Embed Size (px)
Citation preview

Facultad de Ciencias Sociales – UBA - Seminario de Doctorado:Análisis de trayectorias y redes sociales a través de métodos cualitativosProf: Donatello, Luis Miguel
Presentación: Análisis cuantitativos de datos Carlos F. De Angelis

Cea D´Ancona Mº A (2001, 112)
Diseños de investigación según los objetivos del estudio

Estrategia o enfoque cuantitativo
Según Hernández Sampieri (2006) el enfoque cuantitativo plantea un problema de investigación delimitado y concreto, genera hipótesis y somete a prueba esas hipótesis en base a datos numéricos recolectados y analizados mediante procedimientos estadísticos.
Si bien puede ser se empleada tanto para diseños exploratorios, y descriptivos algunos autores lo identifican con el modelo explicativo también denominado por algunos autores como «correlacional»En este sentido también algunos autores clasifican a los modelos surgidos de los enfoque cuantitativos investigaciones experimentales o cuasi experimentales
La investigación social cuantitativa está directamente basada en el paradigma explicativo. Este paradigma, … utiliza preferentemente información cuantitativa o cuantificable para describir o tratar de explicar los fenómenos que estudia, en las formas que es posible hacerlo en el nivel de estructuración lógica en el cual se encuentran las ciencias sociales actuales. (Briones G, 1996)
Los modelos explicativos tienen una serie de supuestos o requisitos, como por ejemplo la normalidad de las distribuciones y que los datos provengan de una muestra probabilística, y la finalidad es la estimación de los parámetros poblacionales.
Los perspectivas más modernas basados en la «extracción de información» o Data Mining plantean otros enfoque basados en los procesos de descubrimiento de nuevas relaciones y tendencias en el análisis de los datos. Si bien se orientan a la exploración de grandes bases de datos, su aplicación permite otra mirada en la exploración de los datos.

Repaso de conceptos básicos I
Variable: Cualquier cualidad o característica de un objeto o evento que contenga al menos dos atributos (categorías o valores) en los que pueda clasificarse un objeto o evento determinado. (Cea D´Ancona, 2001 ,126)
Según las formas en que sean expresadas las categorías que la variable podrá identificarse como cuantitativa (o numérica/métrica) ej.: edad o cualitativa ej.: nivel educativo
Dentro de las variables cualitativas si las categorías pueden ser ordenadas siguiendo un criterio conocido se denomina «ordinal», si entre las categorías no puede establecerse ninguna relación será un variable «nominal»
Criterios para la formulación de un sistema de categorías: exhaustividad, exclusividad, precisión y relevancia teórica
Variable ordinal: Nivel educativo:
Sin instrucciónPrimaria Secundaria Universitaria Posgrado
Variable nominal: Religión
CatólicoJudíoMusulmánBudistaTaoístaSin religión
Variable numérica: Ingreso
0----
∞

Repaso de conceptos básicos II
Matriz de datos: Es una modalidad de organización de los datos, previamente registrados mediante los instrumentos respectivos: permite identificar en forma simultánea el carácter tripartito del dato: (Galtung, 1967)
Unidad de análisis
Variable
Categoría

Repaso de conceptos básicos III
La finalidad de enfoque cuantitativo clásico es la estimación de los parámetros poblacionales. Existen unos valores «verdaderos» en la población que se deben estimar. Estas técnicas son llamadas paramétricas y suponen que los datos provienen de una muestra probabilística, es decir una donde cada unidad de análisis de la población posee la misma probabilidad de ser seleccionada.
La teoría del muestreo se basan es la ley de los grandes números y la teoría del límite centralSe basa en las propiedades de la distribución normal. Las estimaciones se obtienen dentro de un intervalo y en un intervalo de estimación.
El tamaño de la muestra se calcula en base a la siguiente fórmula:
n= s2*z2 / e2
Donde s2 es la varianza, z es la puntación típica para la confianza correspondiente y e es el error absoluto de estimación considerado
La estimación sigue la siguiente forma µ =¯x± z*s/ √ n
xx x xx
xx
xx
x
xx
xx xx
x x

Análisis de datos cuantitativos I
Son cuatro los criterios básicos para identificar las técnicas apropiadas: 5.Tipo de variables (nivel de medición)6.Cantidad de variables involucradas,7.Rol que cumplen en la relación o modelo 8.Si se busca explorar los datos o realizar inferencia 1. Tipo de variables Cualitativas - Cuantitativas
2. Cantidad de variablesUna variable: Análisis univariado Dos variables: Análisis bivariadoTres o más: Análisis multivariado
3. Rol que cumplen en la relación o modelo Independiente – Dependiente – Interviniente
4. Si se busca explorar los datos o realizar inferencia Muestreo estadísticoPruebas de significación

