Embed Size (px)
Citation preview

UNIVERSITATEA BABEŞ-BOLYAI CLUJ-NAPOCA
FACULTATEA DE MATEMATICǍ ŞI INFORMATICǍ
SPECIALIZAREA INFORMATICĂ
LUCRARE DE DIPLOMǍ
Conducător ştiinţific
Prof. univ. dr. Czibula Gabriela
Absolvent
Morariu Alina Bianca
2013

UNIVERSITATEA BABEŞ-BOLYAI CLUJ-NAPOCA
FACULTATEA DE MATEMATICǍ ŞI INFORMATICǍ
SPECIALIZAREA INFORMATICĂ
LUCRARE DE DIPLOMǍ
Tehnici de clasificare în diagnosticarea
medicală
Conducător ştiinţific
Prof. univ. dr. Czibula Gabriela
Absolvent
Morariu Alina Bianca
2013

CUPRINS
INTRODUCERE ………….........……………………………………..1
1. Învăţare automată .................…………………………………………3
1.1 Aspecte generale ....……………………………………………3
1.2 Taxonomia învăţării automate ...................……………………8
1.3 Voting feature interval .........…………………………………12
2. Învăţare bazată pe instanţe ..............…………………………………13
2.1 Reprezentarea învăţării bazate pe instanţe .......................……13
2.2 K-Nearest Neighbors .........…………………………………18
2.3 Weighted Nearest Neighbor ..................……………………21
3. Tehnici de clasificare în diagnosticarea medicală ..........……………24
3.1 Importanţa sistemelor inteligente în diagnosticarea medicală..24
3.2 Modelul unui sistem inteligent ........…………………………26
3.3 Exemple reprezentative ..........,………………………………28
4. Aplicaţia practică ............................................................……………31
4.1 Descrierea problemei şi abordări existente în literatură ..........31
4.2 Aplicaţia ...................................................................................35
4.2.1 Analiza şi proiectare ....................................................35
4.2.2 Implementare ...............................................................45
4.2.3 Manual de utilizare ......................................................51
4.3 Rezultate comparative .................……………………………52
4.4 Extinderi posibile ....................………………………………54
CONCLUZII .........................................................................................56
BIBLIOGRAFIE ...................................................................................57

1
INTRODUCERE
Diagnosticarea este o etapă a actului medical care permite identificarea naturii şi cauzei afecţiunii
de care suferă un pacient. În unele situaţii, precum şi cazul bolilor de piele, acest proces este
îngreunat de similitudinea simptomelor şi de caracteristici specifice altor boli în diferite momente
ale afecţiunii.
Scopul proiectului este de a demonstra necesitatea asistării doctorilor de către sistemele
inteligente. Din cauza numărului mare de informaţii, a erorii umane şi a dificulaţii ridicate a
procesului de diagnosticare în anumite situtatii, aceste sisteme pot fi mai precise şi mai rapide
decât cadrele medicale.
Studiul de caz urmăreşte realizarea unui sistem inteligent, sub forma unui instrument vizual, care
să ajute dermatologii la determinare exactă a tipului de boală erythemato-squamous. Se urmăreşte
catalogarea pacientului într-una din cele şase categorii: psoriasis, seboreic dermatitis, lichen
planus, pityriasis rosea, cronic dermatitis şi pityriasis rubra pilaris.
Pentru realizarea obiectivului se folosesc trei algoritim de clasificare K-Nearest Neighbor (cel
mai apropiat vecin de distanta K), Distance Weighted Nearest Neighbor şi Voting Feature
Intervals. Pe baza unui set de date existent, aplicaţia permite catalogarea unui nou pacient oferind
un diagnostic şi o explicaţie a deciziei luate. Lucrare conţine şi o comparaţie şi o analiză a
rezultatelor obţinute.
Setul de date este preluat din baza de date de pe site-ul UCI Machine Learning
(http://archive.ics.uci.edu/ml). O înregistrare are 34 de caracteristici, fiecare pacient fiind evaluat
cu 12 atribute clinice şi 22 atribute histopatologice (valoarea acestora este obţinută prin analiza
microscopică a ţesutului).
Pe baza acestui set de date cei trei algoritmi şi-au dezvoltat propria schemă de clasificare. Aşadar,
pentru diagnosticarea unui pacient, fiecare clasificator dă un diagnostic şi rezultatele sunt
prezentate utilizatorului, împreună cu explicaţiile corespunzatoare.

2
Partea practică a lucrării este o aplicaţie având o interfata grafică care permite doctorilor
gestiunea pacienţilor şi a fişelor lor medicale, un istoric al consultaţiilor şi posibilitatea
diagnosticării cu ajutorul celor trei clasificatori. Aplicaţia conţine şi o bază de date pentru
salvarea tututor datelor.
Primul capitol al lucrării oferă o perspectivă de ansamblu asupra învăţării automate, iar al doilea
se axează pe o categorie particulară, învăţarea bazată pe instanţe. Aici sunt prezentaţi şi algoritmii
KNN şi DWNN. Capitolul trei urmăreşte evoluţia diagnosticării în medicină accentuând
importanţa sistemelor inteligente în acest domeniu, arată modelul unui sistem inteligent, iar
partea finală a acestui capitol descris cele mai reprezentative exemple de aplicaţii. Ultimul capitol
este un studiu de caz asupra diagnosticarii bolilor de piele, prezentând rezultatele utilizării
algoritmilor de clasificare K-Nearest Neighbor (cel mai apropiat vecin de distanta K), Weighted
Distance Nearest Neighbor şi VFI în aplicaţia practică. Secţiunea finală reprezintă concluziile
desprinse din lucrare.

3
CAPITOLUL 1
Învăţare automată
1.1 Aspecte generale
Capacitatea de a învăţa reprezintă o caracteristică centrală a inteligenţei, motiv pentru care devine
o preocupere importantă atât pentru psihologia cognitivă cât şi pentru inteligenţa artificială.
Domeniul învăţării automate, care întrepătrunde aceste disciplini, studiază procesul
computaţional care marchează învăţarea umană, cât şi automată.
Deşi au o identitate separată, există două aspecte principale pentru care învăţarea automată este o
parte integrală a acestor domenii mari. În primul rând, cercetatorii nu pot ignora problemele
legate de reprezentarea cunoştinţelor, organizarea memoriei şi performanţa, acestea fiind
preocupări majore pentru ambele domenii. În al doilea rând, învăţarea are loc în orice domeniu
care necesiţă inteligenţă, fie că sarcinile de bază implică diagnosticarea, planificarea, limbajul
natural sau altceva. Astfel, învăţarea automată poate fi privită mai puţin ca un subdomeniu al
Inteligenţei Artificiale şi al ştiinţelor cognitive, şi mai mult ca o paradigma pentru cercetare şi
dezvoltare.
Interesul pentru abordarea inteligenţei din punct de vedere computaţional apare o data cu
începuturile inteligenţei artificiale, la mijlocul anilor 1950. Diversitatea problemelor atinge
subiecte precum rezolvarea jocurilor, recunoaşterea literelor, concepte abstracte şi memoria
verbală. Învăţarea era privită ca o trăsătură definitorie a sistemelor inteligente, iar îmbunătăţirea
acesteia era în strânsă legătură cu dezvoltarea mecanismelor generale pentru cunoaştere,
percepţie şi acţiune.
Puncte istorice
În anii 1960, cercetătorii IA au realizat importanţa cunoaşterii specializate a unui domeniu,
apărând astfel primele sisteme intensive în cunoştinţe. Totuşi, oamenii de ştiinţă şi-au concentrat
atenţia în continuare pe metode generale, independente de vre-un domeniu şi cu aplicaţii pe cele

4
perceptibile. În final, recunoaşterea şabloanelor şi inteligenţa artificială s-au dezvoltat în două
branşe separate. Diferenţele s-au accentuat şi mai mult, pe măsură ce cercetătorii în recunoaşterea
tiparelor au subliniat importanţa algoritmilor şi a metodelor numerice care erau în contrast cu
euristicile şi metodele simbolice asociate paradigmelor de IA.
În această perioadă, cercetătorii IA evitau discuţiile legate de învăţare, în timp ce încercau să
înţeleagă rolul cunoştinţelor în comportamentul inteligent. Această eră era dominată de studii
asupra reprezentării cunoştinţelor, a limbajului natural şi a sistemelor expert. Cu toate acestea, pe
fundal au continuat şi studiile având la bază inteligenţa, manifestate prin reprezentări şi metode
euristice care au devenit punctul central al inteligenţei artificiale.
Anii 1970 aduc un interes crescut în domeniul învăţării automate, având ca motivaţie atât
frustrarea datorată accentului pus pe sistemele expert, orientate pe domenii specifice, în ciuda
faptului că învăţarea însemna întoarcerea la principiile generale, cât şi entuziasmul automatizării
acestor cunoştinţe legate de un anumit câmp, precum şi speranţa modelării gândirii umane. Se
propun multe metode noi şi se reînoieşte interesul asupra reţelelor neuronale, aducând din nou în
atenţie tehnici care au fost abandonate în anii anteriori.
Învăţarea automată se extinde în anii 1980 pe domeniile de planificare, diagnosticare, control şi
modelare. Oamenii de ştiinţă devin mai serioşi în ce priveşte potenţialul algoritmilor de învăţare
în rezolvarea problemelor din lumea reală, iar numarul aplicaţiilor de succes demonstrează că
aceste tehnologii pot avea impact asupra industriei. De asemenea, meotodologia îşi formează o
bază din ce în ce mai solidă, experimentele sistematice pe baze de date şi analizele teoretice
precise devenind o normă şi nu o excepţie.
Primul workshop despre învăţarea automată a avut loc la Universitatea Carnegie Mellon în anul
1980 şi a avut doar 30 de participanţi. Domeniul a cunoscut o creştere rapidă, apărând cărţi pe
subiecte generale şi specializate, jurnale, articole şi conferinţe anuale cu un număr mai mare de
participanţi de la an la an.

5
Învaţarea
O definiţie clară, neambiguuă pentru învăţare nu se poate formula astfel încât să surprindă toată
complexitatea conceptului. Conform dicţionarului, învăţarea poate fi definită ca procesul de
dobândire a cunoştinţelor prin studiu, experienţă sau educare; dobândirea conştiinţei prin
informaţie sau observaţie; angajamentul memoriei. Aceste definiţii au mai multe neajunsuri, fiind
imposibil de testat dacă învăţarea a fost dobândită.
Totuşi, o definiţie practică, cu ajutorul căreia să pastrăm subiectul sub studiu, este următoarea:
“Învăţarea este îmbunătăţirea performanţei într-un mediu prin achiziţionarea cunoştinţelor
rezultate din experienţa obţinută în acel domeniu”. Astfel, obiectele învaţă când sunt capabile să-
şi schimbe comportamentul astfel încât să aibă o execuţie mai performantă în viitor.1
Scopul învăţării automate
Deşi învăţarea automată are la bază preocuparea pentru învăţare, literatura de specialitatea
prezintă patru scopuri explicite, de bază, fiecare cu propriile metodologii, abordări de evaluare şi
poveşti de succes.
Un prim scop implică modelarea mecanismului care stă la baza învăţării umane. În acest cadru
psihologic, cercetătorii dezvoltă algoritmi de învăţare care sunt consistenţi cu cunoştinţele
arhitecturii cognitive umane şi care sunt proiectaţi să explice anumite comportamente de învăţare
observate. Această abordare produce o varietate largă de modele computaţionale, unele dintre ele
explicând comportamentul la un nivel calitativ, pe când altele ajustează rata erorilor şi timpurile
de răspuns a subiecţilor umani. O problemă tipică de învăţare poate fi definită de diagrama
următoare:
1 Ian W. & Eibe F,- “Data Mining- Practical machine learning tools and techniques”, 2005, pg-12

6
Figura 1. Diagrama unei probleme de învăţare.
Sursa: Rob Schapire – “Foundations of machine learning”, 2003
Un al doilea grup de interes se referă la abordările empirice ale studiului învăţării automate.
Scopul, în acest caz, este de a descoperi principii generale care corelează caracteristicile
algoritmilor de învăţare şi a domeniului în care acţionează, cu comportamentul de învăţare.
Abordarea standard este de a face experimente în care variază fie algoritmul, fie domeniul şi
observarea impuctului rezultatelor asupra învăţării. Unele studii se bazează pe comparaţii între
diferite clase de algoritmi, pe când altele examinează variaţiuni ale unuia singur; unele
experimente consideră comportamentul în medii naturale, pe când altele variază caracteristicile
mediilor sintetice. Studiile experimentale au ca rezultat o serie de generalizări empirice
referitoare la metode alternative care sugerează zonele de slăbiciune, idei de îmbunătăţire a
algoritmilor şi surse de dificultate în realizarea sarcinilor.
O a treia categorie de preocupare are în vedere principiile generale, tratând învăţarea automată ca
un domeniu aparţinând studiului matematic, cu scopul de a formula şi demonstra teoreme.
Abordarea tipică presupune definirea unei probleme de învăţare, presupunând că poate sau nu
poate fi rezolvat cu un număr rezonabil de cazuri de antrenament şi demonstrând această ipoteză
pe caz general. Dacă abordarea empirică împrumută tehnici experimentale din fizică şi
psihologie, abordarea matematică foloseşte instrumente şi concepte din informatică şi statistică.
O ultima abordare este cea aplicativă, având ca scop principal utilizarea învăţării automate în
problemele din lumea reală. Majoritatea aplicaţiilor de acest fel se bazează pe sisteme expert care
necesită ani pentru dezvoltarea şi depanarea cunoştinţelor extensive specifice domeniului.
Datorită faptului ca prin utilizarea învăţării automate se pot transforma datele de antrenament în

