Embed Size (px)
Citation preview

Griglie computazionali - a.a. 2008-09 1
LEZIONELEZIONE N. 5• Caratterizzazione di un sistema di calcolo
distribuito convenzionale• High Throughput Computing a High Performance
Computing• Calcolo Parallelo: MPI• Resource Management Systems: PBS, MAUI• Caratterizzazione di un sistema di calcolo Grid
Griglie computazionali Griglie computazionali
Università degli Studi di Napoli Federico IICorso di Laurea Magistrale in Informatica – I Anno

Griglie computazionali - a.a. 2008-09 2
Il calcolo distribuitoIl calcolo distribuito
• Risorsa distribuita: è un concetto molto generale che può indicare risorse HW, software, dati, periferiche, persone (virtual organization) che cooperano allo stesso problema essendo distribuite – su una LAN – geograficamente – eventualmente eterogenee.
• Obiettivo: risoluzione di problemi di larga scala attualmente non fattibile, nei tempi desiderati, con le macchine a disposizione.

Griglie computazionali - a.a. 2008-09 3
Problematiche calcolo distribuitoProblematiche calcolo distribuito
• Prestazioni;• Modularità e facilità di espansione;• Condivisione di risorse;• Load balancing;• Buone prestazioni anche in caso di overload.• Molteplicità di risorse eterogenee;• Interconnessioni;• Unità di controllo (coordinamento);• Trasparenza di programmazione e di utenza;• Autonomia di componenti;• Affidabilità
Non sono concetti nuovi, ma è cambiato nel tempo, con l’evoluzione delle tecnologie, il modo di affrontare i problemi

Griglie computazionali - a.a. 2008-09 4
Computer Computer FoodFood ChainChain ((originaloriginal ))
Big Fishes Eating Little Fishes

Griglie computazionali - a.a. 2008-09 5
MPP (Massive Parallel Processor)Supercomputer: SMP(Symmetric Multi Processor)

Griglie computazionali - a.a. 2008-09 6
Griglie computazionali - a.a. 2008-09 7
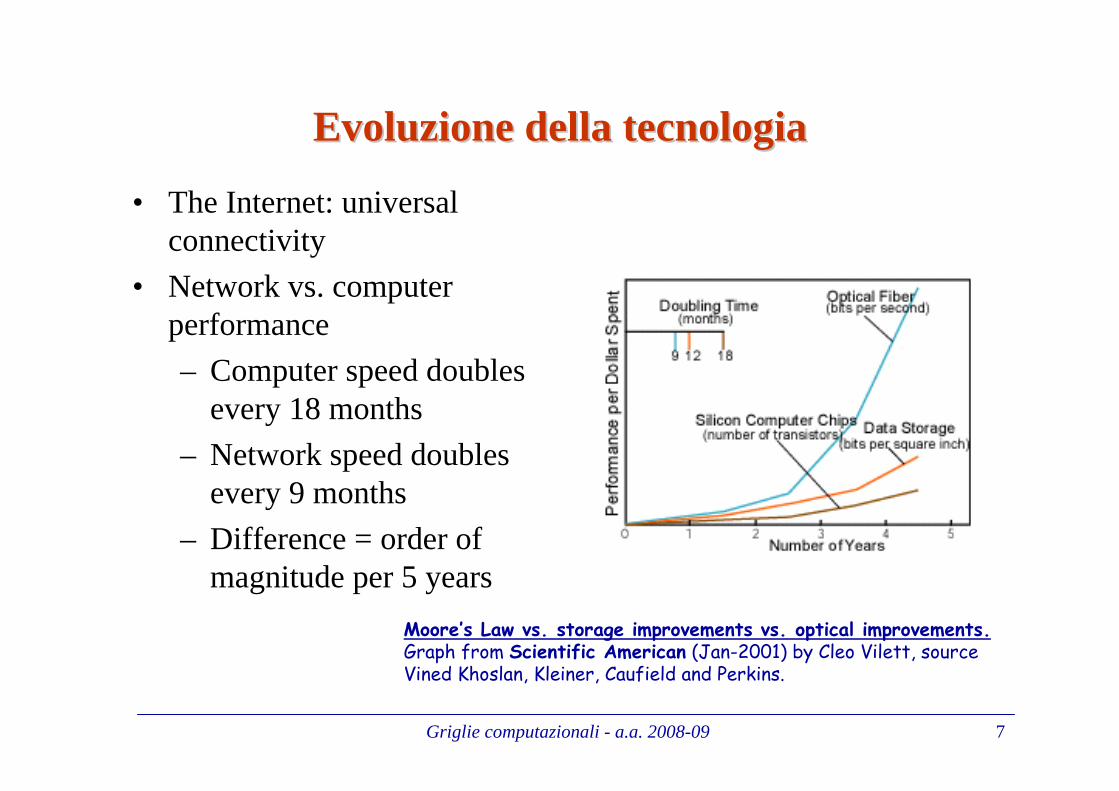
EvoluzioneEvoluzionedelladella tecnologiatecnologia
• The Internet: universal connectivity
• Network vs. computer performance
– Computer speed doubles every 18 months
– Network speed doubles every 9 months
– Difference = order of magnitude per 5 years
Moore’s Law vs. storage improvements vs. optical improvements.Graph from Scientific American (Jan-2001) by Cleo Vilett, source Vined Khoslan, Kleiner, Caufield and Perkins.

