Embed Size (px)
Citation preview

UNIVERZA V LJUBLJANI
SKUPNI INTERDISCIPLINARNI PROGRAM DRUGE STOPNJE
KOGNITIVNA ZNANOST
V SODELOVANJU Z UNIVERSITAT WIEN,
UNIVERZITA KOMENSKEHO V BRATISLAVE IN
EOTVOS LORAND TUDOMANYEGYETEM
Benjamin Fele
Pridobivanje in uporaba metaznanja za ucinkovitejso izbiro ucnihprimerov
Magistrsko delo
Ljubljana, 2020

UNIVERZA V LJUBLJANI
SKUPNI INTERDISCIPLINARNI PROGRAM DRUGE STOPNJE
KOGNITIVNA ZNANOST
V SODELOVANJU Z UNIVERSITAT WIEN,
UNIVERZITA KOMENSKEHO V BRATISLAVE IN
EOTVOS LORAND TUDOMANYEGYETEM
Benjamin Fele
Pridobivanje in uporaba metaznanja za ucinkovitejso izbiro ucnihprimerov
Magistrsko delo
Mentor: izr. prof. dr. Danijel Skocaj
Ljubljana, 2020

Zahvala
Profesorju Danijelu Skocaju za
konstruktivno usmerjanje razvoja
magistrskega dela,
Eli Praznik za poslusanje mojega
kontempliranja in
starsem za podporo tekom
studija.

PovzetekPodrocje umetne inteligence je bilo v svoji zgodovini veckrat navdahnjeno s clovesko kognicijo.
V tem magistrskem delu vzamemo visokonivojski pogled na metakognicijo in implementiramo
sistem s podobnimi karakteristikami. Nasa motivacija za to je dveh vrst: prva izhaja iz zelje
po prispevku k metodam strojnega ucenja, natancneje polnadzorovane klasifikacije, druga pa iz
moznosti primerjave ucenja ljudi in umetnih sistemov. Nas sistem skladno z literaturo razde-
limo na objektni in meta del, pri cemer s prvim resujemo klasifikacijski problem, z drugim pa
z dolocanjem pragov prepricanosti v napovedi izbiramo ucne primere glede na znanje prvega.
Podobno kot pri ljudeh se tudi v nasem sistemu ucnih strategij naucimo skozi nabiranje znanja
o resevanju problema, za kar uporabimo spodbujevalno ucenje. Pri nacrtovanju nasega sistema
je eno izmed pomembnih vodil splosnost, zaradi cesar eksperimente izvedemo z variiranjem ar-
hitektur klasifikatorjev (nevronskih mrez) in podatkovnih zbirk. Sistem ucimo tako od zacetka,
kot tudi s prenosom znanja z enega problema na drugega. Pridobimo mesane rezultate, ki so
v najvecji meri odvisni od ucinkovitosti nasega pristopa k polnadzorovanemu ucenju. Ob pri-
merjavi nase metode z “naivnimi” pristopi dobimo najvec 1 % slabse, pogosto pa tudi boljse
rezultate kot pri uporabi pragov, najdenih z nakljucnim iskanjem. S prenosom ucnih strategij iz
enega problema na drugega za 80 % zmanjsamo cas, potreben za resitev problema izbire ucnih
primerov ter dobimo primerljive rezultate kot pri ucenju od zacetka. Z nasim delom pokazemo,
da se je v danem okviru ucnega nacrta mogoce nauciti in da le-ta pohitri ucenje, ter da je izbira
ucnih primerov z uporabo metaznanja eden od ucinkovitih pristopov za uspesno ucenje klasi-
fikatorjev. Nastete lastnosti so tudi kljucne podobnosti implementiranega sistema s cloveskim
ucenjem.
Kljucne besede: klasifikacija, metakognicija, metaucenje, polnadzorovano ucenje, prenos znan-
ja, spodbujevalno ucenje, ucni nacrt

AbstractThe field of artificial intelligence has been throughout its history repeatedly inspired by human
cognition. In this master’s thesis, we take a high-level view of meta-cognition and implement
a system with similar characteristics. Our motivation for this is of two kinds: the first stems
from the desire to contribute to machine learning methods, more specifically semi-supervised
classification, and the second from the ability to compare human learning and artificial sy-
stems. According to the literature, our system is divided into object and meta parts, with the
former solving the classification problem, and the latter selecting learning examples based on
its knowledge by determining the appropriate confidence thresholds. Similarly to humans, we
learn learning strategies in our system through the accumulation of knowledge about solving
a particular problem, for which we use reinforcement learning. While designing our system,
one of the important guidelines is generality, which is why we perform experiments by varying
the architectures of classifiers (neural networks) and datasets. We train the system both from
the beginning and by transferring knowledge from one problem to another. We obtain mixed
results that depend largely on the effectiveness of our approach to semi-supervised learning.
When comparing our method with “naive” approaches, we get at most 1% worse, but often bet-
ter results than using confidence thresholds found by random search. By transferring learning
strategies from one problem to another, we reduce the time required to solve the sample selec-
tion problem by 80% and obtain comparable results as when learning from the beginning. Our
work shows that it is possible to learn a curriculum within a given framework, that it accelerates
learning and that the selection of learning samples using meta-knowledge is one of the effective
approaches for successful classifier training. The listed properties are also key similarities of
the implemented system when compared to human learning.
Keywords: classification, curriculum, meta-cognition, meta-learning, reinforcement learning,
semi-supervised learning, transfer learning

Kazalo
1 Uvod 1
2 Pregled podrocja 3
2.1 Sorodno delo s podrocja strojnega ucenja . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Pristopi k modeliranju ucnega procesa . . . . . . . . . . . . . . . . . . 3
2.1.2 Metaucenje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.3 Polnadzorovano ucenje . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.4 Spodbujevalno ucenje . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.5 Prenos znanja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Navezava na kognitivno psihologijo . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Metakognicija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.2 Lastnosti metakognitivnih procesov in ucenja . . . . . . . . . . . . . . 15
2.2.3 Relacija med tezavnostjo, spretnostjo in zanimivostjo naloge . . . . . . 16
2.3 Kibernetika kot okvir za primerjavo cloveske kognicije in nasega sistema . . . 18
2.4 Navezava na nase raziskave . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3 Metoda 20
3.1 Osnovni problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.1.1 Inicializacija parametrov klasifikatorja . . . . . . . . . . . . . . . . . . 22
3.1.2 Posodabljanje ciljnih razredov neoznacenih ucnih primerov . . . . . . 22
3.1.3 Generiranje stanj . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1.4 Oblikovanje ucnih mnozic . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.5 Ucenje klasifikatorja . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2 Metaproblem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2.1 Ucenje meta-agenta . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3 Prenos znanja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28

4 Zasnova eksperimentov 30
4.1 Potek ucenja sistema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2 Hiperparametri . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.3 Podatki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.4 Arhitekture nevronskih mrez . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.4.1 Arhitekture nevronskih mrez klasifikatorjev . . . . . . . . . . . . . . . 35
4.4.2 Arhitekture nevronskih mrez za resevanje metaproblema . . . . . . . . 37
4.5 Vrednotenje rezultatov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5 Eksperimentalni rezultati 41
5.1 Ucenje ucnih strategij . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.1.1 Ucenje klasifikatorja . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.1.2 Rezultati ucenja meta-agenta . . . . . . . . . . . . . . . . . . . . . . . 48
5.2 Prenos ucnih strategij . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2.1 Prenos brez uglasevanja na ciljni problem . . . . . . . . . . . . . . . . 52
5.2.2 Prenos z uglasevanjem na ciljni problem . . . . . . . . . . . . . . . . . 53
5.2.3 Prenos s povecevanjem stevila oznacenih ucnih primerov . . . . . . . . 54
5.3 Diskusija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.3.1 Diskusija rezultatov iz prejsnjih poglavij . . . . . . . . . . . . . . . . . 56
5.3.2 Primerjava s cloveskim ucenjem . . . . . . . . . . . . . . . . . . . . . 58
6 Zakljucek 61
Literatura 63

1 Uvod
Strojno ucenje se v mnogih pogledih odvija s pomocjo podobnih mehanizmov kot ucenje ljudi.
Tako na primer ucni nacrt oziroma stopnjevanje tezavnosti danega problema, ki je kljucen za
uspesen razvoj otrok (Oudeyer et al., 2007), pripomore tudi k ucenju nevronskih mrez (Bengio
et al., 2009). Za hitrejse ucenje ljudi je kljucno tudi raziskovanje, ki je pomembna tema tudi na
podrocju spodbujevalnega ucenja (Oudeyer in Kaplan, 2008). V zelji po raziskovanju splosnih
mehanizmov, ki pripomorejo k boljsi generalizaciji pri ljudeh in imajo moznost uporabe v
okviru strojnega ucenja, se v tem magistrskem delu obrnemo na metakognicijo in z njo po-
vezane procese. Nase delo izvira iz uporabe visokonivojskih idej s podrocja kognitivne psiho-
logije, ki jih uporabimo za snovanje novega pristopa k resevanju klasifikacijskih problemov. Pri
tem je eno izmed glavnih vodil nase metode splosnost, ki za delovanje predpostavlja cim manj
lastnosti podatkovnih zbirk ter uporabljenih arhitektur klasifikatorjev.
Posluzujemo se dveh pristopov, katerih motivacija za uporabo na podrocju strojnega ucenja je
zmanjsanje kolicine eksplicitnega znanja, podanega s strani raziskovalca ali uporabnika: spod-
bujevalnega in polnadzorovanega ucenja. Polnadzorovano ucenje izkorisca neoznaceno ucno
mnozico za dvig koncne klasifikacijske tocnosti (Zhu in Goldberg, 2009), medtem ko spodbu-
jevalno ucenje problem modelira le s pomocjo nagrade brez eksplicitno podanih resitev. Oba
pristopa imata ustreznika na podrocju cloveskega ucenja; spodbujevalno ucenje se pogosto pri-
merja s klasicnim pogojevanjem (Dayan in Abbott, 2001), polnadzorovano ucenje pa je nacin
prejemanja znanja v vsakdanjem zivljenju ljudi (Gibson et al., 2013; Zhu in Goldberg, 2009).
Ucenje ljudi pogosto poteka z vpogledom v potek resevanja ter kognitivne procese, povezane
s tem (Flavell, 1979). Poleg dveh v prejsnjem odstavku omenjenih znacilnosti, ki si jih delijo
cloveski in umetni sistemi, v nasem delu tako uvedemo se tretjo; pridobivanje in uporaba meta-
znanja. To je v sklopu strojnega ucenja povezano s podrocjem metaucenja, ki zajema zbiranje
in ucenje iz podatkov o poteku resevanju nekega drugega problema (Lemke et al., 2015).
V sklopu te magistrske naloge zelimo nastete lastnosti na inovativen zdruziti z resevanjem pol-
nadzorovanega klasifikacijskega problema ter pridobivanjem in uporabo metaznanja s spodbu-
jevalnim ucenjem. Arhitekturo nasega sistema razdelimo na dva dela; objektnega in meta, kjer
je prvi zadolzen za resevanje klasifikacijskega problema, drugi pa skrbi za izbiro primernih
ucnih primerov za ucenje prvega in s tem resuje metaproblem. Komponenti ustrezata meta in
objektnemu nivoju procesiranja pri ljudeh, ki ju nadalje opisemo v razdelku 2.2.1.
V nasem sistemu je metanivo zadolzen za oblikovanje ucnih strategij, ki se odrazijo v uspesnosti
resevanja klasifikacijskega problema na objektni ravni. Ucne strategije so udejanjene s postav-
ljanjem pragov prepricanosti, prek katerih so izbrani neoznaceni ucni primeri. Razvoj sistema,
ki taksno ucenje omogoca, je prvi izmed treh ciljev tega magistrskega dela. Poleg tega je nas
1

cilj tudi izvedba eksperimentov prenosa metaznanja med razlicnimi klasifikacijskimi problemi,
za katerega raziskave kazejo, da je v dolocenih pogojih prisotno tudi pri ljudeh in zivalih. Ta
in ostale lastnosti sluzijo kot iztocnice za primerjavo rezultatov nasega sistema z ugotovitvami
kognitivne psihologije, opisanimi v razdelku 2.2.2; to je tretji cilj te magistrske naloge.
Nekatera sorodna dela, ki jih opisujemo v podpoglavju 2.1, ze zdruzujejo polnadzorovano,
spodbujevalno in metaucenje (Wu et al., 2018; Chen et al., 2018; Buchler et al., 2018). Nasa
metoda ima vec podobnosti z omenjenimi deli, a je po drugi strani relativno neodvisna od izbire
arhitekture klasifikatorja in podatkovne zbirke. Pri prenosu metaznanja z enega problema na
drugega implementiramo pristop, podoben metodi avtorjev Julian et al. (2020), ki kljub rela-
tivni enostavnosti bistveno zmanjsa stevilo potrebnih iteracij za najdbo resitve.
Nadaljnja poglavja imajo sledeco strukturo: poglavje 2 predstavlja pregled sorodnih del, ki ga
zacnemo z deli iz podrocja strojnega ucenja (podpoglavje 2.1), cemur sledi pregled relevan-
tne literature s podrocja kognitivne psihologije (podpoglavje 2.2), ki sestoji iz opisov modelov
ucenja in metakognicije ter predstavitve relacije med tezavnostjo, spretnostjo in zanimivostjo
pri resevanju problemov. V poglavju 3 opisemo naso metodo, ki je razdeljena na opis ucenja
klasifikatorja (podpoglavje 3.1), resevanja metaproblema (podpoglavje 3.2) in prenosa znanja
(podpoglavje 3.3). V poglavju 4 opisemo uporabljene arhitekture nevronskih mrez, podatkovne
zbirke, hiperparametre in zasnovo eksperimentov. Nadalje v poglavju 5 predstavimo rezultate,
cemur sledita diskusija (podpoglavje 5.3) ter zakljucek (poglavje 6).
2

2 Pregled podrocja
Nase delo spaja podrocji strojnega ucenja in kognitivne psihologije. Modeli metakognicije,
katerih pregled ponudimo v podpoglavju 2.2, sluzijo kot baza, na podlagi katere delimo kom-
ponente nasega sistema, ter opisujejo nekatere predpostavke, ki veljajo tudi za nase delo. Opi-
sani modeli metakognicije torej sluzijo kot ogrodje, ki ga uporabimo za oblikovanje metode,
ki spada na podrocje strojnega ucenja. Z vidika slednjega se posluzujemo metod polnadzo-
rovanega, spodbujevalnega in metaucenja ter prenosa znanja, ki jih opisujemo v podpoglavju
2.1.
V podpoglavju 2.2 poleg modelov metakognicije opisujemo tudi tokovni model in ucenje po
ucnem nacrtu, katerih lastnosti postavljajo temelje odlocitev o nacinu implementacije pripa-
dajocih delov nasega sistema.
2.1 Sorodno delo s podrocja strojnega ucenja
Problem, ki ga resujemo, lahko razdelimo na vec podproblemov, kjer vsak ustreza skupini pri-
stopov s podrocja strojnega ucenja. Kot bo postalo jasno v nadaljevanju, ti pristopi pogosto za
uresnicevanje podobnih ciljev uporabljajo razlicna imena in so med seboj povezani.
Magistrsko delo se dotika podrocij kot so sledenje znanju (angl. knowledge tracing) in ucenje po
ucnem nacrtu (angl. curriculum learning), ki so opisani v razdelku 2.1.1. Sledi opis metaucenja
(razdelek 2.1.2), pregledi polnadzorovanega (razdelek 2.1.3) in spodbujevalnega ucenja (razde-
lek 2.1.4) ter prenosa znanja (razdelek 2.1.5).
2.1.1 Pristopi k modeliranju ucnega procesa
Modeliranje vrstnega reda ucnih primerov, iz katerih se racunalniski model uci, je mogoce
resevati z vec pristopi, katerih osrednji cilj je pohitritev ali izboljsanje tocnosti modelov z obli-
kovanjem ucnega procesa. Tovrstna dela je mogoce uvrstiti na podrocja aktivnega ucenja (Gal
et al., 2017; Majnik in Skocaj, 2013; Yu et al., 2017; Skocaj et al., 2012; Amiri, 2019) in ucenja
po ucnem nacrtu (Bengio et al., 2009; Matiisen et al., 2019; Elman, 1993; Jiang et al., 2015;
Kumar et al., 2010). Settles (2009) aktivno ucenje opredeli kot pristop k strojnemu ucenju ob
predpostavki, da se ucenec uci hitreje v primeru moznosti izbire ucnih primerov, iz katerih se
uci. Ucenje po ucnem nacrtu po drugi strani izkorisca zunanjo oceno o primernosti ucnega
procesa, kar sicer temelji na podobni ideji: reguliranje vrstnega reda ucnih primerov vodi do hi-
trejsega ucenja in/ali visje klasifikacijske tocnosti (Elman, 1993; Bengio et al., 2009). Ucenje po
ucnem nacrtu na podlagi podanega opisa torej zajema skupino pristopov, kjer je aktivno ucenje
3

podmnozica metod, pri katerih je vrstni red ucnih primerov odvisen od povratne informacije
“ucenca”.
Omenjena dela za delovanje zahtevajo razlicno kolicino vnesenega znanja s strani raziskovalca
o problemu ter omogocajo razlicno sirino nabora problemov, ki jih lahko resujejo. Vecina ome-
njenih pristopov deluje na omejeni kolicini problemov oziroma za resitev problema zahtevajo
relativno veliko znanja s strani raziskovalca. Relativno splosen pristop opisejo Kumar et al.
(2010), ki v funkcijo izgube uvedejo dodaten regulatorni clen, ki determinira tezavnost ucnega
primera, ter Amiri (2019), ki v clanku razvije sistem, ki ucne primere razvrsca v Leitnerjevo vr-
sto (Leitner, 1972) in nato iz nje vzorci ucne primere. S samodejnim dolocanjem vrstnega reda
ucnih primerov se ukvarja tudi domena sledenja znanju (angl. knowledge tracing), katere glavni
cilj je modeliranje ucencevega znanja o podproblemih (Corbett in Anderson, 1994; Pardos et
al., 2012; Piech et al., 2015). Sledenje znanju eliminira potrebo po rocnem dolocanju vrstnega
reda ucnih primerov, saj so za oblikovanje le-tega lahko uporabljeni podatki spremljanja zna-
nja ucencev. Ti pristopi se vedno predvidevajo raziskovalcev vnos znanja v obliki razdelitve
problema na podprobleme, katerih uspesnost resevanja je nato spremljana v procesu sledenja
znanju.
2.1.2 Metaucenje
Skupina pristopov, ki se ukvarja z ucenjem ucenja, spada tudi na podrocje metaucenja (Piech et
al., 2015; Wu et al., 2018; Chen et al., 2018; Buchler et al., 2018). Definicije metaucenja dajejo
poudarek razlicnim vidikom le-tega. Lemke et al. (2015) termin definirajo v okviru sistema,
sposobnega metaucenja. Gre za
“[S]istem, sestavljen iz podsistema, sposobnega ucenja in resitve danega problema,
ki je posledica uporabe metaznanja pridobljenega v a) preteklih ucnih iteracijah
in/ali b) drugih problemskih domenah”. (Str. 119)
V zgornjem citatu je potrebno izpostaviti “uporabo metaznanja”, ki ta sistem razlikuje od tistih
brez sposobnosti metaucenja. O metaznanju Lemke et al. (2015) pisejo kot o znanju o samem
problemu (npr. stevilo ciljnih razredov in njihove statisticne znacilnosti), njegovi tezavnosti in
nacinu resevanja (npr. intervali zaupanja napovedi in klasifikacijske tocnosti).
Uporaba metaucenja za avtomatsko razvrscanje ucnih primerov sicer ni nujna, kot na primer
pokazejo Kumar et al. (2010) in Amiri (2019). V nasem delu metaucenje uporabimo kot sred-
stvo za dinamicno izbiro ucnih primerov oziroma snovanje ucnih strategij. Primeri del, ki za
modeliranje vrstnega reda ucnih primerov uporabijo pristop metaucenja, so na primer ze prej
4

omenjeni Piech et al. (2015), Wu et al. (2018), Chen et al. (2018) in Buchler et al. (2018). V pri-
meru zadnjih treh clankov avtorji metaznanje izkoriscajo prek uporabe spodbujevalnega ucenja,
kar je podoben pristop, kot je uporabljen v tem delu. Del pristopa, povezan z metaucenjem,
nadalje opisujemo v podpoglavju 3.2.
Clanek avtorjev Wu et al. (2018) opravlja metaucenje nad tekstovnimi podatki, ki jih glede na iz-
brano metriko podobnosti razdeli v n gruc. V fazi ucenja so nato iterativno preizkusene razlicne
gruce za ucenje ob razlicnih kompetentnostih modelov. Skozi nabiranje razlicnih kombinacij
se algoritem spodbujevalnega ucenja priuci vrstnega reda ucenja iz skupin, kar vodi do novega
najboljsega rezultata na dveh podatkovnih zbirkah. V vsaki gruci izberejo predstavnika, kate-
rega verjetnostne porazdelitve napovedanih ciljnih razredov se uporabijo za generiranje stanj,
na podlagi katerih se naucijo optimalnega vrstnega reda gruc, iz katerih se modeli ucijo. Chen
et al. (2018) po drugi strani generirajo bolj kompleksna stanja, ki zajemajo naucene reprezenta-
cije, nivo prepricanosti in splosne karakteristike podatkovne zbirke za vsak primer. V vsakem
koraku spodbujevalnega ucenja nato izvedejo akcijo, ki nakljucno izbran primer uporabi ali ne
uporabi za nadaljnje ucenje. To ponovno vodi v strategijo, ki maksimizira koncno klasifikacij-
sko tocnost modela. V tem magistrskem delu je reprezentacija stanj klasifikatorja podobna Wu
et al. (2018), prav tako pa nagrado po izvedeni akciji definiramo s spremembo klasifikacijske
tocnosti.
2.1.3 Polnadzorovano ucenje
Polnadzorovano ucenje lezi na sticiscu nadzorovanega in nenadzorovanega ucenja. Izkorisca
mnozico neoznacenih podatkov v namen izboljsanja klasifikacijske tocnosti pri resevanju pro-
blema, za katerega je na voljo majhno stevilo oznacenih primerov (Chapelle et al., 2010). Da
polnadzorovane metode v splosnem lahko izboljsajo klasifikacijsko tocnost v primerjavi z upo-
rabo zgolj oznacenih podatkov, mora biti zadosceno naslednjim predpostavkam (Chapelle et al.,
2010):
• Predpostavka zveznosti: ce sta dve tocki (primera) xi in x j blizu v obmocju z visoko
gostoto primerov, morata biti blizu tudi ciljna razreda yi in y j.
• Predpostavka gruc: Ce sta tocki (primera) xi in x j v isti gruci, potem verjetno pripadata
istemu ciljnemu razredu.
• Predpostavka zmanjsanja dimenzionalnosti (angl. manifold assumption): Visokodimen-
zionalni podatki so lahko opisani z manjsim stevilom dimenzij oziroma lezijo v nizje-
dimenzijskem prostoru.
5

Zgornja xi in x j ustrezata dvema ucnima primeroma, medtem ko yi in y j ustrezata pripadajocima
ciljnim razredoma. Prva in druga izmed zgoraj omenjenih predpostavk opisujeta, da je za delo-
vanje polnadzorovanih metod potrebna organizacija podatkov, kjer je iz podobnosti med primeri
in gostote tock, ki jih le-ti predstavljajo, mogoce sklepati o kategorijah, ki jim pripadajo. Pred-
postavka dimenzionalnosti pa je po drugi strani potrebna zaradi iskanja funkcije, ki najbolje
opise ciljne razrede v podatkih, pri cemer izobilje (neoznacenih) ucnih primerov lahko sluzi
za dosego visje natancnosti. Poenostavljeno, polnadzorovano ucenje deluje zaradi gruc, ki so
prisotne v podatkih, ki omogocajo iskanje parametrov funkcije, ki opisujejo njihove kategorije,
tudi ce te niso eksplicitno podane.
Bagherzadeh in Asil (2019) povzemata glavne kategorije polnadzorovanega ucenja. Med ka-
tegorije pristopov spadajo samoucenje (angl. self-learning, self-teaching), generativni modeli,
sotrening (angl. co-training) in tri-trening ter metode, osnovane na grafih (angl. graph-based
methods). Med primere samoucenja, ki mu pripada tudi nase delo, poleg clankov, omenjenih
v Bagherzadeh in Asil (2019), spadajo tudi Laine in Aila (2016), Tarvainen in Valpola (2017),
in Lee (2013), ki vsak na svoj nacin izkoriscajo s strani modela dodeljene ciljne razrede, svoje
metode pa preizkusijo z nevronskimi mrezami. Lee (2013) za dodelitev ciljnih razredov upo-
rabi trenutne napovedi modela, Laine in Aila (2016) pa te napovedi povprecita skozi epohe, kar
vodi do vecje robustnosti. Tarvainen in Valpola (2017) v svojem delu povprecita utezi sekun-
darne nevronske mreze in ciljne razrede dolocata glede na izhod le-te. Samoucenje v nekaterih
implementacijah uporablja prag zaupanja ali n primerov z najvisjimi prepricanji v napovedi, s
cimer so izbrani ucni primeri, ki zmanjsajo moznost ucenja iz ucnih primerov z napacnimi ka-
tegorijami (Mihalcea, 2004; McClosky et al., 2006; Rosenberg et al., 2005) – dolocanje pragov
prepricanosti v tem delu sledi tej ideji.
Zavoljo celovitosti opisujemo se ostale pristope k polnadzorovanemu ucenju. Polnadzorovano
ucenje z generativnimi modeli uporabi neoznaceno ucno mnozico za ucenje parametrov ne-
vronske mreze, katere cilj je modeliranje distribucije P(Xu). Primeri tovrstnega pristopa utezi
nevronske mreze najprej ucijo s samokodirnikom in ucnimi primeri Xu, ter nato utezi kodirnika
uporabijo pri nadaljnjem ucenju verjetnostne distribucije P(Yl|Xl) (Amiri, 2019; Adiwardana et
al., 2016). So- in tri-trening izkoriscata razlicne “poglede” v podatke in ucne algoritme, za ka-
tere se predpostavlja, da bodo v sistem vnesli nove informacije. Tako so pri so-treningu atributi
podatkov razdeljeni na dve podmnozici, iz katerih sta naucena dva modela, ki nato iterativno en
za drugega dolocata kategorije ucnih primerov (Blum in Mitchell, 1998). Tri-trening po drugi
strani uporablja konsenz med klasifikatorji, kjer strinjanje o kategoriji dveh modelov doloci
ciljni razred na podlagi katerega je naucen tretji (Zhou in Li, 2005). Metode, osnovane na gra-
fih, na razlicne nacine racunajo podobnost primerov in glede na to propagirajo kategorije med
oznacenimi in neoznacenimi primeri (Zhan et al., 2018; Haeusser et al., 2017; Mallapragada et
al., 2008).
6