7
cunoştinţe, aceasta deţine potenţialul de a automatiza procesul de dobândire a cunoştinţelor. Paşii
tipici de dezvoltare presupun forumlarea unei probleme interesante, proiectarea unei reprezentări
pentru cazurile de antrenament şi dobândirea cunoştinţelor, colectarea datelor de antrenament şi
utilizarea învăţării automate pentru generarea bazei de cunoştinţe.
Un punct central al acestor abordări este preocuparea pentru dezvoltarea, înţelegerea şi evaluarea
algoritmilor de învăţare. Dacă învăţarea automată este o ştiinţă, este, în mod cert, o ştiinţă a
algoritmilor.2
Un avantaj al învăţării automate este faptul că presupune căutarea într-un spaţiu mare de posibile
ipoteze pentru a determina cea mai buna dintre cele care se potriveşte datelor observate pe baza
cunoştinţelor deţinute a-priori.
Domenii de aplicare
O măsură a progresului realizat în învăţarea automată este numărul aplicaţiilor dezvoltate pentru
lumea reală. Câteva din aplicaţiile de succes, din diferite domenii, sunt următoarele:
Recunoaşterea vocală: aceasta are ca motivaţie faptul că recunoaşterea vocii are o mai
mare acurateţe dacă este învăţată şi nu programată manual. În general există două faze de
învăţare: prima, înainte ca produsul soft să fie livrat şi presupune învăţarea sistemului
independent de utilizator şi a doua, dependentă de utilizator.
Computer vision: Aceste sistemele vizuale includ aplicaţii precum recunoaşterea feţei (de
exemplu, identificarea feţelor în imagini), sisteme care clasifică automat imaginile
microscopice a celulelor şi recunoaşterea caracterelor optice. Ultimul tip de aplicaţie este
utilizată la un nivel foarte mare de Oficiul Poştal US, pentru sortarea automată a
scrisorilor cu adresele scrise de mână, peste 85% din corespondenţa din Statele Unite este
sortată utilizând software de acest fel.
Bio-supraveghere: multe eforturi guvernamentale sunt făcute pentru a identifica şi urmări
apariţia focarelor de boli. Un exemplu de aplicaţie de succes este proiectul RODS care
colectează în timp real fişele de internare în sălile de urgenţe a spitalelor din Pennsylvania
pentru a determina şabloane de simptome care prezintă anomalii.
2 Langley P. – „Elements of Machine Learning”, 1998, England, p. 1-7

8
Controlul robortic: învăţarea automată a fost folosită cu succes în sistemele robotice.
Ştiinţele empirice: ştiinţele intensive în date utilizează invăţarea automată pentru a uşura
procesul descoperirilor ştiinţifice (de exemplu, modelarea expresiei genelor din celule,
descoperirea obiectelor astronomice suspecte, caracterizarea tiparelor de activitate a
creierului uman).3
Filtarea spam-urilor: identificarea mailurilor ca fiind spam-uri sau nu.
Înţelegerea limbii vorbite: în contextul unui domeniu limitat, algoritmul determină sensul
cuvintelor utilizatorului.
Diagnosticarea medicală: diagnostichează un pacient ca suferind sau nu de o boală.
Segmentarea clienţilor: utilizat, spre exemplu, pentru a prezice reacţia unui pacient la o
campanie promoţională.
Detectarea fraudei: un exemplu de acest fel este identificarea tranzacţiilor de o natură
frauduloasa.
Predicţia vremii.4
1.2 Taxonomia învăţării automate
În funcţie de rezultatul dorit al algoritmului sau de datele de intrare disponibile se propune
următoarea taxonomie pentru învăţarea automată: supervizată, nesupervizată, semi-supervizată,
de întărire, învăţare prin învăţare.
Învăţarea supervizată
Acest tip de învăţare presupune că algoritmul generează o funcţie de mapare a datelor de intrare
la rezultatul dorit. O formulare standard a sarcinilor de învăţare supervizată sunt problemele de
clasificare: algoritmul trebuie să înveţe (să aproximeze comportamentul) o funcţie care clasifică o
instanţă într-una dintre clasele disponibile observând mai multe exemple de input-output ale
funcţiei.
3 Tom M. Mitchell- “The discipline of machine learning”, 2006
4 Rob Schapire – “Foundations of machine learning”, 2003

9
Primul pas în aplicarea învăţării supervizate este colectarea datelor. În cazul diponibilităţii unui
expert, acesta ar trebui să sugereze atributele relevante. Altfel, cea mai simplă metodă este
aplicarea „forţei brute”, adică măsurarea tuturor datelor disponibile în speranţa că atributele
corecte (informative, relevante) pot fi izolate. Totuşi, această metodă are dezavantajul de a
introduce zgomot şi atribute cu valori lipsă, necesitând un grad mare de preprocesare. Pregătirea
datelor şi preporcesarea este al doilea pas aplicat, în scopul detectării zgomotului. O tehnică de
reducere a acestuia este selectarea instanţelor. Selectarea instanţelor este o problemă de
optimizare care încearcă să menţină calitatea datelor interesante extrase dintr-o bază de date, în
timp ce reduce dimensiunea înregistrărilor. O altă tehnică presupune identificarea şi eliminarea
atributelor irelevante care, prin reducerea cantităţii de date, ajută la îmbunătăţirea performanţei
algoritmilor. Totuşi, multe atribute depind unele de altele şi combinaţia lor influenţează
acurateţea modelelor de învăţare supervizată. O soluţie pentru această problemă este
transformarea atributelor, prin contruirea unor atribute noi din setul de date iniţial. Atributele
generate pot duce la crearea unor clasificiatori cu o precizie şi acurateţe mai ridicată. În plus,
descoperirea atributelor seminficative ajută la o mai bună întelegere a procesului de clasificare şi
a conceptului învăţat.
Algoritmii specifici învăţării supervizate sunt grupaţi în mai multe categorii: clasificatori liniari
(regresie logică, clasificatorul bayesian naiv, perceptron, maşinile cu suport vectorial),
clasificatoriul quadratic, k-Means Clustering, arborii de decizie, reţele neuronale şi reţele
bayesiane.
Procesul învăţarii supervizate este descris în următoarea figură:

10
Figura 2: Procesul învăţării automate supervizare
Sursa: Taiwo Oladipupo Ayodele –“Types of Machine Learning Algorithms”, 2010
Învaţarea nesupervizată
În acest tip de învăţare, instanţele pe care se face învăţarea nu sunt catalogate, urmărindu-se
modelarea datelor de intrare. La prima vedere, această învăţare pare mai dificilă, calculatorul
fiind nevoit să înveţe ceva fără să ştie cum. Există două abordări pentru învăţarea nesupervizată.
Prima este învăţarea agentului fără a da categorizările explicite, ci folosind un sistem de
recompensare pentru a indica succesul. Acest tip de antrenament intră în categoria problemelor
de decizie, scopul fiind de a lua decizii care maximizează recompensa şi nu de de clasificare.
Abordarea este o generalizare a lumii reale, agenţii fiind recompensaţi pentru anumite acţiuni şi
pedepsiţi pentru altele.
De multe ori, învăţarea nesupervizată foloseşte o formă de învăţare prin întărire, agenţii bazându-
şi acţiunile pe recompensele şi pedepsele anterioare, fără a învăţa informaţii despre felul în care

11
acţiunilor lor afectează mediul. Într-un fel, aceste informaţii nu sunt necesare deoarece prin
învăţarea funcţiei de recompensare, agentul ştie ce trebuie să facă fară procesări ulterioare,
deoarece ştie ce recompensă se aşteaptă să primească pentru fiecare acţiune pe care poate să o
facă. Această abordare este avantajoasă în cazul în care calcularea fiecărei posibilităţi durează
mult (chiar dacă sunt cunoscute toate posibilităţile de tranziţie între stări). Totuşi, la fel de mult
poate dura şi acest tip de învăţare, bazat pe încercări şi eşecuri, însă puterea acestui tip de învăţare
constă în presupunerea că nu există clasificări ale exemplelor pre-descoperite.
A doua abordare a învăţării nesupervizate se numeşte clustering, prin care nu se urmăreşte
maximizarea funcţiei de utilitate, ci descoperirea similitudinilor în cadrul setului de date. Se
presupune că grupurile (clustere) descoperite pot fi folosite pentru clasificările intuitve. De
exemplu, aplicarea metodei pe seturi de date demografice pot grupa indivizii în grupuri în funcţie
de bunăstare, bogaţi şi săraci. Deşi algoritmul nu oferă nume pentru clusterele descoperite, prin
găsirea lor, sunt utilizate la clasificarea noile instanţe într-unul sau în altul. Această abordare este
bazată pe date şi poate fi aplicată dacă există un număr suficient de mare de date.
Algoritmii de învăţare nesupervitată sunt proiectaţi să extragă structuri din datele de antrenament.
Calitatea structurilor este măsurată cu ajutorul funcţiilor de cost care este minimizată prin
deducerea parametrilor optimi care caracterizeaza structurile ascunse din date.
Învăţarea semi-supervizată
Acest tip de învăţare combină instanţele clasificate cu cele neclasificate cu scopul construirii unei
funcţii sau a unui clasificator corespunzător. Un sub-tip din această categorie este “transducţia”,
sau inferenţa transductivă, care încearcă să prezică rezultate noi bazându-se pe nişte cazuri de
testare specifice şi fixate, deduse din observarea datelor de antremanet.
Învăţarea prin întărie
Algoritmii din această categorie învaţă un comportament bazat pe observarea mediului
înconjurător. Fiecare acţiune a agentului are o consecinţă asupra mediului, iar mediul oferă un
răspuns care ghidează algorimul de învăţare.

12
Învăţarea prin învăţare
Acest algoritm face un set de presupuneri pe care le utilizează în predicţia clasificărilor
instanţelor necunoscute. În funcţie de rezultatele obţinute, algoritmul obţine o anumită experienţă
care formează baza porcesului de învăţare.5
1.3 Voting feature interval
În continuare este prezentat algoritmul Voting feature interval, cum se realizează învaţarea şi cum
se face clasificarea unui obiect nou. VFI este asemănător clasificatorului bayesian naiv deoarece
fiecare trasătură a unui obiect este prelucrată individual. Astfel, unitatea de lucru a acestui
algoritm este “intervalul caracteristic”: pentru fiecare atribut al unui obiect se calculează
intervalele sale caracteristice. Fiecare interval conţine instanţe ale mai multor clase, rezultând că
fiecare atribut are o pondere în acestea. Pe baza acestor ponderi se acordă voturi iar scorul final
este calculat ca suma a voturilor individuale raportate la fiecare atribut. În clasa cu scorul cel mai
mare este clasificată noua instanţă.
Etapa de învăţare
VFI este un algoritm de clasificare non-incremental. Fiecare exemplar este reprezentat ca un
vector de valori ale caracteristicilor sale şi o etichetă care precizează clasa din care obiectul face
parte. Prima etapa a algoritmului presupune construirea intervalelor caracteristice pentru fiecare
caracteristică. Un interval caracteristic apare sub forma unui set de valori pentru o anumită
trăsătură, valori pentru care se observă aceleaşi subset de date dintr-o clasă.
Găsirea intervalelor specifice unui atribut presupune determinarea punctelor minime şi maxime
pentru fiecară clasă, pentru acel atribut (în cazul celor liniare). Lista punctelor găsite este
ordoantă crescător, fiecare pereche de puncte consecutive considerându-se un interval. Pentru
atributele nominale, se consideră fiecare valoare un punct diferit, respectiv un interval cuprinzând
o sigura valoare.6
5 Taiwo Oladipupo Ayodele –“Types of Machine Learning Algorithms”, 2010
6 Narin Emeksiz Havelsan, Ankara Turke, Application of Machine Learning Techniques to Differential Diagnosis of
Erythemato-Squamous Diseases

