Embed Size (px)
Citation preview

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 1 -
UUSSOO DDEE EEXXCCEELL EENN LLAA EEDDUUCCAACCIIÓÓNN MMssCC LLuuiiss AAllbbeerrttoo RRuubbiioo JJaaccoobboo
IINNDDIICCEE
PPAARRTTEE 11.. CCOONNCCEEPPTTOOSS GGEENNEERRAALLEESS
11.. DDeeffiinniicciióónn ddee EEssttaaddííssttiiccaa
22.. CCllaassiiffiiccaacciióónn ddee llaa EEssttaaddííssttiiccaa
33.. UUnniivveerrssoo
44.. PPoobbllaacciióónn
55.. MMuueessttrraa
66.. MMuueessttrreeoo
77.. UUnniiddaadd ddee eessttuuddiioo
88.. OObbsseerrvvaacciióónn
99.. VVaarriiaabbllee
1100.. PPaarráámmeettrroo
1111.. EEssttiimmaaddoorr
1122.. TTééccnniiccaass ddee rreeccoolleecccciióónn ddee ddaattooss
1133.. IInnssttrruummeennttooss ddee rreeccoolleecccciióónn ddee ddaattooss
PPAARRTTEE 22.. PPRREESSEENNTTAACCIIÓÓNN DDEE LLAA IINNFFOORRMMAACCIIÓÓNN
11.. CCuuaaddrroo ddee ddiissttrriibbuucciióónn ddee ffrreeccuueenncciiaass ((CCDDFF))
22.. PPaarrtteess ddee uunn CCDDFF
33.. EElleemmeennttooss ppaarraa ccoonnssttrruuiirr uunn CCDDFF
44.. PPrrooppiieeddaaddeess ddee uunn CCDDFF
55.. CCoonnssttrruucccciióónn ddee CCDDFF
66.. EExxcceell eenn llaa ccoonnssttrruucccciióónn ddee CCDDFF
77.. GGrrááffiiccoo eessttaaddííssttiiccoo
88.. PPaarrtteess ddee uunn ggrraaffiiccoo eessttaaddííssttiiccoo
99.. CCrriitteerriiooss ppaarraa ccoonnssttrruuiirr ggrrááffiiccooss
1100.. TTiippooss ddee ggrrááffiiccooss eessttaaddííssttiiccooss
1111.. CCoonnssttrruucccciióónn ddee ggrrááffiiccooss eessttaaddííssttiiccooss ccoonn MMeeggaaSSttaatt--EEXXCCEELL
PPAARRTTEE 33.. MMEEDDIIDDAASS EESSTTAADDÍÍSSTTIICCAASS UUNNIIVVAARRIIAANNTTEESS
11.. MMeeddiiddaass ddee tteennddeenncciiaa cceennttrraall
22.. MMeeddiiddaass ddee llooccaalliizzaacciióónn
33.. MMeeddiiddaass ddee vvaarriiaabbiilliiddaadd
44.. MMeeddiiddaass ddee FFoorrmmaa
55.. FFoorrmmuullaass ppaarraa ccaallccuullaarr llaass mmeeddiiddaass ddee tteennddeenncciiaa cceennttrraall
66.. FFoorrmmuullaass ppaarraa ccaallccuullaarr llaass mmeeddiiddaass ddee ddiissppeerrssiióónn oo vvaarriiaacciióónn
77.. MMeeddiiddaass eessttaaddííssttiiccaass ccoonn MMeeggaaSSttaatt--EEXXCCEELL
PPAARRTTEE 44.. AANNAALLIISSIISS DDEE CCOORRRREELLAACCIIOONN YY RREEGGRREESSIIÓÓNN
11.. AAnnáálliissiiss ddee ccoorrrreellaacciióónn
22.. AAnnáálliissiiss ddee rreeggrreessiióónn

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 2 -
33.. AAnnáálliissiiss ddee rreeggrreessiióónn ccoonn MMeeggaaSSttaatt--EEXXCCEELL
PPAARRTTEE 55:: DDIISSTTRRIIBBUUCCIIOONNEESS DDEE PPRROOBBAABBIILLIIDDAADD
11.. LLaa ddiissttrriibbuucciióónn BBiinnoommiiaall
22.. LLaa ddiissttrriibbuucciióónn PPooiissssoonn
33.. LLaa ddiissttrriibbuucciióónn nnoorrmmaall
44.. AApplliiccaacciióónn ccoonn MMeeggaaSSttaatt--EEXXCCEELL
PPAARRTTEE 66:: EESSTTIIMMAACCIIOONN EESSTTAADDIISSTTIICCAA
11.. EEssttiimmaacciióónn ppuunnttuuaall
22.. EEssttiimmaacciióónn iinntteerrvváálliiccaa
33.. AApplliiccaacciióónn uuttiilliizzaannddoo MMeeggaaSSttaatt--EEXXCCEELL
PPAARRTTEE 77:: PPRRUUEEBBAA DDEE HHIIPPOOTTEESSIISS
11.. DDeeffiinniicciioonneess pprreelliimmiinnaarreess
22.. CCllaasseess ddee HHiippóótteessiiss
33.. EErrrroorreess qquuee ssee ccoommeetteenn eenn uunnaa pprruueebbaa ddee hhiippóótteessiiss
44.. TTiippooss ddee pprruueebbaass ddee hhiippóótteessiiss
55.. EEttaappaass ddee uunnaa pprruueebbaa ddee hhiippóótteessiiss
66.. FFoorrmmuullaass ddee aallgguunnooss eessttaaddííssttiiccooss ddee pprruueebbaa
77.. PPrruueebbaa ddee HHiippóótteessiiss ccoonn MMeeggaaSSttaatt--EEXXCCEELL

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 3 -
PPAARRTTEE 11:: CCOONNCCEEPPTTOOSS GGEENNEERRAALLEESS
1. DEFINICIÓN DE ESTADÍSTICA:
La Estadística es una ciencia que nos ofrece un conjunto de métodos y técnicas
para recopilar, organizar, presentar, analizar e interpretar un conjunto de datos
respecto a variables en estudio de una población, con el fin de obtener conclusiones
y tomar decisiones sobre determinados hechos o fenómenos en estudio.
La estadística es una rama de la matemática y es parte del método científico. En la
actualidad, para hacer investigación científica se necesita conocer de estadística.
2. CLASIFICACION DE LA ESTADÍSTICA
La Estadística se clasifica de la siguiente manera:
2.1. Estadística Descriptiva
Es aquella área de la Estadística que describe y analiza una población, sin
pretender sacar conclusiones de tipo general. Es decir, las conclusiones
obtenidas con validas solo para dicha población.
2.2. Estadística Inferencial
Es aquella área de la Estadística, cuyo propósito es inferir o inducir leyes de
comportamiento de una población, a partir del estudio de una muestra. Es
decir las conclusiones obtenidas a partir de una muestra, son validas para
toda la población.
3. UNIVERSO:
Es el conjunto de individuos, objetos o entes que tienen características comunes,
definidas en forma general en un espacio y tiempo.
Ejemplo:
Conjuntos de alumnos, conjunto de docentes universitarios, conjunto de de
pacientes, conjunto de clientes, conjunto de proveedores, conjunto de viviendas,
conjunto de establecimientos, conjunto de documentos, etc.; de una determinada
región o zona en un tiempo determinado.
4. POBLACIÓN:
Es un conjunto grande y completo de individuos, elementos o unidades que
presentan como mínimo una característica en común y observable. Para definir una
población esta debe contener los siguientes elementos: contenido, espacio y
tiempo. Al número de elementos de una población de denota por “N”. Una
población puede clasificarse de la siguiente manera:
A. Según su extensión:
Población Finita:
Es aquella que tiene un determinado número de elementos.
Población Infinita:
Es aquella cuyos elementos no se pueden contar.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 4 -
B. Según su ámbito o naturaleza:
Población Objeto:
Esta dada por los elementos que forman la población.
Población Objetivo: esta dada por la información que da la población objeto
Nota: De un universo se pueden desprender muchas poblaciones, pero
operativamente se pueden hablar indistintamente como población o universo.
5. MUESTRA
Es una parte o un subconjunto de la población en estudio. También se puede decir
que es una colección de unidades de muestreo seleccionados de un marco muestral
o de varios marcos muestrales. Al número de elementos de la muestra se denota
por “n”. Una muestra tiene las siguientes características:
a. Es representativa.
b. Es adecuada.
Para la determinación del tamaño de muestra se utilizan técnicas de muestreo
donde dependiendo de esta, se utiliza correctamente las formulas adecuadas.
66.. MMUUEESSTTRREEOO
Es una técnica estadística por la cual se realizan inferencias o generalizaciones para
una población examinando solo una muestra de ella. Es una técnica empleada para
seleccionar elementos de una población.
Su propósito es proporcionar diferente tipo de información estadística de naturaleza
cuantitativa o cualitativa. Por su gran importancia los investigadores lo utilizan en
los diferentes campos de saber y también lo usamos en la vida diaria.
7. UNIDAD DE ESTUDIO:
Es el animal persona o cosa de quien se dice algo. Es el elemento quien nos va a
dar la información. Es el individuo u objeto del cual se toman las mediciones u
observaciones.
Ejemplos:
Un docente, un auxiliar de educación, un votante, una factura, una empresa, una
botella de cerveza, una universidad, una vaca, una gota de sangre, etc.
8. OBSERVACIONES:
Estadísticamente son los datos que se recolectan para un estudio. Una observación
o dato es cuando una variable en si toma un valor especifico.
9. VARIABLE:
Una variable es una característica de estudio de una población. Una variable es lo
que se quiere evaluar en una investigación. Las características toma diferentes
valores que varían de individuo a individuo o de objeto a objeto. Aquellas
características que permanecen inalterables en las unidades de estudio reciben el
nombre de constantes.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 5 -
Generalmente, las variables se designan con las últimas letras mayúsculas del
abecedario: X, Y, Z; y los valores de las variables se designan con letras
minúsculas: xi , yi , etc.
Las variables se clasifican de la siguiente manera:
Por su relación: Variable dependiente - variable independiente.
Por su escala de medición: Nominal – Ordinal – Intervalo – Razón.
Por su naturaleza: Cuantitativas - Cualitativas.
Ejemplos:
Unidad de estudio Variable
Estudiante Peso, talla, edad, ci, número de hermanos, raza, color
de ojos, tipo de sangre, etc.
Empresa Ganancia, costos, producción, número de
trabajadores, numero de computadoras, etc.
PYME Número de trabajadores, años de funcionamiento,
ganancias, etc.
10. PARAMETRO:
Es un valor, una cantidad, un indicador que se obtiene con información de la
población. Dentro de estos tenemos:
a. El promedio poblacional
b. La varianza poblacional.
c. La proporción poblacional, etc.
11. ESTIMADOR:
Es un valor, una cantidad, un indicador que se obtiene con información de la
muestra. Dentro de estos tenemos:
VVaarriiaabbllee
Cualitativa Cuantitativa
Nominal
Ordinal Discreta Continua
Cualidad o
Atributo
Cantidad o
Número
Conteo Medición No orden Orden