2.1.4 Spodbujevalno ucenje
V nasem delu nimamo dostopa do ucnih strategij, ki pripeljejo do uspesnejsega ucenja, zaradi
cesar moramo prostor moznih strategij raziskati s poskusanjem in se uciti iz zbranih interakcij.
Ucinkovito resevanje tega problema omogoca spodbujevalno ucenje, s katerim se ucimo stra-
tegij, ki maksimizirajo tocnost klasifikatorja. Spodbujevalno ucenje je torej v nasem sistemu
zadolzeno za pridobitev in uporabo metaznanja in je v splosnem definirano kot
“[R]acunski pristop k razumevanju in avtomatiziranju ciljno orientiranega ucenja
in odlocanja. Od ostalih metod ucenja se razlikuje zaradi poudarka na neposre-
dno interakcijo agenta z njegovim okoljem, brez uporabe neposrednega nadzora ali
modela okolja”. (Sutton in Barto, 2018, str. 15)
Formalno spada spodbujevalno ucenje v skupino Markovih odlocitvenih procesov, definiranimi
s prostorom stanj S , prostorom akcij A , nagradami R in verjetnostnimi porazdelitvami P , ki
oznacujejo verjetnost prehoda iz stanja st v stanje st+1 (st ,st+1 ∈S ). Spodbujevalno ucenje je
poseben primer Markovih odlocitvenih procesov, pri katerem verjetnostne porazdelitve preho-
dov stanj in nagrade niso znane vnaprej (Sutton in Barto, 2018).
Pomemben del spodbujevalnega ucenja je vrednostna funkcija stanj in akcij (angl. state-action
value function) Q(s,a):
Qπ(s,a) = Eπ
[∞
∑t=0
γtR(st ,at)
∣∣∣∣ s0 = s, a0 = a
](1)
in vrednostna funkcija (angl. value function) V (s):
V π(s) = Eπ
[∞
∑t=0
γtR(st ,at)
∣∣∣∣ s0 = s
]. (2)
Spremenljivka γ ∈ [0,1] v enacbah (1) in (2) doloca tezo nagrad, ki jih strategija prinese v
prihodnosti. Funkcija R(st ,at) vraca nagrado ob izvedbi akcije at v stanju st , spremenljivka t pa
doloca casovni korak. Gre za podobni funkciji, pri cemer Qπ(s,a) definira pricakovano vsoto
nagrad ob zacetnem stanju s in izvedbi akcije a ter V (s) definira pricakovano vsoto nagrad iz
stanja s. V obeh primerih so nadaljnje akcije odvisne od strategije π (Sutton in Barto, 2018).
Zavoljo celovitosti pokazimo se na povezavo med funkcijama V (s) in Q(s,a):
Qπ(s,a) = Eπ
[R(st ,at)+ γV π(st+1)
∣∣∣∣ st = s, at = a]. (3)
7

Optimalna strategija je nato tista, ki maksimizira vrednost funkcije V (s):
π∗ = argmax
πV π(s), ∀s ∈S . (4)
Za resitev nasega problema uporabimo algoritem SAC (angl. soft actor-critic) (Haarnoja et al.,
2018), ki je nadgradnja algoritma odvoda strategije (angl. policy gradient). Odvod strategije v
primerjavi z ostalimi metodami agentovo strategijo posodablja neposredno z uporabo funkcije
Q(s,a) (Sutton in Barto, 2018):
∇φ J(φ) = ∑s
Prπ(s)∑a
πφ (a|s)Qπ(s,a)∇φ logπφ (a|s)
= Eπ
[Qπ(s,a)∇φ logπφ (a|s)
]// v obliki pricakovanja.
(5)
Parametri strategije π so nato posodobljeni z gradientnim dvigom:
φt+1← φt +∇φ J(φt). (6)
V enacbah (5) in (6) φt in φt+1 predstavljata parametre agenta v trenutnem in naslednjem
casovnem koraku. Prπ(s) predstavlja verjetnost pojavitve stanja s, Qπ(s,a) pa predstavlja
pricakovano nagrado do konca epizode, kjer je v obeh primerih predvidevana uporaba trenutne
strategije π . Clen ∇π logπφ (a|s) predstavlja odvod parametrov φ v odvisnosti od logπφ (a|s) –
logaritma verjetnosti akcije a v stanju s. Enacba (5) predstavlja izracun potrebne spremembe
parametrov φ , medtem ko enacba (6) predstavlja dejansko posodobitev parametrov. Intuicija za
posodabljanje parametrov φ neposredno z vrednostmi funkcije Q(s,a) lezi v predpostavki, da
so visje vrednosti funkcije posledica tistih akcij, katerih verjetnost π(a|s) zelimo povecati.
Enacbi (5) in (6) opisujeta le posodabljanje parametrov agenta, ki je v tem primeru idealizirano
s predpostavljanjem ze naucene funkcije Q(s,a) in znanih vrednosti Pr(s). Funkcija Pr(s) je
dana implicitno in je odvisna od strategije π , medtem ko je funkcija Q(s,a) naucena. Kot smo
ze omenili, v nasem delu uporabimo algoritem SAC (soft actor-critic) (Haarnoja et al., 2018),
katerega kljucni prispevek je ucenje strategije, ki maksimizira tudi entropijo agentovih akcij.
Strategije delovanja se uci iz spomina preteklih interakcij (angl. off-policy) in ne neposredno
po izvedeni akciji (angl. on-policy) ter uporabi dve funkciji Q(s,a) za povecanje stabilnosti
algoritma. Algoritem podrobneje opisujemo v razdelku 3.2.1.
2.1.5 Prenos znanja
Prenos znanja je proces, ki ga je pogosto uporabljamo ljudje in nam omogoca hitrejse prido-
bivanje novih spretnosti; na podrocju strojnega ucenja je motivacija za deljenje znanja med
8

domenami podobna (Pan in Yang, 2009). Pan in Yang (2009) prenos znanja razdelita na in-
duktivnega, transduktivnega in nenadzorovanega, pri cemer poimenovanja sovpadajo z dostop-
nostjo oznacenih podatkov na ciljni, primarni in nobeni izmed domen. V vseh primerih gre
za uresnicevanje cilja izboljsanja rezultatov na ciljni domeni s pomocjo podatkov iz izhodiscne
domene.
V nasem pregledu metod se bomo osredotocili predvsem na prenos znanja v sklopu spodbuje-
valnega ucenja, saj je to domena, v katero spada tudi nase delo. V tej domeni je prenos mogoce
uporabljati ob spremembah naloge, prostora stanj in akcij za resevanje iste naloge ali variiranja
obeh lastnosti, pri cemer lahko prenos poteka iz ene ali vec izhodiscnih nalog (Lazaric, 2012).
Za nase delo je posebej relevanten primer prenosa, pri katerem se spremeni tako naloga (ozi-
roma dinamika okolja T ), kot tudi prostor moznih stanj S . Ta problem je lahko resen s pre-
nosom interakcij, ki obsega rocne ali naucene preslikave Abase → Atarget , Sbase →Starget in
Tbase→ Ttarget . Poleg prenosa samih interakcij mozni pristopi vkljucujejo tudi razsiritve pro-
stora stanj v Markovem odlocitvenem procesu in prenos parametrov naucenih funkcij π(a|s),Q(s,a) ali V (s) (Lazaric, 2012).
Veliko sodobnih del vkljucuje ucenje preslikav interakcij z generiranjem reprezentacij, ki so
nato uporabljene v algoritmu spodbujevalnega ucenja (Ammar et al., 2015; Hu in Montana,
2019). Kot pa so pokazali Julian et al. (2020) pa relativno kompleksno generiranje preslikav ni
nujno potrebno, pac pa je prenos v njihovem primeru mogoc ze s prenosom parametrov funkcij
π(a|s), Q(s,a) in V (s) brez sprememb algoritma ali generiranja vmesnih reprezentacij . Avtorji
svoje eksperimente izvedejo na robotski roki, katere karakteristike (stevilo sklepov, nacin pri-
jemanja) po zacetnem ucenju variirajo v fazi uglasevanja (angl. fine-tune) resitve. Poleg tega
spreminjajo tudi osvetljavo okolja, ozadje in dodajajo prej nevidene predmete. Pri spreminjaju
naloge prenasajo parametre prej naucenih funkcij, ki ocenjujejo pricakovane nagrade in modeli-
rajo akcije glede na trenutno stanje ter spomin preteklih interakcij. Kljub temu, da Ammar et al.
(2015) ter Hu in Montana (2019) v svojih delih razvijejo metode, katerih prednost je splosnost,
se izkaze, da metoda, podobna Julian et al. (2020), ki jo uporabimo tudi v nasem delu, vseeno
bistveno pohitri ucenje agenta.
2.2 Navezava na kognitivno psihologijo
V nasem delu zelimo vzpostaviti moznost primerjave nasih rezultatov z ucenjem ljudi, zato
bomo v tem podpoglavju predstavili relevantno literaturo s podrocja kognitivne psihologije. Za
primerjavo nasega dela s cloveskim ucenjem sta pomembna dva konteksta; kaksno vlogo ima
metakognicija pri pridobivanju novega znanja ter kako je metaznanje, pridobljeno za resevanje
enega problema, lahko preneseno na resevanje drugega. V tem podpoglavju predstavimo nekaj
9

relevantnih modelov ucenja (razdelek 2.2.1), lastnosti metakognicije (razdelek 2.2.2) ter pove-
zavo med zanimivostjo in tezavnostjo naloge (razdelek 2.2.3), ki je izhodisce za utemeljitev
nasega pristopa k polnadzorovanemu ucenju.
2.2.1 Metakognicija
Pred odgovarjanjem na zgornji vprasanji je potrebno definirati termin metakognicija. Flavell
(1979) metakognicijo v splosnem definira kot (poudarek je nas)
“[S]premljanje kognitivnih procesov, ki se zgodi kot posledica izvajanja in medse-
bojnih vplivov med stirimi razredi pojavov: a) metakognitivnega znanja, b) meta-
kognitivnih izkusenj, c) ciljev (ali nalog) in d) akcij (ali strategij)”. (Str. 906)
V sklopu magistrskega dela zelimo poustvariti sistem, ki ima najbolj eksplicitno navezavo na
metakognitivno znanje. Flavell (1979) le-tega definira kot
“[Z]nanje in prepricanja o tem, katere spremenljivke ter na kaksen nacin vplivajo
na potek in rezultat kognitivnih procesov”. (Str. 906)
Pri dolocanju, ali je neko znanje metakognitivno, lahko razlikujemo med kognitivnimi procesi,
povezanimi z resevanjem samega problema, in kognitivnimi procesi, povezanimi s prepricanji
o teh kognitivnih procesih. Rekurzivno nanasanje enega kognitivnega procesa na drugega nima
omejitve globine (Nelson in Narens, 1994); metanivo lahko v nekem kontekstu postane objek-
tni, nadomesti pa ga nov metakognitivni proces, ki se nanasa nanj – vsebina kognitivnega pro-
cesa torej ni inherentno objektna ali meta, pac pa prva in druga vrsta kognitivnih procesov
obstajata samo v navezavi en na drugega. Ne glede na nivo rekurzivnega nanasanja, je diho-
tomijo mogoce opisati z diagramom prikazanim na sliki 1 (Nelson in Narens, 1994). Diagram
prikazuje 2 entiteti, ki ustrezata objektnemu in meta nivoju kognicije, pri cemer objektni nivo
informira metakognitivne procese, ki v zameno nadzirajo prve. Na sliki 1 je na metanivoju
viden tudi model, ki ustreza modelu problema, prisotnem na objektni ravni (Nelson in Narens,
1994). Kot izpostavita Nelson in Narens (1994), je kljucno, da obratno ne velja; objektna raven
nima modela oziroma vpogleda v meta raven.
Vec nivojev, prisotnih med ucenjem, pa je mogoce zaslediti tudi v drugih delih. Kot pisemo v
nadaljevanju, ta dela pogosto presegajo le opisovanje metakognicije in predstavljajo se druge
komponente, kljucne za ucenje. Te komponente le omenjamo zaradi sirse umestitve metako-
gnicije v kognitivni sistem, vendar bomo podrobne opise izpuscali, ker presegajo tematiko te
10

MODEL
SpremljanjeNadzor
Meta nivo
Tok informacij
Objektni nivo
Slika 1: Prikaz razdelitve objektnega- in metakognitivnega nivoja ter smeri izmenjave informa-
cij med njima. Prevedeno po Nelson in Narens (1994)
magistrske naloge. Navajamo modele, katerih kompleksnost pogosto presega nas sistem, a da-
jejo vpogled v paradigme na tem podrocju in omogocajo primerjavo z rezultati nasega sistema
v podpoglavju 5.3.
Model ucenja z dvojno zanko
Tako znanje o resevanju problema kot tudi nadzor in spremljanje s strani metakognitivnih proce-
sov so nauceni (Baer, 1994; Flavell, 1979). V sklopu pridobivanja metakognitivnega znanja pri
resevanju dolocenega problema Argyris (1991) razlikuje med ucenjem z enojno in dvojno zanko
(angl. single- in double-loop learning). Argyris (1991) pristopa k ucenju razlikuje v kontekstu
svetovalcev v podjetjih. Kljub temu, da njegovo delo ni podprto s psiholoskimi raziskavami,
pac pa gre za analizo pristopa k resevanju problemov s strani prej omenjenih svetovalcev, avtor
poudari, da izboljsanje rezultatov ni le posledica iteriranja znotraj enojne zanke, pac pa tudi po-
sledica iteriranja znotraj drugega nivoja, ki spreminja predpostavke in strategije resevanja (slika
2) in da se je zavestnega spremljanja slednjega mogoce nauciti.
King in Kitchener (2004) na podoben nacin kot Argyris (1991) piseta o odsevni presoji (angl.
reflective judgement), ki nastopi, ko ucenec ne presoja le, kako resevati sam problem (kogni-
tivni nivo) ter svoje resevanje tega problema (metakognitivni nivo), pac pa tudi izvor znanja,
ki oblikuje njegove strategije resevanja (epistemolosko-kognitivni nivo), kar je nivo, ki ustreza
zunanji zanki v modelu z dvojno zanko.
Samonadzirano ucenje
11

Predpostavke Akcije Rezultati
Učenje z enojno zanko:izboljšanje razumevanja z analiziranjem rezultatov
Učenje z dvojno zanko:izboljšanje razumevanja z analiziranjem predpostavk
Slika 2: Diagram ucenja z dvojno zanko. Prevedeno po Argyris (1991)
Z metakognicijo v okviru ucenja se ukvarja tudi samonadzirano ucenje (angl. self-regulated
learning), katerega pregled ponudi Panadero (2017). Samonadzirano ucenje raziskuje vec fe-
nomenov; od kognitivnih strategij, vpliva custev na ucenje, metakognicije in motivacije. Med
prvimi ga je definiral Zimmerman (1989), in sicer kot “metakognitivno, vedenjsko in motiva-
cijsko vkljucenost ucencev v lasten ucni proces”. Samonadzirano ucenje je krovni izraz, pod
katerim je moc najti vec modelov ucenja. Nekateri ucenje razdelijo glede na tip motivacije, ka-
terih skrajnosti opredelijo kot potrebo po samoohranitvni (zunanja motivacija) in notranjo zeljo
po povecanju spretnosti pri resevanju dolocenega problema (notranja motivacija) (Boekaerts,
2011). Drugi proces razdelijo na soodvisne podprocese brez ali z manjsim ozirom na custvene
komponente ter se osredotocijo na izbiro ciljev, strategij ter spremljanje uspesnosti (Winne,
1996; Zimmerman in Moylan, 2009). Vsi modeli vsebujejo navezavo na metakognitivne pro-
cese, veliko pa jih tudi eksplicitno opredeli pomen povratne zanke oz. faze samorefleksije pri
spremljanju lastnega procesa ucenja, kot je na primer vidno na slikah 3 in 4. Se posebej bi
radi opozorili na model avtorjev Winne (1996), ki precej natancno specificira razlicne korake
procesiranja med ucenjem in izvajanjem naloge. Nas sistem prepricanj, ciljev in rezultatov ne
modelira eksplicitno, vendar podobno kot model avtorja Winne (1996) iz zunanjega sveta dobi
povratno informacijo ter s spremljanjem procesa ucenja vpliva na znanje in nadaljnje resevanje
naloge. Podobno, kot je vidno na sliki 4, tudi Oudeyer et al. (2007) in Flavell (1979) pisejo o
potrebi po interakcijah agenta z okoljem, s katerimi imajo moznost pridobitve izkusenj o pri-
mernih ucnih strategijah. Slednje je glavna utemeljitev za uporabo spodbujevalnega ucenja v
nasem sistemu.
Zimmerman (2013) opisuje eksperimente, izvedene v podporo ciklicnemu modelu samoreguli-
ranega ucenja. V podporo premisljevalni, izvedbeni in samoreflektivni fazi je bil izveden ekspe-
12
Premišljevalna faza
Analiza nalogeZastavljanje ciljev
Planiranje
Samo-motivacijska prepričanja
SamoučinkovitostPričakovani izidi
Zanimanje za nalogo
Izvedbena faza
SamonadzorStrategije reševanja
SamoučenjeMiselne slike
Upravljanje s časomStrukturiranje okolja
Iskanje pomočiKazanje interesaSamokaznovanje
SamospremljanjeMetakognitivno spremljanje
Samosnemanje
Samo-reflektivna faza
SamosojenjeSamoevalvacija
Atribuiranje kavzalnosti
ReakcijaSamozadovoljstvo
Prilagoditev/obramba
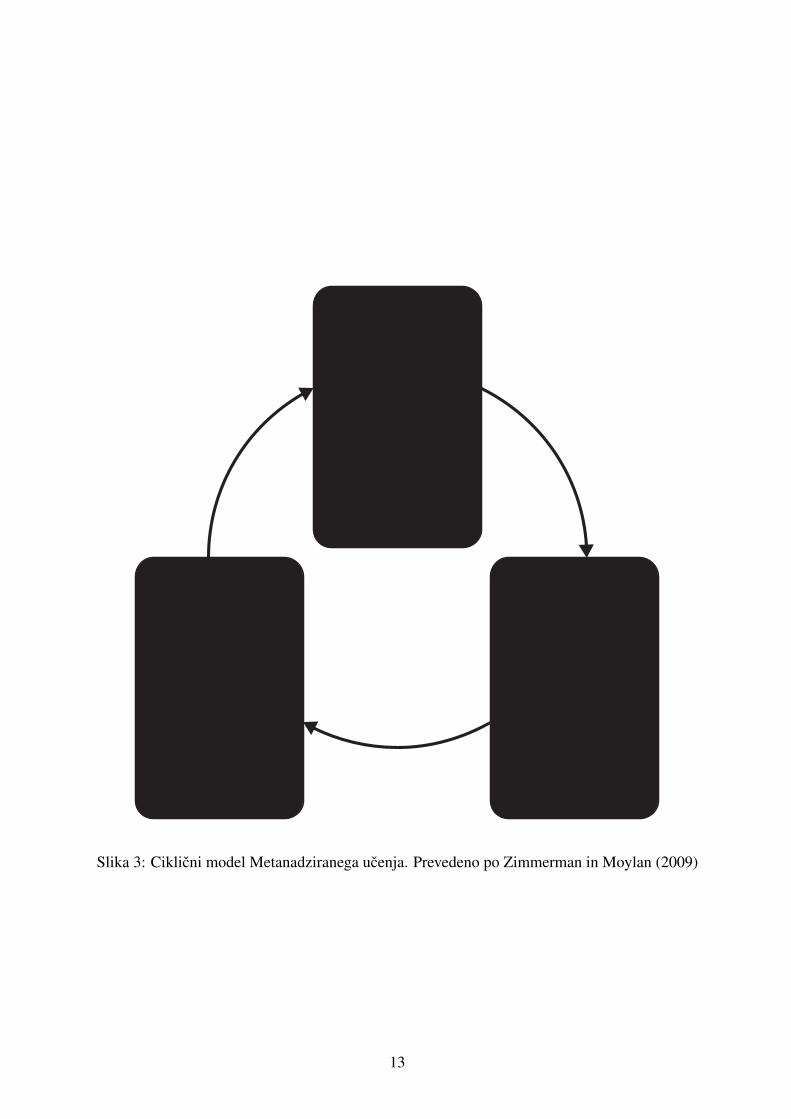
Slika 3: Ciklicni model Metanadziranega ucenja. Prevedeno po Zimmerman in Moylan (2009)
13

Znanje in prepričanja
Domensko znanje
Strateško znanje
Motivacijska prepričanja
Cilji
A B C D
karakterizacija ciljev:
A B C D E
Rezultatikarakterizacija
trenutnegastanja:
Strategije
Spremljanje
karakterizacijanapak:
A: ni napakeB: precenitevC: podcenitevD: ...
IzvedbaZunanja povratna informacija
NalogaLastnost 0Lastnost 1...Lastnost n
Kognitivni sistem
Slika 4: Winne et al.-ov model ucenja. Prevedeno po Winne (1996)
riment, kjer je s spodbujanjem uporabe elementov katere izmed teh treh faz pokazal na linearno
korelacijo, ki ga imajo na koncno uspesnost ucnega procesa. Greene in Azevedo (2007) na drugi
strani opravita pregled Winneovega modela ucenja: predstavita vrsto raziskav, ki utemeljujejo
elemente modela. V njunem delu se izraz metakognitivno spremljanje navezuje na spremljanje
resevanja in evalvacijo napak med resevanjem naloge, medtem ko kognitivno spremljanje opi-
suje sposobnost ovrednotenja uspesnosti resevanja pred in po ucenju ter resevanju. Glede meta-
kognitivnega spremljanja navedejo mesane rezultate, ki ne utemeljujejo izkazane pomembnosti
le-tega v modelu na sliki 4. Po drugi strani pri kognitivnem spremljanju opisejo ugotovljeno
korelacijo med oceno znanja po testu in uspesnostjo resevanja ter pomembnost notranjega pov-
zemanja naucenega.
Povezava predstavljenih modelov
Predstavljeni modeli variirajo po kompleksnosti, a je kljub temu vsem skupen nacin procesira-
nja, ki deli lastnosti z delom avtorjev Nelson in Narens (1994). Avtorja Zimmerman in Moylan
(2009) v svojem delu tako na primer znotraj faze delovanja (angl. performance phase) ome-
njata elementa nadzora in spremljanja, medtem ko ima model Winne (1996) povezave v in iz
elementa, ki doloca proces spremljanja. Nacin resevanja problema v sklopu tega magistrskega
dela je podoben; na objektni ravni imamo osnovni problem, katerega resevanje se ne izboljsuje
le skozi povratno informacijo o funkciji napake, pac pa tudi s spremembo akcij in strategije, ki
14

jo omogoca metanivo procesov.
2.2.2 Lastnosti metakognitivnih procesov in ucenja
Tu predstavljamo nekatere lastnosti metakognicije, s katerimi primerjamo nas sistem. Izmed
lastnosti, navedenih v clanku avtorja Dawson (2008), izberemo in podrobneje opisemo tiste,
ki so relevantne za primerjavo in izpustimo lastnosti, ki zajemajo motivacijo, razmisljanje ter
ostale sposobnosti, vezane na delovanje ljudi.
Metakognitivne vescine so naucene: Baer (1994) preucuje razvitost metakognicije pri 11- in
15-letnikih ter odraslih. Vlogo metakognicije raziskuje v kontekstu pisanja besedila. Eksperi-
ment je zasnovan kot delo v paru, ki omogoca premislek o procesu pisanja skozi analizo dialoga
med udelezencema raziskave. Ugotovljeno je bilo, da 11- in 15-letniki v splosnem uporabljajo
manj metakognitivnih vescin, medtem ko so le-te pri odraslih bolj pogoste. Razlike so bile med
drugim najdene v kolicini casa, posvecenega predhodni analizi problema, strukturiranju bese-
dila pred pisanjem in evalvaciji dosege cilja po pisanju. Naucenost metakognitivnih sposobnosti
je kljucna tudi za nase delo; podobno kot to pocnejo ljudje tudi v nasih eksperimentih zacnemo
z nakljucno strategijo, ki se nadalje oblikuje glede na uspesnost interakcij agenta s problemom.
Ucenci z metakognitivnimi vescinami se ucijo hitreje: Borkowski et al. (1987) raziskujejo
metakognitivne vescine pri umsko zaostalih in normalno razvitih mladostnikih. Skozi meta-
analizo ustvarijo model, katerega osrednja komponenta je uporaba metakognicije za uspesno
ucenje. Kot primer uporabe metakognicije v prvi vrsti opisujejo pomembnost formiranja stra-
tegij, odsotnost katerih je bila najdena pri umsko zaostalih mladostnikih. Pisejo tudi o pred-
hodnem zavedanju, da je za resitev problema potreben trud, izpostavijo pa tudi pomembnost
reevalvacije strategij in zavedanje o lastnih zmoznostih. To so lastnosti, ki so prav tako bolj
pogoste v primeru normalno razvitih kognitivnih sposobnosti.
Za razvoj je potrebno tako domensko znanje kot tudi metakognitivne sposobnosti: avtorji
Bransford et al. (1986) v svojem clanku primerjajo vlogo domenskega znanja ter metakognitiv-
nih procesov. Predstavijo metaanalizo raziskav, iz katerih sledi, da je vzpodbujanje k prepozna-
vanju splosnih vzorcev in strukturiranju znanja (ki po njihovem tvorita metakognitivne procese)
kljucno za uspesen priklic potrebnega domenskega znanja, ko je to potrebno. Ob razlagi ene
izmed raziskav tako izpostavijo:
“Sahovski mojstri so morda razvili bazo znanja, ki jim omogoca zaznavanje po-
membnosti razlicnih stanj v igri in s tem ustvarjanje kvalitativno boljsih potez”,
(Bransford et al., 1986, str. 1079)
15

