Embed Size (px)
Citation preview

Kỷ yếu Hội nghị KHCN Quốc gia lần thứ XI về Nghiên cứu cơ bản và ứng dụng Công nghệ thông tin (FAIR); Hà Nội, ngày 09-10/8/2018
DOI: 10.15625/vap.2018.00022
ĐÓNG GÓP CỦA ĐẶC TRƯNG VĂN BẢN TRONG BÀI TOÁN PHÂN LỚP ẢNH
Hà Thị Phương Anh1, Phạm Thế Phi
2, Đỗ Thanh Nghị
2
1 Khoa Công nghệ thông tin, Trường Đại học Bạc Liêu 2 Khoa Công nghệ thông tin & Truyền thông, Trường Đại học Cần Thơ
[email protected], [email protected], [email protected]
TÓM TẮT: Trong bài viết này, chúng tôi đề xuất phương pháp phân lớp ảnh kết hợp các bộ phân lớp dựa trên đặc trưng ảnh và đặc
trưng văn bản ở bộ phân lớp thứ ba sử dụng giải thuật hồi quy logistic. Đặc trưng văn bản sẽ được xây dựng dựa trên các văn bản
đi kèm với ảnh, các bức ảnh này là ảnh láng giềng gần nhất với ảnh đầu vào trong tập ảnh chuẩn. Các đặc trưng ảnh được trích
chọn với các phương pháp khác nhau để xác định phương pháp phù hợp nhất. Kết quả thực nghiệm trên tập dữ liệu hình ảnh di sản
văn hóa phi vật thể cho thấy phương pháp được đề xuất đã cải thiện được hiệu quả phân lớp ảnh, đặc biệt là đối với những đặc
trưng ảnh tốt và những lớp có số lượng ảnh tương đối và không bị nhiễu.
Từ khóa: Phân lớp ảnh, đặc trưng ảnh, đặc trưng văn bản, hồi quy logistic.
I. GIỚI THIỆU
Một trong những nhiệm vụ quan trọng hiện nay trong lĩnh vực thị giác máy tính đó là phân lớp đối tượng. Phân
lớp đối tượng là một nhiệm vụ dễ dàng cho con người nhưng lại là một vấn đề khá phức tạp đối với máy học, đặc biệt
là phân lớp đối tượng trong ảnh. Hiện nay, đã có nhiều nghiên cứu về lĩnh vực nhận dạng và phân lớp ảnh như nghiên
cứu của Torralba [2] về nhận dạng đối tượng trong ảnh có kích thước nhỏ 32x32 pixels dùng phương pháp trích đặc
trưng SIFT; nghiên cứu của Đỗ Thanh Nghị [4] về phân lớp ảnh với giải thuật giảm gradient ngẫu nhiên đa lớp dựa vào
phương pháp biểu diễn ảnh bằng đặc trưng SIFT và mô hình túi từ. Ngoài ra, còn có các nghiên cứu khác về lĩnh vực
này [6, 7, 14, 16] sử dụng cách tiếp cận rút trích đặc trưng dựa trên phát hiện của các điểm, màu sắc, kết cấu, tổ chức
đồ. Các nghiên cứu này phần lớn tập trung vào quá trình phân lớp dựa vào các đặc trưng cấp thấp như màu sắc, kết cấu,
SIFT,... Nếu như chúng ta có hàng triệu bức ảnh trong tập huấn luyện thì những đặc trưng này sẽ có ý nghĩa, nhưng
trong thực tế thì việc thu thập hàng triệu ảnh là một vấn đề vô cùng khó khăn và tốn kém về mặt chi phí, vì thế nếu tập
dữ liệu không đủ lớn thì nó có thể gây khó khăn trong vấn đề phân khúc các đối tượng trong ảnh.
Trong tình huống khác, ở đó chúng ta có sẵn một số lượng tương đối các bức ảnh đã được gán nhãn, đồng thời
có các văn bản đi kèm với chúng, các văn bản này có thể sẽ cung cấp cho chúng ta thêm thông tin để phân tích hình
ảnh. Khi đó, những đặc trưng cấp thấp được rút trích từ ảnh kết hợp với thông tin văn bản đi kèm có thể sẽ đủ làm đại
diện biểu diễn cho ảnh. Như vậy, các văn bản đi kèm sẽ hỗ trợ cho việc phân lớp đối tượng trong ảnh chính xác và dễ
dàng hơn [1, 15].
Ý tưởng chính trong bài viết này đó là chúng tôi sẽ tiến hành xây dựng các bộ phân lớp ảnh dựa trên các đặc
trưng ảnh khác nhau và các bộ phân lớp văn bản dựa trên đặc trưng văn bản đại diện cho ảnh. Trọng tâm là xây dựng
bộ phân lớp thứ ba kết hợp các giá trị tin cậy của hai bộ phân lớp trên sử dụng giải thuật hồi quy logistic (Hình 1). Kết
quả thực nghiệm trên tập dữ liệu di sản văn hóa phi vật thể cho thấy các đặc trưng văn bản khi đưa vào các mô hình
phân lớp kết hợp với các bộ phân lớp ảnh đã giúp cải thiện được hiệu quả phân lớp.
Phần tiếp theo của bài viết được tổ chức như sau: phần II trình bày về tập dữ liệu hình ảnh văn hóa phi vật thể,
phần III trình bày các phương pháp rút trích đặc trưng ảnh, phần IV trình bày phương pháp xây dựng đặc trưng văn
bản, phần V giới thiệu về các giải thuật phân lớp, phần VI trình bày kết quả thực nghiệm, phần VII trình bày kết luận
và hướng phát triển.
