Embed Size (px)
Citation preview

UNIVERZA V MARIBORU
FAKULTETA ZA ELEKTROTEHNIKO, RA�UNALNIŠTVO IN
INFORMATIKO
Janko HERLAH
PRAKTI�NA UPORABA ALGORITMOV STISKANJA
PODATKOV
Diplomska naloga
Maribor, Julij 2009

I
UNIVERZA V MARIBORU
FAKULTETA ZA ELEKTROTEHNIKO, RA�UNALNIŠTVO IN INFORMATIKO 2000 Maribor, Smetanova ul. 17
Diplomska naloga univerzitetnega študijskega programa
PRAKTI�NA UPORABA ALGORITMOV STISKANJA
PODATKOV
Študent: Janko HERLAH
Študijski program: Univerzitetni, ra�unalništvo in informatika
Smer: Programska oprema
Mentor: red. prof. dr. Borut ŽALIK
Maribor, Julij 2009

II

III
PRAKTI�NA UPORABA ALGORITMOV STISKANJA
PODATKOV
Klju�ne besede: algoritmi, brezizgubno stiskanje podatkov, algoritem
Deflate, kode CRC, vmesnik IMAPI
UDK: 004.627 (043.2)
Povzetek
V diplomskem delu smo izdelali in opisali aplikacijo za arhiviranje podatkov.
Opisali smo algoritme za brezizgubno stiskanje podatkov RLE, LZ77 in
Huffmanovo kodiranje, strukturo datoteke ZIP ter algoritem Deflate. Prav tako
razložimo teoreti�ne osnove ra�unanja kode CRC. Za zapisovanje na medije
CD/DVD smo uporabili programski vmesnik IMAPI ter opisali njegovo uporabo.

IV
PRACTICAL USE OF DATA COMPRESSION
ALGORITHMS
Keywords: algorithms, lossless data compression, algorithm
Deflate, CRC codes, IMAPI interface
UDK: 004.627 (043.2)
Abstract
As a result of the diploma thesis, a data archiving program is described. Firstly,
a ZIP file structure is explained and some lossless data compression algorithms
are presented: RLE, LZ77, Huffman coding and Deflate. Additionally, theoretical
principles of CRC arithmetics are introduced. For staging and burning image files
to CD/DVD optical media, an IMAPI programming interface is used and a very
simplified procedure for CD/DVD burning is provided.

V
VSEBINA
1 UVOD................................................................................................................ 1
2 PREDSTAVITEV ALGORITMOV STISKANJA ................................................. 5
2.1 Algoritem RLE ...................................................................................... 5
2.2 Algoritem LZ77 ..................................................................................... 6
2.3 Huffmanovo kodiranje........................................................................... 9
3 ALGORITEM DEFLATE.................................................................................. 15
3.1 Na�ini kodiranja.................................................................................. 19
3.2 Dinami�ne kodne tabele ..................................................................... 23
4 STRUKTURA DATOTEKE ZIP ....................................................................... 28
5 KODA CRC..................................................................................................... 34
6 IMAPI .............................................................................................................. 42
6.1 Znani problemi.................................................................................... 43
6.2 Vmesniki IMAPI .................................................................................. 45
7 PROGRAM ..................................................................................................... 51
7.1 Razredni diagrami .............................................................................. 51
7.2 Predstavitev delovanja programa ....................................................... 57
7.3 Parametri za samodejni zagon ........................................................... 63
8 ZAKLJU�EK ................................................................................................... 65
LITERATURA....................................................................................................... 67
PRILOGA A: Seznam slik..................................................................................... 68
PRILOGA B: Seznam tabel .................................................................................. 69
PRILOGA C: Vsebina zgoš�enke......................................................................... 70

Prakti�na uporaba algoritmov stiskanja podatkov 1
1 UVOD
V diplomskem delu bomo prikazali prakti�no uporabo nekaterih algoritmov
stiskanja podatkov. V ta namen bomo napisali program, ki bo omogo�al
arhiviranje. Arhiviranje bo možno izvesti ro�no ali samodejno ob prej nastavljenem
�asu. Datoteke bomo kodirali z algoritmom Deflate ([1], [2], [3] in [4]), rezultat pa
zapisali v arhiv ZIP ([5]). Za arhiv ZIP smo se odlo�ili, ker je najbolj razširjen
format arhivskih datotek in ga je možno odpreti tudi z drugimi programi. Program
bomo nadgradili še z dodatnimi možnostmi kot so: obnovitev podatkov iz arhiva in
zapisovanje na medije CD in DVD.
Proces stiskanja podatkov pretvarja poljubno vhodno zaporedje znakov v
kodirano izhodno zaporedje, ki pa je manjše po velikosti. Ta trditev v splošnem
velja, poznamo pa tudi algoritme, ki lahko v posebno neugodnih primerih tvorijo
daljše izhodno zaporedje. Takšnemu pojavu pravimo negativno stiskanje in se mu
poskušamo izogniti. Omenimo tudi, da ne obstaja algoritem, ki bi vse vrste
podatkov stisnil optimalno. Nekateri postopki so boljši za stiskanje slik, drugi za
stiskanje besedila, spet tretji za stiskanje zvoka ali videa itd.
U�inkovitost algoritma merimo z razmerjem stiskanja. Razmerje stiskanja
definiramo kot razmerje med velikostjo kodiranega in originalnega zaporedja.
Stiskanje dosežemo, �e je razmerje stiskanja manjše od ena.
Razmerje stiskanja = zaporedja vhodnega velikost
zaporedja kodiranega izhodnega velikost (1.1)
Ko razmišljamo, kako bi �imbolj optimalno stisnili podatke, se nam takoj
prikrade vprašanje: ali lahko izboljšamo stisljivost že samo s tem, �e stisnjene
datoteke stisnemo še enkrat? Odgovor je: NE. Stisnjene datoteke imajo ni� ali zelo
malo odve�ne informacije, saj je bila odstranjena v prvem postopku stiskanja, zato

Prakti�na uporaba algoritmov stiskanja podatkov 2
ni ve� kaj odvzeti. Lahko pa na vprašanje odgovorimo tudi intuitivno. �e bi lahko
stiskali že stisnjene datoteke, bi vsak nadaljni postopek stiskanja še dodatno
zmanjšal velikost datoteke. Postopek bi ponavljali poljubno dolgo, dokler ne bi na
koncu dobili zelo majhno datoteko, npr. dolžine enega zloga (angl. byte). To pa je
nesmisel, saj v en zlog ne moremo shraniti informacijo, ki jo vsebuje poljubno
dolga datoteka.
Kako torej dosežemo stiskanje? Vsako zaporedje znakov, ne glede na to, ali
predstavlja sliko, zvok ali kaj drugega, lahko vsebuje odve�no informacijo, ki jo
imenujemo redundanca. �e odve�no informacijo odstranimo, dobimo zaporedje, ki
je manjše po velikosti. Da dobimo �imbolj optimalen rezultat, izhodno zaporedje
kodiramo. Simbolom, ki se v zaporedju pojavljajo velikokrat, dodelimo �im krajše
kode. Simboli, ki se pojavijo redko, lahko imajo daljše kode, ker ne bodo bistveno
vplivali na velikost izhodnega niza. Za proces kodiranja potrebujemo kodirnik
(angl. encoder), za obratni proces dekodiranja, ki nam iz kodiranega niza vrne
original, pa dekodirnik (angl. decoder). Lastnosti obeh so dolo�ene z izbranim
algoritmom stiskanja.
Podrobna predstavitev nekaterih algoritmov stiskanja bo predstavljena v
drugem poglavju. Najprej bomo opisali algoritem RLE (angl. Run-Length
Encoding), ki daje dobre rezultate pri ponavljajo�ih se vrednostih. Kadar se nek
znak vhodnega zaporedja ponovi n-krat, v izhodno zaporedje zapišemo en sam
znak in njegovo število ponovitev. Sledil bo opis algoritma LZ77 (angl. Sliding
Window). Osnovna ideja algoritma je, da del vhodnega niza, ki smo ga že obdelali,
uporabimo kot slovar. Ko �itamo vhodni niz znak za znakom, poskušamo v
slovarju najti enak niz. V izhodni niz zapišemo troj�ek (odmik od konca slovarja,
dolžina ujemanja, znak). Algoritem daje tem boljše rezultate, �e uspemo v slovarju
najti dolge nize. Na koncu si bomo ogledali še Huffmanovo kodiranje. Huffmanovo
kodiranje je zelo priljubljeno, ker generira najbolj optimalne kode – simbolom, ki
nastopajo najve�krat, dodeljuje najkrajše kode. Slaba stran algoritma je, da
zahteva veliko korakov. V prvem koraku ugotovi verjetnosti pojavljanja
posameznih simbolov. Nato gradi binarno drevo tako, da v vsakem koraku poiš�e

Prakti�na uporaba algoritmov stiskanja podatkov 3
dva simbola A in B z najmanjšo verjetnostjo pojavljanja in ju združi v nov simbol
AB. Nov simbol vstavi v seznam, znaka A in B pa odstrani iz seznama. Tako se
seznam z vsakim korakom skr�i za en element. Postopek je kon�an, ko v
seznamu ostane samo en element, ki predstavlja koren Huffmanovega drevesa.
Vsako vozliš�e drevesa prispeva en bit v kodi posameznega simbola.
V tretjem poglavju bomo uporabili vse znanje iz drugega poglavja in opisali
algoritem Deflate, ki spada v skupino algoritmov brez izgub. Napisal ga je Philip
W. Katz. Njegov originalni algoritem je patentno zaš�iten, vse ostale razli�ice pa
so v javni lasti (angl. public domain). Je splošno namenski algoritem, primeren za
stiskanje vseh vrst podatkov, zato ga danes sre�amo v mnogih priljubljenih
programih, kot so:
• WinZip in Gzip: programa za arhiviranje podatkov
• operacijski sistem Windows™: od Windows XP dalje se uporablja za
arhiviranje (stisnjene mape in datoteke)
• format Adobe PDF: format za opis dokumentov
• protokol HTTP: protokol, ki nam omogo�a brskanje po internetu
• format PNG: vrsta zapisa slike
• Zlib: knjižnica, ki sta jo razvila Jean-Loup Gailly in Mark Adler in jo
razvijalci lahko prosto uporabijo v svojih aplikacijah itd.
V �etrtem poglavju bomo opisali osnovno strukturo datoteke ZIP, zato se ne
bomo spuš�ali v vse podrobnosti specifikacije. Želimo dose�i zapisovanje v arhiv
in branje iz njega. Eden izmed pomembnejših podatkov v arhivu ZIP je koda CRC
([6] in [7]), ki jo moramo priložiti k vsaki stisnjeni datoteki. Služi za odkrivanje
napak v arhivu (ali je bila datoteka spremenjena). Ker so datoteke kodirane, lahko
že sprememba enega bita povzro�i, da datoteke ni možno odkodirati. Generiranje
kode CRC bo opisano v petem poglavju.
V šestem poglavju bomo opisali programski vmesnik IMAPI (angl. Image
Mastering API) in njegovo uporabo. IMAPI ([8]) služi za zapisovanje na medije

Prakti�na uporaba algoritmov stiskanja podatkov 4
CD/DVD. Od Windows XP dalje je del Microsoftovih operacijskih sistemov.
Omogo�a zelo natan�no kontrolo nad procesom zapisovanja podatkov, saj
vsebuje kar osemintrideset vmesnikov (angl. Interface). Opisan bo postopek, kako
v program dodamo funkcionalnost, ki jo nudi IMAPI. Opisani bodo tudi najvažnejši
vmesniki in njihove metode.
V sedmem poglavju bo predstavljena zgradba in delovanje programa. Program
omogo�a arhiviranje, obnovitev podatkov in zapisovanje na medije CD/DVD.
Opisani bodo najvažnejši razredi in metode. Predstavljen bo grafi�ni vmesnik
programa, s katerim upravljamo, ko se nahajamo v interaktivnem na�inu. Podali
bomo tudi opis ukaznih parametrov, s katerimi krmilimo program, ko se izvaja v
ozadju, brez posredovanja uporabnika.
Zaklju�ek bomo izkoristili za opis splošnih ugotovitev glede razvoja programa.
Nakazane bodo nekatere omejitve in možne rešitve.

Prakti�na uporaba algoritmov stiskanja podatkov 5
2 PREDSTAVITEV ALGORITMOV STISKANJA
V drugem poglavju bomo pripravili osnovo za opis algoritma Deflate.
Predstavljeni bodo trije algoritmi: RLE, LZ77 in Huffmanovo kodiranje. Za boljše
razumevanje bomo pri vsakem opisu podali tudi podroben primer.
2.1 Algoritem RLE
Ideja algoritma je zelo preprosta. Kadar se nek znak vhodnega zaporedja
ponovi n-krat, v izhodno zaporedje zapišemo dvoj�ek (število ponovitev, znak).
Oklepajev in vejic ne pišemo v izhodni kodirani niz, prikazujemo jih zaradi boljše
berljivosti. Edini problem pri takšnem kodiranju je, kako dekodirnik lo�i med
znakom in številom ponovitev. Rešitev je ve�, naštejmo jih samo nekaj.
Dodajanje posebnega znaka: izberemo katerikoli znak, ki ne nastopa v vhodnem
zaporedju in ga zapišemo pred številom ponovitev. Algoritem je neuporaben, �e
lahko v vhodnem zaporedju pri�akujemo celoten nabor znakov (noben znak ne
moremo »žrtvovati« kot poseben znak). Ker moramo v izhodni niz zapisati troj�ek
(poseben znak, število ponovitev, znak), lahko ta pristop uporabimo samo, �e se
znak ponovi vsaj trikrat.
Primer: kodirajmo vhodno zaporedje AAABCDDDDEEFFFFF. Za poseben znak si izberemo znak
@. Dobimo: @3ABC@4DEE@5F.
Zaporedje treh enakih znakov: ko kodirnik naleti na zaporedje vsaj treh enakih
znakov, v izhodni niz zapiše znak trikrat, ki pa mu takoj sledi preostalo število
ponovitev. Slaba stran tega pristopa je, da pri treh enakih znakih dosežemo
razširitev, stisljivost pa šele pri petih enakih znakih.

Prakti�na uporaba algoritmov stiskanja podatkov 6
Primer: kodirajmo vhodno zaporedje AAABCDDDDEEFFFFF.Dobimo: AAA0BCDDD1EEFFF2.
Uporaba kontrolnega zloga: kadar imamo vsaj tri enake zaporedne znake, jih v
izhodni niz zapišemo kot dvoj�ek (število ponovitev, znak), pri tem pa v kontrolnem
zlogu z ustreznim bitom ozna�imo, kje v naslednjih osmih zlogih se nahaja število
ponovitev. V izhodni niz najprej zapišemo kontrolni zlog, ki mu sledi osem
podatkovnih zlogov, nato sledi kontrolni zlog za naslednjih osem podatkovnih
zlogov itd. Na ra�un kontrolnih zlogov se izhodno zaporedje pove�a za 1/8 celotne
dolžine. Pri sodobnih ra�unalnikih lahko ta prirastek zmanjšamo z uporabo 32-
bitnih ali 64-bitnih kontrolnih zlogov.
Primer: kodirajmo vhodno zaporedje AAABCDDDDEEFFFFF.Dobimo: 100010002 3ABC4DEE 102
5F… Kontrolni zlog je prikazan kot binarno število. Iz bitov kontrolnega zloga lepo vidimo položaje
zlogov, ki ozna�ujejo število ponovitev.
2.2 Algoritem LZ77
Algoritem LZ77 je doživel mnogo sprememb. Številni avtorji so izboljšali
posamezne dele algoritma in tako ustvarili celo vrsto razli�ic kot so: LZX (Jonathan
Forbes), LZH (Bernd Herd), LZSS (Storer in Szymanski), LZFG (Edward Fiala in
Daniel Greene), LZRW1 in LZRW4 (Ross Williams), QIC-122 itd.
Mi se bomo osredoto�ili na osnovno izvedbo algoritma. Vhodni niz znakov, ki
jih želimo kodirati, razdelimo na dva dela. Leva stran je slovar (angl. dictionary) in
vsebuje znake, ki smo jih že kodirali. Na za�etku kodiranja je slovar prazen. Desna
stran predstavlja zaporedje znakov, ki jih še moramo obdelati. Iz desne strani po
vrsti jemljemo znake in iz njih tvorimo besedo, ki je najprej dolžine enega znaka,
nato dveh, treh itd. Besedo pove�ujemo z dodajanjem znakov dokler lahko v
slovarju najdemo ujemanje. Ko pridemo do besede, ki je ni v slovarju, v izhodno
zaporedje namesto besede zapišemo troj�ek (odmik od konca slovarja, dolžina
ujemanja, zadnji znak besede). Oklepajev in vejic ne pišemo v izhodni kodirani niz,
prikazujemo jih zaradi berljivosti. Na za�etku, ko je slovar majhen, ne najdemo
ujemanja niti za besede dolžine enega znaka, zato moramo v izhodno zaporedje

Prakti�na uporaba algoritmov stiskanja podatkov 7
zapisati troj�ek (0, 0, znak). Pravkar obdelano besedo nato pomaknemo na levo
stran v slovar. Algoritem daje tem boljše rezultate, �e uspemo v slovarju najti
dolge besede.
Primer: z algoritmom LZ77 kodirajmo stavek »Ra�unalnik ra�una …«. Na za�etku je slovar prazen.
R a � u n a l n i k r a � u n a ...slovar besedilo
Slika 2.2.1: Algoritem LZ77 (prazen slovar)
Obdelujemo R, prvo �rko besedila. Ker je slovar prazen, v izhodni niz zapišemo (0,0,R), �rko R pa
prestavimo v slovar.
R a � u n a l n i k r a � u n a ...slovar besedilo
Slika 2.2.2: Algoritem LZ77 (prvi korak)
Nadaljujemo z a, drugo �rko besedila. Ker v slovarju ne najdemo �rke a, v izhodni niz zapišemo
(0,0,a), �rko pa prestavimo v slovar. Podobno velja tudi za naslednje �rke: �, u, n. Ker v slovarju ne
najdemo ujemanja, v izhodni niz zapišemo (0,0,�), (0,0,u) in (0,0,n).
R a � u n a l n i k r a � u n a ...slovar besedilo
Slika 2.2.3: Algoritem LZ77 (po nekaj korakih)
Sedaj je spet na vrsti �rka a, ki se že nahaja v slovarju in sicer na odmiku 4 (slovar preiskujemo od
konca proti za�etku). Ker smo našli ujemanje, preberemo naslednjo �rko l, da dobimo besedo »al«
in pogledamo, ali na odmiku 4 najdemo ujemanje. Na tem mestu nimamo ujemanja, zato si
zapomnimo odmik 4 in dolžino ujemanja 1. Nato celoten postopek ponovimo od odmika 4 dalje. V
slovarju poskušamo najti naslednji a. Ker ga ne najdemo, v izhodni niz zapišemo (4,1,l), »al« pa
prestavimo v slovar.

