Embed Size (px)
Citation preview

Machine Learning, 38, 157–180, 2000.c© 2000 Kluwer Academic Publishers. Printed in The Netherlands.
Multistrategy Discovery and Detection of NoviceProgrammer Errors
RAYMUND C. SISON [email protected] of Computer Science, De La Salle University, Manila, Philippines
MASAYUKI NUMAO [email protected] of Computer Science, Tokyo Institute of Technology, Tokyo, Japan
MASAMICHI SHIMURA [email protected] of Industrial Administration, Science University of Tokyo, Chiba, Japan
Editors: Floriana Esposito, Ryszard Michalski, & Lorenza Saitta
Abstract. Detecting and diagnosing errors in novice behavior is an important student modeling task. In thispaper, we describe MEDD, an unsupervised incremental multistrategy system for the discovery of classes oferrors from, and their detection in, novice programs. Experimental results show that MEDD can effectively detectand discover misconceptions and other knowledge-level errors that underlie novice Prolog programs, even whenmultiple errors are enmeshed together in a single program, and when the programs are presented to MEDD in adifferent order.
Keywords: multistrategy learning, unsupervised learning, conceptual clustering, student modeling
1. Introduction
An intelligent tutoring system(ITS) is a computer program for educational support thatcan diagnose problems of individual learners. This diagnostic capability enables it to adaptinstruction or remediation to the needs of individuals.
The diagnostic and adaptive capabilities of an ITS are due primarily to its use of astudent model(McCalla, 1992), which is an approximate, qualitative representation ofstudent knowledge about a particular domain, that fully or partially accounts for studentbehavior. Student modeling, i.e., the construction of a student model, is a complex task thatinvolves the examination of student behavior in light of a system’sbackground knowledge.
Constructing the background knowledge of a student modeling system entails not onlyanalyzing the facts, rules, and schemas of a domain (called thetheoryof that domain),but, more critically, analyzing and categorizing the erroneous solutions of a population ofstudents in that domain, and encoding this knowledge of novice errors in abug library.Constructing or extending the background knowledge, particularly the bug library, is la-borious, time-consuming, and requires a certain amount of knowledge of the domain. Thecombined problems of automatically constructing the bug library, as well as the studentmodel, make student modeling a very difficult task.

158 SISON, NUMAO & SHIMURA
Machine learning, which deals with the automatic induction of new knowledge or com-pilation of existing knowledge, can be used to expedite, if not automate, the task of buglibrary extension or construction, as is done in PIXIE (Sleeman et al., 1990) and ASSERT(Baffes & Mooney, 1996). The domains of these systems are sufficiently understood so thattheir domain theories are completely specifiable, and the tasks of the students they model,therefore readily automatable.1 Our work deals with automatic bug library and studentmodel construction in a richer domain, namely, computer programming, in which problemsolving operators are not as readily and completely specifiable.
How, then, can student models as well as bug libraries in a programming domain be auto-matically constructed? More specifically, how can the discovery and subsequent detectionof novice programmer errors be automated? Before we answer the question, we first clarifywhat we mean by novice errors.
Errors can be analyzed at various levels (Sison & Shimura, 1998). For example,behavior-levelanalysis, in a programming domain, looks at which portions of a student’s programare erroneous.Knowledge-levelanalysis, on the other hand, looks at which behavior-levelerrors are related, as these relationships might indicate: (a)knowledge errors,i.e, errors inthe student’s knowledge about the domain (e.g.,misconceptions,i.e., incorrect knowledge;insufficient knowledge), or (b)slips due, for example, to fatigue, boredom or depressedaffect. These knowledge-level errors can, in turn, account for the errors that occur at thebehavior level.
Identifying the knowledge-level errors (if any) underlying a novice program can beviewed as a classification task:
Given: - novice program- definitions of knowledge-level errors
Find: - classification of novice program with respect to theknowledge-level error(s) it manifests, if any
Note, however, that our classification task is further complicated by several factors:
1. A complete and universal set of knowledge-level errors that can be manifested in incorrectprograms is difficult, if not impossible, to have;
2. Several knowledge-level errors can underlie the behavior-level errors exhibited by asingle program;
3. A program that looks unfamiliar may be correct; that is, there can be more than onecorrect approach to solving a programming problem; and
4. There can be many variants, correct as well as incorrect, per approach.
The first factor indicates the need forunsupervisedlearning, i.e., learning in which classes(knowledge-level errors) are not known beforehand. The second factor implies that multi-ple classifications of a single object (incorrect program) should be allowed. The third andfourth factors characterize the variability inherent in programming and signify the needfor intention-based diagnosis (Johnson, 1990), i.e., the diagnosis of program errors withrespect to a program’sintentionor intended approach. Finally, these factors collectively

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 159
suggest a two-stage classification. Specifically, the last two factors suggest classificationof a novice program with respect to its intention, and the first two factors suggest fur-ther classification of an incorrect program with respect to the knowledge error(s) that itexhibits.
All these are accomplished by a learning student modeling system called MEDD (Multi-strategy Error Detection and Discovery). The incremental nature of MEDD (pronounced|med|) enables it to construct and extend a bug library (MEDD’s main learning task: errordiscovery) at the same time that it infers student models (MEDD’s main performance task:error detection).
The difficulty of MEDD’s general learning task—the unsupervised learning of classes ofcorrect and incorrect logic programs—necessitates the use of multiple strategies. To learnclasses of correct programs, where each class represents a different intention, MEDD usesa technique that is similar to that of exemplar-based learners such as PROTOS (Bareiss,Porter, & Wier, 1987) in that similarity between exemplars is determined by matchingsurface as well as abstract features, and no intensional definitions of concepts are stored;instead, concepts (intentions) in MEDD are defined by specific exemplars (programs).
On the other hand, to learn classes of incorrect programs, or more specifically, to learnclasses of errors that incorrect programs exhibit, where each class represents a differ-ent knowledge-level error, MEDD uses an incremental relational clustering technique thatconsiders causal relationships in the background knowledge as well as regularities in thedata. Discrepancies between the incorrect novice programs and their associated intentions(rather than the incorrect programs themselves) are the ones that are clustered by MEDDbecause of the need to characterize knowledge-level errors and detect multiple knowledgeerrors in a single program.
In the rest of this paper, we first provide an overview of MEDD, after which we providefurther detail about the two modules that MEDD uses to carry out its two-stage learning andclassification tasks. We then report and discuss experimental results that show the viabilityand potential of the approach. Finally, we describe related work and give our concludingremarks.
2. MEDD: an overview
MEDD is a learning student modeling system whose target and implementation language isProlog. In this section, we provide an overview of MEDD in terms of its inputs, backgroundknowledge, outputs, and the two modules it uses to accomplish its tasks, namely IDD/LPand MMD. We also identify ways of putting MEDD’s output to practical use.
2.1. Inputs
The primary input to MEDD are Prolog programs written by students learning the lan-guage. Student programs would typically includereverse/2 programs (where 2 is thenumber of arguments of a predicate namedreverse) for reversing the order of a list ofelements, andsumlist/2 programs for summing the elements of a list of integers.