Hình 1. Quy trình phân lớp ảnh truy vấn sử dụng bộ phân lớp kết hợp các bộ phân lớp ảnh và bộ phân lớp văn bản sử dụng
giải thuật hồi quy logistic
Các bộ phân lớp
văn bản
Ảnh truy
vấn
Trích đặc trưng
ảnh
Các bộ phân
lớp ảnh
Trích lọc k ảnh
láng giềng gần
nhất
Đặc trưng
văn bản Nhãn Tập ảnh
chuẩn
Kết hợp các
bộ phân lớp

Hà Thị Phương Anh, Phạm Thế Phi, Đỗ Thanh Nghị 169
II. CHUẨN BỊ TẬP DỮ LIỆU
Tập dữ liệu thực nghiệm chúng tôi sử dụng là tập hình ảnh di sản văn hóa phi vật thể khu vực Đồng bằng sông
Cửu Long được thu thập từ Internet, gồm 17 di sản (17 lớp) đó là: 1- Đờn ca tài tử Nam Bộ; 2- Nghệ thuật Chầm Riêng
Chà pây của người Khmer; 3- Nghề dệt chiếu; 4- Lễ hội Cúng biển Mỹ Long; 5- Nghệ thuật sân khấu Dù Kê của người
Khmer; 6- Lễ hội Ok Om Bok của người Khmer; 7- Lễ hội miếu Bà Chúa Xứ Núi Sam; 8- Đại lễ Kỳ yên đình Tân
Phước; 9- Lễ hội vía Bà Ngũ Hành; 10- Lễ làm chay; 11- Nghề đóng xuồng ghe Long Hậu; 12- Nghề dệt chiếu lác; 13-
Tục cúng việc lề; 14- Hội đua bò Bảy Núi; 15- Lễ hội Nghinh Ông; 16- Lễ hội Trương Định; 17- Văn hóa Chợ nổi Cái
Răng (xem Hình 2).
Hình 2. Hình ảnh minh họa của 17 di sản văn hóa phi vật thể (17 lớp)
Tập dữ liệu ảnh này được thu thập từ các trang Internet bằng cách sử dụng công cụ thu thập dữ liệu tự động
Web Crawler, chúng tôi xử lý dữ liệu thu thập được bằng cách đưa đầu vào để thu thập ảnh là tên của từng di sản. Tập
ảnh thu thập được có ảnh và văn bản mô tả đi kèm, văn bản này là chú thích của chính bức ảnh đó, mỗi văn bản có
trung bình khoảng 10 từ. Số lượng ảnh ở mỗi di sản không cố định tùy vào công cụ thu thập được. Vấn đề được đặt ra
ở đây là tập ảnh thu thập được rất phức tạp và bị nhiễu. Chúng tôi tiến hành tính toán độ tương đồng của các ảnh trong
cùng một lớp và chọn lọc lại tập ảnh ít hơn và chất lượng hơn, số lượng ảnh ở mỗi lớp sẽ không giống nhau.
Ngoài ra, chúng tôi sẽ lọc từ tập ảnh thu thập được mỗi lớp 50 ảnh có hình ảnh và văn bản mô tả đi kèm chính
xác nhất, tập ảnh này gọi là tập ảnh chuẩn để xây dựng các đặc trưng văn bản cho ảnh huấn luyện và ảnh truy vấn, gồm
có 820 ảnh. Tập văn bản của các ảnh này sẽ góp phần xây dựng các đặc trưng văn bản hạn chế nhiễu, giúp cho các đặc
trưng văn bản có ý nghĩa hơn.
III. RÚT TRÍCH ĐẶC TRƯNG ẢNH
Chúng tôi sử dụng 4 đặc trưng ảnh khác nhau để tìm ảnh láng giềng và huấn luyện các mô hình phân lớp.
3.1. Đặc trưng màu sắc Color
Lược đồ màu của ảnh đại diện cho sự phân bố của các thành phần màu sắc trong hình ảnh đó [8]. Để trích được
đặc trưng màu sắc, mỗi ảnh được tiền xử lý và rời rạc hóa từng điểm ảnh. Mỗi điểm ảnh sẽ nhận giá trị từ 1 đến 512 và
phân vào 8 bin tương ứng. Mỗi ảnh đầu vào, sau khi trích đặc trưng màu sắc, sẽ thu được véctơ đặc trưng là sự kết hợp
của ba kênh màu Red, Green, Blue (RGB). Vậy mỗi ảnh được biểu diễn dưới dạng véctơ có 8*8*8=512 chiều.
3.2. Đặc trưng mô tả toàn cục GIST
Để trích được đặc trưng mô tả toàn cục GIST [10], mỗi ảnh được tiền xử lý và đưa về dạng lưới 4x4 các tổ chức
đồ với 8 hướng, các biểu đồ theo hướng sẽ được rút trích tương ứng. Nguyên lý trích đặc trưng dựa vào phép biến đổi
Gabor theo các hướng và tần số khác nhau. Đặc trưng mô tả được biểu diễn dưới dạng một véctơ được tính toán từ kết
quả của việc áp dụng bộ lọc Gabor lên ảnh. Mỗi ảnh sau khi trích đặc trưng GIST, thu được bộ mô tả 960 chiều.
3.3. Đặc trưng HOG
Lược đồ gradient được tính toán dựa trên thông tin về hướng và cường độ biến thiên màu/mức xám tại mỗi vùng
trên ảnh [9]. Ảnh đầu vào được tiền xử lý sau đó chuẩn hóa Gamma và Colour. Chia ảnh đầu vào thành 4x4 bin với
kích thước mỗi tổ chức đồ là 8x8. Sau đó chia không gian hướng biến thiên Gradient thành 4x4 bin. Giá trị mỗi bin
được định lượng bởi tổng cường độ biến thiên của các pixel thuộc về bin đó. Cuối cùng tính véctơ đặc trưng cho ảnh, ở
đây mỗi cửa sổ được thiết lập là một khối. Như vậy ảnh sau khi trích đặc trưng HOG, thu được véctơ 256 chiều.

170 ĐÓNG GÓP CỦA ĐẶC TRƯNG VĂN BẢN TRONG BÀI TOÁN PHÂN LỚP ẢNH
3.4. Đặc trưng cục bộ bất biến SIFT
Đặc trưng SIFT của ảnh được giới thiệu bởi David G. Lowe [3] là đặc trưng bất biến với việc thay đổi tỉ lệ ảnh,
quay ảnh, đôi khi là thay đổi điểm nhìn và thêm nhiễu ảnh hay thay đổi cường độ chiếu sáng của ảnh.