Prakti�na uporaba algoritmov stiskanja podatkov 8
R a � u n a l n i k r a � u n a ...slovar besedilo
Slika 2.2.4: Algoritem LZ77 (nadaljevanje)
Tudi �rko n najdemo v slovarju, na odmiku 3, zato preberemo naslednjo �rko i, da dobimo besedo
»ni«. Ponovno preverimo, ali na odmiku 3 najdemo ujemanje za besedo »ni«. Ujemanja ni, zato si
zapomnimo odmik 3 in dolžino ujemanja 1 ter poskušamo v slovarju najti še kakšen n. Ker ga ne
najdemo, v izhodni niz zapišemo (3,1,i), »ni« pa prestavimo v slovar. �rke k ni v slovarju, zato jo
kodiramo kot (0,0,k). Podobno velja tudi za presledek: (0,0, ) in �rko r: (0,0,r).
R a � u n a l a � u n a ...slovar besedilo
n i k r
Slika 2.2.5: Algoritem LZ77 (zadnji korak)
Prišli smo do �rke a, ki jo v slovarju najdemo na odmiku 7. Ker smo našli ujemanje, pove�amo
besedo na »a�«. Na odmiku 7 nimamo ve� ujemanja za besedo »a�«, zato si zapomnimo odmik 7
in dolžino ujemanja 1 in v slovarju poskušamo najti še kakšen a. Naslednjo �rko a najdemo na
odmiku 11. Po vrsti beremo �rke u, n, a in za besede »a�u«, »a�un« in »a�una« vsaki� najdemo
ujemanje na odmiku 11. Na koncu pridemo do besede »a�una «, ki pa je ni v slovarju. Ker je
dolžina ujemanja daljša od tiste na odmiku 7, v izhodni niz zapišemo (11,5, ), besedo »a�una « pa
dodamo v slovar. Kon�ni izhodni niz se glasi: (0,0,R), (0,0,a), (0,0,�), (0,0,u), (0,0,n), (4,1,l), (3,1,i),
(0,0,k), (0,0, ), (0,0,r), (11,5, ).
Prednost zgornjega pristopa je v tem, da si vedno zapomnimo samo eno,
najdaljše ujemanje, s �imer privar�ujemo pri pomnilniku. �e se zgodi, da imamo
ve� ujemanj enake dolžine, v izhodni niz zapišemo tisto, ki smo ga našli nazadnje
(ki je najbolj oddaljeno od konca slovarja). Ker moramo vsaki� v izhodni niz
zapisati troj�ek (odmik, dolžina, znak), smo na zgornjem kratkem primeru dosegli
negativno stiskanje, t.j. izhodni niz je daljši od originala. V praksi pa imamo slovar
dolžine nekaj tiso� zlogov, zato je velika verjetnost, da bomo v slovarju našli
ujemanje daljših besed in tako dosegli boljše razmerje stiskanja. Omenimo še, da

Prakti�na uporaba algoritmov stiskanja podatkov 9
besedo, ki smo jo nazadnje obdelali, ne selimo fizi�no po pomnilniku iz desne na
levo stran v slovar, temve� si pomagamo s kazalcem, ki ozna�uje konec slovarja.
S pomikanjem kazalca v desno selimo besede v slovar. Ko smo obdelali celoten
vhodni niz, imamo dve možnosti: preberemo nove podatke in za�nemo s praznim
slovarjem. S tem bomo na za�etku postopka spet pridelali veliko troj�kov (0, 0,
znak), kar je slabo za u�inkovitost stiskanja. Boljši rezultat dosežemo, �e del
slovarja pomaknemo po pomnilniku v levo, ustrezno popravimo kazalec na konec
slovarja, preostanek pomnilnika pa napolnimo z novimi podatki.
2.3 Huffmanovo kodiranje
Je eden najbolj priljubljenih algoritmov za stiskanje podatkov. K priljubljenosti je
gotovo prispevalo dejstvo, da ga je enostavno implementirati, kakor tudi, da tvori
optimalne kode – simbolom, ki se pojavljajo najve�krat, dodeljuje najkrajše kode. V
prvem koraku moramo pregledati vhodno zaporedje in ugotoviti, kolikokrat se
posamezni simbol pojavlja (v literaturi obi�ajno navajamo verjetnosti posameznih
simbolov, v praksi pa zaradi hitrosti izvajanja rajši operiramo s frekvenco
pojavljanja, ki je celo število). Nato tabelo simbolov glede na število pojavljanj
uredimo v padajo�em vrstnem redu in vsak simbol predstavimo kot vozliš�e
drevesa. Sedaj lahko za�nemo graditi binarno drevo. Posebnost Huffmanovega
algoritma je, da gradi drevo od spodaj navzgor, t.j. od listov h korenu. Na vsakem
koraku izberemo dve vozliš�i VA in VB z najnižjo frekvenco pojavljanja. Ker je
tabela urejena padajo�e, nam vozliš� ni treba iskati, temve� vedno vzamemo
zadnji dve. Obe vozliš�i povežemo v novo delno drevo, katerega levi list je
vozliš�e VA, desni list vozliš�e VB, koren pa novo vozliš�e VAB. Frekvenco
pojavljanja novega vozliš�a VAB dobimo tako, da seštejemo frekvenci vozliš� VA in
VB. Nato vozliš�i VA in VB odstranimo iz seznama, vozliš�e VAB pa vstavimo tako,
da je seznam še vedno urejen padajo�e. Po vsakem koraku se seznam zmanjša
za en element. Postopek je kon�an, ko se število elementov v seznamu skr�i na
ena. Zadnji element predstavlja koren celotnega binarnega drevesa. Kode za
posamezni simbol dobimo tako, da obiš�emo vsa vozliš�a drevesa. Vsako
vozliš�e prispeva en bit v izhodni kodi simbola. Omenimo, da obstaja tudi razli�ica

Prakti�na uporaba algoritmov stiskanja podatkov 10
algoritma, kjer tabele simbolov ne urejamo po padajo�em vrstnem redu. V tem
primeru moramo na vsakem koraku pregledati celotno tabelo, da najdemo simbola
z najnižjo frekvenco pojavljanja. �eprav je iskanje bolj zamudno, pa odpade
vzdrževanje urejenosti tabele.
Primer: s Huffmanovim algoritmom kodirajmo stavek »Ra�unalnik ra�una …«. Najprej moramo
ugotoviti, kolikokrat se posamezni simbol pojavlja. Presledek je predstavljen s simbolom �.
VR1
Va4
V�
2
Vu2
Vn3
Vl1
Vi1
Vk1
V�
2
Vr1
Slika 2.3.1: Huffmanovo kodiranje (prvi korak)
Nato seznam uredimo padajo�e glede na frekvenco pojavljanja posameznega simbola. Primeren je
katerikoli algoritem, ki zna urediti seznam števil, npr. QuickSort.
VR1
Va4
V�
2
Vu2
Vn3
Vl1
Vi1
Vk1
V�
2
Vr1
Slika 2.3.2: Huffmanovo kodiranje (drugi korak)
Za�nemo graditi binarno drevo. Izberemo dva simbola z najmanjšo frekvenco pojavljanja: Vk in Vr
ter tvorimo novo vozliš�e Vkr s frekvenco 2 (seštejemo frekvenci simbolov Vk in Vr). Vozliš�i Vk in Vr
odstranimo iz seznama, vozliš�e Vkr pa vstavimo v seznam na šesto mesto tako, da je seznam še
vedno urejen padajo�e. Dejansko lahko vozliš�e Vkr uvrstimo poljubno na mesta 3, 4, 5 ali 6, pa se
optimalnost kode ne bi spremenila. Spremenile bi se samo kode posameznih simbolov.
VR1
Va4
V�
2
Vu2
Vn3
Vl1
Vi1
V�
2
Vk1
Vr1
Vkr2
Slika 2.3.3: Huffmanovo kodiranje (tretji korak)
V naslednjem koraku zopet izberemo dva simbola z najnižjo frekvenco pojavljanja: Vl in Vi. Tvorimo

Prakti�na uporaba algoritmov stiskanja podatkov 11
novo vozliš�e Vli, ki ima spet frekvenco 2. Simbola Vl in Vi odstranimo iz seznama, simbol Vli pa
vstavimo v seznam na sedmem mestu (ker mora biti seznam ves �as urejen padajo�e glede na
frekvenco pojavljanja).
VR1
Va4
V�
2
Vu2
Vn3
V�
2
Vk1
Vr1
Vkr2
Vl1
Vi1
Vli2
Slika 2.3.4: Huffmanovo kodiranje (�etrti korak)
Postopek ponavljamo in na vsakem koraku izberemo dve vozliš�i z najnižjo frekvenco, t.j. zadnji
dve vozliš�i v seznamu. Nadaljujemo z izbiro vozliš� Vli in VR in tvorimo novo vozliš�e VliR s
frekvenco 3. Vozliš�i Vli in VR odstranimo iz seznama, novo vozliš�e VliR uvrstimo v seznam na
tretjem mestu.
Va4
V�
2
Vu2
Vn3
V�
2
Vk1
Vr1
Vkr2
VR1
Vl1
Vi1
Vli2
VliR3
Slika 2.3.5: Huffmanovo kodiranje (peti korak)
Iz vozliš� V� in Vkr tvorimo vozliš�e V�kr. Vozliš�i V� in Vkr odstranimo iz seznama, novo vozliš�e
V�kr s frekvenco 4 pa vstavimo v seznam na drugem mestu.

Prakti�na uporaba algoritmov stiskanja podatkov 12
Va4
V�
2
Vu2
Vn3
VR1
Vl1
Vi1
Vli2
VliR3
V�
2
Vk1
Vr1
Vkr2
V�kr4
Slika 2.3.6: Huffmanovo kodiranje (šesti korak)
Vozliš�i V� in Vu nam data novo vozliš�e V�u s frekvenco 4, ki ga uvrstimo v seznam na tretjem
mestu.
Va4
Vn3
VR1
Vl1
Vi1
Vli2
VliR3
V�
2
Vk1
Vr1
Vkr2
V�kr4
V�
2
Vu2
V�u4
Slika 2.3.7: Huffmanovo kodiranje (sedmi korak)
Naslednji korak izbere vozliš�i Vn in VliR. Iz njih tvorimo vozliš�e VnliR s frekvenco 6, ki ga moramo
dati v seznam na prvo mesto.
Va4
V�
2
Vk1
Vr1
Vkr2
V�kr4
V�
2
Vu2
V�u4
Vn3
VR1
Vl1
Vi1
Vli2
VliR3
VnliR6
Slika 2.3.8: Huffmanovo kodiranje (osmi korak)

Prakti�na uporaba algoritmov stiskanja podatkov 13
V devetem koraku izberemo vozliš�i V�kr in V�u. Tvorimo novo vozliš�e V�kr�u s frekvenco 8, ki ga
moramo uvrstiti v seznam na prvo mesto.
Va4
Vn3
VR1
Vl1
Vi1
Vli2
VliR3
VnliR6
V�
2
Vk1
Vr1
Vkr2
V�kr4
V�
2
Vu2
V�u4
V�kr�u8
Slika 2.3.9: Huffmanovo kodiranje (deveti korak)
Ostaneta še dva koraka. V prvem izberemo vozliš�i VnliR in Va. Tvorimo novo vozliš�e VnliRa s
frekvenco 10, ki ga moramo dati v seznam na prvo mesto.
V�
2
Vk1
Vr1
Vkr2
V�kr4
V�
2
Vu2
V�u4
V�kr�u8
Va4
Vn3
VliR3
VR1
Vl1
Vi1
Vli2
VnliR6
VnliRa10
Slika 2.3.10: Huffmanovo kodiranje (deseti korak)
Na koncu sta nam ostali samo dve vozliš�i VnliRa in V�kr�u, ki ju združimo v vozliš�e VnliRa�kr�u s
frekvenco 18. Ker se je seznam skr�il na samo eno vozliš�e, je postopek kon�an, vozliš�e VnliRa�kr�u
pa predstavlja koren binarnega drevesa.

Prakti�na uporaba algoritmov stiskanja podatkov 14
V�
2
Vk1
Vr1
Vkr2
V�kr4
V�
2
Vu2
V�u4
V�kr�u8
Va4
Vn3
VliR3
VR1
Vl1
Vi1
Vli2
VnliR6
VnliRa10
VnliRa kr� �u18
Slika 2.3.11: Huffmanovo kodiranje (zadnji korak)
Da dobimo kode za naš nabor simbolov, moramo obiskati vsa vozliš�a drevesa. Prehod v vozliš�e
na levi ozna�imo z 0, prehod v vozliš�e na desni pa z 1. Tako vsako vozliš�e prispeva en bit v
kon�ni kodi simbola. Zapišimo Huffmanove kode za naše simbole:
Simbol Koda n 000 l 00100 i 00101 R 0011 a 01 � 100 k 1010 r 1011 � 110 u 111
Tabela 2.3.1: Huffmanove kode za primer »Ra�unalnik ra�una «
Iz primera lahko vidimo, da algoritem dodeljuje najkrajše kode ravno tistim
simbolom, ki se pojavljajo najve�krat. Pri gradnji drevesa bi lahko simbole izbirali
tudi kako druga�e. Dokler se držimo na�ela, da na vsakem koraku izberemo dva
simbola z najnižjo frekvenco pojavljanja, ne vplivamo na optimalnost kod, temve�

Prakti�na uporaba algoritmov stiskanja podatkov 15
kve�jemu na to, kakšno kodo bo dobil posamezni simbol. V praksi to dejstvo
predstavlja velik problem, saj obstaja ve� razli�nih enakovrednih dreves, iz katerih
dobimo optimalne Huffmanove kode. Ker optimalne kode niso enoli�ne, jih
dekodirnik ne more izra�unati. Zato moramo poleg kodiranih podatkov priložiti še
Huffmanovo drevo, iz katerega smo pridobili kode.
3 ALGORITEM DEFLATE
Kodirano zaporedje, ki ga tvori algoritem Deflate, se sestoji iz blokov poljubne
dolžine. Vsak blok kodiramo lo�eno. Pri tem uporabimo algoritme RLE, LZ77 in
Huffmanovo kodiranje v rahlo izboljšani obliki.
Prva izboljšava: vsako ujemanje, ki ga najdemo v slovarju, predstavimo z
dvoj�kom (dolžina ujemanja, odmik). Algoritem Deflate dovoljuje dolžino ujemanja
od najmanj tri do najve� dvestooseminpetdeset znakov. Simbole, ki jih ne najdemo
v slovarju oz. je njihova dolžina ujemanja manjša od treh znakov, zapišemo brez
kodiranja kot literale direktno v izhodni niz. Njihove vrednosti ležijo v intervalu
[0..255]. Odmik je lahko podan z najve� petnajstimi biti, zato je velikost slovarja
omejena na 32 kB (215=32768).
Druga izboljšava: posebnost algoritma Deflate je tudi, kako poskuša najti
najdaljše ujemanje v slovarju. Ni� ga ne moti, �e se ujemanje nadaljuje preko
zadnjega znaka slovarja, t.j. v vhodno zaporedje, ki ga moramo šele obdelati.
Uporaba te izboljšave ni obvezna.
Primer: imejmo stavek »Ra�unalnik ra�una, ra�una, ra�una!« in slovar naj obsega besedi
»Ra�unalnik ra�una,«.

Prakti�na uporaba algoritmov stiskanja podatkov 16
slovar besedilo
r a � u n a , r a � u n a !r a � u n a ,...
Slika 3.1: Algoritem Deflate (izboljšano iskanje v slovarju)
Obdelujemo presledek. Ujemanje najdemo na odmiku 8. Po vrsti beremo znake vhodnega
zaporedja, ki so vsi v slovarju, dokler ne pridemo do naslednjega presledka. Ker smo slovar
iz�rpali, bi po izvornem algoritmu LZ77 zaklju�ili in v izhodno zaporedje zapisali (8,8, ). Algoritem
Deflate pa spretno izkoriš�a ponavljanje in nadaljuje s primerjanjem vse dokler najde ujemanje.
Tako v izhodno zaporedje zapiše (15,8) in za�ne z novim iskanjem za znak »!«. Spomnimo, da ima
dvoj�ek pri algoritmu Deflate na prvem mestu dolžino ujemanja, na drugem pa odmik.
Tretja izboljšava: ki jo uporablja algoritem Deflate, je sekundarno iskanje. Najprej
po že opisanem postopku dolo�imo najdaljše ujemanje. Nato shranimo prvo �rko
pravkar obdelane besede in poskušamo najti daljše ujemanje za preostanek. �e
nam uspe, v izhodni niz shranimo prvo �rko kot literal, nato pa še dvoj�ek za
sekundarno ujemanje. V nasprotnem primeru shranimo dvoj�ek za prvotno
ujemanje. Uporaba te izboljšave ni obvezna.
�etrta izboljšava: ko gradimo Huffmanovo drevo, ne moremo vplivati, kje v
drevesu se bo posamezni simbol pojavil. Tako lahko imamo dolge in kratke kode
pomešane, dolge kode lahko nastopajo na levi strani drevesa, kratke na desni itd.
Algoritem Deflate zahteva, da so kode urejene po dolžini od leve proti desni, kode
enakih dolžin pa morajo biti urejene po simbolih, ki jih predstavljajo. Kode, ki jih
dobimo iz takšnega drevesa, imenujemo kanoni�ne Huffmanove kode in imajo
lepo lastnost, da jih lahko predstavimo kot zaporedje dolžin. V splošnem
Huffmanovo drevo ni urejeno, zato ga moramo najprej pretvoriti v kanoni�no
obliko. Pri tem si lahko pomagamo s preprostim algoritmom, ki ga je napisal P.
Deutsch [2]. Ideja je zelo u�inkovita. Namesto, da urejamo drevo, rajši
posameznim simbolom dodelimo nove kode, ki pa morajo biti enake dolžine kot
prej. Sledi algoritem:

