Embed Size (px)
DESCRIPTION
Curso: Ingeniería del software
Citation preview

INGENIERÍA DEL SOFTWARE
C A P Í T U L O 2 : M É T O D O S
C O N V E N C I O N A L E S P A R A L A
I N G E N I E R Í A D E L S O F T W A R E
I S T P - K H I P U
W I L B E R T D A L G U E R R E
O R D Ó Ñ E Z
2 0 1 3 - I
SESIÓN NÚMERO 12
MODELADO DEL
ANÁLISIS Conocer los conceptos para el modelado de un Sistema en
el Análisis.

Modelado del Análisis
1
Contenido
MODELADO DEL ANÁLISIS .......................................................................... 2
1. LOS ELEMENTOS DEL MODELO DE ANÁLISIS .................................................................... 2
2. MODELADO DE DATOS ..................................................................................................... 4
Objetos de Datos Atributos y Relaciones ............................................................................. 4
Cardinalidad y Modalidad. ................................................................................................... 7
Diagramas Entidad Relación ................................................................................................. 9
3. MODELADO FUNCIONAL Y FLUJO DE INFORMACIÓN .................................................... 11
Diagramas de Flujo de Datos .............................................................................................. 12
4. MODELADO DE COMPORTAMIENTO ............................................................................. 14
5. MECANISMOS DEL ANÁLISIS ESTRUCTURADO ............................................................... 16
Creación de un Diagrama Entidad Relación ....................................................................... 16
Creación de un Modelo de Flujo de Datos ......................................................................... 17
Creación de un Modelo de Flujo de Control. ..................................................................... 18
La Especificación de Control ............................................................................................... 19
La Especificación del Proceso ............................................................................................. 19
6. EL DICCIONARIO DE DATOS ............................................................................................ 19
BIBLIOGRAFÍA ................................................................................................................ 22

Modelado del Análisis
2
MODELADO DEL ANÁLISIS
En un nivel técnico, la
ingeniería del software
empieza con una serie
de tareas de modelado
que llevan a una
especificación completa de
los requisitos y a una
representación del diseño
general del software a
construir. El modelo de análisis,
realmente un conjunto de
modelos, es la primera
representación técnica de un sistema. Con los años
se han propuesto muchos métodos para el modelado del
análisis. Sin embargo, ahora dos tendencias dominan el panorama del
modelado del análisis. El primero, análisis estructurado, es un método de
modelado clásico y el otro enfoque es, el análisis orientado a objetos.
El análisis estructurado es una actividad de construcción de modelos.
Mediante una notación que satisfaga los principios de análisis operacional,
creamos modelos que representan el contenido y flujo de la información
(datos y control); partimos el sistema funcionalmente, y según los distintos
compohamientos establecemos la esencia de lo que se debe construir. El
análisis estructurado no es un método sencillo aplicado siempre de la misma
forma por todos los que lo usan. Más bien, es una amalgama que ha
evolucionado durante los últimos 30 años.
1. LOS ELEMENTOS DEL MODELO DE ANÁLISIS
El modelo de análisis debe lograr tres objetivos primarios:
1. Describir lo que requiere el cliente,
2. Establecer una base para la creación de un diseño de software,
3. Definir un conjunto de requisitos que se pueda validar una vez
que se construye el software.

Modelado del Análisis
3
Para lograr estos objetivos, el modelo de análisis extraído durante el
análisis estructurado toma la forma ilustrada en la Figura:
En el centro del modelo se encuentra el diccionario de datos “un
almacén que contiene definiciones de todos los objetos de datos
consumidos y producidos por el software”. Tres diagramas diferentes
rodean el núcleo.
El diagrama de entidad-relación (DER) representa las relaciones entre
los objetos de datos. El DER es la notación que se usa para realizar la
actividad de modelado de datos. Los atributos de cada objeto de
datos señalados en el DER se puede describir mediante una
descripción de objetos de datos.
El diagrama de flujo de datos (DFD) sirve para dos propósitos: (1)
proporcionar una indicación de cómo se transforman los datos a
medida que se avanza en el sistema, y (2) representar las funciones
(y subfunciones) que transforman el flujo de datos. El DFD
proporciona información adicional que se usa durante el análisis del
dominio de información y sirve como base para el modelado de
función. En una especificación de proceso (EP) se encuentra una
descripción de cada función presentada en el DFD.
El diagrama de transición de estados (DTE) indica cómo se comporta
el sistema como consecuencia de sucesos externos. Para lograr esto,
el DTE representa los diferentes modos de comportamiento (llamados
estados) del sistema y la manera en que se hacen las transiciones de
estado a estado. El DTE sirve como la base del modelado de
comportamiento. Dentro de la especificación de control (EC) se

