Embed Size (px)
Citation preview

Poznaj Firebird w dwie minuty(fragmenty artykułu Carlosa H. Cantu)
Firebird wywodzi się z kodu źródłowego Borland InterBase 6.0. Jest to produkt typu open source – nie ma podwójnej licencji. Jeżeli użyjesz go we własnych aplikacjach, zarówno komercyjnych, jak i open source, Firebird zawsze jest całkowicie DARMOWY!
Technologia Firebird jest nieustannie rozwijana przez ostatnie 20 lat. Dzięki temu jest to produkt dojrzały oraz stabilny.
Pomimo małych rozmiarów zarówno programu instalującego jak i samego serwera, Firebird jest w pełni funkcjonalnym serwerem baz danych. Może zarządzać bazami danych o wielkości od kilku kilobajtów do wielu gigabajtów, charakteryzując się dobrą wydajnością oraz niemal zupełnie nie wymaga administrowania.

Lista najważniejszych cech Firebird:
✔ Pełna obsługa procedur wbudowanych oraz wyzwalaczy; ✔ Pełna obsługa transakcji ACID; ✔ Integralność danych (ang. Referential Integrity); ✔ Obsługa wielu wersji tego samego rekordu (ang. Multi Generational
Architecture); ✔ Nie wymaga specjalnego środowiska do działania; ✔ W pełni rozwinięty wewnętrzny język dla procedur wbudowanych oraz
wyzwalaczy (PSQL); ✔ Możliwość korzystania z zewnętrznych bibliotek funkcji (UDF); ✔ Praktycznie nie wymaga obsługi przez wyspecjalizowanych
administratorów; ✔ Niemal w ogóle nie wymaga konfigurowania – wystarczy go zainstalować
i używać!

✔ Duża społeczność użytkowników oraz wiele miejsc, gdzie można otrzymać darmową, skuteczną pomoc;
✔ Opcjonalna kilkuplikowa wersja embedded – świetnie nadaje się między innymi do tworzenia katalogów na płytach CD oraz jednostanowiskowych lub demonstracyjnych wersji aplikacji;
✔ Wiele narzędzi, między innymi graficzne narzędzia do administrowania, narzędzia do replikacji i inne;
✔ Pieczołowite zapisywanie do bazy danych – umożliwia szybkie przywrócenie możliwości pracy z bazą danych, bez potrzeby zapisywania transakcji w plikach LOG!
✔ Wiele możliwości połączenia aplikacji z bazami danych: natywne poprzez API, sterowniki dbExpress, ODBC, OLEDB, .Net, natywny sterownik JDBC typu 4, moduły Python, PHP, Perl, Ruby i inne;
✔ Wersje dla wszystkich najważniejszych systemów operacyjnych, włączając Windows, Linux, Solaris, MacOS, HP_UX i FreeBSD;
✔ Przyrostowe kopie bezpieczeństwa (ang. Incremental Backups);

✔ Dostępne wersje 64-bitowe; ✔ Pełna implementacja kursorów w PSQL; ✔ Tabele monitorujące; ✔ Wyzwalacze dla połączeń oraz transakcji; ✔ Tabele tymczasowe; ✔ TraceAPI – monitorowanie działania serwera.
Graficzne programy do administrowania
FlameRobin (Open Source, działa w Windows, Linux, MacOSX i FreeBSD) IBExpert (dostępna jest DARMOWA wersja personal) DB Workbench EMS SQL Management Studio Firebird Development Studio

Wersja embedded to zadziwiająca odmiana serwera. Jest to w pełni funkcjonalna wersja, dostępna w postaci kilku plików. Jest bardzo łatwa do ins ta lo wania razem z aplikacją, ponieważ tej wersji Firebird nie trzeba instalować.
Zob:http://firebird-pl.blogspot.com/http://www.firebirdnews.org/http://www.firebird.org/

Tabele pomocniczeTabele pomocnicze nie są częścią modelu danych, więc nie powinny pojawiać się na etapie projektowania koncepcyjnego.
Wyróżnimy dwa rodzaje takich tabel: tabele słownikowe i tabele funkcyjne. Rozważmy dwa przypadki tabel słownikowych: listę nazw województw oraz listę nazw państw świata. Obie listy powinny być używane zawsze wtedy, gdy użytkownik bazy danych będzie mógł wprowadzać te nazwy jako dane. Wprowadzanie to powinno być zawsze (w tego rodzaju przypadkach) ograniczone do wyboru elementu z listy!...
Sprawa nie jest jednak prosta (por. alfabetyczny wykaz krajów…).

Tabela funkcyjna jest sposobem zdefiniowania funkcji. Tabela ta jest wykorzystywana do wykonywania zapytań.
Często tworzoną tabelą funkcyjną jest kalendarz. Jest tak m. in. dlatego, że daty świąt są bardzo nieregularne (np. wyznaczanie świąt ruchomych, takich jak Wielkanoc czy Ramadan, przy użyciu funkcji byłoby bardzo trudne). Wielkość kalendarza na 20 lat to tylko około 7000 wierszy, czyli bardzo mała tabela. Tabelę taką zapełniamy danymi przygotowanymi w arkuszu kalkulacyjnych bądź pobranymi z Internetu i zabraniamy modyfikacji tych danych użytkownikom bazy (z wyłączeniem administratora danych, bo przecież mogą następować zmiany ustawowe regulujące liczbę i terminy świąt, terminy wakacji szkolnych itp.).
Por. kalendarz świąt …

