Embed Size (px)
Citation preview

Projet tutoré en laboratoire
o
Étude d’un algorithmede débruitage et estimation
de l’enveloppe d’erreur correspondante
Application aux données hyperspectralesde l’instrument MUSE
Auteurs
Jacques-Robert DELORME
Cédric CHINCA-NÉVACHE
Manuel VERMILLAC
Encadrant
M. MARY
9 mai 2011
Projet tutoré 2010/2011

1 Introduction
1.1 MUSEDe nombreuses zones d’ombre demeurent quant aux mécanismes à l’origine de la formation de notre ga-
laxie 1, il y a 10 milliards d’années, et à son histoire, c’est-à-dire, son évolution.De nos jours, il nous est possible d’observer une galaxie à l’aide de grands télescopes. Par exemple, en 2007,grâce au VLT 2 de l’ ESO 3, une équipe d’astrophysiciens est parvenue à étudier 27 proto galaxies, qui ont brilléaux premiers temps de l’Univers. Selon certaines estimations, près de 90 % des galaxies de l’Univers lointainauraient jusqu’à présent échappé à nos télescopes 4. Les confins de l’Univers répresentent donc l’espoir de leverle voile sur quelques mystères du passé du cosmos, à l’aide de nouveaux instruments et en observant de jeunesgalaxies. Une des idées est de collecter dans une image, à plusieurs longueurs d’onde (spectrographe intégral dechamp), la lumière de galaxies très éloignées à l’aide de grands téléscopes et en effectuant des temps de pausetrès longs.MUSE 5 est un instrument développé dans ce contexte. C’est un spectrographe intégral de champ en cours deconstruction au Centre de Recherche Astronomique de Lyon, qui équipera le VLT en 2012. MUSE permettrala découverte d’objets impossibles à détecter avec les techniques actuelles d’imagerie : nous serons donc enmesure d’observer le ciel avec une sensibilité encore jamais atteinte jusqu’à présent. Cet instrument permettraainsi d’explorer l’Univers en trois dimensions (deux dimensions pour les positions du ciel (les coordonnées(x,y)), une dimension pour les longueurs d’onde (λ )).MUSE produira des matrices cubiques (tenseurs) de données constituées de la même image du ciel dans envi-ron 4 000 longueurs d’onde différentes. Chaque image est constituée de 300 × 300 pixels. Les 4 000 longueursd’onde couvrent le spectre visible de la lumière de λmin = 480 nm à λmax = 930 nm avec une résolution del’ordre de ∆λ = 0,13 nm.L’instrument étant encore en construction, aucun cube de données n’a été produit pour l’heure. Une équipede chercheurs a pourtant déjà simulé, de la façon la plus réaliste possible, des données, afin de préparer desalgorithmes en vue d’analyser des données réelles. Dans chaque matrice cubique de données, deux types d’in-formations sont enregistrées :
– La première est dite spatiale, si on regarde une image à une longeur d’onde particulière.– La seconde est dite spectrale, dans le cas où on s’intéresse au même pixel sur l’ensemble des images de
longueurs d’onde différentes.Le cadre de notre étude se restreint à l’information spectrale enregistrée dans ces matrices cubiques. À chaquepixel est donc associé un spectre que l’on notera "−→y ". Chaque bloc de données fourni par MUSE est donccomposé de 300 × 300 = 90 000 spectres. Dans ce projet, nous ne traiterons qu’un seul spectre à la fois.
1.2 Données et bruit de MUSEIl faut dans un premier temps garder à l’esprit que chaque corps céleste possède un spectre d’émission qui
lui est propre. Il sera donc possible de caractériser les objets célestes à partir des spectres que nous transmettraMUSE.Or, le spectre que nous fournit le spectrographe n’est pas sans "erreurs". Celles-ci sont dûes aux autres sourceslumineuses interférant sur notre image de la Galaxie lointaine, car tout objet absorbant ou émettant de la lumièreentre le VLT et les objets observés est source de bruit. Le bruit considéré ici sera essentiellement produit paratmosphère terrestre (raies d’absorption et d’émission de molécules en suspension), ainsi que par les erreursinduites par les détecteurs (CCD), puis les miroirs et les fluctuations naturelles de la lumière (bruits de photons).Le bruit total résultant sera donc inévitable, variable en longueur d’onde (cf figure 2) et ne pourra pas êtrenégligé. Les données sont donc altérées par un bruit provenant d’une multitude de facteurs. Voici un exemple :
1. Une galaxie est, en cosmologie, un assemblage d’étoiles, de gaz, de poussières, de matière noire. Elle contient parfois un trou noirsupermassif en son centre. La Voie lactée est la galaxie dans laquelle se trouve le Système Solaire. On dénombre aussi des galaxies naineset des galaxies géantes. Il est cependant très difficile d’estimer le nombre de galaxies naines, du fait de leur masse et leur luminosité trèsfaibles.
2. Very Large Telescope, Chili3. European Southern Observatory4. http ://www.planet-techno-science.com/ciel-et-espace/pourquoi-90-des-galaxies-lointaines-restent-non-detectees-lors-de-nombreux-
grands-releves-%E2%80%A6-enfin-une-explication/5. Multi Unit Spectroscopic Explorer
2
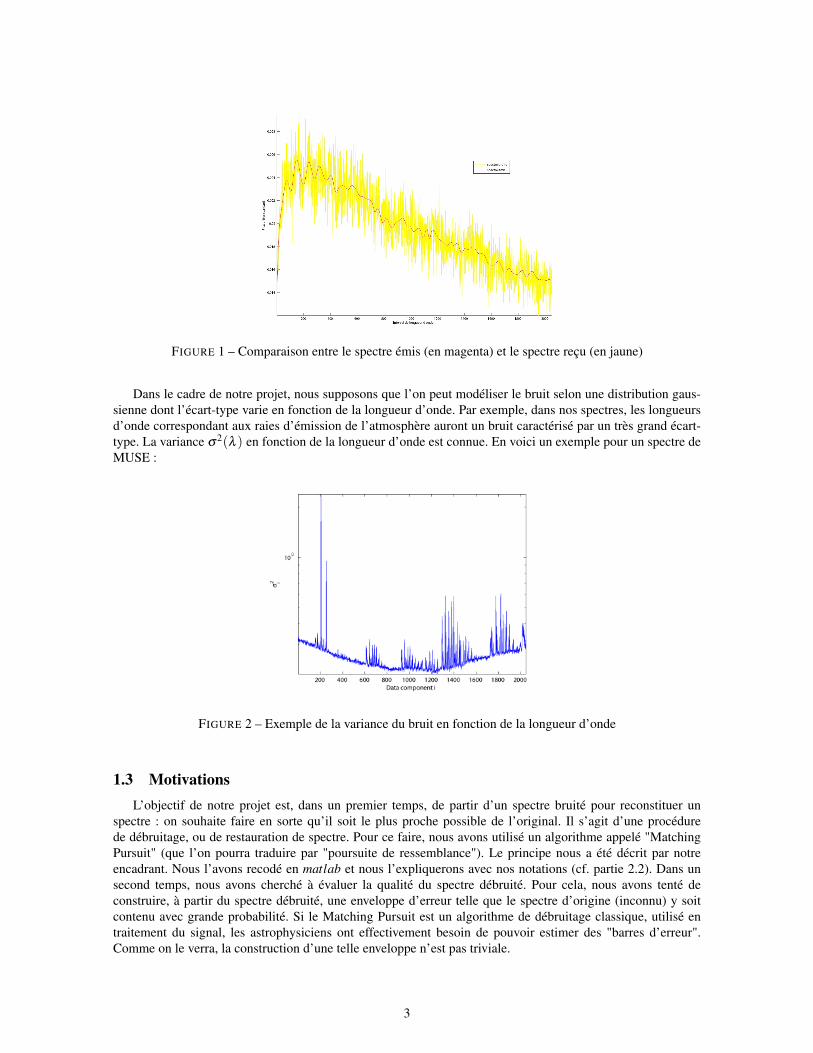
FIGURE 1 – Comparaison entre le spectre émis (en magenta) et le spectre reçu (en jaune)
Dans le cadre de notre projet, nous supposons que l’on peut modéliser le bruit selon une distribution gaus-sienne dont l’écart-type varie en fonction de la longueur d’onde. Par exemple, dans nos spectres, les longueursd’onde correspondant aux raies d’émission de l’atmosphère auront un bruit caractérisé par un très grand écart-type. La variance σ2(λ ) en fonction de la longueur d’onde est connue. En voici un exemple pour un spectre deMUSE :
FIGURE 2 – Exemple de la variance du bruit en fonction de la longueur d’onde
1.3 MotivationsL’objectif de notre projet est, dans un premier temps, de partir d’un spectre bruité pour reconstituer un
spectre : on souhaite faire en sorte qu’il soit le plus proche possible de l’original. Il s’agit d’une procédurede débruitage, ou de restauration de spectre. Pour ce faire, nous avons utilisé un algorithme appelé "MatchingPursuit" (que l’on pourra traduire par "poursuite de ressemblance"). Le principe nous a été décrit par notreencadrant. Nous l’avons recodé en matlab et nous l’expliquerons avec nos notations (cf. partie 2.2). Dans unsecond temps, nous avons cherché à évaluer la qualité du spectre débruité. Pour cela, nous avons tenté deconstruire, à partir du spectre débruité, une enveloppe d’erreur telle que le spectre d’origine (inconnu) y soitcontenu avec grande probabilité. Si le Matching Pursuit est un algorithme de débruitage classique, utilisé entraitement du signal, les astrophysiciens ont effectivement besoin de pouvoir estimer des "barres d’erreur".Comme on le verra, la construction d’une telle enveloppe n’est pas triviale.
3