13
Reprezentarea fiecărui interval se face sub forma unui vector cu valorile: <atribut,
limitaInferioară, numărClasa1, numărClasa2, …, numărClasak>, unde atribut este caracteristica
pentru care este definit intervalul, limitaInferioară este limita inferioară a acelui interval, k este
numarul de clase şi numărClasai este egal cu numărul de instanţe ale clasei care aparţin
intervalului. Astfel, un interval poate reprezenta mai multe clase. Se utilizează doar limita
inferioară deoarece, în cazul caracteristicilor liniare, limiat superioară a unui interval este limita
superioară a intervalului următor, iar în cazul trăsăturilor nominale limitele superioare şi
inferioare a unui interval sunt egale. Un caz special apare când o instanţă a unei clase are ca
valoare punctul limită al unui interval. În această situaţie, se consideră că obiectul respectiv face
parte din ambele intervale care au ca limită punctul respectiv şi se adauga 0.5 la numărul
instanţelor din acea clasă (pentru fiecare interval). Se poate observa că nu este necesară o
normalizare a datelor deoarece fiecare caracteristică este procesată individual.7
Etapa de clasificare
Apartenenţa unei noi instanţe la o clasă se face pe baza voturilor acordate de fiecare
caracteristică, pentru fiecare clasă. Se calculează voturile primite de fiecare clasă, ca şi suma
voturilor acordate de fiecare atribut pentru acea clasă. Obiectul nou este clasificat în clasa cu cel
mai mare punctaj.
Pentru acordarea voturilor, pentru fiecare atribut se caută intervalul în care este cuprinsă valoarea
atributului corespunzator a obiectului care trebuie clasificat. Fie <atribut1, limitaInferioară,
numărClasa1, numărClasa2, …, numărClasak> intervalul găsit pentru atributul atribut1. Se
calculează pentru fiecare clasă votul acordat de acest atribut ca raportul dintre numărul de
instanţe ale clasei din acel interval şi numărul total de instanţe din acea clasă. Un caz special
apare atunci când obiectul de catalogat are valori lipsă pentru unele atribute. În această situaţie,
votul atributelor respective este 0 pentru fiecare clasă. O altă situaţie deosebită este în cazul în
care valoarea atributului obiectului nou reprezintă limita unui interval. Valoarea votului este
egală cu media voturilor celor două intervale corespunzătoare. Următorul pas din această etapa
7 Narin Emeksiz Havelsan, Ankara Turke, Application of Machine Learning Techniques to Differential Diagnosis of
Erythemato-Squamous Diseases

14
are în vedere normalizarea acestor rezultate astfel încât suma voturilor acordate de un atribut
fiecarei clase sa fie egală cu unu.
Se calculează voturile totale obţinute de fiecare clasă prin însumarea voturilor individuale
obţinute din partea fiecărei caracteristici. Clasa cu cel mai mare vot este clasa în care obiectul
necunoscut este catalogat.8
8 Narin Emeksiz Havelsan, Ankara Turke, Application of Machine Learning Techniques to Differential Diagnosis of
Erythemato-Squamous Diseases

15
CAPITOLUL 2
Învăţare bazată pe instanţe
2.1 Reprezentarea învăţării bazate pe instanţe
În contrast cu alte metode de învăţare, care construiesc o funcţie de evaluare generală şi explicită
pentru antrenarea datelor, metodele învăţării bazate pe instanţe pur şi simplu memorează aceste
date. Generalizarea dincolo de aceste exemple este amânată până în momentul în care trebuie
clasificată o nouă instanţă. De fiecare dată când se găseşte o instanţă necunoscută, se examinează
relaţia sa cu celelalte exemplare memorate, cu scopul de a ataşa acesteia o nouă valoare pentru
funcţia de evaluare.
O dată ce datele de antrenament au fost memorate, pentru realizarea unei noi clasificări se caută
între aceste instanţe cea care se aseamană cel mai mult cu cea studiată. Problema care apare este
cum se interpretează aceste “asemanări”, comparând instanţele noi, a căror clasificare este
necunoscută cu cele a căror clasă se cunoaşte. Într-un fel, şi celelate metode de învăţare sunt
bazate pe instanţe deoarece toate au ca punct de pornire un set de date care reprezintă baza
iniţială de obţinere a informaţie. Însă, în contrast cu aceasta, reprezentarea cunoştinţelor bazată pe
instanţe foloseşte instanţele în sine pentru a reprezenta ce se învaţă, şi nu se deduce o regulă care
să se memoreze.
Învăţarea bazată pe instanţe include metoda celui mai apropiat vecin şi metoda regresiei
ponderate locale, care presupun că instanţele pot fi memorate ca puncte în spaţiul Euclidian. De
asemenea, include şi metode de case-based reasoning care presupun reprezentări simbolice mult
mai complexe. Într-un fel diferenţa dintre învăţarea bazată pe instanţe şi celelate este momentul
în care are loc procesul de învăţare. Toate aceste metode sunt catalogate ca fiind “lazy” deoarece
amână procesul de învăţare panâ când o nouă instanţă trebuie clasificată. Un avantaj pentru
această abordare este faptul că în loc să se estimeze o funcţie de evaluare de la început, pentru tot
spaţiul de instanţe, metodele estimează funcţia local şi diferit pentru fiecare dată nouă care
trebuie clasificată.

16
Calcularea distanţei dintre două exemplare este trivială când acestea au un singur atribut numeric:
se calculează diferenţa dintre valorile celor două atribute. La fel de uşor este tratat şi cazul mai
multor atribute numerice: în general, se utilizează distanţa Euclidiană. Totuşi, trebuie ţinut cont
de normalizarea atributelor şi de importanţa lor diferită.9
În cazul atributelor nominale, este necesară gasirea unei “distanţe” între valorile diferite ale
atributelor. De exemplu, cum se poate calcula distanţa dintre valorile roşu, galben şi verde? De
obicei, se consideră distanţa zero pentru valori identice şi unu în caz contrar, astfel că distanţa
dintre roşu şi roşu este zero, pe când distanţa dintre roşu şi verde este unu. Totuşi, este de dorit o
reprezentare mai sofisticată a acestor atribute, spre exemplu, având mai multe culori se poate
utiliza o măsură metrică a nuanţelor din spaţiul culorilor, punând galbenul mai apropiat de
portocaliu decât verde. Unele atribute au o importanţă diferită care este reflectată în distanţa
metrică cu ajutorul anumitor ponderi. Derivarea ponderilor pentru fiecare atribut din setul de
antrenament este o problemă importantă în învăţarea bazată pe instanţe.
Nu este necesar sau indicat să fie reţinute toate datele de antrenament, o primă motivaţie fiind
încetinirea procesului de calculm, iar a doua spaţiul enorm ocupat. În general, există regiuni ale
spaţiului atributelor sunt mai stabile decât altele, raportate la clasă, astfel că sunt necesare câteva
exemple din interiorul regiunilor stabile. Spre exemplu, se cere o densitate mai mică a
exemplarelor din interiorul regiunilor stabile decât densitatea necesară în jurul limitelor claselor.
Decizia de a renunţa saun nu la anumite instanţe este un alt punct cheie în învăţarea bazată pe
instanţe.
Un inconvenient al reprezentărilor din acest model este că nu fac explicite structurile care se
învaţă, violând asftel noţiunea de “învăţare”, prin faptul că nu descriu şabloanele datelor. Totuşi,
instanţele împreună cu distanţele metrice consturiesc anumite bariere care diferenţiază o clasa de
alta şi astfel reuşesc să reprezinte explicit cunoştinţele obţinute. Spre exemplu, avand două clase,
fiecare cu o singură instanţă, regula celui mai apropiat vecin împarte spaţiul de-a lungul
bisectoarei perpendiculare a liniei care uneşte cele două instanţe. Având un număr mai mare de
instanţe, spaţiul este împărţit de o mulţime de linii care reprezintă bisectoarele perpendiculare ale
liniilor selectate care unesc instanţele dintr-o clasă cu cele din cealalată.
9 Tom M. Mitchell- “Machine Learning”, ed. McGraw Hill, 1997

17
Figura de mai jos ilustrează un poligon cu nouă laturi care separă clasa cercurilor umplute de
clasa cercurilor goale. Renunţând la o parte din datele de antrenament, se păstrează instanţele
care sunt de fapt folosite în luarea deciziei conform celui mai apropiat vecin. Figura . (b) prezintă
cercurile colorate cu gri ca fiind instanţele la care se poate renunţa fară a afecta rezultatul final.
De asemenea, exemplele prototipice servesc ca o reprezentare explicită a cunoştinţelor.10
Figura 3 . Partiţionarea spaţiului instanţelor şi reprezentarea cunoştinţelor (pg 79)
Sursa: Ian W. & Eibe F, “Data Mining- Practical machine learning tools and techniques”, 2005, pg.79
Un dezavantaj al abordărilor bazate pe instanţe este costul ridicat pentru fiecare nouă clasificare,
datorită faptului că majoritatea calculelor se fac în momentul clasificării şi nu atunci când sunt
memorate iniţial datele de test. Ca o consecinţă, se caută tehnici eficiente de indexare a datelor de
antrenament cu scopul reducerii calculelor necesare la fiecare nouă interogare. Un alt dezavantaj
are în vedere faptul că iau în considerare toate atributele instanţelor, chiar dacă numai câteva sunt
relevante pentru o corectă clasificare.11
Alte puncte slabe sunt faptul că acurateţea algorimului
scade pe măsura apariţiei zgomotului, precum şi faptul că funcţiile pentru calcularea distanţelor
sunt neadecvate pentru aplicaţii cu atribute liniare şi nominale, cât şi din lipsa abilităţii de a
modifica barierele de decizie o dată ce datele au fost salvate.
Principalele avantaja ale acestor tehnici sunt învăţarea rapidă, faptul că nu pierd informaţii şi
capacitatea de a învăţa funcţi de evaluare complexe.
10
Ian W. & Eibe F,- “Data Mining- Practical machine learning tools and techniques”, 2005, 76-79
11 Tom M. Mitchell- “Machine Learning”, ed. McGraw Hill, 1997

18
2.2 K-Nearest Neighbors
În acest capitol este prezentat algoritmul k-nearest neighbor, utilizat pentru clasificări sau pentru
predicţii (în cazul rezultatelor numerice). Pentru a clasifica sau prezice o noua dată, metoda se
bazează pe găsirea altor înregistrări similare în datele de antrenament. Aceşti “vecini” sunt apoi
folosiţi pentru a deriva o clasificare/ predicţie pentru noul obiect prin votare (pentru clasificare)
sau printr-o medie (pentru predicţie).12
Pe parcursul capitolului se arată cum se determină
similitudinile, modalitatea prin care se alege numărul de vecini şi cum se realizează clasificarea.
Ultima parte a capitolului prezintă avantajele şi dezavantajele algoritmului din perspectiva
performanţei şi a altor considerente de ordin practic, de exemplu timpul computaţional.
În recunoaşterea modelelor, algoritmul KNN este o metodă de clasificare a obiectelor folosindu-
se de cele mai apropiate k obiecte din setul de antrenament. KNN foloseşte învăţarea bazată pe
instanţe (sau învaţarea întârziată), unde funcţia este aproximată local iar calculele efective sunt
amânate până la clasificare. KNN este unul dintre cei mai simpli algoritmi de învaţare automată:
un obiect este clasificat în funcţie de votul majoritar al vecinilor săi, de cele mai multe ori fiind
clasat în categorie din care fac parte cei mai multi dintre cei k vecini. K este un număr întreg,
pozitiv, în general mic. Dacă k este 1, obiectul este adăugat în clasa din care face parte cel mai
apropiat vecin.13
Se consideră reprezentare noului obiect ca fiind (x1,x2,..xp), unde x1,x2..xp
reprezintă valorile atributelor obiectului. Căutam date în setul de antrenament care sunt similare
sau apropiate înregistrării care urmează să fie clasificată (datele care au valori apropiate lui x1,
x2,.. xp). Apoi, pe baza claselor din care fac parte datele găsite, atribuim o clasă obiectului
necatalogat.14
Determinarea vecinilor
Algoritmul K-NN este o metodă de clasificare care nu ţine cont de relaţiile dintre membrii
claselor şi a atributelor (X1..Xp), ci se foloseşte de informaţiile extrase din similitudinile dintre
12
Bruce P. et all (2010), Data Mining for Business Intelligence: Concepts, Techniques, and Applications in
Microsoft Office Excel with XLMiner, ed John Wiley & Sons Inc, Hoboken, New Jersey 137-145 13
Zheming L. et all (2010)- Three-Dimensional Model Analysis and Processing, ed. Zhejiang University Press,
Hangzhou, p. 277- 279 14
Bruce P. et all (2010), Data Mining for Business Intelligence: Concepts, Techniques, and Applications in
Microsoft Office Excel with XLMiner, ed John Wiley & Sons Inc, Hoboken, New Jersey 137-145

19
valorile atributelor înregistrărilor. Vecinii sunt aleşi dintr-un set de obiecte pentru care se
cunoaşte clasificarea corectă. Ei pot fi consideraţi ca fiind echivalentul datelor de învăţare, deşi
nu există o etapă specifică de antrenare. Se poate considera, totuşi, că etapa de antrenament a
algortimului constă numai în memorarea vectorilor caracteristici şi a etichetelor claselor pentru
datele de antrenament.15
Dupa cum este menţionat mai sus, pentru identificarea vecinilor, obiectele sunt reprezentate ca
vectori de poziţie într-un spaţiu multi-dimensional caracteristic. În momentul actual de
clasificare, datele de test (a caror clasă e necunoscută) sunt reprezentate şi ele ca un vector în
spaţiul caracteristic. Se calculează distanţa de la noul vector la cei existenţi şi se selectează primii
k cu cea mai mică distanţă. Problema care apare în acest moment este modalitatea de determinare
a distanţei dintre obiecte pe baza atributelor lor. Cea mai utilizată metoda de calcul a distanţei
este distanţa Euclidiană. Astfel, distanţa Euclidiană dintre două obiecte, unul din setul de date de
antrenament (x1,..,xp) şi unul nou care trebuie catalogat (u1,..,up) este:
.
Reguli de clasificare
După calcularea distanţei dintre obiectul care trebuie clasificat şi celelate înregistrări, este
necesară o regulă de asociere a acestuia la una din clasele primilor k vecini cu cea mai mică
distanţă. Spaţiul este împărţit în regiuni de locaţie şi etichete pentru datele de antrenament. Un
punct în spaţiu este atribuit unei clase c, dacă c este cea mai frecvetă etichetă a claselor celor mai
apropiate k date de antrenament. 16
Există mai multe tehnici de clasificare a noului vector la o clasă particulară, cea mai utilizată
fiind adăugarea acestuia la clasa predominantă a celor k vecini. Principala problemă este faptul că
clasele cu exemplare numeroase influenţează catalogarea noului vector deoarece apar mai des
15
Zheming L. et all (2010)- Three-Dimensional Model Analysis and Processing, ed. Zhejiang University Press,
Hangzhou, p. 280- 283 16
Bruce P. et all (2010), Data Mining for Business Intelligence: Concepts, Techniques, and Applications in
Microsoft Office Excel with XLMiner, ed John Wiley & Sons Inc, Hoboken, New Jersey 137-145

