Embed Size (px)
Citation preview
Word2vec for windows 10 64bit
Install python
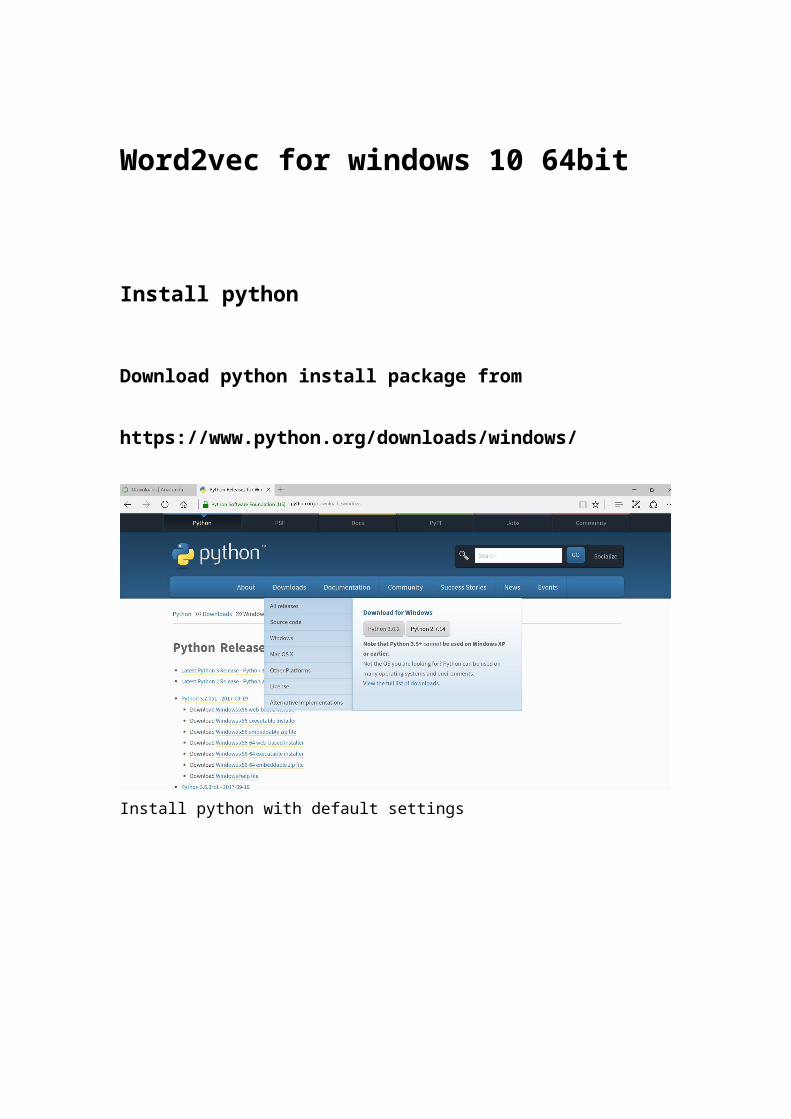
Download python install package from
https://www.python.org/downloads/windows/
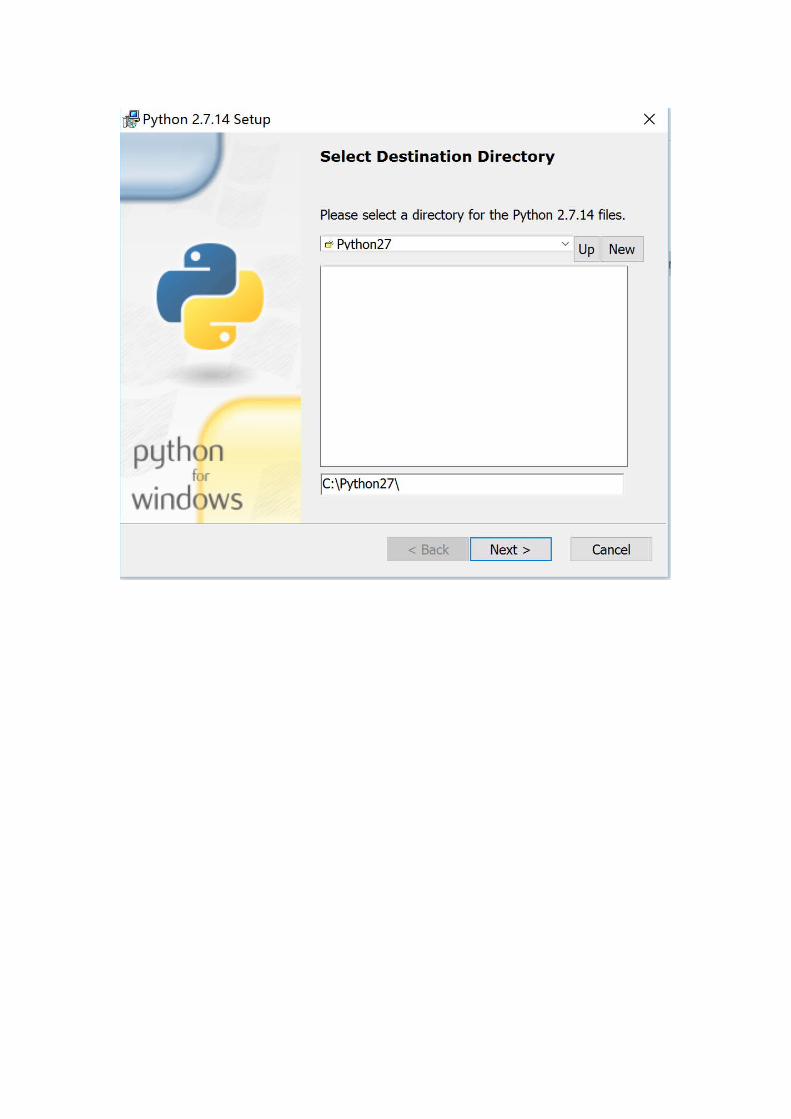
Install python with default settings
Modify environment
