Embed Size (px)
Citation preview

Universidade Federal do Vale do São Francisco Curso de Engenharia de Computação
Prof. Jorge Cavalcanti
www.univasf.edu.br/~jorge.cavalcanti
www.twitter.com/jorgecav
Introdução a Algoritmos – Parte 09 (Baseado no Material do Prof. Marcelo Linder)

2
Noções de Classificação
Conceitos
O acesso a um conjunto de dados é facilitado se o mesmo está armazenado conforme uma certa ordem, baseada num critério conhecido.
O objetivo básico da classificação ou ordenação é facilitar o acesso aos dados, propiciando a localização rápida de uma entrada, por um algoritmo.
O interesse na ordenação se justifica por sua aplicação na adequação das tabelas (vetores de registros) à consulta.

3
Noções de Classificação
Conceitos
Além disso, o desenvolvimento de métodos e processos de ordenação também se constitui em campo de pesquisa na aplicação de técnicas básicas de construção de algoritmos.
Talvez não haja outro problema de programação que, para uma mesma formulação (no caso: “ordenar uma lista”), tenha tantas soluções diferentes, cada uma com qualidades e defeitos, relacionados com desempenho (complexidade em tempo e uso da memória), facilidade de programação, tipo e condição inicial dos dados, etc.
Obs.: O termo lista será utilizado, deste ponto em diante, com o sentido de generalizar o termo vetor.

4
Noções de Classificação
Conceitos
A operação de classificação (ordenação) pode ser entendida
como um rearranjo (ou permutação) de uma lista, por exemplo, do menor para o maior, aplicado sobre um dos campos (a chave da ordenação).
Os processos de classificação diferem quanto à área de trabalho necessária. Enquanto uns métodos trabalham sobre o próprio vetor a ordenar (métodos in situ), outros exigem um segundo vetor para armazenar o resultado, e até mesmo outras áreas auxiliares.
É interessante notar que nem sempre o uso de áreas auxiliares aumenta a eficiência dos processos, pois elas podem servir apenas para simplificar as operações, aumentando, no entanto, o número de operações a realizar.

5
Objetivos e Caracterizações
A eficiência dos processos pode ser avaliada pelo número C de operações de comparação entre chaves conjuntamente com o número M de movimentos de
dados (transposições) necessários.
Tanto C como M são funções de n, o número de chaves. Daí, têm-se os processos ditos diretos, assim
chamados por serem de formulação relativamente simples, de manipulação in situ.
Nesses processos o normal é acontecer um grande número de operações de comparação e de troca de valores.

6
Objetivos e Caracterizações
Existem também os processos avançados, que são aqueles de formulação baseada em expedientes não tão óbvios, com algoritmos, portanto, mais elaborado. Nesses métodos as operações tendem a ser mais complexas, porém há menos trocas, o que explica seu melhor desempenho.
Por outro lado, os diversos processos de ordenação partem de alguma proposta básica, a qual caracteriza uma família de métodos. Os diversos processos se diferenciam numa família conforme os meios e truques que usam para realizar a proposta básica.
Assim, os métodos diretos in situ, particularmente, pertencem às famílias de processos de ordenação por troca, por inserção e por seleção.

7
Os métodos avançados podem ser refinamentos ou
combinações de processos diretos ou podem
implementar outras propostas, identificando-se famílias
como da ordenação por intercalação, por
particionamento e por distribuição de chaves.
Toda ordenação está baseada na permutação dos elementos do vetor; logo, sempre dependerá de trocas. São, no entanto, ditos processos por troca aqueles em que a operação de troca é dominante.
A ordenação pode ser feita de 03 maneiras distintas: por troca, por seleção e por inserção.
Objetivos e Caracterizações

8
Classificação por Troca - bubble sort
Analisaremos agora um método de classificação por troca, conhecido como classificação por troca simples, classificação por bolha ou bubble sort.
A idéia básica por trás do bubble sort é percorrer a lista seqüencialmente várias vezes.
Cada passagem consistem em comparar cada elemento na lista com seu sucessor e trocar os dois elementos se eles não estiverem na ordem correta.
Para uma melhor compreensão examinaremos o seguinte exemplo:
25 57 48 37 12 92 86 33

