Embed Size (px)
Citation preview

OPM3001 - Techniques quantitatives de gestion
Eric LALLET , Jean-Luc RAFFY
TELECOM ÉCOLE DE MANAGEMENT - 1re ANNÉE
Décembre 2011

ii Eric L ALLET , Jean-Luc RAFFY

Table des matières
Avant propos v
I Théorie des graphes 1
1 Graphes orientés : définitions et généralités 3
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 3
1.2 Graphes orientés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 3
2 Les problèmes d’ordonnancement 5
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 5
2.2 L’analyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . 5
2.3 Le diagramme de GANTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . 6
2.4 La méthode potentiel-tâches . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . 8
3 Graphes non orientés : définitions et généralités 15
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 15
3.2 Graphes non orientés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . 15
3.3 Matrice d’adjacence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . 17
4 Les Arbres 19
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 19
4.2 Définitions et propriétés . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . 19
4.3 L’algorithme de Kruskal . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . 20
4.4 L’algorithme de Prim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . 21
5 Recherche du plus court chemin 27
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 27
5.2 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . 27
5.3 Exemples de problèmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . 27
5.4 Algorithme de Ford-Moore . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . 28
6 Flot Maximal 33
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 33
6.2 Description du problème . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . 33
6.3 Exemple de problème . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 33
Eric LALLET , Jean-Luc RAFFY iii

6.4 L’algorithme de Ford-Fulkerson . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . 34
6.5 Exemple de flot max . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . 35
6.6 Flot maximal à coût minimal . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . 37
6.7 L’algorithme de Busacker et Gowen . . . . . . . . . . . . . . . . . . .. . . . . . . . . . 37
6.8 Exemple flot max coût min . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 38
6.9 Variantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . 40
II Programmation linéaire 41
7 La programmation linéaire 43
7.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 43
7.2 La forme canonique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 43
7.3 Exemple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . 44
8 La méthode géométrique 47
8.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 47
8.2 La méthode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . 47
8.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . 48
9 Le simplexe 51
9.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 51
9.2 La forme standard et son tableau associé . . . . . . . . . . . . . .. . . . . . . . . . . . . 51
9.3 L’algorithme du simplexe . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . 53
9.4 Interprétation du tableau final . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . 54
9.5 Exemple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . 55
9.6 Plus loin au sujet des valeurs marginales . . . . . . . . . . . . .. . . . . . . . . . . . . . 57
9.7 Unités et simplifications . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . 58
III Modélisation 61
10 Modélisation 63
10.1 Chemin de la question à la réponse . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . 63
10.2 Les erreurs à ne pas faire . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . 64
iv Eric LALLET , Jean-Luc RAFFY

Avant propos
Combien d’hommes et en combien de temps une armée peut-elle emmener sur tel ou tel terrain d’opé-ration en cas de besoin ?
Existe-t-il des cas où une entreprise doit produire moins pour gagner plus ?
Quel est le coût minimal pour installer un réseau ? et par où lefaire passer ?
Quelles sont les tâches d’un projet sur lesquelles il ne fautpas prendre de retard sous peine de pénalisertout le projet ?
Tôt ou tard le directeur d’une entreprise, d’une équipe ou d’un projet devra répondre à ce genre dequestions. Évidemment il lui faudra réunir diverses informations et paramètres pour pouvoir le faire. Maisune fois toutes les cartes en main il devra mettre en œuvre destechniques de calcul pour trouver la bonneréponse.
Ce sont ces «techniques quantitatives de gestion» qui vont être présentées dans ce cours. Elles utilisentdes algorithmes issus de deux types de théories différents :certains reposent sur la théorie des graphes, etd’autres sur la programmation linéaire.
Cependant ce cours n’est ni un cours de théorie des graphes, ni un cours de programmation linéaire. Ilva présenter les bases nécessaires à la compréhension des algorithmes utilisés par les différentes techniques,mais il n’en fera pas une présentation formelle ou complète.Ainsi les algorithmes seront décrits, mais lesthéories sous-jacentes ne seront qu’éffleurées, leurs preuves ne seront pas faites.
Ne pensez pas pour autant qu’il faille laisser votre intelligence au vestiaire. Certes, une fois l’algorithmecompris, il devient vite une technique «automatique» et assez facile à appliquer. Mais la vraie difficultén’est pas ici. Le véritable problème à résoudre est de trouver comment modéliser votre question et doncquelle technique appliquer pour avoir la réponse. Ainsi l’enjeu de ce cours n’est pas tant de savoir commentmarchent les techniques (même si vous allez effectivement devoir le savoir !), mais plutôt de savoir à quellesquestions et à quels types de problèmes elles répondent.
Eric LALLET , Jean-Luc RAFFY v

vi Eric LALLET , Jean-Luc RAFFY

Première partie
Théorie des graphes
Eric LALLET , Jean-Luc RAFFY 1


Chapitre 1
Graphes orientés : définitions etgénéralités
1.1 Introduction
Beaucoup d’algorithmes d’optimisation, d’ordonnancement, de recherche d’optimum reposent sur desgraphes. Un bon dessin valant souvent plus qu’un long discours, les gens formalisent naturellement beau-coup de leur problèmes avec des graphes.
Il existe deux grandes familles de graphes : les graphes orientés, et les graphes non orientés. Dans cepremier chapitre nous allons décrire le minimum à savoir pour les diverses techniques utilisant les graphesorientés.
1.2 Graphes orientés
Un graphe orienté est composé de sommets et d’arcs allant d’un sommet vers un autre (éventuellementle même).
Un graphe fini orienté (G) se définit grâce deux ensembles finis : un ensemble de sommets(X), et unensemble d’arc (U ).
G = [X,U ] avec X = {x1, x2, x3, . . . , xn} et U = {u1, u2, u3, . . . , um}
Un arcuk deU est défini par une paire ordonnée de sommets(xi, xj). On dit que l’arcuk va dexi àxj .
FIG. 1.1 – Exemples de graphe orienté
Sur la figure 1.1G = [X,U ] avecX = {1, 2, 3, 4, 5, 6, } et U = {u1, u2, u3, u4, u5, u6, u7, u8}. L’arcu1 va de1 vers2 et l’arcu3 va de2 vers2.
Définition 1.1 (extrémité initiale) Soit un arcuk = (xi, xt). xi est dite l’extrémité initiale deuk. Ondéfinit aussi une fonctionI(uk) = xi qui donne l’extrémité initiale d’un arc.
Eric LALLET , Jean-Luc RAFFY 3

Définition 1.2 (extrémité terminale) Soit un arcuk = (xi, xt). xt est dite l’extrémité terminale deuk.On définit aussi une fonctionT (uk) = xt qui donne l’extrémité terminale d’un arc. On nomme aussi cetteextrémité, l’extrémité finale.
Définition 1.3 (successeur)On dit que le sommetxt est successeur du sommetxi s’il existe au moins unarc ayantxi comme extrémité initiale, etxt comme extrémité terminale.
Définition 1.4 (prédécesseur)On dit que le sommetxi est prédécesseur du sommetxt s’il existe au moinsun arc ayantxi comme extrémité initiale, etxt comme extrémité terminale.
Sur l’exemple le sommet2 a2 , 3 et4 pour successeurs. Le sommet2 a1 et2 pour prédécesseurs
Définition 1.5 (application multivoqueΓ+) Soit un grapheG = [X,U ]. On définitΓ+ comme l’applica-
tion qui à tout sommetx deX associe l’ensemble des sommets successeurs dex.
Sur l’exemple de la figure 1.1Γ+(2) = {2, 3, 4}.
Γ+(2) peut se noterΓ+2 .
Définition 1.6 (application multivoqueΓ−) Soit un grapheG = [X,U ]. On définitΓ− comme l’applica-
tion qui à tout sommetx deX associe l’ensemble des sommets prédécesseurs dex.
Sur l’exempleΓ−(2) = {1, 2}.
Γ−(2) peut se noterΓ−
2 .
Définition 1.7 (Graphe simple) Un graphe simple est un graphe dans lequel il n’y pas deux arcsayant lamême extreminité initiale et la même extréminité terminal.
FIG. 1.2 – Exemples de graphe orienté
Le graphe 1.1 n’est pas un graphe simple (u1 etu2 ont les même extrémités), mais le graphe 1.2 est ungraphe simple.
Dans le cas d’un graphe simple la connaissance de l’ensembledes sommetsX et de l’applicationΓ+
définit totalement le graphe. Voila pourquoi dans ce cas, il est possible de définir un grapheG commeG = [X,Γ+].
De plus dans un graphe simple il est possible de désigner les arcs par leurs extrémités sans la moindreambigüité. Sur le graphe 1.2 l’arcu1 peut aussi être nomé l’arc(1, 2).
Définition 1.8 (chemin) Un chemin est une suite d’arcs(u0, u1, . . . , un) avecT (ui) = I(ui+1) pour iallant de0 à n− 1.
(u1, u3, u6) est un chemin allant de 1 à 4. Sur un graphe simple on peut noter le chemin en indiquantles sommets parcourus.(1, 2, 2, 4) désigne le même chemin.
4 Eric LALLET , Jean-Luc RAFFY

Chapitre 2
Les problèmes d’ordonnancement
2.1 Introduction
On se pose des problèmes d’ordonnancement lorsque l’on est confronté à un problème d’organisation. Ilfaut accomplir de multiples tâches qui demandent un certaintemps d’exécution et qui doivent être exécutéesdans un certain ordre. Il est donc nécessaire d’identifier les tâches prioritaires en fonction de l’objectif àatteindre et, lors de leur exécution, il faut détecter les retards et les dépassements de moyens.
Les nombreuses méthodes d’ordonnancement peuvent se regrouper en deux grandes familles selon leprincipe de base qu’elles utilisent. On distingue :
– les méthodes du type diagramme à barres : GANTT– les méthodes à chemin critique : potentiel-tâches, potentiel-étapes (PERT).Dans ce cours nous allons traiter les diagrammes de GANTT et le potentiel-tâches.
2.2 L’analyse
La première étape d’un problème d’ordonnancement consisteà obtenir une liste de tâches, leur du-rée, et les contraintes de temps les unes par rapport aux autres (quelles tâches doivent être finies pour encommencer une autre).
Voici un petit exemple d’ordonnancement pour illustrer ce chapitre :
Pour mieux rentabiliser ses cours, un organisme de formation mutualise ses modules dans diverscursus différents. Ainsi avec 8 modules de cours il arrive à proposer les trois cursus suivants :– Le premier cursus commence par le modules A, puis le D, suividu F, et enfin se termine par
le H.– Le deuxième cursus commence au choix par le module A ou B, puis le E, suivi du G, et enfin
se termine par le H.– Le troisième cursus commence par le module C, puis le G et enfin se termine par le H.Pour chacun des cursus, on ne peut commencer un module que si le précédent est terminé.Voici la durée des divers modules :
Modules A B C D E F G HDurée
(semaines) 3 2 5 3 3 5 2 2
Quelle va être le temps minimum pour terminer toutes les formations ?
L’analyse des divers cursus nous apprend :– Les modules A, B, C peuvent commencer dès le début.– Le module D commence après la fin de A (à cause du premier cursus)– le module E commence après la fin de A et de B (à cause du deuxième cursus)– le module F commence après la fin de D (à cause du premier cursus)– le module G commence après la fin de E (à cause du deuxième cursus) et après la fin de C (à cause
du troisième cursus).
Eric LALLET , Jean-Luc RAFFY 5

– le module H commence après la fin de F (à cause du deuxième cursus) et après la fin de G (à causedu deuxième et du troisième cursus).
On obtient donc le tableau des tâches, durées et contraintessuivant :
Tâches Durées ContraintesA 3 semainesB 2 semainesC 5 semainesD 3 semaines A achevéeE 3 semaines A, B achevéesF 5 semaines D achevéeG 2 semaines C, E achevéesH 2 semaines F, G achevées
2.3 Le diagramme de GANTT
Un diagramme de GANTT se présente sous la forme d’un tableau àdeux dimensions. Les colonnes re-présentent l’avancement du temps (par exemple chaque colonne pourra symboliser la durée d’une semaine),et les lignes contiennent les différentes tâches à accomplir. En face de chaque tâche on va dessiner une barreallant du temps début de la tâche à son temps de fin.
On va dessiner le diagramme de GANTT des divers cursus de formations en utilisant le tableau obtenuaprès analyse dans la section précédente.
Les trois premières tâches (A, B et C) n’ont aucune contrainte. Elles peuvent commencer au temps0.On peut donc les représenter dans notre table en traçant une barre partant du temps 0, et parcourant la duréede la tâche : 3 semaines pourA, 2 pourB, et 6 semaines pourC :
Tâches 1 2 3 4 5 6 7 8 9 10 11 12 13
A
B
C
Par contre la tâcheD ne peut commencer qu’après la tâcheA et E ne peut commencer qu’après lestâchesA et B. Comme ces tâches sont déjà dans notre diagramme, on connaîtleurs temps de fin (après lasemaine 3 et 2), il est donc possible de tracer la barre ces deux tâches :
Tâches 1 2 3 4 5 6 7 8 9 10 11 12 13
A
B
C
D
E
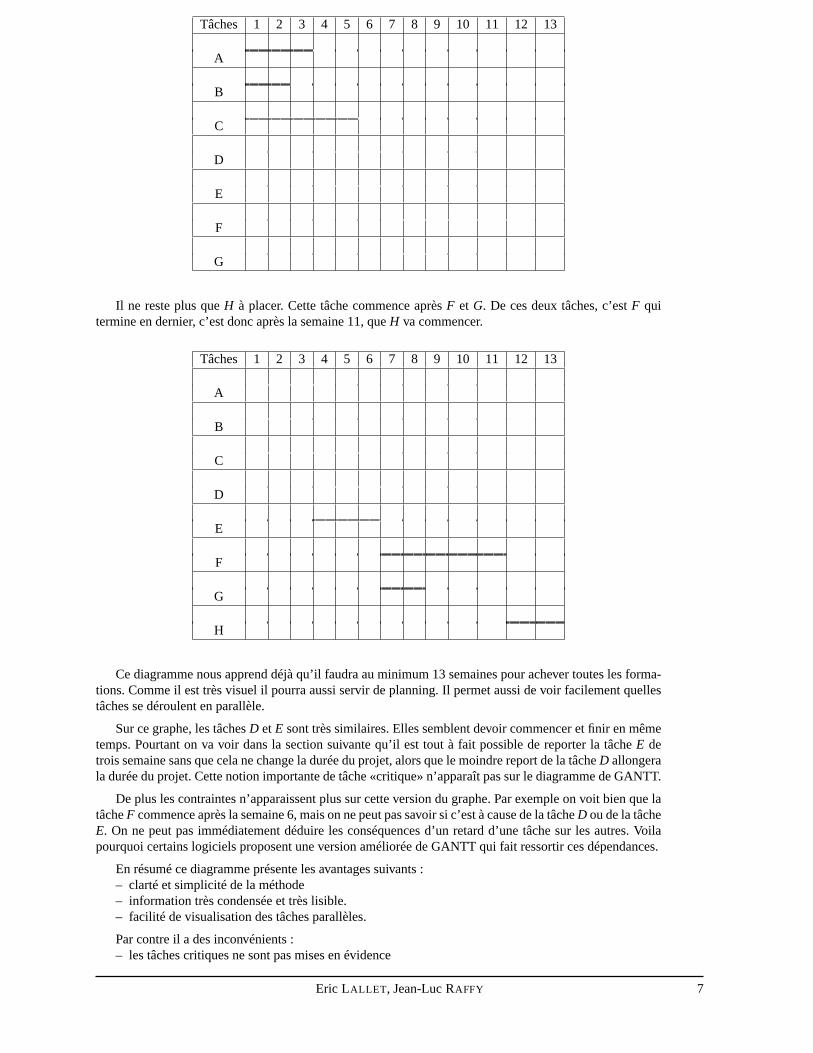
Les contraintes deF etG sont maintenant résolues.F commence aprèsD donc après la sixième semaine.G ne peut commencer qu’aprèsC etE, c’est le temps de fin deE (6) la plus grande contrainte qui va imposerle début deG :
6 Eric LALLET , Jean-Luc RAFFY
Tâches 1 2 3 4 5 6 7 8 9 10 11 12 13
A
B
C
D
E
F
G
Il ne reste plus queH à placer. Cette tâche commence aprèsF et G. De ces deux tâches, c’estF quitermine en dernier, c’est donc après la semaine 11, queH va commencer.
Tâches 1 2 3 4 5 6 7 8 9 10 11 12 13
A
B
C
D
E
F
G
H
Ce diagramme nous apprend déjà qu’il faudra au minimum 13 semaines pour achever toutes les forma-tions. Comme il est très visuel il pourra aussi servir de planning. Il permet aussi de voir facilement quellestâches se déroulent en parallèle.
Sur ce graphe, les tâchesD etE sont très similaires. Elles semblent devoir commencer et finir en mêmetemps. Pourtant on va voir dans la section suivante qu’il esttout à fait possible de reporter la tâcheE detrois semaine sans que cela ne change la durée du projet, alors que le moindre report de la tâcheD allongerala durée du projet. Cette notion importante de tâche «critique» n’apparaît pas sur le diagramme de GANTT.
De plus les contraintes n’apparaissent plus sur cette version du graphe. Par exemple on voit bien que latâcheF commence après la semaine 6, mais on ne peut pas savoir si c’est à cause de la tâcheD ou de la tâcheE. On ne peut pas immédiatement déduire les conséquences d’unretard d’une tâche sur les autres. Voilapourquoi certains logiciels proposent une version améliorée de GANTT qui fait ressortir ces dépendances.
En résumé ce diagramme présente les avantages suivants :– clarté et simplicité de la méthode– information très condensée et très lisible.– facilité de visualisation des tâches parallèles.
Par contre il a des inconvénients :– les tâches critiques ne sont pas mises en évidence
Eric LALLET , Jean-Luc RAFFY 7

– l’élaboration d’un plan d’action se révèle malaisé car cette méthode ne fait pas apparaître les liaisonsentre les tâches.
La mise en évidence de ces tâches critiques et de l’enchaînement des tâches est au contraire le point fortde la méthode «potentiel-tâches» présentée dans la sectionsuivante.
2.4 La méthode potentiel-tâches
2.4.1 Construction du graphe
Le but de cette méthode est de mettre en valeur l’enchaînement des tâches, de déterminer les dates dedébut et de fin de chaque tâche, de connaître les marges de manœuvre possibles sur ces dates. Pour cela onva construire un graphe dont les sommets seront les tâches duprojet et les arcs les contraintes qui les lient.Ces arcs seront étiquetés (valués) par la durée de la tâche dont ils sont issus.
La première étape de cette méthode va être de dessiner le graphe des tâches. Reprenons l’exemple de lasection précédente :
Tâches Durées ContraintesA 3 semainesB 2 semainesC 5 semainesD 3 semaines A achevéeE 3 semaines A, B achevéeF 5 semaines D achevéeG 2 semaines C, E achevéesH 2 semaines F, G achevées
On commence le graphe en plaçant un sommet pour toutes les tâches n’ayant aucune contrainte. Pourl’exemple, on place donc les sommetsA, B et C (cf l’étape 1 sur la figure 2.1). Ensuite on ajoute étape parétape les sommets qui ne dépendent que des sommets déjà placés. On ajoute un arc entre les sommets desétapes pré-requises et le sommet ajouté. Sur cet arc on indique la durée de la tâche pré-requise. Donc pourl’exemple, après les tâchesA, B etC, on peut placer les tâchesD etE. On trace aussi les arcs partant deA etB vers ces deux tâches, en indiquant dessus leur durée. Donc lavaleur 3 pour la tâcheA et 2 pour la tâcheB (cf l’étape 2 de la figure 2.1).
A
B
C
Etape 1
A
B
C
E
D
Etape 2
3
3
2
FIG. 2.1 – Début de la construction du graphe
On continue ainsi à placer les autres tâches et les arcs qui indiquent les dépendances jusqu’à la dernière.On arrive alors au graphe de la figure 2.2.
Il nous reste à finaliser ce graphe. Pour cela il faut ajouter une ou deux tâches fictives de durée nulle. Sile projet débute par plusieurs tâches en parallèle, on ajoute avant celles-ci une tâcheα qui va symboliser ledébut du projet. On va la relier à toutes les tâches qui débutent le projet (les tâches sans dépendance, donc
8 Eric LALLET , Jean-Luc RAFFY

