Embed Size (px)
Citation preview

UNIVERZITA JANA EVANGELISTY PURKYNĚ V ÚSTÍ NAD LABEMPŘÍRODOVĚDECKÁ FAKULTA
PARALELNÍ POČÍTÁNÍ
Martin Lísal
2006

Studijní opora je určena studentům, kteří jsou zběhlí v programování v jazyce FORTRANči v jazyce C nebo C++. Nejdříve je proveden úvod do problematiky paralelního programování.Jsou vysvětleny důvody paralelizace a její efektivita. Dále je uveden přehled úloh a architek-tury počítačů z hlediska paralelizace a přehled prostředků pro paralelizaci numerických výpočtů.Vlastní část studijní opory se týká úvodu do jedné z nejpoužívanějších technik paralelizace, tzv.„Message Passing Interfaceÿ (MPI) knihovny. Nejdříve jsou na jednoduchých programech vjazyce FORTRAN 90 demonstrovány základní MPI příkazy. Poté následuje přehled nejpoužíva-nějších MPI příkazů doplněný ilustračními programy. V závěrečné části jsou uvedeny konkrétnípříklady paralelizace dvou počítačových metod: paralelizace metody paralelního temperingu napříkladu pohybu částice v jednorozměrném silovém poli a paralelizace molekulární dynamiky napříkladu Lennardovy-Jonesovy tekutiny.
Recenzoval: RNDr. Zdeněk Moravec, Ph.D.
c© Martin Lísal, 2006
ISBN 80-7044-784-2

Obsah
1 ÚVOD 41.1 Co je to paralelní počítání? . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2 Proč potřebujeme paralelní počítače? . . . . . . . . . . . . . . . . . . . . . 41.3 Problémy spojené s vývojem paralelního počítání . . . . . . . . . . . . . . 51.4 Kdy se vyplatí paralelizace? . . . . . . . . . . . . . . . . . . . . . . . . . . 51.5 Závisí způsob paralelizace výpočtů na architektuře paralelních počítačů? . 61.6 Rozdělení paralelních úloh z hlediska jejich spolupráce během výpočtu . . . 81.7 SPMD úlohy a strategie paralelizace . . . . . . . . . . . . . . . . . . . . . 10
2 MPI 112.1 Co je to MPI? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2 Vytvoření prostředí pro paralelní počítání . . . . . . . . . . . . . . . . . . 112.3 Program typu „Hello Worldÿ . . . . . . . . . . . . . . . . . . . . . . . . . 122.4 Argumenty příkazů MPI SEND a MPI RECV . . . . . . . . . . . . . . . . 142.5 Více o MPI SEND a MPI RECV . . . . . . . . . . . . . . . . . . . . . . . 15
2.5.1 Numerická integrace lichoběžníkovou metodou . . . . . . . . . . . . 152.5.2 Paralelní program pro numerickou integraci lichoběžníkovou metodou 16
2.6 Vstup a výstup v paralelních programech . . . . . . . . . . . . . . . . . . . 182.6.1 Vstup z terminálu s použitím MPI SEND a MPI RECV . . . . . . 192.6.2 Vstup z terminálu s použitím MPI BCAST . . . . . . . . . . . . . . 212.6.3 Vstup z terminálu s použitím MPI PACK a MPI UNPACK . . . . 222.6.4 Vstup ze souboru . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.6.5 Srovnání jednotlivých metod . . . . . . . . . . . . . . . . . . . . . . 25
2.7 Příkazy MPI REDUCE a MPI ALLREDUCE . . . . . . . . . . . . . . . . 252.8 Často používané MPI příkazy . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.8.1 Příkazy pro vytvoření a správu paralelního prostředí . . . . . . . . 282.8.2 Příkazy pro kolektivní komunikaci . . . . . . . . . . . . . . . . . . . 292.8.3 Příkazy pro operace na proměnných distribuovaných na jednotlivých
procesech . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3 APLIKACE 413.1 Paralelní „temperingÿ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.1.1 Částice v jednorozměrném silovém poli . . . . . . . . . . . . . . . . 413.1.2 Monte Carlo metoda . . . . . . . . . . . . . . . . . . . . . . . . . . 423.1.3 Metoda paralelního „temperinguÿ . . . . . . . . . . . . . . . . . . . 47
3.2 Paralelní molekulární dynamika . . . . . . . . . . . . . . . . . . . . . . . . 563.2.1 Úvod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.2.2 Paralelizace dvojnásobného cyklu v MD programu . . . . . . . . . . 56
3

1 ÚVOD
1.1 Co je to paralelní počítání?
Paralelní počítání je počítání na paralelních počítačích či jinak řečeno využití více nežjednoho procesoru při výpočtu (viz obr. 1).
(a) Jednoprocesorový po íta
(b) Paralelní po íta typu výpo tový cluster
CPU
memory
CPU
memory
CPU
memory
CPU
memory
Obrázek 1: Schema (a) jednoprocesorového a (b) paralelního počítače typu výpočtovýcluster; paměť (memory), procesor (CPU).
1.2 Proč potřebujeme paralelní počítače?
• Od konce 2. světové války dochází k bouřlivému rozvoji počítačových simulací (com-putational science). Počítačové simulace řeší problémy, které teoretická věda (the-oretical science) nedokáže vyřešit analyticky či problémy, které jsou obtížné nebonebezpečné pro experimentální vědu (experimental science). Jako příklad uveďmeproudění okolo trupu letadla, které teoretická věda dokáže popsat parciálními dife-renciálními rovnicemi; ty ale nedokáže analyticky řešit. Dalším příkladem je určenívlastností plazmy. Jelikož plazma existuje při vysokých teplotách, je experimentálníměření většiny jejich vlastností obtížné či přímo nemožné. Počítačové simulace vy-žadují náročné numerické výpočty, které se v současnosti neobejdou bez nasazeníparalelizace.
4

• Vývoj procesorů naráží (či v budoucnu narazí) na svůj materiálový limit t.j. vývojprocesorů nepůjde zvyšovat do nekonečna. (To pull a bigger wagon, it is easier toadd more oxen than to grow a gigantic ox.)
• Cena nejvýkonějších (advanced) procesorů na trhu obvykle roste rychleji než jejichvýkon. (Large oxen are expensive.)
1.3 Problémy spojené s vývojem paralelního počítání
• Hardware: v současné době lze konstruovat paralelní počítače mající společnou (sdí-lenou) paměť pro maximálně asi 100 procesorů. Trendem je tedy spojení jednoproce-sorových či několikaprocesorových počítačů do clusteru pomocí rychlé komunikačnísítě tzv. switche. Pozornost v oblasti hardwaru se proto převážně zaměřuje na vývojswitchů, které umožňují rychlost meziprocesorové komunikace srovnatelnou s rych-lostí komunikace mezi procesorem a vnitřní pamětí počítače.
• Algoritmy: bohužel se ukazuje, že některé algoritmy používané na jednoprocesorovýchpočítačích nelze dobře paralelizovat. To vede k nutnosti vytvářet zcela nové paralelníalgoritmy.
• Software: existují prostředky pro automatickou paralelizaci jakými jsou např. para-lelní kompilátory [High Performance Fortran (HPF) Standard] či paralelní numerickéknihovny. Platí (a pravděpodobně dlouho bude platit), že nejlepší paralelizace je ta,kterou si uděláme sami.
1.4 Kdy se vyplatí paralelizace?
Zrychlení výpočtu paralelizací lze odhadnout pomocí Amdahlova pravidla:
100− P +P
n(1)
kde P je část programu, kterou lze paralelizovat a n je počet použitých procesorů. Amdah-lovo pravidlo nám říká, kolik procent výpočtového času bude trvat paralelizovaný programoproti stejnému programu spuštěnému na jednoprocesorovém počítači.
Uveďme si jednoduchý ilustrativní příklad. Představme si, že máme sečíst 1 000 000 000prvků vektoru a. Načtení prvků trvá 8 % celkového výpočtového času, vlastní výpočetsoučtu trvá 90 % celkového výpočtového času a tisk trvá 2 % celkového výpočtového času.Je zřejmé, že jen výpočet součtu lze paralelizovat t.j. P = 90 % (viz. obr. 2). V případěpoužití n = 10 procesorů dostaneme z Amdahlova pravidla výsledek 19 % t.j. zrychlenívýpočtu paralelizací přibližně 5-krát. Z Amdahlova pravidla a uvedeného příkladu plynou
5

dva závěry: (i) neplatí přímá úměra mezi počtem procesorů a urychlením výpočtu („užití10 procesorů neznamená urychlení výpočtu 10-krátÿ) a (ii) pro limitní případ n → ∞ jeurychlení výpočtu konečné a rovno 100/(100− P ).
(a) Sériový program
S1
P
S2
(b) Paralelní program
a.out
S1
S2
S1
S2
S1
S2
S1
S2
P P P P
Obrázek 2: Schéma (a) sériového a (b) paralelního programu (běžícího na 4 procesorech). S1
a S2 jsou části programu, které nelze paralelizovat a P je paralelizovatelná část programu.
1.5 Závisí způsob paralelizace výpočtů na architektuře paralel-ních počítačů?
Způsob paralelizace výpočtů bohužel závisí na architektuře paralelních počítačů. V sou-časnosti se nejvíce používají dva typy architektur: (i) paralelní počítače se sdílenou pamětí(shared memory) a (ii) paralelní počítače s distribuovanou pamětí (distributed memory);viz obr. 3.
6

(a) Paralelní po íta
se sdílenou pam tí
(shared memory)
(b) Paralelní po íta
s distribuovanou pam tí
(distributed memory)
(shared) memory
CPU CPU CPU CPUmemory
CPU
memory
CPU
memory
CPU
memory
CPU
switch ~ komunikace
Obrázek 3: Schema paralelního počítače (a) se sdílenou pamětí (shared memory) a (b)s distribuovanou pamětí (distributed memory).
Z hlediska způsobu paralelizace je výhodnější architektura se sdílenou pamětí, neboťsdílení a výměna informací mezi procesory během výpočtu se děje přes sdílenou (společ-nou) paměť. Paralelizace na „shared-memoryÿ počítačích se provádí pomocí tzv. OpenMP.OpenMP je seznam direktiv, které se vkládají na místa, které chceme paralelizovat. Jinýmislovy říkáme počítači „kde a coÿ paralelizovat. Uveďme si jako příklad paralelizaci cyklu(do) pomocí OpenMP:!$OMP PARALLEL DOdo i = 2, nb(i) = (a(i) + a(i-1)) / 2.0
end do!$OMP END PARALLEL DO
Direktiva před začátek cyklu, !$OMP PARALLEL DO, říká: „paralelizuj cyklusÿ, zatímcodirektiva na konci cyklu, !$OMP END PARALLEL DO, říká: „ukonči paralelizaci cykluÿ.1
Paralelní počítače se sdílenou pamětí jsou oproti paralelním počítačům s distribuovanoupamětí dražší a počet procesorů sdílející jednu paměť je v současnosti omezen maximálněasi na 100. Proto se běžněji setkáváme s „distributed-memoryÿ počítači. „Distributed-memoryÿ počítače mají fyzicky oddělené paměti a komunikace (sdílení dat) mezi procesoryzajišťuje switch. Paralelizace na „distributed-memoryÿ počítačích je obtížnější než para-lelizace na „shared-memoryÿ počítačích, neboť musíme zajistit a pracovat s předáváním
1Jelikož direktivy OpenMP začínají ”!” a ten se ve FORTRANu90 interpretuje jako začátek komentářo-vého řádku, lze programy s direktivami OpenMP spouštět bez problému na jednoprocesorových počítačích.
7

informací (message passing) mezi procesory během výpočtu. Na paralelních počítačíchs distribuovanou pamětí se používají dva systémy: (i) Parallel Virtual Machine (PVM)vhodný pro heterogenní clustery a (ii) Message Passing Interface (MPI) vhodný pro homo-genní clustery. PVM a MPI je knihovna příkazů pro FORTRAN, C a C++, jež umožňujípředávání informací mezi procesory během výpočtu.
Komunikace představuje časovou ztrátu, o kterou se sníží zrychlení výpočtu paralelizacídané Amdahlovým pravidlem. Čas komunikace (overhead) jako funkce množství předávanéinformace je znázorněn na obr. 4. Z obr. 4 je patrno, že čas komunikace závisí na latenci(času, který potřebuje procesor a switch k „navázání komunikaceÿ) a dále, že „overheadÿroste s množstvím předávané informace mezi procesory. Z obr. 4 plynou následující zásady,které bychom měli dodržovat při paralelizaci na počítačích s distribuovanou pamětí: (i)přenášet co nejméně informací a (ii) komunikovat co nejméně.
množství p enášené informace
as k
om
un
ikace (
overh
ead
)
latence
Obrázek 4: Čas komunikace (overhead) versus množství předávané informace mezi proce-sory.
1.6 Rozdělení paralelních úloh z hlediska jejich spolupráce bě-hem výpočtu
Podle spolupráce během výpočtu můžeme rozdělit paralelní úlohy na• MPMD (Multiple Program Multiple Data) úlohy
8

• SPMD (Single Program Multiple Data) úlohy
MPMD úlohy lze dále rozdělit na typ
• „Master/Workerÿ (obr. 5a)
• „Coupled Multiple Analysisÿ (obr. 5b)
Úlohy typu „Master/Workerÿ jsou charakteristické existencí řídícího procesu (master,a.out v obr. 5a), který řídí ostatní procesy (worker, b.out v obr. 5a) a nechává si odnich počítat mezivýsledky. Úlohy typu „Coupled Multiple Analysisÿ jsou charakteristicképoužitím nezávislých procesů (a.out, b.out a c.out v obr. 5b), které řeší různé aspektyurčitého problému. Např. při návrhu trupu letadla by program a.out řešil proudění, b.outby řešil pevnostní analýzu a c.out analýzu teplotní.
SPMD úlohy (obr. 5c) používají stejnou kopii programu (single program) na všechprocesorech. Procesy ale během výpočtu zpracovávají různá data (multiple data). SPMDúlohy jsou typické pro numerické výpočty a my se SPMD úlohami budeme výhradně za-bývat v rámci tohoto předmětu.
(a) MPMD úloha typu "Master/Worker"
(b) MPMD úloha typu "Coupled Multiple Analysis"
a.out b.out c.outb.outa.out
(c) SPMD úloha
a.out
Obrázek 5: Paralelní úlohy z hlediska jejich spolupráce během výpočtu. (a) MPMD(Multiple Program Multiple Data) úloha typu „Master/Workerÿ, (b) MPMD úloha typu„Coupled Multiple Analysisÿ a (c) SPMD (Single Program Multiple Data) úloha.
9

