Embed Size (px)
Citation preview

1
Universita di Roma Tor Vergata
Corso di Laurea Magistrale
in Matematica Pura e Applicata
Appunti per il corso di
Laboratorio di Calcolo
anno 2017-18
Paolo Baldi

2

Indice
1 Primi passi 7
1.1 Primi passi: le matrici . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Primi passi: un po’ di grafica . . . . . . . . . . . . . . . . . . 14
2 scilab 17
2.1 Comandi di sistema . . . . . . . . . . . . . . . . . . . . . . . 17
2.2 Tipi di dati: numerici . . . . . . . . . . . . . . . . . . . . . . 19
2.3 Ancora sul calcolo di matrici . . . . . . . . . . . . . . . . . . 22
2.4 Numeri complessi . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5 Tipi di dati: caratteri . . . . . . . . . . . . . . . . . . . . . . 27
2.6 Input e output . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.7 Tipi di dati: logici . . . . . . . . . . . . . . . . . . . . . . . . 30
2.8 Programmazione . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.9 Grafica in scilab . . . . . . . . . . . . . . . . . . . . . . . . 40
2.10 Grafica avanzata: personalizzare il grafico . . . . . . . . . . . 42
2.11 scilab e C . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3 Analisi multivariata 51
3.1 Statistica Descrittiva . . . . . . . . . . . . . . . . . . . . . . . 51
3.2 Dati multidimensionali . . . . . . . . . . . . . . . . . . . . . . 56
3.3 Statistica descrittiva in scilab . . . . . . . . . . . . . . . . 58
3.4 Analisi in componenti principali . . . . . . . . . . . . . . . . . 63
3.5 Analisi discriminante . . . . . . . . . . . . . . . . . . . . . . . 77
3.6 Approfondimenti sulla gestione della grafica . . . . . . . . . . 84
4 Esplorazioni numeriche 87
4.1 Equazioni differenziali . . . . . . . . . . . . . . . . . . . . . . 87
4.2 Fourier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.3 Integrazione numerica: le somme di Riemann . . . . . . . . . 98
3

4 Indice
4.4 Polinomi d’interpolazione e il metodo di Simpson . . . . . . . 1014.5 Un altro approccio: simulazione . . . . . . . . . . . . . . . . . 1064.6 Esercizi sull’integrazione numerica . . . . . . . . . . . . . . . 1104.7 Probabilita e simulazione in scilab . . . . . . . . . . . . . . 113
5 Simulazione, processi e EDP 119
5.1 Simulazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1195.2 Stima di densita . . . . . . . . . . . . . . . . . . . . . . . . . 1215.3 La simulazione del moto browniano . . . . . . . . . . . . . . . 1235.4 Moto browniano e EDP . . . . . . . . . . . . . . . . . . . . . 1275.5 La simulazione della distribuzione d’uscita . . . . . . . . . . . 1325.6 Il problema di Dirichlet e la distribuzione d’uscita . . . . . . 1365.7 Un altro metodo di risoluzione: gli autovalori . . . . . . . . . 1405.8 L’equazione del calore . . . . . . . . . . . . . . . . . . . . . . 146

Introduzione
Questi appunti riguardano un corso di Laboratorio di Calcolo per studentidi Matematica. Qual e lo scopo di questo corso? Non e proprio facilespiegarlo: le motivazioni che hanno guidato la redazione di questi appuntisono comunque tre.
• Innanzitutto avvicinare lo studente alla risoluzione di problemi concre-ti. Gia al secondo anno lo studente di questo corso di laurea ha acquisito unamole di conoscenze in matematica abbastanza rilevante, molto piu che unostudente piu anziano di altri corsi di laurea. Pero e in genere poco coscientedelle applicazioni che queste conoscenze gli permettono di affrontare. Anchese l’impostazione del corso di laurea in Matematica resta soprattutto diret-ta alla comprensione ed all’approfondimento teorico, e utile avere chiara laportata degli strumenti che si sono acquisiti.
• Reciprocamente, la pratica della risoluzione di problemi applicativi por-ta sempre ad una migliore comprensione della teoria. Non si contano le volteche il risultato di un calcolo o di una simulazione risulta inatteso e costringea riflettere e a meglio comprendere gli aspetti teorici sottostanti.
• Infine, una familiarita con lo strumento numerico e uno strumentopotente anche nell’approccio a un problema di ricerca. Spesso un calcolonumerico o una simulazione danno informazioni importanti sul problema.Naturalmente al ricercatore resta poi da fare la dimostrazione. Quella ilcomputer non la fa. . .
Roma dicembre 2013
5

6 Indice
PRIMA PARTE:
INTRODUZIONE A SCILAB

Capitolo 1
Primi passi
In questo primo capitolo vediamo i primi elementi che permetteranno comun-que di fare i primi calcoli e i primi grafici. Nei capitoli successivi vedremogli stessi argomenti in maniera piu sistematica e approfondita.
1.1 Primi passi: le matrici
Le matrici sono l’elemento di base di scilab . In questo ambiente di calcolotutto e matrice. Cominciamo con gli elementi di base di questo linguaggio.Una cosa utile: che si possono richiamare i comandi precedenti con i tasti↑, ↓.La regola generale in scilab e che tutti gli oggetti sono matrici. Comin-ciamo con le operazioni elementari. Definire un vettore (riga)
-->vv=[.2 .9]
vv =
.2 .9
La regola e che le coordinate si possono separare con uno spazio vuoto (comequi) oppure con una virgola. Per definire una matrice: le righe sono separateda ;
-->pp=[1/3 2/3;1/2 1/2]
pp =
7

8 Capitolo 1. Primi passi
.3333333 .6666667
.5 .5
Moltiplicare un vettore per una matrice
-->pp * vv
--error 10
inconsistent multiplication
Ooops le dimensioni non andavano bene: vv e un vettore riga e quindi ppha un numero di colonne che non e uguale al numero di righe di vv ; persistemare le cose si puo fare il trasposto di vv , che si fa con un apostrofo:vv’ e il trasposto di vv ; vv’ e dunque un vettore colonna ed ora
-->pp * vv’ans =
.6666667
.55
Avremmo anche potuto moltiplicare vv per pp da destra :
-->vv * pp
ans =
.5166667 .5833333
Moltiplicare delle matrici
-->pp * pp
ans =
.4444444 .5555556
.4166667 .5833333

1.1. Primi passi: le matrici 9
Fare la potenza di una matrice
-->ppˆ10
ans =
.4285714 .5714286
.4285714 .5714286
Le operazioni * e
ˆ
s’intendono sempre nel senso del prodotto righe per colonne. Se si scrive . *oppure
.ˆ
(con un puntolino davanti), s’intende invece nel senso di termine a termine
-->pp.ˆ10
ans =
.0000169 .0173415
.0009766 .0009766
Il puntolino si usa anche per fare un quoziente termine a termine tra duevettori. v./w produce il vettore che ha come coordinate i quozienti dellecoordinate di v e di w. Naturalmente occorre che i due vettori (o ma-trici) abbiano le stesse dimensioni. Attenzione pero: se si da il comando2./(2:4) , ad esempio, scilab da una risposta inattesa. Probabilmenteperche il punto dopo una cifra indica anche l’inizio di uno sviluppo decimale.Occorre in questo caso scrivere (2)./(2:4) mettendo la cifra incriminatatra parentesi ed evitando cosı ogni ambiguita.Altre operazioni elementari sui vettori e le matrici: la somma delle coordi-nate:
-->xx=[1 2 3 4 5 6 7 8 9 10];

10 Capitolo 1. Primi passi
-->sum(xx)
ans =
55.
il massimo e il minimo delle coordinate
-->min(pp),max(pp)
ans =
0.3333333
ans =
0.6666667
Come si vede in una stessa riga si possono dare piu comandi, separandolicon un punto e virgola o una virgola, a seconda che se ne voglia visualizzareo no il risultato.Come estrarre un elemento da una matrice? Quello di posto (1,2), adesempio
-->pp(1,2)
ans =
.6666667
Come estrarre una colonna da una matrice; la seconda ad esempio
-->pp(:,2)
.6666667
.5
o la prima riga
-->pp(1,:)
.3333333 .6666667

1.1. Primi passi: le matrici 11
Alcuni modi speciali di definire una matrice oppure un vettore: con deivalori in progressione
-->1:10
ans =
1. 2. 3. 4. 5. 6. 7. 8. 9. 10.
oppure lo stesso con degli incrementi diversi da 1
-->1:.1:10
ans =
column 1 to 10
1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.81.9
column 11 to 20
2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.82.9
column 21 to 30
3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.83.9
column 31 to 40
4. 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.84.9
column 41 to 50
5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.85.9

12 Capitolo 1. Primi passi
column 51 to 60
[More (y or n ) ?] n
Osserviamo che quando si da un comando il programma restituisce imme-diatamente sullo schermo il risultato dell’operazione. Qualche volta, comenel caso appena visto, il risultato occuperebbe troppo spazio sullo schermo.Per evitarlo basta terminare il comando con ; . E quello che faremo spessod’ora in avanti. Ci sono anche comandi per produrre una matrice di tuttiuni.
-->ones(2,2)
ans =
1. 1.
1. 1.
o di tutti zeri
-->zeros(2,2)
ans =
0. 0.
0. 0.
-->zeros(3,1)
ans =
0.
0.
0.
Matrici con 1 sulla diagonale principale e zero fuori

1.1. Primi passi: le matrici 13
-->eye(3,3)
ans =
1. 0. 0.
0. 1. 0.
0. 0. 1.
-->eye(5,3)
ans =
1. 0. 0.
0. 1. 0.
0. 0. 1.
0. 0. 0.
0. 0. 0.
I comandi sum, max e min possono operare selettivamente sulle righe e sullecolonne. Ad esempio
-->sum(pp,2)ans =
1.1.
Piu precisamente sum(pp,2) produce un vettore colonna, con tante righequante quelle della matrice pp le cui coordinate sono le somme degli elementidelle righe. Intuitivamente sum(pp,2) significa “fare la somma lungo se-condo indice, cioe l’indice di colonna. Analogamente sum(pp,1) avrebbeprodotto un vettore riga contenente le somme degli elementi delle colonne.
Sotto scilab sono disponibili le principali funzioni elementari: seno (sin ),coseno (cos ), esponenziale (exp ), logaritmo (in base e: log ). . . Inutile

14 Capitolo 1. Primi passi
elencarle tutte, dato che non e difficile scoprirne il nome. Quello che eimportante osservare e che queste funzioni operano direttamente su matricie vettori: se mme una matrice e si scrive, ad esempio
-->exp(mm)
allora si ottiene una matrice che ha gli elementi che sono gli esponenzia-li dei corrispondenti elementi di mm. Vedremo piu in la come si calcolal’esponenziale di una matrice.
1.2 Primi passi: un po’ di grafica
Il comando piu semplice per fare un grafico e plot . L’idea e semplice, mavedremo piu tardi che il controllo di tutte le opzioni puo essere difficile daricordare. Vediamo di disegnare il grafico della funzione seno tra 0 e 2π.Prima ci procuriamo dei numeri compresi tra 0 e 2π, regolarmente spaziatied i valori della funzione seno in corrispondenza. La costante π in scilabsi chiama %pi mentre e e %pi .
-->xx=(0:.02:1) * 2* %pi;
-->yy=sin(xx);
e poi diamo il comando grafico
-->plot(xx,yy)
Se volessimo aggiungere al grafico quello della funzione coseno, basterebbecalcolare i valori della funzione coseno e ridare il comando plot :
-->yy2=cos(xx);
-->plot(xx,yy2)
Quindi nuovi comandi grafici aggiungono elementi nuovi al grafico vecchio.Se invece avessimo voluto disegnare il grafico ex novo, avremmo primadovuto cancellare il vecchio. Il comando e
-->clf()

1.2. Primi passi: un po’ di grafica 15
Non era facile da immaginare. . . Uno sguardo ai grafici di poco fa mostrache le unita di misura lungo le ordinate e le ascisse erano diverse. scilabsceglie le coordinate in modo da sfruttare al meglio lo schermo. Questo esgradevole talvolta; ad esempio volendo disegnare un cerchio, basta chiedereil grafico dei punti di coordinate sin(xx) e cos(xx), che abbiamo memorizzatonelle variabili yy e yy2 . Ma se diamo il comando
-->plot(yy,yy2)
il risultato non e proprio quello che si vorrebbe. Il comando plot ha mol-te opzioni che discuteremo in dettaglio piu tardi; per ora ci limitiamo aconsiderare le opzioni piu semplici ad esempio:a) il colore; per default le curve dei grafici sono in blu. Per disegnare una
curva in rosso, ad esempio si deve scrivere
-->plot(xx,yy,"r")
dove r sta per “red”, rosso in inglese. Altri colori disponibili immedia-tamente sono k (nero), g (verde), y (giallo), c (ciano), m (magenta) e w(bianco, talvolta utile, cercate di immaginare quando. . . ). Altri colori sonodisponibili o si possono definire.b) il tipo di tratto. Per default i punti vengono tracciati con tratto conti-
nuo. Ci sono altre possibilita, per ora limitiamoci a considerare quella checonsiste nel disegno dei singoli punti con le ascisse in xx e le ordinate in yy .Per questo si possono usare vari simboli. Ad esempio
-->plot(xx,yy,".")
usera dei punti (un po’ cicciottelli), " * " usera degli asterischi, "o" useradei cerchi vuoti e cosı via.Forse e il momento di imparare dove recuperare queste informazioni: scilabdispone di uno help in linea che si ottiene scrivendo nella riga comandi helpseguito da uno spazio e dal nome del comando. Nel nostro caso:
-->help plot
Si tratta di una sorgente d’informazioni importante ma, come si vede, nonsempre di facile comprensione. Comunque dalla pagina d’informazioni diplot , cliccando LineSpec si puo trovare la lista completa dei colori e deisimboli. Per ogni altra informazione rinviamo a piu tardi, nei §§2.9,2.10,quando analizzeremo dettagliatamente plot e gli altri comandi grafici.

16 Capitolo 1. Primi passi

Capitolo 2
scilab
2.1 Comandi di sistema
Questo paragrafo contiene le informazioni generali riguardanti la gestionedella memoria, delle variabili, e del loro display sullo schermo. Molte diqueste informazioni sono premature per un lettore che si trovi agli inizidell’uso di scilab e possono essere tralasciate in prima lettura.
In una sessione lunga e in cui si sono definite molte variabili puo succederedi voler vedere quali variabili sono state definite ed avere informazioni su diloro. Il comando who fa la lista delle variabili attualmente definite. Compa-riranno pero anche le variabili predefinite di scilab e quindi la lista risultasempre piuttosto lunga e le variabili che v’interessano risulteranno sempremischiate a quelle predefinite.Il comando whos() (ricordarsi di scrivere anche le parentesi) ha un risultatosimile, ma produce anche delle informazioni utili, come ad esempio il tipodella variabile e lo spazio che occupa in memoria. Quando si eseguono deicalcoli molto lunghi ed e opportuno disporre di tutto lo spazio possibile inmemoria conviene cancellare le variabili che non servono piu con il comandoclear : clear mm (senza parentesi) cancellera dalla memoria la variabilemm. In effetti non e raro di trovarsi ad effettuare dei calcoli e di ricevere dascilab il messaggio stacksize exceeded! , che indica che l’operazioneche si sta cercando di effettuare richiede troppa memoria. In questo casoconviene cancellare le variabili non piu utilizzate. E anche possibile aumen-tare la memoria utilizzabile da scilab con il comando stacksize (vedilo help di scilab per maggiori informazioni).
All’inizio scilab si posiziona nella directory
C:\Programmi\scilab-5.3.2
17

18 Capitolo 2. scilab
(per la versione 5.3.2). Per cambiare di directory il comando e chdir :
chdir("c:\mydir")
rende
c:\mydir
la directory di lavoro. Il cambio di directory si puo anche fare a partire dalmenu a tendina “file”. Per sapere qual e la directory in cui si sta lavorando,il comando e il classico pwd di unix (print working directory).
scilab effettua tutte le operazioni usando 22 cifre decimali, e dovrebbequindi essere abbastanza preciso. Pero scrive sullo schermo i valori numericiusando 10 cifre (comprese quelle prima della virgola), allo scopo di nonintasare lo schermo con un eccesso d’informazioni. Se si vuole cambiarequesto parametro ed avere allo schermo piu informazioni (oppure meno) c’e ilcomando format : format(’v’,7) istruisce il sistema di scrivere i valorinumerici usando 7 cifre solamente. Il parametro ’v’ indica che si richiedeun formato “variabile”. Cio significa che scilab scegliera se scrivere ilnumero nel formato usuale oppure, se esso e particolarmente grande o moltopiccolo, in formato esponenziale. L’alternativa e il parametro ’e’ che forzala scrittura in forma esponenziale in ogni caso. Esempi
-->x=0.5148455718211526477290;
-->xx =
0.5148456
-->format(’v’,15);
-->xx =
0.514845571821
-->format(’e’,15);
-->xx =
5.14845572D-01

2.2. Tipi di dati: numerici 19
2.2 Tipi di dati: numerici
Abbiamo detto che l’elemento di base in scilab e la matrice. Gli elementidi una matrice possono essere di tre tipi diversia) numerici (interi, reali o complessi)b) caratteri (alfanumerici)c) booleani o logici (cioe Vero-Falso)
Per ognuno di questi tipi di variabili ci sono delle operazioni possibili. Ab-biamo visto nel capitolo precedente un certo numero di operazioni che sipossono fare sulle variabili di tipo numerico (somme, prodotti, potenze,. . . ).Vedremo ora che ci sono molti altri operatori utili sui vettori numerici. Iseguenti due operatori operano su qualunque tipo di variabili e sono moltoutili.size(xx) produce un vettore di dimensione due, la cui prima coordinatafornisce il numero di righe della matrice xx , la seconda il numero di colonne.length(xx) da la dimensione del vettore xx . Se xx e una matrice, ilrisultato e il numero totale di elementi (=numero di righe moltiplicato pernumero di colonne). Esempi:
-->xx=[1,2,3,4];length(xx)ans =
4.
-->xx=[1,2,3;4,5,6];si=size(xx),length(xx)si =
2. 3.ans =
6.
Tornando alle matrici/vettori numerici, passiamo in rivista i comandi princi-pali. Alcuni di questi sono gia stati visti, ma necessitano un approfondimen-to. Per questi esempi ci serviremo del comando rand : rand(m,n,"n")produce una matrice m×n di numeri scelti a caso con distribuzione normaleN(0, 1). Se invece dell’opzione "n" avessimo dato l’opzione "u" i numerisarebbero stati scelti a caso con distribuzione uniformesu [0, 1]. Prima diservirsi di questo comando occorre pero inizializzare il generatore:
-->rand("seed",9071948)

20 Capitolo 2. scilab
(al posto del numero 9071948, usate un numero di vostra scelta). Se nonsi da questo comando il generatore produce sempre la stessa sequenza dinumeri. Vedremo piu tardi in dettaglio le questioni della generazione deinumeri a caso e delle loro applicazioni. Per ora pero ci serviremo di questocomando per produrre rapidamente delle matrici o dei vettori per i nostriesempi. Passiamo in rivista i comandi piu utili.
-->[m,lm]=min(xx)
Il comando min , che abbiamo gia incontrato in realta produce due valori: ilvalore mdel minimo delle coordinate del vettore xx ed l’indice lm della coor-dinata in cui il minimo viene raggiunto (si tratta di un doppio indice se xx euna matrice). Ricordiamo che se xx e una matrice, allora e possibile cercareil minimo riga per riga o colonna per colonna. Ad esempio min(xx,"c")produrra un vettore colonna, con tante righe quante sono le righe di xx edavente come coordinate i valori del minimo delle singole righe. Ad esempio
-->xx=rand(4,4,"n")xx =
0.1034169 0.2044185 0.3501626 - 1.03847340.8915736 - 0.7414362 1.0478272 - 1.73503131.2429914 - 0.7437914 - 1.3218008 0.5546874
- 1.3925211 - 0.2589642 - 1.4061926 - 0.2143931
-->min(xx,"c")ans =
- 1.0384734- 1.7350313- 1.3218008- 1.4061926
-->min(xx,"r")ans=
- 1.3925211 - 0.7437914 - 1.4061926 - 1.7350313
Simile la sintassi del comando max. Questa possibilita di operare separata-mente per righe e per colonne, con le opzioni "c" e "r" e tipica di molticomandi che operano su vettori e matrici.

2.2. Tipi di dati: numerici 21
Un altro comando utile
-->yy=cumsum(xx);
che produce le somme cumulative del vettore xx : yy(1)=xx(1) , yy(2)=xx(1)+xx(2)e cosı via fino a yy(n)=xx(1)+...+xx(n) . Questo comando si puo appli-care anche ad una matrice. Se xx e una matrice, cumsum(xx,1) produrrale somme cumulative di ogni riga, cumsum(xx,2) quelle di ogni colonna.Vedi lo help di scilab per i dettagli. Simile comportamento per il comandocumprod , che fa i prodotti cumulativi.Abbiamo gia visto che scilab provvede tutte le funzioni elementari cheagiscono sui valori numerici: , come
sqrt, sin, cos, tan, asin, acos, atan,..., exp, log
Si tratta di funzioni che agiscono sia su vettori che su matrici: se m e unamatrice di elementi mij, allora exp(m) e la matrice di elementi emij e lostesso per la altre funzioni. E bene precisare che queste funzioni si possonoapplicare anche a variabili complesse, come vedremo meglio piu in la.Altre funzioni utiliabs : valore assoluto oppure modulo nel caso si applichi a un numero com-plessofloor : la funzione parte intera, cioe floor(x) e il piu grande intero chesia ≤ x.ceil(x) invece e il piu piccolo intero che sia ≥ x e round(x) e l’interopiu vicino a x. (in inglese “floor” vuole dire pavimento, mentre “ceiling” eil soffitto. . . ).
Un altro tipo di comandi utile in molte applicazioni e quello che riguarda ilriordinamento dei valori di un vettore. Ad esempio
-->xx=rand(1,5,"n")xx =
0.2044185 - 0.7437914 - 0.2589642 0.35016261.0478272
-->[ss k]=sort(xx)k =
5. 4. 1. 3. 2.

22 Capitolo 2. scilab
ss =
1.0478272 0.3501626 0.2044185 - 0.2589642- 0.7437914
Dunque, dato un vettore numerico xx , il comando [ss k]=sort(xx) ge-nera due nuovi vettori. Il primo, ss , contiene le coordinate di xx riordinatein ordine decrescente (quindi ss(1) e il valore piu grande, ss(2) il secon-do in classifica. . . ) mentre il vettore k contiene la permutazione che e statonecessario effettuare per passare da xx a ss . sort riordina in ordine decre-scente. Per riordinare in ordine crescente avremmo dovuto usare il comandogsort : con il comando [ss k]=gsort(xx,"g","i") si avranno in ssi numeri del vettore xx riordinati in ordine crescente ("i" =“increasing”).
2.3 Ancora sul calcolo di matrici
Vediamo di approfondire il calcolo matriciale in scilab approfittando permettere in evidenza alcune proprieta ben note (ma poi neanche tanto. . . ).Costruiamo una matrice a caso.
-->mm=rand(6,6,’n’)
ricordiamo che mme dunque una matrice 6×6 a coefficienti scelti a caso conlegge normale e indipendenti. Calcoliamone gli autovalori.
-->spec(mm)
Verosimilmente avrete trovato che alcuni degli autovalori sono complessi.Vediamo di farne il grafico sul piano complesso; real(zz) e imag(zz)sono i comandi che danno rispettivamente la parte reale e quella immaginariadel numero (o del vettore) complesso zz .
-->zz=spec(mm)
-->clf();plot(real(zz),imag(zz),’.’);
Osservate che se un numero λ e autovalore, anche il suo coniugato lo e, comeben noto (esame di coscienza. . . ). Se vogliamo lavorare con una matricesimmetrica e facile procurarsene una facendo la somma della matrice e dellasua trasposta

2.3. Ancora sul calcolo di matrici 23
-->m1=(mm+mm’)/2
-->spec(m1)
Naturalmente ora gli autovalori sono tutti reali. Oppure
-->m2=mm* mm’
Anche m2 e simmetrica.
-->spec(m2)
Cosa osservate degli autovalori di m2? Sapreste dimostrare che tutti gliautovalori di m2 sono necessariamente positivi?
Vediamo come si calcolano gli autovettori e si diagonalizza la matrice. ilcomando e bdiag che produce 3 risultati
-->[dg,cb,dim]=bdiag(m1);
dg e la matrice dopo la diagonalizzazione (cioe e una matrice diagonale congli autovalori sulla diagonale), mentre cb e la matrice del cambio di base.Dunque le colonne di cb sono gli autovettori di m1. Verifichiamolo:
-->m1 * cb(:,1)./cb(:,1)
Si vede che il vettore formato dalla prima colonna della matrice cb vienetrasformato da m1 in se stesso moltiplicato per una costante (che quindi euno degli autovalori). Proprieta importante degli autovettori di una matricesimmetrica: gli autovettori sono ortogonali. Verifichiamolo: il prodottoscalare dei vettori che costituiscono le prime due colonne e
-->sum(cb(:,1). * cb(:,2))
(osservare il puntolino prima dell’* ). Questa verifica si puo fare in manierapiu intelligente moltiplicando cb per la sua trasposta:
-->cb * cb’
Si vede anzi che scilab sceglie gli autovettori in modo che abbiano modulouguale a 1.

24 Capitolo 2. scilab
Esempio 2.1 Data una matrice simmetrica (reale) A, esistera una ma-trice simmetrica (reale) B tale che BB = A? Cioe, si puo fare la radicequadrata di A?Se si considera il caso che la matrice sia 1 × 1, si vede subito che larisposta e, in generale, no: basta considerare il caso A = −1. Se perotutti gli autovalori fossero positivi. . .Se tutti gli autovalori sono positivi, allora la risposta e facile se A e dia-gonale (si fanno le radici quadrate degli elementi sulla diagonale). Al-trimenti, basta prendere la relazione di diagonalizzazione A = UDU−1.La matrice diagonale D ha tutti gli elementi sulla diagonale che so-no positivi (sono gli autovalori di A). Possiamo quindi fare la radi-ce quadrata, diciamo D1, di D e porre B = UD1U
−1. Verifichiamoche effettivamente B e la radice quadrata di A che stavamo cercando:B2 = BB = UD1U
−1UD1U−1 = UD1D1U
−1 = UDU−1 = A. Vediamocome si fa in concreto a realizzare questi calcoli con scilab , conside-rando la matrice m2di poco fa, che e definita positiva. La cosa e facileperche la matrice cb fornita dal comando bdiag e proprio la U delladiagonalizzazione ed e una matrice ortogonale, dunque la sua inversa euguale alla trasposta
-->[dg2,cb2,dim]=bdiag(m2);
-->b=cb2 * sqrt(dg2) * cb2’;
Verifica
-->m2,b * b
Il calcolo che abbiamo fatto e istruttivo ed e un buon ripasso di proprietadelle matrici e della diagonalizzazione. Comunque scilab provvededirettamente una funzione per il calcolo della radice quadrata di unamatrice, sqrtm , che anzi opera anche con matrici non deifinte positi-ve o anche complesse (producendo eventualmente una radice quadratacomplessa).Attenzione comunque: sqrtm(mm) produce la radice quadrata dellamatrice mmmentre sqrt(mm) produce una matrice i cui elementi sonole radici quadrate dei corrispondenti elementi di mm.

2.4. Numeri complessi 25
2.1 a) Generare a caso piu volte due matrici di ordine 5 simmetriche.Verificare che il loro prodotto non e, in generale, una matrice simmetrica enemmeno diagonalizzabile.b) Verificare sperimentalmente, generando ripetutamente due matrici a
caso, che se una delle due e definita positiva, allora il loro prodotto non e ingenerale una matrice simmetrica ma risulta sempre diagonalizzabile. None una prova formale ma almeno e un buon indizio. Sapreste produrre unadimostrazione formale di questo fatto?c) Verificare che, per le matrici diagonalizzabili trovate come in b) (pro-
dotto di due matrici simmetriche di cui una definita positiva) in generale gliautovettori non sono ortogonali. Sapreste dimostrare che una matrice dia-gonalizzabile avente autovettori ortogonali e necessariamente simmetrica?
2.2 Ricordiamo che la traccia di una matrice quadrata e la somma deglielementi sulla diagonale.a) Generare a caso una matrice quadrata e calcolarne la traccia (per
questo ci sarebbe anche il comando scilab trace ).b) Calcolare, della stessa matrice, la somma degli autovalori. Cosa osser-
vate?c) Sapreste dimostrare che la traccia di una matrice e sempre uguale alla
somma degli autovalori (contati con la loro molteplicita)?d) Date due matrici quadrate A e B aventi lo stesso ordine, mostrare che
tr(AB) = tr(BA).
2.4 Numeri complessi
Come abbiamo detto, scilab e capace di fare i conti con numeri complessi.L’unita immaginaria si indica %i :
-->ww=3+4 * %i
ww =
3. + 4.i
-->zz=1/ww
zz =
.12 - .16i

26 Capitolo 2. scilab
wwmoltiplicato per il suo inverso fa. . .
-->zz * ww
ans =
1. - 5.551E-17i
quasi 1.
Esempio 2.2 Consideriamo il numero complesso eit con t = π7
-->zz=cos(%pi/7)+%i * sin(%pi/7)
zz =
.9009689 + .4338837i
e mettiamo in un vettore tutte le sue potenze da 1 a 200. Naturalmentesi tratta di numeri di modulo uguale a 1.
-->zz2=zzˆ[1:200];
Disegniamo sul piano il numero complesso zz e le sue potenze. Ricor-diamoci di usare l’opzione "." per disegnare i punti senza congiungerlicon un segmento.
-->plot(real(zz2),imag(zz2),".");
Si osservera che nel grafico compaiono pochi punti. In effetti zz14 = 1 epoi i punti si ripetono. Se invece scegliamo il numero complesso, sempredi modulo 1,
-->zz=cos(%pi * %pi/7)+%i * sin(%pi * %pi/7)
zz =
.1601601 + .9870911i
il cui argomento e un multiplo irrazionale di π, e poi facciamo le potenzee le disegniamo sul piano,

2.5. Tipi di dati: caratteri 27
-->zz2=zzˆ[1:200];
-->clf();plot(real(zz2),imag(zz2),".");
-->a=gca();a.isoview="on";
si vede che le cose vanno diversamente. Avreste una idea di un teoremache viene suggerito da questo grafico?
2.5 Tipi di dati: caratteri
Un vettore o una matrice possono avere le loro componenti di tipo “carat-tere”. Ad esempio
-->vc=["Ugo";"Ciro";"Massimiliano";"3"]vc =
!Ugo !! !!Ciro !! !!Massimiliano !! !!3 !
In generale i valori di un vettore di tipo carattere sono indicati tra apici: " "oppure ’ ’ . Inoltre un carattere puo essere una lettera, oppure un caratterediverso, come #, @oppure un numero. In questo caso naturalmente il numeroviene trattato come un carattere (e quindi non gli si possono applicare leusuali operazioni aritmetiche).Operazioni sui caratteri. Concatenazione
-->"3"+"4"ans =
34
-->"Nel "+"mezzo "+"del "+"cammin"+"..."

28 Capitolo 2. scilab
ans =
Nel mezzo del cammin...
Aggiunta di coordinate
-->lista1=["nome","voto";"Arduini","23";"Belli","25 "]lista1 =
!nome voto !! !!Arduini 23 !! !!Belli 25 !
-->lista2=["Bollero","19"];lista1=[lista1;lista2]lista1 =
!nome voto !! !!Arduini 23 !! !!Belli 25 !! !!Bollero 19 !
Numeri si possono convertire nei corrispondenti caratteri e viceversa:
-->string(3)+string(4)ans =
34
-->evstr("3")+evstr("4")ans =
7.
Molti altri comandi sono disponibili per la manipolazione di caratteri, maquesti che abbiamo visto saranno sufficienti per i nostri scopi.

