Embed Size (px)
Citation preview

基于中文文本的图像自动分类
研究 Study on the Categorization of
Images Using Associated Chinese Text
(申请清华大学工程硕士专业学位论文)
培 养 单 位 : 计算机科学与技术系
工程领域 : 计算机技术
申 请 人 : 曹 红 光
指导教师 : 孙 茂 松 教 授
二○○九年十一月

基
于
中
文
文
本
的
图
像
自
动
分
类
研
究
曹
红
光

关于学位论文使用授权的说明
本人完全了解清华大学有关保留、使用学位论文的规定,即:
清华大学拥有在著作权法规定范围内学位论文的使用权,其中包
括:(1)已获学位的研究生必须按学校规定提交学位论文,学校可以
采用影印、缩印或其他复制手段保存研究生上交的学位论文;(2)为
教学和科研目的,学校可以将公开的学位论文作为资料在图书馆、资
料室等场所供校内师生阅读,或在校园网上供校内师生浏览部分内
容。
本人保证遵守上述规定。
作者签名: 导师签名:
日 期: 日 期:


摘 要
I
摘 要
随着互联网及多媒体技术的蓬勃发展, Internet上各种形式的数字化信息如
图像资源正呈指数级态势增长着。图像能够以更加直观、更容易让人们理解的
方式传递信息,“一幅图胜千言”充分说明了图像在信息传播方面的重要作用。
图像分类是 Web数据挖掘领域的一个重要的研究方向。通过对图像自动分
类不仅可以将图像按照类别信息建立相应的信息资源库,方便科研人员进行研
究和利用,而且可以用来提高搜索引擎的搜索准确性,便于普通用户查找及使
用,最大程度上满足用户各种需求。
目前基于内容和基于文本的图像分类技术仍存在不少缺陷与不足,分类的
质量不高。本课题即着眼于这一方向对基于文本的图像自动分类方法进行一些
研究。
论文的主要成果如下:
1. 参照大百科全书中文分类体系,从中选取军事、体育、交通、航空航天、电
影、民族、生物学、天文学、考古学、戏曲曲艺 10 个相互之间较为独立的
类别,以这 10个类别为基础构建了一个包括 1000篇文档的中文图文数据集
用于图像自动分类研究。
2. 根据构建的 10 类中文图文数据集进行了一系列基于文本的图像分类实验,
表明综合图像内容与关联文本一起对图像标注类别这种方式是最为合理的;
并在图文数据集上进一步通过交叉验证实验,证明使用支持向量机(SVM)
的分类系统对图像基于全文本进行分类的方法可以达到较满意的分类效果。
3.3.3.3. 本文使用基于图的排序方法在自然语言处理领域的具体实现-TextRank自动
抽取出文档关键词应用于基于文本的图像分类研究上。实验结果表明,从关
联文本中抽取的关键词包含了图像的重要信息,适当增加关键词在文档中文
本的所占比例然后将其用于对图像分类,比同样实验环境下使用全文本在评
测指标 F1-measure上取得了约 0.1%至 6%的提高;将关键词用于对图像分类
可以大大降低文本分类特征空间的高维性,降低计算复杂度,减少训练时间
开销和分类过程中无用词语产生的噪声,进而提高分类效率。
关键词关键词关键词关键词::::图像分类 图像标注 图文数据集 关键词抽取 TextRank

Abstract
II
Abstract
With the flourish of Internet and multimedia technology, the various forms of
digital information is growing rapidly. The image resources are also growing at the
exponential trend. Through the color, texture, shape and so rich in visual features,
images can be more intuitive and easier way to make people understand the
transmission of information. "A picture is worth a thousand words" fully describes the
the important role of image in information dissemination.
Image classification is an important research direction in the field of
Web data mining. By auto-classification of images we can not only establish
the appropriate the image information resource database according to
information of categories and provide better image retrieval and management
services to facilitate researchers to research and use, but also can improve the
accuracy of search engines and facilitate ordinary users easy to find and use.It
will meet the needs of customers in the maximum extent.
At present, the content-based image auto-classification technology can
only be applied to some special image retrieval due to technology and
implementation which there is many limitations, such as fingerprint
identification and trademark retrieval. There are still many shortcomings and
inadequacies of the text-based image auto-classification technology,and so
the classification quality is not good. All of these need the further research
and improvements. This thesis is to focus on these gaps on how to improve the
method of Chinese text-based image auto-classification.
The main contributions of this thesis are as follows:
1. Refer to the classification system of the Chinese Encyclopedia, we
selected the military, sports, transportation, aerospace, film, ethnic,
biology, astronomy, archeology, drama to establish a images and texts
dataset which be make up of 10 separate categories for image
auto-classification study. There are 1000 documents in the data set, 100
documents in each category, each document that contains an image and

Abstract
III
associated text.
2. According to the images and texts dataset, we perform a series of
text-based image auto-classification experiments. We have demonstrated
that it’s the most reasonable way that image was annotated with image
content and the relevant text together through experiments. And further
more, through cross-validation experiments we confirmed that by the using
of support vector machine (SVM) classification system in the 10
categories of self-built images and texts dataset we can achieve a more
satisfactory classification results based on the text-based image
auto-classification method.
3. In this thesis we use the TextRank which is the concrete realization in
natural language processing area with graph-based ranking method for
automatic keyword extraction to study on the text-based image
auto-classification. Experimental results show that the keywords extracted
from the relevant text contain important information about the image.
Increasing the keywords proportion appropriately in the document for
image classification, this has achieved about 0.1% to 6% increasing of the
F1-measure compared with using the full-text in the same experimental
conditions. By using the keywords to classify images can greatly reduce
the high-dimensional of features in text categorization, and as well can
reduce the computational complexity and training time. Similarly, the
keywords reduce the noise generated by the useless words in the process of
classification, and thus can improve the classification efficiency.
Keywords: Image Classification Image Annotation Images and Texts
dataset Keyword Extraction TextRank

目录
IV
目目目目 录录录录
第 1章 引言 ...............................................................................................................1
1.1 论文背景及意义 ............................................................................................1
1.2 图像分类技术研究现状..............................................................................1
1.2.1 基于内容图像的分类技术 ......................................................................1
1.2.2 基于文本的图像分类技术 ......................................................................2
1.3 文本分类技术现状......................................................................................3
1.4 论文主要内容..............................................................................................4
第 2章 图像及关联文本数据集的构造 ...................................................................5
2.1 网络爬虫 ........................................................................................................5
2.2 图文数据集的创建 ........................................................................................6
2.2.1 图像关联文本的选取方法 ......................................................................6
2.2.2 文档中图像的标注 ..................................................................................7
2.3 小结 ..............................................................................................................12
第 3章 基于不同关联文本的图像分类 .................................................................13
3.1 实验系统结构框架图 ..................................................................................13
3.2 实验中所使用的文本分类器系统 ECTCS.................................................13
3.2.1 该系统对中文文本的预处理 ................................................................15
3.2.2 该系统的特征选择 ................................................................................16
3.2.2 该系统的特征权重的计算方法 ............................................................18
3.3 实验中使用的数据集 ..................................................................................19
3.4 实验评价指标 ..............................................................................................20
3.4.1 准确率和召回率 ....................................................................................20
3.4.2 F1测度值 ...............................................................................................20
3.5 只含标题的图文数据集的分类 ..................................................................21
3.6 只含正文的图文数据集的分类 ..................................................................23
3.7 包含标题与正文的图文数据集的分类 ......................................................24
3.8 只根据图像内容标注的图文数据集的分类 ..............................................26
3.9 使用创建的图文数据集进行交叉验证分类实验 ......................................29

目录
V
3.10 小结 ............................................................................................................30
第 4章 基于 TextRank抽取的文档关键词的图像分类........................................31
4.1 基于 TextRank的文档关键词抽取技术.....................................................31
4.1.1 关键词抽取技术 ....................................................................................31
4.1.2 基于 TextRank算法抽取文档关键词...................................................32
4.1.3 使用文档关键词进行图像分类的实验模型 ........................................34
4.2 使用 TextRank提取的文档关键词对图像进行分类.................................35
4.2.1 仅使用关键词进行图像分类 ................................................................36
4.2.2 使用文档标题与关键词组合对图像分类 ............................................37
4.2.3 将全文本与关键词组合对图像分类 ....................................................38
4.3 使用关键词与原文档文本组合进行交叉验证实验 ..................................40
4.3.1 使用文档标题与关键词组合进行交叉验证 ........................................42
4.3.2 使用全文本与关键词组合进行交叉验证 ............................................43
4.4 不同倍数的关键词序列与原文档组合用于图像分类 ..............................44
4.5 小结 ..............................................................................................................45
第 5章 总结与展望 .................................................................................................48
参考文献 .....................................................................................................................50
致 谢 .........................................................................................................................53
声 明 .........................................................................................................................53
附录 A 参照大百科全书中文分类体系 55个类别 ...............................................54
附录 B 图像多标签标注情况统计表......................................................................56
个人简历、在学期间发表的学术论文与研究成果 .................................................57

第 1章 引言
1
第 1 章 引言
1.1 论文背景及意义
随着互联网及多媒体技术的迅速发展, Internet上各种形式的数字化信息正
在迅猛增长。图像作为数字化多媒体信息的重要表现形式之一,它通过颜色、
纹理、形状等丰富的视觉特征,能够以更加直观、更容易让人们理解的方式传
递信息,并且数据规模正在迅速膨胀, Web 上图像信息的利用越来越受到人们
的关注。
处理 Web上海量图像信息的一个重要方法就是将它们进行自动分类。图像
分类是 Web数据挖掘领域的一个重要的研究方向,它是一种非常重要的图像信
息组织和管理手段,通过对图像自动分类不仅可以将图像按照类别信息建立相
应的信息资源库,更好的提供图像检索和管理服务,方便科研人员进行研究和
利用,而且可以用来提高搜索引擎的搜索准确性,便于普通用户查找及使用,
最大程度上满足用户的需求。
因此,对图像进行合理有效的自动分类研究工作对图像资源的管理和检索
具有现实、积极的意义。本文即是针对这个问题研究基于文本的图像自动分类
方法,通过建立合理的分类体系,使用有效地方法通过关联文本把图像准确划
分到多个预先定义好的类别中,这将为图像的管理使用及研究工作带来方便。
1.2 图像分类技术研究现状
目前图像分类技术研究主要集中在基于内容的图像分类和基于文本的图像
分类两个方向。
1.2.1 基于内容图像的分类技术
基于内容的图像分类是根据图像的视觉特征即颜色、纹理、形状、空间关
系等,将图像区分为不同的类别,分类的结果是同类图像在视觉特征上的相似
度很大,不同类图像在视觉特征上的差异度很大。 目前基于内容的图像分类技
术已经取得了不少成就, 该领域已经建立了不少图像视频分类检索系统,其中
较著名的有 QBIC[2]、Photobook[3]等。这些系统主要利用了如颜色、形状、纹

第 1章 引言
2
理、布局等图像的低层次信息。不过颜色、形状、纹理等这些低级的视觉特征,
无法直接反映出图像的主题及其属性等高层语义信息。如果使用颜色、纹理等
这些普通用户并不熟悉的底层特征作为检索标识,无疑会增加用户的操作难度,
而且其实现的复杂度及成本都比较高,所以,这种技术并不适用于面向普通大
众的 Web图像资源的检索,著名信息搜索引擎如 Google、Baidu等都没有采纳
其作为 Web图像的检索技术,而是通过改进传统的基于文本的图像检索方法,
自动从文本中提取表达图像语义的关键词以实现有效的 Web图像检索。
由于技术和实现上存在着许多局限性,这种基于内容的图像分类技术目前
只能应用于一些特殊图像检索中,如指纹识别、商标检索等。
1.2.2 基于文本的图像分类技术
基于文本的图像分类技术,就是通过对图像所在页面进行解析,得到一系
列与图像相关的描述文本,然后利用描述文本关键字对图像进行分类。如
Google、Baidu、Yahoo 等多数著名搜索引擎图像检索部分就是基于这种方法利
用计算机自动获取图像的文件名、目录名、路径名、链接文本、属性(alt ) 标签
以及图像所处的网页的标题( Title) 、元信息(Meta) 等作为图像相关的文本描述
信息,并从文本中提取表达图像语义的关键词用于图像分类与检索,但从目前
的实际应用情况调查来看,利用这种方法实现的 Web图像检索,其检索结果的
质量仍存在着一定偏差,需要进一步研究与分析并进行改进,才能有效地满足
不同用户对于图像资源的检索需求。文献[4]的作者介绍了如何进一步准确高效
地从网页中提取 Web图像的关联文本,在他的研究中对图像周围文本的提取率
能达到了 85%。
在国外相关研究中,哥伦比亚大学的 Carl Sable[5]自建了包括灾难、政治、
事件等几个类别的英文图文数据集,然后使用一些传统的文本分类技术进行基
于英文文本的图像分类研究,在他的研究中发现,目前普遍使用的文本分类方
法中某一种分类技术只能对其中一或几种图像的分类取得较好的准确率,对其
他类别图像的分类效果则表现平平,其中概率标引法(Probabilistic Indexing)和
支持向量机(SVM)的文本分类方法表现整体相对较好。在他的论文中对灾难、
政治、事件、户内和户外这几种自定义类别的图像进行的基于文本的分类实验
结果中,对户内、户外图像分类概率标引法的准确率最好,可以达到 86.3%;对
事件类图像的分类实验中 SVM 分类方法的准确率最好,达到了 88.7%;但对灾

第 1章 引言
3
难类、政治类图像的分类试验中所有的文本分类方法准确率都很一般,基本为
百分之五十至六十之间。此外,他尝试将 NLP 技术应用到基于英文文本的图像
分类上来,如抽取句子中的主语和谓语用于分类。他研究发现将 NLP 技术应用
在某些特定领域的分类任务中有助于提高其分类质量,这种方法作者仍在进一
步深入研究中。
从以上论述可以看出,Web图像数量的猛增,使得 Web图像自动分类进一
步的研究工作迫在眉睫。本文即着眼于这一方向对基于文本的图像自动分类进
行一些研究。
1.3 文本分类技术现状
在目前使用的文本分类算法中,主要可以分为三类:基于统计的,代表的
有Bayes方法、KNN方法、类中心向量和支持向量机等;基于规则的,代表的有
决策树和粗糙集;还有一类就是人工神经网络。
朴素贝叶斯算法[7]是分类领域中一种简单但性能比较优越的的分类算法。
Naive Bayes方法具有较高的准确性,但它有个前提假设就是各特征间,必须是
独立无关的,当样本的各个特征不是相互独立的时候,Naive Bayes分类的准确
度就会大大降低。而且,各个类的概率密度分布的估计将对分类结果起着决定
性的影响,但是往往在现实世界中概率密度分布函数是难以估计的。
KNN 法[8]即 k- Nearest Neighbor 分类方法。这是一种稳定有效的文档分类
方法。KNN 是一种懒惰的学习方法,它存放所有的训练样本,直到测试样本需
要分类时才建立分类器,这样与测试样本比较的可能近邻数量( 训练样本) 较大
时,会招致很高的计算开销。
BP神经网络[9]是人工神经网络(ANN)众多模型中的一种[10]。ANN 是参照
生物神经元模型发展起来,其基本单元为人工神经元。BP网络能够对输入进行
并行处理,有效地解决了非正态分布、非线性的评价问题等,但它对初始权重
非常敏感,极易收敛于局部极小,而且存在着过拟合的问题,此外它也无法避
免所有人工神经网络存在的需要更多训练数据,运行速度慢等弱点,而且许多
参数的选择必须根据人工经验进行人工调整设置,尤其是网络隐含结点数的选
择对分类结果有直接的影响。
支持向量机(Support Vector Machine)[11]是一种基于结构风险最小化原则

