventi inaspettati, senza alcun intervento umano. Si parla in questo caso non più di roboetica, ma piuttosto di etica dei robot intesi come entità decisionali autonome.
Questa seconda declinazione di etica sicuramente richiama alla nostra mente le tre leggi della Robotica formulate da Isaac Asimov, uno dei padri della narrativa di fantascienza e pubblicate nell’antologia “Io, Robot” [102]. Riportiamo le tre leggi della robotica [103] qui nel seguito.
1. “Un robot non può recare danno a un essere umano, né può permettere che, a causa del suo mancato intervento, un essere umano riceva danno”.
2. “Un robot deve obbedire agli ordini impartiti dagli esseri umani, purché tali ordini non contravvengano alla Prima Legge.”
3. “Un robot deve proteggere la propria esistenza, purché questa autodifesa non contrasti con la Prima e la Seconda Legge.”
A queste leggi, successivamente, se ne aggiunge una quarta, superiore per importanza a tutte le altre definita “legge zero”:
4. “Un robot non può recar danno all’umanità e non può permettere che, a causa di un suo mancato intervento, l’umanità riceva danno.”

L’applicazione delle leggi di Asimov richiederebbe la creazione di una sorta di “autocoscienza etica” all’interno del robot stesso da utilizzarsi in piena autonomia. Anche se oggi agenti intelligenti possono riconoscere forme o immagini in modo molto accurato o imparare a fare previsioni in autonomia, la prospettiva di una “autocoscienza etica” per i robot risulta per ora ancora lontana dal realizzarsi e per certi versi appare ancora fantascientifica.
In prospettiva però potrebbe porsi un problema etico e di responsabilità decisionale davanti a sistemi di IA che agiscono autonomamente in specifici domini applicativi. Quale esempio si consideri l’area della guida autonoma in cui l’IA sta producendo sempre più interessanti applicazioni. Molti mezzi di trasporto su rotaia già funzionano senza un guidatore umano fisicamente presente, e presto avremo anche automobili senza guidatore. Stanno lavorando all'auto senza pilota grandi aziende quali Google, Apple, Uber, e la maggior parte delle grandi case automobilistiche, a cominciare da Ford e BMW che hanno prospettato una produzione in serie già a partire dai prossimi anni.
Si consideri il caso di un’automobile senza guidatore che venga a trovarsi in una situazione di incidente inevitabile, ma che può avere differenti conseguenze su persone e cose in base ad alcune decisioni di guida. Ad esempio, si potrebbe scegliere di preservare comunque il guidatore, oppure di salvare il massimo numero di persone ecc. Il comportamento etico da adottare in questo caso può in linea di principio essere imposto alla macchina da scelte esterne, variabili di caso in caso e quindi di carattere relativo. Su questo tema si veda ad esempio l’esperimento della “moral machine” [104], in cui mediante una serie di test a cui i guidatori umani sono sottoposti, si cerca di produrre un insieme di informazioni sul comportamento etico che dovrebbe seguire la macchina dotata di autonomia nella guida in vari casi di incidente.
Un altro esempio è rappresentato al caso di un aereo senza pilota che deve colpire un bersaglio dopo averlo individuato tra molti bersagli possibili ed in condizioni ambientali complesse. A fronte di situazioni di incertezza provocate da condizioni esterne non previste quale deve essere il principio etico da adottare? [105]
È quasi certo che nel futuro avremo sistemi di IA sempre più autonomi e in grado di prendere decisioni complesse in diversi campi applicativi. Risulta quindi attuale e pertinente porsi alcune domande ora senza risposta, ma fonte di interessanti dibattiti: “A chi (o a cosa) attribuire la responsabilità dell’operato di queste macchine?”; “Sarà possibile rendere autonome queste macchine, ed equipaggiarle di una coscienza, cioè fornire loro un’etica delle loro azioni?”, e ancora “In caso di autonomia, come garantire la conformità di tali sistemi a regole e norme?”.
È quindi oggetto di discussione se le problematiche etiche relative ai sistemi autonomi di IA debbano portarci a fermare/contrastare lo sviluppo tecnologico, oppure se ci sia un modo per attuare uno sviluppo tecnologico utile e responsabile con indubbi vantaggi per l’uomo. Riprendendo il caso delle automobili a guida autonoma, tale tecnologia potrebbe contribuire a ridurre drasticamente gli incidenti stradali, causati ad esempio da stili di guida pericolosi, o da parte di umani stanchi, o distratti, o sotto effetto di alcool o sostanze stupefacenti. Da una statistica dell’Unione Europea, risulta che solo nel 2014 ci sono stati 25.900 morti in incidenti stradali e, per ogni morto, vi sono mediamente 4 persone che hanno riportato disabilità permanenti [106]. I sistemi di guida autonoma promettono implicitamente di ridurre ai minimi termini (se non di azzerare) tali costi in termini di vite umane: alla luce di ciò, la necessità di sviluppare sistemi di guida autonoma appare urgente, e non soggetta a dubbi.