Modelado del Análisis
4
encuentra más información sobre los aspectos de control del
software.
El modelo de análisis acompaña a cada diagrama, especificación y
descripción, y al diccionario señalado en la Figura anterior.
2. MODELADO DE DATOS
El modelado de datos responde a una serie de preguntas específicas
importantes para cualquier aplicación de procesamiento de datos:
1. ¿Cuáles son los objetos de datos primarios que va a procesar
el sistema?
2. ¿Cuál es la composición de cada objeto de datos y qué
atributos describe el objeto?
3. ¿Dónde residen actualmente los objetos?
4. ¿Cuál es la relación entre los objetos y los procesos que los
transforman?
Para responder estas preguntas, los métodos de modelado de datos
hacen uso del diagrama de entidad-relación (DER). El DER, descrito
con detalle posteriormente en esta sección, permite que un ingeniero
del software identifique objetos de datos y sus relaciones mediante
una notación gráfica. En el contexto del análisis estructurado, el DER
define todos los datos que se introducen, se almacenan, se
transforman y se producen dentro de una aplicación.
El diagrama entidad-relación se centra solo en los datos (y por
consiguiente satisface el primer principio operacional de análisis),
representando una «red de datos» que existe para un sistema dado.
El DER es específicamente Útil para aplicaciones en donde los datos
y las relaciones que gobiernan los datos son complejos. A diferencia
del diagrama de flujo de datos usado para representar como se
transforman los datos, el modelado de datos estudia los datos
independientemente del procesamiento que los transforma.
Objetos de Datos Atributos y Relaciones
El modelo de datos se compone de tres piezas de información

Modelado del Análisis
5
interrelacionadas: el objeto de datos, los atributos que describen el
objeto de datos y la relación que conecta objetos de datos entre sí.
Objetos de datos. Un objeto de datos es una representación de
cualquier composición de información compuesta que deba
comprender el software. Por composición de información,
entendemos todo aquello que tiene un número de propiedades o
atributos diferentes. Por tanto, el «ancho» (un valor sencillo) no sería
un objeto de datos válido, pero las «dimensiones» (incorporando
altura, ancho y profundidad) se podría definir como objeto.
Un objeto de datos puede ser una entidad externa (por ejemplo,
cualquier cosa que produce o consume información), una cosa (por
ejemplo, un informe o una pantalla), una ocurrencia (por ejemplo, una
llamada telefónica) o suceso (por ejemplo, una alarma), un puesto
(por ejemplo, un vendedor), una unidad de la organización (por
ejemplo, departamento de contabilidad), o una estructura (por
ejemplo, un archivo). Por ejemplo, una persona o un coche (Fig.) se
pueden ver como un objeto de datos en el sentido en que cualquiera
se puede definir según un conjunto de atributos. La descripción de
objeto de datos incorpora el objeto de datos y todos sus atributos.
Los objetos de datos se relacionan con otros. Por ejemplo, persona
puede poseer coche, donde la relación poseer implica una
«conexión» específica entre persona y coche. Las relaciones siempre
se definen por el contexto del problema que se está analizando.
Un objeto de datos solamente encapsula datos “no hay referencia
dentro de un objeto de datos a operaciones que actúan en el dato”.
Por consiguiente, el objeto de datos se puede representar como una
tabla de la forma en que se muestra en la siguiente Figura. Los
encabezamientos de la tabla reflejan atributos del objeto. En este
caso, se define un coche en términos de fabricante, modelo, número

Modelado del Análisis
6
de bastidor, tipo de carrocería, color y propietario. El cuerpo de la
tabla representa ocurrencias del objeto de datos. Por ejemplo, un
Honda CRV es una ocurrencia del objeto de datos coche.
Atributos. Los atributos definen las propiedades de un objeto de
datos y toman una de las tres características diferentes. Se pueden
usar para (1) nombrar una ocurrencia del objeto de datos, (2) describir
la ocurrencia, o (3) hacer referencias a otra ocurrencia en otra tabla.
Además, uno o varios atributos se definen como un identifcador “es
decir, el atributo identificador supone una «clave» cuando queramos
encontrar una instancia del objeto de dato”. En algunos casos, los
valores para los identificadores son únicos, aunque esto no es un
requisito. Haciendo referencia al objeto de datos coche, un
identificador razonable podría ser el número de bastidor.
El conjunto de atributos apropiado para un objeto de datos dado se
determina mediante el entendimiento del contexto del problema. Los
atributos para coche descritos anteriormente podrían servir para una
aplicación que usara un Departamento de Vehículos de Motor, pero
estos atributos serían menos útiles para una compañía de
automóviles que necesite fabricar software de control. En este último
caso, los atributos de coche podrían incluir también número de
bastidor, tipo de carrocería, y color, pero muchos atributos adicibnales
(Por ejemplo: código interior, tipo de dirección, selector de
equipamiento interior, tipo de transmisión) se tendrían que añadir para
que coche sea un objeto significativo en el contexto del control de
fabricación.
Relaciones. Los objetos de datos se conectan entre sí de muchas
formas diferentes. Considere dos objetos de datos, libro y librería.
Estos objetos se pueden representar mediante la notación simple
señalada en la Figura. Se establece una conexión entre libro y librería
porque los dos objetos se relacionan. Pero, ¿qué son relaciones?
Para determinar la respuesta, debemos comprender el papel de libro