kar je odgovor na zavrnjeno hipotezo raziskovalcev originalne raziskave, da sahovski mojstri
vnaprej predvidijo vec potez (in se torej bolj znasajo na domensko znanje) kot zacetniki.
Ucenci spontano uporabijo splosne metakognitivne sposobnosti za resevanje problema nanovi domeni: Mathan in Koedinger (2005) izvedejo eksperiment na ljudeh, kjer prakticno
ovrednotijo pristope k podajanju povratne informacije med ucenjem. V njihovem delu osred-
njo vlogo prevzame model “inteligentnega novinca”, ki kot mehanizem povratne informacije
uporablja tudi lastne sposobnosti zaznavanja in popravljanja napak. Eksperiment zastavijo kot
ucenje novih funkcionalnosti v programu za urejanje preglednic (npr. Microsoft Excel). Ugo-
tovijo, da se inteligentni novinci ucijo hitreje, ter da njihovo ucenje vodi k boljsi generalizaciji
in razumevanju problema.
Prenos metakognitivnega znanja je pogosto prisoten pri ucenju resevanja novega pro-blema, a ne vedno: Garner in Alexander (1989) problem prenosa znanja razdelita na prenos
med bolj in manj podobnimi domenami; prenos med prvimi je bolj pogost, kar je mogoce raz-
lagati s podobnostjo strategije, ki jo lahko ucenec uporabi za ucenje. Podobnost strategij ucenja
pa sicer na vprasanje prenosa ne odgovori v celoti. Avtorja navajata tudi druge dejavnike, kot
so na primer navada na uporabo ene strategije in posledicno neuspesno resevanje problema v
drugi domeni ter metodologije samih eksperimentov, ki pogosto eksplicitno zahtevajo uporabo
specificnih strategij, kar omejuje udelezence pri prenosu metakognitivnega znanja.
Kljub temu, da so rezultati raziskav mesani, Borkowski et al. (1987) pridejo do podobnih za-
kljuckov kot Garner in Alexander (1989) in omenijo tudi vlogo podobnosti problemov na objek-
tni ravni pri prenosu metakognitivnega znanja. Everson (1997) pokaze na bolj ociten prenos
vescin metakognitivnega spremljanja med resevanjem jezikovnega in matematicnega problema.
Kornell et al. (2007) pokazejo na prenos metakognitivnega znanja pri opicah, kjer so le-tega
preverjali z ucenjem strategije za resitev enega problema, ki je pohitrila resevanje druge naloge,
ki je bila povezana s strategijo resevanja, a ne v sami resitvi.
2.2.3 Relacija med tezavnostjo, spretnostjo in zanimivostjo naloge
V tem razdelku bi radi na kratko opisali dva modela, ki se ukvarjata s korelacijo med zanimi-
vostjo in tezavnostjo danega problema. Ta modela predstavljata vedenjski pogled na delova-
nje ljudi in ne vkljucujeta navezave na metakognicijo. Opisali bomo Foggov vedenjski model
(Fogg, 2009) ter tokovni model (angl. flow model) (Csikszentmihalyi, 2014).
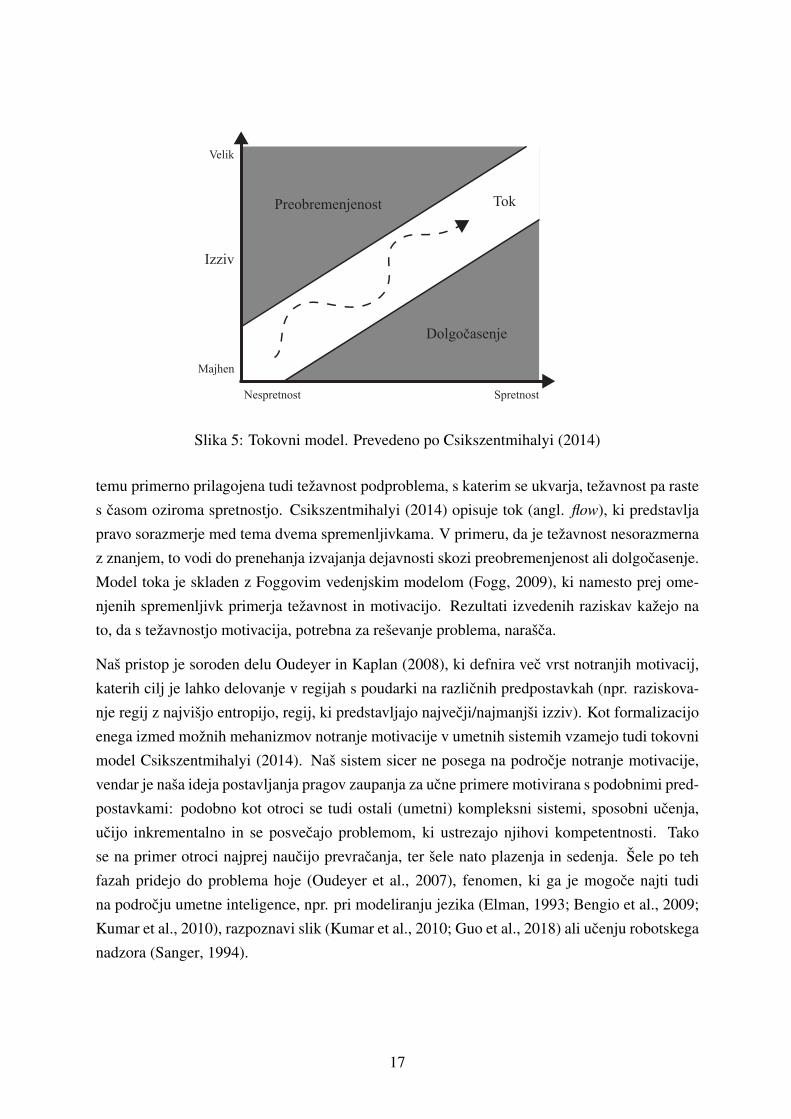
Na sliki 5 je viden tokovni model (Csikszentmihalyi, 2014). Delo se sicer v prvi vrsti ukvarja
z motivacijo in z njo povezano korelacijo med izzivom in znanjem pri resevanju dolocenega
problema. Za nas je to delo povezano z metodo dolocanja pragov prepricanosti, ki je opisana v
podpoglavju 3.1. Iz slike 5 je razviden glavni princip: v primeru, da ima agent manj znanja, je
16
Preobremenjenost
Dolgočasenje
Tok
Spretnost
Izziv
Velik
Majhen
Nespretnost
Slika 5: Tokovni model. Prevedeno po Csikszentmihalyi (2014)
temu primerno prilagojena tudi tezavnost podproblema, s katerim se ukvarja, tezavnost pa raste
s casom oziroma spretnostjo. Csikszentmihalyi (2014) opisuje tok (angl. flow), ki predstavlja
pravo sorazmerje med tema dvema spremenljivkama. V primeru, da je tezavnost nesorazmerna
z znanjem, to vodi do prenehanja izvajanja dejavnosti skozi preobremenjenost ali dolgocasenje.
Model toka je skladen z Foggovim vedenjskim modelom (Fogg, 2009), ki namesto prej ome-
njenih spremenljivk primerja tezavnost in motivacijo. Rezultati izvedenih raziskav kazejo na
to, da s tezavnostjo motivacija, potrebna za resevanje problema, narasca.
Nas pristop je soroden delu Oudeyer in Kaplan (2008), ki defnira vec vrst notranjih motivacij,
katerih cilj je lahko delovanje v regijah s poudarki na razlicnih predpostavkah (npr. raziskova-
nje regij z najvisjo entropijo, regij, ki predstavljajo najvecji/najmanjsi izziv). Kot formalizacijo
enega izmed moznih mehanizmov notranje motivacije v umetnih sistemih vzamejo tudi tokovni
model Csikszentmihalyi (2014). Nas sistem sicer ne posega na podrocje notranje motivacije,
vendar je nasa ideja postavljanja pragov zaupanja za ucne primere motivirana s podobnimi pred-
postavkami: podobno kot otroci se tudi ostali (umetni) kompleksni sistemi, sposobni ucenja,
ucijo inkrementalno in se posvecajo problemom, ki ustrezajo njihovi kompetentnosti. Tako
se na primer otroci najprej naucijo prevracanja, ter sele nato plazenja in sedenja. Sele po teh
fazah pridejo do problema hoje (Oudeyer et al., 2007), fenomen, ki ga je mogoce najti tudi
na podrocju umetne inteligence, npr. pri modeliranju jezika (Elman, 1993; Bengio et al., 2009;
Kumar et al., 2010), razpoznavi slik (Kumar et al., 2010; Guo et al., 2018) ali ucenju robotskega
nadzora (Sanger, 1994).
17

2.3 Kibernetika kot okvir za primerjavo cloveske kognicije in nasega sis-tema
Kibernetika je omenjana kot kljucna disciplina, ki je pripeljala do rojstva kognitivne znanosti
(Dupuy, 2009). Gre za transdisciplinaren pristop k raziskovanju nadzora in komunikacije v
zivih bitjih in strojih (Wiener, 2019). Primerjava nasega sistema in cloveske kognicije, ki jo
opravimo v razdelku 5.3.2, ni enostavna; cloveska kognicija in nas model imata bistvene razlike,
ki se zacnejo z razliko v kompleksnosti in vodijo do umescenosti enega in drugega v svetu. Iz
tega razloga bi na tem mestu radi predstavili argument o zmoznosti primerjave obeh sistemov
skozi paradigmo kibernetike.
Modeli metakognicije in ucenja, predstavljeni v razdelku 2.2.1, si delijo marsikatero podobnost
z naslednjim opisom kibernetike:
“Osnovna vloga kibernetike je posledica temeljne ideje, da je mogoce razlicne stop-
nje procesiranja pri ljudeh in strojih obravnavati kot nadzorne sisteme z medsebojno
povezanimi stopnjami in povratnimi zankami”. (Xiong in Proctor, 2018, str. 1)
Vsebino zgornjega citata je mogoce neposredno videti na slikah 1, 2, 3 in 4, kjer puscice pred-
stavljajo tok informacij, ki tvori povezave med entitetami modelov in povratne zanke. Podobno
lastnost kot omenjeni modeli ima tudi nas sistem, predstavljen v naslednjem poglavju: na sliki 6
je viden skupek soodvisnih entitet, ki so namenjene resevanju podobnega problema kot opisani
modeli metakognicije.
2.4 Navezava na nase raziskave
V nasem delu se najbolj neposredno zgledujemo po dveh clankih: Wu et al. (2018) in Chen et al.
(2018). Oba za resitev polnadzorovanega problema uporabita spodbujevalno ucenje, pri cemer
v vsakem koraku algoritma dolocata, ali je ucni primer ali skupina le-teh iz zbirke tekstovnih
podatkov primerna za nadaljnje ucenje. Pristop k problemu je v tem delu enak, z razliko, da
nas sistem razvijamo z mislijo na uporabo tako v okviru tekstovnih podatkov kot tudi z drugimi
vrstami problemskih domen. V teoriji je mogoca razsiritev nasega dela na poljuben klasifikator,
ki omogoca vpogled v verjetnostne porazdelitve napovedi za vsak ucni primer (npr. metodo
naivnega Bayesa ali nakljucnih gozdov), a smo se v nasem delu odlocili omejiti na klasifikacijo
z umetnimi nevronskimi mrezami. Znotraj domene nevronskih mrez uporaba nase metode ni
omejena z arhitekturo le-te.
Za dosego splosnosti se odrecemo grucenju ucnih primerov, ki je uporabljeno v clanku Wu et al.
(2018), saj ni trivialno za vse tipe podatkov (npr. slike). Za pridobivanje in uporabo metaznanja
18

se odlocimo uporabiti pragove prepricanosti, ki na zadosten nacin razdelijo primere glede na
primernost za ucenje in so uporabljeni tudi v nekaterih drugih delih s podrocja polnadzorova-
nega ucenja s samoucenjem. Za razliko od Wu et al. (2018) in Chen et al. (2018) nas problem
posledicno resujemo v zveznem prostoru akcij, za kar uporabimo algoritem spodbujevalnega
ucenja SAC (Haarnoja et al., 2018).
Pri prenosu metaznanja uporabimo podoben pristop, kot ze opisana metoda v delu avtorjev
Julian et al. (2020). Pri tem za razliko od Julian et al. (2020) variiramo dimenzionalnost stanja
brez ucenja skritih reprezentacij, kot to pocnejo Ammar et al. (2015) ter Hu in Montana (2019).
S tem pokazemo, da je spreminjanje dimenzionalnosti stanj lahko resljivo na preprost nacin.
Omeniti je sicer potrebno, da pri tem ne zagovarjamo, da je nasa metoda prenosa reprezentacij
stanj splosna, pac pa le, da deluje na nasem specificnem problemu, ki dopusca spremembo stanj,
kot opisujemo v podpoglavju 3.3.
19

3 Metoda
V preteklih poglavjih smo orisali ozadje nasega sistema, v tem poglavju pa bomo konkretno
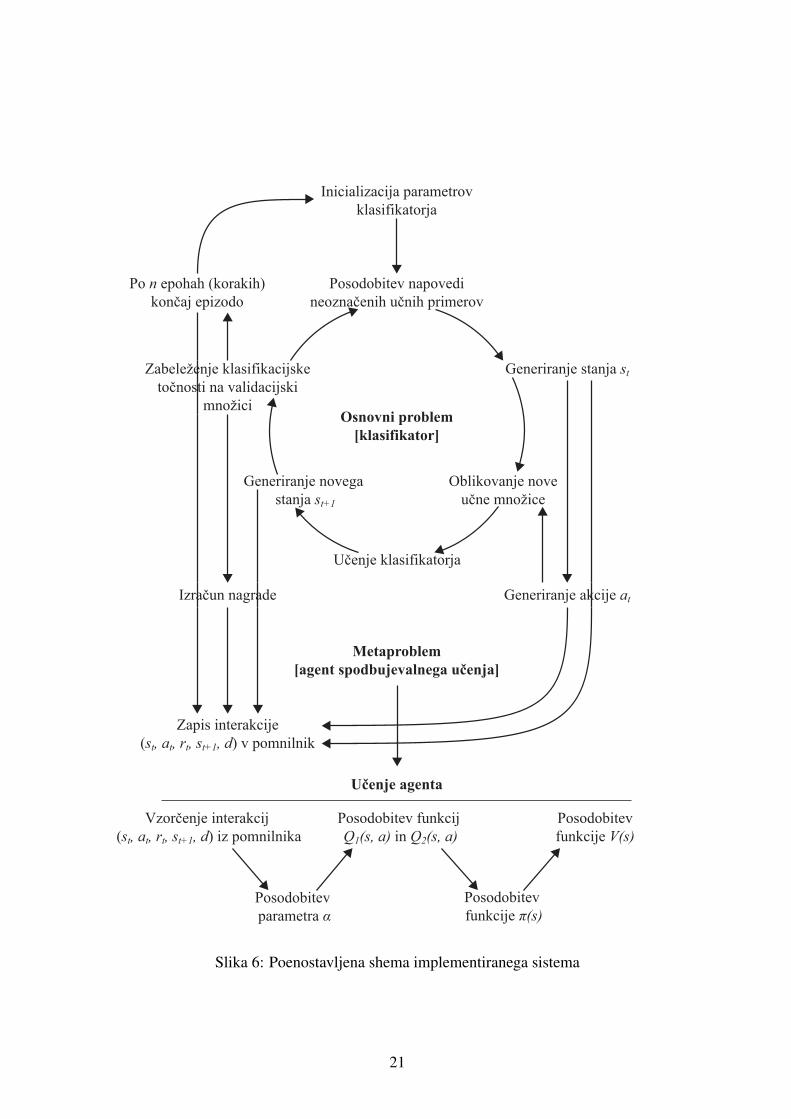
opisali komponente in interakcije med njimi. Na sliki 6 je vidna shema modela, ki jo je mogoce
razdeliti na dva dela. Ta dva dela ustrezata dvema problemoma, ki ju resujemo v sklopu tega ma-
gistrskega dela in ju imenujemo osnovni problem in metaproblem. Osnovni problem resujemo
s klasifikatorjem, medtem ko metaproblem resujemo z agentom spodbujevalnega ucenja (v na-
daljevanju uporabljamo tudi termina RL agent in meta-agent). Povezave med vozlisci v sklopu
osnovnega problema definirajo ucenje in evalvacijo klasifikatorja ter na sliki 6 tvorijo krozno
zanko. Ta zanka poleg resitve danega klasifikacijskega problema omogoca tudi nabiranje me-
tapodatkov, potrebnih za resevanje metaproblema. Interakcije RL agenta s klasifikatorjem se
zgodijo s postavljanja pragov prepricanosti ter shranjevanjem potrebnih informacij v pomnilnik
(angl. replay buffer), ki so na sliki 6 karakterizirane z vzporednimi puscicami na levi in desni.
Z resevanjem metaproblema je povezana tudi aproksimacija funkcij algoritma spodbujevalnega
ucenja s ciljem ucenja agenta (oziroma funkcije π(·|s)). Kot bomo opisali kasneje, se to iz-
vaja loceno zaradi ucenja iz pomnilnika preteklih interakcij. To pomeni, da se agent ne uci
neposredno iz interakcije po tem, ko se le-ta zgodi. Potrebno je omeniti, da se nauceno znanje
tekom poganjanja eksperimenta se vseeno odrazi v spreminjanju njegove strategije, ki vpliva na
interakcijo. Potek ucenja RL agenta je specificiran v spodnjem delu slike 6.
V tem poglavju najprej opisemo elemente nasega sistema (t. j. vozlisca na sliki 6), cemur sledi
opis nase metode prenosa znanja v podpoglavju 3.3. V nadaljevanju bomo izmenicno uporablja-
li besedi korak in epoha, ki v prvem primeru oznacuje interakcijo meta-agenta s klasifikatorjem,
v drugem pa eno iteracijo skozi ucno mnozico, iz katere se klasifikator uci. Beseda korak je torej
uporabljena v kontekstu spodbujevalnega ucenja, medtem ko je epoha uporabljena v okviru
polnadzorovanega. Poleg tega z epizodo naslovimo n interakcij RL agenta s klasifikatorjem, ki
predstavljajo zakljuceno celoto; to v okviru polnadzorovanega ucenja predstavlja n epoh in s
tem zakljuceno ucenje. S pari terminov korak-epoha in epizoda-zakljuceno ucenje oznacujemo
razlicne vidike enakih procesov znotraj nasega sistema, pri cemer terminologija sledi tisti, ki je
uporabljena v pripadajoci disciplini.
3.1 Osnovni problem
V tem podpoglavju opisujemo ucenje klasifikatorja – nevronske mreze – ter korake, ki so
umesceni v zanko ucenja in so povezani z belezenjem interakcij. Ucenje klasifikatorja po-
teka v okviru polnadzorovanega ucenja in sestoji iz posodabljanja napovedi neoznacenih ucnih
primerov, oblikovanja ucne mnozice in samega ucenja. Med temi koraki se generirata se sta-
nji modela st in st+1 ter belezenje klasifikacijske tocnosti na validacijski mnozici, ki je kasneje
20
Osnovni problem[klasifikator]
Inicializacija parametrovklasifikatorja
Posodobitev napovedineoznačenih učnih primerov
Po n epohah (korakih)končaj epizodo
Oblikovanje noveučne množice
Zabeleženje klasifikacijsketočnosti na validacijski
množici
Generiranje stanja st
Učenje klasifikatorja
Generiranje novega stanja st+1
Učenje agenta
Vzorčenje interakcij (st, at, rt, st+1, d) iz pomnilnika
Posodobitev funkcij Q1(s, a) in Q2(s, a)
Posodobitev parametra α
Posodobitev funkcije π(s)
Posodobitevfunkcije V(s)
Metaproblem[agent spodbujevalnega učenja]
Izračun nagrade Generiranje akcije at
Zapis interakcije(st, at, rt, st+1, d) v pomnilnik
Slika 6: Poenostavljena shema implementiranega sistema
21

uporabljena za izracun nagrade. Ob zacetku ucenja in vsakih n epoh se parametri klasifikatorja,
oznacimo jih z W, inicializirajo na nakljucne vrednosti. V nadaljevanju podrobneje opisujemo
vse omenjene podprocese z izjemo belezenja klasifikacijske tocnosti, za katerega mislimo, da
je razumljiv sam po sebi.
Nas problem pripada podrocju polnadzorovanega ucenja, kar pomeni, da so podatkovne zbirke,
nad katerimi izvajamo eksperimente, razdeljene na oznaceni del {Xl,Yl} in neoznaceni del {Xu}.Poleg teh dveh mnozic podatkov uporabljamo tudi oznaceno testno {Xtest ,Ytest} in validacijsko
mnozico {Xval,Yval}.
3.1.1 Inicializacija parametrov klasifikatorja
Ob vsakem zacetku ucenja utezi nakljucno inicializiramo v skladu z distribucijo, za katero velja,
da je primerna za dolocen tip nivoja v uporabljeni nevronski mrezi. Utezi inicializiramo, kot je
specificirano v dokumentaciji knjiznice PyTorch (Paszke et al., 2019):
wi =Uni f orm(−bound,bound),wi ∈W
bound =
√6
n f an
(7)
V enacbi (7) funkcija Uni f orm() generira enakomerno porazdeljena nakljucna stevila na in-
tervalu [−bound,bound]. V primeru polno povezanega nivoja nevronske mreze utezi iniciali-
ziramo z enakomerno Hejevo distribucijo (He et al., 2015) – to dobimo ob uporabi vrednosti
n f an = f an in. Ob inicializaciji konvolucijskega nivoja pa uporabimo enakomerno Glorotovo
porazdelitev (Glorot in Bengio, 2010). Ta vrednost n f an postavi na f an in+ f an out. Vredno-
sti f an in in f an out ustrezata stevilu vhodov in izhodov nivoja nevronske mreze, ki ji pripada
parameter wi.
3.1.2 Posodabljanje ciljnih razredov neoznacenih ucnih primerov
V koraku posodabljanja napovedanih ciljnih razredov se posluzimo povprecenja napovedi mo-
dela skozi cas. To vodi k vecji robustnosti napovedanih kategorij in je pristop podoben delu
avtorjev Laine in Aila (2016). Ob vsakem zacetku ucenja napovedi yi za vsak ucni primer
xi ∈ Xu napovedi inicializiramo z:
yi,0 = f0(xi), (8)
kjer je f (x) funkcija, ki jo implementira nas klasifikator in vraca vektor dolzine |y|, v katerem
vsaka vrednost predstavlja verjetnost, da primer pripada ciljnemu razredu c ∈ {0, . . . , |y|− 1}.Nadalje po vsaki zakljuceni epohi napovedi posodobimo z:
yi,t = (1−αlabel)∗ yi,t−1 +αlabel ∗ ft(xi), (9)
22

kjer je αlabel hiperparameter, ki doloca hitrost spreminjanja (ucenja) ciljnih razredov.
Dolocimo se mnozico, v katero shranjujemo povprecene distribucije ciljnih razredov, ki sluzijo
kot ocene ciljnih razredov neoznacenih ucnih primerov:
Yest = {y0,t , ...yn,t}, n = |Xu|.
3.1.3 Generiranje stanj
Generiranje stanj se na sliki 6 izvaja na dveh mestih1: pred in po ucenju klasifikatorja, kar
ustreza stanjema st in st+1. Trenutno stanje modela, ki je izhodisce za dolocanje akcij s strani
meta-agenta, opisemo s povprecnimi porazdelitvami po ciljnih razredih na validacijski mnozici
ter s petimi drugimi metrikami ucenja:
• delez izbranih ucnih primerov v prejsnji epohi,
• vrednost funkcije izgube na validacijski mnozici – definirana v enacbi (16),
• vrednost funkcije izgube na ucni mnozici – definirana v enacbi (16),
• klasifikacijska tocnost na validacijski mnozici – definirana v enacbi (26) in
• klasifikacijska tocnost na ucni mnozici – definirana v enacbi (26).
Pri generiranju povprecnih verjetnostnih distribucij ciljnih razredov na validacijski mnozici le-
-te shranimo v matriko m velikosti |y|× |y|, kjer je |y| stevilo ciljnih razredov. Vsaka vrstica i
predstavlja povprecno distribucijo i-tega ciljnega razreda:
mi =1|Yi|
|Yi|
∑k=0
f (xk), i ∈ [0, |y|], (10)
kjer xk v predstavlja k-ti primer iz validacijske ucne mnozice {Xi,Yi}, f (x) pa je uporabljen
klasifikator. Mnozica {Xi,Yi} vsebuje ucne primere, katerih argmaxyk = i. To pomeni, da
vrstice matrike m predstavljajo glede na resnicni ciljni razred razdeljeno validacijsko mnozico,
kjer vsaka vrstica vsebuje trenutna povprecja napovedi klasifikatorja za ta ciljni razred.
Zaradi zahtev nase implementacije spodbujevalnega ucenja matriko m sploscimo, s cimer do-
bimo vektor dolzine |y|2. Vrednostim dodamo se prej omenjene metrike, kot so delez izbranih
primerov v prejsnjem koraku ter klasifikacijske tocnosti in vrednosti funkcije napake.
1Da zmanjsamo kolicino racunskih operacij potrebnih za generiranje stanj, v implementaciji sistema kot st
shranimo stanje klasifikatorja po koncu prejsnje epohe, medtem ko za st+1 uporabimo stanje po zadnji posodobitvi.Namesto da so stanja generirana dvakrat, kot je prikazano na sliki 6, torej le-ta generiramo le enkrat na epoho.
23

3.1.4 Oblikovanje ucnih mnozic
Za vsako epoho iz neoznacene ucne mnozice Xu vzamemo primerne ucne primere skupaj z
nasimi izracunanimi ciljnimi razredi, katerih izracun je opisan v razdelku 3.1.2. Da v sistem
vnesemo nekaj zunanjega znanja, v vsaki epohi vzamemo tudi (pogosto manjso) oznaceno ucno
mnozico {Xl,Yl}. Iz slednje vzamemo vse ucne primere, medtem ko primere iz Xu izberemo na
podlagi akcije podane s strani meta-agenta. Kot je opisano tudi v podpoglavju 3.2, RL agent
vraca 1-dimenzionalni vektor at = [a0,a1] z vrednostmi na intervalu (−1, 1). Vrednosti a0 in
a1 najprej skrcimo na interval (0, 1):
ai =ai +1
2, i ∈ {0,1} (11)
in nato preoblikujemo v spodnja in zgornja pragova τmin in τmax z:
τmin = a0−δ
τmax = a0 +δ ,(12)
pri cemer je δ definiran z:
δ = a1 ∗ (0.5−abs(0.5−a0)). (13)
V praksi izbrana metoda spreminjanja agentovih akcij v pragove prepricanosti povzroci, da
vsaka vrednost a0 predstavlja sredino pasu, v katerem so izbrani ucni primeri, medtem ko se
vrednost a1 skrci glede na a0, tako, da sta τmin in τmax zagotovo v intervalu [0,1]. Transformacija
povzroci, da vsak par [a0,a1] predstavlja unikatno akcijo brez potrebe po dodatnem definiranju
robnih pogojev (na primer, ko je τmin > τmax).
Z izracunanima vrednostima τmin in τmax ucne primere za epoho t iz neoznacene ucne mnozice
izberemo z:
{Xu,t ,Yu,t}= {xu, yu}, s.t. τmin < maxyu < τmax, (14)
kjer je yu ciljni razred iz mnozice Yest , pripadajoc primeru xu.
Ucna mnozica {Xt ,Yt} je za t-to epoho definirana z:
Xt = Xl ∪Xu,t
Yt = Yl ∪Yu,t .(15)
3.1.5 Ucenje klasifikatorja
Po izbiranju ucnih primerov in generiranju ucne mnozice posodobimo utezi nasega klasifika-
torja, pri cemer minimiziramo precno entropijo, kot je implementirana v knjiznici PyTorch
24