Griglie computazionali - a.a. 2008-09 8
High High ThroughputThroughput ComputingComputing -- HTCHTC
• Una grande quantità di dati indipendenti da processare• Calcolo “in parallelo” e non calcolo parallelo• Prestazioni di insieme piuttosto che alte prestazioni del singolo
programma.• Ridondanza piuttosto che totale affidabilità dei singoli
componenti.
Applicazioni nella fisica delle alte energie, nella biologia, nell’utilizzo condiviso di risorse da parte di molti utenti indipendenti• Condor è un sistema HTC

Griglie computazionali - a.a. 2008-09 9
High Performance High Performance ComputingComputing -- HPCHPC
• Grande potenza computazionale da utilizzare nel singolo programma.
• Dati complessi e correlati.• Porta naturalmente al calcolo parallelo• Sviluppo nei supercomputer e nel cluster computing.• Richiede totale affidabilità del sistema.
Applicazioni nelle previsioni metereologiche, nella mappatura del DNA, nelle simulazioni geofisiche

Griglie computazionali - a.a. 2008-09 10
Il Calcolo ParalleloIl Calcolo Parallelo
Limiti del calcolo seriale su singolo computer:• limiti fisici: numero di cicli al secondo, velocità di
trasmissione.• limiti tecnici: clock estremamente alti causano alta
dissipazione.• limiti applicativi: insufficienza della memoria• limiti economici: utilizzare “Commodity off the shelf”
Notare che:• già adesso i processori seriali presentano un parallelismo
interno (funzionale): più pipeline indipendenti• già adesso un singolo chip può presentare più processori
Griglie computazionali - a.a. 2008-09 11
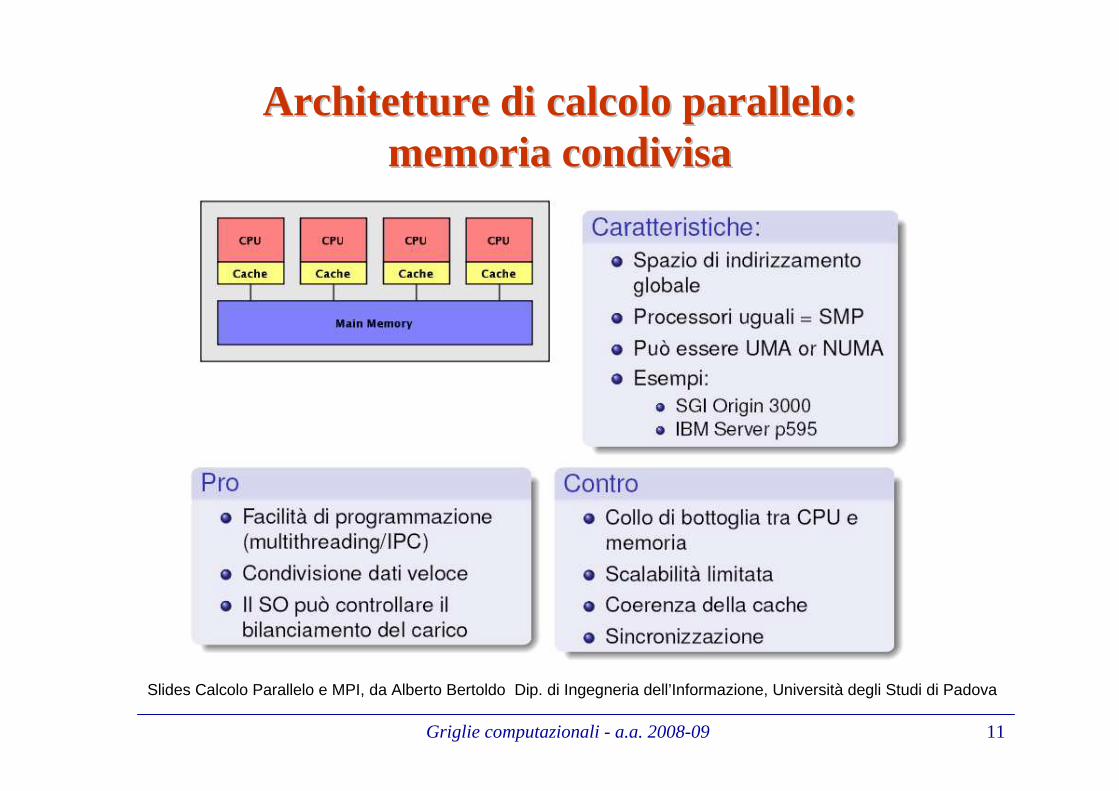
Architetture di calcolo parallelo: Architetture di calcolo parallelo: memoria condivisamemoria condivisa
Slides Calcolo Parallelo e MPI, da Alberto Bertoldo Dip. di Ingegneria dell’Informazione, Università degli Studi di Padova
Griglie computazionali - a.a. 2008-09 12
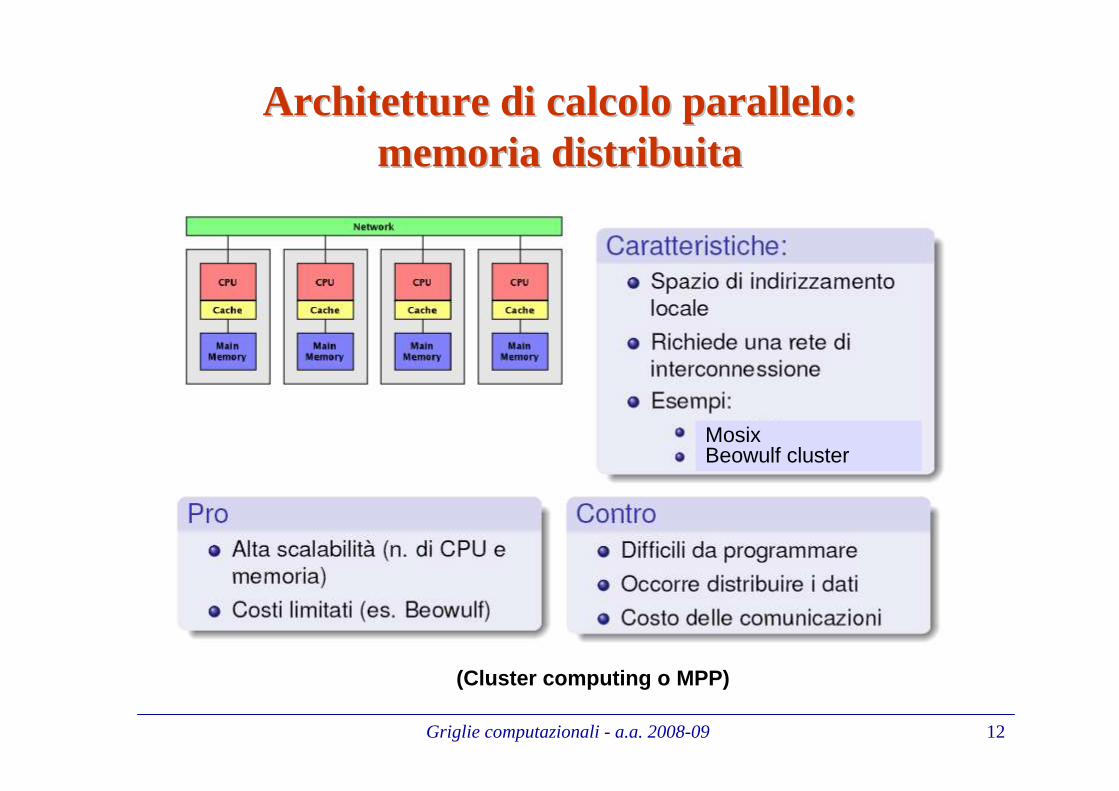
Architetture di calcolo parallelo: Architetture di calcolo parallelo: memoria distribuitamemoria distribuita
(Cluster computing o MPP)
MosixBeowulf cluster