Modelado del Análisis
7
y librería dentro del contexto del software que se va construir.
Podemos definir un conjunto de parejas objeto-relación que definen
las relaciones relevantes. Por ejemplo:
una librería pide libros
una librería muestra libros
una librería almacena libros
una librería vende libros
una librería devuelve libros
Las relaciones pide, muestra, almacena y devuelve define las
conexiones relevantes entre libro y librería. La Figura (b) ilustra estas
parejas objeto-relación gráficamente. Es importante destacar que las
parejas objeto-relación tienen dos direcciones; esto es, se pueden
leer en cualquier dirección. Una librería pide libros o los libros son
pedidos por una librería.
Cardinalidad y Modalidad.
Los elementos básicos del modelado de datos “objetos de datos,
atributos, y relaciones” proporcionan la base del entendimiento del
dominio de información de un problema. Sin embargo, también se
debe comprender la información adicional relacionada con estos
elementos básicos.
Hemos definido un conjunto de objetos y representado las parejas
objeto-relación que los limitan. Una simple referencia: el objeto X que
se relaciona con el objeto Y no proporciona información suficiente
parapropósitos de ingeniería del software. Debemos comprender la
cantidad de ocurrencias del objeto X que están relacionadas con
ocurrencias del objeto Y. Esto nos conduce al concepto del modelado
de datos llamado cardinalidad.

Modelado del Análisis
8
Cardinalidad. El modelo de datos debe ser capaz de representar el
número de ocurrencias de objetos que se dan en una relación. Tillman
define la cardinulidad de una pareja objeto-relación de la forma
siguiente:
La cardinalidad es la especificación del número de ocurrencias de un
objeto que se relaciona con ocurrencias de otro objeto. La
cardinalidad normalmente se expresa simplemente como «uno» o
«muchos». Por ejemplo, un marido puede tener solo una esposa (en
la mayoría de las culturas), mientras que un padre puede tener
muchos hijos. Teniendo en consideración todas las combinaciones de
«uno» y «muchos», dos objetos se pueden relacionar como:
1. Uno a uno (1 : l); Una ocurrencia [de un objeto] «A» se puede
relacionar a una y sólo una ocurrencia del objeto «B», y una
ocurrencia de «B» se puede relacionar sólo con una ocurrencia
de «A».
2. Uno a muchos (1:N); Una ocurrencia del objeto «A» se puede
relacionar a una o muchas ocurrencias del objeto «B», pero
una de «B» se puede relacionar sólo a una ocurrencia de «A».
Por ejemplo, una madre puede tener muchos hijos, pero un hijo
sólo puede tener una madre.
3. Muchos a muchos (M:N); Una ocurrencia del objeto «A» puede
relacionarse con una o más ocurrencias de «B», mientras que
una de «B» se puede relacionar con una o más de «A». Por
ejemplo, un tío puede tener muchos sobrinos, mientras que un
sobrino puede tener muchos tíos.
La cardinalidad define «el número máximo de relaciones de objetos
que pueden participar en una relación». Sin embargo, no proporciona
una indicación de si un objeto de datos en particular debe o no
participar en la relación. Para especificar esta información, el modelo
de datos añade modalidad a la pareja objeto-relación.
Modalidad. La modalidad de una relación es cero si no hay una
necesidad explícita de que ocurra una relación, o que sea opcional.
La modalidad es 1 si una ocurrencia de la relación es obligatoria. Para
ilustrarlo, consideremos el software que utiliza una compañía
telefónica local para procesar peticiones de reparación. Un cliente
indica que hay un problema. Si se diagnostica que un problema es