Prakti�na uporaba algoritmov stiskanja podatkov 17
1. Vse simbole imamo v tabeli Simbol[255]
2. Ugotovimo najdaljšo dolžino kode: MAXBITS
3. Preštejemo število simbolov za vsako dolžino in rezultat shranimo v tabelo Count[MAXBITS]
for (int n = 0; n <= 255; n++)
Count[dolžina kode za n-ti simbol]++
4. Za vsako dolžino poiš�emo za�etno kodo in jo shranimo v tabelo NextCode[MAXBITS]
Code = 0
Count[0] = 0
for (int bits = 1; bits <= MAXBITS; bits++)
{
Code = (Code + Count[bits - 1]) << 1
NextCode[bits] = Code
}
5. Posameznim simbolom dodelimo nove (zaporedne) kode
for (int n = 0; n <= 255; n++)
{
int len=dolžina kode za n-ti simbol
if (len != 0)
{
Simbol[n] = NextCode[len]
NextCode[len]++
}
}
Primer: Huffmanove kode iz tabele 2.3.1 pretvorimo v kanoni�ne Huffmanove kode z uporabo
zgoraj opisanega algoritma. Najprej kode predstavimo z zaporedjem njihovih dolžin: (n=3, l=5, i=5,
R=4, a=2, �=3, k=4, r=4, �=3, u=3). Vidimo, da je najdaljša dolžina kode 5 bitov: MAXBITS=5.
Tvorimo tabelo Count[5]:
Dolžina kode Število simbolov 0 0 1 0 2 1 3 4 4 3 5 2
Tabela 3.1: Tabela Count[5] - število kod glede na njihovo dolžino
Prakti�na uporaba algoritmov stiskanja podatkov 18
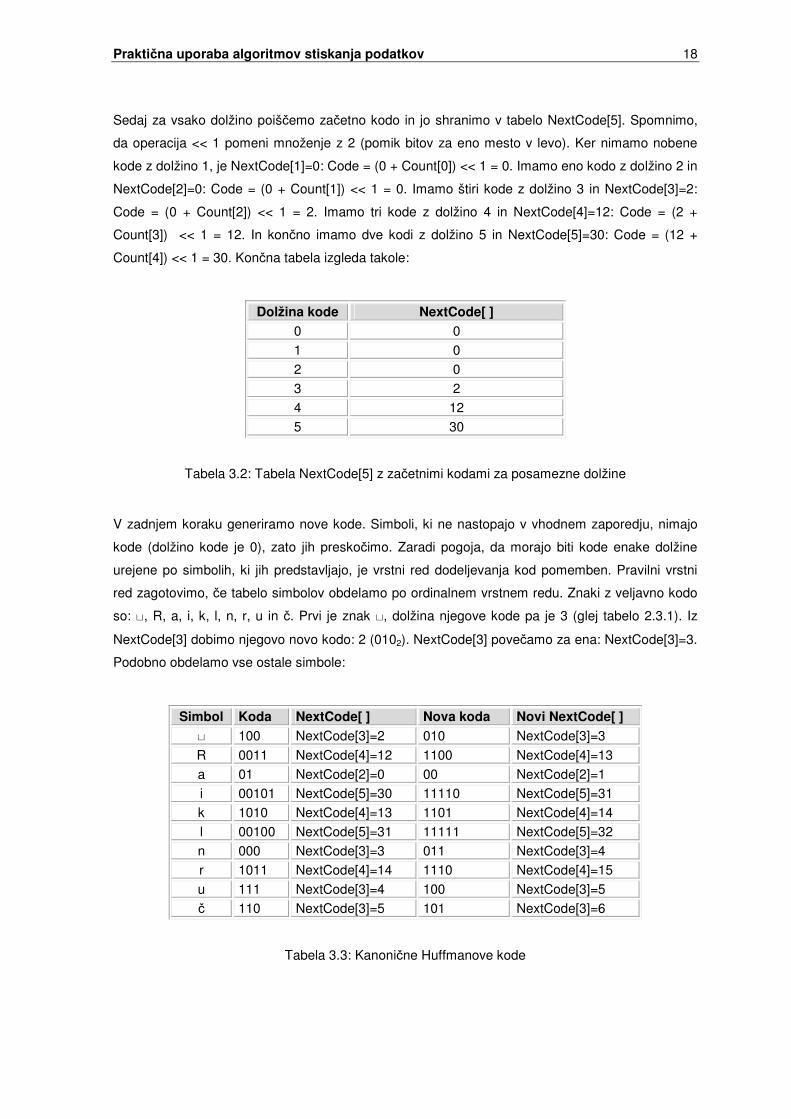
Sedaj za vsako dolžino poiš�emo za�etno kodo in jo shranimo v tabelo NextCode[5]. Spomnimo,
da operacija << 1 pomeni množenje z 2 (pomik bitov za eno mesto v levo). Ker nimamo nobene
kode z dolžino 1, je NextCode[1]=0: Code = (0 + Count[0]) << 1 = 0. Imamo eno kodo z dolžino 2 in
NextCode[2]=0: Code = (0 + Count[1]) << 1 = 0. Imamo štiri kode z dolžino 3 in NextCode[3]=2:
Code = (0 + Count[2]) << 1 = 2. Imamo tri kode z dolžino 4 in NextCode[4]=12: Code = (2 +
Count[3]) << 1 = 12. In kon�no imamo dve kodi z dolžino 5 in NextCode[5]=30: Code = (12 +
Count[4]) << 1 = 30. Kon�na tabela izgleda takole:
Dolžina kode NextCode[ ] 0 0 1 0 2 0 3 2 4 12 5 30
Tabela 3.2: Tabela NextCode[5] z za�etnimi kodami za posamezne dolžine
V zadnjem koraku generiramo nove kode. Simboli, ki ne nastopajo v vhodnem zaporedju, nimajo
kode (dolžino kode je 0), zato jih presko�imo. Zaradi pogoja, da morajo biti kode enake dolžine
urejene po simbolih, ki jih predstavljajo, je vrstni red dodeljevanja kod pomemben. Pravilni vrstni
red zagotovimo, �e tabelo simbolov obdelamo po ordinalnem vrstnem redu. Znaki z veljavno kodo
so: �, R, a, i, k, l, n, r, u in �. Prvi je znak �, dolžina njegove kode pa je 3 (glej tabelo 2.3.1). Iz
NextCode[3] dobimo njegovo novo kodo: 2 (0102). NextCode[3] pove�amo za ena: NextCode[3]=3.
Podobno obdelamo vse ostale simbole:
Simbol Koda NextCode[ ] Nova koda Novi NextCode[ ] � 100 NextCode[3]=2 010 NextCode[3]=3 R 0011 NextCode[4]=12 1100 NextCode[4]=13 a 01 NextCode[2]=0 00 NextCode[2]=1 i 00101 NextCode[5]=30 11110 NextCode[5]=31 k 1010 NextCode[4]=13 1101 NextCode[4]=14 l 00100 NextCode[5]=31 11111 NextCode[5]=32 n 000 NextCode[3]=3 011 NextCode[3]=4 r 1011 NextCode[4]=14 1110 NextCode[4]=15 u 111 NextCode[3]=4 100 NextCode[3]=5 � 110 NextCode[3]=5 101 NextCode[3]=6
Tabela 3.3: Kanoni�ne Huffmanove kode

Prakti�na uporaba algoritmov stiskanja podatkov 19
Celotno drevo lahko zapišemo kot zaporedje dolžin: (3,4,2,5,4,5,3,4,3,3) in vsak dekodirnik lahko
dejanske kode izra�una po zgoraj opisanem algoritmu. Za pravilno predstavitev bi morali zaporedje
zapisati z dvestošestinpetdesetimi dolžinami, kajti iz zgornjega zapisa lahko dekodirnik dolo�i kode
za posamezni simbol, ne pa tudi kateremu simbolu koda pripada. Pravilen zapis bi bil: (0, 0, 0, 0
…, 3, 0,0, …, 4, 0, 0, 0, …, 2, 0, 0, 0, … itd).
V praksi algoritem deluje s celotnim naborom znakov z ordinalnimi vrednostmi
od 0 do 255, ki pa po navadi ne nastopajo vsi pri kodiranju bloka. Tako ima
zaporedje dolžin veliko zaporednih ni�el. Tudi simboli, ki so bili uporabljeni pri
kodiranju, imajo zelo pogosto kode enakih dolžin. To pa so lastnosti, ki kar kli�ejo
po uporabi algoritma RLE.
3.1 Na�ini kodiranja
Algoritem Deflate kodira podatke v blokih. Dolžina bloka in število blokov sta
poljubna, obi�ajno pa vsako datoteko kodiramo v svojem bloku. Prvi zlog bloka
ima naslednji pomen:
• BFINAL (prvi bit): je 1 za zadnji blok v nizu in 0 za vse ostale bloke.
• BTYPE (naslednja dva bita): ozna�ujeta vrsto kodiranja. Lahko imata
vrednosti: 00-nekodirano, 01-kodirano s fiksnimi (vnaprej definiranimi)
kodnimi tabelami in 10-kodirano z dinami�nimi kodnimi tabelami.
Nekodirano (BTYPE=00): prvi zlog bloka se za�ne z 000 ali 100. Preostali biti
niso pomembni. Nato sledi dolžina bloka v zlogih (LEN) in eniški komplement
istega podatka (NLEN). Obe števili sta nepredzna�eni 16-bitni števili, zato je
dolžina bloka omejena na 64 kB (216=65535). Sledijo nekodirani podatki.
Kodirano z vnaprej definiranimi kodnimi tabelami (BTYPE=01): prvi zlog bloka
se za�ne z 001 ali 101. Simbol v kodiranem bloku je lahko: nekodiran znak oz.
literal (vrednosti iz intervala [0..255]) ali pa dvoj�ek (dolžina ujemanja, odmik), kjer
je dolžina ujemanja iz intervala [3..258] in odmik iz intervala [1..32768]. Literale in
dolžine ujemanja združimo v eno kodno tabelo z vrednostmi iz intervala [0..287].

Prakti�na uporaba algoritmov stiskanja podatkov 20
Vrednosti iz intervala [0..255] pripadajo literalom, vrednost 256 predstavlja konec
bloka, vrednosti [257..287] pa predstavljajo dolžine ujemanja. Ker se kodi 286 in
287 ne smeta uporabljati (sta rezervirani), dobimo uporaben interval v razponu
[0..285]. Slednjih devetindvajset kod iz intervala [257..285] je premalo, da bi lahko
enoli�no kodirali dvestošestinpetdeset dolžin ujemanja iz intervala [3..258], zato
jim dodamo dodatne bite kot prikazuje tabela 3.1.1. Tabela 3.1.2 prikazuje
Huffmanove kode za literale/dolžine ujemanja, ki jih zapisujemo v izhodni kodirani
blok.
Koda Dodatni biti
Dolžina Koda Dodatni biti
Dolžina Koda Dodatni biti
Dolžina
257 0 3 267 1 15-16 277 4 67-82 258 0 4 268 1 17-18 278 4 83-98 259 0 5 269 2 19-22 279 4 99-114 260 0 6 270 2 23-26 280 4 115-130 261 0 7 271 2 27-30 281 5 131-162 262 0 8 272 2 31-33 282 5 163-194 263 0 9 273 3 35-42 283 5 195-226 264 0 10 274 3 43-50 284 5 227-257 265 1 11-12 275 3 51-58 285 0 258 266 1 13-14 276 3 59-66
Tabela 3.1.1: Kodna tabela za dolžine ujemanja
Koda Dolžina Huffmanova koda 0-143 8 00110000-10111111
144-255 9 110010000-111111111 256-279 7 0000000-0010111 280-287 8 11000000-11000111
Tabela 3.1.2: Huffmanove kode za literale/dolžine ujemanja
Primer: kako z uporabo zgornjih tabel kodiramo dolžine ujemanja? (A) �e je algoritem LZ77 v
slovarju našel niz dolžine štirih znakov, ji pripada koda 258 (glej tabelo 3.1.1), Huffmanova koda za
258 pa se glasi 0000010 (glej tabelo 3.1.2). To kodo zapišemo v izhodni kodirani blok. (B) �e
najdemo ujemanje dolžine dvanajstih znakov, ji pripada koda 265, ustrezna Huffmanova koda pa je
0001001. Da lo�imo med dolžinama enajst in dvanajst znakov (obema pripada koda 265), moramo
dodati še en bit: za dolžino enajst je ta bit 0, za dolžino dvanajst pa 1. Cela koda se tako glasi:
0001001{1}. Dodatni bit je v oklepajih zaradi lepšega prikaza. (C) Za ujemanje dolžine
Prakti�na uporaba algoritmov stiskanja podatkov 21
štiriindvajsetih znakov dobimo kodo 270, Huffmanova koda je: 0001110{01}. (D) Za dolžino
dvestošestinpetdeset dobimo kodo 284, Huffmanova koda pa se glasi: 11000100{11101}. (E) Kodo
256, ki ozna�uje konec bloka, zapišemo kot 0000000.
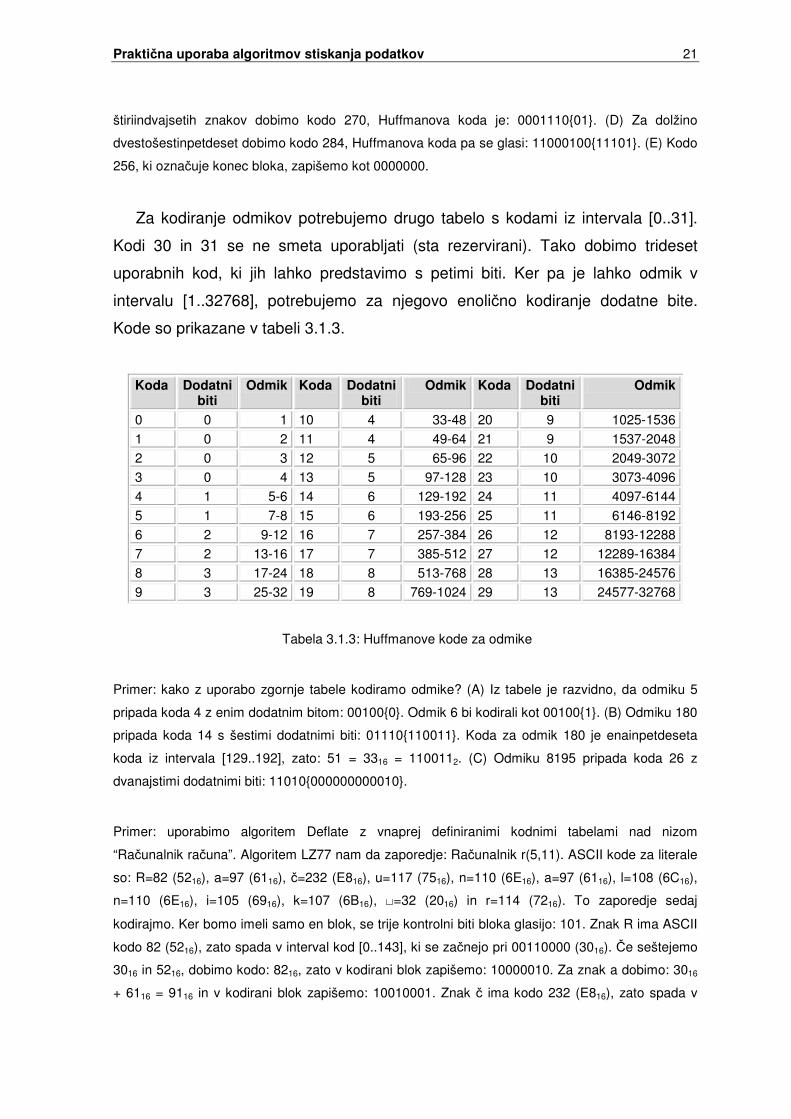
Za kodiranje odmikov potrebujemo drugo tabelo s kodami iz intervala [0..31].
Kodi 30 in 31 se ne smeta uporabljati (sta rezervirani). Tako dobimo trideset
uporabnih kod, ki jih lahko predstavimo s petimi biti. Ker pa je lahko odmik v
intervalu [1..32768], potrebujemo za njegovo enoli�no kodiranje dodatne bite.
Kode so prikazane v tabeli 3.1.3.
Koda Dodatni biti
Odmik Koda Dodatni biti
Odmik Koda Dodatni biti
Odmik
0 0 1 10 4 33-48 20 9 1025-1536 1 0 2 11 4 49-64 21 9 1537-2048 2 0 3 12 5 65-96 22 10 2049-3072 3 0 4 13 5 97-128 23 10 3073-4096 4 1 5-6 14 6 129-192 24 11 4097-6144 5 1 7-8 15 6 193-256 25 11 6146-8192 6 2 9-12 16 7 257-384 26 12 8193-12288 7 2 13-16 17 7 385-512 27 12 12289-16384 8 3 17-24 18 8 513-768 28 13 16385-24576 9 3 25-32 19 8 769-1024 29 13 24577-32768
Tabela 3.1.3: Huffmanove kode za odmike
Primer: kako z uporabo zgornje tabele kodiramo odmike? (A) Iz tabele je razvidno, da odmiku 5
pripada koda 4 z enim dodatnim bitom: 00100{0}. Odmik 6 bi kodirali kot 00100{1}. (B) Odmiku 180
pripada koda 14 s šestimi dodatnimi biti: 01110{110011}. Koda za odmik 180 je enainpetdeseta
koda iz intervala [129..192], zato: 51 = 3316 = 1100112. (C) Odmiku 8195 pripada koda 26 z
dvanajstimi dodatnimi biti: 11010{000000000010}.
Primer: uporabimo algoritem Deflate z vnaprej definiranimi kodnimi tabelami nad nizom
“Ra�unalnik ra�una”. Algoritem LZ77 nam da zaporedje: Ra�unalnik r(5,11). ASCII kode za literale
so: R=82 (5216), a=97 (6116), �=232 (E816), u=117 (7516), n=110 (6E16), a=97 (6116), l=108 (6C16),
n=110 (6E16), i=105 (6916), k=107 (6B16), �=32 (2016) in r=114 (7216). To zaporedje sedaj
kodirajmo. Ker bomo imeli samo en blok, se trije kontrolni biti bloka glasijo: 101. Znak R ima ASCII
kodo 82 (5216), zato spada v interval kod [0..143], ki se za�nejo pri 00110000 (3016). �e seštejemo
3016 in 5216, dobimo kodo: 8216, zato v kodirani blok zapišemo: 10000010. Za znak a dobimo: 3016
+ 6116 = 9116 in v kodirani blok zapišemo: 10010001. Znak � ima kodo 232 (E816), zato spada v

Prakti�na uporaba algoritmov stiskanja podatkov 22
interval kod [144..255], ki se za�nejo pri 110010000 (19016). Koda 232 je oseminosemdeseta koda
v tem zaporedju: 232-114=88 (5816). �e seštejemo 19016 + 5816, dobimo kodo 1E816 in v kodirani
blok zapišemo: 111101000. Po istem postopku kodiramo tudi vse ostale literale: u=10101001
n=10011110 a=10010001 l=10011100 n=10011110 i=10011001 k=10011011 �=10010000
r=10100010. Kodirati moramo še dvoj�ek (5,11). Dolžina 5 nam da kodo 259, ki jo kodiramo s
sedmimi biti: 0000011 (glej tabeli 3.1.1 in 3.1.2). Odmik kodiramo s pomo�jo tabele 3.1.3. Za odmik
11 dobimo kodo 6, potrebujemo pa še dva dodatna bita. Dobimo: 00110{10}. Na konec bloka
moramo dodati še kodo 256: 0000000. Celoten kodirani blok se glasi: 101 10000010 10010001
111101000 10101001 10011110 10010001 10011100 10011110 10011001 10011011 10010000
10100010 0000011 0011010 0000000.
Obe kodni tabeli sta vgrajeni v kodirnik in dekodirnik, zato ju ni potrebno
prilagati h kodiranemu bloku. Kodirani podatki sledijo takoj za tremi kontrolnimi biti
prvega zloga. Blok se zaklju�i s Huffmanovo kodo za simbol 256: 00000002.
Kodirano z dinami�nimi kodnimi tabelami (BTYPE=10): prvi zlog bloka se
za�ne z 010 ali 110. Sledijo opisi kodnih tabel:
• Število kod v tabeli literalov/dolžin (HLIT): pet bitov. Literali lahko
zavzamejo vrednosti iz intervala [0..255], vrednost 256 predstavlja konec
bloka, vrednosti iz intervala [257..285] pa predstavljajo dolžine (glej
tabelo 3.1.1). Nekatere dolžine lahko manjkajo, zato HLIT pove, katera
koda dolžine je zadnja uporabljena (npr. �e je zadnja uporabljena koda
dolžine enaka 259, je HLIT enak 2: 259 - 257 = 2).
• Število kod v tabeli odmikov (HDIST): pet bitov. V tabeli je trideset kod
(glej tabelo 3.1.3), ker pa nekatere kode lahko manjkajo, HDIST pove,
kateri odmik je zadnji uporabljen (npr. �e je zadnji uporabljeni odmik s
kodo 6, je HDIST enak 6).
• Število kod v tabeli (HCLEN), s katerimi sta kodirani tabeli literalov/dolžin
in odmikov: štirje biti. Vrednosti so lahko iz intervala [0..15], pomenijo pa
kode iz intervala [4..19]. Ker nekatere kode lahko manjkajo, (HCLEN +
4) pove, koliko kod je v tabeli.
• Zaporedje dolžin (HCLIST) za kode, s katerimi sta kodirani tabeli
literalov/dolžin in odmikov. Spomnimo, da namesto kod v kanoni�ni