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 6 -
a. El promedio muestral.
b. La varianza muestral.
c. La proporción muestral, etc.
12. TÉCNICAS DE RECOLECCIÓN DE DATOS:
Las técnicas de recolección de datos permiten la obtención sistemática de
información acerca de los objetos de estudio (personas, objetos y fenómenos) y de
su entorno.
Como ya se mencionó, la recolección de datos tiene que ser sistemática, ya que, si
los datos se recolectan al azar será difícil responder las preguntas de investigación
de una manera concluyente.
Las técnicas de recolección de datos son
1. Utilización de la información disponible
2. Observación
3. Entrevista( cara a cara)
4. Cuestionarios auto administrados
5. Discusión con grupos focales
6. Otras
OBSERVACIÓN:
La observación es una técnica que implica seleccionar ver y registrar
sistemáticamente, la conducta y características de seres vivos, objetos o
fenómenos. La observación de la conducta humana es una técnica de recolección de
datos muy utilizada que puede llevarse a cabo de diferentes formas:
a. Observación participativa: El observador participa en la situación que observa
b. Observación no participativa: El observador no participa en la situación que
observa
Las observaciones pueden servir para diferentes propósitos. Pueden dar
información adicional y más confiable de la conducta de las u.e. que las entrevistas
o los cuestionarios. Los cuestionarios pueden ser incompletos ya que se pueden
olvidar algunas preguntas o porque los entrevistados olvidan o no desean contestar
algunas cosas. Con la observación se puede, entonces, verificar la información
recolectada (especialmente sobre temas como alcoholismo, drogadicción, sida,)
pero también puede ser una fuente primaria de información (observación
sistemática de los juegos de los niños).
La observación de la conducta humana puede formar parte de algún estudio, pero
como consume tiempo se usa con mayor frecuencia en estudios de pequeña escala.
ENTREVISTA:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 7 -
La entrevista es una técnica de recolección de datos que involucra el
cuestionamiento oral de los entrevistados ya sea individualmente o en grupo. Las
respuestas a las preguntas durante la entrevista pueden ser registradas por escrito
o grabadas en una cinta. La entrevista puede conducirse con diferentes grados de
flexibilidad.
Las entrevistas utilizan una cédula para asegurar que se discuten todos los puntos,
pero dando suficiente tiempo y permitiendo seguir cualquier orden. El entrevistador
puede hacer preguntas adicionales para obtener tanta información adicional como
sea posible, Las preguntas son abiertas y no hay restricciones para las respuestas.
Este método poco estructurado de hacer las preguntas puede ser útil para
entrevistas individuales o grupales con informantes claves.
Un método de entrevista flexible es útil si el investigador sabe poco del problema o
de la situación que esta investigando. Se aplica en estudios exploratorios y en los
estudios de caso.
ENCUESTAS:
Hoy en día la palabra "encuesta" se usa más frecuentemente para describir un
método de obtener información de una muestra de individuos. Esta "muestra" es
usualmente sólo una fracción de la población bajo estudio. Una "encuesta" recoge
información de una "muestra." Una "muestra" es usualmente sólo una porción de la
población bajo estudio.
Las encuestas pueden ser clasificadas en muchas maneras. Una dimensión es por
tamaño y tipo de muestra. Las encuestas pueden ser usadas para estudiar
poblaciones humanas o no humanas (por ejemplo, objetos animados o inanimados,
animales, terrenos, viviendas). Mientras que muchos de los principios son los
mismos para todas las encuestas, el foco aquí será en métodos para hacer
encuestas a individuos. Las encuestas pueden ser clasificadas por su método de
recolección de datos. Las encuestas por correo, telefónicas y entrevistas en persona
son las más comunes. En los métodos más nuevos de recoger datos, la información
se entra directamente a la computadora ya sea por un entrevistador adiestrado o
aún por la misma persona entrevistada. Un ejemplo bien conocido es la medición
de audiencias de televisión usando aparatos conectados a una muestra de
televisores que graban automáticamente los canales que se observan
OTRAS TÉCNICAS DE RECOLECCION DE DATOS
a. Técnica de grupo nominal
b. Técnica delphi
c. Historias de vida
d. Escalas
e. Ensayos
f. Estudios de casos
g. Mapeo
h. Técnicas rápidas de evaluación de sondeo
i. Encuestas participativas.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 8 -
13. INSTRUMENTOS DE RECOLECCIÓN DE DATOS:
Si tenemos presente el tema de investigación por el que nos estarnos guiando se
percibirá que, una vez obtenidos los indicadores de los elementos teóricos y
definido el diseño de la investigación, se hará necesario estructurar las técnicas dé
recolección de datos correspondientes, para así poder construir los instrumentos
que nos permitan obtener tales datos de la realidad.
Un instrumento de recolección de datos es, en principio, cualquier recurso de que
pueda valerse el investigador para acercarse a los fenómenos y extraer de ellos
información. Ya adelantábamos que dentro de cada instrumento concreto pueden
distinguirse dos aspectos diferentes: una forma y un contenido.
La forma del instrumento se refiere al tipo de aproximación que establecemos con
lo empírico, a las técnicas que utilizamos para esta tarea; una exposición más
detallada de las principales es la que se ofrece al lector en este mismo capítulo. En
cuanto al contenido éste queda expresado en la especificación de los datos
concretos que necesitamos conseguir; se realiza, por lo tanto, en una serie de
ítems que no son otra cosa que los indicadores bajo la forma de preguntas, de
elementos a observar, etc.
De este modo, el instrumento sintetiza en sí toda la labor previa de investigación:
resume los aportes del marco teórico al seleccionar datos que corresponden a los
indicadores y, por lo tanto, a las variables o conceptos utilizados; pero también
expresa todo lo que tiene de específicamente empírico nuestro objeto de estudio,
pues sintetiza a través de las técnicas de recolección que emplea, el diseño
concreto escogido para el trabajo.
PRÁCTICA Nº 01 Docente: Luis Alberto Rubio Jácobo
Instrucción: En los siguientes casos identificar la unidad de estudio, tipo de variable, la
población y la muestra en los siguientes casos que se presentan. CASO Nº 01:
Unidad de estudio
Variable de estudio Tipo:
Población
Muestra
TESIS: “Aplicación del Programa Informático MATHEMATICA
en el Rendimiento Académico en la asignatura de Matemática I, en los estudiantes del primer ciclo de la especialidad de
Matemática de la Carrera Profesional de Educación
Secundaria de la Universidad Nacional de Trujillo ”

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 9 -
CASO Nº 02
CASO Nº 03
CASO Nº 04
CASO Nº 05
Unidad de estudio
Variable de estudio Tipo:
Población
Muestra
Unidad de estudio
Variable de estudio Tipo:
Población
Muestra
Unidad de estudio
Variable de estudio Tipo:
Población
Muestra
TESIS: Aplicación del Programa “Esquematizando
problemas” y su influencia en el desarrollo de
capacidades de las alumnas del 5to. Grado de Educación
Primaria del Colegio Estatal N° 81007 “Modelo” de Trujillo, en el área lógico matemática. Año 2004
TESIS: La implementación de un Sistema de Gestión Académica mejora la
Gestión de los Colegios Estatales de la Ciudad de Trujillo.
TESIS: Propuesta metodológica basada en Infoescuela en el
desarrollo de habilidades, destrezas y actitudes para el diseño
de programas computacionales en los alumnos de
Computación Aplicada a la Educación Primaria de la U.N.T.
TESIS: PROPUESTA METODOLÓGICA PROTESIPSI Y EL
DESARROLLO DE HABILIDADES Y ACTITUDES PARA LA
PRODUCCIÓN DE CUENTOS, FÁBULAS Y LEYENDAS EN
LOS ALUMNOS DEL 6º GRADO DE LA I. E. 80461 DEL
DISTRITO DE TAURIJA – PATAZ.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 10 -
CASO Nº 06
“Un gran profesional es aquel que no encuentra obstáculos sino retos”
Unidad de estudio
Variable de estudio Tipo:
Población
Muestra
Unidad de estudio
Variable de estudio Tipo:
Población
Muestra
TESIS: PROGRAMA DE DESARROLLO DE INTELIGENCIA LINGÜÍSTICA Y SU EFECTO
EN LA COMPRENSIÓN LECTORA, EN LOS ALUMNOS DEL 5º GRADO DE PRIMARIA DE LA
INSTITUCIÓN EDUCATIVA “REPÚBLICA ARGENTINA–TRUJILLO.2005.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 11 -
PPAARRTTEE 22:: PPRREESSEENNTTAACCIIÓÓNN DDEE LLAA IINNFFOORRMMAACCIIÓÓNN
En la Estadística se trabaja generalmente con una gran cantidad de datos los cuales por
facilidad de análisis y cálculos se organizan en Cuadros de Distribución de Frecuencias
(CDF) y Gráficos Estadísticos (GE).
1. CUADRO DE DISTRIBUCIÓN DE FRECUENCIAS (CDF):
Un cuadro de distribución de frecuencias, es una tabla resumen rectangular de un
conjunto de datos que muestra el comportamiento o distribución de la variable en
estudio en forma rápida y resumida.
Aún cuando un cuadro de frecuencias se construye a libre criterio de quien lo
ejecuta, generalmente es común seguir algunos pasos que de alguna forma
homogenizan criterios y ayudan a los fines didácticos.
Para realizar este análisis se tienen que tener en cuenta el tipo de variable que se
esta evaluando.
2. PARTES DE UN CUADRO DE DISTRIBUCION DE FRECUENCIAS:
Las partes de un CDF son las siguientes:
a. Número del cuadro de frecuencias en forma correlativa.
b. Título: Especificar la variable y la población en estudio
c. Encabezado o conceptos.
d. Cuerpo o contenido del cuadro de frecuencias
e. Nota de pie (no siempre es necesaria)
f. Fuente
g. Elaboración
3. ELEMENTOS PARA CONSTRUIR UN CDF:
Para construir un cuadro de frecuencias se utilizan los siguientes elementos:
A. Valores de la variable Xi:
Los valores de la variable o datos se representan por Xi. Ejm: Si se tienen 50
datos sus valores correspondientes no agrupados se representan como X1, X2,
X3, ..., X50 .
B. Intervalos de clase:
Los intervalos son subconjuntos de la recta real Ron que están definidos por
un límite menor o inferior Li y un límite mayor o superior Ls.
C. Frecuencia:
1. Frecuencia absoluta simple:
Se denotan por fi. Está constituida por el número de veces que se repite
un valor. En el caso de intervalos es el número de observaciones
comprendidas en dicho intervalo. Estas frecuencias siempre son enteros
positivos y además la suma de todos ellos es el tamaño de la muestra
“n”.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 12 -
2. Frecuencia relativa:
Se denotan por hi. Indica la relación o proporción existente entre la
frecuencia absoluta simple y el número total de datos. Estas frecuencias
son numeros fraccionarios positivos entre o y 1. Para fines
interpretativos estas frecuencias se expresan en % (hi%) . Así:
n
fihi ó 100(%) x
n
ifhi
3. Frecuencia absoluta acumulada:
Se denotan por Fi. Resulta de la suma de las frecuencias cuyas marcas
de clase son iguales o menores a la marca de clase del intervalo dado o
considerado, es decir:
F1 = f1
F2 = f1 + f2
F3 = f1 + f2 + f3
.............................................
……………………………………………………
Fj = f1 + f2 + f3 + ....... + fi
4. Frecuencia relativa acumulada:
Se denotan Hi. Resulta de la suma de las frecuencias relativas simples
hasta la frecuencia del intervalo considerado. Así:
H4 = h1 + h2 + h3 + h4
H6 = h1 + h2 + ....+ h6
Para fines interpretativos estas frecuencias se expresan en % (Hi%)
D. Marca de clase:
Se denota por “Yi”. Es el promedio de los valores correspondientes a los
límites inferior y superior de cada uno de los intervalos determinados.
4. PROPIEDADES DE UN CDF:
A. Las fi y Fi son siempre números enteros positivos. Es decir: fi , Fi ≥ 0
B. Las hi y Hi son siempre números fraccionarios positivos comprendidos entre 0
y 1, es decir 0≤ hi , Hi ≤ 1
C. F1 siempre es igual f1 y H1 siempre es igual a h1.
D. La suma de todas las fi es igual a n y la suma de las hi es igual a 1.
E. Fm siempre es igual a n y Hm siempre es igual a 1.
5. CONSTRUCCIÓN DE CUADROS DE FRECUENCIAS:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 13 -
Para la construcción de los CDF hay que tener en cuenta el tipo de variable que se
esta analizando, es decir, si es cuantitativa continua, cuantitativa discreta o
variable cualitativa.
A. CDF PARA UNA VARIABLE CUANTITATIVA CONTINUA:
Para la construcción de este cuadro hay que realizar los siguientes pasos:
PASO 1. Determinar el Rango del conjunto de datos.
PASO 2. Determinar el número de intervalos “m”.
Este valor siempre es un número entero (Redondeo)
PASO 3. Determinar la amplitud “A” interválica (de cada intervalo).
Este valor esta en función de la estructura de la base de datos (tomar el
inmediato superior)
PASO 4. Determinar el nuevo rango “R2” (Solamente si se tomo un
inmediato superior)
A: es la amplitud teniendo en cuenta el inmediato superior.
PASO 5. Determinar los intervalos y finalmente construir el cuadro.
B. CDF PARA UNA VARIABLE CUANTITATIVA DISCRETA:
Para la construcción de un CDF para una variable cuantitativa discreta
(valores discretos) ya no se utiliza los pasos anteriores solamente colocar en
los intervalos a los diferentes valores discretos.
C. CDF PARA UNA VARIABLE CUALITATIVA:
Para la construcción de un CDF para una variable cualitativa se sigue los
mismos pasos que para una variable cuantitativa discreta, es decir, solamente
colocar en los en los intervalos a las diferentes categorías de la variable
cualitativa.
6. CONSTRUCCION DE CDF CON EXCEL:
Si bien es cierto que el EXCEL no es un programa exclusivamente diseñado para
análisis de datos, es muy utilizado dentro del análisis de estos cuando se realiza
una investigación científica. Una de las ventajas y razones de su uso, está en su
fácil acceso, pues en todas las computadoras está instalado y así se podrá explorar
el funcionamiento de las herramientas que se presentan en este programa.
R = Valor máximo - Valor mínimo
m = 1 + 3.322 log ( n )
A = R / m
R2 = A * m

