Embed Size (px)
Citation preview

PRZEGLĄD WYBRANYCH BAZ
NOSQL
Sławomir Dadas
30.01.2012

PLAN PREZENTACJI
Bazy dokumentowe (document store): MONGODB ORIENTDB
Bazy klucz-wartośd (key-value store):
REDIS ORACLE NOSQL DATABASE
Bazy grafowe (graph database):
NEO4J


• strona oficjalna: www.mongodb.org
• wersje dla 32 i 64 bitowych systemów operacyjnych
• sterowniki dla większości popularnych języków programowania (C/C++, Java, Scala, Python, Ruby, Perl itd.)
• oficjalne wsparcie w springu (spring-data-mongodb)
• obecnie jedna z najpopularniejszych baz NoSQL

Ograniczenia: • wersja 32 bitowa nie nadaje się do zastosowao
produkcyjnych (ograniczenie wielkości bazy do 2.5 GB)
• ograniczenie na rozmiar pojedynczego dokumentu (odpowiednik wiersza w bazie relacyjnej) – starsze wersje 4 MB, nowsze – 16 MB

Elastyczna baza dokumentowa będąca alternatywą dla baz relacyjnych. • pojedyncza instancja mongo może zawierad wiele baz
(odpowiednik schematów)
• bazy składają się z kolekcji (odpowiedników tabel)
• kolekcje zawierają dokumenty (odpowiedniki wierszy)
• dokumenty posiadają pola (odpowiedniki kolumn)
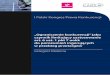
Nie wymaga skomplikowanej konfiguracji. Uruchamianie serwera mongo: Uruchamianie domyślnego klienta (shell bazujący na JavaScripcie):
mongod --dbpath [sciezka] lub mongod --config [sciezka]
mongo

Schema-less. Nie jest wymagane definiowanie struktury danych w kolekcji. Do każdej kolekcji możliwe jest wstawianie dowolnych dokumentów, zawierających dowolny zestaw atrybutów. Natywną reprezentacją danych w dokumentach jest BSON (Binary JSON) – JSON zserializowany do postaci binarnej. Obiekty są serializowane i deserializowane przez bazę, użytkownik może posługiwad się zwykłą reprezentacją JSON.
{type: 'monster', name: 'goblin', attack: 5, defense: 1}

Wstawianie dokumentu do kolekcji : Kolekcja jest tworzona automatycznie po dodaniu pierwszego dokumentu. Każdy dokument posiada unikalne pole _id: Identyfikator może byd nadany przez użytkownika (dowolna unikalna wartośd). W przeciwnym przypadku zostanie wygenerowany automatycznie.
db.monsters.insert({name: 'goblin', attack: 5})
{ "_id" : ObjectId("4f2460d47d69f6b5db16b55b"), "name" : "goblin", "attack" : 5 }

Wyszukiwanie dokumentów w kolekcji: Polecenie zwraca kursor. • Kursor służy do iteracji po wynikach zapytania. • Wyniki nie są zwracane od razu. Możliwe jest ustawienie
dodatkowych opcji na kursorze przed pobraniem wyników.
db.monsters.find() db.monsters.find({name: 'goblin'}) db.monsters.find({name: {$ne: 'vampire'}, attack: {$gt: 4, $lt: 10}}) db.monsters.find({defense: {$exists: false}}) db.monsters.find($or: [name: 'goblin', likes: 'chocolate'])

Możliwe jest wyszukiwanie elementów tablic oraz zagnieżdżonych obiektów. Możliwośd wykonywania dowolnie skomplikowanych zapytao: przekazywanie funkcji javascriptowej jako argumentu zapytania.
db.monsters.insert({name: 'dragon', likes: ['virgins', 'sheep', 'lollypops'], attack: {type: 'fire', damage: 12}}) db.monsters.find({likes: 'virgins', 'attack.type': 'fire'})
f = function() { return this.attack > 3; } db.monsters.find(f);

Tworzenie indeksów. Rodzaje indeksów: • standardowe • unikalne (unique) • rzadkie (sparse) – indeksują tylko te dokumenty w
kolekcji, które zawierają indeksowane pole • przestrzenne (geospatial) – indeksowane po parach
współrzędnych, umożliwiają wykonywanie zapytao z operatorami $near oraz $within
db.monsters.ensureIndex({attack:1});

