Embed Size (px)
Citation preview

Pentaho データ統合 4.1 ユーザーガイド
Pentaho データ統合 4.1
ユーザーガイド
株式会社 KSK ソリューションズ

Pentaho データ統合 4.1 ユーザーガイド
~ i ~
目次
イントロダクション ................................................................................................................................... 1
このガイドの対象と前提条件 ................................................................................................................. 1
このガイドの内容 ................................................................................................................................... 2
Pentaho データ統合アーキテクチャ .......................................................................................................... 2
Pentaho データ統合コンポーネント ...................................................................................................... 3
Pentaho データ統合の起動 ........................................................................................................................ 3
Pentaho データ統合サーバーを起動する ............................................................................................... 4
Spoon を起動する ................................................................................................................................... 4
リポジトリへの接続 ............................................................................................................................... 4
コンテンツの分類方法 ........................................................................................................................ 5
インタフェースの紹介 ............................................................................................................................... 6
パースペクティブの紹介 ........................................................................................................................ 6
データ変換(ETL)パースペクティブ ................................................................................................... 7
Modeling(モデリング)パースペクティブ ........................................................................................... 9
Visualization(ビジュアライズ)パースペクティブ ............................................................................ 10
Spoon インタフェースのカスタマイズ ................................................................................................. 11
用語と基本的なコンセプト ...................................................................................................................... 14
データ変換、ステップ、およびホップ ................................................................................................ 14
ジョブ ................................................................................................................................................... 15
ホップの詳細 ........................................................................................................................................ 16
最初のデータ変換を作成する ............................................................................................................... 20
データ変換の保存 ................................................................................................................................. 22
データ変換をローカルで実行する ....................................................................................................... 22
ジョブの構築 ........................................................................................................................................ 23
データ変換の実行 ................................................................................................................................. 24
スレーブサーバーのセットアップ ....................................................................................................... 24
データ変換とジョブをリモートで実行 ................................................................................................ 26
クラスタスキーマを作成する ............................................................................................................... 28
クラスタでデータ変換を実行する ....................................................................................................... 29
インパクト解析 ..................................................................................................................................... 29
エンタープライズリポジトリでコンテンツを管理する ....................................................................... 29
エンタープライズリポジトリを追加する............................................................................................. 30
エンタープライズリポジトリの詳細を編集する .................................................................................. 30
エンタープライズリポジトリ/Kettle データベースリポジトリを削除する ......................................... 31
エンタープライズリポジトリでコンテンツを管理する ....................................................................... 31
フォルダーレベルパーミッションの設定............................................................................................. 32
バージョン履歴を使用する .................................................................................................................. 33
バージョン履歴を確認する ............................................................................................................... 33
データ変換またはジョブを以前保存したバージョンに戻す ............................................................ 34
マッピング(Mapping)ステップでデータ変換フローを再び利用する ................................................. 35
変数を使用する ........................................................................................................................................ 36
変数の範囲 ............................................................................................................................................ 37

Pentaho データ統合 4.1 ユーザーガイド
~ ii ~
環境変数 ............................................................................................................................................ 37
Kettle 変数 ......................................................................................................................................... 37
内部変数 ................................................................................................................................................ 37
Pentaho データ統合でプロトタイピング ................................................................................................ 38
PDI データソース以外でプロトタイプスキーマを作成する ................................................................ 38
PDI データソースでプロトタイプスキーマを作成する ....................................................................... 39
Pentaho 分析レポートとレポートウィザードをテストする................................................................ 39
実稼働環境におけるプロトタイプ ....................................................................................................... 40
接続の管理 ................................................................................................................................................ 40
JDBC ドライバーを追加する ............................................................................................................... 41
データベース接続を定義する ............................................................................................................... 42
JNDI 接続を使用する ............................................................................................................................ 43
Carte と Spoon JNDI 接続を使用する .............................................................................................. 43
データベース特有のオプション ........................................................................................................... 44
データベース特有のオプションを追加す ......................................................................................... 44
データベース接続の高度な設定 ........................................................................................................... 44
引用に関する詳細 ................................................................................................................................. 45
接続プーリング ..................................................................................................................................... 45
クラスタリング ..................................................................................................................................... 46
接続の編集、複製、コピー、削除 ....................................................................................................... 46
Hadoop を使用する .................................................................................................................................. 48
Hadoop ジョブプロセスフロー ............................................................................................................ 48
Hadoop データ変換プロセスフロー ..................................................................................................... 50
Hadoop から PDI データ型への変換 ................................................................................................... 51
データ変換とジョブのスケジューリング ................................................................................................ 52
データ変換ステップ リファレンス ......................................................................................................... 53
Hadoop ................................................................................................................................................. 54
入力 ....................................................................................................................................................... 54
出力 ....................................................................................................................................................... 54
変換 ....................................................................................................................................................... 55
フロー ................................................................................................................................................... 55
参照 ....................................................................................................................................................... 55
結合 ....................................................................................................................................................... 55
データウェアハウス ............................................................................................................................. 55
統計 ....................................................................................................................................................... 55
スクリプト ............................................................................................................................................ 56
CSV 入力 ................................................................................................................................................... 57
CSV 入力 オプション ........................................................................................................................... 57
Excel 入力................................................................................................................................................ 59
ファイル タブ ...................................................................................................................................... 59
シート タブ .......................................................................................................................................... 59
全般 タブ .............................................................................................................................................. 59
エラー処理タブ ..................................................................................................................................... 60
フィールド タブ ................................................................................................................................... 60
追加出力フィールド タブ .................................................................................................................... 61

Pentaho データ統合 4.1 ユーザーガイド
~ iii ~
Excel 出力................................................................................................................................................ 62
ファイル タブ ...................................................................................................................................... 62
全般 タブ .............................................................................................................................................. 62
フィールド タブ ................................................................................................................................... 63
固定幅ファイル入力 ................................................................................................................................. 64
固定幅ファイル入力オプション ........................................................................................................... 64
行生成 ....................................................................................................................................................... 65
行生成 オプション ............................................................................................................................... 65
Google Analytics 入力 ........................................................................................................................... 66
認証 ....................................................................................................................................................... 66
クエリ ................................................................................................................................................... 66
フィールド ............................................................................................................................................ 66
Google Docs 入力 .................................................................................................................................... 67
ファイル ................................................................................................................................................ 67
シート ................................................................................................................................................... 67
内容 ....................................................................................................................................................... 67
エラーハンドリング ............................................................................................................................. 68
フィールド ............................................................................................................................................ 68
テーブル入力 ............................................................................................................................................ 69
テーブル入力 オプション .................................................................................................................... 69
テキストファイル入力 ............................................................................................................................. 70
JMS コンシューマ ..................................................................................................................................... 76
JMS コンシューマ オプション .............................................................................................................. 76
JMS プロデューサー ................................................................................................................................. 78
JMS プロデューサー Options ............................................................................................................... 78
テーブル出力 ............................................................................................................................................ 80
テキストファイル出力 ............................................................................................................................. 82
テキストファイル出力 ............................................................................................................................. 82
ファイル タブ ...................................................................................................................................... 82
全般 タブ .............................................................................................................................................. 82
フィールド タブ ................................................................................................................................... 83
選択/名前変更 .......................................................................................................................................... 85
選択フィールド タブ ........................................................................................................................... 85
除去フィールド ..................................................................................................................................... 85
メタ情報 ................................................................................................................................................ 85
ダミー(何もしない) ............................................................................................................................. 87
フィルター ................................................................................................................................................ 88
Filter Row Options ............................................................................................................................. 88
変数からの値に基づいての行のフィルタ ............................................................................................ 88
データベース参照 ............................................................................................................................. 90
ストリーム参照 ........................................................................................................................................ 91
ストリーム参照 オプション ................................................................................................................ 91
ウェブサービス参照 ................................................................................................................................. 92
基本的な Web Services - Web Service Lookup ステップ ................................................................. 92
行結合(デカルト積) ............................................................................................................................. 93

Pentaho データ統合 4.1 ユーザーガイド
~ iv ~
行マージ(比較) ..................................................................................................................................... 94
コンビネーション 参照/更新 .................................................................................................................. 95
コンビネーション 参照/更新 オプション .......................................................................................... 95
ディメンジョン 参照/更新 ...................................................................................................................... 98
Lookup ................................................................................................................................................... 99
Update ................................................................................................................................................... 99
グループ化 .............................................................................................................................................. 103
グループ化 オプション ...................................................................................................................... 103
JAVA スクリプト ..................................................................................................................................... 104
Java スクリプト関数 .......................................................................................................................... 104
Java スクリプト .................................................................................................................................. 104
フィールド .......................................................................................................................................... 104
ボタン ................................................................................................................................................. 104
Java スクリプト内部 API オブジェクト ........................................................................................... 104
Advanced Web Services – JAVAスクリプト と HTTP Post ステップ ............................................. 105
Hadoop File Input ................................................................................................................................. 106
ファイル タブ .................................................................................................................................... 106
全般 タブ ............................................................................................................................................ 107
エラー処理 タブ ................................................................................................................................. 108
フィルタ タブ .................................................................................................................................... 109
フィールド タブ ................................................................................................................................. 109
Hadoop File Output ................................................................................................................................112
ファイル タブ .....................................................................................................................................112
全般 タブ .............................................................................................................................................112
フィールド タブ ..................................................................................................................................113
S3 File Output .......................................................................................................................................115
ファイル タブ .....................................................................................................................................115
全般 タブ .............................................................................................................................................115
フィールド タブ ..................................................................................................................................116
RSS 入力 ..................................................................................................................................................117
全般 タブ .............................................................................................................................................117
コンテンツ タブ ..................................................................................................................................117
フィールド タブ ..................................................................................................................................117
エラー処理に関する注意点 .................................................................................................................118
ジョブステップ リファレンス ...............................................................................................................119
全般 ......................................................................................................................................................119
メール ..................................................................................................................................................119
条件 ......................................................................................................................................................119
スクリプト ...........................................................................................................................................119
ファイル管理 .......................................................................................................................................119
ファイル転送 .......................................................................................................................................119
Hadoop ................................................................................................................................................. 120
Start ....................................................................................................................................................... 121
Dummy ....................................................................................................................................................... 122
ジョブ ..................................................................................................................................................... 123

Pentaho データ統合 4.1 ユーザーガイド
~ v ~
ジョブ詳細 .......................................................................................................................................... 123
拡張 ..................................................................................................................................................... 123
ログ設定 .............................................................................................................................................. 124
引数名 ................................................................................................................................................. 124
パラメータ .......................................................................................................................................... 124
データ変換 ...................................................................................................................................... 125
変換ジョブの詳細 ............................................................................................................................... 125
拡張 ..................................................................................................................................................... 125
ログ設定 .............................................................................................................................................. 126
引数名 ................................................................................................................................................. 126
パラメータ .......................................................................................................................................... 126
メール ..................................................................................................................................................... 127
アドレス .............................................................................................................................................. 127
サーバ ................................................................................................................................................. 127
メッセージ .......................................................................................................................................... 128
添付ファイル ...................................................................................................................................... 128
ファイル確認 .......................................................................................................................................... 130
テーブル確認 .......................................................................................................................................... 131
Java スクリプト ..................................................................................................................................... 132
シェル ..................................................................................................................................................... 133
全般 ..................................................................................................................................................... 133
スクリプト .......................................................................................................................................... 134
SQL .......................................................................................................................................................... 135
HTTP......................................................................................................................................................... 136
FTP ファイル取得 ................................................................................................................................... 137
一般 ..................................................................................................................................................... 137
ファイル .............................................................................................................................................. 137
拡張 ..................................................................................................................................................... 138
Socks Proxy ........................................................................................................................................ 138
SFTP ファイル取得 .................................................................................................................................. 140
Hadoop Copy Files ................................................................................................................................. 141
全般 ..................................................................................................................................................... 141
結果ファイル名 ................................................................................................................................... 141
Hadoop Job Executor ............................................................................................................................. 142
General ............................................................................................................................................... 142
ジョブ設定 .......................................................................................................................................... 142
クラスター .......................................................................................................................................... 142
Hadoop Transformation Job Executor ................................................................................................. 144
一般 ..................................................................................................................................................... 144
Map/Reduce .......................................................................................................................................... 144
ジョブ設定 .......................................................................................................................................... 144
クラスター .......................................................................................................................................... 145
Amazon EMR Job Executor ...................................................................................................................... 146

Pentaho データ統合 4.1 ユーザーガイド
~ 1 ~
©株式会社 KSK ソリューションズ
イントロダクション
Pentaho データ統合(PDI)は、データベース、ファイル、アプリケーション等の異なるデータソースから
データを集め、エンドユーザーにとって適切で統一されたフォーマットに変換する柔軟なツールです。
Pentaho データ統合は、正しいデータを取得し、データのクレンジングをして、一貫性のあるフォーマ
ットを使用してデータをソートするプロセスを進める Extraction(抽出)、Transformation(変換)、Loading
(ロード)エンジンを提供します。
Pentaho データ統合は slowly changing dimensions(以下を参照)、データウェアハウスのための代理キ
ーをサポートし、データベースとアプリケーションの間のデータの移行を可能にし、巨大なデータベー
スのロードに耐えうる柔軟性を持っていて、さらにクラウド、クラスタリング、大規模な並列処理環境
を十分に活用することができます。
最終的に、Pentaho Reporting のためのデータソースとして ETL を利用することができます。
とてもシンプルなものから複雑なものまで広範にわたるデータ変換ステップを使用して、データのクレ
ンジングをすることができます。最終的には、Pentaho レポートのデータソースとして ETL を利用可能
です。
注意: ディメンションとは製品、顧客、または地理情報といったデータの論理的なグルーピングのこと
を指すデータウェアハウス用語です。Slowly Changing Dimensions(SCD)時間とともにゆっくりと
変化するディメンションのことです。例えば多くの場合、従業員の役職は時間が経つにつれゆっくりと
変化します。
Pentaho データ統合の一般的な利用方法:
・ 異なるデータベースやアプリケーション間でのデータを移行する。
・ クラウド、クラスタリング、大規模な並列処理環境を十分に活用して膨大なデータセットをロード
する。
・ とてもシンプルなものから複雑なものまで様々なデータ変換ステップを使用して、データのクレン
ジングを行う。
・ Pentaho レポーティングのデータソースとしてリアルタイム ETL を利用できる機能を含むデータ
統合。
・ slowly changing dimensions のための組み込みサポートによるデータウェアハウスポピュレーショ
ンと代理キーの作成(上で説明したように)。
このガイドの対象と前提条件
このガイドは、ETL に関する高度な知識と Pentaho データ統合エンタープライズエディションの特徴と
機能を理解されている、IT マネージャー、データベース管理者、ビジネスインテリジェンスソリューシ
ョン設計者の方に向けたものです。
本ドキュメント中のステップ関連の情報を検証される場合は、Pentaho データ統合 4.0(またはそれ以
降)をインストールする必要があります。
Pentaho データ統合を初めてご使用される場合
Pentaho を初めてご利用される場合は、「Pentaho データ統合 4.0 評価ガイド」から開始されることをお
すすめします。Petaho データ統合で必要な基本的な操作技術を確認されてからこちらのドキュメント
をご利用ください。

Pentaho データ統合 4.1 ユーザーガイド
~ 2 ~
©株式会社 KSK ソリューションズ
このガイドの内容
このドキュメントは最もよく使用されるステップに関する情報が記載されています。140 以上のデータ
変換ステップと 60 以上のジョブエントリが Pentaho データ統合には存在します。将来的には、このガ
イドでさらに多くの PDI ステップやジョブをカバーしていく予定です。
Pentaho データ統合の管理や LDAP や MSAD 関連のセキュリティについての情報は「Pentaho データ
統合管理者ガイド」と「Pentaho セキュリティガイド」を参照ください。
Pentaho データ統合アーキテクチャ
Pentahoデータ統合エンタープライズエディション以下の図で示すコンポーネントで構成されています。
Spoon は ETL ジョブとデータ変換を構築するためのデザインインタフェースです。Spoon はローカル
上にある Spoon、データ統合専用サーバーまたはクラスターサーバー上で実行するデータ変換で行いた
いことを、ドラッグ・アンド・ドロップでグラフィカルに表現できます。
データ統合サーバー(Data Integration Server)は ETL 専用サーバーで主に以下の機能があります。:
エンタープライズコンソール(Enterprise Console)は、エンタープライズエディションライセンスの
管理を含め、Pentaho データ統合エンタープライズエディションのデプロイメントを管理するためのシ
ンクライアントです。これには、エンタープライズエディションライセンスの管理、リモート Pentaho
データ統合サーバーでのアクティビティの監視と制御、登録したジョブやデータ変換に関するパフォー
実行 Pentaho データ統合エンジンを使用して、ETL ジョブとデータ変換を実行します。
セキュリティ ユーザーやロール(デフォルトセキュリティ)の管理や、LDAP や Active Directory といった既
存のセキュリティプロバイダーにセキュリティを統合することができます。
コンテンツ管理 ジョブとデータ変換をまとめて保存・管理する機能があります。これにはコンテンツの全履歴
の閲覧や共同開発環境のための共有とロックといった機能があります。
スケジューリング Spoon デザイン環境から、データ統合サーバー上のアクティビティをスケジュール・監視がで
きるサービスを提供しています。

Pentaho データ統合 4.1 ユーザーガイド
~ 3 ~
©株式会社 KSK ソリューションズ
マンスの傾向の分析などが可能です。
Pentaho データ統合コンポーネント
Pentaho データ統合は以下の主なコンポーネントで構成されます。:
Spoon. これより前で説明されたように、Spoon はデータ変換とジョブのためのグラフィカルインタフ
ェースとエディタを使用するデスクトップアプリケーションです。Spoon は複雑な ETL ジョブをコー
ドの読み書きなしで作成することができます。Pentaho データ統合の製品というと、Spoon がまず初め
に思い浮かびます。これはデータベース開発者の方が、一番多くの時間ご利用になるアプリケーション
です。Spoon を使っていつでもデータ変換またはジョブを作成、編集、実行、そしてデバッグすること
が可能です。
Pan. Spoon で作成したデータ変換とジョブを実行する際に使用できる、スタンドアロンのコマンドラ
イン処理です。データ変換エンジンの Pan はデータの読み込みと書き込みにおいて様々なデータソース
に対応しています。また、Pan ではデータを操作することもできます。
Kitchen. ジョブの実行で使用できるスタンドアロンのコマンドライン処理です。XML またはデータベ
ースリポジトリのどちらかにある、Spoon グラフィカルインタフェースで設計されたジョブを実行する
プログラムです。通常、ジョブは一定間隔のバッチモードで実行するようにされます。
Carte. Carte は専用/リモート ETL サーバーをセットアップできる軽量の Web コンテナです。データ統
合サーバー同様のリモート実行機能を持っていますが、スケジュール、セキュリティ統合、およびコン
テンツ管理システムといった機能は持っていません。
これら料理に関連する語の意味
Pentaho のご利用を開始されたばかりであれば、時折 Pentaho データ統合が「Kettle」と呼ばれている
のを見たり聞いたりされたかもしれません。混乱を避けるために、Pentaho データ統合はオープンソー
スプロジェクトとして、「Kettle」と呼ばれています。K.E.T.T.L.E という語は、Kettle Extraction
Transformation Transport Load Environment を略したものです。Pentaho が Kettle を買収した際に、
Pentaho データ統合(Pentaho Data Integration)に名前が変更されました。Spoon, Pan, Kitchen といっ
た他の PDI コンポーネントは、元々ETL で提供されるものをレストランに関連づけて名前を付けられて
います。
Pentaho データ統合の起動
Pentaho データ統合をインストールしたルートディレクトリである¥pdi-ee にはデータ統合サーバー
(Data Integration Server)やエンタープライズコンソール(Enterprise Console)を含むすべてのコ
アサーバーモジュールの起動・停止を簡単に行えるスクリプトが含まれています。
Windows へ BI サーバーをインストールした際にインストールされた Pentaho データ統合を使用してい
る場合、スタート(Start)→プログラム(Programs)を使用して、BI Server(BI サーバー)、Data Integration
Server(データ統合サーバー)、および design tool(デザインツール: データ統合で使用するのは Spoon)
を起動してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 4 ~
©株式会社 KSK ソリューションズ
ファイルパスは利用したインストール方法によって異なります。インストーラを使用した場合のファイ
ルパスは以下の例のようになります。:
...¥pentaho¥server¥data-integration-server, ...¥pentaho¥design-tools¥data-integration.
.zip または.tar からのインストールではファイルパスは以下の例のようになります。:
...¥pdi-ee¥data-integration
Pentaho データ統合サーバーを起動する
Pentaho データ統合サーバーを起動するには…
1. Pentaho データ統合をインストールしたフォルダーに移動します。例えば… ...¥Program
Files¥pdi-ee
2. start-servers.bat をダブルクリックして、サーバーを起動してください。
注意: Linux または Macintosh を利用している場合は、start-servers.sh をダブルクリックしてください。
Spoon を起動する
Spoon を起動するには…
1. Pentaho データ統合をインストールしたフォルダーに移動します。例えば… ...¥Program
Files¥pdi-ee
2. launch-designer.bat をダブルクリックして、サーバーを起動します。
注意: Linux を使用している場合は、launch-designer.sh をダブルクリックしてください。Mac を
使用している場合は、Spoon アイコンをクリックしてください。32 ビットのデバイス上では、斜
めの線が入った Spoon アイコンをご利用ください。
リポジトリへの接続
デザイナー(Spoon)を起動する度に、Pentaho エンタープライズリポジトリへのログインを求めるリ
ポジトリ接続ダイアログボックスが表示されます。Pentaho エンタープライズリポジトリは、ETL ジョ
ブとデータ変換をまとめて保存する場所を提供します。作業を始める前に、リポジトリにアクセスする

Pentaho データ統合 4.1 ユーザーガイド
~ 5 ~
©株式会社 KSK ソリューションズ
ためのユーザー名とパスワードが必要です。
注意: 実稼動環境で、Pentaho データ統合へのユーザーアクセスはおそらく LDAP かカスタム認証サー
バーを使用して確立されます。Pentaho データ統合のための LDAP と MSAD セットアップに関する情
報は、「セキュリティガイド」を参照ください。
デザイナーを開くごとにリポジトリ接続ダイアログボックスを表示させたくない場合は、「スタート時
にこのダイアログを表示する」というチェックボックスを無効にしてください。
エンタープライズリポジトリへ接続するには…
1. リポジトリ接続ダイアログボックスの中で、 (追加)をクリックしてください。
2. 「エンタープライズレポジトリ:Enterprise Repository」を選択して、OK をクリックしてくださ
い。リポジトリ設定ダイアログボックスが表示されます。
3. ご利用のリポジトリで使用される URL を入力してください。ご利用のレポジトリの ID と名前
(Name)を入力してください。
4. Test(テスト)をクリックして、接続が適切に設定されていることを確認してください。 エラー
メッセージが表示された場合は、データ統合サーバーが起動していて、リポジトリ URL が正しい
ことを確認してください。
5. OK をクリックして、Success(成功)ダイアログボックスを閉じてください。
6. OK をクリックして、リポジトリ設定ダイアログボックスを終了してください。利用できるリポジ
トリのリストに新規接続が表示されていることを確認してください。
7. Pentaho エンタープライズリポジトリの認証情報、ユーザー名、およびパスワードを入力してくだ
さい。それから、OK をクリックしてください。
コンテンツの分類方法
Pentaho データ統合は以下で説明されるように、2 つの方法でデータ変換、ジョブ、およびデータベー
ス接続を分類します。:
・ Pentaho エンタープライズリポジトリ ‐
コンテンツ管理、共同開発、強力なセキュリティ等を提供する Pentaho エンタープライズリポジト
リに、ジョブ、データ変換、データベース接続を保存することができます。
・ ファイルベース –
共同チームに参加していない場合や、Pentaho エンタープライズレポジトリに関連する付帯的コス
トを避けたい場合、ジョブやデータ変換をファイルとしてローカルデバイスに保存できます。デー
タベース接続情報がジョブまたはデータ変換と一緒に保存されます。このオプションを選択する場
合、ジョブ(.kjb)とデータ変換(.ktr)は XML 形式で保存されます。

Pentaho データ統合 4.1 ユーザーガイド
~ 6 ~
©株式会社 KSK ソリューションズ
注意: 既に Pentaho データ統合をご利用いただいている場合は、前のバージョンで使用されていた
Kettle データベースレポジトリを代わりに使用できないので、ご注意ください。アップグレードに関す
る説明は、「Pentaho データ統合アップグレードガイド」を参照ください。
インタフェースの紹介
ようこそページはドキュメント、Pentaho データ統合プロジェクトにかかわるコミュニティ、Pentaho
データ統合プロジェクトへの貢献者のブログ等へのリンクが貼ってあります。
パースペクティブの紹介
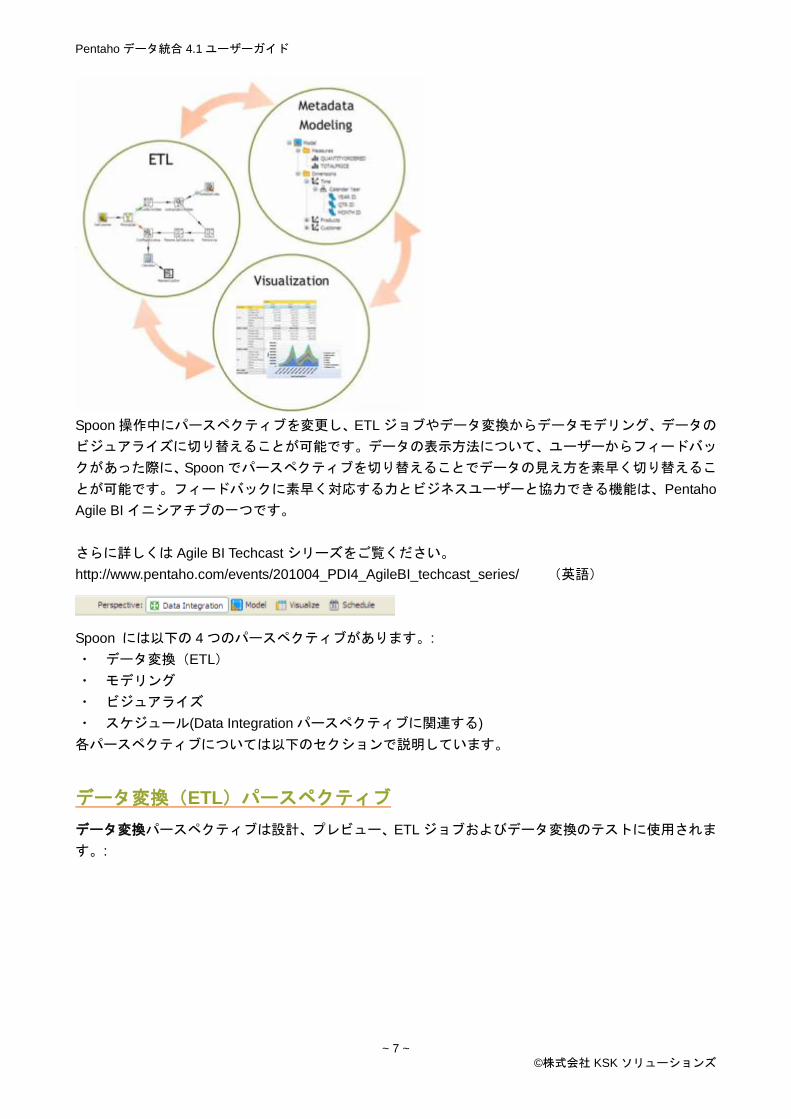
Pentaho データ統合では、ETL、モデリング、ビジュアライズを含んだツールを 1 つの統合された Spoon
インタフェースという環境で提供しています。この統合された環境では、BI 開発者の方がビジネスイン
テリジェンス・ソリューションを素早く・効果的に構築するために、ビジネスユーザーの方と緊密に連
携していくことが可能です。
Pentaho データ統合 4.1 ユーザーガイド
~ 7 ~
©株式会社 KSK ソリューションズ
Spoon 操作中にパースペクティブを変更し、ETL ジョブやデータ変換からデータモデリング、データの
ビジュアライズに切り替えることが可能です。データの表示方法について、ユーザーからフィードバッ
クがあった際に、Spoon でパースペクティブを切り替えることでデータの見え方を素早く切り替えるこ
とが可能です。フィードバックに素早く対応する力とビジネスユーザーと協力できる機能は、Pentaho
Agile BI イニシアチブの一つです。
さらに詳しくは Agile BI Techcast シリーズをご覧ください。
http://www.pentaho.com/events/201004_PDI4_AgileBI_techcast_series/ (英語)
Spoon には以下の 4 つのパースペクティブがあります。:
・ データ変換(ETL)
・ モデリング
・ ビジュアライズ
・ スケジュール(Data Integration パースペクティブに関連する)
各パースペクティブについては以下のセクションで説明しています。
データ変換(ETL)パースペクティブ
データ変換パースペクティブは設計、プレビュー、ETL ジョブおよびデータ変換のテストに使用されま
す。:

Pentaho データ統合 4.1 ユーザーガイド
~ 8 ~
©株式会社 KSK ソリューションズ
データ統合パースペクティブは下の表で表されるコンポーネントで構成されています。:
データ変換パースペクティブのツールバーアイコン
コンポーネント名 概要
1 メニューバー メニューバーではプロパティ、アクション、ツールなどの一般的な機能にアクセスできます。
2 メインツールバー メインツールバーは新規ファイルの作成、既存のドキュメントを開く、保存、名前を付けて保存
といった一般的なアクションへクリックすることでアクセスできます。
データ変換パースペクティブ(上の画像で表示されています)は ETL データ変換とジョブを作成
するために使用されます。スケジュールパースペクティブ(ここでは表示されていません)は、デ
ータ変換パースペクティブに関係して、データ統合サーバーでスケジュールされた ETL アクティ
ビティを管理するために使用されます。
3 デザインパレット データ変換パースペクティブ中にある、デザインパレットはデータ変換とジョブを構築するため
に使用するデータ変換ステップとジョブエントリの全リストがあります。データ変換はデザイン
パレットからグラフィカルワークスペースまたはキャンバスにデータ変換ステップをドラッグ
して、データフローを表現するためにステップどうしをホップで結んで作成できます。
4 グラフィカルワー
クスペース
グラフィカルワークスペースまたはキャンバスは、実行したい ETL アクティビティを表現するデ
ータ変換やジョブのためのメインデザインエリアです。
5 サブツールバー サブツールバーは、特にデータ変換またはジョブの実行、プレビュー、デバッグといった一般的
なアクションに素早くアクセスするためのボタンがあります。
アイコン 概要
新規ジョブまたはデータ変換を作成します。
リポジトリに接続していない場合はファイルから、リポジトリに接続している場合はレポジトリからデータ
変換/ジョブを開きます。

Pentaho データ統合 4.1 ユーザーガイド
~ 9 ~
©株式会社 KSK ソリューションズ
Modeling(モデリング)パースペクティブ
モデリングパースペクティブは、ビジュアライズパースペクティブ内でテストされるか、Pentaho BI
サーバーにパブリッシュすることのできる、レポートや OLAP メタデータモデル設計するために使用さ
れます。
レポジトリを照会します。
データ変換/ジョブファイルをファイルまたはレポジトリに保存します。
データ変換/ジョブを別名で保存します。(別名で保存)
データ変換/ジョブを実行します。XML ファイルまたはリポジトリからカレントデータ変換を実行します。
データ変換を一時停止します。
データ変換を停止します。
データ変換をプレビューします。メモリからカレントデータ変換を実行します。選択されたステップで生成
される行をプレビューすることができます。
デバッグモードでデータ変換を実行します。実行エラーのトラブルシューティングが行えます。
データ変換処理を再実行します。
データ変換の確認をします。
データベースへの影響分析を実行します。
データ変換の実行に必要な SQL を生成します。
データのプレビュー、SQL クエリー、DDL の生成などを行うためのデータベースエクスプローラを起動し
ます。
実行結果エリアを非表示にします。
データ変換をロックします。

Pentaho データ統合 4.1 ユーザーガイド
~ 10 ~
©株式会社 KSK ソリューションズ
Visualization(ビジュアライズ)パースペクティブ
ビジュアライズパースペクティブは、レポートデザインウィザードやアナライザークライアントをそれ
ぞれ使用してモデルパースペクティブで作成された、レポートや OLAP メタデータモデルを確認するこ
とができます。
コンポーネント名 概要
1 メニューバー メニューバーではプロパティ、アクション、ツールなどの一般的な機能にアクセスできます
2 メインツールバー メインツールバーは新規ファイル作成、ファイルを開く、名前を付けて保存といった、一般的
な機能にワンクリックでアクセスできます。メインツールバーの右側ではパースペクティブ間
を切り替えることが可能です。
3 データエリア OLAP ディメンショナルモデル内でメジャーまたはディメンションレベル(属性)のいずれか
として利用できるデータソースから、利用できるフィールドのリストを表示します。
4 モデルエリア データパネルのフィールドからアナリシスキューブのメジャーとディメンションを作成するた
めに使用します。データパネルから Model(モデル)ツリーの Measures(メジャー)または
Dimension(ディメンション)フォルダーにフィールドをドラッグして、新規メジャーまたは
ディメンジョンを作成します。
5 プロパティエリア Model(モデル)エリアツリーで選択したものに関連するプロパティを変更するために使用さ
れます。
コンポーネント名 概要

Pentaho データ統合 4.1 ユーザーガイド
~ 11 ~
©株式会社 KSK ソリューションズ
Spoon インタフェースのカスタマイズ
Kettle のオプションでは、Spoon インタフェースの動作や外観に関連するプロパティをカスタマイズす
ることができます。例えば今日のヒントやようこそページ、を表示させるかどうかや、フォントや色と
いったユーザーインタフェースのオプション等があります。オプションを利用するには、メニューバー
でツール→オプションを選択してください。
以下の表では一般と外観タブオプションに関してそれぞれ説明しています。最初に設定されたデフォル
トオプションのままにしておくこともできます。Pentahoデータ統合をより快適にご利用いただくには、
必要に応じてオプションを設定してください。
一般
1 メニューバー メニューバーではプロパティ、アクション、ツールなどの一般的な機能にアクセスできます
2 メインツールバー メインツールバーは新規ファイルの作成、既存のドキュメントを開く、保存、名前を付けて保
存といった一般的なアクションへワンクリックでアクセスできます。メインツールバーの右側
でパースペクティブを切り換えることができます。
3 フィールドリスト フィールドリストにはモデルで定義されたメジャーと属性のリストが含まれています。これら
のフィールドはクエリーを作成するためにレポートエリアにドラッグすることができます。
4 レポートエリア クエリーを作成するためにフィールドリストからフィールドをドラッグします。レポートのサ
ブトータル、フォーマット等をさらにカスタマイズするにはメジャーまたはレベルを右クリッ
クしてください。
5 ビジュアライズプ
ロパティ
ビジュアライズプロパティは Model(モデル)エリアツリーで選択したものに関連するプロパ
ティを変更するために使用されます。
オプション 概要
プレビューのデフ
ォルトレコード数
Spoon のプレビューダイアログボックスに表示されるデフォルトレコード数を設定します。
ログウィンドウの
最大レコード数
ログウィンドウで表示するレコードの最大数を指定します。
重要なログレコー
ドの保存タイムア
ウト(分)
値を 0 以上に設定すると、ログのレコードは自動的に中央ログバッファから削除されます。これは
長時間の実行または常時実行される(リアルタイム)データ変換またはジョブにおいて重要です。
これによってログバッファによるメモリ不足からデータ変換を保護します。以下の Carte に関する
注意をご覧ください。
注意: Carte サーバーをご使用の場合、configuration.xml ファイルでこのオプションを設定する必要
があります。(.../data-integration-server/pentaho-solutions/system/kettle/slave-server-config.xml)
<slave_config>
<max_log_lines>10000</max_log_lines>
<max_log_timeout_minutes>2880</max_log_timeout_minutes>
<object_timeout_minutes>240</object_timeout_minutes>
</slave_config>
また、Kettle 変数で値を設定することも可能です。(kettle.properties からファイルエディタへコピ

