Embed Size (px)
Citation preview

Lezioni di genetica medica
Specializzazioni2013-2014

Programma, parte 1genetica umana generale
• Il genoma umano: geni ed organizzazione• Next generation sequencing (NGS), l'exoma• Eterogeneità clinica ed eterogeneità genetica• Penetranza ed espressività, anticipazione• Omozigosità ed eterozigosità composta• Aploinsufficienza• Meccanismo dello splicing e sue alterazioni• Classi di mutazioni puntiformi, transizione e trasversione, conservative,
missenso, nonsenso, nonstop• Inserzioni, delezioni con frame-shift e non, duplicazioni, conversione
genica• Significato patologico delle varie classi di variazioni del DNA: alleli
equivalente, amorfo, ipomorfo, ipermorfo, neomorfo e antimorfo• Nomenclatura internazionale delle variazioni genetiche e significato della
refertazione

Programma, parte 2:la consulenza e le cromosopatie
• La consulenza genetica: rischio riproduttivo dipendente ed indipendente dal partner
• Diagnostica prenatale e presintomatica• L'analisi del cariotipo e i bandeggi, la FISH• Cariotipo molecolare mediante arrayCGH• Aneuploidie negli aborti e rischio di ricorrenza• Triploidia da doppio corredo paterno o materno, tetraploidia• Il cromosoma X e la sua inattivazione, regioni PAR• Trisomie autosomiche e dei cromosomi sessuali• Le monosomie, la sindrome di Turner• Delezioni cromosomiche, inversioni paracentriche e pericentriche• Traslocazioni sbilanciate e bilanciate, robertsoniane, markers
cromosomici• Delezioni e duplicazioni submicroscopiche (s. di Williams, s. di
DiGeorge, s. Cri du Chat)

Programma, parte 3genetica medica mendeliana
• Malattie mendeliane monoalleliche con mutazioni de novo (craniosonostosi, acondroplasia)
• Malattie mendeliane monoalleliche a trasmissione autosomica dominante (neurofibromatosi, s. di Marfan, rene policistico, osteogenesi imperfetta)
• Malattie mendeliane monoalleliche legate al cromosoma X (distrofia muscolare di Duchenne e Becker, emofilia, ritardi mentali legati all’X)
• Malattie mendeliane bialleliche a trasmissione autosomica recessiva (fibrosi cistica, alfa e beta talassemia, amiotrofia spinale, emocromatosi, glicogenosi)

Programma, parte 4,eccezioni all’eredità mendeliana
• Mutazioni dinamiche in regioni non codificanti (X-fragile, distrofia miotonica), anticipazione
• Mutazioni dinamiche in regioni codificanti (corea di Huntington, atassie spino-cerebellari)
• Mutazioni in regioni cromosomiche con imprinting (Prader-Willi, sindrome di Angelman, Beckwith-Wiedemann, Silver-Russel) Disomia uniparentale
• Mutazioni del DNA mitocondriale (MERFF, MELAS, LHON, KS, s. di Leigh)
• Caratteri multifattoriali e studi GWAs• Epigenetica

Testi consigliati
• Neri-GenuardiGenetica umana e medicaEditore Elsevier Masson
• Moncharmont-LeonardiPatologia GeneraleEditore Idelson Gnocchi
• Strachan-ReadGenetica Molecolare UmanaEditore Zanichelli
• LewisGenetica UmanaEditore Piccin
• Sito web http://www.vincenzonigro.it (glossario)

• Il genoma è l'intero patrimonio genetico di un organismo vivente
• Il genoma è "scritto" in un composto chimico chiamato DNA (DeoxyriboNucleic Acid, acido desossiribonucleico) a cui si aggiungono informazioni epigenetiche
• La grandezza totale del genoma umano aploide è di 3.070.000.000 basi di cui 2.843.000.000 sono di eucromatina
• Il DNA è identico per tutte le cellule di un individuo ed ècontenuto quasi tutto nel nucleo, con l’eccezione del DNA mitocondriale
1953
2001
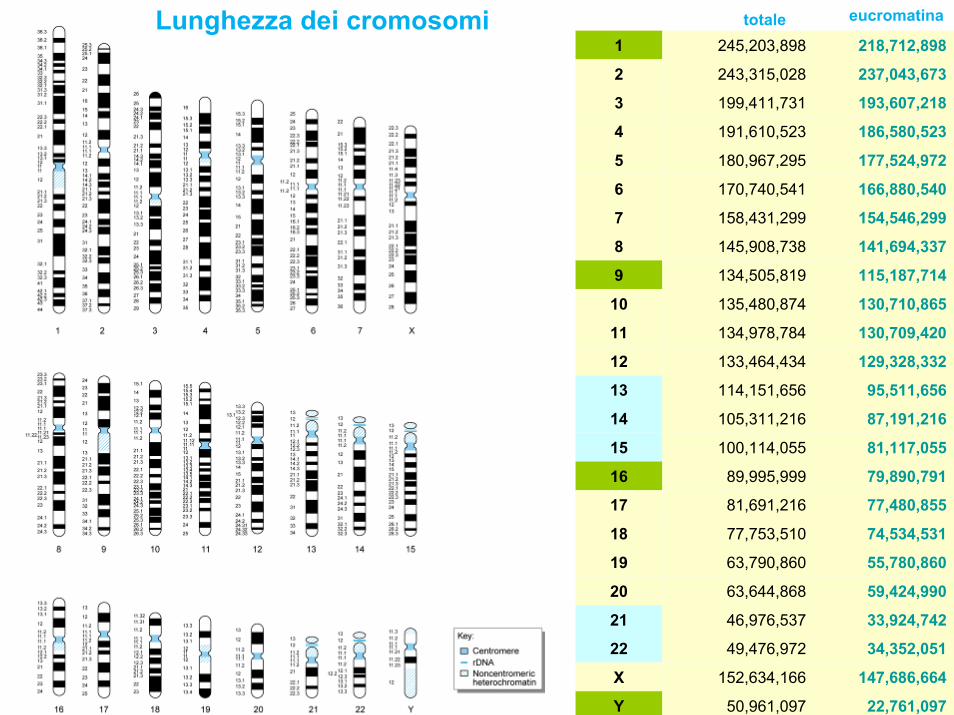
1 245,203,898 218,712,898
2 243,315,028 237,043,673
3 199,411,731 193,607,218
4 191,610,523 186,580,523
5 180,967,295 177,524,972
6 170,740,541 166,880,540
7 158,431,299 154,546,299
8 145,908,738 141,694,337
9 134,505,819 115,187,714
10 135,480,874 130,710,865
11 134,978,784 130,709,420
12 133,464,434 129,328,332
13 114,151,656 95,511,656
14 105,311,216 87,191,216
15 100,114,055 81,117,055
16 89,995,999 79,890,791
17 81,691,216 77,480,855
18 77,753,510 74,534,531
19 63,790,860 55,780,860
20 63,644,868 59,424,990
21 46,976,537 33,924,742
22 49,476,972 34,352,051
X 152,634,166 147,686,664
Y 50,961,097 22,761,097
Lunghezza dei cromosomi totale eucromatina
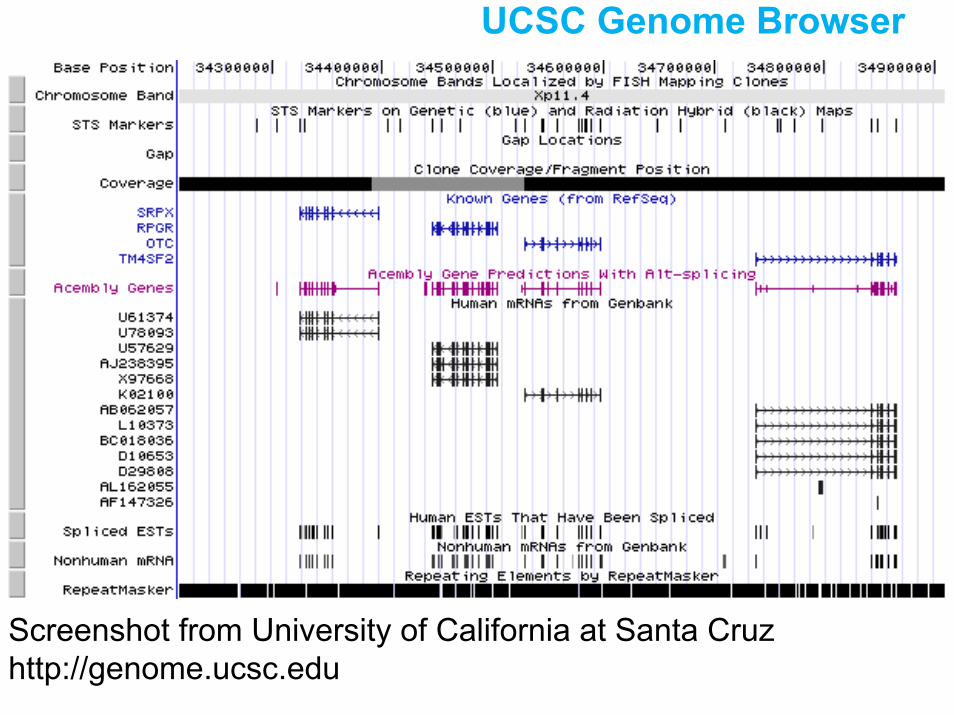
UCSC Genome Browser
Screenshot from University of California at Santa Cruz http://genome.ucsc.edu
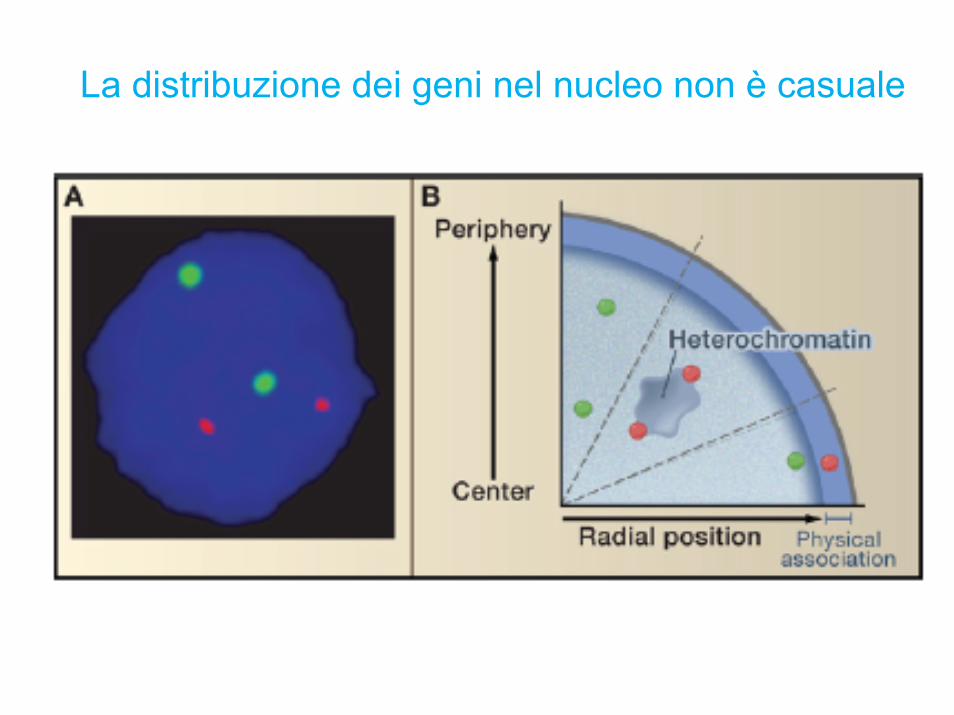
La distribuzione dei geni nel nucleo non è casuale
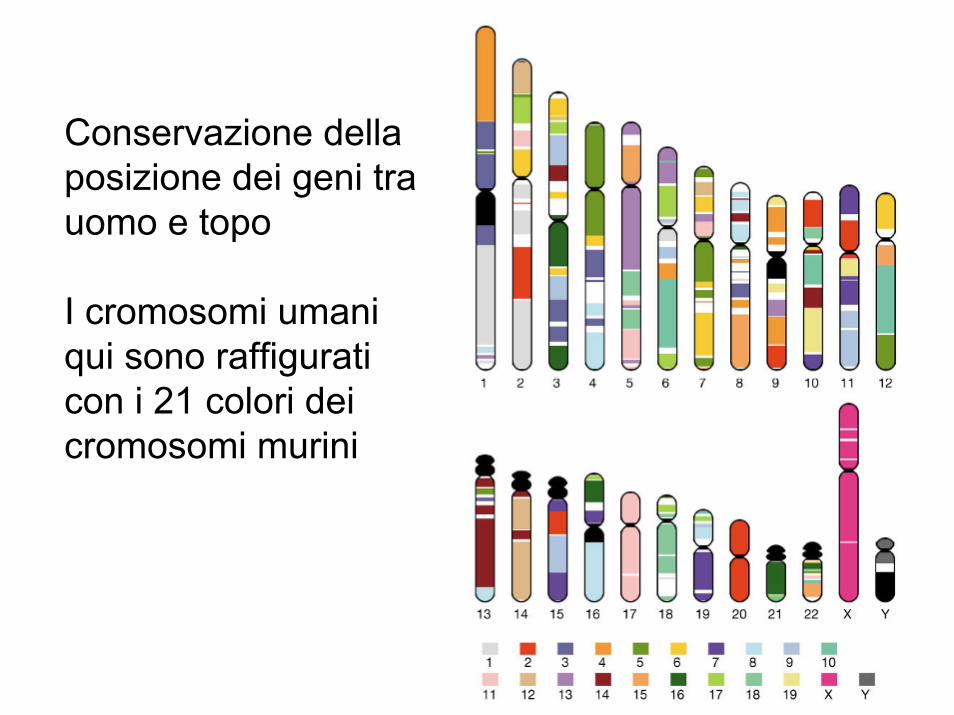
Conservazione della posizione dei geni tra uomo e topo
I cromosomi umani qui sono raffigurati con i 21 colori dei cromosomi murini
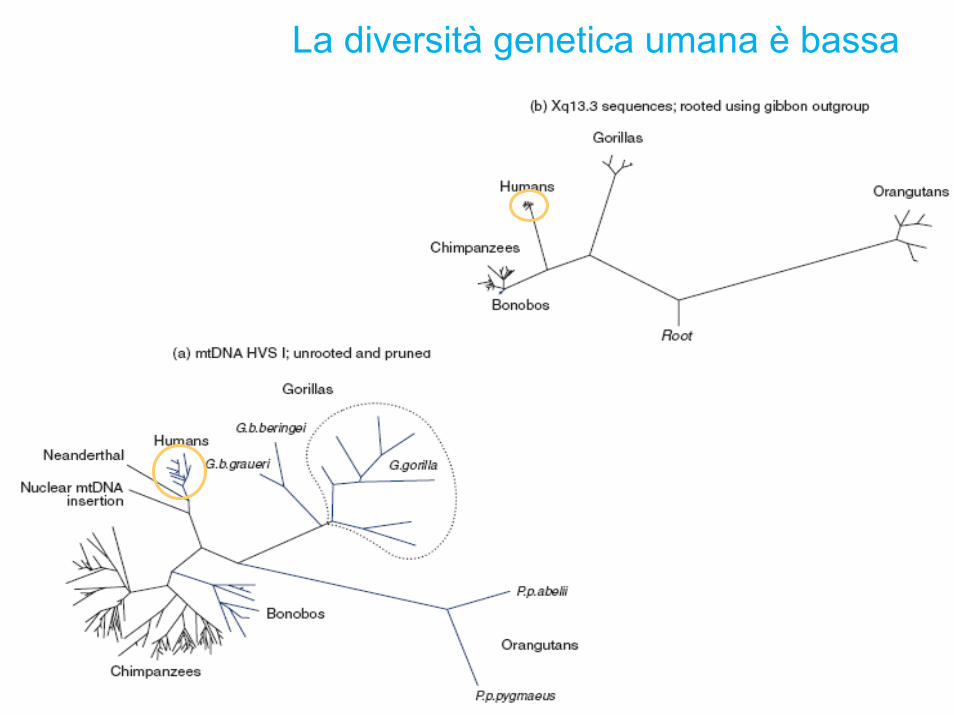
La diversità genetica umana è bassa