2.6. Input e output 29
2.6 Input e output
Ogni linguaggio di programmazione dispone di comandi che permettono dileggere o di scrivere dei file esterni. Si tratta in genere della parte piu noiosada imparare. . . Ci sono molti comandi di input-output sotto scilab , chepermettono di scrivere e leggere dai file in formato ascii e binario, di aggiun-gere a file gia esistenti nuovo materiale etc. Noi ci limiteremo al minimoindispensabile per la realizzazione dei progetti che vedremo piu tardi.
Supponiamo che dei dati si trovino nel file ascii filemio.txt e che si trattidi una matrice (numerica) di tre righe e 216 colonne. Il comando
-->xx=read("filemio.txt",216,3);
legge i valori numerici e li dispone in una variabile xx di scilab del tipomatrice 216 × 3. Il nome del file e una stringa e quindi va indicato tra " "oppure ’ ’ . Se il file filemio.txt non si trova nella directory di lavoro,occorre specificare tutto il cammino:
-->xx=read("C:\dida\lc2\filemio.txt",216,3);
ad esempio, oppure cambiare di directory di lavoro (vedi p.18). Il numerodi colonne nel comando precedente deve essere sempre specificato, mentreindicando come numero di righe -1 il comando read leggera tutte le righefino all’ultima. Ad esempio se il file filemio.txt conteneva 300 righe ilcomando precedente avrebbe letto solo le prime 216 mentre
-->xx=read("filemio.txt",-1,3)
le avrebbe lette tutte. Il comando read puo anche leggere una matricedi caratteri, ma in questo caso bisogna specificare che il formato dei datida leggere non e numerico, che si fa aggiungendo alla fine del comando laspecificazione ’(a)’ . Se filemio.txt contenesse tre righe di testo, le sipotrebbe leggere con il comando
-->cc=read("filemio.txt",-1,1,’(a)’)
Ora avremmo a disposizione un vettore cc composto da tre righe di testo.
2.3 Importate in scilab il testo contenuto nel file prova3.txt .
In parallelo con read , il comando write scrive un file sul disco. Ad esempio

30 Capitolo 2. scilab
-->write("file2.txt",xx)
avrebbe scritto il contenuto della variabile xx nel file file2.txt . Talvoltascilab protesta e risponde con il messaggio d’errore
File file2.txt already exists or directory writeaccess denied
Non e il caso di farsi prendere dal panico. In genere semplicemente un filecon quel nome esiste gia e il comando write non ha il diritto di sovrascrivereun file esistente. Ricordate che un file puo esistere ed essere vuoto (magariprodotto da un precedente tentativo con write ).write puo essere usato anche per scrivere dati che non siano di numeri realiaggiungendo il formato ’(a)’ , come si faceva con il comando read .
2.4 Il file exspec1 contiene una matrice simmetrica 77× 77. Leggerla inscilab e stabilire se essa sia definita positiva o no.
2.7 Tipi di dati: logici
I dati di tipo logico permettono di controllare e di fare operazioni sullevariabili. Una variabile logica puo prendere i valori T (True=vero) o F(=falso). Una matrice a valori logici puo essere definita o assegnando ivalori vero/falso, che in scilab sono definiti %t e %f rispettivamente. Disolito pero verra definita mediante gli operatori logici che, applicati ad unamatrice numerica o di caratteri producono una matrice logica. Ad esempio
-->xx=(1:7);yy=(xx>=3)ans =
F F T T T T T
Il vettore yy e a valori logici: le sue coordinate prendono i valori T o F aseconda che la corrispondente coordinata di xx sia ≥ 3 o no.Altri operatori che producono valori logici ed il cui significato e piu o menoevidente sono
== < <= >=
Da notare che l’operatore logico di uguaglianza e == e non =. A questi siaggiungono gli operatori & (et), || (or) e ∼ (not). Ad esempio

2.7. Tipi di dati: logici 31
-->xx=(1:7);(xx>=3)&(xx<=6)ans =
F F T T T T F
-->xx=(1:7);(xx>=6)||(xx<=3)ans =
T T T F F T T
Vediamo degli esempi di applicazione delle variabili logiche. Ad esempio
-->xx=(1:7);yy=(xx>=3)&(xx<=6);xx2=xx(yy)xx2 =
3. 4. 5. 6.
Quindi abbiamo estratto dal vettore xx i soli valori che soddisfacevano allacondizione logica
(xx>=3)&(xx<=6)
.
Esempio 2.3 Supponiamo che il vettore xx contenga i risultati (voti)ottenuti ad un esame, mentre il vettore di caratteri yy contenga l’infor-mazione del sesso dello studente. Vorremmo calcolare la media dei votiseparatamente per maschi e femmine. Supponiamo che i dati siano
-->xx=[21 23 14 27 29 28 26];
-->yy=[’M’,’F’,’M’,’M’,’F’,’M’,’F’];
Allora le medie cercate sono
-->mean(xx(yy==’F’))ans =
26.

32 Capitolo 2. scilab
-->mean(xx(yy==’M’))ans =
22.5
Una proprieta molto utile delle variabili logiche e che esse possono essereutilizzate nei calcoli numerici, poiche in questo caso scilab le converteautomaticamente in valori numerici con le conversioni %t 7→1, %f 7→0. Adesempio, generiamo 512 numeri a caso con distribuzione N(0, 1). Quanti diessi risulteranno piu grandi di 1
2?
-->xx=rand(512,1,"n");sum(xx>=.5)ans =
153.
Cioe, in presenza di un’operazione numerica, come sum, i valori del vettorelogico (xx>=.5) sono stati convertiti in valori numerici con la regola in-dicata prima. In un certo senso le variabili logiche funzionano come dellefunzioni indicatrici.
2.8 Programmazione
Finora abbiamo visto come usare scilab dando dei comandi uno dopol’altro nella finestra comandi. Ma si puo anche usare questo software comeun vero e proprio linguaggio di programmazione.Ci sono due modi per farlo. Il primo e quello di realizzare uno script: si scriveuna sequenza di comandi in un file esterno, diciamo il file script1.sci , epoi lo si esegue mediante il comando exec scrivendo
-->exec(’script1.sci’)
scilab comunque provvede un editor per la scrittura dello script e l’esecu-zione puo anche essere lanciata a partire dall’editor. scilab allora eseguetutti i comandi del file script1.sci uno dopo l’altro.scilab prevede dei costrutti con i quali si possono scrivere dei veri pro-grammi: in particolare sono possibili cicli e istruzioni condizionali come nei

2.8. Programmazione 33
normali linguaggi di programmazione. Occorre pero ricordare che scilab ecomunque un linguaggio interpretato e quindi di esecuzione piu lenta rispettoai programmi realizzati con linguaggi compilati come C o FORTRAN.Ad esempio, volendo risolvere il problema del calcolo della radice quadratadi una matrice simmetrica, come visto a p.24, si scrivera un file con le dueistruzioni
[dg2,cb2,dim]=bdiag(m2);b=cb2 * sqrt(dg2) * cb2’;
dopo di che, eseguendo questo file con il comando exec , si trovera nellavariabile b la radice quadrata richiesta. La matrice m2, di cui si vuolecalcolare la radice quadrata, naturalmente andra preventivamente definitanella finestra comandi.Questa procedura e particolarmente comoda quando si devono ripetere piuvolte delle lunghe sequenze di comandi.Un secondo modo di sfruttare le possibilita di programmazione di scilabe di scrivere una funzione. La sintassi e la seguente
function [a1,a2...]=acp(x1,x2,...)
... (comandi scilab)
endfunction
Le variabili a1,a2,... costituiscono lo output della funzione, mentre x1,x2,... sono gli argomenti; acp e il nome che abbiamo deciso di dare allafunzione. Per poter usare una funzione occorrera• scriverla in un file, diciamo fun.sci usando l’editor di scilab (piu
comodo) o comunque qualunque altro editor.• caricarla in scilab , usando i comandi che compaiono nell’editor op-
pure dalla riga comandi con il comando exec (meno comodo).A questo punto la funzione e disponibile. Ad esempio, se la funzione e laseguente
function b=sqrmat(m2)[dg2,cb2,dim]=bdiag(m2);b=cb2 * sqrt(dg2) * cb2’;endfunction
Ora, dopo avere eseguito le operazioni precedenti (salvataggio in un file ecaricamento in scilab del file), scrivendo

34 Capitolo 2. scilab
-->smm=sqrmat(mm)
si otterra la radice quadrata della matrice mm. Da notare che il nome dellafunzione e quello del file in cui essa e salvata possono essere diversi, ma cheper caricarla in scilab occorre fare exec("nome del file") mentreper invocarla occorre scrivere il nome della funzione. Del resto in uno stessofile e possibile scrivere molte funzioni (molto comodo).Ricordare che una funzione deve essere sempre caricata (attarverso l’editoro con il comando exec ) e, se viene modificata, occorre caricare la nuovaversione. E tipico di correggere una funzione e poi invocarla senza primacaricarla di nuovo, per poi disperarsi vedendo che le modifiche apportatenon danno l’effetto sperato.Se la funzione e composta da una sola istruzione, allora la si puo definiredirettamente dalla riga comandi di scilab senza dover aprire l’editor epoi caricare la funzione in scilab . Il comando e deff . Ad esempio unafunzione che dia la densita di una gaussiana centrata e ridotta puo esseredefinita mediante
-->deff("y=ga(x)","y=exp(-x.ˆ2/2)/sqrt(2 * %pi)")
Dopo avere dato questo comando la funzione ga e equivalente a
x 7→ 1√2π
e−1
2x2
.
Il cuore di un programma e dato naturalmente dalle istruzioni che permetto-no di realizzare dei loop o dalle scelte condizionate. I due costrutti principaliper realizzare un loop sono
for...end e while...end;
Vediamo come funzionano in un esempio concreto: supponiamo di volercalcolare la somma di sin k per k che va da 1 a 106. Prima possibilita:
ll=0;for i=(1:10ˆ6)ll=ll+sin(i);end;
Seconda possibilita

2.8. Programmazione 35
ll=0;i=1;while (i<=10ˆ6)ll=ll+sin(i);i=i+1;end;
In altre parole l’istruzione for esegue le istruzioni che seguono fino allo endper tutti i valori assegnati della variabile i , che non e necessariamente interao formata da numeri consecutivi. Invece while costruisce un loop duranteil quale tutte le istruzioni fino allo end successivo vengono eseguite fintantoche una certa condizione logica e vera.
Conviene usare il costrutto for oppure while ?
In generale il primo e piu semplice se si tratta di effettuare una stessa ope-razione un numero prefissato di volte. Qualche volta il ciclo pero deve essereeffettuato un numero di volte che dipende dal risultato dei calcoli effettuatifino ad allora e in questo caso solo while puo essere utilizzato. Vedremodelle applicazioni nel capitolo sulla simulazione.
Ma c’e un’altra osservazione importante da fare su questo punto. Prima ditutto provate a fare lo stesso calcolo ma fino a n = 107. Trovereste che,usando for , scilab vi risponde che il calcolo richiede troppa memoria.Cos’e successo? Il fatto e che con for il programma deve prima generareeffettivamente il vettore
1:10ˆ7
che e cosı lungo che finisce per occupare tutta la memoria. Il comandowhile non ha bisogno di effettuare questa operazione e con questo costruttoil calcolo puo essere effettuato senza problemi. Questa questione si presentaregolarmente quando si fa una simulazione molto lunga. In realta la memoriadi scilab si puo aumentare, ma e chiaro che con while la memoria sarebbecomunque meno intasata e utilizzata in maniera piu efficiente.
Sempre per questo esempio ci sono altre due osservazioni da fare. Intantolo stesso risultato si sarebbe potuto ottenere con il comando
sum(sin(1:10ˆ6))
Provate a misurare il tempo che s’impiega con il comando for e con laprocedura precedente. Per misurare il tempo impiegato ad eseguire una

36 Capitolo 2. scilab
serie d’istruzioni bisogna fare precedere il comando timer(); e poi seguireil comando timer() (senza ; ). Vedrete che for e una trentina di volte piulento:
-->timer();ll=0;for i=(1:10ˆ6),ll=ll+sin(i);end;time r()ans =
5.390625
-->timer();sum(sin(1:10ˆ6)),timer()ans =
0.15625
In altre parole, i due costrutti for e while vanno usati solo quando non cisono altre possibilita e invece bisogna sempre cercare di utilizzare le capacitadi calcolo vettoriale e matriciale che sono il punto di forza di scilab . Que-sta e la principale differenza tra la filosofia di programmazione in scilabed i principali linguaggi di programmazione come C e FORTRAN.Osserviamo comunque che il comando
sum(sin(1:10ˆ6))
e anch’esso limitato dalla capacita della memoria:
sum(sin(1:10ˆ7))
produrrebbe lo stesso segnale d’errore di prima. Ma anche in questo casosi possono sfruttare le capacita di calcolo vettoriale di scilab nel modoseguente
ll=0;for i=(0:9)ll=ll+sum(sin((1:10ˆ6)+i * 10ˆ6);end;
In questo modo il calcolo si svolge in soli 10 cicli (invece che in 107) inognuno dei quali vengono sommati 106 numeri.
2.5 Confrontate il tempo che s’impiega per calcolare sin 1 + · · ·+ sin(107)con un ciclo while (potete prevedere di farvi un caffe nell’attesa. . . ) e conla procedura precedente.

2.8. Programmazione 37
Infine, beh forse non c’era proprio bisogno di mettere scilab a fare tuttiquesti conti. Come si potrebbe calcolare la somma della funzione seno sututti gli interi da 1 a 106, senza ridursi a fare numericamente la somma diun milione di numeri? Ricordate la definizione della funzione esponenzialecomplessa
eiθ = cos θ + i sin θ
che gode della proprieta di moltiplicazione della funzione esponenziale eiθeiφ =ei(θ+φ). Dunque (formula di una somma geometrica)
1 + ei + e2i + · · · + ein =1− ei(n+1)
1− ei
e dunque
sin 1 + · · ·+ sinn = =(1 + ei + · · · + ein
)= =
(1− ei(n+1)
1− ei
).
Ma
(1− ei(n+1))(1− e−i)
(1− ei)(1− e−i)=
1− ei(n+1) − e−i + ein
1− ei − e−i + 1=
1− ei(n+1) − e−i + ein
2− 2 cos 1
e dunque
sin 1 + · · ·+ sinn =− sin(n+ 1)− sin 1 + sinn
2− 2 cos 1·
Software di alto livello come scilab sono preziosi, ma sono anche unacontinua tentazione e si finisce per servirsene anche quando non ce ne sarebbeproprio bisogno. In conclusione,
1) i costrutti che creano dei cicli come for...end; e while...end;vanno usati solo dopo avere riflettuto se non sia possibile ottenere lo stessorisultato usando i comandi vettoriali di scilab ;2) software di alto livello come scilab non sono un’alternativa al ragio-
namento matematico (o un’incitazione alla pigrizia. . . ) e devono essere usatiinvece per estendere le capacita di calcolo a propria disposizione. O ancheper verificare numericamente un calcolo svolto a mano, se si teme di averefatto degli errori di conto.
Un altro elemento tipico dei linguaggi di programmazione sono le istruzionicondizionali. Un esempio tipico e il comando if...else , la cui sintassipiu precisamente e

38 Capitolo 2. scilab
if (espressione logica1) then (istruzioni1)elseif (espressione logica2) then (istruzioni2)...else (istruzioni)end;
Se (espressione logica1) e vera allora le (istruzioni1) vengonoeseguite, altrimenti si passa alla (espressione logica2) , se essa e veravengono eseguite le (istruzioni2) e cosı via. Se nessuna delle variabililogiche risulta vera, allora vengono eseguite le istruzioni successive a else .Da notare che i comandi elseif e else sono opzionali.
Esempio 2.4 Una funzione di uso frequente in teoria del segnale e lafunzione seno cardinale, definita da
sincx =sinx
x
con l’intesa sinc 0 = 1. Come fare per definire la funzione sinc inscilab ? Il problema naturalmente e di come dire a scilab che de-ve distinguere quando x=0 e quando x e diverso da 0. Ci sono variepossibilita: usando if...else :
function y=sinc1(x)y=ones(x);if (x˜=0) then y=sin(x)./x;end;endfunction
La funzione cosı definita funziona, ma ha il difetto di non essere vet-toriale. Cioe, se x e un vettore, sinc1(x) potrebbe non produrre ilrisultato desiderato, poiche la condizione logica (x =0) produrrebbeun vettore logico e if considera allora che la condizione logica e verasolo se tutte le coordinate di questo vettore sono uguali a T. Provate,ad esempio, a calcolare sinc1([-.2,0]) . Il comando if e quindi daevitare con delle condizioni vettoriali.Seconda possibilita: con un po’ di astuzia, combinando le variabililogiche.

2.8. Programmazione 39
function y=sinc2(x)y=(x˜=0). * sin(x)./(x+(x==0))+(x==0)endfunction
Occorre ricordare che le variabili logiche vengono convertite nelle espres-sioni numeriche ai valori 1 quando sono vere e 0 quando sono false. Sicomportano quindi come delle funzioni indicatrici d’insieme, in un certosenso. Quindi il termine (x ∼=0). * sin(x)./(x+(x==0)) e sempreben definito, poiche il denominatore ora non si puo annullare. Questotermine da il valore sinx
x se x 6= 0, ma vale 0 in 0. Dunque aggiungendo(x==0) che vale 1 per x = 0, si ottiene la funzione seno cardinale,Da notare comunque che sinc e una funzione gia prevista in scilab .E quindi possibile andare a vedere come essa e definita, leggendo il file
C:\Program Files\scilab-4.1.2\macros\elem\sinc.sci
Si trova
function y=sinc(x)y=ones(x)kz=find(x<>0)y(kz)=sin(x(kz))./(x(kz));
endfunction
Quando si scrive una funzione e sempre molto opportuno fare in modo che ilrisultato accetti un argomento vettoriale. Ad esempio, volendo programmarela funzione x 7→ x sinx, si puo scrivere
-->deff("y=xsin(x)","y=x * sin(x)")
Ora scrivendo
xsin(%pi/5)
si ottiene effettivamente il numero π5 sin
π5 , ma se poniamo
x=[%pi/3,%pi/5]
e poi scriviamo xsin(x) scilab dara un messaggio di errore, invece dicalcolare x sinx per x = π
3 e x = π5 . Questo non sarebbe successo se avessimo
scritto

40 Capitolo 2. scilab
-->deff("y=xsin(x)","y=x. * sin(x)")(cioe con un puntolino in piu).Talvolta pero non e possibile scrivere la funzione che interessa in manierache possa accettare come argomento un vettore di valori. In questo caso,se poi occorre effettivamente calcolare la funzione ottenuta su un vettore divalori, scilab dispone del comando feval . Supponiamo ad esempio diavere definito una funzione fun1 e di volerla calcolare sui valori contenutiin un vettore x . Cio si puo fare dando il comando
-->y=feval(x,fun1)
Il vettore y ora contiene i valori di fun1 calcolati in x . Questo comando eequivalente a y=fun1(x) se la funzione fun1 accettasse valori vettoriali (ein questo caso questo secondo modo e sicuramente piu veloce e preferibile).Il comando feval puo anche essere usato, ed e molto utile, per funzioni didue variabili. Se fun2 e una funzione di due variabili e x e y sono vettori,allora con il comando
-->z=feval(x,y,fun2)
si ottiene una matrice z che al posto ij contiene il valore di fun2 calcolatain (xi, yj).
2.6 Scrivere una funzione scilab che, dato un punto del piano in coor-dinate cartesiane, ne calcoli modulo e argomento in coordinate polari.
2.9 Grafica in scilab
Uno dei grandi vantaggi dei linguaggi di alto livello come scilab , matlab,R o Splus e la facilita di accesso alla grafica.Come vedremo le cose sono veramente facili se ci si limita ai comandi dibase accettando i default di scilab ma diventano un po’ piu delicate se sicomincia a voler personalizzare il risultato.Cominciamo con un esempio. Il comando base per fare un grafico e plot .L’idea e semplice: vediamo come si disegna il grafico della funzione seno tra0 e 2π. Prima ci procuriamo dei numeri compresi tra 0 e 2π, regolarmentespaziati (diciamo spaziati di un cinquantesimo) ed i valori della funzioneseno in corrispondenza.
-->xx=(0:.02:1) * 2* %pi;
-->yy=sin(xx);

2.9. Grafica in scilab 41
e poi diamo il comando grafico
-->plot(xx,yy)
Se volessimo aggiungere al grafico quello della funzione coseno, basterebbecalcolare i valori di quest’ultima ridare il comando plot :
-->yy2=cos(xx);
-->plot(xx,cos(xx))
Quindi ulteriori invocazioni di plot aggiungono al grafico elementi nuovi. Seinvece avessimo voluto disegnare il grafico ex novo, avremmo prima dovutocancellare il vecchio grafico. Il comando e
-->clf()
che non era proprio facile da immaginare. . . Per generare il grafico simulta-neamente delle due funzioni seno e coseno, con colori diversi, c’era comunqueun metodo piu veloce. Sarebbe bastato fare
-->y=[yy;yy2]
-->plot(xx,y)
Infatti ora il vettore y contiene due righe, la prima con i valori della fun-zione seno, la seconda con i valori di coseno. Quando si da come secondoargomento in plot una matrice viene fatto il grafico di tutte le righe, ognigrafico cambiando di colore, secondo uno schema prestabilito di colori (chel’utilizzatore coraggioso puo anche cercare di personalizzare). Nel comandoplot e possibile quindi dare come argomenti x e y quindi non solo dei vet-tori ma anche delle matrici con vari risultati. Non entreremo nel dettaglio,chi avesse bisogno di queste informazioni puo andare a vedere lo help delcomando plot .Vediamo ora le opzioni elementari del comando plot . Le opzioni vengonoindicate con una stringa di caratteri (quindi tra ” ”) dopo i nomi delle va-riabili. Come si e visto nell’esempio precedente, come default plot disegnai punti di cui gli si danno le coordinate collegandoli l’uno all’altro con unsegmento. Se si desidera che essi siano invece indicati con un simbolo e senzaessere collegati l’uno all’altro, basta specificare il simbolo. Se si vuole che ilgrafico venga eseguito con un colore diverso dal blu, che e il default, si puoindicare il colore. Ad esempio: fare un grafico di dati, in rosso e usando unpunto per indicare i valori:

42 Capitolo 2. scilab
-->plot(xx,yy,".r")
dove “.” indica che si vuole usare il punto come simbolo, mentre r e l’abbre-viazione di red . Si tratta solo di una comodita: plot(xx,yy,".red")avrebbe prodotto lo stesso risultato. I simboli ed i colori disponibili sonoillustrati nelle tabelle che si trovano nello help del comando plot , nelsottomenu Linespec .
Qualche volta ad un grafico e opportuno aggiungere dei dettagli: un titolo,ad esempio,:
-->tt=[-1:.01:1] * %pi;plot(tt,sin(tt));
-->xtitle("la funzione seno");
Da notare che questo comando aggiunge il titolo alla pagina corrente e che ilcomando puo essere dato in un secondo momento rispetto al grafico. Quandosi disegnano piu curve su un medesimo grafico, magari si vorrebbe indicarecosa rappresenta ognuna delle curve: i comandi
-->tt=[-1:.01:1] * %pi;plot(tt,sin(tt));plot(tt,cos(tt),"r");
-->legend(’seno’,’coseno’)
produrranno i due grafici delle funzioni seno e coseno con una leggenda chespiega che il grafico in blu e quello del seno e quello in rosso quello del coseno(provare).
Ulteriori approfondimenti sul comando plot vengono fatti in §3.6.
2.10 Grafica avanzata: personalizzare il grafico
Quando si da il comando plot scilab disegna il grafico scegliendo oppor-tunamente la scala delle ascisse, quella delle ordinate, le tacche da segnaresugli assi, la posizione degli assi stessi. Talvolta pero queste scelte del sistemanon vanno e l’utilizzatore deve cambiarli. Soprattutto in alcuni casi e im-perativo che le unitdi misura sui due assi siano le stesse (se volete disegnareun cerchio, ad esempio). Come fare?
Ci sono due modi, entrambi basati sul fatto che ogni grafico di scilabha degli attributi che si possono modificare, anche dopo che il grafico estato disegnato. Il primo modo utilizza il modo edit che si trova in alto a

2.10. Grafica avanzata: personalizzare il grafico 43
sinistra della finestra grafica. Ad esempio, supponiamo di voler disegnare lacirconferenza unitaria. Un modo per farlo consiste nel disegnare sul piano ipunti di coordinate (cos θ, sin θ). Cio si puo fare con i comandi
-->tt=[0:.01:1] * 2* %pi;yy2=sin(tt);
-->yy1=cos(tt);clf();plot(yy1,yy2)
In questo modo si ottiene una cosa che non sembra proprio una circonfe-renza. Questo e dovuto al fatto che lo schermo del PC non e quadrato escilab cerca sempre di sfruttare al massimo lo spazio disponibile, per cuiusa unita di misura diverse sull’asse delle ascisse e su quelle delle ordinate.Per rimettere le cose a posto cliccate su Edit nella finestra grafica e sele-zionate Figure properties e poi Axes e infine Aspect . Nella finestrache compare ora c’e una finestrella che si chiama isoview . Selezionatela evedrete che la circonferenza diventa una circonferenza vera.
Un secondo modo consiste nel recuperare gli handles della figura e editarlidirettamente dalla riga comandi. Il comando che produce gli handles delgrafico corrente e gca() :
-->a=gca();
Se ora scrivete
-->a
compaiono tutti gli handles. Tra di questi vi e l’attributo isoview . Se dateil comando
-->a.isoview="on"
scilab ridisegna il grafico e le unita di misura sui due assi diventano uguali.In maniera abbastanza intuitiva si capisce come fare per modificare, se neces-sario, gli altri attributi. Ad esempio se si vuole disegnare gli assi coordinatifacendoli passare dall’origine, occorrera cambiare i valori dei parametri
x_location
e
y_location

44 Capitolo 2. scilab
, che per default sono posti rispettivamente uguali a left e bottom e porliuguali a middle . Ricordando che le stringhe di caratteri vanno sempreindicate tra apici o virgolette, il comando da dare sara quindi
-->a.x_location="middle";a.y_location="middle";
Puo capitare di avere bisogno di numerosi grafici simultaneamente. scilabpuo aprire simultaneamente diverse finestre grafiche. Quando si da un co-mando grafico per la prima volta scilab sceglie di realizzare il grafico nellafinestra numero 0. Se si vuole che i grafici successivi vengano effettuati nellafinestra numero 1 occorrera dare il comando scf(1) (scf=select currentfigure). Dopo questo comando, tutti i comandi grafici verranno indirizzatialla finestra numero 1. Per tornare alla finestra iniziale occorrera scriverescf(0) , per aprire un’altra nuova finestra si dovra scrivere scf(i) dovei e un numero intero.In questo modo e possibile disporre simultaneamente di piu grafici. Qualchevolta invece si desidera realizzare piu grafici sulla stessa finestra. Supponia-mo ad esempio di voler suddividere la finestra grafica corrente in quattro edi disegnare in ognuna delle sottofinestre un grafico diverso. Il comando
-->subplot(2,2,1);
indica che la finestra grafica e suddivisa in 2 righe ciascuna formata da 2sottofinestre. Inoltre che d’ora in avanti tutti i comandi grafici andrannoindirizzati alla prima di queste sottofinestre (quella in alto a sinistra). Perpassare alle altre sottofinestre bastera dare i comandisubplot(2,2,2); , subplot(2,2,3); e subplot(2,2,4); che pas-seranno a considerare rispettivamente la sottofinestra 2 (in alto a destra, la3 (in basso a sinistra) e la 4 (l’ultima, in basso a destra).
Esempio 2.5 Qual e il risultato dei comandi seguenti?
-->tt=[-1:.01:1] * %pi;scf(1);subplot(2,2,1);
-->plot(tt,sin(tt));xtitle("la funzione seno");subplot(2,2,2);
-->plot(tt,cos(tt));xtitle("la funzione coseno");

2.11. scilab e C 45
-->tt=[-1:.01:1];scf(1);subplot(2,2,3);plot(tt,sinh(tt),"r");
-->xtitle("la funzione seno iperbolico");
-->tt=[-1:.01:1];scf(1);subplot(2,2,4);plot(tt,cosh(tt),"r");
-->xtitle("la funzione coseno iperbolico");
E abbastanza facile: viene selezionata la finestra grafica numero 1 chepoi viene suddivisa in quattro. Nelle due finestre superiori vengonodisegnati i grafici delle funzioni seno e coseno, nelle due finestre inferioriquelli delle corrispondenti funzioni seno iperbolico e coseno iperbolico.
2.7 Com’e fatta l’immagine dell’asse reale mediante l’applicazione z− >(z − i)/(z + i)? E l’immagine della retta =z = a, a > 0?
2.11 scilab e C
Puo essere utile usare insieme scilab ed un linguaggio compilato tradizio-nale, come FORTRAN oppure C. scilab e molto potente e flessibile quandosi tratta di fare trattamenti grafici mantre questi linguaggi compilati sonodi esecuzione molto piu rapida
In particolare questo e molto evidente quando si fanno lunghe simulazio-ni, nelle quali non e possibile evitare costrutti come for...end oppurewhile...end . In questi casi si effettuera la simulazione in C, ad esem-pio, mentre l’analisi statistica, gli istogrammi. . . etc verranno effettuati inscilab .
E possibile chiamare da scilab un programma esterno in C, e quindi ac-quisire i risultati della simulazione, che poi verranno analizzati con scilab .Vediamo come si fa. Vedremo che la cosa richiede un po’ di pazienza. Inol-tre il modo di collegare i due programmi dipende dal sistema operativo edal compilatore che si usano. Quindi quanto segue vale solo per il sistemaWindows e per il compilatore mingw . Per altri compilatori alcuni detta-gli potrebbero essere diversi, mentre per i sistemi Unix le differenze sonosostanziali (ma abbastanza ben descritte nei manuali scilab , che invece

46 Capitolo 2. scilab
non spiegano niente per chi lavora sotto Windows). Per prima cosa si deve
installare il compilatore: vedi in
http://atoms.scilab.org/toolboxes/mingw/0.9.3/files /gcc-4.6.3-64.exe
se si ha un sistema a 64 bit,
http://atoms.scilab.org/toolboxes/mingw/0.9.3/files /gcc-4.6.3-32.exe
altrimenti. Dopo avere eseguito il file e quindi installato il compilatoreoccorre riavviare il computer, lanciare scilab ed eseguire i comandi
atomsInstall("mingw");atomsLoad("mingw");
Vediamo ora come si deve operare, usando come esempio un programma perla generazione di numeri aleatori di legge esponenziale di media 1. Da unpunto di vista algoritmico, la cosa e molto semplice: ricordiamo che, se Xe una variabile aleatoria uniforme su [0, 1], allora logX e esponenziale dimedia 1. Il programma per realizzare un vettore di lunghezza n di numerialeatori indipendenti di legge esponenziale di media 1 e quindi
#include <stdio.h>#include <stdlib.h>#include <windows.h>#include <time.h>#include <math.h>#define STRICT#define pig 4 * atan(1)
double nrandom (void)
{return ((double)rand()/(double)RAND_MAX);}
/ * il programma seguente genera n numeri aleatoriindipendenti con distribuzione esponenziale * /
void rexp(unsigned int * n,double x[]){
unsigned int ii;double z1;

2.11. scilab e C 47
for (ii=0;ii< * n;++ii){z1=nrandom();x[ii]=-log(z1);}}
Guardiamo piu da vicino la riga
void rexp(unsigned int * n,double x[])
e mettiamo in evidenza un paio di cosette importanti. Intanto le funzioni Cche si possono chiamare da scilab devono essere del tipo void , cioe nondevono restituire un valore, ma solo cambiare il valore degli argomenti iningresso.Inoltre notiamo che gli argomenti della funzione rexp devono essere deipuntatori. Questo e un punto importante che si deve tenere da conto nellarealizzazione del programma. Anche la variabile x e un puntatore, anche senon compare la stellina, perche in C sono puntatori tutte le array.Il corpo del programma produce un vettore di lunghezza * n di numeri alea-tori indipendenti di legge esponenziale di parametro 1. Il programma cosıscritto deve essere poi compilato e collegato (linkato, come si dice) a scilabcon i comandi
ilib_for_link("rexp","fun1.c",[],"c")exec loader.sce
dove fun1.c e il nome del file in cui avremo salvato il programma (assi-curarsi che si trovi nella directory corrente, altrimenti occorre indicarne ilpercorso). Dovendo effettuare piu volte questa operazione si puo definireuna funzione per semplificare la scrittura. Ad esempio
function y=cl(ep,nomefile)//ricordare: argomenti tra " "y=ilib_for_link(ep,nomefile,[],"c");exec loader.sceendfunction
Una volta caricata la funzione cl in scilab , per fare la compilazione dellanostra funzione rexp bastera scrivere

48 Capitolo 2. scilab
cl("rexp","fun1.c")
Attenzione: occorrera mettere i nomi degli argomenti tra apici ’ ’ o virgolette” ”.A questo punto la nostra funzione rexp e caricata in scilab . Se vogliamoservircene per generare 100 numeri a caso, dobbiamo scrivere
-->nn=100;xx=call("rexp",nn,1,"i","out",[1 nn],2,"d" );
La sintassi della funzione call e un po’ complessa. Il primo argomentoindica il nome della funzione da chiamare. Seguono poi le descrizioni dellevariabili di input della funzione. Qui ce n’e una sola, il numero di valorisimulati: nn e il valore della variabile, 1 il posto che occupa nell’ordinedi chiamata nel programma rexp , "i" indica che e una variabile di tipointero. "out" indica che ora comincia l’indicazione delle variabili di output,nel nostro caso il vettore di nn numeri aleatori. [1 nn] indica che si trattadi un vettore riga di nn elementi, 2 che la variabile in questione si trovaal secondo posto nell’ordine di chiamata, "d" che si tratta di una variabilein doppia precisione. Dovendo chiamare la funzione esterna piu volte evolendo risparmiarsi questa sintassi arzigogolata anche qui si puo definireuna funzione che faccia il lavoro per noi. Ad esempio
function xx=genexp(nn)xx=call("rexp",nn,1,"i","out",[1 nn],2,"d");endfunction
Una volta caricata, la funzione, genexp(nn) produrra i nostri nn numerialeatori usando il programma esterno.Se si vogliono generare dei numeri aleatori di legge diversa, si possono uti-lizzare risultati sulle trasformazioni delle leggi di probabilita che si vedonodi solito nei corsi di base. Ad esempio:1) Per simulare dei numeri aleatori di legge esponenziale di parametro λ,
basta simularli con parametro 1 e poi dividerli per λ.2) per generare dei numeri con distribuzione Gamma(n, 1), bastera ri-
cordare che, se X1X2, . . . ,Xn sono v.a. esponenziali di media 1, alloraX1 +X2 + · · ·+Xn e appunto Gamma(n, 1).Una discussione a parte merita la generazione di numeri aleatori di leggeN(0, 1), per i quali bisogna sviluppare metodi appositi. L’idea consiste nel-l’osservare che se X e Y sono v.a. indipendenti e N(0, 1), allora X2 + Y 2
segue una legge esponenziale di parametro 12 . Cercheremo di generare la
v.a. congiunta (X,Y ) in coordinate polari; questo si chiama l’algoritmo di

2.11. scilab e C 49
Box-Muller. Abbiamo gia visto come si fa a simulare il modulo del vettore(X,Y ): si simula una v.a. esponenziale, Z, di parametro 1 e poi si prende√2Z. L’argomento del vettore e invece evidentemente uniforme su [0, 2π].
In conclusione, se Z e esponenziale di parametro 1 e U e uniforme su [0, 1],le due v.a. √
2Z cos(2πU) e√2Z sin(2πU)
sono indipendenti ed hanno legge N(0, 1).
2.8 Generare, usando il programma in C appena sviluppato, nn= 512numeri aleatori di legge esponenziale e verificare la bonta del generatoreeffettuando istogrammi e test grafico dei quantili. Fare il test dei quantiliconfrontando il campione prodotto con i quantili di una legge di student t(3)e poi con una t(9). Cosa si osserva?
2.9 Modificare il programma C di poco fa per la generazione a casodi numeri aleatori con distribuzione Gamma e t di student. Modifica-re il programma del grafico dei quantili per verificare la bonta dei nuovigeneratori.(ricordate che i comandi scilab per ottenere i quantili delle leggi gammae delle t di Student sono cdfgam e cdft rispettivamente). E inoltre utile
segnalare che, quando si fa una simulazione bisogna sempre accertarsi cheil generatore di numeri a caso che si usa (sia che la simulazione venga fattasotto scilab che sotto C) abbia un periodo abbastanza lungo. Infatti ungeneratore aleatorio e sempre periodico, cioe produce un numero fissato dinumeri, dopo di che ricomincia da capo. Quindi occorre sempre verificare,prima di una simulazione che il numero di numeri aleatori di cui si ha bisognosia inferiore al periodo del generatore. Informazioni sui generatori buoni esul loro periodo si trovano nello help del comando scilab grand . Perdare un’idea, i generatori aleatori che si trovano di solito, come rand discilab , oppure nrandom di C, hanno un periodo dell’ordine di 109. Inpratica si tratta di generatori semplici, buoni per operazioni d poco impegno.Per lavori di simulazione impegnativi occorrera ricorrere al comando grandoppure, sotto C, a generatori piu raffinati come quello di Marsaglia o diKnuth (vedi §5.3).

