Embed Size (px)
Citation preview

Ograničeni Boltzmanov stroj
Doc.dr.sc. Marko Subašić

Generativni modeli
● Nije cilj naučiti funkciju koja povezuje uzorke iz skupa za učenje sa odgovarajućim oznakama – Diskrimativni modeli
– Jednostavniji problem ali ...
● Generativni modeli mogu generirati nove uzorke koji odgovaraju skupu za treniranje– Iz uzoraka za učenje bitno je naučiti distribucije svih
elemenata ulaznih uzoraka kako bi se generirali odgovarajući uzorci

Generativni modeli
● Modelira se distribucija vjerojatnosti više varijabli
– Kod nekih modela je moguće evaluirati model distribucije direktno, a kod nekih samo indirektno
● Neki potpadaju pod strukturirane stohastičke modele– Grafovi
● Generativno učenje– drugačiji pristup od diskriminativnog učenja
p(x)
p(x)
p(d∣x)
p(d∣x)=p (d ) p (x∣d )
p(x )

Generativni modeli
● Poznavanje distribucije vjerojatnosti otvara neke nove mogućnosti:– Bolja, efikasnija reprezentacija sadržaja
● Efikasnije od “sirovih” piksela za sliku
– Pronalazak bitnih značajki
– Kompresija
– Prepoznati neuobičajeni uzorak
– ...

Generativni modeli
● Procjene vjerojatnosti u praksi rijetko idu direktno● Često uključuju nekoliko ili puno uzimanja
uzoraka kako bi na temelju zastupljenosti uzoraka procijenili funkciju vjerojatnosti
● Treba se naviknuti na to...● ... a možda i ne ● Ako je algoritam efikasan uzorkovanja će biti malo

Korisni alati iz teorije vjerojatnosti
● Markovljevi lanci – Markov Chain● Monte Carlo metoda● Markov Chain Monte Carlo● Gibbs sampling
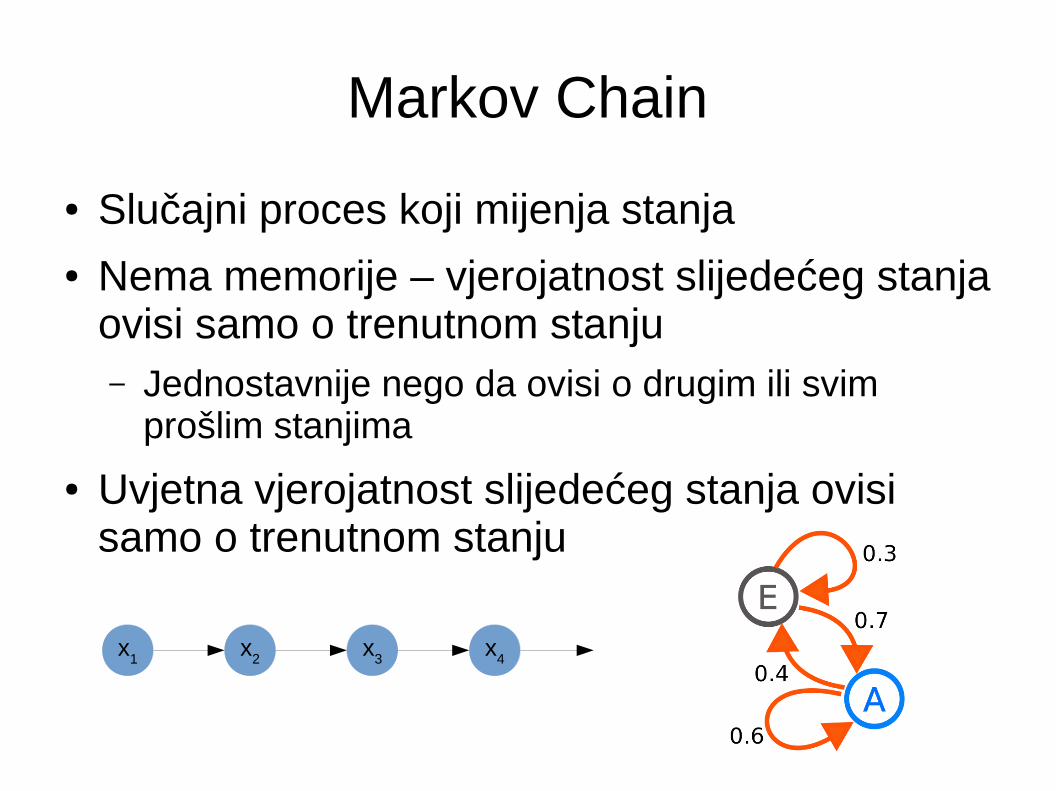
Markov Chain
● Slučajni proces koji mijenja stanja● Nema memorije – vjerojatnost slijedećeg stanja
ovisi samo o trenutnom stanju– Jednostavnije nego da ovisi o drugim ili svim
prošlim stanjima
● Uvjetna vjerojatnost slijedećeg stanja ovisi samo o trenutnom stanju
x4
x3
x2
x1

Monte Carlo metoda
● Eksperiment u kojem se slučajno uzimaju uzorci da bi se dobila kvalitetna procjena rezultat– Bitno je da se radi o stvarnoj slučajnosti
● Bitna primjena je uzorkovanje funkcije vjerojatnosti– Na temelju učestalosti pojedinih uzoraka
zaključujemo o funkciji vjerojatnosti
● Što više uzoraka to bolja procjena rezultata

Markov Chain Monte Carlo
● Metode za uzorkovanje funkcija vjerojatnosti● Konstruira se Markovljev lanac čija je ravnotežna
distribucija (ekvilibrij) jednaka traženoj distribuciji● Nakon inicijalizacije, mijenjaju se stanja kako bi
dosegao ekvilibrij– Tada konkretno inicijalno stanje više nije bitno
● Nakon dosezanja ekvilibrija uzimaju se uzorci za procjenu distribucije– Kvaliteta uzorka se povećava sa brojem promjena stanja

Gibbsovo uzorkovanje
● MCMC algoritam za pribavljanje uzoraka združene funkcije vjerojatnosti za više slučajnih varijabli
● Koristi se kada direktno uzorkovanje nije moguće● Rezultat je aproksimacija
● Naizmjence se uzorkuju pojedine varijable (xn, jedna po jedna)– Mora biti poznata uvjetna vjerojatnost jedne varijable uz
zadane sve ostale varijable
p(x1 , x2 , x3 ,... , xn)
p(xk∣x1 , x2 , ... , xn)

Gibbsovo uzorkovanje
● Nakon dosezanja ekvilibrija uzimamo uzorke koji dobro predstavljaju traženu distribuciju
● Susjedni uzorci su međusobno zavisni (Markovljevo polje)– Ako se traže nezavisni uzorci, preskačemo neki broj promjena
stanja
● Može se ubrzati simuliranim hlađenjem– Veće vjerojatnosti u ranim iteracijama
● Ispravan način za pribavljanje kvalitetnih uzoraka za procjenu združene funkcije vjerojatnosti

Kako radi ograničeni Boltzmanov stroj
● Glavni princip rada je minimizacija energetske funkcije
● Neuroni su stohastički i binarni● Nije feed forward mreža

Modeli temeljeni na energetskoj funkciji
● Definira se energetska funkciju na temelju stanja neurona u mreži i težina koje ih povezuju
● Na primjeru hopfieldove mreže pokazano je da binarni neuroni uz simetrične veze i potpunu povezanost iterativno idu prema (lokalnom) minimumu “pogodne” energetske funkcije

Hopfieldova mreža
● Memorije koje koriste lokalne minimume energetske funkcije
● Čitanje iz memorije – pronalazak lokalnog minimuma energetske funkcije
● Asocijativna memomirija– Mreža vraća naučeni vektor najsličniji ulaznom
vektoru– Zašumljena naučena slika → naučena slika– Odrezana naučena slika → cijela naučena slika
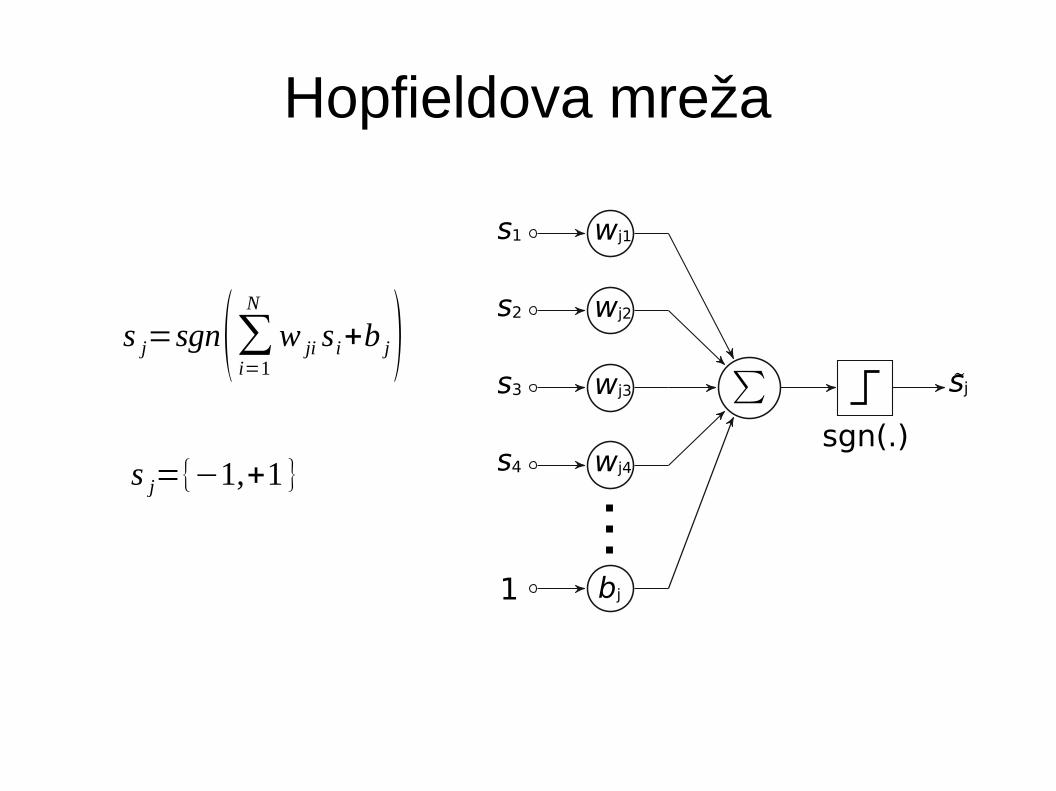
Hopfieldova mreža
s j=sgn(∑i=1
N
w ji si+b j)
s1
s2
s3
s4
1
wj1
wj2
wj3
wj4
bj
sgn(.)
sj
s j={−1,+1 }

Sakrijmo pomak
● Radi preglednosti u nastavku se neće spominjati pomak b svakog neurona iako on uvijek postoji!
● Možemo ga sakriti među težine– Dodatna težina čiji je ulaz uvijek 1
Σ
x1
x2
1
.
.
.
xn
w1
w2
wn+1
=b
wn

Hopfieldova mreža
● Poslužit će nam kao primjer mreže čiji rad je zasnovan na minimizaciji energetske funkcije
● Neuroni nisu stohastički● Koristi se funkcija praga● Binarni neuroni (0,1) ili (-1,1)