Se non esiste una risposta univoca alle ansie o paure determinate da sistemi intelligenti e autonomi, possiamo comunque affermare che allo stato attuale le migliori soluzioni nascono da una utile e proficua interazione fra i sistemi di IA e l’uomo, in cui l’uomo ha la piena responsabilità sulla progettazione e poi sull’utilizzo di tali sistemi. Scrivono Omicini e Sartor al riguardo in [105]:
“It appears that in many domains, the transport system, robotic, healthcare, online trading, nuclear power plants and other critical systems, the best performance today can be obtained neither by humans alone, nor by machines alone, but rather through the integration of humans

and machines ... Thus, we should not aim at substituting humans with machines. We should but rather aim at a symbiotic partnership between humans and machines…”.
In tale prospettiva una caratteristica molto importante dei sistemi di IA è la “trasparenza”, intesa come la possibilità di rendere manifesta e comprensibile all’uomo la modalità di operare dei sistemi autonomi, le motivazioni che hanno portato a certe scelte, ed i relativi rischi. L’obiettivo è quello di mantenere il controllo dell’uomo sulla macchina, comunicare ed interagire con i sistemi di IA ed avere conoscenza del perché del loro operato. Recentemente l’Unione Europea ha emesso alcune raccomandazioni in tale senso [107]. Alcune note applicazioni che operano ad esempio nel settore dell’assistenza sanitaria, dei servizi di tipo finanziario e legale già adottano strumenti capaci di operare in modo trasparente9 mostrando in modo esplicito le modalità di ragionamento seguite.
Si può notare, tuttavia, che questa trasparenza non è sempre possibile e può essere influenzata da fattori tecnici progettuali. Basti pensare, ad esempio, ad applicazioni di una certa complessità che si basano, per assumere decisioni di tipo autonomo, su tecniche di apprendimento utilizzando sistemi sub-simbolici o connessionisti. In questi casi può risultare molto difficile, se non impossibile, riuscire a spiegare le motivazioni di una particolare decisione o comportamento. Su questo tema, ovvero sulla capacità dei sistemi autonomi di essere in grado di spiegare il loro comportamento, cioè di presentare la linea di ragionamento seguita e di mostrare le fonti delle informazioni interagendo utilmente con l’uomo, si sono svolti recentemente numerosi workshop tematici nell’area dell’IA fra cui menzioniamo il “Workshop on Human Interpretability in Machine Learning” [108] e il “Workshop on Explainable Artificial Intelligence (XAI)” [109].
L’argomento relativo ad etica e IA è al centro di numerose ricerche e studi che coinvolgono molteplici discipline tra cui l’informatica, la filosofia, la sociologia, la giurisprudenza, le scienze cognitive, la psicologia, la biologia ed altre ancora. La trattazione qui presentata va intesa quindi come limitata e riassuntiva. Per approfondimenti sottolineiamo che esiste a questo proposito una vasta bibliografia costituita soprattutto da resoconti di sempre più numerosi e prestigiosi convegni internazionali sull’argomento. Fra i tanti, citiamo l’IEEE AI &Ethics Summit del 2016 [110] e lo studio “European Civil Law Rules in Robotics- European Union”, sempre del 2016 [111].
Con intenti simili, nel 2016, è nata anche una collaborazione fra le più importanti compagnie interessate ai temi dell’IA quali Google, Apple, Amazon, IBM, Microsoft, denominata “Partnership on Artificial Intelligence to Benefit People and Society”10, con l’obiettivo di aprire un tavolo di discussione sulle migliori tecniche nel campo dell’IA affinché tale disciplina sia uno strumento utile e positivo e si possano evitare impatti negativi sulla società. Analogamente, citiamo un’iniziativa recente promossa da IEEE: “IEEE Global Initiative for Ethical Considerations in Artificial Intelligence and Autonomous Systems” 11 . Obiettivo dell’iniziativa è favorire, per chi si occupa di tecnologie, una formazione che consideri prioritari i principi etici nel progetto e nello sviluppo di sistemi autonomi intelligenti.
“The mission of the initiative is to ensure every technologist is educated, trained, and empowered to prioritize ethical considerations in the design and development of autonomous and intelligent systems. By technologist, we mean anyone involved in the research, design, manufacture or messaging around AI/AS including universities, organizations, and corporations making these technologies a reality for society.”