2 Matching Pursuit
2.1 Notations et notions préliminairesPour modéliser un spectre, nous avons à notre disposition un "dictionnaire" que l’on notera "D". Un diction-
naire est une collection de formes élémentaires susceptibles d’être présentes dans les spectres. Pour les donnéesde MUSE, celui-ci est une matrice carrée de 2 048 lignes et 15 449 colonnes. En effet, nous travaillerons avec desspectres de 2 048 longueurs d’onde et un dictionnaire de 15 449 fonctions élémentaires. Dans chaque colonnedu dictionnaire est stockée une fonction qui peut être :
– soit une fonction de Dirac, pouvant représenter une raie d’émission ou d’absorbtion non résolue.– soit une fonction cosinus, décrivant les variations douces et globales des spectres d’émission des corps
noirs.– soit une fonction spline (forme proche de celle d’une gaussienne) : elle peut représenter une raie d’émis-
sion ou d’absorbtion étalée par effet Doppler.– soit une fonction de Heaviside (avec la forme d’une marche d’escalier), pouvant représenter les "break
light". Effectivement, certains nuages de poussière absorbent la lumière dans une partie du spectre biendéfinie, atténuant ainsi brutalement le spectre dans cette région en particulier.
Ces fonctions ont des fréquences et des phases différentes et nous les appelleront par la suite des "atomes", quel’on notera
−→Di, avec i = 1,2,3, ...,15449.
Dans la suite, nous noterons :– X , une matrice.– −→x et
−→X , des vecteurs (spectre ou une colonne issue de X).
– x, un scalaire.– −→x t et
−→X t , les transposées respectives de −→x et
−→X .
– I, la matrice identité.
Enfin, pour les spectres, nous utiliserons les notations et le code couleur suivants :–−→Y , le spectre de référence, sera en magenta.
– −→y , le spectre bruité reçu par MUSE, en jaune.–−→Yf , le spectre débruité une première fois, en noir.
–−→YM , le spectre moyen, en bleu.
–−−→Ymin et
−−→Ymax, les spectres constituant l’enveloppe, seront en rouge.
2.2 L’algorithme de débruitageNous commençons par isoler un spectre bruité, noté −→y , de la matrice cubique des données produite par
MUSE. Nous supposons qu’un tel spectre bruité peut être représenté comme une combinaison linéaire d’unfaible nombre de fonctions de référence appelées atomes.
FIGURE 3 – Décomposition d’un spectre en fonctions de références (atomes) plus un bruit.
L’objectif du Matching Pursuit est de décomposer ce spectre en quelques atomes, auquel on ajoute du bruit,que l’on notera "−→εc ". Chaque spectre peut donc être estimé (et donc débruité) à partir de la combinaison lineairede plusieurs atomes, auxquels on attribue des coefficients (amplitudes) appropriés, sans oublier le bruit.
4