Binarni neuron
● Nelinearna funkcija praga kao aktivacijska funkcija● Loše:
– Gubitak informacija
● Dobro:– Efikasnost
– Otpornost na šum
– Robusnost
– Generalizacija !!!
– ...
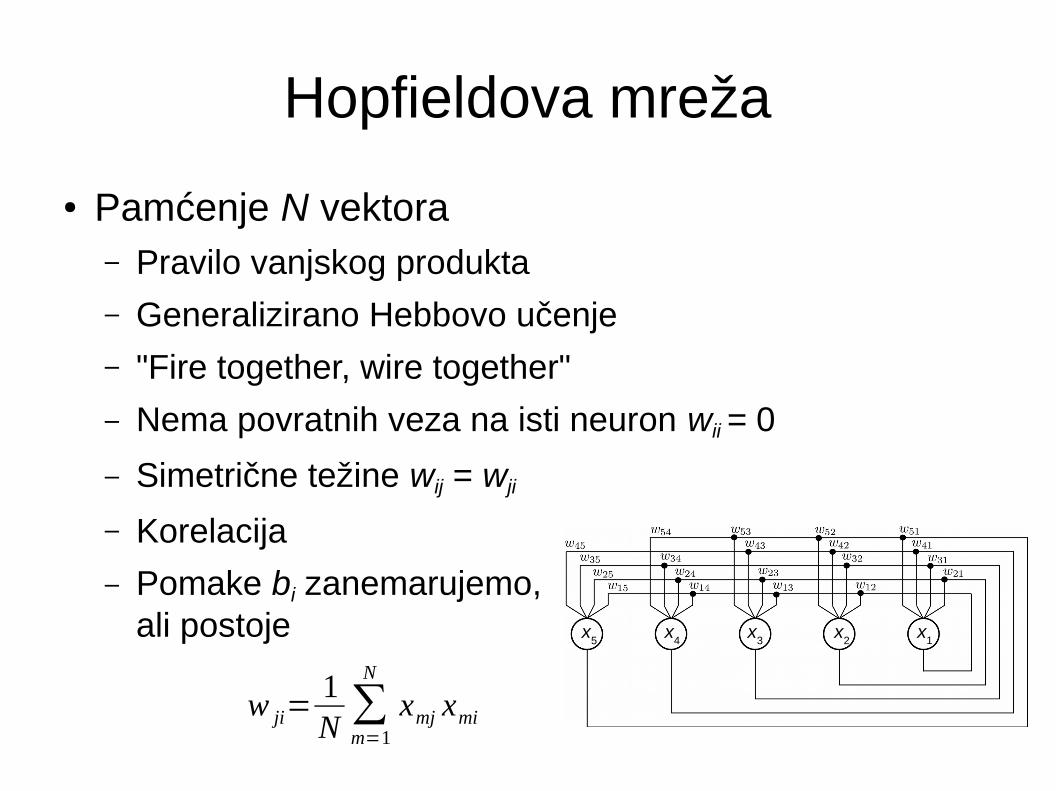
Hopfieldova mreža
● Pamćenje N vektora– Pravilo vanjskog produkta
– Generalizirano Hebbovo učenje
– "Fire together, wire together"
– Nema povratnih veza na isti neuron wii = 0
– Simetrične težine wij = wji
– Korelacija
– Pomake bi zanemarujemo, ali postoje
w ji=1N∑m=1
N
xmj xmi
x1
x2
x3
x4
x5
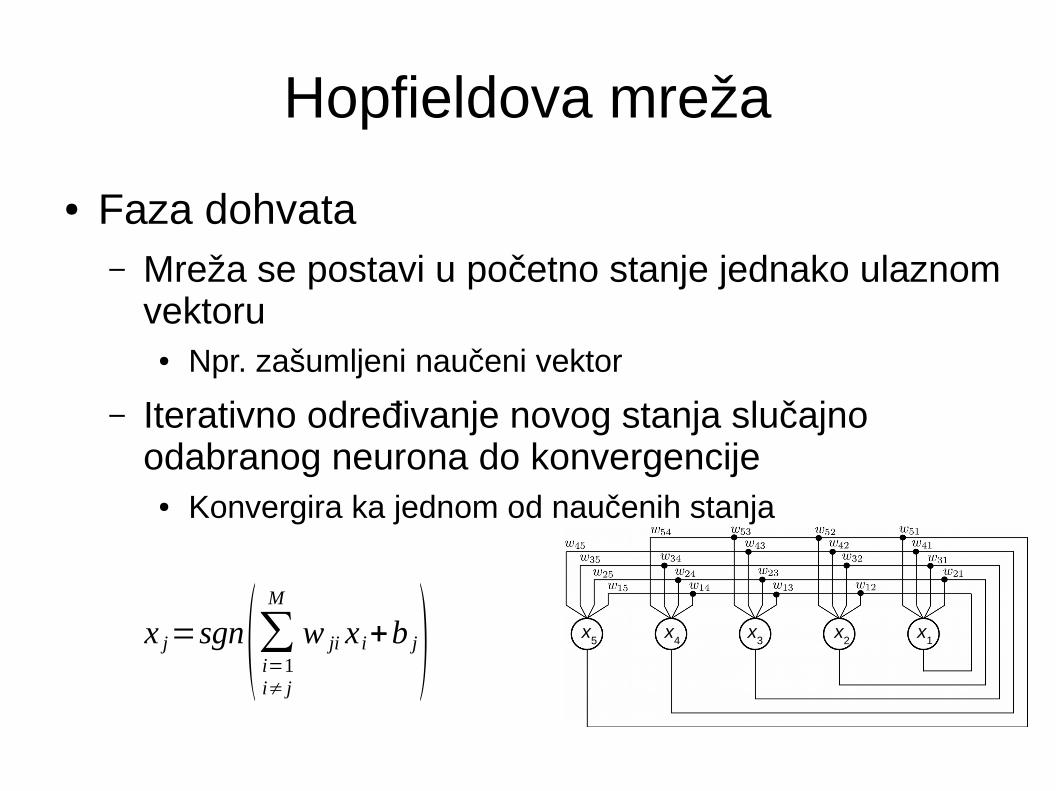
Hopfieldova mreža
● Faza dohvata– Mreža se postavi u početno stanje jednako ulaznom
vektoru● Npr. zašumljeni naučeni vektor
– Iterativno određivanje novog stanja slučajno odabranog neurona do konvergencije
● Konvergira ka jednom od naučenih stanja
x j=sgn(∑i=1i≠ j
M
w ji x i+b j) x1
x2
x3
x4
x5

Hopfieldova mreža
● Ilustracija konvergiranja
(1,1,1)
(1,-1,1)
(-1,1,1)
(-1,-1,1)
(-1,1,-1)
(-1,-1,-1) (1,-1,-1)
(1,-1,-1)stabilno stanje
stabilno stanje

Hopfieldova mreža
● Energetska funkcija
● Promjena energije uslijed promjene stanja– Uvijek je negativna – traženje lokalnog minimum
energetske funkcije
E=−12∑i=1
N
∑j=1j≠i
N
w ji x j x i
Δ E=−Δ x j∑i=1i≠ j
N
w ji x i
Izraz za novo stanje xj

Hopfieldova mreža
● Energija ovisi o stanju mreže uz neki dani skup težina● Lokalni minimumi energetske funkcije predstavljaju memorirane
uzorke● Postoje i lažna stanja
– Negativ memoriranog uzorka
– Mješavine više uzoraka
● Kapacitet je 0.138N● Jedno rješenje za povećanje memorije: Unlearning - zaboravljanje
– Nakon konvergencije iz slučajnog stanja uči se negativnim Hebbovim pravilom
– Lažna stanja u pravilu imaju višu energiju
Δ w ji=−ε x j x i , 0<ε≪1

Hopfieldova mreža
● Binarni deterministički neuroni (-1, 1)– Ne može pobjeći iz lošeg lokalnog minimuma
● Faza dohvata = minimizacija energije ● Naučena stanja = lokalni minimumi energije● Zaboravljanje neželjenih stanja kako bi bolje
zapamtili željena● Dvosmjerne veze
– Bez povratnih veza
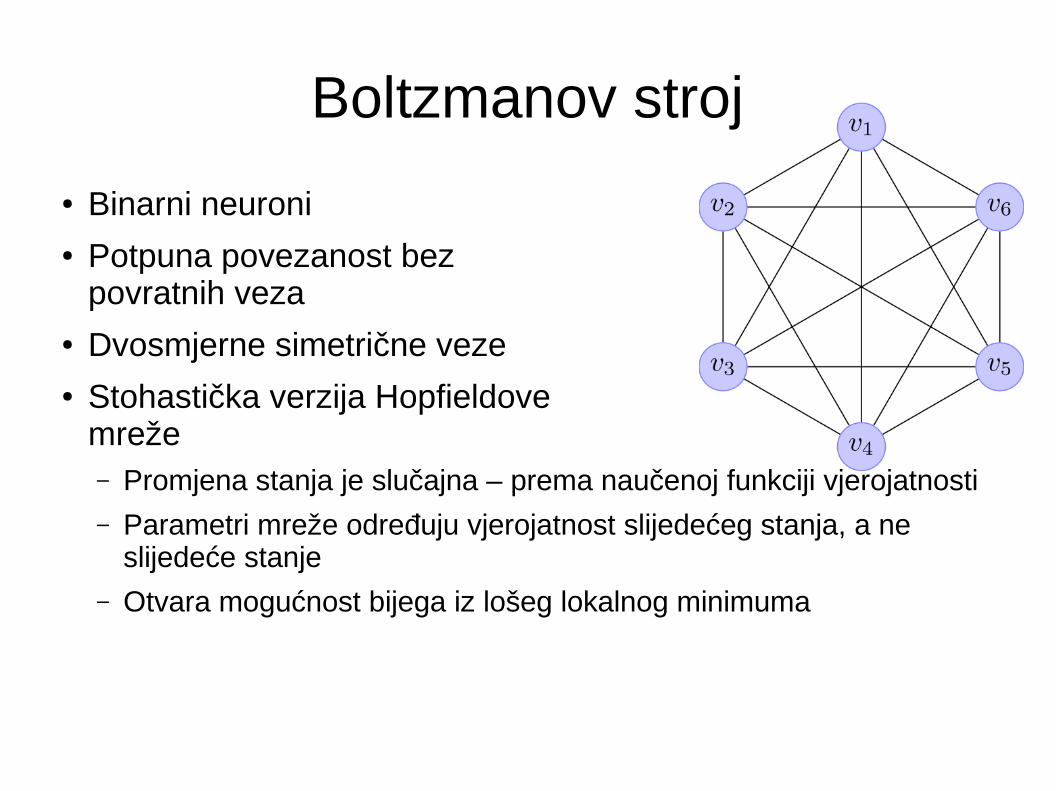
Boltzmanov stroj
● Binarni neuroni● Potpuna povezanost bez
povratnih veza● Dvosmjerne simetrične veze● Stohastička verzija Hopfieldove
mreže– Promjena stanja je slučajna – prema naučenoj funkciji vjerojatnosti
– Parametri mreže određuju vjerojatnost slijedećeg stanja, a ne slijedeće stanje
– Otvara mogućnost bijega iz lošeg lokalnog minimuma

Boltzmanov stroj
● Vjerojatnost definirana pomoću energetske funkcije● Boltzmanova (Gibbsova) distribucija
– k – Boltzmanova konstanta
– T – Termodinamička temperatura – ignoriramo je za sada
– Z(W) je particijska funkcija (partition function)
● Uključuje sva stanja mreže
P(x ;W )=e−E (x)/T
∑x
e−E (x )/T =e
12
xT W x
Z (W )∑
x
P (x)=1
P(x)∝e−E (x )
kT
E( x)=−12∑i=1
N
∑j=1j≠i
N
w ji x j x i=−12
xT W x

Boltzmanov stroj
● Energetska razlika za stanja 0 i 1
● Promjena stanja neurona
– T – temperatura sustava (uključuje Boltzmanovu konstantu)
Δ E j=Ex j=0−Ex j=1=−12∑i=1k≠i
N
∑k=1k≠ik≠ j
N
wki xk x i+12∑i=1k≠ j
N
∑k=1k≠ik≠ j
N
w ki xk xi+∑i=1i≠ j
N
w ji xi
=∑i=1
N
w ji x i
x j={1, s vjerojatnošću1
1+e−Δ E j /T
=1
1+e−∑
i=1
N
w ji x i
0 , inače

Boltzmanov stroj
● Promjena stanja neurona – uzorkovanje!
– Logistička funkcija
x j={1, s vjerojatnošćuP(x j=1, x j)
P (x j=0, x j)+P(x j=1,x j)=
e∑i≠ j
w ji x i
1+e∑i≠ j
w ji xi=
1
1+e−∑
i≠ j
w ji x i
0 , inače
f (x)=1
1+e−k (x− x0)
0
0.5
1
−6 −4 −2 0 2 4 6
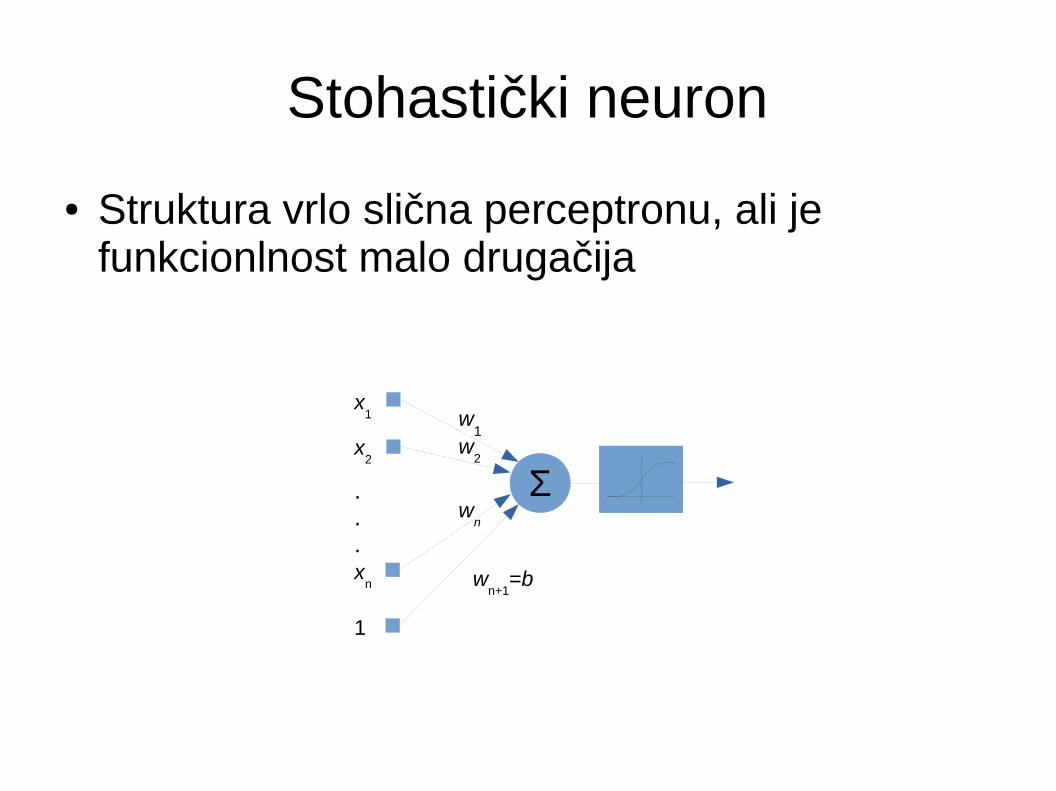
Stohastički neuron
● Struktura vrlo slična perceptronu, ali je funkcionlnost malo drugačija
Σ
x1
x2
1
.
.
.x
n
w1
w2
wn+1
=b
wn