9
Classificação por Troca - bubble sort
As seguintes comparações são feitas na primeira passagem:
x[0] com x[1] (25 com 57) nenhuma troca
x[1] com x[2] (57 com 48) troca
x[2] com x[3] (57 com 37) troca
x[3] com x[4] (57 com 12) troca
x[4] com x[5] (57 com 92) nenhuma troca
x[5] com x[6] (92 com 86) troca
x[6] com x[7] (92 com 33) troca
x = { 25, 57, 48, 37, 12, 92, 86, 33 }
10
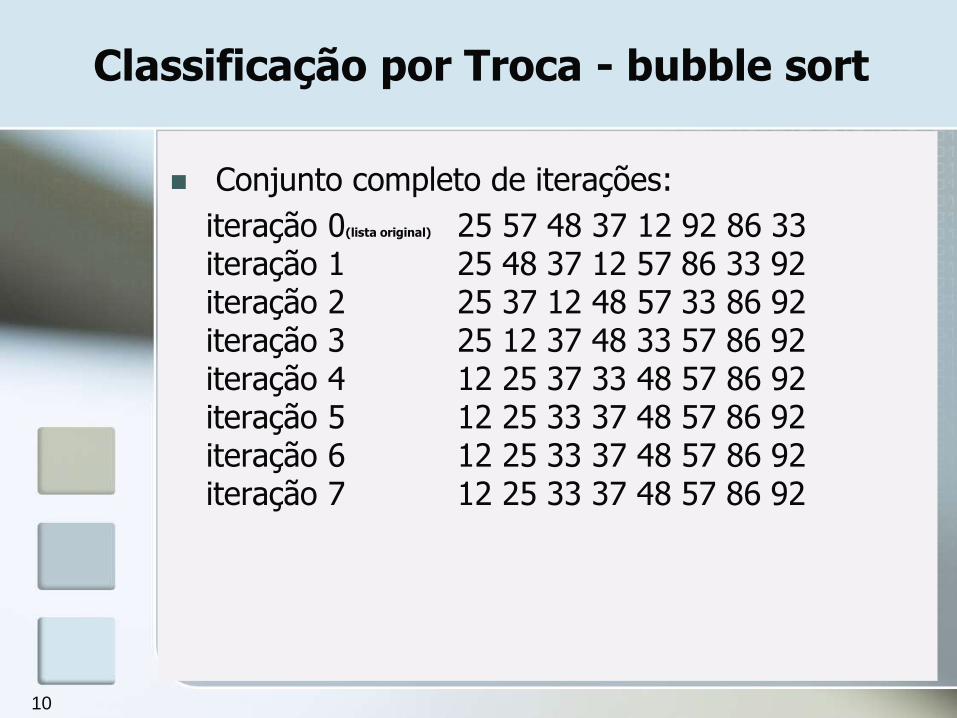
Classificação por Troca - bubble sort
Conjunto completo de iterações:
iteração 0(lista original) 25 57 48 37 12 92 86 33 iteração 1 25 48 37 12 57 86 33 92 iteração 2 25 37 12 48 57 33 86 92 iteração 3 25 12 37 48 33 57 86 92 iteração 4 12 25 37 33 48 57 86 92 iteração 5 12 25 33 37 48 57 86 92 iteração 6 12 25 33 37 48 57 86 92 iteração 7 12 25 33 37 48 57 86 92

11
Classificação por Troca - bubble sort
Exercício
Com base no que foi visto, construa um módulo que recebe, como parâmetros, um vetor de reais, com 10 elementos. O algoritmo deve ordenar o vetor por meio da aplicação do bubble sort.

12
algoritmo "Bubble Sort" var a, b : inteiro temp : real x : vetor[1..10] de real inicio // Leitura dos dados aleatorio 0,100,3 //gera nºs de 0 a 100, com 03 // casas decimais para a de 1 ate 10 faca leia(x[a]) fimpara
Classificação por Troca - bubble sort
// Ordenação para a de 1 ate 10 faca para b de 1 ate 9 faca se x[b] > x[b+1] entao temp <- x[b] x[b] <- x[b+1] x[b+1] <- temp fimse fimpara fimpara // Impressão dos dados //ordenados para a de 1 ate 10 faca escreval(a:3," - ", x[a] :10:3) fimpara fimalgoritmo

13
Classificação por Troca - bubble sort
Pode se fazer melhorias no algoritmo anterior? Sim.
Quais? Não existe necessidade de verificar o sub vetor
ordenado;
e ao se verificar que o vetor está ordenado pode-se parar a ordenação.
Mas isso fica para AED...

