Embed Size (px)
Citation preview

SVEUČILIŠTE U ZAGREBU
FAKULTET ELEKTROTEHNIKE I RA ČUNARSTVA
DIPLOMSKI RAD br. 1749
KRIPTOANALIZA JEDNOSTAVNIH KRIPTOGRAFSKIH ALGORITAMA UZ POMOĆ GENETSKOG ALGORITMA
Valent Cerovečki
Zagreb, rujan 2008.

Sažetak
U ovom se diplomskom radu ispituje primjena genetskih algoritama u
kriptoanalizi tekstova zaštićenih jednostavnim kriptografskim algoritmima. Na
početku teksta dan je kratak pregled kriptografskih i genetskih algoritama. U
praktičnom su dijelu izrañeni i ispitani programi za kriptoanalizu algoritma
supstitucije i Vigenérove šifre. Kod algoritma supstitucije pristup genetskim
algoritmima daje loše rezultate dok su kod Vigenérove šifre rezultati mnogo bolji.
Abstract
This thesis tests the usage of genetic algorithms in cryptanalysis of texts
encrypted with simple cryptographic algorithms. The text begins with a short
introduction into cryptographic and genetic algorithms. As a practical part of the
thesis two programs were built and tested. One for simple substitution algorithm
and one for Vigenére cipher. Use of genetic algorithms has shown very poor
results with substitution algorithm but much better ones with Vigenére cipher.

Sadržaj
1 Uvod .............................................................................................................. 1
2 Kriptografija i kriptoanaliza ............................................................................. 2
2.1 Osnovni pojmovi ...................................................................................... 2
2.2 Kriptografski algoritmi .............................................................................. 3
2.2.1 Algoritam supstitucije ........................................................................ 4
2.2.2 Vigenérova šifra ................................................................................ 5
2.2.3 Ostali simetrični kriptografski algoritmi .............................................. 7
2.3 Kriptoanaliza ............................................................................................ 8
3 Genetski algoritmi .......................................................................................... 9
3.1 Metode selekcije .................................................................................... 10
4 Praktični rad ................................................................................................. 12
4.1 Platforma ............................................................................................... 12
4.2 Općeniti opis rada programa .................................................................. 12
4.3 Odabir ispitnih datoteka i jezika ............................................................. 13
4.4 Funkcija dobrote i kazne ........................................................................ 14
4.5 Metode selekcije .................................................................................... 15
4.6 Metode križanja ..................................................................................... 15
4.6.1 Binarno križanje kod algoritma supstitucije ..................................... 15
4.6.2 Binarno križanje kod Vigenérove šifre ............................................. 16
4.6.3 Frekvencijsko križanje kod algoritma supstitucije ............................ 17
4.7 Mutacija ................................................................................................. 19
4.8 Programsko rješenje .............................................................................. 20
4.9 Rad programa za supstituciju ................................................................ 21
4.10 Rad programa za Vigenérovu šifru ..................................................... 33
5 Ispitivanje ..................................................................................................... 35
5.1 Ispitivanje programa za algoritam supstitucije ....................................... 35
5.2 Ispitivanje programa za Vigenérovu šifru ............................................... 39
5.3 Različitost rezultata ................................................................................ 42
6 Zaključak ...................................................................................................... 43
7 Literatura ...................................................................................................... 44

1
1 Uvod
Ljudi su oduvijek željeli zaštititi svoje osobne informacije, slike, pisma ili
nešto drugo, što nisu željeli da vide drugi ljudi bez njihovog odobrenja. Metode
zaštite bile su razne, ali sve su se svodile na jedan jednostavan princip. Ako je
netko želio ukrasti ili vidjeti informacije, morao je fizički doći do mjesta gdje su se
čuvale. Dakle, dovoljno je bilo zaštiti mjesto čuvanja, bila to neka škrinja ili
knjižnica.
Pojavom modernih tehnologija, postalo je moguće ukrasti informaciju bez
fizičkog pristupa mjestu čuvanja. Postalo je moguće kopirati informaciju, sliku ili
pismo, tako da se nikad ne primijeti da je ukradena, jer u biti i nije, još uvijek je
tamo. Polako su se počele razvijati sve maštovitije i naprednije metode zaštite,
te sve maštovitiji i napredniji načini probijanja tih zaštita, ali još uvijek vrijedi isti
princip. Tko ima ključ, bilo fizički ili virtualni, ima pristup podacima.
U šezdesetim godinama prošlog stoljeća pojavila se nova metoda u
računarstvu, genetski algoritmi, koji su se počeli koristiti u raznim sferama
računarskih znanosti. Pojavilo se nekoliko istraživača koji su pokušali
implementirati analizu kriptiranih tekstova pomoću genetskih algoritama. Jedan
od rijetkih radova na tu temu je magistarski rad Bethanya Delmana pod
naslovom "Genetski algoritmi u kriptografiji" [1] (eng. Genetic Algorithms in
Cryptography) koji se bavi pregledom prošlih radova u kriptoanalizi genetskim
algoritmima.
Ovaj rad će pokušati dati bolje rezultate od onih spomenutih u radu
Bethanya Delmana koristeći spoznaje i rezultate prijašnjih pokušaja.

2
2 Kriptografija i kriptoanaliza
2.1 Osnovni pojmovi
Pod pojmom kriptografije podrazumijeva se dio matematike i računalne
znanosti koja se bavi zaštitom informacija. Pod zaštitom informacije pretežno se
misli na zaštitu od neovlaštenog čitanja, ali se izraz takoñer može odnositi na
zaštitu informacije od gubitka, bilo zbog pogreške računalne opreme ili pogreške
korisnika.
Kriptoanaliza je kao i kriptografija dio matematike i računalne znanosti, koji
se bavi čitanjem kriptirane informacije bez podataka tipično potrebnih da bi se
pročitala.
Pod pojmom čisti ili izvorni tekst podrazumijeva se informacija, bilo u
elektroničkom obliku, na papiru ili bilo kojem drugom mediju, koja je razumljiva,
čitljiva, korištenjem odgovarajućih alata, na primjer štampana knjiga ili pdf
dokument čitljiv na računalu.
Kriptografski algoritam je slijed precizno opisanih koraka kojima se iz čistog
teksta dobiva kriptirani tekst ili obratno.
Ključ je ulazni parametar u kriptografski algoritam temeljem kojeg se čisti
tekst pretvara u kriptirani ili obrnuto, kriptirani tekst u čisti. Za različite ključeve iz
istog čistog teksta dobivamo različite kriptirane tekstove.
Kriptirani tekst je reprezentacija čistog teksta dobivena pomoću
kriptografskog algoritma, koja se više ne može pročitati bez poznavanja
odgovarajućeg ključa.
Enkripcija je proces dobivanja kriptiranog teksta iz čistog teksta, dok je
dekripcija obrnuti proces. Pojam enkripcija ne koristi se kao glagol (enkriptirati)
nego se u tu svrhu koristi glagol kriptirati.

3
Kriptirati se mogu bilo koji binarni podaci bez obzira na njihovo značenje.
Takoñer se mogu kriptirati bilo koji drugi podaci u odreñenoj reprezentaciji. Ovaj
će se rad baviti tekstovima prezentiranim znakovima neke abecede.
Da bi se znakovi abecede mogli promatrati u okvirima algoritma potrebno ih
je kodirati na primjereni način. U daljnjem tekstu pretpostavljat će se engleska
abeceda kodirana na način kako je to prikazano u tablici 2.1.
SLOVO A B C D E F G H I J K L M KOD 0 1 2 3 4 5 6 7 8 9 10 11 12 SLOVO O P R Q R S T U V W X Y Z KOD 13 14 15 16 17 18 19 20 21 22 23 24 25
Tablica 2.1 - Kodiranje znakova izvornog teksta
2.2 Kriptografski algoritmi
Kriptografski algoritmi se mogu grubo podijeliti u dvije kategorije, simetrične
i asimetrične. Simetrični koriste isti ključ za kriptiranje i dekriptiranje, dok
asimetrični koriste različite ključeve.
Asimetrični su algoritmi inherentno izuzetno sigurni jer se oslanjaju na teške
matematičke probleme, poput faktorizacije velikih brojeva ili izračunavanja
konačnih Galoisovih polja te je kriptografska analiza nad njima izuzetno težak
problem.
Simetrični su algoritmi jednostavniji za proučavanje. Može ih se podijeliti u
dvije grupe ovisno o vremenu primjene. Povijesni, koji su se primjenjivali prije
pojave računala, te sadašnji koji su se razvili zahvaljujući računalima koja mogu
izvršavati veliki broj matematičkih operacija u sekundi.
U ovom će se radu promatrati kriptoanaliza povijesnih simetričnih algoritama
kako bi se pokušali dati neki okvir i rezultati za buduće radove koji će
primjenjivati sličan pristup.

4
2.2.1 Algoritam supstitucije
Algoritam supstitucije [2] je jedan od najjednostavnijih kriptografskih
algoritama. Ključ je permutacija slova neke abecede. U našem slučaju engleske
abecede koja ima 26 znakova. Algoritmi enkripcije i dekripcije prikazani su na
slikama 2.1 te 2.2.
SupstitucijaE(ulazna datoteka, izlazna datoteka, kl ju č) { dok(ima znakova ulazne datoteke) { c = u čitaj znak(ulazna datoteka); //jedan od znakova abecede, bez interpunkc ija //razmaka i sli čno i = kodiraj znak c u broj; d = uzmi iz klju ča znak na poziciji i; //pretpostavljamo da prvi znak ima indeks 0 spremi znak u datoteku(izlazna datoteka, d); } }
Slika 2.1 - Algoritam enkripcije za supstituciju
SupstitucijaD(ulazna datoteka, izlazna datoteka, kl ju č) { dok(ima znakova ulazne datoteke) { c = u čitaj znak(ulazna datoteke); i = pozicija znaka c u klju ču; d = kodiraj broj i u znak; spremi znak u datoteku(izlazna datoteka, d); } }
Slika 2.2 - Algoritam dekripcije za supstituciju

5
Primjer : Potrebno je kriptirati tekst «TREATY IMPOSSIBLE» pomoću ključa
ADGKMPSVYBEHJBQTWZCFILORUX.
Prikaz ključa kao tablice zajedno s pozicijama slova dan je u tablici 2.2.
0 1 2 3 4 5 6 7 8 9 10 11 12 A D G K M P S V Y N E H J 13 14 15 16 17 18 19 20 21 22 23 24 25 B Q T W Z C F I L O R U X
Tablica 2.2 - Kodiranje slova u brojke
Korak 1 : kodirati izvorni tekst prema tablici 1.1
19 17 4 0 19 24 8 12 15 14 18 18 8 1 11 4
Korak 2 : kriptirati izvorni tekst tako da se za svaki kodirani znak izvorne poruke
iz koraka 1 uzme slovo uz taj broj u tablici 2.2.
Kriptirani tekst je: FZMAFU YJTQCCYDHM
2.2.2 Vigenérova šifra
Vigenérova šifra [3] je jednostavan primjer višeabecednog kriptografskog
algoritma. Višeabecednost znači da se za razliku od algoritma supstitucije ne
primjenjuje jedna abeceda nego više njih u postupku kriptiranja i dekriptiranja.
Ključ je niz znakova proizvoljne duljine.
Potrebno je definirati matematičku operaciju modulo: a mod b ili a % b,
čitamo a modulo b, označava ostatak pri cjelobrojnom dijeljenju broja a brojem
b.
Kod Vigenérove šifre znak kriptirane poruke ne ovisi samo o odgovarajućem
znaku izvorne poruke nego i o njegovoj poziciji u toj poruci. Algoritmi enkripcije i
dekripcije prikazani su na slikama 2.3 te 2.4.