Pentaho データ統合 4.1 ユーザーガイド
~ 12 ~
©株式会社 KSK ソリューションズ
ー)
KETTLE_MAX_LOG_SIZE_IN_LINES 0
PDI 内部に保持されるログレコードの最大数。全てのレコードを保持するには 0 に設定してくださ
い。(デフォルト)
KETTLE_MAX_LOG_TIMEOUT_IN_MINUTES 0
PDI 内部にログレコードが保持される最大時間(分)。全てのレコードを無期限に保持するには、0
に設定してください。(デフォルト)
注意: スレーブサーバーの設定に関しては「スレーブサーバーの設定」を参照ください。
ログ履歴ビューの
最大レコード数
ログ履歴ビューで表示する最大レコード数を指定します。
起動時に Tips を
表示する
起動時に今日のヒントを表示するかどうか設定します。
起動時にようこそ
ページを表示する
Spoon 起動時に、ようこそページを表示するかどうかを決定します。
データベースキャ
ッシュを使用する
ソースまたはターゲットデータベースに保存された Spoon キャッシュ情報。データベースに変更
を加えている場合、キャッシュは時折正しくない結果をもたらす可能性があります。エラーを避け
るために、毎回キャッシュをクリアーする代わりにキャッシュをすべて無効にできます。
起動時に最後に開
いたファイルを開
く
最後に利用したデータ変換(開くまたは保存されたもの)を XML またはリポジトリから自動的に
ロードします。
変更したファイル
を自動保存する
実行前に変更のあるデータ変換を自動的に保存します。
メインツリーに使
用中のファイルの
み表示する
左側のメインツリーで現在使用中のファイルのみ表示して、データ変換とジョブアイテムの数を減
らします。
XML へ使用済み
接続だけを保存す
る
データ変換の XML エクスポートをデータ変換で使用された接続に制限をします。サンプルデータ
変換で、定義された全ての含まれないようにする際に役に立ちます。
開くまたはインポ
ート時、既存の接
続に置き換えるか
確認する
インポート時に、既存のデータベース接続に置き換える前に許可を求めます。
開くまたはインポ
ート時、既存の接
続に置き換える
ダイアログボックスが表示されない時に起こるアクションです。(前のオプションを参照ください)
―保存‖ダイアログ
を表示する
データ変換に変更があった際に、表示される確認ダイアログをオフにできます。
ホップを自動的に
分岐する
ホップを分岐する際に表示される確認メッセージをオフにします。
―コピーまたは分
岐 ‖のダイアログ
を表示する
ステップを複数のアウトプットにリンクさせる際に表示される警告メッセージをオフにします。こ
の警告メッセージでは複数アウトプットを処理するための 2 つの選択肢が表示されます。
1.行の分配 – 目的ステップは順番にレコードを受け取ります。

Pentaho データ統合 4.1 ユーザーガイド
~ 13 ~
©株式会社 KSK ソリューションズ
外観
2.行のコピー – すべてのレコードが全目的ステップに送られます。
開始時にリポジト
リダイアログを
表示する
開始時にリポジトリダイアログボックスを表示するかを決定します。
終了時に確認する アプリケーションを終了する時に確認ダイアログを表示するかどうかを設定します。
カスタムパラメー
タをクリアーする
(ステップ /プラ
グイン)
プラグインまたはステップダイアログボックスで設定されるパラメータやフラグをすべて消去し
ます。
ツールチップを表
示する
メインツールバーでツールチップボタンを表示するかどうかをコントロールします。
オプション 概要
固定フォント ダイアログボックス、ツリー、インプットフィールド等で使用されるフォント。フォントを編集す
るにはオプションを編集(鉛筆のアイコン)をクリックしてください。またフォントをデフォルト
値に戻すにはこのオプションをデフォルト値にリセット(赤い丸に×のアイコン)をクリックして
ください。
ワークスペースの
フォント
Spoon インタフェースで使用されるフォント。フォントを編集するにはオプションを編集(鉛筆の
アイコン)をクリックしてください。またフォントをデフォルト値に戻すにはこのオプションをデ
フォルト値にリセット(赤い丸に×のアイコン)をクリックしてください。
メモのフォント Spoon で表示される注意事項のフォント。フォントを編集するにはオプションを編集(鉛筆のアイ
コン)をクリックしてください。またフォントをデフォルト値に戻すにはこのオプションをデフォ
ルト値にリセット(赤い丸に×のアイコン)をクリックしてください。
背景色 Spoon の背景色を設定します。この設定は全てのダイアログボックスにも反映されます。色を編集
するにはオプションを編集(鉛筆のアイコン)をクリックしてください。また色をデフォルト値に
戻すにはこのオプションをデフォルト値にリセット(赤い丸に×のアイコン)をクリックしてくだ
さい。
ワークスペースの
背景色
Spoon のグラフィカルビューの背景色を設定します。背景色を編集するにはオプションを編集(鉛
筆のアイコン)をクリックしてください。また背景色をデフォルト値に戻すにはこのオプションを
デフォルト値にリセット(赤い丸に×のアイコン)をクリックしてください。
タブの色 アクティブまたは選択されたタブを示す色です。タブ色を編集するにはオプションを編集(鉛筆の
アイコン)をクリックしてください。またタブ色をデフォルト値に戻すにはこのオプションをデフ
ォルト値にリセット(赤い丸に×のアイコン)をクリックしてください。
ワークスペースの
アイコンサイズ
グラフィカルウィンドウのアイコンサイズに反映されます。元のアイコンのサイズは 32x32 ピク
セルです。(画像として)最も良い結果になるのは、おそらく 16,24,32,48,64 サイズまたは 32 の
倍数になります。
ワークスペースの
線幅
Spoon グラフィカルビューのホップの線の幅とステップの周りの線の幅を設定します。
ワークスペースの
影のサイズ
このサイズが 0 よりも大きい場合、ステップ、ホップ、および注意事項の影が表示され、キャンバ
ス上に浮いているように見えます。
ダイアログの中心
(%)
デフォルトで、パラメータは左を起点にしてダイアログボックスの幅の 35%で表示されます。通
常より大きなフォントを使用している場合に、このオプションを使用して変更することができま
す。

Pentaho データ統合 4.1 ユーザーガイド
~ 14 ~
©株式会社 KSK ソリューションズ
用語と基本的なコンセプト
データ変換とジョブの設計を開始する前に、Pentaho データ統合関連の用語の基本を理解しておく必要
があります。
データ変換、ステップ、およびホップ
データ変換は、ステップと呼ばれる論理的なタスクのつながりです。データ変換は基本的にはデータフ
ローです。以下の例では、データベース開発者がフラットファイルを読み込んで、それをフィルター、
ソートし、それからリレーショナルデータベーステーブルにロードします。
データベース開発者がエラー条件を発見した場合は、ダミー(何もしない)ステップにデータを送る代
わりにデータはテーブルにログバックされます。
基本的にデータ変換は、データ変換設定の論理的なセットの有向グラフです。データ変換ファイル名に
は、.ktr 拡張子がつきます。
データ変換に関連する 2 つの主要な要素は、ステップとホップです。:
ステップはデータ変換を組み立てるための要素で、例えば、テキストファイルインプットやテーブルア
ウトプットがあります。
Pentaho データ統合には利用できるステップが 140 以上あり、それらは、機能によって分類されます。
例えば、インプット、アウトプット、スクリプトなど。
データ変換中の各ステップは、特定のタスクを実行するように設計されています。例えば上記の例で示
キャンバスのアン
チエイリアス
Windows、OSX、および Linux のようないくつかのプラットホームでは、GDI、Carbon または Cairo
によってアンチエイリアスをサポートしています。グラフビューで線やアイコンをなめらかに表示
したいときは、このオプションを有効にしてください。オプションが有効で、お使いの環境で対応
していない場合は、(Windows では C:¥Documents and Settings¥<user>¥.kettle¥.spoonrc にある)
$HOME/.kettle/.spoonrc ファイルで"EnableAntiAliasing"オプションの値を"N"に変更してくださ
い。
OS の外観を使用
する
Windows でこのオプションを有効にすると、Spoon でデフォルトシステム設定のフォントや色を
使用できます。その他のプラットホームではデフォルトが常に有効です。
ブランドロゴなど
の画面を表示する
このオプションを有効にすると、Pentaho データ統合はキャンバス上に Pentaho データ統合のブラ
ンドロゴが、展開バーの左上に表示されます。
推奨言語(1 次言
語)
ご利用の言語を設定します。
代替言語(2 次言
語)
その他の言語設定を指定します。Pentaho データ統合はもともと英語で作られているため、このロ
ケールは English に設定するのが最適です。

Pentaho データ統合 4.1 ユーザーガイド
~ 15 ~
©株式会社 KSK ソリューションズ
されるようにフラットファイルからのデータの読み込みや、レコードのフィルター、またデータベース
ログの記録などです。ステップは必要なタスクを実行するよう設定できます。
ホップはステップどうしをつなげる経路であり、あるステップから別のステップへメタデータスキーマ
を渡すことができます。上の画像では、一連の実行が行われているのが見ていただけますが、これは正
しいものではありません。ホップはステップからからデータフローを決定しますが、必ずしも実行する
シーケンスとなるわけではありません。データ変換実行時に、各ステップはそれぞれのスレッドで起動
し、データのプッシュやパスを行います。
注意: 全てのステップは並行して開始・実行されるので、初期化シーケンスは予測できません。そのた
め例えば、最初のステップで変数を設定して、続くステップで変数を使用することが出来ません。
Pentaho データ統合 4.0 では、ステップどうしの接続、ステップの編集、ステップのコンテキストメニ
ューを開く新しい方法が追加されました。編集するステップをクリックしてください。そして下矢印を
クリックしてコンテキストメニューを開いてください。ホップでステップ同士を接続することについて
詳しくは、「ホップの詳細」をご覧ください。
ステップは複数のつながりを持つことができます。2 つのステップをつなぐものもあれば、ステップの
インプットまたはアウトプットとしてのみ働くものもあります。データ変換においてデータストリーム
は様々なステップに流れていきます。Spoon ではホップは矢印で表されます。ホップはステップからス
テップへデータを通し、ステップを通るデータの方向やフローも決定します。1 つのステップから複数
のステップにアウトプットを送る場合、データはそれぞれのステップにコピーすることもできますし、
各ステップに分配することも可能です。
ジョブ
ジョブは、ETL アクティビティのリソース、実行、および依存関係を調整する、ワークフロー系のモデ
ルです。

Pentaho データ統合 4.1 ユーザーガイド
~ 16 ~
©株式会社 KSK ソリューションズ
ジョブは、プロセス全体を実行するために個々の機能を集めたものです。FTP ファイルの取得、必要な
ターゲットデータベースのテーブルが存在するかどうか等の条件確認、テーブルをポピュレートするデ
ータ変換の実行、データ変換が失敗した際にエラーログをメールするといったものが、ジョブで実行さ
れる一般的なタスクの例になります。例えば最終的なジョブ結果は、毎晩のデータウェアハウスをアッ
プデートすることにつながります。
ジョブはジョブホップ、ジョブエントリ、およびジョブ設定で構成されます。ホップはジョブで使用さ
れる際は異なるはたらきをします。詳しくは「ホップの詳細」を参照ください。ジョブエントリは、上
の例で示されているように個々の設定された要素で、これらはジョブを組みたてる基本的な要素です。
データ変換では、これらの要素はステップと呼ばれます。ジョブエントリはデータ変換の実行から、
Web サーバーからのファイルの入手に及ぶさまざまな機能を提供します。1 つのジョブエントリを何度
でもキャンバス上に置くことができます。例えば、データ変換の実行のようなジョブエントリを 1 つ選
んで、異なる設定で複数個キャンバス上に置くことができます。ジョブ設定は、ジョブの振舞いとジョ
ブアクションのログの方式を決定するオプションです。ジョブファイル名には.kjb 拡張子が付きます。
ホップの詳細
A hop connects one transformation step or job entry with another.
ホップはあるデータ変換ステップまたはジョブエントリを他のものとつなげます。
The direction of the data flow is indicated by an arrow.
データフローの方向は矢印によって表されます。
To create the hop, click the source step, then press the <SHIFT> key down and draw a line to the target
step.
ホップを作成するには、ソースステップをクリックして<SHIFT>キーを押します。それから、ターゲッ

Pentaho データ統合 4.1 ユーザーガイド
~ 17 ~
©株式会社 KSK ソリューションズ
トステップに向かって線を引きます。
Alternatively, you can draw hops by hovering over a step until the hover menu appears.
または、ホバーメニューが表示されるまで、ステップ上に舞っているメニューが現れるまでステップの
上方に浮かぶことによって、ホップを描くことができます。
Drag the hop painter icon from the source step to your target step.
ソースステップから目標ステップまでホップ画家アイコンをドラッグします。
Additional methods for creating hops include:
ホップを作成するための追加メソッドは:
・ Click on the source step, hold down the middle mouse button, and drag the hop to the target step.
・ ソースステップをクリックします、そして、マウス中ボタンを押さえます、そして、目標ステップ
にホップをドラッグします。
・ Select two steps, then choose New Hop from the right-click menu.
・ 2 ステップを選択して、次に、右クリック・メニューから New Hop を選びます。
・ Use <CTRL + left-click> to select two steps the right-click on the step and choose New Hop.
・ <CTRL+左クリック>を使用して、ステップのときに 2 ステップで右クリックを選択して、New Hop
を選びます。
To split a hop, insert a new step into the hop between two steps by dragging the step over a hop.
ホップを分けるために、新しいステップでホップの上のステップをドラッグすることによって、2 ステ
ップの間のホップを差し込みます。
Confirm that you want to split the hop.
ホップを分けたいと確認します。
This feature works with steps that have not yet been connected to another step only.
この機能はまだもう 1 ステップだけにつなげられていないステップで働いています。
Mixing rows that have a different layout is not allowed in a transformation; for example, if you have two
table input steps that use a varying number of fields.
異なったレイアウトを持っている列を混合するのはデータ変換で許されていません。 例えば、それが 2
テーブル・インプット・ステップでありましたら異なった数のフィールドを使用します。
Mixing row layouts causes steps to fail because fields cannot be found where expected or the data type
changes unexpectedly.
列のレイアウトを混合すると、予想されるところでフィールドを見つけることができないので、失敗す
るステップかデータ型変化が不意に引き起こされます。
The trap detector displays warnings at design time if a step is receiving mixed layouts.
ステップが混成式配置を受けることであるければ、罠探知器は、デザイン時に警告を表示します。
You can specify if data can either be copied or distributed between multiple hops leaving a step.
ステップを出る複数のホップの間にデータをコピーするか、または分配できるかを指定できます。
Select the step, right-click and choose Data Movement.
ステップを選択します、そして、右クリックします、そして、Data Movement を選びます。
Notice the (copy icon) inside the hops that indicate data must be copied.
データを示すホップがそうしなければならない(コピーアイコン)内部がコピーされるのに注意します。
Hover over hop icons to display their descriptions.

Pentaho データ統合 4.1 ユーザーガイド
~ 18 ~
©株式会社 KSK ソリューションズ
ホップ・アイコンの上方に浮かんで、彼らの記述を表示します。
A hop can be enabled or disabled (for testing purposes for example). Right-click on the hop to display
the options menu.
ホップを可能にするか、または無能にすることができます(例えば、テスト目的のために)。 ホップの上
で右クリックして、オプションメニューを表示します。
Hop Colors in Transformations
データ変換におけるホップ色
Hops in transformations display in different colors based on the properties and state of the hop. The
following table describes the meaning behind hop colors:
データ変換におけるホップはプロパティに基づく異なった色とホップの状態に表示します。 以下のテ
ーブルはホップ色の後ろで意味について説明します:
色 意味
緑 ローの分配。複数の結合がステップから出ているとき、データのローはターゲットステップへ均等
に分配されます。
赤 ローのコピー。複数の結合がステップから出ているとき全てのデータのローは、全ての目的のステ
ップへコピーされている。
黄 ステップに情報を提供して、ローを分配します。
灰 無効な結合。
黒 命名された目標ステップがある結合。
青 ドルボタンでドラッグすることでできる候補結合。

Pentaho データ統合 4.1 ユーザーガイド
~ 19 ~
©株式会社 KSK ソリューションズ
Job Hops
ジョブ・ホップ
Besides the execution order, a hop also specifies the condition on which the next job entry will be
executed.
また、実行注文以外に、ホップは次のジョブエントリが実行される条件を指定します。
You can specify the Evaluation mode by right clicking on the job hop.
ジョブ・ホップの上を右クリックすることによって、Evaluation モードを指定できます。
A job hop is just a flow of control.
ジョブ・ホップはただコントロールのフローです。
Hops link to job entries and, based on the results of the previous job entry, determine what happens
next.
前のジョブエントリの結果に基づいて、ホップは、ジョブ・エントリーにリンクして、何が次に起こる
かを決定します。
Hop Colors in Jobs
Hops in jobs display in different colors based on the properties and state of the hop. The following table
describes the meaning behind hop colors:
Hop Icons
ホップ・アイコン
Below are descriptions of the icons that appear inside job hops.
赤(太い点線) ソースステップでエラーを引き起こしたローを伝達するのに使用される結合。
Option 概要
Unconditional Specifies that the next job entry will be executed regardless of the result of the originating job entry
Follow when
result is true
Specifies that the next job entry will be executed only when the result of the originating job entry is
true; this means a successful execution such as, file found, table found, without error, and so on
Follow when
result is false
Specifies that the next job entry will only be executed when the result of the originating job entry
was false, meaning unsuccessful execution, file not found, table not found, error(s) occurred, and
so on
色 意味
黒 The target entry executes regardless of the result of the source entry (Unconditional)
目標エントリーはソースの結果にかかわらずエントリー(無条件の)を実行します。
緑 The target entry executes only if the result of the source entry is successful (Result is true)
ソース・エントリーの結果がうまくいく場合にだけ(結果は本当です)エントリーが実行する目標
赤 The target entry executes only if the source entry failed (Result is false)
ソース・エントリーが失敗した場合にだけ(結果は誤っています)エントリーが実行する目標

Pentaho データ統合 4.1 ユーザーガイド
~ 20 ~
©株式会社 KSK ソリューションズ
以下に、ジョブ・ホップの中に現れるアイコンの記述があります。
Hover over the hop icon to see its description.
ホップ・アイコンの上方に浮かんで、記述を見ます。
最初のデータ変換を作成する
この演習は、ステップとホップの扱いや、データ変換のプレビューと実行に関連する基本的なスキルを
身につけることを意図しています。データ変換の作成、実行、スケジューリングに関して総合的な実際
に演習を行うには「データ統合 4.0 評価ガイド」を参照ください。
以下の説明に沿って、データ変換の作成を開始してください。
1. Spoon 左上隅の新規をクリックします。
2. リストから Transformation を選択します。
3. デザインタブの下で、入力ノードを展開します。 次に、行生成のステップを選択して、右のキャ
ンバスにドラッグします。
注意: どこにステップがあるか分からない時には、Spoon の左隅にある検索機能を使用します。検
索ボックスでステップの名前を入力します。検索条件に一致したものが関連するノードの下に表示
されます。検索が終了したら、テキストボックスの検索条件をクリアーしてください。
アイコン 意味
The target entry executes regardless of the result of the source entry (Unconditional)
目標エントリーはソースの結果にかかわらずエントリー(無条件の)を実行します。
The target entry executes only if the result of the source entry is successful (Result is true)
ソース・エントリーの結果がうまくいく場合にだけ(結果は本当です)エントリーが実行する目標
The target entry executes only if the source entry failed (Result is false)
ソース・エントリーが失敗した場合にだけ(結果は誤っています)エントリーが実行する目標
Job entry working
ジョブエントリの働き
Pentaho データ統合 4.1 ユーザーガイド
~ 21 ~
©株式会社 KSK ソリューションズ
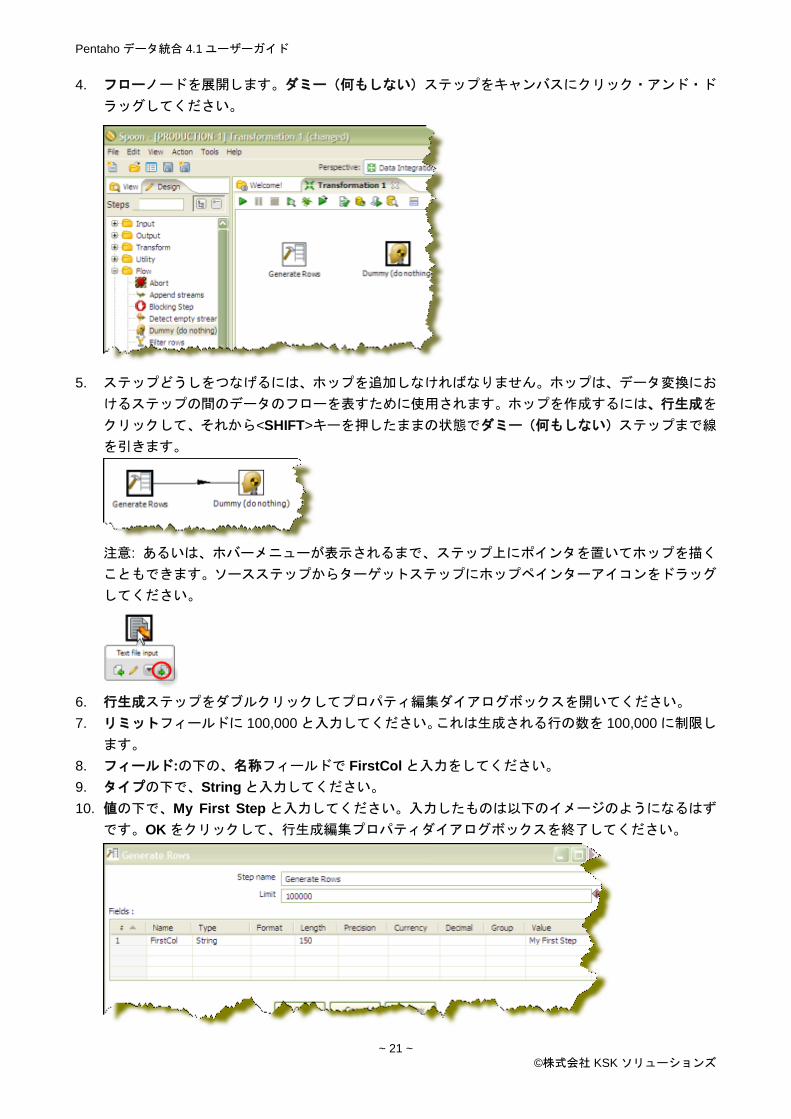
4. フローノードを展開します。ダミー(何もしない)ステップをキャンバスにクリック・アンド・ド
ラッグしてください。
5. ステップどうしをつなげるには、ホップを追加しなければなりません。ホップは、データ変換にお
けるステップの間のデータのフローを表すために使用されます。ホップを作成するには、行生成を
クリックして、それから<SHIFT>キーを押したままの状態でダミー(何もしない)ステップまで線
を引きます。
注意: あるいは、ホバーメニューが表示されるまで、ステップ上にポインタを置いてホップを描く
こともできます。ソースステップからターゲットステップにホップペインターアイコンをドラッグ
してください。
6. 行生成ステップをダブルクリックしてプロパティ編集ダイアログボックスを開いてください。
7. リミットフィールドに 100,000 と入力してください。これは生成される行の数を 100,000 に制限し
ます。
8. フィールド:の下の、名称フィールドで FirstCol と入力をしてください。
9. タイプの下で、String と入力してください。
10. 値の下で、My First Step と入力してください。入力したものは以下のイメージのようになるはず
です。OK をクリックして、行生成編集プロパティダイアログボックスを終了してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 22 ~
©株式会社 KSK ソリューションズ
11. データ変換を保存してください。詳しくは「データ変換の保存」を参照ください。
データ変換の保存
以下の説明に沿ってデータ変換で保存します。
1. Spoon で、ファイル->名前を付けて保存をクリックしてください。データ変換プロパティダイアロ
グボックスが表示されます。
2. データ変換名フィールドで、First Transformation と入力してください。
3. ディレクトリフィールドで、 (フォルダーアイコン)をクリックしてデータ変換を保存するレポ
ジトリフォルダを選択してください。
4. Home ディレクトリを展開して、joe フォルダをダブルクリックしてください。データ変換がエン
タープライズリポジトリの joe フォルダに保存されます。
5. OK をクリックして、データ変換プロパティダイアログボックスを終了してください。コメント入
力ダイアログボックスが表示されます。
6. コメント入力ダイアログボックスをクリックし、<Delete>を押してデフォルトのテキスト文字列を
削除してください。データ変換について説明をするコメントを入力してください。
コメントとデータ変換はバージョン管理目的でエンタープライズリポジトリにトラックされます。
7. OK をクリックして、コメント入力ダイアログボックスを終了して、データ変換を保存してくださ
い。
データ変換をローカルで実行する
ここまでの演習で簡単なデータ変換を作成しました。次はローカルでデータ変換を実行します。「ロー
カルで実行」では、(ローカルデバイス上にある)Spoon デザイン環境からデータ変換またはジョブを
実行できます。これはデータ変換または軽量の ETL アクティビティの設計やテストに理想的です。
1. Spoon で、ファイル->開くを選択してください。リポジトリのコンテンツが表示されます。
2. データ変換を含むフォルダに移動します。管理者権限を持つユーザーであれば、他のユーザーのフ
ォルダも表示される可能性があります。
3. データ変換をダブルクリックして、Spoon ワークスペースで開いてください。
注意 : ここの演習の説明に沿って作業をしている場合は、データ変換の名前は First
Transformation です。
4. ワークスペースの左上隅で、 (実行)をクリックします。データ変換の実行ダイアログボックス
が表示されます。ローカルで実行がデフォルトで有効になっていることを確認してください。
5. 実行をクリックします。実行結果が下のエリアに表示されます。
6. Step Metrics で内容を確認してください。Step Metrics タブはデータ変換の各ステップについて、
読み込み・書き込みの行数、エラーが発生したもの、処理速度(行/秒)などの数値を提供します。デ
ータ変換失敗の原因にとなったステップは赤色で強調されます。

Pentaho データ統合 4.1 ユーザーガイド
~ 23 ~
©株式会社 KSK ソリューションズ
注意: 実行結果に関するその他のタブはさらに設定が必要です。「パフォーマンスの監視とログ」を
参照ください。
ジョブの構築
最初のデータ変換を作成、保存、実行が完了しました。次は簡単なジョブを構築します。ジョブを使用
して、1 つ以上のデータ変換を実行して、ウェブサーバーからのファイルを取得し、ターゲットディレ
クトリにファイルを置く等を行います。さらに、指定した日時にジョブを実行するようスケジュールが
可能です。「Pentaho データ統合 4.0 評価ガイド」には、ジョブの構築で実際に必要になる演習がありま
す。
1. Spoon メニューバーで、ファイル->新規->Job を選択してください。またはツールバーで (新規)
をクリックしてください。
2. デザインタブをクリックします。ジョブエントリを含んだノードが表示されます。
3. 全般ノードを展開して、START ジョブエントリを選択します。
4. 右のワークスペース(キャンバス)に START ジョブエントリをドラッグしてください。
START ジョブエントリは、実行を開始する場所を定義します。
5. 全般ノードを展開してデータ変換ジョブエントリを選択し、ワークスペースにドラッグします。
6. ホップを使用して、START ジョブエントリとデータ変換ジョブエントリを繋ぎます。
7. データ変換ジョブエントリをダブルクリックして、プロパティダイアログボックスを開いてくださ
い。
8. 変換ジョブの詳細で、データ変換名をクリックします。
9. (参照)をクリックして、エンタープライズリポジトリの中のデータ変換の場所を見つけてくだ
さい。
10. レポジトリオブジェクト選択ビューで Home と joe ディレクトリを展開します。First
Transformation の場所を指定して OK をクリックしてください。データ変換とそのロケーション
がデータ変換名のとなりに表示されます。
11. 変換ジョブの詳細で、OK をクリックします。
12. First Job という名前でジョブを保存してください。ジョブを保存する手順はデータ変換保存の手
順とほとんど同じです。ジョブを保存する際に分かりやすいコメントを付けてください。詳しくは
「データ変換の保存」を参照ください。
13. ツールバーで (ジョブの実行)をクリックします。ジョブの実行ダイアログボックスが表示され
たら、そして、ローカルで実行を選択して実行をクリックします。
14. 実行結果パネルが開いて、ジョブの実行状況やジョブ実行のジョブ実行のログ情報を表示します。

Pentaho データ統合 4.1 ユーザーガイド
~ 24 ~
©株式会社 KSK ソリューションズ
データ変換の実行
データ変換またはジョブの変更が終了した後で、クリックすることでメインメニューツールバーから
(実行)をクリックするか F9 を押して実行できます。データ変換の実行は 3 つの選択肢から選ぶこと
ができます。
・ ローカルで実行 データ変換またはジョブは現在使用しているマシン上で実行されます。
・ リモートで実行 実行したいリモートサーバーを指定できます。この機能はデータ統合サーバー
が実行中であるか、Pentaho データ統合をインストールして Carte サービスを実行しているリモー
トサーバーが必要です。リモートで実行を使用するには最初にスレーブサーバーをセットアップす
る必要があります。(「スレーブサーバーのセットアップ」を参照ください。)
・ クラスタで実行 クラスタ環境でデータ変換またはジョブを実行できます。
スレーブサーバーのセットアップ
大きなデータ変換は、すぐにネットワークに負荷がかかりメモリ不足や他の関連する問題を引き起こす
可能性があります。Pentaho データ統合は 1 つ以上の専用サーバーにデータ変換を送信して、ワークス
テーションでの実行時間を劇的に減らすことができます。専用サーバーはオンデマンドで実行してジョ
ブとデータ変換の実行全体をコントロールできます。
Pentaho データ統合の旧バージョンを使用している場合、リモートデバイスにインストールする小さな
Web サーバーである Carte のことをご存じかと思います。Pentaho データ統合 4.0 では、Carte を続け
てご利用いただくか、(一つまたは複数の)データ統合スレーブサーバーを使用できます。
注意: カルテサーバーインスタンスはよりクラスタ環境に適しています。詳しくは「Pentaho データ統
合 4.0 管理者ガイド」を参照ください。

Pentaho データ統合 4.1 ユーザーガイド
~ 25 ~
©株式会社 KSK ソリューションズ
スレーブサーバーをセットアップするには
1. データ変換を開きます。
2. Spoon のエクスプローラービューで、スレーブサーバーを選択します。
3. 右クリックをして、新規を選択します。スレーブサーバーダイアログボックスが表示されます。
4. スレーブサーバーダイアログボックスに、データ統合(または Carte)スレーブサーバーの適切な
接続情報を入力してください。以下のイメージはデータ統合スレーブサーバーへの接続を説明して
います。
オプション 概要
サーバー名 スレーブサーバーの名前
ホスト名ま
たは IP アド
レス
スレーブとして使用されるデバイスのアドレス
ポート番号
(空白は 80)
リモートサーバーと通信するためのポートを定義します。
ウェブアプ
リ名(オプシ
ョン)
DI サーバーの接続に使用され、デフォルトで pentaho-di に設定されています。
ユーザー名 リモートサーバーにアクセスするためのユーザー名を入力します。
パスワード リモートサーバーにアクセスするためのパスワードを入力します。
マスターサ
ーバーにす
データ変換のクラスタ実行全てにおいてこのサーバーをマスターサーバーとして有効化します。

Pentaho データ統合 4.1 ユーザーガイド
~ 26 ~
©株式会社 KSK ソリューションズ
注意: クラスタ環境でデータ変換またはジョブを実行する時、1 つのサーバーをマスタとして、そ
してクラスタ中の残りの全サーバーをスレーブとしてセットアップする必要があります。
以下で、プロキシタブオプションについて説明しています。:
5. OK をクリックして、ダイアログボックスを終了します。エクスプローラービューのスレーブサー
バーの隣に(+)が現れていることを確認してください。
データ変換とジョブをリモートで実行
データ変換とジョブは両方ともリモートサーバーで実行できます。データ変換またはジョブのリモート
での実行のオプションはほぼ同一です。
る
オプション 概要
ホスト名 使用するプロキシサーバのホスト名を設定します。
ポート番号 プロキシと通信するために使用されるポート番号を設定します。
プロキシを
無視 :正規表
現、|で分割
プロキシがアクティブではないサーバーを指定します。このオプションは正規表現を使用した複数
のサーバーの指定をサポートしています。'| 'の文字で分割して複数のサーバーと正規表現を追加す
ることが可能です。

Pentaho データ統合 4.1 ユーザーガイド
~ 27 ~
©株式会社 KSK ソリューションズ
以下の説明に沿って、データ変換またはジョブのリモートでの実行を行います。
1. データ統合サーバーが実行中で、データ変換(またはジョブ)を開いていることを確認してくださ
い。
2. (実行)をクリックして、データ変換(またはジョブ)の実行ダイアログボックスを開きます。
3. リモートで実行を選択し、それから利用可能なサーバーのリスト(ホスト名)からスレーブサーバ
ー(データ統合または Carte)を選択してください。
リモートサーバーへエクスポートを渡すを有効にしてください。データ変換またはジョブが、必要
な Pentaho データ統合メタデータにアクセス権を持っていないリモートサーバーで実行できるよ
うになります。
このオプションは、クラウドやグリッド・コンピューティングを容易にするために利用出来ます。
これはジョブ(またはデータ変換)同様、元となる全てのリソース(データ変換とジョブ)を一つ
の.zip アーカイブへエクスポートします。この.zip アーカイブは実行の前に転送されます。このア
ーカイブは、データ変換またはジョブがアーカイブから直接実行される際に解凍されることはあり
ません。
セーフモードを有効にするを使用して、一つのホップに送られる各行が同じ構造をしていることを
確認します。: 例えばフィールド名、タイプ、フィールドの連番など
適切なら、ログレベルでどのくらい詳細なログを取得したいかを設定してください。(詳しくは「パ

Pentaho データ統合 4.1 ユーザーガイド
~ 28 ~
©株式会社 KSK ソリューションズ
フォーマンスとログの詳細」を参照ください。)
データ変換を繰り返し実行したい場合、再実行日時を入力してください。
パラメータグリッドでは、データ変換(またはジョブ)を実行するときには使用されるパラメータ
値を設定できます。
引数グリッドでは、データ変換(またはジョブ)を実行するときに使用する引数を設定できます。
変数グリッドでは、データ変換(またはジョブ)を実行するときに使用する変数の値を設定できま
す。
4. 実行をクリックします。
5. スレーブサーバータブをクリックして、データ変換をモニターします。
6. データ統合サーバーにログオンします。
7. モニターしたいデータ変換(またはジョブ)をクリックして選択します。以下のイメージにあるよ
うに、データ変換(またはジョブ)をモニターできるステータスページが表示されます。
クラスタスキーマを作成する
クラスタリングでは、データ変換とデータ変換ステップを 1 つ以上のサーバーで並行で実行できます。
クラスタリングスキーマは、クラスタに割り振りたいスレーブサーバーや様々なクラスタ実行オプショ
ンスを定義します。
Spoon エクスプローラビューでクラスタスキーマノードを選択して開始します。
右クリックして新規を選択し、クラスタリングスキーマダイアログボックスを開いてください。
オプション 概要
スキーマ名 クラスタスキーマの名前