A
B
C
F
G
D
E H
3 3
53
2
5
3 2
FIG. 2.2 – Graphe avec toutes les tâches
qui n’ont pas de prédécesseur). Enfin une tâcheω va symboliser la fin du projet. Tous les sommets sanssuccesseur vont y être reliés. Il faut bien sûr penser à placer sur les arcs la durée des tâches correspondantes.On arrive alors au graphe finalisé de la figure 2.3.
FIG. 2.3 – Graphe finalisé
Pour appliquer l’algorithme du potentiel-tâches on va calculer pour chaque tâche trois valeurs (la dateau plus tôt, la date au plus tard, et la marge totale). Pour pouvoir faire ces calculs directement sur le grapheon transforme chaque sommet en une case divisée en trois sections pour recevoir ces trois valeurs.
FIG. 2.4 – Préparation du potentiel-tâches pour les calculs
Eric LALLET , Jean-Luc RAFFY 9

2.4.2 Calcul des dates au plus tôt
Pour qu’une tâche puisse commencer il faut que toutes les tâches qui la relient au début du projet soientréalisées.
Définition 2.1 (date au plus tôt) On définit doncti, la date au plus tôtde la tâchei comme la date au plustôt de l’exécution de la tâchei.
Par exemple, pour commencer la tâcheE, il faut avoir finit la tâcheA et B. CommeA dure 3 semaineset B 2 semaines, ce sont les 3 semaines deA qui sont la véritable contrainte pourE. La tâcheE ne pourradonc commencer au plus tôt que 3 semaines après le début du projet. En fait pour retrouver ce temps on acherché le plus long chemin sur le graphe entreα etE.
Définition 2.2 (durée du projet) On définit la durée du projet comme la date au plus tôt de la tâcheω.
Cette date va donc se calculer en trouvant le plus long chemindeα àω.
Pour trouver les dates au plus tôt des différentes tâches, ilsuffit d’appliquer l’algorithme de recherchedu plus long chemin sur le graphe du potentiel-tâches.
Pour cela on commence par fixer la date au plus tôt de tâcheα à 0. Ensuite on traite étape après étapetoutes tâches dont la date au plus tôt des prédécesseurs est connue. Pour chaque prédécesseur on fait lasomme de sa date au plus tôt et de sa durée. On conserve la plus grande valeur qui devient la date au plustôt de la tâche.
On débute avec un graphe avec des cases vides, sauf pour letα qu’on initialise à 0 (voir figure 2.5).
FIG. 2.5 – Calcul de la date au plus tôt : état initial
Ensuite on traite tous les sommets dont les prédécesseurs sont déjà traités. Pour chaque arc arrivant surle sommet, on calcule la somme la valeur duti du sommet initial de l’arc et de la valeur de l’arc. On met lemaximum sur le sommet terminal.
Pour la première étape, on peut remplir les sommetsA, B etC. Ils n’ont qu’un seul prédécesseur chacun,et donc la maximum est vite trouvé (voir figure 2.6).
FIG. 2.6 – Calcul de date au plus tôt : première étape A, B et C
Pour la seconde étape, le calcul est simple pourD. Il n’y a qu’un seul prédécesseur, il suffit donc defaire la somme du sommet initial (A=0) et de l’arc (3).Par contreE à 2 prédécesseurs. La somme en partantA est plus grande, c’est donc cette valeur (3) que l’on prend (voir figure 2.7).
10 Eric LALLET , Jean-Luc RAFFY

FIG. 2.7 – Calcul de la date au plus tôt : seconde étape D et E
La troisième étape permet de remplir la date au plus tôt deF etG. PourF il n’y a que l’arc venant deDà prendre en compte, mais pourG il y a deux choix. La plus grande valeur vient parE (voir figure 2.8).
FIG. 2.8 – Calcul de la date au plus tôt : troisième étape F, et G
En continuant avec la même logique on remplit la date au plus tôt deH (un maximum à choisir parmi 2arcs) et deω (voir figure 2.9).
FIG. 2.9 – Calcul de la date au plus tôt : fin
2.4.3 Recherche de la date au plus tard
On sait maintenant quand une tâche pourra commencer au plus tôt. On va maintenant calculer quand ilsera possible de commencer au plus tard une tâche sans que cela ne retarde la fin du projet.
Définition 2.3 (date au plus tard) On définit doncTi, la date au plus tardde la tâchei comme la date auplus tard où l’on puisse commenceri sans augmenter la durée du projet.
Par exemple, prenons la tâcheG. Cette tâche dure 2 semaines et doit être faite pour commencer la tâcheH. La tâcheH commence la11me semaine. Donc on peut décider de commencer la tâcheG que 2 semainesavant c’est à dire la9me semaine sans que le projet ne prenne de retard. En résumé on peut commencer auplus tôtG la 6me semaine et au plus tard la9me semaine (TG = 9).
Eric LALLET , Jean-Luc RAFFY 11

Pour calculer la date au tard de chaque tâche, on va remonter le graphe depuis la tâcheω jusqu’à la tâcheα. On initialiseTω, la date au plus tard d’ω avec la valeur de sa date au plus tôt que l’on vient de calculer.On obtient le graphe initial de la figure 2.10.
FIG. 2.10 – Calcul de la date au plus tard : état initial
Ensuite on déroule l’algorithme du calcul de la date au plus tard : on regarde tous les sommets dont lessuccesseurs sont déjà traités. On choisit parmi les successeurs celui qui à le plus petitTi, et on lui retire lavaleur de l’arc.
Pour la première étape, on peut remplir le sommetH. Il n’a qu’un seul successeur et donc la minimumest vite trouvé (voir figure 2.11).
FIG. 2.11 – Calcul de date au plus tard : première étape H
Le seconde étape permet de trouver la date au plus tard pourF etG. Ces deux sommets n’ont qu’un seulsuccesseur, donc il suffit de retirer la valeur de l’arc auTi du successeur. On arrive au graphe de la figure2.12
FIG. 2.12 – Calcul de la date au plus tard : seconde étape (F etG)
Les tâches D et E se traitent exactement de la même façon. Par contre la tâche A a deux successeurs.On retient la date au plus tard la plus petite (TD = 3) et on rejette la plus grande (TE = 6). On obtient legraphe de la figure 2.13.
Pour la dernière étape, lorsque les dates au plus tard deA, B et C sont calculées, on peut trouver celledeα. Il a trois successeur, et c’estA qui avecTA = 0 a leTi minimum alors queB avecTB = 4 et C avecTC = 3 sont rejetés.
12 Eric LALLET , Jean-Luc RAFFY

FIG. 2.13 – Calcul de la date au plus tard de la tâcheA
FIG. 2.14 – Calcul de la date au plus tard : fin
On finit par le sommet initial du graphe (iciα). Sa date au plus tard est obligatoirement0. Trouver uneautre valeur prouve qu’il y a des erreurs dans les calculs.
2.4.4 Calcul des marges
Définition 2.4 (marge totale) La marge totaleMi d’une tâchei est le délai dont on peut retarder cettetâche sans affecter l’achèvement du projet.
Cette marge est donnée par la différence entre la date au plustard et la date au plus tôt :Mi = Ti − ti.
Les tâches critiques sont celles qui ont une marge totale nulle. Il est impossible de prendre du retarddessus sans retarder tout le projet. Le chemin critique passe par les tâches critiques. On le visualise sur legraphe en doublant les arcs de ce chemin : les arcs doublés sont ceux dont les deux extrémités ont une margetotale nulle. Sur notre exemple (voir figure 2.15) il n’y qu’un seul chemin critique, mais il est possible d’enobtenir plusieurs. Ce chemin critique va deα à ω en passant partA, D, F et H qui sont donc les quatretâches critiques sur lesquelles aucun retard n’est permis.
FIG. 2.15 – Calcul des marges et du chemin critique
Eric LALLET , Jean-Luc RAFFY 13

14 Eric LALLET , Jean-Luc RAFFY

Chapitre 3
Graphes non orientés : définitions etgénéralités
3.1 Introduction
Les graphes orientés ont été décrits dans le premier chapitre de cette documentation. Pour certainsmodèles l’orientation des arcs n’apporte rien. Seule la liaison entre deux sommets est interessante, peuimporte le sens de cette liaison. Dans ce cas on n’oriente plus cette liaison, les arcs deviennent des arêtes,et on parle alors de graphe non-orienté.
3.2 Graphes non orientés
FIG. 3.1 – Exemple de graphe non orienté
Un graphe fini non orienté (G) se définit grâce deux ensembles finis : un ensemble de sommets(X), etun ensemble d’arêtes (U ).
G = [X,U ] avec X = {x1, x2, x3, . . . , xn} et U = {u1, u2, u3, . . . , um}
Une arêteuk deU est définie par une paire non-ordonnée de sommets(xi, xj).
Sur la figure 3.1G = [X,U ] avecX = {1, 2, 3, 4, 5, 6, 7} et U = {u1, u2, u3, u4, u5, u6, u7, u8,u9, u10, u11}.
Définition 3.1 (extrémité) xi etxj sont appelés les extrémités deuk.
Sur la figure 3.1 les sommets6 et7 sont les extrémités deu9.
Eric LALLET , Jean-Luc RAFFY 15

Définition 3.2 (adjacent) Deux sommets reliés par une arête sont adjacents
Sur la figure 3.1 les sommets6 et7 sont adjacents.
Définition 3.3 (incident) Une arête est incidente aux sommets qu’elle relie. On dit aussi qu’un sommet estincident aux arêtes qui l’ont pour extrémité.
Sur la figure 3.1u9 est une arête incidente à6 et7.
Définition 3.4 (boucle) Une arêteu = (xi, xi) dont les extrémités coïncident est appelée une boucle.
Définition 3.5 (graphe simple) Un graphe est dit simple s’il ne contient aucune boucle et si aucun couplede sommet n’est relié par deux arêtes ou plus. Un graphe qui n’est pas simple est appelé un multigraphe.
L’exemple de la figure 3.1 est un multigraphe : il y a par exemple deux arêtes entre les sommets1 et2,et une boucle sur le sommet7.
Définition 3.6 (ordre) L’ordre N d’un graphe est son nombre de sommets.N = |X|
Le graphe de la figure 3.1 est d’ordre 7.
Définition 3.7 (degré) Le degréd(xi) d’un sommet est le nombre d’arêtes incidentes. Les arêtes qui bouclentcomptent pour2. Le degréD(G) d’un graphe est le degré maximum de tous ses sommets.
Sur la figure 3.1d(7) = 4, d(2) = 5, etD(G) = 5.
Définition 3.8 (cocycle)Soit A un sous ensemble de sommets deX. Le cocycle deA (noté ω(A)) estl’ensemble des arêtes ayant une extrémité dansA et l’autre dansX −A.
FIG. 3.2 – Cocycle
Sur la figure 3.2 on aω(A) = {u1, u2, u4, u7, u9, u11}
Définition 3.9 (chaîne) Une chaîne joignantx1 àxn est une suite de la forme(x1, u1, x2, u2, x3, u3 . . . un−1, xn)qui commence parx1, se finit parxn et qui alterne sommets et arêtes incidents.
Les sommets étant implicites, la chaîne est souvent notée qu’avec ses arêtes :(u1, u2, u3, . . . un−1). Lorsquele graphe est simple, la chaîne peut aussi être notée uniquement qu’avec ses sommets(x1, x2, . . . xn).
Définition 3.10 (chaîne élémentaire)Une chaîne est élémentaire si tous les sommets qui la composentsont différents.
Définition 3.11 (chaîne simple)Une chaîne est simple si elle ne contient pas deux fois la mêmearête.
Définition 3.12 (chaîne fermée)Une chaîne est fermée si elle termine sur le sommet où elle a commencé(x1 = xn).
16 Eric LALLET , Jean-Luc RAFFY

Définition 3.13 (cycle) Un cycle est une chaîne fermée simple qui n’a aucun sommet en double mis à partle premier qui est identique au dernier.
(u8, u4, u6) est une chaîne élémentaire simple allant de5 à4.
(u9, u10) est une chaîne simple qui va de6 à7. Elle n’est pas élémentaire car elle passe deux fois par7
(5, u8, 2, u2, 1, u1, 2, u8, 5) est une chaîne fermée allant de5 à5, mais n’est pas un cycle.
(1, u2, 2, u7, 4, u5, 1) est un cycle.
Définition 3.14 (connexité)Un graphe est dit connexe si pour tout couple de sommetsxi etxj soit il existeune chaîne allant dexi à xj , soit on axi = xj .
Pour exprimer cette définition autrement, utilisons la relationR suivante :
xiRxj ⇔
xi = xj
ouIl existe une chaîne allant dexi a xj
Cette relationR définit une relation d’équivalence (relation réflexive, symétrique, et transitive). Elleforme ainsi des classes d’équivalence qui divisent le graphe en plusieurs partitions. Par exemple, le graphede la figure 3.1 est divisé en deux classes d’équivalence avecdans une classe les sommets 1, 2, 3, 4 et 5 etdans l’autre les sommets 6 et 7.
Définition 3.15 (nombre de connexité)Le nombrep de classes d’équivalence distinctes de la relationRest appelé le nombre de connexité du graphe.
Il existe alors une deuxième façon de définir la connexité :
Définition 3.16 (connexité (2e)) Un graphe est dit connexe si et seulement si son nombre de connexitépvaut 1
3.3 Matrice d’adjacence
Dans les cas réels, le dessin d’un graphe peut être fastidieux (car trop grand, trop complexe), et tota-lement illisible (trop d’arètes ou d’arcs qui se croisent dans tous les sens). Il faut alors choisir une autreréprésentation. Il en existe plusieurs et dans ce cours on aura l’occasion d’utiliser les «matrices d’adja-cence».
Une matrice d’adjacence permet la représentation d’un graphe simple orienté ou non-orienté.
SoitG = [X,U ] un graphe simple avec|X| = N .
Sa matriceA d’adjacence est une matriceN ×N remplis de booléens avec
aij =
{
1 si (xi, xj) ∈ U0 sinon
On peut aussi représenter des multigraphes avec ce type de matrice en remplaçant les booléens par desentiers :
aij = |Uij | avecUij = {u ∈ U/(I(u) = xi etT (u) = xj)}
Pour les graphes non-orientés on peut décider de ne pas remplir une moitié de la matrice (copie del’autre moitié).
Eric LALLET , Jean-Luc RAFFY 17

Voici des exemples de matrices d’adjacence.
02(u1, u2) 01(u3) 1(u4) 01(u5) 1(u7) 1(u6) 00 1(u8) 0 0 00 0 0 0 0 00 0 0 0 0 2(u9, u11) 1(u10)
0 2(u1, u2) 1(u3) 0 0 0 00 0 1(u4) 1(u7) 1(u8) 0 00 0 0 0 0 0 01(u5) 0 1(u6) 0 0 0 00 0 0 0 0 0 00 0 0 0 0 0 1(u9)0 0 0 0 0 1(u11) 1(u10)
18 Eric LALLET , Jean-Luc RAFFY

Chapitre 4
Les Arbres
4.1 Introduction
FIG. 4.1 – Quel est le réseau de coût minimum permettant de reliertoutes les succursales ?
Imaginons que l’on veuille construire un réseau privé pour faire communiquerN succursales d’uneentreprise avec pour objectif d’obtenir le coût le plus bas.On connaît tous les raccordements possibleset leur coût (voir la figure 4.1). Comme le but est d’avoir le prix le plus bas, on ne va garder que lesraccordements strictement nécessaires. On s’aperçoit déjà que l’on n’a pas besoin de cycles dans ce graphe.Par contre pour que toute succursale puisse joindre toutes les autres, le graphe devra permettre de trouverun chemin entre tous les sommets (on aura donc un graphe connexe).
Ainsi la solution est de trouver un graphe connexe simple sans cycle qui offre le moindre coût deconstruction. Or un graphe connexe simple sans cycle est un arbre. Nous allons donc étudier les arbres,leurs propriétés et deux algorithmes qui permettront de trouver la solution à ce genre de problème.
4.2 Définitions et propriétés
Définition 4.1 (arbre) Un arbre est un graphe connexe simple sans cycle.
Par exemple une rivière et ses affluents forme un arbre. On utilise aussi beaucoup les arbres pour clas-sifier. Par contre, avec notre définition, en théorie de graphe, un «arbre généalogique» ne reste un arbre que
Eric LALLET , Jean-Luc RAFFY 19

si on ne remonte pas trop loin (on finira souvent par trouver deux ancêtres communs à deux conjoints, etdonc on formera un cycle).
Définition 4.2 (sous graphe)On dit qu’un grapheG′ = [X ′, U ′] est un sous-graphe deG = [X,U ] siX ′ ⊆ X etU ′ ⊆ U .
Définition 4.3 (sous graphe couvrant)Un sous grapheG′ = [X ′, U ′] est dit couvrant siX ′ = X et G′
est connexe.
Définition 4.4 (poids d’un graphe) Soit un grapheG = [X,U ] où chaque arêteui est valuée avec unpoidspi. Le poids du graphe est la somme des poids des arêtes du graphe.
Les arbres sont des graphes qui ont de nombreuses propriétés. En voici quelques-unes :
1. un arbre est toujours un graphe simple.
2. un arbre à N sommets possède N-1 arêtes.
3. Un sous-graphe deG couvrant et sans cycle est un arbre couvrant deG. On appelle ces arbres, des«arbres de recouvrement» du grapheG.
4. Si un graphe a toutes ses arêtes de poids positif ou nul, il admet un sous-graphe couvrant de poidsminimal, et ce sous-graphe couvrant de poids minimal est un arbre.
Pour résoudre le problème de l’introduction, il faut donc trouver le graphe de recouvrement de poidsminimum. Ce graphe est un arbre. Comme le nombre d’arbres de recouvrement croît de façon exponentielleavec le nombre de sommets, il n’est pas du tout intéressant detous les calculer pour connaître celui qui ale poids minimum. Pour éviter cela, il existe des algorithmes qui permettent de construire d’entrée un arbrede poids minimal et dont le nombre d’étapes est une fonction linéaire du nombre d’arêtes. Nous allons voirces algorithmes.
4.3 L’algorithme de Kruskal
Soit un grapheG = [X,U ], avec|X| = N et |U | = M .
On va construite un arbre recouvrement deG de poids minimum :τ = [X,T ].
Algorithme 4.1 (Kruskal)
1. Classer les arêtes par ordre croissant de poids.U = {u1, u2, u3, ...., um}.
2. Commencer avec un graphe vide :T = ∅ et i = 1.
3. Regarder si l’ajout deui au graphe crée un cycle.
(a) Si ce nouveau graphe est sans cycle, ajouterui àT : T ← T ∪ ui.
(b) Si ce nouveau graphe contient un cycle, rejeterui qui ne sera pas retenue dans l’arbre.
4. Incrémenteri de1.Si |T | = N − 1 Stop, sinon retourner à l’étape 3.
On peut remarquer que durant les phases intermédiaires de l’algorithme de Kruskal, le sous grapheformé parT n’est pas forcement connexe. On a un ensemble d’arbres disjoints. Un graphe de cette formes’appelle une «forêt».
Faisons tourner cet algorithme sur l’exemple de l’introduction : N = 6 et M = 10. Après classementdes arêtes par ordre croissant de poids on obtientU = {u1, . . . , u10} de la figure 4.2.
On poseT = ∅ et i = 1.
Donc on commence par ajouteru1 dans notre arbre :T = {u1} et i = 2.
Ensuite on ajouteu2 :T = {u1, u2} et i = 3.
On peut ajouteru3 toujours sans créer de cycle, doncT = {u1, u2, u3} et i = 4.
À l’étape suivanteu4 peut aussi être ajouter, doncT = {u1, u2, u3, u4} et i = 5.
A ce stade on obtient la figure 4.3.
20 Eric LALLET , Jean-Luc RAFFY