Griglie computazionali - a.a. 2008-09 13
Modelli di programmazione parallelaModelli di programmazione parallela
Ci occupiamo del paradigma “Message passing”, che è
di livello più basso, poiché è quello usato in GRID.

Griglie computazionali - a.a. 2008-09 14
MPIMPI -- MessageMessagePassingPassingInterfaceInterface
� Paradigma di programmazione a scambio di messaggi.� Insieme di specifiche che definiscono una API
(protocollo di comunicazione e semantica delle operazioni).� Libreria per la programmazione di applicazioni parallele.
MPI non è riconosciuto come standard, esistono altri pacchetti per il massage passing come PVM (Parallel Virtual Machine).Tuttavia è lo standard de facto per la programmazione messagepassing.Se ne occupa un apposito forum: http://www.mpi-forum.org .Esistono varie implementazioni di MPI, es: OpenMPI, MPICH, IBM

Griglie computazionali - a.a. 2008-09 15
PerchePerche’’ MPI?MPI?

Griglie computazionali - a.a. 2008-09 16
Gestione dellGestione dell’’ ambiente di esecuzione MPIambiente di esecuzione MPI

Griglie computazionali - a.a. 2008-09 17
Comunicazione tra due processi MPIComunicazione tra due processi MPI

Griglie computazionali - a.a. 2008-09 18
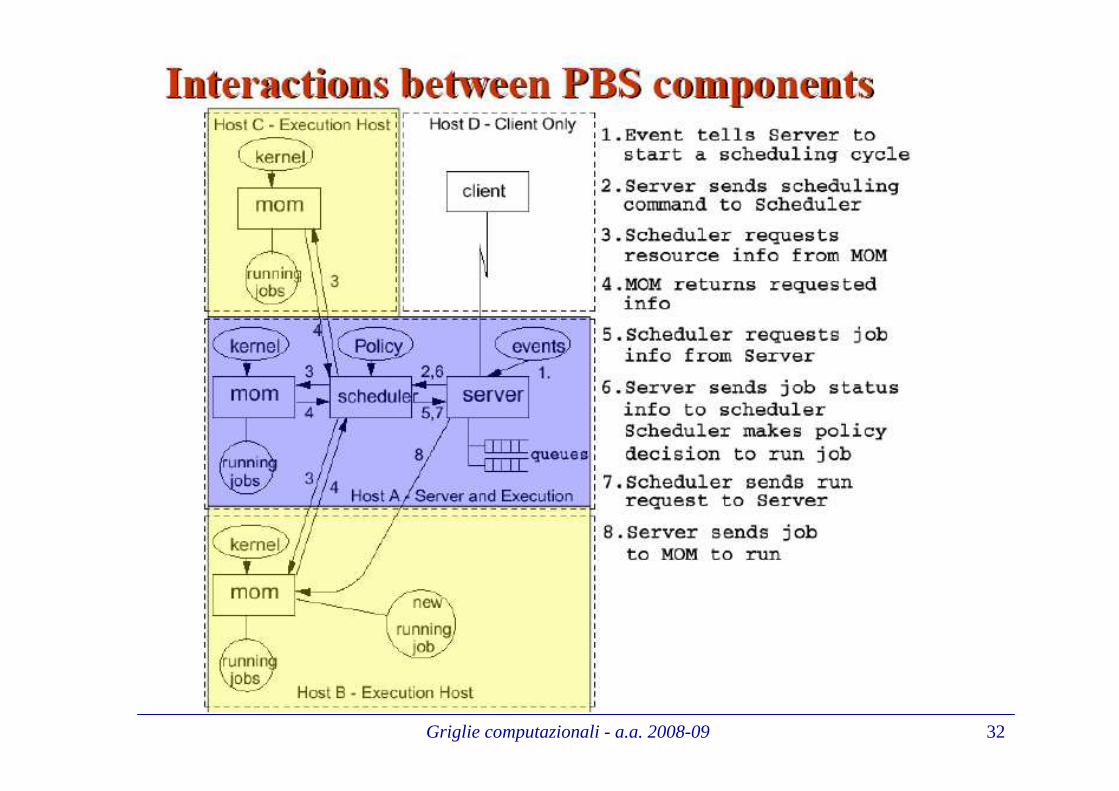
Il gestore di risorse e lo Il gestore di risorse e lo schedulerscheduler
Un ambiente di High Throughput Computing (HTC) può essere realizzato da un sistema software per l'esecuzione di lavori (job) in modalità a lotti (batch) su workstation collegate in rete:• regolamentare l’esecuzione di un gran numero di programmi • ottimizzare l’utilizzo delle risorse di un cluster.
Utilizzo un Resource Manager, in particolare un sistema di code:• Il sistema si basa sulla definizione di "code" (queue), analoghe ad una coda di stampa.• Un programma destinato all'esecuzione (JOB) viene sottomesso ad una coda e il Resource Manager si occupa di assegnarlo ad un processore disponibile, sulla base del carico corrente e delle caratteristiche del job.• Lo scheduler stabilisce la priorità di esecuzione di ciascun job in base alle policy implementate.

Griglie computazionali - a.a. 2008-09 19
LRMS (LRMS (LocalLocal ResourceResourceManagement System)Management System)
In ambito GRID l’insieme del sistema di code e dello scheduler si chiama LRMS (Local ResourceManagement System)• Ci occupiamo di uno dei sistemi più diffusi in Grid per la gestione delle risorse distribute a livello LOCALE.• Un SITO Grid è un insieme di risorse sotto un singolo dominio amministrativo, generalmente su LAN.• Un sito, al suo interno, gestisce le risorse in modo non molto diverso da un cluster tradizionale.

Griglie computazionali - a.a. 2008-09 20
PBS/PBS/TorqueTorque + MAUI + MAUI schedulerscheduler
PBS (Portable Batch System)ed il suo successore open source Torque, sono tra i sistemi di code maggiormente utilizzati al’interno dei siti Grid.
MAUI/MOAB è lo schedulergeneralmente associato a PBS per implementare policies e algoritmi elaborati di condivisione delle risorse

Griglie computazionali - a.a. 2008-09 21

Griglie computazionali - a.a. 2008-09 22

Griglie computazionali - a.a. 2008-09 23

Griglie computazionali - a.a. 2008-09 24
Lo scheduler predefinito puo’ essere sostituito a seconda delle esigenze

Griglie computazionali - a.a. 2008-09 25

Griglie computazionali - a.a. 2008-09 26

Griglie computazionali - a.a. 2008-09 27

Griglie computazionali - a.a. 2008-09 28

Griglie computazionali - a.a. 2008-09 29

Griglie computazionali - a.a. 2008-09 30

Griglie computazionali - a.a. 2008-09 31
Griglie computazionali - a.a. 2008-09 32

Griglie computazionali - a.a. 2008-09 33

Griglie computazionali - a.a. 2008-09 34

Griglie computazionali - a.a. 2008-09 35

Griglie computazionali - a.a. 2008-09 36

Griglie computazionali - a.a. 2008-09 37

Griglie computazionali - a.a. 2008-09 38

Griglie computazionali - a.a. 2008-09 39

Griglie computazionali - a.a. 2008-09 40

Griglie computazionali - a.a. 2008-09 41

Griglie computazionali - a.a. 2008-09 42
To To submitsubmita job to PBS server a job to PBS server writewrite a PBS Job Script . a PBS Job Script .
Job script Job script containscontains::
First First lineline isis a a shellshell::
#!/#!/binbin//shsh
ThenThenPBS PBS commandscommands::
-- to to assignassigna job a job namename
#PBS#PBS--N <N <jobnamejobname>>
FinallyFinally programsprogramsyouyou wantwant to to submitsubmit
cd cd $HOME$HOME//pbstestpbstest
echoecho"Test job "Test job startingstartingat `date`" at `date`"
././ackermann.plackermann.plechoecho
"Test job "Test job finishedfinishedat `date`" at `date`"
PBS Job ScriptPBS Job Script