Pentaho データ統合 4.1 ユーザーガイド
~ 29 ~
©株式会社 KSK ソリューションズ
クラスタでデータ変換を実行する
クラスタ環境でデータ変換を実行する際は、以下のオプションがあります。:
・ データ変換を送信する
データ変換を分割して、それぞれマスターとスレーブサーバーに送信します。
・ 実行の準備をする
マスターとスレーブサーバーでデータ変換の初期設定段階を実行します。
・ 実行を開始する
マスターとスレーブデータ変換で実際に実行を開始します。
・ データ変換を表示する
ラスターで実行される予定の、データ変換を表示します。
さ ら に 詳 し く は 、 Basic Clustering Example ( ク ラ ス タ リ ン グ の 基 本 的 な 例 :
http://wiki.pentaho.com/display/EAI/.13+Running+a+Transformation)と Clustering and Clouds Made
Easy(クラスタリングとクラウドを容易にする: http://www.ibridge.be/?p=160)を参照ください。
インパクト解析
データ変換がそれに含まれるデータソースにどのような影響を与えるかを確認するには、アクションメ
ニューに進んで、インパクト(Impact)をクリックしてください。PDI はデータ変換が成功した際にデ
ータソースがどのような影響を受けるかを決定するためにインパクト解析を行います。
エンタープライズリポジトリでコンテンツを管理する
ジョブとデータ変換のソートと管理に加えてエンタープライズリポジトリは、ドキュメントの全履歴が
あり、トラックの変更、修正の比較、必要なであれば前のバージョンに変更するといったことが可能で
す。エンタープライズセキュリティやコンテンツのロックといった機能と組み合わせることによって、
ポート番号 スレーブサーバーを何番のポートから起動するかを指定します。スレーブサーバーでさらにステッ
プをクラスタで実行する場合は追加でポートが必要になります。
注意: ネットワーク上の問題を避けるために、同じ範囲にネットワークプロトコルが他にない
ことを確認してください。
ソケットバッファ
サイズ
使用する内部バッファサイズ
ソケットフラッシ
ュ間隔(レコード)
内部バッファーがネットワークに完全に送信されて空になった後の行数
ソケットデータを
圧縮する
有効にすると、すべてのデータが、Gzip 圧縮アルゴリズムを使用して圧縮されます。
動的クラスタ スレーブサーバー実行時のみ知られるクラスタスキーマス。クラウドコンピューティングの設定の
ように自由にホストが追加または削除される場合に使用されます。
スレーブサーバー クラスタで使用されるサーバーのリスト。1 つのマスターサーバーと複数のスレーブサーバーが必
要になります。クラスタにサーバーを追加するには、スレーブサーバー選択をクリックして利用で
きるスレーブサーバーのリストから選択してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 30 ~
©株式会社 KSK ソリューションズ
共同 ETL 環境を提供するエンタープライズレポジトリと理想的なプラットフォームを作ります。
注意: ファイルシステムのファイルとしてドキュメントを管理したい場合は、リポジトリ接続ダイアロ
グボックスでキャンセルをクリックします。 また、スタート時にこのダイアログを表示するを無効に
して、起動時にリポジトリ接続ダイアログボックスが表示されないようにしてください。
エンタープライズリポジトリを追加する
新規エンタープライズリポジトリを追加するには…
1. リポジトリ接続ダイアログボックスで、 追加をクリックします。
2. エンタープライズリポジトリを選択して、OK をクリックしてください。エンタープライズリポジ
トリダイアログボックスが表示されます。
3. Repository Configuration ダイアログボックスに、以下の値を入力して OK にクリックしてくださ
い。:
4. OK をクリックします。リポジトリ接続ダイアログボックスで新規リポジトリが利用可能なリポジ
トリのリストに追加されていることを確認してください。
5. リポジトリにアクセスするための適切な認証情報(ユーザー名とパスワード)を入力して、OK を
クリックしてください。
エンタープライズリポジトリの詳細を編集する
エンタープライズリポジトリの詳細を編集するには
1. リポジトリ接続ダイアログボックスで、詳細を編集したいリポジトリを選択します。
2. (編集)クリックします。リポジトリ接続ダイアログボックスが表示されます。
3. 必要に応じて変更を行い、完了したら OK をクリックします。
フィールド名 概要
URL Test をクリックして、リポジトリ URL が正しいことを確認してください。
ID このレポジトリのユニークな ID を入力してください。
名前 リポジトリの名前を入力してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 31 ~
©株式会社 KSK ソリューションズ
エンタープライズリポジトリ/Kettle データベースリポジトリを削除する
必要な場合は、エンタープライズリポジトリまたは Kettle データベースリポジトリを削除できます。
リポジトリを削除するには…
1. リポジトリ接続ダイアログボックスで、利用可能なリポジトリのリストから削除したいリポジトリ
を選択します。
2. (削除)をクリックします。確認ダイアログが表示されます。
3. はいをクリックして、リポジトリを削除します。
エンタープライズリポジトリでコンテンツを管理する
リポジトリエクスプローラービュー(ツール->リポジトリ-> 照会)を表示している時に、右クリックを
メニューで以下に記載した一般的なタスクを実行してみてください。
・ リポジトリコンテンツを照会する。
・ 他のリポジトリユーザーとコンテンツを共有する。
・ リポジトリに新規フォルダを作成する。
・ フォルダ、ジョブ、またはデータ変換を開く。
・ フォルダ、データ変換またはジョブの名称を変更します
・ フォルダ、ジョブ、またはデータ変換を削除します。
・ データ変換またはジョブをロックします。
注意: レポジトリ内で閲覧・実行するためのパーミッションは、管理者の方によって設定されています。
フォルダ、ジョブ、またはデータ変換を移動するには、オブジェクトを選択してそれから左側のナビゲ
ーションエリアの任意の場所にクリック・アンド・ドラッグします。自分のフォルダから別のユーザー
のフォルダへオブジェクトを移動することができます。
削除したオブジェクトを復元するには、 (Trash)をダブルクリックします。右側のエリアに削除した
オブジェクトが表示されます。復元したいオブジェクトを右クリックして、そしてメニューから Restore
を選択します。
他のユーザーが編集できないようにデータ変換またはジョブをロックするには、ジョブまたはデータ変
換を選択して右クリックし、Lock を選択します。表示された Notes ボックスに分かりやすいコメント
を入力してください。レポジトリ中のオブジェクトのロックとロック解除はトグルスイッチのように動

Pentaho データ統合 4.1 ユーザーガイド
~ 32 ~
©株式会社 KSK ソリューションズ
作します。オブジェクトのロックを解除したらロックオプションの隣にあるチェックマークが消えます。
ジョブやデータ変換といったコンテンツの管理に加えて、エンタープライズリポジトリでデータベース
接続について管理(作成・編集・削除)するには接続タブをクリックしてください。データベース接続
について詳しくは「接続の管理」を参照ください。
ユーザーやロールを管理するにはセキュリティタブをクリックしてください。Pentaho データ統合には
デフォルトセキュリティプロバイダがあります。LDAP または MSAD などの既存のセキュリティをお持
ちでない場合は Pentaho セキュリティを使用してユーザーやロールを定義できます。セキュリティを管
理するには管理者権限が必要です。詳しくは、「Pentaho データ統合管理者ガイド」を参照ください。
スレーブタブをクリックして、スレーブサーバー(データ統合と Carte インスタンス)を管理できます。
詳しくは「スレーブサーバーのセットアップ」を参照ください。
パーティションとクラスタータブをクリックして、パーティションとクラスタを管理します。詳しくは
「クラスタスキーマを作成する」を参照ください。
フォルダーレベルパーミッションの設定
リポジトリ中のフォルダにジョブとデータ変換のためのパーミッションを設定できます。パーミッショ
ンを設定するときに、どのユーザーまたはロールがコンテンツにアクセスする権限を持っているかを定
義します。パーミッションはユーザーまたはロールで定義できます。リポジトリで各オブジェクトにパ
ーミッションを設定するには下で説明される方法でも行えます。しかしその場合、各ジョブ、データ変
換を選択して、パーミッションを設定してください。
以下の説明に沿って、フォルダーレベルパーミッションを設定します。
1. リポジトリエクスプローラーを開いてください(ツール-> リポジトリ-> 照会)。

Pentaho データ統合 4.1 ユーザーガイド
~ 33 ~
©株式会社 KSK ソリューションズ
2. パーミッションを設定したいフォルダを表示し、クリックして選択してください。
パーミッションを設定する前に右側のエリアにフォルダが表示されるはずです。
3. アクセス制御タブの下側のエリアで、Inherit security settings from parent のチェックを外してく
ださい。
4. (追加)をクリックして、Select User or Role ダイアログボックスを開いてください。
5. ユーザーまたはロールを選択してパーミッションリストに追加してください。パーミッションリス
トにユーザーまたはロールを追加・削除するには黄色い矢印を使用してください。完了したら OK
をクリックしてください。
6. アクセス制御タブの下側のエリアで、選択したユーザーまたはロールに適切な権限が与えられてい
ます。以下の例では、「suzy」というユーザーに作成・削除・編集権限が与えられています。
削除するには (削除)をクリックしてユーザーとロールをリストから削除します。
7. パーミッションを適用するには Apply をクリックしてください。
バージョン履歴を使用する
エンタープライズレポジトリでジョブまたはデータ変換を保存する時は常に、コメントの入力を求めら
れます。コメントはジョブまたはデータ変換と一緒に保存されるため、変更をトラックすることが可能
です。ジョブまたはデータ変換に不必要な変更を加えてしまった場合、ジョブまたはデータ変換を特定
のバージョンに復元することが可能です。そのためバージョン履歴には分かりやすいコメントを残して
おくことが重要です。これでジョブまたはデータ変換のバージョンを変更する際に適切に判断すること
ができます。
バージョン履歴を確認する
データ変換またはジョブのバージョン履歴を確認するには…
1. Spoon メニューバーで、ツール -> リポジトリ -> 照会に進んでください。 あるいは、 Spoon
メニューバーをクリックします。 リポジトリエクスプローラーウィンドウが開きます。

Pentaho データ統合 4.1 ユーザーガイド
~ 34 ~
©株式会社 KSK ソリューションズ
2. 左のナビゲーションエリアで、データ変換またはジョブを含むフォルダを見つけて、ダブルクリッ
クしてください。 以下の例は、「joe」というフォルダに 1 つのデータ変換があります。
3. リストからデータ変換またはジョブをクリックして選択します。データ変換またはジョブに関連す
るバージョン履歴が下側のエリアに表示されるので確認してください。
管理ユーザーはシステムの上のすべてのユーザーの home フォルダを閲覧できます。管理者でない
場合は、ご自身の home フォルダと public(共有)フォルダが表示されています。home フォルダ
は、例えば「進行中」のデータ変換やジョブのような個人のコンテンツを管理するところです。
public フォルダは他の人と共有したいコンテンツを保存する場所です。
4. 確認したいデータ変換またはジョブを含むバージョン履歴で、行を右クリックしてください。Open
(開く)を選択して Spoon でデータ変換またはジョブを開いてください。
データ変換またはジョブを以前保存したバージョンに戻す
ジョブとデータ変換のバージョンを元に戻すには…
1. Spoon メニューバーで、ツール -> リポジトリ -> 照会に進みます。リポジトリエクスプローラー
ウィンドウが開きます。
2. フォルダから、複数のバージョンを持っているデータ変換またはジョブの場所を特定します。
3. リストからデータ変換またはジョブを右クリックして選択してください。
4. Restore を選択してください。
5. Commit Comment ダイアログボックスに有意味なコメントを書き、それから OK をクリックしま
す。 バージョンが元に戻ります。次にデータ変換またはジョブを開く時に、リストアされバージ

Pentaho データ統合 4.1 ユーザーガイド
~ 35 ~
©株式会社 KSK ソリューションズ
ョンが表示されます。
マッピング(Mapping)ステップでデータ変換フローを再び利用する
特定のステップシーケンスを再び利用したい場合、繰り返し部分をマッピングできます。マッピングは
プレースホルダとしてマッピングインプットとアウトプットを定義できることを除いて標準のデータ
変換です。
・ マッピングインプット仕様 —親データ変換から使用されるインプットのためのプレースホルダ
・ マッピングアウトプット仕様— どの親データ変換がプレースホルダからデータを読み込むか
注意 : マッピング使用のデモンストレーションをする Pentaho データ統合サンプル
は...samples¥mapping¥Mapping にあります。
以下は、Mapping(サブ・データ変換)ステップのリファレンスです。:
オプション 概要
ステップ名 任意、必要に応じてこのステップの名前を変更できます。
データ変換のマッ
ピング(Mapping
transformation)
実行時に実行するためのマッピングデータ変換ファイルの名前を指定します。リポジトリから
ファイル名(XML/.ktr)またはデータ変換のどちらかを指定できます。編集ボタンで、Spoon
Designer の別々のステップのもとで指定したデータ変換を開きます。
パラメータ パラメータタブの下のオプションでマッピングへの PDI 変数を定義またはパスできます。
注意: 変数名のための文字列値で変数式を含むことが可能です。
注意: 重要! これらの指定される変数/値のみが、サブデータ変換へパスされます。
入力タブ( Input
Tabs)
各入力タブ (ない可能性もあります )はマッピングまたはサブデータ変換における特定の
Mapping Input Specification ステップと対応します。これは、一つの Mapping ステップに複数
の入力タブが持てることを意味します。入力タブを追加するには入力タブを追加(Add Input)
をクリックします。
・ 入力ソースステップ名
読み込む親データ変換(マッピングでない)のステップ名
・ 入力ソースステップ名
読み込む親データ変換(マッピングでない)のステップ名
・ マッピングターゲットステップ名
入力ソースステップからデータ行を送るマッピング(サブデータ変換)のステップ名
・ これはメインデータパスですか?
1 つの入力マッピングしかない場合有効にしてください。マッピングソースステップ名と
アウトプットターゲットステップ名フィールドをブランクにしておくことができます。
・ これらの値をアウトプットで名前を変更するかどうか

Pentaho データ統合 4.1 ユーザーガイド
~ 36 ~
©株式会社 KSK ソリューションズ
変数を使用する
データ変換にステップとジョブエントリーを含む Pentaho データ統合中で変数を使用できます。データ
変換の Set Variable ステップでそれらを設定するか、またはディレクトリ中の kettle.properties ファイ
ルでそれらを設定することで、変数を定義します。:
$HOME/.kettle (Unix/Linux/OSX)
C:¥Documents and Settings¥<username>¥.kettle¥ (Windows)
それらを使用するには、Get Variable ステップを使用してそれらを取得するか、以下に示すようにメタ
データ文字列を指定します。:
* ${VARIABLE} or * %%VARIABLE%%
1 番目は UNIX 由来のもので、二番目のものは Microsoft Windows 由来のもので、両方または混ぜて使
うことも可能です。Pentaho データ統合から変数の使用をサポートするダイアログボックスは赤い$マ
ーク( )で視覚的に示されています。プロパティ値に挿入される変数を選択するためにスペースホッ
トキーが使用できます。ショトカットヘルプを表示するには、変数アイコンをにカーソルを合わせてく
ださい。
マッピングデータ変換にフィールドを移動する前にこれらの名前を変更されます。
注意: このオプションを有効にすると、マッピングアウトプットステップに移行するとき
に、値はそれらのオリジナルの名前に戻されます。このオプションによって、サブデータ
変換がより分かりやすく、再利用しやすくなります。
・ ステップマッピングの説明
マッピングステップの説明を追加します。
・ ソース
データ変換マッピングのマッピング。フィールド名の変更が必要なところに入力します。
出力タブ 各出力タブ (ない可能性もあります )はマッピングまたはサブデータ変換における特定の
Mapping Output Specification ステップと対応します。これは、一つの Mapping ステップに複数
の出力タブが持てることを意味します。出力タブを追加するには出力タブを追加(Add Output)
をクリックします。
・ マッピングソースステップ
読まれるマッピングデータ変換(サブデータ変換)におけるステップ名
・ 出力ターゲットステップ名
マッピングデータ変換ステップからデータを送るためのデータ変換(親)の中のステップ
名
・ これはメインデータパスですか?
1 つの出力マッピングしかない場合有効にしてください。マッピングソースステップ名と
アウトプットターゲットステップ名フィールドをブランクにしておくことができます。
・ ステップマッピングの説明
出力ステップマッピングの説明を追加します。
・ データ変換のマッピング
ターゲットステップフィールドのマッピング。フィールド名の変更が必要なところに入力
します。
入力の追加 /出力
の追加
特定のサブデータ変換のための入力または出力マッピングを追加します。

Pentaho データ統合 4.1 ユーザーガイド
~ 37 ~
©株式会社 KSK ソリューションズ
変数の範囲
変数の範囲はそれが定義される場所によって決定します。
環境変数
最初の用法((そして、以前の Pentaho データ統合バージョンでは唯一の)は環境変数です。通常は、-D
オプションで Java 仮想マシン(JVM)にオプションをパスすることで達成されていました。また
platform-independent で一時ファイルの場所をしていることも簡単にできます。例えば${java.io.tmpdir}
といったようになります。この変数は Unix/Linux/OSX 上ではディレクトリ/tmp を指し、Windows マシ
ン上では Settings¥<username¥Local Settings¥Temp を指します。
環境変数の使用に関する唯一の問題は、ダイナミックでなくダイナミックな方法でそれらを使用しよう
とすると問題が生じることです。例えば、1 つのアプリケーションサーバー(たとえば BI サーバー)上
で 2 つ以上のデータ変換またはジョブを実行する場合、コンフリクトが生じます。仮想マシンで実行し
ているすべてのソフトウェアに見えるよう環境変数を変更してください。
Kettle 変数
環境変数の範囲は広過ぎるので、Kettle 変数は変数が設定されるジョブにたいしてローカルである変数
を定義する方法を提供します。データ変換における Set Variable ステップで、どのジョブに変数の範囲
を設定したいかを指定できます。例えば、親ジョブ、グランドペアレントジョブ、ルートジョブ等です。
内部変数
以下の変数は常に定義されます。:
これらの変数はデータ変換で定義されます。:
これらは、ジョブで定義される内部変数です。:
変数名 サンプル値
Internal.Kettle.Build.Date 2010/05/22 18:01:39
Internal.Kettle.Build.Version 2045
Internal.Kettle.Version 4.1.0
変数名 サンプル値
Internal.Transformation.Filename.Directo
ry
D:¥Kettle¥samples
Internal.Transformation.Filename.Name Denormaliser - 2 series of key-value pairs.ktr
Internal.Transformation.Name Denormaliser - 2 series of key-value pairs sample
Internal.Transformation.Repository.Direct
ory
/
変数名 サンプル値

Pentaho データ統合 4.1 ユーザーガイド
~ 38 ~
©株式会社 KSK ソリューションズ
These variables are defined in a transformation running on a slave server, executed in clustered mode:
これらの変数はクラスタリングモードで実行されるスレーブサーバー上のデータ変換で定義されます。:
注意: 上記に加えてコマンドライン引数を含む System パラメータがあります。データ変換で Get
System Info ステップを使用することでこれらにアクセスできます。
注意: さらにデータ変換実行ダイアログボックスで変数の値を指定できます。データ変換に変数名を含
める場合、それらがダイアログボックスに現れます。
Pentaho データ統合でプロトタイピング
バージョン 4.0 現在、Pentaho データ統合は、Agile BI として知られている様々なプロセスとツールを
融合したもので素早くアナリシススキーマのプロトタイピングができます。Agile BI 機能はこのセクシ
ョンで説明されますが、PDI インストール、設定、ROLAP スキーマ作成以外のことは説明していませ
ん。PDI 一般についての情報がほしい場合は、Pentaho Knowledge Base の Pentaho Data Integration
Installation Guide または、Pentaho データ統合ユーザーガイドを参照ください。
PDI データソース以外でプロトタイプスキーマを作成する
この作業を続ける前に、データソースが、設定、実行されて利用可能な状能でなければなりません。
以下の手順に沿って、既存のデータベース、ファイル、またはデータウェアハウスから ROLAP スキー
マプロトタイプを作成します。
注意: データソースの作成にすでに PDI を使用している場合、これらの説明は読み飛ばして、「PDI デー
タソースでプロトタイプスキーマを作成する」を参照ください。
1. Spoon を起動し、リポジトリを使用している場合これに接続します。
cd ~/pentaho/design-tools/data-integration/ && ./spoon.sh
2. ファイルメニューに進み、次に新規サブメニューを選択して、それからモデリングをクリックしま
す。 インタフェースがモデルパースペクティブに切り替わります。
3. 右のプロパティエリアで、選択(Select)をクリックします。データソース選択ウィンドウが現れ
ます。
4. ウィンドウの右上隅で丸い緑色の(+)アイコンをクリックします。データベース接続ダイアログが現
れます。
5. 入力してデータソースの接続詳細を選択し、それからテスト(Test)をクリックしてすべて正しい
ことを確認します。完了したら OK をクリックします。
6. 新たに加えられたデータソースを選択して、次に OK をクリックします。データベースエクスプロ
ーラが現れます。
7. モデルを作成したいテーブルにたどり着くまでデータベース階層構造の中を探します。テーブルを
右クリックして、次にコンテキストメニューからモデルを選択します。データベースエクスプロー
Internal.Job.Filename.Directory /home/matt/jobs
Internal.Job.Filename.Name Nested jobs.kjb
Internal.Job.Name Nested job test case
Internal.Job.Repository.Directory /
変数名 サンプル値
Internal.Slave.Transformation.Number 0..<cluster size-1> (0,1,2,3 or 4)
Internal.Cluster.Size <cluster size> (5)

Pentaho データ統合 4.1 ユーザーガイド
~ 39 ~
©株式会社 KSK ソリューションズ
ラが閉じて、モデルパースペクティブに戻ります。
8. 左側のデータエリアからアイテムをドラッグし、そして中央のモデルエリアでメジャー(Measures)
かディメンジョン(Dimensions)グループのどちらかにドロップします。メジャーとディメンジョ
ングループがドラッグしたアイテムを含んで展開します。
9. それぞれ新しいメジャーとディメンジョンアイテムを選択し、そして右のプロパティ(Properties)
エリアで適宜詳細を変更します。
10. ファイルメニューからモデルを保存するか、モデルエリアの上のパブリッシュアイコンを使用して
BI サーバーにそれをパブリッシュします。
これで、基本的な ROLAP スキーマができました。実稼働環境に移行する前にテストを行う必要があり
ます。これを行うには、「Pentaho 分析レポートとレポートウィザードをテストする」に進んでくださ
い。
PDI データソースでプロトタイプスキーマを作成する
1. Spoon を起動し、リポジトリを使用している場合これに接続します。
cd ~/pentaho/design-tools/data-integration/ && ./spoon.sh
2. ROLAP スキーマを作成したいデータソースを生成するデータ変換を開きます。
3. アウトプットステップを右クリックして、次にコンテキストメニューからモデルを選択します。
4. 左のデータ(Data)エリアからアイテムをドラッグし、そして中央のモデルエリアでメジャー
(Measures)かディメンジョン(Dimensions)グループのどちらかにドロップします。メジャー
とディメンジョングループがドラッグしたアイテムを含んで展開します。
5. それぞれ新しいメジャーとディメンジョンアイテムを選択し、そして右のプロパティ(Properties)
エリアで適宜詳細を変更します。
6. ファイルメニューからモデルを保存するか、モデルエリアの上のパブリッシュアイコンを使用して
BI サーバーにそれをパブリッシュします。
これで、基本的な ROLAP スキーマができました。実稼働環境に移行する前にテストを行う必要があり
ます。これを行うには、「Pentaho 分析レポートとレポートウィザードをテストする」に進んでくださ
い。
Pentaho 分析レポートとレポートウィザードをテストする
尐なくとも 1 つのメジャーとディメンジョンがあるアナリシススキーマが必要で、Spoon 上のモデルパ
ースペクティブで開いて選択されている必要があります。
このセクションでは、組み込みのアナライザートレポートデザインウィザードをプロトタイプアナリシ
ススキーマのテストのために使用する方法を説明します。
1. モデルパースペクティブにいる間、データエリアの上の(左側に新規があります)ドロップダウン
ボックスから可視化の方法を選択し、次へ(Go)をクリックします。Analyzer と Report の 2 つの
選択肢です。これらのプレビューツールを使用するために Pentaho アナリシスと Pentaho レポー
ティングのライセンスキーは必要ありません。
2. レポートデザインウィザードが新しいサブウィンドウで開始するか、分析レポートが新しいタブで
開始します。レポートデザイナーまたは Pentaho ユーザーコンソールと同じように使用します。
Report Designer か Pentaho ユーザーコンソールに使用するように、それを使用します。
3. 新規スキーマを確認するには、すべてのパースペクティブボタンがある Spoon ツールバーの右上隅
のモデルをクリックしてモデルパースペクティブに戻ります。タブを閉じるとファイルが閉じるた
め開いたままにし、スキーマの調整のためにそれを再び開いていください。

Pentaho データ統合 4.1 ユーザーガイド
~ 40 ~
©株式会社 KSK ソリューションズ
4. モデルパースペクティブでスキーマの調整を続けるには、アナライザーまたはレポートウィザード
で見るごとにもう一度次へ(Go)ボタンをクリックする必要があります。可視化(Visualize)パー
スペクティブではモデラーで行った変更に沿って自動的にアップデートされません。
これで、実稼働環境と同様のモデルのプレビューができました。モデルパースペクティブから調整を続
けるには、最初に想定していた要件を満たすまで可視化(Visualize)パースペクティブからテストして
ください。
実稼働環境におけるプロトタイプ
実稼働環境へアナリシススキーマを移行する準備ができたら、モデルパースペクティブのモデルエリア
の上のパブリッシュボタンを使用して、実稼働環境の BI サーバーに接続するために使用します。
必要であればスキーマの調整を続けることができますが、再びデプロイする毎に再びパブリッシュしな
ければなりません。
接続の管理
Pentaho データ統合では、様々なデータベースベンダー(MySQL, Oracle, Postgres 等々)から提供さ
れる複数データベースへの接続を定義できます。Pentaho データ統合はサポートするデータベースの最
も適した JDBC ドライバーが付属して出荷されます。データベースへの主要インターフェースは JDBC
になっています。拡張デバッグまたはその他の用途がない限り、ご自身のデータベースドライバーを書
く必要はありません。
注意: Pentaho は、ODBC 接続の使用を避けられることを推奨します。ODBC から JDBC へのブリッジ
ドライバーは常にきちんと合うとは限らず、パフォーマンスに影響する可能性のある別のレベルの問題
が出てきます。どの JDBC ドライバーも利用出来ない時のみ、ODBC を使用する必要があります。
データベース接続を定義するとき、接続情報(ユーザー名、パスワード、ポートナンバーなど)は、Pentaho
エンタープライズリポジトリで保存されて、他のユーザーがリポジトリに接続するときに利用可能です。
Pentaho エンタープライズリポジトリを使用する場合は、データベース接続情報はデータ変換またはジ
ョブに関連する XML ファイルに保存されます。
データ変換またはジョブで使用される利用可能な接続は、Spoon のエクスプローラビューにリストされ
ています。

Pentaho データ統合 4.1 ユーザーガイド
~ 41 ~
©株式会社 KSK ソリューションズ
新規データベース接続を定義するにはいくつかの方法があります。:
・ Spoon で、ファイル→新規->データベース接続をクリックします。
・ Spoon で、ビュー(View)の下でデータベース接続を右クリックし、新規(New)を選びます。
・ Spoon で、ビュー(View)の下でデータベース接続を右クリックし、新規接続ウィザードを選択
します。
JDBC ドライバーを追加する
注意: JDBC ドライバーバージョン 4 以前には、Java6 で問題がある可能性があります。ドライバーJAR
をダウンロードする前に、データベースベンダーの互換性に関する注意を読みます。
注意: Microsoft SQL Server ユーザーの方は代替のものを頻繁に使用しています。非ベンダーサポートの
ドライバーは JTDS と呼ばれます。
インストールする前に必ず必要なドライバーをダウンロードしてください。
Pentaho サーバーまたはクライアントツールにデータソースを追加する前に、適切な JDBC ドライバー
JAR を特定のディレクトリにコピーしなければなりません。
データベースのサポートを追加するには、データベースベンダーから適切な JDBC のバージョンを取得
して、どの製品をこのデータベースに接続するかによって以下の場所にコピーしてください。
注意: ドライバーJAR をコピーする前に、これらのディレクトリに同じベンダーの JDBC ドライバーの
他のバージョンがインストールされていないことを確認してください。
同じドライバーの他のバージョンがある場合、混乱とクラス読み込みの潜在的な問題を避けるためにそ
れらを削除する必要があります。
Pentahoソリューションリポジトリと同じデータベースタイプのデータソース用のドライバーJARをイ
ンストールする時は、特に注意が必要です。
手順に関してご不明な点がありましたら、Pentaho のサポート担当までご連絡ください。
・ BI サーバー: /pentaho/server/biserver-ee/tomcat/lib/
・ データ統合サーバー: /pentaho/server/data-integration-server/tomcat/lib/
・ BI サーバーとデータ統合サーバー: /pentaho/server/enterprise-console/jdbc/
・ データ統合クライアント: /pentaho/design-tools/data-integration/libext/JDBC/
・ レポートデザイナー: /pentaho/design-tools/report-designer/lib/jdbc/
・ スキーマワークベンチ: /pentaho/design-tools/schema-workbench/drivers/
・ アグリゲーションデザイナー: /pentaho/design-tools/agg-designer/drivers/

Pentaho データ統合 4.1 ユーザーガイド
~ 42 ~
©株式会社 KSK ソリューションズ
・ メタデータエディター: /pentaho/design-tools/metadata-editor/libext/JDBC/
注意: BI サーバーまたは DI サーバーに新しいドライバーをインストールした場合、新しいデータベース
ドライバーをロードするために、すべての影響を受けるサーバー(BI サーバー、DI サーバー、および
Pentaho エンタープライズコンソール)を再起動しなければなりません。
データベース接続を定義する
データベース接続を定義する前に、データベースタイプ、ポート番号や、ユーザー名やパスワードなど
のデータベースに関する情報が必要です。変数を使用して接続プロパティを設定することもできます。
変数( )は同じデータ変換とジョブを使用している複数のデータベース複数のデータベースタイプか
らデータにアクセスすることができます。
注意: 後者の全ての場合で使用されるクリーンな ANSI SQL を必ず使用してください。
1. ツリーでデータベース接続を右クリックし、新規(New)または新規接続ウィザード(New
Connection Wizard)を選びます。
注意: その他の方法ではデータベース接続をダブルクリックするかデータベース接続を選択して
<F3>キーを押します。接続ウィザードでは接続をすばやく定義できます。プーリング/クラスタリ
ング等のさらなる機能が必要な場合は、接続ウィザードは使用しないでください。
選択に応じて、データベース接続ダイアログボックス(またはウィザード)が表示されます。デー
タベース接続(Database Connection)ダイアログボックスで必要な基本情報と同じものを提供す
るよう求めるウィザードを以下に示しています。:
2. Connection Name(接続名)フィールドで、新規接続を指定するユニークな名称を入力します。
3. Connection Type(接続タイプ)の下で、(例えば、MySQL、オラクルなど)接続しているデータベ
ースを選択します。
4. Access(アクセス)の下では、アクセスの方法を選択します。これは、Native (JDBC)、ODBC、
または JNDI になります。 利用できるアクセスタイプは接続しているデータベースタイプによりま
す。.
5. Settings(設定)の下で、Host Name(ホスト名)フィールドで、接続しているデータベースをホ
スティングするサーバー名を入力します。その他の方法では、IP アドレスでホストを指定できます。
6. Database Name(データベース名)フィールドに、接続しているデータベース名を入力します。
ODBC 接続を使用している場合、Data Source Name(DSN)をこのフィールドに入力します。

Pentaho データ統合 4.1 ユーザーガイド
~ 43 ~
©株式会社 KSK ソリューションズ
7. Port Number(ポート番号)フィールドで、デフォルトと異なる場合 TCP/IP ポート番号を入力しま
す。
8. 任意で、データベースに接続するために使用するユーザー名を入力します。
9. 任意で、データベースに接続するために使用するパスワードを入力します。
10. Test(テスト)をクリックします。Spoon がターゲットデータベースで接続を構築できた倍確認メ
ッセージが表示されます。
11. OK をクリックして、入力事項を保存してデータベース接続(Database Connection)ダイアログボ
ックスを終了してください。既存の接続を検索する場合はエクスプローラをクリックするか、ビュ
ー(View)モードで接続を右クリックして照会(Explore)をクリックして、データベースエクス
プローラを開いてください。
Feature List をクリックして、JDBC URL、クラス、および予約語のリストなどの接続に関する様々
なデータベース設定を表示します。
JNDI 接続を使用する
JBoss 上で実行する BI プラットホームなどのアプリケーションサーバーでデプロイされるデータ変換
やジョブを開発している場合、JNDI を使用してデータベース接続を設定できます。、データ変換のテス
ト・開発中に継続して実行できるアプリケーションサーバーがない場合、Pentaho にはローカルで
Pentaho データ統合を使用するのための JNDI 接続を設定する方法があります。設定するに
は、...¥data-integration-server¥pentaho-solutions¥system¥simple-jndi にある jdbc.properties というプロ
パティファイルを編集します。
注意: アプリケーションサーバーデータソースのコンテンツと同じ情報を jdbc.properties に保存してい
ることに注意してください。
Carte と Spoon JNDI 接続を使用する
Carte サーバーと Spoon は同じ方法で JNDI を使用します。以下の情報は JNDI データソース接続を使
用するデータ変換があり、これがリモート Carte サーバーで実行される場合に有用です。Simple-JNDI

Pentaho データ統合 4.1 ユーザーガイド
~ 44 ~
©株式会社 KSK ソリューションズ
jdbc.propertie ロケーションのロケーションを設定するには 3 つの方法があります。
1. <pdi-install>/simple-jndi/jdbc.properties ファイルに接続を追加します。これは Carte のデフォルト
ロケーションです。
2. コ マ ン ド ラ イ ン オ プ シ ョ ン で 実 行 す る た め に carte.bat に 変 更 を 加 え ま す 。 :
org.osjava.sj.root=<simple-jndi-path>
3. コ マ ン ド ラ イ ン オ プ シ ョ ン で 実 行 す る た め に carte.bat に 変 更 を 加 え ま す 。 :
KETTLE_JNDI_ROOT=<simple-jndi-path>
データベース特有のオプション
データベース接続(Database Connection)ダイアログボックスのオプションで、生成される URL にパ
ラメータを追加することで接続に関するデータベース特有のオプションを設定します。
データベース特有のオプションを追加す
以下での説明に沿ってデータベース接続(Database Connection)ダイアログボックスの中のオプショ
ンに関連するパラメータを追加します。:
1. パラメータテーブルで次の利用可能な行を選択します。
2. 有効なパラメータ名とその対応する値を入力します。
注意: データベース特定設定に関して詳しくは、ヘルプをクリックします。ブラウザが起動して現
在選択しているデータベースタイプのための JDBC 接続の設定に関する追加情報が表示されます。
3. OK をクリックして、エントリーを保存します。
データベース接続の高度な設定
データベース接続(Database Connection)ダイアログボックスにおける高度なオプションで、ほとん
どの場合 SQL の生成方法と関連するプロパティを設定できます。すべてのデータベースのテーブル名
と列名はツールでユーザーがなにを行っても全て大文字または全て小文字になります。

Pentaho データ統合 4.1 ユーザーガイド
~ 45 ~
©株式会社 KSK ソリューションズ
引用に関する詳細
Pentahoはサポートしているデータベースの命名規則に対応できる全ての名前や文字を使用できるデー
タベース固有の引用システムを実装しています。
Pentaho データ統合はサポートしているデータベースの大部分の予約語のリストを含んでいます。 引
用が正しく行われているのを確認するために、Pentaho はテーブルのスキーマ(ユーザー/所有者)とテー
ブル名自体を明確に分離した実装になっています。別の方法だと、テーブルとフィールドの間に 1 つ以
上のピリオドを正確に打つのは困難です。テーブルとフィールド名の間にピリオドを置くのは ERP シ
ステムでは一般的です。(例えば、フィールドでは"V.A.T."といったように)
引用関連のエラーを避けるために、テーブル名またはスキーマで開始または終了の引用があるとき、
Pentaho データ統合で引用アクティビティを停止します。これによって引用メカニズムを自ら指定する
ことができます。
接続プーリング
データ変換の各ステップで開かれる接続の代わりに、接続プールをセットアップして、初期のプールサ
イズ、最大のプールサイズ、および接続プールパラメータといったオプションを定義できます。例えば、
10 または 15 の接続のプールから開始する場合ジョブまたはデータ変換を実行するとき、使用しない接
続は減らしていきます。プーリングは、データベースアクセスのコントロールを特に、多くのステップ
と多くの接続を必要とするデータ変換がある場合に役立ちます。
また、データベースライセンスがアクティブな同時接続の数を制限するときも、プーリングを実装でき
ます。
機能 概要
ブールデータ型をサポ
ー ト す る ( Supports
boolean data types)
データベースでサポートされる場合、固有のブールデータ型を使用するよう Pentaho デー
タ統合に指示を出します。
データベースですべて
を引用する(Quote all
in database)
大文字と小文字を区別するテーブル名を使用するようデータベースに指示を出します。(例
えば、MySQL は Linux で大文字と小文字を区別していますが、Windows で大文字と小文字
を区別していません。識別子を引用すると、データベースは大文字と小文字を区別するテー
ブル名を使用します。)
すべて小文字にする
( Force all to lower
case)
すべての識別子を小文字にすることができます。
すべて大文字にする
( Force all to upper
case)
すべての識別子を大文字にすることができます。
スキーマ名を決定する
( Preferred schema
name...)
使用したいスキーマ名を入力します。 (例: MYSCHEMA)
SQL 名 を 入 力 す る
( Enter SQL name...)
接続の初期化するのに使用される SQL ステートメントを入力します。