S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
U1
U2
U4U5
U6
U8
U9U10
U3
U7
FIG. 4.2 – Kruskal : tri des arêtes (lesui numérotées dans par ordre croissant de poids)
S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
U1
U2
U4U5
U6
U8
U9U10
U3
U7
=(X,T)tt
S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
U1
U2
U4U5
U6
U8
U9U10
U3
U7
=(X,T)tt
FIG. 4.3 – Kruskal : étape avec 4 arêtes et étape finale
On tente alors d’ajouteru5. Mais(u1, u4, u5) forment un cycle.u5 est donc rejeté, eti = 6.
On tente alors d’ajouteru6. Mais(u1, u4, u6, u2) forment un cycle.u6 est donc rejeté, eti = 7
Par contreu7 peut aussi être ajoutée. On obtientT = {u1, u2, u3, u4, u7}, et i = 8. Comme|T | = 5 =N − 1, l’algorithme est terminé. On aτ = [X,T ] un arbre de recouvrement minimal (voir la figure 4.3).
On peut maintenant évaluer le coût du réseau à mettre en place: c’est le poids de notre arbre de recou-vrement minimal. Donc sipi est le poids de l’arêteui :
coût= p1 + p2 + p3 + p4 + p7 = 1 + 1 + 2 + 2 + 5 = 11.
Notez qu’un arbre de recouvrement minimal n’est pas obligatoirement unique. D’autres peuvent peserle même poids. On va d’ailleurs en trouver un autre pour notreproblème lorsqu’on va utiliser l’algorithmede Prim dans la section suivante.
4.4 L’algorithme de Prim
4.4.1 Description
Soit un grapheG = [X,U ], avec|X| = N et |U | = M .
On va construite un arbre recouvrement minimal deG : τ = [X,T ].
Voici le principe de l’algorithme de Prim :
Algorithme 4.2 (Prim)
1. Commencer avec un ensemble de sommetsA contenant un des sommets deX (au choix, par exemplex1) : A = {x1}. Et commencer unT l’ensemble des arêtes à vide :T = ∅
2. Calculq, l’ensemble des arêtes du cocycle deA : q = ω(A).
3. Choisir dansq une des arêtes de poids minimalu.
Eric LALLET , Jean-Luc RAFFY 21

(a) ajouteru àT .
(b) u relie un sommetxi de l’ensembleA à un sommetxj hors deA. Ajouterxj à A.
4. Si |T | = N − 1, fin,sinon retourner en 3.
4.4.2 Exemple sur un graphe dessiné
Faisons tourner cet algorithme sur notre exemple.
– Pour démarrer, on va choisir d’initialiserA avecS1 (voir figure 4.4)1
A = {S1}
q = ω(A) = ωS1= {u1, u2, u3, u4}
T = ∅
S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
u1
u2
u3u4
u5
u6
u7
u8
u9
u10
A
S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
u1
u2
u3u4
u5
u6
u7
u8
u9
u10
A
FIG. 4.4 – Prim : Initialisation de l’algorithme et première étape (u2 ajoutée)
– On doit choisir une arête de moindre poids dansq. L’arêteu1 (de poids 8) est donc exclue. Les 3autres (de poids 2) peuvent convenir. On va prendreu2. Elle est reliée àS4 qui rentre donc dansl’ensembleA (voir figure 4.4).
T = {u2}
A = {S1, S4}
q = ω(A) = {u1, u3, u4, u6, u7, u8}
– Les trois arêtes de poids2 deq sont éligibles :u3, u4 etu8. On va choisiru3. Son extrémitéS6 entredonc dansA (voir la figure 4.5).
T = {u2, u3}
A = {S1, S4, S6}
q = ω(A) = {u1, u4, u6, u7, u9, u10}
– A cette étape, seule l’arête de poids1, u9 peut être choisie. On ajoute son extrémitéS5 dans l’en-sembleA (voir la figure 4.5).
T = {u2, u3, u9}
A = {S1, S4, S5, S6}
q = ω(A) = {u1, u6, u7, u10}
– L’arête de plus faible poids deq estu10. Son extrémitéS3 entre dansA (voir la figure 4.6).
T = {u2, u3, u9, u10}
A = {S1, S3, S4, S5, S6}
q = ω(A) = {u1, u6, u5}
1Notez que pour cette algorithme les arêtes n’ont pas besoin d’être triées. Donc leur numérotation a juste été faite «au vol»lors dudessin du graphe
22 Eric LALLET , Jean-Luc RAFFY

S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
u1
u2
u3u4
u5
u6
u7
u8
u9
u10
AS1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
u1
u2
u3u4
u5
u6
u7
u8
u9
u10
A
FIG. 4.5 – Prim : Deuxième étape (u3 ajoutée) et troisième étape (u9 ajoutée)
S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
u1
u2
u3u4
u5
u6
u7
u8
u9
u10
A
S1
S6
S3
S5
S4
S2
8
1
2
2
6
6
5
2
1
2
u1
u2
u3u4
u5
u6
u7
u8
u9
u10
A
FIG. 4.6 – Prim : Quatrième étape (u10 ajoutée) et dernière étape (arbre trouvé)
– L’arête u5 de poids 1 complète notre arbre. Le nombre d’arêtes vautN − 1 et A enrichi deS2
l’extrémité deu5 couvre maintenant tout l’ensemble. L’algorithme se termine donc ici (voir figure4.6).
T = {u2, u3, u5, u9, u10}
A = {S1, S2, S3, S4, S5, S6}
q = ω(A) = ∅
L’arbre trouvé ici n’est pas le même que dans la section précédente, mais il pèse bien le même poids(11). Aussi bien pour Kruskal que pour Prim, il y a des choix à faire (par exemple, lorsqu’il y a plusieursarêtes avec le même minimum), et il y a donc plusieurs «bonnes» solutions.
4.4.3 Exemple sur la matrice du graphe
Pour ce genre de problème, le graphe dessiné est parfois illisible : le graphe n’est pas planaire et pleind’arêtes se croisent dans tous les sens. Essayer de trouver sur le dessin le cocycle des sommets déjà traitésdevient vite impossible. On peut bien sûr dérouler l’algorithme à la main, mais il est aussi possible detravailler sur la matrice d’adjacence qui représente le graphe. Dans ce cas le booléen qui indique s’il existeune arête entre deux sommets est remplacé par le poids de l’arête.
La matrice d’adjacence du graphe des succursales donne :
S1 S2 S3 S4 S5 S6
S1
S2 8S3 1S4 2 6 6S5 2S6 2 5 2 1
Eric LALLET , Jean-Luc RAFFY 23

Le cocycle d’un ensemble réduit à un seul sommet sur une tellematrice est très simple à trouver : ils’agit de la colonne et de la ligne du sommet.
Donc la matrice qui donne les arêtes du cocycle deA = {S4} est :
S1 S2 S3 S4 S5 S6
S1
S2
S3
S4 2 6 6S5
S6 2
Imaginons maintenant qu’on veuille ajouterS6 à notre ensemble (pour former l’ensemble de sommets{ S4, S6 }). Comment trouver le nouveau cocycle ?
Il faut ajouter toute la ligne et la colonne deS6 mais en retirant toutes les valeurs qui étaient déjàprésentes.
On obtient :
S1 S2 S3 S4 S5 S6
S1
S2
S3
S4 2 6 6S5
S6 2 5 �A2 1
Pour illustrer cela une fois de plus, ajoutonsS1 à l’ensemble. On procède de la même manière pourtrouver le cocycle du nouvel ensemble ({S1, S4, S6 }). On ajoute la ligne et la colonne deS1 mais enrayant les éléments déjà présents.
Cela donne :
S1 S2 S3 S4 S5 S6
S1
S2 8S3
S4 �A2 6 6S5 2S6 �A2 5 �A2 1
Utilisons ce principe sur l’algorithme de Prim.
Imaginons un cas d’étude : Six fleuves majeurs coulent dans laprovince de Primlande : l’Armoise, laBellis, le Comaret, la Douve, l’Erine et le Fragon. Le gouverneur de Primlande voudrait créer un réseaude canaux pour permettre de naviguer d’un fleuve à l’autre. Ilveut aussi que ça lui coûte le moins cherpossible. Il a demandé une étude pour évaluer le coût de la jonction des fleuves pris deux à deux. Voici lerésultat :
Armoise Bellis Comaret Douve Erine FragonArmoiseBellis 10Comaret 6 8Douve 4 2 4Erine 9 4 7 2Fragon 3 3 3 1 5
Il faut maintenant trouver quels canaux creuser pour que tous les fleuves ne forment plus qu’un seulréseau qui coûte le moins cher possible. Prim est parfaitement adapté. On va donc le dérouler, mais sur lamatrice.
24 Eric LALLET , Jean-Luc RAFFY
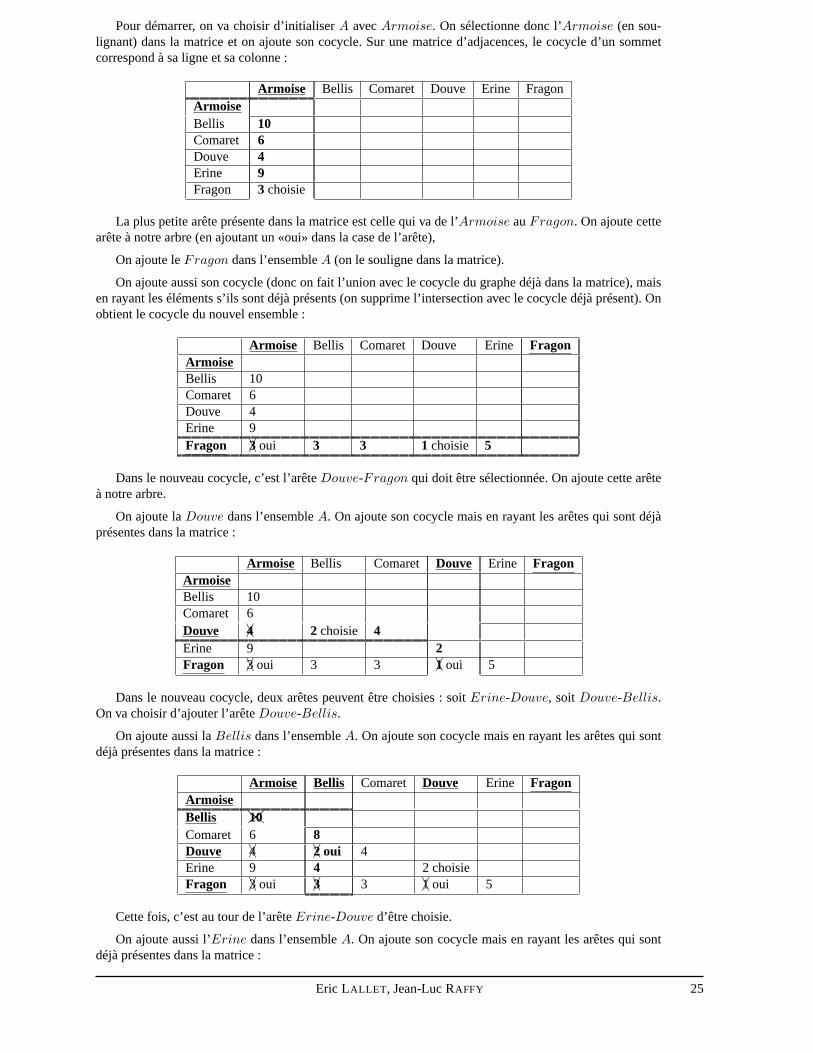
Pour démarrer, on va choisir d’initialiserA avecArmoise. On sélectionne donc l’Armoise (en sou-lignant) dans la matrice et on ajoute son cocycle. Sur une matrice d’adjacences, le cocycle d’un sommetcorrespond à sa ligne et sa colonne :
Armoise Bellis Comaret Douve Erine FragonArmoiseBellis 10Comaret 6Douve 4Erine 9Fragon 3 choisie
La plus petite arête présente dans la matrice est celle qui vade l’Armoise auFragon. On ajoute cettearête à notre arbre (en ajoutant un «oui» dans la case de l’arête),
On ajoute leFragon dans l’ensembleA (on le souligne dans la matrice).
On ajoute aussi son cocycle (donc on fait l’union avec le cocycle du graphe déjà dans la matrice), maisen rayant les éléments s’ils sont déjà présents (on supprimel’intersection avec le cocycle déjà présent). Onobtient le cocycle du nouvel ensemble :
Armoise Bellis Comaret Douve Erine FragonArmoiseBellis 10Comaret 6Douve 4Erine 9Fragon �A3 oui 3 3 1 choisie 5
Dans le nouveau cocycle, c’est l’arêteDouve-Fragon qui doit être sélectionnée. On ajoute cette arêteà notre arbre.
On ajoute laDouve dans l’ensembleA. On ajoute son cocycle mais en rayant les arêtes qui sont déjàprésentes dans la matrice :
Armoise Bellis Comaret Douve Erine FragonArmoiseBellis 10Comaret 6Douve �A4 2 choisie 4Erine 9 2Fragon �A3 oui 3 3 �A1 oui 5
Dans le nouveau cocycle, deux arêtes peuvent être choisies :soit Erine-Douve, soit Douve-Bellis.On va choisir d’ajouter l’arêteDouve-Bellis.
On ajoute aussi laBellis dans l’ensembleA. On ajoute son cocycle mais en rayant les arêtes qui sontdéjà présentes dans la matrice :
Armoise Bellis Comaret Douve Erine FragonArmoiseBellis ��ZZ10Comaret 6 8Douve �A4 �A2 oui 4Erine 9 4 2 choisieFragon �A3 oui �A3 3 �A1 oui 5
Cette fois, c’est au tour de l’arêteErine-Douve d’être choisie.
On ajoute aussi l’Erine dans l’ensembleA. On ajoute son cocycle mais en rayant les arêtes qui sontdéjà présentes dans la matrice :
Eric LALLET , Jean-Luc RAFFY 25
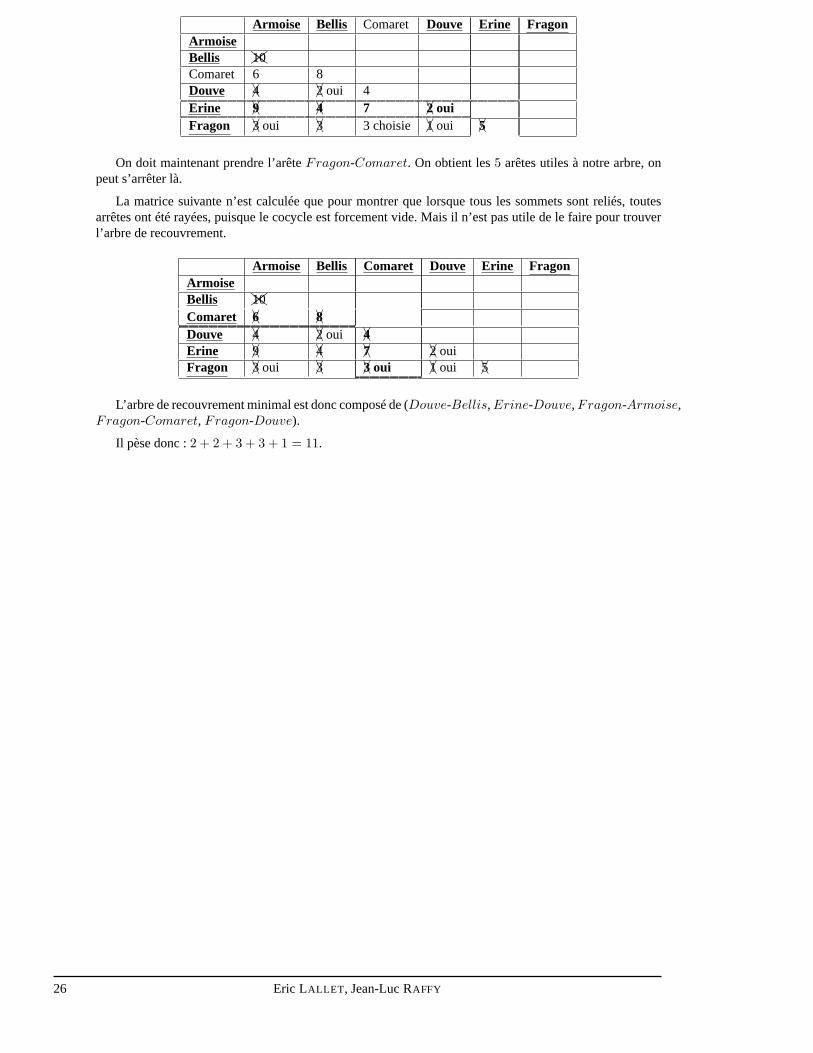
Armoise Bellis Comaret Douve Erine FragonArmoiseBellis ��ZZ10Comaret 6 8Douve �A4 �A2 oui 4Erine �A9 �A4 7 �A2 ouiFragon �A3 oui �A3 3 choisie �A1 oui �A5
On doit maintenant prendre l’arêteFragon-Comaret. On obtient les5 arêtes utiles à notre arbre, onpeut s’arrêter là.
La matrice suivante n’est calculée que pour montrer que lorsque tous les sommets sont reliés, toutesarrêtes ont été rayées, puisque le cocycle est forcement vide. Mais il n’est pas utile de le faire pour trouverl’arbre de recouvrement.
Armoise Bellis Comaret Douve Erine FragonArmoiseBellis ��ZZ10Comaret �A6 �A8Douve �A4 �A2 oui �A4Erine �A9 �A4 �A7 �A2 ouiFragon �A3 oui �A3 �A3 oui �A1 oui �A5
L’arbre de recouvrement minimal est donc composé de (Douve-Bellis, Erine-Douve, Fragon-Armoise,Fragon-Comaret, Fragon-Douve).
Il pèse donc :2 + 2 + 3 + 3 + 1 = 11.
26 Eric LALLET , Jean-Luc RAFFY

Chapitre 5
Recherche du plus court chemin
5.1 Introduction
Les problèmes de cheminement dans les graphes sont parmi lesplus anciens de la théorie des graphes.Ce type de recherche se rencontre soit directement, soit sous la forme d’un problème dans de nombreusesapplications.
Quelques exemples :– les problèmes de tournées– les problèmes de gestion de stock, d’investissements– les problèmes d’optimisation de réseaux.
5.2 Définitions
Définition 5.1 (graphe valué) Étant donné un grapheG = (X,U), on associe à chaque arcu ∈ U unnombrel(u) ∈ R. On dit queG est valué par la longueurl(u).
Définition 5.2 (plus court chemin) Le problème du plus court chemin (PCCH) entre 2 sommetsi etj serade trouver un cheminpi,j dont la longueur totalel(pi,j) est minimale.
Avecl(pi,j) =∑
u∈pi,j
l(u)
5.3 Exemples de problèmes
L’interprétation la plus évidente del(u) est une distance. Mais toute autre valeur peut être modélisée :un coût de transport, une dépense de construction, une durée, . . . .
Voici deux exemples pour illustrer des cas où on est confronté à ce type de problème :– Considérons une carte routière et cherchons la route la plus courte pour se rendre d’une localité à une
autre. Le graphe est obtenu en prenant comme sommets les localités et en remplaçant chaque routeentre deux localités par 2 arcs d’orientations opposées, etayant pour longueur la longueur de la route.
– Considérons le projet de construction d’une autoroute entre les villes A et K. Sur le graphe les arcsreprésentent les différents tronçons possibles de l’autoroute ; chaque arc est valué par le coût total deréalisation du tronçon correspondant.
Pour illustrer ce chapitre nous allons utiliser un problèmede remplissage d’un bassin de rétention d’eau.Une commune doit réussir à faire monter chaque jour 10m3 d’eau jusqu’à un bassin nomméH. Pour celaelle puise dans une sourceA. Entre les deux, elle a à sa disposition une série de réservoirs intermédiairesreliés par des pompes (qui consomment de l’énergie), ou des turbines (qui restituent de l’énergie). Toutesles conduites ont la capacité nécessaire pour faire transiter les 10m3 d’eau, mais les rendements n’étant pastous égaux, les coûts en énergie varient beaucoup.
Eric LALLET , Jean-Luc RAFFY 27

