Embed Size (px)
Citation preview

ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƢỜNG ĐẠI HỌC CÔNG NGHỆ
Nguyễn Tuấn Dũng
PHÁT TRIỂN ỨNG DỤNG WEB VỚI
SERVER – SIDE JAVASCRIPT
KHÓA LUẬN TỐT NGHIỆP ĐẠI HỌC CHÍNH QUY
Ngành: Công nghệ Thông tin
HÀ NỘI – 2012

ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƢỜNG ĐẠI HỌC CÔNG NGHỆ
Nguyễn Tuấn Dũng
PHÁT TRIỂN ỨNG DỤNG WEB VỚI
SERVER – SIDE JAVASCRIPT
KHÓA LUẬN TỐT NGHIỆP ĐẠI HỌC CHÍNH QUY
Ngành: Công nghệ Thông tin
Cán bộ hƣớng dẫn: TS Nguyễn Hải Châu
HÀ NỘI – 2012

LỜI CẢM ƠN
Lời đầu tiên, tôi xin gửi lời cảm ơn sâu sắc nhất tới Tiến sĩ Nguyễn Hải Châu,
ngƣời đã tận tình hƣớng dẫn và giúp đỡ tôi trong suốt quá trình thực hiện khóa luận tốt
nghiệp.
Tôi chân thành cảm ơn các thầy, cô đã tạo những điều kiện thuận lợi cho tôi học
tập và nghiên cứu tại trƣờng Đại học Công nghệ. Các thầy cô đã giảng dạy và cho tôi
những kiến thức quý báu, làm nền tảng để tôi hoàn thành khóa luận cũng nhƣ công việc
trong tƣơng lai.
Tôi cũng xin gửi lời tri ân tới các bạn trong lớp K53CC đã ủng hộ và giúp đỡ tôi
trong suốt quá trình học tập tại trƣờng.
Cuối cùng, tôi muốn gửi lời cảm ơn vô hạn tới gia đình và bạn bè – những ngƣời
thân yêu luôn ở bên, khuyến khích và động viên tôi trong cuộc sống cũng nhƣ trong học
tập.
Tôi xin chân thành cảm ơn.
Hà nội, tháng 5 năm 2012
Sinh viên
Nguyễn Tuấn Dũng

PHÁT TRIỂN ỨNG DỤNG WEB VỚI SERVER-SIDE JAVASCRIPT
Nguyễn Tuấn Dũng
Khóa QH-2008-I/CQ, ngành Công nghệ thông tin
Tóm tắt Khóa luận tốt nghiệp:
Ngày nay với kỉ nguyên công nghệ bùng nổ, thời kì của mạng xã hội đã khiến cho số lƣợng
ngƣời dùng truy cập vào cùng một hệ thống ngày càng tăng.Điển hình nhƣ Facebook một ngày
phục vụ hơn 1000 tỉ lƣợt xem với khoảng hơn 800 triệu lƣợt khách vào ra trong một tháng thì ta
mới hình dung đƣợc sự bùng nổ của thông tin nhƣ thế nào.Để giải quyết vấn đề bùng nổ nhƣ trên
thì chúng ta đã mở rộng các hệ thống máy chủ siêu lớn, phân thành nhiều các cụm đặt khắp nơi
trên thế giới.Nhƣng với tốc độ tăng trƣởng theo cấp số hiện nay thì việc tăng số lƣợng máy chủ
lên thôi có lẽ không đủ.Ta cần xem xét và nâng cấp các giải pháp xây dựng web cho tƣơng lai.
Đầu tiên là về mặt ngôn ngữ và máy chủ.Các websever hiện hay với cách truyền thống là
phục vụ theo luồng tự nó đã giới hạn khả năng của các máy chủ cho việc đáp ứng số lƣợng yêu
cầu đến từ ngƣời dùng và không tốt cho các bài toàn cần tính toán thời gian thực.Giải pháp
hƣớng sự kiện của nodeJS có vẻ khả khi trong trƣờng hợp này.Nó sẽ giảm số luồng hoạt động
của máy chủ xuống, giảm thời gian trễ nên đáp ứng rất tốt các ứng dụng thời gian thực.Ngoài ra
việc tận dụng tốt hơn sẽ khiến cho số truy vấn đến nhiều hơn khiến cho việc giảm thiểu số máy
chủ xuống.
Thứ hai là về mặt cơ sở dữ liệu.Với các hệ thống với số lƣợng lên đến hàng triệu cho đến
hàng tỉ thì việc hiệu năng tốt là việc bắt buộc.Hệ thống máy chủ cơ sở dữ liệu đòi hỏi phải rất
mạnh mẽ nếu không máy chủ sẽ bị quá tải.Với các hệ RBDMs hiện nay thì vấn đề hiệu năng
thƣờng không tốt cho trƣờng hợp này.Ngôn ngữ SQL là ngôn ngữ thông dịch với các ràng buộc
trong các bảng khiến cho hiệu năng thực sự của hệ thống cơ sở dữ liệu khi thực thi là khá ì ạch
với hệ thống lớn nhƣ kể trên.Chƣa kể là với hệ thống lớn thì vấn đề phân tán dữ liệu, tính toàn
vẹn dữ liệu là việc rất quan trọng.NoSQL đáp ứng đƣợc tất cả các yêu cầu này.Với tốc độ nhanh
do không phải qua các câu truy vấn SQL, có tính sẵn sàng, phân tán cao và độ ổn định tuyệt
vời.Rất thích hợp cho các hệ thống có lƣợt truy vấn lớn.Ở trong khóa luận của tôi, tôi sẽ nghiên
cứu về một NoSQL khá phổ biến - CouchDB.Với khả năng chịu lỗi tốt và tính ổn định cao, đồng
bộ giữa các thiết bị tốt, hỗ trợ các phiên bản khi offline tốt.CouchDB xứng đáng là một cơ sở dữ
liệu đáng tin cậy.
Từ khóa: Nodejs, javascript server side, nosql, couchdb

LỜI CAM ĐOAN
Tôi xin cam đoan đây là công trình nghiên cứu và thực hiện khóa luận thực sự của
riêng tôi, dƣới sự hƣớng dẫn của ThS Nguyễn Hải Châu
Mọi tham khảo từ các tài liệu, công trình nghiên cứu liên quan trong nƣớc và quốc
tế đều đƣợc trích dẫn rõ ràng trong luận văn. Mọi sao chép không hợp lệ, vi phạm quy
chế hay gian trá tôi xin hoàn toàn chịu trách nhiệm và chịu mọi kỷ luật của ĐHQG Hà
Nội và Nhà trƣờng.
Hà Nội, ngày 18 tháng 05 năm 2012
Sinh viên
Nguyễn Tuấn Dũng

MỤC LỤC
MỞ ĐẦU ....................................................................................................................................... 1
CHƢƠNG 1: TÌM HIỂU VỀ NODE WEB: NODE.JS – THƢ VIỆN VIẾT ỨNG DỤNG
SERVER-SIDE JAVASCRIPT ...................................................................................................... 2
1.1. Javascript và lập trình server ............................................................................................. 2
1.2. NodeJs là gì? ...................................................................................................................... 2
1.3. Khác nhau giữa Blocking và Non-Blocking ..................................................................... 3
1.3.1. Blocking ..................................................................................................................... 3
1.3.2. Non-Blocking ............................................................................................................. 4
1.3.3. Lợi ích even-driven so với lại tốt hơn thread-driven .................................................. 4
1.4. Node package manager (NPM) ......................................................................................... 7
1.4.1 Giới thiệu về NPM ...................................................................................................... 7
1.4.2. Định dạng một gói cài npm ........................................................................................ 7
1.4.3. Sử dụng npm ............................................................................................................... 8
1.4.4. Gói toàn cục và gói cục bộ trong khi npm cài đặt ...................................................... 9
Chƣơng 2 TÌM HIỂU VỀ CÁC GIẢI PHÁP CƠ SỞ DỮ LIỆU DẠNG NOSQL (NOT
ONLY SQL) ................................................................................................................................. 10
2.4 Đặc điểm của NoSQL? .................................................................................................... 11
2.5 Phân loại NoSQL? ............................................................................................................ 12
2.5.1. Wide Column Store / Column Families ................................................................... 12
2.5.2. Key-Value Store/Tuple store .................................................................................... 12
2.5.3. Document Store ........................................................................................................ 12
2.5.4. Graph Database ........................................................................................................ 13
2.6 Hiệu năng NoSQL ........................................................................................................... 13
2.6.1. Xử lý việc suy giảm hiệu năng ..................................................................................... 13
2.6.2. Xử lý một dữ liệu cực lớn ............................................................................................. 14
2.7. Các loại NoSQL phổ biến ................................................................................................ 15
2.7.1. MongoDB [2][3] ....................................................................................................... 15
2.7.2. CouchDB [4] ............................................................................................................ 16
2.7.3. Cassandra[5] ............................................................................................................. 17
2.7.4. Membase [6] ............................................................................................................. 19

Chƣơng 3 TÌM HIỂU VỀ COUCHDB ....................................................................................... 20
3.1. CouchDB là gì ................................................................................................................. 20
3.2. Lịch sử CouchDB ............................................................................................................ 20
3.3. Các đặc điểm của CouchDB ............................................................................................ 20
3.3.1. Document storage ..................................................................................................... 21
3.3.2. Map/Reduce Views và Indexes ................................................................................ 21
3.3.3. Kiến trúc phân tán với việc nhân bản [10] [11] ........................................................ 21
3.3.4. REST API ................................................................................................................. 22
3.3.5. Tính nhất quán cuối cùng. ........................................................................................ 23
3.3.6. Sử dụng Offline ........................................................................................................ 23
3.4. Sử dụng CouchDB ........................................................................................................... 23
3.4.1. Khởi động ................................................................................................................. 23
3.4.2. Xử lý truy vấn trong CouchDB ................................................................................ 23
3.4.3. Views ........................................................................................................................ 24
3.4.6. Futon ............................................................................................................................. 28
3.5. Tìm hiểu phần mở rộng GEO của COUCHDB ............................................................... 29
3.5.1. GeoCouch là gì ......................................................................................................... 29
3.5.2. Cài đặt GeoCouch ..................................................................................................... 30
3.5.3. Kết nối NodeJs và GeoCouch .................................................................................. 31
3.5.4. Sử dụng GeoCouch ................................................................................................... 31
Chƣơng 4 ỨNG DỤNG MAPCHAT ........................................................................................... 33
4.1. ExpressJS ......................................................................................................................... 33
4.2. SocketIO .......................................................................................................................... 34
4.3. Cài đặt project .................................................................................................................. 35
4.3.1. Phần Chatting ........................................................................................................... 35
4.3.2 Phần map ................................................................................................................... 36
KẾT LUẬN ................................................................................................................................. 39

DANH SÁCH CÁC BẢNG
Bảng 1: So sánh CSDL quan hệ và NoSQL………………………………………..11
Bảng 2: Bảng tƣơng ứng các câu lệnh truy vấn ……...……………………………23

DANH SÁCH CÁC HÌNH VẼ
Hình 1:Bảng so sánh hiệu n……………………………………………………….13
Hình 2: Giao diện Futon……………………………………………………………28
Hình 3: Tạo temporary view……………………………………………………….29
Hình 4: Ứng dụng mapchat………………………………………………………...38

DANH SÁCH CÁC TỪ VIẾT TẮT
Từ viết tắt Nghĩa của từ viết tắt
SQL Structured Query Language
API Application on Programming Interface
ACID Atomicity, Consistency, Isolation, Durability
CSDL Cơ sở dữ liệu

