Embed Size (px)
Citation preview

Nuero-Fuzzy System
Toolbox
For use with CEMTool
User's Guide
Park Jang-Hyun, Park Gwi-Tae
e-mail: [email protected]
School of Electrical Engineering,
Korea University

사용자 지침서
1.0 Version
고려대학교 전기․전자․전파공학부
자동 제어 연구실
박장현, 박귀태
이 책은 셈툴(CemTool)에서 뉴로퍼지 시스템과 이를 이용한 제어기를 설
계하기 위한 ToolBox에 대하여 설명한다. 우선 대표적인 뉴로퍼지 시스템
의 모델들을 제시하고, 이러한 모델들을 통하여 실제로 퍼지시스템의 학습
이 어떻게 구현되는지를 설명한다.
뉴로퍼지 시스템으로 널리 쓰이고 있는 FALCON, ANFIS 그리고 FBFN등
을 소개한 다음 이들을 구현하는 함수 사용법에 대해 설명하며 기타 다양
한 퍼지시스템의 학습 또는 파라메터 결정 알고리즘을 소개한다.

- 3 -
목차
1. 개요 - 뉴로퍼지 시스템(Neuro-Fuzzy System, NFS) ······························5
2. 퍼지 시스템 ···········································································································5
2.1 퍼지 시스템 데이터구조 ········································································6
2.2 소속함수와 퍼지연산자 그리고 퍼지규칙 ········································10
2.2.1 퍼지 툴박스에서 제공하는 소속함수 ··································10
2.2.2 논리 연산자 ··············································································15
2.2.3 추가적인 논리연산자 ······························································17
2.2.4 퍼지 IF-THEN 규칙 ·····························································18
2.3 퍼지시스템의 종류 ················································································20
2.3.1 Mamdani타잎의 퍼지시스템 ·················································20
2.4.2 Sugeno타잎의 퍼지 시스템 ··················································21
3. 뉴로 퍼지 시스템 ·······························································································22
3.1 Fuzzy Adaptive learning Control Network (FALCON) ·············22
3.2 Adaptive Network-based fuzzy Inference System (ANFIS) ··· 29
3.3 FBF(퍼지 Basis Function) Network ···············································38
3.4 직접비교를 이용한 퍼지규칙 추출 ····················································44
Reference ··············································································································50
퍼지 시스템 관련 함수
함수명 설명 사용처
genfis 퍼지 시스템 생성 3장
getfis 퍼지 시스템에 관한 정보 취득 3장
setfis 퍼지 시스템에 특정 파라메터 값 설정 3장
plotmf 소속함수 도시 3장
fisout 퍼지 시스템 출력 계산 3장

- 4 -
뉴로퍼지 시스템 관련 함수
함수명 설명 사용처
selforg FALCON의 구조 학습3.1절
suplearn FALCON의 파라메터 학습
train_anfis ANFIS의 파라메터 학습 3.2절
getFBFs FBF 벡터 생성 3.3절
ruleext 퍼지 규칙 생성 3.4절
소속함수
함수명 설명 사용처
dsigmf difference of two sigmoid MF
2.2절
gauss2mf two-sided Gaussian curve MF
gaussmf Gaussian curve MF
gbellmf generalized bell curve MF
pimf ∏-shaped curve MF
psigmf product of two sigmoid MF
smf S-shaped curve MF
sigmf sigmoid curve MF
trapmf trapezoidal MF
trimf triangular MF
zmf Z-shaped curve MF
그 외의 법용 함수
함수명 설명 사용처
fplot 함수의 모양을 도시 기타
str2num 문자열을 숫자로 변환 기타
str2vec 문자열을 벡터로 변환 기타
- 5 -
1. 개요 - 뉴로퍼지 시스템(Neuro-Fuzzy System, NFS)
NFC는 기존의 퍼지논리시스템에 신경망의 학습능력을 도입한 것이다.
즉 전문가지식기반의 퍼지논리 시스템에 학습이라는 유연한 기능을 부가하
여 기존의 개념으로 해결하기 어려운 점들을 풀어가는 방식이다.
퍼지시스템은 입력 소속함수와 퍼지규칙(fuzzy rule) 그리고 출력 소속함
수로 구성되어 있다. 퍼지추론은 이러한 구성요소들을 퍼지논리연산을 이
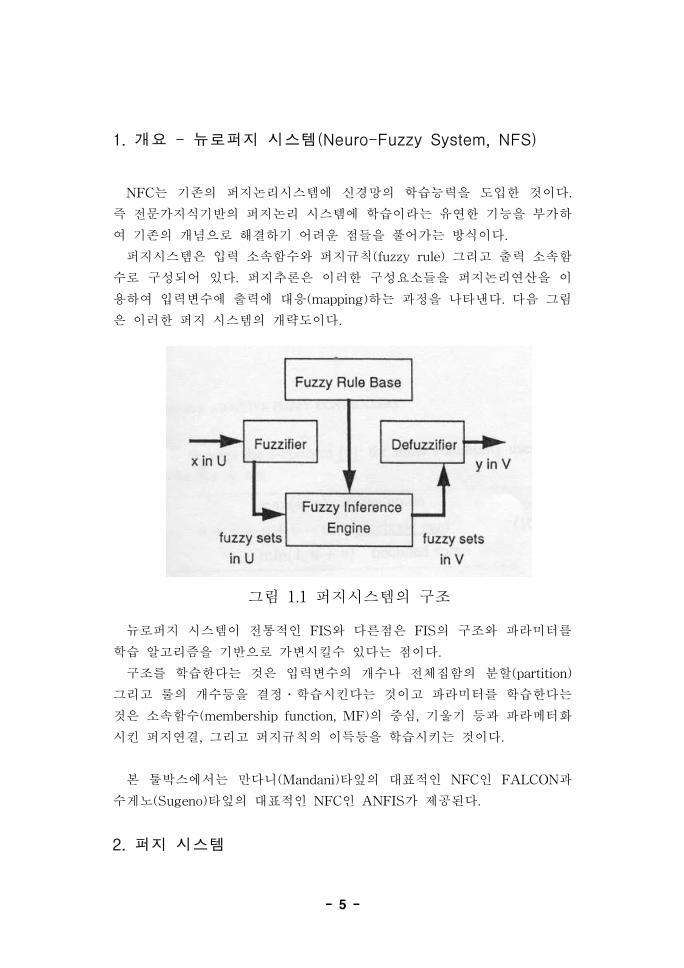
용하여 입력변수에 출력에 대응(mapping)하는 과정을 나타낸다. 다음 그림
은 이러한 퍼지 시스템의 개략도이다.
그림 1.1 퍼지시스템의 구조
뉴로퍼지 시스템이 전통적인 FIS와 다른점은 FIS의 구조와 파라미터를
학습 알고리즘을 기반으로 가변시킬수 있다는 점이다.
구조를 학습한다는 것은 입력변수의 개수나 전체집함의 분할(partition)
그리고 룰의 개수등을 결정․학습시킨다는 것이고 파라미터를 학습한다는
것은 소속함수(membership function, MF)의 중심, 기울기 등과 파라메터화
시킨 퍼지연결, 그리고 퍼지규칙의 이득등을 학습시키는 것이다.
본 툴박스에서는 만다니(Mandani)타잎의 대표적인 NFC인 FALCON과
수게노(Sugeno)타잎의 대표적인 NFC인 ANFIS가 제공된다.
2. 퍼지 시스템
- 6 -
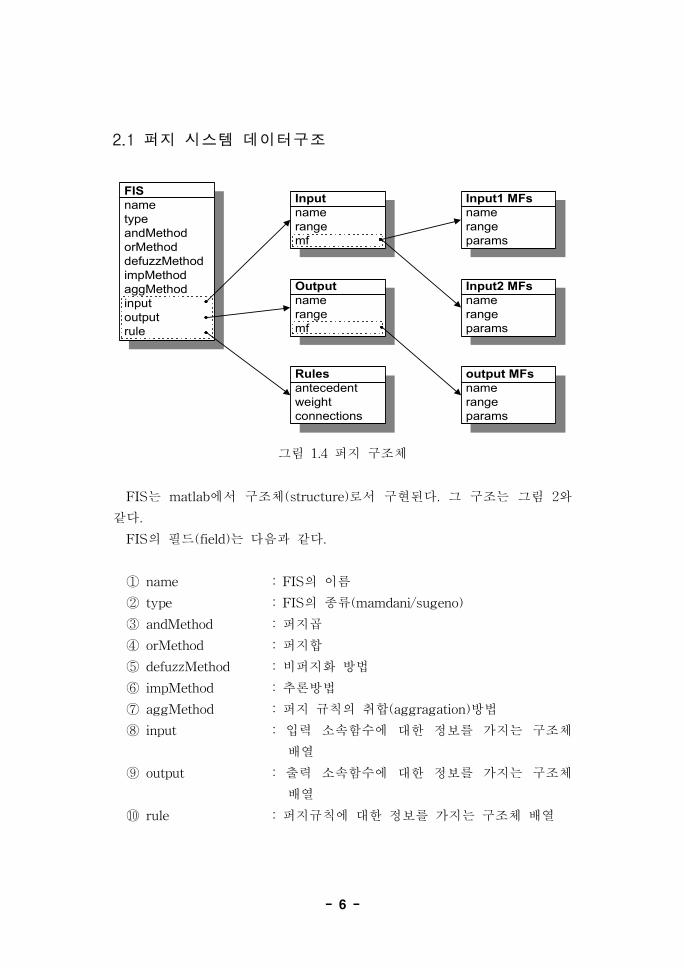
2.1 퍼지 시스템 데이터구조
FISnametypeandMethodorMethoddefuzzMethodimpMethodaggMethodinputoutputrule
Inputnamerangemf
Outputnamerangemf
Rulesantecedentweightconnections
Input1 MFsnamerangeparams
Input2 MFsnamerangeparams
output MFsnamerangeparams
그림 1.4 퍼지 구조체
FIS는 matlab에서 구조체(structure)로서 구현된다. 그 구조는 그림 2와
같다.
FIS의 필드(field)는 다음과 같다.
① name : FIS의 이름
② type : FIS의 종류(mamdani/sugeno)
③ andMethod : 퍼지곱
④ orMethod : 퍼지합
⑤ defuzzMethod : 비퍼지화 방법
⑥ impMethod : 추론방법
⑦ aggMethod : 퍼지 규칙의 취합(aggragation)방법
⑧ input : 입력 소속함수에 대한 정보를 가지는 구조체
배열
⑨ output : 출력 소속함수에 대한 정보를 가지는 구조체
배열
⑩ rule : 퍼지규칙에 대한 정보를 가지는 구조체 배열

- 7 -
즉 전체적으로 FIS는 구조체를 필드로 하는 중첩된 구조체이다. 퍼지구
조체안의 구조체는 input, output 그리고 rule 세가지이고 각각 다음과 같
은 필드를 가진다.
① input(i)
- name : i번째 입력변수의 이름을 갖는 문자열
- range : i번째 입력변수의 범위정보를 갖는 1X2의 벡터
- mf : 소속함수정보를 갖는 구조체
② output(j)
- name : j번째 출력변수의 이름을 갖는 문자열
- range : j번째 출력변수의 범위정보를 갖는 1X2의 벡터
- mf : 소속함수정보를 갖는 구조체
③ rule(k)
- antecedent : k번째 퍼지 규칙의 전건부의 정보를 갖는 벡터
- consequent : k번째 퍼지 규칙의 후건부의 정보를 갖는 벡터
- weight : k번째 퍼지 규칙의 중요도
- connections : k번째 퍼지 규칙의 연결방법(1이면 OR 2이면
AND)
위에서 ①②에 mf라는 이름을 갖는 구조체를 포함하고 있다는 것을 알
수 있다. 이 구조체는 다음과 같은 필드를 갖는다.
④ mf(l)
- name : l번째 소속함수의 이름을 갖는 문자열
- type : l번째 소속함수의 종류 (다음절에서 자세히
설명)
- params : l번째 소속함수의 파라메터들(소속함
수의 종류에 따라 다르다)