Análisis de datos cuantitativos I
2. Cantidad de variablesUna variable: Análisis univariado
Es el nivel más básico de análisis descriptivo1. Distribución de frecuencias (porcentualización)¿A quien voto?
Frecuencia PorcentajeVálidos Michetti 195 31,1
Heller 73 11,6Prat Gay 119 19,1Solanas 152 24,2Ibarra 21 3,3Ripoll 5 ,7Zamora 13 2,0Polino 15 2,4Altamira 4 ,7Otros 14 2,2En blanco 9 1,4Impugnado 9 1,4
Total 627 100,0
23.Medidas de tendencial central y dispersión•Tendencia central:, mediana y moda, media•Medidas de dispersión: varianza, desvío estándar, rango, máximo y mínimo
EstadísticosEdadN 627Media 43,64Mediana 42,00Moda 20Desv. típ. 17,174Varianza 294,939Rango 78Mínimo 18Máximo 96
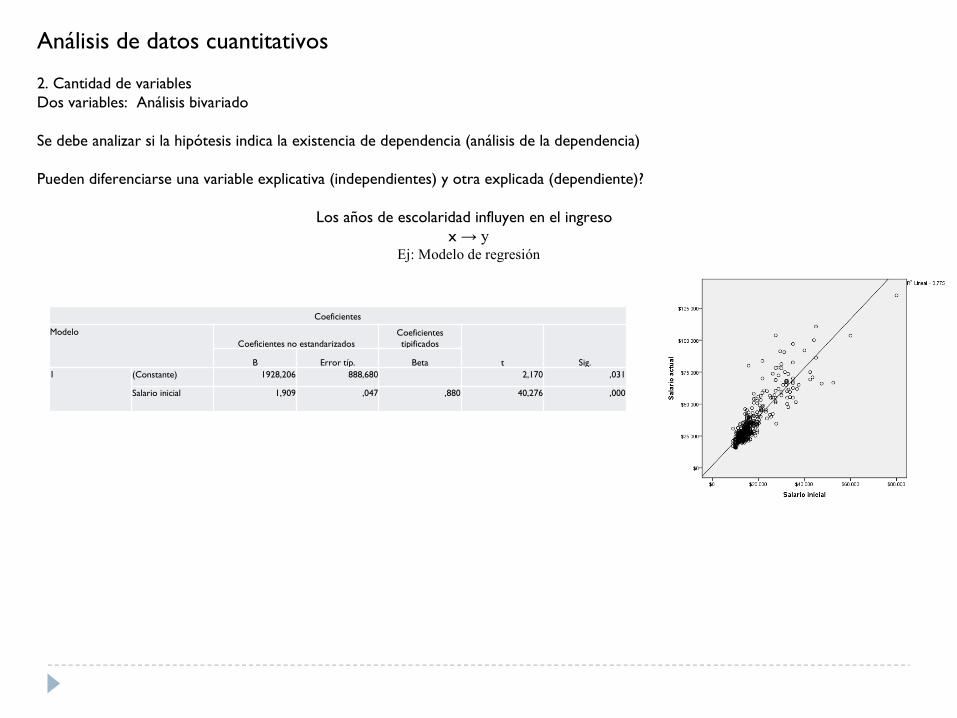
Análisis de datos cuantitativos
2. Cantidad de variablesDos variables: Análisis bivariado
Se debe analizar si la hipótesis indica la existencia de dependencia (análisis de la dependencia)
Pueden diferenciarse una variable explicativa (independientes) y otra explicada (dependiente)?
Los años de escolaridad influyen en el ingreso x → y
Ej: Modelo de regresión
Coeficientes
ModeloCoeficientes no estandarizados
Coeficientes tipificados
t Sig.B Error típ. Beta1 (Constante) 1928,206 888,680 2,170 ,031
Salario inicial 1,909 ,047 ,880 40,276 ,000

Análisis de datos cuantitativos II
2. Cantidad de variablesDos variables: Análisis bivariado
No se puede establecer dependencia: Ej: Matriz de correlaciones
Matriz de Correlaciones
Esperanza de vida fem.
Esperanza de vida masc.
Personas Alfabetizadas
(%)
Mortalidad infantil (muertes por 1000
nacidos vivos)PIB per-capita
Esperanza de vida femenina
R 1 ,982 ,865 -,962 ,642
Sig ,000 ,000 ,000 ,000
N 109 109 107 109 109
Esperanza de vida masculina
R ,982 1 ,809 -,936 ,639
Sig ,000 ,000 ,000 ,000
N 109 109 107 109 109
Personas Alfabetizadas (%)
R ,865 ,809 1 -,900 ,552
Sig ,000 ,000 ,000 ,000
N 107 107 107 107 107
Mortalidad infantil (muertes por 1000 nacimientos vivos)
R -,962 -,936 -,900 1 -,640
Sig ,000 ,000 ,000 ,000
N 109 109 107 109 109
Producto interior bruto per-capita
R ,642 ,639 ,552 -,640 1
Sig ,000 ,000 ,000 ,000 N 109 109 107 109 109
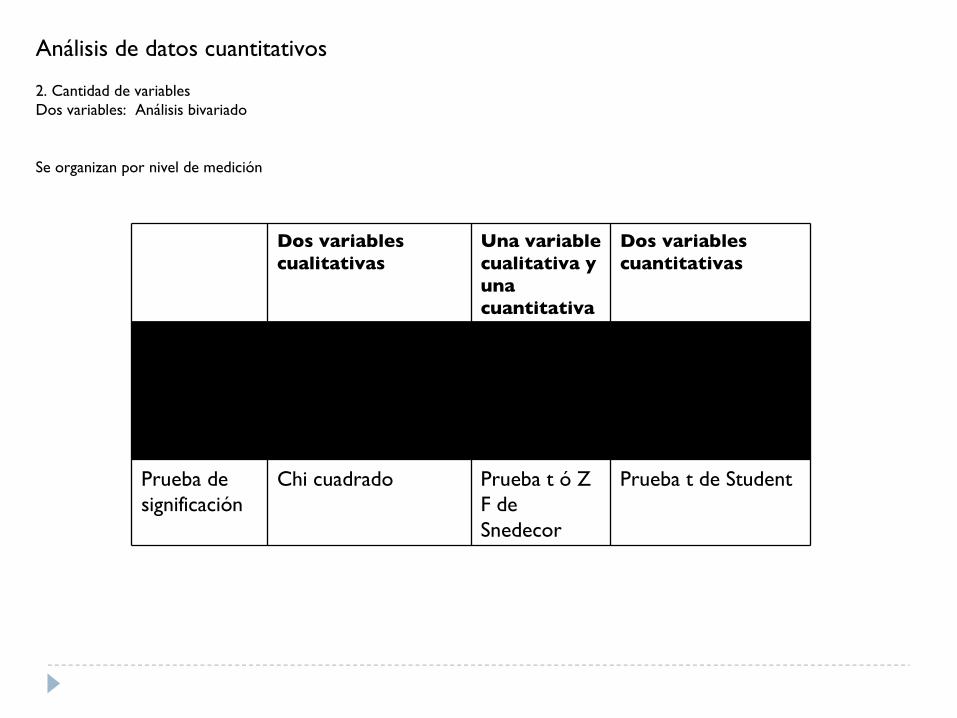
Análisis de datos cuantitativos
2. Cantidad de variablesDos variables: Análisis bivariado
Se organizan por nivel de medición
Dos variables cualitativas
Una variable cualitativa y una cuantitativa
Dos variables cuantitativas
Técnica Tablas (porcentajes) / CoeficientesAnálisis de correspondencia simple
Diferencias de mediasAnálisis de la varianza
Correlación / Regresión simple
Prueba de significación
Chi cuadrado Prueba t ó ZF de Snedecor
Prueba t de Student