dimensione dei geni
• Gli esoni interni hanno una dimensione media di 145 bp
• Gli esoni più corti richiedono enhancer di splicing• Il gene della distrofina è il più lungo del genoma
umano (2.220.000)• Il gene della titina ha il maggiore numero di esoni 324
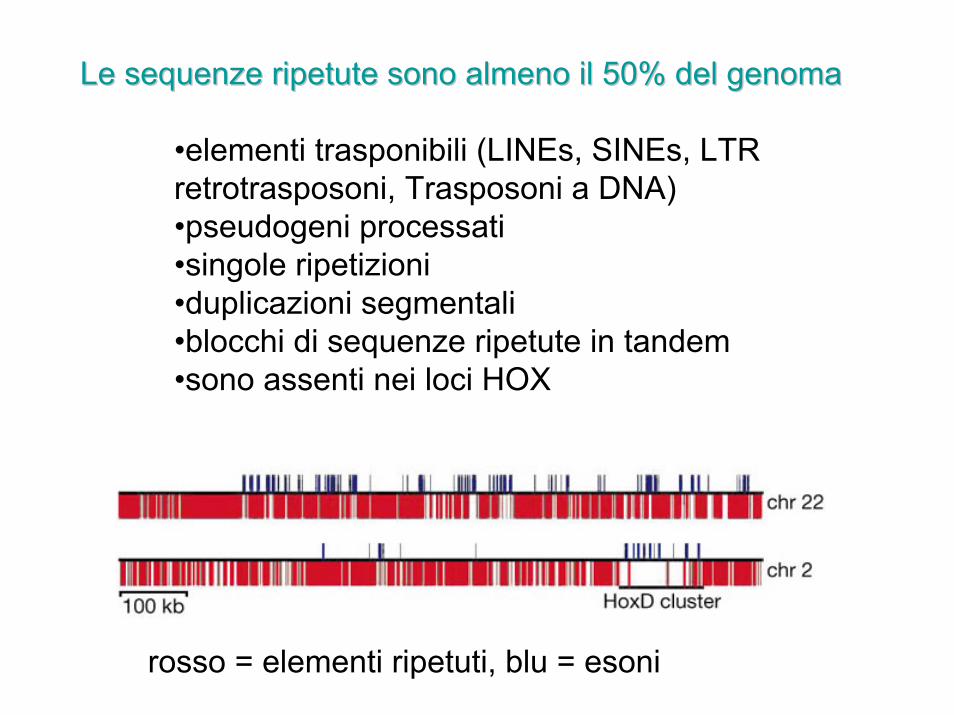
rosso = elementi ripetuti, blu = esoni
Le sequenze ripetute sono almeno il 50% del genomaLe sequenze ripetute sono almeno il 50% del genoma
•elementi trasponibili (LINEs, SINEs, LTR retrotrasposoni, Trasposoni a DNA)•pseudogeni processati•singole ripetizioni •duplicazioni segmentali•blocchi di sequenze ripetute in tandem•sono assenti nei loci HOX

ACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACCGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGAACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGATAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATTATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTTATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGATAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTT
Variazioni di sequenza in un segmento di DNA
Ogni cromosoma è differente da tutti gli altri
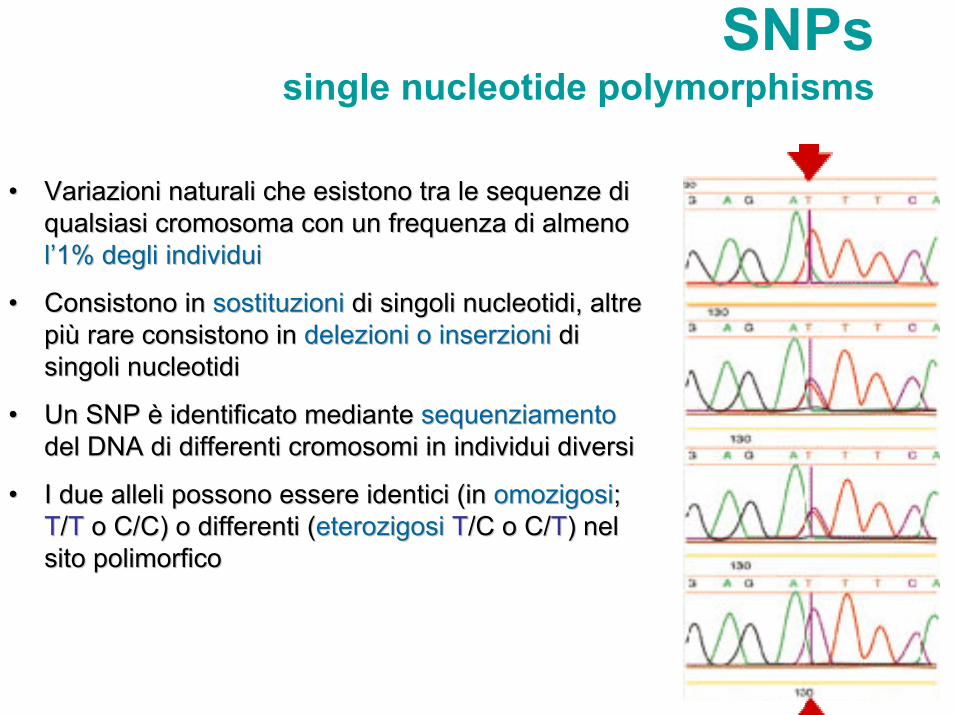
SNPssingle nucleotide polymorphisms
•• Variazioni naturali che esistono tra le sequenze di Variazioni naturali che esistono tra le sequenze di qualsiasi cromosoma con un frequenza di almeno qualsiasi cromosoma con un frequenza di almeno ll’’1%1% degli individuidegli individui
•• Consistono in Consistono in sostituzioni sostituzioni di singoli nucleotidi, altre di singoli nucleotidi, altre pipiùù rare consistono in rare consistono in delezioni o inserzionidelezioni o inserzioni di di singoli nucleotidisingoli nucleotidi
•• Un SNP Un SNP èè identificato mediante identificato mediante sequenziamentosequenziamentodel DNA di differenti cromosomi in individui diversidel DNA di differenti cromosomi in individui diversi
•• I due alleli possono essere identici (in I due alleli possono essere identici (in omozigosiomozigosi; ; TT//TT o o CC//CC) o differenti () o differenti (eterozigosieterozigosi TT//C o C/C o C/TT) nel ) nel sito polimorficosito polimorfico

ACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACCGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGAACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGATAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATTATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTTATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGATAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACA

ACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACCGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGAACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACTATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGATAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGACGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTGACCTGACACGTGCTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTCGAGACCTTAGCTAGCTCCTCTCGAGACGTAGGGCTCTCGATATAGCTCGCGACACACACAGATATATAGCGCTCCCTGAAACAGCTCCGACACAGCTCGCACACCGCTC
1
2
Copy Number VariationCNV
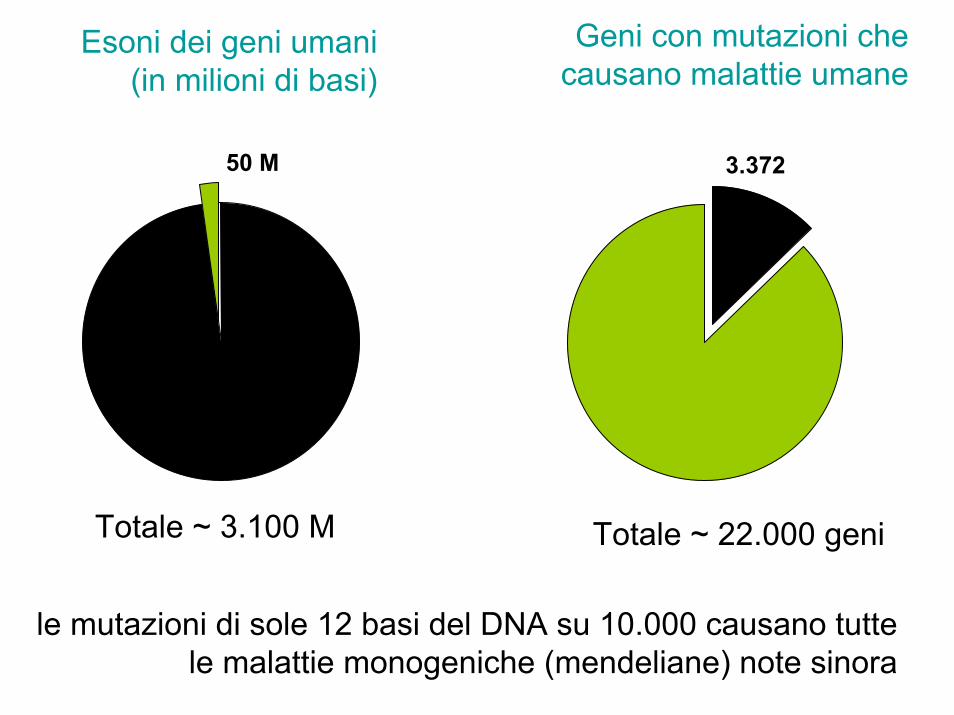
Esoni dei geni umani(in milioni di basi)
Geni con mutazioni che causano malattie umane
Totale ~ 22.000 geni
3.37250 M
Totale ~ 3.100 M
le mutazioni di sole 12 basi del DNA su 10.000 causano tutte le malattie monogeniche (mendeliane) note sinora
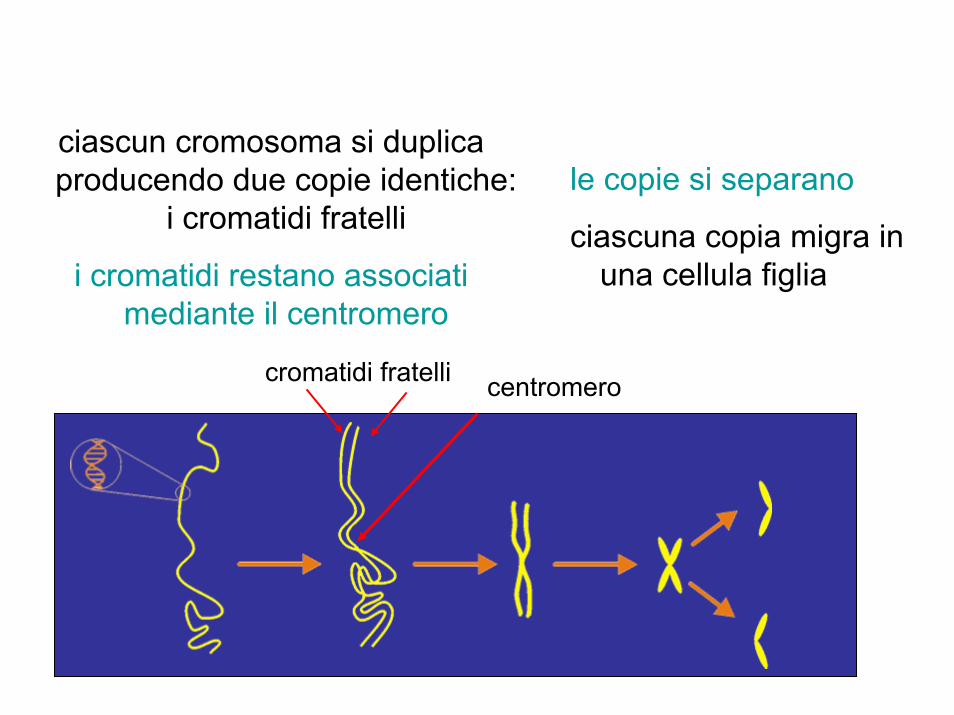
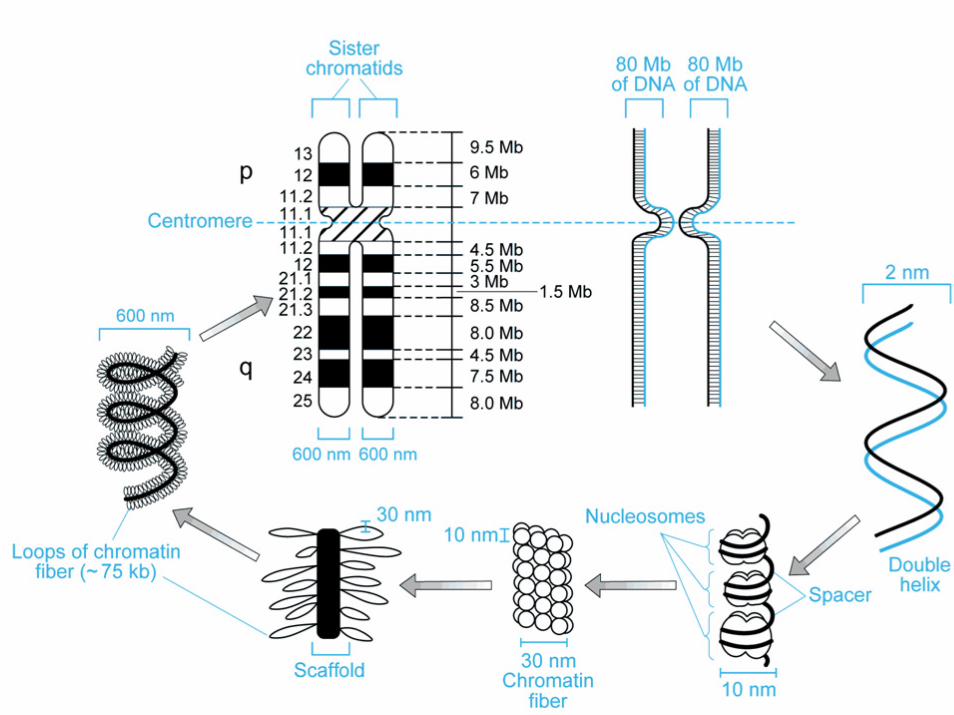
centromero
ciascun cromosoma si duplica producendo due copie identiche:
i cromatidi fratelli le copie si separano
i cromatidi restano associati mediante il centromero
ciascuna copia migra in una cellula figlia
cromatidi fratelli
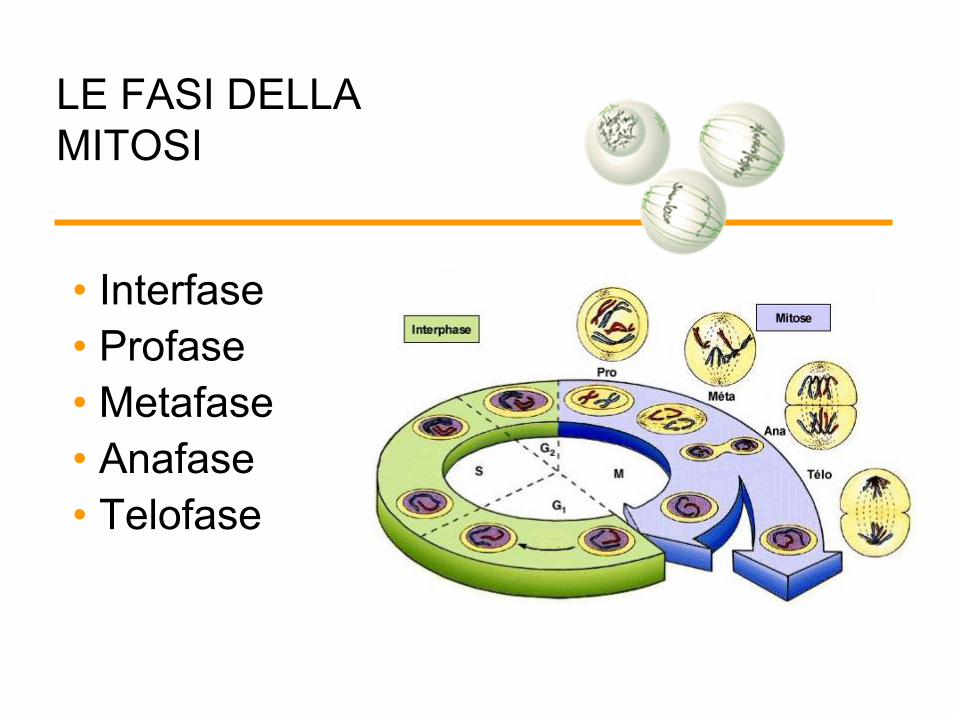
LE FASI DELLAMITOSI
• Interfase• Profase• Metafase• Anafase• Telofase
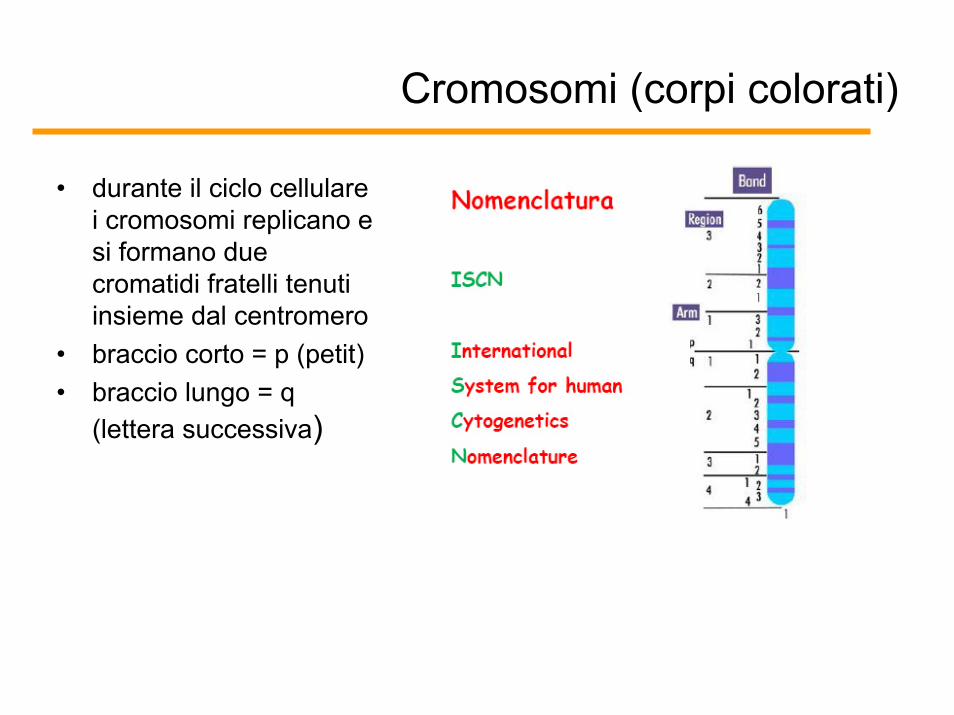
Cromosomi (corpi colorati)
• durante il ciclo cellulare i cromosomi replicano e si formano due cromatidi fratelli tenuti insieme dal centromero
• braccio corto = p (petit)• braccio lungo = q
(lettera successiva)
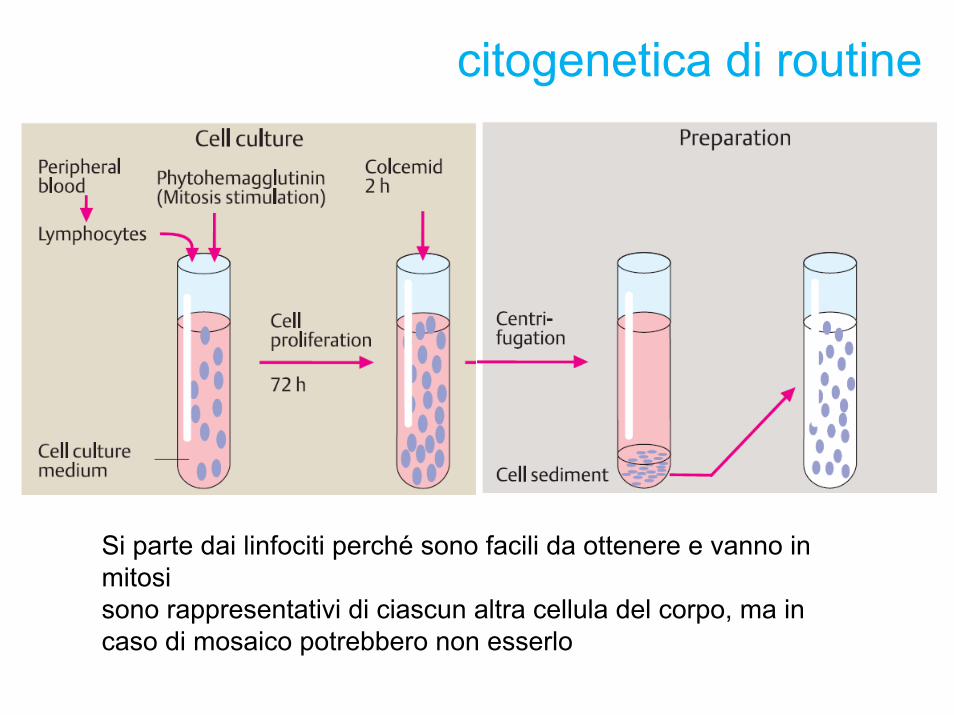
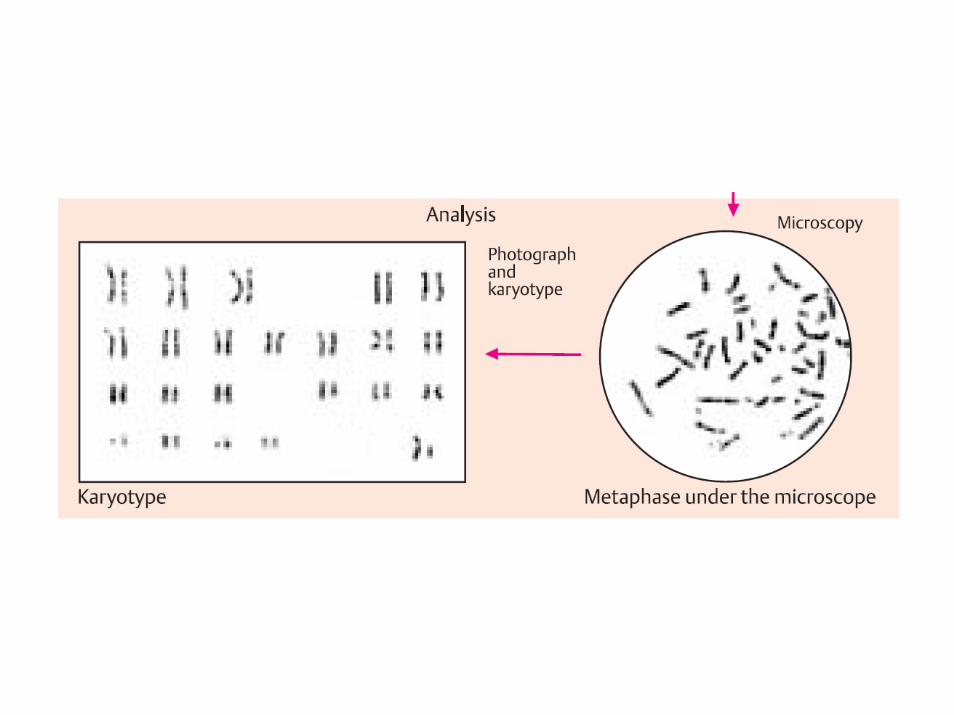
citogenetica di routine
Si parte dai linfociti perché sono facili da ottenere e vanno in mitosi sono rappresentativi di ciascun altra cellula del corpo, ma in caso di mosaico potrebbero non esserlo
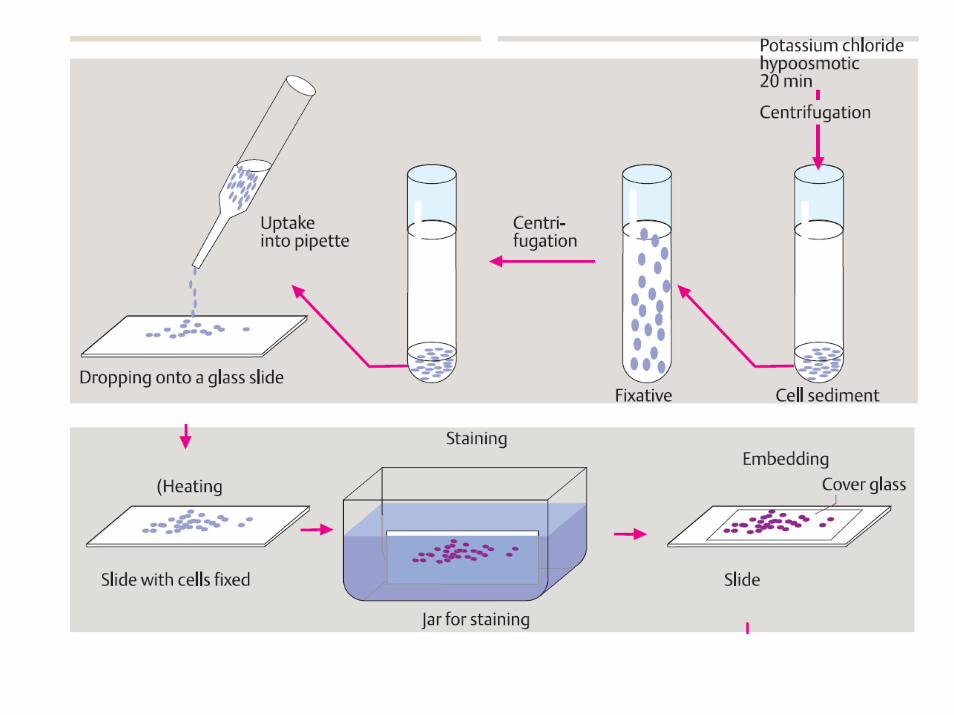