第 1章 引言
4
(Structure Risk Minimization)的通用学习算法,它的基本思想是在样本输入空间
或特征空间构造出一个最优超平面,使得超平面到两类样本集之间的距离达到
最大,从而取得最好的泛化能力。不同于神经网络,支持向量机的解是全局最
优的,而且支持向量机不需要人工设计网络结构。
支持向量机在解决小样本、非线性及高维模式识别问题中表现出了许多特
有的优势,并能够推广应用到函数拟合等其他机器学习问题中,在文本分类方
面 SVM 的表现尤为突出,其分类的查全率和查准率几乎超过了现有的所有方
法。在本文基于中文文本的图像自动分类研究中所使用的文本自动分类系统
ECTCS就是采用现今流行的支持向量机(SVM)方法,实验表明,该系统在封
闭测试时,具有约 90%的分类准确率。
1.4 论文主要内容
本论文共分为五章。
第 1 章主要介绍该课题研究的背景和意义,并回顾了图像分类技术的研究
现状及几种常用文本分类技术的优缺点,同时简单描述了本文的主要研究工作。
第2章介绍了本文如何参考中文大百科分类体系,从中选取军事、体育、交
通、航空航天、电影、民族、生物学、天文学、考古学、戏曲曲艺这10个类别
建立图文数据集以及对图像的标注和文本选取的方法。所建的数据集用于本文
后面章节的实验。
第3章给出了基于文本的图像自动分类的实验系统结构框架图,并对本文实
验中所使用的基于支持向量机(SVM)方法的文本自动分类系统ECTCS及相关
技术进行了介绍。然后根据第2章中所建立的军事、体育、交通等10个类别的图
文数据集进行了一系列基于文本的图像自动分类实验,并对实验结果进行了分
析。
第4章中首先介绍了自动抽取文档关键词技术及其在文本分类等文本处理
领域里的重要作用,接下来给出了基于图的排序方法的基本原理以及在自然语
言处理领域的具体应用- TextRank算法[6],并将使用TextRank方法抽取到的文档
关键词应用于基于文本的图像自动分类,进行了相关研究与实验。
第 5 章为结论部分,对全文研究工作进行了总结,并阐述了作者的一些想
法,提出了将来的研究重点,对下一步研究工作做了展望。

第 2章 图像及关联文本数据集的构造
5
第 2 章 图像及关联文本数据集的构造
目前并没有通用的标准的包含图像的中文数据集合用于图像分类试验研
究,本文为了准确有效的进行基于中文文本的图像自动分类研究实验,参照大
百科全书中文分类体系(见附录A)中的55个相互独立的类别中选取了10个类别
用于建立中文图文数据集。中文大百科分类体系全面、系统、概括了包括哲学、
社会科学、文学艺术、文化教育、自然科学、工程技术以及军事科学等学科领
域。 所选用的这10个类别分别为军事、体育、交通、航空航天、电影、民族、
生物学、天文学、考古学、戏曲曲艺。
本文所建立的这10个类别的图文数据集都是在互联网上收集并整理的,具
体实现中本文使用了网络爬虫(Web Crawler)从新浪、搜狐等各大门户网站上
下载了大量包含图像及文本的中文网页用于建立所需数据集。
2.1 网络爬虫
网络爬虫(Web Crawler)是一个自动提取网页的程序,它可以从因特网上
下载所需网页,基本原理是从一个或若干初始网页的URL开始,获得初始网页
上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,
直到满足系统的一定停止条件。
本文所使用的是一种聚焦爬虫Teleport Pro v 1.40,它可以根据既定的抓取目
标,有选择的访问互联网上的网页与相关的链接,获取所需要的信息。与通用
爬虫(general purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标
定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资
源。聚焦爬虫的工作流程比较复杂,它需要根据一定的网页分析算法过滤与主
题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将
根据一定的搜索策略从等待队列中选择下一步要抓取的网页URL,并重复上述
过程,直到达到系统的某一条件时为止。另外,所有被爬虫抓取的网页将会被
系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对
于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反
馈和指导。

第 2章 图像及关联文本数据集的构造
6
Teleport Pro是个功能强大的网络聚焦爬虫工具,它可以选择下载内容,是纯
文本,还是文本加图像等共四种选项。下载完成后,单击浏览窗口中的索引文
件,即可浏览下载内容。本文使用Teleport Pro从新浪等各大门户网站下载了约5G
大小的相关数据到本地磁盘。
使用爬虫将网页下载到本地磁盘的好处一是在抽取网页相关内容时不用再
受到是否已连接上互联网的制约,二是在抽取网页时处理速度很快不用受到网
络速度过慢的影响。
2.2 图文数据集的创建
如本章开始介绍,因为没有通用的标准的包含图像及关联文本的中文数据
集合可用,作者决定新创建一个这样的文档集合。首先是类别的确定,本文经
过认真参考比较后决定参照大百科全书中文分类体系,从其中55个类别中选取
军事、体育、交通、航空航天、电影、民族、生物学、天文学、考古学、戏曲
曲艺这10个类别建立中文图文数据集作为研究使用。所选的这10个类别相互之
间相对较为独立,有利于更准确有效的进行分类实验。
2.2.1 图像关联文本的选取方法
在使用web crawler从新浪等门户网站下载了与这10个类别相关的约5G大小
的中文网页数据到本地后,接下来的工作就是抽取网页中的主题图像与关联文
本建立实验需要的数据集。
为保证数据集的可靠性和准确性,作者人工从这些中文网页中选取并建立
了共1000篇其中每篇都包含一副图像及关联文本的文档,这是一个非常费时费
力的工作。每个类别各由100篇文档组成,其中每篇文档都包含了一幅图像以及
与该图像相关联的文本,文本选择的原则是与图像在同一网页页面且内容相关
联,在选取的时候考虑到今后实验研究的实际需要,在提取文本时分为了三种
情况:
1. 文本只包括图像所在网页的标题;
2. 文本只包括图像所在网页的正文内容;
3. 文本同时包括图像所在网页的标题与正文,即全文本。
这就相当于一次同时创建了3个图文数据集,这三个数据集中每篇文档中的

第 2章 图像及关联文本数据集的构造
7
图像是一样的,但对应着三种不同内容的与之相关的文本,这些数据集都将用
于后面章节的实验中,实验过程与结果分析将在后续章节中进行介绍。
2.2.2 文档中图像的标注
接下来要对图像进行类别标注。由于目前对图像进行自动类别标注的方法
准确率仍然普遍比较低,考虑到实验结果的准确性,本文对创建的图文数据集
中的图像采用手人工标注方式。
本文对这10个类别的图文数据集中每篇文档中的每一副图像都进行了人工
判断和类别标注,标注的方法有以下三种方式:
1. 只唯一根据图像画面内容对图像标注
第一种方式是只通过观察图像画面内容来作为唯一的判断标准然后将图像
标注为这10类中的某一个类别,而并不看其文档中关联文本的实际内容,这种
不经过文本的图像标注方法简单直接,适合对那些图像内容本身语义明确,不
会使人产生二义性的图像进行标注。
下面是按这种方式所标注的数据集中两个文档的示例,这两个文档分别属
于军事和交通类别,每个示例文档中均包含了一幅图像以及与图像相关的正文
和标题,如下图2.1、2.2所示。
示例示例示例示例1111::::(标题)印度媒体担心中国借联合军演刺探印军情报印度媒体担心中国借联合军演刺探印军情报印度媒体担心中国借联合军演刺探印军情报印度媒体担心中国借联合军演刺探印军情报
中印可能于12月底在印度境内举行联合反恐军事演习,这是自1962年中印边
境冲突以来,两国首次在印度境内举行的联合军演。印度多数媒体对此次军演
给予正面报道,不过也有媒体报道时仍带着“有色眼镜”。印度快报24日的报道
就称,要当心中国趁联合军演之机刺激印度情报。印度快报的文章称,随着经
济全球化的不断发展,世界各国在国际事务上互相依赖的程度不断加深,地区
国家间举行联合军事演习也越来越多。正是在这一背景下,中印作为最大的发
展中国家,决定于12月底在举行联合反恐军事演习。文章称,按照国际公约与惯
例,参与联合军事演习的国家都需要签署谅解备忘录,而其武装部队则必需接
受相关条款与条件的约束。不过,每当联合军演期间,总会有谍报人员趁机搜
集对手军事情报,这已成为公开的秘密。文章据此认为,“中国可能会借中印联
合军演期间,收集有关印度军事能力与部署的情报,并培养永久性的‘消息来
源’,不能不防”······

第 2章 图像及关联文本数据集的构造
8
图图图图 2.1 2.1 2.1 2.1 军事类文档举例军事类文档举例军事类文档举例军事类文档举例
示例示例示例示例2222::::(标题)上周的降雨给本市的交通增加了很大压力上周的降雨给本市的交通增加了很大压力上周的降雨给本市的交通增加了很大压力上周的降雨给本市的交通增加了很大压力
上周持续降雨,给道路交通带来巨大影响,由于雨天路滑,车辆剐蹭事故有所上升,使得路上行车比较缓慢,早、晚高峰时段比平日时间延长。由于大雨将至,北京市气象台也在昨天的预报中特别提醒有关单位,注意及时检查立交桥下等地的排水系统,以免造成积水,外出的人们也要注意交通安全。据交管部门介绍,近日的几次降雨造成较严重的积水路段有,海淀区:车道口桥东西双向、学知桥下北向南辅路。朝阳区:东营桥下、将台乡北岗子桥下、肖村桥南铁路桥下。丰台区:程庄路南口、马家楼西侧双向。希望雨天时,广大司机尽量绕行上述路段,免得因为积水而延误了您的出行。一旦遇到积水路段被堵在途中,一定要保持好心态,交管部门会通过交通台、路况大屏提示绕行信息,服从交警指挥,有序绕离积水路段。

第 2章 图像及关联文本数据集的构造
9
图图图图 2 2 2 2.2 .2 .2 .2 交通类文档举例交通类文档举例交通类文档举例交通类文档举例
但这种只唯一根据图像画面内容对其标注的方式容易产生偏颇性,标注时
经常会遇到图像语义并不明确,只通过观察图像内容无法对图像进行准确标注
的情况。如下图2.3:
图图图图 2 2 2 2....3333 二义二义二义二义性图像举例性图像举例性图像举例性图像举例

第 2章 图像及关联文本数据集的构造
10
如果只是看这幅图像内容可能会认为是哪个娱乐明星,而无法将图片中的
人物与奥运会冠军林丹联系到一起,更不会将该图像标注为体育,很可能最终
只是简单的将其错误标注为人物或者娱乐。这时候就需要参考图像关联文本的
内容来对其进行标注。下面介绍本文使用的第二种图像标注方式。
2. 通过图像画面与关联文本内容一起对图像标注
举例来说,以下是图2.3的相关的标题及正文内容:
林丹林丹林丹林丹::::荣誉从来都是自己拼来的荣誉从来都是自己拼来的荣誉从来都是自己拼来的荣誉从来都是自己拼来的
4 年前的雅典,21 岁的林丹搞砸了自己在奥运会上的处子战,排名世界第一的他第一轮即遭淘汰。当他拎着球拍寂寞地走出场外的时候,很多人把他比赛之前说过的那句“我是最棒的羽毛球运动员”当成笑谈,但只有他自己相信:4年后,我会回来。2008 年北京奥运会,林丹一路过关斩将,直取男单冠军。当他仰天长啸地庆祝胜利的时候,他的名字换成了“超级丹”。
和战场一样,成王败寇从来就是竞技运动的一条铁律。2008 年北京奥运会对于林丹来说,从一开始,就不得不面对这个没有退路的命题—早在 4 年前的雅典,他就是冠军的一号种子。比赛之前,媒体的赞美几乎将他淹没:“林丹如今已经霸气十足,连续夺冠让国际羽联也不吝将‘超级丹’的称号给予了这个 20出头的中国青年,连续稳坐国际羽联男单排行第一多日的林丹为中国羽毛球男队重夺汤姆斯杯的重要砝码。2004 年雅典奥运会更为林丹提供了充分证明自己的机会……”但那次,这个所向披靡的“超级丹”却只收获了无尽的失落,首轮即惨遭淘汰。那时的林丹只有 21 岁。当他垂着头,拎着球拍寂寞地走出场外,很多人把他比赛之前的那句“我是最棒的羽毛球运动员”当成笑谈,但只有他自己相信:4 年后,我会回来—要像一个真正的男人那样回来。……
此时通过这段文本并与图像画面内容结合起来一起对图像2.3进行标注,则
很容易将其正确标注为体育。由于每个文档中的图像跟文本(这里的文本指抽
取时选取的是图像周围的文本)是在同一个网页中相邻位置抽取的,它们在同
一页面相邻位置出现必然有其相关性,如果只看图像内容或文本内容都有其偏
颇性,只有将两者综合起来考虑才更准确也更容易。
对于只根据图像内容作为唯一的判断标准对图像进行类别标注和根据图像
画面内容并与其关联文本内容一起来对图像进行标注这两种方式所建立的数据
集,然后再使用基于文本的方法对图像分类的实验将在第四章中进行实验并对
结果比较分析。

第 2章 图像及关联文本数据集的构造
11
3. 其他特殊情况
有时对图像进行类别标注时会遇到一种特殊情况,如下例:
温俊武因故意杀人被判死缓温俊武因故意杀人被判死缓温俊武因故意杀人被判死缓温俊武因故意杀人被判死缓 行凶逃债终遭法律严惩行凶逃债终遭法律严惩行凶逃债终遭法律严惩行凶逃债终遭法律严惩
记者鲁钇山、通讯员穗法宣报道:月黑杀人,两个亡命之徒将地点选在了
海珠区的一条古街。夜色中,滴血的刀映衬着两人狰狞的脸。其中一个看着暗
红色的双手,长出了一口气,如释重负,他欠的赌债,终于不用还了。路边,
一个摄像头不声不响地记录下了这一切。今天上午,这个赌徒在广州中院接受
法庭庄严的判决。他叫温俊武。
图图图图 2 2 2 2.4 .4 .4 .4 容易混淆图像举例容易混淆图像举例容易混淆图像举例容易混淆图像举例
温俊武的名号,在上世纪 90 年代末,在广东球迷中几乎无人不知。那时,他被视为彭伟国的接班人。而今,“江湖”已老,物是人非。他再次成为人们街谈巷议的话题,却是因为杀人。和他一同接受宣判的,还有他的两个朋友,23岁的谢炜成和 22 岁的刘思敏。温俊武 1978 年出生于广州番禺,他的身高不足170 厘米,但脚下技术十分出众。1997 年,他年少成名,随后足球生涯一路顺风顺水。然而,年收入高达 20 多万元,对于年少轻狂的温俊武来说,并不是一件好事。打上职业联赛不到两年,温俊武就跟“赌球”、“嗑药”等字眼沾上了边。1999 年,22 岁的温俊武因陷入一场赌球风波而负气出走,随后更沉迷于赌球漩涡无法自拔,匆匆结束了自己的足球职业生涯……
该例从图像内容来看应该被标注为法学,而从文档标题及文本内容来看,
则可以被归类为法学或者体育,像这种二义性较强,容易引起混淆的文档,本

第 2章 图像及关联文本数据集的构造
12
文不将其归类到所选取的10个类别之中,而是一般将其标注为其它类,另行存
储下来留作今后研究使用,如可用在基于文本的多类别多标签图像自动分类研
究上。
2.3 小结
本章针对目前没有通用的标准的包含图像的中文图文数据集合用于分类试
验研究这种情况,参照大百科全书中文分类体系,从中选取军事、体育、交通、
航空航天、电影、民族、生物学、天文学、考古学、戏曲曲艺这10个类别建立
了图文数据集,并详细介绍了数据集中图像和文本数据的选取及对图像的具体
标注方法。其中对图像标注主要采取只根据图像画面内容进行标注和根据图像
画面与关联文本内容一起标注这两种方式;对图像关联文本选择的方法是与图
像在同一网页页面且内容相关,提取文本时考虑了三种情况:只包括标题、只
包括正文、同时包括标题与正文(即全文本)。所创建的图文数据集将用于后面
章节的实验中,具体实验过程与分类结果分析将在后续章节中进行介绍。

