Embed Size (px)
Citation preview

PLANEJAMENTO ECONÔMICO DOS
GRÁFICOS DE CONTROLE DE X ̅
PARA O MONITORAMENTO DE
PROCESSOS
AUTOCORRELACIONADOS
Bruno Chaves Franco (UNESP)
Antonio Fernando Branco Costa (UNESP)
Marcela Aparecida Guerreiro Machado (UNESP)
O presente artigo trato do planejamento econômico dos gráficos de
controle de X ̅ usados para monitorar uma característica de
qualidade cujas observações se ajustam a um modelo auto-regressivo
de primeira ordem com erro aleatório adiccional. O modelo de custos
de Duncan é usado para selecionar os parâmetros de controle do
gráfico, ou seja, o tamanho da amostra, o intervalo de amostragem e o
fator de abertura dos limites de controle, e o algoritmo genético é
aplicado na busca de um melhor custo de monitoramento no longo
prazo. Cadeias de Markov são utilizadas para determinar o número
médio de amostras até o sinal e no número esperado de alarmes falsos.
Uma análise de sensibilidade mostrou que a autocorrelação provoca
efeitos adversos sob os parâmetros do gráfico e seus custo de
monitoramento, em que um crescimento da autocorrelação reduz
significativamente a eficiência deste dispositivo.
Palavras-chaves: Gráfico de Controle de X ̅, Planejamento
Econômico, Autocorrelação, Cadeia de Markov, Algoritmo Genético
XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
2
1. Introdução
Os gráficos de controle de são projetados a partir dos princípios de Shewhart, em
que se pressupõe a média do processo uma variável que pode assumir apenas dois valores:
quando está em controle e quando ainda em controle sofre uma mudança resultante da
ocorrência de uma causa especial. Para o emprego desta ferramenta no monitoramento de
processos, é importante determinar três parâmetros de projeto: limites de controle, tamanho da
amostra e o intervalo de amostragem. Para que o dispositivo seja ajustado aos processos,
muitos pesquisadores desde 1950, vem incorporando os custos de monitoramento para
determinação destes parâmetros.
Duncan (1956) apresentou o primeiro planejamento inteiramente econômico de
gráficos de controle que buscava atender as características de custo do processo. Porém
Woodall (1985) já mencionava que o projeto econômico de gráficos de controle possuem
fraquezas, devido ao desempenho estatístico, pois há um aumento do número de alarmes
falsos e também na produção de itens não-conformes. Então em função da preocupação dos
pesquisadores em implementar uma ferramenta de monitoramento adequada para o processo
com baixo custo e estatisticamente eficiente, consideraram o emprego de restrições
estatísticas ao modelo econômico que teve como pioneiros Saniga (1989 ) e Saniga et al.
(1995) e então a técnica passou a se chamar planejamento econômico-estatístico.
Pesquisadores como Zimmer e Burr (1963), Baker (1971), Banerjee e Rahim (1988),
Yourstone e Zimmer (1992), Rahim e Banerjee (1993), Chou, Chen e Liu (2000), Chen
(2003) e Chen e Yeh (2009) modificarm o modelo de Duncan pois consideraram que a
escolha apropriada dos mecanismos do processo de falha ou a distribuição de probabilidade
que modela a ocorrência do desvio no processo, com base nas informações sobre o processo
de produção, é um requisito importante para ser considerado no dimensionamento econômico
de gráficos de controle.
Assim, como Duncan (1956), todos esses estudos assumem que a média de processo é
independente; no entanto, em algumas situações, pode ser mais realista supor que o processo
de média oscila, mesmo na ausência de qualquer causa especial específica, ver Reynolds Jr.,
Arnold e Baik (1996) e Lu e Reynolds (1999a, 1999b, 2001). Este efeito tem sido a
preocupação de alguns pesquisadores que vêm trazendo propostas de como monitorar estes
processos, como: Wardell et al. (1992); Reynolds Jr., Arnold e Baik (1996); VanBrackle e
Reynolds (1997); Lu e Reynolds (1999a, 1999b, 2001); Claro, Costa e Machado (2008);
Costa e Claro (2008); Zou, Wang e Tsung (2008); Lin (2009); Costa e Machado (2011); Costa
e Castagliola (2011).
O emprego do planejamento econômico para processos autocorrelacionados, tem sido
objeto de pesquisa de: Chou, Liu e Chen (2001); Liu, Chou e Chen (2002); Chen e Chiou
(2005); Chen, Hsieh e Chang (2007); Torng et al (2009) e mais recentemente Costa e Claro
(2009) que estenderam seu trabalho com o modelo autoregressivo de primeira ordem AR(1),
freqüentemente empregado em pesquisas anteriores (Montgomery e Mastrangelo, 1991;
Wardell et al, 1994; Runger e Willemain, 1996). Em todos esses trabalhos emprega-se
modelo de autocorrelação entre observações proposto por Yang e Hancock (1990).
O objetivo deste artigo é apresentar um planejamento econômico-estatístico de
gráficos de controle de para o monitoramento de processos cuja a autocorrelação dá-se
entre as médias do processo, como proposto por Reynolds Jr., Arnold e Baik (1996).
Assim para um melhor esclarecimento do modelo proposto, o presente artigo está
estruturado da seguinte forma: a próxima sessão apresenta o modelo que descreve as

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
3
observações de X. Na sessão 3 é apresentado o modelo de custo baseado no modelo de
Duncan, bem como as característicoas das cadeias de Markov mencionadas. A sessão 4
apresenta uma aplicação do modelo proposto, bem como um pequena revisão a respeito de
algoritmos genéticos (AG) e o procedimento para a solução. Na sessão 5 discute-se o efeito da
autocorrelação com uma análise de sensibilidade. E as conclusões estão na última sessão.
2. Modelo que descreve as observações de X
Ao longo deste trabalho assume-se que as observações da característica de qualidade a
serem monitoradas ajustam-se à um modelo auto-regressivo de primeira ordem AR(1) com
erro adicional, como proposto por Reynolds Jr., Arnold e Baik (1996). Este modelo possui
dois componentes aleatórios; o primeiro diz respeito ao erro associado ao comportamento
oscilatório da média do processo entre subgrupos racionais e o segundo erro está associado à
variabilidade natural entre as observações de X que pertencem ao mesmo subgrupo racional.