Voici les diverses conduites possibles avec leur coût en kWh (lorsque la conduite passe par une turbineet redonne de l’énergie, le coût est mis en négatif).
Réservoir Réservoir Coûtde départ d’arrivée (kWh)
A B 5A C 4A D 3B C -2B E 4C F 3C G -1D C 1D H 8E H 0F E 2G F 5G H 7
Par quelles conduites cette commune doit faire transiter l’eau pour consommer le moins d’énergie pos-sible ?
La première étape consiste à construire le graphe valué de ceproblème :
B
C
D
3
−1
E
H
F
G
4
2
7
8
0
4
5
3
A
−2
1
5
FIG. 5.1 – Par quelles conduites faire transiter l’eau ?
Ensuite il faute calculer le chemin le plus court allant deA à H sur ce graphe. Pour cela on va utiliserl’algorithme de Ford-Moore.
5.4 Algorithme de Ford-Moore
On va dérouler l’algorithme de Ford-Moore sur un tableau. Pour cela on commence par créer un tableauavec une colonne pour chaque sommet, une pour la liste des sommets qui ont changé, et une dernière pourleurs successeurs. L’algorithme de Ford-Moore est un algorithme itératif. Il y aura une nouvelle ligne pourchaque itération (on ajouter une colonne au début juste pournuméroter ces itérations).
Pour l’itération 0, le tableau est initialisé avecλ(A) = 0 et tous les autres avec∞. On place justeAdans les sommets changés, on indique tous les successeurs deA dans la colonneΓ+.
m λ(A) λ(B) λ(C) λ(D) λ(E) λ(F ) λ(G) λ(H) Sommets Γ+
changés0 0 ∞ ∞ ∞ ∞ ∞ ∞ ∞ A B,C,D
Maintenant à chaque itération il faut reprendre un à un tous les sommets qui apparaissent dans la colonneΓ+ de l’itération précédente. Un sommet peut apparaître plusieurs fois, il faut alors le traiter plusieurs fois.En fait, on traite tous les arcs (Sommets changés→ Γ+) que l’itération précédente a fait apparaître.
28 Eric LALLET , Jean-Luc RAFFY
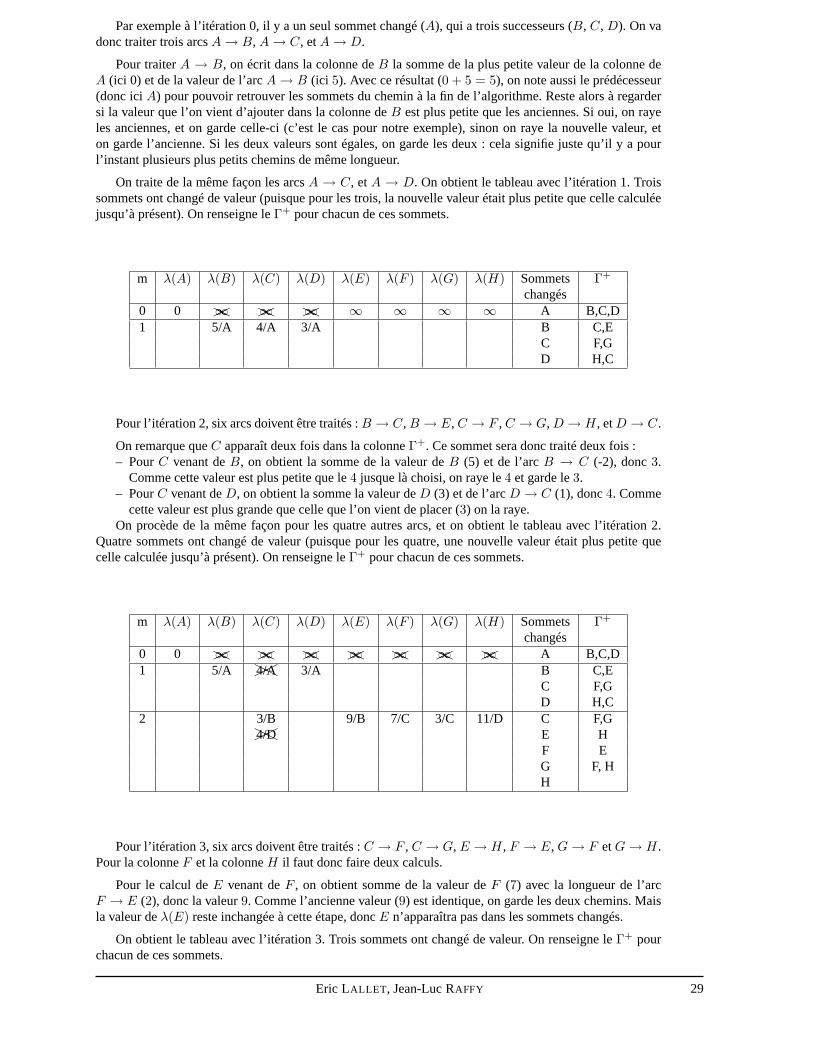
Par exemple à l’itération 0, il y a un seul sommet changé (A), qui a trois successeurs (B, C, D). On vadonc traiter trois arcsA→ B, A→ C, etA→ D.
Pour traiterA → B, on écrit dans la colonne deB la somme de la plus petite valeur de la colonne deA (ici 0) et de la valeur de l’arcA→ B (ici 5). Avec ce résultat (0 + 5 = 5), on note aussi le prédécesseur(donc iciA) pour pouvoir retrouver les sommets du chemin à la fin de l’algorithme. Reste alors à regardersi la valeur que l’on vient d’ajouter dans la colonne deB est plus petite que les anciennes. Si oui, on rayeles anciennes, et on garde celle-ci (c’est le cas pour notre exemple), sinon on raye la nouvelle valeur, eton garde l’ancienne. Si les deux valeurs sont égales, on garde les deux : cela signifie juste qu’il y a pourl’instant plusieurs plus petits chemins de même longueur.
On traite de la même façon les arcsA → C, etA → D. On obtient le tableau avec l’itération 1. Troissommets ont changé de valeur (puisque pour les trois, la nouvelle valeur était plus petite que celle calculéejusqu’à présent). On renseigne leΓ+ pour chacun de ces sommets.
m λ(A) λ(B) λ(C) λ(D) λ(E) λ(F ) λ(G) λ(H) Sommets Γ+
changés0 0 ��HH∞ ��HH∞ ��HH∞ ∞ ∞ ∞ ∞ A B,C,D1 5/A 4/A 3/A B C,E
C F,GD H,C
Pour l’itération 2, six arcs doivent être traités :B → C, B → E, C → F , C → G, D → H, etD → C.
On remarque queC apparaît deux fois dans la colonneΓ+. Ce sommet sera donc traité deux fois :– PourC venant deB, on obtient la somme de la valeur deB (5) et de l’arcB → C (-2), donc3.
Comme cette valeur est plus petite que le4 jusque là choisi, on raye le4 et garde le3.– PourC venant deD, on obtient la somme la valeur deD (3) et de l’arcD → C (1), donc4. Comme
cette valeur est plus grande que celle que l’on vient de placer (3) on la raye.On procède de la même façon pour les quatre autres arcs, et on obtient le tableau avec l’itération 2.
Quatre sommets ont changé de valeur (puisque pour les quatre, une nouvelle valeur était plus petite quecelle calculée jusqu’à présent). On renseigne leΓ+ pour chacun de ces sommets.
m λ(A) λ(B) λ(C) λ(D) λ(E) λ(F ) λ(G) λ(H) Sommets Γ+
changés0 0 ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ A B,C,D1 5/A ��HH4/A 3/A B C,E
C F,GD H,C
2 3/B 9/B 7/C 3/C 11/D C F,G��HH4/D E H
F EG F, HH
Pour l’itération 3, six arcs doivent être traités :C → F , C → G, E → H, F → E, G→ F etG→ H.Pour la colonneF et la colonneH il faut donc faire deux calculs.
Pour le calcul deE venant deF , on obtient somme de la valeur deF (7) avec la longueur de l’arcF → E (2), donc la valeur9. Comme l’ancienne valeur (9) est identique, on garde les deux chemins. Maisla valeur deλ(E) reste inchangée à cette étape, doncE n’apparaîtra pas dans les sommets changés.
On obtient le tableau avec l’itération 3. Trois sommets ont changé de valeur. On renseigne leΓ+ pourchacun de ces sommets.
Eric LALLET , Jean-Luc RAFFY 29
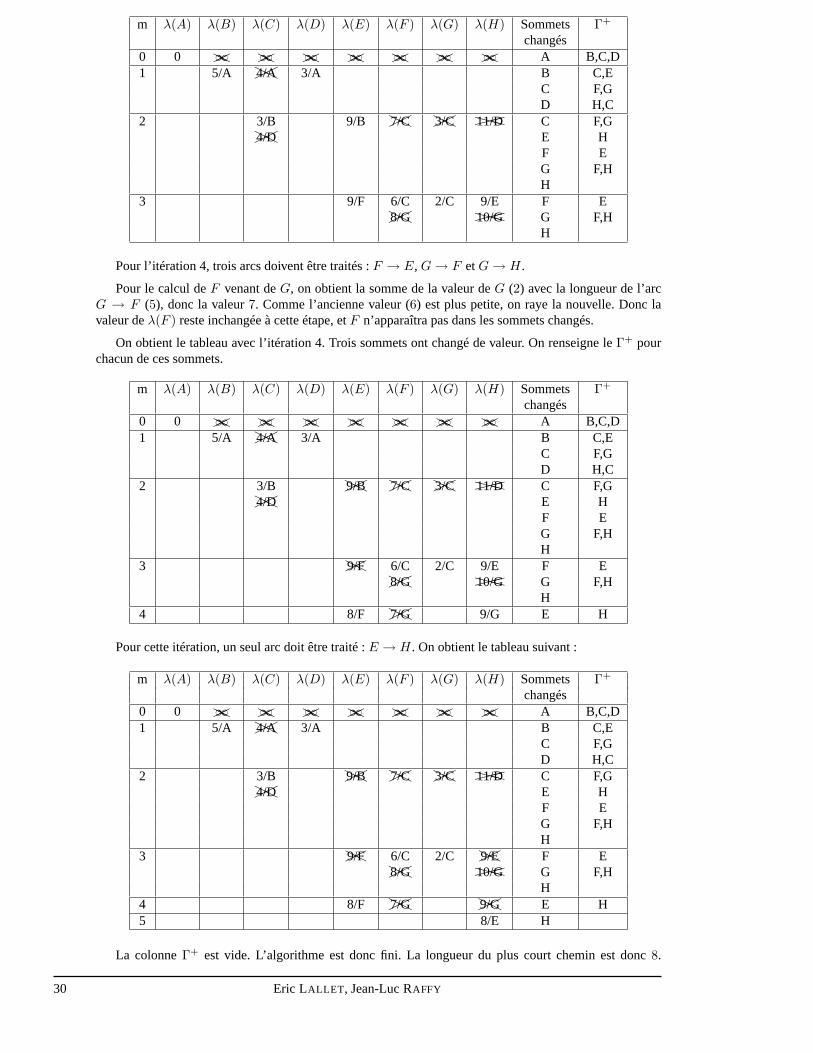
m λ(A) λ(B) λ(C) λ(D) λ(E) λ(F ) λ(G) λ(H) Sommets Γ+
changés0 0 ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ A B,C,D1 5/A ��HH4/A 3/A B C,E
C F,GD H,C
2 3/B 9/B ��HH7/C ��HH3/C ���XXX11/D C F,G��HH4/D E H
F EG F,HH
3 9/F 6/C 2/C 9/E F E��HH8/G ���XXX10/G G F,H
H
Pour l’itération 4, trois arcs doivent être traités :F → E, G→ F etG→ H.
Pour le calcul deF venant deG, on obtient la somme de la valeur deG (2) avec la longueur de l’arcG → F (5), donc la valeur7. Comme l’ancienne valeur (6) est plus petite, on raye la nouvelle. Donc lavaleur deλ(F ) reste inchangée à cette étape, etF n’apparaîtra pas dans les sommets changés.
On obtient le tableau avec l’itération 4. Trois sommets ont changé de valeur. On renseigne leΓ+ pourchacun de ces sommets.
m λ(A) λ(B) λ(C) λ(D) λ(E) λ(F ) λ(G) λ(H) Sommets Γ+
changés0 0 ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ A B,C,D1 5/A ��HH4/A 3/A B C,E
C F,GD H,C
2 3/B ��HH9/B ��HH7/C ��HH3/C ���XXX11/D C F,G��HH4/D E H
F EG F,HH
3 ��HH9/F 6/C 2/C 9/E F E��HH8/G ���XXX10/G G F,H
H4 8/F ��HH7/G 9/G E H
Pour cette itération, un seul arc doit être traité :E → H. On obtient le tableau suivant :
m λ(A) λ(B) λ(C) λ(D) λ(E) λ(F ) λ(G) λ(H) Sommets Γ+
changés0 0 ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ ��HH∞ A B,C,D1 5/A ��HH4/A 3/A B C,E
C F,GD H,C
2 3/B ��HH9/B ��HH7/C ��HH3/C ���XXX11/D C F,G��HH4/D E H
F EG F,HH
3 ��HH9/F 6/C 2/C ��HH9/E F E��HH8/G ���XXX10/G G F,H
H4 8/F ��HH7/G ��HH9/G E H5 8/E H
La colonneΓ+ est vide. L’algorithme est donc fini. La longueur du plus court chemin est donc8.
30 Eric LALLET , Jean-Luc RAFFY

Pour connaître ce chemin le plus court, il suffit de partir de la colonne deH et de remonter la route :H → 8/E → 8/F → 6/C → 3/B → 5/A.
Le plus court chemin passe donc parA→ B → C → F → E → H et il faudra utiliser 8 kwh par jourpour remplir les 10m3 du bassinH.
Eric LALLET , Jean-Luc RAFFY 31

32 Eric LALLET , Jean-Luc RAFFY

Chapitre 6
Flot Maximal
6.1 Introduction
Dans ce chapitre nous allons voir un algorithme qui permet detrouver le flot maximal entre deux pointsd’un graphe. De nombreux problèmes de natures très différentes se modélisent avec ce genre de graphe :le calcul de la capacité d’un réseau routier ou informatique, le calcul de flux migratoires ou financiers, lecalcul des possibilités logistiques d’une armée. . .
En ajoutant des coûts de transit sur les arcs, on verra aussi comment trouver le flot maximal qui nedépasse pas un coût donné, ou bien comment trouver le coût minimal pour faire transiter un flot donné.
6.2 Description du problème
Le problème du flot maximal consiste à faire passer un flot optimal à travers un «réseau de transport».Un réseau de transport est un grapheG = [X,U ] orienté sans boucle, dont chaque arc est valué par unnombre représentant sa capacité de transport. On distinguedeux sommets particuliers dans ce graphe :S, lasource, etP , le puits. Le problème sera de trouver la capacité du transitmaximal entre la source et le puits.La capacité d’un arcu sera notéec(u), et le flot attribué à cet arc sera notéϕ(u).
Le réseau de transport ne doit pas générer l’apparition d’unflot venu de nulle part. Donc pour tous lessommets il faut vérifier que la somme des flots sortants est égale à la somme des flots entrants.
∀x ∈ X on a∑
u/I(u)=x
ϕ(u) =∑
u′/T (u′)=x
ϕ(u′)
Pour que cette propriété soit vraie y compris pour le puits etla source, il faut placer un arc allant dupuits vers la source. Même si par la suite cet arc ne sera généralement pas représenté sur les graphes de cecours, il faudra imaginer sa présence, et surtout vérifier lapropriété sous-jacente : le flot arrivant au puitsvaut celui sortant de la source.
6.3 Exemple de problème
Pour illustrer ce chapitre, imaginons un exemple :
Un producteur de betteraves de Picardie décide de faire circuler sa production d’Épénancourt jusqu’àMaizy. Il veut profiter pour cela du réseau de voies navigables. Après s’être renseigné, il sait qu’il a lacapacité de faire circuler deux péniches par jour entre Épénancourt et Maizy sur le canal qui passe parNoyon et Quierzy. Mais en profitant du canal qui passe par Chauny, il peut aussi faire circuler deux pénichessupplémentaires entre Épénancourt et Quierzy. De plus à partir de Noyon, il a possibilité de faire passer versMaizy une péniche de plus en utilisant le canal qui passe par Venizel (voir figure 6.1).
On va déterminer combien de péniches ce producteur peut faire passer chaque jour.
Eric LALLET , Jean-Luc RAFFY 33

Épénancourt
Noyon
Quierzy
Maizy2 2 2
2
1
FIG. 6.1 – Capacités de transport entre Épénancourt et Maizy
6.4 L’algorithme de Ford-Fulkerson
6.4.1 Introduction
L’algorithme de Ford-Fulkerson part d’un graphe avec un premier flot établi. Ce premier flot est quel-conque, il peut même être nul. Mais pour diminuer le nombre d’itérations mieux vaut essayer de faire passer«au jugé» le meilleur flot possible. Ensuite on va déterminerdans quelle mesure ce flot peut être amélioré.Pour cela on va répéter de façon cyclique trois phases :
1. Le marquage du graphe : on va faire utiliser un premier algorithme pour marquer le graphe. Cemarquage permettra de trouver un chemin où le flot peut être augmenté, si un tel chemin existe.
2. Le calcul de l’amélioration : si on a réussi à marquer un chemin, on détermine ensuite le gain quel’on peut obtenir sur le flot grâce à celui-ci.
3. L’augmentation du flot : enfin, avant de reboucler sur le marquage, on augmente le flot du graphe dugain calculé à la phase 2.
6.4.2 Le marquage du graphe
Cette première phase va permettre soit de trouver un chemin non saturé allant de sourceS au puitsP ,soit de trouver une chaîne permettant de dérouter une partiedu flot pour désaturer un arc au profit d’un flotparallèle. Pour cela on va construire «une chaîne améliorante» allant deS àP .
Algorithme 6.1 (Algorithme de Ford-Fulkerson : phase du marquage)
1. Marquer la sourceS d’une *.
2. Pour tout sommetx marqué :– s’il existe des arcs(x, y), avec y non marqué tel queϕ(x, y) < c(x, y) marquery par+x.– s’il existe des arc(y, x), avec y non marqué tel queϕ(y, x) > 0 marquery par−x.
3. Tant queP n’est pas marqué et qu’il est possible de marquer d’autres sommets, retourner en 2.Sinon FIN.
A fin du marquage, si le puitsP n’est pas marqué, le flot est déjà à son maximum. Sinon, il peutêtreamélioré. On calcule alors la valeur du gain grâce à l’algorithme de la seconde phase.
6.4.3 Le calcul du gain
La marquage a créé une «chaîne améliorante»C allant de la source au puits composée d’arcs parcourusdans le bon sens (orientation directe), d’arcs parcourus à contre sens (orientation inverse)
On va appeléC+, l’ensemble des arcs d’orientation directe de la chaîne améliorante, etC−, l’ensembledes arcs d’orientation inverse. On a doncC = C+ ∪ C−.
Les arcs deC+ sont des arcs non-saturés sur lesquels il va être possible defaire passer un flot supplé-mentaire. Les arcs deC− sont des arcs sur lesquels il existe déjà un flot que l’on va pouvoir rediriger pouraugmenter le flot des arcs deC+. Il faut calculer ce flot supplémentaire.
Soit δ+ = min(c(u) − ϕ(u)) ∀u ∈ C+. C’est le flot maximal que l’on peut rediriger vers les arcs deC+ avant de saturer l’un d’entre eux.
34 Eric LALLET , Jean-Luc RAFFY

