Embed Size (px)
Citation preview

Recommendation Algorithms:
Collaborative Filtering
CSE 6111 Presentation Advanced Algorithms Fall. 2013
Presented by: Farzana Yasmeen
2013.11.29

2
Contents
● What are recommendation algorithms?
– Recommendations
– Recommender Systems
– Recommender Algorithms
● Focus: Collaborative Filtering – Nearest Neighbour
● Conclusions
– Pros and Cons
● Discussion

3
Recommendations
● What are recommendations?
– Alternative to ‘search’
– Relevant content : movies, online shopping, radio stations….
●
•Customer is looking for a product
•Receive personal offerings
•Receive tips

4
Recommendations
● Benefits?
5
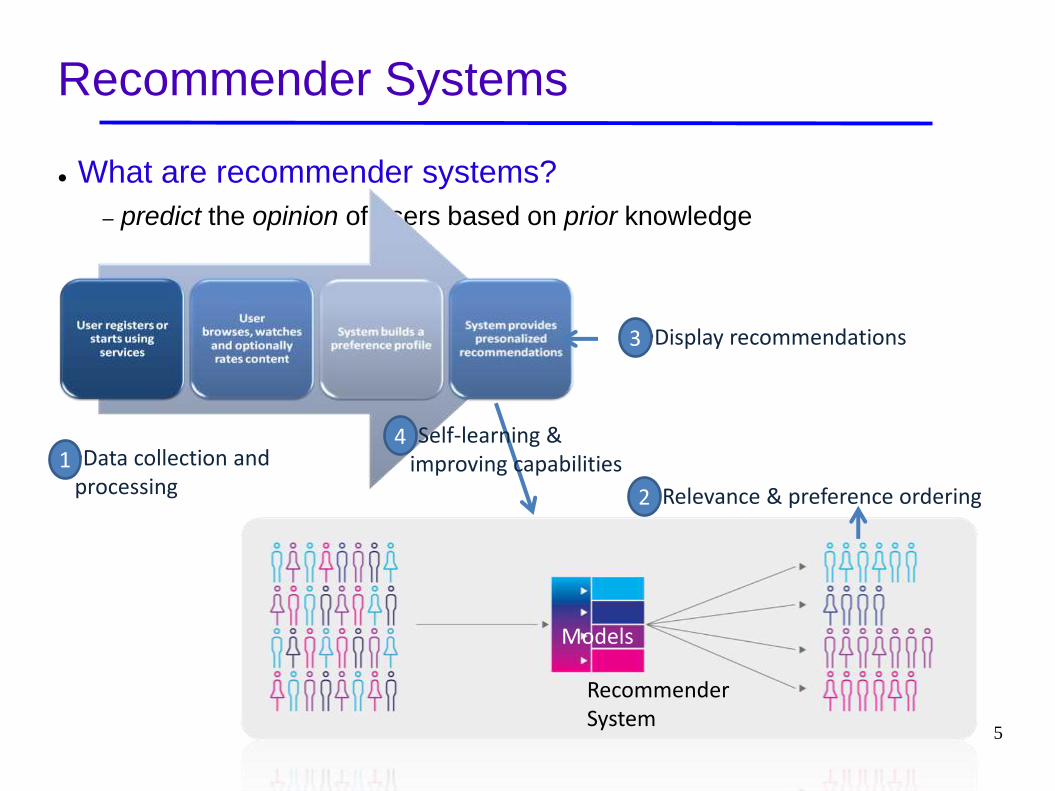
Recommender Systems
● What are recommender systems?
– predict the opinion of users based on prior knowledge
Models
•Data collection and processing •Relevance & preference ordering
•Display recommendations
•Self-learning & improving capabilities 1
2
3
4
Recommender System
6
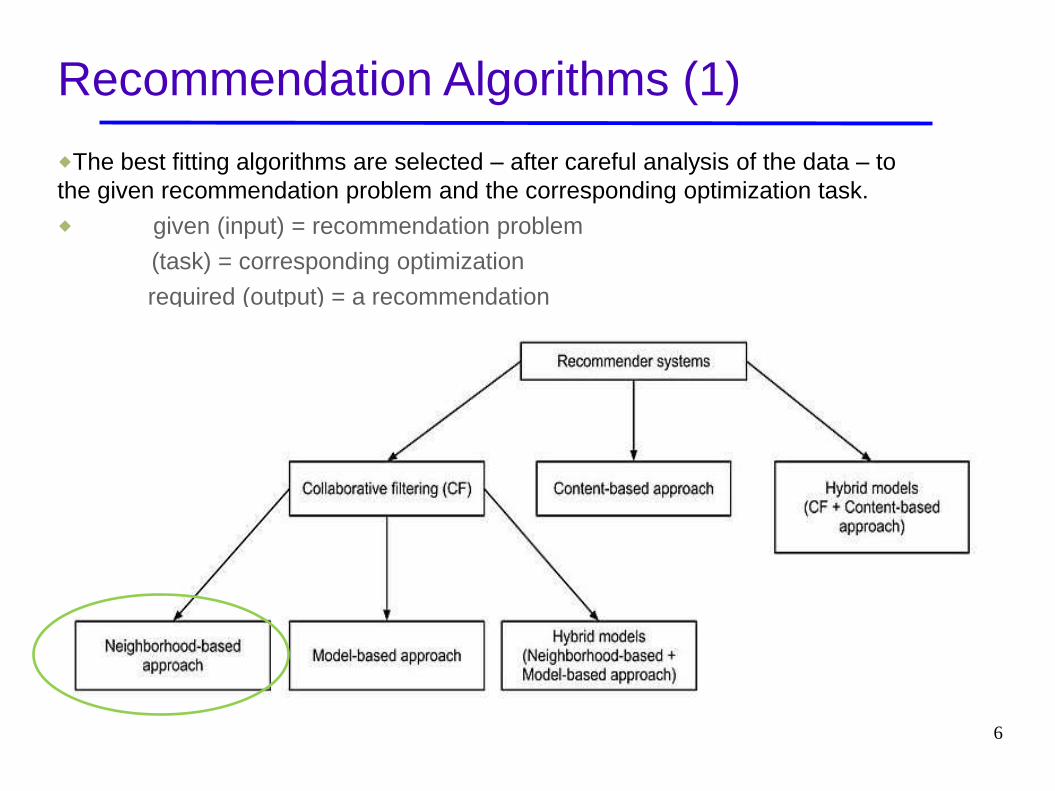
Recommendation Algorithms (1)
The best fitting algorithms are selected – after careful analysis of the data – to
the given recommendation problem and the corresponding optimization task.
given (input) = recommendation problem
(task) = corresponding optimization
required (output) = a recommendation