Análisis de datos cuantitativos
2. Cantidad de variablesTres variables o más variables
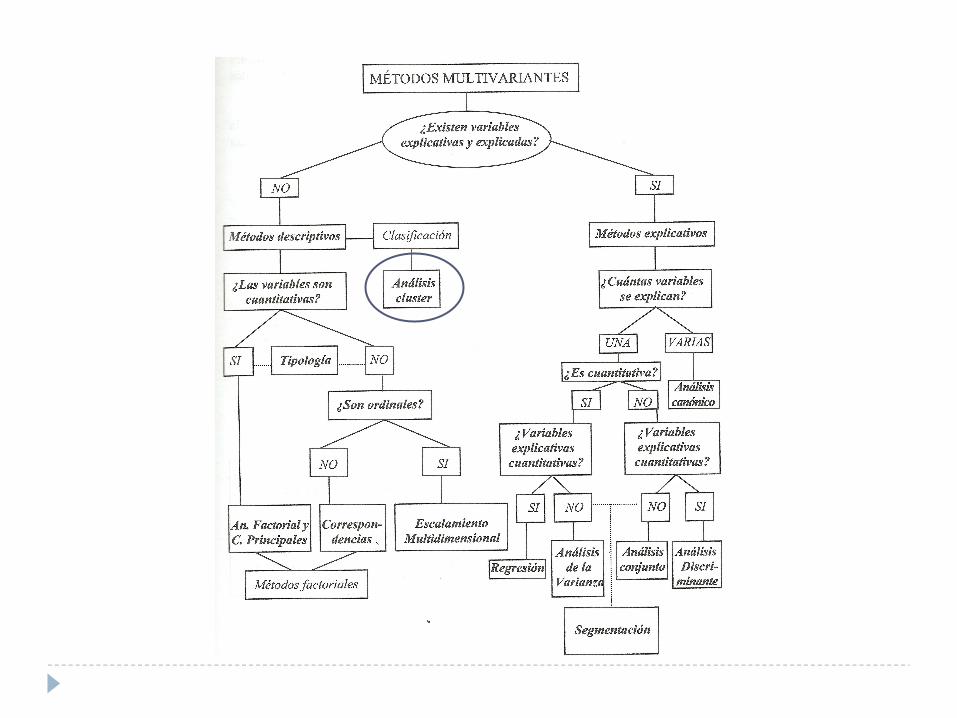

Análisis de clúster o conglomerados
Es una técnica de clasificación o agrupamiento. Trata de situar todos los casos en grupos homogéneos no conocidos de antemano pero sugeridos por el conocimiento sobre los datos.
Se utiliza la información de una serie de variables para cada sujeto u objeto y, conforme a estas variables se mide la similitud entre ellos.
Una vez medida la similitud se agrupan en: grupos homogéneos internamente y diferentes entre sí.La "nueva dimensión" lograda con el cluster se aprovecha después para facilitar la aproximación "segmentada" de un determinado análisis.
Se divide en dos modelos: jerárquicos y no jerárquicos
Fuero inicialmente creados para su uso con variables cuantitativas pero existen técnicas permite el uso de cualitativas e incluso ambos tipos de variables.
Se basan en la medición de la distancía o similitud entre los objetos en los modelos no jerárquicos y de cada objeto con el centroide de su grupo en los no jeráquicos.