Nel dicembre 2016, IEEE ha inoltre annunciato la pubblicazione della prima versione del documento “Ethically Aligned Design: A Vision for prioritizing Human Wellbeing with artificial Intelligence and Autonomous Systems”. Il documento è stato realizzato con la partecipazione di oltre un centinaio di personalità
9 https://futurumresearch.com/ethics-artificial-intelligence/ 10 https://www.partnershiponai.org/ 11 https://standards.ieee.org/develop/indconn/ec/autonomous_systems.html

provenienti dal campo dell’IA, etica, filosofia, legge e politica ed appartenenti al mondo dell’accademia e dell’industria [112]. Secondo Konstantinos Karachalios, direttore della IEEE Standard Association:
“As we move towards a more fully autonomous world, the first version of Ethically Aligned De-sign represents a milestone for creating consensus around and developing the methodologies that will ensure humanity utilizes technology that inherently supports and prioritizes our wellbeing and values. By providing technologists with peer-driven, practical recommendations for creating ethically aligned autonomous and intelligent products, services, and systems, we can move be-yond the fears associated with these technologies and bring valued benefits to humanity today and for the future.” [112]
Un grosso stimolo alla costruzione di Sistemi di Intelligenza Artificiale orientati a portare benefici per l’umanità è dato da Stuart Russel in [113], che conia a questo riguardo il termine di “Beneficial AI”:
“Up to now, AI has focused on systems that are better at making decisions; but this is not the same as making better decisions. No matter how excellently an algorithm maximizes, and no mat-ter how accurate its model of the world, a machine’s decisions may be ineffably stupid, in the eyes of an ordinary human, if its utility function is not well aligned with human values.”
“This problem requires a change in the definition of AI itself, from a field concerned with pure intelligence, independent of the objective, to a field concerned with systems that are provably beneficial for humans.”
Vanno inoltre segnalate le iniziative rivolte a scoraggiare l’utilizzo delle tecnologie di IA per scopi bellici e militari [114] [115]. Va ricordato a questo proposito anche il recente appello che nell'ambito del congresso International Joint Conference on Artificial Intelligence (IJCAI 2017) 116 fondatori delle maggiori aziende di robotica e intelligenza artificiale hanno inviato all’ONU per “prevenire una corsa agli armamenti autonomi, per proteggere i civili dagli abusi e per evitare gli effetti destabilizzanti di queste tecnologie”, con particolare riferimento al blocco della realizzazione di sodati robot.
Nel mese di giugno del 2016 si è tenuto a questo proposito presso l’ITU – International Telecommunication Union delle Nazioni Unite – un incontro intitolato “AI for Good Global Summit” [116] che ha visto la parte-cipazione oltre che di esperti nei vari settori dell’IA, anche di rappresentanti delle principali organizzazioni umanitarie governative e non governative mondiali. L’obiettivo del Summit era quello di accrescere la sensi-bilità dei governi e del mondo economico a destinare finanziamenti al settore dell’IA per sostenere un maggiore impegno della ricerca nel settore umanitario.
Questi temi sono anche riportati in una lettera aperta firmata da molti ricercatori e scienziati fra cui Stephen Hawking, Elon Musk, Erik Brynjolfsson, dal titolo “Research Priorities for Robust and Beneficial Artificial Intelligence” [117]:
“There is now a broad consensus that AI research is progressing steadily, and that its impact on society is likely to increase. The potential benefits are huge, since everything that civilization has to offer is a product of human intelligence; we cannot predict what we might achieve when this
intelligence is magnified by the tools AI may provide, but the eradication of disease and poverty are not unfathomable. Because of the great potential of AI, it is important to research how to reap its benefits while avoiding potential pitfalls.”

7 Le maggiori Associazioni Scientifiche e Conferenze di IA Esistono molte associazioni scientifiche e conferenze che hanno come principale obiettivo lo studio dell’IA, le sue applicazioni e la sua diffusione e promozione come disciplina. Nel seguito menzioniamo le più rappresentative:
AAAI: Association for the Advancement of Artificial Intelligence (AAAI) (prima denominata American Association for Artificial Intelligence). Fondata nel 1979, rappresenta principalmente la comunità americana e organizza la AAAI Conference on Artificial Intelligence. [118]
EurAI: European Association for Artificial Intelligence (EurAI), (prima denominata ECCAI). Fondata nel 1982, rappresenta principalmente la comunità europea e organizza la ECAI European Conference on Artificial Intelligence [119].
AI*IA: Associazione Italiana per l'Intelligenza Artificiale . Fondata nel 1988, rappresenta principalmente la comunità Italiana e organizza la Conferenza Italiana di IA [120].
La maggiore conferenza mondiale dell’IA è l’International Joint Conference on Artificial Intelligence (IJCAI) che si è svolta in anni alterni a partire dal 1969.