Boltzmanov stroj
● Učenje prilagođava distribuciju podacima za učenje– Maksimiziranje vjerojatnosti za podatke za učenje
● Radi preglednosti privremeno zaboravljamo T mada ju u konačnici možemo koristiti● Maksimizirati možemo i logaritam vjerojatnosti
– Linearna funkcija težina
– Jednostavno određivanje gradijenta
– Jednostavno optimiziranje
ln [∏n=1
N
P( x(n) ;W ) ]=∑n=1
N
[ 12
x(n )TW x(n)−ln Z (W )]
P(x ;W )=e−E (x)/T
∑x
e−E (x )/T =e
12
xT W x
Z (W )

Boltzmanov stroj
● Možemo koristiti stohastic gradient descent● Učenje mijenja težine kako bi se povećalo umnožak logaritama
vjerojatnosti stanja mreže na slijedeći način:
– η je faktor učenja
– Pratimo gradijent
∂∂wij
ln [∏n=1
N
P (x(n) ;W )]=∑n=1
N
[x i(n) x j
(n )−∑
x
x i x jP (x ;W )]=N [⟨ x i x j⟩Data−⟨ x i x j⟩P( x ;W )]
Δ wij=η [⟨ x i x j⟩Data−⟨ x i x j⟩P( x∣W ) ]

Komponente gradijenta
● Empirijska korelacija– Jednostavno se određuje – iz trenutne mini grupe
– Wake rule
– Istovjetno učenju Hopfieldove mreže● Hebbovo učenje
– Koje vrijednosti može poprimiti xixj?
⟨ xi x j⟩Data=1N∑n=1
N
[x i(n )x j
(n)]

Komponente gradijenta
● Korelacija prema modelu– Komponenta dolazi od normalizacijskog člana Z koji
bi trebao uključivati sva stanja
– Određivanje nije jednostavno
– Estimira se pomoću Monte Carlo metode
● Prosječna vrijednost xi xj dok BM iterira● Treba prvo doći u ekvilibrij
– Sleep rule – zaboravljanje (Hebbovo učenje)
⟨ xi x j⟩P (x ;W )=∑x
x i x jP (x ;W )
Δ wij=η [⟨ x i x j⟩Data−⟨ x i x j⟩P( x∣W ) ]

Thermal equilibrium
● Pojam posuđen iz fizike● Ne odnosi se na stacionarno stanje mreže● Odnosi se na stacionarnost funkcije gustoće
vjerojatnosti– Konvergencija funkcije gustoće vjerojatnosti
– Za zadanu temperaturu T
● Teško je odrediti kada je dosegnut

Thermal equilibrium
● Vjerojatnost konfiguracije je eksponencijalna funkcija energije samo u termalnom ekvilibriju– Ne ovisi o početnom stanju
● Smanjenjem temperature postižemo se da energije stanja mreže približavaju lokalnom minimumu– Simulirano hlađenje
P(x)∝e−E (x )
kT

Boltzmanov stroj
● Wake (poztivna) faza – povećava se vjerojatnost uzoraka iz skupa za treniranje– Ne svih uzoraka već iz dotične mini grupe
● Sleep (negativna) faza – smanjuju se vjerojatnosti "svih" uzoraka (stanja) modela– Ne svih stanja već karakterističnog uzorka stanja prema "mišljenju"
modela
● Konvergencija kada su ove dvije faze u ravnoteži– Kada model distribucija modela odgovara distribuciji skupa za treniranje
● Samo wake faza vodi u zasićenje– Sleep faza to sprječava

Boltzmanov stroj
● Problemi:● Uzorkovanje za sleep fazu je potencijalno
dugotrajno● Istrenirani model se temelji na korelaciji drugog
reda– Za opisivanje kompleksnijih odnosa trebaju i
korelacije viših redova● Rješenje je BM višeg reda – broj parametara (težina)
modela brzo raste
⟨ xi x j xk ...⟩
P '(x ;W ,V ,...)=e
12 ∑
ij
w ij x i x j+16 ∑ijk
v ijk x i x j x k+...
Z '

Boltzmanov stroj
● Uvode se skrivene varijable● Njihov zadatak je ubaciti
korelacije višeg reda vidljivih varijabli u model koji koristi samo korelaciju drugog reda
● Jedno stanje mreže čine i vidljive i skrivene varijable
● Skriveni neuroni obično se označavaju sa h● Vidljivi neuroni obično se označavaju sa v

Skriveni neuroni
● Nemaju zadane vrijednosti pa mogu poprimiti bilo koje vrijednosti
● Ulaze u model distribucije i ponašaju se u skladu s modelom
● Mogu imati korisne uloge i otvoriti nove mogućnosti– Recimo mogu raditi ekstrakciju značajki
● Ukupno stanje mrežex=( v ,h)

Skriveni sloj
● Kako su neuroni skrivenog sloja slobodni, maksimizira se vjerojatnost vidljivih neurona
– A ne vjerojatnost stanja svih neurona
– Opet maksimiziramo logaritam vjerojatnosti
P(v ;W )=∑hP (v ,h ;W )=∑
h
e12
xT W x
Z (W )
P(x ;W )=P(v ,h ;W )

Skriveni neuroni
● Gradijent težina opet ima dvije komponente
● Prva komponenta je korelacija stanja mreže ako je vidljivi sloj fiksiran na ulazni uzorak– Skriveni sloj je slobodan i varira prema modelu
● Druga komponenta je korelacija kada BM generira uzorke iz svoje distribucije– I vidljivi i skriveni sloj su slobodni
∂∂w ij
ln [∏n=1
N
P(v(n) ;W )]=N [⟨ x i x j⟩P (h∣v ( n) ;W )−⟨x i x j ⟩P (v ,h ;W ) ]

Skriveni neuroni
● Konačni izraz za treniranje je
● Relativno je jednostavan zahvaljujući– Linearnoj ovisnosti logaritma vjerojatnosti o energiji
stanja
– Linearnoj ovisnosti energije o težinama
Δ wij=η [⟨ x i x j⟩P(h∣v( n ) ;W )−⟨x i x j ⟩P (v , h;W ) ]
P(v ;W )=∑hP (v ,h ;W )=∑
h
e−E ( x)
Z (W )=∑
h
e12
xT W x
Z (W )
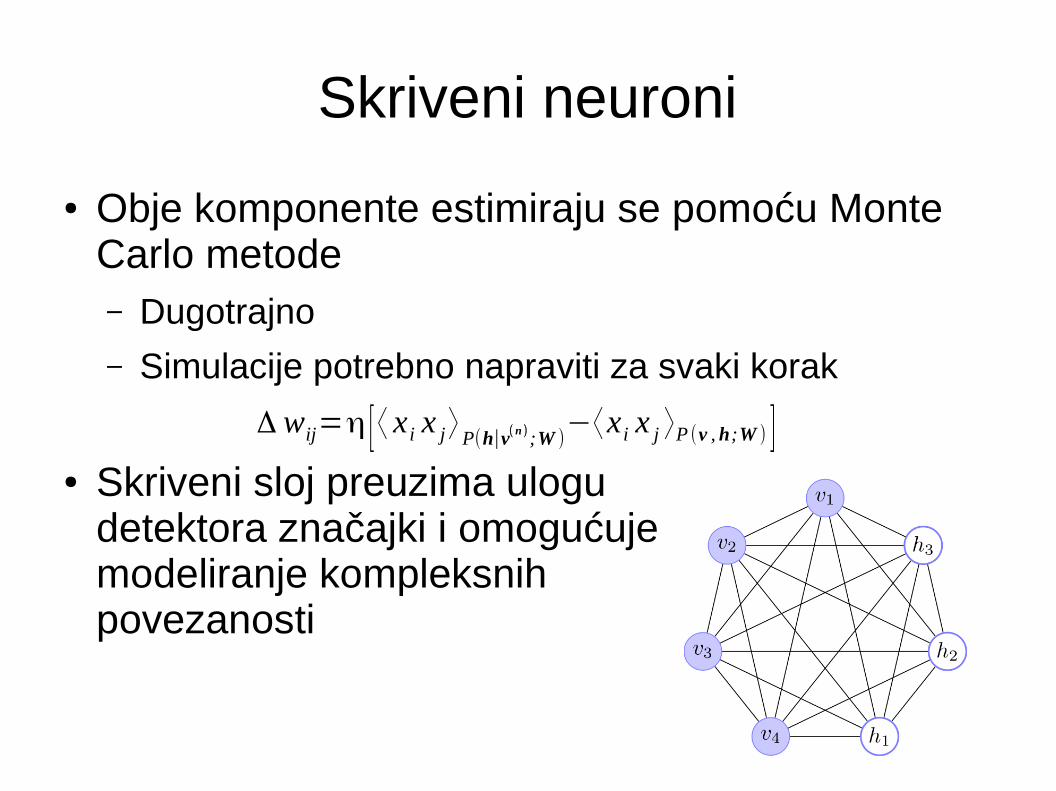
Skriveni neuroni
● Obje komponente estimiraju se pomoću Monte Carlo metode– Dugotrajno
– Simulacije potrebno napraviti za svaki korak
● Skriveni sloj preuzima ulogu detektora značajki i omogućuje modeliranje kompleksnih povezanosti
Δ wij=η [⟨ x i x j⟩P(h∣v( n ) ;W )−⟨x i x j ⟩P (v , h;W ) ]
Bitne značajke
Izlaz Ulaz Izlaz Ulaz
Bitne značajke

Energetska funkcija
● Određena je binarnim stanjima neurona i težinama koje ih povezuju
● Jednadžba sa međusobnim vezama skrivenih i međusobnim vezama vidljivih
● Dvije komponente odbacujemo kod RBM
E(v , h)=−vT Rv−vTW h−hT Sh

Treniranje Boltzmanovog stroja
● Izraz za korekciju težina
● Simulirano hlađenje kombinirano sa gradient descent● Lokalnog je karaktera – određivanje težina ovisi samo o neuronima
koje ona povezuje (korelacije)– Moguća paralelizacija kada ne bi svi bili međusobno povezani
– Efikasno, praktično – prihvatljiva interpretacija bioloških mreža
● Faktor učenja mora biti malen zbog– Šuma stohastičkog uzorkovanja
– Uvest ćemo još neke aproksimacije● To će nas malo udaljiti od cilja – maksimizacije p(v)
Δ wij=η [⟨ x i x j⟩P(h∣v( n ) ;W )−⟨x i x j ⟩P (v , h;W ) ]

Treniranje Boltzmanovog stroja
k = broj Gibbsovih koraka za doseg ekvilibrija
dok nema konvergencije
uzorkuj minibatch {v(1) , . . . , v( m ) } iz skupa za treniranje
inicijaliziraj uzorke {h(1) , . . . , h( m ) }, x(n) = [v(n), h(n)]
for n = 1 do m for i = 1 do k
h(n) ← gibbs_update(h(n) | v(n))
gij ← 1/m Σxi(n) xj
(n)
inicijaliziraj m slučajnih uzoraka { (1) , . . . , ( m ) } xx xxfor n = 1 do m
for i = 1 do k xx(n) ← gibbs_update(xx(n))
gij ← gij - 1/m Σxxi(n) xxj(n)
wij = wij + ηgij
+
-