Soit δ− = min(ϕ(u)) ∀u ∈ C−. C’est le flot maximal que peut puiser dans les arcs deC− avantd’épuiser l’un d’entre eux.
Le gain que l’on peut gagner sur le flot grâce à la chaîne amélioranteC est doncδ = min(δ+, δ−).
L’algorithme pour calculer ce gain part du puits, et remontela chaîne jusqu’à la source :
Algorithme 6.2 (Algorithme de Ford-Fulkerson : Calcul du gain)
1. Poserg ←∞ etx← P
2. – six est marqué+y alorsg ← min(g, c(y, x)− ϕ(y, x)).– six est marqué−y alorsg ← min(g, ϕ(x, y))
x← y.
3. Six = S alors FIN
Sinon aller en 2.
Une fois ce gain évalué, il faut le reporter sur le flot du graphe.
6.4.4 L’augmentation du flot
Maintenant que l’on connaît la valeur du gain, il suffit de reparcourir la chaîne améliorante comme onvient de le faire, mais cette fois ci, en ajoutant le flot aux arc deC+, et en le prélevant sur les arcs deC−.
Algorithme 6.3 (Algorithme de Ford-Fulkerson : Augmentation du flot)
1. Poserx← P
2. – six est marqué+y alors augmenterϕ(y, x)) deg.– six est marqué−y alors diminuerϕ(x, y)) deg.
x← y.
3. Six = S alors FIN
Sinon aller en 2.
6.5 Exemple de flot max
Reprenons l’exemple de la figure 6.1. Pour accélérer le calcul de la solution, on va déjà considérer qu’unflot de deux péniches emprunte le canal direct Épénancourt, Noyon, Quierzy, Maizy. Si on garde ces deuxpéniches ainsi, il n’est pas possible d’en faire passer par le canal Épénancourt-Quierzy puisqu’au delà deQuierzy le canal est saturé. Et il n’est pas possible de profiter du canal Noyon-Maizy, puisque la section quimène à Noyon est saturée (Voir Figure 6.2).
FIG. 6.2 – Ford-Fulkerson : Établissement d’un flot au jugé
On va donc utiliser l’algorithme de Ford-Fulkerson pour voir s’il est possible de faire mieux que cesdeux péniches. On débute par la phase de marquage.
– La source Épénancourt est marquée d’une *.– Seul Épénancourt est marqué. L’arc Épénancourt-Quierzy n’est pas saturé, donc on marque Quierzy
avec «+Épénancourt». Aucun arc n’arrive sur Épénancourt, donc aucun sommet ne peut être marquéde «-Épénancourt».
Eric LALLET , Jean-Luc RAFFY 35

– Quierzy est marqué. Tous les arcs partant de Quierzy sont saturés. Donc aucun sommet ne peut êtremarqué «+Quierzy». Par contre l’arc qui arrive de Noyon a un flot non nul, et Noyon n’est pas encoremarqué, donc on marque Noyon avec «-Quierzy».
– Noyon est marqué. Son seul voisin non marqué est Maizy. L’arc qui va de Noyon à Maizy n’est passaturé. On peut donc marquer Maizy avec «+Noyon».
– Le puits Maizy est marqué, on arrête le marquage (voir Figure 6.3).
Épénancourt
Noyon
Quierzy
Maizy2/2 2/2 2/2
0/2
0/1
* +Ép
énan
cour
t
−Qui
erzy
+Noy
on
FIG. 6.3 – Ford-Fulkerson : Premier marquage
On peut maintenant calculer le gain qu’il est possible d’ajouter au flot grâce à la chaîne amélioranteque l’on vient de marquer. Pour cela on démarre du puits (Maizy) et on remonte le marquage de la chaînejusqu’à la source (Épénancourt).
– g ←∞ etx←Maizy– Maizy est marqué par «+Noyon». La capacité de l’arc Noyon-Maizy est de1 et son flot de0. Donc
g = min(∞, 1− 0) = 1.x← Noyon.
– Noyon est marqué de «-Quierzy». Le flot de l’arc Noyon-Quierzy est de2. Doncg = min(1, 2) = 1.x← Quierzy.
– Quierzy est marqué «+Épénancourt». La capacité de l’arc Épénancourt-Quierzy est de2 et son flotde0. Doncg = min(1, 2− 0) = 1.x← Épénancourt.
– x est vaut la source, on arrête l’algorithme ici. Le gain possible grâce à cette chaîne est donc de1.
Donc, cette itération nous permet de faire passer une troisième péniche dans le flot. On va reporterce gain sur les flots du graphe. On reparcourt la même chaîne enajoutant le gain lorsqu’on remonte unmarquage «+» et en prélevant lorsqu’on remonte un marquage «-».
– x←Maizy– Maizy est marqué par «+Noyon». Le flot de l’arc Noyon-Maizy était de0. On l’augmente de1. Il
passe donc à1.x← Noyon.
– Noyon est marqué de «-Quierzy». Le flot de l’arc Noyon-Quierzy était de2. On le diminue de1. Ilpasse donc à1.x← Quierzy.
– Quierzy est marqué «+Épénancourt». Le flot de l’arc Épénancourt-Quierzy était de0. On l’augmentede1. Il passe donc à1.x← Épénancourt.
– x est la source, on arrête l’algorithme ici (Voir figure 6.4).
Épénancourt
Noyon
Quierzy
Maizy2/2 1/2 2/2
1/2
1/1
* +Ép
énan
cour
t
−Qui
erzy
+Noy
on
FIG. 6.4 – Ford-Fulkerson : Augmentation du flot
L’exemple est simple et une seule itération a suffit à saturertous les canaux arrivants à Maizy. Doncon sait que le flot est maximal. Mais on va quand même continuerl’algorithme de Ford-Fulkerson pourmontrer que dans ce cas on ne trouve plus de chaîne améliorante.
36 Eric LALLET , Jean-Luc RAFFY

On recommence la phase de marquage.
– La source Épénancourt est marquée d’une *.– Seul Épénancourt est marqué. L’arc Épénancourt-Quierzy n’est pas saturé, donc on marque Quierzy
avec «+Épénancourt». Aucun arc n’arrive sur Épénancourt, donc aucun sommet ne peut être marquéde «-Épénancourt».
– Quierzy est marqué. Tous les arcs partant de Quierzy sont saturés. Donc aucun sommet ne peut êtremarqué «+Quierzy». Par contre l’arc qui arrive de Noyon a un flot non nul, et Noyon n’est pas encoremarqué, donc on marque Noyon avec «-Quierzy».
– Noyon est marqué. Son seul voisin non marqué est Maizy. L’arc qui va de Noyon à Maizy est saturé.On ne peut donc pas marquer Maizy.
– Plus aucun marquage n’est possible, le puits n’est pas marqué. Il n’existe plus de chaîne améliorante(voir Figure 6.5).
Épénancourt
Noyon
Quierzy
Maizy2/2 1/2 2/2
1/2
1/1
* +Ép
énan
cour
t
−Qui
erzy
FIG. 6.5 – Ford-Fulkerson : Deuxième marquage, et fin de l’algorithme
Notre cultivateur pourra donc faire passer 3 péniches par jour entre Épénancourt et Maizy.
Comme on vient de le voir dans cette exemple, le flot max sera toujours au mieux égal à la capacité quisort le source ou qui arrive dans le puits :
ϕmax ≤ min(∑
u∈ω+(source)
c(u),∑
u′∈ω−(puits)
c(u′))
6.6 Flot maximal à coût minimal
On va ajouter une composante à notre problème : le coût du transit. Donc maintenant le grapheG =[X,U ] va être doublement valué. Chaque arcu est muni d’une capacitéc(u) mais aussi d’un coût unitairede transita(u). Donc si le flot transitant par l’arcu estϕ(u), le coût de transit de ce flot par cet arc estϕ(u)× a(u). Dans ces conditions, le coût global du flot sur tout le grapheest :
coût global=∑
u∈U
ϕ(u)× a(u)
Dans un premier temps, le problème que l’on va résoudre consiste à trouver quel est le coût minimalpour faire passer le flot maximal (calculé précédemment par l’algorithme de Ford-Fulkerson)
Pour cela on va utiliser l’algorithme de Busacker et Gowen.
6.7 L’algorithme de Busacker et Gowen
Cet algorithme utilise de façon itérative la recherche d’unplus court chemin pour trouver où faire passerun flot à moindre coût. Flot après flot, on va saturer le graphe jusqu’à atteindre le coût ou le flot fixé. Àchaque fois qu’on va ajouter un flot, cela va saturer des arcs ou éventuellement en libérer d’anciens quiétaient saturés. Il va donc falloir à chaque étape construire un nouveau graphe associé qui représentera lesvéritables capacités restantes une fois pris en compte les flots déjà envoyés.
Regardons comment construire ce graphe associé :
Soit le grapheG = [X,U ] où c(u) est la capacité de transit de l’arcu, eta(u) le coût de transit unitairede cet arc. On noteraϕ(u) le flot qui transit sur l’arcu.
Eric LALLET , Jean-Luc RAFFY 37

Le graphe associé seraG′ = [X,U ′] avecc′(u) la capacité de transit,a′(u) le coût de transit unitaire.On le construit de la façon suivante :
– Pour tout arc(x, y) ∈ U tel queϕ(x, y) < c(x, y) ajouter un arc(x, y) dansU ′ avecc′(x, y) =c(x, y)− ϕ(x, y) eta′(x, y) = a(x, y).
– Pour tout arc(x, y) ∈ U tel queϕ(x, y) > 0 ajouter un arc(y, x) dansU ′ avecc′(y, x) = ϕ(x, y) eta′(y, x) = −a(x, y).
Pour la première version de l’algorithme de Busacker et Gowen, on se fixe le but d’atteindreϕmax,la valeur du flot maximal qui peut transiter sur ce graphe (valeur calculée grâce à l’algorithme de Ford-Fulkerson).S est sommet source etP le sommet puits.
Algorithme 6.4 (Algorithme de Busacker et Gowen)
a) On part avec le graphe vierge de tout flot (ϕ(u) = 0 ∀u ∈ U ), et on poseϕ = 0.
b) Calculer le grapheG′ associé àG.
c) Chercher surG′ un plus court cheminPCCH deS à P , la longueur des arcs étant le coût de transit(avec l’algorithme de Ford-Moore).
d) Calculer∆ϕ, la valeur de flot pouvant transiter parPCCH.
∆ϕ = Min(c′(u))u∈PCCH
e) Pour tout arc(x, y) ∈ PCCH– Si l’arc (x, y) ∈ U alors faireϕ(x, y)← ϕ(x, y) + ∆ϕ.– Sinon faireϕ(y, x)← ϕ(y, x)−∆ϕ.
f) ϕ← ϕ + ∆ϕ.Si ϕ = ϕmax alors FINSinon allez en «b».
6.8 Exemple flot max coût min
Pour illustrer cet algorithme, prenons le graphe de la figure6.6.
S PB C
Ac(u)a(u)
3100
3500
2200
2100
3100
2100
2300
FIG. 6.6 – Busacker et Gowen : le graphe exemple
Avant d’utiliser Busacker et Gowen, on va calculer le flot maximal de ce graphe. Pour cela on commencepar lancer deux flots au jugé : le premier de 2 unités par le chemin S → B → C → P et le second de 3unités par le cheminS → A→ P (voir la figure 6.7).
Comme la capacité maximale de la source est saturée avec les 5unités envoyées, on sait que l’on a leflot maximal.
On peut maintenant commencer l’algorithme de Busacker et Gowen :
1. a) On démarre avec les flots à0 et avecϕ = 0. Le ϕmax à atteindre est de 5.
b) Comme les flots sont nuls, le graphe associé est exactementle même que le graphe de référence(celui de la figure 6.6).
38 Eric LALLET , Jean-Luc RAFFY

S PB C
A
3/3100
3/3500
2200
2/2100
2/3100
2/2100
2300
FIG. 6.7 – Flots au jugé
c) On recherche le plus court chemin (au sens du coût) de S à P sur ce graphe. On trouve le cheminS → B → C → P (pour une «longueur» de 300).
d) ∆ϕ = Min(c(S,B), c(B,C), c(C,P )) = Min(2, 3, 2) = 2
Le coût de ce premier flot est donc de2× longueur(S → B → C → P ) = 2× 300 = 600.
e) On ajoute ce flot au graphe d’origine (voir figure 6.8).
f) ϕ← ϕ + ∆ϕ = 0 + 2 = 2
ϕ < ϕmax donc on refait une itération de l’algorithme de Busacker et Gowen.
2. b) On calcule le nouveau graphe associé. Seul l’axeS → B → C → P évolue : les arcsS → Bet C → P saturés disparaissent du graphes. La capacité de l’arcB → C tombe à1. Et les arcsP → C, C → B et B → S apparaissent avec un coût de−100 et une capacité de2 (voir figure6.8).
FIG. 6.8 – Busacker et Gowen : deuxième itération
c) Le nouveau plus court chemin de S à P sur ce graphe estS → A → C → B → P (pour unelongueur de 500 ; attention àC → B qui a une longueur négative de -100).
d) ∆ϕ = Min(c(S,A), c(A,C), c(C,B), c(B,P )) = Min(3, 2, 2, 2) = 2.Le coût de ce second flot est donc2× longueur(S → A→ C → B → P ) = 2× 500 = 1000.
e) On ajoute ce flot au graphe d’origine (voir figure 6.9).
f) ϕ← ϕ + ∆ϕ = 2 + 2 = 4
ϕ < ϕmax donc on refait une itération de l’algorithme de Busacker et Gowen.
3. b) On calcule le nouveau graphe associé. Plutôt que de repartir de zéro, on peut prendre pour basele dernier graphe associé (celui de la figure 6.8) et ajouter dessus notre nouveau flot. Donc sur lechemin de ce flot, l’arcS → A perd2 sur sa capacité, et un arcA→ S apparaît avec une capacitéde2 et un coût de−100. Ensuite l’arcA → C disparaît, mais un arcC → A apparaît avec unecapacité de 2 et coût de−200. L’arc B → C retrouve une capacité de3 et l’arc C → B quiétait apparu sur le premier graphe associé n’existe plus. Enfin l’arc B → P disparaît mais un arcP → B apparaît avec une capacité de2 et un coût de−300 (voir figure 6.9).
c) Le nouveau plus court chemin de S à P sur ce graphe estS → A → P (pour une longueur de600).
d) ∆ϕ = Min(c(S,A), c(A,P )) = Min(1, 3) = 1.Le coût de ce troisième flot est donc1× longueur(S → A→ P ) = 1× 600 = 600.
Eric LALLET , Jean-Luc RAFFY 39

FIG. 6.9 – Busacker et Gowen : troisième itération
e) On ajoute ce flot au graphe d’origine (voir figure 6.10).
f) ϕ← ϕ + ∆ϕ = 4 + 1 = 5
ϕ = ϕmax. On a donc atteint notre objectif et l’algorithme se finit là.
S PB C
A
3/3100
1/3500
2/2200
2/2100
3100
2/2100
2/2300
FIG. 6.10 – Busacker et Gowen : le flot maximal à coût minimum
L’algorithme s’est fini en trois itérations. Le premier flot aun coût de 600, le deuxième de 1000 et ledernier de 600. Donc le coût total de notre flot est de 2200.
6.9 Variantes
Il est possible de changer la condition de fin de l’algorithmede Busacker et Gowen.
On peut décider d’arrêter pour tout flot inférieur au flot maximal. On peut donc trouver ainsi le coûtminimal pour tout flot compris entre 0 et le flot maximal.
On peut aussi décider d’arrêter lorsqu’on a atteint un coût fixé. On peut alors trouver le flot maximalque l’on peut faire passer pour un coût donné. Dans ce cas, il faut aussi vérifier à chaque itération que l’ona pas atteint le flot maximal. Si tel est le cas, cela signifie que l’on peut faire passer le flot maximal pour uncoût inférieur ou égal au coût donné.
40 Eric LALLET , Jean-Luc RAFFY

Deuxième partie
Programmation linéaire
Eric LALLET , Jean-Luc RAFFY 41


Chapitre 7
La programmation linéaire
7.1 Introduction
Un des problèmes le plus classique en gestion consiste à optimiser un gain, un coût, ou toutes autresvaleurs fonctions de nombreux paramètres. De plus ces paramètres ne peuvent généralement pas être fixésà volonté, mais sont soumis à des contraintes.
La valeur à optimiser et les contraintes sont très souvent des fonctions linéaires des paramètres. Il existealors diverses techniques pour résoudre ce problème. Nous allons présenter deux d’entre elles : la méthodegéométrique et le simplexe.
7.2 La forme canonique
L’objectif de la programmation linéaire est de trouver la valeur optimale d’une fonction linéaire souscontraintes linéaires. La fonction à optimiser est baptisée fonction coût ou fonction économique. On lanomme généralementZ.
Un problème de programmation linéaire se modélise de la façon suivante :
Soit la fonction économique Z que l’on souhaite optimiser (maximiser ou minimiser).
Z = C1 ×X1 + C2 ×X2 + ... + Cn ×Xn
où lesXi sont des variables qui influent sur la valeur deZ, et lesCi les poids respectifs de ces variablesmodélisant l’importance relative de chacune de ces variables sur la valeur de la fonction économique.
Les contraintes relatives aux variables s’expriment de la façon suivante :
A1.1 ×X1 + A1.2 ×X2 + . . . + A1.n ×Xn ≤ B1
A2.1 ×X1 + A2.2 ×X2 + . . . + A2.n ×Xn ≥ B2
...Am.1 ×X1 + Am.2 ×X2 + . . . + Am.n ×Xn ≤ Bm
avecXi ≥ 0 ∀i
Le modèle ci-dessus contient des contraintes de type «≤» et d’autres de type «≥». Cependant lorsqu’onvoudra résoudre un problème, la première étape consistera àle modéliser sous une forme dite «canonique».Pour un problème de maximisation la forme canonique se décrit qu’avec des contraintes de type «≤» etpour un problème de minimisation la forme canonique se décrit qu’avec des contraintes de type «≥». Silors de la modélisation des contraintes de l’autre type sontapparues, il suffit de multiplier par−1 les deuxmembres pour renverser l’opérateur.
Eric LALLET , Jean-Luc RAFFY 43