160 SISON, NUMAO & SHIMURA
An example of a buggy student program for reversing a list is shown below, whose errorswe discuss shortly:
% buggy program 1reverse([],[]).reverse([H|T],[T1|H]) :-
reverse(T,T1).
2.2. Background knowledge
The main components of the background knowledge of MEDD are sets ofreference pro-grams,and associatederror hierarchies. We describe these components with reference tothereverse/2 problem.
There are at least four kinds of solutions to the problem of list reversal in Prolog, namely,the naive reverse, accumulator, inverse naive, and railway shunt algorithms. The naivereverse solution shown below is the most intuitive of the four, as it is the logical equi-valent of the recursive formulation of the reverse task in any language (Sterling & Shapiro,1986).
% a correct program (naive reverse)reverse([],[]).reverse([H|T],R) :-
reverse(T,T1),append(T1,[H],R).
append([],L,L).append([H|T],L,[H|T1]) :-
append(T,L,T1).
In declarative terms, the correct program above states that the reverse of a list[H | T],whose first element isH and whose remaining elements form a list calledT, is the concate-nation of the reverse ofT and the single-element list[H]. Procedurally, this means that toget the reverse of a list[H | T], one must accomplish two subgoals. First, one must get thereverse ofT and call thisT1. Then one has to appendT1 andH to form one list,R, which isthe reversed list. Of course, if the given list is empty, then its reverse is just the empty list.
We call the correct program above, as well as the programs for the otherreverse/2algorithms,reference programsfor reverse/2. The reference program above has twopredicates, namely,reverse/2andappend/3. We callreverse/2 themainpredicate. Thepredicate that it calls other than itself, i.e.,append/3, is called anauxiliary predicate.
Reference programs embody theintentionof a programmer. An intention can be expressedas a partially ordered set of goals and plans (where plans are implementations of goals, andcan either be subgoals or code) for solving problems (Johnson, 1990). Since, in Prolog, thereference program and intention are one, this paper treats the two terms synonymously.
In MEDD, reference programs are stored inframes, as illustrated in figure 1. Thoughnot shown in the figure, reference program frames can also include abstract properties suchas:

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 161
Figure 1. Representation of problems and reference programs.
• relations between clauses and literals (e.g., ordering constraints) used when searchingfor the reference program that is least dissimilar to the novice program;• relations between components of a clause (e.g., causal relationships), used when cluster-
ing discrepancies between student and reference programs;• test cases, used when determining whether discrepancies are indeed behavior-level errors;• correct stylistic variants of the reference program, and a counter for student programs
that perfectly match the reference program or its variants; and• natural language snippets explaining the function and type of each component of the
reference program, which can be used when remediating students.
While MEDD can learn reference programs, it is preferred that as many reference pro-grams per problem be provided to MEDD as possible. We explain this in Section 3.2.
The other main item in the background knowledge of MEDD areOR trees callederrorhierarchies. Each subtree under the root node of an error hierarchy corresponds to a class oferrors committed by students, and each such class denotes an error at the knowledge level,of which the subtree forms an intensional definition. Each reference program has one errorhierarchy associated with it. We will see examples of error hierarchies for naive reverse inSection 4.
2.3. Outputs
The primary outputs of MEDD are the intentions and knowledge-level errors, if any, un-derlying the input programs. For example, MEDD would determine: (1) the naive reversesolution as the intention underlying buggy program 1 above, and (2) theinvalid appenderror below as the knowledge-level error that the buggy program manifests:

162 SISON, NUMAO & SHIMURA
invalid_append:-remove(subgoal2),( replace(head,R,[X?|H]) ;
replace(subgoal1,T1,[X?|H]) ).
The operational definition of theinvalid append error above states that this error isidentified by the existence of two discrepancies: (1) the omission of theappend/3 subgoal(of the correctreverse/2 clause), and (2) the replacement of an output variable in either thehead or the first subgoal (of the correctreverse/2 clause) with a list which has a tailH andwhich is formed using the[ | ] operator. This can, in turn, be interpreted as characterizinga misconception in which theappend/3 predicate and the[|] operator are thought to befunctionally the same, at least as far as concatenating two lists is concerned. This is in factthe misconception that underlies the buggy program given earlier.
MEDD’s outputs can be used in several ways. For example, the intensional definition ofa knowledge-level error detected in a student program can be used to provide graded hintsand explanations to the student, select or construct (using case-based techniques) similarbuggy programs for the student to analyze, or select similar problems (again using case-based techniques) for the student to solve. MEDD’s error hierarchy can also be used todifferentiate severe and common errors from minor or infrequently occurring errors andslips. This knowledge can be used to direct the course of remediation, or to design a coursein such a way that severe and common errors are minimized if not avoided. Further detailsregarding the use of MEDD’s output are found in (Sison, 1998).
2.4. IDD and MMD
To accomplish its learning and classification tasks, MEDD uses two modules, namely,IDD/LP (Intention and Discrepancy Detection for Logic Programs), or IDD for short,and MMD (Multistrategy Misconception Discovery).2 IDD determines the intention un-derlying a student program, computes the discrepancies between the student’s actual andintended programs, and then checks whether these discrepancies are associated with knownknowledge-level errors or not. If not, it tests the student program to help confirm whether thesyntactic discrepancies between the student and reference programs are indeed behavior-level errors, or are stylistic differences that result in correct program variants. In the processof detecting intentions and discrepancies, IDD learns new intentions and variants.
Behavioral discrepancies are expressed naturally as atomic formulas in the function-freefirst order logic. Consider again the buggy and correct programs presented earlier, whoserecursivereverse/2 clauses we reproduce below.
% buggy clause 1 % correct clausereverse(H|T],[T1|H]) :- reverse([H|T],R) :-
reverse(T,T1). reverse(T,T1),append(T1,[H],R).
The buggy clause differs from the correct clause in two ways. First, in place of the variableR in the head of the correct clause, the buggy clause has the list[T1 | H]. This discrepancy

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 163
can be expressed in relational terms asreplace(head,R,[T1 | H]). Second, the secondsubgoal in the correct clause is omitted in the buggy clause. This discrepancy can beexpressed in relational terms asremove(subgoal2). The two discrepancies just describedform adiscrepancy set.The second module, MMD, then takes such a discrepancy set asone input object, and clusters the discrepancy set into the error hierarchy associated with thestudent program’s underlying intention, revising the error hierarchy in the process. As statedearlier, each subtree under the root node of an MMD-induced error hierarchy operationallydefines a knowledge-level error.
3. Detecting intentions and discrepancies
We now provide more detail about IDD/LP. IDD/LP (whose outline is shown in Table 1)detects intentions, computes behavioral discrepancies, determines behavior-level errors,and learns, in the process, new intentions and variants.
3.1. Detecting intentions
IDD/LP begins by canonicalizing the student program, i.e., by renaming predicates andvariables, and performing simple equivalence-preserving transformations usingunfold/foldrules (Tamaki & Sato, 1984) for logic programs (Table 1, step 1). IDD then proceeds todetermine the reference program that reflects the student program’s underlying intention(step 2).
3.1.1. Focal discrepancies and dissimilarity function.Determining the intention that un-derlies the student program is accomplished via an A* search (Hart, Nilsson, & Raphael,1968) through a space of partial mappings and discrepancies, at each level of which ab-stract properties and specific literals of student and reference programs are compared anddiscrepancies computed. Perfectly matching literals, and literals that are equivalent accord-ing to a set ofequiv operators (e.g.,equiv(X<Y,Y>X), equiv(X+Y,Y+X)), do not haveany discrepancies.
The literals that are matched at each level are called thefocus(also calledfocal literals)of that level. The focus of the first level is nil, since the task of IDD at that level is simply toretrieve the reference programs; no matching is done yet. The focus of the second level arethe heads of the clauses of the main predicate. The focus of the third level are the subgoalsof the clauses of the main predicate. The focus of the fourth level are the heads of theclauses of the first auxiliary predicate, while the focus of the fifth level are the subgoals ofthe clauses of the first auxiliary predicate, and so on.
Nodes are scored according to the dissimilarity function:Dif (n) = g(n)+ h(n), whereg(n) is the cumulative weighted number of discrepancies so far, excluding the current focaldiscrepancies; andh(n) is 2(2−d) ∗ discs(n), whered is the current depth or level, anddiscs(n) is the number of current focal discrepancies. Note thatg(n) is just theDif scoreof the current node’s parent. Note also that sinceh(n) is a lower bound on the number ofdiscrepancies remaining, including the current ones, the search algorithm is admissible,i.e., it always terminates in an optimal path whenever one exists.