citogenetica prenatale
• da amniociti (più difficili da ottenere)
• da villi coriali (sono presenti cellule in attiva riproduzione)
• dovrebbero essere rappresentativi delle cellule del feto

Cromatina (DNA+proteine)
• Eucromatina - meno condensata contiene il DNA codificante
• Eterocromatina - più condensata non contiene DNA codificante, ma solo DNA non codificante
• Telomeri - cappucci all’estremità dei cromosomi che comprendono ripetizioni multiple della sequenza TTAGGG
• Centromeri - regioni specializzate di DNA che forniscono il sito di ancoraggio del fuso mitotico
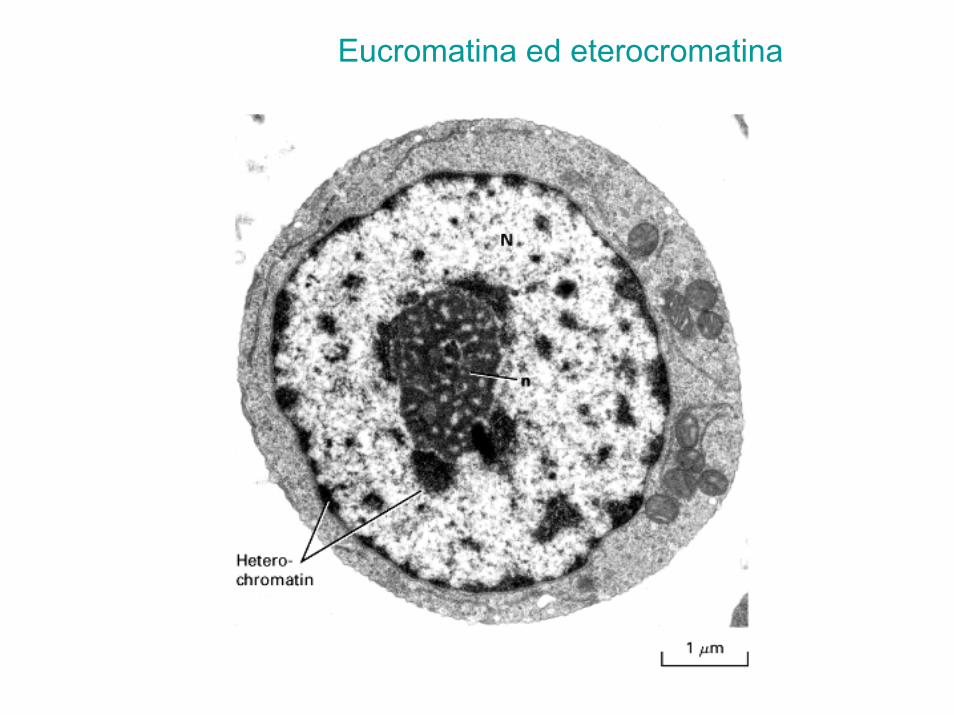
Eucromatina ed eterocromatina

