Embed Size (px)
Citation preview

1
NII Lectures: Challenges andOpportunities of Parallelism
Lawrence Snyderwww.cs.washington.edu/home/snyder
17 September 2008
有り難うございます The opportunity to visit NII is appreciated Thank you for the forum to speak on the
interesting topic of parallel computation Thank you for allowing me to speak in
English
I prefer US style: ask questions real-time

2
The Plan
Today’s lecture is 1st of a series of 5 Premise:
Overall goal of lectures:Give a complete picture of the state-of-the-art inparallel programming, how to use it today andwhere to take research studies
Parallel programming is no longer for ‘ivory tower’
The Lectures The New Opportunities and Challenges of
Parallelism 35 Years of Research: Positive Results;
Negative Results A Model Of Parallelism To Guide Thinking Parallel Languages of Today -- OpenMP to
Fortress Next Parallel Languages -- Access To
Parallelism For All

3
The Situation Today … The performance of consumer and
business software, which has ridden thewave of faster processors and moretransistors for years, cannot achieve furtherperformance improvements withoutparallelism.
Some see a problem … but it’s anopportunity
Software written to take advantage ofparallelism today will ride the performancewave just like in the past
Outline Of This Talk
Small Parallelism technology facts of 2008 A Closer Look -- Facts of Life Large Parallelism technology facts of 2008 A Closer Look -- Living with Parallelism A trivial exercise focuses our attention

4
Facts2008
Figure courtesy of Kunle Olukotun, Lance Hammond, Herb Sutter & Burton Smith
2x in 2yrsSingleProcessor
OpportunityMoore’s lawcontinues, souse more gates
Facts In 2008
Laptops, desktops, servers, etc. now areparallel (mulitcore) computers … why?
Multi-core gives more computation andsolves difficult hardware problems What to do with all of the transistors: Replicate Power Issues Clock speeds
… consider each issue

5
Multi-core Replicates Designs
Traditionally we have used transistors tomake serial processors more aggressive Deeper pipelining, more look-ahead Out of order execution Branch prediction Large, more sophisticated TLBs, caches, etc.
Why not continue the aggressive design?… Diminishing returns, limit on ILP, few new ideas
Bottom Line: Sequential instruction execution reaching limits
Size vs Power Power5 (Server)
389mm^2 120W@1900MHz
Intel Core2 sc (laptop) 130mm^2 15W@1000MHz
ARM Cortex A8 (automobiles) 5mm^2 0.8W@800MHz
Tensilica DP (cell phones / printers) 0.8mm^2 0.09W@600MHz
Tensilica Xtensa (Cisco router) 0.32mm^2 for 3! 0.05W@600MHz
Intel Core2
ARM
TensilicaDP
Xtensa x 3
Power 5
Each processor operates with 0.3-0.1 efficiencyof the largest chip: more threads, lower power

6
Multi-core Design Space
Smaller, slower implies more modest design
Gflops/W200.9power capacity
Gflops/mm130.6area capacity
Gflop/s12832peak throughput
words wide164vector operations
relative perf0.31single thread
42threads
GHz44frequency
W6.2537.5power
mm^21050size
in orderout of ordermicro-architecture
Source: Doug Carmean, Intel
Traditional Core Design
Multi-cores Have Their Problems Single threaded computation doesn’t run faster (it
may run slower than a 1 processor per chip design) Few users benefit from m-c ||ism today
Existing software is single threaded Compilers don’t help and often harm parallelism It’s often claimed that OS task scheduling is one easy
way to keep processors busy, but there are problems limited numbers of tasks available contention for resources, e.g. I/O bandwidth co-scheduled tasks often have dependences -- no
advantage to or prevented from running together

7
Legacy Code
Even casual users use applications with atotal code base in the 100s of millions LOC… and it’s not parallel
There are not enough programmers torewrite this code, even if it had || potential
With single processor speeds flat or falling,this code won’t improve
ChallengeHow to bring performanceto existing programs
Legacy Code
Even casual users use applications with atotal code base in the 100s of millions LOC… and it’s not parallel
There are not enough programmers torewrite this code, even if it had || potential
With single processor speeds flat or falling,this code won’t improve
ChallengeHow to bring performanceto existing programs
OpportunityMuch legacy codesupports backwardcompatibility -- ignore

