Embed Size (px)
Citation preview


� K-NN merupakan instance-based learning,
� Maksudnya: data training disimpan sehingga klasifikasi untuk record baru yg belum diklasifikasi dpt ditemukan dengan membandingkan kemiripan yang paling banyak dalam data training.
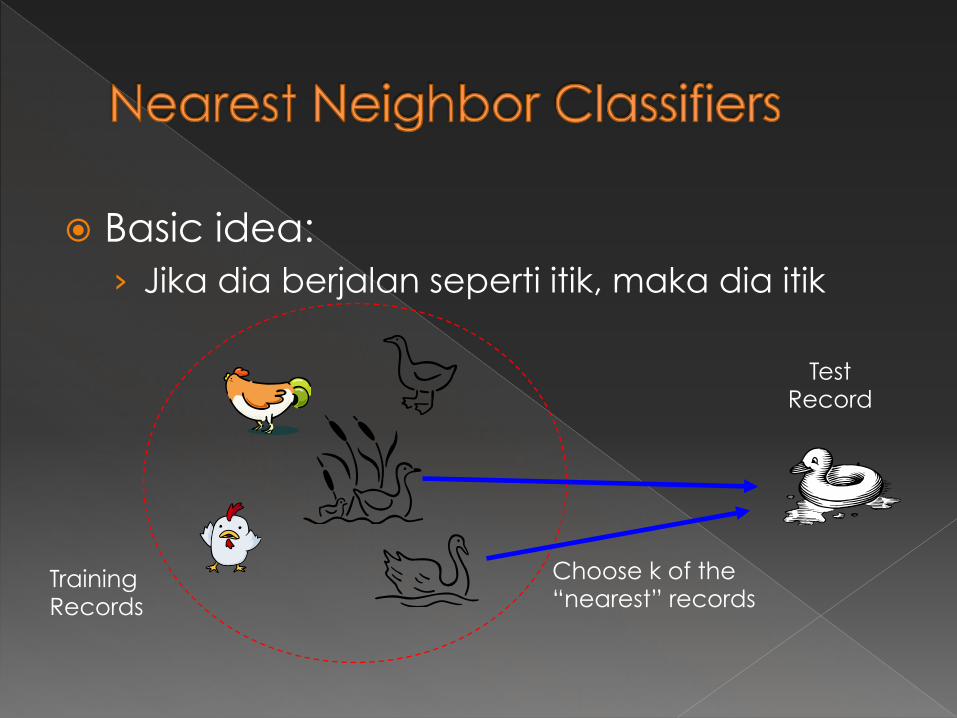
� Basic idea: › Jika dia berjalan seperti itik, maka dia itik
Training Records
Test Record
Choose k of the “nearest” records
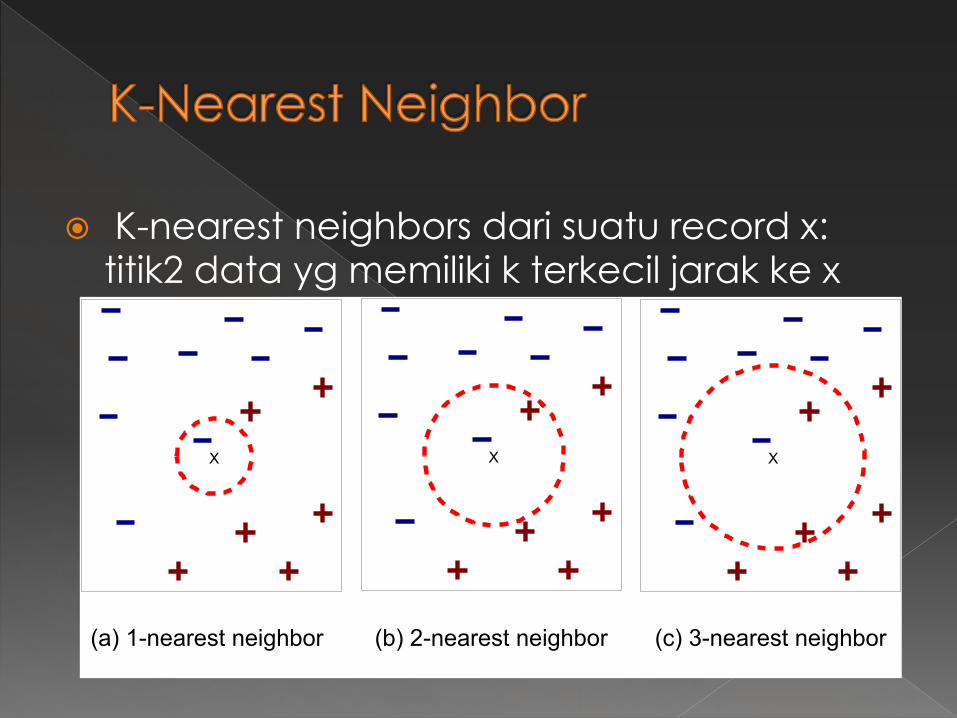
� K-nearest neighbors dari suatu record x: titik2 data yg memiliki k terkecil jarak ke x
X X X
(a) 1-nearest neighbor (b) 2-nearest neighbor (c) 3-nearest neighbor