Tecnica Procedura Banding pattern
bandeggio G proteolisi limitata seguita dalla colorazione Giemsa
Le bande scure sono ricche in ATLe bande chiare sono ricche in GC
bandeggio R denaturazione al calore seguita dalla colorazione con Giemsa
Le bande scure sono ricche in GCLe bande chiare sono ricche in AT
bandeggio Qdigestione enzimatica e colorazione con un colorante fluorescente, la Quinacrina
Le bande scure sono ricche in ATLe bande chiare sono ricche in GC
bandeggio Cdenaturazione con idrossido di bario e poi colorazione con Giemsa
Le bande scure sono ricche in eterocromatina costitutiva
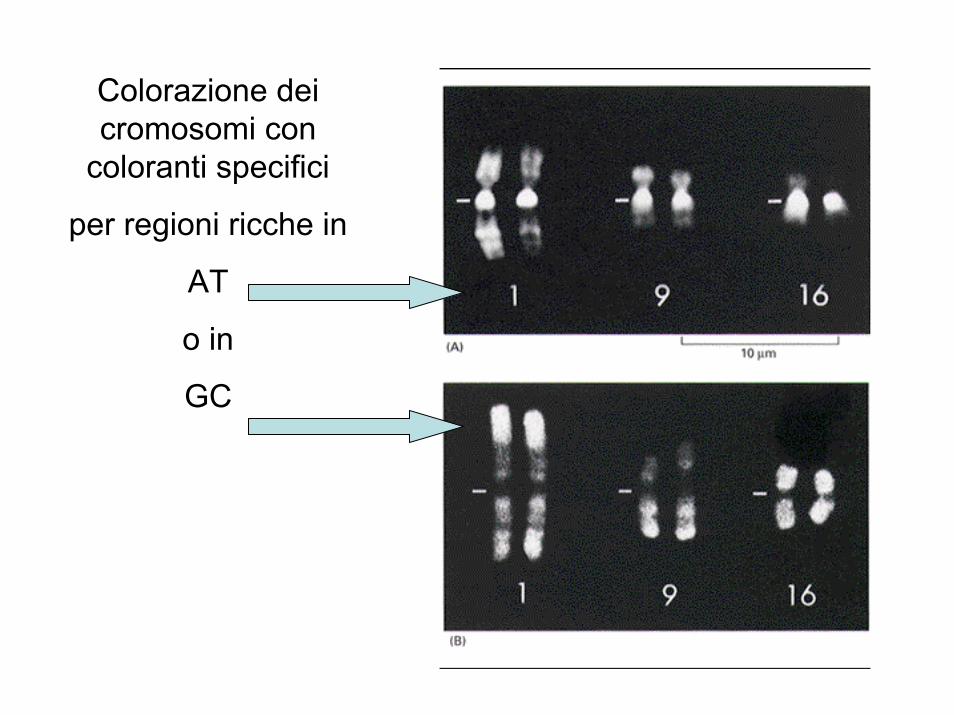
Colorazione dei cromosomi con
coloranti specifici
per regioni ricche in
AT
o in
GC
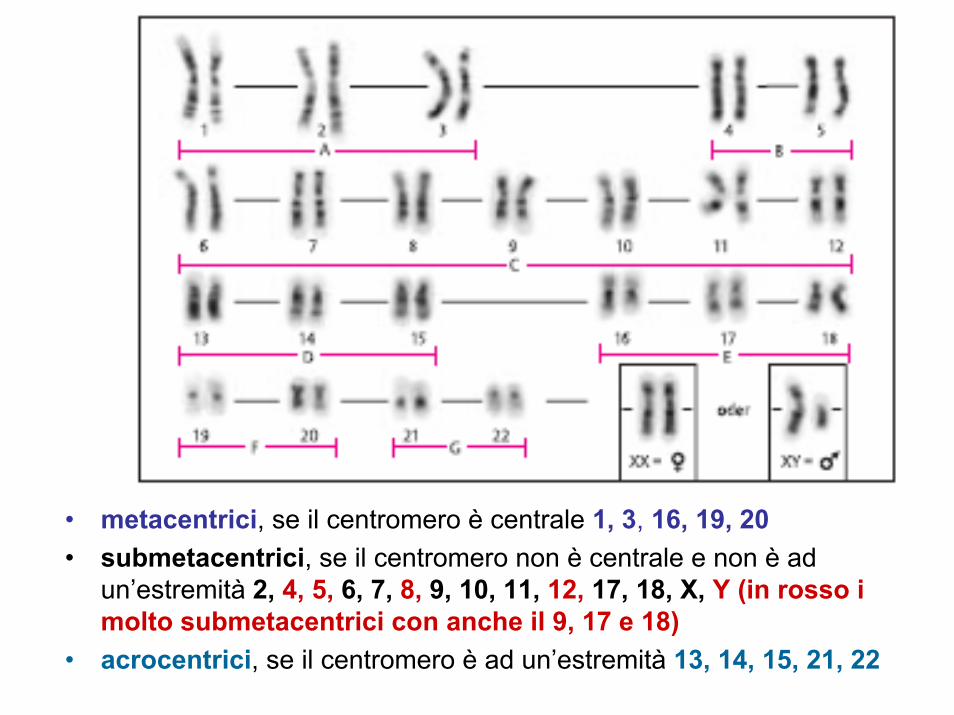
• metacentrici, se il centromero è centrale 1, 3, 16, 19, 20• submetacentrici, se il centromero non è centrale e non è ad
un’estremità 2, 4, 5, 6, 7, 8, 9, 10, 11, 12, 17, 18, X, Y (in rosso i molto submetacentrici con anche il 9, 17 e 18)
• acrocentrici, se il centromero è ad un’estremità 13, 14, 15, 21, 22
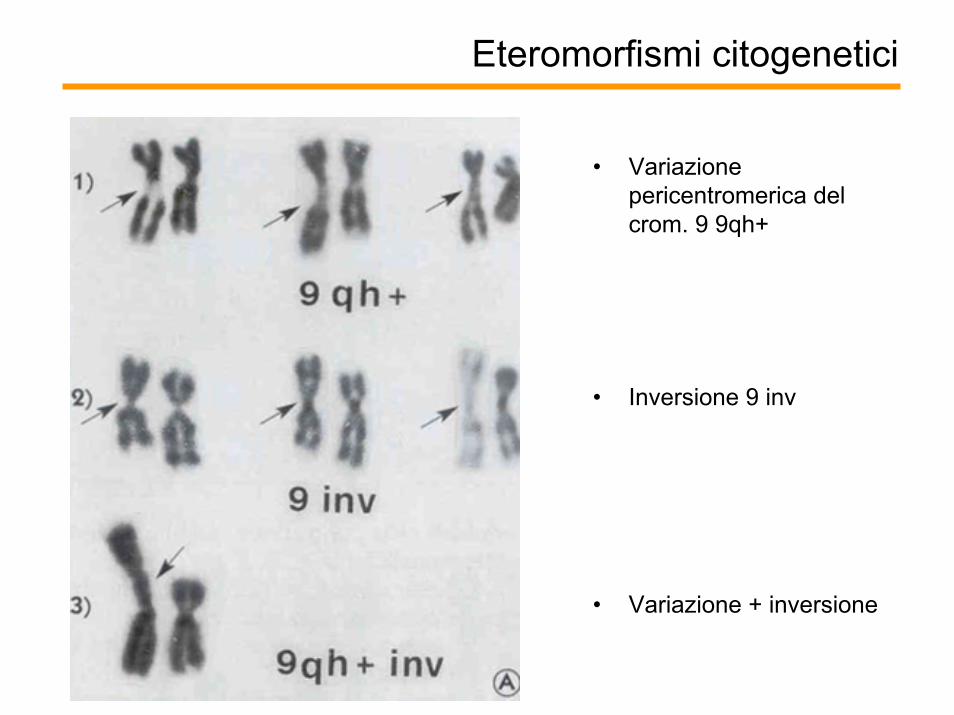
Eteromorfismi citogenetici
• Variazione pericentromerica del crom. 9 9qh+
• Inversione 9 inv
• Variazione + inversione
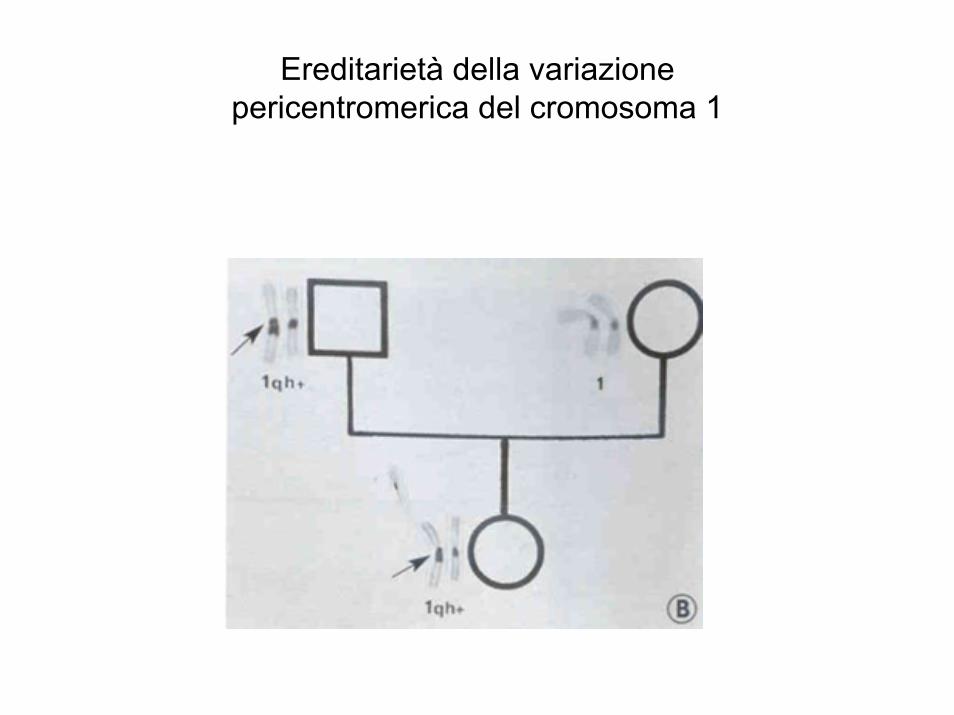
Ereditarietà della variazionepericentromerica del cromosoma 1