此电脑-属性-高级系统设置-环境变量Choose Path and add a new item ‘C:\python27’
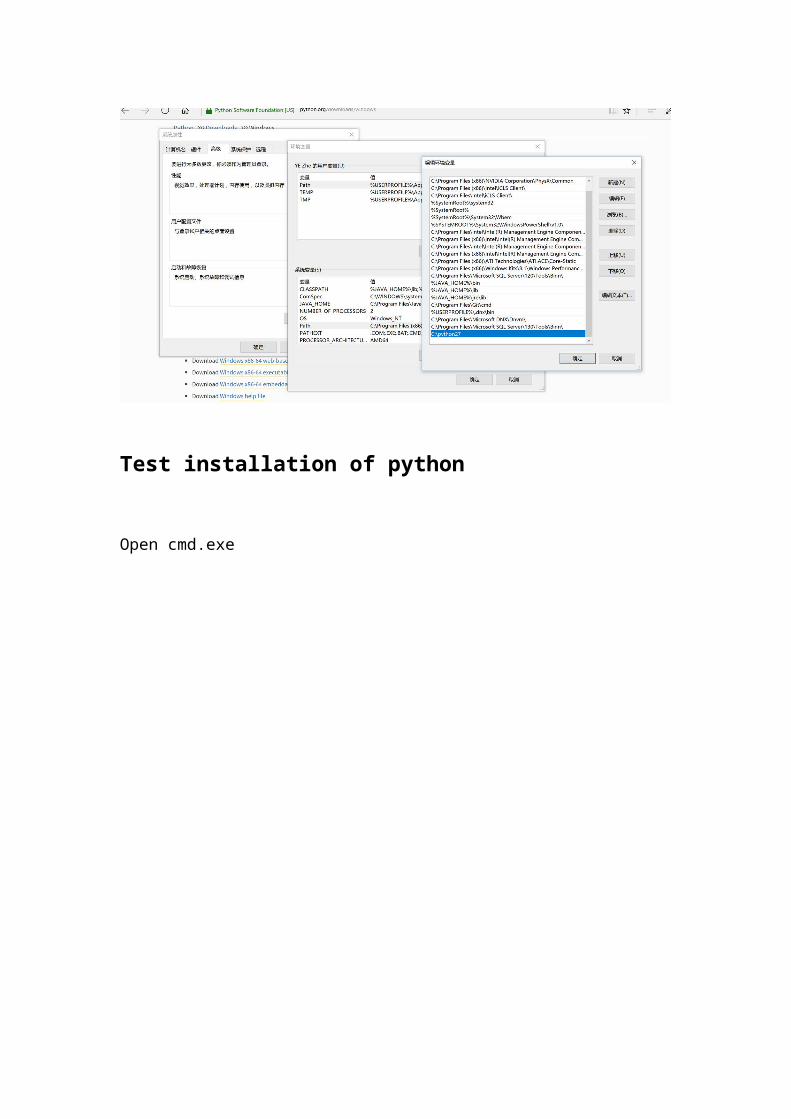
Test installation of python
Open cmd.exe
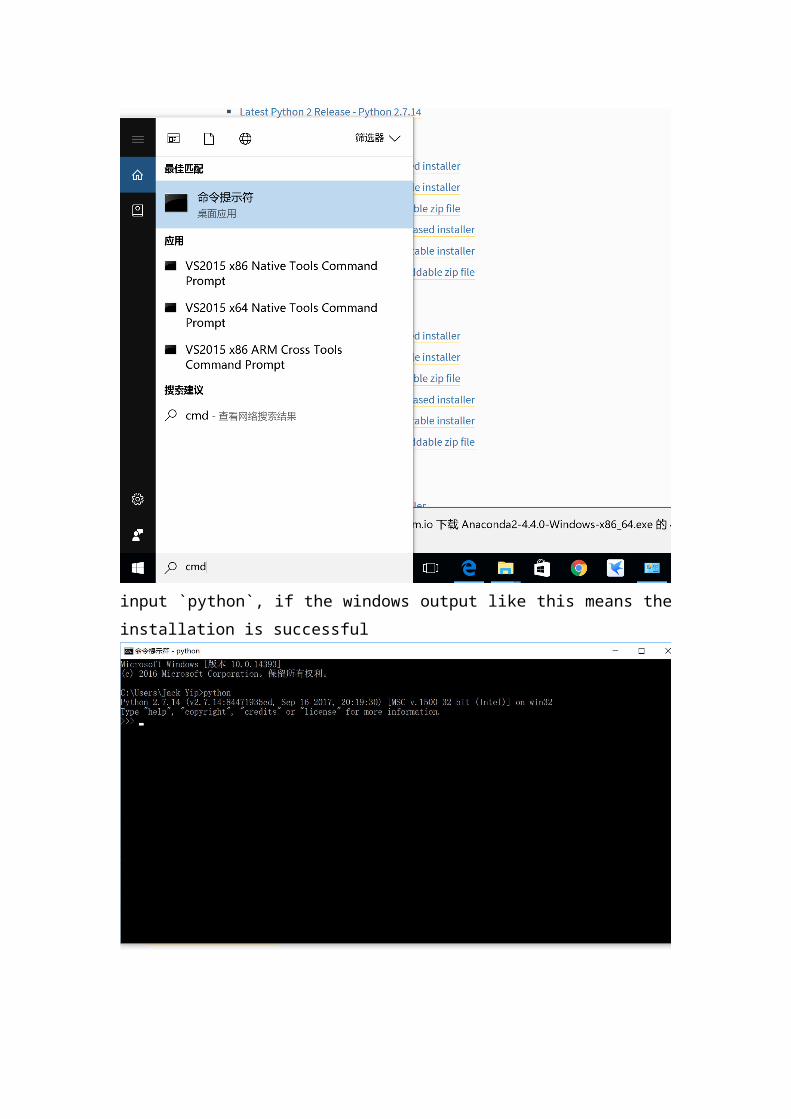
input `python`, if the windows output like this means the installation is successful
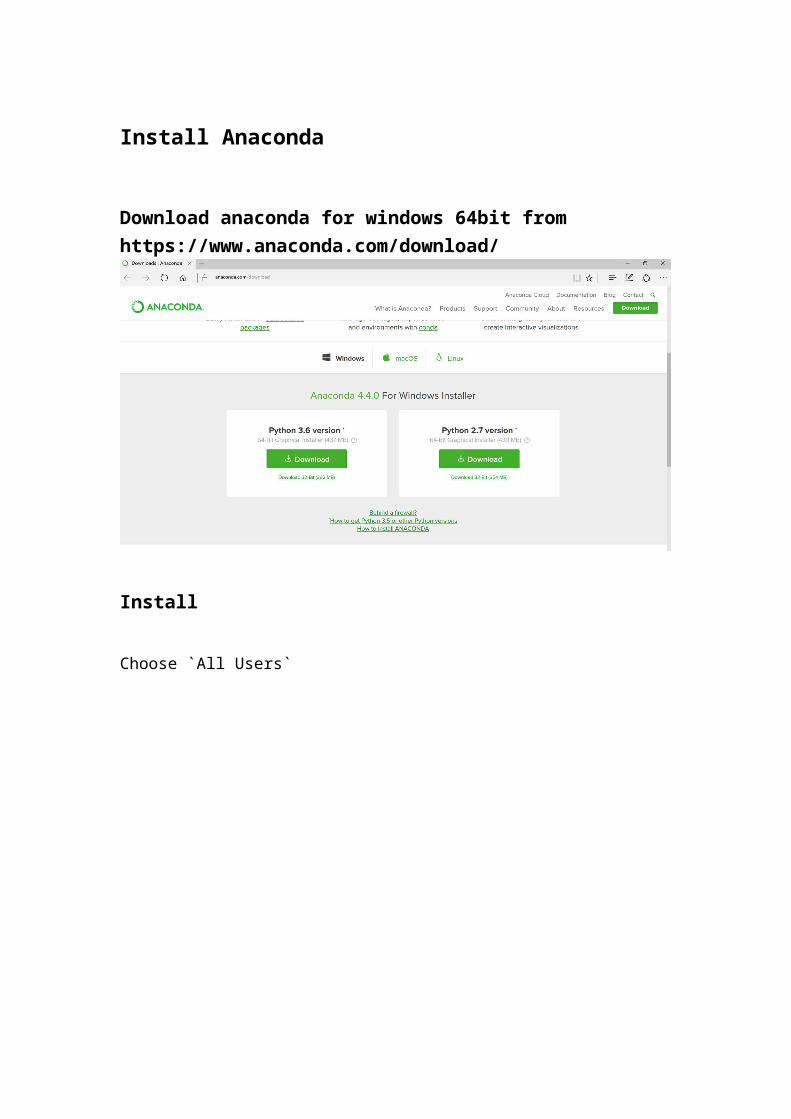
Install Anaconda