- 8 -
참고로 앞으로 사용할 예제에 대한 퍼지 데이터 구조는 실제로는 다음과
같이 문자열의 행렬로 처리된다.
[System]
Name=test
Type=Mamdani
NumInputs=2
NumOutputs=1
NumRules=9
AndMethod=prod
OrMethod=max
ImpMethod=prod
AggMethod=prod
DefuzzMethod=centroid
[Input1]
Name=input1
Range=[-1.4660 1.4660]
NumMFs=4
MF1=MF11:gaussmf,[0.5000 -1.4660]
MF2=MF12:gaussmf,[0.5000 -0.4887]
MF3=MF13:gaussmf,[0.5000 0.4887]
MF4=MF14:gaussmf,[0.5000 1.4660]
[Input2]
Name=input2
Range=[-1 1]
NumMFs=4
MF1=MF21:gaussmf,[0.5000 -1]
MF2=MF22:gaussmf,[0.5000 -0.3333]
MF3=MF23:gaussmf,[0.5000 0.3333]
MF4=MF24:gaussmf,[0.5000 1]

- 9 -
[Output1]
Name=output1
Range=[-1.4660 1.4660]
NumMFs=5
MF1=MF11:gaussmf,[0.5000 -1.4660]
MF2=MF12:gaussmf,[0.5000 -0.7330]
MF3=MF13:gaussmf,[0.5000 0]
MF4=MF14:gaussmf,[0.5000 0.7330]
MF5=MF15:gaussmf,[0.5000 1.4660]
[Rules]
2 2,2 (1):1
2 3,3 (1):1
3 3,3 (1):1
4 4,5 (1):1
4 3,4 (1):1
3 2,3 (1):1
2 1,2 (1):1
1 1,1 (1):1
1 2,2 (1):1
위의 뉴로퍼지 툴박스는 위와 같은 문자열에 저장된 퍼지 추론 시스템의
데이터를 이용하여 어떤 값을 구한다거나 위의 문자열을 수정하는 함수들
로 구성되어 있다. 만약 위의 퍼지 시스템의 변수명이 fis라면 다음과 같이
getfis()함수를 이용하여 이 퍼지시스템의 전반적인 정보를 얻을 수 있다.
CEMTool>>getfis(fis)
Name=test
Type=Mamdani
NumInputs=2
NumOutputs=1
NumRules=9
AndMethod=prod

- 10 -
OrMethod=max
ImpMethod=prod
AggMethod=prod
DefuzzMethod=centroid
2.2 소속함수와 퍼지연산자 그리고 퍼지규칙
2.2.1 퍼지 툴박스에서 제공하는 소속함수
소속함수가 실제로 만족하는 조건은 그것이 0과1사이의 값을 가져야한다
는 것이다. 함수 그 자체는 우리가 간결성(simplicity), 편의성
(convenience), 계산의 속도와 효율성(speed and efficiency)이라는 관점으
로부터 우리에게 알맞은 함수로서 정의 할 수 있는 임의의 곡선이 될 수
있다.
전통적인 집합(set)은
A={x∣x>6}
과 같이 표현한다. 퍼지집합은 전통적인 집합의 확장이다. 만일 X가 전체
집합이고 그것의 요소가 x로 표시되면 X안의 fuzzy 집합 A는
A={x, μ A (x)∣x∈X}
로 정의된다. μ A (x)는 A안에서 x의 소속함수(membership function,
MF)라고 한다. 소속함수는 X의 각 요소를 0과 1사이의 소속함수값으로 대
응 시킨다.
Fuzzy Logic Toolbox는 11개의 소속함수 형태를 포함하고 있다. 이런
11개의 함수들은 몇 가지 기본적인 함수들과 그들의 합성으로 구성되어진
다 기본적인 함수들이란 부분선형(piecewise linear)함수, 가우스 분포
(gaussian distribution) 함수, 시그모이드(sigmoid) 함수, 그리고 quadratic
and cubic polynomial curve등 이다. 아래에 설명되어질 소속함수들에 대
한 자세한 정보는 help 명령어를 이용하거나 또는 MATLAB Fuzzy
Toolbox의 레퍼런스를 참조하길 바란다. 관습적으로 소속함수들의 이름 뒤
- 11 -
에는 mf라는 글자가 있다.
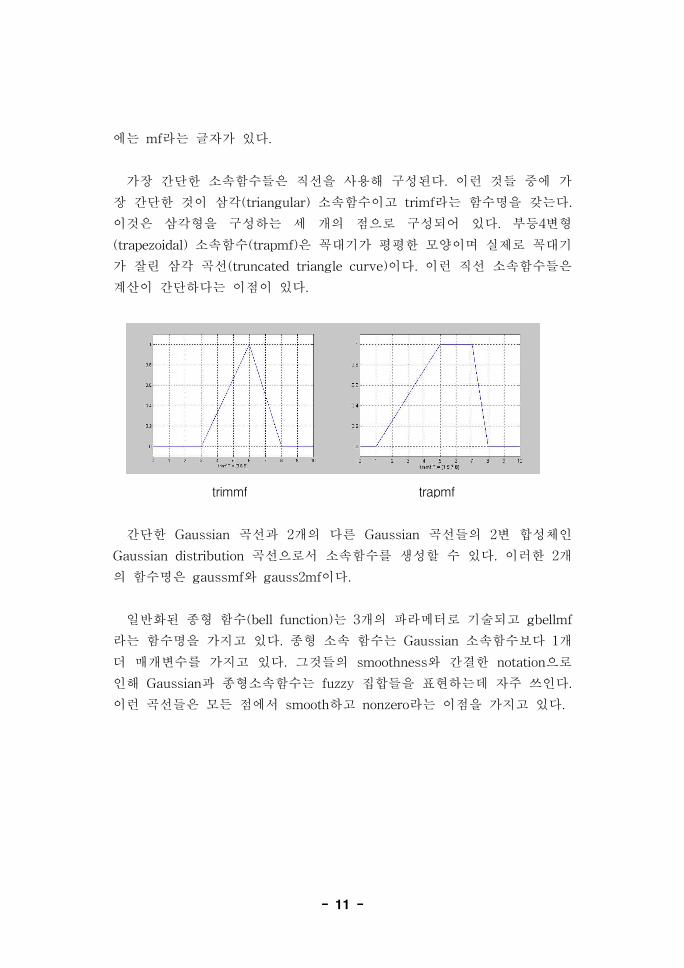
가장 간단한 소속함수들은 직선을 사용해 구성된다. 이런 것들 중에 가
장 간단한 것이 삼각(triangular) 소속함수이고 trimf라는 함수명을 갖는다.
이것은 삼각형을 구성하는 세 개의 점으로 구성되어 있다. 부등4변형
(trapezoidal) 소속함수(trapmf)은 꼭대기가 평평한 모양이며 실제로 꼭대기
가 잘린 삼각 곡선(truncated triangle curve)이다. 이런 직선 소속함수들은
계산이 간단하다는 이점이 있다.
trimmf trapmf
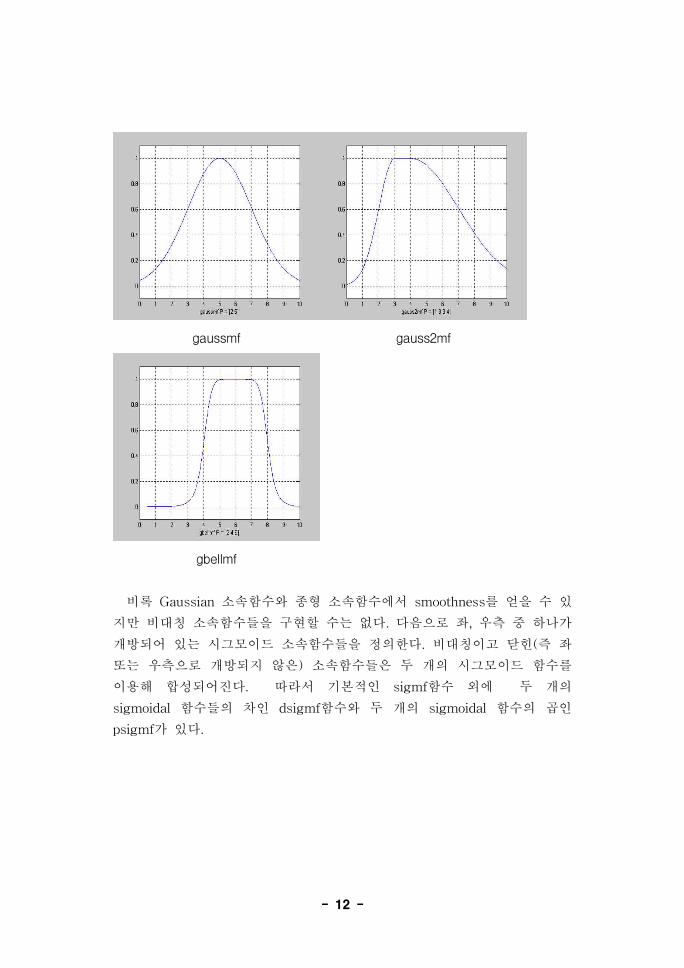
간단한 Gaussian 곡선과 2개의 다른 Gaussian 곡선들의 2변 합성체인
Gaussian distribution 곡선으로서 소속함수를 생성할 수 있다. 이러한 2개
의 함수명은 gaussmf와 gauss2mf이다.
일반화된 종형 함수(bell function)는 3개의 파라메터로 기술되고 gbellmf
라는 함수명을 가지고 있다. 종형 소속 함수는 Gaussian 소속함수보다 1개
더 매개변수를 가지고 있다. 그것들의 smoothness와 간결한 notation으로
인해 Gaussian과 종형소속함수는 fuzzy 집합들을 표현하는데 자주 쓰인다.
이런 곡선들은 모든 점에서 smooth하고 nonzero라는 이점을 가지고 있다.
- 12 -
gaussmf gauss2mf
gbellmf
비록 Gaussian 소속함수와 종형 소속함수에서 smoothness를 얻을 수 있
지만 비대칭 소속함수들을 구현할 수는 없다. 다음으로 좌, 우측 중 하나가
개방되어 있는 시그모이드 소속함수들을 정의한다. 비대칭이고 닫힌(즉 좌
또는 우측으로 개방되지 않은) 소속함수들은 두 개의 시그모이드 함수를
이용해 합성되어진다. 따라서 기본적인 sigmf함수 외에 두 개의
sigmoidal 함수들의 차인 dsigmf함수와 두 개의 sigmoidal 함수의 곱인
psigmf가 있다.
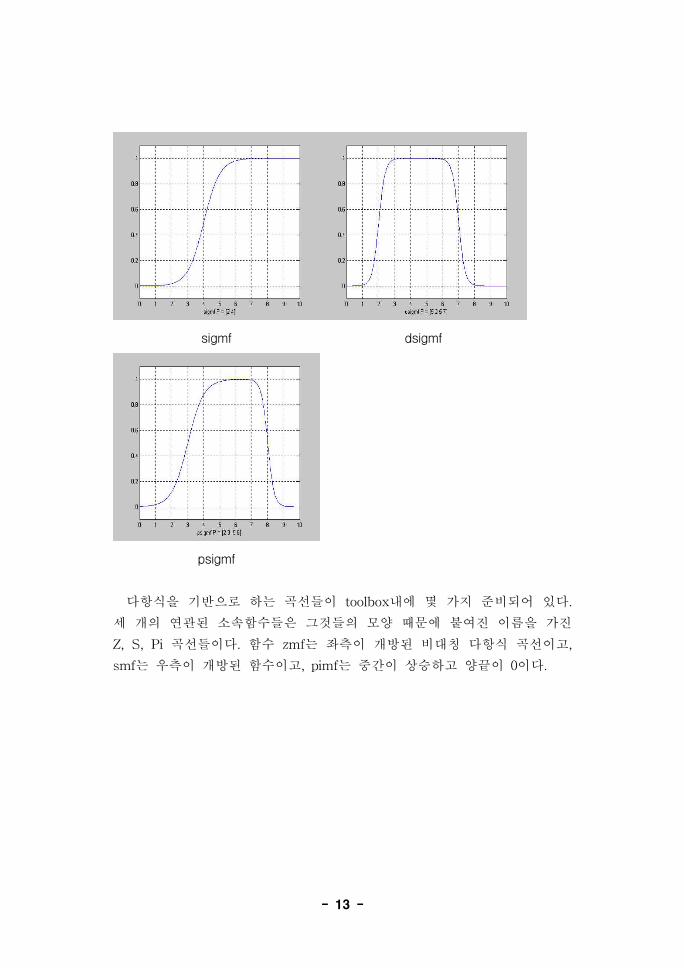
- 13 -
sigmf dsigmf
psigmf
다항식을 기반으로 하는 곡선들이 toolbox내에 몇 가지 준비되어 있다.
세 개의 연관된 소속함수들은 그것들의 모양 때문에 붙여진 이름을 가진
Z, S, Pi 곡선들이다. 함수 zmf는 좌측이 개방된 비대칭 다항식 곡선이고,
smf는 우측이 개방된 함수이고, pimf는 중간이 상승하고 양끝이 0이다.
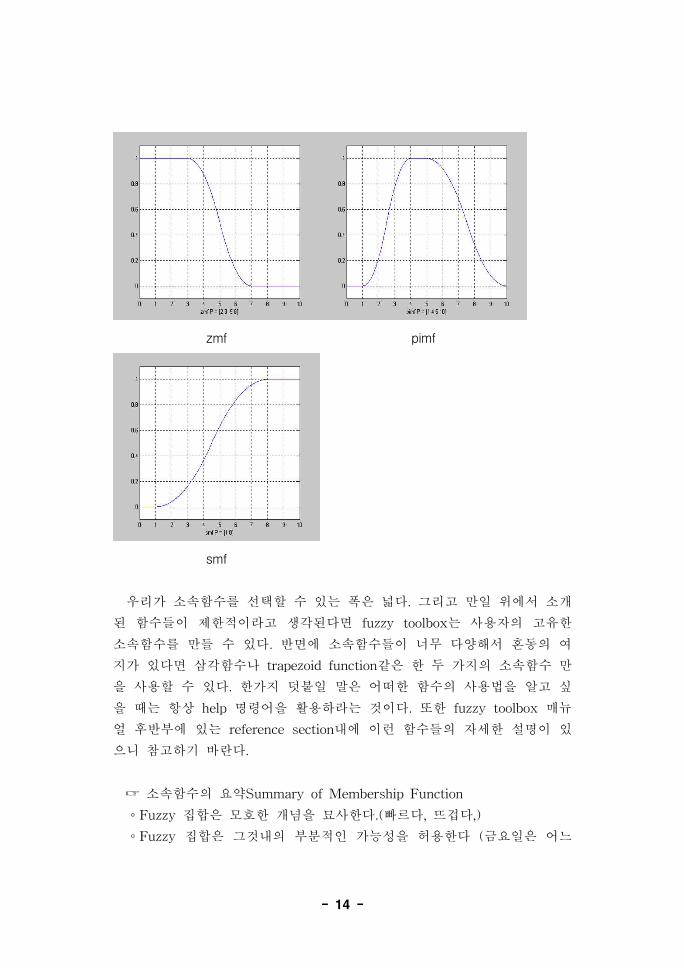
- 14 -
zmf pimf
smf
우리가 소속함수를 선택할 수 있는 폭은 넓다. 그리고 만일 위에서 소개
된 함수들이 제한적이라고 생각된다면 fuzzy toolbox는 사용자의 고유한
소속함수를 만들 수 있다. 반면에 소속함수들이 너무 다양해서 혼동의 여
지가 있다면 삼각함수나 trapezoid function같은 한 두 가지의 소속함수 만
을 사용할 수 있다. 한가지 덧붙일 말은 어떠한 함수의 사용법을 알고 싶
을 때는 항상 help 명령어을 활용하라는 것이다. 또한 fuzzy toolbox 매뉴
얼 후반부에 있는 reference section내에 이런 함수들의 자세한 설명이 있
으니 참고하기 바란다.
☞ 소속함수의 요약Summary of Membership Function
∘Fuzzy 집합은 모호한 개념을 묘사한다.(빠르다, 뜨겁다,)
∘Fuzzy 집합은 그것내의 부분적인 가능성을 허용한다 (금요일은 어느