On suppose donc que −→y est de la forme :
−→y = αvrai1−→D1 +α
vrai2−→D2 + ....+α
vrain−→Dn +
−→εc (1)
Où :– −→y est le spectre reçu par le télescope, il est donc bruité.– αvrai
i est le coefficient (l’amplitude) du ième atome du spectre non bruité (le vrai spectre du corps céleste),avec α ∈R.
–−→Di correspond au ième atome contenu dans −→y .
– −→εc représente le bruit, détaillé dans la partie (1.2), ainsi que les atomes non significatifs (structures nondétectables et noyées dans le bruit).
– n est le nombre d’atomes contenus dans −→y .
On a vu que le bruit contenu dans −→y n’est pas un bruit blanc (en effet, certaines longueurs d’onde λ sont plusaffectées que d’autres par le bruit). On connaît la façon avec laquelle le bruit est coloré : les prétraitements de
MUSE fournissent le vecteur contenant les variances pour chaque longueur d’onde que l’on notera "−→σ2" (cf. fig
2). Pour décolorer le bruit, il suffit de faire l’opération suivante :
−→εd = (diag
{−→σ
2})−1/2−→εc = Σ−1/2−→
εc
où −→εd est le bruit décoloré, −→εc est le bruit coloré, et où (diag{−→
σ 2}) = Σ est la matrice diagonale de diagonale
−→σ 2. Le bruit décoloré −→εd est dit blanc : sa variance vaut 1 pour tout λ . En effet :
E(−→εd−→εd
t) = E(
Σ−1/2−→εc
)(Σ−1/2−→
εc
)t= Σ−1/2 E
(−→εc−→εc
t)︸ ︷︷ ︸Σ
Σ−1/2 = Σ−1/2 Σ Σ−1/2 = I
Soit
E−→εc,i
2 = 1 pour tout i (2)
On verra l’importance de la décoloration du bruit plus tard, lorsqu’on discutera de la condition d’arrêt de l’al-gorithme.En prémultipliant l’équation (1) par Σ−1/2 , on obtient :
Σ−1/2−→y =n
∑i=1
αiΣ−1/2−→Di +Σ−1/2−→
εc
Qu’on peut réécrire comme :
−→yd =n
∑i=1
αi−→Di +
−→εd (3)
Où :– −→yd est le spectre "bruité décoloré".–−→Di = Σ−1/2−→Di correspond au ième atome "décoloré" contenu dans −→yd .
– −→εd est le bruit blanchi.– n est le nombre d’atomes contenus dans −→yd .
Le principe du Matching Pursuit est de sélectionner un par un les atomes les plus significatifs et de soustraireleur contribution pour déterminer un nouveau résidu. Ainsi, à la première itération, le Matching Pursuit supposeque le résidu est de la forme :
−→yd ≈ αm−→Dm +−→εd
On cherche donc l’atome "m" et le coefficient αm qui permettent de reconstruire le plus fidèlement possible −→yd .Pour cela, on cherche à minimiser : ∥∥∥−→yd −αv
−→Dv
∥∥∥2(4)
5