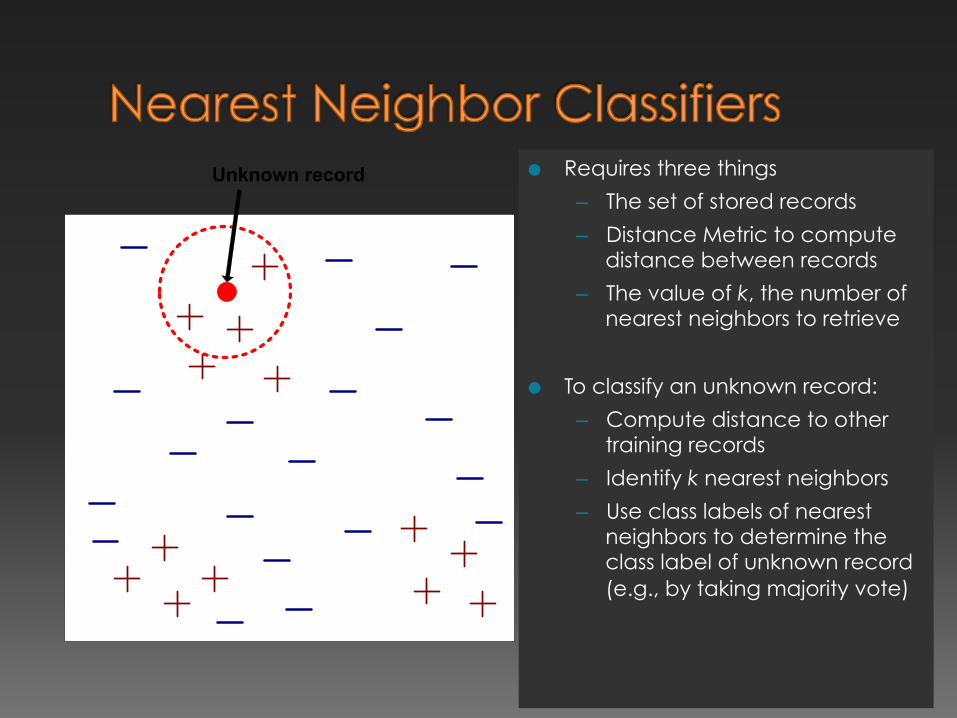
Unknown record ● Requires three things
– The set of stored records
– Distance Metric to compute distance between records
– The value of k, the number of nearest neighbors to retrieve
● To classify an unknown record:
– Compute distance to other training records
– Identify k nearest neighbors
– Use class labels of nearest neighbors to determine the class label of unknown record (e.g., by taking majority vote)
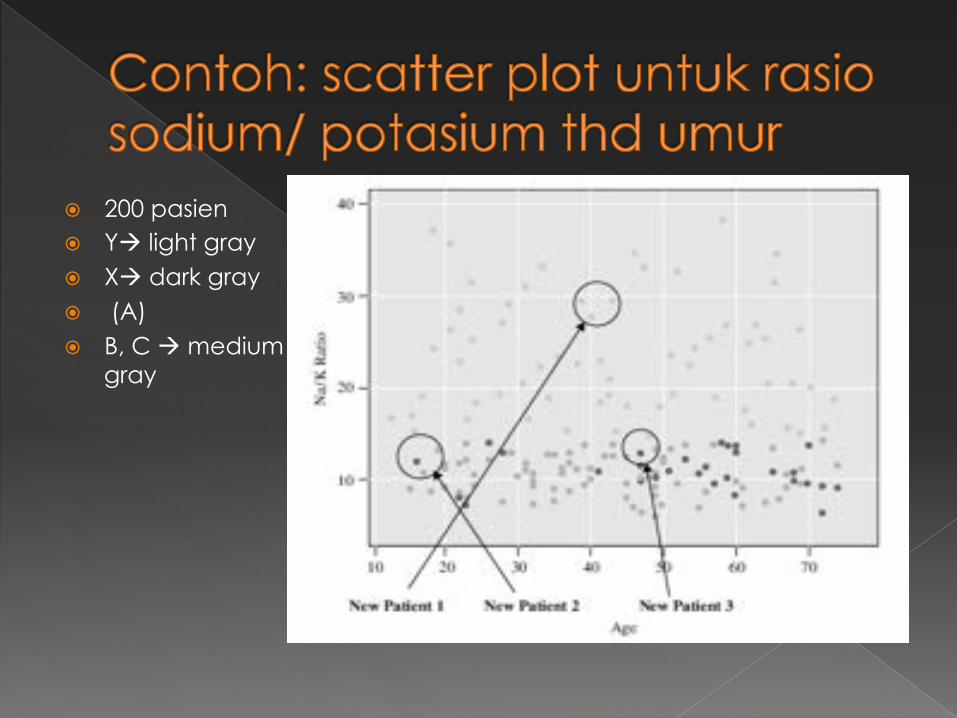
� 200 pasien � Yà light gray � Xà dark gray � (A) � B, C à medium
gray