1.7 SPMD úlohy a strategie paralelizace
Uveďme si jednoduchý příklad paralelizace programu pro součet prvků vektoru, kterýozřejmí pojem SPMD úlohy a naznačí strategii paralelizace SPMD úloh. Představme si,že máme vektor a mající 9 000 000 000 prvků. Úkol je sestavit paralelní program pro sou-čet prvků vektoru a (
∑9 000 000 000i=1 ai), přičemž máme k dispozici 3 procesory. Rozdělme si
úlohu pomyslně na 3 části: (i) načtení vektoru a, S1, (ii) vlastní výpočet součtu, P , a (iii)tisk součtu, S2. Je zřejmé, že jen vlastní výpočet součtu P lze paralelizovat.2 Paralelizaciprovedeme tak, že každý procesor spočte 1/3 součtu a tu pak pošle na jeden procesor,který provede celkový součet, jež následně vytiskne. Paralelní program pro součet prvkůvektoru zapsaný v jazyce FORTRAN může vypadat následovně (v místech programu, ježby měla obsahovat MPI paralelní příkazy, jsou komentáře označeny jako „. . .ÿ):
program soucetimplicit noneinteger :: i,my_rank,p,n_loc,i_begin,i_endreal :: a(9000000000), &
sum_loc,sum_tot!open(10,file=’input.dat’)do i=1,9000000000read(10,*) a(i)end doclose(10)
!"MPI: zjisti počet procesů ’p’, které se podílí na výpočtu"
"MPI: zjisti moje pořadí ’my_rank’ ve výpočtu; my_rank=0,1,...,p-1"!n_loc=9000000000/p ! Předpokládáme dělitelnost beze zbytku :-)i_begin=my_rank*n_loc+1i_end=(my_rank+1)*n_locsum_loc=0.0do i=i_begin,i_endsum_loc=sum_loc+a(i)end do
!"MPI: zajisti sečtení jednotlivých ’sum_loc’ do ’sum_tot’a pošli ’sum_tot’ např. na proces mající ’my_rank=0’"
!if(my_rank == 0) thenwrite(*,*) sum_totend ifstop "soucet: Konec vypoctu!"
!end program soucet
2Načtení dat se nedoporučuje paralelizovat, neboť způsob načítání dat se liší systém od systému.
10

2 MPI
2.1 Co je to MPI?
MPI (Message Passing Interface) je knihovna funkcí a podprogramů, která umožňuje:• vytvořit prostředí pro paralelní počítání;
• komunikaci mezi procesy během výpočtu např. posílání informací z procesu na proces;
• kolektivní operace např. sečtení mezivýsledků z procesů a uložení celkové součtu naurčitý proces;
• topologizaci procesů t.j. např. seskupení určitého počtu procesů za účelem jejichspolupráce v rámci výpočtů.
MPI lze použít ve spojení s programovacími jazyky FORTRAN, C a C++.
2.2 Vytvoření prostředí pro paralelní počítání
Vytvořením prostředí pro paralelní počítání rozumíme:• inicializaci a ukončení používání MPI;
• definování celkového počtu procesů nprocs, které se účastní výpočtu;
• definování pořadí procesu myrank.
Demonstrujme si vytvoření paralelního prostředí na jednoduchém programu, který vy-píše na obrazovku pořadí jednotlivých procesů.3
program par_envimplicit noneinclude ’mpif.h’ ! Budeme pouzivat MPI knihovnu
!integer :: ierr,nprocs,myrank
!call MPI_INIT(ierr) ! INITializuje MPI
!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)
! Default COMMunikator a celkovy pocet (SIZE) procesu ’nprocs’!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
! Poradi (RANK) ’myrank’; myrank = 0, 1, ..., nprocs-1!print*," Poradi procesu =",myrank
!call MPI_FINALIZE(ierr) ! Ukonci (FINALIZE) MPI
end program par_env
3Pokud nebude řečeno jinak, pracujeme s SPMD modelem paralelního programu: na všech uzlech serozběhne stejná kopie programu (SP, single program), každá kopie programu pracuje s různými daty (MD,multiple data).
11

Komentář k programu:
• Include ’mpif.h’ říká, že budeme používat MPI knihovnu.
• MPI INIT(ierr) inicializuje MPI; ierr je „chybováÿ proměnná typu INTEGER(ierr = 0 když je vše v pořádku).
• MPI COMM SIZE(MPI COMM WORLD,nprocs,ierr) definuje celkový po-čet procesů nprocs, které se účastní výpočtu.
• MPI COMM RANK(MPI COMM WORLD,myrank,ierr) definuje pořadíprocesu myrank.
• MPI FINALIZE(ierr) ukončí MPI.
• V celém programu používáme předdefinovaný (default) tzv. „komunikátorÿMPI COMM WORLD – označení pro skupinu spolupracujících procesů.
2.3 Program typu „Hello Worldÿ
Při učení nového programovacího jazyka se pravděpodobně každý setkal s programem,který vypíše na obrazovku „pozdravÿ - program typu „Hello Worldÿ. Napišme si takovouverzi programu pomocí MPI. MPI „Hello Worldÿ program pošle z procesů majících pořadímyrank = 1, 2, . . . , nprocs −1 informaci o svém pořadí na proces s pořadím 0 a process pořadím 0 vytiskne tuto informaci na obrazovku.
program hello_worldimplicit noneinclude ’mpif.h’ ! Budeme pouzivat MPI knihovnu
!integer :: STATUS(MPI_STATUS_SIZE)
! Pomocna promenna pouzita v MPI_RECVinteger :: ierr,nprocs,myrank,tag,isource,act_proc
!call MPI_INIT(ierr) ! INITializujeme MPI
!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)
! Default COMMunikator a celkový pocet (SIZE) procesu ’nprocs’!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
! Poradi (RANK) ’myrank’; myrank = 0, 1, ..., nprocs-1!tag=1if(myrank /= 0) then ! Ne_Mastr procesyact_proc=myrankcall MPI_SEND(act_proc,1,MPI_INTEGER,0,tag,MPI_COMM_WORLD,ierr)
! Ne_Mastr procesy SEND info ’act_proc’else ! Mastr procesdo isource=1,nprocs-1call MPI_RECV(act_proc,1,MPI_INTEGER,isource,tag,MPI_COMM_WORLD, &
STATUS,ierr)! Mastr proces RECV info ’act_proc’
12

print*," Hello World =",act_procenddoendif
!call MPI_FINALIZE(ierr) ! Ukonci (FINALIZE) MPI
end program hello_world
Komentář k programu:
• MPI SEND(. . . ) posílá informace.
• MPI RECV(. . . ) zajistí obdržení informace.
• 1. argument v MPI SEND/MPI RECV je posílaná/obdržená informace.
• 2. argument v MPI SEND/MPI RECV je velikost posílané/obdržené informace (1 proskalár, počet prvků vektoru či matice, atd.).
• 3. argument v MPI SEND/MPI RECV značí MPI typ, který přibližně odpovídá ty-pům v jazycích FORTRAN, C a C++.
• 4. argument v MPI SEND značí, na jaký proces se má zpráva poslat (v našem případěna proces 0).
• 4. argument v MPI RECV značí, z jakých procesů zpráva přichází (v našem případěz procesů 1, 2, . . . , nprocs −1).
• 5. argument v MPI SEND/MPI RECV je proměnná typu INTEGER (0 – 32767),která umožňuje dodatečné (pomocné) označení zprávy.
• Proměnná STATUS v MPI RECV zpětně „informujeÿ MPI SEND o úspěšném do-ručení zprávy.4
• MPI RECV je až na STATUS zrcadlovým obrazem MPI SEND.
• MPI SEND a MPI RECV jsou vzájemně synchronizované příkazy t.j. běh programupokračuje, až když se oba příkazy dokončí.
4Ostatní argumenty v MPI SEND/MPI RECV byly již vysvětleny.
13

2.4 Argumenty příkazů MPI SEND a MPI RECV
V programu typu „Hello Worldÿ jsme použili příkaz MPI SEND pro posílání informacez uzlu na uzel a příkaz MPI RECV pro přijímání informací z uzlů. Popišme si detailněargumenty těchto příkazů. Tyto dva příkazy lze obecně zapsat jako:
call MPI_SEND(send_message,count,MPI_data_type,dest,tag,comm, &ierr)
call MPI_RECV(recv_message,count,MPI_data_type,source,tag,comm, &status,ierr)
kde
• send message je posílaná informace, jejíž typ specifikuje MPI data type a jež můžebýt skalár, vektor či matice.
• recv message je přijímaná informace, jejíž typ specifikuje MPI data type a jež můžebýt skalár, vektor či matice.
• count je typu INTEGER a vyjadřuje velikost posílané resp. přijímané informace;např. 1 pro skalár či 10 pro matici (2,5).
• MPI data type:
MPI data type FORTRANMPI INTEGER INTEGER
MPI REAL REALMPI DOUBLE PRECISION DOUBLE PRECISION
MPI COMPLEX COMPLEXMPI LOGICAL LOGICAL
MPI CHARACTER CHARACTERMPI PACKED
MPI BYTE
• dest je typu INTEGER a vyjadřuje pořadí procesu, na který se send message posílá.
• source je typu INTEGER a vyjadřuje pořadí procesu, z kterého se recv messagepřijímá.
• tag je proměnná typu INTEGER, která může nabývat hodnot od 0 do 32767 a kteráumožňuje dodatečné (pomocné) označení posílané resp. přijímané informace.
• comm je označení pro skupinu spolupracujících procesů („komunikátorÿ);MPI COMM WORLD je předdefinovaný (default) „komunikátorÿ.
14

• status je vektor typu INTEGER deklarovaný jako
integer :: status(MPI_STATUS_SIZE)
status zpětně „informujeÿ MPI SEND o úspěšném doručení zprávy.
• ierr je „chybováÿ proměnná typu INTEGER; ierr = 0 když je vše v pořádku.
2.5 Více o MPI SEND a MPI RECV
Ukažme si další použití MPI SEND a MPI RECV na paralelní verzi programu pronumerický výpočet určitého integrálu lichoběžníkovou metodou.
2.5.1 Numerická integrace lichoběžníkovou metodou
Úkolem je spočíst integrál funkce f (x):
I =∫ b
af (x) dx (2)
Krok 1: rozdělme interval 〈a, b〉 na n stejných dílů:
xi = a + ih i = 0, 1, 2, . . . , n− 1, n (3)
x0 = a (4)
xn = b (5)
kde
h =b− a
n(6)
Krok 2: aproximujme funkci f (x) mezi body xi a xi+1 přímkou.Krok 3: body xi, xi+1, f (xi) a f (xi+1) tvoří lichoběžník, jehož obsah je
Ai = hf (xi) + f (xi+1)
2(7)
Krok 4: sečtením obsahů všech lichoběžníků, dostaneme přibližnou hodnotu integrálu (2):
I ≈ h
[f (a) + f (b)
2+
n−1∑
i=1
f (xi)
](8)
≈[f (a)
2+ f (a + h) + f (a + 2h) + . . . + f (b− h) +
f (b)2
](9)
15

Sériový program pro numerickou integraci lichoběžníkovou metodou může vypadat ná-sledovně:
program ser_lich_intimplicit none
!integer :: i,nreal :: f,a,b,h,x,int_sum,Int
!print *,"Dolni mez intervalu a:"read *,aprint *,"Horni mez intervalu b > a:"read *,bprint *,"Zadejte deleni intervalu n > 0:"read *,n
!h=(b-a)/REAL(n) ! "krok"int_sum=(f(a)+f(b))/2.0 ! [f(a)+f(b)]/2do i=1,n-1x=a+REAL(i)*h ! x=a+i*hint_sum=int_sum+f(x) ! pomocna sumaend doInt=h*int_sum ! vysledny integral
!print *,"Integral =",Int
end program ser_lich_int!function f(x)implicit none
!real :: f,xf=x*x
end function f
2.5.2 Paralelní program pro numerickou integraci lichoběžníkovou metodou
Paralelní verze programu pro numerickou integraci lichoběžníkovou metodou1. rozdělí interval 〈a, b〉 na podintervaly 〈ai, bi〉 dle celkového počtu procesů nprocs,
2. pro jednotlivé podintervaly spočtou jednotlivé procesy integrály
∫ bi
ai
f (x) dx
pomocí lichoběžníkové metody
3. a tyto integrály se pošlou na proces mající pořadí 0, kde se sečtou a proces majícípořadí 0 součet (celkový integrál) vytiskne.
Paralelní program pro numerickou integraci lichoběžníkovou metodou může vypadatnásledovně:5 6
5Abychom se vyhnuli problematice načítání vstupních dat v paralelních programech, zadejme vstupníhodnoty a, b a n přímo do programu.
6Dále předpokládáme, že n je beze zbytku dělitelné nprocs.
16