(Paszke et al., 2019):
loss(y,c) =− log
exp(yc)
∑|y|j=0 exp(y j)
, (16)
kjer je spremenljivka y izhod nevronske mreze (brez pretvorbe v verjetnosti z aktivacijsko funk-
cijo Softmax) za dolocen primer x in c resnicen ciljni razred tega primera, ki je v primeru
neoznacene ucne mnozice definiran kot
c = argmax yt , yt ∈ Yu,t .
Funkcijo izgube minimiziramo s stohaticnim gradientnim spustom z algoritmom Adam (Kingma
in Ba, 2014). Zaradi narave nasih podatkov, t. j. relativno majhne oznacene ucne mnozice
v primerjavi z neoznaceno, koncno funkcijo izgube izracunamo z utezevanjem primerov in
vzorcenjem iz vsake mnozice po algoritmu 1. Kljucno pri algoritmu je, da v vsaki iteraciji
vzame batch size primerov iz oznacene in neoznacene ucne mnozice (vrstici 4 in 5) ter nato
izracuna funkcijo napake, pri cemer je napaka pri napovedi neoznacenih primerov utezena s hi-
perparametrom αloss. Stevilo iteracij dolocimo tako, da ustreza stevilu primerov v vecji izmed
obeh mnozic in s tem poskrbimo, da se model vedno uci iz vseh primerov (vrstica 1). Ker je
stevilo primerov v vsaki izmed ucnih mnozic razlicno, se model v vsaki epohi iz nekaterih uci
dvakrat. Funkcija sample() poskrbi, da so primeri vzorceni nakljucno, a tudi, da je vsak vedno
vzorcen vsaj enkrat.
Algoritem 1: Potek vzorcenja ucnih primerov in ucenja klasifikatorja iz {Xl,Yl} in
{Xu,t ,Yu,t}.Podatki: {Xl,Yl}, {Xu,t ,Yu,t}, batch size, model, αweight
1 n batch = max(|{Xl,Yl}|, |{Xu,t ,Yu,t}|) / batch size;
2 i = 0;
3 while i < n batch do4 X batchl,Y batchl = sample(Xl,Yl , batch size);
5 X batchu,Y batchu = sample(Xu,t ,Yu,t , batch size);
6 lossl = cross entropy(Y batchl , model.predict(X batchl));
7 lossu = cross entropy(Y batchu, model.predict(X batchu));
8 loss = lossl + αloss ∗ lossu;
9 model.update(loss, adam optimizer);
10 i = i + 1;
11 end
Po posodobitvi parametrov klasifikatorja proces posodabljanja oznak neoznacenih ucnih prime-
rov, generiranja stanja st in ucenja ponavljamo, dokler ni dosezeno specificirano stevilo epoh,
po cemer utezi modela in izracunane ciljne razrede ponovno inicializiramo.
25

3.2 Metaproblem
Kot ze omenjeno, lahko resevanje metaproblema razdelimo na dva dela: napovedovanje in
ucenje RL agenta. Napovedovanje sestoji iz vhoda st iz katerega agent π napove akcijo at :
at = πφ (·|st), (17)
kjer φ predstavlja trenutne parametre funkcije π .
Po izvedbi akcije je na podlagi spremembe klasifikacijske tocnosti izracunana nagrada, ki pred-
stavlja izboljsanje modela kot posledico izvedbe akcije:
Rt = acct(Yval, ft(Xval))−acct−1(Yval, ft−1(Xval)). (18)
Funkcija acc() predstavlja klasifikacijsko tocnost, ki jo definiramo v enacbi (26), funkcija
f (Xval) pa je klasifikator, ki vrne napovedi za ucne primere Xval . Poleg stanj st in st+1, ak-
cije at ter nagrade rt , belezimo se vrednost d, s katero ovrednotimo, ali je epizoda po izvedeni
akciji at koncana. Vrednosti nato shranimo v pomnilnik (angl. replay buffer) D .
3.2.1 Ucenje meta-agenta
Medtem ko je napovedovanje akcij relativno enostavno, saj poteka na enak nacin kot inferenca v
obicajnem strojnem ucenju ter vkljucuje le en model, je algoritem SAC (Haarnoja et al., 2018),
ki je zadolzen za spodbujevalno ucenje, v tem smislu bolj kompleksen. Algoritem vkljucuje vec
komponent:
• π(a|s) parametrizirana s φ : definira strategijo (angl. policy) agenta,
• Q1(s,a) in Q2(s,a) parametrizirani s θ1 in θ2: definirata pricakovano nagrado ob izvedbi
akcije a v stanju s do konca epizode,
• V (s) in V (s) parametrizirani z ω in ω : definirata pricakovano nagrado v stanju s do
konca epizode,
• α: definira utez entropije akcij.
Vsaka izmed zgornjih funkcij je na zacetku ucenja (razen v primeru prenosa znanja) iniciali-
zirana na nakljucne vrednosti in naucena na podlagi interakcij meta-agenta z okoljem, ki je v
nasem primeru klasifikator.
26

Algoritem SAC za ucenje strategije minimizira Kullback-Leiblerjevo entropijo (Kullback in
Leibler, 1951):
DKL(π(·,st) ||exp( 1α
Q(st , ·))) = ∑a′t∼πφ ,σ
π(a′t |st) logπ(a′t |st)
exp( 1α
Q(st ,a′t)). (19)
Enacba (19) opisuje razliko med verjetnostnima distribucijama π(·,st) in exp( 1α
Q(st , ·)), pri
cemer je cilj optimizacije priblizanje prve distribucije drugi. Parameter α tu regulira raziskova-
nje oziroma entropijo akcij; visje vrednosti vodijo do relativno bolj enakomerno porazdeljene
verjetnostne distribucije Q(st , ·), kar vodi k bolj stohasticnim akcijam, ki so posledica minimi-
ziranja Kullback-Leiblerjeve entropije. Po zapisu enacbe (19) v obliki pricakovanja in nekaj
drugih poenostavitev, minimiziramo:
Jπ = Est∼D
[Ea′t∼πφ ,σ
[α log(πφ (a′t |st))−Q(st ,a′t)]]. (20)
Bistvena razlika med osnovnim algoritmom odvoda strategije iz enacbe (5) in enacbo (20) je v
spremembi maksimiziranja pricakovane nagrade v minimizacijo Kullback-Leiblerjeve entropije
med verjetnostjo dolocene akcije in pricakovano nagrado do konca epizode. Poleg tega so v
algoritmu SAC stanja vzorcena iz pomnilnika interakcij D ter ne neposredno iz interakcij kot v
enacbi (5). V nadaljevanju bomo definirali le ciljne funkcije, s katerimi optimiziramo preostale
funkcije in za dodatne razlage in izpeljave bralca napotili k Haarnoja et al. (2018).
Zavoljo jedrnatosti v enacbah (19) in (20) izpuscamo generiranje stohasticne akcije a′t , ki je
pridobljena z vzorcenjem iz normalne distribucije N (πφ (·,s),σ). Tovrstno vzorcenje poskrbi
za raziskovanje agenta, poleg tega pa za uspesno ucenje iz spomina uporabi tudi reparame-
trizacijski trik (angl. reparametrization trick), ki omogoci uporabo interakcij, zgeneriranih z
zgodnejsimi parametri agenta brez potrebe po shranjevanju vseh preteklih utezi funkcije π .
Vrednosti σ in α sta nauceni; σ je del izhoda funkcije π in se uci skupaj z akcijami glede na
vhodno stanje s. Parameter α je po drugi strani naucen z maksimiziranjem:
Jα = Est∼D ,a′t∼πφ ,σ
[logα ∗ (− logπφ (a′t |st)−Htarget)
]. (21)
Spremenljivka Htarget v enacbi (21) je hiperparameter, ki doloca ciljno entropijo. V enacbah
(19) in (20) se pojavi funkcija Q(s,a), ki predstavlja pricakovano nagrado ob izvedbi akcije a v
stanju s. Funkcija je naucena z minimiziranjem pricakovanja:
JQ = E(st ,at ,rt ,st+1,d)∼D
[Qφ (st ,at)− (Rt + γ ∗ (1−d)∗Est+1[V ω(st+1)])
]. (22)
V enacbi (22) hiperparameter γ doloca pomembnost prihodnjih nagrad; visje vrednosti dajejo
visjo tezo prihodnjim interakcijam, medtem ko nizje dajejo poudarek trenutni nagradi. Para-
meter d ∈ {0,1} je dolocen glede na to, ali je interakcija zadnja v epizodi. V algoritmu SAC
27

sta uporabljeni dve Q-funkciji, Q1(s,a) in Q2(s,a), pri cemer je v primeru ucenja parametrov
φ konsistentno uporabljana prva ali druga. Za obe funkciji je pricakovanje (angl. expectation),
ki je minimizirano tekom ucenja, enako. Uporaba dveh Q-funkcij razresi problem precenje-
vanja prihodnjih stanj, ki ga je mogoce zaslediti v algoritmih vzpodbujevalnega ucenja DDPG
(Lillicrap et al., 2015) in DQN (Mnih et al., 2013). Pri minimiziranju ciljne funkcije aproksima-
torja V (s) je uporabljena vrednost Q-funkcije, ki da bolj pesimisticno napoved. Funkcija V (s)
je uporabljena v enacbi (22) in je naucena z minimiziranjem pricakovanja:
JV = Est∼D ,a′t∼πφ ,σ
[Vω(st)−
(mini=1,2
Qi(st ,a′t)−α ∗ logπφ (a′t |st)
)]. (23)
V enacbi (23) je vidno, da poleg spreminjanja V (s) proti trenutni oceni nagrade do konca epi-
zode, ki jo poda ena izmed funkcij Q(s,a), maksimiziramo tudi s parametrom α obtezeno en-
tropijo, kar je pomemben prispevek k uspesnosti algoritma. Funkcija V (s) je uporabljena za
stabilnejse ucenje Q-funkcije in je ob zacetku ucenja inicializirana z enakimi parametri kot
funkcija V (s). Po vsaki posodobitvi parametrov ω so parametri ω izracunani z:
ω t+1 = (1−λ )∗ω t +λ ∗ωt , (24)
kjer je λ hiperparameter, ki doloca hitrost spreminjanja utezi ω .
Ciljne funkcije minimiziramo z algoritmom Adam (Kingma in Ba, 2014). Nasa implementacija
v veliki meri sledi definicijam v Haarnoja et al. (2018). Kot izhodisce vzamemo tudi opise in
razlage na spletni strani SpinningUp (Achiam, 2018) in Github repozitorij Nips2017Learning-
2Run (Ding, 2020).
3.3 Prenos znanja
Kljub temu, da v razdelku 2.1.5 opisemo vec metod prenosa znanja, pri cemer nekatere upo-
rabljajo naucene reprezentacije razlicnih okolij, v nasem delu posezemo po preprosti metodi,
podobni Julian et al. (2020). Prednost metode je relativna enostavnost, ki ne zahteva sprememb
arhitekture, pac pa le preprosto uglasitev (angl. fine-tune) na novo okolje. Pri tem je potrebno
resiti problem razlicnih dimenzionalnosti stanj, ki so posledica razlicnih klasifikacijskih pro-
blemov. Ce povzamemo, stanje s je zgenerirano na podlagi povprecnih verjetnostnih distribucij
po ciljnih razredih na validacijski mnozici. V primeru, da ima bazni problem |ybase| ciljnih ra-
zredov, ta del reprezentacije stanja vsebuje |ybase|2 vrednosti, ki je pogosto razlicno od stevila
vrednosti |ytarget |2 v reprezentaciji ciljnega stanja.
Za resitev omenjenega problema reprezentacije stanj ustrezno spremenimo. V primeru, da je
|ybase| < |ytarget |, pri generiranju stanja za ciljni problem povprecno distribucijo za vsak ciljni
28

razred skrcimo tako, da obdrzimo prvih |ybase| vrednosti. Enacba (10) se zaradi tega spremeni
v:
mi =1
|Yi,target |
|Yi,target |
∑k=0
f (xk)(0, · · · , |ybase|), i ∈ [0, |ybase|]. (25)
Notacija je podobna kot v enacbi (10); kljucno je, da vzamemo vse primere iz ciljne validacijske
mnozice Yi,target , a stevilo vrednosti in ciljnih razredov omejimo na |ybase|. V primeru, da je
|ybase| > |ytarget |, dodatne vrednosti porazdelitev napovedi ciljnih razredov zapolnimo z 0, po
cemer je proces generiranja stanja enak kot v enacbi (10). V obeh primerih je stanju pripetih se
5 dodatnih vrednosti, ki so nastete v razdelku 3.1.3.
Z resenim problemom spremembe stevila ciljnih razredov iz baznega na ciljni problem ostaja
odprto se vprasanje, katero znanje ohraniti v prenosu. Pri resevanju prvega (baznega) metapro-
blema je ob koncu ucenja na voljo pomnilnik s preteklimi interakcijami meta-agenta in naucene
funkcije π(a|s), V (s), V (s), Q1(s,a) in Q2(s,a) ter parameter α . Za resevanje ciljnega problema
po preizkusanju razlicnih kombinacij uporabimo le naucene funkcije, medtem ko interakcije
zbiramo od zacetka. Preostanek ucenja nato poteka enako, kot je ze opisano v podpoglavjih 3.1
in 3.2.
29

4 Zasnova eksperimentov
V tem poglavju bomo opisali eksperimente, ki jih izvedemo za preizkus nase metode. Najprej
opisujemo potek ucenja sistema in nacin vrednotenja rezultatov. Temu sledijo hiperparametri
in opis podatkov ter arhitekture nevronskih mrez, ki jih uporabimo za izvedbo eksperimentov.
4.1 Potek ucenja sistema
Potek algoritma, ki ga implementiramo, je realiziran z zacetnim nabiranjem interakcij z na-
kljucno strategijo, ki se shranjuje v pomnilnik interakcij, ucenje meta-agenta pa se zacne sele
po zadostnem stevilu primerov v pomnilniku, ki je podano kot hiperparameter. S tem je po-
skrbljeno, da se meta-agent uci iz celotnega prostora stanj ter akcij in ne le iz tistih, ki bi bili
sicer generirani kot posledica nakljucno inicializiranih parametrov. Ucenje meta-agenta se torej
zacne po k izvedenih korakih z nakljucno strategijo. Ucenje klasifikatorja se po drugi strani ne
spreminja v odvisnosti od stevila ze opravljenih korakov.
Tekom poganjanja sistema periodicno preizkusamo znanje meta-agenta, pri cemer uporabimo
akcije brez dodanega suma, ki je sicer uporabljen za raziskovanje kot v razlagi enacbe (20).
Vsako vmesno testiranje sestoji iz vec epizod, pri cemer rezultate vsakega povprecimo in po
zakljucenem ucenju izvedemo koncno testiranje z agentom, parametriziranim z utezmi, ki so
privedle do najboljsega rezultata. To je razlicica pristopa zgodnjega ustavljanja (angl. early
stopping) (Prechelt, 1998), ki za dosego cim boljse kakovosti modela v casu testiranja vzame
tistega, ki tekom ucenja doseze najboljsi rezultat. Testiranje z vsakim agentom ponovimo 10-
-krat, po cemer dobljene klasifikacijske tocnosti povprecimo ter s tem dobimo rezultate enega
eksperimenta.
Med prenosom znanja, kot ze omenjeno, prenesemo le prednaucene parametre aproksimacij-
skih funkcij π(a|s), V (s), V (s), Q1,2(s,a) in α in ucenje inicializiramo s praznim pomnilnikom
preteklih interakcij. Obicajne eksperimente ucenja od zacetka za vsako konfiguracijo problema
ponovimo 5-krat in med prenosom metaznanja brez uglasevanja na ciljni problem preizkusimo
vseh pet shranjenih naborov aproksimacijskih funkcij. Zaradi velikega stevila moznih kombi-
nacij prenos z uglasevanjem na ciljni problem izvedemo 2-krat, pri cemer nakljucno izberemo
eksperimenta, katerih naucene aproksimacijske funkcije sluzijo za inicializacijo poskusov.
Ucni, validacijsko in testno mnozico z vsakim zacetkom ucenja sistema inicializiramo z razlicnimi
nakljucnimi semeni, ki poskrbijo za nadzorovano inicializacijo sistema in ponovljivost rezulta-
tov.
30

4.2 Hiperparametri
V nasem delu preizkusimo vec konfiguracij hiperparametrov, ki ne privedejo vedno do konver-
gence nasih modelov. Koncna izbira uporabljenih vrednosti je v tabelah 1, 2 in 3.
Hiperparametri, nasteti v tabeli 1, so uporabljeni za algoritem spodbujevalnega ucenja ter ve-
cinoma ne potrebujejo dodatne razlage. Hitrost ucenja αlr je hiperparameter, ki ga sprejme
uporabljen optimizator funkcij V (s), Q(s,a) in π(·|s) ter parametra α , ki doloca utez entro-
pije. Zacetek ucenja predstavlja stevilo interakcij, ki so opravljene z nakljucno strategijo pred
zacetkom ucenja agenta. Vsakih 50 epizod izvedemo preizkusanje trenutne strategije agenta,
ki se izvede v petih epizodah, kar je zapisano v zadnjih dveh vrsticah v tabeli 1. V tabeli 2
specificiramo hiperparametre, ki jih uporabljamo med prenosom metaznanja. Preostanek hiper-
parametrov med prenosom metaznanja je sicer enak kot med obicajnim ucenjem.
Ime hiperparametra VrednostHitrost ucenja (αlr) 0,00005
Hitrost ucenja V (λ ) 0,003
Ciljna entropija akcij (Htarget) 2
Velikost paketov (angl. batch size) 16
Velikost pomnilnika interakcij (|D |) 200.000
Zacetek ucenja 20.000
Zacetek uporabe agentovih akcij 20.000
Stevilo korakov/interakcij 300.000
St. nevronov na skritih nivojih 128, 128
Preizkusanje strategije agenta 50 (epizod)
Stevilo epizod za preizkusanje agenta 5 (epizod)
Tabela 1: Hiperparametri algoritma SAC, uporabljeni med nasimi eksperimenti
Ime hiperparametra VrednostZacetek ucenja 10.000
Zacetek uporabe agentovih akcij 0
Stevilo korakov/interakcij 60.000
Tabela 2: Hiperparametri algoritma SAC, uporabljeni med prenosom metaznanja
Nadalje za ucenje klasifikatorjev uporabimo hiperparametre, nastete v tabeli 3. Stevila nevro-
nov in filtrov ne pisemo neposredno v to tabelo, saj so opisani ter razvidni iz slik v razdelku
4.4.1.
31

Ime hiperparametra VrednostHitrost ucenja (αlr) 0,001
Stevilo epoh (t. j. korakov v epizodi) 300
Velikost paketov (angl. batch size) 128
Hitrost ucenja neoznacenih primerov (αlabel) 0,3
Utez funkcije izgube neoznacenih ucnih primerov (αloss) 0,1
Tabela 3: Hiperparametri, vezani na ucenje klasifikatorja
4.3 Podatki
Nas sistem preizkusimo na stirih podatkovnih zbirkah, ki jih na kratko opisujemo v tem podpo-
glavju:
• MNIST (LeCun in Cortes, 2010):
Podatkovna zbirka MNIST je sestavljena iz slik rocno zapisanih stevk 0–9. Slike stevk
so velikosti 28× 28× 1; vsaka slika ima torej visino in sirino 28 slikovnih tock ter en
kanal za zapis intenzitete tocke. Originalna ucna mnozica je razdeljena na 60.000 ucnih
primerov in 10.000 testnih. Prvo mnozico za uporabo v nasem sistemu nadalje razdelimo,
kot je zapisano v tabeli 4.
• CIFAR-10 (Krizhevsky in Hinton, 2009):
Podatkovna zbirka CIFAR-10 vsebuje 50.000 ucnih in 10.000 testnih primerov, pri cemer
ucno mnozico nadalje razdelimo, kot je prikazano v tabeli 4. Razlicne konfiguracije
oznacene in neoznacene ucne mnozice so uporabljene za preizkusanje razsirljivosti nase
metode, ki jo izvedemo le v primeru prenosa znanja. V eksperimentih, kjer sistem
ucimo od zacetka, je uporabljenih 1.000 oznacenih in 47.500 neoznacenih ucnih prime-
rov. Zbirka vsebuje slike predmetov in zivali, ki so kategorizirane v 10 ciljnih razredov:
letalo, avtomobil, ptica, macka, jelen, pes, zaba, konj, ladja, tovornjak. Vsaka slika je
dimenzije 32×32 s tremi barvnimi kanali.
• AG News (Zhang et al., 2015):
Zbirka AG NEWS je podatkovna zbirka novic, ki v nasi razlicici vsebuje 120.000 ucnih
in 7.600 testnih primerov, razdeljenih v 4 kategorije: sport, znanost/tehnologija, novice
iz sveta ter podjetnistvo. Vsakemu primeru je dodeljen ciljni razred 0–3, ki ustreza eni
od prej omenjenih kategorij. Ucno mnozico nadalje razdelimo podobno kot v primeru
uporabe prej omenjenih podatkovnih zbirk. Vhod, na podlagi katerega klasifikator odloca
o kategoriji primera, je sestavljen iz naslova in prvega odstavka clanka, ki ju za uporabo
v nasem sistemu spojimo v en niz. Dolzina najkrajsega niza znasa 8 besed, najdaljsega
32

pa 196. Povprecna dolzina vhodnega niza je 37,4 besed s standardnim odklonom 10,5.
Zaradi razlicnih dolzin besedil dolzino vhoda v nevronsko mrezo omejimo na 60, s cimer
v polni dolzini zajamemo 97,5 % vseh primerov. Primere, katerih dolzina je manjsa od
60, po tokenizaciji oblozimo s simbolom <pad>.
MNIST CIFAR10 AG NEWS
Oznacena ucna mnozica 5001.000/
2.000/
4.000
500
Neoznacena ucna mnozica 58.00047.500/
46.500/
44.500
118.000
Validacijska mnozica 1.500 1.500 1.500
Testna mnozica 10.000 10.000 7.600
Tabela 4: Stevilo primerov za ucenje in preizkusanje nasega sistema v odvisnosti od uporabljene
podatkovne zbirke
Konkretni primeri iz vsake podatkovne zbirke so vidni na slikah 7 in 8 ter v tabeli 5. Za slikovne
podatkovne zbirke je vidnih po 5 primerov za ciljni razred, medtem ko je pri AG NEWS za
vsakega predstavljen en primer. Kot omenimo v opisu slednje, je vsak ucni primer sestavljen iz
dveh nizov, naslova in prvega odstavka, ki so navedeni v tabeli 5. Izbira podatkovnih zbirk je
zastavljena tako, da nas sistem preizkusimo na razlicno tezkih problemih, ki obsegajo 4 ali 10
ciljnih razredov ter razlicne velikosti in tipe vhodnih podatkov.
0 2 3 4 5 6 7 8 91
Slika 7: Primeri iz podatkovne zbirke MNIST
33

letalo avtomobil ptica mačka jelen pes žaba konj ladja tovornjak
Slika 8: Primeri iz podatkovne zbirke CIFAR-10
Kategorija PrimeriNovice iz sveta “Venezuelans Rush to Vote in Referendum on Chavez”,
“CARACAS, Venezuela (Reuters) - Venezuelans crowded polling
stations on Sunday to vote on whether to recall left-wing President
Hugo Chavez or back his mandate to govern the world’s No. 5 oil
exporter for the next two years.”
Sport “US NBA players become the Nightmare Team after epic loss
(AFP)”,
“AFP - Call them the ‘Nightmare Team’.”
Znanost/tehnologija “Studies Find Rats Can Get Hooked on Drugs (AP)”,
“AP - Rats can become drug addicts. That’s important to know, sci-
entists say, and has taken a long time to prove. Now two studies
by French and British researchers show the animals exhibit the same
compulsive drive for cocaine as people do once they’re truly hooked.”
Podjetnisvo “Switching Titles, if Not Gears, at Dell”,
“Kevin B. Rollins, the new chief executive of Dell, talks about Dell’s
transitory slip in customer service, and why he sees a broader tech-
nology recovery taking place.”
Tabela 5: Primeri iz podatkovne zbirke AG NEWS
34

4.4 Arhitekture nevronskih mrez
Nas sistem smo se odlocili preizkusiti na vec problemih, za kar je potrebnih vec arhitektur
nevronskih mrez. Poleg tega zelimo preizkusiti tudi razlicne nacine resevanja istega problema,
ki so posledica uporabe variacij nevronskih mrez nad isto podatkovno zbirko. To podpoglavje
je razdeljeno na opise nevronskih mrez klasifikatorjev in aproksimacijskih funkcij V (s), V (s),
Q1,2(s,a) ter π(·|s).
4.4.1 Arhitekture nevronskih mrez klasifikatorjev
Svoje delo smo se odlocili omejiti na eno konfiguracijo nevronske mreze, namenjene za klasifi-
kacijo besedil, ter dve nevronski mrezi, namenjeni klasifikaciji slik; polno povezano ter konvo-
lucijsko.
Konvolucijska nevronska mreza je vidna na sliki 9 in sestoji iz dveh serij konvolucijskega ni-
voja in zdruzevalnega nivoja z maksimizacijo. Na prvem konvolucijskem nivoju uporabimo 32
filtrov in na drugem 16, ki mu v slednjem primeru sledi se izpustni sloj. Uporabljena mreza je
zakljucena z dvema polno povezanima nivojema.
Vhodni podatkiCIFAR10: 32 × 32 × 3MNIST: 28 × 28 × 1
Konvolucijski slojCIFAR10: 32 × 32 × 32MNIST: 32 × 28 × 28
Združevalni sloj z maksimizacijoCIFAR10: 32 × 16 × 16
MNIST: 32 × 14 × 14
Konvolucijski slojCIFAR10: 48 × 16 × 16MNIST: 48 × 14 × 14
Izpustni slojrazmerje: 0.2
Združevalni sloj z maksimizacijoCIFAR10: 48 × 8 × 8
MNIST: 48 × 7 × 7
Polno povezani slojCIFAR10: 128MNIST: 128
Izpustni slojrazmerje: 0.2
Polno povezani slojCIFAR10: 10MNIST: 10
Slika 9: Konvolucijska nevronska mreza, uporabljena za preizkusanje nasega sistema
Druga, manjsa nevronska mreza, ki jo uporabimo za klasifikacijo slikovnih podatkov, je vidna
na sliki 10. Sestavljenja je iz treh blokov polno povezanih nivojev, pri cemer prvima dvema sledi
izpustni sloj. Zaradi implementacije polno povezanih nivojev, ki sprejmejo 1-dimenzionalen
35
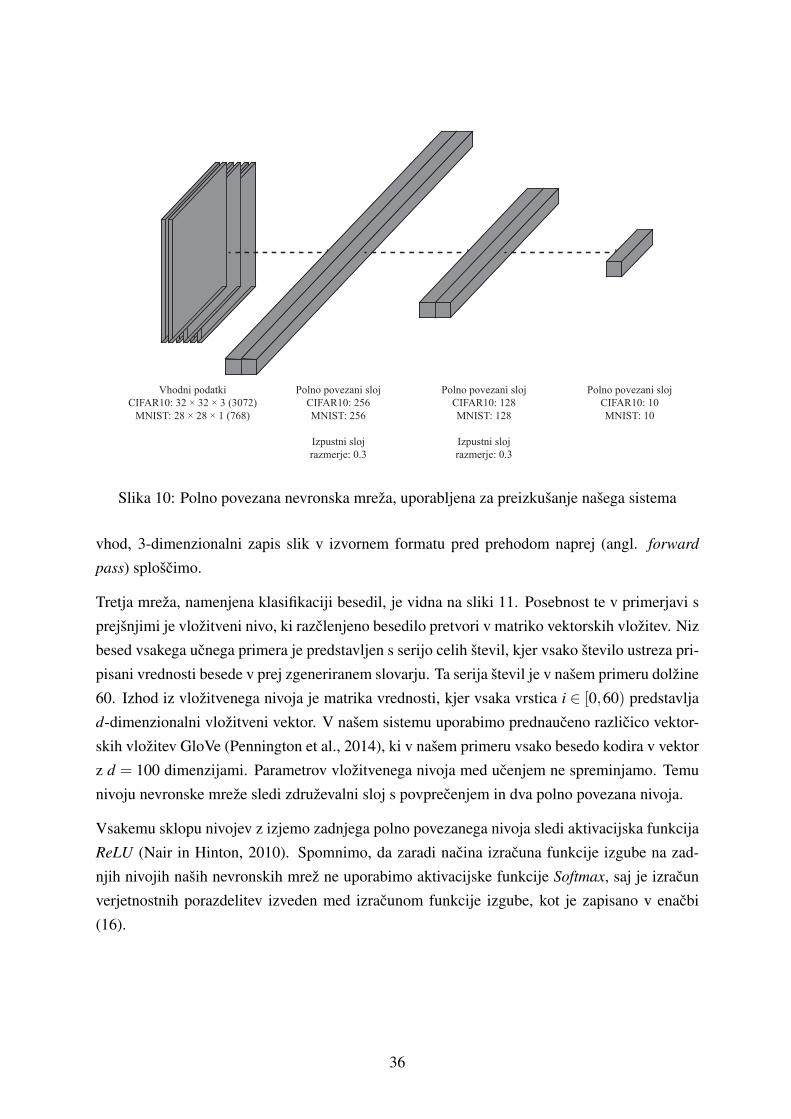
Vhodni podatkiCIFAR10: 32 × 32 × 3 (3072)
MNIST: 28 × 28 × 1 (768)
Polno povezani slojCIFAR10: 128MNIST: 128
Izpustni slojrazmerje: 0.3
Polno povezani slojCIFAR10: 10MNIST: 10
Polno povezani slojCIFAR10: 256MNIST: 256
Izpustni slojrazmerje: 0.3
Slika 10: Polno povezana nevronska mreza, uporabljena za preizkusanje nasega sistema
vhod, 3-dimenzionalni zapis slik v izvornem formatu pred prehodom naprej (angl. forward
pass) sploscimo.
Tretja mreza, namenjena klasifikaciji besedil, je vidna na sliki 11. Posebnost te v primerjavi s
prejsnjimi je vlozitveni nivo, ki razclenjeno besedilo pretvori v matriko vektorskih vlozitev. Niz
besed vsakega ucnega primera je predstavljen s serijo celih stevil, kjer vsako stevilo ustreza pri-
pisani vrednosti besede v prej zgeneriranem slovarju. Ta serija stevil je v nasem primeru dolzine
60. Izhod iz vlozitvenega nivoja je matrika vrednosti, kjer vsaka vrstica i ∈ [0,60) predstavlja
d-dimenzionalni vlozitveni vektor. V nasem sistemu uporabimo prednauceno razlicico vektor-
skih vlozitev GloVe (Pennington et al., 2014), ki v nasem primeru vsako besedo kodira v vektor
z d = 100 dimenzijami. Parametrov vlozitvenega nivoja med ucenjem ne spreminjamo. Temu
nivoju nevronske mreze sledi zdruzevalni sloj s povprecenjem in dva polno povezana nivoja.
Vsakemu sklopu nivojev z izjemo zadnjega polno povezanega nivoja sledi aktivacijska funkcija
ReLU (Nair in Hinton, 2010). Spomnimo, da zaradi nacina izracuna funkcije izgube na zad-
njih nivojih nasih nevronskih mrez ne uporabimo aktivacijske funkcije Softmax, saj je izracun
verjetnostnih porazdelitev izveden med izracunom funkcije izgube, kot je zapisano v enacbi
(16).
36