O modelo de observações do processo segue os conceitos do modelo clássico aplicado à
processos cujos dados são independentes, em que é a média do processo e é o erro
aleatório associado ao item i da k-ésima amostra resultante da imprecisão do instrumento de
medida e a variabilidade natural do processo. Então, para i = 1, 2,..., n e k = 1, 2,...,
Em geral, supõe-se segue uma distribuição normal em que, ~ N (0, 1). Porém, o
processo não é centrado em um valor alvo como descrito nos modelos de Shewhart para dados
independentes, e sim ajusta-se à um modelo autoregressivo de primeira ordem AR (1),
onde determina o nível de autocorrelação entre , e representa o erro aleatório adicional associado à oscilação da média. é a esperança da média
do processo: quando o mesmo está sob controle e quando fora de controle , diferindo do modelo proposto por Reynolds, Arnold e Baik (1996), pois
quando o processo está fora de controle.
Alguns pesquisadores utilizaram este modelo para avaliar a eficiência de diferentes
esquemas de controle, tais como: Reynolds, Arnold e Baik (1996), VanBrackle e Reynolds
(1997), Lu e Reynolds (1999, 1999a, 2001), Lin e Chu (2008), Zou, Wang e Tsung (2008) e
Lin (2009), Costa e Machado (2011).
De acordo com Reynolds, Arnold e Baik (1996), se , então:
A expressão (1) mostra que as observações de X possuem duas compoetes da
variabilidade:
O grau de oscilação da média devido ao erro adicional é dada pela proporção da
variabilidade de X e da média do processo:
Quando n > 1 a expressão (1) passa a ser , em que e a
variância de é dada pela expressão (6):

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
4
Com a expressão (6) e a definição do grau de oscilação da média em (5) tem-se:
Assim, os limites de controle são , onde e L é o fator de
abertura dos limites de controle. Quando não há oscilação da média do processo a expressão
(7) se reduz a . Portanto, para compensar o comportamento oscilatório da média
os limites de controle ( ) são aumentados de .
A influência dos valores de n e Ψ no fator de abertura dos limites de controle, devido
ao movimento oscilatório, mostra que um aumento de Ψ, alonga os limites de controle e este
efeito é intensificado à medida que se aumenta o tamanho da amostra (n).
Outra questão que deve ser discutida é a relação entre o intervalo de amostragem (h), a
variância do erro aleatório adicional ( ) e a autocorrelação entre , que de acordo
com as expressões (2) e (3) , à medida que se aumenta h, também aumenta, porém a
autocorrelação entre (uma função ), reduz, de forma que mantém-se
independente de h. Exemplificando: quando os intervalos de amostragem (h) se tornam
grande o suficiente, depende mais do comportamento oscilatório que de , no entanto,
a sua variância é constante e igual a para qualquer valor de h, e quando determinado
modelo torna-se independente ( ), este depende apenas do comportamento oscilatório
da média (Ex.: ).
3. Modelo de Custo
Duncan (1956) propôs um planejamento dos gráficos de controle com foco nos custos
de monitoramento no longo prazo, em que assume-se que um ciclo de produção inicia-se em
um estado sob controle, e em um dado instante aleatório, há a ocorrência de uma causa
especial de magnitude que desajusta o processo fazendo com que o mesmo entre em um
estado fora de controle. A partir deste instante, inicia-se uma busca pela causa especial e então
é realizado o reajuste do processo. Como os gráficos de controle apresentam riscos estatísticos
pode-se parar o processo sem que o mesmo tenha se desajustado ou mesmo continuar
operando em um estado fora de controle produzindo itens não conformes.
Assim, os custos associados ao modelo são:
: Custo fixo de retirada de uma amostra;
: Custo variável de retirada de amostra;
: Custo de determinação de uma causa especial;
: Custo de investigação de um alarme falso;
: Custo horário da penalidade associada à produção no estado fora de
controle.
O período sob controle tem seu mecanismo de falha baseado na distribuição de
Poisson. O tempo esperado do processo continuar em controle segue uma distribuição
exponencial com média . E quando o processo está efetivamente fora de controle o
mesmo segue uma distribuição geométrica com média , no qual a probabilidade de

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
5
detecção do desvio da média ou o poder de detecção do gráfico em qualquer amostra
subsequente é . Então, espera-se que o tempo de ocorrência de uma causa especial
seja:
No entanto, devido a presença da autocorrelação o poder de detecção do gráfico e o
risco de alarmes falsos não são constantes, e não podem ser determinados da mesma maneira
que para dados independentes. Portanto, como o poder pode ser determinado pelo inverso do
número médio de amostras retiradas até que o gráfico produza um sinal (NMA) e a
propriedade de o processo não possuir memória devido a distribuição exponencial, permite
que o cálculo do NMA seja efetuado através da utilização de Cadeias de Markov.
Como a média µ do processo oscila de acordo com um modelo AR (1), utiliza-se seu
valor a cada instante de amostragem para definir os estados transientes da cadeia de Markov.
Para se trabalhar com uma cadeia de Markov finita, discretiza-se µ em m valores
. Caso o valor de da amostra (i) pertença à região central do gráfico de
controle, então o valor da média do processo quando a amostra (i+1) é formada define o
estado transiente da cadeia de Markov. Se , o estado (l) é alcançado, onde l
∈{1,2,…., m}. O estado absorvente é alcançado quando o gráfico de controle sinaliza um
desajuste do processo, isto é, quando um valor de surgir na região de ação. A matriz de
transição é dada por ∈ , onde (a) denota os estados
anteriores da cadeia de Markov e (b) denota o estado atual. Em que representa a
probabilidade de transição de estado (a) para o estado (b):
Da propriedade elementar das cadeias de Markov (ver exemplo em Çinlar,1975),
NMA pode ser determinado como:
onde sendo o vetor de
probabilidades iniciais e o intervalo entre amostragens, respectivamente.