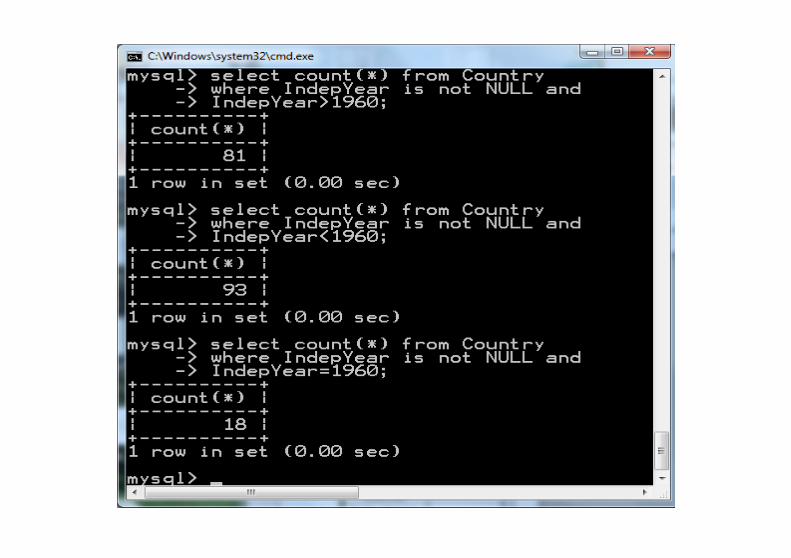
Statystyki w języku SQLW różnych produktach SQL spotkamy rozmaite funkcje wbudo-wane ułatwiające analizy statystyczne. Jeżeli nie zależy nam na przenośności kodu, to lepiej użyć funkcji wbudowanych.

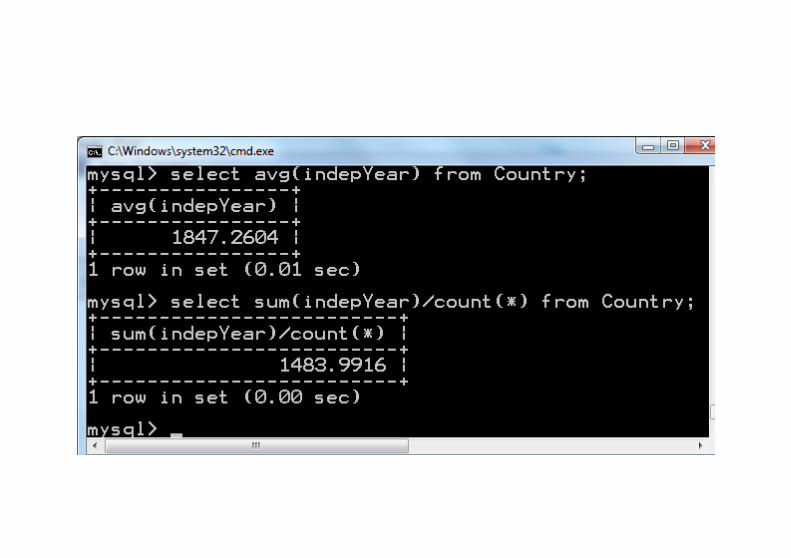
Zacznijmy od najprostszych statystyk (dla bazy World):
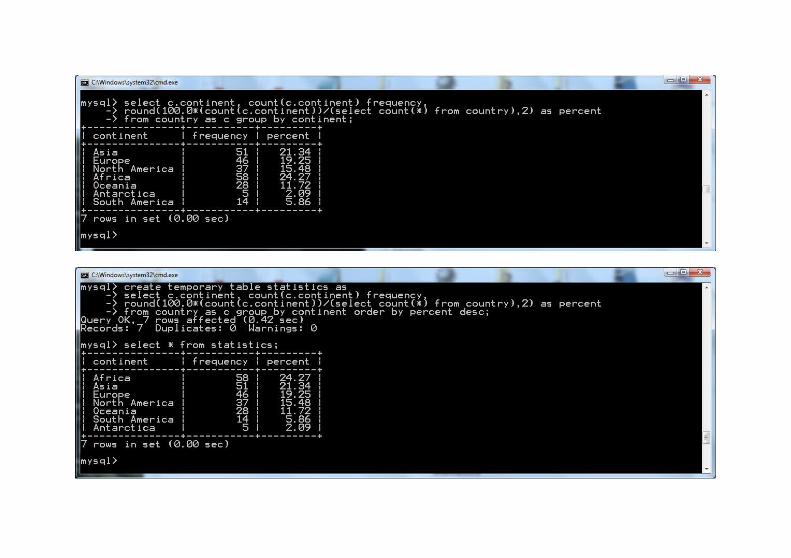
select c.continent, count(c.continent) as frequency, round(100.0*(count(c.continent))/ (select count(*) from country),2) as percentfrom country as c group by continent;
create temporary table statistics as select c.continent, count(c.continent) frequency, round(100.0*(count(c.continent))/ (select count(*) from country),2) as percent from country as c group by continent order by percent desc;
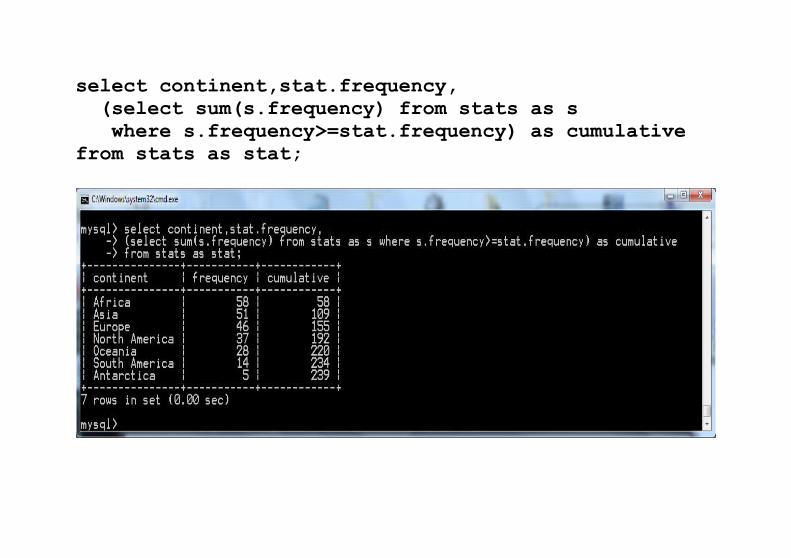
select continent,stat.frequency, (select sum(s.frequency) from stats as s where s.frequency>=stat.frequency) as cumulativefrom stats as stat;
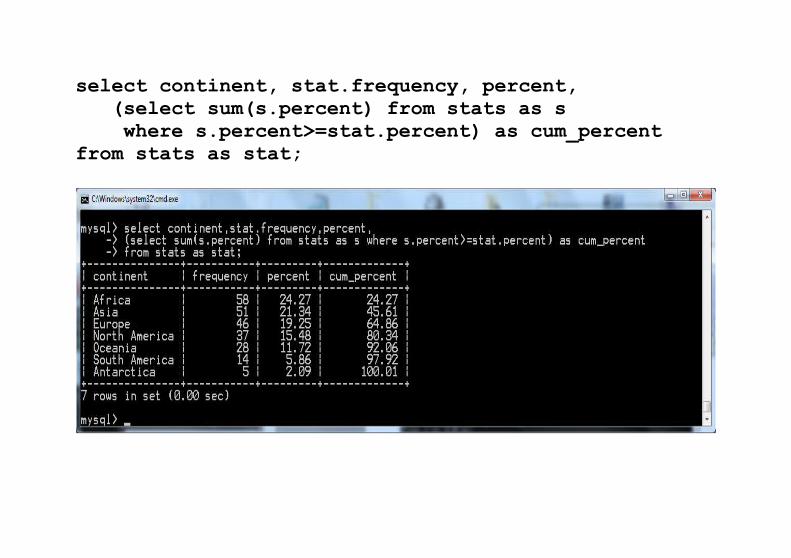
select continent, stat.frequency, percent, (select sum(s.percent) from stats as s where s.percent>=stat.percent) as cum_percentfrom stats as stat;