Prakti�na uporaba algoritmov stiskanja podatkov 23
obliki lahko pišemo zaporedje dolžin, iz katerega lahko rekonstruiramo
kodno tabelo. Vseh dolžin je (HCLEN+4), vsaka je dolžine treh bitov.
• Zaporedje dolžin (HLITLIST) za kode iz tabele literalov/dolžin. Vseh
dolžin je (257+HLIT) in so kodirane po postopku, opisanem v poglavju
3.2.
• Zaporedje dolžin (HDISTLIST) za kode iz tabele odmikov. Vseh dolžin je
(HDIST+1) in so kodirane po postopku, opisanem v poglavju 3.2.
• Sledijo kodirani podatki: podatki so kodirani s pomo�jo obeh kodnih tabel
za literale/dolžine in odmike.
• Koda za konec bloka: Huffmanova koda za simbol 256.
3.2 Dinami�ne kodne tabele
Kodirnik med postopkom kodiranja sam generira dve kodni tabeli, eno za
literale/dolžine ujemanja in drugo za odmike. Tabeli dobimo iz Huffmanovih
dreves. Kakšno bo drevo, je povsem odvisno od algoritma. Bolj izpopolnjen
algoritem lahko zbere boljšo statistiko in tako generira krajši izhodni niz. Slabši
algoritem se bo morda zadovoljil s krajšim ujemanjem, a bo kodiranje hitrejše. Pri
izbiri algoritma moramo tako vedno delati kompromis med hitrostjo kodiranja in
velikostjo kodiranega niza. Ker se tabeli tvorita dinami�no glede na vhodne
podatke, ju moramo priložiti k vsakemu kodiranemu bloku. Algoritem Deflate kodni
tabeli zapiše v zelo strnjeni obliki. V grobem je postopek za zapis kodnih tabel
slede�i:
• Za vsako od obeh tabel (tabela literalov/dolžin in tabela odmikov)
zgradimo Huffmanovo drevo.
• Obe Huffmanovi drevesi pretvorimo v kanoni�no obliko.
• Kanoni�ne kode zapišemo kot zaporedje dolžin. Vsako drevo ima svoje
zaporedje dolžin: SLIT in SDIST,
• Obe zaporedji dolžin združimo v eno zaporedje S = SLIT + SDIST, pri
�emer ni�le s konca posameznega zaporedja odstranimo.
• Novo zaporedje S kodiramo z algoritmom RLE, da dobimo še krajše

Prakti�na uporaba algoritmov stiskanja podatkov 24
zaporedje SRLE.
• Iz krajšega zaporedja SRLE zgradimo novo Huffmanovo drevo.
• Novo Huffmanovo drevo pretvorimo v kanoni�no obliko.
• Kode iz tako dobljenega drevesa predstavimo z zaporedjem dolžin.
Zapišemo dolžine za vse kode [0..18], neuporabljene kode inicializiramo
na 0.
• Zaporedje premešamo. Vrstni red je predpisan in sicer si kode sledijo v
tem zaporedju: 16 17 18 0 8 7 9 6 10 5 11 4 12 3 13 2 14 1
15.
• Odstranimo ni�le s konca zaporedja, preostanek pa zapišemo v glavo
kodiranega bloka (HCLIST).
• Zaporedje SRLE kodiramo s prej pridobljenimi kanoni�nimi Huffmanovimi
kodami. Zaporedje zapišemo v glavo kodiranega bloka takoj za
zaporedjem (HCLIST) in predstavlja kodirani tabeli za literale/dolžine
(HLITLIST) in odmike (HDISTLIST).
Postopek kodiranja z algoritmom RLE: kako pridemo do Huffmanovih kod, smo
opisali v poglavju 2.3. Tudi pretvorbo Huffmanovih kod v kanoni�ne Huffmanove
kode smo že opisali v poglavju 3 (�etrta izboljšava). Zato na tem mestu
predpostavimo, da zaporedje dolžin že imamo. Dolžine v tem zaporedju se
obi�ajno ponavljajo, zato jih lahko dobro stisnemo z uporabo algoritma RLE, da
dobimo še krajše zaporedje. Algoritem Deflate iz vhodnega zaporedja dolžin tvori
novo zaporedje in sicer na naslednji na�in:
• �e se dolžina ponovi trikrat ali manj, jo prepišemo v novo zaporedje.
• �e se dolžina ponovi ve� kot trikrat, jo kodiramo z uporabo algoritma
RLE. V novo zaporedje zapišemo dolžino, ki ji sledi koda 16 in število
ponovitev (kolikokrat se dolžina ponovi). Število ponovitev je dolžine
dveh bitov in ozna�uje od tri do šest ponovitev (002 predstavlja tri
ponovitve, 112 predstavlja šest ponovitev).
• Izkušnje kažejo, da se dolžina ni� pojavlja zelo pogosto, zato ima dve
posebni kodi. Prva posebna koda je 17, ki ji sledi 3-bitno število, ki
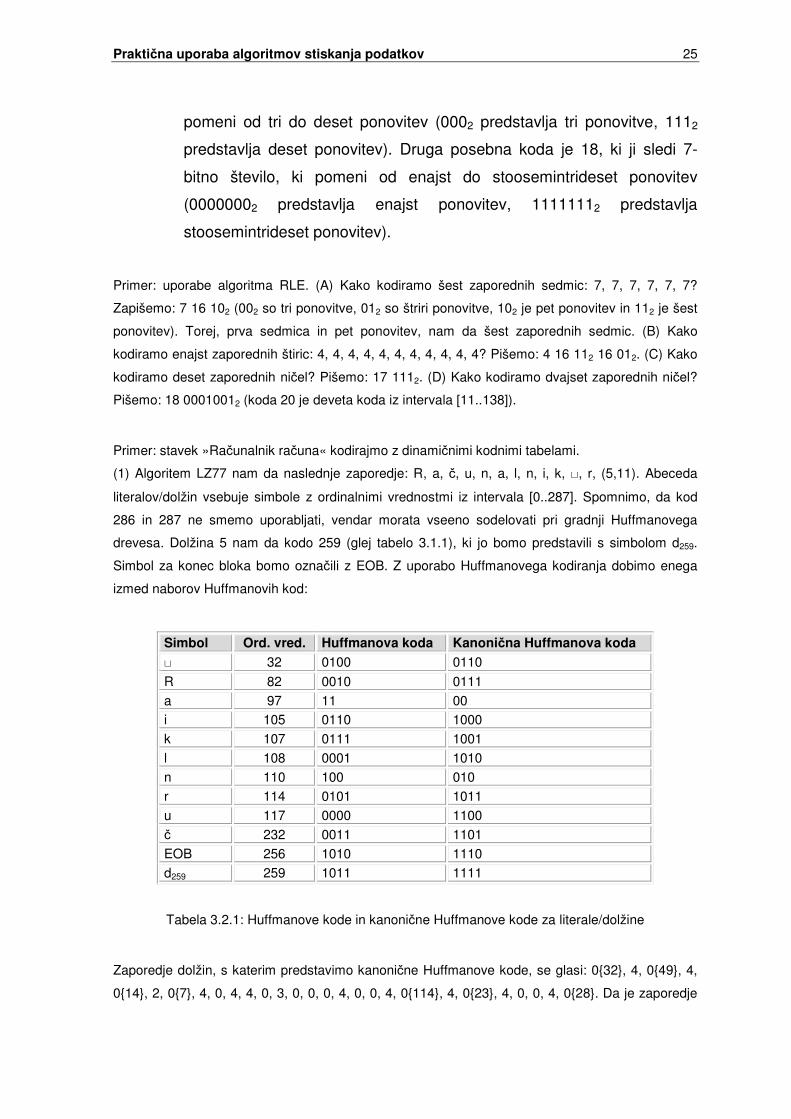
Prakti�na uporaba algoritmov stiskanja podatkov 25
pomeni od tri do deset ponovitev (0002 predstavlja tri ponovitve, 1112
predstavlja deset ponovitev). Druga posebna koda je 18, ki ji sledi 7-
bitno število, ki pomeni od enajst do stoosemintrideset ponovitev
(00000002 predstavlja enajst ponovitev, 11111112 predstavlja
stoosemintrideset ponovitev).
Primer: uporabe algoritma RLE. (A) Kako kodiramo šest zaporednih sedmic: 7, 7, 7, 7, 7, 7?
Zapišemo: 7 16 102 (002 so tri ponovitve, 012 so štriri ponovitve, 102 je pet ponovitev in 112 je šest
ponovitev). Torej, prva sedmica in pet ponovitev, nam da šest zaporednih sedmic. (B) Kako
kodiramo enajst zaporednih štiric: 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4? Pišemo: 4 16 112 16 012. (C) Kako
kodiramo deset zaporednih ni�el? Pišemo: 17 1112. (D) Kako kodiramo dvajset zaporednih ni�el?
Pišemo: 18 00010012 (koda 20 je deveta koda iz intervala [11..138]).
Primer: stavek »Ra�unalnik ra�una« kodirajmo z dinami�nimi kodnimi tabelami.
(1) Algoritem LZ77 nam da naslednje zaporedje: R, a, �, u, n, a, l, n, i, k, �, r, (5,11). Abeceda
literalov/dolžin vsebuje simbole z ordinalnimi vrednostmi iz intervala [0..287]. Spomnimo, da kod
286 in 287 ne smemo uporabljati, vendar morata vseeno sodelovati pri gradnji Huffmanovega
drevesa. Dolžina 5 nam da kodo 259 (glej tabelo 3.1.1), ki jo bomo predstavili s simbolom d259.
Simbol za konec bloka bomo ozna�ili z EOB. Z uporabo Huffmanovega kodiranja dobimo enega
izmed naborov Huffmanovih kod:
Simbol Ord. vred. Huffmanova koda Kanoni�na Huffmanova koda � 32 0100 0110 R 82 0010 0111 a 97 11 00 i 105 0110 1000 k 107 0111 1001 l 108 0001 1010 n 110 100 010 r 114 0101 1011 u 117 0000 1100 � 232 0011 1101 EOB 256 1010 1110 d259 259 1011 1111
Tabela 3.2.1: Huffmanove kode in kanoni�ne Huffmanove kode za literale/dolžine
Zaporedje dolžin, s katerim predstavimo kanoni�ne Huffmanove kode, se glasi: 0{32}, 4, 0{49}, 4,
0{14}, 2, 0{7}, 4, 0, 4, 4, 0, 3, 0, 0, 0, 4, 0, 0, 4, 0{114}, 4, 0{23}, 4, 0, 0, 4, 0{28}. Da je zaporedje

Prakti�na uporaba algoritmov stiskanja podatkov 26
bolj pregledno, smo ponovitve ni�el zapisali v zavitih oklepajih.
(2) Podobno moramo storiti tudi za odmike. V našem primeru imamo samo en odmik: 11, kar nam
da kodo 6 (glej tabelo 3.1.3) z dvema dodatnima bitoma: 102. Huffmanovo drevo je trivialno, z enim
samim vozliš�em, ki mu priredimo kodo 0. �e bi imeli ve� odmikov, bi s pomo�jo tabele 3.1.3 in
Huffmanovega kodiranja za vsak odmik dolo�ili kanoni�no Huffmanovo kodo. Ustrezno zaporedje
dolžin se glasi: 0{6}, 1, 0{25}. �eprav kod 30 in 31 ne smemo uporabljati, morata vseeno sodelovati
pri gradnji Huffmanovega drevesa, zato ima zaporedje dvaintrideset elementov.
(3) Oba zaporedja dolžin združimo v eno zaporedje, kjer lahko ponavljajo�e se ni�le na koncu
posameznega zaporedja izpustimo. Dobimo: 0{32}, 4, 0{49}, 4, 0{14}, 2, 0{7}, 4, 0, 4, 4, 0, 3, 0, 0,
0, 4, 0, 0, 4, 0{114}, 4, 0{23}, 4, 0, 0, 4, 0{6}, 1. Dobljeno zaporedje kodiramo z algoritmom RLE: 18
00101012 4 18 01001102 4 18 00000112 2 17 1002 4 0 4 4 0 3 17 0002 4 0 0 4 18 11001112 4 18
00011002 4 0 0 4 17 0112 1.
(4) Za novo zaporedje generiramo Huffmanove kode. V abecedi za Huffmanovo drevo sodelujejo
samo simboli iz intervala [0..18], bitne vrednosti so dopolnilo h kodam in jih ne kodiramo. Imamo
simbole: 18, 4, 18, 4, 18, 2, 17, 4, 0, 4, 4, 0, 3, 17, 4, 0, 0, 4, 18, 4, 18, 4, 0, 0, 4, 17 in 1. Pri
Huffmanovem kodiranju potrebujemo tudi njihove frekvence, zato zapišimo še te: 0{6}, 1{1}, 2{1},
3{1}, 4{10}, 17{3} in 18{5}.
Simbol Huffmanova koda Kanoni�na Huffmanova koda 0 01 00 1 1011 1110 2 10100 11110 3 10101 11111 4 00 01 17 100 110 18 11 10
Tabela 3.2.2: Huffmanove kode in kanoni�ne Huffmanove kode za zaporedje RLE
(5) Zapišimo zaporedje dolžin za vse simbole [0..18]:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 2 4 5 5 2 0 0 0 0 0 0 0 0 0 0 0 0 3 2
in ga premešajmo v skladu s predpisom:

Prakti�na uporaba algoritmov stiskanja podatkov 27
16 17 18 0 8 7 9 6 10 5 11 4 12 3 13 2 14 1 15 0 3 2 2 0 0 0 0 0 0 0 2 0 5 0 5 0 4 0
(6) Odstranimo ni�le s konca zaporedja: v našem primeru imamo na koncu samo eno ni�lo, zato v
kodirani blok zapišemo zaporedje prvih osemnajstih števil. To je naše zaporedje HCLIST, ki ga
zapišemo v glavo kodiranega bloka: 0 3 2 2 0 0 0 0 0 0 0 2 0 5 0 5 0 4.
Primer: za prejšnji primer zapišimo celotno glavo bloka:
(1) Trije biti na za�etku bloka: 110.
(2) Pet bitov za HLIT: 2 (000102). Zadnji uporabljeni simbol v tabeli literalov/dolžin je simbol
259 (259 - 257 = 2).
(3) Pet bitov za HDIST: 6 (001102). Zadnji uporabljeni simbol iz tabele odmikov je 6.
(4) Štirje biti za HCLEN: 14 (11102). Pomenijo, da imamo 18 kod (HCLEN+4).
(5) Zaporedje dolžin HCLIST. V prejšnjem primeru smo dobili: 0 3 2 2 0 0 0 0 0 0 0 2 0 5 0 5 0
4. Vsako dolžino zapišemo kot 3-bitno število: 000 011 010 010 000 000 000 000 000
000 000 010 000 101 000 101 000 100.
(6) Zaporedje, kodirano z algoritmom RLE, kodiramo še s kanoni�nimi Huffmanovimi kodami:
18 00101012 4 18 01001102 4 18 00000112 2 17 1002 4 0 4 4 0 3 17 0002 4 0 0 4 18
11001112 4 18 00011002 4 0 0 4 17 0112 1 102. Dobimo: 10 0010101 01 10 0100110 01 10
0000011 11110 110 100 01 00 01 01 00 11111 110 000 01 00 00 01 10 1100111 01 10
0001100 01 00 00 01 110 011 1110 10. To zaporedje nam predstavlja obe kodni tabeli za
literale/dolžine (HLITLIST) in odmike (HDISTLIST).
(7) Sledijo podatki, kodirani s pomo�jo obeh kodnih tabel: R=01112, a=002, �=11012, u=11002,
n=0102, a=002, l=10102, n=0102, i=10002, k=10012, �=01102, r=10112, dolžina
5=d259=11112, odmik 11=0 102.
(8) Konec bloka: koda za simbol 256=11102.
Ker je postopek kodiranja bitno naravnan, povejmo še, kako moramo
združevati bite, da bodo podatki pravilno predstavljeni. Vsa števila so
predstavljena v obliki: b7 b6 b5 b4 b3 b2 b1 b0, kjer je najmanj pomemben bit b0
na desni in najbolj pomemben bit b7 na levi. Bite polnimo po vrsti od b0 do b7:
• Vse vrednosti, ki niso Huffmanove kode, zapišemo po bitih od najmanj
pomembnega proti najbolj pomembnemu bitu.
• Huffmanove kode podajamo v obratnem vrstnem redu, t.j. bite

Prakti�na uporaba algoritmov stiskanja podatkov 28
zapisujemo od najbolj pomembnega proti najmanj pomembnemu bitu.
Primer: blok, kodiran z dinami�nimi kodnimi tabelami, mora imeti na za�etku oznako 102. Sledi mu
5-bitno število uporabljenih kod v tabeli literalov/dolžin, HLIT. Recimo, da je HLIT=7. Tedaj prvi zlog
bloka zapišemo: 00111 10 1 (b0=1, b1=0, b2=1, b3=1, b4=1, b5=1, b6=0 in b7=0). Huffmanovo
kodo 10112 moramo zapisati v obratnem vrstenm redu: 11012 (b0=1, b1=0, b2=1, b3=1 itd).
4 STRUKTURA DATOTEKE ZIP
Datoteke ZIP so namenjene arhiviranju in izmenjevanju podatkov. Za
specifikacijo [5] skrbi podjetje PKWare Inc., katerega ustanovitelj je bil P. W. Katz
(1962 – 2000), ki je med drugim tudi avtor algoritma Deflate.
Mi se bomo omejili na osnovno zgradbo datoteke ZIP, ki bo omogo�ala zgolj
arhiviranje in branje arhivskih datotek. Izpustili pa bomo razli�ne možnosti
kodiranja ZIP datotek, uporabo certifikatov in kreiranje velikih Zip64™ arhivov, ki
dovoljujejo arhiviranje datotek, ve�jih od 4 GB.
Ni nujno, da se arhiv ZIP nahaja v eni datoteki ZIP. Lahko ga razbijemo na ve�
delov poljubne dolžine, npr. za prenos podatkov z disketo. Poznamo dve vrsti
segmentiranja. Kadar arhiv delimo na ve� disket, je ime arhiva na vseh disketah
enako, npr. Podatki20080901.ZIP. Številko segmenta razberemo iz oznake
diskete (angl. volume label) in mora biti v obliki PKBACK#nnn, kjer nnn predstavlja
številko segmenta. Pri delitvi na disk moramo upoštevati, da v mapi ne moreta
obstajati dve datoteki z enakim imenom. Zato ima samo zadnja datoteka
(segment) kon�nico ZIP, vse prejšnje pa imajo številko segmenta v imenu.
Primer: �e datoteko Podatki20080901.ZIP razbijemo na tri segmente v isto mapo, morajo biti
ustrezna imena datotek: Podatki20080901.Z01, Podatki20080901.Z02 in Podatki20080901.ZIP.
Datoteke, ki jih dodamo v arhiv ZIP, so lahko shranjene v poljubnem vrstnem
redu. Celotna zgradba datoteke ZIP je naslednja (elementi, ki so obarvani sivo, za