Análisis de clúster o conglomerados
Métodos jerárquicos
La agrupación se realiza mediante proceso un con fases de agrupación o desagrupación sucesivas. El resultado final es unajerarquía de unión completa en la que cada grupo se une o separa en una determinada fase.Método jerárquico aglomerativo: Se parte de cada unidad de análisis para llegar a en las distintas etapas a un único grupoMétodo jerárquico divisivo: Toda la muestra es un único grupo para ir separándose en grupos hasta que en se detiene al llegar a cada unidad de análisis (árbol).
Como paso previo a aplicar el análsis de clusters el investigador debe tomar dos decisiones, qué medida de similaridad o distancia va a utilizar y algoritmo de formación de clusters va a emplear.
La medida de distancia más universal es la distancia euclídea o euclídea al cuadrado.Las algorítmos más utilizados distancias mínimas o vecinos más cercanos, vecinos más lejanos, distancia promedio entres clusters entre otras muchas.
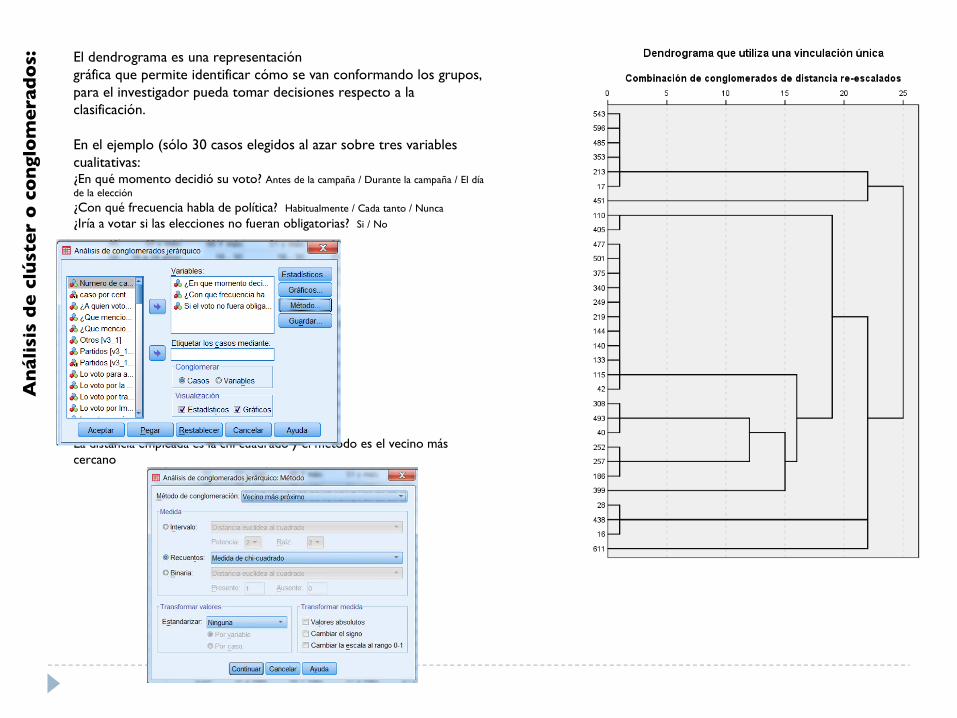
El dendrograma es una representacióngráfica que permite identificar cómo se van conformando los grupos, para el investigador pueda tomar decisiones respecto a la clasificación.
En el ejemplo (sólo 30 casos elegidos al azar sobre tres variables cualitativas: ¿En qué momento decidió su voto? Antes de la campaña / Durante la campaña / El día de la elección
¿Con qué frecuencia habla de política? Habitualmente / Cada tanto / Nunca
¿Iría a votar si las elecciones no fueran obligatorias? Si / No
La distancia empleada es la chi cuadrado y el método es el vecino más cercano
An
áli
sis
de
clú
ste
r o