Modelado del Análisis
9
relativamente simple, sólo ocurre una única acción de reparación. Sin
embargo, &el problema es complejo, se pueden requerir múltiples
acciones de reparación. La Figura ilustra la relación, cardinalidad y
modalidad entre los objetos de datos cliente y acción de reparación.
Diagramas Entidad Relación
La pareja objeto-relación es la piedra angular del modelo de datos.
Estas parejas se pueden representar gráficamente mediante el
diagrama entidad relación (DER). El DER fue propuesto originalmente
por Peter Chen para el diseño de sistemas de bases de datos
relacionales y ha sido ampliado por otros. Se identifica un conjunto de
componentes primarios para el DER: objetos de datos, atributos,
relaciones y varios indicadores tipo. El propósito primario del DER es
representar objetos de datos y sus relaciones.
Los objetos de datos son representados por un rectángulo etiquetado.
Las relaciones se indican mediante una línea etiquetada conectando
objetos. En algunas variaciones del DER, la línea de conexión
contiene un rombo que se etiqueta con la relación. Las conexiones
entre objetos de datos y relaciones se establecen mediante una
variedad de símbolos especiales que indican cardinalidad y
modalidad.
La relación entre los objetos de datos coche y fabricante se
representarían como se muestra en la Figura. Un fabricante construye
uno o muchos coches. Dado el contexto implicado por el DER, la
especificación del objeto de datos coche (consulte la tabla de objetos
de datos de la Figura) sería radicalmente diferente de la primera
especificación. Examinando los símbolos al final de la línea de
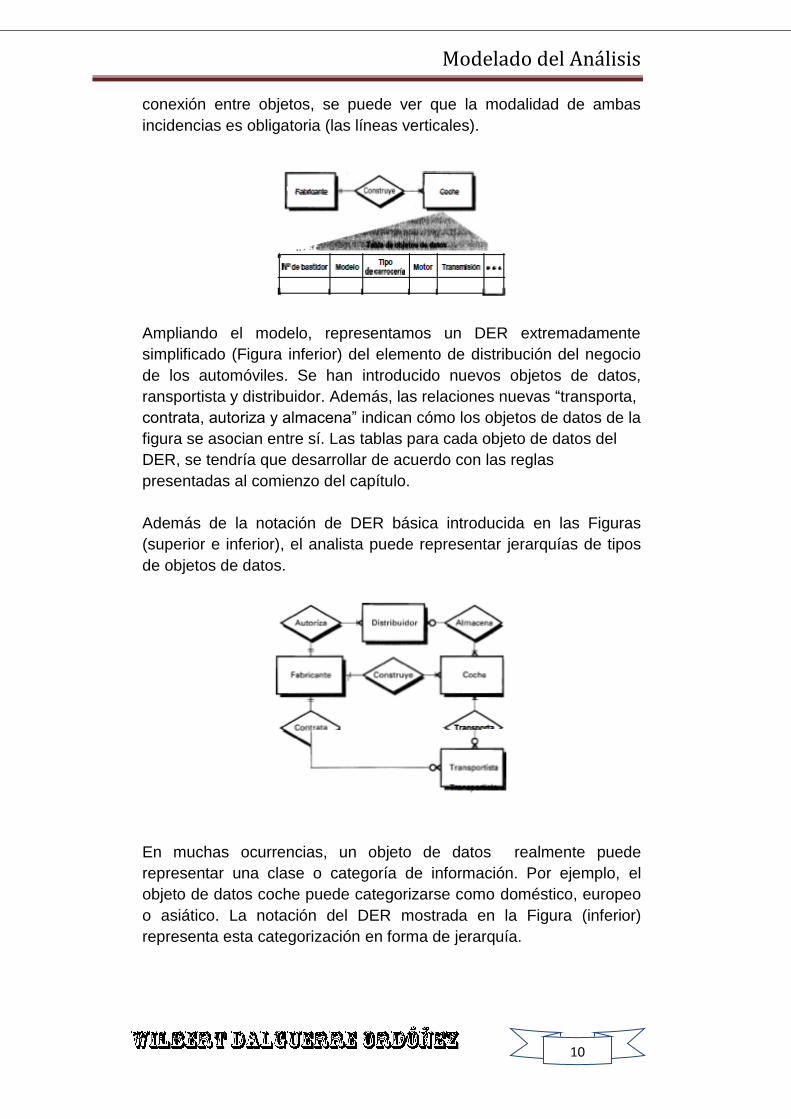
Modelado del Análisis
10
conexión entre objetos, se puede ver que la modalidad de ambas
incidencias es obligatoria (las líneas verticales).
Ampliando el modelo, representamos un DER extremadamente
simplificado (Figura inferior) del elemento de distribución del negocio
de los automóviles. Se han introducido nuevos objetos de datos,
ransportista y distribuidor. Además, las relaciones nuevas “transporta,
contrata, autoriza y almacena” indican cómo los objetos de datos de la
figura se asocian entre sí. Las tablas para cada objeto de datos del
DER, se tendría que desarrollar de acuerdo con las reglas
presentadas al comienzo del capítulo.
Además de la notación de DER básica introducida en las Figuras
(superior e inferior), el analista puede representar jerarquías de tipos
de objetos de datos.
En muchas ocurrencias, un objeto de datos realmente puede
representar una clase o categoría de información. Por ejemplo, el
objeto de datos coche puede categorizarse como doméstico, europeo
o asiático. La notación del DER mostrada en la Figura (inferior)
representa esta categorización en forma de jerarquía.