Vhodni podatki200 (besed)
Vložitveni sloj60 × 100
Združevalni sloj s povprečenjem1 × 100
Polno povezani sloj4
Polno povezani sloj128
Slika 11: Nevronska mreza z vlozitvenim in polno povezanim nivojem, uporabljena za pre-
izkusanje klasifikacije s podatkovno zbirko AG NEWS
4.4.2 Arhitekture nevronskih mrez za resevanje metaproblema
Za aproksimiranje funkcij π(·|s), V (s), V (s) in Q1,2(s,a) uporabljamo nevronske mreze, katerih
shematike so vidne na sliki 12. Vsaka nevronska mreza je parametrizirana s svojimi utezmi, a si
kljub temu delijo podobne arhitekture, katerih razlike so dimenzionalnosti vhodov in izhodov.
Nevronska mreza, ki se uci funkcij Q1(s,a) in Q2(s,a), sprejme vektor z vrednostmi stanja in
akcije, V (s) in V (s) pa le stanje; v obeh primerih je izhod nevronske mreze ena vrednost, ki
napoveduje pricakovano vrednost stanja (in akcije) do konca epizode. Podobno, kot V (s), tudi
π(·|s) sprejme stanje, izhod nevronske mreze pa sta dva vektorja. Spomnimo, da meta-agent
napoveduje 2 vrednosti iz katerih pridobimo spodnji in zgornji prag za izbiro ucnih primerov.
Prvi vektor torej napoveduje ti dve vrednosti, ki sta na sliki 12 imenovani povprecna akcija
37

a. Ti dve vrednosti sluzita tudi kot povprecje normalne porazdelitve N (µ,σ), medtem ko
drugi vektor sluzi kot standardni odklon σ , ki ga modeliramo v odvisnosti od stanja. Ponovno
omenimo, da je uporaba stohasticnih akcij, ki je posledica uporabljene konfiguracije, potrebna
za raziskovanje med ucenjem in reparametrizacijski trik, o katerem bolj podrobno pisemo v
razdelku 3.2.1.
Vsaka nevronska mreza, vidna na sliki 12, uporablja 3 polno povezane nivoje. Na prvih dveh
je aktivacijska funkcija zopet ReLU (Nair in Hinton, 2010). Za nevronske mreze V (s), V (s)
in Q1,2(s,a) na zadnjih nivojih ne uporabimo aktivacijskih funkcij, saj pricakovane vrednosti
stanj in akcij niso omejene. Pri nevronski mrezi funkcije π(·|s) na zadnjem nivoju za izhod µ
uporabimo aktivacijsko funkcijo tanh(x), ki vrednost izhoda omeji na interval (-1,1).
4.5 Vrednotenje rezultatov
Uspesnost ucenja merimo s klasifikacijsko tocnostjo, ki sluzi v namen racunanja nagrade meta-
agenta ter kot koncna metrika, s katero ocenjujemo uspesnost ucenja klasifikatorja. Klasifika-
cijska tocnost je definirana kot:
acc(t)(Y, f (X)) =# pravilnih napovedi
# vseh napovedi. (26)
Med ucenjem so rezultati vedno ovrednoteni na validacijski mnozici, medtem ko v postopku
testiranja po zakljucenem ucenju uporabljamo testno mnozico. Po ucenju uspesnost nasega RL
agenta primerjamo s klasifikacijsko tocnostjo v primerih uporabe:
• oznacene ucne mnozice ter znanih pravilnih ciljnih razredov primerov iz neoznacene ucne
mnozice,
• oznacene ucne mnozice in vseh neoznacenih ucnih primerov ne glede na prepricanost
klasifikatorja v njihove ciljne razrede,
• oznacene ucne mnozice in pragov prepricanosti, najdenih z nakljucnim preiskovanjem, in
• samo oznacene ucne mnozice brez dostopa do neoznacenih ucnih primerov.
V poglavju 5 se na zgornje alineje sklicujemo z besedno zvezo konfiguracije ucnih mnozic,
medtem ko se na resevanje specificnega problema z enim izmed nacinov izbire ucnih primerov
sklicujemo z besedno zvezo testna konfiguracija.
Prva tocka zgornjega seznama predstavlja klasicen nadzorovan pristop in idealen primer, ko za
vse ucne primere poznamo njihove pravilne ucne razrede. Klasifikacijske tocnosti v tem pri-
meru odrazajo zmogljivost klasifikatorja in s tem zgornjo mejo nasih rezultatov. Zadnja alineja
38
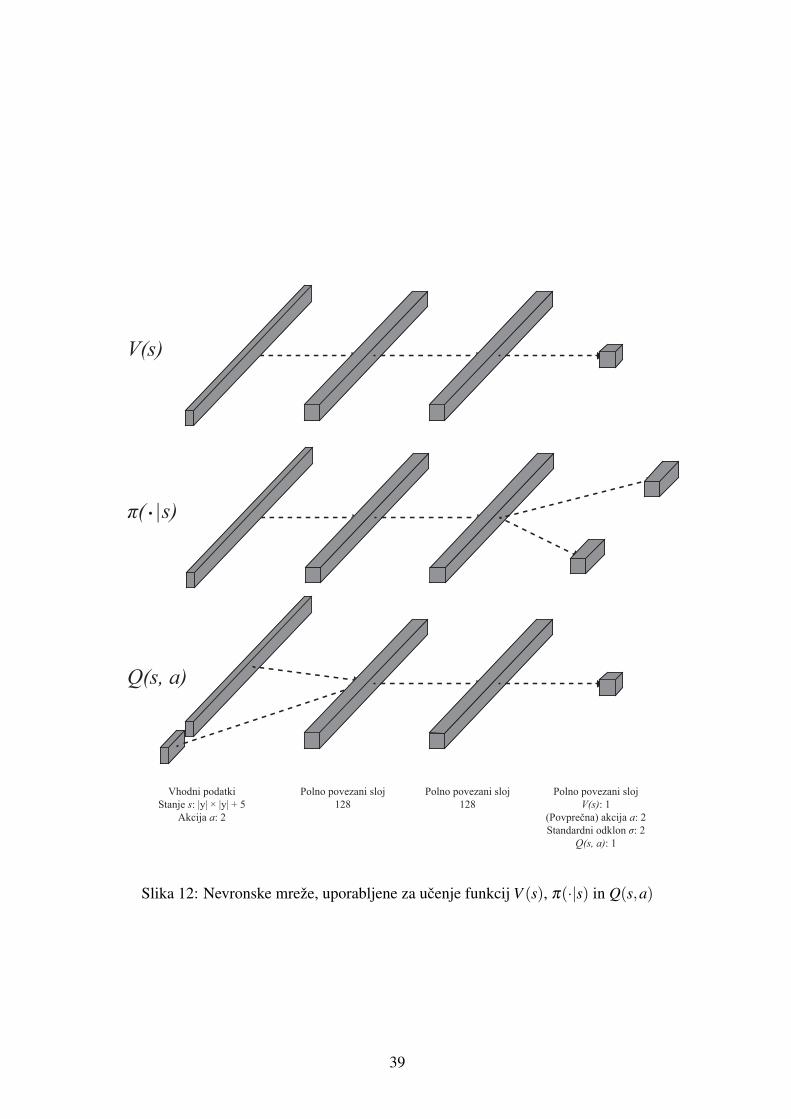
Vhodni podatkiStanje s: |y| × |y| + 5
Akcija a: 2
Polno povezani sloj128
Polno povezani slojV(s): 1
(Povprečna) akcija a: 2Standardni odklon σ: 2
Q(s, a): 1
Polno povezani sloj128
V(s)
Q(s, a)
π( |s)
Slika 12: Nevronske mreze, uporabljene za ucenje funkcij V (s), π(·|s) in Q(s,a)
39

predstavlja izhodiscno klasifikacijsko tocnost, ki je posledica uporabe le relativno majhnega
stevila oznacenih ucnih primerov, kot je zapisano v tabeli 4. Preostali dve alineji opisujeta iz-
biro neoznacenih ucnih primerov z uporabo “naivnih” pristopov: uporabo vseh neoznacenih
primerov v neodvisnosti od prepricanosti klasifikatorja ter izbiro ucnih primerov z nakljucno
najdenimi pragovi prepricanosti, ki se ne spreminjajo v odvisnosti od znanja modela.
Nakljucno preiskovanje pragov za izbiro ucnih primerov poteka skladno z algoritmom, ki ga
opise Zabinsky (2010). Preiskovanje je opravljeno pred koncnim testiranjem ter sestoji iz izbire
pragov:
τmin,max ∼U (0,1), s.t. τmin < τmax, (27)
kjer sta τmin,max pragova zaupanja, U (0,1) pa funkcija, ki vraca enakomerno porazdeljena
stevila iz intervala [0,1). Vsako izbiro 5-krat preizkusimo z uporabo validacijske mnozice in
klasifikacijske tocnosti za vsak par pragov (τmin,τmax) povprecimo. V poglavju 5 porocamo
o rezultatih na testni mnozici ob uporabi pragov, ki so privedli do najvisjih klasifikacijskih
tocnosti.
Pred koncno evalvacijo vsake testne konfiguracije preizkusimo 500 razlicnih nakljucno izbranih
pragov, kar zahteva primerljivo kolicino casa kot 5-kratno ucenje meta-agenta od zacetka. Glede
na to, da porocamo o povprecnih rezultatih petih pognanih eksperimentov ucenja meta-agenta z
razlicnimi razdelitvami ucnih mnozic (t. j. inicializacijo z razlicnimi nakljucnimi semeni), tudi
nakljucno najdene pragove preizkusimo z enakimi razdelitvami.
40

5 Eksperimentalni rezultati
Nas sistem se odlocimo preizkusiti na relativno sirokem naboru problemov in konfiguracij.
Nase eksperimente delimo na preizkusanje sistema z ucenjem od zacetka ter preizkusanje s
prenosom znanja. Konfiguracije ucnih mnozic, nastetih v prejsnjem poglavju, so uporabljene
pri ucenju nasega sistema od zacetka. Porocamo o rezultatih z uporabo testnih konfiguracij:
• MNIST s polno povezano nevronsko mrezo,
• MNIST s konvolucijsko nevronsko mrezo,
• CIFAR-10 s polno povezano nevronsko mrezo in 1.000 oznacenimi ter preostalimi ne-
oznacenimi ucnimi primeri,
• CIFAR-10 s konvolucijsko nevronsko mrezo in 1.000 oznacenimi ter preostalimi neozna-
cenimi ucnimi primeri, in
• AG NEWS z nevronsko mrezo z vlozitvenim nivojem.
Nadalje porocamo se o rezultatih prenosa metaznanja, ki vkljucujejo:
• prenos iz vseh konfiguracij eksperimentov na zgornjem seznamu iz ene konfiguracije na
drugo,
• prenos iz CIFAR-10, naucenega v konfiguraciji s 1.000 oznacenimi ucnimi primeri in
konvolucijsko nevronsko mrezo, na konfiguracijo z 2.000 in 4.000 anotiranimi ucnimi
primeri.
V diskusiji najprej povzamemo dosezene rezultate ter ugotovitve o delovanju cloveske kognicije
iz razdelka 2.2.1, ki jih primerjamo z delovanjem nasega sistema.
5.1 Ucenje ucnih strategij
V tem podpoglavju predstavljamo rezultate nasega sistema v primeru ucenja od zacetka, ki jih
primerjamo s stirimi drugimi konfiguracijami ucnih mnozic. Najprej predstavljamo rezultate
ucenja z vidika klasifikatorja, nato pa se iz vidika resevanja metaproblema oziroma ucenja ucne
strategije.
41

5.1.1 Ucenje klasifikatorja
Kot je vidno v tabeli 7, nas sistem preizkusamo proti ucenju z:
• vsemi ucnimi primeri z znanimi ciljnimi razredi (Vsi ucni primeri – oznaceni),
• vsemi ucnimi primeri, kjer uporabimo stevilo oznacenih in neoznacenih primerov, kot je
specificirano v tabeli 4 (Vsi ucni primeri – oznaceni in neoznaceni),
• izbiro ucnih primerov s pragovi, najdenimi z nakljucnim preiskovanjem, kot je opisano v
podpoglavju 4.1 (Pragovi, najdeni z nakljucnim preiskovanjem) in
• le podmnozico oznacenih ucnih primerov.
Te konfiguracije ustrezajo tistim, nastetim in opisanim v podpoglavju 4.5. Rezultati, dosezeni
ob uporabi nasega sistema, so vidni v zadnji vrstici tabele 7.
Kvantitativni rezultati
Tabela 7 vsebuje koncne rezultate vsake izmed prej opisanih konfiguracij. Prvo skrajnost pred-
stavljajo rezultati uporabe vseh ucnih primerov z znanimi ciljnimi razredi; v tem primeru so
klasifikacijskih tocnosti najvisje. Drugo skrajnost predstavljajo rezultati, dosezeni ob uporabi
oznacenih in neoznacenih ucnih primerov, ne glede na prepricanost v ciljni razred primera; v
tem primeru so klasifikacijske tocnosti najnizje. Rezultati uporabe le oznacene ucne mnozice
so boljsi od slednjih in predstavljajo izhodiscne klasifikacijske tocnosti za vsako testno konfi-
guracijo.
Uporaba pragov, najdenih z nakljucnim preiskovanjem (navedeni so v tabeli 6) ali nasega meta-
agenta privede do najboljsih rezultatov, z absolutno razliko med pristopi najvec 1 %. Uporaba
pragov, najdenih z nakljucnim preiskovanjem, v polovici tesnih konfiguracij privede do boljsih
rezultatov kot uporaba nase metode, kar implicira, da strategije meta-agenta ne konvergirajo
vedno do optimalne resitve.
Pomembno je omeniti, da so razlike med rezultati ob uporabi le oznacenih ucnih primerov v
primerjavi z ucinkovitostjo nase metode odvisne tudi od izbire problema in nacina resevanja.
Vidno je, da je v primeru resevanja problema AG NEWS in CIFAR-10 s polno povezano ne-
vronsko mrezo razlika med izhodiscno in klasifikacijsko tocnostjo, dosezeno z uporabo nasega
RL agenta, najmanjsa. Glede na to, da so v teh dveh primerih tudi ostali rezultati ob uporabi
nase metode polnadzorovanega ucenja blizu izhodiscnim, lahko recemo, da je za resevanje teh
dveh konfiguracij problema nas pristop neucinkovit.
Kljub temu pa je koncna dosezena klasifikacijska tocnost nasega pristopa k problemu AG
NEWS za 1,34 % visja od rezultatov, ki so jih dosegli Wu et al. (2018), kar primerjamo v tabeli
42