Outro método também simples de ordenação é a ordenação por seleção.
Princípio de funcionamento:
1. Selecione o menor item do vetor (ou o maior).
2. Troque-o com o item que está na primeira posição do vetor.
Repita estas duas operações com os n-1 itens restantes, depois com os n-2 itens, até que reste apenas um elemento.
Classificação por Seleção - selection sort
14

A ordenação por seleção consiste, em cada etapa, em selecionar o maior (ou o menor) elemento e colocá-lo em sua posição correta dentro da futura lista ordenada.
Durante a aplicação do método de seleção a lista com n registros fica decomposta em duas sub listas, uma contendo os itens já ordenados e a outra com os restantes ainda não ordenados.
No início a sub lista ordenada é vazia e a outra contém todos os demais.
No final do processo a sub lista ordenada apresentará (n-1) itens e a outra apenas 1.
Classificação por Seleção - selection sort
15

As etapas (ou varreduras) como já descrito consistem em buscar o maior (ou menor) elemento da lista não ordenada e colocá-lo na lista ordenada.
Para uma melhor compreensão trabalharemos com um exemplo, visando demonstrar o resultado das etapas da ordenação de um vetor de inteiros, consideraremos o ordenamento crescente dos elementos e selecionaremos em cada etapa o maior elemento do subvetor não ordenado.
Classificação por Seleção - selection sort
16
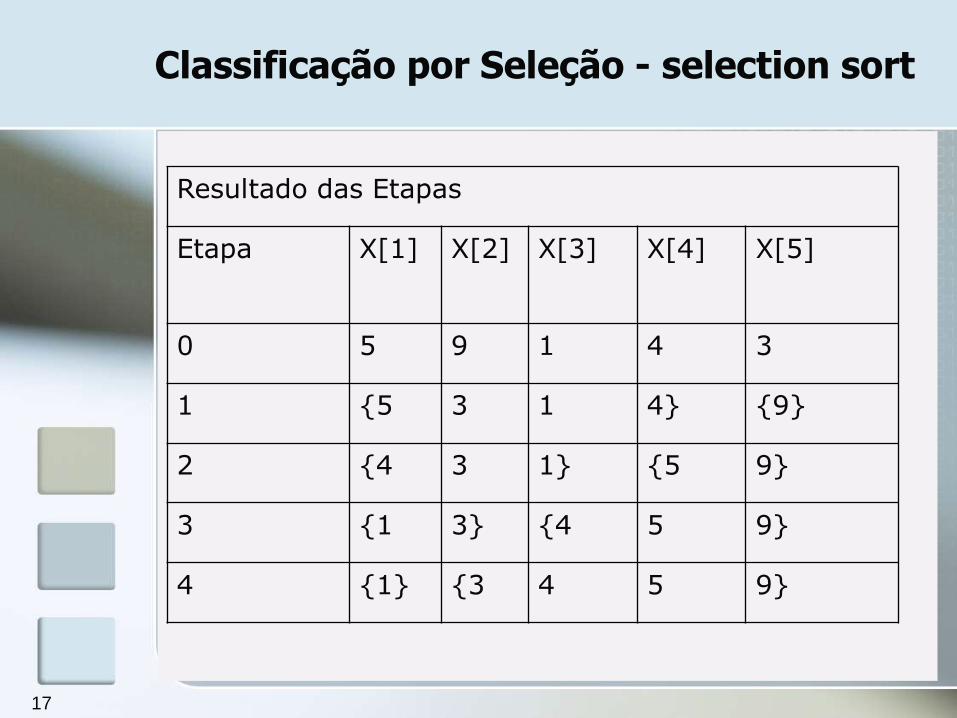
Resultado das Etapas
Etapa X[1] X[2] X[3] X[4] X[5]
0 5 9 1 4 3
1 {5 3 1 4} {9}
2 {4 3 1} {5 9}
3 {1 3} {4 5 9}
4 {1} {3 4 5 9}
Classificação por Seleção - selection sort
17

18
Classificação por Seleção - selection sort
Exercício
Com base no que foi visto, construa um módulo que recebe, como parâmetros, um vetor de reais, com 10 elementos. O algoritmo deve ordenar o vetor por meio da aplicação do selection sort.