Download anaconda for windows 64bit from https://www.anaconda.com/download/
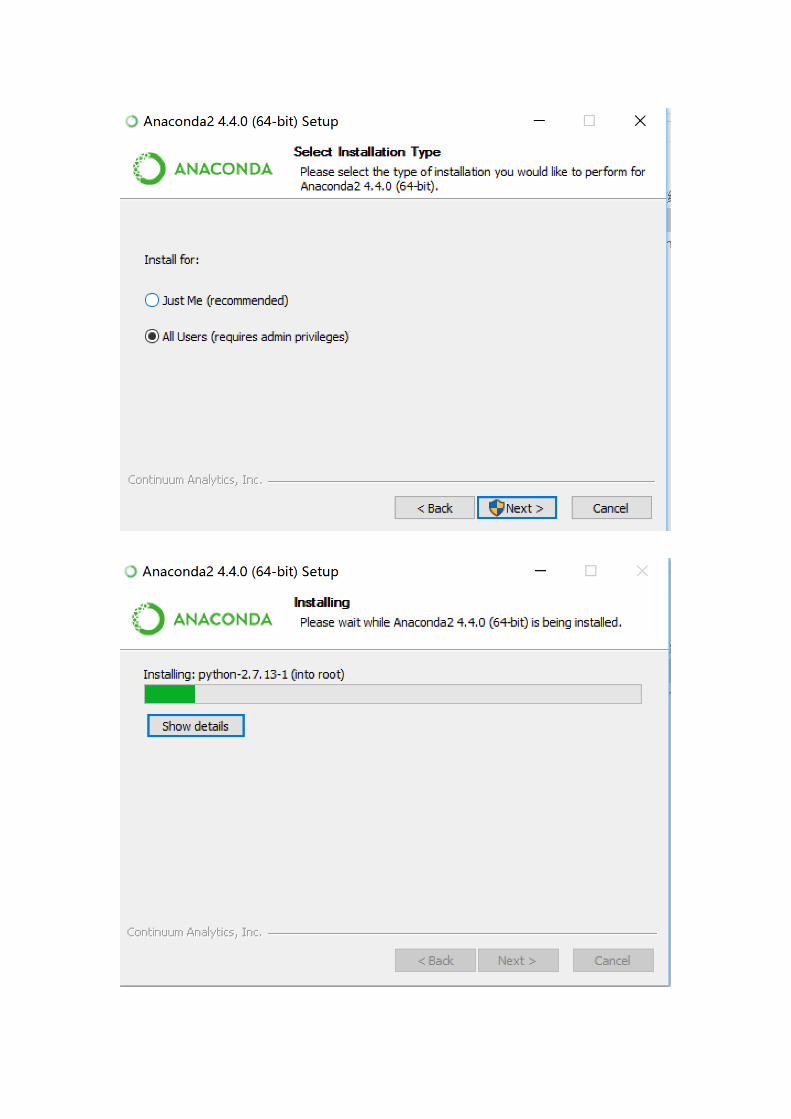
Install
Choose `All Users`
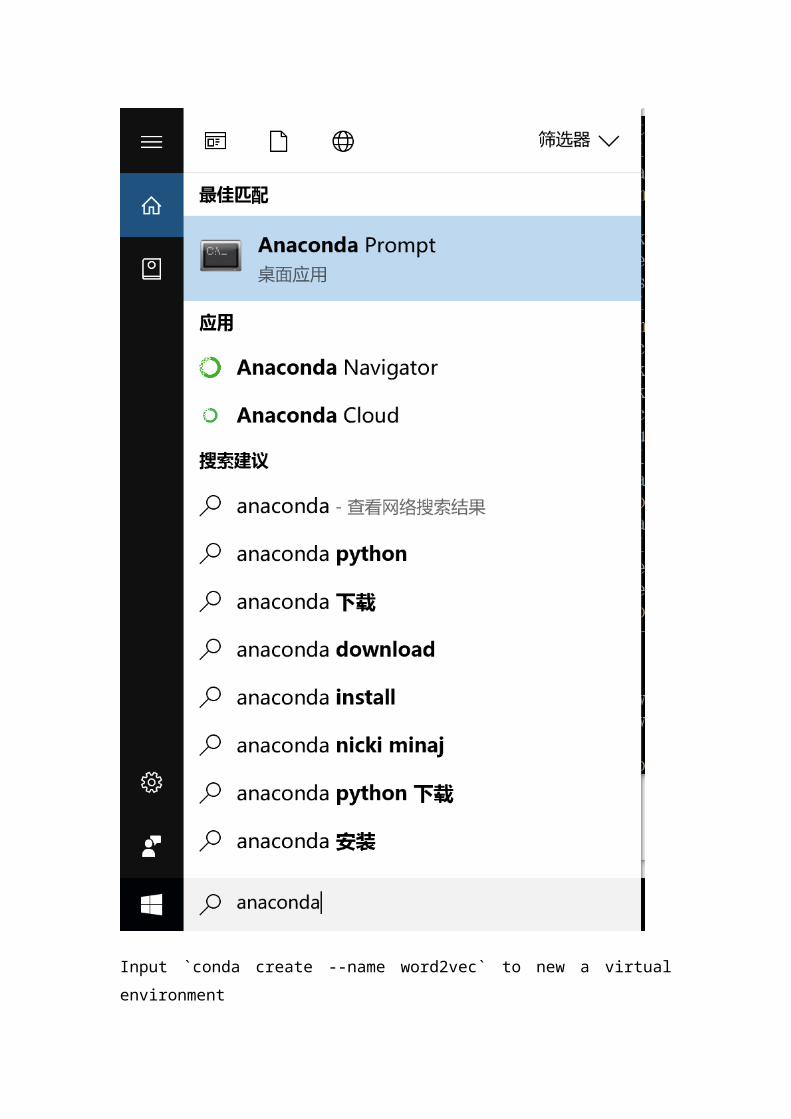
New a virtual environment
Open anaconda prompt

Input `conda create --name word2vec` to new a virtual environment
Change the current environment to the virtual