Sortowanie i paginacja: Wykonywanie update (zastępowanie i aktualizacja):
Brak operacji JOIN. Dwa podejścia w przypadku łączenia dokumentów: • przechowywanie listy pól _id zależnych rekordów,
manualne pobieranie • przechowywanie listy obiektów DBRef, automatyczne
pobieranie przez bazę
db.monsters.find().sort({attack: 1}) db.monsters.find().limit(10).skip(20)
db.monsters.update({name: 'goblin'}, {attack: 10}) db.monsters.update({name: 'goblin'}, {$set: {attack: 10}})

Inne możliwości: • Replikacja danych pomiędzy serwerami na kilku
maszynach.
• Sharding, dzielenie danych na kilka maszyn w celu poprawy wydajności.
• Operacje atomowe na bazie
• Wparcie dla map/reduce do agregacji i przetwarzania dużych ilości danych

Gdzie szukad informacji? • Manual
www.mongodb.org/display/DOCS/Manual
• Java Tutorial www.mongodb.org/display/DOCS/Tutorial
• Java API api.mongodb.org/java/current
• The Little Mongo Book
openmymind.net/mongodb.pdf


• strona oficjalna: www.orientechnologies.com
• działa na JVM
• przechowywane dokumenty są obiektami javowymi
• może działad w trybie embedded (wystarczy dodad jedno
dependency do mavena) lub jako oddzielny proces
• natywnie wspiera przechowywanie dowolnych obiektów javowych

Baza z szerokim zestawem funkcjonalności, doskonale zintegrowana z javą. Trzy poziomy abstrakcji danych, realizowane przez trzy różne API dostępu do bazy: • baza dokumentowa – Document API, najniższy poziom,
manualne tworzenie dokumentów • baza obiektowa – Object API, automatyczne
zapisywanie dowolnych obiektów javowych • baza grafowa – Graph API, opakowuje obiekty javowe
do postaci wierzchołków oraz krawędzi grafu

Obiekty w bazie zorganizowane są klastrach (cluster) oraz klasach (class) : • Klasy definiują logiczną organizację danych (grupują
wszystkie obiekty danego typu np. obiekty tej samej klasy javowej lub dokumenty z tym samym zestawem pól)
• Klastry definiują fizyczną lub logiczną organizację
danych (grupują obiekty reprezentujące wspólny zbiór dokumentów, są odpowiednikiem tabeli w bazie relacyjnej). Mogą zawierad obiekty z różnych klas.

• Klastry są numerowane, podobnie jak dokumenty.
• Każdy dokument zawiera unikalny RecordID wygenerowany przez bazę danych. RecordID jest postaci:
[numer_klastra]:[numer_dokumentu_w_klastrze] np. 5:11, 3:128, 1:0...

Zapisywanie rekordów. • Dla Document API:
• Dla Object API:
ODocument monster = new ODocument(db, "Monster"); monster.field("name", "Goblin"); monster.field("attack", 5); monster.field("likes", new ODocument(db, "Food").field("name", "apple")); monster.save();
Monster monster = new Monster(); monster.setName("Goblin"); monster.setAttack(5); monster.setLikes(Arrays.asList(new Food().setName("apple")); db.save(monster);

Orient domyślnie działa w trybie schema-less, ale umożliwia zdefiniowanie schematów dla wszystkich klas lub tylko dla pewnego podzbioru. W zależności od preferencji programisty, można definiowad bazy: • schema-less • schema-full • schema-hybrid OSchema schema = database.getMetadata().getSchema(); OClass keywordClass = schema.createClass(OKeyword.class); keywordClass.createProperty("language", OType.STRING); keywordClass.createProperty("name", OType.STRING); keywordClass.createProperty("key", OType.STRING); keywordClass.createIndex("IDX_KC_KEY", OClass.INDEX_TYPE.UNIQUE, "key");

Łączenie obiektów realizowane jest na dwa sposoby: • embedded relationship - zagnieżdżanie obiektów
podrzędnych wewnątrz obiektu nadrzędnego • referenced relationship - przechowywanie referencji do
zależnych obiektów Łączenie obiektów wykonywane jest automatycznie. Domyślnie orient leniwie pobiera zależne obiekty (w momencie odwołania do tych obiektów). Możliwe jest zdefiniowanie planów zapytania (fetch plan), które określają, w jaki sposób pobierad zależności.