!! Trapezoidal Rule, MPI version 1.!! a, b, and n are in DATA statement!! Algorithm:! 1. Each process calculates "its" interval of integration.! 2. Each process estimates the integral of f(x) over its interval! using the trapezoidal rule.! 3a. Each process /= 0 sends its integral to 0.! 3b. Process 0 sums the calculations received from the individual! processes and prints the result.!program par_lich_int1implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process ranksource, & ! process sending integerdest, & ! process receiving integertag,ierr
integer :: status(MPI_STATUS_SIZE)integer :: n, & ! # of trapezoids
local_n ! # of trapezoids for a processor!
real :: a, & ! left endpointb, & ! right endpointh, & ! trapezoid base lengthlocal_a, & ! left endpoint for a processorlocal_b, & ! right endpoint for a processorintegral, & ! integral over a processortotal ! total integral
!data a,b,n /0.0,1.0,1024/ ! data for integration, n must be evendata dest,tag /0,50/
! ! start up MPI !call MPI_INIT(ierr)
! ! find out how many processes are being used !call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)
! ! get my process rank !call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!if(mod(n,nprocs) /= 0) stop "par_lich_int1: Wrong n/nprocs ratio!"h=(b-a)/REAL(n) ! h is the same for all processeslocal_n=n/nprocs ! # of trapezoids
! ! length of interval of integration for a process !local_a=a+REAL(myrank)*REAL(local_n)*hlocal_b=local_a+REAL(local_n)*h
! ! calculate integral on a process !call Trap(local_a,local_b,local_n,h,integral)
! ! add up the integrals calculated by each process !if(myrank /= 0) thencall MPI_SEND(integral,1,MPI_REAL,dest,tag, &
MPI_COMM_WORLD,ierr)elsetotal=integraldo source=1,nprocs-1call MPI_RECV(integral,1,MPI_REAL,source,tag, &
MPI_COMM_WORLD,status,ierr)total=total+integralenddoendif
! ! print the results !if(myrank == 0) then
17

write(*,’(1x,a,e13.5)’) " Integral =",totalendif
! ! shut down MPI !call MPI_FINALIZE(ierr)
end program par_lich_int1! ! Subroutine trapezoid for a processor !subroutine Trap(local_a,local_b,local_n,h,integral)implicit none
!integer :: local_n,ireal :: local_a,local_b,h,integral,x,f
!integral=(f(local_a)+f(local_b))/2.0x=local_ado i=1,local_n-1x=x+hintegral=integral+f(x)enddointegral=integral*h
end subroutine Trap! ! Function for integration !function f(x)implicit none
!real :: f,xf=x*x
end function f
2.6 Vstup a výstup v paralelních programech
MPI standard neobsahuje speciální příkazy pro načítání dat či jejich výstup na terminálnebo do souboru. Vstup a výstup v paralelních programech se proto musí řešit pomocípříkazů programovacího jazyka read, write či print a MPI příkazů pro komunikaci meziuzly.
Je nutno si uvědomit, že např. způsob načtení dat použitý v sériovém programu pronumerickou integraci lichoběžníkovou metodou:
print *,"Dolni mez intervalu a:"read *,aprint *,"Horni mez intervalu b > a:"read *,bprint *,"Zadejte deleni intervalu n > 0:"read *,n
může v paralelním programu fungovat různě v závislosti na systému a architektuře počítače.Při podobném použití příkazu read v paralelních programech může dojít k následujícímsituacím:
• Pokud jen jeden proces „umíÿ číst z terminálu, data se načtou jen na tento proces ane na ostatní procesy.
18

• Pokud „umíÿ všechny procesy číst, pak může nastat případ zadávat data tolikrát,kolik procesorů používáme.7
Situace se dále komplikuje, pokud načítáme data ze souboru a např. více procesů musíčíst současně data z jednoho souboru. Obdobné problémy a nejednoznačnosti jsou spojenys výstupem na terminál či do souborů.
Systémy a architektury počítačů vždy minimálně umožňují následující:
• Alespoň jeden proces dokáže číst z terminálu a alespoň jeden proces dokáže zapisovatna terminál.
• Každý proces dokáže číst ze souboru či do souboru zapisovat, pokud ostatní procesyz tohoto souboru nečtou či do něj nezapisují.
• Procesy dokáží číst současně z různých souborů či do různých souborů zapisovat.
Na základě těchto „minimálníchÿ schopností systémů a architektur počítačů se doporu-čuje používat následující dvě zásady při řešení vstupu a výstupu do paralelních programůpřes terminál:
1. Načíst data jen jedním procesem (např. procesem s myrank= 0) a následně rozeslatdata z tohoto procesu na ostatní procesy.
2. Poslání výsledků výpočtů z jednotlivých procesů na jeden určitý proces (např. process myrank= 0) a tisk výsledků z tohoto procesu na terminál.
V následujícím si ukažme různá řešení vstupů dat do paralelních programů z terminálua souboru na příkladu paralelního programu pro numerickou integraci lichoběžníkovoumetodou. Abychom se vyhnuli opakovanému psaní paralelního programu pro numerickouintegraci lichoběžníkovou metodou, nahradíme příkaz
data a,b,n /0.0,1.0,1024/ ! data for integration, n must be even
podprogramem, který provede načtení dat. Zbytek programu se nezmění.
2.6.1 Vstup z terminálu s použitím MPI SEND a MPI RECV
V první verzi vstupu z terminálu načte proces s pořadím myrank = 0 data a tato datapošle s použitím příkazů MPI SEND a MPI RECV na ostatní procesy. Příslušný podpro-gram může vypadat následovně:
!! Algorithm:! 1. Process 0 reads data.
7Dále není zaručeno, že čtení proběhne podle pořadí procesů.
19

! 2. Process 0 sends data to other processes.!subroutine Get_Data1(a,b,n,myrank,nprocs)implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: myrank, & ! my process rank
nprocs, & ! # of processessource, & ! process sending integerdest, & ! process receiving integertag,ierr
integer :: n ! # of trapezoidsinteger :: status(MPI_STATUS_SIZE)
!real :: a, & ! left endpoint
b ! right endpoint!if(myrank == 0) thenprint *," a:"read*,aprint *," b:"read*,bprint *," n:"read*,n
!do dest=1,nprocs-1tag=0call MPI_SEND(a,1,MPI_REAL,dest,tag,MPI_COMM_WORLD,ierr)tag=1call MPI_SEND(b,1,MPI_REAL,dest,tag,MPI_COMM_WORLD,ierr)tag=2call MPI_SEND(n,1,MPI_INTEGER,dest,tag,MPI_COMM_WORLD,ierr)enddoelsetag=0call MPI_RECV(a,1,MPI_REAL,0,tag,MPI_COMM_WORLD, &
status,ierr)tag=1call MPI_RECV(b,1,MPI_REAL,0,tag,MPI_COMM_WORLD, &
status,ierr)tag=2call MPI_RECV(n,1,MPI_INTEGER,0,tag,MPI_COMM_WORLD, &
status,ierr)endif
end subroutine Get_Data1
Tato verze programu volá několikrát příkazy MPI SEND a MPI RECV. Někdy protobývá výhodnější načtená data nejdříve uložit do pomocného vektoru a ten poslat s použitímpříkazů MPI SEND a MPI RECV na ostatní procesy. V takovém případě se sníží latentníčas komunikace. Příslušný podprogram může vypadat následovně:
!! Algorithm:! 1. Process 0 reads data and save them to a vector.! 2. Process 0 sends data as vector to other processes.!subroutine Get_Data11(a,b,n,myrank,nprocs)implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: myrank, & ! my process rank
20

nprocs, & ! # of processessource, & ! process sending integerdest, & ! process receiving integertag,ierr
integer :: n ! # of trapezoidsinteger :: status(MPI_STATUS_SIZE)
!real :: a, & ! left endpoint
b, & ! right endpointtemp_vec(3) ! temporary vector
!if(myrank == 0) thenprint *," a:"read*,aprint *," b:"read*,bprint *," n:"read*,n
!temp_vec=(/a,b,REAL(n)/)
!do dest=1,nprocs-1tag=0call MPI_SEND(temp_vec,3,MPI_REAL,dest,tag,MPI_COMM_WORLD, &
ierr)enddoelsetag=0call MPI_RECV(temp_vec,3,MPI_REAL,0,tag,MPI_COMM_WORLD,status, &
ierr)a=temp_vec(1)b=temp_vec(2)n=INT(temp_vec(3))endif
end subroutine Get_Data11
2.6.2 Vstup z terminálu s použitím MPI BCAST
V druhé verzi vstupu z terminálu načte opět proces s pořadím myrank = 0 data a tatodata se rozešlou s použitím příkazu MPI BCAST8 na ostatní procesy. Příslušný podpro-gram může vypadat následovně:
!! Algorithm:! 1. Process 0 reads data.! 2. Process 0 broadcasts data to other processes.!subroutine Get_Data2(a,b,n,myrank)implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: myrank, & ! my process rank
ierrinteger :: n ! # of trapezoids
!real :: a, & ! left endpoint
b ! right endpoint
8Příkaz MPI BCAST si můžeme představit jako „sloučeníÿ příkazů MPI SEND a MPI RECV do jed-noho.
21

!if(myrank == 0) thenprint *," a:"read*,aprint *," b:"read*,bprint *," n:"read*,nendifcall MPI_BCAST(a,1,MPI_REAL,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(b,1,MPI_REAL,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(n,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr)
end subroutine Get_Data2
Příkaz MPI BCAST lze obecně zapsat jako:
call MPI_BCAST(broadcast_message,count,MPI_data_type,root,comm,ierr)
kde význam všech argumentů kromě root je zřejmý z předchozích probíraných MPI příkazů.root je typu INTEGER a vyjadřuje pořadí procesu, z kterého se broadcast message rozesílá.
2.6.3 Vstup z terminálu s použitím MPI PACK a MPI UNPACK
V třetí verzi vstupu z terminálu načte opět proces s pořadím myrank= 0 data. Tato datapřed rozesláním „zabalíÿ do pomocné proměnné buffer s použitím příkazu MPI PACK.Proměnná buffer se pak rozešle na ostatní procesy s pomocí příkazu MPI BCAST, kde sezpětně „rozbalíÿ s použitím příkazu MPI UNPACK.9 Příslušný podprogram může vypadatnásledovně:
!! Use of Pack/Unpack!subroutine Get_Data3(a,b,n,myrank)implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: myrank, & ! my process rank
position, & ! in the bufferierr
integer :: n ! # of trapezoids!real :: a, & ! left endpoint
b ! right endpoint!character(len=100) :: buffer
!if(myrank == 0) thenprint *," a:"read*,aprint *," b:"
9Užití MPI PACK a MPI UNPACK je výhodné při posílání velkého množství dat různých typů.
22

read*,bprint *," n:"read*,n
!! Pack the data into buffer.! Beginning of buffer ’position=0’!
position=0 ! Position is in/outcall MPI_PACK(a,1,MPI_REAL,buffer,100,position, &
MPI_COMM_WORLD,ierr)! Position has been incremented;! the first free location in buffer
call MPI_PACK(b,1,MPI_REAL,buffer,100,position, &MPI_COMM_WORLD,ierr)
! Position has been incremented againcall MPI_PACK(n,1,MPI_INTEGER,buffer,100,position, &
MPI_COMM_WORLD,ierr)! Position has been incremented again
!! Broadcast contents of buffer!
call MPI_BCAST(buffer,100,MPI_PACKED,0,MPI_COMM_WORLD, &ierr)
elsecall MPI_BCAST(buffer,100,MPI_PACKED,0,MPI_COMM_WORLD, &
ierr)!! Unpack the data from buffer!
position=0call MPI_UNPACK(buffer,100,position,a,1,MPI_REAL, &
MPI_COMM_WORLD,ierr)call MPI_UNPACK(buffer,100,position,b,1,MPI_REAL, &
MPI_COMM_WORLD,ierr)call MPI_UNPACK(buffer,100,position,n,1,MPI_INTEGER, &
MPI_COMM_WORLD,ierr)endif
end subroutine Get_Data3
Příkazy MPI PACK a MPI UNPACK lze obecně zapsat jako:
call MPI_PACK(pack_data,count,MPI_data_type,buffer,size,position, &comm,ierr)
call MPI_UNPACK(buffer,size,position,unpack_data,count,MPI_data_type, &comm,ierr)
kde význam všech argumentů kromě buffer, size a position je zřejmý z předchozích pro-bíraných MPI příkazů. Všiměte si, že proměnné „zabalenéÿ pomocí příkazu MPI PACK(buffer v našem příkladu) jsou v MPI příkazech typu MPI PACKED.
• buffer je pomocná proměnná, jež musí být deklarovaná jako typ CHARACTER.
23

• size je typu INTEGER a vyjadřuje velikost („délkuÿ) pomocné proměnné buffer.10
• position je typu INTEGER a vyjadřuje pozici v buffer, od které se pack data ukládajíči unpack data jsou uloženy. Před prvním použitím MPI PACK či MPI UNPACKje nutno position vynulovat a pak je position automaticky aktualizována volánímMPI PACK či MPI UNPACK.
2.6.4 Vstup ze souboru
Předpokládejme, že vstupní data a, b a n jsou v souboru input.dat. Aby došlo ke správ-nému načtení dat jednotlivými procesy, je nutno zajistit načítání dat z tohoto souborupostupně. To lze docílit použitím příkazu MPI BARRIER. Příslušný podprogram můževypadat následovně:
!! Reading from file!subroutine Get_Data4(a,b,n,myrank,nprocs)implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: myrank, & ! my process rank
nprocs, & ! # of processesirank,ierr
integer :: n ! # of trapezoids!real :: a, & ! left endpoint
b ! right endpoint!do irank=0,nprocs-1if(irank == myrank) thenopen(10,file="input.dat",status="old")read(10,*) aread(10,*) bread(10,*) nclose(10)endifcall MPI_BARRIER(MPI_COMM_WORLD,ierr)enddo
end subroutine Get_Data4
Příkaz MPI BARRIER funguje tak, že program pokračuje až poté, když všechny procesyzavolají tento příkaz.
Obecný tvar příkazu MPI BARRIER je:
call MPI_BARRIER(comm,ierr)
kde význam argumentů je zřejmý z předchozích probíraných MPI příkazů.
10size musí být větší než součet velikostí („délekÿ) „balenýchÿ dat.
24