Modelado del Análisis
11
La notación del DER también proporciona un mecanismo que
representa la asociabilidad entre objetos. Un objeto de datos
asociativo se representa como se muestra en la Figura (inferior). En la
figura, los objetos de datos que modelan los subsistemas individuales
se asocian con el objeto de datos coche.
El modelado de datos y el diagrama entidad relación proporcionan al
analista una notación concisa para examinar datos dentro del
contexto de una aplicación de procesamiento de datos. En la mayoría
de los casos, el enfoque del modelado de datos se utiliza para crear
una parte del modelo de análisis, pero también se puede utilizar para
el diseño de bases de datos y para soportar cualquier otro método de
análisis de requisitos.
3. MODELADO FUNCIONAL Y FLUJO DE INFORMACIÓN
La información se transforma a medida que fluye por un sistema
basado en computadora. El sistema acepta entradas en una gran
variedad de formas; aplica elementos de hardware, software y
humanos para transformar la entrada en salida, y produce salida en

Modelado del Análisis
12
una gran variedad de formas. La entrada puede ser una señal de
control transmitida por un controlador, una serie de números escritos
por un enlace de una red o un archivo voluminoso de datos
recuperado de un almacenamiento secundario. La transformación
puede ser, desde una sencilla comparación lógica, hasta un complejo
algoritmo numérico o un mecanismo de reglas de inferencia de un
sistema experto. La salida puede ser el encendido de un diodo de
emisión de luz (LED) o un informe de 200 páginas. Efectivamente,
podemos crear un modelo de flujo para cualquier sistema de
computadora, independientemente del tamaño y de la complejidad.
El análisis estructurado es una técnica del modelado del flujo y del
contenido de la información. Tal como muestra la Figura, el sistema
basado en computadora se representa como una transformación de
información. Se utiliza un rectángulo para representar una entidad
externa, esto es, un elemento del sistema (por ejemplo, un elemento
hardware, una persona, otro programa) u otro sistema que produce
información para ser transformada por el software, o recibe
información producida por el software. Un círculo (también llamado
burbuja) representa un proceso o transformación que es aplicado a
los datos (o al control) y los modifica. Una flecha representa uno o
más elementos de datos (objetos de dato). Toda flecha en un
diagrama de flujos de datos debe estar etiquetada. Las líneas en
paralelo representan un almacenamiento “información almacenada
que es utilizada por el software”. La simplicidad de la notación del
DFD es una razón por la que las técnicas del análisis estructurado
son ampliamente utilizadas.
Diagramas de Flujo de Datos
A medida que la información se mueve a través del software, es
modificada por una serie de transformaciones. El diagrama depujo de
datos (DFD) es una técnica que representa el flujo de la información y

Modelado del Análisis
13
las transformaciones que se aplican a los datos al moverse desde la
entrada hasta la salida. En la Figura se muestra la forma básica de un
diagrama de flujo de datos. El DFD es también conocido como grafo
depujo de datos o como diagrama de burbujas.
Se puede usar el diagrama de flujo de datos para representar un
sistema o un software a cualquier nivel de abstracción. De hecho, los
DFDs pueden ser divididos en niveles que representen un mayor flujo
de información y un mayor detalle funcional. Por consiguiente, el DFD
proporciona un mecanismo para el modelado funcional, así como el
modelado del flujo de información. Al hacer esto, se cumple el
segundo principio de análisis operacional (esto es, crear un modelo
funcional).
Un DFD de nivel O, también denominado modelo fundamental del
sistema o modelo de contexto, representa al elemento de software
completo como una sola burbuja con datos de entrada y de salida
representados por flechas de entrada y de salida, respectivamente.
Al dividir el DFD de nivel O para mostrar más detalles, aparecen
representados procesos (burbujas) y caminos de flujo de información
adicionales. Por ejemplo, un DFD de nivel 1 puede contener cinco o
seis burbujas con flechas interconectadas. Cada uno de los procesos
representados en el nivel 1 es una subfunción del sistema general en
el modelo del contexto.
La notación básica que se usa para desarrollar un DFD no es en sí
misma suficiente para describir los requisitos del software. Por
ejemplo, una flecha de un DFD representa un objeto de datos que
entra o sale de un proceso. Un almacén de datos representa alguna
colección organizada de datos. Pero ¿cuál es el contenido de los
datos implicados en las flechas o en el almacén? Si la flecha (o el
almacén) representan una colección de objetos, ¿cuáles son? Para