Korištenje BM
● Na vidljivi sloj fiksira se ulazni uzorak, skriveni sloj se slučajno inicijalizira
● Uzorkuju se skriveni neuroni– Mijenjaju se jedan po jedan u skladu s trenutnom energijom
● Nakon nekog vremena dostiže se termalni ekvilibrij● Skriveni uzorci koji se često pojavljuju (imaju veliku
vjerojatnost p(h|v)), dobro predstavljaju ulazni uzorak– Oni više ne ovise o početnom stanju
skrivenih neurona
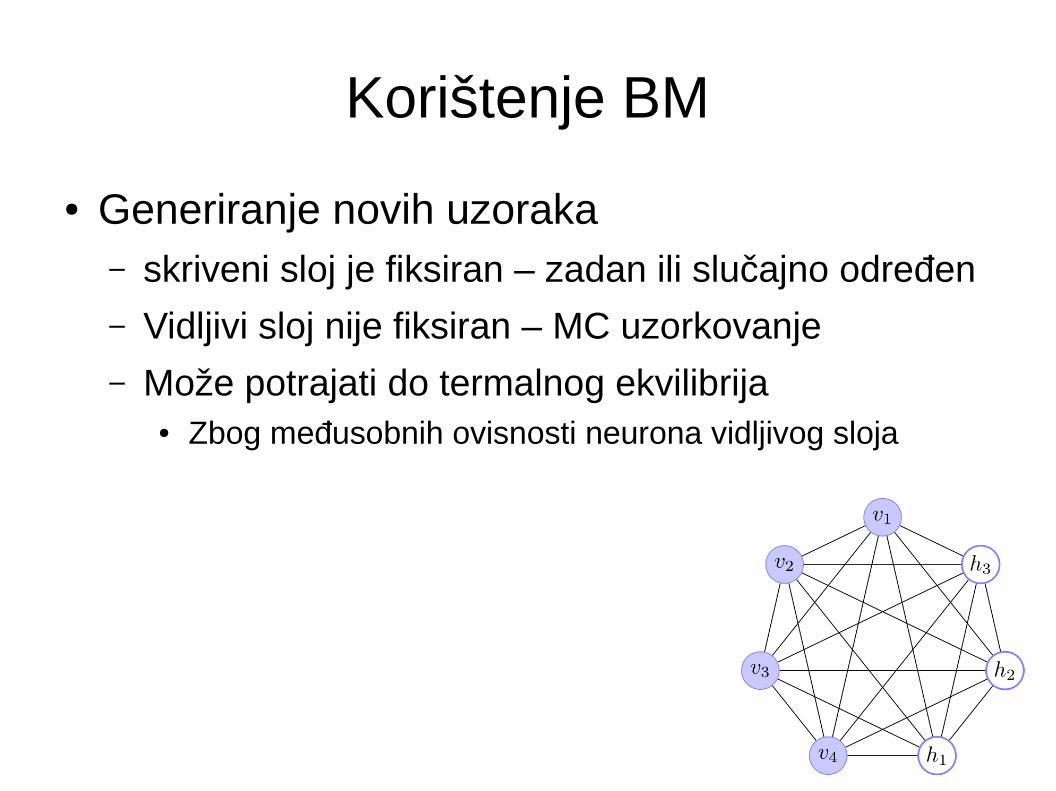
Korištenje BM
● Generiranje novih uzoraka– skriveni sloj je fiksiran – zadan ili slučajno određen
– Vidljivi sloj nije fiksiran – MC uzorkovanje
– Može potrajati do termalnog ekvilibrija● Zbog međusobnih ovisnosti neurona vidljivog sloja

Razlika u odnosu na backpropagation
● Traženje značajki– MLP, konvolucijske mreže traže značajke koje omogućuju dobro
predviđanje oznaka
– BM traži značajke koje dobro opisuju što se događa u skupu za treniranje
● Ulazni vektori i oznake posljedica su toga što se događa pa ovaj pristup ima smisla
● BP ima dva posve drugačija koraka– Prolaz unaprijed
– Propagacija greške unazad
● BM ima dva identična koraka koja se koriste u treniranju
Δ wij=η [⟨ x i x j⟩P(h∣v( n ) ;W )−⟨x i x j ⟩P (v , h;W ) ]

Razlika u odnosu na backpropagation
● Lokaliziranost– Nova vrijednost težine u BM ovisi samo o stanjima
neurona koje povezuje
– Nova vrijednost težina kod BP ovisi o svim neuronima iz slijedećeg sloja
● Lokalizirana varijanta je jednostavnija i stoga bolji kandidat za interpretaciju bioloških neuronskih mreža

Ograničeni Boltzmanov stroj
● Izumio ga je Paul Smolensky 1986.● Zasluge se pripisuju Geoffreyu Hintonu koji je
predstavio brze algoritme učenja za RBM● Može se trenirati pod nadzorom ili bez nadzora● Bipartitni graf
– Vidljivi sloj
– Skriveni sloj
h1
h3
h2
h4
v2
v1
v3

Ograničeni Boltzmanov stroj
● Svaki neuron skrivenog sloja povezan je sa svakim neuronom vidljivog sloja
● Ograničenje na međusobne povezanosti skrivenih i međusobne povezanosti vidljivih neurona– Povlači i ograničenu funkcionalnost, ali i bitnu
prednost● Odbacujemo korelacijske veze drugog reda!● 7Skriveni neuroni su nezavisni uz zadani vidljivi sloj!

Ograničeni Boltzmanov stroj
● I dalje se maksimizira vjerojatnost vidljivih uzoraka iz skupa za treniranje
E(v ,h)=−12
vT W h
P(v ,h)=e−E (v , h)/T
Z
Z=∑v∑
h
e−E (v , h)
P(v )=
∑h
e−E (v , h)/T
Z
E(v ,h)=−vT Rv−v TW h−hT S h

RBM particijska funkcija
● Njena svrha je normalizirati vjerojatnosti
● Particijska funkcija BM-a postaje prekompleksna za praktični izračun s povećanjem broja neurona
● Stoga nije moguće izračunati ni vjerojatnost vidljivog uzorka P(v)
● Potrebna je mala pomoć koju donosi sama struktura RBM
P(v ,h)=e−E (v , h)/T
ZZ=∑
v∑
h
e−E (v , h)
∑x
P (x)=1

RBM partition function
● p(h|v) i p(v|h) se mogu faktorizirati, jednostavno se mogu uzorkovati i izračunati– To je posljedica strukture RBM-a i odabrane
energetske funkcije
– Izbjegavamo potrebu za puno uzorkovanja
h1
h3
h2
h4
v2
v1
v3

Treniranje RBM-a
● Trenira se isto kao i običan BM
● Razlika u arhitekturi omogućuje jednostavnije treniranje pozitivne faze
● Negativna faza je još uvijek problem
Δ wij=η [⟨ x i x j⟩P(h∣v( n ) ;W )−⟨x i x j ⟩P (v , h;W ) ]
Δ wij=η [⟨ v ih j ⟩P (h∣v (n ) ;W )−⟨v ih j⟩P(v ,h ;W )]
h1
h3
h2
h4
v2
v1
v3

Pozitivna faza
● Vidljivi sloj je vezan (fixiran) na ulazne uzorke● Odgovarajući skriveni sloj određuje se u jednoj iteraciji
jer nema međusobnih veza u skrivenom sloju (ograničenje kod RBM)
● "Instantni termalni ekvilibrij!!"● Može se interpretirati kao
prilagođavanje distribucije modela vidljivim uzorcima za treniranje– Maksimizira se brojnik p(v)
h1
h3
h2
h4
v2
v1
v3

Negativna faza
● Ispravan način povećava energije svih vjerojatnih stanja– Nećemo ga baš slijediti u potpunosti...
● Minimizira se nazivnik p(v)– Suprotn efekt od pozitivne faze
P(v )=
∑h
e−E (v ,h)/T
∑v∑
h
e−E (v , h)/T

Negativna faza
● Uzorkovanje distirbucije modela – Onu u što model vjeruje
● Pretpostavka je da je model u krivu pa to treba zaboraviti– To je točno za lažna stanja
– Nije istina za stanja čiji vidljivi sloj odgovara uzorcima za treniranje
– Konvergencija nastaje kada su pozitivna i negativna faza u ravnoteži
● MCMC sa slučajnom inicijalizacijom -> termalni ekvilibrij– nije praktično
● Moguće su aproksimacije ali one neće povećavati energiju tamo gdje treba– Možda će ipak dobro funkcionirati

Neefikasno treniranje RBM
k = broj Gibbsovih koraka za doseg ekvilibrija
dok nema konvergencije
uzorkuj minibatch {v(1) , . . . , v( m ) } iz skupa za treniranje
h(j) ← gibbs_update(h(n) | v(n))
gij ← 1/m Σxi(n) xj
(n)
inicijaliziraj m slučajnih uzoraka { (1) , . . . , ( m ) } xx xxfor n = 1 do m
for i = 1 do k xx(n) ← gibbs_update(xx(n))
gij ← gij - 1/m Σxxi(n) xxj(n)
wij = wij + ηgij
+
-
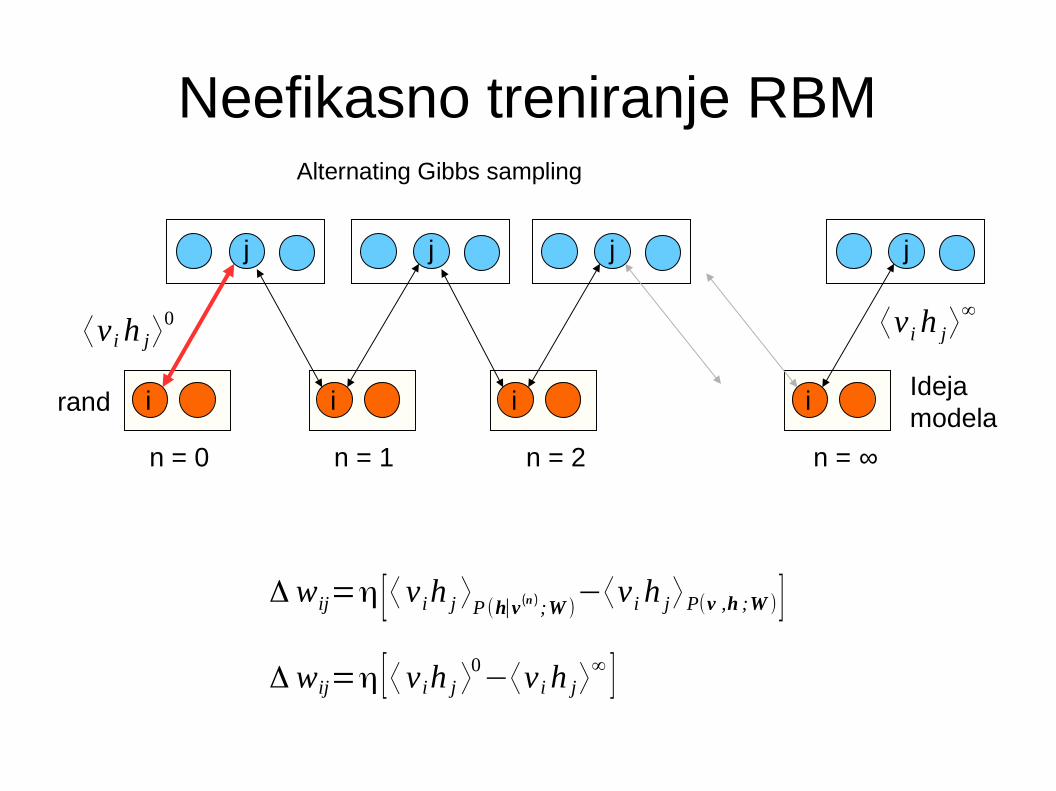
Neefikasno treniranje RBM
i
j
i
j
i
j
i
j
n = 0 n = 1 n = 2 n = ∞
Ideja modela
rand
Δ wij=η [⟨ v ih j ⟩P (h∣v (n ) ;W )−⟨v ih j⟩P(v ,h ;W )]
Δ wij=η [⟨ v ih j ⟩0−⟨v ih j⟩
∞ ]
⟨v ih j⟩0 ⟨v ih j⟩
∞
Alternating Gibbs sampling

Contrastive divergence (CD)
● Modifikacija u negativnoj fazi● MCMC se inicijaliziraju sa ulaznim uzorcima
– Radi se manji broj (k) Gibsovih uzorkovanja (CD-k)
– Što veći k, manje pristrana estimacija gradijenta● k=1 je obično dobro
– To nije ispravno uzorkovanja distribucije modela
● Negativna faza treba zaboravljati ono u što model vjeruje– Ulazni podaci nisu on u što model vjeruje
– Pozitivna faza će to postići s vremenom pa CD postaje korisnija
– Ne korigiraju se lažna stanja daleko od uzoraka za treniranje

Contrastive divergence (CD)
● Samo približna aproksimacija negativne faze– Ne postižemo gradient descent – aproksimiramo ga
– Mreža možda neće konvergirati
● Ipak radi dosta dobro i brzo● Zašto radi dobro
– Nije potrebno doći do termalnog ekvilibrija
– Dovoljno je da model odluta od ulaznog uzorka u ulaznom sloju da bi ga znali korigirati
– Dovoljna je jedna ili par iteracija
– Nesavršenost vodi do loše detekcije značajki
– dodatne informacije propuštaju se u više slojeve kod dubokih mreža?