CCDS IDs per chromosomeChromosome Count1 2,5132 1,5483 1,2994 8985 1,0286 1,2367 1,0948 8079 92110 97111 1,50912 1,24013 38514 74915 71116 96717 1,37018 35019 1,61620 67221 28222 530X 967Y 53XY 23
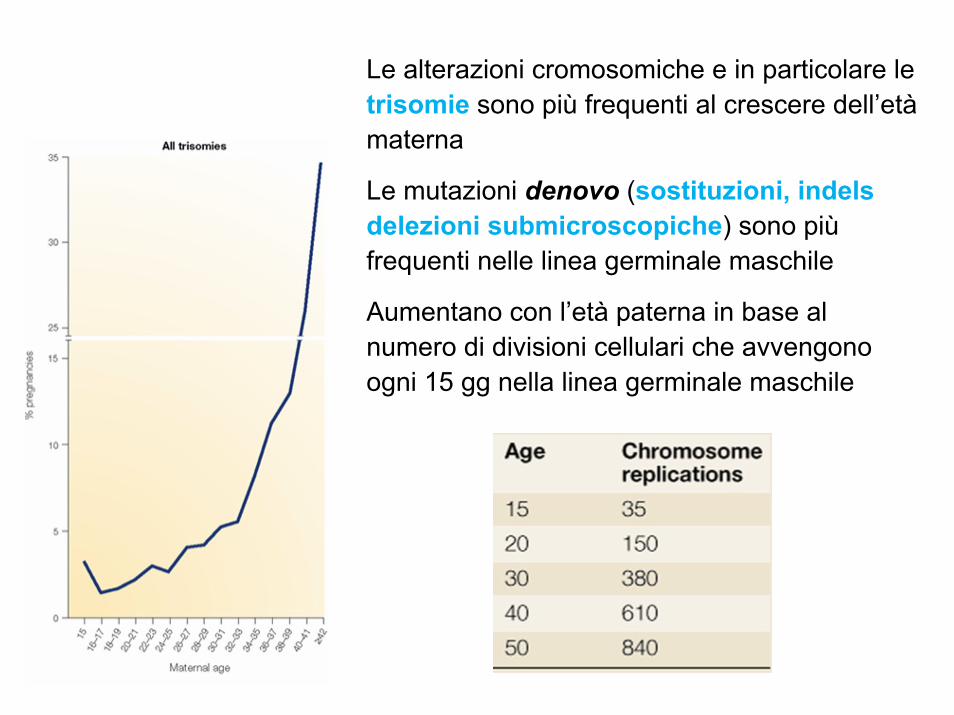
Le alterazioni cromosomiche e in particolare le trisomie sono più frequenti al crescere dell’etàmaterna
Le mutazioni denovo (sostituzioni, indels delezioni submicroscopiche) sono piùfrequenti nelle linea germinale maschile
Aumentano con l’età paterna in base al numero di divisioni cellulari che avvengono ogni 15 gg nella linea germinale maschile
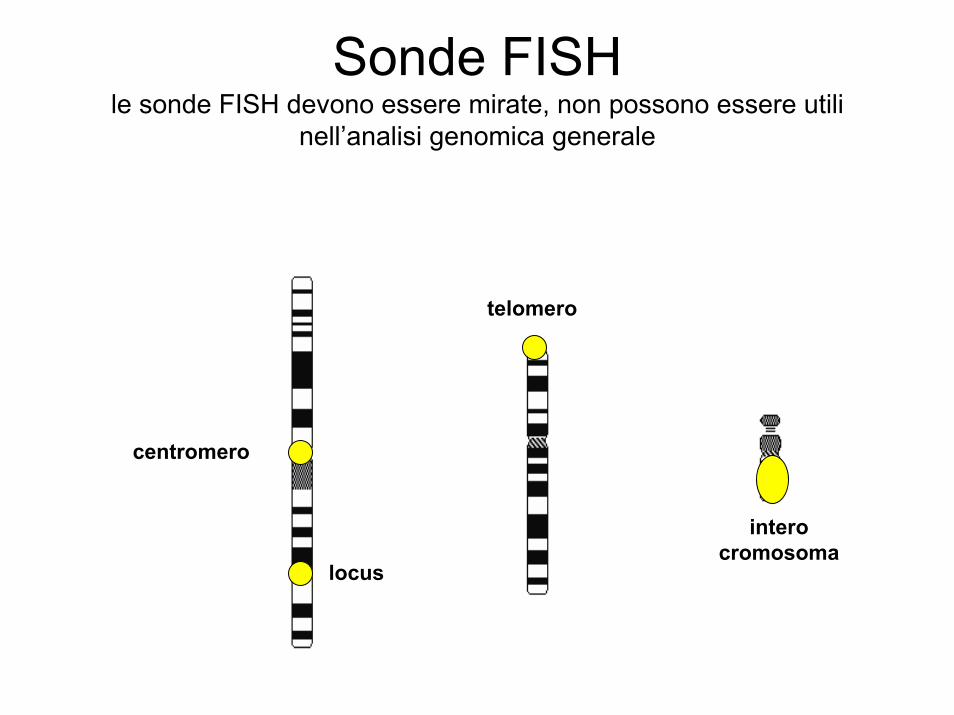
Sonde FISHle sonde FISH devono essere mirate, non possono essere utili
nell’analisi genomica generale
centromero
telomero
intero cromosoma
locus
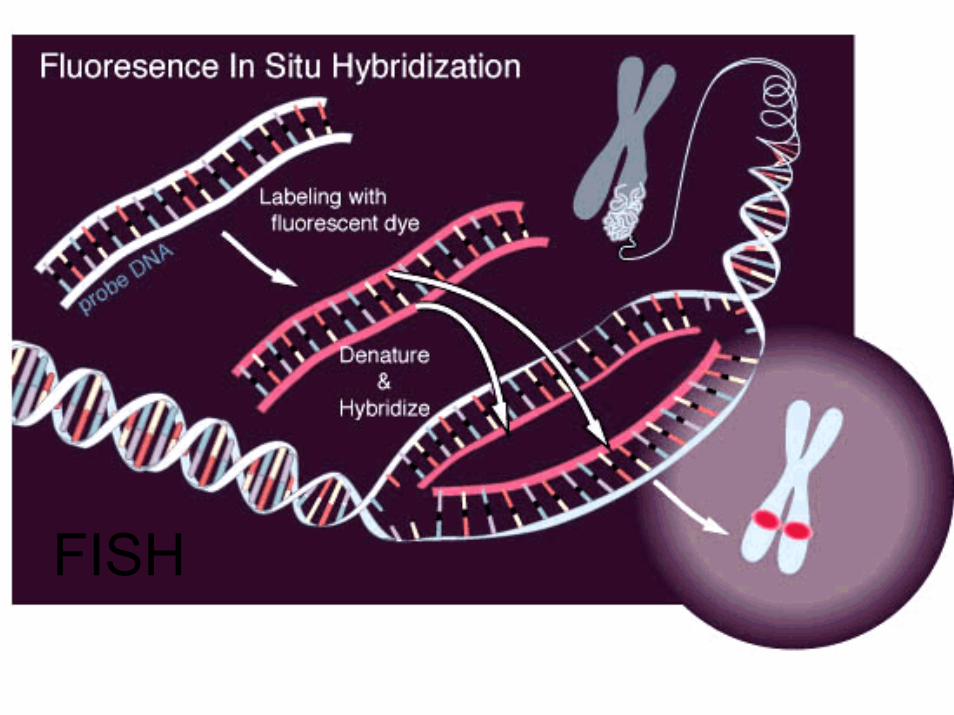
FISH
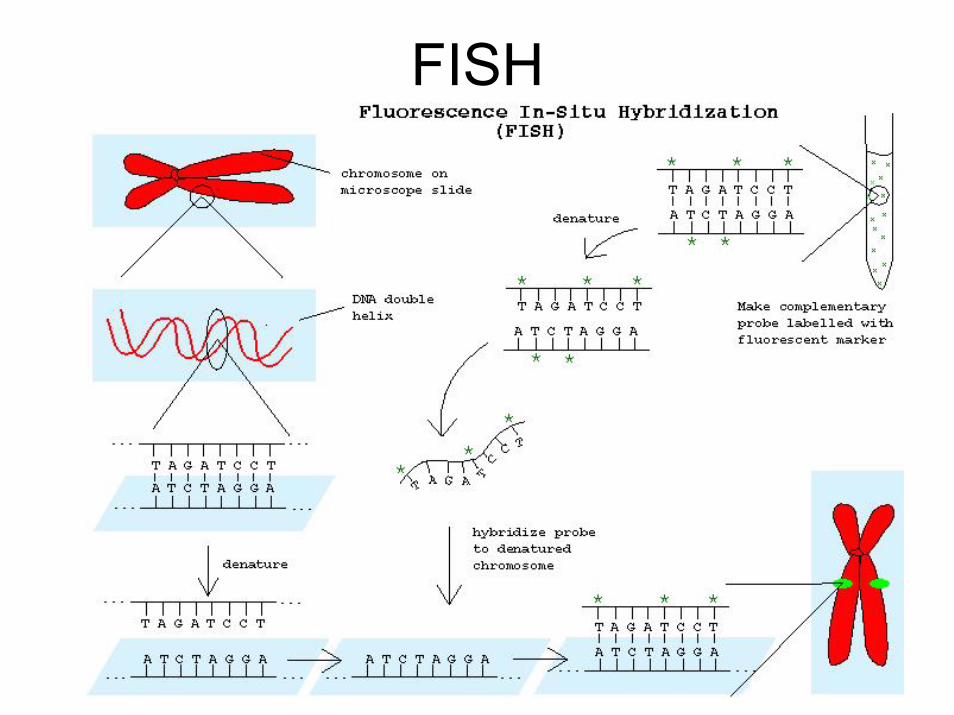
FISH
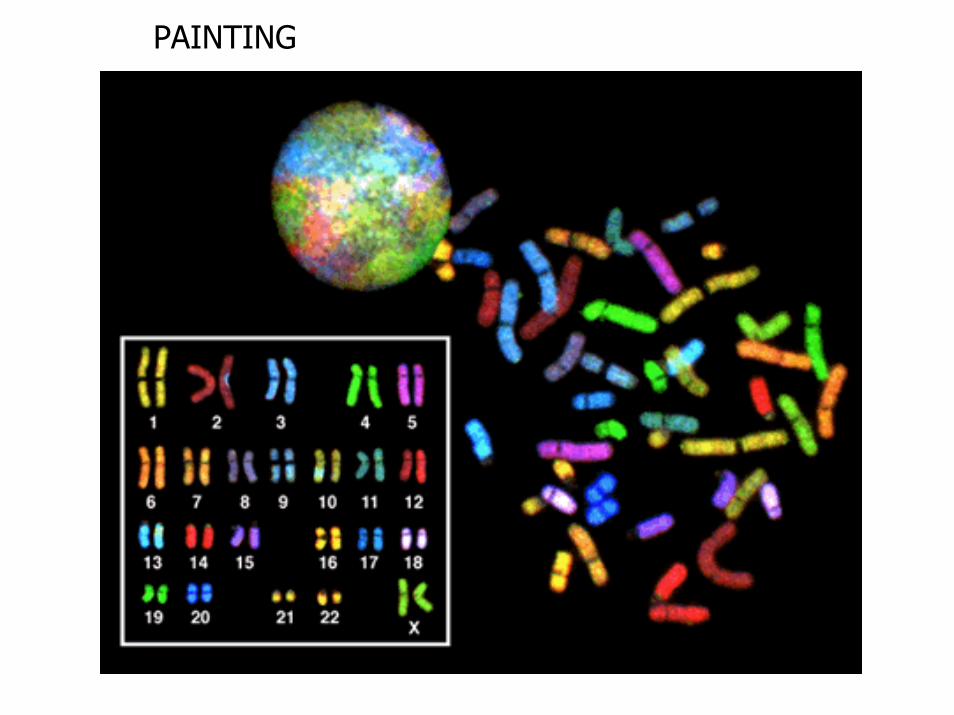
PAINTING
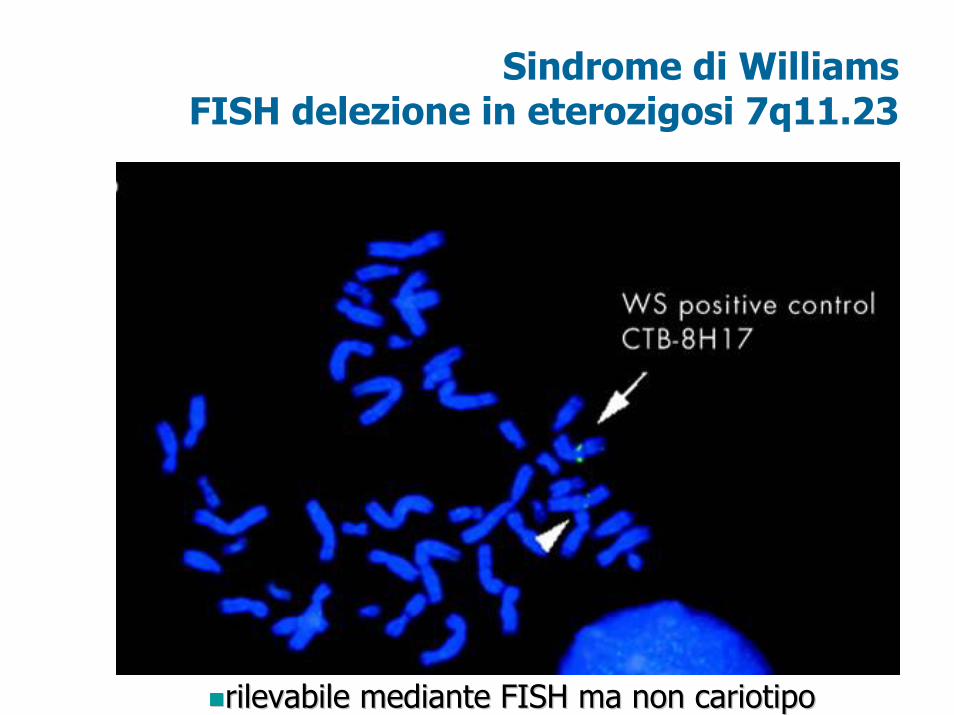
Sindrome di WilliamsFISH delezione in eterozigosi 7q11.23
rilevabile mediante FISH ma non cariotiporilevabile mediante FISH ma non cariotipo
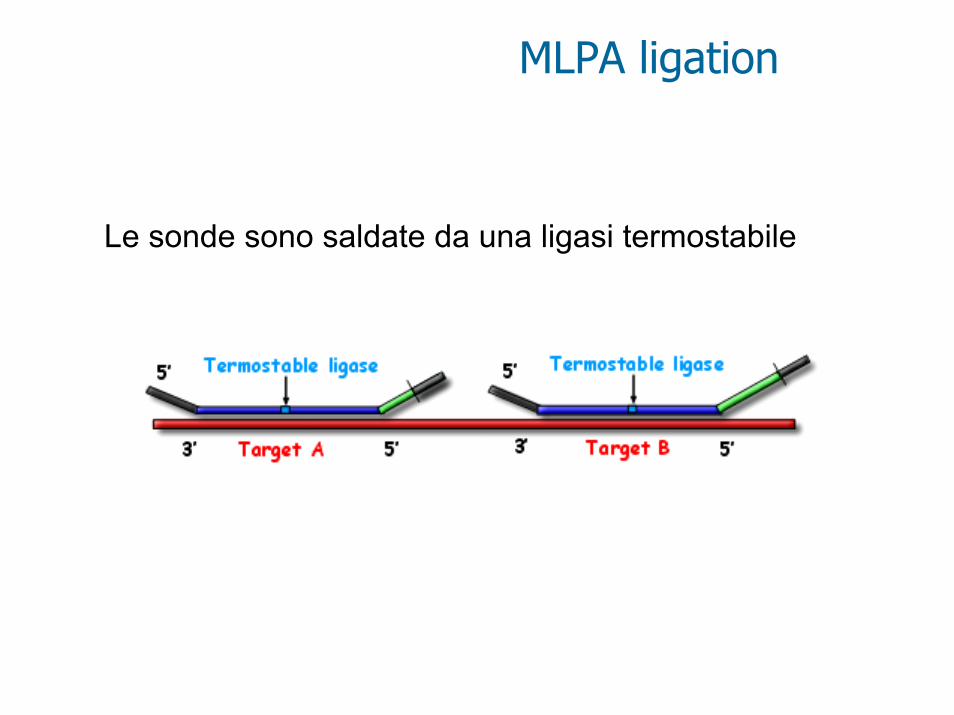
MLPA ligation
Le sonde sono saldate da una ligasi termostabile