6
VigenereE(ulazna datoteka, izlazna datoteka, klju č) { i = 0; dok(ima znakova ulazne datoteke) { c = u čitaj znak(ulazna datoteka); d = kodiraj znak c u broj; k = znak klju ča na lokaciji i; l = kodiraj znak k u broj; j = (d + l) mod 26; o = kodiraj broj j u znak; spremi znak u datoteku(izlazna datoteka, o); i = (i + 1) mod duljina klju ča; } }
Slika 2.3 - Algoritam enkripcije Vigenérove šifre
VigenereD(ulazna datoteka, izlazna datoteka, klju č) { i = 0; dok(ima znakova ulazne datoteke) { c = u čitaj znak(ulazna datoteka); d = kodiraj znak c u broj; k = znak klju ča na lokaciji i; l = kodiraj znak k u broj; j = (d – l + 26) mod 26; o = kodiraj broj j u znak; spremi znak u datoteku(izlazna datoteka, o); i = (i + 1) mod duljina klju ča; } }
Slika 2.4 - Algoritam dekripcije Vigenérove šifre
7
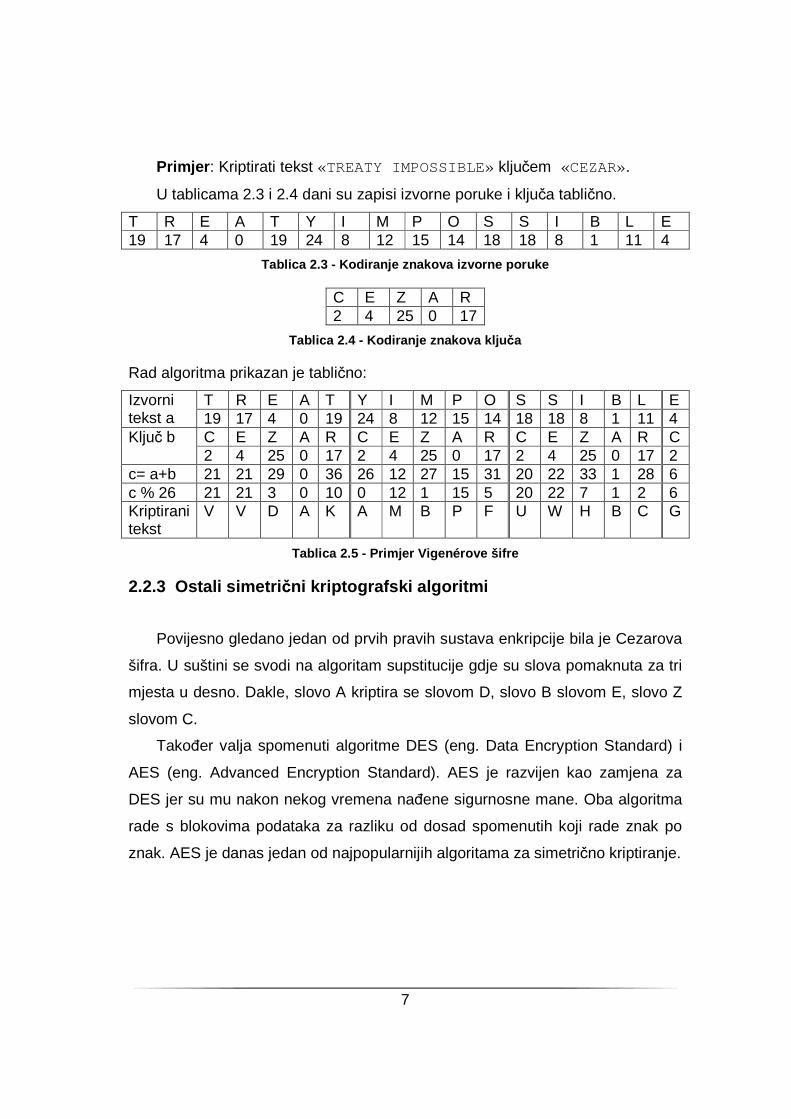
Primjer : Kriptirati tekst «TREATY IMPOSSIBLE» ključem «CEZAR».
U tablicama 2.3 i 2.4 dani su zapisi izvorne poruke i ključa tablično.
T R E A T Y I M P O S S I B L E 19 17 4 0 19 24 8 12 15 14 18 18 8 1 11 4
Tablica 2.3 - Kodiranje znakova izvorne poruke
C E Z A R 2 4 25 0 17
Tablica 2.4 - Kodiranje znakova klju ča
Rad algoritma prikazan je tablično:
Izvorni tekst a
T R E A T Y I M P O S S I B L E 19 17 4 0 19 24 8 12 15 14 18 18 8 1 11 4
Ključ b C E Z A R C E Z A R C E Z A R C 2 4 25 0 17 2 4 25 0 17 2 4 25 0 17 2
c= a+b 21 21 29 0 36 26 12 27 15 31 20 22 33 1 28 6 c % 26 21 21 3 0 10 0 12 1 15 5 20 22 7 1 2 6 Kriptirani tekst
V V D A K A M B P F U W H B C G
Tablica 2.5 - Primjer Vigenérove šifre
2.2.3 Ostali simetri čni kriptografski algoritmi
Povijesno gledano jedan od prvih pravih sustava enkripcije bila je Cezarova
šifra. U suštini se svodi na algoritam supstitucije gdje su slova pomaknuta za tri
mjesta u desno. Dakle, slovo A kriptira se slovom D, slovo B slovom E, slovo Z
slovom C.
Takoñer valja spomenuti algoritme DES (eng. Data Encryption Standard) i
AES (eng. Advanced Encryption Standard). AES je razvijen kao zamjena za
DES jer su mu nakon nekog vremena nañene sigurnosne mane. Oba algoritma
rade s blokovima podataka za razliku od dosad spomenutih koji rade znak po
znak. AES je danas jedan od najpopularnijih algoritama za simetrično kriptiranje.

8
2.3 Kriptoanaliza
Kriptoanaliza je proces dobivanja izvornog teksta poruke bez poznavanja
ključa potrebnog za dekriptiranje. U širem smislu kriptoanaliza je takoñer i
proces kojim se pokušava otkriti nepoznati ključ ili algoritam.
Najstariji poznati tekst vezan uz kriptoanalizu je „Udžbenik za dešifriranje
kriptiranih poruka“ Abu Yusuf Yaqub ibn Ishaq al-Sabbah Al-Kindia [4], arapskog
učenjaka iz devetog stoljeća. U tekstu je objašnjena frekvencijska analiza koja je
do danas ostala najjači alat za kriptoanalizu većine klasičnih kriptografskih
algoritama.
Frekvencijska analiza je usporedba frekvencija pojavljivanja odreñenih slova
u kriptiranom tekstu, te zamjena tih slova sa slovima koja imaju sličnu
frekvenciju u dotičnom jeziku. Takoñer umjesto slova mogu biti promatrani i
digrami (parovi slova) te trigrami (tri povezana slova). Frekvencijska je analiza
vrlo učinkovita za napade na jednoabecedne kriptografske algoritme jer oni ne
sakrivaju frekvencije pojavljivanja slova, digrama i trigrama..
Uobičajeno se proces kriptoanalize dijeli prema informacijama koje su
dostupne analitičaru:
• samo kriptirani tekst • algoritam i kriptirani tekst • originalni i kriptirani tekst • kriptirani tekst i ključ
Kompleksnost kriptoanalize dijeli se prema zauzeću memorije, vremenu
potrebnom za analizu i količini potrebnog teksta.

9
3 Genetski algoritmi
Genetski algoritam∗ [5] je heuristička (iskustvena) metoda optimiranja koja
imitira prirodni evolucijski proces, točnije modeliraju se neki osnovni evolucijski
procesi poput selekcije, križanja i mutacije nad računalnim podacima u svrhu
dobivanja optimalnog rješenja nekog problema.
O čemu se točno radi najlakše je opisati primjerom. Neka se u zadatku traži
maksimum funkcije f(x) u nekom intervalu. Nasumično se stvori n rješenja
(brojeva) iz tog intervala. Broj n naziva se veličinom populacije.
Takoñer je potrebno definirati takozvanu funkciju dobrote. Funkcija dobrote
ima veću vrijednost čim je neko rješenje bliže optimalnom. U primjeru s
traženjem maksimuma funkcije, funkcija dobrote bi mogla biti funkcijska
vrijednost neke točke podijeljena s najvećom funkcijskom vrijednošću unutar
populacije. Time će funkcija dobrote biti normirana.
Zatim se sve dok nije zadovoljen uvjet zaustavljanja radi sljedeće:
• Iz populacije se nasumično odabere nekoliko jedinki,
• jedinke se izkrižaju da se dobiju nove jedinke,
• nad nastalim jedinkama (djecom) primijeni se operator mutacije,
• djeca se pospreme natrag u populaciju umjesto nekih od odabranih
jedinki
Križanje jedinki je proces kombiniranja značajki jedinki roditelja, kako bi se
dobile nove jedinke, djeca, sa sličnim ali potencijalno boljim svojstvima. U
gornjem primjeru rezultat križanja dvije jedinke bi mogla biti njihova aritmetička
sredina.
Mutacija je proces izmjene neke značajke jedinke s odreñenom
vjerojatnošću. U danom primjeru mutacija jedinke mogla bi biti nasumična
promjena jedne znamenke.
∗ Terminologija, primjeri te opisi raznih postupaka u ovom poglavlju su većinom iz [5]

10
Uvjet zaustavljanja može biti odreñeni broj ponavljanja koraka genetskog
algoritma, postizanje odreñenog rješenja za koje se smatra da je dovoljno
dobro, konvergencija populacije ili neki drugi uvjet.
Ovaj pregled daje najosnovnije principe iza genetskih algoritama. U
nastavku ovog poglavlja biti će opisane različite metode selekcije. Metode
križanja i mutacije će biti objašnjene u dijelu o praktičnom radu zbog njihove
ovisnosti o prezentaciji podataka u računalu.
3.1 Metode selekcije
Postoje dvije osnovne metode selekcije, turnirska i jednostavna (eng.
roulette wheel) selekcija. Turnirska ne pravi razliku izmeñu jedinki u procesu
odabira, dok jednostavna daje prednost jedinkama s većom dobrotom.
Kod turnirske selekcije se nasumično odabere odreñeni broj jedinki, dok se
kod jednostavne selekcije zbroje vrijednosti funkcije dobrote svih jedinki, te se
zatim nasumično generira broj s vrijednošću izmeñu nule i dobivene sume.
Zatim se dobrote ponovno zbrajaju te se odabire prva jedinka pribrajanjem čije
dobrote se dobiva broj veći ili jednak nasumično generiranom broju.
Primjer : Potrebno je iz populacije od 10 jedinki odabrati jednu jedinku
jednostavnom selekcijom.
Prvi korak je zbrajanje svih vrijednosti dobrota jedinki populacije.
Slika 3.1 - Zbrajanje dobrota kod jednostavne selek cije
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10
D=Σd

11
Zatim se stvara nasumična vrijednost u intervalu [0,D]. Kad se ta
vrijednost preslika na pravac na slici 3.1, odabrana je neka od 10 jedinki.
Jedinka s najvećom dobrotom čini najveći dio pravca te je vjerojatnost da će ona
biti odabrana najveća.
Kod obje metode se pojavljuje problem višestruke selekcije iste jedinke. Ako
se to dogodi može se proces selekcije ponavljati dok se ne dobiju različite
jedinke ili se može raditi s dupliciranim jedinkama.
Nakon što je odabran odreñeni broj jedinki potrebno je odrediti koje će biti
roditelji, a koje će se izbaciti iz populacije da se na njihovo mjesto spreme
novonastala djeca. Dvije osnovne mogućnosti su nasumičan odabir ili elitizam.
Elitizam znači da će jedinka ili jedinke s najvećom dobrotom biti roditelji i
neće biti izbačene iz populacije.
Takoñer postoji drugačiji pristup prisutan u eliminacijskoj selekciji. U gore
opisanim metodama selekcije odabiru se jedinke koje će postati roditelji, dok se
kod eliminacijske problem promatra s druge strane i odabiru se jedinke koje će
se izbaciti iz populacije. Zbog toga se kod eliminacijske selekcije ne radi s
funkcijom dobrote, nego s funkcijom kazne koja ima veću vrijednost što je
jedinka lošija. Osim tih razlika proces odabira jednak je turnirskoj selekciji.
Sam proces selekcije bitno utječe na brzinu i kvalitetu algoritma. Takoñer se
može primijeniti neka kombinacija navedenih pristupa.