Orient wspiera SQL*. Zapytania można definiowad w postaci natywnych javowych obiektów zapytao lub za pomocą pseudo-SQL: Dla Graph API dostępne są dodatkowe grafowe języki zapytao np. gremlin. * język zapytao, który przypomina SQL
select from Monster order by name desc select * from Monster order by name desc select * from animal where races contains (name.toLowerCase().subString(0,1) = 'e') select from profile where any() like '%danger%' update Profile remove nick update Account put addresses = 'Luca', #12:0

Tworzenie indeksów: Rodzaje indeksów: • NOTUNIQUE – standardowy nieunikalny indeks • UNIQUE – indeks unikalny, nie pozwala na dodawanie
duplikatów • FULLTEXT – indeks pełnotekstowy, indeksuje wszystkie
słowa w polach typu String • DICTIONARY – indeks unikalny z zastępowaniem
rekordów
CREATE INDEX user.id UNIQUE; CREATE INDEX thumbsValue ON Movie (thumbs by value) NOTUNIQUE; CREATE INDEX books ON Book (author, title, publicationYear) DICTIONARY;

Optymalizacja wydajności. Orient może byd przełączony w tryb optymalizacji operacji odczytu lub zapisu danych.
Tryb masowego zapisu: Tryb masowego odczytu: Powrót do domyślnego trybu:
declare intent massiveinsert
declare intent massiveread
declare intent null

Inne możliwości: • Wsparcie dla dziedziczenia klas, wyszukiwanie po
klasach dziedziczących
• Security, możliwośd tworzenia użytkowników i nadawania im uprawnieo
• Transakcje
• Wsparcie dla dokumentów zawierających pliki (pola typu BLOB)

Jeszcze więcej możliwości: • Możliwośd definiowania hooków implementowanych w
javie (odpowiednik triggerów w bazach relacyjnych) • Replikacja i sharding
• Konfiguarowalny automatyczny backup danych
• Dostęp do bazy przez interfejs RESTowy
• Konfigurowalne logowanie do plików


• strona oficjalna: redis.io
• wydajna baza typu klucz-wartośd działająca w pamięci operacyjnej
• zaimplementowana w ANSI C, wspierana przez VMware
• oficjalne wsparcie w springu (spring-data-redis)
• brak oficjalnego wydania na systemy Windows

Redis przechowuje wszystkie dane w pamięci operacyjnej (i w pamięci wirtualnej). Dane te są okresowo zapisywane na dysk. Awaria bazy powoduje utratę części danych… Możliwe jest wyszukiwanie tylko po kluczach. Wartości znajdujące się pod kluczami nie mają większego znaczenia. Wartości mogą byd jednym z pięciu zdefiniowanych typów danych. Do typów tych należą stringi (skalary, lub typy proste) oraz cztery różne kolekcje typów prostych.
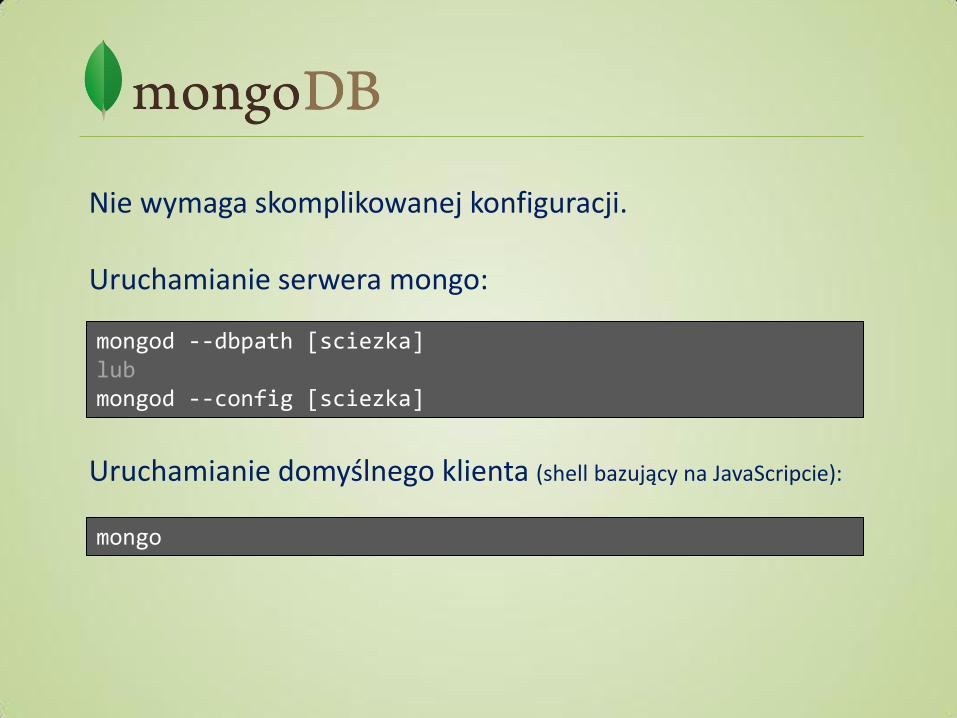
Klucze mogą byd tylko łaocuchami znaków. Redis nie wymusza formatu kluczy, ale przyjęta jest konwencja:
[sciezka_oddzielona_dwukropkami]:[id_obiektu]:[opcja_atrybut_obiektu] np. user:12 user:jacekplacek user:jacekplacek:roles user:roles:45 publication:15:keyword:name:12