1
MỞ ĐẦU
Ngày nay với kỉ nguyên công nghệ bùng nổ, thời kì của mạng xã hội đã khiến cho số
lƣợng ngƣời dùng truy cập vào cùng một hệ thống ngày càng tăng. Điển hình nhƣ
Facebook một ngày phục vụ hơn 1000 tỉ lƣợt xem với khoảng hơn 800 triệu lƣợt khách
vào ra trong một tháng thì ta mới hình dung đƣợc sự bùng nổ của thông tin nhƣ thế nào.
Để giải quyết vấn đề bùng nổ nhƣ trên thì chúng ta đã mở rộng các hệ thống máy chủ siêu
lớn, phân thành nhiều các cụm đặt khắp nơi trên thế giới. Nhƣng với tốc độ tăng trƣởng
theo cấp số hiện nay thì việc tăng số lƣợng máy chủ lên thôi có lẽ không đủ. Ta cần xem
xét và nâng cấp các giải pháp xây dựng web cho tƣơng lai.
Chƣơng 1: Tìm hiểu về node web: node. js – Thƣ viện viết ứng dụng server-side
javascript. Giới thiệu cho chúng ta tổng quan về một thƣ viện mới đƣợc viết bằng
javascript có khả năng chạy đƣợc trên server. Chúng ta sẽ giới thiệu qua về cách hoạt
động, các đặc điểm của nó và điểm mạnh điểm yếu của bộ thƣ viện này.
Chƣơng 2: Tìm hiểu về các giải pháp CSDL dạng NoSQL (Not-Only-SQL).
Chƣơng này giới thiệu cho chúng ta tổng quan về khái niệm NoSQL, các đặc điểm nổi bật
của nó. So sánh tƣơng quan giữa NoSQL và SQL truyền thống. Từ đó đƣa ra đƣợc các
giải pháp cho các trƣờng hợp nào nên dùng NoSQL.
Chƣơng 3: Tìm hiểu về CouchDB. Chƣơng này giới thiệu về một NoSQL khá phổ
biến hiện nay - CouchDB. Nêu ra đặc điểm, điểm yếu mạnh và cách dùng cơ bản của nó.
Chƣơng 4: Tìm hiểu phần mở rộng GEO của CouchDB. Trong phần này chúng ta
sẽ tìm hiểu về một phần mở rộng của CouchDB có khả năng hỗ trợ các định dạng địa lý
nhƣ điểm, vecto ... v..v đó là GeoCouch.Sẽ hƣớng dẫn cách dùng và cách sử dụng cơ bản
của nó
Kết luận: NoSQL và Javscript server side có thể sẽ là tƣơng lai của web trong một
tƣơng lai không xa. Khi mà yêu cầu về tốc độ, thống nhất ngôn ngữ, tính sẵn sàng và khả
năng mở rộng cao đƣợc đặt lên hàng đầu

2
CHƢƠNG 1: TÌM HIỂU VỀ NODE WEB: NODE.JS – THƢ VIỆN VIẾT ỨNG
DỤNG SERVER-SIDE JAVASCRIPT
1.1. Javascript và lập trình server
Mặc dù các ứng dụng trên nền web chở nên phổ biến trong những năm gần đây,
nhƣng chúng vẫn rất khó để phát triển, duy trì và mở rộng. Nhiều thách thức ở đây là việc
ngăn cách giữa các thành phần client và server. Các thành phần phía client thƣờng đƣợc
sử dụng bao gồm HTML, CSS, Javascript, Ajax(một phần của javascript), ảnh và các file
mà ta có thể tải về từ trình duyệt. Phía server, thì ta cần lắng nghe từ các yêu cầu, xuất ra
tài nguyên hoặc thông tin và thao tác với chúng để chúng có thể gửi trả về phía client.
Điều này thƣờng đƣợc thực hiện bằng cách sử dụng XML, JSON hoặc là định dạng theo
kiểu HTML, cái mà gửi thông qua đƣờng truyền sử dụng Ajax. Ta có vô số các công nghệ
cạnh tranh đƣợc chọn ở đây. Phụ thuộc vào đƣờng truyền, phần cứng, hệ điều hành, băng
thông, chuyên môn công nghệ và vô vàn các yếu tố khác. Mỗi một công nghệ mang lại
một trải nghiệm khác nhau. Các ngôn ngữ phía server đƣợc dùng phổ biến đến bây giờ là
PHP, java và .NET.
Điều này dẫn đến việc cần có một chuẩn để thống nhất lập trình giữa server và
client. Và phong trào ServerJS với mục đích ra xóa bỏ hàng rào ngăn cách giữa client và
server. Họ tìm cách giữ lại các thành phần chủ đạo và tìm điểm chung cho client và
server. Các thành phần đƣợc giữ lại là HTML, javscript và CSS, cái mà đã quá quen thuộc
với ngƣời dùng cuối. Còn về phía server. Họ xây dựng server dựa theo Javascript có thể
làm web server và nhiều hơn thế nữa. Rất nhiều dịch vụ server đƣợc viết bằng JavaScript
đã ra đời ví dụ nhƣ Jaxer đƣợc phát triển bởi Aptana, Jaxer là một web serve dựa Ajax
để xây dựng một trang web nhiều tính năng cũng nhƣ các ứng dụng sử dụng mô hình ajax
cái có thể đƣợc viết hoàn toàn bằng JavaScirpt
Chúng ta sẽ tập trung vào một Javascript-server-side khác: Nodejs
1.2. NodeJs là gì?
Javascript trƣớc đây chỉ chạy đƣợc trên trình duyệt web. Nhƣng gần đây nó đƣợc
dùng ở phía server. Có những môi trƣờng Javascript ở phía server nhƣ là Jaxer và
Narwhal, tuy nhiên Nodejs có một chút khác biệt so với những cái trên. Bởi vì nó dựa trên
sự kiện hơn là dựa theo luồng (thread). Các máy chủ Web nhƣ Apache thƣờng sử lý PHP
và các script CGI khác dựa theo luồng bởi chúng sinh ra một hệ thống luồng cho mỗi
request đến. Trong khi cách đó là ổn cho rất nhiều ứng dụng thì các mô hình dựa theo

3
luồng không thể mở rộng một cách có hiệu quả với nhiều kết nối tồn tại lâu. Ví dụ nhƣ
bạn muốn dùng các dịch vụ thời gian thực nhƣ Friendfeed hay Google Wave.
Nodejs, sử dụng một sự kiện lặp thay cho các luồng, và nó có thể mở rộng lên hàng
triệu kết nối một lúc. Điều này rất có lợi vì thực tế các máy chủ sử dụng phần lớn thờti
gian vào việc đợi các xử lý vào ra (ví dụ nhƣ đọc một file từ ổ cứng, truy vấn đến một
dịch vụ web bên ngoài hoặc là đợi file đƣợc tải lên hoàn tất) bởi vì các xử lý đó chậm
hơn rất nhiều so với xử lý bộ nhớ. Với kiến trúc hƣớng sự kiện thì lƣợng bộ nhớ dùng ít
hơn, lƣu nƣợng tăng cao và mô hình lập trình thì đơn giản hơn.
Mỗi một xử lý vào ra trong Nodejs là không đồng bộ, nghĩa là máy chủ có thể tiếp
tục sử lý các request đến trong khi các sử lý vào ra đang diễn ra. Javascript mà một ngôn
ngữ phù hợp cho việc lập trình hƣớng sự kiện bởi vì nó có các hàm không đồng bộ và sự
bao đống cái mà tạo ra một hàm callbacks đảm bảo. Và lập trình viên Javascript thì đã
biết cách lập trình theo cách này rồi. Mô hình hƣớng sự kiện khiến cho Nodejs chạy rất
nhanh và có thể triển khai và mở rộng cho các ứng dụng thời gian thực một cách dễ dàng.
Một lợi ích lớn lao của NodeJS đó là nó đƣợc viết bằng javascript. Nó cũng hỗ trợ
các hệ NoSQL dùng javascript để truy vấn. Từ đây ta chỉ cần học một ngôn ngữ là
javascript để thực thi từ phía trình duyệt, phía webserver và cả cho database server.
1.3. Khác nhau giữa Blocking và Non-Blocking
1.3.1. Blocking
Theo cách truyền thống (thread-based) thì hãy tƣởng tƣợng một ngân hàng đang áp
dụng mô hình phục vụ:Phục vụ hoàn toàn một yê u cầu rồi mới chuyển sang yêu cầu
khác. Trong đó nhân viên trong ngân hàng. Tƣơng ứng mỗi nhân viên là một Thread. Và
mỗi một yêu cầu tƣơng ứng là 1 request đến server. Bạn yêu cầu là muốn gửi tiền vào
ngân hàng. Bạn sẽ phải điền 1 số form nhƣ tên ngƣời gửi, số tài khoản của họ, số tiền cần
gửi. v...v. Trong thời gian bạn điền thông tin cần rút tiền vào tờ khai. Cô nhân viên phải
chờ bạn. Bạn đã "khóa" cô ấy không cho cô ấy phục vụ các khách hàng khác vì lúc đó cô
ấy đang rảnh vì phải đợi bạn. Hành động đợi ở đây phần lớn là hành động vào/ra, truy
suất file, hoặc đợi kết quả truy vấn SQL trong Webservice. Đó là cơ chế Blocking.
Theo cách này. Nếu ngân hàng đang quá tải vì có quá nhiều ngƣời chờ đƣợc phục
vụ. Thì ngân hàng chỉ còn một cách duy nhất là. Tăng thêm số nhân viên phục vụ lên. Ở
trƣờng hợp này trong ví dụ chúng ta là tăng số server phục vụ lên.

4
Vấn đề xảy ra ở đây ra. Khi tăng số lƣợng nhân viên lên để đáp ứng nhu cầu phục vụ
khách hàng thì ngân hàng phải tăng chi phí (tiền để trả lƣơng, mặt bằng văn phòng...)
(tƣơng ứng với việc tăng phần cứng máy chủ lên để đáp ứng). Nhƣ thế sẽ gây ra các vấn
đề về lãng phí. Và không tận dụng đƣợc nguồn lực và tiết kiệm đƣợc chi phí
1.3.2. Non-Blocking
Ở một ngân hàng khác, họ lại áp dụng theo một phƣơng thức mới (event-
driven):Tận dụng mọi khả năng của tất cả các nhân viên khi họ rảnh và nhân viên khi có
yêu cầu mới phục vụ.Tức là khi bạn có một yêu cầu muốn gửi tiền nhƣ ở trên. Cô nhân
viên chỉ cần đƣa bạn bút và giấy để bạn điền vào và bảo bạn hãy ngồi ở ghế chờ để điền
xong thông tin gửi tiền. Trong khi đó cô ấy có thể phục vụ những vị khách tiếp theo. Ở
đây bạn đã không "khóa" cô ấy lại. Và cô nhân viên tranh thủ lúc đợi bạn điền các thông
tin. Cô ấy có thể làm việc khác. Thành ra ở đây không có hành động đợi vô nghĩa ở đây.
Khi bạn điền xong thông tin, bạn có thể trở lại gặp cô ấy báo là đã hoàn thành. Cô ấy sẽ
tiếp tục phục vụ bạn để bạn hoàn thành việc của mình. Đây là cơ chế Non-Blocking.
Bạn có thể thấy, theo mô hình áp dụng của ngân hàng này (event-driven), họ sẽ tận
dụng đƣợc khoảng thời gian rỗi của nhân viên. Khiến cho việc một nhân viên có thể phục
vụ nhiều khách hàng hơn so với ngân hàng dùng mô hình theo cách cũ ở trên. Nếu có quá
tải. Bạn chắc chắn vẫn phải thêm nhân viên để đáp ứng kịp thời. Nhƣng chắc chắn sẽ
thêm ít nhân viên hơn. Tiết kiệm đƣợc rất nhiều tài nguyên. (Đây cũng là mô hình đƣợc
áp dụng phổ biến ở các ngân hàng).
1.3.3. Lợi ích even-driven so với lại tốt hơn thread-driven
Nói đến đây, chắc chắn sẽ có một vài câu hỏi đƣợc đặt ra:
- Mặc định, Nodejs chỉ có một luồng đƣợc thực thi. Nó không cần đợi các tác vụ
vào ra hoặc là chuyển nội dung. Thay vào đó, các tác vụ vào/ra sẽ tự động tạo
ra một hàm điều khiển gửi tới các sự kiện khi mà mọi thứ đã xong. Các sự kiện
lặp và mô hình điều hƣớng lặp cũng giống nhƣ cách mà javascript ở phía trình
duyệt thực hiện. Chƣơng trình sẽ xử lý các hành động và nhanh chóng quay về
vòng lặp để gửi các tác vụ khác đến. Khi load 1 trang và đang chờ nó truy xuất
cơ sở dữ liệu, thì nodejs sẽ tranh thủ phục vụ request khác. Trong khi việc chờ
truy xuất cơ sở dữ liệu vẫn tiếp tục. Vậy cũng thể coi đó là 2 tiến trình hoàn
tòan khác nhau.