50 Capitolo 2. scilab
II PARTE:
APPLICAZIONI E CASE STUDIES

Capitolo 3
Analisi multivariata
3.1 Statistica Descrittiva
In questo primo capitolo vedremo dei metodi di analisi di insiemi di dati.Vedremo che queste tecniche si riconducono essenzialmente a delle questionidi algebra e di geometria, che si acquisiscono tipicamente nei primi due annidi corso. Cominciamo con un insieme di dati semplice: vengono osservatin individui e per ciascuno di essi viene osservata una quantita numerica. Ilricercatore si trova quindi di fronte a n numeri x1, . . . , xn.Si chiama media del campione la quantita
x =1
n(x1 + · · ·+ xn) =
1
n
n∑
i=1
xi . (3.1)
La media di un campione e uno di quelli che si chiamano indici di centralita.In altre parole la media indica il centro del campione.Si vede subito che se poniamo yi = axi+b con a, b ∈ R, allora la media y delcampione y1, . . . , yn e uguale a ax+ b. In altre parole la media e invarianteper un cambio di unita di misura: fare un cambio di scala e poi la media elo stesso che calcolare la media e poi fare il cambio di scala. Infatti
y =1
n
n∑
i=1
yi =1
n
n∑
i=1
(axi + b) = a( 1
n
n∑
i=1
xi
)+
1
n
n∑
i=1
b =
= ax+ b .
Si chiama varianza del campione la quantita
1
n
n∑
i=1
(xi − x)2 . (3.2)
51

52 Capitolo 3. Analisi multivariata
La varianza si indica σ2, oppure σ2x per indicare che si tratta della varianzadel campione x = {x1, . . . , xn}, nel caso si stia lavorando con piu di uncampione e ci sia pericolo di confusione. La radice quadrata σ (oppure σx)della varianza e lo scarto quadratico o deviazione standard.
La varianza e un indice di dispersione: essa misura se i valori del campionesiano o no lontani dal loro baricentro x. Valori grandi della varianza indicanoche vi sono valori del campione lontani da x. Viceversa se σ2 = 0 allora tuttigli xi sono necessariamente uguali a x, perche cio vorrebbe dire che nellasomma della formula (3.2) tutti i termini sono nulli.
Se b ∈ R e yi = xi + b, allora σ2x = σ2y . Infatti sappiamo gia che y = x+ b edunque σ2y e uguale a
1
n
n∑
i=1
(yi − y)2 =1
n
n∑
i=1
(xi + b− x− b)2 = 1
n
n∑
i=1
(xi − x)2 = σ2x .
Del resto, intuitivamente, sommare b a tutti gli elementi del campione si-gnifica spostare di b anche il baricentro x, ma cio non cambia la dispersionedel campione rispetto al baricentro. E anche facile verificare che se yi = a xiallora σ2y = a2σ2x.
Un’altra espressione per la varianza si ottiene sviluppando il quadrato nella(3.2):
1
n
n∑
i=1
(xi − x)2 =1
n
n∑
i=1
x2i −2x
n
n∑
i=1
xi + x2 =
=1
n
n∑
i=1
x2i − x2 .
Media e varianza danno quindi delle indicazioni utili sui dati: ne indicanoil valore centrale e una misura della dispersione dei valori rispetto al valorecentrale.
Vediamo ora cosa si puo dire quando su ogni individuo vengono fatte duemisurazioni. Nel prossimo paragrafo affronteremo invece il caso, piu com-plesso e interessante, in cui, per ogni individuo, vengono invece misurate nquantita numeriche.
In questo caso quindi i dati si presentano sotto forma di vettori (x1, y1),(x2, y2),. . . , (xn, yn). Chiediamoci se vi sia una relazione di tipo lineare trai due caratteri, ovvero se esistano due numeri a e b tali che, grosso modo,si abbia yi = axi + b, i = 1, . . . , n. Dobbiamo cioe cercare la retta ax+ b =y che approssima meglio y come funzione di x (e la chiameremo la retta

3.1. Statistica Descrittiva 53
di regressione). Piu precisamente: in generale non esisteranno dei numeria, b ∈ R tali che si abbia esattamente yi = axi + b per ogni i = 1, . . . , n.Esistera pero una retta che rende minimi gli scarti tra i valori yi e axi+b, inun certo senso la retta che meglio delle altre spiega i valori yi come funzionelineare-affine degli xi.
Cerchiamo dunque due numeri a, b ∈ R in maniera che la quantita
S(a, b) =
n∑
i=1
(yi − axi − b)2
sia minima. Conviene sommare e sottrarre le medie all’interno del quadrato,cioe
S(a, b) =
n∑
i=1
((yi − y)− a(xi − x) + (y − b− ax))2 .
Sviluppando il quadrato si trova
S(a, b) =
=
n∑
i=1
(yi − y)2 + a2n∑
i=1
(xi − x)2+
+n(y − b− ax)2 − 2an∑
i=1
(yi − y)(xi − x)+
+(y − b− ax)n∑
i=1
(yi − y)︸ ︷︷ ︸
=0
−2a(y − b− ax)n∑
i=1
(xi − x)︸ ︷︷ ︸
=0
.
Le due quantita indicate sono nulle perche, ad esempio,
n∑
i=1
(yi − y) =n∑
i=1
yi − ny = ny − ny = 0 .
Se poniamo
σxy =1
n
n∑
i=1
(xi − x)(yi − y) , (3.3)
allora si puo scrivere
1
nS(a, b) = σ2y + a2σ2x − 2aσxy + (y − b− ax)2 .

54 Capitolo 3. Analisi multivariata
Poiche b compare unicamente nell’ultimo termine, e chiaro che, per ottenereil minimo, deve essere b = y − ax. Basta quindi trovare il valore di a cherende minimo il trinomio
a→ a2σ2x − 2aσxy + σ2y .
Derivando e uguagliando a 0 si trova 2aσ2x − 2σxy = 0. Dunque,
a =σxyσ2x
, b = y − σxyσ2x
x . (3.4)
La retta y = ax + b si chiama la retta di regressione del carattere y sulcarattere x. In realta i valori di a e b appena calcolati sono solo dei valorinei quali le derivate parziali di S si annullano (cioe quello che si chiama unpunto critico) e cio in generale non garantisce che si tratti di un punto diminimo (potrebbe anche essere di massimo o di sella o altro ancora). Non edifficile pero vedere che se la variabile (a, b) tende all’infinito, allora ancheil valore di S tende all’infinito. Inoltre sappiamo che una tale funzione,continua e che vale infinito all’infinito, possiede necessariamente un minimoed inoltre che tale punto e necessariamente un punto critico. Poiche il punto(a, b) calcolato in (3.4) e l’unico punto critico di S, se ne deduce che esso eanche l’unico punto di minimo della funzione S.La quantita σxy si chiama la covarianza di x e y. Sviluppando i prodottinella (3.3), si trova l’espressione equivalente
σxy =1
n
n∑
i=1
xiyi − xy .
Osserviamo che il coefficiente angolare a =σxy
σ2x
della retta di regressione ha
lo stesso segno della covarianza σxy. Se dunque σxy > 0, cio indica che ytende a crescere al crescere di x. Ci si puo aspettare qualcosa del genere, adesempio, se x e y fossero rispettivamente il peso e l’altezza di individui. Seinvece σxy < 0, l’effetto di x su y sara antagonista: al crescere dei valori di xi valori di y tenderanno a decrescere. Si chiama coefficiente di correlazione
dei caratteri x e y la quantita
ρx,y =σxyσxσy
·
Si puo dimostrare che si ha sempre −1 ≤ ρx,y ≤ 1. Un valore di ρx,y vicino a0 indica scarsa correlazione tra i due caratteri. Viceversa valori di ρx,y vicinia −1 indicheranno una forte correlazione antagonista e valori vicini a 1, al

3.1. Statistica Descrittiva 55
•
•
••
•
•
•
•
• •
•
• •
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
• •
•
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
• •
•
•
•
•
••
•
•
•
•
•
•
•
••
• •
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•• •
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
Figura 3.1: Esempio di grafico di due caratteri con una correlazione positiva,con la relativa retta di regressione.
•
•
••
•
•
•
•
•
•
•
•
• •
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
• •
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
••
••
•
•
•
•
•
•
•
•
•
••
•
•
•
•
••
• ••
•
•
•
•
•
•
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
••
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
Figura 3.2: Qui, invece, la correlazione e negativa.

56 Capitolo 3. Analisi multivariata
contrario, una forte correlazione all’unisono. Il pregio del coefficiente ρx,y,rispetto alla covarianza, e che esso e insensibile ai cambiamenti di scala: setutti i valori di xi vengono moltiplicati per uno stesso numero a > 0 ed ivalori di yi per uno stesso numero b > 0, il coefficiente di correlazione noncambia. Infatti σxy risulterebbe moltiplicato per ab, σx per a e σy per b.
3.1 Scrivere una funzione scilab che, date due variabili, ne fa il plot eaggiunge al grafico la loro retta di regressione.
3.2 Dati multidimensionali
Si puo dire che lo scopo della statistica descrittiva e di estrarre dai datiraccolti le informazioni piu rilevanti che essi contengono.
Nella situazione piu semplice, in cui i dati consistono nel rilevamento diun singolo carattere per ogni individuo di un campione, media e varianzaforniscono delle informazioni semplici sul baricentro e sulla dispersione deivalori osservati. In presenza di 2 caratteri un’informazione supplementaree data dalla covarianza (o dal coefficiente di correlazione), che misura ladipendenza tra i caratteri. Sono pero possibili situazioni piu complesse incui occorre considerare piu di 2 caratteri per individuo. In questo casoinfatti e piu difficile tenere conto delle dipendenze tra i caratteri e non e piupossibile fare un grafico dei dati come nelle figure del paragrafo precedente.
In questo capitolo svilupperemo dei metodi di analisi di piu caratteri. Adifferenza dei casi semplici del capitolo precedente, in cui calcoli e grafici sisarebbero potuti fare con un po’ di pazienza anche a mano, per i metodi diquesto capitolo sara inevitabile l’uso di calcolatori e di software specializzato.Lo studio della teoria dovra dunque avanzare di pari passo con l’acquisizionedella capacita di utilizzare questi strumenti di calcolo. In generale suppor-remo che i dati siano della forma seguente. Vengono osservati n individui,per ciascuno dei quali sono rilevati p caratteri (o variabili) che supporre-
mo tutti numerici. Siamo quindi in presenza di p variabili che indicheremoX(1), . . . ,X(p). Rappresenteremo i dati nella forma della matrice
X = (xij) i=1,...,n
j=1,...,p
in cui le righe corrispondono agli individui e le colonne ai caratteri: xijsara dunque il valore del carattere j-esimo misurato sull’individuo i-esimo.I dati si possono anche vedere come una nuvola di n punti in R
p (sonoi punti le cui coordinate sono date dalle righe della matrice X dei dati).Indicheremo con x1, . . . , xn questi vettori. Viceversa ognuna delle colonne

3.2. Dati multidimensionali 57
1avar.↓ . . .
pavar.↓
1◦ individuo→ x11 . . . x1p2◦ individuo→ x21 . . . x2p
. . . . . .
n◦ individuo→ xn1 . . . xnp
Figura 3.3: Il tipico aspetto di una matrice dei dati: con molte righe (quantisono gli individui recensiti) rispetto alle colonne. Ognuna delle righe puoessere pensata come un vettore di Rp (p e il numero delle variabili).
della matrice X contiene i valori assunti da una delle variabili X(1), . . . ,X(p).Possiamo iniziare l’analisi calcolando per ciascuna delle variabili le medie,che indicheremo con x·1, . . . , x·p, e le varianze e poi le covarianze di ognunadelle variabili con le altre. Chiameremo baricentro dei dati considerati ilvettore x di cui i numeri x·1, . . . , x·p sono le coordinate. Si chiama matrice
di covarianza delle variabili X(1), . . . ,X(p) la matrice p × p che ha comeelemento di posto ij la covarianza tra la variabile X(i) e la variabile X(j). Sitratta quindi di una matrice che ha sulla diagonale le varianze delle singolevariabili (la covarianza di X(i) con se stessa non e altro che la varianza diX(i)) mentre riporta fuori della diagonale le covarianze delle variabili tra diloro. Si tratta chiaramente di una matrice simmetrica, poiche la covarianzadi X(i) con X(j) e la stessa di quella di X(j) con X(i). Numericamente glielementi della matrice di covarianza, che indicheremo con Γ, sono espressiin termini della matrice X dei dati da
Γij =1
n
n∑
h=1
(xhi − x·i)(xhj − x·j) =1
n
n∑
h=1
xhixhj − x·ix·j .
Analogamente si definisce la matrice di correlazione: sara la matrice che hacome elemento di posto ij il coefficiente di correlazione tra la variabile X(i)
e la variabile X(j). Naturalmente gli elementi sulla diagonale della matricedi correlazione sono tutti = 1, perche il coefficiente di correlazione tra unavariabile e se stessa vale sempre 1.

58 Capitolo 3. Analisi multivariata
3.3 Statistica descrittiva in scilab
Cominciamo a vedere i comandi che manipolano dei dati. Per prima co-sa bisogna “importarli”. Prendiamo per cominciare i dati sulla concentra-zione di ozono che si trovano nel file dei dati http://160.80.10.11/ proces-si/lc2data.htm . Occorre catturare i dati e fare un copia/incolla su un editorascii. Quindi salvarli (solo i numeri) in un file. Diciamo
c:\dida\lc2\ozono.txt
.Per acquisirlo sotto scilab il comando e
-->xx=read(’c:\dida\lc2\ozono.txt’,-1,4);
Ricordiamo che nel comando read , bisogna prima dare il nome del file nelquale si trovano i dati (tra ’ ’ o ” ”), poi il numero di righe che si vuoleleggere (-1 indica fino all’ultima) ed il numero di colonne (qui sono 4). Idati della concentrazione di ozono si trovano nella prima colonna. Quindi,per mettere i dati relativi in un vettore,
-->oz=xx(:,1);
Ora il vettore oz contiene i dati che ci interessano. Calcolare la media efacile:
-->mean(oz)
ans =
42.099099
Per la varianza e la deviazione standard bisogna sempre fare attenzione.Una possibilita consiste nel farsela a mano. Per la varianza basta fare
-->s2oz=mean((oz-mean(oz)).ˆ2)
s2oz =
1097.3145
Mentre la deviazione standard si ottiene facendo la radice quadrata

3.3. Statistica descrittiva in scilab 59
-->sqrt(s2oz)
ans =
33.125738
Per la deviazione standard ci sarebbe un comando apposta
-->st_deviation(oz)
ans =
33.275969
Che da pero un risultato un po’ diverso. In effetti spesso la varianza vienedefinita dividendo per n−1 invece che per n. Si tratta di una scelta motivatadall’uso che si fa della deviazione standard in statistica inferenziale, ed e ineffetti la scelta di scilab . Verifichiamolo
-->st_deviation(oz) * sqrt(length(oz)-1)/sqrt(length(oz))
ans =
33.125738
Un altro comando utile e mvvacov , che produce la matrice di varianza-covarianza:
-->mvvacov(xx)
ans =
1097.3145 1047.0647 - 71.857982 219.52504
1047.0647 8233.8886 - 40.873225 253.16614
- 71.857982 - 40.873225 12.543294 - 16.7053
219.52504 253.16614 - 16.7053 90.00211

60 Capitolo 3. Analisi multivariata
avremmo anche potuto usarlo per calcolare la varianza
-->mm=mvvacov(oz)
ans =
1097.3145
E opportuno sottolineare che mvvacov usa la normalizzazione che ci in-teressa (dividendo per n). Qualche volta avremo bisogno della matrice dicorrelazione, cioe di quella che ha al posto ij il coefficiente di correlazionetra i caratteri xi e xj. Come la si puo ottenere? Due possibilita. La primausa calcola uno per uno gli elementi della matrice con il costrutto for ...end :
-->for ii=1:4,for jj=1:4,mcor(ii,jj)=mm(ii,jj)/sqrt(m m(ii,ii))/sqrt(mm(jj,jj));end;end;
-->mcor
mcor =
1. .3483417 - .6124966 .6985414
.3483417 1. - .1271835 .2940876
- .6124966 - .1271835 1. - .4971897
.6985414 .2940876 - .4971897 1.
Il secondo metodo e il migliore ed usa il comando diag . Questo comando emultiforme.
• applicato ad una matrice quadrata mproduce un vettore contenente glielementi sulla diagonale di m.
• applicato a un vettore produce una matrice diagonale, con sulla diago-nale le coordinate del vettore.
Dunque diag(diag(m)) e la matrice diagonale con la stessa diagonale dim. Un attimo di riflessione indica che la matrice di correlazione si ottieneanche con il comando

3.3. Statistica descrittiva in scilab 61
-->sqrt(diag(diag(mm)))ˆ(-1) * mm*sqrt(diag(diag(mm)))ˆ(-1)
ans =
1. .3483417 - .6124966 .6985414
.3483417 1. - .1271835 .2940876
- .6124966 - .1271835 1. - .4971897
.6985414 .2940876 - .4971897 1.
Osserviamo che la variabile v1 (concentrazione di ozono) e leggermentecorrelata con la v2 (irraggiamento solare), fortemente correlata con la v4(temperatura) e fortemente correlata negativamente con la v3 (forza delvento).Nell’analisi di dati unidimensionali uno strumento utile sono gli istogrammi.Dato un insieme di misurazioni, il loro istogramma si ottiene suddividendole osservazioni in intervalli e costruendo sopra ognuno di questi intervalli deirettangoli le cui aree siano proporzionali al numero di osservazioni che cadononell’intervallo. Per tracciare un istogramma scilab prevede il comandohistplot :
-->clf();histplot(21,xx)
produce l’istogramma dei valori contenuti nel vettore xx suddividendoli in 21intervalli (di uguale ampiezza). Da notare che sta all’operatore di decidereil numero d’intervalli in cui suddividere i dati. Il problema di stabilire inquante classi bisogna suddividere i dati sembra stupido ma ha in realta unalunghissima storia. Sono state proposte molte formule per decidere il numerodi classi. Occorre infatti trovare un giusto mezzo tra troppe classi (che fannocomparire dettagli senza importanza) e troppo poche. Una formula semplicea cui si fa riferimento di solito e quella di Sturges: il numero di classi k e
k = 1 + blog2 nc
dove b c indica la funzione parte intera e n e il numero di osservazioni.Si tratta di una regoletta semplice e molto rozza, ma una discussione suquesto punto richiederebbe troppo tempo e regole piu raffinate sono di usopiu complicato.

62 Capitolo 3. Analisi multivariata
Anche qui sono possibili molte opzioni (ad esempio si possono suddividerei dati in intervalli che non sono di eguale ampiezza). Anche qui e megliorinviare allo help di scilab piuttosto che disperdersi in dettagli. C’e perouna opzione che e utile indicare. I due comandi
-->histplot(21,xx)
e
-->histplot(21,xx,normalization=%f)
producono due istogrammi simili che differiscono solo per la scala delleordinate. Nel secondo (con l’opzione
normalization=%f
) sulle ordinate compaiono gli effettivi, cioe i numeri di osservazioni che ap-partengono alle varie classi. Nel primo invece compare la proporzione di indi-vidui appartenenti alle varie classi. Dunque se xx contiene 1000 osservazionidi cui 82 nella prima classe, lo istogramma con l’opzione
normalization=%f
produrra il primo rettangolo alto 82, altrimenti si otterrebbe un rettangoloalto 0.082 = 82/1000. I due istogrammi sembrano identici perche scilabcomunque provvede a riscalare le unita di misura sugli assi per approfittareal massimo dello schermo del computer.
3.2 Generare un campione di 512 numeri casuali con distribuzione N(0, 1),farne l’istogramma e poi sovrapporre al grafico ottenuto quello della densitadella legge N(0, 1).
3.3 Definire una funzione scilab che, dato un insieme di osservazioniproduce un istogramma con un numero di classi calcolato automaticamentecon la regola di Sturges.
3.4 I dati del file xx2006 contengono i risultati di un test a rispostemultiple composto da 30 domande (le colonne) al quale hanno partecipato530 studenti (le righe): 1=risposta giusta, 0=risposta sbagliata, il voto finaledi ognuno essendo il numero totale di risposte giuste. Il file e composto di530 righe (gli individui) e 30 colonne (le risposte).a) Importare i dati sotto scilab .b) Per ogni esercizio calcolare la media di risposte giuste. Qual esercizio
sembra essere il piu facile? Quale il piu difficile?

3.4. Analisi in componenti principali 63
c) Produrre la lista dei voti dei 530 studenti. Qual e lo studente piubravo? E il piu scadente? Qual e la media dei voti? E la mediana? Il votodi superamento era fissato a 16. Quanti studenti hanno superato il test?Fare un istogramma dei voti.d) Per l’esercizio n.11 calcolare la media delle risposte tra gli studenti con
voto finale ≥ 24, quelli tra 16 et 23 e quelli con voto ≤ 15.e) Per ognuno dei 30 esercizi calcolare la correlazione con il voto finale.
Quale degli esercizi e probabilmente poco adatto a fornire una valutazioneefficace delle capacita degli studenti?f) Quale degli esercizi invece pare piu adatto a discriminare gli studenti
bravi da quelli meno validi? Calcolare per questo esercizio la media disoluzioni esatte tra gli studenti che hanno la sufficienza (voto finale≥ 16) etra gli altri. Ripetere questa operazione per l’esercizio individuato in e) econfrontare.
3.4 Analisi in componenti principali
In questo paragrafo e nel prossimo vedremo dei metodi di analisi di dati mul-tidimensionali. L’idea dell’analisi multivariata e di proiettare i punti su unpiano ed osservare il grafico dei punti proiettati. Naturalmente facendo cosısi perde dell’informazione: punti che appaiono vicini nella proiezione possonoin realta essere molto distanti tra di loro. Per questo sara importantea) innanzitutto cercare il piano migliore su cui effettuare la proiezione;b) essere in grado di stimare quanto si e perso facendo la proiezione, in
modo da valutare quanto i punti della proiezione siano una rappresentazionefedele dei punti originali. Discutiamo ora il punto a), partendo dal caso piu
semplice della proiezione degli n punti su una retta per l’origine. Cerchiamocioe la retta “migliore” su cui proiettare i punti, ricordando che la proiezionedi un punto x su una retta e il punto della retta che si trova piu vicino ax. Osserviamo intanto che una retta per l’origine puo essere individuata daun vettore v ∈ R
p di lunghezza 1: dato un tale vettore l’insieme dei puntidi Rp della forma tv, al variare di t ∈ R descrive una retta, e d’altra parteogni retta passante per l’origine e di questa forma. Osserviamo comunqueche, data una retta per l’origine, questo vettore non e unico, dato che v e−v individuano la stessa retta.La proiezione di un punto x ∈ R
p sulla retta individuata dal vettore unitariov e il punto tv (un punto della retta, quindi) dove t e pari al prodotto scalare〈x, v〉. Ricordiamo infatti che il prodotto scalare 〈x, y〉 di due vettori di Rp
e il numero |x||y| cos θ, dove θ e l’angolo compreso tra i due vettori x e

64 Capitolo 3. Analisi multivariata
.....................................................................................................................................................................................................................................................
.
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
..
............
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
........
........
........
........
........
........
........
........
........
........
........
........
........
........
.
.
.
.
.
.
.
.
..
.
..
..
.
.
.
.
..
.
.
.
.
.
..
.
..
.........
........ •
•
v
x
θ
0
•↖
Figura 3.4: Se |v| = 1, il valore del prodotto scalare dei vettori x e v e datodalla distanza tra l’origine ed il punto segnato con una freccia. Quest’ultimoe anche la proiezione di x sulla retta individuata da v. Si tratta chiaramentedel punto della retta che si trova piu vicino a x.
y. Poiche nel nostro caso supponiamo |v| = 1, dunque 〈x, v〉 = |x| cos θ.La Figura 3.4 illustra questo rapporto tra prodotto scalare e proiezione diun punto su una retta. Il prodotto scalare di due vettori x e v si esprimefacilmente anche in termini delle loro coordinate. Si puo infatti mostrareche, se x = (x1, . . . , xp), y = (y1, . . . , yp) vale la formula
〈x, y〉 =p∑
i=1
xiyi . (3.5)
In particolare il prodotto scalare e lineare, cioe si ha
〈x, αy + βz〉 = α〈x, y〉+ β〈x, z〉
per ogni α, β ∈ R e x, y, z ∈ Rp. Tornando agli n punti x1, . . . , xn in R
p,quale sara il vettore unitario v tale che la loro proiezione sulla retta indivi-duata da v sia la piu fedele possibile? Ricordando il significato intuitivo dellanozione di varianza, una proiezione sara tanto piu fedele quanto piu gran-
de sara la dispersione dei punti ottenuti dalla proiezione sulla retta, ovveroquanto piu grande sara la varianza dell’insieme di punti 〈v, x1〉, . . . , 〈v, xn〉,che ora costituiscono un campione di numeri reali. Osserviamo comunqueche, grazie alla (3.5), possiamo vedere questi punti come i valori di unanuova variabile (o carattere). Si trattera del carattere che nell’osservazionei-esima prende il valore
v1xi1 + · · · + vpxip

3.4. Analisi in componenti principali 65
e che quindi e combinazione lineare delle variabili X(1), . . . ,X(p) con i coef-ficienti v1, . . . , vp. Cominciamo col calcolare la media µ(v) di questi valori:poiche il prodotto scalare e lineare,
µ(v) =1
n
n∑
k=1
〈v, xk〉 =⟨v,
1
n
n∑
k=1
xk⟩= 〈v, x〉 .
Dunque la media µ(v) dei punti proiettati non e altro che la proiezione sullaretta individuata da v del baricentro x dei punti x1, . . . , xn. Calcoliamonela varianza. Anzi cerchiamo una formula per trovare la covarianza dei puntiproiettati su due direzioni v e w, che indicheremo σ(v,w). Poiche 〈xk, v〉 −〈x, v〉 = 〈xk − x, v〉, si ha
σ2(v,w) =1
n
n∑
k=1
(〈xk, v〉 − 〈x, v〉)(〈xk , w〉 − 〈x, w〉) =
=1
n
n∑
k=1
〈xk − x, v〉〈xk − x, w〉 .
Sviluppando il prodotto
〈xk − x, v〉〈xk − x, w〉 =p∑
i=1
(xki − x·i)vip∑
j=1
(xkj − x·j)wj =
=
p∑
i,j=1
(xki − x·i)(xkj − x·j)viwj .
e riprendendo il calcolo e scambiando le due somme vediamo apparire deitermini legati alla matrice di covarianza Γ;
σ2(v,w) =1
n
n∑
k=1
p∑
i,j=1
(xki − xi)(xkj − xj)viwj =
=
p∑
i,j=1
viwj1
n
n∑
k=1
(xki − xi)(xkj − xj)︸ ︷︷ ︸
=Γij
=
p∑
i,j=1
Γijviwj .
Quest’ultima espressione si puo scrivere in maniera compatta
p∑
i,j=1
Γijviwj =
p∑
i=1
vi
p∑
j=1
Γijvj
︸ ︷︷ ︸(Γv)i
= 〈Γv,w〉 .

66 Capitolo 3. Analisi multivariata
In conclusione (la matrice Γ e simmetrica)
σ2(v,w) = 〈Γv,w〉 = 〈Γw, v〉 .
Scegliendo v = w si ha dunque che la varianza dei punti proiettati nelladirezione v e
σ2(v) = 〈Γv, v〉 .Poiche una varianza e sempre ≥ 0, si ottiene dunque che, per ogni vettore v(unitario o no),
〈Γv, v〉 ≥ 0 .
Dunque la matrice di covarianza Γ e sempre semidefinita positiva e tutti isuoi autovalori sono ≥ 0. Quindi il problema di trovare il vettore unitario vlungo il quale la nuvola di punti considerata abbia la massima dispersioneequivale a trovare il vettore unitario v per il quale la quantita 〈Γv, v〉 siamassima.E abbastanza facile vedere che il vettore v di modulo 1 per cui la quan-tita 〈Γv, v〉 e massima e il vettore v1, autovettore relativo all’autovalore piugrande λ1 di Γ. Proveremo questo fatto in due modi diversi e che fanno usodi due tipi di ragionamento completamente diversi.1◦ modo. Indichiamo con v1, . . . , vn gli autovettori di Γ, che possiamo sce-gliere di modulo unitario e a due a due ortogonali. Essi costituiscono unabase e, se v e un vettore tale che |v| = 1, allora si puo scrivere
v =
p∑
i=1
αivi .
Poiche supponiamo |v| = 1, deve essere∑p
i=1 α2i = 1. Infatti
1 = |v|2 = 〈v, v〉 =⟨ p∑
i=1
αivi,
p∑
j=1
αjvj⟩=
p∑
i,j=1
αiαj〈vi, vj〉 =p∑
i=1
α2i .
Infatti i vettori v1, . . . , vp sono a due a due ortogonali e 〈vi, vj〉 = 0 se i 6= j,mentre 〈vi, vi〉 = |vi|2 = 1). D’altra parte poiche Γvi = λivi
〈Γv, v〉 =⟨ p∑
i=1
αiΓvi,
p∑
j=1
αjvj⟩=
p∑
i,j=1
λiαiαj〈vi, vj〉 =p∑
i=1
λiα2i .
Se supponiamo α1 = 1, α2 = · · · = αp = 0, e cioe v = v1, allora
〈Γv, v〉 = λ1 .

3.4. Analisi in componenti principali 67
Per ogni altro vettore v di modulo 1 d’altra parte si ha, poiche λ1 e il piugrande degli autovalori,
〈Γv, v〉 =p∑
i=1
λiα2i ≤ λ1
p∑
i=1
α2i = λ1 .
In conclusione la quantita 〈Γv, v〉 e sempre ≤ λ1 ed e = λ1 solo se |α1| = 1,cioe se v = v1 oppure v = −v1. Dunque v = v1 e v = −v1 sono i vettoridi modulo 1 per cui la quantita σ2(v) = 〈Γv, v〉 e massima. In realta siamostati un po’ inesatti nel ragionamento appena fatto. Perche?
2◦ modo. Il problema considerato non e altro che la determinazione delmassimo della funzione F (u) = 〈Γu, u〉 sulla sfera di raggio 1. Si trattaquindi di un problema di massimo vincolato, che si puo affrontare col metododei moltiplicatori di Lagrange. La sfera si puo indicare come {G = 1}, doveG(u) = |u|2. Poiche sappiamo che la sfera e compatta e F e continua,esiste sicuramente un punto di massimo di F su {G = 1} ed il metododei moltiplicatori di Lagrange assicura che questo punto di massimo u deveessere soluzione di
F ′(u) + λG′(u) = 0 . (3.6)
Calcoliamo il gradiente F ′. Scrivendo in coordinate si ha
∂F
∂u`=
∂
∂u`
p∑
i,j=1
Γijuiuj =
p∑
i=1
(Γ`iui + Γi`ui) = (2Γu)` (3.7)
ovvero, dato che Γ e simmetrica,
F ′(u) = 2Γu .
Se ne deduce che anche G′(u) = 2u, dunque l’equazione dei moltiplicatori(3.6) diventa
Γu+ λu = 0
ed ha soluzione se e solo se −λ e un autovalore di Γ ed u e l’autovettorecorrispondente. Se ui e l’autovettore associato a λi, allora
F (ui) = λi .
Il massimo e quindi raggiunto in corrispondenza dell’autovettore associatoal piu grande degli autovalori ed il massimo e appunto il piu grande de-gli autovalori. Abbiamo dunque visto una caratterizzazione del piu grande

68 Capitolo 3. Analisi multivariata
autovalore di una matrice simmetrica Γ come il massimo della forma quadra-tica u→ 〈Γu, u〉 sulla sfera unitaria. Questa caratterizzazione (che e validaanche se la matrice non e definita positiva come le matrici di covarianza) eun risultato d’interesse generale.Sottolineiamo comunque che questo risultato vale solo se la matrice e sim-metrica: la simmetria di Γ e stata utilizzata nella (3.7).
3.5 Sapreste esprimere in termini di autovalori la quantitta
sup|u|=1〈Au, u〉
quando la matrice A non e simmetrica?
Una volta stabilito che la direzione individuata da v1 e quella per cui laproiezione dei punti ha dispersione massima, si puo dimostrare allo stessomodo che v2 e il vettore per cui 〈Γv, v〉 e massima, tra i vettori che sono or-togonali a v1, che v3 e la direzione ortogonale sia a v1 che a v2 per cui 〈Γv, v〉e massima e cosı via. I vettori v1, . . . , vp si chiamano anche le direzioni prin-cipali. Anzi v1 e la prima direzione principale, v2 la seconda e cosı via. Inconclusione il piano individuato dalle direzioni v1 e v2 e quello cercato: laproiezione della nuvola di punti su questo piano e quella nella quale i puntiproiettati hanno la massima dispersione. Questo piano si chiama anche ilprimo piano principale; anche gli altri piani individuati da coppie di dire-zioni principali vi, vj vanno tenuti in considerazione e le proiezioni relativepossono fornire informazioni utili; le proiezioni su questi (che chiameremopiani principali) possono infatti dare informazioni complementari a quellefornite dalla proiezione sul primo piano principale.
Prima di vedere degli esempi concreti poniamoci la questione di valutarequanto i valori proiettati siano una immagine fedele dei dati: come abbiamogia osservato e possibile che punti in realta distanti tra di loro appaianovicini nella proiezione. Chiameremo dispersione totale dei dati la quantita
1
n
n∑
i=1
|xi − x|2 .
Osserviamo che, se (vi)i=1,...,p e una base formata da vettori ortogonali e dimodulo uguale a 1, allora si ha, per ogni z ∈ R
p,
|z|2 =p∑
j=1
〈z, vj〉2 . (3.8)

3.4. Analisi in componenti principali 69
Infatti (vj)j=1,...,p costituisce una base ortonormale per cui si ha
z =
p∑
j=1
〈z, vj〉vj .
Dunque
|z|2 = 〈z, z〉 =⟨ p∑
i=1
〈z, vi〉vi,p∑
j=1
〈z, vj〉vj⟩=
=
p∑
i,j=1
〈z, vi〉〈z, vj〉〈vi, vj〉 =p∑
i=1
〈z, vi〉2
da cui segue la (3.8) osservando che i prodotti scalari 〈vi, vj〉 sono uguali a0 per i 6= j e uguali a 1 per i = j. Torniamo al calcolo della dispersione:
1
n
n∑
i=1
|xi − x|2 =1
n
n∑
i=1
p∑
j=1
〈xi − x, vj〉2 =p∑
j=1
1
n
n∑
i=1
〈xi − x, vj〉2
︸ ︷︷ ︸=dispersione del carattere vj =λj
=
p∑
j=1
λj .
Dunque la dispersione totale e sempre uguale alla somma degli autovalori
della matrice di covarianza. Quanto vale la dispersione dei punti proiettatisul piano principale? Basta osservare che la loro matrice di covarianza e
Γ =
(〈Γv1, v1〉 〈Γv1, v2〉〈Γv1, v2〉 〈Γv2, v2〉
)=
(λ1 00 λ2
).
Per il calcolo appena fatto dunque la dispersione dei punti proiettati sulprimo piano principale e uguale alla traccia di Γ, e dunque a λ1 + λ2. Piuin generale, la dispersione della proiezione sul piano principale formato daicaratteri vh e vk e uguale a λh + λk. Definiremo la fedelta della proiezionesu un piano come il rapporto tra la dispersione dei punti proiettati e ladispersione totale. Per la proiezione sul primo piano principale la fedeltavale dunque
λ1 + λ2λ1 + · · ·+ λp
·
Si tratta di un numero sempre compreso tra 0 e 1 (gli autovalori sono tutti≥ 0 e quindi il denominatore e sempre piu grande del numeratore), e che siusa come indicatore della bonta della proiezione: tanto piu la fedelta risultaprossima a 1, tanto piu i punti proiettati costituiscono una immagine fedeledei dati originali.