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 14 -
A. CONSTRUCCION DE CUADROS DE FRECUENCIA UTILIZANDO TABLAS
DINAMICAS:
Para construir cuadros de distribución de frecuencias a través de Excel se
utiliza la herramienta TABLAS DINAMICAS ver el uso de este programa
analizaremos la siguiente base de datos respecto a 50 casos y 10 variables de
estudio. (Archivo BASE 01.exe).
Teniendo en cuenta esta base de datos realizar los siguientes pasos:
Hacemos clic en Insertar /tabla dinámica ….. aparece la siguiente pantalla:
Luego aparecen las siguientes ventanas de trabajo…….activamos (a) lista de
base de datos de Excel y (b) Tabla Dinámica. Luego siguiente …
seleccionamos el rango respectivo, luego
siguiente…..luego seleccionamos la opción
diseño.
En la opción diseño seleccionamos la variable
que vamos a analizar y con el cursor activamos
dicha variable y lo arrastramos hasta la opción
FILA y luego la misma variable la arrastramos hasta la opción DATOS.
Finalmente aceptamos y obtenemos los resultados.
En función a lo que se quiera obtener como
resultados de la variable analizada, se
selecciona OPCIONES DE TABLA
DINÁMICA para obtener ya sea totales, promedio o frecuencia de dicha
variable. Esta ventana de trabajo es la siguiente:
B. CONSTRUCCION DE CUADROS DE FRECUENCIA UTILIZANDO
MEGASTAT:
Para construir cuadros de distribución de frecuencias con Megaestat se utiliza
la opción Complementos/MegaStat… Distribución de Frecuencias. Luego se
debe seleccionar para variables cuantitativas o variables cualitativas.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 21 -
Si se selecciona variable cuantitativa se aprecia la siguiente ventana, donde
debemos ingresar el rango de los datos de la variable, luego se hace la
selección de datos respectiva y activamos algún tipo de grafico. Se puede
realizar algunas modificaciones al CDF dependiendo del investigador como
tamaño de intervalos, número de intervalos, límite superior, límite inferior,
etc.
7. GRAFICO ESTADÍSTICO
Un gráfico estadístico es una representación pictórica, cuyo objetivo es
expresar el comportamiento de una variable en estudio.
Los gráficos estadísticos son representaciones de información real que existe
en nuestro mundo, es una expresión artística de datos reales y observados.
Un gráfico sirve también para comparar visualmente el comportamiento de
dos o más variables similares o relacionadas.
8. PARTES DE UN GRAFICO ESTADISTICO:
Numeración.
Titulo: Aquí se señala la población en estudio y la variable de interés.
Diagrama: esta dado por el propio dibujo el cual representa el
comportamiento de los datos.
Escalas y/o leyendas: Son indicadores donde se precisa la correspondencia
entre los elementos del gráfico y la naturaleza de las medidas representadas.
Fuente: Aquí se señala el CDF que permitió obtener el respectivo gráfico.
9. CRITERIOS PARA CONSTRUIR GRAFICOS:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 22 -
No existe una regla específica para la construcción de gráficos, pero si es
posible considerar algunas recomendaciones o criterios.
Se emplea una diversidad de gráficos, cuya estructura o forma dependerá del
tipo de variable que se está estudiando.
Este gráfico debe tener rasgos simples y de fácil comprensión.
10. TIPOS DE GRAFICOS ESTADISTICOS
Hay varias tipos de gráficos, los cuales dependen del tipo de variable que esta
evaluando. Presentaremos aquí los mas importantes:
a. Gráfico de bastones: Se utiliza cuando se tienen datos de una variable
cuantitativa discreta.
b. Histograma: Se utiliza cuando se tienen datos de una variable cuantitativa continua.
c. Gráfico de Barras: Se utiliza cuando se tienen datos de una variable
cualitativa.
d. Gráfico Sectorial o Pastel: Se utiliza cuando se tienen información de una
variable cualitativa o cuantitativa discreta.
e. Polígono de frecuencias: Se utiliza para indicar el comportamiento de un
conjunto de datos.
f. Gráfico de series de tiempo: Se utiliza para analizar variables cuantitativas
continuas pero expresadas en el tiempo.
g. Grafico de Cajas y Bigote: Se utiliza para analizar el comportamiento de una
variable cuantitativa. Se obtiene en base a los cuartiles.
h. Grafico de la telaraña: Sirve para visualizar el comportamiento de una
variable cuantitativa cuando evalúa ciertos criterios de evaluación.
11. CONSTRUCCIÓN DE GRAFICOS ESTADISTICOS DE EXCEL:
Excel puede crear gráficos a partir de datos previamente seleccionados en una hoja
de cálculo. El usuario puede “insertar” un gráfico en una hoja de cálculo, o crear el
gráfico en una hoja especial para gráficos. En cada caso el gráfico queda vinculado
a los datos a partir de los cuales fue creado, por lo que si en algún momento los
datos cambian, el gráfico se actualizará de forma automática. Los gráficos de Excel
contienen muchos objetos, títulos, etiquetas en los ejes que pueden ser
seleccionados y modificados individualmente según las necesidades del usuario.
Para crear un gráfico con el Asistente para Gráficos, se deben seguir los
siguientes pasos:
1. Seleccionar los datos a representar.
2. Ejecutar el comando Insertar / Gráfico o hacer clic en el botón

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 23 -
A continuación aparece el siguiente cuadro de diálogo del Asistente para
Gráfico..que permite elegir el tipo y subtipo de gráfico que se va a utilizar entre dos
listas que son estándares y personalizados.
Luego seleccionar el rango de los datos a evaluar, señalando correctamente las
series que están evaluando.
Luego debemos configurar los aspectos que conciernen a la presentación del
gráfico, aportando una vista preliminar del mismo. Así, se determinan el título, las
inscripciones de los ejes, la apariencia de éstos, la leyenda, la aparición o no de
tabla de datos y los rótulos. Las opciones de <Atrás, Siguiente> y Finalizar son
las mismas que en los otros cuadros. Finalmente hacer clic en el botón Finalizar, el
gráfico aparece ya en el lugar seleccionado. Si se quiere desplazar a algún otro
lugar sobre la propia hoja en que se encuentra basta seleccionar todo el gráfico y
arrastrarlo con el mouse.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 24 -
PPAARRTTEE 33:: MMEEDDIIDDAASS EESSTTAADDÍÍSSTTIICCAASS
La estadística descriptiva es una técnica que consiste en obtener indicadores que
describen el comportamiento de un conjunto de datos. Dentro de estas medidas
estadísticas tenemos:
A. Las medidas de Posición: Dentro de estas tenemos:
a. Medidas de tendencia central: Media, Moda, Mediana.
b. Medidas de localización: cuartiles, deciles y percentiles.
B. Las medidas de variación: rango, varianza, desviación estándar, coeficiente de
variación.
C. Las medidas de deformación: asimetría y kurtosis.
1. MEDIDAS DE TENDENCIA CENTRAL
1.1. MEDIA ARITMÉTICA:
Se denota por x
Es la medida estadística más fácil de calcular.
La media o promedio es el punto central de un conjunto de datos.
Para calcular la media aritmética se utilizan las formulas adecuadas ya sea sin son datos agrupados o datos no agrupados.
1.2. MEDIANA:
Se denota por Me.
Es un valor que divide al conjunto de datos en dos partes iguales, es
decir, cada segmento tiene el 50% de los datos.
Para calcular la media aritmética se utilizan las formulas adecuadas ya
sea sin son datos agrupados o datos no agrupados.
1.3. MODA:
Se denota por Mo.
La moda es el valor que más se repite en un conjunto de datos.
En un conjunto de datos se presentan los siguientes casos:
a. No existir datos Amodal
b. 1 moda Unimodal.
c. 2 modas Bimodal
d. 3 a más modas Multimodal
Para calcular la media aritmética se utilizan las formulas adecuadas ya
sea sin son datos agrupados o datos no agrupados.
2. MEDIDAS DE LOCALIZACIÓN:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 25 -
2.1. CUARTILES:
Se denotan por Qk, donde k=1,2,3
Son valores que dividen a un conjunto de datos en 4 partes iguales, es
decir, cada sector tiene el 25% de los datos.
Para calcular la media aritmética se utilizan las formulas adecuadas ya
sea sin son datos agrupados o datos no agrupados.
2.2. DECILES:
Se denotan por Dk, donde k=1,2,3,4,5,6,7,8,9
Son valores que dividen a un conjunto de datos en 10 partes iguales, es
decir, cada sector tiene el 10% de los datos.
2.3. PERCENTILES:
Se denotan por Pk, donde k=1,2,3,4,5,6,7,8,9,10, … , 99
Son valores que dividen a un conjunto de datos en 100 partes iguales,
es decir, cada sector tiene el 1% de los datos.
Para calcular la media aritmética se utilizan las formulas adecuadas ya
sea sin son datos agrupados o datos no agrupados.
3. MEDIDAS DE VARIABILIDAD:
3.1. RANGO:
Se denota por R y la medida de variabilidad más fácil de calcular.
Es la diferencia que existe entre el valor máximo y el valor mínimo del
conjunto de datos.
3.2. VARIANZA:
Mide la variabilidad de un conjunto de datos respecto a un valor
central(promedio)
Mide la variabilidad pero en unidades elevadas al cuadrado, por lo tanto
es ilógica su interpretación.
Para calcular la media aritmética se utilizan las formulas adecuadas ya
sea sin son datos agrupados o datos no agrupados.
3.3. DESVIACIÓN ESTANDAR:
Mide la variabilidad de un conjunto de datos respecto a su valor central
pero en unidades originales.
Esta es la medida de variabilidad que tiene una interpretación lógica.
Se obtiene al sacra la raíz cuadrada de la varianza.
3.4. COEFICIETE DE VARIACIÓN:
Se denota por C.V.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 26 -
El C.V. sirve para determinar si un conjunto de datos tiene un
comportamiento homogéneo o heterogéneo.
Para llegar a determinar la homogeneidad se compara con un valor
convencional del 33%.
Si el CV ≤ 33% el conjunto de datos tiene un comportamiento
homogéneo.
Si el CV > 33% el conjunto de datos tiene un comportamiento
heterogéneo.
4. MEDIDAS DE FORMA:
4.1. ASIMETRIA:
La asimetría se entiende como la deformación horizontal de un conjunto
de datos.
Para conocer esta asimetría se calcula el coeficiente de asimetría As.
En un conjunto de datos pueden presentar los siguientes casos:
a. As= 0, el conjunto de datos es simétrica.
b. As<0, el conjunto de datos es asimétrica negativa.
c. As>0, el conjunto de datos es asimétrica positiva.
4.2. KURTOSIS:
Se entiende por Kurtosis a la deformación vertical de un conjunto de
datos, es decir, mide el apuntamiento o achatamiento de un conjunto de
datos.
Para conocer que tipo de asimetría tiene un conjunto de datos, se
utilizan las siguientes formulas:
A. Kurtosis en función de los momentos:
Si K1>3, el conjunto de datos es leptocúrtica.
Si K1=3, el conjunto de datos es mesocútica.
Si K1<3, el conjunto de datos es platicúrtica.
M4: Momento de orden cuatro respecto a la media
M2: Momento de orden dos respecto a la media
S
MoXAs
S
MeXAs
)(3
13
123 2
QQQAs
2
2
4
)(1
M
MK