Wartość modalnaWartość modalna to wartość najczęściej pojawiająca się w zbiorze (jeśli są takie dwie wartości, to mówimy że rozkład jest dwumodalny, podobnie trzymodalny etc.).Wykonajmy to zapytanie w kilku krokach:
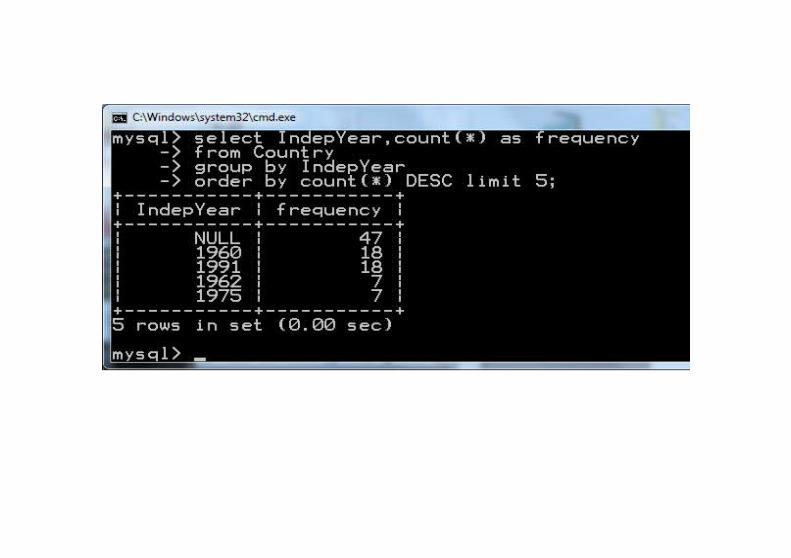
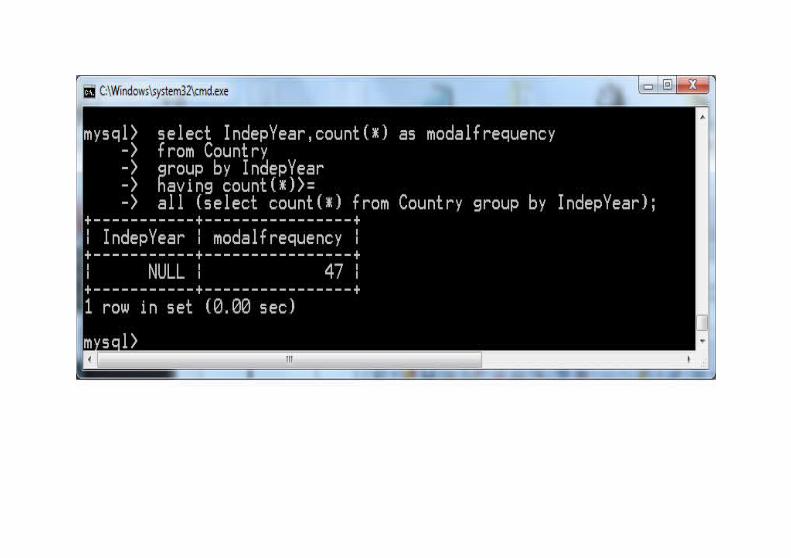
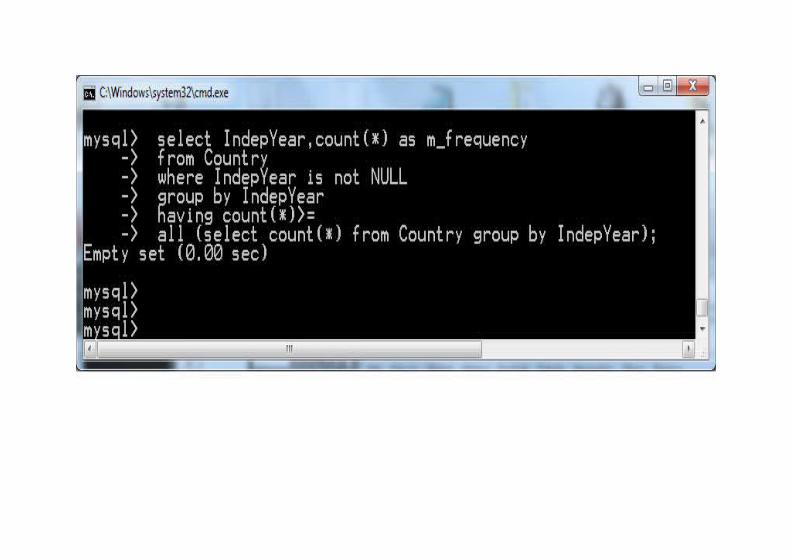
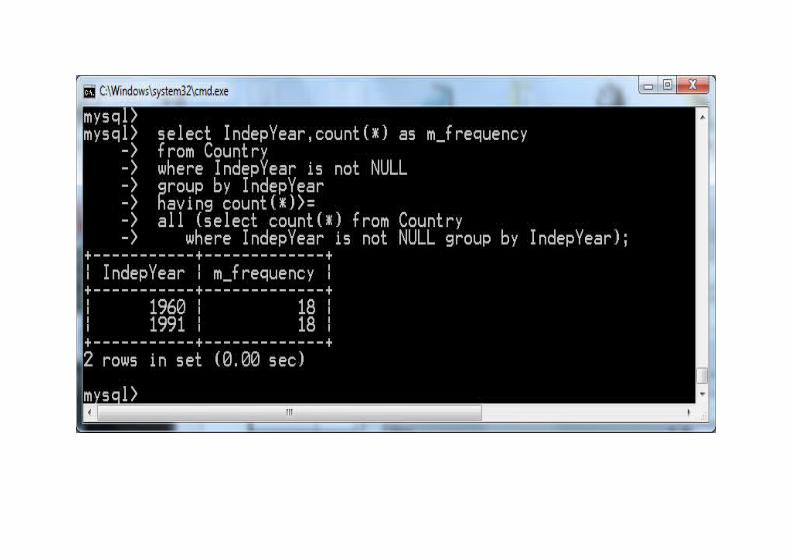