par rapport aux deux variables αv et ν . Supposons, dans un premier temps, avoir trouvé l’atome qui correspondle mieux (on l’a désigné comme étant le mème atome). Il faut alors déterminer le coefficient αm qui minimiseral’équation précédente. On note :
αm = argminαν
(∥∥∥−→yd −αv−→Dv
∥∥∥2)
La fonction à minimiser peut encore s’écrire :∥∥∥−→yd −αv−→Dv
∥∥∥2=(−→yd
t −αv−→Dv
t)(−→yd −αv
−→Dv
)=−→yt
d−→yd −αv
−→ydt−→Dv−αv
−→Dv
t−→yd +α2v−→Dv
t−→Dv
= ‖−→yd‖2−2αv−→yd
t−→Dv +α2v
∥∥∥−→Dv
∥∥∥2
Cette dernière équation est de la forme ax2 + bx+ c avec a≥ 0 et en posant x = αv. On trouve le minimum dedette fonction de αv lorsque la dérivée s’annule. On dérive donc par rapport à αv :
∂
∥∥∥−→yd −αv−→Dv
∥∥∥2
∂αv= 2αv
∥∥∥−→Dv
∥∥∥2−2−→yd
t−→Dv
La dérivée s’annule quand :
2αv
∥∥∥−→Dv
∥∥∥2−2−→yd
t−→Dv = 0
Ce qui nous donne :
αv =−→yd
t−→Dv∥∥∥−→Dv
∥∥∥2 =
⟨−→yd ,−→Dv
⟩∥∥∥−→Dv
∥∥∥2
Où :⟨−→a ,−→b⟩
désigne le produit scalaire entre les vecteurs −→a et−→b .
On connaît donc la valeur du coefficient qu’il faut attribuer à chaque atome pour minimiser l’équation (4) à ν
fixé. On va maintenant déterminer l’indice v qui minimise l’équation (4) :
m = argminν
∥∥∥−→yd −αv−→Dv
∥∥∥2= argminν
∥∥∥∥∥∥∥−→yd −
⟨−→yd ,−→Dv
⟩∥∥∥−→Dv
∥∥∥2−→Dv
∥∥∥∥∥∥∥2
Pour cela, on cherche :
m = argminν
∥∥∥∥∥∥∥−→yd −
⟨−→yd ,−→Dv
⟩∥∥∥−→Dv
∥∥∥2−→Dv
∥∥∥∥∥∥∥2
Comme : ∥∥∥∥∥∥∥−→yd −
⟨−→yd ,−→Dv
⟩∥∥∥−→Dv
∥∥∥2−→Dv
∥∥∥∥∥∥∥2
=
−→ytd −
⟨−→yd ,−→Dv
⟩∥∥∥−→Dv
∥∥∥2−→Dv
t−→yd −
⟨−→yd ,−→Dv
⟩∥∥∥−→Dv
∥∥∥2−→Dv
= ‖−→yd‖2−2
⟨−→yd−→Dv
⟩2
∥∥∥−→Dv
∥∥∥2 +
⟨−→yd−→Dv
⟩2
∥∥∥−→Dv
∥∥∥2
= ‖−→yd‖2−
⟨−→yd−→Dv
⟩2
∥∥∥−→Dv
∥∥∥2
6

On constate que minimiser l’équation (4) revient à maximiser le terme négatif. Donc finalement, on obtient :
m = argmaxν
(−→yd
t−→Dv
)2
∥∥∥−→Dv
∥∥∥2
= argmaxν
∣∣∣⟨−→yd ,
−→Dv
⟩∣∣∣∥∥∥−→Dv
∥∥∥ (5)
À la première itération, nous savons donc comment choisir l’atome qui représente le mieux le spectre décoloré,et lui attribuer le coefficient qui maximisera sa corrélation avec le spectre bruité. Nous faisons alors l’opérationsuivante :
−→yr,1 =−→yd −αm
−→Dm
Où : −→yr,1 est le 1er résidu. Pour les itérations successives, on recommence en trouvant l’atome et le coefficientqui seront le mieux corrélés avec −→yr,1. On obtient le résidu −→yr,2, et ainsi de suite. Idéalement, après n itérations(on rappelle que n est le nombre d’atomes composant le spectre non bruité), on a soustrait au spectre bruité tousles atomes le constituant, et il ne reste donc plus que le bruit blanc : −→yr,n =
−→εd . On peut donc reconstruire un
spectre débruité "−→Y " à partir des atomes sélectionnés et de leurs coefficients respectifs :
−→Y =
n
∑i=1
αi−→Di =D×−→α
On remonte alors au spectre débruité final−→Yf par :
−→Yf = Σ+ 1/2−→Y = Σ+ 1/2D×−→α = D×−→α
À la fin de l’algorithme, on obtient un vecteur colonne−→α qui sera organisé de la façon suivante : on enregistreradans la jème case le coefficient "α j" correspondant au jème atome. Si un atome n’a jamais été sélectionné, on luiassocie le coefficient "0".
Par exemple, si le "Matching Pursuit" a sélectionné les atomes 3, 8, 13, 21 et 24 respectivement avec lescoefficients -0.22, 0.66, 0.02, -3.25 et 1.12, −→α sera construit de la manière suivante :
– à la 3ème case, on enregistrera le coefficient -0.22,– à la 8ème case, on enregistrera le coefficient 0.66,– à la 13ème case, on enregistrera le coefficient 0.02,– à la 21ème case, on enregistrera le coefficient -3.25,– à la 24ème case, on enregistrera le coefficient 1.12,– et le reste sera rempli de "0".
FIGURE 4 – Représentation des données blanchies comme une combinaison linéaire de 5 atomes.
7