5
- Ngay trong hệ điều hành đã áp dụng mô hình dựa theo sự kiện (event-based)
rồi. Nó sẽ không chỉ có 1 thread mà sẽ có rất nhiều thread. Và khi 1 thread tiến
trình đang bị blocking I/O. Thì hệ điều hành sẽ cho các thread khác đƣợc chạy
thay thế. Và nhƣ thế sẽ không có thời gian trễ. Nhƣ vậy sẽ không có lợi ích gì
đáng kể của mô hình hƣớng sự kiện so với không hƣớng sự kiện.
Có thể trả lời 2 câu hỏi trên nhƣ sau bằng 1 ví dụ: (Ở đây ta sẽ so sánh Nodejs với
Apache)
1 đoạn code sau:
result = query( "select A from B" );
do_something(result);
Theo cách thông thƣờng nhƣ trên. Nếu một request đƣợc gửi đến yêu cầu xử lý đoạn
code trên. Webservice sẽ phải tạo ra 1 thread để xử lý. Vấn đề là thread đƣợc tạo ra đó sẽ
không làm gì cả trong khi hàm query() vẫn đang chạy. Cho đến khi kết quả của câu lệnh
truy vấn SQL trên xử lý thành công, lâu hay nhanh thì tùy thuộc vào độ phức tạp của câu
truy vấn. Sau đó thread sẽ gọi hàm do_something. Đó thực sự không tốt bởi vì trong khi
toàn bộ các tiến trình đang trong trạng thái đợi(trừ tiến trình SQL) thì các yêu cầu mới
vẫn tiếp tục đƣợc gửi đến. Lúc này sẽ sinh ra rất nhiều các tiến trình đang đợi thực thi câu
lệnh, theo đúng cơ chế Blocking, vẫn ngốn tài nguyên máy chủ nhƣng không làm gì cả.
Và nếu tất cả các tiến trình nhiều đến mức ngốn hết tài nguyên trong khi các tác vụ vẫn
chƣa xong vì phải đợi thì lúc đó hệ thống sẽ sụp đổ. Quả thực là rất lãng phí. Mà việc
chuyển trạng thái giữa các tiến trình là luôn có một khoảng thời gian trễ nào đó, mà càng
nhiều tiến trình thì CPU càng mất nhiều thời gian để lƣu trữ và khởi động lại các trạng
thái, kéo theo tổng thời gian trễ đợi chuyển giữa các tiến trình là tăng lên. Đơn giản bằng
cách không đồng bộ, Node sẽ tận dụng triệt để tài nguyên do không có tài nguyên nào
phải đợi lãng phí nữa.
Một điểm yếu của lập trình hƣớng luồng là việc đồng bộ và tính đồng nhất của nó.
Độ phức tạp của nó đến từ việc trao đổi giữa các biến và các hàm để tránh việc deadlock
và xung đột giữa các luồng với nhau.
Node khiến cho chúng ta phải hiểu theo một nghĩa khác thế nào là đồng nhất. Các
hàm callback đƣợc gọi một cách không đồng bộ trong các sự kiện lặp xử lý khá tốt trong
việc đồng nhất, khiến cho mô hình đồng nhất trở nên đơn giản hơn, dễ hiễu hơn và dễ

6
thực hiện hơn. Nhất là khi với việc trễ trong truy xuất các đối tƣợng. Nếu truy suất trong
bộ nhớ thì ta chỉ mất với thời gian là nano giây, truy suất đĩa cứng hoặc qua mạng cục bộ
thì có thể mất thời gian là mili giây hoặc thậm trí cả giây. Nhƣng việc truy suất đó chƣa
hẳn đã xong, sẽ còn khá nhiều các tác vụ khác nữa trƣớc khi đƣợc đƣa đến ngƣời dùng
cuối, họ sẽ phải chờ rất nhiều thời gian để kết quả có thể hiện ra.
Còn với NodeJs thì câu truy vấn sẽ nhƣ thế này:
query(statement: "select A from B",
function(result){
// Xu ly ket qua sau khi tra ve
do_something();
} );
Theo cách viết dƣới thì nó, tức nodejs, sẽ báo cho môi trƣờng hoạt động (ở đây là
OS và webserver) là khi nào cần tạo tiến trình và phải làm gì. Đơn giản ở trên đoạn viết
trên, chƣơng trình vẫn sẽ tạo ra một thread và sẽ báo là khi nếu có câu truy vấn query() thì
chƣơng trình sẽ đợi hàm đó chạy xong. Trong lúc đợi query() chạy nó có thể phục vụ các
truy vấn khác. Khi nào query() truy vấn cơ sở dữ liệu xong. Chƣơng trình sẽ quay trở lại
gọi lại hàm callback ở trên là do_something(). Do đó, thread đó sẽ không phải đợi. Việc
tính toán giữa nhiều request có thể thực hiện một cách song song.
Cách viết code ở trên thực hiện y hệt nhƣ code ở phía trƣớc nữa thực hiện. Chỉ có
điểm khác biệt là kết quả của việc truy vấn không phải là trả về kết quả truy vấn mà là trả
về 1 hàm callback sẽ đƣợc thực thi sau khi truy vấn đƣợc thực thi hoàn toàn. Lúc này khi
sau khi truy vấn đƣợc thực thi xong.Ta có thể toàn quyền xử lý với kết quả trả về, đặt
thêm các sự kiện khác đến với nó. Ta có thể thấy event-driven khá giống với lập trình
socket .
Tóm lại, sức mạnh của nodejs không dựa vào vòng lặp bắt sự kiện của nó hoặc là
đồng bộ vào/ra mà lại dựa vào hệ thống callback của nó đã làm giảm rất nhiều thời gian
chờ của hệ thống.

7
1.4. Node package manager (NPM)
1.4.1 Giới thiệu về NPM
Đƣợc viết tắt bởi Node Package Manager (Trình quản lý gói của nodejs). Nó vừa là
một trình quản lý gói vừa là một hệ thống phân tán phục vụ cho NodeJs. Mục đích chính
của nó là tạo ra và phân phối các gói Node, các module qua internet sử dụng dòng lệnh.
Với npm chúng ta có thể dễ dàng tìm các module một cách tự động qua mạng. Chỉ với
một câu lệnh, ta có thể tải, cài và sử dụng các module.
1.4.2. Định dạng một gói cài npm
Một gói cài npm miêu tả trúc thƣ mục của nó ở trong file package.json. Nó bao gồm
tên gói, phiên bản, cấu trúc các cấp của thƣ mục bên trong gói cài, các module nào cần
thiết, phụ thuộc cần phải cài trƣớc.
Một file package.json đơn giản nhất sẽ có cấu trúc nhƣ dƣới:
{ name: "PackageA",
version: "1.0",
main: "mainModuleName",
modules: {
"module1": "abc/module1",
"module2": "abc/module2"
}
}
Hai thẻ quan trọng nhất trong file này là thẻ name và thẻ version. Thẻ name sẽ miêu
tả tên của gói và đƣợc dùng để tìm gói dễ dàng hơn.
#npm search packageName
Ở đây package name chính là tên trong thẻ name. Thẻ version là thẻ khai báo tên
phiên bản của gói cài. Mặc định npm nếu không có các tham số nó sẽ tải gói cài với phiên
bản mới nhất

8
Trong một module trong NodeJs cũng có thể đi kèm các module phụ thuộc nó. Khai
báo trong file json thì npm sẽ tự động cài các module khác đi kèm với module đó. Khai
báo các gói phụ thuộc nhƣ sau
"dependencies":
{
"one": "1.0 - 2.5"
"two": ">= 0.9 <2.3"
}
Ngoài ra còn các tham số khác:
"description": "module của tôi"
"homepage" : "http://localhost"
"author" dung_b1991
1.4.3. Sử dụng npm
Mặc định npm tìm các gói từ trên Internet và chính xác hơn là từ trang chủ
http://npmjs.org. Nếu biết rõ tên module thì ta dùng câu lệnh sau:
#npm install moduleName
Nhƣng nếu bạn không nhớ đầy đủ tên module mà chỉ nhớ một phần tên thì sao.
Ngoài việc vào trang http://search.npmjs.org thì bạn có thể dùng npm để cài.
#npm search key_name
Sau khi cài đặt module, để tìm kiếm tài liệu hƣớng dẫn, trang chủ của module đó,
hoặc thông tin chi tiết về module này thì ngoài việc vào file package.json của chính
module đó, ta có thể dùng npm:
#npm view moduleName
Nếu muốn tìm chi tiết hơn ví dụ là tìm trang chủ hay phiên bản của module:
#npm view moduleName version

9
1.4.4. Gói toàn cục và gói cục bộ trong khi npm cài đặt
Mặc định khi dùng câu lệnh install trong npm sẽ là cài 1 gói ở dạng local, tức là nó
chỉ có tác dụng trên thƣ mục mình cài
Ví dụ tại thƣ mục nodejs/dirA/ có gói là testcase
cd nodejs/dirA/
npm install testcase
Trong thƣ mục nodejs/dirB/ ta tạo 1 file.js có gọi gói testcase
var HTTPServer = require('testcase');
Thì sẽ báo lỗi không tìm thấy gói testcase, vì gói testcase ta install nó trong thƣ mục
dirA, nên npm sẽ hiểu testcase là gói cục bộ trong thƣ mục dirA.
Để có thể dùng gói testcase trong dirB ta có thể dùng 2 cách sau:
Cục bộ:Ta vào lại thƣ mục dirB và cài lại gói testcase bằng npm, lúc
đó gói testcase sẽ là gói cục bộ trong thƣ mục dirB.
cd anotherapp/
npm install http-server
Toàn cục:Ta sẽ cài gói testcase là 1 gói toàn cục. Tức là bất cứ thƣ
mục nào (kể cả không phả dirA và dirB cũng có thể gọi gói testcase đƣợc.
#npm install http-server -g
Mặc định thì npm cài thêm module theo cách cục bộ tức là nó sẽ cài vào mục
node_modules tại thƣ mục hiện thời. Để thay đổi việc cài module sao cho khi cài npm sẽ
mặc định sẽ cài vào toàn cục. Đây là cách mà các chƣơng trình có thể dùng các module
toàn cục mà không cần cài thêm.
#npm set global=true
Để kiểm tra xem biến global đã đƣợc set chƣa. ta dùng tham số get
#npm get global