Konfiguracija eksperimenta τmin τmax
MNIST, polno povezan 0,9952 0,9998
MNIST, konvolucija 0,981 0,9985
CIFAR-10, polno povezan 0,966 0,9843
CIFAR-10, konvolucija 0,8914 0,9726
AG NEWS 0,0637 0,1952
Tabela 6: Vrednosti pragov, najdenih z nakljucnim preiskovanjem ob uporabi razlicnih konfi-
guracij
8. Te rezultate avtorji dosezejo ob uporabi 12.000 oznacenih ucnih primerov in kompleksnejsih
nevronskih mrez za resevanje problema na isti podatkovni zbirki. Ta rezultat izpostavljamo,
ker je v mnogih pogledih nas pristop osnovan na njihovem delu, a kljub relativni enostavnosti
klasifikatorjev dosegamo visje klasifikacijske tocnosti.
V primeru delovanja nase metode (t. j. ob resevanju problema MNIST z obema tipoma nevron-
ske mreze ter CIFAR-10 s konvolucijsko nevronsko mreze) smo dosegli za 2,1-3,0 % boljse
rezultate kot ob uporabi le oznacene ucne mnozice.
Graficno ovrednotenje rezultatov
Tabela 7 pokaze le del rezultatov nasega pristopa, zato v nadaljevanju le-tega ovrednotimo se
graficno. Na sliki 13 so prikazane klasifikacijske tocnosti s standardnimi odkloni v odvisnosti
od epohe ucenja. Vsak graf prikazuje en tip problema, medtem ko vsaka barva predstavlja eno
testno konfiguracijo. Te ustrezajo vrsticam iz tabele 7 oziroma 5 konfiguracijam ucnih mnozic,
s katerimi preizkusamo nas sistem. Poudarimo, da zaradi razlicnih vrednosti na osi Y rezultati
med seboj niso neposredno primerljivi ter da posledicno velikost razlik na posameznih grafih ni
zrcalo absolutnih razlik v rezultatih.
Iz slike 13 je razvidno, da v nasprotju s prej ugotovljeno relativno neuspesnostjo resevanja pro-
blemov AG NEWS in CIFAR-10 s polno povezano nevronsko mrezo nasa metoda v dolocenih
pogledih vseeno doseze boljse rezultate. V primeru AG NEWS vidimo, da klasifikacijska
tocnost ob uporabi meta-agenta na zacetku ucenja da slabse rezultate kot uporaba le pod-
mnozice oznacenih ucnih primerov ali nakljucno najdenih pragov za izbiro primerov. Situa-
cija pa se spremeni po 200-ti epohi, ko meta-agent bolje vzdrzuje pridobljeno klasifikacijsko
tocnost v nasprotju z ostalima dvema primerljivima nacinoma ucenja. Za razliko od AG NEWS
pa resevanje problema CIFAR-10 s polno povezano nevronsko mrezo zaznamujejo visje klasi-
fikacijske tocnosti na zacetku ucenja, kasneje pa se te ustalijo na vrednostih, ki so primerljive
z ostalimi pristopi. Padajoce krivulje med resevanjem problemov AG NEWS in CIFAR-10 s
polno povezano nevronsko mrezo nakazujejo tudi na mozen simptom nedelovanja polnadzo-
rovanega ucenja; klasifikacijske tocnosti po zacetni rasti med ucenjem namrec pocasi padajo
43
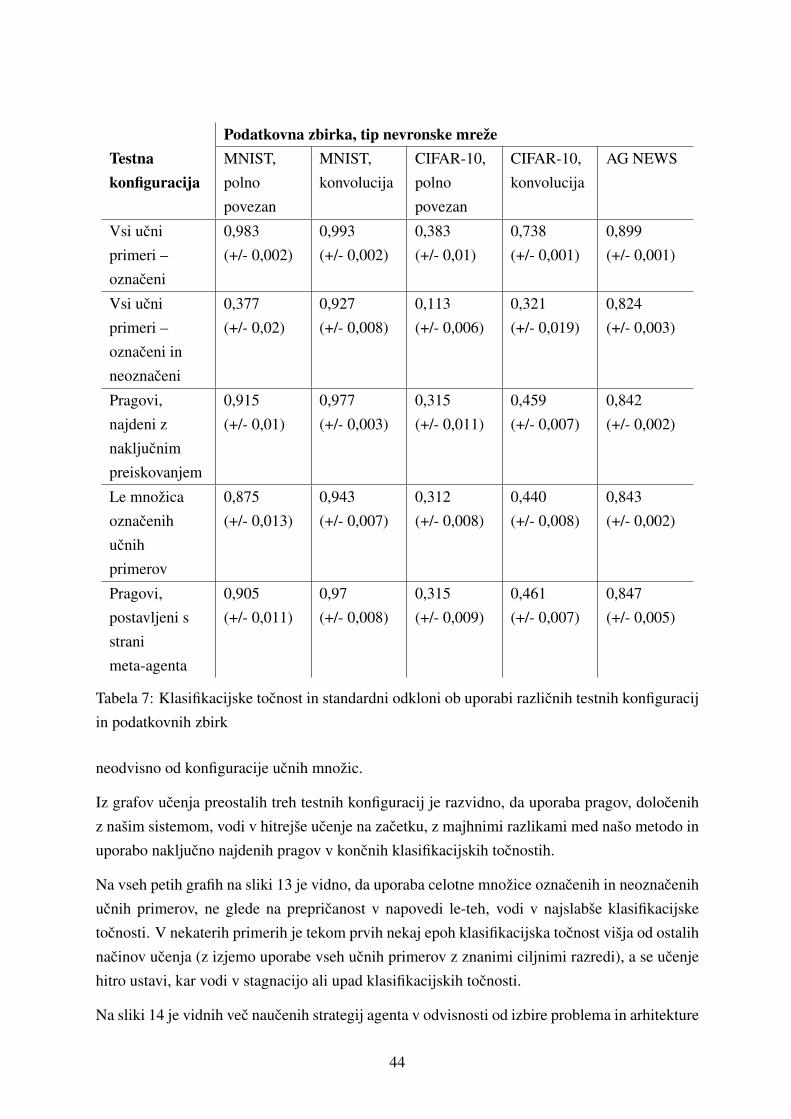
Podatkovna zbirka, tip nevronske mrezeTestnakonfiguracija
MNIST,
polno
povezan
MNIST,
konvolucija
CIFAR-10,
polno
povezan
CIFAR-10,
konvolucija
AG NEWS
Vsi ucni
primeri –
oznaceni
0,983
(+/- 0,002)
0,993
(+/- 0,002)
0,383
(+/- 0,01)
0,738
(+/- 0,001)
0,899
(+/- 0,001)
Vsi ucni
primeri –
oznaceni in
neoznaceni
0,377
(+/- 0,02)
0,927
(+/- 0,008)
0,113
(+/- 0,006)
0,321
(+/- 0,019)
0,824
(+/- 0,003)
Pragovi,
najdeni z
nakljucnim
preiskovanjem
0,915
(+/- 0,01)
0,977
(+/- 0,003)
0,315
(+/- 0,011)
0,459
(+/- 0,007)
0,842
(+/- 0,002)
Le mnozica
oznacenih
ucnih
primerov
0,875
(+/- 0,013)
0,943
(+/- 0,007)
0,312
(+/- 0,008)
0,440
(+/- 0,008)
0,843
(+/- 0,002)
Pragovi,
postavljeni s
strani
meta-agenta
0,905
(+/- 0,011)
0,97
(+/- 0,008)
0,315
(+/- 0,009)
0,461
(+/- 0,007)
0,847
(+/- 0,005)
Tabela 7: Klasifikacijske tocnost in standardni odkloni ob uporabi razlicnih testnih konfiguracij
in podatkovnih zbirk
neodvisno od konfiguracije ucnih mnozic.
Iz grafov ucenja preostalih treh testnih konfiguracij je razvidno, da uporaba pragov, dolocenih
z nasim sistemom, vodi v hitrejse ucenje na zacetku, z majhnimi razlikami med naso metodo in
uporabo nakljucno najdenih pragov v koncnih klasifikacijskih tocnostih.
Na vseh petih grafih na sliki 13 je vidno, da uporaba celotne mnozice oznacenih in neoznacenih
ucnih primerov, ne glede na prepricanost v napovedi le-teh, vodi v najslabse klasifikacijske
tocnosti. V nekaterih primerih je tekom prvih nekaj epoh klasifikacijska tocnost visja od ostalih
nacinov ucenja (z izjemo uporabe vseh ucnih primerov z znanimi ciljnimi razredi), a se ucenje
hitro ustavi, kar vodi v stagnacijo ali upad klasifikacijskih tocnosti.
Na sliki 14 je vidnih vec naucenih strategij agenta v odvisnosti od izbire problema in arhitekture
44
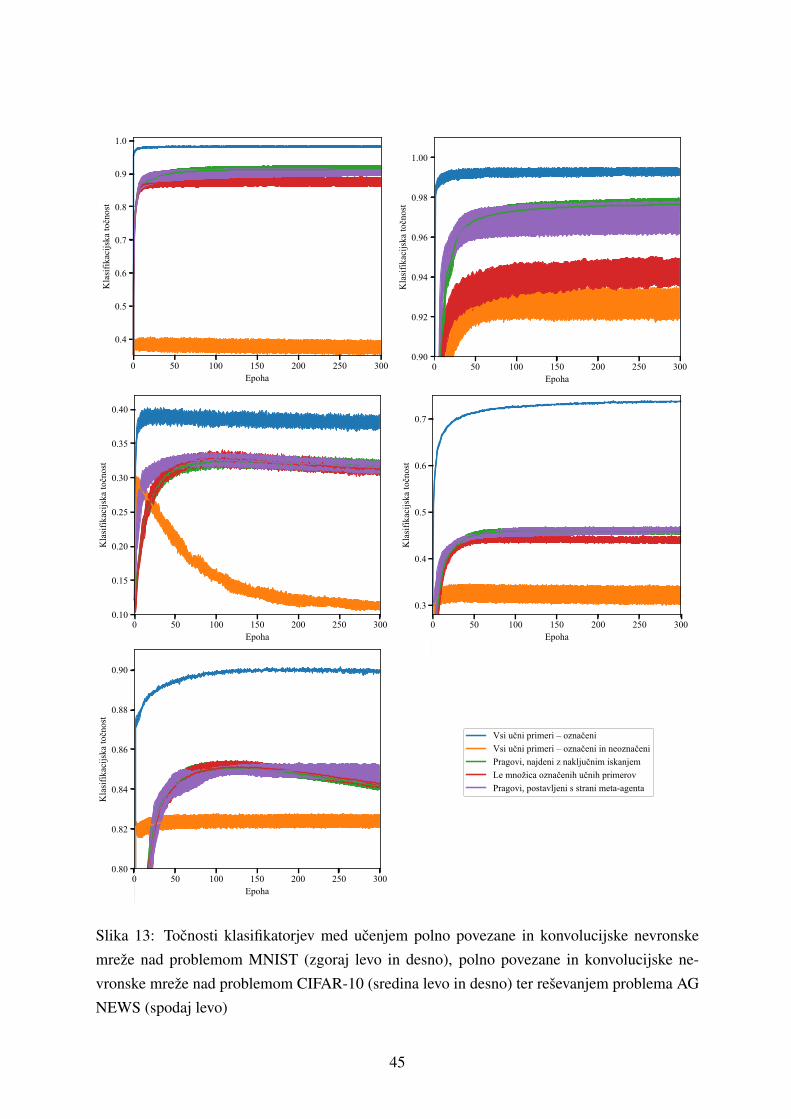
Slika 13: Tocnosti klasifikatorjev med ucenjem polno povezane in konvolucijske nevronske
mreze nad problemom MNIST (zgoraj levo in desno), polno povezane in konvolucijske ne-
vronske mreze nad problemom CIFAR-10 (sredina levo in desno) ter resevanjem problema AG
NEWS (spodaj levo)
45
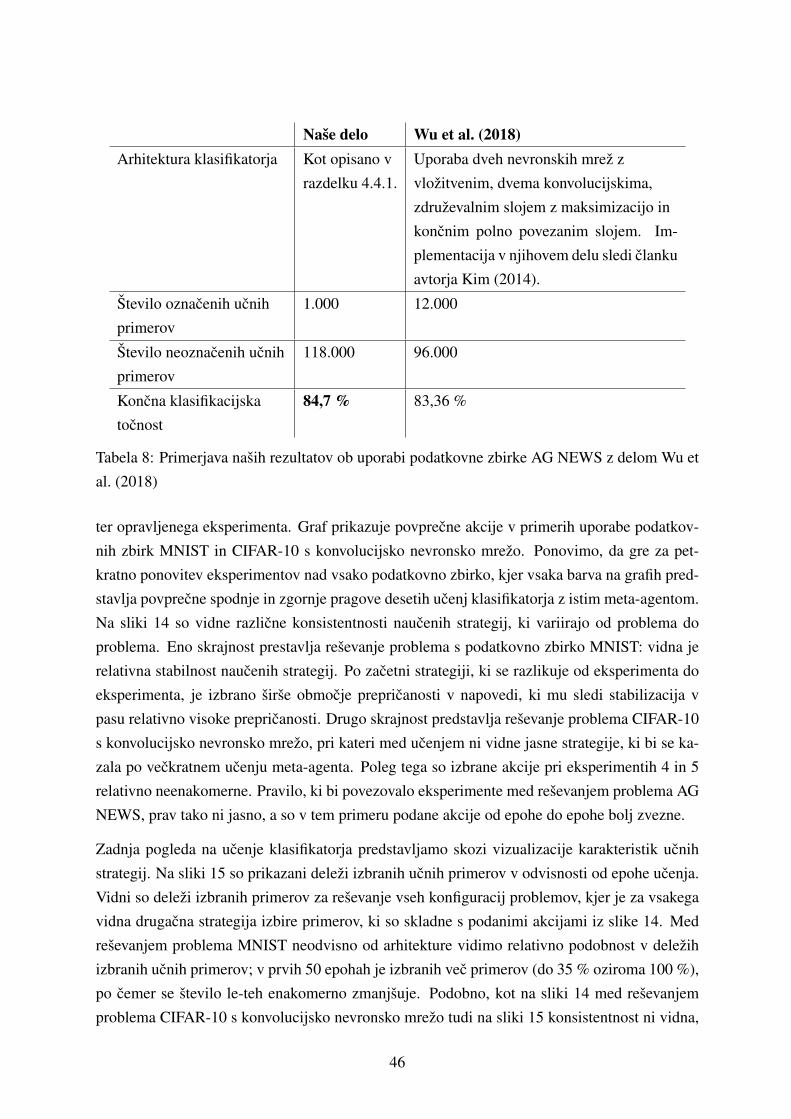
Nase delo Wu et al. (2018)Arhitektura klasifikatorja Kot opisano v
razdelku 4.4.1.
Uporaba dveh nevronskih mrez z
vlozitvenim, dvema konvolucijskima,
zdruzevalnim slojem z maksimizacijo in
koncnim polno povezanim slojem. Im-
plementacija v njihovem delu sledi clanku
avtorja Kim (2014).
Stevilo oznacenih ucnih
primerov
1.000 12.000
Stevilo neoznacenih ucnih
primerov
118.000 96.000
Koncna klasifikacijska
tocnost
84,7 % 83,36 %
Tabela 8: Primerjava nasih rezultatov ob uporabi podatkovne zbirke AG NEWS z delom Wu et
al. (2018)
ter opravljenega eksperimenta. Graf prikazuje povprecne akcije v primerih uporabe podatkov-
nih zbirk MNIST in CIFAR-10 s konvolucijsko nevronsko mrezo. Ponovimo, da gre za pet-
kratno ponovitev eksperimentov nad vsako podatkovno zbirko, kjer vsaka barva na grafih pred-
stavlja povprecne spodnje in zgornje pragove desetih ucenj klasifikatorja z istim meta-agentom.
Na sliki 14 so vidne razlicne konsistentnosti naucenih strategij, ki variirajo od problema do
problema. Eno skrajnost prestavlja resevanje problema s podatkovno zbirko MNIST: vidna je
relativna stabilnost naucenih strategij. Po zacetni strategiji, ki se razlikuje od eksperimenta do
eksperimenta, je izbrano sirse obmocje prepricanosti v napovedi, ki mu sledi stabilizacija v
pasu relativno visoke prepricanosti. Drugo skrajnost predstavlja resevanje problema CIFAR-10
s konvolucijsko nevronsko mrezo, pri kateri med ucenjem ni vidne jasne strategije, ki bi se ka-
zala po veckratnem ucenju meta-agenta. Poleg tega so izbrane akcije pri eksperimentih 4 in 5
relativno neenakomerne. Pravilo, ki bi povezovalo eksperimente med resevanjem problema AG
NEWS, prav tako ni jasno, a so v tem primeru podane akcije od epohe do epohe bolj zvezne.
Zadnja pogleda na ucenje klasifikatorja predstavljamo skozi vizualizacije karakteristik ucnih
strategij. Na sliki 15 so prikazani delezi izbranih ucnih primerov v odvisnosti od epohe ucenja.
Vidni so delezi izbranih primerov za resevanje vseh konfiguracij problemov, kjer je za vsakega
vidna drugacna strategija izbire primerov, ki so skladne s podanimi akcijami iz slike 14. Med
resevanjem problema MNIST neodvisno od arhitekture vidimo relativno podobnost v delezih
izbranih ucnih primerov; v prvih 50 epohah je izbranih vec primerov (do 35 % oziroma 100 %),
po cemer se stevilo le-teh enakomerno zmanjsuje. Podobno, kot na sliki 14 med resevanjem
problema CIFAR-10 s konvolucijsko nevronsko mrezo tudi na sliki 15 konsistentnost ni vidna,
46
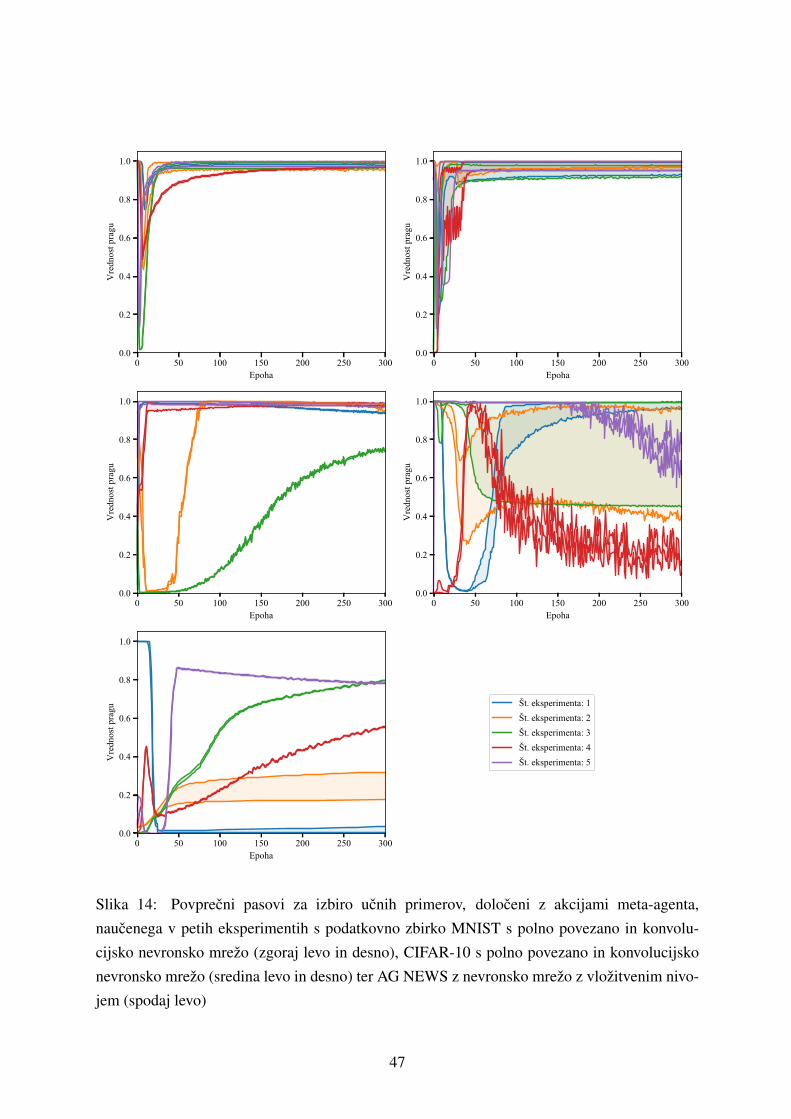
0 50 100 150 200 250 300Epoha
0.0
0.2
0.4
0.6
0.8
1.0
Vre
dnos
t pra
gu
0 50 100 150 200 250 300Epoha
0.0
0.2
0.4
0.6
0.8
1.0
Vre
dnos
t pra
gu
0 50 100 150 200 250 300Epoha
0.0
0.2
0.4
0.6
0.8
1.0
Vre
dnos
t pra
gu
0 50 100 150 200 250 300Epoha
0.0
0.2
0.4
0.6
0.8
1.0V
redn
ost p
ragu
0 50 100 150 200 250 300Epoha
0.0
0.2
0.4
0.6
0.8
1.0
Vre
dnos
t pra
gu
t. eksperimenta: 1t. eksperimenta: 2t. eksperimenta: 3t. eksperimenta: 4t. eksperimenta: 5
Slika 14: Povprecni pasovi za izbiro ucnih primerov, doloceni z akcijami meta-agenta,
naucenega v petih eksperimentih s podatkovno zbirko MNIST s polno povezano in konvolu-
cijsko nevronsko mrezo (zgoraj levo in desno), CIFAR-10 s polno povezano in konvolucijsko
nevronsko mrezo (sredina levo in desno) ter AG NEWS z nevronsko mrezo z vlozitvenim nivo-
jem (spodaj levo)
47

izstopata pa relativno visok delez izbranih ucnih primerov ali povecevanje deleza tudi na koncu
ucenja klasifikatorja. To je v kontrastu z vsemi ostalimi konfiguracijami, kjer je izbran majhen
del (< 2 %) neoznacenih ucnih primerov za vsako podatkovno zbirko. Posebnost pri resevanju
problema AG NEWS in CIFAR-10 s polno povezano nevronsko mrezo je, da je v petih ucenjih
meta-agenta prislo do strategij, pri katerih je vecji delez primerov izbran na razlicnih tockah
v ucnem procesu klasifikatorja, v enem primeru pa meta-agent za ucenje klasifikatorja celo ne
izbere nobenega neoznacenega ucnega primera. V splosnem je med izbranimi akcijami na sliki
14 in delezi izbranih ucnih primerov na sliki 15 vidna korelacija – vecja konsistentnost akcij je
povezana s konsistentnostjo v kolicini izbranih primerov.
Nazadnje eno nauceno ucno strategijo ovrednotimo se s konkretnimi ucnimi primeri, ki so bili
izbrani med ucenjem. Na sliki 16 so prikazani primeri stevil 1, 2 in 8 iz podatkovne zbirke
MNIST, izbrani ob ucenju s konvolucijsko nevronsko mrezo. Pri ucenju med 10. epoho je
izbranih manj kot 8 primerov za vsako stevko, zato so nekatera mesta prazna. Subjektivna ocena
napredka med ucenjem je, da so z nabiranjem znanja izbrani in pravilno klasificirani vse bolj
raznovrstni ucni primeri, kar je ocitno predvsem pri stevkah 1 in 2. Ucenje razpoznave stevke
1 na primer napreduje od enostavnega zapisa z eno crto prek zapisa z dvema crtama do bolj
nenavadnih stevk, kot je vidno v zadnji epohi ucenja. Podobno pravilo je mogoce razpoznati
tudi pri stevki 8, a pri njej napredek ni tako zvezen. Prikazane primere smo iz ucne mnozice za
vsako epoho izbrali nakljucno brez rocnega kuriranja prikazanih primerov.
Pri izbranih napacno klasificiranih stevkah smo pricakovali, da si bodo te sledile od bolj do manj
ocitno napacno klasificiranih, a iz slike 16 tega ne moremo razpoznati; zdi se, da klasifikator za
vsako stevko tekom celega ucenja dela kvalitativno podobne napake.
5.1.2 Rezultati ucenja meta-agenta
V tem razdelku predstavljamo se ucenje z vidika spodbujevalnega ucenja, ki pogled iz ene
epizode ucenja, opisanega v prejsnjem razdelku, prestavi na prikaz pridobivanja metaznanja
med izvajanjem vec epizod nad danim problemom.
Slika 17 prikazuje ucenje agenta na naboru petih konfiguracij problema, ki smo jih preizkusili.
Grafi prikazujejo klasifikacijske tocnosti na koncu epizod v odvisnosti od stevila opravljenih
korakov. Omenimo, da so prikazane klasifikacijske tocnosti pridobljene med ucenjem (in ne
med vmesnimi testiranji), kar pomeni, da so rezultati dosezeni z vkljucenim raziskovanjem
agenta.
Napredek meta-agenta je najbolj ociten v primeru uporabe polno povezane nevronske mreze
in resevanja problema CIFAR-10 ali MNIST, manj ociten v primeru uporabe konvolucijske ne-
vronske mreze s podatkovno zbirko MNIST ter AG NEWS. Na sliki 17 napredek ni viden pri
48
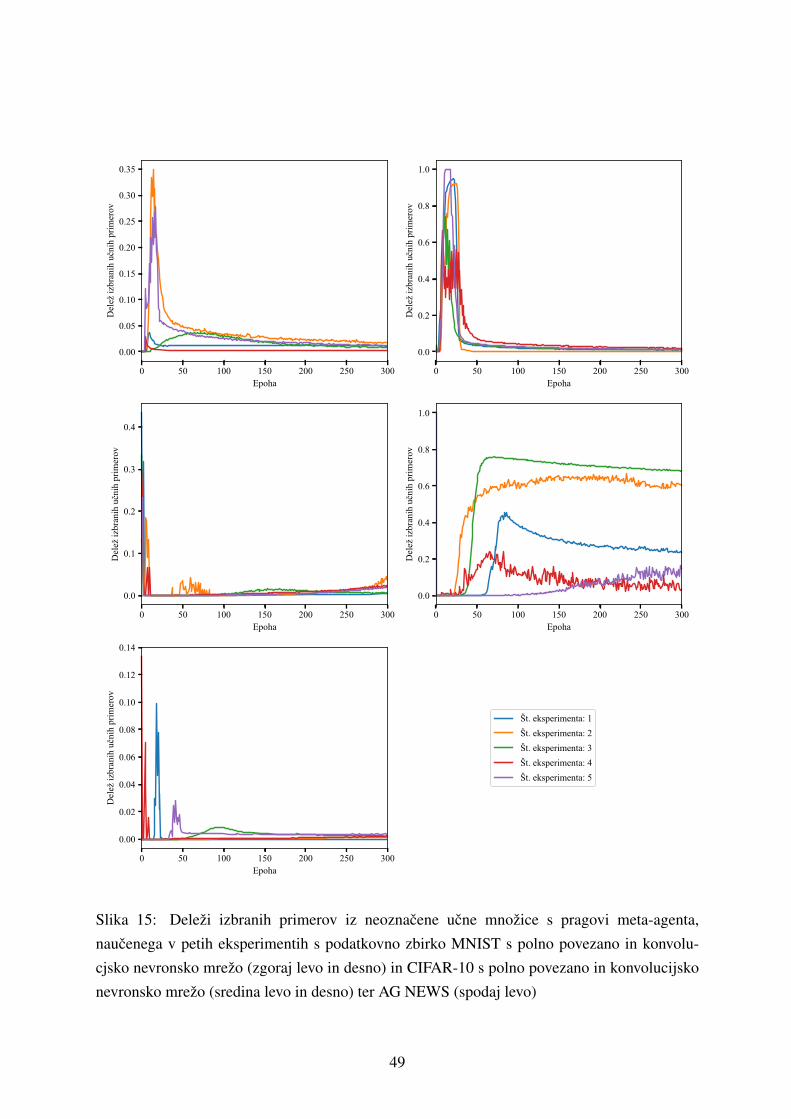
0 50 100 150 200 250 300Epoha
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
Del
e iz
bran
ih u
nih
prim
erov
0 50 100 150 200 250 300Epoha
0.0
0.2
0.4
0.6
0.8
1.0
Del
e iz
bran
ih u
nih
prim
erov
0 50 100 150 200 250 300Epoha
0.0
0.1
0.2
0.3
0.4
Del
e iz
bran
ih u
nih
prim
erov
0 50 100 150 200 250 300Epoha
0.0
0.2
0.4
0.6
0.8
1.0D
ele
izbr
anih
uni
h pr
imer
ov
0 50 100 150 200 250 300Epoha
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
Del
e iz
bran
ih u
nih
prim
erov
t. eksperimenta: 1t. eksperimenta: 2t. eksperimenta: 3t. eksperimenta: 4t. eksperimenta: 5
Slika 15: Delezi izbranih primerov iz neoznacene ucne mnozice s pragovi meta-agenta,
naucenega v petih eksperimentih s podatkovno zbirko MNIST s polno povezano in konvolu-
cjsko nevronsko mrezo (zgoraj levo in desno) in CIFAR-10 s polno povezano in konvolucijsko
nevronsko mrezo (sredina levo in desno) ter AG NEWS (spodaj levo)
49

Epoha 10
Epoha 20
Epoha 40
Epoha 80
Epoha 160
Epoha 300
Slika 16: Izbrani neoznaceni ucni primeri v odvisnosti od epohe ucenja. Prva vrstica vsake sku-
pine vsebuje pravilno klasificirane (oznaceni z zeleno piko), druga pa nepravilno klasificirane
ucne primere (oznaceni z rdeco piko)
50
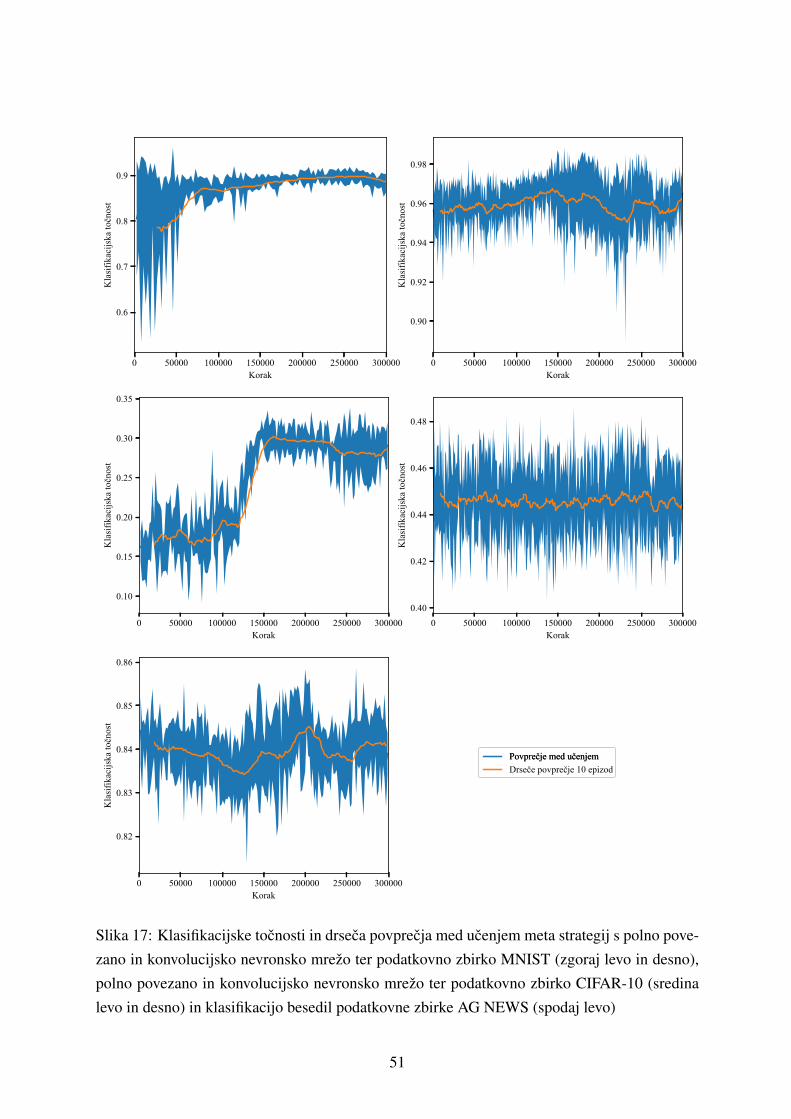
Slika 17: Klasifikacijske tocnosti in drseca povprecja med ucenjem meta strategij s polno pove-
zano in konvolucijsko nevronsko mrezo ter podatkovno zbirko MNIST (zgoraj levo in desno),
polno povezano in konvolucijsko nevronsko mrezo ter podatkovno zbirko CIFAR-10 (sredina
levo in desno) in klasifikacijo besedil podatkovne zbirke AG NEWS (spodaj levo)
51