2.6.5 Srovnání jednotlivých metod
Použití výše zmíněných metod závisí na množství a typech rozesílaných dat:• V případě rozesílání malého množství dat různých typů, několikanásobné použití
MPI SEND a MPI RECV či MPI BCAST je nejjednodušším řešením.
• V případě rozesílání většího množství dat podobných typů (např. REAL, INTE-GER), uložení dat do pomocného vektoru a použití MPI SEND a MPI RECV čiMPI BCAST se jeví jako nejvýhodnější řešení.
• V případě rozesílání velkého množství dat podobných typů (např. REAL, INTE-GER) či většího množství dat různých typů (např. REAL, INTEGER, COMPLEX,CHARACTER) je užití MPI PACK a MPI UNPACK nejlepším řešení.
2.7 Příkazy MPI REDUCE a MPI ALLREDUCE
Příkazy MPI REDUCE a MPI ALLREDUCE umožňují provést určité typy operací(např. sčítání či násobení) na proměnných („mezivýsledcíchÿ), které se nachází na jednot-livých procesech. Zároveň umožňují výsledek těchto operací buď poslat na určitý proces(MPI REDUCE) či rozeslat na všechny procesy (MPI ALLREDUCE). Ukažme si opětpoužití těchto příkazů v paralelním programu pro numerickou integraci lichoběžníkovoumetodou. Připomeňme si, že paralelní program pro numerickou integraci lichoběžníkovoumetodou: (i) rozdělil celkový interval na podintervaly podle celkového počtu procesů; (ii)jednotlivé procesy spočetly integrály pro jednotlivé podintervaly pomocí lichoběžníkovémetody a (iii) tyto integrály se poslaly pomocí MPI SEND a MPI RECV na proces ma-jící pořadí 0, kde se sečetly a výsledek se vytiskl. Bod (iii) nyní nahradíme příkazemMPI REDUCE a modifikovaná verze paralelního programu pro numerickou integraci li-choběžníkovou metodou může vypadat následovně:
!! Trapezoidal Rule, MPI version 6.!! Algorithm:! 1. Each process calculates "its" interval of integration.! 2. Each process estimates the integral of f(x) over its interval! using the trapezoidal rule.! 3a. MPI_REDUCE sums the integrals on 0.! 3b. Process 0 prints the result.!program par_lich_int6implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr
integer :: n, & ! # of trapezoidslocal_n ! # of trapezoids for a processor
!
25

real :: a, & ! left endpointb, & ! right endpointh, & ! trapezoid base lengthlocal_a, & ! left endpoint for a processorlocal_b, & ! right endpoint for a processorintegral, & ! integral over a processortotal ! total integral
!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!! get data!call Get_Data2(a,b,n,myrank)
!if(mod(n,nprocs) /= 0) stop "par_lich_int6: Wrong n/nprocs ratio!"h=(b-a)/REAL(n) ! h is the same for all processeslocal_n=n/nprocs ! # of trapezoids
!! length of interval of integration for a process!local_a=a+REAL(myrank)*REAL(local_n)*hlocal_b=local_a+REAL(local_n)*h
!! calculate integral on a process!call Trap(local_a,local_b,local_n,h,integral)
!! add up the integrals calculated by each process using MPI_REDUCE!call MPI_REDUCE(integral,total,1,MPI_REAL,MPI_SUM,0, &
MPI_COMM_WORLD,ierr)!! print the results!if(myrank == 0) thenwrite(*,’(1x,a,e13.5)’) " Integral =",totalendif
!! shut down MPI!call MPI_FINALIZE(ierr)
end program par_lich_int6!! Subroutine trapezoid for a processor!subroutine Trap(local_a,local_b,local_n,h,integral)implicit none
!integer :: local_n,ireal :: local_a,local_b,h,integral,x,f
!integral=(f(local_a)+f(local_b))/2.0x=local_ado i=1,local_n-1x=x+h
26

integral=integral+f(x)enddointegral=integral*h
end subroutine Trap!! Algorithm:! 1. Process 0 reads data.! 2. Process 0 broadcasts data to other processes.!subroutine Get_Data2(a,b,n,myrank)implicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: myrank, & ! my process rank
ierrinteger :: n ! # of trapezoids
!real :: a, & ! left endpoint
b ! right endpoint!if(myrank == 0) thenprint *," a:"read*,aprint *," b:"read*,bprint *," n:"read*,nendifcall MPI_BCAST(a,1,MPI_REAL,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(b,1,MPI_REAL,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(n,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr)
end subroutine Get_Data2!! Function for integration!function f(x)implicit none
!real :: f,xf=x*x
end function f
Argument MPI SUM v příkazu MPI REDUCE říká, že se má provést součet proměnnýchintegral z jednotlivých procesů do proměnné total. Šestý argument 0 v příkazu MPI REDUCEříká, že se výsledek total (součet proměnných integral) má poslat na proces s pořadím 0.
Obecný tvar příkazu MPI REDUCE lze obecně zapsat jako:
call MPI_REDUCE(operand,result,count,MPI_data_type,operation,root, &comm,ierr)
kde význam argumentů kromě operand, result, operation a root je zřejmý z předchozíchprobíraných MPI příkazů.
• operand je proměnná, s kterou MPI REDUCE provádí určité typy operací.
27

• result je proměnná typu MPI data type, která obsahuje výsledek určitého typu ope-race na proměnných operand.
• operation říká, jaký typ operace se provádí:11
operation VýznamMPI SUM součet,
∑
MPI PROD násobení,∏
MPI MAX maximumMPI MIN minimum
MPI MAXLOC maximum a pořadí procesu, kde se maximum nacházíMPI MINLOC minimum a pořadí procesu, kde se minimum nachází
• root je typu INTEGER a vyjadřuje pořadí procesu, na který se result posílá.
Kdybychom použili v předchozím programu příkaz MPI ALLREDUCE místo příkazuMPI REDUCE, pak by se total rozeslal na všechny procesy. Je tedy zřejmé, že syntaxe pří-kazu MPI ALLREDUCE je totožná se syntaxí příkazu MPI REDUCE s tím, že neobsahujeargument root.
2.8 Často používané MPI příkazy
Uveďme si pro přehlednost probrané MPI příkazy a doplňme si je o nové.
2.8.1 Příkazy pro vytvoření a správu paralelního prostředí
A. Inicializace MPI
call MPI_INIT(ierr)
B. Ukončení MPI
call MPI_FINALIZE(ierr)
C. Definování komunikátoru a určení celkového počtu procesů
call MPI_COMM_SIZE(comm,nprocs,ierr)
11Uvádíme jen nejpoužívanější operace.
28

D. Definování pořadí jednotlivých procesů
call MPI_COMM_RANK(comm,myrank,ierr)
E. Zastavení paralelního programu
call MPI_ABORT(comm,errorcode,ierr)
Příkaz MPI ABORT je paralelní verzí příkazu programovacího jazyka STOP. Použije-lijakýkoliv proces příkaz MPI ABORT (např. dojde-li k chybě během čtení na procesu),ukončí se běh paralelního programu na všech procesech.
2.8.2 Příkazy pro kolektivní komunikaci
A. Synchronizace či blokace paralelního programu
call MPI_BARRIER(comm,ierr)
B. Rozeslání informace na jednotlivé procesy
call MPI_BCAST(broadcast_message,count,MPI_data_type,root,comm,ierr)
C. Distribuce informací stejné velikosti na jednotlivé procesy
call MPI_SCATTER(sendbuf,sendcount,send_MPI_data_type, &recvbuf,recvcount,recv_MPI_data_type,root,comm,ierr)
Funkce příkazu je vysvětlena na obr. 6 a použití MPI SCATTER demonstruje násle-dující program.
program scatterimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr
integer :: i!real :: sendmsg(4), & ! send message
recvmsg ! recieve message!! start up MPI!
29

call MPI_INIT(ierr)!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " scatter: nprocs > 4!"
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!if(myrank == 0) thendo i=1,nprocssendmsg(i)=real(i)enddoendif
!call MPI_SCATTER(sendmsg,1,MPI_REAL,recvmsg,1,MPI_REAL,0, &
MPI_COMM_WORLD,ierr)!print*," myrank =",myrank," recvmsg =",recvmsg
!! shut down MPI!call MPI_FINALIZE(ierr)
end program scatter
Obrázek 6: Schematický popis funkce příkazu MPI SCATTER.
D. Shromáždění informací stejné velikosti z jednotlivých procesů
call MPI_GATHER(sendbuf,sendcount,send_MPI_data_type, &recvbuf,recvcount,recv_MPI_data_type,root,comm,ierr)
Funkce příkazu je vysvětlena na obr. 7 a použití MPI GATHER demonstruje následujícíprogram.
30

program gatherimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr
!real :: sendmsg, & ! send message
recvmsg(4) ! recieve message!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " gather: nprocs > 4!"
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!sendmsg=real(myrank+1)
!call MPI_GATHER(sendmsg,1,MPI_REAL,recvmsg,1,MPI_REAL,0, &
MPI_COMM_WORLD,ierr)!if(myrank == 0) thenprint*," recvmsg:",recvmsgendif
!! shut down MPI!call MPI_FINALIZE(ierr)
end program gather
processes in comm need to call this routine.
Obrázek 7: Schematický popis funkce příkazu MPI GATHER.
E. Distribuce informací nestejné velikosti na jednotlivé procesy
31

call MPI_SCATTERV(sendbuf,sendcounts,displs,send_MPI_data_type, &recvbuf,recvcount, recv_MPI_data_type, &root,comm,ierr)
Funkce příkazu je vysvětlena na obr. 8 a použití MPI SCATTERV demonstruje násle-dující program.
program scattervimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr
integer :: send_count(0:3), & ! send countrecv_count, & ! receive countdispl(0:3) ! displacement
!real :: sendmsg(10), & ! send message
recvmsg(4) ! recieve message!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " scatterv: nprocs > 4!"
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!if(myrank == 0) thensendmsg=(/1.0,2.0,2.0,3.0,3.0,3.0,4.0,4.0,4.0,4.0/)send_count=(/1,2,3,4/)displ=(/0,1,3,6/)endifrecv_count=myrank+1
!call MPI_SCATTERV(sendmsg,send_count,displ,MPI_REAL, &
recvmsg,recv_count, MPI_REAL, &0,MPI_COMM_WORLD,ierr)
!print*," myrank =",myrank," recvmsg:",recvmsg
!! shut down MPI!call MPI_FINALIZE(ierr)
end program scatterv
32

Obrázek 8: Schematický popis funkce příkazu MPI SCATTERV.
F. Shromáždění informací nestejné velikosti z jednotlivých procesů
call MPI_GATHERV(sendbuf,sendcount, send_MPI_data_type, &recvbuf,recvcounts,displs,recv_MPI_data_type, &root,comm,ierr)
Funkce příkazu je vysvětlena na obr. 9 a použití MPI GATHERV demonstruje následujícíprogram.
program gathervimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr,i
integer :: send_count, & ! send countrecv_count(0:3), & ! receive countdispl(0:3) ! displacement
!real :: sendmsg(4), & ! send message
recvmsg(10) ! recieve message!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " gatherv: nprocs > 4!"
!! get my process rank!
33

call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)!do i=1,myrank+1sendmsg(i)=myrank+1enddosend_count=myrank+1
!recv_count=(/1,2,3,4/)displ=(/0,1,3,6/)
!call MPI_GATHERV(sendmsg,send_count, MPI_REAL, &
recvmsg,recv_count,displ,MPI_REAL, &0,MPI_COMM_WORLD,ierr)
!if(myrank == 0) thenprint*," recvmsg:",recvmsgendif
!! shut down MPI!call MPI_FINALIZE(ierr)
end program gatherv
Obrázek 9: Schematický popis funkce příkazu MPI GATHERV.
Příkazy MPI GATHER a MPI GATHERV mají ještě „ALLÿ verze MPI ALLGATHERa MPI ALLGATHERV, které shromažďují informace na všechny procesy a tudíž neobsahujíargument root.
G. Posílání informací stejné velikosti z jednotlivých procesů na všechny procesy
call MPI_ALLTOALL(sendbuf,sendcount,send_MPI_data_type, &recvbuf,recvcount,recv_MPI_data_type, &comm,ierr)
34

Funkce příkazu je vysvětlena na obr. 10 a použití MPI ALLTOALL demonstruje násle-dující program.
Obrázek 10: Schematický popis funkce příkazu MPI ALLTOALL.
program alltoallimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr,i
!real :: sendmsg(4), & ! send message
recvmsg(4) ! recieve message!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " gather: nprocs > 4!"
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!do i=1,nprocssendmsg(i)=REAL(i+nprocs*myrank)enddoprint*," myrank =",myrank," sendmsg:",sendmsg
!call MPI_ALLTOALL(sendmsg,1,MPI_REAL, &
recvmsg,1,MPI_REAL, &MPI_COMM_WORLD,ierr)
!print*," myrank =",myrank," recvmsg:",recvmsg
!! shut down MPIcall MPI_FINALIZE(ierr)
end program alltoall
35

H. Posílání informací nestejné velikosti z jednotlivých procesů na všechny procesy
call MPI_ALLTOALLV(sendbuf,sendcounts,sdispls,send_MPI_data_type, &recvbuf,recvcounts,rdispls,recv_MPI_data_type, &comm,ierr)
Funkce příkazu je vysvětlena na obr. 11 a použití MPI ALLTOALLV demonstruje ná-sledující program.
program alltoallvimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr,i
integer :: scnt(0:3), & ! send countssdsp(0:3), & ! send displacementsrcnt(0:3), & ! recv countsrdsp(0:3) ! recv displacements
real :: sendmsg(10),recvmsg(16)!sendmsg=(/1.0,2.0,2.0,3.0,3.0,3.0,4.0,4.0,4.0,4.0/)scnt=(/1,2,3,4/)sdsp=(/0,1,3,6/)
!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " gather: nprocs > 4!"
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!! sendmsg!do i=1,10sendmsg(i)=sendmsg(i)+REAL(nprocs*myrank)enddoprint*," myrank =",myrank," sendmsg:",sendmsg
!! rcnt and rdsp!do i=0,nprocs-1rcnt(i)=myrank+1rdsp(i)=i*(myrank+1)enddo
!call MPI_ALLTOALLV(sendmsg,scnt,sdsp,MPI_REAL, &
recvmsg,rcnt,rdsp,MPI_REAL, &MPI_COMM_WORLD,ierr)
!
36

print*," myrank =",myrank," recvmsg:",recvmsg!! shut down MPI!call MPI_FINALIZE(ierr)
end program alltoallv
Obrázek 11: Schematický popis funkce příkazu MPI ALLTOALLV.
2.8.3 Příkazy pro operace na proměnných distribuovaných na jednotlivýchprocesech
A. Příkaz „Reduceÿ
call MPI_REDUCE(operand,result,count,MPI_data_type,operation,root, &comm,ierr)
Příkaz MPI REDUCE má ještě „ALLÿ verzi, které neobsahuje argument root.
B. Příkaz „Scanÿ
call MPI_SCAN(sendbuf,recvbuf,count,MPI_data_type,operation,comm,ierr)
Funkce příkazu je vysvětlena na obr. 12 a použití MPI SCAN demonstruje následujícíprogram.
37

program scanimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr
real :: sendmsg,recvmsg!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " gather: nprocs > 4!"
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!! sendmsg!sendmsg=REAL(myrank+1)
!call MPI_SCAN(sendmsg,recvmsg,1,MPI_REAL,MPI_SUM, &
MPI_COMM_WORLD,ierr)!print*," myrank =",myrank," recvmsg:",recvmsg
!! shut down MPI!call MPI_FINALIZE(ierr)
end program scan
Obrázek 12: Schematický popis funkce příkazu MPI SCAN.
C. Příkaz „Reduce Scatterÿ
call MPI_MPI_REDUCE_SCATTER(sendbuf,recvbuf,recvcounts,MPI_data_type, &operation,comm,ierr)
38

Funkce příkazu je vysvětlena na obr. 13 a použití MPI REDUCE SCATTER demon-struje následující program.
Obrázek 13: Schematický popis funkce příkazu MPI REDUCE SCATTER.
program reduce_scatterimplicit noneinclude ’mpif.h’ ! preprocessor directive
!integer :: nprocs, & ! # of processes
myrank, & ! my process rankierr,i
integer :: rcnt(0:3) ! recv counts!real :: sendmsg(10), & ! send message
recvmsg(4) ! recieve message!rcnt=(/1,2,3,4/)
!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > 4) stop " scatter: nprocs > 4!"
!
39

! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!do i=1,10sendmsg(i)=real(i+myrank*10)enddoprint*," myrank =",myrank," sendmsg:",sendmsg
!call MPI_REDUCE_SCATTER(sendmsg,recvmsg,rcnt,MPI_REAL,MPI_SUM, &
MPI_COMM_WORLD,ierr)!print*," myrank =",myrank," recvmsg =",recvmsg
!! shut down MPI!call MPI_FINALIZE(ierr)
end program reduce_scatter
40

3 APLIKACE
3.1 Paralelní „temperingÿ
Paralelní „temperingÿ je způsob jak zefektivnit, urychlit či zlepšit vzorkování v MonteCarlo (MC) metodě.12 Ukážeme si princip paralelního „temperinguÿ na jednoduchém pří-padu částice v jednorozměrném silovém poli.
3.1.1 Částice v jednorozměrném silovém poli
Představme si, že máme částici v jednorozměrném silovém poli. Částice má teplotu Ta silové pole je charakterizované potenciálem U(x):
U(x) = ∞ x < −2
= 1 · [1 + sin (2πx)] − 2 ≤ x ≤ −1.25
= 2 · [1 + sin (2πx)] − 1.25 ≤ x ≤ −0.25
= 3 · [1 + sin (2πx)] − 0.25 ≤ x ≤ 0.75 (10)
= 4 · [1 + sin (2πx)] 0.75 ≤ x ≤ 1.75
= 5 · [1 + sin (2πx)] 1.75 ≤ x ≤ 2
= ∞ x > 2
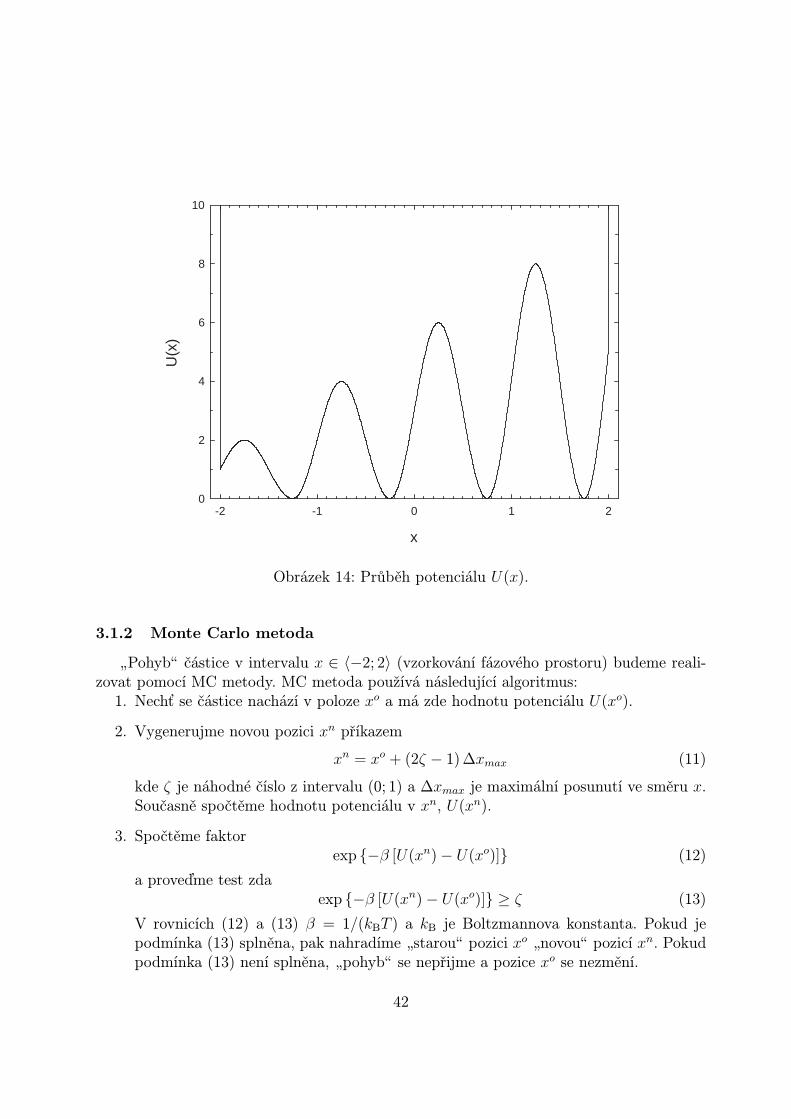
Průběh U(x) je graficky zobrazen na obr. 14. Potenciál U(x) je charakterizován čtyřmilokálními minimy oddělenými bariérami vzrůstající velikosti ve směru kladné osy x.
12Význam anglického výrazu „temperingÿ je zřejmý z dalšího výkladu.
41
x
-2 -1 0 1 2
U(x
)
0
2
4
6
8
10
Obrázek 14: Průběh potenciálu U(x).
3.1.2 Monte Carlo metoda
„Pohybÿ částice v intervalu x ∈ 〈−2; 2〉 (vzorkování fázového prostoru) budeme reali-zovat pomocí MC metody. MC metoda používá následující algoritmus:
1. Nechť se částice nachází v poloze xo a má zde hodnotu potenciálu U(xo).
2. Vygenerujme novou pozici xn příkazem
xn = xo + (2ζ − 1) ∆xmax (11)
kde ζ je náhodné číslo z intervalu (0; 1) a ∆xmax je maximální posunutí ve směru x.Současně spočtěme hodnotu potenciálu v xn, U(xn).
3. Spočtěme faktorexp {−β [U(xn)− U(xo)]} (12)
a proveďme test zdaexp {−β [U(xn)− U(xo)]} ≥ ζ (13)
V rovnicích (12) a (13) β = 1/(kBT ) a kB je Boltzmannova konstanta. Pokud jepodmínka (13) splněna, pak nahradíme „starouÿ pozici xo „novouÿ pozicí xn. Pokudpodmínka (13) není splněna, „pohybÿ se nepřijme a pozice xo se nezmění.
42

Výše popsaný postup se opakuje dostatečně dlouho než dojde k náležitému „provzorkováníÿfázového prostoru.
MC procesem spočteme pravděpodobnost nalezení částice v místě x, P (x), pro různéteploty T . P (x) určíme následujícím způsobem:
1. Nadefinujeme velikost BIN u pro histogram, ∆x.
2. PříkazemBIN = INT ((xo − xmin)/∆x) + 1 (14)
spočteme pořadí BIN u v histogramu. V rovnici (14) je BIN deklarován jako INTE-GER, xmin je minimální hodnota x, kterou částice může dosáhnout (v našem případěxmin = −2) a INT je vnitřní FORTRANská funkce, jež převádí čísla typu REAL načísla typu INTEGER.
3. Akumulujeme histogram příkazem
histogram(BIN ) = histogram(BIN ) + 1 (15)
4. Po skončení MC procesu normalizujeme histogram celkovým počtem MC pokusů.
MC program pro částici v jednorozměrném silovém poli může vypadat následovně:
!! A Single Particle on a 1D Potential with Multiple Local Minima!program SerPTimplicit noneinteger,parameter :: maxhist=1000real(8),parameter :: x_min=-2.0d0,x_max=2.0d0integer :: idum,ncyclus,nprint, &
nacp_loc,ntri_loc,nc,ih, &histogram(maxhist)
real(8) :: temp,beta, &dxmax,x,Ux, &dx,rat_loc
!! Auxiliary Variables!dxmax=0.1d0dx=0.025d0
!! Init idum!idum=-471
!! Input!print*," # MC Cyclus:"read(*,*) ncyclusprint*," Print Frequency:"read(*,*) nprint
!! Iput Values (Hard Wired)!
43

x=-1.2d0 ! Initial x (1st valley)temp=2.00d0 ! kB.Tbeta=1.0d0/temp ! 1/(kB.T)
!! Zero Accumulators!nacp_loc=0ntri_loc=0histogram=0
!! Initial Potential!call potential(x,Ux)
!! Begin Loop Over Cyclus!do nc=1,ncyclus
!! Local Updates!
call update_loc(beta,dxmax,x,x_min,x_max,Ux, &dx,histogram,idum,nacp_loc)
ntri_loc=ntri_loc+1!! Output Every ’nprint’ Steps!
if(mod(nc,nprint) == 0) thenrat_loc=dble(nacp_loc)/dble(ntri_loc)print*," # MC Cylus =",nc," Rat_Loc =",rat_locprint*," x =",x," U(x) =",Uxendifenddo
!! Final Output!x=x_min+(dx/2.0d0)do ih=1,maxhistwrite(10,"(1x,e13.5,1x,e13.5)") x,dble(histogram(ih))/dble(ntri_loc)x=x+dxif(x > x_max) exitenddostop " SerPT: End of Calc!"
end program SerPT!! Local Updates!subroutine update_loc(beta,dxmax,x,x_min,x_max,Ux, &
dx,histogram,idum,nacp_loc)implicit noneinteger :: idum,nacp_loc,bin, &
histogram(*)real(8) :: randomreal(8) :: beta,dxmax,x,x_min,x_max,Ux,dx, &
x_new,Ux_new,DelUx,beta_DelUx!! Accumulate Histogram!bin=INT((x-x_min)/dx)+1histogram(bin)=histogram(bin)+1
!! Move Particle!x_new=x+(2.0d0*random(idum)-1.0d0)*dxmax
!! Check Boundaries
44

!if(x_new < x_min) returnif(x_new > x_max) return
!! Calculate a New Value of Potential!call potential(x_new,Ux_new)
!! Check for Acceptance!DelUx=Ux_new-Uxbeta_DelUx=beta*DelUxif(dexp((-1.0d0)*beta_DelUx) > random(idum)) THEN
!! Bookkeeping!
Ux=Ux_newx=x_newnacp_loc=nacp_loc+1endif
end subroutine update_loc!! Potential!subroutine potential(x,Ux)implicit nonereal(8) :: pi,x,Ux
!pi=dacos(-1.0d0)
!! Calculate Potential at x!if(x <= -1.25d0) thenUx=1.0d0*(1.0d0+sin(2.0d0*pi*x))else if(x <= -0.25d0) thenUx=2.0d0*(1.0d0+sin(2.0d0*pi*x))else if(x <= 0.75d0) thenUx=3.0d0*(1.0d0+sin(2.0d0*pi*x))else if(x <= 1.75d0) thenUx=4.0d0*(1.0d0+sin(2.0d0*pi*x))elseUx=5.0d0*(1.0d0+sin(2.0d0*pi*x))endif
end subroutine potential!! RANDOM GENERATOR!FUNCTION RANDOM(IDUM)implicit none
!! Long period (>2x10e18) RANDOM number generator of L’Ecuyer! with Bays-Durham shuffe and added safeguards. Returns a uniform! RANDOM deviate between 0.0 and 1.0 (exclusive of the endpoint! values). Call with idum a negative integer to initialize;! thereafter, do not alter idum between successive deviates in! a sequence. RNMX should approximate the largest floating value! that is less than 1.!real(8) :: RANDOMINTEGER(4) :: IM1,IM2,IMM1,IA1,IA2,IQ1,IQ2,IR1,IR2,NTAB,NDIVREAL(8) :: AM,EPS,RNMXPARAMETER (IM1=2147483563,IM2=2147483399,AM=1./IM1,IMM1=IM1-1, &
IA1=40014,IA2=40692,IQ1=53668,IQ2=52774,IR1=12211, &IR2=3791,NTAB=32,NDIV=1+IMM1/NTAB,EPS=1.2e-7,RNMX=1.-EPS)
INTEGER(4) :: idum2,j,k,iv(NTAB),iy
45