10
Chƣơng 2 TÌM HIỂU VỀ CÁC GIẢI PHÁP CƠ SỞ DỮ LIỆU DẠNG NOSQL
(NOT ONLY SQL)
2.1 NoSQL là gì ?
noSQL, viết tắt của non-relational, hoặc theo cách hiểu khác thì có nghĩa là Not only
SQL (không chỉ là SQL). NoSQL đặc biệt nhấn mạnh đến mô hình lƣu trữ cặp giá trị -
khóa và hệ thống lƣu trữ phân tán.
Hệ CSDL này có thể lƣu trữ, xử lý từ lƣợng rất nhỏ đến hàng petabytes dữ liệu với
khả năng chịu tải, chịu lỗi cao nhƣng chỉ đòi hỏi về tài nguyên phần cứng thấp. NoSQL
thiết kế đơn giản, nhẹ, gọn hơn so với RDBMs, thiết kế đặc biệt tối ƣu về hiệu suất, tác
vụ đọc-ghi, ít đòi hỏi về phần cứng mạnh và đồng nhất, dễ dàng thêm bớt các node
không ảnh hƣởng tới toàn hệ thống, …
2.2 So Sánh NoSQL và RDBM?
Các RDBMs hiện tại đã bộc lộ những yếu kém nhƣ việc đánh chỉ mục một lƣợng
lớn dữ liệu, phân trang, hoặc phân phối luồng dữ liệu media (phim, ảnh, nhạc, ...). Cơ
sở dữ liệu quan hệ đƣợc thiết kế cho những mô hình dữ liệu nhỏ thƣờng xuyên đọc viết
trong khi các Social Network Services lại có một lƣợng dữ liệu cực lớn và cập nhật liên
tục do số lƣợng ngƣời dùng quá nhiều ở một thời điểm. Thiết kế trên Distributed NoSQL
giảm thiểu tối đa các phép tính toán, I/O liên quan kết hợp với batch processing đủ đảm
bảo đƣợc yêu cầu xử lý dữ liệu của các mạng dịch vụ dữ liệu cộng đồng này. Facebook,
Amazon là những ví dụ điểm hình.
Về cơ bản, các thiết kế của NoSQL lựa chọn mô hình lƣu trữ tập dữ liệu theo cặp
giá trị key-value. Khái niệm node đƣợc sử dụng trong quản lý dữ liệu phân tán. Với các
hệ thống phân tán, việc lƣu trữ có chấp nhận trùng lặp dữ liệu. Một request truy vấn tới
data có thể gửi tới nhiều máy cùng lúc, khi một máy nào nó bị chết cũng không ảnh
hƣởng nhiều tới toàn bộ hệ thống. Để đảm bảo tính real time trong các hệ thống xử lý
lƣợng lớn, thông thƣờng ngƣời ta sẽ tách biệt database ra làm 2 hoặc nhiều database. Một
database nhỏ đảm bảo vào ra liên tục, khi đạt tới ngƣỡng thời gian hoặc dung lƣợng,
database nhỏ sẽ đƣợc gộp (merge) vào database lớn có thiết kế tối ƣu cho phép đọc (read
operation). Mô hình đó cho phép tăng cƣờng hiệu suất I/O - một trong những nguyên
nhân chính khiến performance trở nên kém.
2.3 Bảng so sánh
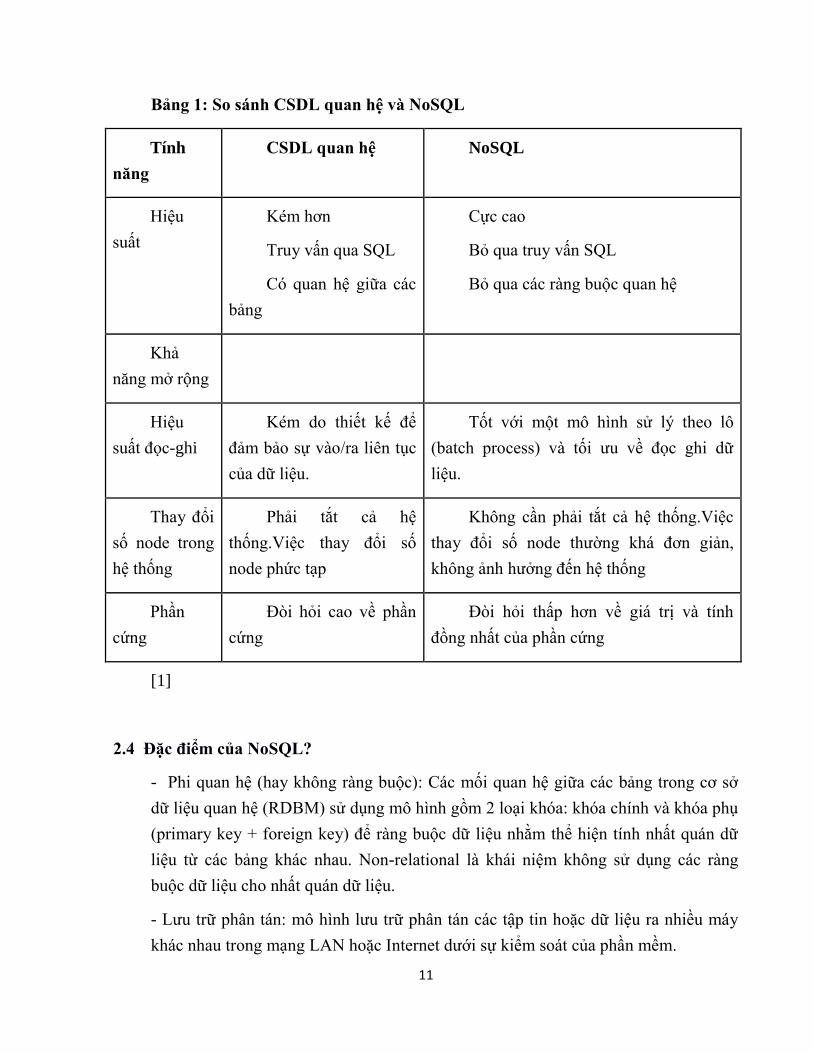
11
Bảng 1: So sánh CSDL quan hệ và NoSQL
Tính
năng
CSDL quan hệ NoSQL
Hiệu
suất
Kém hơn
Truy vấn qua SQL
Có quan hệ giữa các
bảng
Cực cao
Bỏ qua truy vấn SQL
Bỏ qua các ràng buộc quan hệ
Khả
năng mở rộng
Hiệu
suất đọc-ghi
Kém do thiết kế để
đảm bảo sự vào/ra liên tục
của dữ liệu.
Tốt với một mô hình sử lý theo lô
(batch process) và tối ƣu về đọc ghi dữ
liệu.
Thay đổi
số node trong
hệ thống
Phải tắt cả hệ
thống.Việc thay đổi số
node phức tạp
Không cần phải tắt cả hệ thống.Việc
thay đổi số node thƣờng khá đơn giản,
không ảnh hƣởng đến hệ thống
Phần
cứng
Đòi hỏi cao về phần
cứng
Đòi hỏi thấp hơn về giá trị và tính
đồng nhất của phần cứng
[1]
2.4 Đặc điểm của NoSQL?
- Phi quan hệ (hay không ràng buộc): Các mối quan hệ giữa các bảng trong cơ sở
dữ liệu quan hệ (RDBM) sử dụng mô hình gồm 2 loại khóa: khóa chính và khóa phụ
(primary key + foreign key) để ràng buộc dữ liệu nhằm thể hiện tính nhất quán dữ
liệu từ các bảng khác nhau. Non-relational là khái niệm không sử dụng các ràng
buộc dữ liệu cho nhất quán dữ liệu.
- Lƣu trữ phân tán: mô hình lƣu trữ phân tán các tập tin hoặc dữ liệu ra nhiều máy
khác nhau trong mạng LAN hoặc Internet dƣới sự kiểm soát của phần mềm.

12
- Nhất quán cuối: tính nhất quán của dữ liệu không cần phải đảm bảo ngay tức khắc
sau mỗi phép ghi. Một hệ thống phân tán chấp nhận những ảnh hƣởng theo phƣơng
thức lan truyền và sau một khoảng thời gian (không phải ngay tức khắc), thay đổi sẽ
đi đến mọi điểm trong hệ thống để cuối cùng dữ liệu trên hệ thống sẽ trở lại trạng
thái nhất quán.
- Triển khai đơn giản, dễ nâng cấp và mở rộng.
- Mô hình dữ liệu và truy vấn linh hoạt. …
2.5 Phân loại NoSQL?
2.5.1. Wide Column Store / Column Families
Hệ cơ sở dữ liệu phân tán cho phép truy xuất ngẫu nhiên/tức thời với khả năng lƣu
trữ một lƣợng cực lớn data có cấu trúc. Dữ liệu có thể tồn tại dạng bảng với hàng tỷ bản
ghi và mỗi bản ghi có thể chứa hàng triệu cột. Một triển khai từ vài trăm cho tới hàng
nghìn commodity hardware dẫn đến khả năng lƣu trữ hàng petabytes nhƣng vẫn đảm bảo
high performance. Dƣới đây là một số sản phẩm thông dụng: Hadoop/HBase – Apache,
BigTable – Google, Cassandra - Facebook/Apache, Hypertable - Zvents Inc/Baidu,
Cloudera, SciDB, Mnesia, Tablets, …
2.5.2. Key-Value Store/Tuple store
Mô hình lƣu trữ dữ liệu dƣới cặp giá trị key-value trong đó việc truy xuất, xóa, cập
nhật giá trị thực thông qua key tƣơng ứng. Với sự bổ trợ bởi các kỹ thuật BTree, B+Tree,
Hash, ... dữ liệu có thể tồn tại trên RAM hoặc đĩa cứng, phân tán hoặc không phân tán.
Hầu hết các NoSQL database đều là key-value store.
2.5.3. Document Store
Thực chất là các document-oriented database - một thiết kế riêng biệt cho việc lƣu
trữ document. Các cài đặt có thể là giả lập tƣơng tác trên relational database, object
database hay key-value store. Một số sản phẩm tiêu biểu: Apache Jackrabbit, CouchDB,
IBM Lotus Notes Storage Format (NSF), MongoDB, Terrastore, ThruDB, OrientDB,
RavenDB, ...
CouchDB là cơ sở dữ liệu thuộc nhánh document store
13
2.5.4. Graph Database
Graph database là một dạng cơ sở dữ liệu đƣợc thiết kế riêng cho việc lƣu trữ thông
tin đồ họa nhƣ cạnh, nút, properties. Một số sản phẩm tiêu biểu: Neo4J, Sones,
AllegroGraph, Core Data, DEX, FlockDB, InfoGrid, OpenLink Virtuoso, ...
2.6 Hiệu năng NoSQL
Hình 1:Bảng so sánh hiệu n
2.6.1. Xử lý việc suy giảm hiệu năng
NoSQL không dùng các câu lệnh thông dịch SQL và các truy vấn rƣờm rà khác
khiến nó cho ta một kiến trúc tối ƣu về tốc độ thực thi (Đọc và ghi và cập nhật dữ
liệu).Các câu lệnh SQL khá dễ đọc dễ hiểu.Nhƣng nếu dữ liệu các đơn giản, các thủ tục
SQL sẽ không cần thiết. Nhƣng với các dữ liệu không có một cấu trúc cố định - ví dụ nhƣ
- bài viết chẳng hạn, có rất nhiều kiểu bài viết, mỗi một kiểu bài viết lại có rất nhiều
trƣờng đi riêng biệt dành riêng cho nó.Tin tức thời sự chỉ có 3 trƣờng là Tiêu đề, miêu tả,
và phần thân, nhƣng với văn bản pháp luật thì ngoài 3 trƣờng trên còn có thêm trƣờng cho
phép đính kèm file văn bản pháp luật sửa đổi mới. Việc lƣu trữ và truy vấn lấy các bài
viết dạng thế này phải dùng khá nhiều câu lệnh join. Càng nhiều câu lệnh Join thì hiệu
năng càng giảm.
Không nhƣ SQL, NoSQL lƣu tất cả các trƣờng tập trung vào trong một phần tử là
document, các document này không nhất thiết phải bị "ràng buộc" phải có các trƣờng

14
giống nhau, nên sẽ có các phần tử có nhiều trƣờng hơn các phần tử khác.Các khái niệm
khóa ngoại khóa chính sẽ đƣợc loại bỏ - vì các document không còn quan hệ với
nhau.Các bài viết đƣợc phân biệt với nhau bởi trƣờng id.Đến lúc này khi truy vấn bài viết
nào đó thì ta chỉ việc truy vấn thẳng đến document đó là có thể lấy chính xác tất cả dữ liệu
cần tìm khiến cho hiệu năng truy vấn tăng lên đáng kể.
2.6.2. Xử lý một dữ liệu cực lớn
NoSQL đƣợc thiết kế cho việc lƣu trữ dữ liệu phân tán cho các dữ liệu cực lớn.Một
ví dụ rất quen thuộc ở đây là Facebook với trên 600 triệu ngƣời dùng đang truy cập hàng
ngày, hàng ngàn tetra ảnh đƣợc tải lên mỗi ngày thì ta mới biết nó khủng khiếp sao.Tất
nhiên không có máy chủ nào có thể xử lý đƣợc khối dữ liệu khổng lồ đó.Ta phải tách nó
ra làm nhiều cụm máy chủ lớn khác nhau gọi là Data Center.Và cũng không thể chỉ có
một Data Center có thể thực hiện đƣợc công việc nhƣ trên.Ta lại chia ra làm các cụm Data
Center.Với nhiều máy chủ nhƣ vậy.Đòi hỏi việc phân tán dữ liệu nhƣ thế nào, quản lý ra
sao, tốc độ cập nhật thế nào là điều cực kỳ quan trọng.NoSQL đáp ứng đƣợc những yêu
cầu này.
Với cơ sở dữ liệu dạng NoSQL, thì không có cấu trúc và không có các câu lệnh nối.
Một RDBMs truyền thống thì muốn mở rộng, nâng cấp thì chỉ có cách là nâng cấp phần
cứng mới hơn, mạnh hơn, mua thêm nhiều máy chủ tập trung thật tốt.Còn với NoSQL,
ngoài cách đó ra thì nó còn mở rộng theo chiều khác nữa, đó là nó có khả năng lan truyền
đều trên toàn hệ thống, tức là có thể giữa các Datacenter với nhau chứ không chỉ riêng
mỗi Datacenter. Đây là một giải pháp ít tốn kém hơn so với RDBMs, tận dụng đƣợc
nguồn tài nguyên nhàn rỗi tốt hơn.
Dƣới đây là các lĩnh vực mà NoSQL đóng một vai trò khá quan trọng và cần thiết:
Lƣu trữ dữ liệu: Tổng dữ liệu số hiện nay đã đƣợc lƣu bằng đơn vị
exabytes.Một exabyte tƣơng đƣơng với 1 tỉ GB dữ liệu.Theo một số liệu
nghiên cứu của trang Internet.com(*) thì tổng lƣu lƣợng internet năm 2006
vào khoảng 161 exabytes.Và chỉ 4 năm sau là vào năm 2010 thì tổng lƣợng dữ
liệu internet là khoảng 1000 exabyte, tăng hơn 500%.Và vì vậy, dữ liệu đƣợc
lƣu trữ ngày càng lớn lên.
Dữ liệu đƣợc kết nối: Dữ liệu ngày càng trở nên "kết nối" hơn, tức là
các trang web này có liên kết các trang web kia, các mạng xã hội tƣơng tác