Để trích đặc trưng SIFT, với mỗi ảnh, tìm các điểm đặc trưng và biểu diễn dưới dạng véctơ 128 chiều. Sau đó
dùng giải thuật k-Means để tiến hành gom cụm các điểm đặc trưng thành 2048 cụm. Như vậy mỗi ảnh được biểu diễn
bằng véctơ đặc trưng SIFT 2048 chiều.
IV. TRÍCH ĐẶC TRƯNG VĂN BẢN
Để rút trích đặc trưng văn bản cho ảnh, chúng tôi đã xây dựng tập dữ liệu chuẩn để chọn ra các ảnh và văn bản
chuẩn nhất. Mỗi ảnh trong tập dữ liệu chuẩn sẽ có kèm theo một đoạn mô tả về bức ảnh đó. Chúng tôi tiến hành phân
tích từ vựng và tách các từ trong nội dung của tập văn bản sử dụng phương pháp tách từ Bigram, sau đó sử dụng mô
hình túi từ để biểu diễn cho đặc trưng văn bản [12]. Đặc trưng văn bản của ảnh huấn luyện và ảnh truy vấn là một véc-
tơ tần suất xuất hiện của các từ trong văn bản đó, được xây dựng dựa trên văn bản của các ảnh láng giềng gần nhất với
ảnh đầu vào trong tập ảnh chuẩn. Quy trình được tóm tắt như sau:
- Mỗi ảnh đầu vào sẽ được rút trích đặc trưng ảnh và tính độ tương đồng với từng ảnh trong tập ảnh chuẩn.
- Từ đó tìm ra 50 ảnh láng giềng có độ tương đồng cao nhất với ảnh đầu vào (xem Hình 3).
- Dựa trên các véc tơ đặc trưng văn bản của các ảnh láng giềng vừa tìm được để xây dựng đặc trưng văn bản
cho ảnh đầu vào, đặc trưng này sẽ được chuẩn hóa.
Như vậy các véc tơ đặc trưng văn bản của ảnh huấn luyện sẽ được dùng để xây dựng các mô hình và véctơ đặc
trưng văn bản của ảnh truy vấn để tiến hành phân lớp.
Hình 3. Ảnh đầu vào và 9 ảnh láng giềng gần nhất trong tập ảnh chuẩn
V. PHÂN LỚP ẢNH
5.1. Giải thuật máy học véctơ hỗ trợ
Trong bài viết này, chúng tôi sử dụng giải thuật máy học véctơ hỗ trợ SVM đa lớp với phương pháp 1 - tất cả
[13] để xây dựng mô hình và phân lớp. Đồng thời, để giải thuật phân lớp SVM đạt kết quả tốt, chúng tôi sẽ sử dụng
hàm nhân Radial Basis Function (RBF): K(u, v)=exp(-γ‖u-v‖2) với γ là tham số của hàm nhân.
Ảnh 2: Hội đua bò Bảy Núi
Ảnh 1: Chợ nổi Cái Răng
Hà Thị Phương Anh, Phạm Thế Phi, Đỗ Thanh Nghị 171
5.2. Bộ phân lớp kết hợp với giải thuật hồi quy logistic
Trước tiên là xây dựng các đặc trưng cho tập ảnh huấn luyện: đặc trưng ảnh và đặc trưng văn bản. Mỗi ảnh đầu
vào sẽ được rút trích đặc trưng ảnh và đặc trưng văn bản bằng các phương pháp đã trình bày ở phần IV. Vấn đề được
đặt ra ở đây là chúng ta không thể xác định được hai đặc trưng này sẽ tương tác với nhau hay không, hoặc kết quả phân
lớp ảnh dựa trên đặc trưng này có quyết định cho kết quả phân lớp ảnh từ đặc trưng còn lại.
Vì thế, chúng tôi đã đưa ra phương pháp là xây dựng bộ phân lớp ảnh và bộ phân lớp văn bản riêng biệt với
nhau. Khi đó mỗi ảnh đầu vào trong tập dữ liệu kiểm chứng sẽ được đưa vào hai bộ phân lớp này, kết quả thu được là
các giá trị tin cậy của mỗi ảnh thuộc về 17 lớp ở hai bộ phân lớp.
Mỗi ảnh sau đó sẽ thu được véctơ đặc trưng mới bằng phương pháp nội suy theo công thức véctơ X = [ *(giá
trị tin cậy của ảnh dựa trên bộ phân lớp ảnh)] ghép với [(1 - )*(giá trị tin cậy của ảnh dựa trên bộ phân lớp văn bản)]. Khi đó bộ phân lớp thứ ba là sự kết hợp của hai bộ phân lớp ảnh và văn bản sẽ sử dụng giải thuật hồi quy logistic [11]
và tập giá trị thu được ở tập dữ liệu kiểm chứng làm dữ liệu huấn luyện.
VI. KẾT QUẢ THỰC NGHIỆM
Để tiến hành đánh giá hiệu quả của phương pháp mới đề xuất, chúng tôi sử dụng độ chính xác trung bình
(Average Precision - AP). Tất cả các thực nghiệm đều được thực hiện trên một máy tính cá nhân (CPU Core i5 2.2GHz
RAM 4GB) chạy hệ điều hành Windows 8.1.
Bảng 1. Thống kê số lượng ảnh thực nghiệm
Số ảnh huấn luyện
(60 %)
Số ảnh điều chỉnh tham số
(20 %)
Số ảnh kiểm tra
(20 %) Số ảnh trong tập chuẩn
5.551 1.841 1.849 820
Tập dữ liệu thực nghiệm là tập di sản văn hóa phi vật thể khu vực Đồng bằng sông Cửu Long gồm 9.241 ảnh
thuộc về 17 lớp. Chúng tôi tiến hành phân chia tập dữ liệu như sau:
Chọn ngẫu nhiên từ 17 lớp, mỗi lớp theo tỷ lệ 60 % số ảnh dùng để huấn luyện và xây dựng mô hình, 20 % số
ảnh thực nghiệm điều chỉnh tham số và 20 % số ảnh làm tập kiểm tra mô hình huấn luyện đã xây dựng (Bảng 1).