Pentaho データ統合 4.1 ユーザーガイド
~ 46 ~
©株式会社 KSK ソリューションズ
以下の表は利用可能なプーリングオプションの詳細な説明です。:
クラスタリング
このオプションでは、データベース接続のためにクラスタリングを有効にしてデータパーティションに
接続を作成します。新しくデータパーティションを作成するには、パーティション ID(Partition ID)、ホ
スト名(Host Name)、ポート(Port)、データベース(Database)、ユーザー名(User Name)、パスワ
ード(Password)をパーティションへの接続のために入力してください。
接続の編集、複製、コピー、削除
以下の表はその他の実行可能なデータベース関連の接続タスクの情報を含んでいます。タスク説明を読
む際に、イメージを参照ください。
機能 概要
接続プーリングを有効
に す る ( Enable
connection pooling)
接続プーリングを有効にします。
プールサイズ( Pool
Size)
続プールの初期サイズを設定します。接続プールでの接続の最大数を設定します。
パ ラ メ ー タ
(Parameters)
追加カスタムプールパラメータを定義できます。適切な場合は Restore Defaults をクリック
します。
概要(Description) パラメータの説明を追加できます。

Pentaho データ統合 4.1 ユーザーガイド
~ 47 ~
©株式会社 KSK ソリューションズ
タスク 概要
接続を編集する(Edit a
Connection)
接続名を右クリックし、そして編集(Edit)を選択します。
接 続 を 複 製 す る
( Duplicate a
Connection)
接続名を右クリックし、そして複製(Duplicate)を選択します。
クリップボードへコピ
ー す る ( Copy to a
Clipboard)
クリップボードへステップを定義する XML をコピーできます。このステップを別のデータ
変換に貼り付けることができます。ツリーで接続名でダブルクリックするか接続名を右クリ
ックして、クリップボードへコピー(Copy to Clipboard)を選択します。
接続を削除する(Delete
a Connection)
ツリーで接続名でダブルクリックするか接続名を右クリックして、削除(Delete)を選択し
ます。
SQL エディタ(SQL
Editor)
既存の接続に対して SQL コマンドを実行するには、接続名で右クリックし SQL エディタ
(SQL Editor)を選択します。
データベースキャッシ
ュ を ク リ ア す る
( Clear the Database
Cache)
接続のスピードを上げるには、Pentaho データ統合はデータベースキャッシュを使用しま
す。これ以上データベースのレイアウトを表示しなくなったら、ツリーの接続で右クリック
してデータベースキャッシュのクリア(Clear DB Cache....)を選択します。
接続を共有する(Share
a Connection)
ローカルデバイスでジョブまたはデータ変換を作成する度に接続を再定義するより、右クリ
ックして共有(Share)を選択して、ジョブまたはデータ変換間で接続情報を共有します。
デ ー タ ベ ー ス 照 会
( Show
dependencies)
ツリーの接続名でダブルクリックするか接続名を右クリックして、照会(Explore)を選択
します。
関係を表示する(Show
dependencies)
接続名を右クリックして関係を表示する(Show dependencies)を選択してこのデータベー
ス接続に使用されている全てのデータ変換とジョブを確認します。

Pentaho データ統合 4.1 ユーザーガイド
~ 48 ~
©株式会社 KSK ソリューションズ
Hadoop を使用する
このセクションは Pentaho データ統合における Hadoop 関連の機能の案内と説明とを含みます。
Hadoopジョブとデータ変換ステップはこのガイドの標準PDIジョブ/ステップリファレンスに含まれて
います。
注意: いくつかの Hadoop の機能は Pentaho BI Suite For Hadoop 限定です。高度な Hadoop の機能に関
しては Pentaho セールス担当者にご連絡ください。
Hadoop ジョブプロセスフロー
PDI のジョブのには 2 つのパラダイムがあります。1 つはネイティブの PDI ジョブで通常データ変換ま
たは他のジョブ実行を含んでいて、もうひとつは Hadoop ジョブで扱っているデータを含む Hadoop ノ
ード上で実行されます。PDI ではネイティブの PDI ジョブと同様に Hadoop ジョブを設計・実行できま
す。関連するステップは Hadoop Job Executor と呼ばれます。
このステップはカスタムマッパ/リデューサ Java のクラスを必要とします:

Pentaho データ統合 4.1 ユーザーガイド
~ 49 ~
©株式会社 KSK ソリューションズ
Amazon Elastic MapReduce (EMR) サービスを利用している場合、Amazon EMR Job Executor という
Hadoop ジョブステップに似たものを使用できます。Amazon S3 の接続情報と EMR のための設定オプ
ションを含んでいるという点で標準の Hadoop Job Executor と異なります。
また、Hadoop Transformation Job Executor を通して Hadoop 指向のデータ変換を含む PDI ジョブを実
行できます。 また、普通のデータ変換に加えて、PDI の中でマッパ/リデューサ機能を設計するために
Java のクラスを提供する場合を除いてこのステップを使用できます。これを行うには、マッパ/リデュ
ーサ機能として動作するデータ変換を作成し、ステップ設定で適切に参照します。

Pentaho データ統合 4.1 ユーザーガイド
~ 50 ~
©株式会社 KSK ソリューションズ
データ変換ジョブ実行のためのワークフローはこのようになります。
Hadoop データ変換プロセスフロー
Pentaho データ統合は、あなたが Hadoop クラスターからデータを持ってきて、通常の方式に変換した
後、クラスターに戻すことが可能です。Hadoop マッパ/リデューサとして特別に設計されたデータ変換
も使用でき、この目的のために Java のクラスを作成する必要は全くありません。しかしながら、適切
に Hadoop と通信するために以下で示すような特定のワークフローに沿ってください。

Pentaho データ統合 4.1 ユーザーガイド
~ 51 ~
©株式会社 KSK ソリューションズ
Hadoop はキー/値のペアでのみ通信をします。したがって、PDI はキーと値のデータ型と名前を定義す
る Injector ステップを使用する必要があります。
そして、Hadoop にアウトプットを戻す Dummy ステップを使います。
真ん中あたりで生じることは全てユーザーに届いています。
Hadoop から PDI データ型への変換
Hadoop Job Executor と Hadoop Transformation Job Executor ステップには、あなたがジョブの入出力
のためのデータ型を指定できる高度な設定モードがあります。PDI 自体では foreign データ型を検出で
きません。したがって、ジョブ設定(Job Setup)タブで入力と出力データを指定しなければなりませ
ん。以下の表は、Apache Hadoop データ型とそれらの PDI で対応するものとの関係について説明しま

Pentaho データ統合 4.1 ユーザーガイド
~ 52 ~
©株式会社 KSK ソリューションズ
す。
データ変換とジョブのスケジューリング
最初のデータ変換とジョブを作成したとき、ローカルデバイスでそれらを実行していました。データ変
換とジョブのローカル実行はテストに役立ちますが、、実稼動環境ではジョブとデータ変換を週の特定
の曜日に実行するようにスケジュールしたくなるかもしれません。また、指定されたスケジュールで繰
り返し実行することもあるかもしれません。例えば、ユーザーが使用するレポート用の新しいデータが
利用できることを想定してみます。ジョブとデータ変換のスケジューリングに関連する実際の演習に関
しては「Getting Started with Pentaho Data Integration」を参照ください。
その他に関しては、スケジューラで将来または再現ベースでジョブとデータ変換の実行をスケジュール
することができます。スケジュールダイアログボックスにアクセスするには、Spoon メニューバーでジ
ョブ(またはデータ変換を開いて)アクション(Action)→スケジュール(Schedule)に進みます。
以下での指示に従って、データ変換またはジョブをスケジューリングします。
1. データ変換のスケジューリングダイアログボックスに、開始日時を入力します。カレンダーアイコ
ン(赤い丸)をクリックしてカレンダーを表示します。データ変換を実行するために、現在(Now)
ラジオボタンを有効にしてください。
データ変換 概要
PDI (Kettle) Data Type Apache Hadoop Data Type
java.lang.Integer org.apache.hadoop.io.IntWritable
java.lang.Long org.apache.hadoop.io.IntWritable
java.lang.Long org.apache.hadoop.io.LongWritable
org.apache.hadoop.io.IntWritable java.lang.Long
java.lang.String org.apache.hadoop.io.Text
java.lang.String org.apache.hadoop.io.IntWritable
org.apache.hadoop.i.LongWritable org.apache.hadoop.io.Text
org.apache.hadoop.io.LongWritable java.lang.Long

Pentaho データ統合 4.1 ユーザーガイド
~ 53 ~
©株式会社 KSK ソリューションズ
2. 終了日時をセットアップします。適切な場合、終了日なし(No end)ラジオボタンを有効にするか、
カレンダーをクリックしてデータ変換終了日時を入力してください。
3. 適切な場合、繰り返し(Repeat)の下で再現を設定します。
終了日時は再現(recurrence)を選択しないかぎり無効です。スケジュールオプションのリストか
ら適する選択肢を選びます。: 一度(Run Once)、毎秒(Seconds)、毎分(Minutes)、毎時(Hourly)、
毎日(Daily)、週次(Weekly)、月次(Monthly)、年次(Yearly)
4. 利用可能な場合、パラメータ、引数、および変数を必ず設定します。OK をクリックします。
5. Spoon メニューバーでは、スケジュール(Schedule)パースペクティブをクリックします。
スケジュール(Schedule)パースペクティブから、ページの左上隅でボタンを使用してデータ変換
のリフレッシュ、開始、一時停止、停止、削除が行えます。
データ変換ステップ リファレンス
Pentaho Data Integration に関連付けられたデータ変換ステップは 140 以上あります。以下のリストは、
使用頻度の高いステップのサブセットです。このドキュメントのより新しいバージョンでは、リストに
より多くのジョブが追加される予定です。現在のところ、入手可能なステップ関連のドキュメントのほ
とんどは Pentaho Wiki で利用できます。しかし、Wiki のドキュメントはオープンソースコミュニティ
によりメンテナンスされているますので、常にすべての情報がそろっていて、性格であるとは限りませ
ん。
Pentaho データ統合 4.1 ユーザーガイド
~ 54 ~
©株式会社 KSK ソリューションズ
Hadoop
名前 説明
Hadoop File Input Hadoop ノードに保存されているデータを取得します。
Hadoop File Output Hadoop ノードにのデータを保存します。
入力
名前 説明
CSV Input CSV ファイルからデータを読み込みます。
Excel 入力 Microsoft Excel または OpenOffice.org Calc ファイルからデータを読み込みま
す。
固定幅ファイル入力 固定長ファイルからデータを読み込みます。
行生成 指定された数の行を出力します。
Google Analytics Google analytics データにアクセスして、レポートを生成したり、BI データウェ
アハウスを設置します。
Google Docs 1 つ以上の Google Docs スプレッドシートを読込み、Pentaho レポート、ダッシ
ュボードやチャートを設置します。
JMS コンシューマ Pentaho Data Integration で JMS サーバーからメッセージを受信します。
テーブル入力 データベース接続と SQL を使用して、データベースから情報を読み込みます。基
本的な SQL ステートメントは自動生成されます。
テキストファイル入
力
さまざまなタイプのテキストファイルからデータを読み込みます。
出力
名前 説明
Excel 出力 Microsoft Excel にデータをエクスポートします。
Hadoop File Output Hadoop ノードに保存されたテキストファイルにデータをエクスポートしま
す。
JMS プロデューサー Pentaho Data Integration 内で、JMS サーバーにメッセージを送信します。
テーブル出力 データベーステーブルにデータをエクスポートします。
テキストファイル出
力
テキストファイルににデータをエクスポートします。
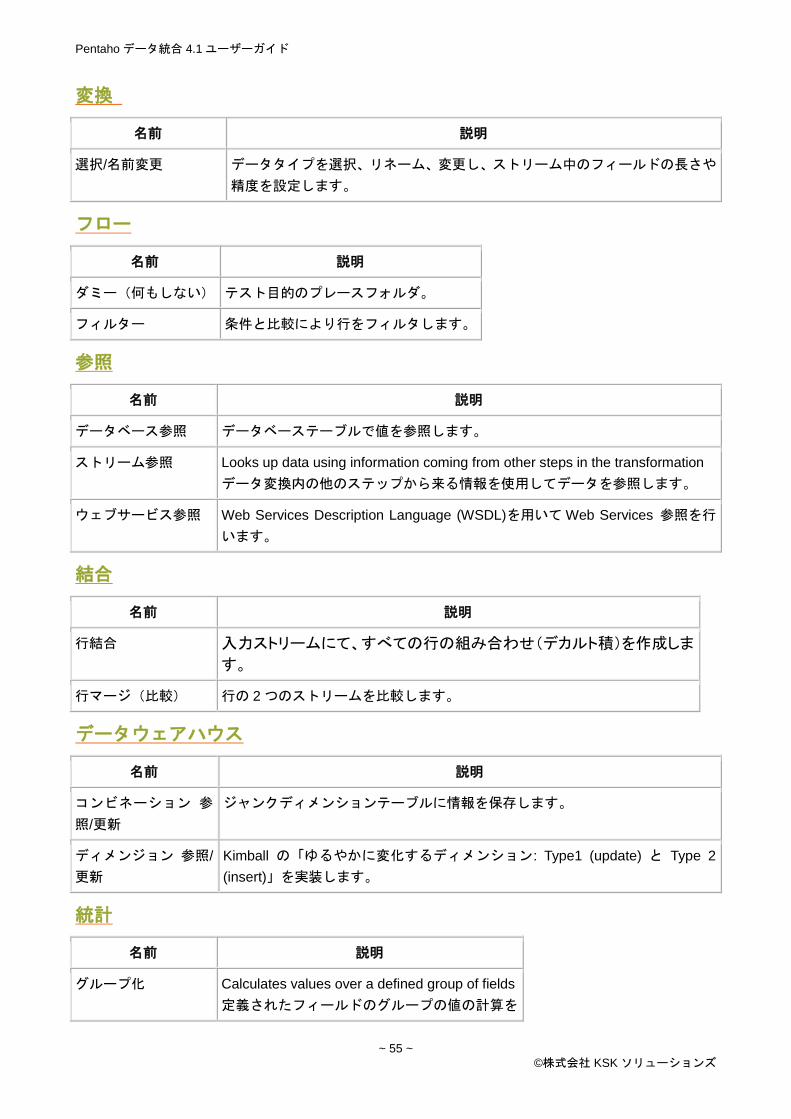
Pentaho データ統合 4.1 ユーザーガイド
~ 55 ~
©株式会社 KSK ソリューションズ
変換
名前 説明
選択/名前変更 データタイプを選択、リネーム、変更し、ストリーム中のフィールドの長さや
精度を設定します。
フロー
名前 説明
ダミー(何もしない) テスト目的のプレースフォルダ。
フィルター 条件と比較により行をフィルタします。
参照
名前 説明
データベース参照 データベーステーブルで値を参照します。
ストリーム参照 Looks up data using information coming from other steps in the transformation
データ変換内の他のステップから来る情報を使用してデータを参照します。
ウェブサービス参照 Web Services Description Language (WSDL)を用いて Web Services 参照を行
います。
結合
名前 説明
行結合 入力ストリームにて、すべての行の組み合わせ(デカルト積)を作成しま
す。
行マージ(比較) 行の 2 つのストリームを比較します。
データウェアハウス
名前 説明
コンビネーション 参
照/更新
ジャンクディメンションテーブルに情報を保存します。
ディメンジョン 参照/
更新
Kimball の「ゆるやかに変化するディメンション: Type1 (update) と Type 2
(insert)」を実装します。
統計
名前 説明
グループ化 Calculates values over a defined group of fields
定義されたフィールドのグループの値の計算を

Pentaho データ統合 4.1 ユーザーガイド
~ 56 ~
©株式会社 KSK ソリューションズ
名前 説明
行います。
スクリプト
名前 説明
JAVA スクリプト JavaScript を使用して、複雑な計算を行います。
CSV 入力
Excel 入力
Excel 出力
固定幅ファイル入力
行生成
Google Analytics 入力 Step
Google Docs 入力
テーブル入力
テキストファイル入力
JMS コンシューマ
JMS プロデューサー
テーブル出力
テキストファイル出力
選択/名前変更
ダミー(何もしない)
フィルター
データベース参照
ストリーム参照
ウェブサービス参照
行結合(デカルト積)
行マージ(比較)
コンビネーション 参照/更新
ディメンジョン 参照/更新
グループ化
JAVA スクリプト
Hadoop File Input
Hadoop File Output
S3 File Output
RSS 入力

Pentaho データ統合 4.1 ユーザーガイド
~ 57 ~
©株式会社 KSK ソリューションズ
CSV 入力
CSV 入力 ステップは、区切り文字でフォーマットされたファイルを読み取ります。しかし、カンマの
みではなく、セパレーターとしてパイプ、タブ、セミコロンなど、使用したいものをなんでも定義する
ことが可能なので、このステップを CSV と呼ぶのには御幣があります。内部的に処理することにより、
このステップでは素早くデータを処理することが可能です。このステップでのオプションは、テキスト
ファイル入力 ステップのサブセットです。シンプルな CSV Input 変換のサンプルは次の場所にありま
す: ...¥samples¥transformations¥CSV Input - Reading customer data.ktr.
CSV 入力 オプション
CSV Input ステップにて使用可能なオプションは以下です:
オプション 説明
ステップ名 必要に応じてステップ名を変更することができます。
ファイル名 読み込む CSVファイル名を指定してください。読む込むファイル名を含むフ
ィールド名を選択してください。このステップが前のステップからデータを
受け取るなら、このオプションはアウトプットにファイル名を含むオプショ
ンと同様に有効です。
フィールド区切り文
字
ターゲットファイルで使用される区切り文字やセパレーターを指定してく
ださい。これにはパイプ、タブ、セミコロンなどが含まれます。サンプルイ
メージではセミコロンが区切り文字となっています。

Pentaho データ統合 4.1 ユーザーガイド
~ 58 ~
©株式会社 KSK ソリューションズ
オプション 説明
引用符 ターゲットファイルで使用される引用符を指定してください。引用符に囲ま
れた文字列には、区切り文字として使用されるセミコロンやコンマを含むこ
とが可能になります。例えば、クオーテーションマークは終わりを示す引用
符が来るまではパースされません。サンプルイメージでは、引用符はクオー
テーションマークです。
バッファサイズ 読み込みバッファのサイズです。一度にディスクから読み込めるバイト数を
表します。
データ型を自動変換 自動変換アルゴリズムは、可能であるなら、不要なデータ型変換を避け、顕
著な性能改良をもたらすことができます。典型的な例は、テキストファイル
から読み込んだものをそのままテキストファイルへ書き込むといった場合
です。
ヘッダー・レコード
を含む
ターゲットファイルに列名を含むヘッダー行がある場合にチェックします。
ファイル名を結果に
含む
CSV ファイル名をこのデータ変換の結果に含めます。例えば、別のデータ変
換で、ユニークなリストは次のジョブエントリでジョブに使用できるメモリ
に保たれています、
フィールド名 このステップのアウトプットにおいて、行番号を含む Integer フィールドの
名前。
分散処理する このステップには複数の複数の実行されているインスタンスがあり(ステッ
プコピー)、各インスタンスに CSV ファイルの別々の部分を読むなら、これ
を有効にしてください。
複数のファイルを読み込むとき、ファイルの総サイズは、ワークロードを分
けるために考慮されます。その特定の場合では、すべてのステップコピーが
ファイルを受け取るのを確認してください。そうでなければ、並行アルゴリ
ズムは正確に動作しないでしょう。
Note:技術的な理由により、CSV ファイルの並列読み込みはフィールド中に
強制改行か改行を持たないファイルでのみサポートされます。
文字コード 読込むファイルのエンコードを指定します。
フィール表 ファイルから読まれるフィールドを番号付きリストで表示します。
プレビューボタン データをプレビューします。
フィールドを取得 現在の設定(区切り文字、引用符など)に基づいて、ファイルからフィール
ドのリストを取得します。フィールドが特定したすべてがフィールドテーブ
ルに追加されます。

Pentaho データ統合 4.1 ユーザーガイド
~ 59 ~
©株式会社 KSK ソリューションズ
Excel 入力
このステップでは Microsoft Excel (2003 または 2007) または OpenOffice.org Calc のスプレッドシー
トファイルからデータをインポートします。
Note: ステップの適切な動作のために、 ファイルタブ、シートタブ、フィールド タブの適切な設定が
必要とされます。
ファイル タブ
ファイル タブは、ステップのアウトプットに関する基本的なファイルのプロパティを定義します。
オプション 概要
ステップ名 データ変換内でのステップの名前。
ファイルとディレク
トリ
読取り対象となるスプレッドシートまたはファイルのディレクトリ。
検索文字列 前のオプションで指定されたディレクトリのファイルを選択するのに使用
したい正規表現を指定します。
除外正規表現 前のオプションで指定されたディレクトリのファイルを選択しないために
使用したい正規表現を指定します。(正規表現にあてはまるものは選択され
ません)。
ファイル名のリスト 前のオプションで指定された基準を満たすファイルのリストです。
先行のステップから
値を引き継ぐ
前のステップからファイル名を読み込みます。どのステップから読み込むか
と、そのステップ中から取得するファイル名を入力するフィールドを指定し
なければなりません。
シート タブ
シート タブでは特定のファイルで使用したいワークシートを指定します。1 つのスプレッドシートは複
数のワークシートを含むことができます。
オプション 概要
シート 使用するワークシートの一覧。ここが空の場合、特定のファイルのすべての
ワークシートが選択されます。行と列には番号が振られ、0から始まります。
シートの取得 このボタンを押すと、すべての指定されたファイルに含まれるワークシート
のリストを取得します。そしてリストから対象とするシートを選択してくだ
さい。
全般 タブ
全般 タブはファイルの内容に関するオプションが含まれます。
オプション 説明
ヘッダーを含む 指定されたシートにヘッダー行がある場合、有効にしてください。
空のレコードを削除 出力のなかに空の行が不必要なら、有効にしてください。
空白のレコードで処 ステップで空の行を見つけると、ファイルの現在のシート読み込みを停止さ

Pentaho データ統合 4.1 ユーザーガイド
~ 60 ~
©株式会社 KSK ソリューションズ
理を停止する せます。
最大レコード数 行の数を制限します。(0はすべての行を意味します)
文字コード 使用するエンコーディングを指定します。デフォルトのエンコーディングを
使用する場合は何も入力しないでください。Unicode を使用するには、UTF-8
または UTF-16 を指定してください。初回使用時に、Spoon はシステムで使
用可能なエンコーディングを検索します。
スプレッドシートタ
イプ (エンジン)
拡張子に関わらず、どのスプレッドシートのフォーマットを使用して処理す
るかを指定します。
ファイル名を結果に
含む
入力ファイル名をアウトプットに渡します。
エラー処理タブ
このタブでは、エラーの記録とレポートに関するオプションを指定します。
オプション 説明
形式の違うファイル
はエラーとする
PDI は入力でのデータタイプエラーをレポートします。
エラーを無視する 入力を解析中のエラーは無視されます。
エラーのレコードを
スキップ
PDI はエラーを含むラインをスキップします。エラーを含むラインは、以降
の「除外した行を保管するディレクトリ」で指定したパスのファイルにダン
プされます。この項目がチェックされていない場合は、エラーのある行は
NULL 値として出力されます。
警告を保管するディ
レクトリ
入力値に関して警告メッセージを含むファイルはこのディレクトリに保存
されます。保存されるファイルの拡張子はここで指定したものになります。
エラーを保管するデ
ィレクトリ
入力値に関してエラーメッセージを含むファイルはこのディレクトリに保
存されます。保存されるファイルの拡張子はここで指定したものになりま
す。
除外した行を保管す
るディレクトリ
入力の有効性エラーチェックに失敗したラインが出力されるファイルはこ
のディレクトリに保存されます。保存されるファイルの拡張子はここで指定
したものになります。
フィールド タブ
フィールド タブでは、出力されるフィールドに関するプロパティを定義します。
オプション 概要
フィールド名 フィールドの名前。
データタイプ フィールドの型; String, Date または Number。

Pentaho データ統合 4.1 ユーザーガイド
~ 61 ~
©株式会社 KSK ソリューションズ
長さ フィールドの長さ。 Number: 数値中の有効桁数; String: 文字列長; Date:
日付としての文字列がどのくらい出力または記録されるかを決定。
精度 フィールドの型が Number の場合の精度に関するオプション; 浮動小数点の
桁数を返します。
空白除去 処理の前にフィールドの左端、右端、または両方を切り捨てます。固定長で
はないフィールドに対して効果的です。
データを代替する 例えば Y に設定されている場合、次のフィールドが空のときにはこの値が
繰り返されます。
書式 フォーマット書式(数値)
通貨記号 通貨を表す記号
桁区切り文字 小数点; ドットまたはカンマ。
数値囲み文字 4 桁もしくはそれ以上の数値を千の位ごとに区切る方法。ドットまたはカン
マを指定。
追加出力フィールド タブ
このタブでは、ステップの出力に加えるための、カスタムのメタデータフィールドを 返される値そ
れぞれのフィールドの役割は名前で定義されますが、フィールドはどのような目的にも使用できます。
それぞれの項目は次に続く情報を含む出力フィールドを定義します:

Pentaho データ統合 4.1 ユーザーガイド
~ 62 ~
©株式会社 KSK ソリューションズ
Excel 出力
このステップでは、Microsoft Excel 2003 スプレッドシートファイルにデータを出力します。
ファイル タブ
File タブではステップの出力に関する基本的なファイルプロパティを定義します。
オプション 概要
ステップ名 データ変換内でのステップの名前。
ファイル名 読取るファイル名
開始時にファイルを
作成しない
チェックされている場合、ステップのの処理が終了するまでファイルを作成
しません。
拡張子 ファイルの拡張子
ファイル名にステッ
プ番号を含む
ステップを複数のコピーで実行する場合(ステップのコピーを実行)、コピ
ー番号(_0)はファイル名に含まれます。
ファイル名に日付を
含む
ファイル名にシステム日付を含みます。(_20101231)
ファイル名に時刻を
含む
ファイル名にシステム時刻 24 時間形式)を含みます。(_235959)
日付の表示形式を指
定する
チェックされている場合、ファイル名にはドロップダウンボックスから選択
した形式による日付と時刻を含みます。このオプションを選択すると、直前
の 2 つのオプションは無効になります。
ファイル名の参照 生成されるファイル名のリストを表示します。これはシミュレーションであ
り、各ファイルの行数に依存します。
ファイル名を結果に
含む
結果ファイル名を作成するのにファイル名フィールドを使用します。チェッ
クされていない場合は、ファイル名フィールドは無視されます。
全般 タブ
全般 タブにはファイルの内容に関するオプションが含まれます。
オプション 説明
既存のファイルに追
加する
チェックされた場合は、指定のファイルの最後から行を追加します。指定の
ファイルが存在しない場合は新規作成します。
ヘッダーレコードを
出力する
ヘッダー行が必要な場合は、このオプションを有効にしてください。
フッターレコードを
出力する
フッター行が必要な場合は、このオプションを有効にしてください。
文字コード 使用するエンコーディングを指定します。デフォルトのエンコーディングを
使用する場合は何も入力しないでください。Unicode を使用するには、UTF-8
または UTF-16 を指定してください。初回使用時に、Spoon はシステムで使

Pentaho データ統合 4.1 ユーザーガイド
~ 63 ~
©株式会社 KSK ソリューションズ
用可能なエンコーディングを検索します。
指定されたレコード
数でシートを分ける
いくつかの出力ファイル上でデータを分けます。
シート名 スプレッドシートファイル中のシート名を指定します。
シートを保護する ターゲットシートのパスワード保護を有効にします。
列サイズを自動変換
する
チェックした場合は、ワークシートのカラムのサイズを最大値に合わせて調
整します。
NULL 値を保持 チェックした場合は、NULL 値が出力ファイルにも保持されます。チェック
しない場合は、空の文字列でリプレイスされます。
テンプレートを使用 チェックした場合は、出力ファイルを作成する場合に特定の Excelテンプレ
ートを使用します。テンプレートは Excel テンプレートフィールドで指定し
てください。
テンプレートに追加
する
Excel テンプレートに出力を追加します。
フィールド タブ
フィールドタブは出力フィールドのプロパティを定義します。フィールドの取得 ボタンを押すと、入
力ストリームから自動的にフィールドのリストが取得されます。最小幅 ボタンを押すと、出力からす
べてのパディングを取り除きます。
オプション 概要
フィールド名 フィールドの名前。
データタイプ フィールドのデータ型; String、 Date または
Number
書式 フォーマット書式(数値型)

Pentaho データ統合 4.1 ユーザーガイド
~ 64 ~
©株式会社 KSK ソリューションズ
固定幅ファイル入力
このステップは固定長のテキストファイルからデータを読込むためにのみ使用されます。固定長ファイ
ルでは、フォーマットはカラム幅、パディング、整列によって指定されます。カラム幅は文字列の単位
で計測されます。例えば、ファイルの中のデータは先頭のカラムに 12 文字分あり、2 番目には 10 文字
分、3 番目には 7 文字分、といったように以降も続きます。それぞれの行に 1 レコードの情報があり、
それぞれのレコードには複数のデータ(フィールド)が任意の文字数であります。データが割り当てら
れている分の文字数に満たない場合はスペース(もしくは他の文字で)パディングされます。加えて、
それぞれのデータ要素は左揃え、または右揃えで整列され、それに応じてパディングされています。
固定幅ファイル入力 変換のサンプルは次の場所にあります: ...¥samples¥transformations¥Fixed Input
- fixed length reading .ktr
以下は、固定幅ファイル入力 ステップで利用可能なオプションの表です:
固定幅ファイル入力オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
ファイル名 読取り対象の CSV ファイル
改行を含む
対象のファイルにラインフィード文字が含まれる場合に有効にしてくださ
い。行幅はバイト単位(キャリッジリターンは除く)で、入力ファイルのそ
れぞれの行幅を定義します。
バッファサイズ 読み込むバッファのサイズです。ディスクから読まれるバイトの量を表す読
みのサイズです。
データ型を自動変換 自動変換アルゴリズムは、可能であるなら、不要なデータ型変換を避け、顕
著な性能改良をもたらすことができます。典型的な例は、テキストファイル
から読み込んだものをそのままテキストファイルへ書き込むといった場合
です。
ヘッダーレコードを
含む
ターゲットファイルに列名を含むヘッダー行がある場合にチェックします。
分散処理する このステップには複数の複数の実行されているインスタンスがあり(ステッ
プコピー)、各インスタンスにファイルの別々の部分を読むなら、これを有
効にしてください。
文字コード 読込むファイルの文字コードを指定します。
ファイル名を結果に
含む
この変換の結果に読込まれたファイルの名前を追加します。メモリに単一の
リストが保持されますので、次の変換などのジョブエントリにそれが使用で
きます。
フィールド表 対象ファイルから読み込まれるフィールドの並び順
プレビュー 対象ファイルから来るデータをプレビューするときにクリックしてくださ
い。
フィールドの取得 区切り文字、囲い文字などに対しての現在の設定に基づき、対象ファイルか
らのフィールドのリストを得るときにクリックしてください。すべての特定
されたフィールドはフィールドテーブルに追加されます。

Pentaho データ統合 4.1 ユーザーガイド
~ 65 ~
©株式会社 KSK ソリューションズ
行生成
行生成 では指定された数の行を出力します。デフォルトでは行は空です。しかし、数個の静的フィー
ルドを含めることが可能です。このステップは主にテスト目的で使用されます。決められた数の行を生
成するのに役立つでしょう。例えば、12 ヶ月に相応する 12 行が欲しい場合などです。変換の開始ポイ
ントとしてを 1 行分生成するために使用することもあるかもしれません。例えば、2か3のフィールド
と値を持つ1つの行を生成し、それらの値を SQL のパラメータとして使用して、その後実際に使用さ
れる行を生成することも考えられます。
行生成 オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
リミット 出力する行数を指定します。
フィールド この表で出力する行のフィールドの構造と値を設定します。これは定数の生
成に使用することも可能です。

Pentaho データ統合 4.1 ユーザーガイド
~ 66 ~
©株式会社 KSK ソリューションズ
Google Analytics 入力
Google Analytics 入力 ステップを使用することで、Google アナリティクスのデータにアクセスしてレ
ポートを作成したり、BI で使用するデータウェアハウスにデータを保存することができます。
認証
Note: クエリの作成を簡単に行うために、リンクが Google Analytics API ドキュメンテーションへの素
早いアクセスを提供します。
オプション 概要
ユーザー名 Google Analytics アカウントの
ユーザー名
パスワード Google Analytics アカウントの
パスワード
クエリ
オプション 概要
ドメインテーブル ID クエリが発行される、Google Analytics に関連付けられているドメインを
指定します。利用可能なドメインのリストの表示は、参照 をクリックして
ください。
開始日 クエリに関連付けられる開始日を指定します。日付は次のフォーマットで入
力してください: 年、月、日 (例: 2010-03-01)
終了日 クエリに関連付けられる終了日を指定します。日付は次のフォーマットで入
力してください: 年、月、日 (例: 2010-03-01)
ディメンション クエリを行うディメンションフィールドを指定してください。Google
Analytics API ドキュメンテーションにて、結合が可能なインプットとメト
リクス(指標)のリストが提供されています。
メトリクス メトリクスフィールドを指定してください。
フィルター フィルタを指定してください(Google Analytics API ドキュメンテーション
に記述があります) 例: 'ga:country==Algeria'
ソート ソートの基準とするフィールドを指定してください。例: 'ga:city'
フィールド
クエリ タブで定義したクエリに基づく結果のフィールドを取得するには、フィールドを取得 をクリッ
クしてください。
定義したクエリに基づきデータをプレビューするには、プレビュー をクリックしてください。

Pentaho データ統合 4.1 ユーザーガイド
~ 67 ~
©株式会社 KSK ソリューションズ
Google Docs 入力
Google Docs 入力 ステップでは、Google Docs スプレッドシートからデータを読込むことができます。
次のセクションには、Google Docs 入力 ステップを設定する上で利用することのできる機能が記述さ
れています。必要に応じて、次の Google サイトを参照してください : Dimensions and Metrics
Reference
ファイル
ファイル タブでは読込み対象となる Google Docs ファイルのロケーションを定義します。下の表はフ
ァイル タブに関連付けられているオプションです。
オプション 概要
ステップ名 必要に応じて変更することが可能です。
Google Docs ユーザ
ー名
Google Docs アカウントのユーザー名
Google Docs パスワ
ード
Google Docs アカウントのパスワード
Google Docs オブジ
ェクト ID
データを読込む対象となる Google ドキュメントのキーです。Note: キーは
ドキュメントに関連付けられた URL に含まれていて、次のフォーマットであ
るはずです。spreadsheet%pBb5yoxtYzKEyXDB9eqsNVG.
利用可能なキーのリストを表示するには、Lookup をクリックしてください。
シート
シート タブのオプションでは、読込み対象となるGoogle Docs ワークブックのシート名を指定します。
それぞれのシート名に対しては、始点となる行とカラムを指定することができます。行とカラム数はゼ
ロ (0) ベースです。始まりの数は 0 です。
内容
内容 タブでは以下のプロパティの設定が可能です。
オプション 概要
ヘッダー 指定されたシートに読込み対象ではないヘッダー行が含まれる場合は有効
にしてください。
空行不可 このステップの出力に空行を含めたくない場合は有効にしてください。
空行で停止 シートの読み込み中に空行に突き当たったときに、ステップをストップしま
す。
ファイル名フィール
ド
ステップの出力にファイル名を含むようにフィールド名を指定します。
シート名フィールド ステップの出力にシート名を含むようにフィールド名を指定します。
シート行フィールド
番号
ステップの出力にシート行番号を含むようにフィールド名を指定します。シ
ート行番号は、Google Docs シートの実際の行番号です。
下記込フィールドの ステップの出力に行番号を含むようにフィールド名を指定します。「記載行