70 Capitolo 3. Analisi multivariata
Figura 3.5:
Esempio 3.1 Vediamo in concreto come si fa una ACP. Cominciamocon i dati delle conchiglie. Si tratta delle 4 misurazioni delle conchiglie atorciglione (sphaeronassa mirabilis) della Figura 3.5. Lo scopo dell’ACPin questo caso e di studiare la forma delle conchiglie per risalire alleproprieta della popolazione.Dopo averli copiati e salvati come indicato prima, importiamoli
-->xx=read(’c:\dida\lc2\conchiglie.txt’,-1,4);
Calcoliamo la matrice di covarianza
-->mm=mvvacov(xx)
mm =
.3242297 .2599237 .1985919 .2110335
.2599237 .2099856 .1608542 .1708110
.1985919 .1608542 .1249035 .1307719
.2110335 .1708110 .1307719 .1413012

3.4. Analisi in componenti principali 71
Osserviamo che le 4 variabili sono tutte correlate positivamente, co-me del resto era ragionevole aspettarsi. Se calcoliamo la matrice dicorrelazione otteniamo
-->mmcor=sqrt(diag(diag(mm)))ˆ(-1) * mm
* sqrt(diag(diag(mm)))ˆ(-1)
mmcor =
1. .9961500 .9868426 .9859437
.9961500 1. .9932308 .9916267
.9868426 .9932308 1. .9843606
.9859437 .9916267 .9843606 1.
Da cui si vede che la correlazione e elevatissima (molto vicina a 1) pertutte le variabili. Calcoliamo autovalori e autovettori
-->[dg,cb,dim]=bdiag(mm);cb,dg
cb =
- .6371866 .6743886 - .3275909 .1785423
- .5135296 - .0457869 .8512392 - .0978913
- .3937586 - .3322839 - .3456081 - .7842809
- .4186105 - .6577925 - .2205243 .5860404
dg =
.7950754 0. 0. 0.
0. .0028923 0. 0.

72 Capitolo 3. Analisi multivariata
0. 0. .0003981 0.
0. 0. 0. .0020541
I due autovalori principali sono il primo e il secondo. Procuriamoci unamatrice 4× 2 avente come colonne i due autovettori principali.
-->vv=cb(:,1:2)
vv =
- .6371866 .6743886
- .5135296 - .0457869
- .3937586 - .3322839
- .4186105 - .6577925
Le coordinate delle proiezioni sul piano generato da questi dueautovettori si ottengono con
-->xxp=xx * vv
Infatti con questo comando si ottiene una matrice, xxp , che e n × 2,e che contiene, nella prima colonna i prodotti scalari delle osservazionicon il primo autovettore (che si trova nella prima colonna di vv ) e nellaseconda i prodotti scalari con il secondo autovettore. Il grafico dei puntiproiettati si puo a questo punto ottenere, come sappiamo, con
-->clf();plot(xxp(:,1),xxp(:,2),".")
Vediamo come si puo interpretare questa analisi. Intanto i due autovaloriprincipali spiegano la maggior parte della variabilita dei dati. La fedeltadella proiezione e infatti
-->(dg(1,1)+dg(2,2))/sum(dg)
ans =
.9969364

3.4. Analisi in componenti principali 73
Cioe una proporzione del 99.69%. E chiaro inoltre che dei due autovet-tori principali di gran lunga il piu rilevante e il primo. Osserviamo chesi tratta di un vettore le cui componenti hanno tutte lo stesso segno, convalori tutti vicini a −1
2 . Si tratta dunque di una variabile che misura la
dimensione. Nel grafico, dunque, si trovano a sinistra le conchiglie gran-di (che hanno tutte le misurazioni con valori elevati), mentre a destra cisono quelle piccole.Il secondo autovettore invece mette in opposizione la prima variabile so-prattutto con la terza e la quarta. Si vede perche la prima componentee positiva mentre la terza e quarta sono negative. Anche la seconda enegativa, ma con un valore piccolo. Si tratta dunque di una variabile diforma, che da valori grandi a conchiglie strette e lunghe e valori piccoli aconchiglie larghe e strette. Questa variabile pero mostra una piccola va-riabilita. Essenzialmente le conchiglie considerate hanno tutte la stessaforma e possono essere solo un po’ piu grandi o un po’ piu piccole.Supponiamo ora di sapere (come e in realta) che le ultime 9 misurazionisi riferiscano a conchiglie diverse (con 5 giri, invece di 6, come nellafigura). Come si puo fare un grafico dei dati sul piano principale, chefaccia apparire in modo diverso i punti relativi ai primi 22 individui equelli relativi agli ultimi 9?Bastera dare prima il comando
-->clf();plot(xxp(:,1),xxp(:,2),".")
in maniera che ora tutti i punti sono indicati con un pallino blu. E poi
-->plot(xxp(23:31,1),xxp(23:31,2), ".g")
Quindi ora gli ultimi 9 punti vengono disegnati in verde nella stessafinestra grafica. Quindi il grafico riporta i primi 22 punti in blu e gliultimi 9 in verde (il verde copre il blu con cui erano stati disegnatiprima).
L’analisi in componenti principali, cosı come l’abbiamo introdotta finora, hapero l’inconveniente di dipendere in maniera artificiosa dalle unita di misura.Se, ad esempio, avessimo deciso di misurare la prima delle quattro variabili(l’altezza) in decimi di millimetro, la matrice di covarianza sarebbe statadiversa, cosı pure come autovalori e autovettori. Ed e chiaro che un metodo

74 Capitolo 3. Analisi multivariata
di analisi corretto dovrebbe essere insensibile a dei cambiamenti di unitadi misura. Da un altro punto di vista, se tra le variabili considerate ce nefosse una che presenta dei valori molto superiori numericamente rispetto allealtre, allora il risultato dell’analisi risulterebbe influenzato indebitamente daivalori di questa variabile e terrebbe poco conto delle altre.
Per questo motivo e opportuno effettuare, prima dell’analisi, una normaliz-zazione dei dati. La cosa naturale consiste nel centrare le singole variabilie poi dividere ciascuna di esse per la sua deviazione standard, in manierache, alla fine, esse abbiano tutte una varianza uguale a 1. Questa operazio-ne evidentemente eliminera ogni effetto del tipo cambio di unita di misuraa cui abbiamo accennato sopra. Nel caso dei dati delle conchiglie questaoperazione non era proprio necessaria, dato che i valori numerici delle quat-tro variabili erano piu o meno dello stesso ordine. Ma in genere questaoperazione di normalizzazione e indispensabile.
Procediamo ad un’analisi in componenti principali per i dati dell’ozono. Perprima cosa dobbiamo procurarci i dati centrati e ridotti. Prima togliamo lemedie: il comando center(xx,1) sottrae a ciascuna delle colonne la suamedia. Naturalmente center(xx,2) avrebbe tolto la media a ciascunadelle righe.
-->xx2=center(xx,1)
Verifichiamo che ora le variabili hanno media nulla
-->mean(xx2,1)
ans =
1.0E-13 *
.0633727 - .3021407 .0793759 - .0256051
Ricordiamo infatti che il comando mean(xx2,1) produce le medie dellecolonne della matrice xx2 . Analogamente mean(xx2,2) produce le mediedelle righe.
Per dividere ogni colonna per la deviazione standard corrispondente il modopiu elegante e di calcolare la matrice di covarianza
-->mm=mvvacov(xx2);

3.4. Analisi in componenti principali 75
e poi fare
-->xx2=xx2 * sqrt(diag(diag(mm)))ˆ(-1);
Con questa operazione infatti viene divisa ogni colonna della matrice dei datiper la radice quadrata della varianza relativa. E facile vedere (verificare!)che la matrice di covarianza dei dati normalizzati xx2 e uguale alla matricedi correlazione dei dati originali xx . Ora possiamo analizzare gli autovalorie gli autovettori della matrice di correlazione.
-->[dg,cb,dim]=bdiag(mcor);cb,dg
cb =
- .5890040 - .7974891 .1146414 .0627912
- .3169087 .1233953 - .2777312 - .8984474
.4970366 - .3017048 .6905372 - .4302177
- .5528090 .5076996 .6579370 .0613370
dg =
2.3598986 0. 0. 0.
0. .2696752 0. 0.
0. 0. .4757499 0.
0. 0. 0. .8946763
I due autovalori piu grandi sono il primo ed il quarto. Calcoliamo la proie-zione sul piano generato dai due autovettori principali (cioe quelli associatiai due autovalori piu grandi) dei dati. Il modo piu elegante consiste nel for-mare una matrice 4×2, avente come colonne i due autovettori. Trasponendodue volte. . .
-->vv=[cb(:,1)’;cb(:,4)’]’
vv =

76 Capitolo 3. Analisi multivariata
- .5890040 .0627912
- .3169087 - .8984474
.4970366 - .4302177
- .5528090 .0613370
Le coordinate delle proiezioni si ottengono quindi moltiplicando
-->xxp=xx2 * vv
Possiamo ora fare il grafico nel piano dei punti proiettati.
-->clf();plot(xxp(:,1),xxp(:,2),".")
Un errore tipico a questo punto e quello di proiettare i dati originali, xx ,invece di quelli normalizzati xx2 . Lo si individua spesso facilmente perche ilplot non risulta avere l’andamento caratteristico delle variabili non correlate.Ricordate, infatti, che le variabili relative alle direzioni principali sono traloro non correlate.Per valutare la fedelta della proiezione facciamo il rapporto tra la sommadei due autovalori principali e la somma di tutti gli autovalori (che e ugualea 4, dato che la somma degli autovalori e uguale alla traccia e la matrice dicorrelazione ha tutti uni sulla diagonale).
-->(dg(1,1)+dg(4,4))/4
ans =
.8136437
Cioe la fedelta e uguale all’81.36%.Prima di procedere con l’analisi di altri esempi di dati sara opportuno scri-vere una funzione che realizzi una dopo l’altra le operazioni che abbiamoeffettuato in linea nell’esempio dell’ozono.Un problema che s’incontra nella redazione di una funzione che effettui l’a-nalisi in componenti principali viene dal fatto che il comando bdiag forniscegli autovalori in ordine sparso ed occorrera, nel programma che ci accingiamoa scrivere, riordinarli per prendere i piu grandi. Ricordando il funzionamen-to del comando sort , come si fa, dopo avere dato il comando bdiag , aricavare l’autovettore relativo all’autovalore piu grande? Voila:

3.5. Analisi discriminante 77
-->[dg,cb,dim]=bdiag(mcor);
-->dg2=diag(dg);
-->[s,k]=sort(dg2);
-->v1=cb(:,k(1));
Infatti, k(1) e la posizione in cui l’autovalore piu grande si trova nellamatrice dg . Dunque ora v1 e l’autovettore (colonna) associato all’autovalorepiu grande.
3.6 Fare un’analisi in componenti principali dei dati dei passeri di Bum-pus. La storia dice che il reverendo Bumpus raccolse, nel febbraio 1898, 49passeri un po’ malconci dopo una tempesta. Li curo, ma alcuni di essi nonsopravvissero (nella base dati sono gli ultimi 28). Il buon reverendo prese4 misurazioni da ciascun animale, cercando poi di vedere se ci fosse unarelazione tra le dimensioni e la capacita di sopravvivenza. Fare un’analisiin componenti principali dei dati dei passeri di Bumpus e farne il grafico,distinguendo con colori diversi le due popolazioni.
3.7 Fare le analisi in componenti principali per i dati sulla qualita del vinodi Bordeaux. In questo set di dati vengono confrontati alcune misurazionimeteorologiche del mese di aprile e la qualita del vino della vendemmia suc-cessiva. Fare il grafico dei dati sul piano principale usando come simbolo ilvoto”, in maniera da mettere in evidenza eventuali dipendenze tra la qualitaed il clima nel mese di aprile precedente. Questi dati verranno analizzatianche con i metodi dell’analisi discriminante, in questo caso piu appropriati.
3.5 Analisi discriminante
Supponiamo di essere in presenza di misurazioni multidimensionali, comenel paragrafo precedente, ma provenienti da piu popolazioni. Cioe le osser-vazioni sono suddivise in gruppi corrispondenti a popolazioni diverse (e lostudioso sa a quale popolazione appartenga ognuna delle osservazioni). Vie una differenza tra le misurazioni di individui appartenenti a popolazionidiverse? E possibile decidere, solo a partire dalle misurazioni, a quale po-polazione appartenga un singolo individuo? Ovvero e possibile determinare

78 Capitolo 3. Analisi multivariata
una regola che ad ogni individuo, in funzione delle sue misurazioni, associla popolazione a cui esso appartiene?Rispondere a queste domande ha un indubbio interesse sia pratico che teori-co. Ad esempio se le misurazioni fossero le osservazioni cliniche su un gruppodi pazienti ed i gruppi fossero due, composti da coloro che sono affetti dauna certa malattia e da quelli sani rispettivamente, si potrebbe determinareuna procedura automatica che a partire dalle misurazioni stabilisca se unnuovo paziente sia malato o no. Da un punto di vista teorico, invece, einteressante determinare il carattere (cioe la funzione delle misurazioni) chemeglio permette di discriminare tra i vari gruppi. Supporremo ancora che i
dati siano della forma di matrice
X = (xij) i=1,...,n
j=1,...,p
dove xij indica la misurazione della variabile j-esima per lo i-esimo indivi-duo; n e ancora il numero totale di individui e p il numero di variabili.Supporremo pero che vi sianom popolazioni (o gruppi) presenti e che i primin1 individui appartengano alla popolazione 1, che quelli con indice compresotra n1+1 e n1+n2 appartengano alla seconda e cosı via fino a quelli con indicecompreso tra n1+ · · ·+nm−1+1 e n1+ · · ·+nm−1+nm, che apparterrannoallam-esima popolazione. Quindi n1 e l’effettivo della prima popolazione, n2quello della seconda e cosı via. Per semplicita indicheremo con Ik l’insiemedegli indici compresi tra nk−1+1 e nk (e quindi corrispondenti agli individuidella k-esima popolazione). Cominceremo col chiederci se non vi sia unadirezione u che discrimini il meglio possibile le diverse popolazioni. Ovverotale che nella proiezione nella direzione u le varie popolazioni appaiano il piupossibile ben separate tra di loro. Si tratta, come si vede, di un problema nonmolto diverso da quello del paragrafo precedente, anche se ancora dobbiamochiarire come si possa caratterizzare matematicamente una tale direzione u.Anche qui la soluzione verra dall’analisi della matrice di covarianza Γ.Ricordiamo che il baricentro dei dati x e stato definito nel paragrafo prece-dente come il vettore le cui coordinate x·j sono date da
x·j =1
n
n∑
i=1
xij .
Possiamo pero considerare anche i baricentri delle singole popolazioni, cioei vettori y1, . . . , ym le cui coordinate sono
y1j =1
n1
∑
i∈I1xij , y2j =
1
n2
∑
i∈I2xij , . . . , ymj =
1
nm
∑
i∈Imxij .

3.5. Analisi discriminante 79
La matrice di covarianza Γ si puo ora scrivere
Γhk =1
n
n∑
i=1
(xih − x·h)(xik − x·k) =
=1
n
m∑
j=1
[∑
i∈Ij(xih − x·h)(xik − x·k)
] (3.9)
dove abbiamo semplicemente spezzato la somma tra le varie popolazio-ni. Studiamo piu da vicino le somme all’interno delle parentesi quadre.Sommando e sottraendo la media della popolazione j-esima e sviluppandoabbiamo
∑
i∈Ij(xih − x·h)(xik − x·k) =
=∑
i∈Ij(xih − yjh + yjh − x·h)(xik − yjk + yjk − x·k) =
=∑
i∈Ij(xih − yjh)(xik − yjk) +
∑
i∈Ij(yjh − x·h)(yjk − x·k)+
+∑
i∈Ij(yjh − x·h)(xik − yjk) +
∑
i∈Ij(xih − yjh)(yjk − x·k) .
Le ultime due somme nella relazione precedente sono nulle. Infatti, poicheil termine yjh − x·h non dipende da i,
∑
i∈Ij(yjh − x·h)(xik − yjk) = (yjh − x·h)
∑
i∈Ij(xik − yjk) =
= (yjh − x·h)[∑
i∈Ijxik − nj yjk
]= 0
(la quantita tra parentesi quadre e nulla, ricordando la definizione dei bari-centri yjk). Sostituendo nella (3.9) abbiamo
Γhk =1
n
m∑
j=1
[∑
i∈Ij(xih − x·h)(xik − x·k)
]=
=1
n
m∑
j=1
[∑
i∈Ij(xih − yjh)(xik − yjk)
]
︸ ︷︷ ︸=Dhk
+

80 Capitolo 3. Analisi multivariata
+1
n
m∑
j=1
[∑
i∈Ij(yjh − x·h)(yjk − x·k)
]
︸ ︷︷ ︸=Thk
.
Uno sguardo alle somme che definiscono la matrice D mostra che quest’ul-tima non e altro che la somma delle covarianze Dentro le singole popola-zioni, mentre T descrive l covarianze Tra le singole popolazioni rispetto albaricentro generale x. Piu precisamente, D si puo scrivere
D =1
n
m∑
j=1
njΓ(j)
dove Γ(j)hk = 1
nj
∑i∈Ij(xih − yjh)(xik − yjk e la matrice di covarianza della j-
esima popolazione. T e invece la matrice di covarianza della nuvola di puntiche si ottiene sostituendo ad ogni osservazione il baricentro della popolazionealla quale essa appartiene. La decomposizione
Γ = D + T (3.10)
che abbiamo appena ottenuto si chiama formula di Huygens. Se ora u e unadirezione, abbiamo visto nel paragrafo precedente che la dispersione lungola direzione u e data da
〈Γu, u〉 = 〈Du, u〉+ 〈Tu, u〉 .
La separazione delle popolazioni lungo la direzione u sara dunque tanto piugrande quanto piu e piccola la dispersione interna delle popolazioni 〈Du, u〉e grande la dispersione esterna 〈Tu, u〉. Tenendo conto che comunque deveessere
〈Du, u〉〈Γu, u〉 +
〈Tu, u〉〈Γu, u〉 = 1
la direzione lungo la quale la separazione tra le popolazioni e la piu grandesara quella per cui la quantita
〈Du, u〉〈Γu, u〉
e minima.
Mostriamo che un tale vettore u e l’autovettore relativo al piu piccolo auto-
valore della matrice Γ−1D.

3.5. Analisi discriminante 81
La funzione F (u) = 〈Du,u〉〈Γu,u〉 e omogenea di grado 0, cioe tale che F (αu) =
F (u) per ogni α > 0. Dunque il problema di determinarne il minimo eequivalente a quello del minimo di v → 〈Dv, v〉 con il vincolo 〈Γv, v〉 = 1;dopo di che bastera scegliere
u =v
|v|per avere un vettore di lunghezza 1. Abbiamo gia visto come si usano imoltiplicatori di Lagrange per questo tipo di problemi. Poiche sappiamo giache i gradienti delle funzioni G(v) = 〈Γv, v〉 e F (v) = 〈Dv, v〉 sono ugualirispettivamente a G′(v) = 2Γv e F ′(v) = 2Dv rispettivamente, l’equazionedei moltiplicatori di Lagrange diviene
Dv + λΓv = 0
ovveroΓ−1Dv = −λv .
Dunque v deve essere autovettore della matrice Γ−1D. Inoltre, poiche si ha
〈Dv, v〉 = −λ〈Γv, v〉 = −λ
il vettore v per cui il minimo di 〈Dv, v〉 e raggiunto tra quelli per cui 〈Γv, v〉 =1 e necessariamente l’autovettore relativo al piu piccolo autovalore dellamatrice Γ−1D.Per completare la nostra analisi occorre studiare gli autovalori di Γ−1D, chenon e in generale una matrice simmetrica, anche se sia Γ−1 che D lo sono. Ilprodotto di due matrici simmetriche non e una matrice simmetrica, a menoche le due matrici commutino.L’analisi spettrale di Γ−1D si puo pero ricondurre a quella di una matricesimmetrica. Sappiamo infatti che esiste una matrice, che indicheremo conD1/2, che e simmetrica e tale che
D1/2D1/2 = D
nel senso del prodotto di matrici. Moltiplicando a sinistra ambo i membrinella relazione
Γ−1Dv = −λvper la matrice D1/2 otteniamo
D1/2Γ−1Dv = −λD1/2v
ovvero(D1/2Γ−1D1/2)D1/2v = λD1/2v .

82 Capitolo 3. Analisi multivariata
In conclusione se v e autovettore per l’autovalore −λ della matrice Γ−1D al-lora D1/2v e autovettore della matrice simmetrica D1/2Γ−1D1/2 rispetto allostesso autovalore e viceversa (veramente questo ragionamento e incompleto:perche?). Inoltre poiche
〈D1/2Γ−1D1/2v, v〉 = 〈Γ−1D1/2v,D1/2v〉 ≥ 0
gli autovalori sono tutti ≥ 0.Abbiamo dunque mostrato che la matrice Γ−1D ha tutti i suoi autovalorireali e positivi. Altre direzioni discriminanti si ottengono considerando gliautovettori associati agli autovalori via via piu grandi di Γ−1D . Si trattadi direzioni lungo le quali la discriminazione tra le varie popolazioni dimi-nuisce man mano che si considerano autovalori piu grandi, ma che possonosempre dare informazioni utili. L’analisi discriminante quindi procede come
l’ACP: si calcolano i due autovettori, w1 e w2, associati ai due piu piccoliautovalori di Γ−1D, e si proiettano i dati sul piano generato da w1 e w2.Sara ragionevole all’inizio centrare e ridurre le variabili, . Ora pero c’e unacomplicazione supplementare: a differenza di quanto accadeva per l’ACP,w1 e w2 non sono ortogonali. Come fare allora per calcolare la proiezioneortogonale?Bastera cercare due vettori ortogonali che individuino lo stesso piano. Adesempio v1 piu un altro vettore w, ortogonale a v1 e complanare a v1 e v2.La scelta naturale e w = v2 − 〈v1, v2〉v1. Essendo una combinazione linearedi v1 e v2, w si trova nello stesso piano di v1 e v2 ed inoltre
〈v1, w〉 = 〈v1, v2〉 − 〈v1, v2〉 〈v1, v1〉︸ ︷︷ ︸=1
= 0 .
Dunque w e v1 sono ortogonali. Il piano discriminante e quindi individuatoda questi due vettori, che sono per di piu di modulo 1 se si sostituisce w conw/|w|.La realizzazione di uno script scilab che effettui l’analisi discriminante pre-senta delle difficolta simili a quelle dell’ACP, ma e nettamente piu delicata.Occorre infatti produrre una funzione che faccia le operazioni seguenti1) Innanzitutto bisogna centrare e ridurre le variabili, per evitare distor-
sioni dovute alla scelta di unita di misura e/o al fatto che per certe variabili ivalori misurati siano troppi. Per questo si usa prima il comando center (chetoglie le medie alle variabili); date pero prima un’occhiata allo help di questocomando, che ha un paio di opzioni. Poi occorre ridurre i dati, in manierache tutte le variabili abbiano varianza uguale a 1. Le analisi successive siintendono tutte effettuate sui dati normalizzati.

3.5. Analisi discriminante 83
2) Occorre poi calcolare la matrice di covarianza interna. A questo scopooccorrera, a meno di idee brillanti, fare un ciclo for...end calcolando lematrici di covarianza delle singole popolazioni.3) Poi bisogna trovare gli autovettori relativi ai piu piccoli autovalori della
matrice Γ−1D. Si procedera come descritto sopra per la determinazione degliautovettori relativi ai piu grandi autovalori della matrice di covarianza (o dicorrelazione) per l’ACP. Puo essere utile il comando gsort(xx,g,i) , cheopera come sort, ma fa un ordinamento dei numeri che si trovano in xx inordine crescente.4) Infine, quando si proietta sul piano determinato dagli autovettori re-
lativi ai due piu piccoli autovalori di Γ−1D, non bisogna dimenticare chequesti non sono ortogonali. . .5) Per quanto riguarda la realizzazione del grafico con i punti proiettati
sarebbe utile potere disegnare i punti usando per ogni popolazione un sim-bolo diverso, che permetta di distinguere facilmente, per ogni punto, a qualepopolazione appartenga. Ci sono due possibilita. Se si vuole indicare ogniindividuo con un numero, il comando e
--> xnumb(x,y,nums)
dove nel vettore x si trovano le ascisse dei punti, in y le ordinate e in numsi numeri che verranno disegnati nei punti di coordinate x e y .Prima di utilizzare questo comando, a differenza di comandi come plot ,occorre pero definire la finestra grafica. Ad esempio con i comandi
-->clf();plot(xx,yy,"w")
-->xnumb(xx,yy,nums)
prima viene fatto un grafico in cui i punti appaiono con un puntino in colorebianco (e quindi viene definita la finestra grafica senza disegnare niente) epoi vengono aggiunti i numeri dei punti.Si puo usare anche il comando xstring :
-->xstring(x,y,"strin")
disegna nel punto di coordinate (x,y) la stringa di caratteri strin . Ilcomando xstring pero non e vettoriale, cioe puo disegnare solo un puntoalla volta. Occorrera dunque pensare a un ciclo for...end (o magari due)per disegnare i punti. Anche per questo comando sara necessario definireprima una finestra grafica vuota con plot .

84 Capitolo 3. Analisi multivariata
Figura 3.6:
3.8 Fare un’analisi discriminante sui dati delle iris. E possibile distinguerele tre specie di iris sulla base delle quattro misurazioni (lunghezza e larghez-za) di petali e sepali? Storicamente si tratta della prima applicazione di que-sto tipo di tecniche (Fisher, R. A. (1936) The use of multiple measurements
in taxonomic problems. Annals of Eugenics, 7, Part II, 179188).
3.9 Fare una analisi discriminante dei dati dei teschi egizi. Si tratta dimisurazioni (vedi Figura 3.6) del cranio di individui appartenenti a diverseepoche dell’antico Egitto. Disegnare i punti sul piano discriminante. Dise-gnare anche le coordinate dei baricentri della popolazioni. Cosa si puo diredell’evoluzione della forma del cranio, con l’andare del tempo?
3.10 Fare una analisi discriminante dei dati dei cani tailandesi. Si puoaffermare che qualcuna delle razze di cani selvatici (sciacallo dorato, lupoindiano, cuon) costituisca un punto di passaggio tra il cane preistorico ed ilcane moderno?
Dalla prima analisi si vede che due di questi gruppi sono lontani sia dalcane moderno che dal cane preistorico. Eliminarle dai dati ed effettuareun’analisi discriminante considerando solo gli ultimi tre gruppi. Cosa si puoconcludere?
3.6 Approfondimenti sulla gestione della grafica
L’analisi discriminante richiede un maggiore controllo dei parametri grafici.Ad esempio, come fare per disegnare i valori osservati usando colori diversiper le singole popolazioni? Come farlo usando un ciclo for...end ?

3.6. Approfondimenti sulla gestione della grafica 85
A questo scopo e opportuno approfondire le possibilita del comando plot .La descrizione che ne abbiamo fatta nel §2.9 riguarda una versione sempli-ficata del comando. Proviamo ad esempio
-->tt=[0:.1:1] * 2* %pi;
-->plot(tt,sin(tt),’colo’,[.7 .13 .13],’linest’,’none ’,’marker’,’.’,’markersize’,4,’clip’,’off’)
Esso produce il grafico di alcuni punti lungo il grafico della funzione senocon le seguenti caratteristiche:
• usa il colore caratterizzato da .7, .13, .13 in formato rgb (= red, blue,green).
• il line style e posto a “none” (cioe nessuno): i punti non sono collegatida segmenti.
• i punti sono indicati dal simbolo “.” (puntolino).
• i puntolini hanno dimensione di 4 punti (il punto e una unita di misuratipografica = 0.035146 cm)
• il parametro clip posto uguale a off impone che quando un simbolo(puntolino in questo caso) si trova ai bordi della finestra grafica esso vengadisegnato intero e non ne venga eliminata la porzione che si trova fuori dellafinestra grafica.
Come si vede, con questa sintassi estesa il comando plot da un controllomolto maggiore e si puo gestire con maggiore precisione lo output grafico.La sintassi consiste in una sequenza di PropertyName seguiti dai rispettivivalori. I PropertyName piu utili sono quelli precedenti, cioe
• color : determina il colore con cui il simbolo verra disegnato. I valoripossibili di questo parametro sono i nomi dei colori predefiniti (red, blue,. . . ),tra apici o virgolette come al solito, oppure un vettore di lunghezza 3 cheda la composizione del colore nel modo rgb; il colore .7, .13, .13 e una speciedi arancio.
Volendo disegnare i punti di p popolazioni conviene definire un vettore dicolori, cioe una matrice p× 3, in cui ogni riga definisce un colore. Se questamatrice, ad esempio, si chiama cmap bastera usare un ciclo for...end eindicare di usare il colore cmap(i,:) per la i-esima popolazione. scilabpossiede un vettore di 32 colori di default le cui composizioni si possonoottenere dando il comando
cmap=get(sdf(),"color_map");

86 Capitolo 3. Analisi multivariata
. Dopo che questo comando e stato dato, la variabile cmap conterra unamatrice 32 × 3 con le definizioni dei colori che potra essere utilizzata comeindicato sopra. Con il comando help colormap si ottengono informazioniper produrre altri vettori di colori.Altri colormap (cioe matrici di colori) si possono ottenere con i comandihotcolormap e jetcolormap . Ad esempio
-->cmap2=hotcolormap(5)
produrra un colormap di cinque colori. Si trattera di una matrice 5 × 3.jetcolormap fa la stessa cosa ma con una diversa scelta di colori (vedi lohelp relativo).• linestyle : lo stile del grafico. Puo prendere i valori ’-’ (tratto soli-
do), ’--’ (a trattini), ’:’ (a puntini), ’-.’ (trattini e puntini), ’none’(nessun tratto).Attenzione che il default e - , quindi se non si vogliono collegare i punti conun segmento occorre specificare ’linest’,’none’ .• marker : il simbolo che si vuole usare per segnare i punti ’.’ e il
punto pieno, ’o’ e invece un cerchio con solo il bordo colorato. Per la listacompleta dei simboli vedi lo help di tt GlobalProperty.• markersize : la dimensione del simbolo in punti. Utile ad esempio per
disegnare con dei puntolini un po’ piu piccoli di quelli di default (che sono a 6pt). In ogni caso ricordare che non e indispensabile scrivere il nome completo
del PropertyName: si puo scrivere ’’colo’’ invece di ’’color’’ oppurelinest invece di linestyle , basta che non ci sia ambiguita. Inoltreminuscole o maiuscole non sono rilevanti. Ci sono altri PropertyName
possibili, vedi sempre lo help di GlobalProperty .