20
printre cei k vecini selectaţi. O soluţie posibilă este predicţia în funcţie de distanţa dintre fiecare k
vecin şi noul vector.17
Alegerea corectă a valorii lui k se face în funcţie de date. De obicei, pentru un k mare se reduce
“zgomotul” în procesul de clasificare, însă trasează bariere clare între clasele asemănătoare.
Pentru alegerea unui k potrivit se pot utiliza diferite metode euristice (de exemplu, cross-
validation- validarea încrucişatş). Cazul special în care un obiect este atribuit clasei cu cel mai
similar exemplar (pentru k=1) este numit algoritmul “nearest neighbor“ (cel mai apropiat
vecin).18
Avantaje şi dezavantaje ale algoritmului
Principalul avantaj al K-NN este simplitatea şi lipsa presupunerilor parametrizate. De asemenea,
în cazul unui set de date de antrenament mare, algoritmul are rezultate foarte bune. Un alt factor
care influenţează performanţa algoritmului este caracterizarea unei clase prin multilple
combinaţii de atribute. Spre exemplu, având o bază de date de imobiliare, există o probabilitate
mai mare ca multiple combinaţii între {tipul locuinţei, numărul de camere, cartier, preţ} să
caracterizeze locuinţele care se vând repede versus cele care rămân pe piaţă o perioada mai mare
de timp.
Dificultăţile observate au în vedere faptul că precizia algoritmului KNN este afectată de existenţa
zgomotului sau a caracteristicilor irelevante, precum şi dacă pondera acestora nu este în
consistenţa cu importanţa. O alta problemă sesizată se referă la durata găsirii celui mai apropiat
vecin, care este destul de mare, mai ales în cazul unui set de date de antrenament voluminos.19
Ultimul dezavantaj observat se referă la “blestemul dimensionalităţii”, făcând referire la numărul
mare de atribute. Pentru un segment de dreapta de coordonate (0,1), lungimea sa este 0, pentru un
pătrat, lungimea între vârfurile opuse, de coordonate (0,0) şi (1,1) este , pentru un cub,
17
Zheming L. et all (2010)- Three-Dimensional Model Analysis and Processing, ed. Zhejiang University Press,
Hangzhou, p. 280- 287 18
Zheming L. et all (2010)- Three-Dimensional Model Analysis and Processing, ed. Zhejiang University Press,
Hangzhou, p. 270- 283 19
Bruce P. et all (2010), Data Mining for Business Intelligence: Concepts, Techniques, and Applications in
Microsoft Office Excel with XLMiner, ed John Wiley & Sons Inc, Hoboken, New Jersey 137-145

21
lungimea diagonalei este dar pentru un hipercub cu 100 de dimensiuni, lungimea e egala cu
100. Cu cât numărul de atribute este mai mare, cu atât datele din acel spatiu sunt mai rare şi este
cu atat mai greu de realizat un model de clasificare precis.20
2.3 Weighted Nearest Neighbor
Un rafinament evident al algoritmului KNN este ponderarea contribuţiei fiecăruia k vecin în
funcţie de distanţa faţă de noua instanţă care trebuie clasificată, acordând o pondere mai mare
vecinilor mai apropiaţi. Dudani introduce pentru prima dată o metodă de ponderare a voturilor,
denumită regula distanţei ponderate a celor mai apropiaţi k-vecini.
Pentru a calcula pondera wi corespunzătoare corespunzătoare celui de-al i-lea vecin al noii
instanţe x’, se aplică următoarea formulă21
:
Pentru a rezolva cazul în care valorile atributelor unui vecin sunt identice cu cele ale noii instanţe
de catalogat, numitorul ponderii devenind zero, se clasifică noua instanţă în aceeaşi clasă cu
prima, renunţându-se la alte calcule. Dacă există mai multe exemplare pentru care se întâmplă
acest lucru, se alege clasa majoritară.
Rezultatul clasificării este dat de majoritatea voturilor ponderate:
Deşi algoritmul KNN consideră doar primii k vecini pentru etapa de clasificare, o dată ce se
introduce ponderarea distanţelor, se reduce riscul unui rezultat greşit, în cazul în care se iau în
considerare toate instanţele, prin faptul că vecinii mai îndepărtaţi vor primi o pondere mai mică.
9 Florin Leon (2012), Inteligenta atificiala: rationament probabilistic, tehnici de clasificare, ed Tehnopress, Iasi
21 Jianping Gou, Lan Du, Yuhong Zhang, Taisong Xiong- A New Distance-weighted k-nearest Neighbor Classier,
2012

22
Singurul dezavantaj în considerarea tututor exemplarelor este încetinirea clasificatorului şi
scăderea performanţei.
Algoritmul care ia în considerare toate exemplarele se numeşte global, iar cel care ia în
considerare doar o parte din vecini, se numeşte local. Dacă se aplică DWNN global, se obţine
algoritmul cunoscut sub numele de “metoda Shepard”.22
Rezultate experimentale comparative
În această secţiune este prezentată performanţa celor doi clasificatori aplicaţei pe douăzeci de
seturi de date preluate din baza de date UCI. În acest experiment, fiecare set de date este împărţit
aleator în date de antreament şi date de test. Proprietăţile generale ale acestor date, precum şi
partiţionarea lor, sunt prezentate în tabelul următor:
Tabel 1. Seturile de date UCI şi partiţionările corespunzătoare
Setul de date Număr
atribute
Număr
instanţe
Număru clase Număr date
antrenament
Număr date
de test
Sticlă 10 214 7 140 74
Vin 13 178 3 100 78
Sonar 60 208 2 120 88
Parkinson 22 195 2 120 75
Ionosferă 34 351 2 200 151
Mosc 166 476 2 276 200
Vehicule 18 846 4 500 346
Segmentarea
imaginii
19 2310 7 1310 1000
Cardiotocografie 21 2126 10 1126 1000
Recunoaşterea
optică a literelor
scrise manual
64 5620 10 3000 2620
Sateliţi 36 6435 7 3435 3000
Recunoaşterea
literelor
16 20000 26 10000 10000
Sursa: Jianping Gou, Lan Du, Yuhong Zhang, Taisong Xiong- A New Distance-weighted k-nearest Neighbor
Classier, 2012
Pentru creşterea confidenţei în performanţa clasificatorilor, se fac experimente de timpul validării
încrucişate cu 20 de sub-seturi şi obţinând o acurateţe de 95%. Valoarea lui k variază de la 1 la
22
Tom M. Mitchell- “Machine Learning”, ed. McGraw Hill, 1997
23
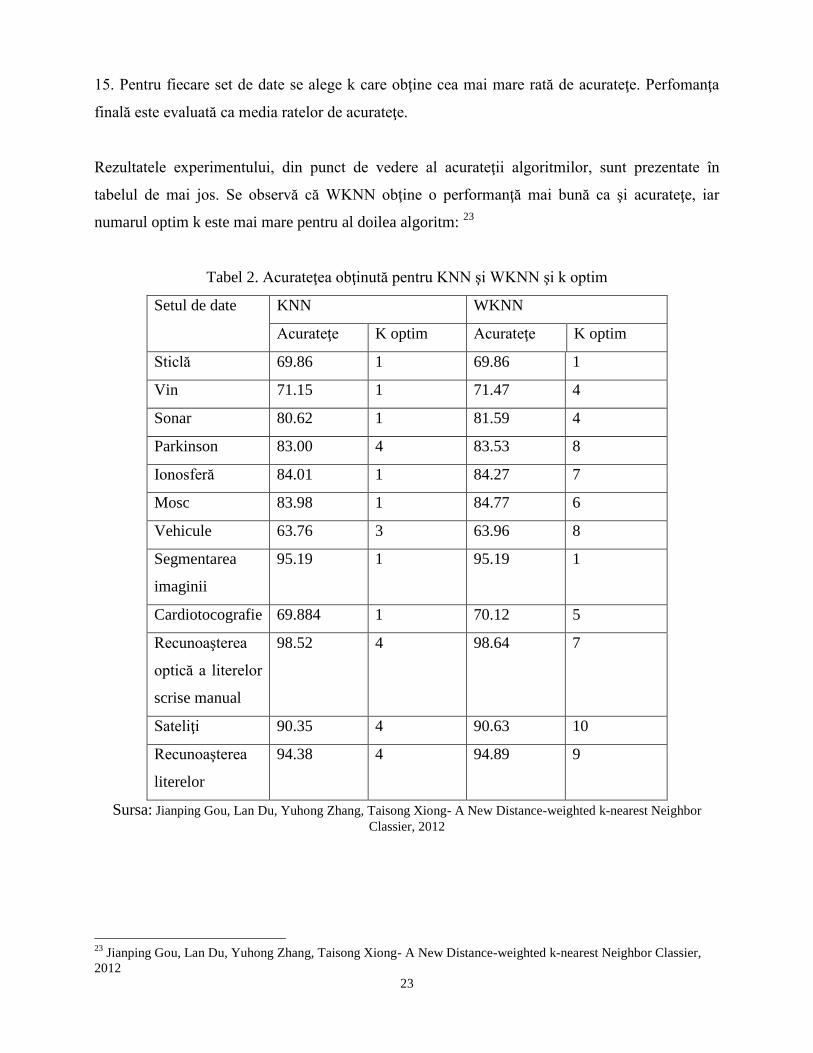
15. Pentru fiecare set de date se alege k care obţine cea mai mare rată de acurateţe. Perfomanţa
finală este evaluată ca media ratelor de acurateţe.
Rezultatele experimentului, din punct de vedere al acurateţii algoritmilor, sunt prezentate în
tabelul de mai jos. Se observă că WKNN obţine o performanţă mai bună ca şi acurateţe, iar
numarul optim k este mai mare pentru al doilea algoritm: 23
Tabel 2. Acurateţea obţinută pentru KNN şi WKNN şi k optim
Setul de date KNN WKNN
Acurateţe K optim Acurateţe K optim
Sticlă 69.86 1 69.86 1
Vin 71.15 1 71.47 4
Sonar 80.62 1 81.59 4
Parkinson 83.00 4 83.53 8
Ionosferă 84.01 1 84.27 7
Mosc 83.98 1 84.77 6
Vehicule 63.76 3 63.96 8
Segmentarea
imaginii
95.19 1 95.19 1
Cardiotocografie 69.884 1 70.12 5
Recunoaşterea
optică a literelor
scrise manual
98.52 4 98.64 7
Sateliţi 90.35 4 90.63 10
Recunoaşterea
literelor
94.38 4 94.89 9
Sursa: Jianping Gou, Lan Du, Yuhong Zhang, Taisong Xiong- A New Distance-weighted k-nearest Neighbor
Classier, 2012
23
Jianping Gou, Lan Du, Yuhong Zhang, Taisong Xiong- A New Distance-weighted k-nearest Neighbor Classier,
2012

24
CAPITOLUL 3
Tehnici de clasificare în diagnosticarea medicală
3.1 Importanţa sistemelor inteligente în diagnosticarea medicală
Simptomele sunt reacţiile fizice sau stările mentale care necesită atenţie medicală. Având un
caracter intrusiv, obstructiv şi indezirabil, precum şi o complexitate dată de felul cum sunt
percepute, interpretate şi tratate, simptomele creează o stare de incertitudine care necestită
explicaţii. Ele trebuie să fie etichetate şi înţelese pentru a se putea găsi o cale de recuperare, de
revenire la “sinele” obişnuit. Toţi oamenii care se îmbolnăvesc vor un diagnostic, fiind prima
speranţă către însănatoşire. Diagnosticul este numele bolii: când se dă un diagnostic, se dă o
boală. De obicei, doctorii sunt cei care diagnostichează şi se luptă cu boala. Aceştia au nevoie de
diagnosticare pentru a afla de ce, pentru a putea discuta şi compara, pentru a găsi soluţii şi pentru
a face presupuneri asupra viitorului. Diagnosticarea transformă starea unei persoane în ceva
tangibil, palpabil, care poate fi biruit, fiind primul şi cel mai crucial pas către vindecare.
Etichetarea este o activitate umană de bază: punând o denumire lucrurilor, omul se orientează în
lume, încearcă să le înţeleagă şi să le stăpânească. Etichetele se referă la modele, la şabloane,
creând categorii în care fiecare fenomen poate fi grupat. Problema care apare este în delimitarea
clara a categoriilor şi catalogarea corectă. La fel şi diagnosticarea, este un proces de etichetare,
fiind rezultatul investigaţiilor care o preced. Aceasta fază poate fi precisă şi rapidă sau poate fi
prelungită şi neorientată către un rezultat. Multe dintre simptomole care fac pacienţii să ceară
ajutor sunt atât de vagi că pot îndrepta diagnosticarea spre direcţii multiple.
În mod traditional, doctorii sunt cei care dau un diagnostic şi prescriu un tratament. În ultima
perioadă se observă o tentinţă de utilizare a programelor soft în medicină pentru a ajuta şi corecta
deciziile cadrelor medicale. O maximă latina spune ca “Errare humanum est”24
, eroarea umană
fiind posibilă şi în acest domeniu, însă cu consecinţe mult mai grave. Diagnosticarea cazurilor
dificile creşte şansele unei greşeli, astfel ca un sistem inteligent care să confirme sau să sugereze
o posibilă boală este indicat şi necesar.