Pięd typów danych. Każdy posiada własny zestaw operacji. Wszystkie operacje na danych są atomowe. Typy danych: • stringi, typy proste (strings) • tablice haszujące (hashes) • listy (lists) • zbiory (sets) • posortowane zbiory (sorted sets)

Skalary, typy proste (strings) Natywną reprezentacją wartości dla typów prostych jest tablica bajtów. Wartości mogą byd czymkolwiek: • Zserializowanymi obiektami Javy • Łaocuchami znakowymi • Dokumentami w formacie JSON itd. set user:jacekplacek "{name: 'jacek', surname: 'placek'}" get user:jacekplacek strlen user:jacekplacek append user:jacekplacek "a to sobie dopisze"

Tablice hashujące (hashes) Zbiór par klucz-wartośd. Operacje: • Dodawanie i pobieranie wartości dla klucza • Usuwanie kluczy, sprawdzanie czy klucz istnieje • Pobieranie wszystkich kluczy i inne… hset moj:hash pole "ala ma kota" hget moj:hash pole hkeys moj:hash hgetall moj:hash
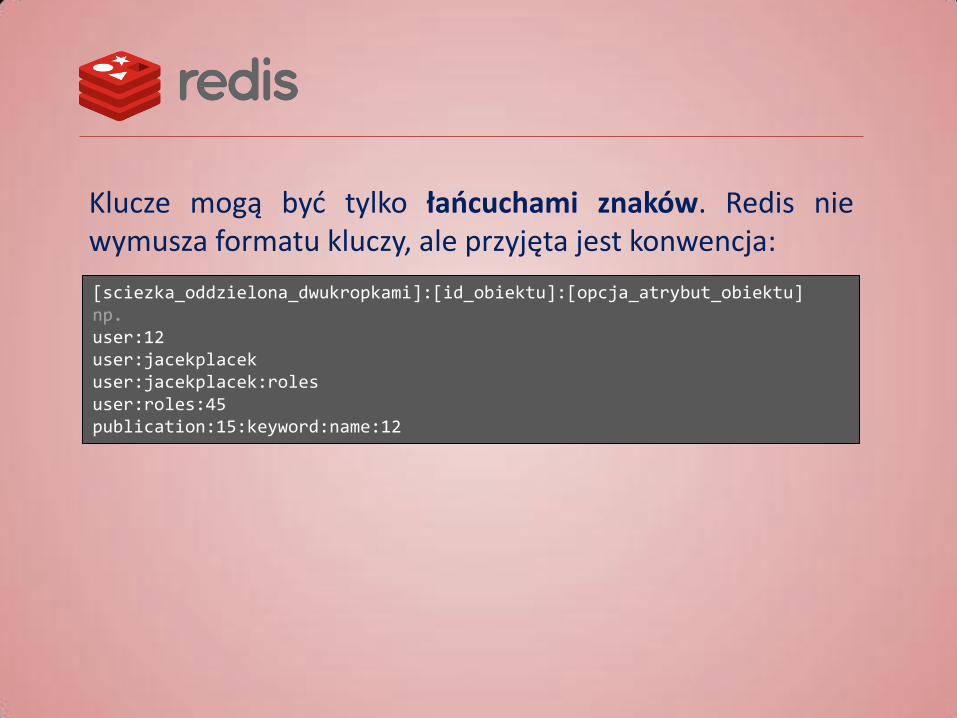
Listy (lists) Uporządkowany zbiór skalarów. Operacje: • Dodawanie elementów na początek i koniec listy • Pobieranie elementów listy • Zamiana elementów, pobieranie zakresu elementów
(paginacja) i inne… rpush moja:lista "element na koniec" lpush moja:lista "element na pocz¹tek" ltrim moja:lista 0 10 llen moja:lista lrange moja:lista 0 10