8
Potential of Many Threads - Amdahl
“Everyone is taught Amdahl’s Law in school,but they quickly forget it” -- T. R. Puzak, IBM
Maximum performance improvement byparallelism is S-fold
More complex in multi-core case: programsthat are 99% parallel get speedup of 72 on256 cores [Hill & Marty]
TP = 1/S⋅TS + (1 - 1/S) ⋅ TS /P
Summary So Far Opportunities --
Moore’s law continues to give us gates Multi-core is easy design via replication Replicating small, slower processors fixes power
problems & improves ops/second Challenges --
Smaller, slower designs are smaller, slower on 1 thread Huge legacy code base not improved Parallelism doesn’t speed-up sequential code. Period.

9
Outline Of This Talk
Small Parallelism technology facts of 2008 A Closer Look -- Facts of Life Large Parallelism technology facts of 2008 A Closer Look -- Living with Parallelism A trivial exercise focuses our attention
But There’s More To Consider Two processors may be
‘close’ on the silicon, butsharing information is stillexpensive
r1 L1 L2 coherencyprotocol L2 L1 r2
Opteron Dual Core: morethan 100 instruction times
Latency between cores onlygets worse
ChallengeOn Chip Latency

10
Latency -- Time To Access Data Latencies (relative to instruction execution) have
grown steadily over the years, but (transparent)caching has saved us
No more Interference of multiple threads reduces the benefits of
spatial and temporal locality Cache coherence mechanisms are
good for small bus-based SMPs slower and complex as size, distance and
decentralization increase
Thus, latency grows as a problem
Bandwidth On/Off Chip
Many applications that are time-consumingare also data intensive e.g. MPEG compress
C cores share the bandwidth to memory:available_bandwidth/C
Caching traditionally solves BW problems,but Si devoted to cache reduces number ofcores
A problem best solved with better technology

11
Memory Model Issues When we program, we usually think of a single
memory image with one history of transitions:s0, s1, …, sk, …
Not true in the parallel context Deep technical problem Two cases
Shared memory Distributed memory (later)
The consequences of this fact are the largestchallenges facing parallel programming
Shared Memory Issues
“Sequential consistency” … the singlememory image … is what we expect
Sequential Consistency -- We believe that ifx = y = 0, then after executing this code
r1 or r2 (or perhaps both) will contain 1 r1 = r2 = 0 is possible
Thread 1x = 1;r1 = y;
Thread 2y = 1;r2 = x;

12
Closer Look
Why do we think r1 or r2 must equal 1? x=1 or y=1 happens first, so the “r-assignment sets
one of the locations to 1 Problems:
“Simultaneous” execution is possible; it’s not concurrency Latency in notifying other thread, which uses cached val Compiler reorders operations, trying to cover latency Hardware executes instructions out of order
Thread 1x = 1;r1 = y;
Thread 2y = 1;r2 = x;
Still Closer Look
Problems: “Simultaneous” execution is possible; it’s not concurrency Latency in notifying other thread, which uses cached val Compiler reorders operations, trying to cover latency Hardware executes instructions out of order
Thread 1x = 1;r1 = y;
Thread 2y = 1;r2 = x;
addi $8,1st $8,y-off(fp)lw $9,x-off(fp)st $9,r2-off(fp)

13
Still Closer Look
Problems: “Simultaneous” execution is possible; it’s not concurrency Latency in notifying other thread, which uses cached val Compiler reorders operations, trying to cover latency Hardware executes instructions out of order
Thread 1x = 1;r1 = y;
Thread 2y = 1;r2 = x;
addi $8,1st $8,y-off(fp)lw $9,x-off(fp)st $9,r2-off(fp)
addi $8,1st $8,y-off(fp)lw $9,x-off(fp)st $9,r2-off(fp)
Write Bufferw($8,y)w($8,y)w($9,r2)
Still Closer Look
Problems: “Simultaneous” execution is possible; it’s not concurrency Latency in notifying other thread, which uses cached val Compiler reorders operations, trying to cover latency Hardware executes instructions out of order
Thread 1x = 1;r1 = y;
Thread 2y = 1;r2 = x;
addi $8,1sw $8,y-off(fp)lw $9,x-off(fp)sw $9,r2-off(fp)
lw $9,x-off(fp)addi $8,1sw $8,y-off(fp)lw $9,x-off(fp)sw $9,r2-off(fp)
addi $8,1sw $8,y-off(fp)lw $9,x-off(fp)sw $9,r2-off(fp)
Write Bufferw($8,y)w($8,y)w($9,r2)