� Jika ada pasien baru, maka dilihat yg paling dekat (k=1) à pasien 2 (drug A)

� Hitung jarak data baru dengan semua data yang ada
� urutkan jaraknya, dan cari k buah data yang memiliki jarak terdekat dengan data baru
� Lakukan voting dari k data tersebut � Kelas dengan nilai voting tertinggi
dijadikan label kelas untuk data baru


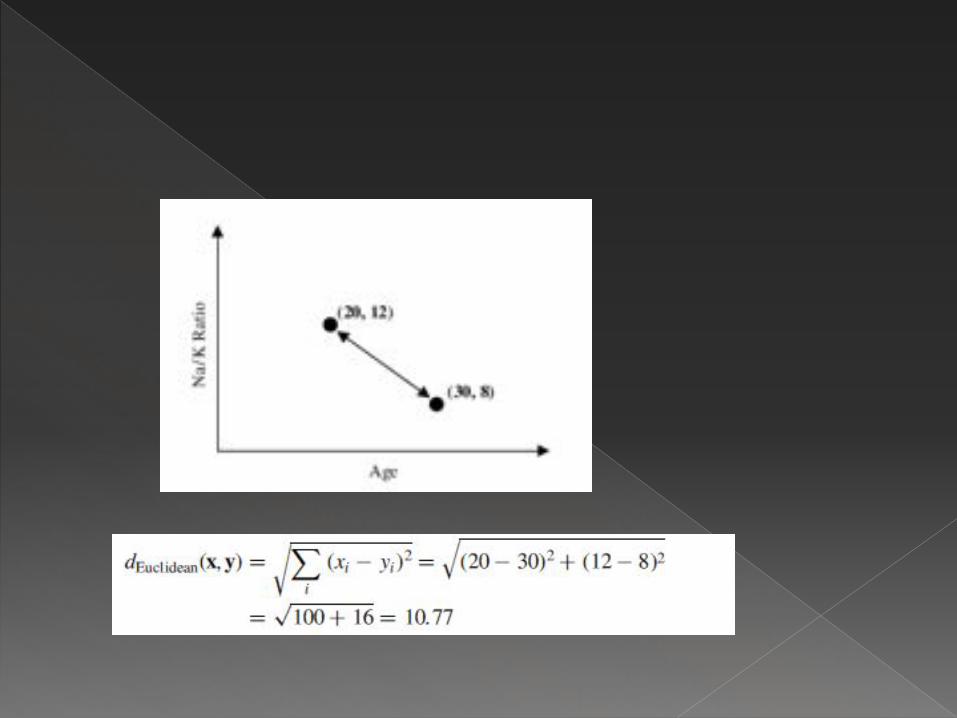
� Fungsi jarak yang paling umum digunakan à Euclidean distance
� Dimana, x=x1,x2,…xm, dan y1,y2,…ym merepresentasikan nilai atribut m dari dua rekord
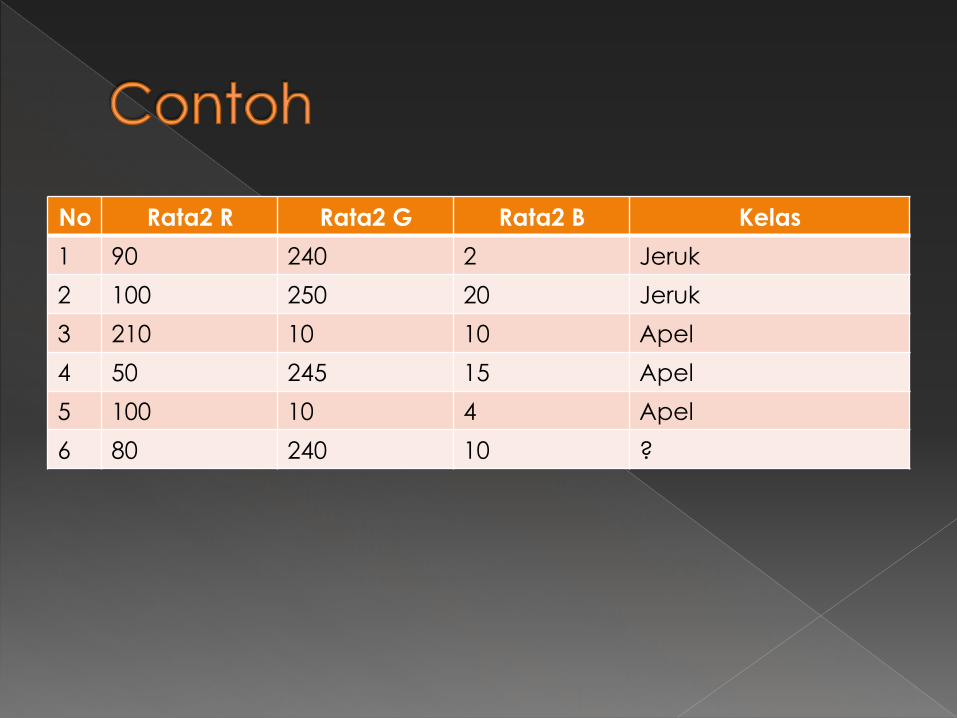
No Rata2 R Rata2 G Rata2 B Kelas
1 90 240 2 Jeruk
2 100 250 20 Jeruk
3 210 10 10 Apel
4 50 245 15 Apel
5 100 10 4 Apel
6 80 240 10 ?