7
Recommendation Algorithms (2)
● Content-based Filtering (CBF):
– item triggered (user, item metadata)
– keyword matching
– key problem: learn and apply cross-content (i.e. decision trees)
● Collaborative Filtering (CF):
– event triggered (vod purchase, live channel watching)
– finds similarities on users and items (vod content, live schedule)
– key problem: how to combine and weight the preferences of user
neighbors (i.e. nearest neighbor)
● Hybrid Model:
– combining the watching and searching habits of similar users
(collaborative filtering)
– offering content with shared characteristics that a user has rated
highly (content-based filtering).
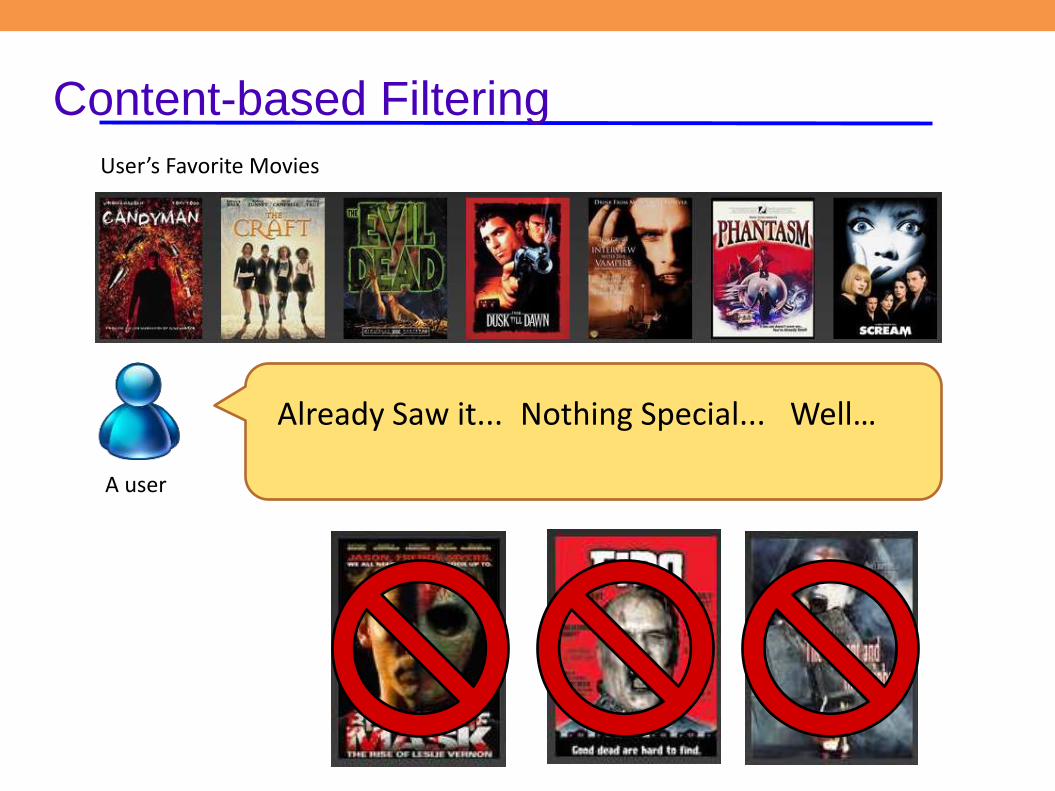
because you saw most of the major horror movies, here is minor horror movies
Content-based Filtering
A user
User’s Favorite Movies
Already Saw it... Nothing Special... Well…