14
Much Research On S-Consistency No need now to go deeply into model -- the
intuitive and efficiently implementable memorymodel has not yet been found Standard programming facilities (Pthreads, Original
Java Mem Model, etc.) allow the r1=r2=0 outcomeOther mechanisms -- locks and monitors -- notsufficient when implemented as libraries, as theyinvariably are
Recent advances such as software transactionalmemory (STM) promising, but many problems remainunresolved Challenge
Create an intuitive, implementable andeasy-to-reason about memory model
Facts of Life Summary: Challenges
Latency on chip will increase as core countincreases significant already both logic complexity and “electronic” distance
Bandwidth to L3 and memory shared Memory model for programmers
Presently broken Extensive research has failed to find alternate May be a “show stopper”

15
Outline Of This Talk
Small Parallelism technology facts of 2008 A Closer Look -- Facts of Life Large Parallelism technology facts of 2008 A Closer Look -- Living with Parallelism A trivial exercise focuses our attention
Large Parallel Facts
A parallel computer (IBM Roadrunner) hasachieved 1 Peta Flop/S (1.03×1015 Flop/S)

16
Large Parallel Facts
A parallel computer (IBM Roadrunner) hasachieved 1 Peta Flop/S (1.03×1015 Flop/S)
?
Roadrunner Specs 6,562 dual-core AMD Opteron® chips and 12,240
STI PowerXCell 8i chips … each AMD core getsits own Cell chip
98 terabytes of memory 3.8 MW total delivering 376 MFlops/W 278 refrigerator-sized racks; 5,200 ft^2 footprint Other Data:
10,000 connections – both Infiniband and GigabitEthernet
55 miles of fiber optic cable 500,000 lbs. Shipped to Los Alamos in 21 tractor trailer trucks

17
Performance: Top 500
Source: Top 500 Supercomputers
Performance: Top 500
Source: Top 500 Supercomputers
We are on track forexa-scale computing
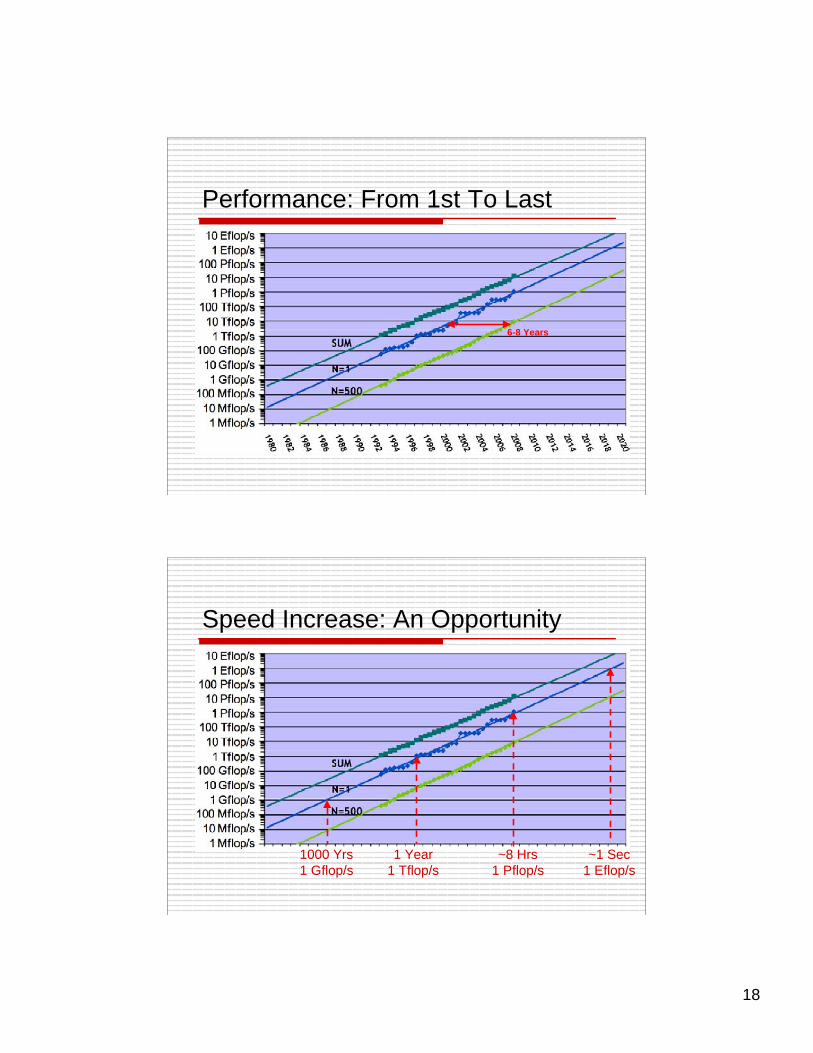
18
Performance: From 1st To Last
6-8 Years
Speed Increase: An Opportunity
1000 Yrs1 Gflop/s
1 Year1 Tflop/s
~8 Hrs1 Pflop/s
~1 Sec1 Eflop/s