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 27 -
B. Kurtosis en función de los momentos de orden 4:
Si K2>0, el conjunto de datos es leptocúrtica.
Si K2=0, el conjunto de datos es mesocútica.
Si K2<0, el conjunto de datos es platicúrtica.
C. Kurtosis en función de loscuantiles:
Si K3>0.263, el conjunto de datos es leptocúrtica.
Si K3=0.263, el conjunto de datos es mesocútica.
Si K3<0.263, el conjunto de datos es platicúrtica.
5. FORMULAS PARA CALCULAR LAS MEDIDAS DE TENDENCIA CENTRAL:
MEDIDAS PARA DATOS NO AGRUPADOS PARA DATOS AGRUPADOS
PROMEDIO n
x
X
n
i
i
1
Xi: datos n = número de datos
n
fY
X
m
ii
ii
Yi: Marca de clase o punto medio fi: frecuencia absoluta simple
n: número de datos.
MODA
Procedimiento:
Observar la base de datos y determinar el valor que más se repite.
21
1ALiMo
Li: limite inferior del intervalo modal.
A: amplitud interválica
12
11
jj
jj
ff
ff
MEDIANA
Procedimiento:
Ordenar la serie en forma ascendente
Cuando “n” impar:
Me = valor central Cuando “n” par:
Me = promedio de los valores centrales
j
j
f
FnALiMe
12/
Li: limite inferior del intervalo mediano. A: amplitud interválica.
2/n es el elemento determinante
Fj-1: Frecuencia acumulada anterior al
intervalo mediano fj: Frecuencia abs. simple del intervalo
mediano
3)(
22
4
s
MK
)(2 1090
13
PP
QQAs

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 28 -
CU
AN
TIL
ES
QUARTILES Seguir pasos similares a la mediana. j
j
Kf
FknALiQ
14/
Similar a la Me. Lo único que cambia es el elemento determinante.
DECILES Seguir pasos similares a la mediana.
j
j
Kf
FknALiD
110/
Similar a la Me. Lo único que cambia es
el elemento determinante.
PERCENTILES Seguir pasos similares a la mediana.
j
j
Kf
FknALiP
1100/
Similar a la Me. Lo único que cambia es
el elemento determinante.
6. FORMULAS PARA CALCULAR LAS MEDIDAS DE DISPERSION O VARIACIÓN
MEDIDAS PARA DATOS NO AGRUPADOS PARA DATOS AGRUPADOS
RANGO minmax VVR
LILSR
Ls: Limite superior
Li: Limite inferior
VARIA
NZA
POBLACIONAL N
uXN
i
i
1
2
2
)(
Xi : Datos de la población u : promedio poblacional
N: Número de elementos de la
población
N
fuYm
i
ii
1
2
2
*)(
Yi : Marca de clase u : promedio poblacional
N: Número de elementos de la
población fi: frecuencia absoluta simple
MUESTRAL
1
)(1
2
2
n
xx
s
n
i
i
Xi : Datos de la muestra
x : promedio muestral
n : Número de elementos de la muestra
1
*)(1
2
2
n
fyy
s
m
i
ii
yi : Marca de clase
y : promedio muestral
n : Número de elementos de la muestra
fi: frecuencia absoluta simple
Formulas
abreviadas
n
i
n
i
i
in
x
xn
s1
1
2
22
)(
1
1 m
i
m
i
ii
iin
fy
fyn
s1
1
2
22
)(
1
1
DESVIACION ESTANDAR 2
D.E. Poblacional
2ss
D.E. Muestral
COEFIENTE DE
VARIACIÓN 100*..
uVC
C.V. Poblacional
100*..x
sVC
C.V. Muestral

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 29 -
7. MEDIDAS ESTADÍSTICAS CON MEGASTAT:
En Excel los pasos a seguir para obtener estas medidas son las siguientes:
a. Tener una base de datos respecto a variables cuantitativas.
b. Seleccionar en MegaStat / Estadística descriptiva/….. aparece la siguiente
ventana, luego hay que ingresar los datos respectivos:
APLICACIÓN: (Evaluación de un caso)
RUBIOJA S.A. es una de las firmas consultoras financieras más importantes del Perú.
Ofrece asesoría financiera y servicios a firmas particulares y a gobiernos regionales.
Grecia Rubio, acababa de ser encargada del departamento de personal de esta empresa.
En los tres años pasados, se han agregado otros ayudantes y hace seis semanas, se
sumó al departamento un estadístico recién graduado. Damne empezó hace poco a
revisar las prácticas de contratación del departamento. Empezó la revisión examinando
el campo más crítico, las personas en adiestramiento financiero. La firma contrata entre
60 y 130 de estas personas al año, según sea el crecimiento de la firma, el movimiento
de empleados y el número de perspectivas “notables" que encuentre. Prácticamente
todos los que están en adiestramiento financiero se contratan entre los estudiantes del
último año de escuelas superiores con especialización financiera. Damne seleccionó al
azar 100 de los 197 candidatos que habían sido contratados hace dos años y aún seguían
trabajando. Cada ficha contenía la información siguiente (los datos van en el apéndice
adjunto):
1. Genero. (0=Femenino y 1=Masculino)
2. Edad al contratarse
3. Promedio ponderado de sus notas universitarias (escala de 0 a 20).
4. Calidad de la universidad de procedencia. (1=Excelente, 2=Muy buena, 3=Buena
y 4=Regular)
5. Nota de la prueba de aptitudes. La prueba produce una puntuación de 0 (muy
improbable que tenga éxito en el trabajo) a 100 (muy probable que tenga éxito
en el trabajo).

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 30 -
6. Evaluación del rendimiento al final del segundo año. Esta evaluación produce una
puntuación numérica desde 0 (muy malo) hasta 100 (excelente).
La Gerencia de RUBIOJA S.A. están seguros de que la escala es de intervalo y también
han decidido, con base en los tres años de experiencia con dicha escala, que una
puntuación inferior a 50 es insatisfactoria, 50-69 es satisfactoria, 70-89 por sobre el
promedio, y por encima de 89 es excelente. Grecia llama al estadístico a su oficina y le
dice: "Estoy encantada de tener un estadístico que nos ayude. No estamos aún listos a
desarrollar un modelo estadístico acabado de lo que constituye una buena contratación,
pero es tiempo de empezar a evaluar algunas de las variables de que tenemos
información. El gran número de personas que contratamos, el alto costo de adiestrarlas
y el hecho de que no podemos evaluar realmente los rendimientos, hasta fines del
segundo año, significan que cualquier mejoría en nuestra eficacia de contratación tendrá
por resultado ahorros sustanciales para la firma. Para comenzar a tratar el tema,
¿Podrías dar respuesta a las siguientes preguntas?
1. Necesitamos un resumen de la edad del personal al contratarse, del promedio de
calificaciones de grado y de la evaluación del rendimiento en el segundo año, para
tener una apreciación general del grupo en adiestramiento financiero. ¿Cuál es el
perfil de este personal?
2. ¿Es más alto el puntaje de varones en la nota de la prueba de aptitudes que el de
mujeres? ¿Y en la evaluación del rendimiento?
3. Un criterio inicial en RUBIOJA S.A era mantener la calificación promedio de grado de
los contratados por encima de 14.00. ¿Se sigue manteniendo este criterio?
4. Otro criterio era mantener por lo menos un tercio de los contratados que provengan
de escuelas de categoría 2. ¿Se sigue manteniendo este criterio?
5. ¿Son diferentes los rendimientos en la prueba de entrada para las diferentes
calidades de escuelas de donde provienen los candidatos? ¿Y en la Evaluación del
rendimiento del segundo año?
Si Ud. fuera el analista que conclusiones le daría a Grecia Rubio respecto al
análisis que realizó. Utilice la siguiente base de datos.
No. Genero Edad Calificación Calidad Universitaria Índice-Éxito Rendimiento 2
1 1 22 15,41 3 62 72
2 1 26 15,71 1 60 71
3 1 22 12,45 2 80 66
4 1 23 15,69 2 86 91
5 1 25 16,05 1 86 48
6 1 26 16,21 3 64 95
7 0 27 14,42 2 54 82
8 1 23 12,87 3 80 92
9 1 23 13,08 2 62 73
10 1 26 16,30 3 77 81
11 1 24 15,82 4 61 67
12 0 24 14,85 3 67 95
13 0 36 13,31 4 95 96
14 1 27 16,67 4 62 59
15 0 26 16,35 2 50 79
16 1 24 12,50 1 62 88
17 1 26 12,32 1 81 52

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 31 -
18 1 23 14,72 2 76 71
19 1 24 13,94 2 87 75
20 1 24 16,92 2 73 75
21 0 25 13,14 3 85 93
22 1 23 14,92 3 57 84
23 1 23 13,81 2 89 90
24 0 26 15,53 3 70 83
25 1 25 15,33 3 65 73
26 0 25 12,95 2 89 97
27 1 24 12,24 4 87 88
28 1 23 14,94 4 89 81
29 1 22 12,57 3 94 74
30 0 30 12,92 3 71 67
31 1 24 15,94 1 63 80
32 1 25 13,80 4 67 64
33 1 23 14,42 3 96 82
34 1 24 14,72 2 73 82
35 1 26 12,60 3 92 81
36 0 23 14,53 3 88 77
37 1 26 14,76 4 82 89
38 0 26 13,12 3 84 95
39 1 26 13,35 4 86 58
40 0 23 14,76 2 72 74
41 1 22 15,27 4 82 89
42 1 26 17,00 2 77 68
43 1 24 16,57 2 66 77
44 1 26 14,02 3 73 67
45 1 25 13,08 1 85 99
46 1 24 13,93 3 58 96
47 1 25 14,17 2 58 97
48 0 24 14,65 3 79 92
49 1 22 13,92 1 50 95
50 1 25 13,28 3 93 67
51 1 25 12,96 2 75 52
52 0 23 13,97 2 82 82
53 1 25 13,92 3 57 83
54 1 24 14,92 3 67 87
55 1 24 16,33 2 60 73
56 0 23 14,25 4 56 67
57 1 23 15,29 1 94 72
58 1 26 15,23 3 92 66
59 1 26 15,73 3 81 95
60 0 23 12,94 1 73 82
61 1 24 15,96 1 91 84
62 1 24 16,96 2 72 98
63 1 27 12,23 3 85 93
64 1 22 15,35 2 96 87
65 0 23 16,77 2 85 57
66 1 24 16,12 2 89 85
67 0 25 14,34 3 92 81
68 1 24 14,69 3 66 95
69 1 22 14,67 2 85 90
70 1 23 15,56 2 54 80
71 1 22 12,35 2 85 48
72 1 24 13,39 3 65 71
73 0 26 16,99 1 76 63
74 0 28 15,29 4 63 87
75 0 26 15,93 2 89 97

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 32 -
76 1 25 13,41 3 83 97
77 1 25 15,55 2 57 79
78 1 25 13,97 1 96 71
79 0 23 12,81 4 72 72
80 1 24 12,99 2 73 89
81 1 25 15,67 2 53 94
82 1 23 12,47 3 86 78
83 1 24 12,77 3 64 89
84 0 24 14,67 1 80 84
85 0 25 13,94 3 77 91
86 1 24 14,90 1 52 69
87 1 23 15,44 2 70 89
88 0 23 16,03 4 90 91
89 1 29 12,15 4 74 89
90 0 22 13,42 2 95 94
91 0 26 12,02 4 84 95
92 0 22 13,04 3 68 78
93 0 30 14,35 4 92 84
94 1 25 13,65 2 52 85
95 1 23 12,66 2 82 69
96 1 26 13,22 3 56 71
97 1 23 13,43 3 85 58
98 1 22 15,54 4 85 93
99 1 26 16,51 3 64 97
100 1 23 16,91 3 61 83