Modelado del Análisis
14
responder a estas preguntas, aplicamos otro componente de la
notación básica del análisis estructurado el diccionario de datos.
La notación gráfica debe ser ampliada con texto descriptivo. Se puede
usar una especificación de proceso (EP) para especificar los detalles
de procesamiento que implica una burbuja del DFD. La especificación
de proceso describe la entrada a la función, el algoritmo que se aplica
para transformar la entrada y la salida que se produce. Además, el EP
indica las restricciones y limitaciones impuestas al proceso (función),
las características de rendimiento que son relevantes al proceso y las
restricciones de diseño que puedan tener influencia en la forma de
implementar el proceso.
4. MODELADO DE COMPORTAMIENTO
El modelado del comportamiento es uno de los principios
fundamentales de todos los métodos de análisis de requisitos. Sin
embargo, sólo algunas versiones ampliadas del análisis estructurado
proporcionan una notación para este tipo de modelado. El diagrama
de transición de estados representa el comportamiento de un sistema
que muestra los estados y los sucesos que hacen que el sistema
cambie de estado. Además, el DTE indica qué acciones (por ejemplo,
activación de procesos) se llevan a cabo como consecuencia de un
suceso determinado.
Un estado es un modo observable de comportamiento. Cada uno de
estos estados representa un modo de comportamiento del sistema.
Un diagrama de transición de estados indica cómo se mueve el
sistema de un estado a otro.
Para ilustrar el uso de las ampliaciones de comportamiento y de
control de Hatley y Pirbhai, consideremos el software empotrado en
una máquina fotocopiadora de oficina. En la Figura se muestra un
flujo de control para el software de fotocopiadora. Las flechas del flujo
de datos se han sombreado ligeramente con propósitos ilustrativos,
pero en realidad se muestran como parte de un diagrama de flujo de
control. Los flujos de control se muestran de cada proceso individual y
las barras verticales representan las «ventanas » EC. Por ejemplo, los
sucesos estado de alimentación del papel y de comienzo/parada
fluyen dentro de la barra de EC. Esto implica que cada uno de estos
sucesos hará que se active algún proceso representado en el DFC. Si

Modelado del Análisis
15
se fueran a examinar las interioridades del EC, se mostraría el suceso
comienzo/parada para activar/desactivar el proceso de gestión de
copiado. De forma similar, el suceso atascada (parte del estado de
alimentación del papel) activaría realizar diagnóstico del problema. Se
debería destacar que todas las barras verticales dentro del DFC se
refieren a la misma EC. Un flujo de suceso se puede introducir
directamente en el proceso como muestra fallo de reproducción. Sin
embargo, este flujo no activa el proceso, sino que proporciona
información de control para el algoritmo de proceso.
Un diagrama de transición de estados simplificado para el software de
fotocopiadora descrito anteriormente se muestra en la Figura inferior.
Los rectángulos representan estados del sistema y las flechas
representan transiciones entre estados. Cada flecha está etiquetada
con una expresión en forma de fracción. La parte superior indica el
suceso (o sucesos) que hace(n) que se produzca la transición. La
parte inferior indica la acción que se produce como consecuencia del
suceso. Así, cuando la bandeja de papel está llena, y el botón de
comienzo ha sido pulsado, el sistema pasa del estado leyendo
órdenes al estado realizando copias. Observe que los estados no se
corresponden necesariamente con los procesos de forma biunívoca.
Por ejemplo, el estado realizando copias englobaría tanto el proceso
gestión de copiado como el proceso producir visualización de usuario
que aparecen en la Figura superior.

Modelado del Análisis
16
5. MECANISMOS DEL ANÁLISIS ESTRUCTURADO
En la sección anterior, hemos visto las notaciones básica y ampliada
del análisis estructurado. Para poder utilizarlas eficientemente en el
análisis de requisitos del software, se ha de combinar esa notación
con un conjunto de heurísticas que permitan al ingeniero del software
derivar un buen modelo de análisis. Para ilustrar el uso de esas
heurísticas, en el resto de este capítulo utilizaremos una versión
adaptada de las ampliaciones de Hatley y Pirbhai a la notación básica
del análisis estructurado.
En las secciones siguientes, se examina cada uno de los pasos que
se debe seguir para desarrollar modelos completos y precisos
mediante el análisis estructurado.
Creación de un Diagrama Entidad Relación
del software especifique los objetos de datos que entran y salen de un
sistema, los atributos que definen las propiedades de estos objetos y
las relaciones entre los objetos. Al igual que la mayoría de los
elementos del modelo de análisis y las relaciones entre objetos, el
DER se construye de una forma iterativa. Se toma el enfoque
siguiente:
1. Durante la recopilación de requisitos, se pide que los clientes
listen las «cosas» que afronta el proceso de la aplicación o del
negocio. Estas «cosas» evolucionan en una lista de objetos de
datos de entrada y de salida, así como entidades externas que
producen consumen información.