Griglie computazionali - a.a. 2008-09 43
-- to to assignassigna job a job namename#PBS#PBS--N <N <jobnamejobname>>
-- stderrstderrfilenamefilename(default: <(default: <jobnamejobname>.e<>.e<jobidjobid>)>)#PBS#PBS--e <e <filenamefilename>>
-- stdoutstdoutfilenamefilename(default: <(default: <jobnamejobname>.o<>.o<jobidjobid>)>)#PBS#PBS--o <o <filenamefilename>>
-- notificationnotificationmail mail addressaddress#PBS#PBS--M M useruser[, [, useruser, ...], ...]
ThenThenjust do just do qsubqsubfilenamefilenameand the job's and the job's identifieridentifier willwill bebereportedreportedback to back to youyou. . WhenWhenthe job the job finishesfinishes, , stdoutstdoutand and stderrstderrofof the job the job willwill bebewrittenwritten to to filesfiles, , namednamedafterafter the job ID, in the the job ID, in the currentcurrentdirectory directory whenwhenqsubqsubwaswasexecutedexecuted(or to (or to filesfiles specifiedspecifiedwithwith the the --o or o or --e e switchesswitches). ).
PBS Job Script PBS Job Script CommandsCommands

Griglie computazionali - a.a. 2008-09 44

Griglie computazionali - a.a. 2008-09 45

Griglie computazionali - a.a. 2008-09 46

Griglie computazionali - a.a. 2008-09 47

Griglie computazionali - a.a. 2008-09 48

Griglie computazionali - a.a. 2008-09 49

Griglie computazionali - a.a. 2008-09 50

Griglie computazionali - a.a. 2008-09 51

Griglie computazionali - a.a. 2008-09 52

Griglie computazionali - a.a. 2008-09 53

Griglie computazionali - a.a. 2008-09 54

Griglie computazionali - a.a. 2008-09 55

Griglie computazionali - a.a. 2008-09 56

Griglie computazionali - a.a. 2008-09 57

Griglie computazionali - a.a. 2008-09 58

Griglie computazionali - a.a. 2008-09 59
MauiMaui / / MoabMoab schedulerscheduler
• Maui Cluster Scheduler, il precursore di Moab Cluster Suite, è un job scheduler open source per cluster e supercomputers.
• É un tool ottimizzato e configurabile, capace di supportare un array di – scheduling policies,
– priorità dinamiche,
– preallocazione delle risorse,
– capacità di fairshare capabilities.
• Maui e Moab sono in uso in centinaia di siti governativi, accademici e commerciali in tutto il mondo.

Griglie computazionali - a.a. 2008-09 60
MauiMaui Job Job PrioritizationPrioritization
Un sito ha spesso numerosi obiettivi indipendenti: � Massimizzare l’utilizzo delle risorse� Dare preferenza a utenti di progetti specifici� Fare in modo che i job non restino in coda per più di un certo
tempo
L’approccio di Maui è di assegnare dei pesi ai diversi obiettivi, in modo che un valore complessivo della priorità possa essere associato ad ogni decisione di scheduling. Con i job prioritizzati, lo scheduler può soddifare gli obiettivi del sito lanciando i job in ordine di priorità.