SAVE iv,iy,idum2DATA idum2/123456789/, iv/NTAB*0/, iy/0/
!! Initialize!if(idum.le.0) then
!! Be sure to prevent idum = 0!
idum=max(-idum,1)idum2=idum
!! Load the shuffe table (after 8 warm-ups)!
do j=NTAB+8,1,-1k=idum/IQ1idum=IA1*(idum-k*IQ1)-k*IR1if(idum.lt.0) idum=idum+IM1if(j.le.NTAB) iv(j)=idumenddoiy=iv(1)endif
!! Start here when not initializing!k=idum/IQ1!! Compute idum=mod(IA1*idum,IM1) without overflows! by Schrage’s method!idum=IA1*(idum-k*IQ1)-k*IR1if(idum.lt.0) idum=idum+IM1k=idum2/IQ2
!! Compute idum2=mod(IA2*idum2,IM2) likewise!idum2=IA2*(idum2-k*IQ2)-k*IR2if(idum2.lt.0) idum2=idum2+IM2
!! Will be in the range 1:NTAB!j=1+iy/NDIV
!! Here idum is shuffed, idum and idum2 are combined! to generate output!iy=iv(j)-idum2iv(j)=idumif(iy.lt.1) iy=iy+IMM1RANDOM=min(AM*iy,RNMX)return
END FUNCTION RANDOM
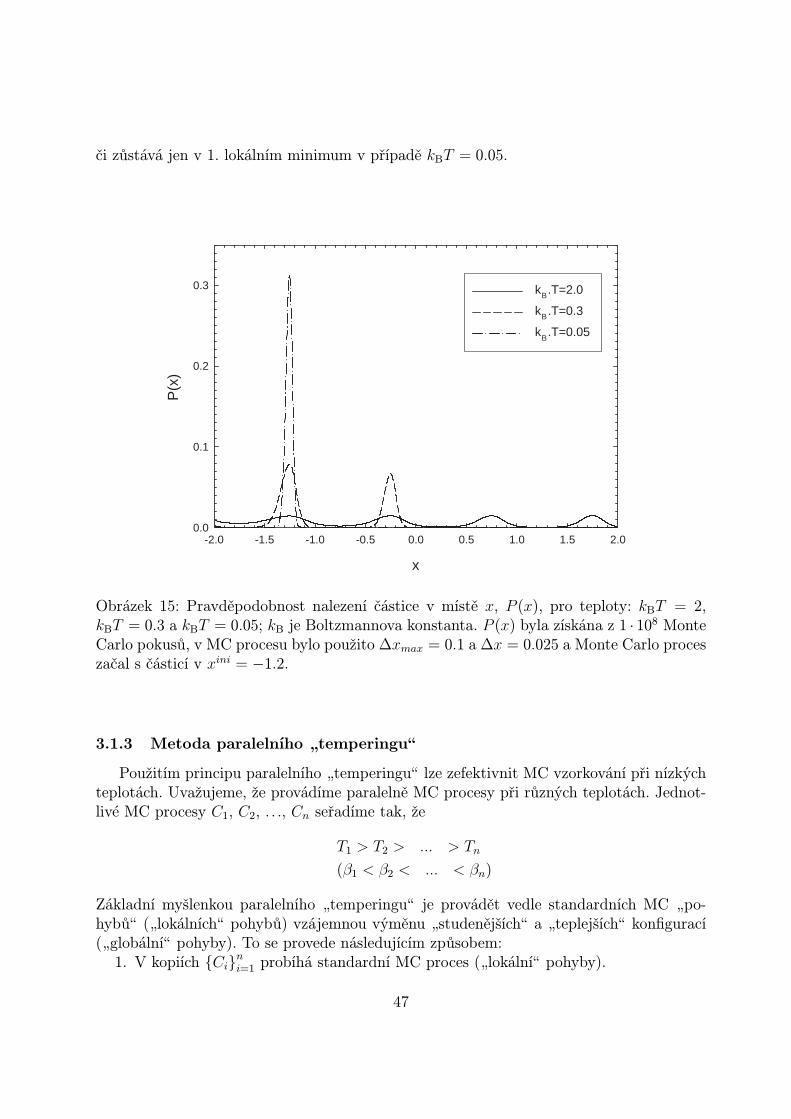
Částice by měla navštívit všechna čtyři lokální minima přibližně stejně často, neboťse nacházejí v nulové potenciálové hladině. Obr. 15 ukazuje P (x) získané z 1 · 108 MCpokusů. V MC procesu bylo použito ∆xmax = 0.1 a ∆x = 0.025, MC proces začal s částicív xini = −1.2 a byl proveden pro tři teploty: kBT = 2, kBT = 0.3 a kBT = 0.05. Z obr. 15je vidět, že částice „navštěvujeÿ všechna čtyři lokální minima pouze pro nejvyšší teplotukBT = 2. Pro nižší teploty částice vzhledem k bariérám není schopna dosáhnout všechnačtyři lokální minima a „navštěvujeÿ jen např. 1. a 2. lokální minimum v případě kBT = 0.3
46
či zůstává jen v 1. lokálním minimum v případě kBT = 0.05.
x
-2.0 -1.5 -1.0 -0.5 0.0 0.5 1.0 1.5 2.0
P(x
)
0.0
0.1
0.2
0.3 kB.T=2.0
kB.T=0.3
kB.T=0.05
Obrázek 15: Pravděpodobnost nalezení částice v místě x, P (x), pro teploty: kBT = 2,kBT = 0.3 a kBT = 0.05; kB je Boltzmannova konstanta. P (x) byla získána z 1 · 108 MonteCarlo pokusů, v MC procesu bylo použito ∆xmax = 0.1 a ∆x = 0.025 a Monte Carlo proceszačal s částicí v xini = −1.2.
3.1.3 Metoda paralelního „temperinguÿ
Použitím principu paralelního „temperinguÿ lze zefektivnit MC vzorkování při nízkýchteplotách. Uvažujeme, že provádíme paralelně MC procesy při různých teplotách. Jednot-livé MC procesy C1, C2, . . ., Cn seřadíme tak, že
T1 > T2 > ... > Tn
(β1 < β2 < ... < βn)
Základní myšlenkou paralelního „temperinguÿ je provádět vedle standardních MC „po-hybůÿ („lokálníchÿ pohybů) vzájemnou výměnu „studenějšíchÿ a „teplejšíchÿ konfigurací(„globálníÿ pohyby). To se provede následujícím způsobem:
1. V kopiích {Ci}ni=1 probíhá standardní MC proces („lokálníÿ pohyby).
47

2. Po určitém počtu MC kroků se proces zastaví a provede se pokus o „globálníÿ pohyb:
• vybere se náhodně jedna konfigurace Ci z {Ci}n−1i=1 ;
• kdyžexp (∆) ≥ ζ (16)
provede se výměna konfigurací Ci ↔ Ci+1. V rovnici (16) je
∆ = ∆β∆U (17)
∆β = βi+1 − βi (18)
∆U = Ui+1 − Ui (19)
Paralelizace „globálníchÿ pohybů pomocí MPI lze provést následujícím způsobem:
1. Proces s pořadím myrank == 0 vygeneruje náhodně jednu konfiguraci Ci z {Ci}n−1i=1
příkazemi = INT (ζ(n− 1)) + 1 (20)
kde n odpovídá počtu paralelních procesů nprocs.
2. Proces s pořadím myrank == 0 rozešle i na ostatní procesy příkazem MPI BCAST.(MPI BCAST zároveň provede synchronizaci všech MC procesů.)
3. Procesy s pořadím myrank /= i − 1 a myrank /= i pokračují dále v „lokálníchÿpohybech.
4. Proces s pořadím myrank == i pošle na proces s myrank == i− 1 hodnotu U(Ci+1)pomocí příkazů MPI SEND a MPI RECV.
5. Na procesu s pořadím myrank == i− 1 se provede test
exp (∆) ≥ ζ
a výsledek testu se pošle na proces s pořadím myrank == i opět pomocí příkazůMPI SEND a MPI RECV.
6. Pokud je podmínka v předchozí rovnici splněna, provede se výměna konfigurací Ci ↔Ci+1 t.j. x(Ci) ↔ x(Ci+1) a U(Ci) ↔ U(Ci+1) mezi procesy s pořadím myrank == ia s pořadím myrank == i− 1 pomocí příkazů MPI SEND a MPI RECV.
Program pro paralelní „temperingÿ částice v jednorozměrném silovém poli může vypa-dat následovně:
48

!! A Single Particle on a 1D Potential with Multiple Local Minima!program ParPTimplicit none
!include ’mpif.h’ ! preprocessor directiveinteger :: nprocs, & ! # of processes
myrank, & ! my process rankierr
!integer,parameter :: maxhist=1000,maxtemp=10,nptemp=50real(8),parameter :: x_min=-2.0d0,x_max=2.0d0integer :: idum,ncyclus,nprint,nc,ih,notemp,iunit, &
nacp_loc,ntri_loc,nacp_pt,ntri_pt, &histogram(maxhist)
real(8) :: temp,beta, &dxmax,x,Ux, &dx,rat_loc,rat_glo, &tempar(maxtemp)
character(len=7) :: cnfilecharacter(len=7),dimension(maxtemp) :: outfil
!! File Names!outfil(1) ="f01.out";outfil(2) ="f02.out";outfil(3) ="f03.out"outfil(4) ="f04.out";outfil(5) ="f05.out";outfil(6) ="f06.out"outfil(7) ="f07.out";outfil(8) ="f08.out";outfil(9) ="f09.out"outfil(10)="f10.out"
!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)if(nprocs > maxtemp) stop "ParPT: # of processes > max # of temperatures!"
!! get my process rank!call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)
!! Define File Unit and Open Ooutput Files!iunit=10+myrank*5cnfile=outfil(myrank+1)open(unit=iunit,file=cnfile,status="unknown")
!! Input!if(myrank == 0) thenprint*," # MC Cyclus:"read(*,*) ncyclusprint*," Print Frequency:"read(*,*) nprintendif
!! broadcast input!call MPI_BCAST(ncyclus,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(nprint,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr)
!! Temperatures kB.T; T1 > T2 > ... > Tn!
49

notemp=4tempar(1)=2.00d0tempar(2)=0.30d0tempar(3)=0.10d0tempar(4)=0.05d0if(nprocs /= notemp) stop "ParPT: # of processes /= # of temperatures!"
!! Auxiliary Variables!dxmax=0.1d0dx=0.025d0
!! Assign Actual Temperature!temp=tempar(myrank+1)
!! Init idum!idum=-471
!! Iput Values (Hard Wired)!x=-1.2d0 ! Initial x (1st valley)beta=1.0d0/temp ! 1/(kB.T)
!! Zero Accumulators!nacp_loc=0nacp_pt=0ntri_loc=0ntri_pt=0histogram=0
!! Initial Potential!call potential(x,Ux)
!! Begin Loop Over Cyclus!do nc=1,ncyclus
!! Local Updates!
call update_loc(beta,dxmax,x,x_min,x_max,Ux, &dx,histogram,idum,nacp_loc)
ntri_loc=ntri_loc+1!! Parallel Tempering After ’nptemp’ Cyclus!
if(mod(nc,nptemp) == 0) thencall update_global(nprocs,myrank, &
idum,beta,x,Ux,tempar,nacp_pt,ntri_pt)endif
!! Output Every ’nprint’ Steps!
if(mod(nc,nprint) == 0) thenrat_loc=dble(nacp_loc)/dble(ntri_loc)if(ntri_pt == 0) ntri_pt=1rat_glo=dble(nacp_pt)/dble(ntri_pt)write(iunit,fmt="(1x,a,i15)") " # MC Cylus =",ncwrite(iunit,fmt="(1x,2(a,e13.5))") " Rat_Loc =",rat_loc, &
" Rat_glo =",rat_glowrite(iunit,fmt="(1x,2(a,e13.5))") " x =",x," U(x) =",Uxendif
50

enddo!! Final Output!x=x_min+(dx/2.0d0)do ih=1,maxhistwrite(iunit,"(1x,e13.5,1x,e13.5)") x,dble(histogram(ih))/dble(ntri_loc)x=x+dxif(x > x_max) exitenddoclose (unit=iunit)
!! shut down MPI!call MPI_FINALIZE(ierr)
!stop " ParPT: End of Calc!"
end program ParPT!! Local Updates!subroutine update_loc(beta,dxmax,x,x_min,x_max,Ux, &
dx,histogram,idum,nacp_loc)implicit noneinteger :: idum,nacp_loc,bin, &
histogram(*)real(8) :: randomreal(8) :: beta,dxmax,x,x_min,x_max,Ux,dx, &
x_new,Ux_new,DelUx,beta_DelUx!! Accumulate Histogram!bin=INT((x-x_min)/dx)+1histogram(bin)=histogram(bin)+1
!! Move Particle!x_new=x+(2.0d0*random(idum)-1.0d0)*dxmax
!! Check Boundaries!if(x_new < x_min) returnif(x_new > x_max) return
!! Calculate a New Value of Potential!call potential(x_new,Ux_new)
!! Check for Acceptance!DelUx=Ux_new-Uxbeta_DelUx=beta*DelUxif(dexp((-1.0d0)*beta_DelUx) > random(idum)) THEN
!! Bookkeeping!
Ux=Ux_newx=x_newnacp_loc=nacp_loc+1endif
end subroutine update_loc!! Potential!subroutine potential(x,Ux)
51

implicit nonereal(8) :: pi,x,Ux
!pi=dacos(-1.0d0)
!! Calculate Potential at x!if(x <= -1.25d0) thenUx=1.0d0*(1.0d0+sin(2.0d0*pi*x))else if(x <= -0.25d0) thenUx=2.0d0*(1.0d0+sin(2.0d0*pi*x))else if(x <= 0.75d0) thenUx=3.0d0*(1.0d0+sin(2.0d0*pi*x))else if(x <= 1.75d0) thenUx=4.0d0*(1.0d0+sin(2.0d0*pi*x))elseUx=5.0d0*(1.0d0+sin(2.0d0*pi*x))endif
end subroutine potential!! Global Updates!subroutine update_global(nprocs,myrank, &
idum,beta,x,Ux,tempar,nacp_pt,ntri_pt)implicit none
!include ’mpif.h’ ! preprocessor directiveinteger :: nprocs, & ! # of processes
myrank, & ! my process rankierr
integer :: status(MPI_STATUS_SIZE)integer :: idum,nacp_pt,ntri_pt,ii,ip1,itag,iacptreal(8) :: randomreal(8) :: beta,x,Ux,Ux1, &
Delta_beta,Delta_U,acp_pt, &tempar(*)
real(8) :: vectrn0(2),vectrn1(2)!! Choose ’i’ Randomly on "mastr" and then Broadcast!if(myrank == 0) THENii=INT(dble(nprocs-1)*random(idum))+1endifcall MPI_BCAST(ii,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr)ii=ii-1 ! synchronize with ’myrank’
!! ’i+1’!ip1=ii+1if((myrank /= ii).and.(myrank /= ip1)) return
!! Send Potential from ’i+1’ on ’i’!itag=10if(myrank == ip1) thencall MPI_SEND(Ux,1,MPI_REAL8,ii,itag,MPI_COMM_WORLD,ierr)else if(myrank == ii) thencall MPI_RECV(Ux1,1,MPI_REAL8,ip1,itag,MPI_COMM_WORLD,status,ierr)endif
!! Check for Acceptance on ’i’:! min[1,exp(DeltaBeta.DeltaU)] (Delta = ’i+1’ - ’i’)!if(myrank == ii) thenDelta_beta=(1.0d0/tempar(ip1+1))-beta
52