- 15 -
정도 주말이다. 날씨가 좀 덥다.)
∘Fuzzy 집합에 속한 대상의 정도값(degree)은 0과 1사이의 소
속함수값으로 표시한다.(금요일은 0.8의 정도로 주말이다.)
∘주어진 Fuzzy 집합과 관련된 소속함수는 입력 값을 그것의
적당한 소속함수값으로 대응시킨다.
2.2.2 논리 연산자
퍼지 논리라는 용어에서 “퍼지”가 무엇을 뜻하는가는 앞에서 살펴본 대
로다. 이제 “논리”가 무엇인지 알아보자.
퍼지추론을 행하기 위한 중요한 것은 그것이 표준 Boolean 논리의 상위
확장(superset)이란 것이다. 다시 말해 만일 우리가 퍼지값을 1(completely
true)과 0(completely false)값만을 갖는다고 하면 이것은 표준 논리연산이
될것이다. 예를 들어 아래의 표준 진리표를 생각해 보자.
퍼지논리에서 어떠한 명제의 참인 여부는 정도(degree 즉 0과 1사이의
임의의 값)의 문제인 것을 기억하기 바란다. 그렇다면 어떻게 위의 진리표
들이 변할 것인가? 입력 값들은 0과 1사이의 정수가 될 수 있다. 어떠한
함수가 AND 진리표의 결과를 유지하고 또한 0과1 사이의 모든 정수로 확
장 할 것인가?
한가지 답은 min 연산이다. 이것은 함수 min(A, B)을 이용해 A AND
B(여기서 A와 B는 0과 1범위의 실수들)라는 문장을 해석한다. 같은 이유
로 이용해 max 함수를 이용해 OR 연산을 대체 할 수 있다. 결국 A OR

- 16 -
B는 max(A, B)와 동치가 된다. 마지막으로 연산 NOT A는 1-A 연산과
동치이다. 이렇게 정의하면 위의 진리표의 값은 불변이 됨을 다음 그림으
로 알 수 있다.
여기에 추가해서 진리표 자체보다도 진리표 이면에 존재하는 함수들 때
문에 우리는 1과 0이외의 다른 값들을 고려 할 수 있다.
다음의 그림들은 같은 정보를 보이기 위해 그래프를 이용한다. 한 개의
fuzzy 집합을 만들기 위해 함께 응용되어진 두 개의 fuzzy 집합의 plot에
진리표를 변환했다. 그림의 상단은 위의 이진 진리표에 대응되는 그림이고
반면에 그림의 하단은 우리가 정의한 퍼지 연산에 따라 0과 1사이의 실수
진리값인 A와B 사이에서 연산들이 어떻게 동작하는지를 보여준다.

- 17 -
주어진 이러한 세 개의 함수들로 우리는 퍼지집합과 퍼지 논리 연산
AND, OR, NOT을 이용한 구조를 해석 할 수 있다.
2.2.3 추가적인 논리연산자
여기서 AND, OR, NOT에 대한 이변수와 다변수 논리 연산자들 사이의
특별한 대응관계를 정의한다. 이러한 대응이 유일한 것은 아니다.
좀더 일반적인 용어를 사용하면 fuzzy intersection 또는
conjunction(AND), fuzzy union 또는 disjunction(OR), fuzzy
complement(NOT)로 알려진 것이 무엇인지 여기서 정의하고 있다. 우리는
위에서 AND = min, OR = max, NOT = additive complement 같은 함수
들에 대한 전통적인 연산자라 불리는 것들을 위에서 정의했다. 대개는 대
부분의 퍼지논리를 이용하는 응용에서 이러한 연산자들을 이용한다. 그러
나 일반적으로 이러한 함수들은 (매우) 임의적이다. fuzzy logic toolbox는
위에서 보듯이 fuzzy complement에 대해 classical operator를 사용하나 또
한 사용자가 AND와 OR operator를 이용할 수도 있다.
두 개의 fuzzy 집합 A와 B의 intersection은 일반적으로 다음과 같이 두
개의 소속함수들 모으는 binary mapping T로 설명되어진다.
μ A∩B (x)=T( μ A (x), μ B (x))
예를 들어 binary operator T는 μ A (x)와 μ B (x)의 곱으로 표현될
수도 있다. 일반적으로 이러한 T-norm(triangular norm)으로 불리우는
fuzzy intersection operator들은 다음의 기본적인 조건들이 있다.
T-norm operator는 다음을 만족하는 binary mapping T(∙,∙)이다.
① boundary : T(0,0) = 0, T(a,1)=T(1,a)=a
② monotonicity : T(a, b)<=T(c, d) if a<=c and b<=d
③ commutativity : T(a, b)=T(b, a)
④ associativity : T(a, T(b, c))=T(T(a, b),c)
첫 번째 조건은 전통적인 집합에 대한 옳은 결과를 부과한다. 두 번째

- 18 -
조건에서는 A나 B의 소속함수값들의 감소가 A intersection B 값의 증가
를 이끌 수 없음을 의미한다. 세 번째 조건에서 intersection은 교환법칙이
성립함을 가리키고 마지막으로 네 번째 조건에서 결합조건이 성립함을 보
여준다.
fuzzy intersection과 같이 fuzzy union도 binary mapping S로 설명 될
수 있다.
μ A∪B (x)=S( μ A (x), μ B (x))
예를 들어 binary operator S는 μ A (x)와 μ B (x)의 합으로 표현될
수 있다.
T-conorm (또는 S-norm) 연산자는 다음이 만족되는 binary mapping
S(․,․)이다.
① boundary : S(1,1) = 1, S(a,0)=S(0,a)=a
② monotonicity : S(a, b)<=S(c, d) if a<=c and b<=d
③ commutativity : S(a, b)=S(b, a)
④ associativity : S(a, S(b, c))=S(S(a, b),c)
몇몇 매개변수화된 T-norm과 S-norm들이 Yager[Yag80], Dubois and
Prade[Dub80], Schweizer and Sklar[Sch63], and Sugeno[Sug77]에서 과거
에 제안되었다.
2.2.4 퍼지 IF-THEN 규칙
퍼지 집합과 퍼지연산자들은 퍼지논리의 주어와 동사이다. 이러한
if-then 규칙은 퍼지 논리를 포함하는 조건문을 구성하는데 이용한다.
하나의 퍼지 if-then 규칙은 다음과 같은 형식이다.
if x is A then y is B
A와 B는 전체집합 X와 Y의 범위에서 퍼지 집합에 의해 정의되는 언어
값(linguistic value)들이다. 퍼직 규칙 "x is A“ 의 if 부분은 전건부

- 19 -
(antecedent or premise)라 하고, 반면에 "y is B"의 then 부분은 후건부
(consequent or conclusion)이라 한다. 이런 규칙의 예를 들면 다음과 같다.
if service is good then tip is average
good은 0과 1사이의 숫자로서 표현되고, 따라서 전건부는 0과 1사이의
어떤 실수값으로 나타난다. 반면에 average는 퍼지 집합으로 표현되고 전
체 퍼지 집합 B를 출력 변수 y에 할당한다. if-then rule에서 “is"라는 단어
는 그것이 antecedent에서 나타나느냐 또는 consequent에 나타냐느냐에 따
라 완전히 다른 방법으로 이용된다. MATLAB의 문법으로 대응해서 설명
하면 이것이 관계연산자인 ”==“과 변수 할당에 사용되는 ”=“로 설명된다.
이것을 이용하여 좀더 의미를 명확하게 하면 다음과 같다.
if service == good then tip = average
일반적으로 if-then rule의 입력은 입력 변수(여기서는 service)에 대한
현재값이고 출력은 퍼지 집합 (여기서는 average)이 된다. 이 퍼지집합은
나중에 비퍼지화(defuzzification)되어 출력에 하나의 값을 할당된다.
if-then 규칙의 해석은 다음과 같이 구분된다. 첫 번째로 (입력을 퍼지화
하고 필요한 퍼지연산을 적용하는것읖 포함하여) 전건부를 해석하고 두 번
째로 그 결과를 후건부에 적용하는데 이 과정을 퍼지추론(implication)이라
고 한다.
이진규칙(binary logic 즉 참, 거짓만을 나타내는 경우)의 경우에도 큰 차
이가 없다. 만일 전건부가 참이라면 결론부도 참이다. 만일 우리가 이진규
칙이라는 제한을 풀고 전건부를 퍼지 문장화하면 결론부(즉 후건분)에 어
떤 영향을 줄 것인가? 답은 간단하다 : 만일 전건부가 어떤 소속함수에 대
해서 어느 정도만 참이라면 결론부 또한 같은 정도로 참이다. 다시 말해
in binary logic: p → q (p와 q는 둘 다 참이거나 거짓)
in fuzzy logic: 0.5p → 0.5q (부분적인 전제조건들은 부분적인 의미를
준다)
규칙의 전건부는 다중부분들을 가질 수 있다. 예를 들면