Pode-se notar que o número de amostras necessárias para produzir um sinal quando o
processo encontra-se em um estado fora de controle, como mencionado anteriormente, é dado
por uma variável aleatória geométrica com média , no qual pode se concluir que a
duração prevista deste estado é .
O tempo exigido para extrair uma amostra, interpretar os resultados e achar a causa
especial é , onde g é uma constante proporcional ao tamanho da amostra e D o tempo
exigido para encontrar a causa especial. Assume-se conhecidos. Desta forma, o
tempo esperado de um ciclo completo é:
Quando uma causa especial é sinalizada no dispositivo mas o processo está sob
controle, trata-se de um alarme falso, no qua sua probabilidade é dada por uma distribuição

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
6
normal quando se trata de um processo de dados independentes. Porém, em um processo
autocorrelacionado torna-se necessário identificar o número esperado de alarmes falsos
(NMAF) gerados durante o período de controle através do mesmo procedimento realizado
para a obtenção do NMA, mas a cadeia de Markov é estruturada de tal maneira que a
probabilidade de transição seja:
em que é a probabilidade de processo estar em um estado sob controle. Então
NMAF é determinado por:
Assim, o NMAF não é o número esperado de amostras extraídas antes da mudança
multiplicado pela probabilidade de alarmes falsos (erro tipo I), como proposto por Duncan
para dados independentes, e sim o número esperado de vezes em que o processo cai na região
de ação quando o mesmo está sob controle determinados por uma cadeia de Markov.
A esperança do custo horário de monitoramento é:
Para garantir a eficiência do gráfico de controle, ou seja, poucos alarmes falsos e
poder de detecção que indique um desvio da média logo que possível, o planejamento
econômico torna-se um planejamento econômico-estatístico, no qual são impostas restrições
para garantir que ocorra um alarme falso em 333 amostras e que o poder de detecção seja
aceitável.
4. Aplicação do modelo
Para investigar os efeitos da autocorrelação no planejamento econômico-estatístico de
gráficos de controle , foi tomado como exemplo a aplicação apresentada por Montgomery
(2004) em que toma-se uma produção de garrafas de vidro descartáveis para envase de
refrigerentes e a espessura da pareda das garrafas é uma característica importante da
qualidade. Assim, se a parede é muito fina, a pressão interna durante o envase fará com que a
garrafa se rompa.
Com base na análise dos salários dos técnicos em controle de qualidade e nos custos
do equipamento de testes, estima-se que o custo fixo de extração de uma amostra seja
$1. O custo variável da amostragem é estimado em $0,01 por garrafa, e a medida e o
registro da espessura da pareda de uma garrafa levam aproximadamente 1 min . As mudanças no processo ocorrem aleatoriamente com uma frequência de uma a
cada 20 horas de operação , o tempo exigido para investigação de um sinal do
dispositivo é de 1h e o custo atribuido a esta investigação, que resulte na
eliminação de uma causa especial é de $25, enquanto o custo de investigação de um
alarme falso é $50. As garrafas são fornecidas a uma empresa de refrigerantes, e quando
há um rompimento da garrafa durante o processo de envase costuma-se cobrar um custo de
limpeza e da produção perdida ao fornecedor, e este custo é cerca de $100 por hora.
Como o processo está sujeito a vários tipos diferentes de causas especiais, adota-se a
magnitude do desvio da média em 1,5 desvios pradrão e para se obter os valores ótimos dos

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
7
parâmetros do gráfico de controle é aplicado o Algoritmo Genético (AG) devido a sua
comprovada eficiência na busca de valores ótimos de funções não lineares. Para melhor
entendimento, na sessão seguinte é dissertado a respeito do AG bem como suas vantagens.
4.1 Algoritmo Genético
O AG foi desenvolvido originalmente por John H. Holland em 1975, apresentado em
seu livro "Adaptation in Natural and Artificial Systems" e popularizado por David Goldberg
em 1989 com a primeira aplicação de sucesso na indústria. Os AG`s compõem uma gama de
técnicas chamadas de computação evolucionária, em que pesquisadores de diferentes partes
dos Estados Unidos e Europa convergiram a idéia de utilizar mecanismos biológicos de
evolução das espécies na resolução de problemas em vários campos da ciência, em particular
o de otimização, resultando em diferentes abordagens como: estratégias evolucionárias
(RECHENBERG, 1973), programação evolucionária (Fogel et al, 1966) e algoritmos
genéticos (DE JONG, 1975; GOLDBERG, 1989, DAVIS, 1991; MICHALEWICZ, 1992).
Concebido como uma ferramenta para estudo do comportamento adaptativo, os AG`s
são procedimentos de busca baseados num processo de aprendizagem de uma população
(BACK e SCHWEFEL, 1993) e através de sua adaptação, aplica-se os mecanismos da seleção
natural da teoria Darwiniana e da genética, ou seja, são algoritmos de busca baseados nos
mecanismos de seleção natural e genética, combinando a sobrevivência entre os melhores
indivíduos com a troca de informação genética formando uma estrutura heurística de busca
(MITCHELL, 1996). O AG ficou largamente conhecido como método para otimização de
funções e é atualmente o Algoritmo Evolutivo mais conhecido e utilizado. Segundo Chou,
Cheng e Lai (2008) e Goldbarg et al (2004) o AG difere dos métodos tradicionais e possui
algumas vantagens na solução de problemas complexos tais como:
Possibilidade de obter o ótimo global permitindo a passagem por soluções de ótimo
local através dos seus operadores genéticos;
Opera sobre uma população de pontos (espaço de soluções codificadas) e não sobre
um ponto isolado (um espaço de busca diretamente);
Necessita somente de informação sobre o valor de uma função de aptidão para cada
membro da população sem qualquer outro tipo de conhecimento;
Usa transições probabilísticas e não regras determinísticas;
Permite a busca de varias soluções possíveis no mesmo tempo.