Contrastive divergence (CD)
k = manji broj Gibbsovih koraka nedostatan za doseg ekvilibrija
dok nema konvergencije
uzorkuj minibatch {v(1) , . . . , v( m ) } iz skupa za treniranje
h(n) ← gibbs_update(h(n) | x(n))
gij ← 1/m Σxi(n) xj
(n)
for n = 1 do mxx(n) ←x(n)
for n = 1 do m for i = 1 do k xx(n) ← gibbs_update(xx(n))
gij ← gij - 1/m Σxxi(n) xxj(n)
wij = wij + ηgij
+
-

Contrastive divergence (CD-k)
i
j
i
j
i
j
i
j
n = 0 n = 1 n = 2 n = k
Ideja modela
uzorak
Δ wij=η [⟨ v ih j ⟩P (h∣v (n ) ;W )−⟨v ih j⟩P(v ,h ;W )]
Δ wij=η [⟨ v ih j ⟩0−⟨v ih j⟩
k ]
⟨v ih j⟩0 ⟨v ih j⟩
k
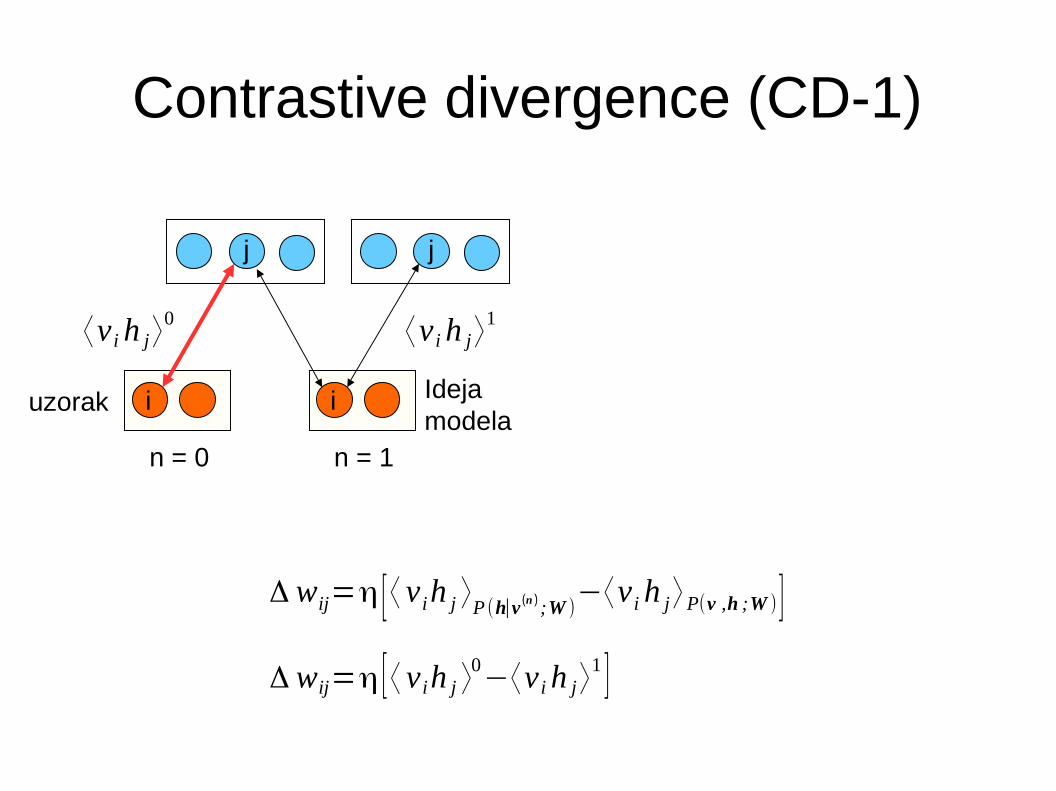
Contrastive divergence (CD-1)
i
j
i
j
n = 0 n = 1
Ideja modela
uzorak
Δ wij=η [⟨ v ih j ⟩P (h∣v (n ) ;W )−⟨v ih j⟩P(v ,h ;W )]
Δ wij=η [⟨ v ih j ⟩0−⟨v ih j⟩
1 ]
⟨v ih j⟩0 ⟨v ih j⟩
1
Poboljšanja CD
● Postepeno povećavati broj iteracija k (CD-k)– Cilj je doseći udaljena lažna stanja
● Persistive CD– Inicijalizirati trenutni korak PCD na zadnje stanje prethodnog koraka PCD
(vidljiva i skrivena stanja)
– Potrebno je pamtiti stanja između koraka (vidljiva i skrivena)
– Između dva koraka se ne očekuje velika promjena modela pa će iz prošlog stanja MCMC brzo doći u ekvilibrij
● Ne funkcionira dobro ako je promjena modela prebrza● Ne funkcionira dobro kod minibatch učenja
– Traženje lažnih stanja nastavlja tamo gdje se prije stalo pa je moguće doći do dalekih lažnih stanja

Persistive Contrastive divergence (PCD)
k = manji broj Gibbsovih koraka nedostatan za doseg ekvilibrija
dok nema konvergencije
uzorkuj minibatch {v(1) , . . . , v( m ) } iz skupa za treniranje
h(n) ← gibbs_update(h(n) | v(n))
gij ← 1/m Σxi(n) xj
(n)
if (vxx (n)) prazan(vxx (n)) ←x(n) #samo prvi puta
for n = 1 do m for i = 1 do k
(vxx (n)) ← gibbs_update( (vxx (n)))
gij ← gij - 1/m Σxxi(v(n)) xxj(v(n))
wij = wij + ηgij
+
-

Poboljšanja CD
● Mean-field aproksimacija– Vjerojatnost da će xj biti 1 ovisi o preostalim
stohastičkim binarnim stanjima xi
– Umjesto stohastičkih binarnih stanja pamtimo realne iznose vjerojatnosti
● Konvergencija (termalini ekvilibrij) se može detektirati i nastupa kada se vjerojatnosti više ne mijenjaju
p(x j=1)=1
1+e−∑
i≠ j
w ji x i
p j (n+1)=1
1+e−∑
i≠ j
w ji pi(n)

Učenje pomoću mini grupa
● Efikasnije učenje● Koristi se manji dio skupa za učenje
– Slučajni odabir
● Svaki uzorak doprinosi korekciji težina– Usrednjavanje korekcije
● Praktično rješenje – ubrzavanje izračuna● Problem je što podskup uzoraka u pravilu ne predstavlja
savršeno distribuciju čitavog skupa za učenje– Unosi se šum u postupak traženja maksimalne vjerojatnosti p(v)
– To je zapravo dobro i korisno za MCMC!
Primjer treniranja
Primjer rekonstrukcije
v
h
W
p(v j=1∣h)=1
1+e−∑
i≠ j
w ji hi
0
0.5
1
−6 −4 −2 0 2 4 6

Belief Nets
● Rijetko povezane mreže s usmjerenim vezama– Efikasni mehanizmi određivanja vjerojatnosti
● Kombinacije s generativnim modelima omogućavaju kvalitetno učenje s manjim brojem označenih uzoraka za učenje
● Rješavanje problema backporagacije u dubokim mrežama

Sigmoid beleief nets
● Kauzalna beleif mreža● Jednosmjerna mreža● Vjerojatnost aktivacije je sigmoidna funkcija● Binarni stohastički neuroni● Lakše se treniraju od BM
– Ne postoji negativna faza – ne bavimo se particijskom funkcijom
– Maksimizira se vjerojatnost uzoraka za treniraje● Isto kao kod RBM maksimizira se log(p(v))

Sigmoid beleief nets
● Generiranje uzoraka– Stohastičko određivanje stanja najvišeg sloja
– Slijedeći slojevi se jednostavno generiraju pomoću prethodnog sloja
– Zadnji se generira vidljivi sloj
● Uzrokovanje onoga u što mreža vjeruje
● Pretpostavlja se da su neuroni najvišeg sloja nezavisni – iako nisu

Sigmoid beleief nets
● Treniranje je nešto kompliciranije nego kod RBM-a
● Teško je odrediti p(h|v)– Treba nam da bi odredili generatinve težine
– Neuroni u skrivenom sloju nisu neovisni
– Teško je i uzimati uzorke od h uz poznati v● Kada bi imali uzorke, treniranje bi bilo jednostavno