- 20 -
if sky is gray and wind is strong and barometer is falling, then ...
이 예에서 전건부의 모든 부분은 동시에 계산되고 다음 section에서 설
명되는 논리연산자(logical operator)를 이용해 단일 숫자로 해석된다.
규칙의 후건부 또한 다중부분들을 가질 수 있다.:
if temperature is cold then hot water valve is open and cold water
valve is shut.
이 예에서 모든 후건부들은 전건부의 결과에 영향을 받는다. 후건부는
전건부에 의해 어떻게 영향을 받는가? 결론부는 출력으로서 어떠한 퍼지
집합을 지정한다. 추론(implication)함수는 결론부의 퍼지집합을 전건부에
의해 설명되는 정도로 변경시킨다. 출력인 퍼지 집합을 변경하는 공통적인
방법은 min 함수를 이용해 절단하거나 prod 집합을 이용해 비례 축소하는
방법이 있다. 모두 MATLAB의 fuzzy logic toolbox에 의해 제공된다.
2.3 퍼지시스템의 종류
2.3.1 Mamdani타잎의 퍼지시스템
input(i)/output(i) 구조체는 i번째 입력/출력 정보를 갖는 구조체로 그
필드로서 name, range 그리고 mf를 갖는다. name은 i번째 입력/출력 변
수명, range는 전체집합의 범위, 그리고 mf는 소속함수에 대한 정보를 갖
는 구조체 배열이다.
mf(j)는 그 필드로서 name, type, 그리고 params를 갖는다. name과 type
은 j번째 소속함수의 이름과 종류(trimf, trapmf, gbellmf, gaussmf,
gauss2mf, sigmf, dsigmf, psigmf, pimf, smf, zmf) 그리고 params는 매개
변수벡터이다.
rule(i)는 i번째 퍼지규칙에 대한 정보를 갖는 구조체로서 그 필드로
antecedent, consequent, weight, connections를 갖는다. antecedent는 전건
부 정보를 갖는 벡터이고 consequent는 후건부 정보를 갖는 벡터이며

- 21 -
weight는 i번째 퍼지규칙의 중요도를 나타내며 connections는 1이면 전건
부 변수들이 ‘퍼지 or'로 결합됨을, 2값을 가지면 ’퍼지 and'로 결합됨을 가
리킨다.
2.4.2 Sugeno타잎의 퍼지 시스템
input구조체는 Mamdani타잎의 구조체와 동일하다.
output(i) 구조체는 i번째 출력 정보를 갖는 구조체로 그 필드로서
name, range 그리고 mf를 갖는다. name은 i번째 입력/출력 변수명, range
는 전체집합의 범위, 그리고 mf는 소속함수에 대한 정보를 갖는 구조체 배
열이다.
mf(j)는 그 필드로서 name, type, 그리고 params를 갖는다. name은 j번째 소속함수의 이름이고 type은 이 경우 ‘linear'또는 ’constant'이다. 그리
고 params는 매개변수벡터이며 type이 ‘linear'인 경우 (입력변수의 개수
+1)차원의 행벡터가되며 type이 ‘constant'인 경우 상수가 된다.
rule(i)는 Mamdano타잎의 구조체와 antecedent 변수는 같고 후건부 조건
을 가지는 consequent변수는 출력측의 한 소속함수를 가리키는 상수라는
점이 다르다.

- 22 -
3. 뉴로 퍼지 시스템
3.1 Fuzzy Adaptive learning Control Network (FALCON)
이 절에서 소개하는 NFC는 mamdani타잎의 퍼지시스템에 네트워크
(network)개념을 도입한 FALCON이다. 그 구조는 그림 2.1에 나타나 있다.
y1y2' ym
ym'
xnx2
x1
Layer 5(output linguistic
nodes)
Layer 4(output term nodes)
Layer 3(rule nodes)
Layer 2(input term nodes)
Layer 1(input linguistic
nodes)
그림 2.1 FALCON의 구조
그림을 자세히 살펴보면 mamdani타잎의 퍼지시스템에서 행하여지는 연
산을 각 층(layer)에서 행해지도록 등가화 한 것임을 알 수 있다. 노드
(node)의 구조는 다음 그림 2.2와 같다.

- 23 -
그림 2.2 노드의 구조
그림 2.2에서 f (⋅)은 net input을 생성하는 함수이고 a(⋅)은 활성
화함수를 나타낸다. 예를 들어 이 노드가 신경망의 뉴론(neuron)이라면 f
와 a 는 다음과 같다.
f= ∑p
i= 1wi
ku ki , a=
1
1+e-f
다음은 각각의 5개 층의 노드의 함수( f와 a )에 대한 설명이다.
1번층: 입력값을 그대로 2번층에 전달한다.
f=u 1i and a=f
2번층: 입력에 대해서 소속함수값을 출력값으로 내보낸다. 소속함수는 종
형함수(bell-shaped function)로서 ‘gaussmf'함수를 사용한다. 이함수는 매
개변수로서 기울기와 중심값을 가지며 그림 2.2와 같은 모양을 갖는다.
f=-(u ( 1)
i -m ij )2
σ2ijand a=e f
m ij , σ ij … center and width of the bell-shaped function
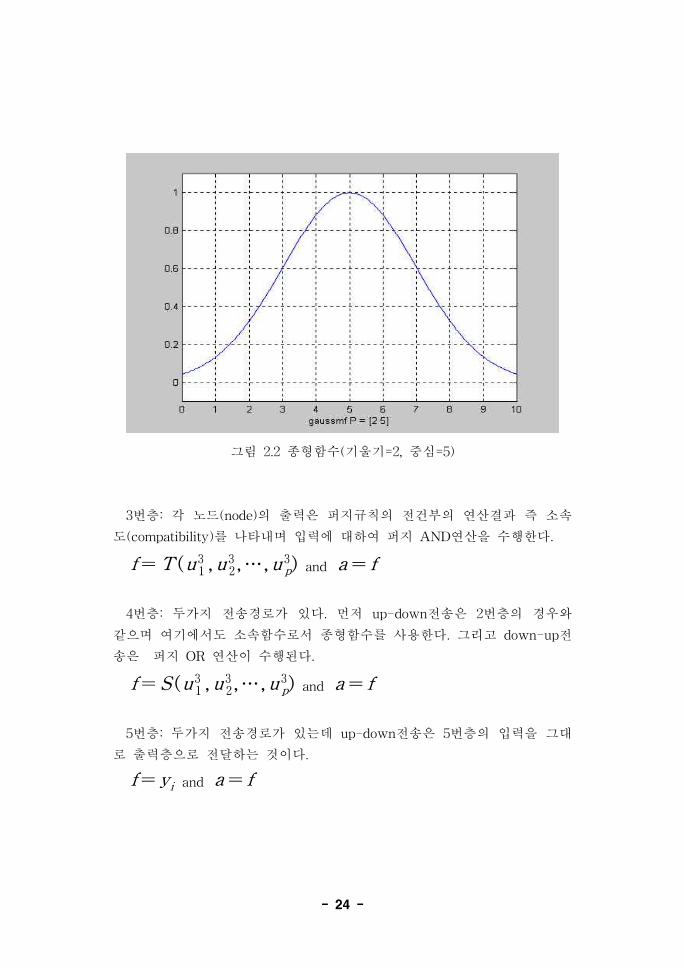
- 24 -
그림 2.2 종형함수(기울기=2, 중심=5)
3번층: 각 노드(node)의 출력은 퍼지규칙의 전건부의 연산결과 즉 소속
도(compatibility)를 나타내며 입력에 대하여 퍼지 AND연산을 수행한다.
f=T (u 31,u
32,⋯,u 3
p) and a=f
4번층: 두가지 전송경로가 있다. 먼저 up-down전송은 2번층의 경우와
같으며 여기에서도 소속함수로서 종형함수를 사용한다. 그리고 down-up전
송은 퍼지 OR 연산이 수행된다.
f=S (u 31,u
32,⋯,u 3
p) and a=f
5번층: 두가지 전송경로가 있는데 up-down전송은 5번층의 입력을 그대
로 출력층으로 전달하는 것이다.
f=yi and a=f

- 25 -
down-up전송은 비퍼지화(defuzzification) 과정으로 무게중심방법(center
of area)을 사용한다면 다음과 같은 수식으로 표현될 수 있다.
f 5=∑j(m ijσ ij)u
5j
∑jσ iju
5j
, and a=f
위에서 기술한 퍼지 시스템의 학습은 크게 두가지 단계로 나뉜다. 첫 번
째는 self-organized learning phase으로서 입/출력변수의 소속함수의 기울
기와 중심값을 학습하고 퍼지규칙을 결정하는 단계이다. 본 툴박스에서 제
공하는 'self_learning'함수는 이 과정을 수행하게 된다.
두 번째는 Supervised learning phase으로서 입/출력 소속함수의 매개
변수값을 정밀하게 조정하는 단계이다. ‘sup_learning'함수가 이 과정을 수
행하게 된다.
시스템을 동정(identification)하는 간단한 예제를 통하여 toolbox함수의
사용법을 설명하도록 한다. 예제 프로그램의 리스트는 다음과 같다.
1: clear all
2:
3: data = [];
4: uk_1 = 0;
5: yk_1 = 0;
6:
7: y = zeros(110,1);
8: u = zeros(110,1);
9:
10: for (k = 1; k<=110; k=k+1) {
11: u(k) = sin(2*pi*k/100);
12: y(k) = yk_1/(1+yk_1^2) +

- 26 -
uk_1^3;
13:
14: data = [data; yk_1 uk_1];
15:
16: uk_1 = u(k);
17: yk_1 = y(k);
18: }
19:
29: fis = genfis([data y], 1, 4,
"gaussmf", 5, "gaussmf")
21: "Self organizing"
22: fis = selforg(fis, data(1:110,
:), y(1:110));
23: yhat1 = evalfis(fis,
data(1:110, :))
24:
25: "Supervsed learning"
26: for (i=1; i<=10; i++)
27: fis = suplearn(fis,
data(1:110:L,:), y(1:110:L));
28:
29: yhat2 = evalfis(fis,
data(1:110:L,:))
30:
31: plot(1:110, y), holdon
32: plot(1:110:L, yhat1)
33: plot(1:110:L, yhat2)

- 27 -
1번줄은 모든 변수와 함수를 클리어하는 명령이다. 위의 예제에서는
‘gen_fis'함수를 이용하여 fis이라는 퍼지구조체를 생성한다. ’gen_fis'는 입
력변수는 ①입출력 데이터, ②FIS의 종류(mamdani, sugeno), ③입력변수의
소속함수의 갯수, ④입력변수의 소속함수 종류, ⑤출력변수의 소속함수의
개수, ⑥출력변수의 소속함수의 종류 들을 입력파라메터로 받는다(레퍼런
스 참조). 위의 값들을 gen_fis함수에 전달하면 이 함수내에서 입/출력 변
수의 개수, 각각의 변수에 지정된 소속함수의 개수등의 정보를 얻어서 퍼
지 구조체를 생성하여 리턴한다.
10번줄에서 18번줄까지의 코드는 다음과 같은 차분방정식으로 표현되는
시스템의 데이터를 생성한다.
y(k)=y(k-1)
1+y(k-1) 2+u (k-1) 3
따라서 FIS의 입력은 두개( y(k-1) 과 u (k-1) )이고 출력은 하
나( y(k) )이다.22번줄에서 self-organizing을 수행한다. ‘self-organizing’함수는 입력으로
①FIS 구조체, ②입력데이터 벡터/행렬, ③원하는 출력값/벡터 순으로 받아
들인다. 이러한 입력데이터를 바탕으로 입/출력 소속함수의 파라메터값을
조절하고 퍼지규칙을 생성한다.
26~27번 줄에서 감독학습(supervised learning)을 수행한다.
‘sup_learning'함수의 입력은 ‘self-organizing’함수와 동일하고 출력은 ①
FIS구조체와 ②FIS의 출력값이다.
31, 32 그리고 33번 줄에서 각각 시스템의 출력, self-organizing후의 출
력 그리고 supervised learning후의 출력을 각각 도시하며 그 결과는 그림
2.4와 같다.

- 28 -
그림 2.4 학습결과
그림에서 실선은 실제 출력이고 긴 점선은 self-organizing후 FIS의 출력
을, 그리고 점선은 supervised learning후 FIS의 출력이다.