No planejamento econômico de gráficos de controle, vem crescendo as aplicações de
AG’s na busca de um melhor planejamento, como pode-se observar em: Celano e Ficheira
(1999); Vommia e Seetalab (2005a, 2005b); Choua, Chenb e Chenc (2005); Choua, Chen e
Liu (2006); Chou, Cheng e Lai (2008); Chau-Chen, Pei-His e Nai-Yi (2009); Chen e Yeh
(2009); Kaya (2009a, 2009b).
Na busca por soluções ótimas o AG utiliza uma combinação de estratégias de
reprodução e mecanismos de recombinação em que são selecionados indivíduos (soluções)
com valores da função de aptidão elevados na busca de aumentar a probabilidade de
convergência em direção a uma região ótima ou quase ótima. Uma vez selecionados os
indivíduos mais aptos, os mecanismos de recombinação, cruzamento e mutação, são
aplicados, propagando assim o que é aprendido a partir de gerações anteriores, permitindo
usar algumas soluções selecionadas aleatoriamente para trocas genéticas gerando novas
soluções possíveis. Para a solução do problema deste estudo foi utilizado o seguinte
procedimento:

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
8
1. População inicial: são as soluções iniciais para n, k, h aleatórias em um espaço de
busca sobre condições de restrição;
2. Avaliação: cada solução gerada (indivíduo) é avaliada através da função de aptidão, no
caso deste estudo, determinado pelo custo horário de monitoramento no longo prazo;
3. Seleção: a seleção dos pais para a formação da nova população é realizado por meio
de torneio em que são selecionados três indivíduos aleatoriamente e escolhido o
melhor dentre eles com relação a sua função de aptidão;
4. Cruzamento: é realizado o cruzamento para números reais em que o intervalo fechado
é composto pelo maior e menor valor dentre um par de pais escolhidos até que a
quantidade de filhos da nova geração seja igual ao tamanho da população;
5. Mutação: a mutação é realizada utilizando o intervalo de busca para geração da
população inicial;
6. Número de gerações: os passos 2 a 6 são repetidos conforme o número de gerações.
4.2 Procedimento para solução
Esta sessão apresenta o emprego do planejamento de experimentos de Taguchi (1987),
com a utilização do arranjo ortogonal L9 para determinação do melhor nível a ser usado nos
parâmetros do AG: tamanho da população (TP), número de geração (NG), probabilidade de
mutação (PM) e probabilidade de cruzamento (PC). Para isso foram determinados três níveis
para cada parâmetro como pode-se observar na Tabela 1.
Parâmetros do AG Nível 1 Nível 2 Nível 3
Tamanho da População (TP) 10 50 100
Número de Gerações (NG) 10 20 100
Probabilidade de Mutação (PM) 0,05 0,1 0,5
Probabilidade de Cruzamento (PC) 0,55 0,75 0,95
Table 1: Planejamento de níveis dos parâmetros do AG
Devido ao emprego de Cadeias de Markov para determinação do NMA e NMAF,
observou-se um tempo elevado de processamento. Foi proposto então uma amplitude maior
aos níveis de tal forma que se obtivesse uma combinação de valores para os parâmetros com
um bom tempo de processamento e bons resultados. Foram fixados os valores de em
para a execução dos experimentos de acordo com a Tabela 2.
O resultado do experimento da matriz L9 é apresentado na Tabela 3, com um total de
nove combinações dos quatros parâmetros do AG obtendo os valores de custo horário.
Através dos valores das réplicas é calculado o sinal-ruído (SN) para cada experimento através
da expressão (15) em que é o valor do custo na tentativa e é o numero de tentativas
do experimento i é :
Experimento TP NG PM PC Custo SN
1 1 1 1 1 11,50067 -16,4432503
2 1 2 2 2 11,40642 -16,3717746
3 1 3 3 3 11,51502 -16,4540814
4 2 1 2 3 11,44806 -16,4034254
5 2 2 3 1 11,43695 -16,3949919

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
9
6 2 3 1 2 11,38315 -16,3540366
7 3 1 3 2 11,48876 -16,4342506
8 3 2 1 3 11,82751 -16,6866539
9 3 3 2 1 11,95446 -16,7793867
Tabela 2: Planejamento de Experimento da Matriz Ortogonal L9
Depois de calculado a relação Sinal-Ruído para os nove experimentos, é calculado o
valor médio de SN para cada parâmetro (fator) e nível, como apresentado na Tabela 3.
Determina-se a melhor combinação apresentada pela técnica com base no menor valor médio
SN para cada nível de cada parâmetro. Observa-se que a melhor combinação apresentada pela
matriz ortogonal L9 é:
Nível TP NG PM PC
1 -16,4230 -16,4270 -16,4946 -16,5392
2 -16,3842 -16,4845 -16,5182 -16,3867
3 -16,6334 -16,5292 -16,4278 -16,5147
Tabela 3: SN médio dos parâmetros do AG
O AG foi desenvolvido em MICROSOFT FORTRAN POWER STATION 4.0, devido
a sua característica de compilar o código desenvolvido obtendo maior agilidade na sua
execução.
5. Análise de Sensibilidade
A análise de sensibilidade é realizada para os parâmetros n, h, L, NMA, NMAF e
Custo de monitoramento em relação ao planejamento econômico para dados independentes,
ou seja, . Assim, para o tamanho da amostra (n), observa-se na Figura 1 que
com o aumento da autocorrelação da média há uma redução significativa do tamanho da
amostra e ainda pode-se observar que para dados independentes em que , o
tamanho da amostra está em torno de 11 e com o aumento do grau de autocorrelação chega a
um tamanho de 1 amostra apenas. Outro fato interessante é que com o aumento da
autocorrelação, na tentativa de tornar o gráfico eficiente, busca extrair amostras cada vez
menores em um espaço de tempo mais curto, como pode ser observado na Figura 2. Já que o
modelo contempla a suposição de que quanto maior o espaçamento entre amostras menor será
a autocorrelação, os dados mostram que esta estratégia não influência no planejamento.