Une question importante est celle de l’arrêt de l’algorithme : nous devons limiter le nombre d’itérations afinde ne pas reconstituer le spectre avec le bruit. Nous cherchons à arrêter les itérations lorsque −→yr,i ≈−→εd , c’est-à-dire lorsque le résidu possède les propriétés statistiques du bruit. Supposons que le résidu ne contienne que lebruit −→yr,i =
−→εd . Alors, dans le processus de sélection, (cf équation 5), on est amené à considérer les quantités :
uν =
⟨−→yr,i,−→Dν
⟩∥∥∥−→Dν
∥∥∥ =
⟨−→εd ,−→Dν
⟩∥∥∥−→Dν
∥∥∥ =1∥∥∥−→Dν
∥∥∥ [ε1,ε2, ... ,εn] .
Dν ,1Dν ,2
...Dν ,n
=1∥∥∥−→Dν
∥∥∥n
∑i=1
Dν ,i εi (6)
uν est donc gaussienne (combinaison de variables aléatoires gaussiennes), de moyenne et de variance :
Euν =1∥∥∥−→Dν
∥∥∥En
∑i=1
Dν ,i εi =1∥∥∥−→Dν
∥∥∥n
∑i=1
Dν ,i Eεi︸︷︷︸=0
= 0
var(uν ) = Eu2ν =
1∥∥∥−→Dν
∥∥∥2 E
(n
∑i=1
Dν ,i εi
)(n
∑j=1
Dν , j ε j
)
=1∥∥∥−→Dν
∥∥∥2
n
∑i=1
Dν ,i Eε2i︸︷︷︸
=1
+2n
∑i 6= j
Dν , jDν ,i Eεiε j︸ ︷︷ ︸=0
=1∥∥∥−→Dν
∥∥∥2
n
∑i=1
D2ν ,i = 1
Où on a utilisé :– E(εa + εb) = Eεa +Eεb.– Eεi = 0 et Eε2
i = 1 (cf équation 2) : (εd suit une loi normale centrée et réduite N (0,1))Le blanchiment du bruit a son intérêt ici. Effectivement, si le bruit n’était pas blanchi, Eε2
i aurait été différentepour chaque longueur d’onde (chaque valeur de i). Le blanchiment égalise Eε2
i à 1 pour tout i. Par conséquent,les coefficients uν , lorsque le résidu−→yr,i =
−→εd , suivent tous une loi normale N (0,1). On choisit donc une valeur
seuil "S ", qui sera utilisée dans notre condition d’arrêt de la façon suivante : Nous déterminons S de sortequ’un atome "ν" inexistant dans le spectre de référence (considéré comme une fausse alarme : FA) ait uneprobabilité très faible d’être sélectionné :
PFA(ν) = P(|uν |> S ) = 2∫
∞
S
1√2π
exp(− t2
2
)dt
FIGURE 5 – Probabilité qu’un atome soit sélectionné par la procédure (5), alors que le résidu ne contient que dubruit.
Par exemple, pour : S = 3, PFA(ν) = 2.7/1000.À chaque itération, le Matching Pursuit aura donc deux alternatives :
– Si le maximum des |uν | (équation 5) est supérieur à S , alors le Matching Pursuit continuera ces itérations,– Sinon, l’algorithme du Matching Pursuit s’arrête.
8

Résumé de l’algorithme du Matching Pursuit
Soit un spectre bruité −→y , on le modélise par :
−→y = αvrai1−→D1 +α
vrai2−→D2 + ...+α
vrain−→Dn +
−→εc
Ayant fixé S , on choisit une probabilité de fausse alarme PFA, puis :
1. On commence par "blanchir" les données :
−→yd = Σ−1/2−→y
2. On cherche le couple atome-coefficient le mieux corrélé à −→yd grâce aux formules :
m = argmaxν
∣∣∣⟨−→yd ,
−→Dv
⟩∣∣∣∥∥∥−→Dv
∥∥∥ et αm =
−→ydt−→Dm∥∥∥−→Dm
∥∥∥2 =
⟨−→yd ,−→Dm
⟩∥∥∥−→Dm
∥∥∥2
On soustrait la contribution de l’atome m à −→yd , ce qui nous donne le résidu −→yr,1 :
−→yr,1 =−→yd −αm
−→Dm
3. On répète l’étape 2 en remplaçant −→yd par le dernier résidu, jusqu’à ce que la condition d’arrêtsoit atteinte, c’est-à-dire jusqu’à ce que le maximum des |uν | (équation 5) soit sous le seuil S fixé.
4. On reconstruit alors−→Yf grâce aux couples atomes-coefficients sélectionnés :
−→Yf =
n
∑i=1
αi−→Di = D×−→α
Conclusion :
À partir de −→y , on obtient le spectre débruité et les coefficients correspondants−→Yf et −→α .
Nous avons programmé cet algorithme et on peut voir les résultats : figures 8 et 9, où−→Yf est représenté en
noir.
3 Construction d’une enveloppe d’erreur
3.1 Les différents spectres et leur notationReprenons l’histoire de notre spectre :– Initialement, une galaxie lointaine émet de la lumière à différentes longueurs d’onde. Après propagation
dans l’espace et à l’arrivée au voisinage de l’atmosphère terrestre, cette lumière, échantillonnée dans lescanaux spectraux de MUSE, constitue le spectre de référence. On le notera :
−→Y .
– Cette lumière traverse l’atmosphère et est analysée par le détecteur qui génère encore du bruit. On obtientun spectre bruité (les données) que l’on a noté : −→y .
– On effectue un débruitage de ce spectre : on lui applique le Matching Pursuit et on obtient le spectredébruité que l’on note
−→Yf .
Bien sûr, à cause du bruit, le Matching Poursuit ne retrouve pas parfaitement le spectre initial (−→Yf 6=
−→Y ). On
peut classer ces erreurs en trois groupes :– Type 0 : Les erreurs d’estimation des composantes principales qui comportent :
? la sélection d’un atome voisin mais non identique par rapport à celui qui serait sélectionné en absencede bruit.
9