Pentaho データ統合 4.1 ユーザーガイド
~ 68 ~
©株式会社 KSK ソリューションズ
オプション 概要
行数 番号」とは、処理される行の番号で、1から始まり
リミット ここで指定した数にまで、行数を制限します(ゼロ (0) はすべての行を意味
します)。
エンコード 文字コードを指定します(TF-8, ASCII など)。
エラーハンドリング
エラーハンドリング タブでは以下のプロパティが設定できます。
オプション 概要
ストリクトタイプ
Google Docs 入力 ステップ内の特定のカラムでは、数値、文字列、日付な
どとしてフラグが立てられることがあります。フラグが立てられると、カラ
ムが正しいデータ型をしていない場合(例えばカラムは数値としてフラグが
立てられたが、文字列の入力があった場合)エラーが発生します。
エラーを無視 入力を解析中のエラーは無視されます。
エラー行をスキップ エラーを含む行をスキップするときは有効にしてください。Note: エラーが
発生した行番号を含む別ファイルを生成することができます。エラー行がス
キップされない場合は、解析でエラーが発生したフィールドは空 (null) に
なります。
警告ファイルディレ
クトリー
入力値に関して警告メッセージを含むファイルはこのディレクトリに保存
されます。保存されるファイル名は次のようになります。
<warning dir>/filename. <date_time>.<warning extension>
エラーファイルディ
レクトリー
入力値に関してエラーメッセージを含むファイルはこのディレクトリに保
存されます。保存されるファイル名は次のようになります。
<errorfile_dir>/filename .<date_time>. <errorfile_extension>
ファイルディレクト
リーでの失敗行の数
行中に解析エラーが発生したとき、行番号がこのディレクトリに保存されま
す。保存されるファイル名は次のようになります。
<errorline dir> /filename.<date_time>.<errorline extension>
フィールド
fields タブはGoogle Docs ファイルから読み込まれるフィールドを指定します。Get fields from header
row (ヘッダー行からフィールドを取得) を使用して、シートがヘッダー行を持っている場合には利用可
能なフィールドから値を取得してください。Type カラムは、フィールドの型変換を行います。例えば、
日付を読込みたくてGoogle Docs ファイルでは文字列の場合、変換マスクを指定することになります。
Note: Number to Date (数値から日付) 変換の場合(例: 20101028--> October 28th, 2010) 、文字列から
日付への変換が行われる前に、暗黙的に数値から文字列への変換が行われるので、変換マスクとして
yyyyMMdd を指定してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 69 ~
©株式会社 KSK ソリューションズ
テーブル入力
接続と SQL を使用してデータベースから情報を読み込みます。Get SQL select statement をクリック
することで、基本的な SQL ステートメントは自動的に生成されます。
テーブル入力 オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
データソース名 データを読み込むデータベース接続
SQL ステートメ
ント
SQLステートメントはデータベース接続から情報を読み込むために使用されま
す。 また、Get SQL select statement をクリックすることで、テーブルや自
動的に生成された基本的な selectステートメントを見ることができます。
データ型を自動
変換
自動変換はできるだけ不要なデータ型変換を避け、大きくパフォーマンスを改
良します。
先行ステップか
ら値を引き継ぐ
スクリプトの変数を置き換えることができます。変数の置き換えのあるなしに
かかわらずテストを可能にします。
ステップ名 Pentahoがどこにあるか入力ステップ名を指定します。この情報を SQL ステート
メントに挿入できます。Pentahoロケーションインサート情報は? (クエスチョ
ンマーク)で表示されます。
レコード単位で
実行
個々の行のデータインサートの実行を有効にします。
最大レコード数 データベースから読まれる行の数を設定します。(“0”はすべての行を読みこ
むことを意味します。)
例
以下に、SQL ステートメント例があります:
SELECT * FROM customers WHERE changed_date BETWEEN ? AND ?
このステートメントはインサートデータ上の二つのデータを必要とします。
注意:データは Get System Info step type を使って提供されます。例えば、昨日データが変更されたす
べての顧客データを読み込みたいなら、昨日の範囲を取得し、読み込むことができます。
プレビュー
ステップをプレビューできます。これは以下の 2 ステップによる新しい変換のプレビューで達成されま
す: Dummy ステップ。 実行に関する詳細なログを見るには、プレビューウィンドウで Logs をクリッ
クしてください。
その他の情報については次を参照してください: Table Input

Pentaho データ統合 4.1 ユーザーガイド
~ 70 ~
©株式会社 KSK ソリューションズ
テキストファイル入力
異なったテキストファイルタイプから日付を読み込みます。最も一般的に使用される形式はスプレ
ッドシートと固定ワイドフラットファイルによって生成された、Comma Separated Values(CSVファ
イル)を含んでいます。
テキストファイル入力ステップは正規表現の形式中のワイルドカードで読み込むファイルのリス
ト、またはディレクトリのリストを指定することができます。さらに多くの前に作成したステップ
ファイル名からファイル名を受け入れることができます。
以下のセクションはテキストファイル入力ステップを設定するための利用可能なオプションにつ
いて説明します。
ファイル
以下の表は File タブで利用可能な機能の詳述を提供します:
オプション 概要
ステップ名 必要に応じて変更することが可能です。
ファイルとディレク
トリ
このフィールドはインプットテキストファイルのロケーション、または名前
を指定します: 追加ボタンを押して、以下の選択されたファイルのリストに
ファイル/ディレクトリ/ワイルドカード組み合わせを追加してください。
検索文字列 前のオプションで指定されたディレクトリのファイルを選択するのに使用
した正規表現を指定してください。
ファイル名のリスト 選択されたファイル(または、ワイルドカード選択)のリストとファイルが
必要であるか指定するプロパティを含んでいます。ファイルが見つからなけ
れば、エラーが発生します。もしくは、ファイル名はスキップされます。

Pentaho データ統合 4.1 ユーザーガイド
~ 71 ~
©株式会社 KSK ソリューションズ
ファイ名の参照 現在の選択されたファイル定義に基づいてロードされるすべてのファイル
のリストを表示します。
ファイル内容の表示 選択されたファイルの全般を表示します。
最初のレコードを表
示
選択されたファイルだけの最初のデータラインから内容を表示します。
どのデータから読み込むかファイルを選択する
データを読み込むファイルを特定できます。ファイルを指定するには:
1. ファイルとディレクトリフィールドにファイルのロケーションを入力するか、または「参照」
をクリックして、ファイルの場所を特定してください。
2. 追加をクリックして、以下の例に示されているように、「ファイル名のリスト」にファイルを
追加してください:
正規表現を使用したファイルの選択... テキストファイル入力 ステップではファイルの検索が正規表
現形式でワイルドカードを使用して行うことができます。正規表現は '*' や '?' のワイルドカードを使
用するより洗練されたものです。以下が正規表現の一例です:
ファイル
名
正規表現 選択されるファイル
/dirA/ .userdata.\.txt /dirA/ にある、名前に userdata を含み .txt で終了するすべ
てのファイルが検索対象になります。
/dirB/ AAA.* /dirB/ にある、AAA で開始するすべてのファイルが検索対象に
なります。
/dirC/ [ENG:A-Z][ENG:0-9].* /dirC/ にある、名前が大文字で始まり、数値(A0-Z9)が続くす
べてのファイルが検索対象になります。
先行のステップからファイル名を引き継ぐ... このオプションにより、"Get File Names"のような、
他のステップとの組み合わせがさらに柔軟になります。ファイル名を作成してこのステップに渡す
ことができます。このようにして、テキストファイル、データベーステーブルなど、どんなソース
からでもファイル名を受け取ることができます;
Option Description
先行のステップから値を
引き継ぐ
前のステップからファイル名を受け取るには、オプションを有効にしま
す。
ステップ名 ファイル名を読込むステップです。
フィールド名 テキストファイルインプットがこのステップを参照して、使用するファ
イル名を決定します。
全般
読み込むテキストファイルの形式を指定できます。 以下に、このタブに関連しているオプション
のリストがあります:
オプション 概要
ファイルタイプ CSV か固定長のどちらを選択できます。最後の「フィールド」タブで「フィ

Pentaho データ統合 4.1 ユーザーガイド
~ 72 ~
©株式会社 KSK ソリューションズ
ールドを取得」というボタンを押すと、この選択に基づいて Spoon はアシス
タントのためにそれぞれことなる GUI を起動します。
フィールド区切り文
字
一つのテキスト行でフィールドを切り離す 1つ以上の文字。 これは通常、
「;」 または tab です。
引用符 いくつかのフィールドはフィールド区切り文字をつかって引用することが
できます。引用符は任意で変更できます。
引用符を除去 引用符を除去します。
エスケープ文字 データ上にエスケープ文字があるのなら、エスケープ文字を指定してくださ
い。
ヘッダー・ヘッダー
行数
テキストファイルにヘッダー行(ファイルの最初の行)があるなら、有効にし
てください。ヘッダーが現れる回数を指定できます。
フッター・フッター
行数
テキストファイルにフッター行(ファイルの最後の行)があるなら、有効にし
てください。フッター行が現れる回数を指定できます。
含むレコード数 特定のページ限界を超えて含まれているデータラインを扱うのなら、使用し
てください。ヘッダーとフッターは含まれないことに注意してください。
ページレイアウト
(印刷)・1ページあ
たりのレコード数・
ヘッダーレコード数
最後の手段としてラインプリンタに印刷するために意味されたテキストに
対処するときにはこれらのオプションを使用してください。 ドキュメント
ヘッダー線の数を使用して、1ページあたりの線の紹介しているテキストと
数をスキップして、データラインを置いてください。
圧縮形式 テキストファイルが Zipか GZip アーカイブに置かれるなら、有効にしてく
ださい。注意: その瞬間、アーカイブの最初のファイルだけが読み込まれま
す。
空のレコードを除去 空の行を次のステップに送りません。
ファイル名を出力に
含む
出力にファイル名を含めたいときは、有効にしてください。
フィールド名 ファイル名を含むフィールド名
レコード数を出力に
含む
出力に行数を含めたいときは、有効にしてください。
フィールド名 行数を含むフィールド名
ファイル毎に行数を
リセットする
行番号がファイル単位でリセットされます。次のファイルに移ると新しい行
番号が割り振られます。
フォーマット UNIX、DOS、または混合であることができます。 UNIX ファイルは、改行で
終えられるラインがあります。 DOS ファイルは、リターンと改行で系列を
切り離します。混ぜられた状態で指定するなら、確かめる必要はありません。
文字コード 使用するテキストファイル文字コードを指定してください。システム上でデ
フォルト文字コードを使用するため、空白を残してください。ユニコードを
使用するには、UTF-8を指定してください、また初めて使用するとき、Spoon
は利用可能な encodingsシステムを検索します。
リミットサイズ ファイルから読まれる系列の数を設定します。 0つの手段がすべての系列
を読みます。
日付を自動処理 データフィールドの詳しい構文解析が必要であれば、無効にします。ケース
レニエント構文解析が可能にされると、1月 32日のような日付は 2月 1日
になります。
ロケール日付書式 このロケールは日付をパースするのに使用されます。例えば、日付書式とし

Pentaho データ統合 4.1 ユーザーガイド
~ 73 ~
©株式会社 KSK ソリューションズ
てすべての年月日が "February 2nd, 2006;" のように記述されている場合
に、フランス語(fr_FR) ロケールでは「February」は「Février」となるの
で、正しく動作しません。
ファイル名を結果に
含む
結果に出力ファイル名がフィールドとして追加されます。
エラー処理
エラーが発生したときのステップの対応を指定できます。 以下の表はエラー処理に利用可能なオ
プションについて説明します:
オプション 概要
エラー処理をする 構文解析の間、エラーを無視したいときは、有効にしてください。
エラーが発生したレ
コードをスキップ
エラーを含む行をスキップしたいときは、有効にしてください。エラーが
発生した行番号を含む付加的なファイルを生成することができます。エラ
ーがあるラインはスキップされず、構文解析エラーがあるフィールドはブ
ランクとされます(NULL)。
エラー回数フィール
ド名
出力ストリーム行にフィールドを追加します。このフィールドは行のエラ
ー回数を含んでいます。
エラー項目フィール
ド名
出力ストリーム行にフィールドを追加します。このフィールドはエラーが
発生したフィールド名を含んでいます。
エラーテキストフィ
ールド名
出力ストリーム行にフィールドを追加します。このフィールドは発生した
構文解析エラーの記述を含んでいます。
警告を保管するディ
レクトリ
警告が発生するとき、警告はこのディレクトリに置かれます。ファイル名
は<warning dir>/filename.<date_time>.<warning extension>です。
エラーを保管するデ
ィレクトリ
エラーが発生するとき、エラーはこのディレクトリに置かれます。 ファイ
ル名は<errorfile_dir>/filename.<date_time>.<errorfile_extension>で
す。
除外したレコードを
保管するディレクト
リ
構文解析エラーがラインに発生するとき、行番号はこのディレクトリに置
か れ ま す 。 フ ァ イ ル 名 は <errorline
dir>/filename.<date_time>.<errorline extension>です。
フィルタ
テキストファイルでスキップするラインを指定できます。 以下の表はフィルタを定義するための
利用可能なオプションについて説明します:
オプション 概要
フィルタ文字列 検索される文字列
フィルタ位置 ラインにあるフィルタ文字列の位置
(0)はラインの第 1ポジションです。もしここで(0)以下の値を指定するな
ら、フィルタ文字列は全体から検索されます。
フィルタで停止する フィルタ文字列が見つかったとき、現在のテキストファイルの処理を停止
したいなら、ここで Yを指定してください。
ポジティブマッチ Includes the rows where the filter condition is found (include). The
alternative is that those rows are avoided (exclude).
フィルタ条件が見つかった行を含みます。別の可能性としては、それらの
行が避けられている(除かれている)ということです。

Pentaho データ統合 4.1 ユーザーガイド
~ 74 ~
©株式会社 KSK ソリューションズ
フィールド
テキストファイルから読み込むフィールド名と形式情報を指定します。 利用可能なオプションは:
オプション 概要
フィールド名 フィールドの名前
データタイプ フィールドのタイプは、String、Date、Number、Boolean、Integer、BigNumber、
Serializable、Binary、のいずれかです。
書式 形式シンボルの完全記述に関して Number書式を見てください。
長さ Number: 数の有効桁数の合計。
String: トータルの文字列数。
Date:出力される文字列の長さ(例えば、4は年を返すだけである)
精度 Number:浮動小数点ケタの数。
String,Date,Boolean: 未使用。
通貨記号 $10,000.00 or E5.000,00 のような数を解釈するために使用
桁区切り文字 "." (10;000.00) or "," (5.000,00)のような桁区切り文字
数値囲み文字 "," (10;000.00) or "." (5.000,00) ドットによる数値囲み文字
NULL 可能 この値を NULLとして扱ってください。
デフォルト デフォルト値はテキストファイルのフィールドのために指定しません
(NULL)。
空白除去 タイプは、処理の前にこのフィールド(左右どちらも)を整えます。
データを代替する この行の換算値が空であるなら、空でなかった最後の時から繰り返します。
(Y:はい/N: いいえ)
数値の書式
こ の 情 報 は Sun Java API ド キ ュ メ ン テ ー シ ョ ン か ら の 引 用 で す :
http://java.sun.com/j2se/1.3/ja/docs/ja/api/java/text/DecimalFormat.html
記号 位置 地域対応
の有無 意味
0 数値 Y 数字
# 数値 Y 数字。ゼロだと表示されない
. 数値 Y 数値桁区切り子または通貨桁区切り子
- 数値 Y マイナス記号
, 数値 Y グループ区切り子
E 数値 Y
科学表記法の仮数と指数を区切る。接頭辞や接尾辞内に引
用符を付ける必要はない
;
サブパ
ターン
境界 Y 正と負のサブパターンを区切る
%
接頭辞
または
接尾辞 Y 100 倍してパーセントを表す
\u2030
接頭辞
または Y 1000 倍してパーミルを表す

Pentaho データ統合 4.1 ユーザーガイド
~ 75 ~
©株式会社 KSK ソリューションズ
接尾辞
¤ 接頭辞
または
接尾辞 N
通貨記号で置換される通貨符号。2 つの場合は、国際通貨
記号で置換される。パターン内にある場合は、数値桁区切
り子ではなく、通貨桁区切り子が使用される (\u00A4)
'
接頭辞
または
接尾辞 N
接頭辞や接尾辞内の特殊文字を引用符で囲む場合に使用
される。たとえば、"'#'#" を使用すると 123 は "#123"
にフォーマットされる。単一引用符自体を作成するために
合は、1 行に 2 つ引用符を使用する ("# o''clock")
科学表記法... パターンでは、指数文字の直後 に 1 つ以上の数字を続けて科学表記法を示します。た
とえば、「0.###E0」では 1234 を「1.234E3」とフォーマットします。
日付の書式
以下の情報は、Sun Java API ドキュメンテーションから引用したものです:
http://java.sun.com/javase/ja/6/docs/ja/api/java/text/SimpleDateFormat.html
文字 日付または時刻のコンポーネント 表示 例
G 紀元 Text AD
y 年 年 1996; 96
M 月 月 July; Jul; 07
w 年における週 Number 27
W 月における週 Number 2
D 年における日 Number 189
d 月における日 Number 10
F 月における曜日 Number 2
E 曜日 Text Tuesday; Tue
a 午前/午後 Text PM
H 一日における時 (0 ~ 23) Number 0
k 一日における時 (1 ~ 24) Number 24
K 午前/午後の時 (0 ~ 11) Number 0
h 午前/午後の時 (1 ~ 12) Number 12
m 分 Number 30
s 秒 Number 55
S ミリ秒 Number 978
z タイムゾーン 一般的なタイムゾーン
Pacific Standard
Time; PST; GMT-08:00
Z タイムゾーン RFC 822 タイムゾーン -800

Pentaho データ統合 4.1 ユーザーガイド
~ 76 ~
©株式会社 KSK ソリューションズ
JMS コンシューマ
Java Messaging Service (JMS) コンシューマ ステップでは、Pentaho Data Integration で JMS サーバ
ーからテキストメッセージを受け取ることが可能になります。例えば、JMS コンシューマ ステップを
使用して、JMS メッセージを受け取るたびにデータウェアハウスを更新するような、長時間実行され
るデータ変換などが可能です。
このステップを使用するには JMS メッセージ作成についての知識が必要です。また、このステップを
設定する前に、 Apache ActiveMQ のようなメッセージブローカーを利用できる状態にしておかなけれ
ばなりません。Java Naming and Directory Interface (JNDI) を JMS に接続するために使用している場
合は、適切な接続情報を保持する必要があります。
JMS コンシューマ オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
ActiveMQ Connection ActiveMQ をメッセージブローカーとして使用しているので、ActiveMQ 接続
を有効にします。
JMS URL 適切なブローカー URL を入力してください。
ユーザー名 ActiveMQ ユーザー名を入力してください。
パスワード ActiveMQ パスワードを入力してください。
Jndi 接続 Java Naming and Directory Interface (JNDI) を JMS に接続するために使
用している場合に、JNDI 接続を有効にします。
Jndi URL The URL for the JNDI connection
JNDI 接続の URL
トピック/キュー トピック、もしくはキューのどちらのデリバリーモデルを使用したいのかに
応じて、ドロップダウンリストからトピックまたはキューを選択してくださ
い。
Topi (トピック) は publish/subscribe (発行/購読)デリバリーモデルを
使用するので、ある一つのメッセージは複数の consumer (コンシュマー)に
届くということです。メッセージはトピックデスティネーションに配信さ
れ、最終的にはトピックを購読しているすべてのアクティブな consumer に
配信されます。また、すべての producer (プロドューサー)がトピックデス
ティネーションにメッセージを送信できます。それぞれのメッセージは購読
者に人数制限なく配信されます。コンシュマーが 1人も登録されていない場
合、durable subscription 機能を非アクティブコンシュマーのために用意
していない限りはトピックデスティネーションにはメッセージが保持され
ません。 durable subscription はメッセージが送信されたときに非アクテ
ィブな登録 consumer の代理になります。
Queue (キュー) はポイントツーポイントの配信モデルを使用します。こ
のモデルでは、メッセージは単一の producer から単一の consumer に配信
されます。メッセージはキューであるデスティネーションに配信され、それ
からキューに登録している一人の consumer に配信されます。キューにメッ

Pentaho データ統合 4.1 ユーザーガイド
~ 77 ~
©株式会社 KSK ソリューションズ
オプション 概要
セージを送信できる producer の数に制限はありませんが、それぞれのメッ
セージは一人の consumer へ配信され、消費されることが保証されています。
メッセージの consumer として誰も登録されていない場合、キューは
consumer が登録されるまでメッセージを保持します。
対象 キューまたはトピックの名前を指定してします。
受信タイムアウト メッセージの受信を待つ時間をミリ秒単位で指定します。
Note: 0を指定すると、期限切れは発生しません。
フィールド名 メッセージ内容を含むフィールド名を指定します。

Pentaho データ統合 4.1 ユーザーガイド
~ 78 ~
©株式会社 KSK ソリューションズ
JMS プロデューサー
Java Messaging Service (JMS) プロデューサー ステップでは Pentaho Data Integration でテキストメ
ッセージを JMS サーバーに送信することができます。例えば、JMS プロデューサー ステップを、デ
ータウェアハウスが更新されるごとに JMS キューに投稿し、アプリケーションのキャッシュをフラッ
シュする他のジョブを開始するようなデータ変換を定義するために使用できます。
このステップを使用するには JMS メッセージ作成についての知識が必要です。また、このステップを
設定する前に、 Apache ActiveMQ のようなメッセージブローカーを利用できる状態にしておかなけれ
ばなりません。Java Naming and Directory Interface (JNDI) を JMS に接続するために使用している場
合は、適切な接続情報を保持する必要があります。
Note: JMS Library jars を ConnectionFactory と他のサポートクラスのために次のディレクトリに配置
してください: .../data-integration/plugins/pdi-jms-plugin/lib
JMS プロデューサー Options
オプション 概要
ステップ名 必要に応じて変更することが可能です。
ActiveMQ 接続 ActiveMQ をメッセージブローカーとして使用しているので、ActiveMQ 接続
を有効にします。
JMS URL 適切なブローカー URL を入力してください。
ユーザー名 ActiveMQ ユーザー名を入力してください。
パスワード ActiveMQ パスワードを入力してください。
Jndi 接続 Java Naming and Directory Interface (JNDI) を JMS に接続するために使
用している場合に、JNDI 接続を有効にします。
Jndi URL JNDI 接続の URL
トピック/キュー トピック、もしくはキューのどちらのデリバリーモデルを使用したいのかに
応じて、ドロップダウンリストからトピックまたはキューを選択してくださ
い。
Topi (トピック) は publish/subscribe (発行/購読)デリバリーモデルを
使用するので、ある一つのメッセージは複数の consumer (コンシュマー)に
届くということです。メッセージはトピックデスティネーションに配信さ
れ、最終的にはトピックを購読しているすべてのアクティブな consumer に
配信されます。また、すべての プロデューサー (プロドューサー)がトピッ
クデスティネーションにメッセージを送信できます。それぞれのメッセージ
は購読者に人数制限なく配信されます。コンシュマーが 1人も登録されてい
ない場合、durable subscription 機能を非アクティブコンシュマーのため
に用意していない限りはトピックデスティネーションにはメッセージが保
持されません。 durable subscription はメッセージが送信されたときに非
アクティブな登録 consumer の代理になります。
Queue (キュー) はポイントツーポイントの配信モデルを使用します。こ

Pentaho データ統合 4.1 ユーザーガイド
~ 79 ~
©株式会社 KSK ソリューションズ
オプション 概要
のモデルでは、メッセージは単一の プロデューサー から単一の consumer
に配信されます。メッセージはキューであるデスティネーションに配信さ
れ、それからキューに登録している一人の consumer に配信されます。キュ
ーにメッセージを送信できるプロデューサー の数に制限はありませんが、
それぞれのメッセージは一人の consumerへ配信され、消費されることが保
証されています。メッセージの consumer として誰も登録されていない場合、
キューは consumer が登録されるまでメッセージを保持します。
対象 キューまたはトピックの名前を指定してします。
ヘッダー要素ファイ
ル
ヘッダープロパティファイルが指定されている場合、name/value (名前/値)
のペアが、JMS 文字列プロパティのメッセージテキストと一緒に送信されま
す。
フィールドがファイ
ル名
メッセージがフィールド名に基づいている場合に有効にします。この場合、
ファイルの内容(フィールド名ではありません)が送信されます。
フィールド名 メッセージ内容を含むフィールド名を指定します。

Pentaho データ統合 4.1 ユーザーガイド
~ 80 ~
©株式会社 KSK ソリューションズ
テーブル出力
テーブル出力 ステップではデータベーステーブルへデータをロードすることができあmす。テー
ブル出力 は DML オペレーターの INSERT と同等のものです。このステップは対象となるテーブ
ルに関するコミットサイズやインサートのためのバッチアップデートなど、維持管理やパフォーマ
ンスに関連する多くのオプションを提供します。
もしアイデンティティ カラム持つ Postgres or MySQL データベースがあって、そこにレコードを
インサートしている場合は、インサート処理の一部として、多くの JDBC ドライバーはインサート
時に自動生成されたキーを返します。
オプション
以下の表はテーブル出力ステップのための利用可能なオプションについて説明します:
オプション 概要
ステップ名 必要に応じて変更することが可能です。
データソース名 データが書き込まれるデータベースへの接続
スキーマ名 テーブルがデータを書き込むスキーマの名前。ピリオドのあるテーブル名
のデータソースにとって、これは重要です。テーブル名にピリオドが含ま
れていてもいいということはデータソースにとって重要なことです。
テーブル名 データが書き込まれているテーブル名
コミットサイズ データベーステーブルにローを挿入するためにトランザクションを使用し
てください。Nが“0”よりも大きいとき、N行毎にデータベースに接続し
ます。そうでないときは、トランザクションを使用しないでください。(遅
いため)
注意: トランザクションはすべてのデータベースプラットホームでサポー
トされるわけではありません。
開始時にテーブル内
容を削除する
最初のローがテーブルに挿入される前に打ち切りたいとき選択してくださ
い。
挿入エラーを無視す
る
違反したプライマリーキーなどのすべてのインサートエラーを無視させま
す。 しかしながら、最大 20 の警告が登録されます。このオプションはバ
ッチインサートには利用できません。
テーブルパーティシ
ョンを生成する
複数のテーブルわたってデータを分配させます。例えば、すべてのデータ
を SALESテーブルに挿入する代わりに、SALES_200510、SALES_200511、
SALES_200512 テーブルにデータを入れてください… パーティションテー
ブルを持っていないか、または、UNION ALL ビューや継承テーブルのマスタ
ーに挿入を許可しないシステムでこれを使用してください。 SALES ビュー
は以下の完全な販売レポートを表示します。
CREATE OR REPLACE VIEW SALES AS
SELECT * FROM SALES_200501
UNION ALL
SELECT * FROM SALES_200502
UNION ALL
SELECT * FROM SALES_200503
UNION ALL

Pentaho データ統合 4.1 ユーザーガイド
~ 81 ~
©株式会社 KSK ソリューションズ
SELECT * FROM SALES_200504
...
インサートにバッチ
更新を使用する
バッチ挿入を使用したいときは、有効にしてください。 この機能グループ
は、ステートメントをデータベースの往復を制限するために挿入します。
これは、最も速いオプションで、デフォルトで有効です。
テーブル名を定義し
たフィールドを含む
これらのオプションを使用して、1個以上のテーブルにわたってデータを分
割します。ターゲットテーブルの名前は指定するフィールドで定義されま
す。例えば、性別フィールドで顧客データを蓄積する場合、データは Mと F
(男性と女性)のテーブルに分けられるかもしれません。テーブルにイン
サートされたテーブル名を含むフィールドを除外するオプションがありま
す。
自動索引キーを生成
する
テーブルに行を挿入したことで生成されたキーを戻したい場合、、有効にし
て下さい。
自動索引キーフィー
ルド名
自動発生したキーを含むアウトプット行で新規フィールドの名前を指定し
ます。
SQL 自動的にアウトプットテーブルを作成するための SQL を作成します。

Pentaho データ統合 4.1 ユーザーガイド
~ 82 ~
©株式会社 KSK ソリューションズ
テキストファイル出力
テキストファイル出力ステップはテキストファイル形式にデータをエクスポートします。これは、
スプレッドシートアプリケーションで読込むことができる Comma Separated Values(CSV ファイル)
の作成に使用されます。また、フィールドタブのフィールド上の長さ設定することで、固定幅のフ
ァイルを作成することも可能です。
ファイル タブ
作成されるファイルについて基本的なプロパティを定義します:
オプション 概要
ステップ名 必要に応じて変更することが可能です。
ファイル名 このフィールドはアウトプットテキストファイルのファイル名とロケーシ
ョンを指定します。
コマンド結果にする
(ファイル出力しな
い)
チェックすると指定するコマンドかスクリプトに結果を渡します。
先行のステップから
値を引き継ぐ
このオプションをチェックすると、入力ストリームのファイル名を含んだフ
ィールドを指定できます。
フィールド名 前のオプションが有効なとき、実行時にファイル名を含むフィールドを指定
できます。
拡張子 ピリオドと拡張子をファイル名の終わりに追加します。 (.txt)
ファイル名にステッ
プ番号を含む
複数のコピーステップを実行した場合、ファイル名の拡張子の前にコピー番
号が含められます。
ファイル名に区切り
番号を含む
ファイル名に区切り番号を含めます。
ファイル名に日付を
含む
ファイル名にシステム日付を含めます。 (_20041231).
ファイル名に時刻を
含む
ファイル名にシステム時間を含めます。 (_235959).
ファイル名を結果に
含む
このオプションは作成されるファイルのリストを表示します。
注意: これはシュミレーションであり、他には各ファイルに入ってくる行の
数によっています。
全般 タブ
読み込まれるコンテンツを説明する以下のオプションがあります:
オプション 概要
既存のファイルに追
加する
有効にすると、指定されたファイルの終りに行を追加します。
区切り文字 テキスト行でフィールドを切り離す文字を指定します。通常、「;」もしく
は tabです。
引用符 一対のの文字列で前後を囲みフィールドを引用できます。 これはフィール
ドで引用符文字を許容します。 引用符文字列は任意です。テキストファイ
ルにヘッダー行(ファイルの最初の行)があってほしいとき、このオプシ
ョンを有効にします。

Pentaho データ統合 4.1 ユーザーガイド
~ 83 ~
©株式会社 KSK ソリューションズ
フィールドを引用符
で囲む
このオプションによって、すべてのフィールド名を上の引用符プロパティ
で指定された文字で引用します。
ヘッダー テキストファイルにヘッダー行があるなら、このオプションを有効にして
ください。(ファイルの最初のライン)
フッター テキストファイルにフッター行があるなら、このオプションを有効にして
ください。(ファイルの最後のライン)
フォーマット DOS か UNIX のいずれか。 UNIXファイルにはラインフィードによって切り
離された行があります。 DOS ファイルでは、行頭復帰と改行で切り離され
た行があります。
圧縮形式 アウトプットを圧縮するときzipまたは.gzipといった圧縮形式を指定しま
す。 注意:今のところ、アーカイブには一つのファイルしか置くことがで
きません。
文字コード 使用するテキストファイル文字コードを指定してください。システムの上
でデフォルト文字コードを使用するなら空欄のままにしておいてくださ
い。ユニコードを使用するには、UTF-8 を指定してください、また最初に使
用するとき、Spoon は利用可能な文字コードのシステムを検索します。
ダンプ出力する フォーマット情報含まず、多量のデータをテキストファイルに落とすとき、
パフォーマンスを向上させます。
フィールドの右側を
空白で埋める
設定された長さまでフィールドの終わりにスペースを追加し、またフィー
ルドの最後で文字を削除します。
指定されたレコード
数でファイルを分け
る
もし Nがゼロより大きいなら、テキストファイルの結果を複数の N行に分
けます。
終了レコードを追加
する
任意データを出力ファイルの最終行に追加します。
フィールド タブ
エクスポートされるフィールドのためにプロパティを定義します。以下の表はフィールドプロパティを
設定するオプションについて説明します:
オプション 概要
フィールド名 フィールドの名前。
フィールドタイプ フィールドのタイプは、String、Date、Number、Boolean、Integer、BigNumber、
Serializable、Binary、のいずれかです。
書式 変換するための形式マスク。 フォーマット記号の詳細を説明した形式に関
して Number フォーマットを見てください。
長さ ・ Number: 数の有効桁数の合計
・ String: トータルの文字列の長さ
・ Date:出力される文字列の長さ(例えば、4は年を返すだけである)
精度 精度オプションは以下のフィールドタイプによります:
・ Number:浮動小数点ケタの数
・ String,Date: 未使用
通貨記号 $10,000.00 or E5.000,00 のような数を解釈するために使用
桁区切り文字 "." (10;000.00) or "," (5.000,00)のような桁区切り文字
数値囲み文字 "," (10;000.00) or "." (5.000,00) ドットによる数値囲み文字

Pentaho データ統合 4.1 ユーザーガイド
~ 84 ~
©株式会社 KSK ソリューションズ
空白除去 XML で見つけられた文字列に適用するためのトリミングメソッド。
Null 可能 フィールドの値が NULLであるなら、この文字列をテキストファイルに挿入
してください。
フィールドを取得 クリックして、入力フィールドストリームからフィールドのリストを検索
してください。
最小長さにする テキストファイルのラインの結果として起こる幅が最小量であるように、
フィールドタブのオプションを変更してください。
例えば 0000001を保存する代わりに、1を書きます。文字列フィールドは指
定された長さに延ばされません。

Pentaho データ統合 4.1 ユーザーガイド
~ 85 ~
©株式会社 KSK ソリューションズ
選択/名前変更
選択、リネーム、データタイプの変更やストリーム上の長さと精度の設定に役立ちます。これらの操作
は異なったカテゴリーに編成されています:
フィールドの選択--フィールドがアウトプットする正確な順序と名前を指定します。
フィールドの除去--アウトプット行から取り除かれなければならないフィールドを指定します。
メタデータ--1 つ以上のフィールドの名前、タイプ、長さ、精度(メタデータ)を変更ください。
データ変換のサンプルは以下の場所に保存されています:
samples/transformations/Select values - some variants.ktr samples/transformations/Select Values - copy
field values to new fields.ktr
選択フィールド タブ
このタブにはデータタイプとフィールドの選択と変更のためののオプションが含まれます。フィー
ルドの取得ボタンにより、入力ステップから利用可能なフィールドが取得されます。マッピングの
編集をクリックすることで、マッピングダイアログが開き、複数のソースとターゲットフィールド
間のマッピングの定義ができます。
Note: マッピングの編集は出力ステップが 1つのときだけ動作します。
オプション 概要
ステップ名 必要に応じて変更することが可能です。
フィールド名 クリックして、すべてのインプットストリームからステップへフィールドを挿
入してください。
変更名称 クリックして、すべてのインプットストリームからステップへフィールドを挿
入してください。
長さ 明示的にフィールドセクションで選択されていない、入力ストリームからの他
のすべてのフィールドを暗黙的に選択するには有効にしてください。
精度 精度オプションは、フィールドタイプによりことなりますが、サポートされて
いるのは数値のみとなっています。浮動小数点の桁数を示します。
未定義のフィー
ルドを含む
フィールドセクションで選択されていない入力ストリームを定義したい場合
は有効にして下さい。
除去フィールド
削除したい入力ストリームからのフィールドを指定してください。
Note: フィールドの削除は生成されるクエリの性質上、実行には時間がかかります。.
メタ情報
このタブ以下のオプションにより、リネーム、データ型の変更、フィールドの長さや精度の変更が可能
です。ひとつ前のステップからフィールドをインポートするには、Get fields to change (変更用にフ
ィールドを取得)をクリックしてください。多くのデータ型変換もこのタブで可能です。
オプション 概要
フィールド名 インポートされたフィールドの名前。
変更フィールド名 フィールド名をリネームしたい場合、ここに新しい名前を設定してくださ
い。

Pentaho データ統合 4.1 ユーザーガイド
~ 86 ~
©株式会社 KSK ソリューションズ
オプション 概要
データタイプ フィールドの型
長さ フィールドの長さ
精度 精度オプションは、フィールドタイプによりことなりますが、サポートされ
ているのは数値のみとなっています。浮動小数点の桁数を示します。
バイナリから変換 適用可能な場合、文字列を数値データに変換します。
書式 フォーマットマスク (数値型もしくは日付型)
文字エンコード 使用するエンコーディングを指定します。デフォルトのエンコーディングを
使用する場合は何も入力しないでください。Unicode を使用するには、UTF-8
または UTF-16 を指定してください。初回使用時に、Spoon はシステムで使
用可能なエンコーディングを検索します。
桁区切り文字 ドットまたはカンマでの、小数点のポイント。
数値囲み文字 4 桁もしくはそれ以上の数値を千の位ごとに区切る方法。ドットまたはカン
マ。
通貨記号 通貨を表す記号
デート型を自動処理 日付型の解析を厳格に行うか緩やかに行うかを決定します。緩やかに行うと
は、無効な日付値を処理することになります。N に設定されている場合、日
付として厳格な解釈のみが受け付けられます。Y に設定されている場合、解
析処理にて不正確な日付の意図を決定し、可能であるならそれを修正しま
す。