15
ngƣời dùng với nhau.Và các hệ thống cũng đƣợc xây dựng để tƣơng tác với
ngƣời dùng.
Cấu trúc dữ liệu phức tạp.NoSQL có thể kiểm soát cấu trúc dữ liệu
phân thành nhiều cấp một cách dễ dàng.Để thực hiện một công việc tƣơng tự
nhƣ vậy trong SQL thì ta phải tạo rất nhiều bảng để lƣu trữ với rất nhiều khóa
ngoại, kéo theo đó là tốc độ khi thực thi các truy vấn sẽ cực kì chậm chạp.Có
một sự tƣơng tác nghịch giữa hiệu năng và độ phức tạp của dữ liệu.Hiệu năng
có thể suy giảm đáng kể trong các hệ RDBMs nếu chúng ta lƣu những dữ liệu
cực kì phức tạp và đồ sộ nhƣ ở các mạng xã hội.
2.7. Các loại NoSQL phổ biến
2.7.1. MongoDB [2][3]
Mongo là một cơ sở dữ liệu NoSQL nguồn mở, hiệu năng cao, có tính mở rộng
cao.Đƣợc viết bằng C++ .Dùng cách lƣu trữ BSON (Json đƣợc biên dịch) với giấy phép
AGPL.Thay vì lƣu trữ dữ liệu theo các bảng nhƣ các cơ sở dữ liệu cổ điển.MongoDB lƣu
cấu trúc dữ liệu thành các văn bản dựa JSON với mô hình động (gọi đó là BSON), khiến
cho việc tích hợp dữ liệu cho các ứng dụng trở nên dễ dàng và nhanh hơn.Với mục tiêu là
kết hợp các điểm mạnh của mô hình key-values (nhanh mà tính mở rộng cao) với mô hình
dữ liệu quan hệ ( giàu chức năng).
Mục tiêu chính của Mongo là giữ lại các thuộc tính thân thiện của SQL.Do đó các
câu truy vấn khá giống với SQL nên MongoDB khá thích hợp cho các lập trình viên đã
quen với ngôn ngữ truy vấn SQL.MongoDB có một khối lƣợng tính năng lớn và hiệu
năng cao.Với các loại dữ liệu phong phú, nhiều truy vấn và việc giảm thời gian phát triển
trong việc mô hình hóa các đối tƣợng.
MongoDB đƣợc sử dụng tốt nhất với nhu cầu cần truy vấn động, nếu bạn muốn định
nghĩa chỉ mục mà không cần các hàm map/reduce.Đặc biệt nếu bạn cần tốc độ nhanh cho
một cơ sở dữ liệu lớn vì MongoDB ngoài tốc độ đọc nhanh ra thì tốc độ ghi của nó rất
nhanh.
Các đặc điểm chính của mongoDB là:
Các truy vấn Ad hoc: Mongo hỗ trợ việc tìm theo trƣờng, khoảng kết quả
tìm và tìm theo cú pháp.Các truy vấn có thể trả về các trƣờng đƣợc qui định

16
trong văn bản và cũng có thể bao gồm các hàm Javascript mà ngƣời dùng
chƣa định nghĩa.
Đánh chỉ mục: Bất cứ một trƣờng nào trong MongoDB đều đƣợc đánh
chỉ mục (giống nhƣ chỉ mục bên RMDBs).
Mô phỏng ( nhân bản): Mongo hỗ trợ mô phỏng Master-slave.Một
master có thể điều khiển việc đọc và ghi.Một slave tạo bản sao sữ liệu từ
master và chỉ đƣợc sử dụng cho việc đọc và backup (không có quyền
ghi).Slave có khả năng chọn ra một master mới nếu master cũ bị hỏng.
Cân bằng tải: Mongo mở rộng theo chiều ngang bằng cách sử dụng
sharding.Các lập trình viên chọn các khóa chia sẻ nhằm xác định dữ liệu sẽ
đƣợc phân tán nhƣ thế nào.Dữ liệu sẽ đƣợc tách thành các khoảng dựa vào
khóa và phân tán dọc theo các Shard
Lưu trữ file: Mongo lƣu trữ bằng file hệ thống, rất tốt cho việc cân bằng
tải và nhân bản dữ liệu.Trong cá hệ thống nhiều máy, các file đƣợc phân
phối và đƣợc sao ra rất nhiều lần giữa các máy một cách trong suốt.Do đó
rất hiệu quả trong việc tạo ra một hệ thống cân bằng tải và dung lỗi tốt
2.7.2. CouchDB [4]
Đƣợc viết bằng Erlang với mục tiêu là tạo ra một cơ sở dữ liệu bền vững, chịu lỗi
cao, dễ dàng trong việc sử dụng.Dùng cách lƣu trữ thông thƣờng là JSON với giấy phép
Apache 2.0.
Với CouchDB thì mỗi một cơ sở dữ liệu là một tập các văn bản riêng biệt.Mỗi văn
bản tự bảo quản chính nó và tự nó bao gồm mô hình của nó ( các trƣờng, loại của mỗi
trƣờng).Mỗi một ứng dụng có thể thực thi rất nhiều cơ sở dữ liệu, ví dụ nhƣ chúng ta
dùng một cơ sở dữ liệu để lƣu thông tin ngƣời dùng điện thoại và cái còn lại là lƣu trên
server.Trên mỗi văn bản(bản ghi) còn bao gồm các thông tin về phiên bản, khiến cho việc
dễ dàng đồng bộ các dữ liêu với nhau khi cơ sở dữ liệu bị mất kết nối một thời gian giữa
các thiết bị.
CouchDB dử dụng MVCC (multi-Version Concurency Control ) để tránh việc
deadlock database trong suốt khi ghi.Tức là nếu trong khi ghi dữ liệu, chúng ta vẫn có thể
đọc dữ liệu vì CouchDB sinh ra một bản copy và chúng ta đọc trên bản copy đó.Sau khi
ghi xong nó sẽ tiến hành nhập dữ liệu giữa các thiết bị và xóa bản ghi cũ đi.

17
Dùng giao thức HTTP theo Restful với cách thiết kế có khả năng chịu lỗi cao với
dùng views đi kèm với map/reduce mang lại một tốc độ cao.Thích hợp cho rất nhiều các
thiết bị khác nhau nhƣ máy chủ, máy bàn hay điện thoại thông minh (smartphone)
CouchDB đƣợc sử dụng tốt nhất cho các hệ thống thỉnh thoảng thay đổi dữ liệu nhƣ
các hệ thống CMS, các hệ thống cho phép triển khai nhiều trang web.
Các đặc điểm chính của CouchDB:
Lưu trữ theo hướng văn bản (document storage)
Sử dụng ngữ nghĩa ACID: Cho phép điều khiển việc đồng bộ việc ghi và
đọc cƣờng độ rất cao mà không lo bị xung đột.
Sử dụng Map/Reduce và các chỉ mục: Mỗi view đƣợc tạo ra bởi một hàm
javascript mà thực thi cả 2 hành động map và reduce.Hàm đó khiến cho các
văn bản kết hợp với nhau thành một giá trị đơn nhất và trả về kết quả đó.
Kiến trúc phân tán có nhân bản: CouchDB đƣợc thiết kế với khả năng
nhân bản 2 chiều với các dữ liệu offline.Tức là ta có thể chỉnh sửa dữ liệu
offline và sau đó đồng bộ chúng sau khi có kết nối trở lại.
REST API: Tất cả dữ liệu đều có một địa chỉ duy nhất đƣợc lấy qua
HTTP.Giao thức REST sử dụng các phƣơng thức của HTTP nhƣ GET,
POST, PUT và DELETE với 4 chức năng cơ bản (Tạo, đọc, ghi, xóa, sửa)
Built for Offline: Có khả năng nhân bản dữ liệu cho từng thiết bị và tự
động đồng bộ dữ liệu khi thiết bị hoạt động trở lại
2.7.3. Cassandra[5]
Cassandra là một hệ quản trị cơ sở dữ liệu nguồn mở, đƣợc viết bằng Java với mục
tiêu chính là trở thành Best of BigTable.Cũng nhƣ CouchDB, nó cũng thuộc tổ chức phần
mềm Apache, đƣợc thiết kế với khả năng xử lý một khối dữ liệu cực lớn đƣợc trải ra trên
rất nhiều máy chủ trong khi cung cấp một dịch vụ có tính sẵn sàng cao và không hỏng.Nó
là một giải pháp NoSQL bƣớc đầu đƣợc phát triển bởi Facebook
Cassandra cung cấp một cấu trúc lƣu trữ theo dạng key/value với khả năng điều
hƣớng tính nhất quán.Các khóa ánh xạ đến nhiều giá trị, cái mà đƣợc gộp thành các nhóm
cột.Các nhóm cột đƣợc cố định khi cơ sở dữ liệu Cassandra đƣợc tạo ra, nhƣng các cột có

18
thể đƣợc thêm vào nhóm đó bất cứ lúc nào.Hơn nữa, các cột đƣợc thêm vào chỉ để làm
các khóa xác định, bởi vậy các khóa khác nhau có thể có số lƣợng cột khác nhau.
Giá trị từ các nhóm cột cho mỗi một khóa đƣợc lƣu trữ cùng nhau.Điều đó khiến cho
Cassandra là một hệ quản trị dữ liệu lai giữa hƣớng cột hoặc là hƣớng bản ghi.
Cassandra đƣợc dùng tốt nhất khi bạn ghi nhiều hơn bạn đọc, ví dụ ở đây là hệ thống
logging nhiều nhƣ các mạng xã hội, hệ thống ngân hàng, tài chính chứng khoán).Với tốc
độ ghi nhanh hơn tốc độ đọc, nó thích hợp cho việc phân tích dữ liệu thời gian thực.
Các đặc điểm nổi bật:
Tính phân cấp: Mỗi node trong một cụm có cùng một luật.Dữ liệu đƣợc
phân tán dọc theo các cụm đó (do đó mỗi node lại có một dữ liệu khác
nhau), nhƣng không có master bởi mỗi một node có thể phục vụ bất kì một
yêu cầu nào.
Hỗ trợ nhân bản và nhân bản nhiều trung tâm dữ liệu: Việc mô phỏng có
thể đƣợc cấu hình.Cassandra đƣợc thiết kế cho các hệ thống phân tán, có thể
triển khai một số lƣợng lớn các node trên nhiều trung tâm dữ liệu khác
nhau.Kiến trúc phân phối các đặc trƣng khóa của Casandra thích hợp cho
việc triển khai nhiều chung tập dữ liệu.Sử lý dữ liệu dƣ thừa, đề phòng việc
hỏng hóc.
Tính đàn hồi: Thông lƣợng đọc và ghi đều tăng tuyến tính khi các máy
mới thêm vào vì giảm đƣợc thời gian chết hoặc bị gián đoạn giữa các ứng
dụng
Tính dung lỗi:Dữ liệu đƣợc nhân bản ra thành nhiều node cho khả năng
dung lỗi.Việc nhân bản giữa các trung tâm dữ liệu khác nhau cũng đƣợc hỗ
trợ.Các node lỗi có thể đƣợc thay thế mà không mất thời gian chờ đợi.
Tính điều hướng nhất quán: Đọc và ghi đƣa ra một yêu cầu về tính nhất
quán với việc "việc ghi không bao giờ bị lỗi"
Hỗ trợ Map/Reduce: Cassandra có tích hợp thêm cả Hadoop đồng nghĩa
với việc hỗ trợ map/reduce