- 29 -
3.2 Adaptive Network-based fuzzy Inference System
(ANFIS)
이 절에서는 TSK 퍼지 규칙을 가지는 퍼지시스템을 고려한다. TSK 퍼
지규칙은 후건부가 전건부의 선형결합의 형태로 이루어진다. 그 형식은 다
음과 같다.
R j: IF x1 is A j
1 AND x2 is A j2 AND … AND xn is A j
n
THEN y= f j=a j0+a j
1x1+a j2x2+⋯+a j
nxn
여기서 xi는 입력변수이고 y는 출력변수이고, A ji는 소속함수
μ Aji(x)를 가지는 언어변수(linguistic term)이고 a j
i∈R 은 선형방정식
f j(x1,x2,⋯xn)의 계수이다. 그리고 j= 1,2,⋯,M ,
i= 1,2,⋯,n 이다.
간단한 예를 입력변수가 두 개( x1 , x2 )이고 출력이 하나( y )이며 퍼
지규칙이 다음과 같이 두 개인 시스템을 고려하자.
R 1: IF x1 is A 1
1 AND x2 is A 12 THEN
y= f 1=a 10+a 1
1x1+a 12x2
R 2: IF x1 is A 2
1 AND x2 is A 22 THEN
y= f 2=a 20+a 2
1x1+a 22x2
주어진 입력변수 x1과 x2에 대해서 추론된 출력 y*는 다음과 같은
식으로 계산 되어 진다.

- 30 -
y*=μ 1f 1+μ 2f 2μ 1+μ 2
여기서 μ j는 R j의 점화도(firing strength) 혹은 적합도(compatibility)
이며 product inference가 쓰인다면 다음과 같이 주어진다.
μ j=μ Aji(x1)⋅μ Aj
2
(x2), j= 1,2
ANFIS구조는 그림 2.6과 같고 노드 함수 계산식은 다음과 같다.
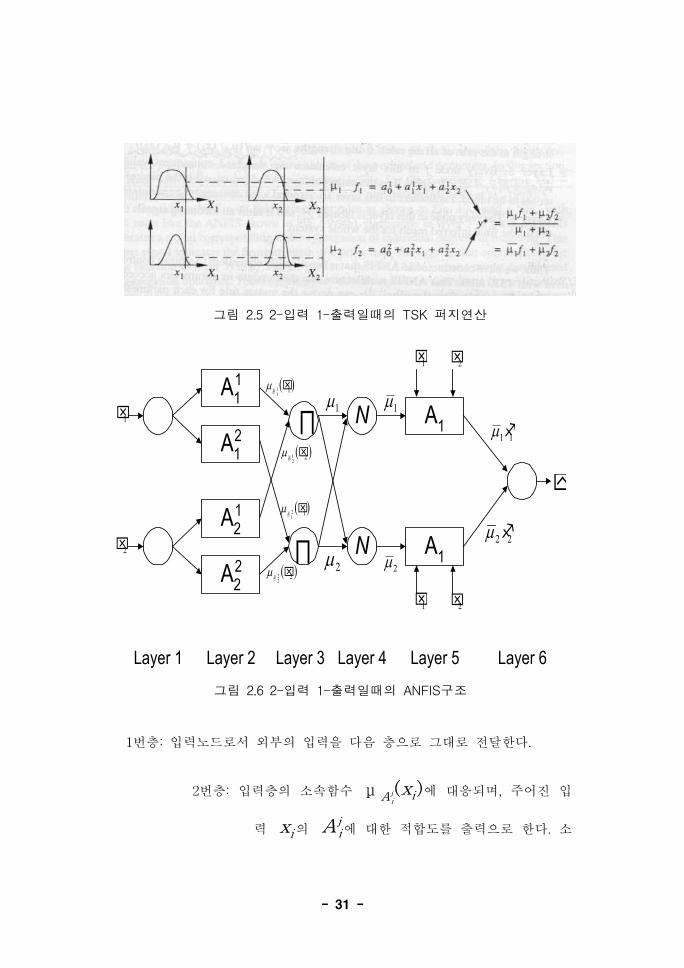
- 31 -
그림 2.5 2-입력 1-출력일때의 TSK 퍼지연산
N
N
A1
A1
A11
A12
A21
A22
∏
∏
Layer 1 Layer 2 Layer 3 Layer 4 Layer 5 Layer 6
( )212x
Am
( )121x
Am
( )222x
Am
( )111x
Am
1m
2m
1m
2m
11fm
22fm
1x 2x
1x 2x
1x
2x
y
그림 2.6 2-입력 1-출력일때의 ANFIS구조
1번층: 입력노드로서 외부의 입력을 다음 층으로 그대로 전달한다.
2번층: 입력층의 소속함수 μ Aji(xi)에 대응되며, 주어진 입
력 xi의 A ji에 대한 적합도를 출력으로 한다. 소

- 32 -
속함수는 보통 종형함수를 쓰며 이 경우 소속함수
값은 다음 식과 같이 계산된다.
f= exp {-( x( 1)i -m j
i
σ ji)2bj
i
}
여기서 {m ji , σ
ji }는 학습되어질 파라메터들이다.
이 층의 파라메터들을 전건부 파라메터
(preconditional parameters)라고 한다.
3번층: 모든 노드는 Π로 표기되며 입력신호를 모두 곱하여
출력신호로 내보내게 된다. 각각의 노드의 출력은 퍼
지 규칙의 적합도를 나타낸다.
4번층: 모든 노드는 N으로 표기되며 어떠한 퍼지규칙의 정
규화된 적합도를 계산한다. 즉 j번째 노드는 j번째퍼지규칙의 적합도를 모든 적합도의 합으로 나눈 값
이다.
μ j=μ j
μ Aj1
(x1)+μ A j2
(x1)
5번층: 가중치와 후건부값을 곱한다. 즉 μ j (aj0+a j
1x1+a j2x2)을
계산한다. 여기서 μ j는 4번층의 출력이며 { a j0 , a j
1 , a j2 }은 학습되어
질 파라메터집합이다. 이 층의 파라메터들은 후건부 파라메터(consequent
parameters)라고 한다.
6번층: ∑이라고 표기하며 5번층의 출력들을 합하여 전체 시스템의 추
론값을 구한다.

- 33 -
따라서 ANFIS는 TSK 퍼지규칙을 사용한 퍼지 출론 계통과 기능적으로
같음을 알 수 있다.
간단한 chaotic time-series 예측(prediction) 예제를 들어보도록 하자. 예
제 프로그램은 다음과 같다.
1: clear all
2;
3; load mgdata.dat
4:
5: t = mgdata(:, 1);
6: x = mgdata(:, 2);
7:
8: plot(t,x)
9:
10: for t = 118:1117
11: w(t-117, :) = [x(t-18) x(t-12) x(t-6) x(t) x(t+6)];
12: t(t-117, 1) = x(t+6);
13: end
14: trnData = Data(1:500, :);
15: chkData = Data(501:end, :);
16:
17: fis = creat_fis(...
18; 'sugeno',...
19; 'gaussmf',...
20: {[.5 .5; 0 1.3]'; [.5 .5; 0 1.3]'; [.5 .5; 0 1.3]'; [.5 .5; 0 1.3]'}...
21: );
22:
23: figure(1), clf
24: for i = 1:4
25: subplot(2,2,i)
26: plotmf(fis, 'input', i)
27: end
28:

- 34 -
29: [yhat, fis] = train_anfis(fis, w, t);
30:
31: figure(2), clf
32: subplot(211)
33: plot(yhat, 'b-'), hold on
34: plot(trnData(:, 5), 'r-')
25:
36: subplot(212)
37: plot(yhat' - trnData(:, 5))
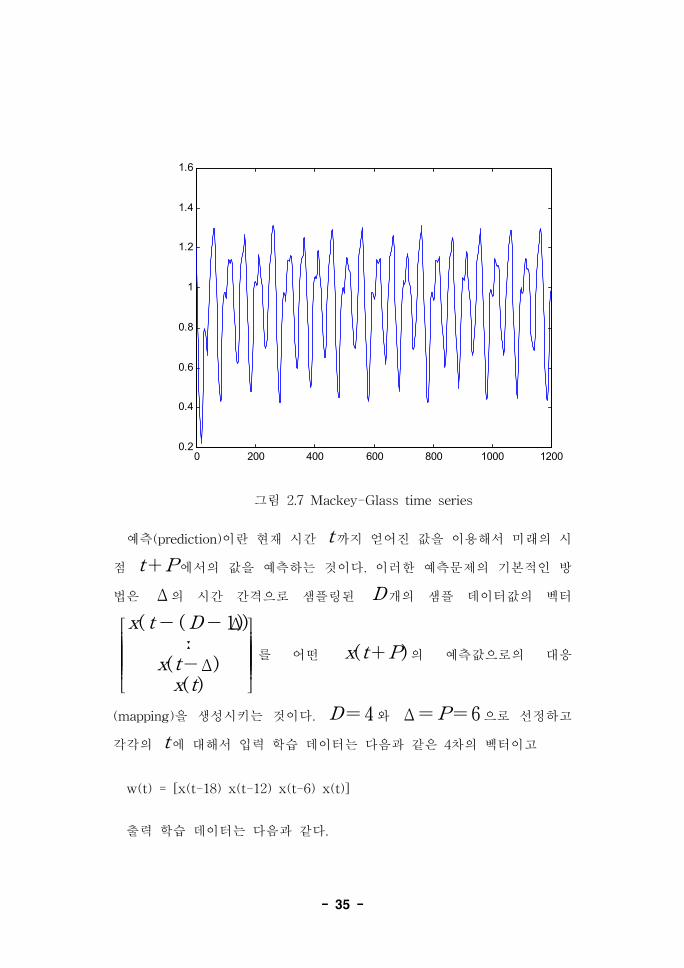
이 예제는 다음의 Mackey-Glass(MG) 시지연 미분방정식으로 생성되는
신호를 ANFIS를 이용해서 예측하는 것이다.
x( t)=0.2x(t-τ)1+x10(t-τ)
-0.1x(t)
이 신호는 수렴하거나 발산하지 않으며 미분 방정식의 해는 초기값에 매
우 민감하다. 이것은 신경망과 퍼지모델링에 있어서 하나의 벤치마크 문제
이다. x(0)= 1.2의 초기값과 τ=17에 대한 이 방정식의 해가
mgdata.var에 저장되어 있다. 이것은 4차의 Runge-Kuttaq방식을 이용하였
으며 3번 줄에서 로딩하여 4, 5번 줄에서 각각 t와 x에 값을 저장하였다. 8
번줄에 의해서 생성되는 그림은 다음과 같다.
- 35 -
0 200 400 600 800 1000 12000.2
0.4
0.6
0.8
1
1.2
1.4
1.6
그림 2.7 Mackey-Glass time series
예측(prediction)이란 현재 시간 t까지 얻어진 값을 이용해서 미래의 시
점 t+P에서의 값을 예측하는 것이다. 이러한 예측문제의 기본적인 방
법은 Δ의 시간 간격으로 샘플링된 D개의 샘플 데이터값의 벡터
x( t- ( D- 1)Δ)ː
x(t-Δ)x(t)
를 어떤 x(t+P)의 예측값으로의 대응
(mapping)을 생성시키는 것이다. D=4와 Δ=P=6으로 선정하고
각각의 t에 대해서 입력 학습 데이터는 다음과 같은 4차의 벡터이고
w(t) = [x(t-18) x(t-12) x(t-6) x(t)]
출력 학습 데이터는 다음과 같다.
- 36 -
s(t) = x(t+6)
위의 w와 s벡터는 10~13번줄에서 생성된다.
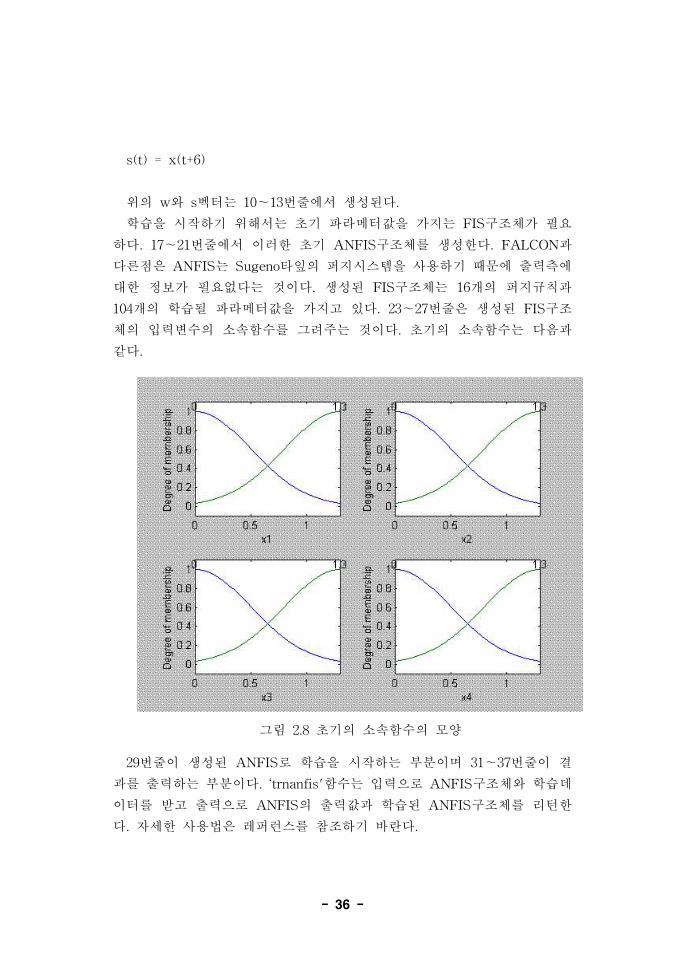
학습을 시작하기 위해서는 초기 파라메터값을 가지는 FIS구조체가 필요
하다. 17~21번줄에서 이러한 초기 ANFIS구조체를 생성한다. FALCON과
다른점은 ANFIS는 Sugeno타잎의 퍼지시스템을 사용하기 때문에 출력측에
대한 정보가 필요없다는 것이다. 생성된 FIS구조체는 16개의 퍼지규칙과
104개의 학습될 파라메터값을 가지고 있다. 23~27번줄은 생성된 FIS구조
체의 입력변수의 소속함수를 그려주는 것이다. 초기의 소속함수는 다음과
같다.
그림 2.8 초기의 소속함수의 모양
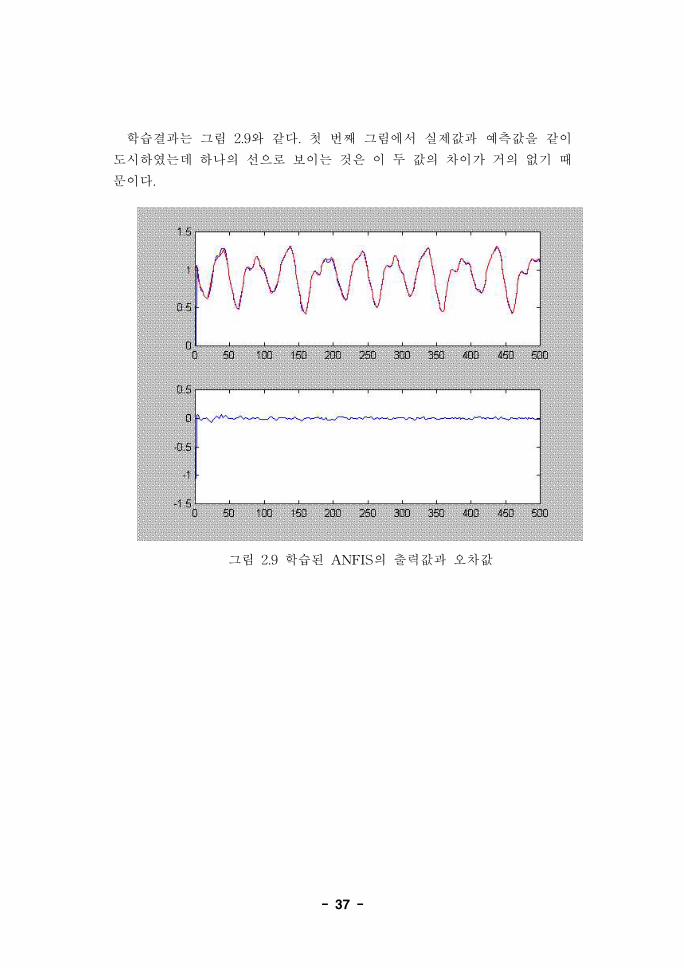
29번줄이 생성된 ANFIS로 학습을 시작하는 부분이며 31~37번줄이 결
과를 출력하는 부분이다. ‘trnanfis'함수는 입력으로 ANFIS구조체와 학습데
이터를 받고 출력으로 ANFIS의 출력값과 학습된 ANFIS구조체를 리턴한
다. 자세한 사용법은 레퍼런스를 참조하기 바란다.
- 37 -
학습결과는 그림 2.9와 같다. 첫 번째 그림에서 실제값과 예측값을 같이
도시하였는데 하나의 선으로 보이는 것은 이 두 값의 차이가 거의 없기 때
문이다.
그림 2.9 학습된 ANFIS의 출력값과 오차값