Griglie computazionali - a.a. 2008-09 61
Calcolo della prioritCalcolo della priorit àà di un jobdi un job
La prorità di un job risulta come somma pesata di un insieme di componenti.Ogni componente è scomposto in sottocomponenti, dando la possibilità di fare
un tuning fine della prioritàIl valore di ogni sottocomponente è determinato dalla formula:<COMPONENT WEIGHT> * <SUBCOMPONENT WEIGHT> *
<PRIORITY SUBCOMPONENT VALUE>Esistono un gran numero di componenti e sottocomponenti, ma un sito
configura solo quelli che interessano per i suoi obiettivi.Di default il valore dei pesi di componenti e sottocomponenti è settato a 1 e 0
rispettivamente. L’unica eccezione è per il sottocomponente QUEUETIME , il cui peso è 1 di default.
Il comportamento default di Maui è quindi che la priorità totale di un job dipende solo dal tempo in coda, risultando quindi come una semplice FIFO
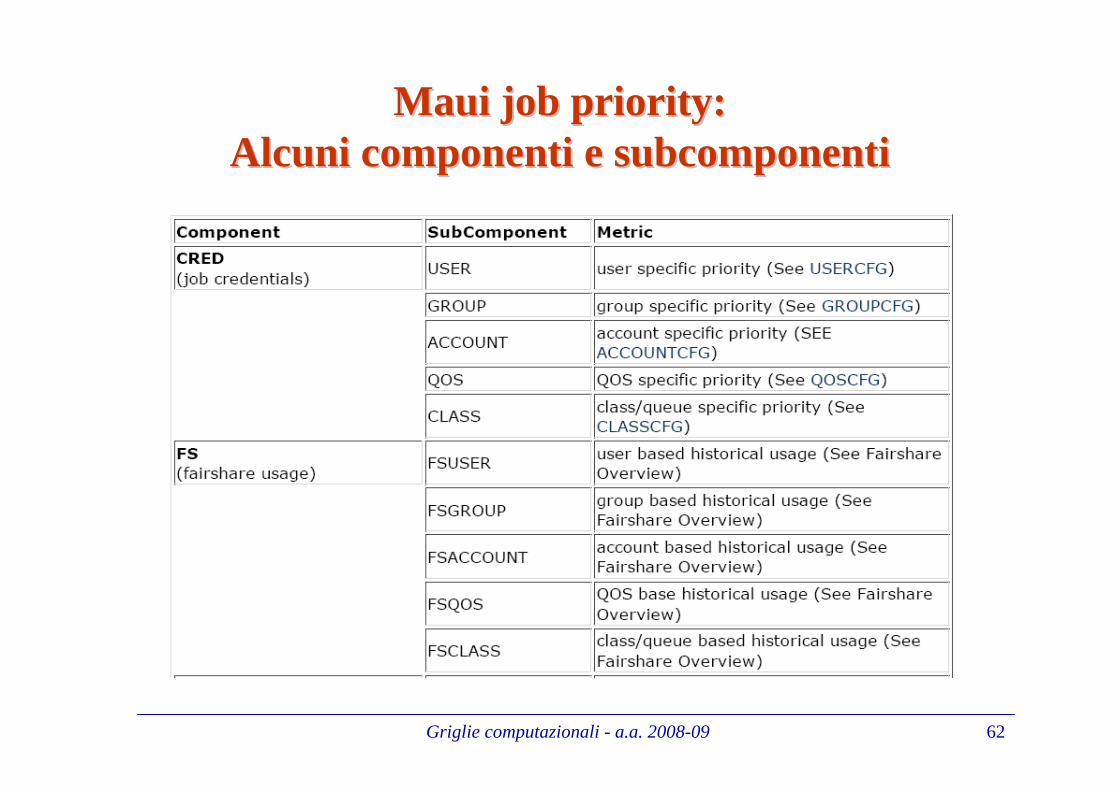
Griglie computazionali - a.a. 2008-09 62
MauiMaui job job prioritypriority ::Alcuni componenti e Alcuni componenti e subcomponentisubcomponenti

Griglie computazionali - a.a. 2008-09 63
Caratterizzazione di un sistema di calcoloCaratterizzazione di un sistema di calcolodistribuito convenzionale distribuito convenzionale (1/2)(1/2)