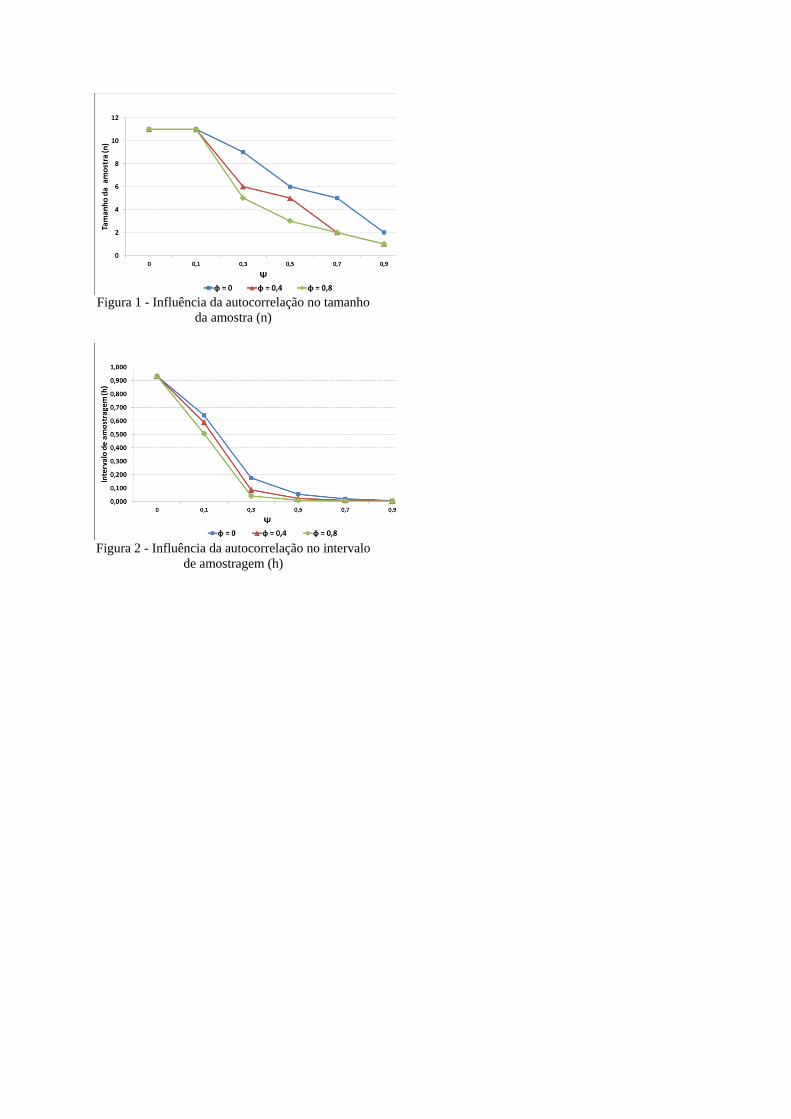
Figura 1 - Influência da autocorrelação no tamanho
da amostra (n)
Figura 2 - Influência da autocorrelação no intervalo
de amostragem (h)

O mesmo ocorre com os limites de controle que são alargados na busca da redução de
alarmes falsos (Figura 3). Porém mesmo com a tentativa de alargar os limites de controle
nota-se que há um aumento no NMAF (Figura 4).
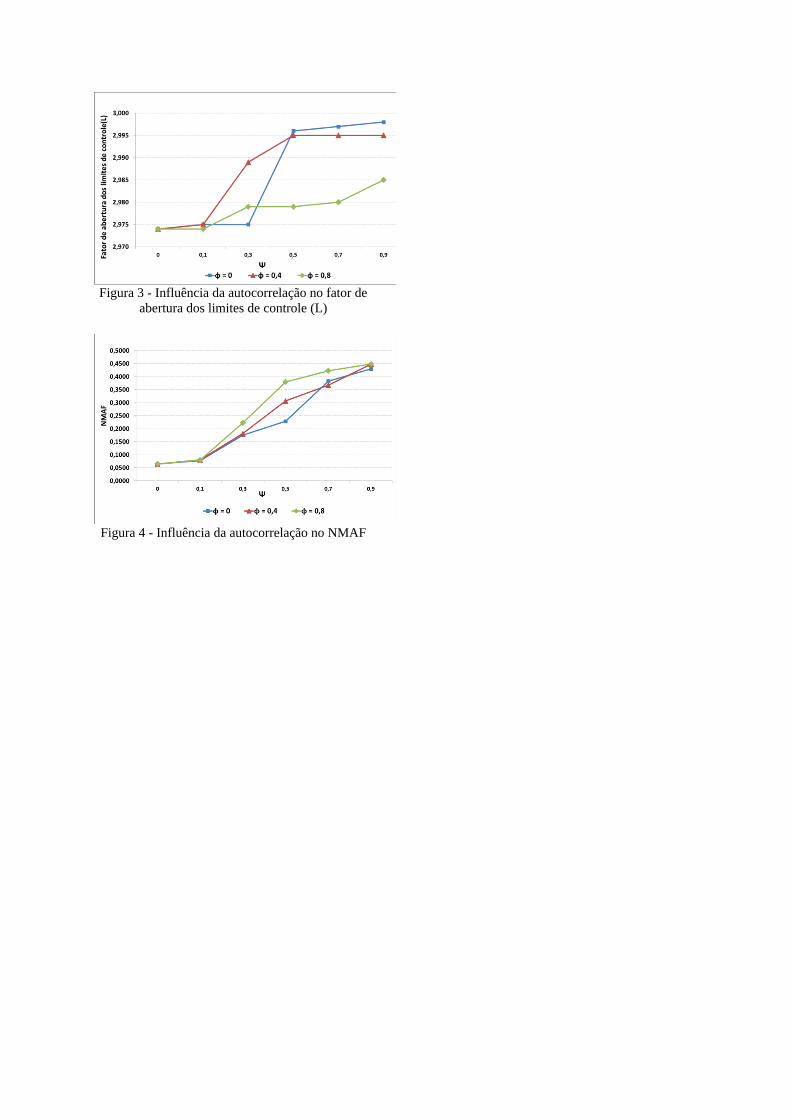
Figura 3 - Influência da autocorrelação no fator de
abertura dos limites de controle (L)
Figura 4 - Influência da autocorrelação no NMAF

O mesmo fenômeno é observado na Figura 5, em que se ilustra a influência da
autocorrelação no NMA. Este efeito pode ser melhor evidênciado no poder de detecção do
gráfico, o qual mostra que graus de oscilação da média de moderado para alto tornam o
gráfico de controle de pouco eficiente para o monitoramento de processos
autocorrelacionados (Figura 6).