Prakti�na uporaba algoritmov stiskanja podatkov 29
našo aplikacijo niso potrebni in jih ne bomo opisovali. Celoten opis lahko bralec
najde v [5]):
• (A) prva datoteka: opis (local file header 1)
• (B) prva datoteka: kodirani podatki (file data 1)
• (C) [prva datoteka: dodatni opis (data descriptor 1)]
• …
• (A) N-ta datoteka: opis (local file header N)
• (B) N-ta datoteka: kodirani podatki (file data N)
• (C) [N-ta datoteka: dodatni opis (data descriptor N)]
• (D) [Podatki za dekodiranje (archive decryption header)]
• (E) [Dodatni podatki (archive extra data record)]
• (F) Katalog (central directory)
• (G) [Konec ZIP64 kataloga (ZIP64 end of central directory record)]
• (H) [Konec ZIP64 lokatorja (ZIP64 end of central directory locator)]
• (I) Konec kataloga (end of central directory)
(A) Opis datoteke (local file header): pred vsako kodirano datoteko moramo
zapisati blok z osnovnimi podatki o datoteki. �eprav so ti podatki na voljo tudi v
katalogu na koncu datoteke ZIP, jih moramo navajati tudi pred kodiranimi podatki
in sicer zaradi naprav, ki ne omogo�ajo naklju�nega iskanja.
A.1: ID bloka (local file header signature) 4 zlogi
Mora biti 04035b5016
A.2: Minimalna verzija za dearhiviranje (version needed to extract) 2 zloga
1.0: privzeto
1.1: datoteka predstavlja disk
2.0: datoteka predstavlja mapo
2.0: datoteka je stisnjena z algoritmom Deflate
2.0: datoteka je zaš�itena (kodirana) z osnovnim algoritmom PKWARE
2.1: datoteka je stisnjena z algoritmom Deflate64
2.5: datoteka je stisnjena s algoritmom PKWARE DCL Implode
2.7: datoteka je popravek (patch)
4.5: datoteka uporablja format ZIP64

Prakti�na uporaba algoritmov stiskanja podatkov 30
4.6: datoteka je stisnjena z algoritmom BZIP2
5.0: datoteka je zaš�itena (kodirana) z algoritmom DES
5.0: datoteka je zaš�itena (kodirana) z algoritmom 3DES
5.0: datoteka je zaš�itena (kodirana) z originalnim algoritmom RC2
5.0: datoteka je zaš�itena (kodirana) z algoritmom RC4
5.1: datoteka je zaš�itena (kodirana) z algoritmom AES
5.1: datoteka je zaš�itena (kodirana) s spremenjenim algoritmom RC2
5.2: datoteka je zaš�itena (kodirana) s spremenjenim algoritmom RC2-64
6.2: katalog je zaš�iten (kodiran)
6.3: datoteka je stisnjena z algoritmom LZMA
6.3: datoteka je stisnjena z algoritmom PPMd+
6.3: datoteka je zaš�itena (kodirana) z algoritmom BlowFish
6.3: datoteka je zaš�itena (kodirana) z algoritmom TwoFish
A.3: Zastavice (general purpose bit flag) 2 zloga
Bit 0: mora biti 1, �e je datoteka zaš�itena (kodirana)
Bit 1 in 2 (odvisno od uporabljenega algoritma stiskanja). Za algoritem Deflate:
00: uporabljen je normalni faktor stiskanja
01: uporabljen je maksimalni faktor stiskanja
10: uporabljeno je hitro stiskanje
11: uporabljeno je super hitro stiskanje
Bit 3: �e 1, ima datoteka tudi blok za dodatni opis
Bit 4: rezervirano za algoritem Deflate64
Bit 5: �e 1, je datoteka popravek (patch)
Bit 6: mora biti 1, �e je datoteka zaš�itena (kodirana) z naprednejšimi algoritmi,
npr. DES, 3DES, AES itd.
Bit 7, 8, 9 in 10: trenutno neuporabljeni, morajo biti 0
Bit 11: �e 1, je ime datoteke kodirano z UTF-8
Bit 12: rezervirano (PKWARE)
Bit 13 (se uporablja samo, �e je katalog zaš�iten): �e je 1, ozna�uje, da so
vrednosti v opisu datoteke maskirane (skrivanje pravih vrednosti)
Bit 14 in 15: rezervirano (PKWARE)
A.4: Uporabljen algoritem stiskanja (compression method) 2 zloga
0 brez stiskanja
1 Shrink (spremenjen algoritem LZW)
2 Reduce: uporabljen je faktor stiskanja 1
3 Reduce: uporabljen je faktor stiskanja 2
4 Reduce: uporabljen je faktor stiskanja 3
5 Reduce: uporabljen je faktor stiskanja 4
6 Implode

Prakti�na uporaba algoritmov stiskanja podatkov 31
7 Tokenizing
8 Deflate
9 Deflate64
10 PKWARE DCL Implode
11 Rezervirano (PKWARE)
12 BZIP2
13 Rezervirano (PKWARE)
14 LZMA
15 Rezervirano (PKWARE)
16 Rezervirano (PKWARE)
17 Rezervirano (PKWARE)
18 IBM TERSE
19 IBM LZ77
97 WavPack
98 PPMd ver. 1
A.5: �as zadnje spremembe (last modification file time) 2 zloga
�as v formatu MS-DOS
A.6: Datum zadnje spremembe (last modification file date) 2 zloga
Datum v formatu MS-DOS
A.7: Kontrolna koda (CRC-32) 4 zlogi
Glej poglavje 5
A.8: Velikost stisnjene datoteke (compressed size) 4 zlogi
A.9: Velikost originalne datoteke (uncompressed size) 4 zlogi
A.10: Dolžina imena datoteke (file name length) – FNAMELEN 2 zloga
A.11: Dolžina polja za dodatne podatke (extra field length) – EXTRALEN 2 zloga
A.12: Ime datoteke (file name) FNAMELEN
Ime datoteke (ki lahko vsebuje tudi relativno pot). Pot ne sme vklju�evati oznake
pogona ali diska. Lo�ilo med mapami mora biti »/«.
A.13: Dodatni podatki (extra field) EXTRALEN
Za razširitve, npr. �e želimo shraniti dodatne informacije o datoteki. Predpisana je
oblika: HEAD1+DATA1+HEAD2+DATA2…, pri �emer je HEAD definiran kot:
ID bloka (HEAD ID): 2 zloga
Dolžina bloka (HEAD LEN): 2 zloga
(B) Kodirani podatki (file data): datoteka mora biti kodirana z enim izmed
predpisanih algoritmov (glej A.4). Kodirani podatki takoj sledijo bloku (A) Opis
datoteke.

Prakti�na uporaba algoritmov stiskanja podatkov 32
(F) Katalog (central directory): katalog vseh datotek v arhivu ZIP. Služi za hiter
dostop do podatkov vseh datotek, ki se nahajajo v arhivu. Zgradba bloka je
naslednja:
• F.1: opis prve datoteke (file header 1)
• F.1: opis druge datoteke (file header 2)
• …
• F.1: opis N-te datoteke (file header N)
• F.2: [digitalni podpis]
F.1: opis datoteke v katalogu (file header): opis posamezne datoteke (za hiter
prikaz in dostop do podatkov datoteke).
F.1.1: ID bloka (central file header signature) 4 zlogi
Mora biti 02014b5016
F.1.2: Verzija programa (version made by) 2 zloga
Zgornji zlog (MSB) predstavlja kompatibilnost z operacijskim sistemom. Vrednosti
so predpisane in pomenijo slede�e:
0 MS-DOS in OS/2 (FAT, VFAT in FAT32)
1 Amiga
2 OpenVMS
3 UNIX
4 VM/CMS
5 Atari ST
6 OS/2 HP FS
7 MacIntosh
8 Z-system
9 CP/M
10 Windows NTFS
11 MVS
12 VSE
13 Acorn RISC
14 VFAT
15 Alternate MVS
16 BeOS
17 Tandem

Prakti�na uporaba algoritmov stiskanja podatkov 33
18 OS/400
19 OS/X
Spodnji zlog (LSB) predstavlja specifikacijo, ki jo program podpira. Npr. za verzijo
6.3 je LSB enak 63.
F.1.3: Minimalna verzija za dearhiviranje (version needed to extract) 2 zloga
Enako kot v A.2
F.1.4: Zastavice (general purpose bit flag) 2 zloga
Enako kot v A.3
F.1.5: Uporabljen algoritem stiskanja (compression method) 2 zloga
Enako kot v A.4
F.1.6: �as zadnje spremembe (last modification file time) 2 zloga
Enako kot v A.5
F.1.7: Datum zadnje spremembe (last modification file date) 2 zloga
Enako kot v A.6
F.1.8: Kontrolna koda (CRC-32) 4 zlogi
Enako kot v A.7
F.1.9: Velikost stisnjene datoteke (compressed size) 4 zlogi
F.1.10: Velikost originalne datoteke (uncompressed size) 4 zlogi
F.1.11: Dolžina imena datoteke (file name length) – FNAMELEN 2 zloga
F.1.12: Dolžina polja za dodatne podatke (extra field length) – EXTRALEN 2 zloga
F.1.13: Dolžina komentarja (file comment length) - COMMLEN 2 zloga
F.1.14: Za�etna številka segmenta (disk number start) 2 zloga
Številka segmenta (datoteke), kjer so dejanski podatki za datoteko iz tega bloka
F.1.15: Interni datote�ni atributi (internal file attributes) 2 zloga
Bit 0: �e 0, je datoteka binarna. �e 1, je datoteka tekstovna
Bit 1 in 2: rezervirano (PKWARE)
Ostali biti so neuporabljeni
F.1.16: Zunanji datote�ni atributi (external file attributes) 4 zlogi
Odvisno od operacijskega sistema
F.1.17: Odmik do podatkov datoteke (relative offset of local file header) 4 zlogi
Odmik, kjer se za�nejo podatki za datoteko iz tega bloka. Odmik kaže na za�etek
bloka A – opis datoteke (local file header) glede na F.1.14
F.1.18: Ime datoteke (file name) FNAMELEN
F.1.19: Dodatni podatki (extra field) EXTRALEN
F.1.20: Komentar (file comment) COMMLEN

Prakti�na uporaba algoritmov stiskanja podatkov 34
(I) Konec kataloga (end of central directory): dodatne informacije o arhivu ZIP.
I.1: ID bloka (end of central directory signature) 4 zlogi
Mora biti 06054b5016
I.2: Številka segmenta (number of this disk) 2 zloga
Številka segmenta (datoteke), ki vsebuje blok (I) Konec kataloga
I.3: Številka segmenta, kjer se za�ne katalog (number of disk with 2 zloga
the start of central directory): katalog se lahko razteza �ez ve� segmentov
(datotek), zato s tem poljem povemo, v katerem segmentu je za�etek kataloga
I.4: Število datotek v katalogu v tem segmentu (total number of entries 2 zloga
in the central directory on this disk)
I.5: Število vseh datotek v katalogu (total number of entries in the 2 zloga
central directory): število vseh datotek v celotnem arhivu, ne glede na to ali se
katalog razteza �ez ve� segmentov (datotek)
I.6: Velikost kataloga v zlogih (size of central directory) 4 zlogi
I.7: Odmik do za�etka kataloga (offset to start of central directory 4 zlogi
with respect to I.3)
I.8: Dolžina komentarja (ZIP file comment length) - COMMLEN 2 zloga
I.9: Komentar (ZIP file comment) COMMLEN
5 KODA CRC
Osnovni namen kode CRC (angl. cyclic redundancy code ali tudi cyclic
redundancy check) je ugotavljanje, ali je bilo dolo�eno sporo�ilo spremenjeno.
Sporo�ilo je lahko spremenjeno iz razli�nih razlogov: zaradi napake pri prenosu
(npr. preko omrežne povezave), zaradi napake medija (npr. pri zapisovanju na
disk ali branju z njega), pri prenosu od uporabnika A do uporabnika B bi ga lahko
spremenil uporabnik C itd. Torej služi kot neke vrste podpis.
Oddajnik iz vsebine sporo�ila izra�una kodo CRC in jo pripne k sporo�ilu. Na
drugi strani prejemnik iz prejetega sporo�ila prav tako izra�una kodo CRC. �e
dobi rezultat razli�en od ni�, lahko z gotovostjo trdi, da je bilo sporo�ilo
spremenjeno. V nasprotnem primeru je lahko skoraj stoodstotno gotov, da je

Prakti�na uporaba algoritmov stiskanja podatkov 35
sporo�ilo nespremenjeno. Stoodstotne zanesljivosti ne moremo dose�i, kajti
razli�na sporo�ila lahko tvorijo enako kodo CRC, na kar pa nimamo vpliva. Tako
dopuš�amo možnost, da bi tudi iz spremenjenega sporo�ila dobili enako kodo
CRC kot iz originala, vendar je verjetnost za kaj takega dovolj majhna, da jo lahko
zanemarimo.
�e si zamislimo, da je naše sporo�ilo dolgo binarno število, ga lahko delimo z
drugim binarnim številom, preostanek pa predstavlja kodo CRC. Obi�ajno obe
števili predstavimo kot polinoma. Deljenje polinomov je v matematiki dobro
poznano, v ra�unalništvu pa so si omislili številne poenostavljene aritmetike in eno
izmed njih uporabljamo tudi pri ra�unanju kode CRC. Imenujemo jo aritmetika
MOD 2, nekateri avtorji pa ji pravijo tudi aritmetika CRC. Ker ra�unamo v
dvojiškem sistemu, koeficienti ob spremenljivki odpadejo, saj so lahko le ni� ali
ena. Torej upoštevamo samo spremenljivke s koeficientom ena. Npr. binarno
število 10110012 lahko zapišemo kot polinom: 1 � X6 + 0 � X5 + 1 � X4 + 1 � X3 + 0 �
X2 + 0 � X1 + 1 � X0 = X6 + X4 + X3 + 1. Druga poenostavitev je, da vse ra�unske
operacije izvajamo brez prenosa. Ob teh predpostavkah lahko v naši aritmetiki
definiramo osnovne štiri operacije: seštevanje, odštevanje, množenje in deljenje.
Seštevanje Odštevanje
1010 1010
+ 1100 - 1100
0110 0110
Slika 5.1: Primer seštevanja in odštevanja dveh števil v aritmetiki CRC
Kot lahko opazimo, obe operaciji dajeta enak rezultat, hkrati pa zelo prikladno
sovpadata z drugim binarnim operatorjem, ki ga v ra�unalništvu dokaj pogosto
uporabljamo, t.j. operator XOR (⊕). Takšen rezultat ima za posledico še eno
zanimivo lastnost: primerjava dveh števil je možna samo na najvišjem koeficientu
(bitu).

Prakti�na uporaba algoritmov stiskanja podatkov 36
Primer: v aritmetiki CRC ne moremo trditi, da je število 10102 ve�je od števila 10012. Npr. 10102 +
00112 = 10012. Hkrati pa je tudi 10102 – 00112 = 10012. �e nekemu številu prištejemo konstanto, bi
pri�akovali, da bomo dobili neko ve�je število. Podobno, �e številu odštejemo isto konstanto,
pri�akujemo manjše število. V našem primeru pa dobimo obakrat enak rezultat, torej morata biti
števili enaki (kar je tudi res glede na prvi bit).
Množenje dveh števil A in B je tudi zelo preprosto. Tako kot v obi�ajni aritmetiki
ga lahko tudi v aritmetiki CRC prevedemo na vsoto. Število A množimo s
posameznimi biti števila B. Bite števila B beremo z desne proti levi (od najmanj
pomembnega bita b0 proti najbolj pomembnemu bitu bN). Po vsakem množenju
moramo tudi število A pomakniti za en bit v levo. Na koncu vse delne rezultate
seštejemo (spomnimo, da seštevanje izvedemo z operatorjem XOR).
Primer: pomnožimo števili A=10112 in B=1012. Prvi bit števila B je enak 1 (gledano z desne proti
levi), zato število 10112 enostavno prepišemo: 10112 � 1 = 10112. Število A pomaknemo za en bit v
levo in ga pomnožimo z drugim bitom števila B, ki je 0: 101102 � 0 = 000002. Število A spet
pomaknemo za en bit v levo in ga pomnožimo s tretjim bitom števila B: 1011002 � 1 = 1011002.
Ni�le, ki smo jih pridobili s pomikanjem števila v levo, smo ozna�ili s pikami.
1011 101�
10 110000 .
10 11 . .100111
Slika 5.2: Primer množenja dveh števil v aritmetiki CRC
Preverimo rezultat še z množenjem polinomov. Število A lahko zapišemo kot: X3 + X + 1, število B
pa kot: X2 + 1. �e pomnožimo (X3 + X + 1) � (X2 + 1), dobimo: X5 + X3 + X3 + X + X2 + 1 = X5 + X2 +
X + 1, kar je natanko naš rezultat: 1001112. Opozorimo še na to, kako smo izgubili oba �lena X3!
Seštevanje izvedemo z operacijo XOR: 1 � X3 ⊕ 1 � X3 = 0 � X3 = 0.
Pri deljenju dveh števil A : B moramo upoštevati pravilo, da sta dve števili
enaki, �e se ujemata na najvišjem bitu. Najvišji bit števila B (delitelja) je vedno
ena, ker vodilnih ni�el ne pišemo. Definirajmo deljenje. �e je najvišji bit števila A

Prakti�na uporaba algoritmov stiskanja podatkov 37
ni�, v rezultat zapišemo 0, odstranimi najvišji bit in nadaljujemo z deljenjem. �e je
najvišji bit števila A ena, v rezultat zapišemo 1, od A odštejemo B (XOR),
odstranimo najvišji bit in nadaljujemo z deljenjem. V bistvu je postopek enak
ro�nemu deljenju dveh števil, kot ga poznamo v matematiki, ob upoštevanju pravil
aritmetike CRC (ni prenosa; za operacijo odštevanja uporabimo operator XOR;
rezultat deljenja je 1, �e je najvišji bit števila, ki ga delimo, enak 1).
Primer: delimo število A=101011002 s številom B=1012. (A) 1012 : 1012 = 1 in ostanek je 0002. (B)
Najvišji bit ostanka odstranimo in pripišemo naslednji bit iz števila A: 0002. 0002 : 1012 = 0. (C)
Odstranimo najvišji bit ostanka in pripišemo naslednji bit števila A: 0012. 0012 : 1012 = 0. (D)
Odstranimo najvišji bit ostanka in pripišemo naslednji bit števila A: 0112. 0112 : 1012 = 0. (E)
Odstranimo najvišji bit ostanka in pripišemo naslednji bit števila A: 1102. 1102 : 1012 = 1 in ostanek
je 0112. (F) Odstranimo najvišji bit ostanka in pripišemo naslednji bit števila A: 1102. 1102 : 1012 = 1
in ostanek je 0112. (G) Odstranimo najvišji bit ostanka in ker nimamo ve� bitov v številu A, je
deljenje zaklju�eno. Torej je 101011002 : 1012 = 1000112, z ostankom 112.
10 11 0 01 1 1 00 : =1 0 1-0 0 0
0 0 00 0 1
0 1 11 1 010 1-0 1 1
1 1 0
1 0 0 0 1 1
1 0 1-0 1 1
1 1[ ]
(A)
(B)(C)(D)
(E)
(F)
(G)
Slika 5.3: Primer deljenja dveh števil v aritmetiki CRC
Opozorimo, da je rezultat deljenja vedno 1, �e je najvišji bit enak 1. Tako je 1012 : 1012 = 1, kot tudi
1102 : 1012 = 1 in tudi 1002 : 1012 = 1. Rezultat preverimo še s polinomi: (X5 + X + 1) � (X2 +1) = X7
+ X5 + X3 + X + X2 + 1 = X7 + X5 + X3 + X2 + X + 1. Prištejmo še ostanek (X + 1). Dobimo: X7 + X5 +
X3 + X2, kar je naše število A: 101011002.