12
4 Prakti čni rad
U praktičnom dijelu rada promatrana je uporaba genetskih algoritama u
procesu kriptoanalize tekstova kriptiranih algoritmom supstitucije i Vigenérovom
šifrom. Nakon početne analize problema slijedio je odabir metoda selekcije,
križanja, mutacije te na kraju implementacija rješenja i ispitivanje.
Za svaki od algoritama razvijen je zasebni program, meñutim oni dijele
mnoge značajke koje će biti zajedno objašnjene.
4.1 Platforma
Za platformu je odabran jezik C# te je korišten Microsoft .NET Framework
3.5. Jezik C# je odabran izmeñu ostalih jezika zbog jednostavnosti rada sa
nizovima znakova te izrade grafičkog sučelja. Odabirom C#-a izgubilo se na
brzini, ali budući da cilj ovog rada nije bio izrada alata za ozbiljnu upotrebu nego
istraživanje ideje, prednosti su veće od gubitka.
Takoñer glavni čimbenik koji utječe na vrijeme izvršavanja programa je
čitanje datoteka s diska te odabrani jezik tu nema utjecaja.
4.2 Općeniti opis rada programa
Nakon pokretanja programa automatski se generira ključ algoritma. Zatim
se odabire datoteka na kojoj će se ispitivati algoritam. Takoñer se odabire
metoda selekcije, metoda križanja, veličina populacije, broj generacija i
vjerojatnost mutacije, nakon čega se može pokrenuti rad programa.
Prvo se početna datoteka kriptira ključem radi kasnije frekvencijske analize i
usporedbe točnosti. Nakon kriptiranja datoteke stvara se populacija ključeva, te

13
se za svaki od njih izračunava dobrota ili kazna ovisno o odabranoj metodi
selekcije.
Nakon stvaranja populacije pokreće se rad genetskog algoritma. Radi se
selekcija, stvaraju se nove jedinke koje mutiraju (s nekom vjerojatnošću) te se
novim jedinkama izračunava dobrota ili kazna i umeću se u populaciju. Genetski
algoritam radi sve dok se ne izvrši zadani broj generacija.
Kada je izvršen zadani broj generacija, iz populacije se vadi jedinka s
najvećom dobrotom ili najmanjom kaznom, te se njome dekriptira tekst i
izračunava točnost dekripcije, gdje je točnost definirana kao postotna vrijednost
ispravno dekriptiranih znakova naspram ukupnog broja znakova teksta.
4.3 Odabir ispitnih datoteka i jezika
Za odreñivanje vrijednosti dobrote pojedine jedinke koriste se principi iz
frekvencijske analize, dakle potrebno je odabrati dovoljno velike datoteke da
frekvencije pojavljivanja znakova budu približno jednake onima iz literature.
Radi dostupnosti slobodnih tekstova u elektroničkom obliku, podataka za
frekvencije pojavljivanja znakova te pojednostavljenja implementacije odabran je
engleski jezik.
Za ispitne tekstove odabrani su Biblija te roman "David Copperfield"
Charlesa Dickensa. Oba teksta preuzeta su sa stranica projekta Gutemberg [6]
koji se bavi digitalizacijom i stavljanjem na korištenje slobodnih tekstova te
tekstova nad kojima više nije primjenjiva zaštita autorskih prava.
Radi postizanja čim veće sličnosti tabličnih frekvencija pojavljivanja slova s
pojavljivanjem slova u tekstu, razmatrani su i ogromni tekstovi, poput sabranih
djela Williama Shakespearea, ali mjerenjem frekvencija utvrñeno je da niti
približno ne odgovaraju tabličnim, a zbog veličine teksta rad programa bi se
previše usporio.
14
4.4 Funkcija dobrote i kazne
Funkcije dobrote i kazne definirane su na sljedeći način:
( ) ( )Z
izmtabk A
Kazna f k f k=
= −∑ (4.1)
1 , 10,
Kazna KaznaDobrota
inače
− ≤=
(4.2)
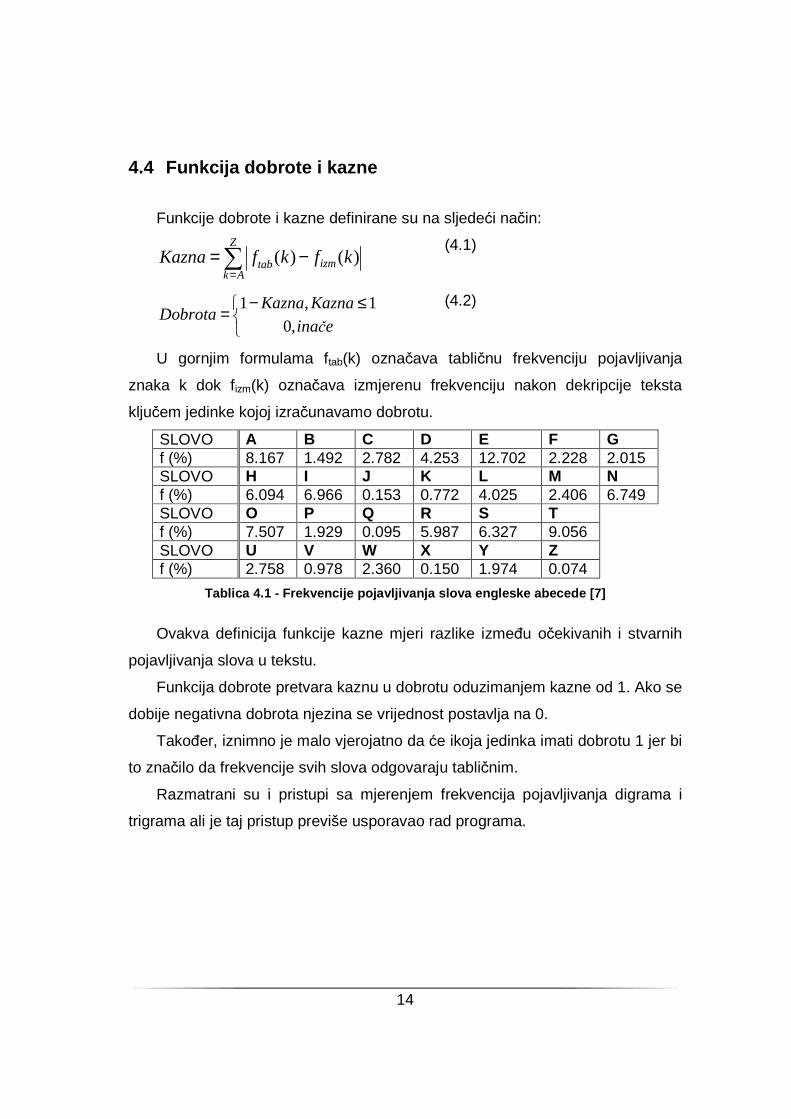
U gornjim formulama ftab(k) označava tabličnu frekvenciju pojavljivanja
znaka k dok fizm(k) označava izmjerenu frekvenciju nakon dekripcije teksta
ključem jedinke kojoj izračunavamo dobrotu.
SLOVO A B C D E F G f (%) 8.167 1.492 2.782 4.253 12.702 2.228 2.015 SLOVO H I J K L M N f (%) 6.094 6.966 0.153 0.772 4.025 2.406 6.749 SLOVO O P Q R S T f (%) 7.507 1.929 0.095 5.987 6.327 9.056 SLOVO U V W X Y Z f (%) 2.758 0.978 2.360 0.150 1.974 0.074
Tablica 4.1 - Frekvencije pojavljivanja slova engle ske abecede [7]
Ovakva definicija funkcije kazne mjeri razlike izmeñu očekivanih i stvarnih
pojavljivanja slova u tekstu.
Funkcija dobrote pretvara kaznu u dobrotu oduzimanjem kazne od 1. Ako se
dobije negativna dobrota njezina se vrijednost postavlja na 0.
Takoñer, iznimno je malo vjerojatno da će ikoja jedinka imati dobrotu 1 jer bi
to značilo da frekvencije svih slova odgovaraju tabličnim.
Razmatrani su i pristupi sa mjerenjem frekvencija pojavljivanja digrama i
trigrama ali je taj pristup previše usporavao rad programa.

15
4.5 Metode selekcije
Korištene su tri metode selekcije: turnirska, jednostavna i eliminacijska
selekcija. Sve tri su elitističke te paze da se ista jedinka ne odabere više puta.
Kod turnirske se selekcije odabiru četiri jedinke od kojih dvije najbolje
postaju roditelji, a dvije lošije postaju djeca.
Kod jednostavne selekcije prvo se metodom jednostavne selekcije odaberu
dvije jedinke koje postaju roditelji, zatim se pretraži populacije te dvije najlošije
jedinke u populaciji postaju djeca. Najlošije jedinke populacije izbacuju se iz
populacije jer ako neka jedinka ima izuzetno nisku dobrotu, to znači da su skoro
sva slova ključa pogrešno smještena te će križanjem i njihova djeca biti izuzetno
loša.
Kod eliminacijske selekcije se nasumično odaberu četiri jedinke, od kojih
dvije s najvećom funkcijom kazne postaju djeca, a druge dvije roditelji.
4.6 Metode križanja
Korištene su dvije metode križanja, binarno i frekvencijsko [1]. Binarno se
koristi kod algoritma supstitucije i Vigenérove šifre dok se frekvencijsko koristi
samo kod algoritma supstitucije. Takoñer, binarno križanje se razlikuje u nekim
detaljima kod supstitucije i Vigenérove šifre.
4.6.1 Binarno križanje kod algoritma supstitucije
Prvo se generira nasumičan niz nula i jedinica dužine 26 znakova (dužina
ključa kod algoritma supstitucije). Budući da se stvaraju dva nova djeteta proces
križanja je sljedeći.
• Ako je kod nasumičnog niza na nekom mjestu jedinica, u prvo se
dijete na to mjesto doda slovo prvog roditelja na tom mjestu.
• Ako je kod nasumičnog niza na nekom mjestu nula, u drugo dijete se
na to mjesto doda slovo drugog roditelja na tom mjestu.

16
• Za svako neispunjeno mjesto prvog djeteta u njega se redom dodaju
znakovi iz drugog roditelja pazeći da se znakovi ne ponavljaju.
• Za svako neispunjeno mjesto drugog djeteta u njega se redom
dodaju znakovi iz prvog roditelja pazeći da se znakovi ne ponavljaju.
Primjer : Dana je abeceda od 6 znakova, ABCDEF, dva roditelja, BCDEFA i
DBFCAE, te nasumičan niz nula i jedinica duljine abecede, 100111.
Masno otisnutim slovima u tablici 4.2 označeni su znakovi djeteta dodani u
prva dva koraka algoritma, a kosim slovima znakovi dodani u trećem i četvrtom
koraku.
1. roditelj B C D E F A
2. roditelj D B F C A E
Binarni niz 1 0 0 1 1 1
1. dijete B D C E F A
2. dijete C B F D E A
Tablica 4.2 - Binarno križanje kod algoritma supsti tucije
4.6.2 Binarno križanje kod Vigenérove šifre
Generira se nasumičan niz nula i jedinica dužine ključa. Nakon toga se za
svaku jedinicu u nasumičnom nizu u prvo dijete prekopira znak na tom mjestu iz
prvog roditelja, a za nulu iz drugog roditelja. U drugo se dijete za nulu upisuje
znak na tom mjestu iz prvog roditelja, a za jedinicu iz drugog roditelja.
Budući da se kod Vigenérove šifre znakovi u ključu mogu ponavljati na to
nije potrebno obraćati pažnju.
Primjer : Dana su dva roditelja, KGRIFJ te GKDPRM, te binarni niz 101011.
U tablici 4.3 prikazan je proces križanja. Masnim slovima označena su slova
djeteta nastala iz prvog roditelja a kosim slovima slova djeteta nastala iz drugog
roditelja.