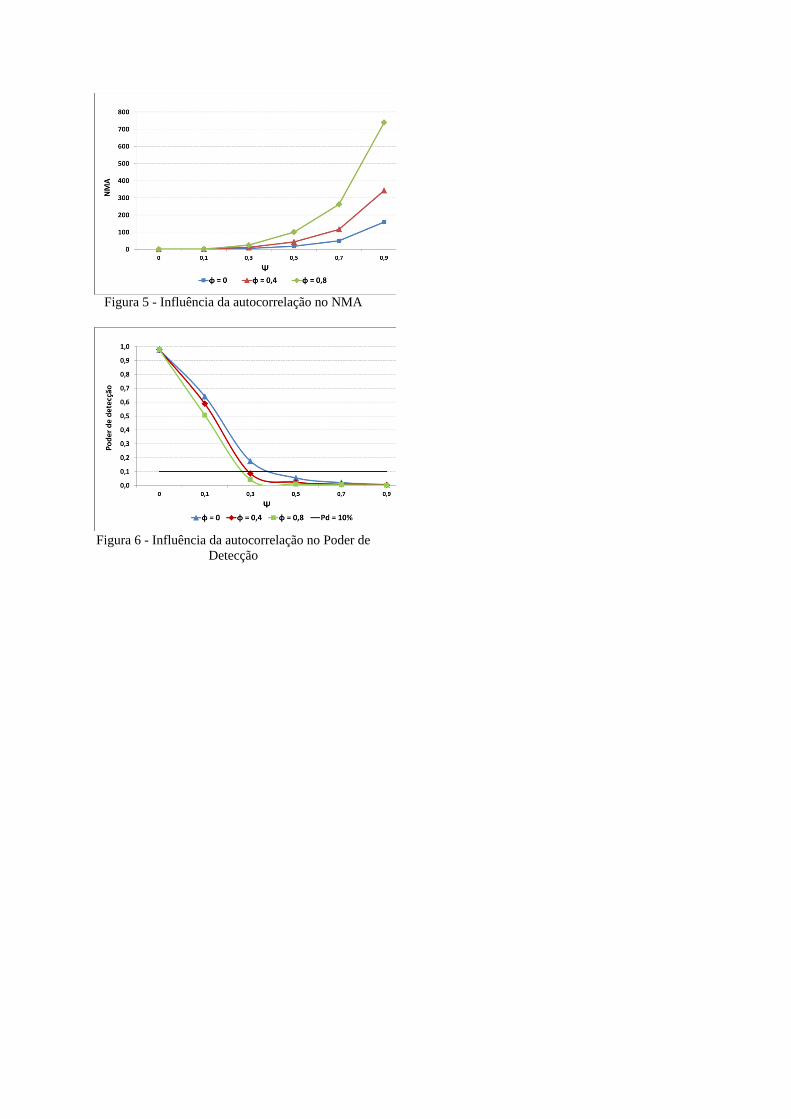
Figura 5 - Influência da autocorrelação no NMA
Figura 6 - Influência da autocorrelação no Poder de
Detecção
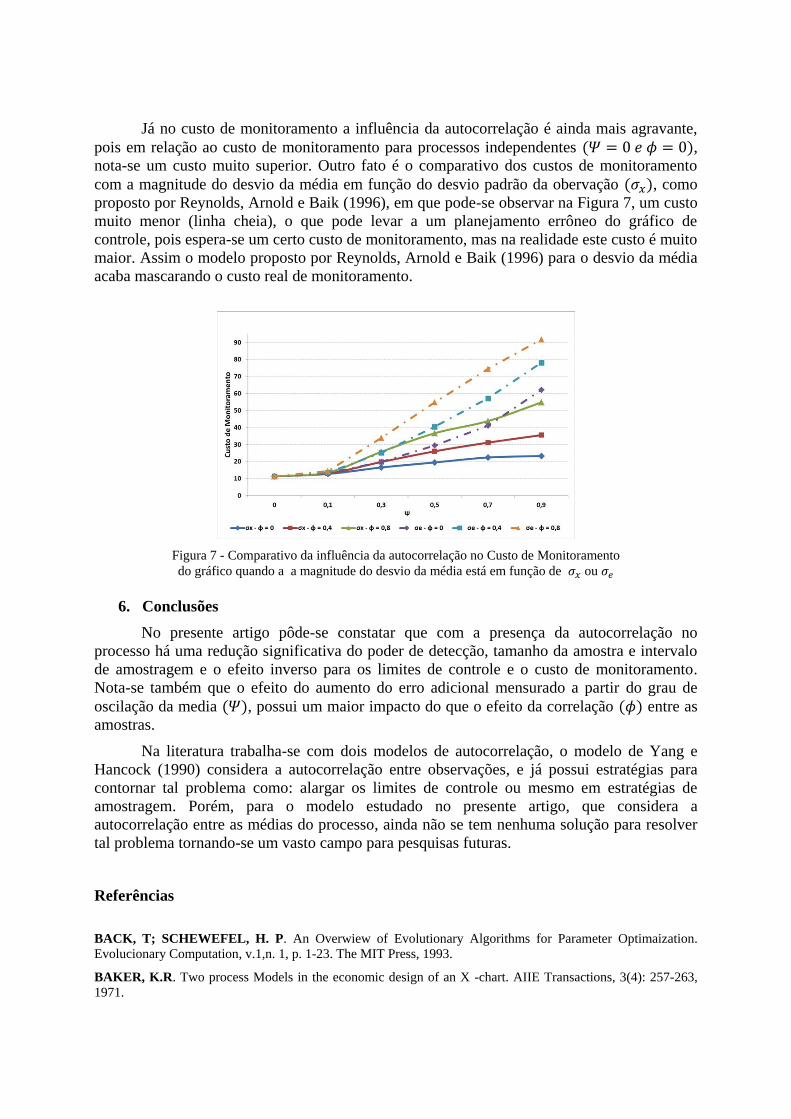
Já no custo de monitoramento a influência da autocorrelação é ainda mais agravante,
pois em relação ao custo de monitoramento para processos independentes , nota-se um custo muito superior. Outro fato é o comparativo dos custos de monitoramento
com a magnitude do desvio da média em função do desvio padrão da obervação , como
proposto por Reynolds, Arnold e Baik (1996), em que pode-se observar na Figura 7, um custo
muito menor (linha cheia), o que pode levar a um planejamento errôneo do gráfico de
controle, pois espera-se um certo custo de monitoramento, mas na realidade este custo é muito
maior. Assim o modelo proposto por Reynolds, Arnold e Baik (1996) para o desvio da média
acaba mascarando o custo real de monitoramento.