25
Diagnosticarea fără asistenţă computerizată presupune că un clinician să ţină minte sute de boli
cunoscute împreună cu numele, simptomele, cauzele şi mecanismele corespunzatoare. Astfel,
bolile uitate sau cele care nu au fost niciodată învaţate, nu vor fi diagnosticate niciodată. Având
în vedere creşterea explozivă a cunoştinţelor medicale este imposibil de memorat toată
informaţia. O soluţie partială este utilizarea specialiştilor medicali, însă aceasta este o soluţie
imprefectă deoarece cunoştinţele sunt atât de vaste încât nici măcar specialiştii nu pot să reţină
toate informaţiile. De asemenea, accesul la această categorie de medici nu este tot timpul facil.
Adăugând complexitatea procesului de diagnosticare, simptomele similare şi investigaţiile
neconcludente, existenţa programelor de diagnosticare este de o importanţă imperativă.
Calculatoarele pot oferi o asistenţă excelentă în astfel de situaţii. Cu o capacitate de memorare
foarte mare, pot memora cu uşurinţă multe textele medicale, iar procesoarele pot aduce rapid
informaţiile dorite. Deşi diagnosticarea medicală computerizată este de o importanţă foarte mare,
asistenţa doctorilor de către aceste programe nu este un fenomen răspândit. Dintre motivele care
împiedică dezvoltarea şi utilizarea sistemelor de diagnosticare se observă:
- problema interdisciplinară: programatorii nu au experienţă necesară pentru a observa
nuanţele din practicile medicale, iar medicii nu au abilitaţile matematice şi logice necesare
în domeniul informaticii;
- dificultatea misiunii: medicina are multe aspecte care nu pot fi traduse în algoritmi
matematici;
- algoritmi bazaţi pe premise false;
- credinţa falsă că toate nuanţele practicilor medicale zilnice pot fi reprezentate cu ajutorul
instrumentelor matematice sofisticate;25
- acurateţea deciziilor: deciziile trebuie sa aibă un grad mare de corectitudine, însă foarte
puţine aplicaţii au atins performaţele de acurateţe a experţilor umani,
- existenţa unui flux de lucru continuu: sistemele nu oferă toate informaţiile de care are
nevoie un clinician (spre exemplu, sistemele nu oferă şi un plan de tratament, medicul
fiind nevoit să caute informaţii în altă parte),
- gradul de utilizabilitate: interfeţele primelor sisteme nu erau orientate către utilizator, iar
pentru utilizarea acestora este nevoie de o perioada de învăţare,
24
A greşi e omeneşte (lat) 25
Carlos Feder- “Computerized Medical Diagnosis: A Novel Solution to an Old Problem”, ed. Infinity, SUA, 2006

26
- lipsa explicaţiilor: un număr mare de sisteme nu oferă explicaţii pentru deciziile
sugerate, reducând gradul de încredere în acestea.26
Un sistem de diagnosticare trebuie să îndeplinească următoarele cerinţe:
- Performanţa bună: acurateţea clasificării noului pacient trebuie să fie cât mai mare, în
general aceasta trebuie să fie cel puţin egală cu acurateţea medicilor.
- Tratarea valorilor lipsă: în diagnosticarea medicală, unele date nu sunt disponibile, iar
algoritmii trebuie trateze aceste situaţii.
- Tratarea “zgomotului” datelor: unele date suferă de incertitudine şi erori, iar algoritmii
trebuie să aibă mijloace de a lucra cu acestea.
- Transparenţa diagnosticării: decizia luată de sistem trebuie să fie transparentă pentru
medic pentru ca acesta să poată analiza şi întelege datele generate.
- Abilitatea de a explica decizia luată: în cazul unei situaţii neaşteptate, medicul poate cere
informaţii suplimentare, în caz contrar nu va lua în serios sugestia dată de sistem.
- Diminuarea numărului de teste: colectarea datelor pacienţilor este costisitoare, motiv
pentru care se preferă un sistem care poate da un diagnostic folosind un număr restrâns de
date.27
3.2 Modelul unui sistem inteligent
De la începuturile sistemelor expert la sfârşitul anilor 1960, începutul anilor 1970, diagnosticarea
şi interpretarea au fost zonele de aplicabilitate favorite. Figura 5 prezintă componentele logice ale
procesului de diagnosticare. În general, un sistem este alcătuit din două componente: o
componentă având la bază cunoştinţe medicale (cuprind informaţii despre raporturile simptome-
boli, inter-simptome şi inter-boli) şi o interfaţă (utilizată pentru interpretarea datelor pacientului
pe baza cunoştinţelor medicale).
26
Kavishwar B. Wagholikar, Vijayraghavan Sundararajan, Ashok W. Deshpande- “Modeling Paradigms for Medical
Diagnostic Decision Support: A Survey and Future Directions”, 2011 27
Józef Karbicz - Fault Diagnosis.: Models, Artificial Intelligence, Applications, ed Springer, Berlin, 2004

27
Figura 4. Componentele logice ale procesului de diagnosticare medicală
Sursa: Kavishwar B. Wagholikar et All- “Modeling Paradigms for Medical Diagnostic Decision Support:
A Survey and Future Directions”, 2011
Complexitatea problemei de diagnosticare depinde de domeniu, numărul de instanţe de învăţare,
de numărul şi tipul atributelor şi de numărul categoriilor de clasificat. Domeniile medicale au un
grad variat de complexitate: de exemplu, bolile cardiovasculare, având un număr mare de
simptome prezintă un grad de complexitate redus faţă de diagnosticările pentru cancer, cu un
număr mic de simptome. În plus, o problemă de diagnosticare poate fi mai complexă din cauza
unui număr mic de instanţe de antrenare sau a atributelor. De asemenea, diagosticările binare,
care presupun afirmarea sau infiramarea prezenţei unei boli, sunt mai puţin complexe decât cele
cu un grad mai mare decât cele cu mai multe diagnosticări posibile.28
În trecut, cele mai multe eforturi de a aplica inteligenţa artificială în diagnosticare utilizau
sitemele bazate pe reguli. Aceste programe erau uşor de creat, deoarece cunoştinţele erau
catalogate sub forma regulilor de tipul “dacă..atunci..”, formând un lanţ de deducţii pentru a
ajunge la o concluzie. În domeniile cu constrângeri bine definite, aceste programe s-au dovedit a
fi foarte exacte. Totuşi, numărul domeniilor era unul mic, iar problemele clinice serioase sunt atât
de complexe încât nu este posibilă crearea unui set de reguli bine format. Problema apare din
faptul că aceste sisteme nu sunt formate pe baza unui model de boala sau pe raţionamente clinice.
În absenţa acestor modele, prin adăugarea unei noi reguli, se ajungea la interacţiuni neanticipate
între reguli, astfel încât performanţa programului avea de suferit.
28
Kavishwar B. Wagholikar, Vijayraghavan Sundararajan, Ashok W. Deshpande- “Modeling Paradigms for Medical
Diagnostic Decision Support: A Survey and Future Directions”, 2011

28
Având în vedere aceste dificultăţi, eforturile recente de a utiliza inteligenţa artificială în
diagnosticare s-au focalizat pe sisteme create în jurul unui model de boală. Astfel, s-au făcut
progrese remarcabile în ce priveşte înţelegerea expertizei clinice şi în translatarea acesteia în
modele cognitive şi apoi, conversia modelelor în programe experimentale.
3.3 Exemple reprezentative
Câteva dintre primele programe de diagnosticare aparute au avut succes şi au devenit “clasice”.
Un exemplu este MYCIN, dezvoltat la începutul anilor 70, sistem utilizat pentru diagnosticarea
infecţiilor bacteriene şi prescrierea antibioticelor. Alte sisteme cunoscute din acest domeniu sunt:
CASNET (pentru diagnosticarea şi tratarea glaucomului), PIP (pentru diagnosticarea bolilor
renale), Internist-I (diagnosticarea bolilor interne). Anii 90 aduc o îmbunătăţire prin combinarea a
două sau mai multe tehnici. Astfel apare ICHT- dezvoltat pentru a reduce mortalitatea copiilor în
special în zonele rurale, HERMES- utilizat în previziunea bolilor de ficat, Neo-Dat- sistem expert
pentru studiile clinice, ISS- folosit pentru diagnosticarea bolilor cu transmitere sexuală. Apar
sistemele de diagnosticare on-line: Experienced Based Medical Diagnostics System şi Case
Based Resoning.
Altă tehnică utilizată în diagnosticare este “data mining”- descoperirea informaţiilor interesante
în bazele de date de dimensiuni mari. Utilizând aceasta tehnică, erau generate diagrame şi noi
reguli pentru îmbunătăţirea sistemelor bazate pe reguli existente. Logica fuzzy şi reţelele
neuronale sunt alte tehnici utilizate frecvent în acest domeniu.29
Diagnosticarea autismului
În Statele Unite, media de vârstă pentru diagnosticarea autismului este de 5 ani jumătate, dar un
sfert din copii rămân nediagnosticaţi până la vârsta de 8 ani. Deşi autismul are o puternică
componentă genetică, diagnosticarea sa se face pe baza comportamentului. Cele mai utilizate
instrumente pentru diagnosticarea autismului sunt ADI-R (Autism Diagnostic Interview
Revised), care constă într-un chestionar de 93 de întrebări şi ADOS (Autism Diagnostic
29
Wan Hussain Wan Ishak, Fadzilah Siraj – “Artificial intelligence in medical applications: an exploration”

29
Observation Schedule), care implică observarea de către un clinician a 27 de atribute de
comportament.
Ambele teste pot dura până la trei ore. Încercările de a diminua durata testelor sunt privite cu
scepticism, experţii considerând că eliminare anumitor întrebări duce la excluderea anumitor
categorii de pacienţi, cum ar fii indivizii cu o funcţionalitate ridicată sau copiii mici. Ultimele
studii dezvoltate de Dennis Wall, directorul Iniţiativei Biologiei Computaţionale de la Şcoala
Medicală Harvard, arată că utilizând inteligenţa artificială şi sistemele expert a identificat un
subset de 7 întrebări din ADI-R şi o serie de comportamente evaluate de ADOS ca fiind cruciale
pentru identificarea autismului. Testând performanţa a 15 algoritmi bazaţi pe învăţare automată
pe cele 93 de întrebări, se observă ca cele mai bune rezultate sunt obţinute de Arborii de Decizie
Alternantă, cu o sesibilitate perfectă de 1 şi o rata de pozitiv fals de 0.013 şi o acurateţe de
ansamblu de 99,9%. Conform acestui clasificator, doar 7 întrebări sunt relevante şi necesare
pentru o diagnosticare corectă, reduând timpul în mod considerabil. Rezultatele celor 15
algoritmi sunt prezentate în tabelul de mai jos.
Table 3. Rezultatele celor 15 algoritmi folosiţi pentru diagnosticarea autismului.
Sursa: Dennis P. Wall et All - “Use of Artificial Intelligence to Shorten the Behavioral Diagnosis
of Autism”

30
Sistemul dezvoltat este aproape în perfectă concordanţă cu diagnosticările specialiştilor în ce
priveşte identificarea autismului. Este mai puţin specific în ce priveşte catalogarea persoanelor
care nu au această boală, şi anume 92%, ceea ce înseamană că 8% din cei care nu suferă de
aceasta afecţiune sunt catalogaţi greşit, ca fiind bolnavi.30
30
Dennis P. Wall, Rebecca Dally, Rhiannon Luyster, Jae-Yoon Jung, Todd F. DeLuca- “
Use of Artificial Intelligence to Shorten the Behavioral Diagnosis of Autism”