Sigmoid beleief nets
● Pojednostavi komplicirano– Pretpostavimo da su neuroni u jednom skrivenom sloju
nezavisni
– Koristi se "pogrešna" distribucia kao zamjena za p(h|v)● Varijacijska metoda● Uzorci h se uzimaju iz zamjenske distribucije● Time se podiže donja varijacijska granica log vjerojatnosti, a
ne sama vjerojatnost ulaznih uzoraka
● Wake sleep algoritam
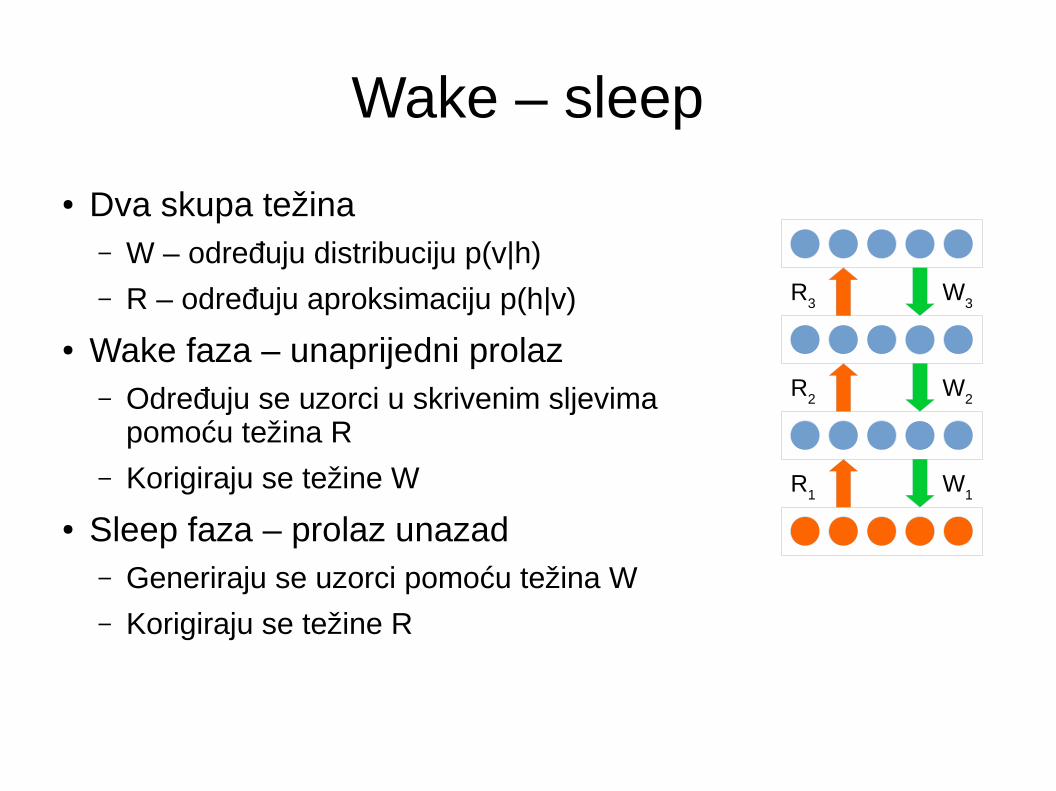
Wake – sleep
● Dva skupa težina– W – određuju distribuciju p(v|h)– R – određuju aproksimaciju p(h|v)
● Wake faza – unaprijedni prolaz– Određuju se uzorci u skrivenim sljevima
pomoću težina R
– Korigiraju se težine W
● Sleep faza – prolaz unazad– Generiraju se uzorci pomoću težina W
– Korigiraju se težine R
W1
W2
W3
R1
R2
R3
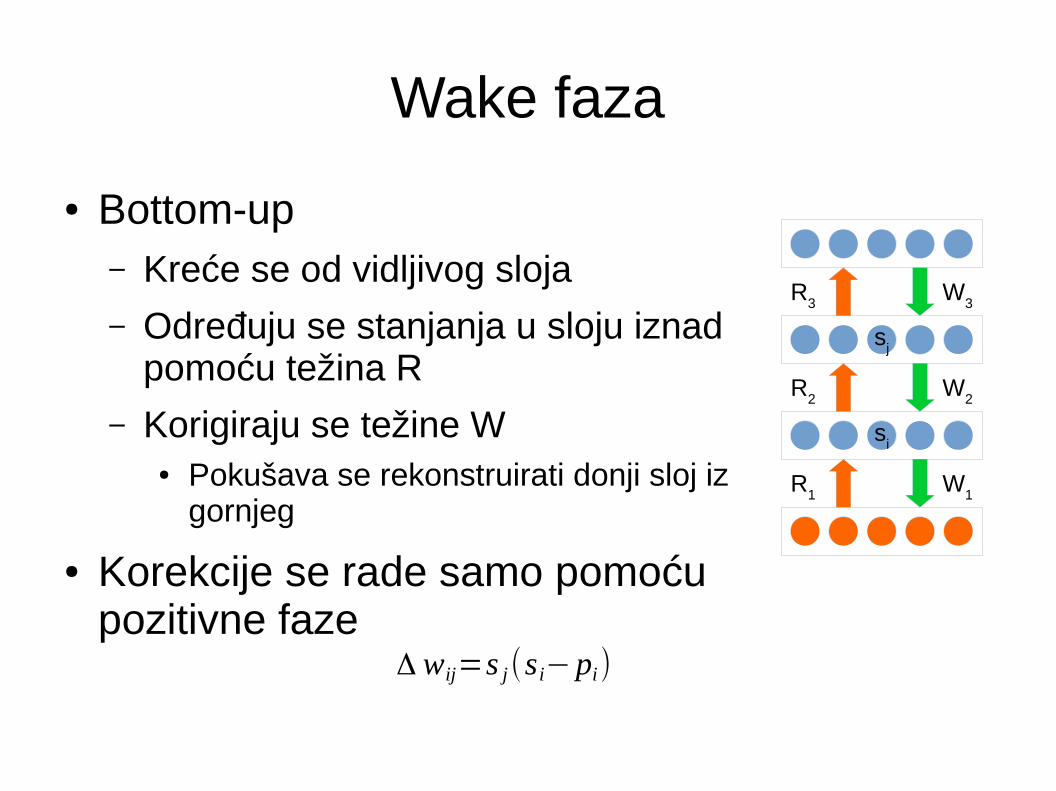
Wake faza
● Bottom-up– Kreće se od vidljivog sloja
– Određuju se stanjanja u sloju iznad pomoću težina R
– Korigiraju se težine W● Pokušava se rekonstruirati donji sloj iz
gornjeg
● Korekcije se rade samo pomoću pozitivne faze
sj
si
W1
W2
W3
R1
R2
R3
Δ wij=s j(si−pi)
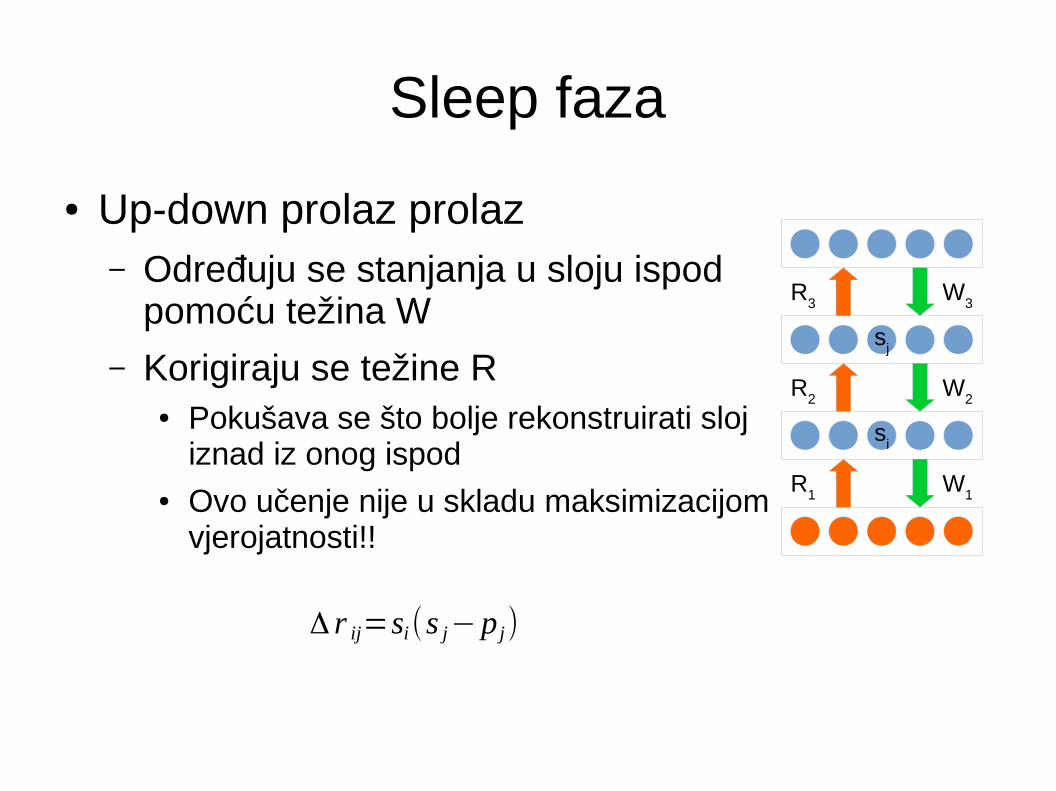
Sleep faza
● Up-down prolaz prolaz– Određuju se stanjanja u sloju ispod
pomoću težina W
– Korigiraju se težine R● Pokušava se što bolje rekonstruirati sloj
iznad iz onog ispod● Ovo učenje nije u skladu maksimizacijom
vjerojatnosti!!
sj
si
W1
W2
W3
R1
R2
R3
Δ r ij=si(s j−p j)
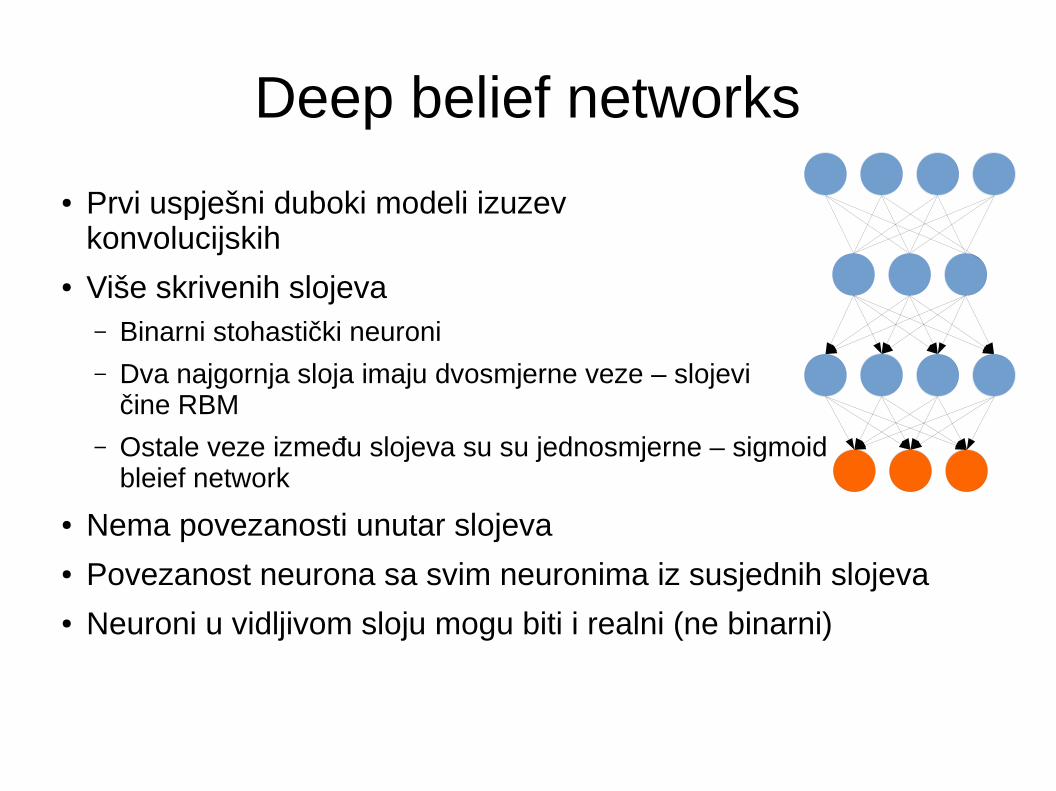
Deep belief networks
● Prvi uspješni duboki modeli izuzev konvolucijskih
● Više skrivenih slojeva– Binarni stohastički neuroni
– Dva najgornja sloja imaju dvosmjerne veze – slojevi čine RBM
– Ostale veze između slojeva su su jednosmjerne – sigmoid bleief network
● Nema povezanosti unutar slojeva● Povezanost neurona sa svim neuronima iz susjednih slojeva● Neuroni u vidljivom sloju mogu biti i realni (ne binarni)

Deep belief networks
● Kod generiranja uzoraka, veze između dva najviša sloja su dvosmjerne ostale su jednosmjerne – prema dolje
● Pohlepno treniranje– Sloj po sloj
● Dodatni slojevi poboljšavaju generatvni model– Poboljšavaju vjerojatnosti uzoraka iz skupa za treniranje p(v)
● Dodatni slojevi mogu poboljšati i diskriminativnost mreže● Dovoljno je treniranje slojeva sa CD-1
– Dobro je da niži slojevi propuštaju i nešto šuma u gornje slojeve
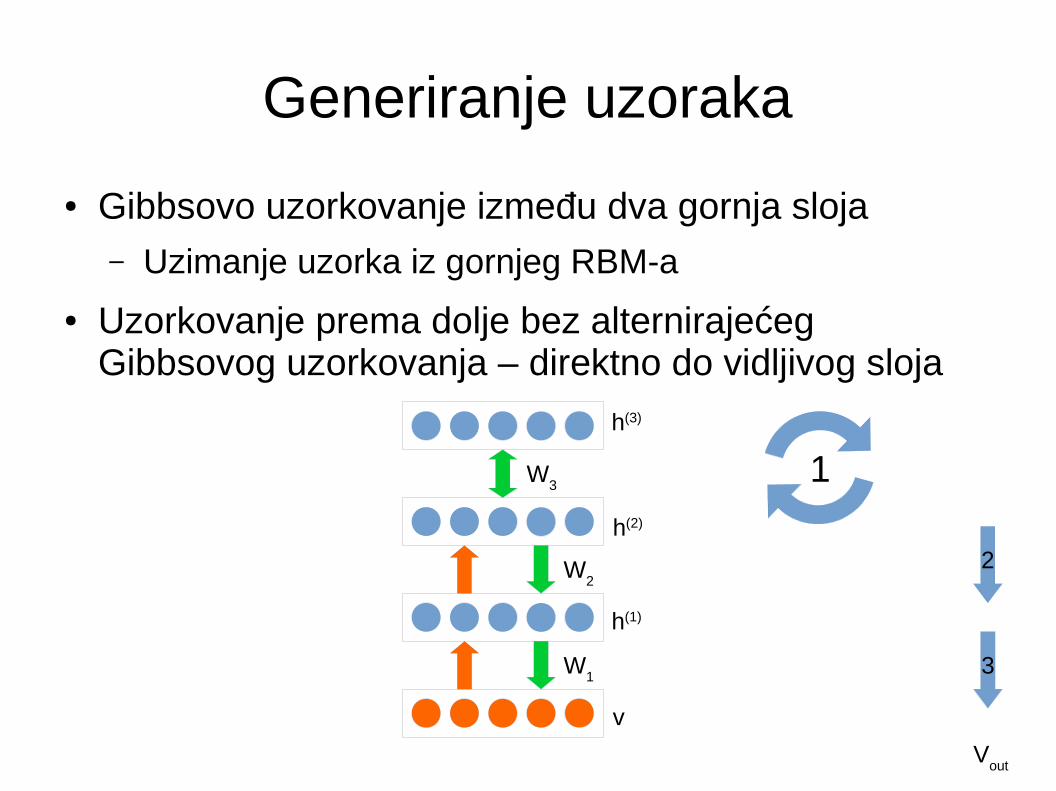
Generiranje uzoraka
W1
W2
W3
h(1)
v
h(2)
h(3)
W1
W2
W3
h(1)
v
h(2)
h(3)
1
2
3
Vout
● Gibbsovo uzorkovanje između dva gornja sloja– Uzimanje uzorka iz gornjeg RBM-a
● Uzorkovanje prema dolje bez alternirajećeg Gibbsovog uzorkovanja – direktno do vidljivog sloja