Prakti�na uporaba algoritmov stiskanja podatkov 38
Z definiranjem operacije deljenja smo dobili osnovni postopek ra�unanja kode
CRC, ki je enaka ostanku pri deljenju. �e želimo, da bo tudi sprejemnik lahko
izra�unal enako kodo CRC, mora vedeti, kakšen je delitelj. Na�eloma je lahko
delitelj kakršenkoli, vendar je praksa pokazala, da so nekateri boljši od drugih. Ker
lahko delitelj prikažemo kot polinom, nam najvišja potenca polinoma pove stopnjo
delitelja. Najve�krat izbiramo delitelje stopnje šestnajst (CRC-16) ali dvaintrideset
(CRC-32), predvsem zaradi lažje prilagoditve algoritma sodobnim ra�unalnikom.
Nekateri avtorji delitelj imenujejo tudi magi�no število (angl. magic number).
Razlog za tako poimenovanje leži v tem, da nam delitelj predstavlja klju�ni
podatek za ra�unanje kode CRC. �e ne poznamo delitelja, ne moremo preveriti
pravilnost sporo�ila s priloženo kodo CRC.
Opis Magi�no število Razred ZIP datoteka DEBB20E316 CRC-32 Ethernet protokol 04C11DB716 CRC-32 X.25 protokol 102116 CRC-16 USB (universal serial bus) 800516 CRC-16
Tabela 5.1: Tabela nekaterih standardnih deliteljev
Opozorimo na to, da ostanek dolžine N bitov ustreza polinomu stopnje (N-1).
Ker pa je ostanek vedno vsaj za eno stopnjo nižji od delitelja, mora biti delitelj
stopnje N, ki zahteva (N+1) bitov. Vemo tudi, da je najvišji koeficient delitelja
vedno ena, zato ga ne pišemo.
Primer: pri CRC-32 je ostanek (naša koda CRC) dolžine 32 bitov in tako predstavlja polinom
stopnje 31 s koeficienti: b0 do b31. Ker je delitelj vedno ve�ji od najve�jega možnega ostanka, mora
biti stopnje 32, za kar potrebujemo 33 bitov: b0 do b32. Ker pa imajo sodobni ra�unalniki 32-bitne
procesorje, je 33-bitno število težko u�inkovito predstaviti. Vemo tudi, da je najvišji koeficient
delitelja b32 vedno 1, zato ga ne pišemo, preostanek pa predstavimo z 32-bitno vrednostjo.
Primer: kateri polinom predstavlja magi�no število za ZIP datoteko? �e magi�no število zapišemo
kot binarno število, dobimo: {1} 1101 1110 1011 1011 0010 0000 1110 00112. Najvišji bit b32, ki ga
ne pišemo, smo zapisali v zavitih oklepajih. Sledi: X32 + X31 + X30 + X28 + X27 + X26 + X25 + X23 + X21
+ X20 + X19 + X17 + X16 + X13 + X7 + X6 + X5 + X + 1.

Prakti�na uporaba algoritmov stiskanja podatkov 39
Preden se lahko lotimo ra�unanja kode CRC, uporabimo še eno ukano. Zaradi
lažjega razumevanja bo postopek opisan za 32-bitne kode CRC in nas bo privedel
do algoritma za ra�unanje kode CRC poljubne dolžine. S stališ�a ra�unanja bi bilo
najlažje, �e bi uporabljali 32-bitne delitelje. Vhodno sporo�ilo bi delili z deliteljem in
dobili 31-bitni ostanek. Vendar bi na ta na�in imeli samo 2147483648 (231)
razli�nih kod CRC, kar je dvakrat manj, kot jih dobimo ob uporabi 33-bitnega
delitelja: 4294967296 (232). Torej moramo najti na�in, kako 32-bitni delitelj
pretvoriti v 33-bitni tako, da nas ne bo oviral pri ra�unanju (ra�unanje s 33-bitnimi
vrednostmi ni ravno pisano na kožo sodobnim ra�unalnikom). Iz matematike
vemo, da se rezultat ne spremeni, �e obe strani izraza pomnožimo z isto
vrednostjo. V našem primeru naj bo ta vrednost X32, ki bo delitelj stopnje
enaintrideset spremenila v delitelj stopnje dvaintrideset (v praksi delitelja ne
množimo, ker je že podan kot polinom dvaintridesete stopnje). Pomnožiti moramo
tudi vhodno sporo�ilo, kar pa je v resnici zelo lahko: na konec sporo�ila pripnemo
niz dvaintridesetih ni�el.
Zapišimo še formalno ena�bo. Naj bo naše sporo�ilo polinom S(x), delitelj D(x),
celoštevil�ni rezultat deljenja S(x) : D(x) = K(x) in ostanek O(x). Tedaj lahko
zapišemo:
S(x) � X32 = K(x) � D(x) + O(x) (5.1)
�e vhodnemu sporo�ilu pripnemo ostanek (kodo CRC), dobimo na sprejemni
strani:
S(x) � X32 + O(x) = K(x) � D(x) (5.2)
Ob predpostavki, da je prenos sporo�ila potekal brez napak, moramo na sprejemni
strani dobiti kodo CRC 0, saj je vhodno sporo�ilo z dodanim ostankom v celoti
deljivo z deliteljem D(x). Zapišimo še splošni algoritem:

Prakti�na uporaba algoritmov stiskanja podatkov 40
1. Inicializiraj delitelj: unsigned long D = predpisani delitelj
2. Na konec sporo�ila dodaj N ni�el, kjer je N število bitov kode CRC (množimo z XN )
3. Inicializiraj Code na 0: unsigned long Code = 0
4. Obdelaj celotno sporo�ilo:
while (ni konec sporo�ila)
{
zapomni si najvišji bit v Code: bN
pomakni Code v levo za en bit (odstrani najvišji bit)
preberi naslednji bit sporo�ila in ga vstavi v Code na bitu b0
if (bN == 1)
Code = Code XOR D
}
5. Code vsebuje ostanek: kodo CRC
Morda na prvi pogled ni jasno, kako zgornji algoritem izvaja deljenje. �e se
spomnimo primera, ko smo ro�no delili dve števili, smo odšteli delitelj vsaki�, ko je
bil najvišji bit enak 1. Prav to po�nemo tudi tukaj: delitelj odštejemo z operacijo
XOR.
�e bo bralec iskal algoritem za ra�unanje kode CRC v literaturi ali na internetu,
bo ugotovil, da ni niti malo podoben zgornjemu algoritmu. Zgornji algoritem je
splošen in primeren za ra�unanje kakršnekoli kode CRC, vendar ima o�itno
slabost: obdeluje en bit naenkrat. Za u�inkovito ra�unanje kode CRC potrebujemo
algoritem, ki bo hitro vrnil rezultat tudi za zelo dolga sporo�ila, npr. datoteke z
dolžinami nekaj MB. Ker je operacija XOR asociativna, t.j. vrstni red izvajanja
operacij XOR ni pomemben, je možno algoritem popraviti tako, da naenkrat
obdela cel zlog. Da proces pospešimo, si prej za vsak znak [0..255] izra�unamo
kodo CRC in jo shranimo v tabelo. Sledi algoritem za inicializacijo tabele:
unsigned long table[255];
unsigned long D = predpisani delitelj;
for (unsigned long i = 0; i < 256; i++)
{
unsigned long Code = i << 24; // Znak i pomaknemo v MSB
for (int j = 0; j < 8; j++) // Za vsak bit znaka

Prakti�na uporaba algoritmov stiskanja podatkov 41
{
bool topBit = (Code & 0x80000000) != 0;
Code <<= 1; // Pomaknemo se na naslednji bit
if (topBit) // Najvišji bit je bil 1
Code ^= D; // Odštejemo delitelj
}
table [i] = Code; // koda CRC za znak i
}
Popravljeni algoritem za izra�un kode CRC je sedaj naslednji:
1. Inicializiraj delitelj: unsigned long D = predpisani delitelj
2. Inicializiraj tabelo: table[255] tako, da uporabiš osnovni algoritem za vsak znak [0..255]
3. Na konec sporo�ila dodaj N ni�el, kjer je N število bitov kode CRC (množimo z XN )
4. Inicializiraj Code na 0: unsigned long Code = 0
5. Obdelaj celotno sporo�ilo:
while (ni konec sporo�ila)
{
byte top= (Code >> 24) & 0xFF; // Najvišji byte v Code
Code = (Code << 8); // Odstrani najvišji byte v Code
Code = Code | naslednji zlog sporo�ila; // Naslednji zlog sporo�ila
Code = Code XOR table[top];
}
6. Code vsebuje ostanek: kodo CRC
V jeziku C++ celotno vsebino zanke while obi�ajno zapišemo v enem stavku, pri
�emer je *p kazalec na naše vhodno sporo�ilo, operator ^ pa operator XOR:
Code = ((Code << 8) | *p++) ^ table[(Code >> 24) & 0xFF] oziroma
Code = ((Code << 8) | *p++) ^ table[(Code >> 24)]
�eprav zgornji algoritem deluje popolnoma pravilno in bi ga težko še bolj strnili,
pa so nekateri avtorji našli še nekaj prostora za optimizacijo. Na za�etku je Code
enak 0 (0000000016), zato potrebujemo štiri prazne cikle, preden pridemo do
zlogov sporo�ila (spomnimo, da v vsaki ponovitvi zanke odstranimo najvišji zlog).
Druga slabost je, da moramo sporo�ilo najprej dopolniti z ni�lami na koncu:

Prakti�na uporaba algoritmov stiskanja podatkov 42
množenje z XN. Spet se izkaže, da sta oba koraka nepotrebna, �e stavek znotraj
zanke while malo popravimo:
Code = (Code << 8) ^ table[(Code >> 24) ^ *p++]
Zgornji stavek bomo najpogosteje sre�ali v literaturi, v�asih pa tudi obrnjeno
razli�ico. �e delitelj obrnemo, tako da ima na levi strani najmanj pomemben bit b0,
na desni pa najbolj pomembnega bN, je možno zgornji stavek še malo optimizirati:
Code = (Code >> 8) ^ table[Code ^ *p++]
Ker je najbolj pomemben zlog sedaj na desni, moramo bite pomikati v desno.
Prednost pa je v tem, da ne potrebujemo nobenega pomika, da pridemo do
najvišjega zloga (prej: Code >> 24). Kadar uporabljamo obrnjeno razli�ico
algoritma, moramo tudi pri ra�unanju tabele upoštevati pomik bitov v desno.
Zapišimo kon�no verzijo algoritma:
1. Inicializiraj delitelj: unsigned long D = predpisani delitelj
2. Inicializiraj tabelo: table[255] tako, da uporabiš osnovni algoritem za vsak znak [0..255]
3. Inicializiraj Code na 0: unsigned long Code = 0
4. Obdelaj celotno sporo�ilo:
while (ni konec sporo�ila)
Code = (Code << 8) ^ table[(Code >> 24) ^ *p++]
5. Code vsebuje ostanek: kodo CRC
6 IMAPI
IMAPI (angl. Image Mastering API) je programski vmesnik, ki omogo�a
zapisovanje podatkov na medije CD in DVD. Programski vmesnik je na voljo od
operacijskega sistema Windows XP dalje, za starejše operacijske sisteme pa
funkcionalnost ni podprta. Obstajata dve razli�ici:

Prakti�na uporaba algoritmov stiskanja podatkov 43
• IMAPI 1.0: je na voljo v operacijskih sistemih Windows XP in Windows
Server 2003. Omogo�a zapisovanje na medije CD, ne pa tudi na medije
DVD.
• IMAPI 2.0: na voljo v operacijskih sistemih Windows Vista in Windows
Server 2008. Omogo�a zapisovanje na medije CD in DVD. Za
operacijska sistema Windows XP in Windows Server 2003 obstajata
dodatka, ki omogo�a enako funkcionalnost, vendar ju je potrebno
posebej namestiti.
IMAPI 2.0 podpira zapis na naslednje vrste opti�nih medijev: CD-R, CD-RW,
DVD-R, DVD+R, DVD-RW, DVD+RW, DVD-RAM ter dvoplastni DVD-R in
DVD+R. Prav tako podpira naslednje oblike zapisa: ISO 9660, Joliet in UDF.
Struktura datote�nega sistema na CD-ju ali DVD-ju omogo�a, da lahko imamo vse
tri hkrati na istem mediju. Program za predvajanje potem sam izbere tisto obliko, ki
mu najbolj ustreza. To je možno zaradi tega, ker so razli�na samo kazala, ki
pripadajo posamezni obliki zapisa, vsebina (npr. glasba, program, slike itd.) pa je
enaka. Kazalo vsebuje seznam datotek, ki so shranjene na mediju. V podrobnosti
standardov se na tem mestu ne bomo spuš�ali, bralec lahko podroben opis najde
v [9] in [10].
6.1 Znani problemi
�e želimo uporabljati IMAPI 2.0 v okolju Windows XP, moramo ustrezen
dodatek posebej namestiti. Dodatek se dobi na Microsoftovih straneh za podporo
in se imenuje WindowsXP-KB932716-v2-x86-ENU.exe. Ob namestitvi se v mapo
C:\Windows\System32\ shranita dve sistemski knjižnici: imapi2.dll in imapi2fs.dll,
vse javno vidne komponente iz obeh knjižnic pa se zapišejo v sistemski register.
Za IMAPI ne obstaja programska knjižnica (angl. type library), zato
programiranje z IMAPI ni možno v jezikih, ki zahtevajo strogo deklaracijo
spremenljivk. Razlog je zelo preprost: ker tipov ni možno uvoziti, jih tudi ni možno
uporabljati. Izjema je programski jezik C++. Za C++ so na voljo datoteke .h, kjer so

Prakti�na uporaba algoritmov stiskanja podatkov 44
deklaracije vseh vmesnikov: imapi2.h in imapi2fs.h.
Na�eloma bi lahko IMAPI programirali tudi v ogrodju .Net, npr. v programskem
jeziku C#. V ogrodju .Net je z dodajanjem povezav na zunanje knjižnice (angl. Add
reference) možno uvoziti obe sistemski knjižnici: imapi2.dll in imapi2fs.dll. Ob
uvozu se kreira dodatni vmesnik, ki služi zgolj za komunikacijo med kodo,
napisano v ogrodju .Net (angl. managed code) in kodo, ki pripada komponentam
IMAPI. Ker pa ogrodje .Net zahteva strogo lo�evanje razredov po imenskih
podro�jih, se pri uvozu glede na knjižnico vmesniki razdelijo na dve imenski
podro�ji: IMAPI2 in IMAPI2FS. Ve�ina vmesnikov in njihovih funkcij deluje dobro.
Težave nastanejo, kadar moramo posredovati vmesnik iz enega imenskega
podro�ja v drugega. Takrat prevajalnik javi napako, �eprav napake v bistvu ni.
Primer: �e želimo zapisati podatke na CD, moramo v vmesniku IDiscFormat2Data klicati metodo
Write(IStream* stream), pri �emer je stream binarna datoteka. Binarno datoteko tvori drug vmesnik
IFileSystemImage preko metode CreateResultImage(). Ker sta oba vmesnika vsak v svojem
imenskem podro�ju, Write() zahteva, da je stream tipa IMAPI2.IStream, IFileSystemImage pa
vra�a IMAPI2FS.IStream.
Vse probleme je možno rešiti tako, da IMAPI programiramo v jeziku C++. Ker
pa želimo programirati v ogrodju .Net, je najbolje, da v jeziku C++ napišemo
komponento, ki bo služila kot vmesnik med IMAPI in programom, napisanim v C#
ali Visual Basic .Net. V tem vmesniku bomo definirali metode, ki nam bodo
posredno omogo�ale dostop do funkcij IMAPI.
Ena izmed metod komuniciranja med razli�nimi aplikacijami v okolju Windows
je uporaba OLE (angl. Object Linking And Embedding). OLE omogo�a urejanje
dokumentov, ki so nastali v drugih aplikacijah, npr. v svoji aplikaciji lahko
omogo�imo urejanje Excelove preglednice. OLE združuje dve vrsti objektov: tiste,
ki imajo grafi�ni vmesnik in jih je možno videti na zaslonu (v obliki komponent
ActiveX) in tiste, ki zagotavljajo zgolj neko funkcionalnost in grafi�nega vmesnika
ne potrebujejo (v obliki komponent COM). OLE ima mnogo prednosti, ima pa tudi
zelo veliko slabost. �e želimo uporabiti katerikoli objekt OLE, ga moramo najprej

Prakti�na uporaba algoritmov stiskanja podatkov 45
registrirati (vpisati v sistemski register ra�unalnika). Obi�ajno registracijo opravi
namestitveni program, možno pa jo je izvesti tudi ro�no. V mapi
C:\Windows\System32\ se nahaja program regsvr32.exe, ki mu je potrebno
posredovati ime knjižnice, ki jo želimo registrirati.
Primer: �e se komponenta nahaja v knjižnici c:\programabc\abc.dll, jo ro�no registriramo z ukazom:
c:\windows\system32\regsvr32.exe c:\programabc\abc.dll.
Za dostop do funkcionalnosti IMAPI ne potrebujemo grafi�nega vmesnika, zato
bomo napisali komponento COM. V jeziku C++ je komponente COM najlaže
napisati s pomo�jo knjižnice ATL (angl. Active Template Library). ATL vsebuje
izbran nabor generi�nih razredov (isti razred lahko uporabimo nad razli�nimi tipi
podatkov). Zaradi tega je kode malo in se izvaja hitro.
6.2 Vmesniki IMAPI
IMAPI omogo�a zelo natan�no kontrolo nad procesom zapisovanja podatkov
na medije CD/DVD. Vsebuje osemintrideset vmesnikov, od tega je za osnovni
zapis potrebnih šest:
• IDiscMaster2: dostop do osnovnih podatkov o nameš�enih pogonih
CD/DVD (število pogonov in enoli�na oznaka vsakega pogona).
• IDiscRecorder2: predstavlja fizi�ni pogon CD/DVD. Omogo�a dostop do
informacij o pogonu (ime, proizvajalec, �rka pogona, lastnosti itd.) ter
odpiranje in zapiranje pogona.
• IFileSystemImage: pretvori strukturo map in datotek, ki jih želimo
zapisati na medij CD/DVD, v obliko, primerno za zapis - slika zapisa.
• IFileSystemImageResult: pretvorjena oblika za zapis.
• IFsiDirectoryItem: predstavlja mapo in datoteke v njej (podobno strukturi
map in datotek na disku).
• IDiscFormat2Data: zapiše podatke na medij CD/DVD.