8 Conclusioni Obiettivo di questo lavoro è stato quello di presentare una panoramica della disciplina dell’Intelligenza Artificiale a partire dalla sua nascita e dalla sua storia fino ad arrivare ai risultati attuali e ai possibili sviluppi futuri. La descrizione è data in modo volutamente semplice e intuitivo e necessariamente non esaustivo, ma speriamo possa costituire comunque una base utile anche per coloro che non hanno profonde competenze di tipo informatico o tecnologico, e un punto di partenza introduttivo nei corsi di Intelligenza Artificiale per poi procedere a successivi approfondimenti su aree specifiche di questa affascinante disciplina. Possiamo concludere, dall’analisi qui presentata, che l’IA ha presentato negli ultimi anni passi avanti inimmaginabili, grazie ad algoritmi sempre più efficienti e sofisticati, a grosse moli di dati ed informazioni a disposizione, e a una sempre crescente potenza di calcolo.
Una tecnologia è vincente quando diventa parte della nostra vita senza che spesso ce ne accorgiamo, e oggi l’IA è ovunque e fra noi: sugli aerei, nelle banche, nella medicina, in borsa, per le previsioni climatiche e finanziarie, ma anche nei piccoli robot domestici, nelle automobili e nei giochi dei bambini.
In “Artificial intelligence and life in 2030”, un documento prodotto dall’Università di Stanford nel 2016, sono stati individuati gli otto domini applicativi in cui l’IA avrà prevedibilmente maggior impatto nei prossimi anni [121]. Li riportiamo nel seguito:
• Trasporti (automobili più intelligenti, veicoli con guida autonoma, pianificazione dei trasporti, tra-sporto su richiesta).
• Domotica (ad esempio, robot di servizio e domestici). • Medicina (supporto clinico, analisi dei dati della sanità, robotica sanitaria, cura degli anziani). • Istruzione (sistemi di tutoraggio intelligente e apprendimento on-line). • Comunità disagiate. • Sicurezza. • Mercato del Lavoro. • Divertimento e tempo libero (piattaforme sociali, gioco, arte e creatività).

Tanti sono i risultati quindi raggiunti dall’IA, come mostra questo articolo, ma tante sono ancora le sfide aperte e le tematiche da approfondire. In una sorta di circolarità concludiamo quindi l’articolo con un’ulteriore frase di Alan Turing tratta dall’articolo del 1950: “Computing machinery and intelligence” [1], già citato in Introduzione, e che è un’affermazione di grande entusiasmo per la ricerca in IA: “We can only see a short distance ahead, but we can see plenty there that needs to be done”.
Verranno quindi sviluppate applicazioni sempre più avanzate nel campo dell’IA, ma al centro di esse ci sarà e ci dovrà essere sempre l’uomo che le progetta, le utilizza, e si interfaccia con esse. L’auspicio è che l’impatto globale di tali tecniche sia comunque sempre positivo sulla nostra società. Affinché ciò sia possibile, è fondamentale che la conoscenza di tali tecniche sia ampia e condivisa, e che l’attenzione e il dibattito su di esse sia sempre aperto e responsabile.
Ringraziamenti Gli autori ringraziano Federico Chesani e Andrea Roli per gli utili consigli e suggerimenti sulla prima versione dell’articolo.

Riferimenti
[1] A. Turing, "Computing machinery and intelligence," Mind, vol. 59, no. 236, pp. 433-460, 1950.
[2] A. Di Caro, PENSARE EX MACHINA: Alan Turing alla Prova, Roma: Aracne, 2016, p. 10.
[3] R. Descartes, Discorso sul metodo, Editori Riuniti, 1996.
[4] K. Gödel, "Über formal unentscheidbare Sätze der Principia Mathematica und verwandter Systeme, I," in Kurt
Gödel Collected works, 1986 ed., vol. I, S. Feferman, Ed., Oxford University Press, 1931, pp. 144-195.
[5] A. M. Turing, "On Computable Numbers, with an Application to the Entscheidungsproblem," Proceedings of the
London Mathematical Society, vol. 2, no. 42, pp. 230-265, 1937.
[6] W. McCulloch and W. Pitts, "A logical calculus of the ideas immanent in nervous activity," Bulletin of
Methematical Biophysics, vol. 5, no. 4, pp. 115-133, 1943.
[7] S. Russel and P. Norvig, Intelligenza Artificiale - Un Approccio Moderno, Milano: Pearson, 2005.
[8] J. Weizenbaum, "ELIZA—a computer program for the study of natural language communication between man
and machine," Communications of the ACM , vol. 9, no. 1, pp. 36-45, 1966.
[9] H. J. Levesque, E. . Davis and L. . Morgenstern, "The Winograd Schema Challenge - aaai.org," , The Winograd
Schema Challenge - aaai.org The Winograd Schema Challenge - aaai.org 2012. [Online]. Available:
http://dblp.uni-trier.de/db/conf/kr/kr2012.html. [Accessed 19 9 2017].