environment
Input `activate word2vec`

Install genism
Input `conda install gensim`
Training word vectors
Save the code as train.pyPS: Change the corpus directory path 1-billion-word-language-modeling-benchmark-r13output/toy
contains several tokenized txt filesclass gensim.models.word2vec.Word2Vec(sentences=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=<built-in function hash>, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False)
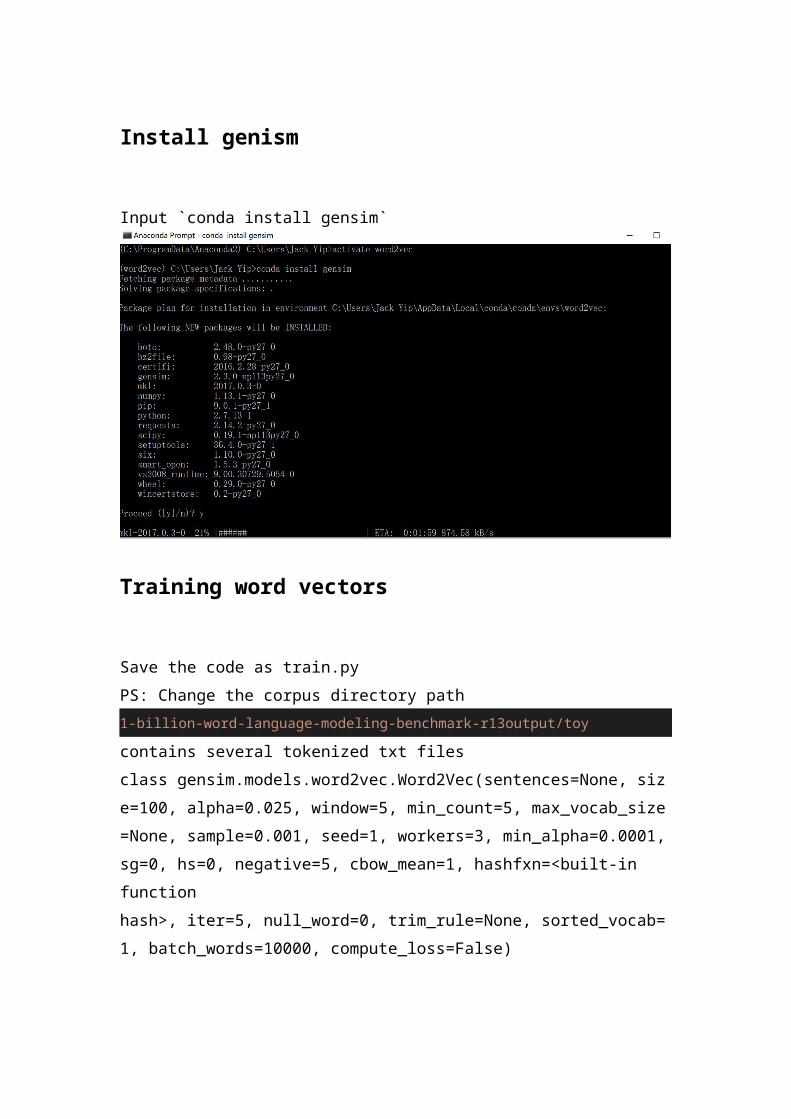
input `python train.py` and the program will save the word vectors as `wv.txt`
Check the word vectors