19
Node Structure of RoadRunner
Hybrid Machine
•Opteron•PPC•SPE
3 ISAs

20
Three Programming Levels: Challenge
Programming Multiple Levels is not simply just 3compilations SPE is difficult to program -- few HW goodies PPC is mostly orchestrating local data flow Opteron (contributes 3% of performance) mostly
orchestrates more global data flow Library support different for each ISA
LINPAC has very favorable work/word character LINPAC benchmark has been developed over
many years; writing new HPC programs for thisarchitecture will be time consuming
Interprocessor Communication
Roadrunner’s communication usesInfiniBand and Gbit Ethernet
Connected Unit Cluster: 192 Opteronnodes (180 w/ 2dual-Cell blades connectedw/ 4 PCIe x 8 links)
17

21
Architectures Keep ChangingArchitecturescome and go
mpp =massivelyparallelprocessor
smp =symmetricmultiprocessor
Summary So Far, Large Scale Opportunities
Moore’s law continues Large Scale on track for exa-scale machines
by about 2019, though there is much to do The advancement will be significant
1Kyears --> seconds Challenges
Hybrid design requires difficult multilevelprogramming
Hardware “lifetimes” are short -- be general Latencies will continue to grow

22
Outline Of This Talk
Small Parallelism technology facts of 2008 A Closer Look -- Facts of Life Large Parallelism technology facts of 2008 A Closer Look -- Living with Parallelism A trivial exercise focuses our attention
Life Times / Development Times Hardware -- has a “half-life” measured in
years Software -- has a “half-life” measured in
decades Exploiting specific parallel hardware
features risks introducing architecturedependences the next platform cannot fulfill
In parallel programming architecture “showsthrough” … don’t make the view too clear

23
Distributed Memory
Each process has it’s own memory, sharedwith no other process Convenience of shared memory lost Interprocess data reference requires heavy
communication -- either by programmer(message passing) or compiler (PGAS langs)
Data races can continue as a headache Problem decomposition, allocation, etc. adds
an extra intellectual load
Decomposing A Problem
In sequential computation we simply build a globaldata structure
In parallel computation we decompose the datastructure to improve the locality
Consider dense matirx multiplication C = AB
How should arrays be allocated to 4 processors?
x=
C A B

24
Alternative Allocations
There are multiple allocations choices Allocation decision
drives algorithm &programming
Increasedcomplexity frompiecing partstogether
x=
x=
x=ChallengeSimplify Allocation
Not The Same Algorithm
Whatever the right allocation, the algorithmis no longer the “triply nested loop”
x=
for (i = 0; i < m; i++) { for (j = 0; j < p; j++) { C[i][j]=0; for (k = 0; k < n; k++) { C[i][j] = A[i][k] * B[k][j]; } }}

25
Sequential Algorithms No Good Guide What makes good sequential and parallel
algorithms are different Resources
S: Reduce instruction count P: Reduce communication
Best practices S: Manipulate references, exploit indirection P: Reduce dependences, avoid interaction
Look for algorithms with S: Efficient data structures P: Locality, locality, locality
Good Algorithms Not Well Known
What is the best way to multiply two densematrices in parallel?
We all know good serial algorithms andsequential programming techniques
Parallel techniques not widely known, andbecause they are different from sequentialtechniques, should we be teaching them toFreshmen in college?
Ans: In A Future Lecture