[10] Special Issue, "Beyond the Turing Test - Special Issue," AI Magazine, vol. 37, no. 1, 2016.
[11] J. McCarthy, M. L. Minsky, N. Rochester and C. Shannon, "A Proposal for the Dartmouth Summer Research
Project on Artificial Intelligence, August 31, 1955," AI Magazine, vol. 27, no. 4, pp. 12-14, 2006.
[12] J. McCarthy, Recursive Functions of Symbolic Expressions and Their Computation by Machine, vol. Parte I,
Cambridge, Mass: MIT, Cambridge, Mass. , 1960.
[13] A. Newell, J. Shaw and H. Simon, " Report on a general problem-solving program," in Proceedings of the
International Conference on Information Processing, 1959.
[14] M. Minsky and S. Papert, Perceptrons: "An introduction to computational geometry", Cambridge, MA: MIT
Press, 1969.
[15] E. Shortliffe and B. Buchanan, "A model of inexact reasoning in medicine," Mathematical Biosciences, vol. 23,
no. 3-4, pp. 351-379, 1975.
[16] T. Moto-oka, "Overview to the Fifth Generation Computer System project," in Proceedings of the 10th annual
international symposium on Computer architecture , 1983.
[17] D. E. Rumelhart, G. Hinton and R. J. Williams, "Learning representations by back-propagating errors," Nature,
vol. 323, Ottobre 1986.
[18] A. . Krizhevsky, I. . Sutskever and G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural ...,"
Advances in Neural Information Processing Systems, vol. 1, no. 1, p. Advances in Neural Information Processing
Systems, Advances in Neural Information Processing Systems Advances in Neural Information Processing
Systems 2012.
[19] O. Stock, "Editorial," Intelligenza Artifciale: The international Journal of the AI*IA, vol. 5, no. 1, pp. 1-2, 2011.
[20] P. Mello, «Enciclopedia Scienza e Fede - Voce Intelligenza artificiale.,» in Dizionario Interdisciplinare di Scienza e
Fede. Cultura scientifica, filosofia e teologia., Roma, Urbaniana University Press - Città Nuova Editrtice, 2002.
[21] M. L. Ginsberg, Essentials of Artificial Intelligence., Morgan Kaufmann, 1993.
[22] B. Copeland, "Artificial intelligence (AI)," Encyclopaedia Britannica, [Online]. Available:
https://www.britannica.com/technology/artificial-intelligence. [Accessed 20 Giugno 2017].
[23] "intelligenza artificiale," TRECCANI, [Online]. Available: http://www.treccani.it/enciclopedia/intelligenza-
artificiale. [Accessed 20 Giugno 2017].
[24] E. Rich and K. Knight, Artificial Intelligence, McGraw-Hill, 1990.
[25] N. J. Nilsson, The Quest for Artificial Intelligence., Cambridge University Press, 2009.
[26] J. R. Searle, "Minds, brains, and programs," Behavioral and Brain Sciences, vol. 3, no. 03, pp. 417-424,
Behavioral and Brain Sciences Behavioral and Brain Sciences 1980.
[27] A. M. Turing, "Intelligent Machinery," in Collected Works of A. M. turing: Mechanical Intelligence, D. C. Ince, Ed.,

Elsevier Science Publisher, 1992.
[28] A. Newell and H. A. Simon, "Completer Science as Empirical Inquiry: Symbols and Search," Communications of
the ACM, vol. 19, no. 3, pp. 113-126, 1975.
[29] R. . Brooks, "Intelligence without representation," Artificial Intelligence, vol. 47, no. 47, p. 139–159, Artificial
Intelligence Artificial Intelligence 1991.
[30] M. Wooldirdge, An Introduction to MultiAgent Systems, Wiley, 2009.
[31] G. Beni, "From Swarm Intelligence to Swarm Robotics," in Swarm Robotics - SAB 2004 International Workshop,
Santa Monica, CA, USA, July 17, 2004, Revised Selected Papers, Santa Monica, 2004.
[32] E. Bonabeau, G. Theraulaz and M. Dorigo, Swarm Intelligence: From Natural to Artificial Systems, Oxford
University Press, 1999.
[33] J. H. Holland, Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology,
Control, and Artificial Intelligence, MIT Press / Bradford Books, 1992.
[34] G. Banavar, "Learning to trust artificial intelligence systems. Accountability, compliance and ethics in the age of
smart machines.," IBM.
[35] B. J. Grosz, "What Question Would Turing Pose Today," Ai Magazine, vol. 33, no. 4, pp. 73-81, Ai Magazine Ai
Magazine 2012.
[36] R. A. Kowalski, "The early years of logic programming," Communications of the ACM, vol. 31, no. 1, pp. 38-43,
1988.