La forme canonique d’un problème de type maximisation est :
Trouver la valeur maximale deZ pour :
Z = C1 ×X1 + C2 ×X2 + ... + Cn ×Xn
A1.1 ×X1 + A1.2 ×X2 + . . . + A1.n ×Xn ≤ B1
A2.1 ×X1 + A2.2 ×X2 + . . . + A2.n ×Xn ≤ B2
...Am.1 ×X1 + Am.2 ×X2 + . . . + Am.n ×Xn ≤ Bm
avecXi ≥ 0 ∀i
La forme canonique d’un problème de type minimisation est :
Trouver la valeur minimale deZ pour :
Z = C1 ×X1 + C2 ×X2 + ... + Cn ×Xn
A1.1 ×X1 + A1.2 ×X2 + . . . + A1.n ×Xn ≥ B1
A2.1 ×X1 + A2.2 ×X2 + . . . + A2.n ×Xn ≥ B2
...Am.1 ×X1 + Am.2 ×X2 + . . . + Am.n ×Xn ≥ Bm
avecXi ≥ 0 ∀i
Nous allons dans un premier temps nous intéresser au problème de type maximisation
7.3 Exemple
Pour illustrer les deux prochains chapitres nous allons modéliser jusqu’à la forme canonique un exemple :
Un atelier d’ébénisterie a obtenu un contrat de sous-traitance de meubles pour deux modèles de bi-bliothèques. Ces deux modèles utilisent du chêne et du hêtrepour être fabriqués. Le modèle «petit chêne»utilise 2 stères de chêne et4 stères de hêtre. Le modèle «grand hêtre» utilise8 stères de hêtre et1 stère dechêne. La construction des 2 modèles nécessite10 heures de travail chacun. La marge obtenu sur le modèle«petit chêne» est de600 euros, et celle sur le modèle «grand hêtre» de400 euros.
Sachant que cet atelier dispose chaque année d’un stock de8.000 stères de hêtre et2.000 stères dechêne, et qu’il peut fournir12.500 heures de travail, quelle quantité de chaque modèle doit-ilproduire pouroptimiser sa marge ?
La première étape du problème est la modélisation.
Il faut en général commencer par trouver la fonction économique. Cela permet de définir les variablesdu problème. Pour notre exemple, en appelantM1 le nombre de modèles «petit chêne» etM2 le nombre demodèles «grand hêtre» fabriqués, la marge dégagée par l’atelier sera de600×M1 +400×M2 euros. Doncla fonction économique à maximiser est :
Z = 600×M1 + 400×M2 (unité : euro)
.
Mais l’atelier ne peut pas produire à l’infini ces deux modèles. Il est limité par ses stocks de bois et sonvolume horaire de travail. Le stock de chêne est de2.000 stères, il en faut2 pour le modèleM1 et1 pour lemodèleM2. Donc on obtient la contrainte suivante :
2×M1 + M2 ≤ 2000
Avec le même raisonnement sur les stères de hêtre il faut respecter la contrainte :
4×M1 + 8×M2 ≤ 8000
Enfin, il faut10 heures de travail pour chaque meuble, et l’atelier en dispose de12.500, donc :
10×M1 + 10×M2 ≤ 12500
44 Eric LALLET , Jean-Luc RAFFY

Donc en résumé on obtient le modèle suivant :
Z = 600×M1 + 400×M2
avec
2×M1 + M2 ≤ 20004×M1 + 8×M2 ≤ 800010×M1 + 10×M2 ≤ 12500M1 ≥ 0 etM2 ≥ 0
Eric LALLET , Jean-Luc RAFFY 45

46 Eric LALLET , Jean-Luc RAFFY

Chapitre 8
La méthode géométrique
8.1 Introduction
Dans ce chapitre nous allons décrire la méthode géométrique. Pour les cas simples (c’est à dire, géné-ralement pas plus de deux variables une fois le modèle simplifié), sa mise en œuvre est très facile et rapide.De plus elle permettra plus tard dans ce cours d’illustrer lecomportement des autres méthodes, et ainsi dedonner une compréhension intuitive des algorithmes.
8.2 La méthode
La méthode géométrique consiste à matérialiser dans un espace àn (le nombre de variables de la fonc-tion économique) dimensions les contraintes sur les variables. Ensuite on représente dans cet espace lafonction économique, et on essaie de faire monter «Z» jusqu’au maximum possible tout en restant dansl’espace limité par les contraintes.
Cette méthode s’applique facilement lorsque le nombre de dimensions est réduit, car dans ce cas lareprésentation géométrique est facile, mais dès que ce nombre est important (plus de 3), cette méthode n’estplus envisageable.
L’exemple de la section précédente utilise 2 variables. On peut donc l’appliquer. Notre espace est justeun plan. On va mettre sur l’axex (horizontal) la variableM1 est sur l’axey (vertical) la variableM2.Comme on sait que l’on doit avoirM1 ≥ 0 et M2 ≥ 0, la solution de notre problème se trouve dans lepremier quadrant (le quart haut droit) de notre espace (voirfigure 8.1.)
Il faut maintenant mettre en place les trois autres contraintes. Pour indiquer que2 × M1 + M2 ≤2000, il faut tracer la droite2 × M1 + M2 = 2000 et supprimer de l’espace de solution tout ce qui setrouve au dessus. On fait de même pour les deux autres contraintes (droites4 ×M1 + 8 ×M2 = 8000 et10×M1 + 10×M2 = 12500). On obtient le schéma de la figure 8.2.
Maintenant que l’on a cerné l’espace des possibilités, il faut trouver le (ou les) point(s) qui nousdonne(nt) la plus grande valeur pour la fonction économiqueZ = 600 × M1 + 400 × M2. Pour celaon va commencer par dessiner la droite avecZ = 0, et on va faire glisser cette droite jusqu’à faire monterZ au maximum tout en restant dans l’espace de solution. Quand on aura atteint ce maximum, le (ou les)point(s) commun(s) à la droite et l’espace des solutions sera notre optimum (voir figure 8.3).
Il reste alors à interpréter le résultat. Sur le schéma, lorsqu’on a fait monterZ, l’ultime point communentreZ et l’espace des solutions admissibles était pourM1 = 750 et M2 = 500. Donc la solution quiapporte la plus grande marge possible à notre atelier consiste à construire750 bibliothèques «petit chêne»et500 bibliothèques «grand hêtre». Sa marge sera alors de750× 600 + 500× 400 = 650.000 euros.
Eric LALLET , Jean-Luc RAFFY 47
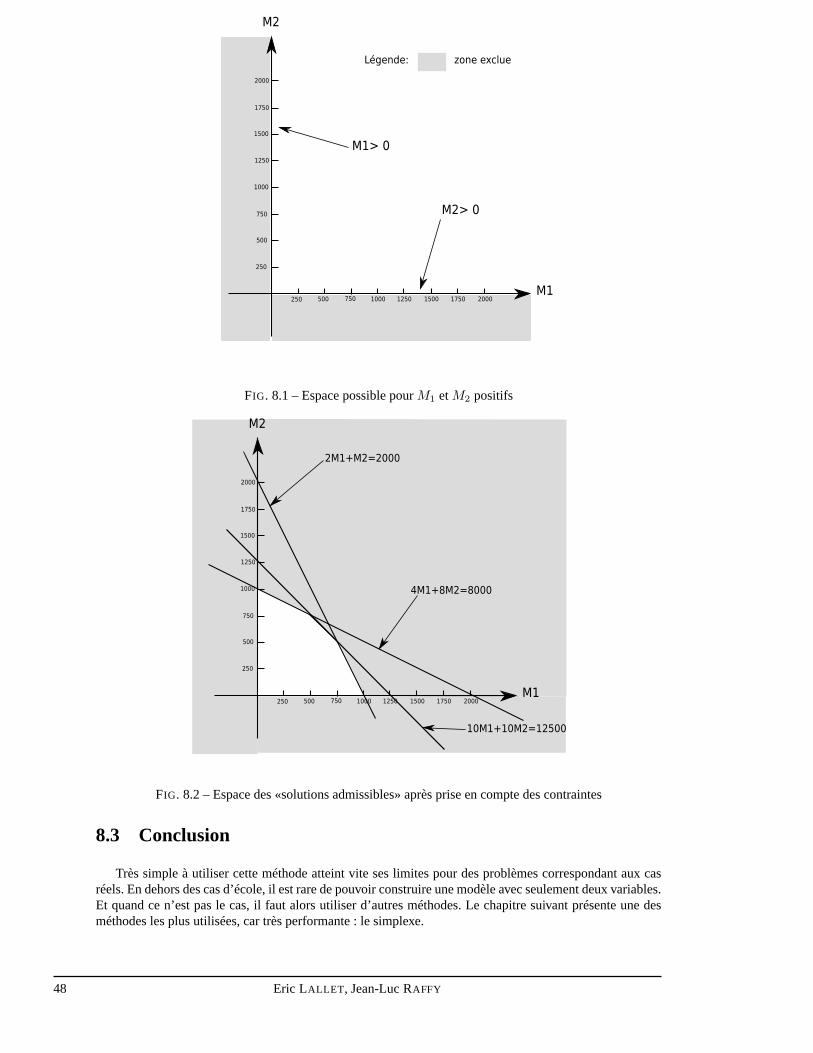
FIG. 8.1 – Espace possible pourM1 etM2 positifs
FIG. 8.2 – Espace des «solutions admissibles» après prise en compte des contraintes
8.3 Conclusion
Très simple à utiliser cette méthode atteint vite ses limites pour des problèmes correspondant aux casréels. En dehors des cas d’école, il est rare de pouvoir construire une modèle avec seulement deux variables.Et quand ce n’est pas le cas, il faut alors utiliser d’autres méthodes. Le chapitre suivant présente une desméthodes les plus utilisées, car très performante : le simplexe.
48 Eric LALLET , Jean-Luc RAFFY
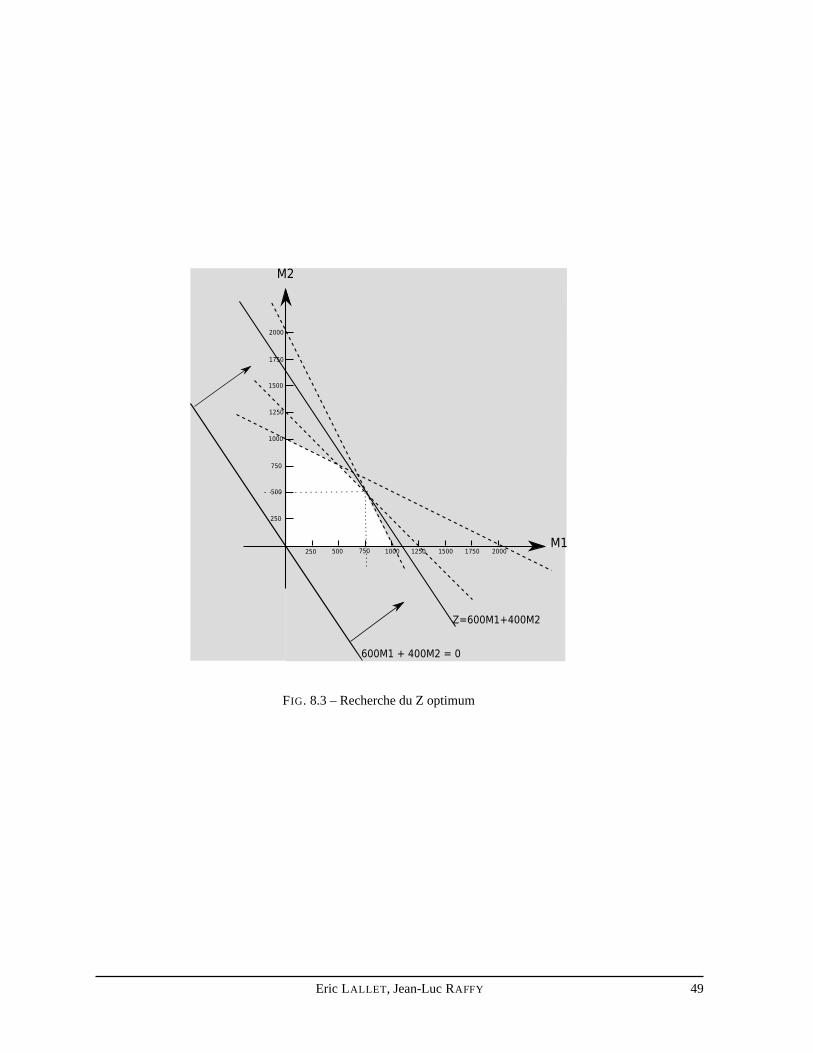
FIG. 8.3 – Recherche du Z optimum
Eric LALLET , Jean-Luc RAFFY 49

50 Eric LALLET , Jean-Luc RAFFY

Chapitre 9
Le simplexe
9.1 Introduction
Le méthode du simplexe a été mise au point par Georges Dantzigdans les années 1950. Elle implémenteune heuristique qui permet dans une très grande majorité descas d’atteindre l’optimum du problème trèsrapidement. Son principe consiste à parcourir un chemin surles frontières du domaine des solutions ad-missibles, en s’approchant à chaque étape un peu plus de l’optimum. L’heuristique essaye de trouver parmitous les chemins un qui soit très court.
9.2 La forme standard et son tableau associé
L’algorithme du simplexe sert à résoudre un problème de programmation linéaire de type maximisationqui s’exprime sous la forme canonique suivante :
Il faut trouver le maximum d’une fonction économiqueZ exprimée par :
Z = C1 ×X1 + C2 ×X2 + ... + Cn ×Xn
en respectant les contraintes :
A1.1 ×X1 + A1.2 ×X2 + . . . + A1.n ×Xn ≤ B1
A2.1 ×X1 + A2.2 ×X2 + . . . + A2.n ×Xn ≤ B2
...Am.1 ×X1 + Am.2 ×X2 + . . . + Am.n ×Xn ≤ Bm
Xj ≥ 0 ∀j
Pour résoudre ce problème, on va commencer par transformer les inégalités en égalités en introduisantune variable «d’écart» positive ou nulle pour chacune des contraintes. Par exemple avec une nouvelle va-riableE1, on peut transformer l’inégalitéA1.1 ×X1 + A1.2 ×X2 + . . . + A1.n ×Xn ≤ B1 pour la fairedevenir l’égalitéA1.1 ×X1 + A1.2 ×X2 + . . . + A1.n ×Xn + E1 = B1.
Avec lesm variables d’écart, notre problème devient :
AvecXj ≥ 0 ∀j etEi ≥ 0 ∀i, trouver le maximum deZ pour :
A1.1 ×X1 + A1.2 ×X2 + . . . + A1.n ×Xn + E1 = B1
A2.1 ×X1 + A2.2 ×X2 + . . . + A2.n ×Xn + E2 = B2
...Am.1 ×X1 + Am.2 ×X2 + . . . + Am.n ×Xn + Em = Bm
C1 ×X1 + C2 ×X2 + ... + Cn ×Xn = Z
Ceci est la forme standard du problème.
Eric LALLET , Jean-Luc RAFFY 51

Avant de mettre en œuvre l’algorithme du simplexe on transforme ces équations sous la forme d’untableau qui auran + m + 2 colonnes, etm + 2 lignes :
– La première ligne contiendra le nom de nos colonnes.– Il y aura une ligne pour chacune des équations1 àm.– La dernière ligne sert pour la fonction économique.– La première colonne sert à connaître ce qu’on va appeler les«variables en base». Au début on y
placera la variable d’écartEi de la ligne. Les variables qui ne seront pas dans cette colonne seront«hors base».
– Ensuite on placen colonnes, une pour chaque variableXj .– Ensuite on placem colonnes, une pour chaque variableEi.– Enfin on place une dernière colonne qui contiendra la somme de chaque ligne (Bi).– Enfin la valeur «Somme» de la ligne∆j est initialisée avec 0 (sauf exception expliquée plus loin).
Donc le tableau obtenu est le suivant :
X1 X2 . . . Xn E1 E2 . . . Em SommeE1 A1.1 A1.2 . . . A1,n 1 0 0 0 B1
E2 A2.1 A2.2 . . . A2,n 0 1 0 0 B2
...Em Am.1 Am.2 . . . Am,n 0 0 0 1 Bm
∆j C1 C2 . . . Cn 0 0 0 0 0
Avant d’aller plus loin, décryptons le sens de ce tableau. Tout le long de l’algorithme du simplexe cetableau va donner des solutions (de plus en plus optimales pour la valeur deZ) du système d’équationsde la forme standard. Dans cette solution toutes les variables hors base ont une valeur nulle. La valeur desvariables en base se lit dans la dernière colonne (la colonne«Somme»). Enfin le∆j de la colonne «Somme»donne l’opposé de la valeur deZ. Donc ce premier tableau du simplexe donne la solution de départ qui vaservir à amorcer l’algorithme du simplexe : toutes les variablesXi sont à0, toutes les variables d’écartEi
valent leBi de leur ligne d’équation et la valeur deZ est 01.
Sur ce tableau la dernière ligne (∆j) donne les gains (ou les coûts, si la valeur est négative) marginauxdes variables de leur colonne. Autrement dit, elle permet desavoir de combien va augmenter (ou diminuersi la valeur est négative) la valeur deZ si on augmente de1 la variable de cette colonne. Par exemple,si on arrive à trouver une solution admissible qui augmente de 1 la valeur deX2, alors la valeur deZ vaaugmenter deC2.
Revenons à l’exemple de l’atelier d’ébénisterie de la section 7.3, et construisons son tableau pour lesimplexe :
Z = 600×M1 + 400×M2 (unité : euro)
avec
2×M1 + M2 ≤ 20004×M1 + 8×M2 ≤ 800010×M1 + 10×M2 ≤ 12500M1 ≥ 0 etM2 ≥ 0
Mis sous la forme standard, avec l’ajout de 3 variables d’écartsE1, E2 etE3 telles que :– E1 désigne le nombre de stères de chêne qui restent sans usage pour la solution courante.– E2 désigne le nombre de stères de hêtre qui restent sans usage pour la solution courante.– E3 désigne le nombre d’heures de travail qui restent sans usagepour la solution courante.
1Certains problèmes donnent un modèle où cette solution de départ n’est pas admissible car certainsBi sont négatifs. Il faut alorstrouver un autre point de départ. Il faut alors utiliser le méthode «générale du simplexe» qui n’est pas exposée dans ce cours. D’autrepart, dans certains cas, la valeur deZ de la solution initiale n’est pas nulle, il faut alors mettre l’opposé de cette valeur dans le∆j dela colonne «Somme».
52 Eric LALLET , Jean-Luc RAFFY
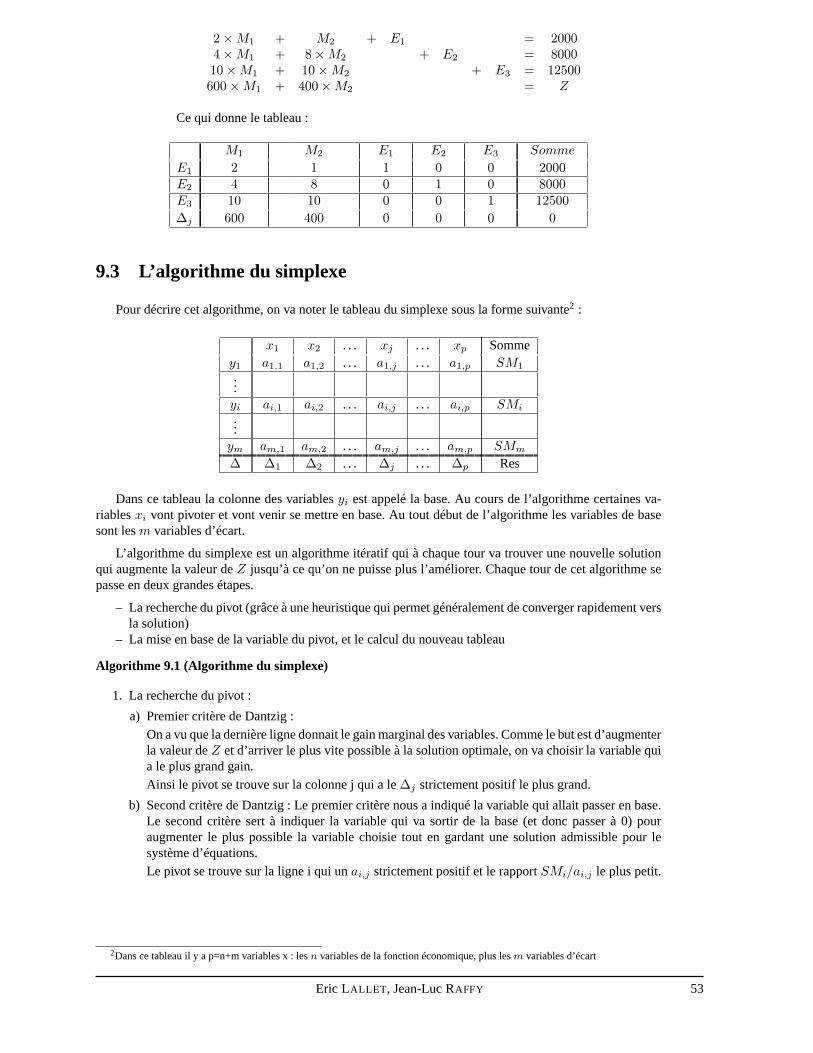
2×M1 + M2 + E1 = 20004×M1 + 8×M2 + E2 = 800010×M1 + 10×M2 + E3 = 12500600×M1 + 400×M2 = Z
Ce qui donne le tableau :
M1 M2 E1 E2 E3 Somme
E1 2 1 1 0 0 2000E2 4 8 0 1 0 8000E3 10 10 0 0 1 12500
∆j 600 400 0 0 0 0
9.3 L’algorithme du simplexe
Pour décrire cet algorithme, on va noter le tableau du simplexe sous la forme suivante2 :
x1 x2 . . . xj . . . xp Sommey1 a1,1 a1,2 . . . a1,j . . . a1,p SM1
...yi ai,1 ai,2 . . . ai,j . . . ai,p SMi
...ym am,1 am,2 . . . am,j . . . am,p SMm
∆ ∆1 ∆2 . . . ∆j . . . ∆p Res
Dans ce tableau la colonne des variablesyi est appelé la base. Au cours de l’algorithme certaines va-riablesxi vont pivoter et vont venir se mettre en base. Au tout début de l’algorithme les variables de basesont lesm variables d’écart.
L’algorithme du simplexe est un algorithme itératif qui à chaque tour va trouver une nouvelle solutionqui augmente la valeur deZ jusqu’à ce qu’on ne puisse plus l’améliorer. Chaque tour de cet algorithme sepasse en deux grandes étapes.
– La recherche du pivot (grâce à une heuristique qui permet généralement de converger rapidement versla solution)
– La mise en base de la variable du pivot, et le calcul du nouveau tableau
Algorithme 9.1 (Algorithme du simplexe)
1. La recherche du pivot :
a) Premier critère de Dantzig :On a vu que la dernière ligne donnait le gain marginal des variables. Comme le but est d’augmenterla valeur deZ et d’arriver le plus vite possible à la solution optimale, onva choisir la variable quia le plus grand gain.Ainsi le pivot se trouve sur la colonne j qui a le∆j strictement positif le plus grand.
b) Second critère de Dantzig : Le premier critère nous a indiqué la variable qui allait passer en base.Le second critère sert à indiquer la variable qui va sortir dela base (et donc passer à 0) pouraugmenter le plus possible la variable choisie tout en gardant une solution admissible pour lesystème d’équations.Le pivot se trouve sur la ligne i qui unai,j strictement positif et le rapportSMi/ai,j le plus petit.
2Dans ce tableau il y a p=n+m variables x : lesn variables de la fonction économique, plus lesm variables d’écart
Eric LALLET , Jean-Luc RAFFY 53