Capitolo 4
Esplorazioni numeriche
4.1 Equazioni differenziali
Vediamo ora come si puo usare scilab per studiare dei sistemi di equazionidifferenziali. Il comando di base e ode . Supponiamo di volere ottenerenumericamente la soluzione dell’equazione
y′ = f(t, y)
con le condizioni y(t0) = y0. Questo si puo fare con il comando
-->y=ode(t0,y0,tt,f)
In questo comando t0 , y0 sono le condizioni iniziali, come indicato prima,mentre tt sono i valori della variabile nei quali si vuole calcolare la soluzione.Perche la cosa funzioni, l’utente dovra definire la funzione f come funzionescilab . Vediamo un esempio concreto:
y′ = y2 − t .
Per questa equazione, che non e lineare, non e possibile trovare delle soluzioniesplicite. Occorrera definire la funzione f . Per definire funzioni che com-prendono una sola istruzione non e necessario scriverle in un file separato.Si puo usare il comando deff . Ad esempio:
-->deff("yprim=fu1(t,y)","yprim=y.ˆ2-t");
Supponiamo di cercare la soluzione nell’intervallo [0,10]. Definiremo allora
-->tt=[0:.1:10];
87

88 Capitolo 4. Esplorazioni numeriche
e poi daremo le condizioni iniziali, ad esempio
-->t0=0;y0=0;
A questo punto i valori della soluzione si ottengono con
-->yy=ode(y0,t0,tt,fu1);
-->clf();plot(tt,yy)
Da notare che nel comando ode il primo argomento e la posizione inizialee il secondo e il tempo iniziale, mentre nella definizione della funzione fu1tempo e posizione sono dati in ordine inverso.Quando si e in presenza di un sistema differenziale, spesso l’interesse si portanon tanto sul calcolo del valore effettivo delle soluzioni, ma sul loro com-portamento asintotico. Nell’esempio precedente il grafico ottenuto suggerivache la soluzione ottenuta converga a −∞ per t→ +∞. Per questo occorrerauna dimostrazione formale. Intanto pero ci si puo chiedere se per altri va-lori delle condizioni iniziali il comportamento sia lo stesso. A questo scoposcilab fornisce il comando champ, che permette di disegnare il campo divettori associato al sistema, che puo dare un’idea. La sintassi e
-->champ(t1,y1,ct,cy)
Il risultato del comando precedente e di disegnare nella posizione (t1,y1)un vettore (sotto forma di freccetta) di coordinate (ct,cy) . Vediamo comesi puo disegnare il campo di vettori del sistema differenziale precedente pert1 in [−3, 5] e y in [−3, 3]. Intanto definiamo le coordinate dei punti in cuivogliamo disegnare il campo
-->t1=[-3:5];y1=[-2:3];
Il campo ad ognuno di questi punti sara un vettore di coordinate 1 e f(t1, y1).Occorrera dunque calcolare il valore della nostra funzione fu1 in tutti i puntidi ascissa −3,−2, . . . , 5 e ordinata −2,−1, . . . , 3. Dato che appare compli-cato calcolare la funzione su un vettore di tempi e un vettore di posizioni,conviene usare il comando feval che e stato introdotto a p.40:
-->cy=feval(t1,y1,fu1);
mentre evidentemente ct sara un campo di tutti uni:

4.1. Equazioni differenziali 89
-->ct=ones(length(t1),length(y1));
possiamo ora disegnare il campo del sistema differenziale precedente:
-->clf();champ(t1,y1,ct,cy);
E abbastanza evidente dalla forma del campo che esiste una curva tale che, sele condizioni iniziali (t0,y0) si trovano a sinistra di essa, allora la soluzionetendera a +∞, mentre se si trovano a destra essa tendera a −∞. Possiamoverificare questa intuizione disegnando, oltre al campo alcune soluzioni condiverse condizioni iniziali. Ad esempio
-->clf();champ(t1,y1,ct,cy);t0=-1.5;tt=[t0:.01:.5];
-->yy=ode(y0,t0,tt,fu1);plot(tt,yy)
disegnera un pezzo di traiettoria che tendera a divergere positivamente. Pos-siamo sovrapporre al grafico altre soluzioni, con altre condizioni iniziali,usando colori diversi:
-->clf();t0=-1.45;tt=[t0:.01:.5];
-->yy=ode(y0,t0,tt,fu1);plot(tt,yy)
-->yy=ode(y0,t0,tt,fu1);plot(tt,yy,"g")
-->yy=ode(y0,t0,tt,fu1);plot(tt,yy,"r")
-->yy=ode(y0,t0,tt,fu1);plot(tt,yy,"c")
-->yy=ode(y0,t0,tt,fu1);plot(tt,yy,"m")
I grafici mettono in evidenza un fenomeno che necessita comunque un trat-tamento analitico.Prima di vedere altri esempi, sottolineiamo un paio di punti utili per l’usodel comando ode :1) Nella definizione della funzione f e sempre necessario indicare tra i
valori in ingresso la variabile t, anche quando il sistema e della forma y′(t) =f(y(t)), cioe omogeneo nel tempo.2) Il comando ode si puo usare anche per un sistema in dimensione piu
grande di 1. In questo caso la variabile yprim restituita dalla funzione fu1dovra essere un vettore della dimensione appropriata.

90 Capitolo 4. Esplorazioni numeriche
Vediamo ad esempio come si possono usare le potenzialita di scilab perstudiare il classico sistema preda-predatore:
y′1(t) = ay1(t)− by1(t)y2(t)y′2(t) = −dy2(t) + cy1(t)y2(t)
dove a, b, c, d sono tre numeri fissati e strettamente positivi. Qui y1, y2 mo-dellizzano la consistenza in un ecosistema di due specie: y1(t) indica laconsistenza della specie 1, preda, y2(t) quella della specie 1, predatore. Laprima equazione indica che la derivata di y1 e la risultante di due fattoridiversi: ay1(t) e l’accrescimento dovuto alla riproduzione della specie, men-tre il termine −by1(t)y2(t) da conto del fatto che la specie 1 viene cacciatadalla specie 2. Dunque i suoi effettivi subiranno una perdita tanto piu gran-de quanto piu e grande la consistenza della specie 2. In maniera simile laseconda equazione indica che il predatore tendera a decrescere quanto piula sua consistenza e numerosa (piu predatori ci sono e meno cibo c’e a di-sposizione) e quanto piu e ridotta la consistenza della preda, che costituisceil suo cibo.
Per studiare questo sistema occorrera definire la funzione f , ad esempiodefinendo in un file esterno
function yprim=fvolt(t,y)yprim(1)=a * y(1)-b * y(1) * y(2);yprim(2)=c * y(1) * y(2)-d * y(2);endfunction
Da notare che ora non e possibile usare il comando deff perche per definirela funzione occorre piu di una riga.
Per disegnare il campo del sistema, per sistemi bidimensionali come questo,e prevista una funzione apposita, fchamp . vediamo come disegnare ilcampo di vettori del sistema nella finestra [0, 8]× [0 : 6]: se scegliamo comeparametri a = 3, b = 1, c = 1, d = 2, ad esempio,
-->a=3;b=1;c=1;d=2;
-->cx=[0:.5:8];cy=[0:.5:6];fchamp(fvolt,0,cx,cy);
Ora per ottenere la soluzione del sistema preda-predatore con dato iniziale(1, 1) bastera dare il comando

4.1. Equazioni differenziali 91
-->y0=[1;1];t=[0:.01:5];yy=ode(y0,0,t,fvolt);
Da notare che occorre che la condizione iniziale sia un vettore colonna. Datoche siamo in dimensione 2 non e possibile visualizzare l’andamento dellatraiettoria in funzione del tempo, bisognera accontentarsi di vedere la curvache ne e l’immagine:
-->plot(yy(1,:),yy(2,:))
4.1 Risolvere l’equazione differenziale ordinaria
y′(t) = max(y(t), t)
e tracciare i grafici delle soluzioni con le condizioni iniziali t0 = −1 e
y0 = .1
y0 = −.1y0 = −.5y0 = −1.1
4.2 Completare lo studio del comportamento del sistema preda-predatoreaggiungendo al grafico altre traiettorie al variare della posizione iniziale.Cosa si osserva? Al variare del tempo che tipo di comportamento hannoi valori delle due variabili? Osservare che esiste una condizione iniziale diequilibrio y∗, cioe tale che, se y0 = y∗, allora la costante y ≡ y∗ e soluzione.Calcolare questo valore e aggiungere al grafico ottenuto precedentemente ildisegno di questo punto.
4.3 Qualche volta, per descrivere il sistema preda-predatore, si usa ilsistema un po’ piu sofisticato
y′1(t) = ay1(t)(ρ− y1(t))− by1(t)y2(t)y′2(t) = −dy2(t) + cy1(t)y2(t)
dove il termine ρ − y1(t) viene aggiunto per tenere conto che, anche inassenza del predatore, la preda non puo crescere all’infinito, perche la suacrescita sarebbe comunque frenata dal fatto che le risorse alimentari nonsono illimitate. Il parametro ρ indica la dimensione massima a cui la preda

92 Capitolo 4. Esplorazioni numeriche
puo arrivare. Effettuare per il nuovo sistema l’analisi indicata nei punti 1) e2) precedenti, scegliendo ρ = 8, disegnando il nuovo campo e traiettorie condiverse posizioni iniziali. Cosa sembra essere cambiato nel comportamentodel sistema? Mostrare che anche per questo secondo sistema esiste unaposizione di equilibrio, calcolarla e riportarla sul grafico.
4.4 In una reazione chimica vi sono quattro componenti. Si supponeche il componente 1 si trasformi nel componente 2 in misura proporzionalealla quantita di componente 1 presente. Allo stesso modo i componenti2 e 3 si trasformano nei componenti 3 e 4 rispettivamente con la stessaregola. Infine il componente 4 si trasforma nel componente 1 ad con untasso proporzionale alla quantita di componente 4 presente. Dunque si puodescrivere il comportamento del sistema, determinato dalle quantita presentidi ciascuno dei 4 componenti, y1, y2, y3, y4, mediante il sistema
y′1(t) = −α1y1(t) + α4y4(t)
y′2(t) = −α2y2(t) + α1y1(t)
y′3(t) = −α3y3(t) + α2y2(t)
y′4(t) = −α4y4(t) + α3y3(t)
ovvero
y′(t) = Ay(t)
dove
A =
−α1 0 0 α4
α1 −α2 0 00 α2 −α3 00 0 α3 −α4
1) Mostrare (analiticamente) che esiste un punto di equilibrio, cioe unacondizione iniziale y0 tale che se il sistema inizia con questa condizioneiniziale allora y rimane costante y ≡ y0. Cosa significa questo in terminidello spettro della matrice A?
2) Risolvere il sistema, mediante il comando ode scegliendo dei valorinumerici per i parametri. Cosa suggeriscono i grafici, per quanto riguardail comportamento asintotico del sistema? Il punto equilibrio sembra esserestabile? O no? Cosa significa l’esistenza di un equilibrio stabile in terminidello spettro della matrice A?

4.2. Fourier 93
4.2 Fourier
Si sa dai corsi di Analisi Matematica che data una funzione f continua atratti e di periodo T , la sua serie di Fourier
a0 +
∞∑
n=1
an cos(2πT nx) + bn sin(
2πT nx)
converge, per n → ∞, puntualmente a f in tutti i suoi punti di continuita,mentre converge alla semisomma dei limiti destro e sinistro nei punti di di-scontinuita. In questo paragrafo vediamo alcuni aspetti di questo risultato emettiamo in evidenza qualche fenomeno inatteso. Naturalmente, ricordiamoche
a0 =1
T
∫ b
af(x) dx, an =
2
T
∫ b
af(x) cos(2πT nx) dx
bn =2
T
∫ b
af(x) sin(2πT nx) dx
dove [a, b] e un intervallo di ampiezza b− a = T . Consideriamo la funzione
f(x) =
{−1 se − π < x ≤ 0
1 se 0 < x ≤ π
(cioe a = −π, b = π e T = 2π). Poiche si tratta di una funzione dispari,an = 0, n = 0, 1, . . . , mentre
bn =2
π
∫ π
0sinnx dx =
{4nπ se n e dispari
0 se n e pari
In altre parole, per x diverso da 0, che e un punto di discontinuita per f ,
f(x) =4
π
∞∑
k=0
1
2k + 1sin((2k + 1)x) .
Notare che la somma della serie per x = 0 vale 0, che e appunto la semisom-ma dei limiti da destra e da sinistra di f .
4.5 Scrivete una funzione scilab che faccia il grafico di f e che aggiungail grafico l’approssimazione con la serie di Fourier troncata al grado 2n+1.
Come si vede (Figure 4.1 e 4.2, il grafico delle somme parziali di Fourierpresentano delle oscillazioni vicino allo 0 che non sembrano ridursi per n→∞.
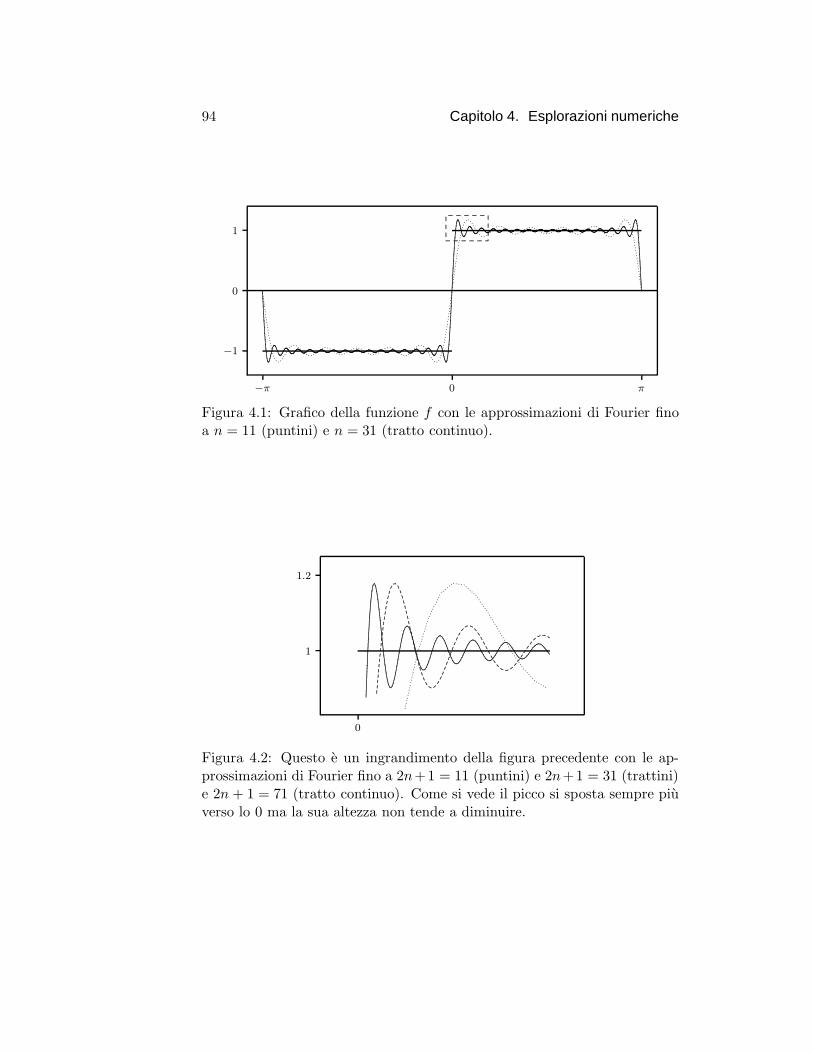
94 Capitolo 4. Esplorazioni numeriche
−1
0
1
−π 0 π
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
..
.
.
.
..
.
.
..
.
..
..................................................................................................................................................................................................................................................................................
..............................................................
................................................................
..............................................................
....
..........................................................
................................................................
..............................................................
..............................................................
....
........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
..............................................................
................................................................
................................................................
..............................................................
..............................................................
....
..........................................................
..............................................................
..............................................................
....
.............................................................................................................................................................................................................................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
...
.
.
.
.
...
.
.
.
.
....
.
.
....
.
.
.
....
.
.
....
.
.
.
....
.
.
.
...
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
...
.
.
.
.
...
.
.
.
....
.
.
.....
.
.
....
.
.
.
....
.
.
.
...
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
........ ........ ........ ........ ........ ........
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.........................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Figura 4.1: Grafico della funzione f con le approssimazioni di Fourier finoa n = 11 (puntini) e n = 31 (tratto continuo).
1
1.2
0
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
..
.
.
..
.
.
.
..
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.......................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
......
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
............
..
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
..
...
............
......
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.....
..................
......
.
.
..
.
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
..
.
......
.................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
....
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Figura 4.2: Questo e un ingrandimento della figura precedente con le ap-prossimazioni di Fourier fino a 2n+1 = 11 (puntini) e 2n+1 = 31 (trattini)e 2n + 1 = 71 (tratto continuo). Come si vede il picco si sposta sempre piuverso lo 0 ma la sua altezza non tende a diminuire.

4.2. Fourier 95
Vediamo come si puo giustificare analiticamente questo comportamento. Seindichiamo con sn la somma della serie fino alla frequenza n, allora
s2n−1(x) =4
π
n−1∑
k=0
1
2k + 1sin((2k + 1)x) =
4
π
n−1∑
k=0
∫ x
0cos((2k + 1)t) dt =
=4
π
∫ x
0
n−1∑
k=0
cos((2k + 1)t) dt
Si ha peron−1∑
k=0
cos((2k + 1)t) =1
2
sin(2nt)
sin t
Come si puo dimostrare per induzione. E facile ora trovare i punti dimassimo della somma parziale s2n−1: la derivata
s′2n−1(x) =2
π
sin(2nx)
sinx
si annulla per x = kn π, k ∈ Z. Lo zero positivo piu piccolo della derivata e
dunque x = πn ed in corrispondenza di questo valore
s2n−1(πn ) =
2
π
∫ π/n
0
sin(2nt)
sin tdt
Si ha pero
2
π
∫ π/n
0
sin(2nt)
sin tdt =
2
π
∫ π/n
0
sin(2nt)
tdt+
2
π
∫ π/n
0sin(2nt)
( 1
sin t− 1
t
)dt
Il secondo integrale tende a 0 per n → ∞, dato che l’integrando e limitato(verificare!). Il primo integrale invece non dipende da n, dato che
∫ π/n
0
sin(2nt)
tdt =
∫ π
0
sin s
sds
Dunque, per n→∞,
limn→∞
s2n−1(πn) =
2
π
∫ π
0
sin s
sds
Un calcolo numerico (vedi anche i prossimi paragrafi. . . ) da per quest’ultimaquantita il valore 1.17897 . . . , quindi all’incirca 0.18 al di sopra del livello 1,in accordo con i grafici delle figure.

96 Capitolo 4. Esplorazioni numeriche
Questo fenomeno (la serie converge puntualmente a f nei punti di continuitama per ogni n ci sono sempre dei punti x in corrispondenza dei quali lo scartoresta minorato da una costante) si chiama il fenomeno di Gibbs.
4.6 Calcolare i coefficienti di Fourier della funzione che si ottiene prolun-gando per periodicita la funzione f(x) = x, x ∈ [−π, π] (la funzione a dentidi sega) e poi fare il grafico delle somme parziali per diversi valori di n.Confrontare infine i risultati con quelli della funzione dell’Esercizio 4.5.
4.7 Stessa cosa per la funzione che si ottiene prolungando per periodicitala funzione f(x) = |x|, x ∈ [−π, π]. scilab prevede delle routine che
effettuano il calcolo numerico di un integrale. Ad esempio
-->deff("y=f(x)","y=1./x");intg(1,2,f)
produrra un valore approssimato (molto bene. . . ) dell’integrale tra 0 e 1 di1x (cioe log 2). Vedremo nel prossimo paragrafo quali sono i metodi nume-rici su cui routine come intg sono basate. Intanto pero sfruttiamo questapotenzialita per approfondire la nostra esplorazione del comportamento del-le serie di Fourier. Mettiamo pero prima in evidenza un punto delicatoper l’uso di intg . Questo comando effettua una serie di approssimazionisempre piu accurate dell’integrale e si arresta quando l’errore assoluto ri-spetto al valore esatto dell’integrale e stimato ≤ 10−16 e l’errore relativo e≤ 10−8. Quando l’integrale vale 0 questo provoca un messaggio di errore(convergence problem... ) dato che l’errore relativo, che e uguale a(valore approssimato-vero valore)/vero valore, risultera sempre infinito. Peraggirare questo inconveniente conviene ricordare che intg prevede delleopzioni:
-->intg(a,b,f,ea,er)
impone a scilab di fornire un’approssimazione con un errore assoluto pariad ea ed un errore relativo pari a er . Nel caso sia possibile che il valoredell’integrale sia uguale a 0 converra scrivere
-->intg(a,b,f,10ˆ(-16),%inf)
%inf e la specificazione dell’infinito in scilab ).
4.8 a) Usare il comando intg per calcolare numericamente i coefficientidello sviluppo in serie di Fourier della funzione
f(x) =√|x|, x ∈ [−π, π]

4.2. Fourier 97
e poi prolungata per periodicita.b) Disegnare il grafico della funzione e aggiungere quello dell’approssima-
zione di Fourier fino alla frequenza n = 5.c) Per vedere meglio cosa succede vicino all’origine, disegnare il grafico
della funzione nell’intervallo [−0.3, 0.3] e aggiungere quello delle approssi-mazioni di Fourier per le frequenze n = 5, 25, 45.
4.9 Consideriamo la funzione
f(x) = x(1− x), x ∈ [0, 1]
a) Modificare lo script scilab dell’Esercizio 4.8 che calcoli lo sviluppodi Fourier di f (ovvero del suo prolungamento per periodicita) fino allafrequenza n e fare il grafico di f e dello sviluppo per n = 3 e n = 7.(Attenzione: in questo esempio il periodo T e uguale a 1).b) Per ottenere un’approssimazione di f con una serie di funzioni trigo-
nometriche si puo anche procedere prolungando f ad una funzione dispari,cioe
f(x) =
{x(1− x) se 0 ≤ x ≤ 1
−x(1− x) se − 1 ≤ x ≤ 0
Si puo ora prolungare questa funzione ad una funzione periodica di periodo
−1 0 1
14
.
.
.
....................................................................................................................................................................................................................................................................................................................................................................................................................................
..............................
.................................................................................
.
........................................................................
.............................................
.................................................................................................................................................................................
........................................................................................................................................................................................................................................... .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..............
............
...........
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Figura 4.3: Grafico di f . A puntini la periodizzata di f
2. Come in a), calcolare lo sviluppo in serie di Fourier di f . Attenzione, orasi tratta di una funzione di periodo 2 e dispari.
4.10 Possiamo ora tornare a considerare la funzione dell’Esercizio 4.6,per la quale si osservava una convergenza particolarmente lenta della serie.Potremmo pensare di prolungare la funzione f(x) =
√(x) in maniera da
renderla dispari, ma questo produrrebbe una discontinuita (vedi Figura 4.4).Per evitarlo si puo allora prolungarla ulteriormente (vedi il grafico a puntininella Figura 4.4). Si puo quindi cercare uno sviluppo in serie di Fourierdi questa nuova funzione. La serie ottenuta, ristretta all’intervallo [0, 1]

98 Capitolo 4. Esplorazioni numeriche
−3 −2 −1 1
−1
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
..
.
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
...
.
.
..
.
..
.
..
.
..
.
..
.
..
.
..
.
..
.
..
.
..
.
..
.
..
.
..
.
..
..........................................................................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
..
.
.
.
..
.
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
.
.
..
..
..
.
..................................................................................................................
...................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Figura 4.4: Grafico dei prolungamenti della funzione radice quadrata.
produrra una serie di funzioni trigonometriche che converge uniformementealla funzione x→ √x.Modificare gli script scilab realizzati precedentemente in modo da cal-colare numericamente gli sviluppi indicati. Fare il grafico della funzionex → √x con gli sviluppi per n = 2 e n = 4. In questo caso a = −3, b = 1,T = b− a = 4.
4.3 Integrazione numerica: le somme di Riemann
Quali sono i metodi numerici che i programmi come scilab usano per cal-colare gli integrali? Il primo metodo che viene in mente sono chiaramentele somme di Riemann. Nei corsi di Analisi Matematica del primo anno sidimostra che, se una funzione f e continua, allora le somme di Riemannconvergono all’integrale. Piu precisamente, se f : [a, b] → R e una funzio-ne continua e suddividiamo l’intervallo [a, b] in n intervallini di ampiezza1n (b−a), allora una somma di Riemann associata a questa suddivisione e laquantita
Sn(f) =1
n(b− a)
n∑
k=1
f(ξk)
dove ξi e un punto qualunque nello k-esimo intervallino Ik = [a + kn (b −
a), a + k+1n (b − a)], k = 0, . . . , n − 1. Qual e l’errore che si commette se si
approssima l’integrale con una somma di Riemann?
Vediamo di stimare, per cominciare, l’errore nel primo intervallino. Persemplicita supporremo a = 0 e indicheremo h = 1
n (b − a) l’ampiezza di

4.3. Integrazione numerica: le somme di Riemann 99
questi intervallini. Usando il teorema di Lagrange, lo scarto tra l’integralesu [0, h] ed il valore hf(ξ) e
∣∣∣∫ h
0f(x) dx− hf(ξ)
∣∣∣ =∣∣∣∫ h
0f(x)− f(ξ) dx
∣∣∣ =
=∣∣∣∫ h
0f ′(cx)(x− ξ) dx
∣∣∣ .
dove cx e un punto compreso tra x e ξ. Ora, se poniamo
M1 = supa≤t≤b
|f ′(x)| ,
si ha
∣∣∣∫ h
0f ′(cx)(x− ξ) dx
∣∣∣ ≤∫ h
0|f ′(cx)(x− ξ)| dx ≤
≤M1
∫ h
0|x− ξ| dx =M1
(∫ ξ
0(x− ξ) dx+
∫ h
ξ(ξ − x)| dx
)=
=M1
(12ξ2 +
1
2(h− ξ)2
).
Si vede facilmente che, al variare di ξ ∈ [0, h], la quantita ξ2 + (h− ξ)2 puovalere al massimo h2, per cui abbiamo trovato che
∣∣∣∫ h
0f(x) dx− hf(ξ)
∣∣∣ ≤ 1
2M1h
2 .
Ora, ricordando che h = 1n(b− a),
∣∣∣∫ b
af(x) dx− h
n∑
k=1
f(ξk)∣∣∣ ≤
≤n∑
k=1
∣∣∣∫
Ik
f(x) dx− f(ξk)∣∣∣ ≤ 1
2M1h
2 · n =
=1
2nM1(b− a)2 .
Quindi l’errore tende a 0 come 1n (n = numero di intervallini). Questa
stima vale qualunque sia il punto ξ scelto all’interno di ogni intervallino.Osserviamo pero che se la funzione e crescente, scegliendo come ξ l’estremosinistro la somma di Riemann fornira comunque una minorazione, mentrecon l’estremo destro dara una maggiorazione.

100 Capitolo 4. Esplorazioni numeriche
Abbiamo visto che l’errore tende a 0 come 1n . Non e un granche. Si puo fare
di meglio? In effetti se si sceglie come ξ il punto di mezzo di ogni intervallino,
succede qualcosa. Ritorniamo a considerare l’intervallino [0, h]. Se ξ = h2 e
supponiamo f due volte derivabile,
∣∣∣∫ h
0f(x) dx− hf(h2 )
∣∣∣ =∣∣∣∫ h
0(f(x)− f(h2 )) dx
∣∣∣ =
=∣∣∣∫ h
0(f ′(h2 )(x− h
2 ) +12f
′′(cx)(x− h2 )
2) dx∣∣∣
dove abbiamo fatto uno sviluppo di f attorno a h2 fino al second’ordine e cx
e sempre un punto compreso tra x e ξ. Ora∫ h
0f ′(h2 )(x− h
2 ) dx = 0
per cui, scrivendo M2 = supa≤t≤b |f ′′(x)|,∣∣∣∫ h
0f(x) dx− hf(h2 )
∣∣∣ =∣∣∣∫ h
0
12f
′′(cx)(x− h2 )
2 dx∣∣∣ ≤
≤ 1
2M2
∫ h
0(x− h
2 )2 dx =
1
24M2h3 .
Quindi in ogni intervallino l’errore e maggiorato da 124 M
2h3 e l’errore globaleinvece
∣∣∣∫ b
af(x) dx− h
n∑
k=1
f(ξk)∣∣∣ ≤
n∑
k=1
∣∣∣∫
Ik
f(x) dx− f(ξk)∣∣∣ ≤
≤ 1
24M2h
3 · n =1
24n2M2(b− a)3
che e un risultato molto migliore.Un terzo metodo: si potrebbe anche pensare di migliorare l’approssimazioneapprossimando la funzione f con una funzione lineare a tratti. La superficiecorrispondente ad ogni intervallino [xi−1, xi]e un trapezio le cui basi sonoalte f(xi−1) e f(xi) rispettivamente. Dunque ognuno di questi trapezi haarea
1
2n(b− a)(f(xi−1) + f(xi))
e l’approssimazione dell’integrale e
I ∼ 1
2n(b−a)
n∑
i=1
(f(xi−1)+f(xi)
)=
1
n(b−a)
(12f(a)+
n−1∑
i=1
f(xi)+1
2f(b)
).

4.4. Polinomi d’interpolazione e il metodo di Simpson 101
x0 x1 x2 x3 x4 x5 x6
.
..........................................................................................................................................................................................................................................................................................................................................................................................................
................................................................................................................................................................................................................................................................................................................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
............................................................................................................................................................................................
.......................................................................................................................................................................
..............................................................................................................................................................................................................................................................................................................................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Figura 4.5: Il metodo dei trapezi.
(ricordare che a = x0, b = xn). Lasciamo in sospeso la stima dell’errore diquesto metodo (per ora).
4.4 Polinomi d’interpolazione e il metodo di Simp-
son
A pensarci bene le somme di Riemann si possono vedere come una approssi-mazione della funzione integranda f mediante una funzione costante a tratti,facile da integrare. Ma ci sono anche altre funzioni facili da integrare: i poli-nomi. L’idea quindi e: approssimiamo f con un polinomio e approssimiamol’integrale di f su ogni intervallino con l’integrale del polinomio approssi-mante. Il metodo dei trapezi rientra in questo tipo di metodi, quando ilpolinomio approssimante e di grado 1.
Siano f una funzione e x0, x1, . . . , xn numeri reali. Si chiama polinomio
interpolante di f di ordine n (associato a x0, x1, . . . , xn) un polinomio P digrado n che coincida con f nei punti x0, x1, . . . , xn. Due questioni
a) Esiste sempre?
b) E unico?
L’unicita e immediata, dato che se P e Q fossero polinomi interpolanti di fdi ordine n, allora il polinomio P −Q si annullerebbe nei punti x0, . . . , xn.Ma un polinomio di ordine n non si puo annullare in n + 1 punti distintisenza essere identicamente nullo. Quindi necessariamente P = Q.

102 Capitolo 4. Esplorazioni numeriche
Anche l’esistenza e facile da stabilire, dato che e facile costruire esplicita-mente il polinomio interpolante. Per ogni i = 0, . . . , n, il polinomio
Qi(x) =∏
j 6=i
x− xjxi − xj
(4.1)
e di grado n e si annulla nei punti xj , j 6= i, mentre e immediato che Qi(xi) =1. Dunque il polinomio
P (x) =
n∑
i=0
Qi(x)f(xi) =
n∑
i=0
∏
j 6=i
x− xjxi − xj
f(xi)
e di grado n ed e tale che P (xi) = f(xi).Sia ora f una funzione definita su un intervallo [0, h]. Il suo polinomiod’interpolazione di ordine 2 associato ai punti 0, h2 , h e
P (x) = Q0(x)f(0) +Q1(x)f(h2 ) +Q2(x)f(h)
dove Q0, Q1, Q2 sono i polinomi (4.1) associati ai punti x0 = 0, x1 = h2 ,
x2 = h. Piu esplicitamente
Q0(x) =2
h2(x− h
2 )(x− h)
Q1(x) = −4
h2x(x− h)
Q0(x) =2
h2x(x− h
2 ) .
L’integrale ∫ h
0f(x) dx
verrebbe quindi approssimato con
f(0)
∫ h
0Q0(x) dx + f(h2 )
∫ h
0Q1(x) dx+ f(h)
∫ h
0Q2(x) dx .
Con pazienza calcoliamo∫ h
0Q0(x) dx =
2
h2
∫ h
0(x− h
2 )(x− h) dx =
= 2h
∫ 1
0(x− 1
2)(x− 1) dx = 2h
∫ 1
0(x2 − 3
2x+ 12 dx =
= 2h(13 − 34 +
12) =
h6
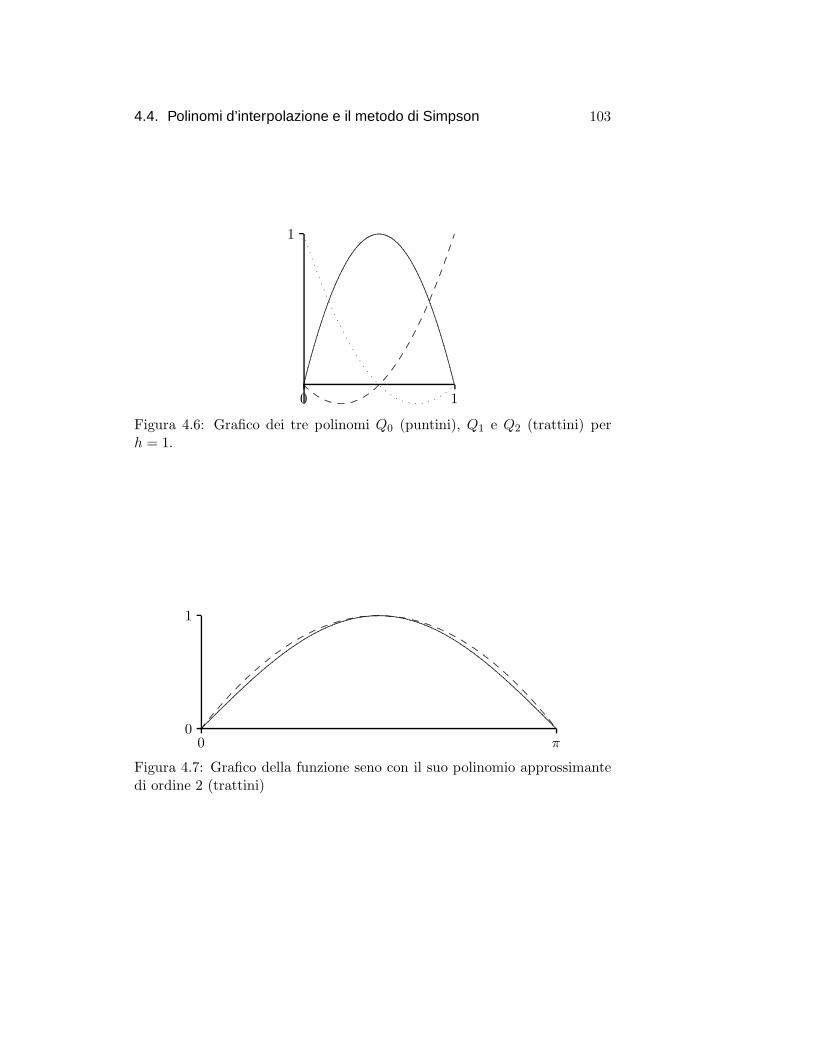
4.4. Polinomi d’interpolazione e il metodo di Simpson 103
0 1
1
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
..
.
.
.
.
..
.
.
.
.
..
.
.
.
.
...
.
.
.
..
.
.
.
..
.
.
.
..
.
.
.
..
........................................................................................
.....................................................................................................................................................................................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
...
.
.
.
.
.
.............
.............
.............
.............
.............
.............
.............
.
............
..
.
..
.
..
.
.
..
.
.
..
.
.
.
..
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Figura 4.6: Grafico dei tre polinomi Q0 (puntini), Q1 e Q2 (trattini) perh = 1.
0 π0
1
.
..............................................................................................................................................................................................................................................................................................................................................................................................................................................
....................................................................................................................................................................................................................
..............................................................................................................................................................................................................................
.
..
..
.
.
..
..
.
.............
..
...........
.............
.
..
.
..
.
..
.
..
.
.............
.............
.............
.............
.............
.............
.............
.............
.............
.............
.............
............. ..........................
.............
.............
.............
.............
.............
.............
.............
.............
.............
.............
.
............
..
...........
..
...........
.
.
..
..
..
.
..
..
Figura 4.7: Grafico della funzione seno con il suo polinomio approssimantedi ordine 2 (trattini)

104 Capitolo 4. Esplorazioni numeriche
mentre∫ h
0Q1(x) dx = − 4
h2
∫ h
0x(x− h) dx =
= −4h∫ 1
0x(x− 1) dx = −4h
∫ 1
0x2 − x dx =
= −4h(13 − 12 ) =
23 h
e ∫ h
0Q2(x) dx =
∫ h
0Q0(x) dx =
h
6.
Dunque l’approssimazione e∫ h
0f(x) dx ' h
(16 f(0) +
23 f(
h2 ) +
16 f(h)
).
Questa e l’approssimazione di Simpson.Supponiamo ora di volere approssimare l’integrale di f su un intervallo [a, b].Suddividiamo questo intervallo in n sottointervalli di uguale ampiezza e indi-chiamo con a = x0 < x1 < · · · < xn = b le estremita di questi sottointervalli.Indichiamo poi con y1, . . . yn i punti di mezzo di questi sottointervalli. Dun-que yi = 1
2 (xi−1 + xi). L’approssimazione di Simpson dell’integrale di fsull’intervallino [xk−1, xk] e
∫ xk
xk−1
f(x) dx ' 1
n(b− a)
(16f(xk−1) +
23f(yk) +
16f(xk)
)
mentre, sommando i contributi dei singoli intervallini,∫ b
af(x) dx '
' 1
n(b− a)
(16(f(a) + f(b)) +
1
3
n−1∑
k=1
f(xk) +2
3
n∑
k=1
f(yk)).
Insomma e come se si mettesse un peso pari a 16 sugli estremi dell’intervallo,
un peso pari a 13 sugli altri estremi degli intervallini ed infine un peso pari a
23 sui punti di mezzo degli intervallini.Quanto e buona l’approssimazione di Simpson?
Teorema 4.1 L’errore dell’approssimazione di Simpson e maggiorato da
1
2880n4M4(b− a)5
dove M4 = supx∈[a,b] |f (4)(x)|.