164 SISON, NUMAO & SHIMURA
Table 1. Outline of IDD/LP.
1. NORMALIZE PROGRAM. Canonicalize predicate and variable names in the input program, then simplify usingunfold/fold rules, producing the programπ .
2. DETECTINTENTION AND COMPUTEDISCREPANCIES.
2.1 Perform an A* search for the reference program that is least dissimilar toπ (for which a dissimilaritymeasureDif is minimal).
2.2 If a goal noden is found, andDif (n) = 0, stop and return the reference program,ρ, associated withn. Else, ifDif (n) > 0, pass to the next step: the reference programρ, and the union,δ, of discrepancysets from the root of the search tree ton. If no n (and therefore noρ) is found, go to step 4(.2).
3. TESTDISCREPANCIES.
3.1 If δ is in the library of known knowledge-level errors (computed by MMD), stop and output thecorresponding knowledge-level error and program error (PD/CI/NC, see below) along withρ.
3.2 Otherwise, testπ using the test cases andρ as oracle, if possible.
3.2.1 Simulateπ on inputx (x are the values of the input variables).
3.2.1.1 Possible divergence.Whenπ ’s computation depth exceeds that ofρ on x (and the currentstack of procedure calls contains a discrepancyδi in δ), return the error code PD (andδi ).
3.2.1.2 Coverage of an incorrect instance.Whenever a procedure call returns an output, check thisoutput if it is correct usingρ. If it is not correct, return the error code CI and the incorrectprocedure call.
3.2.2 Noncoverage of a correct instance.Simulateπ on inputx and outputy (x and y are the valuesof the input and output variables, respectively). If a particular ground instance ofρ cannot becovered byπ , return the error code NC and the uncovered instance.
4. OUTPUT BEHAVIOR-LEVEL ERRORS ORLEARN NEW INTENTIONS/VARIANTS.
4.1 If ρ could serve as an oracle for testingπ :
4.1.1 andπ tests correctly, then learn (i.e., store)π as a correct variant ofρ;
4.1.2 but ifπ does not test correctly, then output (to MMD) the intentionρ, the discrepanciesδ (asbehavior-level errors), and the effect (PD/CI/NC) of the behavioral errors.
4.2 If there is noρ, or ρ could not serve as an oracle,
4.2.1 and ifπ runs correctly at the top level (i.e., using the test cases alone), then learnπ as a newintention;
4.2.2 otherwise (ifπ does not run correctly given the test cases), attempt to debugπ interactively andlearn (i.e., store) the debugged program as a new intention.
3.1.2. Intention search. The search for a program’s intention (step 2.1) begins with theretrieval of the reference programs (and their correct variants, if any) associated with theproblem that the student program is supposed to solve, and the creation of a node for eachreference program (figure 2, level 1). Each node is scored according to the dissimilarityfunctionDif .
From all end nodes of the search tree, IDD then selects the node whoseDif score isminimal. If this node is not yet a goal node (i.e., there still remain reference programliterals to be examined), IDD expands the node by determining the focal literals, focaldiscrepancies, and remaining literals of the reference program associated with the currentnode in the next level, and the same process of scoring and selection continues. However, if

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 165
Figure 2. Intention recognition.
the selected node is a goal node, the search stops and returns this node’s associated referenceprogram, and the union of the focal discrepancies on the path from the start node to this goalnode, if any (Table 1, step 2.2). Figure 2 shows the sequence of nodes created by MEDDgiven buggy program 1 and the four reference programs mentioned in Section 2.2. (Thoughnot shown in the figure, MDD examines all alternative mappings between the focal literalsof the reference and student programs given the ordering constraints associated with thereference program literals.) Since a goal node (node 7) is reached in the subtree rooted inthe node for naive reverse, the naive reverse algorithm is assumed to be the intention behindthe buggy program.
3.2. Detecting errors and learning new intentions/variants
The set of discrepancies between the student program and the chosen reference programare then checked whether they are symptoms of a knowledge-level error. This is done

166 SISON, NUMAO & SHIMURA
in two steps. First, the discrepancies are looked up in a rule base or hierarchy of errors(generated by MMD); if found, IDD considers the behavioral discrepancies as behavioralerrors, and immediately outputs the intention together with the associated knowledge-levelerror (Table 1, step 3.1). If this step fails, the student program is tested using a slightlymodified version of Shapiro’s (1983) diagnosis routines, modified to use the referenceprogram as oracle (step 3.2).
If the program terminates correctly given the test cases in the background knowledgeand the reference program as oracle, the discrepancies will not be treated as errors; instead,the student program will simply be learned, i.e., stored, as a correct variant of the cur-rent intention (step 4.1.1).3 However, if the student program does not terminate correctly(step 4.1.2), the discrepancies detected earlier will be treated as behavior-level errors andwill be output (into MMD), unless the associated reference program could not be used as anoracle, in which case the reference program will not be considered the student’s intention forobvious reasons; instead, a debugging substep will be triggered, during which the studentprogram will be revised to make it correct (step 4.2.2). Currently, we use a prototype PDS6-based (Shapiro, 1983) inductive debugger, which we modify to allow it to reuse previouslyobtained information (from step 3) about the program’s errors.
It will be noted, however, that student programs can become quite buggy, thus violatingthe assumption of first-order minimal theory revision systems such as PDS6 and FORTE(Richards & Mooney, 1995) that the initial theory be approximately correct. Hence ourstatement in Section 2.2 that we prefer as many reference programs to be provided toMEDD as possible, because if a reference program could not be found, MEDD would onlybe able to learn new intentions from student programs when the latter are either correct(step 4.2.1), or almost correct (step 4.2.2).
4. Discovering classes of errors
We now turn to the other module used by MEDD, namely, MMD, whose function isthe discovery of knowledge-level errors underlying behavior-level discrepancies of buggyprograms via multistrategy conceptual clustering.
4.1. Error hierarchy formation via incremental relational clustering
Conceptual clustering(Michalski & Stepp, 1983) is the grouping of unlabeled objects intocategories for which conceptual descriptions are formed. Basically an objectO is classifiedinto a category with concept descriptionC with which it is quite similar (or not quitedissimilar).
4.1.1. Similarity measure. To measure this degree of similarity/dissimilarity, we adaptTversky’s (1977)contrast model:
Sim(C,O) = θ f (C ∩ O)− α f (C − O)− β f (O − C)