17
1. roditelj K G R I F J
2. roditelj G K D P P M
Binarni niz 1 0 1 0 1 1
1. dijete K K R P F J
2. dijete G G D I P M
Tablica 4.3 - Binarno križanje kod Vigenérove šifre
4.6.3 Frekvencijsko križanje kod algoritma supstitu cije
Frekvencijsko križanje za jedno dijete provodi se na sljedeći način:
• Stvori se lista neiskorištenih slova u kojoj su na početku sva slova
abecede.
• Za svako slovo abecede a:
o Izračuna se očekivano pojavljivanje slova a.
o Za svaki od roditelja izmjeri se pojavljivanje slova a nakon
dekriptiranja teksta ključem tog roditelja.
o Usporede se dobivena pojavljivanja znaka a, te se odabire znak b,
kojim se kriptira znak a, iz onog roditelja čije izmjereno
pojavljivanje bolje odgovara očekivanom.
o Ako se znak b već nalazi u djetetu prelazi se na sljedeće slovo
abecede, a trenutno mjesto u djetetu ostavlja se praznim.
o Ako se znak b ne nalazi u djetetu stavlja ga se na odgovarajuću
poziciju (poziciju na kojoj će se znak a kriptirati znakom b).
• Za svaku praznu poziciju u djetetu izračuna se očekivanje znaka a na
toj poziciji.
• Za svaki znak c iz liste neiskorištenih znakova izmjeri se dobiveno
pojavljivanje znaka a u slučaju da je kriptiran znakom c.
• Znak c čije pojavljivanje najbolje odgovara očekivanom pojavljivanju
stavlja se u dijete na mjesto trenutno promatrane praznine te se miče
iz liste neiskorištenih znakova.

18
Razlika izmeñu stvaranja djeteta je u smjeru provjeravanja. Kod stvaranja
prvog djeteta radi se od početka prema kraju abecede dok se kod drugog
provjerava od kraja prema početku abecede.
Primjer : U tablici 4.4 su dana očekivana pojavljivanja svih slova neke
šesteroslovne abecede te izmjerena pojavljivanja slova u nekom kriptiranom
tekstu od 100 znakova. Takoñer su zadana dva ključa roditelja, BCDAEF i
FABCDE.
A B C D E F
Očekivana pojavljivanja 22 10 25 3 34 6
Izmjerena pojavljivanja 9 25 30 6 20 10
Tablica 4.4 - Pojavljivanja znakova
Prvo dijete dobiva se obilaskom abecede s lijeva na desno, znači od znaka
A prema znaku F. Na početku je lista neiskorištenih slova ABCDEF, te je dijete
xxxxxx gdje x označava za sad nepoznati znak.
Očekivanje znaka A u nekriptiranom tekstu je 22%, dakle u zadanom se
tekstu od 100 znakova mora pojaviti 22 puta. Kod prvog roditelja se znak A
kriptira znakom B čije je pojavljivanje 25 puta. Kod drugog se roditelja znak A
kriptira znakom F čije je pojavljivanje 10. Slovo B bolje odgovara nego slovo F
(|25-22|<|25-10|) dakle na prvo mjesto stavlja se znak B te dijete postaje Bxxxxx
a lista neiskorištenih slova je ACDEF.
Sljedeći znak abecede je B čije je očekivano pojavljivanje 10 puta. Prvi
roditelj kriptira znak B znakom C čije je pojavljivanje 30 puta, a drugi roditelj
znakom A čije je pojavljivanje 9 puta. Dakle na drugo mjesto djeteta stavlja se
znak A čije pojavljivanje bolje odgovara te dijete postaje BAxxxx, a lista
neiskorištenih slova CDEF.
Znak C se očekuje 25 puta. Kod prvog se roditelja kriptira znakom D čije je
pojavljivanje 6, a kod drugog znakom B čije je pojavljivanje 25 puta. Znak B

19
bolje odgovara, ali se više ne nalazi u listi neiskorištenih znakova te se na tom
mjestu ključa ostavlja nepoznanica i prelazi se na sljedeći znak.
Nakon još tri koraka potrebnih da se proñe cijela abeceda dijete ima sljedeći
izgled: BAxxEF. U listi neiskorištenih slova su još C i D.
Na treće mjesto djeteta ide znak čije pojavljivanje bolje odgovara
pojavljivanju slova C. Slovo C ima očekivanje od 25 puta. U kriptiranom tekstu
slovo C se pojavilo 30 puta, a slovo D šest puta. Dakle bolje odgovara da se
znak C kriptira znakom C te dijete postaje: BACxEF, a u listi neiskorištenih slova
je još samo slovo D te ga se umetne na jedino preostalo mjesto. Konačni izgled
djeteta je BACDEF.
Drugo dijete dobiva se identičnim postupkom samo s kraja abecede prema
početku: CDBAEF.
4.7 Mutacija
Mutacija je iznimno jednostavna kod oba algoritma. S obzirom na
vjerojatnost mutacije zamijene se dva znaka ključa na nasumičnim pozicijama.
Ovo je jedina moguća mutacija kod algoritama supstitucije. Kod Vigenérove šifre
moguće je još nasumični znak ključa promijeniti u neki drugi, ali s obzirom na
kvalitetu rezultata nema potrebe za mijenjanjem.
Mutacija(klju č, vjerojatnost) { p = nasumi čan broj izme ñu 0 i 1; ako je (p < vjerojatnost) { a = nasumi čan broj(0, duljina klju ča -1); b = nasumi čan broj(0, duljina klju ča -1) razli čit od a; zamijeni(kljuc[a], kljuc[b]); } }
Slika 4.1 - Algoritam mutacije

20
4.8 Programsko rješenje
Slika 4.2- Izgled programa za algoritam supstitucij e
Na slici 4.2 prikazan je izgled programa za algoritam supstitucije. Program
za Vigenérovu šifru se razlikuje od programa za supstituciju u polju za odabir
ključa, gdje se kod Vigenérove šifre može odabrati i dužina ključa, te u
metodama križanja gdje Vigenérova šifra ima samo binarno križanje.
U programu se može zadati više konfiguracija testova koji će biti slijedno
izvršeni. Konfiguracija testa sastoji se od broja generacija, veličine populacije,
iznosa mutacije, metode selekcije te metoda križanja. Nakon što je neki test
izvršen, u tablicu će se uz taj test dodati duljina trajanja te dobrota i točnost

21
najbolje jedinke populacije. U slučaju eliminacijske selekcije polje točnost će
odgovarati kazni.
Program takoñer pruža mogućnost spremanja svih rezultata testova,
nakon što su izvršeni, u csv formatu koji se može obrañivati bilo kojim tabličnim
kalkulatorom.
4.9 Rad programa za supstituciju
Rad programa će biti prikazan na programu za supstituciju te će kasnije biti
spomenute razlike kod programa za Vigenérovu šifru.
Program se sastoji od dvije klase, supstitucija i driver. Objekt tipa
supstitucija je zadužen za grafičko sučelje, stvaranje početne kriptirane datoteke
te pozivanje objekta tipa driver kao posebne dretve sa svim podacima potrebnim
za rad genetskog algoritma. Nakon završetka rada objekt tipa driver vraća
rezultate trenutne konfiguracije testa objektu supstitucija koji ih upisuje u tablicu.
Supstitucija() { stvori klju č; u čitavaj konfiguracije dok nije pritisnut gumb start; kriptiraj odabranu datoteku klju čem; za svaku konfiguraciju { stvori dretvu klase driver(parametri testa); pokreni dretvu; čekaj rezultate; unesi rezultate u tablicu; } }
Slika 4.3 - Osnovni rad programa za supstituciju
Slijedi prikaz važnijih metoda klase supstitucija. Neće biti prikazane sve
metode poput onih za rad s grafičkim sučeljem te neke pomoćne metode koje
nisu bitne za objašnjenje rada programa.

22
private char encryptedChar( Char in_a, String key)
Metoda kriptira slovo in_a ključem key te vraća rezultat.
Slika 4.4 – Isje čak iz koda metode encryptedChar
private void createEncryptedFile()
Metoda koja kriptira odabranu datoteku pomoću trenutnog ključa. Datoteka
služi za kasniju analizu frekvencija i točnosti. Metoda takoñer mjeri
pojavljivanje svih slova u kriptiranoj datoteci. Pojavljivanje slova služi kod
odreñivanja dobrote pojedine jedinke jer kod algoritma supstitucije koji je
jednoabecedni nema potrebe za naknadnim pregledavanjem kriptirane
datoteke u svrhu odreñivanja pojavljivanja slova.
Slika 4.5 – Isje čak iz koda metode createEncryptedFile
Char a = Char .ToUpper(in_a); if (a >= 'A' && a<= 'Z' ) return key[( int )a - ( int )( 'A' )]; else return a;
do { ucitano = reader.Read(buffer, 0, 1024); for ( int i = 0; i < ucitano; i++) { buffer[i] = encryptedChar(buffer[i], KeyLabel.T ext); if (buffer[i] >= 'A' && buffer[i] <= 'Z' ) sifriranaPojavljivanja[( int )buffer[i] - ( int ) 'A' ]++; } writer.Write(buffer, 0, ucitano); } while (ucitano == 1024);

23
private String KeyGenerator()
Metoda se pokreće prvi put prilikom pokretanja programa te stvara
nasumični ključ. Takoñer se pokreće svaki put prilikom pritiska gumba
Ključ.
Slika 4.6 – Isje čak iz koda metode KeyGenerator()
private void Start_Click( object sender, EventArgs e)
Za svaku testnu konfiguraciju metoda stvara dretvu tipa driver te joj
predaje sve parametre potrebne za rad genetskog algoritma. Takoñer joj
predaje ključ, referencu na pokazivač napretka „Trenutni napredak“ i ime
kriptirane datoteke. Pokreće mjerač vremena te zatim rad dretve. Nakon
završetka prihvaća dobrotu te točnost jedinke s najboljom dobrotom,
zaustavlja mjerač vremena i zapisuje primljene podatke u tablicu uz
konfiguraciju trenutnog testa.
List <Char > key = new List <Char >(); List <Char > slova = new String ( "ABCDEFGHIJKLMNOPRSTUVZXYWQ"). ToCharArray().ToL ist< Char >(); int n; while (key.Count < 26) { n = randomizer.Next(slova.Count - 1); key.Add(slova[n]); slova.Remove(slova[n]); } return new String (key.ToArray());

24
Važnije metode klase driver:
public Driver( int genNum, int opNum, float mutNum, int mSelekcije, int
mKrizanja, int ukupnoSlova, String key, List <int >
sifriranjaPojavljivanja, String fileName, ProgressBar currentProgress)
Konstruktor klase driver. Prima sve ulazne parametre potrebne za rad
genetskog algoritma i izračunavanje rezultata testa.
genNum – broj generacija,
popNum – veličina populacije,
mutNum – vjerojatnost mutacije,
mSelekcije – odabrana metoda selekcije,
mKrizanja – odabrana metoda križanja,
ukupnoSlova – ukupan broj slova u kriptiranoj datoteci,
sifriranaPojavljivanja – polje s iznosom pojavljivanja svakog
slova kriptirane datoteke,
fileName – ime kriptirane datoteke,
currentProgress – pokazivač napretka trenutnog testa