26
Outline Of This Talk
Small Parallelism technology facts of 2008 A Closer Look -- Facts of Life Large Parallelism technology facts of 2008 A Closer Look -- Living with Parallelism A trivial exercise focuses our attention
Programmer Challenge: Education Most college CS graduates have
No experience writing parallel programs No knowledge of the issues, beyond
concurrency from OS classes Little concept of standard parallel algorithms No model for what makes a parallel algorithm
good Add to that -- enrollments are dropping, at
least in the US Where do the programmers come from?

27
Illustrating the Issues
Consider the trivial problem of counting thenumber of 3s in a vector of values on m-c
Try # 1
Assume array in shared memory; 8 way ||-ismvoid count3s() { int count=0; int i=0; /* Create t threads */ for (i=0;i<t;i++){ thread_create(count3s_thread,i); } return count;}void count3s_thread(int id){ int j; int length_per_thread=length/t; int start=id*length_per_thread; for (j=start; j<start+length_per_thread;j++) { if (array[j]==3) count++; }}
…

28
Try #1 Assessment
Try #1 doesn’t even get the right answer! The count variable is not protected, so
there is a race as threads try to increment itThread i...lw $8,count-off(gp)addi $8,1sw $8,count-off(gp)...
Try #2 Protect the shared count with a mutex lock
This solution at least gets the right answer
void count3s_thread(int id){ int j; int length_per_thread=length/t; int start=id*length_per_thread; for (j=start; j<start+length_per_thread;j++) { if (array[j]==3) { mutex_lock(m); count++; mutex_unlock(m); } }}

29
Try #2 Assessment
It doesn’t perform, however
Try #3 Include a private variable
Contention, if it happens is limited
void count3s_thread(int id){ int j; int length_per_thread=length/t; int start=id*length_per_thread; for (j=start; j<start+length_per_thread;j++) { if (array[j]==3) { private_count[id]++; } } mutex_lock(m); count += private_count[id]; mutex_unlock(m);}

30
Try #3 Assessment
The performance got better, but still no||-ism
Try #3 False Sharing
The private variables were allocated to oneor two cache lines
Cache coherency schemes, which keepeveryone’s cache current operate on thecache-line granularity … still contention Suppose two processors have the cache line When one writes, other is invalidated; refetch
priv_count[0] priv_count[1] priv_count[2] priv_count[3] …

31
Try #4
By simply adding padding to give eachprivate count its own cache line Try #3 works
Notice that false sharing is a sensitivityhardware dependent on the f cache size line
Machine features “show through”
struct padded_int { int val; char padding [60];} private_count[t];
Try #4 Assessment
Finally, speed-up over serial computation
It wasn’t so easy, and it wasn’t so great
1 processor : 0.912 processors: 1.64 processors: 3.18 processors: 3.2

32
Programming Challenges Today’s programmers not ||-programmers Much to worry about
Standard abstractions (locks, etc.) too low level Memory Model (mentioned before) busted Parallelism “shows through” Hardware sensitivity (false sharing) Heavy intellectual investment
Small task took serious effort Modest performance achieved Not yet a general solution
Houston, We Have Problem
The Bottom Line …
The talk has cited much very good news,and much very bad news about parallelism…
There is little choice if we need moreperformance … we need to embrace ||ism
Opportunities Challenges---------- ---------- ---------------- ----- -- ------- ---------------- -- --- ---- -----__________ _________------ --- ------------

33
Summary of Main Opportunities Appetite for computing grows without limit, and for
many applications -- entertainment, science,finance -- more performance is essential
Large machines seem to be strongly on track tocontinue to get faster!
Adding cores is an easy way to use gates, andwill continue to be available
Once programmed, software can ride the wave ofincreasing processor count
Summary of Main Challenges Workable Parallel Memory Model Still Open Current ||-programming abstractions too low Legacy software receives no benefit … new
programming is required Technical problems abound
Latency is high, increasing Hybrid architectures imply multi-ISA code Bandwidth is bottleneck, likely getting worse
New programmers not learning ||-ism,installed base must be retrained

34
Anticipating Future Lectures …
… And there is no silver bullet
Further questions?





