� d(6,1)=12.80624847 � d(6,2)=24.49489743 � d(6,3)=264.1968963 � d(6,4)=30.82207001 � d(6,5)=230.9458811 Jika K = 3, maka dicari 3 data terdekat dengan data ke-6, yaitu data ke-1, 2, dan 4 Diantara ketiga data itu, 1(jeruk), 2(jeruk) dan 4(apel) ada 2 jeruk dan 1 apel. Sehingga data ke 6 diklasifikasikan sebagai Jeruk

� Bagaimana mengukur jarak? � Berapa banyak neighbor yg seharusnya
dipertimbangkan (k)? � Haruskah seluruh titik sama bobotnya,
atau beberapa titik memiliki informasi lebih dari yg lain
� Bagaimana mengombinasikan informasi dari lebih dari satu observasi?
� Bagaimana jika tiap atribut memiliki rentang nilai yang berbeda?

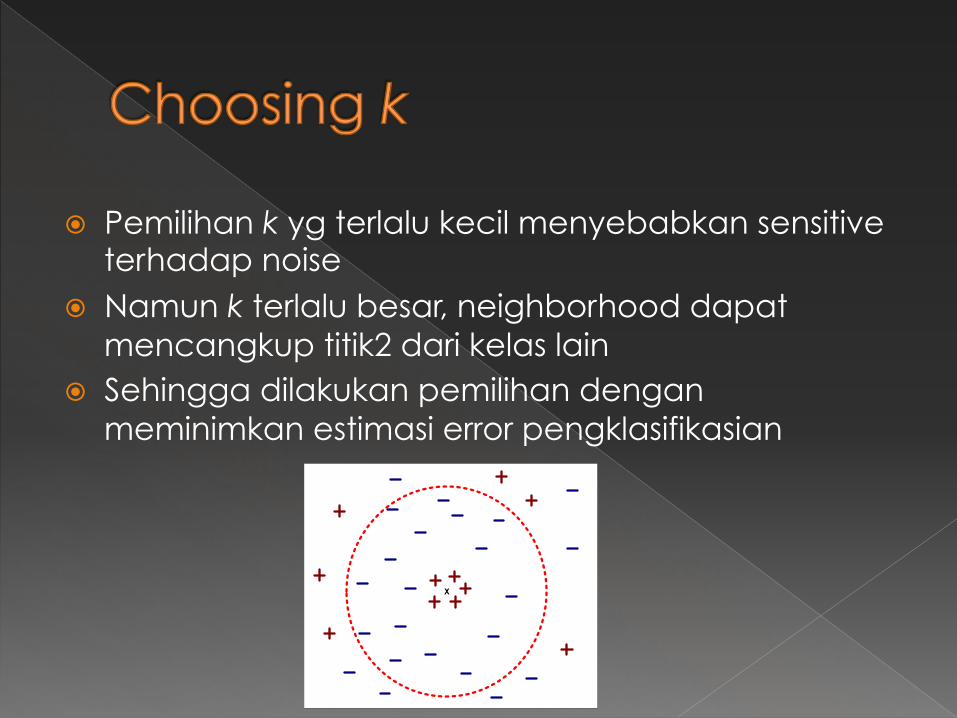
� Pemilihan k yg terlalu kecil menyebabkan sensitive terhadap noise
� Namun k terlalu besar, neighborhood dapat mencangkup titik2 dari kelas lain
� Sehingga dilakukan pemilihan dengan meminimkan estimasi error pengklasifikasian
X