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 33 -
PPAARRTTEE 44:: AANNAALLIISSIISS DDEE CCOORRRREELLAACCIIOONN YY RREEGGRREESSIIOONN
11.. AANNAALLIISSIISS DDEE CCOORRRREELLAACCIIÓÓNN::
El análisis de correlación es una técnica estadística que mide el grado de
asociación o afinidad entre las variables cuantitativas consideradas en un
estudio.
Se llamará CORRELACION SIMPLE cuando se trata de analizar la relación
entre dos variables. Se llamará CORRELACION LINEAL O RECTILINEA si la
función es una recta, y de CORRELACION NO LINEAL cuando la función es una
curva o una función de grado superior.
El COEFICIENTE DE CORRELACION DE PEARSON, es el estadígrafo que mide
el grado de asociación o afinidad entre las variables cuantitativas y se denota
por “r” la cual se define como:
Interpretación:
-1 -0.7 -0.4 0 0.4 0.7 +1
Perfecta Alta Regular Baja Baja Regular Alta Perfecta
N E G A T I V A P O S I T I V A
22.. AANNAALLIISSIISS DDEE RREEGGRREESSIIOONN
2.1. ANALISIS DE REGRESION LINEAL SIMPLE:
El análisis de regresión es una técnica estadística que consisten en
determinar la relación funcional entre dos variables cuantitativas en
estudio.
Esta relación funcional entre las variables, es una ecuación matemática
de la forma Y= A + B X, que recibe el nombre también de Función de
Regresión o Modelo de Regresión.
A la variable Y se le denomina variable dependiente, a la variable X
independiente y a A,B se les llama parámetros de la ecuación de
regresión.
La finalidad del Análisis de Regresión es hacer pronósticos es decir,
hacer estimaciones futuros de la variable dependiente.
PASOS A SEGUIR:
a. Realizar el diagrama de dispersión y ver el comportamiento de la
variable.
n
i
n
i
i
n
i
n
i
ii
n
i
n
i
n
i
iiii
YYnXXn
YXYXn
r
1
2
1
1
2
1 1
22
1 1 1
)()(

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 34 -
b. Aplicar el método de los Mínimos Cuadrados Ordinarios para estimar los
parámetros de la ecuación. Las formulas son las siguientes:
n
i
n
iii
n
i
n
iii
n
iii
XXn
YXYXn
B
1
2
1
2
1 11
)(
XBYA
c. Para hacer el pronóstico o el valor estimado de Y, reemplazar en la
ecuación matemática el respectivo valor de Xo, de la siguiente manera:
Y = A + B (Xo)
2.2. REGRESION LINEAL MULTIPLE:
El ARLM es una técnica estadística que consiste en determinar el modelo
de regresión linel múltiple de una variable respuesta (Y) y un conjunto
de variables independientes (Xs).
El modelo de regresión lineal múltiple esta dado por la siguiente
ecuación:
KKXXXY ...22110
Para encontrar este modelo, es decir, estimar sus coeficientes también
se utiliza el Método de los Mínimos Cuadrados Ordinarios.
Los elementos de este modelo de regresión múltiple son los siguientes:
Y es la variable dependiente o variable respuesta.
A las Xs se le llama variables independientes.
Bs se les llama coeficientes de regresión.
En el ARLM se prueban las siguientes Hipótesis:
Ho: Los Bs son iguales a cero (No hay efecto de las variables
independientes en Y);
H1: Los Bs son diferentes de cero (Por lo menos un X influye en Y).
Para dar respuesta a esta Hipótesis se utiliza el análisis de varianza.
2.3. REGRESION LINEAL CON EXCEL (MEGASTAT):
Para realizar estos ejercicios se deben realizar los siguientes pasos: Hacer clic
en Complementos / MegaStat / …… y aparece la siguiente ventana….

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 35 -
Luego aparece la ventana de dialogo donde hay que ingresar el rango de Y, el
rango de X, activar rótulos, las opciones de salida y algunas alternativas de
interés para el investigador.
Luego tomar las decisiones respectivas.
APLICACIÓN 01
LA EMPRESA HIDRANDINA de la ciudad de
Trujillo, esta haciendo un estudio sobre los
consumos de energía (en miles de kilowatts -
hora) y el número de áreas de trabajo en un
conjunto de Empresas Privadas Para este
estudio se selecciona una muestra aleatoria
de 10 Empresas Privadas, en la cual se
obtuvo los siguientes resultados:
a. Estimar la ecuación de regresión lineal.
b. Evalúe el consumo (en miles de kilowatts-
hora), para una Empresa que tiene 6 áreas
de trabajo.
SALIDA DEL MEGASTAT:
Regression Analysis
r² 0.857 n 10
r 0.926 k 1
Std. Error 2.021 Dep. Var. Consumo de energía (miles de kw)
ANOVA table
Source SS df MS F p-value
Regression 196.2333 1 196.2333 48.06 .0001
Residual 32.6667 8 4.0833
Total 228.9000 9
Nº de
casa
Número de
áreas de
trabajo
Consumo
de
energía
(miles de
kw)
1 2 4
2 4 11
3 4 10
4 3 5
5 1 3
6 3 6
7 1 3
8 5 18
9 5 14
10 3 7
Total

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 36 -
Regression output
confidence interval
variables coefficients std. error t (df=8) p-value 95% lower 95% upper
Intercept -1.8889 1.5763 -1.198 .2651
-
5.5237 1.7460
Número de
áreas de trabajo 3.2222 0.4648 6.932 .0001 2.1504 4.2941
APLICACIÓN 02:
El Gerente de la UNT está haciendo un estudio entre
el gasto de mantenimiento de sus computadoras y
el año de antigüedad de dichas maquinas. Para esto
recurre a la oficina de Mantenimiento y Contabilidad
obteniendo la siguiente información:
a. Estime la ecuación de regresión lineal.
b. Estime cuanto sería el costo de mantenimiento de
una computadora que tiene 7 años.
c. Calcule e interprete el valor del coeficiente de
regresión lineal “ r ”
APLICACIÓN 03:
El jefe de personal de una institución educativa cree que
existe una relación entre la tardanza al trabajo y la edad
del trabajador. Con el propósito de estudiar el problema
tomó en cuenta la edad de diez trabajadores escogidos
al azar y contabilizó los días de tardanza durante todo
un año. Los resultados fueron como se observa en la
tabla que sigue:
a. Construya el diagrama de dispersión.
b. Obtenga la ecuación de la recta de regresión
c. Si un docente tiene 38 años, ¿Cuántos tardanzas se
espera que falte al año?
d. Si un trabajador tiene 3 tardanzas al año ¿Qué edad
se puede esperar que tenga este trabajador?
e. Determinar el grado de relación entre las variables
en estudio
Nº de
maquina
Tiempo de
antigüedad
(años)
Costo de
mantenimiento.
($)
1 1 14
2 1 16
3 2 20
4 2 24
5 3 30
6 3 28
Total
Nº
Edad en
años
Nº de
Tardanza e
un año
1 25 20
2 50 5
3 35 10
4 20 20
5 45 8
6 50 2
7 30 15
8 40 12
9 62 1
10 40 8
Total

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 37 -
PPAARRTTEE 55:: DDIISSTTRRIIBBUUCCIIOONNEESS DDEE PPRROOBBAABBIILLIIDDAADD 1. LA DISTRIBUCIÓN BINOMIAL
La Distribución Binomial es una las distribuciones de probabilidad discretas
más importantes, la cual tiene muchas aplicaciones en Ingeniería,
Administración, etc..
Esta distribución se origina en los Ensayos o Experimentos Bernoulli que
consiste en realizar 1 experimentos que tiene dos resultados posibles,
llamados “éxito” y “fracaso”.
Ejemplos:
1. Lanzar una moneda
2. Rendir un examen. Ensayos de Bernoulli
3. Observar el sexo de un recién nacido.
4. Encender una maquina, etc
Experimento Binomial:
Es aquel que consiste en realizar “n” veces ensayos de Bernoulli, en el cual
se debe cumplir lo siguiente:
a. Cada ensayo tienen solo dos resultados posibles.
b. Los ensayos son independientes.
c. La probabilidad de éxito “p” es constante en cada ensayo.
Esta distribución tienen las siguientes características:
1. Su variable aleatoria esta definida como:
X: Numero de éxitos en “n” ensayos.
2. Su recorrido o rango es:
Rx = {0,1,2,3,4,5, …, n}
3. Su función de probabilidad esta dada por:
4. Sus parámetros son :
n : Numero de veces que se repite el experimento o tamaño de
muestra.
p : Probabilidad de éxito en cada uno de los ensayos o proporción de
interés.
5. Su notación es : X B ( n, p )
6. Uso de tabla: Para el uso de tabla tener en cuenta lo siguiente
A. P ( X ≤ a ) = Usar directamente la tabla B. P ( X > a ) = 1 - P ( X ≤ a ) C. P ( X ≥ a ) = 1 - P ( X ≤ a - 1 ) D. P ( X = a ) = P ( X ≤ a ) - P ( X ≤ a - 1 ) E. P ( a ≤ X ≤ b ) = P ( X ≤ b ) - P ( X ≤ a-1 ) F. P ( a ≤ X < b ) = P ( X ≤ b-1 ) - P ( X ≤ a-1 ) G. P ( a < X < b ) = P ( X ≤ b-1 ) - P ( X ≤ a )
nxqpx
nxXPxf xnx ,...,2,1,0,)()(

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 38 -
APLICACIÓN CON MEGASAT:
APLICACIÓN 01:
En el almacén de la Empresa MAESTROS, hay 12 artículos eléctricos de los cuales 3 de
ellos son defectuosos. Si se extrae una muestra aleatoria de 5 a partir del grupo. Cual es
la probabilidad de que:
a. Exactamente 1 sea defectuosos.
b. Ninguno sea defectuoso.
c. Menos de 2 sean defectuosos.
d. Más de 3 sean defectuosos.
SOLUCION:
Binomial distribution
5 n
0.25 p
cumulative
X P(X) probability
0 0.23730 0.23730
1 0.39551 0.63281
2 0.26367 0.89648
3 0.08789 0.98438
4 0.01465 0.99902
5 0.00098 1.00000
1.00000
1.250 expected value
0.938 variance
0.968 standard deviation

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 39 -
APLICACIÓN 02:
En la UNT – Escuela de Postgrado se está aplicando un nuevo método de enseñanza del
aprendizaje del Idioma Portugués. Después de completar con la aplicación de este
método se evalúa que el 1% salio desaprobado. El director académico selecciona en
forma aleatoria estudiantes al azar de la Universidad:
a. Cual es la probabilidad de que exista más de 3 desaprobados.
b. Cual es la probabilidad de que exista menos de 3 desaprobados.
c. Cual es la probabilidad de que haya entre 2 y 4 desaprobados inclusive.
APLICACIÓN 03:
Según información de Secretaría Académica de la UNT, el 65% de los estudiantes son del
sexo masculino y el resto mujeres. Para la aplicación de una encuesta por parte de la
asistenta social, se selecciona aleatoriamente a 10 estudiantes:
a. Cual es la probabilidad de encuestar a menos de 5 hombres.
b. Cual es la probabilidad de encuestar mas de 5 hombres
c. Cual es la probabilidad de encuestar a 3 y 8 hombres inclusive.
d. Cual es la probabilidad de encuestar a ningún hombre.
2. LA DISTRIBUCIÓN POISSON
La Distribución de Poisson es otra de las distribuciones de probabilidad discretas
más importantes por que se aplica en muchos problemas reales.
Esta distribución se origina en problemas que consiste en observar la ocurrencia
de eventos discretos en un intervalo continuo (unidad de medida).
Ejemplos:
1. Numero de manchas en un metro cuadrado de un esmaltado de un
refrigerador.
2. Numero de vehículos que llegan a una estación de servicios durante una hora.
3. Numero de llamadas telefónicas en un día.
4. Numero de clientes que llegan a un banco durante las 10 y 12 p.m.
5. Numero de bacterias en un cm3 de agua.
Esta distribución tienen las siguientes características:
7. Su variable aleatoria esta definida como:
X: Numero de ocurrencias en 1 unidad de medida (Tiempo, Volumen,
Superficie, etc)
8. Su recorrido o rango es:
0.00
0.20
0.40
0.60
0 1 2 3 4 5
P(X
)
X
Binomial distribution (n = 5, p = 0.25)

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 40 -
Rx = {0,1,2,3,4,5, ….}
9. Su función de probabilidad esta dada por:
10. Su parámetro es λ : tasa promedio de ocurrencia en 1 unidad de medida.
11. Su notación es : X P( λ )
12. Uso de tabla: Para el uso de tabla tener en cuenta lo siguiente
APLICACIÓN CON MEGASTAT
APLICACIÓN 01:
En un estudio de Satisfacción del Cliente en la UNT, se determino que las personas llegan
aleatoriamente a la ventanilla de caja, con una tasa promedio de 24 personas por hora,
durante la hora punta comprendida entre 11:00 am y 12:00 am de cierto día. El jefe
administrativo desea calcular las siguientes probabilidades:
a. Cual es la probabilidad de que lleguen exactamente 5 personas durante esa hora?
b. Cual es la probabilidad de que lleguen mas de 5 personas durante esa hora?
c. Cual es la probabilidad de que lleguen menos de 5 personas durante esa hora?
d. Cual es la probabilidad de que lleguen más de 8 personas durante esa hora?
SOLUCION:
,...2,1,0,!
)()()( x
x
exXPxf
x
H. P ( X ≤ a ) = Usar directamente la tabla I. P ( X > a ) = 1 - P ( X ≤ a ) J. P ( X ≥ a ) = 1 - P ( X ≤ a - 1 ) K. P ( X = a ) = P ( X ≤ a ) - P ( X ≤ a - 1 ) L. P ( a ≤ X ≤ b ) = P ( X ≤ b ) - P ( X ≤ a-1 ) M. P ( a ≤ X < b ) = P ( X ≤ b-1 ) - P ( X ≤ a-1 ) N. P ( a < X < b ) = P ( X ≤ b-1 ) - P ( X ≤ a )