2. Le pivotement : soitai,j le pivot trouvé à l’étape 1.
a) Mise en base dexj
Lors du pivotement, la variablesyi de la base est remplacée parxj .
b) Modification de la ligne du pivot :
On divise la ligne par le pivot.Pourl allant de1 àp faire :
a′
i,l ←ai,l
ai,j
Notez que le pivot passe donc à 1.
c) Modification des autres lignes
On soustrait à toutes les lignes k, aveck 6= i la ligne du pivot proportionnellement àak,j/ai,j :
SM ′
k ← SMk −(SMi × ak,j)
ai,j
Res′ ← Res−(SMi ×∆j)
ai,j
Pourl allant de1 àp faire :
a′
k,l ← ak,l −(ai,l × ak,j)
ai,j
∆′
l ← ∆l −(ai,l ×∆j)
ai,j
Notez que sur la colonne du pivot, mis à part le pivot lui même,toutes les valeurs sont passées à0.
3. La boucle
Si après le nouveau calcul il existe encore un∆j strictement positif, on peut encore augmenterZ :retournez à l’étape 1.
Pour simplifier la description de l’étape «2c» de l’algorithme, il y une formule qui fonctionne pourtoutes les valeurs qui ne sont pas sur la ligne du pivot (même sur la colonne «Somme» ou sur la ligne«∆j») :
On recherchev′, la nouvelle valeur dev. Soitp le pivot,x et y les valeurs qui sont à l’intersection deslignes et colonnes dev et du pivot, alors :v′ = v − x× y/p
p . . . x...
...y . . . v′ = v − x× y/p
9.4 Interprétation du tableau final
À la fin de l’algorithme, le tableau du simplexe continue à se lire de la même manière. Ainsi les solutionsdu problème d’origine se lisent directement dans ce tableau.
Les valeurs des variablesXj passées en base à la place deEi se lisent dans la colonne «Somme» :SMi.Les variablesXj qui ne sont pas passées en base sont nulles.
La valeur optimale deZ est l’opposé de la valeur de «Res».
Les valeurs des variables d’écart qui ont quitté la base sontnulles.
Les variables d’écartEi qui sont toujours en base indiquent qu’une contrainte n’a pas atteint son maxi-mum. La valeur de cette variable d’écart se lit dans la colonne «Somme» :SMi.
54 Eric LALLET , Jean-Luc RAFFY

Si à la fin de l’algorithme il y a des variables hors base avec un∆j nul, alors il existe d’autres solutionsoptimales (une infinité en fait). Vous pouvez faire un pivotement de plus en choisissant la colonne d’une deces variables pour trouver la solution optimale qui privilégie cette valeur.
Si alors qu’il reste des∆j strictement positifs, il n’est plus possible de trouver un pivot strictementpositif sur leur colonne, alors la fonction économique n’est pas bornée. Il existe des solutions qui permettentde monter sa valeur à l’infini . Mais dans le cadre de modèles degestion, il est peu probable que vouspuissiez dégager des bénéfices infinis. Ce diagnostic cache dont très certainement un problème dans votremodélisation (probablement des contraintes oubliées).
9.5 Exemple
Reprenons l’exemple de l’ébénisterie. On avait déjà construit letableau du simplexe suivant. Il correspond à une première solution(non optimale pourZ) du système d’équations :M1 = 0 etM2 = 0.
M1 M2 E1 E2 E3 SommeE1 2 1 1 0 0 2000E2 4 8 0 1 0 8000E3 10 10 0 0 1 12500∆j 600 400 0 0 0 0
Il y a des∆j strictement positifs : on peut trouver une meilleuresolution. Faisons la première itération :
1. a) Le premier critère de Dantzig (le plus grand∆j) permet de sélectionner la colonne deM1 pour lepivot.
b) Le second critère de Dantzig (le plus petitSMi/ai, j) permet de sélectionner la ligne deE1 pourle pivot.
M1 M2 E1 E2 E3 Somme
E1 2 1 1 0 0 2000
E2 4 8 0 1 0 8000E3 10 10 0 0 1 12500∆j 600 400 0 0 0 0
2. a) La variableM1 passe en base à la place deE1.
b) La ligne du pivot est divisée par2.
c) on retire à la ligne deE2 4/2 = 2 fois la ligne du pivot.
on retire à la ligne deE3 10/2 = 5 fois la ligne du pivot.
on retire à la ligne des∆j 600/2 = 300 fois la ligne du pivot.
On obtient un nouveau tableau du simplexe. Son interprétationcorrespond à la solutionM1 = 1000 etM2 = 0.
M1 M2 E1 E2 E3 SommeM1 1 1/2 1/2 0 0 1000E2 0 6 -2 1 0 4000E3 0 5 -5 0 1 2500∆j 0 100 -300 0 0 -600000
Eric LALLET , Jean-Luc RAFFY 55

3. Il reste un∆j strictement positif. On peut encore améliorer la valeur deZ. Donc on fait une autreitération.
Seconde itération :
1. a) Le premier critère de Dantzig permet de sélectionner lacolonne deM2 pour le pivot.
b) Le second critère de Dantzig permet de sélectionner la ligne deE3 pour le pivot.
M1 M2 E1 E2 E3 SommeM1 1 1/2 1/2 0 0 1000E2 0 6 -2 1 0 4000
E3 0 5 -5 0 1 2500
∆j 0 100 -300 0 0 -600000
2. (a) La variableM2 passe en base à la place deE3
(b) La ligne du pivot est divisée par5
(c) On retire à la ligne deM1 (1/2)/5 = 1/10 fois la ligne du pivot.On retire à la ligne deE2 (6/5) fois la ligne du pivot.On retire à la ligne des∆j 100/5 = 20 fois la ligne du pivot.
On obtient un nouveau tableau du simplexe. Son interprétationcorrespond à la solutionM1 = 750 etM2 = 500.
M1 M2 E1 E2 E3 SommeM1 1 0 1 0 -1/10 750E2 0 0 4 1 6/5 1000M2 0 1 -1 0 1/5 500∆j 0 0 -200 0 -20 -650000
3. Il ne reste plus aucun∆j strictement positif. La solution est optimale. L’algorithme s’arrête ici.
Il nous reste à interpréter le tableau final.– La somme au bout de la ligne deM1 est 750 : il faut construire 750 bibliothèquesM1 («petit chêne»).– La somme au bout de la ligne deM2 est 500 : il faut construire 500 bibliothèquesM2 («grand hêtre»).– La valeur de Res est -650000 : le Z optimal est de 650000, qui sera (en euros) la marge dégagée par
la vente des bibliothèques construites.– La variable d’écartE2 est toujours en base. La valeur dans sa colonne somme est1000. Donc pour la
solution optimaleE2 = 1000. E2 est la variable d’écart qui donne le nombre de stères de hêtrenonutilisés. Donc la solution optimale du problème laisse1000 stères de hêtre sans usage.
Trois nombres restent à interpréter. Les valeurs des∆j pour les colonnes des variables d’écart. Ce sontles «coûts marginaux». Elles indiquent combien on pourraitdégager de marge en plus si on augmentait nosstocks de chêne, de hêtre et d’heures de travail (ou au contraire à quel prix minimum il faudrait vendre cestock pour qu’il rapporte au moins autant que la production faite avec).
– La valeur marginale pourE1 est -200. EtE1 est la variable d’écart qui désigne les stères de chênenon-utilisés. Cela signifie qu’augmenter de1 E1, c’est à dire de laisser sans usage 1 stère de chêne,coûterait200 Euros. Et au contraire, disposer de 1 stère de chêne de plus permettrait de gagner200euros supplémentaires. Donc si le stère de chêne coûte moinsde200 euros, il sera intéressant d’enacheter pour produire plus, et s’il coûte plus de200 euros, il vaudra mieux vendre notre stock plutôtque de produire avec.
– La valeur marginale pourE2 est 0. Cela signifie qu’acheter du hêtre en plus ne rapporterait rien. Cequi est logique puisqu’on vient de voir que l’on n’avait déjàpas épuisé notre propre stock. Et doncon peut vendre ce sur-stock à n’importe quel prix sans perdred’argent.
56 Eric LALLET , Jean-Luc RAFFY

– La valeur marginale pourE3 est -20.E3 est la variable qui sert à désigner le nombre d’heures detravail non utilisées. Ainsi augmenter le nombre d’heures de travail de1, permet de gagner20 eurosde plus. Donc l’entreprise n’a intérêt à augmenter le nombred’heures de travail que si cela ne luicoûte pas plus de 20 euros de l’heure.
9.6 Plus loin au sujet des valeurs marginales
Attention l’interprétation des coûts marginaux n’est valable qu’à la marge. Dans ce type de problèmeon parcourt des paliers avec des effets de seuil. Dès qu’on franchit un seuil les coûts marginaux changent.
Dans l’exemple de la section précédente, il reste 1000 stères de hêtre sans usage. Donc les coûts mar-ginaux associés à cette variable sont nuls : on peut vendre cebois à n’importe quel prix, cela augmenterales gains. Mais cette remarque n’est vrai que pour le stock inutilisé. Au delà des 1000 stères, continuer àvendre du hêtre diminuerait la production de meuble, et doncles gains. C’est le seuil à partir duquel le coûtmarginal pour les bois de hêtre va changer.
Pour le cas des stocks inutilisés le seuil est assez simple à trouver (c’est la grandeur du stock), maispour les autres variables il faut procéder différemment.
Examinons un autre cas : le coût marginal associé au bois de chêne est de200 euros le stère. Autrementdit si on arrive à vendre ce bois plus cher que200 euros le stère on a intérêt à le vendre plutôt que de produireavec. Par contre si on arrive à trouver du chêne à moins de200 euros le stère, on a intérêt à l’acheter et àproduire avec pour augmenter les gains. Imaginons que l’ébénisterie trouve un marché où elle peut acheterdu chêne à150 euros le stère. Elle devrait l’acheter. Chaque stère obtenuainsi va lui permettre d’augmenterses gains de50 euros. Mais ce gain ne peut monter que jusqu’à un certain seuil : la production est limitéepar le stock de hêtre et le nombre d’heure de travail dont dispose l’ébénisterie. Au delà de ce seuil, ellene pourra plus produire de meubles avec le chêne acheté, et elle dépensera donc150 euros pas stère sanspouvoir rien en faire.
Quel est ce seuil ? On retombe sur un nouveau problème de programmation linéaire. Si l’ébénisterieaccepte d’acheter du chêne tant que c’est rentable, on retrouve le même problème que précédemment avecune contrainte de moins : celle concernant le stock de chêne.Sa modélisation est donc identique à avant,excepté l’inégalité concernant cette contrainte qui disparaît :
Z = 600×M1 + 400×M2
avec
((((((((((hhhhhhhhhh2×M1 + M2 ≤ 2000 la contrainte sur le chêne n’existe plus4×M1 + 8×M2 ≤ 8000 contrainte sur le hêtre10×M1 + 10×M2 ≤ 12500 contrainte sur les heures de travailM1 ≥ 0 etM2 ≥ 0
On obtient ainsi le même tableau du simplexe que précédemment mais avec la variableE1 (celle concer-nant le chêne) en moins :
M1 M2 E2 E3 SommeE2 4 8 1 0 8000E3 10 10 0 1 12500∆j 600 400 0 0 0
Ce simplexe se résout en une seule itération :
M1 M2 E2 E3 SommeE2 0 4 1 -2/5 3000M1 1 1 0 1/10 1250∆j 0 -200 0 -60 750000
Grâce à l’achat de stères supplémentaires, une nouvelle solution optimale se dessine :– M1 vaut 1250. Il faut produire 1250 bibliothèques «petit chêne».– M2 n’est pas en base, doncM2 vaut 0. Il ne faut plus produire de bibliothèques «petit hêtre»
Eric LALLET , Jean-Luc RAFFY 57

– E2 vaut 3000. Il reste donc 3000 stères de hêtre inutilisé.Chaque bibliothèque «petit chêne» consomme 2 stères de chênes. Il a donc fallu un total de1250× 2 =
2 500 stères de chêne pour la production. Comme le stock initial était de2 000, il a fallu acheter500 stèressupplémentaires. Le coût de cet achat est :150× 500 = 75 000 euros.
Et attention le nouveau gain pour l’ébénisterie est donc de675 000 euros. En effet, même si le gain quiapparaît dans le dernier tableau du simplexe est750 000 euros, il faut penser à lui soustraire le prix desstères de chêne qu’il fallut acheter pour obtenir la nouvelle solution :750 000− 75 000 = 675 000.
Il existe un autre moyen de calculer ce nouveau gain : dans le problème précédent le gain était de650 000 euros. On a vu qu’en achetant le chêne à150 euros le stère, on augmentait le gain de50 euros parstères. Donc les500 stères ont augmenté le gain de500× 50 = 25 000. Et 650 000 + 25 000 redonne bienla même valeur :675 000.
9.7 Unités et simplifications
9.7.1 Les unités des variables
Un risque important d’erreurs dans l’interprétation du tableau du simplexe est de se tromper dans lesunités. En effet entre les données originales du problème, leur interprétation, la mise en équation, les sim-plifications, la construction du tableau et les pivotementsil y a de nombreuses occasions d’erreurs. Dans letableau du simplexe les nombres qui ont besoin d’être interprétés sont dans la dernière ligne et la dernièrecolonne. Leurs unités sont directement liées aux variablesdans la première ligne et la première colonne. Ilfaudra donc veiller à toujours bien indiquer le nom de ces variables lors de la création du tableau et lors desdivers pivotements.
L’unité d’un nombre sur la dernières colonne est celle de la variable en première colonne. Attention,celle-ci peut changer lors d’un pivotement.
L’unité d’un nombre sur la dernière ligne est celle deZ divisée par celle de la variable en premièreligne.
X1 . . . Xp SommeY1 Unité deY1
......
Ym Unité deYm
∆j Unité deZ/Unité deX1 . . . Unité deZ/Unité deXp Unité deZ
Dans un problème classique les unités des variables du problème et l’unité deZ sont généralement bienidentifiées. Par contre il y a souvent plus d’incertitudes sur les unités des variables d’écart. Tant qu’on necherchera qu’à connaître la valeur deZ et des variables du problèmes il sera possible de laisser ce flou surles variables d’écart, mais si on doit interpréter les valeurs marginales liées à ces variables, il faudra êtretrès rigoureux.
Un des risques majeurs de se tromper dans leur unités apparaît lors de la simplification des inégalités duproblème. Reprenons l’exemple traité précédemment, mais cette fois ci en simplifiant les nombres lorsquecela est possible.
9.7.2 Simplification de la fonction économique
Toutes les simplifications faites sur la fonction économique apportent un changement d’unité deZ.
Pour illustrer cela, reprenons l’exemple de la modélisation de la page 44. On avait décritZ avec lafonction :Z = 600×M1 + 400×M2.
M1 et M2 étaient le nombre de modèles de chaque étagère. Chaque modèle M1 rapporte600 euros,et chaque modèleM2, 400 euros. Donc ici l’unité deZ est l’euro. Mais on peut décider de simplifier lesnombres, et dire que chaque modèleM1 rapporte6 «hecto euros3» et chaque modèleM2 4 «hecto euros».Alors on obtient une fonctionZ ′ = 6×M1 + 4×M2 exprimée en «hecto euros».
31 hecto euro = 100 euro
58 Eric LALLET , Jean-Luc RAFFY