31
CAPITOLUL 4
Aplicaţia practică
4.1 Descrierea problemei şi aborări existente în literatură
Descrierea problemei
Dermatologia este o ramură a medicinii care urmăreşte explicarea, diagnosticarea şi tratarea
bolilor de piele, păr şi unghii. O clasă particulară a bolilor dermatologice este denumită
erythemato-squamous, indicând înroşirii pielii (erythemato) cauzată de pierderea celulilor de
piele (squamous). În general, cauza bolii este fie genetică, fie dată de factori de mediu şi se
manifestă în perioade specifice ale vieţii (copilărie, adolescenţă timpurie).
Erythemato-squamous este o categorie generică pentru o varietate de condiţii medicale care
prezintă simptome care coincid. Se practică trei metode principale pentru diagnosticarea
condiţiilor medicale: clinic, hispatologic şi recent, o nouă metodă prin examinare microscopică
specializată. Examinarea clinică se bazează pe un control non-invaziv, vizual al simptomelor
(cum ar fi locaţia, mărimea, prezenţa pustulelor, culoarea). Examinarea hispatologică necesită
prelevarea unei mostre de ţesut (biopsie) şi o analiză de sânge pentru detectarea eventualelor
surse virale. Cea mai recentă metodă de diagnosticare se bazează pe o microscopie confocală
non-invazivă.
Există şase sub-tipuri ale acestei boli (psoriasis, seboreic dermatitis, lichen planus, pityriasis
rosea, cronic dermatitis şi pityriasis rubra pilaris), iar diagnosticarea corectă a uneia dintre ele
este o problemă des întâlnită. Încadrarea într-una dintre cele saşe categorii este o îngreunată din
cauza faptului că au multe simptome similare (de exemplu eritemul - roseata a pielii). O altă
dificultate în diagnosticare apare în cazul în care o boală prezintă caracteristicile alteia în faza
incipientă, crescând astfel şansele unei diagnosticări greşite.31
31
Kenneth Revett, Florin Gorunescu, Abdel-Badeeh Salem & El-Sayed El-Dahshan –„ Evaluation of the Feature
Space of an Erythematosquamous Dataset Using Rough Sets”, 2009

32
În lucrearea de faţă sunt considerate 12 atribute clinice şi 22 de atribute hispatologice. Acestea
sunt ilustrate în tabelul de mai jos:
Tabel 4: Datele (atribute şi clase) folosite în aplicaţie
Sursa: H. Altay Guvenir, Gulsen Demiroz, Nilsel Ilter –”Learning differential diagnosis of erythemato-squamous
diseases using voting feature intervals”, 1988
Setul de date folosi în aplicaţie este preluat din data de baze UCI şi conţine 266 de pacienţi,
diagnosticaţi cu una dintre cele şase subtipuri ale erythemato-squamous, menţionate mai sus.
Fiecare pacient are cele 34 de atribute şi o clasă de decizie, indicând cu ce tip de boală este
diagnosticat pacientul. Valorile atributelor sunt nominale şi, cu excepţia vârstei, sunt cuprinse
între 0 şi 3. Zero indică lipsa atributului, 3 este valoarea maximă posibilă, iar 1 şi 2 sunt valori
intermediare. Atributul de vârstă conţine valorile reale, cuprinse între 17 şi 69, iar pentru acest
atribut există 8 valori lipsă. Distribuţia pacienţilor în fiecare clasă de decizie este prezentată în
tabelul următor:

33
Tabel 5: Distribuţia pacienţilor în fiecare clasa de decizie
Studii existente
Literatura care analizează boala erythemato-squamous este relativ recentă, iar cele mai multe
studii exploatează setul de date oferit de UCI, folosit şi în această lucrare. H. A. Guvenir publică
o serie de studii bazate pe aceste date în care analizeaza noua schemă de clasificare, voting
feature intervals. Rezultatele arată că datele pot fi clasificate corect cu o acurateţe ridicată
(aproximativ 99%). VFI (şi versiunea îmbunătăţită, VFI-5) produce un set de reguli, însă aceste
reguli sunt bazate pe intervale şi descrise valori numerice greu de interpretat pentru neiniţiaţi. Ca
extensie a acestui studiu, cu ajutorul unui algoritm genetic, se găseşte ponderea fiecărui atribut.
Confom acestuia, koebner phenomenon are cea mai mare influenţă în luarea deciziei de
clasificare, primind o pondere de 0.062, fiind urmat de inflammatory mononuclear infiltrare, cu
0.0527. La polul opus, atribute precum acanthosis, follicular horn plug sau vârsta sunt cele mai
puţin relevante.
Tot pe aceste date, Castellano realizează un sistem neuro-fuzzy bazat pe reguli în mai mulţi paşi,
denumit Kernel. Sistemul Kernel are o abordare pe trei etape: în prima fază, un algoritm
supervizat de grupare (cluster) este folosit pentru a găsi informaţii de pe datele iniţiale. Apoi, o
învăţare supervizată de tipul fuzzy- reţele neuronale pentru ajustarea parametrilor din
algormitmul fuzzy. Ultimul pas este procesul de rafinare a regulilor cu scopul de a minimiza setul
de reguli final. Autorii constată că atributul de vârstă reduce acurateţea clasificatorului, de la o
acurateţe de 95% în cazul eliminării acestui atribut, la 71% în cazul prezenţei sale.
Alţi autori au implementat maşini cu suport vectorial (SVM) pentru clasificarea datelor specifice
bolii erythemato-squamous. Într-un raport realizat de Nanni, un ansamblu de clasificatori, fiecare

34
utilizând un subset de date, sunt combinaţi pentru a forma o schema de clasificare holistică
superioară altor SVM-uri pentru acest set particular de date, cu o rată de eroare între 2 şi 3%.
Derya şi Dogdu publică rezultatele unui studiu bazat pe o abordare k-means clustering având ca
rezultat o acurateţe a clasificării de 94%, utilizând datele corespunzătoare pentru 5 clase din 6
(este omisă pityriasis rubra pilaris, cu 20 de instanţe). Czibula şi alţi colaboratori discută
utilizarea unui sistem suport de decizie de tip multi-agent pentru clasificarea acestor date
dermatologice, prezentând un MDSS care dispune de o reţea neuronală antrenată cu
backpropagation, obţinând ca rezultat o acurateţe de peste 99%. Karabatak prezintă un algoritm
hibrid oferind ca date de intrare pentru reţelele neuronale, reguli de asociere. Regulile de asociere
reflectă date interesante conţinute în setul de date şi, prin definiţie, acestea reduc spaţiul
atributelor prin extragerea relaţiilor utile care păstrează esenţa informaţiilor. Noile date obţinute
sunt date apoi reţelei neuronale spre prelucrare. Regulile de asociere reduc spaţiul atributelor de
la 34 la 20, iar algorimul obţine o acurateţe de 99%.
Prezentarea studiilor asupra diagnosticării acestui tip de boală nu este exhaustivă, însă oferă o
indicaţie asupra abordărilor diferite folosite în investigarea conţinutului informaţiilor din acest set
de date. O observaţie imediată este acurateţea ridicată a clasificării pentru mulţi din algoritmii
menţionaţi – peste 99%. Acest procent ridicat este neaşteptat din perspectiva faptului că setul de
date conţine şase clase de decizie şi un număr relativ mic de înregistrări (366). O explicaţie
posibilă este dimensiunea mare a spaţiului atributelor (34). Importanţa fiecăruit atribut constituie
preocuparea cercetătorului Kenneth Revett în studiul referitor la evaluarea atributelor cu ajutorul
datelor neprelucrate. Metoda seturilor de date brute (Rough Sets) are ca filosofie de bază
reducerea elementelor (atributelor) pe baza conţinutului informaţiilor despre fiecare atribut sau
colecţie de atribute (obiecte) astfel încât să existe o mapare între obiectele similare şi clasa de
decizie corespunzătoare. Rezultatele studiului arată că deciziile de clasificare sunt influenţate de
valorile intermediare (1 şi 2) ale atributelor şi nu de cele maximale. Valorile intermediare sunt
mai puţin precise decât cele extreme, generând astfel un număr ridicat de reguli. De asemenea,
utilizând doar atributele clinice, acurateţea este de 50%. Atributele histopatologice produc o
acurateţe a clasificării mai ridicată, de 85%.32

35
4.2 Aplicaţia
4.2.1 Analiză şi proiectare
Document de specificare functională
Cerinţele funcţionale se referă la serviciile pe care un sistem software trebuie să le ofere.
Programul va executa acţiuni precum afişarea, procesarea şi managementul datelor în funcţie de
aceste specificări funcţionale.
Funcţionalitatea aplicaţiei constă în gestionarea pacienţilor, a fişelor medicale, a tratamentelor
precum şi probleme de diagnosticare. Detalierea acestor activităţi este realizată în tabelul
următor:
Nr crt Funcţionalitate
1 Autentificarea medicilor prin userul şi parola personală
2 Doctorii vor putea introduce noi pacienţi şi modifica datele pacienţilor deja existenţi
3 Doctorii au posibilitatea de a consulta fişa medicalş a pacienţilor, de a vedea
istoricul şi date medicale personale.
4 Doctorii vor putea vedea istoricul consultaţiilor şi prescrie noi tratamente
5 Doctorii vor putea folosi algoritmii de diagnosticare pentru boala de piele
„erythemato-squamous”.
Acest sistem este until în multe acţiuni de management al pacienţilor unui spital, ajutând la o mai
bună organizare a datelor şi a muncii.
32
Kenneth Revett, Florin Gorunescu, Abdel-Badeeh Salem & El-Sayed El-Dahshan –„ Evaluation of the Feature
Space of an Erythematosquamous Dataset Using Rough Sets”, 2009

36
Cazuri de utilizare
Caz de utilizare: Autentificare
Actor: Doctor
Descriere: Doctorul doreşte să înceapă o sesiune de lucru în sistem.
Scenariu: CU începe când un doctor doreşte să efectueze diferite acţiuni
1. Terminalul afişează un mesaj prin care cere doctorului userul şi parola.
2. Doctorulul introduce datele cerute.
3. Sistemul verifică credenţialele primite.
4. Sistemul afişează pagina de start a aplicaţiei.
5. CU se incheie.
Scenarii alternative: A1. La pasul 3, autentificarea eşuează, se afisează un mesaj corespunzător
şi acţiunea este reluată de la pasul 1.
Preconditii: Doctorul are credenţiale valide.
Postconditii: Doctorul este autentificat şi poate să acceseze data pacienţilor.
Caz de utilizare: Gestionează pacient
Actor: Doctor
Descriere: Doctorul doreşte să înregistreze/modifice datele unui pacient nou

37
Scenariu: CU începe când un doctor doreşte să gestioneze un pacient
1. Doctorul selectează adăugarea unui nou pacient / un pacient existent
2. Doctorulul introduce datele personale ale pacientului (nume, prenume, CNP, adresa,
telefon)/ modifică date existente
3. Sistemul actualizează datele datele.
4. CU se incheie.
Scenarii alternative: A1. La pasul 3, actualizarea eşuează în cazul în care datele introduse nu
sunt valide, se afişeaza un mesaj corespunzător şi acţiunea este reluată de la pasul 2.
Preconditii: Doctorul este autentificat.
Postconditii: Daca CU se încheie cu succes,un nou pacient este creat/ datele unui vechi pacient
sunt actualizate.
Caz de utilizare: Caută pacient
Actor: Doctor
Descriere: Doctorul doreşte să caute un pacient în BD
Scenariu: CU începe când un doctor doreşte să caute un pacient
1. Doctorul intoduce datele numele sau CNP-ul
2. Doctorul apasă butonul de căutare corespunzator: căutare dupa CNP sau după nume
3. Sistemul afişează datele găsite.
4. CU se incheie.
Scenarii alternative: A1. La pasul 2, cautarea eşuează în cazul în care datele introduse nu sunt
valide, se afisează un mesaj corespunzator şi acţiunea este reluată de la pasul 1.
Preconditii: Doctorul este autentificat, pacientul căutat există în sistem.
Postconditii: Daca CU se încheie cu succes, pacientul căutat este afişat.
Caz de utilizare: Adaugă consultaţie
Actor: Doctor
Descriere: Doctorul doreşte să adauge o nouă consultaţie
Scenariu: CU începe când un doctor doreşte să prescrie un tratament.
1. Doctorul selectează adăugarea unui tratament nou.
2. Doctorul introduce data, diagnosticul şi tratamentul.
3. Sistemul actualizează lista tratamentelor prescrise şi istoricul medical al pacientului.
4. CU se incheie.

38
Preconditii: Doctorul este autentificat şi pacientul există în baza de date.
Postconditii: Daca CU se incheie cu succes,un nou tratament este prescris pacientului şi este
actualizat istoricul său medical.
Caz de utilizare: Gestionează fişa medicală
Actor: Doctor
Descriere: Doctorul doreşte să vizualizeze şi să modifice fişa medicală a pacientului.
Scenariu: CU începe când un doctor doreşte să vizualizeze fişa medicală.
1. Doctorul selectează vizualizarea fişei medicale.
2. Doctorul modifică datele din fişa şi apasă butonul de salvare.
3. Sistemul actualizează fişa medicală.
4. CU se încheie.
Preconditii: Doctorul este autentificat şi pacientul există în baza de date.
Postconditii: Dacă CU se încheie cu succes, fişa medicală a pacientului este actualizată.
Caz de utilizare: Diagnosticare
Actor: Doctor
Descriere: Doctorul doreşte ca pacientul să fie diagnosticat pentru una din cele şase tipuri de boli
de piele erythemato-squamous.
Scenariu: CU începe când un doctor doreşte să diagnosticheze un pacient.
1. Doctorul introduce datele necesare pentru diagnosticare.
2. Doctorul selectează metoda de diagnosticare.
3. Sistemul procesează datele şi execută algoritmul.
4. Sistemul returnează rezultatul diagnosticării.
5. Sistemul salvează datele primite ca noi date de învăţare.
6. CU se încheie.
Preconditii: Doctorul este autentificat, pacientul există în baza de date şi doctorul deţine toate
informaţiile necesare pentru efectuarea diagnosticării.
Postconditii: Daca CU se încheie cu succes, lista datelor de învaţare este actualizată, doctorul
primeşte un rezultat iar istoricul medical al pacientului este actualizat.