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 41 -
Poisson distribution
24
mean rate of occurrence
cumulative
X P(X) probability
0 0.00000 0.00000
1 0.00000 0.00000
2 0.00000 0.00000
3 0.00000 0.00000
4 0.00000 0.00000
5 0.00000 0.00000
6 0.00001 0.00001
7 0.00003 0.00005
8 0.00010 0.00015
9 0.00027 0.00043
10 0.00066 0.00108
11 0.00144 0.00252
12 0.00288 0.00540
13 0.00531 0.01072
14 0.00911 0.01983
15 0.01457 0.03440
16 0.02186 0.05626
17 0.03086 0.08713
18 0.04115 0.12828
19 0.05198 0.18026
20 0.06238 0.24264
21 0.07129 0.31393
22 0.07777 0.39170
23 0.08115 0.47285
24 0.08115 0.55400
25 0.07791 0.63191
26 0.07191 0.70382
27 0.06392 0.76774
28 0.05479 0.82253
29 0.04534 0.86788
30 0.03628 0.90415
0.90415
24.000 expected value
24.000 variance
4.899 standard deviation

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 42 -
APLICACIÓN 02:
Si la secretaria de la Escuela de Postgrado de la UNT, recibe un promedio de 2 llamadas
cada 3 minutos por motivos académicos. Calcular lo siguiente:
a. Cual es la probabilidad de que reciba más de 3 llamadas en 3 minutos.
b. Cual es la probabilidad de que reciba menos de 2 llamadas en tres minutos.
c. Cual es la probabilidad de que reciba exactamente 2 llamadas en tres minutos.
d. Cual es la probabilidad de reciba 5 llamadas en 6 minutos.
e. Cual es la probabilidad de que reciba menos de 2 llamadas en un minuto.
APLICACIÓN 03:
En un estudio por parte del Ministerio de Transporte y Comunicaciones (MTC), se ha
determinado que en la carretera panamericana con destino a Lima, hay en promedio de
20 accidentes por semana (7 días), calcular las siguientes probabilidades:
a. Cuál es la probabilidad de que en una semana no haya ningún accidente.
b. Cual es la probabilidad de que en dos semanas haya 10 accidentes.
c. Cual es la probabilidad de que en 1semana ocurra menos de 15 accidentes.
d. Cual es la probabilidad de que en un día haya tres o menos accidentes.
e. Cual es la probabilidad de que en un día haya tres o más accidentes.
APLICACIÓN 04:
En el Centro de impresiones de la UNT se comete dos fallas en las impresiones debido a
causas externas cada vez que imprime 2,500 hojas como promedio. Con esta
información determinar:
a. La probabilidad de que en una impresión de 500 hojas, ocurra uno más errores.
b. La probabilidad de que no ocurrirán errores en una impresión de 50 hojas.
APLICACIÓN 05:
Los clientes de una empresa llegan a la tienda de venta aleatoriamente a una tasa de
300 personas por hora. Calcular la probabilidad de que:
a. Una persona llegue durante un periodo de 1 minuto
b. Por lo menos dos personas lleguen durante un periodo dado de un minuto.
c. Ninguna persona legue durante un periodo de 1 minuto
0.00
0.02
0.04
0.06
0.08
0.10
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
P(X
)
X
Poisson distribution (µ = 24)

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 43 -
3. LA DISTRIBUCIÓN NORMAL:
La distribución normal, llamada también Curva de Gauss (en recuerdo al
científico que lo descubrió), es la distribución de probabilidad más importancia en
la Estadística y por ende del Calculo de Probabilidades.
Esta distribución de probabilidad es importante porque las variables aleatorias
continuas (peso, edad, talla, producción, gasto en publicidad, temperatura,
ventas, PBI, ganancias, etc) que son variables que más se evalúan en una
investigación científica o investigación de mercados se aproximan a esta
distribución de probabilidad.
También es importante porque se utiliza como aproximación de las distribuciones
discretas tales como: la Binomial, la Poisson, etc.
CARACTERÍSTICAS
1. Tiene como parámetros a y
2. Su función de probabilidad está dada por:
Xxf
X
,2
1)(
2
2
1
Además: - +
- < < + y > 0
3. El promedio puede tomar valores entre – y + mientras que > 0, entonces
existen infinitas curvas normales.
4. Esta función de probabilidad es asintótica con respecto al eje X, (a pesar de tener
recorrido infinito, la curva nunca toca el eje X); además es unimodal y es
simétrica con respecto a la media .
5. El areá bajo esta función o curva es 1 ó 100%, de la misma manera se sabe que
las áreas comprendidas bajo la curva normal son :
1. = 68.3%
2. 2 = 95.5%
3. 3 = 99%
- 3 2 1 1 2 3 +
5. Para calcular probabilidades en la distribución normal se necesitaran infinitas
tablas de probabilidad.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 44 -
4. LA DISTRIBUCIÓN NORMAL ESTÁNDAR:
1. Es una distribución a la cual se le ha modificado la escala original; esta
modificación se ha logrado restando la media al valor de la variable original y
dividiendo este resultado por , la nueva variable se denota por Z y recibe el
nombre de variable estandarizada
ZX
2. La modificación de la escala ha permitido elaborar una tabla para el cálculo de las
probabilidades; si esto no hubiera sido posible, sería necesario construir una tabla
para cada valor de y .
3. La función de densidad de la variable estandarizada es:
f z ez
( )1
2
1
2
2
4. El promedio (valor esperado) y la varianza de Z son: E(Z) = 0 , V(Z) = 1
5. Notación:
Si X es v.a. continua distribuida normalmente con media y varianza 2 , la
denotamos por : X N( , 2).
Aplicando esta notación a la variable normal estandarizada Z, escribimos:
Z N(0 , 1) , esto se interpreta como, Z tiene distribución normal con media 0
y varianza 1.
6. La superficie bajo la curva normal Z estandarizada también es igual a 1. Por
consiguiente, las probabilidades pueden representarse como áreas bajo la curva
normal escandalizada entre dos valores.
7. Debido a que la distribución normal es simétrica muchas de las tablas disponibles
contienen solo probabilidades para valores positivos de Z.
USO DE TABLA:
Si se conoce el comportamiento de una variable, es decir, se sabe que tienen una
distribución normal, para calcular las diferentes probabilidades se tiene que
estandarizar la variable. Una vez estandarizada la variable, recién utilizar la tabla de
la distribución normal estandarizada o tabla Z.
FORMULAS:
a. )()()(a
ZPax
PaxP
b. )(1)(1)(1)(a
ZPax
PaxPaxP
c. )()()()()(ax
Pbx
PaxPbxPbxaP

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 45 -
APLICACIÓN CON MEGASTAT
APLICACIÓN 01:
El rendimiento académico de los estudiantes de la UNT-Escuela de Postgrado, tiene una
distribución normal con media igual a 15 y varianza igual a 4. Si se selecciona un
estudiante de esta Universidad, encuentre la probabilidad de que:
a. El rendimiento sea menor que 16
b. El rendimiento sea menor que 14
c. El rendimiento este entre 14 y 18
d. El rendimiento sea mayor 15.5
SOLUCION
Reemplazando valores:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 46 -
APLICACIÓN 02:
Los salarios mensuales de los trabajadores administrativos de la UNT tiene un
comportamiento normal cuya media es S/. 2100 y una desviación estándar de S/. 50.
Cuantos trabajadores tienen salarios:
a. Menores de S/. 2150.
b. Menos de S/. 2200.
c. Mas de S/. 2180.
d. Entre 2080 y 2150 soles.
APLICACIÓN 03:
El tiempo de duración de los focos eléctrico de los cañones proyectores tienen una
distribución normal con una media de 1000 horas y una desviación estándar de 250
horas. Determinar la probabilidad de que:
a. Un foco tomado al azar se queme antes de las 990 horas de funcionamiento
b. Un foco se que queme entre 980 y 1120 horas de funcionamiento.
c. Un foco dure mas de 998 horas
APLICACIÓN 04:
NEUMA Perú, es una empresa que produce llantas para automóviles en nuestro país. La
vida útil de estas llantas se distribuye aproximadamente como una normal con media y
desviación estándar iguales a 32000 y 1000 millas respectivamente. Esta empresa quiere
exportar estas llantas por lo que empieza a hacer ciertos cálculos acerca de la calidad de
estas llantas, para lo cual se hace las siguientes preguntas:
a. Cual es la probabilidad de una llanta producida por esta empresa tenga una vida útil
de 31900 millas.
b. Cual es la probabilidad de una llanta producida por esta empresa tenga una vida útil
desde 31000 y 33000 millas.
c. Si las empresa fija una garantía de 30000 millas. ¿Qué porcentaje de esta producción
necesitará ser reemplazada?

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 47 -
PPAARRTTEE 66:: EESSTTIIMMAACCIIÓÓNN EESSTTAADDÍÍSSTTIICCAA
A. ESTIMACION PUNTUAL:
Es aquel único valor que se obtiene de la muestra, es decir, que para su cálculo se
debe tener información muestral. Las formulas para calcular o realizar estas
estimaciones son las siguientes:
PROMEDIO VARIANZA PROPORCION
PARAMETRO
2 P
ESTIMACION PUNTUAL
B. ESTIMACIÓN INTERVÁLICA:
Al realizar una estimación, siempre se va a cometer un error. Entonces, cuando
estimamos un parámetro nunca va a ser exacto, ese valor será mayor o menor al
verdadero. Entonces se obtendrá un intervalo de valores posibles. Ese intervalo se
llama estimación interválica. A esa diferencia mayor o menor se llama error de
estimación, el cual esta en relación directa con la variabilidad del estimador y el nivel
de confianza determinado por el investigador. La estimación intervalica para un
parámetro en general, esta dada por:
2/2/ˆˆ ZZ
Error de Estimación Error de estimación
También se puede escribir de la siguiente manera:
2/ˆ: Z
Para determinar este intervalo se necesita de:
a. La estimación puntual
b. La desviación estándar del estimador.
c. Nivel de confianza, el cual será repartido para cada lado del intervalo.
n
x
x
n
i
i
1ˆ
1
)(
ˆ1
2
22
n
xx
s
n
i
i
n
apP̂
ESTIMACIÓN: Es el proceso mediante el cual se intenta determinar el valor del
parámetro de la población a partir de la información de una muestra. Al realizar una
estimación siempre se va a cometer un error. Existen dos tipos de estimación:
A. ESTIMACIÓN PUNTUAL B. ESTIMACIÓN INTERVÁLICA

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 48 -
FORMULAS DE LOS INTERVALOS DE CONFIANZA
I. INTERVALO DE CONFIANZA PARA EL PROMEDIO POBLACIONAL
A. Si la muestra (n) es mayor de 30 y la varianza poblacional es conocida:
n
Zx2/
:
B. Si la muestra (n) es menor o igual a 30 y la varianza poblacional es desconocida:
n
stx
n )1,2/(:
II. INTERVALO DE CONFIANZA PARA LA PROPORCION POBLACIONAL
A. Si la proporción poblacional se conoce:
n
PQZpP
2/:
B. Si la proporción poblacional No se conoce: (entonces hay que calcularla en la
muestra)
n
pqZpP
2/:
III. INTERVALO DE CONFIANZA PARA LA DIFERENCIA DE MEDIAS
A. Si las muestras son de tamaño n1>30 y n2>30 (grandes) y además las varianzas
poblacionales se CONOCEN:
2
2
2
1
2
1
2/2121)(:
nnZxx
B. Si las muestras son de tamaño n1<30 y n2<30 (pequeñas) y además las varianzas
poblacionales DESCONOCIDAS:
)11
()(:21
2
)2,2/(2121 21 nnstxx cnn
Donde :
2nn
s)1n(s)1n(s
21
2
22
2
112
c , se llama varianza mancomunada
IV. INTERVALO DE CONFIANZA PARA LA DIFERENCIA DE PROPORCIONES:
A. Si p1 y p2 se determinan a partir de muestras:
2
22
1
11
2/2121)(:
n
qp
n
qpZppPP