Figura 7 - Comparativo da influência da autocorrelação no Custo de Monitoramento
do gráfico quando a a magnitude do desvio da média está em função de ou
6. Conclusões
No presente artigo pôde-se constatar que com a presença da autocorrelação no
processo há uma redução significativa do poder de detecção, tamanho da amostra e intervalo
de amostragem e o efeito inverso para os limites de controle e o custo de monitoramento.
Nota-se também que o efeito do aumento do erro adicional mensurado a partir do grau de
oscilação da media , possui um maior impacto do que o efeito da correlação entre as
amostras.
Na literatura trabalha-se com dois modelos de autocorrelação, o modelo de Yang e
Hancock (1990) considera a autocorrelação entre observações, e já possui estratégias para
contornar tal problema como: alargar os limites de controle ou mesmo em estratégias de
amostragem. Porém, para o modelo estudado no presente artigo, que considera a
autocorrelação entre as médias do processo, ainda não se tem nenhuma solução para resolver
tal problema tornando-se um vasto campo para pesquisas futuras.
Referências
BACK, T; SCHEWEFEL, H. P. An Overwiew of Evolutionary Algorithms for Parameter Optimaization.
Evolucionary Computation, v.1,n. 1, p. 1-23. The MIT Press, 1993.
BAKER, K.R. Two process Models in the economic design of an X -chart. AIIE Transactions, 3(4): 257-263,
1971.

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
16
BANERJEE, P. K.; RAHIM, M. A. Economic design of X control charts under Weibull shock models.
Technometrics, 30(4), 407–414, 1988
CELANO, G; FICHEIRA, S. Multiobjective economic design of an X control chart. Computers & Industrial
Engineering, 129-132, 1999.
CHAU-CHEN, T.; PEI-HIS, L.; NAI-YI, L. An economic-statistical design of double Xbar sampling control
chart. International Journal of Production Economics, 2009
CHEN, Y. K. An evolutionary economic-statistical design for VSI X control charts under non-normality. The
International Journal of Advanced Manufacturing Technology, v.22, p.602–610, 2003.
CHEN, Y.K.;CHIOU, K.C.. s s s . Quality
and Reliability Engineering International 21, 757–768, 2005.
CHEN, Y-K; HSIE, K-L; CHANG C-C. Econom s s .
International journal Production Economics, 107: 528–539, 2007.
CHEN, F.L. ;YEH, C.H. Economic statistical design of non-uniform sampling scheme X bar control charts
under non-normality and Gamma shock using genetic algorithm. Expert Systems with Applications 36: 9488–
9497, 2009.
CHOU, C. Y.; CHEN, C. H.; LIU, H. R.. Economic-statistical design of X chart for non-normal data by
considering quality loss. Journal of Applied Statistics, 27(8), 939–951, 2000.
CHOU, C. ; CHENG, J; LAI, W. Economic design of variable sampling intervals EWMA charts with
sampling at fixed times using genetic algorithms . Expert Systems with Applications 34 : 419–426, 2008.
CHOU, C. Y. ; LIU, H. R.; CHEN, C. H.. Economic Design of Averages Control Charts for Monitoring a
Process with Correlated Samples. International Journal Advanced Manufacturing Technolgy, 18:49–53, 2001.
CHOUA, C; CHEN, C. ; LIU, H. Economic Design of EWMA Charts with Variable Sampling Intervals,
Quality & Quantity 40: 879–896, 2006
CHOUA, C.; CHENB, C.; CHENC, C. Economic design of variable sampling intervals T2 control charts using
genetic algorithms. Expert Systems with Applications 30, 233–242, 2005.
ÇINLAR, E.,Introductionto Stochastic Processes. Prentice-Hall,Englewood Cliffs, 1975
CLARO, F. A.; COSTA, A. F. B.; MACHADO, M. A. G. Sampling X bar control chart for a first order
autoregressive process. Pesquisa Operacional, v.28, p.545-562, 2008.
COSTA, A.F.B.; CASTAGLIOLA, F. C. Effect of measurement error and autocorrelation on the X chart.
Journal of Applied Statistics, v.38, n.4, p.661-673, 2011.
COSTA, A. F. B.; CLARO, F. A. E. Double sampling control chart for a first-order autoregressive and
moving average process model. The International Journal of Advanced Manufacturing Technology, v. 39, p.
521-542, 2008.
COSTA, A. F. B.; CLARO, F. A. E. Economic design of Xbar control charts for monitoring a first order
autoregressive process. Brazilian Journal of Operations and Production Management, v.6, p.07-26, 2009.
COSTA, A. F. B.; MACHADO, M. A G. s s s
correlation: The Markov chain approach. Internationl. Journal of Production Economics. (In press), 2011.
DAVIS, L. Handbook of Genetic Algorithms. Van Nostrand Reinhold, New York, 1991.
DE JONG, K. Analysis of Behavior of a Class of Genetic Adaptive Systems. PhD thesis, The University of
Michigan, 1975.
DUNCAN, A.J. The economic design of X-charts used to maintain current control of a process. J. Am. Stat.
Assoc., LI: 228-242, 1956.