L’applicazione distribuita assume l’esistenza di un pool dinodi di calcoloche implementano una macchina virtuale
Il pool consiste in un insieme di PC, supercomputer, ... su cuiha accesso (login + password) l’utente che esegue l’applicazione distribuita
L’operazione di login alla macchina virtuale consiste nellaautenticazione su ciascun nodo. In generale assumiamo chel’utente autenticato su un nodo del pool viene automaticamenteautorizzato all’utilizzo di tuttii nodi del pool

Griglie computazionali - a.a. 2008-09 64
Caratterizzazione di un sistema di calcoloCaratterizzazione di un sistema di calcolodistribuito convenzionale distribuito convenzionale (2/2)(2/2)
L’utente di un sistema di calcolo distribuito convenzionaleconoscele caratteristiche dei nodi a disposizione(sistema operativo, potenza del processore, spazio disco, ...)
Inoltre, l’insieme di nodi è per lo piùstatico in quanto cambia molto raramente le sue caratteristiche
Infine la dimensionedi un sistema di calcolo distribuitoconvenzionale tipicamente non supera il migliaio di nodi
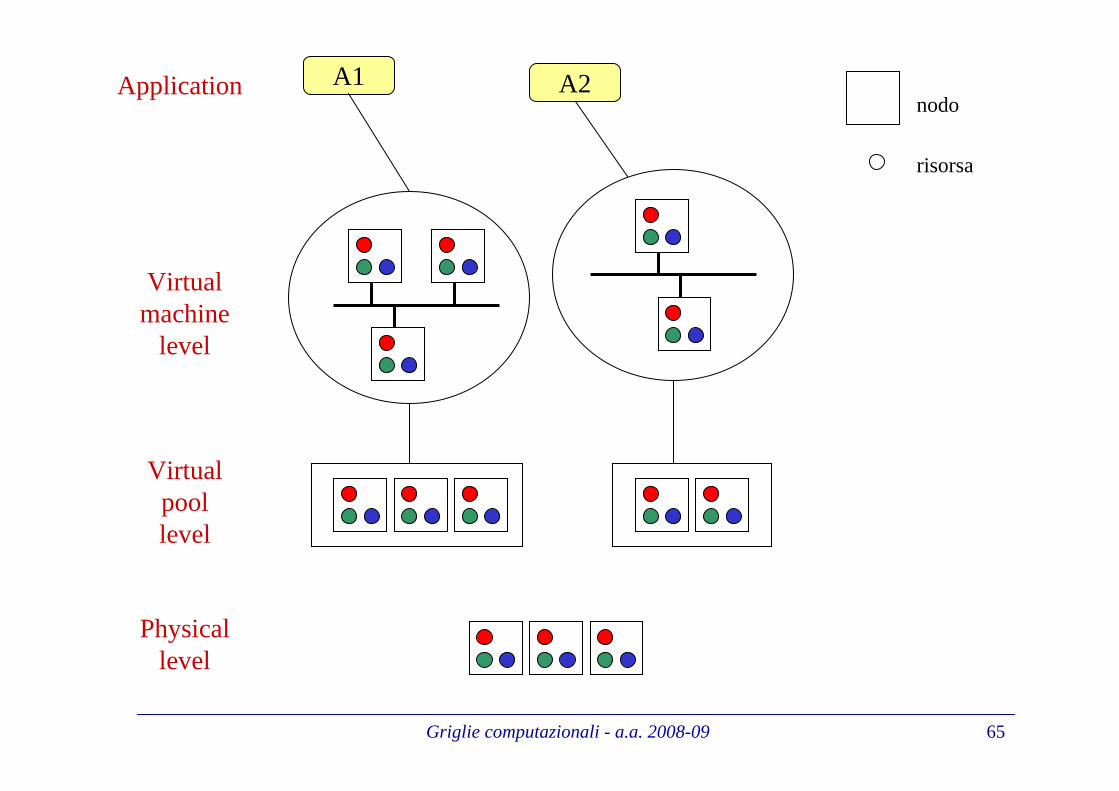
Griglie computazionali - a.a. 2008-09 65
A1 A2
risorsa
nodoApplication
Virtualmachine
level
Virtualpoollevel
Physicallevel