[37] A. . Colmerauer and P. . Roussel, "The birth of Prolog - alain.colmerauer.free.fr," ACM SIGPLAN Notices, vol. 28,
no. 3, p. 37, ACM SIGPLAN Notices ACM SIGPLAN Notices 1993.
[38] S. Galvan, Logica dei predicati, EDUCatt Università Cattolica, 2005.
[39] M. Minsky, "A Framework for Representing Knowledge," Massachusetts Institute of Technology, 1974.
[40] R. J. Brachman, A Structural Paradigm for Representing Knowledge, Harvard: Harvard University, 1977.
[41] E. A. Feigenbaum, "The Art of Artificial Intelligence: Themes and Case Studies of Knowledge Engineering," in
International Joint Conference on Artificial Intelligence - IJCAI, Cambridge, 1977.
[42] "Drools Web Site," [Online]. Available: https://www.drools.org/.
[43] D. Luckham, The Power of Events: An Introduction to Complex Event Processing in Distributed Enterprise
Systems, Addison-Wesley Professional, 2002.
[44] D. B. Lenat and R. V. guha, Building Large Knowledge-Based Systems: Representation and Inference in the Cyc
Project, Addison-Wesley, 1990.
[45] J. F. Sowa, "Semantic Networks," in Encyclopedia of Artificial Intelligence, Wiley, 1987.
[46] "W3C OWL Standard," [Online]. Available: https://www.w3.org/OWL/.
[47] C. Fellbaum, Ed., WordNet: An Electronic Lexical Database, Cambrdge, MA: The MIT Press, 1998.
[48] D. Lenat, "Cyc," [Online]. Available: http://www.cyc.com/.
[49] "Semantic Web," W3C, [Online]. Available: https://www.w3.org/standards/semanticweb/.
[50] "DBpedia," [Online]. Available: http://wiki.dbpedia.org/.
[51] "Wikipedia," [Online]. Available: https://www.wikipedia.org/.
[52] N. Shadbolt, T. Berners-Lee and W. Hall, "The Semantic Web Revisited," IEEE Intelligent Systems, vol. 21, no. 3,
2006.
[53] J. A. Robinson, "A Machine-Oriented Logic Based on the Resolution Principle," Journal of the ACM (JACM), vol.
12, no. 1, p. 23–41, 1965.
[54] L. Console, E. Lamma, P. Mello and M. Milano, Programmazione Logica e Prolog, UTET, 1997.
[55] "Deep Mind," [Online]. Available: https://deepmind.com/.
[56] J. MacQueen, "Some methods for classification and analysis of multivariate observations," in Fifth Berkeley
Symposium on Mathematical Statistics and Probability, 1967.
[57] B. V. Dasarathy, Ed., Nearest Neighbor (NN) Norms: NN Pattern Classification Techniques, IEEE Computer
Society, 1990.
[58] P. Domingos, L'algoritmo definitivo. La macchina che impara da sola e il futuro del nostro mondo, Bollati
Boringhieri, 2016.
[59] T. M. Mitchell , MACHINE LEARNING, McGraw-Hill Education, 1997.

[60] J. Misiti, "Awesome Machine Learning," [Online]. Available: https://github.com/josephmisiti/awesome-
machine-learning.
[61] J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann, 1992.
[62] S. Muggleton, "Inverse Entailment and Progol," New Generation Computing, vol. 13, no. 3&4, pp. 245-286,
1995.
[63] F. . Rosenblatt, "The Perceptron: A Probabilistic Model For Information Storage And Organization In The Brain,"
Psychological Review, vol. 65, no. 6, p. 386–408, 1958.
[64] B. Widrow and M. E. Hoff, "ssociative Storage and Retrieval of Digital Information in Networks of Adaptive
"Neurons"," in Biological Prototypes and Synthetic Systems, Boston, MA, Springer, 1962, pp. 160-160.
[65] A. E. Bryson and Y.-C. Ho, Applied Optimal Control: Optimization, Estimation, and Control, Blaisdell Pub. Co.,
1969.
[66] M. Nielsen, "Neural Networks and Deep Learning," [Online]. Available:
http://neuralnetworksanddeeplearning.com/chap5.html.
[67] G. . Cybenko, "Approximation by superpositions of a sigmoidal function," Mathematics of Control, Signals, and
Systems, vol. 2, no. 4, pp. 303-314, 1989.
[68] K. Hornik, "Approximation capabilities of multilayer feedforward networks," Neural Networks, vol. 4, no. 2, pp.
251-257, 1991.
[69] A. Krizhevsky, I. Sutskever and G. E. Hinton, "ImageNet classification with deep convolutional neural networks,"
Communications of the ACM, vol. 60, no. 6, pp. 84-90, 2017.