co
ngl
om
era
do
s:
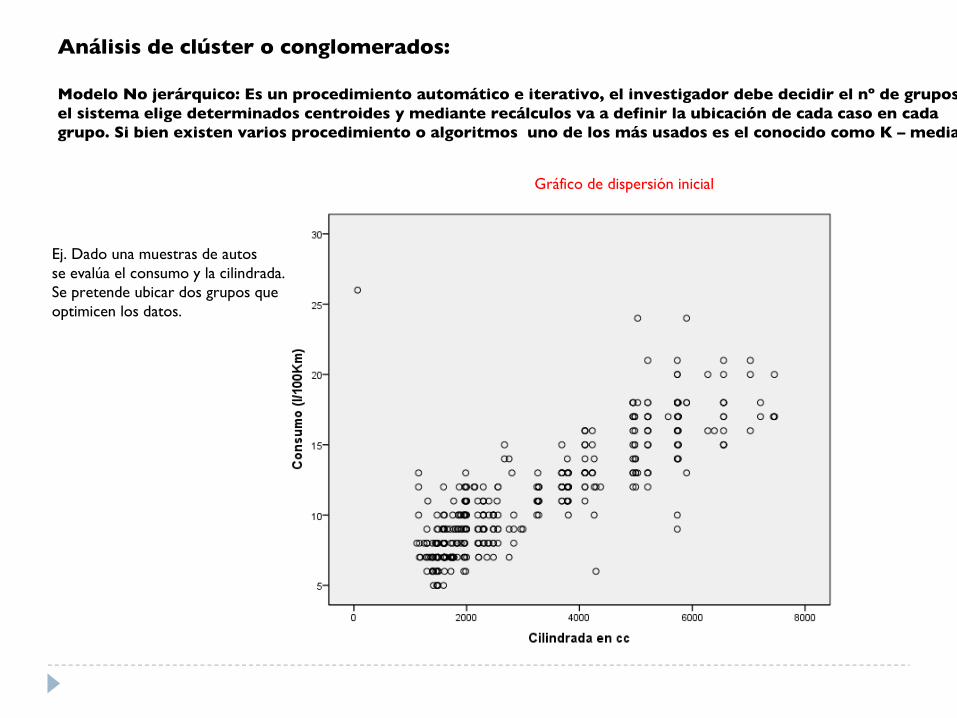
Análisis de clúster o conglomerados:
Modelo No jerárquico: Es un procedimiento automático e iterativo, el investigador debe decidir el nº de grupos, el sistema elige determinados centroides y mediante recálculos va a definir la ubicación de cada caso en cada grupo. Si bien existen varios procedimiento o algoritmos uno de los más usados es el conocido como K – medias
Gráfico de dispersión inicial
Ej. Dado una muestras de autos se evalúa el consumo y la cilindrada.Se pretende ubicar dos grupos queoptimicen los datos.
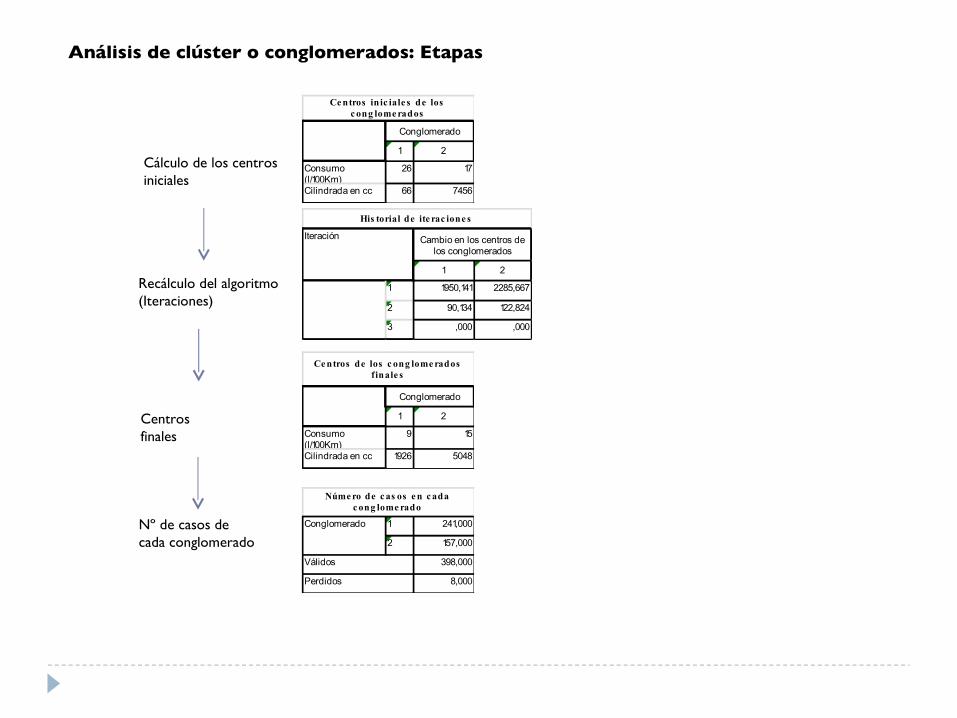
1 2
1 1950,141 2285,667
2 90,134 122,824
3 ,000 ,000
His torial de ite rac ione s
Iteración Cambio en los centros de los conglomerados
1 2
Consumo (l/100Km)
26 17
Cilindrada en cc 66 7456
Ce ntros in ic iale s de losc ong lome rados
Conglomerado
1 2
Consumo (l/100Km)
9 15
Cilindrada en cc 1926 5048
Ce ntros de los c ong lome radosfinale s
Conglomerado
1 241,000
2 157,000
398,000
8,000
Válidos
Perdidos
Núme ro de c as os e n c adac ong lome rado
Conglomerado
Análisis de clúster o conglomerados: Etapas
Cálculo de los centros iniciales
Recálculo del algoritmo(Iteraciones)
Centros finales
Nº de casos decada conglomerado
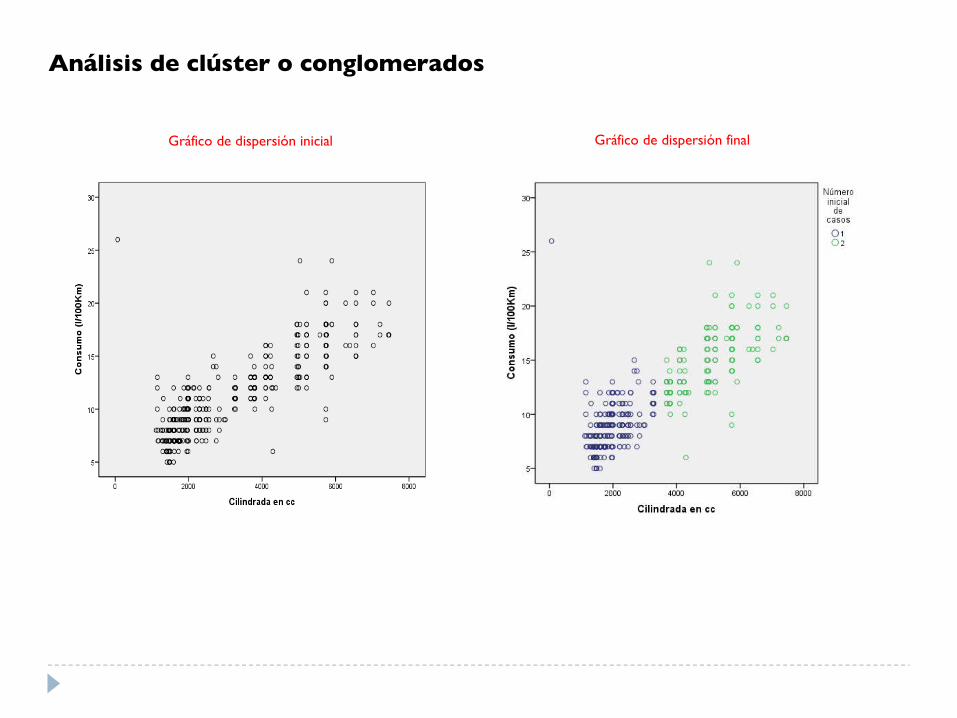
Gráfico de dispersión inicial Gráfico de dispersión final
Análisis de clúster o conglomerados
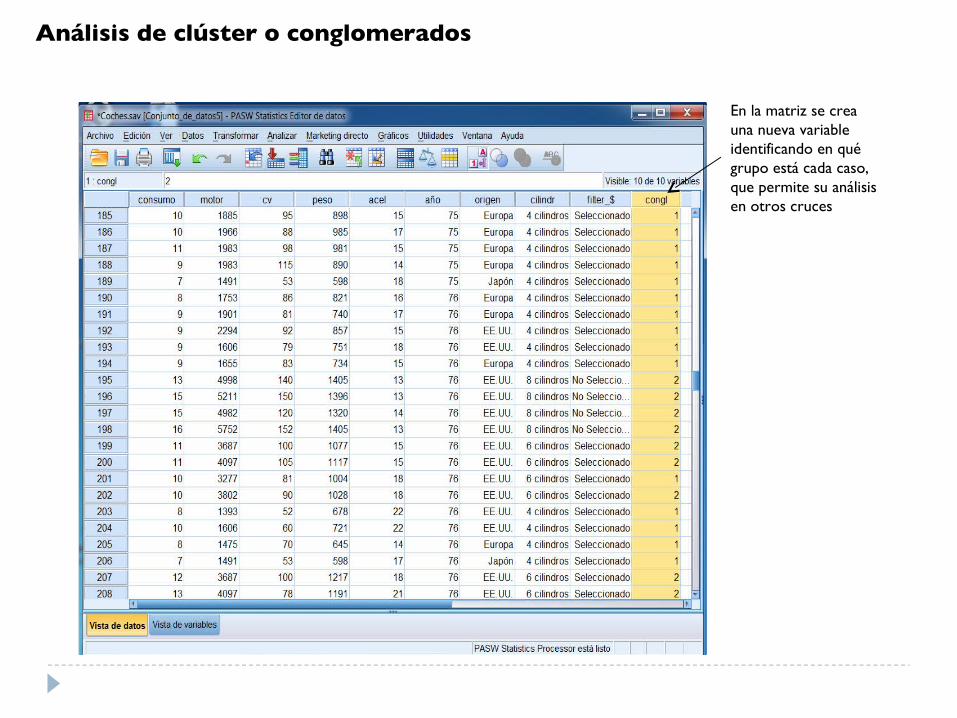
En la matriz se crea una nueva variableidentificando en quégrupo está cada caso,que permite su análisisen otros cruces
Análisis de clúster o conglomerados
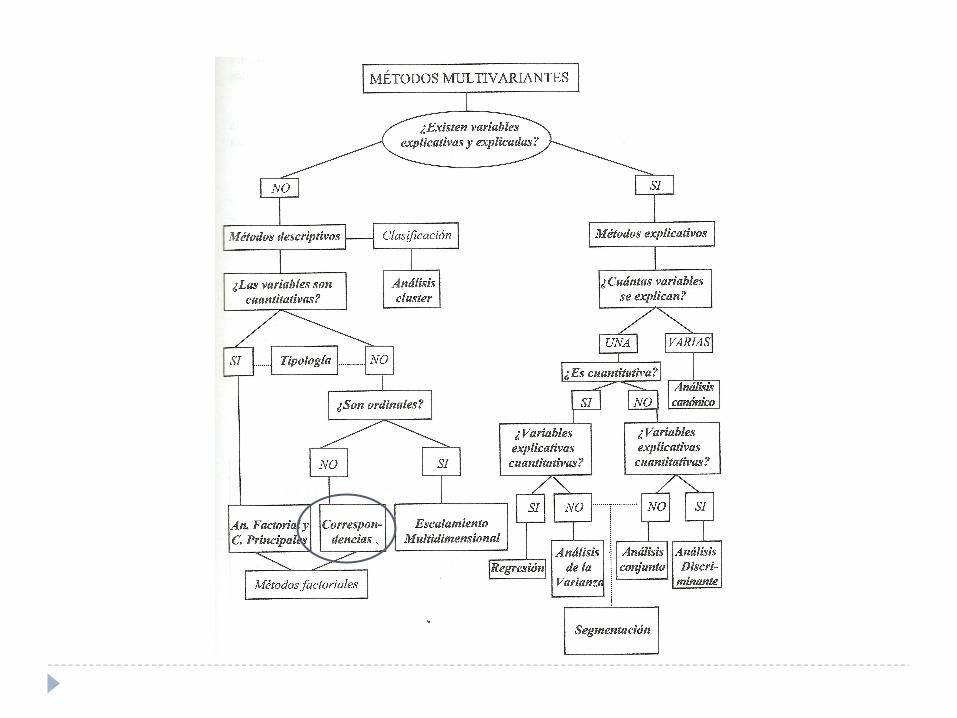