第 3章 基于不同关联文本的图像分类
13
第 3 章 基于不同关联文本的图像分类
3.1 实验系统结构框架图
本章实验中基于文本的图像自动分类的系统结构框架图见下图 3.1。
从系统结构图可以看出,实验首先是提取网页中的图像与关联文本建立测试
文档集,接着将有标记的训练集加入到文本自动分类系统 ECTCS中进行训练,
训练时根据预先设定好的训练参数对文本进行预处理和特征选择及特征权重计
算,完成对整个模型学习训练的过程。此后,可以将训练好的模型保存到指定
目录中以便后续或其他分类任务调用。最后,传入测试图文数据集,根据之前
训练好或者加载好的模型,对测试集中每个文档进行分类,输出其类别,完成
分类过程,并计算准确率、召回率及 F1测度值作为评价分类系统的指标。
图图图图 3 3 3 3.1 .1 .1 .1 基于文本的图像自动分类系统结构图基于文本的图像自动分类系统结构图基于文本的图像自动分类系统结构图基于文本的图像自动分类系统结构图
3.2 实验中所使用的文本分类器系统 ECTCS
本文试验中所使用的中英文文本自动分类系统 ECTCS(English Chinese Text
Classification System)是由作者所在的清华大学计算机系自然语言处理课题组研
训练文本
预处理
特征项选
择
文 本
自 动
分 类
系 统
ECTCSECTCSECTCSECTCS
训练过程 分类过程
分
类
和
输
出
图像及关联
文本提取
临时库(图
像、网页)
图文数据集 特征权重
计算

第 3章 基于不同关联文本的图像分类
14
究设计,采用 Java语言编写,可以很方便的在 Windows、Linux 等操作系统上运
行。该系统提供了清晰的程序接口,可方便为其它程序所调用。其就是采用现
今流行的支持向量机(SVM)方法,结合预先给定的有标记的训练集,进而训
练出高效准确的分类模型,最后利用该分类模型对测试数据集进行分类,完成
整个分类过程。该系统同时支持中文和英文两种语言的文本分类问题,实验表
明,在封闭测试时,具有约 90%的分类准确率。本文主要使用了该系统的中文
文本自动分类功能。
该系统具有以下几个特点:
1. 系统同时支持分词特征、Bigram 特征表示中文文本。利用 Bigram(中
文二字串)特征可以避免中文自动分词问题。实验表明,在较高维度上,
Bigram 特征较之词特征具有更高的分类准确率。而在较低维度上,词
特征较之 Bigram 特征具有更高的分类准确率,在实际应用中,可以根
据具体情况选择不同的特征表示方法。
2. 在实现时,采用的是基于开方(chi-square)的特征选择方法,相关论文
表明,和其他特征选择方法相比,该特征选择方法更适用于中文文本分
类问题。
3. 支持指定维度下的文本分类问题,该软件将维度作为一个参数传入。一
般来说,较高的维度具有较高的分类准确率,但要花费更多的训练时间;
较低的维度训练开销较小,但分类准确率有所降低。在实际应用中,可
以根据具体的情况对这一参数进行设定。
4. 系统实现了可扩展的特征选择方法。相比于开方检验的特征选择方法,
该方法更适应于在低维情况下的中英文文本分类问题,能较大地提高在
低维情况下的分类准确率。
5. 系统对英文文本处理有较好的支持,实现了基于 porter stemming的英文
文本预处理方法,且具有较好的扩展性,可以很方便的扩展到其他语种
的文本处理任务。
6. 系统提供了良好的清晰的程序接口,可以方便的被其他程序或系统所调
用。软件全部采用 Java语言进行开发,可以很方便的提供基于网页的
文本自动分类服务。

第 3章 基于不同关联文本的图像分类
15
3.2.1 该系统对中文文本的预处理
文本预处理的功能主要在于将文本形式化成计算机能理解的格式,对于英
文来说,一般需要进行 stemming处理,将某些单词的词根去除。相对于英文
来说,中文文本的特征单元问题要复杂很多。在每种语言中,都有词或者类似
的概念作为语言使用的自然单元。但在中文或者日语等一些东亚语言中,要用
词作为文本处理的特征单元并不是那么的简单直接。最明显地,中文文本中没
有类似英文中空格之类的显示的表示词编辑的标志,所以自动分词一般是中文
处理的重要组成步骤,但中文分词[1]到目前来说仍然是一个没有被完善解决的
问题。另一方面,汉语中词的定义也并不明确,这种不一致性也给计算机的处
理带来了困难。
在该系统的具体实现中,采用了两种中文文本预处理的方法。一是采用了
中科院开发的 ICTCLAS 中文分词系统,二是引入了中文二字串 Bigram的处理
方法,从而避免了中文自动分词问题。在本文的实验中使用的是该系统的第二
种中文文本预处理的方法,下面重点介绍这种预处理方式。
由于中文的特殊性,该系统也选用了另外一种特征表示的方法,即为二字
串。利用二字串特征的好处是可以避免中文自动分词的问题。首先解释一下中
文二字串的概念。
例如这样一句话:“今天天气不错”,如果用中文分词则将其切分为:“今
天 天气 不错”,如果用二字串的表示方法,则表示为:“今天 天天 天气 气
不 不错”。两种表示方法各有优缺点,利用词表示的方法,可以有效的降低特
征的维度,且符合人的直观理解和感觉。利用二字串的表示方法,会使得特征
的维度升高,但是也能带来一定的好处,可能会包含词特征所不能包含的信息。
另一方面,中文自动分词本身就存在一定的错误,可能对分类造成负面的影响。
相关论文及实验表明,在较高维度的情况下, Bigram特征较之词特征具有更
高的分类准确率;而在较低维度上,词特征较之 Bigram 特征具有更高的分类
准确率。
在实现中,该系统实现了两种中文二字串的切分方法,BigramWordSegment
和 NaiveBigramWordSegment。其主要区别在于对于非中文字符的处理方式上,
NaiveBigramWordSegment不区分非中文字符和中文字符,只是简单的从当前
位置开始,向后取两个字符。而 BigramWordSegment做了更为细节的处理,例
如:连续的英文或者数字不切开,保持不变,遇到标点符号等断开等操作。在

第 3章 基于不同关联文本的图像分类
16
系统进行的实验中的结果表明,BigramWordSegment的特征分类效果要略好于
NaiveBigramWordSegment方法。在本文的实验中使用的是 BigramWordSegment
的中文二字串的切分方法,该方法具体参见流程图 3.2。
图图图图 3333.2 BigramWordSegment.2 BigramWordSegment.2 BigramWordSegment.2 BigramWordSegment 的中文二字串的切分流程图的中文二字串的切分流程图的中文二字串的切分流程图的中文二字串的切分流程图
3.2.2 该系统的特征选择
由于文本的特殊性,文本分类的一个核心难题就是特征空间的高维性,一个
文档集中的特征项通常在上万维左右,对于中文文本这一问题更为明显。这么
高的维数特征不仅带来极高的计算复杂度,产生维度灾难,也给分类过程带来
了大量的噪声,且容易产生过度拟合的问题,因而有必要简化原始的特征集,
必须通过一些办法选择出有效的特征进行分类。
现今有很多的特征选择的方法,例如基于互信息,信息增益、文本频度、
开方统计量等。该系统中实现了基于开方统计的特征选择方法和可扩展的特征
取连续两个字符
取下一个字符
读文本
判断字符类型
中文
退出
是否结束
是
否
取连续字符
数字或字母
断开处理
标点符号

第 3章 基于不同关联文本的图像分类
17
选择方法。可扩展的特征选择方法在低维条件下具有较高的分类准确率,而在
实际中,如果关注的是最终文本分类的准确率,则应将维度设置的较高,选择
开方的特征选择方法具有较好的效果。在本文的试验中使用的是基于开方统计
的特征选择方法。下面主要介绍这种特征选择方法。
用 | ' |D 表示训练集合中的文档个数,t 表示特征,c 表示类别。 ( , )i kP t c 表示
特征 ti和类别 ck同现的概率, ( , )i kP t c 表示特征 ti和类别 ck都不出现的概率,
( , )i kP t c 表示特征 ti出现类别 ck不出现的概率, ( , )i kP t c 表示特征 ti不出现类别
ck出现的概率。在实际系统中,我们用文档频率 df 来衡量两者同现情况的概率。
有了上述定义之后,可以定义特征 ti对于类别 ck的开方校验量为
开方统计量源于统计学,度量了 ti和 ck之间的相关程度,有以下两种方法来计
算全局的开方指标
实验表明第二种是目前表现最好的特征选择指标之一,甚至是最好的,因此,
在该系统中,采用它作为默认的特征选择指标和比照对象。实际中,对于每一
个特征可以计算一个特征选择的指标,按照上述的公式计算,按照这个指标对
特征进行排序,然后根据事先设定好的阈值 N,取前 N 个特征作为最后的特征
集合。
对于中文文本来说,一般 N 要选择上万维有较好的分类准确率,而对于英
文文本来说,一般 N 到几千维的水平即有不错的效果。一般来说,较高的维度
能带来较高的分类准确率,但要花费更多的训练时间;较低的维度训练开销较
小,但分类准确率有所降低。在本文的试验中 N 一般取 60000维。

第 3章 基于不同关联文本的图像分类
18
3.2.2 该系统的特征权重的计算方法
在进行完特征选择之后,必须给每个特征以合适的权重计算方法,常用的权
重公式有:布尔权重,TF权重,TFIDF权重等。
1. 布尔权重,也称二值权重,是最简单的权重计算方法,即特征 tj在文本
dj中的权重为
布尔权重的缺点是比较粗糙,丢失了特征在文本内部出现的具体信息,效
果略差于较精密的权重。但布尔权重适用于一些采用二值特征的分类模型,比
如决策树或者概率分类器等。
2. 频度权重,用特征频度作为权重是最直观的方法,特征频度的定义为:
特征 tj在文本 dj中出现的次数。这种方法基于的思想为:特征在文本中出现次
数越多,它就越重要。其缺点在于会过于强调一些常用词的权重。例如:“我们”、
“好的”之类的词条几乎在所有的文本中都会出现。
3. TFIDF权重:TFIDF权重计算方法是文本分类中使用最广泛的权重计算
方法,其来源于信息检索。基本的形式为
这种方法基于两个观点:
(1)特征在文本中出现的次数越多,越重要;体现在 tf 项;
(2)特征在越多的文本中出现,越不重要;体现在 idf 项。
通常在特征权重计算完之后,经常要进行归一化的操作,这是因为同一个特
征在长文本出现的 tf 比在短文本中大,从而在长文本中具有更大的权重;长文
本通常包含更多的特征数,从而在分类时与类别的相似度更大。通常,采用的
是余弦规格化方法

第 3章 基于不同关联文本的图像分类
19
该系统默认选择的权重计算公式为效果较好的 TFIDF 权重计算方法,且对
最后的权重向量进行了归一化处理。
3.3 实验中使用的数据集
实验中所使用的训练集选自中文大百科全书电子版(包括社会学、现代医学、
军事、生物学等 55个类别)共计 71674篇文档,其中每篇文档都为单标签文档,
只被标注为这 55类中的其中的一个类别,此外我们又根据中文大百科全书同样
的的分类体系新创建了 24016 个中文文档,本实验中将两个数据集合成一个训
练集使用中文文本自动分类系统 ECTCS 进行训练,该训练集经合并后共包含
95690篇文档。在本文的研究中根据实验需要从该数据集中抽取出军事、体育、
交通、航空航天、电影、民族、生物学、天文学、考古学、戏曲曲艺这 10个类
别的相关文档共计 19010篇,其中包括军事类文档 3149篇,体育类文档 1160
篇,交通类文档 1362篇,航空航天类文档 1497篇,电影类文档 1969篇,民族
类文档 1391篇,生物学类文档 3733篇,天文学类文档 1583篇,考古学类文档
1322篇,戏曲曲艺类文档 1844篇。然后对其进行训练得出 10类训练模型,训
练过程结束后,将其存储在接下来的实验中使用。该训练集中的文档都是纯文
本文档,目的是为了验证这样训练出来的分类模型应用于基于文本的图像自动
分类是否可以达到较理想的分类效果。
训练时对文本预处理采用基于 BigramWordSegment的中文二字串的切分方
法,特征维数选取 60000 维,对于中文文本来说,一般要选择上万维有较好的
分类准确率,而对于英文文本来说,一般几千维的水平即有不错的效果。一般
来说,较高的维度能带来较高的分类准确率,但要花费更多的训练时间;较低
的维度训练开销较小,但分类准确率有所降低。经过实验证明,选取 60000 维
这个特征维数下训练出的训练模型分类准确度较高,可以满足实验的需要。
实验中所使用测试集是本文创建的包括军事、体育、交通、航空航天、电影、
民族、生物学、天文学、考古学、戏曲曲艺这 10个类别的图文数据集。如 2.2.1
小节提及,每篇文档在建立时都考虑了只取标题、只取正文和同时取标题及正
文的 3种情况,这就相当于建立了 3个文档集合,每个集合中都包括 10个类别,
1000篇文档,每个类别由 100篇文档组成,其中每篇文档都包含了一幅图像以
及与该图像相关联的文本。本章针对这 3 个包含了不同关联文本的图文数据集

第 3章 基于不同关联文本的图像分类
20
分别使用文本自动分类系统 ECTCS进行了 5次图像分类实验。
3.4 实验评价指标
在本研究中继承了信息检索的性能评估方法,采用准确率(Presision,又称
查准率)和召回率(Recall,又称查全率)以及二者的调和平均值 F1 来评价分
类性能。
3.4.1 准确率和召回率
准确率定义为正确分为某类的文档数 / 测试集中分为该类型的文档总数得
到的比率。
准确率 =
准确率定义为正确分为某类的文档数 / 测试集中属于该类型的文档总数得
到的比率。
召回率 =
准确率和召回率反映了分类质量的两个不同方面,两者必须综合考虑,不
可偏废。
3.4.2 F1测度值
F1 测度值是准确率和召回率的调和平均值,是一种综合了查准率与召回率
的指标,只有当两个值均比较大的时候,对应的 F1测度值才比较大,因此是一
种比单一的查准或召回率更加具有代表性的指标。
F1 =
F1值越大,分类器的分类性能就越好。
%100×文档总数测试集中分为该类型的
正确分为某类的文档数
%100×文档总数测试集中属于该类型的
正确分为某类的文档数
%100Precison Recall
Precison 2Recall ×+×

第 3章 基于不同关联文本的图像分类
21
3.5 只含标题的图文数据集的分类
如3.1节描述的实验过程,首先使用文本自动分类系统ECTCS对10类训练文
档集训练,特征维数选取60000维,进而训练出10类分类模型,然后利用该分类
模型对只包含标题的图文测试集进行分类并输出结果,完成整个分类过程。实
验采用准确率(Presision)和召回率(Recall)以及二者的平衡值F1测度值来评
价分类性能,实验为开放测试,分类实验结果如下表:
表表表表 3333.1 .1 .1 .1 只只只只含标题含标题含标题含标题图文图文图文图文测试集分类结果测试集分类结果测试集分类结果测试集分类结果
从结果来看 10个类别的F1测度值普遍比较低,最低的军事类别只有 38.1%,
最高的电影类别也只有 83.1%。特别对于交通这个类别,准确率有 94.3%,而召
回率只达到 33%,所以 F1测度值只有 48.9%;对于军事类则准确率只有 25.4%,
而召回率达到 76%。下图 3.3是本次实验中分类正确的例子:
图图图图 3.3 3.3 3.3 3.3 分类正确例子分类正确例子分类正确例子分类正确例子
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航航空航航空航航空航
天天天天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲曲戏曲曲戏曲曲戏曲曲
艺艺艺艺
训练文档数训练文档数训练文档数训练文档数 1969 1497 1362 3149 1322 1391 3733 1160 1583 1844
测试文档数测试文档数测试文档数测试文档数 100 100 100 100 100 100 100 100 100 100
准确率准确率准确率准确率((((%%%%)))) 91.6 55.7 94.3 25.4 97 91.2 87 72.3% 87.9 76.8
召回率召回率召回率召回率((((%%%%)))) 76 59 33 76 65 62 60 69 58 86
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 83.1 57.3 48.9 38.1 77.8 73.8 71 70.8 69.9 81.1