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 49 -
APLICACIÓN UTILIZANDO MEGASTAT
RESPECTO AL PROMEDIO:
APLICACIÓN 01:
Los estudiantes de Administración de Empresa de una Universidad realizaron un trabajo
de aplicación respecto a los sueldos de los trabajadores de la mina YANACOCHA, para lo
cual seleccionaron una muestra aleatoria de 24 trabajadores en el cual se determinó que
el sueldo promedio semanal es de $160 y una varianza de 10 dolares2.
a. Calcular un intervalo de confianza para el sueldo promedio con el 90% de confianza.
b. Calcular un intervalo de confianza para el sueldo promedio con el 95% de confianza.
SOLUCION:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 50 -
APLICACIÓN 02:
La Gerencia de la empresa HAMILTON LIGH esta interesado en conocer el contenido de
nicotina promedio de su marca de cigarrillos. Para lo cual selecciona una muestra de 14
cigarros obteniendo un promedio de 25 miligramos y una varianza de 16 miligramos2.
a. Calcular un intervalo de confianza para el sueldo promedio con el 99% de confianza.
b. Calcular un intervalo de confianza para el sueldo promedio con el 95% de confianza.
c. Calcular un intervalo de confianza para el sueldo promedio con el 90% de confianza.
APLICACIÓN 03:
Nuestro amigo BRUNO se dedica al negocio de los AUTOS, el sospecha que su margen de
beneficios mensual promedio por auto vendido está por debajo del promedio nacional de
S/. 700. Para evaluar su margen de beneficio toma información (muestra) respecto a 8
meses cuya información es la siguiente:
MES 1 2 3 4 5 6 7 8 Promedio Varianza
BENEFICIO 800 840 780 850 810 790 805 800
a. Calcular un intervalo de confianza para el margen de beneficio promedio con el 99%
de confianza.
b. Calcular un intervalo de confianza para el margen de beneficio promedio con el 95%
de confianza.
c. Calcular un intervalo de confianza para el margen de beneficio promedio con el 90%
de confianza.
RESPECTO A LA PROPORCION:
APLICACION 04:
Según un vendedor de automóviles, de todos los vehículos adquiridos por los docentes
universitarios, en más del 80% de los casos el color es elegido por la mujer. Para
verificar esta hipótesis se toma una muestra de 400 parejas que han comprado autos
nuevos durante el último año, hallándose que en 310 casos el color fue en efecto elegido
por la dama. Calcular:
a. El intervalo confidencial para la proporción considerando el 99 % de confianza.
b. El intervalo confidencial para la proporción considerando el 90% de confianza.
SOLUCION

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 51 -
RESPECTO A LA DIFERENCIA DE PROMEDIOS:
1. La SUNAT esta haciendo auditoria en ciertos grifos gasolineras. Selecciona en forma
aleatoria 05 grifos de 2 empresas diferentes (Texaco y Repsol). Los ingresos en miles
de soles semanales se presentan a continuación:
TEXACO : 90 85 95 76 80
REPSOL : 84 87 90 92 90
a. Estimar un intervalo de confianza para la diferencia de medias (DIFERENCIA DE
LOS INGRESOS PROMEDIOS) con el 90% de confianza.
b. Estimar un intervalo confidencial para la diferencia de medias (DIFERENCIA DE
LOS INGRESOS PROMEDIO) con el 99% de confianza.
RESPECTO A LA DIFRENCIA DE PROPORCIONES:
1. Se toman muestras independientes para determinar el la proporción de personas que
esta a favor de un impuesto al combustible. La primera muestra consiste en 100
personas que solamente trabajan en Trujillo y la segunda muestra es de 100
personas del cercado de Trujillo. Se determina que 50 y 60 personas de las
respectivas muestras están de acuerdo con el aumento.
a. Calcular un intervalo de confianza para la diferencia de proporciones
considerando el 99% de confianza.
b. Calcular un intervalo de confianza para la diferencia de proporciones
considerando el 90% de confianza.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 52 -
PPAARRTTEE 77:: DDEETTEERRMMIINNAACCIIOONN DDEELL TTAAMMAAÑÑOO DDEE MMUUEESSTTRRAA
DETERMINACIÓN DEL TAMAÑO DE MUESTRA:
Para determinar el tamaño, primeramente hay que identificar la variable a estudiar
(Cuantitativa o cualitativa). Luego depende de cuatro factores o elementos que son los
siguientes:
PARA UNA VARIABLE CUANTITATIVA:
a. Un nivel de confianza: Que es adoptado por el investigador, el cual puede ser 90%,
95% o 99% y que origina el valor de Z.
b. El error de estimación (E): Que también es fijado por el investigador
c. La desviación estándar ó varianza: que son valores que se obtienen por estudios
anteriores, por la muestra piloto o por la distribución de la población.
d. El Tamaño de la población (N): Que generalmente no se conoce.
PARA UNA VARIABLE CUALITATIVA:
a. Un nivel de confianza: Que es adoptado por el investigador, el cual puede ser 90%,
95% o 99% y que origina el valor de Z.
b. El error de estimación (E): Que también es fijado por el investigador
c. La proporción poblacional (P): que son valores que se obtienen por estudios
anteriores, por la muestra piloto y si no se conoce asumir p=0.5.
d. El Tamaño de la población (N): Que generalmente no se conoce.
MUESTREO
Es una TÉCNICA ESTADÍSTICA por la cual se realizan inferencias a la población
examinando solo una parte de ella, ésta parte recibe el nombre de MUESTRA, la cual
debe ser estadísticamente representativa y adecuada.
Ventajas: Desventajas:
Costo reducido • Presencia del error de muestreo
Mayor rapidez y exactitud • Presencia de gran variabilidad de las obs.
Minimiza los costos.
TÉCNICAS DE MUESTREO
Existen 2 tipos de técnicas de muestreo:
A. TECNICAS PROBABILISTICAS: B. TECNICAS NO PROBABILISTICAS
Muestreo aleatorio simple • El muestreo a criterio o juicio.
Muestreo aleatorio estratificado • El muestreo por cuotas.
Muestreo sistemático • El muestreo por conveniencia.
Muestreo por conglomerados • etc
Etc.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 53 -
FORMULAS PARA DETERMINAR EL TAMAÑO DE MUESTRA:
VARIABLE Cualitativa
(Proporción Poblacional)
Cuantitativa
(Promedio Poblacional)
POBLACION
INFINITA
(Cuando no se conoce N)
2
2
0
)1(
E
PPZn
2
22
0E
SZn
POBLACION
FINITA
(Cuando se conoce N)
)1()1(
)1(22
2
PPZNE
NPPZn
222
22
)1( SZNE
NSZn
Z= es el valor de la distribución normal estandarizada para un nivel de confianza fijado por el investigador.
S= Desviación estándar de la variable fundamental del estudio o de interés para el investigador. Obtenida por estudios anteriores, muestra piloto, criterio de experto o distribución de la variable de interés.
P= es la proporción de la población que cumple con la característica de interés.
E= % del estimador o en valor absoluto (unidades). Fijada por el investigador.
N= Tamaño de la población.
PASOS A SEGUIR PARA DETERMINAR LA MUESTRA ÓPTIMA:
A. Identificar eL tipo de variable a analizar.
B. Asumir que la población es infinita y aplicar la formula respectiva señaladas
anteriormente. Esta muestra se llama muestra previa.
C. Luego si se conoce el tamaño de la población N, obtener la fracción de muestreo N
n0
Si %50
N
n, entonces la muestra definitiva es n0 (muestra previa)
Si %50
N
n, entonces se ajusta la muestra.
D. Para ajustar la muestra se tiene que aplicar la siguiente formula:
N
n
nn
0
0
1 , n es la muestra final.
ESTIMACION DE LOS VALORES A APLICAR EN LAS FORMULAS
A. Valor de Z: es el valor de la abcisa de la distribución normal estandarizada
teniendo en cuenta el nivel de confianza fijado por el investigador, por lo tanto
este valor se encuentra en las tablas estadística respectiva. Para hacer el trabajo
menos tedioso, presentamos a continuación los diferentes valores de Z

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 54 -
TABLA N° 01
VALORES DE LA DISTRIBUCIÓN NORMAL
ESTANDARIZADA(Z)
Nivel de confianza
(1- )
Nivel de significancia
( )
Valor Z
Bilateral Unilateral
90% = 0.90
95% = 0.95
98% = 0.98
99% = 0.99
10% = 0.10
5% = 0.05
2% = 0.02
1% = 0.01
1.64
1.96
2.32
2.57
1.28
1.64
2.05
2.32
B. Cálculo del Valor de P: Se calcula este valor cuando la variable de estudio es
cualitativa. TABLA N° 02
COMPORTAMIENTO DE P y Q
P Q=1-P PQ
0.05
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
0.95
0.95
0.90
0.80
0.70
0.60
0.50
0.40
0.30
0.20
0.10
0.05
0.0475
0.090
0.160
0.210
0.240
0.250
0.240
0.210
0.160
0.090
0.0475
C. Cálculo del Valor de la varianza (Si la variable es CUANTITATIVA): este
valor es obtenida por estudios anteriores, muestra piloto, criterio de experto o
distribución de la variable de interés.
D. Cálculo del error de estimación: Generalmente se asume 2%, 5%, y 8% de
error. Este valor es fijado por el investigador. Es la diferencia entre el parámetro
(población) y el estimador (Muestra). Es decir: ooE ˆ .Este error puede ser
absoluto o relativo. Si E=±0.35 se denomina error absoluto. Si consideramos un
error del 10% de la media, es decir, E=10%( x )=0.10(3.5)=0.35 se denomina
error relativo.
APLICACIÓN UTILIZANDO MEGASTAT
APLICACIÓN 01:
Cuál será el tamaño de corridas de producción adecuado si se requiere estimar el tiempo
promedio para efectuar la producción de un producto químico con una confianza del
95%. Además en un estudio piloto se encontró 5.3x horas y s = 2.2 horas y además
el investigador asume E = 0.35 horas.
APLICANDO MEGASTAT:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 55 -
APLICACIÓN 02:
El Director de la sección de control de la rabia del Dpto. de Salud Pública de la Ciudad de
Chiclayo desea obtener una muestra de los registros de dicho Dpto. acerca de las
mordidas de perro reportadas durante el año anterior, para estimar la edad media de las
personas mordidas. El director desea una seguridad del 95%, con un E=2.5 y en base a
estudios anteriores conoce que la desviación estándar es de 15 años. ¿De que tamaño
debe ser la muestra?
APLICACIÓN 04:
Se desea estimar el tiempo medio de duración de artefactos eléctricos (focos) producidos
por la empresa PHILIPSS. Se sabe por un estudio piloto de 10 focos que la desviación
estándar del tiempo de duración es de 20 meses. De que tamaño debe ser la muestra
para estimar el tiempo medio de duración con un error máximo de 4 meses y con una
confianza del 95%?.
APLICACIÓN 05:
Por estudios científicos se sabe que el Coeficiente de Inteligencia promedio para jóvenes
según la escala de Weshler es de 100 puntos con una desviación estándar de 15 puntos.
Determinar el tamaño de muestra para realizar una investigación sobre niveles de
inteligencia en la UPN, si se admite un error del 2% del promedio y una seguridad del
95%.
APLICACIÓN 06:
Se desea estimar la proporción de jóvenes de la ciudad de CHICLAYO que hacen uso de
Internet como mínimo una hora diaria con un 95% de confianza. De estudios anteriores
se conoce que P=0.70 y se desea un E = 5%. Cual debe ser el tamaño de muestra.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 56 -
PPAARRTTEE 88:: PPRRUUEEBBAA DDEE HHIIPPOOTTEESSIISS 1. DEFINICIONES PRELIMINARES:
a. HIPÓTESIS: Es una respuesta a priori a un problema.
b. HIPÓTESIS ESTADÍSTICA: En un enunciado acerca del valor de un parámetro
poblacional.
c. PRUEBA DE HIPOTESIS: Es un procedimiento basado en la información
muestral y en la teoría de probabilidad, para determinar si una hipótesis
estadística debe ser aceptada o rechazada.
2. CLASES DE HIPOTESIS:
2.1. HIPOTESIS NULA.
Se denota por Ho.
Es una afirmación o enunciado tentativo que se realiza acerca del valor de
un parámetro poblacional.
Por lo común es una afirmación acerca del parámetro de población cuando
toma un valor específico.
2.2. HIPOTESIS ALTERNATIVA.
Se denota por H1.
Es una afirmación o enunciado contraria a la presentada en la hipótesis
nula.
3. ERRORES QUE SE COMETEN EN UNA PRUEBA DE HIPOTESIS:
Error Tipo I:
•Se comete este error cuando se rechaza la hipótesis nula, cuando es verdadera.
•Se denota por α = P(Rechazar Ho/Ho es verdadera)
Error Tipo II:
•Se comete este error cuando se acepta la hipótesis, cuando es falsa.
•Se denota por β = P(Aceptar Ho/Ho es falsa)
Decisión
posibleHo Verdadera Ho Falsa
Aceptar Ho Decisión
correcta
Error Tipo II
Rechazar Ho Error tipo I
Decisión
Correcta