Análisis de correspondencias múltiple
Las dos finalidades principales del análisis de correspondencia son describir y sintetizar las relaciones existentes entre un grupo de variables nominales (César Pérez López, 2008). El análisis de correspondencia múltiple es una técnica multivariada factorial de reducción de la dimensión de una tabla de casos-variables con datos cualitativos en el caso del análisis de correspondencias simples, o su generalización cuando el número de variables cualitativas es superior a dos (n tablas).
La cuantificación se realiza en dos etapas sucesivas. Primero se debe calcular la puntuación de los sujetos (filas) y luego la de las variables (columnas). Las puntuaciones filas se obtienen a través de un algoritmo matemático y luego permiten cuantificar las categorías.
Al igual que las técnicas de análisis factorial, en el análisis de correspondencias la información queda explicitada en torno a los espacios dimensionales que formulan los factores, estos factores pueden ser interpretados o nombrados, dado que se constituyen en nuevas variables que contienen información optimizada de las variables originales.
A diferencia de las conocidas pruebas de independencia de chi cuadrada, que proporcionaban información sobre la relación significativa o no entre variables, sin identificar las categorías más comprometidas en la relación, las técnicas de análisis de correspondencia permite, incluso gráficamente, observar entre relaciones las categorías, permitiendo la verificación de hipótesis de trabajo que de otra forma se mantendrían ocultas.