Zbiory (sets) Nieuporządkowany zbiór skalarów z szybkimi operacjami pobierania i modyfikacji elementów. Operacje: • Dodawanie, usuwanie, pobieranie, przenoszenie
elementów • Operacje sumy, przecięcia, różnicy zbiorów • Pobieranie losowych elementów i inne… sadd przyjaciele:gosia jacek agatka monika natasza sismember przyjaciele:gosia jacek sinter przyjaciele:gosia przyjaciele:krysia sinterstore przyjaciele:gosia przyjaciele:krysia przyjaciele:jacek
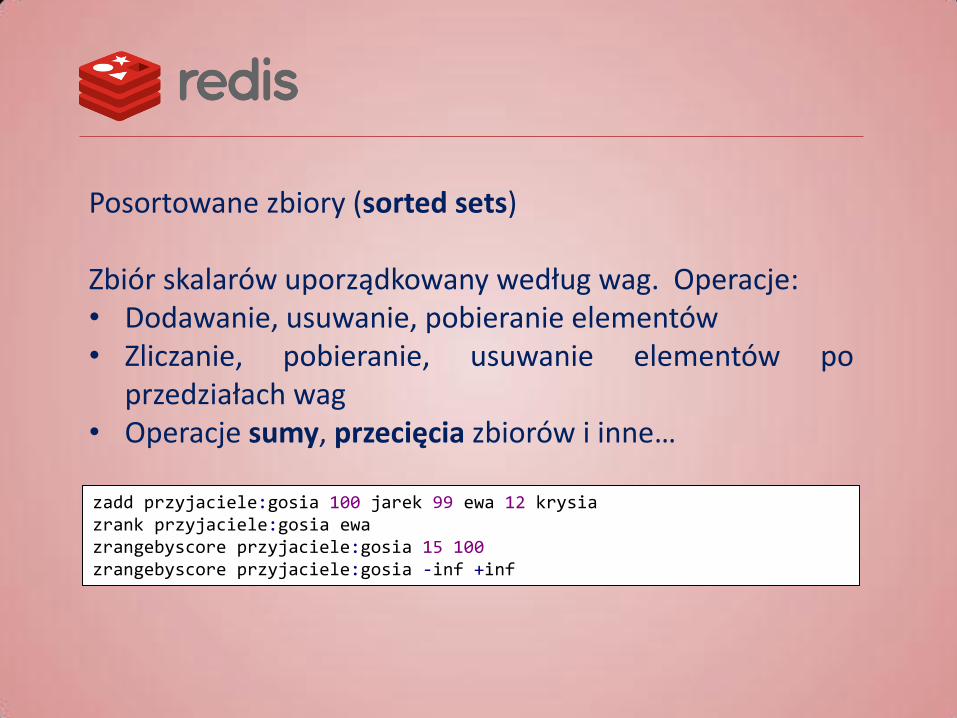
Posortowane zbiory (sorted sets) Zbiór skalarów uporządkowany według wag. Operacje: • Dodawanie, usuwanie, pobieranie elementów • Zliczanie, pobieranie, usuwanie elementów po
przedziałach wag • Operacje sumy, przecięcia zbiorów i inne… zadd przyjaciele:gosia 100 jarek 99 ewa 12 krysia zrank przyjaciele:gosia ewa zrangebyscore przyjaciele:gosia 15 100 zrangebyscore przyjaciele:gosia -inf +inf

Inne możliwości: • Wsparcie dla transakcji
• Liczniki (odpowiedniki sekwencji w bazach relacyjnych) • Tworzenie kluczy czasowych (expiration) – dane będą
automatycznie usuwane po upłynięciu określonej liczby sekund
• Pipelining – przesyłanie do serwera wielu poleceo na raz
• Replikacja i tworzenie klastrów maszyn