Griglie computazionali - a.a. 2008-09 66
Caratterizzazione di un sistema di calcoloCaratterizzazione di un sistema di calcoloGridGrid (1/2)(1/2)
Un’applicazione distribuita assume l’esistenza di un pool dirisorse(processori, memoria, disco, ...) distribuite su scalageografica
La macchina virtuale, nel caso Grid, e’ costituita da un set dirisorse del pool
L’operazione di login alla macchina virtuale presuppone chel’utente possiede delle credenziali accettate dai proprietari delle risorse del pool. Un utente può essere autorizzato all’utilizzo diuna risorsa senzaavere un account sul nodo che ospita la risorsa.

Griglie computazionali - a.a. 2008-09 67
Caratterizzazione di un sistema di calcoloCaratterizzazione di un sistema di calcoloGridGrid (2/2)(2/2)
• L’utente di un sistema di calcolo distribuito Gridnonha bisogno di conoscerele caratteristiche delle risorse a disposizione
• L’insieme di nodi e’dinamico
• Infine la dimensionedi un sistema di calcolo Gridpuò senza problemi essere di decine di migliaia risorse
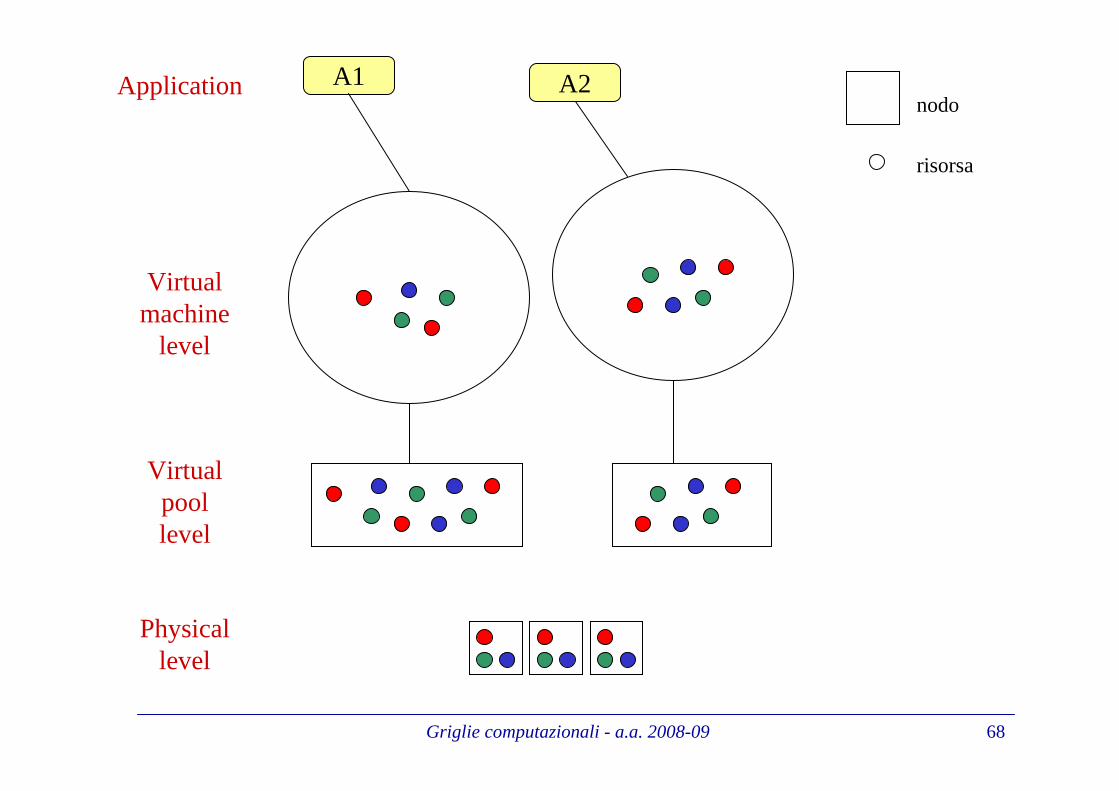
Griglie computazionali - a.a. 2008-09 68
A1 A2
risorsa
nodoApplication
Virtualmachine
level
Virtualpoollevel
Physicallevel
Griglie computazionali - a.a. 2008-09 69
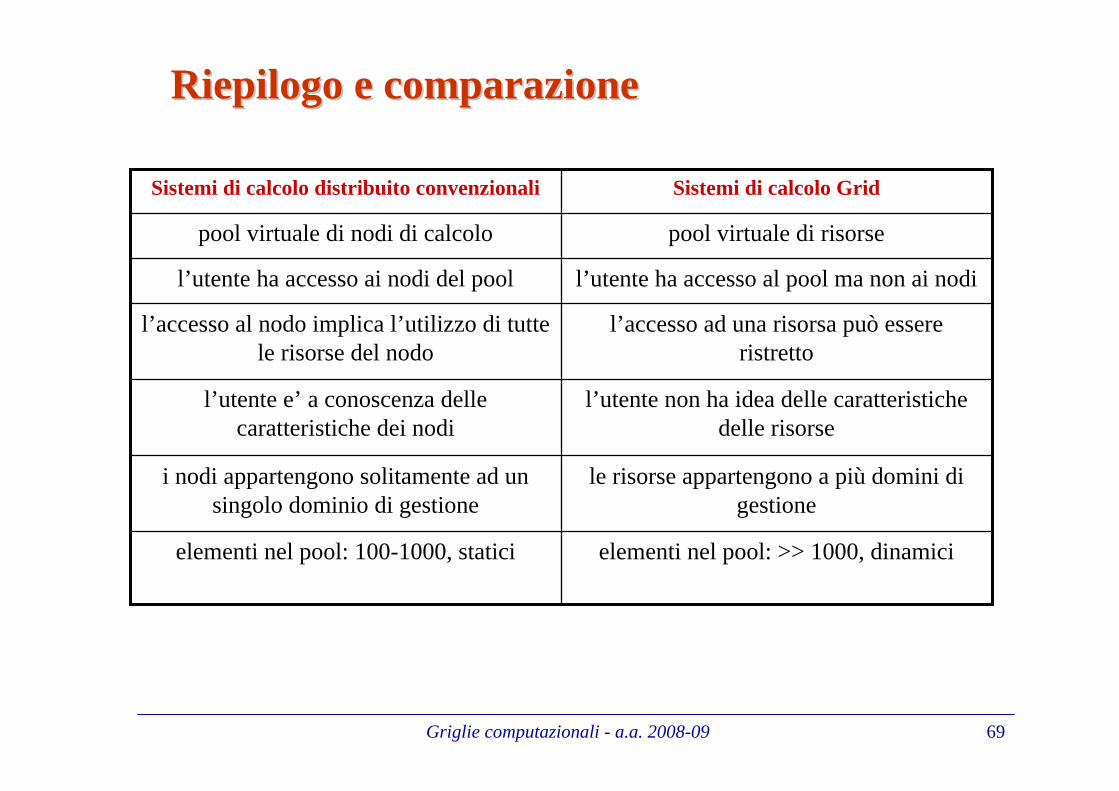
elementi nel pool: >> 1000, dinamicielementi nel pool: 100-1000, statici
le risorse appartengono a più domini di gestione
i nodi appartengono solitamente ad un singolo dominio di gestione
l’utente non ha idea delle caratteristiche delle risorse