Bên cạnh đó, trong tập ảnh thu thập được, chọn từ mỗi lớp các ảnh có ảnh và văn bản mô tả đúng và chính
xác là thuộc về lớp đó để xây dựng tập dữ liệu chuẩn, tập này sẽ gồm 820 ảnh.
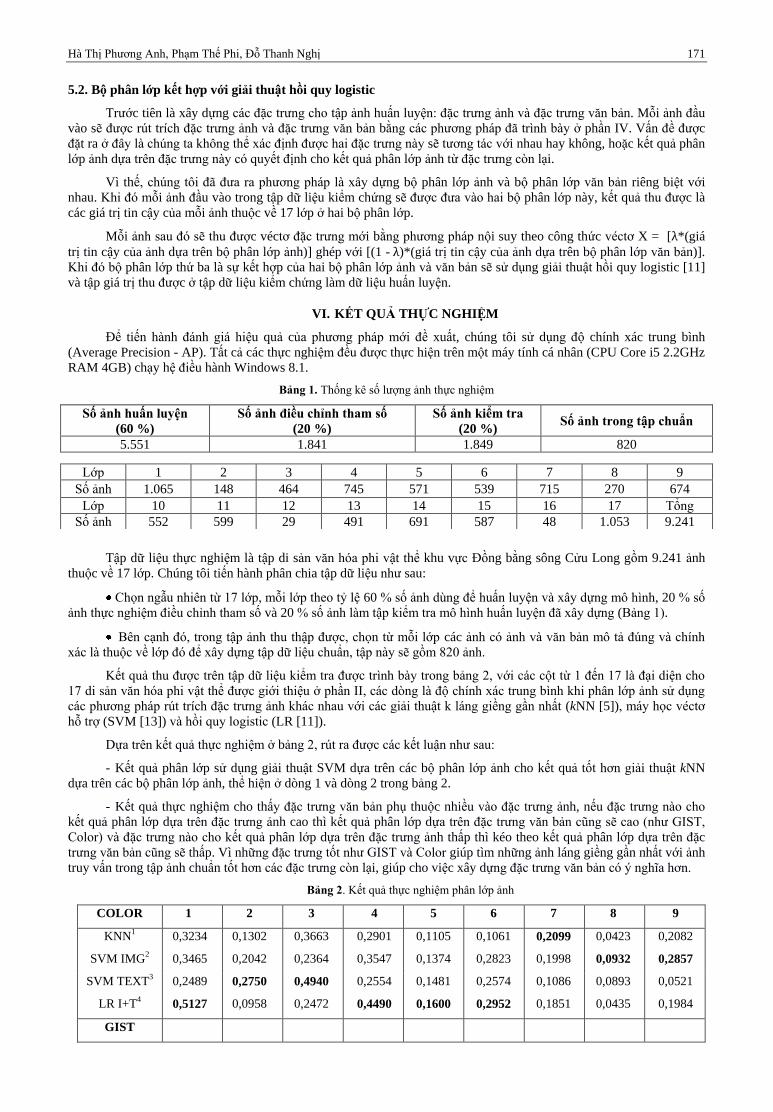
Kết quả thu được trên tập dữ liệu kiểm tra được trình bày trong bảng 2, với các cột từ 1 đến 17 là đại diện cho
17 di sản văn hóa phi vật thể được giới thiệu ở phần II, các dòng là độ chính xác trung bình khi phân lớp ảnh sử dụng
các phương pháp rút trích đặc trưng ảnh khác nhau với các giải thuật k láng giềng gần nhất (kNN [5]), máy học véctơ
hỗ trợ (SVM [13]) và hồi quy logistic (LR [11]).
Dựa trên kết quả thực nghiệm ở bảng 2, rút ra được các kết luận như sau:
- Kết quả phân lớp sử dụng giải thuật SVM dựa trên các bộ phân lớp ảnh cho kết quả tốt hơn giải thuật kNN
dựa trên các bộ phân lớp ảnh, thể hiện ở dòng 1 và dòng 2 trong bảng 2.
- Kết quả thực nghiệm cho thấy đặc trưng văn bản phụ thuộc nhiều vào đặc trưng ảnh, nếu đặc trưng nào cho
kết quả phân lớp dựa trên đặc trưng ảnh cao thì kết quả phân lớp dựa trên đặc trưng văn bản cũng sẽ cao (như GIST,
Color) và đặc trưng nào cho kết quả phân lớp dựa trên đặc trưng ảnh thấp thì kéo theo kết quả phân lớp dựa trên đặc
trưng văn bản cũng sẽ thấp. Vì những đặc trưng tốt như GIST và Color giúp tìm những ảnh láng giềng gần nhất với ảnh
truy vấn trong tập ảnh chuẩn tốt hơn các đặc trưng còn lại, giúp cho việc xây dựng đặc trưng văn bản có ý nghĩa hơn.