Collaborative Filtering

Collaborative Filtering
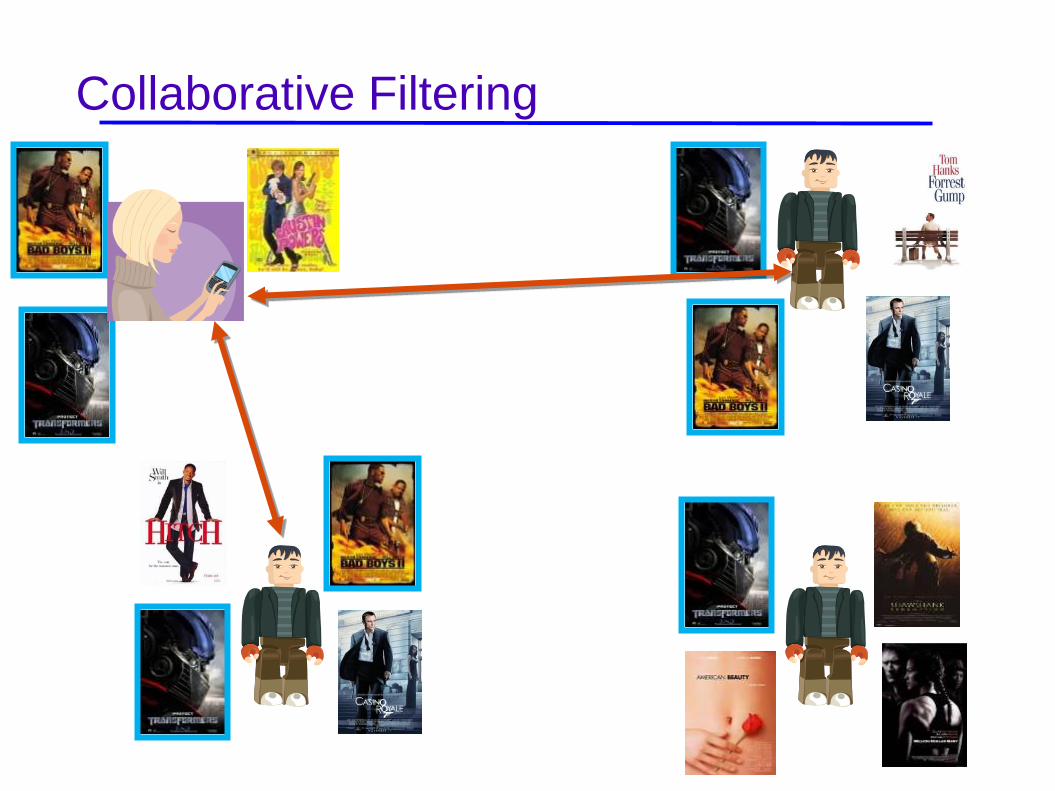
Collaborative Filtering