第 3章 基于不同关联文本的图像分类
22
该图原类别为航空航天,在实验中也被正确归类为航空航天。分类中使用
的关联文本是该图像所属文档的标题:美国航空和航天局遭遇“中年危机”。
图图图图 3.4 3.4 3.4 3.4 分类错误例子分类错误例子分类错误例子分类错误例子
图 3.4所列举的是个分类错误的例子:该图原被标注为考古学,结果则被分
为天文学。该图相关文档标题是:专家探秘三星堆称:古蜀人仇恨太阳。
而该图片所属文档文本内容如下:
三星堆距今约 5000 年历史,古蜀国的繁荣持续了 1500 多年。然而,在历史
的某一天,三星堆突然神秘消失,历史中间留了 2000 多年的空白段。古蜀国为
何突然灭亡?人们提出了种种原因,但至今仍无一个回答可以让三星堆消失之
谜尘埃落定。6 日,在由四川省科普作家协会等多家学会组织的“多学科全息研
究破解三星堆千古之谜”报告会中,成理理工大学教授刘兴诗、四川省科普作
家协会主席董仁威等多位三星堆研究者各抒已见,欲破解三星堆之谜。 灾难说:
消亡与天灾有关。我认为是洪水!一场突袭性的洪水使三星堆的古蜀国毁亡。”
成都理工大学教授刘兴诗讲起三星堆为何会被洪水毁灭的原因:“三星堆遗址北
临鸭子河,马牧河从城中穿过。虽然择水而居,孕育了古蜀国的繁荣,但一旦
洪灾泛滥,位于三星堆遗址的古蜀国必然被毁灭。”
在三星堆出土文物中的青铜太阳轮,一直被考古专家和三星堆研究者推论
是农耕时代古蜀人民对太阳的崇拜。对此说法,刘兴诗提出另一种解释。“你们

第 3章 基于不同关联文本的图像分类
23
看,这轮‘太阳’被一圈圆形紧紧包围,与金沙遗址光芒四射的太阳完全呈现
两种风格。所以,这个图形表达的不是古蜀人对太阳的膜拜,而是要将它禁锢
起来的愿望,是一种恐惧和仇恨。” ······
从关联文本内容来看,该图片应该被归类到考古学,但分类时关联文本只
使用了标题,结果是被错分到了天文学,从中可以得出只通过图像标题,也即
类似于使用超短文本进行图像分类的效果并不理想,必须增加分类时所使用的
关联文本内容以进一步改善分类效果,在下面小节的实验中不同程度的增加了
测试集中文档所包含的文本内容,实验结果表明,这种做法可以在较大程度上
改善使用文本进行图像分类的准确性。本节所举的分类错误的图 3.4这个例子在
下面小节的试验中被分到了正确的类别中。
3.6 只含正文的图文数据集的分类
实验环境同上节,对于只含正文的数据集分类实验结果如下:
表表表表 3333.2.2.2.2 只含正文只含正文只含正文只含正文图文图文图文图文测试集分类结果测试集分类结果测试集分类结果测试集分类结果
与 3.5 节文本只含标题的分类实验结果比较,10 个类别的准确率、召回率
和 F1测度值这几个评价指标在大部分类别上都有了大幅提高。表 3.2中的实验
结果与表 3.1中的相比,军事类准确率从 25.4%提升至 66.1%,召回率从 76%提
升至 82%,F1值从 38.1%提升至 73.2%;交通类准确率从 94.3%微降至 93.8%,
但召回率从 33%提升至 76%,F1值从 48.9%提升至 84%;而戏曲曲艺类准确率
从 76.8%提升至 93%,召回率从 86%提升至 92%,F1测度值则达到了 10个类别
中最高的 92.5%;最低的航空航天类 F1 值也达到了 73.1%。实验表明基于文本
对图像自动分类中选用图像相关正文的分类结果要远远好于只使用标题的情
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航航空航航空航航空航
天天天天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲曲戏曲曲戏曲曲戏曲曲
艺艺艺艺
训练文档数训练文档数训练文档数训练文档数 1969 1497 1362 3149 1322 1391 3733 1160 1583 1844
测试文档数测试文档数测试文档数测试文档数 100 100 100 100 100 100 100 100 100 100
准确率准确率准确率准确率((((%%%%)))) 85.6 68.1 93.8 66.1 95.7 95.6 91.8 82 95.4 93
召回率召回率召回率召回率((((%%%%)))) 84.6 79 76 82 89 87 81.7 100 83 92
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 85.1 73.1 84 73.2 92.2 91.1 86.4 90.1 88.8 92.5

第 3章 基于不同关联文本的图像分类
24
况。
3.7 包含标题与正文的图文数据集的分类
本小节实验将前两次实验中所使用的文档的标题与正文综合在一起对图像
进行分类以验证全文本情况下对分类结果的改善效果,实验环境同上,本次实
验分类结果如下:
表表表表 3333....3333 包含标题正文包含标题正文包含标题正文包含标题正文((((全文本全文本全文本全文本))))图文图文图文图文测试集分类结果测试集分类结果测试集分类结果测试集分类结果
从表 3.3的实验结果来看,在最重要的评价指标 F1测度值上,这 10个类别整
体上都有了一定程度的提高,提升率约为 1%至 7%,提高最多的是电影类,从 85.1%
提高至 92% ;在个别类别上有非常少的下降,降幅最大为 0.6 个百分点。而且 F1
值得到提高的类别有 8个,只有 2个类别有微小的降低,基本可以忽略不计。由此
可见,使用与图像相关的全文本(标题加正文)对图像进行分类可以达到比较理想
的分类结果。
以上实验结果表明,使用文本分类系统 ECTCS对图像进行基于关联文本的图
像自动分类,这种方法可以在大部分类别上取得较好的分类效果。
从实验得出,使用全文本这种情况下对图像进行分类的结果比较理想,本文今
后的实验中如无特别说明,均采用全文本形式对图像进行自动分类。在图 3.5 中举
例显示了体育类图像正确分类后的效果图。
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航航空航航空航航空航
天天天天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲曲戏曲曲戏曲曲戏曲曲
艺艺艺艺
训练文档数训练文档数训练文档数训练文档数 1969 1497 1362 3149 1322 1391 3733 1160 1583 1844
测试文档数测试文档数测试文档数测试文档数 100 100 100 100 100 100 100 100 100 100
准确率准确率准确率准确率((((%%%%)))) 92 69.2 93 70.6 96.8 95.6 90.7 85.5 96.5 95.8
召回率召回率召回率召回率((((%%%%)))) 92 81 80 84 90 86 88 100 82 92
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92 74.7 86 76.7 93.3 90.5 89.3 92.2 88.6 93.9

第 3章 基于不同关联文本的图像分类
25
体育类 体育类 体育类
体育类 体育类 体育类
体育类 体育类 体育类
图图图图 3.53.53.53.5 体育类图片正确分类效果图体育类图片正确分类效果图体育类图片正确分类效果图体育类图片正确分类效果图
表 3.4将以上三次试验结果中最重要的评价指标F1测度值放在一起进行了
对比。
表表表表 3333.4 .4 .4 .4 基于三种不同基于三种不同基于三种不同基于三种不同关联关联关联关联文本图像分类文本图像分类文本图像分类文本图像分类实验实验实验实验 F1F1F1F1 测度值对比测度值对比测度值对比测度值对比表表表表
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
训练文档数训练文档数训练文档数训练文档数 1969 1497 1362 3149 1322 1391 3733 1160 1583 1844
测试文档数测试文档数测试文档数测试文档数 100 100 100 100 100 100 100 100 100 100
只含标题只含标题只含标题只含标题 F1F1F1F1 值值值值((((%%%%)))) 83.1 57.3 48.9 38.1 77.8 73.8 71 70.8 69.9 81.1
只含正只含正只含正只含正文文文文 F1F1F1F1 值值值值((((%%%%)))) 85.1 73.1 84 73.2 92.2 91.1 86.4 90.1 88.8 92.5
全文本全文本全文本全文本 F1F1F1F1 值值值值((((%%%%)))) 92 74.7 86 76.7 93.3 90.5 89.3 92.2 88.6 93.9

第 3章 基于不同关联文本的图像分类
26
三种不同关联文本图像分类实验F1值对比结果如图3.6。
图图图图 3.63.63.63.6 基于三种不同基于三种不同基于三种不同基于三种不同关联关联关联关联文本图像分类实验文本图像分类实验文本图像分类实验文本图像分类实验 F1F1F1F1 测度值对比图测度值对比图测度值对比图测度值对比图
以上几节中的实验所使用的图文数据集中对图像类别的标注方式都是采用
观察图像画面内容并与其关联文本内容一起最终决定的。这样标注的原因是图
像跟其周围文本在同一个页面相邻位置出现有其相关性,而只看图像内容或文
本内容任何一方来对图像进行标注都有偏颇性。下面3.8小节中对于只根据图像
画面内容对图像标注再对其进行基于文本分类实验的这种情况进行了实验研
究。
3.8 只根据图像内容标注的图文数据集的分类
本节对于只根据图像内容来作为唯一的判断标准对其进行类别标注,然后
使用关联文本来对图像进行分类的这种情况特别进行了实验和分析。实验过程
具体实现如下:
实验是在 3.7 小节实验的基础上对图文数据集中图像的标注方式上进行了
0
10
20
30
40
50
60
70
80
90
100
电影
航空航天
交通
军事
考古学
民族
生物学
体育
天文学
戏曲曲艺
图像类别
F1测度值(%)
只含标题F1值
只含正文F1值
全文本F1值
第 3章 基于不同关联文本的图像分类
27
一些修改,具体做法是将每个类别中的图像只唯一根据图像内容进行标注,而
不考虑文档中关联文本内容。重新标注后,测试集中有些在标注时参考了文本
内容的图片被剔除掉了。这样处理后,测试集每个类别中只剩下了唯一根据图
片内容标注的文档,即此种标注情况下不考虑文本内容,图像与其所属得类别
保持了高度的一致性,然后使用全文本对图像进行分类实验,实验的主要目的
是测试这种情况下准确率、召回率跟 F1-measure这几个评价指标与使用图像内
容和关联文本一起对图像标注然后再用全文本进行分类的情况下两者的实验结
果的变化。经过如此标注处理后,测试图文集中共有军事类文档 100 篇,交通
类文档 76篇,航空航天类文档 77篇,体育类文档 100篇,电影类文档 91篇,
民族类文档 91篇,生物学类文档 89篇,天文学类文档 86篇,考古学类文档 83
篇,戏曲曲艺类文档 97 篇。其它实验环境同上面小节,采用 10 类中文大百科
训练集训练好的分类模型,测试图文集文档文本部分使用全文本。实验结果见
表 3.5。
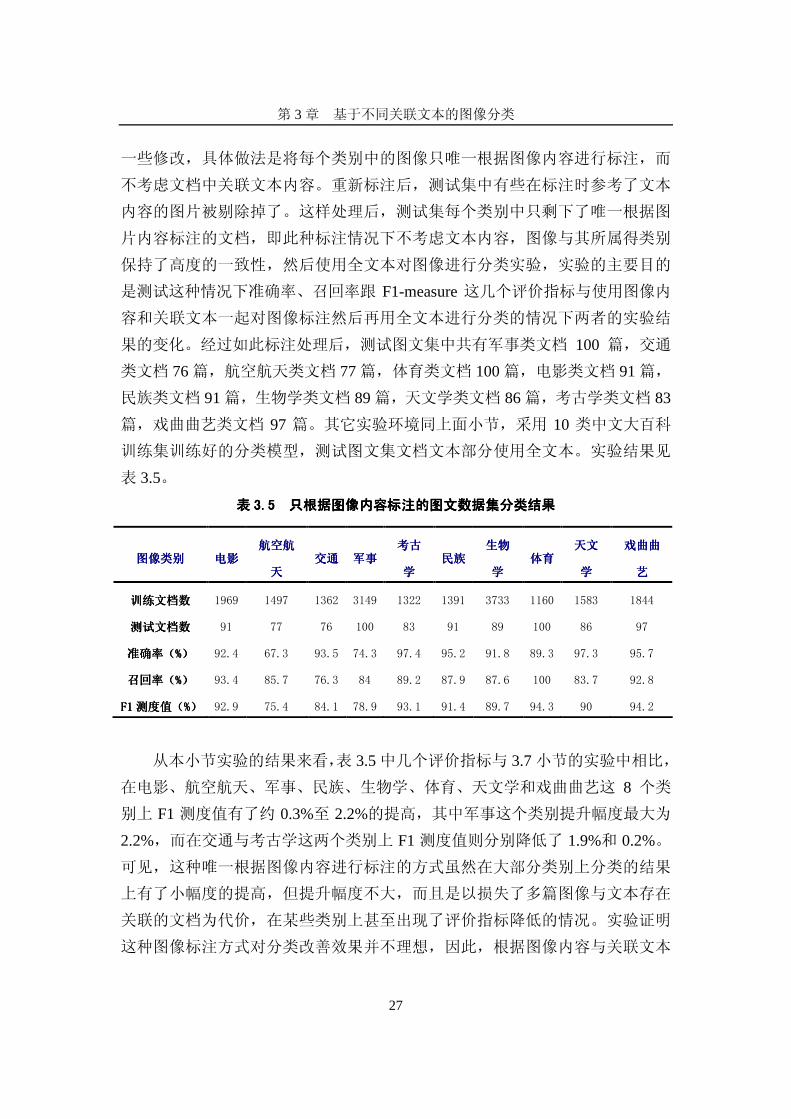
表表表表 3333.5.5.5.5 只只只只根据图像内容根据图像内容根据图像内容根据图像内容标注的标注的标注的标注的图文数据集图文数据集图文数据集图文数据集分类分类分类分类结果结果结果结果
从本小节实验的结果来看,表 3.5中几个评价指标与 3.7小节的实验中相比,
在电影、航空航天、军事、民族、生物学、体育、天文学和戏曲曲艺这 8 个类
别上 F1 测度值有了约 0.3%至 2.2%的提高,其中军事这个类别提升幅度最大为
2.2%,而在交通与考古学这两个类别上 F1测度值则分别降低了 1.9%和 0.2%。
可见,这种唯一根据图像内容进行标注的方式虽然在大部分类别上分类的结果
上有了小幅度的提高,但提升幅度不大,而且是以损失了多篇图像与文本存在
关联的文档为代价,在某些类别上甚至出现了评价指标降低的情况。实验证明
这种图像标注方式对分类改善效果并不理想,因此,根据图像内容与关联文本
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航航空航航空航航空航
天天天天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天天天天文文文文
学学学学
戏曲曲戏曲曲戏曲曲戏曲曲
艺艺艺艺
训练文档数训练文档数训练文档数训练文档数 1969 1497 1362 3149 1322 1391 3733 1160 1583 1844
测试文档数测试文档数测试文档数测试文档数 91 77 76 100 83 91 89 100 86 97
准确率准确率准确率准确率((((%%%%)))) 92.4 67.3 93.5 74.3 97.4 95.2 91.8 89.3 97.3 95.7
召回率召回率召回率召回率((((%%%%)))) 93.4 85.7 76.3 84 89.2 87.9 87.6 100 83.7 92.8
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92.9 75.4 84.1 78.9 93.1 91.4 89.7 94.3 90 94.2

第 3章 基于不同关联文本的图像分类
28
一起对其进行标注的方式是比较合理有效的,本文以后的试验中数据集都采用
这种图像标注方式。
表 3.6与图 3.7将本节实验的结果与 3.7节中根据图像内容与关联文本一起
对图像进行标注然后使用全文本对图像分类结果中的 F1测度值放在一起进行了
比较,可见变化幅度比较小。
表表表表 3333....6666 两种不同图像标注方式分类实验的两种不同图像标注方式分类实验的两种不同图像标注方式分类实验的两种不同图像标注方式分类实验的 F1F1F1F1 测度值测度值测度值测度值对比表对比表对比表对比表
图图图图 3.73.73.73.7 两种不同图像标注方式分类实验的两种不同图像标注方式分类实验的两种不同图像标注方式分类实验的两种不同图像标注方式分类实验的 F1F1F1F1 测度值对比图测度值对比图测度值对比图测度值对比图
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
根据图像内容与文本根据图像内容与文本根据图像内容与文本根据图像内容与文本
标注标注标注标注 F1F1F1F1 值值值值((((%%%%))))
92 74.7 86 76.7 93.3 90.5 89.3 92.2 88.6 93.9
只根据图像内容标注只根据图像内容标注只根据图像内容标注只根据图像内容标注
F1F1F1F1 值值值值((((%%%%))))
92.9 75.4 84.1 78.9 93.1 91.4 89.7 94.3 90 94.2
0
10
20
30
40
50
60
70
80
90
100
电影
航空航天
交通
军事
考古学
民族
生物学
体育
天文学
戏曲曲艺
图像类别
F1测度值(%)
根据图像内容与文本标注F1值
只根据图像内容标注F1值