Gdzie szukad informacji? • lista poleceo (dla każdego informacja o złożoności obliczeniowej)
redis.io/commands
• dokumentacja redis.io/documentation
• sterownik dla Javy github.com/xetorthio/jedis
• The Little Redis Book openmymind.net/redis.pdf


• strona oficjalna: www.oracle.com/technetwork/database/nosqldb
• baza NoSQL firmy Oracle
• zbudowana na podstawie Berkeley DB, popularnej bazy typu klucz-wartośd wspieranej przez Oracle

Klucze składają się z dwóch części: • Major components – częśd klucza reprezentująca
identyfikator kolekcji lub zbioru atrybutów
• Minor components – częśd klucza reprezentująca elementy kolekcji lub atrybuty
Key key = Key.createKey("monster", "goblin"); byte [] value = SerializationUtils.serialize(goblinObject); store.put(key, value);

Wartości są tablicami bajtów. Można w nich przechowywad pliki, zserializowane obiekty, łaocuchy znaków itd. Możliwe jest zwracanie wartości dla konkretnego klucza lub wszystkich wartości dla major component i opcjonalnie zakresu minor components.
Iterator<KeyValueVersion> iterator = store.multiGetIterator(Direction.FORWARD, 1000, Key.createKey("monster"), null, Depth.PARENT_AND_CHILDREN); SortedMap<Key, ValueVersion> results = store.multiGet(Key.createKey("monster"), null, Depth.PARENT_AND_CHILDREN);

Inne możliwości: • Transakcyjnośd w obrębie pojedynczego major
component
• Replikacja oraz sharding
• Konsola administracyjna w postaci aplikacji webowej

Gdzie szukad informacji? • Manual
docs.oracle.com/cd/NOSQL/html/GettingStartedGuide • Administracja
docs.oracle.com/cd/NOSQL/html/AdminGuide • Java API
docs.oracle.com/cd/NOSQL/html/javadoc/index.html


• strona oficjalna: neo4j.org
• baza przechowująca dane o strukturze grafowej: obiekty przechowywane w bazie reprezentują wierzchołki lub krawędzie grafu
• działa w trybie embedded lub jako oddzielny proces
• zaimplementowana w Javie
• oficjalne wsparcie w springu (spring-data-neo4j)

Neo4j przeznaczony jest do przechowywania obiektów (dokumentów) oraz zależności między nimi. Sprawdza się najlepiej w przypadku danych z dużą liczbą powiązao. Wierzchołki i krawędzie w grafie są obiektami i mogą posiadad dowolną liczbę atrybutów. Poza wydajnymi operacjami łączenia obiektów (wydajniejszymi
od relacyjnych JOINów), neo4j umożliwia również tworzenie indeksów na atrybutach i wyszukiwanie obiektów z ich użyciem.

Neo4j posiada dedykowane narzędzie Neoclipse do łączenia się z bazą, modelowania struktury danych, wykonywania zapytao itp. Jest to zmodyfikowana wersja Eclipsa.

Neo4j umożliwia wykonywanie zapytao w językach zaprojektowanych do wyszukiwania danych w bazach grafowych. Domyślnym językiem tego typu opracowanym dla Neo4j jest cypher. Wspierany jest również inny popularny język przeszukiwania grafów – gremlin.

Inne możliwości: • Transakcje
• Wbudowane implementacje popularnych algorytmów
grafowych (wyszukiwanie ścieżek, dijkstra, A*)
• Webowa aplikacja do administracji bazą
• Dodatkowe funkcjonalności związane z utrzymaniem bazy (np. automatyczne backupy w wersji Enterprise)
• API RESTowe

Gdzie szukad informacji? • neo4j manual
docs.neo4j.org/chunked/milestone
• Java API api.neo4j.org/current
• spring-data-neo4j www.springsource.org/spring-data/neo4j