25
public void Start( object in_retVal)
Metoda kojom se pokreće rad algoritma. Ulazni parametar je polje od dva
elementa tipa float prikazanih kao objekt tipa object, preko kojih se
vraćaju rezultati pozivajućoj dretvi. Metoda stvara početnu populaciju,
izvršava potrebni broj iteracija genetskog algoritma, izračunava točnost
dekripcije za jedinku s najboljom dobrotom te vraća parametre preko
objekta in_retVal.
Slika 4.7 - Isje čak iz koda metode Start
List <String > populacija = new List <String >(); List <float > dobrote = new List <float >(); for ( int i = 0; i < popNum; i++) { populacija.Add(KeyGenerator()); if (mSelekcije == 2) // eliminacijska selekcija dobrote.Add(izracunajKaznu(populacija[i])); else dobrote.Add(izracunajDobrotu(populacija[i])); } for ( int i = 0; i < genNum; i++) { if (mKrizanja == 0) // binarno krizaj0(populacija, dobrote, mutNum, mSelekcije ); else // frekvencijsko krizaj1(populacija, dobrote, mutNum, mSelekcije ); } String rezultat = null ; if (mSelekcije == 2) // eliminacijska selekcija rezultat = populacija[dobrote.IndexOf(dobrote.Min ())]; else rezultat =populacija[dobrote.IndexOf(dobrote.Max( ))]; int pogodjeno = 0; /* Dekriptiranje datoteke znak po znak i usporedba s nekriptiranom datotekom. Za svaki pogodjeni znak po godjeno se povecava za jedan. Ne će biti prikazano. */ float [] retVal = ( float [])in_retVal; retVal[0] = ( float )pogodjeno / ( float )ukupnoSlova; retVal[1] = dobrote[populacija.IndexOf(rezultat)]; in_retVal = ( object )retVal;

26
private float izracunajDobrotu( String key)
Metoda izračunava dobrotu jedinke predstavljene ključem key . Za svako
slovo abecede se pogleda kojim je slovom a ključa to slovo kriptirano.
Zatim se iz polja pojavljivanje uzme broj pojavljivanja slova a te se podijeli
s ukupnim brojem slova teksta i oduzme od očekivane frekvencije slova a.
Slika 4.8- Isje čak iz koda metode izracunajDobrotu
private float izracunajKaznu( String key)
Metoda izračunava kaznu neke jedinke u slučaju da je odabrana
eliminacijska selekcija. Petlja je identična petlji u metodi izracunajKaznu
prikazanoj na slici 4.8.
Slika 4.9 - Isje čak iz koda metode izracunajKaznu
int pojavljivanja; float dobrota = 0; for ( int i = 0; i < 26; i++) { pojavljivanja = sifriranaPojavljivanja[( int )key[i] - ( int ) 'A' ]; dobrota += Math .Abs(frekvencije[i]/100 – (( float )pojavljivanja / ( float )ukupnoSlova)); } dobrota = 1 - dobrota; if (dobrota < 0) return 0; return dobrota;
int pojavljivanja; float kazna = 0; for ( int i = 0; i < 26; i++) { pojavljivanja = sifriranaPojavljivanja[( int )key[i] - ( int ) 'A' ]; kazna += Math .Abs(frekvencije[i] / 100 – (( float )pojavljivanja / ( float )ukupnoSlova)); } return kazna;

27
private List <int > selekcija0( List <float > dobrote)
Metoda za turnirsku selekciju. Prima listu dobrota svih jedinki populacije,
radi selekciju i vraća listu indeksa odabranih jedinki gdje su prva dva
elementa roditelji, a druga dva djeca.
Slika 4.10 - Isje čak iz koda metode selekcija0
List <int > indeksi = new List <int >(); while (indeksi.Count < 4) { int a = randomizer.Next(dobrote.Count); if (!indeksi.Contains(a)) indeksi.Add(a); } // klasican bubble sort za sortiranje po dobrotama for ( int i = 0; i < 4; i++) for ( int j = 3; j >= i + 1; j--) if (dobrote[indeksi[j - 1]] < dobrote[indeksi[j]]) { int temp = indeksi[j - 1]; indeksi[j - 1] = indeksi[j]; indeksi[j] = temp; } return indeksi;

28
private List <int > selekcija1( List <float > dobrote)
Metoda za roulette selekciju. Prima listu dobrota svih jedinki populacije,
radi selekciju i vraća listu indeksa odabranih jedinki gdje su prva dva
elementa roditelji, a druga dva djeca. Roditelji su odabrani roulette
selekcijom, a djeca su dvije najlošije jedinke populacije.
Slika 4.11 - Isje čak iz koda metode selekcija1
float duljinaRuleta = 0; for ( int i = 0; i < dobrote.Count; i++) duljinaRuleta += dobrote[i]; List <int > indeksi = new List <int >(); while (indeksi.Count < 2) // odabir roditelja { float rnd = ( float )randomizer.NextDouble() * duljinaRuleta; float temp = 0; int i; for (i = 0; i < dobrote.Count - 1; i++) { temp += dobrote[i]; if (temp > rnd) break ; } if (!indeksi.Contains(i)) indeksi.Add(i); } indeksi.Add(0); indeksi.Add(0); // stvaranje dva prazna mjesta for ( int i = 0; i < dobrote.Count; i++) if (i != indeksi[0] && i != indeksi[1]) if (dobrote[i] < dobrote[indeksi[2]]) indeksi[2] = i; for ( int i = 0; i < dobrote.Count; i++) if (i != indeksi[0] && i != indeksi[1] && i != indeks i[2]) if (dobrote[i] < dobrote[indeksi[3]]) indeksi[3] = i; return indeksi;

29
private List <int > selekcija2( List <float > dobrote)
Metoda za eliminacijsku selekciju. Prima listu kazni svih jedinki populacije,
radi selekciju i vraća listu indeksa odabranih jedinki gdje su prva dva
elementa roditelji, a druga dva djeca.
Slika 4.12 - Isje čak iz metode selekcija2
private String mutiraj( List <char > dijete, float mutNum)
Metoda koja mutira jedinku. Ulazni parametri su ključ te vjerojatnost
mutacije. Metoda vraća novo dijete.
Slika 4.13 - Isje čak iz koda metode mutiraj
if (( float )randomizer.NextDouble() < mutNum) { int a = randomizer.Next(26); int b = randomizer.Next(26); while (a == b) b = randomizer.Next(26); char temp = dijete[a]; dijete[a] = dijete[b]; dijete[b] = temp; } return new String (dijete.ToArray());
List <int > indeksi = new List <int >(); while (indeksi.Count < 4) { int a = randomizer.Next(dobrote.Count); if (!indeksi.Contains(a)) indeksi.Add(a); } for ( int i = 0; i < 4; i++) for ( int j = 3; j >= i + 1; j--) if (dobrote[indeksi[j - 1]] > dobrote[indeksi[j]]) { int temp = indeksi[j - 1]; indeksi[j - 1] = indeksi[j]; indeksi[j] = temp; } return indeksi;

30
private void krizaj0( List <String > populacija, List <float > dobrote,
float mutNum, int mSelekcije)
Metoda za binarno križanje. Prima listu svih ključeva te listu svih dobrota,
vjerojatnost mutacije te odabranu metodu selekcije.
Slika 4.14 - Isje čak iz metode krizaj0
List <char > dijete1 = new List <char >(); List <char > dijete2 = new List <char >(); List <int > indeksi; if (mSelekcije == 0) indeksi = selekcija0(dobro te); else if (mSelekcije == 1) indeksi = selekcija1(dobrote); else indeksi = selekcija2(dobrote); for ( int i = 0; i < 26; i++) { if (randomizer.Next(2) == 1) { dijete1.Add(populacija[indeksi[0]][i]); dijete2.Add( '\0' ); } else { dijete1.Add( '\0' ); dijete2.Add(populacija[indeksi[1]][i]); } } for ( int i = 0; i < 26; i++) { if (dijete1[i] == '\0' ) for ( int j = 0; j < 26; j++) if (!dijete1.Contains(populacija[indeksi[1]][j])) dijete1[i] = populacija[indeksi[1]][j], break ; if (dijete2[i] == '\0' ) for ( int j = 0; j < 26; j++) if (!dijete2.Contains(populacija[indeksi[0]][j])) dijete2[i] = populacija[indeksi[0]][j], break ; } populacija[indeksi[2]] = mutiraj(dijete1, mutNum); populacija[indeksi[3]] = mutiraj(dijete2, mutNum); if (mSelekcije == 2) { dobrote[indeksi[2]] = izracunajKaznu(populacija[i ndeksi[2]]); dobrote[indeksi[3]] = izracunajKaznu(populacija[i ndeksi[3]]); } else { dobrote[indeksi[2]] = izracunajDobrotu(populacija [indeksi[2]]); dobrote[indeksi[3]] = izracunajDobrotu(populacija [indeksi[3]]); }

31
private void krizaj1( List <String > populacija, List <float > dobrote,
float mutNum, int mSelekcije)
Metoda za frekvencijsko križanje. Prima listu svih ključeva te listu svih
dobrota, vjerojatnost mutacije te odabranu metodu selekcije.
List <char > dijete = new List <char >(); List <int > indeksi; if (mSelekcije == 0) indeksi = selekcija0(dobrot e); else if (mSelekcije == 1) indeksi = selekcija1(dobrote); else indeksi = selekcija2(dobrote); List <char > neiskoristena = "ABCDEFGHIJKLMNOPRSTUVZXYWQ".ToCharArray().ToList(); for ( int i = 0; i < 26; i++) { dijete.Add( '\0' ); int ocekivano = ( int )(ukupnoSlova * frekvencije[i]); int prvi = sifriranaPojavljivanja[( int )populacija[indeksi[0]][i] – ( int ) 'A' ]; int drugi = sifriranaPojavljivanja[( int )populacija[indeksi[1]][i] – ( int ) 'A' ]; prvi = Math .Abs(ocekivano - prvi); drugi = Math .Abs(ocekivano - drugi); if (prvi < drugi) { if (!dijete.Contains(populacija[indeksi[0]][i])) { dijete[i] = populacija[indeksi[0]][i]; neiskoristena.Remove(dijete[i]); } } else { if (!dijete.Contains(populacija[indeksi[1]][i])) { dijete[i] = populacija[indeksi[1]][i]; neiskoristena.Remove(dijete[i]); } } }

32
Slika 4.15 - Isje čak iz koda metode krizaj1
for ( int i = 0; i < 26; i++) if (dijete[i] == '\0' ) { float min = 1000; int minI = 0; for ( int j = 0, len = neiskoristena.Count; j < len; j++) { float temp = Math .Abs(frekvencije[i] – sifriranaPojavljivanja[( int )neiskoristena[j] – ( int ) 'A' ] / ( float )ukupnoSlova); if (temp < min) { minI = j; min = temp; } } dijete[i] = neiskoristena[minI]; neiskoristena.RemoveAt(minI); } String novo = mutiraj(dijete, mutNum); populacija[indeksi[2]] = novo; if (mSelekcije == 2) dobrote[indeksi[2]] = izracunajKaznu(novo); else dobrote[indeksi[2]] = izracunajDobrotu(novo);

33
4.10 Rad programa za Vigenérovu šifru
Rad programa za Vigenérovu šifru ne razlikuje se mnogo od programa za
algoritam supstitucije tako da će biti prikazane samo veće razlike, od kojih
većina proizlazi iz činjenice da se kod Vigenérove šifre znakovi ključa mogu
ponavljati te da je ključ proizvoljne duljine.
Metoda keyGenerator kod programa za Vigenérovu šifru stvara ključ
odabrane duljine s time da se znakovi mogu ponavljati. Metode selekcije te
mutacija su identične onima kod programa za supstituciju osim što je drugačija
duljina ključa. Jedina dostupna metoda za križanje je binarna koja je identična
onoj kod programa za supstituciju samo što se dozvoljava ponavljanje znakova.
Izračunavanje točnosti se radi znak po znak u skladu s algoritmom
dekripcije Vigenérove šifre na slici 2.4.
Jedina bitna razlika javlja se kod izračunavanja dobrota i kazni. S obzirom
da se za odreñivanje dobrote kod Vigenérove šifre mora proći kroz cijelu
datoteku postoje dvije metode za izračunavanje dobrote ili kazne kojima se
pokušava minimizirati broj čitanja datoteke.
private void pocetneDobrote( List <String > populacija, List <float >
dobrote, int mSelekcije)
Metoda izračunava početne dobrote ili kazne cijele populacije. Prima listu
svih jedinki, te listu dobrota u koju će zapisati izračunate dobrote. Takoñer
prima metodu selekcije temeljem koje se odreñuje izračunava li se kazna
ili dobrota. Osim što radi s cijelom populacijom a ne samo s dvije jedinke,
kod je identičan onom za metodu izračunajDobrote na slici 4.16.