Prakti�na uporaba algoritmov stiskanja podatkov 46
IDiscMaster2: je vmesnik za dostop do podatkov o nameš�enih pogonih CD/DVD.
Kreiramo ga z ukazom:
CComPtr<IDiscMaster2> dm;
HRESULT hr = dm.CoCreateInstance(CLSID_MsftDiscMaster2);
(a) get_Count(): vrne število nameš�enih pogonov CD/DVD.
HRESULT get_Count
(
[out] LONG* value // vrne št. Pogonov
);
(b) get_Item(): vrne enoli�no oznako pogona (ID).
HRESULT get_Item
(
[in] LONG index, // zaporedna št. Pogona, >= 0
[out] BSTR* value // vrne id pogona
);
IDiscRecorder2: je vmesnik, ki predstavlja posamezni fizi�ni pogon CD/DVD.
Kreiramo ga z ukazom:
CcomPtr<IdiscRecorder2> dr;
HRESULT hr = dr.CoCreateInstance(CLSID_MsftDiscRecorder2);
(a) InitializeDiscRecorder():poveže vmesnik s fizi�nim pogonom CD/DVD.
HRESULT InitializeDiscRecorder
(
[in] BSTR id // ID pogona (ki ga vrne IdiscMaster2)
);
IFileSystemImage: vmesnik, ki pretvori mape in datoteke, ki jih želimo zapisati na
medij CD/DVD, v obliko, primerno za zapis. Kreiramo ga z ukazom:
CcomPtr<IfileSystemImage> im;
HRESULT hr = im.CoCreateInstance(CLSID_MsftFileSystemImage);

Prakti�na uporaba algoritmov stiskanja podatkov 47
(a) get_Root(): vrne korensko mapo. V to mapo dodajamo ostale mape in datoteke, ki jih želimo
zapisati na medij CD/DVD.
HRESULT get_Root
(
[out] IfsiDirectoryItem** dir // vrne korensko mapo
);
(b) SetMaxMediaBlocksFromDevice(): vmesnik vpraša zapisovalnik po številu prostih blokov.
HRESULT SetMaxMediaBlocksFromDevice
(
[in] IdiscRecorder2* rec // zapisovalnik
);
(c) put_FileSystemToCreate(): povemo, katere oblike zapisa želimo kreirati: ISO 9660, Joliet ali
UDF. Možne so tudi kombinacije vseh treh. FsiFileSystems je naštevalni tip in je definiran:
FsiFileSystemNone=0, FsiFileSystemISO9660=1, FsiFileSystemJoliet=2, FsiFileSystemUDF=4,
FsiFileSystemUnknown=0x40000000.
HRESULT put_FileSystemsToCreate
(
[in] FsiFileSystems value // ISO9660, Joliet, UDF
);
(d) put_VolumeName(): povemo ime medija CD/DVD. Ime je vidno v Raziskovalcu, kadar je
medij vstavljen v pogon.
HRESULT put_VolumeName
(
[in] BSTR name // ime medija
);
(e) CreateResultImage(): pretvori mape in datoteke v obliko, primerno za zapis.
HRESULT CreateResultImage
(
[out] IfileSystemImageResult ** res // vrne obliko, primerno za zapis
);

Prakti�na uporaba algoritmov stiskanja podatkov 48
IFileSystemImageResult: vmesnik, ki omogo�a dostop do binarne datoteke, ki se
bo zapisala na medij CD/DVD. Datoteka je že v obliki, primerni za zapis. Objekta
ne moremo kreirati, dobimo ga kot rezultat metode CreateResultImage().
(a) get_ImageStream(): vrne binarno datoteko, do katere dostopamo preko vmesnika Istream.
HRESULT get_ImageStream
(
[out] Istream** stream // vrne binarno datoteko
);
IFsiDirectoryItem: vmesnik, ki omogo�a gradnjo datote�nega sistema (map in
datotek), ki jih bomo zapisali na medij CD/DVD. Vmesnika ni mogo�e kreirati,
dobimo ga kot rezultat razli�nih metod.
(a) AddTree(): v IfsiDirectoryItem doda celotno mapo, z vsemi podmapami in datotekami.
HRESULT AddTree
(
[in] BSTR path, // pot do mape
[in] BOOL include // TRUE, �e naj se mapa doda kot
); // podmapa
(b) AddDirectory(): v IFsiDirectoryItem doda mapo.
HRESULT AddDirectory
(
[in] BSTR path // ime mape
);
(c) AddFile(): v IFsiDirectoryItem doda datoteko.
HRESULT AddFile
(
[in] BSTR path, // pot do mape
[in] IStream* stream // datoteka
);

Prakti�na uporaba algoritmov stiskanja podatkov 49
IDiscFormat2Data: vmesnik, ki omogo�a zapis. Kreiramo ga z ukazom:
CComPtr<IDiscFormat2Data> dw;
HRESULT hr = dw.CoCreateInstance(CLSID_MsftDiscFormat2Data);
(a) Write(): zapiše podatke na medij CD/DVD.
HRESULT Write
(
[in] IStream* stream // datoteka, ki jo želimo zapisati
);
(b) put_ClientName(): ime programa, ki dostopa do zapisovalnika. Ime se mora ujemati z
imenom programa zaradi tega, ker se pri zapisovanju zahteva ekskluzivni dostop do
zapisovalnika (�eprav Microsoft trdi, da je lahko ime kakršnokoli, se izkaže, da mora biti enako
imenu programa, druga�e ekskluzivni dostop do zapisovalnika ni možen).
HRESULT put_ClientName
(
[in] BSTR name // ime programa
);
(c) put_Recorder(): povežemo zapisovalnik s fizi�nim pogonom CD/DVD.
HRESULT put_Recorder
(
[in] IDiscRecorder2* rec // fizi�ni pogon CD/DVD
);
Primer: preprostega programa, ki bo zapisal podatke na CD. Da bo primer bolj pregleden, bomo
zapisali zgolj osnovni postopek, brez obravnave napak, deklaracij metod itd. Preden nadaljujemo,
moramo v projektu v seznam datotek .h (»Header files«) dodati datoteki imapi2.h in imapi2fs.h (�e
imamo Windows XP in smo namestili dodatek, bi jih morali najti v mapi: C:\Program Files\Microsoft
SDKs\Windows\v6.1\Include\).
#include »imapi2.h« #include »imapi2fs.h« HRESULT hr=S_OK; CComBSTR volname("Test_ATL"); CComBSTR path("C:\\Temp\\Slike"); CComBSTR client(theApp.m_pszAppName); CComBSTR id;

Prakti�na uporaba algoritmov stiskanja podatkov 50
CComPtr<IDiscMaster2> dm; CComPtr<IDiscRecorder2> dr; CComPtr<IFileSystemImage> im; CComPtr<IDiscFormat2Data> dw; CComPtr<IFsiDirectoryItem> root=NULL; CComPtr<IFileSystemImageResult> res=NULL; CComPtr<IStream> stream=NULL; hr=dm.CoCreateInstance(CLSID_MsftDiscMaster2); hr=dr.CoCreateInstance(CLSID_MsftDiscRecorder2); hr=im.CoCreateInstance(CLSID_MsftFileSystemImage); hr=dw.CoCreateInstance(CLSID_MsftDiscFormat2Data); hr=dm->get_Item(0,&id); hr=dr->InitializeDiscRecorder(id); hr=dw->put_Recorder(dr); hr=dw->put_ClientName(client); hr=im->put_VolumeName(volname); hr=im->SetMaxMediaBlocksFromDevice(dr); hr=im->put_FileSystemsToCreate(FsiFileSystems::FsiFileSystemISO9660); hr=im->get_Root(&root); hr=root->AddTree(path,TRUE); hr=im->CreateResultImage(&res); hr=res->get_ImageStream(&stream); hr=dw->Write(stream);

Prakti�na uporaba algoritmov stiskanja podatkov 51
7 PROGRAM
Zahteve programa so že od samega za�etka bile, da mora podpirati ve�
razli�nih opravil: arhiviranje, obnovitev podatkov iz arhiva in zapisovanje na medije
CD/DVD. Upoštevali smo tudi možnost, da bo potrebno program neko� nadgraditi
in dodati funkcionalnost, ki trenutno ni podprta. Zato je program zgrajen
modularno.
7.1 Razredni diagrami
Strukturo smo si zamislili tako, da ima vsako opravilo svoj nabor razredov.
Razredi so razdeljeni po imenskih podro�jih (angl. Namespace). Ker se nahajajo v
lo�eni knjižnici, imenovani DipZipClasses, jih lahko enostavno vklju�imo v druge
projekte. To je možno tudi zaradi tega, ker smo se pri razvoju strogo držali pravila,
da morajo razredi predstavljati zgolj programsko logiko. Na ta na�in smo dosegli
neodvisnost med funkcionalnim in predstavitvenim delom programa.
DipZipClasses
Docs
Document
DocumentFolderDocumentItem
DocumentRoot
DocumentItemProgramDocumentItemArchiveDocumentItemDearchiveDocumentItemBackupDocumentItemBackupSettings
Zip
ZipArchiveZipCodecZipFileHeaderZipLocalFileHeaderZipEndOfCentralDir
Burn
BurnManager
Slika 7.1.1: Imenska podro�ja in razredi knjižnice DipZipClasses

Prakti�na uporaba algoritmov stiskanja podatkov 52
Imensko podro�je »Docs«: program shranjuje nastavitve v datoteko (dokument).
Razredi v imenskem podro�ju »Docs« nam omogo�ajo ravnanje z dokumenti:
odpiranje, shranjevanje in vzpostavljanje hierarhi�ne strukture dokumenta. Ker
nam služijo zgolj za predstavitev in urejanje opravil, jih na tem mestu ne bomo
podrobneje opisovali.
Slika 7.1.2: Razredni diagram (dokument)

Prakti�na uporaba algoritmov stiskanja podatkov 53
Imensko podro�je »Zip«: za kreiranje oz. odpiranje arhivskih datotek Zip
uporabljamo razred ZipArchive. Ostali razredi so pomožni in predstavljajo
posamezne gradnike datoteke ZIP.
Slika 7.1.3: Razredni diagram (arhiviranje)
Programski vmesnik razreda ZipArchive:
Public Property ExtractTo() As String
Mapa (celotna pot), kamor se bodo shranile datoteke pri obnovitvi podatkov.
Public Property ExtractWhat() As String
Ime datoteke ali vzorec, ki dolo�a, katere datoteke bodo obnovljene iz arhiva ZIP.
Privzeta vrednost je *.* za obnovitev vseh datotek v arhivu.

Prakti�na uporaba algoritmov stiskanja podatkov 54
Public Property Filename() As String
Ime (celotna pot) datoteke ZIP.
Public ReadOnly Property FilenameVersion() As String
Vrne ime datoteke ZIP z dodano verzijo datoteke. �e pri arhiviranju datoteka ZIP
že obstaja in je ne smemo prepisati, se dolo�i novo ime tako, da se na konec
prvotnega imena pripne verzija. Verzije se ozna�ujejo z A, B, C itd.
Public Property Overwrite() As Boolean
Nastavitev, ali lahko pri arhiviranju datoteko ZIP prepišemo, �e že obstaja.
Vrednost TRUE dolo�a, da se datoteka prepiše. Privzeta vrednost je FALSE;
datoteke ne smemo prepisati.
Public Sub AddArchiveCopy(ByVal Path As String)
Doda mapo v seznam map za dodatne kopije arhivske datoteke. Po arhiviranju je
možno shraniti dodatno kopijo arhivske datoteke v razli�ne mape, npr. na drug
disk ali ra�unalnik. Parametri:
• Path: mapa (celotna pot), kamor naj se po arhiviranju shrani dodatna kopija
arhivske datoteke.
Public Sub AddExclude(ByVal Path As String, ByVal Subfolders As Boolean)
V seznam doda ime datoteke ali vzorec, ki pove, katere datoteke naj program pri
arhiviranju presko�i. Parametri:
• Path: ime datoteke ali vzorec, npr. C:\Programi\*.exe
• Subfolders: vrednost TRUE dolo�a, da program preiš�e tudi vse podmape
Public Sub AddInclude(ByVal Path As String, ByVal Subfolders As Boolean)
V seznam doda ime datoteke ali vzorec, ki pove, katere datoteke naj program
arhivira. Parametri:
• Path: ime datoteke ali vzorec, npr. C:\Programi\*.*

Prakti�na uporaba algoritmov stiskanja podatkov 55
• Subfolders: vrednost TRUE dolo�a, da program preiš�e tudi vse podmape
Public Function Create() As Boolean
Kreira datoteko ZIP. �e je arhiviranje potekalo brez napak, vrne vrednost TRUE,
druga�e FALSE.
Public Function Extract() As Boolean
Obnovi datoteke iz arhiva ZIP. �e so bile vse datoteke v arhivu uspešno
obnovljene, vrne vrednost TRUE, druga�e FALSE.
Primer: opišimo, kako s programom izvedemo arhiviranje. Arhivirati želimo datoteko
C:\FERI\Diploma\Diploma.doc in podatke v mapi C:\Programi z vsemi podmapami, vendar ne
želimo arhivirati programov. Arhivska datoteka se bo imenovala Podatki_20090618.ZIP in jo želimo
kreirati v mapi C:\Arhiv. Dodatno kopijo arhivske datoteke želimo imeti v mapi F:\Backup, ki se
nahaja na izmenljivem disku.
Dim Zip As ZipArchive=New ZipArchive Zip.Filename="C:\Arhiv\Podatki_20090618.zip" Zip.AddArchiveCopy("F:\Backup\") Zip.AddInclude("C:\FERI\Diploma\Diploma.doc", False) Zip.AddInclude("C:\Programi\*.*", True) Zip.AddExclude("C:\Programi\*.exe", True) Zip.Create()
Za obnovitev datotek iz arhivske datoteke v mapo C:\Temp pišemo:
Dim Zip As ZipArchive=New ZipArchive Zip.Filename="C:\Arhiv\Podatki_20090618.zip" Zip.ExtractWhat="*.*" Zip.ExtractTo="C:\Temp\" Zip.Overwrite=True Zip.Extract()
Imensko podro�je »Burn«: zaradi znanih problemov pri uvozu knjižnic IMAPI v
ogrodje .Net smo morali dostop do vmesnikov IMAPI zagotoviti v jeziku C++.
Napisali smo komponento ATL COM, ki jo lahko uvozimo v ogrodje .Net in preko
nje posredno omogo�ili funkcionalnost zapisovanja na medije CD/DVD. Razred
BurnManager olajša komunikacijo med programom in komponento ATL COM.

Prakti�na uporaba algoritmov stiskanja podatkov 56
Slika 7.1.4: Razredni diagram (zapisovanje na medij CD/DVD)
Programski vmesnik razreda BurnManager:
Public ReadOnly Property LastError() As String
Vrne opis napake. IMAPI vra�a kodo napake, zato smo v komponenti ATL COM
poskrbeli za uporabniku bolj prijazen opis napake.
Public ReadOnly Property ListOfRejectedFiles() As List(Of
DipZipClasses.Docs.DocumentFile)
Vrne seznam zavrnjenih datotek. Pri dodajanju datotek v sliko IMAPI zapisa se
lahko zgodi, da je velikost datoteke ve�ja kot pa je prostora na mediju CD/DVD.
Public Property SelectedRecorder() As Integer
Zaporedna številka pogona CD/DVD, ki bo uporabljen pri zapisovanju. IMAPI
dostopa do pogonov preko številke pogona.
Public Property SessionLabel() As String
Oznaka seje zapisovanja. Ker je omogo�eno ve�kratno snemanje, lahko ima
vsako seja svojo oznako. Oznaka je vidna v Raziskovalcu, ko vstavimo medij
CD/DVD v pogon.
Public Sub AddFile(ByVal Path As String, Optional ByVal Subfolders As
Boolean = False)
V seznam datotek, ki �akajo na zapis, doda ime datoteke. Parametri:

Prakti�na uporaba algoritmov stiskanja podatkov 57
• Path: ime datoteke (polna pot)
• Subfolders: vrednost TRUE dolo�a, da program preiš�e tudi vse podmape
Public Function Burn() As Boolean
Zapiše datoteke na medij CD/DVD.
Public Sub Clear()
Pripravi BurnManager na novo sejo zapisovanja.
Public Function ListOfBurnDevices() As List(Of String)
Vrne seznam imen vseh pogonov CD/DVD, ki omogo�ajo zapisovanje.
Primer: opišimo, kako s programom izvedemo zapisovanje na medij CD/DVD. Zapisali bomo
arhivsko datoteko C:\Arhiv\Podatki_20090618.ZIP in sliko C:\Slike\LogarskaDolina.jpg. Ime seje
zapisovanja naj bo Podatki.
Dim Burner As BurnManager=New BurnManager Burner.Clear() Burner.SelectedRecorder=0 Burner.SessionLabel="Podatki" Burner.AddFile("C:\Arhiv\Podatki_20090618.zip") Burner.AddFile("C:\Slike\LogarskaDolina.jpg") Burner.Burn()
7.2 Predstavitev delovanja programa
Pri razvoju programa smo najve�ji poudarek namenili enostavnosti uporabe.
Program je smiselno razdeljen v štiri skupine opravil: zagon programov,
arhiviranje, obnovitev podatkov iz arhiva in kopiranje na CD/DVD. Vsaka skupina
je predstavljena z velikim gumbom. Kratek opis daje uporabniku namig glede
namembnosti.
Vse nastavitve je možno shraniti v datoteko (dokument). Program si zapomni
zadnji odprt dokument in ga ob naslednjem zagonu samodejno prebere. S tem
smo manj veš�im uporabnikom omogo�ili, da lahko takoj za�nejo z delom. Bolj

Prakti�na uporaba algoritmov stiskanja podatkov 58
izkušeni uporabniki pa imajo na voljo tudi ukaze za ravnanje z dokumenti:
kreiranje novega dokumenta, odpiranje že obstoje�ega dokumenta, shranjevanje
sprememb in shranjevanje dokumenta pod drugim imenom (kopija dokumenta).
Ime dokumenta je vidno v naslovni vrstici okna.
Slika 7.2.1: Pozdravno okno programa
Dokument je možno organizirati v sistem map in podmap, ki jih lahko uporabnik
poljubno odpira in s tem doseže ve�jo preglednost. Uporabniški vmesnik je, ne
glede na opravilo, vedno enak in ga je enostavno osvojiti. Na levi strani okna so
prikazane mape, na desni pa vsa opravila, ki se nahajajo v izbrani mapi. Za lažje
prepoznavanje vsako opravilo prikaže ime in kratek opis. Pri programih je dodatno
prikazana še ikona programa. Opis se z ve�jimi �rkami izpiše tudi v statusni vrstici
na dnu okna, �e potujemo s kazalcem miške preko opravila. Opravilo poženemo z
dvoklikom miške ali z izbiro iz kontekstnega menuja.