Pentaho データ統合 4.1 ユーザーガイド
~ 87 ~
©株式会社 KSK ソリューションズ
ダミー(何もしない)
ダミーステップは何もしません。主な機能は、テスト目的のプレースホルダです。例えば、データ変換
をするために、尐なくとも 2 ステップをお互いにつなげる必要があります。 ファイルインプットステ
ップをテストしたいとき、ダミーのステップとつなぐことができます。

Pentaho データ統合 4.1 ユーザーガイド
~ 88 ~
©株式会社 KSK ソリューションズ
フィルター
条件と比較に基づいて行をフィルタにかけることができます。このステップがいったん前のステップ(1
以上のステップと受信インプット)につなげられると、条件を構成するために"<field>"、"=" 、"<value>"
エリアをクリックすることができます。右側の「Add condition」アイコンをクリックして、条件を追加
してください。
Note: IN LIST 演算子に入力を行うためには、セミコロンで分割された文字列を使用してください。数
値などの値にも同様です。値のリストは文字列で入力されなければなりません。(例)2;3;7;8
Filter Row Options
オプション 概要
ステップ名 必要に応じて変更することが可能です。
条件式が真のときに
実行する処理
指定された条件が、真である行をこのステップに送ります。
実行式が偽のときに
実行する処理
指定された条件が、偽である行をこのステップに送ります。
フィルタ条件 左上で'NOT'ボタンをクリックして、条件を否定してください。
条件を構築し、 入力ストリームからのフィールドのリストを選択するため
に< field >ボタンをクリックしてください。
< value >ボタンをクリックして、特定の値を条件に含めてください。
状態を削除するために、右クリックして、Delete condition を選択してく
ださい。
条件追加 (条件追加) をクリックして条件を追加してください。条件追加は元々の
条件をサブレベルの条件に変換します。条件追加をクリックして、条件ツ
リー項目を 1レベル下って編集してください。
変数からの値に基づいての行のフィルタ
フィルター ステップは入力ストリーム中のフィールドのみ検知します。変数に基づいて行をフィルタ
したい場合、一つ前のステップ(例えば table input など)を変更し、もうひとつのフィールドとしてそ
の変数を含まなければなりません。次に例を示します。
${myvar}=5
クエリ:
SELECT field1,
field2,

Pentaho データ統合 4.1 ユーザーガイド
~ 89 ~
©株式会社 KSK ソリューションズ
${myvar} AS field3
FROM table
WHERE field1=xxxx
そして filter row 条件にて、以下のようにしてください。
field1 = field3
もしくは、Get Variables ステップを使用して、パラメータをフィールドにセットできます。

Pentaho データ統合 4.1 ユーザーガイド
~ 90 ~
©株式会社 KSK ソリューションズ
データベース参照
概要
データベーステーブルで値をルックアップできます。 ルックアップ値は新しいフィールドとしてスト
リームに追加されます。
オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
データソース名 ルックアップのデータベース接続を選んでください。
スキーマ名 ルックアップに使用するスキーマを指定してください。
テーブル名 ルックアップをするテーブルの名前。
キャッシュを使用 このオプションはデータベースルックアップをキャッシュします。特定のル
ックアップ値のために常時同じ値をかえすデータベースを除くことを意味
します。
キャッシュサイズ 行で使用するキャッシュのサイズを指定してください。
データをすべて読み
込みする
ルックアップテーブルのすべてのデータをプリロードしてキャッシュする。
これはルックアップの遅延時間を低下させることでパフォーマンスを向上
させます。しかし、大きいテーブルの場合はメモリを使い果たす危険性があ
ります。
参照キー ルックアップを実行するのに必要なキーを指定してください。
ルックアップが失敗
した場合は中止する
ルックアップが失敗したとき、行が通過しないようにするには、有効にして
ください。
ルックアップが重複
した場合は中止する
ルックアップが複数個の答えを返す場合に中止するには、有効にしてくださ
い。
並び替え ルックアップクエリが複数の結果を返す場合、 ORDER BY 句が取得すべきレ
コードの選択に役立ちます。例えば、ORDER BYは特定の地域での最高の売
上高を探し出しやすくします。
フィールドの取得 クリックすると、ステップの入力ストリームから利用できるフィールドのリ
ストをかえします。
参照フィールドの取
得
クリックすると、ステップの出力ストリームに追加できるルックアップテー
ブルから、利用可能なフィールドのリストを取得します。
重要: 他のプロセスがルックアップを実行するテーブルで値を変更している場合、値をキャッシュしな
いでください。 その他の状況では、値をキャッシュしてください。データベースルックアップは比較
的遅いので、性能はかなり向上されます。もしキャッシュを使用しない場合、いくつかのコピーを同時
に実行することを考慮してください。同時実行を行うことで、データベースへの接続に異なるものが使
用されて、データベースはビジー状態になります。

Pentaho データ統合 4.1 ユーザーガイド
~ 91 ~
©株式会社 KSK ソリューションズ
ストリーム参照
データ変換で他のステップから来る情報を使用し、データをルックアップします。参照元ステップから
来るデータは最初にメモリから読み取られて、次にメインストリームのデータルックアップに使用され
ます。
ストリーム参照 オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
ステップ名(ルック
アップステップ)
ルックアップデータが来るステップ名
フィールド名(ルッ
クアップ)参照キー
値を検索するために使用されるフィールドの名前を指定します。検索時の
値の比較には「等しい」が使用されます。
メモリにキャッシュ
する
ソート中、メモリを保存するためにデータの行をエンコードします。
取得するフィールド
の指定
ルックアップが成功したときに取得するフィールドを指定します。
キーと値が整数 ソートを実行中、メモリを保存します。
メモリへキャッシュ
されたデータを並替
えする
有効にすると、ソートされたリストを使用して値を保存します。大きな行
を含むデータセットで作業しているときに、より効率的にメモリを使用し
ます。
フィールドの取得 ソースサイドで利用可能なすべてのフィールド名を、自動的に表示します。
そこからルックアップに使用しないフィールドをすべて削除してくださ
い。
ルックアップフィー
ルドの取得
ルックアップサイド上で利用可能なすべてのフィールド名を、自動的に表
示します。そこから取得しないフィールドを削除できます。

Pentaho データ統合 4.1 ユーザーガイド
~ 92 ~
©株式会社 KSK ソリューションズ
ウェブサービス参照
Web Services Description Language (WSDL) を使用してウェブサービスルックアップを提供します。
このステップには以下の制限があります。
・ SOAP WSDL 要求/応答だけが理解されます。WSDL 規格の他のバリエーションはまだ実装されて
いません。
・ すべての WSDL XML 方言が簡単に読み込めるわけではありません。その場合には、手動で入出力
フィールドがどいったものであるかを指定する必要があります。
・ データ変換はステップ中で実行されます。日付や数値がある場合には、エラーが発生することもあ
ります。もし変換エラーになったら、文字列を返すように設定し、Select Values ステップにて変
換してください。
オプション 概要
ステップ名 必要に応じて変更することが可能です。
URL 検索される WSDLドキュメントを示すベース URL
オペレーション 指定された URLで WSDLをロードし、自動的に入出力タブやフィールド埋め
込もうとします。
注意: これが動作しない場合、、「入力を追加」と「出力を追加」ボタンを使
用することで、手動でインプットとアウトプットフィールド指定することが
できます。
操作 各 WSDL call で送る行の数
入力データを出力デ
ータに渡す
無効にすると、インプットは使用されず WSDL アウトプットだけが次のステ
ップに渡されます。
v2.x/3.0互換性モー
ド
バージョン 2.0エンジンは、以前のステップでも正しく動作するように保持
されています。
要素名を繰り返し (もしあれば)アウトプット XMLの繰り返している要素の名前を指定してく
ださい。
HTTP 認証 Web サービスに必要な場合、ユーザー名とパスワードを入力します。
使用するプロキシ ここは、任意でプロキシホストとポート情報を入力します。
出力追加、または入
力追加
これらのボタンで、手動で WSDL サービスの入出力仕様を指定できます。
基本的な Web Services - Web Service Lookup ステップ
このシナリオでのアクセス対象のウェブサービスは WSDL 1.1 仕様で記述されているものです。ステッ
プは一つの動作でこの仕様をロードすることができ、入出力パラメータの選択と設定が可能になります。
出力パラメータはステップの出力ストリームに加えられ、処理のために他のプロセスに渡されます。 こ
のシナリオでは、ウェブサービスは送信されるパラメータ以外に情報を必要としていないので、SOAP
リクエストを修正する必要はありません。.
このシナリオのサンプルである Web Services - NOAA Latitude and Longitude.ktr はサンプルフォルダ
に保存されています。(...¥data-integration¥samples¥transformations)

Pentaho データ統合 4.1 ユーザーガイド
~ 93 ~
©株式会社 KSK ソリューションズ
行結合(デカルト積)
以下に示すように、入力ストリームにおける、すべての行を組み合わせ(直積集合)を作成できます:
Years x Months x Days のアウトプットは Year、Month、および Day すべての組み合わせを出力し(例、
1900、1、1 2100、12、31) 日付ディメンションなどで使用することができます。
多くの場合 Merge Join ステップの方がよりよいパフォーマンスを期待できます。
オプション
以下の表は行結合ステップを設定するオプションについてです:
オプション 概要
ステップ名 必要に応じて変更することが可能です。
一時ディレクト
リ
行がキャッシュされている数より多く結合したい場合、システムが一時ファイ
ルを保存するディレクトリ名を指定してください。
一時ファイルの
接頭子
作成される一時ファイルの接頭子です。
キャッシュサイ
ズ
システムが一時ファイルからデータを読み込む前にキャッシュする行の数。メ
モリに適合しない大きな行のセットを結びつけるときに必要です。
結合条件 アウトプット行の数を制限する複合条件を入力します。
注意: 条件中のフィールドは、各ストリームでユニークな名前にしなければな
りません。

Pentaho データ統合 4.1 ユーザーガイド
~ 94 ~
©株式会社 KSK ソリューションズ
行マージ(比較)
2 つの行のストリームを比較できます。 これは 2 回にわたり別々の時間に来るデータを比較するのに役
立ちます。例えば、データウェアハウスのソースシステムが、最終更新日付を含まない状況などでよく
使用されます。
行の 2 つのストリームである、参照ストリーム(古いデータ)と比較ストリーム(新しいデータ)がマージさ
れます。行の最後のバージョンだけがその都度、次のステップに向かいます。行は以下のように表示さ
れます:
identical — キーは両方のストリームで見つかり、比較する値は同じです。
changed — キーは両方のストリームで見つけられましたが、1 つ以上異なる値があります。
new — キーは参照ストリームで見つけられませんでした。
deleted — キーは比較ストリームで見つけられませんでした。
比較ストリームから来る行は、‖deleted‖ の時を除いて次のステップへ向かいます。
重要: 両方のストリームは指定されたキーで分類しなければなりません。
オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
比較 1のステップ名 参照行の元となるステップを指定してください。
比較 2のステップ名 比較行の元となるステップ originを指定してください。
フラグとなるフィー
ルド
出力ストリームでフラグフィールドの名前を指定してください。
フィールド(比較 1) 一致するキーを含むフィールドを指定してください; 「フィールドの取得
(K)」をクリックすると、参照行ステップから来ているすべてのフィールド
が挿入されます。
フィールド(比較 2) 比較のための値を含むフィールドを指定してください;「フィールドの取得
(V)」をクリックすると、値の行のステップ(value rows step)から来て
いるすべてのフィールドが挿入されます。

Pentaho データ統合 4.1 ユーザーガイド
~ 95 ~
©株式会社 KSK ソリューションズ
コンビネーション 参照/更新
コンビネーション 参照/更新 ステップはジャンクディメンションテーブルに情報を保存します。
Kimball pure Type 1 ディメンジョンを維持するためなどに使用されます。
以下は使用例です。
・ ディメンションテーブルの入力ストリームからのビジネスキーフィールド(field 1…field n)の組み
合わせをルックアップします。
・ ビジネスキーフィールドの組み合わせが存在する場合、テクニカルキー(サロゲート ID)を返します。
・ ビジネスキーの組み合わせがまだ存在していない場合、新しいキーフィールドで行を挿入し、(新
しい)テクニカルキーを返します。
・ 返されたテクニカルキーを含む出力ストリームに、すべての入力フィールドを配置します。ただし、
「ルックアップフィールドを除く」の項目が有効な場合、すべてのビジネスキーフィールドを削除
します。
このステップは、ビジネスキーを持つデータからテクニカルキーを作成、または保持します。このステ
ップの後、ビジネスキーに対応する行はすでに存在または作成されていますので、残りのデータ変更は
アップデートとして行われます。
このステップはキー情報を保持するだけとなります。ディメンションテーブルのキーでない情報を更新
しなければなりません。(例:コンビネーション 参照/更新ステップの後にテクニカルキーに基づく
Update ステップを置くことによる更新)
Pentaho Data Integration は情報をテーブルに保存します。そのテーブルとは、プライマリーキーがテ
ーブル中のビジネスキーフィールドの組み合わせであるものです。このプロセスは、多くのフィールド
があとき非常に遅くなることがあるので、Pentaho Data Integration はディメンションにおけるすべての
フィールドを表す「ハッシュコード」フィールドをサポートします。これは索引をつけるフィールドを
1 に制限する一方で、ルックアップの速度を劇的に向上させます。
コンビネーション 参照/更新 オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
データソース名 ディメンションテーブルがあるデータベース接続の名前。
スキーマ名 引用の精度を改善するためにスキーマ名を指定し、スキーマ名をドット’.’に
より区切りテーブル名を入れることができます。
テーブル名 ディメンションテーブルの名前。
コミットサイズ 10に設定すると、インサートまたはアップデートが 10回される毎にコミットし
ます。
キャッシュサイ
ズ
これはデータベースへの往復数を減尐させることによってルックアップを速く
するために、メモリに保持される行数のキャッシュサイズです。
注意: ディメンションエントリーの最後のバージョンだけがメモリに保たれま
す。メモリに保てる以上に、パスするエントリーがあるのなら、最も高い値を
持ったテクニカルキーがメモリに保存されます。
キャッシュサイズ 0は可能な限り多くの行をキャッシュし、JVMが out of memory
になるまでキャッシュします。それを避けるには、ディメンションと共にこの

Pentaho データ統合 4.1 ユーザーガイド
~ 96 ~
©株式会社 KSK ソリューションズ
オプションを有効に使用してください。キャッシュサイズ-1 は、キャッシュが
無効であることを意味します。
ルックアップキ
ー
ストリームとディメンションテーブルのキーの名前を指定してください。ステ
ップがルックアップをするのを有効にします。
キーフィールド
名
ディメンションのプライマリーキーを示します。また、それはサロゲートキー
として参照もされます。
キーの生成 テクニカルキーを生成する方法を指定してください。
・ 最大値+1: 新しいテクニカルキーはテーブルの最大キーから作成されます。
常に新しい最大値がキャッシュされることに注意してください。よって各新
しい行ごとに最大値が計算される必要はありません。
・ シーケンスを使用: テクニカルキーの作成に、接続されているテーブルのデ
ータベースシーケンスを使用したいならシーケンス名を指定してください
(例えばオラクルで典型的)。
・ 自動増分: テクニカルキーの作成に、データベーステーブル中にある、自動
的にインクリメントされるフィールドの値を使用する場合に使用してくだ
さい(DB2などで典型的に使用されています)。
ルックアップフ
ィールドを除く
アウトプットにおいて入力ストリームからすべてのルックアップフィールドを
取り除きたいなら、このオプションを有効にしてください。追加された唯一の
付加フィールドが、テクニカルキーです。
ハッシュコード
を使用
ハッシュコードを使用するには有効にしてください。
フィールド名 数字の形式で(64 ビット整数、Double)キーフィールドの全ての値を表して、
ハッシュコードを生成することができます。このハッシュコードはテーブルで
保存します。
重要: このハッシュコードはユニークではないので、ユニークなインデックス
を置いても意味がありません。
フィールドの最
終更新日(オプ
ション)
必要な場合、データウェアハウスにコピーされるために、最終更新フィールド
の日付(タイムスタンプ)をソースシステムから指定してください。例えば、
プライマリーキーなしにアドレスがある場合です。フィールドは、ルックアッ
プフィールドの一部ではありません(またハッシュコード計算の一部でもあり
ません)。どのような変更も新しいレコードとして書き込まれるので、値は一度
だけ書き込まれまsす。
フィールドの取
得
指定したキーを除いて、インプットストリームのすべての利用可能なフィール
ド取得します。
SQL ディメンションを生成するために SQL を作成して、SQL を実行します。
Note: コンビネーション 参照/更新ステップでは、他のデータ変換/アプリケーションが保持するディメ
ンションテーブルは、並列処理により更新されないと仮定しています。例えば、テクニカルキーを作成
するために「Table Max + 1」メソッドを使用するとき、ステップは次のテクニカルキーを取得するため
にデータベース検索を常に行うわけではありません。テクニカルキーはローカルでキャッシュされるの
で、複数のデータ変換が並列でディメンションテーブルを更新すると、おそらく 2 重に複製されたテク
ニカルキーによりエラーが発生します。Pentaho ではディメンションテーブルを並列処理により更新す
ることは勧めません。仮にテクニカルキーを作成するためにデータベースシーケンスかオートインクリ
メントのテクニカルキーを使用しているとしても、データ変換の間で衝突する可能性があります。
Note: テクニカルキーは、ディメンションテーブルのプライマリーキーである、もしくはユニークなイ
ンデックスを持っていると推定されます。「常に」というわけではありませんが、ディメンションテー

Pentaho データ統合 4.1 ユーザーガイド
~ 97 ~
©株式会社 KSK ソリューションズ
ブルに同一のテクニカルキーが複数個存在する場合は、コンビネーション 参照/更新 ステップの結果は
信頼できないものとなります。

Pentaho データ統合 4.1 ユーザーガイド
~ 98 ~
©株式会社 KSK ソリューションズ
ディメンジョン 参照/更新
Ralph Kimball のゆっくり変化するディメンションを「タイプ I (更新) 」と「タイプ II (挿入) 」両方の
タイプの実装を可能にします。ディメンションテーブルの更新だけにこのステップを使用できるのでは
なく、ディメンションにて値をルックアップするためにも使用できます。
このディメンションの実装では、ディメンションテーブルの各エントリは以下のプロパティを持ってい
ます:
オプション 概要
キーフィールド名 ディメンションのプライマリーキーです。
バージョンフィール
ド
ディメンションエントリ(改訂番号)のバージョンを示しています。
開始日付フィールド 始まりの期日を含むフィールド名です。
終了日付フィールド 終わりの期日を含むフィールド名です。
キー ソースシステムで使用されるキーです。 例えば: 顧客番号、製品 IDなど
フィールド これらのフィールドはディメンションの実際の情報を含んでいます。
このステップのルックアップか更新処理の結果、フィールドはディメンションのテクニカルキーを含む
ストリームに追加されます。フィールドが見つからない場合、見つからないというディメンションエン
トリの値(データベースのタイプにより 0 または 1)が返されます。
Note: 更新が最初に実行されたとき、このディメンションエントリは自動的にディメンションテーブル
に追加されます。テーブルに"NOT NULL"フィールドがあるときは、空の行を追加するとステップ全体
が失敗に終わります。PDI が、無効なデータである空のレコードをインサートさせたくない場合は、テ
ーブルに ID フィールド=0 または 1 のレコードがあることを確認してください。
バージョン 3.2.0 では、ステップによって自動的に管理される(「フィールド」タブの)オプションフィ
ールドがいくつか追加されています。「ディメンションフィールド」カラムでテーブルフィールド名を
指定することができます。以下はオプションフィールドです:
・ 最終インサート/アップデートの日付(ソースとしてのストリームフィールドなしで): 日付フィー
ルドを追加・管理します。
・ 最終インサート日付(ソースとしてのストリームフィールドなしで): 日付フィールドを追加・管
理します。
・ 最終アップデート日付(ソースとしてのストリームフィールドなしで): 日付フィールドを追加・
管理します。
・ 最終バージョン(ソースとしてのストリームフィールドなしで): 論理式フィールドを追加・管理

Pentaho データ統合 4.1 ユーザーガイド
~ 99 ~
©株式会社 KSK ソリューションズ
します(データベース接続の設定やデータ型の使用可否によって、Char(1)またはブール型に変換
されます)。
Lookup
読み込み専用モード(update オプションが無効)のとき、ステップはゆっくり変化するディメンション
でのみ lookup を行います。ステップは指定したデータベース接続とスキーマのテーブルで lookup を
行います。Lookup を行うには指定した主キー("equals"条件で)だけでなく、特定の"Stream datefield"
も使用します。(以下参照)適用される条件は次の通りです: "Start or table date range" >= "Stream
datefield" AND "End or table date range" < "Stream datefield"
"Stream datefield"が指定されていない場合は、正しいディメンションバージョンレコードを見つけるた
めに現在のシステム日付を使用します。
注意: "alternative start date"(バージョン 3.2 以降)を使用している場合、上の SQL 節とは若干異なっ
たものになります。
行が見当たらない場合は、"unknown"キーを返します。キーフィールドとして自動増分フィールドを選
択しているかどうかによって、0 か 1 になります。その場合には、"Unknown"、"Not found"、"Empty"、
"Illegal format"等を区別していないことに注意してください。しかし、これらのニュアンスはマニュア
ルで追加できます。フィルタ、正規表現等でこのステップでデータを見つける前に、これらのタイプを
排除することは可能です。これらのように特別なディメンションエントリの場合には、-1, -2, -3 のよう
な値をマニュアルで追加することをお勧めします。例えば、ディメンションテーブルの配置に先立ち
"Unknown" 行に特定の詳細を追加するようなものです。
重要: テクニカルキーをディメンションテーブルで見つけるために SQL を使用しているので、以下のこ
とに注意してください。
・ キー項目に NULL 値を使用しないでください。NULL 値はほとんどのデータベースで、比較・イン
デックス化が出来ません。
・ キー項目のデータ型と異なるデータ型が入力ストリームに存在する場合、データコンバージョンで
問題が発生する可能性に注意してください。例えば、入力ステップに文字列があり、使用している
データベース中に数値型を使用している場合は、文字列を数値型に変換することが可能であること
を確認してください。このステップの前に、計画通りに作動することを確認することが最も大事な
ことであると認識してください。もうひとつ、問題の典型的な例としてあげられるのが、浮動小数
点の数値の比較です。Pentaho では Integer もしくは Long Integers といったデータ型を使用する
ことをお勧めします。Double, Decimal または Oracle の Number (長さや精度が存在しない型; 暗
黙的に精度として 38 を使用するので、速度の遅い BigNumber データ型が使用されます) のよう
な、catch-all タイプのデータ型を使用しないでください。
Update
Update モード(update オプションが有効)では、上述の「Lookup」セクションで説明があったように、
最初にディメンションエントリの lookup を行います。しかし lookup の結果は異なります。テクニカル
キーだけでなく、ディメンション属性フィールドも検索します。それに続いて、フィールドごとの比較
を行います。結果は以下の状況のいずれかになります:

Pentaho データ統合 4.1 ユーザーガイド
~ 100 ~
©株式会社 KSK ソリューションズ
・ レコードが見つかりません、テーブルに新しいレコードをインサートします。
・ レコードが見つかりました以下のものはすべて true です:
・ 一つ以上の属性が異なり、"Insert" (Kimball Type II)設定が存在: あたらしいすべてのディメンシ
ョンレコードバージョンをインサートします。最新のディメンションレコードバージョンでこれら
の属性をアップデートします。
・ 一つ以上の属性が異なり、"Punch through" (Kimbal Type I)設定が存在: すべてのディメンションレ
コードバージョンでこれらの属性をアップデートします。
・ 一つ以上の属性が異なり"Update"設定がが存在: 最新ディメンションレコードバージョンでこれら
の属性をアップデートします。
・ すべての属性(フィールド)が同じ: 何もインサート/アップデートしません。
Note: Insert, Punch Through と Update オプションをこのステップにて混在させた場合、当アルゴリズ
ムは、Hybrid Slowly Changing Dimension のように振る舞います (その場合には単なる Type I や II で
はなく、コンビネーションになります)
以下の表はディメンジョン 参照/更新ステップのオプションの、より詳細な説明です:
オプション 概要
ステップ名 必要に応じて変更することが可能です。
更新する 入力ストリームの情報に基づくディメンションをアップデートしたいな
ら、このオプションをチェックしてください。このオプションが有効にさ
れないなら、ディメンションは、ルックアップするだけであり、テクニカ
ルキーフィールドをストリームに追加するだけです。
データソース名 ディメンションテーブルがあるデータベース接続の名前。
スキーマ名 引用の精度を改善し、ドット’.’によりテーブル名を許可するためにスキ
ーマ名を指定します。
テーブル名 ディメンションテーブルの名前。
コミットサイズ 10 に設定すると、10回インサートかアップデートされる毎にコミットしま
す。
キャッシュサイズ
キャッシュの有効化 Enable data caching in this stepこのステ
ップでのデータキャッシュを有効にします。version 3.2 からは、
キャッシュサイズとして>=0 を設定し、-1 ではキャッシュを無効化
します。
キャッシュのプリロード version 3.2 からは、lookup のパフォー
マンス速度を向上させる目的で lookups の実行に先立ち(アップデ
ートはまだサポートされていません)ディメンションテーブルのす
べての内容を読取ることが可能になりました。パフォーマンスの向
上は、データベースへのラウンドトリップを取り除き、sorted list
lookup algorithm を採用することで実現されました。
行のキャッシュサイズ データベースへのラウンドトリップを減尐
し、lookup の速度を向上させるために、メモリに保持される行のキ
ャッシュサイズを数値で指定します。
Note: (プリロードが有効でない限り)ディメンションエントリの最新バー

Pentaho データ統合 4.1 ユーザーガイド
~ 101 ~
©株式会社 KSK ソリューションズ
ジョンのみメモリに保持されます。メモリに保持されるよりも、保持され
ない方が多い場合、最も関連が高いと思われる最大値を持つテクニカルキ
ーがメモリに保持されます。
重要: キャッシュサイズ 0は可能な限り多くの行をキャッシュし、JVMが
out of memory になるまでキャッシュします。それを避けるには、ディメン
ションと共にこのオプションを有効に使用してください。キャッシュサイ
ズ-1は、キャッシュが無効であることを意味します。
キータブ ストリームとディメンションテーブルでキーの名前を指定してください。
ステップがルックアップするのを有効にします
フィールドタブ ディメンション内のそれぞれのフィールドに、値をアップデートするか、
または新バージョンとして値をディメンションに挿入するか指定できま
す。スクリーンショットに使用した例で、生年月日は変数ではありません。
もし生年月日が変われば、旧バージョンが間違っていたことを意味します。
それは論理的にはそうですが、前の値はディメンションエントリのすべて
のバージョンで修正されます。
キーフィールド名 ディメンションのプライマリーキーを示します。また、サロゲートキーと
呼ばれます。新しい名前オプションを使用して、ルックアップの後にテク
ニカルキーを改名してください。 例えば、ORIGINAL_PRODUCT_TK,
REPLACEMENT_PRODUCT_TK, ...のような異なった Product タイプのルックア
ップが必要である場合です。
注意:ルックアップモードの間にのみテクニカルキーを改名することがで
きます。アップデートの時ではありません。
キーの生成 テクニカルキーを生成する方法を指定してください。
・ 最大値+1: 新しいテクニカルキーはテーブルの最大キーから作成され
ます。常に新しい最大値がキャッシュされることに注意してください。
よって各新しい行ごとに最大値が計算される必要はありません。
・ シーケンスを使用: テクニカルキーの作成に、接続されているテーブ
ルのデータベースシーケンスを使用したいならシーケンス名を指定し
てください(例えばオラクルで典型的)。
・ 自動増分: テクニカルキーの作成に、データベーステーブル中にある、
自動的にインクリメントされるフィールドの値を使用する場合に使用
してください(DB2 などで典型的に使用されています)。
バージョンフィール
ド
バージョン(改訂番号)を保存するためにフィールド名を指定します。
ストリームデータ 最後にディメンションエントリを変更された日付があるなら、そのフィー
ルドの名前を指定できます。ディメンションエントリがその日付の範囲に
関して正確に記述されます。そのような日付がないと、システム日付を取
ります。ディメンションエントリがルックアップされる(アップデートディ
メンションが選択されていない)時に、ストリーム Date フィールドに入力
された Dateフィールドは、ディメンジョンレコードの date from や date to
date に基づき、適切なディメンジョンのバージョンを選択されます。
開始日付フィールド ディメンションエントリーのスタート範囲の名前を指定してください。
代替開始日を使用す
る
有効にされた場合、使用されている日付である "Min. Year" /01/01
00:00:00 に対して、別の日付を選択できます。以下のどれかが使用できま

Pentaho データ統合 4.1 ユーザーガイド
~ 102 ~
©株式会社 KSK ソリューションズ
す:
システム日付: date/time としてシステム日付を使用します。
データ変換の開始日付: データ変換の開始時のシステム日付を開始
日付とします。
Empty (null) value
カラム値: カラムから値を選択します。
重要: これらのオプションを使用してノンコンフォームドディメンション
を作成することが可能ですので、有効活用してください。しかし、すべて
の可能性が意味を成すわけではありません。
終了日付テーブル ディメンションエントリーの端の範囲の名前を指定してください。
フィールドの取得 指定したキーを除いて、利用可能なインプットストリーム上利用可能なフ
ィールドを取得します。
SQL ディメンション構築するために SQL を作成して、SQL を実行します。

Pentaho データ統合 4.1 ユーザーガイド
~ 103 ~
©株式会社 KSK ソリューションズ
グループ化
定義されたフィールドのグループの値について計算します。一般的な使用例は以下の通りです。
・ 1 製品あたりの平均売上高を計算する
・ 在庫がある黄色いシャツの数を取得する
サンプルは以下に保存されています:
・ .../samples/transformations/Group By - Calculate standard deviation.ktr
・ .../samples/transformations/Group by - include all rows and calculations .ktr
・ .../samples/transformations/Group By - include all rows without a grouping.ktr
グループ化 オプション
オプション 概要
ステップ名 必要に応じて変更することが可能です。
すべての行を含む アグリゲーションだけでなくアウトプットですべての行が必要なとき、有
効にしてください。アウトプットで 2種類の行を区別するために、フラグ
がアウトプットで必要です。その場合フラグのフィールドの名前を指定し
なければなりません(タイプは論理演算子です)。
一時ディレクトリ 必要に応じて一時ファイルが保存されるディレクトリ。デフォルトはシス
テムの標準の一時ディレクトリです。
一時ファイルの接頭
子
一時ファイルを命名するとき使用されるファイル接頭子を指定してくださ
い。
レコード番号を含む 有効にして、各グループで 1から再開する行番号を追加してください。
フィールド名 有効にして、各グループで 1から再開する行番号を追加してください。
戻り値を常に返す このオプションをチェックすると、インプット行が全くなくてもグループ
化ステップはいつも結果行を返すでしょう、行の数を数えたいときに役に
立つ場合があります。 このオプションがなければ、(0)をカウントするこ
とができません。
フィールド(グルー
プ)
グループ化したいフィールドを指定してください。フィールドを取得をク
リックすると、インプットストリームからすべてのフィールドを追加しま
す。
フィールド(集計) 集約したいフィールド、メソッド、処理結果の新しいフィールドの名前を
指定してください。ここに、利用できる集約メソッドがあります:
・ Sum
・ Average (Mean)
・ Minimum
・ Maximum
・ Number of values (N)
・ Concatenate strings separated by , (comma)
・ First non-null value
・ Last non-null value
・ First value (including null)
・ Last value (including null)
・ Cumulative sum (all rows option only!)
・ Cumulative average (all rows option only!)
・ Standard deviation
・ Concatenate strings separated by <Value>: specify the separator
in the Value column

Pentaho データ統合 4.1 ユーザーガイド
~ 104 ~
©株式会社 KSK ソリューションズ
JAVA スクリプト
JAVA スクリプト ステップは JavaScript 構文を作成するためのユーザーインターフェースです。
また、このステップによりそれぞれのステップのために複数のスクリプトを作成することもできま
す。このステップについて、詳細は Pentaho Wiki の Modified JavaScript Value を参照してく
ださい。
Java スクリプト関数
関数 説明
スクリプト このステップで作成したスクリプトのリストを表示します。
定数 定義済の静的定数のリストで、次を含みます : _TRANSFORMATION,
ERROR_TRANSFORMATION, and CONTINUE_TRANSFORMATION
関数 String, Numeric, Date, Logic その他特定の関数など、スクリプト作成の
ために使用できるものが用意されています。自作のスクリプトに関数を追加
するには、関数名をダブルクリックするか、スクリプト中の挿入したい場所
にドラッグしてください。
入力フィールド ステップへの入力のリストです。ダブルクリック、またはドラッグアンドド
ロップしてスクリプトにフィールドを挿入してください。
出力フィールド ステップの出力のリスト。
Java スクリプト
このセクションは、このステップのためにスクリプトを編集する場所になります。左側のツリーコント
ロールから挿入したいノードをダブルクリックする、またはオブジェクトを Java Script パネルへドラ
ッグすることで、関数、定数、入力フィールドなどを挿入することができます。
フィールド
Fields 表には、作成しているスクリプトの変数のリストです。また、記述名のようなメタデータを追加
することもできます。
ボタン
変数を取得
スクリプトから変数のリストを取得します。
テスト
スクリプトの構文をテストします。
Java スクリプト内部 API オブジェクト
次の内部 API オブジェクトを使用することが可能です:
オブジェクト 説明