39
Diagrama entitate-relaţie

40
Diagrame de secvenţe
a) Pentru cazul de utilizare de diagnosticare
b) Pentru cazul de utilizare de adaugare consultaţie

41
Diagrama de activităţi
c) Pentru algoritmul VFI

42
Structura bazei de date:

43
Diagrama de componente

44
Interfaţa grafică
Fereastra pentru introducerea valorilor atributelor:
Fereastra pentru vizualizarea rezultatelor

45
4.2.2 Implementare
Programul este scris în limbajul Java şi implementează şablonul “Model-View-Controler”.
Interfaţa este realizată cu ajutorul GWT Designer iar pentru popularea tabelelor cu date este
folosit Beans Binding. Pentru manipularea datelor la nivelul bazei de date se utilizează
Activejdbc.
public class DiagnosisInstance {
int[] instance;
public DiagnosisInstance(int[] instance) {
this.instance = instance;
}
public int[] getInstance() {
return instance;
}
public void setInstance(int[] instance) {
this.instance = instance;
}
}
public class DiagnosisTrainingSet {
int[][] data;
public DiagnosisTrainingSet(int[][] data) {
this.data = data;
}
public int[][] getData() {
return data;
}
public void setData(int[][] data) {
this.data = data;
}
}
public class DiagnosisModel {
private static final int NUMBER_OF_INSTANCES = 366;
private static final int NUMBER_OF_FEATURES = 34;
public DiagnosisTrainingSet readTrainingData() {
int[][] rez = new int[NUMBER_OF_INSTANCES][NUMBER_OF_FEATURES + 1];
try {
BufferedReader br = new BufferedReader(new FileReader(
"trainingData"));
String linie;
int i = 0;
while ((linie = br.readLine()) != null) {
String[] line = linie.split(",");
for (int j = 0; j < line.length; j++) {
rez[i][j] = Integer.parseInt(line[j]);
}
i++;
}
br.close();
} catch (IOException e) {
System.err.println("Eroare" + " " + e);
}
return new DiagnosisTrainingSet(rez);
}
}
public class VotingFeatureInterval {
private int NUMBER_OF_INSTANCES;
private static final int NUMBER_OF_FEATURES = 34;
private static final int NUMBER_OF_CLASSES = 6;

46
private static final double MIN_VALUE = -100;
private static final double MAX_VALUE = 100;
public static final Map<Integer, String> diseases = new HashMap<Integer, String>() {
{
put(1, "psoriasis");
put(2, "seboreic dermatitis");
put(3, "lichen planus");
put(4, "pityriasis rosea");
put(5, "cronic dermatitis");
put(6, "pityriasis rubra pilaris");
}
};
public String message = "";
public int votingFeatureInterval(DiagnosisInstance instance,
DiagnosisTrainingSet testData) {
int[] unknown = instance.getInstance();
NUMBER_OF_INSTANCES = testData.getData().length;
LinkedList<double[][]> intervals = train(testData.getData());
double[][] vote = new double[NUMBER_OF_FEATURES][NUMBER_OF_CLASSES];
for (int i = 0; i < intervals.size(); i++) {
LinkedList<Integer> intervalNumber = findIntervalForFeature(
intervals.get(i), unknown[i]);
for (int iclass = 0; iclass < NUMBER_OF_CLASSES; iclass++) {
double classVote = 0;
if (intervalNumber.size() == 1) {
classVote = intervals.get(i)[intervalNumber.get(0)][iclass + 1]
/ count(testData.getData(), i, -100.0, 100.0,
iclass + 1);
} else if (intervalNumber.size() == 2) {
double cv1 = intervals.get(i)[intervalNumber.get(0)][iclass + 1];
double cv2 = intervals.get(i)[intervalNumber.get(1)][iclass + 1];
classVote = (cv1 + cv2)
/ (count(testData.getData(), i, -100.0, 100.0,
iclass + 1) * 2);
}
vote[i][iclass] = classVote;
}
}
normalizeVotes(vote);
double[] result = new double[NUMBER_OF_CLASSES];
int found = 0;
for (int ii = 0; ii < NUMBER_OF_FEATURES; ii++) {
for (int j = 0; j < NUMBER_OF_CLASSES; j++) {
result[j] = result[j] + vote[ii][j];
}
}
List<Double> aux = new LinkedList<Double>();
for (int j = 0; j < NUMBER_OF_CLASSES; j++) {
aux.add(result[j]);
}
Collections.sort(aux);
double max = (double) aux.get(NUMBER_OF_CLASSES - 1);
for (int j = 0; j < NUMBER_OF_CLASSES; j++) {
if (result[j] == max) {
found = j;
}
}
found++;
return found;
}
public LinkedList<double[][]> train(int[][] data) {
LinkedList<double[][]> matrix = new LinkedList<>();
for (int j = 0; j < NUMBER_OF_FEATURES; j++) {
double[][] aux = new double[NUMBER_OF_CLASSES][2];

47
matrix.add(aux);
}
// get end point of each feature for each class
for (int j = 0; j < NUMBER_OF_FEATURES; j++) {
for (int i = 1; i <= NUMBER_OF_CLASSES; i++) {
(matrix.get(j))[i - 1][0] = findEndPoints(data, j, i)[0];
(matrix.get(j))[i - 1][1] = findEndPoints(data, j, i)[1];
}
}
// sort end points
LinkedList<double[][]> matrix2 = new LinkedList<>();
for (int j = 0; j < NUMBER_OF_FEATURES; j++) {
ArrayList<Double> val = createInterval(matrix.get(j));
double[][] aux = new double[val.size() + 2][NUMBER_OF_CLASSES + 1];
matrix2.add(aux);
// count(data,j,val.get(0),val.get(1));
// count each instance
for (int ji = 0; ji < val.size() - 1; ji++) {
(matrix2.getLast())[ji + 1][0] = val.get(ji);
for (int cls = 1; cls < NUMBER_OF_CLASSES + 1; cls++) {
(matrix2.getLast())[ji + 1][cls] = count(data, j,
val.get(ji), val.get(ji + 1), cls);
}
}
// set values for (-infinity,x)
(matrix2.getLast())[0][0] = MIN_VALUE;
for (int cls = 1; cls < NUMBER_OF_CLASSES + 1; cls++) {
(matrix2.getLast())[0][cls] = count(data, j, MIN_VALUE,
val.get(0), cls);
}
(matrix2.getLast())[matrix2.getLast().length - 2][0] = val.get(val
.size() - 1);
for (int cls = 1; cls < NUMBER_OF_CLASSES + 1; cls++) {
(matrix2.getLast())[matrix2.getLast().length - 2][cls] = count(
data, j, val.get(val.size() - 1), MAX_VALUE, cls);
}
// set values for (x, infinity)
(matrix2.getLast())[matrix2.getLast().length - 1][0] = MAX_VALUE;
for (int cls = 1; cls < NUMBER_OF_CLASSES + 1; cls++) {
(matrix2.getLast())[matrix2.getLast().length - 1][cls] = 0;
}
}
return matrix2;
}
public LinkedList<Integer> findIntervalForFeature(double[][] interval,
int value) {
LinkedList<Integer> aux = new LinkedList();
for (int i = 0; i < interval.length - 1; i++) {
if ((value >= interval[i][0] && value <= interval[i + 1][0])) {
aux.add(i);
}
}
if (value >= interval[interval.length - 1][0]) {
aux.add(interval.length - 1);
}
return aux;
}
public double[] findEndPoints(int[][] data, int feat, int cls) {
double[] aux = new double[2];
int min = Integer.MAX_VALUE;
int max = Integer.MIN_VALUE;
for (int i = 0; i < data.length; i++) {
if (data[i][NUMBER_OF_FEATURES] == cls) {
if (data[i][feat] > max)

48
max = data[i][feat];
if (data[i][feat] < min)
min = data[i][feat];
}
}
aux[0] = min;
aux[1] = max;
return aux;
}
private double count(int[][] data, int feat, Double min, Double max, int cls) {
double nr = 0;
for (int i = 0; i < NUMBER_OF_INSTANCES; i++) {
if (data[i][NUMBER_OF_FEATURES] == cls && data[i][feat] < max
&& data[i][feat] > min) {
nr++;
} else if (data[i][NUMBER_OF_FEATURES] == cls
&& (data[i][feat] == min || data[i][feat] == max)) {
nr = nr + 0.5;
}
}
return nr;
}
private ArrayList<Double> createInterval(double[][] ds) {
ArrayList<Double> d = new ArrayList<Double>();
for (int i = 0; i < NUMBER_OF_CLASSES; i++) {
if (!d.contains(ds[i][0])) {
d.add(ds[i][0]);
}
if (!d.contains(ds[i][1])) {
d.add(ds[i][1]);
}
}
Collections.sort(d);
return d;
}
private void normalizeVotes(double[][] vote) {
for (int i = 0; i < vote.length; i++) {
double sum = 0;
for (int j = 0; j < vote[i].length; j++) {
sum = vote[i][j] + sum;
}
for (int j = 0; j < vote[i].length; j++) {
vote[i][j] = vote[i][j] / sum;
}
}
}
}
public class KNearestNeighbour {
public int KNearestNeighbour(Integer k, DiagnosisInstance instance,
DiagnosisTrainingSet testData2) {
int[] unknown = instance.getInstance();
NUMBER_OF_INSTANCES = testData2.getData().length;
double[][] testData = normalizare(testData2.getData());
Double[][] distance = getDistance(testData, unknown);
// order distance
bubbleSort(distance);
// take first sorted k-neighbers's classes
List<Integer> foundClass = new LinkedList<Integer>();
for (int i = 0; i < k; i++) {
int index = (int) Math.round(distance[i][0]);

49
foundClass.add((int) testData[index][34]);
}
int clasa = 0;
int max = 0;
for (int i = 1; i <= NUMBER_OF_CLASSES; i++) {
int nr = Collections.frequency(foundClass, i);
if (nr > max) {
max = nr;
clasa = i;
}
}
return clasa;
}
public Double[][] getDistance(double[][] testData, int[] unknown) {
Double[][] distance = new Double[NUMBER_OF_INSTANCES][2];
// 366 instances for testing
for (int i = 0; i < NUMBER_OF_INSTANCES; i++) {
distance[i][0] = (double) i;
// calculate distance
distance[i][1] = 0.0;
for (int j = 0; j < NUMBER_OF_FEATURES; j++) {
distance[i][1] = distance[i][1]
+ Math.pow(testData[i][j] - unknown[j], 2);
}
distance[i][1] = Math.sqrt(distance[i][1]);
}
return distance;
}
public static void bubbleSort(Double[][] distance) {
int n = distance.length;
for (int pass = 1; pass < n; pass++) { // count how many times
for (int i = 0; i < n - pass; i++) {
if (distance[i][1] > distance[i + 1][1]) {
// exchange elements
Double temp = distance[i][0];
distance[i][0] = distance[i + 1][0];
distance[i + 1][0] = temp;
temp = distance[i][1];
distance[i][1] = distance[i + 1][1];
distance[i + 1][1] = temp;
}
}
}
}
public double[][] normalizare(int[][] data) {
double[][] aux = new double[NUMBER_OF_INSTANCES][NUMBER_OF_FEATURES + 1];
int[] min = new int[NUMBER_OF_FEATURES];
int[] max = new int[NUMBER_OF_FEATURES];
for (int i = 0; i < NUMBER_OF_FEATURES; i++) {
min[i] = Integer.MAX_VALUE;
max[i] = Integer.MIN_VALUE;
}
for (int i = 0; i < data.length; i++) {
for (int j = 0; j < data[i].length - 1; j++) {
if (data[i][j] > max[j])
max[j] = data[i][j];
if (data[i][j] < min[j])
min[j] = data[i][j];
}
}

50
for (int i = 0; i < data.length; i++) {
for (int j = 0; j < NUMBER_OF_FEATURES; j++) {
aux[i][j] = ((double) data[i][j] - (double) min[j])
/ ((double) max[j] - (double) min[j]);
}
}
for (int i = 0; i < data.length; i++) {
aux[i][NUMBER_OF_FEATURES] = ((double) data[i][NUMBER_OF_FEATURES]);
}
return aux;
}
}
public class DistanceWeightedNearestNeighbor {
public int distanceWeightedNearestNeighbor(Integer k,
DiagnosisInstance instance, DiagnosisTrainingSet testData2) {
int[] unknown = instance.getInstance();
NUMBER_OF_INSTANCES = testData2.getData().length;
double[][] testData = normalizare(testData2.getData());
Double[][] distance = getDistance(testData, unknown);
// order distance
bubbleSort(distance);
// take first sorted k-neighbers's classes
double[] weight = new double[NUMBER_OF_CLASSES];
for (int i = 0; i < NUMBER_OF_CLASSES; i++) {
weight[i] = 0;
}
int clasa = 0;
for (int i = 0; i < k; i++) {
int index = (int) Math.round(distance[i][0]);
int disease = (int) testData[index][NUMBER_OF_FEATURES];
if ((distance[i][1]) == 0) {
clasa = disease;
return clasa;
}
weight[disease - 1] = weight[disease - 1] + (1 / (distance[i][1]));
}
Double max = MIN_VALUE;
for (int i = 0; i < NUMBER_OF_CLASSES; i++) {
if (weight[i] > 0 && weight[i] > max) {
max = weight[i];
clasa = i;
}
}
return (clasa + 1);
}
public Double[][] getDistance(double[][] testData, int[] unknown) {
Double[][] distance = new Double[NUMBER_OF_INSTANCES][2];
// 366 instances for testing
for (int i = 0; i < NUMBER_OF_INSTANCES; i++) {
distance[i][0] = (double) i;
// calculate distance
distance[i][1] = 0.0;
for (int j = 0; j < NUMBER_OF_FEATURES; j++) {
distance[i][1] = distance[i][1]
+ Math.pow(testData[i][j] - unknown[j], 2);
}
distance[i][1] = Math.sqrt(distance[i][1]);
}
return distance;
}