Bảng 2. Kết quả thực nghiệm phân lớp ảnh
COLOR 1 2 3 4 5 6 7 8 9
KNN1
0,3234 0,1302 0,3663 0,2901 0,1105 0,1061 0,2099 0,0423 0,2082
SVM IMG2
0,3465 0,2042 0,2364 0,3547 0,1374 0,2823 0,1998 0,0932 0,2857
SVM TEXT3
0,2489 0,2750 0,4940 0,2554 0,1481 0,2574 0,1086 0,0893 0,0521
LR I+T4
0,5127 0,0958 0,2472 0,4490 0,1600 0,2952 0,1851 0,0435 0,1984
GIST
Lớp 1 2 3 4 5 6 7 8 9
Số ảnh 1.065 148 464 745 571 539 715 270 674
Lớp 10 11 12 13 14 15 16 17 Tổng
Số ảnh 552 599 29 491 691 587 48 1.053 9.241
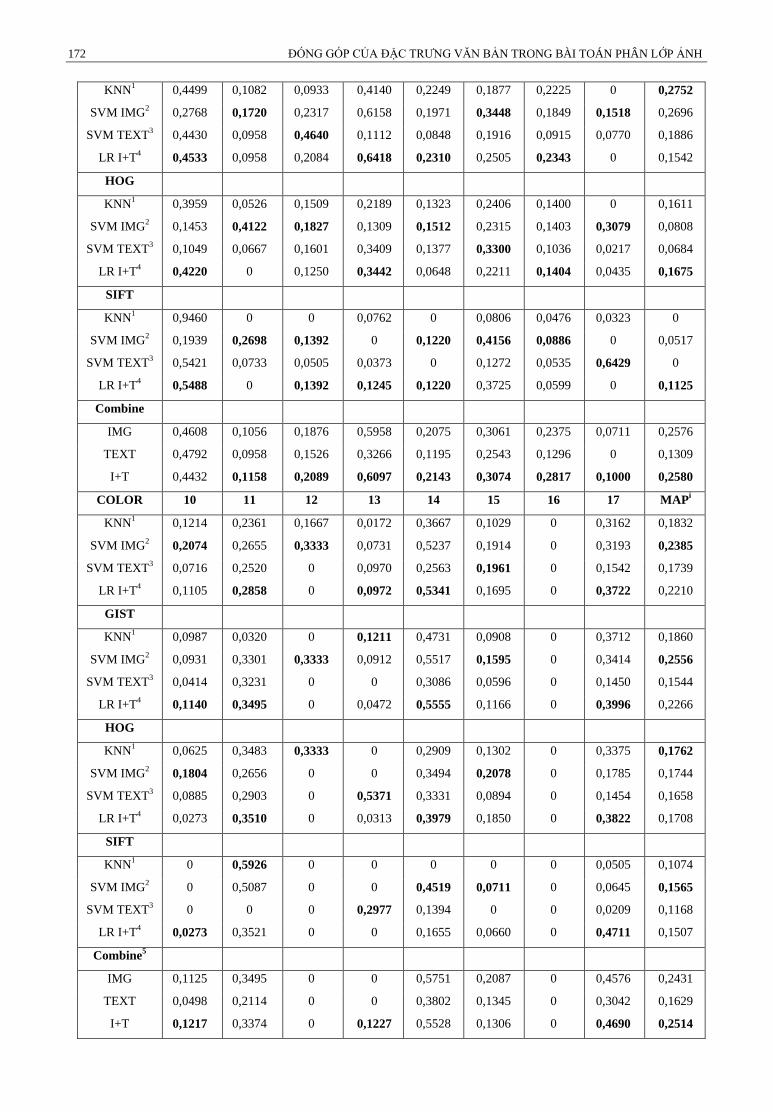
172 ĐÓNG GÓP CỦA ĐẶC TRƯNG VĂN BẢN TRONG BÀI TOÁN PHÂN LỚP ẢNH
KNN1
0,4499 0,1082 0,0933 0,4140 0,2249 0,1877 0,2225 0 0,2752
SVM IMG2
0,2768 0,1720 0,2317 0,6158 0,1971 0,3448 0,1849 0,1518 0,2696
SVM TEXT3
0,4430 0,0958 0,4640 0,1112 0,0848 0,1916 0,0915 0,0770 0,1886
LR I+T4
0,4533 0,0958 0,2084 0,6418 0,2310 0,2505 0,2343 0 0,1542
HOG
KNN1
0,3959 0,0526 0,1509 0,2189 0,1323 0,2406 0,1400 0 0,1611
SVM IMG2
0,1453 0,4122 0,1827 0,1309 0,1512 0,2315 0,1403 0,3079 0,0808
SVM TEXT3
0,1049 0,0667 0,1601 0,3409 0,1377 0,3300 0,1036 0,0217 0,0684
LR I+T4
0,4220 0 0,1250 0,3442 0,0648 0,2211 0,1404 0,0435 0,1675
SIFT
KNN1
0,9460 0 0 0,0762 0 0,0806 0,0476 0,0323 0
SVM IMG2
0,1939 0,2698 0,1392 0 0,1220 0,4156 0,0886 0 0,0517
SVM TEXT3
0,5421 0,0733 0,0505 0,0373 0 0,1272 0,0535 0,6429 0
LR I+T4
0,5488 0 0,1392 0,1245 0,1220 0,3725 0,0599 0 0,1125
Combine
IMG 0,4608 0,1056 0,1876 0,5958 0,2075 0,3061 0,2375 0,0711 0,2576
TEXT 0,4792 0,0958 0,1526 0,3266 0,1195 0,2543 0,1296 0 0,1309
I+T 0,4432 0,1158 0,2089 0,6097 0,2143 0,3074 0,2817 0,1000 0,2580
COLOR 10 11 12 13 14 15 16 17 MAPi
KNN1
0,1214 0,2361 0,1667 0,0172 0,3667 0,1029 0 0,3162 0,1832
SVM IMG2
0,2074 0,2655 0,3333 0,0731 0,5237 0,1914 0 0,3193 0,2385
SVM TEXT3
0,0716 0,2520 0 0,0970 0,2563 0,1961 0 0,1542 0,1739
LR I+T4
0,1105 0,2858 0 0,0972 0,5341 0,1695 0 0,3722 0,2210
GIST
KNN1
0,0987 0,0320 0 0,1211 0,4731 0,0908 0 0,3712 0,1860
SVM IMG2
0,0931 0,3301 0,3333 0,0912 0,5517 0,1595 0 0,3414 0,2556
SVM TEXT3
0,0414 0,3231 0 0 0,3086 0,0596 0 0,1450 0,1544
LR I+T4
0,1140 0,3495 0 0,0472 0,5555 0,1166 0 0,3996 0,2266
HOG
KNN1
0,0625 0,3483 0,3333 0 0,2909 0,1302 0 0,3375 0,1762
SVM IMG2
0,1804 0,2656 0 0 0,3494 0,2078 0 0,1785 0,1744
SVM TEXT3
0,0885 0,2903 0 0,5371 0,3331 0,0894 0 0,1454 0,1658
LR I+T4
0,0273 0,3510 0 0,0313 0,3979 0,1850 0 0,3822 0,1708
SIFT
KNN1