Análisis de correspondencias múltiple:«Y lo que es cierto para los conceptos es cierto para las relaciones, que sólo adquieren su significado dentro de un sistema de relaciones. Del mismo modo, si yo hago un uso amplio del análisis de correspondencias, prefiriéndolo por ejemplo a la regresión multivariada, es porque el análisis de correspondencia es una técnica relacional de análisis de datos cuya filosofía se corresponde exactamente, a mi modo de ver, con aquello que es la realidad del mundo social. Se trata de una técnica que "piensa" en términos de relación, precisamente como yo intento hacerlo con la noción de campo» Pierre Bourdieu en Una invitación a la sociología reflexiva / Bourdieu y Wacquant 2005-
Senioriy en la Burguesía francesa (Bourieu (1984)
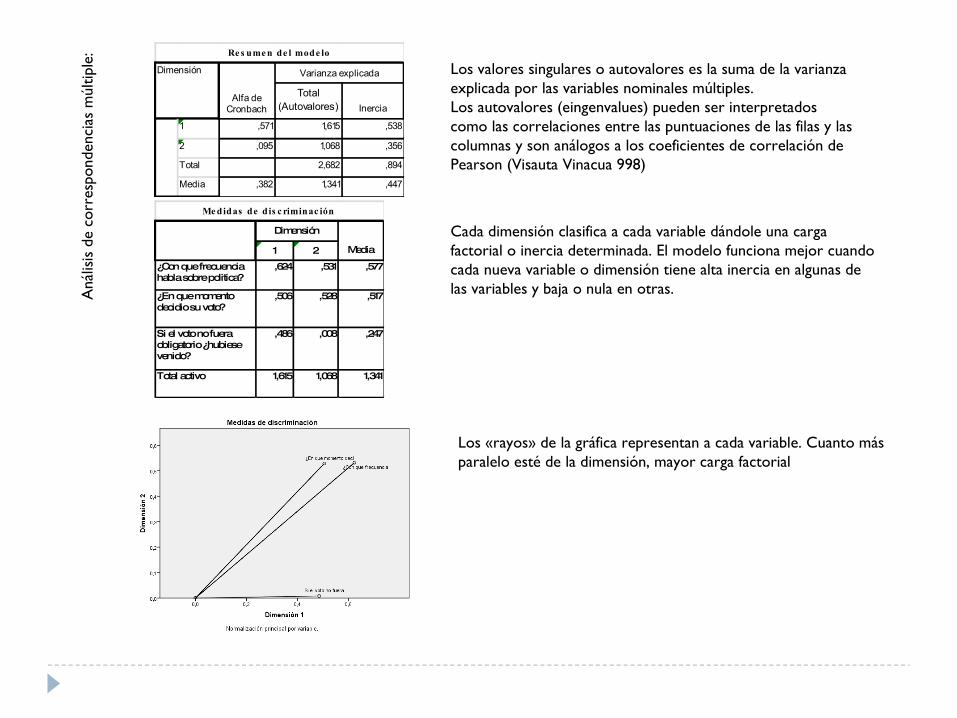
Total (Autovalores) Inercia
1 ,571 1,615 ,538
2 ,095 1,068 ,356
Total 2,682 ,894
Media ,382 1,341 ,447
Re s ume n de l mode lo
Dimensión
Alfa de Cronbach
Varianza explicada
1 2
¿Con que frecuencia habla sobre politica?
,624 ,531 ,577
¿En que momento decidio su voto?
,506 ,528 ,517
Si el voto no fuera obligatorio ¿hubiese venido?
,486 ,008 ,247
Total activo 1,615 1,068 1,341
Me didas de dis c riminac ión
Dimensión
Media
Los valores singulares o autovalores es la suma de la varianza explicada por las variables nominales múltiples. Los autovalores (eingenvalues) pueden ser interpretados como las correlaciones entre las puntuaciones de las filas y las columnas y son análogos a los coeficientes de correlación de Pearson (Visauta Vinacua 998)
Cada dimensión clasifica a cada variable dándole una carga factorial o inercia determinada. El modelo funciona mejor cuando cada nueva variable o dimensión tiene alta inercia en algunas de las variables y baja o nula en otras.