� Simple Unweighted Voting 1. Menentukan k, jml rekord yg memiliki suara
dalam pengklasifikasian rekord baru 2. Membandingkan rekord baru ke k-nn, yakni k
rekord yg berjarak minim dalam ukuran jarak 3. Sekali k rekord dipilih, maka Satu record satu
vote � Maka bila terdapat k=3, dan terdapat 2 rekord
yg lebih dekat ke suatu record (misal: medium gray), maka memiliki confidence 66.67%

� Weighting Voting › Diharapkan memperkecil kesalahan
› Merupakan kebalikan proporsi jarak dari rekord baru dengan klasifikasi.
› Vote dibobotkan dengan inverse square dari nilai jarak
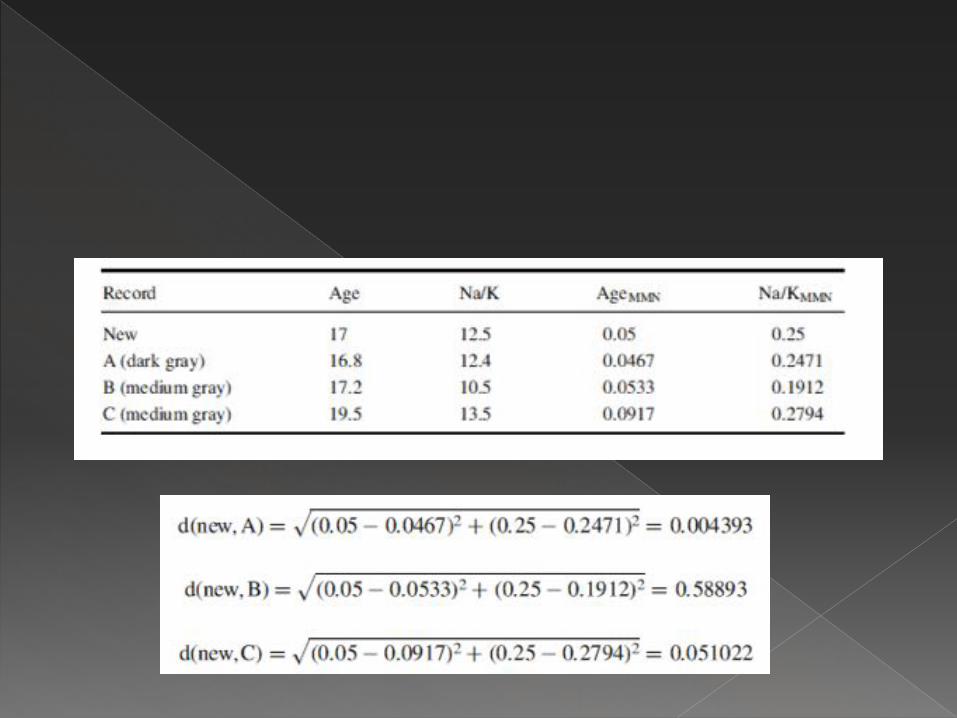

� Vote (dark grey)> vote (medium grey) � Sehingga dipilih vote tertinggi yakni dark
gray
Lima puluh satu ribu delapan ratus delapan belas


� Adanya kemungkinan suatu atribut memiliki informasi yg penting thd yg lain, maka dilakukan pengalian terhadap nilai tertentu. Misal adanya informasi Na/K ratio tiga kali lebih penting dari age, maka untuk pencarian jarak sbb:


� Rentang nilai yang terlalu berbeda menyebabkan proses pengukuran jarak hanya didominasi oleh fitur yan bernilai besar.
� Contoh No. Gaji/bulan Jumlah
Anak Golongan
1 3.000.000 1 Menengah
2 6.000.000 6 Kaya
3 2.500.000 7 ?