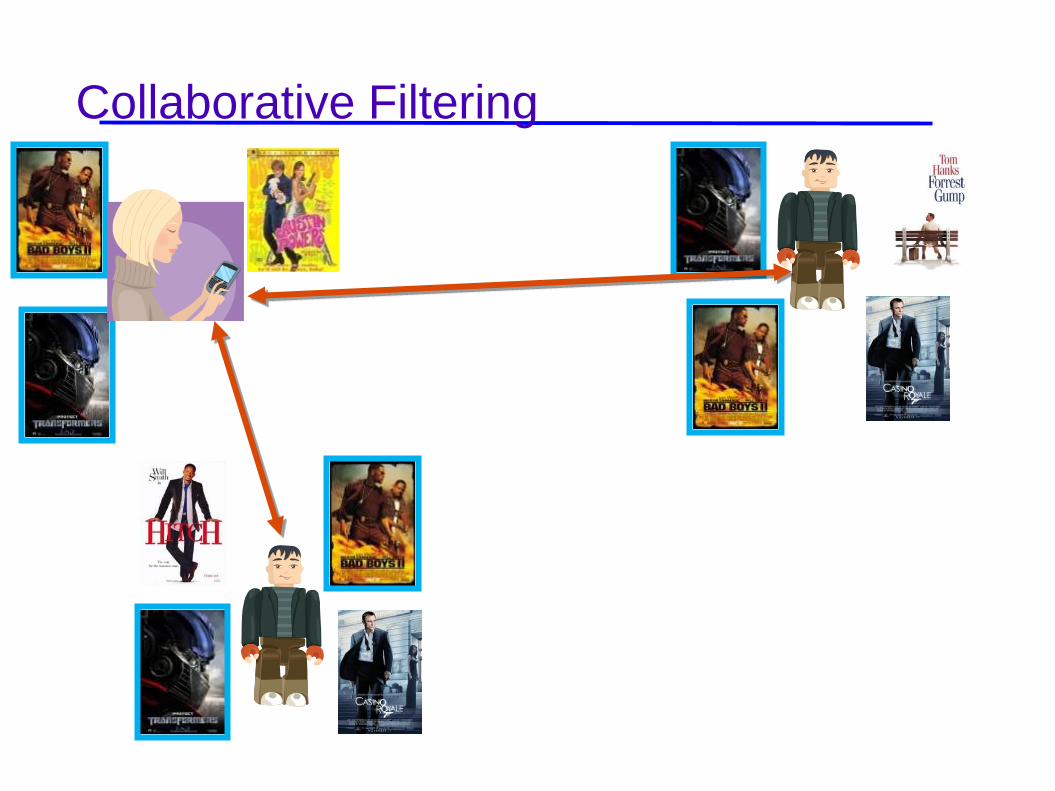
Collaborative Filtering
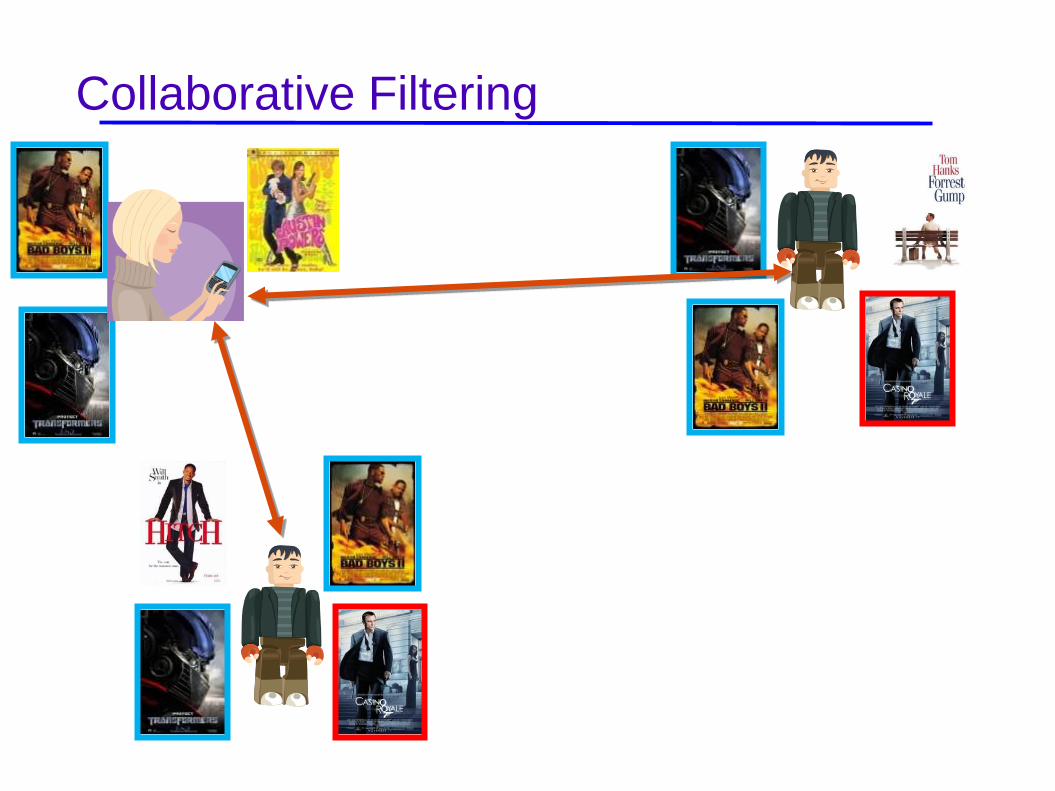
Collaborative Filtering