Input `python` and enter the interactive mode of pythonInput following code to load the word vectors in the `wv.txt`import genismmodel=genism.models.Word2Vec(‘wv.txt’)
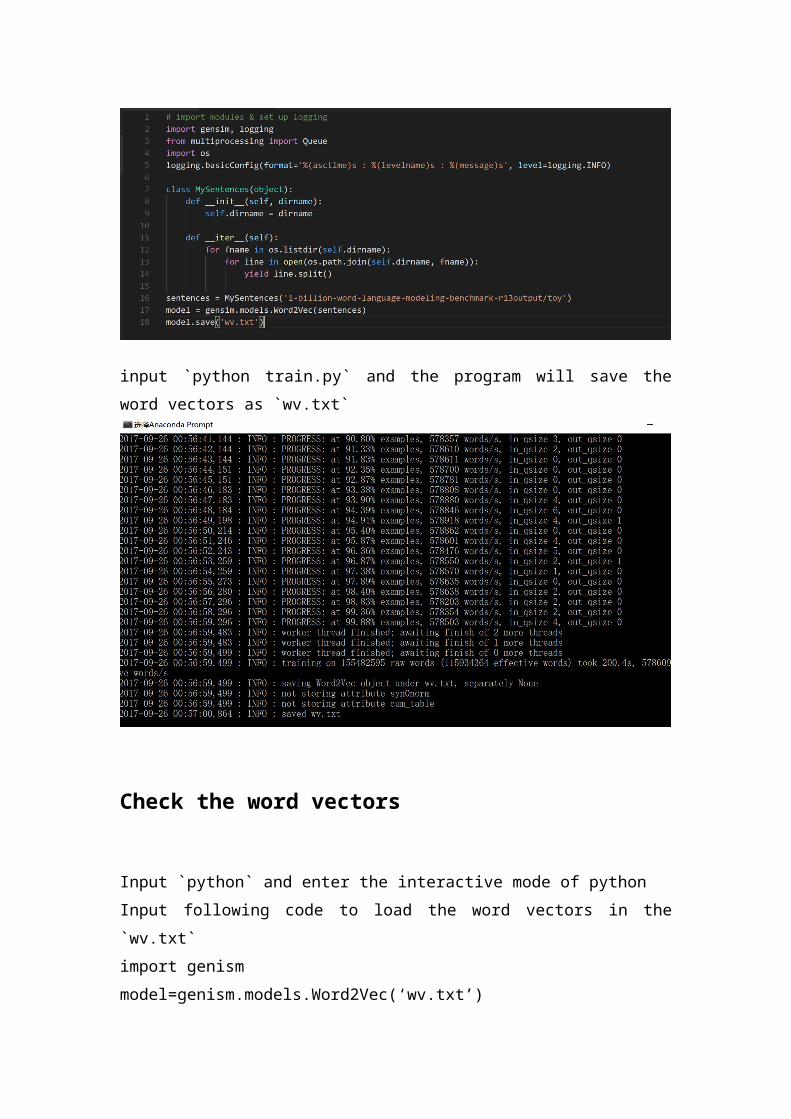
input `model.most_similar(positive=[‘good’],topn=10)` to output the 10 most similar words of `good` in the word vector space.