19
Có truy vấn theo ngôn ngữ riêng: CQL ( viết tắt của Cassandra Query
Language) là một thay thể của SQL - like với các giao thức RPC truyền
thống.Nó đƣợc điều khiển bởi Java và python
2.7.4. Membase [6]
Là một cơ sở dữ liệu nguồn mở với giấy phép Apache 2.0, nhƣ cassandra, là một hệ
quản trị dữ liệu theo dạng key-value đƣợc tối ƣu cho việc lƣu trữ dữ liệu tƣơng tác với các
ứng dụng web.Các ứng dụng đó phải phục vụ rất nhiều ngƣời dùng đồng thời: tạo, lƣu trữ
thu hồi, tập hợp, thao tác và trình bày dữ liệu.Membase đƣợc thiết kế để cung cấp một
cách đơn giản, nhanh chóng và dễ dàng để mở rộng dữ liệu key-value với độ trễ thấp và
băng thông cao.Nó đƣợc thiết kế để phân cụm thành một máy tính duy nhất để triển khai
qui mô lớn.
Membase đƣợc viết bằng C và Erlang tƣơng thích với memcache nhƣng có khả năng
lƣu trữ lâu bền và phân tán.Với tốc độ thực thi rất nhanh (hơn 200 ngàn bản ghi / giây)
bằng cách truy xuất dữ liệu bằng khóa và trên ram.Với việc truy xuất trên Ram thì hầu hết
việc truy suất các toán tử đều đƣợc thực thi trong khoảng thời gian ít hơn 1ms..Ngoài ra
còn cung cấp việc lƣu trữ dữ liệu lâu bền trên đĩa
Membase đƣợc sử dụng tốt nhất cho các ứng dụng yêu cầu tuy xuất dữ liệu với độ
trễ cực thấp, tính đồng nhất cao và khả năng mở rộng cao.Ví dụ nhƣ các chƣơng trình
gaming online, rất cần độ trễ truy xuất thấp

20
Chƣơng 3 TÌM HIỂU VỀ COUCHDB
3.1. CouchDB là gì
CouchDB là một hệ quản trị cơ sở dữ liệu NoSQL lƣu trữ theo hƣớng văn bản,
nguồn mở, truy cập bằng cách sử dụng hệ thống hàm (API) bằng JSON RESTful, có khả
năng khả chuyển cao trong việc tƣơng tác dữ liệu giữa các nút.Điều này khiến cho nó rất
thích hợp trong các trƣờng hợp liên quan đến việc thống nhất và bền vững dữ liệu.Việc
tích hợp các bản sao (ở đây là các view) làm cho nó là nền tảng lý tƣởng cho việc đồng bộ
hóa dữ liệu giữa điện thoại di động, máy tính và máy chủ.Couchdb không có mô hình cố
định.Thay vào đó nó lƣu trữ các bản ghi (hay văn bản) theo định dạng JSON, khá nhẹ và
dễ hiểu cấu trúc dữ liệu, rất thích hợp cho việc lƣu trữ dữ liệu.
Thuật ngữ "Couch" là từ viết tắt của "Cluster Of Unreliable Commodity
Hardware"(dịch là ) đã phản ánh mục tiêu của CouchDB là một cơ sở dữ liệu có khả năng
mở rộng cực tốt, đƣa ra tính sẵn sàng và độ tin cậy cao ngay cả khi chạy trên phần cứng
mà thƣờng dễ hỏng hoặc lỗi.
3.2. Lịch sử CouchDB
CouchDB ban đầu đƣợc viết bằng C++ bởi Damien Katz, trƣớc đây là làm ngƣời
trong nhóm phát triển Lotus notes của IBM.Ban đầu nó ở dƣới dạng nguồn mở với giấy
phép GNU ( GNU Genaral Public License).
Nhƣng vào tháng 2 năm 2008 thì nó đã trở thành một dự án của Apache và giấy
phép đƣợc chuyển thành giấy phép Apache License.Nó cũng đƣợc chuyển sang nền tảng
ErLang OTP với thiết kế nhằm việc tăng cƣờng khả năng chịu lỗi.
Vào đầu tháng 12 nhà sáng lập Damien Katz chuyển sang tập trung cho dự án
CouchBase, về bản chất là CouchDB + membase.Đầu tháng 4 thì phiên bản CouchDB 1.2
đã ra đời với rất nhiều cải tiến mới về tốc độ thực thi và nhiều tính năng nổi bật khác.
3.3. Các đặc điểm của CouchDB
Là một cơ sở dữ liệu NoSQL, CouchDB cũng có các đặc điểm của một NoSQL nhƣ
khả năng mở rộng, tốc độ cao.Ngoài ra CouchDB còn có các đặc điểm riêng sau

21
3.3.1. Document storage
Một máy chủ CouchDB chứa các cơ sở dữ liệu lƣu các văn bản.Mỗi văn bản là duy
nhất trong cơ sở dữ liệu và CouchDB cung cấp một thƣ viện hàm RESTful HTTP cho
việc đọc và cập nhât (Thêm, xóa, sửa) các văn bản.
CouchDB lƣu dữ liệu ở dạng văn bản với một hoặc nhiều cặp giá trị key/value bằng
JSON.Các giá trị của trƣờng có thể đơn giản nhƣ là kiểu chuỗi, kiểu số hoặc ngày tháng,
cũng có thể phức tạp hơn nhƣ kiểu danh sách thứ tự hoặc không thứ tự, hoặc là một mảng
liên kết.Mỗi một văn bản trong cơ sở dữ liệu CouchDB có một ID duy nhất và không cần
có cấu trúc.Tức là các văn bản(bản ghi) không cần phải tuân theo một cấu trúc nhƣ bắt
buộc phải có một trƣờng nào đó và có thể thêm các trƣờng đặc biệt khác mà không phụ
thuộc các bản ghi khác nhƣ bên RDBMs.
CouchDB .Văn bản thay đổi bởi các ứng dụng client theo trình tự nhƣ sau.Các ứng
dụng client tải văn bản cần dùng, sử dụng chúng bằng cách tƣơng tác nó, sau đó là lƣu
chúng vào cơ sở dữ liệu.Nếu có một máy khách khác cũng sửa cùng văn bản đó và lƣu
thay đổi của họ trƣớc thì client sẽ nhận một thông báo lỗi vì xung đột không lƣu đƣợc.Để
giải quyết xung đột này, thì phiên bản văn bản mới nhất sẽ đƣợc mở sửa lại một lần nữa
và cố gắng cập nhật lại.
Việc cập nhật cho các văn bản là hoàn toàn.Tức là nếu đã cập nhật hoặc là cập nhật
thành công hoặc là không đƣợc cập nhật.CouchDB không cho phép việc cập nhật văn bản
một phần.
3.3.2. Map/Reduce Views và Indexes
Dữ liệu đƣợc lƣu trữ có cấu trúc sử dụng các views.Trong CouchDB, vỡi mỗi một
view thì đƣợc cấu trúc bởi một hàm Javascript mà có nhiệm vụ ánh xạ (Map) các giá trị
và ghép các giá trị (reduce) đó lại thành một văn bản duy nhất.CouchDB có thể đánh chỉ
mục views và thực hiện các tác vụ y nhƣ với các văn bản khác nhƣ cập nhật(update),
thêm(add), xóa(delete).
3.3.3. Kiến trúc phân tán với việc nhân bản [10] [11]
CouchDB là một mạng ngang hàng dựa trên hệ thống cơ sở dữ liệu phân tán.Bất cứ
một máy nào trong các máy dùng CouchDB(Máy chủ và các máy client) đều có một
"nhân bản" cơ sở dữ liệu độc lập, mà các ứng dựng tƣơng tác đầy đủ với cơ sở dữ liệu
(truy vấn, thêm xóa sửa).Khi các ứng dụng kết nối lại (online) hoặc theo một chu kỳ, thì

22
dữ liệu sẽ đƣợc đồng bộ 2 chiều.Rất thích hợp với các ứng dụng web hiện nay.Ví dụ nhƣ
google docs.Bạn có thể soạn thảo offline khi không kết nối mạng.Khi kết nối mạng.Thì sẽ
đồng bộ lại dữ liệu với máy chủ.Vậy điều này sẽ dẫn đến một vấn đề là nếu có 2 hay
nhiều máy chủ cùng thay đổi dữ liệu trên cùng một văn bản thì sao.Có thể sẽ xảy ra xung
đột.Vậy CouchDB xử lý vấn đề này nhƣ thế nào?
Couch DB đƣợc xây dựng để phát hiện và xử lý những xung đột và quá trình sao
chép là tăng dần và nhanh, sao chép văn bản nào thay đổi so với các nhân bản trƣớc.Điều
này dẫn đến việc cập nhật các bản ghi và đồng bộ rất nhanh.
Mô hình nhân bản trong CouchDB là mô hình đƣợc thiết kế tốt để tăng tốc, thích
hợp cho phân phối.Nền tảng nhân bản này cung cấp một tập các tính năng sau:
Nhân bản từ Master đến máy Slave
Đồng bộ nhân bản giữa máy 2 máy Master với nhau
Lọc các nhân bản
Nhân bản tăng dần và 2 chiều (chỉ cập nhật các các văn bản thay đổi từ
hai chiều)
Quản lý các xung đột
Các đặc điểm nhân bản có thể đƣợc sử dụng để kết hợp tạp ra các giải pháp mạnh
mẽ tới rất nhiều vấn đề trong ngành Công nghệ thông tin.Ngoài các tính năng nhân bản
trên, thì ƣu thế của CouchDB về tính ổn định và khả năng mở rộng là một ƣu thế lớn.Nó
đƣợc tăng cƣờng hơn nữa khi đƣợc viết trên ngôn ngữ lập trình Erlang.Erlang đƣợc xây
dựng để hỗ trợ tối đa cho việc phân phối, khả năng tức thời, khả năng chịu lỗi cao và đã
có uy tín trong nhiều năm trong việc xây dựng các hệ thống đáng tin cậy trong ngày công
nghiệp viễn thông.Theo thiết kế thì ngôn ngữ Erlang và thời gian chạy đƣợc tận dụng lợi
thế phần cứng có nhiều lõi CPU
3.3.4. REST API
CouchDB dùng chuẩn REST.Tất cả các mục có một định danh duy nhất đƣợc lấy
thông qua giao thức HTTP.Chuẩn REST sử dụng các phƣơng thức của HTTP nhƣ POST,
GET, PUT và DELETE cho bốn toán tử cơ bản (tạo, đọc, cập nhật và xóa) cho tất cả dữ
liệu.

23
3.3.5. Tính nhất quán cuối cùng.
CouchDB đảm bảo tính nhất quán cuối cùng:
● Mỗi tài liệu tự nó đã đảm bảo tính đầy đủ
● Mỗi document đều có một resivion, một version riêng.
● Cơ chế Append-only cho phép ghi trong khi vẫn phục vụ truy vấn đọc.a
3.3.6. Sử dụng Offline
CouchDB có thể tạo một bản sao đến các thiết bị (ví dụ nhƣ máy tính xách tay hoặc
điện thoại) mà sau đó có thể hoạt động offline và dữ liệu đƣợc đồng bộ khi thiết bị kết nối
trở lại.
3.4. Sử dụng CouchDB
3.4.1. Khởi động
Mặc định câu lệnh #couchdb là khởi động couchdb.Nhƣng nó chỉ khởi động tiến
trình trực tiếp, không khởi động nhƣ một ứng dụng nền vì vậy.Ta dùng cách sau
Khởi động couchdb nhƣ 1 tiến trình nền #couchdb -b
Tắt couchdb nhƣ một tiền trình nền #couchdb -d
Localhost đến Futon:http://localhost:5984/_utils/
3.4.2. Xử lý truy vấn trong CouchDB
CouchDB dùng chuẩn REST với HTTP API nên chỉ có 4 câu lệnh đặc trƣng GET,
PUT, DELETE, POST.Dƣới đây là bảng so sánh công dụng tƣơng ứng:
Bảng 2:Bảng tƣơng ứng các câu lệnh truy vấn
Câu lệnh Tƣơng ứng SQL
GET SELECT
PUT CREATE hoặc UPDATE
DELETE DELETE
POST BULK các toán tử

24
3.4.3. Views
Định nghĩa
Việc sử lý truy vấn đƣợc thực hiện qua một thành phần trong CouchDB gọi là view.
Dƣới đây là một thể hiện ví dụ của một views
{
"_id": "_design/people",
"_rev": "6-2b78f1ce2c09d3d703e68ddb5fa7f9bc",
"vendor": {
"timing": "var timing = {};\ntiming.YearToSeconds =
function(years){\n\tvar curDate = new Date();\n\tvar startDate = new
Date();\n\tstartDate.setFullYear(curDate.getFullYear() - years);\n\treturn
(curDate.getTime() - startDate.getTime())/1000;\n}",
"couchapp": {
"metadata": {
"name": "couchapp",
"fetch_uri": "git://github.com/couchapp/couchapp.git",
"description": "official couchapp vendor"
}
}
},
"language": "javascript",
"views": {
"ageByYear": {
"map": "function(doc) {\n\t//Next line is CouchApp directive\n\tvar
timing = {};\ntiming.YearToSeconds = function(years){\n\tvar curDate = new
Date();\n\tvar startDate = new