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 167
which expresses the similarity between two objectsC andO that are each expressed as aset of features, as a function of the weighted measures of their commonalties (C ∩ O) anddifferences (C−O,O−C). In our system,θ , α, β and f (X) are user-redefinable. Since theobjects we deal with are sets of behavioral discrepancies represented as atomic formulas,we do not compute the commonalities between an input set of discrepanciesO and a nodeC in an error hierarchy using mere set intersection, but as follows:
(C ∩ O) = Com(C,O) =m⋃
i=1
n⋃j=1
lgg(Ci ,Oj )
wherelgg(Ci ,Oj ) is theleast general generalization(Plotkin, 1970) of two atomic formulasin the function-free first order logic, andm andn are the number of discrepancies inC andO, respectively. Specifically, thelgg of two function-free terms,x and y, is x if x = y;otherwise, thelgg is a variableV (which we call apattern variable), where the same variableis used everywhere as thelgg of these terms. Thelgg of two function-free atomic formulasp(s1, s2, . . . , sn) and p(t1, t2, . . . , tn) is p(lgg(s1, t1), lgg(s2, t2), . . . , lgg(sn, tn)). We calla generalization that contains a pattern variable avariabilization generalization; one thatdoes not contain a pattern variable is called anintersectiongeneralization.
4.1.2. Similarity-based relational clustering.Since it is desirable that an error hierarchybe revised rather than reconstructed from scratch each time new data arrives, the basicsimilarity-based clustering algorithm (Table 2), which we call SMD (Similarity-based Mis-conception Discovery), is incremental, and therefore takes one discrepancy set at a time and
Table 2. Outline of SMD.
1. MATCH DISCREPANCIES. From the childrenN1, . . . , Nm of a given nodeN of the error hierarchy, determinethose thatmatchthe set of input discrepancies,D. Specifically, compute, for every child nodeNi :
• the set of commonalities,Com(Ni , D), between a node,Ni , andD, and
• the degree of similarity,Sim(Ni , D), betweenNi andD
and determine whetherSimexceeds a system threshold,γ .
2. POSITION DISCREPANCIES. If no match is found, placeD underN. Otherwise, for everyNi that matchesD,perform one of the following and increase weight counters:
2.1 If both(D−Com(Ni , D)) and(Ni −Com(Ni , D)) are empty, simply increase theweightcounter ofNi ;
2.2 If (D − Com(Ni , D)) is empty but (Ni − Com(Ni , D)) is not, replaceNi with D and insert(Ni − D) underD i ;
2.3 If (Ni −Com(Ni , D)) is empty but(D−Com(Ni , D)) is not, cluster(D− Ni ) underNi , i.e., repeat theprocedure, this time matching(D − Ni ) with the children ofNi ;
2.4 Otherwise (if both(D − Com(Ni , D)) and (Ni − Com(Ni , D)) are nonempty), create a new node,Com(Ni , D), underN, representing the commonalities ofD and Ni , and place their differences underthis node.
3. FORGET OCCASIONAL SLIPS. Nodes whose weights fall below a system parameter may be discarded on aregular or demand basis. (No nodes are discarded in the current implementation.)

168 SISON, NUMAO & SHIMURA
Figure 3. Clustering a set of behavioral discrepancies into an error hierarchy.
classifies this recursively into the nodes of the error hierarchy that match the discrepancyset to a certain degree (Table 2, steps 1 and 2). To illustrate, recall buggy program 1 fromSection 2.1, or more specifically, the discrepancies of buggy program 1 vis-a-vis the correctprogram for naive reverse, which were computed by IDD, and which we reproduce infigure 3A.
Now consider the error hierarchy in the same figure, and note that the single discrepancyin the node [remove(subgoal2)] below theroot of the error hierarchy is actually oneof the discrepancies in the input discrepancy set. Thus, an intersection generalization isfound. Assuming that theγ parameter of step 1 indicates that this is a match, the inputdiscrepancy set will therefore be classified into this subtree, among possible others (Table 2,step 2.3).
Next, the remaining discrepancyreplace(head,R,[T1 | H]) of the input discrepancyset is compared against the child node [replace(head,R,[T | H]), remove(subgoal1)].This time, a variabilization generalization (replace(head,R, [X? | H])) occurs, so a nodefor this variabilization is created, and the instantiations of the pattern variableX? (i.e.,X?=TandX?=T1), among others, are pushed down to the next level (Table 2, step 2.4). Figure 3Bshows the revised hierarchy. We have already seen this subtree’s clausal form (invalidappend) in Section 2.3.

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 169
4.2. Strengthening the coherence of concept (knowledge-level error) descriptions
Similarity measures like the one above ignore qualitative relationships among features. How-ever, the presence of qualitative, e.g., causal, relationships between the features that makeup a conceptual description can strengthen the coherence of the concept and provide anexplanationfor the co-occurrence of the concept’s features.
MMD uses causal relationships in the background knowledge and causality heuristicsin order to determine the presence and direction of causal relationships within and amongconceptual descriptions. One such heuristic that we use is thecomponent-level causalityheuristic, which simply states that causal (or enabling or determination) relationships amongthe components of the reference behavior/program that are present in a set of discrepanciessuggest causal relationships among these discrepancies.
To illustrate, consider again the correct recursive clause for naive reverse, reproducedbelow. The correct clause states that the reverse of a list is the concatenation of the reverseof its tail, and its head. Note that this can be viewed as describing relationships amongfour objects, namely, the headH and tailT of the list to be reversed, the reversed listR,and a temporary entityT1 representing the reverse ofT; and the relationsreverse/2 andappend/3.
% correct clause % buggy program 1’s discrepanciesreverse([H|T],R) :- replace(head,R,[T1|H]),
reverse(T,T1), remove(subgoal2)append(T1,[H],R).
Now consider again the discrepancies between buggy clause 1 and the correct clauseabove. Note that the reference program components of the two discrepancies of buggyprogram 1 both involve the user variableR, and that theR involved in the second discrepancycan be viewed as causing theR involved in the first. (Of course, theR in the head and theR in the second subgoal of the correct clause refer to one and the same thing. To be moreprecise, therefore, what we mean by theR in the subgoal ‘causing’ theR in the head is this:given that bothR’s are output variables, the subgoal, rather than the head, is responsiblefor bindingR to a value.) Thus, the component-level causality heuristic suggests that thereexists a causal relationship between the two discrepancies.
Although the above heuristic can help determine the presence of a causal relationship be-tween two discrepancies, it cannot determine the direction of causality. It cannot determine,for example, that the use of the[|] operator to concatenate, albeit incorrectly, some listwith H causes or results in the omission of anappend/3 subgoal. Causative discrepanciesare inferred using other causality heuristics. However, while knowing which discrepanciesare causative is useful when remediating a student, it does not affect MMD’s classificationand clustering abilities. Hence, this paper focuses only on the component-level causalityheuristic and its effect on hierarchy reorganization, to be discussed next. Interested read-ers are referred to (Sison, Numao, & Shimura, 1997; Sison, 1998) for the other causalityheuristics.

170 SISON, NUMAO & SHIMURA
Table 3. Outline of MMD.
1. MATCH DISCREPANCIES. From the childrenN1, . . . , Nm of a given nodeN of the error hierarchy, determinethose thatmatchthe set of input discrepancies,D. Specifically, compute, for every child nodeNi :
• the set of commonalities,Com(Ni , D), between a node,Ni , andD, and
• the degree of similarity,Sim(Ni , D), betweenNi andD
and determine whetherSimexceeds a system threshold,γ . In addition, determine causal relationships amongdiscrepancies in D using the component-level causality heuristic.
2. POSITION DISCREPANCIES. (same as SMD’s step 2)
3. SEVER FALSE TIES. For every new node created in step 2, determine, using the causality heuristics, concept-and subconcept-level causalities. Then,
3.1 if no component- or concept-level causality exists among discrepancies in this node, retain the node nev-ertheless. (If the node needs to be split, it will be split in step 2 on another occasion.)
3.2 if this node is a leaf node, and no (subconcept-level) causality exists between components of this node(that are not mere pattern variable instantiations) and its parent, sever the link between this child and itsparent, and reclassify it (and the current subtree) into the hierarchy.
4. FORGETOCCASIONAL SLIPS. (same as SMD’s step 3)
4.3. Similarity and causality-based relational clustering
Existing multistrategy approaches (e.g., Lebowitz, 1986; Pazzani, 1994) to using similarityand causality in the formation of concepts with causative features use separate similarity andtheory (i.e., causality) driven learning components one after the other. However, Wisniewskiand Medin (1994) argue cogently that such loosely coupled approaches to using data andtheory, while undoubtedly useful, still remain inadequate as models of concept formation. InMMD, the similarity and causality-based components are tightly coupled in the concept(i.e., knowledge-level error) formation process. This tight coupling entails three revisionsto the basic SMD algorithm above (instead of a separate algorithm altogether): (1) causalrelationships are determined using the component-level causality heuristic, (2) the directionsof causalities are determined whenever possible using the other (concept and subconcept-level) heuristics, and (3) the link between a parent node and its child is severed if the twoare found to be (causally) unrelated.
These revisions to the SMD procedure are shown in slanted type style in Table 3, whichsummarizes the procedure of MMD. Note that step 3.2 (SEVER) effectively functions asa reorganization operator that is causality-based. Step 4 likewise reorganizes (prunes) thehierarchy, though it does this based on frequencies. Reorganization operators are especiallyimportant for incremental learners in mitigating so-calledordering effects.We shall returnto the issue of ordering effects later in Section 5.2. For now, we discuss the mechanism ofthe SEVER operator.
In addition to the hierarchical reorganization that step 2 entails, the absence of causalrelationships between a parent and a child in a hierarchy can cause further reorganization:said child can be severed from its parent and then reclassified (step 3.2 (SEVER)). Thisallows MMD to separate unrelated discrepancies so that the generalized discrepancies thatmake up an intensional definition of an error class form a coherent set. The effect of this