Wartość modalna jest słabą statystyką. Na przykład
1. gdy liczymy modalne pobory wśród pracowników, to dokładna wartość tej zmiennej nie jest dobra – lepiej dopuścić kilkuprocentowe odchylenie:
having count(*)>=all (select count(*)*0.95 from …
2. gdy dwie częstości są blisko siebie to dobrym rozwiązaniem jest dopuszczenie odchylenia k wartości
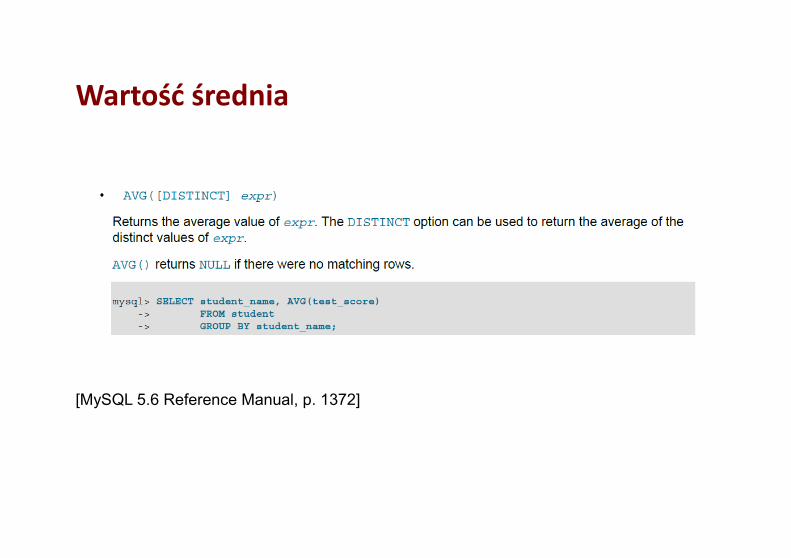
Wartość średnia
[MySQL 5.6 Reference Manual, p. 1372]