Los «rayos» de la gráfica representan a cada variable. Cuanto más paralelo esté de la dimensión, mayor carga factorial
Aná
lisis
de
corr
espo
nden
cias
múl
tiple
:
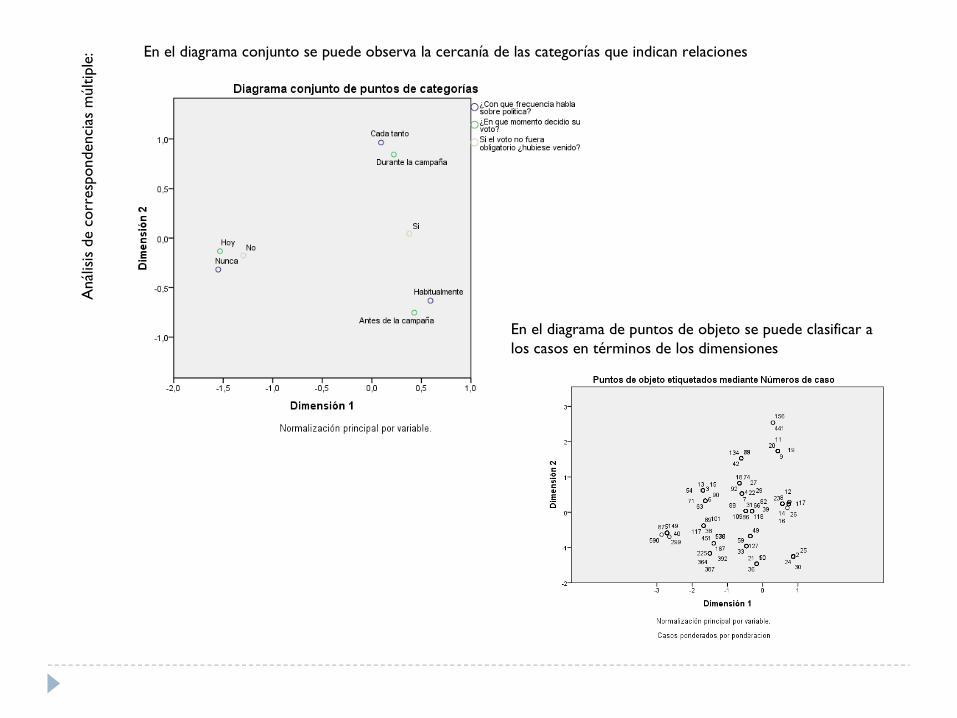
Aná
lisis
de
corr
espo
nden
cias
múl
tiple
: En el diagrama conjunto se puede observa la cercanía de las categorías que indican relaciones
En el diagrama de puntos de objeto se puede clasificar a los casos en términos de los dimensiones
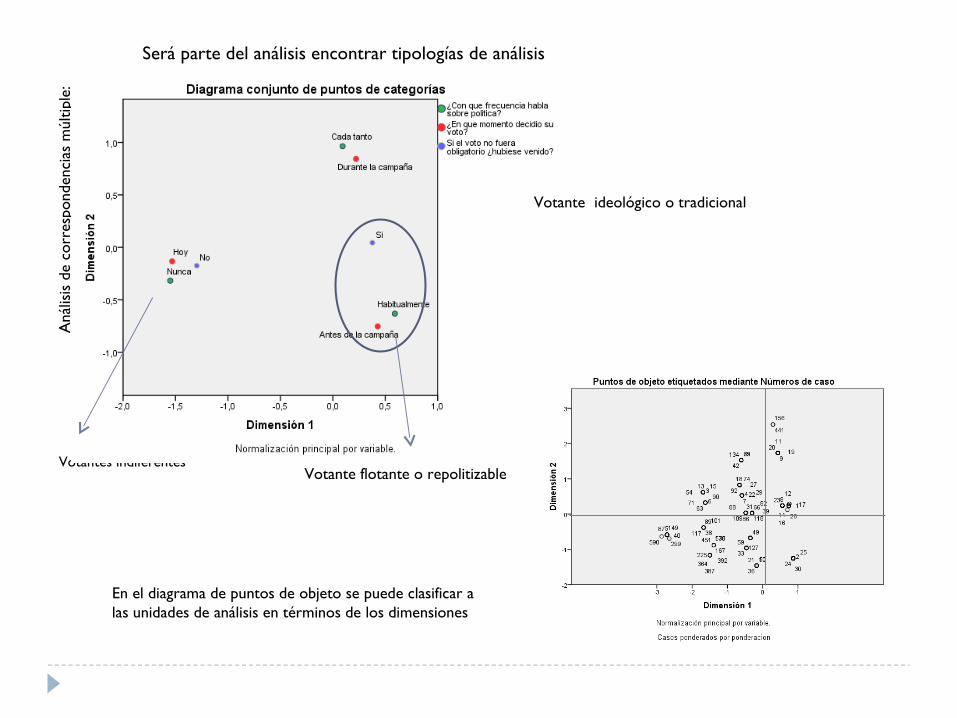
Aná
lisis
de
corr
espo
nden
cias
múl
tiple
:Será parte del análisis encontrar tipologías de análisis
En el diagrama de puntos de objeto se puede clasificar a las unidades de análisis en términos de los dimensiones
Votantes indiferentes
Votante ideológico o tradicional
Votante flotante o repolitizable
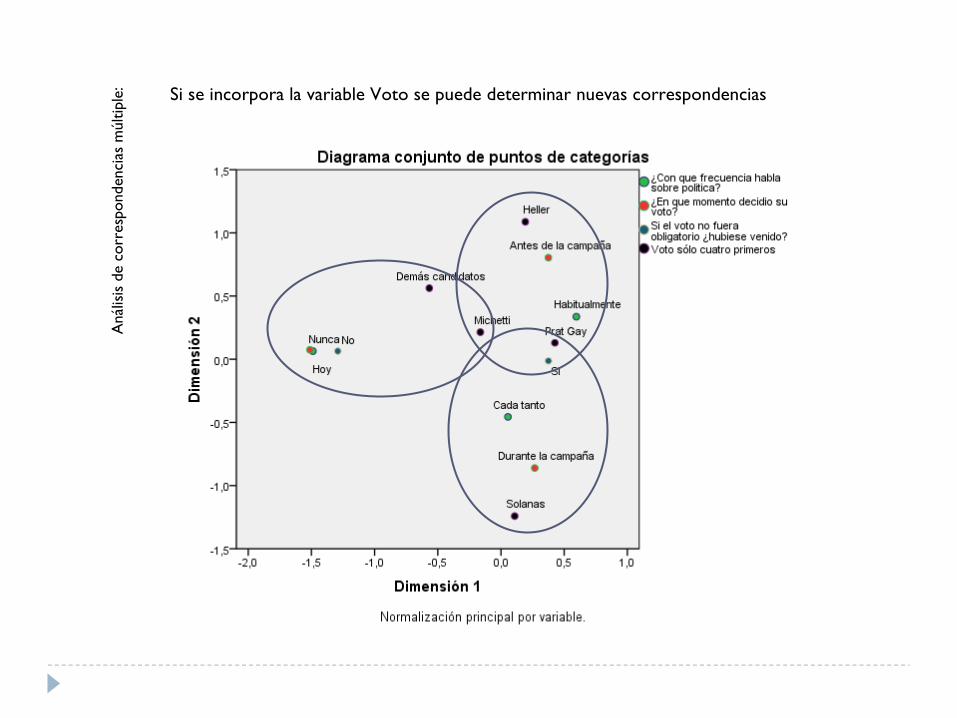
Aná
lisis
de
corr
espo
nden
cias
múl
tiple
: Si se incorpora la variable Voto se puede determinar nuevas correspondencias

BibliografíaBriones Guillermo (1996) Metodología de la investigación cuantitativa en las ciencias sociales, Bogotá, ICFESBourdieu Pierre y Loïc Wacquant. Una invitación a la sociología reflexiva / - Buenos Aires: Siglo XXI Editores. 2005. Pérez, César (2004) Técnicas de Análisis Multivariante de Datos, Madrid Ed, Pearson – PrenticeGreenacre Michael. La páctica del análisis de correspondencias. Fundación BBVV, Madrid, 2008Meulman Jacqueline J., Optimal Scaling Methods for Multivariate Categorical Data Analysis, SPSS, Chicago. 2009Visauta Vinacua, B. Análisis estadístico con SPSS para Windows, Vol II, Editorial Mc Graw Hill, México, 1998





