? la sélection du "bon" atome mais avec une amplitude différente de celle qui serait obtenue en absencede bruit.
– Type 1 : Les "fausses alarmes" : ce sont des atomes sélectionnés alors qu’ils ne sont pas significatifs dansla décomposition du spectre de référence non bruité (le bruit à "imité" la forme d’un atome).
– Type 2 : Les erreurs dues aux atomes manqués (noyés dans le bruit, donc non sélectionnés).Notre second objectif est donc d’estimer l’erreur commise par le Matching Poursuit, entre
−→Yf et
−→Y . Pour ce
faire, nous allons construire une enveloppe de confiance constituée de deux courbes−−→Ymin et
−−→Ymax, de sorte que−→
Y , qu’on souhaite quantifier, ait de grandes chances de s’y trouver. Ces spectres suivent le code couleur établiprécédemment (partie 2.1).
3.2 Démarche empiriqueAfin de pouvoir construire une enveloppe de confiance préliminaire, nous avons dans un premier temps
cherché à estimer les erreurs de type 0. Notre démarche est empirique, elle est basée sur de nombreuses simu-lations numériques (Méthode de Monte-Carlo). L’idée est la suivante : Si le Matching Pursuit n’a pas fait defausse alarme et n’a manqué aucune structure importante de
−→Y , alors la seule erreur contenue dans
−→Yf provient
des erreurs de type 0 (erreurs d’estimation des composantes principales). Elle se traduit par une erreur "e(i)" àchaque longueur d’onde. Comme e(i) est une variable aléatoire, nous proposons d’étudier ses statistiques. Parexemple, si e(i) est additif et si e(i) ∼N (0,σ2
ei), ceci signifie que :
Yfi =Yi + ei et PY (Yi−3σei < Yfi <Yi + 3σei) = 1− 2.71000
Mais de même :
PY
Yfi −3σei︸ ︷︷ ︸Ymin
<Yi < Yfi + 3σei︸ ︷︷ ︸Ymax
= 1− 2.71000
(7)
L’équation (7) nous permet de déduire, à partir de de−→Yfi , dans quelle plage de valeur peut se situer Yi
FIGURE 6 – Vraisemblance de Yi sachant Yfi en (a), et de Yfi sachant Yi en (b).
Pour chaque Yfi du signal débruité, cette démarche nous permettrait donc d’estimer la vrai valeur de Yi.
3.2.1 Générer des "données après coup"
Etudier les statistiques de e(i) nécessite une grande quantité de données que nous devrons générer nous-même. Pour cela, nous allons créer, à partir d’un spectre de référence
−→Y , plusieurs spectres bruités −→y . Nous
bruiterons avec un bruit gaussien de variance −→σ 2 connue, dont l’amplitude est directement liée à l’amplitudeinitiale du signal
−→Y (en effet, la variance du bruit sera plus forte quand l’amplitude du signal augmente et
réciproquement). On construit −→y comme suit :– Dans un premier temps, on choisit une amplitude a qui règlera la puissance du bruit par rapport au signal.
10

– Ensuite, on multiplie le signal initial par a, pour obtenir un vecteur−→Σ . Ce vecteur contient pour chaque
valeur de "λ " (pour chaque fréquence du spectre), la variance du bruit, que l’on va générer, en chaquepoint du spectre.
– Puis, on crée le bruit −→εc tel que :−→εc = (diag{Σ})+ 1/2−→g
Où −→g est un vecteur gaussien centré et réduit(E (−→g −→g t) = I
).
– Finalement, on construit −→y :−→y =
−→Y+−→εc
Cette méthode nous permet de construire un grand nombre de spectres−→y , auxquels nous pouvons appliquerle Maching Pursuit pour obtenir un spectre
−→Yf et faire des statistiques. Grâce à ces étapes, nous pourrons par la
suite confronter−→Y et les résultats que nous avons.
En pratique, les vraies données seront uniques : on ne disposera que d’un seul spectre −→y et de son spectredébruité
−→Yf . Comme
−→Yf contient en première approximation les structures principales de
−→Y , afin d’estimer les
erreurs de type 0 commises par l’algorithme, on peut utiliser−→Yf en guise de
−→Y . Par conséquent, afin d’obtenir
la statistique des e(i), nous rebruitons à plusieurs reprises les données débruitées−→Yf :
1. Nous générons une nouvelle réalisation du bruit −→εc , que nous ajoutons à−→Yf .
2. Ensuite, nous appliquons le Matching Pursuit pour obtenir un nouveau spectre−→Y1 , ainsi qu’un vecteur −→α1
3. Nous répétons les étapes 1 et 2 un très grand nombre de fois (N), afin d’obtenir un grand nombre decouples
−→Yi -−→αi .
Ceci nous permet d’obtenir la distribution des−→Yfi à une longueur d’onde donnée et donc d’en déduire l’enve-
loppe. Pour faciliter le traitement des données, nous organisons les résultats en deux matrices A et S :– Dans la matrice A, nous stockerons les −→αi , chaque −→αi sera enregistré dans une colonne.– Dans la matrice S, nous stockerons les spectres
−→Yi , un
−→Yi par ligne.
Résumé de la génération de "données après coup" pour l’enveloppe d’erreur liée aux erreurs d’itérationsNous générons nos données ainsi :
1. Initialement, on sélectionne un spectre connu−→Y , qui sera notre spectre de référence.
2. Nous produisons ensuite un bruit −→εc , que nous ajoutons à−→Y afin d’obtenir un spectre bruité −→y .
3. Nous appliquons la Maching Pursuit à −→y pour obtenir−→Yf .
4. À partir de−→Yf , nous obtenons un grand nombre de couples
−→Yi -−→αi .
Conclusion :
À partir de−→Yi , nous étudions la distribution de e(i) à chaque longueur d’onde.
Nous déduirons l’enveloppe des σe(i).
3.2.2 Estimation des erreurs de type 0 à chaque longueur d’onde.
Pour cette étude, nous nous servirons essentiellement de la matrice S dans laquelle, rappelons-le, sont enre-gistrés les N spectres générés précédemment. Cette étude est relativement simple et intuitive. Dans un premiertemps, on calcule la moyenne et l’écart-type des spectres débruités
−→Yi pour toutes les longueurs d’onde : dans
chacune des colonnes de S sont enregistrées les valeurs des intensités lumineuses des différents spectres−→Yi , cor-
respondant à la longueur d’onde λ de la colonne. Nous pouvons alors étudier la statistique des Yi, pour chaqueλi. Voici (Figure 7) un exemple pour une longueur d’onde particulière i : On voit que :
−→Yi =
−→Yfi + e(i)
11