CF Algorithms
Collaborative Filtering
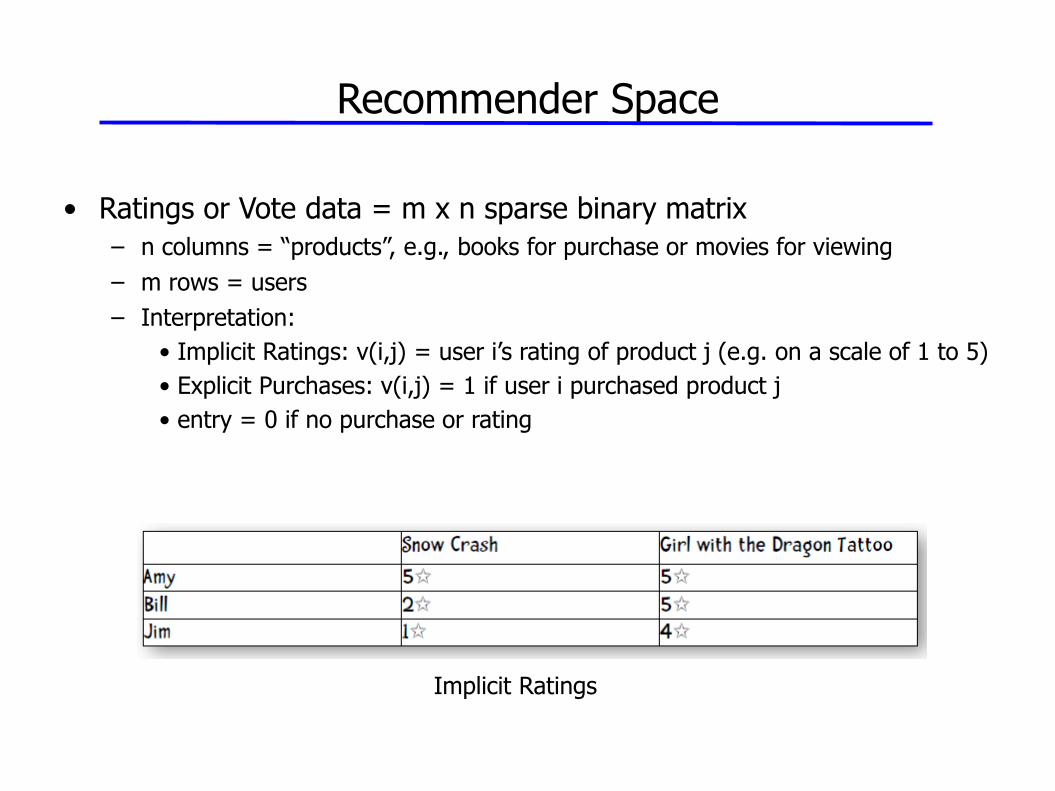
Recommender Space
• Ratings or Vote data = m x n sparse binary matrix
– n columns = “products”, e.g., books for purchase or movies for viewing
– m rows = users
– Interpretation:
• Implicit Ratings: v(i,j) = user i’s rating of product j (e.g. on a scale of 1 to 5)
• Explicit Purchases: v(i,j) = 1 if user i purchased product j
• entry = 0 if no purchase or rating
Implicit Ratings
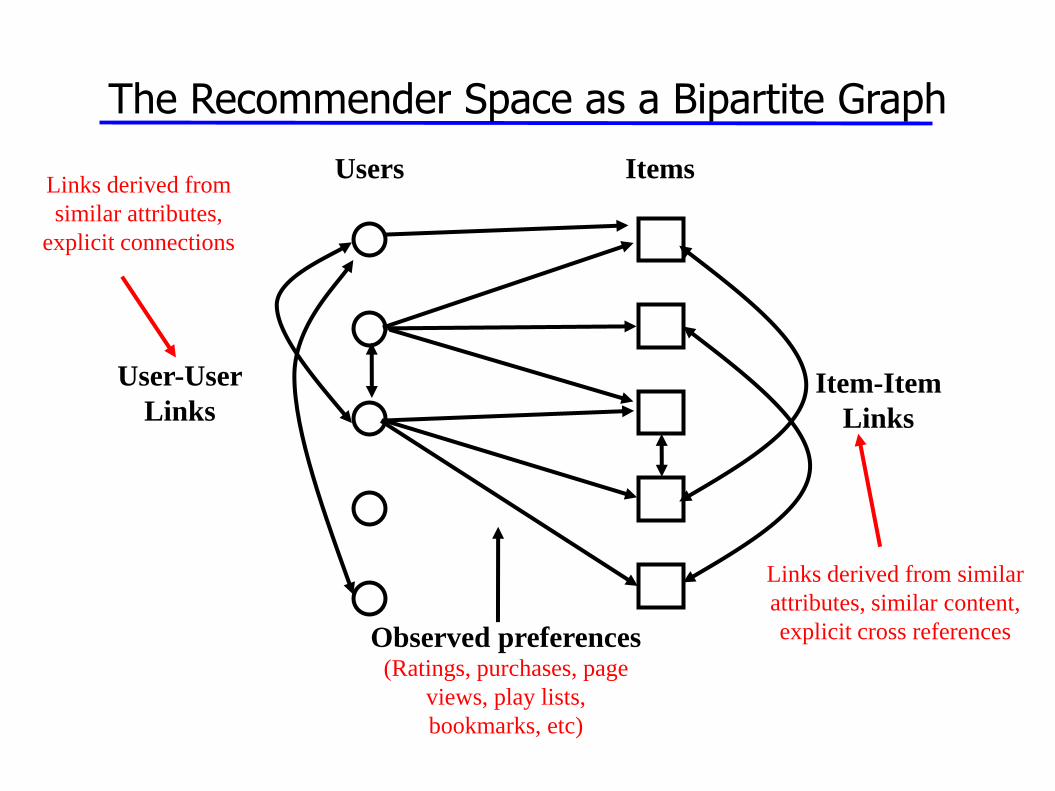
Users Items
Observed preferences
The Recommender Space as a Bipartite Graph
Item-Item
Links
User-User
Links
Links derived from similar
attributes, similar content,
explicit cross references
Links derived from
similar attributes,
explicit connections
(Ratings, purchases, page
views, play lists,
bookmarks, etc)