input model.wv[‘good’] to retrieve the vector of `good`
Analogy
v(king)-v(man)=v(queen)-v(woman)
input model.most_similar(positive=['king','woman'],negative=['man'])
More information
https://radimrehurek.com/gensim/models/word2vec.html
Word2vec for Ubuntu 16.04 64bit
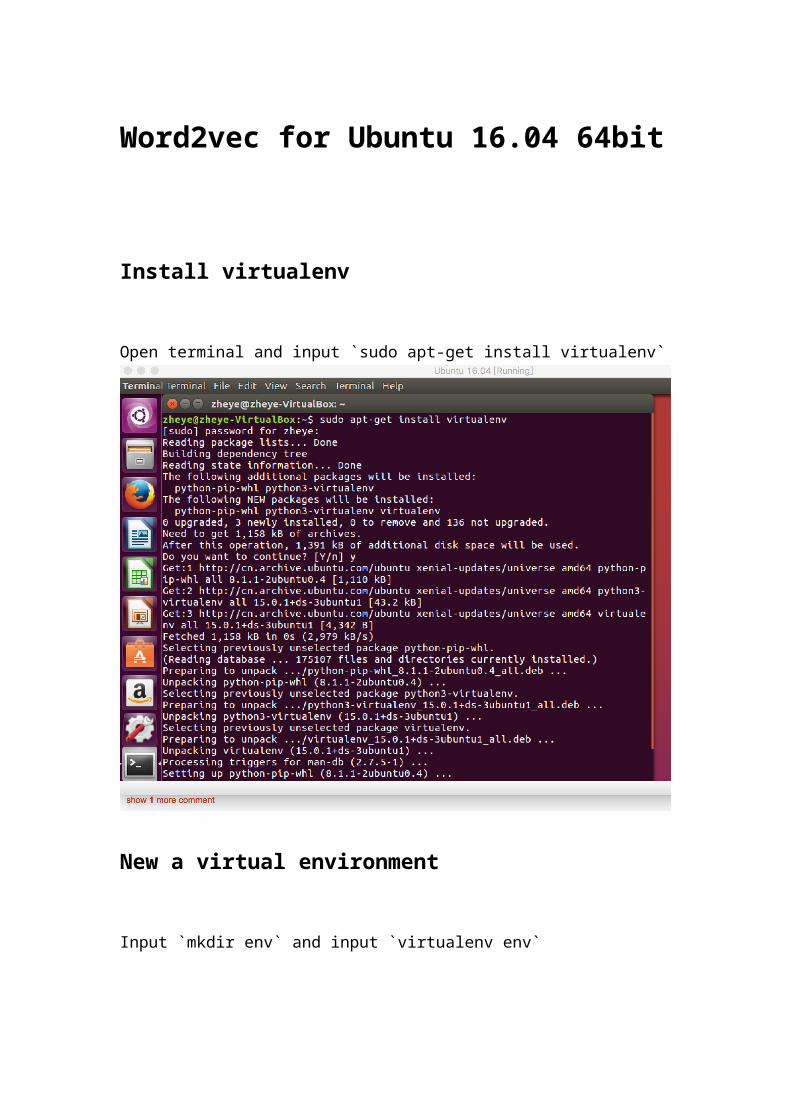
Install virtualenv
Open terminal and input `sudo apt-get install virtualenv`

New a virtual environment
Input `mkdir env` and input `virtualenv env`
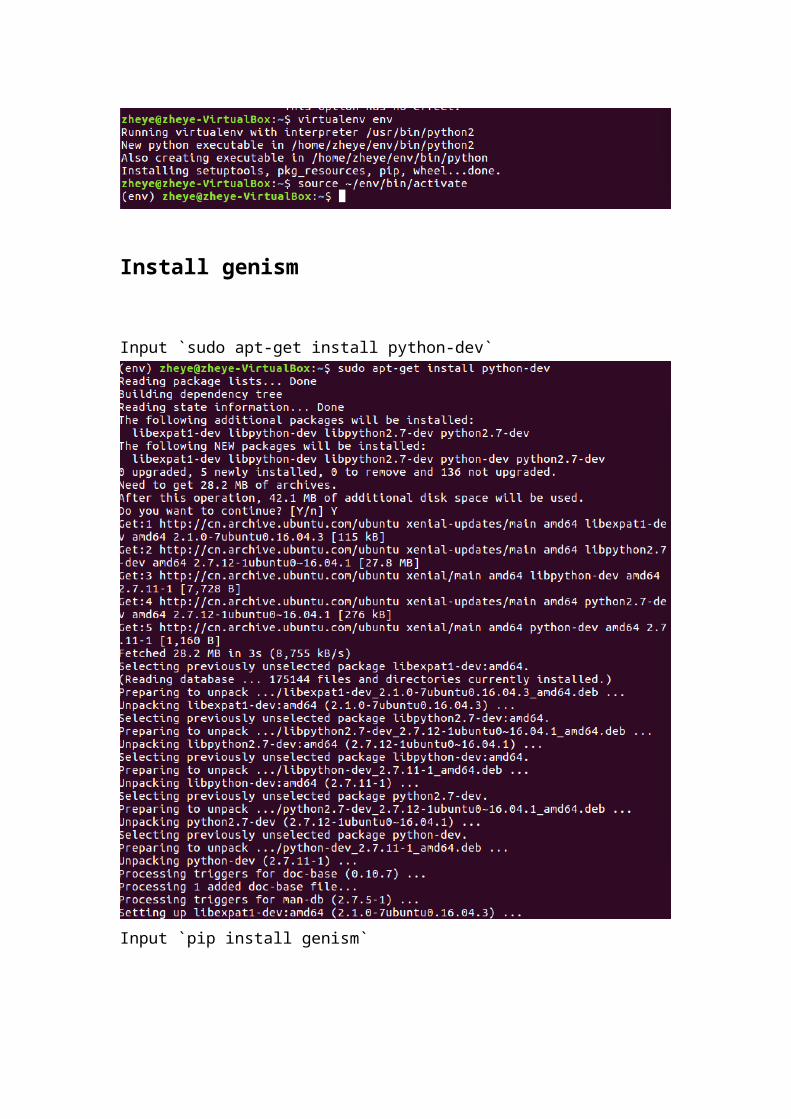
Install genism
Input `sudo apt-get install python-dev`