34
private float [] izracunajDobrote( String in_key1, String in_key2, int
mSelekcije)
Metoda izračunava dobrotu za dvije jedinke odjednom budući da se
prilikom križanja uvijek stvaraju dvije nove jedinke. Metoda prima jedinke
te odabranu metodu selekcije pomoću koje se odreñuje da li se
izračunava dobrota ili kazna.
Slika 4.16 – Isje čak iz koda metode funkcije izra čunajDobrote
int [] pojavljivanja1 = new int [26]; int [] pojavljivanja2 = new int [26]; int ucitano, int j = 0; char [] buffer = new char [1024]; float [] dobrota = new float [2] { 0, 0 }; do { ucitano = reader.Read(buffer, 0, 1024); for ( int i = 0 ; i < ucitano ; i++) if (buffer[i] >= 'A' && buffer[i] <= 'Z' ) { int temp = ( int )buffer[i] - ( int )in_key1[j]; if (temp < 0) temp += 26; pojavljivanja1[temp]++; temp = ( int )buffer[i] - ( int )in_key2[j]; if (temp < 0) temp += 26; pojavljivanja2[temp]++; j = (j + 1) % keySize; } } while (ucitano == 1024); for ( int i = 0; i < 26; i++) { dobrota[0] += Math .Abs(frekvencije[i] / 100 – (( float )pojavljivanja1[i] / ukupnoSlova)); dobrota[1] += Math .Abs(frekvencije[i] / 100 – (( float )pojavljivanja2[i] / ukupnoSlova)); } if (mSelekcije != 2) { dobrota[0] = 1 - dobrota[0]; if (dobrota[0] < 0) dobrota[0] = 0; dobrota[1] = 1 - dobrota[1]; if (dobrota[1] < 0) dobrota[1] = 0; } return dobrota;
35
5 Ispitivanje
Ispitivanje je rañeno slijedom uzastopnih testova s raznim konfiguracijama.
Prvi ispitivani tekst je bio Biblija te zatim „David Copperfield“. Rezultati su dati i
prikazani samo za Bibliju jer su kvalitativno jednaki onima za „Davida
Copperfileda“ dok se kvantitativno malo razlikuju. Kvantitativna razlika proizlazi
iz drugačijih frekvencija pojavljivanja slova u ta dva teksta.
5.1 Ispitivanje programa za algoritam supstitucije
Izvršena su ukupno 432 testa za svaki od tekstova. Ispitane su sve
kombinacije metoda selekcije te križanja. Broj generacija i veličina populacije su:
1000 generacija i 50 jedinki, 5000 generacija i 250 jedinki, 10000 generacija i
500 jedinki, 50000 generacija i 2500 jedinki, 100000 generacija i 5000 jedinki te
200000 generacija i 10000 jedinki. Korištene vjerojatnosti mutacija su: 1%, 5%,
10%, 15%, 20% i 25%. U ranijim ispitivanjima isprobane su i razne druge
kombinacije, ali se rezultati nisu značajno razlikovali od ovih ovdje prikazanih.
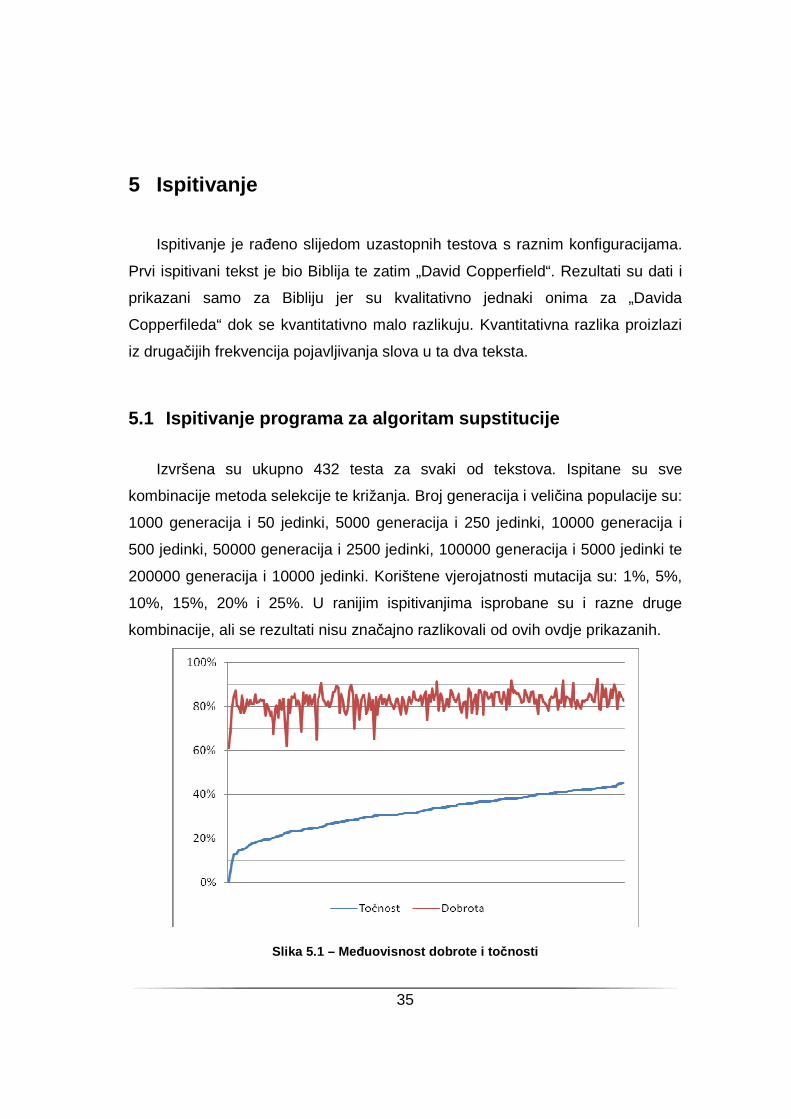
Slika 5.1 – Meñuovisnost dobrote i to čnosti
36
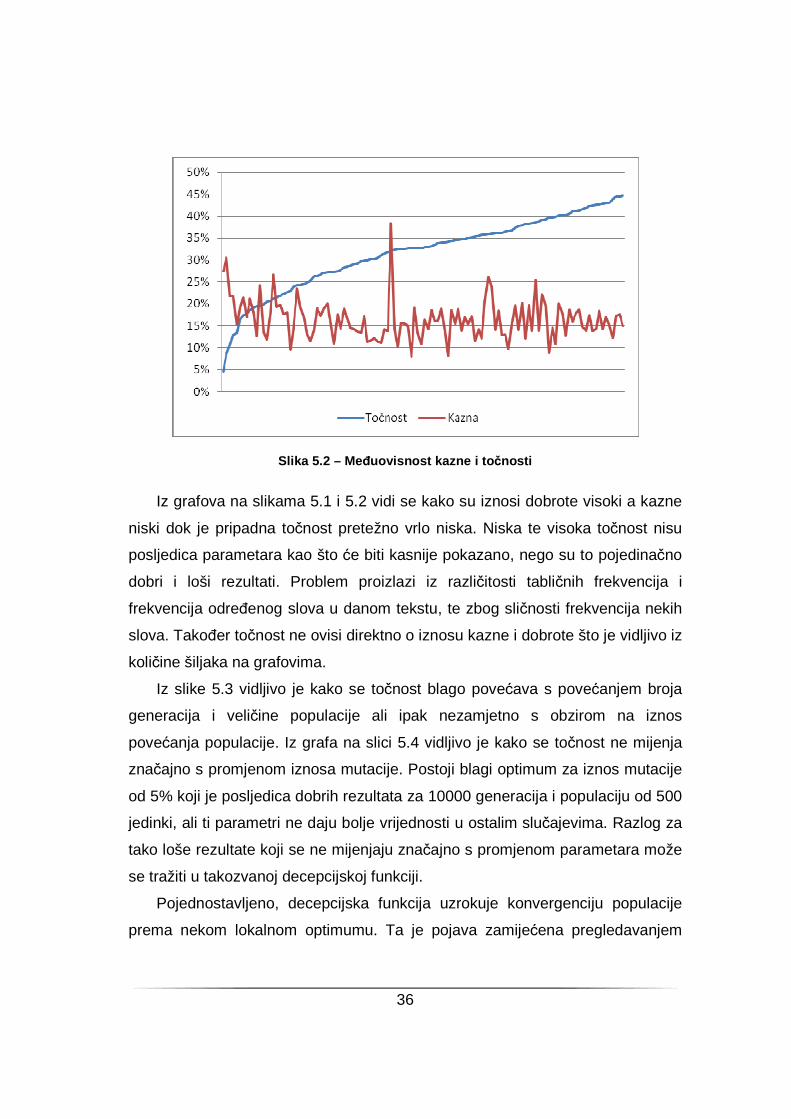
Slika 5.2 – Meñuovisnost kazne i to čnosti
Iz grafova na slikama 5.1 i 5.2 vidi se kako su iznosi dobrote visoki a kazne
niski dok je pripadna točnost pretežno vrlo niska. Niska te visoka točnost nisu
posljedica parametara kao što će biti kasnije pokazano, nego su to pojedinačno
dobri i loši rezultati. Problem proizlazi iz različitosti tabličnih frekvencija i
frekvencija odreñenog slova u danom tekstu, te zbog sličnosti frekvencija nekih
slova. Takoñer točnost ne ovisi direktno o iznosu kazne i dobrote što je vidljivo iz
količine šiljaka na grafovima.
Iz slike 5.3 vidljivo je kako se točnost blago povećava s povećanjem broja
generacija i veličine populacije ali ipak nezamjetno s obzirom na iznos
povećanja populacije. Iz grafa na slici 5.4 vidljivo je kako se točnost ne mijenja
značajno s promjenom iznosa mutacije. Postoji blagi optimum za iznos mutacije
od 5% koji je posljedica dobrih rezultata za 10000 generacija i populaciju od 500
jedinki, ali ti parametri ne daju bolje vrijednosti u ostalim slučajevima. Razlog za
tako loše rezultate koji se ne mijenjaju značajno s promjenom parametara može
se tražiti u takozvanoj decepcijskoj funkciji.
Pojednostavljeno, decepcijska funkcija uzrokuje konvergenciju populacije
prema nekom lokalnom optimumu. Ta je pojava zamijećena pregledavanjem
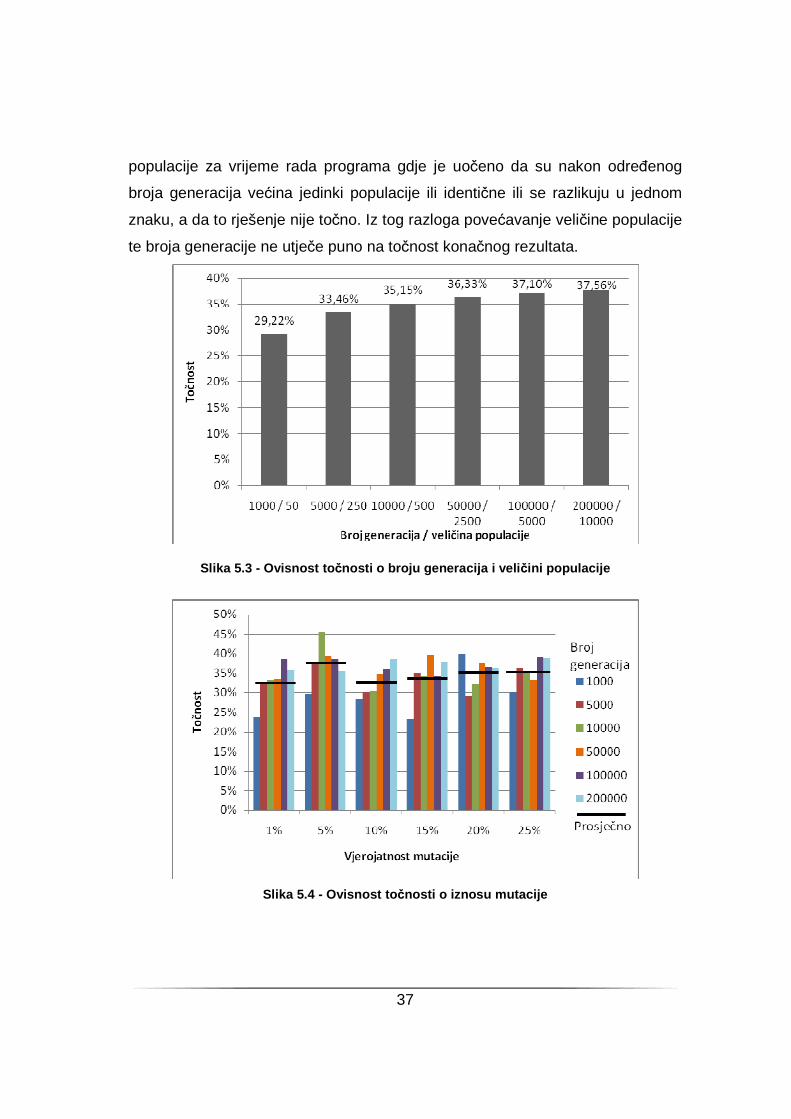
37
populacije za vrijeme rada programa gdje je uočeno da su nakon odreñenog
broja generacija većina jedinki populacije ili identične ili se razlikuju u jednom
znaku, a da to rješenje nije točno. Iz tog razloga povećavanje veličine populacije
te broja generacije ne utječe puno na točnost konačnog rezultata.
Slika 5.3 - Ovisnost to čnosti o broju generacija i veli čini populacije
Slika 5.4 - Ovisnost to čnosti o iznosu mutacije
38
Moguće je rješenje da se ne dozvoljava postojanje dvije iste jedinke u
populaciji, ali se tim pristupom kvalitetna jedinka ne bi mogla više puta pojaviti u
populaciji što bi ponovo davalo loše rezultate.
Sljedeće moguće rješenje je povećavanje iznosa mutacije na iznose blizu
100% da se spriječi konvergencija populacije, ali to bi samo uzrokovalo
nasumično prebacivanje znakova što ne bi pridonijelo kvaliteti.
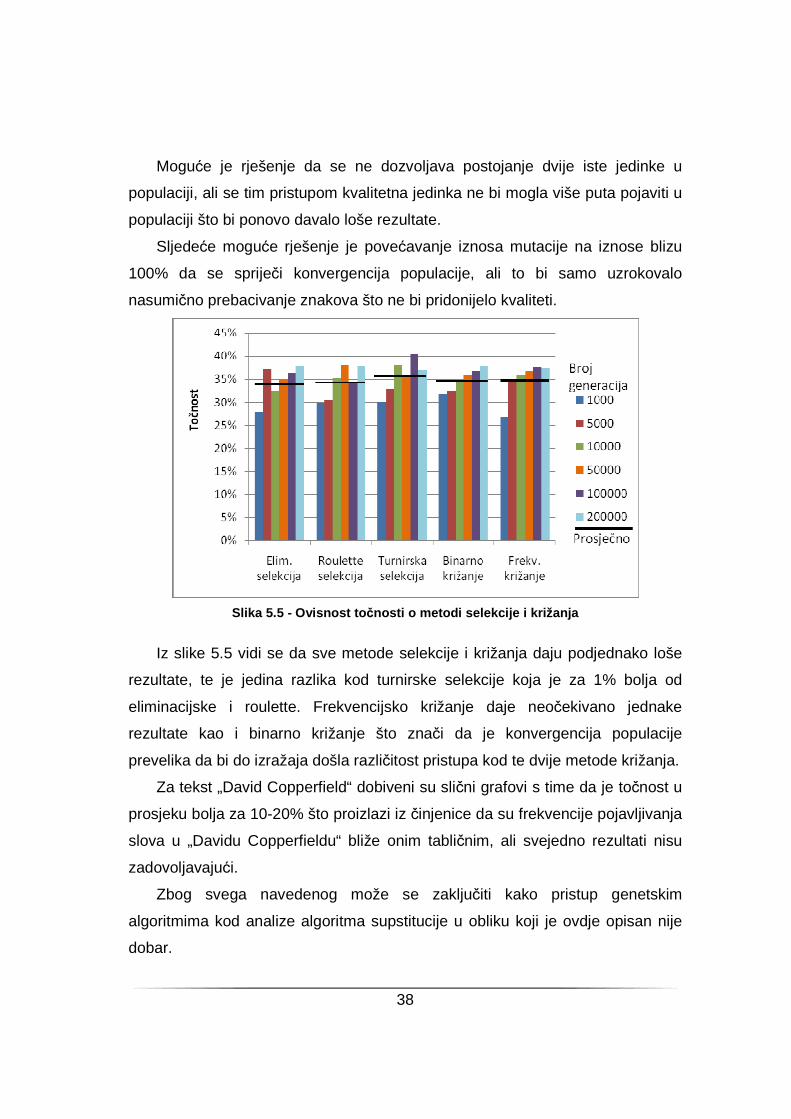
Slika 5.5 - Ovisnost to čnosti o metodi selekcije i križanja
Iz slike 5.5 vidi se da sve metode selekcije i križanja daju podjednako loše
rezultate, te je jedina razlika kod turnirske selekcije koja je za 1% bolja od
eliminacijske i roulette. Frekvencijsko križanje daje neočekivano jednake
rezultate kao i binarno križanje što znači da je konvergencija populacije
prevelika da bi do izražaja došla različitost pristupa kod te dvije metode križanja.
Za tekst „David Copperfield“ dobiveni su slični grafovi s time da je točnost u
prosjeku bolja za 10-20% što proizlazi iz činjenice da su frekvencije pojavljivanja
slova u „Davidu Copperfieldu“ bliže onim tabličnim, ali svejedno rezultati nisu
zadovoljavajući.
Zbog svega navedenog može se zaključiti kako pristup genetskim
algoritmima kod analize algoritma supstitucije u obliku koji je ovdje opisan nije
dobar.