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 171
Figure 4. Clustering a set of behavioral discrepancies into an error hierarchy, II.
is that MMD can disentangle the multiple misconceptions or knowledge errors that mayhave produced the discrepancies in a student’s behavior. Consider the following buggyclause:
% buggy clause 2reverse([H|T],R) :-
append(T,[H],R).
The discrepancies between the above clause and the correct naivereverse/2 clausepresented earlier areremove(subgoal1) andreplace(subgoal2,T1,T). Clustering thediscrepancies of buggy clause 2 into the error hierarchy in figure 4A produces the revisederror hierarchy in figure 4B. Now note that the node [replace(subgoal2,[H],H)] in theright subtree of figure 4B is not at all (causally) related to its parent ([remove(subgoal1),replace(subgoal2,T1,T)]).
Since the child is not related to its parent, MMD severs the child from the parent and thenreclassifies the child into the hierarchy. This particular severing operation is consistent withthe fact that omitting or forgetting to put the list brackets[] around a variable (denoted

172 SISON, NUMAO & SHIMURA
by the discrepancyreplace(subgoal2,[H],H)) has nothing to do with omitting the firstsubgoal of the correct clause (i.e., the discrepancyremove(subgoal1)), and the naturalconsequence of the latter, which is using some other variable in place ofT1 in the secondsubgoal of the correct clause (i.e., the discrepancyreplace(subgoal2,T1,T)).
Note carefully that the SEVER operator only applies between a child and an unrelatedparent; i.e., a subset of discrepancies will not be severed from its original set,S, even if nocausal relationships can be found between it andS, unless it has already been ‘gently pushedout of’ S, only connected to the rest ofSby a parent-child link. In other words, the SEVER
operator will not split a node even though its contents are unrelated with respect to thebackground knowledge. This conservative approach of retaining nodes despite the absenceof component-level causalities thus takes into account the possibility that the backgroundknowledge may be incomplete.
5. Experiments
We now examine the performance of MEDD in terms of its ability to recognize and classifynovice programs, discover knowledge-level errors, and mitigate ordering effects.
5.1. Classification and discovery: MEDD with SMD, CMD, and MMD
5.1.1. Experiment. To empirically evaluate the ability of MEDD to discover and detect,from discrepancies in real-world behavior, error classes that represent knowledge-levelerrors, sufficiently large corpora of incorrect novice behavior, here in the form of 64 buggynaivereverse/2 and 56 buggysumlist/2 programs were obtained.4,5 The buggy naivereverse andsumlist programs were then given to a team of experts (Prolog teachers)who were asked to identify the programs’ knowledge-level errors. Simultaneously, thediscrepancies between the buggy programs and their associated intentions were computedvia IDD/LP and then fed in random order into MMD. The error hierarchies generated byMEDD were then also given to the experts, who were then asked to produce two listsof knowledge-level errors (see appendix) and to identify the correspondence between theknowledge-level errors they have listed and the error classes generated by MEDD.
MEDD’s performance is examined from two perspectives: (1) program classification and(2) error discovery. A buggy program is said to be correctly classified if its computed errorclass corresponds to a knowledge-level error that has been identified as being exhibitedby the buggy program. Similarly, an error class is said to be correctly discovered if itcorresponds to a knowledge-level error that has been identified as being exhibited by certainbuggy programs in the dataset. Furthermore, since buggy programs may exhibit more thanone knowledge-level error, we consider a buggy program asfully classified only if all theknowledge-level errors underlying it are detected; otherwise, it is onlypartially classified,and receives only a partial point (fraction of the total number of knowledge-level errorsunderlying the program). Similarly, an error class is consideredfully discovered (withrespect to past data) only if the class contains all the manifestations that it can assume in abuggy program; otherwise, it is onlypartially discovered, and receives only a partial point(fraction of the total number of possible ways that it can appear in a buggy program).
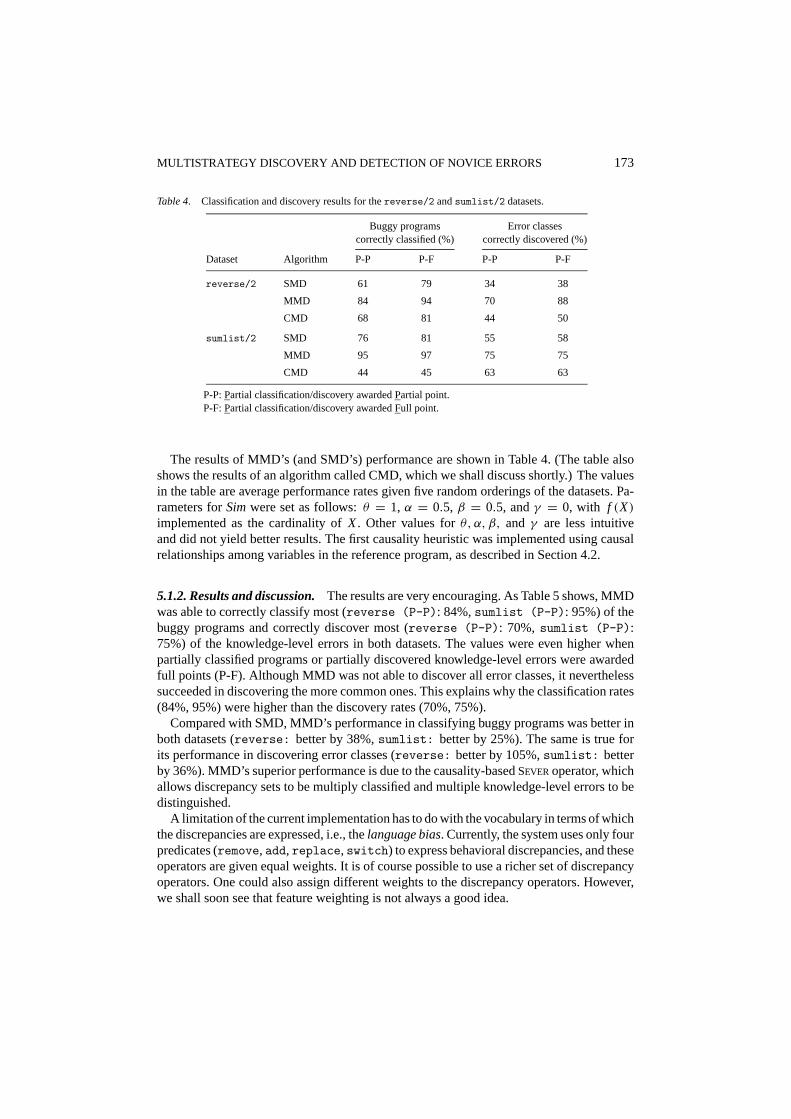
MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 173
Table 4. Classification and discovery results for thereverse/2 andsumlist/2 datasets.
Buggy programs Error classescorrectly classified (%) correctly discovered (%)
Dataset Algorithm P-P P-F P-P P-F
reverse/2 SMD 61 79 34 38
MMD 84 94 70 88
CMD 68 81 44 50
sumlist/2 SMD 76 81 55 58
MMD 95 97 75 75
CMD 44 45 63 63
P-P: Partial classification/discovery awarded Partial point.P-F: Partial classification/discovery awarded Full point.
The results of MMD’s (and SMD’s) performance are shown in Table 4. (The table alsoshows the results of an algorithm called CMD, which we shall discuss shortly.) The valuesin the table are average performance rates given five random orderings of the datasets. Pa-rameters forSimwere set as follows:θ = 1, α = 0.5, β = 0.5, andγ = 0, with f (X)implemented as the cardinality ofX. Other values forθ, α, β, and γ are less intuitiveand did not yield better results. The first causality heuristic was implemented using causalrelationships among variables in the reference program, as described in Section 4.2.
5.1.2. Results and discussion.The results are very encouraging. As Table 5 shows, MMDwas able to correctly classify most (reverse (P-P): 84%,sumlist (P-P): 95%) of thebuggy programs and correctly discover most (reverse (P-P): 70%, sumlist (P-P):75%) of the knowledge-level errors in both datasets. The values were even higher whenpartially classified programs or partially discovered knowledge-level errors were awardedfull points (P-F). Although MMD was not able to discover all error classes, it neverthelesssucceeded in discovering the more common ones. This explains why the classification rates(84%, 95%) were higher than the discovery rates (70%, 75%).
Compared with SMD, MMD’s performance in classifying buggy programs was better inboth datasets (reverse: better by 38%,sumlist: better by 25%). The same is true forits performance in discovering error classes (reverse: better by 105%,sumlist: betterby 36%). MMD’s superior performance is due to the causality-basedSEVER operator, whichallows discrepancy sets to be multiply classified and multiple knowledge-level errors to bedistinguished.
A limitation of the current implementation has to do with the vocabulary in terms of whichthe discrepancies are expressed, i.e., thelanguage bias. Currently, the system uses only fourpredicates (remove, add, replace, switch) to express behavioral discrepancies, and theseoperators are given equal weights. It is of course possible to use a richer set of discrepancyoperators. One could also assign different weights to the discrepancy operators. However,we shall soon see that feature weighting is not always a good idea.