› d(3,1) = √250.000.000.036 › d(3,2) = √12.250.000.000.001
� Dari jarak yang dihitung, jumlah anak seperti tidak berguna sama-sekali, sebab rentangnya terlalu kecil.
No. Gaji/bulan Jumlah Anak
Golongan
1 3.000.000 1 Menengah
2 6.000.000 6 Kaya
3 2.500.000 7 ?

� Gunakan rumusan normalisasi/ standardisasi sebelum dilakukan klasifikasi:
� Untuk variabel kategori:

� Maka jarak antara pasien A & B à d(A,B)=√[(50-20)2 + 02]= 30;
dan jarak antara A & C à d(A,C)= √[(50-50)2 + 12]=1 � Hal ini berarti pasien A lebih similar ke C daripada ke B

� Jika dilakukan normalisasi min-max, maka ditemukan: d(A,B)=0.6, d(A,C)=1 sehingga dihasilkan pasien B lebih mirip ke pasien A
� Dan juga bila dilakukan Z-score standarization, maka dihasilkan: d(A,B)=0.6, d(A,C)=1, sehingga didapatkan pasien C yg lebih mirip ke pasien A
� Sering terjadi penyimpangan yg dilakukan oleh normalisasi min-max

� Cari k tetangga terdekat � Dari semua kemungkinan kelas pada
tetangga tersebut hitung derajad keanggaotaan dengan

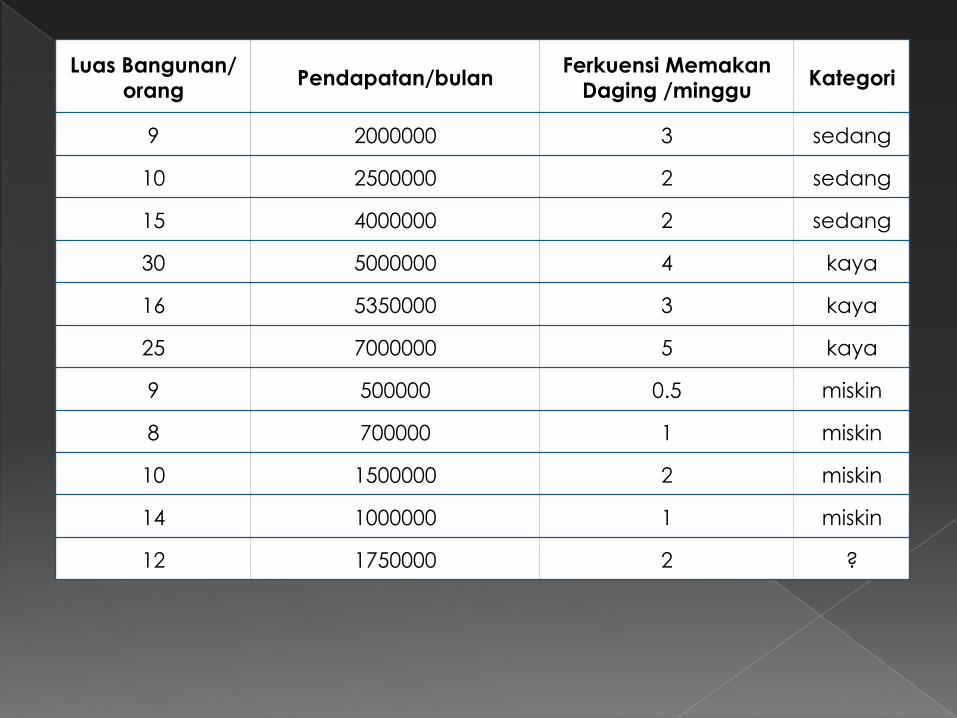
Luas Bangunan/orang Pendapatan/bulan Ferkuensi Memakan
Daging /minggu Kategori
9 2000000 3 sedang
10 2500000 2 sedang
15 4000000 2 sedang
30 5000000 4 kaya
16 5350000 3 kaya
25 7000000 5 kaya
9 500000 0.5 miskin
8 700000 1 miskin
10 1500000 2 miskin
14 1000000 1 miskin
12 1750000 2 ?





