第 3章 基于不同关联文本的图像分类
29
3.9 使用创建的图文数据集进行交叉验证分类实验
以上实验所使用的训练集均选自中文大百科全书电子版(55个类别)95690
篇文档中抽取出的军事、体育、交通、航空航天、电影、民族、生物学、天文
学、考古学、戏曲曲艺这10个类别的相关文档共计19010篇,而测试集使用的是
作者创建的1000篇图文数据集,两个数据集是不同源的,经过以上实验证明在
不同源数据集情况下,使用本课题组实现的文本自动分类系统ECTCS基本可以
达到较满意的分类结果。为了进一步验证基于文本对图像进行自动分类在同源
数据集上的分类效果,在本节的实验中本文在创建的1000篇图文数据集上进行
了交叉验证分类实验。
交叉验证是分析中的一个标准工具,同时也是一项重要的功能,可帮助开
发和优化数据挖掘模型。在创建了一个挖掘结构及其关联的挖掘模型之后,可
使用交叉验证来确定该模型的有效性。
在交叉验证分类试验中本文选择训练集和测试集的方法如下:将作者所建
立的10类图文数据集共1000篇文档平均分成五份,选择其中一份作为开放测试
集,剩余的四份作为训练集。这样每一份都依次轮流作为开放测试集,运行分
类算法进行交叉验证,实验中文本预处理采用基于BigramWordSegment的中文二
字串的切分方法,根据数据集的规模,特征维数选取10000维,共执行五次分类
操作,实验结束后计算其各个评价指标的平均值,实验结果取平均值后如表3.7
所示
表表表表 3333....7777 对对对对创建的图文数据集进行创建的图文数据集进行创建的图文数据集进行创建的图文数据集进行交叉验证交叉验证交叉验证交叉验证分类实验分类实验分类实验分类实验
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航航空航航空航航空航
天天天天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲曲戏曲曲戏曲曲戏曲曲
艺艺艺艺
训练文档数训练文档数训练文档数训练文档数////
次次次次
80 80 80 80 80 80 80 80 80 80
测试文档数测试文档数测试文档数测试文档数////
次次次次
20 20 20 20 20 20 20 20 20 20
准确率准确率准确率准确率((((%%%%)))) 89.35 81.17 92.81 91.90 97.37 97.69 91.53 97.21 93.44 96.29
召回率召回率召回率召回率((((%%%%)))) 98.33 81.41 94 89.67 95.67 89.67 97.33 91 90.33 97.67
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 93.56 80.47 93.09 90.56 96.40 93.29 94.25 93.92 91.25 96.91

第 3章 基于不同关联文本的图像分类
30
结果显示,分类的结果在几乎所有的类别上都比较好,调和平均值 F1测度
值除去航空航天这个类别是 80.47%,在其他 9个类别上都达到了 90%以上,其
中考古学和戏曲曲艺这两个类别上达到了 96%以上。 由此可见,使用文本自动
分类系统ECTCS对图像进行基于相关全文本的图像自动分类方法可以得到较满
意的分类结果。
3.10 小结
本章首先给出了基于文本的图像自动分类的实验系统结构框架图,对本文
实验中所使用的文本自动分类系统 ECTCS及相关技术进行了介绍。 接着根据
第 2 章中所建立的文本只含标题、只包括正文、同时包括标题与正文(即全文
本)这三种情况下的图文数据集进行了一系列基于文本的图像自动分类实验。
从相关实验结果来看,使用支持向量机(SVM)方法的文本自动分类系统 ECTCS
对图像进行基于关联文本的自动分类在军事、体育、交通等这 10 个类别基本都
取得了较好的分类效果;并且通过实验证明只根据图像内容作为唯一的判断标
准来对图像类别标注,再使用关联文本对其分类的这种方式对分类性能指标没
有明显改善,本文以后的试验中都将采用根据图像内容与关联文本一起对图像
标注这种比较合理的标注方式。在本章的最后,本文使用自建的 1000篇图文数
据集进行了交叉验证实验,进一步验证了使用相关全文本对图像进行自动分类
的方法基本可以达到较为满意的分类效果。

第 4章 基于 TextRank抽取的文档关键词的图像分类
31
第 4 章 基于 TextRank抽取的文档关键词的图像分类
关键词自动抽取又称作关键词自动标引,是依靠计算机处理技术从文档中
自动选择出反映主题内容的词,能够为用户提供一个文档简洁的内容摘要,使
信息定位更加简单。关键词抽取在文本分类、文本摘要等许多文本处理领域里
都有着重要作用。比如在文本分类中,用关键词作为文本的的特征表示,可以
减少或避免和文本内容无关的名词、动词等引起的误分类,在本章中本文使用
TextRank方法自动抽取关键词对基于文本的图像分类进行了一些研究。
4.1 基于 TextRank的文档关键词抽取技术
4.1.1 关键词抽取技术
关键词抽取的任务就是要从文档中找出能够描述文档内容的词和短语。目
前总体上来说,关键词抽取的实现算法主要包括两大类,基于规则的关键词抽
取和基于统计的关键词抽取。在本文下面对关键词抽取技术的论述中部分参考
了文献[12]。
基于规则的抽取算法主要利用启发式规则来实现,启发式算法的实现基于
一系列带参数的启发式规则。例如Turney开发的采用启发式算法来实现关键词抽
取的系统GenEx,该系统通过训练文本来优化这些启发式规则的参数[13]。
基于统计的关键词抽取算法主要利用文档中词的统计信息实现关键词的抽
取,例如EibeFrank等人提出的用于实现关键词抽取的KEA算法。该算法基于朴
素贝叶斯分类器,使用已标注出关键词的文档对分类器进行训练,得到分类模
型,然后应用所得的分类器实例从新的文档中抽取出关键词。在实验中他们采
用全局的上下文信息,例如词或词组的频率,以及词或词组在文档中首次出现
的位置[14]作为机器学习算法的特征属性。Tang等人将文档中词之间的关联信息
作为特征属性用于贝叶斯学习算法中来解决关键词抽取的问题,实验表明,抽
取效果比KEA算法有所改进[15]。
关键词自动抽取一般需要解决三方面的问题:
1. 候选关键词短语抽取
通常关键词中有一部分是短语,关键词短语比关键词包含的信息更加丰富,

第 4章 基于 TextRank抽取的文档关键词的图像分类
32
也更具概括能力。关键词短语一般由两或者三个词组成。有三种比较常用的获
取候选关键词短语的方法:第一种方法从文中抽取的N-gram词对作为候选关键
词短语;第二种方法抽取名词短语组块作为候选关键词短语;第三种方法根据
词性标注的匹配模式抽取词对。研究表明,名词短语组块与满足一定词性模式
的规则更加适合进行关键词短语的自动抽取。
2. 词语的重要性评价
很多研究将词语的重要性评价看作一个有指导的机器学习问题。评价词语
重要性需要综合考虑其相关特征,比较重要的特征有:词语的全文频率、词语
的首次出现位置及词性等等。
3. 冗余消除
文档集合中出现次数唯一的词语的个数少至几百多至数千个,因此要求抽
取的关键词要比较精炼,能够反映出原文档的主要内容。在经过关键词重要性
评价处理后,权值较高的词语可能存在冗余,比如同义词或某些有较强语义相
似度的词以及一些存在简略关系的词语都容易产生冗余。例如“气象”和“天
气”这两个词,“自然语言处理”和“NLP”等。为了消除冗余现象产生,可以
首先构造一个按照重要性程度排序的候选关键词集合,对其进行冗余处理后再
输出关键词[17]。
关键词抽取的过程一般为“词语抽取—权重计算—排序输出”三个主要步
骤。在词语抽取步骤中,一般有两种方法:一是用词典直接进行匹配来抽取词
语,匹配时无须对词语的字间关系进行分析,词语抽取速度快,但存在词典构
造困难、更新滞后等不足,而且词典中词语的数量和质量直接影响到词语抽取
的效果[18];另外一种方法是基于统计的无词表抽词法(基于字同现频率的字串
获取),或者切分后重新捆绑碎片[19],然而这种方法会导致高频字串含有太多
的垃圾信息而关键字串又组配不够的问题。在权重计算步骤中首先对抽取出的
词语在文中的词频(tf 值)、词的倒文档频率(idf值)、词在文中的位置、词性
等进行分析,并对词相应加权。在排序输出步骤中,将抽取出的词语按权值大
小排序并输出权值较大的一些词语为关键词。由于大部分关键词为名词、动词
等实词,因此可以对这些词语进行重点加权。
4.1.2 基于 TextRank算法抽取文档关键词
TextRank方法[6]是基于图的排序方法在自然语言处理领域的具体应用,本

第 4章 基于 TextRank抽取的文档关键词的图像分类
33
节将给出基于图的排序算法的基本原理,进而对TextRank方法进行介绍。基于图
的排序算法是决定图中点的重要性的一种方法,它通过对图的全局信息(图的
结构)进行递归的计算来对节点排序,而不是仅仅依靠局部某些点的信息。利
用自然语言文本中存在的词汇或语义信息来构建图,可以使基于图的排序算法
应用于多种自然语言处理领域中,例如文本摘要和关键词抽取。
自然语言处理领域中运用基于图的排序算法过程一般为:
1. 首先需要构建一个和文本内容相关的图,并且在词语或其他文本实体之
间建立联系;
2. 确定完成任务所需要选择不同大小和特点的“文本单元”(如句子,单
个的词,短语等),将这些单元作为图中的节点;
3. 确定节点之间的“关系”,如节点之间存在某种关系,例如:词汇、语
义关系,文本交叉率等,则在这两个点之间连一条边。边可为有向/无
向,带权重/不带权重;
4. 运用图排序算法进行运算,直到结果收敛于给定阈值;
5. 根据计算出的得分对“文本单元”排序,选取较高得分的单元组成结果。
文献[6]将在自然语言处理领域中应用的基于图的排序算法称为TextRank,
一般TextRank模型可以表示为一个带权有向图 ),( EVG = ,由点集合V 和边集合
E 组成,E 是 VV × 的子集,图中两点 i , j 之间边的权重为
其中,d为阻尼因数,取值范围为0到1,代表从图中某一特定点指向其他任
意点的概率。因数d通常设为0.85。需要注意,基于图的排序算法计算图中点的
分数时,需要给图中的点指定任意的初值并递归计算直到某个词语分数收敛,
收敛后每个点都获得一个分数,代表该点在图中的重要性。点的最后分数不受
给定初值的影响,点的初值只影响该算法达到收敛的迭代次数。
本文使用的基于TextRank的文档关键词抽取方法是由作者所在的清华大学
计算机系自然语言处理课题组参照文献[6]研究实现,采用Java语言编写,其框架
结构如图4.1。
该方法对目标文档集进行分词、词性标注等预处理,统计文档集中名词、
形容词等重要词语信息并根据TextRank方法来构建词汇网络模型,最后递归计算
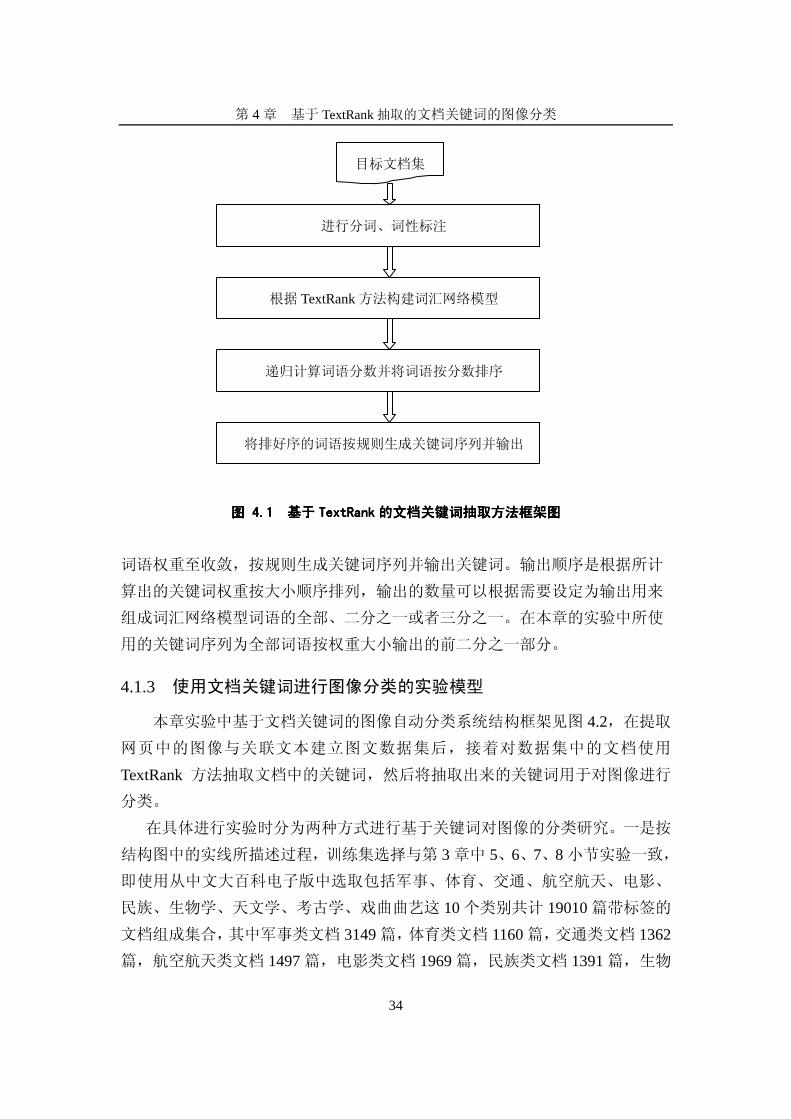
第 4章 基于 TextRank抽取的文档关键词的图像分类
34
图图图图 4 4 4 4.1 .1 .1 .1 基于基于基于基于 TextRankTextRankTextRankTextRank 的文档关键词抽取方法框架图的文档关键词抽取方法框架图的文档关键词抽取方法框架图的文档关键词抽取方法框架图
词语权重至收敛,按规则生成关键词序列并输出关键词。输出顺序是根据所计
算出的关键词权重按大小顺序排列,输出的数量可以根据需要设定为输出用来
组成词汇网络模型词语的全部、二分之一或者三分之一。在本章的实验中所使
用的关键词序列为全部词语按权重大小输出的前二分之一部分。
4.1.3 使用文档关键词进行图像分类的实验模型
本章实验中基于文档关键词的图像自动分类系统结构框架见图 4.2,在提取
网页中的图像与关联文本建立图文数据集后,接着对数据集中的文档使用
TextRank方法抽取文档中的关键词,然后将抽取出来的关键词用于对图像进行
分类。
在具体进行实验时分为两种方式进行基于关键词对图像的分类研究。一是按
结构图中的实线所描述过程,训练集选择与第 3章中 5、6、7、8小节实验一致,
即使用从中文大百科电子版中选取包括军事、体育、交通、航空航天、电影、
民族、生物学、天文学、考古学、戏曲曲艺这 10个类别共计 19010篇带标签的
文档组成集合,其中军事类文档 3149篇,体育类文档 1160篇,交通类文档 1362
篇,航空航天类文档 1497篇,电影类文档 1969篇,民族类文档 1391篇,生物
进行分词、词性标注
根据 TextRank方法构建词汇网络模型
递归计算词语分数并将词语按分数排序
将排好序的词语按规则生成关键词序列并输出
目标文档集