174 SISON, NUMAO & SHIMURA
5.1.3. Causality-based relational clustering.Since MMD’s superior performance is dueto the causality-based SEVER operator, the question now arises as to the extent to whichcausality can be used without being abused.
Consider a variant of MMD which requires that for two sets of discrepancies to match,their commonalities must be causally related. This implies that every discrepancy in everyconcept node thus formed will be causally related with some other discrepancy in thesame node. Let us call this variant CMD (Causality-based Misconception Discovery). Notethat CMD’s procedure would be similar to that for MMD (recall Table 3) except for twothings. First, the last part of step 1 of CMD’s procedure would read “. . . system threshold,γ andcausal relationships exist among the discrepancies inCom.” Second, steps 3.1 and3.2 of MMD’s procedure would be omitted (because they would never happen).
Our experimental procedure and parameter settings for evaluating CMD’s classificationand discovery performance follow those in Section 5.1.1. Results (Table 4) show that CMD’sperformance was not so good. MMD’s classification performance (P-P) was 24% better thanCMD’s on thereverse dataset, and more than 100% better than CMD’s on thesumlistdataset. As far as discovery performance is concerned, MMD (P-P) was almost 50% betterthan CMD on thereverse dataset, and 19% better than CMD on thesumlist dataset. Thedifferences were even greater when partially classified programs or partially discovered errorclasses were given full points (P-F). This lackluster performance can be traced to the fact thatCMD requires that two similar discrepancy sets have (the same) inter-discrepancy causalrelationships. Thus, for example, CMD was not able to learn the error class [replace(sub-goal2,T1,H), replace(subgoal2,[H],X?)] because the discrepancies in this node arenot causally related according to the first causality heuristic and the background knowledgeof causal relationships among the variables in the correct program. (Futher details may befound in Sison, 1998).
Unfortunately, not all co-occurring discrepancies in the above experiments had causalrelationships that could be found in or explained by the background knowledge. This is notto say that there are no causal relationships between these co-occurring discrepancies; thisonly says that the background knowledge of causal relationships might be incomplete. Byretaining such robust (i.e., frequently co-occurring but unseparatable into parent and child)groups of discrepancies in spite of the absence of causal relationships in the backgroundknowledge, MMD can in fact correctly discover more errors and classify more programs thanCMD. (In addition, such as-yet-not-fully-explainable but apparently robust co-occurrencescan be used to trigger a new kind of discovery process involving the search for new causalrelationships or heuristics.)
5.2. Mitigating ordering effects: feature weighting, reclassification, and MEDD
5.2.1. Mitigating ordering effects. Heuristic incremental systems that summarize datagenerally suffer fromordering effects: different orderings of the input data may yielddifferent classifications. Though there may be a number of ways of dealing with orderingproblems (see e.g., Fisher, Xu, & Zard, 1992), what seems to be a generally preferredapproach when no significant amount of data is known a priori would be to introducecontrol operators that reorganize the classification hierarchies. One such approach is to use

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 175
a node splitting (or merging) operator whenever a node is considered to be ‘misplaced’ (e.g.,COBWEB, Fisher, 1987; UNIMEM, Lebowitz, 1987). Another approach is to recluster aclassification hierarchy until the hierachy has ‘stabilized’ (e.g., ITERATE (Biswas et al.,1991); experiments by Fisher, 1987).
It will be recalled that MMD’s SEVERoperator enables the separation of multiple classes oferrors that are manifested in a single complex behavior. Actually, this operator can also serveto mitigate ordering effects in a manner similar to the splitting operators of COBWEB orUNIMEM, and to the reclassification approach of ITERATE, though it is more powerful thanprevious splitting operators in the sense that it can split not only categories but objects (thediscrepancy sets) as well, and is more informed and efficient than the general reclassificationapproach in the sense that only subtrees containing causally unrelated parents and childrenare reclustered.
5.2.2. Experiment. To evaluate the effectiveness of MEDD/MMD’s causality-based SEVER
operator in mitigating ordering effects, we compare the performance of MMD against thatof a general reclassificationscheme and afeature weightingscheme, on the discrepancysets of 64 buggyreverse/2 and 56 buggysumlist/2 Prolog programs. The generalreclassification scheme is one in which an entire hierarchy is repeatedly reclassifiedρ
number of times whileρ is less than some user-defined parameter, or until no more reclas-sifications are possible (i.e., further reclassifications do not change the structure of the errorhierarchy). In thefeature weightingscheme, more ‘severe’ discrepancies are given greaterweights (e.g., the omission of an entire subgoal in a buggy program is given more weightthan the use of a different argument, say T instead of T1, in some subgoal).
As in the previous experiments, performance is examined from the perspective of pro-gram classification and error discovery, and results for partial as well as full classifi-cation/discovery were taken. The results (meanX̄ and standard deviationσ ) of SMD,MMD, and SMD or MMD combined with the general reclassification and feature weight-ing schemes for 5 random orderings of the input datasets are shown in Table 5. For theMMD-based algorithms,Simparameters were set as before. The first causality heuristicwas also implemented as before, using causal relationships between variables of the refer-ence program. For the algorithms that used a general reclassification scheme,ρ = 1. Thisvalue will be explained shortly. For the algorithms that used a feature weighting scheme,discrepancies that involved the omission of entire subgoals or the incorrect switching of theorder of two subgoals were each given a weight of 5; all other discrepancies were given aweight of 1. Experiments on weights 5± 3 for the ‘severe’ discrepancies yielded the sameresults; weights below or above this range did not yield better results.
5.2.3. Results and discussion.The main result is that MMD can effectively mitigateordering effects while still achieving high performance rates. MMD’s overall performancegiven different orderings of the input data varied only slightly atσ = 0 andσ < 1 for thereverse andsumlist datasets, respectively. On the other hand, SMD’s performance inbuggy program classification and error class discovery was much more unstable, with itsσ
values going as high as 20 times those of MMD.The results also confirm Fisher’s (1987) and Biswas and colleagues’ (1991) finding that
general reclassification is a useful mechanism for mitigating ordering effects, although by