Prakti�na uporaba algoritmov stiskanja podatkov 59
Slika 7.2.2: Okno z opravili za zagon programov
Izbrana mapa oz. vsa izbrana opravila so obarvana oranžno in se jasno lo�ijo
od ostalih elementov. Medtem ko lahko izberemo samo posamezno mapo, pri
opravilih te omejitve ni. Izbiranje ve� opravil je v skladu s standardi v okolju
Windows:
• s tipko SHIFT in klikom miške za izbiranje ve� zaporednih elementov
hkrati.
• s tipko CTRL in klikom miške za izbiranje posameznih elementov.
Na vrhu okna smo dodali priro�en menu, ki uporabniku omogo�a, da od
koderkoli doseže vse funkcije programa z enim klikom miške. Tako mu ni treba
nazaj na prvo stran, da bi zamenjal opravilo.
Zagon programov in datotek: omogo�a hiter dostop do najpogosteje
uporabljanih programov in datotek. Program/datoteka se odpre v novem oknu.
Arhiviranje podatkov: na enostaven na�in arhiviramo podatke (datoteke), ne da

Prakti�na uporaba algoritmov stiskanja podatkov 60
bi pri tem morali poznati podrobnosti. Napredek arhiviranja lahko opazujemo v
novem oknu. Le-ta prikazuje ime datoteke, ki se trenutno arhivira ter procent
kon�anega dela. Za bolj nazorno predstavitev se procent kon�anega dela izrisuje
tudi grafi�no.
Slika 7.2.3: Napredek arhiviranja
Arhiviranje je možno med izvajanjem tudi preklicati, kar pa ne pomeni, da bo
arhivska datoteka neuporabna. Program bo samo prej zaklju�il z delom in izpisal
opozorilo, da vse datoteke niso bile arhivirane.
Dodatno vrednost predstavlja samodejno arhiviranje, ki ga je možno pognati ob
vnaprej dolo�enem �asu s pomo�jo Razporejevalnika opravil (sistemski program v
okolju Windows). Recimo, da želimo arhiviranje izvajati vsak dan ob 22:00. Najprej
moramo v lastnostih arhiviranja ozna�iti »Omogo�i samodejni zagon« in pod
»Oznaka za samodejni zagon« vpisati oznako, npr. dnevno. Nato v
Razporejevalniku opravil definiramo novo opravilo, ki zažene program vsak dan ob
22:00. Kot parameter ob zagonu programa podamo /a:dnevno.
Obnovitev podatkov iz arhiva: opravilo prekrije trenutne podatke s starejšo
razli�ico, zato moramo biti pri uporabi te izbire še posebej pazljivi. Priporo�amo
arhiviranje trenutnih podatkov in šele nato obnovitev.
Ob zagonu opravila moramo najprej izbrati arhivsko datoteko, iz katere bomo
obnavljali podatke. Za lažje iskanje so arhivske datoteke organizirane po letu in
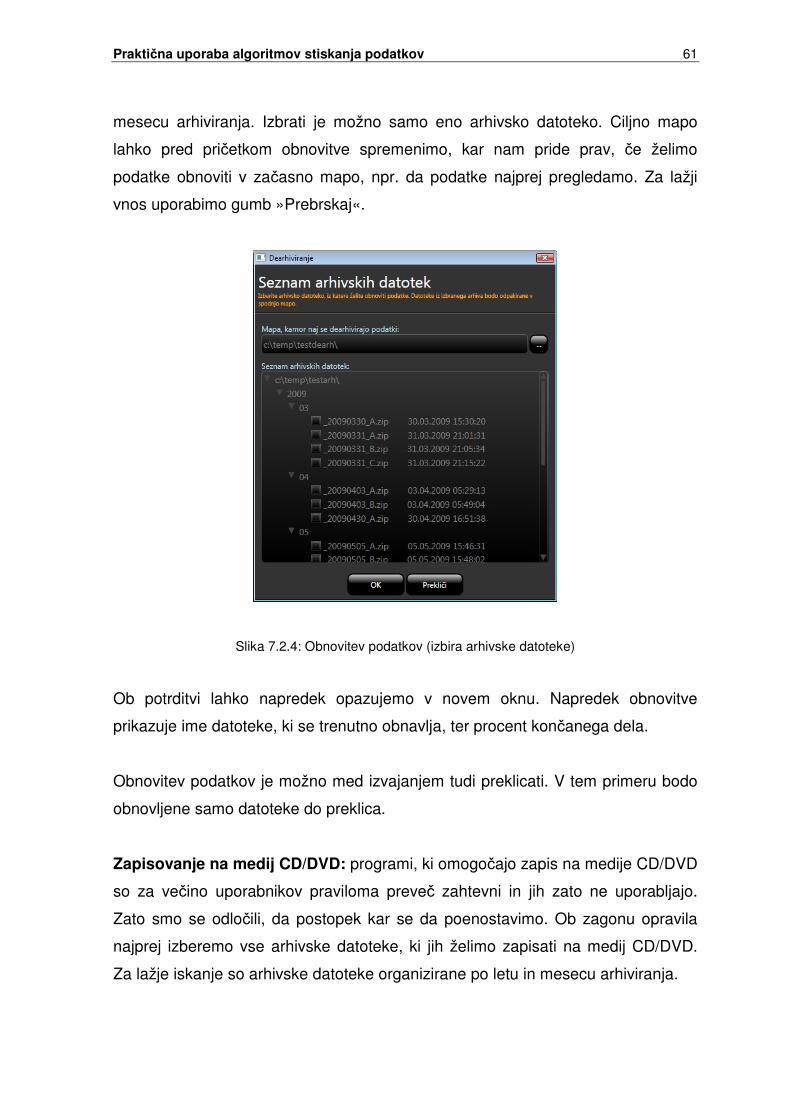
Prakti�na uporaba algoritmov stiskanja podatkov 61
mesecu arhiviranja. Izbrati je možno samo eno arhivsko datoteko. Ciljno mapo
lahko pred pri�etkom obnovitve spremenimo, kar nam pride prav, �e želimo
podatke obnoviti v za�asno mapo, npr. da podatke najprej pregledamo. Za lažji
vnos uporabimo gumb »Prebrskaj«.
Slika 7.2.4: Obnovitev podatkov (izbira arhivske datoteke)
Ob potrditvi lahko napredek opazujemo v novem oknu. Napredek obnovitve
prikazuje ime datoteke, ki se trenutno obnavlja, ter procent kon�anega dela.
Obnovitev podatkov je možno med izvajanjem tudi preklicati. V tem primeru bodo
obnovljene samo datoteke do preklica.
Zapisovanje na medij CD/DVD: programi, ki omogo�ajo zapis na medije CD/DVD
so za ve�ino uporabnikov praviloma preve� zahtevni in jih zato ne uporabljajo.
Zato smo se odlo�ili, da postopek kar se da poenostavimo. Ob zagonu opravila
najprej izberemo vse arhivske datoteke, ki jih želimo zapisati na medij CD/DVD.
Za lažje iskanje so arhivske datoteke organizirane po letu in mesecu arhiviranja.

Prakti�na uporaba algoritmov stiskanja podatkov 62
Slika 7.2.5: Kopiranje na CD/DVD (izbira arhivske datoteke)
Preden za�nemo z zapisovanjem, moramo izbrati še osnovne nastavitve zapisa.
Program predlaga najbolj verjetne vrednosti, tako da v ve�ini primerov predlagane
vrednosti samo potrdimo:
• CD/DVD zapisovalnik izbiramo, �e jih je nameš�enih ve�. Program
predlaga prvega, ki ga najde.
• Ker je omogo�eno ve�kratno snemanje, lahko za vsako sejo zapisovanja
podamo drugo oznako. Oznaka je vidna v Raziskovalcu, ko vstavimo medij
CD/DVD v pogon. Ve�ina programov zna prikazati samo vsebino zadnje
seje zapisovanja. Privzeta oznaka se sestoji iz trenutnega datuma.
• Seznam arhivskih datotek smo pridobili z izbiro v prejšnjem koraku. Pred
zapisom imamo možnost, da katero od datotek izlo�imo, ne da bi morali
nazaj na izbiro.
• Statusna vrstica prikazuje opis ter grafi�ni prikaz napredka.

Prakti�na uporaba algoritmov stiskanja podatkov 63
Slika 7.2.6: Zapisovanje na medij CD/DVD (prikaz napredka)
Postopek zapisovanja je možno med izvajanjem tudi preklicati, vendar tega ne
priporo�amo, ker bo medij CD/DVD neuporaben. Razlog je v samem postopku
zapisovanja. Pred zapisovanjem se kreira binarna slika zapisa, na za�etku katere
se nahaja kazalo, ki mu sledijo datoteke. Slika se potem v enem kosu zapiše na
medij CD/DVD. �e postopek vmes prekinemo, bomo zapisali nepopolno kazalo ali
pa bo le-to kazalo na datoteke, ki niso bile zapisane. Tako bodo v najboljšem
primeru datoteke vidne v Raziskovalcu, vendar do njih ne bo možno dostopati.
7.3 Parametri za samodejni zagon
�e program poženemo brez parametrov, preidemo v interaktivni na�in, kjer
sami komuniciramo z uporabniškim vmesnikom: izbiramo vrsto opravila, ro�no
zaganjamo opravila itd. Program omogo�a tudi izvajanje v ozadju, brez
uporabniškega vmesnika. V ta namen moramo v ukazni vrstici podati stikala, ki
programu povedo, kaj naj stori. Stikalo mora biti podano v obliki /x:vrednost, kjer x
predstavlja oznako akcije. Možno je podati ve� stikal hkrati. Stikala, ki jih program
prepoznava so:

Prakti�na uporaba algoritmov stiskanja podatkov 64
• /d:ime dokumenta: naloži dokument s podanim imenom.
• /a:oznaka: zaženi vsa opravila arhiviranja s podano oznako.
• /p:oznaka: zaženi vse programe s podano oznako.
Ko so vsa samodejna opravila kon�ana, se program sam zapre.

Prakti�na uporaba algoritmov stiskanja podatkov 65
8 ZAKLJU�EK
Izdelava diplomskega dela nas je obogatila z mnogimi novimi znanji, saj je bilo
potrebno veliko raziskovalnega dela na razli�nih podro�jih. Zastavljeni cilj se je
izkazal za zelo interdisciplinarnega. V teoreti�nem delu diplomskega dela smo
tako obdelali nekatere kodirne tehnike, ra�unanje kode CRC, strukturo datotek ZIP
po predpisani specifikaciji ter vmesnike IMAPI za zapisovanje na medije CD/DVD.
Prakti�ni del diplomskega dela predstavlja program, s katerim smo teoreti�no
znanje povezali med sabo. Program omogo�a arhiviranje, obnovitev podatkov in
zapisovanje na medije CD/DVD. Da je program odziven tudi med izvajanjem
opravil, ki trajajo dalj �asa, npr. arhiviranje, smo morali vsa opravila napisati tako,
da izrabljajo mo� porazdeljenega izvajanja (angl. multithreaded execution).
Grafi�ni vmesnik temelji na novem Microsoftovem konceptu programiranja,
WPF (angl. Windows Presentation Foundation), ki je bil prvi� uporabljen pri
operacijskem sistemu Windows Vista. Glavna prednost WPF je, da popolnoma
lo�uje programsko logiko od predstavitvenega nivoja. V ta namen je nastal nov
deklarativni programski jezik XAML (angl. Extensible Application Markup
Language), s katerim definiramo izgled okna. Izgled se shrani v lo�eno datoteko s
kon�nico .xaml. Jezik ima tudi mo�no podporo za multimedijske vsebine in
vizualne u�inke, kar smo v programu izdatno izkoristili.
Program je nastal zaradi nenehnega povpraševanja uporabnikov, ki so želeli
enostavno rešitev za arhiviranje podatkov in zapis arhivskih datotek na medije
CD/DVD, ki bi služili kot varnostna kopija. Že pri na�rtovanju smo imeli v mislih
razli�ne izboljšave in dodatke, ki bi ga naredili še bolj uporabnega, zato je program
napisan modularno. Nakažimo nekaj izboljšav:

Prakti�na uporaba algoritmov stiskanja podatkov 66
• Arhivska datoteka trenutno ne podpira arhivov ve�jih od 4 GB. Razlog
ti�i v tem, da je odmik, na katerem se nahaja datoteka znotraj arhiva,
podan s štirimi zlogi (najve�ji odmik je tako 232 = 4 GB). Specifikacija
datoteke ZIP dolo�a dodatne strukture, kjer so vsa števila predstavljena
z osmimi zlogi (264). Program bi lahko uporabil te strukture ali pa težavo
rešil s segmentiranjem (razbitjem arhivske datoteke na ve� datotek).
• Podatkov v arhivski datoteki trenutno ni možno zaš�ititi z geslom.
Specifikacija datoteke ZIP predpisuje, kako je potrebno shraniti geslo in
kako kodirati podatke, �e je geslo podano. Program bi lahko ob uporabi
gesla samodejno kodiral podatke.
• Pri zapisovanju na pogon CD/DVD ni možno podati hitrosti zapisovanja.
Zaradi enostavnosti uporabe smo to opcijo izpustili, ker ve�ina
zapisovalnikov deluje brez napak tudi pri najvišji hitrosti. Problem bi
lahko nastopil pri starejših zapisovalnikih.
• Kadar se opravilo izvaja v ozadju preko Razporejevalnika opravil,
uporabnik ne vidi, ali je šlo kaj narobe. Program bi lahko poslal sporo�ilo
po elektronski pošti enemu ali ve� prejemnikom.
• Program bi lahko omogo�al, da se arhivske datoteke pošiljajo preko
interneta na strežnik. Postopek bi bilo možno avtomatizirati. V ta namen
bi na strežniku definirali spletno storitev, preko katere bi shranjevali
poslane datoteke. Opcija bi bila dostopna samo uporabnikom, ki bi
izrazili željo po takšnem arhiviranju.
• Ker stranke uporabljajo tudi naše druge programe, bi program lahko
omogo�al posodobitve programov, obveš�anje o novostih, popravkih itd.
V ta namen bi pridobival podatke od spletnega strežnika.

Prakti�na uporaba algoritmov stiskanja podatkov 67
LITERATURA
[1] D. Salomon, Data compression, The complete reference, 3. izd., Springer-
Verlag, New York, 2004
[2] P. Deutsch, RFC 1951: Deflate compressed data format specification,
Network Working Group, 1996
[3] A. Feldspar, An explanation of Deflate algorithm,
http://www.gzip.org/deflate.html
[4] Wikipedia, Deflate, http://en.wikipedia.org/wiki/DEFLATE
[5] PKWare Inc., .ZIP File Format Specification ver. 6.3.2, 1989-2007,
http://www.pkware.com/documents/casestudies/APPNOTE.TXT
[6] R. N. Williams, A painless guide to CRC error detection algorithms, ver. 3,
Rocksoft Pty Ltd, 1993
[7] Reliable Software, Cyclic Redundancy Check,
http://www.relisoft.com/Science/CrcMath.html
[8] Microsoft Visual Studio 2008 Documentation, Image Mastering API, Microsoft
Corp., 2007
[9] Standard ECMA-130: Data interchange on read-only 120mm optical data
disks (CD-ROM), 2. izd., 1996
[10] Standard ECMA-119: Volume and File Structure of CD-ROM for information
Interchange, 2. izd., 1998
[11] Microsoft Visual Studio 2008 Documentation, Windows Presentation
Foundation, Microsoft Corp., 2008

Prakti�na uporaba algoritmov stiskanja podatkov 68
PRILOGA A: Seznam slik
Slika 2.2.1: Algoritem LZ77 (prazen slovar) ................................................................................... 7
Slika 2.2.2: Algoritem LZ77 (prvi korak) ......................................................................................... 7
Slika 2.2.3: Algoritem LZ77 (po nekaj korakih) .............................................................................. 7
Slika 2.2.4: Algoritem LZ77 (nadaljevanje)..................................................................................... 8
Slika 2.2.5: Algoritem LZ77 (zadnji korak)...................................................................................... 8
Slika 2.3.1: Huffmanovo kodiranje (prvi korak) ............................................................................ 10
Slika 2.3.2: Huffmanovo kodiranje (drugi korak) .......................................................................... 10
Slika 2.3.3: Huffmanovo kodiranje (tretji korak) ........................................................................... 10
Slika 2.3.4: Huffmanovo kodiranje (�etrti korak) .......................................................................... 11
Slika 2.3.5: Huffmanovo kodiranje (peti korak) ............................................................................ 11
Slika 2.3.6: Huffmanovo kodiranje (šesti korak)........................................................................... 12
Slika 2.3.7: Huffmanovo kodiranje (sedmi korak)......................................................................... 12
Slika 2.3.8: Huffmanovo kodiranje (osmi korak)........................................................................... 12
Slika 2.3.9: Huffmanovo kodiranje (deveti korak)......................................................................... 13
Slika 2.3.10: Huffmanovo kodiranje (deseti korak)......................................................................... 13
Slika 2.3.11: Huffmanovo kodiranje (zadnji korak)......................................................................... 14
Slika 3.1: Algoritem Deflate (izboljšano iskanje v slovarju) ....................................................... 16
Slika 5.1: Primer seštevanja in odštevanja dveh števil v aritmetiki CRC .................................. 35
Slika 5.2: Primer množenja dveh števil v aritmetiki CRC .......................................................... 36
Slika 5.3: Primer deljenja dveh števil v aritmetiki CRC ............................................................. 37
Slika 7.1.1: Imenska podro�ja in razredi knjižnice DipZipClasses ............................................... 51
Slika 7.1.2: Razredni diagram (dokument) ................................................................................... 52
Slika 7.1.3: Razredni diagram (arhiviranje) .................................................................................. 53
Slika 7.1.4: Razredni diagram (zapisovanje na medij CD/DVD) .................................................. 56
Slika 7.2.1: Pozdravno okno programa ........................................................................................ 58
Slika 7.2.2: Okno z opravili za zagon programov......................................................................... 59
Slika 7.2.3: Napredek arhiviranja ................................................................................................. 60
Slika 7.2.4: Obnovitev podatkov (izbira arhivske datoteke) ......................................................... 61
Slika 7.2.5: Kopiranje na CD/DVD (izbira arhivske datoteke) ...................................................... 62
Slika 7.2.6: Zapisovanje na medij CD/DVD (prikaz napredka)..................................................... 63

Prakti�na uporaba algoritmov stiskanja podatkov 69
PRILOGA B: Seznam tabel
Tabela 2.3.1: Huffmanove kode za primer »Ra�unalnik ra�una « .................................................. 14
Tabela 3.1: Tabela Count[5] - število kod glede na njihovo dolžino............................................. 17
Tabela 3.2: Tabela NextCode[5] z za�etnimi kodami za posamezne dolžine.............................. 18
Tabela 3.3: Kanoni�ne Huffmanove kode .................................................................................... 18
Tabela 3.1.1: Kodna tabela za dolžine ujemanja ............................................................................ 20
Tabela 3.1.2: Huffmanove kode za literale/dolžine ujemanja.......................................................... 20
Tabela 3.1.3: Huffmanove kode za odmike ..................................................................................... 21
Tabela 3.2.1: Huffmanove kode in kanoni�ne Huffmanove kode za literale/dolžine....................... 25
Tabela 3.2.2: Huffmanove kode in kanoni�ne Huffmanove kode za zaporedje RLE...................... 26
Tabela 5.1: Tabela nekaterih standardnih deliteljev..................................................................... 38

Prakti�na uporaba algoritmov stiskanja podatkov 70
PRILOGA C: Vsebina zgoš�enke
Priložena zgoš�enka vsebuje besedilo diplome v obliki datoteke PDF: diploma.pdf.
V mapi »Program« se nahaja namestitveni paket za program DipZip, ki omogo�a
arhiviranje v datoteke ZIP. V mapi sta dve datoteki: DipZipSetup.msi in program
Setup.exe. Program DipZip namestimo z zagonom programa Setup.exe.
Uporabniki WinXP: pri zapisovanju na medije CD/DVD uporabljamo vmesnik
IMAPI 2.0, ki ni del operacijskega sistema WinXP, zato ga je potrebno posebej
namestiti. Namestitveni paket dobite na Microsoftovih straneh za podporo:
http://support.microsoft.com/kb/932716.
Uporabniki starejših razli�ic: za starejše razli�ice operacijskih sistemov
Windows vmesnik IMAPI 2.0 ni podprt.





