TESTY WYDAJNOŚCI
Przetestowane bazy: • MONGODB • ORIENTDB (W WERSJI EMBEDDED) • REDIS • ORACLE NOSQL DATABASE
Przetestowano na domyślnej konfiguracji, na sprzęcie dostępnym w pracy, w środowisku Windows.
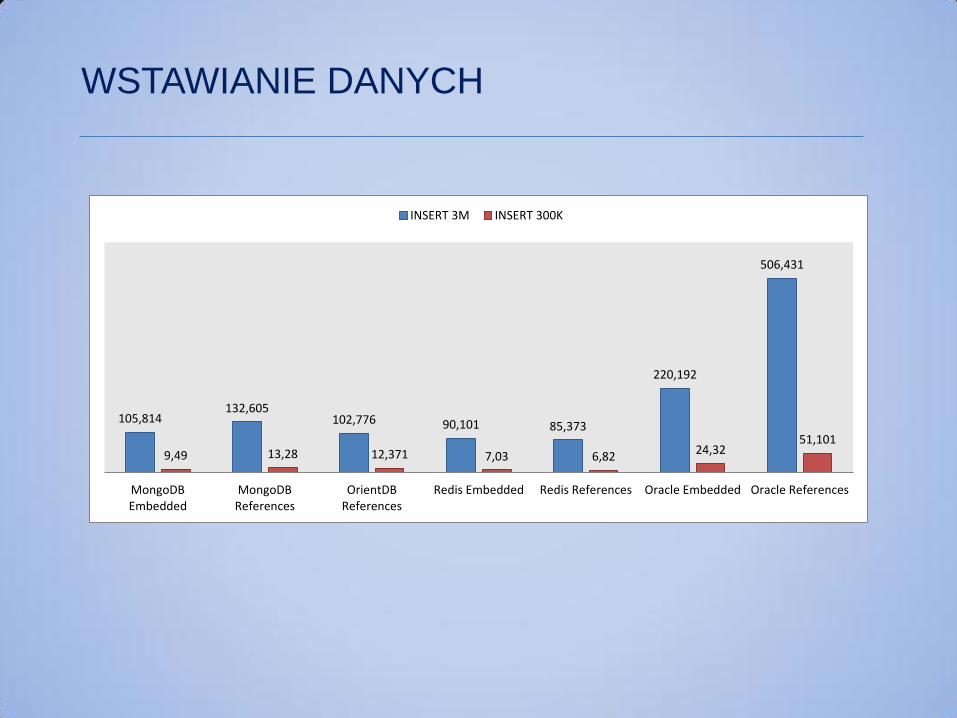
105,814 132,605
102,776 90,101 85,373
220,192
506,431
9,49 13,28 12,371 7,03 6,82 24,32
51,101
MongoDBEmbedded
MongoDBReferences
OrientDBReferences
Redis Embedded Redis References Oracle Embedded Oracle References
INSERT 3M INSERT 300K
WSTAWIANIE DANYCH