25
Date();\n\tstartDate.setFullYear(curDate.getFullYear() - years);\n\treturn
(curDate.getTime() - startDate.getTime())/1000;\n}\n\n\t\n \temit(doc.name,
{\n\t\"age\":\n\t{\n\t\t\"seconds\": timing.YearToSeconds(doc.age), \n\t\t\"age\":
doc.age\n\t}\n\t\n\t});\t\n}"
},
"age": {
"map": "function(doc) {\n\temit(doc.name, doc.age); \n}",
"reduce": "function(keys, values, rereduce) {\n\treturn sum(values);
\n}"
},
"recent-items": {
"map": "function(doc) {\n if (doc.created_at) {\n var p = doc.profile ||
{};\n emit(doc.created_at, {\n message:doc.message, \n gravatar_url:
p.gravatar_url, \n nickname: p.nickname, \n name: doc.name\n });\n
}\n};"
}
},
"lists": {
},
"updates": {
},
"_attachments": {
"index.html": {
"content_type": "text/html",
"revpos": 3,
"digest": "md5-lScL+LCwuZFHXvbLkTUoHA==",
"length": 2307,

26
"stub": true
},
"vendor/couchapp/md5.js": {
"content_type": "text/x-js",
"revpos": 3,
"digest": "md5-p777iQdVR/HkNU2OXNRcDA==",
"length": 8656,
"stub": true
},
}
}
Muốn thực hiện truy vấn, ta chỉ cần gọi tên view với đƣờng dẫn chính xác, có thể
thêm các tham số cần thiết là ta có đƣợc truy vấn SQL tƣơng ứng.Ví dụ:
#CURL http://localhost:5984/test/_design/people/_view/age
Phân loại view cố định và views tạm thời
View cố định: Đƣợc lƣu trữ trong document đặc biệt (design
view), có khả năng truy cập qua HTTP qua yêu cầu GET tới URI cố định
theo định dạng sau /DBname/docID/viewName
View tạm thời: Không đƣợc lƣu trữ trên database, nhƣng đƣợc
thực thi theo tùy loại yêu cầu (temporary view).Để thực thi view này ta cần
sử dụng phƣơng thức yêu cầu HTTP - POST tới URI theo định dạng
/DBname/temp_view_name, nơi mà phần phân của yêu cầu chứa code của
hàm view mà content-type đƣợc thiết đặt đến application/ JSON
Ví dụ về view tạm thời
#curl -X PUT -d '{"spatial":{"points":"function(doc) {\n if (doc.loc) {\n
emit({\n type: \"Point\", \n coordinates: [doc.loc[0], doc.loc[1]]\n
}, [doc._id, doc.loc]);\n }};"}}' http://127.0.0.1:5984/geocouch/_design/main

27
Câu lệnh trên tạo view tạm thời cho cơ sở dữ liệu là geocouch với design là main
Chú ý: việc sử dụng view tạm thời chỉ hợp lý trong quá trình phát triển, vì các view
này đƣợc thực thi lúc nào đƣợc gọi đến, không nhƣ view cố định, dữ liệu đã đƣợc sinh
sẵn.Và thời gian để chạy Javascript làm chậm đáng kể việc truy xuất dữ liệu từ database
Các thành phần trong views
View gồm hai thành phần:Map và reduce.Có chức năng đúng nhƣ tên gọi của
nó.Một hàm với chức năng gắn các văn bản với các yêu cầu, mong muốn của ngƣời phát
triển với nhau.Một hàm có chắc năng nén dữ liệu
a, Map function
Ví dụ cơ bản
function(doc){
emit(null, doc);
}
Hàm trên trả về toàn bộ các document trong database mà không trả lại khóa.doc ở
đây ám chỉ là toàn bộ document của CouchDB.Hàm emit có chức năng sinh ra dữ liệu với
2 tham số đầu vào là key và values.Giá trị value có thể là một phần tử hoặc là một đối
tƣợng.
Dƣới đây là một ví dụ chi tiết hơn:
function(doc) {
emit(doc.name, doc.age);
}
Hàm này trả về tất cả các giá trị trƣờng age của bản ghi nào có trong cơ sở dữ liệu
doc, với khóa là trƣờng name
b, Reduce function
Đây là một hàm hữu ích của CouchDB.Nó làm tăng hiệu năng rất lớn cho
CouchDB.Nó có chức năng thu gọn các kết quả đƣợc trả về từ hàm map hoặc từ chính các
hàm reduce khác.
28
Nếu view có sử dụng hàm reduce.Nó có thể sử dụng việc kết hợp các kết quả cho
view đó.Hàm reduce chấp nhận các tập nhƣ đầu vào, các kết quả đã đƣợc trả về qua hàm
emit
3.4.6. Futon
CouchDB cũng cung cấp một ứng dụng web application tên là Futon, là một công cụ
quản trị nhƣ phpmyadmin của MySQL, phpMoadmin của mongoDB.Nó cho phép bạn
bảo trì cơ sở dữ liệu, kiểm soát.
Mặc định CouchDB chiếm cổng 5984 và chạy tại địa chỉ
http://127.0.0.1:5984/_utils/
Hình 4: Giao diện Futon
29
Hình 5: Tạo temporary view
3.5. Tìm hiểu phần mở rộng GEO của COUCHDB
3.5.1. GeoCouch là gì
GeoCouch là một nhánh của Couchdb và đƣợc viết bởi Volker Mische.Dự án
GeoCouch đƣợc lƣu ở github tại địa chỉ
https://github.com/couchbase/geocouch.GeoCouch tồn tại dƣới dạng một phần mở rộng
của Couchbase(là một cơ sở dữ liệu kết hợp giữa CouchDB và Membase), nhƣng vẫn
tƣơng thích tuyệt đối cho các phiên bản couchdb của Apache.
Ngoài việc hỗ trợ trợ tất cả tính năng của CouchDB, thì GeoCouch còn hỗ trợ thêm
một cách đánh chỉ mục mới, R-tree.Cấu trúc R-tree đƣợc sử dụng bởi rất nhiều cho việc
lƣu trữ dữ liệu không gian địa lý bởi vì nó đƣợc tối ƣu tốc độ cho việc tìm kiếm.R-tree
đơn giản là tập các ô hoặc mảnh khung hoặc có thể gọi là khoảng không gian.Nó bao gồm
các điểm ánh xạ tới các điểm thực sự trong khoảng đó hoặc giữa các khoảng nhỏ hơn với
nhau đƣợc bao gồm trong các khoảng lớn hơn.Nó giảm đƣợc số mảnh phải truy vấn, bởi

30
vì các tập dữ liệu thƣờng đƣợc giới hạn thành các tập nhỏ hơn trong các các điểm ánh xạ
đƣợc lƣu trữ.GeoCouch cung cấp một cách dễ dàng nhất để xây dựng các ứng dụng liên
quan đến không gian một cách đơn giản bao gồm hỗ trợ định dạng vật lý GeoJSON trong
CouchDB view.
3.5.2. Cài đặt GeoCouch
Mặc định GeoCouch chỉ là một phần mở rộng, tức là nếu muốn dùng phải phải cài
đặt riêng.
Chúng ta sẽ tải bản geocouch từ github tại địa chỉ sau
https://github.com/couchbase/geocouch/ .Tại dây tùy vào phiên bản CouchDB hiện tại ta
dùng là phiên bản nào mà ta sẽ chọn nhánh tƣơng ứng đến phiên bản đó.Ở đây trong ví dụ
hiện tại ta đang dùng phiên bản CouchDB 1.1.1.Do đó ta sẽ dùng phiên bản sau.
https://github.com/couchbase/geocouch/tree/couchdb1.1.x
Tải GeoCouch về máy.
#git clone https://github.com/couchbase/geocouch.git
#cd geocouch
Chọn nhánh đúng với phiên bản của CouchDB mình đang dùng
#git checkout couchdb1.1.x
Tiếp theo ta sẽ tạo biến môi trƣờng CouchDB để biên dịch GeoCouch
#export COUCH_SRC=/path/to/source/src/couchdb
Ở đây sẽ lấy ví dụ ở máy hiện tại thì câu lệnh đúng là:
#export COUCH_SRC=/usr/lib64/couchdb/erlang/lib/couch-1.1.1/include/
Sau đó ta chạy lệnh make
#make
Sau khi biên dịch xong thì ta sẽ tiến hành copy file cấu hình từ trong thƣ mục
geocouch sang thƣ mục cấu hình của couchdb
#cp etc/couchdb/local.d/geocouch.ini /etc/couchdb/local.d/
Để kiểm tra xem phần cài đặt đã thành công chƣa.Ta sẽ copy các file test vào futon:
#cp share/www/script/test/* /usr/local/share/couchdb/www/script/test/

31
Tạo file test và add nội dung
#vi /usr/local/share/couchdb/www/script/couch_tests.js
#loadTest("spatial.js");
loadTest("list_spatial.js");
loadTest("etags_spatial.js");
loadTest("multiple_spatial_rows.js");
loadTest("spatial_compaction.js");
loadTest("spatial_design_docs.js");
loadTest("spatial_bugfixes.js");
Việc cuối cùng để có thể tiến hành chạy GeoCouch là xuất biến chạy cho nó(lƣu
ý.nên xuất biến này cùng với khởi động hệ điều hành, không có biến này, CouchDB và
GeoCouch sẽ gặp lỗi)
#export ERL_FLAGS="-pa <geocouch>/build"
#export ERL_FLAGS="-pa /home/tuandung/KLTN/Data-KLTN/geocouch/build/"
3.5.3. Kết nối NodeJs và GeoCouch
Nhƣ đã nói ở chƣơng trƣớc.Để có thể kết nối đƣợc NodeJS với CouchDB thì ta phải
dùng một module có tên là Cradle.Tuy nhiên, mặc định cradle không hỗ trợ kiểu views
spatial.Ta phải dùng một nhánh khác của Cradle do thompson viết, có đầy đủ có chức
năng của module Cradle và ngoài ra có thêm việc hỗ trợ GeoCouch.
Địa chỉ download tại đây: https://github.com/dthompson/cradle và chọn nhánh thứ 2.
#git clone https://github.com/dthompson/cradle.git
#cd cradle
#git checkout add_spatial_support
Mặc định trong thƣ mục down về chỉ có code mà chƣa có các module đi kèm.Để tải
dùng lệnh sau
#npm install -d
3.5.4. Sử dụng GeoCouch
Trƣớc tiên ta sẽ tạo cơ sở dữ liệu

32
#curl -X PUT http://127.0.0.1:5984/geocouch
Tiếp theo là nhập dữ liệu.ví dụ về dữ liệu tại địa chỉ:
https://github.com/dthompson/example_geocouch_data
Tải thƣ mục về và chạy file import.js dữ liệu.
Vậy là ta đã có cơ sở dữ liệu và dữ liệu để test.Bây giờ là tạo một design
document.Có hai cách để tạo.Một là tạo trực tiếp, cách hai là tạo bằng futon.
Cách một
Sau khi chạy xong thì ta sẽ tạo ra 1 request để kiểm tra.
#curl -X PUT -d '{"spatial":{"points":"function(doc) {\n if (doc.loc) {\n
emit({\n type: \"Point\", \n coordinates: [doc.loc[0], doc.loc[1]]\n
}, [doc._id, doc.loc]);\n }};"}}'
http://127.0.0.1:5984/geocouch/_design/main
Khá dài dòng và không thân thiện, nhƣng chỉ với một câu lệnh thì ta đã thành công
trong một bƣớc tạo design.Trong câu lệnh này ta đã add cả hàm map vào trực tiếp vào câu
lệnh.Mặc định spatial view không có hỗ trợ hàm reduce, chỉ có hàm map
Cách hai
Dùng couchapp.Ta tạo thêm thƣ mục spatial.Trong thƣ mục đó tạo 1 file tên là
point.js.Ở đây tên file chính là design document.Và nội dung trong file đó chính là hàm
map tƣơng ứng với câu lệnh ở cách 1.Cuối cùng là ta chỉ cần push lên là xong.
#couchapp push geocouch
Ta có thể thấy, dùng cách hai đơn giản hơn nhiều cách 1.
Cuối cùng là ta sẽ tạo ra một request để truy vấn.
#curl -X GET 'http://localhost:5984/geocouch/_design/main/_spatial/points?bbox=0,
0, 180, 90'