39
Iako pristup genetskim algoritmima nije intuitivan kod algoritma supstitucije,
nego se kao rješenje nameće direktna frekvencijska analiza, pokušaj izrade
takvog alata za testiranje zamisli koja bi se kasnije mogla proširiti na
kompleksnije algoritme kod kojih nije moguća direktna analiza ipak je ukazala na
probleme koji se javljaju u takvom pristupu.
Zbog loših rezultata izrañen je još jedan jednostavan program koji analizira
tekst direktnom frekvencijskom analizom za usporedbu rezultata s onima
dobivenim genetskim algoritmom. Postignute točnosti su 55% za tekst Biblija te
73% za tekst „David Copperfield“ koje su obje bolje od skoro svih dobivenih
pristupom genetskim algoritmom. Ako bi se u program dodatno uvela heuristika
prije samog početka rada genetskog algoritma program bi vrlo vjerojatno davao
izvrsne rezultate.
Prosječno vrijeme za svaki test je zanemarivo, te se kreće od ispod sekunde
za 1000 generacija te do prosječno 16 sekundi za 50000 generacija. Jedino
vrijeme koje iskače je ono kod roulette selekcije čije se vrijeme kreče do 4
minute za 200000 generacija, što je bilo i očekivano s obzirom na količinu posla
prilikom svake selekcije.
5.2 Ispitivanje programa za Vigenérovu šifru
Ispitivanje programa za Vigenérovu šifru rañeno je na 45 testova jednakih
konfiguracija za dvije duljine ključa, 7 te 11. Korišteni iznosi broja generacija i
veličine populacije su 1000 i 50, 2000 i 100 te 4000 i 200. Korišteni iznosi
mutacija su 1%, 5%, 10%, 15% te 20%.
Prosječno vrijeme je 4 i pol minute za 1000 generacija, 9 minuta za 2000
generacija te 18 minuta za 4000. S obzirom na kvalitetu rezultata, ispitivanja za
veći broj generacija nisu rañena.
40
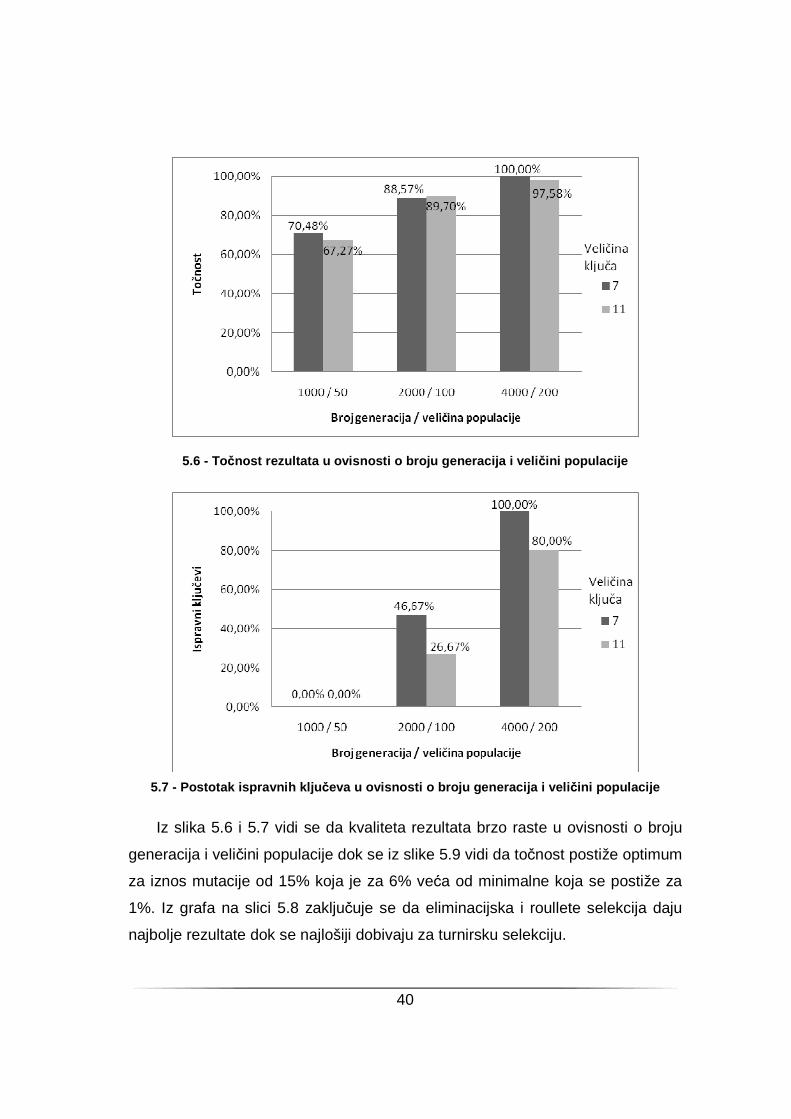
5.6 - Točnost rezultata u ovisnosti o broju generacija i vel ičini populacije
5.7 - Postotak ispravnih klju čeva u ovisnosti o broju generacija i veli čini populacije
Iz slika 5.6 i 5.7 vidi se da kvaliteta rezultata brzo raste u ovisnosti o broju
generacija i veličini populacije dok se iz slike 5.9 vidi da točnost postiže optimum
za iznos mutacije od 15% koja je za 6% veća od minimalne koja se postiže za
1%. Iz grafa na slici 5.8 zaključuje se da eliminacijska i roullete selekcija daju
najbolje rezultate dok se najlošiji dobivaju za turnirsku selekciju.
41
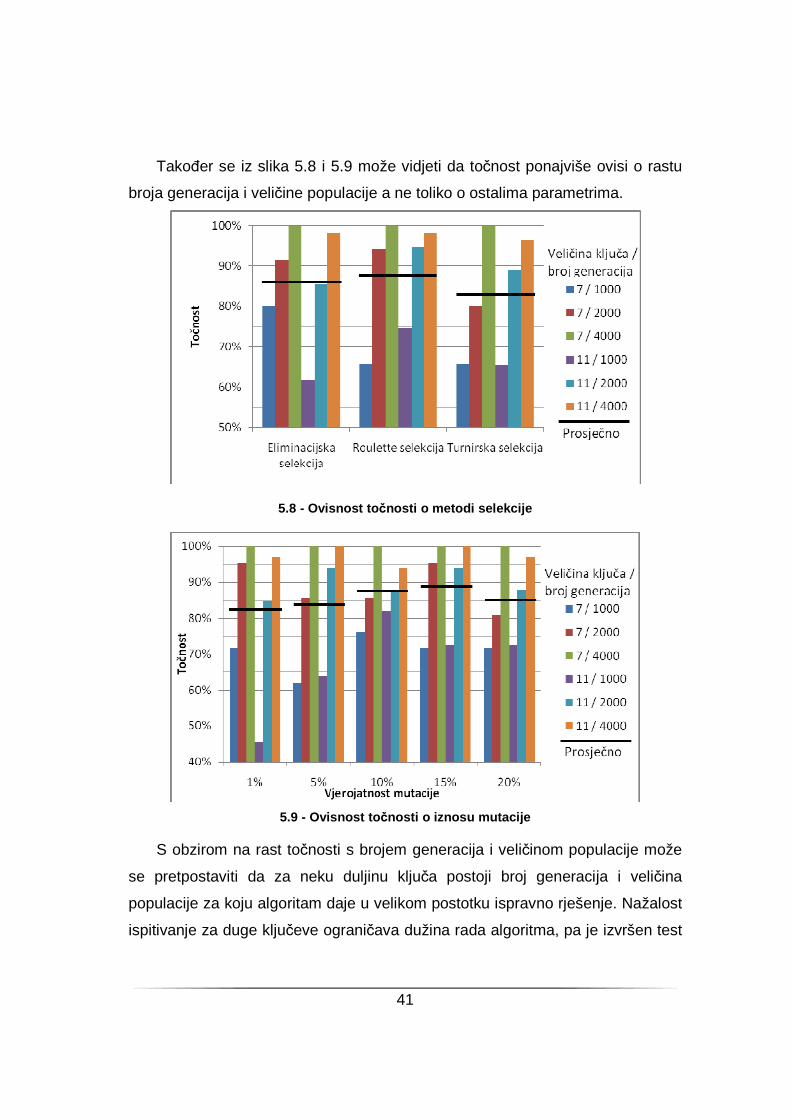
Takoñer se iz slika 5.8 i 5.9 može vidjeti da točnost ponajviše ovisi o rastu
broja generacija i veličine populacije a ne toliko o ostalima parametrima.
5.8 - Ovisnost to čnosti o metodi selekcije
5.9 - Ovisnost to čnosti o iznosu mutacije
S obzirom na rast točnosti s brojem generacija i veličinom populacije može
se pretpostaviti da za neku duljinu ključa postoji broj generacija i veličina
populacije za koju algoritam daje u velikom postotku ispravno rješenje. Nažalost
ispitivanje za duge ključeve ograničava dužina rada algoritma, pa je izvršen test
42
na duljini ključa 15 samo za roulette selekciju te iznos mutacije od 15% koji daju
nešto bolje rezultate od ostalih parametara.
Generacija Populacija Mutacija Selekcija Križanje Točnost Dobrota 2000 100 0,15 Roulette Binarno 0,9333333 0,899719 2000 100 0,15 Roulette Binarno 0,9333333 0,908097 4000 200 0,15 Roulette Binarno 1 0,908393 4000 200 0,15 Roulette Binarno 0,8666666 0,89419 8000 400 0,15 Roulette Binarno 1 0,908393 8000 400 0,15 Roulette Binarno 1 0,908393
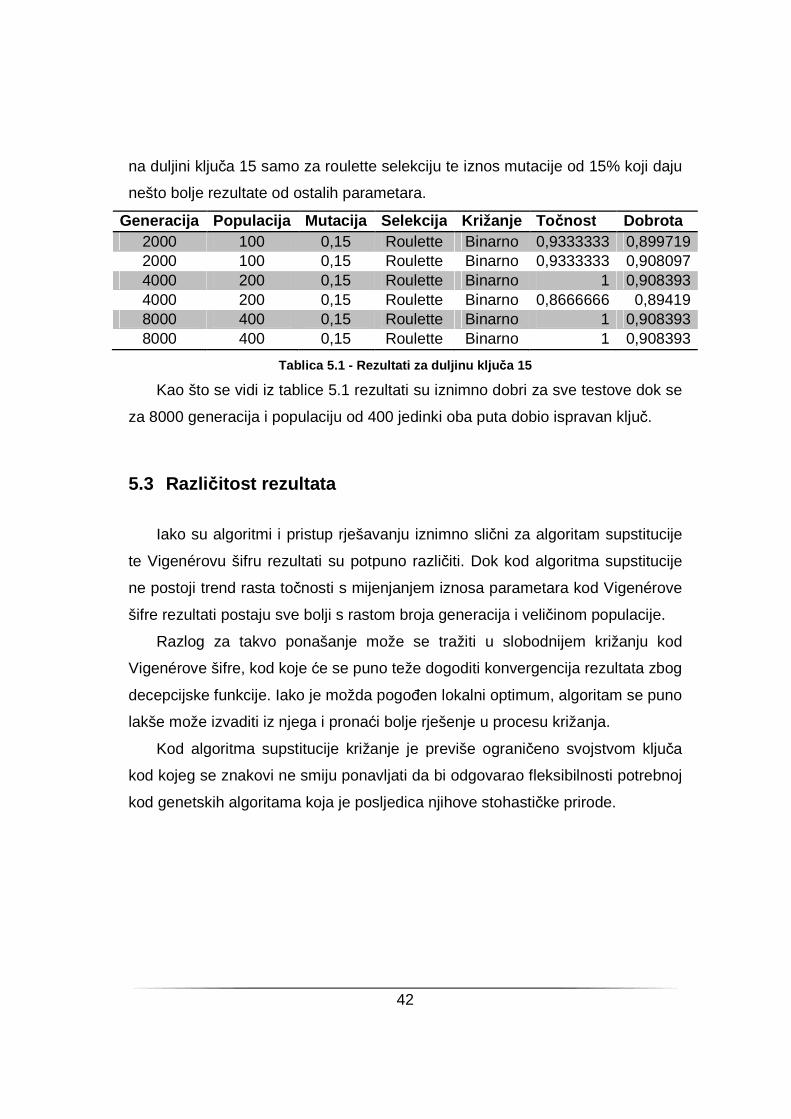
Tablica 5.1 - Rezultati za duljinu klju ča 15
Kao što se vidi iz tablice 5.1 rezultati su iznimno dobri za sve testove dok se
za 8000 generacija i populaciju od 400 jedinki oba puta dobio ispravan ključ.
5.3 Različitost rezultata
Iako su algoritmi i pristup rješavanju iznimno slični za algoritam supstitucije
te Vigenérovu šifru rezultati su potpuno različiti. Dok kod algoritma supstitucije
ne postoji trend rasta točnosti s mijenjanjem iznosa parametara kod Vigenérove
šifre rezultati postaju sve bolji s rastom broja generacija i veličinom populacije.
Razlog za takvo ponašanje može se tražiti u slobodnijem križanju kod
Vigenérove šifre, kod koje će se puno teže dogoditi konvergencija rezultata zbog
decepcijske funkcije. Iako je možda pogoñen lokalni optimum, algoritam se puno
lakše može izvaditi iz njega i pronaći bolje rješenje u procesu križanja.
Kod algoritma supstitucije križanje je previše ograničeno svojstvom ključa
kod kojeg se znakovi ne smiju ponavljati da bi odgovarao fleksibilnosti potrebnoj
kod genetskih algoritama koja je posljedica njihove stohastičke prirode.