4.4. Polinomi d’interpolazione e il metodo di Simpson 105
Dunque l’approssimazione di Simpson e molto buona se f e almeno 4 voltederivabile e con una derivata quarta non troppo grande.
Esempio 4.2 Cerchiamo un’approssimazione di
log 2 =
∫ 2
1
1
xdx .
L’approssimazione di Simpson con n = 1 da
log 2 ' 1
6+
2
3
2
3+
1
6
1
2= 0.6944 .
Il Teorema 4.1 dice che l’errore e minore di 24/1780 = 0.008 (qui e facilevedere cheM4 = 24). In realta log 2 = 0.6931 e | log 2−0.6944| = 0.0012.
Osservazioni 4.3 a) I metodi con le somme di Riemann con i punti asinistra e a destra sono in generale piu lenti. Osservare pero che se la fun-zione e monotona crescente, il metodo col punto a sinistra fornisce unaminorazione mentre il metodo del punto a destra da una maggiorazione.Se la funzione e monotona decrescente succede il viceversa.b) Sia il metodo dei trapezi che quello del punto di mezzo danno un
risultato esatto se la funzione e lineare tra due punti della discretizza-zione. I trapezi danno una minorazione se la funzione e concava ed unamaggiorazione se e convessa. Il punto di mezzo, al contrario da unamaggiorazione per le funzioni concave ed una minorazione per le con-vesse. In entrambi i casi basta che la funzione sia concava o convessarispettivamente tra due punti della discretizzazione.c) E evidente che il metodo di Simpson da un risultato esatto se la
funzione e un polinomio di grado due tra due punti della discretizza-zione, dato che in questo caso il polinomio interpolante coincidera conla funzione stessa. Meno evidente e che esso fornisce un risultato esat-to anche se la funzione e un polinomio di grado 3 tra due punti delladiscretizzazione.

106 Capitolo 4. Esplorazioni numeriche
4.5 Un altro approccio: simulazione
5 Sia f : [0, 1] → R una funzione integrabile (senza nessuna ipotesi di rego-larita) e sia (Xn)n una successione di v.a. indipendenti uniformi su [0, 1].Allora la successione di v.a. (f(Xn))n e ancora formata da v.a. indipendenti,tutte di media E(f(X1)); per la legge dei grandi numeri quindi
1
n
n∑
k=1
f(Xk)P→
n→∞E(f(X1)) . (4.2)
D’altra parte sappiamo che
E(f(X1)) =
∫ 1
0f(x) dx .
Queste osservazioni suggeriscono un metodo di calcolo numerico dell’inte-grale di f : bastera disporre di un generatore aleatorio X1,X2, . . . di leggeuniforme su [0, 1] e quindi calcolare
1
n
n∑
k=1
f(Xk) .
Questa quantita per n grande e un’approssimazione di
∫ 1
0f(x) dx .
Piu in generale, se f e una funzione integrabile su un aperto limitato D ⊂ Rd,
allora l’integrale di f su D si puo approssimare numericamente in modosimile: se X1,X2, . . . e un generatore aleatorio uniforme su D, allora
1
n
n∑
k=1
f(Xk)P→
n→∞1
|D|
∫
Df(x) dx .
Ad esempio, sappiamo che se (Xn)n una successione di v.a. indipendentiuniformi su [0, 1] e a < b, allora Zn = a+(b−a)Xn e una successione di v.a.indipendenti e uniformi sull’intervallo [a, b]. Dunque, se f e una funzioneintegrabile su [a, b], allora
1
n
n∑
k=1
f(Zk) →n→∞
E[f(Z1)] =1
b− a
∫ b
af(x) dx

4.5. Un altro approccio: simulazione 107
Questo algoritmo per il calcolo d’integrali o di medie e un tipico esempiodi quelli che si chiamano metodi Montecarlo. Vedremo ora di sperimentarlosu alcune situazioni concrete, per vedere quali sono i suoi vantaggi ed i suoidifetti.
Esempio 4.4 Come fare per calcolare con il metodo Monte Carlol’integrale ∫ π
0sinx dx ?
(che sappiamo beve essere uguale a 2)? Prima di procedere occorreapprendere l’uso dei generatori aleatori in scilab . Questo sara l’og-getto del prossimo paragrafo. per ora accontentiamoci di sapere che ilcomando
-->xx=rand(10000,1,"u")
produce un vettore xx di numeri aleatori e uniformi su [0, 1] dunque coni comandi
-->yy=%pi * xx;app=%pi * mean(sin(yy))
vengono ottenuti prima i numeri yy che sono uniformi su [0, π] e poi ilvalore app che e appunto l’approssimazione Monte Carlo dell’integrale.Provate ora a• Fare questa operazione e controllare il risultato.• Ripetere questa operazione 200 volte mettendo i valori ottenuti in
un vettore e fare poi l’istogramma dei risultati. Quanto vale la varianzadei numeri ottenuti?• Ripetere l’operazione, ma stavolta facendo la media su 40 000
numeri aleatori ogni volta. Come si e comportata la varianza?
Come si puo valutare la velocita di convergenza? Come si puo paragonarequesto metodo con quelli numerici dei paragrafi precedenti. Vedremo che Imetodi Monte Carlo sono molto lenti, ma hanno anche dei vantaggi di altrotipo.
Lo strumento di base per valutare la velocita di convergenza e il TeoremaLimite Centrale. Infatti, se indichiamo Yi = (b − a)f(Xi) e con Y n =1n (Y1 + · · · + Yn) l’approssimazione dell’integrale, per il Teorema Limite

108 Capitolo 4. Esplorazioni numeriche
Centrale √n (Y n − µ) =
Y1 + · · · + Yn − nµ√n
∼ N(0, σ2) (4.3)
dove abbiamo indicato con µ = E(Y1) =∫ ba f(x) dx l’integrale da appros-
simare e con σ2 la varianza delle v.a. Yi. Quest’ultima si puo calcolarefacilmente, almeno in teoria, dato che
E[Y 21 ] = E[(b− a)2f(a+ (b− a)Xi)] = (b− a)
∫ b
af(x)2 dx
per cui
σ2 = (b− a)∫ b
af(x)2 dx−
(∫ b
af(x) dx
)2.
Per ottenere σ2 occorre quindi calcolare degli integrali, tra cui proprio quel-lo che speravamo di ottenere con il metodo Monte Carlo. In realta vedre-mo che si puo fare a meno del valore esatto di σ2, di cui basta avere unamaggiorazione.
La (4.3) permette di scrivere che, per n grande, la v.a.√nσ (Y n − µ) segue
approssimativamente una legge N(0, 1). Dunque se indichiamo con Z unav.a. N(0, 1), per δ > 0 e n grande si ha
P(|Y n − µ| ≥ δσ√
n
)' P(|Z| ≥ δ) .
Ma
P(|Z| ≥ δ) = P(Z ≤ −δ) + P(Z ≥ δ) = Φ(−δ) + 1−Φ(δ) =
= 2(1 − Φ(δ)) .
In conclusione
P(|Y n − µ| ≥ δσ√
n
)' 2(1 −Φ(δ)) .
Se vogliamo che Y n approssimi µ =∫ ba f(x) dx con un errore che e ≤ ε con
probabilita α, possiamo procedere nel modo seguente. Prima scegliamo δ inmaniera che
2(1 − Φ(δ)) = α
ovvero δ deve essere tale che Φ(δ) = 1− α2 . Il che e lo stesso che richiedere
δ = φ1−α/2, quantile di ordine 1 − α2 della legge N(0, 1). Dopo di che n
dovra essere scelto in modo che δσ√n≤ ε.

4.5. Un altro approccio: simulazione 109
Esempio 4.5 (continuazione dell’Esempio 4.4) Quanto deve esseregrande n perche Y n approssimi l’integrale con un errore che e ≤ 10−3
con una probabilita del 99%?Qui α = 0.99 e quindi 1− α
2 = 0.995. Dalle tavole si ricava φ.995 = 2.576.n dovra dunque essere tale che
2.576σ√n≤ 10−3
ovveron ≥ 106 · 2.5762 · σ2 .
Resta da determinare il valore di σ2. Come indicato prima, in realtabasta una maggiorazione, che in questo caso potrebbe essere
σ2 ≥ π∫ π
0f(x)2 dx ≥ π2
si ottiene dunque che deve essere
n ≥ 106 · 2.5762 · π2 ≥ 65 492 484
che e un valore molto grande, se paragonato con i metodi numerici deiparagrafi precedenti. Anche il vero valore di σ2, che qui e π2
2 −4 = 0.935,si sarebbe ottenuto n ≥ 6 203 138, che e sempre un numero molto grande.
C’e un altro modo di stimare σ2, ancora a partire dalla Legge dei GrandiNumeri. In effetti sappiamo che
1
n
n∑
i=1
(Yi − Y n)2 →
n→∞σ2 .
E quindi possibile, calcolando la varianza empirica dei risultati della simula-zione ricavare una stima di σ2, che puo permettere di ridurre l’effetto dellamaggiorazione, come si vede nell’Esempio 4.5.In realta occorre molta precauzione quando si sostituisce il valore stimatodella varianza a quello vero come in questo caso. Qui pero il valore di n ein genere talmente elevato da giustificare questa operazione.Osserviamo pero che questo metodo di stima della varianza (a partire dairisultati della simulazione) non permette di stabilire a priori quanto debba

110 Capitolo 4. Esplorazioni numeriche
essere grande n, dato che il valore approssimato di σ2 sara noto solo alla fine.Come si vede dall’Esempio 4.5 il numero di simulazioni richiesto per ottenereuna approssimazione ragionevole e comunque molto elevato. I metodi MonteCarlo sono quindi inferiori come prestazioni a quelli dei paragrafi precedenti.Hanno pero due vantaggi
• Convergono sempre anche se la funzione da integrare non e regolare (men-tre le stime che avevamo ottenuto per i metodi del paragrafo precedenterichiedevano comunque l’esistenza di un certo numero di derivate).
• Funzionano anche per gli integrali in dimensione piu grande di 1 (lastima della velocita di convergenza e esattamente la stessa), laddove gli altrimetodi numerici diventano molto piu complicati.
4.6 Esercizi sull’integrazione numerica
4.11 Sia
f(x) = ex2
. (4.4)
Vogliamo calcolare ∫ 1
0f(x) dx .
a) Determinare un’approssimazione di I con i metodi delle somme diRiemann con punto a destra, a sinistra, di mezzo e trapezi, per n = 5.
b) Calcolare per n = 10, 20, 50, 100 le stesse approssimazioni di a).
b1) produrre e stampare una matrice avente come prima colonna il valore din, come seconda l’approssimazione ottenuta, come terza colonna la maggio-razione teorica dell’errore (tranne che per i trapezi) e come quarta colonnal’errore numerico (=valore approssimato-valore dell’integrale, ottenuto conil comando intg di scilab )
b2) Disegnare un grafico con n in ascisse e le approssimazioni ottenute inordinate. Aggiungere al grafico la retta orizzontale di ordinata uguale al ele stime degli errori dei due metodi. (Per il calcolo delle quantita M1 =sup0≤t≤1 |f ′(t)| e M2 = sup0≤t≤1 |f ′′(t)| si potra ammettere che la funzionef ha le derivate di tutti gli ordini che sono delle funzioni crescenti
c) Quale evidenza si puo ricavare sull’errore con il metodo dei trapezi?(confrontando con i metodi con i punti di mezzo e quello con i punti agliestremi.
Vogliamo ottenere numericamente un’approssimazione di I con un errore inmodulo ≤ 10−4. Che valore di n bisogna scegliere se si usano i metodi

4.6. Esercizi sull’integrazione numerica 111
1. punto di sinistra2. punto di destra3. punto di mezzo.d) Scrivere una funzione scilab che, in funzione di n, effettua le opera-
zioni precedenti.
4.12 Sia f la funzione
f(x) =1
x
di cui vogliamo calcolare l’integrale da 1 a 2.Determinare quanto grande deve essere n per ottenere un’approssimazionedell’integrale con un errore ≤ 10−4 con i metodia) delle somme di Riemann con punto a sinistrab) delle somme di Riemann con punto a destrac) delle somme di Riemann con punto di mezzod) dei trapezie) di Simpson. Con quest’ultimo metodo, qual e l’errore che si commette
con n = 1 e con n = 2?
4.13 Ripetere le operazioni precedenti per le funzionia)
I =
∫ π
0sinx dx .
b)
I =
∫ π
0e−x2/2 sin(12x) dx
(per questa funzione si potranno ammettere le approssimazioni M1 = 1,M2 ' 134.)c)
I =
∫ π
0
√x sinx dx .
4.14 Per le funzioni degli Esercizi 4.11 e 4.13 calcolare le approssimazionicon il metodo di Simpson e confrontare per n = 5 e n = 10 e confrontarecon i risultati degli altri metodi.
4.15 Trovare una stima del valore dell’integrale
∫ π
0
sin t
tdt
con un errore inferiore a 10−5 (con un metodo a vostra scelta. . . ).

112 Capitolo 4. Esplorazioni numeriche
4.16 Vogliamo calcolare numericamente l’integrale
I =
∫ π2
0sin√x dx .
a) In quanti sottointervalli occorrerebbe suddividere l’intervallo [0, π2] perchesi possa essere sicuri che l’errore commesso sia ≤ 10−2 con il metodo delpunto di sinistra? Et del punto di mezzo? E dei trapezi? E di Simpson?b) Decidiamo piuttosto di calcolare l’integrale per simulazione:
I ' 1
Nπ2
N∑
i=1
f(Xi) := IN
dove le v.a. Xi sono uniformi su [0, π2].b1) A priori, come si deve scegliere N perche l’errore dello stimatore IN sia≤ 10−2 con probabilita 99%?b2) Calcolare IN per N = 25000 et determinare qual e l’errore, sempre adun livello 99%, prima con la maggiorazione delle varianza e poi stimandola varianza a partire dai dati. In questo caso, confrontare il risultato conquello dei vicini.c) Improvvisamente una illuminazione! Con un cambio di variabile si ha
I =
∫ π2
0sin√x dx = 2
∫ π
0y sin y dy .
Se si e disposti ad una maggiorazione grossolana della derivata quarta del-la funzione y → y sin y, in quanti sottointervalli bisogna suddividere [0, π]perche l’errore sia ≤ 10−2 con il metodo di Simpson?d) Rispondere alle domande di b) per il calcolo dell’integrale
J =
∫ 1/π2
0sin 1√
xdx .
4.17 Calcolare con il metodo Montecarlo l’integrale∫
Ae−(x2+y2)/2 dx dy
dove A ea) il quadrato [−1, 1]× [−1, 1];b) il cerchio di raggio 1 e di centro l’origine. In questo secondo caso con-frontare i risultati ottenuti con il valore esatto.

4.7. Probabilita e simulazione in scilab 113
4.7 Probabilita e simulazione in scilab
scilab ha varie funzioni per gli aspetti numerici della Probabilita e dellaStatistica e le simulazioni.Prima di tutto ci sono i calcoli relativi alle funzioni di ripartizione. Adesempio per le leggi gaussiane il comando cdfnor produce la funzione diripartizione ed i quantili delle leggi gaussiane. L’uso di questi comandi none proprio amichevole. Vediamo un po’. Se viene dato il comando
-->[P,Q]=cdfnor("PQ",x,mu,sigma)
P sara il valore della funzione di ripartizione di una legge gaussiana di mediamue deviazione standard sigma calcolato in x . Il secondo valore restituitodal programma, Q e semplicemente uguale a 1-P . Attenzione agli aspettiseguenti:• sigma e la deviazione standard e non la varianza.• x puo essere un vettore e in questo caso anche P e Q saranno dei vettori.Per approfittare di questa possibilita pero anche mue sigma devono esseredei vettori, anche se le medie e le varianze sono tutte uguali. Ad esempio peravere i valori della funzione di ripartizione di una N(0, 1) nei valori 1, 1.5, 2occorrera scrivere
-->x=[1,1.5,2];-->[P,Q]=cdfnor("PQ",x,zeros(x),ones(x));
Cambiando la sintassi il comando cdfnor produce i quantili: scrivendo
-->x=[1,1.5,2];
-->x=cdfnor("X",0,1,P,Q);
il valore ottenuto x sara il quantile corrispondente alla probabilita P (quicome prima Qdeve essere uguale a 1-P ). Come prima il comando e vettoriale,nel senso che P puo essere un vettore. In questo caso anche tutti gli altriargomenti devono essere dei vettori aventi la stessa dimensione.Per distribuzioni diverse dalla normale esistono i comandi appropriati:cdfbet (leggi beta)cdfbin (binomiali)cdfchi (chiquadrato)cdfchn (chiquadrato decentrato)cdfgam (gamma)cdff (F )

114 Capitolo 4. Esplorazioni numeriche
cdffnc (F decentrata)cdfnbn (binomiale negativa)cdfpoi (Poisson)cdft (t di student)La loro sintassi e simile a quella di cdfnor , sia per il calcolo delle funzionidi ripartizione che per quello dei quantili.Per la simulazione esistono due generatori aleatori in scilab
Esempio 4.6 (Il grafico dei quantili) Siano X1, . . . ,Xn delle v.a. indi-pendenti, aventi tutte la stessa legge (continua o discreta, poco importa).Indichiamo con F la loro f.r. Se poniamo At =] −∞, t], allora si vedesubito che
E(1At(X1)) = P(X ≤ t) = F (t) .
Quindi per la (4.2) applicata alla funzione f = 1At si ha
1
n
n∑
k=1
1At(Xk)P→
n→∞E(1At(X1)) = F (t) . (4.5)
Indichiamo con Fn(t) il termine a sinistra nella (4.5), cioe
Fn(t) =1
n
n∑
k=1
1At(Xk) =1
n× numero di indici k tali che Xk ≤ t .
La funzione Fn(t) e una funzione di t che si chiama funzione di riparti-
zione empirica [empirica]. Un altro modo, per certi versi piu semplice,di vedere la f.r. empirica e il seguente. Indichiamo con X(1), . . . ,X(n) inumeri X1, . . . ,Xn riordinati in senso crescente: in particolare X(1) e ilvalore piu piccolo e X(1) ≤ X(2) ≤ · · · ≤ X(n). Allora e chiaro che si haanche
Fn(t) =
0 se t < X(1)
k
nse X(k) ≤ t < X(k+1), k = 1, . . . , n− 1
1 se X(n) ≤ t .Infatti se X(k) ≤ t < X(k+1), cio vuol dire che vi sono esattamente kindici i tali che Xi ≤ t e dunque
1
n
n∑
k=1
1At(Xk) =k
n·

4.7. Probabilita e simulazione in scilab 115
x(1) x(2) x(3) x(4) x(5) x(6) x(7)
1
•
•
•
•
•
•
•
...................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
...................
Figura 4.8: Esempio di funzione di ripartizione empirica per un campionedi rango 7 di una legge N(0, 1), a confronto con la funzione di ripartizioneteorica (a puntini).
Osserviamo comunque che, per ogni valore di t, Fn(t) e una quantita
aleatoria, dato che dipende dai valori X1, . . . ,Xn. Dunque la (4.5) nonfa che affermare che, per ogni t fissato, la f.r. empirica converge inprobabilita alla f.r. F .
Queste osservazioni hanno delle conseguenze pratiche interessanti. Talvoltain presenza di dati sperimentali X1, . . . ,Xn e interessati a stabilire se essiseguano una distribuzione assegnata, N(0, 1) ad esempio. Se n e abbastanzagrande, per la Legge dei Grandi Numeri, la differenza tra la f.r. empiricaFn e quella teorica F e piccola. Poiche sappiamo che Fn assume il valorein nel punto X(i), cio vuol dire che i numeri i
n e Φ(X(i)) devono essere
molto vicini. Applicando la funzione Φ−1, che e continua, ai due numeri in
e Φ(X(i)), otteniamo che anche i due valori
Φ−1( in) e X(i)
devono trovarsi vicini tra loro. Il punto Φ−1( in) e il numero in cui la f.r.
Φ prende il valore in e dunque non e altro che il quantile φi/n. Cio signi-
fica che se si disegnano sul piano i punti di coordinate X(i) e φi/n, essi sidevono disporre lungo la bisettrice del primo e terzo quadrante. Questaosservazione fornisce un metodo per valutare “ad occhio” (e il caso di dirlo)se le osservazioni seguano o no una legge N(0, 1). Esso naturalmente puoessere applicato anche ad altre distribuzioni continue (esponenziali, χ2,. . . ),semplicemente sostituendo ai quantili φi/n quelli della f.r. appropriata.

116 Capitolo 4. Esplorazioni numeriche
...
.
.
.
.
.
.
.. .
..
.
. .. ..
. .
..
.
.
..
..
.
.
..
..
.
.
.
.
..
.
..
..
. . ....
.. .
. ....
..
.
.
.
...
.
...
.
...
...
.
. .
.
.
.
. . ..
.
...
.
. .. .
..
.. ..
..
.
..
. .
..
.
.. ..
.
.
.
.... ..
Grafico dei quantili per un campione ottenuto per simulazione di una leggenormale.
L’interesse di questo metodo grafico e pero ancora limitato perche esso per-mette di vedere se le osservazioni seguano una prefissata distribuzione, men-tre spesso si e interessati piuttosto a vedere se esse seguono una distribuzionedi una determinata famiglia, ad esempio se esse sono normali N(µ, σ2) perqualche valore ignoto di µ e σ2. Gli argomenti precedenti possono pero esse-re perfezionati per ricavare un metodo grafico per trattare questo problemapiu complesso (anche se ci limiteremo, qui, al caso di leggi normali).Basta per questo ricordare la relazione tra i quantili di una legge N(µ, σ2)e quelli di una N(0, 1): il quantile di ordine i
n di una N(µ, σ2) e ugualea σφi/n + µ. Riprendendo il ragionamento precedente, se le osservazioniseguono una distribuzione N(µ, σ2), allora i numeri
σφi/n + µ e X(i)
devono essere vicini tra loro; in altre parole i punti di coordinate X(i) eφi/n devono allinearsi lungo la retta di equazione x = σy + µ. Basta quindidisegnare questi n punti sul piano e poi vedere se essi si dispongono lun-go una retta o no (ora non piu necessariamente la bisettrice del primo eterzo quadrante). Il grafico dei punti (X(i),Φ
−1( in)) si chiama, nel gergo
della statistica il grafico quantili contro quantili, poiche si tratta di confron-tare i quantili della distribuzione empirica Fn contro quelli della N(0, 1).La sua realizzazione manuale puo risultare laboriosa, ma di solito tutti isoftware statistici hanno prevedono questa operazione. Vediamo come sipuo realizzare il grafico dei quantili. Cominciamo col procurarci dei datisui quali effettueremo l’analisi. Generiamo 100 numeri aleatori indipendenticon distribuzione N(0, 1).
-->xx=rand(1,100,’n’);
Dobbiamo poi procurarci i valori dei quantili corrispondenti alle probabilita1
100 ,2
100 , . . . Intanto mettiamo questi numeri in un vettore
-->p=(1:100)/100;

4.7. Probabilita e simulazione in scilab 117
.
.
.
.. .
..
. .
.
.
....
. .
..
.
. ..
..
..
..
.
.
.
.
.
.
..
.
. .
...
.
.
.
.
.
.
.
..
.
..
.
..
.
. .
..
...
.
.
. .
..
.
.
.
.
.
. .. .
.
.
. .
.
..
...
.
..
.
.
..
.
.
..
. .
. ...
.
..
..
.
.
.
.....
.
..
..
.
Grafico dei quantili per un campione ottenuto per simulazione di una leggeχ2(4). L’andamento si discosta da una retta.
Il comando per il calcolo dei quantili e
-->cdfnor("X",med,devst,p,1-p)
dove med e devst sono rispettivamente la media e la deviazione standarddella legge gaussiana, nel nostro caso 0 e 1, naturalmente. Occorre pero chemed e devst siano vettori della stessa dimensione di p. Il comando dunquee
-->zz=cdfnor("X",zeros(p),ones(p),p,1-p);
Il programma da un messaggio d’errore perche tra i valori dei quantili dacalcolare c’e anche quello per p = 1, cioe +∞. Conviene allora correggere ivalori di p di un po’:
-->p=(1:100)/100-1/200;
Si vede subito che, per la legge dei grandi numeri, il plot dei quantili sicomporta allo stesso modo se invece delle probabilita k
n si considerano lekn + 1
2n .
-->zz=cdfnor("X",zeros(p),ones(p),p,1-p);
Occorre poi riordinare i numeri aleatori in senso crescente e farne il graficomettendoli in ascissa, con i quantili in ordinata
-->xx=gsort(xx,"g","i");
-->clf();plot(xx,zz,".");

118 Capitolo 4. Esplorazioni numeriche
Per completare il grafico e mettere in evidenza se i punti sono allineati, sipuo aggiungere la retta di regressione di zz rispetto a xx . Si tratta dellaretta di equazione y = ax+ b, dove a e uguale al quoziente tra la covarianzadi xx e zz divisa per la varianza di xx , mentre b e uguale alla media di zzmeno a moltiplicato per la media di xx . Cioe
-->mm=mvvacov([xx’ zz’])
-->a=mm(1,2)/mm(1,1);b=mean(zz)-a * mean(xx);
-->x1=[min(xx) max(xx)];y1=a * x1+b;
-->plot(x1,y1)
4.18 Scrivere una funzione scilab che, dato un set di dati, effettui ilplot dei quantili per confrontare con la distribuzione gaussiana.

Capitolo 5
Simulazione, processi e EDP
5.1 Simulazione
Il punto di partenza dei metodi di simulazione e la Legge dei Grandi Numeri:se (Xn)n e una successione di v.a. i.i.d. aventi speranza matematica finita,allora
Xn :=1
n(X1 + · · ·+Xn)
q.c.→n→∞
E(X1) .
Una prima applicazione e data dall’integrazione numerica: se f : [0, 1] → R
e una funzione integrabile e (Xn)n una successione di v.a. i.i.d. uniformi su[0, 1], allora anche le v.a. f(Xn) sono tra loro indipendenti e identicamentedistribuite. Dunque per la Legge dei Grandi Numeri
1
n(f(X1) + · · ·+ f(Xn))
q.c.→n→∞
E(f(X1)) =
∫ 1
0f(x) dx .
Dunque volendo calcolare l’integrale di f si potra semplicemente istruire uncomputer a produrre n numeri aleatori i.i.d. uniformi su [0, 1] e a calcolarela media aritmetica dei valori f(Xi) ottenuti. Si tratta di un metodo moltosemplice da applicare. Negli esempi seguenti vediamo di metterne in evi-denza pregi e inconvenienti. Si ricorda che il comando per generare numerialeatori indipendenti uniformi su [0, 1] in scilab e rand(n,m,"u") , cheproduce una matrice n×m di numeri aleatori con queste proprieta.
Esempio 5.1 Scegliamo f(x) = x2. Sappiamo quindi che l’integrale dif su [0, 1] vale 1
3 .
119

120 Capitolo 5. Simulazione, processi e EDP
a) Dare un’approssimazione dell’integrale di f su [0, 1] usando la leggedei grandi numeri con n = 1000, usando scilab .b) Dare un’approssimazione dell’integrale di f su [0, 1] usando la legge
dei grandi numeri con n = 100000, usando scilab .c) Dare un’approssimazione dello stesso integrale approssimando-
lo con una somma di Riemann, suddividendo l’intervallo [0, 1] in 10sotto-intervalli. Quale dei due metodi vi sembra meglio?d) Scrivere un programmino che effettua per 100 volte il calcolo
approssimato come in a) e poi fare l’istogramma dei risultati ottenuti.e) Ripetere le simulazioni come in a) e b) e calcolare l’intervallo di
fiducia della stima dell’integrale al livello 95%. Ricordiamo che si trattadell’intervallo
[Zn −
s√nt0.975(n− 1), Zn +
s√nt0.975(n− 1)
]
dove indichiamo con Zi = f(Xi) i valori simulati, con Zn la loro mediae con
s2 =1
n− 1
n∑
i=1
(Zi − Zn)2
la varianza empirica dei valori Zi = f(Xi). Inoltre t0.975(n − 1) e ilquantile di ordine 0.975 della legge t di Student con n−1 gradi di liberta‘.Per valori di n cosı grandi i quantili della t di Student coincidono conquelli della N(0, 1). Il comando scilab per ottenere questo quantile ecdfnor("X",0,1,0.975,1-0.975) .
Naturalmente il metodo di simulazione si applica anche al calcolo d’integralisu domini piu generali che [0, 1]. Ad esempio siano D ⊂ R
d un dominio dimisura finita e (Xn)n una successione di v.a. i.i.d. uniformi su D. Cio vuoldire che Xi ha densita
g(x) =
{1
mis(D) se x ∈ D0 altrimenti .
Dunque, se f : D → R e una funzione integrabile, allora
1
n(f(X1) + · · · + f(Xn))
q.c.→n→∞
E(f(X1)) =1
mis(D)
∫
Df(x) dx .

5.2. Stima di densita 121
5.1 Scegliamo f(x) = sinx e D = [0, π]. Sappiamo quindi che l’integraledi f su D vale 2.
a) Dare un’approssimazione dell’integrale di f su [0, π] usando la legge deigrandi numeri con n = 1000, usando scilab .
c) Dare un’approssimazione dello stesso integrale approssimandolo conuna somma di Riemann, suddividendo l’intervallo [0, 1] in 10 sotto-intervalli.Quale dei due metodi vi sembra meglio?
5.2 Poniamo f(x) = e−1
2(x2+y2).
a) Dare un’approssimazione dell’integrale di f sul quadratoD = {(x, y); |x| ≤1, |y| ≤ 1} usando la legge dei grandi numeri con n = 10000 e n = 1000000,sempre usando scilab . Confrontare con il valore esatto che si puo ricavaredalle tavole della legge N(0, 1) (che si ricavano con il comando cdfnor )
b) Stessa cosa con D = {(x, y);x2 + y2 ≤ 1} e confrontare con il valoreesatto calcolando l’integrale in coordinate polari (= 2π(1 − e−1/2 = 2.472).
c) Dare un’approssimazione dell’integrale di f(x) = e−1
2|x|2 su D = {x ∈
R4; |x| ≤ 1} usando la legge dei grandi numeri con n = 1000, n = 10000,
n = 100000 , n = 1000000, sempre usando scilab e determinare i rela-tivi intervalli di fiducia. Confrontare ancora con il valore esatto (semprericonducendosi alla funzione di ripartizione della legge N(0, 1). Consiglio: ilcomando cdfnor produce i quantili e i valori della funzione di ripartizionedella legge N(0, 1), ma e‘ il suo uso e un po’ complicato da ricordare. peravere facilmente i valori della f.r di una legge N(0, 1) puo convenire definirlacome
deff("y=ph(x)","[y,z]=cdfnor(""PQ"",x,zeros(x),ones (x))")
Gli esempi precedenti mettono in evidenza i due aspetti fondamentali deimetodi di simulazione:
a) richiedono valori di n molto elevati per dare risultati soddisfacenti;
b) sono molto semplici da implementare e rimangono molto semplici an-che quando la dimensione cresce e altri metodi numerici come le somme diRiemann non sono piu disponibili oppure diventano molto complicati.
5.2 Stima di densita
Nel paragrafo precedente abbiamo parlato di simulazione con l’obiettivo dicalcolare degli integrali. Altre volte l’obiettivo e un altro.