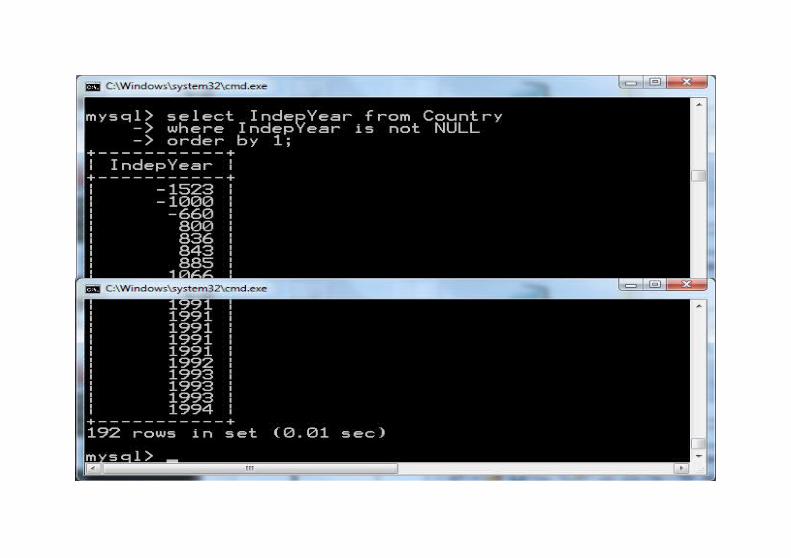
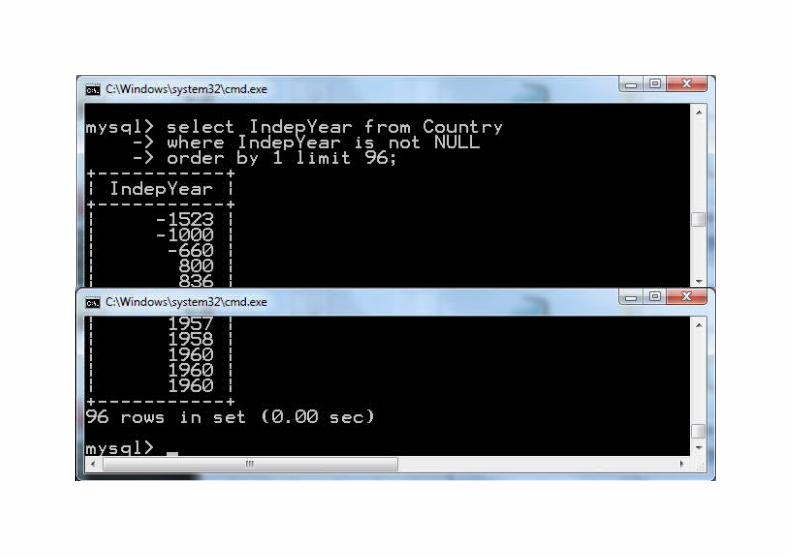
MedianaJest to wartość, dla której jest dokładnie tyle samo elementów o wartościach od niej niższych, co elementów o wartościach od niej wyższych. Jeśli taka wartość istnieje w zbiorze danych to nazywamy ją medianą statystyczną, jeżeli nie, to oblicza się medianę finansową. Zbiór danych dzieli się wtedy na dwa równoliczne, tak by elementy pierwszego były mniejsze od elementów drugiego, następnie oblicza się średnią między maksimum pierwszego i minimum drugiego.
Inne nazwy: wartość środkowa, wartość przeciętna.
Z medianą statystyczną jest problem, gdy wartości środkowych jest kilka (wskazany wyżej podział jest wówczas niemożliwy).

KwartyleKwartyle dzielą wszystkie obserwacje na cztery równe co do ilości grupy .Kwartyl pierwszy (Q1) dzieli obserwacje w stosunku 25% do 75%, co oznacza, że 25% obserwacji jest niższa bądź równa wartości Q1, a 75% obserwacji jest równa bądź większa niż Q1.
Kwartyl drugi (Q2), inaczej zwany medianą(!), dzieli obserwacje na dwie części w stosunku 50% do 50%.
Kwartyl trzeci (Q3) dzieli obserwacje w stosunku 75% do 25%, co oznacza, że 75% obserwacji jest niższa bądź równa wartości Q3, a 25% obserwacji jest równa bądź większa niż Q3.
Odchylenie ćwiartkowe (Q), to połowa różnicy między trzecim a pierwszym kwartylem.