第 4章 基于 TextRank抽取的文档关键词的图像分类
35
学类文档 3733篇,天文学类文档 1583篇,考古学类文档 1322篇,戏曲曲艺类
文档 1844篇;测试集使用本文创建的 10 类图文数据集抽取出的关键词与原文
档中的文本不同方式的组合,接着使用文本自动分类系统 ECTCS进行训练和分
类操作,并将结果与第 3 章中的实验进行比较,分析使用关键词与原文本不同
组合对图像分类性能的影响;二是如结构图中虚线描述的过程,训练集与测试
集都使用自建的 10类 1000篇图文数据集,进行交叉验证实验。同第 3章 3.9节,
在交叉验证试验中本文选择训练集和测试集的方法是将这 10 类 1000篇文档平
均分成五份,选择其中一份作为开放测试集,剩余的四份作为训练集。这样每
一份都依次轮流作为开放测试集,执行分类算法,共运行五次分类,然后计算
五次实验得出的准确率、召回率及 F1测度值等评价指标的平均值。
图图图图 4 4 4 4.2.2.2.2 基于文档关键词的图像自动分类系统结构图基于文档关键词的图像自动分类系统结构图基于文档关键词的图像自动分类系统结构图基于文档关键词的图像自动分类系统结构图
4.2 使用 TextRank提取的文档关键词对图像进行分类
本节实验按照系统结构框架图 4.2中第一种实现方式,训练模型与第四章中
二至五小节的实验一致,即是从中文大百科中选取的包括军事、体育、交通等
这 10 个类别组成的有标记的文档集合加入到文本自动分类系统 ECTCS中进行
训练文本
预处理
特征项选
择
文 本
自 动
分 类
系 统
ECTCSECTCSECTCSECTCS
训练过程 分类过程
分
类
和
输
出
图像及关联
文本提取
临时库(图
像、网页)
图文数据集 特征权重
计算
使用 Textrank抽
取文档关键词
文档关键词与数据集
中原文本不同组合
交
叉
验
证
交叉验证

第 4章 基于 TextRank抽取的文档关键词的图像分类
36
训练,训练时对文本预处理采用基于 BigramWordSegment的中文二字串的切分
方法,特征维数选取 60000维,完成学习训练后,将训练好的 10类 model保存
下来以便调用。最后,传入图文测试数据集,根据训练好的模型,对测试集中
每个文档进行分类,输出分类结果,计算准确率等评价指标,完成分类过程。
4.2.1 仅使用关键词进行图像分类
在本小节实验中,首先使用TextRank算法对创建的图文数据集中的1000篇文
档中的每一篇都抽取出关键词,然后将抽取的关键词代替原文本作为测试集中
图像的关联文本,每篇文档抽取的关键词数量一般从十几个至二十几个不等,
少数文档抽取的关键词数只有几个或者超过了30个,接着将测试集传入文本自
动分类系统ECTCS中对图像进行分类,分类系统使用训练好的10类model,其他
实验环境参数同本节开始描述。最后将实验结果与第3章中只使用标题和只使用
正文对图像分类这两种情况下的实验结果进行了比较,见表4.1
表表表表4.1 4.1 4.1 4.1 基于三种不同基于三种不同基于三种不同基于三种不同关联关联关联关联文本图像分类实验结果对比表文本图像分类实验结果对比表文本图像分类实验结果对比表文本图像分类实验结果对比表
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
准确率准确率准确率准确率((((%%%%)))) 95.29 64.10 91.80 48.50 96.05 89.01 89.77 79.51 93.33 82.76
召回率召回率召回率召回率((((%%%%)))) 81 75.76 56 81 73.74 81 79 97 70 96
只只只只
用用用用
关关关关
键键键键
词词词词
F1F1F1F1 测度值测度值测度值测度值
((((%%%%))))
87.57 69.44 69.57 60.67 83.43 84.82 84.04 87.39 80 88.89
准确率准确率准确率准确率((((%%%%)))) 91.6 55.7 94.3 25.4 97 91.2 87 72.3 87.9 76.8
召回率召回率召回率召回率((((%%%%)))) 76 59 33 76 65 62 60 69 58 86
只只只只
用用用用
标标标标
题题题题 F1F1F1F1 测度值测度值测度值测度值
((((%%%%))))
83.1 57.3 48.9 38.1 77.8 73.8 71 70.8 69.9 81.1
准确率准确率准确率准确率((((%%%%)))) 85.6 68.1 93.8 66.1 95.7 95.6 91.8 82 95.4 93
召回率召回率召回率召回率((((%%%%)))) 84.6 79 76 82 89 87 81.7 100 83 92
只只只只
用用用用
正正正正
文文文文 F1F1F1F1 测度值测度值测度值测度值
((((%%%%))))
85.1 73.1 84 73.2 92.2 91.1 86.4 90.1 88.8 92.5

第 4章 基于 TextRank抽取的文档关键词的图像分类
37
图 4.3为基于三种不同关联文本的图像分类实验的 F1测度值对比。
图图图图4444.3 .3 .3 .3 基于三种不同文本图像分类实验基于三种不同文本图像分类实验基于三种不同文本图像分类实验基于三种不同文本图像分类实验F1F1F1F1测度值对比图测度值对比图测度值对比图测度值对比图
从实验结果来看,只使用标题对图像分类的效果是最差的,在 F1测度值上
只有电影和戏曲曲艺这两个类别达到了 80%以上,最低在军事上只有 38.1%,而
使用关键词或者使用正文对图像分类的效果相比就要要好得多,只使用关键词
时 F1 值普遍在八十几个百分点,只使用正文时 F1 值则要更高一些,此时在考
古学、民族、体育和戏曲曲艺这 4 个类别上都超过了 90%。实验结果表明使用
TextRank方法抽取的关键词包含了比文档标题更多的关于图像的有用信息,而
文档中的正文包含的有用信息比关键词更多。在此基础上本文进行了下面小节
的实验。
4.2.2 使用文档标题与关键词组合对图像分类
本小节试验中将文档标题与关键词组合在一起对图像进行分类实验,并将
实验结果与只使用文档正文以及使用标题加正文(即全文本)这两种情况下的
分类结果进行了比较分析。
同上节实验环境,系统使用训练好的 10 类 model,文本预处理采用基于
0
10
20
30
40
50
60
70
80
90
100电影
航空航天
交通
军事
考古学
民族
生物学
体育
天文学
戏曲曲艺
图像类别
F1测度值(%)
只用关键词F1值
只用标题F1值
只用正文F1值

第 4章 基于 TextRank抽取的文档关键词的图像分类
38
BigramWordSegment中文二字串切分方法,特征维数选取 60000维。从分类结果
来看,使用标题与关键词组合用于图像分类的方法在评价指标上对于 F1测度值,
只在电影和体育这两个类别上略高于只使用正文的分类方法,而远远低于(低 1
至 15个百分点不等)使用标题加正文即全文本的分类方法,结果对比见表 4.2。
表表表表4.2 4.2 4.2 4.2 基于三种不同文本组合方式图像分类实验基于三种不同文本组合方式图像分类实验基于三种不同文本组合方式图像分类实验基于三种不同文本组合方式图像分类实验结果对比结果对比结果对比结果对比表表表表
图 4.4为基于三种不同文本组合方式的图像分类实验的 F1测度值对比。
4.2.3 将全文本与关键词组合对图像分类
在本小节实验,将使用 TextRank方法抽取出的文档关键词与原文档中全文
本(即标题加正文)组合在一起对图像进行分类实验,组合采用简单的方式,
即将关键词序列直接加在原文本后面,每个关键词中间加以空格,用以避免在
文本预处理时使用 BigramWordSegment中文二字串切分方法对加了关键词的文
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲曲曲曲艺艺艺艺
准确率准确率准确率准确率((((%%%%)))) 85.6 68.1 93.8 66.1 95.7 95.6 91.8 82 95.4 93
召回率召回率召回率召回率((((%%%%)))) 84.6 79 76 82 89 87 81.7 100 83 92
只只只只
用用用用
正正正正
文文文文 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 85.1 73.1 84 73.2 92.2 91.1 86.4 90.1 88.8 92.5
准确率准确率准确率准确率((((%%%%)))) 93.33 62.70 92.96 51.33 94.94 89.89 88.89 87.96 92.5 82.05
召回率召回率召回率召回率((((%%%%)))) 84 79 66 77 75 80 80 95 74 96
标标标标
题题题题
加加加加
关关关关
键键键键
词词词词
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 88.42 69.91 77.19 61.6 83.80 84.66 84.21 91.35 82.22 88.48
准确率准确率准确率准确率((((%%%%)))) 92 69.2 93 70.6 96.8 95.6 90.7 85.5 96.5 95.8
召回率召回率召回率召回率((((%%%%)))) 92 81 80 84 90 86 88 100 82 92
标标标标
题题题题
加加加加
正正正正
文文文文
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92 74.7 86 76.7 93.3 90.5 89.3 92.2 88.6 93.9

第 4章 基于 TextRank抽取的文档关键词的图像分类
39
图图图图4444.4 .4 .4 .4 基于三种不同文本组合方式图像分类实验基于三种不同文本组合方式图像分类实验基于三种不同文本组合方式图像分类实验基于三种不同文本组合方式图像分类实验F1F1F1F1测度值对比图测度值对比图测度值对比图测度值对比图
本切分时产生多余噪声,并与只用全文本的分类方法进行比较。其它实验环境
仍同上小节,系统使用 10类 model,特征维数取 60000维。实验结果及对比情
况见表 4.3及图 4.6。
经过对实验结果对比分析,使用全文本与关键词组合对图像分类的方法在
电影、航空航天等 7 个类别上调和平均值 F1-measure都有了一定程度的提高,
提高幅度为约 0.1%至 5.75%,在天文学类别上提升幅度最小为 0.1%,在交通类
别上提高最大,提高了 5.75%,但在考古学、民族和生物这三个类别上出现了降
低的情况,降低幅度较小,分别为 0.59%、1.61%和 0.52%。从表 4.3 列出的分
类结果比较来看,采取这种把用 TextRank从原文档中抽取的关键词与原文档全
文本组合再对图像进行基于组合后文本分类的方法能够取得一定程度的改善效
果。举例如图像 4.5,该图原被标注为体育类图像,在只使用全文本对其进行分
类时,该图被错误的归类到了交通类,经过将关键词与全文本组合再对其进行
分类,该图被正确分类到了体育类别中。
0
10
20
30
40
50
60
70
80
90
100
电影
航空航天
交通
军事
考古学
民族
生物学
体育
天文学
戏曲曲艺
图像类别
F1测度值(%)
只用正文F1值
标题加关键词F1值
标题加正文F1值

第 4章 基于 TextRank抽取的文档关键词的图像分类
40
图图图图 4.5 4.5 4.5 4.5 使用全文本与使用全文本与使用全文本与使用全文本与关键词组合后关键词组合后关键词组合后关键词组合后图像图像图像图像被正确被正确被正确被正确分类分类分类分类图例图例图例图例
这是与该图像相关联的全文本(标题加正文)例子。
雷诺雷诺雷诺雷诺F1车队印度路演车队印度路演车队印度路演车队印度路演 皮奎特和格拉西携手出席皮奎特和格拉西携手出席皮奎特和格拉西携手出席皮奎特和格拉西携手出席
印度当地时间 11 月 8 日~9 日,雷诺 F1 车队前往新德里路演。出席的车手
有皮奎特和格拉西。图为路演活动现场的画面。
这是将关键词与全文本组合后(标题加正文)例子。
雷诺雷诺雷诺雷诺F1车队印度路演车队印度路演车队印度路演车队印度路演 皮奎特和格拉西携手出席皮奎特和格拉西携手出席皮奎特和格拉西携手出席皮奎特和格拉西携手出席
印度当地时间 11 月 8 日~9 日,雷诺 F1 车队前往新德里路演。出席的车手
有皮奎特和格拉西。图为路演活动现场的画面。路演 车手 f1 车队 雷诺 活动
现场 画面
在本章的第 4.4节中将采取更多的增加关键词在文档中的文本所占比例(也
就是更多的增加关键词在文本中的权重)以谋求进一步改善分类效果。
4.3 使用关键词与原文档文本组合进行交叉验证实验
本节实验按照系统结构框架图4.2中虚线描述的第二种实现方式,对使用关
键词与原文档文本进行不同组合方式用于图像分类的方法进行了交叉验证实
验,并与第3章3.9节使用全文本(标题加正文)这种情况下的交叉验证分类结果
进行比较分析,来验证基于关键词与原文本组合的方法对图像自动分类性能提

第 4章 基于 TextRank抽取的文档关键词的图像分类
41
升确实有效。
表表表表4444.3 .3 .3 .3 使用全文本与关键词组合的使用全文本与关键词组合的使用全文本与关键词组合的使用全文本与关键词组合的图像分类图像分类图像分类图像分类实验结果对比实验结果对比实验结果对比实验结果对比表表表表
图图图图4444.6.6.6.6 使用全文本与关键词组合的使用全文本与关键词组合的使用全文本与关键词组合的使用全文本与关键词组合的图像分类实验图像分类实验图像分类实验图像分类实验F1F1F1F1测度值对比图测度值对比图测度值对比图测度值对比图
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
准确率准确率准确率准确率((((%%%%)))) 92 69.2 93 70.6 96.8 95.6 90.7 85.5 96.5 95.8
召召召召回率回率回率回率((((%%%%)))) 92 81 80 84 90 86 88 100 82 92
全全全全
文文文文
本本本本
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92 74.7 86 76.7 93.3 90.5 89.3 92.2 88.6 93.9
准确率准确率准确率准确率((((%%%%)))) 93 69.67 94.68 77.57 96.74 94.38 90.63 89.19 96.47 92.31
召回率召回率召回率召回率((((%%%%)))) 93 85 89 83 89 84 87 99 82 96
全全全全
文文文文
本本本本
加加加加
关关关关
键键键键
词词词词
F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 93 76.58 91.75 80.19 92.71 88.89 88.78 93.84 88.7 94.12
0
10
20
30
40
50
60
70
80
90
100
电影
航空航天
交通
军事
考古学
民族
生物学
体育
天文学
戏曲曲艺
图像类别
F1测度值(%)
全文本与关键词组合F1值
全文本F1值