0 0,5926 0 0 0 0 0 0,0505 0,1074
SVM IMG2
0 0,5087 0 0 0,4519 0,0711 0 0,0645 0,1565
SVM TEXT3
0 0 0 0,2977 0,1394 0 0 0,0209 0,1168
LR I+T4
0,0273 0,3521 0 0 0,1655 0,0660 0 0,4711 0,1507
Combine5
IMG 0,1125 0,3495 0 0 0,5751 0,2087 0 0,4576 0,2431
TEXT 0,0498 0,2114 0 0 0,3802 0,1345 0 0,3042 0,1629
I+T 0,1217 0,3374 0 0,1227 0,5528 0,1306 0 0,4690 0,2514
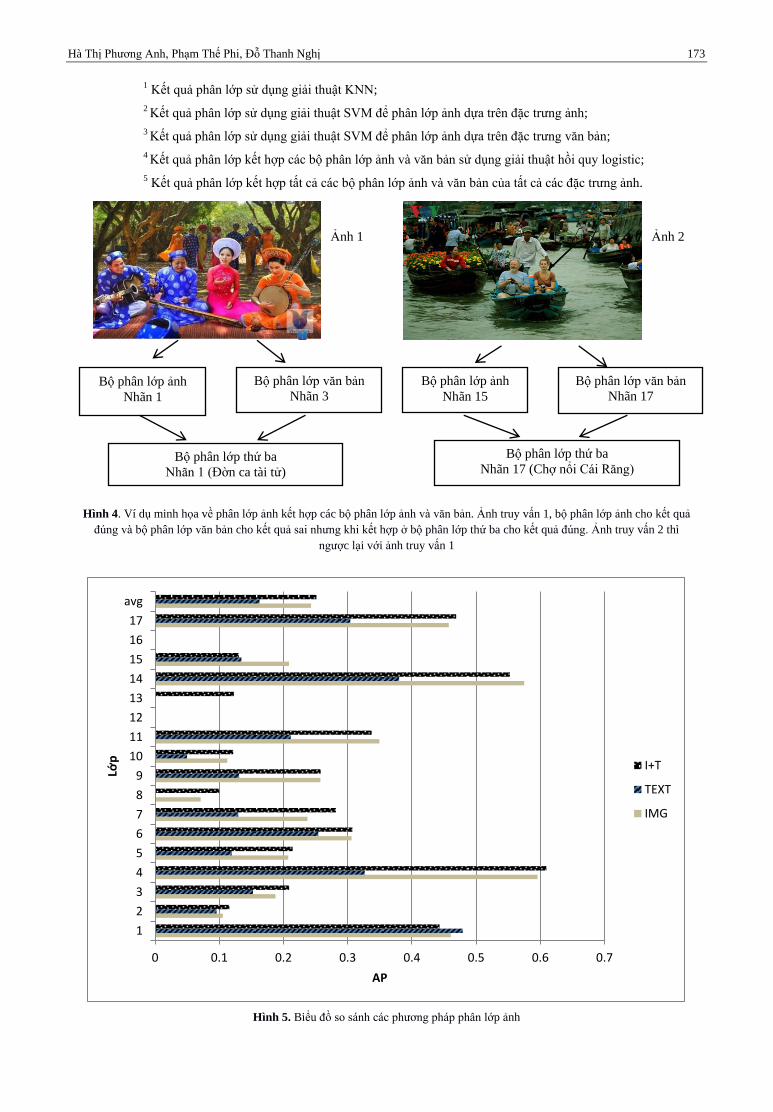
Hà Thị Phương Anh, Phạm Thế Phi, Đỗ Thanh Nghị 173
1 Kết quả phân lớp sử dụng giải thuật KNN;
2 Kết quả phân lớp sử dụng giải thuật SVM để phân lớp ảnh dựa trên đặc trưng ảnh;
3 Kết quả phân lớp sử dụng giải thuật SVM để phân lớp ảnh dựa trên đặc trưng văn bản;
4 Kết quả phân lớp kết hợp các bộ phân lớp ảnh và văn bản sử dụng giải thuật hồi quy logistic;
5 Kết quả phân lớp kết hợp tất cả các bộ phân lớp ảnh và văn bản của tất cả các đặc trưng ảnh.
Hình 5. Biểu đồ so sánh các phương pháp phân lớp ảnh
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
avg
AP
Lớp
I+T
TEXT
IMG
Ảnh 1
Bộ phân lớp ảnh
Nhãn 1
Bộ phân lớp văn bản
Nhãn 3
Bộ phân lớp thứ ba
Nhãn 1 (Đờn ca tài tử)
Ảnh 2
Bộ phân lớp ảnh
Nhãn 15
Bộ phân lớp văn bản
Nhãn 17
Bộ phân lớp thứ ba
Nhãn 17 (Chợ nổi Cái Răng)
Hình 4. Ví dụ minh họa về phân lớp ảnh kết hợp các bộ phân lớp ảnh và văn bản. Ảnh truy vấn 1, bộ phân lớp ảnh cho kết quả
đúng và bộ phân lớp văn bản cho kết quả sai nhưng khi kết hợp ở bộ phân lớp thứ ba cho kết quả đúng. Ảnh truy vấn 2 thì
ngược lại với ảnh truy vấn 1
174 ĐÓNG GÓP CỦA ĐẶC TRƯNG VĂN BẢN TRONG BÀI TOÁN PHÂN LỚP ẢNH
Bảng 3. Kết quả số ảnh phân lớp đúng dựa trên bộ phân lớp ảnh và bộ phân lớp văn bản
COLOR 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Ảnh kiểm tra0 213 30 93 149 114 108 143 54 135 110 120 6 98 138 117 10 211
Ảnh đúng (T)1 36 4 30 28 12 17 15 3 6 8 8 0 6 29 19 0 34
Ảnh đúng (I)2 65 5 8 25 10 23 24 4 19 19 20 2 9 57 19 0 63
GIST 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Ảnh đúng (T)1 94 2 40 13 6 15 12 2 8 5 19 0 0 37 3 0 31
Ảnh đúng (I)2 61 5 14 62 13 26 20 9 20 12 25 1 5 64 17 0 60
HOG 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Ảnh đúng (T)1 17 1 14 41 13 28 12 1 5 8 4 0 47 34 10 0 26
Ảnh đúng (I)2 32 6 15 12 16 16 18 15 5 13 22 0 0 36 19 0 32
SIFT 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Ảnh đúng (T)1 101 1 2 2 0 11 4 15 0 0 0 0 37 6 0 0 1
Ảnh đúng (I)2 38 8 6 0 11 30 9 0 5 0 2 0 0 60 4 0 11
o Số ảnh kiểm tra ở mỗi lớp (20 % số ảnh huấn luyện);