- 38 -
3.3 FBF(퍼지 Basis Function) Network
또다른 NFC로서 퍼지 기조 함수 네트웤(퍼지 Basis Function Network,
FBFN)이 있는데 Wang과 Mendel[ ]에 의해서 제안된 것이다. FBFN에서
퍼지시스템은 퍼지 기저 함수(퍼지 basis functions. FBFs)의 series
expansion으로 표현되며 이 FBF는 소속함수의 대수적인 중첩이다. FBF표
현식을 기반으로 orthogonal least squares(OLS) 학습 알고리즘이 적절한
퍼지규칙의 개수와 퍼지규칙의 후건부의 파라메터들을 입출력 학숩 데이터
값으로부터 결정한다.
전문가의 언어적인 퍼지 IF-THEN 규칙이 FBF에 의해 바로 해석되므
로 FBFN은 수치와 언어정보를 동일한 형식으로 취합, 합성하는 기초를 제
공하게 된다.
다입력, 단일출력 퍼지 시스템을 고려하자: X⊂Rn→Y∈R. 그리고다음과 같은 M개의 퍼지논리규칙이 있다고 가정하자.
R j: IF x1 is A j
1 AND x2 is A j2 AND … AND xn is A j
n
THEN y is B j
여기서 xi (i=1,2 …,n)은 입력변수이고 y는 출력변수이고 A ji와 B j
i
는 소속함수 μ Aji
(xi)와 μ Bji
(xi)를 가지는 언어항이다(j=1,2,…,M). 또
한 싱글톤(singlton)퍼지화기, 곱추론기(product inference), 무게중심비퍼지
화기(centroid defuzzifier) 그리고 가우시안(Gaussian) 소속함수가 사용되었
다. 따라서 주어진 입력벡터 x= [x1 x2 ⋯ xn]T∈X는 다음과
같은 추론된 비퍼지화 출력을 갖는다.
y=f ( x)=∑M
j=1yj (∏
n
j=1μ A j
i(xi ))
∑M
j=1(∏
n
j=1μ A j
i
(xi ))(2.3.2)

- 39 -
여기서 f :X⊂Rn→R, yj는 소속함수 μ Bj
i(xi)가 최대값이 되는
출력공간 Y에서의 한 점이며 μ Aji(xi)는 가우시안 소속함수로서 다음
과 같이 정의된다.
μ A ji(xi )=a j
iexp {- 12 ( x( 1)
i -m ji
σ ji)2
} (2.3.3)
여기서 a ji , m j
i와 σji는 실수 파라메터이다. ( 0< a j
i≤1)
(2.3.2)로 부터 FBF를 다음과 같이 정의할 수 있다.
y=f ( x)=∏n
j=1μ A j
i
(xi )
∑M
j=1(∏
n
j=1μ A j
i(xi ))
,j=1,2,⋯,M
(2.3.4)여기서 μ Aj
i
(xi )는 (2.3.3)으로 정의되는 가우시안 소속함수이다. 따라
서 (2.3.2)로 정의되는 FIS는 다음과 같은 FBF의 확장으로 기술된다.
f ( x)= pT θ (2.3.5)
여기서 p=
p1
p2
ːpM
, θ=
y1
y2
ː
yM
이다. 다른 말로 (2.3.2)로 정의되
는 퍼지 시스템은 FBF들의 선형 결합(linear combination)으로 표현될 수
있다.
FBFN을 학습시키는데는 두가지 관점이 있다. 먼저 pj( x)의 모든 파
라메터 a ji , m j
i와 σji를 디자인 파라메터라고 본다면 FBFN은 파라메터

- 40 -
에 대해 비선형이다. 따라서 이 경우 Backpropagation과 같은 비선형 최적
화 알고리즘이 사용되게 된다. 이것은 2.1절의 FALCON의 경우와 유사하
게 된다. 반면 pj( x)의 모든 파라메터는 FBFN설계과정에서 고정되어
있다고 가정하면 θ j만이 디자인 파라메터가 된다. 이 경우 (2.3.5)의
f ( x)는 파라메터에 대하여 선형이 되며 매우 효율적인 선형 최적화 예측
방법이 FBFN을 학습시키는데 사용되어질 수 있다. 그 중 본 toolbox에서
는 Gram-Schmidt orthogonal least squares (OLS)알고리즘이 제공된다.
이 알고리즘은 FBF의 적절한 숫자까지 자동적으로 결정하게 된다. 따라서
일종의 hybrid structure-parameter 학습방법이다. 즉 이 방법은 중용한
FBF의 개수는 물론 그에 해당하는 θj까지 찾아주게 된다.
FALCON에서 다루었던 예제를 위에서 소개한 알고리즘을 이용하여 구
현하여 보자. 학습 데이터와 초기의 퍼지시스템은 다음과 같이 결정된다.
clear all
fis = create_fis(...
'mamdani',...
'gaussmf',...
{[.5 .5 .5 .5; -1.5 -0.7 .7 1.5]'; [.5 .5 .5 .5;-1 -0.3 0.3 1;]'},...
'gaussmf',...
{[.5 .5 .5 .5 .5; -1.5 -0.7 0 0.7 1.5]'});
uk_1 = 0;
yk_1 = 0;
disp('Creating data sequences...')
data = [];
y = zeros(200, 1);
for k = 1:200
u(k) = sin(2*pi*k/100);
y(k) = yk_1/(1+yk_1^2) + uk_1^3;
data = [data; yk_1 uk_1];

- 41 -
uk_1 = u(k);
yk_1 = y(k);
end
disp('self-organizing...')
fis = self_organizing3(fis, data, y);
save fbfdata.mat fis data y
위에서 초기 퍼지시스템을 생성하는데 self_organizing()함수를 이용하였
음을 알 수있다. 이제 위에서 만들어진 데이터를 이용하여 OLS학습을 시
키는 예제 프로그램은 다음과 같다.
1: clear all, clf
2: load fbfdata.mat
3:
4: disp('computing FBFs...')
5: P = getfbfs(fis, data);
6: [theta, ind] = OLS(P, y, 8)
7: yhat = fbf_out(P, theta, ind);
8:
9: plot(y, 'b'), hold on
10: plot(yhat, 'r'), grid on
5번 줄에서 getfbfs()함수를 이용하여 P행렬을 얻는다. P행렬은 다음과
같은 구조로 이루어져 있다.
P=
p1(1) p2(1) ⋯ pM(1)p1(2) p2(2) ⋯ pM(2)⋯ ⋯ ⋯ ⋯
p1(N) p2(N) ⋯ pM(N)
=
pT(1)
pT(2)
⋯
pT(N)
- 42 -
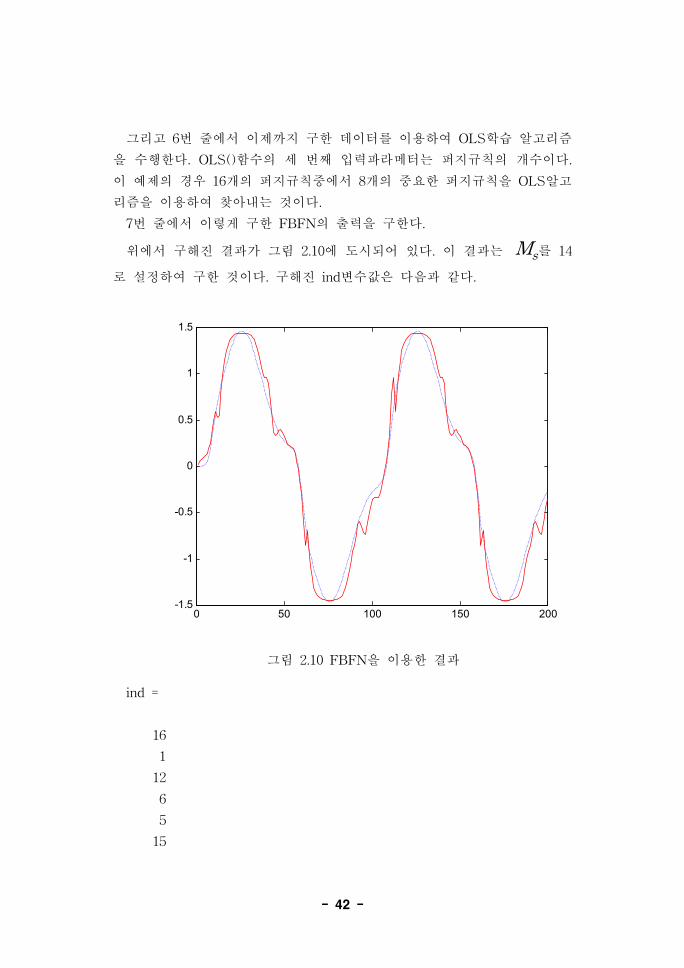
그리고 6번 줄에서 이제까지 구한 데이터를 이용하여 OLS학습 알고리즘
을 수행한다. OLS()함수의 세 번째 입력파라메터는 퍼지규칙의 개수이다.
이 예제의 경우 16개의 퍼지규칙중에서 8개의 중요한 퍼지규칙을 OLS알고
리즘을 이용하여 찾아내는 것이다.
7번 줄에서 이렇게 구한 FBFN의 출력을 구한다.
위에서 구해진 결과가 그림 2.10에 도시되어 있다. 이 결과는 Ms를 14
로 설정하여 구한 것이다. 구해진 ind변수값은 다음과 같다.
0 50 100 150 200-1.5
-1
-0.5
0
0.5
1
1.5
그림 2.10 FBFN을 이용한 결과
ind =
16
1
12
6
5
15