第 4章 基于 TextRank抽取的文档关键词的图像分类
42
同第 3 章 3.9 节交叉验证试验中选择训练集和测试集的方法:将自建的 10
类图文数据集中的 1000篇文档经过与关键词不同组合处理后平均分成五份,选
择其中一份作为开放测试集,剩余的四份作为训练集。这样每一份都依次轮流
作为开放测试集,运行分类算法进行交叉验证,在实验中文本预处理仍采用基
于 BigramWordSegment的中文二字串的切分方法,根据数据集的规模,特征维
数选取 10000维,共执行五次分类操作,实验结束后计算准确率、召回率及 F1
测度值几个评价指标的平均值。
4.3.1 使用文档标题与关键词组合进行交叉验证
本小节中将文档标题与关键词组合在一起用于对图像进行交叉验证分类实
验,实验环境及参数配置如上描述,实验结果取平均值后见表4.4。
与第 3章 3.9节中使用全文本的交叉验证实验结果对比发现,在大部分图像
类别上使用标题加关键词对图像分类的方法与使用全文本方法相比,在 F1测度
值都低一些,只在航空航天、军事和体育这 3 个类别上有所提高,且提升幅度
不大,但考虑到每篇文档抽取的关键词数量一般从十几个至二十几个,只有少
数文档抽取的关键词数超过了 30个,用其代替原文本进行训练和测试可以大大
降低文本分类特征空间的高维性,降低计算复杂度,减少训练时间开销和分类
过程中的噪声,进而提高分类效率。可见使用关键词序列替代原文本进行分类
的这种方法有一定的可取性。
表表表表4444.4 .4 .4 .4 标题与标题与标题与标题与关键词组合的关键词组合的关键词组合的关键词组合的图像图像图像图像交叉验证交叉验证交叉验证交叉验证分类分类分类分类实验结果实验结果实验结果实验结果
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
训练文档数训练文档数训练文档数训练文档数////次次次次 80 80 80 80 80 80 80 80 80 80
测试文档数测试文档数测试文档数测试文档数////次次次次 20 20 20 20 20 20 20 20 20 20
准确率准确率准确率准确率((((%%%%)))) 97.92 81.93 85.04 92.31 87.06 97.78 84.66 98.41 88.57 93.63
召回率召回率召回率召回率((((%%%%)))) 86.67 81.67 93.33 96.67 90 78.33 95 93.33 88.33 96.67
标标标标
题题题题
加加加加
关关关关
键键键键
词词词词
F1F1F1F1 测度值测度值测度值测度值
((((%%%%)))) 91.84 81.57 88.73 94.30 88.50 86.82 89.28 95.63 87.47 95.04
第 4章 基于 TextRank抽取的文档关键词的图像分类
43
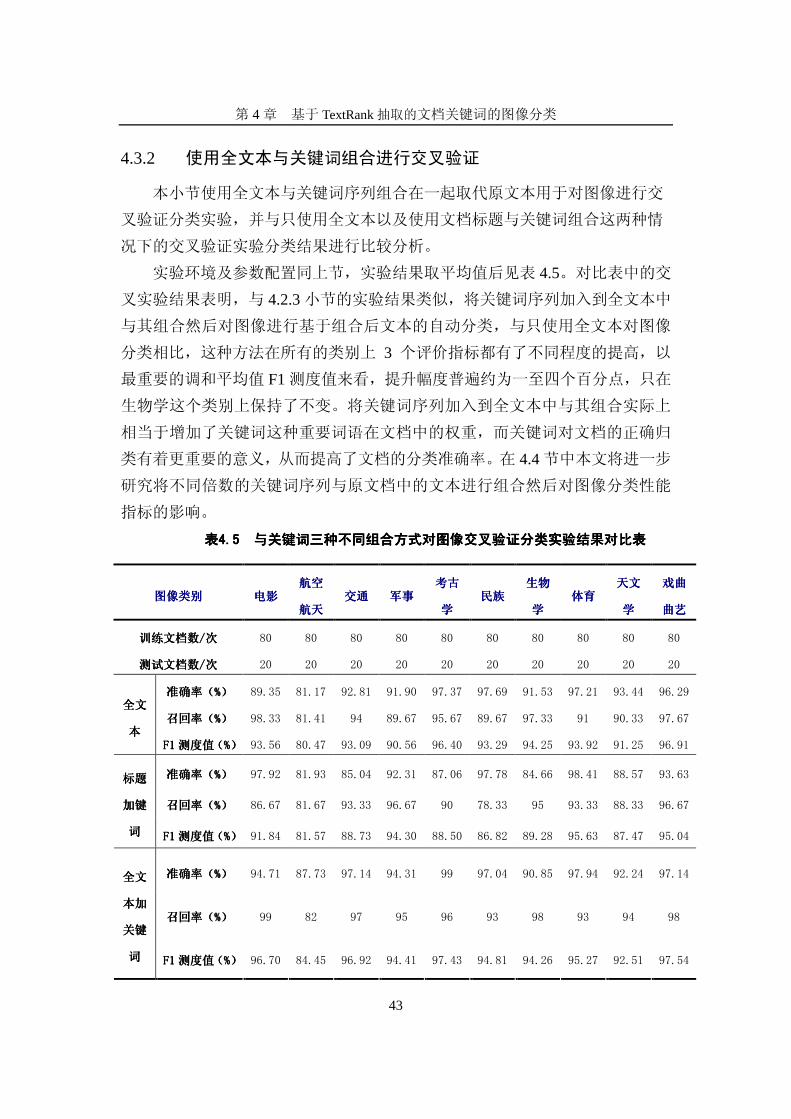
4.3.2 使用全文本与关键词组合进行交叉验证
本小节使用全文本与关键词序列组合在一起取代原文本用于对图像进行交
叉验证分类实验,并与只使用全文本以及使用文档标题与关键词组合这两种情
况下的交叉验证实验分类结果进行比较分析。
实验环境及参数配置同上节,实验结果取平均值后见表 4.5。对比表中的交
叉实验结果表明,与 4.2.3小节的实验结果类似,将关键词序列加入到全文本中
与其组合然后对图像进行基于组合后文本的自动分类,与只使用全文本对图像
分类相比,这种方法在所有的类别上 3 个评价指标都有了不同程度的提高,以
最重要的调和平均值 F1测度值来看,提升幅度普遍约为一至四个百分点,只在
生物学这个类别上保持了不变。将关键词序列加入到全文本中与其组合实际上
相当于增加了关键词这种重要词语在文档中的权重,而关键词对文档的正确归
类有着更重要的意义,从而提高了文档的分类准确率。在 4.4节中本文将进一步
研究将不同倍数的关键词序列与原文档中的文本进行组合然后对图像分类性能
指标的影响。
表表表表4444.5 .5 .5 .5 与关键词三种不同组合方式对图像交叉验证分类实验结果与关键词三种不同组合方式对图像交叉验证分类实验结果与关键词三种不同组合方式对图像交叉验证分类实验结果与关键词三种不同组合方式对图像交叉验证分类实验结果对比对比对比对比表表表表
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
训练文档数训练文档数训练文档数训练文档数////次次次次 80 80 80 80 80 80 80 80 80 80
测试文档数测试文档数测试文档数测试文档数////次次次次 20 20 20 20 20 20 20 20 20 20
准确率准确率准确率准确率((((%%%%)))) 89.35 81.17 92.81 91.90 97.37 97.69 91.53 97.21 93.44 96.29
召回率召回率召回率召回率((((%%%%)))) 98.33 81.41 94 89.67 95.67 89.67 97.33 91 90.33 97.67 全文全文全文全文
本本本本 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 93.56 80.47 93.09 90.56 96.40 93.29 94.25 93.92 91.25 96.91
准确率准确率准确率准确率((((%%%%)))) 97.92 81.93 85.04 92.31 87.06 97.78 84.66 98.41 88.57 93.63
召回率召回率召回率召回率((((%%%%)))) 86.67 81.67 93.33 96.67 90 78.33 95 93.33 88.33 96.67
标题标题标题标题
加加加加键键键键
词词词词 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 91.84 81.57 88.73 94.30 88.50 86.82 89.28 95.63 87.47 95.04
准确率准确率准确率准确率((((%%%%)))) 94.71 87.73 97.14 94.31 99 97.04 90.85 97.94 92.24 97.14
召回率召回率召回率召回率((((%%%%)))) 99 82 97 95 96 93 98 93 94 98
全文全文全文全文
本加本加本加本加
关键关键关键关键
词词词词 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 96.70 84.45 96.92 94.41 97.43 94.81 94.26 95.27 92.51 97.54

第 4章 基于 TextRank抽取的文档关键词的图像分类
44
图 4.7 将只使用全文本、使用文档标题与关键词序列组合及全文本与关键
词序列组合对图像进行交叉验证分类的实验结果中最重要的评价指标 F1测度值
放在一起进行了对比。
图图图图4444.7.7.7.7 与关键词三种不同组合方式与关键词三种不同组合方式与关键词三种不同组合方式与关键词三种不同组合方式对图像交叉验证分类实验结果对比图对图像交叉验证分类实验结果对比图对图像交叉验证分类实验结果对比图对图像交叉验证分类实验结果对比图
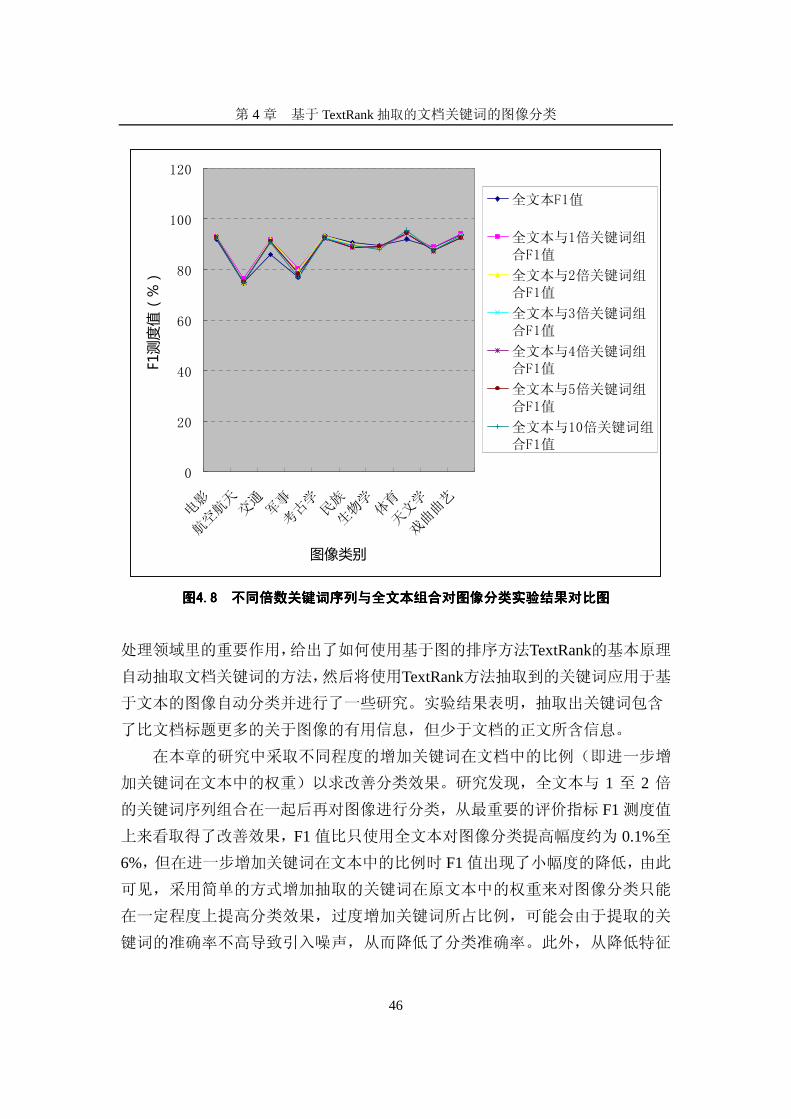
4.4 不同倍数的关键词序列与原文档组合用于图像分类
本节实验中,将使用TextRank从本文创建的图文数据集1000文档中抽取出的
关键词序列分别复制1倍、2倍、3倍、4倍、5倍与10倍和原文档中全文本组合并
将其替代,然后再对图像进行基于不同组合文本的分类实验。
本节分类实验的环境及参数配置与4.2节同,训练模型使用已保存的中文大
百科10类model,文本预处理采用基于BigramWordSegment的中文二字串的切分
方法,特征维数选取60000维,表4.6中将这6种文本组合方式下的分类实验结果
与在同样实验环境下使用全文本对图像分类结果进行了比较,为了简单起见,
表中只列出了每次实验结果评价指标中最重要的F1测度值。
图 4.8 显示了不同倍数关键词序列与全文本组合对图像自动分类实验结果
对比情况。
0
20
40
60
80
100
120电
影
航空
航天
交通
军事
考古
学
民族
生物
学
体育
天文
学
戏曲
曲艺
图像类别
F1测度值(%) 全文本与关键词组
合F1值
全文本F1值
标题与关键词组合F1值

第 4章 基于 TextRank抽取的文档关键词的图像分类
45
表表表表4444.6 .6 .6 .6 不同倍数关键词序列与全文本组合对图像分类实验结果不同倍数关键词序列与全文本组合对图像分类实验结果不同倍数关键词序列与全文本组合对图像分类实验结果不同倍数关键词序列与全文本组合对图像分类实验结果对比表对比表对比表对比表
从结果可见,全文本与 1 倍和 2 倍关键词序列组合对图像分类分类的结果
基本一致,与只使用全文本对图像进行分类相比,从调和平均值 F1测度值上看,
在一定程度上取得了改善效果,提高幅度约 0.1%至 6%,然而在关键词序列增加
到 3 倍、4 倍、5 倍与 10倍时,F1值没有再进一步增加,而是出现了微小幅度
的降低,其中增加 4 倍与 5 倍的分类结果是一致的。可见,只是简单的采用增
加关键词序列在原文本中的比例(也即采用简单的方式增加抽取的关键词在原
文本中的权重)来对图像分类,这种方法只能在一定程度上提高分类效果,过
多增加关键词的比例,可能会由于提取的关键词的准确率不高反而会引入噪声,
从而导致降低了分类准确率。
4.5 小结
本章首先介绍了关键词自动抽取技术及在文本分类、文本摘要等许多文本
图像类别图像类别图像类别图像类别 电影电影电影电影 航空航空航空航空
航天航天航天航天 交通交通交通交通 军事军事军事军事
考古考古考古考古
学学学学 民族民族民族民族
生物生物生物生物
学学学学 体育体育体育体育
天文天文天文天文
学学学学
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
全文本全文本全文本全文本 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92 74.7 86 76.7 93.3 90.5 89.3 92.2 88.6 93.9
全文本与全文本与全文本与全文本与 1111 倍关键词倍关键词倍关键词倍关键词
组合组合组合组合 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 93 76.58 91.75 80.19 92.71 88.89 88.78 93.84 88.7 94.12
全文本与全文本与全文本与全文本与 2222 倍关键词倍关键词倍关键词倍关键词
组合组合组合组合 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 93.07 75.11 91.75 79.43 93.26 89.95 89.23 94.29 88.04 93.60
全文本与全文本与全文本与全文本与 3333 倍关键词倍关键词倍关键词倍关键词
组合组合组合组合 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92.54 75.34 91.19 78.85 92.71 89.47 89.23 94.29 88.04 93.14
全文本与全文本与全文本与全文本与 4444 倍关键词倍关键词倍关键词倍关键词
组合组合组合组合 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92.54 75 91.19 78.26 92.23 88.89 89.23 94.29 87.43 92.68
全文本与全文本与全文本与全文本与 5555 倍关键词倍关键词倍关键词倍关键词
组合组合组合组合 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92.54 75 91.19 78.26 92.23 88.89 89.23 94.29 87.43 92.68
全文本与全文本与全文本与全文本与 10101010 倍关键倍关键倍关键倍关键
词组合词组合词组合词组合 F1F1F1F1 测度值测度值测度值测度值((((%%%%)))) 92.54 75 90.63 76.78 92.23 89.36 88.08 95.69 87.43 93.20
第 4章 基于 TextRank抽取的文档关键词的图像分类
46
图图图图4444.8.8.8.8 不同倍数关键词序列与全文本组合对图像分类实验结果对比图不同倍数关键词序列与全文本组合对图像分类实验结果对比图不同倍数关键词序列与全文本组合对图像分类实验结果对比图不同倍数关键词序列与全文本组合对图像分类实验结果对比图
处理领域里的重要作用,给出了如何使用基于图的排序方法TextRank的基本原理
自动抽取文档关键词的方法,然后将使用TextRank方法抽取到的关键词应用于基
于文本的图像自动分类并进行了一些研究。实验结果表明,抽取出关键词包含
了比文档标题更多的关于图像的有用信息,但少于文档的正文所含信息。
在本章的研究中采取不同程度的增加关键词在文档中的比例(即进一步增
加关键词在文本中的权重)以求改善分类效果。研究发现,全文本与 1 至 2 倍
的关键词序列组合在一起后再对图像进行分类,从最重要的评价指标 F1测度值
上来看取得了改善效果,F1值比只使用全文本对图像分类提高幅度约为 0.1%至
6%,但在进一步增加关键词在文本中的比例时 F1值出现了小幅度的降低,由此
可见,采用简单的方式增加抽取的关键词在原文本中的权重来对图像分类只能
在一定程度上提高分类效果,过度增加关键词所占比例,可能会由于提取的关
键词的准确率不高导致引入噪声,从而降低了分类准确率。此外,从降低特征
0
20
40
60
80
100
120
电影
航空航天
交通
军事
考古学
民族
生物学
体育
天文学
戏曲曲艺
图像类别
F1测度值(%)
全文本F1值
全文本与1倍关键词组合F1值
全文本与2倍关键词组合F1值
全文本与3倍关键词组合F1值
全文本与4倍关键词组合F1值
全文本与5倍关键词组合F1值
全文本与10倍关键词组合F1值