Treniranje DBN
● Treniranje svih slojeva od jednom nije praktično– Dobra inicijalizacija je ključna
● Problem je u tome što više nije istina da su skriveni neuroni jednog sloja međusobno nezavisni
● Kod Sigmoid belief mreža to se jednostavno ignorira– Sleep wake algoritam
– Obično dobro radi

Pohlepno treniranje sloj po sloj
W1
RBM1
h(1)
v
W1
W2
W3
h(1)
v
h(2)
h(3)
W1
W2
h(1)
v
h(2)
RBM2
RBM3

Pohlepno treniranje sloj po sloj
● Pronalaženje značajki na temelju prethodno pronađenih značajki– Značajke više razine
– Čini se logičnim, ali...
● Nije maksimiziranje vjerojatnosti– Ne maksimizira se p(v)!
● Može se pokazati, u određenim uvjetima, dodavanje RBM slojeva podiže donju granicu vjerojatnosti p(v)– Uvjeti ne dozvoljavaju korištenje CD koji se u praksi koristi
– Nema garancije da se doista povećava p(v)
– Samo pokazatelj da se ipak može očekivati povećanje p(v)
– Vjerojatno proizvodi dobre značajke za npr. klasifikaciju

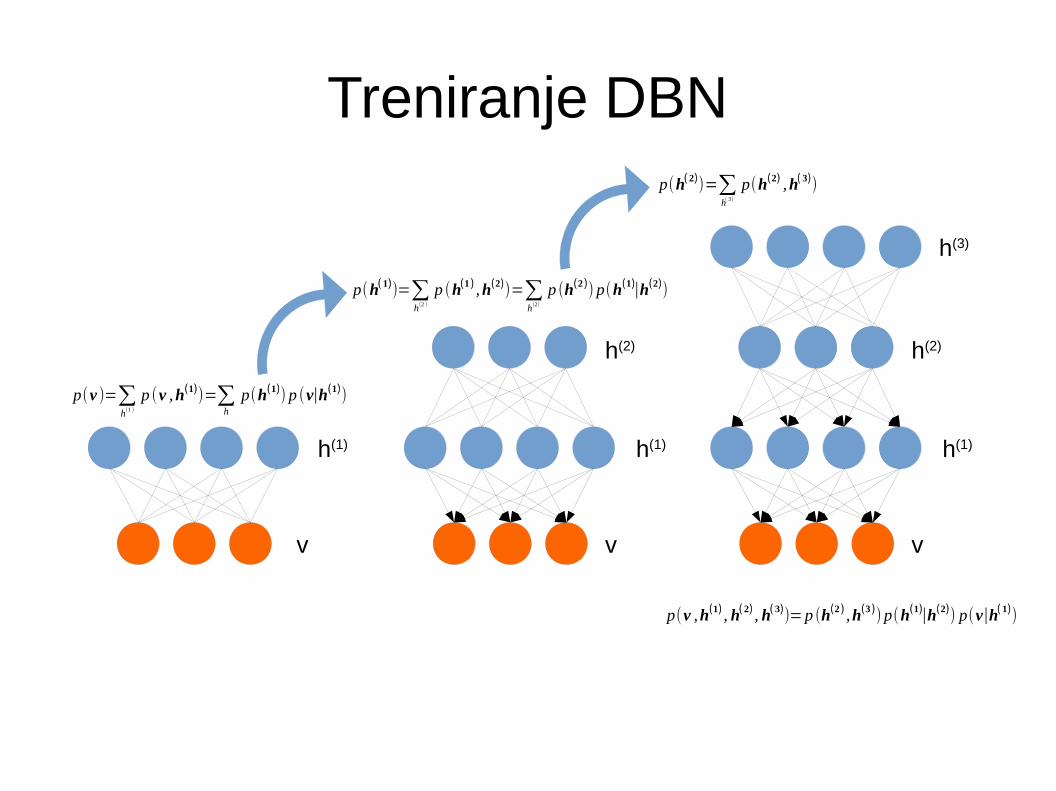
Treniranje DBN
● Treniranje sloj po sloj počevši od dna● U najnižem sloju maksimizira se vjerojatnost
ulaznih uzoraka u vidljivom sloju● U svakom slijedećem sloju maksimizira se
vjerojatnost prethodnog skrivenog sloja– Modelira se distribucija prethodnog skrivenog sloja
p(h)
– Traži se bolji model prethodnog skrivenog sloja
p(v )=∑h
p (h) p(v∣h)
Treniranje DBN
p(v )=∑h(1 )
p (v ,h(1))=∑
h
p(h(1)) p (v∣h(1)
)
p(h( 1))=∑
h(2 )
p (h(1 ) ,h(2))=∑
h(2)
p (h(2 )) p(h(1)
∣h(2))
p(h( 2))=∑
h( 3)
p(h(2) ,h( 3))
v
h(1)
v
h(1)
h(2)
h(1)
v
h(2)
h(3)
p(v ,h(1) , h( 2) , h( 3))=p (h(2 ) ,h(3 )
) p(h(1)∣h(2)
) p(v∣h( 1))

Treniranje DBN
● Kod dodavanja slijedećeg sloja, težine novog sloja se inicijaliziraju pomoću težina prethodnog sloja– Time se osigurava da će novi sloj poboljšati p(h(1)), a
onda i p(v)
– Ako je broj novih skrivenih varijabli veći (Nh(2) > Nv), preostale težine se inicijaliziraju na 0
– Nije nužan korak i često se ne prakticira
v
h(1)
v
h(1)
h(2)
WW W
WT

Generativni fine-tunning
● Moguće je raditi fine-tuning za bolje generiranje uzoraka – bolji model
● Nakon pohlepnog treniranja slojeva, rezultat nije optimalan p(v)
● Dvosmjerne težine pretvaraju se u dva skupa jednosmjernih težina koji se korigiraju zasebno– Generativne težine – generiraju podatke u sloju ispod
– Težine prepoznavanja – generiraju podatke u sloju iznad
– Slično kao sigmoidne duboke mreže
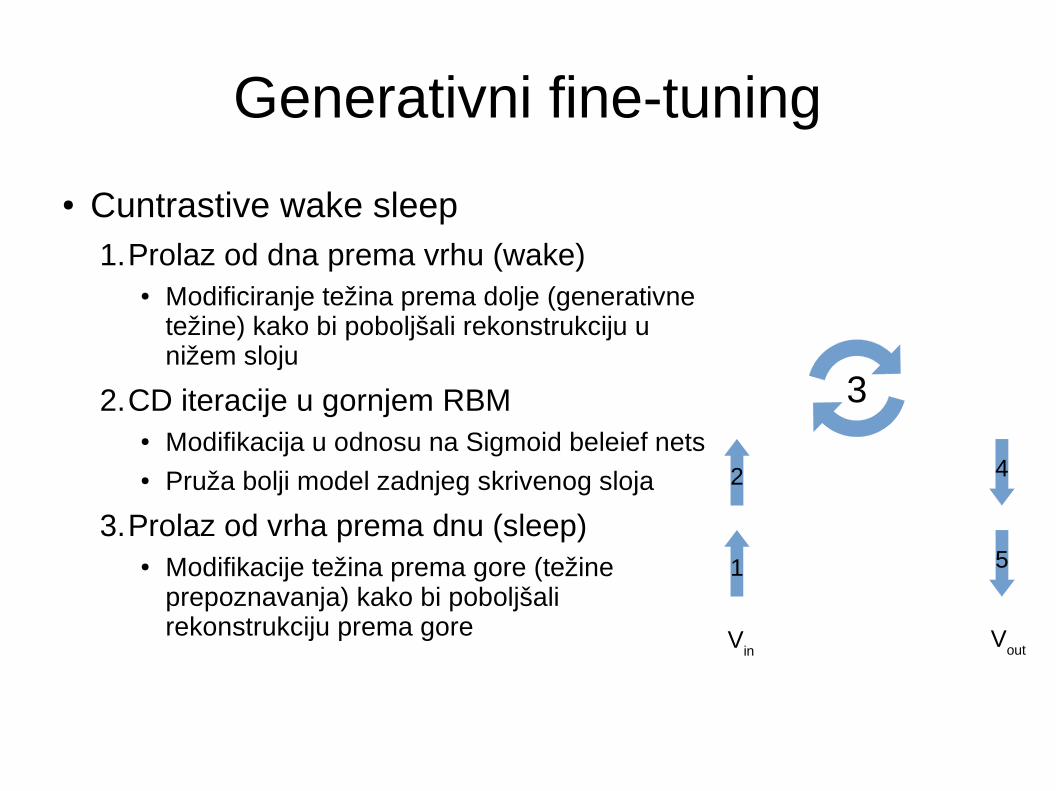
Generativni fine-tuning
● Cuntrastive wake sleep1.Prolaz od dna prema vrhu (wake)
● Modificiranje težina prema dolje (generativne težine) kako bi poboljšali rekonstrukciju u nižem sloju
2.CD iteracije u gornjem RBM ● Modifikacija u odnosu na Sigmoid beleief nets● Pruža bolji model zadnjeg skrivenog sloja
3.Prolaz od vrha prema dnu (sleep)● Modifikacije težina prema gore (težine
prepoznavanja) kako bi poboljšali rekonstrukciju prema gore V
in
R1
R2
W1
W2
W3
h(1)
v
h(2)
h(3)
1
2
3
4
5
Vout
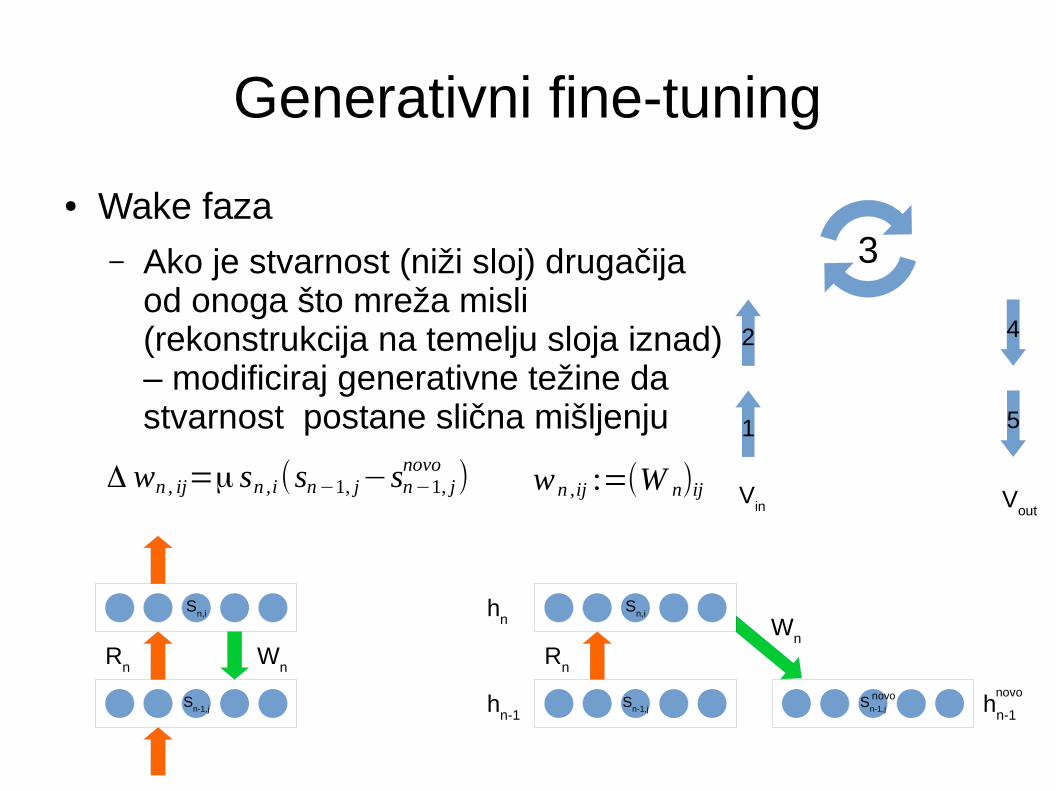
Generativni fine-tuning
● Wake faza– Ako je stvarnost (niži sloj) drugačija
od onoga što mreža misli (rekonstrukcija na temelju sloja iznad) – modificiraj generativne težine da stvarnost postane slična mišljenju
Vin
R1
R2
W1
W2
W3
h(1)
v
h(2)
h(3)
1
2
3
4
5
Vout
Δ wn , ij=μ sn ,i(sn−1, j−sn−1, jnovo
)
Sn,i
Sn-1,j
Wn
Rn
Sn,i
Sn-1,j
Wn
Rn
Sn-1,j
novohn-1
hn
hn-1
novo
wn ,ij :=(W n)ij