Near-Neighbor Algorithms for Collaborative Filtering
ri,k = rating of user i on item k
Ii = items for which user i has generated a rating
Mean rating for user i is
Predicted vote for user i on item j is a weighted sum
weights of K similar users Normalization constant
(e.g., total sum of weights)
Value of K can be optimized on a validation data set

Near-Neighbor Weighting
• K-nearest neighbor
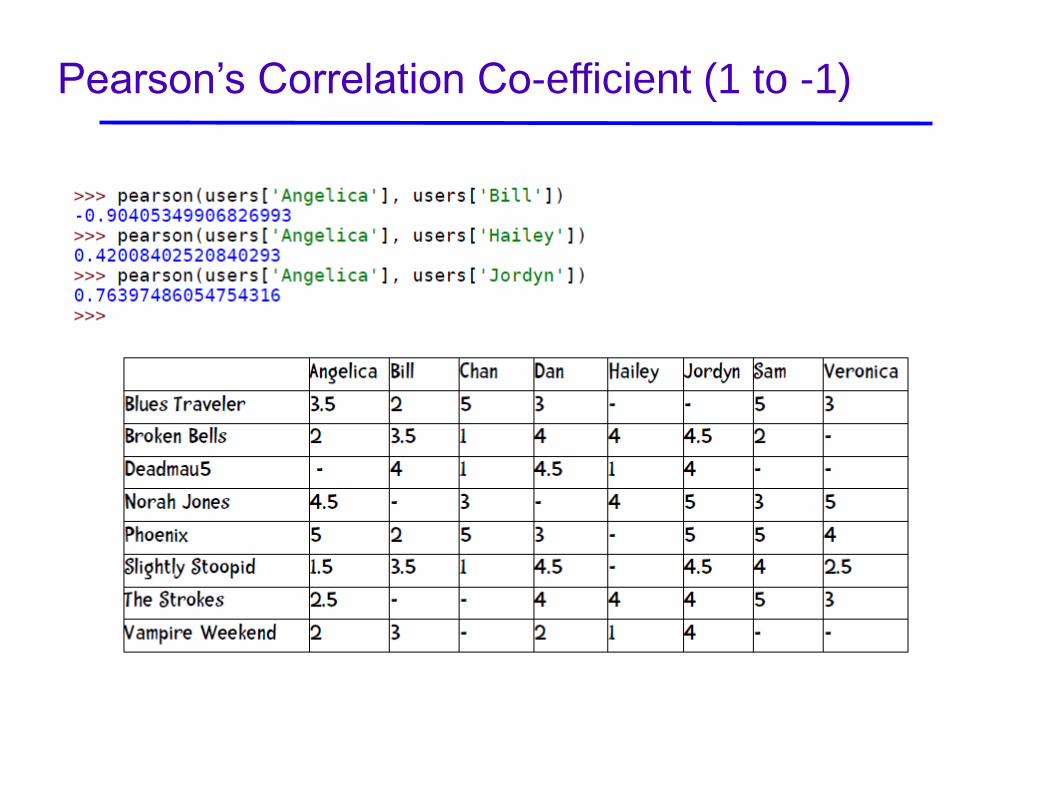
• Pearson correlation coefficient (Resnick ’94, Grouplens):
Sums are over items rated by both users