Modelado del Análisis
17
2. Tomando objetos uno cada vez, el analista y el cliente definen
si existe una conexión (sin nombrar en ese punto) o no entre el
objeto de datos y otros objetos.
3. Siempre que existe una conexión;el analista y el cliente crean
una o varias parejas de objeto-relación.
4. Para cada pareja objeto-relación se explOra la cardinalidad y la
modalidad.
5. Interactivamente se continúan los pasos del 2 al 4 hasta que se
hayan definido todas las parejas objetorelación. Es normal
descubrir omisiones a medida que el proceso continúa. Objetos
y relaciones nuevos se añadirán invariablemente a medida que
crezca el número de interacciones.
6. Se definen los atributos de cada entidad.
7. Se formaliza y se revisa el diagrama entidad-relación.
8. Se repiten los pasos del 1 al 7 hasta que se termina el
modelado de datos.
Creación de un Modelo de Flujo de Datos
El diagrama dejujo de datos (DFD) permite al ingeniero del software
desarrollar los modelos del ámbito de información y del ámbito
funcional al mismo tiempo. A medida que se refina el DFD en
mayores niveles de detalle, el analista lleva a cabo implícitamente una
descomposición funcional del sistema. Al mismo tiempo, el
refinamiento del DFD produce un refinamiento de los datos a medida
que se mueven a través de los procesos que componen la aplicación.
Unas pocas directrices sencillas pueden ayudar de forma
considerable durante la derivación de un diagrama de flujo de datos:
1. el diagrama de flujo de datos de nivel O debe reflejar el
software/sistema como una sola burbuja;
2. se deben anotar cuidadosamente la entrada y la salida
principales;
3. el refinamiento debe comenzar aislando los procesos, los
objetos de datos y los almacenes de datos que sean
candidatos a ser representados en el siguiente nivel;
4. todas las flechas y las burbujas deben ser rotuladas con
nombres significativos;
5. entre sucesivos niveles se debe mantener la continuidad del
pujo de información;

Modelado del Análisis
18
6. se deben refinar las burbujas de una en una. Hay una
tendencia natural a complicar en exceso el diagrama de flujo
de datos. Esto ocurre cuando el analista intenta reflejar
demasiados detalles demasiado pronto o representa aspectos
procedimentales en detrimento del flujo de información.
Creación de un Modelo de Flujo de Control.
Para muchos tipos de aplicaciones de procesamiento de datos, todo
lo que se necesita para obtener una representación significativa de los
requisitos del software es el modelo de flujo de datos. Sin embargo,
como ya hemos mencionado anteriormente, existe una clase de
numerosas aplicaciones que están «dirigidas» por sucesos en lugar
de por los datos, que producen información de control más que
informes o visualizaciones, que procesan información con fuertes
limitaciones de tiempo y rendimiento. Tales aplicaciones requieren un
modelado del flujo de control además del modelado del flujo de
información.
Ya hemos señalado que los sucesos o los elementos de control se
implementan como valores lógicos (por ejemplo, verdadero o falso, si
o no, 1 ó 0) o como una lista discreta de condiciones (vacia, atascada,
ffena). Para seleccionar posibles candidatos a sucesos, se pueden
sugerir las siguientes directrices:
1. Listar todos los sensores que son «leídos» por el software.
2. Listar todas las condiciones de interrupción.
3. Listar todos los «interruptores» que son accionados por el
operador.
4. Listar todas las condiciones de datos.
5. De acuerdo con el análisis de nombres y verbos que se aplicó
a la narrativa de procesamiento, revisar todos los «elementos
de control» como posibles entradas/salidas de ECs.
6. Describir el comportamiento del sistema identificando sus
estados; identificar cómo se alcanza cada estado y definir las
transiciones entre los estados.
7. Centrarse en las posibles omisiones -un error muy común en la
especificación del control (por ejemplo, preguntarse si existe
alguna otra forma en la que se puede llegar a un estado o salir
de él.

Modelado del Análisis
19
La Especificación de Control
La especificación de control (EC) representa el comportamiento del
sistema (al nivel al que se ha hecho referencia) de dos formas
diferentes. La EC contiene un diagrama de transición de estados
(DTE) que es una especificación secuencial del comportamiento.
También puede contener una tabla de activación de procesos (TAP)
“una especificación combinatoria del comportamiento”.
La Especificación del Proceso
Se usa la especificación de proceso (EP) para describir todos los
procesos del modelo de flujo que aparecen en el nivel final de
refinamiento. El contenido de la especificación de procesamiento
puede incluir una narrativa textual, una descripción en lenguaje de
diseño de programas (LDP) del algoritmo del proceso, ecuaciones
matemáticas, tablas, diagramas o gráficos. Al proporcionar una EP
que acompañe cada burbuja del modelo de flujo, el ingeniero del
software crea una «mini-especificación» que sirve como primer paso
para la creación de la Especifrcación de Requisitos del Sofware y
constituye una guía para el diseño de la componente de programa
que implementará el proceso.
6. EL DICCIONARIO DE DATOS
El modelo de análisis acompaña representaciones de objetos de
datos, funciones y control. En cada representación los objetos de
datos y/o elementos de control juegan un papel importante. Por
consiguiente, es necesario proporcionar un enfoque organizado para
representar las características de cada objeto de datos y elemento de
control. Esto se realiza con el diccionario de datos.
Se ha propuesto el diccionario de datos como gramática casi formal
para describir el contenido de los objetos definidos durante el análisis
estructurado. Esta importante notación de modelado ha sido definida
de la siguiente forma:
El diccionario de datos es un listado organizado de todos los
elementos de datos que son pertinentes para el sistema, con