33
Chƣơng 4 ỨNG DỤNG MAPCHAT
Trong chƣơng này tôi sẽ làm một ứng dụng cho phép ngƣời dùng tƣơng tác với nhau
bằng các đoạn chat thời gian thực trong khi vẫn gắn vị trí hiện thời của họ trên bản
đồ.Ứng dụng đó có tên là mapchat.Cách vận hành và bản chất của chƣơng trình này giống
với trang www.mapchat.im .Ứng dụng sẽ sử dụng Google Maps để hiển thị bản đồ và
đánh dấu vị trí ngƣời dùng.NodeJS chạy các ứng dụng thời gian thực hoặc theo sự kiện rất
tốt,trong khi CouchDB thì có nhiệm vụ lƣu lịch sử các đoạn chat.
4.1. ExpressJS
ExpressJs là một framework trong NodeJS với việc hỗ trợ khá nhiều tiện ích cho
nodeJS
Lệnh cài đặt :
#npm install express
Để khởi tạo một http server với ExpressJS ta chỉ cần thêm vài dòng code sau :
var express = require('express') ;
var app = express.createServer();
app.get('/', routes.index);
app.listen(3000);
Đoạn mã trên nói nói rằng khi vào trang chủ (tức /) thì sẽ chuyển đến file index.js và
đƣợc lắng nghe trên cổng 3000.
Việc tiếp theo là ta sẽ cấu hình server để chuẩn bị cho chƣơng trình.Ta sẽ đặt cho
views,tức các file để dành cho việc hiển thị đƣợc đặt trong thƣ mục /views với kiểu file là
ejs.Các file trình bày CSS đƣợc dùng theo định dạng stylus, tức là có thể dùng đƣợc theo
2 dạng abc.stylus hoặc abc.css.Và cuối cùng là các file static,các file chứa js tĩnh đƣa về
phía trình duyệt, các file ảnh hay file css sẽ đƣợc lƣu trong thƣ mục /public.Dƣới đây là
đoạn mã thực hiện :
app.configure(function(){
app.set('views', __dirname + '/views');
app.set('view engine', 'ejs');

34
app.use(express.bodyParser());
app.use(express.methodOverride());
app.use(require('stylus').middleware({
src: __dirname + '/public'
}));
app.use(app.router);
app.use(express.static(__dirname + '/public'));
});
4.2. SocketIO
Socket.io là một module trong NodeJS.Nó cung cấp một tập các thƣ viện (API) cho
các ứng dụng để điểu kiển các thông điệp giữa client và server.Nó tự động sử dụng kiểu
kết nối tốt nhất có thể đƣợc để liên lạc giữa client và server.Các kết nối đó bao gồm
websockets, flash proxy,XHR-long và một vài cách kết nối khác.Nó cũng bao gồm các
thƣ việc con khác với chức năng phụ trợ cho nó ví dụ nhƣ now.js để đồng bộ thời gian
giữa client và server.Socket.io tự nó tạo ra các chuẩn dữ liệu để chuyển qua lại dữ liệu
giữa nhiều ngôn ngữ khác nhau
Để cài đặt Socket.io ta có thể dùng trình quản lý gói của Nodejs - NPM :
#npm install socket.io
Để khai báo module và khởi tạo server thì đầu tiên server phải khởi động một sự
kiện lắng nghe đƣợc quản lý bởi socket.io thay vì http nhƣ thƣờng lệ
var io = require('socket.io);
var socket = io.listen(app);
Module socket.io hoạt động theo đúng mô hình socket client-server tức là việc giữa
2 bên tạo ra các sự kiện và tiến hành bắt sự kiện khi có hành động tƣơng ứng.Dƣới đây là
code ví dụ về phía server
socket.on('connection',function(client){
socket.send({message : "abc"});
});

35
4.3. Cài đặt project
4.3.1. Phần Chatting
Phía server có 2 sự kiện nhận:
register : Ngƣời dùng sẽ đăng kí tên đến server và server sẽ lƣu tên ngƣời
dùng.
message: Khi có thông điệp (message) từ client đến,server sẽ nhận thông
điệp,gán tên ngƣời dùng đã gửi và sau đó gửi lan truyền cho tất cả số ngƣời đang
chat đều nhận đƣợc thông điệp.
Đây là đoạn mã :
client.on('message',function(data){
//phan chatting
var username = 'noname';
console.log("User " + client.id + " send " + data);
client.get('username', function (err, name) {
console.log('Chat message by ', name);
console.log('error ', err);
username = name;
});
client.broadcast.emit('updateStatus',{
message : data,
user: username
});
});
//server nhan duoc ten nguoi dung vao chat
client.on('register',function(name){

36
client.set('username', name);
})
Phía client thì có một sự kiện:
Nếu server gửi dữ liệu broadcast về client thì nó sẽ updateStatus vào log chat
Chi tiết đoạn mã
function updateStatus(user,message){ var status = $('#status'); var result = '
' + user + ' : '+ message + '
'; status.append(result);
}
socket.on('updateStatus',function(data){updateStatus(data.user,data.message);})
4.3.2 Phần map
Ứng dụng của chúng ta dùng HTML5 để định vị vị trí ngƣời dùng.Mặc định khi vào
trang web thì client sẽ load toàn bộ phần bản đồ và thiết đặt vị trí ngƣời dùng.
Để tự động tải khi load trang ta thêm vào thẻ body nhƣ sau :
<body onload="loadMap();">
Ứng dụng của chúng ta sẽ định vị bằng GPS.Nếu trình duyệt hoăc thiết bị có hỗ trợ
dùng HTML5 để xác định vị trí ngƣời dùng thì sẽ trả về vị trí ngƣời dùng và sau đó tạo
marker vị trí ngƣời dùng đó.Chi tiết hàm loadMap:
function loadMap(){
//Neu trinh duyet ho tro dinh vi vi tri nguoi dung
if(navigator.geolocation) { navigator.geolocation.getCurrentPosition(getPosition);
}
//neu khong,tra ve vi tri mac dinh
else{
var myLatlng = new google.maps.LatLng(40.334, -103.644);
var yourOption = {

37
zoom : 8,
center : myLatlng,
mapTypeId : google.maps.MapTypeId.ROADMAP
};
map = new google.maps.Map(document.getElementById("map"),yourOption);
}
}
Hàm getPosition thực hiện việc sử lý sau khi đã nhận tham số truyền vào là tọa độ
điểm vị trí của ngƣời dùng :
function getPosition(position){
var lat = position.coords.latitude,
lng = position.coords.longitude;
var yourPoint = new google.maps.LatLng(lat, lng ),
yourOption = { zoom: 10,
center: yourPoint,
mapTypeId: google.maps.MapTypeId.ROADMAP };
//tao ban do mapPos = document.getElementById("map");
map = new google.maps.Map(mapPos,yourOption);
//danh dau vi tri cua ban
marker = new google.maps.Marker({ position: yourPoint, map: map,
title: "You are here" });
}
Sau khi xong thì ta bắt đầu chạy project :
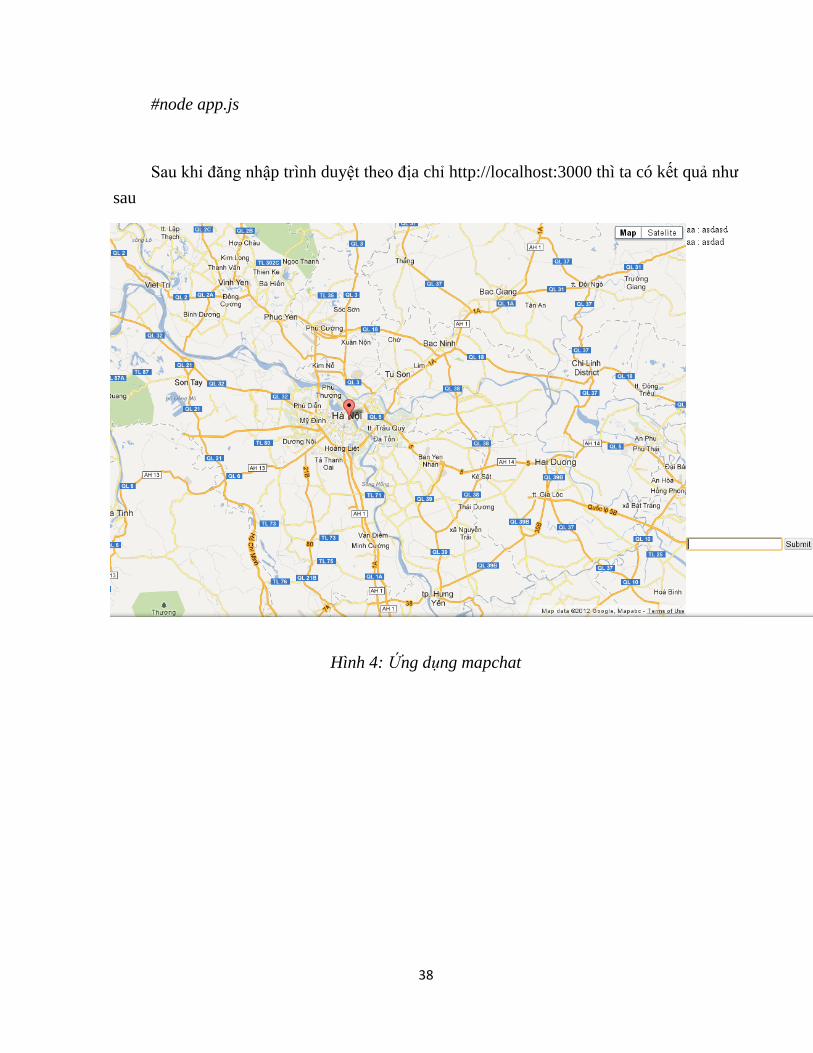
38
#node app.js
Sau khi đăng nhập trình duyệt theo địa chỉ http://localhost:3000 thì ta có kết quả nhƣ
sau
Hình 4: Ứng dụng mapchat

39
KẾT LUẬN
Kết quả đạt đƣợc của khóa luận
Khóa luận đã đƣa ra một cái nhìn tổng quát về xu hƣớng webserver, ngôn ngữ và cơ
sở dữ liệu trong tƣơng lai gần.Các bài benmark kết quả đã cho thấy đƣợc hiệu quả rõ ràng
so với các giải pháp cũ.Với webserver thì ta có thêm một cách tiếp cận mới so với giải
pháp hƣớng luồng cũ.Với cơ sở dữ liệu thì ta có một cách lƣu trữ và tổ chức dữ liệu mới
đạt hiệu quả cao mà không thông qua các câu truy vấn cũ.
Định hƣớng nghiên cứu tiếp theo
Hiện tại tôi mới tìm hiểu sơ qua về các khái niệm, đặc điểm của các giải pháp.Chƣa
đi sâu về nghiên cứu việc triển khai nó với các bài toán lớn, cụ thể.
Trong giai đoạn tiếp theo tôi sẽ nghiên cứu thêm các ứng dụng nữa của NodeJS đáp ứng
đƣợc tốt hơn các giải pháp cũ ngoài các ứng dụng thời gian thực nhƣ mapchat.Còn về
NoSQL sẽ nghiên cứu thêm các cơ sở dữ liệu khác nhƣ MongoDB hay Cassandra.Các hệ
NoSQL cách lƣu trữ khác theo cách lƣu trữ theo văn bản (document storage) nhƣ Key
value, column oriented nhƣ C-store.

40
TÀI LIỆU THAM KHẢO
NoSQL
● [1] http://www.pcworld.com.vn/articles/cong-nghe/cong-
nghe/2011/03/1222905/nosql-phan-tan-khong-rang-buoc/
● [2] http://en.wikipedia.org/wiki/MongoDB
● [3] http://www.10gen.com/what-is-mongodb
● [4] http://en.wikipedia.org/wiki/CouchDB
● [5] http://en.wikipedia.org/wiki/Cassandra
● [6] http://en.wikipedia.org/wiki/Membase
● [7] http://artur.ejsmont.org/blog/content/insert-performance-comparison-of-nosql-
vs-sql-servers
● [8] http://www.cubrid.org/blog/dev-platform/nosql-benchmarking
● [9] http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
CouchDB
● [10] http://newtech.about.com/od/databasemanagement/a/Nosql.htm
● [11] http://www.ibm.com/developerworks/opensource/library/os-
couchdb/index.html





