51
4.2.3 Manual de utilizare
Utilizare aplicaţiei
Pentru a utiliza aplicaţia, dupa rularea programului, este necesarcă o autentificare cu credenţiale
valide.
Cautarea unui pacient
Prima ferestra care se deschide, după autentificare, perminte căutarea pacienţilor în baza de date.
Căutarea se poate face după nume sau prenume, prin introducerea datelor şi apăsarea butonului
„Search by name”. Rezultatul căutării este afişat în tabelul din partea de jos a ferestrei. De
asmenea, pacienţii pot fi cautaţi dupa CNP, prin introducerea datelor şi apasarea butonului
„Search by CNP”. Rezultatul căutării este afişat în tabelul din partea de jos a ferestrei. În lipsa
unui text de căutare, prin apăsarea unuia dintre cele două butoane menţionate, toţi pacienţii sunt
afişaţi în tabel.
Adaugarea unui nou pacient
Prin apăsarea butonului „New Pacient”, se deschide o nouă fereastră care permite introducerea
datelor de identificare a pacientului. Nu este permisă introducerea unui pacient cu un CNP care
exista deja în baza de date, un numar de telefon cu cifre sau o data care nu respecta formatul
„dd/mm/yyyy”. Butonul „Save pacient” salveaza datele în baza de date.
Vizualizarea datelor unui pacient
Selectând din listă un pacient, se deschide o nouă fereastră unde sunt afişate datele personale ale
pacientului. Datele pot fi modificate, iar prin apăsarea butonului „Save changes” se realizează
salvarea în baza de date. Simultan, se pot vizualiza datele mai multor pacienţi.

52
Vizualizarea fişei medicale
Prin apasarea butonului „Medical Chart” din fereastra „Pacient’s personal data” se deschide o
noua fereastra unde sunt afişate datele medicale ale pacientului. Informaţiile medicale ale
pacientului pot fi modificate, salvarea acestora fiind facută prin apăsarea butonului “Save
changes”. Adăugarea unei noi consultaţii în fişa pacientului se face prin apăsarea butonului „New
Exam”, completarea datelor şi salvarea acestora. Consulaţiile pacientului sunt afişate în tabel.
Diagnosticarea bolii de piele
Prin apăsarea butonului de „Skin disease diagnosis” se deschide o fereastră care permite
introducerea datelor specifice diagnosticării bolilior de piele. Apasarea butonului „Diagnosticate”
actualizează datele în baza de date şi deschide o nouă fereastră pentru procesarea datelor. După
introducerea valorii k (numărul de vecini) şi apăsarea butonului “Results”, diagnosticul dat de
fiecare algoritm este afişat în dreptul numelui său. În partea de mijloc a ferestrei sunt afişate
pentru fiecare algoritm, motivaţia alegerii diagnosticului. Partea de jos a ferestrei prezintă
informaţii generale despre algorimti, şi anume, acurateţea fiecăruia, pe baza metodei de validare
cross-validation de tipul “leave-one-out”.
4.3 Rezultate comparative
Utilizând cross-validation cu metoda “leave-one-out”, pe un set de 366 de instanţe, VFI obţine
cele mai bune rezultate, clasificând corect 91,8% dintre ele. Pentru un k =3, DWNN clasifică
corect un procent de 76,5%, fiind mai precis decat KNN, cu doar 72,67% de instanţe clasificate
corect.

53
Figura 5. Rezultatele obţtinute de VFI, KNN, DWNN (numărul de răspunsuri corecte/ greşite din
366 de instanţe)
Se observă variaţii ale datelor pentru algoritmii KNN şi DWNN, în funcţie de numărul de vecini,
k. KNN are cea mai mare acurateţe pentru un k de valoare 2, catalogând corect 270 de instanţe
din 365. DWNN obţine cele mai bune rezultate pentru un k = 3, catalogând corect 280 de
instanţe.
Figura 6. Rezultatele obţinute de KNN şi DWNN în funcţie de numărul k (% de catalogări
corecte)

54
Pentru cei doi algoritmi datele sunt normalizate, însă se obţin rezultate mai bune înainte de
normalizare. Astfel, pentru un k de valoare 1, KNN cataloghează greşit doar 36 de instanţe, iar
pentru k de valoare 5, DWNN cataloghează greşit doar 35. Această anomalie a datelor este pusă
pe faptul ca atributele au ponderi diferite, fapt de care nu se ţine cont în algoritmul curent.
Figura 7. Rezultatele obţinute de KNN şi DWNN în funcţie de numărul k (% de catalogări
corecte) – fără normalizare
4.4 Extinderi posibile
Aplicaţia de faţă poate suferi mai multe îmbunăţări, existând neajunsuri specifice algorimilor cât
şi specifice problemei studiate.
KNN şi WDNN au câteva ingrediente principale care pot influenţa performanţa acestora: distanţa
metrică, numarul de vecini aleşi pentru a face clasificarea, ponderea vecinilor (pentru WDNN) şi
funcţia de predicţie. Distanţa metrică, care determină cele mai apropiate instanţe, poate fi
imbunătăţite prin utilizarea unui calcul mai complex decât distanţa euclidiană. Acest lucru se
aplică şi în cazul funcţiei de predicţie şi a calcului ponderilor, prin complicarea metodelor
actuale. Acurateţea algoritmului este influenţată de numarul k, motiv pentru care se sugerează

55
căutarea unui k optim. De asemnea, trebuie luate în considerare cazurile de conflic, când două
clase de decizie obţin acelaşi rezultat deoarece implementarea curentă alege prima variantă
găsită.
Normalizarea datelor este o altă problemă cu care se confruntă KNN şi WDNN, însă nu şi VFI.
Deşi aplicaţia de faţă ia în considerare normalizarea datelor, după cum s-a arătat, algoritmii obţin
rezultate mai bună evitând acest proces. Cauzele şi eliminarea acestui fenomen necesită o viitoare
analiză.
O problemă menţionată de-a lungul lucrării este tratarea în mod egal a tuturor atributelor. Din
acest punct de vedere, este necesară folosirea unui algoritm care să determine ponderile în care
fiecare atribut influenţează decizia de diagnosticare. Un alt aspect este eliminarea atributelor care
au o influenţă redusă asupra rezultatului final.
O altă imbunătătire este reducerea numărului de instanţe de învăţare pentru o mai bună
performanţă a algoritmilor. Astfel, este necesară identificarea instanţelor care se afla la limita
spaţială a claselor şi eliminarea celorlate, primele fiind cele care influenţează decizia de
clasificare.
În ce priveşte setul de date curent, există o lipsă de proporţionalitate a numărului de instanţe din
fiecare clasă, acesta variind de la 20 la 112, dezavantajând clasa cu un număr redus de atribute. O
altă posibilă extindere ar fi aplicarea algoritmilor pe alte seturi de date, colectate real. De
asemenea, există multe atribute cu valoarea zero, indicând lipsa acestora. Pentru atributul vârstă,
există 8 valori lipsă în baza de date, caz care trebuie tratat corespunzător (VFI rezolvă această
problemă prin acordarea unui vot de valoare zero).
O ultimă îmbunătăţire poate fi făcută prin extinderea comparaţiei cu alte tehnici de învăţare.

56
CONCLUZII
Diagnosticarea are o mare putere de influenţă: filtrează şi sortează, orientează deciziile,
guvernează asupra emoţiilor şi duce la formarea unui lanţ de acţiuni. Diagnosticarea este un
paradox prin faptul că este dorită şi nedorită în acelaşi timp, fiind o confirmare a prezenţei unei
boli în organism, dar şi o promisiune de recuperare a sănătaţii.
Procesul de diagnosticare este unul complex, care necesită un volum mare de informaţii pe care
specialistul uman nu poate să le deţină în totalitate. Astfel, sistemele inteligente sunt necesare şi
de dorit în a oferi suport medicilor.
Datorită numărului de cazuri reprezentative de succes, consider că în viitor, aceste sisteme vor
face parte integrantă din sistemul medical, crescând astfel acurateţea diagnosticărilor şi reducând
erorile umane.
Diagnosticarea bolilor de piele Erytemato-Squamous este un proces dificil, însă algoritmii
prezentaţi au avut rezultate satisfăcătoare. Îmbunătăţirea acestora (de exemplu, prin acordarea
ponderilor diferite atributelor) poate duce la creşterea acurateţii lor şi a încrederii acordate în
deciziile acestora.

57
BIBLIOGRAFIE
1. Adrian A. Hopgood (2001), Intelligent system for engineers and scientists, ed.CRP Press,
New York
2. Tom M. Mitchell- Instance based learning, ed. McGraw-Hill Science/Engineering/Math,
1997
3. Zheming Lu, Hao Luo,Faxin Yu, Pinghui Wang (2010)- Three-Dimensional Model
Analysis and Processing, ed. Zhejiang University Press, Hangzhou, p. 277- 287
4. Peter C. Bruce, Galit Shmueli, Nitin R. Patel (2010), Data Mining for Business
Intelligence: Concepts, Techniques, and Applications în Microsoft Office Excel with
XLMiner, ed John Wiley & Sons Inc, Hoboken, New Jersey 137-145
5. Florin Leon (2012), Inteligenta atificiala: rationament probabilistic, tehnici de clasificare,
ed Tehnopress, Iasi
6. Maarten van Someren,Gerhard Widmer (1997), Machine Learning: ECML'97: 9th
European Conference on Machine Learning, ed. Springer-Verlag, Berlin
7. Józef Karbicz - Fault Diagnosis.: Models, Artificial Intelligence, Applications, ed
Springer, Berlin, 2004
8. Narin Emeksiz Havelsan, Ankara Turke, Application of Machine Learning Techniques to
Differential Diagnosis of Erythemato-Squamous Diseases
9. Repository http://archive.ics.uci.edu/ml/datasets/Dermatology
10. Carlos Feder- “Computerized Medical Diagnosis: A Novel Solution to an Old Problem”,
ed. Infinity, SUA, 2006
11. Kavishwar B. Wagholikar, Vijayraghavan Sundararajan, Ashok W. Deshpande-
“Modeling Paradigms for Medical Diagnostic Decision Support: A Survey and Future
Directions”, 2011, http://kwagholikar.files.wordpress.com/2012/08/joms2012modeling-
preprint.pdf, accesat la 23.04.2013
12. Fadzilah Siraj – “Artificial intelligence în medical applications: an
exploration”, http://www.hi-europe.info/files/2002/9980.htm, accesat la 23.04.2013
13. Dennis P. Wall, Rebecca Dally, Rhiannon Luyster, Jae-Yoon Jung, Todd F. DeLuca-
“Use of Artificial Intelligence to Shorten the Behavioral Diagnosis of Autism”,

58
http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0043855#pone-
0043855-t002, accesat la 23.04.2013
14. David H. Freedman- “Machine-learning tool offers rapid autism diagnosis”, 2011
https://sfari.org/news-and-opinion/conference-news/2011/machine-learning-tool-offers-
rapid-accurate-autism-diagnosis, accesat la 23.04.2013
15. Langley Pat – “Elements of Machine Learning”, 1998, ed. Cassell Publishers, England,
pg. 1-7
16. Witten Ian & Frank Eibe- “Data Mining- Practical machine learning tools and
techniques”, editia 2, 2005, ed Elsevier Inc, San Francisco pg-12, 76-79
17. Rob Schapire – “Foundations of machine learning”, 2003
(http://www.cs.princeton.edu/courses/archive/spring03/cs511/scribe_notes/0204.pdf)
18. Tom M. Mitchell- “Machine Learning”,ed. McGraw Hill, 1997
19. Mitchell, T. M. (2006). The Discipline of Machine Learning. Machine Learning
Department technical report CMU-ML-06-108, Carnegie Mellon University.
20. Taiwo Oladipupo Ayodele –“Types of Machine Learning Algorithms”, New Advances in
Machine Learning, 2010 http://www.intechopen.com/books/new-advances-in-machine-
learning/types-of-machine-learning-algorithms
21. Jianping Gou, Lan Du, Yuhong Zhang, Taisong Xiong- A New Distance-weighted k-
nearest Neighbor Classier, 2012
22. H. Altay Guvenir, Gulsen Demiroz, Nilsel Ilter –”Learning differential diagnosis of
erythemato-squamous diseases using voting feature intervals”, 1988
23. Kenneth Revett, Florin Gorunescu, Abdel-Badeeh Salem & El-Sayed El-Dahshan –„
Evaluation of the Feature Space of an Erythematosquamous Dataset Using Rough Sets”,
2009





