1 Số ảnh phân lớp đúng dựa trên các bộ phân lớp ảnh;
2 Số ảnh phân lớp đúng dựa trên các bộ phân lớp văn bản.
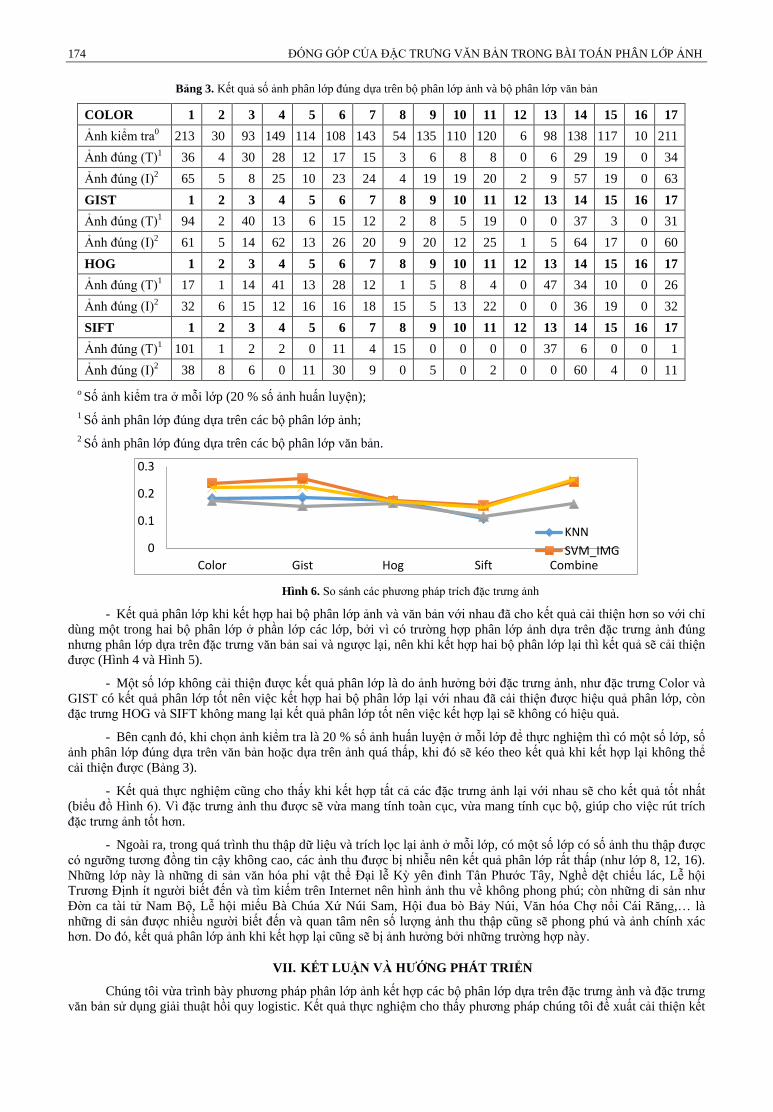
Hình 6. So sánh các phương pháp trích đặc trưng ảnh
- Kết quả phân lớp khi kết hợp hai bộ phân lớp ảnh và văn bản với nhau đã cho kết quả cải thiện hơn so với chỉ
dùng một trong hai bộ phân lớp ở phần lớp các lớp, bởi vì có trường hợp phân lớp ảnh dựa trên đặc trưng ảnh đúng
nhưng phân lớp dựa trên đặc trưng văn bản sai và ngược lại, nên khi kết hợp hai bộ phân lớp lại thì kết quả sẽ cải thiện
được (Hình 4 và Hình 5).
- Một số lớp không cải thiện được kết quả phân lớp là do ảnh hưởng bởi đặc trưng ảnh, như đặc trưng Color và
GIST có kết quả phân lớp tốt nên việc kết hợp hai bộ phân lớp lại với nhau đã cải thiện được hiệu quả phân lớp, còn
đặc trưng HOG và SIFT không mang lại kết quả phân lớp tốt nên việc kết hợp lại sẽ không có hiệu quả.
- Bên cạnh đó, khi chọn ảnh kiểm tra là 20 % số ảnh huấn luyện ở mỗi lớp để thực nghiệm thì có một số lớp, số
ảnh phân lớp đúng dựa trên văn bản hoặc dựa trên ảnh quá thấp, khi đó sẽ kéo theo kết quả khi kết hợp lại không thể
cải thiện được (Bảng 3).
- Kết quả thực nghiệm cũng cho thấy khi kết hợp tất cả các đặc trưng ảnh lại với nhau sẽ cho kết quả tốt nhất
(biểu đồ Hình 6). Vì đặc trưng ảnh thu được sẽ vừa mang tính toàn cục, vừa mang tính cục bộ, giúp cho việc rút trích
đặc trưng ảnh tốt hơn.
- Ngoài ra, trong quá trình thu thập dữ liệu và trích lọc lại ảnh ở mỗi lớp, có một số lớp có số ảnh thu thập được
có ngưỡng tương đồng tin cậy không cao, các ảnh thu được bị nhiễu nên kết quả phân lớp rất thấp (như lớp 8, 12, 16).