- 43 -
11
2
10
8
9
3
14
13
create_fis함수내에서는 입력변수 공간을 격자 분할(grid partition)하여
전건부를 생성한다.(레퍼런스 참조) 즉 다음과 같다.
ruleList =
Columns 1 through 12
1 2 3 4 1 2 3 4 1 2 3
4
1 1 1 1 2 2 2 2 3 3 3
3
Columns 13 through 16
1 2 3 4
4 4 4 4
위에서 보인 ind변수의 내용은 이렇게 격자분할된 전건부중 16번째 규칙
이 예제 시스템을 동정하는데 가장 중요하다는 것을 보여준다. 그 다음으
로 첫 번째 규칙이 중요하고 마지막(Ms번째) 규칙으로 13번째 규칙이 선
정되었다.

- 44 -
3.4 직접비교를 이용한 퍼지규칙 추출
이 절에서는 Wang과 Mendel[ ]에 의해서 제안된 입출력 학습 데이터를
이용한 간단하고 직관적인 퍼지규칙 생성방법을 알아본다. 이 방법은 시간
이 많이 소모되는 학습을 지양한 온라인 빌드업(on-line bulid-up) 과정이
다. 다음과 같은 입출력 데이터쌍이 주어졌다고 가정하자.
( x( 1)1 , x( 1)
2 ; y ( 1)), ( x( 2)
1 , x( 2)2 ; y ( 2)
) …
여기서 x1과 x2는 입력이고 y는 출력이다. 이러한 원하는 입출력
데이터를부터 퍼지 규칙들의 집합을 만들고 이러한 퍼지 규칙으로부터
f:(x1,x2)→y의 대응을 결정하는 방법은 다음과 같은 세 단계로 이루
어 진다.
▶ 1단계 : 입출력 공간을 퍼지 구간으로 분할한다.
x1과 x2 그리고 y의 정의구역(domain interval)이 각각
[x+1 ,x-
1 ] , [x+2 ,x-
2 ] , [y+,y-]라고 하자. 각각의 정의구역을
N개의 구역으로 나누고 각 구간에 퍼지 소속함수를 지정한다. 그림 _._에
예제가 주어져 있다. 예제에서 x1은 5구간으로, x2는 4구간으로 그리고
y는 5구간으로 나뉘어져 있다. 소속함수의 모양은 삼각형(triangular
membership)이다. 이것은 한 예제일 뿐이므로 다른 모양의 소속함수와 다
른 숫자로의 구간 나눔도 물론 가능하다.
▶ 2단계 : 주어진 데이터로부터 파지규칙을 생성한다.
먼저 주어진 데이터 x( i)1 , x
( i)2 , y
( i)에서 급수(degree)를 결정한다. 예
로서 그림 _._의 x( 1)1 는 B1에서 0.8값을 B2에서 0.2값을 그리고 다른 모
든 구간에서 0값을 갖는다. 유사하게 x( 2)2 는 CE에서 1값을 그리고 다른
구간에서도는 모두 0값을 갖는다.

- 45 -
그 다음으로 x( 1)1 , x( 1 )
2 , y ( 1 )에 최대의 급수를 갖는 소속함수를 지
정한다. 예를 들면 x( 1)1 은 B1, x( 2 )
2 는 CE를 지정한다.
마지막으로 한 쌍의 입출력 데이터로부터 한 개의 규칙을 생성한다. 예
를 들면
( x( 1)1 , x( 1)
2 ; y ( 1)) ⇒ [ x( 1)
1 (0.8 in B1), x( 1)2 (0.7 in S1), y ( 1)
(0.9 in CE)]⇒ rule 1;
R1 : IF x1 is B1 AND x2 is S1, THEN y is CE;
( x( 2)1 , x( 2)
2 ; y ( 2)) ⇒ [ x( 2)
1 (0.6 in B1), x( 2 )2 (1 in CE), y ( 2)
(0.7 in B1)]⇒ rule 2;
R2 : IF x1 is B1 AND x2 is CE, THEN y is B1;
▶ 3 단계 : 각각의 규칙에 급수를 지정한다.
규칙의 수를 줄이기 위해서 그리고 IF부분(전건부)는 같은데 THEN부분
(후건부)가 다른 규칙들이 있는 경우의 해결책으로서 각각의 데이터 쌍에
서 생성된 퍼지규칙에 급수를 지정하고 전건부가 같은 규칙들 중에서 죄대
의 급수를 가지는 규칙만을 사용한다.
다음과 같은 생성방법이 각각의 규칙에 급수를 지정하느데 쓰인다. :
D로 표기되는 “IF x1 is A and x2 is B"라는 규칙의 급수는 다음과
같이 정의된다.
D(rule)=μA(x1 )μB(x2 )μ c(y)
예를 들어 규칙 1은 다음과 같은 급수를 갖는다.
D(rule 1) = μA(x1 )μB(x2 )μ c(y)=0.8×0.7×0.9=0.504
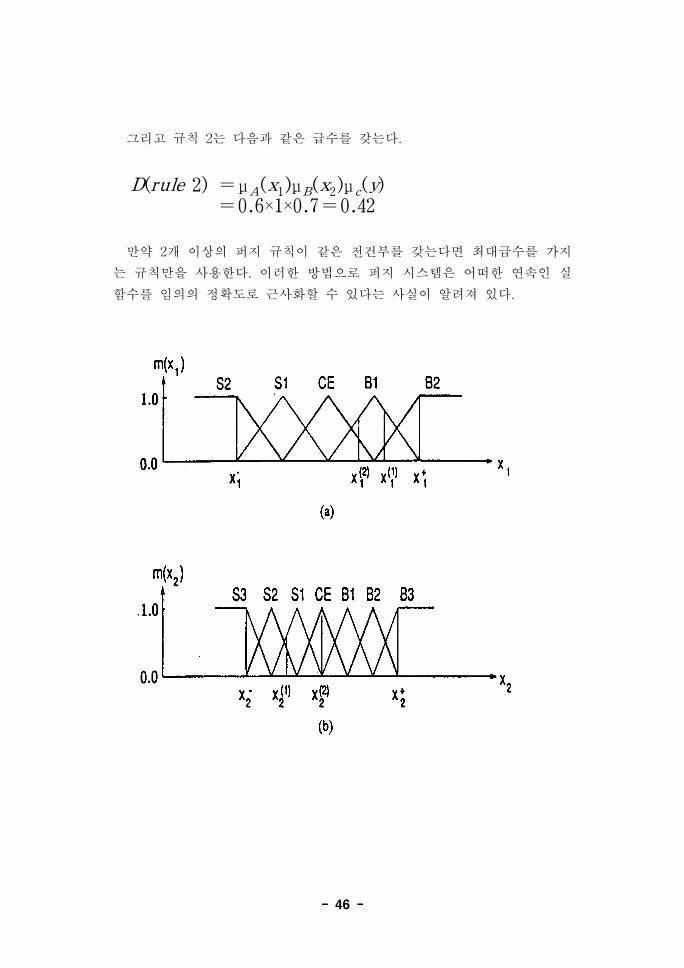
- 46 -
그리고 규칙 2는 다음과 같은 급수를 갖는다.
D(rule 2) =μA(x1)μB(x2)μ c(y)=0.6×1×0.7=0.42
만약 2개 이상의 퍼지 규칙이 같은 전건부를 갖는다면 최대급수를 가지
는 규칙만을 사용한다. 이러한 방법으로 퍼지 시스템은 어떠한 연속인 실
함수를 임의의 정확도로 근사화할 수 있다는 사실이 알려져 있다.

- 47 -
이 방법을 구현하기 위해서 셈툴의 툴박스에 ruleext()라는 함수가 마련
되어 있다.
CEMTool>>fis = ruleext(fis,data,y)
이 함수의 입력변수는 fis 변수와 입력데이터(data), 그리고 원하는 출력
데이터(yd)이다. fis는 초기에 생성된 FIS 구조체이고 data는 FIS로의 입력
데이터로서 다음과 같은 구조를 가진다.
x11 x12 ⋯ x1m
x21 x22 ⋯ x2m
ː ː ːːxn1 xn2 ⋯ xnm
여기서 m은 FIS의 입력 변수의 개수를, n은 입력벡터의 개수를 나타낸
다. 그리고 yd는 원하는 출력벡터로서 길이(length)는 m이어야 한다. 출력
변수는 fis로서 학습된 결과를 되돌린다.
앞에서 사용한 예제에 이 방법을 적용한 예는 다음과 같다.
1: clear all
2:
3: data = [];
4: uk_1 = 0;

- 48 -
5: yk_1 = 0;
6:
7: y = zeros(110,1);
8: u = zeros(110,1);
9:
10: for (k = 1; k<=110; k=k+1) {
11: u(k) = sin(2*pi*k/100);
12: y(k) = yk_1/(1+yk_1^2) + uk_1^3;
13:
14: data = [data; yk_1 uk_1];
15:
16: uk_1 = u(k);
17: yk_1 = y(k);
18: }
19: L=5;
20: fis = genfis([data y], 1, 4, "gaussmf", 5, "gaussmf");
21: fis = ruleext(fis,data,y)
22:
23: yhat = evalfis(fis, data);
24: plot(1:110, yhat);
아래에 계산된 fis문자열중 퍼지규칙에 대한 부분을 결과가 도시되어 있
다. 9개의 규칙이 추출된 것을 알 수 있다.
[Rules]
2 2,2 (1):1
2 3,3 (1):1
3 3,3 (1):1
4 4,5 (1):1
4 3,4 (1):1
3 2,3 (1):1
2 1,2 (1):1
1 1,1 (1):1

- 49 -
1 2,2 (1):1

- 50 -
Reference
genfis
getfis
setfis
selforg
suplearn
train_anfis
getFBFs
OLS
plotmf
fplot
fisout

- 51 -
genfis
퍼지 구조체를 생성한다.
fis = genfis(data)
fis = genfis(data, fistype, numInMFs, InMFtype)
fis = genfis(data, fistype, numInMFs, InMFtype, numOutMFs,
OutMFtype)
주어진 데이터를 이용하여 퍼지구조체(FIS)를 생성한다. 입력변수들은
다음과 같다.
․ data: 입출력 데이터 쌍으로서 다음과 같은 구조를 갖는다.
x11 x12 ⋯ x1m yd1
x21 x22 ⋯ x2m yd2
ː ː ːːxn1 xn2 ⋯ xnm ydn
여기서 {xi1 xi2 ⋯ x∈}은 i번째 입력 데이터 쌍을 나타내며 ydi
는 i번째 출력을 나타낸다.
․ fistype: FIS의 종류를 나타내는 상수로서 1이면 Mamdani
type을 2면 Sugeno type을 가리킨다.
․ InMFtype/OutMFtype: 입력변수/출력변수의 소속함수의
종류를 나타내는 문자열
이 함수는 mamdan타잎과 sugeno타잎의 FIS를 모두 생성할 수 있다. 만
약 type이 sugeno라면 퍼지규칙의 후건부는 선형함수이므로 이것에 대한
정보는 필요없게 된다. 즉 'numOutMFs', 'OutMFtype'값은 쓰이지 않는
다.