122 Capitolo 5. Simulazione, processi e EDP
Consideriamo ad esempio delle osservazioni X1, . . . ,Xn che si possono con-siderare indipendenti ed equidistribuite: spesso si e interessati a stimare lalegge di queste osservazioni. Seguiranno una legge gaussiana? O binomiale?
Vediamo qui come si possono realizzare dei metodi grafici per valutare visi-vamente se le osservazioni seguano una legge data. Nel caso di osservazioniche prendono solo numeri interi si possono costruire degli istogrammi, o me-glio dei diagrammi a barre, che danno una indicazione dell’andamento delleprobabilita delle varie modalita.
Quando invece si tratta di osservazioni aventi una legge continua l’istogram-ma si deve considerare solo un primo approccio, un po’ rozzo dal punto divista grafico.
Un metodo piu raffinato e il seguente: attorno ad ognuna delle osservazioniXi si considera la funzione
fi(x) =
1
nh
(1− 1
h|x−Xi|
)se |x−Xi| < h
0 altrimenti
che e la funzione a “ tendina” della Figura 5.1. Qui n e il numero di osserva-zioni e h (l’apertura della tendina) e un parametro da scegliere. Dalla figura
Xi−h Xi Xi+h
1nh
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
......................................................................................................................................................................................................................................................................................................
Figura 5.1:
si vede facilmente che l’area del sottografico di fi e uguale a 1n . Dunque
la somma delle funzioni fi (intuitivamente, la somma di tanti triangolinicentrati sulle osservazioni) avra un’area pari a 1. Cioe la somma di que-ste funzioni e sempre una densita di probabilita. Non e difficile rendersiconto che facendo la somma delle funzioni fi (che dipende dalle osserva-zioni, naturalmente) si trova una funzione che approssima la densita delleosservazioni.

5.3. La simulazione del moto browniano 123
Esempio 5.2 Esempio Provate a chiedere a scilab di generare a ca-so 1600 numeri aleatori N(0, 1). Stimate poi, a partire da essi la lorodensit‘a di probabilita e fatene il grafico, sovrapponendovi sopra il gra-fico di una N(0, 1). Naturalmente dovrete andare un po’ per tentativinella scelta dell’apertura della finestra h. Il problema della determina-zione, a partire dai dati, del migliore valore di h e una questione che haimpegnato a lungo molti ricercatori fino a una ventina di anni fa.In pratica per la stima della densita un codice pronto e il seguente
function yy=schauder2(xdat,tt,h)//xdat: i dati della simulazione//tt: i punti in cui volete stimare la densita‘//h: apertura della tendina//i valori yy ottenuti corrispondono ai valori della//densita‘ stimata nei valori ttnn=length(xdat);yy=zeros(tt)deff("z=tnd(t,xc)","z=(1-abs(xc-t)/h). *(abs(xc-t)<h)/h/nn");jj=1;while jj<=length(xdat)yy=yy+tnd(tt,xdat(jj));jj=jj+1;end;endfunction
5.3 La simulazione del moto browniano
Un moto browniano e un processo, cioe una famiglia di v.a. (Bt)t, t > 0, conle proprieta seguenti.
• Per ogni ω l’applicazione t→ Bt(ω) e continua.
• Gli incrementi sono indipendenti, cioe per ogni s1 < t1 < s2 < t2 <. . . sk < tk le v.a. Bt1 −Bs1 , Bt2 −Bs2 , . . . , Btk −Bsk sono indipendenti.
• Se s ≤ t, Bt −Bs ha legge N(0, t − s).

124 Capitolo 5. Simulazione, processi e EDP
−3 −2 −1 0 1 2 3
..................................................................
..........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
....................................................................................................................................................................................................
.........................................................................................................................................................................................................................................................
.......
.................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.......
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.............................
Figura 5.2: La densita stimata a confronto con quella vera (a puntini). Quierano stati simulati 1600 numeri a caso con densita N(0, 1) e si e usatauna finestra h = 0.3. Valori di h piu piccoli avrebbero prodotto un grafi-co stimato piu bitorzoluto. Forse un valore piu grande sarebbe stato piuindicato.
−3 −2 −1 0 1 2 3
.......................................................
.....................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
................................................................................................................................................................................................................................................................................
...................................................................................................................................................................................................................................................
.......
..................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..........
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
............................
Figura 5.3: La densita stimata a confronto con quella vera (a puntini) conuna finestra h = 0.5.
Un moto browniano m-dimensionale e un processo (Bt)t, t > 0 a valori Rm
dove Bt = (B1(t), . . . Bm(t)) e i processi (Bi(t))t, t > 0 sono moti brownianilineari (cioe unidimensionali) indipendenti.
Prima di procedere osserviamo che il MB gode di alcune proprieta interes-santi:• Se (Bt)t e un MB. allora anche (−Bt)t e un MB. Infatti le tre proprieta
indicate sopra rimangono vere per (−Bt)t (ricordare che se X e una v.a.gaussiana centrata, allora X e −X hanno la stessa legge).• Piu in generale, se (Bt)t e un MB m-dimensionale e O e una matrice
ortogonale m ×m, allora (OBt)t e ancora un MB m-dimensionale. Anchequi si tratta di una proprieta d’invarianza delle leggi gaussiane.

5.3. La simulazione del moto browniano 125
Tra breve vedremo dei problemi in cui occorrera simulare delle traiettoriedel moto browniano. Con scilab questa simulazione e abbastanza sempli-ce, dato che basta simulare delle v.a. N(0, 1), rinormalizzarle per otteneregli incrementi e poi addizionarli (con il comando cumsum) per ottenere leposizioni successive della traiettoria.
Ad esempio, per simulare una traiettoria bidimensionale di un moto brow-niano per t ∈ [0, 1] e per tracciarne il grafico si daranno i seguenti comandi
ns=100;// 1/ns e‘ l’ampiezza della discretizzazione della//traiettoriaxw=rand(ns,2,"n")/sqrt(ns);// xw e‘ una matrice con ns righe e 2 colonne// contenente gli incrementi del processoxw=cumsum(xw,"r")// cumsum( ,"r") effettua le somme cumulative lungo//le righe.// xw ora contiene le posizioni della traiettoria//simulata// la prima colonna quelle della prima coordinata// la seconda quelle della secondaxw=[[0,0];xw]// ora aggiungiamo l’origine che e‘ il punto inizialeplot(xw(:,1),xw(:,2));a=gca();a.isoview="on";// ecco il grafico
Quando pero occorre simulare numerose traiettorie per risolvere i problemidi EDP che incontreremo non e opportuno usare scilab , dato che si trattadi un linguaggio interpretato, quindi lento nelle simulazioni “vere” (quandooccorre simulare tantissime traiettorie). Per questo e opportuno impararea simulare delle traiettorie del moto browniano in C. La programmazionenei due linguaggi si effettua in modi molto diversi, dato che scilab ha lacapacita di manipolare direttamente dei vettori, mentre la simulazione in Cva fatta passo passo.
Per realizzare in C una traiettoria del moto Browniano occorre rivedere perprima cosa come si chiama un programma in questo linguaggio da scilabcome viene spiegato nel §2.11. Un’altra precauzione da prendere quando sifanno delle simulazioni in un linguaggio come C e di procurarsi un generatorealeatorio valido. Quello gia presente nel linguaggio non e buono: ha un ciclodi circa 2.1 · 109: dopo circa due miliardi di numeri aleatori ricomincia da

126 Capitolo 5. Simulazione, processi e EDP
capo a produrre gli stessi numeri, che quindi aleatori non sono piu. Il listatoche segue presenta uno schema di programma pronto per simulare delle v.a.gaussiane.
Utilizza una subroutine knuth (che non compare nel listato) che producenumeri aleatori con distribuzione uniforme su [0, 1]. Inoltre una subroutineBMche, a partire dalle v.a. uniformi produce numeri aleatori con distribuzio-ne gaussiana con l’algoritmo di Box-Muller: se X1,X2 sono v.a. uniformi su[0, 1] e indipendenti, allora
√−2 logX1 cos(2πX2) e√−2 logX1 sin(2πX2)
sono entrambe N(0, 1) e indipendenti. Piu precisamente produce due vet-tori, c1 , c2 , contenenti delle v.a. N(0, 1) indipendenti.
#define STRICT#include <windows.h>#include <stdio.h>#include <time.h>#include <stdlib.h>#include <math.h>#define pig 4 * atan(1)
double knuth(void) {/ * ...programma di generazione di v.a. uniformisu [0,1] * /}void BM(unsigned int * nn,double c1[], double c2[]){
unsigned int jj;double z1,z2;
for(jj=0;jj< * nn;++jj){z1=knuth();z2=knuth();c1[jj]=sqrt(-2 * log(z1)) * cos(2 * pig * z2);c2[jj]=sqrt(-2 * log(z1)) * sin(2 * pig * z2);}}
5.3 Compilare il programma precedente, linkarlo con scilab . Effettuarel’istogramma dei valori ottenuti per ciascuno dei due vettori e confrontarlo

5.4. Moto browniano e EDP 127
con la densita N(0, 1). Disegnare sul piano i punti che hanno le ascisse inc1 e le ordinate in c2 .
5.4 Modificare il programma precedente per produrre una traiettoriadi un moto browniano bidimensionale e disegnarla con scilab . Basteramodificare l’ultima parte del programma in
double gg(void){double z1,z2;
z1=knuth();z2=knuth();return sqrt(-2 * log(z1)) * cos(2 * pig * z2);}void BM(unsigned int * nn,double c1[],double c2[]){unsigned int jj;
c1[0]=0.;c2[0]=0.;for(jj=1;jj< * nn;++jj){c1[jj]=c1[jj-1]+gg()/sqrt( * nn);c2[jj]=c2[jj-1]+gg()/sqrt( * nn);}}
5.4 Moto browniano e EDP
In questo paragrafo e nei successivi esploreremo il rapporto tra questo pro-cesso ed alcuni problemi alle derivate parziali da un punto di vista numerico.Questo fornira dei metodi di risoluzione di questi problemi mediante delletecniche di simulazione che paragoneremo con i metodi (elementi finiti. . . )analitici.
Sia D ⊂ Rm un dominio limitato e indichiamo
4 =∂2
∂x21+ · · ·+ ∂2
∂x2m

128 Capitolo 5. Simulazione, processi e EDP
il Laplaciano. Il primo problema e
{12 4u = −1 in D
u = 0 su ∂D(5.1)
che si puo rappresentare (sotto ipotesi di regolarita per ∂D. . . )
u(x) = E(τx) (5.2)
dove τx e il tempo d’uscita di (x+Bt)t, t > 0 da D, cioe
τx = inf{t, x+Bt ∈ ∂D}
(questo e un teorema). Ora vogliamo fare le cose seguenti, considerandoD = {|x| ≤ 1}, la palla unitaria di Rm.
• Simulare traiettorie del moto browniano per vari valori del punto ini-ziale, ottenendo quindi un’approssimazione numerica della soluzione u delproblema (5.1).
• Risolvere (in dimensione 2) il problema (5.1) con il metodo degli ele-menti finiti (usando Freefem ).
• Confrontare i risultati ottenuti con il risultato esatto. Infatti non edifficile vedere che
u(x) =1
m(1− |x|2)
e soluzione (ricordare che m e la dimensione). In particolare, per x = 0,vediamo che il tempo medio d’uscita del moto browniano dalla palla unitariapartendo dall’origine e 1 diviso per la dimensione.
Le prime sperimentazioni: indicheremo con m la dimensione e con ns ilnumero d’intervallini in cui suddividiamo l’intervallo temporale [0, 1].
5.5 Per m= 2, x=(0,0) e ns= 100, modificare il programma precedente(che simulava una singola traiettoria) in maniera che ora ne simuli molte edi ciascuna calcoli il tempo d’uscita dalla palla di raggio 1. Simulare 1000traiettorie e calcolarne la media dei tempi d’uscita. Confrontare il risultatoottenuto con il vero valore 1
2 . Ripetere con ns= 400, ns= 1600 e ns= 7200.Cosa si osserva? Quanto velocemente tende a 0 l’errore?
5.6 Modificare il codice C in maniera da poter simulare il moto brownianoa partire da un punto eventualmente diverso da (0, 0). Ad esempio inserendoil codice

5.4. Moto browniano e EDP 129
void tm(unsigned int * nn,double * hh,double * u,double * v,double et[])/ *nn=numero di simulazioni, hh=passo di discretizzazione,u,v=coordinate iniziali, et=tempi di uscita
* /{
unsigned int jj;double c1,c2,ct,sh;
sh=sqrt( * hh);for(jj=0;jj< * nn;++jj){c1= * u;c2= * v;ct=0.;while (c1 * c1+c2 * c2<1){c1=c1+gg() * sh;c2=c2+gg() * sh;ct=ct+ * hh;}et[jj]=ct;}}
Usarlo poi per calcolare la soluzione di (5.1) a partire da (0, 12) e da (0.9, 0)usando come passo di approssimazione hh= 1/400 e hh= 1/7200. Confron-tare con il valore esatto e discutere la bonta dell’approssimazione.
5.7 Correggere il codice dell’esercizio precedente per calcolare il tempomedio dalla palla di raggio 1 partendo dal centro in dimensione 5. Ricordareche il valore esatto e 1
5 .
5.8 Costruiamo una soluzione del problema (5.1) con Freefem e mediantesimulazione e confrontiamo i due metodi.a) Calcolare la soluzione con Freefem dando le istruzioni per scrivere
i risultati su un file esterno per la visualizzazione con scilab . Fare ilgrafico. Controllare numericamente l’errore fatto da Freefem nei puntidella triangolazione. Un programma Freefem a questo scopo puo essere
border C(t=0,2 * pi){x=cos(t); y=sin(t);}

130 Capitolo 5. Simulazione, processi e EDP
mesh Th = buildmesh (C(50));fespace Vh(Th,P1);Vh u,v;func f= 1; // definition of a called f functionreal cpu=clock(); // get the clock in secondsolve Poisson(u,v,solver=LU) = // defines the PDEint2d(Th)(0.5 * dx(u) * dx(v) + 0.5 * dy(u) * dy(v)) // bilinear part- int2d(Th)( f * v) // right hand side+ on(C,u=0) ; // Dirichlet boundary conditionplot(u);cout << " CPU time = " << clock()-cpu << endl;// to build an output data file{ ofstream ff("graph.txt");
for (int i=0;i<Th.nt;i++){ for (int j=0; j <3; j++)ff<<Th[i][j].x << " "<< Th[i][j].y<< " "<<u[][Vh(i,j)]<<e ndl;ff<<Th[i][0].x << " "<< Th[i][0].y<< " "<<u[][Vh(i,0)]<<e ndl;
}}
Per visualizzare in scilab un grafico in formato Freefem , conviene im-portare i dati in una variabile, diciamo gr , con il solito comando di letturadi file esterno:
gr=read("nomefile",-1,3);
(”nomefile” e il file di output di Freefem , nel nostro caso ”graph.txt”) epoi eseguire il programmino
sg=size(gr);nt=sg(1)/4;//nt e‘ il numero di facce triangolariclf();//cancella la pagina grafica precedentefor i=1:nt
ind=1+4 * (i-1);xt=gr(ind:ind+3,1);yt=gr(ind:ind+3,2);zt=gr(ind:ind+3,3);plot3d(xt,yt,zt);//disegna le triangolazioni una a una
enda=gca();a.isoview="on";//impone le stesse unita‘ di misu ra

5.4. Moto browniano e EDP 131
0
−1
1
−0.8−0.6−0.4−0.20.20.40.60.8
−0.9−0.7−0.5−0.3−0.10.10.30.50.70.9
0
−1
1
−0.8−0.6
−0.4−0.2
0.20.4
0.60.8
0
0.2
0.4
0.6
0.1
0.3
0.5
0.05
0.15
0.25
0.35
0.45
0.55
X
Y
Z
Figura 5.4: Il grafico della soluzione di (5.1) ottenuta col metodo degli ele-menti finiti (Freefem). Il grafico e molto regolare e, facendo un confrontocon il valore esatto, anche preciso.
I dati Freefem sono una successione di pacchetti di 4 righe. Ogni riga econtiene tre coordinate: le prime tre righe individuano il valore della fun-zione nei punti di un triangolo, la quarta “chiude” il triangolo ripetendo laprima riga. Il programmino qui sopra disegna uno dopo l’altro i triangoliche messi insieme costituiscono la superficie.
b) Vediamo ora come si puo calcolare la soluzione del problema (5.1) me-diante simulazione. Negli esercizi precedenti abbiamo calcolato un’appros-simazione della soluzione in un singolo punto. Per arrivare a fare il graficooccorrera fare il calcolo in una griglia di punti e poi far disegnare a scilabla superficie. Un modo interessante di fare tutto cio consiste nel prenderecome griglia i punti generati da Freefem (le cui coordinate si trovano nelledue prime colonne del file ”graph.txt”. Si trattera di leggere quel file, cal-colare facendo le simulazioni i valori della soluzione e poi fare il grafico conla stessa tecnica che per la Figura 5.4. Questo viene fatto con il seguentescript:
nn=7200;hh=1/100;gr=read(’graph.txt’,-1,3);coord=gr(:,1:2);ctr=size(coord);while ctr(1,1)>0xc=coord(1,1);yc=coord(1,2);index=find(gr(:,1)==xc&gr(:,2)==yc);index2=find(coord(:,1)==xc&coord(:,2)==yc);//trova tutti i punti della griglia che hanno//le stesse coordinateet=call("tm",nn,1,"i",hh,2,"d",xc,3,"d",yc,4,"d","out",[nn 1],5,"d");

132 Capitolo 5. Simulazione, processi e EDP
gr(index,3)=mean(et);//calcola in un colpo solo la soluzione in tutti//i punti della griglia che hanno le stesse coordinatecoord(index2,:)=[];//eliminiamo dalla griglia i punti in cui//la soluzione e‘ stata calcolatactr=size(coord)end//segue il programma di disegno dei triangoli a uno//a uno che gia‘ conosciamosg=size(gr);nt=sg(1)/4;clf();for i=1:nt
ind=1+4 * (i-1);xt=gr(ind:ind+3,1);yt=gr(ind:ind+3,2);zt=gr(ind:ind+3,3);plot3d(xt,yt,zt);//disegna le triangolazioni una a unaenda=gca();a.isoview="on";
Usare questo script per disegnare il grafico della soluzione per i valori nn=400,hh=1/100 , nn=7200, hh=1/100 , nn=7200, hh=1/7200 .Che conclusioni trarre?1) Il metodo di simulazione e molto impreciso e richiede molte traiettorie
e un passo di discretizzazione molto piccolo per dare risultati affidabili. Inrealta ci sono metodi per migliorare i risultati, ma non siamo in grado diparlarne.2) Rimane comunque il fatto che la simulazione si puo implementare fa-
cilmente anche in dimensione grande, senza grosse difficolta, quando altrimetodi numerici diventano rapidamente molto complicati, o addirittura nonsono piu disponibili.3) Da notare che talvolta interessa solo il valore della soluzione in un
singolo punto. A differenza della simulazione, metodi come gli elementifiniti richiedono in ogni caso di calcolare la soluzione ovunque.
5.5 La simulazione della distribuzione d’uscita
Prima di vedere altri problemi del tipo di (5.1), vediamo come si puo simularela posizione d’uscita del MB dalla palla di raggio 1. Si tratta di modificare

5.5. La simulazione della distribuzione d’uscita 133
0
−1
1
−0.8−0.6
−0.4−0.2
0.20.4
0.60.8
0
−1
1
−0.8 −0.6 −0.4 −0.20.2 0.4 0.6 0.8
−0.9 −0.7 −0.5 −0.3 −0.1 0.1 0.3 0.5 0.7 0.9
0
0.2
0.4
0.6
0.1
0.3
0.5
0.05
0.15
0.25
0.35
0.45
0.55
XY
Z
nn=400,hh=1/100
Figura 5.5: Soluzione calcolata per simulazione, con n = 400 traiettorieogni volta ed un passo h = 1/100. Il grafico e bitorzoluto. Si vede anche chei valori calcolati sono abbastanza piu grandi del valore vero. Ad esempioall’origine questo grafico prende il valore 0.56, con un errore del 12%.
0
−1
1
−0.8−0.6−0.4−0.20.20.40.60.8
−0.9−0.7−0.5−0.3−0.10.10.30.50.70.9
0
−1
1
−0.8−0.6
−0.4−0.2
0.20.4
0.60.8
0
0.2
0.4
0.6
0.1
0.3
0.5
0.05
0.15
0.25
0.35
0.45
0.55
X
Y
Z
nn=7200,hh=1/100
Figura 5.6: Soluzione calcolata per simulazione, ma ora con n = 7200 tra-iettorie ogni volta ed un passo h = 1/100. Il grafico e molto migliorato. Sivede pero che i valori calcolati sono ancora abbastanza piu grandi del valorevero. Inoltre la superficie “non si incolla bene” al bordo.

134 Capitolo 5. Simulazione, processi e EDP
0
−1
1
−0.8−0.6−0.4−0.20.20.40.60.8
0
−1
1
−0.8 −0.6 −0.4 −0.20.2 0.4 0.6 0.8
0
0.2
0.4
0.6
0.1
0.3
0.5
XY
Z
nn=7200,hh=1/7200
Figura 5.7: Soluzione calcolata per simulazione, con n = 7200 traiettorieogni volta ed un passo h = 1/7200. Il grafico e ora abbastanza buono, anchese ancora meno bello di quello ottenuto con gli elementi finiti, in particolareil valore al bordo e ancora un po’ ondivago. Ora il valore all’origine e 0.507,con un errore dell’1.4%: un errore ancora non trascurabile nonostante unpasso di discretizzazione molto piccolo
il programma di simulazione realizzato precedentemente in modo da fargliprodurre la posizione al momento dell’uscita invece che il tempo trascorso.Occorre pero fare attenzione: la traiettoria attraversa infatti la circonferenzaad un istante compreso tra il primo istante della discretizzazione in cui essasi trova al di fuori e l’istante immediatamente precedente (vedi Figura 5.8).Per una buona approssimazione del vero punto in cui la traiettoria esce dalcerchio occorre determinare il punto in cui il segmento che congiunge que-sti due punti della traiettoria incrocia il cerchio. Un modo e il seguente.Indichiamo con y il punto della discretizzazione immediatamente prima del-l’uscita e con x il punto successivo (che dunque sta fuori della palla). Ilsegmento che congiunge questi due punti si puo parametrizzare
[0, 1] 3 t→ t(x− y) + y
Occorre quindi trovare il valore di t per cui si ha
t→ |t(x− y) + y|2 = 1 . (5.3)
Sviluppando il modulo si trova l’equazione di secondo grado
t2|x− y|2 + 2t(〈x, y〉 − |y|2) + |y|2 − 1 = 0
Dunque se poniamo
a = |x− y|2, b = 〈x, y〉 − |y|2, c = |y|2 − 1

5.5. La simulazione della distribuzione d’uscita 135
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
..
.
.
.
.
.
..
.
.
.
.
..
.
.
.
..
.
.
..
.
.
.
..
.
.
..
.
.
..
.
..
.
.
..
.
..
.
..
.
..
.
..
.
..
• ••
• •
•B(it+ k
ns)
B(it+ k+1ns )
......................................................................................................................................................
....................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
......................................
Figura 5.8:
si vede che delle due radici quella con il meno:
t0 =1
a(−b−
√b2 − ac )
e compresa tra 0 e 1 (l’altra e piu grande di 1) ed e dunque il valore di tcercato. Dunque il punto d’uscita e approssimato da t0(x− y) + y.
5.9 Sempre in dimensione 2 simulare n = 200 punti di uscita dalla pallaunitaria partendo dall’origine. Poi fare il grafico della circonferenza e segnarei punti di uscita risultanti dalla simulazione. Cosa si osserva?Ripetere l’operazione per la dimensione 3. Per fare il grafico di una nube dipunti tridimensionale il comando scilab e param3d1 : se i vettori (riga)xx , yy e zz contengono i valori delle tre direzioni dei punti ottenuti dallasimulazione, il comando
param3d1(xx,yy,list(zz,zeros(zz)));
disegnera nello spazio i punti corrispondenti. Ricordare che i vettori devo-no essere vettori riga. Se i punti vengono disegnati troppo piccoli, la lorodimensione puo essere modificata con il comando
p=get("hdl");p.mark_size=1;
Sapreste dedurre dalle proprieta d’invarianza del moto browniano che ladistribuzione d’uscita e uniforme sulla circonferenza? E che, in qualunquedimensione m, e uniforme sulla sfera Sm−1di R
m?
5.10 Ripetere la simulazione della distribuzione di uscita dalla palla uni-taria di R2 partendo dai punti (12 , 0), (
34 , 0) e ( 9
10 , 0) (cioe da punti che sitrovano sempre piu vicini alla frontiera).

136 Capitolo 5. Simulazione, processi e EDP
5.6 Il problema di Dirichlet e la distribuzione d’u-
scita
Possiamo ora affrontare un secondo problema interessante: e il problema diDirichlet {
12 4u = 0 in D
u = φ su ∂D(5.4)
dove φ e una funzione definita sul bordo e abbastanza regolare. E il problemadi Dirichlet. Piu in generale dato il problema
{124u− cu = f in D
u|∂D = φ.(5.5)
(che ha soluzione sotto opportune ipotesi di regolarita sulle funzioni f , φ esul bordo ∂D del dominio) la soluzione u si puo rappresentare
u(x) = E[e−
∫ τx0
c(x+Bs) dsφ(x+Bτx)]−E
[e−
∫ τx0
c(x+Bs) ds
∫ τx
0f(x+Bs) ds
].
(5.6)Ricordiamo che τx e il primo istante in cui il processo (x + Bt)t esce dallapalla. Dunque x+Bτx e la posizione in cui avviene l’uscita.Quindi per il caso particolare del problema (5.4), la soluzione sara data da
u(x) = E[φ(x+Bτx)] (5.7)
cioe dalla media di φ fatta rispetto alla distribuzione d’uscita. Piu preci-samente, indichiamo con P (x, dy) la legge di uscita cioe la legge della v.a.x + Bτx . Si tratta, per ogni x ∈ D, di una probabilita sulla frontiera ∂D ela soluzione del problema di Dirichlet risulta essere data da
u(x) =
∫
∂Dφ(y)P (x, dy)
Come abbiamo messo in evidenza nel paragrafo precedente, se D e una pallain R
m e consideriamo x = 0 (l’origine), allora la probabilita P (0, dy) non ealtro che la probabilita uniforme sulla superficie della sfera.
5.11 a) Calcolare con Freefem la soluzione del problema (5.5) quandoD e la palla unitaria (in dimensione 2) e φ(x) = x2 ∨ 0. Fare il grafico inscilab con la procedura descritta a p.130.b) Determinare, usando la rappresentazione (5.7), la soluzione del proble-
ma (5.5) quando D e la palla unitaria (in dimensione 2) e φ(x) = x2 ∨ 0,

5.6. Il problema di Dirichlet e la distribuzione d’uscita 137
usando diversi valori per il numero di traiettorie nn e il passo di discre-tizzazione hh . Anche qui usare come punti di partenza per le simulazioniquelli forniti dalla griglia di Freefem e fare il grafico come descritto a p.131.Confrontare il risultato con quello ottenuto con Freefem .c) Confrontare anche con la soluzione esatta che si puo calcolare dato che,
se D e la palla di raggio R in Rm, la soluzione e data da
u(x) =
∫
∂Dφ(y)P (x, y) dσm(y)
dove σm e la misura superficiale della sfera di raggio R e
P (x, y) =1
Rωm
R2 − |x|2|x− y|2
dove ωm e l’area della superficie sferica della sfera unitaria di Rm. Dunqueper m = 2 e R = 1
u(x) =1
2π(1− |x|2)
∫ 2π
0
φ(θ)
|x− y(θ)|2 dθ (5.8)
dove y(θ) = (cos θ, sin θ). Nel caso della scelta φ(x) = x2 ∨ 0, dunqueφ(θ) = sin θ per 0 ≤ θ ≤ π e φ(θ) = 0 altrimenti. Dunque
u(x) =1
2π(1− |x|2)
∫ π
0
sin θ
|x− y(θ)|2 dθ (5.9)
Occorrera dunque considerare la griglia di punti ottenuta con Freefem eper ciascuno di essi calcolare numericamente con scilab l’integrale della(5.9). Fare il grafico in 3D dell’errore commesso dalla simulazione.d) Calcolare, prima con la simulazione ma con un numero elevato di tra-
iettorie e poi calcolando la soluzione esatta, il valore di u all’origine. Danotare che, tramite la (5.9) oppure usando la proprieta di media delle fun-zioni armoniche, il valore di u in 0 si calcola molto facilmente (= 1
π ). Va-lutare l’errore al variare del numero di traiettorie simulate e del valore delpasso di discretizzazione delle traiettorie (ns nel programma delle pagineprecedenti).
5.12 Ripetere le valutazioni dell’esempio precedente, punto d) (confron-to tra il risultato della simulazione ed il valore esatto) all’origine, ma indimensione 3 e con il dato al bordo
φ(x, y, z) = z1z>0 . (5.10)

138 Capitolo 5. Simulazione, processi e EDP
Si ricorda che le coordinate sferiche sono θ, φ, 0 ≤ θ ≤ π, 0 ≤ φ ≤ 2π dove
z = cos θ
y = sin θ cosφ
x = sin θ sinφ
e che l’elemento di superficie e
σ3(dθ, dφ) = sin θ dθdφ
5.13 Calcolare la soluzione del problema (5.4) in dimensione 2 per lafunzione φ che vale 1 per x > 0 e zero se no. Si tratta cioe di calcolare laprobabilita che la traiettoria esca dalla palla dalla meta di destra. Da notareche, grazie alla rappresentazione (5.7) ed alle proprieta d’invarianza del MB,gia sappiamo che la soluzione vale 1
2 per i punti della palla che si trovanosull’asse y. Come precedentemente, usando la griglia di punti fornita daFreefem , calcolare per simulazione il valore della soluzione e fare il grafico(con la procedura descritta a p.131). Controllare i valori numerici ottenu-ti e verificare se effettivamente la soluzione vale 1
2 sull’asse delle ordinate.Confrontare il risultato con la soluzione ottenuta con Freefem ).
Osservazioni 5.3 Le formule di rappresentazione delle soluzioni delproblema di Dirichlet come media di funzionali del moto browniano sonoutili per trovare soluzioni approssimate mediante simulazione, ma hannoanche delle conseguenze teoriche interessanti.a) Ricordiamo che una funzione u si dice armonica in x se 4u(x) = 0.
Ricordiamo che la distribuzione d’uscita del moto browniano da una sfe-ra partendo dal suo centro e la distribuzione uniforme. La formula dirappresentazione (5.7) da quindi immediatamente una proprieta impor-tante delle funzioni armoniche: se u e armonica in un aperto D, allorau(x) e uguale alla media di u fatta su ogni sfera di centro x e contenutain D. Questa proprieta e anzi caratterizzante delle funzioni armoniche:una funzione u continua su D e che gode della proprieta di media enecessariamente armonica.b) Un’altra proprieta importante delle soluzioni di problemi come
quello in (5.4) (quindi in particolare per le funzioni armoniche) e il prin-cipio del massimo che afferma che la soluzione raggiunge il suo valore

5.6. Il problema di Dirichlet e la distribuzione d’uscita 139
massimo sul bordo ∂D. Alla luce della formula di rappresentazione (5.7)questa proprieta e evidente, dato che u appare come una media dei valoriche essa assume sul bordo.c) Un altro caso particolare del problema (5.5) e dato da
{124u− θu = 0 in D
u|∂D = 1.(5.11)
La formula di rappresentazione (5.6) qui diviene
u(x) = E[e−θτx ] (5.12)
Dunque u(x) non e altro che la trasformata di Laplace, calcolata in θdel tempo d’uscita, τx, dalla palla unitaria partendo da x. Osserviamoche la formula di rappresentazione (5.12) gia da delle informazioni sullasoluzione: se θ > 0 ci si aspettera che la funzione u prenda dei valoritanto piu piccoli quanto piu il punto x si trova all’interno di D: infattiin questo caso piu il punto si trova all’interno tanto piu il tempo d’uscitaτx tendera ad essere grande e cosı pure u(x). Inversamente, se θ < 0,u tendera ad essere grande tanto piu il punto si trovera all’interno. Seθ = 0 troviamo u ≡ 1, come soluzione evidente.
5.14 Per θ = −1 e θ = 2 risolvere come prima il problema (5.11) con idue metodi, simulazione ed elementi finiti.
5.15 Studiare il problema (5.11) calcolando la soluzione in x = 0 per unagriglia di valori θ tra −4 e −1 e farne il grafico (in funzione di θ). Osservareche basta fare una simulazione di tempi d’uscita (si consiglia di provare con1000000 di traiettorie), a partire dalla quale si possono trovare tutti i valoridi u(0) al variare di θ.