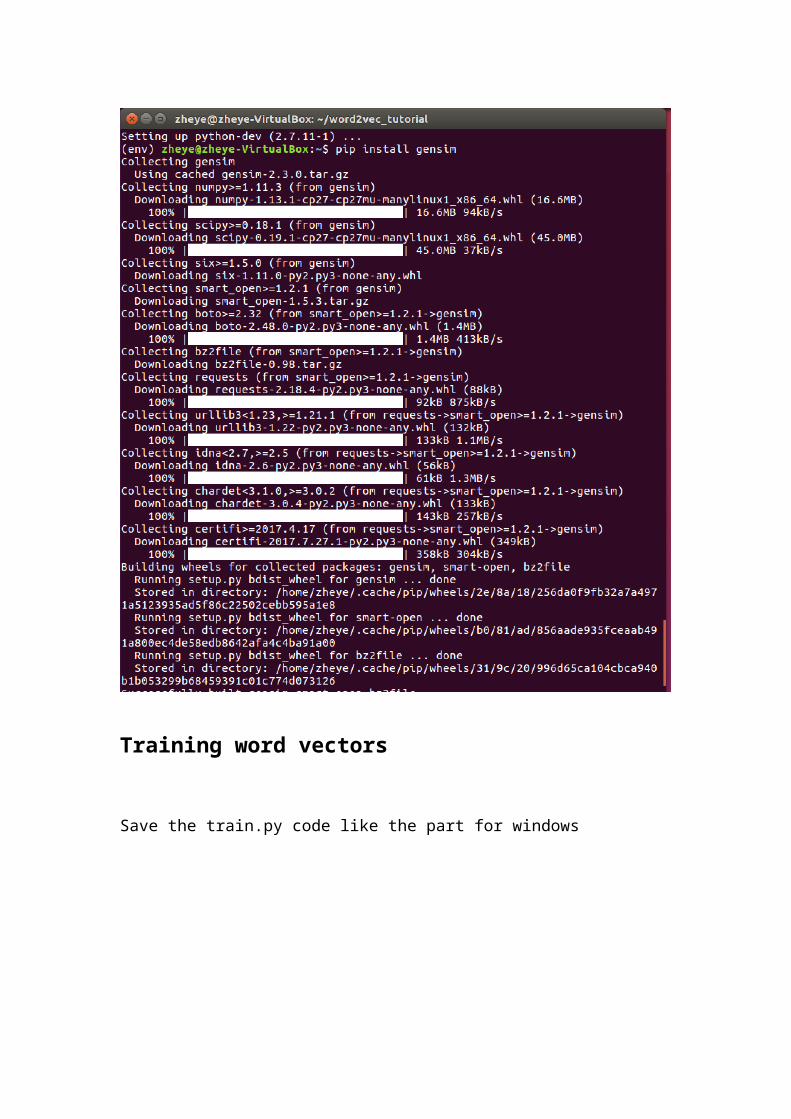
Input `pip install genism`
Training word vectors
Save the train.py code like the part for windows
Input `python train.py` to run the code
Check the word vectors
Same with the part for windows





![The Python/C APIpierre.dimo.free.fr/.../UPB/Python/python_notes-en/c-api.pdf · 2009-03-24 · The Python/C API, Release 2.6.1 sys.version[:3]. On Windows, the headers are installed](https://img.pdfslide.tips/doc/110x75/5f868136bc2cc435f87900ee/the-pythonc-2009-03-24-the-pythonc-api-release-261-sysversion3-on-windows.jpg)