- 52 -
또한 data만으로도 FIS를 생성할 수 있으며 이 경우 나머지 파라메터의
지정치(default value)는 다음과 같다.
fistype = 1
numInMFs = 2
InMFtype = “gaussmf"
numOutMF = 2
OutMFtype = "gaussmf"
fis = genfis([data y], 1, 4, "gaussmf", 5, "gaussmf")
MATLAB의 퍼지 toolbox의 genfis1, genfis2함수

- 53 -
selforg
입/출력 소속함수의 파라미터와 퍼지규칙을 주어진 데이터를 이용하여
학습시킨다.
fis = selforg(fis, data, yd)
주어진 데어터를 이용하여 fis의 입/출력 파라메터를 학습․결정하고, 퍼
지규칙을 생성한다. 입력변수들은 다음과 같다.
․ fis : 초기에 생성된 FIS 구조체
․ data : FIS로의 입력 데이터로서 다음과 같은 구조를 가진다.
x11 x12 ⋯ x1m
x21 x22 ⋯ x2m
ː ː ːːxn1 xn2 ⋯ xnm
여기서 m은 FIS의 입력 변수의 개수를, n은 입력벡터의 개수를 나타낸
다.
․ yd : 원하는 출력벡터로서 길이(length)는 m이어야 한다. 출력변수는
fis로서 학습된 결과를 되돌린다.
falcon = self_organizing(falcon, data, y);

- 54 -
suplearn
입/출력 소속함수의 파라미터를 정밀하게 학습시킨다.
fis = suplearn(fis, data, yd)
주어진 데어터를 이용하여 fis의 입/출력 소속함수의 파라메터를 정밀하
게 학습․결정한다. 학습은 gradient decent방법을 이용한다. 입력변수들은
다음과 같다.
․ fis: 초기에 생성된 FIS 구조체
․ data: FIS로의 입력 데이터로서 다음과 같은 구조를 가진다.
x11 x12 ⋯ x1m
x21 x22 ⋯ x2m
ː ː ːːxn1 xn2 ⋯ xnm
여기서 m은 FIS의 입력 변수의 개수를, n은 입력벡터의 개수를 나타낸
다.
․ yd: 원하는 출력벡터로서 길이(length)는 m이어야 한다.
출력변수는 fis로서 학습된 결과를 되돌린다.
falcon = suplearn(falcon, data, y);

- 55 -
train_anfis
ANFIS를 학습시킨다.
[yhat, fis] = train_anfis(fis, data, yd)
주어진 데어터를 이용하여 ANFIS의 입력 소속함수의 파라메터와 퍼지
규칙의 후건부의 선형함수의 계수를 학습․결정한다. 학습은 hybrid방법을
이용한다. 입력변수들은 다음과 같다.
․ fis: 초기에 생성된 ANFIS 구조체
․ data: FIS로의 입력 데이터로서 다음과 같은 구조를 가진다.
x11 x12 ⋯ x1m
x21 x22 ⋯ x2m
ː ː ːːxn1 xn2 ⋯ xnm
여기서 m은 FIS의 입력 변수의 개수를, n은 입력벡터의 개수를 나타낸
다.
․ yd: 원하는 출력벡터로서 길이(length)는 m이어야 한다.
출력변수는 fis로서 학습된 결과를 되돌리며 yhat벡터를 생성하여
ANFIS의 출력값을 되졸린다.
[yhat, fis] = train_anfis(fis, w, t);

- 56 -
plotmf
입․출력 소속함수를 도시한다
[x0,y0]=plotmf(fis,varType,varIndex);
기술
fuzzy inference system에서 사용되는 variable의 membership
function을 plot해준다.
[x0,y0]=plotmf(fis,"Input",1)

- 57 -
getFBFs
주어진 퍼지구조체를 이용하여 퍼지 기조 함수 행렬을 생성한다.
P = getfbfs(fis, data)
․ fis: 초기에 생성된 ANFIS 구조체
․ data: FIS로의 입력 데이터로서 다음과 같은 구조를 가진다.
x11 x12 ⋯ x1m
x21 x22 ⋯ x2m
ː ː ːːxn1 xn2 ⋯ xnm
여기서 m은 FIS의 입력 변수의 개수를, n은 입력벡터의 개수를 나타낸
다.

- 58 -
getfis
주어진 퍼지구조체를 이용하여 퍼지구조체의 데이터를 추출한다.
․fisdat=getfbfs(fis)는 FIS의 일반적인 정보를 리턴한다. fisdat=getfis(fis,
"fisprop")는 “fisprop"로 지정되는 fis의 현재값을 리턴한다. "fisprop"는 다
음과 같은 값을 가진다.
Name
Type
NumInputs
NumOutputs
NumRules
AndMethod
OrMethod
ImpMethod
AggMethod
DefuzzMethod
․fisdat=(fis,"vartype",varIndex)는 지정된 FIS의 변수에 대한 일반적인 정보
를 리턴한다. "vartype"은 “Input", "Output", "Rules"중 하나이다.
․fiddat=getfis(fis,"varType",varIndex,"varProp")은 “varProp”과 varIndex로
지정된 변수의 특정값을 리턴한다. “varProp"는 다음과 같은 값을 가진다.
Name
Range
NumMFs
․fisdat=getfis(fis,"varType",varIndex,"MF"',mfIndex)은 지정된 FIS의 소속
함수에 대한 일반적인 정보의 리스트를 리턴한다.
․fisdat=getfis(fis,"varType",varIndex,"MF",mfIndex,"mfProp")은 “mfProp"로

- 59 -
지정된 소속함수의 특정값을 리턴한다. "mfProp"는 다음과 같은 값을 갖는
다.
Name
Type
Params
․fisdat=getfis(fis,"Rules",varIndex,"varProp"')은 지정된 퍼지규칙의 소속함
수에 대한 정보를 리턴한다. 여기서 “varProp"는 다음과 같은 값을 갖는다.
antecedent
consequent
SETFIS and SHOWFIS.

- 60 -
OLS
주어진 퍼지기조함수행렬로 Orthogonal Least Squares 학습을 시킨다.
[theta, ind] = OLS(P, y, 8)

- 61 -
fplot
함수와 구간을 지정하면 그 구간에서의 함수값을 도시한
다.
[x0, y0] = fplot ("fun_name",limits, params)
[x0, y0] = fplot ("sin",[0 2*pi])
; sin(x)를 x-axis의 범위가 0~2*pi까지 도시한다.

- 62 -
fisout
주어진 퍼지기조함수네크웍의 출력을 생성한다.
yhat = fisout(P, theta, ind)

- 63 -
Membership Functions.
- Difference of two sigmoid membership functions.
y = dsigmf(x,params)
y = dsigmf(x,[a1 c1 a2 c2])
이 sigmoid 곡선은 다음식에서 주어진 a와 c 파라미터에
의해 결정된다.
f(x;a,c)=1
1+e -a ( x- c)
disigmf는 f 1(x ;a 1,c 1)-f 2(x ;a 2,c 2)와같이 단순히 다른
두 개의 곡선의 차로 표현된다.
- Two-sided Gaussian curve membership function.
y = gauss2mf(x,params)
y = gauss2mf(x,[sig1 c1 sig2 c2])
Gaussian 곡선은 다음 식에서 주어지는 sig 와 c의 두
파라미터에 의해 결정된다.
f(x ;σ,c )= e- (x- c) 2
2σ 2
gauss2mf는 단지 두 개의 다른 곡선을 병합시킨 것으로,
c1과 c2사이의 영역에서는 1의 값을 가지게 된다.
파라미터들은 다음과 같은 순서로 정의한다.
[sig1, c1, sig2, c2] ,c1<c2

- 64 -
- Gaussian curve membership function.
y = gaussmf(x, params)
y = gaussmf(x, [sig c])
Gaussian 곡선은 다음식에서 주어진 sig와 c라는 파라미
터에 의해 결정된다.
f(x ;σ,c )= e- (x- c) 2
2σ 2
- Generalized bell curve membership function.
y = gbellmf(x, params)
y = gbellmf(x, [a, b])
일반화된 종형곡선은 다음식에서 주어진 a와 b 그리고 c
의 세 파라미터들에의해 결정된다.
f(x;a,b,c)=1
1+ | x-ca
2b
|여기에서 b 파라미터는 대게 양의 값을 가지며, 파라미
터 c는 곡선의 중심을 나타내어준다.
- Pi-shaped curve membership function.
y = pimf(x, params)
y = pimf(x, [a, b, c, d])

- 65 -
Spline을 기반으로한 이 곡선은 곡선의 모양에의해 이름
이 붙여진다. a와 d 파라미터들은 곡선의 “feet" 위치를
나타내며, b와 c파라미터들은 곡선의 ”shoulder"의 위치를
나타낸다.
- Product of two sigmoid membership functions.
y = psigmf(x, params)
y = psigmf(x, [a1 c1 a2 c2])
Sigmoid 곡선은 다음식에서 주어지는 a와 c 두 파라미
터에의해 결정된다.
f(x;a,c)=1
1+e -a( x- c)
Psigmf는 두 개의 다른 sigmoid 곡선들의 단순 곱으로
나타내어진다.
- S-shaped curve membership function.
y = smf(x, params)
y = smf(x, [a b])
Spline을 기반으로한 이 곡선은 그 모양에의해 이름이
붙여졌다 두 개의 파라미터 a와 b는 곡선에서의 경사의
시작위치와 끝위치를 나타내어준다.
- Sigmoid curve membership function.
y = sigmf(x, params)

- 66 -
y = sigmf(x, [a c])
이 sigmoid 곡선은 다음식에서 주어진 a와 c 파라미터에
의해 결정된다.
f(x;a,c)=1
1+e -a ( x- c)
- Trapezoidal membership function.
y = trapmf(x, parms)
y = trapmf(x, [a b c d])
사다리꼴 곡선은 다음식에서 주어지는 네 개의 파라미터
들에의해 결정된다.
f(x;a,b,c,d )=
0 x≤ax-ab-a
a≤x≤b
1 b≤x≤cd-xd-c
c≤x≤d
0 d≤x
파라미터 a와 b는 사다리꼴의 “feet" 위치를 표시하게되
며, c와 d는 ”shoulder"의 위치를 표시하게된다.
- Triangular membership function.
y = trimf(x, params)
y = trimf(x, [a b c])
삼각형 곡선은 다음식에서 주어지는 세 개의 파라미터들
에의해 결정된다.

- 67 -
f(x;a,b,c )=
0 x≤ax-ab-a
a≤x≤b
c-xc-b
b≤x≤c
0 c≤x
파라미터 a와 c는 삼각형 곡선의 “feet"의 위치를 표시하
며, b는곡선의 첨두점의 위치를 표시한다.
- Z-shaped curve membership function.
y = zmf(x, params)
y = zmf(x, [a b])
Spline에 기반된 함수는 그 형태에따라 이름이 불리워진
다. 파라미터 a와 b는 곡선에서의 경사면이 시작되는 지
점과 끝지점의 위치를 나타내어준다.


![พรปีใหม่ - WordPress.com · ¢ ¢ ¢ ¢ Fl. Cl. Alto Sax. Ten. Sax. Tpt. Hn. Tbn. Euph. Tba. Dr. Gtr. Bass Pno. Voice [31] 31 mf mf mf mf mf mf mf F G F G F G C F](https://img.pdfslide.tips/doc/110x75/602730e009222f5192711bf8/aaaaafaaa-fl-cl-alto-sax-ten-sax-tpt-hn-tbn.jpg)


























![측정 현미경 MF 시리즈 / MF-U14003_16]MF-MF-U(K... · 2021. 1. 18. · 또한, mf 시리즈용 대물렌즈에는 jis 규격을 뛰어넘는 축 미쓰도요 독자 규격에](https://img.pdfslide.tips/doc/110x75/60e1ea8ffedf2f03760c771d/-ee-mf-oee-mf-u-1400316mf-mf-uk-2021-1-18-eoe.jpg)