Generativni fine-tuning
● Sleep faza– Ako je zamišljeno drugačije od
stvarnosti, modificiraj težine prepoznavanja da mišljenje postane slično stvarnosti
Vin
R1
R2
W1
W2
W3
h(1)
v
h(2)
h(3)
1
2
3
4
5
Vout
Δ r n ,ij=μ sn−1, j(sn ,i−sn ,inovo
)
Sn,i
Sn-1,j
Wn
Rn
Sn,i
Sn-1,j
Rn
Sn,i
novo
hn-1
hn h
n
novo
Wn
rn , ij :=(Rn)ij

Generativni fine-tuning
● Za razliku od Sigmoid beleief mreža, treniranje kreće iz vrlo dobre inicijalizacije– Pohlepno treniranje RBM-ova je samo predtreniranje
● Fine-tunning cijele mreže nakon čega mreža generira uzorke koji više nalikuju skupu za treniranje
● Kod predtreniranja težine u nižim slojevima nisu "svjesne" utjecaja težina u višim slojevima – to se rješava fine-tuningom
● RBM na vrhu predstavlja puno bolji model za bitne značajke– Bolji generativni model
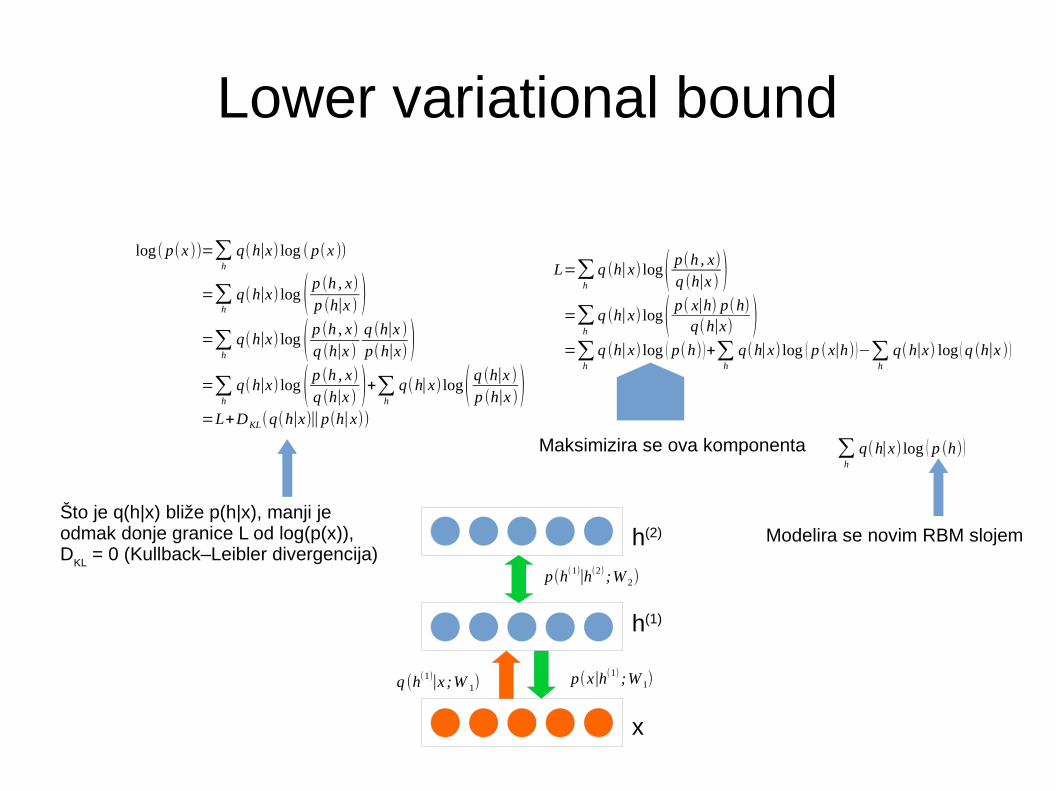
Lower variational bound
log( p(x ))=∑h
q(h∣x) log ( p(x ))
=∑hq(h∣x) log ( p (h , x)
p (h∣x ) )=∑
h
q(h∣x) log ( p (h , x)q (h∣x )
q (h∣x )p(h∣x) )
=∑h
q(h∣x) log ( p (h , x)q (h∣x ) )+∑
h
q(h∣x) log( q (h∣x )p (h∣x ))
=L+DKL(q(h∣x)∥p(h∣x))
L=∑h
q (h∣x) log( p(h , x)q (h∣x ) )=∑
h
q (h∣x) log( p( x∣h) p(h)q(h∣x) )=∑
h
q (h∣x) log ( p(h))+∑h
q(h∣x) log ( p (x∣h))−∑h
q(h∣x) log (q (h∣x ))
Što je q(h|x) bliže p(h|x), manji je odmak donje granice L od log(p(x)),D
KL = 0 (Kullback–Leibler divergencija)
Maksimizira se ova komponenta ∑h
q(h∣x) log ( p (h))
Modelira se novim RBM slojem
x
h(2)
p(h(1)∣h(2) ;W 2)
p(x∣h(1) ;W 1)q (h(1)∣x;W 1)
h(1)
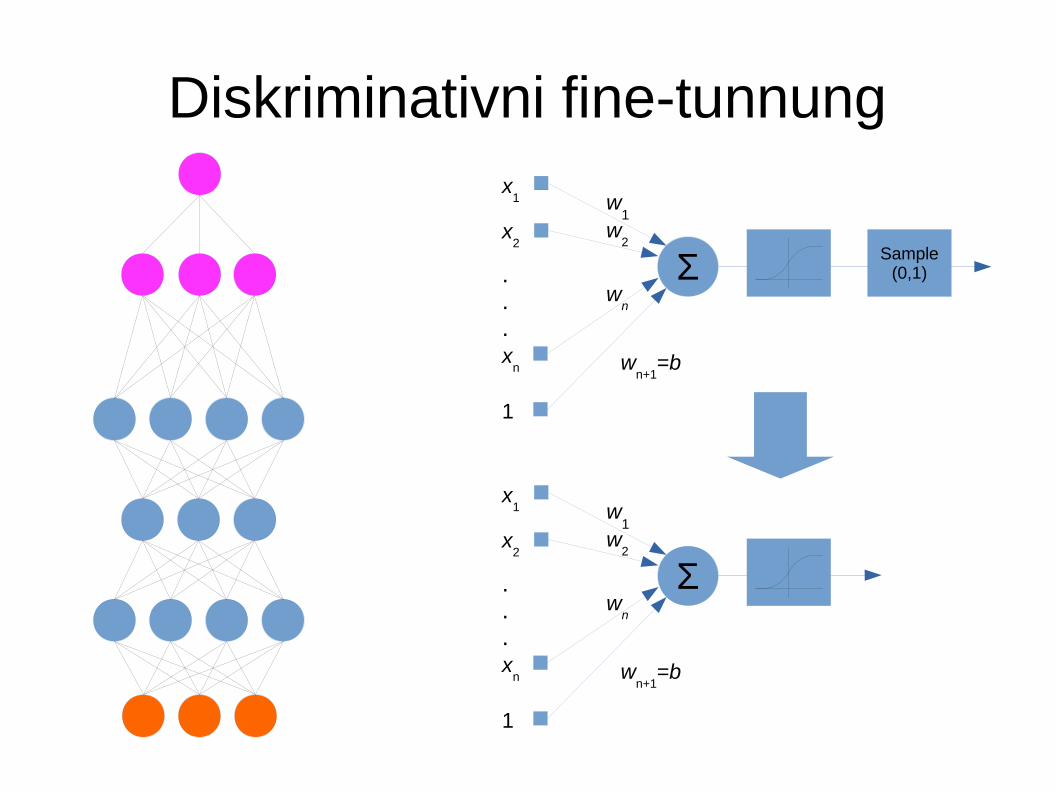
Diskriminativni fine-tunnung
Σ
x1
x2
1
.
.
.x
n
w1
w2
wn+1
=b
wn
Sample(0,1)
Σ
x1
x2
1
.
.
.x
n
w1
w2
wn+1
=b
wn

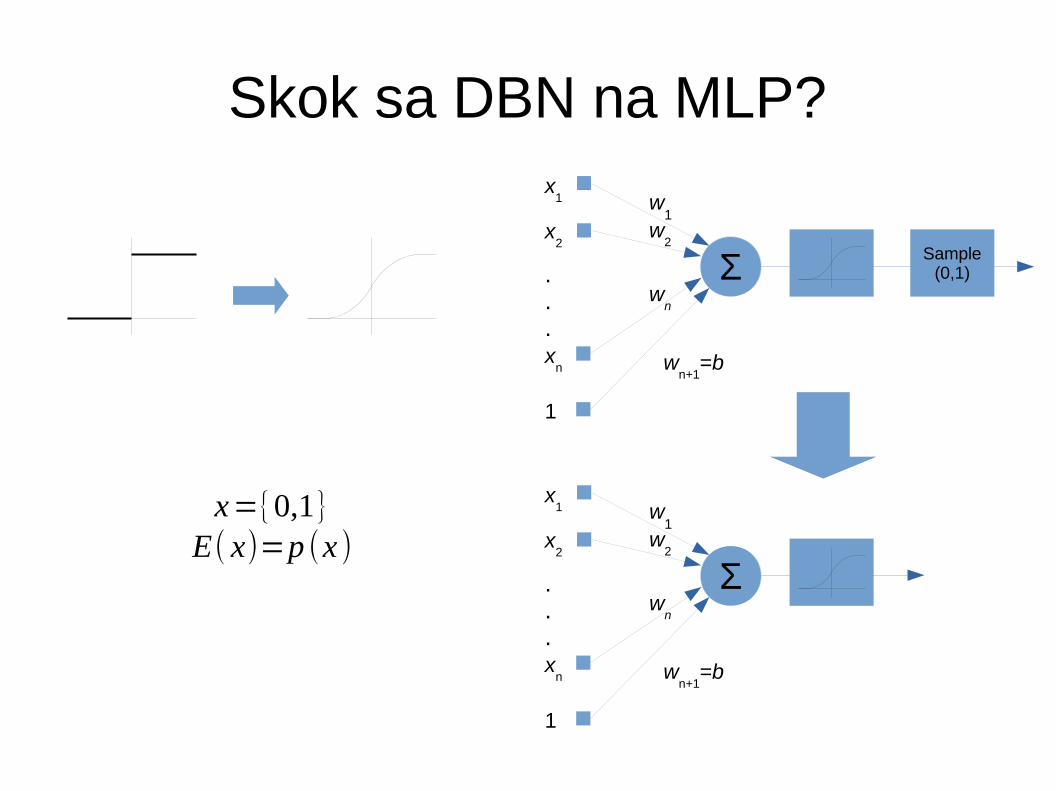
Diskriminativni fine-tunnung
● Duboki generativni modeli se često koriste za klasifikaciju
● Naučene težine koriste se za inicijalizaciju MLP-a– Slijedi backpropagation pomoću označenih uzoraka
za učenje● Nužni su označeni uzorci, ali označen može biti samo manji
dio skupa za treniranje!!● Treniranje generativnog modela ne traži označene uzorke!!
– Heurističko rješenje
Neoznačeni uzorciOznačeni uzorci

Diskriminativni fine-tunnung
● Treniranje DBN može se gledati kao predtreniranje MLP-a– Koristi se za pametnu inicijalizaciju težina
● Težine su podešene predtreniranjem na traženje dobrih značajki što bi trebalo biti korisno za klasifikaciju
– Neke značajke neće biti korisne za klasifikaciju, ali neke hoće!● Te korisne značajke mogu dobiti veće težine za klasifikaciju, a kroz fine-tuning se
mogu malo i poboljšati
– MLP i backpropagation ne moraju tražiti značajke – fino podešavaju granice klasa
● Očekuju se manje promjene težina – fine-tunning
– Predtreniranjem se izbjegavaju uobičajeni problemi Backpropagationa na dubokoj mreži
● Modeliranje podataka u fazi predtreniranja povećava šansu za dobru generalizaciju
Skok sa DBN na MLP?
Σ
x1
x2
1
.
.
.x
n
w1
w2
wn+1
=b
wn
Sample(0,1)
Σ
x1
x2
1
.
.
.x
n
w1
w2
wn+1
=b
wn
x={0,1}
E( x)=p (x )

Primjer DBN - Hinton

Primjer DBN - Hinton

Je li DBN bolji od RBM?
● Rekonstrukcije nakon višekratnih Gibbsovih uzorkovanja
● Neparni stupci – početne vjerojatnosti vidljivog sloja
● Parni stupci – trenutne vjerojatnosti vidljivog sloja

Kuda dalje?
● Ako razmotamo RBM dobijemo strukturu koja podsjeća na autoenkodere...
v
h
W
h
v
v
W
WT





