How do I find someone similar
• Manhattan Distance
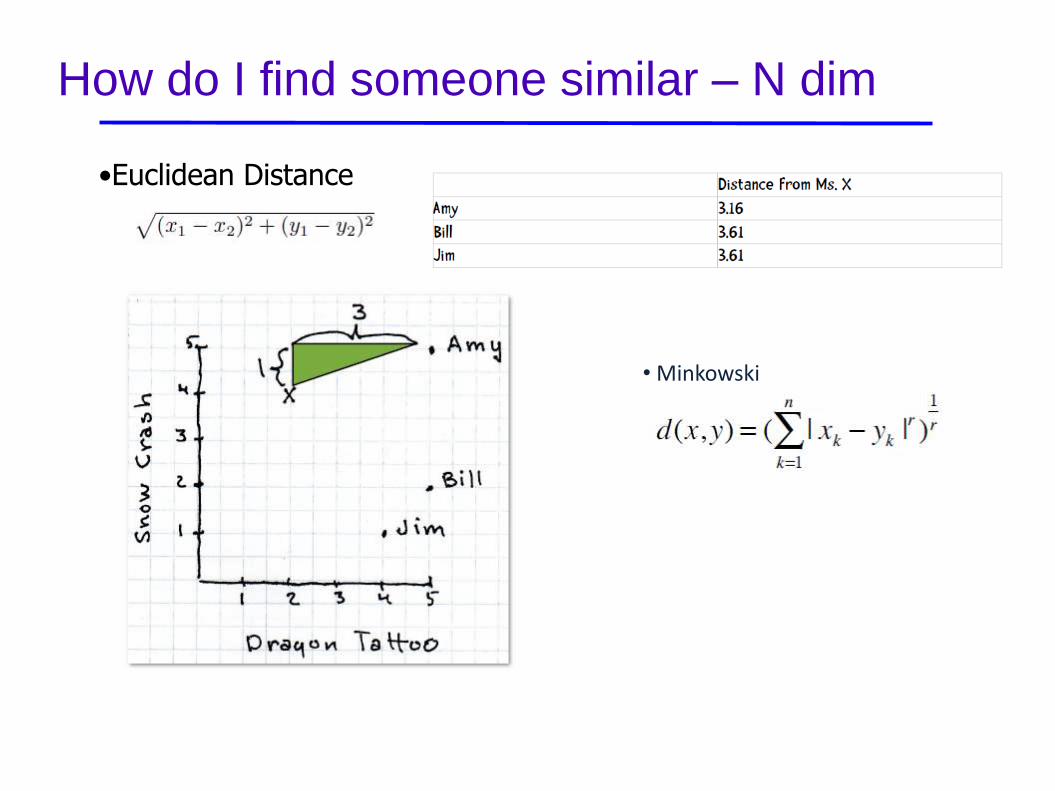
•Euclidean Distance
How do I find someone similar – N dim
• Minkowski
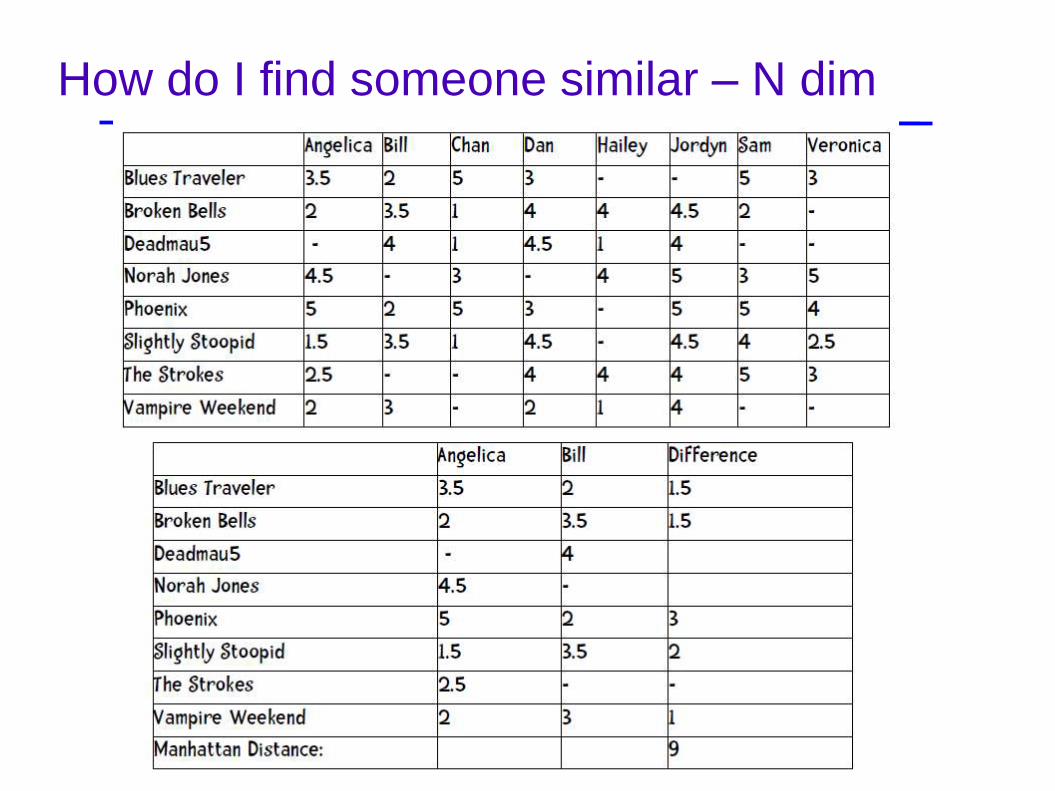
How do I find someone similar – N dim