[70] A. . Canziani, A. . Paszke and E. . Culurciello, "An Analysis of Deep Neural Network Models for Practical
Applications," arXiv: Computer Vision and Pattern Recognition, vol. , no. , p. , 2017.
[71] I. Goodfellow, Y. Bengio and A. Courville, Deep Learning, The MIT Press, 2016.
[72] D. . Silver, A. . Huang, C. J. Maddison, A. . Guez, L. . Sifre, G. v. d. Driessche, J. . Schrittwieser, I. . Antonoglou, V. .
Panneershelvam, M. . Lanctot, S. . Dieleman, D. . Grewe, J. . Nham, N. . Kalchbrenner, I. . Sutskever, T. P. Lillicrap,
M. . Leach, K. . Kavukcuoglu, T. . Graepel and D. . Hassabis, "Mastering the game of Go with deep neural
networks and tree search," Nature, vol. 529, no. 7587, pp. 484-489, 2016.
[73] V. . Mnih, K. . Kavukcuoglu, D. . Silver, A. . Graves, I. . Antonoglou, D. . Wierstra and M. A. Riedmiller, "Playing
Atari with Deep Reinforcement Learning," arXiv: Learning, vol. , no. , p. , 2013.
[74] D. . Ravì, C. . Wong, F. . Deligianni, M. . Berthelot, J. . Andreu-Perez, B. . Lo and G.-Z. . Yang, "Deep learning for
health informatics," IEEE Journal of Biomedical and Health Informatics, vol. 21, no. 1, pp. 4-21, 2017.
[75] G. . Hinton and R. . Salakhutdinov, "Reducing the Dimensionality of Data with Neural Networks," Science, vol.
313, no. , p. 504–507, .
[76] G. E. Hinton, S. . Osindero and Y. W. Teh, "A fast learning algorithm for deep belief nets," Neural Computation,
vol. 18, no. 7, p. , 2006.
[77] R. Salakhutdinov and G. E. Hinton, "Deep Boltzmann Machines," in AISTATS, 2009.
[78] R. J. Williams and D. . Zipser, "A learning algorithm for continually running fully recurrent neural networks,"
Neural Computation, vol. 1, no. 2, pp. 270-280, 1989.
[79] Y. . LeCun, "Gradient-based learning applied to document recognition," Proceedings of the IEEE, vol. 86, no. 11,
p. 2278–2324, .
[80] A. . Aamodt and E. . Plaza, "Case-based reasoning: foundational issues, methodological variations, and system
approaches," Ai Communications, vol. 7, no. 1, pp. 39-59, 1994.
[81] A. M. Turing, "Chess, subsection of chapter 25 "Digital Computers Applied to Games"," in Faster than Though,
B. V. Bowden, Ed., London, Pitman, 1953.
[82] C. E. Shannon, "Programming a Computer for Playing Chess," Philosophical Magazine, vol. 41, no. 7, pp. 256-
275, 1950.
[83] J. von Neumann and O. Morgenstern, Theory of Games and Economic Behavior, Princeton University Press,
1944.
[84] IBM, "Deep Blue," IBM, [Online]. Available: http://www-
03.ibm.com/ibm/history/ibm100/us/en/icons/deepblue.
[85] D. A. Ferrucci, E. W. Brown, J. . Chu-Carroll, J. . Fan, D. . Gondek, A. . Kalyanpur, A. . Lally, J. W. Murdock, E. .
Nyberg, J. M. Prager, N. . Schlaefer and C. A. Welty, "Building Watson: An Overview of the DeepQA Project ...,"
Ai Magazine, vol. 31, no. 3, pp. 59-79, 2010.

[86] D. A. Ferrucci, "Introduction to This is Watson," Ibm Journal of Research and Development, vol. 56, no. 3, pp.
235-249, 2012.
[87] IBM, "The DeepQA Project," [Online]. Available:
http://researcher.watson.ibm.com/researcher/view_group.php?id=2099.
[88] "Regole del Go," [Online]. Available: https://it.wikipedia.org/wiki/Regole_del_go.
[89] V. L. Allis, Searching for solutions in games and artificial intelligence, Maastricht University, 1994.
[90] "RoboCup," [Online]. Available: http://www.robocup.org/.
[91] D. . Nardi, I. . Noda, F. . Ribeiro, P. . Stone, O. v. Stryk and M. M. Veloso, "RoboCup Soccer Leagues," Ai
Magazine, vol. 35, no. 3, pp. 77-85, 2014.
[92] J. M. Keynes, "Economic Possibilities for Our Grandchildren," in Essays in Persuasion, London, Palgrave
Macmillan, 2010, pp. 321-332.