Những lớp này là những di sản văn hóa phi vật thể Đại lễ Kỳ yên đình Tân Phước Tây, Nghề dệt chiếu lác, Lễ hội
Trương Định ít người biết đến và tìm kiếm trên Internet nên hình ảnh thu về không phong phú; còn những di sản như
Đờn ca tài tử Nam Bộ, Lễ hội miếu Bà Chúa Xứ Núi Sam, Hội đua bò Bảy Núi, Văn hóa Chợ nổi Cái Răng,… là
những di sản được nhiều người biết đến và quan tâm nên số lượng ảnh thu thập cũng sẽ phong phú và ảnh chính xác
hơn. Do đó, kết quả phân lớp ảnh khi kết hợp lại cũng sẽ bị ảnh hưởng bởi những trường hợp này.
VII. KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
Chúng tôi vừa trình bày phương pháp phân lớp ảnh kết hợp các bộ phân lớp dựa trên đặc trưng ảnh và đặc trưng
văn bản sử dụng giải thuật hồi quy logistic. Kết quả thực nghiệm cho thấy phương pháp chúng tôi đề xuất cải thiện kết
0
0.1
0.2
0.3
Color Gist Hog Sift Combine
KNN
SVM_IMG

Hà Thị Phương Anh, Phạm Thế Phi, Đỗ Thanh Nghị 175
quả phân lớp. Kết quả cũng thể hiện được ở các đặc trưng cho kết quả tốt thì kết hợp lại sẽ cải thiện, còn những đặc
trưng cho kết quả thấp thì kết hợp lại sẽ không cải thiện.
Ngoài ra do tập ảnh và văn bản thu thập được bị nhiễu nên kết quả phân lớp dựa trên đặc trưng văn bản vẫn còn
thấp, làm ảnh hưởng đến kết quả khi kết hợp các bộ phân lớp lại với nhau.
Trong tương lai gần, để cải tiến hiệu quả phân lớp ảnh chúng tôi sẽ tập trung vào chuẩn hóa tập dữ liệu huấn
luyện và các đặc trưng văn bản đi kèm cho ảnh, phân tích ngữ nghĩa của các nội dung văn bản đi kèm, xác định được
những từ đồng nghĩa và gom nhóm lại để phân lớp ảnh dựa trên văn bản có thể chính xác hơn.
VIII. TÀI LIỆU THAM KHẢO
[1] A. Quattoni, M Collins and T. Darrell. Learning visual representations using images with captions. In CVPR, 2007.
[2] A. Torralba, R. Fergus and W. T. Freeman. Tiny images, Technical Report MIT-CSAIL-TR-2007-024. Computer
Science and Artificial Intelligence Lab, Massachusetts Institute of Technology, 2007.
[3] David G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer
Vision, 60(2): 91-110, 2004.
[4] Đỗ Thanh Nghị và Phạm Nguyên Khang. Phân lớp ảnh với giải thuật giảm gradient ngẫu nhiên đa lớp. Tạp chí
Khoa học Trường Đại học Cần Thơ, 29: 1-7, 2013a.
[5] Fix E and Hodges J.. Discriminatoiry Analysis: Small Sample Performance. Technical Report 21-49-004, USAF
School of Aviation Medicine, Randolph Field, USA, 1952.
[6]. J. Hays and A. A. Efros. IM2GPS: Estimating geographic information from a single image. Proceedings of the
IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 1-8, 2008.
[7] Kamarudin N. S., Makhtar M., Fadzli S. A., Mohamad M., Mohamad F. S. and Kadir M. F. A.. Comparison of
Image Classification Techniques using Caltech 101 Dataset. Journal of Theoretical and Applied Information
Technology, 71(1):79-86, 2015.
[8] M. J. Swain and D. H. Ballard. Color indexing. International Journal of Computer Vision, vol. 7, no. 1, pp. 11-32,
1991.
[9] N. Dalal and B. Triggs. Histograms of Oriented Gradients for Human Detection. In CVPR, pp. 886-893, 2005.
[10]. Oliva and A. Torralba. Modeling the shape of the scene: a holistic representation of the spatial envelope. IJCV,
42(3): 145-175, 2001.
[11] Peng J., Lee K. L. and Ingersoll G. M.. An Introduction to Logistic Regression Analysis and Reporting. In The
Journal of Educational Research, 96(1):3-14, 2002.
[12] Phạm Nguyên Khang, Trần Nguyễn Minh Thư, Phạm Thế Phi, Đỗ Thanh Nghị. Sự ảnh hưởng của Phương pháp
tách từ trong bài toán phân lớp văn bản tiếng Việt. Kỷ yếu Hội thảo FAIR’9, pp 668-677, 2016.
[13] Vapnik V.. The Nature of Statistical Learning Theory. Springer-Verlag, NewYork. 314 pp, 1995.
[14] Viola P. A., Jones M. J.. Rapid object detection using a boosted cascade of simple features. In IEEE Conference
on Computer Vision and Pattern Recognition, pp. 511-518, 2001.
[15]. Wang G., Hoiem D. and Forsyth D.. Building text features for object image classification. In CVPR, pp. 1367-
1374, 2009.
[16] Zheng H. and Daoudi M.. Blocking adult images based on statistical skin detection. Electronic Letters on
Computer Vision and Image Analysis, 4(2):1-1, 2004.
CONTRIBUTION OF TEXT FEATURES IN IMAGE CLASSIFICATION
ABSTRACT: In this paper, we introduce a new image classification approach, combine separate text classifiers and image
classifiers in a third classifier, which uses logistic regression algorithm. Text features are extracted from texts associated with
images, which are nearest neighbor images in standard dataset. Visual features are extracted by types of features to determine a
best feature. The numerical test result on a intangible cultural heritage dataset showed that our approach improves the performance
in image classification with the good visual features and the training dataset is not too small and noisy.
Keywords: Image Classification, Visual feature, Text feature, Logistic Regression.
i MAP: Độ chính xác trung bình của tất cả các lớp.