176 SISON, NUMAO & SHIMURA
itself and in our domain, general reclassification is not as powerful as MMD’s SEVER oper-ator, which can be viewed as incorporating a knowledge-driven, local (subtree) reclassifica-tion. Thus, although general reclassification consistently brought down the standard devia-tions on SMD and MMD’s average performances (withρ = 1 sufficient to stabilize MMD’sperformance on thesumlistdataset, and reclassification completely unnecessary for MMDworking on thereverse dataset), the classification and discovery rates of SMD+R onlyamounted to about half of those achieved by MMD in thereverse dataset. Moreover,general reclassification did not significantly improve MMD’s performance (X̄) in bothdatasets. This can be explained by the fact that general reclassification does not introduce astrong enough bias when clustering discrepancies. Nevertheless, said mechanism can easilybe incorporated into MEDD and turned off when memory space is limited.
In contrast to the results for general reclassification, the results for feature weightingindicate that the latter is not always helpful in mitigating ordering effects. In thesumlistdataset, for example, feature weighting (“+W” in Table 5) was able to decrease allσ ’s. Inthereverse dataset, however, theσ value when feature weighting was used together withMMD (i.e., MMD+W) for error discovery shot up toσ = 7.2, over seven points higher than
Table 5. Mitigation results for thereverse/2 andsumlist/2 datasets.
Buggy programs Error classescorrectly classified (%) correctly discovered (%)
P-P P-F P-P P-F
Dataset Algorithm X̄ σ X̄ σ X̄ σ X̄ σ
reverse/2 SMD 61 17.6 79 19.2 34 8.8 38 12.5
SMD+R 44 4.1 59 4.3 28 4.3 35 5.0
SMD+W 38 5.0 53 7.2 19 6.3 20 6.8
SMD+R+W 41 0.0 58 0.0 25 0.0 25 0.0
MMD 84 0.0 94 0.0 70 0.0 88 0.0
MMD+R 84 0.0 94 0.0 70 0.0 88 0.0
MMD+W 73 2.9 91 3.4 58 7.2 75 0.0
MMD+R+W 84 0.0 94 0.0 70 0.0 88 0.0
sumlist/2 SMD 76 17.1 81 18.3 55 10.8 58 18.3
SMD+R 88 0.0 95 0.0 61 0.0 63 0.0
SMD+W 90 0.0 98 0.0 63 0.0 63 0.0
SMD+R+W 90 0.0 98 0.0 63 0.0 63 0.0
MMD 95 1.0 97 0.6 75 0.2 75 0.0
MMD+R 96 0.0 98 0.0 75 0.0 75 0.0
MMD+W 96 0.0 98 0.0 75 0.0 75 0.0
MMD+R+W 96 0.0 98 0.0 75 0.0 75 0.0
P-P/P-F: as in Table 4.R: General Reclassification.W: Feature Weighting.

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 177
that obtained when MMD was used alone (σ = 0). This can be explained by the fact thatfeature weighting introduces too strong a bias when classifying discrepancies: each mainsubtree will tend to have at least one severe (i.e., heavily weighted) discrepancy. However,not all error classes involve severe discrepancies.
6. Related work
MEDD’s IDD/LP, when viewed as an intention-based program diagnoser, would be relatedto the PROUST (Johnson, 1990) and APROPOS2 (Looi, 1991) debuggers, which are alsointention-based. IDD/LP is closer to APROPOS2 in the sense that dynamic analysis (i.e.,program testing) `a la Shapiro (1983) is used after static analysis (i.e., syntactic matching)in both. However, MEDD further adapts Shapiro’s routines to take full advantage of theavailability of (1) the reference program and (2) the discrepancies computed between thestudent and reference programs, in order to more fully automate this task. Of course,the most important difference between IDD/LP and other intensional diagnosers is that theothers rely on hand-coded, static libraries of bugs, whereas IDD/LP has the ability to: (1)extend its background knowledge of intentions and correct variants, and (2) use and supportthe construction of an automatically constructed and extendable bug library.
The similarity component of MEDD’s MMD is similar to UNIMEM (Lebowitz, 1987) andCOBWEB (Fisher, 1987), both of which are also incremental, hierarchical conceptual clus-terers. However, UNIMEM and COBWEB deal with attribute-value descriptions, whereasMMD deals with relational descriptions. More importantly, MMD considers causalities inthe background knowledge as well as similarities in the data in the formation of concepts.
To determine causal relationships, particularly the causative features, among the featuresthat make up an induced concept definition, the multistrategy UNIMEM extension proposedin (Lebowitz, 1986) uses the frequency of occurrence of a feature. In MMD, causative dis-crepancies are determined by whether a generalized discrepancy is an intersection or a vari-abilization, or if it is a parent or a child. In (Pazzani, 1994), which likewise uses a UNIMEM-like clusterer, there are two kinds of features, namely, actions and state changes, and actionsare always the causative features. In MMD, any discrepancy is potentially causative.
7. Conclusion
We have presented a system, MEDD, that learns, without supervision, how to classifylogic programs written by novices. This is accomplished in a multistrategic manner bythe exemplar-based classification and learning of novice and reference programs, and thesimilarity- and causality-based clustering of discrepancies between student and referenceprograms into an error hierarchy, whose main subtrees form intensional definitions of errorclasses, which, in turn, denote knowledge-level errors. We have seen how well MEDD per-forms (on novice Prolog programs) in terms of both classification and discovery, and howMEDD can correctly detect the occurrence of knowledge-level errors in these programs,even when multiple errors are enmeshed together in a single program, and when the pro-grams are presented to MEDD in a different order. The applicability of MEDD’s approach

178 SISON, NUMAO & SHIMURA
should extend naturally to other languages or domains in which the internal workings ofbehavioral components (e.g., clauses, subgoals) are abstracted away and do not interferewith those of other components.
Appendix: Knowledge-level errors listed by experts
Note: The bracketed number alongside each knowledge-level error indicates the number ofbuggy programs that exhibited the error.
Knowledge-level errors in the reverse/2 dataset
• Slip or misconception:[X] is the same asX [19]• Misconception:[|] is the same asappend/3 [26]• Lack of background knowledge: Introducing variables in the body of a clause [11]• Lack of background knowledge: Output variables [2]• Lack of background knowledge: Recursion [4]• Lack of task knowledge: Reversing [17]• Repair: Incorrect analogy with a solution in which recursion comes last [4]• Repair: Making arguments in a subgoal consistent with previously (but erroneously)specified arguments [6]• Lack of background knowledge: Termination [9]
Knowledge-level errors in the sumlist/2 dataset
• Slip or misconception:[X] is the same asX [6]• Misconception: Arithmetic expression as output variable [1]• Lack of background knowledge: Introducing variables in the body of a clause [39]• Lack of background knowledge (or misconception): Recursion in Prolog [6]• Lack of background knowledge: Recursion: No recursion [2]• Lack of background knowledge: Recursion: “Can’t wait” [3]• Repair: Incorrect analogy with a solution in which recursion comes last, Making
arguments in a subgoal consistent with previously (but erroneously) specified arguments[30]• Lack of background knowledge: Termination [8]
Acknowledgments
We would like to thank Lorenza Saitta, Katharina Morik, and the editors and reviewersfor their invaluable comments; Rhodora Reyes, Ethel Chua Joy, and Philip Chan for theirhelp with the buggy programs; Tsuyoshi Murata, Oscar Ortega Lobo, Ryutaro Ichise, andJefferson Tan for their technical assistance; and the Ministry of Education (Monbusho) ofJapan for its generous financial support.