KwantyleKwantylem rzędu p z przedziału (0,1) jest taka wartość xp zmiennej losowej, że wartości ≤xp są przyjmowane z prawdopodobieństwem co najmniej p, a wartości ≥xp są przyjmowane z prawdopodobieństwem co najmniej 1−p.
Kwantyl rzędu ½ to inaczej mediana.
Kwantyle rzędu ¼ , 2/4 , 3/4 to kwartyle
Kwantyle rzędu ⅕ , ⅖ , ⅗ , ⅘ to kwintyle.
Kwantyle rzędu 1/10, 2/10, … to decyle.
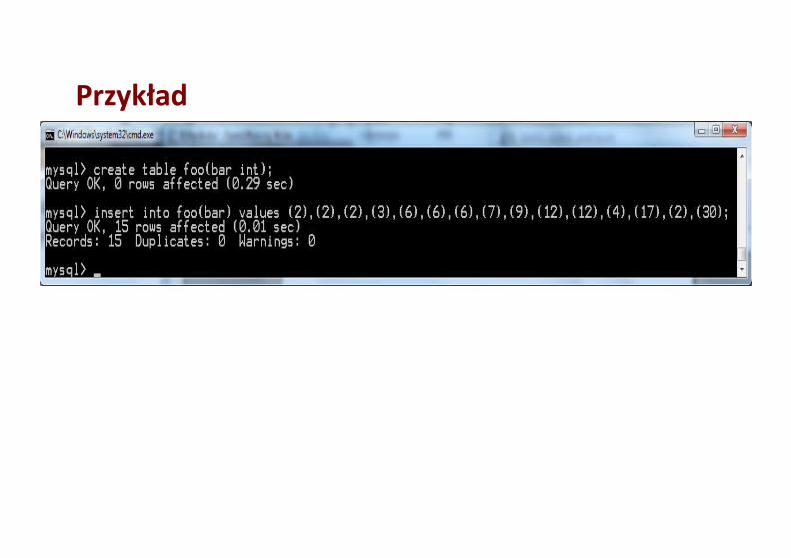
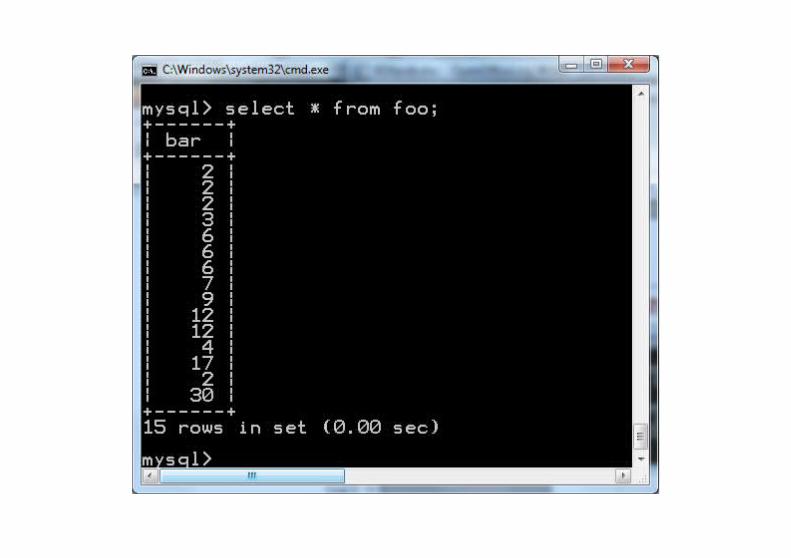
Przykład
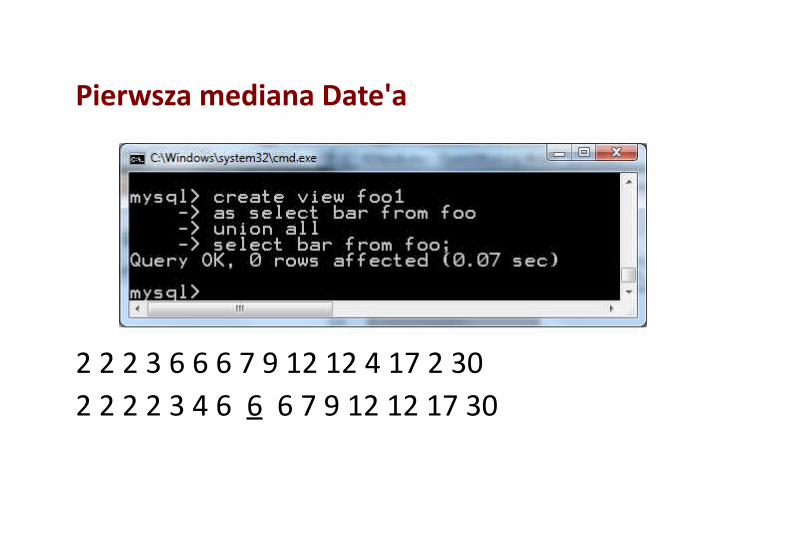
Pierwsza mediana Date'a
2 2 2 3 6 6 6 7 9 12 12 4 17 2 302 2 2 2 3 4 6 6 6 7 9 12 12 17 30
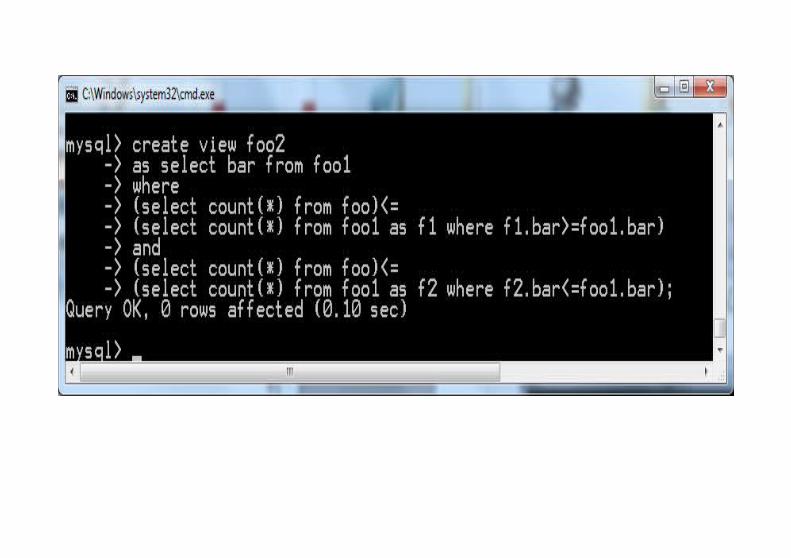
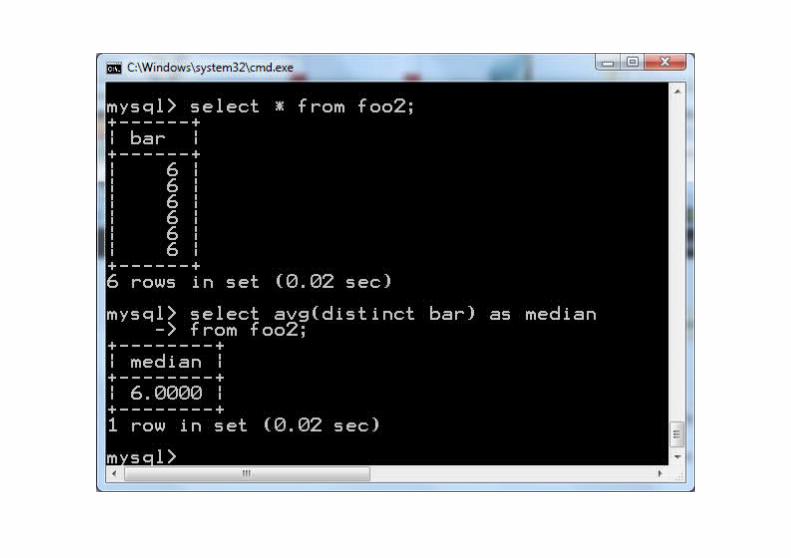