uporabi konvolucijske nevronske mreze med resevanjem problema CIFAR-10. Zanimivo pri
slednjem je, da so koncne klasifikacijske tocnosti v tabeli 7 ob uporabi nasega agenta v pov-
precju vseeno za 2,1 % visje od izhodiscnega rezultata, kljub temu, da med ucenjem agent v
povprecju ne doseze primerljivih klasifikacijskih tocnosti. Ta pojav izvira iz dejstva, da agen-
tove strategije najvisje nagrade dosezejo po razlicnih kolicinah interakcij s problemom CIFAR-
-10. Vsak izmed pognanih eksperimentov nad to testno konfiguracijo najvisje vrednosti doseze
okoli korakov 69.200, 250.200, 23.700, 30.600 in 234.000, po cemer zbrane nagrade vsako
epizodo upadejo nazaj na zacetne vrednosti. Zanimivo pri tem je, da v nekaterih primerih
zbrane nagrade dosezejo vrhunec ze po zelo majhnem stevilu interakcij agenta s problemom.
Zaradi opisanih razlik iz povprecij in standardnih odklonov na grafu pridobivanja metaznanja
med resevanjem problema CIFAR-10 s konvolucijsko nevronsko mrezo napredka ni mogoce
razbrati. Resevanje problemov AG NEWS ter MNIST in CIFAR-10 s konvolucijsko nevronsko
mrezo nakazuje na pomembnost uporabe zgodnjega ustavljanja, saj meta-agent pridobi nekaj
znanja, po cemer padec klasifikacijske tocnosti nakazuje na katastroficno pozabljanje (angl.
catastrophic forgetting).
5.2 Prenos ucnih strategij
V tem podpoglavju pisemo o resevanju prej opisanih problemov s prenosom znanja, ki zajema
uporabo modelov z metaznanjem o enem problemu na drugem. Poleg primerjave z izhodiscnimi
rezultati v prejsnjih poglavjih tu primerjamo rezultate tudi med pristopoma brez (razdelek 5.2.1)
in z (razdelek 5.2.2) uglasitvijo na ciljni problem. S slednjim zelimo pokazati na kolicino
pridobljenega metaznanja, ki ga agent ob prenosu sploh pridobi. V razdelku 5.2.2 predstavimo
tudi napredek meta-agenta pri prenosu v odvisnosti od koraka ucenja. Nazadnje v razdelku
5.2.3 predstavimo eksperimente s prenosom znanja, pri katerih povecujemo stevilo oznacenih
ucnih primerov v ucni mnozici.
5.2.1 Prenos brez uglasevanja na ciljni problem
Za primerjavo rezultatov, ki jih dobimo ob prenosu z uglasevanjem na ciljni problem, v tem
razdelku predstavljamo klasifikacijske tocnosti prenosa brez uglasevanja. Te pridobimo tako,
da vzamemo meta-agenta, naucenega na izvornem problemu, in ga uporabimo za dolocanje
pragov na ciljnem. V tabeli 9 so predstavljeni rezultati, dosezeni na testnih mnozicah vseh
kombinacij problemov.
Ob primerjavi rezultatov s tabelo 7 je v 10 izmed 20 testnih eksperimentov na ciljnih pro-
blemih dosezena nizja klasifikacijska tocnost v primerjavi z uporabo le oznacene podmnozice
podatkov. V 9 primerih je dosezena visja klasifikacijska tocnost kot ob uporabi le oznacene
52
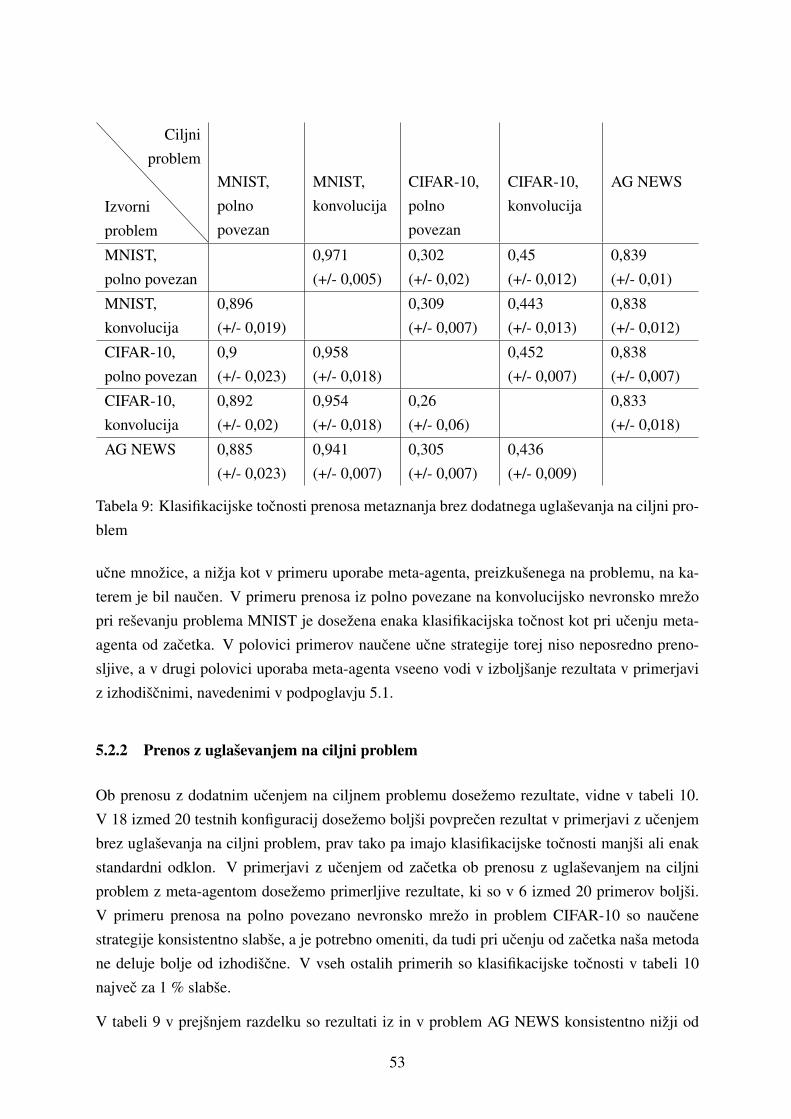
Izvorni
problem
Ciljni
problemMNIST,
polno
povezan
MNIST,
konvolucija
CIFAR-10,
polno
povezan
CIFAR-10,
konvolucija
AG NEWS
MNIST,
polno povezan
0,971
(+/- 0,005)
0,302
(+/- 0,02)
0,45
(+/- 0,012)
0,839
(+/- 0,01)
MNIST,
konvolucija
0,896
(+/- 0,019)
0,309
(+/- 0,007)
0,443
(+/- 0,013)
0,838
(+/- 0,012)
CIFAR-10,
polno povezan
0,9
(+/- 0,023)
0,958
(+/- 0,018)
0,452
(+/- 0,007)
0,838
(+/- 0,007)
CIFAR-10,
konvolucija
0,892
(+/- 0,02)
0,954
(+/- 0,018)
0,26
(+/- 0,06)
0,833
(+/- 0,018)
AG NEWS 0,885
(+/- 0,023)
0,941
(+/- 0,007)
0,305
(+/- 0,007)
0,436
(+/- 0,009)
Tabela 9: Klasifikacijske tocnosti prenosa metaznanja brez dodatnega uglasevanja na ciljni pro-
blem
ucne mnozice, a nizja kot v primeru uporabe meta-agenta, preizkusenega na problemu, na ka-
terem je bil naucen. V primeru prenosa iz polno povezane na konvolucijsko nevronsko mrezo
pri resevanju problema MNIST je dosezena enaka klasifikacijska tocnost kot pri ucenju meta-
agenta od zacetka. V polovici primerov naucene ucne strategije torej niso neposredno preno-
sljive, a v drugi polovici uporaba meta-agenta vseeno vodi v izboljsanje rezultata v primerjavi
z izhodiscnimi, navedenimi v podpoglavju 5.1.
5.2.2 Prenos z uglasevanjem na ciljni problem
Ob prenosu z dodatnim ucenjem na ciljnem problemu dosezemo rezultate, vidne v tabeli 10.
V 18 izmed 20 testnih konfiguracij dosezemo boljsi povprecen rezultat v primerjavi z ucenjem
brez uglasevanja na ciljni problem, prav tako pa imajo klasifikacijske tocnosti manjsi ali enak
standardni odklon. V primerjavi z ucenjem od zacetka ob prenosu z uglasevanjem na ciljni
problem z meta-agentom dosezemo primerljive rezultate, ki so v 6 izmed 20 primerov boljsi.
V primeru prenosa na polno povezano nevronsko mrezo in problem CIFAR-10 so naucene
strategije konsistentno slabse, a je potrebno omeniti, da tudi pri ucenju od zacetka nasa metoda
ne deluje bolje od izhodiscne. V vseh ostalih primerih so klasifikacijske tocnosti v tabeli 10
najvec za 1 % slabse.
V tabeli 9 v prejsnjem razdelku so rezultati iz in v problem AG NEWS konsistentno nizji od
53
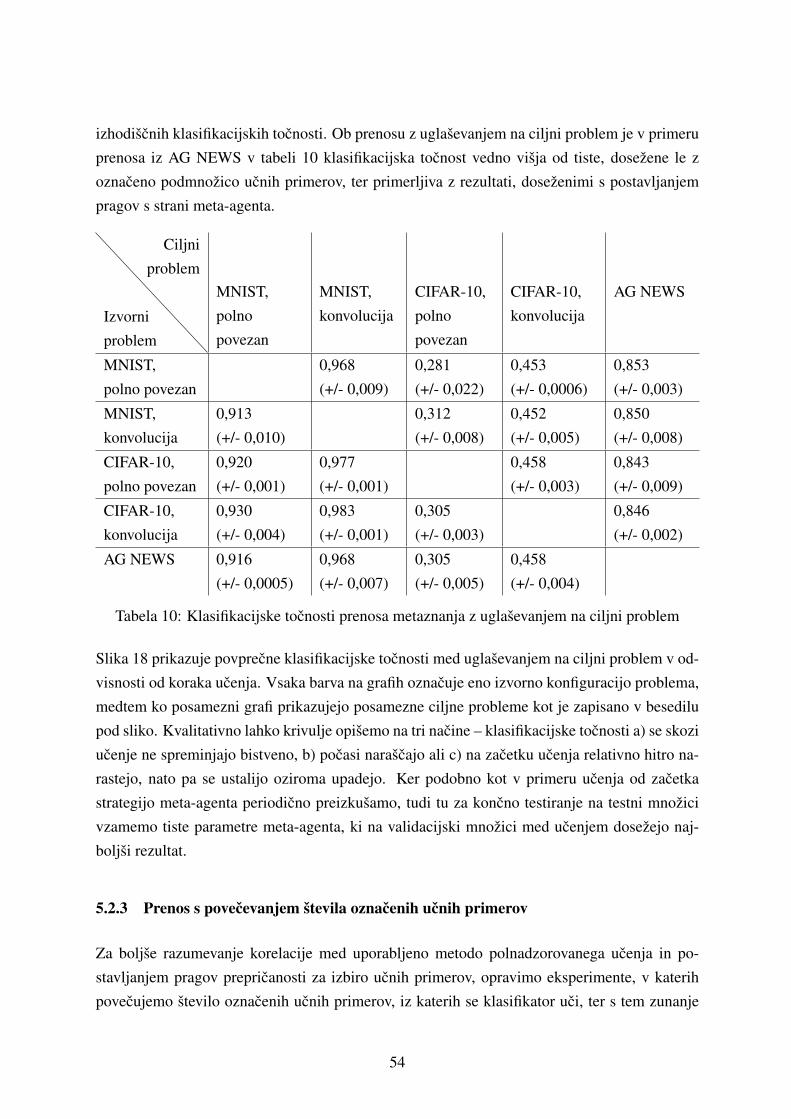
izhodiscnih klasifikacijskih tocnosti. Ob prenosu z uglasevanjem na ciljni problem je v primeru
prenosa iz AG NEWS v tabeli 10 klasifikacijska tocnost vedno visja od tiste, dosezene le z
oznaceno podmnozico ucnih primerov, ter primerljiva z rezultati, dosezenimi s postavljanjem
pragov s strani meta-agenta.
Izvorni
problem
Ciljni
problemMNIST,
polno
povezan
MNIST,
konvolucija
CIFAR-10,
polno
povezan
CIFAR-10,
konvolucija
AG NEWS
MNIST,
polno povezan
0,968
(+/- 0,009)
0,281
(+/- 0,022)
0,453
(+/- 0,0006)
0,853
(+/- 0,003)
MNIST,
konvolucija
0,913
(+/- 0,010)
0,312
(+/- 0,008)
0,452
(+/- 0,005)
0,850
(+/- 0,008)
CIFAR-10,
polno povezan
0,920
(+/- 0,001)
0,977
(+/- 0,001)
0,458
(+/- 0,003)
0,843
(+/- 0,009)
CIFAR-10,
konvolucija
0,930
(+/- 0,004)
0,983
(+/- 0,001)
0,305
(+/- 0,003)
0,846
(+/- 0,002)
AG NEWS 0,916
(+/- 0,0005)
0,968
(+/- 0,007)
0,305
(+/- 0,005)
0,458
(+/- 0,004)
Tabela 10: Klasifikacijske tocnosti prenosa metaznanja z uglasevanjem na ciljni problem
Slika 18 prikazuje povprecne klasifikacijske tocnosti med uglasevanjem na ciljni problem v od-
visnosti od koraka ucenja. Vsaka barva na grafih oznacuje eno izvorno konfiguracijo problema,
medtem ko posamezni grafi prikazujejo posamezne ciljne probleme kot je zapisano v besedilu
pod sliko. Kvalitativno lahko krivulje opisemo na tri nacine – klasifikacijske tocnosti a) se skozi
ucenje ne spreminjajo bistveno, b) pocasi narascajo ali c) na zacetku ucenja relativno hitro na-
rastejo, nato pa se ustalijo oziroma upadejo. Ker podobno kot v primeru ucenja od zacetka
strategijo meta-agenta periodicno preizkusamo, tudi tu za koncno testiranje na testni mnozici
vzamemo tiste parametre meta-agenta, ki na validacijski mnozici med ucenjem dosezejo naj-
boljsi rezultat.
5.2.3 Prenos s povecevanjem stevila oznacenih ucnih primerov
Za boljse razumevanje korelacije med uporabljeno metodo polnadzorovanega ucenja in po-
stavljanjem pragov prepricanosti za izbiro ucnih primerov, opravimo eksperimente, v katerih
povecujemo stevilo oznacenih ucnih primerov, iz katerih se klasifikator uci, ter s tem zunanje
54
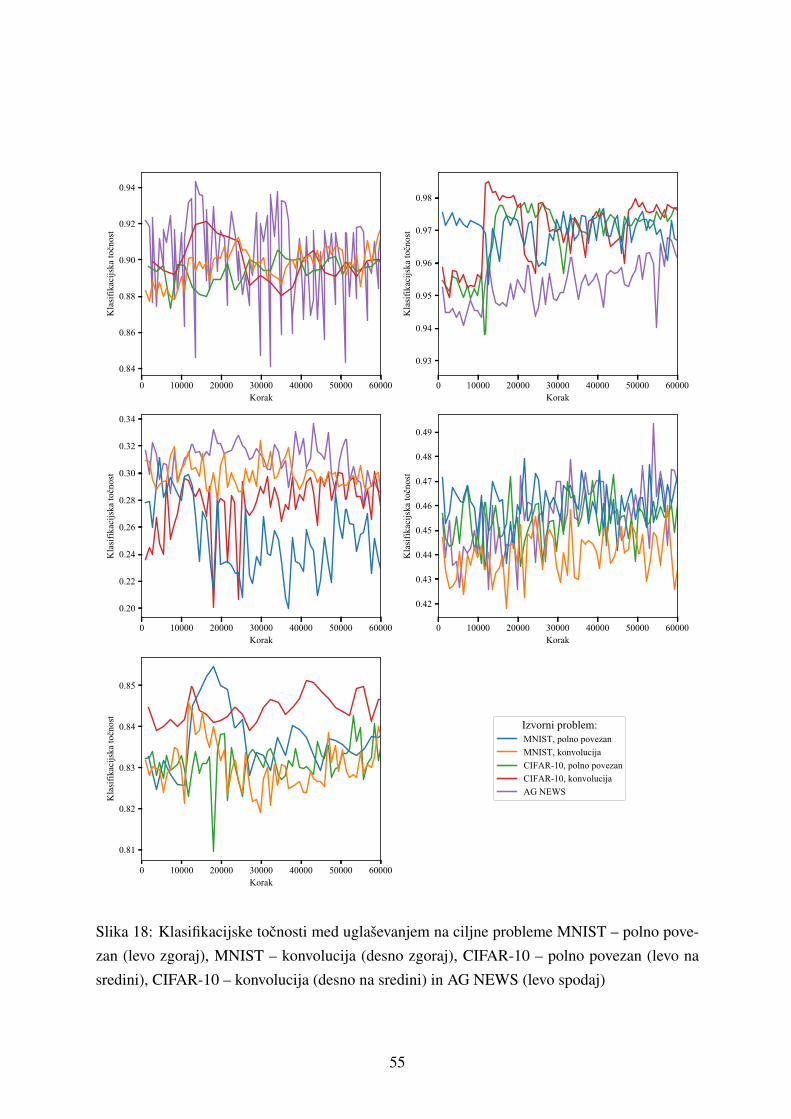
0 10000 20000 30000 40000 50000 60000Korak
0.84
0.86
0.88
0.90
0.92
0.94
Kla
sifik
acijs
ka to
nost
0 10000 20000 30000 40000 50000 60000Korak
0.93
0.94
0.95
0.96
0.97
0.98
Kla
sifik
acijs
ka to
nost
0 10000 20000 30000 40000 50000 60000Korak
0.20
0.22
0.24
0.26
0.28
0.30
0.32
0.34
Kla
sifik
acijs
ka to
nost
0 10000 20000 30000 40000 50000 60000Korak
0.42
0.43
0.44
0.45
0.46
0.47
0.48
0.49
Kla
sifik
acijs
ka to
nost
0 10000 20000 30000 40000 50000 60000Korak
0.81
0.82
0.83
0.84
0.85
Kla
sifik
acijs
ka to
nost Izvorni problem:
MNIST, polno povezanMNIST, konvolucijaCIFAR-10, polno povezanCIFAR-10, konvolucijaAG NEWS
Slika 18: Klasifikacijske tocnosti med uglasevanjem na ciljne probleme MNIST – polno pove-
zan (levo zgoraj), MNIST – konvolucija (desno zgoraj), CIFAR-10 – polno povezan (levo na
sredini), CIFAR-10 – konvolucija (desno na sredini) in AG NEWS (levo spodaj)
55

znanje, ki je vneseno v sistem. Na primeru problema CIFAR-10 z uporabo konvolucijske ne-
vronske mreze opazimo povecevanje relativne razlike med uporabo le oznacene podmnozice
ucnih primerov in pragov zaupanja, postavljenih s strani meta-agenta, v odvisnosti od veliko-
sti oznacene ucne mnozice, kar je vidno v tabeli 11. Preverjanje hipoteze, da je povprecje ob
uporabi 4.000 v primerjavi s 1.000 oznacenimi primeri visje, vrne p = 0,311, kar pomeni, da
razlika za stevilo ponovitev eksperimenta n = 2 ni znatna (p >α,α = 0,05). Za dosego morebi-
tne statisticne pomembnosti rezultatov bi morali eksperimente za vsako konfiguracijo ponoviti
veckrat.
CIFAR-10,1.000 primerov
CIFAR-10,2.000 primerov
CIFAR-10,4.000 primerov
Le oznaceni ucni
primeri
0,440
(+/- 0,008)
0,501
(+/- 0,0003)
0,554
(+/- 0,002)
Z uporabo pragov,
postavljenih s strani
meta-agenta
0,461
(+/- 0,007)
0,525
(+/- 0,004)
0,580
(+/- 0,005)
Relativna razlika 0,021
(+/- 0,011)
0,024
(+/- 0,004)
0,026
(+/- 0,0054)
Tabela 11: Klasifikacijske tocnosti ob uporabi razlicnega stevila oznacenih ucnih primerov
5.3 Diskusija
Poglavje zakljucujemo z diskusijo, v kateri povezemo in umestimo rezultate, opisane v podpo-
glavjih 5.1 in 5.2. Cilj razdelka 5.3.1 je splosna razlaga rezultatov, medtem ko v razdelku 5.3.2
le-te, kjer je to mogoce, primerjamo s clovesko kognicijo.
5.3.1 Diskusija rezultatov iz prejsnjih poglavij
Ce bi zeleli dosezene rezultate povzeti z eno besedo, bi lahko rekli, da so le-ti mesani. Ko nasa
metoda deluje, daje primerljive rezultate kot uporaba pragov, najdenih z nakljucnim preisko-
vanjem. Kljub temu, da je slednja implementacijsko bolj enostavna, za prednost nase metode
oznacujemo relativno fleksibilnost, ki jo pokazemo s prenasanjem strategij meta-agenta med
problemi. Podobnost pa ni le v dosezeni koncni klasifikacijski tocnosti, pac pa tudi v najdenih
pragovih prepricanosti; tako nakljucni pragovi kot tudi nasa metoda (v kasnejsih epohah ucenja)
za uspesno ucenje vecinoma konvergirajo k visjim vrednostim. Ko naso metodo uporabimo v
konfiguracijah eksperimentov, v katerih doseze boljse rezultate od izhodiscnih, v prvih epohah
56

konsistentno dosegamo visje klasifikacijske tocnosti v primerjavi z ostalimi “naivnimi” me-
todami dolocanja pragov za izbiro primerov. Kljub temu pa so koncne klasifikacijske tocnosti
sicer le primerljive in ne nujno visje kot rezultati izbire primerov z nakljucno najdenimi pragovi.
Morda celo bolj pomembno kot vprasanje delovanja nasega sistema pa je vprasanje nedelo-
vanja. Nedelovanje na problemu CIFAR-10 ob resevanju s konvolucijsko nevronsko mrezo
je mogoce pripisati relativno nizki klasifikacijski tocnosti, ki jo doseze klasifikator. Brez za-
nesljivosti napovedi klasifikatorja nasa polnadzorovana metoda ne more delovati, saj v ucno
mnozico prinese relativno vec suma v primerjavi s tistim, ki dosega boljsi rezultat. Relativno
majhno izboljsanje resevanja problema AG NEWS v primerjavi z izhodiscnimi klasifikacij-
skimi tocnostmi je mogoce pripisati majhnemu stevilu izbranih neoznacenih ucnih primerov s
strani meta-agenta. Rezultati z uporabo nakljucno najdenih pragov orisejo del slike, zakaj je
temu tako. Glede na to, da je najboljsi rezultat nizji kot uporaba le oznacene podmnozice ucnih
podatkov, je smiselno predpostaviti, da za resevanje tega problema neoznaceni ucni primeri,
izbrani z naso metodo, klasifikatorju ne prinesejo veliko koristnega znanja.
Razlike med pognanimi eksperimenti nad istimi konfiguracijami problema (npr. nekonsisten-
tnost v podanih akcijah in posledicne razlike v delezih izbranih neoznacenih ucnih primerov)
razlagamo z relativno veliko odvisnostjo ucenja od izbranih hiperparametrov in inicializacije
parametrov aproksimacijskih funkcij. Med implementacijo in prvimi preizkusanji nase imple-
mentacije algoritma smo uporabljali prakticne nasvete Green (2018) in Falcon (2017), ki poleg
preizkusanja hiperparametrov in vizualizacij ucenja za koncno ovrednotenje algoritma predla-
gata tudi veckratno ucenje. Z nestabilnostjo ucenja algoritma SAC je povezan tudi upad zbranih
nagrad po tem, ko agent ze pridobi nekaj znanja. Preizkusili smo vecino predlaganih resitev iz
clanka avtorja Green (2018), ki se spopada s podobnim problemom, in na koncu implementirali
zgodnje ustavljanje, ki predvideva uporabo modela, ki med ucenjem zbere najvec nagrade.
Nasa analiza pokaze tudi na hitrejse ucenje klasifikatorja v prvih epohah v primeru izbire ucnih
primerov z meta-agentom in povecevanje variabilnosti ucnih primerov tekom ucenja, o katerih
podrobneje pisemo v naslednjem razdelku. Glede na to, da je ucenje hitrejse v primeru uporabe
pragov, postavljenih s strani meta-agenta, ter tudi v primeru ucenja po ucnem nacrtu (Bengio et
al., 2009), lahko delovanje nasega sistema interpretiramo tudi z naslednjim stavkom:
“Nasa metoda deluje bolje, ko osvojeno meta znanje prek mehanizma postavljanja
pragov prepricanosti lahko tvori specificno ucno strategijo, katere ucinkovitost je
odvisna od dane podatkovne zbirke in arhitekture klasifikatorja.”
Uporaba prenosa metaznanja bistveno zmanjsa stevilo korakov, potrebnih za dosego primer-
ljivih rezultatov v primerjavi z ucenjem od zacetka, saj se stevilo korakov za osvojitev ucne
57

strategije za resevanje ciljnega problema zmanjsa iz 300000 na 60000. Rezultati kazejo, da pri
prenosu z uglasevanjem na ciljni problem dosezemo boljse rezultate kot v primeru uporabe le
oznacene podmnozice podatkov. Zanimivo je, da so povprecni rezultati v 6 izmed 20 konfigu-
racijah eksperimentov boljsi tudi od uporabe meta-agentov, naucenih na ciljnem problemu od
zacetka, in v nekaterih primerih presezejo klasifikacijske tocnosti ob uporabi pragov najdenih z
nakljucnim preiskovanjem.
S prenosom na ciljni problem, pri katerem povecujemo stevilo oznacenih ucnih primerov, sicer
opazimo povecevanje absolutne razlike med uporabo nase metode in le oznacene ucne mnozice,
a s statisticno analizo pokazemo na sibko korelacijo med kolicino vnesenega znanja v nas sistem
in izboljsanjem klasifikacijske tocnosti s polnadzorovanim ucenjem.
Uporaba prenosa znanja ima sicer iz vidika ucenja meta-agenta podobne tezave kot ucenje od
zacetka; zbrane nagrade oziroma koncne klasifikacijske tocnosti med ucenjem namrec kazejo
podobne vzorce.
5.3.2 Primerjava s cloveskim ucenjem
Na zacetku tega razdelka najprej poudarjamo, da motivacija pri nacrtovanju te magistrske na-
loge ni le visoka klasifikacijska tocnost, pac pa sistem, sposoben resevanja klasifikacijskih pro-
blemov, ki temelji na nekaterih lastnostih cloveskega ucenja. Temu primerno rezultatov ne
zelimo ovrednotiti le v navezavi na strojno ucenje, pac pa, zaradi sorodne strukture nasega
sistema in (sicer v omejenem pogledu) podobne funkcionalnosti, tudi v navezavi na clovesko
kognicijo. Primerjava nasega sistema z modeli metakognicije je smiselna ravno zaradi kompo-
nent in povezav, ki jih le-ti vsebujejo. Kot smo ze pisali v podpoglavju 2.3, je bila kognitivna
psihologija v casu odkritja opisanih modelov (tudi) pod vplivom kibernetike, kar je vidno iz
strukture le-teh. Tudi na nas sistem je mogoce gledati kot na skupino medsebojno povezanih
komponent in procesov, kar je najbolj konkretno vidno na sliki 6. Z visokonivojskega vidika
nas sistem vsebuje objektno in meta raven, kjer slednja deluje na podlagi ustvarjenega modela
problema na prvi; to je v skladu z modelom metakognicije avtorjev (Nelson in Narens, 1994).
Ze opisane lastnosti meta-kognicije, pa nakazujejo tudi tezavnost primerjave z nasim sistemom.
V podpoglavju 2.2 s pregledom modelov metakognicije nakazemo, da ima clovesko ucenje vec
in v odvisnosti od modela razlicne komponente v primerjavi z nasim sistemom. Opisani modeli
imajo tudi razlicne predpostavke, prav tako pa so rezultati ovrednoteni s kvalitativno drugacnimi
eksperimenti. To na nek nacin kaze tudi na nekonsistentnost modelov ucenja; modeli samo-
nadzorovanega ucenja dajejo poudarek razlicnim procesom, s cimer otezijo ze primerjavo med
sabo, kaj sele z ne-kognitivnimi procesi nasega sistema. Omenjena Garner in Alexander (1989)
pojavitev prenosa metakognitivnega znanja med problemi sicer v prvi vrsti utemeljujeta s po-
58
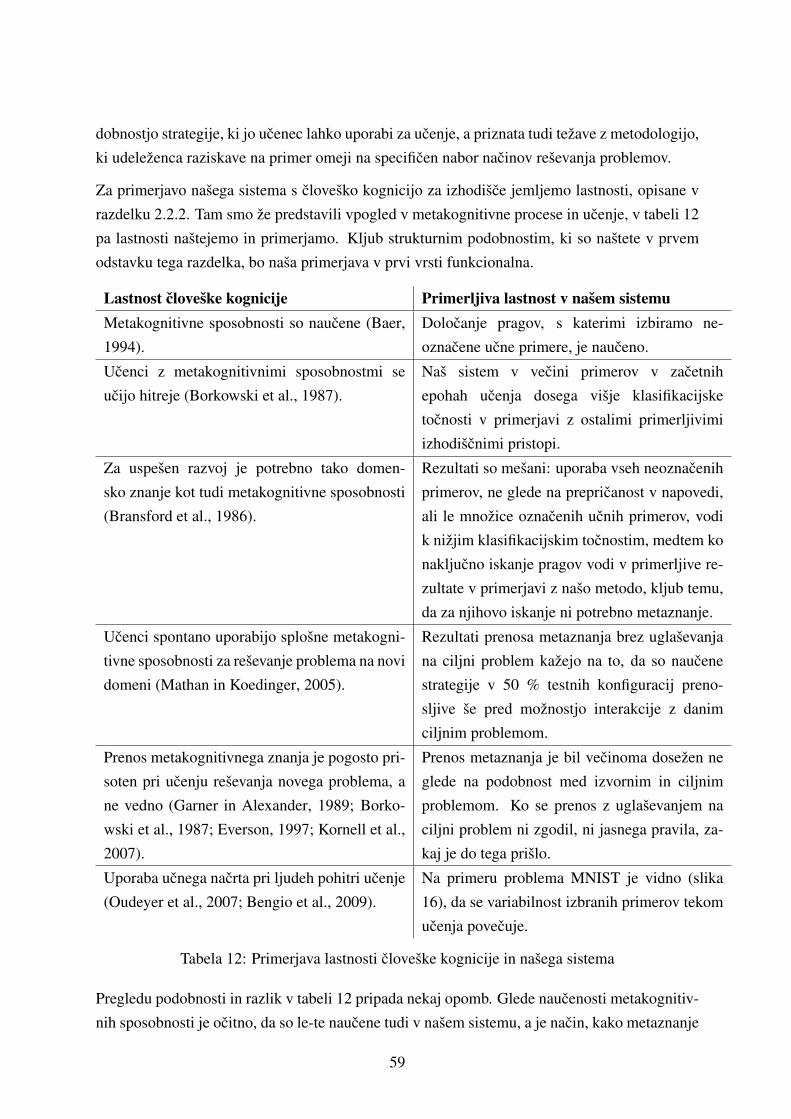
dobnostjo strategije, ki jo ucenec lahko uporabi za ucenje, a priznata tudi tezave z metodologijo,
ki udelezenca raziskave na primer omeji na specificen nabor nacinov resevanja problemov.
Za primerjavo nasega sistema s clovesko kognicijo za izhodisce jemljemo lastnosti, opisane v
razdelku 2.2.2. Tam smo ze predstavili vpogled v metakognitivne procese in ucenje, v tabeli 12
pa lastnosti nastejemo in primerjamo. Kljub strukturnim podobnostim, ki so nastete v prvem
odstavku tega razdelka, bo nasa primerjava v prvi vrsti funkcionalna.
Lastnost cloveske kognicije Primerljiva lastnost v nasem sistemuMetakognitivne sposobnosti so naucene (Baer,
1994).
Dolocanje pragov, s katerimi izbiramo ne-
oznacene ucne primere, je nauceno.
Ucenci z metakognitivnimi sposobnostmi se
ucijo hitreje (Borkowski et al., 1987).
Nas sistem v vecini primerov v zacetnih
epohah ucenja dosega visje klasifikacijske
tocnosti v primerjavi z ostalimi primerljivimi
izhodiscnimi pristopi.
Za uspesen razvoj je potrebno tako domen-
sko znanje kot tudi metakognitivne sposobnosti
(Bransford et al., 1986).
Rezultati so mesani: uporaba vseh neoznacenih
primerov, ne glede na prepricanost v napovedi,
ali le mnozice oznacenih ucnih primerov, vodi
k nizjim klasifikacijskim tocnostim, medtem ko
nakljucno iskanje pragov vodi v primerljive re-
zultate v primerjavi z naso metodo, kljub temu,
da za njihovo iskanje ni potrebno metaznanje.
Ucenci spontano uporabijo splosne metakogni-
tivne sposobnosti za resevanje problema na novi
domeni (Mathan in Koedinger, 2005).
Rezultati prenosa metaznanja brez uglasevanja
na ciljni problem kazejo na to, da so naucene
strategije v 50 % testnih konfiguracij preno-
sljive se pred moznostjo interakcije z danim
ciljnim problemom.
Prenos metakognitivnega znanja je pogosto pri-
soten pri ucenju resevanja novega problema, a
ne vedno (Garner in Alexander, 1989; Borko-
wski et al., 1987; Everson, 1997; Kornell et al.,
2007).
Prenos metaznanja je bil vecinoma dosezen ne
glede na podobnost med izvornim in ciljnim
problemom. Ko se prenos z uglasevanjem na
ciljni problem ni zgodil, ni jasnega pravila, za-
kaj je do tega prislo.
Uporaba ucnega nacrta pri ljudeh pohitri ucenje
(Oudeyer et al., 2007; Bengio et al., 2009).
Na primeru problema MNIST je vidno (slika
16), da se variabilnost izbranih primerov tekom
ucenja povecuje.
Tabela 12: Primerjava lastnosti cloveske kognicije in nasega sistema
Pregledu podobnosti in razlik v tabeli 12 pripada nekaj opomb. Glede naucenosti metakognitiv-
nih sposobnosti je ocitno, da so le-te naucene tudi v nasem sistemu, a je nacin, kako metaznanje
59