9.7.3 Simplification des inégalités
Les simplifications faites sur les inégalités obtenues grâce aux diverses contraintes laissent inchangéesles unités des variables du modèle, mais changent les unitésdes variables d’écarts.
Reprenons encore le problème de la page 44 pour illustrer ce type de simplification. Le modèle avait 3contraintes, et donc trois inégalités.
– La première concernait la consommation des stères de chêneà disposition. Chaque modèleM1
consomme 2 stères de chêne et chaque modèleM2 consomme 1 stère de chêne. Comme on ne dis-pose que de2000 stères de chêne on a :2 ×M1 + M2 ≤ 2000. L’unité des variables du modèleM1 etM2 est «le nombre de modèle». Mais les coefficients placés devant (2 pourM1 et1 pourM2)sont en «stère de chêne par modèle». Donc l’unité des membresde cette inégalité est le «stère dechêne». Lors du passage à la forme standard, la variable d’écart ajoutée (E′
1) sera homogène avec lesautres membres de cette inégalité, et sera donc exprimée en «stère de chêne». Il n’y aucun intérêt àsimplifier cette inégalité qui va donc rester inchangée.
– Le seconde contrainte concernait la consommation de stères de hêtre. Chaque modèleM1 consomme4 stères de hêtre et chaque modèleM2 consomme 8 stères de hêtre. Comme on ne dispose que de8000 stères de hêtre on a :4×M1 +8×M2 ≤ 8000. L’unité des variables du modèleM1 etM2 restetoujours «le nombre de modèle», mais les coefficients placésdevant (4 pourM1 et 8 pourM2) sonten «stère de hêtre par modèle». Donc l’unité des membres de cette inégalité est le «stère de hêtre».Il est intéressant de simplifier cette inégalité par 4. On obtient : M1 + 2 ×M2 ≤ 2000. Mais si ondevait maintenant interpréter cette inégalité, il faudrait changer d’unités. Il faudrait parler le «4 stèresde hêtre». Chaque modèleM1 consomme1 «4 stères de hêtre», chaque modèleM2 consomme2 «4stères de hêtre», et on dispose de2000 «4 stères de hêtres». Donc l’unité des membres de l’inégalitésimplifiée est «4 stères de hêtre». La variable d’écart qui sera ajoutée lors du passage à la formestandard (E′
2) devra être homogène avec les autres membres, et aura donc pour unité «4 stères dehêtre».
– Enfin, la troisième contrainte concernait la consommationd’heures de travail. Chaque modèleM1
et M2 nécessite10 heures de travail. Comme on ne dispose que de12500 heures de travail on a :10 × M1 + 10 × M2 ≤ 12500. Les unités deM1 et M2 reste «le nombre de modèle», mais lescoefficients placés devant (10 pourM1 et M2) sont en «heure de travail par modèle». Donc l’unitédes membres de cette inégalité est «l’heure de travail». Il est intéressant de simplifier cette inégalitépar 10. On obtient :M1 +M2 ≤ 1250. Les coefficients devantM1 etM2 ont (en apparence) disparu.Et une lecture rapide pourrait interpréter cette inégalitéen «nombre de modèle». Mais en fait devantles variableM1 et M2 se cache un «1×» qui dit 1× «10 heures de travail» par modèle. Donc lavéritable unité des membres de cette inégalité est «10 heures de travail». La variable d’écart qui seraajoutée lors du passage à la forme standard (E′
3) devra être homogène avec les autres membres, etaura donc pour unité «10 heures de travail».
En résumé on obtient, trouver le maximum deZ ′ avec :
avec
2×M1 + M2 ≤ 2000 unité des membres : stère de chêneM1 + 2×M2 ≤ 2000 unité des membres : 4 stères de hêtreM1 + M2 ≤ 1250 unité des membres : 10 heures de travailZ ′ = 6×M1 + 4×M2 unité des membres : 100 eurosM1 ≥ 0 etM2 ≥ 0
9.7.4 Calculs et interprétations
Il faut ensuite tenir compte de ces changements d’unités lors des calculs et des interprétations.
Durant la phase de calcul il n’y en fait aucun changement, sauf bien sûr des nombres plus simples àmanipuler. Continuons le traitement de l’exemple après la simplification :
Lorsque l’on passe à la forme standard il faut ajouter 3 variables d’écart au problème. Ces 3 variablesvont récupérer l’unité de leur équation. On va donc avoir :
– E′
1 : le nombre de stères de chêne non utilisés.– E′
2 : le nombre de «4 stères de hêtre» non utilisés.– E′
3 : le nombre de «10 heures de travail» non utilisés.Ainsi l’unité deE′
1 est «1 stère de chêne», celle deE′
2 est «4 stères de hêtre» et celle deE′
3 est «10
Eric LALLET , Jean-Luc RAFFY 59
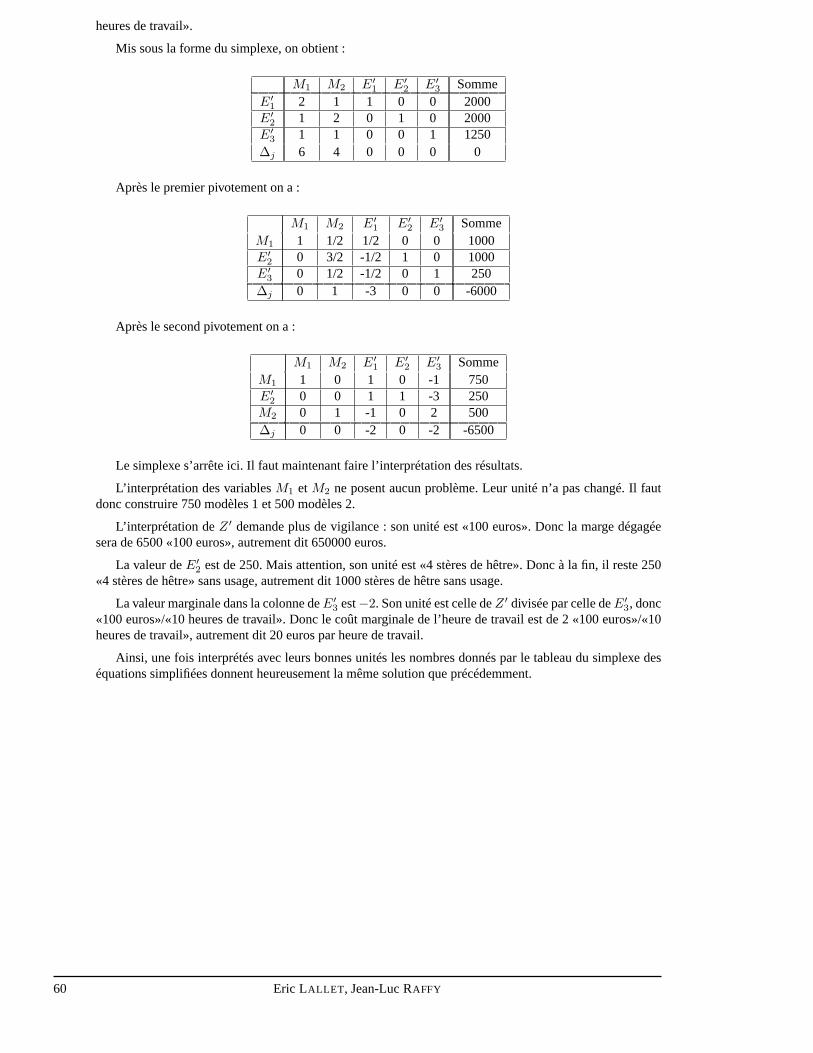
heures de travail».
Mis sous la forme du simplexe, on obtient :
M1 M2 E′
1 E′
2 E′
3 SommeE′
1 2 1 1 0 0 2000E′
2 1 2 0 1 0 2000E′
3 1 1 0 0 1 1250∆j 6 4 0 0 0 0
Après le premier pivotement on a :
M1 M2 E′
1 E′
2 E′
3 SommeM1 1 1/2 1/2 0 0 1000E′
2 0 3/2 -1/2 1 0 1000E′
3 0 1/2 -1/2 0 1 250∆j 0 1 -3 0 0 -6000
Après le second pivotement on a :
M1 M2 E′
1 E′
2 E′
3 SommeM1 1 0 1 0 -1 750E′
2 0 0 1 1 -3 250M2 0 1 -1 0 2 500∆j 0 0 -2 0 -2 -6500
Le simplexe s’arrête ici. Il faut maintenant faire l’interprétation des résultats.
L’interprétation des variablesM1 et M2 ne posent aucun problème. Leur unité n’a pas changé. Il fautdonc construire 750 modèles 1 et 500 modèles 2.
L’interprétation deZ ′ demande plus de vigilance : son unité est «100 euros». Donc lamarge dégagéesera de 6500 «100 euros», autrement dit 650000 euros.
La valeur deE′
2 est de 250. Mais attention, son unité est «4 stères de hêtre».Donc à la fin, il reste 250«4 stères de hêtre» sans usage, autrement dit 1000 stères de hêtre sans usage.
La valeur marginale dans la colonne deE′
3 est−2. Son unité est celle deZ ′ divisée par celle deE′
3, donc«100 euros»/«10 heures de travail». Donc le coût marginale de l’heure de travail est de 2 «100 euros»/«10heures de travail», autrement dit 20 euros par heure de travail.
Ainsi, une fois interprétés avec leurs bonnes unités les nombres donnés par le tableau du simplexe deséquations simplifiées donnent heureusement la même solution que précédemment.
60 Eric LALLET , Jean-Luc RAFFY

Troisième partie
Modélisation
Eric LALLET , Jean-Luc RAFFY 61


Chapitre 10
Modélisation
10.1 Chemin de la question à la réponse
D’une manière générale, les problèmes auxquels on est confronté dans le monde réel sont d’une com-plexité telle qu’il est difficile, voire impossible, de les résoudre directement
On dispose également d’une masse d’informations dont certaines ne sont pas utiles à la résolution duproblème considéré.
C’est pour cette raison que l’on passe par une phase de modélisation. Un modèle estUNE représentationsimplifiée du monde réel, pertinente au regard du problème à résoudre. Il doit inclure toutes les informationsutiles mais uniquement celles-ci.
Le choix du modèle dépend donc directement du type de problème à résoudre mais aussi de la techniquede résolution que l’on a choisie.
Des simplifications peuvent être éventuellement effectuées sur le modèle de façon à réduire le nombred’itérations de l’algorithme.
La solution du problème trouvée, il faut revenir à la réalitépour apporter la réponse à la question initiale.
FIG. 10.1 – Modélisation et résolution d’un problème
La principale difficulté est dans l’étape de modélisation. On vient cependant de voir des techniquespermettant de répondre à certaines questions.
– Ordonner, planifier des tâches : GANTT et potentiel-tâches.– Construire un réseau à moindre coût : Arbre de recouvrementminimal.– Minimiser un stock, un coût, une tournée,. . . : le plus courtchemin.– Maximaliser un flot, une production, un transport, . . . : le flot max.
Eric LALLET , Jean-Luc RAFFY 63

– Maximaliser un flot, une production, un transport à moindrecoût : le flot max coût min.– Optimiser un problème à multiples variables et multiples contraintes : programmation linéaire
Mais il faut aussi savoir les utiliser dans des cas moins attendus :– Le plus court chemin peut aussi trouver un maximum ! Par exemple en transformant des coûts en
gains (ou réciproquement), la recherche d’un minimum de l’un donnera le maximum de l’autre. Tantqu’on ne crée pas de cycle ayant une longueur négative, il esttout à fait possible d’avoir des valeursnégatives sur les arcs d’un plus court chemin.
– Le chemin critique du potentiel-tâches est en fait une recherche du plus long chemin. Donc cettetechnique peut servir aussi à maximaliser un gain, ou tout autre chose.
– Les marges totales d’un potentiel-tâches peuvent être vu comme du «temps disponibles» dans unemploi du temps. On peut s’en servir pour synchroniser des plannings pour trouver une date deréunion sur des emplois du temps a priori déjà plein.
– Le flot max à coût min peut être décliné de bien des façons. On peut essayer d’obtenir le maximumde choses (objets, services, . . . ) pour un coût donné. Il suffit de décider d’arrêter l’algorithme quandon atteint le coût fixé plutôt que de l’arrêter quand on atteint le flot maximum. On peut aussi s’enservir pour connaître le coût minimum pour tout flot inférieur au maximum.
– . . .
10.2 Les erreurs à ne pas faire
Il est bien d’apprendre de ses erreurs. Mais parfois ces erreurs se payent un peu cher. Alors autantapprendre des erreurs des autres. Dans cette section vous allez trouver une collection d’erreurs trouvéesdans diverses copies lors des contrôles. Essayez de bien comprendre quelle erreur a été faite, et ne la faitespas vous même à l’avenir.
Erreur 10.1 (Diagramme de GANTT) Utiliser un diagramme de GANTT pour trouver le chemin critiqueet les marges totales des tâches.
Le diagramme de GANTT est parfait pour calculer la durée d’unprojet et donner un planning facilementlisible à une équipe. Mais il n’est pas adapté à la recherche du chemin critique. Pour ce genre de rechercheil faudra par exemple utiliser un potentiel-tâches.
Erreur 10.2 (Potentiel-tâches)Placer sur le graphe d’un potentiel-tâches, la durée des tâches sur les arcsentrants.
Sur le graphe d’un potentiel-tâches la durée des tâches se place sur les arcs qui partent de la tâche, et nonpas sur ceux qui y arrivent. Le graphe erroné pourra éventuellement vous donner la durée du projet, maispar contre les dates au plus tôt et les dates au plus tard seront toutes fausses. Ainsi, de par leur constructionles arcs qui partent du sommetα ajouté à la source du graphe doivent obligatoirement être valués avec unedurée nulle (voir figure 10.2).
Erreur 10.3 (Potentiel-tâches)Placer des valeurs différentes sur deux arcs partants d’un même sommet(c’est à dire d’une même tâche).
L’arc qui part d’un sommet est valué par la durée de la tâche qui est modélisée par ce sommet. Une tâchene peut pas avoir plusieurs durées. Donc obligatoirement, tous les arcs qui partent d’un sommet reçoiventla même valeur.
64 Eric LALLET , Jean-Luc RAFFY

FIG. 10.2 – Sur un potentiel-tâches, la durée des tâches se placesur les arcs SORTANT des sommets
Erreur 10.4 (Graphes avec arcs valués)Mettre la valeur (capacité, longueur, coût, durée) sur les som-mets.
Les valeurs des graphes valués vus dans ce cours (potentiel-tâches, plus court chemin, flot max, flot-maxcoût-min. . . ) se placent sur les arcs et non pas sur les sommets. Même pour le potentiel-tâches, les valeursque l’on place lorsqu’on déroule l’algorithme directementsur le graphe sont les résultats de l’algorithmeet non pas les valeurs obtenues lors de la modélisation. Pourtous ces graphes, si dans votre modélisationune valeur est apparue sur un sommet, c’est qu’il y a une erreur. Généralement vous avez tout simplementoublié des arcs dans votre modèle.
Erreur 10.5 (Modélisation et simplifications) Simplifier votre modèle avant d’avoir fini la modélisation.
Il faut éviter de simplifier votre modèle trop tôt. Même si desarcs ou des contraintes sont visiblement in-utiles, gardez les dans votre modèle s’ils en font vraiment partie. Ensuite une fois la modélisation finie, avantde mettre la technique en œuvre, simplifier ce qui peut l’être. Les arcs ou les contraintes a priori inutilespeuvent devenir nécessaires après le changement de la valeur d’un simple paramètre de votre problème. Ilspeuvent aussi être très utiles pour donner une interprétation complète et correcte de votre solution.
Prenons un exemple pour illustrer cette démarche. Imaginons un problème de programmation linéaireoù il faut trouver le maximum de Z avec le modèle suivant :
(Modèle 1)
(1)X1 + X2 ≤ C1
(2)X1 + X2 ≤ C2
(3)X1 ≤ C3
Z = 2×X1 + X2
M1 ≥ 0 etM2 ≥ 0
Si C1 ≤ C2 on peut faire disparaître l’inégalité(2) pour obtenir le modèle :
(Modèle 2)
(1)X1 + X2 ≤ C1
(3)X1 ≤ C3
Z = 2×X1 + X2
M1 ≥ 0 etM2 ≥ 0
Et par contre siC2 ≤ C1 on peut faire disparaître l’inégalité(1) pour obtenir le modèle :
(Modèle 3)
(2)X1 + X2 ≤ C2
(3)X1 ≤ C3
Z = 2×X1 + X2
M1 ≥ 0 etM2 ≥ 0
Lors de votre modélisation vous serez forcement dans l’un des deux cas. Donc vous serez fortementtenté de faire disparaître de votre modèle l’inégalité inutile. Il est vrai que si votre problème est bien fixe etque les paramètres ne risquent pas de changer, le modèle simplifié fera très bien l’affaire. Mais imaginonsqu’immédiatement après ce premier problème, vous rencontrez le même avec juste des paramètres quichangent (par exemple deC1 ≤ C2 on est passé àC2 ≤ C1). Si vous avez modélisé avec le modèlecomplet (modèle 1), votre modélisation reste exacte, vous avez juste à procéder à la bonne simplification
Eric LALLET , Jean-Luc RAFFY 65

avant d’utiliser la technique de résolution (par exemple unsimplexe). Si vous avez d’office utilisé un modèlesimplifié, il ne correspond plus au nouveau problème et vous devez refaire une nouvelle modélisation.
Erreur 10.6 (Simplexe) Utiliser le simplexe pour ensuite refaire les calculs à la main.
Le simplexe est un algorithme très complet. Il ne se contentepas de trouver la valeur des variables de votreproblème, il calcule aussi celles de la fonction économique, des variables d’écarts, des valeurs marginales.Alors évitez d’utiliser le simplexe en ne calculant que la valeur des variables en base pour ensuite faire lecalcul à la main pour trouver la valeur de la fonction économique. Par contre à titre de vérification, vouspouvez effectivement recalculer à la main la valeur de la fonction économique à partir de la valeur desvariables pour la comparer à celle trouver par votre simplexe : une différence démontre une erreur de calcul.
66 Eric LALLET , Jean-Luc RAFFY

Index
adjacence, 23algorithme,
arbre de recouvrement minimal, 20, 21Busacker et Gowen, 37, 38, 40dates au plus tôt, 10dates au plus tard, 12Ford-Fulkerson, 33Ford-Moore, 28Kruskal, 20plus court chemin, 28, 37Prim, 21–23simplexe, 53
arête, 15arête,
boucle, 16cocycle, 16extrémité, 15incidence, 16
arbre, 18, 19arbre de recouvrement minimal, 20, 21, 63arbre,
Kruskal, 20recouvrement (de), 20
arc, 3arc,
extréminité initiale, 3extrémité terminale, 4
Busacker et Gowen, 37, 38, 40
chemin, 4chemin critique, 5, 7, 13, 64cocycle, 16, 21, 24connexité, 17connexité,
nombre, 17
date au plus tôt, 9date au plus tard, 11degré, 16durée de projet, 10
flot max, 31, 63flot max,
Busacker et Gowen, 37, 38, 40coût minimal, 37, 38, 40, 63Ford-Fulkerson, 33
Ford-Fulkerson, 33Ford-Moore, 28forme canonique, 43, 51forme standard, 51, 53, 59
GANTT, 5, 64GANTT,
diagramme, 6graphe, 8graphe
prédécesseur, 4successeur, 4
graphe,Γ+, 4Γ−, 4adjacence, 17arête, 15arc, 3boucle, 16chaîne, 16chemin, 4cocycle, 16, 21connexité, 17couvrant, 20cycle, 17degré, 16multigraphe, 16, 17multivoque, 4non orienté, 3, 13, 15, 17ordre, 16orienté, 3, 17poids, 20simple, 16, 17sommet, 15sous-graphe, 20valué, 27
Kruskal, 20
méthode géométrique, 45marge totale, 12matrice,
adjacence, 17, 23
ordonnancement, 5
PERT, 5plus court chemin, 26, 37, 63plus court chemin,
Ford-Moore, 28plus long chemin, 64poids, 20potentiel-tâches, 5, 8, 63, 64potentiel-tâches,
date au plus tôt, 9date au plus tard, 11
Eric LALLET , Jean-Luc RAFFY 67

durée de projet, 10marge totale, 12
prédécesseur, 4Prim, 21programmation linéaire, 43, 45, 48, 64programmation linéaire,
forme canonique, 43, 51forme standard, 51, 53, 59méthode géométrique, 45simplexe, 48
simplexe, 48, 64, 66simplexe,
algorithme, 53base, 52, 53forme canonique, 43, 45, 51forme standard, 51, 53, 59marge, 56pivot, 53premier critère de Dantzig, 53second critère de Dantzig, 53valeur marginale, 56variable d’écart, 51, 54
sommet, 15sommet,
adjacence, 16prédécesseur, 4successeur, 4
successeur, 4
68 Eric LALLET , Jean-Luc RAFFY

Bibliographie
[1] Jean-Claude Papillon.Eléments de recherche opérationnelle. Dalloz-Sirey, 1992.
[2] Roseaux. Exercices et problèmes résolus de recherche opérationnelle : Tome 3 : Programmation li-néaire et extensions - Problèmes classiques. DUNOD, 1985.
[3] Roseaux.Exercices et problèmes résolus de recherche opérationnelle : Tome 1, Graphes : leurs usages,leurs algorithmes. DUNOD, 1998.
[4] Daniel Thiel. Recherche opérationnelle et management des entreprises. Economica, 1990.
Eric LALLET , Jean-Luc RAFFY 69





