PCR
una coppia universale di primers è utilizzata per amplificare tutte le sonde saldate. Il prodotto ha una lunghezza unica che dipende dalla regione stuffer (verde)
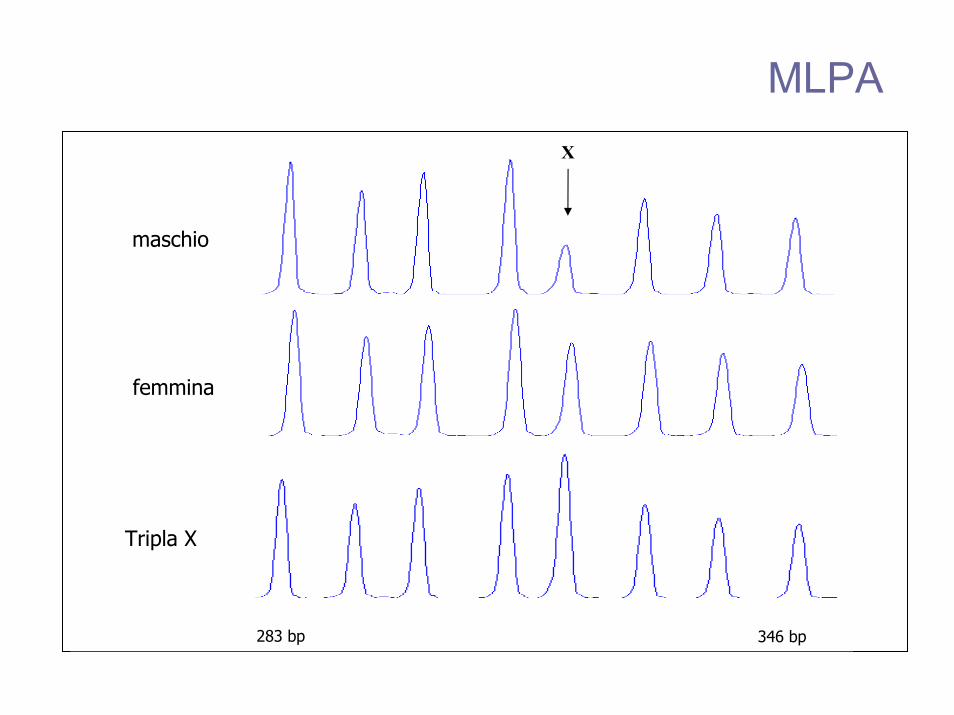
Tripla X
femmina
maschio
283 bp 346 bp
MLPAX
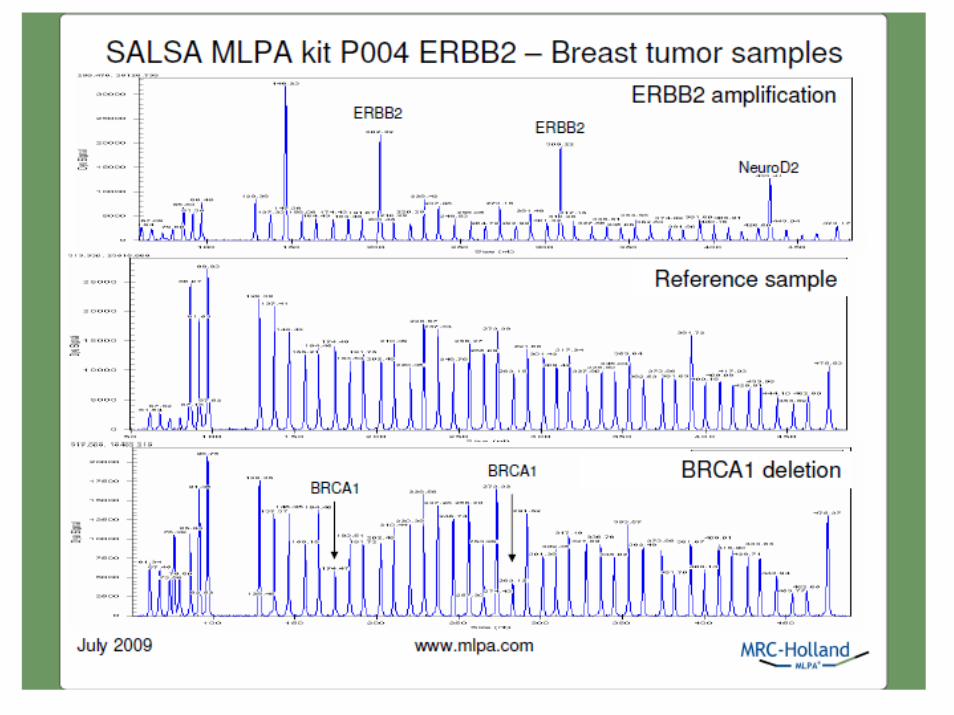

• Rileva il numero di copie contemporaneamente su 40-50 loci
• Richiede solo 20ng di DNA umano (circa 3.000 cellule/0.5ml di liquido amniotico)
• Discrimina differenze anche di un singolo nucleotide• Richiede un termociclatore ed un sequenziatore• Il protocollo è identico per differenti applicazioni• I risultati si hanno max dopo 24 ore• Tutti i reagenti sono liquidi e questo semplifica i controlli
di qualità• I costi totali sono < 25€/reazione tutto incluso certificato
CE ed ISO 13485
vantaggi MLPA

• Non può essere usato su campioni preamplificati mediante WGA
• Sono necessarie circa 3.000 cellule/0,5ml di liquido amniotico e quindi non può essere usato su singole cellule
• Non identifica le traslocazioni bilanciate• Non identifica la triplodia femminile• Non si può usare sulla quantizzazione dell’RNA• Non identifica i mosaici con certezza
limiti dell’MLPA
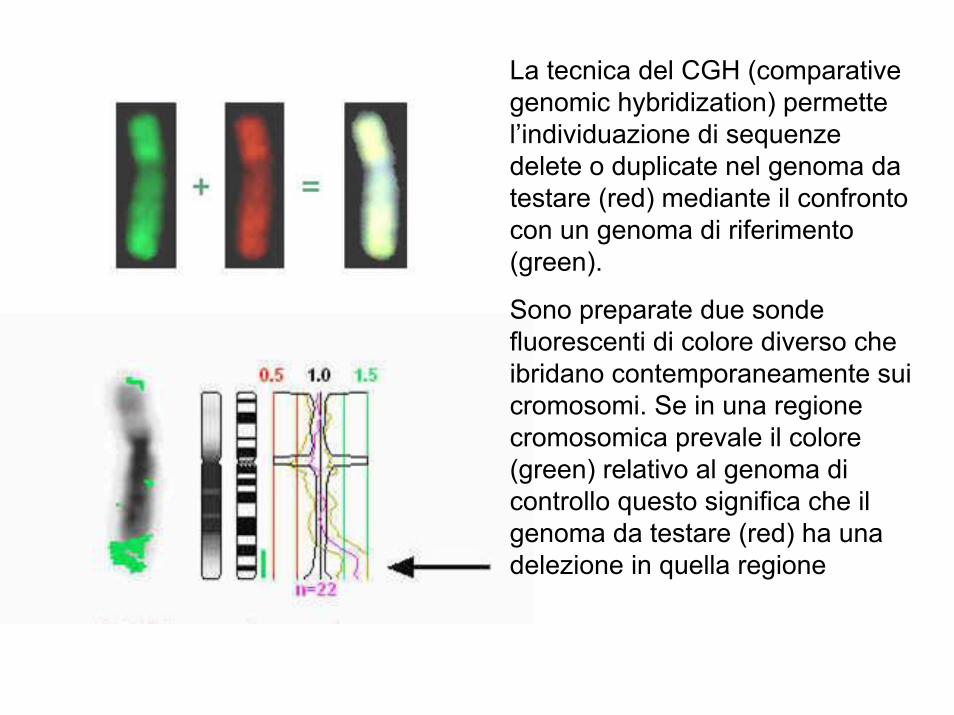
La tecnica del CGH (comparative genomic hybridization) permette l’individuazione di sequenze delete o duplicate nel genoma da testare (red) mediante il confronto con un genoma di riferimento (green).
Sono preparate due sonde fluorescenti di colore diverso che ibridano contemporaneamente sui cromosomi. Se in una regione cromosomica prevale il colore (green) relativo al genoma di controllo questo significa che il genoma da testare (red) ha una delezione in quella regione
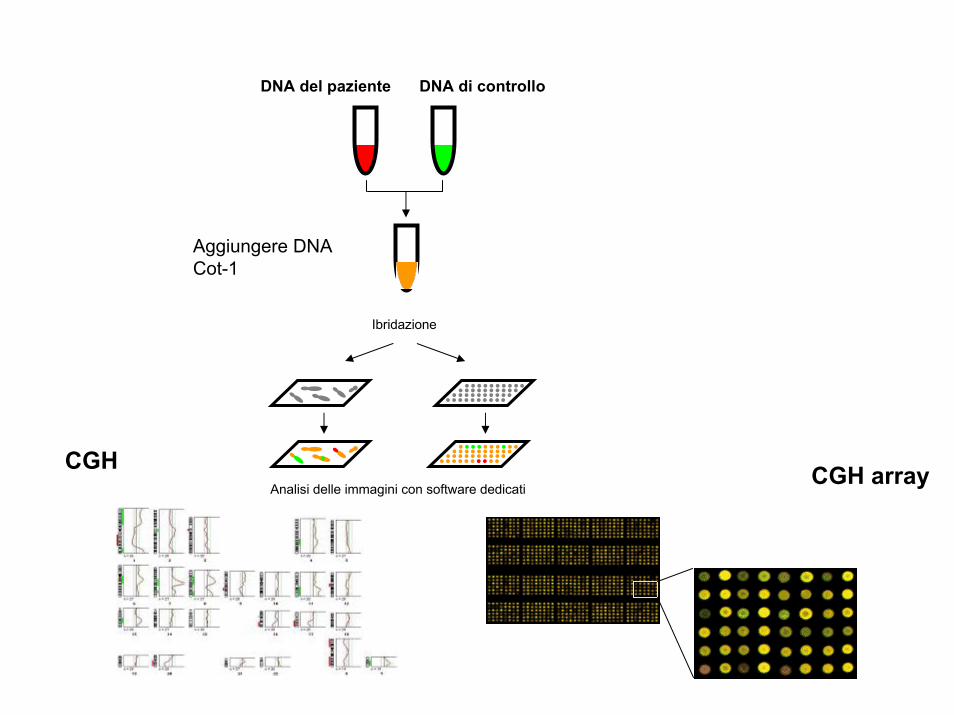
CGH
DNA del paziente DNA di controllo
Aggiungere DNA Cot-1
Ibridazione
Analisi delle immagini con software dedicatiCGH array
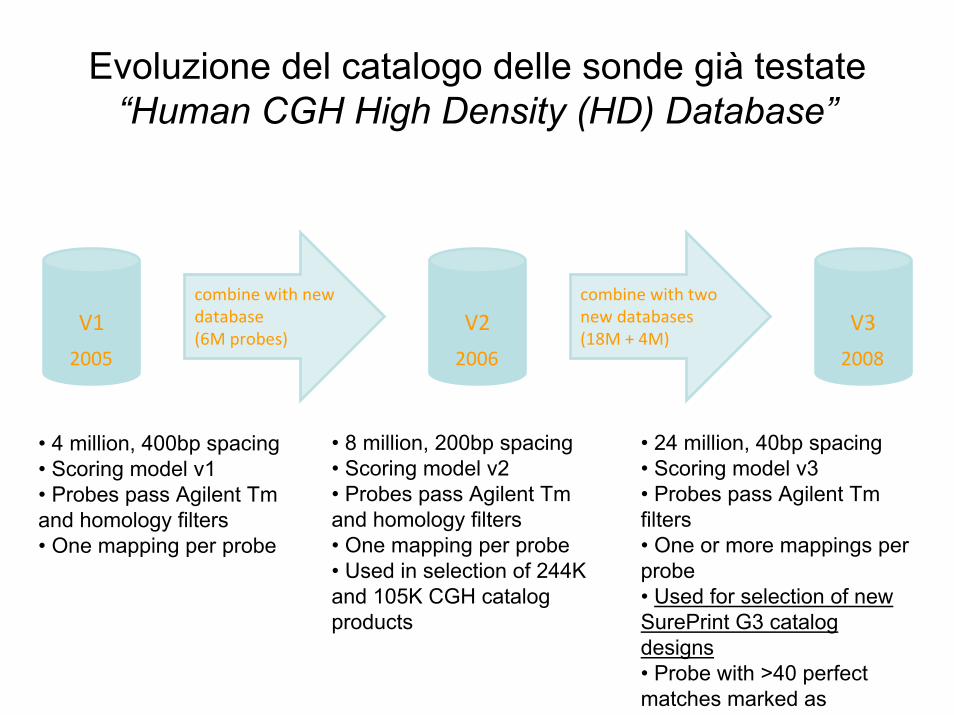
combine with new database (6M probes)
V1
2005
combine with two new databases (18M + 4M)
V2
2006
V3
2008
• 4 million, 400bp spacing • Scoring model v1• Probes pass Agilent Tm and homology filters• One mapping per probe
• 8 million, 200bp spacing• Scoring model v2• Probes pass Agilent Tm and homology filters• One mapping per probe• Used in selection of 244K and 105K CGH catalog products
• 24 million, 40bp spacing• Scoring model v3• Probes pass Agilent Tm filters• One or more mappings per probe• Used for selection of new SurePrint G3 catalog designs• Probe with >40 perfect matches marked as
d
Evoluzione del catalogo delle sonde già testate “Human CGH High Density (HD) Database”