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 57 -
4. TIPOS DE PRUEBAS DE HIPOTESIS:
A. PRUEBA BILATERAL O PRUEBA DE DOS COLAS
B. PRUEBA UNILATERAL O PRUEBA DE UNA SOLA COLA:
5. ETAPAS DE UNA PRUEBA DE HIPOTESIS:
Ho: = 0 H1: 0
•Prueba de cola inferior o izquierda
Ho: = 0
H1: < 0
•Prueba de cola superior o derecha
Ho: = 0 H1: > 0
/2 /2

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 58 -
6. FORMULAS DE ALGUNOS ESTADÍSTICOS DE PRUEBA:
FORMULAS DE LOS ESTADISTICOS DE PRUEBA
I. PRUEBA DE HIPOTESIS PARA EL PROMEDIO POBLACIONAL:
C. Si n es mayor de 30 y la varianza poblacional es conocida:
Estadístico de prueba:
n
xZ
2/ZZ
t (distribución normal)
D. Si n es menor o igual a 30 y la varianza poblacional es desconocida:
Estadístico de prueba:
n
s
xt
)1,2/( nttt (distribución t de student)
II. PRUEBA DE HIPOTESS PARA LA PROPORCION POBLACIONAL
Estadístico de prueba:
n
PQ
PpZ
2/ZZ
t
Esta formula es tanto para muestras grandes como para muestras pequeñas.
III. PRUEBA DE HIPOTESIS PARA LA DIFERENCIA DE MEDIAS
C. Si las muestras son de tamaño n1>30 y n2>30 (grandes) y además las varianzas
poblacionales se CONOCEN:
Estadístico de prueba:
2
2
1
1
21)(
nn
DxxZ
2/ZZ
t
D. Si las muestras son de tamaño n1<30 y n2<30 (pequeñas) y además las varianzas
poblacionales DESCONOCIDAS:
21
21
11
)(
nnS
Dxxt
c
)1,2/( nt
tt (distribución t de student)
Donde :
2nn
s)1n(s)1n(s
21
2
22
2
112
c, se llama varianza mancomunada
IV. PRUEBA DE HIPOTESIS PARA LA DIFERENCIA DE PROPORCIONES:
B. Si p1 y p2 se determinan a partir de muestras:
2
22
1
11
21)(
n
qp
n
qp
DppZ
2/ZZ
t
Esta formula es tanto para muestras grandes como para muestras pequeñas.

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 59 -
PRUEBA DE HIPOTESIS CON MEGASTAT:
PRUEBA DE HIPOTESIS PARA LA MEDIA:
PRUEBA DE HIPÓTESIS PARA LA PROPORCION:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 60 -
PRUEBA T DE STUDENT PARA MUESTRAS INDEPENDIENTES:
PRUEBA T DE STUDENT PARA MUESTRAS INDEPENDIENTES:
PRUEBA Z PARA COMPARAR PROPORCIONES:

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 61 -
APLICACIÓN UTILIZANDO MEGASTAT:
APLICACIÓN 01:
Las ganancias en miles de dólares de 10 centros educativos de nuestro medio han
producido la siguiente información:
15.8, 12.7, 13.2 16.9, 10.6, 18.8, 11.1, 14.3, 17.0 y 12.5.
Otro conjunto de centros educativos fueron evaluados también respecto a sus ganancias
en miles dólares, obteniendo los siguientes resultados:
24.9, 23.6, 19.8, 22.1, 20.4, 21.6, 21.8 y 22.5
Realizar una prueba de hipótesis para verificar si las ganancias de este último grupo es
superior a las ganancias de las empresas de nuestro medio. Para probar esta hipótesis
utilice un = 0.05.
SOLUCION: (Aquí se utiliza la prueba T para muestras independientes)
Hypothesis Test: Independent Groups (t-test, pooled variance)
T1 T2
14.290 22.088 mean
2.738 1.637 std. dev.
10 8 n
16 df
-7.7975 difference (T1 - T2)
5.3911 pooled variance
2.3219 pooled std. dev.
1.1014 standard error of difference
0 hypothesized difference
-7.08 t
2.61E-06 p-value (two-tailed)

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 62 -
APLICACIÓN 02::
JORGE MELENDEZ, Administrador deL BCP está interesado en saber si existe diferencia
significativa entre los tiempos de atención al cliente de los mismos empleados que
trabajan en los dos turnos: mañana y tarde. Al respecto, ayer personalmente registró los
tiempos que utilizaron los empleados para atender a sus clientes en ambos turnos. Los
tiempos en minutos que registró fueron los siguientes:
Mañana 2.10 4.10 4.70 3.70 6.00 3.90
Tarde 4.00 4.50 3.70 4.00 4.10 3.45
A la luz de estos resultados, ¿A qué conclusión llegó Jorge Meléndez?. Utilice un nivel de
confianza del 95%.
SOLUCION: (Aquí se utiliza la prueba T para muestras pareadas)
Hypothesis Test: Paired Observations
0.00000 hypothesized value
4.08333 mean Mañana
3.95833 mean Tarde
0.12500 mean difference (Mañana - Tarde)
1.30987 std. dev.
0.53475 std. error
6 n
5 df
0.23 t
.8244 p-value (two-tailed)
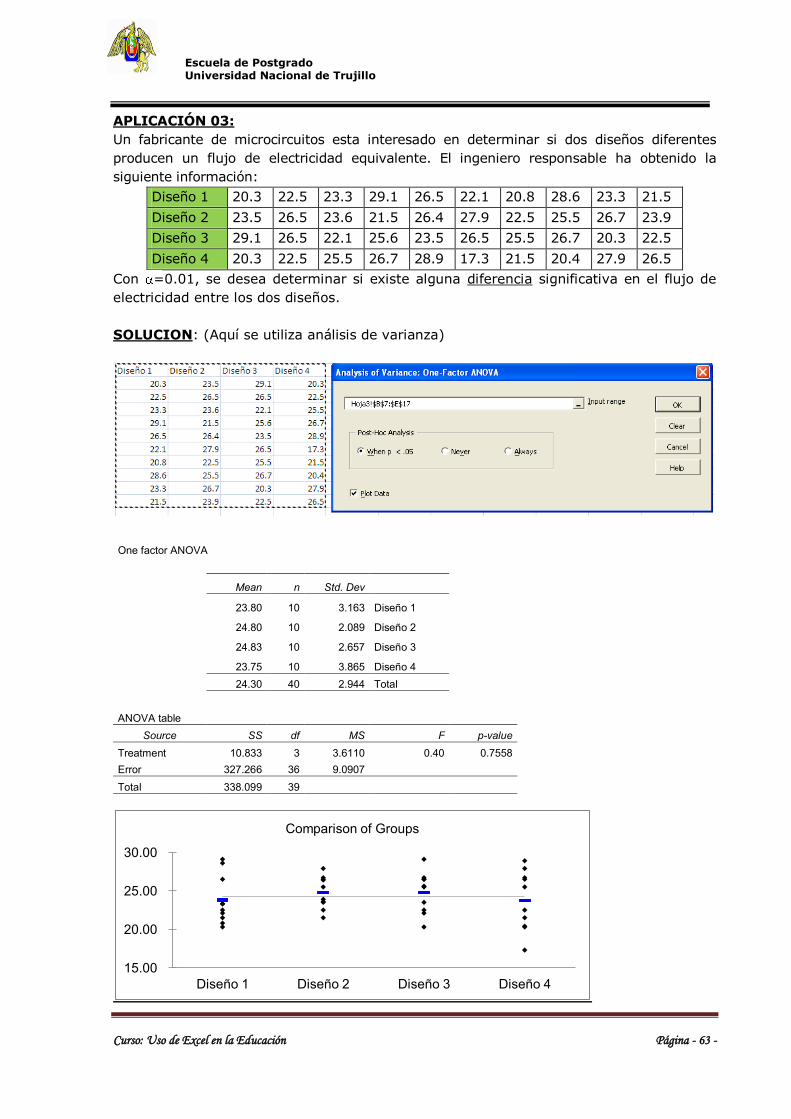
Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 63 -
APLICACIÓN 03:
Un fabricante de microcircuitos esta interesado en determinar si dos diseños diferentes
producen un flujo de electricidad equivalente. El ingeniero responsable ha obtenido la
siguiente información:
Diseño 1 20.3 22.5 23.3 29.1 26.5 22.1 20.8 28.6 23.3 21.5
Diseño 2 23.5 26.5 23.6 21.5 26.4 27.9 22.5 25.5 26.7 23.9
Diseño 3 29.1 26.5 22.1 25.6 23.5 26.5 25.5 26.7 20.3 22.5
Diseño 4 20.3 22.5 25.5 26.7 28.9 17.3 21.5 20.4 27.9 26.5
Con =0.01, se desea determinar si existe alguna diferencia significativa en el flujo de
electricidad entre los dos diseños.
SOLUCION: (Aquí se utiliza análisis de varianza)
One factor ANOVA
Mean n Std. Dev
23.80 10 3.163 Diseño 1
24.80 10 2.089 Diseño 2
24.83 10 2.657 Diseño 3
23.75 10 3.865 Diseño 4
24.30 40 2.944 Total
ANOVA table
Source SS df MS F p-value
Treatment 10.833 3 3.6110 0.40 0.7558 Error 327.266 36 9.0907
Total 338.099 39
15.00
20.00
25.00
30.00
Diseño 1 Diseño 2 Diseño 3 Diseño 4
Comparison of Groups

Escuela de Postgrado Universidad Nacional de Trujillo
Curso: Uso de Excel en la Educación Página - 64 -
APLICACIÓN 04:
Una compañía desea estudiar el efecto que tiene la pausa para el café, sobre la
productividad de sus obreros. Selecciona 6 obreros y mide su productividad en un día
cualquiera (sin pausa para el café), y luego mide la productividad de los mismos 6
obreros en un día que se concede la pausa para el café. Las cifras que miden la
productividad son las que siguen: Con = 0,05. ¿A qué conclusión llegará la compañía?.
TRABAJADOR 1 2 3 4 5 6
Sin pausa 23 35 29 33 43 32
Con pausa 28 38 29 37 42 30
APLICACIÓN 05:
En fecha reciente fue descubierto un neurotransmisor cerebral endógeno llamado
galanina. Según parece, éste afecta de manera directa el deseo de ingerir alimentos con
un alto contenido de grasa. Mientras más alta sea la cantidad de este neurotransmisor de
origen natural en un individuo, mayor será el apetito que este sienta por la comida con
alto contenido de grasa. Recientemente una compañía farmacéutica desarrolló una
sustancia experimental que bloquea la galanina sin alterar el apetito por otros alimentos
más saludables (es decir con menos grasas). Un neurocientífico piensa que esa sustancia
experimental será muy útil para controlar la obesidad. Se realiza un experimento para lo
cual se elige 10 mujeres obesas todas ellas voluntarias y se les administra el
medicamento experimental durante 06 meses. Se registra el peso inicial y el peso final
(después de 6 meses) de cada persona. Los pesos se presentan en la siguiente tabla.
Probar si el uso del medicamento experimental produce pérdida de peso en las personas.
Utilice un nivel de significancia de 0.05.
Persona PESO INCIAL
(libras)
PESO FINAL
(libras)
1
2
3
4
5
6
7
8
9
10
165
143
175
135
148
155
158
140
172
164
145
137
170
136
141
138
137
125
161
156
Fin





