[93] C. B. Frey and M. A. Osborne, "The future of employment: how susceptible are jobs to computerisation?,"
Technological Forecasting and Social Change, vol. 114, pp. 254-280, 2017.
[94] "Report Citigroup," [Online]. Available: http://www.corrierecomunicazioni.it/digital/40554_fintech-allarme-
occupazione-2-milioni-di-licenziamenti-in-vista.htm.
[95] "World Economic Forum," [Online]. Available: https://www.weforum.org/events/world-economic-forum-
annual-meeting-2017.
[96] E. Brynjolfsson and A. McAfee, The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant
Technologies, W. W. Norton & Company, 2016.
[97] M. Ford, Rise of the Robots: Technology and the Threat of a Jobless Future, Basic Books, 2016.
[98] G. o. Longo, "Etica e responsabilità nell'era del postumano," Mondo Digitale, no. 54, 2014.
[99] G. Veruggio and F. Operto, "Roboethics: Social and Ethical Implications of Robotics," in Springer Handbook of
Robotics, Springer Berlin Heidelberg, 2008, pp. 1499-1524.
[100] "RoboLaw," [Online]. Available: http://www.robolaw.eu/.
[101] [Online]. Available:
http://www.europarl.europa.eu/RegData/etudes/STUD/2016/571379/IPOL_STU%282016%29571379_EN.pdf.
[102] "Io, Robot (Asimov)," [Online]. Available: https://it.wikipedia.org/wiki/Io,_robot_(Asimov).
[103] "Tre leggi della robotica," [Online]. Available: https://it.wikipedia.org/wiki/Tre_leggi_della_robotica.
[104] MIT, "The Moral Machine," [Online]. Available: http://moralmachine.mit.edu.
[105] G. Sartor and A. Omicini, "The autonomy of technological systems and responsibilities for their use," in
Autonomous Weapons Systems: Law, Ethics, Policy, Cambridge, Cambridge University Press, 2016.
[106] J. Dokic, B. Müller and G. Meyer, "European Roadmap Smart Systems for Automated Driving," 2015.
[107] C. Muller, "L'intelligenza artificiale - Le ricadute dell'intelligenza artificiale sul mercato unico (digitale), sulla
produzione, sul consumo, sull'occupazione e sulla società," Comitato Economico e Sociale Europeo - Unione
Europea, 2017.
[108] "Workshop on Human Interpretability in Machine Learning," [Online]. Available:
https://sites.google.com/site/2016whi/.
[109] "Workshop on Explainable Artificial Intelligence (XAI)," [Online]. Available:
http://home.earthlink.net/~dwaha/research/meetings/ijcai17-xai/.
[110] "IEEE 2016 Summit on AI and Ethics," [Online]. Available: https://ieeetv.ieee.org/mobile/event-showcase/ai-
and-ethics-summit-2016.
[111] "European Civil Law Rules in Robotics," 2016.
[112] "Ethically Aligned Design: A Vision for Prioritizing Human Wellbeing with Artificial Intelligence and Autonomous
Systems," IEEE, 2016.
[113] S. Russell, "Provably Beneficial Artificial Intelligence," in The Next Step: Exponential Life, BBVA-Open Mind,
2017.
[114] "Autonomous Weapons: an Open Letter from AI & Robotics Researchers," [Online]. Available:
https://futureoflife.org/open-letter-autonomous-weapons/.
[115] "Losing Humanity The Case against Killer Robots," [Online]. Available:
https://www.hrw.org/report/2012/11/19/losing-humanity/case-against-killer-robots.

[116] "AI for Good Global Summit," [Online]. Available: http://www.itu.int/en/ITU-T/AI/Pages/201706-default.aspx.
[117] "An Open Letter Research Priorities for Robust and Beneficial Artificial Intelligence," [Online]. Available:
https://futureoflife.org/ai-open-letter.
[118] "Association for the Advancement of Artificial Intelligence," [Online]. Available: http://www.aaai.org/.
[119] "European Association for Artificial Intelligence," [Online]. Available: https://www.eurai.org/.
[120] "Associazione Italiana per l'Intelligenza Artificiale," [Online]. Available: http://www.aixia.it/.
[121] "One Hunderd Year Study on Artificial Intelligence (AI100) - 2016 Report," 2016.























![Anghel, Paul - [Zdauv 02] Fluviile v0.9](https://img.pdfslide.tips/doc/110x75/55cfe4825503467d968b7fab/anghel-paul-zdauv-02-fluviile-v09.jpg)



![Cartland, Barbara - Iubire, Minciuni, Casatorie [v0.9]Hy](https://img.pdfslide.tips/doc/110x75/55cf8dec550346703b8cb1f1/cartland-barbara-iubire-minciuni-casatorie-v09hy.jpg)

