Embed Size (px)
Citation preview

La partecipazione del Gruppo Informatica di LecceLa partecipazione del Gruppo Informatica di Lecceal Progetto EU-US GRIDal Progetto EU-US GRID
Earth Observation Systems
High Energy Physics
ASI
ESA
Intervento trasversale
Sezione INFN-Lecce
High Energy Physics
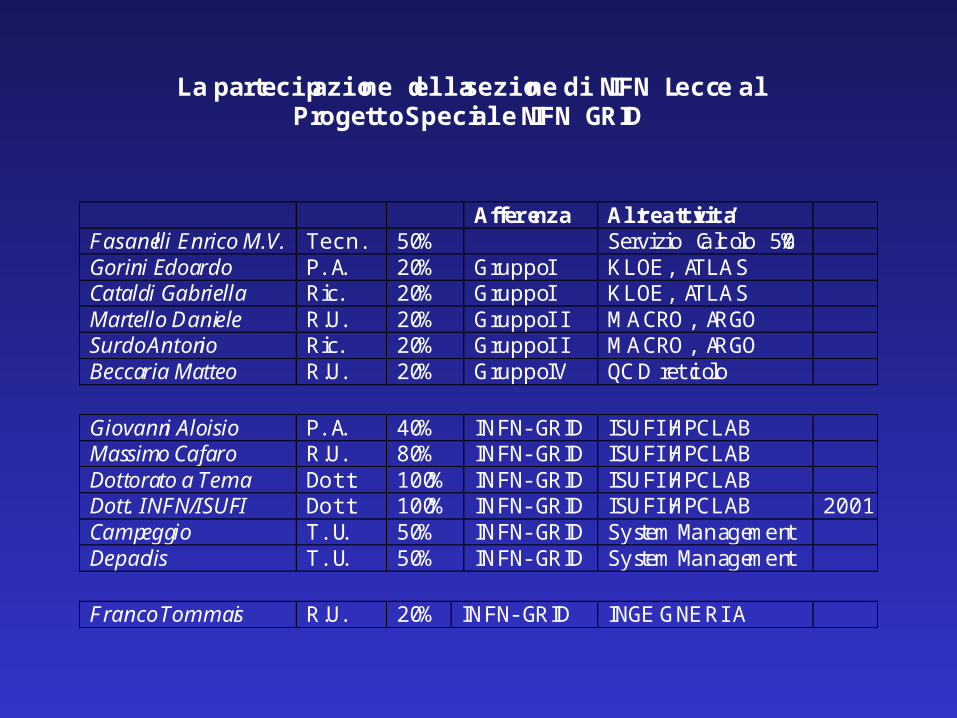
La partecipazione della sezione di INFN Lecce alProgetto Speciale INFN GRID
Afferenza Altre attivita’Fasanelli Enrico M.V. Tecn. 50% Servizio Calcolo 50%Gorini Edoardo P.A. 20% Gruppo I KLOE, ATLASCataldi Gabriella Ric. 20% Gruppo I KLOE, ATLASMartello Daniele R.U. 20% Gruppo II MACRO, ARGOSurdo Antonio Ric. 20% Gruppo II MACRO, ARGOBeccaria Matteo R.U. 20% Gruppo IV QCD reticolo
Giovanni Aloisio P.A. 40% INFN-GRID ISUFI/HPCLABMassimo Cafaro R.U. 80% INFN-GRID ISUFI/HPCLABDottorato a Tema Dott. 100% INFN-GRID ISUFI/HPCLABDott. INFN/ISUFI Dott. 100% INFN-GRID ISUFI/HPCLAB 2001Campeggio T.U. 50% INFN-GRID System ManagementDepaolis T.U. 50% INFN-GRID System Management
Franco Tommasi R.U. 20% INFN-GRID INGEGNERIA
ATLASALICECMS
VIRGO
Cookbook Requirements
GRID Middleware development