Agilent Manufacturing Facility
- Industrial manufacturing –Class 10,000 clean-room
- Ability to easily scale production capacity
- FAB wired directly into “e-array” allowing direct customer access to fully customizable microarrays
- High-performance Ink Jet Printing Enables High Levels of Spatial Multiplexing and Flexible Designs
Advances to printing technology continue to occur against which Agilent can capitalize upon without having to make significant investments.
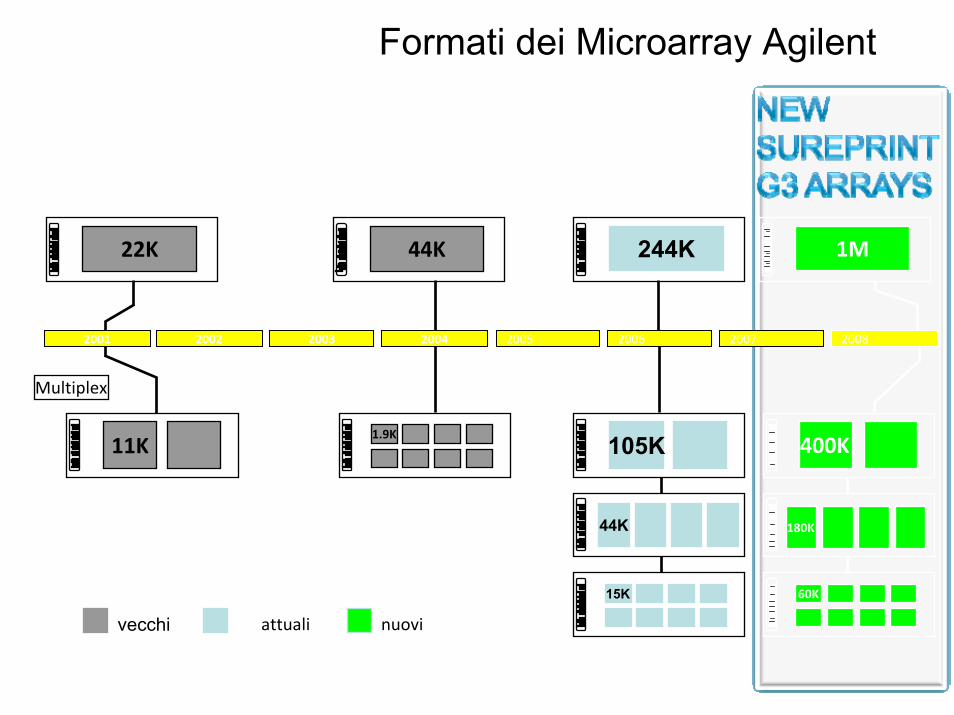
1M
400K
180K
60K
nuovi
Formati dei Microarray Agilent
2005 2006 2007 20082001 2002 2003 2004
244K
44K
105K
15K
attuali
22K 44K
1.9K11K
Multiplex
vecchi
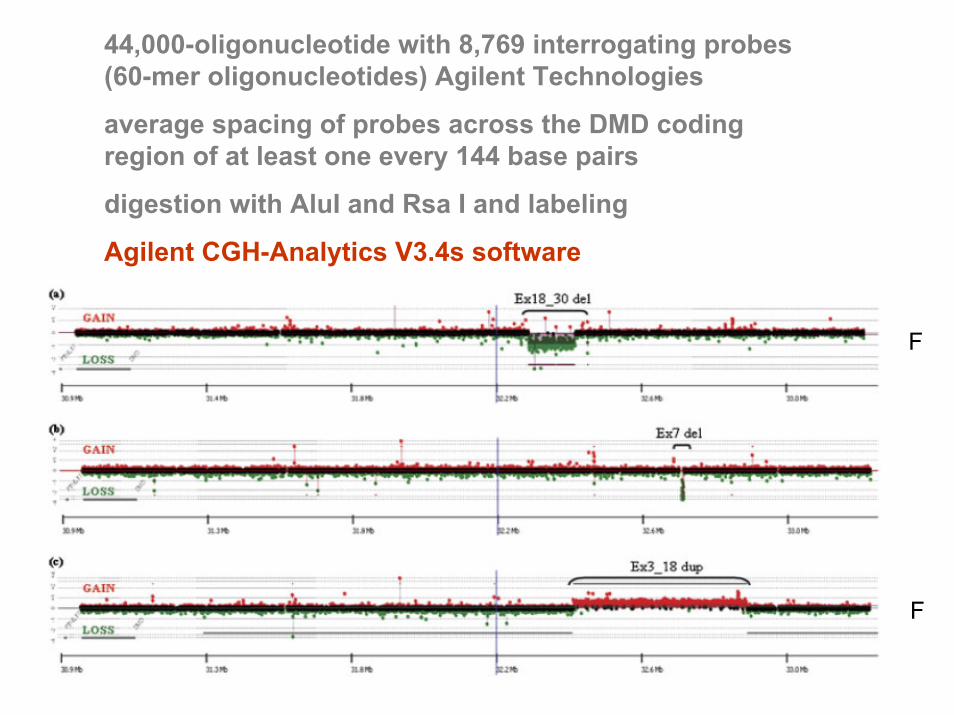
44,000-oligonucleotide with 8,769 interrogating probes (60-mer oligonucleotides) Agilent Technologies
average spacing of probes across the DMD coding region of at least one every 144 base pairs
digestion with AluI and Rsa I and labeling
Agilent CGH-Analytics V3.4s software
F
F
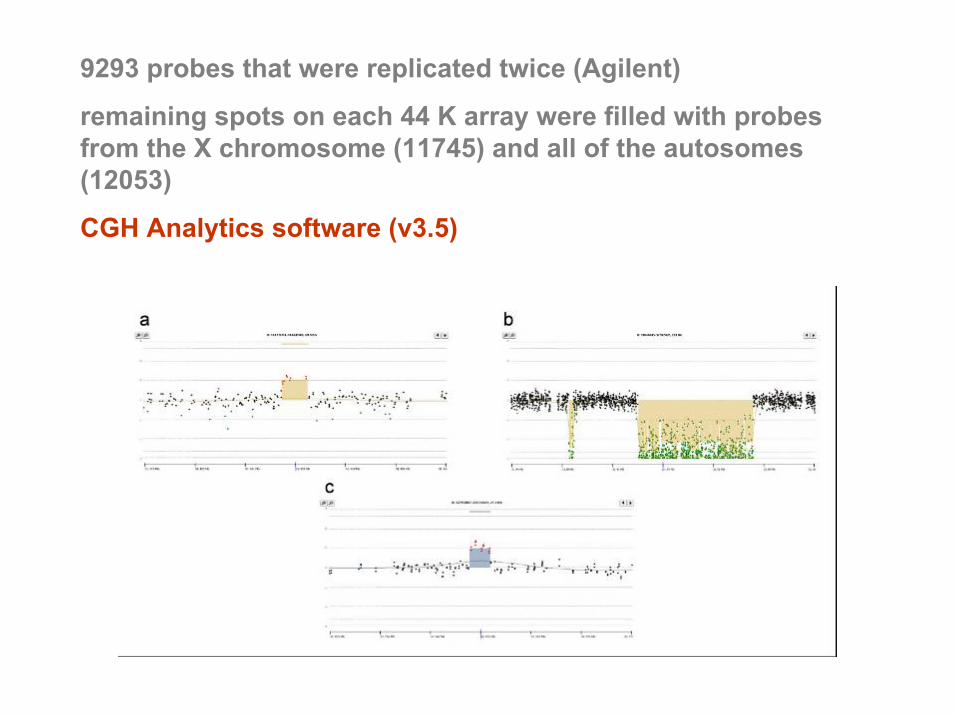
9293 probes that were replicated twice (Agilent)
remaining spots on each 44 K array were filled with probes from the X chromosome (11745) and all of the autosomes (12053)
CGH Analytics software (v3.5)