2 2 2 2 3 4 6 6 6 7 9 12 12 17 30 30 130 104 105
a teraz dodam 4 i powinno być
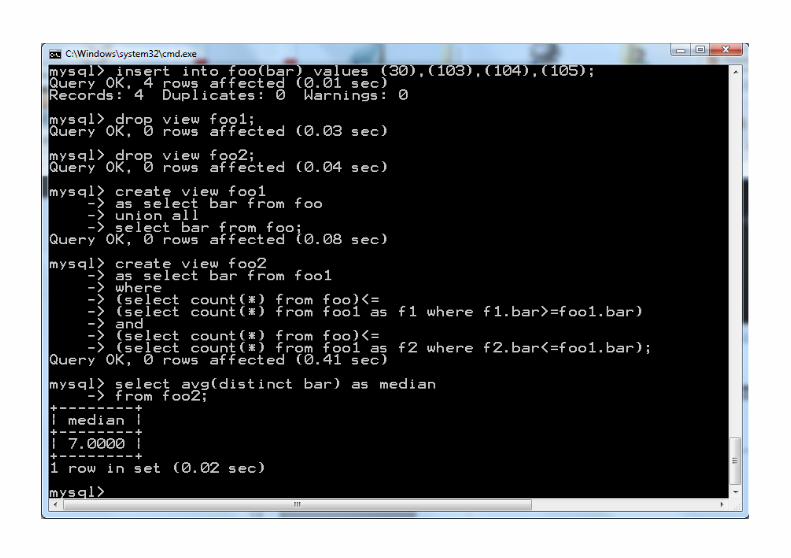
2 2 2 2 3 4 4 6 6 6 7 9 12 12 17 30 30 130 104 105 6.5

skrypt.txtinsert into foo(bar) value (4);drop view foo1;drop view foo2;create view foo1 as select bar from foo union all select bar from foo;create view foo2 as select bar from foo1 where (select count(*) from foo)<= (select count(*) from foo1 as f1 where f1.bar>=foo1.bar) and (select count(*) from foo)<= (select count(*) from foo1 as f2 where f2.bar<=foo1.bar);select avg(distinct bar) as median from foo2;
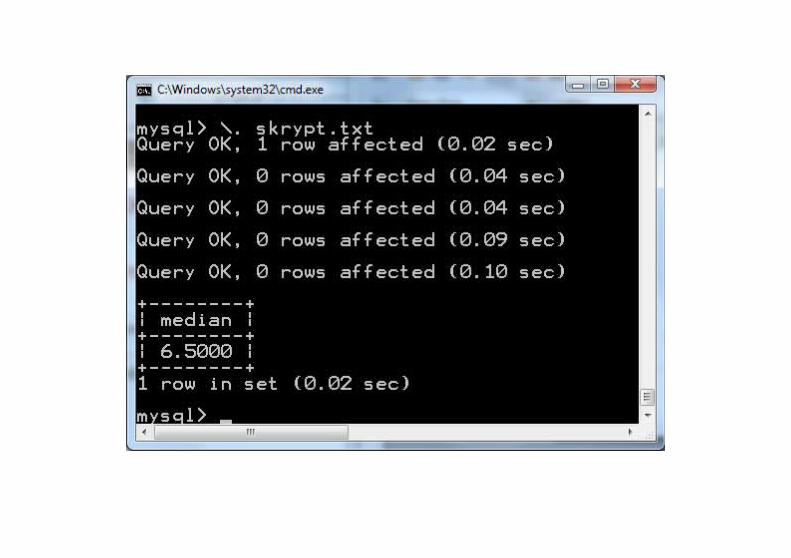
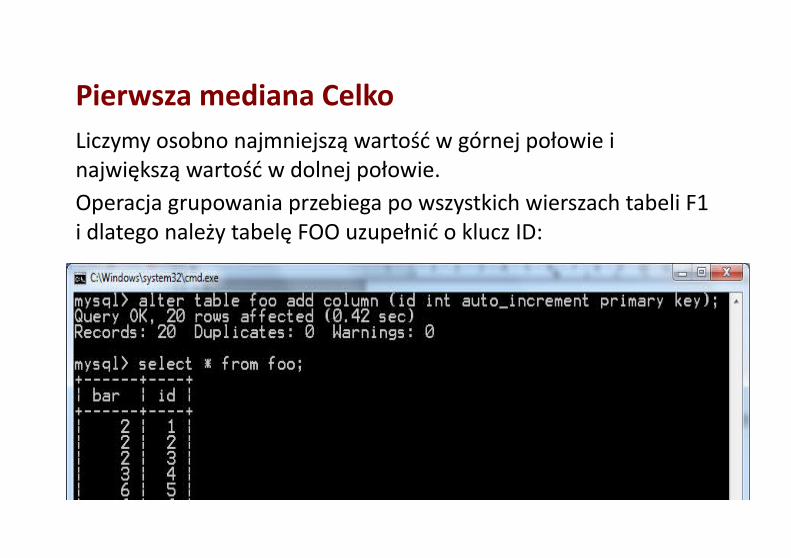
Pierwsza mediana CelkoLiczymy osobno najmniejszą wartość w górnej połowie i największą wartość w dolnej połowie.Operacja grupowania przebiega po wszystkich wierszach tabeli F1 i dlatego należy tabelę FOO uzupełnić o klucz ID:


Tabela krzyżowaTworzymy tabelę pomocniczą a następnie połączymy ją z tabelą danych sprzedaży z czterech lat od 2003 do 2006.
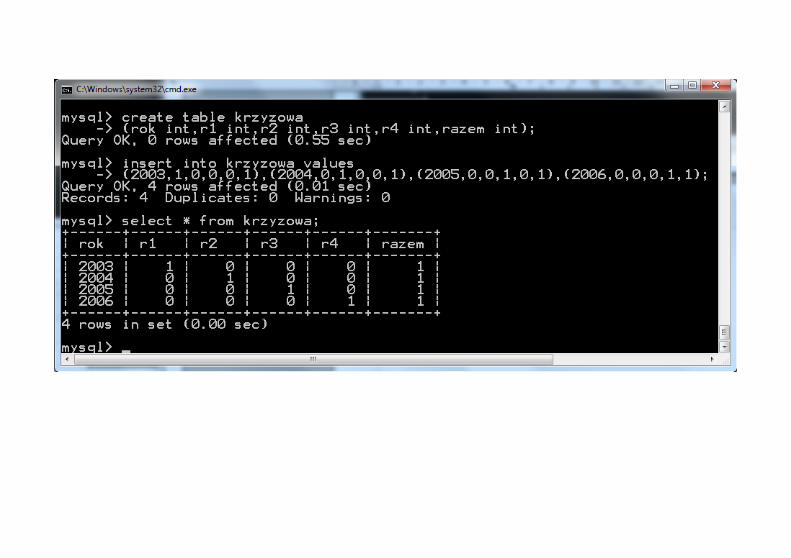
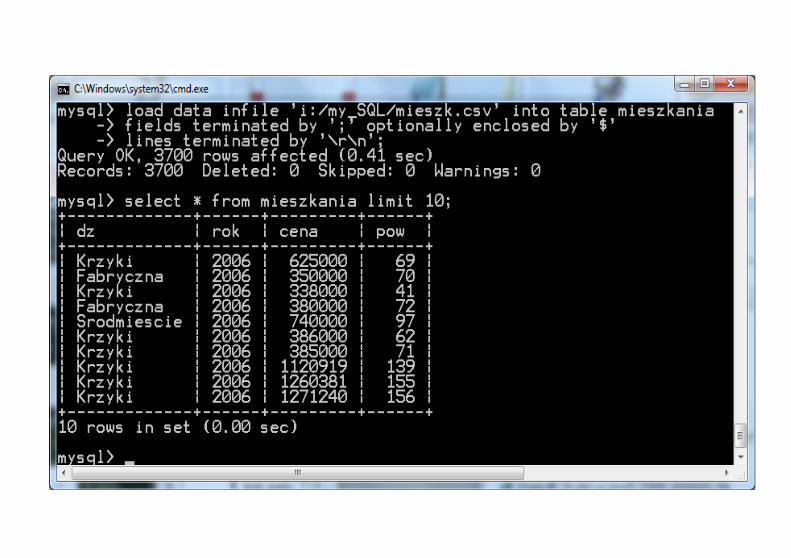
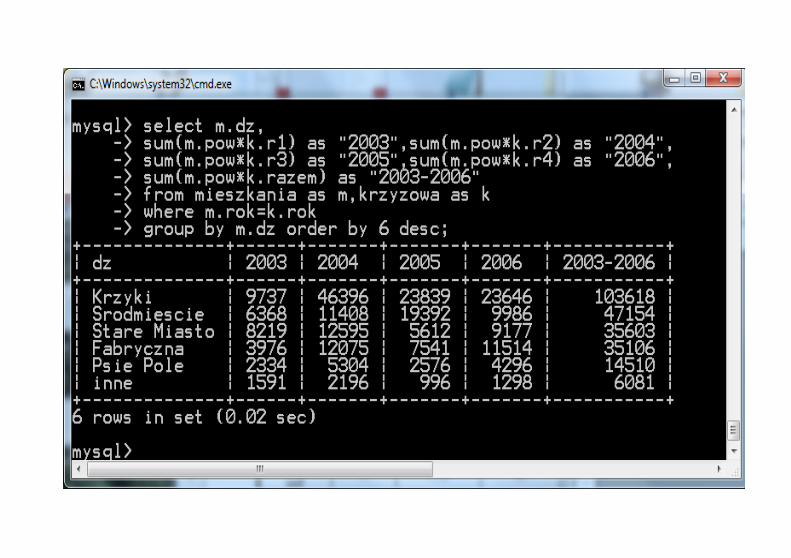

Ćwiczenie:Wygeneruj wypłaty dla kilku bankomatów dla jednego miesiąca i wykonaj dla takich danych tabelę krzyżową.






