FIGURE 7 – Distribution empirique des Yi à une longueur d’onde i particulière (a) et modélisation gaussiennedu bruit introduit par l’algorithme (b)
avec e(i) approximativement gaussien, d’écart-type σe(i). L’algorithme produit des erreurs de type 0 qui sont
essentiellement additives et gaussiennes . On stocke les écarts-types de chaque λi dans un vecteur−→Ect, et la
valeur moyenne des N spectres bruités dans le spectre−→YM . On obtient l’enveloppe inférieure
−−→Ymin et supérieure−−→
Ymax de la manière suivante :−−→Ymin =
−→YM− c×−→Ect
−−→Ymax =
−→YM + c×−→Ect
où c est un coefficient (par exemple c = 3 pour une enveloppe à 3σ ). Les figures ci-dessous donnent desexemples d’enveloppe résultante : (en rouge)
FIGURE 8 – Différentes courbes obtenues grâce à l’étude statistique des spectres pour des "c" différents
3.2.3 Analyse de la méthode
Cette méthode nous permet d’obtenir une enveloppe d’erreur relativement satisfaisante (l’originale, incon-nue, est contenue dans l’enveloppe quasiment partout). Cependant, on remarque que les deux types d’erreurnégligés (oublis et fausses alarmes) apparaissent dans cette méthode (cf Figure 9) :
– Les erreurs, dues aux fausses alarmes, qui élargissent ponctuellement l’enveloppe.– Les "oublis", dus à des écarts trop importants entre
−→Y et
−→Yf , et qui font que
−→Y n’est pas compris dans
l’enveloppe à certains endroits.
12

FIGURE 9 – Agrandissement d’une partie de la figure (8 (a) et 8 (b)) mettant en évidence la présence d’oubliset de fausses alarmes.
Gardons à l’esprit que cette méthode traite uniquement les erreurs de type 0. Or, le bruit peut masquercertains atomes (ce qui est à l’origine des "oublis"), ou au contraire en imiter certains autres (causant les faussesalarmes). Il serait possible de modifier le premier Matching Pursuit qui nous a permis d’obtenir
−→Yf à partir de
−→Y
en augmentant la valeur seuil S qui interrompt l’algorithme. Le Matching Pursuit sélectionnera par conséquentmoins d’atomes et il y aura donc moins de fausses alarmes. Néanmoins, ceci augmentera le nombre d’oublis etvice-versa. Pour un taux de fausses alarmes fixé (par S ), nous allons tenter de prendre en compte non seulementles erreurs de type 0 traitées précédemment, mais aussi les erreurs de type 2 (les oublis).
3.3 Proposition pour améliorer l’enveloppe : estimation des erreurs de type 2Comme nous l’avons dit plus haut, notre algorithme a limité le nombre de fausses alarmes (suivant S )
au prix de l’oubli d’atomes initialement présents dans le spectre de référence. L’idée pour estimer un signald’erreur prenant en compte ces oublis est d’estimer, dans le résidu final, la probabilité que chaque atomes ait àce stade de la décomposition une amplitude significative, mais qu’il soit jugé non significatif à cause du bruit.En supposant qu’il n’y a pas eu d’erreur de type 0 ou 1 dans la décomposition jusqu’au résidu final, on peutécrir le résidu comme :
−→r f =−→εd +
N
∑i=1
αisans bruit
−→Di
où : αisans bruit est l’amplitude qui serait atribuée au ième atome pour une décomposition sans bruit avec S =
0.Dans le résidu final, on peut calculer pour chaque atome−→Dν uν (< S pour toutν) et αν (l’amplitude qu’on
lui attribuerait si nous on sélectionnerait) :
uv =
⟨−→Dv,−→r f
⟩∥∥∥−→Dv
∥∥∥ < S pour tout ν , et αv =
⟨−→Dv,−→r f
⟩∥∥∥−→Dv
∥∥∥2 (a)
La question que l’on peut se poser est la suivante : si on observe dans le résidu final, uν et αν , quelle est laprobabilité pour que uν sans bruit (qui aurait été obtenu pour cet atome en décomposant le spectre au-delà de Ssans bruit) soit en réalité supérieurs à S , et qu’il ait été mis sous le seuil S par le bruit ?
Dans le cas général :
uv =
⟨−→Dv,−→r f
⟩∥∥∥−→Dv
∥∥∥ =
⟨−→Dv,−→εd
⟩∥∥∥−→Dv
∥∥∥︸ ︷︷ ︸(wn)
+
⟨−→Dv,∑N
i=1 αi−→Di
⟩∥∥∥−→Dv
∥∥∥︸ ︷︷ ︸(uν sans bruit)
13