43
6 Zaklju čak
Kod genetskih algoritama presudan čimbenik njihove uspješnosti je
mogućnost definiranja kvalitetne funkcije dobrote. Ako takvu funkciju nije
moguće definirati, niti algoritam neće biti kvalitetan.
Funkcija dobrote je u ovom radu definirana na takav način kod kojeg iznos
dobrote uvelike ovisi o karakteristikama samog teksta koji je promatran, a ne
samo o kvaliteti neke jedinke iz populacije. Nažalost, to je i jedini moguć pristup.
Pristup genetskim algoritmima moguć je i daje kvalitetne rezultate kod nekih
jednostavnih kriptografskih algoritama, dok kod kompleksnijih kriptografskih
algoritama, poput AES-a, pristup genetskim algoritmom nije moguć zbog
nemogućnosti definiranja metode križanja. Naime kod algoritama koji rade znak
po znak, poput algoritma supstitucije ili Vigenérove šifre, promjenom jednog
znaka ključa mijenja se samo n-ti znak teksta, gdje je n duljina ključa, dok se
kod algoritama koji rade s blokovima podataka mijenja cijeli tekst te dobrota
roditelja ne utječe na dobrotu djeteta. Pristup genetskim algoritmima kod takvih
algoritama ne bi se znatnije razlikovao od nasumičnog pogañanja ključeva čija
se kvaliteta zatim rangira temeljem frekvencijske analize.
Iz svega navedenog može se zaključiti da pristup genetskim algoritmima
nije dobar pristup kod algoritama koji se u današnje vrijeme koriste.
Valent Cerovečki

44
7 Literatura
Sva literatura s interneta dostupna je 24.08.2008. [1] Bethany Delman, Genetic Algorithms in Cryptography, dostupno na internet stranici https://ritdml.rit.edu/dspace/bitstream/1850/263/1/thesis.pdf [2] Substitution cipher – Simple substitution, dostupno na internet stranici http://en.wikipedia.org/wiki/Substitution_cipher#Simple_substitution [3] Vigenère cipher, dostupno na internet stranici http://en.wikipedia.org/wiki/Vigen%C3%A8re_cipher [4] Al-Kindi - Cryptography and mathematics, dostupno na internet stranici http://en.wikipedia.org/wiki/Al-Kindi#Cryptography_and_mathematics [5] Marin Golub, Genetski algoritmi, prvi dio, dostupno na internet stranici http://www.zemris.fer.hr/~golub/ga/ga_skripta1.pdf [6] Project Gutenberg, dostupno na internet stranici http://www.gutenberg.org/wiki/Main_Page [7] Relative frequencies of letters in the English language, dostupno na internet stranici http://en.wikipedia.org/wiki/Letter_frequencies





