vpliva na ucenje, relativno enostaven. To omeji obseg interakcije med objektnim in meta nivo-
jem nasega sistema.
Ko je problem, ki ga z nasim sistemom zelimo resiti, primeren, pristop s spreminjanem pragov
tekom ucenja (t. j. uporabo meta-agenta) v prvih epohah vodi v hitrejse ucenje, kar je primer-
ljivo s pojavitvijo razlike med ucenjem umsko zaostalih in normalno razvitih ljudi (Borkowski et
al., 1987). Ko pride do primerjave z uspesnostjo razvoja pri ljudeh (ki sicer zajema sposobnost
resevanja problemov na vec domenah hkrati), z nasimi eksperimenti pokazemo, da metaznanje
ni nujno potrebno za resitev danega problema v okviru danih zmoznosti uporabljenega klasifi-
katorja. Pragovi, najdeni z nakljucnim preiskovanjem za resevanje dveh izmed petih problemov,
namrec privedejo do boljsih klasifikacijskih tocnosti kot uporaba meta-agenta, medtem ko so
ostali rezultati podobni. V dveh izmed petih primerih se metaznanje izkaze kot koristno za bolj
ucinkovito resitev problema.
Do zanimivega pojava pride pri prenosu metaznanja z enega problema na drugega. Rezultati
prenosa brez uglasevanja na ciljni problem so pokazali, da v nekaj manj kot polovici konfigura-
cij prenosa znanja pride do rezultatov boljsih od izhodiscnih – uporabe le oznacene podmnozice
ucnih podatkov. Ze brez identifikacije, kaj je lastnost nasega sistema, ki omogoca prenos me-
taznanja iz enega problema na drugega, lahko recemo, da na podlagi teh rezultatov poseduje
znanje, ki je do neke mere splosno.
Med lastnosti cloveske metakognicije, ki so v literaturi oznacene kot splosne, spadajo sposob-
nosti, kot so nacrtovanje ter zaznavanje in popravljanje napak (Matiisen et al., 2019). Kljub
temu, da v sklopu nasega sistema splosnosti ucnih strategij ne moremo opisati z omenjenimi
atributi, lahko govorimo o drugem nacinu splosnosti. Metastrategije se brez uglasevanja na
ciljni problem namrec prenasajo, ker je nas pristop s postavljanjem pragov prepricanja splosen
v smislu podobnosti pasov pragov prepricanosti, uporabljenih za resevanje razlicnih problemov.
Ta splosna lastnost pa po nasem mnenju poleg naucenosti obmocij vrednosti stanj vodi tudi do
hitrejsega ucenja med prenosom z uglasevanjem na ciljni problem. Za nas sistem bi veljala
trditev, ki velja tudi za clovesko metakognicijo: prenos metaznanja je bolj pogost pri resevanju
podobnih problemov. Hipotetiziramo, da se podobnost med problemi v nasem sistemu odrazi v
potrebni prepricanosti klasifikatorja za zanesljivo klasifikacijo.
Postavljanje pragov, s katerimi izbiramo ucne primere po vizualizaciji s podatkovno zbirko
MNIST, nakazuje na ucni nacrt, iz katerega se klasifikator uci. Izbrani pravilno klasificirani
ucni primeri so si namrec na zacetku ucenja med sabo bolj podobni, proti koncu pa vsebujejo
vec variabilnosti. To je v skladu s trditvami Bengio et al. (2009), ki pravi, da se modeli na
podrocju strojnega ucenja ucijo hitreje, ce imajo ustrezno prilagojen vrstni red ucnih primerov,
ki so jim na voljo, ter s cimer nas sistem poseduje podobno lastnost kot clovesko ucenje.
60

6 Zakljucek
V tej magistrski nalogi smo implementirali sistem, osnovan na podlagi modelov cloveske meta-
kognicije in ucenja. Nas sistem ima podobne komponente kot model, predlagan s strani Nelson
in Narens (1994), ki kognitivne procese med ucenjem razdeli na objektno in meta raven. Z
nasim delom pokazemo, da nas sistem pride do podobnih koncnih rezultatov kot najboljsa iz-
med ostalih “naivnih” metod izbire ucnih primerov. Ko nasa metoda polnadzorovanega ucenja
deluje nad izbranim klasifikacijskim problemom, uporaba metaznanja vodi k hitrejsemu ucenju
v prvih epohah.
Pri prenosu metaznanja z uglasevanjem na ciljni problem sicer ne dosezemo vedno enakih re-
zultatov kot pri ucenju meta-agenta od zacetka. V primerih, ko nas pristop k prenosu znanja
deluje, se stevilo korakov, potrebnih za pridobitev metaznanja zmanjsa za 80%, kar je prednost,
ki je ostali preizkuseni nacini izbire ucnih primerov nimajo. Pri tem v 6 izmed 20 primerov
dosezemo boljso povprecno klasifikacijsko tocnost kot pri ucenju od zacetka, ter na problemih,
za katere je nasa metoda ucinkovita, konsistentno dosegamo visje rezultate kot ob uporabi le
oznacenih ucnih primerov.
Enkratna ponovitev eksperimenta z ucenjem od zacetka skupaj s testiranjem traja od 40 do 100
GPU ur v odvisnosti od izbrane arhitekture nevronske mreze. Sistem smo preizkusali z relativno
majhnimi nevronskimi mrezami klasifikatorjev z razlogom – ucenje na globokih nevronskih
mrezah z vec milijoni parametrov bi enostavno trajalo predolgo. Ze samo za ucenje strategij
od zacetka za pridobitev rezultatov, zapisanih v tem delu, smo vse skupaj potrebovali priblizno
1650 GPU ur. Ce vkljucimo se opravljene eksperimente prenosa znanja, se ta cas vsaj podvoji.
Zaradi trajanja posameznih eksperimentov je bil otezen tudi razvoj metode – razhroscevanju in
iskanju hiperparametrov je bil posvecen velik del casa.
Nasa metoda je zaradi trajanja ucenja v najvecji meri omejena z velikostjo danega problema.
Prenos znanja to tezavo do neke mere omili, a dokoncno bi bila ta omejitev razresena z ucenjem
resevanja vec klasifikacijskih problemov hkrati z vecciljnim ucenjem (angl. multi-task lear-
ning). Pri slednjem je mogoca se hitrejsa posplositev na se nevidene probleme.
Druga vpadljiva slabost nase metode so reprezentacije stanj klasifikatorjev, ki predstavljajo po-
memben razlog za nestabilnost pri ucenju ucnih strategij. V nasem delu se sicer zgledujemo
po stanjih iz clanka Wu et al. (2018), a si je lahko predstavljati, da samo izhodi klasifikatorja
skupaj z nekaj metrikami ucne in validacijske mnozice ne opisejo stanja modela v celoti. Iz-
hodi klasifikatorja namrec niso vezani le na eno konfiguracijo utezi, sploh ko so ti povpreceni
za vec ucnih primerov, kot je to storjeno v nasem sistemu. Posledicno ima meta-agent manjso
sposobnost zanesljive napovedi pasov izbire ucnih primerov. Kljub tem pomanjkljivostim se
meta-agent sicer nauci pragov prepricnosti in s tem strategije ucenja, ki je primerna trenutnemu
61

znanju klasifikatorja.
V diskusiji smo navedli nekaj visokonivojskih podobnosti in razlik nasega sistema s clovesko
kognicijo. Eno od odprtih vprasanj ostaja izbira modelov metakognicije in rezultatov eksperi-
mentov, s katerimi naso metodo sploh primerjati, kar omejuje globino nase primerjave.
V splosnem je nase delo se en primer pristopa, v katerem model cloveske kognicije sluzi kot
dobra iztocnica za snovanje pristopov k strojnemu ucenju. Ob povecanju priljubljenosti me-
taucenja v kontekstu strojnega ucenja nasa metoda doda vpogled v nov pristop k temu problemu.
V primerjavi s sistemi iz sorodnih del, nasega ovrednotimo na vec problemskih domenah in s
tem k podrocju doprinesemo relativno splosno metodo, katere prednosti lezijo tudi v moznosti
prenosa metaznanja med arhitekturami klasifikatorjev in podatkovnimi zbirkami.
62

Literatura
Achiam, J. (2018). Spinning Up in Deep Reinforcement Learning. Pridobljeno 2.9.2020, iz
https://spinningup.openai.com/
Adiwardana, D. D. F., Matsukawa, A., in Whang, J. (2016). Using generative models for semi-
supervised learning. V Medical image computing and computer-assisted intervention–
MICCAI (str. 106–114).
Amiri, H. (2019). Neural self-training through spaced repetition. V Proceedings of the 2019
Conference of the North American Chapter of the Association for Computational Lingu-
istics: Human Language Technologies, Volume 1 (long and short papers) (str. 21–31).
Minneapolis, Minnesota, USA: Association for Computational Linguistics.
Ammar, H. B., Eaton, E., Ruvolo, P., in Taylor, M. E. (2015). Unsupervised cross-domain
transfer in policy gradient reinforcement learning via manifold alignment. V Twenty-
ninth AAAI conference on artificial intelligence. AAAI Press.
Argyris, C. (1991). Teaching smart people how to learn. Harvard business review, 69(3).
Baer, M. (1994). How do expert and novice writers differ in their knowledge of the writing
process and its regulation (metacognition) from each other, and what are the differences
in metacognitive knowledge between writers of different ages? Clanek predstavljen na
letnem srecanju Society for American Educational Research Association.
Bagherzadeh, J., in Asil, H. (2019). A review of various semi-supervised learning models with
a deep learning and memory approach. Iran Journal of Computer Science, 2(2), 65–80.
Bengio, Y., Louradour, J., Collobert, R., in Weston, J. (2009). Curriculum learning. V Procee-
dings of the 26th annual international conference on machine learning (str. 41–48). New
York, NY, USA: Association for Computing Machinery.
Blum, A., in Mitchell, T. (1998). Combining labeled and unlabeled data with co-training.
V Proceedings of the eleventh annual conference on computational learning theory (str.
92–100). New York, NY, USA: Association for Computing Machinery.
Boekaerts, M. (2011). Emotions, emotion regulation, and self-regulation of learning (Vol. 5).
Routledge.
Borkowski, J. G., Carr, M., in Pressley, M. (1987). “Spontaneous” strategy use: Perspectives
from metacognitive theory. Intelligence, 11(1), 61–75.
Bransford, J., Sherwood, R., Vye, N., in Rieser, J. (1986, 10). Teaching thinking and problem
solving. research foundations. American Psychologist, 41, 1078-1089. doi: 10.1037/
0003-066X.41.10.1078
Buchler, U., Brattoli, B., in Ommer, B. (2018). Improving spatiotemporal self-supervision by
deep reinforcement learning. V Proceedings of the european conference on computer
vision (ECCV) (str. 770–786).
63

Chapelle, O., Schlkopf, B., in Zien, A. (2010). Semi-supervised learning (1. izdaja). The MIT
Press.
Chen, C., Zhang, Y., in Gao, Y. (2018). Learning how to self-learn: Enhancing self-training
using neural reinforcement learning. V 2018 international conference on Asian language
processing (IALP) (str. 25–30).
Corbett, A. T., in Anderson, J. R. (1994). Knowledge tracing: Modeling the acquisition of
procedural knowledge. User modeling and user-adapted interaction, 4(4), 253–278.
Csikszentmihalyi, M. (2014). Toward a psychology of optimal experience. V Flow and the
foundations of positive psychology: The collected works of Mihaly Csikszentmihalyi (str.
209–226). Dordrecht: Springer Netherlands.
Dawson, T. L. (2008). Metacognition and learning in adulthood. Prepared in response to
tasking from ODNI/CHCO/IC Leadership Development Office, Developmental Testing
Service, LLC.
Dayan, P., in Abbott, L. (2001). Classical conditioning and reinforcement learning. Theoretical
Neuroscience, 331–39.
Ding, Z. (2020). Nips2017learning2run. Pridobljeno 2.9.2020, iz https://github.com/
quantumiracle/Nips2017Learning2Run
Dupuy, J.-P. (2009). On the origins of cognitive science: The mechanization of the mind. The
MIT Press.
Elman, J. L. (1993). Learning and development in neural networks: The importance of starting
small. Cognition, 48(1), 71–99.
Everson, H. T. (1997). Do metacognitive skills and learning strategies transfer across doma-
ins? Clanek predstavljen na letnem srecanju Society for American Educational Research
Association.
Falcon, W. (2017). Deeprlhacks. Pridobljeno 2.9.2020, iz https://github.com/
williamFalcon/DeepRLHacks
Flavell, J. H. (1979). Metacognition and cognitive monitoring: A new area of cognitive–
developmental inquiry. American psychologist, 34(10), 906.
Fogg, B. J. (2009). A behavior model for persuasive design. V Proceedings of the 4th interna-
tional conference on persuasive technology (str. 1–7).
Gal, Y., Islam, R., in Ghahramani, Z. (2017). Deep bayesian active learning with image data.
V Proceedings of the 34th international conference on machine learning-volume 70 (str.
1183–1192).
Garner, R., in Alexander, P. A. (1989). Metacognition: Answered and unanswered questions.
Educational psychologist, 24(2), 143–158.
Gibson, B. R., Rogers, T. T., in Zhu, X. (2013). Human semi-supervised learning. Topics in
cognitive science, 5(1), 132–172.
Glorot, X., in Bengio, Y. (2010). Understanding the difficulty of training deep feedforward
64

neural networks. V Proceedings of the thirteenth international conference on artificial
intelligence and statistics (str. 249–256).
Green, A. (2018). DQN debugging using Open AI gym Cartpole. Pridobljeno 2.9.2020, iz
https://adgefficiency.com/dqn-debugging/
Greene, J. A., in Azevedo, R. (2007). A theoretical review of Winne and Hadwin’s model of
self-regulated learning: New perspectives and directions. Review of educational research,
77(3), 334–372.
Guo, S., Huang, W., Zhang, H., Zhuang, C., Dong, D., Scott, M. R., in Huang, D. (2018).
Curriculumnet: Weakly supervised learning from large-scale web images. V Procee-
dings of the european conference on computer vision (ECCV) (str. 135–150). Springer
International Publishing.
Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., . . . Levine, S. (2018). Soft
actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905.
Haeusser, P., Mordvintsev, A., in Cremers, D. (2017). Learning by association–a versatile semi-
supervised training method for neural networks. V Proceedings of the ieee conference on
computer vision and pattern recognition (str. 89–98).
He, K., Zhang, X., Ren, S., in Sun, J. (2015). Delving deep into rectifiers: Surpassing human-
level performance on imagenet classification. V Proceedings of the IEEE international
conference on computer vision (str. 1026–1034).
Hu, Y., in Montana, G. (2019). Skill transfer in deep reinforcement learning under morpholo-
gical heterogeneity. arXiv preprint arXiv:1908.05265.
Jiang, L., Meng, D., Zhao, Q., Shan, S., in Hauptmann, A. G. (2015). Self-paced curriculum
learning. V Twenty-ninth AAAI conference on artificial intelligence. AAAI Press.
Julian, R., Swanson, B., Sukhatme, G. S., Levine, S., Finn, C., in Hausman, K. (2020).
Efficient adaptation for end-to-end vision-based robotic manipulation. arXiv preprint
arXiv:2004.10190.
Kim, Y. (2014). Convolutional neural networks for sentence classification. arXiv preprint
arXiv:1408.5882.
King, P. M., in Kitchener, K. S. (2004). Reflective judgment: Theory and research on the deve-
lopment of epistemic assumptions through adulthood. Educational psychologist, 39(1),
5–18.
Kingma, D. P., in Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Kornell, N., Son, L. K., in Terrace, H. S. (2007). Transfer of metacognitive skills and hint
seeking in monkeys. Psychological Science, 18(1), 64–71.
Krizhevsky, A., in Hinton, G. (2009). Learning multiple layers of features from tiny images.
Citeseer.
Kullback, S., in Leibler, R. A. (1951). On information and sufficiency. The annals of mathe-
65

matical statistics, 22(1), 79–86.
Kumar, M. P., Packer, B., in Koller, D. (2010). Self-paced learning for latent variable models. V
Advances in neural information processing systems (str. 1189–1197). Curran Associates,
Inc.
Laine, S., in Aila, T. (2016). Temporal ensembling for semi-supervised learning. arXiv preprint
arXiv:1610.02242.
Lazaric, A. (2012). Transfer in reinforcement learning: a framework and a survey. V Reinfor-
cement learning (str. 143–173). Springer.
LeCun, Y., in Cortes, C. (2010). MNIST handwritten digit database. Pridobljeno 2.9.2020, iz
http://yann.lecun.com/exdb/mnist/
Lee, D.-H. (2013). Pseudo-label: The simple and efficient semi-supervised learning method
for deep neural networks. V Workshop on challenges in representation learning, ICML
(Vol. 3, str. 2).
Leitner, S. (1972). So lernt man lernen. Freiburg im Breisgau, Germany: Herder.
Lemke, C., Budka, M., in Gabrys, B. (2015). Metalearning: a survey of trends and technologies.
Artificial intelligence review, 44(1), 117–130.
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., . . . Wierstra, D. (2015).
Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971.
Majnik, M., in Skocaj, D. (2013). Aktivno ucenje in vzajemnost med uciteljem in ucencem.
Elektrotehniski vestnik, 4(80), 189–194.
Mallapragada, P. K., Jin, R., Jain, A. K., in Liu, Y. (2008). Semiboost: Boosting for semi-
supervised learning. IEEE transactions on pattern analysis and machine intelligence,
31(11), 2000–2014.
Mathan, S. A., in Koedinger, K. R. (2005). Fostering the intelligent novice: Learning from
errors with metacognitive tutoring. Educational psychologist, 40(4), 257–265.
Matiisen, T., Oliver, A., Cohen, T., in Schulman, J. (2019). Teacher-student curriculum learning.
IEEE transactions on neural networks and learning systems.
McClosky, D., Charniak, E., in Johnson, M. (2006). Effective self-training for parsing. V
Proceedings of the main conference on human language technology conference of the
north american chapter of the association of computational linguistics (str. 152–159).
Mihalcea, R. (2004). Co-training and self-training for word sense disambiguation. V Procee-
dings of the eighth conference on computational natural language learning (str. 33–40).
Boston, Massachusetts, USA: Association for Computational Linguistics.
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., in Ried-
miller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint
arXiv:1312.5602.
Nair, V., in Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines.
V Proceedings of the twenty-seventh (27th) international conference on machine learning
66

(str. 807–814). Madison, Wisconsin, USA: Omnipress.
Nelson, T. O., in Narens, L. (1994). Why investigate metacognition. Metacognition: Knowing
about knowing, 13, 1–25.
Oudeyer, P.-Y., in Kaplan, F. (2008). How can we define intrinsic motivation. V Proc. of the
8th conf. on epigenetic robotics (Vol. 5, str. 29–31).
Oudeyer, P.-Y., Kaplan, F., in Hafner, V. V. (2007). Intrinsic motivation systems for autonomous
mental development. IEEE transactions on evolutionary computation, 11(2), 265–286.
Pan, S. J., in Yang, Q. (2009). A survey on transfer learning. IEEE Transactions on knowledge
and data engineering, 22(10), 1345–1359.
Panadero, E. (2017). A review of self-regulated learning: Six models and four directions for
research. Frontiers in psychology, 8, 422.
Pardos, Z. A., Trivedi, S., Heffernan, N. T., in Sarkozy, G. N. (2012). Clustered knowledge
tracing. V International conference on intelligent tutoring systems (str. 405–410).
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., . . . Chintala, S. (2019).
Pytorch: An imperative style, high-performance deep learning library. V H. Wallach,
H. Larochelle, A. Beygelzimer, F. dAlche-Buc, E. Fox, in R. Garnett (uredniki), Advances
in neural information processing systems 32 (str. 8024–8035). Curran Associates, Inc.
Pennington, J., Socher, R., in Manning, C. D. (2014). Glove: Global vectors for word represen-
tation. V Proceedings of the 2014 conference on empirical methods in natural language
processing (EMNLP) (str. 1532–1543).
Piech, C., Bassen, J., Huang, J., Ganguli, S., Sahami, M., Guibas, L. J., in Sohl-Dickstein, J.
(2015). Deep knowledge tracing. V Advances in neural information processing systems
(str. 505–513).
Prechelt, L. (1998). Early stopping-but when? V Neural networks: Tricks of the trade (str.
55–69). Springer.
Rosenberg, C., Hebert, M., in Schneiderman, H. (2005). Semi-supervised self-training of object
detection models. V 2005 seventh IEEE workshops on applications of computer vision
(WACV/MOTION’05) (Vol. 1, str. 29-36).
Sanger, T. D. (1994). Neural network learning control of robot manipulators using gradually
increasing task difficulty. IEEE transactions on Robotics and Automation, 10(3), 323–
333.
Settles, B. (2009). Active learning literature survey (Computer Sciences Technical Report No.
1648). Madison, Wisconsin, USA: University of Wisconsin–Madison.
Skocaj, D., Majnik, M., Kristan, M., in Leonardis, A. (2012). Comparing different learning
approaches in categorical knowledge acquisition. V Proceedings of the 17th computer
vision winter workshop (str. 65–72).
Sutton, R. S., in Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
Tarvainen, A., in Valpola, H. (2017). Mean teachers are better role models: Weight-averaged
67

consistency targets improve semi-supervised deep learning results. V Advances in neural
information processing systems (str. 1195–1204).
Wiener, N. (2019). Cybernetics or control and communication in the animal and the machine.
MIT press.
Winne, P. H. (1996). A metacognitive view of individual differences in self-regulated learning.
Learning and individual differences, 8(4), 327–353.
Wu, J., Li, L., in Wang, W. Y. (2018). Reinforced co-training. arXiv preprint
arXiv:1804.06035.
Xiong, A., in Proctor, R. W. (2018). Information processing: The language and analytical tools
for cognitive psychology in the information age. Frontiers in psychology, 9, 1270.
Yu, Y., Eshghi, A., in Lemon, O. (2017). Learning how to learn: an adaptive dialogue
agent for incrementally learning visually grounded word meanings. arXiv preprint
arXiv:1709.10423.
Zabinsky, Z. B. (2010). Random search algorithms. Wiley encyclopedia of operations research
and management science.
Zhan, X., Liu, Z., Yan, J., Lin, D., in Change Loy, C. (2018). Consensus-driven propagation in
massive unlabeled data for face recognition. V Proceedings of the european conference
on computer vision (eccv) (str. 568–583).
Zhang, X., Zhao, J., in LeCun, Y. (2015). Character-level convolutional networks for text
classification. V Advances in neural information processing systems (str. 649–657).
Zhou, Z.-H., in Li, M. (2005). Tri-training: Exploiting unlabeled data using three classifiers.
IEEE Transactions on knowledge and Data Engineering, 17(11), 1529–1541.
Zhu, X., in Goldberg, A. B. (2009). Introduction to semi-supervised learning. Synthesis lectures
on artificial intelligence and machine learning, 3(1), 1–130.
Zimmerman, B. J. (1989). A social cognitive view of self-regulated academic learning. Journal
of educational psychology, 81(3), 329.
Zimmerman, B. J. (2013). From cognitive modeling to self-regulation: A social cognitive
career path. Educational psychologist, 48(3), 135–147.
Zimmerman, B. J., in Moylan, A. R. (2009). Self-regulation: Where metacognition and moti-
vation intersect. V Handbook of metacognition in education (str. 311–328). Routledge.
68





