Modelado del Análisis
20
definiciones precisas y rigurosas que permiten que el usuario y el
analista del sistema tengan una misma comprensión de las entradas,
salidas, de las componentes de los almacenes y también de los
cálculos intermedios.
Actualmente, casi siempre se implementa el diccionario de datos
como parte de una «herramienta CASE de análisis y diseño
estructurados». Aunque el formato del diccionario varía entre las
distintas herramientas, la mayoría contiene la siguiente información:
1. Nornbre; el nombre principal del elemento de datos o de
control, del almacén de datos, o de una entidad externa.
2. Alias; otros nombres usados para la primera entrada.
3. Dónde se usa y cómo se usa; un listado de los procesos que
usan el elemento de datos o de control y cómo lo usan (por
ejemplo, como entrada al proceso, como salida del proceso,
como almacén de datos,
4. como entidad externa).
5. Descripción del contenido, el contenido representado mediante
una notación.
6. Información adicional; otra información sobre los tipos de
datos, los valores implícitos (si se conocen), las restricciones o
limitaciones, etc.
Una vez que se introducen en el diccionario de datos un nombre y sus
alias, se debe revisar la consistencia de las denominaciones. Es decir,
si un equipo de análisis decide denominar un elemento de datos
recién derivado como xyz, pero en el diccionario ya existe otro
llamado xyz, la herramienta CASE que soporta el diccionario muestra
un mensaje de alerta sobre la duplicidad de nombres. Esto mejora la
consistencia del modelo de análisis y ayuda a reducir errores.
La información de «dónde se usa/cómo se usa» se registra
automáticamente a partir de los modelos de flujo. Cuando se crea una
entrada del diccionario, la herramienta CASE inspecciona los DFD y
los DFC para determinar los procesos que usan el dato o la
información de control y cómo lo usan. Aunque esto pueda no parecer
importante, realmente es una de las mayores ventajas del diccionario.
Durante el análisis, hay una corriente casi continua de cambios. Para
proyectos grandes, a menudo es bastante difícil determinar el impacto
de un cambio. Algunas de las preguntas que se plantea el ingeniero
del software son «¿dónde se usa este elemento de datos? ¿qué mas

Modelado del Análisis
21
hay que cambiar si lo modificamos? ¿cuál será el impacto general del
cambio?». Al poder tratar el diccionario de datos como una base de
datos, el analista puede hacer preguntas basadas en «dónde se
usa/cÓmo se usan y obtener respuestas a peticiones similares a las
anteriores.

Modelado del Análisis
22
BIBLIOGRAFÍA
Ingeniería del software – un enfoque práctico. Roger S. Pressman
http://www.google.com.pe/search?num=10&hl=es&site=imghp&tb
m=isch&source=hp&biw=1366&bih=677&q=EL+PRODUCTO&oq=
EL+PRODUCTO&gs_l=img.3..0l10.1430.3454.0.4143.11.9.0.2.2.0
.186.986.4j5.9.0...0.0...1ac.1.Fl7oAV4lIQw#hl=es&tbo=d&site=img
hp&tbm=isch&sa=1&q=software+de+inteligencia+artificial&oq=soft
ware+de+inteligencia+artificial&gs_l=img.3..0j0i24l5.134002.1409
50.6.141169.26.11.0.15.15.1.196.1908.0j11.11.0...0.0...1c.1.9iim2
AMAFfQ&pbx=1&bav=on.2,or.r_gc.r_pw.r_qf.&fp=ba1326681ff2cb
8&bpcl=38897761&biw=1366&bih=634
http://es.wikipedia.org/wiki/Ingenier%C3%ADa_de_software
http://www.ctic.uni.edu.pe/files/insoft01.pdf
Todos son links o enlaces a diferentes páginas web que se
consultaron para el desarrollo de esta sesión de clases.













![Wyzwania [ISW]](https://img.pdfslide.tips/doc/110x75/547da46db379594e2b8b52cd/wyzwania-isw.jpg)














![Korzyści [ISW]](https://img.pdfslide.tips/doc/110x75/558c4668d8b42aea348b4705/korzysci-isw.jpg)