98,825 141,545 157,751
85,307 134,334
23,171 1,869 14,294 5,938 8,557 12,322 1,848 3,271
MongoDBEmbedded
MongoDBReferences
OrientDBReferences
Redis Embedded Redis References Oracle Embedded Oracle References
READ 3M READ 300K
1582,464
ODCZYT DANYCH
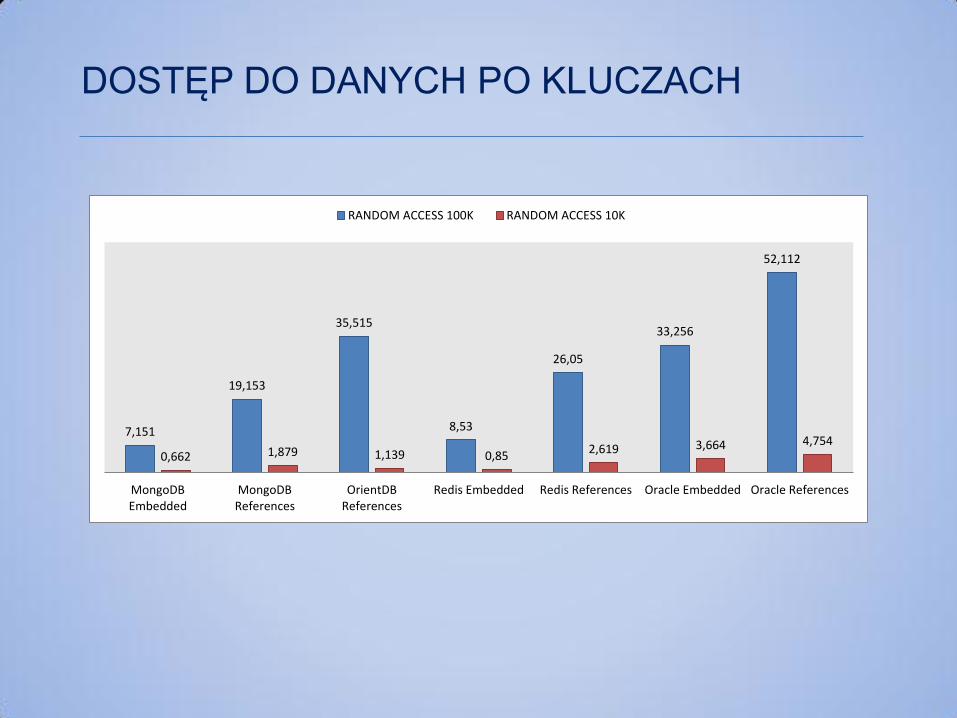
7,151
19,153
35,515
8,53
26,05
33,256
52,112
0,662 1,879 1,139 0,85 2,619 3,664 4,754
MongoDBEmbedded
MongoDBReferences
OrientDBReferences
Redis Embedded Redis References Oracle Embedded Oracle References
RANDOM ACCESS 100K RANDOM ACCESS 10K
DOSTĘP DO DANYCH PO KLUCZACH
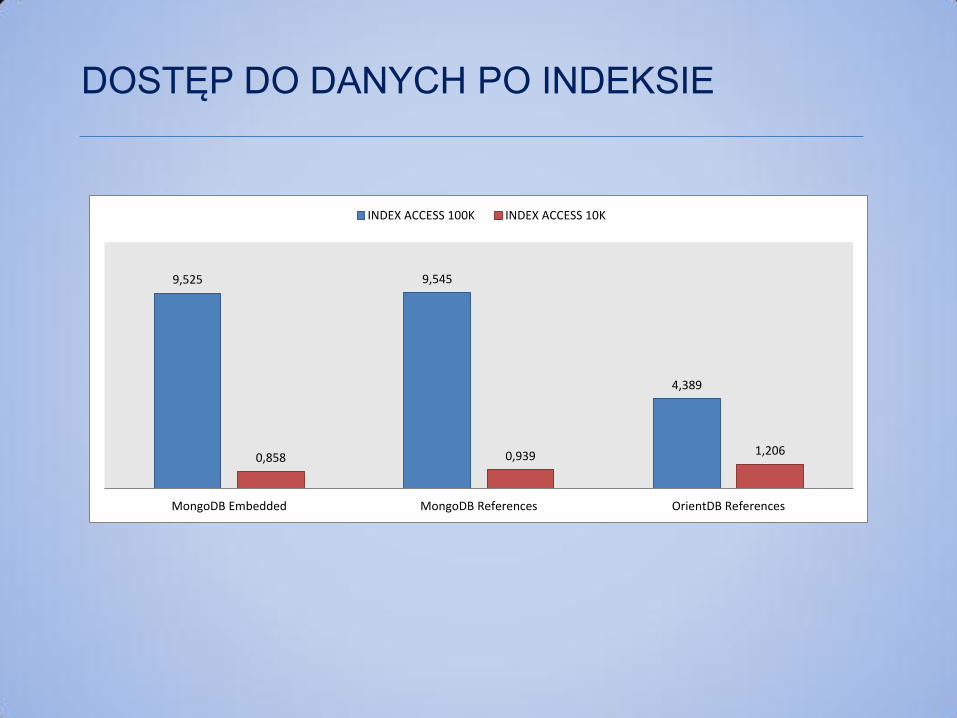
DOSTĘP DO DANYCH PO INDEKSIE
9,525 9,545
4,389
0,858 0,939 1,206
MongoDB Embedded MongoDB References OrientDB References
INDEX ACCESS 100K INDEX ACCESS 10K

dziękuję za uwagę













![Co to jest mapa bitowa - Helionpdf.helion.pl/photo4/dodateka.pdf · 2001-11-27 · Mapa bitowa 319 Rys. A.1.3LNVHOHVNÆDGDM FHVL QDPDS ELWRZ Co to jest mapa bitowa 3U]H]PDS ELWRZ](https://img.pdfslide.tips/doc/110x75/5e57792c95567756d272bbff/co-to-jest-mapa-bitowa-2001-11-27-mapa-bitowa-319-rys-a13lnvhohvndgdm-fhvl.jpg)