Pentaho データ統合 4.1 ユーザーガイド
~ 105 ~
©株式会社 KSK ソリューションズ
オブジェクト 説明
_TransformationName_ 実際のデータ変換の名前の文字列です。
_step_ 実 際 の ス テ ッ プ の
org.pentaho.di.trans.steps.scriptvalues_mod.ScriptValuesMod のイン
スタンスです。
rowMeta org.pentaho.di.core.row.RowMeta の実際のインスタンスです。
row 実際のデータの Object[] の実際のインスタンスです。
Advanced Web Services – JAVAスクリプト と HTTP Post ステップ
ウェブサービス参照 ステップにより SOAP メッセージが生成されていたことがありましたが、それで
は不十分でした。多くのウェブサービスが、SOAP リクエストヘッダーに含まれるべきセキュリティ上
の認証情報を必要とします。ネームスペースのようなレスポンスとして返ってくる値より多くの情報を
入手するためには、レスポンス XML をパースする必要があるかもしれません。
このアプローチには JAVA スクリプト ステップを使用します。SOAP エンベロープを必要に応じて作
成できます。ステップはその後、HTTP Post ステップにたどりつき、そこで入力ストリームを通じて
SOAP リクエストを受け付け、 Web サービスにポストします。これは、その次にまた異なる JAVA
スクリプト ステップにたどり着き、Web サービスからのレスポンスをパースします。
このアプローチを使用した PDI 4.1 サンプルが次のフォルダーに保存されています : General -
Annotated SOAP Web Service call.ktr (...¥data-integration¥samples¥transformations)
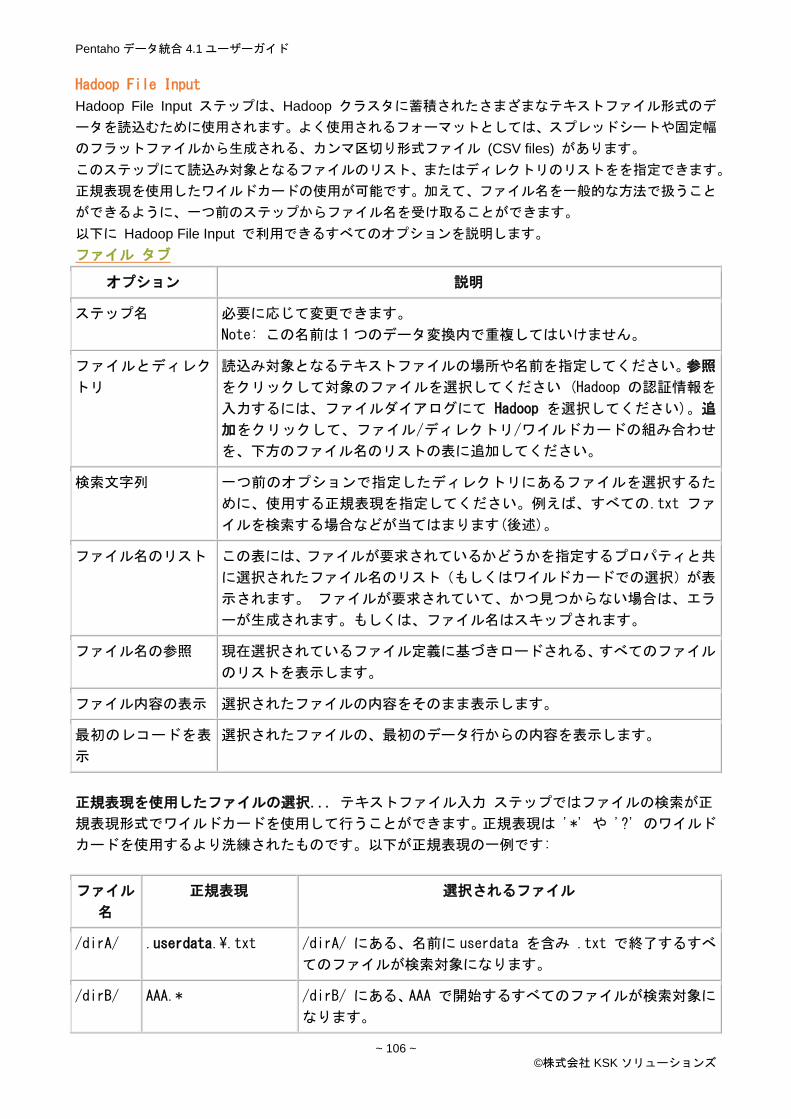
Pentaho データ統合 4.1 ユーザーガイド
~ 106 ~
©株式会社 KSK ソリューションズ
Hadoop File Input
Hadoop File Input ステップは、Hadoop クラスタに蓄積されたさまざまなテキストファイル形式のデ
ータを読込むために使用されます。よく使用されるフォーマットとしては、スプレッドシートや固定幅
のフラットファイルから生成される、カンマ区切り形式ファイル (CSV files) があります。
このステップにて読込み対象となるファイルのリスト、またはディレクトリのリストをを指定できます。
正規表現を使用したワイルドカードの使用が可能です。加えて、ファイル名を一般的な方法で扱うこと
ができるように、一つ前のステップからファイル名を受け取ることができます。
以下に Hadoop File Input で利用できるすべてのオプションを説明します。
ファイル タブ
オプション 説明
ステップ名 必要に応じて変更できます。
Note: この名前は 1つのデータ変換内で重複してはいけません。
ファイルとディレク
トリ
読込み対象となるテキストファイルの場所や名前を指定してください。参照
をクリックして対象のファイルを選択してください (Hadoop の認証情報を
入力するには、ファイルダイアログにて Hadoop を選択してください)。追
加をクリックして、ファイル/ディレクトリ/ワイルドカードの組み合わせ
を、下方のファイル名のリストの表に追加してください。
検索文字列 一つ前のオプションで指定したディレクトリにあるファイルを選択するた
めに、使用する正規表現を指定してください。例えば、すべての.txt ファ
イルを検索する場合などが当てはまります(後述)。
ファイル名のリスト この表には、ファイルが要求されているかどうかを指定するプロパティと共
に選択されたファイル名のリスト(もしくはワイルドカードでの選択)が表
示されます。 ファイルが要求されていて、かつ見つからない場合は、エラ
ーが生成されます。もしくは、ファイル名はスキップされます。
ファイル名の参照 現在選択されているファイル定義に基づきロードされる、すべてのファイル
のリストを表示します。
ファイル内容の表示 選択されたファイルの内容をそのまま表示します。
最初のレコードを表
示
選択されたファイルの、最初のデータ行からの内容を表示します。
正規表現を使用したファイルの選択... テキストファイル入力 ステップではファイルの検索が正
規表現形式でワイルドカードを使用して行うことができます。正規表現は '*' や '?' のワイルド
カードを使用するより洗練されたものです。以下が正規表現の一例です:
ファイル
名
正規表現 選択されるファイル
/dirA/ .userdata.\.txt /dirA/ にある、名前に userdata を含み .txt で終了するすべ
てのファイルが検索対象になります。
/dirB/ AAA.* /dirB/ にある、AAA で開始するすべてのファイルが検索対象に
なります。

Pentaho データ統合 4.1 ユーザーガイド
~ 107 ~
©株式会社 KSK ソリューションズ
ファイル
名
正規表現 選択されるファイル
/dirC/ [ENG:A-Z][ENG:0-9].* /dirC/ にある、名前が大文字で始まり、数値(A0-Z9)が続くす
べてのファイルが検索対象になります。
先行のステップから値を引き継ぐ... このオプションにより、"Get File Names"のような、他のステップ
との組み合わせがさらに柔軟になります。ファイル名を作成してこのステップに渡すことができます。
このようにして、テキストファイル、データベーステーブルなど、どんなソースからでもファイル名を
受け取ることができます;
オプション 説明
先行のステップから
値を引き継ぐ
前のステップからファイル名を受け取るには、オプションを有効にします。
ステップ名 ファイル名を読込むステップです。
フィールド名 テキストファイルインプットがこのステップを参照して、使用するファイル
名を決定します。
全般 タブ
全般タブ内の内容は、読込まれるテキストファイルのフォーマットを指定します。このタブに関連する
オプションは以下です:
オプション 説明
ファイルタイプ CSV または固定長です。Spoon はここでの選択に基づいて、フィールドタブ
のフィールドを取得をクリックしたときに、様々なヘルパーGUI を起動しま
す。
フィールド区切り文
字
一行のテキストのフィールドを分割する、ひとつ以上の文字です。典型的に
は、; やタブになります。
引用符 フィールドの中には、フィールド区切り文字を有効にするため、文字列のペ
アにより囲まれていることもありえます。引用符はオプションです。引用符
を繰り返した場合、例えば 'Not the nine o''clock news.'. は、「' 」が
引用符名ので、これは「Not the nine o'clock news」のようにはパースさ
れません。
引用符を除去 実装されていません
エスケープ文字 エスケープ文字がデータに含まれる場合はここで指定してください。例えば
\ がエスケープ文字の場合は、「Not the nine o\'clock news」(「'」が引
用符) 、「Not the nine o'clock news」のようにパースされます。
ヘッダー&ヘッダ
ー・レコード数
テキストファイルにヘッダー行(ファイルの 1行目)が存在する場合は有効に
してください。ヘッダー行が出現する回数を指定できます。
フッター&フッタ
ー・レコード数
テキストファイルにフッター行(ファイルの最終行)が存在する場合は有効
にしてください。ヘッダー行が出現する回数を指定できます。
含むレコード数&含 特定のページの制限を越えて、ページがラップされるデータ行を取り扱う場

Pentaho データ統合 4.1 ユーザーガイド
~ 108 ~
©株式会社 KSK ソリューションズ
オプション 説明
まれる回数 合に使用してください。ヘッダーとフッターはラップされていると考えられ
うことはありませんので、注意してください。
ページレイアウト
(印刷)&1 ページ
あたりのレコード数
&ヘッダー・レコー
ド数
ラインプリンタでの印刷を想定されたテキストを対象にする最後の手段と
してこれらのオプションを使用してください。ドキュメントのヘッダー行の
数を使用して、導入行のテキストをスキップして、1 ページあたりのレコー
ド数を指定してデータ行を設定してください。
圧縮形式 使用するテキストが Zip もしくは GZip アーカイブの場合は有効にしてく
ださい。
Note: 現段階では、アーカイブ中の最初のファイルしか読込まれません。
空のレコードを除去 空のレコードを次のステップに送りません。
ファイル名を出力に
含む
ファイル名を出力の一部に含めたい場合は有効にしてください。
フィールド名 ファイル名を含むフィールドの名前
レコード数を出力に
含む
レコード数を出力の一部に含めたい場合は有効にしてください。
フィールド名 レコード数を含むフィールドの名前
フォーマット DOS, UNIX またはその混合の両方になります。UNIX ファイルの行はラインフ
ィードで終了します。DOS ファイルの行はキャリッジリターンとラインフィ
ードで終了します。混合が選択された場合、検証は行われません。
文字コード テキストファイルの文字コードを指定してください。システムのデフォルト
の文字コードを使用するにはブランクのままにしてください。Unicode を使
用するには、UTF-8 または UTF-16 を指定してください。
日付を自動処理 データフィールドを厳密にパースしたい場合は無効にしてください。
ケースレニエントでのパースを有効にすると、1月 32 日のような日付は 2月
1日になります。
ロケール日付書式 このロケールは日付をパースするのに使用されます。例えば、日付書式とし
てすべての年月日が "February 2nd, 2006;" のように記述されている場合
に、フランス語(fr_FR) ロケールでは「February」は「Février」となるの
で、正しく動作しません。
エラー処理 タブ
エラー処理タブのオプションにより、エラーが発生した場合にどのように振舞うかを指定できます(例え
ば次のような場合: 整形されていないレコード、不正な引用符、不正なフィールド数、フィールド数が
規定より尐ない)。このタブに関連するオプションは以下です:
オプション 説明
エラー処理をする パース中に発生したエラーを無視する場合に有効にしてください。

Pentaho データ統合 4.1 ユーザーガイド
~ 109 ~
©株式会社 KSK ソリューションズ
オプション 説明
エラーが発生したレ
コードをスキップ
エラーを含む行をスキップしたい場合に有効にしてください。エラーの発生
した行番号を記録する別のファイルを作成することができます。エラーの発
生した行はスキップされません解析エラーとなったフィールドは、空(null)
になります。
エラー回数フィール
ド名
出力ストリームの行にフィールドを追加します。このフィールドにはその行
で発生したエラーの数が設定されます。
エラー項目フィール
ド名
出力ストリームの行にフィールドを追加します。このフィールドにはその行
でエラーが発生したフィールドの名前が設定されます。
エラーテキストフィ
ールド名
出力ストリームの行にフィールドを追加します。このフィールドにはその行
で発生したエラーに関する説明が記載されます。
警告を保管するディ
レクトリ
警告が生成されたとき、それらはこのディレクトリに保管されます。ファイ
ル名は次の形式です : <warning dir>/filename.<date_time>.<warning
extension>
エラーを保管するデ
ィレクトリ
エラーが生成されたとき、それらはこのディレクトリに保管されます。ファ
イ ル 名 は 次 の 形 式 で す :
<errorfile_dir>/filename.<date_time>.<errorfile_extension>
除外したレコードを
保管するディレクト
リ
解析エラーがある行で発生したとき、その行番号がこのディレクトリに保管
さ れ ま す 。 フ ァ イ ル 名 は 次 の 形 式 で す : <errorline
dir>/filename.<date_time>.<errorline extension>
フィルタ タブ
フィルタ タブ内のオプションにより、テキストファイル内でスキップしたい行を指定できます。次の
表にフィルタの定義に利用可能なオプションを掲載します:
オプション 概要
フィルタ文字列 検索対象となる文字列
フィルタ位置 行中にフィルタ文字列があるべき位置を指定します。ゼロ(0) が行の開始の
位置になります。ゼロ(0) 以下の値を指定した場合、フィルタ文字列は行中
のすべての位置で検索されます。
フィルタで停止する フィルタ文字列が検知された場合に、処理を停止したい場合には Y を指定
してください。
フィールド タブ
フィルタ タブ内のオプションにより、テキストファイル内でスキップしたい行を指定できます。次の
表にフィルタの定義に利用可能なオプションを掲載します:
オプション 説明
フィールド名 フィールドの名前

Pentaho データ統合 4.1 ユーザーガイド
~ 110 ~
©株式会社 KSK ソリューションズ
オプション 説明
データ・タイプ フィールドのタイプは、String、Date、Number(文字列、日付、数値)のど
れかになります。
書式 フォーマット記号の詳細については、以下の数値書式を参照してください。
長さ Number: 数値の桁数です。
String: 文字列の長さです。
Date: 出力される文字列の長さです(例: 4 の場合は年のみを返します)。
精度 Number: 浮動小数点の桁数です。
String, Date, Boolean: 使用されません。
通貨記号 数値を $10,000.00 や E5.000,00 のように記号を付加するために使用され
ます。
小数点区切り文字 小数点区切り文字として"." (10,000.00) や "," (5.000,00) などがありま
す。
桁区切り文字 桁区切り文字として"," (10,000.00) や "." (5.000,00) などがあります。
NULL 可能 ここで設定した値を NULL として扱います。
デフォルト テキストファイルのフィールドが空の場合の既定値。
空白除去 処理前にこのフィールドをトリムするタイプ(左、右、両側)です。
データを代替する この行で相対する値が空の場合、空でなかった最後の回から繰り返して設定
します(Y/N で指定)。
数値の書式
こ の 情 報 は Sun Java API ド キ ュ メ ン テ ー シ ョ ン か ら の 引 用 で す :
http://java.sun.com/j2se/1.3/ja/docs/ja/api/java/text/DecimalFormat.html
記号 位置 地域対応
の有無 意味
0 数値 Y 数字
# 数値 Y 数字。ゼロだと表示されない
. 数値 Y 数値桁区切り子または通貨桁区切り子
- 数値 Y マイナス記号
, 数値 Y グループ区切り子
E 数値 Y
科学表記法の仮数と指数を区切る。接頭辞や接尾辞内に引
用符を付ける必要はない
;
サブパ
ターン
境界 Y 正と負のサブパターンを区切る

Pentaho データ統合 4.1 ユーザーガイド
~ 111 ~
©株式会社 KSK ソリューションズ
%
接頭辞
または
接尾辞 Y 100 倍してパーセントを表す
\u2030
接頭辞
または
接尾辞 Y 1000 倍してパーミルを表す
¤ 接頭辞
または
接尾辞 N
通貨記号で置換される通貨符号。2 つの場合は、国際通貨
記号で置換される。パターン内にある場合は、数値桁区切
り子ではなく、通貨桁区切り子が使用される (\u00A4)
'
接頭辞
または
接尾辞 N
接頭辞や接尾辞内の特殊文字を引用符で囲む場合に使用
される。たとえば、"'#'#" を使用すると 123 は "#123"
にフォーマットされる。単一引用符自体を作成するために
合は、1 行に 2 つ引用符を使用する ("# o''clock")
科学表記法... パターンでは、指数文字の直後 に 1 つ以上の数字を続けて科学表記法を示します。た
とえば、「0.###E0」では 1234 を「1.234E3」とフォーマットします。
日付の書式
以下の情報は、Sun Java API ドキュメンテーションから引用したものです:
http://java.sun.com/javase/ja/6/docs/ja/api/java/text/SimpleDateFormat.html
文字 日付または時刻のコンポーネント 表示 例
G 紀元 Text AD
y 年 年 1996; 96
M 月 月 July; Jul; 07
w 年における週 Number 27
W 月における週 Number 2
D 年における日 Number 189
d 月における日 Number 10
F 月における曜日 Number 2
E 曜日 Text Tuesday; Tue
a 午前/午後 Text PM
H 一日における時 (0 ~ 23) Number 0
k 一日における時 (1 ~ 24) Number 24
K 午前/午後の時 (0 ~ 11) Number 0
h 午前/午後の時 (1 ~ 12) Number 12
m 分 Number 30
s 秒 Number 55
S ミリ秒 Number 978
z タイムゾーン 一般的なタイムゾーン
Pacific Standard
Time; PST; GMT-08:00
Z タイムゾーン RFC 822 タイムゾーン -800

Pentaho データ統合 4.1 ユーザーガイド
~ 112 ~
©株式会社 KSK ソリューションズ
Hadoop File Output
Hadoop File Output ステップは Hadoop クラスタ上に保存されているテキストファイルへデータをエ
クスポートするために使用されます。これは、スプレッドシートアプリケーションで読込むことができ
る Comma Separated Values(CSV ファイル)の作成に使用されます。また、フィールドタブのフィール
ド上の長さ設定することで、固定幅のファイルを作成することも可能です。
以下で Hadoop File Output で使用できるオプションを説明します。
ファイル タブ
作成されるファイルについて基本的なプロパティを定義します:
オプション 概要
ステップ名 必要に応じて変更することが可能です。
Note: この名前は 1つのデータ変換内で重複してはいけません。
ファイル名 このフィールドはアウトプットテキストファイルのファイル名とロケーシ
ョンを指定します。パスとファイル名がわからない場合は、参照をクリック
して対象のファイルを選択してください (Hadoop の認証情報を入力するに
は、ファイルダイアログにて Hadoop を選択してください)。
拡張子 ピリオドと拡張子をファイル名の終わりに追加します。 (.txt)
先行のステップから
値を引き継ぐ
このオプションをチェックすると、入力ストリームのファイル名を含んだフ
ィールドを指定できます。
フィールド名 前のオプションが有効なとき、実行時にファイル名を含むフィールドを指定
できます。
ファイル名にステッ
プ番号を含む
複数のコピーステップを実行した場合、ファイル名の拡張子の前にコピー番
号が含められます。
ファイル名に区切り
番号を含む
ファイル名に区切り番号を含めます。
ファイル名に日付を
含む
ファイル名にシステム日付を含めます。 (_20101231).
ファイル名に時刻を
含む
ファイル名にシステム時間を含めます。 (_235959).
ファイル名を結果に
含む
生成されるファイルのリストを表示します。
Note: これはシミュレーションであり、それぞれのファイルに書き込まれる
行によります。
全般 タブ
全般タブには以下のオプションがあります:
オプション 概要
既存のファイルに追
加する
有効にすると、指定されたファイルの終りに行を追加します。
区切り文字 テキスト行でフィールドを切り離す文字を指定します。通常、「;」もしく
は tabです。
引用符 一対のの文字列で前後を囲みフィールドを引用できます。 これはフィール
ドで引用符文字を許容します。 引用符文字列は任意です。テキストファイ
ルにヘッダー行(ファイルの最初の行)があってほしいとき、このオプシ
ョンを有効にします。

Pentaho データ統合 4.1 ユーザーガイド
~ 113 ~
©株式会社 KSK ソリューションズ
フィールドを引用符
で囲む
このオプションによって、すべてのフィールド名を上の引用符プロパティ
で指定された文字で引用します。
ヘッダー テキストファイルにヘッダー行があるなら、このオプションを有効にして
ください。(ファイルの最初のライン)
フッター テキストファイルにフッター行があるなら、このオプションを有効にして
ください。(ファイルの最後のライン)
フォーマット DOS か UNIX のいずれか。 UNIXファイルにはラインフィードによって切り
離された行があります。 DOS ファイルでは、行頭復帰と改行で切り離され
た行があります。
文字コード 使用するテキストファイル文字コードを指定してください。システムの上
でデフォルト文字コードを使用するなら空欄のままにしておいてくださ
い。ユニコードを使用するには、UTF-8 を指定してください、また最初に使
用するとき、Spoon は利用可能な文字コードのシステムを検索します。
圧縮形式 アウトプットを圧縮するときzipまたは.gzipといった圧縮形式を指定しま
す。 注意:今のところ、アーカイブには一つのファイルしか置くことがで
きません。
ダンプ出力する フォーマット情報含ませないことにより、多量のデータをテキストファイ
ルに落とすときのパフォーマンスを向上させます。
フィールドの右側を
空白で埋める
設定された長さまでフィールドの終わりにスペースを追加し、またフィー
ルドの最後で文字を削除します。
指定されたレコード
数でファイルを分け
る
もし Nがゼロより大きいなら、結果として出力されるテキストファイルを、
N行ごとに複数に分けます。
終了レコードを追加
する
任意データを出力ファイルの最終行に追加します。
フィールド タブ
フィールドタブでは、エクスポートされるフィールドのためにプロパティを定義します。以下の表はフ
ィールドプロパティを設定するオプションについて説明します:
オプショ
ン
概要
フィール
ド名
フィールドの名前。
データタ
イプ
フィールドのタイプは、String、Date、Number、Boolean、Integer、BigNumber、
Serializable、Binary、のいずれかです。
書式 変換するための形式マスク。 フォーマット記号の詳細を説明した形式に関して
Numberフォーマットを見てください。
長さ ・ Number: 数の有効桁数の合計
・ String: トータルの文字列の長さ
・ Date:出力される文字列の長さ(例えば、4は年を返すだけである)
精度 精度オプションは以下のフィールドタイプによります:
・ Number:浮動小数点ケタの数
・ String,Date: 未使用
通貨記号 $10,000.00 or E5.000,00 のような数を解釈するために使用

Pentaho データ統合 4.1 ユーザーガイド
~ 114 ~
©株式会社 KSK ソリューションズ
小数点区
切り文字
小数点区切り文字として"." (10,000.00) や "," (5.000,00) などがあります。
桁区切り
文字
桁区切り文字として"," (10,000.00) や "." (5.000,00) などがあります。
空白除去 文字列に適用されるトリミング方法
Note: トリミングはフィールド長が指定されていないときにのみ機能します。
Null 可能 フィールドの値が NULLであるなら、この文字列をテキストファイルに挿入します。

Pentaho データ統合 4.1 ユーザーガイド
~ 115 ~
©株式会社 KSK ソリューションズ
S3 File Output
このステップでは、 Amazon Simple Storage Service (S3) 上のテキストファイルにデータを出力しま
す。
ファイル タブ
ファイルタブではこのステップの出力への基本的なファイルプロパティを定義します。
オプション 概要
ステップ名 必要に応じて変更することが可能です。
Note: この名前は 1つのデータ変換内で重複してはいけません。
ファイル名 出力となるテキストファイルの名前
先行のステップから
値を引き継ぐ
このオプションをチェックすると、入力ストリームのファイル名を含んだフ
ィールドを指定できます。
フィールド名 前のオプションが有効なとき、実行時にファイル名を含むフィールドを指定
できます。
拡張子 ピリオドと拡張子をファイル名の終わりに追加します。 (.txt)
ファイル名にステッ
プ番号を含む
複数のコピーステップを実行した場合、ファイル名の拡張子の前にコピー番
号が含められます。
ファイル名に区切り
番号を含む
ファイル名に区切り番号を含めます。
ファイル名に日付を
含む
ファイル名にシステム日付を含めます。 (_20101231).
ファイル名に時刻を
含む
ファイル名にシステム時間を含めます。 (_235959).
ファイル名を結果に
含む
生成されるファイルのリストを表示します。
Note: これはシミュレーションであり、それぞれのファイルに書き込まれる
行によります。
全般 タブ
全般タブには以下のオプションがあります。
オプション 概要
既存のファイルに追
加する
有効にすると、指定されたファイルの終りに行を追加します。
区切り文字 テキスト行でフィールドを切り離す文字を指定します。通常、「;」もしく
は tabです。
引用符 一対のの文字列で前後を囲みフィールドを引用できます。 これはフィール
ドで引用符文字を許容します。 引用符文字列は任意です。テキストファイ
ルにヘッダー行(ファイルの最初の行)があってほしいとき、このオプシ
ョンを有効にします。
フィールドを引用符
で囲む
このオプションによって、すべてのフィールド名を上の引用符プロパティ
で指定された文字で引用します。
ヘッダー テキストファイルにヘッダー行があるなら、このオプションを有効にして
ください。(ファイルの最初のライン)
フッター テキストファイルにフッター行があるなら、このオプションを有効にして
ください。(ファイルの最後のライン)
フォーマット DOS か UNIX のいずれか。 UNIXファイルにはラインフィードによって切り

Pentaho データ統合 4.1 ユーザーガイド
~ 116 ~
©株式会社 KSK ソリューションズ
離された行があります。 DOS ファイルでは、行頭復帰と改行で切り離され
た行があります。
圧縮形式 アウトプットを圧縮するときzipまたは.gzipといった圧縮形式を指定しま
す。 注意:今のところ、アーカイブには一つのファイルしか置くことがで
きません。
文字コード 使用するテキストファイル文字コードを指定してください。システムの上
でデフォルト文字コードを使用するなら空欄のままにしておいてくださ
い。ユニコードを使用するには、UTF-8 を指定してください、また最初に使
用するとき、Spoon は利用可能な文字コードのシステムを検索します。
フィールドの右側を
空白で埋める
設定された長さまでフィールドの終わりにスペースを追加し、またフィー
ルドの最後で文字を削除します。
ダンプ出力する フォーマット情報含ませないことにより、多量のデータをテキストファイ
ルに落とすときのパフォーマンスを向上させます。
指定されたレコード
数でファイルを分け
る
Nがゼロより大きい場合、結果として出力されるテキストファイルを、N行
ごとに複数のファイルに分けます。
終了レコードを追加
する
任意データを出力ファイルの最終行に追加します。
フィールド タブ
フィールドタブでは、エクスポートされるフィールドのためにプロパティを定義します:
オプション 概要
フィールド名 フィールドの名前。
データタイプ フィールドのタイプは、String、Date、Number、Boolean、Integer、BigNumber、
Serializable、Binary、のいずれかです。
書式 変換するための形式マスク。 フォーマット記号の詳細を説明した形式に関
して Number フォーマットを見てください。
長さ ・ Number: 数の有効桁数の合計
・ String: トータルの文字列の長さ
・ Date:出力される文字列の長さ(例えば、4は年を返すだけである)
精度 精度オプションは以下のフィールドタイプによります:
・ Number:浮動小数点ケタの数
・ String,Date: 未使用
通貨記号 $10,000.00 or E5.000,00 のような数を解釈するために使用
小数点区切り文字 小数点区切り文字として"." (10,000.00) や "," (5.000,00) などがあり
ます。
桁区切り文字 桁区切り文字として"," (10,000.00) や "." (5.000,00) などがあります。
空白除去 文字列に適用されるトリミング方法
Note: トリミングはフィールド長が指定されていないときにのみ機能しま
す。
Null 可能 フィールドの値が NULLであるなら、この文字列をテキストファイルに挿入
します。

Pentaho データ統合 4.1 ユーザーガイド
~ 117 ~
©株式会社 KSK ソリューションズ
RSS 入力
このステップでは RSS または Atom フィードからデータをインポートします。RSS versions 1.0, 2.0,
0.91, 0.92, と Atom versions 0.3 と 1.0 がサポートされています。
全般 タブ
全般タブでは使用対象となる RSS/Atom URL を定義します。またオプションで URL を含むフィール
ドも定義します。
オプション 説明
ステップ名 データ変換内のステップ名
フィールドに URL が
定義される
チェックした場合、どのフィールドから URL を検索するのかを指定します。
URL フィールド 上のオプションがチェックされた場合、ここにURLフィールドを指定します。
URL リスト 記事を抜き出したい RSS/Atom URL のリストです。
コンテンツ タブ
コンテンツ タブには入力を制限し、出力を変更するオプションが含まれます。
オプション 説明
読み込み先 yyyy-MM-dd HH:mm:ss 形式で日時を指定します。ここで指定した日時より後
の記事のみが読込まれます。
項目の最大数 検索する記事の数を指定します。一番古い記事からの数です。
出力に URLを含む チェックされた場合、URL を渡すフィールド名を指定してください。
出力に行番号を含む チェックされた場合、行番号を渡すフィールド名を指定してください。
フィールド タブ
フィールドタブはエクスポートされるフィールドのプロパティを定義します。
オプション 概要
名称 フィールドの名前。
タイプ フィールドのタイプは、String、Date、Number、Boolean、Integer、BigNumber、
Serializable、Binary、のいずれかです。
長さ ・ Number: 数の有効桁数の合計
・ String: トータルの文字列の長さ
・ Date:出力される文字列の長さ(例えば、4は年を返すだけである)
精度 精度オプションは Number 型のみサポートされています。
・ Number:浮動小数点ケタの数
空白除去 文字列に適用されるトリミング方法(左、右、両側)。トリミングはフィー
ルド長が指定されていないときに便利です。
繰り返し Yに設定された場合、次のフィールドが空のとき、この値を繰り返す。
形式 フォーマットのためのマスク。(Number 型)

Pentaho データ統合 4.1 ユーザーガイド
~ 118 ~
©株式会社 KSK ソリューションズ
通貨記号 通貨を表す記号
小数点区切り文字 小数点区切り文字として"." (10,000.00) や "," (5.000,00) などがあり
ます。
桁区切り文字 4桁もしくはそれ以上の数値を千の位ごとに区切る方法。ドットまたはカン
マを指定。
エラー処理に関する注意点
エラー処理がこのステップを含むデータ変換内で実行される場合、例外メッセージの全部、エラーが発
生したフィールド番号、1 つ以上の下記のコードがエラーストリームのエラー行に送信されます。
・ UnknownError: 予期できないエラー。詳細は "Error description" フィールドをチェックしてくださ
い。
・ XMLError: 指定されたファイルが XML でないことを意味します。
・ FileNotFound: HTTP 404 エラー。
・ UnknownHost: ドメイン名が解決されないことを指します。ネットワークにつながらない可能性が
あります。
・ TransferError: 404 HTTP サーバーエラーコード以外のいずれか(401, 403, 500, 502, etc.) を指し
ます。
・ BadURL: URL が解釈できないことを指します。プロトコルが記述されていないか、認識できない
プロトコルが指定されている可能性があります。
・ BadRSSFormat: XML は有効ですが、サポートされていない RSS または Atom ドキュメントタ
イプを指します。
Note: ハンドルされたエラーのスタックトレースを完全に見るためには、 detailed logging をオンにし
てください。

Pentaho データ統合 4.1 ユーザーガイド
~ 119 ~
©株式会社 KSK ソリューションズ
ジョブステップ リファレンス
Pentaho Data Integration に関連付けられたジョブエントリは 60 以上あります。以下のリストは、使用
頻度の高いジョブエントリのサブセットです。このドキュメントのより新しいバージョンでは、リスト
により多くのジョブが追加される予定です。現在のところ、入手可能なジョブエントリ関連のドキュメ
ントのほとんどは Pentaho Wiki で利用できます。しかし、Wiki のドキュメントはオープンソースコミ
ュニティによりメンテナンスされているますので、常にすべての情報がそろっていて、性格であるとは
限りません。
全般
名前 説明
Start ジョブのスタート。
Dummy 何もしません。エントリポイントとなるもの
です。
ジョブ ジョブを実行します。
データ変換 あらかじめデザインされたデータ変換を実
行します。
メール
名前 説明
メール Email を送信します。
条件
名前 説明
ファイル確認 Pentaho Data Integration が実行されているサーバーに指定されたファイ
ルが存在するか検証します。
テーブル確認 データベースに指定されたファイルが存在するか検証します。
スクリプト
名前 説明
Java スクリプト ブール値を計算します。この結果により、次にどのステップが実行されるの
かを決定します。
シェル ジョブが実行されているホスト上のシェルスクリプトを実行します。
SQL SQL スクリプトを実行します。
ファイル管理
名前 説明
HTTP Gets a file from a Web サーバーから HTTP プロトコルを使用してファイ
ルを取得します。
ファイル転送
名前 説明

Pentaho データ統合 4.1 ユーザーガイド
~ 120 ~
©株式会社 KSK ソリューションズ
名前 説明
FTP ファイル取得 FTP サーバーから 1つ以上のファイルを取得します。
SFTP ファイル取得 FTP サーバーから 1 つ以上のファイルを、Secure FTP プロトコルを使用し
て取得します。
Hadoop
名前 説明
Hadoop Copy Files いずれかが Hadoop クラスタである、ある場所からある場所へ 1つ以上のフ
ァイルをコピーします。
Hadoop Job Executor Java クラスを経由して、 Hadoop ジョブを実行します。
Hadoop
Transformation Job
Executor
データソースとして Hadoop を使用するデータ変換を実行します。Java ク
ラスの代わりに PDI-based map/reduce 関数を作成するときによく使用され
ます。
Amazon EMR Job
Executor
Hadoop ジョブを Amazon Elastic Map/Reduce アカウントを使用して実行し
ます。
Start
Dummy
ジョブ
データ変換
メール
ファイル確認
Table Exists
Java スクリプト
シェル
SQL
HTTP
FTP ファイル取得
SFTP ファイル取得
Hadoop Copy Files
Hadoop Job Executor
Hadoop Transformation Job Executor
Amazon EMR Job Executor

Pentaho データ統合 4.1 ユーザーガイド
~ 121 ~
©株式会社 KSK ソリューションズ
Start
Start はジョブの実行開始ポイントを定義します。すべてのジョブには Start が 1 つ必要です。. 無条
件のジョブのホップは Start ジョブエントリからのみ可能です。start ジョブエントリの設定には、基本
的なスケジューリング機能が含まれています。しかし、スケジューリングは永続性のものではなく、デ
バイスが実行されているときのみ利用可能です。
ジョブやデータ変換の実行に関しては、Data Integration Server がより強固なスケジューリング機能を
提供しますので、こちらの使用が推奨されます。デーモンプロセスのようにジョブを実行したければ、
ジョブ設定ダイアログボックスで Repeat. 有効にしてください。

Pentaho データ統合 4.1 ユーザーガイド
~ 122 ~
©株式会社 KSK ソリューションズ
Dummy
Dummy ジョブエントリは何も行いません。キャンバス上のエントリポイントであるだけです。しかし、
一度に1つの行を処理するデータ変換があるとしましょう。最初に5レコードを取得して、さらに5つ
のレコードを同時に処理するようにデータ変換を設定しました。ジョブスクリプトは処理が完了したか
を決定しなければなりません。何度か一巡して元に戻ることが必要かもしれません。ジョブワークフロ
ーの配置では、このタイプのシナリオを読取るのは難しいかもしれません。Dummy ジョブエントリは、
ループをさせるためのジョブワークフローの配置をよりわかりやすくします。Dummy そのものは何の
評価も行いません。

Pentaho データ統合 4.1 ユーザーガイド
~ 123 ~
©株式会社 KSK ソリューションズ
ジョブ
ジョブ ジョブエントリを使用して、あらかじめ定義されたジョブを実行してください。ジョブ ジョブ
エントリにより、"functional decomposition (機能的分解)" をすることが可能になります。要するに、ジ
ョブを管理しやすい単位に分割することです。例えば、500 のエントリを含む 1 つのジョブを使用して、
その中でデータウェアハウスのロード処理を書くことはないでしょう。それをするには、より小さい単
位のジョブを作成しその後集約したほうがよいでしょう。
以下に、ジョブのオプションをタブ名毎に記述します。ジョブエントリの名称はそれぞれのタブの上方
に記載されています。
ジョブ詳細
オプション 説明
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
ジョブファイル名 レポジトリを使用していない場合は、開始するデータ変換の XML ファイル名
を指定してください。 をクリックしてローカルのファイルを参照してくだ
さい。
レポジトリー:名前を
特定してください。
Enterprise Repository (またはデータベースレポジトリ) を使用して作業
している場合は、開始するデータ変換の XML ファイル名を指定してくださ
い。 をクリックしてレポジトリを参照してください。
レポジトリー:参照元
によって特定
データ変換またはジョブリファレンスを指定する場合は、レポジトリにてリ
ネームまたは移動が可能です。リファレンス(識別子)は保存されています
が、名前とディレクトリではありません。
拡張
Option Description
先行のジョブエント
リから値を引き継ぐ
(上)
先行のデータ変換からの結果は、Copy rows to result ステップを使用して
このエントリに送信できます。
先行のジョブエント
リから値を引き継ぐ
(下)
Execute for every input row が有効な場合、それぞれの行は、データ変換
へ引き渡されるコマンドライン引数のセットです。そうでない場合は、コマ
ンドライン引数を生成するのに先頭行のみが使用されます。
ループ処理を行う ループ処理を実装します。先行のジョブエントリが結果行のセットを返す場
合、すべての行に対して一度ずつジョブが実行されます。例えば、ディレク
トリにあるファイルそれぞれに対してジョブを実行することが可能です。
スレーブサーバ ジョブを実行するスレーブサーバです。
リモートでのジョブ
完了を待つ
スレーブサーバーでのジョブの実行が完了するまでブロックするには、有効
にします。
ジョブが失敗した場
合はローカルで実行
する
有効にすると、ローカルで呼び出された場合に、リモートジョブにアボート
(中止)シグナルを送信します。