第 4章 基于 TextRank抽取的文档关键词的图像分类
47
空间的维数特征角度来看,每篇文档抽取的关键词数量有限,用其代替原文本
进行训练和测试可以大大降低文本分类特征空间的高维性,降低计算复杂度,
减少训练时间开销和分类过程中的噪声,进而提高分类效率,从这方面来说,
使用抽取的关键词对文档进行分类这种方法也具有一定可取性。
在今后的研究中作者将进一步研究如何更合理的增加关键词在文档文本中
的权重进而改善对图像进行基于关联文本分类的质量。

第 5章 总结与展望
48
第 5 章 总结与展望
图像语义内容丰富,“百闻不如一见”,“一幅图胜过千言万语”都充分说明
了图像在信息传播方面的重要作用。随着互联网及多媒体技术的蓬勃发展,
Internet上各种形式的数字化信息正在迅猛增长,图像资源也呈指数级态势增长。
图像自动分类作为 Web数据挖掘领域的一个重要的研究方向,对图像进行
高效准确的自动分类工作对图像资源的管理和检索具有现实、积极的意义。而
基于内容的图像分类技术由于技术和实现上存在着许多局限性,目前只能应用
于一些特殊的图像检索中。为此,本文围绕如何改进基于文本的图像自动分类
方法,经过深入的调查研究与文献查阅,相继完成了论文的选题、开发与写作
工作,主要工作有:
1. 针对没有通用的标准的包含图像的中文图文数据集合用于分类研究的
现状,参照大百科全书中文分类体系,从中选取军事、体育、交通、航
空航天、电影、民族、生物学、天文学、考古学、戏曲曲艺共 10 个类
别,使用网络爬虫从新浪等门户网站下载并人工建立和标注了共 1000
篇包括图像及关联文本的图文数据集。
2. 根据建立的图文数据集进行了一系列基于文本的图像自动分类实验。实
验证明使用支持向量机(SVM)方法的文本自动分类系统 ECTCS对图
像进行基于关联文本的自动分类在本文创建的军事等 10 个类别图文数
据集上都取得了较好的分类质量。并且通过使用创建的图文数据集进行
交叉验证实验,进一步验证了基于相关全文本对图像进行自动分类的方
法可以达到较为满意的分类效果。
3. 使用基于图的排序方法 TextRank自动抽取出文档关键词应用于基于文
本的图像自动分类研究上。相关实验结果表明,关键词包含了比文档标
题更多的关于图像的有用信息。在此基础上进一步通过实验研究发现,
在一定程度上的增加关键词在文档中的比例然后用于对图像分类在 F1
测度值上取得了比使用全文本约 0.1%至 6%的提高,但过度增加关键词
在文档文本中的比例会造成 F1 值小幅降低,由于目前使用的各种关键
词抽取技术抽取的关键词的准确率普遍不高,会导致引入噪声,从而降
低分类准确率。但从降低特征空间的维数特征角度来看,由于从文档中

第 5章 总结与展望
49
抽取的关键词数目有限,用其代替原文本进行训练和测试可以大大降低
文本分类特征空间的高维性,降低计算复杂度,减少训练时间开销和分
类过程中的噪声,进而提高分类效率,从这方面来说,使用抽取的关键
词对文档进行分类这种方法也具有一定可取性。
尽管本文对基于中文文本的图像自动分类技术进行了大量实验和基础性原
理研究,也取得了一定的成果及进展,但总体来说目前的研究还比较浅显,在
今后的研究中作者将从以下几方面着手进行研究:
1. 本文创建的中文图文数据集规模较小,类别数量有限,不能全面的反映
出基于文本的图像自动分类方法在其它更多图像类别上的分类效果。而
且人工创建图文数据集费时费力,下一步作者将研究如何对 Web 页面
结构进行深度解析,分析图像信息特征,找到更准确的抽取网页中主题
图像以及关联文本的方法,建立更多类别的图文数据集以便用于基于文
本的图像自动分类研究。
2. 进一步研究如何更合理的通过改变关键词在文档中的权重(也即增加关
键词在文档中的重要程度)进而改善基于关键词与原文档组合方式的图
像自动分类的质量。
3. 在本文基于文本对图像自动分类的研究中,假定所有的图像都是唯一可
分类的,即每个图像只能属于一类,然而,大多数真实世界的图像属于
多标签学习问题,即一幅图像往往可能归到多个类,附录 B 中的表格列
出了本文对创建的图文数据集进行人工多标签标注的情况,标注的类别
参照了大百科全书中文分类体系中的 55 个类别。如何对图像进行多标
签自动标注以及基于文本的多类多标签图像自动分类都将是作者今后
的研究重点。

参考文献
50
参考文献
[1] 孙茂松,王洪君,董秀芳. 《信息处理用现代汉语分词词表》规范. 语言计算与基
于内容的文本处理. 清华大学出版社,2003:391-398.
[2] M.Flickner,H.S.Sawhney,W.Niblack et al."Query by image and video content:The
QBIC System".IEEE Computer,Vol.28,No.9,pp.23-32,September 1995.
[3] A. Pentland,R. W. Picard,S. Sclaroff. Photobook: Content-based manipulation of
image databases.International Journal of Computer Vision, 1996.
[4] 张华. WWW 图像语义信息提取方法研究. [硕士论文].2004.
[5] Carl Sable. Robust Statistical Techniques for the Categorization of Images Using
Associated Text .2003.
[6] Mihalcea R.,Tarau P. TextRank:Bringing Order into Texts. In Proceedings of
Empirical Methods in Natural Language Processing .Barcelona,Spain,404-410,2004
[7] http://blog.csdn.net/DL88250/archive/2008/02/20/2108164.aspx.朴素贝叶斯中文
文本分类器的研究与实现.
[8] 张浩,汪楠. 文本分类技术研究进展.计算机与信息技术.2007.
[9] J. L MccLelland, D. E Rumelhart. Parallel Distributed Processing, Exploration in
the Microstructure of Cognition, MIT Press,1986.
[10] 杨杰,陈晓云. 图像分类方法比较研究. 微计算机应用.2007.
[11] V.Vapnik. The nature of statistical learning theory. New York: Springer, 1995.
[12] 杨杰. 多文档关键词抽取技术的研究. [硕士论文].2009.
[13] Azcarraga A,Yap T.J,Chua T.S.Comparing Keyword Extraction Techniques for
WEBSOM Text Archives. International Journal of Artificial Intelligence
Tools,2002,11(2):219-232.
[14] Frank E,Paynter G.W,Wittem I.H. Domain-Specific Keyphrase Extractuon. In
Proceedings of the 16th International Joint Conference on Artificial
Intelligence.Stockholm,Sweden.Morgan Kaufmann,1999:668-673.
[15] Hulth A. Combining Machine Learning and Natural Language Processing for
Automatic Keyword Extraction.Stockholm University:Ph.D.diss.Dept.of Computer
and Systems Sciences,2004.
[16] 王晓龙,关毅.计算机自然语言处理.清华大学出版社,2006:128-129.
[17] 吴 春 玉 . 中 文 全 文 检 索 系 统 中 实 现 主 题 词 标 引 思 路 . 情 报 杂
志,2005,24(01):115-117.

参考文献
51
[18] 马颖华 ,王永成 ,苏贵洋 ,等 .一种基于字同现频率的汉语文本主题抽取方法 .计算
机研究与发展,2003,40(6):874-878.
[19] Matsuo Y.,Ishizuka M..Keyword Extraction from a Single Document using Word
Co-occurrences Statistical Information. International Journal on Artificial
Intelligence Tools,2004,13(1):157-169.
[20] Tang J.,Li J.Z.,Wang K.H.,Cai Y.R...Loss Minimization based Keyword
Distillation.In Proceedings of 6th Asia-Pacific Web Conference.Springer LNCS
2007,2004:572-577.
[21] Truney P.D..Learning Algorithms for Keyphrase Extraction. Information
Retrieval,2000,2(4): 303-336.
[22] 孙建涛,沈抖,陆玉昌,石纯一. 网页分类技术. 清华大学学报(自然科学版) 2004
年第 44 卷第 1 期:65-68.
[23] Cai Deng , He Xiaofei , Li Zhiwei ,et al. Hierarchical Clustering of WWW Image
Search Result s Using Visual Textual and Link Information. Proc of the 12th Annual
ACM Int’l Conf on Multimedia. 2004.
[24] SALTON G, BUCKLEY C. Term-weighting approaches in automatic text retrieval.
Information Processing and Management,1988.
[25] 徐择峰 , 陈世鸿 . 一种统一的文本与图像分类算法 . 武汉大学学报 (理学版 ),
2004:79-82.
[26] Heng Tao Shen,Beng Chin 0oi,Kian-Lee Tan.Giving Meanings to WWW Images.In
ACM MM,39-47,2000.
[27] Chen Jilin,Zhang Benyu,Shen Dou,et al.Diverse Topic Phrase Extraction Throught
Latent Semantic Analysis[A].In proceeding of the IEEE International Conference
on Data Mining 2006.2006:834-838.
[28] 石军,常义林.图像检索技术综述.西安电子科技大学学报(自然科学版),2003.
[29] 陈迎,丁明跃,唐洁茹.一种 www 图像搜索引擎的模型与实现.武汉理工大学学
报,2001.
[30] Pantel PA.Clustering by Committee.Ph.D.dissertation,Canada:University of
Alberta,2003.
[31] S.K.Chang, C.W.Yan, D.C.Dimitroff, T.Arndt.An intelligent image database
system.IEEE Transactions on Software Engineering,1988,Vol.14,No.5:681-688.
[32] 孟祥增,杨晓娟. 结合主题与内容的 Web图象分类.山东师范大学学报(自然科
学版),2005.
[33] 樊兴华,孙茂松.一种高性能的两类中文文本分类方法.清华大学计算机科学与技
术系.计算机学报.2006.

参考文献
52
[34] Filippo Menczer,Gautam Pant,Padmini Srinivasan.Topica lweb crawlers: Evaluating
adaptive algorithms. ACM Transations on Internet Technology, 2004 ,
Volume1Issue4:378-419.
[35] Bun Khoo Khyou,Ishizuka Mitsuru.Topic Extraction from News Archive Using
TF*PDF Algorithm.The Third International Conference on Web Information
Systems Engineering(WISE'02).Singapore:IEEE CS press,2002:73-82.
[36] Hammouda Khaled M.,Matute Diego N.,Kame Mohamed S..CorePhrase:Keyphrase
Extraction for Document Clustering.Machine Learning and Data Mining in Pattern
Recognition(2005),2005:265-274.
[37] John C P.Probabilistic outputs for support vector machines and comparisons to
regularized likelihood methods.Advances in Large Margin Classifiers,MIT
Press,1999.61273.
[38] Goldstein Jade,Kantrowitz Mark,Mittal Vibhu,et al.Summarizing Text
Documents:Sentence Selection and Evaluation Metrics.In Proceedings of
SIGIR-99.Berkeley,CA,1999:121-128.

致谢与声明
53
致 谢
衷心感谢我的导师孙茂松教授,本文的研究工作是在他的悉心指导和严格
要求下完成的。在我学习和完成论文期间,始终得到了他的悉心指导。孙老师
渊博的知识、开阔的视野、严谨的治学态度和强烈的事业心对我产生了深远的
影响。
感谢研究生期间所有给我关心和支持的老师和同学们! 在研究期间,我得到
了实验室许多同学的关心和帮助。在此向司献策,刘知远,郑亚斌,李伟,张
燕,蒋琪夏,杨麟儿,李鹏等同学表示衷心的感谢!
我还要感谢我的家人和朋友,是你们全力的支持和无私的奉献给了我精神
上最大的鼓励,使得我的学业得以顺利地完成。
最后要特别感谢答辩委员会的各位老师评审我的论文和出席我的毕业答辩
会。
声 明
本人郑重声明:所呈交的学位论文,是本人在导师指导下,独立进行研究
工作所取得的成果。尽我所知,除文中已经注明引用的内容外,本学位论文的
研究成果不包含任何他人享有著作权的内容。对本论文所涉及的研究工作做出
贡献的其他个人和集体,均已在文中以明确方式标明。
签 名: 日 期:

附录
54
附录 A 参照大百科全书中文分类体系 55个类别
类别序号类别序号类别序号类别序号 类别名称类别名称类别名称类别名称 类别序号类别序号类别序号类别序号 类别名称类别名称类别名称类别名称
0 财政税收金融价格 28 生物学
1 大气海洋水文科学 29 世界地理
2 地理学 30 数学
3 地质学 31 水利
4 电工 32 体育
5 电影 33 天文学
6 电子学与计算机 34 图书馆情报档案
7 法学 35 土木工程
8 纺织 36 外国历史
9 固体地球物理学测绘学
空间科学 37 外国文学
10 航空航天 38 文物博物馆
11 化工 39 物理学
12 化学 40 戏剧
13 环境科学 41 戏曲曲艺
14 机械工程 42 现代医学
15 建筑园林城市规划 43 新闻出版
16 交通 44 心理学
17 教育 45 音乐舞蹈
18 经济学 46 语言文字
19 军事 47 哲学
20 考古学 48 政治学
21 矿冶 49 中国传统医学
22 力学 50 中国地理
23 美术 51 中国历史

附录
55
24 民族 52 中国文学
25 农业 53 自动控制与系统工程
26 轻工 54 宗教
27 社会学 - -

附录
56
附录 B 图像多标签标注情况统计表
序号序号序号序号 类别类别类别类别 每个类别中的每个类别中的每个类别中的每个类别中的 100100100100 篇文档中的图像又被标为其他类别的数目统计篇文档中的图像又被标为其他类别的数目统计篇文档中的图像又被标为其他类别的数目统计篇文档中的图像又被标为其他类别的数目统计
2222 个标个标个标个标
签图像签图像签图像签图像
数数数数
1111 个标个标个标个标
签图像签图像签图像签图像
数数数数
1111
航空航空航空航空
航天航天航天航天
体育 3
军事 12
个
交通
20
新闻出
版 10
天文
学 2
生物
学 1
物理学 1
航空航
天 100
49494949 51515151
2222 交通交通交通交通
建筑园
林城市
规划 1
化工 1 法学4
新闻出
版 16
教育
3
机械
工程
1
自动控制
与系统工
程 2
土木
工程
2
大气海
洋水文
科学 2
农业
1
交通
100
33333333 67676767
3333 电影电影电影电影
建筑园
林城市
规划 1
美术 1
电影
100
2222 98989898
4444 军事军事军事军事
航空航
天 12
中国地
理 1
军事
100
13131313 87878787
5555
考古考古考古考古
学学学学
地质学
2
文物博
物馆 18
中国
历史7
外国历
史 6
地理
学 4
教育
1
生物学 3
宗教
1
美术 2
土木
工程
1
考古学
100
45454545 55555555
6666 民族民族民族民族
音乐舞
蹈 18
语言文
字 1
中国
历史1
建筑园
林城市
规划 2
新闻
出版
3
宗教
2
体育 1
美术
1
考古学
1
交通
1
民族
100
31313131 66669999
7777
生物生物生物生物
学学学学
农业 4
考古学
1
地理
学 1
环境科
学 1
现代
医学
2
生物学
100
9999 91919191
8888 体育体育体育体育
新闻出
版 6
体育
100
6666 94949494
9999
天文天文天文天文
学学学学
航空航
天 19
物理学
1
新闻
出版1
中国历
史 1
天文学
100
22222222 78787878
10101010
戏曲戏曲戏曲戏曲
曲艺曲艺曲艺曲艺
戏剧 97
音乐舞
蹈 2
电影1
戏曲曲
艺 100
100100100100 0000
总计总计总计总计 310310310310 690690690690

个人简历、在学期间发表的学术论文与研究成果
57
个人简历、在学期间发表的学术论文与研究成果
个人简历
1977年 1 月 10 日出生于新疆石河子市。
1996 年 9 月考入中国人民解放军信息工程大学通信工程系数字通信
专业,2000年 7 月本科毕业并获得工学学士学位。
2007 年 3 月进入清华大学计算机科学与技术系攻读计算机应用专业
工程硕士至今,师从孙茂松教授。
主要参加的科研项目
[1] 国家高技术研究发展计划(863 计划),大规模网络图文数据的语义分类和适
度理解技术研究(编号:2007AA01Z148)





