140 Capitolo 5. Simulazione, processi e EDP
5.7 Un altro metodo di risoluzione: gli autovalori
Sia D ⊂ Rm un aperto limitato abbastanza regolare. Cerchiamo dei numeri
λ (gli autovalori) tali che il problema di Dirichlet
1
24u = λu
u|∂D = 0
abbia delle soluzioni diverse da 0. Si puo dimostrare che
• Esiste una successione
. . . λk ≤ · · · ≤ λ2 ≤ λ1 < 0
di autovalori. Che sono dunque tutti strettamente negativi (sapreste farlovedere?). Inoltre limn→∞ λn = −∞ e quindi non ci sono punti di accumu-lazione.
• Inoltre gli autovalori sono tutti semplici e si puo scegliere una famiglia(un)n di autofunzioni in maniera che essi costituiscano una base ortonormaledi L2(D).
Per capire un po’ meglio vediamo come vanno le cose in dimensione 1 perD = [−1, 1]. Per quali valori di λ esiste una soluzione non nulla di
1
2u′′ = λu
u(−1) = u(1) = 0
Se λ e negativo l’integrale generale dell’equazione 12 u
′′ = λu e
c1 cos(√−2λx) + c2 sin(
√−2λx)
Perche tra queste funzioni ce ne sia una che si annulla in 1 e in −1 occorreche ci sia una soluzione non nulla del sistema (nelle incognite c1 e c2)
c1 cos(√−2λ ) + c2 sin(
√−2λ ) = 0
c1 cos(√−2λ )− c2 sin(
√−2λ ) = 0

5.7. Un altro metodo di risoluzione: gli autovalori 141
ovvero che si annulli il determinante della matrice(cos(√−2λ) sin(
√−2λ)
cos(√−2λ) − sin(
√−2λ)
)
cioe −2 cos(√−2λ) sin(
√−2λ) = 2 sin(2
√−2λ) = 0. Poiche il seno si annulla
nei punti x = kπ, gli autovalori sono i numeri λ per cui si ha 2√−2λ = kπ,
ovvero
λk = −k2 π2
8
Si vede che le autofunzioni sono
u1(x) = cos(π2 x)
u2(x) = sin(π x)
. . .
u2m+1(x) = cos((2m+ 1) π2 x)
u2m(x) = sin(mπ x)
. . .
Come indicato sopra si tratta di una base ortonormale di L2([−1, 1], dx)(queste funzioni hanno tutte norma L2 uguale a 1).
5.16 Calcolare e disegnare a confronto con l’originale con scilab glisviluppi in questa base ortonormale (sull’intervallo [−1, 1]) delle funzioni
a) 1 prendendo la somma dei primi n termini per n = 20, 40, 100;b) f(x) = 1− |x| per n = 3, 7, 11;
c) f(x) = 1− x2 per n = 2, 3;
d) f(x) = 1− |x|3/2 per n = 3, 7, 11.
e) f(x) = x(1− x2).Da notare che le funzioni in a), b), c) e d) sono pari. Dunque nello sviluppointerverranno solo i coefficienti dei termini dispari (cos k π
2 ). La funzione ine) invece e dispari. . . Per risolvere questo esercizio si potra usare la funzioneintg di scilab . Ad esempio con il codice
nn=3;tt=linspace(-1,1);deff("y=fun(x)","y=1-abs(x)")deff("y=fc(x)","y=cos((2 * kk-1) * x* %pi/2). * fun(x)")ll=zeros(1,nn);for ii=(1:nn),kk=ii;ll(ii)=intg(-1,1,fc);end;

142 Capitolo 5. Simulazione, processi e EDP
vv=(1:nn);deff("y=f2(x)","y=sum(ll. * cos((2 * vv-1). * x* %pi/2))");yy=feval(tt,f2);scf(1);plot(tt,yy,"g");plot(tt,fun(tt),"k");
che risolve il punto b) con n = 3. Per applicarlo alle altre situazioni basteracambiare la definizione della funzione fun . La conoscenza di autovalori eautofunzioni permette di trovare la soluzione del problema di Poisson
12 4u = fu|∂D = 0
(5.13)
Infatti se f ∈ L2(D), vale lo sviluppo (convergente in L2, per lo meno)
f =∑
k
ak uk
e basta osservare che una soluzione e data da
u =∑
k
akλk
uk .
5.17 Calcolare numericamente e fare il grafico della soluzione del problemadi Poisson (5.13) in dimensione 1 per D = [−1, 1] e con f data dalle funzionidi a), b), c), d) dell’Esempio 5.16.
5.18 Consideriamo il problema di Dirichlet per il laplaciano sul quadratoQ = [−1, 1] × [−1, 1].a) Sapreste indicare delle autofunzioni della forma v(x, y) = v1(x)v2(y)?
Quali sarebbero gli autovalori corrispondenti?
b) Sapreste dimostrare che tutte le autofunzioni sono di questa forma?
5.19 Calcolare numericamente e fare il grafico della soluzione del problemadi Poisson (5.13) in dimensione 2 per D = il quadrato [−1, 1]× [−1, 1] e per
f(x, y) = (1− |x|)(1 − |y|) .
Confrontare poi con la soluzione ottenuta con Freefem . Vediamo invece,almeno parzialmente, cosa succede quando D = il cerchio, che prenderemodi raggio 1 per comodita.

5.7. Un altro metodo di risoluzione: gli autovalori 143
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Z
−1.0−0.6
−0.20.2
0.61.0
X
−1.0
−0.6
−0.2
0.2
0.6
1.0Y
Figura 5.9: Il grafico dell’autofunzione u1 per D = Q il quadrato. L’auto-valore corrispondente e λ1 = 1
4 π2. Da notare che si tratta di una funzione
positiva o meglio di segno costante (anche −u1 e autofunzione associata allostesso autovalore).
−1.0
−0.8
−0.6
−0.4
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
Z
−1.0−0.6
−0.20.2
0.61.0 X
−1.0−0.6
−0.20.2
0.61.0Y
Figura 5.10: Il grafico di un autofunzione per l’autovalore λ = −58 π
2 perD = Q il quadrato (questo autovalore ha due autofunzioni indipendenti).

144 Capitolo 5. Simulazione, processi e EDP
−1.0
−0.8
−0.6
−0.4
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
Z
−1.0
−0.6
−0.2
0.2
0.6
1.0X
−1.0
−0.6−0.2
0.20.6
1.0Y
Figura 5.11: Il grafico dell’autofunzione per l’autovalore λ = −π2 perD = Qil quadrato (anche qui due autofunzioni indipendenti).
Se ci limitiamo a cercare delle autofunzioni che siano funzioni radiali, questee gli autovalori corrispondenti sono legati alla funzione di Bessel J0. Questafunzione speciale e definita come la soluzione dell’equazione
xw′′(x) + w′(x) + xw = 0
ed e anzi l’unica (a meno di costanti moltiplicative, naturalmente) soluzio-ne di questa equazione che sia limitata (tutte le altre hanno una singola-rita in 0). Oltre che a soddisfare l’equazione ordinaria precedente, J0 ecaratterizzata da J0(0) = 1.
Come conseguenza, la funzione u(x) = J0(|x|), x ∈ R2, e un autofunzione
dell’operatore di Laplace. Infatti in coordinate polari il laplaciano di Rd siscrive
4 =d2
dρ2+d− 1
ρ
d
dρ+ . . .
dove . . . indica un operatore differenziale nelle coordinate angolari. Dunque,se u(x) = J0(|x|) e d = 2,
4u(x) = J ′′0 (|x|) +
1
|x| J′0(|x|) = −J0(|x|) = −u(x)

5.7. Un altro metodo di risoluzione: gli autovalori 145
0 2 4 6 8 10 12
1 ...................................................................................................................................................................................................................................................................................................................
...................................................................................................................................................................................................................................................................................................................................................................................................................................
............................................................................................................................
• • • •
Figura 5.12: Grafico della funzione di Bessel J0.
e quindi u e autofunzione per l’autovalore λ = −1. Per ottenere una funzioneche si annulli sul bordo di D, occorre sapere che la funzione di Bessel J0 hauna infinita di zeri (vedi il grafico nella Figura 5.12). Se indichiamo conζ1 < ζ2 < . . . gli zeri della funzione J0, allora le funzioni ui(x) = u(ζix) =J0(ζi|x|) sono nulle su ∂D e soddisfano
4ui(x) = ζ2i (4u)(ζix) = −ζ2i u(ζix) = −ζ2i ui(x) .
Dunque le ui sono autofunzioni per l’operatore di Laplace con autovalore−ζ2i , o meglio, per i nostri scopi, autofunzioni per l’operatore 1
24 con au-
tovalore −12 ζ
2i . E chiaro che le funzioni ui sono le sole autofunzioni del
laplaciano che siano funzioni radiali e che si annullano su ∂D.In pratica per disporre di queste autofunzioni e necessario procurarsi unmodo di calcolare la funzione di Bessel J0 e di determinarne gli zeri. scilabdispone della funzione besselj che calcola la funzione J0: besselj(0,x)fornisce i valori di J0 calcolati nei punti del vettore x . Il comando fsolveda gli zeri:
deff("y=f(x)","y=besselj(0,x)")zer=fsolve([2.4,5.8,8,12,15,18,22,25,28,31,34,37,40 ,44,47,50,52,56,58,62,65,68,72,75,78,81,84,87,90,93,96,99],f);
produce gli zeri della funzione che sono “vicini” ai punti 2.4, 5.8, , . . . e limette nella variabile zer . Per verifica facciamo il grafico di J0 e dei valoridegli zeri che abbiamo trovato.
tl=linspace(0,100);scf(21);clf();plot(tl,besselj(0,tl));plot([0,100],[0,0],"k");plot(zer,zeros(zer),".");
5.20 . Quanto vale il piu grande autovalore di 12 4 per il problema di
Dirichlet sul cerchio? Fare il grafico dell’autofunzione.

146 Capitolo 5. Simulazione, processi e EDP
5.21 Determinare le prime 5 autofunzioni radiali del Laplaciano norma-lizzate perche abbiano norma L2 uguale a 1 (le funzioni ui(x) = J0(ζi|x|)introdotte prima sono normalizzate dalla condizione ui(0) = 1 e non dalfatto di avere norma L2 uguale a 1).
Verificare anche, numericamente, che le funzioni cosı ottenute sono orto-gonali in L2 (limitarsi a un paio di casi). Naturalmente sappiamo gia chequeste funzioni sono ortogonali in L2. Perche?
Si tratta di fare uso del comando intg di scilab per calcolare norme L2
e prodotti scalari. Ricordare che stiamo parlando di funzioni sulla palla diraggio 1 e non su [−1, 1].
5.22 Risolvere il problema in dimensione d = 2
1
24u = f
u|D = 0
dove D e il cerchio (la palla) di raggio 1 e f(x) = 1− |x|.a) con Freefem ;
b) calcolando lo sviluppo in autofunzioni del laplaciano di f .
c) con la simulazione del moto browniano usando la (5.6).
5.23 Risolvere con Freefem il problema (5.11) con D =il cerchio di raggio1 per θ = −2, θ = −2.8 e θ = −3. Cosa si osserva? Sempre per per θ = −2,θ = −2.8 e θ = −3 stimare per simulazione il valore di u(0) = E[e−θτ0 ](partendo da 0, quindi). Per ognuno di questi valori di θ fare 20 volte lasimulazione con 105 traiettorie ogni volta. Cosa si osserva?
5.8 L’equazione del calore
Formule di rappresentazione ed elementi finiti permettono anche di risolvereequazioni paraboliche. Per limitarci al caso del laplaciano il problema e, perun aperto D ⊂ R
d,
σ2
24u− cu+
∂u
∂t= f in D × [0, T [
u(x, T ) = φ(x) per x ∈ Du(x, t) = g(x, t) su ∂D × [0, T ]
(5.14)

5.8. L’equazione del calore 147
0.0
0.2
0.4
0.6
0.8
1.0
1.2
Z
−1.0−0.8−0.6−0.4−0.20.00.20.40.60.81.0 X
−1.0
−0.6
−0.2
0.2
0.6
1.0Y
Figura 5.13: Il grafico dell’autofunzione u1 per D =il cerchio unitario. Danotare che si tratta di una funzione positiva.
−1.0
−0.5
0.0
0.5
1.0
1.5
2.0
Z
−1.0−0.6
−0.20.2
0.61.0 X
−1.0
−0.6
−0.2
0.2
0.6
1.0Y
Figura 5.14: Il grafico dell’autofunzione u2 per D =il cerchio unitario. Danotare che evidentemente non si puo trattare di una funzione positiva (deveessere ortogonale a u1. labelfig-eigen1

148 Capitolo 5. Simulazione, processi e EDP
0 T
← φ(x)
↖g(x, t)
g(x, t)
↘
In un problema parabolico i dati al bordo vengono assegnati solo per i valorifinali del tempo (o solo per i valori iniziali nel caso del problema (5.15)). Nel
problema (5.14) naturalmente occorrono delle ipotesi per avere esistenza eunicita. Un set di ipotesi e ad esempio:
a) g una funzione continua su ∂D × [0, T ] tale che g(x, T ) = φ(x) sex ∈ ∂D;
b) c e f sono funzioni holderiane D × [0, T [→ R e c ≥ 0.
c) ∂D e C1.
Nel seguito vedremo delle situazioni in cui le funzioni g, f, c non dipendonodal tempo. In questo caso si vede facilmente che se u e soluzione di (5.14),allora la funzione v(x, t) = u(x, T − t) e soluzione del problema di Cauchy
σ2
24v − cv − ∂v
∂t= f in D×]0, T ]
v(x, 0) = φ(x) in D
v(x, t) = g(x) su ∂D × [0, T ]
(5.15)
Questo problema modellizza la diffusione del calore nel dominioD, quando altempo 0 la distribuzione delle temperature e data da φ(x) e la temperaturadel bordo e tenuta fissata a g(x). Il fatto che nell’operatore di Laplacenon compaiano derivate del prim’ordine significa che non c’e convezione. Ilfatto che la matrice dei coefficienti sia un multiplo dell’identita significa checonsideriamo che il calore si possa diffondere in tutte le direzioni allo stessomodo (cioe che il mezzo che consideriamo sia isotropo). σ2 e il coefficientedi diffusione e rappresenta la conducibilita termica: piu questo parametro egrande piu nel mezzo considerato il calore si diffonde velocemente.
Nel seguito considereremo tre metodi di risoluzione dell’equazione del calore.
a) Il primo consistera nel metodo degli elementi finiti, Freefem .

5.8. L’equazione del calore 149
b) Il secondo fara ricorso alla simulazione del moto browniano. Infattianche per i problemi (5.14) e (5.15) esistono formule di rappresentazionedelle soluzioni in termini di medie di funzionali del moto browniano. Laformula e, nel caso di coefficienti che non dipendono dal tempo e per σ2 = 1,
u(x, t) = E[g(Bτx) e
−∫ τx0
c(x+Bs) ds1{τ<T−t}]+
+E[φ(x+BT−t) e
−∫ T−t
0c(x+Bs) ds1{τx≥T−t}
]−
−E[∫ τx∧(T−t)
0 f(x+Bs) e−
∫0
t−sc(x+Bu) du ds
] (5.16)
per la soluzione u del problema (5.14). Nel caso φ ≡ 1, g ≡ 0, c ≡ 0, f ≡ 0considerato nell’Esercizio 5.24 qui sotto, la formula diviene semplicemente
u(x, t) = E[φ(x+BT−t)1{τx≥T−t}
]= P(τx ≥ T − t) . (5.17)
Per la soluzione v della (5.15) si avra dunque
v(x, t) = u(x, T − t) = P(τx ≥ t) . (5.18)
Il caso in cui σ2 e diverso da 1 si ricava facilmente da quanto visto finoraosservando che se v e soluzione di (5.15) con σ2 = 1, allora
v(x, t) = v(x, σ2t)
e soluzione di (5.15). Dunque la formula di rappresentazione per le soluzionidel problema (5.15) e
v(x, t) = v(x, σ2t) = P(τx ≥ σ2t) . (5.19)
Questa relazione e anche utile su un piano intuitivo. Ad esempio si vedesubito che se σ2 cresce, l’evento {τx ≥ σt} diventa piu piccolo e quindila soluzione v decresce (ricordiamo che stiamo considerando il problema(5.15), e quindi con φ(x) ≡ 1, g(x) ≡ 0, c = 0 e f = 0. Questo fatto eabbastanza intuitivo se si pensa al significato fisico del problema (dominioin cui all’inizio la temperatura e positiva ma e tenuta a 0 sulla frontiera),ma e meno evidente a partire dal problema (5.15).
Da notare ancora i due vantaggi dei metodi di simulazione: la formula (5.18)permette di calcolare la soluzione anche in un solo punto (x, t), senza chesi sia costretti a trovare la soluzione dappertutto, ed il fatto che la formulavale in ogni dimensione, oltre alla semplicta della implementazione. Anchel’errore e lo stesso in qualunque dimensione. Abbiamo pero visto che gli

150 Capitolo 5. Simulazione, processi e EDP
elementi finiti producono una soluzione molto piu precisa e sono senz’altropreferibili in dimensione bassa.c) Lo sviluppo in autofunzioni del Laplaciano puo produrre la soluzione
del problema in forma di serie. Se
φ(x) =∑
k
akuk(x)
e lo sviluppo del dato iniziale φ in autofunzioni di 12 4 con l’assegnato dato
al bordo, allora la funzione
v(x, t) =∑
k
akeλkσ
2tuk(x)
e soluzione del problema (5.15).
5.24 Realizzare un codice Freefem che produca la soluzione del problemaprecedente per D = [−1, 1] (quindi in una dimensione), T = 3, φ(x) ≡ 1,g(x) ≡ 0, c = 0 e f = 0. Usare per la conducibilita i valori σ2 = .1 e σ2 = .4.Il problema (5.15) diventa quindi
σ2
24v − ∂v
∂t= 0 in D×]0, T ]
v(x, 0) = 1 x ∈ Dv(x, t) = 0 su ∂D × [0, T ]
(5.20)
(naturalmente, dato che siamo in una dimensione 4v(x, t) = ∂2v∂x2 ). Stiamo
quindi considerando una sbarra che al tempo 0 si trova a temperatura 1, male cui estremita vengono tenute a temperatura 0.La realizzazione del programmino Freefem non e complicata. Si trattera diadattare uno dei programmi gia realizzati. Si trattera sempre di un problemaEDP di una funzione di due variabili x e y, solo che ora una delle variabiliandra intesa come il tempo. Il programma dovra dunque contenere il solitoset d’istruzioni:a) innanzitutto il bordo andra definito in quattro pezzi, dato che il domi-
nio e rettangolare e che inoltre occorrera assegnare valori diversi su diversipezzi del bordo stesso;b) occorrera dare i soliti comandi per la costruzione della griglia e dello
spazio degli elementi finiti e scrivere il problema in forma variazionale;d) infine dare le istruzioni per scrivere i risultati su un file esterno per
la visualizzazione con scilab . Quest’ultima si fara meglio, piuttosto checon il comando plot3d , prima importando i dati in una variabile gr con ilsolito comando di lettura di file esterno:

5.8. L’equazione del calore 151
gr=read("nomefile",-1,3);
e poi eseguendo il programmino
sg=size(gr);nt=sg(1)/4;//nt e‘ il numero di facce triangolariclf();//cancella la pagina grafica precedentefor i=1:nt
ind=1+4 * (i-1);xt=gr(ind:ind+3,1);yt=gr(ind:ind+3,2);zt=gr(ind:ind+3,3);plot3d(xt,yt,zt);//disegna le triangolazioni una a una
enda=gca();a.isoview="on";//impone le stesse unita‘ di misura
5.25 Risolvere e fare il grafico del problema dell’esercizio precedente usan-do il metodo dello sviluppo in serie di autofunzioni del laplaciano e fare ilgrafico.
5.26 a) Scrivere un codice scilab che calcoli mediante simulazione lasoluzione di (5.15) usando la rappresentazione (5.18) per x = 0 (e sempreper i valori σ2 = .1 e σ2 = .4).
5.27 Fare i grafici sovrapposti delle temperature al tempo T = 3 ottenutesviluppando la soluzione in autofunzioni per i valori σ2 = .1 e σ2 = .4.
5.28 Per valutare la precisione della soluzione fornita dalla simulazione,calcolare la soluzione della equazione del calore al tempo T = 3 e con σ2 =0.1 nei punti x = −0.9,−0.8, . . . , 0.9 usando le tre discretizzazioni ns=100, 400, 1600. Fare i tre grafici sovrapposti. Aggiungere al grafico quello

152 Capitolo 5. Simulazione, processi e EDP
Figura 5.15: Grafico della diffusione del calore con conducibilita σ2 = 0.1.
della soluzione esatta che e data in forma di serie
u(x, t) =
∞∑
n=−∞
(Φ(
1σ√T−t
(2n + 1− x))− Φ
(1
σ√T−t
(2n − x))+
+Φ(
1σ√T−t
(−2n− x))− Φ
(1
σ√T−t
(−2n− 1− x)))
dove Φ indica la funzione di ripartizione della legge gaussiana N(0, 1). Incondizioni normali i termini per n = −3,−2, . . . , 3 danno il contributo es-senziale. Vedi Figura 5.12. Ricordiamo che il comando per ottenere i valoridella funzione di ripartizione di una legge N(0, 1) in scilab e
y=cdfnorm("PQ",x,0,1)
Si tratta di un comando vettoriale, quindi l’argomento x puo essere unvettore. In questo caso pero anche i valori 0, della media, e 1 della varianzadevono essere vettori della stessa dimensione di x. Di fatto quindi occorrescrivere y=cdfnorm("PQ",x,zeros(x),ones(x)) . Data la lunghezza

5.8. L’equazione del calore 153
Figura 5.16: Grafico della diffusione del calore con conducibilita σ2 = 0.4.Si vede l’effetto del raffreddamento piu veloce a causa dell’aumento dellaconducibilita.
di questo comando, puo convenire di definire una funzione che ha il soloscopo di semplificare la scrittura. Ad esempio
deff("y=cn(x)","y=cdfnor(""PQ"",x,zeros(x),ones(x)) ")
Dopo di che si puo definire una funzione che calcoli i termini per n =−4, . . . , 4 della serie:
deff("y=solheat(x)","y=sum(cn(((2 * n+1)-x)/sqrt(T)/sig)-cn((2 * n-x)/sqrt(T)/sig))-sum(cn((-(2 * n)-x)/sqrt(T)/sig)-cn((-(2 * n+1)-x)/sqrt(T)/sig))")
dopo avere definito il vettore n=[-4:4] . Si potra infine calcolare la sommadella serie per dei valori di x compresi tra 0 e 1 mediante
n=[-4:4];x=[.01:.01:.99];y=feval(x,solheat);x=[0,x,1];y=[0,y,0];plot(x,y,"r")

154 Capitolo 5. Simulazione, processi e EDP
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.00.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
Figura 5.17: Il grafici della soluzione dell’equazione del calore (σ2 = 0.1 perdiversi valori della discretizzazione: ns= 100 (in blu, il grafico piu in alto),= 400 (in verde, quello subito sotto), = 1600 (in rosso, quello piu sottoancora). Infine il quarto grafico (in nero, quello piu basso di tutti) e quellodella soluzione esatta. Come si vede la simulazione ha un errore abbastanzaimportante che decresce piuttosto lentamente all’aumentare della finezzadella discretizzazione. E comunque possibile correggere questo errore conprocedure di simulazione piu raffinate.
(la seconda riga di questo programmino serve solo ad estendere i valoricalcolati agli estremi dell’intervallo).
5.29 Confrontare la soluzione esatta al tempo T = 3 descritta nell’esercizioprecedente con quella fornita dallo sviluppo in autofunzioni arrestando losviluppo ai primi n = 10 termini e poi n = 30 termini.
Il codice Freefem++ per la risoluzione dell’equazione del calore (σ2 =0.1)
verbosity=0; //to remove all default output
// boundary

5.8. L’equazione del calore 155
border C1(t=-1,1){x=t;y=0;}border C2(t=0,3){x=1;y=t;}border C3(t=1,-1){x=t;y=3;}border C4(t=3,0){x=-1;y=t;}// plot(C1(40)+C2(20)+C3(40)+C4(20))// Triangulated domain Thmesh Th=buildmesh(C1(10)+C2(30)+C3(10)+C4(30));plot(Th,wait=1,ps="th1.eps");fespace Vh(Th,P1);Vh u,v;solve Heat(u,v,solver=LU)=int2d(Th)(0.2 * dx(u) * dx(v))+int2d(Th)(dy(u) * v)+on(C4,u=0)+on(C2,u=0)+on(C1,u=1);plot(u,wait=1,ps="heat01.eps");// to build an output data file{ ofstream ff("graph-heat.txt");
for (int i=0;i<Th.nt;i++){ for (int j=0; j <3; j++)
ff<<Th[i][j].x << " "<< Th[i][j].y<< " "<<u[][Vh(i,j)]<<endl;ff<<Th[i][0].x << " "<< Th[i][0].y<< " "<<u[][Vh(i,0)]<<endl;
//<<endl//<<endl;
}}
5.30 a) Calcolare per simulazione la soluzione v del problema (5.15) quan-do D =palla di raggio 1 di R2, in modo da produrre il grafico della soluzioneal tempo T = 3. Operare sempre per i due valori σ2 = 0.1 e σ2 = 0.4 (VediFigura 5.19).
b) Calcolare la soluzione e farne il grafico usando lo sviluppo della soluzio-ne in autofunzioni del laplaciano, facendo lo sviluppo con i primi 10 terminie poi con i primi 25. L’equazione a cui soddisfa il profilo di una membranaomogenea sottoposta ad una forza −f e
−4u = f

156 Capitolo 5. Simulazione, processi e EDP
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.00.00
0.05
0.10
0.15
0.20
0.25
0.30
Figura 5.18: Confronto tra la soluzione esatta dell’equazione del calore (inrosso, quella piu grande delle due) e quella ottenuta con il codice Freefem .
dove 4 indica l’operatore di Laplace
L =∂2
∂x2+∂2
∂y2
Per applicare Freefem dobbiamo trasformare questo problema in formavariazionale. Ricordiamo la formula di Green: date due funzioni u, v regolarisu un aperto U , si ha
−∫
Uv4u dx =
∫
U∇v∇u−
∫
∂Uv〈∇u, ~n〉 dσ
dove ~n indica la normale esterna a ∂U e σ l’elemento di superficie di ∂U . Aquesta equazione occorre aggiungere, se il caso, la condizione alla frontiera.Ad esempio u = 0 su ∂U se la membrana e vincolata a stare fissa a zero albordo. In generale il profilo al bordo sara della forma u = ψ su Γ1 ⊂ ∂U ,dove ψ : R2 → R
2.Se in una parte Γ ⊂ ∂U la membrana e lasciata libera, essa rimane perovincolata dalla condizione 〈∇u, ~n〉 = 0, dovuta alla rigidita della membrana.

5.8. L’equazione del calore 157
Figura 5.19: Grafico della soluzione dell’equazione del calore sulla pallaunitaria. Metodo usato: simulazione, n = 1000 traiettorie simulate per ognipunto della griglia. In due dimensioni spaziali (quindi 3 dimensioni contandoil tempo) i metodi numerici diventano meno praticabili.
Se u e vincolata su Γ1 ⊂ ∂U e la forma variazionale del problema diventa
∫
U∇v∇u dx =
∫
Ufv dx
a cui bisognera aggiungere le condizioni al bordo. Per vedere come sipresentano le soluzioni di questo problema cominciamo con il seguente.
5.31 Scrivere un codice Freefem per risolvere il problema della membranasull’ellisse di equazione parametrica x = a cos θ, y = b sin θ, a = 2, b = 1, conuna forza f = −1 (che spinge in su uniformemente) e con la condizione albordo u = 0. Fare poi il grafico in scilab .Il codice Freefem di questo problema si trova in
www.mat.uniroma2.it\ ∼processi\membrana1.edp
Questo codice scrive i valori della funzione nei vertici della triangolazione nelfile graph-membrane.txt . scilab non possiede un comando per fare ilgrafico 3D di una funzione descritta mediante una triangolazione. Abbiamogia visto che questo si puo fare con il programmino p.151.
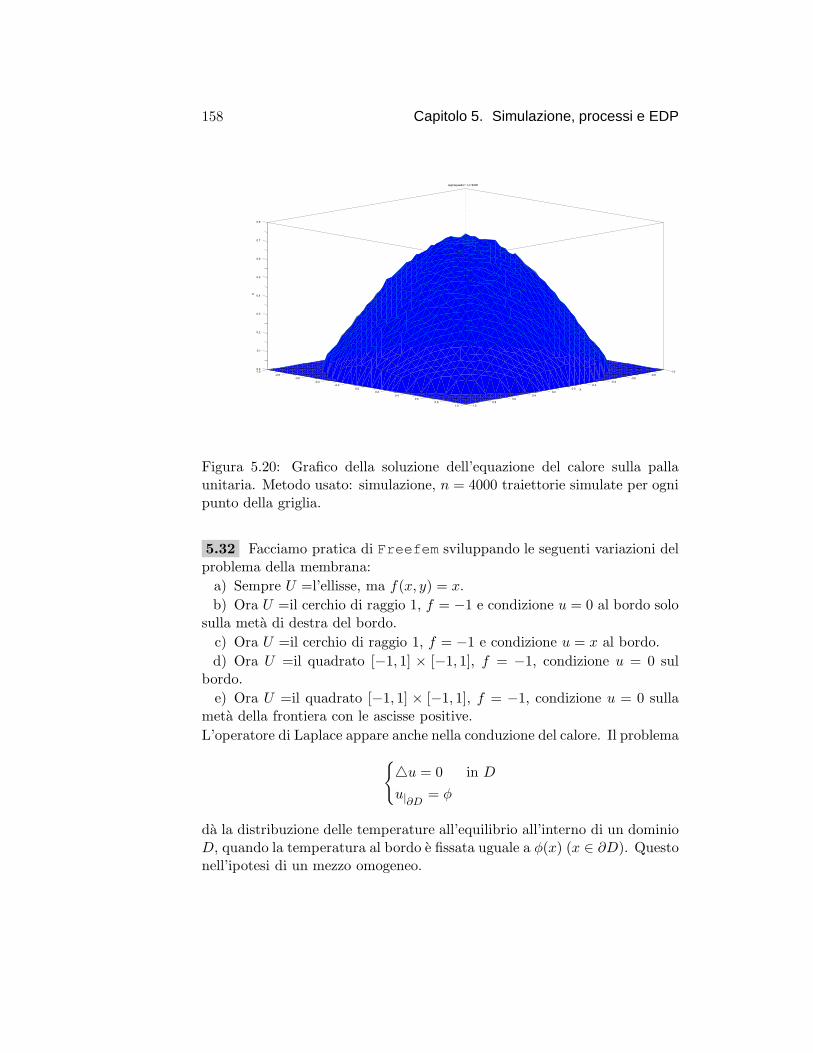
158 Capitolo 5. Simulazione, processi e EDP
Figura 5.20: Grafico della soluzione dell’equazione del calore sulla pallaunitaria. Metodo usato: simulazione, n = 4000 traiettorie simulate per ognipunto della griglia.
5.32 Facciamo pratica di Freefem sviluppando le seguenti variazioni delproblema della membrana:
a) Sempre U =l’ellisse, ma f(x, y) = x.
b) Ora U =il cerchio di raggio 1, f = −1 e condizione u = 0 al bordo solosulla meta di destra del bordo.
c) Ora U =il cerchio di raggio 1, f = −1 e condizione u = x al bordo.
d) Ora U =il quadrato [−1, 1] × [−1, 1], f = −1, condizione u = 0 sulbordo.
e) Ora U =il quadrato [−1, 1] × [−1, 1], f = −1, condizione u = 0 sullameta della frontiera con le ascisse positive.
L’operatore di Laplace appare anche nella conduzione del calore. Il problema
{4u = 0 in D
u|∂D = φ
da la distribuzione delle temperature all’equilibrio all’interno di un dominioD, quando la temperatura al bordo e fissata uguale a φ(x) (x ∈ ∂D). Questonell’ipotesi di un mezzo omogeneo.

5.8. L’equazione del calore 159
Figura 5.21: Grafico della soluzione dell’equazione del calore sulla pallaunitaria (σ2 = 0.1). Metodo usato: sviluppo in autofunzioni, n = 10. Unosviluppo con un numero maggiore di termini non avrebbe portato a differenzedi rilievo. Da notare che la soluzione ottenuta con il metodo di simulazionetende a sovrastimare.

160 Capitolo 5. Simulazione, processi e EDP
5.33 a) Scrivere un codice Freefem che dia la distribuzione delle tem-perature all’equilibrio nella corona circolare D = {.2 ≤ |x| ≤ 1}, con latemperatura imposta uguale a 0 sul bordo esterno e uguale a 1 su quellointerno.b) Stessa cosa ma con il cerchio interno spostato in maniera da avere il
centro nel punto (.3, 0).c) Come in a) ma con un mezzo non omogeneo, quindi sostituendo il
Laplaciano con l’operatore
L = σ2∂2
∂x2+∂2
∂y2
con diversi valori di σ2 (= 8 per cominciare). Cio significa che la conduzionedel calore e maggiore (se σ2 > 1) lungo l’asse x rispetto all’asse y.d) Come in b), ma con un secondo cerchietto di raggio .1 centrato in
(−.3, 0). Ricordare: il bordo deve sempre essere descritto nel verso che
lascia il dominio a cui si e interessati alla sinistra. Quindi il cerchio esternova dato in senso antiorario, quelli interni in senso orario. Per il quadratooccorrera indicare i vari segmenti nell’ordine giusto.

Indice analitico
%i, 23acos, 19asin, 19atan, 19bdiag, 21cdfbet, 114cdfbin, 114cdfchi, 114cdfchn, 114cdff, 114cdffnc, 114cdfgam, 114cdfnbn, 114cdfpoi, 114cdft, 114center, 74champ, 88clear, 15clf(), 12cos, 19cumprod, 19cumsum, 19deff, 32evstr, 26fchamp, 90feval, 38find, 37for, 32format, 16gsort, 20histplot, 62if, 36
imag, 20intg, 96linespec, 40max, 8mean, 30min, 8, 18ode, 87plot, 12, 38rand, 17read, 27real, 20seed, 17sin, 19sort, 20spec, 20sqrt, 19stacksize, 15string, 26tan, 19timer, 34while, 32who, 15whos(), 15write, 27xnumb, 83xstring, 83
autovalori, 20
coefficiente di correlazione,di due caratteri, 54
covarianza, di due caratteri,54
161

162 Indice analitico
funzione di ripartizione, 114
Gibbs, fenomeno, 96
matrice di covarianza, 57
parte immaginaria, 20parte reale, 20
regola di Sturges, 61retta di regressione, 54
Simpson, approssimazione, 104Sturges,regola, 61





