l’utente e’ a conoscenza delle caratteristiche dei nodi
l’accesso ad una risorsa può essere ristretto
l’accesso al nodo implica l’utilizzo di tutte le risorse del nodo
l’utente ha accesso al pool ma non ai nodil’utente ha accesso ai nodi del pool
pool virtuale di risorsepool virtuale di nodi di calcolo
Sistemi di calcolo GridSistemi di calcolo distribuito convenzionali
Riepilogo e comparazioneRiepilogo e comparazione

Griglie computazionali - a.a. 2008-09 70
Definizione di Definizione di GridGrid
Insieme di servizi che consentono il calcolo distribuito su risorseappartenenti a diversi domini di gestione e che fornisce:
• virtualizzazione degli utenti
• virtualizzazione delle risorse
In base alla definizione e alla caratterizzazione di Grid è possibiledeterminare se un sistema di calcolo è “Grid-enabled”

Griglie computazionali - a.a. 2008-09 71
RiferimentiRiferimenti
• Calcolo Parallelo e MPI:– Laboratorio di Calcolo Parallelo
http://www.dei.unipd.it/~cyberto/lezione1.pdf– www.mpi-forum.org
• Sistemi di gestione delle risorse(PBS/TORQUE) e scheduler– An introduction to PORTABLE BATCH SYSTEM (PBS)
http://hpc.sissa.it/pbs/pbs.html– Torquehttp://www.clusterresources.com/pages/products/torque-
resource-manager.php– Maui/Moabhttp://www.clusterresources.com/pages/products/maui-
cluster-scheduler.php– http://www.dcsc.sdu.dk/docs/maui/mauidocs.html

























![Angry Fishes [Злые Рыбы]](https://img.pdfslide.tips/doc/110x75/55acc3711a28ab2b698b46ce/angry-fishes-.jpg)