Pentaho データ統合 4.1 ユーザーガイド
~ 124 ~
©株式会社 KSK ソリューションズ
ログ設定
オプション 概要
ログファイルを設
定する
ジョブの実行に、別のログファイルを指定したければ、これをチェックし
てください。
既存のファイルに
追加する
新規にファイルを作成するのではなく、既存のファイルに追加する場合に
有効にしてください。
ログファイル名 ログファイル名とディレクトリ(例、C:\logs)
親フォルダを作成 Create the parent folder for the log file if it does not exist
ログファイルに親フォルダが存在しない場合は、作成します。
拡張子 ファイルの拡張子(例、log・txt)
ファイル名に日付
を付ける
システム日付をファイル名に追加します。
ファイル名に時刻
を付ける
システム時間をファイル名に追加します。
ログレベル
ジョブの実行にログレベルを指定します。 Pentaho データ統合ユーザーガ
イド.14ログのログウィンドウを参照ください。
引数名
データ変換にジョブのコマンドライン引数を渡すことが可能です。
パラメータ
データ変換にパラメータを渡すことが可能です。

Pentaho データ統合 4.1 ユーザーガイド
~ 125 ~
©株式会社 KSK ソリューションズ
データ変換
データ変換 ジョブエントリは、あらかじめ定義されたデータ変換を実行するために使用されます。
以下に、ジョブのオプションをタブ名毎に記述します。ジョブエントリの名称はそれぞれのタブの上方
に記載されています。
変換ジョブの詳細
オプション 説明
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
データ変換ファイル
名
レポジトリを使用していない場合は、開始するデータ変換の XML ファイル名
を指定してください。 をクリックしてローカルのファイルを参照してくだ
さい。
データ変換名 Enterprise Repository (またはデータベースレポジトリ) を使用して作業
している場合は、開始するデータ変換の XML ファイル名を指定してくださ
い。 をクリックしてレポジトリを参照してください。
参照元を特定 データ変換またはジョブリファレンスを指定する場合は、レポジトリにてリ
ネームまたは移動が可能です。リファレンス(識別子)は保存されています
が、名前とディレクトリではありません。
拡張
オプション 説明
先行のジョブ・エン
トリから値を引き継
ぐ(上)
先行のデータ変換からの結果は、Copy rows to result ステップを使用して
このエントリに送信できます。
先行のジョブ・エン
トリから値を引き継
ぐ(下)
Execute for every input row が有効な場合、それぞれの行は、データ変換
へ引き渡されるコマンドライン引数のセットです。そうでない場合は、コマ
ンドライン引数を生成するのに先頭行のみが使用されます。
ループ処理を行う データ変換を、すべての入力行に対して 1度ずつ実行されるようにします(ル
ープ処理)。
実行前にレコードの
リストを消去する
データ変換が始まる前に、結果ファイルのリストをクリアします。
実行前にファイルの
リストを消去する
項目名のとおりです。
スレーブサーバー ジョブを実行するスレーブサーバーです。
リモートでのジョブ
完了を待つ
スレーブサーバーでのジョブの実行が完了するまでブロックするには、有効
にします。
ジョブが失敗した場
合はローカルで実行
有効にすると、ローカルで呼び出された場合に、リモートジョブにアボート
(中止)シグナルを送信します。

Pentaho データ統合 4.1 ユーザーガイド
~ 126 ~
©株式会社 KSK ソリューションズ
オプション 説明
する
ログ設定
既定では、特にログ設定を行わない場合、Pentaho Data Integration は、生成されたログエントリを取
得し、ジョブ内にログレコードを作成します。例えば、ジョブには実行するデータ変換が 3 つあり、ロ
グ設定を行っていないとしましょう。データ変換はファイル、ロケーション、特別な設定に関するログ
情報を出力しません。この場合は、ジョブはマスタージョブログにログ情報を出力します。
多くの場合、ログ情報をジョブログ内にて利用することは可能です。例えば、ディメンションをロード
した場合、表示されているロードしたディメンションに関するログが、ジョブログでも欲しいとします。
データ変換内にエラーが発生した場合、ジョブログ内に表示されます。しかし、すべてのログ情報が 1
つの場所に保存されて欲しい場合は、ログ取得設定を変更してください。
オプション 概要
ログファイルを設
定する
ジョブの実行に、別のログファイルを指定したければ、これをチェックし
てください。
既存のファイルに
追加する
新規にファイルを作成するのではなく、既存のファイルに追加する場合に
有効にしてください。
ログファイル名 ログファイル名とディレクトリ(例、C:\logs)
親フォルダを作成 Create the parent folder for the log file if it does not exist
ログファイルに親フォルダが存在しない場合は、作成します。
ログファイルの拡
張子
ファイルの拡張子(例、log・txt)
ファイル名に日付
を付ける
システム日付をファイル名に追加します。
ファイル名に時刻
を付ける
システム時間をファイル名に追加します。
ログレベル ジョブの実行にログレベルを指定します。 Pentaho データ統合ユーザーガ
イド.14ログのログウィンドウを参照ください。
引数名
データ変換にジョブのコマンドライン引数を渡すことが可能です。
パラメータ
データ変換にパラメータを渡すことが可能です。

Pentaho データ統合 4.1 ユーザーガイド
~ 127 ~
©株式会社 KSK ソリューションズ
メール
メール ジョブエントリを使用して、オプションでファイルを添付し、テキストまたは HTML email を
送信してください。多くの場合、このジョブエントリは一連のジョブの最後で使用されます。またジョ
ブの成功か失敗をアナウンスするためにも使用できます。例えば、ジョブの実行結果として、問題なく
実行されたことを配布先リストの対象者に email で連絡することはよくあることです。もしエラーが発
生した場合は、配布先リストの人にアラートを通知することも可能です。
重要: 実行中にジョブがクラッシュした場合、メッセージは送信されません。service level agreements
または quality of service agreements の規定に拘束されている場合、このジョブエントリを通知方法と
して使用しない方がよい可能性があります。
Mail ジョブエントリは SMTP サーバーを必要とします。接続の一部として、認証とセキュリティが使
用できますが、SMTP 認証情報が必要です。
email メッセージに、エラーログや通常のログなど、ファイルを添付することができます。加えて、ロ
グは1つのファイルに圧縮することもできます。
アドレス
オプション 説明
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
宛先 メールの宛先。複数のアドレスを指定するには、スペースで区切ってくださ
い。
Note:ジョブの中に配布先リスト を保管しないでください。Email の管理者
にリストを設定させて、ジョブ作成時にはそのリストに必要に応じて送信す
ることにしてください。Email 内容、ルーティング、人に関する情報などは
Pentaho Data Integration の外部で管理してください。
Cc: メッセージのコピーは Cc: フィールドに記載されたアドレスに送信されま
す。Cc: フィールドに 1つ以上のアドレスを入力するには、コンマで分けて
ください。
BCc: アドレスが表示されずに、メッセージを送信します。
差出人 名前 送信者の名前
差出人 メールアド
レス
送信者の email アドレス。
返信先 返信を送信する先となる email アドレス。
返信名 Email に記載される名前
電話番号 Email に記載される電話番号。
サーバ
オプション 説明
SMTP サーバー SMTP サーバーアドレス。
ポート番号 SMTP サーバーが実行されているポート。

Pentaho データ統合 4.1 ユーザーガイド
~ 128 ~
©株式会社 KSK ソリューションズ
オプション 説明
認証を使用する SMTP サーバーに認証を設定する場合は有効にしてください。
ユーザ名 SMTP ユーザーアカウント名。
パスワード SMTP ユーザーパスワード名。
セキュリティで保護
された認証を使用す
る
セキュア認証を有効にします。
タイプ 認証タイプを選択します。
メッセージ
オプション 説明
メッセージに日付を
含む
メッセージに日付を含めます。
コメントのみ送信 無効の場合、email には、ジョブとその実行に関する情報が本文に含まれま
す。
HTML メールを使用す
る
項目名のとおり。
文字コード 文字コードの選択
優先度 優先度を管理するには有効にしてください。
件名 項目名のとおり。
本文 項目名のとおり。
添付ファイル
オプション 説明
ファイルを添付する Email にファイルを添付するには有効にしてください。
タイプ 項目名のとおり。
圧縮アーカイブする 添付ファイルを Zip 形式で圧縮するには有効にしてください。
圧縮アーカイブファ
イル名
項目名のとおり。
ファイル名 単一のイメージファイルの名前
コンテンツ ID 自動的に入力されます。
画像 イメージへのフルパス(複数のイメージを掲載する場合に使用されます)。
Edit をクリックしてパスを編集し、Delete をクリックしてイメージのパス
を削除してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 129 ~
©株式会社 KSK ソリューションズ
オプション 説明
コンテンツ ID イメージの content ID (複数のイメージを掲載する場合に使用されます) 。
Edit をクリックして content IDを編集し、Delete をクリックして content
IDを削除してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 130 ~
©株式会社 KSK ソリューションズ
ファイル確認
ファイル確認 ジョブエントリを使用して、Pentaho Data Integration が実行されているサーバーに特定
のファイルが存在するかを検証してください。ファイル名を入力してください。Pentaho Data
Integration はファイルが存在するかしないかによって、True または False を返します。
ファイル確認 ジョブエントリは、他のシステムとの簡単なインテグレーションポイントになることが
できます。例えば、3 部構成のデータウェアハウスのロードプロセスがあったとしましょう。初めのパ
ートは PERL で動きます。リモートの場所にアクセスするバッチスクリプトがあり、第 1 段階の行プ
ロセスを行い、特定のディレクトリにデータを出力します。これが完了するまでジョブを実行したくな
いので、ジョブをスケジューラーに託しました。タスクが完了し次第、ファイルは指定された場所に配
置されるので「ファイルが存在する」となります。それが最後の処理を実行するシグナルとなるのです。
Note: このジョブエントリはチェックを 1 つ行って、それから次に進みます。ファイルが存在するまで
ポールしたい場合は、ポーリングパラメータを持つ Wait for File または Wait for SQL ジョブエント
リを使用してください。

Pentaho データ統合 4.1 ユーザーガイド
~ 131 ~
©株式会社 KSK ソリューションズ
テーブル確認
テーブル確認 ジョブエントリを使用して、データベース上に特定のテーブルが存在するか確認できま
す。データベース接続とテーブル名の情報が必要になります。Pentaho Data Integration はテーブルが
存在するかしないかによって、True または False を返します。
サマリーテーブルを作成、または昨日のデータを抽出する外部システムがあるとしましょう。外部シス
テムはまだアクションを行っていない可能性があるので、データベースにステージされたデータを待機
するポーリングピースを設定します。データが入手可能になるまで、ジョブを処理するポイントがない
ので、このジョブエントリを、データベースにテーブルが存在するかしないをポールするセマフォとし
て使用してします。
Note: このジョブエントリはチェックを 1 つ行って、それから次に進みます。テーブルが存在するまで
ポールしたい場合は、ポーリング間隔パラメータを持つ Wait for File または Wait for SQL ジョブエ
ントリを使用してください。
オプション 説明
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
データソース名 使用する接続情報。
スキーマ名 データベースに適用されるスキーマ名
テーブル名 チェック対象のデータベーステーブル
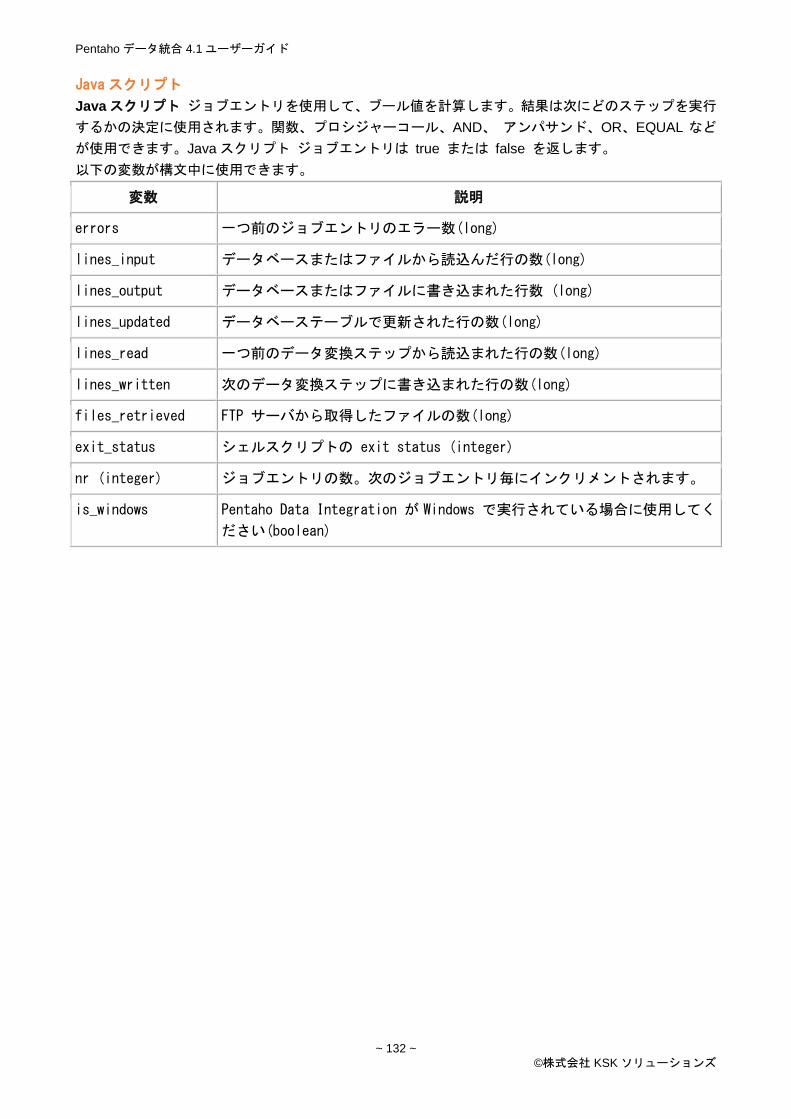
Pentaho データ統合 4.1 ユーザーガイド
~ 132 ~
©株式会社 KSK ソリューションズ
Java スクリプト
Java スクリプト ジョブエントリを使用して、ブール値を計算します。結果は次にどのステップを実行
するかの決定に使用されます。関数、プロシジャーコール、AND、 アンパサンド、OR、EQUAL など
が使用できます。Java スクリプト ジョブエントリは true または false を返します。
以下の変数が構文中に使用できます。
変数 説明
errors 一つ前のジョブエントリのエラー数(long)
lines_input データベースまたはファイルから読込んだ行の数(long)
lines_output データベースまたはファイルに書き込まれた行数 (long)
lines_updated データベーステーブルで更新された行の数(long)
lines_read 一つ前のデータ変換ステップから読込まれた行の数(long)
lines_written 次のデータ変換ステップに書き込まれた行の数(long)
files_retrieved FTP サーバから取得したファイルの数(long)
exit_status シェルスクリプトの exit status (integer)
nr (integer) ジョブエントリの数。次のジョブエントリ毎にインクリメントされます。
is_windows Pentaho Data Integration が Windows で実行されている場合に使用してく
ださい(boolean)

Pentaho データ統合 4.1 ユーザーガイド
~ 133 ~
©株式会社 KSK ソリューションズ
シェル
シェル ジョブエントリを使用して、ジョブが実行されているホスト上でシェルスクリプトを実行
してください。例えば、5 つのデータテーブルを読込み、指定されたフォーマットのファイルを作
成します。プログラムが作動することが認識され、シェルにより Pentaho Data Integration の作
業の一部を行うことが可能になりますが、必要に応じてプログラムを再度利用してデータテーブル
を読込みます。
シェル ジョブエントリはプラットフォームに依存しません。バッチファイル、UNIX などを使用で
きます。シェル ジョブエントリを使用するとき、Pentaho Data Integration は特定の場所のプロ
グラムを実行するために、Java をコールします。戻り値は OSのコールにより作成されます。例え
ば、バッチスクリプトでは戻り値1がスクリプトの実行は成功であったことを示します。戻り値 0
は失敗したことを表します。コマンドライン引数を渡してシェル ジョブエントリのログ設定を設
定できます。
全般
オプション 説明
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
スクリプトを挿入 シェルスクリプトの挿入を行うには有効にしてください。手作業でスクリプ
トを入力するには、スクリプトタブをクリックしてください。
スクリプト・ファイ
ル名
実行するシェルスクリプト名。
作業ディレクトリ コマンドまたはスクリプトの作業ディレクトリです。
ログファイルを設定
する。
このデータ変換の実行に、別々のログファイルを指定するなら、チェックし
てください。
既存のファイルに追
加する
新規にファイルを作成するのではなく、既存のファイルに追加する場合に有
効にしてください。
ログファイル名 ログファイル名とディレクトリ(例、C:\logs)
拡張子 ファイルの拡張子(例、log・txt)
ファイル名に日付を
付ける
システム日付をファイル名に追加します。
ファイル名に時刻を
付ける
システム時間をファイル名に追加します。
ログレベル ジョブの実行にログレベルを指定します。
先行のジョブ・エン
トリから値を引き継
ぐ
先行のデータ変換からの結果は、Copy rows to result ステップを使用して
このシェルスクリプトに送信できます。
ループ処理を行う ループ処理を実装します。前のジョブエントリが結果行を返す場合は、シェ

Pentaho データ統合 4.1 ユーザーガイド
~ 134 ~
©株式会社 KSK ソリューションズ
オプション 説明
ルスクリプトはすべての入力行に対して 1度ずつ実行されるようにします。
copy previous result to arguments との組み合わせにて、すべての実行動
作に対して、行が 1つこのスクリプトに渡されます。相対する結果行の値は、
コマンドライン引数 $1, $2, ... (%1, %2, %3, ... on Windows) に見る
ことが出来ます。
フィールド コマンドライン引数としてコマンド/スクリプトに渡される値です(Not used
if Copy previous results to args が使用されている場合は使用されませ
ん)。
スクリプト
「スクリプトを挿入」が有効の場合に、ファイルの内容として使用される任意のスクリプトです。

Pentaho データ統合 4.1 ユーザーガイド
~ 135 ~
©株式会社 KSK ソリューションズ
SQL
SQL ジョブエントリを使用して、SQL スクリプトを実行してください。セミコロンで分けられている
なら、1 つ以上の SQL ステートメントを実行できます。SQL ジョブエントリは柔軟です。プロ氏ジャ
ーコールを行えますし、テーブルの作成や分析なども可能です。SQL ジョブエントリに関連するよく
ある使用法は、truncating tables, drop index, partition loading, refreshing materialized views, disabling
constraints, disabling statistics などです。
オプション 説明
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
データソース名 使用するデータベース接続
ファイルを入力する ファイルから SQL スクリプトを使用するには有効にしてください。
SQL ファイル名 SQL ファイル名を指定してください。
単体のステートメン
トとして SQL を発行
有効な場合は、データベース上の単一のステートメントとしてブロック全体
が送信されます。無効な場合は、それぞれのステートメント(‘;’によっ
て区切られる)が各々で実行されます。
変数の値を置き換え Pentaho Data Integration の変数に対して、SQL ブロックを解決します。
SQL ステートメント 実行する SQL スクリプトです。

Pentaho データ統合 4.1 ユーザーガイド
~ 136 ~
©株式会社 KSK ソリューションズ
HTTP
HTTP ジョブエントリを使用して、HTTP プロトコルを使用してウェブサーバーからファイルを取得し
ます。このジョブエントリはパートナーウェブサイトへのアクセスにも使用することもできます。例え
ば、日次データエクスポートや日次顧客リストは指定されたウェブサイトに配置されています。また、
SaaS プロバイダーがレポートを保存する場所の URL を伝えることもあるでしょう。この URL をコ
ールして、データを含む Excel ファイルや zip ファイルを取得します。Salesforce のデータの取得に
は、SOAP API の使用が必要になります。
企業内の環境での HTTP トラフィックにかなりの負担がある場合は、HTTP 認証を行うプロキシサー
バーの使用が考えられます。.

Pentaho データ統合 4.1 ユーザーガイド
~ 137 ~
©株式会社 KSK ソリューションズ
FTP ファイル取得
FTP ファイル取得 ジョブエントリを使用して、1 つ以上のファイルを FTP サーバーから取得します。
このジョブエントリは "crawl" システムではありません。例えば、リモートディレクトリにはアクセス
したり、ワイルドカードに一致するファイルを検索するために他のディレクトリには行きません。この
ジョブは1つのディレクトリからのみファイルを取得します。
一般
オプション 説明
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
ホスト名 サーバー名または IP アドレス。
ポート番号 FTP サーバーのポート番号。
ユーザー名 FTP サーバーアカウントに関連付けられたユーザー名。
パスワード FTP サーバーアカウントに関連付けられたパスワード。
プロキシホスト プロキシサーバーのホスト名
プロキシポート プロキシサーバーのポート番号
プロキシユーザ名 プロキシサーバーアカウントユーザー名
プロキシパスワード プロキシサーバーアカウントのパスワード
バイナリモード バイナリモードでファイルを転送する場合は有効にしてください。
タイムアウト FTP サーバーのタイムアウトを秒単位で指定します。
常時接続する アクティブモードで FTP サーバーに接続する場合は有効にします。FTP クラ
イアントがオープンするポートへのアクセスを受け付けるように、ファイア
ウォールを設定してください。デフォルトはパッシブモードです。
文字コード 文字コードは、特殊文字を含むファイル名を取得するときに関連します。西
欧と米国には、ISO-8859-1 が通常使用する上では問題ありません。お使い
になるサーバーに合わせて文字コードを選択してください。
ファイル
オプション 説明
リモートディレクト
リ
ファイルを取得する FTP サーバーのリモートディレクトリです。
検索文字列 複数ファイルを選択するための正規表現です。
例).*txt$ : すべてのテキストファイルを取得
A.*[ENG:0-9].txt : A で始まり数値で終わる .txt ファイルを取得
転送後にファイルを
削除する
すべての選択したファイルを問題なく移動させた後でのみ、FTP サーバー上
のファイルを削除します。
転送後にファイルを 指定したフォルダにファイルを移動。

Pentaho データ統合 4.1 ユーザーガイド
~ 138 ~
©株式会社 KSK ソリューションズ
オプション 説明
移動する
移動ディレクトリ ファイルを含むフォルダを作成します。
ディレクトリを作成 取得したファイルを保存するディレクトリです。
ファイル名に日付を
つける
ファイル名に日付を付加します(_20101231)。
ファイル名に時刻を
つける
ファイル名に時間を付加します(_235959)。
日付と時刻の表示形
式を指定する
自分で設定した日付/時間のフォーマットを使用するには有効にしてくださ
い。デフォルトは yyyyMMdd'_'HHmmss です。
表示形式 日時のフォーマットを指定します。
日付と時刻を拡張子
にする
ファイル名の拡張子の前に日付を付加します。
ファイルを上書きし
ない
ターゲットのディレクトリに既に同じ名前のファイルが存在する場合に、ス
キップまたはリネーム、fail させたい場合は有効にしてください。
ファイルが存在して
いた場合の処理
ターゲットのディレクトリに既に同じ名前のファイルが存在する場合に、と
るべき行動です。
ファイル名を結果に
含む
このジョブの結果にファイル名を付加する場合は有効にしてください。
拡張
オプション 説明
条件 成功になる条件を設定してください。
許可する回数 成功になる条件に関連づけられたファイルの数を設定してく
ださい。
Socks Proxy
オプション 説明
ホスト Socks Proxy ホスト名
ポート Socks Proxy ポート番号
ユーザ名 Socks Proxy アカウントに関連付けられた
ユーザー名
パスワード Socks Proxy アカウントに関連付けられた
パスワード

Pentaho データ統合 4.1 ユーザーガイド
~ 139 ~
©株式会社 KSK ソリューションズ

Pentaho データ統合 4.1 ユーザーガイド
~ 140 ~
©株式会社 KSK ソリューションズ
SFTP ファイル取得
SFTP ファイル取得 ジョブエントリを使用して、セキュア FTP プロトコルを使用して FTP サーバー
から1つ以上のファイルを取得します。
Option Description
ジョブ名 キャンバス上でユニークな名前。ジョブエントリは何度かキャンバス上で移
動させることができます。
ホスト名 SFTP サーバー名もしくは IP アドレスです。
ポート番号 使用する TCP ポートです。通常 22 番です。
ユーザ名 SFTP サーバーにログオンするユーザー名です。
パスワード SFTP サーバーにログオンするパスワードです。
先行のジョブ・エント
リから値を引き継ぐ
静的なファイルリストの代わりに、前のジョブエントリからの結果ファイル
のリストを使用するには有効にしてください。
リモート・ディレクト
リ
ファイルを取得する SFTP サーバーのリモートディレクトリです。
検索文字列 複数ファイルを選択するための正規表現です。
例).*txt$ : すべてのテキストファイルを取得
A.*[ENG:0-9].txt : A で始まり数値で終わる .txt ファイルを取得
転送後にファイルを
削除する
すべての選択したファイルを問題なく移動させた後でファイルを削除する
には有効にしてください。
ローカル・ディレクト
リ
取得したファイルを保存するディレクトリです。
ファイル名を結果に
含む
このジョブの結果にファイル名を付加する場合は有効にしてください。

Pentaho データ統合 4.1 ユーザーガイド
~ 141 ~
©株式会社 KSK ソリューションズ
Hadoop Copy Files
このジョブエントリでは、Hadoop クラスタ上のファイルを、ある場所からある場所へコピーします。
全般
オプション 説明
サブ・ディレクトリ
を含む
選択された場合、選択されたディレクトリ内のすべてのサブディレクトリが
同様にコピーされます。
移動先がファイル 移動先がファイルかディレクトリかを決定します。
空のディレクトリに
コピー
選択された場合、空のディレクトリであっても、すべてのディレクトリをコ
ピーします。「サブ・ディレクトリを含む」オプションが選択されていないと
このオプションは有効にはなりません。
移動先のディレクト
リを作成する
選択された場合、移動先のディレクトリが存在しない場合は作成します。
既存のファイルを置
き換え
選択された場合、移動先のディレクトリのファイルを上書きします。
移動後に参照元のフ
ァイルを削除
選択された場合、参照元のファイルあコピー後に削除されます(移動するこ
とになりま)。
先行のジョブ・エン
トリから値を引き継
ぐ
選択された場合、先行するステップの結果をソースとして使用します。
参照元のファイルと
ディレクトリ
コピーの参照元となるファイルまたはディレクトリです。Browse クリック
し、 Hadoop を選択して Hadoop クラスタの接続情報を入力してください。
移動先のファイルと
ディレクトリ
コピーの移動先となるファイルまたはディレクトリです。Browse クリック
し、 Hadoop を選択して Hadoop クラスタの接続情報を入力してください。
検索文字列 (ファイル名を静的にではなく)正規表現でコピーされるファイルを定義し
ます。例えば、「.*\.txt」は拡張子が .txt のファイルが当てはまります。
ファイルとディレク
トリ
選択された参照元と移動先のリストです。
結果ファイル名
オプション 説明
ファイル名を結果に
含む
コピーされたファイルはこのステップの結果として扱われます。このステッ
プにてコピーされたファイルのリストを表示します。

Pentaho データ統合 4.1 ユーザーガイド
~ 142 ~
©株式会社 KSK ソリューションズ
Hadoop Job Executor
このジョブエントリは Hadoop ジョブを Hadoop ノードで実行します。2 つのモードがあります。
Simple (デフォルト): あらかじめ作成した Java JAR をジョブのコントロールのために渡すのみ。
Advanced: static main メソッドを指定することが可能です。以下のオプションのほとんどは Advanced
モードでのみ使用できます。Advanced モードの User Defined タブは、Job Setup と Cluster タブ
で定義されない Hadoop option name/value ペアのためのものです。
General
オプション 定義
ジョブ名 この Hadoop Job Executer ステップのインスタンスの名前です。
Hadoop ジョブ名 実行する Hadoop ジョブの名前です。
Jar Hadoop mapper and reducer ジョブインストラクションを static mainメソ
ッドに持っている Java JAR です。
コマンドライン引数 指定した JAR の static main メソッドに渡すコマンドライン引数です。
ジョブ設定
オプション 定義
出力キークラス 出力キーのデータ型を表す Apache Hadoop クラス名です。
出力値クラス 出力値のデータ型を表す Apache Hadoop クラス名です。
Mapper クラス map オペレーションを実行する Java クラスです。Pentaho デフォルトの
mapper クラスはほとんどの場合に十分な性能があります。map を自作の
Java クラスで扱う場合にのみ、この値を変更してください。
Combiner クラス combine オペレーションを実行する Java クラスです。Pentaho デフォルト
の combiner クラスはほとんどの場合に十分な性能があります。combine を
自作の Java クラスで扱う場合にのみ、この値を変更してください。
Reducer クラス reduce オペレーションを実行する Java クラスです。Pentaho デフォルトの
reducerクラスはほとんどの場合に十分な性能があります。reduce を自作の
Java クラスで扱う場合にのみ、この値を変更してください。
入力パス Hadoop クラスタ上の入力ファイルのパスです。
出力パス Hadoop クラスタ上の出力ファイルのパスです。
入力フォーマット 入力ファイルのデータ型を表す Apache Hadoop クラス名です。
出力フォーマット 出力ファイルのデータ型を表す Apache Hadoop クラス名です。
クラスター
オプション 定義
作業ディレクトリ Hadoop クラスタ上のジョブの一時ディレクトリです。

Pentaho データ統合 4.1 ユーザーガイド
~ 143 ~
©株式会社 KSK ソリューションズ
HDFS ホスト名 Hadoop クラスタのホスト名です。
HDFS ポート Hadoop クラスタのポート番号です。
ジョブトラッカーホ
スト名
ジョブトラッカー ノードが別にある場合、ホスト名をここに入力してくだ
さい。もしくは HDFS ホスト名を使用してください。
ジョブトラッカーポ
ート
ジョブトラッカー ポート番号; これは HDFS ポート番号と同じではいけま
せん。
Mapper タスクの数 このジョブに割り当てる Mapper プロセスの番号です。
Reducerタスクの数 このジョブに割り当てる Reducer プロセスの番号です。
ブロックを有効にす
る
次のステップに進む前に、それぞれのジョブが完了するまで待機させます。
PDI が Hadoop のジョブの状態を認識するにはこれが唯一の方法となりま
す。チェックされないままだと、Hadoop のジョブは実行され続け、PDI で
は次のステップに進みます。エラー処理/割当て はこのオプションがチェッ
クされない限り機能しません。
ログのインターバル ログメッセージを記録する間隔を秒数で指定します。

Pentaho データ統合 4.1 ユーザーガイド
~ 144 ~
©株式会社 KSK ソリューションズ
Hadoop Transformation Job Executor
このジョブエントリでは、Hadoop データソースを必要とするデータ変換を実行します。これは、従来
からある Hadoop Java クラスの変わりに mapper と reducer として振舞うデータ変換を実行するた
めによく使用されます。User Defined タブは、Job Setup と Cluster タブで定義されない Hadoop
option name/value ペアのためのものです。
一般
オプション 定義
ジョブ名 この Hadoop Job Executer ステップのインスタンスの名前で
す。
Hadoop ジョブ名 実行する Hadoop ジョブの名前です。
Map/Reduce
オプション 定義
Mapper データ変換 このジョブで mapping 関数を実行する KTR です。
Mapper 入力ステップ
名
Hadoop から Mapping データを受け取るステップの名前です。これは
injector ステップである必要があります。
Mapper 出力ステップ
名
Mapping 出力を Hadoop へ戻すステップの名前です。これは dummy ステップ
である必要があります。
Reducer データ変換 このジョブで reducer 関数を実行する KTR です。
Reducer 入力ステッ
プ名
Hadoop から Reducing データを受け取るステップの名前です。これは
injector ステップである必要があります。
Reducer 出力ステッ
プ名
Reducing 出力を Hadoop へ戻すステップの名前です。これは dummy ステッ
プである必要があります。
ジョブ設定
オプション 定義
出力キークラス 出力キーのデータ型を表す Apache Hadoop クラス名です。
出力バリュークラス 出力値のデータ型を表す Apache Hadoop クラス名です。
Mapper クラス map オペレーションを実行する Java クラスです。Pentaho デフォルトの
mapper クラスはほとんどの場合に十分な性能があります。map を自作の
Java クラスで扱う場合にのみ、この値を変更してください。
Combiner クラス combine オペレーションを実行する Java クラスです。Pentaho デフォルト
の combiner クラスはほとんどの場合に十分な性能があります。combine を
自作の Java クラスで扱う場合にのみ、この値を変更してください。
Reducer クラス reduce オペレーションを実行する Java クラスです。Pentaho デフォルトの
reducerクラスはほとんどの場合に十分な性能があります。reduce を自作の

Pentaho データ統合 4.1 ユーザーガイド
~ 145 ~
©株式会社 KSK ソリューションズ
Java クラスで扱う場合にのみ、この値を変更してください。
入力パス Hadoop クラスタ上の入力ファイルのパスです。
出力パス Hadoop クラスタ上の出力ファイルのパスです。
入力形式 入力ファイルのデータ型を表す Apache Hadoop クラス名です。
出力形式 出力ファイルのデータ型を表す Apache Hadoop クラス名です。
クラスター
オプション 定義
作業ディレクトリー Hadoop クラスタ上のジョブの一時ディレクトリです。
HDFS ホスト名 Hadoop クラスタのホスト名です。
HDFS ポート Hadoop クラスタのポート番号です。
ジョブトラッカー
ホスト名
ジョブトラッカー ノードが別にある場合、ホスト名をここに入力してくだ
さい。もしくは HDFS ホスト名を使用してください。
ジョブトラッカーポ
ート
ジョブトラッカー ポート番号; これは HDFS ポート番号と同じではいけま
せん。
Mapper タスク数 このジョブに割り当てる Mapper プロセスの番号です。
Reducerタスク数 このジョブに割り当てる Reducer プロセスの番号です。
ブロックの有効化
次のステップに進む前に、それぞれのジョブが完了するまで待機させます。
PDI が Hadoop のジョブの状態を認識するにはこれが唯一の方法となりま
す。チェックされないままだと、Hadoop のジョブは実行され続け、PDI で
は次のステップに進みます。エラー処理/割当て はこのオプションがチェッ
クされない限り機能しません。
ログ間隔 ログメッセージを記録する間隔を秒数で指定します。

Pentaho データ統合 4.1 ユーザーガイド
~ 146 ~
©株式会社 KSK ソリューションズ
Amazon EMR Job Executor
このジョブエントリでは、Amazon Elastic MapReduce (EMR) アカウントの Hadoop ジョブを実行し
ます。このステップを使用するためには、EMR 向けに設定された Amazon Web Services (AWS) ア
カウントと、リモートジョブのコントロールのためにあらかじめ作成された Java JAR が必要です。
オプション 定義
ジョブ名 この Amazon EMR Job Executer ステップのインスタンスの名前です。
EMR ジョブフロー名 実行する Amazon EMRジョブの名前です。
AWS Access キー Amazon Web Services のアクセスキーです。
AWS Secret キー Amazon Web Servicesのシークレットキーです。
S3 ステージングディ
レクトリ
この Hadoop ジョブのための Amazon Simple Storage Service (S3) のワー
キングディレクトリのアドレスです。このディレクトリには MapReduce JAR
を含み、ログファイルが作成されたときにはここに保存されます。
MapReduce JAR Hadoop mapper and reducer クラスを含む Java JAR です。ジョブは、JAR の
クラスの static mainメソッドを使用して設定、送信される必要があります。
コマンドライン引数 指定した JAR の static main メソッドに渡すコマンドライン引数です。
インスタンス数 このジョブに割り当てたい Amazon Elastic Compute Cloud (EC2) インスタ
ンスの数です。
Master インスタンス
タイプ
map/reduce task distribution を扱う、クラスタ中で Hadoop "master" と
して振舞う Amazon EC2 インスタンスのタイプです。
Slave インスタンス
タイプ
クラスタ中で 1つ以上の Hadoop " slaves " として振舞う Amazon EC2 イン
スタンスのタイプです。Slaves は master からタスクを割り当てられます。
これはインスタンスの数が1より大きい場合にのみ有効です。
ブロックの有効化
次のステップに進む前に、それぞれのジョブが完了するまで待機させます。
PDI が Hadoop のジョブの状態を認識するにはこれが唯一の方法となりま
す。チェックされないままだと、Hadoop のジョブは実行され続け、PDI で
は次のステップに進みます。エラー処理/割当て はこのオプションがチェッ
クされない限り機能しません。
ログ間隔 ログメッセージを記録する間隔を秒数で指定します。