αv =
⟨−→Dv,−→r f
⟩∥∥∥−→Dv
∥∥∥2 =
⟨−→Dv,−→εd
⟩∥∥∥−→Dv
∥∥∥2
︸ ︷︷ ︸(w′n)
+
⟨−→Dv,∑N
i=1 αi−→Di
⟩∥∥∥−→Dv
∥∥∥2
︸ ︷︷ ︸(αν sans bruit)
Où : wn suit une loi normale telle que wn ∼N (0,1).On ne connait pas les vraies valeurs uv sans bruit et αv sans bruit sans bruit, mais compte tenu des équations (a) et(b) les valeur les plus vraisemblables sont uv et αv.
Donc l’atome v, qui n’a pas été sélectionné, a une probabilité :
τv =∫ −S
−∞
1√2π
exp−(12 (t−uν )2) dt︸ ︷︷ ︸
I
+∫
∞
S
1√2π
exp−(12 (t−uν )2) dt︸ ︷︷ ︸
II
d’avoir une amplitude significative dans la décomposition sans bruit alors qu’il a été jugé non significatif à causedu bruit (figure 10).
FIGURE 10 – (a) Probabilité d’être sélectionné pour uν négatif - (b) Probabilité d’être sélectionné pour uν positif
Ce phénomène nous oblige à envisager deux cas :– Si τv >
2.71000 , on le garde pour l’enveloppe.
– Sinon, on le considère définitivement comme non significatif.On obtient donc pour chaque atome v une valeur uv et une probabilité τv, représentées sur les graphes ci-
dessous :
FIGURE 11 – (a) Valeur de uv pour chaque atome ν - (b) Probabilité de chaque atome d’être en réalité au dessus du seuil
14

À partir de ces données, on peut à présent construire une enveloppe pour les atomes oubliés. Ceux qui ont uncoefficient αv > 0 seront utiles à l’élaboration de l’enveloppe supérieure
−−→Ysup, ces coefficients étant enregistrés
dans un vecteur−−→αsup, tandis que les atomes ayant un coefficient αv < 0 permettront de construire l’enveloppe in-férieure
−→Yin f , dont les coefficients sont stockés dans un vecteur−−→αin f . On rapelle que αv se calcule par la formule :
αv =uv∥∥∥−→Dv
∥∥∥On pondère chaque atome v par la probabilité τv qu’il a d’être, en réalité, un atome significatif. On construitalors les enveloppes
−→Yin f et
−−→Ysup de la manière suivante :
−→Yin f = D×
[−−→αin f ×−→τ
]−−→Ysup = D×
[−−→αsup×−→τ
]Ces enveloppes correspondent au minimum et au maximum des signaux obtenus en prenant la valeur moyennedes atomes qui ont une probabilité supérieur à d = 2.7/1000 d’avoir des amplitudes significaives lors d’une dé-composition sans bruit. On trace cette nouvelle enveloppe sur la figure ci-dessous :
FIGURE 12 – (a) Enveloppe des atomes oubliés - (b) Zoom
3.4 Enveloppe finaleOn a finalement construit deux enveloppes d’erreur :– La première est basé sur l’étude statistique du bruit (figure 8) : son enveloppe évalue les erreurs d’estima-
tion des comportements principaux (type 0). Elle considère qu’il n’y a ni fausse alarme (erreur de type1), ni atome oublié (erreur de type 2).
– La seconde repose sur l’étude des atomes qui auraient put être oubliés lors du premier Matching Pursuitpermettant d’obtenir Yf (figure 12). On admet également qu’il n’y a pas de fausse alarme.
Ces deux méthodes sont complémentaires. Si on choisit la même valeur seuil pour les deux enveloppes (cet d), on peut les additionner afin d’obtenir une enveloppe cohérente. Ce résultat est amélioré par rapport à la
15

figure (9) On remarque en particulier qu’il n’y a plus d’oublis par rapport à la figure 9. Voici une illustration dela superposition des deux méthodes :
FIGURE 13 – (a) Somme des deux types d’enveloppe - (b) Zoom
L’enveloppe verte et celle que l’on aurait obtenu en ne considérant que l’écart-type du bruit en chaque pointdu spectre (ici 4σ ).
4 ConclusionCe projet nous a permis, dans un premier temps, de coder en matlab l’algorithme du Matching Pursuit déjà
existant. Notre implémentation fonctionne comme illustré sur les figures de ce rapport. Nous avons ensuite ana-lysé les différents types d’erreur de cet algorithme et les avons répertoriés en 3 classes : composantes principales,fausses alarmes et oublis. Le problème de l’analyse de ces erreurs est compliqué car elles interagissent entreelles. Notre approche a consisté à tenter d’isoler et d’estimer chaque type d’erreur séparément. La constructionde notre enveloppe se déroule en deux étapes :
– Une première méthode suppose que le spectre fourni par le Matching Pursuit−→Yf a les mêmes structures
principales que le spectre de référence−→Y que l’on cherche à estimer. Elle évalue les statistiques des
erreurs de type 0 créées par le Matching Pursuit en utilisant−→Yf . Puisque
−→Yf a une structure principale
similaire à celle de−→Y , ses statistiques sont bien estimées à l’aide de
−→Yf plutôt qu’avec
−→Y qui sera inconnu
en pratique. Ceci nous permet de construire la première enveloppe, prenant uniquement en compte leserreurs de type 0. Cependant, elle présente des défauts dus aux erreurs de type 1 et 2 ignorées lors de sonélaboration.
– La seconde méthode prend en compte cette fois-ci les erreurs de type 2 en supposant qu’il n’y a pasd’erreurs de type 0 et 1 dans la décomposition jusqu’au résidu final−→r f . Elle estime dans−→r f , la probabilitéque chaque atome a d’avoir, à ce stade de la décomposition, une amplitude significative mais qu’elle soitjugée non significative à cause du bruit. On construit ainsi la seconde enveloppe, en évaluant uniquementles erreurs de type 2.
Ces deux méthodes complémentaires nous permettent d’obtenir une enveloppe satisfaisante et cohérente car elletient compte de deux types d’erreur sur trois. L’amplitude de l’enveloppe finale est exploitable et raisonnable.
Finalement, il serait possible de prendre en compte également les erreurs de type 1 en élaborant un procédécomparable au deuxième, qui estimerait, à l’inverse, la probabilité que chaque atome sélectionné a d’avoir uneamplitude non significative mais que celle-ci soit jugée significative à cause du bruit.
16





