Delta_U=Ux1-Uxacp_pt=dexp(Delta_beta*Delta_U)if(acp_pt > random(idum)) theniacpt=1nacp_pt=nacp_pt+1elseiacpt=0endifntri_pt=ntri_pt+1endif
!! Send ’iacpt’ from ’i’ on ’i+1’!itag=20if(myrank == ii) thencall MPI_SEND(iacpt,1,MPI_INTEGER,IP1,itag,MPI_COMM_WORLD,ierr)else if(myrank == IP1) THENcall MPI_RECV(iacpt,1,MPI_INTEGER,ii,itag,MPI_COMM_WORLD,status,ierr)endifif(iacpt == 0) return
!! Exchange Replicas between ’i’ and ’i+1’!! Send Replica from ’i’ on ’i+1’!itag=30if(myrank == ii) thenvectrn0(1)=xvectrn0(2)=Uxcall MPI_SEND(vectrn0,2,MPI_REAL8,ip1,itag,MPI_COMM_WORLD,ierr)else if(myrank == ip1) thencall MPI_RECV(vectrn0,2,MPI_REAL8,ii,itag,MPI_COMM_WORLD,status,ierr)endif
!! Send Replica from ’i+1’ on ’i’!itag=40if(myrank == ip1) thenvectrn1(1)=xvectrn1(2)=Uxcall MPI_SEND(vectrn1,2,MPI_REAL8,ii,itag,MPI_COMM_WORLD,ierr)else if(myrank == ii) thencall MPI_RECV(vectrn1,2,MPI_REAL8,ip1,itag,MPI_COMM_WORLD,status,ierr)endif
!! Update Information!if(myrank == ii) then
!! on ’i’!
x=vectrn1(1)Ux=vectrn1(2)else if(myrank == ip1) then
!! on ’i+1’!
x=vectrn0(1)Ux=vectrn0(2)endif
end subroutine update_global!! RANDOM GENERATOR!FUNCTION RANDOM(IDUM)
53

implicit none!! Long period (>2x10e18) RANDOM number generator of L’Ecuyer! with Bays-Durham shuffe and added safeguards. Returns a uniform! RANDOM deviate between 0.0 and 1.0 (exclusive of the endpoint! values). Call with idum a negative integer to initialize;! thereafter, do not alter idum between successive deviates in! a sequence. RNMX should approximate the largest floating value! that is less than 1.!real(8) :: RANDOMINTEGER(4) :: IM1,IM2,IMM1,IA1,IA2,IQ1,IQ2,IR1,IR2,NTAB,NDIVREAL(8) :: AM,EPS,RNMXPARAMETER (IM1=2147483563,IM2=2147483399,AM=1./IM1,IMM1=IM1-1, &
IA1=40014,IA2=40692,IQ1=53668,IQ2=52774,IR1=12211, &IR2=3791,NTAB=32,NDIV=1+IMM1/NTAB,EPS=1.2e-7,RNMX=1.-EPS)
INTEGER(4) :: idum2,j,k,iv(NTAB),iySAVE iv,iy,idum2DATA idum2/123456789/, iv/NTAB*0/, iy/0/
!! Initialize!if(idum.le.0) then
!! Be sure to prevent idum = 0!
idum=max(-idum,1)idum2=idum
!! Load the shuffe table (after 8 warm-ups)!
do j=NTAB+8,1,-1k=idum/IQ1idum=IA1*(idum-k*IQ1)-k*IR1if(idum.lt.0) idum=idum+IM1if(j.le.NTAB) iv(j)=idumenddoiy=iv(1)endif
!! Start here when not initializing!k=idum/IQ1
!! Compute idum=mod(IA1*idum,IM1) without overflows! by Schrage’s method!idum=IA1*(idum-k*IQ1)-k*IR1if(idum.lt.0) idum=idum+IM1k=idum2/IQ2
!! Compute idum2=mod(IA2*idum2,IM2) likewise!idum2=IA2*(idum2-k*IQ2)-k*IR2if(idum2.lt.0) idum2=idum2+IM2
!! Will be in the range 1:NTAB!j=1+iy/NDIV
!! Here idum is shuffed, idum and idum2 are combined! to generate output!iy=iv(j)-idum2iv(j)=idum
54
if(iy.lt.1) iy=iy+IMM1RANDOM=min(AM*iy,RNMX)return
END FUNCTION RANDOM
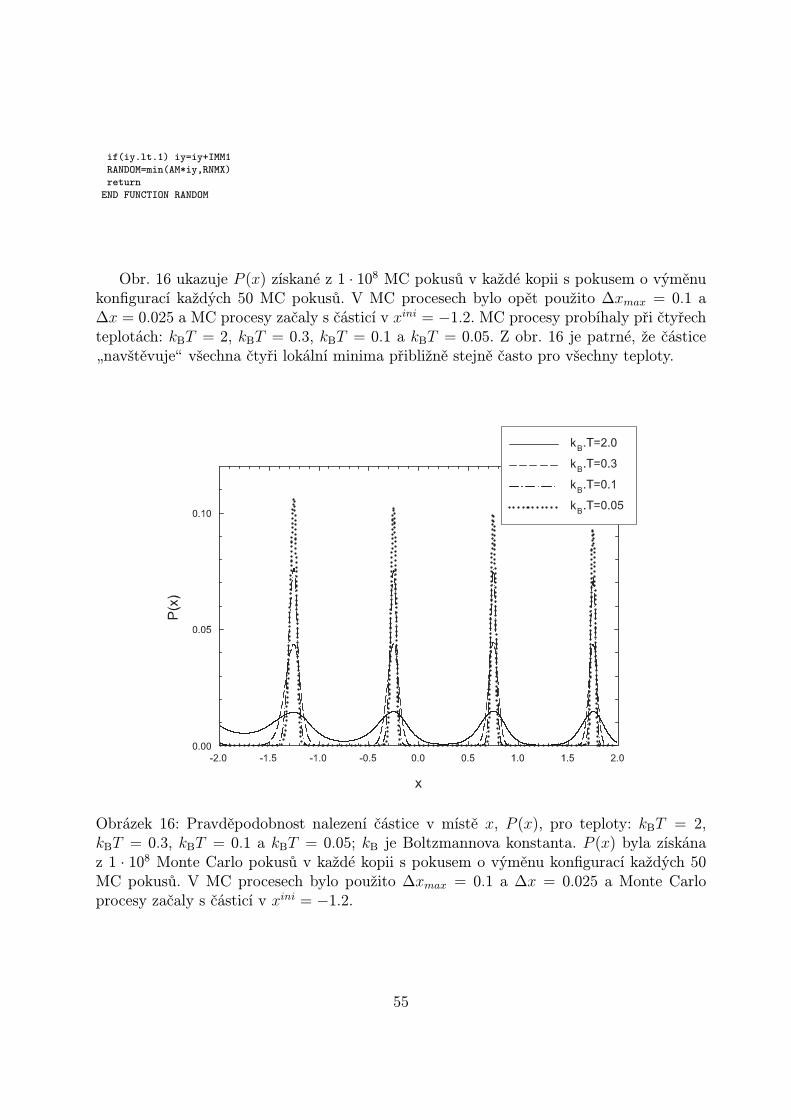
Obr. 16 ukazuje P (x) získané z 1 · 108 MC pokusů v každé kopii s pokusem o výměnukonfigurací každých 50 MC pokusů. V MC procesech bylo opět použito ∆xmax = 0.1 a∆x = 0.025 a MC procesy začaly s částicí v xini = −1.2. MC procesy probíhaly při čtyřechteplotách: kBT = 2, kBT = 0.3, kBT = 0.1 a kBT = 0.05. Z obr. 16 je patrné, že částice„navštěvujeÿ všechna čtyři lokální minima přibližně stejně často pro všechny teploty.
Obrázek 16: Pravděpodobnost nalezení částice v místě x, P (x), pro teploty: kBT = 2,kBT = 0.3, kBT = 0.1 a kBT = 0.05; kB je Boltzmannova konstanta. P (x) byla získánaz 1 · 108 Monte Carlo pokusů v každé kopii s pokusem o výměnu konfigurací každých 50MC pokusů. V MC procesech bylo použito ∆xmax = 0.1 a ∆x = 0.025 a Monte Carloprocesy začaly s částicí v xini = −1.2.
55

3.2 Paralelní molekulární dynamika
3.2.1 Úvod
Molekulární dynamika (MD) slouží k řešení pohybu N molekul, jejichž interakce jepopsána potenciálem u. Uvažujme pro jednoduchost systém částic reagujích Lennardovým-Jonesovým (LJ) potenciálem
uLJ (rij) = 4ε
(σ
rij
)12
−(
σ
rij
)6 (21)
kde rij = |ri − rj| je vzdálenost mezi molekulami i a j, ε a σ jsou resp. energetický adélkový LJ parametr. V MD programech se více než 90 % výpočtového času spotřebujena výpočet celkové energie systému U , viriálu W a sil fij. Ty se spočtou pro LJ tekutinunásledujícím způsobem:
U = Uc + ULRC
=N−1∑
i=1
N∑
j=i+1
uLJ (rij) +83πNερσ3
[13
(σ
rc
)9
−(
σ
rc
)3]
(22)
kde rc je poloměr ořezání a ρ je hustota.
W = Wc + WLRC
= −13
N−1∑
i=1
N∑
j=i+1
wLJ (rij) +163
πNερσ3
[23
(σ
rc
)9
−(
σ
rc
)3]
(23)
kde wLJ = r(duLJ/dr
).
fij = − 1rij
[duLJ (rij)
drij
]rij (24)
= −fji (25)
3.2.2 Paralelizace dvojnásobného cyklu v MD programu
Paralelizací dvojnásobného cyklu
do i=1,N-1 ! Vnejsi cyklusdo j=i+1,N ! Vnitrni cyklus...enddo
enddo
ve výpočtu Uc, Wc a fij lze docílit značného urychlení běhu MD programů. Paralelizacidvojnásobného cyklu lze provést následujícím způsobem:
56

1. Každý proces spočte jen část vnějšího cyklu t.j. spočte jen část z Uc, Wc a fij. To lzeprovést následujícím způsobem:
do i=1+myrank,N-1,nprocs ! Vnejsi cyklusdo j=i+1,N ! Vnitrni cyklus...
enddoenddo
2. Použitím MPI příkazu MPI ALLREDUCE sečteme části Uc, Wc a fij z jednotlivýchprocesů a výsledné Uc, Wc a fij se „uložíÿ na všechny procesy.
Program pro paralelní MD Lennardovy-Jonesovy tekutiny může vypadat následovně:
!! Parallel NVT MD of Lennard-Jones Fluids!! uLJ=4*eps*[(sig/r)^12-(sig/r)^6]!program ParNVTmdLJimplicit noneinclude ’mpif.h’ ! preprocessor directive
!! System Data!integer,parameter :: nmax=5000 ! Max # of Moleculesreal(8),parameter :: dt=0.005d0 ! Time Stepreal(8) :: rcut=1.0d0 ! Cut-Off Radiusinteger,parameter :: nom=500 ! # of Moleculesreal(8),parameter :: temp=2.0d0 ! Reduced Temperaturereal(8),parameter :: dens=0.4d0 ! Reduced Number Density
!! Declaration of Variables!integer :: nrun,nprint,nstepreal(8) :: vol,box,boxinv,rcutsq,time, &
U,W,U_LRC,W_LRC,u_ac,P_ac, &sum_u,sum_P,ssq_u,ssq_P
real(8),dimension(nmax) :: x,y,z, &vx,vy,vz, &fx,fy,fz
character(len=3) :: yesnocharacter(len=30) :: cnfileinteger :: nprocs, & ! # of processes
myrank, & ! my process rankierr,ip
!! start up MPI!call MPI_INIT(ierr)
!! find out how many processes are being used!call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)
!! get my process rank!
57

call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)!! Input!if(myrank == 0) thenprint*,"# of Time Steps:"read*,nrunprint*,"# of Time Steps for Printing:"read*,nprintprint*,"Read Configurational File (yes/no):"read*,yesnoprint*,"Name of Configurational File:"read*,cnfileendif
!! broadcast input!call MPI_BCAST(nrun,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(nprint,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(yesno,3,MPI_CHARACTER,0,MPI_COMM_WORLD,ierr)call MPI_BCAST(cnfile,30,MPI_CHARACTER,0,MPI_COMM_WORLD,ierr)
!! Simulation Set-Up Values!call values(nom,rcut,dens,vol,box,boxinv,rcutsq,U_LRC,W_LRC)
!! Initial Output!if(myrank == 0) thencall output(1,nstep,nrun,nom,rcut,temp,dens,vol,box, &
time,u_ac,P_ac,sum_u,sum_P,ssq_u,ssq_P)endif
!! Initialization!if((yesno == ’yes’).or.(yesno == ’YES’)) then
!! Read from File; One Processor at a Time!
do ip=0,nprocs-1if(myrank == ip) thencall readcn(nmax,x,y,z,vx,vy,vz,cnfile)
endifcall MPI_BARRIER(MPI_COMM_WORLD,ierr)enddoelse
!! Positions from fcc Lattice and! Velocity from Maxwell-Boltzmann’s Distribution!
call init_conf(nom,temp,box,x,y,z,vx,vy,vz)endif
!! Zeroth Thermo Accumulators!call zero(sum_u,sum_P,ssq_u,ssq_P)
!! MD cyclus!time=0.0d0do nstep=1,nrun
!! Energy, Virial and Forces!
call force(nom,box,boxinv,rcutsq,U,W, &
58

x,y,z,fx,fy,fz, &myrank,nprocs)
!! Leap-Frog Algorithm!
call Leap_Frog(nom,dt,temp,box,boxinv, &x,y,z,vx,vy,vz,fx,fy,fz)
!! Termodynamic Quantities!
call thermo(nom,temp,dens,vol,U,U_LRC,W,W_LRC,u_ac,P_ac, &sum_u,sum_P,ssq_u,ssq_P)
!! Periodic Output!
time=time+dtif(myrank == 0) thenif(mod(nstep,nprint) == 0) thencall output(2,nstep,nrun,nom,rcut,temp,dens,vol,box, &
time,u_ac,P_ac,sum_u,sum_P,ssq_u,ssq_P)endifendifenddo
!! Final Write to File!if(myrank == 0) thencall writcn(nmax,x,y,z,vx,vy,vz,cnfile)
!! Final Output!
call output(3,nstep,nrun,nom,rcut,temp,dens,vol,box, &time,u_ac,P_ac,sum_u,sum_P,ssq_u,ssq_P)
endif!! shut down MPI!call MPI_FINALIZE(ierr)
!stop "ParNVTmdLJ: End of Calcs!"
end program ParNVTmdLJ!! Simulation Set-Up Values!subroutine values(nom,rcut,dens,vol,box,boxinv,rcutsq,U_LRC,W_LRC)implicit none
!! Declaration of Variables!integer :: nomreal(8) :: rcut,rcutsq,dens,vol,box,boxinv, &
pi,ircut3,ircut9,U_LRC,W_LRC!! Volume, Length of Box and Cut-Off Radius!vol=dble(nom)/densbox=vol**(1.0/3.0)boxinv=1.0d0/boxif(rcut > 1.0d0) rcut=1.0d0rcut=rcut*(box/2.0d0)rcutsq=rcut**2
!! LJ LRC!pi=dacos(-1.0d0)
59

ircut3=1.0d0/(rcutsq*rcut)ircut9=ircut3*ircut3*ircut3
!U_LRC=(8.0d0/3.0d0)*pi*dble(nom)*dens*((1.0d0/3.0d0)*ircut9-ircut3)W_LRC=(16.0d0/3.0d0)*pi*dble(nom)*dens*((2.0d0/3.0d0)*ircut9-ircut3)
end subroutine values!! Positions from fcc Lattice and! Velocity from Maxwell-Boltzmann’s Distribution!subroutine init_conf(nom,temp,box,x,y,z,vx,vy,vz)implicit none
!! Declaration of Variables!integer :: nom,ncc,m,ix,iy,iz,iref,i,iseedreal(8) :: gaussreal(8) :: temp,box, &
x(*),y(*),z(*), &vx(*),vy(*),vz(*), &cell,cell2,rtemp, &sumvx,sumvy,sumvz,sumv2, &temp_conf,fs
!! Check # of Molecules!ncc=(nom/4)**(1.0/3.0)+0.1d0if(4*ncc**3 /= nom) stop "init_conf: Wrong # of Molecules!"
!! Positions of Molecules, fcc Lattice!cell=1.0d0/dble(ncc)cell2=0.5d0*cell
!x(1)=0.0d0y(1)=0.0d0z(1)=0.0d0
!x(2)=cell2y(2)=cell2z(2)=0.0d0
!x(3)=0.0d0y(3)=cell2z(3)=cell2
!x(4)=cell2y(4)=0.0d0z(4)=cell2
!! Construct Lattice from Unit Cell!m=0do iz=1,nccdo iy=1,nccdo ix=1,nccdo iref=1,4x(iref+m)=x(iref)+cell*dble(ix-1)y(iref+m)=y(iref)+cell*dble(iy-1)z(iref+m)=z(iref)+cell*dble(iz-1)enddom=m+4
enddoenddoenddo
60