How do I find someone similar – N dim

Problem – 1: entry matching

Problem – 2 : blame the users
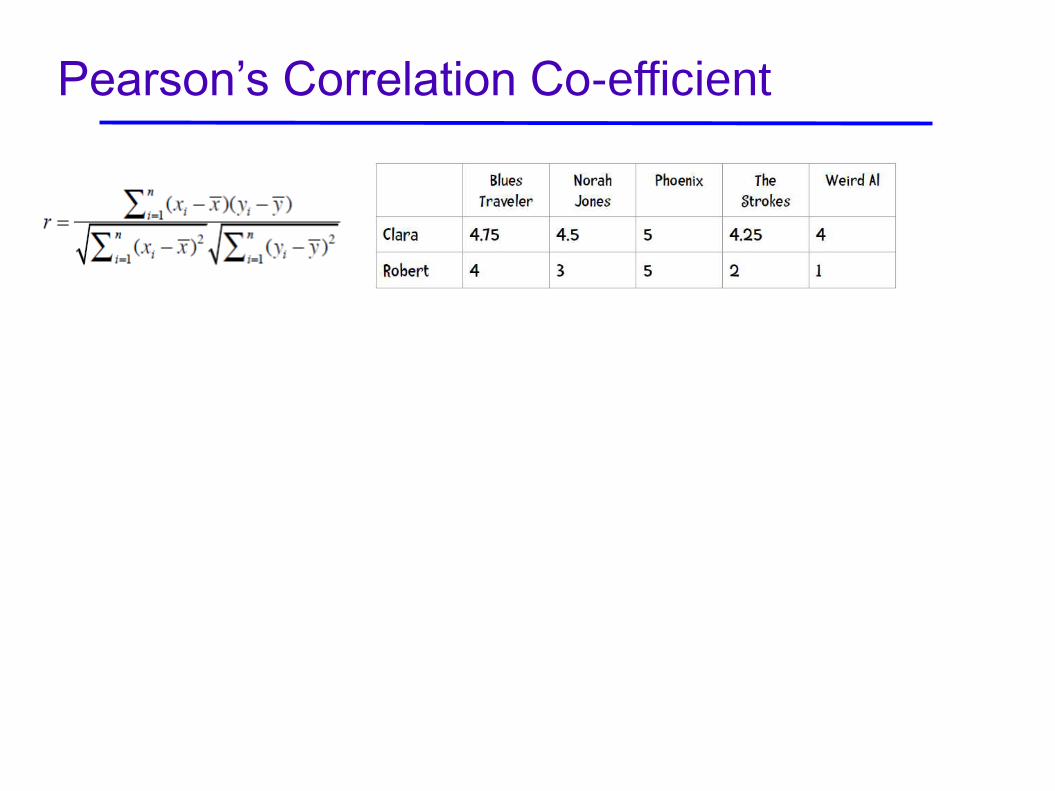
Pearson’s Correlation Co-efficient

Pearson’s Correlation Co-efficient

Pearson’s Correlation Co-efficient

Pearson’s Correlation Co-efficient (1 to -1)

Pearson’s Correlation Co-efficient (1 to -1)
Approximation:
(x)
(y)
Pearson’s Correlation Co-efficient (1 to -1)

What to Use?

Comments on Neighbor-based Methods
• Here we emphasized user-user similarity
– Can also do this with item-item similarity, i.e.,
– Find similar items (across users) to the item we need a rating for
• Simple and intuitive
– Easy to provide the user with explanations of recommendations
• Computational+ Issues • In theory we need to calculate all n2 pairwise weights
• So scalability is an issue (e.g., real-time)
• Cold start – data sparsity
• For recent advances in neighbor-based approaches see Y. Koren, Factor in the neighbors: scalable and accurate collaborative filtering, ACM
Transactions on Knowledge Discovery in Data, 2010

33
Technology thrives simply because we create the
‘supply’ as opposed to the ‘demand’ first…

34
References
● Corporate presentations of Random company executives
● Lots of Google’ing and YouTube
● Wikipedia
● Programmers Guide to Data Mining
35
s