19
algoritmo "Selection Sort" var vet : vetor[1..10] de real i, cont, posMenor : inteiro temp : real inicio //ler o vetor aleatorio 0,100, 3 para cont de 1 ate 10 faca leia(vet[cont]) fimpara //percorrer o vetor para cont de 1 ate 9 faca //define a posição do menor //como sendo a posição atual posMenor <- cont //percorre o restante do //vetor procurando o menor valor para i de cont+1 ate 10 faca
Classificação por Seleção - selection sort
//compara o elemento atual //com o da posição do menor se (vet[i] < vet[posMenor])
entao posMenor <- i //guarda a posição do elemento fimse fimpara //se encontrou elemento menor //troca a posição se (cont <> posMenor) entao temp <- vet[cont] vet[cont] <- vet[posMenor] vet[posMenor] <- temp fimse fimpara // Escrever o vetor ordenado para cont de 1 ate 10 faca escreval(cont,"-", vet[cont]:10 :3) fimpara fimalgoritmo

Método preferido dos jogadores de cartas.
O jogador vai recebendo cartas uma por uma, e inserindo-as na posição adequada em sua mão, fazendo com que as cartas permaneçam ordenadas durante todo o jogo.
ou seja,
Em cada passo, a partir de i=2, o i-ésimo item da seqüência fonte é apanhado e transferido para a seqüência destino, sendo inserido no seu lugar apropriado.
Classificação por Inserção - insertion sort
20

21
A proposta da ordenação por inserção é a seguinte:
Para cada elemento do vetor faça Inseri-lo na posição que lhe corresponde;
Um processo in situ, chamado inserção direta, pode ser assim descrito:
Considerar o subvetor ordenado v[1..k] Para j de k+1 até n faça Inserir v[j] na sua posição em v [1..k]
Classificação por Inserção - insertion sort

22
Para encontrar o lugar de v[k], basta comparar as chaves de índices [1..k-1] até encontrar uma chave v[k_ins] que seja maior que ele. v[k_ins] será a sucessora de v[k] depois deste ser inserido no subvetor ordenado (i.e., depois de ser localizado).
O problema que surge agora é: como arranjar lugar em v[1..k - 1] para o valor v[k]?
Bem, como v[k] vai deixar seu lugar, este pode ser ocupado pelo elemento v[k-1], ao se fazer avançar uma posição para frente todo o subvetor v[k_ins..k – 1].
Classificação por Inserção - insertion sort

23
Observe no exemplo a seguir o comportamento de um vetor submetido á classificação por inserção direta.
Em cada linha é listado um vetor depois de uma passagem completa sobre o mesmo, estando sublinhado o subvetor [1..k-1] e em negrito o elemento nele inserido por último.
Vetor original: 75 25 95 87 64 59 86 40 16 49 passagem vetor resultante 1 25 75 95 87 64 59 86 40 16 49
2 25 75 95 87 64 59 86 40 16 49
3 25 75 87 95 64 59 86 40 16 49 4 25 64 75 87 95 59 86 40 16 49 5 25 59 64 75 87 95 86 40 16 49 6 25 59 64 75 86 87 95 40 16 49 7 25 40 59 64 75 86 87 95 16 49 8 16 25 40 59 64 75 86 87 95 49 9 16 25 40 49 59 64 75 86 87 95
Classificação por Inserção - insertion sort

24
Classificação por Inserção - insertion sort
Exercício
Com base no que foi visto, construa um módulo que recebe, como parâmetros, um vetor de reais, com 10 elementos. O algoritmo deve ordenar o vetor por meio da aplicação do insertion sort.

25
algoritmo “insertion_sort" var v : vetor [1..10] de inteiro j,k,i,temp : inteiro inicio aleatorio 1,100 para j de 1 ate 10 faca leia(v[j]) fimpara para j de 1 ate 9 faca k <- j para i de (j+1) ate 10 faca se v[i] < v[k] entao k <- i fimse fimpara
Classificação por Inserção - insertion sort
se k > j entao temp <- v[j] v[j] <- v[k] v[k] <- temp fimse fimpara para j de 1 ate 10 faca escreval(v[j]) fimpara fimalgoritmo





