!! Shift Positions!do i=1,nomx(i)=(x(i)-0.5d0)*boxy(i)=(y(i)-0.5d0)*boxz(i)=(z(i)-0.5d0)*boxenddo
!! Velocity from Maxwell-Boltzmann’s Distribution,! Total Momentum and Kinetic Energy!iseed=425001rtemp=dsqrt(temp)sumvx=0.0d0sumvy=0.0d0sumvz=0.0d0sumv2=0.0d0do i=1,nomvx(i)=rtemp*gauss(iseed)vy(i)=rtemp*gauss(iseed)vz(i)=rtemp*gauss(iseed)sumvx=sumvx+vx(i)sumvy=sumvy+vy(i)sumvz=sumvz+vz(i)sumv2=sumv2+vx(i)*vx(i)+vy(i)*vy(i)+vz(i)*vz(i)enddosumvx=sumvx/dble(nom)sumvy=sumvy/dble(nom)sumvz=sumvz/dble(nom)
!! Actual Temperature!temp_conf=sumv2/dble(3*nom-4)
!! Scaling Factor!fs=dsqrt(temp/temp_conf)
!! Remove Total Momentum and Scale Velocities!do i=1,nomvx(i)=fs*(vx(i)-sumvx)vy(i)=fs*(vy(i)-sumvy)vz(i)=fs*(vz(i)-sumvz)enddo
end subroutine init_conf!! Calculate Energy, Virial and Forces!subroutine force(nom,box,boxinv,rcutsq,U,W, &
x,y,z,fx,fy,fz, &myrank,nprocs)
implicit noneinclude ’mpif.h’ ! preprocessor directive
!! Declaration of Variables!integer :: nom,i,jreal(8) :: box,boxinv,rcutsq,U,W, &
xij,yij,zij,fxij,fyij,fzij, &rijsq,sr2,sr6,uij,wij,fij
real(8) :: x(*),y(*),z(*), &fx(*),fy(*),fz(*)
integer :: nprocs, & ! # of processes
61

myrank, & ! my process rankierr,ip
real(8) :: qU,qWreal(8) :: qfx(nom),qfy(nom),qfz(nom)
!! Zeroth Energy, Virial and Forces!qU=0.0d0qW=0.0d0qfx=0.0d0qfy=0.0d0qfz=0.0d0
!! Outer Cycle!do i=1+myrank,nom-1,nprocs
!! Inner Cycle!
do j=i+1,nom!! Distance Between Molecules!
xij=x(i)-x(j)yij=y(i)-y(j)zij=z(i)-z(j)
!! Periodic Boundary Conditions!
xij=xij-dnint(xij*boxinv)*boxyij=yij-dnint(yij*boxinv)*boxzij=zij-dnint(zij*boxinv)*box
!! Cut-Off!
rijsq=xij*xij+yij*yij+zij*zijif(rijsq < rcutsq) then
!! Auxiliary Variables!
sr2=1.0d0/rijsqsr6=sr2*sr2*sr2
!! Potential Energy!
uij=4.0d0*sr6*(sr6-1.0d0)qU=qU+uij
!! Virial!
wij=(-1.0d0)*24.0d0*sr6*(2.0d0*sr6-1.0d0)qW=qW-(wij/3.0d0)
!! Forces!
fij=(-1.0d0)*(wij/rijsq) ! - w(r_ij)/r_ij^2fxij=fij*xijfyij=fij*yijfzij=fij*zijqfx(i)=qfx(i)+fxijqfy(i)=qfy(i)+fyijqfz(i)=qfz(i)+fzijqfx(j)=qfx(j)-fxijqfy(j)=qfy(j)-fyijqfz(j)=qfz(j)-fzij
62

endifenddoenddo
!! Add Results Together!call MPI_ALLREDUCE(qfx,fx,nom,MPI_REAL8,MPI_SUM, &
MPI_COMM_WORLD,ierr)call MPI_ALLREDUCE(qfy,fy,nom,MPI_REAL8,MPI_SUM, &
MPI_COMM_WORLD,ierr)call MPI_ALLREDUCE(qfz,fz,nom,MPI_REAL8,MPI_SUM, &
MPI_COMM_WORLD,ierr)call MPI_ALLREDUCE(qU,U,1,MPI_REAL8,MPI_SUM, &
MPI_COMM_WORLD,ierr)call MPI_ALLREDUCE(qW,W,1,MPI_REAL8,MPI_SUM, &
MPI_COMM_WORLD,ierr)end subroutine force!! Leap-Frog Algorithm!subroutine Leap_Frog(nom,dt,temp,box,boxinv, &
x,y,z,vx,vy,vz,fx,fy,fz)implicit none
!! Declaration of Variables!integer :: nom,ireal(8) :: dt,temp,box,boxinv,sum_vx,sum_vy,sum_vz, &
K,temp_ac,betareal(8) :: x(*),y(*),z(*), &
vx(*),vy(*),vz(*), &fx(*),fy(*),fz(*)
!! Zeroth Accumulators!K=0.0d0sum_vx=0.0d0sum_vy=0.0d0sum_vz=0.0d0do i=1,nom
!! v_u(t)=v(t-dt/2)+(dt/2)*[f(t)/m]!
vx(i)=vx(i)+(dt/2.0d0)*fx(i)vy(i)=vy(i)+(dt/2.0d0)*fy(i)vz(i)=vz(i)+(dt/2.0d0)*fz(i)
!! Kinetic Energy!
K=K+vx(i)*vx(i)+vy(i)*vy(i)+vz(i)*vz(i)!! Total Momentum!
sum_vx=sum_vx+vx(i)sum_vy=sum_vy+vy(i)sum_vz=sum_vz+vz(i)enddosum_vx=sum_vx/dble(nom)sum_vy=sum_vy/dble(nom)sum_vz=sum_vz/dble(nom)
!! Actual Temperature!temp_ac=K/dble(3*nom-4)
!
63

! Scaling Factor!beta=dsqrt(temp/temp_ac)
!! v(t)=beta*v_u(t)! v(t+dt/2)=(2-1/beta)*v(t)+(dt/2)*[f(t)/m]! r(t+dt)=r(t)+dt*v(t+dt/2)!K=0.0d0do i=1,nom
!! v(t)=beta*v_u(t)!
vx(i)=beta*(vx(i)-sum_vx)vy(i)=beta*(vy(i)-sum_vy)vz(i)=beta*(vz(i)-sum_vz)
!! Kinetic Energy!
K=K+vx(i)*vx(i)+vy(i)*vy(i)+vz(i)*vz(i)!! v(t+dt/2)=(2-1/beta)*v(t)+(dt/2)*[f(t)/m]!
vx(i)=(2.0d0-(1.0d0/beta))*vx(i)+(dt/2.0d0)*fx(i)vy(i)=(2.0d0-(1.0d0/beta))*vy(i)+(dt/2.0d0)*fy(i)vz(i)=(2.0d0-(1.0d0/beta))*vz(i)+(dt/2.0d0)*fz(i)
!! r(t+dt)=r(t)+dt*v(t+dt/2)!
x(i)=x(i)+vx(i)*dty(i)=y(i)+vy(i)*dtz(i)=z(i)+vz(i)*dt
!! Periodic Boundary Conditions!
x(i)=x(i)-dnint(x(i)*boxinv)*boxy(i)=y(i)-dnint(y(i)*boxinv)*boxz(i)=z(i)-dnint(z(i)*boxinv)*boxenddo
end subroutine Leap_Frog!! Zeroth Thermo Accumulators!subroutine zero(sum_u,sum_P,ssq_u,ssq_P)implicit none
!! Declaration of Variables!real(8) :: sum_u,sum_P,ssq_u,ssq_P
!! Zeroth sum Accumulators!sum_u=0.0d0sum_P=0.0d0
!! Zeroth ssq Accumulators!ssq_u=0.0d0ssq_P=0.0d0
end subroutine zero!! Termodynamic Quantities!subroutine thermo(nom,temp,dens,vol,U,U_LRC,W,W_LRC,u_ac,P_ac, &
sum_u,sum_P,ssq_u,ssq_P)
64

implicit none!! Declaration of Variables!integer :: nomreal(8) :: temp,dens,vol,U,U_LRC,W,W_LRC,u_ac,P_ac, &
sum_u,sum_P,ssq_u,ssq_P!! Instantaneous Thermodynamic Quantities!u_ac=(U+U_LRC)/dble(nom) ! energy per particleP_ac=dens*temp+(W+W_LRC)/vol ! pressure
!! sum Accumulators!sum_u=sum_u+u_acsum_P=sum_P+P_ac
!! ssq Accumulators!ssq_u=ssq_u+u_ac**2ssq_P=ssq_P+P_ac**2
end subroutine thermo!! Output!subroutine output(kk,nstep,nrun,nom,rcut,temp,dens,vol,box, &
time,u_ac,P_ac,sum_u,sum_P,ssq_u,ssq_P)implicit none
!! Declaration of Variables!integer :: kk,nstep,nrun,nomreal(8) :: rcut,temp,dens,vol,box,time,u_ac,P_ac, &
sum_u,sum_P,ssq_u,ssq_P, &avr_u,avr_P,flc_u,flc_P
if(kk == 1) then!! Initial Output!
write(*,*) " *** Initial Output ***"write(*,fmt="(a,e13.5)") "Temperature: ",tempwrite(*,fmt="(a,e13.5)") "Density: ",denswrite(*,*)write(*,fmt="(a,i4)") "# of Molecules: ",nomwrite(*,fmt="(a,e13.5)") "Cut-Off Distance: ",rcutwrite(*,fmt="(a,e13.5)") "Volume of Box: ",volwrite(*,fmt="(a,e13.5)") "Length of Box: ",boxreturnendifif(kk == 2) then
!! Periodic Output!
write(*,*)write(*,fmt="(a,i8,a,e13.5)") " # of time steps:",nstep, &
" time:",timewrite(*,fmt="(5(a))") " u* "," P*"write(*,fmt="(8(e13.5))") u_ac,P_acwrite(*,fmt="(8(e13.5))") sum_u/dble(nstep),sum_P/dble(nstep)returnendifif(kk == 3) then
!! Final Output
65

!! Ensemble Averages!
avr_u=sum_u/dble(nrun)avr_P=sum_P/dble(nrun)
!! Ensemble Fluctuations!
flc_u=dsqrt(dabs((ssq_u/dble(nrun))-avr_u**2))flc_P=dsqrt(dabs((ssq_P/dble(nrun))-avr_P**2))write(*,*)write(*,*) " *** Final Output ***"write(*,*) " Ensemble Averages"write(*,fmt="(5(a))") " u* "," P*"write(*,fmt="(8(e13.5))") avr_u,avr_Pwrite(*,*) " Ensemble Fluctuations"write(*,fmt="(5(a))") " u* "," P*"write(*,fmt="(8(e13.5))") flc_u,flc_Preturnendif
end subroutine output!! Read from File!subroutine readcn(nmax,x,y,z,vx,vy,vz,cnfile)implicit none
!! Declaration of Variables!integer :: nmaxreal(8) :: x(nmax),y(nmax),z(nmax), &
vx(nmax),vy(nmax),vz(nmax)integer,parameter :: cnunit=10character(len=*) :: cnfile
!! Unformatted File!open(unit=cnunit,file=cnfile,status="old",form="unformatted")read(cnunit) x,y,zread(cnunit) vx,vy,vzclose(unit=cnunit)
end subroutine readcn!! Write to File!subroutine writcn(nmax,x,y,z,vx,vy,vz,cnfile)implicit none
!! Declaration of Variables!integer :: nom,nmaxreal(8) :: x(nmax),y(nmax),z(nmax), &
vx(nmax),vy(nmax),vz(nmax)integer,parameter :: cnunit=10character(len=*) :: cnfile
!! Unformatted File!open(unit=cnunit,file=cnfile,status="unknown",form="unformatted")write(cnunit) x,y,zwrite(cnunit) vx,vy,vzclose(unit=cnunit)
end subroutine writcn!! RANDOM VARIATE FROM THE STANDARD NORMAL DISTRIBUTION.
66

! THE DISTRIBUTION IS GAUSSIAN WITH ZERO MEAN AND UNIT VARIANCE.! KNUTH D, THE ART OF COMPUTER PROGRAMMING, ADDISON-WESLEY, 1978!function gauss(iseed)implicit none
!! Declaration of Variables!integer :: iseed,Ireal(8) :: gaussreal(8),parameter :: A1=3.949846138d0,A3=0.252408784d0, &
A5=0.076542912d0,A7=0.008355968d0, &A9=0.029899776d0
real(8) :: SUM,R,R2!SUM=0.0d0do I=1,12SUM=SUM+dble(ran(iseed))enddo
!R=(SUM-6.0d0)/4.0d0R2=R*Rgauss=((((A9*R2+A7)*R2+A5)*R2+A3)*R2+A1)*R
end function gauss
67

Reference
[1] Y. Aoyama, J. Nakano, RS/6000: Practical MPI Programming, International Techni-cal Support Organization, 1999.
[2] W. Gropp, E. Lusk, A. Skjellum, Using MPI. Portable Parallel Programming with theMessage-Passing Interface, 2. vydání, MIT Press, 1999.
[3] P. S. Pacheco, W. C. Ming, MPI Users’ Guide in FORTRAN, 1997.
[4] P. S. Pacheco, A Users’ Guide to MPI, 1998.
[5] MPI: A Message-Passing Interface Standard, verze 1, 1995.
[6] MPI-2: Extension to the Message-Passing Interface, verze 2, 1997.
68