GOLDBARG, M. C.; GOLDBARG, E. F. G.; MEDEIROS NETO, F. D. An Evolutionary Approach for the
P s P M U P . P MC ’04 F C C
Sciences. v.1, p.281-290, 2004.
GOLDBERG, D. Genetic algorithms in search, optimization, and machine learning. Addison-Wesley Reading,
MA, 1989.

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
17
HOLLAND, J. H. Adaptation in Natural and Artificial Systems. University of Michigan Press, Ann Arbor,
1975.
KAYA, I. A genetic algorithm approach to determine the sample size for attribute control charts. Information
Sciences 179, 1552–1566, 2009a
KAYA, I. A genetic algorithm approach to determine the sample size for control charts with variables and
attributes. Expert Systems with Applications 36: 8719–8734, 2009b.
LIN, Y. C. The variable parameters control charts for monitoring autocorrelated processes. Communications in
Statistics - Simulation and Computation, v.38, p.729-749, 2009.
LIN, Y. C.; CHOU, C. Y. The variable sampling rate control charts for monitoring autocorrelated processes.
Quality and Reliability Engineering International, v.24, p.855-870, 2008.
LIU, H-R; CHOU, C-Y; CHEN, C-H. Minimum-loss design of x-bar charts for correlated data. Journal of Loss
Prevention in the Process Industries 15, 405–411, 2002.
LU, C. W.; REYNOLDS JR., M. R.. EWMA control charts for monitoring the mean of autocorrelated
processes. Journal of Quality Technology, v.31, n.2, p.166-188, 1999a.
LU, C. W.; REYNOLDS JR., M. R.. EWMA control charts for monitoring the mean and variance of
autocorrelated processes. Journal of Quality Technology, v.31, n.3, p.259-274, 1999b.
LU, C. W.; REYNOLDS JR., M. R.. CUSUM Charts for Monitoring na Autocorrelated Process. Journal of
Quality Technology, v.33, n.3, p.316-334, 2001.
MICHALEWICZ, Z. Genetic Algorithms + Data Structures = Evolution Programs. Springer-Verlag, New
York, 1992.
MITCHELL, M. An Introduction a Genetic Algorithm. MIT Press, Massachusets, London, England, 1996.
MONTGOMERY, D. C. Introduction to Statistical Quality Control, 5o edição, Wiley Sons, 2004.
MONTGOMERY, D. C.; MASTRAGELO, C. M. Some Statistical Process Control Methods for
Autocorrelated Data. Journal of Quality Technology, v.23, n.3, p.179-193, 1991.
RAHIM, M. A.; BANERJEE, P. K.. A generalized economic model for the economic design of X control
charts for production systems with increasing failure rate and early replacement. Naval Research Logistics,
40(6), 787–809, 1993.
RECHENBERG, I. Evolutiosstrategie: Optimierung technischer Systeme nach Prinzipien der biologischen
Evolution. Frommann–Holzboog, Stuttgart, 1973.
REYNOLDS JR, M. R.; ARNOLD, J. C.; BAIK, J. W. C s P s
of Correlation. Journal of Quality Technology, Vol. 28, No. 1, January, 1996.
RUNGER, C. G.; WILLEMAIN, T. R. Batch means control charts for autocorrelated data. IIE Transactions,
v.28, p.483-487, 1996.
SANIGA, E. M.. Economic statistical control chart designs with an application to X and R charts.
Technometrics, 31(3), 313–320, 1989.
SANIGA, E. M.; DAVIS, D. J.; McWILLIAMS, T. P. Economic, Statistical and Economic- Statistical Design
of Attribute Charts. Journal of Quality Technology, v. 27, p. 56-73, 1995.
TAGUCHI, G. System of Experimental design: Engeneering methods to optimize quality and minimize costs.
New York, NY, USA: UNIPUB. 1987
TORNG, J C-C; LEE, P-H; LIAO, H-S.; LIAO, N-Y. An economic design of double sampling X charts for
correlated data using genetic algorithms. Expert Systems with Applications 36, 12621–12626, 2009.
VANBRACKLE, L. N.; REYNOLDS, M. R. Jr. EWMA and CUSUM Control Charts in the Presence of
Correlation. Communications in Statistics-Simulation and Computation, v.26, n.4, p.979-1008, 1997.
WARDELL, D. G.; MOSKOWITZ, H.; PLANTE, R. D. Control charts in the presence of data
autocorrelation. Management Science, v.38, n.8, p.1084-1105, 1992.
WARDELL, D. G.; MOSKOWITZ, H.; PLANTE, R. D. Run-length distributions of special-cause control
charts for correlated process. Technometrics, v.36, n.1, p.3-27, 1994.

XXXI ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO Inovação Tecnológica e Propriedade Intelectual: Desafios da Engenharia de Produção na Consolidação do Brasil no
Cenário Econômico Mundial Belo Horizonte, MG, Brasil, 04 a 07 de outubro de 2011.
18
WOODALL, W. H.. The statistic design of quality control charts. Technometrics, 28, 408–409, 1985.
VOMMIA, V. B.; SEETALAB, M. S. N.. A simple approach for robust economic design of control charts.
Computers & Operations Research 34, 2005a.
VOMMIA, V. B.; SEETALAB, M. S. N.. A new approach to robust economic design of control charts.
Applied Soft Computing, 211- 228, 2005b.
YANG, K.; HANCOCK, W. M.. Statistical quality control for correlated samples. International Journal of
Production Research, 28, 595–608, 1990.
YOURSTONE, S. A.; ZIMMER, W. J.. Non-normality and the design of control charts for averages. Decision
Science, 23, 1099–1113, 1992.
ZIMMER, W. J.; BURR, I. W.. Variables sampling plans based on non-normal populations. Industrial Quality
Control(July), 18–36, 1963.
ZOU, C.; WANG, Z.; TSUNG, F. Monitoring autocorrelated process using variable sampling schemes at
fixed-times. Quality and Reliability Engineering International, v.24, p.55-69, 2008.





