MULTISTRATEGY DISCOVERY AND DETECTION OF NOVICE ERRORS 179
Notes
1. Problem solving (solving elementary algebraic equations) was the task of students modeled by PIXIE. On theother hand, classification (of given C++ programs as correct or incorrect) was the task of students modeledby ASSERT. In addition to the use of machine learning to automate background knowledge construction, asin PIXIE and ASSERT, machine learning techniques can also be used to infer student models, e.g., ACM(Langley & Ohlsson, 1984), SIERRA (VanLehn, 1987), ASSERT, and (Neri, 1999). Sison & Shimura (1998)provide a review and discussion of the application of machine learning and machine learning-like techniquesin student modeling.
2. IDD is called MDD (Multistrategy Discrepancy Detection) in (Sison, 1998). However, since what is mul-tistrategic in MDD is its approach to program diagnosis—it performs both static and dynamic analysis ofprograms—rather than its approach to learning (in the current implementation), we do not use the term ’mul-tistrategy’ here to avoid confusion.
3. For speedup, the discrepancy set can also be learned as a transformation rule viaexplanation-based gener-alization (Mitchell, Keller, & Kedar-Cabelli, 1986) by showing that each element in the discrepancy set ispart of a successful application of a sequence of proven correct transformation rules. However, the learningof transformation rules is not currently implemented, as this does not affect MEDD’s accuracy, which is ourcurrent concern. Moreover, note that the learning of correct variants of reference programs is already a formof speedup learning.
4. From a total of 73reverse/2 and 90sumlist/2 programs written by third-year undergraduate students whowere learning Prolog, 64 buggy naivereverse and 56 buggysumlist programs were obtained. Three ofthe 73reverse programs were rightly found by IDD/LP to be correct, while 6 used an accumulator, albeitincorrectly. We did not perform any experiments on the buggy accumulatorreverse programs, as these weretoo sparse. Thirty-four of the 90sumlist programs were rightly determined by IDD/LP as correct.
5. It is important to note that although thereverse/2 andsumlist/2 problems are simple from an expert’spoint of view, these problems are not that simple from the point of view of novices, as evidenced by the buggyprograms. Thereverse/2 andsumlist/2 programs form part of a suite of problems which Gegg-Harrison(1994) has empirically shown to be sufficient for novice Prolog programmers. The rest of the programs in thissuite arelength/2, product/2, count/2, enqueue/3, andappend/3. Thereverse/2 problem is the mostdifficult in this suite.
MMD has only been tested on novice programs, specifically, on programs written by students for Gegg-Harrison’s suite of problems. However, the approach and results should extend naturally to programs writtenby more advanced programmers for as long as the so-called competent programmer assumption (Shapiro,1983) holds, i.e., that a program is written with the intention of being correct, and that if it is not correct, thena close variant of it is.
References
Baffes, P. & Mooney, R. (1996). Refinement-based student modeling and automated bug library construction.Jour-nal of Artificial Intelligence in Education, 7, 75–116.
Bareiss, E., Porter, B., & Wier, C. (1987). PROTOS: An exemplar-based learning apprentice.Proceedings of theFourth International Workshop on Machine Learning.
Biswas, G., Weinberg, J., Yang, Q., & Koller, G. (1991). Conceptual clustering and exploratory data analysis.Proceedings of the Eighth International Workshop on Machine Learning(pp. 591–595).
Fisher, T. (1987). Knowledge acquisition via incremental conceptual clustering.Machine Learning, 2, 139–172.Fisher, D., Xu, L., & Zard, N. (1992). Ordering effects in clustering.Proceedings of the Ninth International
Workshop on Machine Learning(pp. 163–168).Gegg-Harrison, T. (1994). Exploiting program schemata in an automated program debugger.Journal of Artificial
Intelligence in Education, 5, 255–278.Hart, P., Nilsson, N., & Raphael, B. (1968). A formal basis for the heuristic determination of minimum cost paths.
IEEE Transactions on Systems, Sience and Cybernetics, 4, 100–107.Johnson, W. L. (1990). Understanding and debugging novice programs.Artificial Intelligence, 42, 51–97.

180 SISON, NUMAO & SHIMURA
Langley, P. & Ohlsson, S. (1984). Automated cognitive modeling.Proceedings of the Second National Conferenceon Artificial Intelligence(pp. 193–197).
Lebowitz, M. (1986). Integrated learning: Controlling explanation.Cognitive Science, 10, 219–240.Lebowitz, M. (1987). Experiments with incremental concept formation: UNIMEM.Machine Learning, 2, 103–
138.Looi, C. (1991). Automatic debugging of Prolog programs in a Prolog intelligent tutoring system.Instructional
Science, 20, 215–263.McCalla, G. (1992). The central importance of student modeling to intelligent tutoring. In E. Costa (Ed.),New
directions for intelligent tutoring systems, Berlin, Springer Verlag.Michalski, R. & Stepp, R. (1983). Learning from observation: conceptual clustering. In R. Michalski, J. Carbonell,
& T. Mitchell (Eds.),Machine learning: an artificial intelligence approach. Palo Alto, CA: Tioga.Mitchell, T., Keller, R., & Kedar-Cabelli, S. (1986). Explanation-based generalization: A unifying view.Machine
Learning, 1, 47–80.Neri, F. (1999). The role of explanation in elementary physics learning.Machine Learning, This issue.Pazzani, M. (1994). Learning causal patterns: making a transition from data-driven to theory-driven learning. In
R. Michalski & G. Tecuci (Eds.),Machine learning: a multistrategy approach(Vol. IV, pp. 267–293). SanFrancisco, CA: Morgan Kaufmann.
Plotkin, G. (1970). A note on inductive generalization.Machine Intelligence, 5, 153–163.Richards, B. & Mooney, R. (1995). Automated refinement of first-order Horn-clause domain theories.Machine
Learning, 19, 95–131.Shapiro, E. (1983).Algorithmic program debugging. Cambridge, MA: MIT Press.Sison, R. (1998).Multistrategy discovery and detection of novice programmer errors. Ph.D. Thesis, Department
of Computer Science, Tokyo Institute of Technology, Tokyo, Japan.Sison, R., Numao, M., & Shimura, M. (1997). Using data and theory in multistrategy (mis)concept(ion) discov-
ery.Proceedings of the Fifteenth International Joint Conference on Artificial Intelligence(pp. 274–279).Sison, R. & Shimura, M. (1998). Student modeling and machine learning.International Journal of Artificial
Intelligence in Education, 9, 128–158.Sleeman, D., Hirsh, H., Ellery, I., & Kim, I. (1990). Extending domain theories: Two case studies in student
modeling.Machine Learning, 5, 11–37.Sterling, L. & Shapiro, E. (1986).The art of prolog. Cambridge, MA: MIT Press.Tamaki, H. & Sato, T. (1984). Unfold/fold transformation of logic programs.Proceedings of the Second Interna-
tional Logic Programming Conference(pp. 127–138).Tversky, A. (1977). Features of similarity.Psychological Review, 84, 327–352.VanLehn, K. (1987). Learning one procedure per lesson.Artificial Intelligence, 31, 1–40.Wisniewski, E. & Medin, D. (1994). On the interaction of theory and data in concept learning.Cognitive Science,
18, 221–281.
Received December 22, 1998
Accepted June 18, 1999
Final manuscript June 18, 1999





