Giovanni Aloisio Giovanni Aloisio Massimo CafaroMassimo Cafaro
UNIV. OF LECCE-ItalyUNIV. OF LECCE-Italy
Roy WilliamsRoy Williams
CACR/CALTECHCACR/CALTECH
Carl KesselmanCarl Kesselman
ISI/USCISI/USC
SARA/Digital PugliaSARA/Digital PugliaA grid enabled remote sensingA grid enabled remote sensing
digital librarydigital library
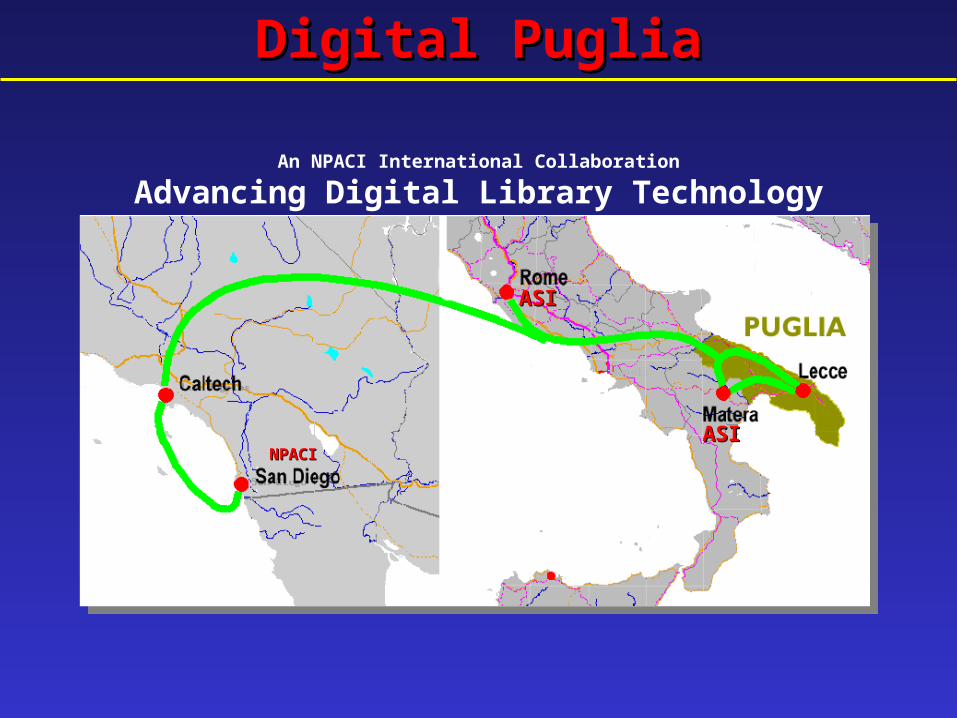
An NPACI International Collaboration
Advancing Digital Library Technology
NPACINPACI
Digital PugliaDigital Puglia
ASIASI
ASIASI

Five Emerging Models of Networked Parallelism From The
Grid
• Distributed Computing– || synchronous processing
• High-Throughput Computing– || asynchronous processing
• On-Demand Computing– || dynamic resources
• Data-Intensive Computing– || databases
• Collaborative Computing– || scientists

EU/US Workshop on Large Scientific DatabasesEU/US Workshop on Large Scientific DatabasesAnnapolis-Maryland
8-11 Sept. 1999
USPaul Messina (DOE/CACR-Caltech)Roy WilliamsMaria Zemankova
EUGiovanni Aloisio (Univ. Lecce)John Darlington (IPC-UK)Fabrizio Gagliardi (CERN)
Organized by CACR-Caltech and CERN
Supported in part by the National Science Foundation (Grant IIS-9910140)and the European Commission (EU Information Society Technology Programme)
Organizing committee

GRID ISSUESGRID ISSUES
Scalability
Information Modeling
Interoperability
Information flow
Preservation of databases
Education and outreach

Data Base ScalabilityData Base Scalability
• the quantity of bulk data in the database
• the geographical separation of the DB components
• size of the user community
• the defining limits of applicability of the DB
• the duration of the DB project
• complexity and heterogeneity of DBs to be federated
Scalability issues must be considered with respect to:

Data Base SizeData Base Size
• Hierarchical storage systems
• Distributed storage systems
• Parallel data delivery
• Interoperability of “big data” systems
Research on:Research on:
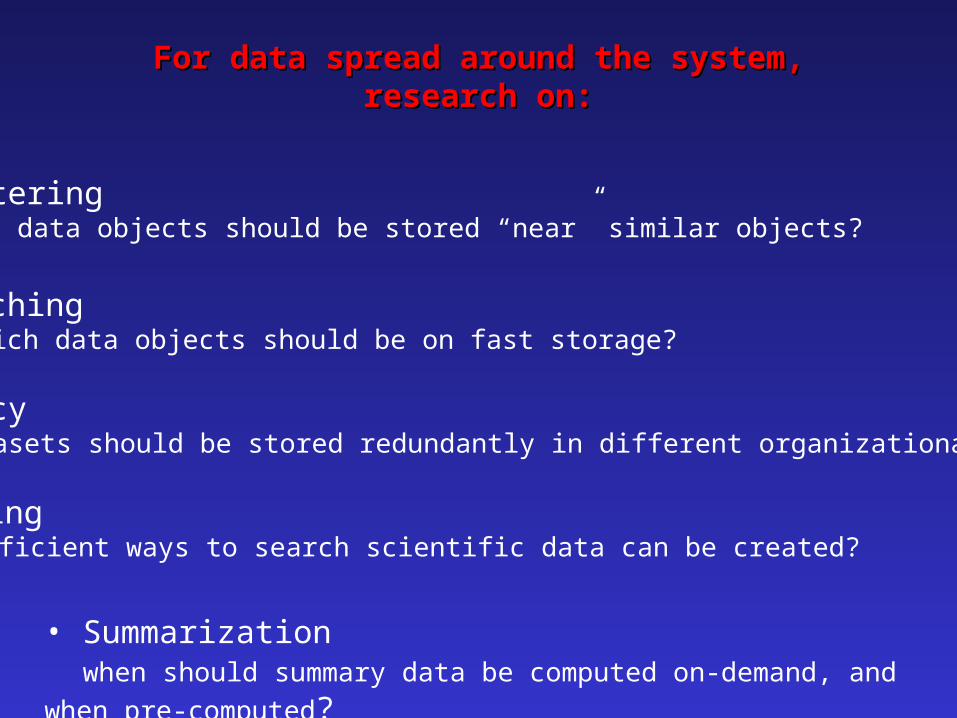
For data spread around the system,For data spread around the system,research on:research on:
• Clustering which data objects should be stored “near” similar objects?
• Caching which data objects should be on fast storage?
•Redundancy which datasets should be stored redundantly in different organizational patterns?
•Indexing how efficient ways to search scientific data can be created?
• Summarization when should summary data be computed on-demand, and when pre-computed?

NetworkingNetworking
A crucial requirement for effective GRID EU-US collaboration is trans-Atlantic data communication that provides:
- high bandwidth
- high availability
- low latency
Regional data centers communicate with each other differently fromthe way they communicate with users
The most important metric is throughput

Scheduled streaming as a new paradigm for the analysis of large amount of data
DataData StreamingStreaming
Data architectures oriented to data movement rather than data storage
Shifting from file-oriented to stream-oriented processing
Constructing new kinds of data management components
Alternative structures for data
New roles for metadata

Distributed DatabasesDistributed Databases
The data movement generated by queries to the globally-distributed database must be optimized
• how queries and processing requests can be formulated to streamline this optimization process?
• how such a query can be split in separate, locally-executed queries, with machine-specific data access?
• how the cost, in terms of computation, communication, and time, can be estimated before and during execution

Distributed DatabasesDistributed Databases
Load-balancing how computational work and data are spread around GRID?
Replication what should be replicated among the regional centers?
Protocols for - high-speed- parallel I/O
- synchronous and asynchronous delivery- real-time steering and control of running jobs

Information modelingInformation modeling
What is the nature of the contents of the database and its catalog?
How the DBs interoperability can be achieved?
Standardization of scientific data objects

Database InteroperabilityDatabase Interoperability
How can information from multiple collections be fusedto extract new knowledge?
A common infrastructure providing interoperability between European and US scientific databases
• common interfaces • common information model
• semantic interoperability

Database InteroperabilityDatabase Interoperability
Federation of collections
- wrappers in front of existing collections that transform the information content into a standard representation
- wrappers or servers are installed in front of the storage systems that support access through a common API
- wrappers tend to be limited to the manipulation of relatively small data sets
- wrappers provide an interoperability capability
Large scale data manipulation requires the tight integrationof data and compute resources

Security and AuthenticationSecurity and Authentication
Log-in once to access multiple, heterogeneous services
Clear and unambiguous Access and control policies

Information flowInformation flow
• How does information move in a complex system?
• How do users discover the database and its capabilities?
• How do users initiate and control a complex processing pipeline?

Preservation of databasesPreservation of databases
How to ensure that digital scientific data is still available, when necessary, many years in the future?
Preservation description information should be associated with digital objects so that:
- the chain of custody and processing history available
- quality of the data specified
- relationships to other digital objects recognized
- digital objects unambiguously identified
- information content not altered in an undocumented manner

EGrid - The European Grid ForumEGrid - The European Grid Forum
Redondo Beach- Agosto 1999Redondo Beach- Agosto 1999

...and many more...and many more
Now, it is time to put things togetherNow, it is time to put things together

![Grid Computing의다양한적용사례 · 2004-09-10 · World Wide Grid is Growing [4] Part I : the Grid 1. “Grid is Global Infrastructure” Grid Computing은분산된컴퓨터,](https://img.pdfslide.tips/doc/110x75/5ea7406767f1675ce51910f3/grid-computingeoee-2004-09-10-world-wide-grid-is-growing-4.jpg)



























